II. 2.6.2. Régressions allométriques
développées à partir des données de terrain
Le but des régressions est de déterminer les
valeurs paramétriques d'une fonction pour un bon ajustement de celles-ci
par rapport aux données observées (expérimentales), dans
ce cas le DBH. Les régressions sont alors des outils statistiques
permettant d'établir une relation de dépendance entre deux
variables ; une dite explicative, l'autre appelée dépendante. Le
but de la régression est triple. Elle permet de résumer la
relation existant entre une variable aléatoire dépendante `y' (la
biomasse sèche) et une variable aléatoire explicative `x' (DBH).
Le lien entre les deux variables se résume en une équation (la
régression) et quelques paramètres de précision et
d'optimisation comme le coefficient de détermination (r2), le
coefficient de corrélation (r) et les résidus du
modèle.
La détermination d'un modèle allométrique
serait un exercice simple s'il existait une relation
simple entre le DBH et
la biomasse totale. Dans de tels cas, la relation est linéaire
(y=ax+b)
DBH
et est caractérisée par une pente `a' (le pas de
la croissance) et l'ordonnée à l'origine `b' (la
valeur de
départ sur l'axe des `y'). Le calcul du modèle linéaire
sur les données collectées
offre cependant un coefficient de
détermination peu convaincant parce que la relation n'est
pas linéaire. Alors la relation entre la biomasse et le
diamètre des arbres est une fonction curviligne. C'est ainsi qu'on fait
recours à plusieurs essais de modèles mathématiques pour
ne retenir que celui (ou ceux) qui facilite grandement l'opération
d'ajustement entre les deux variables (Scherrer, 1984).
Le principe de base des régressions non
linéaires consiste à transformer les données pour arriver
à une courbe représentative de la relation entre les deux
variables (ajustement). Ainsi pour une série de données on
cherche le ou les modèles les plus adéquats pour pouvoir
prédire la valeur de la variable dépendante (biomasse) en
utilisant une fonction de la variable indépendante (DBH).
Il existe plusieurs types de régressions statistiques
(voir liste des équations plus bas). Chacune d'entre elles prédit
la variable dépendante en utilisant les paramètres p0 et p1 qui
constituent les paramètres de la régression. Le paramètre
X représente ici le DBH qui est la variable explicative, et `y' la
biomasse qui est la variable expliquée.
Liste des équations de base qui ont été
testées pour élaborer les modèles allométriques.
(1) Linéaire : y= p0 + p1 * X
(2) Logarithmique : y= p0 + p1 *ln (X)
(3) Quadratique : y= p0 + p1 *X+ p2 *X2
(4) Cubique: y= p0 + p1 *X+ p2 *X2+ p3
*X3
(5) «Compound» : y= p0 * p1X
(6) Puissance: y= p0 *X p1
(7) «Growth»: y= exp(p0 + p1 *X)
(8) Exponentiel: y= p0 * e (p1*X)
(9) Polynomial: y= p0 * X+ p1 *X1 + p2 *
X2+ p3 * X3... p0 *Xn+p
Le test de ces régressions a été
effectué avec le logiciel SPSS et le tableau 6 donne les formules, les
coefficients de détermination et la transcription de la formule sur le
logiciel Excel.
