àtude du projet d'implémentation d'un intranet collaboratif dans une entreprise multi sites sous la plateforme Sharepoint Foundation 2010. Cas de la société Katanga Outsourcing Group( Télécharger le fichier original )par Merlec MPYANA Université protestante de Lubumbashi - Licence en ingénierie des systèmes d'informations 2010 |

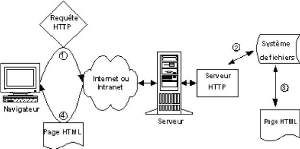
I.5 Le protocole HTTP et HTTPSHTTP est un protocole applicatif basé sur un paradigme requête/réponse. Un client établit une connexion avec un serveur et lui émet une requête composée de la méthode à invoquer, une URI, une version de protocole et un message de type MIME6 comportant des informations sur le client, des paramètres et un éventuel contenu de message. Le serveur renvoie un message comportant la version du protocole utilisé, un code d'erreur ou de réussite de la requête, suivis d'un message MIME contenant des informations sur le serveur, des méta-informations sur la requête et un éventuel contenu de message (le code HTML, XHTML, XML, XAML, interprété localement). Sur l'Internet comme dans l'Intranet, les communications HTTP utilisent généralement des connexions TCP/IP, mais ce protocole n'est en aucun cas comminatoire : HTTP nécessite l'usage d'une couche transport fiable ; n'importe quel protocole de communication garantissant cette fiabilité peut être utilisé. Le protocole HTTP s'est largement inspiré du protocole FTP, adapté aux documents hypertextes (d'où HTTP au lieu de FTP). La volonté de gérer un très grand nombre d'accès simultanés, présente des l'origine de HTTP, s'est concrétisée par un mode non connecté.
Figure I.8 : Un serveur Web « passif » inspiré du modèle FTP»7. La session du client n'est établie avec le serveur que pendant la breve durée de transfert du fichier spécifié par l'URL. Ce mode non connecté, efficace dans le cadre d'accès concurrents vers des documents (hyper) textuels, est pénalisant dans certains cas : 1. Un même client accédant à plusieurs documents d'un même serveur (ce qui englobe le cas du document contenant des images) établit autant de sessions que de documents requis, d'où une perte 6Multipurpose Internet Mail Extensions (MIME) est un standard internet qui étend le format de données des courriels pour supporter des textes en différents codage de caractères autres que l'ASCII, des contenus non textuels, des contenus multiples, et des informations d'en-tête en d'autres codages que l'ASCII. Les courriels étant généralement envoyés via le protocole SMTP au format MIME, ces courriels sont souvent appelés courriels SMTP/MIME. 7John SÉRAPHIN, Réalisation d'un Intranet : Cohérence d'un Ensemble Réparti et Communicant, autour d'une Architecture Réflexive, Thèse, Université René Descartes, Paris V, février 1998 Sujet T.F.E. : « Etude du projet d'implémentation d'un Intranet collaboratif dans une entreprise multi-sites sous la plate-forme SharePoint Fondation 2010 ». MPYANA MWAMBA Merlec +243812886356 - mlecjm@gmail.com, Licence Académique en Ingénierie des Systèmes d'Informations - Université Protestante de Lubumbashi, Ed. 2010-2011 de temps pour ré-établir une session à chaque accès. Cela est d'autant plus dommageable que le protocole TCP, conçu pour optimiser les accès au réseau en fonction du temps de connexion, pénalise du fait de leur brièveté les sessions HTTP, intermittentes; 2. Il est difficile de gérer une persistance de l'utilisateur pour simuler une session transactionnelle et maintenir un contexte de l'utilisateur (ou des variables globales d'une application) entre deux requêtes. La version 1.1 du protocole HTTP, dont la normalisation se heurte à un certain nombre de problèmes d'implémentation depuis près d'un an, essaye entre autres de pallier ces défauts par certains mécanismes à savoir :
