2.2 Rappel sur l'estimation d'une densité par la
méthode du noyau
" Il s'agit d'un problème fondamental de la
statistique non paramétrique qui a
connu, durant ces quarante dernières années, des
développements théoriques et pratiques a la
fois rapides et nombreux "[181.
Soit (X1,...Xn) un
échantillon de densité marginale inconnue f.
L'idée la plus naturelle consiste a évaluer la densité
f au point x en comptant le nombre d'observations
"tombées" dans un certain voisinage de x. Sur
IRp (p = 1), on peut par exemple choisir un
voisinage cubique de x =
(x1,...,xp) de la forme [x1 - h
2,x1 + h 2] x ... x
[xp - h 2,xp + h 2]
qu'on note [x - h 2,x + h
2] oi h est un nombre réel strictement positif
dépendant de n, ce qui conduit a l'estimateur
[181
Cette dernière expression peut encore s'écrire:
|
1
fh(x) = mhp
|
Xn
i=1
|
(x _ Xi
1[_ 1 . (2.2)
2 , 1 2 ]p h
|
oi la fonction 1[_ 1
2]p.
2 , 1 2 ]p est la densité de
probabilité uniforme sur [_1
2,1
En s'inspirant alors de la dernière formule, et en
définissant K comme étant une fonction réelle,
bornée d'intégrale 1 sur IRp, on
définit l'estimateur fh associé au noyau
K par:
|
1
fh(x) = mhp
|
Xn
i=1
|
K(x _ Xi
h ) (2.3)
|
Lorsque le noyau K est choisi
positif, l'estimation fh est une densité de probabilité
et on parle alors parfois de la densité de probabilité
empirique de noyau K. Parmi les multiples
estimateurs non paramétriques de la densité
aujourd'hui a la disposition des utilisateurs, l'estimateur a noyau,
est de loin le plus populaire (Akaike, Rosenblatt, 1956, Parzen, 1962,
Silverman, 1986, Bosq et Lecoutre, 1987 ...). Ce succès peut
essentiellement s'expliquer en trois points:
1. L'expression théorique de
fh(x) est simple, puisque il s'écrit comme
une somme de m variables aléatoires i.i.d..
2. fh converge vers f en de
nombreux sens, et en particulier au sens L1 pour toute densité
f dès que1 h et mhp tendent tous
les deux vers l'infini. D'autre part si l'estimateur est convergent,
il est convergent dans tous les modes, i.e. en probabilité,
en moyenne, presque sürement et presque
complètement [21.
3. Enfin, cet estimateur est flexible, dans la mesure oi il
laisse a l'utilisateur une grande latitude non seulement dans le
choix du noyau, mais encore dans le choix du paramètre
réel h.
" Lorsqu'on se limite aux noyaux K
positifs, les vitesses de convergences varient peu en fonction
de K et les critères essentiels du choix du noyau
sont alors la simplicité et la vitesse de calcul d'une part, la
régularité de la courbe a obtenir d'autre part "[181.
En revanche, le choix du paramètre de lissage h se
révèle crucial aussi bien pour la précision locale
que pour la pécision globale de l'estimateur
fh, c'est l'objet du paragraphe suivant.
2.2.1 Choix du noyau et de la fenêtre de lissage
" La décision d'un choix optimal pour le
noyau K et la constante de lissage h,
suppose la spécification d'un critère d'erreur qui
puisse etre éventuellement optimisé. Bien slir,
l'optimalité n'est pas un concept absolu: elle est intimement
liée au choix du critère, qui peut faire intervenir a
la fois la densité inconnue f et l'estimateur fh donc
h et le noyau K " [181. Dans le cas qui
nous intéresse, on cherche a minimiser l'erreur
quadratique intégrée
moyenne, que nous noterons par MISE (mean
integrated square error), qui est
définie par:
Z Z
MISE(h) = E
IR'[fh(x) -- f(x)]2 =
IR' E[fh(x) -- f(x)]2
(2.4)
Cette écriture signifie que l'erreur
quadratique intégrée
moyenne est a la fois une mesure de l'erreur globale
moyenne et une mesure de l'erreur moyenne ponctuelle
accumulée.
On s'intéressera dans la suite de cette partie au cas
particulier oi p = 1. On a alors le théorème suivant.
Théorème 2.2.1 (Rosenblatt, 1956)
