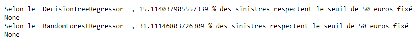Amélioration l’estimation des sinistres responsabilité civile automobile par machine learningpar Mohamed HOUNSINOU École supérieure des technologies de l'information appliquées aux métiers - Paris - MBA - Big Data & Business Intelligence 2021 |

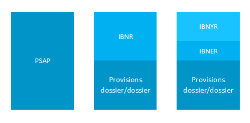
IntroductionEn assurance, les acteurs du marché s'engagent à couvrir les sinistres occasionnés par leur client moyennant le paiement d'une prime. Le caractère incertain et aléatoire que revêtent ces sinistres font de ceux-ci des charges futures inconnues qu'auront à supporter les assureurs lors de leur occurrence. Le défi de ces assureurs est de pouvoir estimer ces charges et de les mettre en provisions, notamment pour les sinistres survenus dont les coûts ne sont pas totalement réglés tout en étant solvables et en respectant les règlementations. La technique majoritairement utilisée pour quantifier ces provisions en assurance Non-Vie est la méthode paramétrique Chain-Ladder. La principale cause de non-solvabilité des sociétés d'assurance étant liée à des pertes causées par des provisions mal estimées, la règlementation en France impose un suivi plus précis des risques, notamment par l'estimation des provisions par les normes Solvabilité 2 et IFRSIFRS17 sera la norme en 2023. Pour l'instant on utilise IFRS4. Donc supprime simplement la référence. Ainsi, il est important pour les assureurs d'obtenir des estimations fiables de leurs provisions, précises et peu volatiles. Les méthodes classiques présentent l'intérêt d'être simples à mettre en place et à utiliser. Toutefois, compte tenu de l'agrégation, les méthodes classiques de provisionnement ne permettent par exemple pas d'associer chaque sinistre à un groupe homogène de sinistres connus lui ressemblant. Cela empêche de profiter d'une information individuelle, pourtant détaillée et de grande valeur. L'information non utilisée peut aussi bien être des données liées au sinistre et à son développement, que des données détaillées sur l'assuré ou également des informations exogènes. Grâce à l'avènement de nouvelles méthodes en data science, ainsi que l'amélioration continue de la puissance de calcul des ordinateurs etla capacité grandissante des assureurs à stocker des données, il parait désormais possible de pouvoir exploiter pleinement ces nombreuses informations individuelles précieuses sur les assurés et les sinistres déclarés détenues par les assureurs. Elles paraissent donc idéales pour alimenter ces nouvelles méthodes. Dans ce mémoire, nous souhaitons alimenter des modèles de data science avec toutes les informations disponibles sur des sinistres touchant deuxgaranties particulières de l'assurance automobile à savoir la responsabilité civile corporelle et la responsabilité civile matérielle afin d'évaluer les provisions à constituer. Notre objectif est d'en estimer la charge et par conséquent, de pouvoir estimer ce que pourrait coûterun sinistre en assurance automobile touchant les garanties suscitées dès sa déclaration. L'un des langages les plus utilisés pour mettre en application les différents algorithmes de data science est Python, nous utiliserons ce langage pour exécuter les algorithmes choisis. Sachant que l'explicabilité de ces algorithmes est assez complexe, les résultats decette étude seront considérés comme un second avis. Nous proposerons quelques astuces pour traiter les données avant de leur appliquer les algorithmes. Après avoir donné le contexte d'étude, nous exposeronsquelques-unes des techniques traditionnelles de provisionnement. Puis nous présenteronsla base de données qui sera au centre de notre étude et la méthodologie de collecte et de traitement de celle-ci.Et enfin nous mettrons en place les algorithmes choisis ainsi que les scripts en langage Python utilisés et les résultats obtenus. 1.1 Définition de l'assurance de responsabilité civile L'assurance de responsabilité civile est un contrat qui garantit les conséquences pécuniaires encourues par l'assuré lorsque celui-ci cause un dommage matériel ou corporel à un tiers que ce soit par sa négligence, son imprudence, ses enfants, préposés, animaux ou choses dont il est responsable. Cependant celle-ci ne couvre pas les faits que l'assuré aurait commis intentionnellement. L'assureur, au titre des garanties souscrites, indemnise la victime d'un préjudice dont son client est responsable mais ne garantit pas les sanctions pénales. L'assurance de responsabilité civile est une assurance de principe indemnitaire, c'est-à-dire que la victime a une indemnité correspondant au dommage subi, dans la mesure où elle apporte trois preuves : le fait générateur de responsabilité imputé à l'auteur de ce dommage, le préjudice subi par la victimeet un lien de causalitéentre ce fait et le dommage.1(*) L'assurance responsabilité civile est réputée pour être difficile à tarifer. En effet, il s'agit d'une assurance particulière avec des risques difficiles à cerner. Les risques de la responsabilité civile ne sont pas toujours connus au moment de la souscription. L'estimation finale des sinistres peut être très longue car il est parfois difficile de prouver la responsabilité de l'assuré face à un sinistre, l'intervention judiciaire peut également ralentir les estimations. De plus, pour certains sinistres, notamment pour les sinistres corporels, l'estimation de la charge des sinistres va dépendre de la consolidation de l'état des victimes. Compte tenu de l'incertitude qui pèse sur certains dossiers, l'estimation finale du coût des sinistres peut être définitive seulement après de longues années. La responsabilité civile est également très rythmée par les évolutions juridiques. 1.2 Les différentes formes de responsabilité civile en assurance automobile En assurance automobile, la responsabilité civile est de deux types : laresponsabilité civile matérielle et laresponsabilité civile corporelle. Laresponsabilité civile matériellecorrespond à « une atteinte à la structure ou à la substance d'une chose ». Il peut s'agir de différents éléments comme : une atteinte à ses biens, meubles ou immeubles ; une perte ou une privation de sa rémunération. Dans le cas d'une assurance automobile, il s'agit souvent du dommage causé aux véhicules impliqués dans un accident ou la destruction d'une infrastructure due à un accident. Le dommage matériel s'oppose au dommage corporel qui représente une atteinte à la personne humaine.2(*) Laresponsabilité civile corporelle :est un dommage portant atteinte à l'intégrité physique d'une personne et peut être à ce titre réparé. Le dommage corporel peut être réparé par la mise en mouvement de l'action civile qui est l'action en réparation d'un dommage directement causé par une infraction pénale (crime, délit ou contravention). L'action civile peut être exercée en même temps que l'action publique devant les tribunaux répressifs ou séparément devant les juridictions civiles.3(*) Une des caractéristiques fondamentales de l'assurance non-vie réside dans la temporalité des flux échangés entre un assureur et ses assurés. Contrairement à la majorité des entreprises, une compagnie d'assurance perçoit les gains relatifs à la vente de ses produits avant de payer les éventuels coûts relatifs à ces produits. On parle du phénomène de cycle inversé de production. Les coûts des sinistres représentent les coûts de production tandis queles primes perçues représentent les gains associés à la vente des produits. Ainsi, l'assureur ne connaissant pas la valeur de ses coûts de production avant de vendre ses produits doit les estimer pour espérer faire une plus-value. Pour couvrir les coûts des sinistres futurs (estimés), la compagnie constitue une réserve appelée provisions techniques. Par ailleurs, les primes perçues suite à la vente des produits d'assurance sont investies dans des actifs, actifs qui sont directement mis en correspondance dans le bilan avec les provisions techniques qui sont au passif. Le provisionnement est donc un enjeu essentiel pour une compagnie d'assurance non-vie et nécessite une véritable expertise des actuaires. En assurance non-vie, ces provisions techniques peuvent être subdivisées en différentes catégories définies par les normes comptables dont les principales sont : la provision pour sinistres à payer (PSAP), la provision pour risque en cours, la provision pour risques croissants (PRC), la provision pour primes non acquises (PPNA). Pour la suite, nous nous intéresserons particulièrement à la provision pour sinistres à payer. L'article R331-6 du Code des Assurances définit la provision pour sinistres à payer (PSAP) comme la "valeur estimative des dépenses en principal et en frais, tant internes qu'externes, nécessaires au règlement de tous les sinistres survenus et non payés (. . .)". Elle est donc destinée à couvrir l'ensemble des coûts restant à régler au titre des sinistres. Notons que le terme PSAP est propre au cadre défini par les Normes comptables françaises et porte un autre nom dans les cadres définis par les normes Solvabilité 2 et IFRS 17. En Solvabilité 2, on parle de Best Estimate de sinistres et en IFRS17, on parle de LIC (Liability for Incurred Claim). Dans les trois cas, il s'agit de créer une réserve pour respecter les engagements futurs relatifs aux sinistres déjà survenus, même si chaque norme possède ses spécificités. Cette PSAP est notamment composée : - d'une provision dossier/dossier (d/d), déterminée par les gestionnaires de sinistres et suivant généralement les règles d'un guide de provisionnement interne, - d'une provision complémentaire destinée à couvrir l'insuffisance (ou la prudence) des dossiers ouverts, les IBNeR (Incurred But Not EnoughReported), - d'uneautre provision complémentaire pour couvrir les dossiers survenus mais dont l'assureur n'a pas encore connaissance, les IBNyR (Incurred But Not YetReported). Le rôle de l'actuaire en charge du provisionnement est d'estimer les IBNR (IBNeR + IBNyR), ce qui revient à prédire la charge totale de tous les sinistres survenus à une date comptable.
