UNIVERSITE PEDAGOGIQUE NATIONALE
B.P 8815 KINSHASA
FACULTE DES SCIENCES
ANNEE ACADEMIQUE 2015 - 2016
TSHIAMUA MUDIKOLELE Juslin
Assistant
RAPPORTEUR : Armel MBENZA
Dr Professeur
DIRECTEUR : Pierre KAFUNDA
KATALAY
ORIENTATION : CONCEPTION DES SYSTEMES
D'INFORMATIONS
MEMOIRE DE FIN DE D'ETUDES PRESENTE ET DEFENDU EN VUE DE
L'OBTENTION DU TITRE DE LICENCIE EN SCIENCES
L2 CONCEPTION DES SYSTEMES D'INFORMATION
MISE EN OEUVRE D'UN SYSTEME DISTRIBUE POUR
L'IDENTIFICATION ET SUIVI DU CASIER JUDICIAIRE
« Cas du Service de casier judiciaire de
Kinshasa »
DEPARTEMENT DES MATHEMATIQUES ET INFORMATIQUE

Epigraphe
En informatique, laminiaturisation augmente la puissance de
calcul. On peut être plus petit et plus intelligent.
Bernard Weber
Dédicace
A Toi Eternel Dieu, source intarissable ; Toi qui nous as
rendus complètement, complètement et absolument complets en
Christ Jésus. Gloire et honneur sont à Toi pour Ton amour
incommensurable envers nous depuis Ta préscience.
A nos parents : Marie Léonie MILOLO TSHIAMUA et
Jean Oscar NYEMBUE TSHIMANGA, qui nous ont soutenu, fortifié et
encouragé, sur tous les plans, durant notre parcourt
académique.
A vous nos frères et soeurs : Suzanne KALANGA
MUAMBADIMUE et votre époux Christian KANKU, Jean Pierre NGANDU MULUMBA
MUPANGA, Marguerite NGALULA TSHIENAMUILA et votre époux Henri MUABILA,
Pauline MILOLO DIKEBELE, Petit Jean NYEMBUE TSHIMANGA, Xavier KENATSHIANDI
BIPENDU et Madeleine YUWANGA KAKUMESA.
A vous oncles : Jean Pierre BADIBANGA TSHIPAMBA et
Albertine KABENA, Jean François BUTEKA.
A vous tous nos cousins et cousines ;
A vous nos frères et soeurs en Christ ;
A vous nos très chers, vous avec qui l'estime est
partagée : Christian LUKETA KANYINDA Browser, Aaron NTUMBA NGINDU
et Goshen MULANGA TSHIVUILA, Rebecca MULUNDA MUIMPE.
A tous ceux que nous aimons et qui nous aiment ;
A tous ceux, de loin ou de près, ont participé
à l'élaboration de ce travail ;
Je dédie ce travail.
Avant-propos
Au terme du cycle de licence, et selon des dispositions
réglementaires régissant l'organisation de l'Enseignement
Supérieur et Universitaire en République Démocratique du
Congo, un travail scientifique doit être présenté par tout
finaliste en vue de sanctionner la fin de sa formation.
C'est à ce titre que ce travail, le fruit de multiples
sacrifices et durs labeurs, a été rédigé.
Puisse-t-il dore et déjà constituer une documentation pour le
monde scientifique en général et pour quiconque serait
passionné d'abonder dans ce même domaine en particulier.
Sur ce, saisissons-nous cette ultime opportunité en vue
de nous acquitter d'un noble devoir, celui d'exprimer notre gratitude au regard
de tous ceux qui ont contribué d'une manière ou d'une autre
à sa complète réalisation.
Nous remercions avec vivacité les Corps
Académique et scientifique de la Faculté des Sciences en
général et celui du Département de Mathématique et
Informatique en particulier, d'avoir mis à notre disposition d'aussi un
personnel qualifié pour notre formation.
A vous Monsieur le Professeur Docteur KAFUNDA KATALAY Pierre,
nonobstant la charge de votre calendrier, avez fait montre d'une preuve
d'éducateur au style rare et dont nous rendons témoignage.
L'élève étant le meilleur inspecteur de son
maître ! Vos remarques et suggestions ainsi que vos conseils si
stratégiques ont pu marquer notre coeur.
A nos parents : Maman Marie Léonie MILOLO TSHIAMUA
et Papa Jean Oscar NYEMBUE TSHIMANGA, ce travail est le fruit de votre amour et
le souci de notre avenir.
A toi notre frère Jean Pierre NGANDU MULUMBA MUPANGA,
tu es dans nos accolades pour aussi bien tes conseils, ta morale que ton
soutien. Nos cordiales gratitudes !
A vous camarades, vous qui avez tenu ensemble d'avec nous
durant tous les cinq ans durant : NGALULA MULUMBA Dyna, TSHIPAMBA KAPUKU
Thierry, MUAMBAYI KALONJI Arnold, MAWETE MALONGO Lovecia, KABAMBA NGOLO Marcel,
MUAKA NTELA Difi, LIKOTELO BINENECamile, MUAMBA MUKENDI Emmanuel ;
Nos cordiales gratitudes à vous tous qui nous avez
aidé d'une façon ou d'une autre, nous pensons à
l'assistant Eddy KIOMBA KAMBILO, à mon frère Sébastien
KASONGA KAYASA.
Notre particulière gratitude s'adresse également
à nos collègues de services, Alain MITEU MUAMBA, Basile MUAMBA
NDUBA, Ange KULUTU NGIMI et à toute la famille AMISTECH.
Nous ne saurons terminer sans remercier de tout coeur toutes
les personnes, membres des familles, toutes comprises, amis et connaissances
qui ont cru à cet aboutissement, qu'ils veuillent bien se
reconnaître dans ce travail.
A vous tous enfin, dont l'anonymat n'affecte en rien cet
attachement indélébile qui nous lie, trouvez ici l'expression de
notre gratitude ainsi que notre sympathie de reconnaissance. Merci !
Liste des
abréviations
|
ACID :
Atomicité-Cohérence-Isolation-Durabilité
|
|
ADN : Acide Désoxyribonucléique
|
|
BD : Base de Données
|
|
BOT : Begin Of Transaction
|
|
BP : Bordereau de Paiement
|
|
CJ : Casier Judiciaire
|
|
CN : Certificat de Naissance
|
|
DAF : Division Administrative et Financière
|
|
DFC : Division du Fichier Central
|
|
DI : Division Informatique
|
|
DIJ : Direction de l'Identité Judiciaire
|
|
ECJ : Extrait du Casier Judiciaire
|
|
ED : Empreinte Digitale
|
|
EOT : End Of Transaction
|
|
FD : Fiche Décadactylaire
|
|
OLAP :OnLineAnalyticalProcessing
|
|
OLTP : OnLine Transaction Processing
|
|
P2P : Peer-to-peer
|
|
PID : Pièce d'Identité
|
|
RMI : Remote Method Invocation
|
|
SGBD : Système de Gestion de Bases de
Données Réparties
|
|
SQL : StructuredQueryLanguage
|
|
UML : UnifiedModelingLanguage
|
|
VSAT : Very SamllAparture Terminal
|
Liste des figures
Figure I.1 : Représentation d'un Système
Distribué
Figure I.2 : Exemple d'un Système
Distribué
Figure I.3 : Fonctionnement du modèle
Client-Serveur
Figure I.4 : Architecture pair à pair
Figure II.5 : Exemple de Base de données
répartie
Figure II.6 : Types de Base de données
répartie
Figure II.7 : Représentation de la conception
ascendante
Figure II.8 : Représentation de la conception
descendante
Figure II.9 : Représentation asymétrique
synchrone
Figure II. 10 : Représentation asymétrique
asynchrone
Figure II.11 : Représentation symétrique
synchrone
Figure II.12 : Représentation symétrique
asynchrone
Figure II.13 : Représentation d'une transaction
Figure II.14: Architecture peer-to-peer
Figure II.15: Architecture Client Serveur de SGBD
Répartie
Figure II.16 : Architecture répartie avec SGBD
répartie homogène
Figure II.17 : Architecture avec Multi SGBD
Figure II.18 : Architecture répartie avec SGBD
fédérée
Figure III.19 : Représentation d'une architecture
d'un système biométrique
Figure III.20 : Capture d'une empreinte digitale
Figure III.21 : Exemple des catégories des
empreintes digitales
Figure III.22 : Différentes formes des minuties
Figure III.23 : Points singuliers d'une empreinte
digitale
Figure III.24 : Squelettisation des empreintes
digitales
Figure III.25 : Exemple de repérage des
minuties
Figure III.26 : Extraction des minuties d'une empreinte
digitale
Figure III.27 : Authentification par empreinte
digitale
Figure VI.28 : Représentation du diagramme de cas
d'utilisation
Figure VI.29 : Représentation du diagramme
d'activité
Figure VI.30 : Représentation du diagramme de
classe
Figure VI.31 : Représentation du schéma
global
Figure VI.32 : Représentation du schéma
local
0. INTRODUCTION
Actuellement, toute organisation se veut d'un fonctionnement
approprié dans le cadre d'une gestion optimale des informations dont
elle engage. Etant donné qu'il y ait une masse d'informations devant
être gérée, un besoin de base de données
bien-maintenue s'impose pour assumer cette gestion.
Certes, au jour le jour, la course à la
productivité se fait sentir et le besoin d'innover se fait voir dans le
but de faire avancer de plus en plus des nouvelles technologies de sorte que
les ressources que dispose chaque entité soient partagées en
toute facilité au sein d'une organisation.
La même problématique se pose dans le secteur
judiciaire, lorsqu'il y a des crimes qui se commettent d'une façon ou
d'une autre et aussi d'un coin à un autre. En effet, l'on ne parvient
pas à maitriser l'état d'une personne ayant été
détenue pour un délit à un endroit lorsqu'elle a eu
à en commettre à un autre.
De ce fait, la maitrise de ce mécanisme serait
quasi-impossible aussi longtemps que ce système s'opère
manuellement dans toute l'étendue de la République
Démocratique du Congo et principalement dans la ville province de
Kinshasa.
Or, l'informatique a apparu pour faciliter le traitement
automatique des processus dans le monde actuel en faisant naitre
différentes technologies pour parvenir à tout contrôler et
à bien développer beaucoup de secteurs là où le
traitement manuel semblait encore inefficace.
De nos jours, nos établissements ou institutions
contiennent des informations importantes à gérer tout en
étant géographiquement dispersées dans toute
l'étendue du pays alors qu'elles ne cessent d'accroitre au jour le jour
aussi.De ce fait, il devient de plus en plus important de mettre en place des
systèmes tendant à gérer dans des environnements
complexes.
Ceci étant, nos organisations judiciaires,aujourd'hui,
fonctionnent sous une mission stratégique pour laquelle les informations
de chaque individu ayant un dossier judiciaire devraient êtredisponibles
partout dans le but d'un suivi permanent de ceux-ci quelque soit leur position
géographique.
C'est ainsi que le recours à la technique de
système distribué est très nécessaire pour arriver
à prendre en compte tout ce processus en vue d'arriver à un
fonctionnement approprié. Ce concept reste un aspect plus motivant dans
l'amélioration des performancesdans le cadre du partage des ressources
d'une organisation.
C'est dans ce cadre que notre travail émet son
importance au travers ce concept de système distribué dans le
processus de suivi du casier judiciaire.
0.1. PROBLEMATIQUE
Le service du casier judiciaire est le seul en charge de
sceller le passé et de suivre la conduite de chaque individu en
République Démocratique du Congo. Ceci étant, le grand
problème s'enregistre dans le cadre de traitement des informations
relatives à chaque individu aussi longtemps que ce travail, demeurant
encore manuel, s'effectue de façon centralisée.
De ce fait, toutes les données de chaque province sont
compilées et envoyées à la direction centrale à
Kinshasa pour être traitées afin d'identifier chaque individu et
de ficher ses informations s'il est condamné afin de le suivre. Ce qui
est théoriquement faisable mais pratiquement de la mer à
boire.
Par-dessus tout, ce travail ne pourra arriver à
satisfaire de façon optimale le pays en matière de suivi
permanent, vu sa complexité, alors que chaque institution judiciaire,
quelque soit son cercle géographique, doit avoir en temps réel,
les données de chaque individu de la république concerné
afin de garantir son suivi.
En effet, l'objectif poursuivi dans ce travail est de
développer une application informatique distribuée, après
une bonne étude sur les systèmes distribués, qui permettra
à nos institutions judiciaires de coopérer facilement grâce
à la disponibilité des données et au partage des
informations afin de suivre en temps réel le casier judiciaire de chaque
citoyen congolais concerné par le cas.
Eu égard à ce qui précède, nous
nous sommes posé des questions suivantes dans le but de mettre en oeuvre
un système distribué de suivi de casier judiciaire :
· Comment arriver à garantir la
disponibilité des services dans des institutions judiciaires pour
un suivi permanent des individus aussi longtemps que ces premières sont
dispersées géographiquement dans toute la
République ?
· Le traitement éventuel des informations
relatives à chaque individu peut-il être facilité par la
distribution ?
· Lors d'un crime ou délit commis par un
prévenu, le système pourrait-il être à mesure de
fournir des informations fiables à son propos?
· L'instauration du casier judiciaire informatisé
pourrait-il occasionner une réduction de taux de crimes ou de
délits en République Démocratique du Congo ?
0.2. HYPOTHESE
La disponibilité des services reste une
caractéristique évidente au sein des organisations actuelles
voulant des grandes performances dans le traitement de leurs informations. Pour
ce faire, la grande solution à mettre en oeuvre reste l'implantation des
systèmes distribués lorsqu'il y a augmentation de la
globalité en vue de permettredavantage le partage des ressources en vue
d'un fonctionnement approprié.
0.3. CHOIX ET INTERET DU
SUJET
L'intérêt de ce travail est d'ordre scientifique
parce qu'il présente le cas pratique de l'application concret du concept
de système distribué.
D'une part, il nous permet d'enrichir les connaissances
acquises en matière des systèmes d'objet répartis, de
bases de données réparties à travers les
réplications en vue de montrer à des institutions qui ont des
succursales éloignées géographiquement et qui sont
ignorantes à la connaissance des systèmes distribués, les
avantages que peut apporter cette notion.
D'autre part, une fois accepté par le jury, ce travail
nous permettra d'obtenir notre diplôme de licence en conception des
Systèmes d'informations.
0.4. DELIMITATION DU SUJET
En vue d'être précis et d'éviter de faire
une étude généralisée, nous délimitons notre
travail dans le temps et dans l'espace.
0.4.1. Dans le temps
Nos recherches ont été menées dans la
période allant de décembre 2015 à Juin 2016.
0.4.2. Dans l'espace
Le cadre spatial de notre travail se limite sur l'étude
et la mise en oeuvre d'un système distribué pour apporter une
solution aux problèmes que traverse notre pays dans le cadre de suivi du
casier judiciaire. Nous allons considérer
trois provinces pour ce travail dont la ville province de Kinshasa, la province
de Congo central ainsi que celle du Kasaï central.
0.5. METHODES ET TECHNIQUES
UTILISEES
0.5.1. METHODES
Pour l'élaboration de notre travail, nous avons
utilisées les méthodes suivantes :
0.5.1.1. Méthode Structuro-fonctionnelle
Cette méthode permet à un chercheur de
comprendre et de découvrir un fait à travers la structure et le
fonctionnement d'une institution.
Elle nous a permis de comprendre la structure et le
fonctionnement du service du casier judiciaire de la Gombe.
0.5.1.2. Méthode Comparative
Elle consiste à observer les faits dans deux ou
plusieurs institutions afin de pouvoir être en mesure de comprendre et
d'expliquer un problème d'une organisation.
Cette méthode nous a permis de faire une étude
comparative de suivi du casier judiciaire d'une institution judiciaire à
une autre.
0.5.2. TECHNIQUES
Les techniques sont des moyens permettant à un
chercheur de recueillir les informations dont il a besoin pour atteindre ses
objectifs. Ainsi, pour la récolte des informations relatives à
notre travail, nous avons utilisé les techniques suivantes :
0.5.2.1. Technique d'interview
Cette technique permet une entrevue entre les personnes
intéressées et le chercheur lors de la récolte des
informations.
C'est elle qui nous a beaucoup aidé à atteindre
nos objectifs en nous entretenant avec le personnel du servicedu casier
judiciaire de la Gombepour des éventuelles précisions et
réponses à toutes nos difficultés.
0.5.2.2. Technique documentaire
Elle consiste à consulter les documents susceptibles en
rapport avec une étude afin de récolter les données dont
on a besoin.
Cette technique nous a servi à la réalisation de
ce travailen faisant recours aux bibliothèques, aux recherches sur
Internet ainsi qu'à d'autres documents qui se rapportent à notre
étude.
0.6. SUBDIVISION DU TRAVAIL
Hormis l'introduction et la conclusion, le présent
travail comporte cinq chapitres que voici :
· Le premier chapitre parle des
généralités sur le système distribué.
· Le deuxième chapitre s'intéresse aux
bases de données réparties.
· Le troisième chapitre parle de
l'authentification par empreintes digitales
· Le quatrième chapitre traite de l'analyse
préalable
· Le cinquième chapitre s'intéresse
à la conception et implémentation du système
CHAPITRE Ière :
GENERALITES SUR LES SYSTEMES DISTRIBUES [1] [6] [4]
Vue l'augmentation de leurs ressources, les entreprises
multi-sites doivent pouvoir compter sur une infrastructure informatique hautes
performances, à même d'assurer l'exécution transparente de
leurs processus informatiques et une communication fiable, en interne (entre
les différents sites) comme en externe (avec les partenaires et
clients). Cela exige une surveillance continue de la disponibilité des
ressources et de l'utilisation de la bande passante des réseaux
localement distribués.
Les systèmes distribués proposent des solutions
d'améliorer l'agilité globale du système d'information au
travers des architectures orientées services (SOA). Ces systèmes
permettent aussi de mettre en place des architectures informatiques permettant
d'améliorer les performances ainsi que la disponibilité des
systèmes informatiques.
Dans ce chapitre, nous décrivons l'architecture et le
fonctionnement des systèmes distribués, tout en présentant
leurs caractéristiques, avantages ainsi que leur mode de
communication.
I.1. Définitions
Un système distribué est un système
disposant d'un ensemble d'entités communicantes, installées sur
une architecture d'ordinateurs indépendants reliés par un
réseau de communication, dans le but de résoudre en
coopération une fonctionnalité applicative commune.
Autrement dit, un système distribué est
défini comme étant un ensemble des ressources physiques et
logiques géographiquement dispersées et reliées par un
réseau de communication dans le but de réaliser une tâche
commune. Cet ensemble donne aux utilisateurs une vue unique des données
du point de vue logique.
Un système distribué est un ensemble
d'entités autonomes de calcul (ordinateurs, PDA, processeurs, processus,
processus léger etc.) interconnectées et qui peuvent
communiquer.
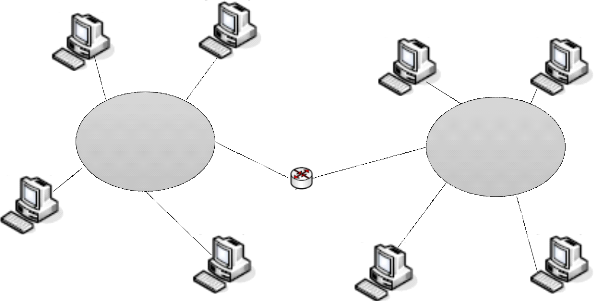
Figure 1: Représentation d'un Système
distribué
I.2. Intérêt des
systèmes distribués
Les systèmes distribués ont plusieurs raisonsde
leur existence.
· Partage des ressources (données, programme,
services) qui permet un travail collaboratif ;
· Accès distant, c'est-à-dire qu'un
même service peut être utilisé par plusieurs acteurs
situés à des endroits différents ;
· Amélioration des performances : la mise en
commun de plusieurs unités de calcul permet d'effectuer des calculs
parallélisables en des temps plus courts ;
· Confidentialité : les données brutes
ne sont pas disponibles partout au même moment, seules certaines vues
sont exportées ;
· Disponibilité des données en raison de
l'existence de plusieurs copies ;
· Maintien d'une vision unique de la base de
données malgré la distribution ;
· Réalisation des systèmes à grande
capacité d'évolution ;
· Augmentation de la fiabilité grâce
à la duplication de machines ou de données,ce qui induit à
une réalisation des systèmes à haute
disponibilité.
I.3. Quelques domaines
d'application des systèmes distribués
Les systèmes distribués sont rencontrés
dans notre vie quotidienne :
· La gestion intégrée des informations
d'une entreprise (guichet de banque, agence de voyage,..) ;
· Internet : l'internet, aujourd'hui, constitue un
grand exemple d'un système distribué le plus large au monde
contenant de nombreux sous-systèmes selon le protocole
considéré. Exemple : Web (http), bittorrent (peer-to-peer).
Des nombreux utilisateurs partout dans le monde peuvent utiliser des services
offerts par l'internet comme le WWW, le FTP (File Transfert Protocol) et tant
d'autres applications. On remarque ici une collection deréseaux
d'ordinateurs interconnectés. Et les programmes s'y exécutant
interagissent grâce aux échanges de messages en utilisant un moyen
de communication ou un autre ;
· Le WWW représente un système
distribué logique consistant en un nombre considérable de
ressources (pages web, fichiers de données et services)
référencées par des URL (Uniform Ressource
Locator) ;
· Les téléphones portables ;
· Le contrôle et organisation d'activités en
temps réel (télévision interactive)
I.4. Difficulté de mise
en oeuvre
La mise en oeuvre des systèmes distribués
engendre un certain nombre de difficultés dont voici
quelques-unes :
· Gestion de
l'hétérogénéité et Cohérence des
données
Lors de la mise en place d'un système distribué,
il est nécessaire que l'ensemble des composants travaillent avec des
données cohérentes.Cette cohérence des données est
d'autant plus problématique lorsque l'on commence à redonder
certains composants pour augmenter la capacité de traitement et/ou la
disponibilité du système.
