Application web. Gestion de pharmacie en Java( Télécharger le fichier original )par Leila Amri Institut supérieur de comptabilité et d'administration des entreprises Tunisie - Licence en informatique de gestion 2009 |

Conclusion et perspective
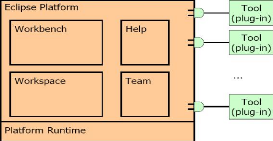
Ces composants de base peuvent être réutilisés pour développer des clients lourds indépendants d'Eclipse grâce au projet Eclipse RCP (Rich Client Platform). L'ensemble des outils de développement Java sont ensuite ajoutés en tant que plugins, regroupés dans le projet Java Development Tools (JDT). Ces plugins sont architecturés selon les recommandations de OSGi. II- Les technologies mise en oeuvre Introduction Dans le présent chapitre, Je détaille les technologies qui concernent la connexion avec la base et la persistance des données. Je m'intéresse tout d'abord à l'API JDBC destinée à la connexion avec la base de données et l'outil « Hibernate » comme outil de persistance de ces données. II-1- Les technologies d'accès aux données 1-1 Java Data Base Connectivity JDBC (Java Database Connectivity) est une API permettant de travailler avec des bases de données relationnelles. Elle permet d'envoyer des requêtes SQL à une base, de récupérer et d'exploiter le résultat ainsi que d'obtenir des informations sur la base elle même et les tables qu'elle comporte. Le code Java utilisant l'API JDBC est indépendant de la base elle même grâce à l'utilisation des pilotes spécifiques fournis par les vendeurs. On distingue quatre types de pilote JDBC :
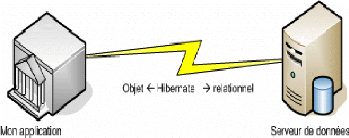
1-2 Hibernate Travailler dans les deux univers de l'orienté objet et de la base de données relationnelle peut être lourd et coûteux en temps. En effet il est plus désireux de travailler avec des objets ayant des comportements que de travailler avec des lignes et des colonnes de données, c'est pour cela qu'on a souvent recours à une couche pour faire le lien entre la représentation objet des données et la représentation relationnelle basée sur le standard SQL. Ainsi, Hibernate se propose de joindre ces deux univers et représente la solution intéressante à ce problème, permettant de gérer la persistance des données selon une architecture adaptable avec n'importe quel système de gestion de bases de données. 1-2-1 Description Hibernate est un outil qui Automatise ou facilite la correspondance entre des données stockées dans des objets et une base de données relationnelle, Le plus souvent les données sont décrites dans des fichiers de configuration (généralement XML). En effet, Hibernate se charge de la recherche et l'enregistrement des données associées à un objet dans une base de données et la détection des modifications apportées à un objet pour les enregistrer en optimisant les accès à la base. Hibernate propose une technique standard de configuration de n'importe quel système de gestion de base de données et assure la correspondance de type entre Java et SQL. On peut donc voir Hibernate comme une surcouche fine de JDBC qui lui ajouterait une dimension objet.
Fig 1 : Description de Hibernate 1-2-2 Avantages Hibernate nous évite l'écriture de code répétitif, inintéressant et source d'erreurs difficiles à déceler, de plus on peut avoir un gain de 30 à 40 % du nombre de lignes de certains projets. D'autre part cet outil améliore la portabilité du code pour des changements de système de gestion de base de données et facilite le travail du développeur qui pense en termes d'objet et
pas en termes de lignes de tables. En effet sans outil ORM le développeur peut hésiter à concevoir un modèle objet « fin » afin d'éviter du codage complexe pour la persistance 1-2-1 Architecture Application Objet Persistant SessionFactory Session Transaction TransactionFactory Connection JNDI JDBC JTA Base de données Fig 2 : Architecture de Hibernate 1' SessionFactory: Un cache threadsafe (permanent) des mappings vers une (et une seule) base de données. Une fabrique (factory) de Session et un client de ConnectionProvider. Peut contenir un cache optionnel de données (de second niveau) qui est réutilisable entre les différentes transactions. 1' Session: Un objet mono-threadé, a durée de vie courte, qui représente une conversation entre l'application et l'entrepôt de persistance. Encapsule une connexion JDBC, fabrique des objets Transaction. Contient un cache (de premier niveau) des objets persistants, ce cache est obligatoire. Il est utilisé lors de la navigation dans le graphe d'objets ou lors de la récupération d'objets par leur identifiant. 1' Transaction: Un objet mono-threadé à vie courte utilisé par l'application pour définir une unité de travail atomique Une Session peut fournir plusieurs Transactions dans certains cas. Toutefois, la délimitation des transactions, via l'API d'Hibernate ou par la Transaction sous-jacente, n'est jamais optionnelle! 1' ConnectionProvider: Une fabrique de (pool de) connexions JDBC c'est à dire gérer la file d'attente pour les connexions à la base 1' TransactionFactory: c'est une fabrique des instances de Transaction.
