|
Epigraphe
Change en toi ce que tu veux changer dans le
monde
Gandhi
Dédicace
Je dédie ce travail à mes amis Christian
KAYEMBE, Serge LUYINDULADIO et Primo KIMBULU
DILU NLEMVO Steve
Remerciement
Je remercie mes parents pour leur soutien tant moral, physique
que spirituel qu'ils ont pu m'apporter tout au long de ma vie, et qu'il ne
cesse de réitérer à chaque instant.
Je remercie le professeur Simon NTUMBA BADIBANGA pour avoir
accepté volontiers de consacrer son temps à la direction de ce
travail.
Je remercie toute tierce personne qui, directement ou
indirectement, a contribué à la réalisation de ce
travail.
DILU NLEMVO Steve
LISTE DES ABREVIATIONS
|
OSI
|
Open SystemsInterconnection
|
|
ISO
|
International Standardization Organisation
|
|
HDLC
|
High-level Data Link Control
|
|
UIT-T
|
Union internationale des
télécommunications-standardisation du secteur
télécommunications
|
|
UDP
|
User Datagram Protocol
|
|
TCP/IP
|
Transmission Control Protocol/Internet Protocol
|
|
IPv4
|
Internet Protocol version 4
|
|
IPv6
|
Internet Protocol version 6
|
|
DNS
|
Domain Name System
|
|
LDAP
|
Lightweight Directory Access Protocol
|
|
RBAC
|
RoleBased Access Control
|
|
DAC
|
Discretionary Access Control
|
|
MAC
|
Mandatory Access Control
|
|
SSO
|
Single Sign One
|
|
UML
|
UnifiedModeling Langage
|
|
UP
|
UnifiedPreocess
|
|
XP
|
eXtremProgramming
|
LISTE DES FIGURES
Figure I-1 Les grandes catégories de
réseau informatique
3
Figure I-2 structure générale d'un
réseaux à commutation : commutateurs et circuits
6
Figure I-3 Topologie en étoile
6
Figure I-4 Topologie en arbre
7
Figure I-5 Topologie maillé
7
Figure I-6 Topologie en Anneau
7
Figure I-7 Architecture OSI
8
Figure I-8 Classe d'adressage IPv4
16
Figure I-9 Fonctionnement du DNS
18
Figure II-1 Extrait (standard) de la gestion des
utilisateurs et des droits d'accès
33
Figure II-2 Modèle de base RBAC
35
Figure II-3 Exemple de l'habilitation
38
Figure IV-1Méthodologie de travail
51
Figure IV-2 Diagramme de cas d'utilisation
52
Figure IV-3 diagramme de séquence:
authentification
53
Figure IV-4 diagramme de séquence :
Création de serveur
54
Figure IV-5 diagramme de séquence : Afficher
les taches en cours
55
Figure IV-6 diagramme de séquence :
Effectuer une tache distante
56
Figure IV-7 diagramme de séquence : Allumer
le PC de l'utilisateur
57
Figure IV-8 diagramme de séquence : basculer
entre application
58
Figure IV-9 diagramme de classe : Modèle du
domaine
59
Figure IV-10 diagramme de navigation : la
navigation de l'utilisateur
60
Figure IV-11 diagramme de classe : partie
réseau
61
LISTE DES TABLEAUX
Tableau I-1 Le modèle OSI
3
Tableau I-2 Le modèle OSI
détaillé
14
Tableau I - 3 Allocation des adresse IPv6
17
Tableau I-4 Pourcentages des catégories des
intranet
21
Tableau II-1Matrice de contrôle
d'accès
37
INTRODUCTION GENERALE
L'informatisation est l'un des phénomènes le
plus important de notre époque. Depuis ces dernières
années, l'informatique est devenue l'un des moteurs important dans les
entreprises. Il s'intègre dans presque tous les domaines et deviens
quasi indispensable pour une meilleur performance et productivité
grâce à son essence, à savoir l'automatisation de
l'information.
Et son outil de prédilection : l'ordinateur est
aussi devenu si indispensable qu'il bat son plein ; tant dans le secteur
économique et jusqu'à l'aéronautique. Ceci met en
flèche le secteur du génie logiciel, qui collabore avec presque
tous les domaines en vue d'un meilleur rendement et d'une meilleure
productivité.
L'internet est le réseau informatique mondial
accessible à tous, c'est un réseau composé de millions de
réseau aussi bien public que privé. Il permet ainsi de rendre
accessible au public une grande quantité d'information et de service, on
y trouve tout. Et chacun dans son domaine se retrouve grâceà des
applications web tel des « moteur de recherches » des sites
web de tout genre « e-commerce »,
« e-Banking » et bien d'autres encore.
Cela crée un vrai système cohérent ou
chimiste, biologiste, médecin, économiste... se sent
poussé à utiliser l'internet dans leur entreprise en vue de mieux
répondre à leur exigence. Chaque acteur dans son entreprise doit
donc pouvoir tirer parti de l'internet avec toute sa diversité s'il veut
arriver à ses fins etêtre compétitif dans le monde
professionnel.
Ceci nous amène à s'intéresser à
la tâche qui revient à chaque individu dans la réalisation
des objectifs de l'entreprise et d'évaluer sa productivité dans
la réalisation de ladite tache.
Pour essayer de délimiter le coût réel sur
la productivité, une étude de SignNow (Une entreprise
Informatique aux USA) s'est penchée sur l'impact d'internet en
entreprise. Il en ressort les statistiques suivantes :
- près de deux tiers des employés (64%) se
rendent sur des sites web qui n'ont aucun rapport avec leur travail. Parmi eux,
39% y passe au plus une heure, 29% deux heures, 21% cinq heures et 3% plus de
10 heures.
