|
Rapport d'avancement « Juin
2009 »
Etudiant : ELARBI Nassim &
TAHAR DJEBBAR Mohamed.
Encadreur : Mr Nassim DENNOUNI
Année universitaire :
2008/2009.
Titre du mémoire:
« Traitement et exploration du fichier Log du
serveur web pour l'extraction des connaissances
»
Mise en contexte
Au cours de ces dernières
années, avec la croissance exponentielle du nombre des
documents en ligne et des nouvelles pages chaque jour, le Web est devenu la
principale source d'information. Ce développement a
entraîné une croissance rapide de l'activité sur le Web, et
une explosion des données résultant de cette activité. En
effet, le nombre des utilisateurs d'Internet dans le monde a atteint 74.4
millions au mois d'Octobre 20051, ce qui correspond à un taux
de pénétration de 14.6% et le nombre de sites Web a atteint 70.39
millions au mois d'Août 2005, soit une augmentation de 2.8 millions par
rapport au mois de juillet selon l'enquête de Netcraft2. Pour
analyser ce nouveau type de données, sont apparues de nouvelles
méthodes d'analyse regroupées sous le terme «Web
Mining» dont les trois axes de développement actuels sont le Web
Content Mining (WCM) qui s'intéresse à l'analyse du contenu des
pages Web, le Web Structure Mining (WSM), qui s'intéresse à
l'étude des liens entre les sites Web et le Web Usage Mining (WUM) qui
s'intéresse à l'étude de l'usage du Web.
Cette dernière branche du Web Mining (Web Usage
Mining) qui se définit comme étant l'application du processus
d'Extraction des Connaissances à partir de bases de Données (ECD)
aux données issues des fichiers Logs HTTP est devenue une pratique de
plus en plus courante et indispensable.
Problématiques de recherche
Notre problématique consiste à
réaliser un outil pour aider les créateurs des sites Web
à fidéliser les internautes fréquentant leurs sites et
à attirer de nouveaux visiteurs en analysant le fichier log relatif
à leurs sites WEB afin d'améliorer et de personnaliser
l'utilisation des sites. Nous voulions au début utiliser le fichier Log
relatif au site Web de notre université mais nous avons constaté
qu'il n'est pas assez riche pour faire une bonne analyse de comportement des
utilisateurs, pour cela nous avons choisi le site
www.coolfilesearch.com.
Objectifs
L'objectif principal de notre travail est la conception
et la réalisation d'un prototype de logiciel utile au Webmaster d'un
site Web pour collecter l'ensemble des connaissances issues du fichier LOG
relatif au site web qu'il gère et répondre aux besoins des
visiteurs du site en vue d'une amélioration ou une personnalisation
nécessaire à bonne utilisation du contenu du site web.
Notre contribution réside principalement dans les
points suivants :
1- faire une étude sur la structure des
différents fichiers log existant.
2- Une structuration des données dans une BD
conçue selon le diagramme de classe UML et au diagramme des cas
d'utilisation UML.
3- Se connecter à la BD pour l'exploiter comme
suit :
3.1. Collecter des connaissances sur les visiteurs
comme :
§ Le pourcentage des visiteurs.
3.2- Analyser les connaissances sur les pages
visitées par les internautes :
§ Les pages les plus et les moins consultées
(pages populaire et pages impopulaire).
§ Les combinaisons des pages consultées.
3.3- Définir la catégorie du site.
Organisation de notre mémoire
Notre travail s'organise autour de deux parties
principales :
A. Partie théorique :
Cette partie permet de faire un tour d'horizon sur les
différents concepts théoriques liés à notre
travail. Pour cela, elle apparait à travers ces trois
chapitres :
Le premier chapitre est consacré à une
introduction sur le Web Mining et le Web Usage Mining.
Dans le deuxième chapitre, on va s'intéresser de
prés à la structure d'un fichier log.
Et enfin dans le dernier chapitre, on va présenter
quelques notions relatives au diagramme de classe UML et au diagramme des cas
d'utilisation UML.
B. Partie pratique :
Dans cette partie, on vise à expliquer les
différentes étapes nécessaires à la mise en oeuvre
de notre projet. Pour cela, nous l'avons organisé en deux
chapitres :
Dans le premier chapitre, nous allons faire une conception
en utilisant le langage UML en s'appuyant sur le digramme des cas d'utilisation
UML pour l'identification des besoins des utilisateurs et sur le diagramme de
classe UML pour représenter issue de notre fichier LOG.
Dans le deuxième chapitre, nous proposons plusieurs
choix techniques pour la réalisation de notre travail, ensuite nous
présentons les différentes étapes nécessaires
à l'implémentation de notre conception comme (le
prétraitement, le nettoyage, l'exploration et l'analyse du fichier log)
et enfin nous décrivons l'environnement de développement en
illustrant quelques interfaces de notre logiciel.
Partie théorique :
Chapitre 1 : Web Mining
Introduction
Dans ce chapitre, nous présentons des techniques
pour extraire des connaissances comme le «Web Mining» et le
«web Usage Mining».
1- Le Web Mining :
Le Web Mining, défini comme l'application
des techniques du Data Mining aux données du Web (documents, structure
des pages, des liens...), Grâce à l'évolution constante des
technologies informatiques, s'est développé à la fin des
années 1990 afin d'extraire des informations pertinentes sur
l'activité des internautes sur le Web.
Le Web Mining sert à l'extraction d'informations
pertinentes et de connaissances réparties dans la volumineuse source de
données qu'est Internet.
L'optimisation des systèmes d'informations,
principalement dans le domaine du e-commerce, est aussi une tâche
importante réalisée à l'aide du Web Mining.
- Web Mining est un domaine de recherche pluridisciplinaire,
associant :
· Data Mining .
· Machine d'apprentissage.
· Récupération des informations.
· Traitement des langues naturelles.
· Multimédia.
· Statistiques.
Le Web Mining poursuit deux principaux objectifs:
1. L'amélioration et la valorisation des sites Web :
L'analyse et la compréhension du comportement des internautes sur les
sites Web permettent de valoriser le contenu des sites en améliorant
l'organisation et les performances des sites.
2. La personnalisation: Les techniques de Data Mining
appliquées aux données collectées sur le Web permettent
d'extraire des informations intéressantes relatives à
l'utilisation du site par les internautes. L'analyse de ces informations permet
de personnaliser le contenu proposé aux internautes en tenant compte de
leurs préférences et de leur profil.
1-1 Processus du Web Mining :
Le processus du Web Mining se déroule en trois
étapes :
1. Collecte des données sur l'utilisateur,
2. Utilisation de ces données à des fins de
personnalisation,
3. Présentation à l'utilisateur d'un contenu
ciblé.
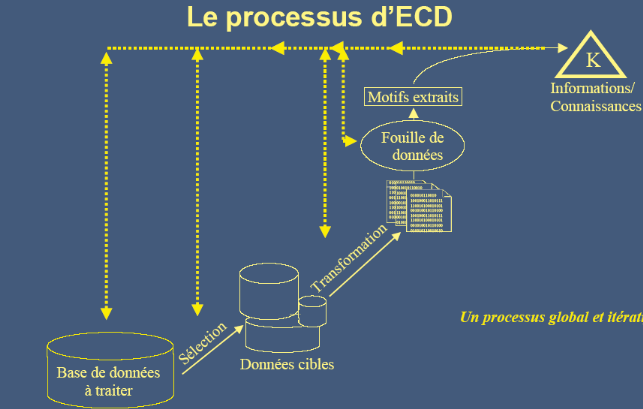
Figure 1 : Processus du Web Mining
1-2 Données du Web et leurs sources :
Les données utilisées dans le Web Mining sont
classifiées en quatre types :
- Données relatives au contenu : données
contenues dans les pages Web (textes, graphiques),
- Données relatives à la structure :
données décrivant l'organisation du contenu (structure de la
page, structure inter-page),
- Données relatives à l'usage:
données fournissant des informations sur l'usage telles que les adresses
IP, la date et le temps des requêtes,
- Données relatives au profil de l'utilisateur :
données fournissant des informations démographiques sur les
utilisateurs du site Web.
Ces données sont généralement
stockées dans un Data-Warehouse, appelé data-Webhouse, dont
l'objectif de construction est de collecter des données propres à
la fréquentation des sites Web afin d'analyser les comportements de
navigation. Les principales sources des données permettant d'alimenter
les Data-Webhouses sont :
- Les fichiers Logs du serveur Web: il s'agit du journal des
connexions qui
conserve une trace des requêtes et des
opérations traitées par le serveur.
- Les bases de données clients : ce sont les sources
des données des entreprises.
- Les cookies (ou Témoins) : ce sont des fichiers que
le serveur d'un site Web glisse au sein du disque dur de l'internaute le plus
souvent à son insu (fichiers temporaires ou dossier Cookies) afin de
stocker de l'information et mémoriser ses visites. Il permet, par
exemple de l'identifier lorsqu'il revient visiter un site
régulièrement.
1.3- Terminologie :
La compréhension du processus du Web Mining
nécessite la définition de certains termes qui se
répèteront tout au long de cette mémoire :
- Une vue de page (ou « page diffusée»)
est le chargement complet d'une page Web suite à une action de
l'utilisateur sur la page (un clic).
- Une session utilisateur est l'ensemble des requêtes
explicites effectuées par l'utilisateur durant la période
d'analyse.
- Une visite est un sous-ensemble des vues de pages
consécutives d'une session durant une connexion. On parle aussi de
« navigation». La pratique courante considère qu'une
absence de consultation de nouvelles pages sur le site dans un délai
excédant 30 minutes met fin à la visite.
- La notion de « visiteur» est à
comprendre au sens d'individu. On appelle ainsi « nombre de
visiteurs» le nombre d'individus ayant consulté le site pendant une
période donnée.
- Un épisode est un sous-ensemble de clics d'une visite
pour la réalisation d'un objectif. Il s'agit d'une phase de la
navigation.