I- UML A l'origine de cette nouvelle notation se trouve l'OMG (Object Management Group) qui partait du constat suivant : v' les méthodes fonctionnelles ne permettaient pas d'exploiter le développement objet. Le mélange de plusieurs paradigmes n'est ni commode, ni naturel. v' Le grand nombre de méthodes n'aidaient pas le choix des utilisateurs. Les méthodes suivantes sont à la base d'UML : v' OMT (Object Modeling Technique) conçue par James Rumbaugh. v' OOD (Object Oriented Design) conçue par Grady Booch. v' OOSE (Object Oriented Software Engineering) conçue par Ivar Jacobson. Il faut insister sur le fait qu'UML n'est pas une méthode mais une notation. Il est donc possible d'utiliser la notation UML avec une démarche de conception inspirée d'OMT. La première version d'UML est sortie le 17 janvier 1997. Entre temps des partenaires importants sont venus collaborer à la mise en oeuvre de cette notation : IBM, DEC, Microsoft, Rational Rose Software, Oracle, Unisys). 1. Principes UML se veut être une notation simple, précise, et homogène, permettant un bon rendu visuel. Elle décrit le réalisé plutôt que le processus de réalisation. UML préconise de séparer les aspects fonctionnels, technologiques et architecturaux. Pour la compréhension entre les différents acteurs d'un projet UML propose des diagrammes qui vont permettre d'éclaircir les spécifications. Enfin, pour répondre à l'évolution rapide des applications, il faut pouvoir facilement effectuer un retour sur chaque phase du cycle de développement. Le cycle de vie objet qui, itératif et incrémental, permet d'effectuer ce retour. Pour la définition des systèmes, UML définit plusieurs modèles : > modèle de classe qui capture la structure statique. > modèle des états qui exprime le comportement dynamique des objets. > modèle des cas d'utilisation qui décrit les besoins de l'utilisateur. > modèle d'interaction qui décrit les scénarios et les flots de messages > modèle de réalisation qui montre les unités de travail. > modèle de déploiement qui précise la répartition du processus. Les modèles sont regardés par les utilisateurs au moyen de vues graphiques qui peuvent être soit statiques, soit dynamique. Vues statiques : + Diagramme de classes : structure statique en termes de classes et de relations. + Diagramme d'objets : instanciation des diagrammes de classes. + Diagramme de déploiement : les composants sur les dispositifs matériels. + Diagramme de composants : composants physiques d'une application. + Vues dynamiques : + Diagramme des activités : comportement d'une opération en termes d'actions. + Diagramme des cas d'utilisation : fonctions du système du point de vue l'utilisateur. + Diagramme de collaboration : représentation spatiale des objets, des liens et des interactions. + Diagramme d'états transitions : comportement d'une classe en terme d'état. + Diagramme de séquence : représentation temporelle des objets et de leurs interactions. 2. Diagrammes UML et notations 2.1. Diagramme des cas d'utilisation Ils décrivent sous la forme d'actions et de réactions le comportement d'un système du point de vue de l'utilisateur et donc le caractère fonctionnel des objets. Les besoins de chaque acteur déterminent l'ensemble des besoins d'un système. La description des cas d'utilisation développeur. Le cas d'utilisation décrit le quoi et le quoi faire et non le comment qui relève de la conception. Il comprend les acteurs, le système, et les cas d'utilisation eux-mêmes. Les acteurs sont représentés par des petits personnages, les cas d'utilisation par des ellipses. Un acteur est une personne qui interagit avec un système en échangeant de l'information (en entrée et en sortie). Délimite le système ; ils seront utilisés tout au long du cycle de vie du projet. C'est un document très important qui sert de contrat entre la personne qui a fait l'analyse et le
