2.1. Introduction
L'étude de l'existant nous a permis de ressortir les
besoins et les fonctionnalités qu'aura le futur système. A ce
stade ce dernier parait comme une boîte noire qui encapsule tous les
mécanismes qui pourront répondre aux fonctionnalités
demandées, nous allons la décomposée en modules dans le
but de réduire son niveau d'abstraction.
Nous avons opté pour la méthode top down design
qui procède par décomposition du problème. Le
problème est ainsi divisé en un certain nombre des sous
problèmes, chacun de complexité moindre. Cette division est
ensuite appliquée aux sous problèmes
générés, et ainsi de suite, jusqu'à ce que la
résolution de chacun des sous problèmes soit trivial [12, Chap.
0].
Dans cette partie du travail, nous ferons la conception
générale de notre futur système qui repose sur le concept
de l'infrastructure comme code25 et nous ferons aussi une conception
détaillée logique qui nous permettra de diminuer le niveau
d'abstraction situé au niveau de la conception
générale.
2.1.1. Niveaux d'abstraction appliqués
à la conception
L'abstraction consiste à ne considérer que les
aspects jugés importants d'un système à un moment
donné, en négligeant les autres aspects.
Dans le traitement d'un problème complexe, il est
conceptuellement impossible de l'appréhender d'un seul bloc dans son
intégralité, notre esprit a besoin de dégrossir le
problème afin de le comprendre petit à petit. Une fois que ce
problème sera subdivisé en sous-problème de taille plus
petite, l'analyse de chacun de ces sous problèmes exige à en
comprendre les grandes lignes, ensuite de rendre plus fine sa
compréhension pour enfin comprendre tous les détails [12, Chap.
2]. L'abstraction permet une meilleure maitrise de la complexité, c'est
pour cela notre processus de conception sera divisé en trois phases :
? La conception générale ;
? La conception logique détaillée
;
? La conception physique ou technique.
25 Nouveau concept pour le contrôle et la
gestion des ressources hétérogènes. L'infrastructure comme
code permet de programmer des infrastructures.
TFE_ESIS_AS 2016
26
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
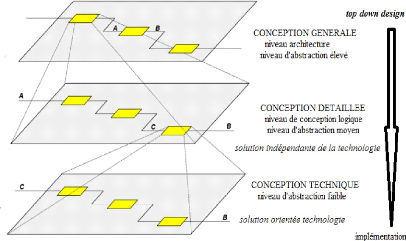
Figure 2.1 niveaux d'abstraction appliqués à
la conception [13, p. 6]
La conception générale avec un niveau
d'abstraction élevé est en fait la description
générale du futur système qui nous permet de faire le
regroupement de tous les composants logiques de la solution qui sont faiblement
couplés entre eux et intervenant dans l'architecture du système,
ceci sera fait sans entrer dans les moindres détails sur la façon
dont ils sont regroupés.
La conception détaillée logique avec un niveau
d'abstraction intermédiaire ou moyen, identifie et inventorie les
composants logiciels nécessaires à l'implémentation de la
solution et décrit les relations existantes entre ces composants tout en
s'appuyant sur les exigences de qualité de service ou
fonctionnalités définies lors de la phase de spécification
des besoins. A ce stade nous ferons abstraction sur la façon dont les
différents composants logiciels seront implémentés.
Pour mettre fin à notre phase de conception, nous
réduirons à nouveau le niveau d'abstraction au plus bas niveau
via la conception physique afin d'offrir les détails maximums avec plus
des concepts de réalisation dans une solution technologique de gestion
des configurations reposant sur les principes de l'infrastructure
définit par le logiciel ou l'infrastructure comme code.
2.2. Conception générale
2.2.1. Adoption de l'infrastructure comme
code
L'infrastructure comme code autrement appelé
infrastructure définie par le logiciel (software defined infrastructure)
est un type d'infrastructure informatique que les équipes d'exploitation
peuvent gérer automatiquement via le code, au lieu d'utiliser un
processus manuel.
TFE_ESIS_AS 2016
27
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
Le concept de l'infrastructure comme code est similaire
à la programmation des scripts, qui sont utilisés pour
automatiser les processus informatiques importants. Cependant, les scripts sont
principalement utilisés pour automatiser une série
d'étapes statiques qui doivent être répétées
plusieurs fois sur plusieurs serveurs par exemple. Au lieu des scripts,
l'infrastructure comme code utilise un niveau supérieur ou langage
descriptif pour coder des processus plus souples et adaptatifs de
provisionnement et de déploiement.
