|

ESIG- SIANTOU
Master 1 Master en Informatique Approfondie
http://www.dep.u-picardie.fr/ines/codes/ressources/modules.php?numform=80
Thème :
Les services d'annuaires LDAP : Application au
référencement dans les transports terrestres Camerounais
Présenté par
ZIE FOMEKONG Dany Stéphane
Encadré par
M.
Guy
MBATCOU
Année académique 2005/2006
DEDICACES
A la femme qui m'a porté pendant plus de 9 mois en son
sein et qui continue encore aujourd'hui de soutenir mes ambitions
exprimées.
A l'homme qui de part sa rigueur dans le travail a su
m'inculquer la vertu et la ténacité dans ma vie au quotidien.
A tous ces êtres qui me sont si chers et qui ont
partagé le sein de ma mère.
REMERCIEMENTS
A l'être suprême qui a rendu possible la
réalisation de ce travail
A la famille FOMEKONG à Bertoua pour
le soutien inconditionnel.
A la famille TOTOUOM à Yaoundé
pour tout.
A M. Guy Mbatchou pour sa
disponibilité.
A mes enseignants de Master pour l'encadrement
pédagogique et le suivi perpétuel pendant ces deux années
d'étude.
A tous mes camarades de Master promotion 2006 : enfin le bout
du tunnel
A tous mes amis et connaissances en particuliers ceux qui
m'ont toujours soutenu et qui ont cultivé mon potentiel humain et
professionnel.
SOMMAIRE
DEDICACES
1
REMERCIEMENTS
3
SOMMAIRE
4
LISTE DES FIGURES
7
LISTE DES TABLEAUX
8
LISTE DES SIGLES ET ABREVIATIONS
9
RESUME
10
INTRODUCTION
12
1. CONTEXTE
12
2. POSITION DU PROBLÈME
13
3. EBAUCHE DE SOLUTION AU PROBLÈME
13
4. PLAN
14
PREMIERE PARTIE : LES SERVICES
D'ANNUAIRES LDAP
15
I. PRÉSENTATION DES ANNUAIRES
16
A. DÉFINITION
16
1. Gestion dynamique de l'annuaire
16
2. Flexibilité
16
3. La recherche
16
4. Gestion de la sécurité
17
B. COMPARAISON AVEC D'AUTRES SYSTÈMES
17
1. Les caractéristiques propres d'un
annuaire électronique
17
2. Comparaison avec les bases de
données
18
3. Comparaison avec d'autres systèmes de
stockage
19
C. DOMAINES D'UTILISATION
19
1. Recherche
19
2. Gestion
19
3. Autres domaines d'utilisation
20
D. HISTORIQUE ET NORME X500
20
1. Historique, avant la norme
20
2. La norme
21
II. PRÉSENTATION DE LA NORME
LDAP
22
A. HISTORIQUE
22
1. Simplification du protocole
d'accès
22
2. Simplification du serveur
23
3. Première évolution: vers la
version 3
23
B. DESCRIPTION DE LA NORME
24
1. Description générale
24
2. Modèle de données
25
3. Modèle de nommage
25
4. Modèle fonctionnel
26
5. Modèle de sécurité
28
6. Étendre LDAP
28
7. Meta recherche
30
III. PRÉSENTATION DE QUELQUES
STANDARDS LDAP
32
A. LES FICHIERS LDIF
32
1. Introduction aux fichiers LDIF
32
2. Syntaxe
32
3. Liste des opérations
33
B. FILTRE DE RECHERCHE
34
1. Présentation
générale
34
2. Les opérations
élémentaires
35
3. Exemples de filtres simples
36
4. Les filtres étendus
36
C. URLS LDAP
37
1. Présentation
37
2. Syntaxe
37
3. Exemples
38
IV. CONCEPTION DES SCHÉMAS LDAP
39
A. MODÈLE DES DONNÉES
39
B. LES ATTRIBUTS
39
1. Description des attributs
39
2. Exemples
40
3. Exemples et descriptions de règles de
comparaison définies dans les [rfc2252]
40
4. Exemples d'attributs définis dans la
[rfc2256]
41
C. LES CLASSES
41
1. Description
41
2. Exemples
42
D. PRÉSENTATION DES OID
42
1. Présentation des OID
42
2. Exemples
43
E. SYNTAXE
43
1. Syntaxe de la définition d'un
attribut
43
2. Syntaxe de la définition d'un
objet
44
F. L'INTÉRÊT DE CRÉER SES
PROPRES SCHÉMAS
45
V. DÉPLOIEMENT D'UNE ARCHITECTURE
LDAP
46
A. PHASE DE CADRAGE
46
B. PHASE DE CONCEPTION
46
1. Choix des données et Identification
des acteurs
47
2. Élaboration du schéma
48
C. SÉCURISATION
49
D. DÉVELOPPEMENT DE L'ARBRE
INFORMATIONNEL
49
1. La structure de l'arbre informationnel
49
2. Le nommage des données
51
E. TOPOLOGIE DU SERVICE
51
1. Conception
51
2. Utilisation de referral
53
3. La réplication
54
F. VUE D'ENSEMBLE
55
DEUXIEME PARTIE : CONCEPTION ET
REALISATION DU SYSTEME
56
CHAPITRE I : PROBLEMATIQUE
57
I ETAT DE L'ART
57
A. LE CONTEXTE DES TRANSPORTS TERRESTRES AU
CAMEROUN
57
A.1 Au premier rang des facteurs de croissance
économique
57
A.2 Les transports urbains
57
A.3 Les transports interurbains de
personnes
57
A.4 Le transport routier de marchandises au
Cameroun
58
I ETUDE CRITIQUE DE L'EXISTANT
59
CHAPITRE II : LA METHOLOGIE
60
I PRÉSENTATION DES OUTILS DE
MODÉLISATION CHOISIS
60
A. UML (UNIFIED MODELING LANGUAGE)
60
1. Historique d'UML
60
2. Pourquoi une méthodologie Objet
61
3. Concepts d'UML
63
II MODÉLISATION DU
SYSTÈME
66
A. PHASE DE CADRAGE
66
B. PHASE DE CONCEPTION
67
1. Cas d'utilisation
67
2. Les séquences
68
3. Les collaborations
79
C. Sécurisation
86
D. Développement de l'arbre
informationnel
87
E. Topologie du service
89
CHAPITRE III : REALISATION DU
SYSTEME
90
A. PRÉSENTATION DES OUTILS
90
A.1 LA PLATE FORME LINUX MANDRAKE 9.2
90
A.2 PRÉSENTATION DE LA SUITE OPENLDAP
90
1. Historique
90
2. Contenu de la suite
91
3. RFC supportées
91
4. Les RFCs non supportées
92
5. La licence
93
6. Points forts/Points faibles
93
D. LE LANGAGE PHP
94
1. Qu'est ce que PHP ?
94
2. Que peut faire PHP?
95
A.3 LE SERVEUR APACHE
97
A.4 LE DNS
97
B. IMPLÉMENTATION
98
B.1 INSTALLATION ET CONFIGURATION DES SERVEURS
98
1. Apache et BIND
98
2. Package OpenLDAP
99
B.2 RÉALISATION DE L'APPLICATION CLIENTE
POUR LA GESTION ET L'ADMINISTRATION DE L'ANNUAIRE
109
1. L'IHM
109
a) La charte graphique
109
b) L'ergononie
109
2. LA PROGRAMMATION
109
III RÉSULTATS ATTENDUS ET
PROBLÈMES RENCONTRÉS
111
A. TEST DES DIFFÉRENTS SERVEURS
111
B. QUELQUES ÉCRANS DE L'APPLICATION
112
B. PROBLÈMES RENCONTRÉS
114
CHAPITRE IV : CONCLUSION ET
PERSPECTIVES
115
BIBLIOGRAPHIE
116
A. LES LIVRES UTILISES
116
B. WEBOGRAPHIE
116
LISTE DES FIGURES
FIGURE 1 : ARBRE PLAT
50
FIGURE 2 : ARBRE À BRANCHAGE FORT
50
FIGURE 3 : UTILISATION DU REFERRAL
53
FIGURE 4 : LA RÉPLICATION
54
FIGURE 5: CAS D'UTILISATION DU
SYSTÈME
67
FIGURE 6: CAS D'UTILISATION ADMINISTRATION DE
L'ANNUAIRE
68
FIGURE 7: IDENTIFICATION
69
FIGURE 8: CRÉATION D'UNE VILLE
69
FIGURE 9: CRÉATION D'UNE AGENCE
70
FIGURE 10: SUPPRESSION D'UNE VILLE
71
FIGURE 11: SUPPRIMER UNE AGENCE
72
FIGURE 12: CAS D'UTILISATION GESTION D'UNE
AGENCE
72
FIGURE 13: IDENTIFICATION ADMINISTRATEUR
D'AGENCE
73
FIGURE 14: CRÉATION D'UN
VÉHICULE
73
FIGURE 15: MODIFIER L'ENREGISTREMENT D'UNE
AGENCE
74
FIGURE 16: MODIFIER L'ENREGISTREMENT D'UN
VÉHICULE
75
FIGURE 17: SUPPRIMER L'ENREGISTREMENT D'UN
VÉHICULE
76
FIGURE 18: CONSULTATION DE L'ANNUAIRE
77
FIGURE 19: CONNEXION ANONYME
77
FIGURE 20: RECHERCHE D'UNE LIGNE PAR
PROVINCE
78
FIGURE 21: RECHERCHE DIRECTE D'UNE LIGNE
78
FIGURE 22: COLLABORATION IDENTIFICATION
79
FIGURE 23: ÉBAUCHE DU DIAGRAMME DE
CLASSE
79
FIGURE 24: ÉTAT TRANSITION
IDENTIFICATION
80
FIGURE 25: COLLABORATION CRÉATION
VILLE
80
FIGURE 26: ÉBAUCHE DIAGRAMME DE
CLASSE
81
FIGURE 27: COLLABORATION CRÉATION AGENCE
81
FIGURE 28: ÉBAUCHE DIAGRAMME DE
CLASSE
82
FIGURE 29: COLLABORATION CRÉATION
VÉHICULE
82
FIGURE 30: COLLABORATION MODIFIER AGENCE
83
FIGURE 31: COLLABORATION MODIFIER
VÉHICULE
83
FIGURE 32 : DIAGRAMME DE CLASSE
84
FIGURE 33: DIRECTORY INFORMATION TREE
88
FIGURE 34: ARCHITECTURE DE NOTRE
SYSTÈME
89
FIGURE 35: INTERFACE DE GESTION DES VILLES
112
FIGURE 36: INTERFACE DE GESTION D'AJOUT D'UNE
AGENCE
113
FIGURE 37: INTERFACE DE RECHERCHE D'UNE LIGNE
DE TRANSPORT
114
LISTE DES TABLEAUX
TABLEAU 1: TABLEAU COMPARATIF LDAP/BASE DE
DONNÉES
18
TABLEAU 2: STANDARDS DE LA NORME X500
21
TABLEAU 3: TERMES TECHNIQUES NORME X500
22
TABLEAU 4: RFCS DÉFINISSANT LA NORME
LDAP VERSION 3
24
TABLEAU 5: DÉFINITION DE LA NORME
LDAP
24
TABLEAU 6: MODÈLE FONCTIONNEL LDAP
26
TABLEAU 7: PARAMÈTRE DE LA FONCTION DE
RECHERCHE LDAP
28
TABLEAU 8: LES CONTRÔLES
29
TABLEAU 9: ATTRIBUTS DU ROOT DSE
30
TABLEAU 10: LES ENTREÉS SUBSCHEMA
31
TABLEAU 11: LES OPÉRATIONS
ÉLÉMENTAIRES
35
TABLEAU 12: LES OPÉRATIONS
35
TABLEAU 13: LES OPÉRATEURS
BOOLÉENS
35
TABLEAU 14: PARAMÈTRES URL LDAP
37
TABLEAU 15: QUELQUES SYNTAXES DE TYPE
40
TABLEAU 16: DESCRIPTION DES RÈGLES DE
COMPARAISON
41
TABLEAU 17: EXEMPLE D'ATTRIBUTS
41
TABLEAU 18: LES OBJETS STANDARD
42
TABLEAU 19: EXEMPLES D'OID
43
TABLEAU 20: EXEMPLES DE HIÉRARCHIE
43
TABLEAU 21: VUE D'ENSEMBLE DU
DÉPLOIEMENT D'UNE ARCHITECTURE LDAP
55
TABLEAU 26: LES PRINCIPAUX
SCÉNARIOS
68
TABLEAU 27: LE LISTING DES CLASSES
85
TABLEAU 28: LE LISTING DES ATTRIBUTS
85
TABLEAU 29: NOMMAGE DES ENTRÉES
87
TABLEAU 22: COMPOSANTES SUITE OPENLDAP
91
TABLEAU 23: LES RFCS NON OBLIGATOIRES
92
TABLEAU 24: LES RFCS NON SUPPORTÉES
93
TABLEAU 25: LES BASES DE DONNÉES
SUPPORTÉES PAR PHP
96
LISTE DES SIGLES ET ABREVIATIONS
LDAP : LightWeight Directory Acces Protocol
DNS : Domain Name Service
HTTP : HyperText Transfert Protocol
OID : Object Identifier
PHP : Hypertext Preprocessor
SQL : Structured Query Language
MTS : Michigan Terminal System
ISO : International Organization for Standardization
SASL : Simple Authentification and Security Layer
SSL : Simple Security Layer
TLS : Transport Layer Security
LDIF : Lightweight Data Information File
API : Application Programming Interface
GNU :
UML : Unified Modeling Language
WWW : World Wide Web
RESUME
S'arrimer à la locomotive technologique dirigée
par les puissances impérialistes est un des principaux défis de
la nouvelle génération africaine.
L'essor fulgurant des nouvelles techniques de l'information et
de la communication via l'Internet en particulier a rendu possible
l'abstraction des limites géographiques pour l'accès à
l'information.
La télématique offre aujourd'hui divers types
de support de communication et d'information facilitant la mise en place de
nouvelles techniques comme l'--business et le télétravail. On
assiste donc à la mondialisation de l'information via des banques de
données, les annuaires électroniques, le commerce
électronique et les réseaux privés virtuels entre autres
avec en parallèle la numérisation des domaines nécessitant
jadis de multiples interventions physiques comme le commerce, les transactions
financières, les opérations pharmaceutiques, les transports
...
C'est justement dans ce dernier que nous concentreront nos
efforts pour essayer de construire un système informationnel et
accessible de manière simple et efficace basée sur une
technologie peu connue et rarement utilisée au Cameroun mais pourtant en
plein essor dans l'environnement informatique occidental.
Ainsi, offrir aux transports terrestres camerounais un
annuaire de référencement pour les agences et ainsi donner la
possibilité à ceux qui se déplacent constamment d'obtenir
l'information nette et précise sur une agence de transport ou sur une
ligne de transport déterminée en fonction du lieu de
départ et de la destination marquera certainement un tournant dans la
gestion de nos transports privés et en commun et permettrai ainsi au
Cameroun d'ajouter un échelon à la construction de son empire
informatique industriel et communicationnel via les nouvelles techniques
qu'offre Internet et ses services associé aux différentes
techniques réseaux comme la technologie de annuaire LDAP.
ABSTRACT
To stow itself/themselves at the technological loco directed
by the imperialistic powers is one of the main challenges of the new African
generation.
The lightning flight of the new techniques of information and
the communication via the Internet made in particular possible the geographical
limit abstraction for the access to information.
The telematics offers today various types of support of
communication and information facilitating the new technique setting up as the
e - business and the administration from afar. One attends the
internationalization of information therefore among others via banks of data,
the electronic directories, the electronic trade and the virtual private
networks with in parallel the digitalization of the domains requiring multiple
physical interventions previously as the trade, the financial transactions, the
pharmaceutical operations, the transportation...
It is exactly in this last that will concentrate us our
efforts to try to construct an informational and accessible system in a based
simple and efficient manner little on a technology known and used rarely in
Cameroon but yet in full flight in the western computer environment.
Thus, to offer to the Cameroonian terrestrial transportation a
directory of reference for the agencies and so to give the possibility to those
that constantly move to get the clean and precise information on an agency of
transportation or on a determined transportation line according to the place of
departure and the destination will mark a turn certainly in the management of
our private transportation and in common and will permit thus to Cameroon to
add an echelon to the construction of his empire computer industrial and
informational via the new techniques that Internet offer and its services
partner to the different techniques networks as the technology of LDAP
directory.
INTRODUCTION
1. Contexte
L'informatique a depuis quelques années
révolutionné presque tous les domaines de la vie des
télécommunications à la médecine en passant par la
gestion des différentes ressources d'une entreprise ou le système
éducatif, tout y passe.
Dans tout ce bouillon technologique, plusieurs techniques sont
employées pour résoudre les divers problèmes
rencontrés au quotidien.
De plus en plus de services numériques sont
disponibles. Ils recouvrent une large panoplie de fonctionnalités :
messagerie, forums, outils de travail collaboratif, accès aux ressources
en lignes, e-business etc. Ils concourent tous à faciliter, moderniser
et rendre plus efficient le niveau de vie ainsi qu'à accroître les
prestations vers tous types de populations.
Ils doivent être accessibles en intranet ou depuis
l'Internet sans que les frontières géographiques n'entravent la
facilité d'utilisation, notamment pour les personnes nomades, pour le
télétravail et l'administration à distance.
Mais ce devoir de facilitation des accès doit
être accompagné d'un contrôle sérieux desdits
accès aux services et ressources afin de respecter une politique de
sécurité digne de ce nom.
Aujourd'hui les pays africains et le Cameroun en particulier
doivent relever un nouveau défi : le partage des ressources et services
numériques pour annuler les barrières géographiques et
optimiser le disponibilité et l'accès à l'information.
A l'heure où les continents voisins ne fonctionnent
plus qu'en termes de banques de données, d'annuaires de type
« pages blanches » ou « pages jaunes »
en ligne, a l'heure où on ne parle que de centralisation de
l'information à travers des Campus numériques, des services
d'authentifications centralisées pour l'entreprise, des supports
d'inventaire ou des bases de configuration d'équipements réseau,
la nécessité de cohérence et de vision globale du
système d'information africain se fait amplement ressentir.
Une des premières étapes passe par la
création d'annuaires internes qui assureront des
référentiels centralisés auxquels les différents
services pourront accéder, assurant ainsi une base opérationnelle
solide au système d'information.
Les diverses collaborations entre entreprises et institutions,
tant au niveau national qu'international, nous dictent de mener un travail de
mise en cohérence de ces annuaires afin de faciliter les
échanges.
La mise en place d'un annuaire pour le
référencement des agences dans les transports terrestres
camerounais représente notre objectif pour rendre disponible, facilement
et rapidement accessible l'accès à l'information dans ledit
domaine et permettre ainsi de réduire les délais et coûts
d'information dans le secteur des transports terrestres camerounais.
2. Position du problème
Au Cameroun le système des transports terrestres ne
possèdent pas de contrôle poussé et une rigueur
organisationnelle comme dans le domaine des transports aériens. Il
n'existe pas de système normalisé pour aider les clients des
transports terrestres à trouver rapidement l'information
recherchée et puis, le renseignement ou l'accès à
l'information sur les transports et services rattachés est relativement
propre à chaque agence ou compagnie. Il devient donc difficile, avec des
contraintes de temps par exemple, d'interroger un maximum d'agences pour
connaître la disponibilité des places ou les horaires de
départ. La difficulté est encore accrue lorsque les contraintes
géographiques s'en mêlent. Il faut également noter que les
moyens d'informations sont assez restreints et limités voire très
coûteux (déplacement sur les lieux, téléphone,
recherches approximatives sur Internet...).
Il serait donc intéressant de proposer un
système complet du point de vue de sa conception et très
évolutif pour gérer les informations sur les acteurs dans les
transports terrestres de manière dynamique et avec une administration
décentralisée par agence.
3. Ebauche de solution au problème
La solution choisie est la mise en place d'un annuaire
électronique pour référencer et centraliser les
informations sur les agences de transport terrestres camerounais.
Un annuaire électronique LDAP est un conteneur
d'informations dynamiques et organisées accessibles via un protocole
normalisé, de façon contrôlée, suivant divers
critères :
a - Conteneur d'informations
Un annuaire LDAP peut stocker tout type d'informations :
numéros de téléphones et adresses bien sûr, mais
aussi adresses de messagerie, identifiants d'accès à des
applications, mots de passe, descriptions de matériels, de
bâtiments, de salles, d'organisations, certificats de clés
publiques, composition de groupes, photos, documents, informations
administratives, etc.
En fait un annuaire LDAP est comparable à une base de
données aux différences près qu'il est optimisé
pour les accès en lecture, les accès en écriture
étant peu performants. Il ne doit toutefois pas se substituer aux bases
de données spécifiques des applications et ne doit contenir que
des données communes, pour des besoins parfaitement identifiés.
Il s'agit ici de la grande difficulté lors de la définition d'un
annuaire LDAP : séparer les données communes des données
spécifiques aux applicatifs.
b - Informations dynamiques
Les informations contenues dans un annuaire LDAP sont mises
à jour aisément et fréquemment contrairement à leur
équivalent traditionnel.
c - Informations organisées
Les informations gérées par un annuaire LDAP
sont typées, nommées et organisées suivant un
schéma arborescent.
d - Informations accessibles
Un annuaire ne serait d'aucune utilité s'il
n'était pas facilement accessible. Une qualité primordiale d'un
annuaire électronique est sa méthode (ou protocole)
d'accès : est-elle normalisée ? Combien d'applications sont
capables d'y accéder ? Il s'agit ici d'une des grandes forces des
annuaires LDAP qui sont normalisés et reconnus par la plupart des
applications professionnelles.
e - Accès contrôlé
De par la nature très diverse des informations qu'il
peut contenir, un annuaire électronique ne peut pas être
accessible de façon indifférenciée à n'importe qui
(ou quoi). Il doit permettre de contrôler précisément qui
accède à quoi et comment il y accède.
4. Plan
L'introduction restitue le contexte du travail, dégage
le problème à résoudre en spécifiant les objectifs
à atteindre et la méthode utilisée pour les atteindre.
La première partie présente et décrit le
fonctionnement des services d'annuaires LDAP
La deuxième partie concerne la conception et la
réalisation du système.
Le chapitre I développe la problématique et
l'état de l'art. D'une part nous présenterons les contours du
problème, et le contexte des transports terrestres camerounais.
Au chapitre II, nous ferons un état de la
méthodologie en étudiant les outils de modélisation et de
réalisation et en présentant les différentes étapes
de la modélisation du système proprement dit.
Le chapitre III concerne la réalisation de notre
système. C'est ici que nous détaillerons les
spécifications de configuration et d'implémentations ainsi que
les résultats de la précédente modélisation.
Enfin, la section conclusion et perspectives
d'évolution de notre système fera l'objet du chapitre IV. Ceci
nous permettra de réaliser une première évaluation du
système réalisé et ainsi de relever les insuffisances et
les améliorations probables.
PREMIERE PARTIE : LES SERVICES D'ANNUAIRES LDAP
I. Présentation des annuaires
Cette section donnera une définition des annuaires
électronique et leurs domaines d'utilisation avec un historique. La
norme X500 sera également présentée.
A. Définition
Selon la définition du Petit Robert, un annuaire est un
[Recueil publié annuellement et qui contient des renseignements
variables d'une année à l'autre]. Nous pouvons définir un
annuaire électronique comme une base de données optimisée
pour les opérations de lecture, et supportant des opérations de
recherche et de navigation avancées.
Néanmoins l'essentiel de la documentation technique
sur les annuaires électroniques s'appuie implicitement d'avantage sur la
définition d'un annuaire donnée par la norme X500, ou par la
norme LDAP, que sur la définition que nous venons de donner.
L'utilisation des annuaires présente un certains
nombres d'avantages que nous allons citer dans les sections suivantes. Ces
avantages proviendront pour la plupart de la définition X500 des
annuaires.
1. Gestion dynamique de l'annuaire
Mise à jour en temps réel.
L'annuaire électronique est sans cesse mis à jour en fonction des
entrées et des sorties des personnels d'une entreprise. Il est par
exemple possible de lier l'annuaire électronique au logiciel de gestion
des ressources humaines.
Coûts de mise à
jour. Les coûts de mise à jour sont très faibles
car cela se fait soit de façon automatique soit par l'utilisateur
lui-même ! Ceci est à comparer avec la réimpression d'un
annuaire papier.