- Un motif de navigation est un usage du site par ses
utilisateurs.
Plusieurs problèmes se posent lors d'une étude
de Web Mining:
- Le stockage des données requiert de très
grands espaces. Il nécessite souvent une machine spécifique.
- L'architecture des sites évolue
régulièrement. Par conséquent, il est parfois difficile
d'opérer des comparaisons entre les différentes périodes
d'analyse.
- La situation géographique des visiteurs est
déterminée à partir des extensions des adresses (.fr, .uk,
.com,). Cependant une adresse se terminant par .com n'est pas forcément
localisée aux Etats-Unis car cette extension est également
devenue une extension commerciale.
Figure 2 : Terminologie.
1-4- Axes de développement du Web Mining:
Les trois axes de développement du Web Mining sont : le
Web Content Mining, le Web Structure Mining et le Web Usage Mining.
1.4.1- Web Content Mining (WCM)
Le Web Content Mining (WCM) consiste en une analyse textuelle
avancée intégrant l'étude des liens hypertextes et la
structure sémantique des pages Web. Ainsi, les techniques de
description, de classification et d'analyse de chaînes de
caractères du Text Mining sont très utiles pour traiter la partie
textuelle des pages. Le WCM s'intéresse également aux images. Il
permet, par exemple, de quantifier les images et les zones de texte, pour
chaque page. Ainsi par l'analyse conjointe de la fréquentation des
pages, il est possible de déterminer si les pages contenant plus
d'images sont plus visitées que les pages contenant plus de texte.
1.4.2- Web Structure Mining (WSM)
Il s'agit d'une analyse de la structure du Web i.e. de
l'architecture et des liens qui existent entre les différents sites.
L'analyse des chemins parcourus permet, par exemple, de déterminer
combien de pages consultent les internautes en moyenne et ainsi d'adapter
l'arborescence du site pour que les pages les plus recherchées soient
dans les premières pages du site. De même, la recherche des
associations entre les pages consultées permet d'améliorer
l'ergonomie du site par création de nouveaux liens.
1.4.3- Web Usage Mining (WUM)
Cette dernière branche du Web Mining consiste à
analyser le comportement de l'utilisateur à travers sa navigation,
notamment l'ensemble des clics effectués sur le site (on parle d'analyse
du clickstream). Cette approche permet de mesurer l'audience et la performance
d'un site Web (combien de temps passé par page, combien de visites,
à quel moment, qui est l'utilisateur, quelle est la fréquence de
ses consultations,..). L'intérêt du WUM est d'enrichir les sources
de données de l'entreprise (bases de données clients, bases
marketing,...) par les données brutes du clickstream afin d'affiner les
profils clients ainsi que les modèles comportementaux.
1.4.4- Comparaison des trois catégories du Web
Mining :
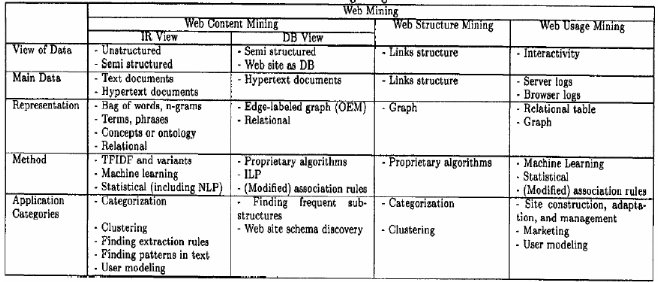
Figure 3 : Comparaison des trois
catégories du Web Mining .
1.5- Les défis du Web Mining :
· Grande quantité de l'information, mais facile
d'accès.
· Couverture de l'information est très large et
varié.
· C'est la première source de recherche
d'information dans toutes sortes de sujets, presque tout le monde (par exemple
la météo, les actualités, les produits, vocabulaire,
etc.).
· Comprend tous les types de l'information
structurée (tableaux, texte, image, audio, image, etc..).
· Semi-structurées avec code HTML dans les liens
hypertexte entre les pages d'un site Web et dans les différents sites
sont disponibles.
· L'information est redondante (même
élément d'information ou de ses variantes apparaissent avec
différentes URL).
1.6- Le Web Mining le pour et le contre :
1.6.1 - Le pour :
Web Mining essentiellement présente de nombreux
avantages de cette technologie qui rend attrayant pour les
sociétés, compris les organismes gouvernementaux. Cette
technologie a permis de faire e-Commerce marketing personnalisées, ce
qui finit par des résultats plus élevés dans les volumes
d'échanges.
Les organismes gouvernementaux utilisent cette technologie
pour classer les menaces et la lutte contre le terrorisme. La capacité
de prévision de la demande de l'exploitation minière peuvent
avantages de la société par l'identification des activités
criminelles. Les entreprises peuvent établir de meilleures relations
avec la clientèle en leur offrant exactement ce dont ils ont besoin. Les
entreprises peuvent comprendre les besoins de la clientèle et mieux ils
peuvent réagir plus rapidement aux besoins des clients. Les entreprises
peuvent trouver, attirer et retenir les clients, ils peuvent économiser
sur les coûts de production en utilisant la connaissance acquise des
besoins des clients. Ils peuvent augmenter la rentabilité de la cible de
tarification basée sur les profils créés. Ils peuvent
même trouver le client qui pourrait à défaut d'un
concurrent de l'entreprise va essayer de garder le client en fournissant
à des offres promotionnelles spécifiques du client,
réduisant ainsi le risque de perdre un client.
1.6.2 - Le contre :
Web Mining la technologie elle-même ne crée pas
de problèmes, mais cette technologie, lorsqu'elle est utilisée
sur des données de nature personnelle pourraient causer des
préoccupations. La plupart des critiques concernant la question
éthique web Mining est l'invasion de la vie privée. Protection de
la vie privée est considérée comme perdu quand
l'information concernant un individu sont obtenus, utilisés ou
diffusés, en particulier si cela se produit sans leur connaissance ou le
consentement. Les données obtenues seront analysées et
regroupées sous forme de profils, les données seront rendues
anonymes avant le regroupement, afin que personne ne puisse être
relié directement à un profil. Mais généralement
les profils de groupe sont utilisés comme si elles sont les profils
personnels. Ainsi, ces applications de personnaliser les utilisateurs en juger
par leurs clics de souris. De-individualisation, peut être définie
comme une tendance de juger et de traiter les gens sur la base des
caractéristiques de groupe plutôt que sur leurs propres
caractéristiques et les mérites.
Une autre
préoccupation importante est que les sociétés de collecte
des données dans un but précis pourrait utiliser les
données pour un tout autre but, et ce essentiellement viole les
intérêts de l'utilisateur. La tendance croissante de la vente de
données à caractère personnel comme un encourage les
propriétaires de sites de commerce des données personnelles
obtenues à partir de leur site. Cette tendance a augmenté la
quantité de données d'être capturés et
commercialisés de plus en plus la probabilité d'une invasion de
la vie privée. Les entreprises qui achètent ces données
sont tenus rendre anonymes et ces sociétés sont
considérées comme les auteurs de toutes les modes de
libération de l'exploitation minière
Et en suite on va présenter e thème du Web
usage Mining, en raison de la difficulté d'approfondir des connaissances
dans une science comprenant autant de types d'application. Dans les nombreuses
pages Web que j'ai explorées.
2- Web Usage Mining :
On peut définit le WUM comme étant
l'application du processus d'Extraction des connaissances à partir de
bases de Données (ECD) aux données issues des fichiers Logs HTTP
afin d'extraire des modèles comportementaux d'accès au Web en vue
de répondre aux besoins des visiteurs de manière
spécifique et adaptée (personnaliser les services) et faciliter
la navigation. Les profils d'accès `a un site Web peuvent être
influences par certains paramètres de nature temporelle (l'heure et le
jour de la semaine, des événements saisonniers, etc.). Cependant,
la plupart des méthodes consacrées `a la fouille de
données d'usage du Web (Web Usage Mining) prennent en compte dans leur
analyse toute la période qui enregistre les traces d'usage : les
résultats obtenus sont ainsi ceux qui prédominent sur la
totalité de la période.
2.1- Historique du Web Usage Mining :
Le Web Usage Mining a été introduit pour la
première fois en 1997 (Cooley et al.1997). Dans cet environnement, la
tache est d'extraire de manière automatique la façon dont les
utilisateurs naviguent sur un site web. Depuis 1995, Catledge et Pitkow ont
étudié la manière de catégoriser les comportements
utilisateurs sur un site web (Catledge 1995). Le processus d'extraction de
connaissance est base sur la disponibilité de données fiables :
divers travaux on été mènes sur la façon de traiter
les données récupérables depuis un site web (Cooley et al.
1999, Pitkow 1997, Chevalier et al. 2003). Une grande majorité de
chercheurs utilisent de manière systématique les informations
conte- Prétraitement des données pour l'utilisation de
l'inférence grammaticale en WUM.
2-2- Motifs du Web Usage Mining :
Il y a cinq motifs du WUM :
1. Évaluation et
caractérisation générale de l'activité sur un site
Web : l'objectif est l'observation et non pas la modélisation. Les
techniques d'analyse utilisées sont souvent simples. Elles
relèvent, en effet, du dénombrement et des statistiques simples
(moyennes, histogramme, indices, tris croisés).
2. Amélioration des modes
d'accès aux informations : le WUM permet de comprendre comment les
utilisateurs se servent d'un site, d'identifier les failles dans la
sécurité et les accès non autorisés.
3. Modification de la structure : le WUM peut
révéler le besoin de restructurer des pages et des liens afin
d'améliorer la structure du site Web. En effet,les pages
considérées comme similaires par des techniques de classification
peuvent être reliées de manière hypertextuelle.
4. Personnalisation de la consultation : cet
enjeu important pour de nombreuses applications Internet ou sites de e-commerce
consiste à proposer des recommandations dynamiques à un
utilisateur en se basant sur son profil et une base de connaissances d'usages
connus.
