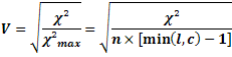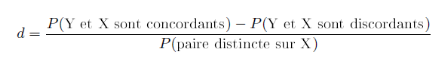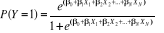Les déterminants du mauvais état de santé auto- déclaré au Cameroun: une analyse à partir des données d'ECAM 3( Télécharger le fichier original )par Nino Alfredo NDJONDO SANDJO Université de Ouagadougou Institut supérieur des sciences de la population - Master en population et santé 2012 |

II.2.3. Evaluation des données de l'ECAM3L'évaluation de la qualité des données est une étape importante dans les études démographiques. Elle vise à déceler les erreurs et les incohérences entachées à ces données et éventuellement à procéder à leur ajustement. Fort de cela, il nous parait nécessaire, avant l'étape de l'analyse des données d'évaluer leur qualité. A cet effet, en dépit de la qualité et de la rigueur appliquée par l'INS, les données de l'ECAM3 ont fait l'objet d'une évaluation sommaire avant leur analyse. Pour cela nous avons opté uniquement pour l'appréciation de l'exhaustivité des variables d'études. a) Exhaustivité des variables L'évaluation des taux de réponse des variables retenues pour l'étude permet de déceler les erreurs éventuelles qui peuvent entacher les analyses, et d'apprécier la précision des estimateurs qui en résulteront. En effet, un taux de non réponse supérieur à 10% pour les variables, affecte sensiblement la précision des estimations, cause des biais de représentativité et entraîne des pertes importantes d'informations. L'exploitation de la base des données de l'enquête ECAM3 montre que le taux de réponse enregistré pour chacune des variables de notre étude est supérieur à 99%. Si l'on s'en tient à ces proportions de non déclarés, on peut conclure que les données relatives à ces variables sont relativement d'assez bonne qualité. II.2.4. Méthodes d'analyse des donnéesPlusieurs méthodes statistiques ont été utilisées pour tester les hypothèses énoncées précédemment. En effet, nous avons successivement fait recours à une analyse statistique univariée, bivariée et multivariée. Les données ont été analysées avec les logiciel SPSS (Statistical Package for Social Sciences) version 18.0 et Microsoft Excel 2007. a) Analyse statistique univariée S'agissant de l'analyse statistique univariée, il s'est agit de faire un calcul des fréquences relatives des différentes variables afin d'étudier les effectifs et les différentes modalités des variables. Pour cela, nous avons procédé à un recodage systématique des variables avant de présenter un tableau descriptif de notre échantillon. b) Analyse statistique bivariée L'intérêt de l'analyse bi-variée est d'étudier les associations brutes entre les différentes variables indépendantes et le mauvais état de santé auto-déclaré (variable dépendante). Elle permet de rechercher les relations statistiques, en fonction des hypothèses, sur le sens de la relation entre chacune des variables explicatives et la variable à expliquer. La significativité des relations est effectuée par des tests statistiques spécifiques dont le choix a été fait en fonction de la nature des variables explicative et à expliquer. A cet effet, la variable à expliquer dans cette étude est ordinale car nous estimons qu'il est existe un ordre (détérioration progressive) dans le passage d'un bon état de santé auto-déclarée à un mauvais état de santé auto-déclarée. Sous cette assertion, à chaque fois que la variable explicative était également ordinale, la mesure d'association retenue a été le D de Somers. Dans le cas où on a eu à faire avec une variable explicative nominale, nous avons plutôt fait recours au V de Cramer. Le V de Cramer est une mesure de l'intensité de l'association entre deux variables dont l'une est nominales (ou une variable nominale et une variable ordinale). Il se base sur le calcul d'un ÷² maximal obtenu théoriquement à l'aide d'un tableau de contingence : ce dernier aurait alors une seule case non nulle par ligne ou par colonne (selon que le tableau a plus de lignes ou plus de colonnes). Ce ÷² max théorique est égal à l'effectif multiplié par le plus petit côté du tableau (nombre de lignes ou de colonnes) moins 1. Le V de Cramer est obtenu en faisant la racine carrée du ÷² divisé par le ÷² max.