Si f a une dérivée seconde absolument continue,
et si K et f00 E L2, oTi K est une
densité continue, symétrique de variance
u2 K, alors, sous les conditions h
--* 0 et nh --* 00, on a le développement
asymptotique:
1 (2.5)
n
(
h4
MISE(h) = 4 u4
KR(f00) +
R(K)
nh + O h5 +
et l'erreur quadratique
intégrée asymptotique
associée noté AMISE est définie par:
|
h4
AMISE =
4
|
u4
KR(f00) +
R(K)
nh
|
.
|
(2.6)
|
oi R(K) = f
K2(x)dx
Choix du noyau
Le choix du noyau optimal K selon le
critère de l'erreur quadratique
intégrée asympthotique pour
estimer une densité de probabilité qu'on choisira
parmi la classe de tous les noyaux
symétriques, vérifiant de plus
f t2K(t) =6 0, et
donné par le théorème suivant:
Théorème 2.2.2 (Epanechnikov, 1969)
Si f a une dérivée seconde absolument continue dans
L2.
Si de plus h ? 0, nh ? +8 et
fIR(f00)2 =6 0, alors le
noyau d'Epanachnikov d'ordre 1, KE défini par:
KE(x) = ( 3 x
4v5)(1 -
5)ll[-v5,v5](x),
(2.7)
est d'erreur quadratique
intégrée asymptotique
minimum.
Silverman (1986) a défini le coefficient
d'efficacité des noyaux appartennant a cette classe, en les
comparant au noyau optimal précédent, il est
donné par la formule suivante.
(J )
3
eff(K) = v5
t2 K(t)dt
1 )-1
K(t)2dt , (2.8)
2 (J
alors pour un noyau de cette classe, il montre
que ce coefficient est très proche de 1,
signifiant ainsi que le choix de ce dernier influe peu
sur l'AMISE.
1)Noyau Gaussian:
Il est défini pour tous x ? RI par:
1 1
KG(x) = v 2
On présentera ici quelques
exemples de noyaux appartenant a la classe pécédente
qu'on utilisera ensuite dans l'étude de l'influence du
noyau sur l'ACP de densités estimées non
paramétriquement.
exp(- x2) (2.9)
2ð
2) Noyau rectangulaire:
|
KR(x) =
|
?
?
?
|
1/2 si |x| = 1
0 sinon
|
(2.10)
|
|
KE(x) =
|
?
?
?
|
(3/4)(1 - 1 5x2) 1
,5 si |x| < v5
0 sinon
|
(2.11)
|
3)Noyau d'Epanechnikov:
4)Noyau triangulaire:
|
KT(x) =
|
|
1 - |x| si |x| = 1
0 simom
|
(2.12)
|
On souhaite alors utiliser le résultat
précédent de Silverman pour visualiser a l'aide d'un exemple de
simulation, l'influence du choix du noyau K parmi les 4
noyaux définis précédemment, sur la courbe
associée a l'estimation de la densité de probabilité
f.
Soit (x1,...,xn), m
réalisations de la variable aléatoire X de
densité f de loi N(4,2). Posons:
~ AMISEG l'erreur quadratique
intégrée asymptotique entre
f et son estimation en utilisant le noyau
gaussien et la fenêtre de lissage noté
hG.
~ AMISET l'erreur quadratique
intégrée asymptotique entre
f et son estimation en utilisant le noyau
triangulaire et la fenêtre de lissage noté
hT.
~ AMISEE l'erreur quadratique
intégrée asymptotique entre
f et son estimation en utilisant le noyau d'Epanechnikov et
la fenêtre de lissage noté hE.
~ AMISEG l'erreur quadratique
intégrée asymptotique entre
f et son estimation en utilisant le noyau
rectangulaire et la fenêtre de lissage noté
hR.
tel que:
AMISEG = AMISET = AMISEE = AMISER.
(2.13)
Remarque
La relation (2.13), va nous permettre de calculer les
fenêtres précédentes, et cela en procédant comme
suit:
Premièrement on fixe une fenêtre parmi hG,
hT, hE, hR, par exemple; hG =
0.40. Les 3 dernières sont respectivement les solutions
réelles positives des 3 équations suivantes:
ó4KT
4
h5 - (AMISEG) h +
1R(KT) = 0 (2.14)
m
ó4 KR
4 h5 - (AMISEG) h +
1 mR(KR) = 0 (2.16)
pour m = 30 on obtient: hT = 0.95,
hE = 0.85, hR = 0.71. L'erreur
quadratique intégrée
asymptotique correspondante est égale a
0.023.
Avec ces fenêtres on trace les courbes associées
a l'estimation de f en utilisant les différents
noyaux. Les graphiques de la figure
2 montrent que sous la condition d'égalité
des AMISE, les courbes estimées par les différents
noyaux ont presque la même allure.
hG = 0.40 hT = 0.95