En effet, les données comme le cache applicatif, le
contenu d'une base de données ou bien les variables de session des
utilisateurs Web doivent être synchronisées entre les
différentes instances d'un composant afin d'assurer une cohérence
dans les traitements réalisés.
· Gestion des composants
Un système distribué étant composé
d'un ensemble de composants logiciels répartis sur plusieurs serveurs
physiques. Il est nécessaire pour assurer la maintenance corrective et
évolutive du système de dresser une cartographie complète
de ce système.
· Disponibilité et détection
d'arrêts
Dans un système distribué,
l'indisponibilité d'un seul composant du système (serveur, base
de données, ...) peut rendre indisponible le système complet. On
mesure alors la disponibilité de ce type de système à
celle de son maillon le plus faible.
Pour couvrir ce risque, il est nécessaire de mettre en
place en amont une architecture permettant d'assurer la disponibilité
cible pour tous les composants. Une fois que cette architecture est en
production, des opérateurs doivent à l'aide de logiciels
s'assurer de la détection au plus tôt d'une défaillance de
l'un des composants de l'architecture.
· Gestion de la séquentialité
La mise en place d'un cluster de type actif/actif provoque la
création de deux points d'entrée au système. Dans le cas
d'un système distribué d'échange de données par
exemple, il est alors possible que deux modifications successives du même
objet soient dirigées vers deux noeuds différents du cluster, ce
qui dans l'absolu peut aboutir à une situation où le message le
plus récent est diffusé en premier vers l'application
destinataire.
Si aucune gestion de la séquentialité des
messages n'est faite, le message le plus ancien viendra écraser dans
les applications destinataires le message le plus récent.
I.5. Caractéristiques
des systèmes distribués
La performance d'un système distribué se
révèle dans ces caractéristiques. Ces
caractéristiques ci-dessous devraient être prises en compte lors
de la conception d'un système distribué.
I.5.1.
Interopérabilité
Dans un système distribué, ilse pose un vrai
problème de coopération entre différents composants du
système. En effet, ce problème peut être vu au niveau de la
couche matériel (différents réseaux physiques et
plateforme matérielle), de la couche système d'exploitation
(divers OS utilisés(UNIX, Windows, Mac OS, Solaris)), de la couche
application (langages de programmation différents) et de la couche
middleware (.NET pour Microsoft, Corba pour le Consortium OMG). On parle de
l'hétérogénéité, un problème dans le
partage des ressources dans un système distribué.
L'interopérabilité est une
caractéristique importante qui désigne la capacité
à rendre compatibles deux systèmes quelconques. A son tour, la
compatibilité est la capacité qu'ont deux systèmes
à communiquer sans ambiguïté.
En effet, l'interopérabilité vise à
réduire le vrai problème de
l'hétérogénéité en la masquant par
l'utilisation d'un protocole unique de communication (exemple de TCP/IP pour
l'Internet). Pour les échanges des messages, il faut utiliser des
standards qui cachent les différences entre les différentes
plateformes.
Actuellement, il existe deux approches principales de
standardisation pour masquer
l'hétérogénéité : les middlewares et
les machines virtuelles.
Concrètement, un middleware est
représenté par des processus et des ressources d'un ensemble
d'ordinateurs, qui interagissent les uns avec les autres. Ils middlewares
améliorent la communication en offrant des abstractions telles
que :
· Le RMI (Remote Method Invocation) qui est la
possibilité, pour un objet, d'invoquer la méthode d'un autre
objet situé sur une plateforme distante ;
· La notification d'événement pour la
propagation d'informations d'une plateforme vers une autre ou plusieurs autres
plateformes ou composants d'une application distribuée ;
· La communication entre groupe de processus ;
· La gestion de la duplication des données
partagées ;
· La transmission de données multimédia en
temps réel.
Les machines virtuelles permettent de supporter le code mobile
désignant la possibilité de transfert de code d'une machine
source à une machine de destination et son exécution sur cette
machine. Au cas des différentes plateformes, le code produit sur l'une
ne peut fonctionner sur l'autre. Pour éviter ce problème, le code
mobile est généré d'un langage source pour une machine
virtuelle donnée (exemple de la JVM). En effet, chaque plateforme doit
disposer d'une couche logicielle qui implémente la machine virtuelle car
cette dernière représente une généralisation des
middlewares offrant les mêmes services.
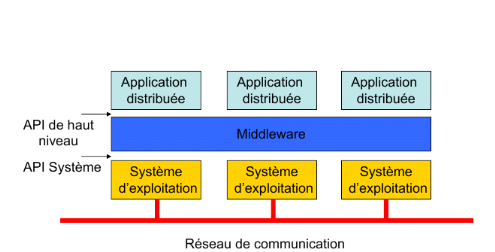
Figure 2: exemple d'un système
distribué
I.5.2. Partage des
ressources
Le partage des ressources est le facteur principal de
motivation pour construire les systèmes répartis. Des ressources
telles que des imprimantes, des dossiers, des pages Web ou des disques de base
de données sont contrôlées par des serveurs du type
approprié. Par exemple, les serveurs Web contrôlent des pages Web
et d'autres ressources d'enchaînement. Des ressources sont
consultées par des clients - par exemple, les clients du web des
serveurs s'appellent généralement les browsers
(navigateurs) ;
I.5.3. Ouverture
Cette caractéristique fait mention de
l'extensibilité dans la mesure où des composants peuvent
être ajoutés, remplacés ou supprimésdans un
système distribué sans en affecter les autres. Et lorsque nous
parlons des composants, nous voyons les matériels (les
périphériques, mémoires, interfaces, etc.) et les
logiciels (protocoles, pilote, etc.). L'ouverture nécessite que les
interfaces logicielles soient documentées et accessibles aux
développeurs d'applications.
Il se pose un vrai problème avec l'ouverture au sens
que les composants d'un système distribué sont
hétérogènes. Alors, cette qualité d'ouverture est
accordée aux systèmes supportant sans ambages :
a) L'ajout de l'ordinateur au niveau de la couche
matérielle ;
b) L'ajout de nouveaux services au niveau application,
middleware et système d'exploitation ;
c) La réimplantation des services anciens.
I.5.4. Expansible
Nous disons qu'un système distribué est
expansible lorsque les modifications du système et des applications ne
sont pas nécessaires quant à l'augmentation de la taille de ce
système.
I.5.5. Performance
Dans ce cas, le système doit s'adapter à bien
fonctionner même quand le nombre d'utilisateurs ou de ressources
augmentent.
I.5.6. Transparence
« To the user, a distributed system should look exactly
like a nondistributed system. »
La transparence cache aux utilisateurs l'architecture, la
distribution des ressources, le fonctionnement de l'application ou du
système distribué pour apparaître comme une application
unique cohérente.
La norme ISO (1995) définit différents niveaux
de transparences telle que la transparence d'accès, de localisation, de
concurrence, de réplication, de mobilité, de panne, de
performance, d'échelle).
o Transparence d'accès :il s'agit
d'utiliser les mêmes opérations pour l'accès aux ressources
distantes que pour les celles locales ;
o Transparence à la localisation :
l'accès aux ressources indépendamment de leur emplacement doit
être inconnue à l'utilisateur ;
o Transparence à la concurrence : il
s'agit de cacherà l'utilisateur l'exécution possible de plusieurs
processus en parallèle avec l'utilisation des ressources
partagées en évitant des interférences ;
o Transparence à la réplication :
la possibilité de dupliquer certains éléments/ressources
(fichiers de base de données) pour augmenter la fiabilité et
améliorer les performances doit être cachée à
l'utilisateur ;
o Transparence de mobilité : il s'agit de
permettre la migration des ressources et des clients à
l'intérieur d'un système sans influencer le déroulement
des applications ;
o Transparence de panne : il s'agit de permettre
aux applications des utilisateurs d'achever leurs exécutions
malgré les pannes qui peuvent affecter les composants d'un
système (composants physiques ou logiques) ;
o Transparence à la modification de
l'échelle : il s'agit de la possibilité d'une extension
importante d'un système sans influence notable sur les performances des
applications.
o Transparence à la reconfiguration: il s'agit
de cacher à l'utilisateur la possibilité de reconfigurer le
système pour en augmenter les performances en fonction de la
charge ;
En effet, la transparence n'est pas toujours possible dans
certains cas. Notons le cas de la duplication d'une imprimante des
caractéristiques différentes pour besoin des performances dans le
système. Cependant, l'utilisateur doit toutefois avoir la
possibilité de spécifier concrètement sur quelle
imprimante il souhaite imprimer ses documents.
I.5.7.
Sécurité
Le problème de sécurité se pose dans tout
système informatique. Dans un système distribué, les
ressources doivent être protégées contre des utilisations
abusives et malveillantes. En particulier, le problème de piratage des
données sur le réseau de communication. En ces raisons, il est
préférable d'utiliser des périphériques ou
logiciels licenciés. Outre, les connexions doivent être
sécurisées par authentification avec les éléments
distants ainsi que les messages circulant sur ce réseau doivent
être cryptés en vue d'éviter des conséquences
graves.
Le concept de sécurité des systèmes
d'information recouvre un ensemble de méthodes, techniques et outils
chargés de protéger les ressources d'un système
d'information afin d'assurer :
· la disponibilité des services : les
services (ordinateurs, réseaux, périphériques,
applications...) et les informations (données, fichiers...) doivent
être accessibles aux personnes autorisées quand elles en ont
besoin ;
· la confidentialité des informations :
les informations n'appartiennent pas à tout le monde ; seuls peuvent y
accéder ceux qui en ont le droit ;
· l'intégrité des systèmes
: les services et les informations (fichiers, messages...) ne peuvent
être modifiés que par les personnes autorisées
(administrateurs, propriétaires...).
I.5.8. Concurrence
Le problème de la concurrence permet l'accès
simultané à des ressources par plusieurs processus. Ce
problème se pose pour les systèmes distribués comme pour
les systèmes centralisés. En effet, il y a bien d'autres
ressources dont l'accès simultané n'est pas possible. Dans ce
cas, leur manipulation ne peut se faire que par un processus à la fois.
Le cas des ressources physiques telles que l'imprimante mais aussi des
ressources logiques telles que les fichiers, les tables des bases de
données, etc. Dans ce cas, les applications distribuées
(reparties)actuelles autorisent l'exécution de plusieurs services en
concurrence (cas de l'accès à une base de données). Chaque
demande est prise en compte par un processus simple appelé thread ;
et la gestion de la concurrence fait appel aux mécanismes de
synchronisation classiques.
I.5.9. Tolérance aux
pannes
Une panne peut être comprise comme une faille au sein du
système pouvant conduire à des résultats erronés
comme aussi engendrer l'arrêt de toute ou partie d'un système
distribué.Les pannes peuvent résulter des différentes
couches et se propager éventuellement aux autres. Peut-être, c'est
une raison matérielle ou logique liée à la conception des
applications, des middlewares et des systèmes d'exploitation.
Ainsi, un système distribué doit être
conçu pour masquer ce genre des pannes aux utilisateurs. La panne de
certains serveurs (ou leur réintégration dans le système
après la réparation) ne doit pas perturber l'utilisation du
système en terme de fonctionnalité.
I.5.10.
Disponibilité
Dans un système distribué,
l'indisponibilité d'un seul composant du système (serveur, base
de données, ...) peut rendre indisponible le système complet
alors qu'il doit rendre en permanence des services et d'une façon
correcte. On mesure alors la disponibilité de ce type de système
à celle de son maillon le plus faible.
Ces risques d'indisponibilité du système peuvent
être dus :
· aux pannes empêchant le système ou
à ses composants de fonctionner correctement ;
· aux surcharges dues à des sollicitations
excessives d'une ressource ;
· aux attaques de sécurité pouvant causer,
d'une façon ou d'une autre, des dysfonctionnements, les
incohérences et pertes de données et même l'arrêt du
système.
Pour couvrir ce risque, plusieurs solutions peuvent être
envisageables :
· mettre en place en amont une architecture permettant
d'assurer la disponibilité cible pour tous les composants. Une fois que
cette architecture est en production, des opérateurs doivent à
l'aide de logiciels s'assurer de la détection au plus tôt d'une
défaillance de l'un des composants de l'architecture.
· veiller à la réplication des
données au sein de ce système (c'est la solution que nous avons
choisi dans le cadre de notre travail).
I.6. Architecture
distribuée
L'architecture d'un environnement informatique ou d'un
réseau est distribuée lorsque toutes les ressources ne se
trouvent pas au même endroit ou sur la même machine. Ce concept
s'oppose à celui d'architecture centralisée dont une version est
l'architecture client-serveur que nous allons aussi voir dans cette partie.
En effet, la programmation orientée objet a permis le
développement des architectures distribuées en fournissant des
bibliothèques de haut-niveau pour faire dialoguer des objets
répartis sur des machines différentes entre eux. Les objets
distribués sur le réseau communiquent par messages en s'appuyant
sur l'une des technologies telles que CORBA, RMI, les services web XML, .Net
Remoting, Windows Communication Foundatation, etc.
Les architectures distribuées reposent sur la
possibilité d'utiliser des objets qui s'exécutent sur des
machines réparties sur le réseau et communiquent par messages au
travers du réseau.
I.6.1. Avantages des
architectures distribuées
· Augmentation des ressources : la
distribution des traitements sur les ordinateurs d'un réseau augmente
les ressources disponibles;
· Répartition des données et des
services : (cas de l'architecture 3-tiers à la base de la
plupart des applications distribuées de commerce électronique
permettant d'interroger et de mettre à jour des sources de
données réparties) ;
I.6.2. Types d'architecture
distribuée
I.6.2.1. Architecture client-serveur
Le client server est avant tout un mode de dialogue entre deux
processus. Le premier appelé client, demande l'exécution de
services au second appelé serveur. Le serveur accomplit les services et
envoi en retour des réponses. En général, un serveur est
capable de traiter les requêtes de plusieurs clients. Un serveur permet
donc de partager des ressources entre plusieurs clients qui s'adressent
à lui par des requêtes envoyées sous forme de messages.
Par extension, le client désigne également
l'ordinateur sur lequel est exécuté le logiciel client, et le
serveur, l'ordinateur sur lequel est exécuté le logiciel
serveur.
Le client serveur étant un mode de dialogue, il peut
être utilisé pour réaliser de multiples fonctions.

Figure 3:Fonctionnement du mode client-serveur
Parlant de l'architecture client-serveur, nous distinguons
trois types d'acteurs principaux:
1) Client
Un client est un processus demandant l'exécution d'une
opération à un autre processus (fournisseur des services) par
l'envoi d'un message contenant le descriptif de l'opération à
exécuter et attendant la réponse à cette opération
par un message en retour.
Caractéristiques d'un client :
· Il est actif le premier (ou maître) ;
· Il envoie des requêtes au serveur ;
· Il attend et reçoit les réponses du
serveur.
Parlant aussi de client, nous en distinguons trois types :
Ø Client léger : est une
application accessible via une interface web consultable à l'aide d'un
navigateur web.
Ø Client lourd : est une application
cliente graphique exécuté sur le système d'exploitation de
l'utilisateur possédant les capacités de traitement
évoluées.
Ø Client riche : est une combinaison du
client léger et client lourd dans lequel l'interface graphique est
décrite avec une grammaire basée sur la syntaxe XML.
2) Serveur
On appelle serveur un processus accomplissant une
opération sur demande d'un client et lui transmettant le
résultat. Il est la partie de l'application qui offre un service, il
reste à l'écoute des requêtes du client et répond au
service demandé par lui.
En effet, un serveur est généralement capable de
servir plusieurs clients simultanément.
Caractéristiques d'un serveur :
· Il est initialement passif (ou esclave, en attente
d'une requête) ;
· Il est à l'écoute, prêt à
répondre aux requêtes envoyées par des clients ;
· Dès qu'une requête lui parvient, il la
traite et envoie une réponse.
Nous distinguons plusieurs types de serveur en fonction des
services rendus : Serveur d'application, serveur de base de données,
serveur des fichiers, etc.
3) Middleware
Le middleware est l'ensemble des services logiciels qui
assurent l'intermédiaire entre les applications et le transport de
données dans le réseau afin de permettre les échanges des
requêtes et des réponses entre client et serveur de manière
transparente.
Le client serveur étant un mode de dialogue, il peut
être utilisé pour réaliser de multiples fonctions. Il
existe donc différents types de client-serveur qui ont été
définis : le client serveur de présentation, le client
serveur de données et le client serveur de procédures.
I.6.2.2. Architecture pair-à-pair (peer-to-peer ou
P2P)
Le pair-à-pair est un modèle de réseau
informatique proche du modèle client-serveur mais où chaque
ordinateur connecté au réseau est susceptible de jouer tour
à tour le rôle de client et celui de serveur.
P2P est une architecture pouvant être centralisée
(les connexions passant par un serveur central intermédiaire) ou
décentralisée (les connexions se faisant directement). Le
pair-à-pair peut servir au partage de fichiers en pair à pair, au
calcul distribué ou à la communication entre noeuds ayant la
même responsabilité dans le système.
La particularité des architectures pair-à-pair
réside dans le fait que les données peuvent être
transférées directement entre deux postes connectés au
réseau, sans transiter par un serveur central. Cela permet ainsi
à chaque ordinateur d'être à la fois serveur de
données et client des autres. On appelle souvent noeud les
postes connectés par un protocole réseau pair-à-pair.
Outre, les systèmes de partage de fichiers
pair-à-pair permettent de rendre les ressources d'autant disponibles
qu'elles sont populaires, et donc répliquées sur un grand nombre
de noeuds. Cela permet alors de diminuer la charge (en nombre de
requêtes) imposée aux noeuds partageant les fichiers dans le
réseau. C'est ce qu'on appelle le passage à
l'échelle. Cette architecture permet donc de faciliter le partage
des ressources. Elle rend aussi la censure ou les attaques légales ou
pirates plus difficiles.
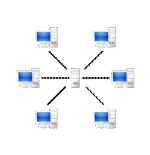
Figure 4: Architecture pair-à-pair
Ces atouts font des systèmes pair-à-pair des
outils de choix pour décentraliser des services qui doivent assurer une
haute disponibilité tout en permettant de faibles coûts
d'entretien. Toutefois, ces systèmes sont plus complexes à
concevoir que les systèmes client-serveur.
Dans ce chapitre, nous nous sommes focalisé
sur les conceptsde base des systèmes distribués. Nous avons
donné en détail les caractéristiques des systèmes
distribués, leurs architectures ainsi que les domaines concrets de leur
application. Dans le prochain chapitre, nous abordons le concept Base de
données répartie.
CHAPITRE
IIème : LES BASE DE DONNEES REPARTIE[3][5][7][9]
L'évolution technologique actuelle depuis quelques
décennies permet d'adapter les outils informatiques à l'ensemble
d'activités au sein des entreprises du point de vue organisationnel.
La puissance des micro-ordinateurs et la croissance des
stations de travail, la fiabilité et la souplesse des systèmes
informatiques répartis et de leurs architectures, les performances des
réseaux permettent d'envisager une répartition des ressources
informatiques tout en préservant l'intégrité et la
cohérence des bases de données.
En effet, les bases de données restent totalement
indispensables dans notre vie courante du fait qu'elles sont un des moteurs
fondamentaux du progrès économique des entreprises actuelles.
Aujourd'hui même, l'information stockée dans une base de
données de l'entreprise peut l'aider à une prise de
décision en vue de veiller sur les objectifs.
II.1. Définitions
Une base de données distribuée est un
ensemble des différentes bases de données stockées sur des
sites (géographiquement distants), reliés par un réseau.
La réunion de ces différentes bases forme la base de
données repartie.
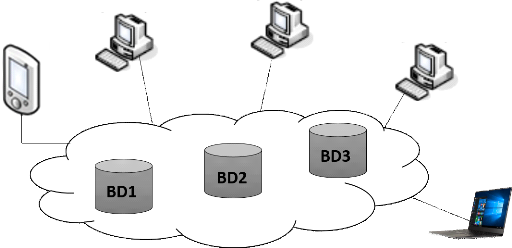
Figure 5: Exemple de bases de données
réparties
II.2.
Caractéristiques
Une base de données répartie doit
répondre aux caractéristiques suivantes :
§ La distribution de données : les
données n'appartiennent pas à un seul processus ;
§ La corrélation logique des
données: les données possèdent les
propriétés qui les tiennent ensemble ;
§ Une structure de contrôle
hiérarchique basée sur un administrateur des bases de
données globales qui est le responsable central sur les bases de
données réparties entières et sur les administrateurs des
bases de données locales, qui ont la responsabilité de leur base
de données respective ;
§ L'indépendance des données et la
transparence de répartition.
§ La redondance des données, une grande
caractéristique permettant l'accroissement de l'autonomie des
applications et la disponibilité des informations en cas de panne d'un
site ;
§ Un plan d'accès réparti
écrit soit par le programmeur ou produit automatiquement par un
optimiseur ;
II.3. Types de bases de
données réparties
Des bases de données réparties peuvent
être largement classifiées dans les environnements
homogènes et hétérogènes de base de données
répartie, chacun avec d'autres subdivisions, comme montré dans
l'illustration suivante.
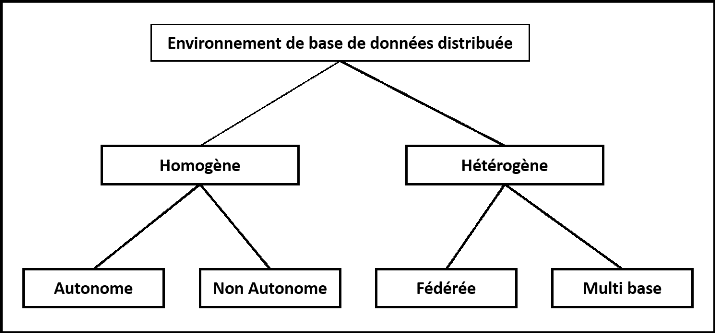
Figure 6: Types de base de données
répartie
II.3.1. Base de données
répartie homogène
Dans une base de données répartie
homogène, tous les sitesutilisent le système de gestion de bases
de données identique et les systèmes d'exploitation.Ses
propriétés sont :
· Les sites utilisent les mêmes logiciels ;
· Les sites utilisent le même SGBD;
· Chaque site se rend compte de tous autres et
coopère entre eux pour traiter des requêtes
d'utilisateur ;
· L'accès à la base de données se
fait par une interface simple comme si c'est une seule base de
données.