5. Mise en oeuvre de l'intelligence
économique: cet objectif concerne en particulier les sites marchands. Il
s'agit de comprendre quand, comment et pourquoi l'utilisateur est attiré
par ce site, les produits qu'il faut lui proposer à la vente...etc.
2.3- Données de l'usage :
Les principales données exploitées dans
le WUM proviennent des fichiers Logs. Cependant, il existe d'autres sources
d'informations qui pourraient être exploitées à savoir les
connaissances sur la structure des sites Web et les connaissances sur les
utilisateurs des sites Web.
2.3.1- Connaissances sur le site Web :
Les pages d'un site sont
matérialisées par une adresse Internet spécifique,
appelée adresse d'allocation de la ressource (Uniform Resource Locator).
La structure d'un site Internet simple peut être
représentée par un arbre dont la racine correspond à la
page d'accueil du site.
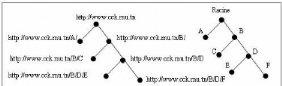
Figure 4 : Exemple d'arbre d'un site
Chaque point (ou noeud) présente l'adresse d'une page
particulière, et les segments reliant ces points indiquent la
présence d'un lien hypertexte amenant aux sous-branches
immédiates de l'arbre. D'après le schéma ci-dessus, il est
possible de retracer le chemin de navigation de l'internaute sur le site.
Cependant, il n'est pas toujours aisé de représenter
l'architecture d'un site, en particulier les sites complexes.
2.3.1- Connaissances sur les utilisateurs du site :
Les connaissances sur les utilisateurs d'un site sont
obtenues directement auprès des utilisateurs eux-mêmes dans
l'approche panéliste (âge, sexe, ancienneté sur le Web).
Dans le cas des sites à base d'inscription, ces connaissances sont
recueillies directement à partir du login et du profil de l'utilisateur
donné par l'internaute au moment de l'inscription. Ces données
dites explicites, fournies directement par les internautes sont très
souvent erronées. Il est également possible d'acquérir des
connaissances sur les utilisateurs du site en reconstituant leurs profils en
fonction de leurs activités passées sur le Web.
2.4- Processus du Web Usage Mining :
Le WUM consiste en «l'application des techniques
de fouille des données pour découvrir des patrons d'utilisation
à partir des données du Web dans le but de mieux comprendre et
servir les besoins des applications Web». La première étape
dans le processus de WUM, une fois les données collectées, est le
prétraitement des fichiers Logs qui consiste à nettoyer et
transformer les données. La deuxième étape est la fouille
des données permettant de découvrir des règles
d'association, un enchaînement de pages Web apparaissant souvent dans les
visites et des «clusters» d'utilisateurs ayant des comportements
similaires en termes de contenu visité. L'étape d'analyse et
d'interprétation clôt le processus du WUM. Elle nécessite
le recours à un ensemble d'outils pour ne garder que les
résultats les plus pertinents.
Un processus WUM comporte trois étapes principales :
prétraitement, fouille de données et analyse de motifs
extraits.
En résumé, le processus général du
Web usage Mining se représente selon figure2:
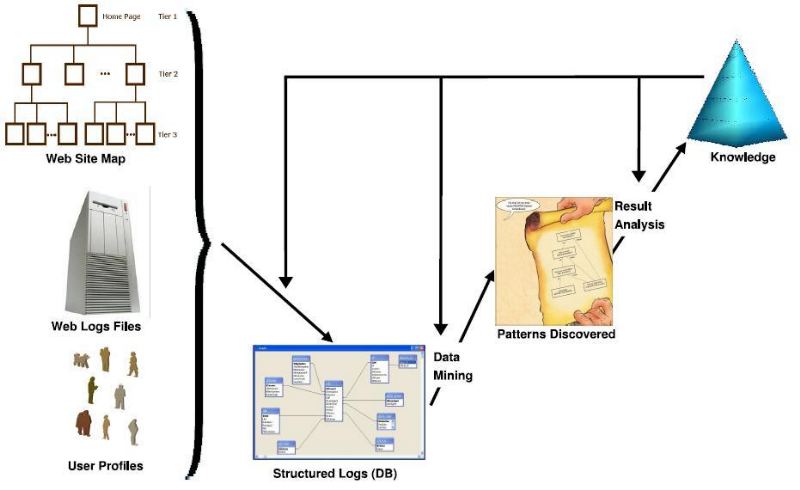
Figure 5 : Processus
général du Web usage Mining
Conclusion
Ce premier chapitre a servi d'introduction au domaine
lié à notre étude. Nous avons défini certaines
notions relatives au Web Mining et plus particulièrement, au Web Usage
Mining sur lequel porte notre étude. Et dans le chapitre qui suit nous
allons nous intéressé à la structure d'un fichier log.
Chapitre 2 : Fichier log
Introduction
Dans ce chapitre, nous expliquons la structure d'un
fichier LOG en général a travers quelques exemples relatifs
à l'observation de quelque sites web.
1- Présentation des fichiers logs :
Le comportement de l'utilisateur sur un site Web
réside en une suite de clics de souris et de saisies sur un clavier. Ces
informations déclenchent des requêtes qui ont pour résultat
l'affichage de certaines pages du site. Ces requêtes sont
enregistrées dans un fichier texte à mesure qu'elles sont
déclenchées par les utilisateurs. Ces données sont
stockées de manière standardisée de façon à
ce qu'il soit possible de procéder à des analyses. Cette base de
données est communément appelée fichier log. Son analyse
permet en principe de savoir quelles sont les requêtes qui n'aboutissent
pas (page manquante, lien erroné...) ou encore quelle est la
fréquentation de chaque page. Cependant la structure et le contenu de ce
fichier permettent d'obtenir de plus amples informations après certains
traitements.
Le format le plus répandu de fichier log est le format
ELF (Extended Log Format). Chaque ligne de ce fichier donne une information sur
l'utilisateur, son matériel, la date et l'heure de la requête, la
page requise, le statut de la page requise, la page de référence
ainsi que quelques informations liées au protocole d'échange de
données (figure 1).
Et le format (Common Log Format) a le même structure que
ELF (Extended Log Format) mais ne contient pas le
« referrer » (désignant le navigateur, le
système exploitation du l'ordinateur client et ainsi d'autres
paramètres éventuelles.
161 .31.1 32 .11 6 - - [21 /Dec/2001:08:42:55 -0500] "GET
/home.htm HTTP/1.0" 200 43 92
http://fr.search.yahoo.com/fr?p=peinture
"Mozilla/4.7 [en] (Win98)"
161 .31.1 32 .11 6 - - [21 /Dec/2001:08:43:59 -0500] "GET
/images/flagfr.jpg HTTP/1.0" 304 - "-" "Mozilla/4.7 [en] (Win98)"
209 .130.181.2 12 - - [21/Dec/2001:08:44:02 -0500] "GET /cs
HTTP/1.1" 301 236 "-" "Mozilla/4 .0 (compatible; MSIE 5.5; Windows 98)"
209 .130.181.2 12 - - [21/Dec/2001:08:44:0 3 -0500] "GET /cs/
HTTP/1.1" 200 1643 "-" "Mozilla/4.0 (compatible; MSIE 5.5; Windows 98)"
209 .130.181.212 - - [21/Dec/2001:08:44:05 -0500] "GET
/cs/frameh.htm HTTP/1.1" 200 7363 "/cs/" "Mozilla/4.0 (compatible; MSIE 5.5;
Windows 98)"
Figure 6 - extrait d'un fichier log.
Selon ce format sept informations sont enregistrées:
1. le nom du domaine ou l'adresse de Protocole Internet (IP)
de la machine appelante,
2. le nom et le login HTTP de l'utilisateur (en cas
d'accès par mot de passe),
3. la date et l'heure de la requête,
4. la méthode utilisée dans la requête
(GET, POST, etc.) et le nom de la ressource Web demandée (l'URL de la
page demandée),
5. le statut de la requête i.e. le résultat de la
requête (succès, échec, erreur, etc.),
6. la taille de la page demandée en octets.
7. le navigateur et le système exploitation
utilisé par le client.
Tout d'abord, il faut remarquer que les lignes arrivent
dans un ordre chronologique au gré des différentes requêtes
et non pas regroupées par visiteur. Chaque ligne a un format bien
défini. La première ligne de la figure 1 servira d'exemple pour
commenter les différents blocs de données.
161.31.132.116 : La
première série de chiffres est l'adresse de Protocole Internet ou
adresse IP. Cette adresse est unique lors d'une connexion. Ceci veut dire que
lorsqu'un utilisateur se connecte à l'Internet, cette adresse sera
déposée dans tous les fichiers log des sites que celui-ci
visitera le temps de sa connexion. Cependant à chaque
déconnexion, l'utilisateur perd cette adresse et en obtient une autre
lors d'une connexion ultérieure1. Pour l'analyse du trafic,
ceci a deux conséquences importantes. Premièrement, il n'est pas
possible de savoir, à partir d'un fichier log standard, si un
utilisateur est déjà venu sur le site ou s'il s'agit d'une
première visite. Deuxièmement, étant donné que le
nombre d'adresses IP disponibles est limité, plusieurs personnes peuvent
obtenir successivement la même adresse. En revanche plusieurs personnes
ne peuvent pas obtenir la même adresse simultanément. L'adresse IP
est unique durant toute la connexion et ne peut être partagée.
[21/Dec/2001:08:42:55 -0500] :
Le deuxième groupe de données est relatif à la date et
à l'heure de la requête.
GET /home.htm: Le
troisième groupe de données concerne la requête. Ici la
page requise est la page home.htm.
HTTP/1.0 : correspond au
protocole utilisé.
200 : Viennent ensuite des
données sur le statut de la page requise (200 pour« disponible
», 404 pour « introuvable »...).
4392 : correspond à la
taille chargée.
http://fr.search.yahoo.com... :
C'est la page de référence, la page à partir de laquelle
la requête est lancée.