Plus V est proche de zéro, plus il y a indépendance entre les deux variables étudiées. Il vaut 1 en cas de complète dépendance. Ø Le D de Somers Le d de Sommers se définit comme une différence de probabilité et dont la normalisation s'effectue uniquement par rapport aux paires distinctes sur la variable indépendante X. Elle mesure l'association des paires concordantes versus les paires discordantes uniquement pour les variables ordinales.
Il atteint la valeur +1 pour association monotone prédictive stricte positive c'est-à-dire que lorsque X augmente, Y augmente, et à chaque valeur de X (explicative, indépendante) correspond une et une seule valeur de Y (expliquée, dépendante). A contrario, la valeur -1 correspond à une association négative, dans ce cas, quand X augmente, Y diminue. Lorsque les variables sont indépendantes, d est égal à 0. c) Analyse statistique multivariée Les étapes d'analyse précédentes ont permis déjà de soupçonner certaines relations statistiques entre les variables, il s'est avéré nécessaire de prendre en compte l'ensemble des variables dans une approche multivariée. Le but étant de faire ressortir l'effet net de chaque variable indépendante sur la variable à expliquer. Ainsi, compte tenu de la nature dichotomique de la variable dépendante, le modèle d'analyse explicatif utilisé est la régression logistique. En effet, c'est une forme de régression multiple où la variable à expliquer est dichotomique et les variables explicatives catégorielles, discrètes ou continues. Son principe est de rendre dichotomique chaque variable nominale ou catégorielle figurant parmi les variables explicatives en autant de variables artificielles que la variable a de modalités moins une unité. Ainsi, pour N variables explicatives catégorielles ayant chacune K modalités par exemple, le modèle de régression logistique fournit N*(K-1) paramètres qui s'interprètent comme la variation de l'effet d'appartenir à la catégorie par rapport à l'effet d'appartenir à la catégorie de référence. Il est également important de rappeler que la variable dépendante est transformée sous forme de probabilité. Il s'agit donc de mesurer l'effet de certaines variables indépendantes sur une variable dépendante qui peut essentiellement prendre les valeurs comprises entre 0 et 1. La formalisation mathématique de la régression logistique se présente comme suit :
Avec : - P (Y=1), la probabilité qu'un individu se déclare en mauvais état de santé. Elle est donc comprise entre 0 et 1; - ß0, la constante du modèle. Autrement dit la contribution des autres variables inconnues (ou non pris en compte dans le modèle) dans la probabilité de déclarer un mauvais état de santé; - ßi (avec i allant de 1 à N), le coefficient respectif lié à la variable indépendante Xi. C'est la contribution marginale de cette variable sur la probabilité qu'un individu se déclare en mauvais état de santé. Autrement dit c'est l'impact d'une unité de plus sur le log des chances (ratio des probabilités). Une autre façon d'interpréter ces coefficients est de les insérer dans la formule des chances. C'est cette dernière option que nous avons retenu dans le cadre de ce travail. Dans ce cas, obtient pour chaque modalité un rapport de cote. Lorsque ce dernier est supérieur à un, alors les individus ayant la caractéristique correspondante ont plus de chance de réaliser le phénomène étudié par rapport aux individus de référence (modalités de référence). Si par contre le rapport de cote est inférieur, ils auront moins de chance. Lorsqu'il est égal à 1 c'est la même chance. Ce modèle d'analyse permet de faire ressortir l'effet des variables explicatives sur la variable à expliquer et de tester l'intensité et le sens des effets escomptés. Chaque variable indépendante a été introduite d'abord individuellement dans le modèle afin de déterminer leurs effets bruts respectifs. Ensuite les variables ont été introduites par différents groupes (démographiques, économiques, socioculturels, ressources sociales et mode de vie) dans le but d'observer l'évolution du R-deux de chaque modèle et le comportement de chacune des variables explicatives introduites. Enfin, la réalisation d'un modèle comportant l'ensemble des variables de l'analyse a permis de faire ressortir les effets nets de chaque variable explicative sur l'auto-déclaration d'un mauvais état de santé au Cameroun. |
|