V.4.- Analyse explicative
L'analyse explicative permet de prendre une décision
quant à la confirmation ou à la réfutation de
l'hypothèse de recherche. A cette phase, il importe de mettre en
évidence les raisons qualitatives ou statistiques pour lesquelles nous
devons retenir ou rejeter une hypothèse. Par conséquent, une
analyse explicative a été mise en oeuvre.
a.- Choix du modèle d'analyse
Compte tenu de la nature trichotomique de la variable
étudiée, en l'occurrence, le revenu moyen journalier des agents
de proximité, le modèle d'analyse retenu est un modèle
multinomial ordonné. Donc, nous avons le choix entre un modèle
logit multinomial et un probit ordonné. Dans le cadre de ce travail,
nous ferons le choix d'estimer un modèle logit pour expliquer le revenu
moyen par jour des agents de proximité dans le secteur du mobile banking
vu que les deux modèles donnent approximativement les mêmes
résultats et aussi le modèle logit est plus facile à
analyser.
b.- Présentation du modèle
Un modèle multinomial ordonné ou polytomique
univarié ordonné est utilisé lorsqu'on a une variable
qualitative ayant plusieurs modalités suivant un ordre
hiérarchique naturel. Ce modèle permet d'obtenir la
probabilité pour un individu « i » de se trouver dans
l'une des catégories « j » de la variable
dépendante en fonction de certaines caractéristiques. Ce
modèle est utilisé lorsque l'on ne dispose que des données
en classes sur la variable dépendante. Supposons que l'on note par cette
variable, l'on a :
? inférieur à c1,
? compris entre et ( > ),
|
? compris entre et
? supérieur à
|
( > ),
|
Dans le cadre de ce travail, il convient de modéliser
la probabilité pour un agent « i », compte tenu de
certaines caractéristiques économiques et
sociodémographiques, de se trouver dans la tranche de revenus «
j ». La variable d'intérêt de l'étude qui est
le revenu moyen par jour est défini de la manière suivante :
- Niveau de revenu faible si l'intervenant gagne moins de 350
gourdes par jour ;
- Niveau de revenu normal si l'intervenant gagne entre 350 et
1500 gourdes par jour ; - Niveau de revenu élevé si l'intervenant
gagne plus de 1500 gourdes.
Nous constatons qu'il existe effectivement un ordre naturel entre
les modalités de cet indicateur allant du niveau de revenu le plus
faible au plus élevé. Ainsi, un agent de proximité se
trouvant dans la dernière catégorie a un niveau de revenu plus
élevé que ceux se trouvant dans les autres.
c.- Spécification du modèle
Un modèle multinomial ordonné s'écrit de la
manière suivante :
. . .
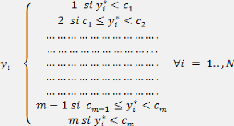
=
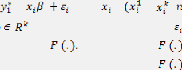
Avec = et où la variable latente42 est
définie par = avec = .... )
vecteur de caractéristiques, = 1, .., N, (un vecteur de
paramètres),
i.i.d. (0, ) et où / suit une loi de fonction de
répartition Si la fonction
correspond à la loi logistique, le modèle est un
modèle logit. Si la fonction
correspond à la loi normale centrée réduite,
le modèle est un modèle probit.
A partir de la définition précédente nous
déduisons la fonction de la variable qualitative yi :
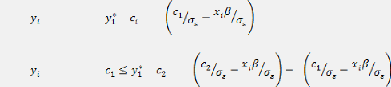
Prob ( = 0) = Prob ( < ) = F
Prob ( = 1) = Prob ( < ) = F F
55 | P a g e
42 Une variable latente est une variable non
observable mais on sait qu'elle existe.

Prob ( = m) = Prob ( < ) =1 F
56 | P a g e
De manière générale, on écrit :
Prob ( = j) = F F
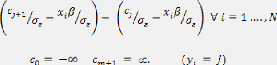
,
Avec, par convention, et Prob étant la probabilité
pour un
individu i de se trouver dans la catégorie j.
1.- Fonction de vraisemblance
Dans les modèles Logit ou Probit multinomial
ordonné, nous ne pouvons pas observer le ratio de chance; ce qui rend
impossible l'utilisation d'un modèle MCO pour l'estimation des
paramètres. Dans ce cas, nous avons recours à la méthode
du maximum de vraisemblance, car elle est une méthode d'estimation
alternative à la méthode des moindres carrés qui consiste
à trouver la valeur des paramètres qui maximisent la
vraisemblance des données.
La vraisemblance en économétrie est
définie comme la probabilité jointe d'observer un
échantillon, étant donné les paramètres du
processus. Pour les modèles Logit et Probit Multinomial la vraisemblance
associée à l'observation I s'écrit:
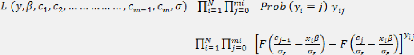
=
=
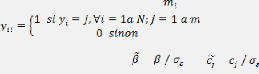
Où représente le nombre d'individus et le nombre de
modalités de la variable qualitative
Avec
En général, seuls les paramètres = et = sont
identifiables. La fonction de
vraisemblance devient :
2.-
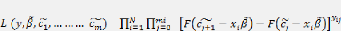
=
Le test de signification des
paramètres
Ce test permettra de déterminer le degré de
contribution de chaque variable dans l'explication du revenu des agents de
proximité dans l'aire métropolitaine de P-au-P. La
significativité des
57 | P a g e
coefficients est appréciée à l'aide des
ratios appelés « z-Statistique » car la distribution des
rapports du coefficient sur son écart-type ne suit pas une loi de
student, comme dans le modèle linéaire général mais
une loi normale. Cette statistique s'interprète de façon
classique à partir des probabilités critiques. Si la
probabilité critique est inférieure à la signification
fixée, on rejette l'hypothèse nulle. Comme dans le cas de
l'analyse bivariée, le seuil est fixé à 5%.
| 

