|
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR ET UNIVERSITAIRE
UNIVERSITE NOTRE DAME DU KASAYI
B.P.70 KANANGA


« Mise en place d'une base de données pour
la gestion des abonnés d'un fournisseur d'accès au
réseau ».
Cas de MicroCom /Kananga
Travail de fin de cycle présenté en vue de
l'obtention du titre de gradué en Informatique de Gestion.
Par MUAMBA TSHIBOLA Jean
Directeur : Professeur Pierre KAFUNDA
Co directrice : Ass. Viviane KASEKA
Septembre 2016
1 EPIGRAPHE
« La gestion des entreprises n'est ni de gauche
ni de droite. Elle est bonne ou mauvaise mais ce qui compte c'est ce qui
marche ».
Tony Blair
«A chaque jour qui passe, tu parles de moins en moins
comme un programmeur et de plus en plus comme le
Tout-Puissant ».
Robert Silverberg, Basileus
« Vous n'avez jamais vécu avant d'avoir
découvert, un simple outil comme un verre, très éclairant
comme une étoile et qui gouverne le monde sous ses
principes».
Jean MUAMBA TSHIBOLA
2 DEDICACE
A toi Eben Ezer mon Berger et mon Protecteur le Dieu de
mes ancêtres, pour ton amour et ta protection envers ton enfant durant
mes bas âges jusqu'à ce jour. Nous te glorifions Eternel pour tes
bienfaisances que ton nom magnifique soit répandu au monde.
A mes très chers parents Joseph TSHIBOLA et
Alphonsine KASEKE qui, par leurs faibles moyens m'ont autorisé à
affronter la vie académique jusqu'à atterrir aujourd'hui, que
leur travail soit béni par le Très Haut.
A vous mes oncles paternels et tantes : Papa MUKEKE,
Clovis NKOLE, Jean-Bosco NKONGOLO qui m'ont aidé
particulièrement, que mes sincères remerciement vous soient
envoyés.
A mon aimable ainé familial Aimé TSHIMANGA
qui me prodiguait avec ses conseils durant toutes les années de mon
premier cycle que son travail couteux ne puisse jamais se limiter qu'à
moi seul.
A vous mes frères et soeurs : Martin MUYAYA,
Robert MPUTU, Mado NZEBA, Henriette KAPINGA, Sylvie TSHIMBILA, Jean NZEWU qui
m'ont soutenu moralement par des bons conseils en vue de ne pas se
dérouter de la vie académique, je vous remercie de tout mon coeur
pour ces inoubliables pratiques.
A vous mes très chers amis Julles NTUMBA et
Brunelle BINYANGA qui, par souci d'être social, vous avez voulu partager
la vie avec moi durant toutes mes années académiques
jusqu'à ce jour, que vos efforts et vos sacrifices fournis soient
bénis par Eben Ezer.
Je dédie ce travail qui est le résultat de
tout un chacun de vous.
Par Jean MUAMBA TSHIBOLA
3 AVANT PROPOS
Qui commence bien termine aussi bien, nous voici à
la fin de notre premier cycle en faculté d'informatique à
l'Université Notre Dame du Kasayi.
Comme la coutume des études universitaires oblige
un travail de fin du premier cycle, censé être candidat du premier
cycle est exigé de rédiger un travail compte tenu de ses souhaits
tout au long de ses années académiques.
Nous remercions profondément et
généralement tout corps académique de l'Université
Notre Dame du Kasayi. Particulièrement le Chapotant de la faculté
informatique Monsieur le Professeur Blaise KATIKISI MUZEMBE.
Nos remerciements vont tout droit vers le Professeur
Pierre KAFUNDA qui nous a montrés et instruit comment déambuler
en programmation et coordonner ce dit travail.
Nous disons ouvertement merci à nos Assistants et
Assistantes de cette belle faculté : Anaclet TSHIKUTU, Nobla
TSHILUMBA, Patient MUSUBAO, Soeur Helene KANKOLONGO, Soeur Marie Alice TSHIELA
NKUNA, Viviane KASEKA pour un meilleur encadrement dans des diverses
disciplines qu'ils disposaient.
Vous ignorer c'est être irreconnaissant dans la
vie, à vous mes compagnons de lutte et ami(e)s qui ont peiné
ensemble avec moi pendant les bons moments et les mauvais : Georges
MUTOMBO, Fortunat KABUNDA, Dorcas MUKAYA, Franck TSHINGOMA, Jean MULAMBA,
Eugénie KABU et Elisabeth NTAMBUE.
A tous ceux dont leurs noms ne sont pas cités dans
ce travail se retrouvent à l'aise avec cette phrase. Nous sommes
reconnaissants de tous vos soutiens.
4 SIGLES ET
ABREVIATIONS
1) B.D. : Bases de Données
2) C# : C Dièse ou C Sharp
3) CIF : Contraintes d'intégrité
Fonctionnelle
4) CPU : Central Processing Unit
5) C.R.C : Codes de Redondance Cyclique
6) D.H.C.P :Dynamic Host Configuration Protocol
7) D.N.S : Domain Name System
8) DB2 : Data Base 2
9) éd. : Edition
10) F.A.I. : Fournisseur d'Accès Internet
11) FDD : Floppy Disk Drive
12) FIG : Figure
13) F.T.P : File Transfer Protocol
14) Ghz : Giga Hertz
15) Go : Giga Octet
16) G2 : Deuxième graduat
17) G3 : Troisième graduat
18) HTTP : HyperText Transfert Protocol
19) HP : Hewlett-Packard Company
20) IBIDEM : Même auteur, même ouvrage
21) IDEM : Même auteur
22) IMPROKA : Imprimerie du Kasayi
23) I.P : Internet Protocol
24) IMP : Internet Messaging Program
25) L1 : Première Licence
26) m : mètre
27) Mo : Mega octet
28) M.A.C : Media Access Control
29) Modem : Modulateur-démodulateur
30) MySQL : My Structered Query Langage
31) M.C : MicroCom
32) M.C.D : Modèle Conceptuel des Données
33) M.L.D : Modèle Logique des Données
34) M.P.D : Modèle Physique des Données
35) N. B. : Noter Bien
36) NPS : Network Policy Server
37) O.S.I : Open System Interconnected
38) POP3 : Post Office Protocol 3
39) R.D.C : République Démocratique du
Congo
40) RAM : Random Access Memory
41) S.Q.L : Structered Query Langage
42) S.G.B.D : Système de Gestion de Base de
Données
43) SQL Sercver: Structered Query Langage Server
44) S.A.R.L : Société à
Responsabilité Limitée
45) S.U : Subcriber Unit
46) SPRL : Société des Personnes à
Rentabilités Limitées
47) U.K.A : Université Notre Dame du Kasayi
48) T.C.P : Transmission Control Protocol
49) TELNET : Terminal Network
50) WIMAX : Worldwide Interoperability for Microwave Access
51) TDD : Test Driven Development
52) km : Kilomètre
53) O.P : Operating System
54) Op.cit : Opus Citatum (Ouvrage cité)
55) P.C : Personnal Computer
56) XP server : Version d'un O.S Server de Microsoft
5 LISTE DES
FIGURES ET TABLEAUX
A. Figures
1. Fig.1.1 : Mode de fonctionnement de l'architecture
client-serveur.
2. Fig.1.2 : Présentation de l'OSI
3. Fig. 1.3 : Client-serveur de présentation
4. Fig. 1.4 : Rhabillage
5. Fig.1.5. : Client/serveur de procédures
6. Fig. 2-2 : Association d'une table
7. Fig.3.1 : Logo de MicroCom
8. Fig. 4.1. : Interface d'authentification (sans aucune
action)
9. Fig. 4.2. : Interface d'authentification (action sur
le bouton radio
« Administrateur »).
10. Fig. 4.3. : Interface d'authentification (action sur le
bouton radio « Client »).
11. Fig. 4.4. : Boite de dialogue (mot de passe ou compte
invalide)
12. Fig. 4.5. : Boite de dialogue
13. Fig. 4.6. : Interface de l'abonné
14. Fig. 4.6. : Interface de l'enregistrement au
serveur
15. Fig. 4.7. : Interface de consultation
A. Tableaux
1. Tableau.1.1. : Liste des protocoles
2. Tableau .1.1 : Structure et contenu d'une table
3. Tableau 2.1. : Tableau représentatif des
différents SGBD et leurs auteurs.
4. Tableau 3.1 : Ressources matérielles de MicroCom
5. Tableau 3.2 : Tableau représentatif des
différentes ressources logicielles de MicroCom
6. Tableau 3.3. : Configuration matérielle minimale du
serveur d'authentification
6
INTRODUCTION
De nos jours, l'informatique présente des nombreux
apports aux domaines de la vie, d'où elle devient une discipline
incontournable.
L'outil informatique, faisant partie du quotidien de
tout travailleur devient de ce fait l'aimable compagnon idéal de
l'homme dans toutes ses activités, en lui facilitant certaines
tâches qui, jadis paraissaient très difficiles à
opérer.
Aujourd'hui, le traitement manuel est devenu un
système très archaïque dans la gestion des abonnés
d'un Fournisseur d'Accès au Réseau et qui pose souvent des
problèmes surtout quand il s'agit de prendre en charge plusieurs
utilisateurs.
Voire certaines difficultés que traverse
MicroCom/Kananga pour gérer ses abonnés, nous avons voulu
l'opter un nouveau système qui le servira à contourner les
difficultés de gestion de ses clients.
C'est ainsi que la conception d'une base de données
client-serveur peut permettre au MicroCom comme Fournisseur d'Accès
Internet de la ville de Kananga à mieux gérer ses
abonnés.
6.1 PROBLEMATIQUE
La problématique se présente dans toute
recherche scientifique, comme un ensemble des préoccupations que se pose
un chercheur, et qui nécessite des réponses dès que l'on
descend sur terrain.
Cela étant, elle est définie comme
l'ensemble des questions que l'on se pose devant un constat que soulève,
une étude, une recherche pour arriver à la
vérité.1(*)
Ainsi, nos préoccupations se résument en
ces termes :
1) Comment parvenir à mettre en place une base des
données permettant à un fournisseur d'accès au
réseau de bien gérer ses abonnés ?
2) Quel sera l'apport de cette base de données dans
la gestion de ses abonnés ?
3) Les erreurs de gestion sont-elles
fréquentes?
6.2 HYPOTHESES
L'hypothèse est entendue comme étant une
réponse provisoire formulée à priori ou à
postériori que le chercheur donne à ses questions de la
problématique en vue de les utiliser comme chaine dorsale dans la
conduite de sa recherche.2(*)
En effet, comme l'hypothèse sert à faire
comprendre le raisonnement difficile, en proposant provisoirement certaines de
ces dimensions, ainsi donc, voici comment se présente la réponse
à notre questionnaire.
- La mise en place d'une base de données pour la
gestion des abonnés, serait possible avec l'implication des
responsables, s'ils découvrent l'importance de cette dernière par
rapport à leur système existant.
- Cette base des données permettra à tout
fournisseur d'accès au réseau de contrôler tous ses clients
et sécuriser le réseau contre tout accès non
autorisé.
6.3 METHODES ET TECHNIQUES
A.
METHODES
La méthode est une technique à utiliser soit
pour rassembler les données, soit pour traiter les résultats des
investigations.3(*)
Ce faisant, nous avons fait recours aux méthodes
ci-après :
1) LA METHODE HISTORIQUE
Elle nous a suffisamment aidés à sonder le
passé de notre champ d'étude, afin de fixer le présent et
projeter l'avenir, dans le souci innover un nouveau système.
2) LA METHODE STRUCTURO-FONCTIONNELLE
Elle nous a servi d'étudier les structures
fonctionnelles de l'entreprise.
3) MERISE
C'est une méthode de conception, de
développement et de réalisation de projets informatiques. Son
rôle est d'arriver à concevoir un système d'information.
Elle est également basée sur la séparation des
données et des traitements à effectuer en plusieurs
modèles.
B. TECHNIQUES
Parmi les techniques étudiées, nous en
avions utilisées deux, qui sont :
1) La technique
documentaire
C'est celle qui consiste à consulter les documents,
les statistiques sociales ou tous les autres écrits, voir les ouvrages,
notes de cours et autres documents.
2) La technique
d'interview
Celle-ci nous a facilités le contact direct avec
les différents personnels de MicroCom/Kananga.
6.4 CHOIX ET INTERET DU SUJET
A. CHOIX DU SUJET
La croissance d'une communauté exige une
intervention de tous dans le but de pousser plus haut la situation de leurs
milieux où ils évoluent.
Les grandes masses d'informations ne font qu'apparaitre
dans chaque contrée et cela en fonction de circonstances. La maitrise de
ces masses d'informations est une preuve palpable et parfaite digne de son
nom.
Devenue une science pour tous, l'informatique vient donner
un soulagement pour le traitement de grandes masses d'informations.
En égard à tout ce qui
précède, MicroCom étant un système comprenant
plusieurs activités, la gestion s'avère une
nécessité pour permettre de faire face et de se maintenir en
ordre utile dans la liste des fournisseurs d'accès au réseau.
Cette gestion ne doit plus être comme dans le temps jadis, elle exige une
migration vers une gestion informatisée.