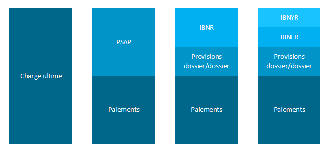
Figure 1.1 Décomposition de la PSAP En ajoutant à cette provision les paiements qui ont déjà été effectués pour les sinistres couverts pendant cet exercice nous obtenons la charge imputable à l'assureur. La valeur de la charge fluctue en fonction du temps puisque les réserves constituées peuvent être revues et ne correspondent pas exactement aux paiements réels réalisés par la suite. A terme, lorsque tous les sinistres survenus pendant l'exercice considéré sont connus et clos, la réserve est nulle et la charge, nommée "charge ultime", est égale à la somme des paiements effectués par l'assureur.
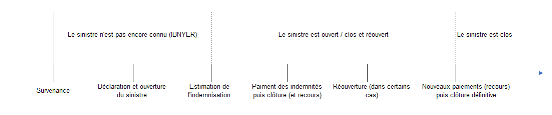
Figure 1.2 Décomposition de la charge ultime Dans cette étude, nous proposons de travailler sur les garanties « RC matérielle » et « RC corporelle »du produit Assurance Automobile Entreprise d'AXA France. Ce produit propose toutes les garanties classiques pour une entreprise voulant assurer son parc automobile (responsabilité civile auto, dommages matériels, assistance. . .). La base de travail correspond à un sous-échantillon de l'ensemble des sinistres de ce produit. Les critères retenus pour définir le contour de ce sous-échantillon sont les suivants : // cette partie mérite une phrase pour dire pourquoi on s'est restreint à cet échantillon : besoin d'avoir suffisamment de recul sur le vieillissement des sinistres. Les sinistres encore en cours sont supprimés, car on veut appliquer un modèle d'apprentissage avec une réponse connue (ce qui peut mettre un biais dans l'analyse car les sinistres clos sont généralement les plus petits et donc on exclu des gros sinistres d'où le seuil à 100K€) nous retenons les sinistres survenus entre 2015 et 2017 vus au 31/12/2020 car nous estimons que ces sinistres sont assez vieux et ne feront plus l'objet d'une éventuelle réouverture après leur clôture. Par ailleurs, à partir de 2015, un nouvel outil de gestion des sinistres permettant d'avoir plus d'information sur ceux-ci a été mis en place ce qui explique pourquoi nos données datent de 2014 ; - nous retenons les sinistres clos car leur charge ultime étant connue à l'avance, elle servira à alimenter les modèles Machine Learning que nous utiliserons; - la date de survenance est antérieure à la date d'ouverture qui est antérieure à la date de réouverture à son tour antérieure à la date de clôture ; ? Est-ce nécessaire ? - nous ne retenons que les sinistres clos dont le coût final est inférieur ou égal à 100 K€ car la grande majorité des sinistres clos présentent la particularité d'avoir une charge ultime inférieure à 100K€. 1.5 Cycle de vie des sinistres Il est important dans un premier tempsd'aborder la notion du cycle de vie des sinistres. Cette étape est nécessaire si l'on souhaite pouvoir modéliser les paiements et réserves à constituer associés aux sinistres. Ainsi, les étapes de la vie d'un sinistre sont les suivantes : - Survenance du sinistre. - Déclaration à l'assureur : si celle-ci s'effectue après la fin de période de couverture du contrat,on dit que le sinistre est tardif. - Estimation du montant d'indemnisation, qui peut être revu plusieurs fois à la hausse ou à labaisse. - Paiements successifs à l'assuré : peuvent s'effectuer en une fois, ou en plusieurs si le montantd'indemnisation est revu plusieurs fois puis clôture du sinistre. - Recours éventuels : remboursement à l'assureur de tout ou partie de l'indemnisation versée àl'assuré par le tiers responsable du sinistre (ou l'assureur de celui-ci) s'il est identifié. - Réouverture éventuelle du sinistre. - Nouveaux paiements et recours. - Fermeture définitive. Ce processus est schématisé sur la figure ci-dessous
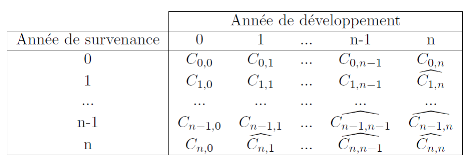
Figure 1.3 Schéma de la vie d'un sinistre 1.6 Particularités du portefeuille Entreprise Le segment de l'assurance automobile à AXA France est subdivisé en deux principales parties : le portefeuille Particuliers et le portefeuille Entreprise. Le premier concerne l'assurance des véhicules à usage personnel tandis que le second concerne les véhicules à usage professionnel. Il s'agit entre autres des entreprises possédant des flottes de véhicules. Cela expose davantage la compagnie d'assurance à des risques de concentration. Aussi dans une année, un même contrat peut être sinistré plusieurs fois alors que dans le portefeuille Particuliers cela reste exceptionnel. Par ailleurs, la sinistralité de ce portefeuille Entreprise est suivi à travers des sous-segments qui sont les garages et concessions, les véhicules pesant moins de 3,5 Tonnes et ceux pesant plus de 3,5 Tonnes.En effet le règlement de l'Autorité des Normes Comptables propose d'utiliser la segmentation « <3,5T / >3,5T / moins de 4 roues » pour être en mesure de modéliser des risques ayant un développement similaire au sein du portefeuille Auto-Entreprise. II. Méthodes classiques de détermination de la provision Après avoir identifié le cadre général et les enjeux liés au provisionnement pour sinistres à payer, nous allons tout d'abord introduire la notion de triangle de développement avant d'étudier quelques méthodes utilisées à AXA France parmi les plus utilisées en provisionnement non-vie. Ce sera un point de départ pour mieux appréhender les avantages et inconvénients relatifs à ces modèles et chercher à améliorer le résultat de ceux-cigrâce aux modèles de la data science. En général, les actuaires utilisent des modèles de provisionnement agrégés. Ces modèles reposent sur l'utilisation d'un triangle de développement des sinistres par année de survenance et année de développement (aussi appelés run-off triangles). Ces triangles reflètent la dynamique des sinistres et les données qui y sont présentéespeuvent être de différentes natures : paiements, charges, nombre de sinistres... Par exemple, un sinistre survenu en 2017 et toujours ouvert est aujourd'hui (2021) à sa 4e année de développement. Les montants payés par l'assureur pour tous les sinistres sont agrégés par année de survenance et année de développement et sont reportés dans la case du triangle de développement correspondante. La table 2.1 illustre le concept de triangle de
développement. Le terme
Table 2.1 Triangle de développement Il faut considérer que ce triangle est construit à la fin de l'année n et reflète l'information dont l'assureur dispose à ce moment-là, c'est-à-dire l'historique des charges pour des sinistres déjà déclarés. La zone incomplète représentée par le point d'interrogation désigne les charges futures relatives aux sinistres survenus de l'année 0 à l'année n. On ne connaît donc pas leurs montants et tout l'enjeu du provisionnement consiste à les estimer pour constituer une réserve adaptée. La méthode Chain-Ladder est sans doute la
méthode de provisionnement la plus connue dans le monde actuariel. Elle
est simple d'utilisation, repose sur un modèle déterministe et
donne des résultats par formule fermée. Le principe
général consiste à estimer des facteurs de
développement caractérisant l'évolution de lacharge
cumulée d'une année de développement à l'autre en
se basant sur l'historique des données, pour ensuite estimer
laliquidationfuture. La définition mathématique du facteur de
développement
Le modèle se base sur l'hypothèse suivante :les sinistres survenus lors d'années de survenance différentes se développent de façon similaire. Ainsi : A partir de ce résultat, on peut directement considérer l'estimateur suivant pour le facteur de développement de l'année de développement j :
L'estimateur de la charge cumulée future liée à l'année de survenance i et l'année de développement j s'écrit alors en fonction des estimateurs des facteurs de développement :
Il est à présent possible de remplir la table précédente grâce aux estimations des charges cumulées obtenues, afin d'obtenir celle ci-dessous.