2.2.1.1. Apport de l'infrastructure comme code
La valeur de l'infrastructure comme code peut être
décomposée en trois catégories mesurables à savoir
:
? Le coût (réduction),
? La vitesse (exécution plus rapide) et
? Les risques (supprimer les erreurs et les violations de
sécurité) [14].
La réduction des coûts vise à aider
l'entreprise non seulement financièrement, mais aussi en termes des
personnes et de l'effort, ce qui signifie qu'en supprimant la composante
manuelle, les administrateurs systèmes sont en mesure de recentrer leurs
efforts vers d'autres tâches de l'entreprise.
L'automatisation de l'infrastructure permet la vitesse
grâce à une exécution plus rapide lors de la configuration
de l'infrastructure et vise également à fournir une
visibilité pour aider d'autres équipes à travers le
travail de l'entreprise rapidement et plus efficacement.
L'automatisation supprime les risques associés
à l'erreur humaine, cela permet de diminuer les temps d'arrêt et
d'augmenter la fiabilité.
2.2.1.2. Types d'approches
Il y a généralement deux approches,
l'infrastructure comme code déclaratif (fonctionnelle) et
l'infrastructure comme code impératif (procédure). La
différence entre l'ap-proche déclarative et impérative est
essentiellement « quoi » par rapport à « comment
».
L'approche déclarative se concentre sur ce que la
configuration cible éventuelle devrait être, tandis que celle
impérative se concentre sur la façon dont l'infrastructure doit
être modifiée pour répondre à cela.
L'approche déclarative définit l'état
désiré et le système exécute ce qui doit arriver
pour atteindre cet état désiré. L'impérative
définit des commandes spécifiques qui doivent être
exécutées dans l'ordre approprié pour mettre fin à
la conclusion souhaitée.
2.2.1.3. Méthodes
Il existe deux méthodes pour l'infrastructure comme
code, la méthode push et la méthode pull :
TFE_ESIS_AS 2016
28
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
? Push
Décrit un style de communication de réseau
où la demande pour une transaction donnée est initiée par
l'éditeur ou le serveur de contrôle.
Les services push sont souvent basés sur les
préférences d'informations exprimées à l'avance.
Ceci est appelé une publication ou abonnement modèle, un noeud
client souscrit à diverses informations (canaux) fournies par le serveur
de contrôle, dès qu'un nouveau contenu est disponible sur un des
canaux, le serveur pousse cette information vers le client ;
? Pull
Décrit un style de communication de réseau
où la demande initiale de données provient d'un noeud client,
puis est rependue par le serveur. Les demandes de Pull constituent le fondement
du réseau informatique, où de nombreux noeuds demandent des
données à partir d'un ou plusieurs serveurs
centralisés.
2.2.1.4. Concepts de base de la programmation
orientée objet
Un objet est l'entité élémentaire dans
le paradigme orienté objet. Il intègre les données et les
procédures ou méthodes qui manipulent ces données. Cela
montre le principe de l'encapsulation qui permet l'abstraction des
données. La classe est l'entité conceptuelle qui décrit
les objets. Les classes d'objets sont organisées en hiérarchie
d'héri-tage. Voici quelques concepts liés à la
programmation orientée objet et qui de même interviendront dans
notre travail :
? Classe
Une classe est une entité qui regroupe sous le
même nom les données et les méthodes qui manipulent ces
données. Une méthode appartenant à une classe ne peut
manipuler que les données de celle-ci et ne peut pas accéder aux
données d'une autre classe. Une classe peut être
considérée comme un module à partir duquel on peut
créer des objets [15, p. 32] ;
? Instance
La classe est un descripteur statique qu'on ne peut pas
utiliser directement, à partir d'une classe on peut construire autant
d'instances ou objets de la classe qui a permis de les créer. Deux
instances différentes faisant parties d'une même classe partagent
la même liste des méthodes et de données mais avec des
valeurs différentes au cas où les données ne sont pas
statiques ;
? Transmission des messages
Le mécanisme de transmission de message assure
l'interaction entre les objets. Un objet qui envoie un message mentionne
toujours le récepteur du message, le nom de la méthode à
exécuter et les arguments de cette méthode. L'objet
récepteur du message recherche le nom de la méthode puis
procède à son activation. Le résultat de
l'exécution de cette méthode sera retourné à
l'objet qui a envoyé le message. La recherche est faite en remontant
l'arbre d'héritage ;
TFE_ESIS_AS 2016
29
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
? Héritage
L'héritage est la propriété la plus
innovatrice et l'une des plus intéressantes dans la programmation
orientée objet. Il se fait sur des classes et non pas sur des objets, ce
mécanisme permet, quand on veut construire une classe ayant des
propriétés communes avec une autre classe qui existe dans le
système, de ne programmer que les différences entre les deux.