Mozilla/4.7 [en] (Win98) : Le
dernier bloc de données renseigne sur la configuration de l'utilisateur.
Ici, le visiteur utilise le navigateur Netscape 4.7 version anglaise sous un
environnement Windows 98.
Quelques explications sont nécessaires sur le type
de requête et le code de retour :
Les principales valeurs de types de requêtes
sont :
Les requêtes généralement utilisées
sont: GET, HEAD, PUT, POST, TRACE et OPTIONS:
- La méthode GET est une requête
d'information. Le serveur traite la demande et renvoie le contenu de
l'objet.
- La méthode HEAD est très
similaire à la méthode GET. Cependant le serveur ne retourne que
l'en-tête de la ressource demandée sans les données. Il n'y
a donc pas de corps de message.
- La méthode PUT permet de
télécharger un document, dont le nom est précisé
dans l'URI, ou d'effacer un document, toujours si le serveur l'autorise.
- La méthode POST est utilisée
pour envoyer des données au serveur.
- La méthode TRACE est employée
pour le déboguage. Le serveur renvoie, dans le corps de la
réponse, le contenu exact qu'il a reçu du client. Ceci permet de
comprendre, en particulier, ce qui se passe lorsque la requête transite
par plusieurs serveurs intermédiaires.
- La méthode OPTIONS permet de
demander au serveur les méthodes autorisées pour le document
référencé
En effet, le code d'état (statut), entier
codé sur trois chiffres, a un sens propre dont la catégorie
dépend du premier chiffre:
- 1xx indique uniquement un message informel,
- 2xx indique un succès,
- 3xx redirige le client sur un autre URL,
- 4xx indique une erreur côté
client,
- 5xx indique une erreur côté
serveur.
Dans cette partie nous analyserons les formats des
fichiers log existants sur le marché, cette analyse nous permettra
d'avoir une idée sur la représentation des différentes
informations contenues dans ces fichiers.
Ensuite nous établirons la liste des bases de
données candidates, cette liste a été faite à
partir d'une analyse du marché des systèmes de gestion de base de
données.
2. Les types des fichiers Logs :
Il existe plusieurs fichiers log sur le marché ainsi
que des logiciels permettant de représenter une partie de leurs
structures :
2.1-Le serveur apache
Un log apache peut renseigner sur plusieurs
paramètres comme l'octet envoyé, le nom d'environnement,
l'adresse IP distante, le hôte distant, le nom utilisateur distant, le
port du serveur, le statut de la requête, l'heure, l'url demandé,
le hôte virtuel du serveur etc.
L'ensemble de ces informations permet d'avoir une idée
générale sur toutes les requêtes qui étaient
envoyées au serveur et les id des machines correspondant à ces
requêtes.
Exemple de log apache :
193.95.3.185 - - [18/Oct/2002:23:00:13 +0200] "GET
/pat/internet/didactic/menusour.gif HTTP/1.0" 200 22102
"http://www-ipst.ustrasbg.fr/pat/internet/didactic/introwin.htm" "Mozilla/4.0
(compatible; MSIE 6.0; Windows 98)"
193.95.3.185 - - [18/Oct/2002:23:00:13 +0200] "GET
/pat/internet/didactic/recherch.gif HTTP/1.0" 200 4255
"http://www-ipst.ustrasbg.fr/pat/internet/didactic/introwin.htm" "Mozilla/4.0
(compatible; MSIE 6.0; Windows 98)"
Figure 7 - Exemple de log apache.
2.2- Le serveur Squid
Tous les 'log' de Squid se trouvent dans le répertoire
/var/log/squid. Il y a des log pour le cache, les accès et l'utilisation
du disque. Le fichier access.log garde la trace des requêtes des clients,
de leur activité, et fournit une ligne pour chaque requête
HTTP& ICP reçue par le serveur Proxy, l'adresse IP du client, la
méthode d'interrogation, l'URL demandée, etc. Les données
de ce fichier peuvent être analysées pour disposer d'information
sur les accès. Des programmes comme sarg, calamaris, Squid-Log- Analyzer
sont disponibles pour analyser ces données et génèrent des
rapports (au format HTML). Ces rapports peuvent être établis par
les utilisateurs, les adresses IP, les sites visités, etc.
Exemples de log Squid :
951403080.162 0 172.31.13.234 TCP_HIT/200 2334 GET
http://lc2.law5.hotmail.passport.com/cgi-bin/confirmuser? -
DEFAULT_PARENT/sat-epinal.ac-nancy-metz.fr text/html
951403080.162 0 172.31.13.234 TCP_HIT/200 2334 GET
http://216.32.182.251/logo_msnhm_468x60.gif - NONE/-
image/gif
951403080.167 3 172.31.13.234 TCP_HIT/200 1314 GET
http://216.32.182.251/logo_passport_110x34.gif - NONE/-
image/gif
951403080.191 23 172.31.13.234 TCP_HIT/200 1576 GET
http://216.32.182.251/buynowFR.gif - NONE/- image/gif
951403080.199 8 172.31.13.234 TCP_HIT/200 619 GET
http://216.32.182.251/walletFR.gif - NONE/- image/gif
951403080.225 25 172.31.13.234 TCP_HIT/200 688 GET
http://216.32.182.251/dosignoutFR.gif - NONE/- image/gif
951403080.232 7 172.31.13.234 TCP_HIT/200 648 GET
http://216.32.182.251/dosigninFR.gif - NONE/- image/gif
951403081.830 1669 172.31.13.234 TCP_MISS/200 1187 GET
http://lc2.law5.hotmail.passport.com/cgi-bin/dasp/FR/hotmail___0.css
-
DEFAULT_PARENT/sat-epinal.ac-nancy-metz.fr text/css
Figure 8 - Exemples de log Squid
2.3- Analog :
Analog est un programme d'analyse des fichiers log. Il
présente de nombreux avantages.
Rapide, flexible, il est facile à installer et à
utiliser. Il donne des statistiques très précises sur l'heure, le
domaine géographique, l'organisation, les termes recherchés, le
système d'exploitation de l'utilisateur connecté, le code statut
(requête incorrecte), le fichier demandé par l'utilisateur
etc...
Exemples de log :
host.analog.cx - - [31/Dec/1999:22:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://referrer.com/" "Mozilla/4.0 (compatible; MSIE 4.01;
Windows 98)"
host.analog.cx - - [31/Dec/1999:23:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://referrer.com/" "Mozilla/4.0 (compatible; MSIE 4.01;
Windows 98)"
host.analog.cx - - [01/Jan/2000:02:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://google.com/search?q=sample%20search" "Mozilla/4.0
(compatible; MSIE 4.01; Windows 98)"
host.analog.cx - - [01/Jan/2000:03:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://google.com/search?q=sample%20search" "Mozilla/4.0
(compatible; MSIE 4.01; Windows 98)"
host.analog.cx - - [01/Jan/2000:04:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://google.com/search?q=sample%20search" "Mozilla/4.0
(compatible; MSIE 4.01; Windows 98)"
host.analog.cx - - [01/Jan/2000:05:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://google.com/search?q=sample%20search" "Mozilla/4.0
(compatible; MSIE 4.01; Windows 98)"
host.analog.cx - - [01/Jan/2000:06:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://google.com/search?q=sample%20search" "Mozilla/4.0
(compatible; MSIE 4.01; Windows 98)"
host.analog.cx - - [01/Jan/2000:07:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://google.com/search?q=sample%20search" "Mozilla/4.0
(compatible; MSIE 4.01; Windows 98)"
host.analog.cx - - [01/Jan/2000:08:11:12 +0000] "GET
/sample.html HTTP/1.0" 200 1234
"http://google.com/search?q=sample%20search" "Mozilla/4.0
(compatible; MSIE 4.01; Windows 98)"
Figure 9 - Exemples de log
Analog.
2.4- Caritig :
Caritig est un des sites qui dispose de statistiques
permettant d'avoir une idée sur le nombre des visiteurs, les pages
consultées et la durée de la recherche sur le site. Les
sociétés améliorent ainsi leurs sites pour le rendre plus
attractif. Ces statistiques sont extraites en général d'un
fichier log, les informations publiées sur le site sont : l'agent
(adresse), l'heure, l'adresse IP, l'hôte etc.
Exemple de statistique :
Internet Explorer 5.0 - Win 98 195.83.96. --- [Srv]
station.adm.ac-versailles.fr 08/01 15:38
Internet Explorer 5.5 - Win NT 80.9.159. --- [Srv]
mix-toulouseabo.wanadoo.fr 08/01 15:37
Internet Explorer 4.0 - Win NT 193.249.234. --- [Srv]
mix-lagnyabo.wanadoo.fr 08/01 15:33
Internet Explorer 5.5 - Win NT 80.9.158. --- [Srv]
mix-toulouseabo.wanadoo.fr 08/01 15:30
Internet Explorer 5.0 - Win 98 80.8.169. --- [Srv]
ca-marseilleabo.wanadoo.fr 08/01 15:19
Yahoo ! (Annuaire)
Netscape 4.7 - Win 95 213.41.22.--- [Srv] disu.chu-lyon.fr
08/01 15:08
http://extrasense.chez.tiscali.fr/
Internet Explorer 5.5 - Win 2000 193.49.200.--- [Srv]
serv.ensicaen.ismra.fr 08/01 15:04
Internet Explorer 5.5 - Win NT 80.14.85. --- [Srv]
afontenayssbabo.wanadoo.fr 08/01 15:03
Voila (gay)
Internet Explorer 5.5 - Win NT 212.234.211. ---
08/01 14:57
http://www.tg-guide.com/
Internet Explorer 5.5 - Win Me 194.250.150. --- [Srv]
cfacb.adsl.oleane.fr 08/01 14:22
http://search.yahoo.com/
Figure 10 - Exemples de log Caritig
3-Problèmes spécifiques aux
données des fichiers LOG :
Bien que les données fournies par les fichiers Logs
soient utiles, il importe de prendre en compte les limites inhérentes
à ces données lors de leur analyse et de leur
interprétation. Parmi les difficultés qui peuvent survenir:
3.1-Les requêtes inutiles :
Chaque fois qu'il reçoit une requête, le serveur enregistre une
ligne dans le fichier Log. Ainsi, pour charger une page, il y'aura autant de
lignes dans le fichier que d'objets contenus sur cette page (les
éléments graphiques). Un prétraitement est donc
indispensable pour supprimer les requêtes inutiles.