Table 2.1 Triangle de développement rempli grâce au modèle de Chain-Ladder A partir de ce tableau complété, nous pouvons facilement calculer les réserves à constituer pour chaque année de survenance pour couvrir les engagements futurs :
On en déduit une estimation de la provision pour sinistres à payer :
La méthode Chain-Ladder permet d'obtenir rapidement et simplement une estimation de la provision pour sinistres à payer à constituer. Elle a fait ses preuves et est souvent utilisée dans les compagnies d'assurance. Néanmoins, elle présente certaines limites que nous développerons dans la section 2.5. 2.3 Méthode de Bornhuetter-Ferguson La méthode de Bornhuetter-Ferguson [Bornhuetter&
Ferguson (1972)] est également une méthode qui découle
d'un modèle déterministe. Cette méthode repose sur une
hypothèse exogène d'estimation préalable de la charge
à l'ultime pour une survenance donnée, à laquelle on
applique un taux de liquidation croissant sur les années de
développement. Ainsi, les estimations récentes dépendent
moins des premiers paiements ou premières charges qu'avec une
méthode du type Chain-Ladder. La méthode Bornhuetter-Ferguson
assure donc une meilleure stabilité des estimations et est donc plus
adaptée aux triangles dont les incréments sont instables sur les
premiers développements. Il repose sur un modèle multiplicatif
sur les
Où Dans cette méthode, on dispose a priori d'estimateurs
exogènes des charges à l'ultime : On retrouve une hypothèse similaire à celle formulée pour la méthode Chain-Ladder selon laquelle les cadences de développement dépendent uniquement de l'année de développement etsont ainsi indépendantes de l'année de survenance. On a donc :
Enfin, les états futurs sont estimés par :
2.4 Méthode de MackC'est une méthode pour évaluer l'incertitude mais elle donne le même résultat que Chain-Ladder en espéranceTu penses que je devrais supprimer cette partie ou la développer davantage ? Ce modèle introduit par Mack en 1993 est un modèle non-paramétrique qui permet d'estimer une marge d'erreur sur le montant des provisions. Il est aussi appelé distribution free Chain-Ladder, car aucune hypothèse de distribution n'est faite sur les composantes du triangle. La méthode de Mack représente le pendant de la méthode de Chain-Ladder au niveau stochastique. On suppose que les hypothèses suivantes sont vérifiées : - Indépendance des années de survenance :
- Il existe des facteurs
Ainsi, sous ces trois hypothèses, et conditionnellement au triangle agrégé initial, nous avons :
On peut estimer les facteurs
Nous obtenons de façon similaire à la méthode Chain-Ladder la charge à l'ultimeestimée :
Le paramètre
Pour estimer - Si - Sinon Il convient de préciser qu'il subsiste une erreur de prédiction mesurée par l'écart quadratique moyen conditionnel (MSEP) :
Dans cette espérance, seule
Cet écart mesure aussi l'incertitude présente dans les provisions :
2.5 Limites des méthodes classiques Le premier avantage des méthodes agrégées est que celles-ci sont très robustes, puisqu'elles reposent sur la loi des grands nombres. Un deuxième avantage des méthodes agrégées est qu'elles sont bien établies et documentées. Utilisées par les actuaires depuis de nombreuses années, ces méthodes ont fait l'objet de nombreuses études. De plus, ces méthodes sont très pratiques pour la comptabilité et l'audit, et sont facilement compréhensibles. Enfin, ces méthodes ont le principal avantage d'être simples à mettre en oeuvre, de nécessiter peu de puissance de calcul et un niveau de granularité des données assez faible. Toutefois, elles présentent certaines limites. Limites de la méthode Chain-Ladder : l'hypothèse d'indépendance des facteurs de développement avec l'année de survenance peut être forte car elle suppose que le portefeuille reste relativement stable d'année en année. Ceci peut ne pas être vérifié dans le cas où on observe une rupture ou une tendance dans le développement des sinistres et peut aboutir à des résultats d'un niveau d'incertitude élevé pour les branches les plus volatiles. En effet, les conditions suivantes doivent être réunies pour qu'elle soit valide: - le passé doit être suffisamment régulier. Par exemple, il ne doit pas y avoir de changements importants dans la gestion des sinistres ou dans le taux d'inflation spécifique de la branche ; - la branche doit être peu volatile : il est compliqué de traiter les sinistres graves, en particulier s'ils sont ponctuels, par cette méthode ; - les données du portefeuille doivent être nombreuses et fiables ; L'utilisation très répandue des méthodes type Chain-Ladder est essentiellement due à leur simplicité de mise en oeuvre, mais également à leur universalité. En effet, adaptées à des valeurs négatives de montants non cumulés (liées notamment aux recours), elles peuvent s'appliquer à des triangles de charges ou à des triangles de paiements comprenant des recours. Limites de la méthode de Bornhuetter-Ferguson : Cette méthode présente à peu près les même avantages (rapidité et simplicité) et inconvénients (absence d'erreur de prédiction, charge à l'ultime uniquement, hypothèse forte d'indépendance, etc....) que la méthode Chain-Ladder. Néanmoins, si l'on ne parvient pas à bien estimer la charge ultime (du fait de sa nature subjective), cette méthode perd de sa précision sur certaines branches. Limites de la méthode de Mack: Grâce à ce modèle stochastique qui émet des hypothèses sur l'espérance et la variance de la charge cumulée, il est possible de quantifier l'erreur de prédiction dans le calcul de la provision pour sinistres à payer. Il convient en revanche de vérifier ces hypothèses avant d'appliquer ce modèle. Par ailleurs, il ne permet toujours pas d'obtenir une distribution de la charge à moins de supposer que cette dernière suit une certaine loi (en pratique, on peut utiliser une loi log-normale). Dans ce cas, la distribution peut être obtenue à partir de l'espérance et de la variance par la méthode des moments. // ajouter une phrase de conclusion disant que devant ces limites, il est intéressant de tester une méthode alternative à l'aide d'approche innovante telle que le ML III. Echantillon d'études et méthodologie de collecte des données 3.1 Présentation de la base de données Notre étude portera sur une base de données constituée de 31 847 sinistres survenus de 2015 à 2017 touchant 11 913 contrats d'assurance automobile. Pour faciliter la prédiction, nous avons choisi de scinder chaque sinistre en deux sous garanties : la garantie RC matérielle et la garantie RC corporelle. Nous obtenons ainsi 56 160 « sinistres » que nous appellerons dossiers pour éviter toute confusion. Pour chaque dossier, nous avons à notre disposition des informations dont le département d'implantation de l'assuré, la cause du sinistre, le taux de responsabilité du conducteur, le nombre de victimes etc... ainsi que le coût supporté par l'assureur que nous appellerons charge pour la suite de notre étude. Toutes ces informations sont qualifiées de variables que nous séparerons en deux catégories : les variables explicatives et la variable réponse pour la section IV. Nous avons 35 variables. La liste exhaustive de ces 35 variables se trouve en annexes (Annexe 1). Le but de cette partie est d'effectuer une première analyse de la base de données. Pour mieux appréhender la notion de cycle de vie d'un sinistre abordée dans la section I, nous avons schématisé dans des histogrammes le nombre de dossiers déclarés, clos et réouvertspar année d'ouverture (Figures 3.1 ; 3.2 ; 3.3). Nous pouvons remarquer qu'environ 92% des dossiers sont ouverts dans leur année de survenance (91,68% en 2015 ; 91,6% en 2016 ; 91,67% en 2017) et que plus de 91% de ces sinistres déclarés dans l'année de survenance sont déjà clos (96,02% en 2015 ; 94,22% en 2016 ; 91,67% en 2017). Cette tendance peut nous faire croire que les sinistres sont clos avec la même cadence d'une année à l'autre. Dans la figure 3.4, nous pouvons remarquer que 9,89% de tousles dossiers survenus en 2015 (toutes années d'ouvertures confondues) ont été clos la première année (contre 10,76% en 2016 et 7,29% en 2017), etque 10,35% de tous les dossiers clos(toutes années de clôture confondues)ont été clos la première année (contre 11,47% en 2016 et 7,97% en 2017). Ce qui dénote que la cadence de clôture varie d'une année à l'autre (Figures 3.5 ; 3.6).
Figure 3.1 Histogramme des dossiers en 2015 par année d'ouverture
Figure 3.2 Histogramme des dossiers en 2016 par
année de survenance Figure 3.3 Histogramme des dossiers en 2017 par année de survenance Je ne comprends pas les graphiques ci-dessous ? L'idée est de montrer que la cadence de clôture et/ou de réouverture des sinistres peut grandement varier par année de survenance malgré le fait que le nombre total de sinistres soit plus ou moins stable. Par exemple la 2ème année, la proportion de dossiers réouverts (par rapport au nombre total de dossiers réouverts par année de survenance) est de 44.11% en 2015, 39.77% en 2016 et 0% en 2017. Ce n'est pas très clair. Mais si tu juges que ce n'est pas pertinent je peux les retirer.