Vu cette situation, nous nous sommes
intéressés à la gestion des abonnés d'un
fournisseur d'accès au réseau de la place en intitulant notre
sujet comme suit « Mise en place d'une base de données pour la
gestion des abonnés d'un fournisseur d'accès au réseau, le
cas pris en compte est celui de MicroCom/Kananga».
B. INTERET DU
SUJET
Cette étude revêt un intérêt
très capital, surtout sur le plan personnel, scientifique et
social.
1) Sur le plan personnel
Ce travail, nous a certainement permis de nouer les
théories apprises à la pratique, de mettre en exergue toute la
connaissance acquise durant les trois années d'études
passées à l'Université Notre Dame du Kasayi.
2) Sur le plan scientifique
Nous ne pouvons pas prétendre dire que nous sommes
derniers à aborder une telle thématique, cela revient à
dire que le présent travail aidera les chercheurs éventuels qui
seront intéressés par ce thème.
3) Sur le plan social
Sur ce plan, les responsables directs de ce F.A.I
ciblé seront en face d'un modèle mis sur pied devant leur
permettre l'informatisation de leurs abonnés.
6.5 DELIMITATION DU SUJET
Notre travail se focalise sur la gestion des abonnés
d'un fournisseur d'accès au réseau au sein de l'entreprise
MicroCom/Kananga, dans une période allant du 01 janvier au 03 septembre
2016.
6.6 DIVISION DU TRAVAIL
Outre l'introduction et la conclusion, cet édifice
est scindé en quatre chapitres que voici :
- Le premier chapitre concerne l'Architecture
Client-serveur ;
- Le deuxième chapitre s'intitule Bases de
Données (B.D);
- Le troisième est nommé Analyse
Préalable ;
- Le quatrième enfin portera sur
l'implémentation de l'application.
6.7 DIFFICULTES RENCONTREES
Pour parvenir au bout de cette oeuvre scientifique, nous
avons été butés à plusieurs difficultés
parmi lesquelles, nous citons :
- La rareté de certains ouvrages cadrant avec notre
sujet ;
- L'insuffisance de moyens financiers.
- Les responsables de l'entreprise choisie
résistaient à répondre à certaines questions
posées.
En dépit de tout ce qui précède,
nous avons fait l'essentiel, en élaborant le présent travail,
fruit de nos efforts.
CHAPITRE 1. ARCHITECTURE CLIENT-SERVEUR
1. INTRODUCTION
Actuellement le mot « Client-serveur »
est une expression incontournable. Elle fait référence à
une mosaïque de concepts qui touchent de nombreux domaines en
informatique.
En plus, nous vivons dans un monde où la
société aspire à une bonne technologie, le modèle
client/serveur nous est l'une des technologies la plus utilisée et
indispensable dans le domaine de Webographie.
Au début des années 90, l'architecture
client-serveur n'était qu'une réalité que pour quelques
rares entreprises à la pointe de l'innovation. Aujourd'hui, le nom est
devenu familier dans le monde des sciences informatiques.
Dans ce chapitre nous allons graviter autour des points
principaux, entre autres : l'historique, la définition des
concepts, le mode de fonctionnement Client/serveur, le middleware, le
modèle OSI, le type d'architecture client/serveur, les avantages ainsi
que les inconvénients
L'objectif de ce chapitre est de donner une vue
générale sur l'architecture client/serveur.
1.1HISTORIQUE
Historiquement l'architecture
client-serveur a connu plusieurs évolutions, mais voici
quelques-unes représentées en périodes
ci-après :
· Les années 1960 : les traitements par
lots
Cette période est celle de spécialisation de
l'informatique c'est-à-dire la saisie des données se
déroulait directement sur l'ordinateur central loin de leur provenance.
Après elle se fait par l'intermédiaire de
cartes perforées dans le cadre d'ateliers de saisie, plus proches de la
source de saisie mais la saisie est toujours dissociée des services
source.
Le serveur reste le seul endroit pour traiter et
sauvegarder les informations.4(*)
· Les années 1970 : les traitements
transactionnels5(*)
Les traitements transactionnels sont possibles grâce
à l'apparition des terminaux passifs (clavier + écran). La saisie
se fait maintenant directement sur le lieu de production de l'information
(bureau du comptable, guichet d'une agence). Les applications deviennent
interactives et sont accessibles via ces terminaux.
De nombreux utilisateurs peuvent accéder et
modifier simultanément les données de l'entreprise : c'est
l'avènement de la technique du temps partagé.
L'ordinateur central reste le seul lieu de traitement et
de stockage de l'information. L'amélioration de cette époque est
la forte baisse des temps de réponse.
Mais il reste que c'est une informatique où les
écrans sont peu ergonomiques et peu conviviaux. De plus, les dialogues
Homme/Machine sont guidés par la machine : l'utilisateur ne peut
avoir d'initiatives
· Les années 1980 : l'apparition de la
micro-informatique
A cette époque il y a eu beaucoup de changements
avec l'apparition de micro-informatique qui a presque corrigé
l'ancienne technologie des ordinateurs.
Un micro-ordinateur offre ces avantages
ci-dessous.
· Tous les systèmes d'exploitation
installés sur ces ordinateurs offrent une interface graphique facile
à utiliser via le bureau de l'utilisateur.
· La saisie des données et leur traitement se
font directement sur le bureau de l'utilisateur,
· L'interface Homme/Machine est de plus en plus
conviviale c'est-à-dire facile à s'accoutumer.
· L'utilisation de l'ordinateur est parfaitement
facile.
Il est à signaler qu'à cette période
il y a eu deux informatiques, l'une centrale qui centralise toutes les
données du système et l'autre locale qui profite les services
offerts par ce dernier.
Or il est fréquent que les données du
système central soient ressaisies sur le micro-ordinateur pour effectuer
des traitements locaux tels que des statistiques, calculs...
Ceci entraîne donc une multiplicité des
saisies et des risques d'erreurs, d'où il faut encore passer à la
correction de ces erreurs.
· Les années 1990 : la naissance du
concept de client-serveur
Ce concept a été mis en place pour mettre la
liaison entre les différents terminaux (postes ordinateurs).
Cette conception visait comme objectifs :
· Le partage des données,
· Le partage des matériels,
· Ainsi que l'accès aux
données.
1.2 DEFINITIONS DES CONCEPTS 6(*)
a) Architecture : est une
représentation ou une organisation des différents
éléments d'une structure dans les différents
domaines.
b) un client est une machine
(ordinateur) qui envoie des requêtes à un autre ordinateur
appelé serveur.
b) Serveur : est un
ordinateur puissant en terme de capacités d'entée-sortie,
offrant des nombreux services aux autres ordinateurs appelés
clients via le réseau, et ce
dernier fonctionne en permanence.
c) Réseau : au sens
général il se définit comme un ensemble d'entités
(objets, personnes, etc.) interconnectées les unes avec les autres en
vue de faire circuler des éléments matériels ou
immatériels entre chacune de ces entités selon des règles
bien définies. 7(*)
d) Webographie : ce mot
désigne une liste de contenus, d'ouvrages ou plus
généralement de pages ou ressources du web relatives à un
sujet donné.8(*)
Selon le type d'entités interconnectées, le
terme sera ainsi différent:
Ce concept en informatique se traduit par l'ensemble de
l'infrastructure de communication permettant le dialogue entre le client et le
serveur.
1.3LE MODE DE FONCTIONNEMENT
Dans la vie courante, si une personne veut envoyer un
colis à quelqu'un il l'emballe, il mentionne les informations
nécessaires sur ce colis entre autres : le nom du
bénéficiaire, le nom de la destination, l'adresse du
bénéficiaire, etc. et il va déposer à l'une des
agences de son choix.
Et c'est comme ça que ce colis pourrait atteindre
la destination sans qu'il n'ait pas la confusion.
Parlant du mode de fonctionnement du modèle
Client/serveur, ici l'ordinateur appelé client et l'autre appelé
serveur sont reliés à l'aide d'un réseau. C'est le
réseau qui offre en premier temps la possibilité de mettre ces
terminaux en connexion.
Le client se sert de logiciels utilisateurs en vue de
transférer des requêtes à l'ordinateur distant
appelé serveur et ce dernier reçoit la demande du client, il l'a
traite afin de la renvoyer à la destination.
Pour qu'une architecture client/serveur puise être
en fonctionnement il faut que toutes les machines connectées soient sous
tension. 9(*)
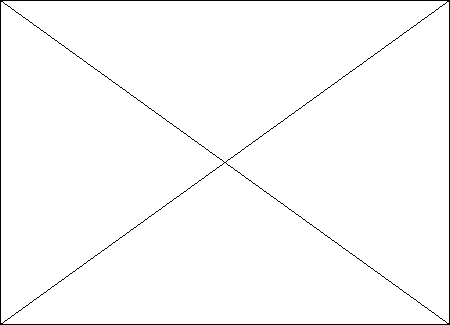
La figure ci-dessous illustre de quelle manière se
passe le dialogue entre un serveur et client.
CLIENT
SERVEUR
RESEAU
Demande
Résultat
Fig.1-1 : Mode de fonctionnement de l'architecture
client-serveur.
N.B. Il n'est toujours pas forcement obligé
d'avoir un réseau dans un modèle Client/serveur. Dans ce cas le
serveur et le client sont installés ou logés sur la même
machine. Ils interagissent à l'aide d'un logiciel bien défini
par exemple le WampServer.10(*)
1.4FONCTIONNEMENT DES APPLICATIONS CLIENT/SERVEUR
Les applications du serveur attendent les requêtes
des clients, sans les demandes des poste-clients le serveur ne fait absolument
rien.
Le comportement du poste client est actif
c'est-à-dire le client est déclencheur de la communication tandis
que celui du serveur est passif comme il est indiqué ci-haut.
C'est l'application cliente qui prend l'initiative du
dialogue, le programme dit « Client » demande, par l'envoi
d'un message, un service extérieur à un autre programme dit
« Serveur ». Une fois le service rendu, le programme
« Serveur » renvoie un message au programme
« Client ». Toute cette communication se fait de
manière transparente.
Le modèle client-serveur est un modèle de
fonctionnement coopératif entre programmes. Une architecture
client-serveur fournit des services distants (base de données,
impression, messagerie) à des clients qui peuvent utiliser de
manière transparente l'ensemble des ressources informatiques mises
à leur disposition.
1.5LE MIDDLEWARE
Etymologiquement ce concept est une contraction de deux
mots : middle qui veut dire milieu en
français et software qui veut dire logiciel ou
programme informatique.11(*)
Le middleware se définit comme tout un ensemble des
logiciels permettant le dialogue entre un poste-client et un serveur
1.5.1MODE DE FONCTIONNEMENT D'UN MIDDLEWARE
L'architecture client-serveur ne peut fonctionner sans
qu'il n'ait l'intermédiaire c'est pourquoi le middleware est
indispensable pour l'échange de cette architecture.
Le middleware prend en charge trois couches de l'OSI qui
signifie Interconnexion des Systèmes Ouverts ayant comme objectif
d'interconnecter les différents types de systèmes.
Les couches utilisées par le middleware sont :
- La couche session
- La couche présentation
- Et la couche application
1.5.2L'OSI (OPEN SYSTEM
INTERCONNECTED) :L'INTERCONNEXION DES SYSTEMES OUVERTS.12(*)
1.4.1. HISTORIQUE
Avant l'apparition de ce modèle, le
client-serveur avait des limites car celles les machines (ordinateurs) ayant
le même type de système d'exploitation qui pouvaient se
communiquer.
Par exemple l'ordinateur qui a le système
d'exploitation Windows ne pouvait s'échanger qu'avec un produit de
Microsoft, le système d'exploitation Ubuntu devait se communiquer
qu'avec un autre d'Ubuntu.
Compte tenu de ce majeur inconvénient un groupe
des gens se sont réunis pour mettre en place un système qui
devait supporter et mettre en communication deux systèmes d'exploitation
différents, autrement dit l'interopérabilité de
systèmes.
Apres cet accord fut la naissance de l'OSI qui est le
modèle standard pour tous les systèmes.13(*)
1.4.2. LES DIFFERENTES COUCHES DE L'OSI
L'OSI est composé de 7 couches qui
sont reprises ci-dessous:
1. La couche physique
2. La couche liaison
3. La couche réseau
4. La couche transport
5. La couche session
6. La couche présentation
7. La couche application
Pour permettre bien le dialogue entre client et serveur,
chaque couche doit jouer son rôle.
1. La couche physique fait
l'adaptation physique de l'information à transmettre par rapport
à la nature de support de transmission c'est-à-dire elle fait
l'adaptation de chaque bit de l'information par rapport au support de
transmission.
2. La couche liaison est
responsable de l'interconnexion de noeuds dans un réseau et de
l'adressage physique (MAC). Elle fait aussi la correction par le
mécanisme CRC (Codes de Redondance Cyclique).
3. La couche réseau fait
l'interconnexion proche en proche, elle s'occupe des qualités de
services. Elle fait gestion des IP appelés adresses logiques des
ordinateurs et celle de routage pour déterminer la meilleure route de
chaque paquet.
