|
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR ET DE LA RECHERCHE
SCIENTIFIQUE UNIVERSITE MOULOUD MAMMERI DE TIZI OUZOU
FACULTE DES SCIENCES
DEPARTEMENT DE MATHEMATIQUES
MEMOIRE DE MAGISTER
SPECIALITE: MATHEMATIQUES
OPTION: PROBABILITES ET
STATISTIQUES
Présenté par: Yousfi Smail
Sujet:
ANALYSE EN COMPOSANTES PRINCIPALES DE DENSITES DE PROBABILITE
ESTIMEES
PAR LA METHODE DU NOYAU
Devant le jury d'examen compose de:
|
M.Hocine Fellag
|
Proffesseur
|
U.M.M.T.O
|
Président
|
|
M.Berkoun Youcef
|
Chargé de recherche
|
U.M.M.T.O
|
Examinateur
|
|
M.Boumaza Rachid
|
Maître de conférences
|
I.N.H., ANGERS
|
Rapporteur
|
|
M.Ibazizen Mohamed
|
Maître de conférences
|
U.M.M.T.O
|
Examinateur
|
|
M.Yousfate Abderrahmane
|
Maître de conférences
|
U.D.L.S.B.A
|
Examinateur
|
Soutenu le / /
A la mémoire de mes grands parents
Remerciements
Au terme de ce modeste travail, je tiens a exprimer ma sincere
gratitude envers M.BOUMAZA Rachid, pour m'avoir accordé
l'honneur d'assurer la direction de ce mémoire. Je le remercie pour ces
conseils précieux, ses critiques, ses orientations et pour sa
grande contribution a l'aboutissement de ce projet.
Je remercie M.FELLAG Hocine, M.IBAZIZEN Mohamed et M.BERKOUN
Youcef pour avoir accepté d'être membres de mon jury.
Je remercie également M.YOUSFATE Abderrahmane qui
ma fait l'honneur de rejoindre la composition du jury.
Parmi les personnes qui mon aidé, je tiens a
remercier chaleureusement
M.BOUDIBA Mohand Arezki et M.MORSLI Mohammed qui ont
participé a la mise au point de certains passages dans ce
mémoire.
Je remercie également mes amis, qui
m'ont porté une affection sans faille. Enfin, et surtout, je pense a ma
précieuse famille a qui j'ai volé tant de bons
moments...
Table des matières
|
1
|
Notations
Introduction
ACP fonctionnelle de densités de probabilité
1.1 Introduction
|
4
5
10
10
|
|
1.2
|
Rappel sur l'analyse en composantes principales d'un
opérateur
|
11
|
|
|
1.2.1
|
Condition d'existence de l'ACP "pas a pas"
|
12
|
|
|
1.2.2
|
ACP totale d'un opérateur compact
|
13
|
|
1.3
|
ACP de densités de probabilité
|
14
|
|
|
1.3.1
|
Introduction
|
14
|
|
|
1.3.2
|
Affinité L2 entre deux densités
de probabilités
|
14
|
|
|
1.3.3
|
Définition de l'ACP de densités
|
15
|
|
|
1.3.4
|
Formule de reconstitution des densités de
probabilités
|
17
|
|
|
1.3.5
|
Qualité Globale de l'ACP
|
17
|
|
|
1.3.6
|
Qualité de représentation de ft suivant
gj
|
17
|
|
|
1.3.7
|
ACP normée
|
18
|
|
|
1.3.8
|
ACP centrée
|
18
|
|
2
|
Estimation de l'ACP de densités de probabilité
|
21
|
|
2.1
|
Introduction
|
21
|
|
2.2
|
Rappel sur l'estimation d'une densité par la
méthode du noyau
|
22
|
|
|
2.2.1
|
Choix du noyau et de la fenêtre de
lissage
|
24
|
|
|
2.2.2
|
Application a l'estimation par noyau de
l'affinité L2
31
|
|
|
2.3
|
ACP de densités estimées par la méthode du
noyau
2.3.1 Cas général
|
33
33
|
|
|
2.3.2 Exemples
|
33
|
|
|
2.3.3 Approche de Kneip et Utikal
|
36
|
|
|
2.3.4 Application de l'approche d'estimation de Kneip and Utikal
a une ACP
|
|
|
|
estimée non centrée et non normée
|
38
|
|
2.4
|
ACP de densités estimées
paramétriquement
|
41
|
|
|
2.4.1 Cas de données gaussiennes
multidimensionnelles
|
41
|
|
|
2.4.2 ACP paramétrique de densités de
Gumbel unidimensionnel
|
44
|
|
2.5
|
Comparaison entre l'approche paramétrique et
non paramétrique
|
46
|
|
3
|
Influence du noyau sur l'ACP de densités
estimées
|
49
|
|
3.1
|
Introduction
|
49
|
|
3.2
|
Cas des fenêtres AMISE
|
51
|
|
3.3
|
Cas d'égalité des AMISE
|
56
|
|
3.4
|
Conclusion
|
62
|
|
4
|
Influence et choix de la fenêtre de lissage
|
63
|
|
4.1
|
introduction
|
63
|
|
4.2
|
Influence de la fenêtre de lissage
|
63
|
|
4.3
|
Choix de la fenêtre de lissage
|
72
|
|
Conclusion
|
81
|
|
Bibliographie
|
84
|
Notations
Notations matricielles
W' transposée de la matrice / vecteur
W
Wt,s élément de la t-ème
ligne et la s-ème colonne de la matice W
W -1 inverse de la matrice W
|W | déterminant de la matrice W
MuM la norme euclidienne de u
kuMM la M-norme de u
Notations statistiques
E(X) espérance
mathématique de la variable X
V (X) variance de variable X
Cov(X,Y ) covariance des variables X
et Y
N(u,Ó) loi normale de vecteur
moyen u et de matrice de variance covariance Ó
MISE Mean Integrated Square
Error
AMISE Asymptotic Mean Integrated
Square Error
Notations fonctionnelles
L2(IRp) espace des
fonctions réelles de carré intégrable sur
IRp
L2IR( × T) espace des fonctions
réelles de carré intégrable par rapport a la
mesure
produit sur × T
U* adjoint de l'opérateur U
< u,v >H produit scalaire dans l'espace de Hilbert
H entre les deux vecteurs
u et v
UoV composée des opérateurs U et
V
kV M norme de l'oprérateur V
II[a,b] indicatrice de l'intervalle
[a,b]
Notations diverses
Pn i fi sommation sur l'ensemble des valeurs de l'indice
i des quantités fi
ps convergence presque sure
Introduction
La statistique, en tant que discipline
des mathématiques appliquées, admet une
grande diversité de dominantes, elle peut être
descriptive ou inférentielle, paramétrique ou non,
asymptotique ou non, uni ou
multidimensionnelle; elle englobe un spectre très
large de problèmes, allant du plus concret (traitement de
données) au plus abstrait (formalisation mathématique
nécessitant des concepts variés, qui peuvent
être des versions stochastiques de la théorie
fondamentale (théorie des opérateurs)). Pour cela, elle utilise
des outils divers issus de l'algèbre linéaire, de
l'analyse fonctionnelle, de la géométrie
(projection orthogonale) et du calcul des probabilités.
L'analyse des données comme méthode
de la statistique descriptive, a vu ses champs d'applications
s'élargir d'une façon considérable,
avec l'introduction et le développement des moyens de calcul
(les ordinateurs), dépassant ainsi son cadre classique [1, 91
en empruntant les chemins du cadre fonctionnel, permettant ainsi
d'étudier des phénomènes rendus plus complexes par le
gros volume de données qu'ils induisent. Par
exemple, lorsqu'on étudie un phénomène
économique comme la consommation mensuelle
d'électricité, il est d'usage de la représenter
par la chronique des consommations mensuelles totales. " Ce choix
présente deux inconvénients " [61
~ On perd une partie de l'information concernant la structure du
système;
Les délais nécessaires a la connaissance des
derniers résultats de cette série sont souvent assez
longs.
" Le premier point nous amène a caractériser le
phénomène étudié par la série
chronologique multiple des consommations mensuelles des
différentes branches de l'industrie et du commerce. Sa visualisation
nous fournira celle du phénomène de facon
globale" [61.
" Le deuxième point pose le problème du choix
d'une ou plus généralement d'un petit
groupe de séries, extraits de la série multiple et la
représentant au mieux. Ce choix est fondamental dans l'étude de
la conjoncture et dans la prévision " [61 . Braun (1973) propose de
résoudre ce problème en faisant une analyse en
composantes principales sur ces séries, dont la première
composante principale va expliquer au mieux la variabilité du
phénomène. Cette dernière n'expliquant
qu'une partie de la variabilité totale, on peut alors
considérer la deuxième composante principale parmi les
combinaisons linéaires des autres séries orthogonales
a la première composante principale, et ainsi de suite.
Depuis les travaux pionniers de Deville (1974), beaucoup
d'attentions ont étés accordé a l'analyse des
données fonctionnelles par la communauté statistique
[11 dont beaucoup d'études sont consacrées a la description
statistique d'un échantillon de courbes (courbe de
croissance, courbe de température, ... ) au moyen de
l'analyse en composantes principales fonctionnelle (voir
Ramsay and Silverman 1991, Boumaza, 1999, Kneip and Utikal,
2001...). L'utilisation de la décomposition spectrale de
l'opérateur de covariance qui est analogue a la
matrice de covariance dans l'espace des fonctions, permet d'obtenir dans un
espace de faible dimension les principaux modes de variations des
données. Prenons par exemple la fonction aléatoire
X(t,w), w E Ù et t varie dans un
intervalle compact T de IR, de moyenne
u(t) et de fonction de covariance
ã(t,s) =
Cov(X(s),X(t)).
L'opérateur de covariance F s'écrit sous la forme
d'un opérateur intégral comme suit [111:
Z
Vf E L2(T ), Vt E T,
Ff(t) =
ã(t,s)f(s)ds (1)
T
La meilleure approximation de X dans un sous-espace
de dimension q, est obtenue par la projection de X sur le
sous-espace de L2IR(Ù x T)
engendré par les q fonctions propres
g1, . . . ,gq de F de la façon
suivante:
X(t) u(t) + X q fj
gj(t) (2)
j=1
Les fj sont des variables aléatoires
centrées de variances ëj (ëj est la
j-ième valeur propre de F). Une approximation obtenue au
moyen de l'analyse en composantes principales
fonctionnelle (FPCA) de la fonction aléatoire X [4, 141.
Si nous intéressons maintenant a la description et a
l'estimation des réalisations des trajectoires Xi d'une
variable aléatoire X prenant ses valeurs dans un espace
fonctionnel,"deux points de vue cohabitent dans la littérature et
conduisent aux memes procédures d'estimation "[11 . Le premier
considère que les observations sont bruitées et
que le vrai signal est contenu dans un espace fonctionnel
de dimension finie [271, Il s'agit alors de reconstuire au mieux les
trajectoires observées. Le second cherche a obtenir une
représentation optimal d'un ensemble de courbes dans un espace de
dimension petite [11].
Lorsqu'on observe un échantillon i.i.d de
variables aléatoires fonctionnelles Xi, i = 1,m
tiré selon la distibution de X, on peut définir
l'opérateur de covariance empirique
n[14l. Deville (1974), Dauxois et Pousse (1976), montrent,
en des sens et sous des hypothéses différentes
(convergence presque sure, convergence en loi,
données dépendantes), la convergence des
opérateurs de covariance au sens de la norme de Hilbert-Schmidth ainsi
la convergence des éléments propres. Ensuite, Dauxois
et al, ont montré la convergence en loi de
n et en ont déduit les convergences en
loi des éléments propres.
En pratique on peut supposer que les
courbes sont observées sur une grille de p points de
discrétisation t1,... ,tp . On note Xi
= (Xi(t1), . . .
,Xi(tp)' la i-ème
trajectoire disctrétisée que l'on suppose
centrée."En approximant l'opérateur de covariance en utilisant
une méthode de quadrature, on peut définir les
composantes principales comme les coordonnées dans la bases des
fonctions propres discrétisées " [11].
" L'estimation "brute" des éléments propres en
présence d'observations discrètes des courbes n'est pas
forcément judicieuse, les fonctions propres estimées pouvant etre
très irrégulières " [71 , d'oi l'idée
pratique de proposer un lissage dans la phase
d'estimation. Ce lissage peut opérer sur les trajectoires
[11, 27] desquelles on fait ensuite l'ACP sur les vecteurs propres
[34, 35] oi encore en lissant simultanément toutes les trajectoires dans
un espace de dimension restreinte [101. Ce lissage permet
également d'améliorer, lorsque la valeur du
paramètre est bien choisie, les estimateurs des éléments
propres [11, 27] et les reconstructions des trajectoires [101.
Une variante de l'analyse des données
fonctionnelles permettant le traitement d'un autre type de
données, appelée: "données ternaires"
(three-way data) qui se présentent sous forme de
L tableaux indicés par un paramètre qui peut
être le temps [12, 21] est l'ACP de densités de probabilité
[3, 20] dont la justification théorique ressort de la
théorie des opérateurs compacts [13, 151. Elle consiste a
remplacer chaque tableau par une densité de
probabilité. L'ensemble de ces densités constitue un
nuage de L vecteurs dans l'espace de Hilbert
L2(IR12) (p
désigne le nombre de colonnes de ces tableaux).
L'objectif est de décrire globalement ces données, en
procédant a une représentation approché dans un
sous-espace de faible dimension.
La méthode suppose que les densités
sont connues, ce qui n'est pas toujours le cas en
pratique. Une façon simple d'y
remédier consiste a supposer que les densités
appartiennent a une famille connue, comportant des paramètres inconnus
dont les estimations par la méthode de vraisemblance permet de
déduire des estimations de ces densités, puis de faire une ACP
sur les densités estimées. Cette ACP fournit une estimation de
l'ACP théorique correspondante.
On peut vérifier dans le cas de données
gaussiennes simulées la convergence rapide de
l'ACP des densités estimées vers l'ACP
théorique correspondante pour des tailles
d'échantillon raisonnables [31.
Notre souci dans ce présent travail est de
présenter une autre approche d'estimation. Elle consiste a estimer les
densités inconnues par la méthode du noyau [2, 16, 31,
32, 331. La convergence de l'ACP estimée est justifiée
par les propriétés de convergence des estimateurs a
noyau [21.
On étudiera ainsi pour une taille d'échantillon
fixée, l'influence des paramètres de lissage
(noyau et fenêtre) sur les résultats de l'estimation,
puis on proposera un critère de sélection de la fenêtre de
lissage. On utilisera ce critère pour calculer une
fenêtre dite "optimale", permettant ainsi d'obtenir une meilleure
estimation de l'ACP théorique correspondante.
L'étude est faite sur des données
simulées de différentes natures (bimodale
symétrique et
asymétrique, unimodale
symétrique et
asymétrique). Les programmes ont
été écrits dans l'environnement Scilab.
Le premier chapitre est consacré a l'étude de
l'ACP de densités. Dans un premier temps on proposera un bref rappel sur
l'analyse factorielle d'opérateur, qui sera
considérée comme un outil mathématique pour
aborder par la suite la deuxième partie, qui est
dédiée a l'ACP de densités.
Dans le deuxième chapitre et après un rappel sur
la notion d'estimation de densité de probabilités par la
méthode du noyau, on présentera dans un premier temps
l'ACP de densités estimées non
paramétriquement, ensuite on donnera un rappel sur l'approche
d'estimation paramétrique et on terminera ce chapitre par une
comparaison entre les deux approches d'estimation.
En se basant sur des exemples simulés, on
étudiera au début du troisième chapitre, l'influence du
noyau sur l'ACP de densités estimées, oi l'on
considérera deux cas particuliers; le cas oi les
densités sont estimées en associant a chacune d'elle la
fenêtre optimale au sens de l'erreur quadratique
intégrée asymptotique et le cas
oii les densités sont estimées sous la condition
d'égalité des erreurs
quadratiques intégrées
asymptotiques.
Le quatrième et dernier chapitre est
réservé a l'influence et choix de la fenêtre de
lissage sur l'ACP de densités. On y proposera un
critère de sélection d'une fenêtre dite "optimale", et on
y comparera a l'aide de quelques exemples
simulés, les résultats obtenus en utilisant cette fenêtre
et les résultats obtenus en utilisant les fenêtres optimales au
sens des erreurs quadratiques
intégrées asymptotiques.
Chapitre 1
ACP fonctionnelle de densités de
probabilité
1.1 Introduction
Le travail dans les espaces fonctionnels s'impose
lorsque les données elles-mêmes sont des fonctions. Le
cas le plus classique est celui d'un individu observé pendant
un certain temps, au cours duquel plusieurs mesures sont
effectuées.
Un autre exemple est celui des mesures climatiques.
Dans ce cas, une région peut être
représentée par une fonction qui a une date associe
des grandeurs comme la température moyenne de la
journée correspondante, la quantité de
précipitations, etc.
Le traitement statistique de ce type de
données nécessite une généralisation de
l'analyse des données classiques, au cas des
données fonctionnelles [10, 14, 26, 27, 34, 35]
On présentera dans ce chapitre une autre méthode
permettant le traitement d'un autre type de données
fonctionnelles qu'on appellera Analyse en Composantes
Principales de densités de probabilités [3, 201. Les
densités jouent le rOle des individus observés; ces
individus sont dans un espace fonctionnel (espace de Hilbert dans notre
cas).
Néanmoins l'adaptation d'une telle méthode a ce
type de données requiert un arsenal
mathématique qui sera considéré
comme un outil indispensable pour aborder les aspects
asymptotiques.
La première partie de ce chapitre fournit le cadre
mathématique (Dauxois et Pousse, 1976) dont l'objectif est de
définir la base de fonctions sur lesquelles sont
décomposées les densités; la deuxième
partie consiste en la présentation de l'ACP de densités.
1.2 Rappel sur l'analyse en composantes principales d'un
operateur
Soit H et H' deux espaces de
Hilbert séparables; l'espace H (resp.
H') est identifié a son dual. On pose < .,.
>H (resp. < .,. >H') le produit scalaire de l'espace
H (resp. H'), et k.kH (resp.
1.1H0) la norme associée.
Soit U un opérateur continu non nul de H
dans H', et U* son adjoint.
Definition 1.2.1 On appelle analyse en composantes
principales "pas a pas" de U, tout couple ({ëi}i?I,
{ui}i?I), où
1. I est N* ou une section
commencante de N*.
2. {ëi}i?I est une suite decroissante de reels
positifs ou nuls.
3. {ui}i?I une suite d'elements de
H' verifiant les conditions suivantes:
|
(i) ?(i,j) ? I2, <
ui,uj >H'=
|
|
1 si i = j
0 sinon
|
(ii) ? i ? I, ëi =
supH; u ? H' et ? j = i<
u,uj >H,= 0l
Si I = {1,..,n}, l'ACP est dite
d'ordre n, et si de plus {ui}i?I est un
système total de H', alors on
dit que l'ACP est totale [13].
1.2.1 Condition d'existence de l'ACP "pas a pas"
Lors de la première étape de l'ACP "pas a pas" de
U, on est amené a l'étude de la borne supérieure
de l'application réelle G définie sur
H' par:
G(u) =
(1.1)
kU*uk2 < U o
U*u,u >H'
H
= .
kuk2 kuk2
H0 H,
On est ainsi conduit a
l'étude de l'opérateur U o U*, noté
V.
Propriété
V est un opérateur continu autoadjoint
positif; son spectre est donc contenu dans l'intervalle [0, V
M][13]. A toute analyse en composantes principales
"pas a pas", on peut alors associer le shéma de dualité
suivant:
H' U
, H
W = U* o U
V = U o U*
I est l'identité
Proposition 1.2.2 (Dauxois et Pousse, 1976)
Le maximum de la fonction G existe et est
inférieur a V k; il est atteint pour au moins un
élément de H' si et seulement si cette norme
est valeur propre de V. De manière plus
générale, si le haut du spectre de V est
formé de q valeurs propres isolées d'ordre de
multiplicité fini nj (j = 1,...,q) et si on
pose n = Pn j=1 nj, U admet une ACP d'ordre
n (au moins):
({ëi}i?I, {ui}i?I)
oiTi {ëi}i?I est la suite pleine
décroissante de valeurs propres de V et
{ui}i?I est une suite orthonormée de vecteurs
propres associés.
1.2.2 ACP totale d'un operateur compact
Proposition 1.2.3 Tout operateur compact U admet une
analyse en composantes principales totale [13].
Dans ce cas la, l'ACP totale de U revient a faire
l'analyse spectrale de l'opérateur V = U o
U*. Si ({ëi}i?I, {ui}i?I) est une ACP
"pas a pas" d'un opérateur compact U, nous avons alors les deux
propriétés suivantes.
1. L'ordre de multiplicité de chaque valeur
propre non nulle ëi est fini.
2. Posons I* = {i ? I; ëi
=6 0}, alors la suite de terme
généralfi = 1 kU*ui,H U*ui,
constitue
un système de vecteurs propres
orthonormés de W.
Remarque: La quantité 1
kU*uikH U*ui existe, car
MU*uil2H =
ëikuik2 H0 =6 0
On a alors la proposition suivante:
Proposition 1.2.4 (Dauxois et Pousse, 1976)
Si ({ëi}i?I, {ui}i?I), est une ACP "pas a pas" de
l'operateur compact U, le couple
({ëi}i?I*, { U*ui
kU*uikH }i?I*), est une ACP "pas a pas"
de U*, dite associee a la precedente.
On appellera {ëi}i?I* la suite des
valeurs principales, {fi}i?I* la suite des composantes
principales normalisées et {ui}i?I* la suite des
facteurs principaux de l'opérateur U.e
La proposition précédente permet de rechercher
l'ACP de U en faisant soit l'analyse spectrale de
V, soit celle de W. L'opérateur V peut
s'écrire comme suit [14]:
|
V =E
i?I*
|
ëi ui ? ui (1.2)
|
pour (x,y) ? H2, y ? x est
l'opérateur défini par: y ? x(f) =< y,f
>H x.
1.3 ACP de densités de probabilité
1.3.1 Introduction
L'ACP classique a entre autres pour objectif de
représenter dans un espace de faible dimension, un nuage de
points représentant m individus ou objets décrits par
p variables numériques, en utilisant soit les
corrélations soit les covariances entres les variables [301.
L'analyse en composantes principales de densités de
probabilité poursuit le même objectif, sauf que les
individus sont des fonctions de densités et l'espace des individus est
un espace fonctionnel de dimension infinie.
On introduit la mesure d'affinité (produit scalaire
entre deux densités) [281 avec laquelle on définit un
opérateur compact autoadjoint V (appelé aussi
opérateur de covariance [291) dont la diagonalisation
fournira une base suivant laquelle seront décomposées
les densités. Grace a la proposition 1.2.4, l'étude se
ramène a la diagonalisation d'une matrice
symétrique et les densités seront
représentées dans la base des vecteurs propres de cette
matrice.
1.3.2 Affinité L2 entre deux densités de
probabilités
Soit f1,...,fL un nuage de L
densités de probabilités, supposées appartenir a
l'espace de Hilbert H = L2(IR") des
fonctions de carrée intégrable par rapport a la mesure
de Lebesgue sur IR".
Definition 1.3.1 (Qannari, 1983)
Considérons deux densités de probabilités
f et g, de carrée intégrable par
rapport a la mesure de référence ? sur
(IR",I3IRP). On appelle affinité
L2 entre f et g la
quantité suivante:
Z< f,g >= IRP
f(x)g(x)d(?(x))
(1.3)
Exemple
Soit f et g deux densités
gaussiennes a p dimensions de paramètres respectifs
(ii, Ó) et (in, V ). L'affinité
L2 entre f et g est donnée par la
formule suivante [31;
|
1
< f,g >= 2 e
(2ð)p 2 |Ó +
V |1
1.3.3 Définition de 1'ACP de densités
|
2 iu-mi2
1 (Ó+V )-1. (1.4)
|
L'objectif de la méthode proposée est d'obtenir
une représentation approchée du nuage des L
densités f1,...,fL. On note
Pg le projecteur orthogonal sur le sous espace
engendré par le vecteur g de H.
Première étape:
On cherche g1 = PL t=1 a(1)
t ft de norme unité dans H, minimisant
la quantité:
Ig1 = XL kPg1(ft) -
ftM2. (1.5)
t=1
Deuxième étape:
On cherche g2 = PL t=1 a(2)
t ft de norme unité dans H,
orthogonale a g1 rendant minimum la
quantité:
Ig2 = XL kPg2(ft) -
ftM2. (1.6)
t=1
Ainsi de suite.
Les fonctions g1,g2... ainsi obtenues,
qui ne sont pas nécessairement des densités de
probabilités, constituent un système orthonormal
[31.
Soit alors l'opérateur compact U défini
sur IRL par:
Vv E IRL, Uv =
XL vtft, v = (v1,...,vL).
(1.7)
t=1
Son adjoint U* est défini par: [31
|
car:
|
< v,U*g
>RL=< g,Uv >H=
|
XL
t=1
|
< ft,g > vt. (1.9)
|
On a alors la définition suivante.
Definition 1.3.2 .
On appelle ACP de densités de probabilités, l'ACP
"pas a pas" de l'opérateur U. La minimisation de (1.5)
est équivalente a la maximisation de la
quantité suivante:
11Pgi(ft)112 =
< ft,g1 >2=
1U*g1l2RL (1.10)
XL
t=1