Figure 3.4 Proportions des dossiers en 2015 par année de clôture
Figure 3.5 Proportions des dossiers en 2016 par
année de clôture Figure 3.6 Proportions des dossiers en 2017 par année de clôture Par la suite, nous étudirons la distribution de quelques unes des variables retenues. La charge qui est la variable « à expliquer ». Ses statistiques descriptives se présentent comme suit :
En regroupant les charges par groupe de 100K€, nous obtenons la distribution suivante de -200K€ à 1000K€ par nature de dommage.
Figure 3.7 Nombre de dossiers par classe de 100K€ D'après la figure ci-dessus, 99% des dossiers ont une charge inférieure à 100K€Ce serait intéressant de zoomer dans le [0 ;100K]J'ai testé mais les résultats ne sont pas très différents. Puisque les dossiers ayant une charge de plus de 100K€ sont assez exceptionnels, notre étude portera sur les 52 803 dossiers ayant une charge inférieure à 100k€ soit 94% de nos dossiers. Par ailleurs, AXA France qualifie les sinistres ayant une chargesupérieure à 150K€ de « graves ». Les variables explicatives La cause du sinistre qui est la variable qui donne des détails brefs sur la cause du sinistre. Ci-dessous la figure représentant la proportion de dossiers par cause de sinistre. Elle montre que les « accident de 2 véhicules » sontlesprincipales causes des sinistres. Par ailleurs, 261 dossiers n'ont pas pu être classés et feront l'objet d'un traitement particulier. Ces données « manquantes » peuvent être supprimées mais cela réduira la taille de notre échantillon. Nous créerons unemodalité « Pas de détails »afin de corriger ce déficit.
Figure 3.8 Nombre de dossiers par cause du sinistre Le département est le département où s'est produit le sinistre. La figure ci-dessous montre que 48% des dossiers ont comme département 00. Il se trouve qu'à la déclaration, les informations ne sont pas toujours disponibles, ce qui empêche les chargés d'indemnisation de remplir la bonne information. Sans tenir compte de ces valeurs manquantes, nous remarquons que le département Bouches-du-Rhône et la ville de Paris sont les plus touchés.
Figure 3.9 Top 10 des départements les plus touchés La ville et le code postal. Il s'agit de la ville où s'est produit le sinistre. Comme avec la variable précédente, 40% dossiers n'ont pas de ville renseignée. Par contre en faisant une exploration des données, nous remarquons que certains dossiers qui n'ont pas de département renseigné ont une ville et/ou un code postal renseignés. Sans tenir compte de ces valeurs manquantes, nous remarquons aussi queles villes deMarseille et Paris sont les plus touchées dans la variable Ville et leurdépartement dans la variable Département. Ce qui rejoint l'information relative au département. Ci-dessous la figure récapitulant le Top 10 des villes les plus touchées.
Figure 3.10 Top 10 des villes les plus touchées Le litige représente la situation dans laquelle le sinistre a été réglé. En cas de dommage corporel, le règlement peut donner lieu à une mise en cause juridique. Ainsi, l'indemnisation peut être faite avec l'acceptation des deux parties ou face à un tribunal. Dans le premier cas, il s'agit d'un règlement à l'amiable et dans le second d'un contentieux.
Figure 3.11Répartition des dossiers par type de litige Une grande partie des dossiers est réglée à l'amiable. Toutefois, les dossiers en contentieux coûtent en moyenne plus cher que les dossiers réglés à l'amiable comme le montre la figure ci-dessous d'où l'intérêt d'en avoir le moins possible en contentieux.
Figure 3.12 Charge moyenne par type de litige La clôturequi informe sur le statut ouvert ou clos des dossiers. Nous travaillerons sur les dossiers clos car nous connaissons leur charge ultime.
Figure 3.13Nombre de dossiers clos et ouverts L'UP permet de distinguer la nature du dommage. En termes de proportions nous n'avons pas le même nombre de dossiers car il peut arriver que certains sinistres entraînent un dommage corporel sans entraîner de dommage matériel ou vice versa. Ainsi, RCA représente le dommage matériel et RCORP le dommage corporel.
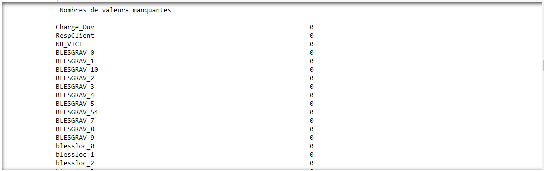
Figure 3.14Nombre de dossiers par type de dommage Letaux de responsabilité représente le taux de responsabilitéqu'ale conducteur dans le sinistre. Ainsi, 0 signifie qu'il n'en a aucune, 1 équivaut à 25%, 2 à 50%, 3 à 75% et 4 à 100%. Ce taux de responsabilité est établi sur la base d'évaluation d'experts et/ou du constat (à l'amiable ou de la police). Nous remarquons que le nombre total de dossiers n'est pas correct car certains dossiers n'ont pas ce taux renseigné dans notre base. Ce qui est dû aux mêmes raisons que celles des départements et villes non renseignés.
Figure 3.15Nombre de dossiers par taux de responsabilité Le nombre de victimesreprésente le nombre de blessés ou de décès occasionnés par le sinistre y compris le conducteur. Les dossiers avec des un grand nombre de victimes sont moins nombreux que les dossiers avec une ou deux victimes. Les valeurs vides représentent les dossiers Tu es pourtant sur le sous-périmètre UP RC_Corpo non ? Il ne s'agit pas plutôt d'info manquante ?Mon hypothèse est que le chargé de règlement a ouvert un dossier sous réserve qu'il y ait une déclaration tardive de victimeoù il n'y aucune victime donc aucun dommage corporel.
Figure 3.16Nombre de dossiers par nombre de victimes Autres variables Notre base de données comporte d'autres variables permettant de mieux appréhender les informations relatives aux victimes. Il s'agit de : LESION : qui décrit le nombre de blessés et décès ; QUALITE : qui décrit le rôle de la victime ; i.e.passagers, conducteur, piéton, cycliste ; VEH : qui décrit la localisation de la victime ; sur la chaussée, dans le véhicule adverse, dans le véhicule de l'assuré ; SEX : le nombre d'hommes et femmes ; CAT_AGE : la catégorie d'âge à laquelle appartient chaque victime ; BLESGRAV et BLESSLOC : la gravité et la localisation de la blessure (selon une nomenclature propre à AXA France) pour les blessés ; CONTEXT : l'état médical des blessés ; De plus, chaque dossier fait l'objet de quelques évaluations à la déclaration ainsi que leur évolution de façon périodique jusqu'à la clôture du sinistre définissant les montants en jeu. Ainsi, pour chaque trimestre nous avons les variables suivantes : 1. RGFR : les règlements des frais; 2. RGPR : les règlements du principal ; 3. EVRE : l'évaluation des récupérations(les recours à encaisser) ; 4. EVRG : l'évaluation des règlements (provisions pour paiements futurs); 5. RECE : les récupérations. La charge est calculée grâce à la formule suivante : 1+2-3+4-5. Nous intégrerons uniquement les évaluations à l'ouverture. Car notre étude ne prendra malheureusementVous n'avez pas réussi à historiser à minima l'évlaution au bout d'1 an ? J'ai en tête que c'était une variable avec un fort pouvoir explicatif chez PP...Puisque je ne savais pas comment exploiter l'information je n'ai pasvraiment creusé le sujetpas en compte l'aspect temporel de l'évolution de charge. A partir de ces variables, nous créerons une nouvelle variable qu'on appellera Charge à l'ouverture. 3.2 Collecte et sélection des données Notre base de données a été constituée grâce à des codes SAS qui avaient été conçus préalablement pour extraire des données dans un but similaire à celui de cette étude sur un autre périmètre. Après quelques adaptations, ces codes nous ont permis de gagner du temps dans l'extraction des données correspondant au périmètre de cette étude. Pour la conception des figures présentées plus haut, nous avons utilisé l'outil Microsoft Power BI qui s'est avéré très pratique pour étudier la distribution de notre jeu de données et procéder à des filtres. Power BI intègre aussi une option tableur, ce qui nous a permis de créer quelques-unes des variables exposées plus haut. Après avoir pris connaissance du jeu de données, il est nécessaire de mettre en applications les critères de sélection exposésdans la section 1.4A vérifierJ'ai apporté des corrections en suivant les recommandations d'Emilie. La mise en application de ces critères entraîne quelques changements. Lesstatistiques descriptives de la charge se présentent désormais comme suit :
Par ailleurs le nombre de dossiers se restreint à 52 427 soit 93% de la base de données initiale. IV. Amélioration de l'évaluation par Machine Learning 4.1 Généralités sur le Machine Learning L'objectif de ce mémoire est de proposer une alternative aux méthodes agrégées qui sont utilisées afin de mieux évaluer la charge de sinistre et par conséquent mieux évaluer la PSAP de ce sinistre plus précisément les IBNER.