3.2- Les firewalls
: Ces protections d'accès à un réseau masquent
l'adresse IP des utilisateurs. Toute requête de connexion provenant d'un
serveur doté d'une telle protection aura la même adresse et ce,
quel que soit l'utilisateur. Il est donc impossible, dans ce cas, d'identifier
et de distinguer les visiteurs provenant de ce réseau.
3.3- Le Web
caching: Afin de faciliter le trafic sur le Web, une copie de
certaines pages est sauvegardée au niveau du navigateur local de
l'utilisateur ou au niveau du serveur Proxy afin de ne pas les
télécharger chaque fois qu'un utilisateur les demande. Dans ce
cas, une page peut être consultée plusieurs fois sans qu'il y' ait
autant d'accès au serveur. Il en résulte que les requêtes
correspondantes ne sont pas enregistrées dans le fichier Log.
3.4- L'utilisation des
robots : Les annuaires du Web, connus sous le nom de moteurs de
recherche, utilisent des robots qui parcourent tous les sites Web afin de
mettre à jour leur index de recherche. Ce faisant, ils
déclenchent des requêtes qui sont enregistrées dans tous
les fichiers Logs des différents sites, faussant ainsi leurs
statistiques.
3.5- L'identification des
utilisateurs : L'identification des utilisateurs à partir
du fichier Log n'est pas une tâche simple. En effet, en employant le
fichier Log, l'unique identifiant disponible est l'adresse IP et
»l'agent» de l'utilisateur. Cet identifiant présente plusieurs
limites :
3.6- Adresse IP unique / Plusieurs sessions
serveurs: La même adresse IP peut être
attribuée à plusieurs utilisateurs accédant aux services
du Web à travers un unique serveur Proxy.
3.7- Plusieurs adresses IP / Utilisateur
unique: Un utilisateur peut accéder au Web à partir
de plusieurs machines.
3.8- Plusieurs agents / Utilisateur unique
: Un internaute qui utilise plus d'un navigateur, même si la
machine est unique, est aperçu comme plusieurs utilisateurs.
3.9- L'identification des sessions :
Toutes les requêtes provenant d'un utilisateur identifié
constituent sa session. Le début de la session est défini par le
fait que l'URL de provenance de l'utilisateur est extérieure au site.
Par contre, aucun signal n'indique la déconnexion du site et par suite
la fin de la session.
3.10- Le manque
d'information : Le fichier Log n'apporte rien sur le comportement
de l'utilisateur entre deux requêtes : Que fait ce dernier? Est-il
vraiment en train de lire la page affichée? De plus, le nombre de
visites d'une page ne reflète pas nécessairement
l'intérêt de celle-ci. En effet, un nombre élevé de
visites peut simplement être attribué à l'organisation d'un
site et au passage forcé d'un visiteur sur certaines.
4- Etude de quelques outils d'analyse de fichiers
« log » :
En effectuant des recherches sur Internet, nous
avons rencontré une multitude d'outils d'analyse de fichiers «
log » de Squid. Dans ce qui suit, nous allons présenter
quelques uns que nous jugeons parmi les plus importants de
point de vue fonctionnalités et parmi les plus couramment
utilisés. Ces outils sont : AWStats,
Sawmill et Log_Report.
4.1- AWStats :
AWStats est un outil puissant d'analyse de
fichiers journaliers de différents formats permettant de
générer des graphes et des rapports de statistiques à
partir des données de ces fichiers. Il peut analyser les fichiers
journaliers de la majorité des serveurs comme les fichiers
« log » d'Apache, WebStar et bien d'autres serveurs Web,
Proxy, Wap, des serveurs de streaming et certains serveurs ftp. Ce
logiciel, bien qu'il soit puissant, n'est pas spécifique au Proxy Squid
et donc les statistiques générées n'exploitent
pas au mieux les riches informations des fichiers journaliers de
Squid.
4.2- Sawmill :
Sawmill est un outil d'analyse de journaux puissant et
hiérarchique qui fonctionne sur toutes
les grandes plateformes. Il est particulièrement bien
adapté aux fichiers journaux de serveur Web, mais peut traiter
presque n'importe quel fichier « log » notamment ceux du
Proxy Squid. Les rapports que Sawmill génère sont
hiérarchiques, attrayants et fortement réticulés pour
faciliter la navigation. Cependant, cet outil n'est pas gratuit ce qui reste un
grand inconvénient par rapport aux autres outils disponibles.
4.3- Modlogan:
Modlogan est un analyseur modulaire de fichiers journaliers
qui est actuellement en mesure
d'analyser les journaux des serveurs web et du Proxy Squid.
Cet outil génère un fichier qui peut être visualisé
par un navigateur web ou un éditeur de texte. Les données sont
traitées de la même façon, que ce soit des données
en provenance d'un serveur web, d'un Proxy Squid, d'un serveur de streaming ou
d'un serveur ftp. Un inconvénient majeur concernant cet outil est la
façon dont il traite les données et qui n'est pas
spécifique au Proxy Squid ce qui rend les statistiques moins riches
qu'elles ne peuvent l'être s'il y avait eu une bonne exploitation de ces
journaux.
Suite à la description de ces quelques outils d'analyse
de journaux, nous constatons que, bien qu'ils soient nombreux, nous n'avons pas
trouvé un outil gratuit, spécifique au Proxy Squid offrant la
possibilité de naviguer entre les statistiques pour tout en exploitant
les données riches des fichiers « log » et en ayant une
interface conviviale qui facilite la lecture de ces statistiques et des graphes
correspondants.
Conclusion
Dans ce chapitre a servi d'introduction au fichier LOG. Nous
avons défini certaines notions
relatives à la structure d'un fichier LOG.
Chapitre 3 : Quelques notions UML
Introduction
Dans ce chapitre, on va décrire deux diagrammes parmi
les neuf que compte le langage UML parce que nous nous intéressons
seulement au diagramme de classe UML et au diagramme des cas d'utilisation.
1. Définition d'UML :
UML, qui se veut un instrument de capitalisation
des savoir-faire puisqu'il propose
un langage qui soit commun à tous les experts du
logiciel, va dans le sens de cet assouplissement des contraintes
méthodologiques.
UML signifie Unified Modeling Language. La
justification de chacun de ces mots nous servira de fil conducteur pour cette
présentation.
UML n'est pas une méthode (i.e. une description
normative des étapes de la modélisation) : ses auteurs ont en
effet estimé qu'il n'était pas opportun de définir une
méthode en raison de la diversité des cas particuliers. Ils ont
préféré se borner à définir un langage
graphique qui permet de représenter, de communiquer les divers aspects
d'un système d'information (aux graphiques sont bien sûr
associés des textes qui expliquent leur contenu). UML est donc un
métalangage car il fournit les éléments permettant de
construire le modèle qui, lui, sera le langage du projet.
Il est impossible de donner une représentation
graphique complète d'un logiciel, ou de tout autre système
complexe, de même qu'il est impossible de représenter
entièrement une statue (à trois dimensions) par des photographies
(à deux dimensions). Mais il est possible de donner sur un tel
système des vues partielles, analogues chacune à une photographie
d'une statue, et dont la juxtaposition donnera une idée utilisable en
pratique sans risque d'erreur grave.
- UML 2.0 comporte ainsi treize types de diagrammes
représentant autant de vues distinctes pour représenter des
concepts particuliers du système d'information. Ils se
répartissent en deux grands groupes :
2- Diagrammes structurels ou diagrammes statiques (UML
Structure)
- diagramme de classes (Class diagram).
- diagramme d'objets (Object diagram).
- diagramme de composants (Component diagram).
- diagramme de déploiement (Deployment diagram).
- diagramme de paquetages (Package diagram).
- diagramme de structures composites (Composite structure
diagram).
3- Diagrammes comportementaux ou diagrammes dynamiques
(UML Behavior)
- diagramme de cas d'utilisation (Use case diagram)
- diagramme d'activités (Activity diagram)
- diagramme d'états-transitions (State machine
diagram)
- Diagrammes d'interaction (Interaction diagram)
· diagramme de séquence (Sequence diagram).
· diagramme de communication (Communication diagram)
· diagramme global d'interaction (Interaction overview
diagram).
· diagramme de temps (Timing diagram).
Ces diagrammes, d'une utilité variable selon les cas,
ne sont pas nécessairement tous produits à l'occasion d'une
modélisation. Les plus utiles pour la maîtrise d'ouvrage sont les
diagrammes d'activités, de cas d'utilisation, de classes, d'objets, de
séquence et d'états transitions.
Les diagrammes de composants, de déploiement et de
communication sont surtout utiles pour la maîtrise d'oeuvre à qui
ils permettent de formaliser les contraintes de la réalisation et la
solution technique
4- Le diagramme des cas (vue fonctionnelle) :
4.1- Les cas d'utilisation :
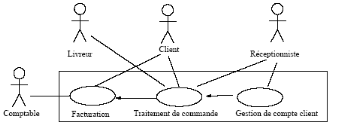
Figure 11 : exemple sur le diagramme cas
d'utilisation.
Un cas d'utilisation (use case) modélise une
interaction entre le système informatique à développer et
un utilisateur ou acteur interagissant avec le système. Plus
précisément, un cas d'utilisation décrit une
séquence d'actions réalisées par le système qui
produit un résultat observable pour un acteur.