=
Ig1
XL
t=1
oil 1.1RL désigne
la norme usuelle de RL.
D'autre part:
1U*g1l2RL
=< U*g1,U*g1
>RL=< g1,UoU*g1
> (1.11)
max (/' ) = max < > . (1.12)
hig111=1 (Ig1)
11g11=1
On déduit de cette derniere définition
que l'ACP de ces densités est équivalente a
l'analyse spectrale de l'opérateur autoadjoint W
= U*oU. Dans la base canonique
e1,...,eL de RL, la matrice W
s'écrit [3]:
<
f1,f1 > ... < f1,fs
> ... < f1,fL >
... ... ...
< ft,f1 > ... < ft,fs >
... < ft,fL >
... ... ...
< fL,f1 > ... < fL,fs >
... < fL,fL >
Remarque
1. Si u de RL est vecteur propre de
l'opérateur W associé a la valeur propre non nulle
ë, alors g = vUu ë est un vecteur
propre de V associé a la meme valeur propre non nulle
ë.
2. Les vecteurs propres de l'opérateur V sont
les facteurs principaux, et leur image par U* sont les
composantes principales.
1.3.4 Formule de reconstitution des densités de
probabilités
Si g1, g2, ..., gT le
système de vecteurs propres de l'opérateur V,
oi T désigne le nombre de valeurs propres non nulles
de V (resp. W), alors chaque densité ft
s'écrit comme suit [31:
ft = XT < ft,gj >H gj
(1.13)
j=1
La coordonnée < ft,gj >H de ft
suivant gj, est égale a la
t-ième composante du vecteur U*gj. De la
relation,
1 1 p
U*gj = pëjU* o Uuj
= v Wuj = ëj uj; (1.14)
ëj
|
on déduit:
|
? ????
????
|
< ft,gj >H = pëj uj,t
= jL 4/ëj uj,t gj
ft j=1 PT
gj = vëj
1t=1 uj,t ft
|
(1.15)
|
oi uj,t désigne la
t-ième composante du vecteur propre uj de W.
Pour obtenir une représentation approchée du
nuage initial, il suffit de tronquer la relation
(1.15).
1.3.5 Qualité Globale de l'ACP
On mesure la qualité globale de
l'ACP par la somme des proportions d'inertie expliquée par
les axes retenus, l'axe j expliquant une
quantité d'inertie égale ëj
>IT r=1 ër.
1.3.6 Qualité de représentation de ft suivant
gj
Elle est égale a:
|
ft = fu +
|
XT
j=1
|
qëjut,j
gj (1.20)
|
1.3.7 ACP normée
L'ACP normée de densités de probabilité
consiste a diviser chaque densité par sa norme
associée dans H; cette ACP conduit alors a
diagonaliser la matrice de terme
général:
1 1
Ws,t = Ilft1111fs11 < ft,fs > (1.17)
Remarque: Cette normalisation conserve dans H
les angles entre les densités mais déforme leurs
distances.
1.3.8 ACP centree
Pour obtenir une représentation approchée
qui restitue les distances entres les densités, on définit
un autre nuage dont le centre de gravité est lui
même l'origine de l'espace vectoriel ou les densités
sont représentées. Kneip et Utikal (2001) ont choisi cette ACP
pour étudier sur plusieurs années, la relation entre le revenu
annuel des foyers britanniques et l'age
moyen des personnes actives au sein de ces foyers.
Théoriquement elle consiste a prendre comme
nuage l'ensemble des fonctions ft = ft -
fu dans L2(Rp), ou
fu = L EsL fs. L'ACP de ce
nuage conduit a diagonaliser la matrice W, de
terme général:
Wt,s =< ft - fu,fs - fu > .
(1.18)
L'opérateur de covariance associé
s'écrit:
T
V = j=1 (ft - fu)
? (ft - fu). (1.19)
Les densités ft, t ? {1,...,L}
s'écrivent dans la bases des fonctions propres
g1,g2,... de
l'opérateur V comme suit [20]
Exemple: ACP centrée de L distributions
gaussiennes multidimensionnelles.
Soient X1, . . . ,XL des variables
aléatoires de distribution gaussienne a p
dimensions, de moyenne u1, . . . ,uL et de
variance Ó1,. . . ,ÓL respectivement. Les
densités f1, f2,..., fL constituent un
nuage F dans l'espace de Hilbert H =
L2(IRp).
L'ACP centrée de ces L densités conduit
a diagonaliser la matrice de terme général
donné par la relation (1.18), qu'on calcule en utilisant la
formule (1.4).
On visualise (Fig.1) les projections des dens
ités ft (t = 1, . . . ,30) sur le premier
plan principal dans les cas suivants:
1. ut = cos(t), Ót =
et,
2. ut = cos(t), Ót =
1,
3. ut = 0, Ót =
et.
Les deux premiers éléments propres de W
( ACP centrée) fournissent une représentation approchée
des densités sur les deux premiers axes principaux et les
pourcentages d'inertie expliquée par ces axes. "Au
cours du temps l'évolution de la moyenne est
périodique et l'évolution de la variance est
exponentielle, l'évolution des densités devrait etre la
résultante" [31.
Les graphiques de la figure 1
donnent les projections des densités sur le premier plan principal.
L'évolution des densités sur ce plan, dans le cas ut =
cos(t) et Ót = et, ne
fait pas apparaItre la périodicité de la moyenne, ceci
est du au fait que la variance croissant exponentiellement,
" L'évolution de la moyenne est "
noyée " dans l'évolution de la variance" [31 . Cet
aspect est bien montrer lorsque ut =
cos(t) et Ót = 1, oi la
périodicité de la moyenne est bien visible sur le
premier plan principal.
11t = cos(t), Ót
= et
2
8% 12%
|
0280
0200
0120
|
|
01700
01275
00850
|
|
|
4 0
11t = cos(t), Ót
= 1
2
21 23 1
7
91% 81%
11t = 0, Ót = et
Fig.1: Nuage centré des
densités sur le premier plan principal
.0850
Chapitre 2
Estimation de l'ACP de densités de
probabilité
2.1 Introduction
Au delà de l'aspect théorique
présenté dans le chapitre précédent, l'ACP de
densités est une méthode statistique permettant le
traitement d'un gros ensemble de données, se
présentant sous forme de plusieurs groupes formés des
valeurs de p variables quantitatives sur plusieurs
individus, oi chaque groupe est considéré
comme un échantillon d'une population donnée. La méthode
va nous permettre de dégager des facteurs,
décrivant au mieux les différences entre les échantillons,
par conséquent entre les différentes populations. Elle
consiste alors à associer à chaque échantillon
une densité de probabilité, qui est la densité
de la variable parente correspondante. La démarche elle-même
exige que les densités soient connues, ce
qui n'est pas toujours le cas en pratique. Boumaza (1999)
a proposé une approche dans laquelle les densités sont
estimées en supposant que les données sont des
réalisations de variables aléatoires dont les lois appartiennent
à une famille de lois connues, comportant des paramètres
inconnus; estimer les densités des ces lois revient alors,
à en estimer les paramètres. Dans le cas de données
gaussiennes unidimensionnelles, il a été
vériflé sur des exemples simulés la convergence
rapide de l'ACP des densités estimées vers l'ACP
théorique correspondante pour des tailles
d'échantillons raisonnables (n>25).
|
fh(x) =
|
] (c)i E {1,...,n} : Xi E
[x - h 2,x + h 2]p
nhp
|
.
|
(2.1)
|
Une autre approche possible qui ne suppose pas
nécessairement la normalité des données, consiste a
estimer les densités inconnues par la méthode du
noyau. Introduite par Kneip et Utikal (2001) dans le cas d'une ACP
centrée non normée, ils proposent dans la méthode, une
procédure en deux étapes d'estimation des éléments
propres de la matrice des produits scalaires [201 . Sans se soucier de la
nature de l'ACP, on étudiera ainsi l'influence du noyau et de
la fenêtre de lissage sur la qualité de
l'estimation. On donnera dans le début du chapitre, un rappel sur
l'estimation d'une densité de probabilité par la méthode
du noyau, ensuite on présentera l'ACP estimée par
noyau, dans laquelle on proposera dans le cas d'une ACP
non centrée et non normée, une procédure d'estimation des
valeurs propres de la matrice des produits scalaires
théorique, permettant d'améliorer leurs
qualités d'estimation. Ensuite on donnera un rappel sur
l'approche d'estimation paramétrique et on terminera ce
chapitre par une comparaison entre les deux approches d'estimation.
2.2 Rappel sur l'estimation d'une densité par la
méthode du noyau
" Il s'agit d'un problème fondamental de la
statistique non paramétrique qui a
connu, durant ces quarante dernières années, des
développements théoriques et pratiques a la
fois rapides et nombreux "[181.
Soit (X1,...Xn) un
échantillon de densité marginale inconnue f.
L'idée la plus naturelle consiste a évaluer la densité
f au point x en comptant le nombre d'observations
"tombées" dans un certain voisinage de x. Sur
IRp (p = 1), on peut par exemple choisir un
voisinage cubique de x =
(x1,...,xp) de la forme [x1 - h
2,x1 + h 2] x ... x
[xp - h 2,xp + h 2]
qu'on note [x - h 2,x + h
2] oi h est un nombre réel strictement positif
dépendant de n, ce qui conduit a l'estimateur
[181
Cette dernière expression peut encore s'écrire:
|
1
fh(x) = mhp
|
Xn
i=1
|
(x _ Xi
1[_ 1 . (2.2)
2 , 1 2 ]p h
|
oi la fonction 1[_ 1
2]p.
2 , 1 2 ]p est la densité de
probabilité uniforme sur [_1
2,1
En s'inspirant alors de la dernière formule, et en
définissant K comme étant une fonction réelle,
bornée d'intégrale 1 sur IRp, on
définit l'estimateur fh associé au noyau
K par:
|
1
fh(x) = mhp
|
Xn
i=1
|
K(x _ Xi
h ) (2.3)
|
Lorsque le noyau K est choisi
positif, l'estimation fh est une densité de probabilité
et on parle alors parfois de la densité de probabilité
empirique de noyau K. Parmi les multiples
estimateurs non paramétriques de la densité
aujourd'hui a la disposition des utilisateurs, l'estimateur a noyau,
est de loin le plus populaire (Akaike, Rosenblatt, 1956, Parzen, 1962,
Silverman, 1986, Bosq et Lecoutre, 1987 ...). Ce succès peut
essentiellement s'expliquer en trois points:
1. L'expression théorique de
fh(x) est simple, puisque il s'écrit comme
une somme de m variables aléatoires i.i.d..
2. fh converge vers f en de
nombreux sens, et en particulier au sens L1 pour toute densité
f dès que1 h et mhp tendent tous
les deux vers l'infini. D'autre part si l'estimateur est convergent,
il est convergent dans tous les modes, i.e. en probabilité,
en moyenne, presque sürement et presque
complètement [21.
3. Enfin, cet estimateur est flexible, dans la mesure oi il
laisse a l'utilisateur une grande latitude non seulement dans le
choix du noyau, mais encore dans le choix du paramètre
réel h.
" Lorsqu'on se limite aux noyaux K
positifs, les vitesses de convergences varient peu en fonction
de K et les critères essentiels du choix du noyau
sont alors la simplicité et la vitesse de calcul d'une part, la
régularité de la courbe a obtenir d'autre part "[181.
En revanche, le choix du paramètre de lissage h se
révèle crucial aussi bien pour la précision locale
que pour la pécision globale de l'estimateur
fh, c'est l'objet du paragraphe suivant.
2.2.1 Choix du noyau et de la fenêtre de lissage
" La décision d'un choix optimal pour le
noyau K et la constante de lissage h,
suppose la spécification d'un critère d'erreur qui
puisse etre éventuellement optimisé. Bien slir,
l'optimalité n'est pas un concept absolu: elle est intimement
liée au choix du critère, qui peut faire intervenir a
la fois la densité inconnue f et l'estimateur fh donc
h et le noyau K " [181. Dans le cas qui
nous intéresse, on cherche a minimiser l'erreur
quadratique intégrée
moyenne, que nous noterons par MISE (mean
integrated square error), qui est
définie par:
Z Z
MISE(h) = E
IR'[fh(x) -- f(x)]2 =
IR' E[fh(x) -- f(x)]2
(2.4)
Cette écriture signifie que l'erreur
quadratique intégrée
moyenne est a la fois une mesure de l'erreur globale
moyenne et une mesure de l'erreur moyenne ponctuelle
accumulée.
On s'intéressera dans la suite de cette partie au cas
particulier oi p = 1. On a alors le théorème suivant.
Théorème 2.2.1 (Rosenblatt, 1956)
Si f a une dérivée seconde absolument continue,
et si K et f00 E L2, oTi K est une
densité continue, symétrique de variance
u2 K, alors, sous les conditions h
--* 0 et nh --* 00, on a le développement
asymptotique:
1 (2.5)
n
(
h4
MISE(h) = 4 u4
KR(f00) +
R(K)
nh + O h5 +
et l'erreur quadratique
intégrée asymptotique
associée noté AMISE est définie par:
|
h4
AMISE =
4
|
u4
KR(f00) +
R(K)
nh
|
.
|
(2.6)
|
oi R(K) = f
K2(x)dx
Choix du noyau
Le choix du noyau optimal K selon le
critère de l'erreur quadratique
intégrée asympthotique pour
estimer une densité de probabilité qu'on choisira
parmi la classe de tous les noyaux
symétriques, vérifiant de plus
f t2K(t) =6 0, et
donné par le théorème suivant:
Théorème 2.2.2 (Epanechnikov, 1969)
Si f a une dérivée seconde absolument continue dans
L2.
Si de plus h ? 0, nh ? +8 et
fIR(f00)2 =6 0, alors le
noyau d'Epanachnikov d'ordre 1, KE défini par:
KE(x) = ( 3 x
4v5)(1 -
5)ll[-v5,v5](x),
(2.7)
est d'erreur quadratique
intégrée asymptotique
minimum.
Silverman (1986) a défini le coefficient
d'efficacité des noyaux appartennant a cette classe, en les
comparant au noyau optimal précédant, il est
donné par la formule suivante.
(J )
3
eff(K) = v5
t2 K(t)dt
1 )-1
K(t)2dt , (2.8)
2 (J
alors pour un noyau de cette classe, il montre
que ce coefficient est très proche de 1,
signifiant ainsi que le choix de ce dernier influe peu
sur l'AMISE.
1)Noyau Gaussian:
Il est défini pour tous x ? RI par:
1 1
KG(x) = v 2
On présentera ici quelques
exemples de noyaux appartenant a la classe pécédente
qu'on utilisera ensuite dans l'étude de l'influence du
noyau sur l'ACP de densités estimées non
paramétriquement.
exp(- x2) (2.9)
2ð
2) Noyau rectangulaire:
|
KR(x) =
|
?
?
?
|
1/2 si |x| = 1
0 sinon
|
(2.10)
|
|
KE(x) =
|
?
?
?
|
(3/4)(1 - 1 5x2) 1
,5 si |x| < v5
0 sinon
|
(2.11)
|
3)Noyau d'Epanechnikov:
4)Noyau triangulaire:
|
KT(x) =
|
|
1 - |x| si |x| = 1
0 simom
|
(2.12)
|
On souhaite alors utiliser le résultat
précédent de Silverman pour visualiser a l'aide d'un exemple de
simulation, l'influence du choix du noyau K parmi les 4
noyaux définis précédemment, sur la courbe
associée a l'estimation de la densité de probabilité
f.
Soit (x1,...,xn), m
réalisations de la variable aléatoire X de
densité f de loi N(4,2). Posons:
~ AMISEG l'erreur quadratique
intégrée asymptotique entre
f et son estimation en utilisant le noyau
gaussien et la fenêtre de lissage noté
hG.
~ AMISET l'erreur quadratique
intégrée asymptotique entre
f et son estimation en utilisant le noyau
triangulaire et la fenêtre de lissage noté
hT.
~ AMISEE l'erreur quadratique
intégrée asymptotique entre
f et son estimation en utilisant le noyau d'Epanechnikov et
la fenêtre de lissage noté hE.
~ AMISEG l'erreur quadratique
intégrée asymptotique entre
f et son estimation en utilisant le noyau
rectangulaire et la fenêtre de lissage noté
hR.
tel que:
AMISEG = AMISET = AMISEE = AMISER.
(2.13)
Remarque
La relation (2.13), va nous permettre de calculer les
fenêtres précédentes, et cela en procédant comme
suit:
Premièrement on fixe une fenêtre parmi hG,
hT, hE, hR, par exemple; hG =
0.40. Les 3 dernières sont respectivement les solutions
réelles positives des 3 équations suivantes:
ó4KT
4
h5 - (AMISEG) h +
1R(KT) = 0 (2.14)
m
ó4 KR
4 h5 - (AMISEG) h +
1 mR(KR) = 0 (2.16)
pour m = 30 on obtient: hT = 0.95,
hE = 0.85, hR = 0.71. L'erreur
quadratique intégrée
asymptotique correspondante est égale a
0.023.
Avec ces fenêtres on trace les courbes associées
a l'estimation de f en utilisant les différents
noyaux. Les graphiques de la figure
2 montrent que sous la condition d'égalité
des AMISE, les courbes estimées par les différents
noyaux ont presque la même allure.
hG = 0.40 hT = 0.95