II.3.1.1. Types de base de données répartie
homogène
Il y a deux types de ces bases de données
a) Autonome : chaque base de données est
indépendante que des fonctions. Elles sont intégrées par
une application de contrôle et utilisent le message passant pour le
partage des mises à jour de données.
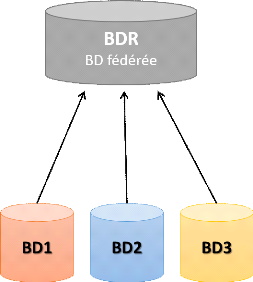
b) Non autonome : des données sont
distribuées à travers les noeuds homogènes et un
système de gestion de bases de données central ou maître
coordonne des mises à jour de données à travers les
sites.
II.3.2. Base de données
hétérogène
Dans une base de données répartie
hétérogène, les différents sites ont
différents systèmes d'exploitation, différents
systèmes de gestion de bases de données et différents
modèles de données.Ses propriétés sont :
a) Les différents sites utilisent les schémas et
le logiciel différents ;
b) Le système peut se composer de variété
de SGBD répartis, relationnel, réseau, hiérarchique ou
orienté objet ;
c) Le traitement de requêtes est complexe dû aux
schémas différents ;
d) Le traitement transactionnel est complexe dû au
logiciel différent ;
e) Une coopération limitée dans le traitement de
requêtes de clients due aux transparences des sites.
II.3.2.1. Types de base de données répartie
hétérogène
· Fédérée : Les
systèmes de base de données hétérogène sont
indépendants en nature et sont intégrés ensemble de sorte
qu'ils fonctionnent comme système simple de base de données.
· Non fédérée : Les
systèmes de base de données utilisent un module central
coordonné par lequel les bases de données sont
consultées.
II.4. Conception d'une base de
données
Une base de données répartie doit être
gérée par plusieurs processeurs ou SGBD. Elle est aussi donc
stockée sur différents ordinateurs situés dans un
même endroit ou étant dispersées sur un réseau
d'ordinateurs interconnectés. Chaque ordinateur de ce réseau
constitue un noeud. La question importante consiste à savoir comment ces
noeuds vont interagir et communiquer entre eux.
En effet, la mise en place d'une base de données
répartie se résume par la conception du schéma global, la
conception de la base de données physique locale dans chaque site, la
conception de la fragmentation ainsi que la conception de l'allocation des
fragments.
II.4.1. Conception du
schéma global
Le schéma global se subdivise en trois schémas
dont :
II.4.1.1. Schéma Interne
Ce schéma décrit l'accès physique aux
occurrences des relations, il est constitué de l'ensemble des
descriptions des fichiers et/ou par un ensemble des schémas de relations
internes.
II.4.1.2. Schéma conceptuel
C'est l'ensemble des schémas des relations de base et
l'ensemble des contraintes d'intégrités, c'est la vue globale de
la base de données. Le schéma conceptuel est composé de
relations fragmentées ou d'une relation composée d'une ou de
plusieurs sous-relations, la distinction de deux approches dans sa mise en
oeuvre.
II.4.1.3. Schéma externe
Le schéma conceptuel est un sous-ensemble du
schéma conceptuel composé de l'ensemble des schémas de
relations abstraites définies sur la relation de base du schéma
conceptuel.
II.4.2. Conception de la base
de données physique locale dans chaque site
Nous distinguons deux façons de concevoir une base de
données répartie dont la conception ascendante et la conception
descendante.
II.4.2.1. Conception ascendante (bottom up design)
L'approche se base sur le fait que la répartition est
déjà faite, mais il faut réussir à intégrer
les différentes bases des données locales existantes en un seul
schéma global. En d'autres termes, les schémas conceptuels locaux
existent et il faut réussir à les unifier dans un schéma
conceptuel global.
Figure 7: Représentation de la conception
ascendante
Cette démarche s'avère la plus difficile
puisqu'en plus des problèmes techniques identiques à ceux
inhérent à une conception descendante, il faudra résoudre
des problèmes d'hétérogénéité du
système ou même de la sémantique de l'information.
II.4.2.2. Conception descendante (top down design)
La conception descendante se fait par la définition
d'un schéma conceptuel global de la base de données
répartie. Ensuite, on distribue sur les différents sites en des
schémas conceptuels locaux.
L'approche top down est intéressante parce que l'on
part du néant en définissant un schéma global qu'on
subdivisera en différentes bases locales. Si les bases des
données existent déjà la méthode bottom up design
est utilisée.
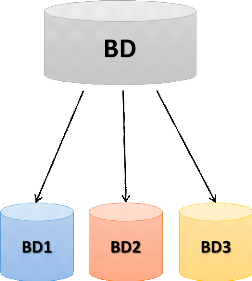
Figure 8: Représentation de la conception
descendante
Outre, il faut ensuite définir la répartition
des données qui s'effectue en trois étapes dont la partition ou
la fragmentation, la réplication et l'hybride.
La répartition se fait donc en deux
étapes : la première étant la fragmentation, et la
deuxième, l'allocation de ces fragments aux sites.
II.4.3. Conception de la
fragmentation
II.4.3.1. Fragmentation
La fragmentation est la tâche de diviser une table en
ensemble de plus petites tables. Cette division doit se faire sans perte
d'informations. Les sous-ensembles de la table s'appellent les fragments.La
fragmentation peut être de trois types :horizontal,
vertical, et hybride (combinaison d'horizontal et de
vertical).
II.4.3.1.1. Avantages de la fragmentation
· Puisque des données sont stockées
près du site de l'utilisation, l'efficacité du système de
base de données est augmentée ;
· Les techniques locales d'optimisation de requêtes
sont suffisantes pour la plupart des requêtes puisque les données
sont localement disponibles ;
· Puisque les données non pertinentes ne sont pas
disponibles aux sites, la sécurité et l'intimité du
système de base de données peuvent être maintenues.
II.4.3.1.2. Limites de la fragmentation
· Lorsque l'on a besoindes données de
différents fragments, les vitesses d'accès peuvent être
très hautes ;
· En cas de fragmentations récursifs, le travail
de la reconstruction aura besoin de techniques chères ;
· Le manque de copies de secours des données dans
différents emplacements peut rendre la base de données inefficace
en cas d'échec d'un emplacement.
II.4.3.1.3. Types de fragmentation
a) Fragmentation Horizontale (Répartition
des occurrences)
Elle consiste à partitionner ou à
découper une table en sous tables par l'utilisation des prédicats
permettant de sélectionner les lignes appartenant à chaque
fragment selonun ou plusieurscritères de sélection suivant les
valeurs d'un ou plusieurs champs.La fragmentation se fait par sélection,
et la reconstitution de la table (relation) initiale se fait grâce
à l'union de sous tables.
Ce type de fragmentation est adapté à la
régionalisation ou départementalisation dans une entreprise. Par
exemple, considérons qu'une base de données du casier judiciaire
contient tous les enregistrements des individus condamnés dans une table
individu ayant le schéma suivant.
|
Id
|
Nom
|
Prenom
|
Genre
|
Mention
|
Province
|
Crime
|
|
1
|
TSHIAMUA
|
Juslin
|
M
|
Avec antécédent judiciaire
|
Kinshasa
|
Viol
|
|
2
|
LUKETA
|
Christian
|
M
|
Avec antécédent judiciaire
|
Kinshasa
|
Vol
|
|
3
|
MULANGA
|
Goshen
|
F
|
Avec antécédent judiciaire
|
Congo central
|
xxx
|
|
4
|
LIKOTELO
|
Camile
|
M
|
Avec antécédent judiciaire
|
Congo central
|
yyy
|
|
5
|
NTUMBA
|
Aaron
|
M
|
Avec antécédent judiciaire
|
Kasaï central
|
zzz
|
Tableau 1: Illustration de la fragmentation
Au cas où le détail de tous les individus de la
province de Congo central doit être envoyé dans la province du
Kasaï central, alors le concepteur réduira horizontalement la base
de données comme suit :
|
CREATE TABLE IND_CONGO_CENTRALAS
SELECT * FROM INDIVIDU WHERE PROVINCE
IN(«CONGO CENTRAL»);
|
Résultat:
|
Id
|
Nom
|
Prenom
|
Genre
|
Mention
|
Province
|
Crime
|
|
3
|
MULANGA
|
Goshen
|
F
|
Avec antécédent judiciaire
|
Congo central
|
xxx
|
|
4
|
LIKOTELO
|
Camile
|
M
|
Avec antécédent judiciaire
|
Congo central
|
yyy
|
Tableau 2: Exemple d'une fragmentation horizontale
b) Fragmentation Verticale (Répartition des
attributs)
Elle se fait non au niveau des données mais de la
structure même de la base où certains champs sont envoyés
dans un fragment et d'autres ailleurs.
La fragmentation verticale consiste à partitionner une
relation en groupes d'attributs et une clé doit apparaitre dans tous les
groupes. Toutes les valeurs des occurrences pour un même attribut se
trouvent dans le même fragment.
Une fragmentation verticale est utile pour distribuer les
parties des données sur le site où chacune de ces parties est
utilisée.Elle se fait par projection et la reconstruction de la relation
initiale se fait grâce à des jointures en vue d'éviter les
pertes d'informations.
Par exemple, dans le schéma individu, on veut juste
savoir le crime de chaque individu, le concepteur réduira la base comme
suit :
|
CREATE TABLEIND_MENTION AS
SELECT ID, CONCAT(NOM,' ',PRENOM)
AS NOMS, CRIME FROM INDIVIDU;
|
Résultat :
|
Id
|
Noms
|
Crime
|
|
1
|
Juslin TSHIAMUA
|
Viol
|
|
2
|
Christian LUKETA
|
Vol
|
|
3
|
Goshen MULANGA
|
Xxx
|
|
4
|
Camile LIKOTELO
|
Yyy
|
|
5
|
Aaron NTUMBA
|
Zzz
|
Tableau 3: Exemple d'une fragmentation verticale
c) Fragmentation hybride (Répartition des
valeurs)
C'est la combinaison des deux techniques de fragmentation
précédentes, horizontale et verticale. Les occurrences et les
attributs peuvent donc être répartis dans des partitions
différentes.C'est la technique de fragmentation la plus flexible
puisqu'elle produit des fragments avec l'information étrangère
minimale.Cependant, la reconstruction de la table originale est souvent une
tâche ardue.
La fragmentation hybride peut être faite de deux
manières alternatives :
· Au début, produire d'un ensemble de fragments
horizontaux ; produire alors des fragments verticaux d'un ou plusieurs des
fragments horizontaux.
· Au début, produire d'un ensemble de fragments
verticaux ;produire alors des fragments horizontaux d'un ou plusieurs des
fragments verticaux.
L'opération de partitionnement est une combinaison de
projections et de sélections et celle de recomposition est une
combinaison de jointures et d'unions.
|
CREATE
TABLEIND_MENTIONASSELECT ID,
CONCAT(NOM,' ',PRENOM) AS NOMS, CRIME
FROM INDIVIDU WHERE PROVINCE
IN(`KINSHASA');
|
Résultat :
|
Id
|
Noms
|
Crime
|
|
1
|
Juslin TSHIAMUA
|
Viol
|
|
2
|
Christian LUKETA
|
Vol
|
Tableau 4: Exemple de fragmentation hybride
II.4.3.1.4. Règles de fragmentation
La fragmentation doit tenir aux trois règles
suivantes :
a) La complétude : pour toute
donnée d'une relation R, il existe un fragment Ri de la relation R qui
possède cette donnée.
b) La reconstruction : pour toute relation R
décomposée en un ensemble de fragments Ri, il existe une
opération inverse de reconstruction : la jointure pour les
fragmentations verticales et l'union pour celles horizontales.
a) La disjonction : aucune donnée ne doit
se trouver dans plus d'un fragment sauf dans le cas d'une fragmentation
verticale où la clé primaire doit être présente
dans l'ensemble des fragments issus d'une relation.
II.4.4.Conception de
l'allocation des fragments
Ayant mis en oeuvre la fragmentation de la base, le
problème réside sur la localisation du fragment. En effet, un
schéma d'allocation doit être élaboré afin de
déterminer la localisation de chaque fragment et sa position dans le
schéma global : c'est l'allocation.
II.4.4.1. Schéma d'allocation
L'affectation des fragments sur le site est
décidée en fonction de l'origine prévue des requêtes
qui ont servi à la fragmentation. Le but est de placer les fragments sur
les sites où ils sont le plus utilisés, dans le but de minimiser
les transferts de données entre différents sites.
II.4.4.2. Techniques de répartition
avancée
D'une part, la méthode classique d'allocation des
fragments est appliquée et d'autre part, si cette méthode ne
s'avère pas satisfaisante, des techniques plus puissantes mais aussi
complexes à mettre en oeuvre doivent être envisagées :
II.4.4.1.1. Allocation avec duplication
Au travers cette technique, certains fragments sont
dupliqués sur un site ou sur l'ensemble de sites selon les besoins. Une
technique très importante car elle offre une amélioration
considérable des performances du système en termes de temps
d'exécution des requêtes étant donné que
l'accès aux données est local grâce aux fragments qui sont
un peu partout dupliqués.
Cependant, la difficulté des mises à jour de
tous les fragments dupliqués reste un inconvénient majeur pour
cette technique.
II.4.4.1.2. Allocation dynamique
Avec cette technique, l'allocation d'un fragment peut changer
en cours d'utilisation d'une base de données répartie. Ce qui
fait qu'un fragment se trouvant sur un site A à l'instant T, peut
être retrouvé sur un autre site B à l'instant T+1.
Néanmoins, elle reste une technique très efficace lorsqu'il y a
le maintien et la mise à jour du schéma d'allocation ainsi que
des schémas locaux.
II.4.4.1.3. Fragmentation dynamique
Cette technique consiste au changement d'allocation dynamique
des fragments ; ce qui peut rendre possible deux fragments
complémentaires (verticalement ou horizontalement) de se retrouver sur
un même site. C'est alors qu'intervient la fusion de ces fragments.
A l'inverse, si une partie est appelée sur un autre
site, il peut être intéressant de décomposer ces fragments
et de ne faire migrer que la partie concernée. Ces modifications du
schéma de fragmentation se répercutent sur le schéma
d'allocation et sur les schémas locaux.
II.4.4.1.4. clichés (snapshots)
Un cliché est une copie figée d'un fragment. Il
représente l'état du fragment à un instant donné et
n'est jamais mis à jour contrairement aux vues et aux copies qui
répercutent toutes les modifications qui ont lieu sur le fragment
original.
L'intérêt d'un cliché diminue donc au fur
et à mesure que le temps passe car toutefois, l'information contenue
dans la base de données peut ne pas rester figée (cas d'un
changement d'adresse non signalé, par exemple). Dans ce cas,
l'utilisation des clichés est intéressante lorsque l'on juge que
la gestion des copies multiples se révélerait trop lourde pour la
base de données considérée alors que des copies même
peu anciennes et non à jours seraient largement suffisantes.
Néanmoins, les deux critères qui sont à
prendre en compte pour définir l'intérêt d'un cliché
sont d'une part l'ancienneté du cliché, et d'autre part le temps
d'attente qui serait nécessaire avant d'obtenir l'information originale
(à jour).
II.5.Réplication des
données
Toute application de base de données repose sur un
modèle client-serveur. Suivant ce modèle, le client se connecte
au SGBD pour passer des ordres. Ces ordres sont de deux natures : lecture (on
parle alors de requêtes) ou mise à jour (on parle alors de
transactions).
Pour les transactions il y a une modification des
données sur le serveur, mais cela reste des ordres de courte
durée. A l'inverse, dans le cas d'une lecture, il n'y a pas de
modification des données mais les traitements peuvent être longs
et porter sur une grande masse de données ; ce qui se passe dans le
cadre d'une application web par exemple, où un nombre important de
requêtes peut surcharger partiellement (ou complètement) le
serveur.
De ce fait, il existe plusieurs solutions pour palier à
ce genre de problèmes et, la réplication en est une.
II.5.1. Définition
La réplication est un processus qui consiste
à copier l'ensemble d'une base de données (la structure et les
données) sur chaque noeud. Elle implique aussi la redondance des
informations dans différents sites.
II.5.2. Objectifs la
réplication
L'objectif principal de la réplication est d'assurer la
fiabilité du système et de faciliter l'accès aux
données en augmentant la disponibilité. Ceci soit parce que les
données sont copiées sur différents sites permettant de
répartir les requêtes, soit parce qu'un site peut prendre la
relève lorsque le serveur principal s'écroule.
Une autre application tout aussi importante est la
synchronisation des systèmes embarqués non connectés en
permanence. Ce qui permet d'éviter les transferts de données et
d'assurer la croissance de la résistance aux pannes.
Grâce à la réplication, les utilisateurs
ne s'en aperçoivent pas lorsqu'un site est momentanément
inaccessible car un autre peut correctement le remplacer.
II.5.3. Technique de la
réplication
La technique de la réplication, qui met en jeu au
minimum deux SGBD, est assez simple et se déroule en trois étapes
:
· La base maître reçoit un ordre de mise
à jour (INSERT, UPDATE ou DELETE).
· Les modifications faites sur les données sont
détectées et stockées dans un fichier ou une file
d'attente en vue de leur propagation.
· Le processus de réplication prend en charge la
propagation des modifications à faire sur une seconde base dite esclave.
Il peut bien entendu y avoir plus d'une base esclave.
Bien entendu, il est tout à fait possible d'appliquer
la réplication dans les deux sens (de l'esclave vers le maître et
inversement). On parlera dans ce cas-là de réplication
bidirectionnelle ou symétrique. Dans le cas contraire où elle se
fait du maitre vers l'esclave, on parle d'une réplication
unidirectionnelle ou en lecture seule ou encore asymétrique. Outre ceci,
la réplication peut être faite de manière synchrone ou
asynchrone.
II.5.4. Avantages de la
réplication
L'intérêt majeur de la réplication
réside dans l'amélioration des performances et l'augmentation de
la disponibilité des données. Les avantages sont les
suivants :
· Fiabilité: en cas d'échec de
n'importe quel site, le système de base de données continue
à fonctionner puisqu'une copie est disponible à un autre
site ;
· Réduction de charge de réseau :
puisque les copies locales des données sont disponibles, le traitement
de requêtes peut être fait avec l'utilisation réduite de
réseau, en particulier pendant des heures de grand travail.La mise
à jour de données peut être faite aux heures
non-principales ;
· Une réponse plus rapide : la
disponibilité des copies locales des données assure le traitement
rapide de la requête et par conséquent le temps de réponse
rapide ;
· Des transactions plus simples :les
transactions exigent moins de nombre de jointures des tables situées
à différents sites et à coordination minimale à
travers le réseau.Ainsi, elles deviennent plus simples en nature.
II.5.5. Limites de
réplication
Si la réplication présente de nombreux
avantages, les problèmes soulevés sont multiples. Tout d'abord,
il faut assurer la convergence des copies.
· Conditions de stockage accrues : Le maintien
des copies multiples des données est associé aux coûts
accrus de stockage. L'espace mémoire exigé est dans les multiples
du stockage exigé pour un système centralisé ;
· Plus grands coût et complexité des
données mises à jour : Chaque fois qu'une donnée
élémentaire est mise à jour, la mise à jour doit
être reflétée dans toutes les copies des données aux
différents emplacements.Ceci exige des techniques et des protocoles
complexes de synchronisation.
· Application indésirable - accouplement de
base de données :Si des mécanismes complexes de mise
à jour ne sont pas employés, le déplacement des
données d'inconsistance exige la coordination complexe au niveau
d'application. Ceci a comme conséquence l'application indésirable
- accouplement de base de données.
II.5.6. Techniques de diffusion
des mises à jour
La diffusion automatique des mises à jour
appliquée à une copie aux autres copies doit être
assurée par le SGBD réparti. Plusieurs techniques de diffusion
sont possibles parmi lesquelles, on distinguera celles basées sur la
diffusion de l'opération de mise à jour, de celles basées
sur la diffusion du résultat de l'opération.
Diffuser le résultat présente l'avantage de ne
pas devoir réexécuter l'opération sur le site de la copie,
mais l'inconvénient de nécessiter un ordonnancement identique des
mises à jour en tous les sites afin d'éviter les pertes de mises
à jour.
Ces mises à jour peuvent de faire d'une manière
synchrone ou asynchrone.
II.5.6.1. Mise à jour synchrone (synchronous
update)
C'est un mode de distribution dans lequel toutes les sous
opérations locales effectuées suite à une mise à
jour globale sont accomplies pour le compte de la même Transaction.
Lors de l'exécution d'une requête en lecture, la
base de données répartie va décomposer la requête
globale en sous requêtes locales à l'aide des
métadonnées de distribution.
a) Avantages
L'avantage essentiel de la mise à jour synchrone est de
garder toutes les données au dernier niveau de mise à jour. Le
système peut alors garantir la fourniture de la dernière version
des données quel que soit la copie accédée.
De ce fait, ce mode de distribution est très utile,
lors des copies, lorsque les mises à jour effectuées sur un site
doivent être prises en compte immédiatement sur les autres
sites ; ce qui garantit l'absence des conflits entre les différents
sites en permettant le maintien de toutes les copies en cohérence.
b) Limites
Ce mode de distribution présente des multiples limites.
Ceci conduit beaucoup d'application à éviter la gestion des
copies synchrones.