Il y a en général deux types de description des
use cases :
- une description textuelle de chaque cas ;
- le diagramme des cas, constituant une synthèse de
l'ensemble des cas ;
Il n'existe pas de norme établie pour la description
textuelle des cas. On y trouve généralement pour chaque cas son
nom, un bref résumé de son déroulement, le contexte dans
lequel il s'applique, les acteurs qu'il met en jeu, puis une description
détaillée, faisant apparaître le déroulement nominal
de toutes les interactions, les cas nécessitant des traitements
d'exceptions, les effets du déroulement sur l'ensemble du
système, etc.
5- Le diagramme des classes (vue
structurelle) :
5.1 Introduction au diagramme des classes :
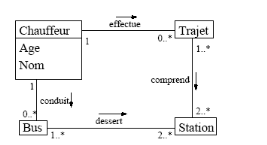
Figure 12 : exemple d'un diagramme de
classe
Un diagramme des classes décrit le type des objets ou
données du système ainsi que les différentes formes de
relation statiques qui les relient entre eux. On distingue classiquement deux
types principaux de relations entre objets :
- les associations, bien connues des vieux modèles
entité/association utilisés dans la conception des bases de
données depuis les années 70 ;
- les sous-types, particulièrement en vogue en
conception orientée objets, puisqu'ils s'expriment très bien
à l'aide de l'héritage en programmation.
La figure 4 présente un exemple de diagramme de classes
très simple, tel qu'on pourrait en rencontrer en analyse. On voit qu'un
simple coup d'oeil suffit à se faire une première idée des
entités modélisées et de leurs relations. Nous allons
examiner successivement chacun des éléments qui le constituent.
Auparavant, nous introduirons les packages.
Conclusion :
Dans ce chapitre a servi de quelques notions UML et plus
précisément le diagramme cas d'utilisation et diagramme de
classe.
Partie pratique :
Chapitre 4 : Analyse et spécification des
besoins
Introduction :
Dans ce chapitre, nous abordons la
phase d'analyse et spécification des besoins. Ainsi, nous
présentons les besoins fonctionnels et non
fonctionnels de notre application. Nous utilisons
le langage UML comme un moyen simple et
compréhensible afin de décrire les principaux cas
d'utilisation.
1 -Besoins fonctionnels :
Cette partie décrit les exigences que le système
doit satisfaire d'une façon informelle.
Les fonctionnalités qu'on se propose de fournir dans
notre logiciel sont les suivantes :
? Générer des statistiques relatives aux
connexions Internet. Ces statistiques concernent
particulièrement :
· Les sites web les plus visités avec des
informations relatives aux nombres de visites,
· le pourcentage des visiteurs par semaine, par mois
et par an.
· le pourcentage des navigateurs les plus
utilisés...etc.
? Assurer une navigation entre les statistiques suivant
certaines relations qui peuvent
exister entre elles.
2 - Besoins non fonctionnels :
? L'application doit présenter des interfaces
conviviales et ergonomiques afin de faciliter l'utilisation de l'application
par un utilisateur qu'il soit spécialiste ou non.
-Afin de mieux comprendre les fonctionnalités de notre
outil nous présentons les diagrammes
de cas d'utilisations et diagramme de classe qui nous jugeons
les plus représentatifs.
3. Analyse du problème et conception de la
solution méthode UML :
3-1. Diagramme de cas
d'utilisation :
Le diagramme de cas d'utilisation représente la
structure des grandes fonctionnalités nécessaires aux
utilisateurs du système. C'est le premier diagramme du modèle
UML, celui
où s'assure la relation entre l'utilisateur et les
objets que le système met en oeuvre.
Dans cette étape, il s'agira de structurer les
besoins des utilisateurs et les objectifs correspondants.
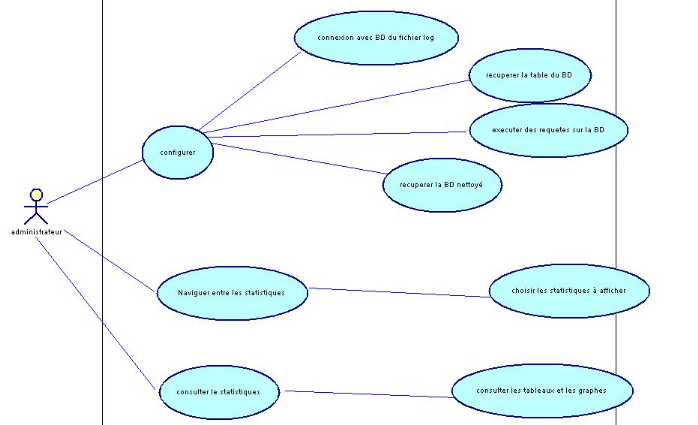
Figure 13 : Diagramme cas d'utilisation.
Le diagramme élaboré après l'étude
des spécifications est représenté par la figure figure13
ci-dessous. Sur ce diagramme, on s'aperçoit qu'il existe essentiellement
acteur
Principale dans le système:
· L'administrateur :
c'est l'utilisateur qui possède tous les privilèges et un
accès total au système.
Dans ce qui suit, nous présentons un formalisme semi
formel de spécification des besoins de
notre système, à l'aide des diagrammes de cas
d'utilisation [figure13] accompagnés par
une explication textuelle de ses principaux cas
d'utilisation
? Le cas d'utilisation « Configuration
» :
L'administrateur peut communiquer à l'outil un fichier
« log ». Ce dernier l'intercepte, l'analyse, le convertit dans un
format générique et le stocke sous ce format dans une base de
données et ensuite faire un nettoyage sur la base de donnée a
l'aide d'un ensemble des requêtes puis on sorte par une autre base de
donnée nettoyée.
? Le cas d'utilisation « Editer rapport
» :
L'administrateur peut introduire directement ou au fur et
à mesure de la navigation les
différentes statistiques.
? Le cas d'utilisation «Naviguer entre les
statistiques » :
L'administrateur peut naviguer aisément entre les
différentes statistiques ; un scénario
possible consiste à explorer les statistiques
relatives aux sites les plus visités...etc.
? Le cas d'utilisation «Consulter tableaux de
statistiques » :
L'administrateur peut visualiser les statistiques
correspondantes sous formes tabulaire et
graphiques.
-Et pout l'utilisateur, il fait seulement la consultation des
tableaux et la visualisation
des statistiques.
3.2- Diagramme de classe :
Le diagramme des classes est
généralement considéré comme le plus important dans
un développement orienté objet. Il représente
l'architecture conceptuelle du système : il décrit les classes
que le système utilise, ainsi que leurs liens, que ceux-ci
représentent un emboîtage conceptuel (héritage) ou une
relation organique (agrégation).
Le diagramme des classes déduit à partir
du diagramme des cas d'utilisation est illustré par la figure ci-dessous
Ce diagramme comporte huit classes, avec leurs propres attributs et
méthodes, reliées entre elles par des
associations. Ces classes sont nommées ainsi :
Fichier log : cette classe comporte
comme attributs : caracteristique, format, Elle représente une
classe-mère.
Log _traitement : cette classe ne
comporte pas des attributs ainsi que des méthodes telles que:
importer, charger dans la BD, nettoyage, traiter.
Set_information : cette classe ne
comporte qu'une méthode : remplir.
Extraire_connaissance : cette classe
comporte deux méthodes :
Extraire, extraire_visiteur, c'est une classe mère des
classes suivantes :
Visiteur_fidel, type de site, pages vues, popularite des
pages.
Visiteur_fidel : cette classe comporte
un seul attribut : Nbr_visiteur en plus une méthode :
consulter.
Type de site, Pages vues, Popularité des
pages : cette classe comporte une seule méthode :
consulter.
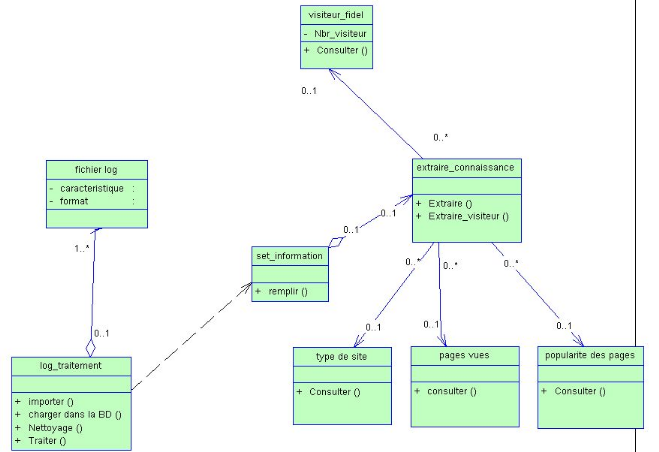
Figure 14 :
Diagramme de classe
Conclusion :
Ce chapitre intitulé « étude conceptuelle
» a décrit l'étape la plus importante du cycle de
vie du logiciel et nous a permis de couvrir tous les cas
d'utilisation concernant l'utilisation de notre présent analyseur de
fichiers « log » et de définir les besoins non fonctionnels
à prendre en considération afin de satisfaire les utilisateurs.
Chapitre 5 : Etude technique
Introduction :
Dans ce chapitre, nous proposons plusieurs choix techniques
pour la réalisation de notre travail, ensuite nous présentons les
différentes étapes nécessaires à
l'implémentation de notre conception comme (le prétraitement, le
nettoyage, l'exploration et l'analyse du fichier log) et enfin nous
décrivons l'environnement de développement en illustrant
quelques interfaces de notre logiciel.
1-Les étapes de l'implémentation :
Fichier Log
Table d'une BDD
Connexion BD
Nettoyage des graphiques, image
Statistiques
Transformation
Exécuter des requêtes
t
Exploration
Prétraitement
Nettoyage
Utiliser LOG ANALYZER
Analyse
Figure 15 : la démarche
adoptée.
Figure 16 : Analyse « manuelle » du
fichier log.
2- Le prétraitement des
données :
2.1 Chargement du fichier Log et transformation en une
Table d'une BDD :
La première étape d'un processus WUM se compose
principalement de deux types de tâches :
- Tâches classiques de prétraitement : fusion des
?chiers logs web, nettoyage et structuration de données.