2. Flexibilité
Un annuaire électronique peut contenir des informations
sur différentes familles d'objets, pas seulement sur des personnes. Par
exemple on peut trouver dans un annuaire : des entités constituant
l'entreprise (département, filiale, etc.) ; n'importe quelle ressource
de l'entreprise (bâtiment, matériel informatique, etc.) ; tout
type d'information qui doit être partagée, et peu
modifiée.
Un annuaire électronique n'est jamais figé.
La structure de l'information contenue dans l'annuaire peut ainsi être
modifiée facilement, à la volée, sans nécessiter de
reconstruire l'annuaire : il est possible d'ajouter des nouveaux champs (de
nouveaux attributs en terminologie annuaire) en fonction des besoins ; il est
également possible d'ajouter des nouvelles familles d'objets.
3. La recherche
Plusieurs types de recherches sont possibles. Il y a la
recherche exacte sur le nom d'une personne par exemple. Il est également
possible de faire une recherche phonétique sur une syllabe, ou bien
encore, une recherche sur une chaîne de caractère : par exemple la
recherche sur la chaîne du renverra Dupont, Durand,
mais aussi Perdu...
4. Gestion de la sécurité
La diffusion de l'information contenue dans un annuaire est
facilement contrôlable. Tout d'abord les utilisateurs doivent
s'authentifier avant d'accéder à l'information. Ceci est un
avantage certain qui différencie les annuaires électroniques sur
leurs équivalents papier.
Mais un annuaire électronique permet un contrôle
bien plus fin que la seule authentification. Ils permettent une centralisation
et un contrôle total de l'accès à l'information.
L'annuaire électronique pourra, par exemple,
contrôler finement l'information délivrée en fonction du
profil de l'utilisateur authentifié. Il sera ainsi possible de
n'afficher que certains attributs, ou biens de rendre accessible uniquement
certaines branches/certains objets de l'annuaire. Cela permet une
granularité forte dans la gestion de l'accès à
l'information, à comparer avec le principe traditionnel de liste rouge,
qui ne peut gérer que deux groupes, les autorisés et les
interdits.
En plus du profil utilisateur, et de l'information cible, il
sera aussi possible de considérer les types de connexion (crypté
ou pas) et d'authentification utilisés, ou bien d'où a lieu la
consultation (réseau interne ou externe).
B. Comparaison avec d'autres systèmes
1.
Les caractéristiques propres d'un annuaire électronique
Nous avons défini un annuaire comme étant «
«une base de données optimisée pour les opérations de
lecture, et supportant des opérations de recherche et de navigation
avancées» ». Un annuaire électronique possède
cependant d'autres caractéristiques essentielles que nous allons citer.
Un annuaire électronique peut ainsi être
caractérisé par le fait que l'information y est stockée de
manière structurée et hiérarchisée. Il existe une
hiérarchie aussi bien dans l'information stockée, que dans la
modélisation des données. On trouve dans cette
modélisation beaucoup des concepts de la programmation orientée
objet, comme des notions de classes, d'objets, d'attributs, et
d'héritage.
L'autre caractéristique des annuaires
électroniques est l'existence d'un protocole de communication
réseau. Les annuaires électroniques sont conçus pour
pouvoir communiquer entre eux, et communiquer avec des clients.
Les annuaires électroniques sont aussi prévus
pour être distribués et répliqués à grande
échelle. Ceci explique la nécessité de ces protocoles de
communication.
En revanche la spécification d'une manière de
stockage n'intervient pas dans la définition d'un annuaire. Seul compte
la modélisation des données et leur transport sur le
réseau.
2.
Comparaison avec les bases de données
Il est important de souligner les différences entre
base de données relationnelles et annuaires. Un annuaire
électronique n'a pas pour vocation de stocker uniquement des
informations sur des personnes. Il peut être utilisé comme base
dans de nombreux types d'applications. C'est donc en connaissant ces
différences, qu'il sera possible de choisir le bon type de stockage pour
chaque type d'application.
La première différence est qu'un annuaire
électronique est conçu pour être consulté, bien plus
que mis à jour. Le rapport lecture sur écriture est donc plus
élevé dans les annuaires électroniques que dans les bases
de données relationnelles.
L'autre différence est la grande
facilité d'extension des annuaires. L'ajout d'attributs,
l'équivalent des champs dans les bases de données relationnelles,
est très aisé à réaliser. Il ne nécessite
pas, par exemple, de reconstruction de la base. Un autre élément
de flexibilité des annuaires par rapport aux bases de données,
est l'héritage multiple. Une entrée d'un annuaire peut être
deux objets différents, alors qu'un objet dans une base de
données n'appartient qu'à une seule table.
La contrepartie de cette facilité est l'absence de
transactions et de procédures stockées. Il faudra donc faire
attention lors de l'exécution d'opérations complexes, et
gérer du côté applicatif les erreurs. Comme autre type de
restriction, il n'existe pas dans les annuaires de notions de cohérence.
Ainsi la notion de clé étrangère n'existe pas. S'il est
possible de modéliser un attribut en lui imposant d'être un lien
vers une entrée de l'annuaire, il est impossible de contrôler si
le noeud pointé appartient à une branche précise ou s'il
appartient à une certaine classe d'objet
(1).
Une différence plus mineure concerne le type de
recherches que l'on peut effectuer sur des bases de données et des
annuaires. Si les annuaires permettent dans un certain sens d'effectuer des
recherches assez évoluées (recherches approximatives ou
phonétiques), ils ne possèdent pas l'équivalent de
l'instruction SQL joint pour fusionner des informations de plusieurs
sources.
Mais les bases de données n'offrent pas les
facilités de déploiement et de réplication que l'on a avec
les annuaires. Il n'existe pas non plus de protocole universel permettant
à un client quelconque de contacter un serveur quelconque, comme c'est
le cas pour la norme LDAP ou la norme X500 avant elle. Chaque base de
données relationnelle a son propre protocole réseau, qu'elle ne
partage pas avec les autres bases.
On peut résumer cette comparaison par le tableau
suivant :
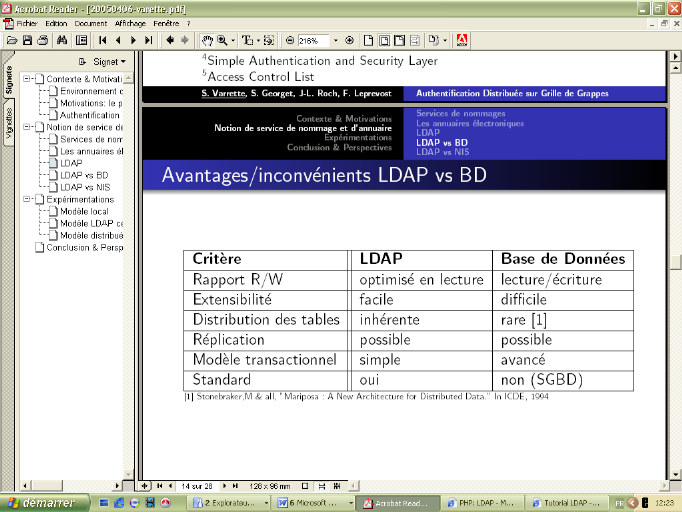
Tableau
1: tableau comparatif ldap/base de données
3. Comparaison avec d'autres
systèmes de stockage
a. Système de
fichiers
Un système de fichiers est aussi un système
d'informations hiérarchisées, les répertoires formant une
hiérarchie, espace de nommage homogène. Néanmoins les
systèmes de fichiers ne permettent pas une gestion fine des droits. De
plus ils peuvent contenir des informations très volumineuses, alors
qu'un annuaire ne contient majoritairement que des informations peu importantes
en taille, de l'ordre du mot, cette information n'est pas du tout
structurée. Ainsi l'analogie entre un système de fichiers et un
annuaire bute sur l'absence de modélisation de l'information en classe
et en attribut.
b. Serveur Web
Les serveurs web sont optimisés eux aussi pour un rapport
lecture sur écriture élevé, à l'instar des
annuaires électroniques. De plus un serveur web est accédé
depuis le réseau, via un protocole universel, partagé entre
client et serveur. Néanmoins l'information d'un serveur web n'est elle
non plus pas assez structurée pour pouvoir comparer ces serveurs
à des serveurs annuaires.
c. Serveur
DNS
Les serveurs DNS sont très similaires aux annuaires
électroniques. Il s'agit en effet d'un système d'information
hiérarchisé et répliquée, possédant des
fonctionnalités de recherche avancée. La différence
fondamentale avec les annuaires concerne l'information stockée qui est
très figée, puisque normalisée dans des RFCs.
Contrairement aux annuaires il n'est pas possible de faire évoluer
l'information contenue dans un serveur DNS.
C. Domaines d'utilisation
1.
Recherche
Les annuaires peuvent être utilisés dans toute
application informatique nécessitant une information
hiérarchisée et répliquée, et des
fonctionnalités de recherche. Néanmoins le type d'information
stockée doit être limité. Pour l'essentiel il doit s'agir
de chaînes de caractères. Et si l'on doit stocker des attributs
binaires, il est préférable que leur taille soit du même
ordre de grandeur, pour éviter des problèmes de performance.
2.
Gestion
Un annuaire peut contenir tout type d'objets qu'une
organisation est amener à gérer: les personnes internes (ses
salariés ou ses membres, etc.), les personnes externes (les contacts,
les fournisseurs, etc.), son parc informatique (les postes clients, les
serveurs, les imprimantes, etc.), ses entités géographiques ou
administratives, etc. Un annuaire électronique permet de centraliser
toutes ces informations dans une même base, et d'unifier leur gestion. Il
permet aussi de créer des liens entre ces informations (tel membre
appartient à telle structure administrative et travaille dans tel
bâtiment).
3.
Autres domaines d'utilisation
a. Applications
légères de base de données
En fait, un annuaire peut aussi servir comme une base de
données allégée pour de petites applications. En effet les
annuaires électroniques offrent beaucoup plus de souplesse que les
traditionnelles bases de données relationnelles. Certaines applications
ne nécessitent pas toutes la rigidité de ces bases de
données.
b. Application de
clé publique
Les applications PKI nécessitent de distribuer des
clés, de les garder à jour, de les révoquer. Avec un
annuaire, à la structure hiérarchisée, ces tâches
sont grandement facilitées.
D. Historique et Norme X500
1.
Historique, avant la norme
Les premiers annuaires électroniques sont apparus avec
les premiers ordinateurs. Ils avaient des tâches ciblées :
authentification, contrôle des accès, information de type
contacts.
Néanmoins il n'existait aucune unification, ni
standard. Chaque système possédait sa propre méthode pour
gérer ses utilisateurs. Unix possédait déjà son
fameux /etc/passwd. Les mainframes avaient Michigan Terminal System (MTS)
(2).
À partir du milieu des années 70, l'utilisation
des réseaux commence à se généraliser. Les
systèmes deviennent distribués et les besoins sont ceux d'une
authentification sur une base distante et commune. De plus, la multiplication
des LAN fait apparaître de nouveaux types de services, que l'on apparente
à des annuaires: Les serveurs DNS et le protocole Whois.
On assiste à partir de la fin des années 80 et
dans les années 90 à une multiplication des annuaires
spécifiques. Il y a tout d'abord les annuaires inclus dans des logiciels
ou des suites logiciels (mail et groupware): Lotus Notes, Novell Groupwise
Directory, Microsoft Exchange Directory, Sendmail UNIX et son /etc/aliases. Il
y a aussi les Annuaires Internet comme Yahoo, ou Bigfoot.
C'est aussi
à la fin des années 90 qu'apparaissent des Network operating
system. Il s'agit d'applications fournissant des services à des clients
et des serveurs à travers un réseau. Ces services permettent le
partage de ressources comme des fichiers ou des imprimantes. Ils incluent
évidemment des annuaires électroniques (Novell NDS, MS Active
Directory).
2.
La norme
a. Apparition de la
norme
Suite à l'apparition dans les années 80
d'annuaires généraux et multi-usage, non limités à
une application, ni à un système spécifique, la
nécessité de standardiser les annuaires électroniques
s'est faite sentir. Deux organismes se sont mis à travailler en
parallèle sur ce projet de standardisation : Le CCITT (International
Telegraph and Telephone Consultative Committee) devenu ITU (International
Telecommunications Unions) depuis; et l'ISO (International Organization for
Standardization). Les deux projets ont finalement fusionné pour donner
naissance à la norme annuaire X500. La première version de la
norme en 1988. La deuxième version de 1993.
b. Description
L'objectif de la norme était de pouvoir être
utilisée par tout type d'applications. Elle devait être un
standard ouvert indépendant de tout système et de tout
fabriquant.
Techniquement, elle devait fournir de nombreuses
possibilités de recherches. Les annuaires devaient pouvoir être
distribués à très grande échelle. L'un des buts du
CCITT consistait en la création d'un service de pages blanches à
l'échelle mondiale. La norme X500 devait donc être capable de
faire dialoguer et cohabiter tous les annuaires pour constituer des services
pages blanches et pages jaunes mondiaux.
La norme X500 est constituée de plusieurs standards:
|
X500
|
Vue d'ensemble des concepts, des modèles et des
services
|
|
X501
|
Modèles associés aux annuaires X500
|
|
X509
|
Procédures d'identification et d'authentification
|
|
X511
|
Définition des services (recherche, création,
suppression)
|
|
X518
|
Description du fonctionnement distribué
|
|
X519
|
Protocoles de communication entre serveurs, et entre serveurs et
clients clients/serveurs
|
|
X520
|
Attributs des annuaires X500 prédéfinis
|
|
X521
|
Classes d'objets des annuaires X500 prédéfinies
|
|
X525
|
Description de la réplication sur les serveurs
|
Tableau 2: standards de la
norme X500
Les standards X520 et X519 définissent un langage
commun minimum pour l'échange d'informations. Ils seront repris pour
partie dans la norme LDAP.
La norme X500 a introduit un certain nombre de termes
techniques:
|
Directory User Agent (DUA)
|
Poste ou logiciel client accédant à un annuaire
|
|
Directory Access Protocol (DAP)
|
Protocole de communication entre un client et un serveur
annuaire
|
|
Directory System Agent (DSA)
|
Un serveur annuaire. Ce terme est encore utilisé dans la
norme LDAP
|
|
Directory System Protocol (DSP)
|
Protocole de communication entre deux serveurs. Proche du DAP.
|
|
Directory Information Shadowing Protocol
|
Protocole pour la réplication entre DSA maître et
DSA miroir
|
Tableau 3: termes techniques
norme X500
c. La réalité
de la norme X500
La mise en place de la norme X500 apparaît comme un
modèle de réussite dans la création d'un standard
réalisé par des acteurs divers. En effet le critère
d'indépendance vis à vis des éditeurs et le critère
d'interopérabilité ont été respectés.
Mais rapidement, cette norme a été jugée trop riche et
trop complexe à mettre en oeuvre. Des problèmes de performance
sont constatés à cause de la modélisation OSI des
protocoles réseau. Il apparaît que la norme a été
décidée et imposée sans tenir compte de la
réalité et des besoins du terrain : le déploiement des
annuaires X500 a été réalisé selon une
démarche inverse au déploiement réussi d'Internet. Aussi,
seuls les grands organismes publics ont déployé de tels
annuaires.
La norme LDAP s'est nourrie de tous ces constats afin de ne
pas connaître le sort de la norme X500.
II. Présentation de la
norme LDAP
Cette section présentera la norme LDAP, en abordant
tout d'abord son historique, puis en décrivant la norme elle même
et les usage qui en sont faits.
A. Historique
1.
Simplification du protocole d'accès
La difficulté rencontrée lors de
l'implémentation du protocole DAP provient de sa modélisation
basée sur la pile OSI. Pour éviter d'avoir à écrire
toutes les couches OSI, d'autres protocoles ont été
définis pour accéder aux annuaires X500 en s'appuyant sur TCP/IP.
Il y a eu ainsi deux nouveaux protocoles de définis au début des
années 90 : Directory Assistance Service (DAS) et Directory Interface to
X.500 Implemented Efficiently (DIXIE). Ces deux protocoles ont malheureusement
été conçus pour s'interfacer à une
implémentation donnée d'un serveur X500.
C'est pour cela qu'un groupe de lIETF, le groupe Open Systems
Interconnection-Directory Services (OSI-DS) s'est réuni pour concevoir
une simplification du protocole DAP. Après deux premières RFC de
1993, le résultat final de ces travaux a été les RFC
[rfc1777], [rfc1778] et [rfc1779] publiées en mars 1995 et
définissant la version 2 du protocole DAP Allégé
(Lightweight), LDAP.
À cette étape, le protocole LDAP est une
simplification avancée de DAP, fournissant quasiment les mêmes
fonctionnalités, mais représentant d'avantages d'informations
sous la forme de chaînes de caractères et utilisant un sous
ensemble de l'encodage de DAP. Et bien sûr LDAP utilise TCP comme couche
réseau.
2.
Simplification du serveur
Le protocole LDAP n'étant qu'une simplification du
protocole DAP, c'est à dire de la couche réseau, les
requêtes LDAP devaient être converties en DAP par des serveurs
intermédiaires avant d'être transmises à des serveur X500.
Début 1995, 99% des serveurs X500 sont accédés par LDAP.
Mais les implémentations des serveurs continuent à être
complexes.
Après avoir écrit la première
implémentation du protocole LDAP l'Université du Michigan
écrit un serveur natif LDAP, pour pouvoir se débarrasser des
serveurs intermédiaires passerelles entre les requêtes DAP LDAP.
Dès le départ ce serveur est fourni avec ses sources et un kit de
développement, ce qui a favorisé la propagation de la norme.
Début 1996 Netscape prend la tête d'une coalition
pour promouvoir l'usage de LDAP.
3.
Première évolution: vers la version 3
Après la version 2 de la norme, il était
nécessaire d'y apporter quelques modifications pour répondre
à quelques difficultés rencontrées. L'évolution de
la norme vers la version 3 a intégré :
L'utilisation de l'encodage UTF-8 pour pouvoir manipuler des
chaînes de n'importe quelle langue.
Les referrals ont été normalisés. Ils
n'étaient pas présents dans la version 2 de LDAP.
L'opération de connexion à un annuaire a
été modifiée pour accepter le protocole Simple
Authentication and Security Layer (SASL), et Transport Layer Security (TLS).
La norme inclut maintenant des mécanismes d'extension.
Il est possible de réaliser des opérations supplémentaires
à celles décrites dans la norme, tout en s'appuyant sur le
protocole existant. Il est aussi possible, par le biais de contrôle, de
modifier le comportement des opérations de base.
Un annuaire peut être interrogé pour
accéder à son schéma, et pour connaître les
extensions et les contrôles qu'il implémente.
Intégration dans la norme LDAP du schéma X500.
Certaines classes d'objets et attributs définis dans la norme X500
doivent être reconnus par les serveurs LDAP.
La norme LDAP version 3 est définie dans la [rfc3377]
qui est en réalité une méta RFC. En effet cette RFC
définit la norme LDAP version 3 comme une liste de RFC.
Cette liste de RFCs est la suivante :
|
[rfc2251]
|
Définition du protocole réseau LDAP, du
modèle LDAP et des différentes opérations.
|
|
[rfc2252]
|
Définition de la syntaxe des attributs.
|
|
[rfc2253]
|
Syntaxe des DN et leur représentation en UTF-8.
|
|
[rfc2254]
|
Définition des filtres de recherche.
|
|
[rfc2255]
|
Définition des urls.
|
|
[rfc2256]
|
Éléments des schémas de base LDAP.
|
|
[rfc2829]
|
Méthodes d'authentification.
|
|
[rfc2830]
|
Description d'une opération Start TLS, qui permet à
un client et à un serveur d'établir une connexion
sécurisée.
|
Tableau 4: RFCs
définissant la norme LDAP version 3
La version 3 de la norme est entièrement compatible avec
la version 2. Les clients se basant encore sur la version 2 peuvent se
connecter sur des serveurs implémentant la version 3. Dans le cas du
serveur d'Openldap à partir de la version 2.1 cela nécessite un
paramétrage particulier.
B. Description de la norme
1.
Description générale
a. Contenu de la norme
Comme on vient de le voir, la norme LDAP est définie
par un ensemble de RFCs. Nous allons maintenant aborder ce que
définissent ces RFCs :
|
Le protocole réseau LDAP
|
Il s'agit du protocole réseau, s'appuyant sur TCP/IP
permettant d'accéder à l'information contenue dans l'annuaire.
C'est de lui qu'est né la norme LDAP.
|
|
Le modèle d'information
|
Il définit la forme et le type d'informations
stockées dans l'annuaire.
|
|
Le modèle de nommage
|
Il définit l'organisation, le référencement
et l'accessibilité de l'information dans l'annuaire.
|
|
Le modèle fonctionnel
|
Il définit l'ensemble des opérations permettant
d'accéder à l'information dans l'annuaire, que ce soit en lecture
ou en écriture.
|
|
Le modèle de sécurité
|
Il définit les mécanismes d'authentification
auprès de l'annuaire.
|
|
Un modèle de répartition
|
Il définit comment un annuaire peut être
réparti entre plusieurs serveurs.
|
|
Des méthodes d'extensions
|
La norme définit des méthodes pour pouvoir d'une
part ajouter de nouvelles opérations à celles définies
dans le modèle fonctionnel, et d'autre part pour modifier le
comportement des fonctions du modèle.
|
Tableau 5: définition
de la norme LDAP
Bien que cela ne soit pas inclus stricto sensu dans la norme
définie par la [rfc3377], il est d'usage de considérer que le
format de fichier LDIF défini dans la [rfc2849] fait partie de la norme,
ainsi que des API de programmation en C.
b. Le protocole LDAP
Le protocole LDAP est défini dans la [rfc3377], qui est
une mise à jour de la [rfc1777]. Ce protocole réseau basé
sur TCP/IP décrit de façon classique les interactions entre un
client et un serveur. Le protocole permet d'effectuer indifféremment des
opérations synchrones ou asynchrones. Les serveurs peuvent
répondent à un client par un referral, c'est à
dire par un pointeur vers un autre serveur que le client devra contacter de lui
même.
Le protocole définit un ensemble de commandes de base
standards, correspondant en fait aux opérations définies par le
modèle fonctionnel. Il existe néanmoins la possibilité
d'effectuer des opérations étendues, pourvu que client et serveur
savent tous deux les gérer.
Bien que la plupart des données transmises soient
encodées sous la forme de chaînes, la syntaxe BER est
utilisée, si bien que les données envoyées ne sont jamais
de l'ASCII. L'avantage de cette syntaxe est bien sûr son
indépendance vis à vis du système d'exploitation et de la
machine. L'inconvénient est qu'il n'est pas possible de tester un
serveur ou un client LDAP avec l'illustre commande telnet.
2.
Modèle de données
Les informations de l'annuaire sont appelées des
entrées. Chaque entrée est constituée d'un ensemble
d'attributs, chaque attribut d'une entrée ayant une ou plusieurs
valeurs. Les attributs ont une syntaxe. Les attributs peuvent aussi avoir des
options. Par exemple une entrée de l'annuaire pourrait modéliser
une personne et posséder un attribut s'appelant telephone, ayant une
syntaxe de numéro de téléphone. Cette
entrée de l'annuaire pourrait avoir deux valeurs, chacune de ces valeurs
devant respecter la syntaxe numéro de téléphone.
Plus précisément chaque entrée de l'annuaire
appartient à une ou plusieurs classes d'objets. Ce sont les classes
d'objets qui définissent quels attributs une entrée peut avoir.
Les classes d'objet qui définissent aussi les attributs qui sont
obligatoires et ceux qui ne le sont pas.
Un annuaire connaît un certains nombres d'attributs et
de classes d'objet. La norme LDAP et en particulier les [rfc2256] et [rfc2252]
en définissent plusieurs issus des annuaires X500. L'ensemble des
classes d'objets et des attributs que connaît un annuaire, ainsi que les
syntaxes et les règles de correspondance que nous verrons plus tard,
constituent le schéma d'un annuaire. Un chapitre dédié
présente en détail les schémas d'annuaire, et par
là même le modèle des données LDAP.
3.
Modèle de nommage
Les entrées d'un annuaire sont stockées dans une
structure arborescente. L'arbre des entrées s'appelle l'arbre
informationnel de l'annuaire (Directory Information Tree en anglais).
Le sommet de l'arbre de l'arbre s'appelle le suffixe, ou bien la racine.