Ainsi, toutes les variables et les procédures de la classe existante
seront ajoutées aux variables et aux procédures de la classe en
construction. La nouvelle entité créée par héritage
sera une nouvelle classe étant capable de créer de nouvelles
instances. [16, p. 12]
2.2.2. Architecture logique
Plusieurs types d'architecture existent, pour notre projet voici
l'architecture qui convient à nos besoins :
Serveur d'attribution
automatique d'IP
Serveur des fichiers
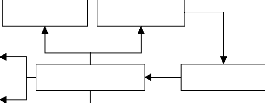
Serveur de noms
Signature des
certificats
Gestionnaire des
configurations
Base de données
Gestionnaire de cycle de vie
Figure 2.2 architecture générale du futur
système
Après avoir ressortit l'architecture
générale du système, voici de façon sommaire
ce que fait chacun des modules :
? Serveur de noms
Fournit la résolution de noms de domaine en adresses IP.
L'inverse est
aussi possible ;
? Serveur d'attribution automatique d'adresse
IP26
Gère l'affectation automatique d'adresse IP sur le
réseau ou les sous
réseaux, cette affection est définie par des
plages d'adresses ;
26 Internet Protocol (Protocole internet), est un
numéro d'identification qui est attribué de façon
permanente ou provisoire à chaque appareil connecté à un
réseau informatique.
TFE_ESIS_AS 2016
30
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
? Serveur des fichiers
Permet de gérer les fichiers et l'installation des
images système disponible via un environnement préalable au boot
;
? Signature des certificats
Permet au gestionnaire de cycle de vie de signer des
certificats SSL27 des clients ou noeuds qui viennent prendre les
configurations sur le gestionnaire des configurations ;
? Gestionnaire des configurations
Permet d'utiliser des recettes, faire des déclarations
des états de configuration dans lesquels les différents noeuds
doivent être, il simplifie l'automatisation et l'orchestration dans
l'environnement afin de fournir un déploiement cohérent ;
? Gestionnaire de cycle de vie
Permet de gérer les cycles de vie complets des
serveurs physiques et virtuels, de la création d'un hôte et
l'installation du système d'exploitation, grâce à une
gestion basée sur un gestionnaire des configurations ;
? Base de données
Permet de collectionner les informations sur les
différents noeuds gérés en vue d'une consultation
future.
2.3. Conception détaillée
logique
A ce stade, nous allons faire des zooms sur les
différents modules intervenant dans l'architecture décrite au
niveau de la conception générale, cela nous permettra de voir
comment les modules interagissent entre eux, leurs constitutions, etc., tout
cela dans le but de réduire le niveau d'abstraction appliqué au
niveau de la conception générale.
2.3.1. Serveur de noms
Dans les réseaux de données, les
périphériques sont identifiés par des adresses IP
numériques pour l'envoi et la réception de données sur les
réseaux, il est difficile de retenir ces adresses numériques,
pour cette raison, des noms de domaines ont été
créés pour convertir les adresses numériques en noms
simples et explicites grâce au protocole servant à la
résolution des noms.
Le protocole DNS28 définit un service
automatisé qui associe les noms des ressources à l'adresse
réseau numérique requise. Il comprend le format des demandes, des
réponses et des données. Les communications via ce protocole
utilisent un format unique nommé message. Ce format de message est
utilisé pour tous les types de demandes clientes et de réponses
serveurs. [17, Chap. 5]
27 Secure Sockets Layer, actuellement Transport
Layer Security, est un protocole de sécurité d'échange sur
internet.
28 Domain Name Service ou système de noms
de domaine, est un service permettant de traduire un nom de domaine en
informations de plusieurs types qui y sont associées, notamment en
adresse IP de la machine portant ce nom.
TFE_ESIS_AS 2016
31
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
Le serveur DNS stocke différents types
d'enregistrements des ressources utilisées pour résoudre les
noms. Ces enregistrements contiennent le nom, l'adresse et le type
d'en-registrement.