4. La couche
transport s'occupe du bon acheminement des messages
complets au destinataire. Son rôle principal est de prendre les messages
de la couche session, les découper en vue de les passer à la
couche réseau.
5. La couche session fait la
gestion de l'ouverture, la fermeture et le maintien de la session, en d'autres
termes elle fait la synchronisation des informations, le transfert de
données entre la session.
6. La couche présentation
s'occupe de la syntaxe des éléments à
représenter à la couche application et à la
sémantique des données transmises. Elle assure l'accès au
service.
7. La couche application est le
point de contact entre l'utilisateur entre le réseau. Les services de
bases offerts par le réseau sont apportés par cette couche. A
titre illustratif la messagerie, le transfert de fichiers...14(*)
Même si ce modèle reste très
théorique, il a le mérite d'être le plus
méthodique. (C'est d'ailleurs sa raison d'être).
Il y a deux points qu'il convient de bien comprendre avant
tout :
· Chaque couche est conçue de
manière à dialoguer avec son homologue, comme si une
liaison virtuelle était établie directement entre elles.
· Chaque couche fournit des services
clairement définis à la couche immédiatement
supérieure, en s'appuyant sur ceux, plus rudimentaires, de
la couche inférieure, lorsque celle-ci existe. 15(*)
1.5.3 PRESENTATION GRAPHIQUE DE L'OSI
Voici la représentation du modèle OSI et
les couches concernées par le middleware.
Client
1.6LA NOTION DE PROTOCOLES ET PORTS
1.6.1NOTION DE PORTS
Lors d'une communication entre deux ordinateurs en
réseau, les informations destinées à plusieurs
applications sont échangées. Chaque information transite par la
même passerelle et transférée selon l'application qu'il la
concerne. On attribue donc chaque port à son application.
Un port est codé sur 16 bits, en
général il y a 65536 ports. Parmi ces ports, 1024 sont
utilisés pour le service web qui sont à la base de
l'architecture client/serveur.
1.6.2NOTION DES PROTOCLES
Un protocole est une série d'étapes à
suivre pour permettre une communication harmonieuse entre plusieurs
ordinateurs. L'Internet est un ensemble de protocoles regroupés sous le
terme "TCP-IP" (Transmission Control Protocol/Internet Protocol).16(*)
Voici quelques protocoles utilisés, leurs
numéros de ports ainsi que leurs services.
|
N° Ports
|
Protocoles
|
Rôles
|
|
21
|
FTP
|
Protocole de transfert des fichiers
|
|
23
|
TELNET
|
Protocole d'accès à distance
|
|
25
|
DHCP
|
Protocole d'admission automatique des IP des clients
|
|
53
|
DNS
|
Protocole qui fait la correspondance entre le nom de
l'ordinateur et l'adresse logique (IP)
|
|
80
|
http
|
Protocole du web
|
|
110
|
POP3
|
Protocoles de messagerie électronique
|
|
119
|
IMP
|
Protocole des échos
|
Tableau.1-1. Liste des protocoles
1.7LES SERVICES D'UN MIDDLEWARE
Chaque middleware est capable d'assumer les services
ci-après :
· La
conversion : ce service est utilisé pour la
communication entre machine mettant en oeuvre de différents types de
données.
· L'adressage : il
permet de localiser et d'identifier la machine serveur le chemin d'accès
d'un service demandé par le client.
· La
sécurité : il permet de garantir la
confidentialité de données entre machines à travers le
mécanisme d'authentification et cryptage des informations.
· La communication :
il fait la transmission des messages entre deux systèmes sans
altération. Il fait la gestion de la connexion au serveur, la
préparation des exécutions des requêtes, la
récupération des résultats et la déconnexion de
l'utilisateur.
1.8DIFFERENTS TYPES D'ARCHITECTURE CLIENT/SERVEUR
On parvient à distinguer les types de
Client/serveur sur base de la nature de services chacun de ce dernier offre.
Vue la répartition des fonctions de présentation graphique, de
gestions de données (accès aux fichiers ou aux bases de
données), d'exécution des programmes applicatifs (calculs de
l'application). On distingue les types de Client/serveur
ci-dessous :
· Client/serveur de présentation
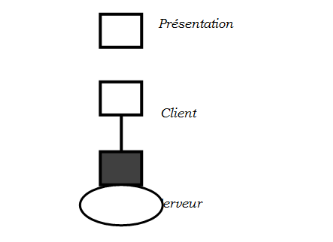
C'est un type dans le quel un processus exécute
seulement les fonctions de dialogue avec l'utilisateur, l'autre gérant
les données et exécutant les codes d'applicatif. Sa
représentation est donnée de cette manière :
Fig. 1.3. Client-serveur de présentation
· Rhabillage
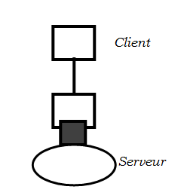
Type de Client/serveur dans le quel un processus
exécute les fonctions de dialoguer sophistiquées avec
l'utilisateur, et l'autre gérant les données, exécutant le
code applicatif, et assurant des dialogues simplifiés avec le
client17(*).
Fig.
1.4. Rhabillage
Remarque : ces deux types
de Client/serveur sont voisins car ils font tous un dialogue Client/serveur
renversé ou la machine gérant les données est cliente de
la machine gérant l'interface utilisateur, ce qui est aussi le cas pour
le serveur de présentation.
· Client/serveur de données
Ici on retrouve un programme applicatif
contrôlé par une interface de présentation sur une machine
cliente, il accède à des données sur une machine serveur
par des requêtes de recherches et les mises à jour. Ce serveur
gère une ou plusieurs bases de données. La base de données
est accédée via le langage SQL (Structered Query Langage).
Client
Fig.1.5. Client/serveur de
procédures
1.9AVANTAGES ET INCONVENIENTS DU MODELE CLIENT/SERVEUR
1.9.1AVANTAGES
Le modèle client/serveur est
particulièrement recommandé pour des réseaux
nécessitant un grand niveau de fiabilité, ses principaux atouts
sont :
· Toutes les ressources sont centralisées :
étant donné que le serveur est au centre du réseau, il
peut gérer des ressources communes à tous les utilisateurs, comme
par exemple une base de données centralisée, afin d'éviter
les problèmes de redondance et de contradiction ; 18(*)
· une meilleure sécurité : car le
nombre de points d'entrée permettant l'accès aux données
est moins important ;
· une administration au niveau serveur : les clients
ayant peu d'importance dans ce modèle, ils ont moins besoin d'être
administrés ;
· un réseau évolutif : grâce
à cette architecture il est possible de supprimer ou rajouter des
clients sans perturber le fonctionnement du réseau et sans modification
majeure 19(*)
1.9.2INCONVENIENTS
L'architecture client/serveur a tout de même
quelques lacunes parmi lesquelles nous citons :
· Un coût élevé dû à
la technicité du serveur et à sa mise en place,
· Si le serveur tombe en panne aucune autre machine
du réseau n'est connectée. Il y n'aura pas l'interconnexion des
machines.
· Un maillon faible : le serveur est le seul maillon
faible du réseau client/serveur, étant donné que tout le
réseau est architecturé autour de lui Cette architecture exige un
personnel qualifié pour sa gestion.20(*)
2 Conclusion
Nous voici au terme de ce chapitre, nous allons retenir
que le modèle Client/serveur joue un grand rôle dans le domaine de
Webographie tout comme dans d'autres domaines en informatique car il est la
base de tous les services réseaux informatiques. Elle offre la
possibilité d'interconnecter plusieurs clients via le réseau afin
de répondre à tout un chacun d'eux selon sa demande.
Ce chapitre a donné une vue générale
sur le modèle client/serveur. Il a expliqué les différents
concepts utilisés sans toucher les bases de données qui feront
l'objet de notre deuxième chapitre.
CHAPITRE 2. LES BASE DE DONNEES
C. INTRODUCTION
Les documents utilisés et produits quotidiennement
sont naturellement structurés. Vue la vision de l'utilisation future,
les gens préfèrent le stockage de données.
Ce chapitre doit introduire de manière intuitive le
lecteur au concept « donnée », au concept
« base de données », au concept
« Système de Gestion de base de données », et
à la conception d'une base de données.
Cette notion nous conduit à une mosaïque de
leçons des bases de données.
Pour bien comprendre ce chapitre dans toute son
entièreté, il faut se poser une ribambelle des questions à
savoir :
- D'où proviennent toutes les données
demandées sur l'Internet ?
- Où vont nos photos, nos textes saisis et nos
commentaires que nous chargeons sur l'Internet (cas de Facebook) ?
Nous répondons à ces questions en disant que
toutes les données que nous chargeons ou téléchargeons
sont stockées dans les bases de données via les
équipements distants.21(*)
2.1LES SYSTEMES DE GESTIONS DE BASES DE DONNEES (SGBD)
Avant d'entamer la notion de bases de données, il
est mieux de commencer d'abord avec celle de Systèmes de Gestion de
Bases de Données (SGBD) parce que sans ce dernier, on ne peut pas parler
de Bases de Données.
On conçoit aisément que la gestion d'une
Base de Données, sa consultation, sa suppression, sa modification sont
les raisons principales qui nous amènent une fois de plus à
l'environnement de Systèmes de Gestion de Bases de
Données.22(*)
Vous avez peut-être attendu parler de Microsoft
Access, de l'oracle, de DB2, SQL Server, MySQL ou bien d'autres. Cette petite
liste des programmes cités ci-hauts font partie des logiciels
communément appelés « Systèmes de Gestion de
Bases de Données » les plus utilisées sur le
marché.
2.1.1Définition
Un Système de Gestion de Base de Données est
un outil qui permet d'organiser, structurer, et de mémoriser les
informations pour servir un nombre d'utilisateurs
simultanément.23(*)
2.1.2Fonctions d'un SGBD
a) Organisation des données
Le Système de Gestion de Base de Données
organise les données d'une base de données sous forme de tables
et de colonnes.
b) Gestion de données
Le SGBD ne s'intéresse non seulement à
l'organisation des données, il s'intéresse aussi à la
gestion des données car il offre la possibilité d'ajouter
et de retirer des lignes dans une table. Il modifie encore les valeurs d'une
colonne dans une table. Le SGBD garantit le respect des contraintes
d'unicité et de référence qui ont été
déclarées.
c) Accès par programme
Les commandes SQL de définitions, d'extractions et
de modification de données peuvent être exécutées
soit à partir d'un terminal (poste client ou poste serveur) ou soit
à partir d'un programme d'application.
d) Autres fonctions
Les SGDB offrent d'autres fonctions telles que la
protection contre les incidents, la gestion des accès et le
contrôle des accès.24(*)
2.2QUELQUES SYSTEMES DE GESTION DE BASES DE DONNEES(SGBD)
UTILISES
Le tableau ci-dessous présente un certain nombre de
Systèmes de Gestion de Bases de Données.
|
Noms
|
création
|
Editeurs
|
Description
|
|
Apache Derby
|
1996
|
Apache Software
|
Embarqué, relationnel, centralisé
|
|
D Base
|
1978
|
Ashton-Tate
|
Relationnel, particulièrement au groupe de
travail
|
|
Microsoft SQL Server
|
1989
|
Microsoft
|
Entreprise, groupes de travail, relationnel et
distribué
|
|
MySQL
|
1996
|
Oracle corporation et MySQLAB
|
Centralisé, embarqué, distribué pour
entreprise, groupes de travail et particuliers
|
|
Oracle Data Base
|
1979
|
Oracle corporation
|
|
|
Open Office.org Base
|
2002
|
Oracle corporation
|
|
|
Paradox
|
1987
|
Cenel
|
|
|
Pick
|
1968
|
Rick System
|
|
|
Postgre SQL
|
1985
|
Michal stone braker
|
|
|
Progress
|
1981
|
Progress software corporation
|
|
|
SQLite
|
2000
|
D.Rihard Hipp
|
Embarqué
|
|
Microsoft Access
|
2003
|
Microsoft
|
Entreprise, groupe de travail, relationnel
|
Tableau 2.1. Tableau représentatif des différents
SGBD et leurs auteurs.
Etant motivé par son aisance dans la conception de
base de données et son nombre d'utilisateurs restreint, nous allons dans
ce travail, utiliser le Système de Gestion de Base de Données
Access dans sa version plus récente.
2.3BASES DE DONNEES
2.3.1Historique
Les premiers systèmes de gestion de base de
données sont apparus vers la fin des années 60 pour permettre de
pallier au manque de souplesse des systèmes d'informations qui
étaient alors uniquement basés sur l'utilisation de fichiers. Ce
sont ainsi succédés trois grands modèles : le
modèle hiérarchique, le modèle réseau et le
modèle relationnel. Ce sont quelques grands événements qui
marquent l'histoire de cette notion.25(*)
D. Introduction
Les bases de données ont pris aujourd'hui une place
prépondérante en informatique au sens général et
plus particulièrement en informatique de gestion au sens large. Cette
notion de base de données est pratiquement utilisée dans
plusieurs applications de gestion.
Un autre courant se dégage aujourd'hui nettement,
résultat des travaux réalisés en génie logiciel et
en intelligence artificielle, et basé sur le concept d'objet. Ce nouveau
modèle est celui des bases de données objets.