- Tâches avancées de prétraitement :
stockage des données structurées dans une base de données
(notée BD par la suite), généralisation et
agrégation des données.
Le fichier LOG est un fichier Texte appelé aussi
journal des connexions, qui conserve les traces des requêtes et des
opérations traitées par le serveur. Généralement il
est de la forme suivante:
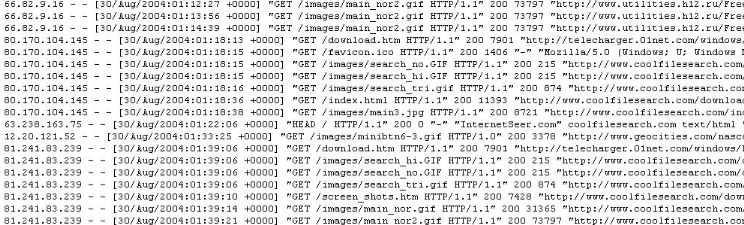
Figure
17 : Un fichier LOG avant le prétraitement.
Dans cette étape, les données structurées
sont enregistrées sous une forme persistante,
généralement, dans une BD.
- Les différent champs de ce fichier vont être,
importé dans une base données déterminée comme
suit :
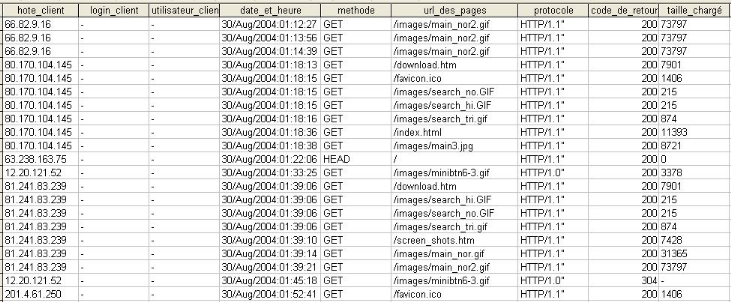
Figure
18 : Un fichier LOG dans une BD.
Le fichier log se transforme en une table composée
de plusieurs colonnes, chaque colonne correspond à un champ
spécifié du fichier LOG :
· La colonne « hote_client » correspond aux
adresses IP des visiteurs
· La colonne « login_client » correspond au
Nom du serveur utilisé par le visiteur
· La colonne « utilisateur_client »
correspond au Nom de l'utilisateur (en cas d'accès par mot de passe).
· La colonne « date_et_heure » correspond
à la date d'accès
· La colonne « méthode » correspond
à la méthode utilisée (GET/POST)
· La colonne « url_des_pages » correspond
au URL demandé
· La colonne « protocole » correspond au
protocole utilisé
· La colonne « code_de_retour »
· La colonne « taille_chargé »
correspond à la taille chargée.
3- Nettoyage des données :
Le nettoyage des données est une étape
cruciale dans le processus du WUM en raison du volume important des
données enregistrées dans les fichiers Log Web. En effet, la
dimension de ces fichiers dans les sites Web et les portails Web très
populaires peut atteindre des centaines de giga-octets par heure.
L'étape du nettoyage consiste à filtrer les données
inutiles à travers la suppression des requêtes ne faisant pas
l'objet de l'analyse et celle provenant des robots Web. La suppression du
premier type de requêtes dépend de l'intention de l'analyste. En
effet, si son objectif est de trouver les failles de la structure du site Web
ou d'offrir des liens dynamiques personnalisés aux visiteurs du site
Web, la suppression des requêtes auxiliaires comme celles pour les images
ou les fichiers multimédia est possible. quand il ne faut pas supprimer
ces requêtes puisque dans certains cas les images ne sont pas incluses
dans les fichiers HTML mais accessibles à travers des liens, ainsi
l'affichage de ces images indique une action de l'utilisateur.
La suppression du second type de requêtes i.e. les
entrées dans le fichier Log produites par les robots Web (WR) permet
également de supprimer les sessions non intéressantes. En effet,
les WRs suivent automatiquement tous les liens d'une page Web. Il en
résulte que le nombre de demandes d'un WR dépasse en
général le nombre de demandes d'un utilisateur normal. Pour
identifier les requêtes et les visites issues des WRs on utilise trois
heuristiques:
1. Identifier les adresses IPs qui ont formulé une
requête à la page « robots.txt».
2. Utiliser des listes des «User agents» connus
comme étant des WRs.
3. Utiliser un seuil pour « la vitesse de
navigation» BS (Browsing Speed), qui représente le rapport entre le
nombre de pages consultées pendant une visite de l'utilisateur et la
durée de la visite. Si BS est supérieure à deux pages par
seconde et la visite dépasse 15 pages, alors la visite a
été initiée par un WR
3.1 Nettoyage des graphiques, image :
Les données concernant les pages possédant
des graphiques, Images, n'apporteront rien à l'analyse. Elles seront
donc filtrées :
Pour cela on est amené à supprimer de notre base
de données les URLs suivants :
Les urls correspondant aux images d'extension « .gif
» par la requête
("delete * from tab where url_des_pages like '*.*gif'")
Les urls correspondant aux images d'extension « .jpg
» par la requête
("delete * from tab where url_des_pages like '*.*jpg'")
Les urls correspondant aux images d'extension « .png
» par la requête
("delete * from tab where url_des_pages like '*.*png'")

Figure 19 : exemple sur les urls (.GIF,
.JPG,....).
Les urls correspondant aux robots par la requête :
- Il est presque impossible aujourd'hui d'identifier tous les
robots Web puisque chaque jour apparaissent des nouveaux. Pour les robots dont
l'adresse IP et le User-Agent sont inconnus, nous procédons à un
examen de leurs comportements sachant que les robots Web procèdent
à une visite relativement exhaustive (nombre de pages visitées
par un robot est supérieur au nombre de pages visitées par un
utilisateur normal) et rapide et qu'ils cherchent généralement un
fichier nommé »robot.txt».
("delete * from tab where url_des_pages like
'\robots.txt'")
4- Réalisation:
Nous présentons le travail réalisé,
le choix de la plate forme utilisée ainsi que l'environnement de
développement, nous commentons les différentes interfaces
graphiques ainsi que quelques statistiques obtenues.
4.1- L'environnement de développement :
? Outil de spécification et conception
:
Notre choix s'est porté sur le logiciel
Power AMC version 11.1_FRENCH-BS qui est un produit
Sybase opérant sur la plateforme Windows. Cet outil
supporte tous les modèles du langage unifié de
modélisation UML en couvrant toutes les étapes du cycle
de développement du logiciel.
? Langage de programmation :
Nous avons opté pour le langage de programmation
JAVA. Ce choix se justifier par la simplicité avec
laquelle il permet d'analyser et de traiter efficacement du texte
structuré. En effet, Java met en oeuvre plusieurs astuces de
programmation qui facilite l'extraction des informations d'un fichier
historique (log) ou d'une base de données. S'ajoute à cet
argument, la richesse de ses bibliothèques graphiques, la
portabilité et la fiabilité de ce langage.
? Système de gestion de base de données
:
Access :
Microsoft Access 2003 est un puissant, pourtant facile
à apprendre, application de base de données relationnelles de
Microsoft Windows. Ce didacticiel est conçu pour des utilisateurs qui
sont nouveaux ou ont peu d'expérience en utilisant Access 2003. Il
introduit les concepts fondamentaux et les opérations de base de
données et illustre la façon dont elles sont
exécutées dans Microsoft Access 2003. Ce tutorial ne couvre pas
toutes les caractéristiques et les fonctions de Microsoft Access 2003,
l'accent sera mis sur la base et fréquemment utilisés, tels que
la création de tables et de requêtes, ou l'importation de feuille
de calcul dans Access.
MySQL :
MySQL est un système de gestion de bases de
données relationnelle dédiée Open Source (Open Source
Software)._ Le mouvement Open source fait qu'il est possible à tous
d'utiliser et de modifier un logiciel. Mysql est très rapide, fiable et
facile à utiliser, il dispose aussi d'un jeu de fonctionnalités
développé en coopération avec d'autres utilisateurs._
MySQL a été développé à l'origine pour
gérer de très grandes bases de données beaucoup plus
rapidement que des solutions déjà établies, et a
été utilisé avec succès dans des conditions de
productions critiques depuis plusieurs années. En développement
constant, MySQL offre aujourd'hui un ensemble de fonctionnalités large
et riche. Sa rapidité et sa sécurisation en font un outil
idéal pour les applications Internet.
Langage SQL :
SQL (Structured Query Language) est un langage de manipulation
de bases de données mis au point dans les années 70 par IBM. Il
permet trois types de manipulations sur les bases de données:
- La maintenance des tables: création, suppression,
modification de la structure des tables.
- Les manipulations des bases de données :
Sélection, modification, suppression d'enregistrements.
- La gestion des droits d'accès aux tables :
Contrôle des données : droits d'accès, validation des
modifications.
L'intérêt de SQL est que c'est un langage de
manipulation de bases de données standard permettant de gérer une
base de données Access, Paradox, MySql, dBase, SQL Server ou Oracle .
Une requête SQL prend généralement le
format suivant :
SELECT [DISTINCT] attribut(s)
FROM table(s)
[WHERE condition] [GROUP BY field(s)] [HAVING
condition] [ORDER BY attribute(s)]
Dans ce mémoire, nous avons recours au langage SQL pour
le nettoyage de la base.
Exemples:
Requête SQL de suppression des images:
DELETE *
FROM TAB
WHERE (TAB Like '*gif') or (TAB Like '*jpg') or (TAB
Like '*jpeg');
4.2- Exploration et Analyse du fichier Log :
Pour l'exploration et l'analyse du fichier Log, un outil
logiciel a été conçu et réalisé : LOG
ANALYZER dans l'interface est comme suit :
Figure 20 : L'interface du
logiciel « LOG ANALYZER »
4.2.1. Interface d'accueil
L'interface d'accueil est la page de garde de notre outil
qui contient son menu principal et qui va donner l'accès soit à
la configuration soit au weka.