Cas du noyau gaussien Cas du
noyau triangulaire
hE = 0.85 hR = 0.71

Cas du noyau d'Epanechnikov Cas du noyau
rectangulaire
Fig.2: Influence du noyau sur la
qualité de l'estimation d'une densité de
probabilité gaussienne
12
de loi N(4,2) sous la condition
d'égalité des AMISE, n = 30.
Choix de la fenêtre de lissage
Le premier terme du développement de MISE est
un terme de biais, alors que le second un terme de variance. On peut
remarquer qu'ils varient en sens inverse par rapport a
h: une largeur de fenêtre trop importante entraInera
une augmentation du biais et une diminution de la variance
(phénomène de sur-lissage), alors qu'une
largeur de fenêtre trop faible provoquera une
inflation de la variance et une diminution du biais (phénomène de
sous-lissage).
Sous les conditions des théorème 2.2.1 et 2.2.2, la
fenêtre h notée hAMISE, qui minimise
l'erreur quadratique asymptotique
est donnée par le théorème suivant.
Théorème 2.2.3 (Rosenblatt, 1956)
hAMISE =
á(K)â(f)n- 1 5
(2.17)
]
ou á(K) = [R(K)
ó4
K
[ 1 ]
5 et â(f) =
R(f00)
1
1
5
.
Remarque
La largeur de fenêtre optimale hAMISE
dépend de la densité inconnue f au travers du
paramètre R(f00) et ne peut donc être
utilisée telle quelle dans les calculs. Une
façon classique d'y remédier
consiste a remplacer la quantité
R(f00) par un estimateur approprié. Cette
approche conduit a un ensemble de méthodes que l'on a coutume
de regrouper sous le vocabulaire général de
méthodes plug-in, et qui font l'objet d'une
recherche active (pour des références, on peut par exemple
voir[16, 18, 24, 25, 311).
Exemples
Pour visualiser l'influence de la fenêtre de
lissage h sur la qualité de l'estimation
d'une densité f, nous avons choisi de présenter ici deux
exemples oi f est estimée par fn en
utilisant le noyau gaussien:
|
Xn
1
1 1
?y E RI fn(y) = e-
2 ( y-xi
h )2
v2ð nhj=1
|
.
|
(2.18)
|
(xj)j=1,n n réalisations de la
variable aléatoire parente X de densité f.
Le premier exemple concerne la densité de la loi
N(0,1), oi pour h E {0.1,
0.3, 0.6, 1} on trace les
courbes associées a l'estimation de f pour chaque
valeur de h.
Les graphiques de la figure 3
montrent que la meilleure fenêtre est h =
0.6, et en peut voir, lorsque h = 0.1
l'estimation est très mauvaise, chose qu'en peut
expliquer par le nombre de piques qu'elle
présente; de même pour h = 1, l'estimation est
beaucoup plus aplatie, ce qui fait une différence importante
de dispersion.
h = 0.1 h = 0.3

h = 0.6 h = 1

(...) courbe estimée + + (-) courbe réelle +
0 +
Fig.3: Influence de la fenëtre de
lissage sur l'estimation par noyau gaussien de
la densité f de loi N(0,1), n =
30
+ + + +
+ + +
+ + +
Le deuxième exemple est celui de la densité
bimodale ø suivante:
1
ø(x) =
2(f(x) + g(x)) (2.19)
avec f = N(0,1) et g =
N(4,1).
Les graphiques de la figure 4
montrent que pour h = 0.2 on a une mauvaise
qualité d'estimation. En lissant plus les densité en
arrive a améliorer la qualité de l'estimation , ici la
meilleur fenêtre est h = 0.6. Pour h = 1,
l'estimation devient moin bonne ce qui est caractérisé
par la diminution de nombre de modes.
h = 0.2 h = 0.4
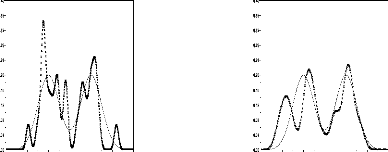
× h = 0.6 h = 1

(...) courbe estimée (-) courbe réelle
× × × × ×
Fig.4: Influence de la fenëtre de
lissage sur l'estimation par noyau gaussien
d'une densité bimodale, n = 30
× ×
× × × × × × × × ×
× × × × × × ×
× × × × ×
| 