Chaque entrée dans l'annuaire possède un identifiant. Cet
identifiant est constitué du chemin qui mène de la racine
à l'entrée. Ce chemin s'appelle le Distinguish Name, que
l'on peut traduire par le nom distinctif. On préférera utiliser
l'abréviation DN par la suite.
Alors que le DN est l'identifiant absolu d'une entrée
dans un annuaire, le RDN, pour Relative Distinguish Name, ou encore
nom distinctif relatif, est son identifiant relatif. Un RDN est
constitué d'un attribut de l'entrée et d'une de ses valeurs.
L'attribut choisi devra donc identifier l'entrée par rapport aux autres
entrées du même parent.
Bien que cela soit peu utilisé il est possible d'avoir
plusieurs attributs qui servent de RDNs.
4.
Modèle fonctionnel
a. Ensemble des
opérations
La norme LDAP définit neuf opérations de bases,
que l'on peut regrouper en trois catégories :
|
Authentification et contrôle
|
Bind
|
Connexion à l'annuaire
|
|
|
Unbind
|
Déconnexion
|
|
|
Abandon
|
Pour interrompre une opération en cours
|
|
Opérations d'interrogation
|
Search
|
l'opération de recherche, détaillée
ci-dessous;
|
|
|
Compare
|
L'opération de comparaison
|
|
Opération d'écriture
|
add
|
Pour ajouter une entrée dans l'annuaire
|
|
|
delete
|
Pour effacer une entrée
|
|
|
modify
|
Pour modifier le contenu d'une entrée, c'est à dire
modifier les valeurs de ses attributs. Éventuellement rajouter des
valeurs, en effacer ou supprimer, quelques valeurs ou toutes
|
|
|
modifyDN
|
L'opération précédente ne permet pas de
modifier l'identifiant d'une entrée. Il n'est pas possible à
l'opération modify de modifier la valeur d'un attribut qui sert de RDN
(3).
L'opération modifyDN est dédiée à cette
action
|
Tableau 6: modèle
fonctionnel LDAP
Nous n'entrerons pas dans le détail de chacune de ces
opérations. Nous nous contenterons d'en étudier une seule,
l'opération de recherche.
b. La fonction
recherche
L'opération de recherche est à la fois l'une des
plus utilisées, et l'une des plus significatives. Connaître son
fonctionnement permet de comprendre comment marche LDAP. Sa description dans la
[rfc2251] est la plus longue parmi celles des neuf opérations. Elle
décrite dans la section 4.5, de la page 25 à la page 31.
La liste des paramètres de cette fonction est donc la
suivante :
|
baseObject
|
Entrée à partir de laquelle la recherche est
effectuée.
|
|
|
scope
|
Profondeur de la recherche. Il y a trois types de profondeur
possible :
|
|
|
|
base
|
La recherche ne s'effectuera que sur le baseObject. La
recherche devient alors l'équivalent d'une lecture, à condition
toutefois que le baseObject réponde positivement au
filtre.
|
|
|
one
|
Tous les enfants directs du baseObject et seulement les
enfants directs sont concernés par la recherche.
|
|
|
sub
|
Tous les descendants de baseObject, ainsi que
baseObject lui même sont concernés par la recherche
|
|
derefAliases
|
Ce paramètre indique comment doivent être
considérés les objets de type alias. Une entrée
de classe alias est une copie d'une autre entrée de l'annuaire,
qui apparaît aussi à plusieurs endroits de l'annuaire. Il y a
trois valeurs possibles :
|
|
|
|
neverDerefAliases
|
La recherche ne va jamais traiter les alias qu'elle rencontrera
au sens où elle n'ira pas effectuer la recherche sur les entrées
originales pointées par les éventuels alias
|
|
|
derefInSearching
|
L'alias est résolu seulement dans les entrées sous
le baseObject, mais pas dans le baseObject lui-même
|
|
|
derefFindingBaseObj
|
L'alias est résolu, l'entrée originale sera lue,
seulement dans le baseObject
|
|
|
derefAlways
|
Les alias seront toujours résolus
|
|
sizeLimit
|
Nombre maximum d'entrées retournées par la
recherche. 0 signifie aucune limite imposée par le client
|
|
|
timeLimit
|
Temps en secondes maximum permis pour l'exécution de la
requête. 0 signifie aucune limite imposée par le
client
|
|
|
typesOnly
|
Booléen indiquant si la recherche doit retourner les
valeurs des attributs, avec leur type ou pas
|
|
|
filter
|
Filtre de recherche. La syntaxe des filtres est explicitée
dans un autre chapitre
|
|
|
attributes
|
Liste des attributs à retourner pour les entrées
récupérées par la recherche. Si ce paramètre
contient une chaîne vide ou bien *, tous les attributs seront
retournés. Certains attributs demandés peuvent ne pas être
retournés si l'utilisateur n'a pas le droit d'accès dessus. Mais
aucun message d'erreur ne sera renvoyé, puisqu'il aura accès aux
autres attributs. Si l'attribut dont l'OID est 1.1 transmis, cela
signifie que le client n'attend aucun attribut
|
|
Tableau 7: paramètre de
la fonction de recherche LDAP
5. Modèle de sécurité
Un annuaire LDAP peut nécessiter une authentification.
L'originalité des serveurs LDAP consiste en ce que l'utilisateur devra
s'authentifier en se présentant comme une entrée de l'annuaire.
Au lieu du traditionnel login utilisé par d'autres types
d'applications, un DN devra être fourni.
L'opération bind est l'opération de
connexion et d'authentification auprès d'un serveur annuaire en
endossant l'identité d'une entrée. Cette opération peut
être simple, auquel cas l'utilisateur doit donner un mot de
passe, ou bien elle peut prendre en paramètre un jeton SASL.
6. Étendre LDAP
Dès la conception du protocole LDAP dans sa version 3,
il a été prévu d'y intégrer la possibilité
d'étendre la norme, soit en modifiant le comportement des
opérations existantes, soit en ajoutant des nouvelles opérations.
Nous allons dans cette section décrire ces deux possibilités.
a. Les contrôles
Les contrôles sont un mécanisme qui permet de
modifier le comportement des opérations standard. Ils sont
envoyés par le client au serveur, en même temps qu'une
requête classique. Ils sont décrits dans le paragraphe 4.1.12 de
la [rfc2251].
Dans une requête, un contrôle est
caractérisé par :
|
Type
|
Il s'agit d'un identifiant du contrôle, sous la forme d'un
OID
|
|
Criticité
|
Un booléen qui indique si le contrôle est critique
ou pas. Si le contrôle est signalé comme étant critique par
le client, le serveur doit absolument exécuter la requête avec le
contrôle associé. S'il ne le peut pas, par exemple parce qu'il
n'implémente pas le contrôle ou parce que le contrôle est
inapproprié avec la requête demandée, il doit retourner
l'erreur unsupportedCriticalExtension et ne pas exécuter la
requête
|
|
Valeur
|
Ce champs est utilisé pour transmettre des valeurs
supplémentaires ; son contenu dépend donc du contrôle
|
Tableau 8: les
contrôles
Les contrôles peuvent être aussi retournés
par un serveur dans une réponse à un client. Ainsi des
interactions sont possibles entre le client et le serveur. Un exemple d'une
telle interaction est le contrôle de recherche paginée,
défini dans la [rfc2696] et supporté par Openldap à partir
de version 2.2.
Ce contrôle permet à un client d'effectuer une
recherche, et de récupérer le résultat de sa recherche par
blocs, au lieu de recevoir toutes les entrées en une seule fois.
Lorsqu'il reçoit une telle requête, le serveur inclus dans sa
réponse le même contrôle, en y incluant un identifiant dans
le champs valeur. Cet identifiant sera ensuite renvoyé par le
client à son tour, afin de demander le bloc suivant.
D'autres contrôles ne nécessitent pas une telle
interaction. C'est le cas du contrôle matchedValuesOnly, dont
l'OID est 1.2.826.0.1.3344810.2.2, et qui est encore à
l'état de draft auprès de l'IETF. Ce contrôle, qui doit
être associé à une recherche, demande à un serveur
de ne retourner, parmi toutes les valeurs des attributs d'une entrée,
que celles qui ont répondu positivement au filtre de la recherche. Ce
contrôle est supporté par Openldap.
b. Les opérations
étendues
La section 4.12 de la [rfc2251] décrit les
opérations étendues. Les opérations étendues sont
des opérations dont la syntaxe et la sémantique pourra être
définies dans des documents futurs. Il est ainsi possible aux clients et
aux serveurs LDAP d'effectuer des opérations supplémentaires aux
neuf opérations vues précédemment. Il faut
évidemment que le serveur implémente l'opération
étendue demandée par le client.
Une opération étendue, et la réponse d'un
serveur à une telle opération, sont décrites très
succinctement par la RFC. Elles sont composées très simplement
d'un identifiant, un OID donc, de la requête ou de la réponse, et
d'un champs supplémentaire contenant des données, dont la
signification dépend du contexte.
Que ce soit pour les
contrôles ou pour les opérations étendues, il est
préférable pour le client de connaître à l'avance
quelles extensions supporte le serveur. La section suivante décrit
comment le client peut obtenir ces informations du serveur, en se basant
toujours sur le protocole LDAP.
7. Meta recherche
La [rfc2251] dans sa section 3.4 a prévu un
mécanisme permettant de découvrir les extensions, les
contrôles et le schéma d'un serveur annuaire. Cela permet au
client d'interagir au mieux avec un serveur, en évitant, par exemple, de
créer ou de modifier des objets de façon illégale vis
à vis du schéma, ou bien de ne demander que les contrôles
et les opérations étendues implémentées par le
serveur.
a. Le Root DSE
Pour obtenir des informations sur les capacités d'un
annuaire il faut interroger une entrée spéciale qui s'appelle le
Root DSE. Cette entrée n'a aucun DN, et doit être
récupérée avec le filtre (objectclass=*). Elle ne
doit pas être retournée autrement que par une requête avec
ce filtre et dont le base_dn est vide. Elle peut être soumise à
des restrictions de contrôle d'accès. La [rfc2251] précise
que le serveur pourrait autoriser la modification des attributs de cette
entrée, mais Openldap lui ne le permet pas.
Voici la liste des attributs d'un Root DSE définis par
[rfc2251] :
|
namingContexts
|
Liste des suffixes gérés par le serveur
|
|
subschemaSubentry
|
DN de l'entrée subschema. Cette entrée contient une
description du schéma gérée par le serveur. Cet attribut
peut être absent si le serveur ne gère pas lui même des
entrées schéma. Il est multiple, dans le cas où le serveur
gère plusieurs annuaires, chacun ayant son propre schéma
|
|
altServer
|
Serveur à contacter si le serveur ne répond plus
|
|
supportedExtension
|
Liste des opérations étendues supportées
|
|
supportedControl
|
Liste des contrôles supportés
|
|
supportedSASLMechanisms
|
Liste des fonctionnalités SASL supportées
|
|
supportedLDAPVersion
|
Version du protocole LDAP supportée par le serveur
|
Tableau 9: attributs du Root
DSE
b. Les entrées
subschema
Nous venons de voir comment récupérer un certain
nombre d'information sur un annuaire, et en particulier comment
récupérer le DN des entrées subschema. Comme le Root DSE,
les entrées subschema sont des entrées particulières d'un
serveur, qui ne sont pas placées sous la racine de l'annuaire. Ces
entrées décrivent le schéma supporté par le
serveur, c'est à dire la liste des objets, des attributs, des
règles de comparaison, etc. qu'il connaît. Il est possible,
d'après la [rfc2251] de modifier ses entrées, mais ce n'est pas
obligatoire pour respecter la version 3 de la norme LDAP.
La section 3.2.2 de cette RFC définit la liste des
attributs d'une entrée subschema. Certains attributs sont obligatoires,
d'autres pas. Cette liste est la suivante:
|
cn
|
Cet attribut doit être le RDN de l'entrée subschema.
Cet attribut est obligatoire dans une entrée subschema
|
|
objectClass
|
Il s'agit des classes de l'entrée subschema. Il doit au
moins contenir les valeurs top et subschema. Cet attribut est
obligatoire dans une entrée subschema
|
|
objectClasses
|
Cet attribut multivalué contient les classes
gérées par le serveur. Il a autant de valeurs que de classes
gérées. Cet attribut est obligatoire dans une entrée
subschema
|
|
attributeTypes
|
Cet attribut multivalué contient les attributs
gérés par le serveur. Il a autant de valeurs que d'attributs
gérés. Cet attribut est obligatoire dans une entrée
|
|
matchingRules
|
Liste des règles de comparaison gérées par
le serveur. Cet attribut a autant de valeur que de règles, et n'est pas
obligatoire
|
|
matchingRuleUse
|
Usage des règles de comparaison. Il y a autant de valeurs
de cet attribut que de règles de comparaison. Et pour chaque
règle, une valeur contient la liste des attributs sur lesquels elle
s'applique. Cet attribut n'est pas obligatoire
|
|
ldapSyntaxes
|
Liste des syntaxes supportées par le serveur. Cet attribut
n'est pas obligatoire
|
Tableau 10: les entreés
subschema
Les attributs dITStructureRules,
dITContentRules, nameForms existent aussi, et
sont optionnels. Ils ne sont pas supportés par Openldap. Ils
décrivent des règles sur l'arbre informationnel.
III. Présentation de
quelques standards LDAP
Dans la section précédente, nous avons vu que la
norme LDAP est une agglomération de différentes RFCs, de
différents standards. Dans ce chapitre quelques uns de ces standards
vont être présentés.
A. Les fichiers LDIF
1.
Introduction aux fichiers LDIF
LDIF est un format de fichier, spécifié dans la
[rfc2849]. Les fichiers de type LDIF sont utilisés d'une part pour
décrire des objets d'un annuaire LDAP, et d'autre part pour
décrire un ensemble d'opérations à effectuer sur le
contenu d'un annuaire. L'utilisation descriptive permet, par exemple, de
créer les premières entrées d'un annuaire, ou bien d'avoir
une sauvegarde d'un annuaire sous la forme d'un fichier.
Le format LDIF a été développé par
l'Université du Michigan, dans ses implémentations d'annuaire
LDAP. La première utilisation a été celle de fichiers
descriptifs, puis le format a évolué pour pouvoir décrire
des modifications apportées à un annuaire.
2.
Syntaxe
La syntaxe d'une entrée dans un fichier LDIF est la
suivante :
dn: <distinguished name>
<attrdesc>: <attrvalue>
<attrdesc>: <attrvalue>
<attrdesc>:: <base64-encoded-value>
<attrdesc>:< <URL>
Soit en premier le DN de l'entrée décrite, ou
bien de l'entrée sur laquelle nous allons effectuer des
opérations, suivi d'une liste d'attributs et de leurs valeurs, les
attributs pouvant décrire une opération en fonction du type de
fichier LDIF.
Les attributs dont la valeur contient des accents doivent
être encodés en UTF-8. Les attributs contenant des
caractères spéciaux doivent être encodés en base 64.
Les attributs peuvent être sur plusieurs lignes, à condition que
les lignes supplémentaires commencent par un blanc. Les attributs dont
la valeur est localisée dans un fichier sont introduit par la :< ou
lieu de :. Les espaces entre les noms d'attributs et leur valeur sont
optionnels, mais utiles à la lisibilité du fichier.
Le DN doit être encodé en base 64, lorsqu'il
commence par une espace, un <, un : , un retour ligne ou un retour chariot.
De même pour les attributs qui se terminent avec une espace.
Un fichier LDIF peut commencer par un numéro de
version, qui doit être 1: version: 1. Les commentaires
commencent par #. Les différentes entrées sont
séparées par une ligne blanche, qui peut être un CR LF ou
LF. Il ne peut y avoir plus deux lignes blanches consécutives.
Il est possible de rajouter des options à un attribut.
L'intitulé de l'option se rajoute au nom de l'attribut, avec un ;. Il
est possible de mettre plusieurs options à la suite. Si un attribut a
une valeur vide, il peut être représenté, la valeur dans le
fichier LDIF restant vide.
Plusieurs opérations sur les attributs (ci-après
changetype: add, delete ou modidy) peuvent
s'enchaîner, en les séparant par une ligne contenant un -.
3.
Liste des opérations
a. Ajout d'une
entrée
dn: <distinguished name>
changetype: add
objectclass: top
objectclass: <objectclassvalue>
<attrdesc>: <attrvalue>
<attrdesc>: <attrvalue>
Il existe certaines commandes d'administration qui permettent
d'insérer dans un annuaire des objets décrits dans un fichier
LDIF, sans qu'il soit nécessaire que ce fichier LDIF contienne la
commande d'insertion ci-dessus.
b. Suppression d'une
entrée
dn: <distinguished name>
changetype: delete
Ce n'est pas la peine de mettre des attributs
supplémentaires. L'objet ne peut être effacé que
s'il n'a pas de descendants.
c. Ajout de valeurs
à un attribut
dn: <distinguished name>
changetype: modify
add: <attribut>
<attribut>: <attrvalue1>
<attribut>: <attrvalue2>
On peut ainsi donner à l'attribut autant de valeurs que
l'on souhaite. Les attributs précédents de l'objet ne sont pas
effacés.
d. Suppression de valeurs
à un attribut
Si l'on souhaite effacer uniquement certaines valeurs, il faut
passer en paramètres ces valeurs. L'opération a la syntaxe
suivante :
dn: <distinguished name>
changetype: modify
delete: attribut
<attribut>: <première valeur à
effacer>
<attribut>: <seconde valeur à effacer>
Si l'on souhaite effacer toutes la valeurs d'un attribut d'un
objet, il ne faut passer en paramètres aucune valeur de l'attribut. La
syntaxe a ainsi la forme suivante :
dn: <distinguished name>
changetype: modify
delete: attribut
e.
Remplacer les valeurs d'un attribut
Similaire au deux cas précédents, les
paramètres contiennent cette fois les valeurs qui remplacent les valeurs
précédentes :
dn: <distinguished name>
changetype: modify
replace: attribut
<attribut>: <nouvelle valeur 1>
<attribut>: <nouvelle valeur 2>
f.
Modification du DN et/ou du RDN
La syntaxe pour modifier le DN d'une entrée, soit
modifier sa position dans l'arbre, ou pour modifier son RDN, soit modifier son
identifiant, sont similaires. La modification d'un DN s'écrit :
dn: <distinguished name>
changetype: moddn
newrdn: <nouveau relative distinguished name>
deleteoldrdn: <1 ou 0>
newsuperior: <nouveau parent>
deleteoldrdn indique si l'on souhaite ou non conserver l'ancienne
entrée. Ce type d'opération ne marche que sur les serveurs LDAP
respectant la version 3 de la norme.
La modification d'un RDN s'écrit :
dn: <distinguished name>
changetype: modrdn
newrdn: <nouveau relative distinguished name>
deleteoldrdn: <1 ou 0>
B. Filtre de recherche
1.
Présentation générale
Un filtre LDAP est comparable à une requête SQL.
C'est une chaîne de caractères destinée à être
exécutée pour récupérer des entrées d'un
annuaire LDAP. Plus précisément elle ne définit que la
partie WHERE d'une requête SQL: un filtre définit sur
quels objets et sur quels attributs doit se faire la recherche.
Un filtre LDAP est donc constitué d'un ensemble
d'opérations, portant sur des attributs, combinées avec les
opérateurs booléens classiques: ET, OU et
NON.
Une opération élémentaire de recherche
s'écrit sous la forme : attribut OPERATEUR valeur La forme
générale d'un filtre est une combinaison : (operator(search
operation)(search operation)...)).
La syntaxe complète des filtres LDAP est décrite
dans le document [rfc2254], qui fait partie de l'ensemble des RFC
définissant la norme LDAP.
2.
Les opérations élémentaires
Une opération élémentaire est
composée d'un attribut, d'un opérateur de comparaison et d'une
valeur. Pour effectuer des filtres sur le type des objets, sur leur classe, il
suffit d'utiliser leur objectclass comme un attribut. Au besoin, il est
possible d'utiliser l'OID de l'attribut plutôt que son nom.
Les opérateurs de recherche sont les suivants :
|
Égalité
|
: =
|
|
Approximation
|
~=
|
|
Supérieur ou égal
|
>=
|
|
Inférieur ou égal
|
<=
|
Tableau 11: les
opérations élémentaires
S'il n'existe pas d'opérateur : "différent de",
"strictement inférieur", ou "strictement supérieur", il est
possible de les obtenir à l'aide des opérateurs autorisés,
en utilisant un opérateur booléen "NON".
La valeur accepte le caractère '*' afin de permet des
recherches sur des parties de chaînes. Ce même caractère,
seul, permet de tester la présence d'un attribut. Ce caractère
n'est valide qu'avec l'opération d'égalité.
Une opération doit obligatoirement se trouver entre
deux parenthèses. Les valeurs qui sont dans la partie droite d'une
opération élémentaire ne sont pas entre quote, mais
certains caractères doivent être échappés :
|
Le caractère
|
Sa valeur ASCII
|
Le caractère dans un filtre
|
|
*
|
0x2a
|
\2a
|
|
(
|
0x28
|
\28
|
|
)
|
0x29
|
\29
|
|
\
|
0x5c
|
\5c
|
|
NULL (caractère vide)
|
0x00
|
\00
|
Tableau 12: les
opérations
Les opérateurs booléens sont les suivants :
|
L'opérateur NON
|
!
|
|
L'opérateur ET
|
&
|
|
L'opérateur OU
|
|
|
Tableau 13: les
opérateurs booléens
Un opérateur booléen s'applique à toutes
les opérations qui suivent jusqu'à l'opérateur suivant.
3.
Exemples de filtres simples
Toutes les personnes ayant leur numéro de
téléphone renseigné dans la base :
(&(objectclass=person)(telephoneNumber=*))
Toutes les personnes dont le nom commence par 'A' et n'habitant
pas Paris :
(&(objectclass=person)(cn=A*)(!(l=Paris)))
Toutes les personnes dont le nom ressemble à Febvre
(Faivre, Fèvre, Lefebvre, ...) :
(&(objectclass=person)(cn~=febvre))
(&(objectclass=person)(cn=*f*vre))
4.
Les filtres étendus
En plus des attributs constituant une entrée d'un
annuaire, il est possible, grâce aux filtres étendus, de
considérer les éléments du DN comme faisant partie aussi
de l'entrée elle même, lors de la recherche. La syntaxe est la
suivante :
attribut:dn:=value
Par exemple le filtre (ou:dn:=users)
récupérera non seulement toutes les entrées qui ont un
attribut ou qui a pour valeur users, mais aussi toutes les
entrées dont le DN contient un attribut ou avec la valeur
users.
L'autre possibilité offerte par les filtres
étendus est de modifier la règle de comparaison sur un attribut.
La syntaxe est la suivante :
attribut:oid-matching-rule:=value
Par exemple, si un attribut a une règle de comparaison
par défaut qui est insensible à la case, mais que l'on veut faire
une recherche avec une valeur précise, qui tienne compte de la case, il
faut modifier la règle de comparaison par défaut.
a. Changement de
règle de comparaison dans un filtre
Dans cet exemple, on rend l'opération
d'égalité sensible à la case
(cn:2.5.13.5:=Mickey)
Les filtres étendus permettent aussi de
spécifier une règle de comparaison, sans spécifier
d'attribut. La recherche s'effectue alors sur tous les attributs qui acceptent
cette règle. On peut aussi étendre cette recherche au DN. Les
syntaxes sont les suivantes:
:oid-matching-rule:=value
:dn:oid-matching-rule:=value
Tous les filtres ne marchent qu'avec l'opérateur
d'égalité, et celui-ci s'écrit :=, lieu de = dans le cas
de filtres simples.
Il n'est pas permis non plus d'utiliser le caractère *
pour faire des recherches sur des sous chaînes avec les filtres
étendus.
C. Urls LDAP
1.
Présentation
Les URL LDAP sont une notation pour identifier, localiser, des
entrées d'un annuaire, résultat d'une recherche. Elles
représentent un moyen simple pour pointer sur un annuaire, ou bien
seulement une partie de l'annuaire, telle une branche ou des objets
disséminés. Elles sont utilisées par des clients web, dans
des fichiers de configuration, ou encore dans des entrées de l'annuaire.
Elles ont l'avantage de ne nécessiter aucune notion de programmation.
La syntaxe URL de LDAP est décrite dans la [rfc2255]
qui est une mise à jour de la [rfc1959], datée de 1996. La
nouvelle RFC intègre la notion d'extension.