En effet, ces limites sont d'une part la
nécessité de gérer les transactions multi listes
coûteuses en ressources ; ce qui demande plus de ressources
réseaux et matérielles, et d'autres parts la complexité
des algorithmes de gestion de concurrence et de panne d'un site. Raison pour
laquelle l'on préfère souvent le mode de mise à jour
asynchrone (encore appelé mise à jour différée). On
notera aussi la perte des performances du fait de la mise en oeuvre de la
validation en deux phases (préparation de l'écriture des
résultats de mises à jour et la validation).
II.5.6.2. Mise à jour asynchrone (asynchronous
update)
Mode de distribution dans le quel certaines sous
opérations locales effectuées suite à une mise à
jour globale sont accomplies dans des transactions indépendantes en
temps différé.
Le temps de mise à jour des copies peut être plus
ou moins différé ; c'est-à-dire que les transactions
de report peuvent être lancées dès que possible où
à des instants fixés, par exemple le soir ou en fin de
semaine.
a) Avantages
Les avantages sont la possibilité de mettre à
jour en temps choisi des données, tout en autorisant l'accès aux
versions anciennes avant la mise à niveau. Il demande moins de
ressources réseau et matériel que le mode synchrone, ce qui
implique une meilleure disponibilité et une meilleure performance.
b) Limites
L'accès à la dernière version n'est pas
garanti, ce qui limite les possibilités de mise à jour à
cause de certains conflits avec les données.
En effet, il y a possibilité d'avoir des conflits avec
les données, dont voici les trois types :
1. conflit de mise à jour : deux ou plusieurs
sites réalisent de transaction de modification sur la même ligne
pratiquement en même temps.
2. conflit d'unicité : Il provient d'une
transaction d'insertion réalisée par deux ou plusieurs sites
différents tentant d'insérer dans une table une donnée
comportant la clé primaire. Autrement dit quand la réplication
d'une ligne tente de violer l'intégrité d'une entité.
3. conflit de suppression : lorsqu'une transaction
tente de modifier ou de supprimer une ligne qui n'existe plus du fait de sa
suppression par un autre site quelque temps plutôt. Cette ligne ne peut
donc être modifiée ou supprimer.
II.5.7. Types de
réplication
II.5.7.1. Réplication asymétrique
Au-delà des techniques de diffusion des mises à
jour se pose le problème du choix de la copie sur laquelle appliquer les
mises à jour. La réplication asymétrique rompt la
symétrie entre les copies en distinguant un site maître
appelé site primaire, chargé de centraliser les mises à
jour. Il est le seul autorisé à mettre à jour les
données, et chargé de diffuser les mises à jour aux copies
dites secondaires.
Le grand défi dans cette gestion asymétrique est
la panne du site primaire. Dans ce cas, il importe à l'administrateur de
choisir un remplaçant si l'on veut continuer les mises à jour, ce
qui nous amène alors à une technique asymétrique mobile
dans laquelle le site primaire change dynamiquement.
On peut donc distinguer l'asymétrique synchrone et
l'asymétrique asynchrone :
a) Réplication asymétrique
synchrone
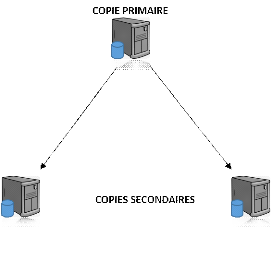
Figure 9: Représentation asymétrique
synchrone
Elle utilise un site primaire qui pousse les mises à
jour en temps réel vers un ou plusieurs sites secondaires. La table
répliquée est immédiatement mise à jour pour chaque
modification par utilisation de trigger sur la table dite maître.
b) Réplication asymétrique
asynchrone
Dans ce cas, le site primaire pousse les mises à jour
en temps différé via une file persistante. Les mises à
jour seront exécutées ultérieurement, à partir d'un
déclencheur externe, l'horloge par exemple.
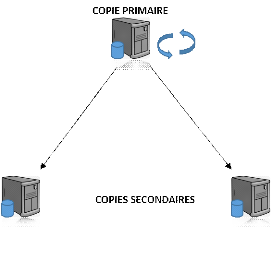
Figure 10: Représentation asymétrique
asynchrone
II.5.7.2. Réplication symétrique
A l'opposé de la réplication asymétrique,
la réplication symétrique ne privilégie aucune
copie ; c'est-à-dire chaque copie peut être mise à
jour à tout instant et assure la diffusion des mises à jour aux
autres copies. C'est une technique de gestion de copies permettant les mises
à jour simultanées de toutes les copies par les transactions
différées.
En effet, cette technique pose un problème de la
concurrence d'accès risquant de faire diverger les copies. Sur ce, une
technique globale de résolution de conflits doit être mise en
oeuvre (exemple : mise à jour d'une copie maitre qui est ensuite
propagée).
On distingue pour ce cas, la réplication
symétrique synchrone et la réplication symétrique
asynchrone.
a) Réplication symétrique
synchrone
Lors de la réplication symétrique synchrone, les
mises à jour s'effectuent à partir de n'importe quel site maitre
et sont diffusées en temps réel.
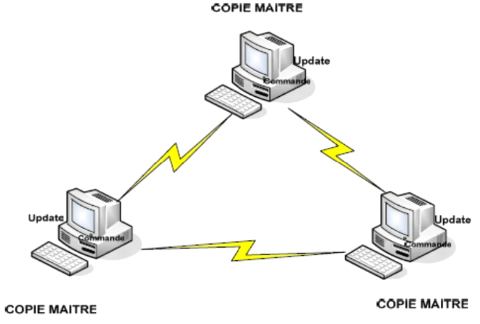
Figure 11: représentation symétriques
synchrone
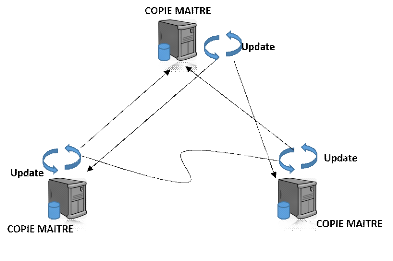
b) Réplication symétrique
asynchrone
Lors de cette réplication, les mises à jour sur
des tables répliquées sonteffectuées par n'importe quel
site en différées. Cette technique risque de provoquer des
incohérences de données car il est tout à fait impossible
de défaire une transaction validée.
Figure 12: Représentation symétriques
asynchrone
II.6. Gestion des transactions
réparties
II.6.1. Définitions
d'une transaction
Une transaction est un ensemble des opérations
menées sur une BD, la transformant d'un état stable
cohérent en un autre état stable cohérent. En cas
d'interruption pour une raison quelconque, la transaction garantit de laisser
la base de données dans l'état dans lequel elle l'avait
trouvée.
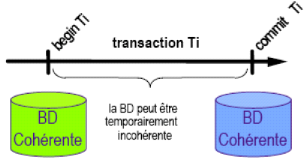
Figure 13: Représentation d'une transaction
Une transaction est soit validée par un
commit, soit annulée par un rollback, soit interrompue
par un abort. Elle a une marque de début (Begin Of Transaction
BOT) ainsi qu'une marque de fin (End Of Transaction EOT).
Autrement, Une transaction est un traitement cohérent
et fiable. La cohérence et la fiabilité d'une transaction sont
garanties par 4 propriétés : l'Atomicité, la
Cohérence, l'Isolation, la Durabilité
qui font l'ACIDité d'une transaction.
Parlant d'opérations d'une transaction, nous en
comptons quatre types dont : le début de la transaction,la
lecture, l'écriture et la terminaison.
II.6.2. Condition de
terminaison
Une transaction n'échoue pas, elle est interrompue pour
diverses raisons, ou arrive à son terme prévu. Pour assurer la
cohérence de la base de données, en cas d'interruption de la
transaction, un mécanisme se charge de défaire toutes les actions
qui ont déjà été effectuées, c'est le
rollback. Si la transaction n'est pas interrompue, elle se définit
correctement et la base de données peut prendre en compte les
changements. On appelle généralement ce signal que donne la
transaction : commit ou validation.
II.6.3.
Propriétés des transactions
Une transaction est composée d'une suite de
requêtes dépendantes de la base qui doivent vérifier les
propriétés d'atomicité, de cohérence, d'isolation
et de durabilité, résumées par le vocable ACID.
· Atomicité : cette
propriété signifie qu'une transaction est traitée comme
une seule opération. Toutes les actions sont toutes menées
à bien ou aucune d'entre elles. C'est-à-dire qu'une transaction
doit effectuer toutes ses mises à jour ou ne rien faire du tout. En cas
d'échec, une transaction doit annuler toutes les modifications qu'elle a
engagées.
· Cohérence : une transaction est un
programme qui amène la BD d'un état cohérent à un
autre état cohérent, tel que toutes les contraintes
d'intégrité restent vérifiées. En cas
d'échec, l'état cohérent initial doit être
restauré.
· Isolation : c'est la propriété
qui impose à chaque transaction de voir la BD cohérente. Une
transaction en exécution ne peut révéler ses
résultats à d'autres transactions concurrentes
(simultanées) avant d'effectuer le commit.
· Durabilité: c'est la
propriété qui garantit lorsqu'une transaction a effectué
son commit, le résultat en permanence, et ne pourra être
effacé de la BD quelques soient les pannes du système
rencontrées.
II.7. Système de Gestion
de Bases de Données Réparties
II.7.1. Définitions
Un système de gestion de bases de données
réparties (SGBDR) est une application centrale qui administre une base
de données répartie comme si toutes les données
étaient stockées sur le même ordinateur.
Il est donc un ensemble des logiciels qui gère des
collections de bases des données logiquement reliées et
distribuées sur un réseau, en fournissant un mécanisme
d'accès qui rend la répartition transparente aux utilisateurs. Il
cache de ce fait aux applications l'existence de multiples bases. C'est
à dire, il contrôle la base de données répartie de
sorte qu'il apparaisse en tant qu'une base de données simple aux
utilisateurs.
Ce système synchronise toutes les données
à des moments donnés et lorsque plusieurs utilisateurs souhaitent
accéder à la même donnée, il s'assure que les mises
à jour, les modifications et suppressions opérées sur la
donnée à un endroit, sont automatiquement
répliquées aux autres endroits de stockage.
A la différence, un SGBD est
dit centralisé lorsque le logiciel contrôle
l'accès à une base de données placée sur un
ordinateur unique. Il est dit distribué lorsqu'il
contrôle l'accès à des données qui sont
dispersées entre plusieurs ordinateurs.
Dans cette construction, un logiciel est placé sur
chacun de différents sites, et ces sites utilisent des moyens de
communication pour coordonner les opérations. Le fait que les
informations sont dispersées est caché à l'utilisateur, et
celles-ci sont présentées comme si elles se trouvaient à
une seule place.
En effet, une base de données centralisée est
gérée par un seul SGBD et est stockée dans sa
totalité à un emplacement physique unique. Ses divers traitements
sont confiés à une seule et même unité de
traitement. Par opposition, une base de données distribuée est
gérée par plusieurs processeurs, sites ou SGBD.
Le SGBD réparti doit offrir une gestion des
priorités, verrous, concurrence de la même façon qu'un SGBD
centralisé. Pour ce faire, il doit disposer de :
· Dictionnaire des données reparties ;
· Communication des données inter site ;
· Gestion de la cohérence et de la
sécurité ;
· Traitement des requêtes reparties ;
· Gestion des transactions reparties ;
Un SGBDR est composé en plusieurs couches :
· Le SGBD externe (user interface
handler) : sa tâche est d'interpréter les commandes
utilisateurs ;
· Le système de gestion des fichiers
(run-time support processor) : il gère le stockage physique de
l'information. Il est dépendant du matériel utilisé.
· Le contrôleur sémantique des
données (semantec data controler) : il utilise les
différentes contraintes définies sur la base de données
afin de vérifier qu'une requête d'un utilisateur peut être
effectuée.
· Le gestionnaire de reprise (recovery
manager) : il s'occupe d'assurer la cohérence des données
lorsque des pannes surviennent.
· Le processeur de requêtes (query
processor) : il détermine une stratégie afin de minimiser le
temps d'exécution d'une requête.
II.7.2. Les
caractéristiques d'un SGBD réparti
Ces caractéristiquesd'un SGBD réparti sont
reprises comme suit :
· Un SGBD réparti est utilisé pour
créer, rechercher, mettre à jour et supprimer les bases de
données réparties ;
· Il synchronise la base de données
périodiquement et fournit des mécanismes d'accès par la
vertu de laquelle la distribution devient transparente aux
utilisateurs ;
· Il s'assure que les données modifiées
à n'importe quel emplacement sont universellement mises à
jour ;
· Il est utilisé dans des domaines d'application
où des grands volumes de données sont traités et
consultés par de nombreux utilisateurs simultanément ;
· Il est conçu pour les plateformes ou
environnements hétérogènes de base de
données ;
· Il maintient la confidentialité et
l'intégrité des données des bases de données.
II.7.3. Intérêt
d'un SGBD réparti
Les facteurs suivants encouragent la migration vers un SGBD
réparti :
II.7.3.1. Nature distribuée des unités
d'organisation :
La plupart des organismes dans les temps courants sont
subdivisés en unités multiples qui sont physiquement
réparties sur le globe. Chaque unité exige son propre ensemble de
données locales. Ainsi, la base de données globale de
l'organisation devient distribuée.
II.7.3.2. Besoin de partage des données :
Les unités d'organisation multiples doivent souvent
communiquer entre eux et partager leurs données et ressources.Ceci exige
les bases de données communes ou les bases de données
repliées qui devraient être employées d'une façon
synchronisée.
II.7.3.3. Support d'OLTP et d'OLAP :
Traitement transactionnel en ligne (OLTP) et le traitement
analytique en ligne (OLAP) travaillent sur les systèmes
diversifiés qui peuvent avoir des données communes.Les
systèmes de base de données répartie facilitent ces deux
traitements en fournissant des données synchronisées.
II.7.3.4. Rétablissement de Base de données
:
Une des techniques communes utilisées dans un SGBD
réparti est la réplication des données à travers
différents sites. Cette technique aide automatiquement dans le
rétablissement de données si la base de données dans
n'importe quel site est endommagée.Les utilisateurs peuvent
accéder à des données d'autres sites tandis que le site
endommagé est reconstruit.Ainsi, l'échec de base de
données peut devenir presque inaperçu aux utilisateurs.
II.7.3.5. Support de multiple logiciel d'application :
La plupart des organismes emploient une variété
de logiciel d'application chacune avec son appui spécifique de base de
données.Le SGBD réparti fournit une fonctionnalité
uniforme pour l'usage des mêmes données parmi différentes
plateformes.
II.7.4. Architecture d'un SGBD
réparti
Des architectures des SGBD répartis sont
généralement développées selon trois
paramètres :
· Distribution : elle énonce la
distribution physique des données à travers les différents
sites.
· Autonomie : elle indique la distribution de
contrôle du système de base de données et du degré
auquel chaque composant du système de gestion de bases de données
peut fonctionner indépendamment.
·
Hétérogénéité : elle se rapporte
à l'uniformité ou à la dissimilitude des modèles de
données, des composants de système et des bases de
données.
II.7.4.1. Modèles d'architecture des SGBD
répartis
Certains des modèles architecturaux communs sont :
II.7.4.1.1. Architecture peer-to-peer
Dans ces systèmes, chaque pair agit à la fois
comme un client et un serveur pour donner des services de base de
données.Les pairs partagent leur ressource avec d'autres pairs et
coordonnent leurs activités.
Cette architecture a généralement quatre niveaux
des schémas :
§ Schéma Conceptuel Global :
Dépeint la vue des données logique globale.
§ Schéma Conceptuel Local :Dépeint
l'organisation logique de données à chaque emplacement.
§ Schéma Interne Local :Dépeint
l'organisation physique de données à chaque emplacement.
§ Schéma Externe :Dépeint la vue
d'utilisateur des données.
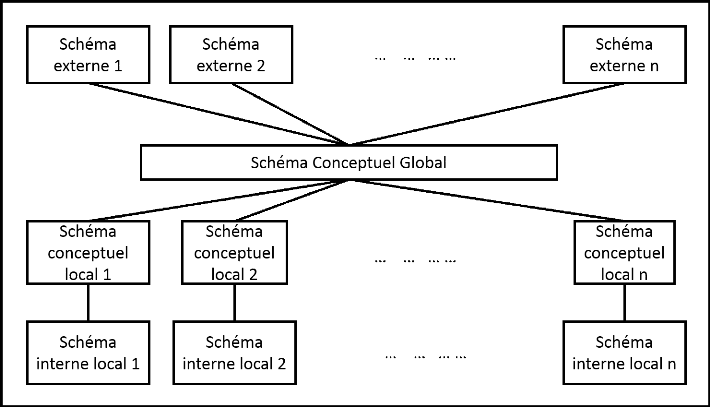
Figure 14: Architecture peer-to-peer
II.7.4.1.2. Architecture Client server
C'est une architecture à deux niveaux où la
fonctionnalité est divisée en serveurs et clients.Les fonctions
de serveur entourent principalement la gestion des données, de
traitement de requête, d'optimisation et de transaction. Les fonctions de
client incluent principalement l'interface utilisateur. Cependant, elles ont
certaines fonctions comme la vérification de l'uniformité et la
gestion de transaction.
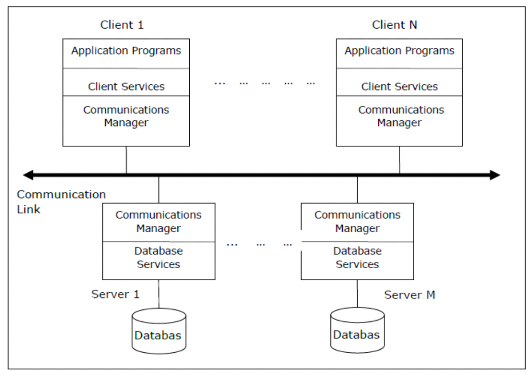
Figure 15: Architecture client-serveur de SGBD
Réparti
Un client de SGBDR est une application qui accède aux
informations distribuées par les interfaces du SGBDR tandis qu'un
serveur de SGBDR est un SGBD gérant une base de données locale
intégrée dans une base de données répartie.
Au-delà des notions de client et de serveur SGBDR, on a
un calculateur dans le réseau gérant la base appelé noeud
ou site.
II.7.4.2. SGBDR homogène
Toutes les BD suivent un même schéma et utilisent
la même technologie (ex: Oracle). L'accès aux données ainsi
quela gestion des transactions réparties sont souvent faits de
manière centralisée. En plus, cette architecture présente
une plus grande fiabilité et performance dû à un meilleur
couplage entre les sites.
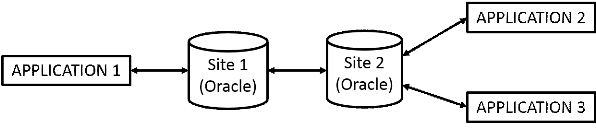
Figure 16: Architecture répartie avec SGBD
répartis homogènes
II.7.4.3. Multi-SGBD réparti
Dans cette architecture, chaque site est autonome et peut
avoir un SGBD de type différent. Ce qui conduit à l'utilisation
des interfaces (ex: schéma conceptuel) différentes et cela peut
devenir très complexe à gérer.
Le Multi-Système de gestion de bases de données
peut être exprimé par six niveaux des schémas :
§ Niveau De Vue Multi-base de données :
Dépeint des vues multiples d'utilisateur comportant des sous-ensembles
de la base de données répartie intégrée.
§ Niveau Conceptuel Multi-base de données
:Dépeint la multi-base de données intégrée qui
comporte des définitions logiques globales de structure de multi-base de
données.
§ Niveau Interne Multi-base de données
:Dépeint la distribution de données à travers
différents emplacements et la multi-base de données aux
données locales traçant.
§ Niveau local de vue de base de données
:Dépeint la vue publique des données locales.
§ Niveau conceptuel de base de données
locale :Dépeint l'organisation locale de données à
chaque emplacement.
§ Niveau interne de base de données
locale :Dépeint l'organisation physique de données à
chaque emplacement.
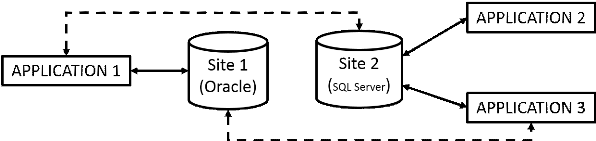
Figure 17: Architecture répartie avec
multi-SGBD
II.7.4.4. SGBD Fédérés
L'architecture fédérée intègre
plusieurs SGBD autonomes et potentiellement hétérogènes en
une seule BD virtuelle dont l'interface d'accès commun doit être
implémentée pour masquer
l'hétérogénéité des BD et la
répartition des données.
L'inconvénient de cette architecture reste
l'intégration du schéma, la réécriture des
requêtes complexes ainsi que les performances limitées.
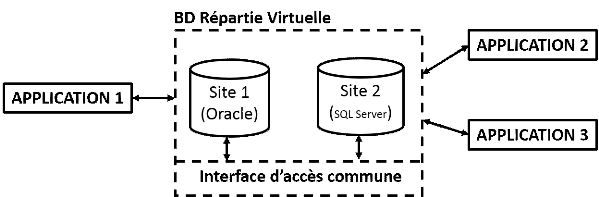
Figure 18: Architecture répartie avec SGBD
fédérés
II.7.5. Objectifs du SGBDR
Les objectifs d'un SGBDR se résument en ces aspects
suivants :
II.7.5.1. Multi client-serveur
Dans le contexte du client serveur, un client peut demander
l'exécution d'une requête à un serveur. La requête,
appelée requête distante peut par exemple être
exprimée en SQL. Pour assurer l'objectif multi clients, le SGBDR doit
fournir des mécanismes de contrôle de concurrence adapté,
garantissant que l'effet de l'exécution simultanée des
transactions est le même que celui d'une exécution
séquentielle : cette propriété est appelée la
sérialisabilité des transactions.