Ces variables rémanentes peuvent être instanciées très finement et associées à l'accès d'un sous-domaine DNS complet (.mlecjm.onmicrosoft.compar exemple), d'un chemin absolu ou relatif, ou même d'une URL particulière. Elles peuvent être enregistrées pour des durées très variables allant de la session de l'utilisateur (jusqu'à sa sortie du navigateur) ou pour des durées précisées en jours/heures/minutes ou en temps absolu. Il est laissé à la charge des applications concernées d'utiliser ces variables comme sémaphores dans les mécanismes complexes de gestion de transactions. I.5.1. Les limites du modèle HTTP/HTML du Web classiqueLe principal défaut de l'association HTTP-HTML réside dans ses faibles capacités d'adaptation au contexte, issues de son héritage de FTP notamment. Une fois épuisée la nouveauté introduite par la navigation dans des documents hypertextes passifs, le besoin s'est fait sentir de définir des mécanismes pour assurer un minimum d'interactivité. Il s'agissait d'abord de transmettre à l'utilisateur des informations sur les données auxquelles il accede (dates de création ou modification, taille des fichiers à télécharger, nombre d'accès, etc.), puis de réaliser des interfaces pour accéder en lecture ou en écriture à des données plus structurées. Ce manque d'extensibilité du modèle HTTP est une des faiblesses originelles de la métaphore avec un système d'exploitation orienté-objet. Le protocole HTTPS (avec S pour secured, soit « sécurisé ») a était créé pour améliorer les limites de http. Il consiste en une simple combinaison de HTTP avec une couche de chiffrement comme SSL ou TLS, pour des raisons suivantes : Sujet T.F.E. : « Etude du projet d'implémentation d'un Intranet collaboratif dans une entreprise multi-sites sous la plate-forme SharePoint Fondation 2010 ». MPYANA MWAMBA Merlec +243812886356 - mlecjm@gmail.com, Licence Académique en Ingénierie des Systèmes d'Informations - Université Protestante de Lubumbashi, Ed. 2010-2011 - Permettre au visiteur de vérifier l'identité du site ou portail auquel il accède grâce à un certificat d'authentification. - Garantir la confidentialité et l'intégrité des données envoyées par l'utilisateur (notamment des informations entrées dans les formulaires) et reçues du serveur. Il est généralement utilisé pour les transactions financières en ligne : commerce électronique, banque en ligne, courtage en ligne, etc. Il est aussi utilisé pour la consultation de données privées, comme les courriers électroniques par exemple. Par défaut, les serveurs HTTPS sont connectés au port TCP 443 tandis le http utilise le port 80. Le HTML comme langage de présentation est très limité, non seulement par le nombre de ses balises, mais surtout il mélange la structure, la présentation et le contenu de documents. Les feuilles de style sont un pas en avant, mais pas suffisant. Les URLs ne permettent de localiser que des ressources présentes sur le Web. Or avec l'avènement du Web 2.0, par exemple, il est nécessaire d'identifier et de décrire même les objets ne se trouvant pas sur le Web. Les moteurs de recherche par mots-clés sont incapables de couvrir et exploiter tout le contenu du Web. En effet, les moteurs ne référencient pas les pages générées dynamiquement, les pages non référencées (volontairement ou non), les pages protégées par un mot de passe, les documents de nature non indexable (exemple : les animations Flash), les bases de données, etc. Le Web classique ne dispose pas de mécanismes pouvant permettre aux agents logiciels de raisonner sur les informations. Il manque des moyens d'intégration d'informations provenant des sources multiples, distribuées et hétérogènes et aussi des mécanismes de collaboration entre les agents logiciels. Tenant compte de toutes ces insuffisances, il était devenu indispensable de mettre au point des méthodes et outils susceptibles de permettre la compréhension, la manipulation et le partage intelligent de documents Web. Une des approches prometteuses aujourd'hui est celle du Web sémantique dit « Web intelligent ». |
|