Optimisation de la fiabilité d'un réseau informatique pour la mise en place d'un cluster d'équilibrage de la charge réseau( Télécharger le fichier original )par Elias ELIYA KAMALEBO Institut Supérieur d'Informatique, Programmation et Analyse; ISIPA - Graduat 2016 |

II.2.2 ArchitectureII.2.2.A Sans répartiteurLa méthode la plus simple d'opérer une répartition de charge consiste à dédier des serveurs à des groupes des clients prédéfinis. Si cette méthode est simple à mettre en oeuvre pour un intranet, elle est très complexe, voire impossible pour des serveurs internet. Dans ce cas, un paramétrage spécifique du DNS (Domain Name Server) au niveau réseau et/ou l'optimisation applicative (Niveau 7) sont un premier pas vers une démarche de répartition de charge sans répartiteur. Dans la majorité des cas, la méthode du DNS en rotation (round robin) est un bon début en matière de répartition de charge. Pour un même nom de serveur particulier, le serveur DNS dispose de plusieurs adresses IP de serveurs, qu'il présente à tour de rôle aux clients, dans un ordre cyclique. Pour l'utilisateur, cette méthode est totalement transparente car il ne verra que l'adresse du site. On utilise généralement la répartition par DNS pour les moteurs de recherche, des serveurs POP (messagerie) ou des sites proposant des contenus statique. Sans répartiteur, il est donc possible d'engager une démarche de répartition de charge. Néanmoins, les méthodes décrites ci-dessus ne fournissent aucun contrôle de la disponibilité et exigent donc des moyens additionnels pour tester en permanence l'Etat des serveurs et basculer le trafic d'un serveur surchargé vers un autre, le cas échéant. Ces méthodes ne constituent donc pas une solution de répartition de charge principale mais conservent leur intérêt et restent complémentaires à la mise en place d'un répartiteur.
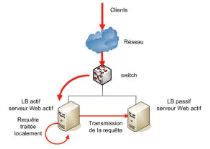
II.2.2.B Avec répartiteur de charge (Load Balancing)Le répartiteur de charge ou Load Balancer est la couche supplémentaire qui permet d'optimiser et de réguler le trafic, tout en soulageant les serveurs, en répartissant la charge selon les algorithmes prédéfinis (niveau 3, 4 et 7) et/ou selon des fonctions intelligentes capables de tenir compte du contenu de chaque requête (Niveau 7)20(*).
Fig. II.1 Load Balancing Le répartiteur peut être un routeur, un Switch, un système d'exploitation ou un logiciel applicatif. Il repartit les demandes en les distribuant automatiquement aux serveurs disponibles. Le destinataire des demandes peut également être imposé. Le répartiteur simule la présence d'un serveur : les clients communiquent avec le répartiteur comme s'il s'agissait d'un serveur21(*). Celui-ci repartit les demandes provenant des clients, les transmets aux différents serveurs. Lorsqu'un serveur répond à une demande, celle-ci est transmise au répartiteur ; puis le répartiteur transmet la réponse au client en modifiant l'adresse IP de l'expéditeur pour faire comme si cette réponse provenait du serveur. La répartition de charge de niveau 3 / 4Celle-ci consiste à travailler sur les paquets réseaux en agissant sur leur routage (TCP/IP). Le répartiteur de niveau 3 / 4 intervient donc à l'ouverture de la connexion TCP puis aiguille les paquets en fonction des algorithmes retenus, selon 3 méthodes : v Le routage direct Avec cette méthode, le répartiteur distribue les cartes. Elles se chargent de repartir les requêtes sur une même adresse entre les serveurs locaux. Les serveurs répondent ensuite directement aux clients On parle alors de DSR (Direct Server return) ; retour direct du serveur en français. Simple à mettre en oeuvre car ne nécessitant aucune modification au niveau IP, cette méthode requiert des solides compétences du modèle TCP/IP pour obtenir une configuration correcte et optimale. Elle implique en outre la proximité des serveurs, qui doivent se trouver sur le même segment réseau que le répartiteur.
v Le tunneling Le tunneling est une évolution du routage direct qui permet de s'amender de la problématique de proximité des serveurs grâce à la mise en place des tunnels entre des serveurs distants et le répartiteur.
v La translation d'adresses IP Dans ce cas, le répartiteur centralise tous les flux : les requêtes (comme dans le cas du routage direct) sont reparties entre les serveurs mais aussi les réponses. Il masque ainsi l'ensemble de la ferme de serveurs, qui ne nécessitent aucun paramétrage particulier. En revanche, cette méthode implique une configuration applicative très stricte afin notamment que les serveurs évitent de retourner leurs adresses internes dans les réponses. En outre, cette méthode augmente considérablement la charge du répartiteur qui doit convertir les adresses dans les deux sens, maintenir lui-même une table des sessions et supporter la charge du trafic retour22(*). * 20 Tarreau W. et Train W. , Le loadbalancing pour les nuls, édition First, Paris, 2010, Pg.10 * 21 Op.cit ; * 22 http://www.cluster.top500.org , samedi 21 novembre 2015, 13h00' |
|