Certains de ces types d'enregistrements sont les suivants :
· A
Sont des enregistrements qui font des mappages entre un nom
d'hôte et une adresse IPv4. Ils représentent
généralement la majorité des enregistrements de ressources
des zones de recherches directes ;
· CNAME (Canonical NAME)
Sont des enregistrements entre un nom d'hôte et un
autre nom d'hôte. Ils permettent de créer des alias pour un nom
d'hôte donné c'est-à-dire plusieurs noms d'hôte
à une même machine ;
· MX (Mail eXchanger)
« Définition d'un serveur de courrier
électronique, information exploitée par les serveurs de
messagerie pour retrouver le serveur correspondant à l'adresse de
destination d'un courrier électronique. Chaque enregistrement MX a une
priorité associée. Le serveur de plus haute priorité
(portant le nombre le plus petit) recevra les connexions SMTP29.
S'il ne répond pas, le deuxième serveur sera contacté,
etc. » cf. [18, p. 177] ;
· PTR (Pointeur)
Correspondance adresse IP vers un nom. Elle est
stockée dans une zone dédiée à la résolution
inverse, nommée en fonction de la plage d'adresses IP ;
· AAAA
Sont des enregistrements qui font les mappages entre un nom
d'hôte et une adresse IPv6 ;
· NS (Name Server)
Sont les enregistrements qui identifient les serveurs DNS de
la zone DNS. Ils sont utilisés dans le cadre de la
délégation DNS.
Lorsqu'un client envoie une requête, le processus de
résolution du serveur cherche d'abord dans ses propres enregistrements
pour résoudre le nom. S'il n'est pas en mesure de résoudre le nom
à l'aide de ses enregistrements stockés, il contacte d'autres
serveurs DNS.
Voici un schéma simple qui explique la requête
de résolution de nom d'un client vers le serveur DNS en passant par le
réseau :
29 Simple Mail Transfert Protocol (Protocole
Simple de Transfert des Courriers) est le protocole standard permettant de
transférer les courriers d'un serveur à un autre en connexion
point à point.
TFE_ESIS_AS 2016
32
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
réseau
DNS
client
Serveur
Figure 2.3 interaction entre un client et le serveur
DNS
La requête peut être transmise à plusieurs
serveurs, cela nécessite un délais supplémentaire et
consomme la bande passante30. Lorsqu'une correspondance est
trouvée, elle et retournée au serveur demandeur d'origine, le
serveur stocke temporairement dans la mémoire cache31
l'adresse numérique correspondant au nom. Si ce même nom est de
nouveau demandé, le premier serveur peut retourner l'adresse en
utilisant la valeur stockée dans sa mémoire cache de noms.
La structure d'attribution de noms est subdivisée en
petites zones générales. Chaque serveur DNS tient à jour
un fichier de base de données spécifique et se charge uniquement
des mappages entre noms et adresses IP dans cette partie de la structure
globale. Lorsqu'un serveur DNS reçoit une demande de traduction d'un nom
qui n'appartient pas à sa zone de traduction, le serveur de noms
transfère la requête à un autre serveur de noms se trouvant
dans la zone de traduction voulue.
2.3.2. Serveur d'attribution automatique d'adresse
IF
Il permet de rapatrier automatiquement la configuration pour
un client qui vient de démarrer et souhaitant configurer son interface
réseau. De cette façon, on centralise la gestion des
configurations réseau et tous les clients de l'infrastructure pourront
recevoir des réglages identiques.
Le serveur DHCP32 va fournir des nombreux
paramètres réseau, notamment une adresse IP et le réseau
d'appartenance de la machine. Mais il peut aussi indiquer d'autres
informations, telles que le serveur de résolution des noms « DNS
», la passerelle par défaut, etc. [18, p. 179]
L'acquisition d'une adresse IP à partir du serveur
DHCP se fait en passant par 4 étapes comme l'indique le diagramme
ci-dessous :
30 Quantité de données transmises par
unité de temps.
31 La mise en cache réduit le trafic
réseau de données de demandes de résolution des noms et
les charges de travail des serveurs situés aux niveaux supérieur
dans la hiérarchie.
32 Dynamic Host Configuration Protocole (Protocole
de Configuration Dynamique d'Hôte) est un protocole de communication
utilisé pour gérer les informations de configuration de
façon centralisée.
