Annexes
Annexe1 Liste des variables
|
N°
|
Variables
|
|
1. Numéro du sinistre
|
|
2. Etat du sinistre
|
|
3. Coût du sinistre
|
|
4. Nature du dommage
|
|
5. Numéro du contrat
|
|
6. Date de survenance
|
|
7. Taux de responsabilité du conducteur
|
|
8. Département
|
|
9. Code postal
|
|
10. Ville
|
|
11. Litige
|
|
12. Règlements des frais à l'ouverture
|
|
13. Règlements du principal à l'ouverture
|
|
14. Evaluation des recettes (les recours) à
l'ouverture
|
|
15. Evaluation des règlements (les recours
encaissés) à l'ouverture
|
|
16. Les recettes à l'ouverture
|
|
17. Règlements des frais à la clôture
|
|
18. Règlements du principal à la
clôture
|
|
19. Evaluation des recettes (les recours)
|
|
20. Evaluation des règlements (les recours
encaissés) à la clôture
|
|
21. Les recettes à la clôture
|
|
22. Date de clôture
|
|
23. Date de réouverture
|
|
24. Date d'ouverture
|
|
25. Cause du sinistre
|
|
26. Nombre de victimes
|
|
27. Catégorie d'âge des victimes
|
|
28. Qualité de la victime
|
|
29. Sexe de la victime
|
|
30. Nombre de blessés
|
|
31. Nombre de décès
|
|
32. Etat médical des blessés
|
|
33. Position des victimes
|
|
34. Gravité de la blessure
|
|
35. Localisation de la blessure
|
Annexe 2 Importance des variables selon l'algorithme des arbres
de décision
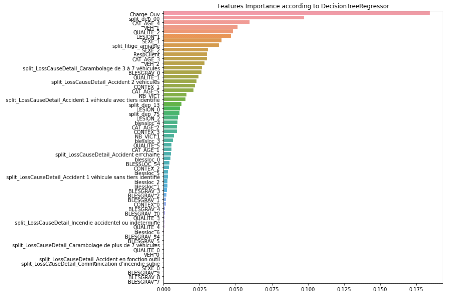
Annexe 3 Importance des variables selon l'algorithme des
forêts aléatoires
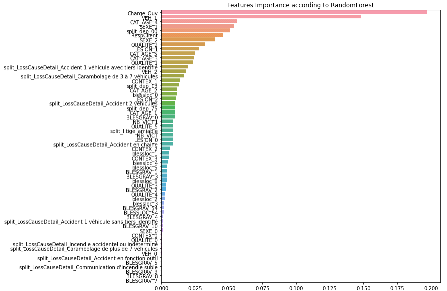
Bibliographies
Leo BREIMAN, Jerome FRIEDMAN, Charles J STONE, and Richard A
OLSHEN. Classification and regression trees. PACIFIC GROVE1984
Leo BREIMAN. Some properties of splitting criteria.
Machine learning.1996
Tom MICHELL. Machine Learning. Mc GRAW HILL1997
Stéphane TUFFÉRY. Data mining and statistics
for decision making. WILEY 2011
EricBIERNATet Michel LUTZ. Data science :
fondamentaux et études de cas. EYROLLES2015
Mathis BARBASTE. Une méthode de provisionnement
individuelle par apprentissage automatique
Pauline LE FALHER.Valorisation par apprentissage statistique
d'un portefeuilleResponsabilité Civile des entreprises dans un contexte
de criseéconomique
Jérémy RIFFAUD. Modélisation de la charge
IBNYR dans le cadre d'un modèle de provisionnement individuel
enassurance non-vie
Damien FABRE RUDELLE. Apport des méthodes
d'apprentissage statistique pour le provisionnement individuel en assurance
non-vie
| 