a Fig 1 : Représentation d'un cas d'utilisation classe 2.2. Diagramme de classe Un diagramme de classes montre la structure statique d'un système. Il permet la visualisation des classes et des relations entre elles. Son but est d'expliquer ce qu'il faut réaliser plutôt que d'expliquer comment le réaliser. Fig 2 : Représentation d'une classe 3 niveaux de visibilités pour les attributs et les opérations : > public : qui rend l'élément visible à tous les clients de la classe (symbole : caractère +) > privé : qui rend l'élément visible à la seule classe (-) > protégé : qui rend l'élément visible aux sous-classes (#). Les associations Elles représentent des relations structurelles entre classes d'objets. Elles peuvent être nommées (souvent par une forme verbale). Le nommage rend l'association plus dynamique. En précisant des rôles, il est possible de le rendre plus statique. Chaque rôle d'une association porte une indication de multiplicité qui montre combien Rô1 Rô2 d`objets de la classe considérée peuvent être liées à un objet de l'autre classe. - 1..1 : un et un seul - 0..1 : zéro ou un - M..N : de M à N - « * » : de zéro à plusieurs - 0..* : de zéro à plusieurs - 1..* : de un à plusieurs
Fig 3 : Représentation d'une association Les agrégations Une des extrémités d'une association joue un rôle plus important : > une classe fait partie d'une autre classe. > les valeurs et attributs d'une classe se propagent dans les valeurs et attributs d'une Classe2 autre classe. > l'agrégation ne concerne qu'un seul rôle de l'association. La composition est une agrégation particulière qui met en valeur l'idée de contenance (traduction des notions « est composé de » ou « est parti de »).
Fig 4 : Représentation d'une relation d'agrégation La généralisation (héritage) : La généralisation s'opère entre un élément plus général et un élément plus spécifique. Elle s'applique plus particulièrement aux classes, aux paquetages et aux cas d'utilisation. La généralisation signifie : est un ou une sorte de. Les attributs, les opérations et les contraintes sont hérités intégralement dans les sous-classes. L'héritage est plus facilement utilisé au niveau de la programmation.
Fig 5 : Représentation d'une relation d'héritage 2.3. Diagramme d'objets Les diagrammes d'objets sont des cas illustrés des diagrammes de classe. Selon un contexte, sse file1 ils montrent la relation entre les objets. Deux compartiments permettent de les décrire. Le Classe fle2 premier qui représente les instances de classe qui sont soulignées. Le deuxième décrit les attributs. Les objets sont reliés par des liens qui sont des instances des relations. Le diagramme d'objet est plus « parlant » qu'un diagramme de classe. Les associations réflexives sont représentées par une boucle qui relie l'objet à lui méme. Les valeurs des clés de restriction des associations peuvent également être ajoutées dans les diagrammes d'objets. 2.4. Diagramme des séquences Les diagrammes de séquence montrent des interactions entre objets selon un point de vue temporel. La représentation se concentre sur l'expression des interactions. Un objet est représenté par un rectangle et une barre verticale appelée ligne de vie de l'objet. Les objets communiquent en échangeant des messages représentés par des flèches horizontales, orientées de l'émetteur du message vers le destinataire. L'ordre d'envoi des messages est montré par la position sur l'axe vertical. En modélisation objet, les diagrammes de séquence s'utilisent de deux manières bien différentes, selon la phase du cycle de vie et le niveau de détail désiré. La première utilisation sert à la documentation des cas d'utilisation ; elle se concentre sur la description de l'interaction (terme proche de l'utilisateur, sans entrer dans les détails de la synchronisation). La deuxième utilisation permet la représentation précise des interactions entre objets. 2.5. Diagramme de collaboration Les diagrammes de collaboration sont une extension des diagrammes d'objet. Ils montrent les interactions entre objets et visent à représenter du point de vue statique et dynamique les objets impliqués dans la mise en place d'une fonction applicative. Le formalisme utilisé pour décrire le contexte est celui des modèles objets ; celui utilisé pour décrire les interactions est celui des scénarios. Les messages qui se déroulent de façon séquentielle sont numérotés car le temps n'est pas représenté de manière implicite. 