2.3.2Définitions
Selon Georges GARDARIN, elle est un ensemble de
données modélisant les objets d'une partie du monde réel
et servant de support à une application informatique.26(*)
Selon Maude MANOUVRIER, elle est une collection
structurée d'informations ou des données qui existent sur une
longue période de temps et qui décrivent les activités
d'une ou plusieurs organisations.27(*)
2.3.3AVANTAGES DE BASES DE DONNEES
2.3.3.1AVANTAGES
Une base de données permet de mettre des
données à la disposition des utilisateurs pour une consultation,
une saisie ou bien une mise à jour, tout en s'assurant des droits
accordés à ces derniers. Cela est d'autant plus nombreux.
Une base de données peut être locale,
c'est-à-dire que les informations sont stockées sur des machines
distantes et accessibles par réseau. L'avantage majeur de l'utilisateur
de la base de données est la possibilité de pouvoir
accéder par plusieurs utilisateurs simultanément.
2.4LES DEFIS DES BASES DES DONNEES
Actuellement les données sont au coeur des grandes
applications informatiques, de même elles sont aussi essentielles dans
la plus part de nos activités quotidiennes. Voici quelques
difficultés qui se posent aujourd'hui :
· Multiplicité de type de
données
Aujourd'hui les données prennent des formes
très variées compte tenu de l'évolution de la science et
des différentes applications que l'on conçoit du jour au
jour.
Parlant de données, nous voyons les fichiers qui
sont créés ou utilisés par les programmes informatiques.
· Information incorrecte ou incomplète
Le fait de stocker une information erronée ceci
engendre aussi une difficulté très exagérée dans le
stockage des informations dans la base de données. Du point de vue
exploitation, il y aura confusion des extensions ou le SGBD utilisé aura
mal à distinguer ces formats des fichiers.
· Volumes et performances
Une massivité de bases de données de temps
jadis a été remplacée par les bases de données
d'aujourd'hui qui enregistrent jusqu'à une centaine de milliards
d'enregistrements et elles ont un taux de croissance plus élevé.
Ceci explique que le nombre d'utilisateurs aujourd'hui sur les sites qui
hébergent des données de ces derniers est entrain
d'augmenter.
Plus il y a l'augmentation des utilisateurs plus on a
besoin d'une grande capacité pour le stockage. Mais il faut savoir que
toutes ces données enregistrées ne sont pas stockées sur
une même mémoire de masse, elles sont reparties ce qui nous
amène à une problématique telle que : comment ces
genres de sites parviennent-ils à gérer, à
sécuriser et à exploiter ces dites données ? Ce qui
engendre un défi majeur en matière de
sécurité.28(*)
· Accès aisé par les non-informaticiens
L'explosion de demande exige que les utilisateurs
eux-mêmes puissent accéder à leurs données sans
intermédiaire. C'est qui cause encore une difficulté grave dans
le modèle Client-serveur déjà exploité dans notre
premier chapitre.
· Bases de données et web
Les bases de données utilisées par le web
sont totalement différentes du point de vue leur mode de stockage, leur
format de données, leur façon de consultation.
· Données distribuées et
nomades
Comme nous l'avions ci-haut dit, beaucoup d'informations
sont stockées sur les machines distantes communicantes, qui sont
généralement des gros serveurs disposant une très grande
capacité en matière de stockage. Vue cette technique de
centralisation de données repose aussi plusieurs difficultés que
nous avons parlées dans les avantages et inconvénients dans le
premier chapitre.
2.5DIFFERENTS TYPES DE BASES DE DONNEES
Actuellement il existe 5 grands types de bases de
données :
· Les bases de données
hiérarchiques ;
· Les bases de données
réseaux ;
· Les bases de données
déductives ;
· Les bases de données
relationnelles ;
· Et enfin les bases de données
objets ;
a) Les bases de données
hiérarchiques ;
L'utilisation d'une base de données
hiérarchique se fait en déplaçant un ou plusieurs
pointeurs ou curseurs dans un parcourt de la base de la racine vers les fils.
Ces curseurs permettent de mémoriser un positionnement sur un segment
particulier dans l'arborescence de la base, et d'effectuer des manipulations
(lecture, écriture, etc.) sur ce segment. L'accès aux
données (aux segments) est navigationnel et suppose donc la connaissance
de la structure physique de la base.
Dans ce type de base de données, il n'est pas
possible de représenter des relations horizontales, comme la relation
qui ordonne les différentes couches entre elles suivant leur ordre de
drapage. Donc, pour représenter entièrement un problème,
il est nécessaire de dupliquer certaines données : par exemple
ici on est obligé de dupliquer les découpages, celles-ci font
à la fois partie de l'arborescence Pièce / Couche /
Découpe et Pièce / Palette / Découpe.
b) Les bases de données réseaux
La base des données réseau
représente les données sous la forme d'enregistrement ou article
(Record) contenant un ensemble d'agrégats (vecteur ou groupe
répétitif) constitués eux même d'atomes ceux-ci
constituant la plus petite unité de données manipulable. Les
bases de données réseau sont une extension des bases de
données hiérarchiques en ce sens qu'elles permettent de
représenter d'autres types de relations que les relations verticales
ensemble/sous-ensemble.
Les bases de données réseau permettent de
modéliser tous les types de relations, c'est en fait le premier
modèle de base de données réellement complet. Il
présente néanmoins un certain nombre de désavantages dont
le principal est que, comme dans le cas des bases de données
hiérarchiques, l'accès aux données est navigationnel et
est totalement lié à la structure physique de la
base.29(*)
c) Les bases de données déductives
Ce type de bases données est aussi appelé
bases de données logiques. Ce sont celles qui permettent d'extraire ou
de déduire des informations. Il y a la possibilité de
définir des règles qui peuvent déduire ou inférer
des informations supplémentaires à partir des informations de la
base.
Ce type de base utilise deux types de spécification
c'est-à-dire les faits et les règles.30(*)
d) Les bases relationnelles
Les bases de données relationnelles sont
basées sur la théorie mathématique de l'algèbre
relationnelle. Dans cette théorie, une relation est
représentée par l'ensemble des lignes d'une table.
On a donc l'équivalence fondamentale RELATION =
TABLE
Les relations (donc les tables) étant
considérées au sens ensembliste, il n'existe aucune notion
d'ordre au sein d'une relation. L'ordre des lignes dans une table est donc
quelconque. Les relations sont manipulées en utilisant les
différents opérateurs de l'algèbre relationnelle.
o o Sélection
o Projection
o Produit
o Jointure
o Union
o Différence
o Intersection
o Division
a) e) Les bases de données objets
L'apparition de la notion de base de données objets
provient du fait qu'un ensemble de fonctionnalités n'était pas
simultanément couvert par les langages objets, et les bases de
données "classiques".
Chaque objet se voit attribué un identifiant
unique, indépendant du type de l'objet (de sa classe), et de sa
localisation physique (en mémoire ou sur disque). Les relations entre
objets ne sont plus sous la forme de pointeur sur des enregistrements (pointeur
physique), mais utilisent les identifiants des objets (pointeur
logique).
Il existe donc un niveau d'indirection, ce qui rend les
mises à jour beaucoup plus simples.31(*)
2.6LES CONCEPTS RELATIFS A UNE BASE DE DONNEES RELATIONNELLE
Dans ce point, il nous sera beaucoup plus important de
graviter à des différents concepts qui dérivent de la
base de données et en particulier base de données relationnelle,
c'est ainsi que nous sommes obligés de définir
quelques-uns.
a. Donnée : ce que
l'on peut stocker, soit sur un support informatique ou un support physique,
à titre illustratif une carte mémoire, un disque dur pour le
support informatique ou un carton, une farde, un classeur, une armoire pour le
support physique.
b. Modèle relationnel :
Modèle permettant d'organiser les données en une
représentation schématique qui autorisera son exploitation par le
SGBD ou l'outil de bureautique de gestion de base de
données.32(*)
c. Tableaux à deux
dimensions : est celui qui est composé de champs
ou d'attributs en colonnes et d'enregistrements en lignes.
d. Clé primaire :
Attribut ou ensemble d'attributs qui identifie de manière unique le
nuplet ou les lignes de la relation.
e. Clé
étrangère : attribut ou ensemble d'attributs
d'une relation qui font référence à la clé
primaire d'une autre relation.
f. Table : est un ensemble
des lignes et des colonnes d'une base de données relationnelle.
g. Une association : est un lien
entre deux ou plusieurs entités.
h. Un attribut : est une
propriété d'une entité ou d'une association.33(*)
2.7CONSTRUCTION D'UNE BASE DE DONNEES
Construire une base de données consiste à
regrouper ou à rassembler les données en paquets
« homogènes », les entités (tables). Chaque
table étant composée d'un nombre fini de données
élémentaires, les attributs ou les champs dont la tautologie
appelée autrement redondance devant être minimale, et d'une suite
des lignes appelées enregistrement ou n_uplet stockées sur un
support externe, généralement un support informatique de base.
Une ligne est une suite de 1 ou plusieurs valeurs, chacune étant d'un
type déterminé.
D'une manière générale, une ligne
regroupe les informations concernant un objet, un concept du monde réel
(externe à l'information), que nous bâtissons parfois une
entité ou un fait.34(*)
2.8STRUCTURE D'UNE TABLE (COLONNES&LIGNES)
Les données d'une base de données sont
organisées sous la forme d'une ou plusieurs tables. Une table contient
une succession ou collection de lignes stockées sur un support de masse.
D'une manière générale une ligne regroupe des informations
concernant un objet, un individu, un événement, etc.
c'est-à-dire un concept du monde réel que nous appelons parfois
une entité ou un fait.
A titre illustratif la figure ci-dessous présente
une table nommée « Client » comportant quatre
lignes, trois colonnes avec les valeurs respectives.
|
Client
|
|
Nom
|
Adresse
|
Catégorie
|
|
Nobla TSHILUMBA
|
Matamba
|
A
|
|
Viviane KASEKA
|
Tshibala
|
B
|
|
Mado NZEBA
|
Kafuba
|
D
|
|
Alphonsine KASEKA
|
Mutefu
|
E
|
Tableau .2.2. Structure et contenu d'une table
2.9LES CARACTERISTIQUES D'UNE BASE DE DONNEES
Cette partie montre les différentes
caractéristiques d'une base de données.
a. Exhaustivité : ici il y a l'implication
de disposer de toutes les informations relatives au sujet donné.
b. La non-redondance : elle implique l'unicité
des informations dans la base de données. En général, on
tante d'éviter la duplication des données car cela pose des
problèmes de cohérence lors de mises à jour de ces
données.35(*)
c. La structure : elle fait appel à l'adaptation
du mode de stockage des renseignements aux traitements qui les exploiteront et
les mettront à jour ; ainsi qu'au coût de stockage de ces
renseignements dans l'ordinateur. Le stockage physique d'une base de
données consiste en un ensemble d'enregistrements physiques,
organisés à l'aide des listes, des pointeurs et
différentes méthodes d'indexation.36(*)
2.10MODELES DE DONNEES
En informatique, un modèle de
données est un
modèle qui
décrit de façon abstraite comment sont représentées
les
données dans
une organisation
métier,
un
système
d'information ou une
base de
données.
Ce terme modèle de données peut
avoir deux significations :
1. Un modèle de
données théorique : une description formelle ou un
modèle mathématique. Voir aussi
modèle
de base de données.
2. Un modèle de données instance :
est celui qui applique un modèle de
données théorique (
modélisation
des données) pour créer un modèle de
données instance.37(*)
a) Instances et
schémas
Toute la description de données à
définir les propriétés d'ensemble d'objet
modélisés dans la base de données, et non pas d'objets
particuliers. Les objets particuliers sont définis par les programmes
d'application lors des insertions et mise à jour de données. Ils
doivent contrôler les propriétés des ensembles auxquels ils
appartiennent. Ainsi on distingue deux notions :
- Type d'objet qui permet de spécifier les
propriétés communes à un ensemble d'objet en termes de
structure de données visible et d'opérations
d'accès.
- L'instance d'objet correspond à un objet
particulier identifiable parmi les objets d'un type.38(*)
2.11LES NIVEAUX D'ABSTRACTION
L'objectif primordial d'un SGBD est d'assurer une
abstraction des données stockées sur un disque pour simplifier la
vision des utilisateurs. Pour cela trois niveaux de description de
données ont été distingués. Ainsi ces niveaux ne
sont pas clairement distingués par tous les SGBD, ils sont
mélangés en deux niveaux dans beaucoup de systèmes
existant. Cependant, la conception d'une base de données
nécessite la considération et spécification de ces trois
niveaux parmi lesquels nous citons :
a) Le niveau
conceptuel
Ce niveau est central car il correspond à la
structure canonique des données existant dans l'entreprise.
C'est-à-dire leur structure sémantique vue de tous les
utilisateurs.
b) Niveau interne
Parlant de ce niveau, il correspond à la structure
de stockage supportant les données. La définition du
schéma interne nécessite préalablement le choix d'un SGBD.
Car elle permet de décrire les données telles qu'elles sont
stockées dans la machine, par exemple :
· Les fichiers qui contiennent (nom, organisation,
localisation...)
