5.4 Présentation de l'heuristique de
résolution
La résolution de ce problème consiste a
déterminer les emplacements des manifolds, les puits reliés a
chaque manifolds ainsi que les diamètres des pipes utilisés en
minimisant la perte de charge, pour notre méthode de résolution
nous avons opté pour l'approche suivante en deux phases:
5.4.1 Phase I: Nuées dynamiques[11]
Dans un premier temps, on détermine les emplacements
des manifolds ainsi que les puits reliés a chaque manifolds, pour cela
nous minimisons la somme des distances des puits aux manifolds et la somme des
distances des manifolds a la source.
La position d'un manifolds est appelée 'centre de
gravité'pour l'ensemble des puits connectés a ce manifolds
(formant une région) et la source.
Pour déterminer les emplacements des manifolds et le
choix des puits qui seront connectés aux manifolds installés, on
applique une méthode de classification automatique appelée
'Méthode des Nuées Dynamiques'.
*La méthode des nuées dynamiques:
La méthode de classification des nuées
dynamiques (Diday et al 1980) repose essentiellement sur la répartition
d'une population en catégories (classes) tout en utilisant la notion de
noyau associé a chaque classe, il peut s'agir, comme dans notre
étude par exemple, de découvrir les principaux regroupements de
puits ayant la particularité d'être proches les uns des autres.
L'information apportée par une classification se situe,
en effet, au niveau sématique: (il ne s'agit pas d'atteindre un
résultat vrai ou faux, probable ou improbable, mais seulement profitable
ou non profitable)(Williams et Lance).
Les principaux problèmes de la classification automatique
diffèrent suivant le type
d'information recherchée: une hiérarchie, un
arbre, une partition, une typologie , des (classes empiétantes). Toutes
ces approches nécessitent le choix de mesures de ressemblance.
Principe :
Le principe des algorithmes des nuées dynamiques est
simple:
Considérer un ensemble d'individus qui appartient a un
ensemble E (par exemple Re ), et chercher la meilleure partition a K
classes fixées de cet ensemble selon le critère d'inertie.
Le processus est itératif et à chaque
étape la qualité de la partition s'améliore. Le nombre de
classe souhaité est déterminé à priori ainsi que le
nombre d'éléments centraux désirés,
c'est-à-dire le nombre d'éléments au centre du noyau qui
seront énumérés. Au départ, un ensemble de points
ou noyaux d'une classe peut être tiré au hasard. Autour de ces
points se regroupent les éléments les plus proches pour former
une partition. La distance calculée par rapport au centre de classe est
la distance euclidiènne. A partir de cette partition
créée, une autre famille de noyaux est définie, elle
regroupe les points les plus proches formant une nouvelle classe et ainsi de
suite jusqu'à obtention d'un nombre fini de classes . Si, aprés
un certain nombre d'itérations, les classes formées sont stables,
les données sont dites "classifiables" et constituent des "formes
fortes". Les individus qui changent de classes selon les tirages sont les
"individus charnières".
Comment se déroule l'algorithme:
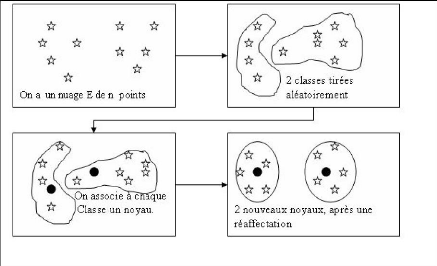
Figure 5.4.1 : Illustration du principe ( K = 2)
Soit un nuage E de N points, on cherche a constituer une
partition de E en k classes, chaque classe est représentée par
son (noyau). On aura une bonne classification si et seulement si le
critére suivant est vérifié: "La somme des distances des
individus aux noyaux soit minimale".