2.
Syntaxe
La syntaxe d'une url est la suivante :
ldap[s]://<hostname>:<port>/<base_dn>?<attributes>?<scope>?<filter>?<extensions>
avec les paramètres suivants :
|
hostname
|
Adresse du serveur. L'adresse peut être absente, le client
est supposé connaître un serveur LDAP à contacter, en
fonction du contexte.
|
|
port
|
Port TCP de la connexion. Par défaut il s'agit du port
389. Il ne peut y avoir de port s'il n'y a pas d'adresse.
|
|
base_dn
|
DN de l'entrée qui est le point de départ de la
recherche.
|
|
attributes
|
Les attributs que l'on veut récupérer,
séparés par des virgules. Si la valeur n'est pas remplie, ou si
elle est rempli avec une *, tous les attributs d'usage userApplication doivent
être retournés.
|
|
scope
|
La profondeur de la recherche dans l'arbre : base,
one ou sub.
|
|
filter
|
Le filtre de recherche, tel que nous venons de le définir.
Le filtre par défaut est (objectClass=*).
|
|
extensions
|
Les extensions sont un moyen pour pouvoir ajouter des
fonctionnalités aux URLs LDAP tout en gardant la même syntaxe. On
peut mettre inclure plusieurs extensions dans une URL, en les séparant
par des virgules. Les extensions ont le format suivant : type=value.
La partie =value est optionnelle. Elles peuvent être
préfixées par un ! pour signaler une extension critique. Une
extension critique signifie que le client et le serveur doivent supporter tous
les deux l'extension, sinon une erreur sera levée.
|
Tableau 14: paramètres
url LDAP
La [rfc2255] définit une extension bindname,
dont la valeur est le DN utilisé par le client pour se connecter au
serveur. Le client a la charge de demander à l'utilisateur de rentrer le
mot de passe associé si nécessaire.
Tous les caractères non autorisés ou
spéciaux dans les urls (voir section 2.2 de [rfc1738]) ainsi que le
caractère '?' lorsqu'il est présent dans un DN, un
filtre ou une extension, doivent être échappé avec la
méthode décrite dans la [rfc1738]. Cette méthode consiste
à écrire le caractère avec '%' suivi des deux
chiffres hexadécimaux, formant sa valeur hexadécimale.
3.
Exemples
Lecture de toutes les personnes du service vente :
ldap://ldap.netscape.com/ou=Sales,o=Netscape,c=US?cn,tel,mail?scope=sub?(objetclass=person)
Lecture des objets personnes d'un annuaire :
ldap://localhost:389/??sub?objectclass=person
Recherche de Valery Febvre :
ldap://ldap.easter-eggs.fr/cn=Valery%20Febvre,ou=Moyens%20Informatiques,dc=easter-eggs,dc=fr
Recherche approximative d'une personne :
ldap://ldap.easter-eggs.fr/o=easter-eggs,dc=fr?mail,uid,sub?(sn=Febvre)
IV. Conception des schémas
LDAP
Dans cette section nous allons étudier comment
écrire un schéma LDAP, c'est à dire comment créer
de nouveaux objets et de nouveaux attributs lorsque cela est nécessaire.
Nous commencerons par présenter le modèle des données de
la norme LDAP.
A. Modèle des données
Chaque entrée de l'annuaire est constituée d'un
ensemble d'attributs, chaque attribut ayant une ou plusieurs valeurs.
Le schéma d'un annuaire définit l'ensemble des
classes et attributs que celui-ci peut contenir. Chaque entrée de
l'annuaire appartient à une ou plusieurs classes d'objet, et ne peut
contenir que des attributs de cette classe.
Chaque classe d'objets est définie par une liste
d'attributs - de propriétés - obligatoires et une liste
d'attributs facultatifs. À chaque attribut sont associés
notamment un nom et une syntaxe, mais aussi une description, et d'autres
informations que nous allons étudier en détail.
B. Les attributs
1.
Description des attributs
Un attribut est caractérisé par les informations
suivantes :
Un nom : Un identifiant sous forme de chaîne de
caractères. Les noms d'attributs sont toujours insensibles à la
case. Un attribut peut avoir plusieurs noms. C'est le cas de l'attribut
givenName qui s'appelle aussi gn.
Un Object Identifier (OID) : Un identifiant numérique.
Voir la section dédiée.
Une description : La description d'un attribut fait partie du
schéma à part entière.
Une syntaxe et des règles de comparaison : La syntaxe
indiquera quel type d'information l'attribut peut contenir. Les règles
de comparaison indiqueront comme effectuer des recherches sur les valeurs de
l'attribut. La [rfc2252] fournit un ensemble de syntaxes et de règles de
comparaison, que les serveurs LDAP doivent savoir gérer.
Sa valuation : S'il est mono ou multivalué
Un indicateur d'usage : Il existe quatre indicateurs d'usages
possible (userApplication, directoryOperation, distributedOperation,
dsaOperation). Les trois derniers types d'attributs sont dit Operational. Cela
signifie qu'ils ne sont pas modifiables par l'utilisateur, ni accessibles, sauf
certains qui peuvent être lus, comme par exemple modifytimestamp.
Un format ou une limite de taille
Il existe des relations d'héritage entre attributs.
Lorsqu'on définit un attribut, il faut donc aussi définir
l'attribut dont il descend, même si cela n'est pas obligatoire.
Ainsi les attributs sn (nom de famille), gn (prénom)
dérivent de l'attribut name. L'aspect pratique de l'héritage
entre attributs est qu'il est possible d'effectuer des recherches sur plusieurs
attributs en même temps: En effectuant une recherche sur l'attribut name,
on fera aussi une recherche sur ses sous-types.
2.
Exemples
a. Exemples de syntaxes
définies dans la [rfc2252]
|
OID
|
Nom
|
Description
|
|
1.3.6.1.4.1.1466.115.121.1.7
|
Boolean
|
Booléen
|
|
1.3.6.1.4.1.1466.115.121.1.12
|
DN
|
Un DN
|
|
1.3.6.1.4.1.1466.115.121.1.15
|
Directory String
|
Une chaîne de caractères, encodée en UTF-8
|
|
1.3.6.1.4.1.1466.115.121.1.26
|
IA5String
|
Une chaîne de caractères ASCII
|
|
1.3.6.1.4.1.1466.115.121.1.27
|
INTEGER
|
Un entier
|
Tableau 15: quelques syntaxes
de type
3. Exemples et descriptions de règles de
comparaison définies dans les [rfc2252]
|
OID
|
Nom
|
Description
|
Syntaxe
|
|
2.5.13.0
|
objectIdentifierMatch
|
Comparaison d'égalité entre deux OIDs.
|
1.3.6.1.4.1.1466.115.121.1.38
|
|
2.5.13.1
|
distinguishedNameMatch
|
Comparaison d'égalité entre deux DN.
|
1.3.6.1.4.1.1466.115.121.1.12
|
|
2.5.13.2
|
caseIgnoreMatch
|
Retourne vrai si les chaînes ont la même taille et
sont identiques, à la case près.
|
1.3.6.1.4.1.1466.115.121.1.15
|
|
2.5.13.3
|
caseIgnoreOrderingMatch
|
Règle d'inégalité, retourne vrai si la
valeur de l'attribut comparé apparaît est avant la valeur
passé en paramètre, une fois les deux chaînes convertis en
majuscules.
|
1.3.6.1.4.1.1466.115.121.1.15
|
|
2.5.13.4
|
caseIgnoreSubstringsMatch
|
Règle d'inclusion, insensible à la case, comme les
deux règles précédentes.
|
1.3.6.1.4.1.1466.115.121.1.58
|
|
2.5.13.8
|
numericStringMatch
|
Règle identique à la règle
caseIgnoreMatch sauf que les espaces sont ignorés
pendant la comparaison.
|
1.3.6.1.4.1.1466.115.121.1.36
|
|
2.5.13.10
|
numericStringSubstringsMatch
|
Règle identique à la règle
caseIgnoreSubstringsMatch sauf que les espaces sont
ignorés pendant la comparaison.
|
1.3.6.1.4.1.1466.115.121.1.58
|
|
2.5.13.23
|
uniqueMemberMatch
|
Retourne vrai si la valeur soumise et la valeur de l'attribut
comparés sont des DN identiques; ou bien si le DN de l'attribut contient
un composant uid, celui-ci peut être absent du DN de la valeur soumise,
ou bien s'il est présent il doit être égal.
|
1.3.6.1.4.1.1466.115.121.1.34
|
Tableau 16: description des
règles de comparaison
4.
Exemples d'attributs définis dans la [rfc2256]
|
Nom
|
Description
|
|
sn
|
Nom de famille, dérive de l'attribut name
|
|
telephoneNumber
|
Numéro de téléphone
|
|
member
|
Membre d'un groupe. Cet atribut contient un DN, donc une
référence vers un noeud de l'annuaire.
|
Tableau 17: exemple
d'attributs
C. Les classes
1.
Description
Chaque entrée de l'annuaire appartient à une ou
plusieurs classes. Les classes modélisent ainsi les objets réels
ou abstraits décrits dans un annuaire. Des exemples de classes sont :
personne, bâtiment, application.
Une classe est constituée de :
Un nom : Un identifiant sous forme de chaîne de
caractères. Exactement comme les noms de classes sont insensibles
à la case. Une classe peut elle aussi avoir plusieurs noms.
Un Object Identifier (OID) : Un identifiant numérique.
Voir la section dédiée.
Une description : La description de la classe fait partie du
schéma.
Un type
Il existe trois type de classes :
Les classses structurelles : C'est une classe
classique qui peut être instanciée.
Les classes auxiliaires : Ce sont des classes
permettant de rajouter des informations complémentaire à des
objets structurels. Des exemples de classes auxiliaires sont: mailRecipient,
labelURIObject. Ces classes contiennent un ensemble d'attributs,
généralement facultatifs. Les classes auxiliaires sont similaires
aux interfaces en java.
Les classes abstraites : Les classes
abstraites ne peuvent pas être instanciées, mais seulement
dérivées.
Il n'est pas possible de faire de l'héritage multiple
entre classes: une classe dérive toujours d'une seule classe.
Néanmoins une entrée de l'annuaire peut être
constituée de plusieurs classes, à condition qu'elle ne soit
constituée que d'une seule classe structurelle, et de zéro, une
ou plusieurs classes auxiliaires.
L'ensemble des classes d'objet forme une hiérarchie,
dont la classe Top est au sommet.
2.
Exemples
Exemples d'objet standards issus de la [rfc2256] :
|
OID
|
Nom
|
Supérieur
|
Type
|
Attributs obligatoires
|
Attributs facultatif
|
Description
|
|
2.5.6.0
|
top
|
Aucun
|
ABSTRACT
|
Aucun
|
Aucun
|
Classe parente de toutes les classes
|
|
2.5.6.6
|
person
|
top
|
STRUCTURAL
|
sn, cn
|
userPassword
telephoneNumber seeAlso description
|
Classe de base modélisant une personne
|
|
2.5.6.9
|
groupOfNames
|
top
|
STRUCTURAL
|
member, cn
|
businessCategory seeAlso
Owner
ou
o
description
|
Groupes d'utilisateurs
|
|
organizationalUnit
|
top
|
STRUCTURAL
|
Ou, objectClass
|
businessCategory
description facsimileTelephoneNumber
location (l)
postalAddress
seeAlso
telephoneNumber
|
Classe modélisant une unité organisationnelle
|
Tableau 18: les objets
standard
D. Présentation des OID
1.
Présentation des OID
Les OID sont des identifiants universels,
représentés sous la forme d'une suite d'entiers. Ils sont
organisés sous forme hiérarchique. Ainsi seul l'organisme
1.2.3 peut dire quelle est la signification de l'OID 1.2.3.4.
Ils ont été définis dans une recommandation de
l'International Telecommunication Union. L'IETF a proposé de
représenter la suite d'entiers constituant les OID séparés
par des points.
L'objectif des OID est d'assure
l'interopérabilité entre différents logiciels. Les OID
sont utilisés dans le monde LDAP mais aussi dans d'autres domaines,
comme par exemple les logiciels SNMP pour identifier des ressources. Il est
possible d'obtenir un OID, et par conséquence toute une branche,
auprès de l'IANA.
Dans le monde LDAP les objets, les attributs, les
syntaxes et les règles de comparaison sont
référencés par un objet OID. La [rfc2256] normalise un
certain nombre de ces objets.
2.
Exemples
a. Exemples d'OID
|
OID
|
Description
|
|
0
|
branche de l'International Telecommunication Union
|
|
1
|
branche ISO
|
|
2
|
branche commune entre l'International Telecommunication Union et
ISO
|
|
2.5
|
fait référence au service X500
|
|
2.5.4
|
définition des types d'attributs
|
|
2.5.6
|
définition des classes d'objets
|
|
1.3.6.1
|
the Internet OID
|
|
1.3.6.1.4.1
|
IANA-assigned company OIDs, used for private MIBs
|
|
1.3.6.1.4.1.4203
|
OpenLDAP
|
|
1.3.6.1.4.1.10650
|
Easter-eggs
|
Tableau 19: exemples d'OID
Supposons qu'un organisme ait le OID 1.1. L'exemple
suivant montre une façon d'ordonner les OID qu'il créera pour ses
propres besoins
b. Exemple de
hiérarchie
|
OID
|
Description
|
|
1.1
|
OID de l'organisme
|
|
1.1.1
|
Branches des identifiants SNMP
|
|
1.1.2
|
Branches des identifiants LDAP
|
|
1.1.2.1
|
Branches des attributs LDAP
|
|
1.1.2.1.1
|
Identifiant du premier attribut LDAP
|
|
1.1.2.2
|
Branche des classes d'objets LDAP
|
|
1.1.2.2.1
|
Identifiant du premier objet LDAP
|
Tableau 20: exemples de
hiérarchie
E. Syntaxe
1.
Syntaxe de la définition d'un attribut
AttributeTypeDescription = "(" whsp
numericoid whsp ; AttributeType
identifier
[ "NAME" qdescrs ] ; name used in
AttributeType
[ "DESC" qdstring ] ; description
[ "OBSOLETE" whsp ]
[ "SUP" woid ] ; derived from this other
; AttributeType
[ "EQUALITY" woid ; Matching Rule name
[ "ORDERING" woid ; Matching Rule name
[ "SUBSTR" woid ] ; Matching Rule name
[ "SYNTAX" whsp noidlen whsp ] ;
[ "SINGLE-VALUE" whsp ] ; default multi-valued
[ "COLLECTIVE" whsp ] ; default not collective
[ "NO-USER-MODIFICATION" whsp ]; default user modifiable
[ "USAGE" whsp AttributeUsage ]; default
userApplications
whsp ")"
Cette syntaxe est extraite de la [rfc2252]. whsp est
un blanc. Le nom de l'attribut doit être entre parenthèses et
entre simples quotes. Des espaces sont obligatoires entre les
parenthèses et le nom entre quote, et entre les différents noms,
s'il y en a plusieurs. La syntaxe de la description est identique,
excepté qu'il ne peut y avoir qu'une seule description.
woid signifie OID. noidlen signifie que la
syntaxe d'un attribut est aussi un OID qui peut être
complété par une taille maximale, contenue entre {}.
AttributeUsage est l'une des quatre valeurs
présentée ci-dessus: userApplications
directoryOperation distributedOperation
dSAOperation.
La [rfc2252] permet à un attribut d'être
collectif, c'est à dire partagé entre plusieurs
entrées. C'est un héritage de la norme X500. Néanmoins la
norme LDAP n'a pas fourni d'indication sur l'implémentation de ces
attributs. Ils ne sont donc pas utilisés actuellement. Une RFC
récente, de décembre 2003, fournit plus d'informations. Il s'agit
de la [rfc3671].
Exemples de déclarations d'attributs :
attributetype ( 2.5.4.4 NAME ( 'sn' 'surname' )
DESC 'RF256: last (family) name(s) for which the entity is known
by'
SUP name )
attributetype ( 2.5.4.20 NAME 'telephoneNumber'
DESC 'RF256: Telephone Number'
EQUALITY telephoneNumberMatch
SUBSTR telephoneNumberSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.50{32} )
( 2.5.4.31 NAME 'member' SUP distinguishedName )
2.
Syntaxe de la définition d'un objet
ObjectClassDescription = "(" whsp
numericoid whsp ; ObjectClass identifier
[ "NAME" qdescrs ]
[ "DESC" qdstring ]
[ "OBSOLETE" whsp ]
[ "SUP" oids ] ; Superior ObjectClasses
[ ( "ABSTRACT" / "STRUCTURAL" / "AUXILIARY" ) whsp ]
; default structural
[ "MUST" oids ] ; AttributeTypes
[ "MAY" oids ] ; AttributeTypes
whsp ")"
Cette déclaration de la syntaxe d'un objet est en tout
point similaire à celle d'un attribut.
Exemples de déclarations d'attributs :
( 2.5.6.0 NAME 'top' ABSTRACT MUST objectClass )
( 2.5.6.3 NAME 'locality' SUP top STRUCTURAL
MAY ( street $ seeAlso $ searchGuide $ st $ l $ description )
)
( 2.5.6.6 NAME 'person' SUP top STRUCTURAL MUST ( sn $ cn )
MAY ( userPassword $ telephoneNumber $ seeAlso $ description )
)
( 2.5.6.9 NAME 'groupOfNames' SUP top STRUCTURAL MUST ( member $
cn )
MAY ( businessCategory $ seeAlso $ owner $ ou $ o $ description
) )
F. L'intérêt de créer ses propres
schémas
Bien qu'il existe de nombreux objets et attributs
normalisés, ceux-ci ne sont pas toujours adaptés au besoin d'une
organisation. Généralement chaque organisation possède des
informations à stocker dans l'annuaire qui lui sont spécifiques.
Sachant que les objets standards sont impossible à modifier, il
reste la possibilité de créer ses propres attributs et ses
propres objets. Cela nécessite la démarche administrative
consistant à récupérer un identifiant auprès de
l'IANA.
V. Déploiement d'une
architecture LDAP
Après avoir vu comment écrire un schéma,
nous allons étudier le processus de mise en oeuvre d'un annuaire LDAP.
A. Phase de cadrage
La première phase du processus de mise en oeuvre d'un
annuaire est la phase de cadrage. C'est pendant cette phase que doivent
être désignés tous les objectifs qui sont assignés
à l'annuaire.
Quelque soit le type d'organisation dans laquelle un annuaire
est déployé, celui-ci a toujours un impact important. Le service
informatique est bien sûr le premier à être concerné,
mais il est loin d'être le seul. Il est donc important que l'organisation
désigne un responsable annuaire, qui sera l'interlocuteur unique entre
le prestataire qui met en oeuvre l'annuaire, mais aussi entre les utilisateurs
finaux et le service informatique.
L'annuaire est amené à devenir le point central
de l'architecture informatique de l'organisation. Toute application
nécessitant une authentification des utilisateurs devrait s'appuyer sur
un annuaire. C'est là sa première vocation et sa première
utilisation. Mais il est aussi possible de l'utiliser pour stocker des
informations supplémentaires sur les personnes, et peut ainsi être
la base de données d'une application de type "pages blanches". On voit
bien alors qu'il peut servir pour gérer presque n'importe quel type de
données, et dans beaucoup d'applications.
Il est donc primordial, pendant la phase de cadrage, de se
donner des priorités parmi toutes ces possibilités d'utilisation
d'un annuaire. Il faut, d'une part, choisir quelles seront les premières
applications qui appuieront leur authentification sur l'annuaire. Il faut
aussi, d'autre part, déterminer quelles sont les premières
applications qui utiliseront les données de l'annuaire en tant que
telles.
L'important à cette étape est de rester modeste
et pragmatique. Avoir une ou deux applications s'appuyant sur l'annuaire est un
bon début, qui permet de démarrer simplement, sans faire la
révolution dans tout le système informatique. Avoir une
application de type pages blanches et un serveur mail dont l'authentification
et les paramètres de messagerie sont basés sur l'annuaire est un
bon début. Ce n'est pas la peine d'y ajouter tout de suite une liaison
avec le logiciel de paie et la gestion des permissions du serveur de fichiers.
L'autre paramètre à intégrer dans cette
phase concerne les utilisateurs. Dans le cas de la mise en oeuvre d'une
application pages blanches, ou bien d'une autre application nouvelle
entièrement basée sur l'annuaire, ils doivent être
intégrés au plus tôt dans la définition des besoins.
En effet, au delà des données techniques, l'utilisateur final
sera le plus compétent pour dire quelles sont les données qui
devront être intégrées à l'annuaire.
B. Phase de conception
1.
Choix des données et Identification des acteurs
a. Déterminer les
données de l'annuaire
Après la phase de cadrage, la première
étape de la phase de conception consiste à énumérer
les données présentes dans l'annuaire. Il s'agit
d'énumérer de manière exhaustive d'une part toutes les
classes d'objets amenées à peupler l'annuaire, et d'autres parts,
pour chaque classe, quelles sont ses propriétés
gérées par l'annuaire.
Pour chaque type de données, en procédant par
classes d'objets puis par propriétés si nécessaire, il
faut alors déterminer les informations suivantes :
Quelles sont les personnes ou les applications manipulant
cette donnée? On se contentera dans un premier temps d'une
réponse sommaire, sachant qu'une réponse plus complète -
par type d'action - sera donnée par la suite.
Quelle est la ou les sources actuelles de cette donnée?
Est-elle déjà sous forme numérique ou pas encore? Est-ce
une donnée statique ou dynamique? Est-elle calculée?
Quelle est le type de cette donnée (chaîne de
caractères, entier, data, etc)? Quelle est son format: la chaînes
est-elle encodée en utf8 ou unicode? Quel format de date est
utilisé? Sa taille?
Quelle est la pérennité de la donnée? Sa
fréquence de mise à jour? Cette mise à jour est-elle
automatique ou manuelle?
b. Cas d'utilisation
Une fois les données de l'annuaire bien
définies, il faut détailler leur utilisation. Pour y parvenir de
façon convenable il est utile d'employer la même méthode
que lorsqu'on décrit des cas d'utilisation, en eXtrem Programming et en
modélisation UML.
Bien que les cas d'utilisation soient centrés sur les
utilisateurs, il faudra, dans notre travail, énumérer aussi les
actions des applications externes à l'annuaire mais qui l'utilisent.
Pour chaque donnée contenue dans l'annuaire il faut
donc noter qui effectue les actions suivantes :
· Recherche. Une recherche s'effectue sur
certains attributs. Pour chaque objet, dans chaque cas d'utilisation, il faudra
donc noter les attributs sur lesquels la recherche s'effectue.
· Lecture. Là encore il faut tenir
compte des attributs. Les cas d'utilisation devront contenir l'information
«de quel attribut a besoin de lire telle personne sur tel objet.»
· Création. Lors du processus de
création des objets dans l'annuaire, il faudra valider que la personne,
ou l'application, qui créée un objet, a bien connaissance de
toute l'information nécessaire. Il peut arriver que cela ne soit pas le
cas. Par exemple, une personne du département ressources humaine ne
pourra pas d'elle même assigner un login à un utilisateur dans
l'annuaire. Il faut prévoir un mécanisme, en dehors de
l'annuaire, qui lui fournisse cette information qui se peut se
révéler nécessaire dans certains cas.
· Modification. Dans l'écriture des
cas d'utilisation comprenant des modifications, il est nécessaire de
noter quels attributs sont modifiés, et de quel type de modifications il
s'agit: ajout d'une valeur, retrait d'une valeur, modification de toutes les
valeurs, etc.
· Suppression.
NB : LDAP ne contient pas
l'équivalent de clé étrangère pour contrôler
la cohérence des données de l'annuaire.
Les cas d'utilisation peuvent dans un premier temps être
effectués sur les classes, sur les catégories d'objets
présents dans l'annuaire. Il sera parfois nécessaire de descendre
à un niveau de précision inférieure et d'écrire les
cas d'utilisation par attribut, ou par groupes d'attributs.
Il sera aussi utile noter la fréquence de chaque cas
d'utilisation.
2.
Élaboration du schéma
Cette étape s'appuie essentiellement sur l'étape
précédente du choix des données contenues dans l'annuaire.
Elle consiste à écrire un schéma qui modélise ces
données.
Écrire un schéma c'est essentiellement
définir :
· les attributs
· les classes
· la hiérarchie entre ces classes
des objets qui constitueront l'annuaire.