2.6. Diagramme d'états-transitions Un diagramme d'états fait intervenir des événements et des états, il est donc composé d'un ensemble de transitions. Il est propre à une classe donnée : ce diagramme décrit les états des objets de cette classe, les événements auxquels ils réagissent et les transitions qu'ils effectuent. 2.7. Diagramme d'activités Ce sont des variantes des diagrammes d'états-transitions. Ils servent à représenter le comportement interne d'une méthode ou d'un cas d'utilisation. L'intérêt est d'avoir une représentation simplifiée des activités. L'activité apparaît comme un stéréotype d'état. Elle est représentée par un rectangle arrondi (plus large que les états). Les activités peuvent être regroupées par objet (découpage vertical). Il est possible de voir clairement les relations entre objets. Il est également possible de représenter les activités comme dans un diagramme de séquence. Les activités apparaissant alors sur la ligne de vie des objets. 2.8. Diagramme de composants Il permet de décrire : ? les modules qui décrivent l'interface de la classe et sa réalisation. ? les dépendances entre composants (ex. : l'ordre de compilation des composants et les relations entre composants). > les programmes principaux > les sous-programmes spécifiques (non rattachés à des classes). ? les sous-systèmes (environnement de compilation). 2.9. Diagramme de déploiement Ce diagramme décrit l'interaction entre les programmes exécutables et les environnements matériels. II- Processus unifié
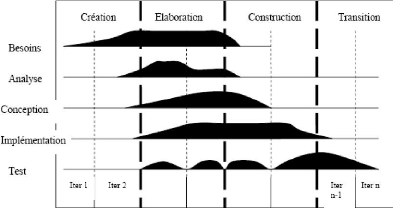
Fig 6 : Les cinq activités se déroulant dans chaque phase. v' Inception (Incubation): c'est la première phase du processus unifié. Il s'agit de délimiter la portée du système, c à d tracer ce qui doit figurer à l'intérieur du système et ce qui doit rester à l'extérieur, identifier les acteurs, lever les ambiguïtés sur les besoins et les exigences nécessaires dans cette phase. Il s'agit aussi d'établir une architecture candidate, c à d que pour une première phase, on doit essayer de construire une architecture capable de fonctionner. Dans cette phase, il faut identifier les risques critiques susceptibles de faire obstacles au bon déroulement du projet. v' Elaboration : c'est la deuxième phase du processus. Après avoir compris le système, dégagé les fonctionnalités initiales, précisé les risques critiques, le travail à accomplir maintenant consiste à stabiliser l'architecture du système. Il s'agit alors de raffiner le modèle initial de cas d'utilisation, voire capturer de nouveaux besoins, analyser et concevoir la majorité des cas d'utilisation formulés, et si possible implémenter et tester les cas d'utilisation initiaux. v' Construction : dans cette phase, il faut essayer de capturer tous les besoins restants car il n'est pratiquement plus d'utilisation. A la fin
de cette phase, les dans la prochaine phase. Ensuite, continuer l'analyse, la conception et surtout l'implémentation de tous les cas v' Transition : c'est la phase qui finalise le produit. Il s'agit au cours de cette phase de vérifier si le système offre véritablement les services exigés par les utilisateurs, détecter les défaillances, combler les manques dans la documentation du logiciel et adapter le produit à l'environnement (mise en place et installation.
Architecture 3 -Tiers Annexe C
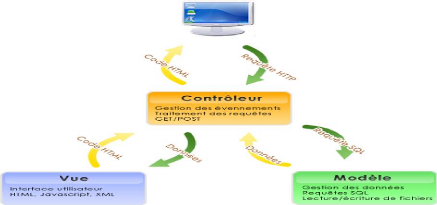
Il est évident que les méthodes et les outils choisis pour concevoir et développer une application doivent être en fonction de l'environnement et du domaine d'application de celleci. Cela est bien expliqué par le génie logiciel. Dans ce chapitre je va mettre l'accent sur les avantages de l'approche orienté objet, les architectures n-tiers et l'approche du Model View Control (MVC) et en dernier lieu justifier notre choix sur les méthodes et outils à appliquer pour faciliter notre tache.