· Les articles de ces fichiers (longueur, champs
composant, modes de placement de fichiers...)
· Les chemins d'accès à ces articles
(index, chainages, fichiers inversés ...).
c) Niveau externe
Ici chaque groupe de travail utilisant des données
possède une description des données perçues,
appelés schéma externe. Cette description est effectuée
selon la manière dont le groupe voit la base dans ses programmes
d'application.
2.12LE MODELE ENTITE-ASSOCIATION
Le modèle entité-association est basé
sur une perception du model réel qui consiste à distinguer des
agrégations de données élémentaires appelées
entités et des liaisons entre entités appelées
associations. Intuitivement, une entité correspond à un objet du
monde réel généralement défini par un nom par
exemple un fournisseur, une connexion, une commande, etc. Une entité est
une agrégation de données élémentaires. Un type
d'entité définit un ensemble d'entités constitué
par des données de même type. Il faut savoir que les types de
données agrégées sont appelées les attributs de
l'entité ; ils définissent ses propriétés.
Une association correspond à un lien logique entre
deux entités ou plus. Elle est souvent définie par un verbe
naturel ou un verbe d'action. Prouvons ceci par un exemple. 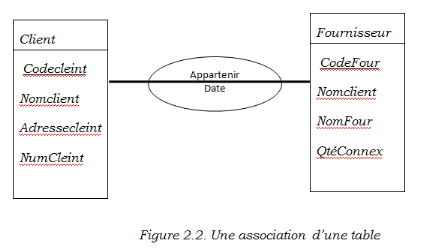
2.13LANGAGES DE REQUETES
Un langage de requête est celui qui permet de
communiquer avec une base de données à travers certaines
commandes et certains critères.
Parlant des langages de requête, il existe plusieurs
langages de requêtes mais le plus utilisé et envisagé est
le langage SQL (Structured Query Langage). Ce langage informatique est
notamment très utilisé par les développeurs web pour
communiquer avec les données d'un site web.
Ce langage a plusieurs instructions lui permettant de
dialoguer avec une base de données mais de notre côté nous
essayerons d'énumérer quelques-unes, parmi
lesquelles :
· Create : pour créer une
table ;
· Insert : pour insérer dans une table
déjà créée ;
· Update : pour modifier une information dans une
table ;
· Delete : pour supprimer une table ou une ligne de
table indiquée ;
· Select : pour consulter les informations d'une
table selon les critères définis ; 39(*)
E. CONCLUSION
Dans ce chapitre, il est à noter que le stockage,
le partage et l'utilisation des données à court terme, à
moyen terme ainsi qu'à long terme nécessitent quant à eux
de faire appel à la technologie de base de données. Les bases de
données aujourd'hui jouent un rôle très important au sein
des entreprises dans le but de stocker les informations pour une future
utilisation.
Dans ce domaine, les systèmes traditionnels se sont
montrés peu, ou mal adaptés, face à la complexité
et au caractère multiforme de données.
Face à ces défis les bases de données
orientés objets ont pris de l'ampleur et gagné le marché
en terme de modélisation d'objets complexes qui sont plus
utilisés par les langages de programmation orientés objets qui
feront l'objet de notre dernier chapitre.
CHAPITRE 3. ANALYSE PREALABLE
F. INTRODUCTION
L'analyse préalable appelée encore analyse
de l'existant ou pré-analyse, c'est la première étape
d'une étude informatique consistant à analyser de manière
approfondie tout ce qui existe au sein du système choisi.
C'est ainsi que ce chapitre traitera sur notre champ de
travail qui est le fournisseur d'accès au réseau
MicroCom/Kananga.
3.1PRESENTATION
La société MicroCom est une
société qui oeuvre dans le domaine des
Télécommunications et de l'Informatique, elle est
actuellement le Leader des fournisseurs d'accès aux services internet,
d'intégrateurs des solutions informatiques et de câblage
réseau avec 11 représentations dans les grandes villes de la
République Démocratique du Congo, notamment :
· · Kinshasa
· Kananga
· Lubumbashi
· Mbuji-Mayi
· Mbandaka
· Likasi
· Kolwezi
· Matadi
· Goma
· Kisangani
· Et afin Bukavu
En dehors de ces provinces il a plus de 20 stations
terriennes modernes placées dans quelques villes que nous n'avons pas
citées.
3.2LOCALISATION
Le siège de la société MicroCom SPRL
à Kananga se situe dans la commune de Kananga, dans le quartier
Hôpital, sur l'avenue Kanyuka N°44.
Elle est bornée :
ü Au nord par le Lycée BUENA MUNTU
ü Au sud par le croisement de deux avenues
respectivement appelées Lulua et de la mission.
ü A l'est par l'Imprimerie Protestante de Kananga
(IMPROKA) ;
ü A l'ouest par l'église catholique Saint
Clément.
3.3CARACTERISTIQUES DE LA SOCIETE
MicroCom se caractérise par deux couleurs
dominantes, la couleur verte et la couleur rouge. Son logo se présente
de la manière suivante :

Fig.3.1 : Logo de
MicroCom
MicroCom est une concaténation de deux mots :
« Micro » qui veut dire micro-information et
« Com » qui signifie communication.
3.4OBJECTIFS DE L'ENTREPRISE
La société MicroCom a pour objectif
principal de fournir des services internet à ses abonnés, parmi
ces services nous pouvons citer :
- Internet Provider
- Connexion satellite
- Et télécommunications40(*)
3.5HISTORIQUE
L'entreprise fut créée en
1982, MicroCom est une société
à responsabilité limitée (S.A.R.L.) aux capitaux à
100% Congolais.
Depuis sa création, la société n'a
cessé de développer ses potentiels et de perfectionner ses offres
en vue d'un meilleur positionnement sur la sphère de la haute
technologie. Aujourd'hui, la société entreprend de nouvelles
orientations stratégiques à mesure de réaliser des
performances professionnelles qui s'accordent aux normes internationales.
Grâce à nos partenaires de
marque, nous sommes désormais un opérateur
qui assurons des services dont les traits marquants sont l'efficacité,
le perfectionnisme et l'innovation.
Son objectif est d'arriver à un taux de
pénétration élevé de l'internet en
République Démocratique du Congo et faire de celui-ci un outil
éducatif.
Depuis cinq ans, MicroCom a acquis et installé un
système de HUB pour réduire le temps d'interconnexion des
réseaux tant sur le plan international (Internet).
Cette infrastructure permettra aux clients de MicroCom de
jouir d'une flexibilité dans la fourniture et la gestion de la bande
passante avec possibilité d'une connectivité intranet à
travers toutes les régions de la République Démocratique
du Congo avec des temps de latence de l'ordre de 600ms.41(*)
3.6BESOINS DE L'ENTREPRISE
a / Besoins généraux
MicroCom a besoin de la main d'oeuvre suffisante pour son
bon fonctionnement compte tenu des divers départements qu'il regroupe
en son sein.
B/ Besoins techniques
Sur le plan technique, MicroCom nous a
présentés comme besoins les matériels à installer
chez le client S.U (Subcriber Unit), électrogènes
véhicules et aussi :
· L'amélioration de la largeur de
bande
· L'amélioration de la bande passante
· La réduction du coût de trafic
· La réduction du délai d'attente du
trafic
· L'échange de trafic avec d'autres FAI de la
ville de manière à satisfaire les besoins de plus en plus les
clients en leur évitant des doubles bonds.
3.7INFRASTRUCTURES
Enfin de répondre efficacement à tous les
besoins des abonnés, la société MicroCom dispose ses
propres infrastructures adéquates dont voici une liste non
exhaustive :
· Téléports à Kinshasa,
Lubumbashi et Goma ;
· Plusieurs plateformes de technologies
différentes (Hubs) ;
· Mémoire de masse importante pour les
services (Intelsat, Eutelsat, etc.) ;
· Un nombre important de BST WIMAX (2.3 GHz et 3.5
Ghz) en FDD/TDD ;
· Un important réseau de fibre optique dans la
ville de Kinshasa (40 km) ;
· Plusieurs pylônes de 40 m et 70 m pour la
distribution ;
· Alimentations en énergie électrique
mixte : cabine moyenne tension privée, groupes
électrogènes et énergie solaire ;
· Plusieurs bâtiments abritant nos bureaux
à Kinshasa et en provinces,
· Un charroi automobile important
équipé du système AVL
3.8QUELQUES EQUIPEMENTS UTILISES PAR L'ENTREPRISE
a) Switch
(commutateur).
Un Switch reconnaît les différents PC
connectés sur le réseau. En recevant une information, il
décode l'entête pour connaître le destinataire et ne
l'envoie que vers celui-ci dans le cas d'une liaison PC vers PC.
b) Le Routeur
Les routeurs sont les
dispositifs permettant de "choisir" le chemin que les datagrammes (paquets
d'information) vont emprunter pour arriver a destination.
c) Modem : l'équipement qui
fait la modulation et la démodulation lors de transfert ou de
réception des données.
Il s'agit des dispositifs ayant plusieurs cartes
réseau dont chacune est reliée à un réseau
différent. Ainsi, dans la configuration la plus simple, le routeur n'a
qu'à "regarder" sur quel réseau se trouve un ordinateur pour lui
faire parvenir les datagrammes en provenance de l'expéditeur16.
d) Les ordinateurs : appareils
électroniques traitant les informations d'une manière
rationnelle et automatique.
e) Le scanneur : appareil capable de
transformer un document physique à un document informatique (logique ou
électronique).
f) Le câble coaxial : il est
largement utilisé comme moyen de transmission. Ce type de câble
est constitué de deux conducteurs concentriques : un conducteur central,
le coeur, entouré d'un matériau isolant de forme
cylindrique.
e) Câble
paire torsadée
Celui-ci est un ancien support de transmission utilisé
depuis très longtemps pour le téléphone ; il est encore
largement utilisé aujourd'hui.
Ce support est composée de deux conducteurs en cuivre,
isolés l'un de l'autre et enroulés de façon
hélicoïdale autour de l'axe de symétrie
longitudinale.
3.9ORGANIGRAMME
La société MicroCom est une grande
entreprise dans le pays en matière de télécommunication et
informatique. Ce qui veut dire qu'elle a son siège national dans la
capitale de la RDC, et dans chaque province on trouve que des
succursales.
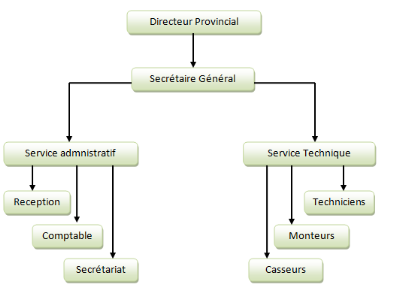
Voici comment l'entreprise s'organise dans la ville de
Kananga.
Commentaire : selon
l'organisation, nous constatons que l'entreprise est chapotée par un
Directeur Provincial, après celui-ci vient le Secrétaire
Général, viennent alors deux grands services respectivement
appelés service administratif et le service technique.
Le service administratif comprend trois services que
voici : la réception, la comptabilité et le
secrétariat tandis que le service technique comprend aussi trois
services qui sont : techniciens, monteurs et enfin casseurs.
3.10ADMINISTRATION RESEAU
a)
Administrateurs
Les administrateurs de réseau ont beaucoup de
responsabilités sur le réseau. Ce sont des groupes de personnes
qui ont tous les droits sur le domaine entier au niveau d'administration de
système.
Le travail de ce groupe est de :
· Installer, configurer des serveurs, des postes
clients, des périphériques, etc.
· Faire marcher le réseau ;
· Gestion des utilisateurs ;
· Gestion des ressources : Partage de données,
programmes, services, périphériques via réseau ;
· Mettre en oeuvre d'une politique pour sauvegarder les
données d'utilisateurs et des programmes ;
· Sécurité : Protéger le piratage
interne et externe ;
· Surveillance des utilisateurs ;
· Protéger le système : antivirus, mettre
a jour des services ;
· Former des utilisateurs... etc.
b) Monteurs
C'est un ensemble des électroniciens, architectes
et électriciens qui, par leurs compétences arrivent à
monter les antennes ou réparer des équipements en cas de pannes.
Non seulement ces travaux, ils occupent encore aux installations des
matériels des nouveaux abonnés.
3.11LE RESEAU DE MICROCOM
Cette partie nous montre les différentes
ressources que possède l'entreprise.