Figure 4.1 Partie de la PSAP à estimer Est-ce que le visuel du graphique (ie a peu près 2x plus d'IBNYR que d'IBNER) correspond à la réalité ? Ca serait plus vendeur de dire qu'on concentre notre modèle sur le plus gros morceau des IBNR ??A mon avis, vu - que les méthodes agrégées estiment les IBNR sans distinction - que dans la réalité les NYR ne sont pas encore déclarés - et que la prédiction par ML ne porte que sur ce qui est déclaré, il me parait logique de dire que la prédiction se fait sur les NER. Cette méthode prendra en compte les différentes caractéristiques de chaque sinistre contrairement aux méthodes agrégées. Nous parlons ainsi de provisionnement ligne à ligne ou individuel car elle considère chaque sinistre comme étant un cas particulier. Dans cette section, nous introduirons quelques notions de data scienceplus précisément celles relatives au Machine Learning. La data scienceest une démarche empirique qui se base sur les données pour apporter une réponse à des problèmes. Un des outils de la data scienceest le Machine Learning.Bien que récemment très porté par les nouvelles technologies et nouveaux usages, iln'est pas un domaine récent. On en trouve une première définition dès 1959, due à Arthur Samuel, l'un des pionniers de l'intelligence artificielle, qui définit le Machine Learning comme « le champ d'étude visant à donner la capacité à une machine à apprendre sans être explicitement programmée ». En 1997, Tom Mitchell, de l'université de Carnegie Mellon, propose unedéfinition plus précise à ceterme : « A computer program is said to learn from E experience with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E». En d'autres termes, la performance P d'un programme informatique dans « l'exécution » de certaines tâches T est haute lorsque que celui-ci « s'améliore » à partird'expériences « vécues ».4(*) Tom Mitchell illustre ensuite cette définition par quelques exemples :
Table 4.1 Quelques exemples de Machine Learning proposés par Mitchell Bien que notre préoccupation ne soit pas d'apprendre à un robot à conduire, il est important de rappeler ce contexte général. L'objectif du Machine Learning est donc d'apprendre à imiter des résultats avec des données existantes pour ensuite pouvoir appliquer ce savoir à des nouvelles situations. Le Machine Learning doit donc créer un programme qui puisse s'adapter à de nouvelles données, il doit être capable de généraliser une analyse et fournir des résultats corrects sur des situations qui n'ont pas servi à créer l'algorithme. Toutefois, tous les algorithmes ne sont pas destinés aux mêmes usages. On les classe usuellement selon deux composantes : - Le mode d'apprentissage : les algorithmes supervisés et les algorithmes non-supervisés ; - Le type de problème à traiter : les algorithmes de régression et les algorithmes de classification. Cette classification n'est pas forcément parfaite car il existe des algorithmes qui appartiennent à plusieurs classes ou d'autres qui n'y trouvent pas leur place. Cette classification est plus ou moins conventionnelle. 4.2 Algorithmes supervisés et non supervisés La différence entre les algorithmes supervisés et non-supervisés est fondamentale. Les algorithmes supervisés se basent sur des données contenant les couples entrée- sortie. Ce couple est déjà connu dans le sens où les sorties sont définies à priori. La valeur de sortie peut être une information fournie par un expert : par exemple, des valeurs de type OUI/NON ou MALADE/SAIN. Ces algorithmes cherchent à définir une représentation compacte des associations entrée-sortie, par l'intermédiaire de fonctions de prédiction. Quant aux algorithmes non-supervisés, il n'intègrent pas la notion d'entrée-sortie. Toutes les données sont équivalentes (on pourrait dire qu'il n'y a que des entrées). Dans ce cas, les algorithmes cherchent à organiser les données en groupes comprenant des données similaires et les données différentes doivent se retrouver dans des groupes distincts. Dans ce cas, l'apprentissage ne se fait plus à partir d'une indication qui peut être préalablement fournie par un expert, mais uniquement à partir des fluctuations observables dans les données. Par exemple, un algorithme entrainé à reconnaître uniquement des chats est un algorithme supervisé, pendant qu'un algorithme classant les différents visiteurs d'un site web suivant leur classe sociale, âge, occupation, revenus, etc. est un algorithme non-supervisé. Notre but est de construire un algorithme qui va apprendre à prédire la variable à expliquer (la charge) suivant lesvariablesexplicatives exposées plus haut. L'objectif est de minimiser les erreurs de prédictionet donc de minimiser l'écart (mesuré par l'erreur absolue moyenne)entre les valeurs observées et les valeurs prédites. Puisque pour entraîner cet algorithme il faut utiliser des données d'apprentissage, nous devons éviter qu'un surapprentissage ne survienne. Il s'agit d'un phénomène qui fait perdre à notre algorithmede sa puissance de généralisation en s'imprégnant trop des données d'apprentissage. Puisque la variable de sortie est connue et peut prendre une infinité de valeurs dans l'ensemble continu des réels, nous utiliserons des algorithmes supervisés de régression. Parmi les algorithmes supervisés de régression enMachine Learning les plus utilisés, nous nous pencherons surles arbres de régression et les forêts aléatoires. L'algorithme par arbre de décision est une méthode classique en statistique. Cette méthode est aussi bien utilisée en régression qu'en classification. On parle alors d'arbre de régression ou d'arbre de classification selon l'objectif qu'on se fixe. Il existe plusieurs types d'algorithme par arbre de décision, comme le C5.0, le CHAID, le MARS ou bien encore le CART. Dans la suite, nous nous intéresserons à la méthode la plus classique, celle des arbres CART (Classification and RegressionTrees), créée par Leo Breiman en 1984. Nous étudierons son fonctionnement, ses avantages et inconvénients. La méthode CART se concentre sur la création de partitions binaires récursives. Tout d'abord, l'algorithme cherche à construire kgroupes d'individus à la fois le plus homogène possible (au sein de chaque groupe) du point de vue de la variable à expliquer, et les plus différents possibles (d'un groupe à l'autre) en tenant compte d'une hiérarchie de la capacité prédictive des variables considérées : il cherche à minimiser la variance intragroupe tout en maximisant la variance intergroupe. Plusieurs itérations sont nécessaires : à chacune d'elle, on divise les individus en k classes (généralement k =2), pour expliquer la variable de sortie. La première division est obtenue en choisissant la variable explicative qui fournira la meilleure séparation des individus. Cette division définit des sous-populations, représentées par les « noeuds » de l'arbre. A chaque noeud est associée une mesure de proportion, qui permet d'expliquer l'appartenance à une classe ou la signification d'une variable de sortie. L'opération est répétée pour chaque sous-population, jusqu'à ce que plus aucune séparation ne soit possible. On obtient alors des noeuds terminaux, appelés « feuilles » de l'arbre. Chaque feuille est caractérisée par un chemin spécifique à travers l'arbre qu'on appelle une règle. L'ensemble des règles pour toutes les feuilles constitue le modèle. La profondeur de l'arbre désigne le nombre maximum d'étapes de séparations au sein de l'arbre. L'interprétation d'une règle est aisée si l'on obtient des feuilles « pures » (par exemple, 100% de variables à expliquer sont VRAI ou FAUX pour une règle donnée). Sinon, il faut se baser sur la distribution empirique de la variable à expliquer sur chaque noeud de l'arbre. Ci-dessous un exemple d'arbre de décision. Nous avons ici un arbre à 4 noeuds, 5 feuilles, de profondeur 4.