Tableau 6. Les modèles calculés et
leur r2 (n = 101 individus)
|
Modèle
|
Formule de la régression (y=)
|
R2
|
Code Excel
|
|
Exponentiel
|
7,15*e(0,151*DBH)
|
0,827
|
=6,89*EXP(0,151*DBH)
|
|
Puissance
|
0,229*DBH(2,237)
|
0,892
|
=0,229*PUISSANCE(DBH;2,237)
|
|
Growth
|
Exp(1,967+0,149*DBH)
|
0,829
|
=EXP(1,9669+0,149689*DBH)
|
|
Quadratique
|
49,84-(10,34*DBH)+
|
0,930
|
=49,84-10,34*DBH+0,89*DBH*DBH
|
|
(0,89*DBH2)
|
|
|
|
Cubique
|
-58,18+13,61DBH-
|
0,936
|
=-58,18+13,61*DBH-0,517*
|
|
0,517DBH2+0,0225DBH3
|
|
DBH*DBH+0,0225*DBH*DBH* DBH
|
|
Compound
|
7,15*1,16DBH
|
0,829
|
=7,15*PUISSANCE(1,16;DBH)
|
|
Polynomial
|
0,0225*DBH3-
|
0,936
|
=0,0225*PUISSANCE(DBH;3)-
|
|
(ordre 3)
|
0,5167*DBH2+13,613*DBH-
|
|
0,5167*PUISSANCE(DBH;2)+13,613*DBH-
|
|
58,18
|
|
58,18
|
|
Linéaire
|
23,48*DBH-178,82
|
0,784
|
= 23,48*DBH-178,82
|
|
Log10 (LN)
|
-556,76+281,17*lnDBH
|
0,547
|
=-556,76+(281,17*LN(DBH))
|
Ces régressions montrent des performances
variées. Nous observons que les coefficients de détermination
(R2) sont très différents expliquant les
différences dans l'ajustement du modèle par rapport aux
données de base. Ainsi pour une bonne approximation de la biomasse
à partir du DBH, nous retenons les régressions de R2
supérieur ou égal à 0,9. Les modèles avec un
R2 élevé conduisent à des résidus
(écarts entre le modèle et les valeurs observés)
très faibles. Les meilleurs modèles sont alors les
régressions quadratique, cubique et polynomial. Les différents
modèles testés sont montrés à la figure 25.
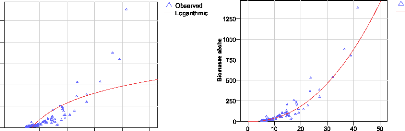
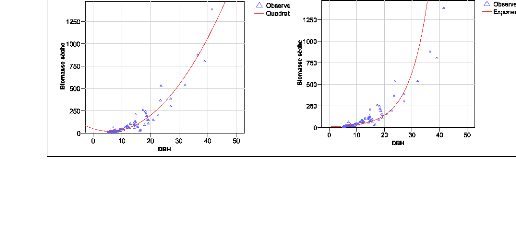
Figure 25. Représentation des courbes des
différentes régressions
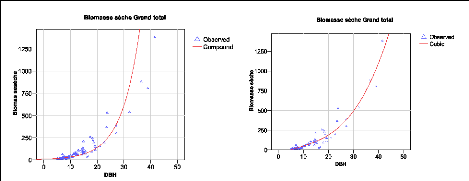
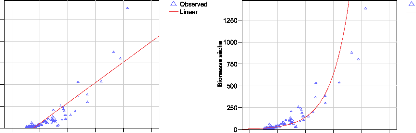

Les modèles montrant une bonne performance ont
amélioré sensiblement les résultats d'estimation de
biomasse à partir du DBH en comparaison avec ceux proposés par la
FAO. La figure 26 montre ces différences.
Figure 26. Comparaison entre les modèles
FAO et les données de terrain (grands décalage surtout par
rapport aux gros diamètres).
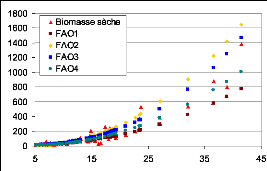
Modèles retenus (moins de décalage par rapport aux
données réelles)
DB
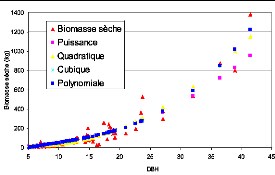
En termes de décalage (somme des résidus) entre les
estimateurs les plus performants et les mesures de biomasse, le tableau 7
montre que le polynomial donne de meilleurs résultats.