Cas du noyau gaussien Cas du
noyau triangulaire
hE = 0.85 hR = 0.71

Cas du noyau d'Epanechnikov Cas du noyau
rectangulaire
Fig.2: Influence du noyau sur la
qualité de l'estimation d'une densité de
probabilité gaussienne
12
de loi N(4,2) sous la condition
d'égalité des AMISE, n = 30.
Choix de la fenêtre de lissage
Le premier terme du développement de MISE est
un terme de biais, alors que le second un terme de variance. On peut
remarquer qu'ils varient en sens inverse par rapport a
h: une largeur de fenêtre trop importante entraInera
une augmentation du biais et une diminution de la variance
(phénomène de sur-lissage), alors qu'une
largeur de fenêtre trop faible provoquera une
inflation de la variance et une diminution du biais (phénomène de
sous-lissage).
Sous les conditions des théorème 2.2.1 et 2.2.2, la
fenêtre h notée hAMISE, qui minimise
l'erreur quadratique asymptotique
est donnée par le théorème suivant.
Théorème 2.2.3 (Rosenblatt, 1956)
hAMISE =
á(K)â(f)n- 1 5
(2.17)
]
ou á(K) = [R(K)
ó4
K
[ 1 ]
5 et â(f) =
R(f00)
1
1
5
.
Remarque
La largeur de fenêtre optimale hAMISE
dépend de la densité inconnue f au travers du
paramètre R(f00) et ne peut donc être
utilisée telle quelle dans les calculs. Une
façon classique d'y remédier
consiste a remplacer la quantité
R(f00) par un estimateur approprié. Cette
approche conduit a un ensemble de méthodes que l'on a coutume
de regrouper sous le vocabulaire général de
méthodes plug-in, et qui font l'objet d'une
recherche active (pour des références, on peut par exemple
voir[16, 18, 24, 25, 311).
Exemples
Pour visualiser l'influence de la fenêtre de
lissage h sur la qualité de l'estimation
d'une densité f, nous avons choisi de présenter ici deux
exemples oi f est estimée par fn en
utilisant le noyau gaussien:
|
Xn
1
1 1
?y E RI fn(y) = e-
2 ( y-xi
h )2
v2ð nhj=1
|
.
|
(2.18)
|
(xj)j=1,n n réalisations de la
variable aléatoire parente X de densité f.
Le premier exemple concerne la densité de la loi
N(0,1), oi pour h E {0.1,
0.3, 0.6, 1} on trace les
courbes associées a l'estimation de f pour chaque
valeur de h.
Les graphiques de la figure 3
montrent que la meilleure fenêtre est h =
0.6, et en peut voir, lorsque h = 0.1
l'estimation est très mauvaise, chose qu'en peut
expliquer par le nombre de piques qu'elle
présente; de même pour h = 1, l'estimation est
beaucoup plus aplatie, ce qui fait une différence importante
de dispersion.
h = 0.1 h = 0.3

h = 0.6 h = 1

(...) courbe estimée + + (-) courbe réelle +
0 +
Fig.3: Influence de la fenëtre de
lissage sur l'estimation par noyau gaussien de
la densité f de loi N(0,1), n =
30
+ + + +
+ + +
+ + +
Le deuxième exemple est celui de la densité
bimodale ø suivante:
1
ø(x) =
2(f(x) + g(x)) (2.19)
avec f = N(0,1) et g =
N(4,1).
Les graphiques de la figure 4
montrent que pour h = 0.2 on a une mauvaise
qualité d'estimation. En lissant plus les densité en
arrive a améliorer la qualité de l'estimation , ici la
meilleur fenêtre est h = 0.6. Pour h = 1,
l'estimation devient moin bonne ce qui est caractérisé
par la diminution de nombre de modes.
h = 0.2 h = 0.4
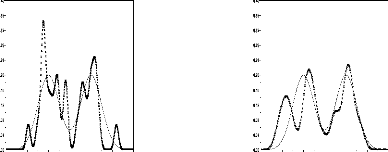
× h = 0.6 h = 1

(...) courbe estimée (-) courbe réelle
× × × × ×
Fig.4: Influence de la fenëtre de
lissage sur l'estimation par noyau gaussien
d'une densité bimodale, n = 30
× ×
× × × × × × × × ×
× × × × × × ×
× × × × ×
2.2.2 Application a l'estimation par noyau de l'affinite
L2
Soient X et Y deux p-vecteurs
aléatoires de densités respectives f et g,
supposons donnés nx (resp. ny)
réalisations de X (resp. Y) et les estimations par la
méthode du noyau fhx et
ghy de f et g respectivement. L'estimation de
la mesure d'afnité L2 entre f et g
est donné par:
|
< fhx,ghy >=
|
1 Xnx Xny Z
K(t - xi ) K(t
- yj
) dt. (2.20)
hy
nxnyhxhy i=1 j=1x
1
|
Exemples
Cas du noyau gaussien:
Si K est le noyau gaussien
alors:
1 1 1 nx ny 1 (xi-yj )2
< fhx ,gh EEe 2
(h2x+q) (2.21)
y
nxny v2ð + hy
i=1 j 1
Cas du noyau triangulaire: Elle est
donnée par:
nx ny
1 (1 |t - xi
| ) (1 dt. (2.22)
|t -- yi
< fhx ,ghy >= h EE
nxnyhx y i=1 j=1 AinAj
hx hy
avec:
Ai = [xi - hx, xi + hx]
et Aj = [yj - hy, yj + hy].
Cas du noyau d'Epanechnikov:
Elle est donnée par:
nx ny I (1 1 (t - xi ) 5
hy
5 hx
2 1 (t - yj)
dt.
EE
< fhx,ghy >= 80 nxnyhxhy i=1
j=1
13%1113j
(2.23)

2
avec:
Bi = [xi - v5 hx, xi +
v5 hx] et Bj = [yj - v5
hy, yj + v5 hy]
Cas du noyau rectangulaire:
>nx
1 >ny fl
< fhx,ghy >= d(Ci Cj).
(2.24)
4 nxnyhxhyi=1 j=1
Ci = [xi - hx, xi +
hx], Cj = [yj - hy, yj +
hy] et d(Ci n Cj) la
mesure de Lebesgue dans RI de CinCj.
Remarque:
Les intégrales données par les
formules (2.22), (2.23) ainsi que d(Ci,Cj) de la
formule (2.24), dépendent respectivement des longueurs des
ensembles (Ai,Aj), (Bi,Bj) et (Ci,Cj), de la
position de xi par rapport a yj sur la droite réelle.
Elles ne peuvent donc avoir une formule analytique
simple. Leurs calculs se font en considérant tous les cas possibles.
2.3 ACP de densites estimees par la methode du
noyau
2.3.1 Cas general
Soit (xt,1,...,xt,nt), t ?
{1,...,L}, nt réalisations de la variable
aléatoire Xt dans Rp de densité
inconnue ft, et soit fht l'estimation par la
méthode du noyau de la fonction ft en tout point
x.
Pour t ? {1,...,L}, les fht
constituent un nuage de L densités dans
L2(Rp). L'ACP sur ce nuage
conduit a diagonaliser la matrice de terme
général donné par:
|
1
àWt,s =
ntns
|
1
|
nt
i=1
|
ns
j=1
|
< K(x - xt,i ) , K(x - xs,j
) > (2.25)
ht hs
|
|
hpt hps
|
K un noyau positif et ht, t ?E
{1,...,L} la fenêtre de lissage associée
a la densité ft
Cette ACP fournit l'estimation par noyau de l'ACP
théorique des densités ft, t ?E
{1,...,L}.
Si fht est l'estimation par la méthode
du noyau gaussien de la densité ft, alors
l'ACP estimée correspondant conduit a diagonaliser la matrice
de terme générall donnépar::
|
àWt,s = 1
ntns
|
1
|
|
|
1
|
|
nt
i=1i
|
nsj=1
|
xxt 2-+xhs2s)))22
|
|
(2.26)
|
|
|
|
|
|
|
|
v2ð
|
|
Vh2t? h2 s +
|
.
·
|
2.3.2 Exemples
ACP de L densités gaussiennes
unidimensionnelles
Si (xt,1,...,xt,n),, t ?
{1,...,L} n réalisations de la variable
aléatoire Xt de loi N(t,vt)) et de
densité ft, on fait une ACP de densités sur les
estimations par le noyau gaussien des densités
ft en associant a chaque densité la fenêtre de
lissage optimale au sens de l'AMISE
égalee dans ce cas a
1.06vtn-15,, t ?E
{1,..,L} et cela pour deux tailles échantillons
différentes;; n=10 et n=40.
Les graphiques de la figure
5, représentant les densités sur le premier plan principal de
l'ACP théorique et des ACP estimées, montrent
que pour une taille d'échantillon petite (n=10) on parvient a
retrouver la forme du nuage théorique. Cela
devient très clair lorsqu'on augmente la taille
d'échantillon (n=40).
26% ACP normée théorique