3.5.1. LES RESSOURCES MATERIELLES
Les ressources matérielles de MicroCom se
ramènent dans le tableau ci-après :
|
Nombres
|
Type d'ordinateur
|
Caractéristiques
|
Etat
|
|
2
|
Acer (lap top)
|
Pentium IV 2.4GHz, RAM: 2 Go, HD: 120 Go
|
Bon
|
|
1
|
Desktop
|
Pentium III de 1.5 GHz, RAM: 2 Go, HD : 300 Go
|
Bon
|
|
5
|
Lenovo Lap top
|
P IV de 2 GHz, RAM: 1Go, HD : 40 Go
|
Bon
|
|
1
|
Imprimantes
|
Trois HP à jet d'encre et deux HP laser
|
Bon
|
|
1
|
Photocopieuse
|
HP multifonctions (scanner, photocopieuse...) en
réseau.
|
Bon
|
|
3
|
Routeurs et Switch
|
Chacun ayant 8 ports
|
Bon
|
Tableau 3.1 : Ressources matérielles de MicroCom
3.5.2. RESSOURCES LOGICIELLES
Ce point traite sur quelques ressources logicielles que
nous avions trouvées au sein de l'entreprise MicroCom reprises par le
tableau ci-après.
|
Systèmes d'exploitation
|
Antivirus
|
Applications
|
|
Windows 7
|
Avast
|
Microsoft Word
|
|
Windows 8
|
Norton
|
Microsoft Excel
|
|
XP server 2003
|
Smadav
|
Manager net
|
Tableau 3.2 : Tableau
représentatif des différentes ressources logicielles de
MicroCom
3.12DIFFICULTES
RENCONTREES
Aucune entreprise n'a jamais manqué des
difficultés, c'est ainsi que nous sommes obligés
d'énumérer quelques-unes rencontrées.
- L'absence de l'électricité pendant les
heures du travail.
- La déconnexion du réseau manuelle des
abonnés.
- La confusion des adresses I.P.
3.13ANALYSE DES BESOINS DU RESEAU EXISTANT
Cette partie nous permet de déterminer si la mise
en place de notre application, dans le réseau existant serait possible
ou si ce dernier doit subir une mise à niveau de ses équipements.
En effet, pour un réseau d'une entreprise, son besoin sera basé
sur l'objectif de centraliser les ressources. Cette centralisation des
ressources à un point unique, exigera la mise en place d'une
infrastructure basée sur l'architecture client/serveur.
En effet, une analyse des besoins du réseau serait
plus efficace et réelle, en déterminant les différents
services que l'entreprise attendra de cette application. Afin de
déterminer ces besoins voici quelques services que nous allons proposer
:
- La communication : chaque interface de
l'utilisateur aura une zone de texte qui l'aidera à communiquer avec
celle du serveur ou de l'administrateur en cas de besoin.
- La déconnexion du réseau : en cas de
non paiement de l'abonné, l'application du coté serveur permettra
de couper la connexion du concerné automatiquement.
- L'accès rapide au réseau :
l'utilisateur n'aura point besoin d'autres choses que d'avoir l'adresse IP,
qu'il mettra pour être couvert.
Notre travail vient de proposer une solution en rapport
avec la sécurité du réseau. En effet, dans la future
application nous implémenterons un mécanisme de
sécurité, qui permettra à l'entreprise de protéger
le réseau contre tout accès, non autorisé au
réseau. A travers ce mécanisme, seuls les utilisateurs ayant les
adresses conforment à celles stockées dans la base de
données auront l'accès au réseau.
3.14PRESENTATION DETAILLEE DE LA SOLUTION RETENUE
Pour que cette application prenne ses avantages au sein de
l'entreprise nous devons avoir quelques équipements.
a) Composants
Matériels et Logiciels nécessaires:
Par composants matériels et logiciels
nécessaires, nous voulons dire l'ensemble des matériels et des
logiciels dont nous aurons besoin pour la mise en place de notre solution. En
effet nous aurons besoin:
1. Composant Logiciel:
Un système d'exploitation serveur «Windows
2008 Server Entreprise Edition» le choix porté sur le
système d'exploitation Windows Server est justifiable, nous l'avons
choisi car il inclut d'une part la gestion des certificats, et d'autre part il
dispose d'un serveur RADIUS intégré sous le nom de NPS (Network
Policy Server) pouvant à lui seul gérer un nombre infini de
clients RADIUS. Ce serveur s'appui sur le service d'annuaire Active Directory
pour gérer les couples login/mot de passe.
Une autre solution, serait d'utiliser Free
Radius, nous avons opté pour Windows 2008 Server.
2. Composants Matériels:
En ce qui concerne les composants matériels, nous
aurons besoins d'un serveur et d'un point d'accès:
a) Serveur:
Le serveur, est le poste de travail, qui jouera le rôle
du système d'authentification, et il devra avoir au minimum les
caractéristiques suivantes:
|
RESSOURCES
|
CONFIGURATION MINIMALE
|
CPU
|
|
Pentium III 850 mégahertz
|
Mémoire vive
|
|
512 Mo (méga-octets)
|
Carte réseau
|
|
2 Cartes réseaux
|
Disque dur
|
|
1 Disque dur de 300Go
|
|
Tableau 3.3.Configuration matérielle minimale du
serveur d'authentification
Comme vous pouvez le remarquer, la configuration
matérielle minimale, ci-haut, permet à ce que l'entreprise ne
puisse pas engager trop de dépenses, car les ordinateurs existants
peuvent être réutilisés comme serveur d'authentification.
Mais pour notre application nous utiliserons un ordinateur portable.
b) Switch managéable :
- En ce qui concerne le Switch managéable, nous
n'avons pas assez de moyen pour nous le procurer, il nous est impossible
d'achever notre travail selon notre vouloir.
3.15. MISE EN PLACE EFFECTIVE DE LA
SOLUTION RETENUE
a) PLAN D'ADRESSAGE:
Dans cette partie, nous donnons juste les informations
concernant l'adressage. Après l'installation de l'application les
équipements auront besoin des informations suivantes :
· Adresse du serveur : 192.168.15.5
· Masque du sous réseau : 255.255.255.0
· Adresse du Switch managéable :
192.168.15.115
· Adresse de postes clients : 192.168.15.10 à
192.168.15.100
G. CONCLUSION
Nous retenons que l'entreprise est informatisée
à moitié mais nous avons constaté quelques limites du
système existant que nous devrons apporter solution lorsque
l'application sera mise en oeuvre.
CHAPITRE 4. IMPLEMENTATION DE L'APPLICATION
4.1CONCEPTION
H. INTRODUCTION
La conception et la réalisation d'un système
d'information ne sont pas une chose évidente car elles exigent que l'on
puisse réfléchir à l'ensemble de l'organisation à
mettre en place. La phase de conception nécessite des méthodes
permettant de mettre en place un modèle sur lequel on va
s'appuyer.
Un modèle est une représentation d'un
système qui vise à en faciliter la compréhension, en
mettant en évidence certains.
La modélisation est l'activité qui consiste
à construire des modèles, soit pour décrire un
système informatique existant, soit pour élaborer un nouveau
système informatique (conception) à partir des perceptions du
monde réel. La réalité est universelle mais sa perception
et son analyse sont spécifiques aux individus qui les font.
La méthode que nous exposons dans le cadre de ce
cours est la MERISE1 (Méthode d'étude et de réalisation
informatique pour les systèmes d'entreprises). Méthode d'analyse
et construction du système informatique des écoles
françaises.
4.1.1LES CYCLES DE MERISE
La MERISE comprend trois cycles que voici :
- Le cycle d'abstraction : avec les formalismes aux 3
niveaux (conceptuel, organisationnel ou logique, opérationnel ou
physique) pour modéliser un système d'information.
- Le cycle de vie : comporte 3 grandes
périodes dont la conception qui va de la période d'étude
de l'existant au système même à mettre en
place ;
Ensuite la réalisation qui concerne la
période de mise en oeuvre et d'exploitation, et enfin la maintenance qui
permet au système d'exploitation et de s'adapter aux modifications de
l'environnement et aux nouveaux objectifs.
- Le cycle de décision : tout au long de
l'étude et de la maintenance, des décisions sont à
prendre, très générales d'abord, puis de plus en plus
ponctuelles.
Les trois cycles se déroulent simultanément.
A chaque étape du cycle de vie, les formalismes du cycle d'abstraction
sont utilisés avec une précision de plus en plus grande, et des
décisions sont prises, d'ordre global au début, puis de plus en
plus détaillées à mesure qu'avancent les travaux.
4.1.2 LES NIVEAUX DU CYCLE
D'ABSTRACTION DE MERISE
MERISE distingue trois niveaux de description de
systèmes d'information suivants :
- Niveau conceptuel : son rôle consiste
à définir précisément les finalités de
l'entreprise. Il précise l'ensemble des règles de gestion
à y appliquer au niveau des concepts.
- Niveau organisationnel ou logique : son rôle
est de définir l'organisation qu'il est souhaitable de mettre en place
dans l'entreprise pour atteindre les objectifs souhaités.
- Niveau physique ou opérationnel : il
définit les choix techniques (logiciels et matériels). Il se
traduit en termes de modèle physique de données (MPD).
4.1.3PRESENTATION DE MODELE
CONCEPTUEL DE DONNEES
A. LE MCD BRUT
|
Mot_pass
|
|
Mot_pass
Nom_d'utilisateur
catégorie
|
|
Administrateur
|
Avoir
1,1
Avoir
Gérer
Nom
Mot_pass
1,1
1,n
1,1
1,1
1,1
|
Abonné
|
|
AdressIP
Nom
Mot_pass
Date d'entrée
Connecté
Payé
|
4.1.2. Fig. Présentation du MCD brut
B. LE MCD VALIDE
|
Mot_pass
|
|
Mot_pass
Nom_d'utilisateur
catégorie
|
|
Administrateur
|
CIF
CIF
CIF
Nom
Mot_pass
|
Abonné
|
|
AdressIP
Nom
Mot_pass
Date d'entrée
Connecté
Payé
|
4.1.2. Fig. Présentation du MCD valide
4.1.1.1. REGLE DE NORMALISATION
v Première forme normale : Chaque
entité doit posséder un identifiant qui caractérise de
manière unique.
v Deuxième forme normale : L'identifiant peut
être composée de plusieurs attributs mais les autres attributs de
l'entité doivent être dépendants de l'identifiant.
Ces deux premières formes normales peuvent
être oubliées si on suit le conseil de n'utiliser que des
identifiants non composés de type numéro.
v Troisième forme normale (importante) : les
attributs d'une entité doivent dépendre directement de son
identifiant.
· Normalisation des relations : les attributs des
associations doivent dépendre des identifiants de toutes les
entités en associations.
|
Administrateur
|
|
Nom
Mot_pass
|
|
Abonné
|
|
adressIP
Nom
Mot_pass
Catégorie
Payé
|
4.1.4PRESENTATION DU MODELE
PHYSIQUE DE DONNEES (MPD)
a) Table administrateur
|
Adresse
|
Nom
|
Mot de passe
|
|
192.168.15.1
|
Ir John
|
Admin
|
|
192.168.15.1
|
Ir Ivo
|
Admin
|
|
192.168.15.1
|
Ir Isaac
|
Admin
|
b) Table Abonné
|
Adresse
|
Nom
|
Mot de passe
|
Date d'entrée
|
Conceté
|
Payé
|
|
192.168.15.2
|
Ir Van
|
Micro
|
03/09/2016
|
Oui
|
Oui
|
|
192.168.15.3
|
Ortho
|
Admin
|
24/10/2016
|
Non
|
Non
|
|
192.168.15.4
|
John
|
KjhgJGJ
|
01/01/2016
|
Oui
|
Oui
|
c) Table mot de passe
|
Nom d'utilisateur
|
Mot de passe
|
Catégories
|
|
Ir Van
|
Micro
|
Abonné
|
|
Ortho
|
KjhgJGJ
|
Abonné
|
|
Ir John
|
Admin
|
Admin
|
MODELE PHYSIQUE DES DONNEES
|
Abonné
|
|
Adresse
Nom
Mot_pass
Dat_d'ent
Connect
Payé
|
|
Mot_pass
|
|
Mot_pass
Nom-d'utilisateur
Categorie
|
|
Administratif
|
|
Adress
Nom
Mot_pass
|
4.1.5PRESENTATION DU MODELE
LOGIQUE DE DONNEES (MLD)
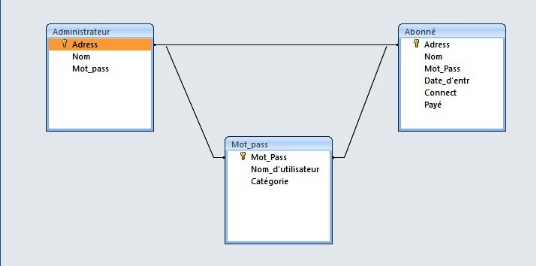
4.2CHOIX DU LANGAGE DE
PROGRAMMATION
Dans le cadre de notre solution informatique, nous
allons considérer le langage de programmation C Sharp (C#)
pour implémenter les différentes interfaces de mise à jour
de notre application. Nous utiliserons en plus une base de données
créée en Microsoft Office Access 2007 comme système de
gestion de base de données. Il sied de noter que le langage de
programmation C Sharp choisi est de l'environnement Microsoft Visual Studio
Team 2008, dans la plate-forme .Net Framework.
Voilà pourquoi, dans ce point de notre travail,
nous illustrerons concrètement l'enchaînement des interfaces tout
en précisant dans certains cas le code-source utilisé.
4.3LES DIFFERENTES
INTERFACES DE L'APPLICATION
A/ INTERFACE DU DEMMARAGE
Au démarrage de l'application, l'interface
nommée authentification se lance, celle-ci a l'importance de
vérifier toute personne ayant l'autorisation au serveur et donner
l'accès à tout abonné ayant été
enregistré. Cette interface nous offre deux boutons radio, deux zones de
texte, deux boutons de commande. Au niveau des boutons radio, il ya un bouton
réservé aux abonnés et un autre réservé aux
administrateurs du réseau.