Parmi les avantages de cette approche, on peut citer : la réutilisabilité des éléments (objets), l'avantage d'utiliser un objet de base afin de produire un autre qui peut être une amélioration de cet objet (phénomène d'héritage), etc. L'objet est le coeur de cette approche. Tout objet donné possède deux caractéristiques : ? Son état courant (attributs) ? Son comportement (méthodes) En approche orientée objet on utilise le concept de classe, celle-ci permet de regrouper des objets de même nature. Une classe est un moule (prototype) qui permet de définir les attributs (champs) et les méthodes (comportement) à tous les objets de cette classe. > J2EE : (Java 2 Entreprise Edition) représente essentiellement des applications d'entreprise. Gela inclut le stockage sécurisé des informations, ainsi que leur manipulation et leur traitement. Ges applications peuvent avoir des interfaces utilisateurs multiples, par exemple une interface Web pour les clients, accessible sur Internet et une interface graphique déployée sur les ordinateurs de l'entreprise sur le réseau privé de celle-ci. J2EE offre un ensemble de composants standardisés facilitant le déploiement des applications, des interfaces définissant la façon dont les modules logiciels peuvent être interconnectés, et les services standards, avec leur protocole associé, grâce auxquels ces modules peuvent communiquer. III- Architecture 3-tiers : L'architecture 3-tiers ou architecture à trois niveaux est l'application du modèle plus général qu'est le multi-tiers. L'architecture logique du système est divisée en trois niveaux ou couches :
Elle correspond à la partie fonctionnelle de l'application, celle qui implémente la « logique », et qui décrit les opérations que l'application opère sur les données en fonction des requêtes des utilisateurs, effectuées au travers de la couche présentation. Les différentes règles de gestion et de contrôle du système sont mises en oeuvre dans cette couche. La couche métier offre des services applicatifs et métier à la couche présentation. Pour fournir ces services, elle s'appuie, le cas échéant, sur les données du système, accessibles au travers des services de la couche inférieure. En retour, elle renvoie à la couche présentation les résultats qu'elle a calculés.
Elle consiste en la partie gérant l'accès aux gisements de données du système. Ces données peuvent être propres au système, ou gérées par un autre système. La couche métier n'a pas à s'adapter à ces deux cas, ils sont transparents pour elle, et elle accède aux données de manière uniforme (couplage faible).
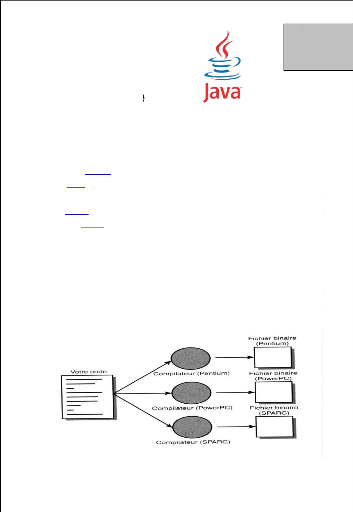
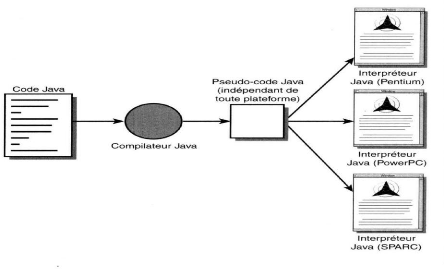
Annexe D Langages Utilisé I. Java : C'est un langage de programmation orienté objet, développé par Sun Microsystems. Il permet de créer des logiciels compatibles avec de nombreux systèmes d'exploitation (Windows, Linux, Macintosh, Solaris). Java donne aussi la possibilité de développer des programmes pour téléphones portables et assistants personnels. Enfin, ce langage peut-être utilisé sur internet pour des petites applications intégrées à la page web (applet) ou encore comme langage serveur (jsp). 1. Les avantages de Java : L'un des avantages évidents de ce langage est une bibliothèque d'exécution qui se veut indépendante de la plateforme: en théorie, il vous est possible d'utiliser le même code pour Windows 95/98/NT, Solaris UNIX Macintosh, etc. Cette propriété est indispensable pour une programmation sur Internet (cependant, par rapport à la disponibilité sur Windows et Solaris les implémentations sur d'autres plates-formes ont toujours un léger décalage). a. Architecture classique avec un bytecode différent pour chaque processeur.