Attention, un arbre de décision peut très vite mener à du sur-apprentissage : il peut décrire parfaitement un jeu de données, avec un individu par feuille dans le cas extrême. Dans ce cas, les règles ne sont absolument pas extrapolables et cette situation doit être évitée. Pour cela, il est nécessaire de s'arrêter à un nombre de feuilles adéquat lors de la réalisation de l'arbre : on parler d'« élaguer » l'arbre. La profondeur de l'arbre est un paramètre gouvernant la complexité du modèle et doit être choisi en fonction des données. Une approche pourrait être de créer un nouveau noeud seulement si la décroissance de l'erreur quadratique liée à la création de ce noeud dépasse un certain seuil. Toutefois, un problème notable lié à cette approche serait qu'une division de premier abord sans valeur, et donc non conservée, aurait pu mener à une deuxième division de bonne qualité. La stratégie généralement utilisée est la suivante : faire croître un arbre le plus profond possible, en utilisant comme critère d'arrêt le nombre d'individus dans les feuilles. Cet arbre est ensuite élagué. L'élagage consiste à enlever les noeuds de l'arbre qui n'apporteraient rien à l'analyse. Il faut toutefois conserver les qualités prédictives de l'arbre, et donc ne pas supprimer trop de noeuds. Les arbres de régression présentent plusieurs avantages. Tout d'abord, et principalement, l'interprétabilité des résultats. Ils fournissent des résultats graphiques, par découpage de l'espace, et permettent de voir facilement comment les individus sont affectés à ces séparations. De plus ils offrent un temps de calcul raisonnable et sont adaptés à des données mixtes et manquantes, et leur maniement est aisé de par le faible nombre de paramètres à optimiser, notamment comparé à d'autres algorithmes, et la présence de nombreux packages leurs étantdédiés. Toutefois les inconvénients liés à cet algorithme sont nombreux. Le premier inconvénient, déjà énoncé, est le risque de surapprentissage. Il survient lorsque l'algorithme s'imprègne trop des caractéristiques de notre échantillon d'apprentissage et perd de son potentiel de généralisation. Le modèle fera des prédictions de moins bonne qualité sur un nouvel échantillon. Cet inconvénient n'est toutefois pas limité aux arbres de régression mais bien à l'ensemble des algorithmes en général, et il doit être généralement monitoré en analysant les données et en appliquant des méthodes d'agrégation et d'échantillonnages. Dans le cas des arbres de régression, ce risque augmente avec la taille de l'arbre. Il est ensuite réduit par l'élagage. Une autre manière de réduire ce risque est d'utiliser une méthode ensembliste comme les forêts aléatoires. De plus, les arbres de régression sont sensibles aux optima locaux. Cela est dû au fait que l'algorithme parcourt les différentes variables explicatives de façon successive, et un critère de division n'est plus réétudié par la suite. Ainsi, la construction de l'arbre en amont peut déterminer la construction de tout le reste de l'arbre. Cela peut notamment entraîner un manque de robustesse et une grande variabilité de résultats. L'usage d'une méthode ensembliste permet aussi de réduire ce risque. Ainsi, nous allons présenter comment améliorer la robustesse des arbres de régression grâce à l'utilisation des forêts aléatoires. Les méthodes ensemblistes de modèles, basées sur des stratégies adaptatives ou aléatoires, permettent d'améliorer l'ajustement et de réduire le surapprentissage par une combinaison d'un grand nombre de modèles. Nous intéresserons au cas particulier des forêts aléatoires. Nous en présenterons les grands principes puis l'algorithme en détail. L'idée de base des méthodes ensemblistes peut être comparée à celle selon laquelle, lorsqu'un (seul) médecin diagnostique à son patient une maladie grave qui nécessite une intervention chirurgicale, il est très probable que celui-ci avant de prendre une quelconque décision demande l'avis d'autres médecins ou experts. Car aussi experte que soit une personne dans un domaine, sa (seule) voix ne suffit pas, en général, pour prendre une bonne décision. Les méthodes ensemblistes fonctionnent sur le même principe. En effet, plutôt que d'avoir un estimateur très complexe censé tout faire, on en construit plusieurs de moindre qualité individuelle. Chaque estimateur a ainsi une vision parcellaire du problème et faire de son mieux pour le résoudre avec les données dont il dispose. Ensuite, ces multiples estimateurs sont réunion pour fournir une vision globale. C'est l'assemblage de tous ces estimateurs qui rend extrêmement performants des algorithmes comme les forêts aléatoires. Comme pour la méthode de l'arbre de décision CART vue précédemment, nous devons l'idée des forêts aléatoires à Leo Breiman (en 2001). Il avait conscience du défaut majeur d'un arbre de décision : sa performance et trop fortement dépendante de l'échantillon de départ. Plutôt que de lutter contre ses défauts, il a eu l'idée d'utiliser plusieurs arbres pour faire des forêts d'arbres. Toutefois, le terme « aléatoires » provient du fait que pour éviter que les arbres soient identiques, il donne à chaque arbre une vision parcellaire du problème, tant sur les observations en entrée que sur les variables à utiliser. Ce double échantillonnage est tout simplement tiré aléatoirement. Notons que l'assemblage d'arbres de décision construits sur la base d'un tirage aléatoire parmi les observations constitue déjà un algorithme à part entière connu sous le nom de bagging ou tree bagging. De plus, les forêts aléatoires ajoutent au tree bagging un échantillonnage sur les variables du problème, qu'on appelle feature sampling. Comme pour l'arbre de décision, la méthode des forêts aléatoires peut être utilisée aussi bien en régression qu'en classification. Le tree bagginga déjà apporté de significatives améliorations de performance pour les arbres de décision. Pour construire des arbres de décision, il faut : - tirer aléatoirement et avec remplacement B échantillons de couples entrée-sortie du jeu de données d'entraînement ; - puis entraîner un arbre de décision sur chaque couple tiréentrée-sortie. Sur de nouvelles données, on applique chacun des B arbres. Il suffit ensuite de prendre la majorité parmi les B réponses. Voici dans la figure ci-dessus une illustration du bagging avec trois arbres sur un jeu de données prédisant le prix d'un appartement.
Figure 4.3 - Illustration du tree bagging avec trois arbres Le feature sampling est un
tirage aléatoire de variables utilisé par plusieurs
méthodes ensemblistes dont celle des forêts aléatoires. Par
défaut, le nombre de variables tirés est de Pour revenir à l'exemple du médecin, c'est comme si le patient demande à chaque médecin et expert dont il prend l'avis de réaliser son diagnostic en se basant sur une partie limitée du diagnostic du premier médecin. Il peut choisir de donner à ceux-ci ses analyses de sang et radios mais pas ses antécédents ou ses IRM. Le feature sampling est une idée majeure qui contribue très fortement à réduire la variance de l'ensemble créé. Bien que l'algorithme des forêts aléatoires soit l'un des algorithmes non linéaires les plus aisés à comprendre, le paramétrer n'est pas simple et ne viendra qu'avec l'expérience. Et pour cause, il dispose d'une multiplicité de paramètres. Son implantation dans la librairie scikit-learn de Python fait appel à pas moins de 14 paramètres dont les plus importants sont : - n_estimators : c'est les nombres d'arbres différents à entraîner ; - criterion : c'est le critère statistiques utilisé pour couper les feuilles de chaque arbre en cours de construction ; - max_depth : c'est la profondeur maximale de chaque arbre, un critère très important qui dépend du niveau d'interaction entre les variables ; - min_samples_split : le nombre d'observations qu'il faut dans une feuille avant séparation, ce critère permet d'éviter le sur-apprentissage ; - max_features : c'est le nombre maximum de
variables qu'on tire aléatoirement pour chaque arbre. Comme dit plus
haut, le critère par défaut est - nb_jobs : indique le nombre de coeurs de CPU que nous utiliserons pour la construction des arbres ; - verbose : ce paramètre nous permet de surveiller la construction des arbres. Les deux derniers critères n'influencent pas le score de la modélisation mais il est intéressant de savoir que pour certains problèmes et même avec huit coeurs, nous attendrons plus de 10h avant d'avoir notre résultat. V. Implémentation des algorithmes VI. Algorithmes de régressions et de classification La distinction régression/classification se fait au sujet des algorithmes supervisés. Elle distingue deux types de valeurs de sorties qu'on peut chercher à traiter. Dans le cadre d'un problème de régression, la valeur de sortie peut prendre une infinité de valeurs dans l'ensemble continu des réels. Ce peut être des poids, le taux de bonheur d'un pays, le prix d'un appartement ou la charge d'un sinistre automobile. Dans le cadre d'un problème de classification, la valeur de sortie prend un nombre fini des valeurs. Ce peut être la notation d'un vin, le fait qu'une cellule soit cancéreuse ou pas ou même le fait qu'un animal soit un chien ou un chat. 5.1 Mise en application en langage Python Après avoir pris connaissance des données, nous sommes fins prêts à établir nos modèles sous Python. Toutefois avant d'appliquer nos modèles, il nous faut faire un nouveau traitement sur les données. Il s'agit des valeurs manquantes et du traitement des variables textuelles. En effet, les algorithmes que nous utilisons ne peuvent pas fonctionner avec des valeurs manquantes. Après avoir traité ces valeurs, la base de données sera divisée en deux. Une proportion 75% servira à entraîner le modèle pendant que les 25% restants serviront à le valider. Ces deux principales actions seront configurées dans des fonctions intitulées parse_model(). Pour effectuer ces actions, nous aurons besoin d'importer certaines librairies que nous importerons grâce au script ci-dessous :
Puis nous importons les données relatives aux dommages. Rappelons que pour des questions d'homogénéités, la base a été scindée en deux partie. Une partie contenant les données relatives aux dommages matériels et l'autre partie, les dommages corporels. Notre exemple portera d'abord sur les dommages matériels puis sur les dommages corporels.
5.2 Exploration des données relatives aux dommages matériels Afin d'avoir une vue d'ensemble sur la base, nous appliquons le code ci-dessous.