33
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
TFE_ESIS_AS 2016
Serveur
Figure 2.4 processus d'acquisition d'une adresse IP via le
serveur DHCP
Comme le montre le diagramme ci-haut, lorsqu'un client
configuré pour recevoir automatiquement une adresse IP démarre ou
se connecte au réseau, le client diffuse un message de détection
(DHCP DISCOVERY) pour identifier le serveur DHCP disponible sur le
réseau. Le serveur DHCP répond par un message d'offre de
configuration IP (DHCP OFFER), ce message contient l'adresse IP et le masque de
sous réseau à attribuer, l'adresse IP du serveur de
résolution des noms et l'adresse de la passerelle par défaut.
L'offre de bail indique également la durée du bail.
Le client peut recevoir plusieurs messages DHCPOFFER au cas
ou dans le réseau nous disposons de plusieurs serveurs d'attribution
automatique d'adresse. Il doit donc opérer un choix et envoyé une
requête DHCPREQUEST qui identifie de façon explicite le serveur
DHCP et l'offre de bail qu'il accepte. Le client peut également choisir
de demander une adresse que le serveur lui avait attribué
précédemment. [17, Chap. 5]
S'il arrive que l'adresse IP demandée par le client ou
celle offerte par le serveur est encore disponible, le serveur renvoie un
message d'accusé de réception (DHCPACK) confirmant au client que
le bail est conclu. Si l'offre n'est plus valide, le serveur
sélectionné répond par un message d'accusé de
réception négatif (DHCPNACK). Si ce dernier est retourné,
le processus de sélection doit recommencer avec la transmission d'un
nouveau message DHCPDISCOVERY et une fois que le client a obtenu le bail, ce
dernier doit être renouvelé avant son expiration via une autre
requête DHCPREQUEST. [17, Chap. 5]
Le serveur DHCP garantit que toutes les adresses IP sont
uniques (une adresse IP ne peut pas être attribuée à deux
périphériques réseau différents en même
temps). Le protocole DHCP permet de reconfigurer aisément les adresses
IP des clients sans devoir apporter des modifications manuelles aux clients.
2.3.3. Serveur des fichiers
Le protocole TFTP utilise le protocole UDP, il ne
sécurise pas le moins du monde les échanges, dans notre
système il est utilisé pour booter les systèmes sur le
réseau via
TFE_ESIS_AS 2016
34
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
le serveur PXE33 qui fait partie de ce module, il
est en interaction avec le serveur TFTP et le serveur DHCP qui sont tous des
proxys intelligents pour le gestionnaire de cycle de vie.
Une première étape essentielle dans
l'amorçage d'un système consiste à préparer le
serveur TFTP avec le fichier de configuration PXE et l'image de
démarrage, cela présuppose que nous avons déjà
configuré notre proxy intelligent DHCP pour l'attribution d'adresse IP,
ainsi pour le début d'un nouveau système à partir du PXE
se passera de cette façon :
? Le boot d'accueil avec le protocole PXE ;
? L'hôte envoie une diffusion à la recherche
d'un serveur DHCP qui peut gérer les demandes PXE ;
? Le serveur DHCP (proxy intelligent) répond et donne
une adresse IP au client ;
? Le serveur PXE sera contacté, il connait la route vers
le serveur TFTP ;
? Le serveur TFTP détient une image de démarrage
pour l'hôte. 2.3.4. Signature des
certificats
La signature de certificats est un processus essentiel du
gestionnaire des configurations visant à renforcer la
sécurité du serveur maître et de ses données.
Le gestionnaire des configurations utilise SSL comme
protocole de transport en-crypté pour protéger les communications
entre les clients et le maître. Les certificats des clients doivent
être signés par le maître pour que la communication soit
possible. Il y a donc un peu de gestion associée à ces
certificats. Cela permet de satisfaire les objectifs de sécurité
suivant :
? De manière optionnelle, l'authentification du client
parce que dans la réalité celle-ci sera assuré par le
serveur maître ;
? La confidentialité des données
échangées (session chiffrée) ; ? L'intégrité
des données échangées.
Quand on branche un nouveau client au maître, celui-ci
va automatiquement générer son propre certificat ainsi qu'une
demande de signature de certificat (CSR34), qui seront
communiqué au serveur maître.
Par défaut, le client quittera ensuite puisque la
communication ne peut pas être établie tant que le maître
n'aura pas signé le certificat du client. Voici un diagramme expliquant
la procédure de signature de certificat par le maître :
33 Pre-boot eXecution Environment, permet à
une station de travail de démarrer depuis le réseau un
système d'exploitation qui se trouve sur un serveur.