De la liste des données, il faut extraire les
informations élémentaires, sous la forme d'une liste d'attributs,
et d'une liste de classes, celles-ci étant définies en regroupant
les attributs. Notre méthode consistera à définir et
modéliser les attributs, indépendamment des classes, les
attributs étant partagés entre classes; puis à constituer
les classes d'objet en agrégeant les attributs adéquats.
Entre la définition des classes et celle des attributs, il peut y
avoir une démarche itérative. Ainsi certaines informations
élémentaires changeront de statut au cours de la
modélisation. Par exemple la catégorie d'une personne pourra
être une classe, plutôt qu'un attribut, parce que l'appartenance
d'une personne à une catégorie implique la présence
obligatoire d'autres attributs.
Lors de la définition des attributs
comme celles des classes, il faut penser à utiliser la relation
d'héritage, lorsque des caractéristiques sont partagées et
qu'il existe des liens de spécialisations, entre attributs ou entre
classes.
En reprenant ce qui a été écrit
précédemment, définir un attribut consiste à
définir :
· son nom;
· s'il est standard, issu d'une RFC, public,
déjà créé et publié, ou encore
spécifique, spécialement créé;
· son attribut père, s'il dérive d'un autre
attribut
· sa syntaxe: est-ce une chaîne de caractères?
un pointeur vers une autre entrée de l'annuaire? etc.
· s'il est mono ou multivalué;
· par quelle(s) classe(s) il est utilisé;
· sa fréquence d'utilisation
NB : Il peut arriver que l'on ait
distingué des attributs contenant exactement le même type
d'information parce qu'ils étaient attributs de classes
différentes. Cette différenciation n'a pas lieu d'être. Au
contraire, il est plus logique d'avoir un même attribut utilisé
par plusieurs classes.
De façon similaire, la définition des classes
d'objets consiste à préciser :
· son nom;
· si elle est standard, issue d'une RFC, publique, ou
spécifique;
· sa classe mère, si elle dérive d'une autre
classe;
· la liste des attributs obligatoires;
· la liste des attributs facultatifs;
C. Sécurisation
Bien qu'étant primordial, ce chapitre sera assez court.
En effet, la sécurisation de l'annuaire s'appuie sur les
éléments cités précédemment, et sur des
éléments à venir.
Tout d'abord, les cas d'utilisation, par classe puis par
attribut, permettent de définir les droits d'accès à la
granularité nécessaire.
Il s'agit donc ensuite d'écrire les règles
d'accès, en s'appuyant sur la syntaxe qui sera présentée
dans la section Fonctionnement des permissions dans OpenLDAP plus bas.
La topologie du service influence aussi la
sécurité.
D. Développement de l'arbre informationnel
Comme on l'a vu aux deux premiers chapitres, les
données d'un annuaire sont organisées sous forme
hiérarchique, en arbre. Concevoir l'arbre informationnel d'un annuaire
c'est spécifier la forme de cet arbre, son organisation, comment les
données vont y être nommées. L'objectif à cette
étape est donc d'organiser les données pour leur
· Consultation
· Mise à jour
· Duplication
· Répartition
1.
La structure de l'arbre informationnel
Un arbre est caractérisé par son branchage plus
ou moins fort. Un arbre a un branchage faible lorsque les entrées
feuilles (sans descendant) sont très regroupées, au lieu
d'être dispersées sous d'autres entrées. On dit aussi qu'il
est plat.
![]()
Figure 1 : Arbre plat
![]()
Figure 2 : Arbre à branchage fort
Les arbres plats ont pour principal avantage que les
recherches s'effectuent rapidement, parce que le serveur n'a pas à
parcourir toutes les branches, et à faire une recherche par branche. Par
ailleurs les arbres plats présentent beaucoup d'inconvénients :
· Les collusions de RDN peuvent se produire
fréquemment;
· La mise en place de referral n'est pas possible (Le
mécanisme de referral peut alors être remplacé par la mise
en place d'un meta annuaire. Néanmoins un meta annuaire est beaucoup
plus lourd à mettre en place.)
Sur ces points les arbres à fort branchage sont bien
plus efficaces. Ils facilitent aussi la délégation.
L'inconvénient des arbres à fort branchage apparaît
essentiellement lorsque la structure de l'arbre reflète la structure de
l'organisation, et que cette structure est amenée à être
modifiée. Dans ce cas, les entrées de l'arbre vont elles aussi
être amenées à changer de place et de DN, ce qui peut
provoquer des problèmes de cohérences.
Il y a donc un certain équilibre à atteindre
entre les deux types d'arbres. Les éléments à prendre en
compte sont les suivants
(4)
:
· Le nombre d'entrées prévu et son
évolution ?
· La nature (type d'objet) des entrées actuelles et
futures ?
· Vaut-il mieux centraliser les données ou les
distribuer ?
· Seront-elles administrées de manière
centrale ou faudra-t-il déléguer une partie de la gestion ?
· La duplication est-elle prévue ?
· Quelles applications utiliseront l'annuaire et
imposent-elles des contraintes particulières ?
· Quelles permissions seront mises en place?
2.
Le nommage des données
a. Choix du suffixe
Contrairement aux annuaires X500 les annuaires LDAP n'ont
à vocation à s'insérer dans un annuaire universel.
Dès lors, contrairement à leurs ancêtres, chaque annuaire
peut avoir la racine qu'il veut. Il n'existe pas d'obligation à
respecter. La norme X500 imposait aux annuaires d'entreprises parisienne par
exemple d'avoir un suffixe de la forme l=paris,o=fr.
Dans la norme LDAP chaque annuaire fait ce qu'il lui
plaît, et peut prendre comme racine, comme suffixe, ce qu'il veut. Le
suffixe est devenu l'identifiant d'un annuaire.
Il existe néanmoins une RFC, la [rfc2377] qui apporte
un peu de cohérence dans le choix des suffixes. Elle permet de
construire un suffixe à partir d'un nom de domaine, et en utilisant
l'attribut dc. Cette RFC propose tout simplement de transformer tous les
éléments d'un nom de domaine en valeur de l'attribut dc. Ainsi
l'annuaire l'entreprise dont le nom de domaine est siantou.com sera
dc=siantou, dc=com.
b. Nommage des
entrées
Le nommage des entrées consiste à choisir un
attribut, qui sera utilisé pour nommer les entrées. Il s'agit
donc de choisir le RDN de chaque branche. Cet attribut doit permettre de
désigner sans ambiguïté une entrée. C'est à
dire que sa valeur doit être unique dans chaque branche. Le
deuxième élément à prendre en compte est sa
stabilité. Il est préférable en effet qu'une entrée
ne change guère d'identité. Cela est d'autant plus vrai dans le
cas des entrées possédant des descendants.
E. Topologie du service
Définir la topologie du service consiste à
définir la répartition géographique de l'annuaire. Un
annuaire LDAP peut en effet être déployé sur des machines
physiques différentes. Cette étape a but de concevoir cette
répartition.
1.
Conception
a. Objectifs
Disposer des serveurs annuaires sur des plusieurs machines
permet de répondre à un besoin en qualité de service.
S'ils sont bien répartis et bien configurés, plusieurs serveurs
seront plus performants et plus fiables qu'un seul serveur. La
répartition de l'annuaire sur plusieurs machines peut aussi faciliter sa
gestion.
La norme LDAP définit deux mécanismes permettant
une répartition géographique des serveurs. Le premier est le
mécanisme de referral qui permet de déléguer une branche
d'un annuaire à un autre annuaire, localisé sur une machine
distante. Le deuxième est le mécanisme de réplication.
La mise en place des deux mécanismes dépend
très fortement de la structure de l'arbre informationnel. Le processus
de conception de la topologie du service peut donc être itératif
avec la conception de l'arbre informationnelle.
b. Recueil des
informations
La première étape consiste à faire
l'inventaire des sites géographiques qui devront se connecter à
l'annuaire. Pour chaque site il est nécessaire ensuite de dessiner son
schéma réseau pour identifier les différents
réseaux, les différents routeurs et surtout par quelle machine
passe les flux sortants. Les liaisons entre sites devront aussi être
répertoriées et leurs caractéristiques (débit,
réseau privé ou public) devront être notées. Cette
étape est donc l'identification des contraintes réseau.
Pour chaque site, il faut ensuite évaluer le nombre
d'utilisateurs et en déduire le nombre de requêtes qu'ils
génèrent et le type de requêtes (interrogations, mise
à jours, création, etc.). Cette étape réutilise
donc les cas d'utilisation déjà produits
précédemment.
La troisième information à noter sur les
requêtes, outre leur nombre et leur type, est l'information
concernée par la requête. Par exemple, est-ce qu'il s'agit de
l'identité des utilisateurs, des attributs de messagerie, ou bien de
leur numéro de téléphone.
c. Les décisions
techniques
Nous avons alors à notre disposition :
· la topologie du réseau;
· les flux générés par certaines
parties du réseau vers l'annuaire, ces flux étant eux même
composés de flux de recherche, de lecture, d'écriture, etc.;
· l'arbre informationnel, qui contient l'information
recherchée, lue ou modifiée par ces flux.
À partir de toutes ces informations nous devons
définir la topologie du service LDAP, soit répondre aux deux
questions suivantes :
· L'information doit-elle être répartie sur un
ou plusieurs serveurs ? Et comment?
· Quelle redondance ?
La répartition du contenu de l'annuaire entre plusieurs
serveurs n'est possible que si l'arbre informationnel le permet. Il y a donc
une démarche itérative entre la définition de la topologie
et le choix de l'espace de nommage.
Les deux sections suivantes donnent d'avantage d'information
sur le service referral, et sur la réplication.
2.
Utilisation de referral
![]()
Figure 3 : Utilisation du referral
Le mécanisme de referral est un
mécanisme de redirection qui permet à un serveur annuaire de
déléguer une partie de ses branches à un autre serveur.
Dans le protocole LDAP décrit dans [rfc2251] le serveur peut toujours
répondre à une opération quelconque par un
referral.
La [rfc2251] décrit en particulier uniquement comment
un serveur doit répondre à une recherche dont les entrées
retournées sont réparties sur plusieurs autres annuaires. La
réponse du serveur doit alors contenir les entrées
gérées par lui même, et une ou plusieurs
references, des urls que le client doit exécuter pour terminer
sa recherche.
Les RFC de la version 3 de la norme ne définissent pas
d'avantage comment un serveur a connaissance des branches qu'il doit
déléguer. La [rfc3296] est une proposition pour remplir cette
lacune. Openldap s'appuie dessus.
Cette RFC introduit une classe d'objets, la classe
referral, possédant pour seul attribut ref. Cette classe
représente une référence inférieure dans
l'annuaire, c'est à dire une branche déléguée
à un autre serveur. L'attribut ref contient une url LDAP.
Néanmoins elle ne doit pas contenir de profondeur, de filtre ou
d'attribut. Son usage est distributedOperation.
À chaque fois qu'un client tente d'accéder
à une entrée située une entrée de type
referral, ou bien sous une de ces entrées, l'annuaire renvoie
donc en referral les valeurs de l'attribut ref de l'entrée
referral. Il est néanmoins possible d'ajouter le contrôle
ManageDsaIT aux opérations, pour pouvoir modifier les entrées
elle même.
Openldap utilise aussi un default referral. Ce
referral est renvoyé par défaut à toute les
requêtes effectuées sur le serveur et dont le base_dn n'est sous
aucun suffixe du serveur.
Le chaînage, mécanisme par lequel le serveur
contacte lui même un autre serveur et envoie sa réponse au client,
n'est pas mis en place dans Openldap et n'est guère
déployé ailleurs pour des raisons de sécurité.
Néanmoins les mécanismes de meta annuaire permettent ce type de
configuration.
3. La réplication
![]()
Figure 4 : la réplication
Alors que le mécanisme de referral permet de
répartir l'information d'un annuaire entre plusieurs serveurs, la
réplication permet quant à elle de dupliquer cette information
sur plusieurs serveurs.
Les mécanisme, referral et réplication,
ont des points communs et des différences. Leur point commun est qu'ils
impliquent tous deux une répartition géographique des serveurs.
En cela ils permettent d'intervenir sur la qualité de service de
l'annuaire. Mais les moyens mis en oeuvre diffèrent.
La réplication introduit de la redondance. Cette
redondance permet :
· Tolérance aux pannes. Si un
serveur ne répond plus, il sera possible pour le client de contacter un
autre serveur contenant l'information.
· Équilibrage de charge. Les clients
LDAP seront configurés pour contacter le serveur annuaire le plus proche
d'eux.
· Gestion locale des données. Le
mécanisme de réplication permet à chaque entité
géographique de gérer elles mêmes les données qui
dépendent d'elle, et de les partager en lecture aux entités.
F. Vue d'ensemble
|
Phase
|
Aspects fonctionnels
|
Aspects techniques
|
|
Phase I
|
Cadrage se limiter à une ou deux applications trouver un
maître d'ouvrage (un sponsor du projet, un groupe d'utilisateurs)
établir des priorités dans les usages possibles de l'annuaire
|
Il n'y a pas d'aspect fonctionnel à cette étape
|
|
Phase II
|
Choix des données et Identification des acteurs
Écriture des cas d'utilisation à la UML Rester dans le cadre
défini en phase I
|
Écriture du schéma Utilisation de la phase II
fonctionnelle Peut être itératif avec la phase III technique
|
|
Phase III
|
Définition des droits d'accès
Utilisation des
cas d'utilisation
|
Écriture des clauses d'accès
Nécessite
une vision de l'arbre informationnel
|
|
Phase IV
|
Conception de l'arborescence
Prise en compte d'un aspect
géographique supplémentaire par rapport aux cas d'utilisation
|
Topologie du service Le service referral Duplication des
données
|
Tableau 21: vue d'ensemble du
déploiement d'une architecture LDAP
DEUXIEME PARTIE : CONCEPTION ET REALISATION DU
SYSTEME
CHAPITRE I : PROBLEMATIQUE
I Etat de l'art
A. Le contexte des
transports terrestres au Cameroun
A.1 Au premier rang des
facteurs de croissance économique
Dans le système camerounais de transports terrestres,
on retrouve les modes courants, route et rail, même si la contribution
de chaque moyen au système global est très inégale, selon
qu'il s'agit de transport de biens ou de personnes, de transports nationaux ou
internationaux.
A l'intérieur du pays, le transport de biens et de
personnes se fait globalement par route et par rail. L'essentiel des
échanges extérieurs des pays voisins enclavés (Tchad et
RCA) transite par le Cameroun par la voie terrestre, rail et route. Ainsi, si
les infrastructures restent à développer, les différents
modes de transport assurent de manière très complémentaire
le transport de biens et de personnes, en contribuant de façon
significative à la croissance économique et à
l'intégration régionale.
Le secteur des transports génère globalement une
activité estimée à 15% du PIB. Depuis près de cinq
ans, il contribue à plus de 50% à la croissance du PIB, faisant
du secteur tertiaire (42% du PIB) le véritable moteur de
l'économie nationale.
A.2 Les transports urbains
Il n'existe pas encore de réseau de
métropolitain ni de tramway au Cameroun.
Les moyens de transports urbains fonctionnels sont, par ordre
d'importance, les taxis, les « motos-taxis », les bus et les minibus.
Les moyens de transports urbains les mieux réglementés sont les
taxis et le bus.
Si les taxis sont exploités exclusivement par le
secteur privé, le transport par bus sort progressivement du secteur
public.
La société publique, Sotuc,
Société des transports urbains du Cameroun, créée
en 1973 et qui jouissait du monopole d'exploitation des transports urbains par
autobus dans les villes de Douala (2 M hab.) et de Yaoundé (1,5M hab.) a
été liquidée en février 1995. Le gouvernement a
pris l'option en 2000 de libéraliser l'exploitation des services de
transports urbains : pas d'exigence de la part de l'Etat ou des
collectivités en dehors des dispositions d'ordre public, pas
d'exonération fiscale ou douanière, pas de monopole, pas de
tarifs imposés mais fixation d'un plafond négocié avec
l'opérateur.
A.3 Les transports
interurbains de personnes
Le transport interurbain de personnes est exploité
essentiellement par des opérateurs privés. On compte quelques
dizaines de compagnies de transport régulier organisées (Garanti
Express, Binam, Centrale, Kami Express, Confort, Castor, Tabo Express, Tala,
Stella, Félicité, Buca, Alliance, Vatican, etc.). Elles
opèrent sur les lignes qui relient les capitales provinciales, en
particulier Douala, Yaoundé et Bafoussam. Les conditions de voyage sont
globalement assez inconfortables à cause des surcharges quasi
systématiques et des arrêts intempestifs, mais quelques-unes de
ces compagnies proposent, sur la ligne Yaoundé-Douala, à prix
double, un service prestige sur des bus climatisés avec presse et
collation à bord.
Il existe également sur ces lignes et sur les lignes
interdépartementales une multitude de petits transporteurs-chauffeurs
souvent propriétaires de leur unique véhicule de 10 à 15
places (en général Toyota-Hiace ou Liteace). Dans
l'arrière-pays, les transports sont assurés en petites voitures
de cinq places reconditionnées localement pour des routes en terre et
toujours surchargées.
Le parc de matériel de transport, est en moyenne d'une
centaine de véhicules par grand transporteur, mais on retrouve chez les
plus importants 200 à 250 unités. Le parc est en
général constitué de minibus de 27 à 30 places type
Toyota-Coaster ou, plus récemment, Nissan-Civilian et Renault-Afribus,
ainsi que de moyens et gros porteurs de 52 à 72 places Mercedes acquis
auprès de concessionnaires locaux (Cami, SHO Tractafric, Mitcam, etc.)
ou ivoirien (Carici). Les compagnies de transport les plus importantes
cèdent après 2 à 3 ans d'exploitation les véhicules
amortis à des transporteurs de moindre importance. La plupart des
compagnies de transport de voyageurs proposent par ailleurs des services de
messagerie et de transport de marchandises.
A.4 Le transport routier de
marchandises au Cameroun
Les activités de transport de marchandises sont
assurées par de petits transporteurs, qui disposent en moyenne de moins
de cinq véhicules. On compte toutefois une dizaine de structures
importantes (UTC, Sodetrans-Cam, Transimex, etc.) qui disposent d'un parc de
plus de 50 camions et poids lourds. Celles-ci interviennent principalement dans
le transport du bois et de produits spécifiques, liées par
contrat aux forestiers, grands transitaires, pétroliers, entreprises
industrielles ou agricoles qui ont sous-traité la gestion de cette
activité. On estime que l'offre régulière de transport de
marchandises est excédentaire au Cameroun. Des réflexions sont en
cours au Ministère des transports en vue d'organiser des centres
logistiques à Douala, Yaoundé, Ngaoundéré et
Bafoussam.
I Etude critique de l'existant
Au Cameroun le secteur des transports terrestres fonctionne
encore de manière assez anarchique. Le fait que toutes les agences ne
soient pas effectivement cataloguées entrave le bon fonctionnement et le
contrôle du secteur des transports terrestres camerounais. Pour un
secteur aussi rentable, il serait intéressant de mettre en place un
système permettant de situer et de connaître les informations sur
les compagnies et agences de transport accessibles au grand public, tâche
qui s'avère difficile car aucune institution ne saurait donner avec
exactitude les informations à la demande sur les agences de transports
de biens, de marchandises ou de personnes au Cameroun. Comment permettre aux
citoyens camerounais d'accéder facilement à l'information sur une
agence comme sa situation géographique exacte par exemple, son par
automobile ou ses différents contacts, comment connaître les
horaires de départ pour une agence déterminée en fonction
de la destination souhaitée, la capacité en terme de nombre de
places disponibles dans les véhicules disponibles.
C'est dans l'optique d'apporter une contribution à
l'harmonisation de la gestion des transports terrestres camerounais que nous
avons réalisé l'ensemble du travail qui va suivre.
CHAPITRE II : LA METHOLOGIE
I Présentation des outils
de modélisation choisis
En ce qui concerne la modélisation de notre
système, nous nous appuierons sur les différentes étapes
de mise en oeuvre d'un service d'annuaire décrites plus haut (dans la
première partie) avec la collaboration d' UML pour l'élaboration
du diagramme de classe de notre système.
A. UML (Unified Modeling
Language)
1. Historique d'UML
UML est une notation pour la modélisation des
applications construites avec des langages objets. A l'origine de cette
nouvelle notation se trouve l'OMG (Object Management Group) qui partait
du constat suivant :
les méthodes fonctionnelles ne permettaient pas
d'exploiter le développement objet. Le mélange de plusieurs
paradigmes n'est ni commode, ni naturel.
Le grand nombre de méthodes n'aidait pas le choix des
utilisateurs.
Les méthodes suivantes sont à la base
d'UML :
OMT (Object Modeling Technique) conçue par James
Rumbaugh.
OOD (Object Oriented Design) conçue par Grady
Booch.
OOSE (Object Oriented Software Engineering) conçue par
Ivar Jacobson.
Il faut insister sur le fait qu'UML n'est pas une
méthode mais une notation. Il est donc possible d'utiliser la
notation UML avec une démarche de conception inspirée d'OMT par
exemple.
La première version d'UML est sortie le 17 janvier
1997. Entre temps des partenaires importants sont venus collaborer à la
mise en oeuvre de cette notation : IBM, DEC, Microsoft, Rational Rose
Software, Oracle, Unisys).
2. Pourquoi une
méthodologie Objet
La technologie objet, tout en n'étant pas la
panacée, offre une solution aux problèmes des systèmes
informatiques d'aujourd'hui, quant à :
La complexité du logiciel
Le logiciel est de plus en plus intégré à
l'entreprise. Il offre de plus grandes fonctionnalités. En outre, les
logiciels doivent pouvoir s'interfacer et communiquer entre eux.
Les évolutions technologiques
Il faut s'assurer de la pérennité de la solution
mise en place. C'est à dire, développer une solution suffisamment
ouverte pour incorporer les technologies de demain.
La taille des équipes
Il faut savoir gérer plusieurs types de
compétences techniques, s'assurer que la communication soit
réelle entre les différentes équipes et gérer le
travail en parallèle sur une même tâche.
Les délais de plus en plus courts
Les entreprises ne peuvent attendre longtemps un
système qui leur permettra de gagner en productivité.
Les spécifications peu précises
L'évolution rapide des applications
2.1 Apports d'UML et de l'objet
UML préconise de séparer les aspects
fonctionnels, technologiques et architecturaux.
Pour la compréhension entre les différents
acteurs d'un projet UML propose des diagrammes qui vont permettre
d'éclaircir les spécifications.
Enfin, pour répondre à l'évolution rapide
des applications, il faut pouvoir facilement effectuer un retour sur chaque
phase du cycle de développement. Le cycle de vie objet qui,
itératif et incrémental, permet d'effectuer ce retour.
2.2 - Le Cycle de vie
Le cycle de vie d'un projet à objets possède
trois caractéristiques fondamentales :
Une traçabilité entre les étapes.
Un caractère itératif.
Un caractère incrémental.
2.2.1
- La traçabilité
Le fait d'utiliser les concepts objets n'engendre plus de
rupture entre les différentes phases lors de la réalisation d'un
système. Les concepts peuvent être utilisés à tous
les stades du cycle de vie (excepté lors de la définition des cas
d'utilisation).
2.2.2
- Le cycle de vie itératif
Lorsqu'un système est trop complexe pour être
réalisé du premier coup, il est plus facile de le
développer par évolutions.
L'approche objet n'est pas nécessaire pour mettre en
oeuvre un développement itératif. Elle le facilite grâce
à l'encapsulation et la modularité.
Le cycle de vie itératif permet de se rendre vite
compte si le système fonctionne correctement. Il permet de tenir compte
des risques suivants :
Méconnaissance des besoins par le client.
Incompréhension des besoins par le client.
Instabilité des besoins.
Le fait de voir une réalisation rapide peut motiver
l'équipe de développement.
Une itération correspond aux phases suivantes :
Expression des besoins
Spécifications fonctionnelles
Analyse
Expression des besoins
Implémentation
Tests de vérification
Validation des besoins
Un cycle de vie itératif n'est réussi que si les
acteurs prennent entièrement part au développement du
système. Les cas d'utilisation sont là pour faire rentrer leurs
besoins dans un cadre structurant et stable.
Le nombre d'itération dépend de la
complexité des systèmes à construire.
L'itération permet :
Les modifications des spécifications.
L'adéquation entre l'analyse, la conception et
l'implémentation.
L'acceptation du client.