II.7.5.2. Transparence à la localisation des
données
Un des objectifs clés de SGBDR est de permettre
l'écriture des programmes d'application sans connaître la
localisation physique des données. Dans ce but, les noms des objets (par
exemple le nom des tables) doivent être indépendants de leurs
localisations. Les requêtes seront en général
exprimées en SQL de manière similaire aux requêtes locales.
Elles référenceront des vues de la base repartie ; ces vues
porteront un nom ne concernant pas la localisation des données.
La transparence à la localisation simplifie la vue
utilisateur et l'écriture de requête, moins surtout d'introduire
la possibilité de déplacer les objets (par exemple les tables)
sans modifier les requêtes.
II.7.5.3. Meilleure disponibilité des
données
L'apport en matière de disponibilité des
données reste sans doute une des justifications essentielles d'un SGBDR.
Tout d'abord, la répartition permet de ne plus dépendre d'un site
central unique et en suite, elle permet de gérer des copies, de se
replier sur une copie lorsqu'une autre est indisponible (site en panne), et
même mettre à jour de manière indépendante les
copies.
Les copies deviennent alors des reliquats qui peuvent
évoluer indépendamment pour converger ultérieurement.
Cette fonctionnalité appelée réplication.
Notons aussi que : assurer une meilleure
disponibilité des données, c'est aussi garantir
l'atomicité des transactions.
II.7.5.4. Autonomie locale des sites
Un autre objectif des SGBDR est d'éviter la
nécessité d'une administration centralisée des bases.
L'autonomie locale vise à garder une administration locale
séparée et indépendante pour chaque serveur participant
à la BD répartie.
Ainsi, les reprises après panne doivent être
accomplies localement et ne pas impacter les autres sites. Les mises à
niveau de logiciel sur un site doivent être possible sans impacter les
autres les autres sites. Bien que chaque base puisse travailler avec les
autres, les gestions de schéma doivent rester indépendantes.
II.7.5.5. Support
d'hétérogénéité
Un SGBDR hétérogène doit être
capable d'unifier modèles et langage comme représenté
Figure suivante. Ceci afin de gérer des bases
fédérées. L'unification s'effectue en
général par un langage pivot afin de limiter le nombre de
conversion de modèle à réaliser.
Nous avons vu tout au long de ce chapitre, ce qu'on
appelle SGBDR, ses avantages et ses limites, ses caractéristiques, ses
objectifset ses différentes sortes existantes. Dans le chapitre que nous
allons aborder ici-bas, nous parlons de l'authentification par mesure
biométrique en utilisant la technique d'empreinte
digitale.
CHAPITRE
IIIème : AUTHENTIFICATION PAR EMPREINTES DIGITALES [2] [8] [11]
De nos jours, toute organisation se veut, en son sein, d'une
sécurité en vue de s'échapper à des fraudes,
tricherie, espionnage et autre forme de menace pouvant nuire à son
bien-être. C'est ainsi que tout commence par un processus pouvant
permettre de déterminer qui a fait quoi, où, pourquoi, avec quoi
et sur quoi. Ce processus n'est rien d'autre que l'authentification.
En effet, l'authentificationprend la tête au niveau de
la sécurité en ensemble et aussi dans les contrôles
d'accès au sein de nos sociétés. Cette mesure est
basée sur deux composantes :
· L'identification dont le rôle est de
définir les identités d'un utilisateur.
· L'authentification permettant de vérifier
les identités présumées des utilisateurs.
Pour ce faire, nous devons recourir à des techniques
permettant de répondre à ces conditions.L'une d'entre elles est
celle de la biométrie et plus particulièrement la reconnaissance
par empreintes digitales.
III.1. Authentification
III.1.1. Définition
L'authentification est la procédure qui consiste,
pour un système informatique, à vérifier l'identité
d'une entité (individu ou ordinateur) afin d'autoriser son accès
à des ressources (systèmes, réseaux, applications,
...).
En effet, l'authentification permet de valider
l'authenticité de l'entité en question.
L'authentification par biométrie consiste à
utiliser un système de reconnaissance basé sur les
caractéristiques physiques ou comportementales d'un individu pour
vérifier son identité.
III.1.2. Type
d'authentification
Nous en distinguons trois types que voici :
III.1.2.1. Authentification simple
On parle de l'authentification simple lorsqu'il existe une
seule preuve de l'identité. (Mot de passe par exemple).
III.1.2.2. Authentification forte
L'authentification forte est une procédure
d'identification qui requiert plusieurs facteurs pour prouver l'identité
de l'utilisateur (mot de passe et empreinte digitale par exemple). C'est la
concaténation d'au moins deux facteurs d'authentification.
III.1.2.3. Authentification unique
C'est une méthode permettant à un utilisateur de
ne procéder qu'à une seule authentification pour accéder
à plusieurs applications informatiques (ou sites internet
sécurisés).
Outre, la notion d'authentification s'oppose à celle de
l'identification d'une personne physique ou morale. Généralement,
dans le cas d'un individu, l'authentification consiste à vérifier
que celui-ci possède une preuve de son identité ou de son statut
sous l'une de bases (éventuellement combinées)
suivantes :
· ce qu'il connait (mot de passe, PIN, phrase
secrète ...) ;
· ce qu'il possède (carte à puce,
clé USB, un PDA, ...) ;
· ce qu'il est : une caractéristique physique
propre à un individu, on parle de la biométrie (empreinte
digitale, ADN, empreinte oculaire, ...) ;
· ce qu'il sait faire ou fait en faisant allusion
à la biométrie comportementale (signature manuscrite,
reconnaissance vocale, geste, un comportement quelconque...)
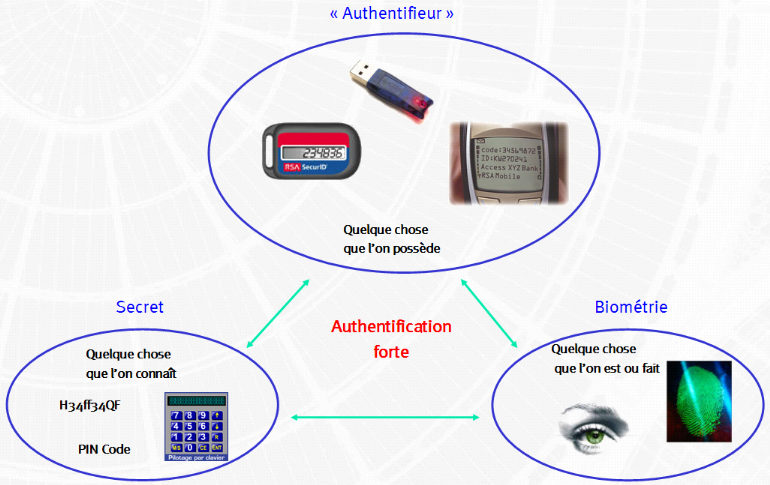
Source: [
https://fr.m.wikipedia.org/wiki/Fichier:Auth-Forte-b.pnge]
Dans la majeure partie, c'est l'individu qui s'authentifie.
Mais cela peut être aussi fait par un objet comme une application web,
par exemple, utilisant le protocole SSL, un serveur SSH, une marchandise, un
animal, etc.
On peut considérer que l'authentification forte est une
des fondations essentielles pour garantir les éléments suivants
dans un système informatique :
· l'autorisation ou contrôle
d'accès (qui a accès au système) ;
· la confidentialité (qui peut le voir) ;
· l'intégrité (qui peut le
modifier) ;
· la traçabilité (qui l'a fait) ;
· l'irrévocabilité (qui peut le
prouver).
Sou forme pyramidale, l'authentification se présente de
manière suivante :
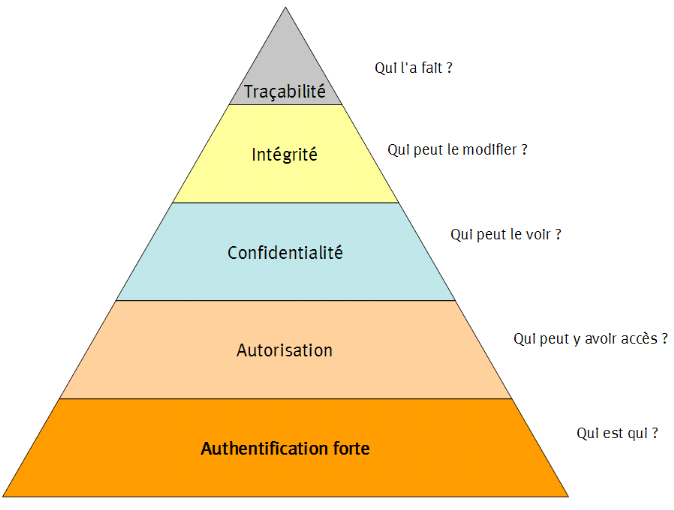
Source: [
https://fr.m.wikipedia.org/wiki/Fichier:Pyramide-auth.png]
III.1.3. Les enjeux de
l'authentification
L'authentification constitue le socle de la
traçabilité des transactions dans un système informatique.
Elle permet :
· la protection des intérêts
supérieurs de l'Etat et du patrimoine informatique des
entreprises consistant à la réduction des coûts qui
résulte d'attaques, de la perte de temps, de la perte d'informations, de
l'espionnage ou des fuites involontaires d'informations ;
· le développement du commerce et des
échanges électroniques. Elle bâtit la confiance dans
l'économie numérique, ce qui est une vive condition indispensable
du développement économique en favorisant la facturation des
services ;
· la protection de la vie privée aussi longtemps
que les données personnelles véhiculant dans des systèmes
d'information sont des données sensibles à protéger.
III.2.Biométrie
III.2.1. Définition
La biométrie est l'étude mathématique
des variations biologiques à l'intérieur d'un groupe
déterminé ; alors que le système de contrôle
biométrique est un système automatique de mesure basé sur
la reconnaissance de caractéristiques propres à un
individu.
La biométrie recouvre l'ensemble des
procédés tendant à identifier un individu à partir
de la « mesure » de l'une ou de plusieurs de ses
caractéristiques physiques, physiologiques ou comportementales. Il peut
s'agir des empreintes digitales, de l'iris de l'oeil, du contour de la main, de
l'ADN ou d'éléments comportementaux (la signature, la
démarche) etc.
A la différence de toute autre donnée
d'identité, et à plus forte raison de toute autre donnée
à caractère personnel, la donnée biométrique n'est
pas attribuée par un tiers ou choisie par la personne : elle est
produite par le corps lui-même et le désigne ou le
représente, lui et nul autre, de façon immuable. Elle appartient
donc à la personne qui l'a générée.
En effet, elle recense nos caractères physiques (et
comportementaux) les plus uniques, qui peuvent être captés par des
instruments et interprétés par des ordinateurs de façon
à être utilisés comme des représentants de nos
personnes physiques dans le monde numérique. Ainsi, nous pouvons
associer à notre identité des données numériques
permanentes, régulières et dénuées de toute
ambiguïté, et récupérer ces données rapidement
et automatiquement à l'aide d'un ordinateur.
III.2.2.
Propriétés de la biométrie
Nous décrivons dans ce cas les propriétés
souhaitables d'une caractéristique biométrique. Cette
caractéristique doit être :
1) universelle : c'est-à-dire que toutes
les personnes de la population à identifier doivent la
posséder ;
2) à la fois facilement et quantitativement
mesurable ;
3) unique : c'est-à-dire que deux
personnes ne peuvent posséder exactement la même
caractéristique. Même les jumeaux, par exemple, venant de la
même cellule, auront des empreintes très proches mais pas
semblables.
4) immuable : cette caractéristique ne
peut donc se modifier au cours de temps (sauf en cas de brûlure ou
accident par exemple) ;
5) permanente : ce qui signifie qu'elle ne doit
pas varier au cours du temps ;
6) performante : c'est-à-dire que
l'identification doit être précise et rapide ;
7) bien acceptée par les utilisateurs du
système ;
8) impossible à dupliquer par un imposteur.
III.2.3. Architecture d'un
système biométrique
Un système biométrique comporte au moins deux
modules, l'un pour l'apprentissage et l'autre pour la reconnaissance ainsi que
l'autre facultatif pour une adaptation.
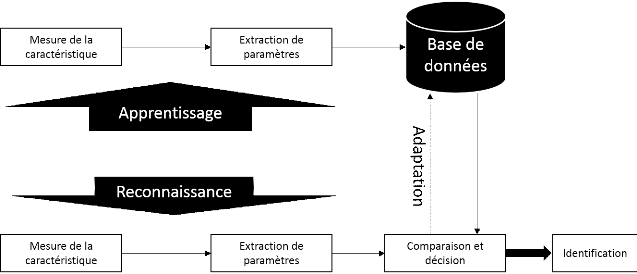
Figure 19: Représentation d'une architecture d'un
système biométrique
III.2.3.1. Module d'apprentissage (enrôlement)
Au cours de ce module, il est question de l'acquisition ou la
capture de la caractéristique. Cette capture n'est stockée dans
la base de données qu'après des certaines transformations lui
appliquées.
En effet, le signal contient de l'information inutile à
la reconnaissance et seuls les paramètres pertinents sont extraits. Le
modèle ou gabarit est une représentation compacte du signal qui
permet de faciliter la phase de reconnaissance, mais aussi de diminuer la
quantité de données à stocker. Il est à noter que
la qualité du capteur peut grandement influencer les performances du
système. Meilleure est la qualité du système
d'acquisition, moins il y aura de prétraitements à effectuer pour
extraire les paramètres du signal.
III.2.3.2. Module de reconnaissance
Au cours de la reconnaissance, la caractéristique
biométrique est mesurée et un ensemble de paramètres est
extrait comme lors de l'apprentissage. Le capteur utilisé doit avoir des
propriétés aussi proches que possibles du capteur utilisé
durant la phase d'apprentissage. Si les deux capteurs ont des
propriétés trop différentes, il faudra en
général appliquer une série de prétraitements
supplémentaires pour limiter la dégradation des performances.
III.2.3.3. Module d'adaptation
Pendant la phase d'apprentissage, le système
biométrique ne capture souvent que quelques instances d'un même
attribut afin de limiter la gêne pour l'utilisateur. Il est donc
difficile de construire un modèle assez général capable de
décrire toutes les variations possibles de cet attribut. De plus, les
caractéristiques de cette biométrie ainsi que ses conditions
d'acquisition peuvent varier.
L'adaptation est donc nécessaire pour maintenir ou
améliorer la performance d'un système utilisation après
utilisation. Elle est quasi indispensable pour les caractéristiques non
permanentes comme la voix.
III.2.4. Applications de la
biométrie
Nous pouvons distinguer quatre grands types d'applications de
la biométrie : le contrôle d'accès (access control),
l'authentification des transactions (transaction authentication), la
répression (lawenforcement) et la personnalisation (personalization).
a) Contrôle d'accès
Le contrôle d'accès peut être
lui-même subdivisé en deux sous catégories : le
contrôle d'accès physique et le contrôle d'accès
virtuel. On parle de contrôle d'accès physique lorsqu'un
utilisateur cherche à accéder à un lieu
sécurisé. On parle de contrôle d'accès virtuel dans
le cas où un utilisateur cherche à accéder à une
ressource ou un service.
b) Authentification des transactions
L'authentification des transactions représente un
marché gigantesque puisqu'il englobe aussi bien le retrait d'argent au
guichet des banques, les paiements par cartes bancaires, les transferts de
fond, les paiements effectués à distance par
téléphone ou sur internet, etc.
c) Répression
Une des applications les plus immédiates de la
biométrie à la répression est la criminologie. La
reconnaissance d'empreintes digitales en est l'exemple le plus connu. Elle fut
acceptée dès le début du XXe siècle comme moyen
d'identifier formellement un individu, et son utilisation s'est rapidement
répandue. Il existe aussi des applications dans le domaine judiciaire.
T-Netixpropose ainsi des solutions pour le suivi des individus en
liberté surveillée en combinant les technologies de l'internet et
de reconnaissance du locuteur.
d) Personnalisation
Les technologies biométriques peuvent être aussi
utilisées afin de personnaliser les appareils que nous utilisons tous
les jours. Cette application de la biométrie apporte un plus grand
confort d'utilisation.
Afin de personnaliser les réglages de sa voiture,
Siemens propose par exemple d'utiliser la reconnaissance des
empreintes digitales. Une fois l'utilisateur identifié, la voiture
ajuste automatiquement les sièges, les rétroviseurs, la
climatisation, etc.
III.2.5. Panorama des
différentes biométries
Il existe plusieurs différentes techniques
biométries utilisées actuellement pour prouver l'identité
d'un individu.
· Pour les caractéristiques physiques, nous avons
la reconnaissance de visage, de thermo-gramme facial,
d'empreintes digitales, de géométrie de la
main, de rétine et d'iris.
· Pour les caractéristiques comportementales, nous
avons les systèmes basés sur la voix et la
signature.
Il existe d'autres méthodes biométriques
basées sur les veines de la main, l'A.D.N.
(acide désoxyribonucléique), l'odeur corporelle, la
forme de l'oreille, la forme des lèvres, le rythme de
frappe sur un clavier, la démarche, etc.
Il est important de noter qu'il n'existe aucune
caractéristique biométrique idéale. À chaque
application correspond une ou plusieurs mesures biométriques
appropriées.Cependant, concernant notre étude, nous allons nous
concentrer sur une des technologies biométriques qu'est la
reconnaissance des empreintes digitales.
III.2.5.1. Empreinte digitale
La technique des empreintes digitales est une des techniques
les plus anciennes. Sur ce, elle a été développée
à la fin du 19è siècle par Alphonse Bertillon, fondateur
de la police scientifique en France.
Par définition, une empreinte digitale est un
dessin formé par les lignes de la peau des doigts, des paumes des mains,
des orteils ou de la plante des pieds pendant la période
foetale.
Appelée aussi dermatoglyphe,une empreinte digitale est
une signature que nous laissons derrière nous à chaque fois que
nous touchons un objet. Les motifs dessinés par les crêtes et plis
de la peau sont différents pour chaque individu ; c'est ce qui motive
leur utilisation par la police criminelle depuis le 19è
siècle.

Figure 20: Capture d'une empreinte digitale
On estime que les empreintes digitales commencent
à se former entre la 10è et la 16è semaine de vie du
foetus, par un plissement des couches cellulaires.
Les circonvolutions des crêtes leur donnant leur dessin
caractéristique vont dépendre de nombreux facteurs, comme la
vitesse de croissance des doigts, l'alimentation du foetus, sa pression
sanguine, etc. Ce qui fait que non seulement chaque individu, mais aussi chaque
doigt, a son empreinte propre.
Alors si deux vrais jumeaux ont des empreintes digitales
ressemblantes, elles sont pourtant différentes. Elles seront
considérées comme identiques lors d'une recherche sur une
scène de crime parce que le nombre de points de comparaison
utilisé est limité.
Une empreinte complète contient en moyenne une centaine
de points caractéristiques mais les contrôles ne sont
effectués qu'àpartir de 14 points. Statistiquement, il est
impossible de trouver 2 individus présentant 14 points
caractéristiquesidentiques, même dans une population de plusieurs
millions de personnes.
En effet, les empreintes digitales sont uniques et
caractéristiques d'un individu ; même les vrais jumeaux
présentent des empreintes digitales différentes.
III.2.5.1.1. Caractéristiques d'une empreinte
digitale
Une empreinte digitale est une marque laissée par les
crêtes des doigts, des mains, des orteils ou des pieds lorsqu'elles
touchent un objet.
Il en existe deux types :
· L'empreinte directe (qui laisse une marque visible)
et
· L'empreinte latente (saleté, sueur ou autre
résidu déposé sur un objet).
Les empreintes digitales sont regroupées en trois
catégories principales regroupant à elles seules 95% des doigts
humains: l'arche ou l'arc (arch), le tourbillon (whorl) et la boucle (loop).
À l'intérieur de chacune de ces catégories, il y a un
très grand nombre d'éléments qui nous différencient
les uns des autres. En plus des cicatrices, il y a les fourches, les
îlots et les espaces qui donnent un caractère unique aux
empreintes latentes.
Les« boucles » constituent les motifs les
plus répandus qui représentent 60% des doigts humains : dans
ce type d'empreinte se replient sur elles même soit vers la droite, soit
vers la gauche. Viennent ensuite les « tourbillons », qui
correspondent à 30% des doigts humains : cette empreinte, dite en
verticille, comprend des lignes qui viennent s'enrouler autour d'un point,
formant un genre de tourbillon. Pour finir, les motifs les moins
répandus sont « les arches » qui regroupent
seulement 5% des doigts humains : cette empreinte, en arc, contient des
lignes disposées les unes au-dessus des autres qui forment des A.
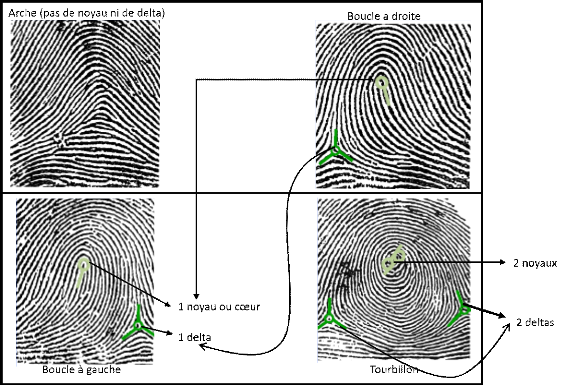
Figure 21: Exemple des catégories principales des
empreintes digitales
On différencie les motifs entre eux à l'aide de
"points singuliers" appelés "minuties" sur les boucles, tourbillons ou
arcs :
a) points singuliers globaux :
· noyau ou centre : lieu de convergences de
stries ;
· delta : lieu de divergences de
stries ;
b) points singuliers locaux (appelés aussi
minuties) : ce sont les points d'irrégularité se trouvant
sur les lignes papillaires (terminaisons, bifurcations, ilots assimilés
à deux terminaisons, lacs).
Quelle que soit sa forme, une empreinte digitale
possède des points précis différents appelés
minuties.