Tableau 7. Comparaison entre la biomasse
sèche (kg) et les estimations des modèles retenus.
|
Biomasse sèche
|
Puissance
|
Quadratique
|
Cubique
|
Polynomial
|
|
Total biomasse
|
10248,21 (kg mesurés)
|
9228,82
|
10194,92
|
10226,56
|
10236,12
|
|
A biomasse (résidus)
|
-1019,39
|
-53,29
|
-21,65
|
-12,09
|
|
Ordre (meilleure estimation)
|
4ème
|
3ème
|
2ème
|
1er
|
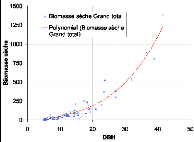
La superposition quasi-nette des modèles (figure 27)
montre que les écarts entre ces derniers sont minimes, mais certains
comme la régression polynomiale minimise mieux les écarts par
rapport aux données observées.
sa
Figure 27. Variations des mesures de biomasse
par les différents des modèles qui ont un bon coefficient de
détermination.
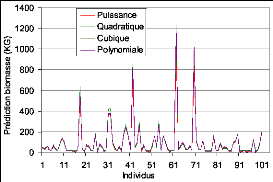
Les modèles retenus sont les plus adaptés du
fait qu'ils présentent moins de biais pour les gros diamètres et
prédisent bien les petits sujets. Dans la plupart des cas, la biomasse
des gros diamètres sont légèrement sous estimés.
Ceci pose moins de problèmes en terme de calcul d'additionalité
que dans le cas de la surestimation pour lequel on prétend comptabiliser
plus de carbone que la réalité.
Par contre, les modèles de la FAO mènent soit
à une forte sous-estimation ou à une surestimation de la biomasse
totale. Ces erreurs peuvent grandement influencer la quantification et la
caractérisation de la dynamique du carbone dans le cadre des projets
MDP. Le tableau 8 donne les résidus issus de l'application des
modèles de la FAO.
Tableau 8. Comparaison entre la biomasse
sèche (kg) et les estimations basées sur les modèles de la
FAO.
|
que Biomasse sèche
|
FAO1
|
FAO2
|
FAO3
|
FAO4
|
|
Total biomasse échantillon
|
ale
10248,21 (kg
mesurés)
|
7050,66
|
13438,96
|
11744,51
|
8424,61
|
|
? biomasse (résidus)
|
- 3197,55
|
3190,75
|
1496,3
|
-1823,6
|
|
Appréciation
|
Forte sous
estimation
|
Forte
surestimation
|
Surestimation
|
Sous
estimation
|
Les modèles proposés par Brown (1997)
présentent en général un grand décalage par 1 4 1 9
1
rapport aux grands sujets comme le montre la figure 28. Alors que
les modèles développés ndividus
présentent une différence aléatoire minime
par rapport aux données observées (figure 29).
Figure 28. Comparaison des résidus des
mesures avec les estimations de la FAO
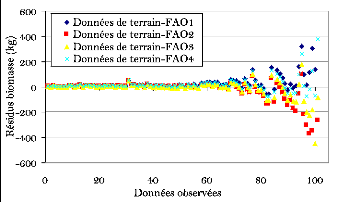
Figure 29. Comparaison des résidus des
mesures avec les modèles in situ.
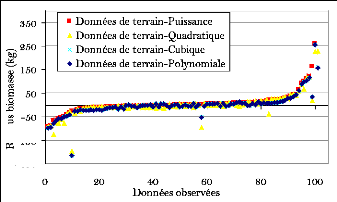
es
m
es de te
de te
L'élaboration de modèles allométriques
propres aux écosystèmes étudiés permet ainsi
Donnée de terrainQuadratique e q
d'améliorer significativement l'estimation de la biomasse
utilisant les données d'inventaire de Dées d tiPlil
la végétation. Les différences
significatives avec les modèles génériques
proposées par la 0FAO, montre qu'il est risqué d'appliquer des
modèles allométriques développés en dehors
20 40 60 80 100
des écosystèmes étudiés. Les
résultats obtenus dans ce travail peuvent permettre d'ajuster
Données observées
les estimations de carbone des projets MDP et les inventaires
de GES effectués
périodiquement pour la CCNUCC. L'absence de
régressions allométriques natives a
constitué une
source de biais pour l'estimation de la biomasse des arbres. Les nouveaux
4 0
modèles développés dans ce travail
pourraient aider à combler cette limite méthodologique.
Il faut toutefois noter que même si les modèles
obtenus permettent de mieux estimer la biomasse, il convient d'analyser leur
performance et leurs limites.
| 