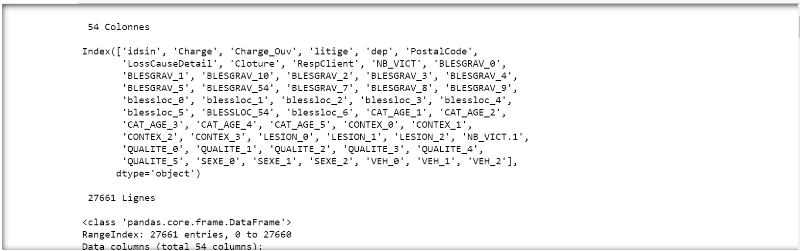
L'exécution de ce script permet entre autres d'obtenir le nombre de valeurs manquantes par variables et le nombre total de valeurs manquantes. Le résultat met en évidence que nous avons 54 colonnes et 27661 lignes dont certaines présentent des valeurs manquantes pour le département, la cause du sinistre, la responsabilité du conducteur et des détails relatifs aux victimes (ce qui n'est pas vraiment un problème, puisque qu'en absence de victimes, il ne peut y avoir de détails à leur sujet).
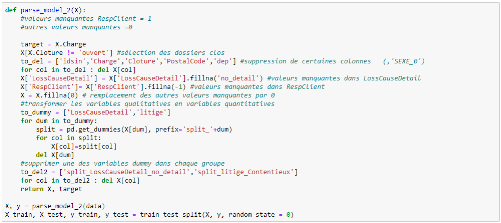
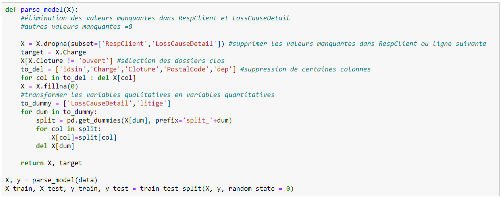
5.3 Traitement des valeurs manquantes : parse_model () Pour le traitement des valeurs manquantes plusieurs choix s'offrent à nous. Nous pouvons soit supprimer purement et simplement les lignes présentant les valeurs manquantes (ce qui réduirait la taille de notre base) ou procéder à des remplacements au cas par cas. Ainsi, notre première fonction de traitement de données a pour but de supprimer les lignes où la responsabilité du conducteur et la cause du sinistre ne sont pas renseignées, de supprimer la variable département ainsi que les variables qui ne nous sont pas utiles. Etant donné les variables type de litige et causes du sinistre sont textuelles, il faut la transformer en des variables dummies. Et enfin, nous procédons au fractionnement 75-25. Ces actions sont réalisées par le script suivant :
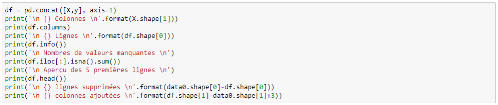
Suite à l'exécution de la fonction parse_model(), nous pouvons à nouveau avoir une vue d'ensemble sur notre base de données grâce au script ci-dessous.
Après le traitement des valeurs manquantes, 8 colonnes ont été ajoutées et 2857 lignes supprimées. Par ailleurs, il n'y a plus aucune valeur manquante, ce qui nous permet de pouvoir exécuter notre premier programme.
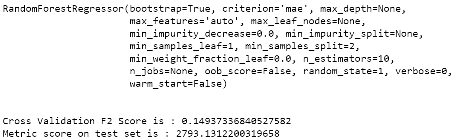
Après exécution à nouveau des scripts d'entraînements et d'évaluation des modèles, nous obtenons les résultats suivants : 5.4 Algorithmes et évaluations Puisque nous travaillons avec les algorithmes des arbres de décision et des forêts élatoires, nous les importerons avec le script suivant.
Pour évaluer nos modèles, de nombreuses mesures sont disponibles. Il s'agit d'indicateurs de performances telles que l'erreur absolue moyenne (MAE, Mean Absolute Error), le carré moyen des erreurs (MSE, Mean Squared Error), le coefficient de détermination R² que nous importons ci-dessous.
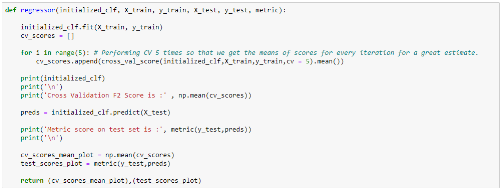
Nous définissons une fonction qui entrainera nos deux
modèles. Cette fonction a par ailleurs pour instruction, de faire une
validation croisée pour chaque modèle. Cette étape est
très importante pour la bonne résolution d'un problème
d'analyse de données. Elle consiste à diviser les données
aléatoirement en
Pour évaluer notre modèle, nous utiliserons l'erreur absolue moyenne (MAE).
Après exécution de ces scripts, nous obtenons les résultats ci-dessous.
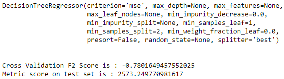
Nous remarquons que l'erreur absolue moyenne des arbres de décision et plus grande que celle des forêts élatoires. Pour que nos modèles soient optimaux, il faut que le l'erreur soit nulle. Cette information reste malgré tout assez difficile à interpréter du fait de la complexité de nos modèles. Pour faciliter l'interprétation des résultats obtenus, nous appliquerons aux données servant à tester nos modèles, une fonction compare () calculant la proportion de sinistres dont l'écart absolu entre la charge réelle et la charge prédite ne dépasse pas un certain seuil en euros (50 euros dans notre cas).
Le résultat montre que l'algorithme des forêts aléatoires a un meilleur taux de prédiction. En d'autres termes, cet algorithme a « bien » prédit 33% des données (à 50 euros près), 20% de plus que celui des arbres de décision.
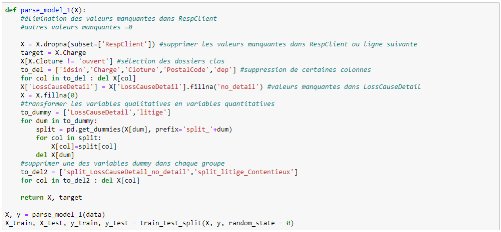
5.5 Autres traitements des valeurs manquantes 1- parse_model_1 () : en important à nouveau nos données et en procédant à quelques changements dans la fonction parse_model () de départ, nous obtenons des variantes différentes. La variante suivante a pour instruction deremplacerles valeurs manquantes dans la cause du sinistre par la modalité no_detailau lieude tout simplement les supprimer, nous obtenons le script suivant :
Cette action nous permettra de mieux appréhender l'impact qu'ont les lignes supprimées à cause de l'absence de la variable Cause du sinistre sur nos modèles.
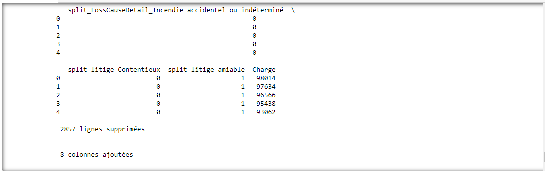
Nous pouvons remarquer que le taux de sinistres prédits dans un seuil de 50 euros a relativement augmenté pour les 2 algorithmes malgré une hausse légère de l'erreur absolue moyenne pour l'algorithme des forêts aléatoires. 2- parse_model_2 () : une autre variante a pour instruction de remplacer les valeurs manquantes relatives à la variable RespClt par -1 et de maintenir le traitement fait sur la variable cause du sinistre. Les lignes de codes ci-dessous permettent de parvenir à ce résultat.
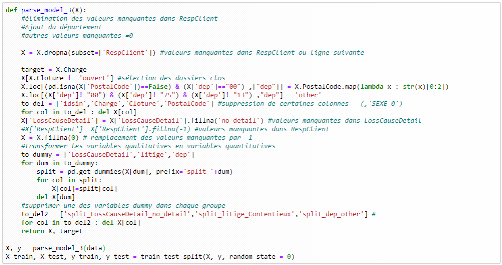
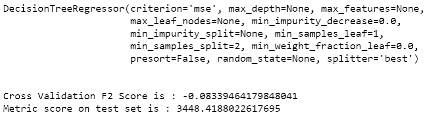
Nous remarquons que les erreurs absolues moyennes ont augmenté et que le taux de prédiction a baissé. Ce qui nous permet de conclure que le fait de remplacerles valeurs manquantes relatives à la variable RespClt par -1 altère davantage les algorithmes. 3- parse_model_ 3 () : la dernière variantesupprime les lignes où la variable RespClt est manquante et conserve la variable Département. Certaines lignes comportent un code postal mais pas de département. Le numéro de département n'étant que les deux premiers caractères du code postal en France, pour les valeurs manquantes du département, nous ferons une extraction de ces deux caractères à partir de la variable Code Postal. Puisque nous avons remarqué plus haut que les villes les plus touchées sont Paris et Marseille, et qu'il en ait de même pour les départements correspondants, nous avons décidé de remplacer toutes les données différentes de ces départements par la modalité dep_other. De plus, une transformation en dummy est nécessaire pour exploiter la variable Département.Ci-dessous le script permettant d'obtenir ce résultat.