34 Certificate Signing Request (demande de
signature de certificat), est un message envoyé à partir d'un
demandeur à une autorité de certification afin de demander un
certificat d'identité numérique.
35
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
Figure 2.7 processus de gestion des configurations
L'outil de gestion des configurations peut recueillir
beaucoup des faits sur un hôte, comme la taille de la mémoire, le
fuseau horaire, le type de processeur, l'environnement dans lequel l'hôte
travaille et beaucoup d'autres informations, une fois ces faits recueillis,
l'outil de gestion des configurations peut les envoyés au gestionnaire
de cycle de vie.
2.3.6. Gestionnaire de cycle de vie
Le gestionnaire de cycle de vie est étroitement
lié au gestionnaire des configurations, il peut fonctionner comme un
noeud classificateur externe pour le gestionnaire des configurations et comme
outil de génération des rapports. Il présente une
alternative au système d'inventaire, et surtout, il peut gérer
l'ensemble du cycle de vie du système, de l'approvisionnement à
la configuration jusqu'au déclassement.
Un cycle de vie complet d'une machine se compose des
étapes suivantes : ? L'installation du système d'exploitation
;
? L'installation et la configuration des autres progiciels,
ainsi que la configuration des utilisateurs et des groupes par exemple ou les
interfaces réseau ;
? Mise à jour, gestion et vérification :
l'installation des correctifs et/ou le changement de la configuration des
serveurs et enfin la surveillance sur toute la durée de vie.
Le gestionnaire de cycle de vie nous aide exactement au point
d'installer automatiquement un système d'exploitation. Après
cela, grâce à une très bonne intégration avec le
gestionnaire des configurations, de cette façon le nouveau
système sera configuré en fonction du cahier de charge. Enfin, le
gestionnaire des configurations envoie des faits sur le système de
gestion de cycle de vie qui nous permet de suivre l'ensemble du système
sur sa durée de vie complète. Avec un plugin de
découverte, le gestionnaire de cycle de
TFE_ESIS_AS 2016
38
CONCEPTION GENERALE ET DETAILLEE LOGIQUE
vie peut aussi découvrir de nouvelles machines de
l'infrastructure en fonction de leur adresses MAC37.
Les serveurs DHCP, DNS et TFTP définis dans
l'architecture au niveau de la conception générale (module
d'attribution automatique d'adresse IP, module du serveur de noms, le module du
serveur des fichiers ainsi que le module pour la signature des certificats)
constituent des proxy intelligents nous permettant d'aider à orchestrer
le processus aux systèmes de fourniture.
Comme mentionné sur le point précèdent
concernant le gestionnaire des configurations, il recueille des
différents faits sur les hôtes, ces faits peuvent ensuite
être utiliser à l'intérieur du gestionnaire de cycle de vie
pour déterminer les paramètres avec lesquels il faudra installer
un logiciel. Par exemple, cela pourrait aider le gestionnaire des
configurations et le gestionnaire de cycle de vie pour décider si un
serveur web pourrait fonctionner sur un certain système sur le port 80
ou 8080. Le gestionnaire de cycle de vie agit comme un noeud classificateur
externe pour le gestionnaire des configurations.
2.3.7. Base de données
La base de données vient s'intégrer au
gestionnaire de cycle de vie pour collectionner ou sauvegarder les
différents faits et paramètres que le gestionnaire des
configurations envoi au gestionnaire de cycle de vie. Cela permet plusieurs
consultations à la demande au niveau du gestionnaire de cycle de vie et
une conservation efficace des informations en rapport avec tous les noeuds de
l'infrastructure gérée par le gestionnaire des configurations.
2.4. Conclusion partielle
Dans cette partie du travail, il était question de
faire la conception générale qui nous a permis de définir
l'architecture générale du système, la conception logique
détaillée quant à elle, nous a permis de faire des zooms
sur les différents modules qui composent l'architecture
générale du futur système, ces zooms ont eu pour mission
de faire voir la façon dont les différents modules interagissent
avec le reste du système afin de réduire l'abstraction à
un niveau moyen. La seconde partie de notre conception réduit
l'abstrac-tion au niveau le plus bas possible.
37 Medium Access Control (sous couche de
contrôle d'accès) est parfois appelé adresse physique,
c'est un identifiant matériel unique en hexadécimal propre
à chaque périphérique réseau.