On estime qu'il y a plus de cent points de convergence entre
deux empreintes identiques relevées. Souvent, ces points de convergence
sont des irrégularités sur les lignes papillaires. Les points les
plus fréquemment utilisés dans les algorithmes lors de la
comparaison sont de quatre types : les lacs, les terminaisons (à
droite et à gauche), les bifurcations (à droite et à
gauche) et les îles.
Plus précisément, une minutie est un point qui
se situe sur le changement de continuité des lignes papillaires. Ce sont
grâce à elles que les empreintes digitales peuvent être
différenciées.
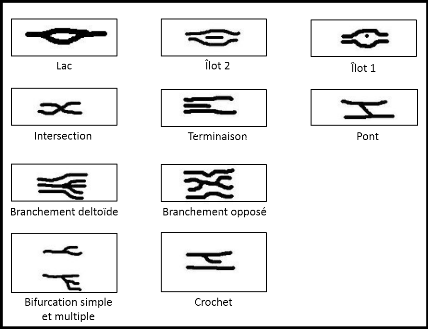
Figure 22: Différentes formes de minuties

Figure 23: Les points singuliers d'une empreinte
La validation d'une identification peut mettre en
évidence jusqu'à quatorze points de comparaison (autrement
appelés points caractéristiques ou minutie).
Selon Francis Galton, la probabilité que deux personnes
aient la même empreinte digitale est de 1 sur 64 milliard, ce qui est
très faible à l'échelle de la population humaine et donc
quasiment impossible.
L'utilisation de l'empreinte digitale comme moyen
d'identification d'une personne n'est pas nouvelle. En fait, la police
scientifique utilise cette technique depuis plus de 100 ans. Aujourd'hui, les
empreintes digitales sont recueillies sur une scène de crime et sont
ensuite comparées à celles contenues dans un serveur central.
III.2.5.1.2. Principe de fonctionnement
Une empreinte digitale étant une des techniques du
système biométrique, repose aussi sur deux modes de
fonctionnement : l'enrôlement et l'authentification en vue de
déterminer l'identité d'un individu.
L'authentification par empreinte digitale repose sur la
concordance entre le fichier d'enregistrement ou signature obtenu lors de
l'enrôlement et le fichier obtenu lors de l'authentification.
Le principe de fonctionnement d'une empreinte digitale se
décompose en deux étapes suivantes :
a) Enrôlement
L'enrôlement d'un individu se réalise comme
suit :
· capture de l'image ;
· numérisation de l'image afin d'en extraire les
minuties ;
· enregistrement sur un support (carte à puce,
disque dur, ...).
b) Authentification
À son tour, l'authentification se fait de la
manière suivante :
· capture de l'image ;
· numérisation de l'image afin d'en extraire les
minuties ;
· comparaison entre échantillon et le gabarit
(signature) ;
· prise de décision.
III.2.5.1.3. Etapes de traitement informatique de
l'empreinte digitale
Plusieurs méthodes sont utilisées pour
reconnaitre les empreintes digitales dont : la localisation des minuties,
le traitement des textures ainsi que d'autres beaucoup d'autres techniques non
encore divulguées dans un but de confidentialité.
Pour ce travail, nous nous intéresserons à la
technique de localisation de minuties. Le traitement de l'empreinte digitale
par cette technique se base sur trois principales étapes : la
numérisation de l'image, l'extraction des minuties et la comparaison des
gabarits.
a) Numérisation de l'image
Cette technique consiste à numériser l'empreinte
digitale et la filtrer de façon à la nettoyer des
caractéristiques inutiles telles que des cicatrices (segmentation).
L'image à numériser peut bien être de format BITMAP pour le
traitement ainsi que l'échange des images avec les applications sous
Windows. L'origine des images n'a pas d'importance (scanner, fichier,
caméra, code barre...).
L'image ainsi numérisée en noir et blanc doit
être filtrée dans le but de supprimer toute ambiguïté
en détectant des zones de bruit et en faisant ressortir la plus grande
partie possible d'information utile au système. Cette étape se
chargera bien également de détecter l'absence d'empreinte, un
niveau élevé de bruit dans l'image (image sale ou lecteur
défectueux), un positionnement incorrect du doigt.
Une fois l'image filtrée, les lignes se voient
clairement mais elles ont des tailles différentes. Pour pouvoir
détecter rapidement les minuties (terminaisons, bifurcations), on
crée un squelette de chaque empreinte grâce aux algorithmes
complexes en vue de rendre chaque ligne (crête) de l'empreinte de 5
à 8 pixels à une épaisseur égale d'un pixel.

Figure 24: Squelettisation d'une empreinte digitale
Chaque minutie est repérée et
répertoriée grâce à son type (bifurcation B ou
terminaison T), à sa position dans l'image (coordonnées x et y)
et à sa direction ).
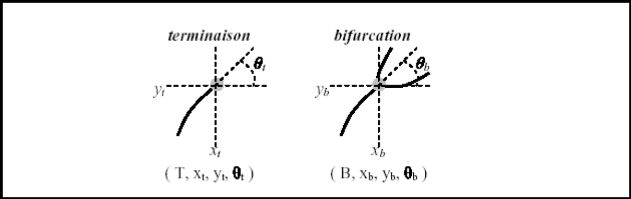
Figure 25: Exemple de repérage des minuties
b) Extraction des minuties
L'extraction des minuties est un processus final qui
complète l'obtention de la signature de l'empreinte grâce à
différents algorithmes.
Le gabarit retenu pour caractériser l'empreinte est
basé sur un nombre minimum allant de douze à quatorze minuties,
ou encore plus, nécessaires pour pouvoir établir des comparaisons
fiables, c'est-à-dire des comparaisons non influencées par
certains défauts lors l'acquisition de l'image ou par
l'altération temporaire (blessure, ....), entre empreintes. Ce qui fait
qu'avec ce minimum de minuties correctement relevées et
localisées, il est possible d'identifier une empreinte parmi plusieurs
millions d'exemplaires.
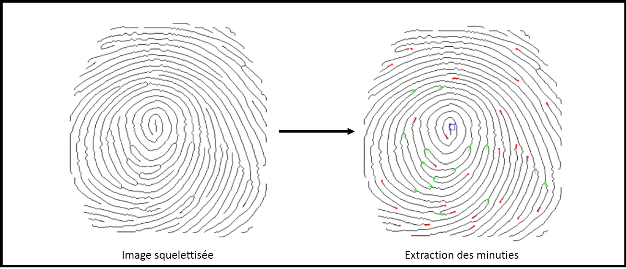
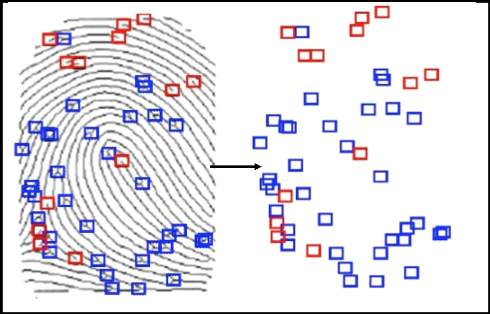
Figure 26: Extraction des minuties d'une empreinte
c) Comparaison des gabarits
La comparaison de deux ensembles de minuties (fichier
"gabarit"), correspondants respectivement à deux doigts à
comparer constitue le système de vérification
d'identité.
Pour déterminer si deux ensembles de minuties extraits
de deux images correspondent à des empreintes du même doigt, il
est nécessaire d'adopter un système de comparaison qui soit
insensible à d'éventuelles translations, rotations et
déformations qui affectent systématiquement les empreintes
digitales.
Normalement, à partir de deux ensembles de minuties
extraites, le système doit être capable de donner un indice de
similitude ou de correspondance qui vaut :
· 0 % si les empreintes sont totalement
différentes ;
· 100 % si les empreintes viennent de la même
image.
Par ailleurs, deux fichiers " gabarit "
calculées à partir de la même empreinte ne donneront jamais
100 % de ressemblance du fait des différences qui existent lors de
l'acquisition de deux images (petites déformations ou
déplacements), ils donneront cependant toujours un niveau
élevé de similitude.

Figure 27: Authentification par empreinte digitale
La décision à partir de cet indice de similitude
de savoir si deux empreintes sont issues du même doigt est une question
purement statistique. Pour décider d'accepter la similitude entre
deux " gabarit ", il faut établir un seuil d'acceptation.
III.2.4.4. Avantages et inconvénients d'une
empreinte digitale informatisée
a) Avantages
Chaque être humain a sa propre empreinte unique. A cet
effet, les empreintes digitales peuvent servir à l'identification des
personnes à de nombreuses fins :
· Prévention des fraudes pour résoudre des
crimes.
· Economie de l'espace avec chaque dossier
numérisé ;
· Temps optimisé pour l'accès au dossier
d'un individu, ce qui peut aider les forces policières à
résoudre des crimes plus rapidement et efficacement ;
· Quasi-impossible d'être craquée ;
· Moins salissant que la méthode de
l'encre ;
· Pas de vol, d'oubli, de copie ni de perte
d'identité ;
b) Limites
· Les empreintes digitales informatisées peuvent
être utilisées pour une fausse identification des
personnes au cas où le système d'empreinte digitale est mal
paramétré ou ne fonctionne pas correctement;
· Elles peuvent être déformées, ce
qui conduit à des erreurs d'identification ;
· Impossible d'être changée lorsqu'elle est
compromise ;
· Difficulté de reconnaissance d'empreintes
lorsque le doigt est crémé, humide, blessé, ...
· L'utilisation des faux doigts peut tromper la machine,
mais ceci demande beaucoup de compétences ;
Nous avons abordé dans ce chapitre, les
concepts de base concernant l'authentification en utilisant la technique
d'empreintes digitale. Nous avons passé la main sur les
différents avantages et limites de cette authentification et avons
aussi relevé le point sur le processus d'authentification par empreinte
digitale.
Dans le chapitre suivant, nous parlerons de
l'entité pour laquelle nous avons mené nos études
correspondant au suivi du casier judiciaire. Nous verrons comment notre domaine
d'étude exploite ce point d'identification et de suivi du casier
judiciaire de citoyens congolais.
CHAPITRE
IVème : ANALYSE PREALABLE
IV.1. Présentation de
la direction du casier judiciaire
IV.1.1. Historique
En 1934, le service du casier judiciaire (CJ) est
organisé au parquet général de Léopoldville
(actuellement Kinshasa) avec comme compétence sur toutes les colonies
(Congo, Rwanda et Burundi).
A l'époque coloniale, il n'existait pas une cours
suprême de justice, et c'est la cours de cassation belge qui remplissait
cette tâche jusqu'au 6 novembre 1956. Il y a eu l'article 3 bisde
l'ordonnance 121365 du 6 novembre 1956 qui donne compétence au procureur
général près de la cours pénale de
Léopoldville ou à son délégué de divulguer
les extraits du casier judiciaire.
En 1969, il y a eu création de la cours suprême
de justice. Cette compétence revient de plein droit au procureur
général de la République Démocratique du Congo.
IV.1.2. Mission
Adoptées par la police du monde entier, les empreintes
digitales sont une des clés des investigations criminelles.
La direction de l'identité judiciaire (DIJ) est un
service purement technique au sein de la direction générale de la
police judiciaire de parquet ayant pour mission d'une part, l'identification
des personnes afin de sceller leurs passés judiciaires plus des
antécédents des individus et d'autre part, un service
général des recettes pour le compte du trésor public.
Elle est l'une des directions la plus importantes de la police
judiciaire du parquet parce qu'elle couvre tous le territoire national. Elle
s'occupe du prélèvement des empreintes digitales, de la
codification, des recherches des antécédents judiciaires dans le
fichier central, de la vérification avant de délivrer l'extrait
du casier judiciaire comportant la formule dactyloscopique et ses
subdivisions.
L'inspecteur judiciaire en chef, le directeur chef des
services du casier judiciaire signent les extraits du casier judiciaire par
délégation du pouvoir du procureur général de la
République.
IV.1.3. Situation
géographique
Géographiquement parlant, la Direction du casier
judiciaire se situe au numéro 30 de l'avenue KALEMIE, sise au croisement
des avenues KALEMIE et MISSION, dans la commune de la Gombe et dans la ville
province de Kinshasa.
IV.1.4. Structure
organisationnelle et fonctionnelle
IV.1.4.1. Structure organisationnelle
La direction du casier judiciaire est une direction de la
police judiciaire comme tant d'autres. L'organisation interne se fait sous une
structure d'échelle suivante :
· La division de l'identité judiciaire (DIJ)
· La division administrative et financière
(DAF)
· La division du fichier central (DFC)
· La division informatique (DI)
Source: [Direction du casier judiciaire]
Chaque division contient des sections qui sont
représentées par chacune des provinces de la République
Démocratique du Congo. C'est-à-dire qu'actuellement, chaque
division compte vingt-six (26) sections.
Dans des sections, nous retrouvons des brigades ou
commissariats où sont identifiés les assujettis et ce fichier est
envoyé à la division du fichier central pour être
centralisé.
La direction du casier judiciaire reste le service
spécialisé du parquet général de la
République. Elle a son siège dans le chef-lieu de chaque province
et elle est attachée au parquet général dans chaque
province.
IV.1.4.2. Structure fonctionnelle
IV.1.4.2.1. Scénario
Ce scénario présente le déroulement des
activités de la Direction du Casier Judiciaire dans le but d'avoir son
extrait du casier judiciaire.
a) Aspect administratif
Le postulant (assujetti ou requérant) arrive à
la réception du service du casier judiciaire et y dépose sa carte
d'identité pour être identifié. Il passe acheter la fiche
décadactylaire qu'il remplit lui-même muni des copies de ses
pièces d'identité (carte d'électeur, passeport,
diplôme, ...).
Il passe à la DIJ où on vérifiera
l'authenticité des renseignements fournis sur la fiche
décadactylaire. Après là, il est orienté chez le
responsable des empreintes digitales qui le confie à son tour à
l'empreintiste pour le prélèvement des empreintes.
Une fois ceci fait, le postulant se rendra à la DGRAD
pour l'établissement de la note de perception avec laquelle il ira payer
à la banque pour le retrait de son extrait du casier judiciaire.
b) Aspect technique
Ensuite, on procède à la codification des
empreintes digitales pour sortir la formule dactyloscopique (exploitation des
empreintes digitales ou analyse des figures).
Après cette phase de codification, vient celle de
recherche au niveau du fichier central pour vérifier si le
requérant a des antécédents judiciaire.
En effet, il y a antécédents judiciaires
lorsqu'il y a condamnation c'est-à-dire, quand le tribunal dit le droit
ou demande l'arrestation immédiate de la personne par le parquet.
Cette technique de recherche se base sur deux méthodes
nommée alphanumérique, c'est-à-dire que la recherche peut
se faire suivant le classement alphabétique ou numérique.
IV.1.5. Etude des
documents
IV.1.5.1. Répertoire des documents internes
Ce sont ces documents produits dans les différents
postes de notre domaine et par rapport avec notre processus, nous n'avons que
les documents internes. Nous les avons consultés dans le but de
récolter les données dont nous avions besoin dans
l'élaboration de ce travail.
|
N°
|
DESIGNATION
|
CODE DOCUMENTS
|
EMETTEUR
|
DESTINATAIRE
|
FREQUENCE
|
|
1
|
Fiche décadactylaire
|
FD
|
DIJ
|
Postulant
|
Journalière
|
|
2
|
Extrait du casier judiciaire
|
ECJ
|
DIJ
|
Postulant
|
Journalière
|
Tableau 5 :Description des documents internes
IV.1.5.2.1. Description des documents
a) Fiche décadactylaire
La fiche décadactylaire est une fiche que le postulant
remplit lui-même son identité et elle contient aussi les
empreintes digitales de celui-ci.

Source: [Direction du casier judiciaire]
b) Extrait du casier judiciaire
L'extrait du casier judiciaire est un document qui sert à
connaitre le passé judiciaire (antécédent judiciaire) de
quelqu'un.

Source: [Direction du casier judiciaire]
1) Catégories d'un extrait de casier
judiciaire
1. Extrait du CJ avec ED
a) Si le postulant ou l'assujetti n'a jamais été
arrêté ou condamné, soit arrêté mais son
jugement n'a pas encore acquis la force des chosées jugées
(c'est-à-dire, son jugement n'a pas encore épuisé toutes
les voies de recourt), l'extrait de son casier judiciaire portera la mention
"PAS D'ANTECEDENT JUDICIAIRE CONNU" ;
b) Si le postulant a fait l'objet de l'amnistie ou de la
réhabilitation suite à une condamnation, il
bénéficie d'un extrait du CJ avec mention : "PAS
D'ANTECEDENT JUDICIAIRE : NEANT". Toutefois, les effets de la condamnation
ne sont pas effacés que par un arrêt de a réhabilitation
d'une cour d'appel ou par une loi d'amnistie internationale. La prescription
des peines ne joue qu'en ce qui concerne leur exécution mais la
condamnation demeure.
2. Extrait du CJ sans ED
a) Si le postulant est âgé entre 0 et 12 ans, il
sera exempté des empreintes digitales et il produira une attestation ou
certificat de naissance. L'extrait du casier judiciaire portera la
mention : « ENFANT A BAS AGE ». On écrira dans
l'extrait le nom, le post nom, et le prénom de l'enfant, le lieu et date
de naissance, les noms des parents (fille ou fils de ...). Et on écrira
aussi autre mention : "ANTECEDENT : NEANT".
b) Pour une quelconque indisponibilité, le postulant ne
peut se présenter au service du casier judiciaire pour se faire
prélever les empreintes digitales. Il obtiendra un extrait avec
mention :"SOUS RESERVE DE L'IDENTIFICATION ULTERIEURE", "ANTECEDENT
JUDICIAIRE : NEANT"
IV.1.5.2. Répertoire des documents externes
Ce sont ces documents que le postulant détient et qui
lui sont demandé par le service pour parvenir à l'obtention d'un
extrait du casier.
|
N°
|
DESIGNATION
|
CODE DOCUMENTS
|
EMETTEUR
|
DESTINATAIRE
|
FREQUENCE
|
|
1
|
Pièce d'identité
|
PID
|
Postulant
|
Réception
|
Journalière
|
|
2
|
Bordereau de paiement
|
BP
|
Banque
|
DGRAD
|
Journalière
|
|
3
|
Certificat de naissance
|
CN
|
Postulant
|
DCJ
|
Journalière
|
Tableau 6 : Description des documents externes
IV.1.5.2.1. Description des documents externes
1. Pièce d'identité
C'est un document qui identifie la personne. Parlant de la
pièce d'identité, nous citons : la carte d'électeur,
le passeport, le diplôme, ...
2. Bordereau de payement
Ce document est la preuve que l'assujetti a payé les
frais d'obtention d'un extrait du casier judiciaire.
3. Certificat de naissance
Le certificat de naissance est un document porté par le
postulant lors de l'obtention d'un extrait du casier judiciaire lorsque
celui-ci est mineur.
IV.6. Critiques de
l'existant
IV.6.1. Aspects positif
La direction du casier judiciaire dans son service
d'identification judiciaire et fichier central est l'unique service
habileté à faire ce service au niveau national. Sa maitrise en
termes de processus est sa spécialité. Grâce à elle,
la conduite de chaqueindividu sur le plan national et international est suivie
et fichée.
Elle dispose des agents très compétents en
matière et capable de rendre complètement le service
malgré que toutes les techniques utilisées sont manuelles.
IV.6.2. Aspect
négatif
Bien que ce service rende bien son service dans le processus
de l'identification des individus en vue de connaitre leur passé par une
mesure de délivrance d'un document appelé "casier judiciaire",
une question de performance et de disponibilité se pose.
En ces qualités, le service devient faillible en
rapport avec les mécanismes mis en place compte tenu d'un grand nombre
d'informations qui doit être traité. En effet,le travail
effectué au sein de ce service est totalement centralisé à
tel point que toutes les données provenant de toutes les provinces de la
République sont compilées et envoyées par
différentes voies pouvant présenter des énormes
possibilités d'insécurité (agences, main à main,
...), afin d'être toutes traitées sur place à la direction
générale à Kinshasa.
Les provinces ne sont pas autonomes car elles dépendent
toutes de la direction générale à Kinshasa, ce qui veut
dire que si un individu est condamné dans une province, son dossier est
envoyé à Kinshasa pour être traité et fiché.
Disons que le temps que ça peut prendre est important lorsque l'on veut
savoir les antécédents judiciaires de cet homme afin de s'assurer
de son passé judiciaire !
D'une façon globale, disons que ce service vit encore
dans le passé car le suivi manuel du casier judiciaire ne donne pas
image de ce qui devrait être fait pour garantir ce secteur partout dans
toute l'étendue de la république.
Autrement, la Direction du Casier Judiciaire ne compte que
quelques outils de travail,actuellement, pour pouvoir traiter toutes les
données de toute la République. Tous ces détails donnent
un aperçu désagréable des services au sein de la Direction
du Casier Judiciaire bien que les techniques d'identification pour avoir une
formule dactyloscopique sont néanmoins efficaces.
IV.6.3. Proposition des
solutions
En vue de promouvoir une meilleure qualité du travail
en termes des performances et un traitement en temps réel au sein de la
direction du casier judiciaire, et vu toute cette masse de données
à traiter dans chaque coin du pays, une architecture distribuée
conviendrait le mieux pour résoudre ce problème.
De ce fait, toute les provinces seront des sites
interconnectés grâce à un réseau informatique et
partageant les ressources en vue de permettre la fiabilité dans ce
système, ce qui est traduit par la disponibilité des
données, au lieu que tous les traitements soient centralisés.
En effet, le but de ce système est de pouvoir suivre en
continu le casier judiciaire de chaque individu, partout où il peut se
retrouver et de lutter aussi contre les récidivistes quelques soient les
fonctions pour lesquelles ils sont élevés en dignité.