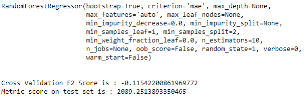
La dernière option présente des résultats plus probants pour le l'algorithme des arbres de décision que pour l'algorithme des forêts aléatoires. Cela pourrait s'expliquer par le fait que le choix des départements n'est pas le plus approprié. Toutefois, l'erreur moyenne de forêts aléatoires reste plus faible que celle des arbres de décision. 5.6 Entraînement des modèles à la prédiction des dommages corporels La dernière étape de notre étude consiste à appliquer la fonction parse_model_1 () sur les données des dommages corporels. Pour cela, nous importerons la base de données puis nous exécuterons les scripts relatifs à l'entrainement du modèle et à son évaluation. Nous obtenons ainsi les résultats suivants.
Les erreurs absolues moyennes sont beaucoup plus élevées que celles observées dans le cadre de la prédiction des dommages matériels. Les taux de prédictions sont quasiment deux fois plus élevés que ceux des dommages matériels. * 1https://www.ffa-assurance.fr/infos-assures/la-responsabilite-civile-du-particulier-et-son-assurance. * 2https://justice.ooreka.fr/astuce/voir/473989/prejudice-materiel. * 3https://justice.ooreka.fr/astuce/voir/ 472289/dommage-corporel. * 4EricBiernat& Michel Lutz. Data science : fondamentaux et études de cas :10-11, 2015 |
|


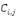
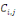 désigne la charge totale soumise à l'assureur pendant
l'année j pour les sinistres survenus en année i.
désigne la charge totale soumise à l'assureur pendant
l'année j pour les sinistres survenus en année i.
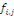
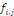 en fonction de l'année de survenance i et de l'année de
développement j est la suivante :
en fonction de l'année de survenance i et de l'année de
développement j est la suivante :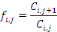
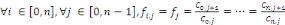
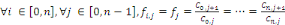
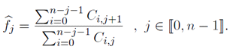

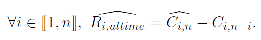
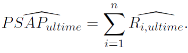
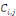
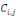 qui vérifie :
qui vérifie : 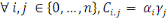

 représentent les charges à l'ultime prévisibles
pour chaque année de survenance i, et
représentent les charges à l'ultime prévisibles
pour chaque année de survenance i, et 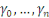
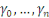 les cadences de paiements cumulés.
les cadences de paiements cumulés.
 .
.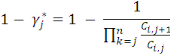
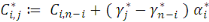
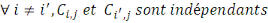
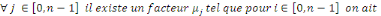 -
- 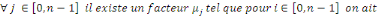
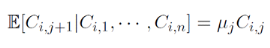
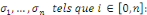
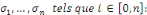
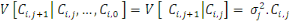
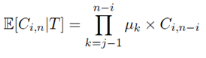
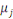
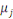 de façon non biaisée par les estimateurs non
corrélés :
de façon non biaisée par les estimateurs non
corrélés : 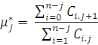
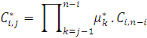
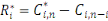
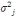
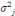 peut être estimé par :
peut être estimé par :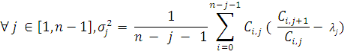
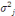
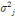 pour
pour 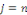
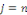 nous avons deux possibilités :
nous avons deux possibilités :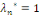
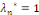 alors
alors 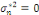
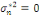
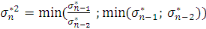
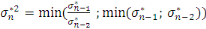
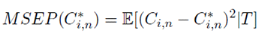
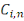
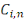 est aléatoire. On en déduit ainsi :
est aléatoire. On en déduit ainsi :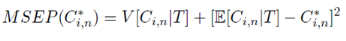
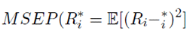
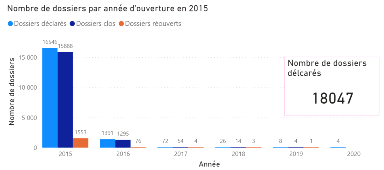
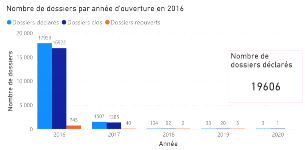
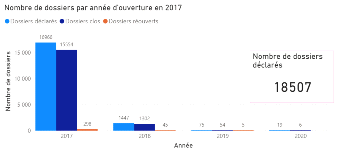
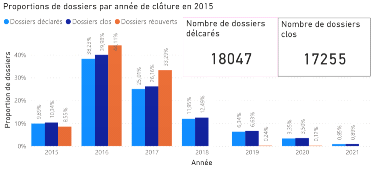
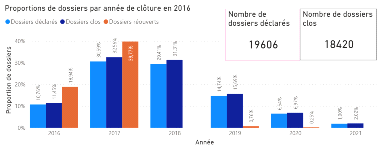
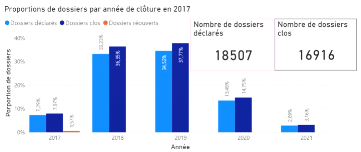
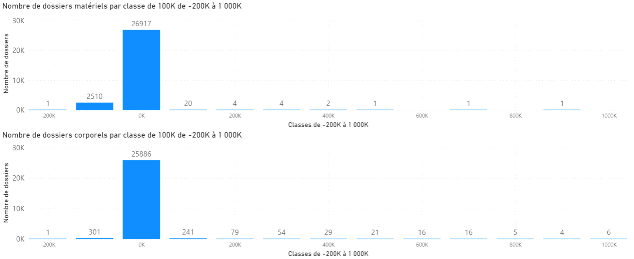
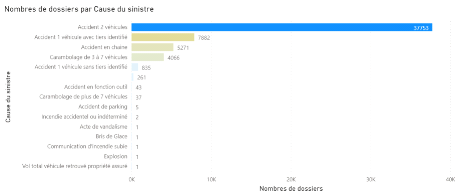
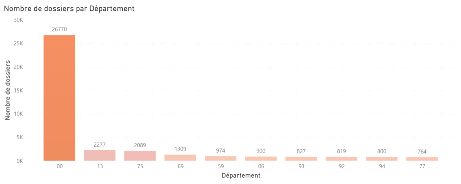
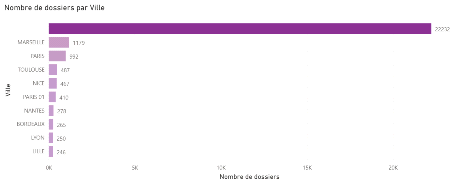
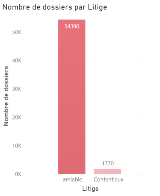
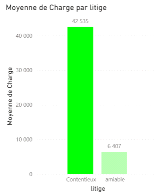
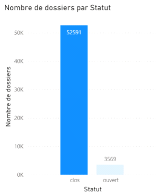
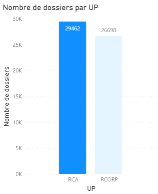
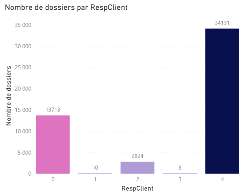
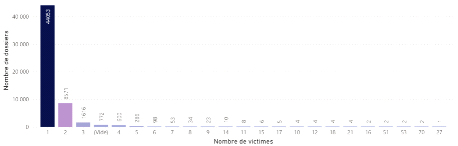
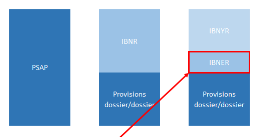
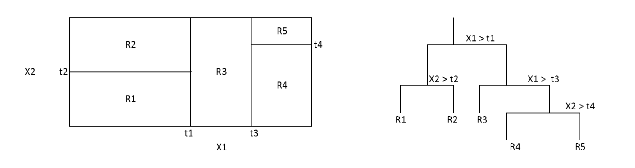 Figure 4.2 - Exemple de partitionnement d'un espace
bidimensionnel et arbre associé
Figure 4.2 - Exemple de partitionnement d'un espace
bidimensionnel et arbre associé 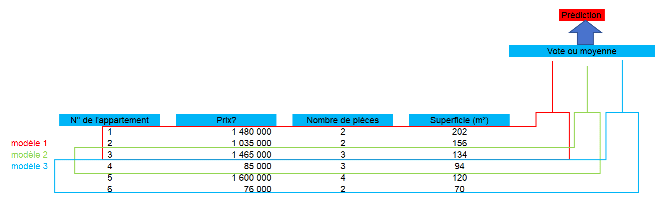
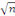
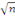 pour un problème à
pour un problème à 
 variables explicatives.
variables explicatives.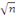
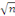 , offre un excellent compromis ;
, offre un excellent compromis ;






 sous-échantillons de tailles égales, dont l'un est
utiliser pour la prévision et les
sous-échantillons de tailles égales, dont l'un est
utiliser pour la prévision et les 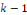
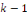 restants pour l'estimation du modèle. L'opération est
répétée
restants pour l'estimation du modèle. L'opération est
répétée 
 fois. Elle permet d'augmenter la significativité de la
validation. Nous utiliserons la moyenne de 5 validations croisées.
fois. Elle permet d'augmenter la significativité de la
validation. Nous utiliserons la moyenne de 5 validations croisées.