b. Architecture Java, le bytecode passe par l'intermédiaire d'un interpréteur. 2. Caractéristiques Les créateurs de Java ont écrit un livre blanc qui présent les caractéristiques fondamentales de Java. Ce livre est articulé autour des 11 termes suivants : > Distribué Java possède une importante bibliothèque de routines permettant de gérer les protocoles TCP/IP tels que HTTP et FTP. Les applications Java peuvent charger et accéder à des sur Internet via des URL avec la même facilité qu'elles accèdent à un fichier local sur le système. « Nous avons trouvé que les fonctionnalités réseau de Java sont à la fois fiables et d'utilisation aisée. Toute personne ayant essayé de faire de la programmation pour Internet avec un autre langage se réjouira de la simplicité de Java lorsqu'il s'agit de mettre en oeuvre des tâches lourdes, comme l'ouverture d'une connexion avec un socket. De plus, Java rend plus facile l'élaboration des scripts CGI (Common Gateway Interface), et un mécanisme élégant, nommé servlet, augmente considérablement l'efficacité du traitement côté serveur, assuré par Java. De nombreux serveurs Web, parmi les plus courants, supportent les
servlets. Le mécanisme > Fiabilité Java a été conçue pour que les programmes qui l'utilisent soient fiables sous différents aspects. Sa conception encourage le programmeur à traquer préventivement les éventuels problèmes, à lancer des vérifications dynamiques en cours d'exécution et à éliminer les situations génératrices d'erreurs... La seule et unique grosse différence entre C++ et Java réside dans le fait que ce dernier intègre un modèle de pointeur qui écarte les risques d'écrasement de la mémoire et d'endommagement des données. > Orienté objet Pour rester simples, disons que la conception orientée objet est une technique de programmation qui se concentre sur les données (les objets) et sur les interfaces avec ces objets. Pour faire une analogie avec la menuiserie, on pourrait dire qu'un menuisier "orienté objet "s'intéresse essentiellement à la chaise l'objet qu'il fabrique et non à sa conception (le "comment"). Par opposition, le menuisier "non orienté objet " penserait d'abord au comment.
Le langage SQL (Structured Query Language) peut être considéré comme le langage d'accès normalisé aux bases de données. Il est aujourd'hui supporté par la plus part des produits commerciaux aussi bien par les systèmes de gestion de bases de données micro comme Access que par les produits plus professionnels tels qu'Oracle ou Sybase. Le succès du langage SQL est du essentiellement à sa simplicité et au fait qu'il s'appuie sur le schéma conceptuel pour énoncer des requêtes en laissant le SGBD responsable de la stratégie d'exécution. Le langage SQL propose un langage de requêtes en laissant le SGBD responsable de la stratégie d'exécution. Le langage SQL propose un langage de requêtes ensembliste. Le langage SQL comporte : -Un langage de Définition des Données (LDD) qui permet de définir des relations, des vues externes et des contraintes d'intégrité. -Un langage de Manipulation de Données (LMD) qui permet d'interroger une base de données sous forme déclarative sans se préoccuper de l'organisation physique de données. -Un langage de Contrôle des Données (LDD) qui permet de contrôler la sécurité et les accès aux données.
Résumé: Ce projet consiste à développer une application permettant à la pharmacie de gérer le stock des médicaments, les ordonnances ainsi que le processus d'achat : commande et livraison. L'environnement de mon projet est Eclipse Galileo. J'ai eu recoure, le long de ce projet au concept UML de conception. Le syst~me a été développé à l'aide du langage Java, utilisant comme base de données Oracle. Mots clés: Gestion des médicaments, Gestion d'ordonnances, Java., Oracle. íÎHÊ ÒJÊ ãiÙæ æ ,ÊíæÏáÇ äæÔÎ~ ÉÑÇÏÅ åT Ê~~Ð~p Ç åIãí ÞIÈ~Ê ÒíllÊ í ÇÐå íÚæÒÔ~ áËã~í . ÚíÓ~~~Ç æ ÈáT Ç :ÁÇÒÔ~Ç Ê~áãÚ æ Ê(È3 Ç Ê~ÕIÇ í ã~Ùì~Ç ËÑ~Ø . "L0U " ã~Ùæ ìáÚ íËÍ~ Êá~Ø ËÐã~ÚÇ ÐÞ~ æ " o eliSac eslilcE "~å íáãÚ Ñ~ØÅ äÅ . Oracle Ë171I~ ìáÚ ß~Ðß ËÐã~ÚÇ æ « Java» æÞ Java, Oracle" Ê~ÈI Ç Ë~TÕI~Ç í ÒJ~~Ç ,ÊíæÏáÇ í ÒJ~~Ç :ÍíÊ~ãáÇ Ê ãHß Abstract: This project consists in developing an application enabling the chemist to run their drug storage, the medical prescriptions as well as the purchase process: orders and deliveries. The environment of my project is Eclipse Galileo. All this project long, I've used the concept UML design. The system has been realized with java language using oracle as data basis. Key words: management medicines, management ordonnances, Java, Oracle |
| ||||||||||||||||||||