Certes, dans tous les domaines où le casier judiciaire
est fortement demandé, notre système interviendra pour pouvoir
identifier les individus en vue de savoir leurs passés
(antécédents judiciaires) dans le but de décider sur leur
sort. Nos institutions judiciaires sont privilégiées dans ce
cadre pour améliorer leur façon de travailler.
Ce système substituera de toute manière la
centralisation des données des individus par la décentralisation
où chaque province deviendrait un site autonome. Il évitera
aussi les déplacements des individus ou de leurs dossiers vers la
Direction du Casier Judiciaire de Kinshasa pour le prélèvement
des empreintes ou l'obtention de leurs extraits de casier judiciaire.
Eu égard à ce chapitre, nous avons
abordé l'analyse de notre système d'étude en parcourant
certains documents utilisés pour pouvoir identifier les individus.
Toutefois, nous avons abordé le processus d'identification des individus
ainsi que les techniques utilisées pour se faire, ce qui nous a
aidé à déceler certaines défaillances dans ce
système pour lesquelles nous avons apporté des solutions au
travers ce travail.
Dans le prochain chapitre, nous nous penchons
à la conception et implémentationd'un nouveau système
informatisé pour le suivi du casier judiciaire.
CHAPITRE
Vème : CONCEPTION ET IMPLEMENTATION DU SYSTEME
V.1. Etude de
l'application
Nous venons d'aborder la matière concernantles
systèmes distribués, les bases de données et leur
réplication ainsi que l'authentification par empreinte digitale. C'est
dans ce chapitre que nous allons réellement rendre pratique toute cette
théorie réalisée tout au long de notre étude.
En effet, nous allons réaliser une application
informatique pour aider le service du casier judiciaire dans le processus de
son métier d'identification et de fichage de données de
condamnés, dans le but de rendre facile le traitement de données
pour un bon suivi de ceux-ci.
Sur ce, nous allons développer cette application sous
un environnement intégré de développement
nomméNetBeans, en utilisant le langage Java pour la programmation. Le
SGBD utilisé est le SQL Server 2008 R2 pour la conception de notre base
des données, le développement même, la configuration ainsi
que la réplication des données.
V.1.1. Architecture
réseau
La mise en oeuvre de ce système ne sera possible que
s'il existe une architecture réseau grâce à laquelle les
données/ressources seront partagées entre sites. Bien entendu,
cette architecture est proportionnelle à l'importance du système
à mettre en oeuvre.
Dans notre cas, vu l'importance des publications en continue
et l'importance de données à répliquer, nous avons
opté pour la technologie Vsat pour interconnecter tous nos sites.
V.1.1.1. VSAT
Le VSAT, pour Very Small Aperture Terminal (`terminal à
très petite ouverture') désigne une technique de communication
par satellite bidirectionnelle qui utilise des antennes paraboliques dont le
diamètre est inférieur à 3 mètres.
Le VSAT est constitué de trois parties principales
à savoir :
§ Le hub : il s'agit du coeur du réseau. Le
hubdispose d'une antenne ayant un diamètre compris entre 7m et 9m, ayant
le même principe de fonctionnement qu'une station terrienne ;
§ Le satellite : c'est un relais hertzien ;
§ Les stations distantes (ou remote) en anglais.

Source: [
http://www.google.com/vsat]
Cette technique de communication nécessite donc un peu
de moyens au sol. Le VSAT peut donc être utile pour relier un site aux
réseaux de communication, que ce soit pour la téléphonie
ou pour l'accès à Internet.
La plupart des réseaux VSAT sont
généralement configurés selon une de ces
topologies :
· Une topologie en étoile (star topology), utilise
un point central, tel qu'un HUB ou NOC (Networks Operations Center), pour
relier les VSAT entre eux à travers le satellite ;
· Une topologie en mesh (meshtopology), où chaque
VSAT est directement connecté à un autre VSAT en passant par le
satellite mais pas par le HUB/NOC. Il n'existe pas, dans ce cas, de point
central ;
· Une combinaison de deux topologies
précédentes (étoile et mesh).
En effet, les VSAT utilisent des plateformes
différentes pour transmettre et recevoir des données via des
satellites.
a) Avantages
· Gestion facile réseau ;
· Provision de Bande passante garantie avec engagement de
livraison ;
· Service à distance indépendante ;
· Couverture globale immédiate ;
· Installation rapide et facile dans des zones difficiles
d'accès ;
· Possibilité d'adaptation aux besoins de chaque
entreprise ;
· Extension et reconfiguration du réseau
facile ;
· Accès avec n'importe quel point dans la zone de
couverture grâce à satellite ;
· Stabilité des coûts d'exploitation du
réseau pendant une longue période ;
· Installation et mise en route rapide ;
· Service fiable : disponibilité minimum
garantie de 99.5% en réception et 99.5% en transmission pour le lien
satellite (données) ;
· Couverture omniprésente sans restriction de zone
géographique ;
· Etc.
b) Inconvénient
· Coût élevé ;
· Couverture fixe ;
c) Exemple d'utilisations fréquentes de
VSAT configuré pour recevoir et envoyerdes informations
· Formation à distance par
téléconférences ;
· Transactions bancaires ;
· Internet ;
· Surveillance et contrôle ;
· Etc.
V.2. Modélisation en
UML du domaine
La modélisation est une étape fondamentale
lorsque l'on veut donner une solution informatique à un problème
posé. Elle couvre des grands concepts parmi lesquels l'analyse et
conception restent une garantie pour un concepteur d'arriver aux bonnes fins
dans le processus de ses activités.
L'approche objet est incontournable dans le cadre du
développement de systèmes logiciels complexes, capables de suivre
les évolutions incessantes des technologies et des besoins applicatifs.
En effet, l'approche objet requiert une modélisation.Donc on analyse
avant de concevoir.
La modélisation apporte une grande rigueur, offre une
meilleure compréhension des logiciels, et facilite la comparaison des
solutions de conception avant leur développement. Cette démarche
se fonde sur des langages de modélisation, qui permettent de
s'affranchir des contraintes des langages d'implémentation.
Pour se faire, nous avons fait recourt au langage UML, dans sa
version 2, dans le cadre de notre étude. UML est une notation graphique
conçue pour représenter, spécifier, construire et
documenter les systèmes logiciels. Ses deux principaux objectifs sont la
modélisation de systèmes utilisant les techniques
orientées objet, depuis la conception jusqu'à la maintenance, et
la création d'un langage abstrait compréhensible par
l'homme et interprétable par les machines.
Il permet de construire plusieurs modèles d'un
système, chacun mettant en valeur des aspects différents :
fonctionnels, statiques, dynamiques et organisationnels. UML est devenu un
langage incontournable dans les projets de développement.
Une méthode de développement définit
à la fois un langage de modélisation et la marche à suivre
lors de la conception. Par ailleurs, le langage UML propose uniquement une
notation dont l'interprétation est définie par un standard, mais
pas une méthodologie complète. C'est à ce titre qu'il ne
faut pas confondre UML comme une méthode de développement.
V.2.1. Objectif dela
modélisation
Un modèle est une représentation
simplifiée d'une réalité. Il permet de capturer des
aspects pertinents pour répondre à un objectif défini a
priori. Par exemple, un astronaute modélisera la Lune comme un corps
céleste ayant une certaine masse et se trouvant à une certaine
distance de la Terre, alors qu'un poète la modélisera comme une
dame avec laquelle il peut avoir une conversation.
Quand le modèle devient compliqué, il est
souhaitable de le décomposer en plusieurs modèles simples et
manipulables.
L'expression d'un modèle se fait dans un langage
compatible avec le système modélisé et les objectifs
attendus. Ainsi, le physicien qui modélise la lune utilisera les
mathématiques comme langage de modélisation. Dans le cas du
logiciel, l'un des langages utilisés pour la modélisation est le
langage UML. Il possède une sémantique propre et une syntaxe
composée de graphique et de texte et peut prendre plusieurs formes
(diagrammes).
Parlant des diagrammes, UML 2 en possède plus d'une
dizaine. Et concernant notre étude, nous allons juste présenter
quatre diagrammes dont : le diagramme de cas d'utilisation, le diagramme
de séquence, le diagramme d'activité et le diagramme de
classe.
V.2.2. Diagramme de cas
d'utilisation
Ce diagramme montre les interactions fonctionnelles entre les
acteurs et le système à l'étude.Autrement, les cas
d'utilisations décrivent sous la forme d'actions et des réactions
le comportement d'un système du point de vue d'un utilisateur.
· Intérêt : Les cas
d'utilisations recentrent l'expression des besoins sur les utilisateurs, en
partant du point de vue qui veut qu'un système soit avant tout construit
pour les utilisateurs.
Nous présentons ici le diagramme de cas d'utilisation
comme suit :
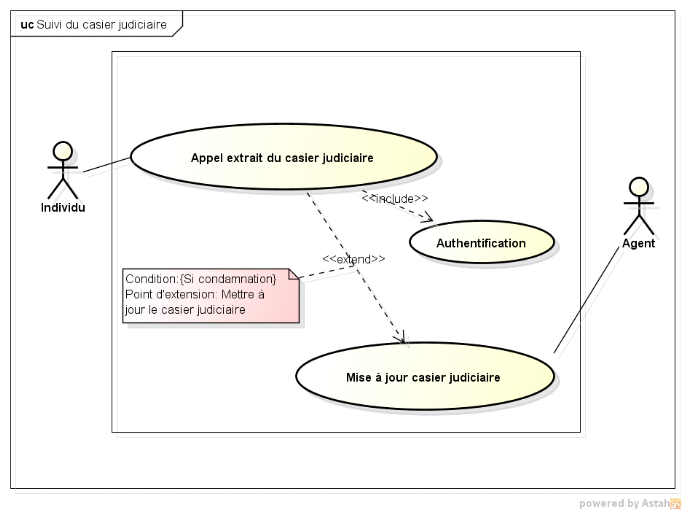
Figure 28: Représentation du diagramme de cas
d'utilisation
V.2.3. Diagramme
d'activité
Le diagramme d'activité permet d'explorer la
totalité de branches du processus. Il permet de mettre l'accent sur les
traitements et sa représentation graphique façonne le
comportement d'une méthode ou le déroulement d'un cas
d'utilisation. D'une façon particulière, ce diagramme est
adapté à la modélisation du cheminement de flots de
contrôle et de flots de données.
Nous représentons notre diagramme d'activité
comme suit :
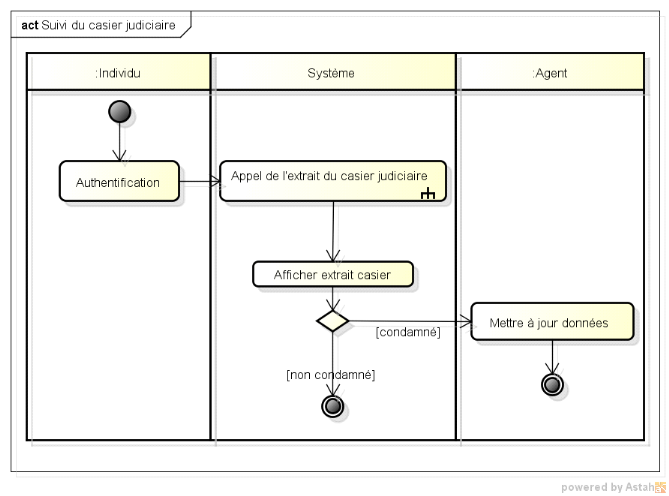
Figure 29: Représentation du diagramme
d'activités
V.2.4. Diagramme de classe
Le diagramme de classes est le point central dans un
développement orienté objet. En analyse, il a pour objet de
décrire la structure des entités manipulées par les
utilisateurs.
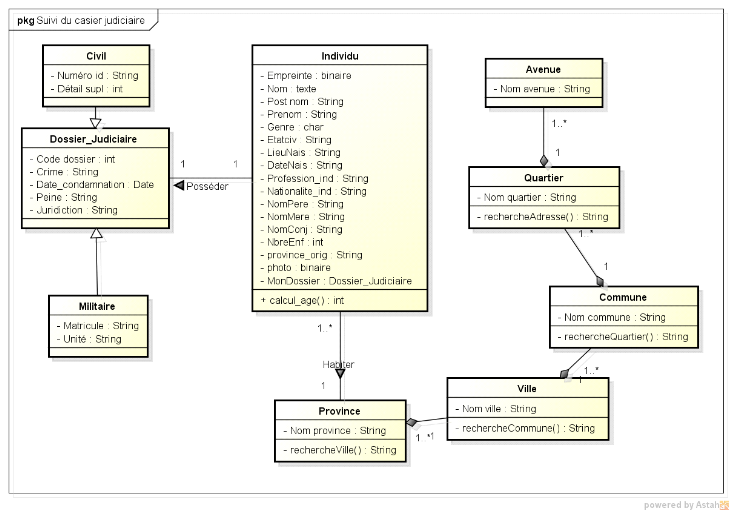
Figure 30: Présentation du diagramme de
classe
V.2.5. Conception du
schéma global
Le schéma global correspondant à notre
système se traduit par le modèle relationnel de la base de
données qui est une traduction du diagramme de classe montré
ci-haut. Notons que chacune des tables du modèle relationnel
bénéficiera d'un identifiant. Ce schéma est
représenté comme suivant :
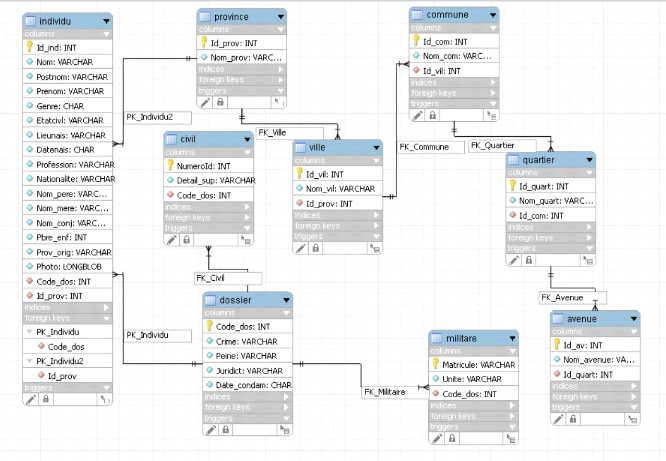
Figure 31: Représentation du schéma
global
V.2.6. Schémas
locaux
Etant donné l'impact du système à mettre
en place, nous avons jugé bon garder le même schéma global
comme schéma dans chaque site local. Donc c'est le modèle
relationnel correspondant à notre schéma global qui serait bien
sûr le schémalocal dans chaque site.
Figure 32: Représentation du schéma
local
V.2.7. Script de
création de la base de données
USE[master]
GO
-- =============================================
-- Author: Juslin TSHIAMUA
-- Script Date: 09/30/2016 06:50:40
-- Object: Database [CasierDB]
-- =============================================
CREATEDATABASE[BD_Casier]ONPRIMARY
(NAME=N'BD_Casier',FILENAME=N'C:\Program Files\Microsoft SQL
Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\BD_Casier.mdf',SIZE=
3072KB,MAXSIZE=UNLIMITED,FILEGROWTH= 1024KB)
LOGON
(NAME=N'BD_Casier_log',FILENAME=N'C:\Program Files\Microsoft SQL
Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\BD_Casier_log.ldf',SIZE=
1024KB,MAXSIZE= 2048GB,FILEGROWTH= 10%)
GO
USE[BD_Casier]
GO
CREATETABLE[dbo].[Dossier](
[Code_dos][int]IDENTITY(1,1)NOTNULL,
[Crime][varchar](30)NOTNULL,
[Peine][varchar](25)NOTNULL,
[Juridict][varchar](25)NOTNULL,
[Date_condam][char](10)NOTNULL,
CONSTRAINT[PK_Dossier]PRIMARYKEYCLUSTERED
(
[Code_dos]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]
GO
CREATETABLE[dbo].[Province](
[Id_prov][int]IDENTITY(1,1)NOTNULL,
[Nom_prov][varchar](25)NOTNULL,
CONSTRAINT[PK_Province]PRIMARYKEYCLUSTERED
(
[Id_prov]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]
GO
CREATETABLE[dbo].[Civil](
[NumeroId][int]IDENTITY(1,1)NOTNULL,
[Detail_sup][varchar](50)NULL,
[Code_dos][int]NULL,
CONSTRAINT[PK_Civil]PRIMARYKEYCLUSTERED
(
[NumeroId]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]
GO
CREATETABLE[dbo].[Ville](
[Id_vil][int]IDENTITY(1,1)NOTNULL,
[Nom_vil][varchar](25)NOTNULL,
[Id_prov][int]NOTNULL,
CONSTRAINT[PK_Ville]PRIMARYKEYCLUSTERED
(
[Id_vil]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]
GO
CREATETABLE[dbo].[Militare](
[Matricule][varchar](10)NOTNULL,
[Unite][varchar](15)NOTNULL,
[Code_dos][int]NULL,
CONSTRAINT[PK_Militaire]PRIMARYKEYCLUSTERED
(
[Matricule]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]
GO
CREATETABLE[dbo].[Commune](
[Id_com][int]IDENTITY(1,1)NOTNULL,
[Nom_com][varchar](25)NOTNULL,
[Id_vil][int]NOTNULL,
CONSTRAINT[PK_Commune]PRIMARYKEYCLUSTERED
(
[Id_com]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]
GO
CREATETABLE[dbo].[Quartier](
[Id_quart][int]IDENTITY(1,1)NOTNULL,
[Nom_quart][varchar](25)NOTNULL,
[Id_com][int]NOTNULL,
CONSTRAINT[PK_Quartier]PRIMARYKEYCLUSTERED
(
[Id_quart]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]
GO
CREATETABLE[dbo].[Avenue](
[Id_av][int]IDENTITY(1,1)NOTNULL,
[Nom_avenue][varchar](25)NOTNULL,
[Id_quart][int]NOTNULL,
CONSTRAINT[PK_Avenue]PRIMARYKEYCLUSTERED
(
[Id_av]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]
GO
CREATETABLE[dbo].[Individu](
[Id_ind][int]IDENTITY(1,1)NOTNULL,
[Nom][varchar](15)NOTNULL,
[Postnom][varchar](15)NOTNULL,
[Prenom][varchar](20)NULL,
[Genre][char](1)NOTNULL,
[Etatcivl][varchar](12)NOTNULL,
[Lieunais][varchar](25)NOTNULL,
[Datenais][char](10)NOTNULL,
[Profession][varchar](20)NOTNULL,
[Nationalite][varchar](15)NOTNULL,
[Nom_pere][varchar](15)NOTNULL,
[Nom_mere][varchar](15)NOTNULL,
[Nom_conj][varchar](15)NOTNULL,
[Nbre_enf][int]NULL,
[Prov_orig][varchar](20)NOTNULL,
[Photo][image]NOTNULL,
[Code_dos][int]NULL,
[Id_prov][int]NULL,
CONSTRAINT[PK_Individu]PRIMARYKEYCLUSTERED
(
[Id_ind]ASC
)WITH
(PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)ON[PRIMARY]
)ON[PRIMARY]TEXTIMAGE_ON[PRIMARY]
GO
SETANSI_PADDINGOFF
GO
/****** Object: ForeignKey [FK_Civil] ******/
ALTERTABLE[dbo].[Civil]WITHCHECKADDCONSTRAINT[FK_Civil]FOREIGNKEY([Code_dos])
REFERENCES[dbo].[Dossier]([Code_dos])
ONUPDATECASCADE
ONDELETECASCADE
GO
ALTERTABLE[dbo].[Civil]CHECKCONSTRAINT[FK_Civil]
GO
/****** Object: ForeignKey [FK_Ville] ******/
ALTERTABLE[dbo].[Ville]WITHCHECKADDCONSTRAINT[FK_Ville]FOREIGNKEY([Id_prov])
REFERENCES[dbo].[Province]([Id_prov])
GO
ALTERTABLE[dbo].[Ville]CHECKCONSTRAINT[FK_Ville]
GO
/****** Object: ForeignKey [FK_Militaire] ******/
ALTERTABLE[dbo].[Militare]WITHCHECKADDCONSTRAINT[FK_Militaire]FOREIGNKEY([Code_dos])
REFERENCES[dbo].[Dossier]([Code_dos])
ONUPDATECASCADE
ONDELETECASCADE
GO
ALTERTABLE[dbo].[Militare]CHECKCONSTRAINT[FK_Militaire]
GO
/****** Object: ForeignKey [FK_Commune] ******/
ALTERTABLE[dbo].[Commune]WITHCHECKADDCONSTRAINT[FK_Commune]FOREIGNKEY([Id_vil])
REFERENCES[dbo].[Ville]([Id_vil])
GO
ALTERTABLE[dbo].[Commune]CHECKCONSTRAINT[FK_Commune]
GO
/****** Object: ForeignKey [FK_Quartier] ******/
ALTERTABLE[dbo].[Quartier]WITHCHECKADDCONSTRAINT[FK_Quartier]FOREIGNKEY([Id_com])
REFERENCES[dbo].[Commune]([Id_com])
GO
ALTERTABLE[dbo].[Quartier]CHECKCONSTRAINT[FK_Quartier]
GO
/****** Object: ForeignKey [FK_Avenue] ******/
ALTERTABLE[dbo].[Avenue]WITHCHECKADDCONSTRAINT[FK_Avenue]FOREIGNKEY([Id_quart])
REFERENCES[dbo].[Quartier]([Id_quart])
GO
ALTERTABLE[dbo].[Avenue]CHECKCONSTRAINT[FK_Avenue]
GO
/****** Object: ForeignKey [FK_Individu] ******/
ALTERTABLE[dbo].[Individu]WITHCHECKADDCONSTRAINT[FK_Individu]FOREIGNKEY([Code_dos])
REFERENCES[dbo].[Dossier]([Code_dos])
ONUPDATECASCADE
ONDELETECASCADE
GO
ALTERTABLE[dbo].[Individu]CHECKCONSTRAINT[FK_Individu]
GO
/****** Object: ForeignKey [FK_Individu2] ******/
ALTERTABLE[dbo].[Individu]WITHCHECKADDCONSTRAINT[FK_Individu2]FOREIGNKEY([Id_prov])
REFERENCES[dbo].[Province]([Id_prov])
ONUPDATECASCADE
ONDELETECASCADE
GO
ALTERTABLE[dbo].[Individu]CHECKCONSTRAINT[FK_Individu2]
GO
V.3. Configuration de la
réplication
Dans la théorie, nous avons signifié l'importance
de la réplication. De ce fait, nous allons ici configurer la
réplication par la configuration d'un serveur de publication et d'un
autre d'abonnement.