11
42%
09
07
05
25% ACP normée estimée, n = 10 26%
|
03
|
ACP normée estimée, n = 40
|
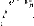
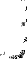
. 9 .
44% 44%
Fig.5: Premier plan principal de l'ACP
nonparamétrique dans le cas de la famille de densités
gaussienne de lois N(t,'t)
0. 1 .
. 20
(ht = 1.06'tn- 0. 1 5)
ACP de L densité de Gumbel
Si (xt,1,...,xt,n), t ?
{1,...,L} m réalisations de la variable aléatoire
Xt de densité de Gumbel ft, de paramétre de
position ut = t + ç
v6 vt et de paramétre
d'échelle ót = v6
vt (ç est la
Ð Ð
constante d'Euler). On fait une ACP des densités
estimées par le noyau gaussien en associant
à chaque densité la fenêtre de
lissage optimale au sens de l'AMISE et cela pour deux
tailles échantillons différentes; n=1O et n=4O.
Dans la figure 6, les
graphiques représentant les densités sur le
premier plan principal de l'ACP normée théorique et
des ACP estimées, montrent qu'à partir d'une taille
d'échantillon petite (n=1O), on arrive à retrouver la forme du
nuage théorique. Cette forme se rapproche encore
plus de la forme réelle en augmentant la taille
d'échantillon (n=4O).
24% ACP normée théorique
ACP normée estimée, n = 10
0.1 ACP normée estimée, n = 40
23% 24%
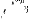
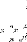
41% 40%


2.3.3 Approche de Kneip et Utikal
Soit (xt,1,...,xt,nt), nt
réalisations de la variable aléatoire Xt de
densité inconnue ft et dans L2(R) muni du
produit scalaire suivant [201:
< ft,fs
>= J RI
ft(x)fs(x)w(x)dx,
(2.27)
w désigne une fonction de poids,
positive, continue et uniformément bornée sur un intervalle
D de R.
Les densités ft, t ? {1,...,L},
forment un nuage dans L2(R) dont l'ACP
centrée conduit a diagonaliser la matrice M de
terme général donné par la formule suivante.
Mt,s =< ft - fu,fs - fu > .
(2.28)
avec: fu = 1
ELr=1 fr .
L
Pour estimer efficacement les éléments de la
matrice M, Kneip and Utikal ont procédé en deux
étapes:
1ereetape:
En se basant sur l'estimation par noyau de
ft, t ? {1,...,L}, définie par:
|
fh,t(x) = 1
nth
|
nt
i=1
|
K (x - hxt,i
(2.29)
|
oil
Xnt Z ux - xt,i
K2 w(x)dx. (2.32)
h
i=1
1
A(t) = n2th2
l'estimation naturelle Mt,s de Mt,s
est donnée par:
|
avec:
|
Mt,s =
|
M(1)
t,s- M(2)
t,s +M(3)
t,s ,
(2.30)
|
|
M(1)
t,s =
|
? ????
????
|
nt ns
1 h2 Z-d vi=nt 1 L-a
vj =1 J h s K(x -x h t,i)
K(x-xs,j) w(x)dx, t
s
1 nt Ent f
Kix- hxt,i,
K(x-Xt,j) w(x)dx +
A(t), t = s
n2th2
Ei=1 ) h
|
(2.31)
|
P P
M(2)
t,s = 1 PL l=1( M(1)
t,l + M(1)
l,s ) et M(3)
t,s = 1 r M(1)
l,r .
L L2 l
2eme etape:
Dans cette etape Kneip et Utikal proposent de prendre comme
estimation de M, la matrice M de terme general:
Mt,s = fM(1) t,sMa(2)
M(3)-- t,s .(2.33)
avec:
|
fM(1)
t,s =
|
? ?
?
|
Mt,s ) t s
(2.34)
M(1)
t,t -- A(t) sinon
|
X
fM(2) t,s1
= L
l=1
(fM(1)
t,l + fM(1)
l,s ). (2.35)
L
|
X
fM(3)
t,s = L2 1
l
|
X
r
|
fM(1)
l,r . (2.36)
|
L'ACP centree estimee de l'ACP centree theorique, par
l'approche de Kneip et Utikal, est obtenue en diagonalisant la
matrice de terme general donne par la relation (2.33).
Remarque
Contrairement a M, M peut avoir des
valeurs propres negatives, en pratique ces valeurs
peuvent etre interpreter par 0.
2.3.4 Application de l'approche d'estimation de Kneip and
Utikal à une ACP estimee non centree et non normee
Soit (xt,1,...,xt,nt), t ?
{1,...,L}, nt réalisations de la variable
aléatoire Xt dans R de densité inconnue ft
dans L2(R) muni du produit scalaire:
< ft,fs >=
Jft(x)fs(x)dx.
(2.37)
Les densités ft, t ? {1,...,L},
forment un nuage dans L2(R) dont l'ACP non
centrée et non normée conduit a diagonaliser la
matrice W de terme général:
Wt,s =< ft,fs > . (2.38)
Les estimations par la méthode du noyau:
|
fh,t(x) = 1
ntht
|
i=nt
i=1
|
K(x - xt,i) (2.39)
ht
|
forment un nuage de L densités
dans L2(R) dont l'ACP non centrée et non
normée conduit a diagonaliser la matrice de terme
général:
|
1
Wts =
ntns
|
1
|
i=nt
i=1
|
j=ns
j=1
|
< K(x - xt,i ),K(x -
xs,j ) > . (2.40)
ht hs
|
|
hths
|
Cette ACP fournit l'estimation de l'ACP
théorique précédente. Soit
fW la matrice de terme général:
|
Wt,s =
|
? ?
?
|
1 'nt r K (
ht x--xt,i
n2t h? dx
si t = s
J
àWt,s sinon
|
(2.41)
|
Considérons maintenant le cas oil nt = n
et ht = h, ?t ? {1, ... ,L} et posons:
àëk l'estimation de
ëk, la k-ieme valeur propre de la matrice W,
obtenue en diagonalisant la matrice des produits scalaires
àW.
Si K est un noyau choisi parmi les 4
noyaux précédents, on a alors la
propriété suivante:
àëk =
eëk + á. (2.42)
avec:
1 1
á = n2
h2
K2(
n I
E x -h xt,i )dx.
(2.43)
i=1
1
á = 2vÐ
Dans le cas du noyau gaussien:
1
(2.44)
nh
Dans le cas du noyau triangulaire:
2
á = v3
1 nh. (2.45)
Dans le cas du noyau d'Epanechnikov:
1 nh. (2.46)
á = 3v5
25
Dans le cas du noyau rectangulaire:
1
á = 2
1 nh. (2.47)
Remarque
On peut aboutir a la relation (2.42), grâce a la
propriété matricielle suivante: 1. Si ë est valeur
propre de M alors:
ë + á est valeur propre de la
matrice M + áI (I est la matrice identité).
Exemple: ACP estimée non centrée et non
normée de densités bimodales.
Soient (xt,1,...,xt,n), t ?
{1,...,30} n réalisations de la variable
aléatoire Xt de lois 21 N(t,vt)+
21N(t+ 15,
v0.1t) et de densité ft. Pour illustrer
la méthode d'estimation précédente dans le cas oil les
densités sont estimées en utilisant le noyau
gaussien et h = n-1, nous avons
procédé a une ACP non centrée et non normée de 3
manieres différentes:
1. En diagonalisant la matrice des produit scalaire
des densités théoriques.
2. En diagonalisant la matrice des produits scalaires
des densités estimées, àW.
3. En diagonalisant la matrice
fW.
On peut voir dans le tablau 1, que la meilleure
estimation des valeurs propres ëk de W, sont les valeurs
propres eëk de fW.
|
k
|
ëk
|
àëk
|
eëk
|
àëk -
eëk
|
|
1
|
0.710
|
0.995
|
0.713
|
0.282
|
|
2
|
0.376
|
0.639
|
0.357
|
0.282
|
|
3
|
0.306
|
0.622
|
0.340
|
0.282
|
|
4
|
0.242
|
0.554
|
0.272
|
0.282
|
|
5
|
0.208
|
0.528
|
0.246
|
0.282
|
|
6
|
0.181
|
0.472
|
0.190
|
0.282
|
|
7
|
0.160
|
0.458
|
0.176
|
0.282
|
|
8
|
0.140
|
0.435
|
0.153
|
0.282
|
|
9
|
0.118
|
0.397
|
0.115
|
0.282
|
|
10
|
0.097
|
0.387
|
0.105
|
0.282
|
Tab.1: Les valeurs propres ëk,
àëk et eëk, obtenue en
diagonalisant les matrices W, àW,
fW respectivement (h = n-1,
n = 30).
La valeur de a dans ce tabeau, est 0.282
v 1
2H
Conclusion
Utiliser la matrice fW a la place de
àW, nous a permis d'améliorer la
qualité de l'estimation des valeurs propres de la matrice des
produits scalaires théoriques W et cela en
réduisant le biais. De plus, le calcul de fW
s'effectue plus rapidement que celui de
àW, dans l'exemple précédent, nous
avons réalisé un calcul de 900 intégrales de
moins en estimant W par fW.
L'inconvénient de cette approche d'estimation
réside dans le fait qu'elle est approuvable seulement dans le
cas particulier oi les tailles d'échantillons sont identiques.
2.4 ACP de densites estimees parametriquement
2.4.1 Cas de donnees gaussiennes multidimensionnelles
L'auteur s'est intéressé aux données
ternaires (individus× variables× instants),
qui sont des tableaux (nt × p) indexés par
t. A chaque instant t, t ? {1,...,L}
on dispose d'un échantillon de taille nt d'un vecteur
aléatoire gaussien a p dimensions, de vecteur
moyen ut et de matrice de variance Ót. En
pratique cela revient a observer les mêmes variables
quantitatives, mais pas nécessairement sur les mêmes
individus.
Pour une description globale de ce type de
données, on applique alors la méthode décrite
précédemment, en procédant comme suit.
On associe a chaque tableau une densité de
probabilité, on obtient alors un nuage de L
densités ft, t ? {1,...,L}, et comme ces
densités sont inconnues, elles sont alors remplacées par leurs
estimations obtenus en estimant les paramêtres ut et
Ót par la méthode du maximum de vraisemblance.
Soit xt = n1t Eint 1 xt,i
et st = n1t Eint1(xt,i
- xt) (xt,i - xt), xt,i ? Rp les
estimations du maximum de vraissemblance de ut et Ót
respectivement.
Les fonctions f(nt)
t définies par:
?x ? Rp, ft
(nt)(x) =1
(2ð)p2
2 (x-xt)'
.c1(x-xt) (2.48)

1 |st|1 2 e

sont appelées les estimations
paramétriques des ft, t ?
{1,2..,L}. Elles constituent alors un nuage
de L densités de probabilité dans H =
L2(Rp). L'ACP de ces L
densités conduit a diagonaliser la matrice de terme
général [3]:
Wt,s < ft
(nt), f(ns) > =
1 1 2 (xt-xs)'
(st+ss)-1(xt-xs)
(2ð)p 2 |st +
ss|1 2 e- (2.49)
1
Considérons maintenant un échantillon
Xt,1,...,Xt,nt de la variable aléatoire parente
Xt,
t ? {1,...,L}, et soit
f(nt)
t , les estimateurs des densités parentes
ft obtenus en estimant ces
paramétres par la méthode du maximum de
vraisemblances. La convergence de l'ACP estimée
définie précédement vers l'ACP théorique
est donnée par le théorême suivant:
Théorème 2.4.1 (Boumaza, 1999)
Soient á etâ deux reels positifs,
supposons qu'il existe deux suites
(nt(n))n>1 et
(ns(n))n>1 telles que:
|
uim
n-400
|
nt(n)
n
|
= á et uim
n-400
|
ns(n)
n
|
= â
|
nous avons alors les deux rCsultats
asymptotiques suivant:
1) <f(nt)
t ,f(ns)
s > converge presque surement
vers <ft,fs> quand n tend vers
l'infini.
2) vn <f(nt)
t ,f(ns)
s > est asymptotiquement
normal.
Exemple:
Pour illuster la convergence de la méthode
définie précédemment nous avons procédé
dans
)
le cas des densités gaussiennes ft,
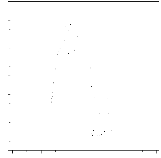
t E {1,...,30} de paramétres ut = (
t ( t 0 )
, Ót =
t 0 t
a une ACP de densités.
Premièrement en utilisant les densités
théoriques, deuxièmement en utilisant les estimations
par la méthode paramétrique et cela pour deux tailles
d'échantillons différentes: n = 10 et n =
40.
Les graphiques de la figure
7, représentant les densités sur le premier plan principal de
l'ACP normée théorique et estimée
paramétriquement, montrent que, pour une taille
d'échantillon petite ( n = 10), la forme du nuage
estimé est proche de celle du nuage réel. En
augmentant la taille d'échantillon ( n=40) cette forme se
rapproche de plus en plus vers la forme réelle.
0.9 0.7 0.5 0.3 0.1 0.1
CHAPITRE 2. ESTIMATION DE L'ACP DE DENSITES DE PROBABILITE 43
ACP normée théorique
23%
t t 0
, Ót =
t 0 t
ut =

1
2
3
4
5
6
7
9
8
10111213
30
14
15
292 8
16
2 7
17
23
24 2 6.25
18
19
20
21
22
0.600 -0.160 0.280 0.720 1.160 1.600
33%
- 0.3 0.5
- 0.7
19% ACP normée estimée, n = 10 22% ACP
normée estimée, n = 40
1.1
0.9
0.7
0.5
0.3
0.1
- 0.1
0.3
- 0.5
1
23
4
5
6
98
11
10
12
16
15
13
14
17
2930
2 8
18
19
.
2 72425
21
20 22
23
26

0.9
0.7
0.5
0.3
0.1
0.1
- 0.3
0.5
- 0.7
1
2
3
4
5
6
7
8.011
12
13 14
30
15
16
22982 72 6
25
18
17
23
19
22
21
24
20
0.600 -0.160 0.280 0.720 1.160 1.600
-0.600 -0.160 0.280 0.720 1.160
27% 1.600 31%
2.4.2 ACP parametrique de densites de Gumbel
unidimensionnel
Les données ternaires définies dans le
paragraphe 2.2.1 sont maintenant des tableaux (nt×1),
oil a chaque instant t, t ? {1,...,L}, on
dispose d'un échantillon de taille nt d'un vecteur
aléatoire Xt unidimensionnel de densité de Gumbel
ft de paramètre de position ut et de paramètre
d'échelle ót.
· -- x
Soit xt = -- nt E 1 xt, . t
· ? R, les estimations par la méthode
z z et s t = nt z
En. t i t (x,z t)2 x t,
des moments de E[Xt] et V
[Xt] respectivement, alors:
= .Vð6vst
et ftt = xt + çàót
sont les estimations par la méthode des moments de ót
et ut respectivement, avec ç = 0.5772
(constante d'Euler). Les fonctions f(nt)
t définies par:
|
x-àut
e àót e
|
--e
|
x7jit
ót
|
(2.50)
|
?x ? R, ft(nt)
(x) = 1
x-Fit x-11s
Wt,s = < J t ,.1 s à1
ót ós IR
f(nt)
f(ns)
e(xàó:t
+xàós
s)e--(e àót
+e àós
)dx.
àót sont appelées les
estimations paramétriques des ft, t ?
{1,...,L}. Elle consituent alors un nuage de L
densités dans L2(R). L'ACP de ces L
densités conduit a diagonaliser la matrice de terme
général:
(2.51)
Exemple
Pour t ? {1,...,30}, on fait une
ACP normée de densités estimées
paramétriquement dans le cas des échantillons
simulés des densités de Gumbel, de paramètre de
position ut = t + ç
.VÐ6vt et de paramètre d'échelle
ót =
\(_/6vt.
On représente alors sur la figure 8 les
densités estimées sur le premier plan principal de l'ACP ainsi
celle des densités théoriques et cela pour voir
comment se comporte la qualité de l'estimation
lorsqu'on augmente la taille d'échantillon.
|
24%
|
ACP normée théorique
|
|
|
|
40%
|
23% ACP normée estimée, n = 10 23% ACP
normée estimée, n = 40