4.2.2. Configuration
a- Configuration du système :
Dans la configuration du système, on fait la
connexion avec BD qui contient le fichier LOG.
Pour définir les paramètres de configuration
:
v Cliquer sur le bouton « Importer la BD »
puis identifier le mot de passe (Figure 21).
Figure 21 : identifier le mot de
passe.
v choisir le type de votre BD qui contient le fichier LOG et
spécifier le nom du BD (Figure 22).
Figure 22 : choisir le type de la base de
données correspondant.
- Puis en intéresse sur la partie
« Nettoyage » : Les données concernant les
pages possédant des graphiques, des images ou des scripts, n'apportent
rien à l'analyse. Elles seront donc éliminées.
v Cliquer sur le bouton « Nettoyage » pour
exécuter quelques requêtes sur la BD (Figure 23).
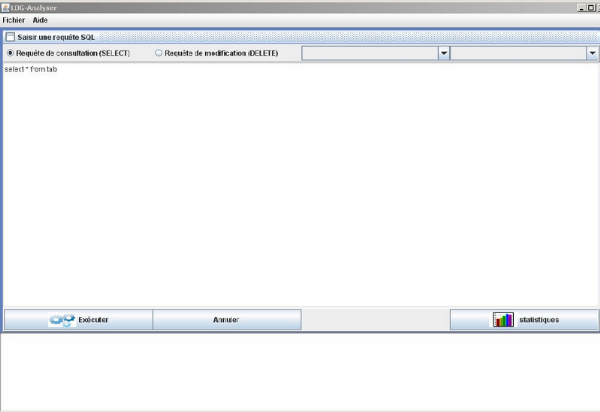
Figure 23 : Nettoyage de la BD.
b- Configuration des statistiques :
Pour définir les paramètres de l'affichage des
statistiques :
v Définir l'intervalle du temps (date du début
et date du fin).
v Cliquer sur le bouton « statistique »
pour voir les statistiques générales (Figure 24).
b.1- Statistiques générales:
Dans cette rubrique on détermine:
v le nombre total de visites (Le temps de mort d'une
visite est 30 minutes).
v le nombre total de pages vues
v le moyen de pages vues par visite
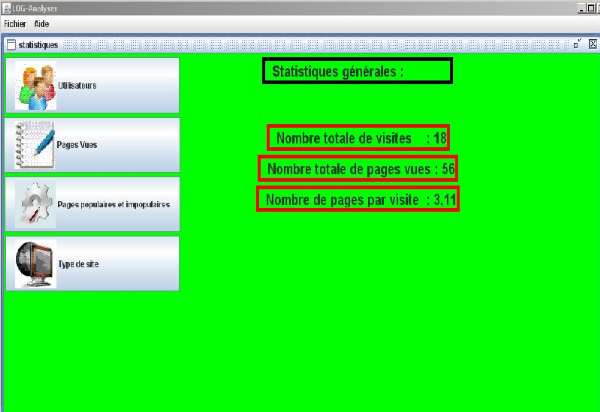
Figure 24 : Statistiques
générales.
b.2- Utilisateurs :
Cette rubrique renseigne le Webmaster sur la
fidélité de ses visiteurs (Figure 25).
NB : chaque adresse IP est équivalente
à un utilisateur ou internaute.
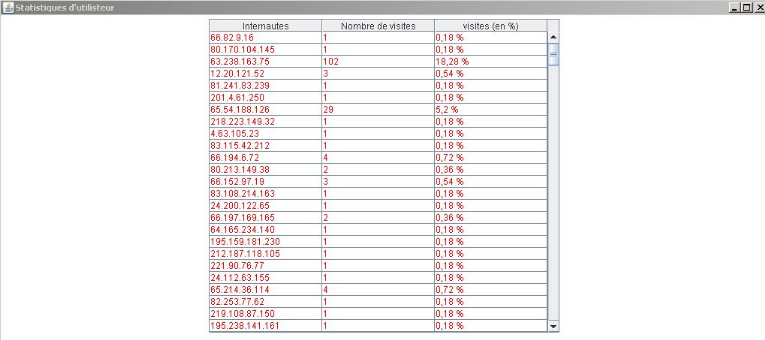
Figure 25 : les utilisateurs.
b.3- Pages vues :
Cette rubrique nous permet de calculer la fréquence
de consultation pour chaque page
(Figure 26).

Figure 26 : les pages vues.
- On peut l'illustrer graphiquement par la Figure
27 :
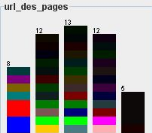
Figure 27 : Graphique des pages fréquemment
consultées
b.4- Pages populaires et
impopulaires :
Cette rubrique nous permet de calculer la fréquence de
consultation des pages populaires et impopulaires (Figure 28).
Ici l'idée est de donner au Webmaster toutes les pages
populaires et impopulaires selon
leurs degrés de popularité, en se basant sur le
nombre de fois qu'une page a été visitée
dans une période spécifiée.

Figure 28 : pages populaires et
impopulaires.
-Et on peut illustrer un exemple graphiquement par la
Figure 29:
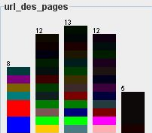
Figure 29 : Graphique des pages populaires et
impopulaire.
b.5- Type de site :
Dans cette rubrique on déterminera si notre site
joue toujours son rôle préalablement défini (consultatif ou
de téléchargement), en utilisant les méthodes sur le site
(GET OU POST) (Figure 30).
Parfois, un site défini préalablement comme
consultatif avec quelques fichiers à télécharger se
transforme en un site de téléchargement, car les utilisateurs ne
le consultent que pour les téléchargements
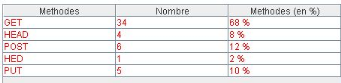
Figure 30 : la catégorie du
site.
- Et graphiquement par la Figure 31 :
Figure 31 : Graphique sur la catégorie du
site
b.6- protocole utilisé :
Dans cette rubrique on soit spécifier le type du
protocole utilisé (http) selon la figure 32 :

Figure 32 : protocole utilisé.
On peut l'illustrer graphiquement comme suit :

Figure 33 : Graphique sur le protocole
utilisé.
4.2.3- Weka:
Weka2 (Waikato Environment for Knowledge Analysis) est un
projet de recherche mené a l'Université de Waikato
(Nouvelle-Zélande) depuis 1994.
L'objectif du projet est de proposer un environnement
d'extraction de connaissances "open source" qui regroupent un ensemble
d'algorithmes de fouille de données. Parmi les algorithmes proposes,
nous trouvons des algorithmes de classification, de régression et
d'extraction de règles d'association. De manière a
facilité les différentes étapes d'extraction, des outils
de prétraitement des données et de visualisation sont
également proposes. Cet environnement (C.f. Figure 28) est _a l'heure
actuelle de plus en plus utilise par les chercheurs de la communauté
Fouille de Données (il a été classé en 2006 dans
les 10 premiers outils d'extraction utilis_es3 et il a reçu en 2005 le
prix du "2005 ACM SIGKDD Service Award "
Cliquer sur le bouton « weka » pour
faire des statistiques et visualiser des histogrammes (Figure 34).
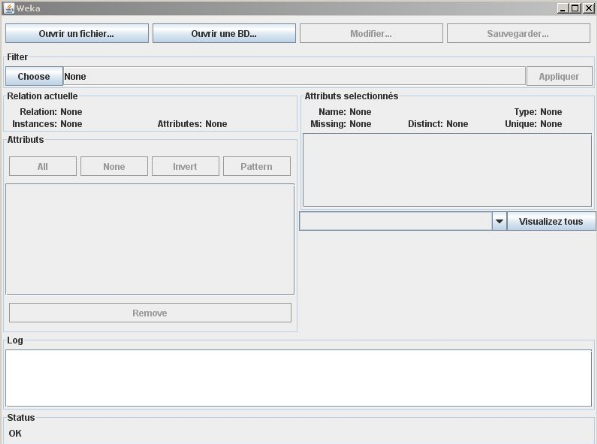
Figure 34 : l'interface du weka.
- Cliquer sur le bouton « ouvrir une
BD » pour faire la connexion avec la BD et ensuite définir son
URL adéquat pour avoir comme résultat les tableaux et visualiser
les graphes (Figure 35).
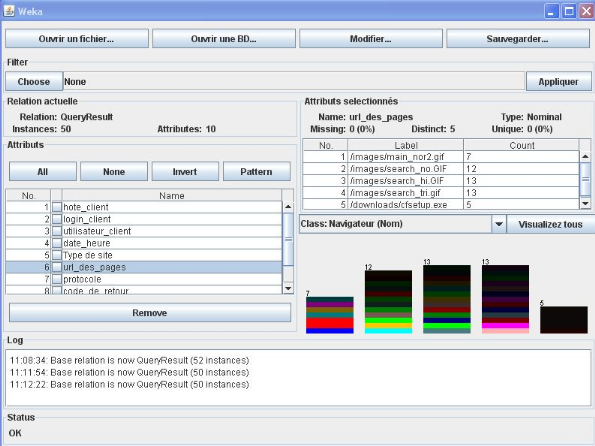
Figure 35 : les tableaux et les histogrammes par
weka.
Conclusion :
Ce chapitre intitulé « étude technique
» a décrit l'étape la plus importante du cycle de
vie du logiciel (démarche adoptée) et nous
présentons le travail réalisé, avec son environnement de
développement.
Conclusion et perspective
ï Notre travail nous a permet de faire comment les
techniques du Web Usage Mining
peuvent contribuer à l'amélioration et au
diagnostic de site Web en explorant
le fichier Log du serveur Web.
ï Ce travail est toujours en cours d'amélioration, en
ce qui concerne la « localisation»
des visiteurs.
| 