Le mot de passe et le compte d'utilisateur sont
obligatoires pour tout le monde, c'est-à-dire ils concernent les
abonnés et les administrateurs du réseau.
Lorsque vous êtes administrateurs vous
sélectionnez le bouton radio « administrateur » les
deux zones de texte s'activent, parmi ces zones, l'une est
réservée au compte d'utilisateur de l'administrateur et l'autre
est réservée au mot de passe.
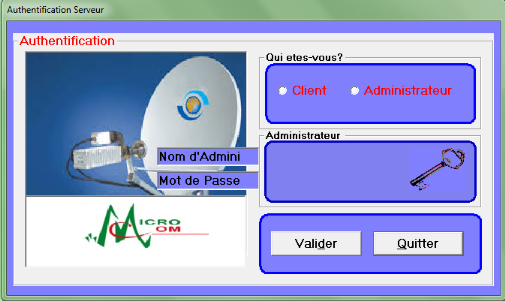
Fig. 4.1. Interface d'authentification (sans aucune action)
Commentaire : sans aucune action, la
fenêtre d'authentification se présente de la manière
ci-dessus, les deux zones de saisie sont invisibles.
· Cas de l'administrateur
Lorsque le mot de passe et le compte sont valides vous
accédez à l'interface administrateur, au cas contraire vous serez
au devant d'une boite de dialogue vous alertant que le mot de passe ou le
compte sont invalides.
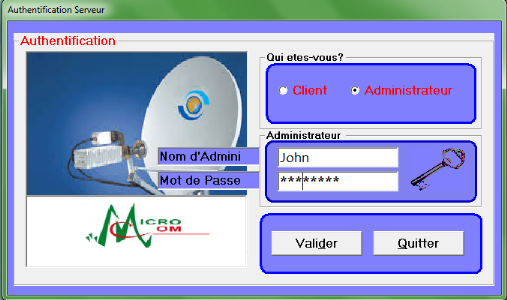
Fig. 4.2. Interface d'authentification (action sur le bouton
radio « administrateur »).
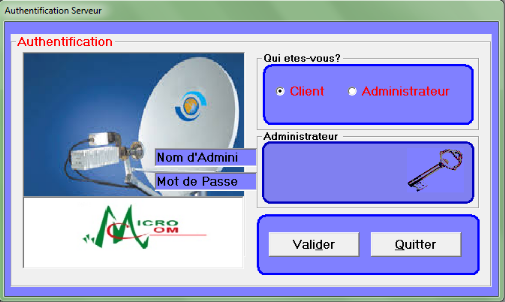
· Cas de l'abonné
Fig. 4.3. Interface d'authentification (action sur le bouton
radio « Client »).
Commentaire : lorsqu'on
sélectionne le bouton radio « client », la
fenêtre d'authentification se présente de la manière
ci-dessus, les deux zones de saisie sont activées, l'abonné peut
alors saisir son compte et son mot de passe afin d'accéder à sa
fenêtre sans aucune contrainte.
Codes sources de l'interface Authentification
OleDbCommand cmd = new OleDbCommand();
cmd.CommandText = "SELECT COUNT(*) FROM Abonné WHERE
login= ' " + textBox1.Text + "' AND motdepasse= '" + textBox2.Text + "'";
cmd.Connection = con;
con.Open();
Int32 cin = (Int32)cmd.ExecuteScalar();
if (cin==0)
{
MessageBox.Show("vous êtes connecteé");
choixDeService cds = new choixDeService();
cds.Show();
}
else {
MessageBox.Show("Le mot de passe ou le compte sont invalides");
}
con.Close();
· En cas de l'invalidité du compte ou mot
de passe
Lorsque le mot de passe ou le compte sont incorrects une
boite de dialogue s'affiche alerter au concerné de vérifier bien
ses cordonnées, que ce soit abonné ou administrateur.
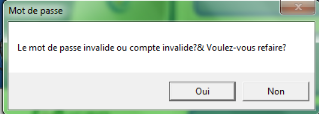
Fig. 4.4. Boite de dialogue (
mot de passe ou compte invalide)
· En cas de l'omission du compte ou du mot de
passe
Fig. 4.5. Boite de dialogue
Commentaire : Lorsqu'il ya
l'omission d'un champ l'application informe toujours et la zone qui n'est
remplie devient rouge.
B/ INTERFACE DE L'ABONNE
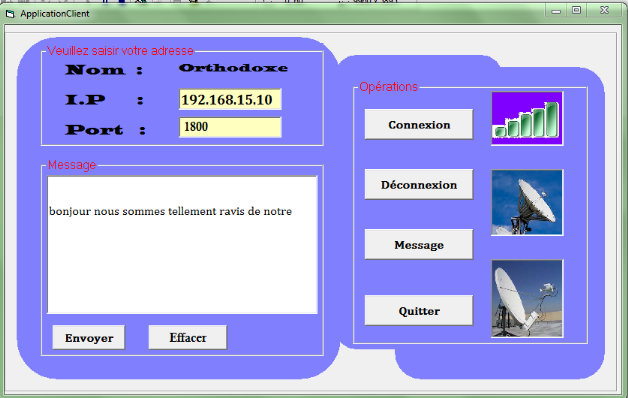
Fig. 4.6. Interface de l'abonné
Commentaire : cette
fenêtre comprend deux trois zones de texte, la première pour
mettre l'adresse I.P, la deuxième qui servira à la saisie du
numéro de port et la troisième sert à saisir le message en
cas de nécessité.
En dessous de la troisième zone il ya deux
boutons :
- Envoyer : pour envoyer le texte saisi
- Effacer : pour supprimer le texte écrit.
A droite de il ya quatre boutons de
commande :
- Connexion : pour se connecter
- Déconnexion : pour se déconnecter
- Message : pour afficher la zone de saisie
- Quitter : qui permet de quitter l'application.
C. INTERFACE DE L'ENREGISTREMENT AU
SERVEUR
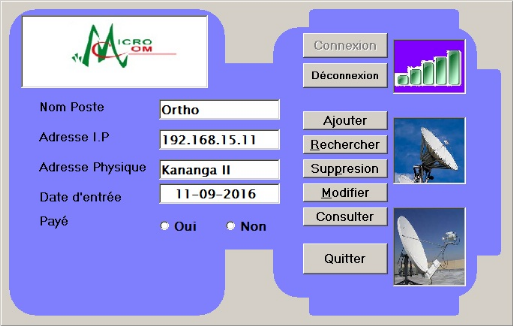
Fig. 4.6. Interface de l'enregistrement au serveur
Commentaire : il est
à signaler que cette fenêtre est uniquement réservée
aux administrateurs du réseau, elle nous permet d'ajouter,
d'enregistrer, de supprimer, de modifier, ou de rechercher un abonné en
cas de besoin.
En dehors de ce, il y a encore les
boutons ci-après:
- Connexion : pour rendre le réseau
actif ;
- Déconnexion : pour se
déconnecter ;
- Consulter : pour scanner tous les abonnés
enregistrés ;
- Et afin quitter : pour la fermeture de
l'application.
D. INTERFACE DE CONSULTATION
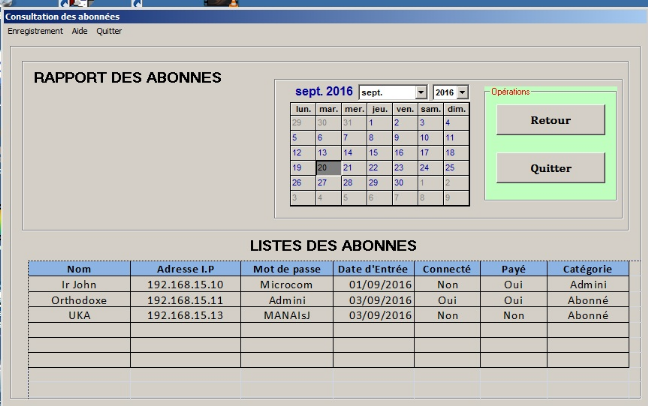
Fig. 4.7. Interface de consultation
Commentaire : le bouton de
commande « consulter » de fig.4.6. permet d'afficher cette
interface qui a l'importance de donner une vue d'ensemble des abonnés.
Le contrôle calendrier est bien programmé pour couper la connexion
de l'abonné qui n'a pas payé à la fin de chaque
moi.
Codes Sources de
l'interface Serveur
using System;
using System.Net;
using System.Net.Sockets;
using System.Collections;
using System.Threading;
using System.IO;
namespace DefaultNamespace
{
public class Server:forwardToAll
{
ArrayList readList=new ArrayList(); //liste utilisée par
Port.select
string msgString=null;
string msgDisconnected=null; //Notification
connexion/déconnexion
byte[] msg;//Message sous forme de bytes pour
public bool useLogging=false;
public bool readLock=false;//Flag aidant à la
synchronisation
private string rtfMsgEncStart="\pard\cf1\b0\f1 ";//Code RTF
private string rtfMsgContent="\cf2 ";//code RTF
private string rtfConnMsgStart="\pard\qc\b\f0\fs20 "; //Code
RTF
public void Start()
{
//réception de l'adresse IP
IPHostEntry ipHostEntry = Dns.Resolve(Dns.GetHostName());
IPAddress ipAddress = ipHostEntry.AddressList[0];
Console.WriteLine("IP="+ipAddress.ToString());
Socket CurrentClient=null;
//Création du port
Port ServerPort = new Port(AddressFamily.InterNetwork,
SocketType.Stream,
ProtocolType.Tcp);
try
{
//On lie la socket au point de communication
ServerSocket.Bind(new IPEndPoint(ipAddress, 1600));
//On la positionne en mode "écoute"
ServerSocket.Listen(10);
//Démarrage du thread avant la première
connexion client
Thread getReadClients = new Thread(new
ThreadStart(getRead));
getReadClients.Start();
Thread pingPongThread = new Thread(new
ThreadStart(CheckIfStillConnected));
pingPongThread.Start();
while(true){
Console.WriteLine("Attente d'une nouvelle connexion...");
CurrentClient=ServerSocket.Accept();
Console.WriteLine("Nouveau
client:"+CurrentClient.GetHashCode());
acceptList.Add(CurrentClient);
}
}
catch(SocketException E)
{
Console.WriteLine(E.Message);
}
}
private void Logging(string message)
{
using (StreamWriter sw = File.AppendText("chatServer.log"))
{
sw.WriteLine(DateTime.Now+": "+message);
}
}
//Méthode démarrant l'écriture du message
private void writeToAll()
Conclusion
Nous retenons que l'application est scindée en deux
grandes parties. La partie pour client ou abonné et partie principale
qui ne concerne qu'administrateurs du réseau. L'application cliente sert
à se connecter au réseau et envoyer le message au serveur en cas
de problème. L'application serveur met la connexion à la
disposition de tous les abonnés. Il permet en plus de faire la mise
à jour des abonnés c'est-à-dire l'ajout, la suppression,
la modification, la recherche et la consultation.
CONCLUSION GENERALE
Nous voici à la fin de notre projet informatique,
celui de mise en oeuvre d'une base de données pour la gestion d'un
fournisseur d'accès au réseau cas pris en charge était
celui de MicroCom/Kananga.
Certes, la gestion est indispensable dans cette entreprise
mais celle-ci reste un grand problème à résoudre c'est
ainsi que nous avons voulu apporter notre contribution en nous soumettant
à la nouvelle technologie.
Pour y arriver, nous avons commencé par
présenter les notions théoriques, qui se subdivisent en quatre
chapitres, respectivement l'architecture client-serveur, les bases de
données, l'analyse préalable et enfin l'implémentation de
l'application.
Dans la troisième partie, nous avons eu à
configurer les différents équipements pour assurer une
interconnexion afin de faciliter chaque utilisateur ou abonné de se
connecter avec assurance au réseau. A ce titre, il était question
de mettre en place une bonne politique d'adressage et de création des
utilisateurs.
Nous ne prétendons pas dire que nous avons
abordé tous les aspects de la gestion des abonnés d'un
fournisseur d'accès au réseau. Néanmoins, nous souhaitons
que ce travail soit un pas qui servira d'autres chercheurs de mener bien leurs
recherches afin de nous combler les lacunes restantes.
BIBLIOGRAPHIE
I. Ouvrages
1. CALECA Constantin., Les réseaux informatiques,
Euriben, 2007.
2. CARTHA Véronique et NAFINA
Barthélémy., Client/serveur, Paris, 1999.
3. Céline ROUVEIROL, Bases de données
relationnelles, Louvain, 2011.
4. Georges GARDARIN et Olivier, Client/serveur, éd.
Eyrolles, Paris,1996.
5. Georges GARDARIN, Bases de données, éd
.Eyrolles, Paris, 2000.
6. Georges GARDARIN, Bases de données Objets,
Eyrolles, 1993
7. Georges GARDARIN, Bases de données objet et
relationnelle, Eyrolles, Paris, 2000.
8. Jean -Luc HAINAUT, bases de données, concepts,
utilisation et développement, 2e éd. Dunod, Paris, 2012.