89
1
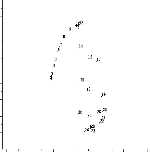
Fig.8: Premier plan principal de l'ACP normée
de densités de Gumbel.
25
30 . 20 -03
2.5 Comparaison entre l'approche paramétrique et
non paramétrique
L'objectif de ce présent paragraphe est de
proposer, a l'aide des deux exemples concernant la famille de densités
gaussiennes et la famille de densités de Gumbel, une
comparaison entre les deux approches d'estimation
(paramétrique et nonparamétrique) dont le
but est de distinguer laquelle est mieux adaptée
aux situations précédentes.
Pour cela nous avons choisi de faire cette comparaison en se
basant sur les deux distances suivantes:
i)Si àcj,t est l'estimation de la
coordonnée de la densité ft sur l'axe principal j
, on définit áj comme la distance entre les deux
vecteurs Cà et C de IRL
dont les composantes sont respectivement àcj,t,
cj,t (t ? {1,...,L}):
áj = XL
|àcj,t - ci,t| (2.52)
t=1
ii)Si àët, t ?
{1,...,L} est l'estimation de la valeur propre ët
de la matrice des produits scalaires théoriques, en
définit â comme la distance entre les deux vecteurs de
IRL de coordonnées respectivement
àët, ët, par:
â = XL
|àët ? ët| (2.53)
t=1
Remarque
Les vecteurs C et Cà étant des
vecteurs propres de W et Wà respectivement,
ils sont définis au signe près; ces
signes sont choisis de sorte que le coefficient de
corrélation linéaire entre C et Cà soit
positif.
On fait alors une ACP de densités estimées dans les
deux situations suivantes:
Lorsque les densité sont estimées en
utilisant l'approche paramétrique, avec n = 30,
L = 30.
Lorsque les densités sont estimées par
noyau en associant a chaque densité la
fenêtre optimale au sens de l'erreur quadratique
intégrée asymptotique, avec
n = 30, L = 30.
Les valeurs des distances
(áj)j=1,3 et , ainsi que les
pourcentages d'inertie expliqués par les trois
premiers axes principaux obtenus par les deux approches d'estimation, sont
données dans le tableau 2.
|
Famille de densités de Gumbel
|
Famille de densités de loi N(t,V't)
|
|
ACP paramétrique
|
ACP non paramétrique (noyau
gaussien)
|
ACP paramétrique
|
ACP non paramétrique (noyau
gaussien)
|
|
á1
|
1.76
|
1.92
|
1.00
|
1.43
|
|
á2
|
2.23
|
2.31
|
1.44
|
1.64
|
|
á3
|
1.60
|
1.71
|
2.34
|
2.37
|
|
â
|
1.07
|
1.61
|
1.50
|
2.81
|
|
Inertie1
|
36%
|
38%
|
43%
|
46%
|
|
Inertie2
|
22%
|
23%
|
26%
|
26%
|
Tab.2 Valeurs des (aj)j=1,3,
â et les pourcentages d'inerties
expliqués par les deux premiers axes principaux lors
d'une
ACP estimée paramétriquement et non
paramétriquement en utilisant le noyau
gaussien.
(cas de la famille de densités de lois
N(t,V't) et celle de la famille de densités de
Gumbel)
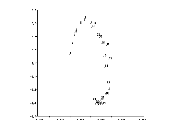
Conclusion
Ces résultats, montrent que dans le cas
d'une famille de densités gaussiennes et celle d'une famille
de densités de Gumbel, les deux approches d'estimation ont donné
des résultats très proches (voir figure 9).
En pratique, l'utilisation de l'approche
paramétrique nécessite un choix rigoureux
des paramètres a estimer, dans le cas oii les données sont des
réalisations de variables aléatoires dont les densités
sont symétriques, l'hypothèse de
normalité permet un choix simple de ces paramètres, contrairement
au cas oi on dispose, soit de densités
asymétriques soit d'un mélange
de densités symétriques et
asymétriques oii un tel choix n'est
guère évident, d'oi l'intérêt
d'utilisation de l'approche d'estimation non paramétrique.
24%
Famille de densités de lois N(t,/t)
Famille de densités de Gumbel
ACP théorique
26%
26%


42%
22%

72
72 62
.
-
36%
ACP paramétrique
ACP paramétrique
ACP par noyau
01
0
05
07
46%
26%
0
Fig.9: Comparaison sur le premier plan principal,
entre l'approche paramétrique et non
paramétrique.
. 1
1 16
7
. 18
cas de famille de densités de loi
N(t.../t) et celle de famille de densités de
Gumbel.
0
Chapitre 3
Influence du noyau sur l'ACP de densités
estimées
3.1 Introduction
Pour étudier l'influence du noyau sur la
qualité de l'estimation d'une ACP de densités, nous
avons considéré les deux cas particuliers suivants.
i) Les estimations fht de ft, t E
{1,...,L} sont obtenues en utilisant des fenêtres ht
minimisant les erreurs quadratiques
intégrées asymptotiques
qu'on notera par: AMISEt, t E {1,..,L} et
cela pour les noyaux gaussien, triangulaire,
Epanechnikov et rectangulaire et des tailles d'échantillons
égales a 30, ?t E {1,...,L}
ii) Les différentes estimations de ft, t
E {1,..,L} sont obtenues en utilisant:
1. La fenêtre noté h(t) G
dans le cas du noyau gaussien, avec nt =
30, ?t E {1,...,L}.
2. La fenêtre noté h(t) T
dans le cas du noyau triangulaire, avec nt
= 30, ?t E {1,...,L}.
3. La fenêtre noté h(t) E
dans le cas du noyau d'Epanechnikov, avec nt = 30,
?t E {1,...,L}.
4. La fenêtre noté h(t) R
dans le cas du noyau rectangulaire, avec nt
= 30, ?t E {1,...,L}.
tel que:
pour t E {1,...,L}, les
h(t)
G , h(t)
T , h(t)
E et h(t)
R vérifient les conditions données par la
relation (2.13). On compare alors les ACP estimées par noyau,
en se basant sur les deux critères définis dans le
paragraphe 2.5.
On présentera ici 4 exemples de simulation:
~ Cas d'un nuage de densités bimodales
symétriques, représenté par
l'exemple de la famille de densités de loi1
2N(t,vt) +1 2N(0,vt),
t {1,...,30}.
~ Cas d'un nuage de densités bimodales
asymétriques, représenté par
l'exemple de la famille de densités de loi1
2N(t,vt) +1 2N(0,1),
t {1,...,30}.
~ Cas d'un nuage de densités unimodales
symétriques, représenté par
l'exemple de la famille de densité de loi N(t,vt),
t {1,...,30}.
~ Cas d'un nuage de densités unimodales
asymétriques, représenté par
l'exemple de la famille de densités de Gumbel de paramètre de
position ut = t+ç
v6vt et de
paramètre d'échelle
Ð
v6 vt, avec ç =
0.5772 (constante d'Euler), t {1,...,30}.
ót = Ð
Soit (xt,1,...,xt,n), t
{1,...,30}, n réalisations de la
variable aléatoire Xt de densité ft, on
fait alors une ACP de densités dans les cas des 4 exemples
précédents;
1. Sur les densités théoriques.
2. Sur les densités estimées en utilisant:
- Le noyau gaussien.
~ Le noyau triangulaire.
- Le noyau d'Epanechnikov.
~ Le noyau rectangulaire.
3.2 Gas des fenêtres AMISE
Les valeurs des áj sur les 3 premiers axes
principaux et celle de 3 données par le tableau 3 dans le cas
oi les densités sont estimées en utilisant les fenêtres
AMISE, montrent que le fait d'utiliser des noyaux
différents, conduit a des résultats trés proches.
|
Noyaux
|
a1
|
a2
|
a3
|
â
|
|
gaussien
|
1.34
|
3.36
|
2.91
|
1.71
|
|
triangulaire
|
1.34
|
3.36
|
2.91
|
1.61
|
|
1 2N(0,/t)
2N(t,/t) + 1
|
Epanechnikov
|
1.33
|
3.34
|
2.89
|
1.58
|
|
rectangulaire
|
1.42
|
3.40
|
2.92
|
2.60
|
|
gaussien
|
2.27
|
1.87
|
2.55
|
7.12
|
|
triangulaire
|
2.24
|
1.87
|
2.56
|
6.97
|
|
1 2N(0,1)
2N(t,/t) + 1
|
Epanechnikov
|
2.23
|
1.87
|
2.55
|
6.93
|
|
rectangulaire
|
2.34
|
1.88
|
2.53
|
7.42
|
|
gaussien
|
1.43
|
1.64
|
2.37
|
2.81
|
|
triangulaire
|
1.42
|
1.66
|
2.38
|
2.82
|
|
N(t,/t)
|
Epanechnikov
|
1.33
|
1.60
|
2.34
|
2.60
|
|
rectangulaire
|
1.45
|
1.66
|
2.38
|
2.99
|
|
gaussien
|
1.93
|
2.31
|
1.71
|
1.61
|
|
triangulaire
|
1.94
|
2.26
|
1.69
|
1.96
|
|
Gumbel
|
Epanechnikov
|
1.94
|
2.26
|
1.66
|
2.02
|
|
rectangulaire
|
1.94
|
2.21
|
1.62
|
2.13
|
Tab.3: Valeurs des áj sur les 3 premiers axes
principaux et celle de â, obtenues en comparant les ACP
estimées et réelles, avec les différents noyaux
(cas des fenëtres AMISE), n = 30.
Les graphiques des figures
10, 11, 12, 13 représentant les projections des densités
estimées par les différents noyaux sur le premier plan
principal, pour les 4 exemples précédents respectivement,
montrent que les ACP estimées avec les différents
noyaux sont trés proches.
a)Famille de densités de lois 1
2N(t,/t) +1
2N(0,/t)
ACP normée théorique
1
12% Noyau gaussien 12% Noyau
triangulaire
0.6
0.4
0.2

3 . 8
65
8
0.6
0.4
70% 0.2
71%
. 16 . . 1 .
12% 12% Noyau rectangulaire
.
Noyau d'Epanechnikov
0 0
0.6
0.4
0.2

23
. 8
65
38
. 2
3
0.6
0.4
71% 0.2
72%
4
Fig.10: allure du nuage estimé sur
le premier plan principal obtenus par l'ACP normée
.
estimée en utilisant les différents
noyaux et des fenëtres optimales aux sens de
. 2829 .
20 24 20 24
27 26 -0.4 2 N(0,V't)), n = 30.
.
l'AMISE. (famille de densités de lois 2 1
N(t,V't) + 1
b)Famille de densités de lois 1
2N(t,/t) +1
2N(0,1)
ACP normée theorique
. 13
7% Noyau gaussien 7% Noyau
triangulaire
|
0.7
0.5
0.3
|
|
75%
|
0.7
0.5
0.3
|
|
75%
|
|
. 16 16
7% Noyau d'Epanechnikov 7% Noyau
rectangulaire
|
0.7
0.5
0.3
|
|
76%
|
0.7
0.5
0.3
|
|
75%
|
|
|
|
|
|
|
|
|
Fig.11: allure du nuage estimé sur
le premier plan principal obtenus par l'ACP
1 16
estimée en utilisant les différents
noyaux et des fenëtres optimales aux sens de
. 8
. 9 . 7
29
27
2 20
. 22 2 1
. . 2 2 2 1
.
. 23 -0.3 2 N(0,1)), n = 30.
3
l'AMISE. (famille de densités de lois 2 1
N(t,V't) + 1
c)Famille de densités de lois N(t,/t)

42%
ACP normée théorique
. 5
2
16
26% Noyau gaussien 26% Noyau
triangulaire
26% Noyau d'Epanechnikov
. Noyau rectangulaire
.
26%
0. 0. 18
Fig.12: Allure du nuage estimé sur
le premier plan principal obtenus par l'ACP normée
1 7
01
estimée en utilisant les différents
noyaux et des fenëtres optimales aux sens de l'AMISE.
(famille de densités de lois N(t,V't)), n =
30.
20
d)Famille des densités de Gumbel
ACP normée théorique
16
23% Noyau gaussien 23% Noyau
triangulaire
10

10
3

38%
38%
3
. 19
24% 24% Noyau rectangulaire
. 9
Noyau d'Epanechnikov
-0. -0.
0
10
0
10