2.2.3
- Un cycle de vie incrémental
Le but est de développer les fonctionnalités du
système en lui ajoutant des améliorations successives à
chaque étape du cycle de développement.
Le développement d'une série de prototypes
exécutables permettra d'aboutir à la réalisation du
système final. L'évolution des prototypes permet de
détecter les défauts et les dérives de la construction
logicielle, permettant ainsi d'évaluer les risques du projet (garder le
cap sur les coûts et les délais).
La réalisation de prototypes peut être
menée en parallèle par plusieurs équipes de
développement. Le prototype peut être précédé
d'une maquette qui va permettre de valider l'enchaînement des
écrans et leur ergonomie.
Enfin, le prototype est parlant pour l'utilisateur. Ce dernier
se trouve plus intégré au projet.
3.
Concepts d'UML
UML se veut être une notation simple,
précise, et homogène, permettant un bon rendu visuel. Elle
décrit le réalisé plutôt que le processus de
réalisation.
3.1 - Les Modèles
Un modèle est une description abstraite d'un
système ou d'un processus, une représentation simplifiée
qui permet de comprendre et de simuler.
Pour la définition des systèmes, UML
définit plusieurs modèles :
modèle de classe qui capture la
structure statique
modèle des états qui exprime le
comportement dynamique des objets
modèle des cas
d'utilisation qui décrit les besoins de
l'utilisateur
modèle d'interaction qui décrit
les scénarios et les flots de messages
modèle de réalisation qui
montre les unités de travail
modèle de déploiement qui
précise la répartition du processus.
Les modèles sont regardés par les utilisateurs
au moyen de vues graphiques.
A une vue d'un ou plusieurs modèles correspondent un ou
plusieurs diagrammes.
3.2 - Les Diagrammes
UML définit 9 diagrammes :
Diagramme des activités :
comportement d'une opération en terme d'actions.
Diagramme des cas d'utilisation : fonctions
du système du point de vue l'utilisateur.
Diagramme de classes : structure
statique en termes de classes et de relations.
Diagramme de collaboration :
représentation spatiale des objets, des liens et des
interactions.
Diagramme de composants : composants
physiques d'une application.
Diagramme de déploiement : les
composants sur les dispositifs matériels.
Diagramme d'états transitions :
comportement d'une classe en terme d'état.
Diagramme d'objets : instanciation des
diagrammes de classes.
Diagramme de séquence :
représentation temporelle des objets et de leurs interactions.
Remarque :
Les diagrammes de collaboration et de séquence sont
également appelés diagramme d'interaction.
Les éléments communs aux
diagrammes :
Stéréotypes
Syntaxe : « nom
stéréotype ».
Les stéréotypes ont pour but de classifier les
éléments en vue de les regrouper par famille. Ils peuvent
également modifier la sémantique des éléments
associés pour créer de nouveaux concepts propres à une
application. Les stéréotypes peuvent être associés
à tout élément du modèle (classe, les associations,
les attributs ...) .
Contraintes (sémantique)
syntaxe : {nom de la contrainte}
Permet de préciser le contexte du diagramme en
positionnant des restrictions.
3.3 - Primitifs utilisés par UML
Booléen : type
énuméré (vrai et faux)
Chaîne : suite de
caractères désignée par un nom
Expression : chaîne de
caractères
Liste : conteneur de parties
ordonnancées
Multiplicité : ensemble non vide
d'entiers positifs
Nom : chaîne de caractères
qui permet de désigner un élément.
Temps : est une chaîne qui
représente un temps absolu ou relatif et dont la syntaxe et hors de
portée de UML
3.4 - Notion de paquetage
Un paquetage (représenté au niveau graphique par
un dossier) est un sous-ensemble du modèle. Il contient des classes, des
objets, des relations, des composants et les diagrammes associés.
Il peut y avoir une arborescence de paquetage et des
paquetages globaux (dans ce cas on ne montre pas toutes les relations avec les
autres paquetages).
Un paquetage peut avoir des éléments publics et
des éléments privés (non visibles de l'extérieur de
la classe).
3.5 - Les Métamodèles
Chaque concept d'UML a été
modélisé avec UML.
Le métamodèle permet de décrire la
notation d'UML à l'aide de modèles basés sur UML.
Il décrit aussi sans ambiguïté la syntaxe
d'un modèle ainsi que la sémantique des concepts
utilisés.
II Modélisation du
système
A. Phase de cadrage
Il s'agit d'offrir aux transports terrestres camerounais un
annuaire de référencement pour ses agences et ainsi donner la
possibilité à ceux qui se déplacent constamment d'obtenir
l'information nette et précise d'une ligne de transport
déterminée en fonction du lieu de départ et de la
destination.
Il s'agit de concevoir un annuaire de type « page
jaunes » qui référence les agences de transport
terrestre (route ou voie ferrée) et facilite ainsi les opérations
de logistique et transport.
Le système à mettre en place doit restituer
à la demande les informations sur une ligne de transport précise
(point de départ - point d'arrivée), une agence et ses
véhicules en fonction des critères de recherche à savoir
la province et la ville de départ ainsi que celle de destination.
Les villes sont regroupées par provinces (10 au total)
et c'est le superviseur de l'annuaire qui gère les informations sur les
provinces et les villes.
Le 10 provinces du Cameroun sont préalablement
enregistrées et figés dans l'annuaire.
Une agence est propre à une ville et
caractérisée par sa raison sociale, son nom commercial, sa
situation géographique, une image de l'agence, les horaires de
départs, le type de transport effectué (voie ferrée ou
terrestre), la catégorie de transport (personne, marchandises,
déménagement...), la boite postale, le téléphone,
email et l'url du site s'il y'en a un.
A une agence crée est automatiquement associé un
administrateur crée pour cette agence.
La suppression d'une agence entraîne automatiquement la
suppression de l'administrateur de cette agence.
Les agences de transport terrestre (route ou voie
ferrée) sont donc référencées par ville. A elles
sont associées les informations sur des véhicules.
Une agence est également caractérisée par
une description générale et sa situation géographique et
son contact (téléphone, fax, e-mail, site web...).
Un véhicule est caractérisé par son
immatriculation, son type (autobus, coaster, wagon, camion...), sa
capacité en terme de kilogrammes ou de nombre de place, son image et sa
ligne de transport.
Le superviseur de l'annuaire s'authentifie pour effectuer des
opérations de gestion et d'administration dans l'annuaire.
Les villes sont ajoutées au fur et à mesure
ainsi que les agences de transport par le superviseur du système.
L'administrateur d'agence s'authentifie également pour
effectuer la mise à jour des informations sur une agence
particulière. Il est chargé d'enregistrer des nouveaux
équipements logistiques (véhicules) pour une agence ainsi que de
la mise à jour des informations relatives à l'agence et ses
différents véhicules.
B. Phase de conception
Cette section présente les différents cas
d'utilisations qui interviennent dans notre système d'annuaire. Nous
allons énumérer les différents cas d'utilisations et
lister les différents scénarios associés.
1. Cas d'utilisation
Les acteurs du système :
- Le superviseur de l'annuaire
- L'administrateur d'agence
- L'utilisateur
Principaux Cas d'utilisation :
1 - Administration de l'annuaire
2 - Gestion d'une agence
3 - Consultation de l'annuaire
Administration de l'annuaire
<< Uses >>
authentification
Superviseur
<< Uses >>
Gestion d'une agence
Administrateur d'agence
Consultation de l'annuaire
Utilisateur
Figure 5: cas d'utilisation du
système
2. Les séquences
Les séquences nous permettrons de présenter les
interactions entre les acteurs et le système.
LES PRINCIPAUX SCENARIOS
|
Administration de l'annuaire
|
Identification
|
|
Administration de l'annuaire
|
Création d'une ville
|
|
Administration de l'annuaire
|
Création d'une agence
|
|
Administration de l'annuaire
|
Supprimer une ville
|
|
Administration de l'annuaire
|
Supprimer une agence
|
|
Gestion d'une agence
|
Identification
|
|
Gestion d'une agence
|
Création d'un véhicule
|
|
Gestion d'une agence
|
Modifier l'enregistrement d'une agence
|
|
Gestion d'une agence
|
Modifier l'enregistrement d'un véhicule
|
|
Gestion d'une agence
|
Supprimer l'enregistrement d'un véhicule
|
|
Utilisateur
|
Connexion au système
|
|
Utilisateur
|
Recherche d'une ligne à partir des provinces
|
|
Utilisateur
|
Recherche d'une ligne à partir d'un critère
|
Tableau 26: les principaux
scénarios
ADMINISTRATION DE L'ANNUAIRE
L'administration de l'annuaire est réalisée par
le superviseur
Administration de l'annuaire
Superviseur
Figure 6: cas
d'utilisation administration de l'annuaire
- Identification
L'administrateur d'agence se connecte au système et
s'identifie
Le système vérifie l'identité su superviseur
et autorise l'accès
: Système
: Superviseur
Login (mot de passe)
Vérification des paramètres
Autorisation
Figure 7: identification
- Création d'une ville
Le superviseur demande la liste des provinces
Le système affiche la liste des provinces
Le superviseur choisit une province
Le système affiche le formulaire d'ajout
Le superviseur insère la ville
Le système enregistre après vérification
Le système renvoie un message de confirmation
: Système
: Superviseur
Ajout d'une ville
Liste des provinces
Choix d'une province
Formulaire de saisie
Insertion des informations
Informations sur la ville
sauvegarde
Message de confirmation
Figure 8:
création d'une ville
- Création d'une agence
Le superviseur demande la liste des provinces
Le système affiche la liste des provinces
Le superviseur choisit une province
Le système affiche la liste des villes correspondantes
à cette province
Le superviseur choisit une ville
Le système affiche le formulaire d'ajout d'agence
Le superviseur insère l'agence
Le système enregistre après vérification
Le système renvoie un message de confirmation
: Système
: Superviseur
Ajout d'une agence
Liste de provinces
Choix d'une province
Liste de villes correspondantes
Choix d'une ville
Formulaire de saisie
Insertion des informations
Informations sur l'agence et son administrateur
Sauvegarde
Message de confirmation
Figure 9: création d'une agence
- Supprimer une ville
Le superviseur demande la liste des provinces
Le système affiche la liste des provinces
Le superviseur choisit une province
Le système affiche la liste des villes correspondantes
à cette province
Le superviseur choisit une ville
Le système supprime la ville après confirmation
Le système renvoie un message de confirmation
: Superviseur
Liste de provinces
Suppression d'une ville
: Système
Choix d'une province
Liste de villes correspondantes
Choix d'une ville
Suppression
Message de confirmation
Figure 10: suppression d'une ville
- Supprimer une agence
Le superviseur demande la liste des provinces
Le système affiche la liste des provinces
Le superviseur choisit une province
Le système affiche la liste des villes correspondantes
à cette province
Le superviseur choisit une ville
Le système affiche la liste des agences correspondantes
à cette ville
Le superviseur choisit l'agence
Le système supprime après confirmation
Le système renvoie un message de confirmation
: Système
Suppression d'une agence
: Superviseur
Liste de provinces
Choix d'une province
Liste de villes correspondantes
Choix d'une ville
Liste des agences correspondantes
Choix d'une agence
Suppression
Message de confirmation
Figure 11: supprimer une agence
GESTION D'UNE AGENCE
La gestion d'une agence est réalisée par
l'administrateur d'agence.
Gestion d'une agence
Administrateur
d'agence
Figure 12: cas
d'utilisation gestion d'une agence
: Système
: Administrateur d'agence
Login (mot de passe)
Vérification des paramètres
Autorisation
Figure 13: identification
administrateur d'agence
- Création d'un véhicule
L'administrateur d'agence demande l'interface d'ajout d'un bus
Le système affiche le formulaire d'ajout d'un bus
L'administrateur d'agence insère les informations sur
le bus
Le système enregistre après vérification
Le système renvoie un message de confirmation
: Système
: Administrateur d'agence
Ajout d'un véhicule
Formulaire de saisie
Insertion des informations
Informations sur le bus
Sauvegarde
Message de confirmation
Figure 14: création d'un
véhicule
- Modifier l'enregistrement d'une agence
L'administrateur d'agence demande la liste des provinces
Le système affiche la liste des provinces
L'administrateur d'agence choisit une province
Le système affiche la liste des villes correspondantes
à cette province
L'administrateur d'agence choisit une ville
Le système affiche la liste des agences correspondantes
à cette ville
L'administrateur d'agence choisit l'agence
Le système affiche le formulaire de modification
L'administrateur d'agence insère les modifications
correspondantes
Le système enregistre après confirmation
Le système renvoie un message de confirmation
Modification d'une agence
: Système
: Administrateur d'agence
Liste de provinces
Choix d'une province
Liste de villes correspondantes
Choix d'une ville
Liste des agences correspondantes
Choix de l'agence
Formulaire de modification
Insertion des informations
Informations sur l'agence et son administrateur
Sauvegarde
Message de confirmation
Figure 15: modifier l'enregistrement d'une
agence
- Modifier l'enregistrement d'un
véhicule
L'administrateur d'agence demande la liste des provinces
Le système affiche la liste des provinces
L'administrateur d'agence choisit une province
Le système affiche la liste des villes correspondantes
à cette province
L'administrateur d'agence choisit une ville
Le système affiche la liste des agences correspondantes
à cette ville
L'administrateur d'agence choisit l'agence
Le système affiche la liste des véhicules
correspondants à cette agence
L'administrateur d'agence choisit le véhicule
Le système affiche le formulaire de modification
L'administrateur d'agence insère les modifications
correspondantes
Le système enregistre après confirmation
Le système renvoie un message de confirmation:
Système
: Administrateur d'agence
Modification d'une agence
Liste de provinces
Liste de villes correspondantes
Choix d'une province
Choix d'une ville
Liste des agences correspondantes
Choix de l'agence
Liste es véhicules
Formulaire de modification
Choix d'un véhicule
Insertion des informations
Informations sur le véhicule
Sauvegarde
Message de confirmation
Figure 16: modifier l'enregistrement d'un
véhicule
- Supprimer l'enregistrement d'un
véhicule
L'administrateur d'agence demande la liste des provinces
Le système affiche la liste des provinces
L'administrateur d'agence choisit une province
Le système affiche la liste des villes correspondantes
à cette province
L'administrateur d'agence choisit une ville
Le système affiche la liste des agences correspondantes
à cette ville
L'administrateur d'agence choisit l'agence
Le système affiche la liste des véhicules
correspondants à cette agence
L'administrateur d'agence choisit le véhicule
Le système supprime l'enregistrement du véhicule
correspondant
Le système renvoie un message de confirmation
Liste de provinces
Modification d'une agence
: Système
: Administrateur d'agence
Choix d'une province
Liste de villes correspondantes
Choix d'une ville
Liste des agences correspondantes
Choix de l'agence
Liste es véhicules
Choix d'un véhicule
Suppression
Message de confirmation
Figure 17: supprimer l'enregistrement d'un
véhicule
CONSULTATION DE L'ANNUAIRE
La gestion d'une agence est réalisée par
l'administrateur d'agence.
Consultation de l'annuaire
Utilisateur
Figure 18: consultation de
l'annuaire
- Connexion
L'utilisateur se connecte au système
Le système et autorise l'accès anonyme
: Système
: Utilisateur
Connexion au système
Vérification des paramètres de connexion
Autorisation
Figure 19: connexion
anonyme
- Recherche d'une ligne par province
L'utilisateur demande la liste des provinces de départ et
de destination
Le système affiche la liste des provinces
L'utilisateur choisit la province de départ et de
destination
Le système affiche la liste des villes correspondantes
à ces provinces
L'utilisateur choisit la ville de départ et de
destination
Le système affiche la liste des agences correspondantes
à ces villes
: Système
: Utilisateur
Recherche d'une ligne
Liste de provinces
Choix des provinces
Liste de villes correspondantes
Choix des villes
Liste des agences correspondantes
Figure 20: recherche d'une ligne par
province
- Recherche directe d'une ligne
L'utilisateur demande le formulaire de recherche
Le système affiche le formulaire
L'utilisateur renseigne les champs du formulaire
Le système affiche la liste des agences correspondantes
: Système
: Utilisateur
Recherche directe d'une ligne
Formulaire de recherche
Critères de recherche
Informations
Recherche
Liste des agences correspondantes
Figure 21: recherche directe d'une ligne
3. Les collaborations
Il s'agit ici ce présenter les différentes
collaborations entre les objets de notre système.
Administration de l'annuaire
- Identification
4 : Cacher ( )
2 : LireMotDePasse
1 : LireCompte
: F_Login
: Login
3 : Correct ? (Mot de passe)
5 : Charger ( )
: Superviseur : user
: F_Administration
Figure 22: collaboration identification
F_Login
Login
F_Administration
user
Figure 23: ébauche du diagramme de
classe
Lectures mot de passe
entry : Invite mot de passe
Connexion
Compte et mot de passe OK
Compte et /ou mot de passe incorrect
Compte lu
Mot de passe lu
Vérification
Lecture compte
entry : Invite compte
Figure 24: état transition
identification
- création d'une ville
L'opération valeur() représente la sauvegarde
: ville
: L_Provinces
: F_administration
: F_ville
1 : afficher()
2 :sélection()
4 : afficher()
5 : valeur()
Figure 25:
collaboration création ville
: ville
: L_Provinces
: F_administration
: F_ville
Figure 26: ébauche diagramme de
classe
- Création d'une agence
: L_Provinces
: F_administration
: agence
: F_agence
1 : afficher()
2 :sélection()
5 : afficher()
6 : valeur()
: L_villes
3 : afficher()
4 :sélection()
Figure 27:
collaboration création agence
: L_Provinces
: F_administration
: agence
: F_agence
: L_villes
Figure 28:
ébauche diagramme de classe
- Ajout d'un véhicule
: L_Provinces
: F_administration
: vehicule
: F_vehicule
1 : afficher()
2 :sélection()
7 : afficher()
8 : valeur()
: L_villes
3 : afficher()
4 :sélection()
: L_agences
5 : afficher()
6 :sélection()
Figure 29:
collaboration création véhicule
- Modifier l'enregistrement d'une agence
L'opération image() représente la lecture
: L_Provinces
: F_administration
: agence
: F_agence
1 : afficher()
2 :sélection()
5 : afficher()
6 : image()
7 : valeur()
: L_villes
3 : afficher()
4 :sélection()
Figure 30:
collaboration modifier agence
- Modifier l'enregistrement d'un
véhicule
: L_Provinces
: F_administration
: vehicule
: F_vehicule
1 : afficher()
2 :sélection()
7 : afficher()
8 : image()
9 : valeur()
: L_villes
3 : afficher()
4 :sélection()
: L_agences
5 : afficher()
6 :sélection()
Figure 31:
collaboration modifier véhicule
Diagramme de classes
ville
des_vill
créer()
supprimer()
consulter()
Province
Des_prov
consulter ()
véhicule
imm_v
type
catégorie
ligne
metric
nbr_place
photo_ag
créer()
supprimer()
consulter()
agence
numero_ag
raison
des_ag
sit_geo
respo
effectif
adr
tel
fax
mail
sit_w
photo_ag
créer()
supprimer()
consulter()
1 1..*
1..*
1
user
login
passwd
nom
prenom
priv
créer()
supprimer()
Figure 32 : diagramme de classe
1. Choix des données et Identification des
acteurs
a. Déterminer les données de l'annuaire
- les classes
|
Classes
|
Description
|
|
province
|
Contient les informations sur les provinces
|
|
ville
|
Contient les informations sur les villes
|
|
agence
|
Contient les informations sur les agences
|
|
véhicule
|
Contient les informations sur les véhicules
|
|
User
|
Contient les informations sur utilisateurs et leurs profils
|
Tableau 27: le listing des
classes
2. Élaboration du
schéma
1 - Attributs
|
ATTRIBUTS
|
DESCRIPTION
|
TYPE
|
|
Des_prov
|
Désignation province
|
Ou : OrganizationalUnit
|
|
Des_vill
|
Désignation ville
|
Ou : OrganizationalUnit
|
|
des_ag
|
Désignation agence
|
Ou : OrganizationalUnit
|
|
Numero_ag
|
Numéro d'agence
|
Integer
|
|
sit_geo
|
Site géographique agence
|
directoryString
|
|
Adr
|
Adresse agence
|
directoryString
|
|
Tel
|
Téléphone agence
|
telephoneNUmber
|
|
Fax
|
Fax agence
|
faxNumber
|
|
Mail
|
e-mail agence
|
Mail
|
|
Sit_w
|
Site web agence
|
directoryString
|
|
Photo_ag
|
Photo agence
|
JPEG
|
|
imm_v
|
Immatriculation véhicule
|
directoryString
|
|
Type
|
Type de transport terrestre
|
directoryString
|
|
catégorie
|
Catégorie de transport
|
directoryString
|
|
Ligne
|
Ligne de transport
|
directoryString
|
|
Metric
|
Kilométrage de la ligne
|
Number
|
|
nbr_place
|
Nombre de place du véhicule
|
Integer
|
|
Iud
|
Identifiant unique utilisateur
|
Iud
|
|
Login
|
Login utilisateur
|
cn
|
|
Passwd
|
Mot de passe utilisateur
|
userPassword
|
|
Nom
|
Nom utilisateur
|
Sn
|
|
Prenom
|
Prénom utilisateur
|
Sn
|
|
Priv
|
Privilèges utilisateur
|
DirectoryString
|
|
Respo
|
Responsable d'exploitation dune agence
|
Sn
|
|
Effectif
|
Effectif d'une agence
|
interger
|
Tableau 28: le listing des
attributs
2 - Classes
o :
organization.
Cette classe permet de définir le nom de la
société ou association qui gère l'annuaire. Elle peut
constituer une racine pour ce même annuaire, avec des ou en dessous.
ou : organizationalUnit.
Un sous-ensemble d'une organisation. On pourrait le traduire
en français par un service, une entité, un secteur d'une
société.
dc : domainComponent.
Composant de nom de domaine (au sens DNS du terme). Le com ou
example dans example.com
person : schéma
standard pour une personne.
Elle permet de définir une personne par son nom et son
prénom (a minima), ainsi que, de façon optionnelle, un mot de
passe, un numéro de téléphone, et une description de la
personne.
agency : schéma spécifique pour
les agences héritant des propriétés de la classe
organizationalUnit
vhicule : schéma spécifique pour
les véhicules.
Cette classe permet de définir les informations sur les
véhicules appartenant à une agence bien précise.
Les classes d'objets permettent donc de regrouper les objets
de même type, avec un plus par rapport à une base de
données : un objet peut appartenir à plusieurs classes en
même temps.
C.
Sécurisation
Il s'agit de définir les droits d'accès des
utilisateurs sur les ressources de l'annuaire (objets et attributs).
Ces règles peuvent s'appliquer à tout l'annuaire,
à un sous ensemble, à des entrées spécifiques, pour
des attributrs spécifiques définis par des filtres sous la forme
d'une expression régulière. On peut appliquer également
des permissions par utilisateur, par groupe, mais aussi suivant les adresses
IP, les noms de domaine ou les jours et heures.
Il n'y a pas encore de standard LDAP concernant les
règles d'accès mais en géréral les logiciels
proposent des fonctionnalités d'ACLs. Netscape Directory utilise par
exemple un attribut aci pour stocker les ACLs.
D. Développement de
l'arbre informationnel
1. La structure de l'arbre informationnel
Nous utiliserons un arbre dynamique à fort branchage car
il permet des options de recherche poussées.
2. Le nommage des données
a. Choix du suffixe
Dans la norme LDAP chaque annuaire fait ce qu'il lui
plaît, et peut prendre comme racine, comme suffixe, ce qu'il veut. Le
suffixe est devenu l'identifiant d'un annuaire.
La racine de l'arborescence est nommée par le nom DNS
de l'établissement conformément aux recommandations
préconisées par l'IETF (Utilisation des Domain Component (dc) -
RFC 2377). Ceci permet d'adresser de manière fiable les informations
notre annuaire puisque l'unicité d'un domaine est assurée au sein
d'Internet.