La base de données étant déjà mise en
place, il est question de spécifier le type de réplication
à configurer. Pour notre cas, nous avons choisi d'appliquer une
réplication symétrique synchrone. Le choix est porté sur
ce type de réplication vu l'importance du service qui doit être
rendu en vue d'assumer le suivi du casier judiciaire en continu. Le fait est
que les données pour chaque individu devront être mises à
jour dans différents sites une fois celles-ci publiées.
V.3.1. Publication
Pour se faire, nous avons, parmi les quatre types de publication
présents dans SQL Serveur 2008 R2, choisi le mode de publication de
fusion pour lequel le serveur de publication et les Abonnés peuvent
mettre à jour les données publiées de manière
indépendante, une fois que les Abonnées ont reçu le
cliché instantané initial des données à publier.
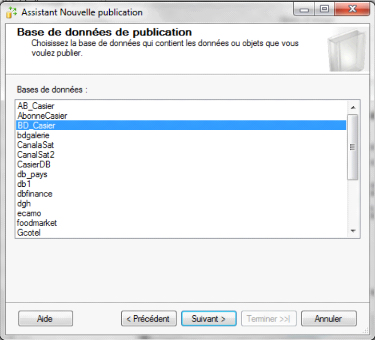
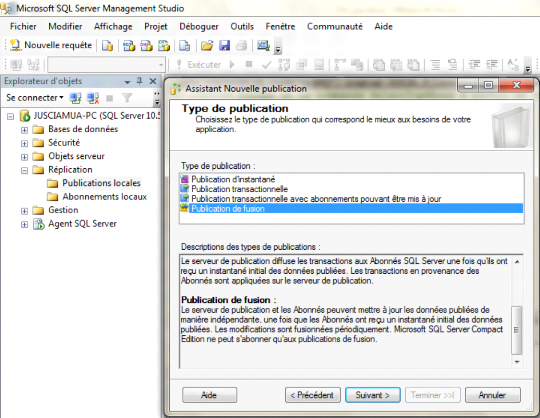
Figure 33: Assistant d'une nouvelle publication
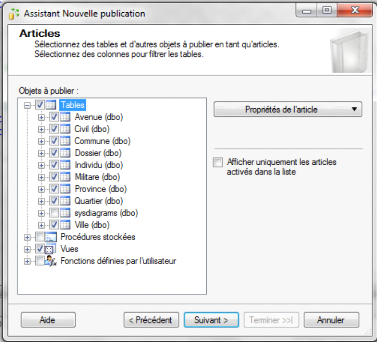
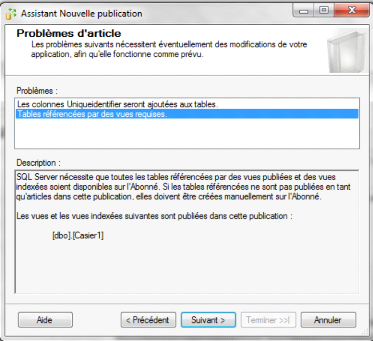
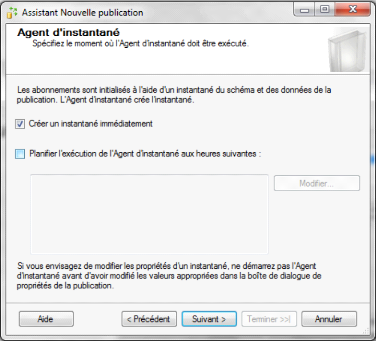
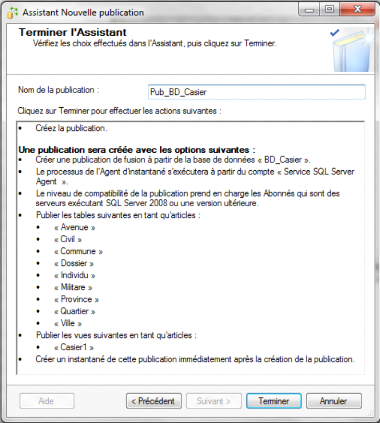
Figure 34: Finalisation de la publication
V.3.2. Abonnement
Nous allons créer un nouvel abonnement après avoir
créé une publication. Cet abonnement se fait en mode pull ;
celui-ci permet aux esclaves d'être actifs en demandant chaque fois au
maitre s'il y a des mises à jour disponibles. Ci-dessous, le choix de la
publication à répliquer et le mode de réplication est en
continu.
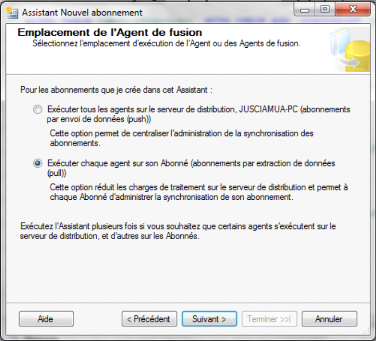
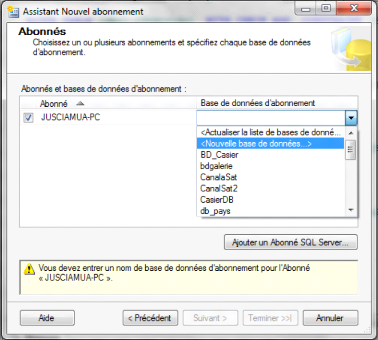
Nous voyons sur la figure suivante, un récapitulatif du
processus de la création de notre abonnement.
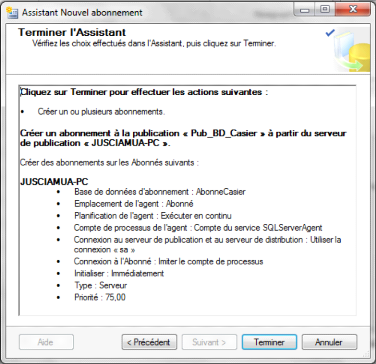
Figure 35: Finalisation de l'abonnement
V.4. Extrait de code
source
V.4.1. Interface Metier
packagemetier;
importgui.People;
importjava.util.List;
/**
*
* @author Jusciamua
*/
public interface AllActivities
{
public voidaddPeople(People pp);
public void identPeople();
public void compareGararits();
public List<People>listPeople();
public List<People>peopleMC(String mc);
public List<Adresses>listeProvince();
public List<Adresses>provVille(String mc);
public List<Adresses>listeVille();
public List<Adresses>villeRech(String mc);
public List<Adresses>listeCommune();
public List<Adresses>listeQuartier();
public List<Adresses>listeAvenue();
}
V.4.2. Class Activité
Implémentant l'interface métier
packagemetier;
importgui.People;
importjava.sql.PreparedStatement;
importjava.sql.ResultSet;
importjava.sql.SQLException;
importjava.util.ArrayList;
importjava.util.List;
importjavax.swing.JOptionPane;
importstaticmetier.ConnexionServeur.cnx;
/**
*
* @author Jusciamua
*/
public class AllActivitiesImplimplementsAllActivities
{
@Override
public void addPeople(People pp) {
throw new UnsupportedOperationException("Not supported yet.");
//To change body of generated methods, choose Tools | Templates.
}
@Override
public List<People>listPeople() {
throw new UnsupportedOperationException("Not supported yet.");
//To change body of generated methods, choose Tools | Templates.
}
@Override
public List<People>peopleMC(String mc) {
throw new UnsupportedOperationException("Not supported yet.");
//To change body of generated methods, choose Tools | Templates.
}
@Override
public List<Adresses>listeProvince()
{
List<Adresses> province=new ArrayList<>();
//diamond inference
try
{
try (PreparedStatementps = cnx.prepareStatement("select * from
province")) {
ResultSet res=ps.executeQuery();
while(res.next()){
Adressesprov=new Adresses();
prov.setProv(res.getString(2));
province.add(prov);
}
ps.close();
}
}catch(SQLException e){JOptionPane.showMessageDialog(null,
e.getMessage());}
return province;
}
@Override
public List<Adresses>villeRech(String mc)
{
List<Adresses>ville=new ArrayList<>();
//diamond inference
try
{
try (PreparedStatementps = cnx.prepareStatement("select * from
ville where id_prov like ?"))
{
ps.setString(1, "%"+mc+"%");
ResultSet res=ps.executeQuery();
while(res.next())
{
Adressesvil=new Adresses();
vil.setVille(res.getString(2));
ville.add(vil);
}
ps.close();
}
}catch(SQLException e){JOptionPane.showMessageDialog(null,
e.getMessage());}
return ville;
}
@Override
public List<Adresses>listeCommune()
{
List<Adresses> commune=new ArrayList<>();
//diamond inference
try
{
try (PreparedStatementps = cnx.prepareStatement("select * from
commune")) {
ResultSet res=ps.executeQuery();
while(res.next()){
Adresses com=new Adresses();
com.setComm(res.getString(2));
commune.add(com);
}
ps.close();
}
}catch(SQLException e){JOptionPane.showMessageDialog(null,
e.getMessage());}
return commune;
}
@Override
public List<Adresses>listeQuartier() {
List<Adresses> quartier=new ArrayList<>();
//diamond inference
try
{
try (PreparedStatementps = cnx.prepareStatement("select * from
quartier"))
{
ResultSet res=ps.executeQuery();
while(res.next())
{
Adresses quart=new Adresses();
quart.setQuart(res.getString(2));
quartier.add(quart);
}
ps.close();
}
}catch(SQLException e){JOptionPane.showMessageDialog(null,
e.getMessage());}
return quartier;
}
@Override
public List<Adresses>provVille(String mc)
{
List<Adresses>ville=new ArrayList<>();
//diamond inference
try
{
try (PreparedStatementps = cnx.prepareStatement("select * from
ville where id_prov like ?"))
{
ps.setString(1, "%"+mc+"%");
ResultSet res=ps.executeQuery();
while(res.next())
{
Adressesvil=new Adresses();
vil.setVille(res.getString(2));
ville.add(vil);
}
ps.close();
}
}catch(SQLException e){JOptionPane.showMessageDialog(null,
e.getMessage());}
returnville;
}
@Override
public List<Adresses>listeVille()
{
List<Adresses>ville=new ArrayList<>();
//diamond inference
try
{
try (PreparedStatementps = cnx.prepareStatement("select * from
Ville")) {
ResultSet res=ps.executeQuery();
while(res.next()){
Adresses vil=new Adresses();
vil.setVille(res.getString(2));
ville.add(vil);
}
ps.close();
}
}catch(SQLException e){JOptionPane.showMessageDialog(null,
e.getMessage());}
returnville;
}
@Override
public List<Adresses>listeAvenue()
{
List<Adresses> avenue=new ArrayList<>();
//diamond inference
try
{
try (PreparedStatementps = cnx.prepareStatement("select * from
avenue")) {
ResultSet res=ps.executeQuery();
while(res.next()){
Adressesav=new Adresses();
av.setAven(res.getString(2));
avenue.add(av);
}
ps.close();
}
}catch(SQLException e){JOptionPane.showMessageDialog(null,
e.getMessage());}
return avenue;
}
@Override
public void identPeople() {
throw new UnsupportedOperationException("Not supported yet.");
//To change body of generated methods, choose Tools | Templates.
}
@Override
public void compareGararits() {
throw new UnsupportedOperationException("Not supported yet.");
//To change body of generated methods, choose Tools | Templates.
}
}
V.5. Présentation de
l'application
Nous présentons quelques interfaces pour notre projet.

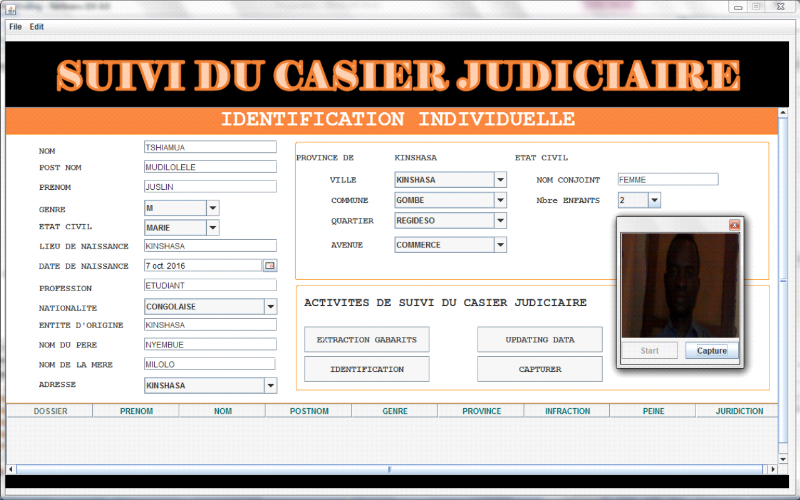
CONCLUSION
Nous voici pleinement au terme de notre travail de dur labeur
qui a porté sur la mise en oeuvre d'un système distribué
pour l'identification et suivi du casier judiciaire.
A la lumière de ce qui précède, nous
avons présenté des notions de base cadrant avec les
systèmes distribués afin de résoudre le problème
d'identification judiciaire grâce à un lecteur d'empreinte digital
dans le but de suivre continuellement les individus ayant un dossier judiciaire
partout où ils se retrouvent dans en République
Démocratique du Congo ; cette pratique étant aussi un moyen
pour lutter contre le récidivisme dans toutes ses formes.
Pour se faire, nous avons développé une
application distribuée comprenant toutes les tâches possibles pour
faciliter le processus d'identification judiciaire des individus, laquelle,
permettra un suivi permanent grâce à un accès
multiutilisateur.
En effet, la diffusion des mises à jour de chaque copie
d'informations aux autres copies se fait de manière continue pour
assurer la disponibilité des informations en rapport avec les individus
concernés dans tous les sites interconnectés.
L'application réalisée dans notre travail est
une solution aux problèmes que court le service du casier judiciaire
dans le processus d'identification judiciaire et suivi de leur casier
judiciaire. Cette solution est effective par le fait qu'elle permet une
optimisation du processus et garantit un suivi permanent du dossier judiciaire
de chaque individu identifié.
Grâce à ce travail, le service du casier
judiciaire peut bénéficier en temps réel des informations
de chaque individu ayant un dossier judiciaire quelque soit sa situation
géographique.
Outre ceci, notre application est une des contributions au
développement de notre pays qui a besoin d'assurer ce secteur pour
réduire le nombre de crimes qui se commettent au jour le jour.
Nous n'avons aucune prétention d'avoir tout
abordé dans ce travail étant donné que le champ est
très vaste pour être développé. Néanmoins,
nous sommes ouvert à toutes vos remarques et suggestions en vue
d'améliorer ce travail dans les jours à venir lors de nos
prochaines publications, étant donné qu'une oeuvre humaine ne
manque d'imperfections.
REFERENCES
BIBLIOGRAPHIQUES
I. OUVRAGES
[1] A.K. Jain, L. Hong, S. Pankantiet R. Bolle. An
identityauthenfication system using fingerprints. Proceedings of the IEEE,
Vol. 85, n° 9, Septembre 1997.
[2] A.K. Jain, S. Shaoyun, K. Karu, N.K. Ratha. A
real-time matching system for large fingerprint databases. IEEE Trans. on
pattern analysis and machine intelligence, Vol.18, n° 8, Août
1996 ;
[3] Eddy MEYLAN. Réplication de
données. Bachelor of science en informatique de gestion, Haute
Ecole de Gestion ARC Neuchâtel Suisse, Février 2005.
[4] G. Coulouris, J. Dollimore, TimKindBerg, G. Blair.
Distributed systems : concepts and design, 5ème éd.;
[5] LadjelBellatreche (Ensma) : Bases de
données réparties ;
[6] N.MAHAMOUD, S. ATELLY, Tolérance aux fautes
dans les systèmes informatiques, Paris 2005 ;
[7] S. SCHILDKNECHT and G. LEJEUNE. Introduction à
la réplication de bases de données, Février
2006 ;
[8] Y. Belgnaoui, J-C. Guézel et T. Mahé. La
biométrie, sésame absolu. Industries et techniques, Juillet
2000 ;
II. NOTES DE COURS
[9] KAFUNDA KATALAY Pierre, Base de données
répartie, notes de cours de 1ère licence
conception des systèmes d'informations, Facultés des sciences,
Université Pédagogique Nationale, 2015-2016 ;
III. ARTICLES ET AUTRES
[10]
http://www.labo-microsoft.org/articles/SQL_Serveur_Replication/8/Default.asp
[11]
http://www.biometrie-online.net/technologies/empreintes-digitales
TABLE DE MATIERES
Epigraphe
Dédicace
ii
Avant-propos
iii
Liste des abréviations
v
Liste des figures
vi
0. INTRODUCTION
1
0.1. PROBLEMATIQUE
2
0.2. HYPOTHESE
2
0.3. CHOIX ET INTERET DU SUJET
3
0.4. DELIMITATION DU SUJET
3
0.4.1. Dans le temps
3
0.4.2. Dans l'espace
3
0.5. METHODES ET TECHNIQUES
UTILISEES
3
0.5.1. METHODES
3
0.5.2. TECHNIQUES
4
0.6. SUBDIVISION DU TRAVAIL
4
CHAPITRE Ière : GENERALITES
SUR LES SYSTEMES DISTRIBUES [1] [6] [4]
5
I.1. Définitions
5
I.2. Intérêt des
systèmes distribués
6
I.3. Quelques domaines d'application des
systèmes distribués
6
I.4. Difficulté de mise en
oeuvre
6
I.5. Caractéristiques des
systèmes distribués
7
I.5.1.
Interopérabilité
7
I.5.2. Partage des ressources
9
I.5.3. Ouverture
9
I.5.4. Expansible
9
I.5.5. Performance
9
I.5.6. Transparence
10
I.5.7. Sécurité
11
I.5.8. Concurrence
11
I.5.9. Tolérance aux
pannes
11
I.5.10. Disponibilité
12
I.6. Architecture
distribuée
12
I.6.1. Avantages des architectures
distribuées
12
I.6.2. Types d'architecture
distribuée
13
CHAPITRE IIème : LES BASE DE
DONNEES REPARTIE [3][5][7][9]
16
II.1. Définitions
16
II.2. Caractéristiques
17
II.3. Types de bases de données
réparties
17
II.3.1. Base de données
répartie homogène
17
II.3.2. Base de données
hétérogène
18
II.4. Conception d'une base de
données
18
II.4.1. Conception du schéma
global
19
II.4.2. Conception de la base de
données physique locale dans chaque site
19
II.4.3. Conception de la
fragmentation
20
II.4.4. Conception de l'allocation des
fragments
24
II.5. Réplication des
données
25
II.5.1. Définition
25
II.5.2. Objectifs la
réplication
25
II.5.3. Technique de la
réplication
26
II.5.4. Avantages de la
réplication
26
II.5.5. Limites de
réplication
26
II.5.6. Techniques de diffusion des mises
à jour
27
II.5.7. Types de
réplication
28
II.6. Gestion des transactions
réparties
31
II.6.1. Définitions d'une
transaction
31
II.6.2. Condition de
terminaison
32
II.6.3. Propriétés des
transactions
32
II.7. Système de Gestion de Bases de
Données Réparties
32
II.7.1. Définitions
32
II.7.2. Les caractéristiques d'un
SGBD réparti
33
II.7.3. Intérêt d'un SGBD
réparti
34
II.7.4. Architecture d'un SGBD
réparti
34
II.7.5. Objectifs du SGBDR
38
CHAPITRE IIIème :
AUTHENTIFICATION PAR EMPREINTES DIGITALES [2] [8] [11]
40
III.1. Authentification
40
III.1.1. Définition
40
III.1.2. Type
d'authentification
40
III.1.3. Les enjeux de
l'authentification
42
III.2. Biométrie
43
III.2.1. Définition
43
III.2.2. Propriétés de la
biométrie
43
III.2.3. Architecture d'un système
biométrique
44
III.2.4. Applications de la
biométrie
45
III.2.5. Panorama des différentes
biométries
46
CHAPITRE IVème : ANALYSE
PREALABLE
55
IV.1. Présentation de la direction
du casier judiciaire
55
IV.1.1. Historique
55
IV.1.2. Mission
55
IV.1.3. Situation
géographique
55
IV.1.4. Structure organisationnelle et
fonctionnelle
56
IV.1.5. Etude des documents
57
IV.6. Critiques de l'existant
60
IV.6.1. Aspects positif
60
IV.6.2. Aspect négatif
60
IV.6.3. Proposition des
solutions
61
CHAPITRE Vème : CONCEPTION
ET IMPLEMENTATION DU SYSTEME
62
V.1. Etude de l'application
62
V.1.1. Architecture
réseau
62
V.2. Modélisation en UML du
domaine
64
V.2.1. Objectif de la
modélisation
65
V.2.2. Diagramme de cas
d'utilisation
65
V.2.3. Diagramme
d'activité
66
V.2.4. Diagramme de classe
67
V.2.5. Conception du schéma
global
68
V.2.6. Schémas locaux
69
V.2.7. Script de création de la base
de données
70
V.3. Configuration de la
réplication
74
V.3.1. Publication
74
V.4. Extrait de code source
81
V.4.1. Interface Metier
81
V.4.2. Class Activité
Implémentant l'interface métier
82
V.5. Présentation de
l'application
86
CONCLUSION
87
REFERENCES BIBLIOGRAPHIQUES
88
TABLE DE MATIERES
89



{kind=link}
{kind=link}