39%
38%
3 3
Fig.13: Allure du nuage estimé sur
le premier plan principal obtenus par l'ACP normée
1 9
01
estimée en utilisant les différents
noyaux et des fenëtres optimales aux sens de
21 2 21 22
l'AMISE. (La famille des densités de Gumbel),
n = 30.
3.3 Cas d'égalité des AMISE
Considerons maintenant le cas oil les densites ft sont
estimees en utilisant les fenetres: (voir tableau 4)
~ h(t)
G = n-1/5 et les
h(t) T ,h(t)
E , h(t)
R correspondantes, dans le cas de la famille de
densites
21 N(t,vt) +
21N(0,vt).
h(t)
G = n-1/8 et les
h(t)
T , h(t)
E , h(t)
R correspondantes, dans le cas de la famille de
densites
21 N(t,vt) +
21N(0,1).
(t) log(t+1)
et hT ), 14),
h(R) correspondantes, dans le cas de la
famille de densites N(t,vt)
hG t
et celle de la famille de densites de Gumbel.
|
1 2 N(0,vt)
2 N(t,vt) + 1
|
1 2 N(t,vt) + 1 2
N(0,v1)
|
N(t,vt)
|
Densité de Gumbel
|
|
t
|
ht
T
|
ht
E
|
ht
R
|
ht
T
|
ht
E
|
ht
R
|
ht
T
|
ht
E
|
ht
R
|
ht
T
|
ht
E
|
ht
R
|
|
1
|
1.17
|
0.91
|
0.93
|
1.27
|
1.13
|
1.05
|
1.64
|
1.47
|
1.23
|
0.35
|
0.31
|
0.26 .
|
|
2
|
1.19
|
1.07
|
0.89
|
1.46
|
1.29
|
1.20
|
1.28
|
1.15
|
0.98
|
1.21
|
1.07
|
0.98
|
|
3
|
1.19
|
1.07
|
0.89
|
1.32
|
1.17
|
1.08
|
1.09
|
0.98
|
0.81
|
1.08
|
0.97
|
0.82
|
|
4
|
1.19
|
1.07
|
0.89
|
1.16
|
1.04
|
0.93
|
0.95
|
0.85
|
0.71
|
0.94
|
0.85
|
0.71
|
|
5
|
1.19
|
1.07
|
0.89
|
1.05
|
0.94
|
0.81
|
0.84
|
0.76
|
0.63
|
0.84
|
0.76
|
0.63
|
|
6
|
1.19
|
1.07
|
0.89
|
0.96
|
0.86
|
0.73
|
0.76
|
0.68
|
0.57
|
0.76
|
0.68
|
0.57
|
|
7
|
1.19
|
1.07
|
0.89
|
0.88
|
0.79
|
0.67
|
0.70
|
0.63
|
0.52
|
0.70
|
0.63
|
0.52
|
|
8
|
1.19
|
1.07
|
0.89
|
0.82
|
0.73
|
0.62
|
0.64
|
0.58
|
0.48
|
0.64
|
0.58
|
0.48
|
|
9
|
1.19
|
1.07
|
0.89
|
0.76
|
0.68
|
0.58
|
0.60
|
0.54
|
0.45
|
0.60
|
0.54
|
0.45
|
|
10
|
1.19
|
1.07
|
0.89
|
0.71
|
0.64
|
0.54
|
0.56
|
0.51
|
0.42
|
0.56
|
0.51
|
0.42
|
|
11
|
1.19
|
1.07
|
0.89
|
0.67
|
0.60
|
0.50
|
0.53
|
0.48
|
0.40
|
0.53
|
0.48
|
0.40
|
|
12
|
1.19
|
1.07
|
0.89
|
0.63
|
0.57
|
0.47
|
0.50
|
0.45
|
0.37
|
0.50
|
0.45
|
0.37
|
|
13
|
1.19
|
1.07
|
0.89
|
0.60
|
0.54
|
0.45
|
0.47
|
0.43
|
0.35
|
0.47
|
0.43
|
0.35
|
|
14
|
1.19
|
1.07
|
0.89
|
0.57
|
0.51
|
0.42
|
0.45
|
0.41
|
0.34
|
0.45
|
0.41
|
0.34
|
|
15
|
1.19
|
1.07
|
0.89
|
0.54
|
0.48
|
0.40
|
0.43
|
0.39
|
0.32
|
0.43
|
0.39
|
0.32
|
|
16
|
1.19
|
1.07
|
0.89
|
0.51
|
0.46
|
0.38
|
0.41
|
0.37
|
0.31
|
0.41
|
0.37
|
0.31
|
|
17
|
1.19
|
1.07
|
0.89
|
0.49
|
0.44
|
0.37
|
0.40
|
0.36
|
0.30
|
0.40
|
0.36
|
0.30
|
|
18
|
1.19
|
1.07
|
0.89
|
0.47
|
0.42
|
0.35
|
0.38
|
0.34
|
0.28
|
0.38
|
0.34
|
0.28
|
|
19
|
1.19
|
1.07
|
0.89
|
0.45
|
0.40
|
0.33
|
0.37
|
0.33
|
0.27
|
0.37
|
0.33
|
0.27
|
|
20
|
1.19
|
1.07
|
0.89
|
0.43
|
0.38
|
0.32
|
0.35
|
0.32
|
0.26
|
0.35
|
0.32
|
0.26
|
|
21
|
1.19
|
1.07
|
0.89
|
0.41
|
0.37
|
0.31
|
0.34
|
0.31
|
0.26
|
0.34
|
0.31
|
0.26
|
|
22
|
1.19
|
1.07
|
0.89
|
0.40
|
0.36
|
0.30
|
0.33
|
0.30
|
0.25
|
0.33
|
0.30
|
0.25
|
|
23
|
1.19
|
1.07
|
0.89
|
0.38
|
0.34
|
0.28
|
0.32
|
0.29
|
0.24
|
0.32
|
0.29
|
0.24
|
|
24
|
1.19
|
1.07
|
0.89
|
0.37
|
0.33
|
0.27
|
0.31
|
0.28
|
0.23
|
0.31
|
0.28
|
0.23
|
|
25
|
1.19
|
1.07
|
0.89
|
0.35
|
0.32
|
0.27
|
0.30
|
0.27
|
0.23
|
0.30
|
0.27
|
0.23
|
|
26
|
1.19
|
1.07
|
0.89
|
0.34
|
0.31
|
0.26
|
0.29
|
0.26
|
0.22
|
0.29
|
0.26
|
0.22
|
|
27
|
1.19
|
1.07
|
0.89
|
0.33
|
0.30
|
0.25
|
0.29
|
0.26
|
0.21
|
0.29
|
0.26
|
0.21
|
|
28
|
1.19
|
1.07
|
0.89
|
0.32
|
0.29
|
0.24
|
0.28
|
0.25
|
0.21
|
0.28
|
0.25
|
0.21
|
|
29
|
1.19
|
1.07
|
0.89
|
0.31
|
0.28
|
0.23
|
0.27
|
0.24
|
0.20
|
0.27
|
0.24
|
0.20
|
|
30
|
1.19
|
1.07
|
0.89
|
0.30
|
0.27
|
0.23
|
0.27
|
0.24
|
0.20
|
0.27
|
0.24
|
0.20
|
Tab.4: Fenetres de lissages corréspondantes aux
cas d'égalité des AMISE pour les diférents
noyaux.
Les valeurs de á sur les 3 premiers axe et
celles de , données par le tableau 5, montrent que les
qualités d'estimations de l'ACP théorique
obtenue en utilisant les différents noyaux, avec des erreurs
quadratiques intégrées
asymptotiques commises sur chaque
densité identiques pour ces noyaux, sont
quasiment les mêmes.
|
Noyaux
|
a1
|
a2
|
a3
|
â
|
|
gaussien
|
4.12
|
3.76
|
3.36
|
13.32
|
|
triangulaire
|
4.13
|
3.78
|
3.38
|
13.33
|
|
1 2N(0,/t)
2N(t,/t) + 1
|
Epanechnikov
|
4.13
|
3.80
|
3.39
|
13.40
|
|
rectangulaire
|
4.13
|
3.77
|
3.35
|
13.36
|
|
gaussien
|
2.35
|
1.86
|
2.55
|
7.39
|
|
triangulaire
|
2.36
|
1.87
|
2.57
|
7.41
|
|
1 2N(0,1)
2N(t,/t) + 1
|
Epanechnikov
|
2.36
|
1.87
|
2.57
|
7.38
|
|
rectangulaire
|
2.37
|
1.92
|
2.60
|
7.37
|
|
gaussien
|
6.61
|
6.41
|
4.90
|
18.65
|
|
triangulaire
|
6.61
|
6.41
|
4.91
|
18.66
|
|
N(t,/t)
|
Epanechnikov
|
6.62
|
6.42
|
4.91
|
18.67
|
|
rectangulaire
|
6.71
|
6.50
|
4.93
|
18.64
|
|
gaussien
|
6.89
|
5.76
|
3.60
|
15.73
|
|
triangulaire
|
6.90
|
5.75
|
3.61
|
15.76
|
|
Famille de densité de Gumbel
|
Epanechnikov
|
6.90
|
5.77
|
3.59
|
15.77
|
|
rectangulaire
|
6.90
|
5.76
|
3.60
|
15.80
|
Tab.5: Valeurs des áj sur les 3 premiers axes
principaux et celle de $, obtenues en comparant les
ACP
estimées et réelles, avec les différents
noyaux (cas d'égalités des AMISE).
Les graphiques des figures
14, 15, 16 et 17, montrent que sous la condition
d'égalité des AMISE, l'allure des nuages
sur les premiers plans principaux, obtenus lors d'une ACP sur les
densités estimées en utilisant les différents
noyaux, sont pratiquement les mêmes.
a)Famille de densités de lois 1
2N(t,/t) +1
2N(0,/t)
ACP normée théorique
1
10% Noyau gaussien 10% Noyau
triangulaire
14 . . 14
10% Noyau d'Epanachnikov 10% Noyau
rectangulaire

2
2 5
4
4
5 1
2
53%
53%
Fig.14: Allure du nuage estimé sur
le premier plan principal obtenu par l'ACP
. 4
estimée en utilisant les différents
noyaux, sous la condition d'égalité des
. 1 . 9
16 16
. 1 18
AMISE. (famille de densités de lois 1
. 2 28
. .
2 N(t,V't) + 1 2 N(0,V't)),
n = 30
7
24 24
b)Famille de densités de lois1
2N(t,/t) +1
2N(0,1)
ACP normée theorique
. 13
8% Noyau gaussien 8% Noyau
triangulaire
|
0.7
0.5
0.3
|
|
75%
|
0.7
0.5
0.3
|
|
75%
|
|
. 16 16
8% Noyau d'Epanechnikov 8% Noyau
rectangulaire

0.7
0.5
0.3
0.7
0.5
75% 0.3
75%
Fig.15: Allure du nuage estimé sur
le premier plan principal obtenu par l'ACP
16 1
estimée en utilisant les différents
noyaux sous la condition d'égalité des
. . 8
. . 9
27
29 2
2 2
. . 21
3 -3 2 N(0,1)), n = 30
23
AMISE. (famille de densités de lois 1 2
N(t,vt) + 1
c)Famille de densités de lois N(t,/t)

42%
ACP normée théorique
. 5
2
16
11% Noyau gaussien 11% Noyau
triangulaire
|
|
|
|
|
|
|
0.8
0.6
|
|
0.8
0.6
|
|
|
|
0.4
|
18%
|
0.4
|
|
18%
|
|
11% 0
Noyau d'Epanechnikov
.
7 9 . 7 9
11% Noyau rectangulaire
0
0
0.8
0.6
0.4

20
4
2

4 0
2
0.8
0.6
18% 0.4
18%
Fig.16: Allure du nuage estimé sur
le premier plan principal obtenu par l'ACP
.
7 1 09 7 1 9
estimée en utilisant les différents
noyaux, sous la condition d'égalité des
AMISE. (famille de densités de lois N(t,vt), n
= 30
.
. 11 -02
19 12
d)Famille de densités de Gumbel
ACP normée théorique
16
15% Noyau gaussien 15% Noyau
triangulaire
2
14 14
15% Noyau d'Epanechnikov 15% Noyau
rectangulaire
01
03
05
07

8
0
8
0

01 03 05 07
22%
22%
Fig.17: allure du nuage estimé sur
le premier plan principal obtenu par l'ACP
1 14
estimée en utilisant les différents
noyaux sous la condition d'égalité des
-0.1
1718 78
AMISE. (famille de densités de Gumbel), n
= 30
19
3.4 Conclusion
Dans la plupart des problèmes statistiques
liés a l'estimation non paramétrique, et plus
particulièrement la méthode du noyau, le choix de ce
dernier n'a pas été d'une grande importance, dans la
mesure oi la plupart des critères de sélection sont basés
sur la minimisation de l'erreur quadratique
intégrée asymptotique [8, 18,
33]
Dans le premier cas oi nous avons utilisé des
fenêtres de lissages minimisant les erreurs
quadratiques intégrées
asymptotiques, les résultats sont restés
inchangés par rapport au choix du noyau.
Dans le deuxième cas, les conditions imposées
aux erreurs quadratiques
intégrées asymptotiques
correspondant a l'estimation des densités ont été
motivés par les résultats de Silverman (1986) dans
lesquelles nous avons abouti a des résultats
équivalents malgré l'utilisation de
différents noyaux.
On peut dire ainsi que pour les 4 exemples
que nous avons traités, l'ACP de densités
estimées dépend plus des différences entres les
densités que du choix du noyau.
Par contre, les hypothèses sur les deux cas
particuliers i) et ii) sont faites essentiellement sur les fenêtres de
lissage, chose qui justifie l'importance de ces valeurs
sur la qualité de l'estimation.
Chapitre 4
Influence et choix de la fenêtre de lissage
4.1 introduction
Nous avons vu, dans le rappel sur l'estimation de la
densité de probabilité par la méthode du noyau
que le choix du paramètre de lissage est crucial
pour la qualité de l'estimation. En ACP de densités,
on est amené a estimer simultanément plusieurs densités.
La qualité de l'estimation dépend comme nous l'avons
constaté dans le paragraphe précédent, des
différences entre les densités et leurs estimations, des
différences qu'on a résumées par les erreurs
quadratiques intégrées
asymptotiques. Une chose qui nous semble
évidente, si nous choisissons ces erreurs comme un critère de
sélection, on est donc amené a chercher pour chaque
densité du nuage une fenêtre correspondante, on parlera
alors de plusieurs fenêtres optimales.
Notre souci dans ce présent chapitre est de proposer un
critère avec lequel on calculera une fenêtre h
dite" optimale", qu'on utilise dans l'estimation
simultanée de toutes les densités.
4.2 Influence de la fenêtre de lissage
Soit (Ù,A,P) un espace probabilisé et
Xt: (Ù,A,P) -? (IR, BIR), t E
{1, . . . ,L}, une famille finie de variables aléatoires
de densités inconnues ft vérifiant:
? t =6 s, P{w E Ù,
Xt(w) = Xs(w)} = 0.
(4.1)
Soit (xt,i,...,xt,nt), t ? {1,...,L},
nt réalisations de la variable aléatoire Xt .
L'estimation par noyau de ft, t ?
{1,...,L} est définie par:
|
?x ? R, fh,t(x) = 1nth
|
nt
i=1
|
K(x (4.2)
h
|
h un nombre réel strictement positif, et
K un noyau uniformément borné,
symétrique autour de zéro et
vérifiant
Z
|t|K(t)dt < 8. RI On a alors le
théoréme suivant:
Theoreme 4.2.1 . Si nt, t ? {1,... ,L}
est fini alors:
a) limh?0 < fh,t,fh,s >= 0, t
=6 s. (p.s)
b) limh?0 < fh,t,fh,s >= +8, t
= s.
<fh,t,fh,s> 0 t s.
(p.s)
c) limh?0
d) limh?+8 kfh,tkkfh,sk = 1.
<fh,t,fh,s>
Demonstration:
Désignant par L1, l'espace des
fonctions Lebesgue-intégrable sur R et
11.111 sa norme associée.
a)
De la formule (2.20), on déduit
nt
i=1
XZns RI j
K(y -h xt,i)
K(y -h xs,j) dy,
=1
1
< fh,t,fh,s >=
ntnsh2
pour montrer alors (a), il suffit de montrer pour tout i
et j, on a
h?0
lim h2 K(y - h xt,i)
K(y - h xs,j) dy = 0. (4.3) RI
Soit le changement de variable z =
y-h xt,i , alors:
h2 h
xt,i)K(h - dy = 1 h
I K(z) K(z + xt,i
h xs,j ) dz, (4.4)
fi
comme K(--z) = K(z), donc
1 1
(4.4) = h K(--z)
K(xt,i h
( z)) dz = K(z)
K(xt,i --xs,jh-- z) dz. RI
K étant dans L1, on peut alors
écrire (voir Buchwalter, page 115)
(4.4) = 1 K * K(xt,i
(4.5)h
(*: désigne le produit de convolution
entre deux éléments de L1).
Posons h = xt,i-xs,j
h , alors:
(4.4) = ( 1
xt,i -- xs,j
) h:K * K(h0),
(4.6)
pour presque siirement xt,i
=6 xs,j, montrer (4.3), revient a montrer
h0K * K(h')
--> 0 quand |h:| --> cc. (4.7)
Soit pour cela la fonction H définie par
bhp E R, H(h') =
h0 K(h'). (4.8)
H et K sont dans L1, on écrit
alors: ( voir Buchwalter, page 115)
H * K(h') = I H(h --
y)K(y)dy = I (h' --
y)K(h: -- y)K(y)dy,
a
=
hIK(h' --
y)K(y)dy -- I K(h' --
y)yK(y)dy,
a a
=
h'K*K(h')--K*H(h').
Mais (voir Buchwalter, page 116)
bhp E R, K *
H(h') = H *
K(h'),
on déduit
Donc pour montrer (4.7), il suffit de montrer:
lim I K(h' - y)yK
(y)dy = 0. (4.10)
|h'|?8
Posons
Gh (y) = yK(h' -
y)K(y), ?h' ? R,
on montre alors (4.10) en utilisant le théoréme de
la convergence dominée (C.D) de Lebesgue dans
L1 (voir Bouyssel, page 147), on vérifie pour
cela les deux conditions suivantes:
1. lim|h0|?8 Gh
(y) = 0, ?y ? R,
2. ?h' ? R, ?G ? L1, tels
que: |Gh'(y)| =
G(y).
1.
Si y = h', on a
Gh0(h0) =
h0K(0)K(h0) -? 0
quand |h:| -? 8,
K(h: - y) = 0,
(car: K(0) < 8 et
lim|h0|?8 h:K(h') =
0). Pour y =6 h' fixé, nous avons
|
lim
|h0|?8
|
Gh0(y) = lim
|h0|?8
|
(car si lim|h0|?8
h:K(h') = 0 on a aussi
lim|h,|?8 K(h:) = 0).
Par conséquent
?y ? R,
Gh0(y) -? 0, quand
|h:| -? 8. (4.11)
2. Comme K est uniformément borné,
donc ? h' ? R, ? y ? R, ?M > 0,
tels que
|K(h: - y)| = M,
donc pour tout h' ? R, et pour tout y
? R, on a
Posons G(y) =
M|H(y)|, H dans L1 donc G est aussi
dans L1, on déduit
?hp ? R, ?G ? L1, tels que
|Gh,(y)| = G(y).
(4.13)
De (4.11) et (4,13), on déduit en appliquant le
théoreme de la (C.D) de Lebesgue:
IIGh,(y)111 =
f|yK(h' - y)K(y)|dy
--> 0, quand --> 8. (4.14)
a
Mais
I
yK(h' -
y)K(y)dy| = I|yK(h-
y)K(y)|dy. a a
Par
conséquent
h'K * K(h') -?
0, quand |h0| -? 8. (4.15)
|
C.Q.F.D b)
|
1
< ft,h,ft,h >= n2 t
|
1 h2 E LK(y - h
xt,i) K(y
xt,) dy. (4.16)
i,j
|
Posons A(i,j) =
{(i,j), tels que xt,i =
xt,j}, alors:
1
< ft,h,ft,h > = n2 t
h E fiK(y )
K(y ) dy,
2
(i
,j)6?A(i,j)
1
+ n2t
1 h2 La
(i,j)?A(i,j) IK2(y
h xt,i)dy.
Nous avons d'aprés (a)
(4.17)
h2 E I K( h xt,i)
K( y tj
, ) dy -?0, quand h
-?0.
,j)0A(i,j)
(i
Soit maintenant le changement de variable z
= y-xt,i h ,alors pour tout i nous avons:
1
h2
I K2(y
xt,i)dy = 1 h I
K2(z)dz, (4.18)
comme K est borné, dans L1, alors (voir
Buchwalter, page 31) K2 est aussi dans
L1, c'est-à-dire R
RIK2(z)dz < 8, on
déduit pour tout i:
K2(y -h
xt,i)dy -? +8, quand h -?
0. (4.19)
ZRI
1
h2
Par conséquent et comme le cardinal de
A(i,j) est fini, alors:
1 1
h I K2 (y
xt,i)dy -?+8, quand h
-?0. (4.20)
2
(i,j)?A(i,j)
De (4.18) et (4.21), on déduit
< ft,h,ft,h >-? +8, quand h -? 0
c) D'aprés (a), nous avons:
< fh,t,fh,s >-? 0, quand h -? 0, ?t
=6 s,
et nous avons d'aprés (b)
Ifh,tl = (< fh,t,fh,t
>)12 -? +8, quand h -? 0, ?t ?
{1, ... ,L}.
On déduit
d)
|
< fh,t,fh,s >
Ifh,t11fh,s1
|
-? 0, quand h -? 0, ?t =6
s. (4.21)
|
Pnt Pnt RIR K(
y-xt,i
h ) K( y-xt,j
h ) dy
i=1 j=1
2 Pns Pns RIR K(
y-xs,i
h ) K( y-xs,j
h ) dy
i=1 j=1
< fh,t,fh,s
>
Ilfh,t1111fh,s11
2
Pnt Pns RIR K(
y-xt,i
h ) K( y-xs,j
h ) dy
i=1 j=1
1 1 .
=
Par des changements de variable, on obtient
Pnt Pns RIR K(z)
K(z + xt,i-xs,j
h ) dy
i=1 j=1
1
Pns
Pns
2 RIR K(z) K(z +
xs,i-xs,j
h ) dy
i=1 j=1
K(z + xt,i h xt,j
) dy
Eint 1 2...7nj
t1fig K(z)
1 ,
2
< fh,t,fh,s
>
Ilfh,t1111fh,s11
=
pour montrer alors (d), il suffit de montrer
ZRI
K(z) K(z + ) dz =
K * K() -?I K2(z)dz, quand h
-?+8.
(4.22)
a
â ? {xt,i - xs,j, xt,i - xt,j, xs,i - xs,j}.
Ce qui revient a montrer
K * K(h') --> I
K2(z)dz, quand h--> 0.
a (4.23)
(où: h0= â
h).
Posons ?h' ? R, ?y ? R,
Øh/(y) =
K(h' - y)K(y)
?y ? R, Ø(y) =
K2(y),
on montre alors (4.23) en utilisant le théoréme
C.D, on vérifie pour cela les deux conditions suivantes:
1. limh'?0
Øh/(y) = Ø(y),
?y ? R,
2. ?h' ? R, ?F ? L1, tels
que: |Øh'(y)| =
F(y).
1.
2.
|
lim
h'?0
|
Øh/(y) = lim
h0?0
|
K(h' - y)K(y)
= K2(y). (4.24)
|
Comme K est uniformément borné, donc ?
h' ? R, ? y ? IR, ?M > 0, tels
que:
|K(h: - y)| = M,
donc pour tout h' ? R, et pour tout y
? R, on a
|Øh'(y)| =
M|K(y)|. (4.25)
Posons F(y) =
M|K(y)|, K dans L1 donc F est aussi
dans L1. On déduit:
?hp ? R, ?F ? L1, tels que
|Øh/(y)| =
F(y). (4.26)
De (4.24) et (4,26), on déduit en appliquant le
théoreme de la (C.D) de Lebesgue:
h?+ h-4
lim 11Ø0111 = lim I
K(z) K(z + ) dz =
11K2111 =
K2(z)dz. (4.27)
00 h 8 RI
Remarque
Ce théorème montre, comment se comporte le
produit scalaire entre fh,t et fh,s,
pour les petites (resp grandes) valeurs de h, ainsi la
qualité de l'estimation de l'ACP théorique,
comme le montre l'exemple suivant.
Exemple
On souhaite alors visualiser a l'aide d'un exemple de
simulation, comment évolue la qualité de l'estimation
de l'ACP théorique des densités, lorsque
les ft sont estimées par les estimations données par la
formule (4.2), oi h parcourt un certain ensemble de valeurs. Pour cela
nous avons procédé a une ACP sur les estimations des
densités ft de la variable aléatoire Xt de loi
N(t,vt), lorsque mt = m = 30 et
h E
{10_3,10_2,10_1,2}.
Les projections des densités estimées sur le
premier plan principal sont données par les
graphiques de la figure 18.
h = 10-3 h =
10-2
3.33% 5%
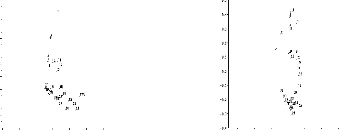
4
3.33% 6%
14% h = 10-1 27% h = 2
.1