*Un algorithme de type "Nuées Dynamiques
Rappelons rapidement le principe de ces méthodes: on
suppose que , appartient a un ensemble E (par exemple R avec P le nombre de
variables), on définit un ensemble L de noyaux, une "distance" d entre
les éléments de E et les noyaux de L. (L'algorithme doit
respecter le primcipe d'homogéméité: les dommées a
classer et les moyaux doivemt être de même nature). Le
critère W de classification est alors le suivant:
W(P, L) = >2K >2 d(x,
ak)
k=1 XEPk
On:
P = (P1, ..., PK) et L = (a1, ..., aK) avec aK 2 L
L'algorithme se construit alors de la manière habituelle,
il se base sur deux fonctions:
*Construction des classes (fonction d'affectation f) :
On range chaque élément de dans la classe dont le
noyau est le plus proche.
*Construction des noyaux (fonction de représentation g) :
On associe a chaque classe Pk un nouveau noyau ak minimisant :
>2 d(x,ak)
XEPk
L'algorithme des nuées dynamiques est une succession
d'appels a ces deux fonctions de façon itérative, le nombre de
groupes K est déterminé soit par une connaissance a priori du
phénomène étudié, soit par une autre méthode
(classification hiérarchique par exemple) .
Organigramme:
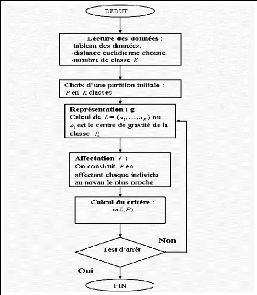
Figure 5.4.2 : Représentation structurée de
l'algorithme des Nuées Dynamiques
*Application de l'algorithme a notre problême:
Algorithme :
1-Diviser les puits en k régions de facon aléatoire
( soient R1, R2, ..., Rk). Avec k= [N/5] on N est le nombre de puits de la
station.
2-Déterminer les emplacements des manifolds (M1, ...,
Mk).
Pour une région R3 donnée, choisir l'emplacement Mj
qui minimise:
|
/ >
f(X, Y ) = X2 + Y 2 +
|
p
(Xi - X)2 + (Y - Y )2
|
PiERj
On (X,Y ) sont les coordonnées du manifolds Mj
Pi E R3: signifie que le puits (i) coordonnées (Xi,Yi) E
R3
3-Répartir les puits en utilisant une fonction de
décision: Pi est dans la région R3 si et seulement si d(Pi, M3)
est minimale.
d(Pi, M3) est la distance euclidienne entre le puits (i) et le
manifold Mj 4-Si le test d'arrêt est vériflé aller a (5)
sinon aller a (2).
5-S'il existe une région ayant un nombre =6 5 alors
réaffecter les puits en utilisant l'organigramme de la page suivante, et
recalculer les nouveaux centres de gravité comme en (2).
REMARQUE:
1-L'étape (5) est due a la contrainte qui exige que le
nombre de puits par région soit égal a 5.
2-Le test d'arrêt est le suivant: s'il n'y a pas
d'amélioration au cours de 2 itérations succussives l'algorithme
est arrêté.
3-d(Pi, M3) est la longueur du pipe reliant Pi a Mj.
qd(Pi, Mj) = (X - X' j)2 + (Yi-
Y j ')2.
· m(R) est le nombre de puits dans la région
R.
Organigramme:
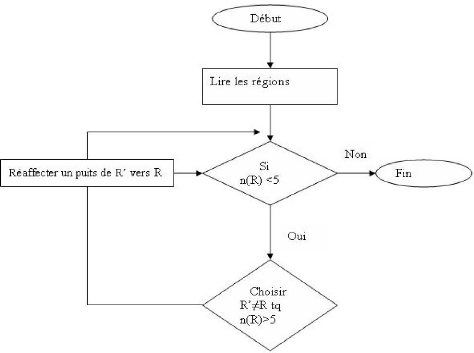
Figure 5.4.3 : Organigramme de la procédure
réaffecter
| 