9. KADIONIK Patrice., Présentation de
l'architecture d'un système client/serveur, ENSEIRB, 2008.
10. KALUNGA, M et KAZADI ; Les méthodes de
recherche et d'analyse en sciences scolaires et humaines, EducaPC/Lubumbashi,
2013.
11. MASIALA MASOLO et NGOMA NDAMBA, Rédaction et
présentation d'un travail scientifique, éd. Enfant et paix,
Kinshasa, 1993, Page 12.
12. Manouvrier MAUDE, bases de données
élémentaires, Dauphine, Paris, 2014.
13. Patrice BOURCIER, Notes de cours de Bases de
données, La Rochelle, UPF, 2012.
14. Philippe MATHIEU, Bases de données et Merise,
Lille, LFL, 1999.
II. Webographie
0.
www.maxicours.com/informatique/next
1. http://fr.wikipedia.org
/wiki/Webographie
2.
www.middleware.smile.fr
3.
www.commentçamarche.netcontents/222-environnement-client-serveur
4. www.maxicours.com
5.
http://www.toutestfacile.com/sql/cours/printables/[SQLFacile.com]sql.php
6.
www.microcom.net/Qui-sommes-nous?
III. Cours
1. André BAKENGE, Notes des
cours d'IRS, ISP/Kananga, G2 Math-Info, 2010.
2. KABASELE Jean-Marie., Notes de cours de
télématique, UKA, G3 Informatique, inédit,
2015-2016.
3. KAFUNDA Pierre., Notes de cours d'architecture
Client/serveur, UKA, L1 Informatique, inédit, 2014-2015.
4. KASONGO.P., Notes de cours de Réseaux, UKA, G2
Info, inédit, 2014-2015.
5. Pascal MULUMBA, Notes de cours de SGBD, U.KA, G2 Info,
inédit, 2014-2015.
6. PINTO R., Notes des cours d'IRS, ISP/Kananga, G2,
Département Math-Info, inédit, 2010.
IV. Dictionnaires
1. Dictionnaire de l'informatique et l'internet.
Tables de matières
EPIGRAPHE......................................................................................................................I
DEDICACE.......................................................................................................................II
AVANT
PROPOS............................................................................................................
III
SIGLES ET
ABREVIATIONS...........................................................................................IV
LISTE DES FIGURES ET
TABLEAUX............................................................................VI
INTRODUCTION
1
0.1. PROBLEMATIQUE
8
0.2. HYPOTHESES
9
0.3. METHODES ET TECHNIQUES
9
A. METHODES
9
B. TECHNIQUES
10
1) La technique documentaire
10
2) La technique d'interview
10
0.3. CHOIX ET INTERET DU SUJET
10
A. CHOIX DU SUJET
10
B. INTERET DU SUJET
10
0.4. DELIMITATION DU SUJET
11
0.5. DIVISION DU TRAVAIL
11
0.6. DIFFICULTES RENCONTREES
11
CHAPITRE 1. ARCHITECTURE CLIENT-SERVEUR
12
1.1. INTRODUCTION
12
1.2. HISTORIQUE
12
1.3. DEFINITIONS DES CONCEPTS
14
1.4. LE MODE DE FONCTIONNEMENT
14
1.5. FONCTIONNEMENT DES APPLICATIONS
CLIENT/SERVEUR
15
1.6. LE MIDDLEWARE
16
1.6.1. MODE DE FONCTIONNEMENT D'UN
MIDDLEWARE
16
1.6.2. L'OSI (OPEN SYSTEM
INTERCONNECTED) :L'INTERCONNEXION DES SYSTEMES OUVERTS.
16
1.6.3. HISTORIQUE
16
1.6.4. LES DIFFERENTES COUCHES DE L'OSI
17
1.6.5. PRESENTATION GRAPHIQUE DE L'OSI
18
1.7. LA NOTION DE PROTOCOLES ET PORTS
19
1.7.1. NOTION DE PORTS
19
1.7.2. NOTION DES PROTOCLES
19
1.8. LES SERVICES D'UN MIDDLEWARE
20
1.9. DIFFERENTS TYPES D'ARCHITECTURE
CLIENT/SERVEUR
20
1.10. AVANTAGES ET INCONVENIENTS DU MODELE
CLIENT/SERVEUR
22
1.10.1. AVANTAGES
22
1.10.2. INCONVENIENTS
23
Conclusion
23
CHAPITRE 2. LES BASE DE DONNEES
24
2.1. INTRODUCTION
24
2.2. LES SYSTEMES DE GESTIONS DE BASES DE
DONNEES (SGBD)
24
2.2.1. Définition
25
2.2.2. Fonctions d'un SGBD
25
2.3. QUELQUES SYSTEMES DE GESTION DE BASES
DE DONNEES(SGBD) UTILISES
26
2.4. BASES DE DONNEES
27
2.4.1. Historique
27
2.4.2. Introduction
27
2.4.3. Définitions
27
2.4.4. AVANTAGES DE BASES DE DONNEES
28
2.5. LES DEFIS DES BASES DES DONNEES
28
2.6. DIFFERENTS TYPES DE BASES DE
DONNEES
29
2.7. LES CONCEPTS RELATIFS A UNE BASE DE
DONNEES RELATIONNELLE
25
2.8. CONSTRUCTION D'UNE BASE DE DONNEES
26
2.9. STRUCTURE D'UNE TABLE
(COLONNES&LIGNES)
26
2.10. LES CARACTERISTIQUES D'UNE BASE DE
DONNEES
27
2.6. MODELES DE DONNEES
27
a) Instances et schémas
28
2.11. LES NIVEAUX D'ABSTRACTION
28
a) Le niveau conceptuel
28
b) Niveau interne
28
c) Niveau externe
29
2.12. LE MODELE ENTITE-ASSOCIATION
29
2.7. LANGAGES DE REQUETES
30
CONCLUSION
30
CHAPITRE 3. ANALYSE PREALABLE
31
3.1. INTRODUCTION
31
3.2. PRESENTATION
31
3.3. LOCALISATION
31
3.4. CARACTERISTIQUES DE LA SOCIETE
32
3.5. OBJECTIFS DE L'ENTREPRISE
32
3.6. HISTORIQUE
32
3.5. BESOINS DE L'ENTREPRISE
33
a) Besoins généraux
33
b) Besoins techniques
33
3.6. INFRASTRUCTURES
33
3.7. QUELQUES EQUIPEMENTS UTILISES PAR
L'ENTREPRISE
34
a) Switch (commutateur).
34
b) Le Routeur
34
c) Modem
34
d) Les ordinateurs
34
e) Le scanneur
34
f) Le câble coaxial
34
e) Câble paire torsadée
34
3.8. ORGANIGRAMME
34
Commentaire
35
3.9. ADMINISTRATION RESEAU
35
a) Administrateurs
35
b) Monteurs
36
3.10. LE RESEAU DE MICROCOM
36
3.10.1. LES RESSOURCES MATERIELLES
36
3.10.2. RESSOURCES LOGICIELLES
37
3.11. DIFFICULTES RENCONTREES
37
3.12. ANALYSE DES BESOINS DU RESEAU
EXISTANT
37
3.13. PRESENTATION DETAILLEE DE LA SOLUTION
RETENUE
38
a) Composants Matériels et Logiciels
nécessaires:
38
CONCLUSION
39
CHAPITRE 4. IMPLEMENTATION DE
L'APPLICATION
40
4.1. CONCEPTION
40
4.1.1. INTRODUCTION
40
4.1.2. LES CYCLES DE MERISE
40
4.1.3. LES NIVEAUX DU CYCLE D'ABSTRACTION DE
MERISE
41
4.1.4. PRESENTATION DE MODELE CONCEPTUEL DE
DONNEES
41
4.1.5. PRESENTATION DU MODELE PHYSIQUE DE
DONNEES (MPD)
43
4.1.6. PRESENTATION DU MODELE LOGIQUE DE
DONNEES (MLD)
44
4.2. CHOIX DU LANGAGE DE PROGRAMMATION
44
4.3. LES DIFFERENTES INTERFACES DE
L'APPLICATION
44
A. INTERFACE DU DEMMARAGE
44
B. INTERFACE DE L'ABONNE
47
C. INTERFACE DE L'ENREGISTREMENT AU
SERVEUR
48
D. INTERFACE DE CONSULTATION
49
Codes Sources de l'interface Serveur
50
Conclusion
51
CONCLUSION GENERALE
52
BIBLIOGRAPHIE
53
I. Ouvrages
53
II. Webographie
53
III. Cours
54
IV. Dictionnaires
54

* 1André BAKENGE,
Notes des cours d'IRS, ISP/Kananga, G2 Math-Info, 2010.
* 2 KALUNGA, M et KAZADI,
Les méthodes de recherche et d'analyse en sciences scolaires et
humaines, EducaPC/Lubumbashi, 2013, Page 116.
* 3 MASIALA MASOLO et NGOMA
NDAMBA, Rédaction et présentation d'un travail scientifique,
éd. Enfant et paix, Kinshasa, 1993, Page 12.
* 4 Georges GARDARIN, Bases
de données relationnelles et objet, Eyrolles, Paris, 1993, Pages
26.
* 5
www.maxicours.com/informatique/next
Consulté le 04 Février 2016 à 11 H 00.
* 6
www.dictionwiki.org
Consulté le 27 Avril 2016 à 14 H : 25.
* 7 Dictionnaire de
l'informatique et l'internet, Page.45
* 8
http://fr.wikipedia.org
/wiki/Webographie, consulté le 28 Juin 2016 à 08
H : 55.
* 9 KAFUNDA Pierre.,
L'architecture Client/serveur, L1 Informatique, UKA, 2014-2015,
Page4.
* 10 KABASELE Jean-Marie.,
Notes de cours de télématique, G3 Informatique, UKA,
2015-2016, Page.36
* 11
www.middleware.smile.fr ,
Consulté le 18 Janvier 2016, 11 Heure : 30'
* 12 KASONGO.P., Cours
de Réseaux, G2 Info, UKA, 2014-2015, Page 33.
* 13 Op.cit. Page 34
* 14 CARTHA Véronique et
NAFINA Barthélémy., Client/serveur, Paris, 1999,
Page : 5-6.
* 15 CALECA Constantin.,
Les réseaux informatiques, Euriben, 2007, Page.28
* 16 Georges GARDARIN,
Réseaux informatiques, Eyrolles, Paris, Pages.26
* 17 Georges GARDARIN et
Olivier, Client/serveur, éd. Eyrolles, Paris 1996, Page 2.
* 18
www.commentçamarche.netcontents/222-environnement-client-serveur
, Consulté le 14 février 2016, 13 H 28'
* 19 Op Cit. Page.2
* 20KADIONIK Patrice.,
Présentation de l'architecture d'un système
client/serveur, ENSEIRB, 2008, Page.5.
* 21 Jean -Luc HAINAUT,
bases de données, concepts, utilisation et
développement, 2e éd. Dunod, Paris, 2012, Page
33.
* 22 Georges GARDARIN,
Bases de données, éd .Eyrolles, Paris, 2000, Pages
12-13.
* 23 Pascal MULUMBA, notes
de cours de SGBD, G2 Informatique, U.KA, 2014-1015, Page 12.
* 24 Georges GARDARIN,
Bases de données Objets, Eyrolles, Paris, Page. 17.
* 25
www.wikipedia.com ,
Consulté le 05 Juin 2016, Heures : 21 H 50.
* 26 Georges GARDARIN,
Bases de données, Eyrolles, Paris, 2007, Page.3
* 27 Manouvrier MAUDE,
bases de données élémentaires, Dauphine,
Paris, 2014, Page.2
* 28 IBIDEM, Page 20-23
* 29
www.maxicours.com,
Consulté le 07 Juin 2016 à 18 H 28.
* 30
www.comment-ca-marche.net,
Consulté le 08 Juin 2016 à 19 H 00.
* 31
www.lamsade.dauphine.fr/rigaux/bd,
Consulté le 12 Juin 2016 à 12 H 25
* 32 Philippe MATHIEU,
Bases de données et Merise, Lille, LFL, 1999, Page 33.
* 33 Céline ROUVEIROL,
Bases de données relationnelles, Louvain, 2011, Page67-68.
* 34 Pascal MULUMBA, Notes
de cours de SGBD, G2 Info, U.KA, 2014-2015, Pages22.
* 35 Patrice BOURCIER,
Notes de cours de Bases de données, La Rochelle, UPF, 2012,
Page 23.
* 36 IBIDEM, Page24.
* 37
www.wikipedia.org/modele-de-données
, Consulté le 07 Aout 2016 à 7 H 13'.
* 38 Georges GARDARIN,
Bases de données objet et relationnelle, Eyrolles, Paris, 2000,
Pages 15-16.
* 39
http://www.toutestfacile.com/sql/cours/printables/[SQLFacile.com]sql.php
Consulté le 17 Juin 2016 à 22 H 08
* 40
www.microcom.net/Qui-sommes-nous?
, Consulté Le 28 Juin 2016 à 16 H 00.
* 41
www.microcom.net/accueil/hsitorique
Consulté Le 26 Juin 2016 à 11 H00.
| 