02
01
18
20%
6
Fig.18:Allure du nuage sur le premier plan
principal en fonction de la fenëtre de lissage h
. 2 . 2
05 12
lors d'une ACP normée sur les densités
estimées par le noyau gaussien.
415 14 15
.
0
6
(cas de la famille de densités de lois
N(t,.../t))
7
L'allure de la matrice des produits scalaires estimées
àW, en fonction des valeurs de h, est
donnée par la figure 19.
?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
1
0.006 1
0.003 0 1
0 0 0.0007 1
...
....
. ..
. ..
..
.
...
. ..
1
0
0 0 ....
. .. .. 0.007 1
....
0 0 0 . . 0 0.005 1
0 0 0 0 0 0.03 0 1
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ? ? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ? ? ?
? ?
1
?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
0.180 1
0.060 0.120 1
0.002 0.100 0.200 1
... .
. . . .
.. .. .. .. 1
0
0 0 ....
. .. .. 0.110 1
0 0 0 ...
. .. 0.036 0.110 1
0 0 0 0 0.056 0.086 0.037 1
h = 10-3 h =
10-2
?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
1
0.64 1
0.36 0.52 1
0.13 0.35 0.62 1
...
0 ...
. .
. . .
.. .. .. 1
....
0 0 . ..
. . 0.43 1
.. .. 0.28 0.41
0 0 0 1
0 0 0 0 0.29 0.35 0.32 1
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ? ? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ? ? ?
? ?
? ?
? ?
1
?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
0.91 1
0.76 0.94 1
0.65 0.86 0.97 1
...
3.10-8 ... ....
. .. .. 1
3.10-9 7.10-8 ...
...
. .. 0.97 1
1.10-6
2.10-5 2.10-5 ... ...
0.91 0.81 1
3.10-8
6.10-6 2.10-5
5.10-5 0.97 0.93 0.96
1
h = 10-1 h = 2
Fig.19: Allure de la matrice
Wà en fonction de la fenëtre de
lissage h, lors d'une ACP normée sur les
densités estimées par le noyau gaussien,
(cas de la famille de densités de lois N(t,V't)).
Pour une taille d'échantillon fixé, les produits
scalaires suivants::
< fht,
fh >= < fhs,fhs>
(4.28)
s 11fht1111fhs11
tendent vers 0 si t =6 s
lorsque h tend vers 0. La matrice des produits scalaires
normés tend vers la matrice identité, elle admet donc une seule
valeur propre égale a 1 d'ordre de multiplicité
L. Chaque axe principal explique une
quantité d'inertie égale a
1L, L étant le nombre de
densités dans le nuage (égale aussi a
l'ordre de W).
Lorsque h tend vers l'infini ces memes
produits scalaires tendent vers 1, ?t ? {1,..,L}. La
matrice W, admet donc une seule valeur propre non nulle
égale a L d'ordre de multiplicité 1 et une
autre valeur propre égale a 0 d'ordre de
multiplicité L-1. Le premier axe principal explique
toute l'information contenue dans le nuage initial.
Ces résultats, montrent ainsi que la fenete de
lissage h, a une grande influence sur les
résultats de l'estimation.
4.3 Choix de la fenêtre de lissage
Posons maintenant:
h4 4 R(K)
AMISE(h,t) = 4
óKR(ft ) +
t ? {1,...,L} (4.29)
nth
l'erreur quadratique
asymptotique entre ft et fh,t. Si les
densités ft, t ? {1,...,L} et le
noyau K vérifient les conditions des
théoremes 2.2.1 et 2.2.2. Nous proposons de choisir la fenetre dite
optimale, celle qui minimisera la fonction suivante:
|
Ö(h) =
|
XL
t=1
|
AMISE(h,t). (4.30)
|
En utilisant le théoreme 2.2.3 on obtient:
|
L
hoptimale = á(K)
[ER(ft ")
t=1
|
#--
|
5 XL
1 !
1
t=1 nt
|
1
5
|
.
|
(4.31)
|
L --
hoptimale = á(K)
[ER(ft )i
5
(L
1 )1 5 .
(4.32)
n
t=1
Si nt = n, pour t ? {1,...,L}
alors:
Exemples de calcul de R(ft "):
a) Cas de la famille de densites de lois
12N(t,vt)+
12N(0,vt)
?x ? R, ft(x) = 1 (2 ( x vt
)2'
e- 1 2 ( x-t
vt )2 + e- 1
(4.33)
2vtv2ð
· vt )2
(x - t
f00
t (x) = 1 vt )2 -
e- 1 2 ( x
v vt )2e- 1 2 (
x-t
vt )2 - e- 1 2 ( x-t
vt )2 + ( x vt)2e-
1 2 ( x . (4.34)
2t 2Ðt
Par un calcul simple on
trouve:
f00t2
(x)dx = 1
R(ft ") = I81E3
[2I1(t) - 4I2(t) +
2I3(t) + 2I4(4) - 4I5(t)
+ 2I6(t)]
avec:
) ( x.vtt )2
dx,
I1(t) = L(x.`7:\ 4e-
I2(t) = fa(x.`7:)2e-(xvt t
2 dx
), I3(t) = RIe-( xvt
t )2dx.
[(w)2#177;( :t)2] dx
I5(t) = 16(t) , )2e
[(w)2#177;(:t)2]dx, = e[(w)2+(
:t)2]dx.
I4(t) = L(
x-tvt )2(
\x/t)2e
Calculons maintenant les Ii(t), i =
1,6.
I1(t) =
L(x-t
t-le-
) (xt t)2dx =
vtL y4e-y2dy
= 4vÐvt.
v
I2(t) = R IR(x-t
vt (xvt
t)2dx = vt L
y2e-y2dy = 1
Ðvt.
2
v
I3(t) = RIe (xvt
t)2 dx = vt L
e-y2dy = Ðvt.
Soit le changement de variable y
= xvt, alors:
I4(t) =
f( ) - t\2( ) X \ 2e- 12
[(x-t)2+( ,74 )2] dx v.
t
a
= f (y -
a I (y -
.0)2y2e-[(y-vt)2+y2]dy
v
t)2y2e-[(y-
1/2t )2- 4]dy = v
te-4 f(y - v
t)2y2e-(yvP2dy
a
= vte- t 4 I y4e-(y-
a v2 t )2dy - 2te- t
4 I y3e-(y-
a 1/2t )2 dy + I
y2e-(y-2t)2dy
a
= v te- 4 f(y+
2)4e-y2dy-2te4
f(y +
2)3e-y2dy I
(y + 2)2 e-y2
a
· v
v v

t(3 v v
Ð + 3 v v
Ðt + 1 Ð + 1 v
Ðt2) - 2t(3
t + 1
v v v t(1 e- t
= Ð Ðt t) + t Ðt) 4
.
4 4 16 4 8 2 4
En utilisant la même démarche on trouve:
v i
I5(t) = vte- t h1
v
Ð + 1
4 Ðt
2 4
(t) = vÐvte- 4. Par
conséquent:
vt ·1
R(f00
t ) = v 8t2e- t 4
- 3 2te- t 4 + 3 2(e- t 4 + 1) (4.35)
8 Ðt3
b) Cas de la famille de densités de lois
12N(t,vt)+
12N(0,1)
?x ? R, ft(x) = 1
2vtv2ð e
2 (xvt t )2 + 1
2v2ð e
1 2
2 x .(4.36)
· 1 2 x2
f00
t (x) = v 1 tvt e-
1 2 ( x-t
tvt(x - t
vt )2e- 2 1 (
x-t
vt )2 - 1 vt )2 +
x2e- 1 2 x2 - e- 1 . (4.37)
2 2Ð
En utilisant les notations de l'exemple précédent,
nous avons:
· 1
R(f00
t ) = 1 t3 I1(t) -
t3 2 I2(t) + t3 1 I3(t) +
2
tvtI0 1(t) - 2
tvtI0 2(t) - 2
tvtI0 3(t) + 2
tvtI0 4(t) +
I0 5(t)
8Ð
(4.38)
avec:
I1 (t) =
fri(xv-tt)2
x2e-12[( x.itt )2+x21 _x,
'd (t) =
fil(x.`7:)2e-12[(
x.7:)2+x2]dx,
I3(t) =
f,x2e-[(x%.7t t)2+x2]dx,
[(x.tt
)2+x21 _x,
4(t) = fit e 'd 4
(t) = fE(x4 -
2x2 +1)e-x2dx.
Il reste a calculer
I0i(t), i = 1,5. En
utilisant le changement de variable y = x
vt,nous avons:
fli,(x v- tt )2
x2e-[(xtt)2+x2]dx
(t) = = tvt (y- vt)2
y2e-[(y-NA)2+ty2]dy
RI
= I(y - .0)2
y2e-[(t+1)y2-2vty]dy
= I(y- vt)2
y2e-11[y2
dy
a
= Wte2+ 2(t+1) f(y
vt)2 y2e-[vt21
(y-t,/Ft1)] 2 dy.
Posons z = qt+1
2 (y- t+1), alors:
vt
2 2
(t) =
z t v+ t1 e-z2dz
Wt\/ 2 e2+
2(tt +1) 2z
t +1 t + 1 t t+ 1 t
+ 2
r " v #
v 2 v
= t t t + 1e- 2 t + t
3 Ð
2(t+1) (t + 1)2 + t3 -
4t2 + t v Ð + t4 Ð
.
(t + 1)3 (t + 1)4
En utilisant la même démarche on trouve:
i.
I02(t) = vt
q 2 hv v
t+1e- t 2 + t Ð
2(t+1) t+1 + t3
Ð
(t+1)2
i.
I0 3(t) = tvt q
2 hv v
t+1e- t 2 + t Ð
2(t+1) t+1 + t Ð
(t+1)2
q 2
I0 4(t) = vt
v 2(t+1)
.
Ð t+1e- t 2 + t
I5(t) =
34vÐ.
En remplacant ces termes dans la formule (4.38), on
obtient:
v2 ·t4 -
6t3 - 3t2 + 6t +
3 vt
R(f00 e- 2 t + t
2(t+1) + 3
t ) = v (t +
1)4vt + 1 v Ð( t3 + 1).
(4.39)
4 Ð 32
c) Cas de la famille de densites de lois
N(t,vt).
1 -
?x ? R, ft(x) = 1
vtv2ð e- 2 ( \ xvt )2
.(4.40)
· vt )2
f00 2 ( x-t
t (x) = 1 (x - t vt
)2 - e- 1
v vt )2e- 1 2 (
x-t . (4.41)
t 2Ðt
Avec les notations de l'exemple 1, nous avons:
vt
R(f00
t ) = 1
2Ðt3 [I1(t) -
2I2(t) + I3(t)] = v 3
(4.42)
8 Ð t3 .
Nous souhaitons maintenant a l'aide des 4 exemples
traités dans le paragraphe 3.1, de faire une comparaison
entre la qualité de l'estimation de l'ACP
théorique obtenue en utilisant la fenêtre optimale
donnée par la relation 4.31 et celle obtenue en associant a
chaque densité la fenêtre optimale au sens de
l'erreur quadratique intégrée
asymptotique donnée par la formule 2.17.
Pour des raisons de simplicité nous avons choisi
d'estimer les densités en utilisant le noyau
gaussien. Le caractére asymptotique des
fenêtres précédentes, nous exige de choisir des
tailles d'échantillons suffissament grandes, ici nt
= n = 30, t ? {1,...,30}.
a) Cas de la famille de densités de
lois1 2N(t,vt) +
1 2N(0,vt).
Les valeurs des aj sur les 3 premiers axes principaux,
ainsi celles des â obtenues dans les deux situations
précédentes sont données par le tableau 6.
|
fenêtres AMISE
|
hoptimale = 1.16
|
|
a1
|
1.34
|
2.38
|
|
a2
|
3.36
|
2.89
|
|
a3
|
2.91
|
2.61
|
|
â
|
1.71
|
5.72
|
Tab.6: Valeurs des áj sur les 3 premiers axes
principaux, ainsi celle de â, obtenues lors d'une ACP sur les
densités estimées, dans le cas des fenëtres AMISE
et la fenëtre hoptimale. (Famille de
densités de lois 1 2 N(t,V't) + 1 2
N(0,V't)), n = 30
Les projections des densités estimées sur le
premier plan principal, ainsi que les pourcentages
d'inertie sur les deux premiers axes principaux dans le cas des deux situations
précédentes, sont données par les
graphiques de la figure 20.
12% Fenëtres AMISE 11% hoptimale =
1.16
0.6
0.4
0.2
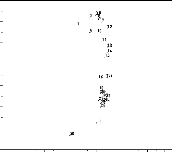
3 . 8
65
0.6
0.4
70% 0.2
64%