Dans notre cas nous utiliserons le domaine
master.net. On aura donc :
dc : master , dc :net
Pour le domaine master.net
b. Nommage des entrées
|
ENTREES
|
Attribut
|
|
Adamaoua
|
Province de l'Adamaoua
|
|
Centre
|
Province du Centre
|
|
Est
|
Province de l'Est
|
|
Littoral
|
Province du littoral
|
|
Nord
|
Province du Nord
|
|
nord-ouest
|
Province du Nord-Ouest
|
|
sud-ouest
|
Province du Sud-Ouest
|
|
Maroua
|
Province de l'Extrême-Nord
|
|
Sud
|
Province duSud
|
|
Ouest
|
Province de l'Ouest
|
Tableau 29: Nommage des
entrées
3. Construction de l'arbre (Directory Information
Tree)
dc=net
dc=master
ou=adamaoua
ou=centre
ou=estm
ou=littoral
ou=extreme-nord
ou=nord
ou=ouest
ou=sud
ou=nord-ouest
ou=sud-ouest
ou=ville2
ou=ville1
vh=vehicule1
ag=agence1
ag=agence2
vh=vehicule2
uid=administrateur d'agence
Figure 33: Directory Information Tree
E. Topologie du
service
1. Conception
a. Objectifs
Le système à mettre en place doit permettre le
déploiement d'un serveur d'annuaire (OpenLDAP), du serveur Web Apache et
du serveur DNS sur un poste Linux pour rendre possible l'accès à
l'annuaire via le protocole HTTP en Intranet/Internet.
b. Architecture du système
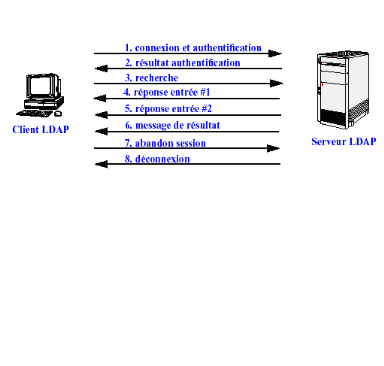
Figure 34: architecture de notre
système
Chapitre III :
REALISATION DU SYSTEME
A. Présentation des outils
Pour réaliser notre système, nous utiliserons
OpenLDAP qui est un serveur d'annuaire sous licence GNU.
Le serveur DNS Bind dans sa version 9
La plate Forme utilisée pour le déploiement des
serveurs OpenLDAP et DNS est LINUX dans sa distribution Mandrake 9.2
Le langage de programmation PHP nous permettra, via ses API
pour LDAP d'implémenter notre application.
Nous utiliserons également le serveur web Apache pour
réaliser l'interface web d'accès au serveur LDAP par le protocole
HTTP.
A.1 La plate forme LINUX
Mandrake 9.2
Mandrake Linux est une distribution GNU/Linux
développée par MandrakeSoft S.A.
La société Mandrake-Soft est née sur
Internet en 1998 ; son ambition première demeure de fournir un
système GNU/Linux convivial et facile à utiliser. Les deux
piliers de MandrakeSoft sont le logiciel libre et le travail
coopératif.
Mandrake Linux possède une facilité
d'installation vraiment intéressante et
L'administration de la machine est grandement facilitée
via l'utilisation du logiciel
drakconf et de commandes telles que urmpi pour l'installation
automatique de paquetages. On note par contre, la distribution souffre toujours
de quelques bugs qui rendent l'ensemble d'une stabilité relative.
A.2 Présentation de la
suite OpenLDAP
Cette section présente la suite logicielle OpenLDAP. Nous
verrons l'historique du projet, le détail des outils fournis par cette
suite et enfin nous aborderons les points forts et les points faibles du
projet.
1. Historique
La suite Openldap est dérivée du logiciel
University of
Michigan LDAP version 3.3, c'est à dire du premier serveur LDAP
indépendant. La dernière version du serveur de
l'Université du Michigan date d'avril 96[5]. Le premier serveur Openldap
est sorti en août 1998[6]. La suite Openldap a totalement remplacé
le logiciel de l'Université du Michigan qui n'est plus supporté
et qui continue d'être distribué pour des raisons historiques
seulement.
Les améliorations apportées par la suite sont
nombreuses: support de la version 3 de la norme LDAP, ajout de nombreux
backend, plus de plates-formes supportées, options de
sécurité plus avancées, et d'inévitables
corrections de bugs. Actuellement Openldap fonctionne sur de nombreuses
plates-formes, dont de nombreux Unix libres (Darwin, FreeBSD, GNU/Linux,
NetBSD, OpenBSD) et commerciaux (HP-UX, IBM AIX, SGI IRIX, Solaris), ainsi que
sur d'autres plates-formes, comme BeOS, Apple MacOS X, IBM zOS, et Microsoft
Windows 2000.
La version 2.0 de la suite, sortie en août 2000, est la
première à supporter la version 3 de la norme LDAP. Chaque
version suivante, les 2.1 et la 2.2, ajoutent des extensions LDAP
supplémentaires à la suite. À ce jour (début 2004)
la version stable d'Openldap est la version 2.1. La version 2.2 est encore en
phase de stabilisation.
Le copyright du logiciel est détenu par la
fondation OpenLDAP.
Son développement est sponsorisé par l'
Internet Software Consortium, qui
sponsorise aussi des outils comme dhcp, bind et inn, qui sont respectivement un
serveur dhcp, un serveur DNS, un serveur de news. L'autre sponsor est
net boolean, une
société de service spécialisée dans les annuaires
électroniques, et dans le logiciel libre.
2. Contenu de la suite
La suite Openldap est composée des
éléments suivants :
|
Slapd
|
Le serveur d'annuaire LDAP. Slapd signifie Stand-alone LDAP
Daemon
|
|
Slurpd
|
Serveur de réplication. Slurpd signifie Standalone
LDAP Update Replication Daemon
|
|
Un kit de développement
|
Ce kit contient des librairies LDAP réutilisées
dans de nombreux projets, et permet de développer des applications LDAP,
en C, C++ ou en Tk
|
|
Des utilitaires clients
|
Il s'agit d'applications utilisables en ligne de commande
permettant d'interroger un annuaire LDAP
|
|
Des contributions
|
Ces contributions sont actuellement des classes java,
développées par Novell, et un pont JDBC-LDAP,
développé par Octet String
|
Tableau 22: composantes suite
OpenLDAP
3. RFC
supportées
a. Les RFCs obligatoires
La suite Openldap respecte la [rfc3377] qui est en fait la
meta RFC définissant la norme LDAP version 3. En se conformant à
cette norme, Openldap respecte intégralement la norme LDAP version 3.
· [rfc2251]
· [rfc2252]
· [rfc2253]
· [rfc2254]
· [rfc2255]
· [rfc2256]
· [rfc2829]
· [rfc2830]
b. Les RFCs non obligatoires
Il existe un certain nombre de RFCs qui ajoutent des
fonctionnalités au protocole LDAP sans pour autant faire partie de la
norme. Openldap implémente plusieurs de ces extensions. Voici une liste
de ces extensions supportées, avec une description pour certaines
d'entre elles :
|
[rfc2596]
|
Cette RFC propose de rajouter une option language aux attributs.
Ainsi la valeur d'un attribut pourra être associée à une
langue
|
|
[rfc2596bis]
|
Il s'agit d'une extension à la RFC
précédente, qui n'est pas devenue une RFC. Cette extension traite
des intervalles de langue.
|
|
[rfc2247]
|
définit un mécanisme qui permet de déduire
le suffixe d'un annuaire LDAP à partir de son nom de domaine
|
|
[rfc3088]
|
décrit l'utilisation du service DNS pour localiser le
serveur annuaire d'un domaine
|
|
[rfc3062]
|
Cette RFC décrit un mécanisme pour modifier le mot
de passe d'un utilisateur, même lorsque celui-ci n'est pas
authentifié auprès de l'annuaire mais avec un autre
procédé SASL
|
|
[rfc3296]
|
Cette RFC propose un moyen de gérer les
referrals. Nous explicitons son contenu dans une autre partie
|
|
Matched Values Control
|
Cette extension permet de limiter les attributs
récupérés, lors d'une recherche, aux valeurs qui
correspondent à un filtre supplémentaire à celui de la
recherche
|
|
[rfc2696]
|
Cette RFC décrit un contrôle qui permet à un
client de recevoir les réponses à une recherche par paquets au
lieu de les recevoir en un seul bloc. Ce contrôle est
implémenté depuis la version 2.2 d'Openldap
|
Tableau 23: les RFCs non
obligatoires
4. Les RFCs non
supportées
Openldap n'implémente pas toutes les extensions
optionnelles LDAP. En particulier les extensions suivantes ne sont pas
respectées :
|
DIT Structure Rules
|
Openldap ne permet pas de spécifier des règles dans
l'arbre informationnel, pour imposer par exemple qu'une branche ne contiendra
que des objets d'une classe donnée. Cette possibilité
était présente dans la norme X500
|
|
Name Forms
|
Il s'agit de la possibilité d'imposer à des objets
d'une classe donnée, ou dans une branche, quel attribut doit être
unique et doit être utilisé comme RDN. Cette possibilité
est aussi issue du monde X500
|
|
Modification de schéma via LDAP
|
Il n'est pas possible, avec le serveur slapd d'Openldap de
modifier le schéma, directement via le protocole LDAP
|
|
[rfc2589]
|
Cette RFC propose un ensemble d'extension et d'objet
spécifique pour permettre à un annuaire de gérer des
objets à courte durée de vie. L'objectif est de pouvoir
gérer avec un annuaire des informations du type: «est-ce que
l'utilisateur est en ligne?»
|
|
[rfc2649]
|
Cette RFC propose un contrôle pour signer des
opérations effectuées sur un annuaire, et de créer ensuite
un journal pour chaque entrée contenant les modifications
effectuées et une signature digitale de l'opération
|
|
[rfc2891]
|
Cette RFC décrit un contrôle permettant à un
client de demander au serveur de trier les résultats d'une recherche,
suivant un attribut donné et éventuellement une règle de
comparaison donnée
|
Tableau 24: les RFCs non
supportées
5. La licence
Openldap est un logiciel libre, au send de la
Free Software Foundation. Cela
signifie qu'il respecte les quatre libertés fondamentales d'un logiciel
libre: liberté d'exécution, liberté d'étude,
liberté de modification et liberté de redistribution.
En revanche ce n'est pas un logiciel copyleft. C'est à
dire qu'il n'impose pas sa licence d'utilisation aux logiciels qui
dérivent de lui. Il peut donc être privatisé. Ce qui ne
l'empêche pas d'être compatible avec la licence GPL. Le code
d'Openldap peut donc être intégré dans un logiciel sous
GPL.
6. Points forts/Points
faibles
1. Points forts
Parmi les atouts d'Openldap on distingue facilement ses atouts
techniques :
· De nombreux backends. Ils permettent au
serveur slapd d'être utilisé à de nombreux usages, (comme
un proxy ou un meta annuaire par exemple).
· Des options de sécurité
avancées. Le serveur slapd est compatible avec les protocoles
SSL et SASL.
· De nombreuses extensions
implémentées. Chaque nouvelle version amène son
lot de nouveautés et d'extentions supplémentaires
implémentées.
L'autre grand atout d'Openldap qu'il ne faut pas
négliger c'est sa qualité de logiciel libre. Évidemment
son coût s'en trouve réduit, puisqu'il n'y a aucun coût de
licence, ni à l'achat, ni à l'exploitation, et quelle que soit la
quantité de données gérées. Le seul coût est
donc celui de son déploiement et de sa maintenance. En tant que logiciel
libre, ses bugs sont corrigés très rapidement, en particulier les
bugs de sécurité.
Mais le principal avantage de ce genre de logiciel reste
l'indépendance qu'il assure vis à vis d'un fournisseur ou d'un
prestataire, la liberté de le modifier (ou de le faire modifier) pour
l'adapter à ses propres besoins, sans avoir à en
référer à personne.
2. Points faibles
Les principaux reproches que l'on faire à Openldap sont
d'ordre technique. L'obligation de redémarrer le serveur à chaque
changement de configuration est assez pénible. En effet le fichier de
configuration n'est lu qu'au démarrrage, et il contient les
règles d'accès et le schéma. Ce qui nécessite
l'arrêt puis le redémarrage après chaque modification d'une
règle ou du schéma. Ceci n'est au fond pas très
gênant dans la mesure où schéma et règle ne
devraient pas être modifiés très souvent, et qu'un annuaire
qui doit être toujours accessible devrait être
répliqué.
L'autre faiblesse, qui peut se révéler plus
gênante, concerne les RFCs optionnelles non implémentées,
et dont certaines organisations ne peuvent pas se passer.
Enfin, le dernier petit reproche concerne la documentation. La
documentation en ligne n'est pas la plus complète. Pour avoir
accès à toutes les directives de configuration, il faut
télécharger le logiciel pour consulter les pages de manuels.
Éventuellement, certaines pages de la FAQ peuvent se
révéler d'un grand secours.
D. Le
langage PHP
1. Qu'est ce que
PHP ?
PHP (officiellement, ce sigle est un acronyme récursif
pour PHP: Hypertext Preprocessor) est un langage de scripts
généraliste et Open Source, spécialement conçu pour
le développement d'applications web. Il peut être
intégré facilement au HTML.
Il est à noter la différence avec les autres
scripts CGI écrits dans d'autres langages tels que le Perl ou le C : Au
lieu d'écrire un programme avec de nombreuses lignes de commandes afin
d'afficher une page HTML, vous écrivez une page HTML avec du code inclus
à l'intérieur afin de réaliser une action précise
(dans ce cas là, afficher du texte). Le code PHP est inclus entre
une
balise de début et une balise de fin qui permettent au serveur web
de passer en "mode PHP".
Ce qui distingue PHP des langages de script comme le
Javascript est que le code est exécuté sur le serveur. Si vous
avez un script similaire sur votre serveur, le client ne reçoit que le
résultat du script, sans aucun moyen d'avoir accès au code qui a
produit ce résultat. Vous pouvez configurer votre serveur web afin qu'il
analyse tous vos fichiers HTML comme des fichiers PHP. Ainsi, il n'y a aucun
moyen de distinguer les pages qui sont produites dynamiquement des pages
statiques.
Le grand avantage de PHP est qu'il est extrêmement
simple pour les néophytes, mais offre des fonctionnalités
avancées pour les experts. On peut plonger dans le code, et en quelques
instants, écrire des scripts simples.
Bien que le développement de PHP soit orienté
vers la programmation pour les sites web, son utilisation peut être
orientée vers bien d'autres usages.
2. Que peut faire PHP?
Tout. PHP est principalement conçu pour servir de
langage de script coté serveur, ce qui fait qu'il est capable de
réaliser tout ce qu'un script CGI quelconque peut faire, comme collecter
des données de formulaire, générer du contenu dynamique,
ou gérer des cookies. Mais PHP peut en faire bien plus.
Il y a trois domaines différents où PHP peut
s'illustrer.
Langage de script coté serveur. C'est l'utilisation la
plus traditionnelle, et aussi le principal objet de PHP. Vous aurez besoin de
trois composants pour l'exploiter : un analyseur PHP (CGI ou module serveur),
un serveur web et un navigateur web. Vous devez exécuter le serveur web
en corrélation avec PHP. Vous pouvez accéder au programme PHP
avec l'aide du navigateur web. Tout ceci peut fonctionner sur votre propre
machine si vous êtes juste expérimenté avec la
programmation en PHP. Voyez la section
d'installation
pour plus d'informations.
Langage de programmation en ligne de commande. Vous pouvez
écrire des scripts PHP et l'exécuter en ligne de commande, sans
l'aide du serveur web et d'un navigateur. Il vous suffit de disposer de
l'exécutable PHP. Cette utilisation est idéale pour les scripts
qui sont exécutés régulièrement (avec un cron sous
Unix ou Linux), ou un Task Scheduler (sous Windows). Ces scripts peuvent aussi
être utilisés pour réaliser des opérations sur des
fichiers texte. Voyez la section sur l'utilisation de PHP en
ligne
de commande pour plus d'informations.
Ecrire des applications clientes graphiques. PHP n'est
probablement pas le meilleur langage pour écrire des applications
clientes graphiques, mais si vous connaissez bien PHP et que vous souhaitez
exploiter des fonctionnalités avancées dans vos applications
clientes, vous pouvez utiliser PHP-GTK pour écrire de tels programmes.
Vous avez aussi la possibilité d'écrire des applications
très portables avec ce langage. PHP-GTK est une extension de PHP, qui
n'est pas fournie dans la distribution de base. Si vous êtes
intéressé par PHP-GTK, visitez
son site web.
PHP est utilisable sur la majorité des systèmes
d'exploitation, comme Linux, de nombreuses variantes Unix (incluant HP-UX,
Solaris et OpenBSD), Microsoft Windows, Mac OS X, RISC OS et d'autres encore.
PHP supporte aussi la plupart des serveurs web actuels : Apache, Microsoft
Internet Information Server, Personal Web Server, Netscape et iPlanet servers,
Oreilly Website Pro server, Caudium, Xitami, OmniHTTPd et beaucoup d'autres
encore. Pour la majorité des serveurs web, PHP fonctionne comme module,
et pour d'autres, il fonctionne comme exécutable CGI.
Avec PHP vous avez le choix de votre système
d'exploitation et de votre serveur web. De plus, vous avez aussi le choix
d'utiliser la programmation procédurale ou objet, ou encore un
mélange des deux. Bien que le support de la couche objet ne soit pas
très standard en PHP 4, beaucoup de bibliothèques et
d'applications d'envergures (incluant la bibliothèque PEAR) ont
été écrites en utilisant uniquement du code orienté
objet. PHP 5 a rectifié les faiblesses de la couche objet de PHP 4 et a
introduit un modèle objet complet.
Avec PHP, vous n'êtes pas limités à la
production de code HTML. Les capacités de PHP lui permettent de
générer aussi bien des images, des fichiers PDF, des animations
Flash (avec l'aide des bibliothèques libswf et Ming),
générés à la volée. Vous pouvez aussi
générer facilement du texte, du code XML ou XHTML. PHP
génère tous ces fichiers, et les sauve dans le système de
fichier, ou bien les envoie directement au navigateur web.
Une des grandes forces de PHP est le support de nombreuses
bases de données et autres méthodes de stockage des
données. Ecrire une page web exploitant une base de données ou un
annuaire électronique est extrêmement simple. Les bases de
données suivantes sont toutes supportées par PHP :
|
Adabas D
|
InterBase
|
PostgreSQL
|
|
dBase
|
FrontBase
|
SQLite
|
|
Empress
|
mSQL
|
Solid
|
|
FilePro (lecture seule)
|
Direct MS-SQL
|
Sybase
|
|
Hyperwave
|
MySQL
|
Velocis
|
|
IBM DB2
|
ODBC
|
Unix dbm
|
|
Informix
|
Oracle (OCI7 et OCI8)
|
LDAP
|
|
Ingres
|
Ovrimos
|
X500
|
Tableau 25: les bases de
données supportées par PHP
Il existe aussi des couches d'abstraction de base de
données comme DBX qui vous permettent de vous connecter de
manière transparente à toute base de données
supportée par cette extension. De plus, PHP supporte ODBC, ce qui vous
permet de vous connecter à toute autre base de données qui
supporte ce standard.
PHP supporte de nombreux protocoles comme LDAP, IMAP, SNMP,
NNTP, POP3, HTTP, COM (sous Windows) et encore d'autres. Vous pouvez ouvrir des
sockets réseau, et interagir avec n'importe quel autre protocole. PHP
supporte le format complexe WDDX, qui permet de communiquer entre tous les
langages web. En terme d'interconnexion, PHP supporte aussi les instanciations
d'objets Java, et les utilise de manière transparente comme objets
intégrés. Vous pouvez aussi exploiter les objets distants avec
CORBA.
PHP dispose de fonctionnalités extrêmement utiles
pour le traitement de texte, allant des expressions rationnelles POSIX
étendues ou Perl aux traitements des fichiers XML, avec les standards
SAX et DOM (PHP 4). Vous pouvez utiliser les transformations XSLT. PHP 5
standardise toutes les extensions XML sur la base solide de libxml2 et en
attendant les fonctionnalités en ajoutant le support de SimpleXML et
XMLReader.
En commerce électronique, vous trouverez des outils de
paiement intégrés comme Cybercash, CyberMut, VeriSign Payflow Pro
et MCVE, pour réaliser des paiements en ligne.
Enfin, PHP dispose d'extensions très pratiques comme le
moteur de recherche mnoGoSearch, la passerelle avec IRC, des outils de
compression (gzip, bz2) et de conversion calendaire, de traduction...
A.3 Le serveur Apache
Le logiciel Apache est actuellement le logiciel serveur http
le plus utilisé dans l'Internet.
Doté de nombreuses fonctionnalités, performant
et gratuit, il constitue un choix très intéressant pour ceux
voulant mettre en place un service WWW.
Mais comme pour tout logiciel, le fait d'offrir de nombreuses
fonctionnalités implique également une complexité plus
grande d'utilisation et en particulier de configuration. Cela entraîne
également très souvent, dans le domaine de l'Internet, des
problèmes potentiels supplémentaires concernant la
sécurité.
A.4 Le DNS
C'est tout simplement ce qui sert à convertir des
adresses noms en adresses IP. Par exemple, quand vous tapez dans votre
navigateur préféré l'adresse :
http://siantou.com. Celui-ci va tout
d'abord faire une requête à un serveur DNS
(généralement le serveur DNS que vous avez configuré pour
votre connexion à l'Internet, donc les serveurs DNS de votre fournisseur
d'accès) en lui demandant : C'est quoi l'adresse IP de siantou.com ?
Et le serveur DNS lui donne l'adresse IP et le navigateur va
alors se connecter à cette adresse IP et afficher le site.
Ceci est valable pour toute autre application qui manipule des
noms DNS (FTP, telnet, mail, ....).
L'annuaire étant destiné à fonctionner
dans un environnement Intranet/Internet, la configuration d'un serveur DNS
s'avère importante.
B.
Implémentation
B.1 Installation et
configuration des serveurs
1. Apache et BIND
Pour ce qui concerne l'installation d'apache et de Bind, nous
n'entrerons pas dans les détails d'installation. On va configurer les
deux serveurs selon nos besoins.
On utilisera le serveur Web Apache dans sa version 2.1.0 et le
serveur de noms Bind dans sa version 9 qui sont par ailleurs
tous gratuits.
a) Apache
Pour rendre accessible la consultation et l'administration de
l'annuaire via un simple navigateur web, il faut compiler apache à
l'installation avec le paquetage auth_ldap.
b) Bind
Pour configurer le DNS nous allons prendre comme domaine
fictif de travail master.net et comme hôte
dany. Notre réseau a une adresse de classe C
192.168.100 car la démonstration sera effectuée
en Intranet et le serveur LDAP avec lequel nous travaillons a l'adresse
192.168.100.2
- Fichier named.conf
Nous allons créer deux zones master.net
et 0.168.192.in-addr.arpa pour la résolution
noms-adresses et adresses-noms.
// Zone master.net
zone "master.net" {
type master;
file "db.master";
};
// zone resolution inverse
zone "0.168.192.in-addr.arpa" {
type master;
file "db.192.168.100";
};
- Fichier db.master
$TTL 38400
master.net. IN SOA dany.master.net. dany.master.net. (
1 ; numéro de série
10800 ; rafraîchissement
3600 ; nouvel essai
604800 ; Obsolescence après une
semaine
86400 ) ; TTL minimal de 1 jour
; serveur de noms
@ IN NS dany.master.net.
; adresse et alias
; adresse des hôtes
IN A 192.168.100.2
localhost.master.net IN A 127.0.0.1
mail.master.net IN A 192.168.100.2
dany IN A 192.168.100.2
dany.master.net IN A 192.168.100.2
; alias
www IN CNAME dany.master.net.
mail IN CNAME dany.master.net.
news IN CNAME dany.master.net.
ldap IN CNAME dany.master.net.
pop IN CNAME dany.master.net.
imap IN CNAME dany.master.net.
; Spécification serveur de messagerie
@ IN MX 10 dany.master.net.
Test DNS avec nslookup
[root@dany named]# nslookup master.net
Note: nslookup is deprecated and may be removed from future
releases.
Consider using the `dig' or `host' programs instead. Run
nslookup with
the `-sil[ent]' option to prevent this message from appearing.
Server: 192.168.100.2
Address: 192.168.100.2#53
Name: master.net
Address: 192.168.100.2
[root@dany named]#
2. Package OpenLDAP
a)
Installation par tarball
On vérifie d'abord qu' Openldap n'est
pas déjà installé sur votre système en tapant :
rpm -qa | grep -i ldap
On supprime du système les packages contenus dans la
liste avec la commande rpm -e nom-du-package (sauf
libldap2 qui sert pour de nombreux packages).