Fig.20: Allure du nuage des densités
sur le premier plan principal, obtenues lors d'une ACP
16 17 19 . 1 17
19
sur les densités estimées en utilisant les
fenëtres AMISE et la fenëtre hoptimale.
-.2
. 18
2829
(cas de la famille de densités de lois 1
. 2 . 21
. 22 25 2 N(t,V't) + 1 2
N(0,V't)), n = 30.
26
b) Cas de la famille de densités de
lois1 2N(t,vt) +
1 2N(0,1).
Les valeurs des aj sur les 3 premiers axes principaux,
ainsi celles des â obtenues dans les deux situations
précédentes sont données par le tableau 7.
|
fenêtres AMISE
|
hoptimale = 0.43
|
|
a1
|
5.32
|
5.36
|
|
a2
|
2.00
|
1.90
|
|
a3
|
2.91
|
2.66
|
|
â
|
9.52
|
9.56
|
Tab.7: Valeurs des áj sur les 3 premiers axes
principaux, ainsi celle de â, obtenues lors d'une ACP sur les
densités estimées,
dans le cas des fenëtres AMISE et la fenëtre
hoptimale. (Famille de densités de lois 1 2
N(t,./t) + 1 2 N(0,1)), n = 30
Les projections des densités estimées sur le
premier plan principal, ainsi que les pourcentages
d'inertie sur les deux premiers axes principaux dans le cas des deux situations
précédentes sont données par les
graphique de la figure 21.
7% Fenëtres AMISE 7% hoptimale =
0.43
Fig.21: Allure du nuage des
densités sur le premier plan principal, obtenues lors d'une ACP
.
17 1 . . 4
1
0.0 17
sur les densités estimées en utilisant les
fenëtres AMISE et la fenëtre hoptimale.
1
18
02
(cas de la famille de densités de lois 1
22 21
. 2 N(0,1)), n =
30.
24526 2 N(t,./t) + 1
c) Cas de la famille de densités de lois
N(t,vt).
Les valeurs des aj sur les 3 premiers axes principaux,
ainsi celles des â obtenues dans les deux situations
précédentes sont données par le tableau 8.
|
fenêtres AMISE
|
hoptimale = 1.00
|
|
a1
|
1.43
|
1.51
|
|
a2
|
1.64
|
1.73
|
|
a3
|
2.37
|
2.38
|
|
â
|
2.81
|
2.76
|
Tab.8: Valeurs des áj sur les 3 premiers axes
principaux, ainsi celle de â, obtenues lors d'une ACP sur les
densités estimées, dans le cas des fenëtres AMISE
et la fenëtre hoptimale. (Famille de
densités de lois N(t,v't)), n = 30
Les projections des densités estimées sur le
premier plan principal, ainsi que les pourcentages
d'inertie sur les deux premiers axes principaux dans le cas des deux situations
précédentes sont données par les
graphique de la figure 22.
26% Fenëtres AMISE 25% hoptimale =
1.00
Fig.22: Allure du nuage des densités
sur le premier plan principal, obtenues lors d'une ACP
16 17 16
. 17
sur les densités estimées en utilisant les
fenëtres AMISE et la fenëtre hoptimale.
. 18
(cas de la famille de densités de lois
N(t,v't)), n = 30.
0.1
20
d) Cas de la famille de densités de Gumbel.
Les valeurs des aj sur les 3 premiers axes principaux,
ainsi celles des â obtenues dans les deux situations
précédentes sont données par le tableau 9.
|
fenêtres AMISE
|
hoptimale = 0.76
|
|
a1
|
1.93
|
2.56
|
|
a2
|
2.31
|
2.66
|
|
a3
|
1.71
|
1.71
|
|
â
|
1.61
|
3.65
|
Tab.9: Valeurs des áj sur les 3 premiers axes
principaux, ainsi celle de â, obtenues lors d'une ACP sur les
densités estimées, dans le cas des fenëtres AMISE
et la fenëtre hoptimale. (Famille de
densités de Gumbel), n = 30
Les projections des densités estimées sur le
premier plan principal, ainsi que les pourcentages
d'inertie sur les deux premiers axes principaux dans le cas des deux situations
précédentes sont données par les
graphiques de la figure 23.
23% Fenëtres AMISE 21% hoptimale =
0.76

13 .

38%
33%
Fig.23: Allure du nuage des densités
sur le premier plan principal, obtenues lors d'une ACP
9 9
sur les densités estimées en utilisant les
fenëtres AMISE et la fenëtre hoptimale.
0
(cas de la famille de densités de Gumbel), n =
30.
. 22
Les résultats obtenus précédemment
concernant les valeurs des áj sur les 3 premiers axes
principaux donnés par les tableaux 6, 7, 8 et 9, ainsi celles des
valeurs des â, montrent que la différence
entre les deux procédures d'estimations n'est pas très
importante.
L'allure du nuage des densités sur le
premier plan principal donnée par les graphiques
des figures 20, 21, 22 et 23 ainsi que les
pourcentages d'inertie expliqués par les deux
premiers axes principaux, montrent aussi que les deux
procédures d'estimation ont donné des résultats
très proches, a l'exception du premier exemple, oi nous avons
enregistré une différence du pourcentage
d'inertie de 6% sur le premier axe principal.
En conclusion, nous pouvons dire que dans les deux
cas, nous sommes amenés a minimiser l'erreur
quadratique entre la densité f et son
estimation. La différence réside dans le fait que,
l'emploi de la fenêtre hoptimale, signifie
que l'ACP sur les densités estimées est faite en
minimisant globalement toutes les erreurs
quadratiques intégrées
asymptotiques. Tandis que dans l'autre
procédure d'estimation, l'ACP est faite en minimisant localement les
erreurs quadratiques intégrées
asymptotiques et cela en associant a chaque
densité la fenêtre de lissage optimale au sens de
l'AMISE.
Remarque.
La largeur de la fenêtre
hoptimale dépend, a travers les paramètres
R(f00
t ), t ? {1,...,L} des
densités inconnues ft, et ne peut donc être
utilisée telle quelle dans les calculs. Pour remédier
a ce problème nous proposons d'estimer les quantités
R(f00
t ), en remplaçant les ft
par un modèle
paramétrique approprié, par exemple le
modèle de Park et Marron (1990) suivant:
|
gë(x) =
ëg1(x
1 ë)
|
(4.43)
|
oi ë représente une mesure d'échelle
de la densité ft, par exemple sont
écart-type, et g1 désigne une
densité de référence connue d'echelle 1.
Si xt,1,...,xt,n, n
réalisations de la variable aléatoire de densité
ft d'ecart-type ót et g1 la
densité gaussienne N(0,1), alors
l'estimation de R(f00
t ) est donnée par:
àR(f0'
t ) = v 3 (4.44)
8 Ðs2 t
st l'estimation par maximum de vraisemblance de
ót
Conclusion
Le travail que nous avons effectué ici
concerne essentiellement la présentation de l'approche d'estimation non
paramétrique d'une ACP de densités, une approche
qu'on peut toujours utiliser quelque soit la
nature des données. Dans le cas d'une ACP non centrée et non
normée, nous avons utilisé l'approche d'estimation de Kneip et
Utikal 2001, pour améliorer la qualité de l'estimation
des valeurs propres de la matrice des produits scalaires, dans le cas
particulier oi les tailles d'échantillons sont identiques et
des densités estimées par noyau en utilisant la
même fenêtre de lissage. Ensuite, on a effectué
une comparaison entre l'approche paramétrique et l'approche
non paramétrique, nous avons alors
remarqué, l'équivalence entre les deux
approches d'estimations dans le cas de densités gaussiennes
et de densités de Gumbel estimées. Dans le troisième
chapitre nous avons étudié sur la base de 4 exemples, l'influence
du noyau sur la qualité de l'estimation, et cela
en considérant deux cas particuliers; le cas oi les
densités sont estimées, par les différents
noyaux, avec des erreurs quadratiques
intégrées asymptotiques
minimales. Le deuxième cas consiste a estimer. les densités en
commettant les mêmes erreurs quadratiques
intégrées asymptotiques suivant
chaque noyau. Les résultats obtenus montrent
que la qualité de l'estimation est
indépendante du choix de ce noyau.
Après avoir choisi d'estimer les densités en
utilisant une seule fenêtre de lissage, et en utilisant le
résultat précédent, nous avons étudié sur la
base de l'exemple de données gaussiennes simulées,
l'influence et le choix de la fenêtre de lissage sur la
qualité de l'estimation. Les résultats obtenus
montrent que cette dernière est cruciale pour obtenir une
bonne estimation de l'ACP théorique. Pour atteindre cet
objectif, nous avons choisi de sélectionner la meilleure fenêtre
qui consiste a minimiser globalement toutes les erreurs
quadratiques intégrées
asymptotiques, que nous avons notée
hoptimal, ensuite nous avons comparé, en se basant
sur les exemples du chapitre précédent,
les qualités d'estimations obtenues en
utilisant cette fenêtre et celles obtenues en associant a
chaque densité du nuage la fenêtre optimale
au sens de l'AMISE. Les résultats obtenus sont très proches.
Cette fenêtre présente un avantage et
un inconvénient. Son avantage réside dans le fait
qu'elle simplifie les calculs et son inconvénient est le fait
qu'elle dépend toujours des densités inconnues. Pour
résoudre ce problème nous avons proposé en utilisant
l'approche d'estimation de Park et Marron, 1990 de remplacer les
densités dans la formule de hoptimal en utilisant un
modèle paramétrique approprié.
Observons maintenant les données traitées par la
méthode proposée (ACP de densités) oi dans
chaque lot (tableau) nous disposons de mesures d'une variable
quantitative. Regardons maintenant le cas oi on dispose a
la fois des mesures d'une variable quantitative (continue) et d'une
variable qualitative ( discrète), est-il alors possible de
développer une analyse factorielle comme celle
présentée auparavant permettant d'obtenir une analyse
globale de ce type de données et quelle
est l'interprétation qu'on peut donner aux différents
facteurs?
Essentiellement cela consiste a définir une mesure
d'affinité entre deux densités de probabilités comme celle
définie dans le chapitre 1, qui sont les densités
conjointes d'un vecteur aléatoire quantitatif (continu) X et
d'un vecteur aléatoire qualitatif (discret) Y, ainsi une
méthode d'estimation en utilisant les données
précédentes. Ce travail nécessite d'introduire des
hypothèses supplémentaire sur la nature des
données, comme la normalité du vecteur aléatoire
conditionnel X/Y.
Le modèle appelé ' location model ' introduit
par Olkin et Tate (1961), généralisé ensuite
par Krzanoswki (1983) sous le nom ' General location model ' est de loin le
modèle statistique le plus recommander pour ce
type de problème. En se basant sur l'affinité de
Bhattacharyya (1943), Krzanoswki a défini une mesure
d'affinité entre deux populations sur lequelles sont
mesuré p caractères quantitatifs et r
caractères qualitatifs.
En utilisant cette mesure d'affinité ou
éventuellement en définissant d'autres mesures en conservant
l'hypothèse de normalité, on peut développer
une analyse factorielle a la manière présentée
dans le premier chapitre, par conséquent une
analyse en composantes principales sur les densités
conjointes des vecteurs aléatoires quantitatifs (continu) et
qualitatifs (discret), et une
méthode d'estimation de ces densités, en
utilisant soit une approche paramétrique ( Krzanowski, 1983)
soit une approche non paramétrique, en adoptant les
différents résultats de ce travail a cette situation. Des
questions auxquelles nous souhaitons répondre dans
le cadre de travaux a venir.
Bibliographie
[11 Benzecri, et al., L'analyse des données,
tome I, 3e éd., Dunod, Paris, 1979.
[21 Bosq, D et Lecoutre, J-P. , Théorie de
l'estimation fonctionnelle. Collection économie et
statistique avancées, 1987.
[31 Boumaza, R. , Analyses factorielles des
distributions marginales de processus. These Doctorat,
Université Joseph Fourier, 1999.
[41 Boumaza, R. , Contribution a l'étude descriptive d'une
fonction aléatoire qualitative,ThCse Doctorat de
Spécialité Université Toulouse, 1980.
[51 Bouyssel, M. , Intégrale de
Lebesgue, mesure et intégration, Edition CEPADUES,
1997. [61 Braun, J.M. , Séries chronologiques
multiples: Recherche d'indicateurs, Revue de Statistique
Appliquée. 1973, vol XXI n°1.
[71 M.Brieuc, C. , Modélisation supervisée de
données fonctionnelles par perceptron multi-couches, These doctorat,
Université Paris IX Dauphine, 2002.
[81 Bruce, Hasen, H. , Bandwith selection for nonparametric
distribution estimation, University of Winsconsin, 2004.
[91 Cailliez, F., Pagés, J-P , Introduction a
l'analyse des données, Smash, Paris 1976.
[101 Cardot, H., Nonparametric estimation of smoothed principal
components analysis of sampled noisy functions, Journal
of Nonparametric Statistics, 2000, vol.12, 503-538.
[111 Cardot, H., Contribution a la modélisation
statistique fonctionnelle, Mémoire d'Habilitation a
diriger des recherches, Laboratoire de Statistique et de
probabilité, Université Paul, Sabatier Toulouse, 2004.
[121 Coppi,R. and Bolasco, S., Multivariate data
analysis North-Holland Amsterdam. Proceedings of the
International Meeting on the Analysis of
Multiway Data Matrices, Rome, Marsch 1988, 28-30.
[131 Dauxois, J et Pousse, A., Les Analyses
factorielles en calcul des probabilités et en statistique,
Essai d'étude synthétique, these
Université Paul Sabatier Toulouse, 1976.
[141 Dauxois, J., Pousse, A., Romain,Y., Asymptotic
theory for the principal component analysis of a vector
random function, Some Application to Statistical inference, Laboratoire de
statistique et probabiltés, Université Paul Sabatie,
Toulouse 1982, page 136-141.
[151 Dauxoiss, J. Nkiet, G.M. Romain, Y., Projecteurs
orthogonaux et opérateurs associes utiles en
statistique multidimensionnelle, Laboratoire de
statistique et probabilités, UMR CNRS C55830,
Université Paul Sabatier Toulouse.
[161 Deheuvels, P. , Estimation non
pararamétrique de la densité par
histogrammes generalisés,
Publication.Inst.Stats.Univ.Paris, 1977 XXII-1-23
[171 Gilles, L. , Introduction a l'intégrale de
Lebesgue, http//
www.isima.fr/leborgne.
2006.
[181 Gérard, B., Estimation a noyau
itérés: Syn these
bibliographique Département des Mathé-
mathiques, Laboratoire de Probabilité et
Statistique, Université Montpelier II, 2005. [191 Henri
Buchwalter, Le calcul intégral, ellipses, 1991
[201 Kneip and Utikal, Inference for density families
using functional principal componant ana-
lysis, Journal off the American Statistical
Association,2001, vol 96, page 519-531.
[211 Kroonenberg, P.M. , Tree-mode principal component
analysis. Theory and applications,
DSWO Press, Leiden. Reprint 1989.
[221 Krzanowski, W.J., Distance between populations
using mixed continuous and categorical variables,
Biometrika 1983, vol 70, p235-234.
[231 Krzanowski, W.J., Mixtures of continuous and
categorical variables in discriminant analysis Biometrika
1980, vol 36, page 493-499
[241 Nadaraya, E.A. , On the integral
mean square error of some nonparametric estimates for
the density function Theory of
Probability and its applications, vol 19, pp 133-141.
[251 Park, B.U, et Marron, J.S , Comparison of data-driven
bandwith selectors, Journals of the
Americain Statistical Association, vol 85 pp 66-72
[261 Pezzuli, S and Silverman, B.W., Some propreties of smoothed
principal components analysis for functional data, Computational
Analysis, 1993, page 1-16.
[271 Phillipe, B and Ramsay, J.O, Principal components
analysis of sampled function, Psychometrika, june 1986,
vol 51, page 285-311
[281 Qannari, E.M, Analyses factorielles de mesures et
applications, These de 3Cme cycle, Université Paul Sabatier,
Toulouse, France 1983.
[291 Romain, Y., Contribution a la Statistique
Multidimensionnelles Opèratorielle, These Labo-
ratoire de Statistique et Probabilité,
Université Paul Sabatier Toulouse 2000.
[301 Saporta, G., Probabilités, analyses des
données et statistique, Technip, Paris 1990.
[311 Scott, D.W., Multivariate Density Estimation:
Theory, Practice and Visualisation, Wiley,
New York, 1992.
[321 Scott, D.W., Tapia, R.A et Tompson, J.R ,Kernel
Density Estimation revisited, Nonlinear Analysis,
Theory, Methods and Applications, Vol1, pp 339-372.
[331 Silverman, B.W., Density estimation for
Statistical and Data analysis, School of Mathematics,
University of Bath, UK 1986.
[341 Silverman, B.W., Smoothed Functional Principal Component
Analysis by Choice of Norm, Annals of Statistics 1990,
vol 24, page 1-24.
[351 Silverman, B.W., Pezzuli, S., Some Properties of Smoothed
Principal Component Analysis for Functional Data, Computational
Statistics, 1993, vol 8 pp 1-16
[361 Thierrry, R., Raphaëte, H. , Mesure et
intégration,
www.cmi.univ-mrs.fr
/gallouet/licence.d /int-poly.pdf
| 