Si pour des histoires
de dépendance vous n'arrivez pas à tout supprimer ce n'est pas
bien grave car par défaut le tarball et les packages mdk ne placent pas
les fichiers au même endroit. Lors du lancement du daemon et des
exécutables il faut juste faire attention d'appeler le bon
exécutable (servez vous de la commande which nom-exe
).
L'archive à récupérer est
openldap-2.2.28.tgz qu'on décompressera en tapant :
tar xvfz openldap-2.2.28.tgz
Cela va nous créer un répertoire
openldap-2.2.28. Avant d'aller plus loin il faudra installer
(commande urpmi nom-package ) les packages suivants de la
Mandrake 9.2
libgdbm2
libgdbm2-devel
En effet par défaut openldap utilise
une base de donnée Berkeley dans sa version 4.2 qui est utilisée,
comme la 10.0 ne propose que la 4.1, je me suis rabattu sur la base de
donnée de type ldbm. Puis on tape successivement :
./configure --enable-crypt --disable-bdb
--enable-ldbm
make depend
make
On peut tester maintenant que tout
marche bien en tapant :
cd tests
make
pour installer les binaires de ldap on
tapera, en tant que root :
cd ..
make install
Les binaires sont installés par défaut
dans /usr/local/sbin et /usr/local/libexec,
les fichiers de config dans /usr/local/etc/openldap et les
bases dans /usr/local/var/openldap-data. Les biblio vont se
trouver sous /usr/local/lib, si ce n'est pas fait, rajouter ce
chemin à la fin du fichier /etc/ld.so.conf et tapez
ldconfig
pour changer l'emplacement de tous ces fichiers taper:
configure -help
b) Installation
par RPM
Il suffit d'installer (commande urpmi openldap)
les packages suivants (dans l'ordre)
:
libldap2-2.1.25-6mdk
openldap-2.1.25-6mdk
perl-ldap-0.31-2mdk
openldap-servers-2.1.25-6mdk
openldap-clients-2.1.25-6mdk
Vous pouvez maintenant installer aussi le package
php-ldap pour le support LDAP de
PHP avec
Apache.
c) Mise en place des classes
d'objet
Le fichier de configuration slapd.conf fait
appel à /usr/local/etc/openldap/schema/core.schema
(/usr/share/openldap/schema/core.schema pour une install avec
package) qui décrit les classes d'objet. Voilà un exemple avec la
classe "person"
objectclass ( 2.5.6.6 NAME
'person'
DESC
'RF256: a person'
SUP top
STRUCTURAL
MUST
( sn $ cn )
MAY
( userPassword $ telephoneNumber $ seeAlso $ description ) )
MUST correspond au attributs obligatoires et
MAY à ceux facultatifs
objectClass
est le nom de la classe qui descend elle même de la classe
top
sn correspond à surname
(nom)
cn correspond à common name (prénom
nom)
Je vous laisse déviner la signification des autres attributs.
On voit qu'il est nécessaire de fournir les attributs
sn (surname) et cn (common name), sont
facultatifs le mot de passe (userPassword), le numéro
de téléphone (telephoneNumber ), les liens
(seeAlso) et la description.
Les attributs sont définis dans le même fichier,
la syntaxe est la suivante pour telephoneNumber par exemple
:
attributetype ( 2.5.4.20 NAME
'telephoneNumber'
DESC 'RF256: Telephone Number'
EQUALITY
telephoneNumberMatch
SUBSTR
telephoneNumberSubstringsMatch
SYNTAX
1.3.6.1.4.1.1466.115.121.1.50{32} )
Pour créer les classes d'objet agency
et vhicule dérivant de
organizationalUnit, disposant de l'attribut obligatoire
title en plus et des arguments facultatifs ou
(groupe de travail) et l (localistation). On tapera
dans le fichier core.schema juste après la
définition de la classe organizationalUnit.
objectclass ( 2.5.6.6.2 NAME `agency' SUP
organizationalUnit STRUCTURAL
MUST (
title )
MAY ( ou $ l ) )
Vous noterez le nombre 2.5.6.6.2, ce nombre doit être
unique dans le fichier, il dérive directement du numéro de la
classe objet organizationalUnit qui a pour numéro
2.5.6.6. Il est évident que comme agency et vhicule
dérivent de organizationalUnit, les attributs
** sont aussi obligatoires.
A noter qu'avec une installation avec package les classes
"locales" peuvent être créées dans le fichier
/etc/openldap/schema/local.schema
d) Choix du
suffixe
Le rootDSE ou suffixe correspond à
l'entrée tout en haut de l'arbre (DIT) de l'annuaire,
on utilise généralement le nom de domaine, avec la syntaxe
suivante dc=master, dc=net pour le domaine
master.net (dc correspond à Domain
Component).
e)
Configuration du serveur LDAP
# $OpenLDAP: pkg/ldap/servers/slapd/slapd.conf,v 1.8.8.6
2001/04/20 23:32:43 kurt Exp $
#
# See slapd.conf(5) for details on configuration options.
# This file should NOT be world readable.
#
# Modified by Christian Zoffoli
<czoffoli@linux-mandrake.com>
# Version 0.2
#
include /usr/share/openldap/schema/core.schema
include /usr/share/openldap/schema/cosine.schema
include /usr/share/openldap/schema/corba.schema
include /usr/share/openldap/schema/inetorgperson.schema
include /usr/share/openldap/schema/java.schema
include /usr/share/openldap/schema/krb5-kdc.schema
include /usr/share/openldap/schema/kerberosobject.schema
include /usr/share/openldap/schema/misc.schema
include /usr/share/openldap/schema/nis.schema
include /usr/share/openldap/schema/openldap.schema
#include /usr/share/openldap/schema/rfc822-MailMember.schema
#include /usr/share/openldap/schema/pilot.schema
#include /usr/share/openldap/schema/autofs.schema
#include /usr/share/openldap/schema/samba.schema
#include /usr/share/openldap/schema/qmail.schema
#include /usr/share/openldap/schema/mull.schema
#include /usr/share/openldap/schema/netscape-profile.schema
#include /usr/share/openldap/schema/trust.schema
#include /usr/share/openldap/schema/dns.schema
#include /usr/share/openldap/schema/cron.schema
include /etc/openldap/schema/local.schema
# Define global ACLs to disable default read access.
include /etc/openldap/slapd.access.conf
# Do not enable referrals until AFTER you have a working
directory
# service AND an understanding of referrals.
#referral ldap://root.openldap.org
pidfile /var/run/ldap/slapd.pid
argsfile /var/run/ldap/slapd.args
modulepath /usr/lib/openldap
#moduleload back_dnssrv.la
#moduleload back_ldap.la
#moduleload back_passwd.la
#moduleload back_sql.la
# SASL config
#sasl-host ldap.master.net
# To allow TLS-enabled connections, create
/usr/share/ssl/certs/slapd.pem
# and uncomment the following lines.
#TLSRandFile /dev/random
#TLSCipherSuite HIGH:MEDIUM:+SSLv2
TLSCertificateFile /etc/ssl/openldap/ldap.pem
TLSCertificateKeyFile /etc/ssl/openldap/ldap.pem
#TLSCACertificatePath /etc/ssl/openldap/
TLSCACertificateFile /etc/ssl/openldap/ldap.pem
#TLSVerifyClient 0
#######################################################################
# ldbm database definitions
#######################################################################
database ldbm
suffix "dc=master,dc=net"
#suffix "o=My Organization Name,c=US"
rootdn "cn=Manager,dc=master,dc=net"
#rootdn "cn=Manager,o=My Organization Name,c=US"
# Cleartext passwords, especially for the rootdn, should
# be avoided. See slappasswd(8) and slapd.conf(5) for
details.
# Use of strong authentication encouraged.
rootpw {SSHA}RK9gP6YyIOOreXm5+oFsZ8W+9AiEL4el
# The database directory MUST exist prior to running slapd AND
# should only be accessable by the slapd/tools. Mode 700
recommended.
directory /var/lib/ldap
# Indices to maintain
#index objectClass eq
index objectClass,uid,uidNumber,gidNumber eq
index cn,mail,surname,givenname eq,subinitial
# logging
loglevel 256
# Basic ACL
access to attr=userPassword
by self write
by anonymous auth
by dn="cn=Manager,dc=master,dc=net" write
by * none
access to *
by dn="cn=Manager,dc=master,dc=net" write
by * read
access to attr=userPassword
by self write
by anonymous auth
by dn="dc=master,dc=net" write
by * none
Le fichier ldap.conf peut être vide
dans un premier temps voire inexistant.
Le mot de passe de l'administrateur est
secret par défaut et en clair. Pour des raisons de
sécurité il vaut mieux le crypté.
slappasswd -v -s Mot_de_Passe -h {SSHA}
A la place de
rootpw secret
Dans slapd.conf, vous mettrez donc:
rootpw
{SSHA}RK9gP6YyIOOreXm5+oFsZ8W+9AiEL4el
f) Lancement du
serveur
Pour une installation par RPM, vous allez retrouver un fichier
de lancement ldap sous /etc/rc.d/init.d. Pour
l'installation par tarball, voici un fichier
ldap à
placer sous /etc/rc.d/init.d, attention ce fichier utilise les
chemins par défaut, vous devez le modifier si nécessaire et lui
donner des droits d'exécution (755). Vous devez aussi modifier (non
nécessaire pour installation par rpm) le fichier
/etc/rc.d/init.d/functions et à la place de :
PATH="/sbin:/usr/sbin:/bin:/usr/bin:/usr/X11R6/bin"
On mettra
PATH="/sbin:/usr/sbin:/bin:/usr/bin:/usr/X11R6/bin:/usr/local/libexec"
pour que serveur LDAP soit lancé
automatiquement à l'état de marche 3, 4 et 5 ( les deux types
d'install) on tapera :
chkconfig --level 345 ldap on
Pour l'arrêter à l'état de marche 0, 1, 2
et 6, on tapera:
chkconfig --level 0126 ldap off
Au prochain reboot le serveur sera lancé
automatiquement, pour éviter un reboot pour lancer le serveur, il suffit
de taper :
/etc/rc.d/init.d/ldap start ou service ldap start
g) Ajouter
un enregistrement
Nous avons différents moyens d'ajouter des
données à l'annuaire, pour des besoins de configurations on va
d'abord aborder la méthode manuelle. Pour ajouter des données au
serveur LDAP nous devons fournir un fichier au format
LDIF (pour LDAP Directory Interchange Format), le fichier est
un format texte facilement lisible au contraire du format interne de
l'annuaire. Notre fichier comportera l'enregistrement du domaine (master.net)
pour notre annuaire et les enregistrements des 10 provinces du Cameroun,
enregistrements figés dans la base de données.
A noter que:
- chaque enregistrement dans le fichier est
séparé du précédent et du suivant par une ligne
vierge,
- les espaces sont pris en compte. ATTENTION,
il est très important qu'il n'y ait aucun espace en fin de ligne.
Creation du fichier LDIF de base
(base.ldif)
# Build the root node.
dn: dc=master,dc=net
dc: master
objectClass: top
objectClass: dcObject
objectClass: organization
o: Annuaire LDAP Master
#Province du Adamaoua
dn: ou=adamaoua,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: adamaoua
#Province du Centre
dn: ou=centre,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: centre
#Province du Littoral
dn: ou=littoral,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: littoral
#Province du Est
dn: ou=est,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: est
#Province du Ouest
dn: ou=ouest,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: ouest
#Province du Sud-ouest
dn: ou=sud-ouest,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: sud-ouest
#Province du Nord-ouest
dn: ou=nord-ouest,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: nord-ouest
#Province du Nord
dn: ou=nord,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: nord
#Province du Extreme-nord
dn: ou=extreme-nord,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: extreme-nord
#Province du Sud
dn: ou=sud,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: sud
Pour ajouter l'enregistrement il faut utiliser la commande
ldapadd qui necessite une authentification.
ldapadd -x -D "description du dn de l'administrateur" -W
-f nom-du-fichier-ldif
Dans notre cas on aura concretement:
[root@dany openldap]#
ldapadd -x -c -D "cn=Manager,dc=master,dc=net» -W -f base.ldif
Enter LDAP Password:
adding new entry "dc=master,dc=net"
adding new entry "ou=adamaoua,dc=master,dc=net"
adding new
entry "ou=centre,dc=master,dc=net"
adding new entry
"ou=littoral,dc=master,dc=net"
adding new entry "ou=est,dc=master,dc=net"
adding new entry "ou=ouest,dc=master,dc=net"
adding new entry "ou=sud-ouest,dc=master,dc=net"
adding new entry "ou=nord-ouest,dc=master,dc=net"
adding new entry "ou=nord,dc=master,dc=net"
adding new entry "ou=extreme-nord,dc=master,dc=net"
adding new entry "ou=sud,dc=master,dc=net"
[root@dany openldap]#
A présent il faut vérifier tout ça. On va
utiliser la fonction ldapserach
[root@dany projet]# ldapsearch -x -b 'dc=master,dc=net'
'(objectclass=*)'
# extended LDIF
#
# LDAPv3
# base <dc=master,dc=net> with scope sub
# filter: (objectclass=*)
# requesting: ALL
# master.net
dn: dc=master,dc=net
objectClass: top
objectClass: dcObject
objectClass: organization
dc: master
o: masterLDAP
# adamaoua, master.net
dn: ou=adamaoua,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: adamaoua
# centre, master.net
dn: ou=centre,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: centre
# littoral, master.net
dn: ou=littoral,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: littoral
# est, master.net
dn: ou=est,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: est
# ouest, master.net
dn: ou=ouest,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: ouest
# sud-ouest, master.net
dn: ou=sud-ouest,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: sud-ouest
# nord-ouest, master.net
dn: ou=nord-ouest,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: nord-ouest
# nord, master.net
dn: ou=nord,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: nord
# extreme-nord, master.net
dn: ou=extreme-nord,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: extreme-nord
# sud, master.net
dn: ou=sud,dc=master,dc=net
objectClass: top
objectClass: organizationalunit
ou: sud
# search result
search: 2
result: 0 Success
# numResponses: 13
# numEntries: 11
[root@dany projet]#
B.2 Réalisation de
l'application cliente pour la gestion et l'administration de l'annuaire
1. L'IHM
a) La charte
graphique
Nous avons choisit les couleurs verte et grise comme couleurs
principales
b) L'ergononie
2. La programmation
Ici nous allons simplement lister les fonctions de l'API PHP
utilisées qui permettent de manipuler un serveur d'annuaire LDAP.
ldap_8859_to_t61 --
Convertit les caractères 8859 en caractères t61
ldap_add -- Ajoute
une entrée dans un dossier LDAP
ldap_bind -- Authentification
au serveur LDAP
ldap_close -- Alias
de
ldap_unbind()
ldap_compare -- Compare
une entrée avec des valeurs d'attributs
ldap_connect -- Se
connecte à un serveur LDAP
ldap_count_entries -- Compte
le nombre d'entrées après une recherche
ldap_delete -- Efface
une entrée dans un dossier
ldap_dn2ufn -- Convertit
un DN en format UFN (User Friendly Naming)
ldap_err2str --
Convertit un numéro d'erreur LDAP en message d'erreur
ldap_errno --
Retourne le numéro d'erreur LDAP de la dernière commande
exécutée
ldap_error --
Retourne le message LDAP de la dernière commande LDAP
ldap_explode_dn -- Sépare
les différents composants d'un DN
ldap_first_attribute -- Retourne
le premier attribut
ldap_first_entry -- Retourne
la première entrée
ldap_first_reference --
Retourne la première référence
ldap_free_result -- Libère
la mémoire du résultat
ldap_get_attributes -- Lit
les attributs d'une entrée
ldap_get_dn -- Lit
le DN d'une entrée
ldap_get_entries -- Lit
toutes les entrées du résultat
ldap_get_option -- Lit/écrit
la valeur courante d'une option
ldap_get_values_len -- Lit
toutes les valeurs binaires d'une entrée
ldap_get_values -- Lit
toutes les valeurs d'une entrée LDAP
ldap_list -- Recherche
dans un niveau
ldap_mod_add -- Ajoute
un attribut à l'entrée courante
ldap_mod_del -- Efface
un attribut à l'entrée courante
ldap_mod_replace -- Remplace
un attribut dans l'entrée courante
ldap_modify -- Modifie
une entrée LDAP
ldap_next_attribute -- Lit
l'attribut suivant
ldap_next_entry -- Lit
la prochaine entrée
ldap_next_reference -- Lit
la référence suivante
ldap_parse_reference --
Extrait les informations d'une référence d'entrée
ldap_parse_result -- Extrait
des informations d'un résultat
ldap_read -- Lit
une entrée
ldap_rename -- Modifie
le nom d'une entrée
ldap_sasl_bind --
Authentification au serveur LDAP en utilisant SASL
ldap_search -- Recherche
sur le serveur LDAP
ldap_set_option -- Modifie
la valeur d'une option LDAP
ldap_set_rebind_proc --
Configure une fonction de callback pour refaire des liaisons lors de recherche
de référants
ldap_sort --
Trie les entrées d'un résultat LDAP
ldap_start_tls --
Démarre TLS
ldap_t61_to_8859 --
Convertit les caractères t6 en caractères 8859
ldap_unbind -- Déconnecte
d'un serveur LDAP
III Résultats
attendus et problèmes rencontrés
A. Test des
différents serveurs
A.1 Test du DNS
root@dany dany]# telnet -x master.net
Trying 192.168.100.2...
Connected to master.net (192.168.100.2).
Escape character is '^]'
[root@dany dany]# service named status
number of zones: 5
debug level: 0
xfers running: 0
xfers deferred: 0
soa queries in progress: 0
query logging is OFF
server is up and running
[root@dany dany]#
A.2 Test serveur Web
[root@dany dany]# telnet -x www.master.net 80
Trying 192.168.100.2...
Connected to www.master.net (192.168.100.2).
[root@dany dany]# service httpd status
Apache est en cours d'exécution.
httpd2: 2816 2806 2732 2716 2301 2300 2299 2298 2297 2283
A.3 Test serveur LDAP
[root@dany dany]# telnet -x ldap.master.net 389
Trying 192.168.100.2...
Connected to ldap.master.net (192.168.100.2).
[root@dany dany]# service ldap stop
Arrêt du serveur LDAP :
[ OK ]
[root@dany dany]# service ldap start
ldaps
Lancement du serveur LDAP (ldap + ldaps) : [
OK ]
[root@dany dany]#
B. Quelques écrans
de l'application
Figure 35: Interface de gestion des
villes
Figure 36: Interface de gestion d'ajout d'une
agence
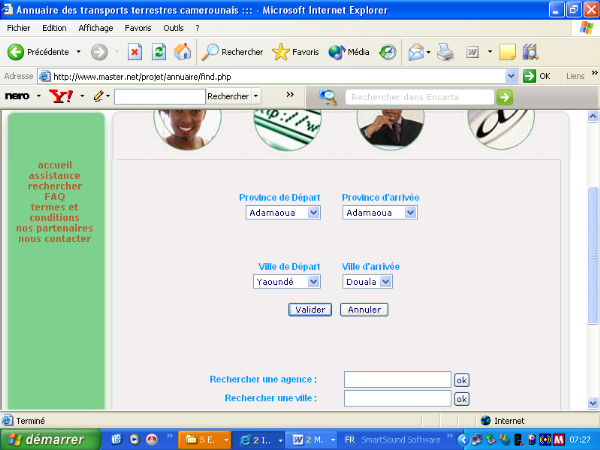
Figure 37:
Interface de recherche d'une ligne de transport
B. Problèmes
rencontrés
Nous avons eu quelques difficultés dans notre
démarche de tant méthodologiques que pratiques. Les
différents problèmes auxquels nous avons du faire face sont les
suivants :
? Le temps qui nous a cruellement fait défaut. Dans un
projet d'une telle envergure nous aurons aimé présentér un
travail encore plus abouti avec la validation des concernés et du
ministère des transports.
? Une indisponibilité affichée dans certaines
compagnies de transport.
? La technologie utilisée pour la mise en place de
notre système étant encore peu connue et utilisée au
Cameroun, nous n'avons pas trouvé l'aide académique suffisante ce
qui a augmenté le coût en terme de recherche de notre travail.
CHAPITRE IV : CONCLUSION ET PERSPECTIVES
Au terme de ce travail, nous pensons avoir
présenté la technologie de annuaires électronique qui
représente un sérieux atout dans la mise en place des
systèmes et applications informatiques distribuées.
Nous avons choisit le domaine des transport pour appliquer les
concepts en mettant sur pied les fondations d'un systèmes de
référencement dans les transports terrestres camerounais qui
permet entre autres d'avoir facilement l'information détaillé et
à moindre coût sur les agences et compagnies de transport
terrestre avec des options de recherches avancées et optimisées
grâce aux annuaire LDAP, le souci étant de réaliser un
système d'information normalisé, accessible à grande
échelle, dynamique et utile comme celui présent dans les
transport aérien.
Dans le cadre de ce mémoire, nous nous sommes
limité à l'implémentation du système à
partir des informations de recueillies dans certaines agences et il nous tient
à coeur que ce projet soit suivi car il offre de nombreuses
possibilités future pour notre système des transports
terrestres.
L'intérêt ici de présenter les services
d'annuaires LDAP réside dans le fait que c'est une technologie du futur
dans ce sens que la plupart des nouveaux systèmes et autres applications
informatiques utilisent LDAP. Son utilisation couvre plusieurs domaines comme
la réalisation des annuaires téléphoniques
interne/externe, gestion des comptes utilisateurs et l'authentification unique
sur le réseau, authentification pour accès aux divers services
informatiques, listes de diffusion, contrôles d'accès aux
bâtiments, des supports d'inventaire, base de configuration
d'équipements réseau, intégration dans un système
de téléphonie sur IP, les outils de systèmes
d'exploitation, les certificats de clé publique PKI pour le paiement
sécurisé sur Internet ...
Ainsi nous savons notre tâche juste entamée dans
ce sens que nous avons mis les fondations d'un système sérieux et
indispensable à notre système de transport. Maintenant, il
serait intéressant qu'un tel projet soit suivi car necessite beaucoup de
ressources tant d'ordres logistique que techniques et financières pour
arriver à mettre en place un système de recherche poussé
comme celui des transports aériens et pourquoi pas obtenir un annuaire
général camerounais référencent plusieurs domaines
clés comme les pharmacies, l'éducation à la hauteur des
systèmes comme « Europages, l'annuaire européen des
affaires » .
BIBLIOGRAPHIE
A. Les livres
utilises
· PHP5 Développemnt d'application Web :
Tobias
RATSCHILLER & Till GERKEN - Campous Presse
· Modélisation Objet avec UML:
Pierre-Alain
MULLER - Eyrolles
B. Webographie
· Understanding X.500 - The Directory.
http://www.isi.salford.ac.uk/staff/dwc/Version.Web/Contents.htm
· Guidelines for the Evaluation of X.500 Directory
Products.
http://snad.ncsl.nist.gov/snad-staff/tebbutt/x5eg/tableofcontents2_1.html
· Introduction to LDAP. Peter Gietz.
http://www.ceenet.org/workshops/lectures2001/Peter%20Gietz/CEENET2001-LDAPl/index.htm
· Linuxworld LDAP in action:
http://linuxworld.com/linuxworld/lw-1999-07/lw-07-ldap_1.html
· Linux LDAP services:
http://www.rage.net/ldap/
· OPenLDAP.org:
http://www.openldap.org
· Netscape Deployment Guide:
http://developer.netscape.com/docs/manuals/directory/deploy30/index.htm
· LDAP FAQ:
http://www.critical-angle.com/ldapworld/ldapfaq.html
· LDAP roadmap and FAQ:
http://www.kingsmountain.com/ldapRoadmap.shtml
· RFC 1777 The Lightweight Directory Access Protocol:
http://www.umich.edu/~dirsvcs/ldap/doc/rfc/rfc1777.txt
· LDAP Version 2 standard:
http://www.ietf.org/rfc/rfc1777.txt
· LDAP Version 3 standard:
http://www.ietf.org/rfc/rfc2251.txt
· The LDAP Extensions Working Group of the IETF:
http://www.ietf.org/html.charters/ldapext-charter.html
· The LDAP Duplication/Update Protocol Working Group of the
IETF:
http://www.ietf.org/html.charters/ldup-charter.html
· Les Annuaires LDAP avec OpenLDAP Par Michaël Parienti
Maire:
http://www.developpez.com
· Le manuel PHP :
http://www.manuel.php/docs/
· Investir en zone franc :
http://www.izf.net
| 