- En moyenne, les employés perdent 2,32 heures chaque
semaine sur des navigations web personnelles ou qui n'ont rien à voir
avec leur travail, ce qui coûte près de 3 000 dollars par
employé par an.
A ce titre,egedian.com en France publie une petite liste non
exhaustive des sites les plus consulté et qui n'ont aucun rapport avec
des sites professionnels :

Etude interne menée en mai 2012 sur plus de 150 000
visites de sites Internet effectuées entre le 1er janvier et le 31 mars
2010 dans les entreprises équipées de la solution Profil Network
Filter et ayant accepté de transmettre de façon anonyme leurs
informations au centre de R&D de Profil Technology.
Sans surprise, Google domine le classement des sites les plus
visités en entreprise grâce à ses nombreux services (moteur
de recherche, Gmail, Google maps, etc.), les réseaux sociaux (avec
forums et chats), plateformes d'hébergement et de partage de
vidéos et de musique en ligne occupent les places suivantes.
L'encadrement des accès et des utilisations par groupes
d'utilisateurs, par tranches horaires devient indispensable afin de limiter les
abus, réguler la productivité des salariés et
protéger l'entreprise.
Mais les sites web visités ne constituent pas la seule
distraction. Les résultats des recherches de l'entreprise SignNow aux
USA suggèrent que :
- Seuls 14% des courriels sont indispensables au travail.
- 62% du panel estime que perdre du temps sur des courriels
non essentiels est l'aspect le plus difficile de l'utilisation d'une
boîte email.
Il faut dire que SignNow estime à 192 milliards le
nombre de courriels envoyés par jour d'ici 2016. Le panel avance que 8%
des courriels reçus sont des spams. 10% de leurs conversations par
courriels sont personnelles ou non rien à voir avec leur travail. Le
nombre d'heures par jour passé pour utiliser sa boîte mail est de
4 heures, ce qui revient à dire que l'impact sur cette activité
est d'environ 50% sur une journée de travail.
Il ressort clairementqu'une importante perte en
productivité est constatée en entreprise ; et cela est
dû entre autre auxactivités connexes effectué par les
utilisateurs pendant les heures de travail au travers de l'internet. Il est
donc nécessaire de mieux superviser et coordonner les taches des
utilisateurs, évaluer et réévaluer leurs performances pour
améliorer la productivité de l'entreprise.
Le présent travail vise donc à réduire ce
déficit en proposant une application qui permet de monitorer les taches
en cours dans un réseau d'entreprise.
INTRODUCTION
Les réseaux composent la structure de base du
septième continent qui se forme sous nos yeux. Par l'immense
séisme qu'il engendre en ce début de siècle, la
planète entre dans une ère nouvelle. Ce nouveau continent est
celui de la communication. Constitué de réseaux se parcourant
à la vitesse de la lumière, il représente une rupture
analogue à l'apparition de l'écriture ou à la grande
révolution industrielle.
Ces réseaux, qui innervent aujourd'hui
complètement la planète, s'appuient sur la fibre optique, les
ondes hertziennes et divers équipements qui permettent d'atteindre de
hauts débits. Internet incarne pour le moment la principale architecture
de ces communications.
Les réseaux modernes sont apparus au cours des
années 1960 à la faveur d'une technologie totalement nouvelle
permettant de transporter de l'information d'une machine à une autre.
Ces machines étaient des ordinateurs de première
génération, guère plus puissants qu'un petit assistant
personnel actuel. Les réseaux de téléphonie existaient
quant à eux depuis longtemps. Ils utilisaient la technologie dite de
commutation de circuits et le support de lignes physiques reliant
l'ensemble des téléphones par le biais de commutateurs.
Lors d'une communication, ces lignes physiques ne pouvaient
être utilisées que par les deux utilisateurs en contact. Le signal
qui y transitait était de type analogique.
La première révolution des réseaux a
été apportée par la technologie numérique des
codecs (codeur-décodeur), qui permettaient de transformer les signaux
analogiques en signaux numériques, c'est-à-dire une suite de 0 et
de 1. Le fait de traduire tout type d'information sous forme de 0 et de 1
permettait d'unifier les réseaux. Dans cette génération,
la commutation de circuits était toujours fortement utilisée.
1.1 1.1 QUELQUES
CONCEPTS
Les réseaux informatiques sont nés du besoin de
relier des terminaux distants à un site central puis des ordinateurs
entre eux et enfin des machines terminales, telles que stations de travail ou
serveurs. Dans un premier temps, ces communications étaient
destinées au transport des données informatiques. Aujourd'hui,
l'intégration de la parole téléphonique et de la
vidéo est généralisée dans les réseaux
informatiques, même si cela ne va pas sans difficulté.
On distingue généralement cinq catégories
de réseaux informatiques, différenciées par la distance
maximale séparant les points les plus éloignés du
réseau :
· Les réseaux personnels, ou PAN (Personal
Area Network), interconnectent sur quelques mètres des
équipements personnels tels que terminaux GSM, portables, organiseurs,
etc., d'un même utilisateur
· Les réseaux locaux, ou LAN (Local Area
Network), correspondent par leur taille aux réseaux intra-entreprises.
Ils servent au transport de toutes les informations numériques de
l'entreprise. En règle générale, les bâtiments
à câbler s'étendent sur plusieurs centaines de
mètres. Les débits de ces réseaux vont aujourd'hui de
quelques mégabits à plusieurs centaines de mégabits par
seconde.
· Les réseaux métropolitains, ou MAN
(Metropolitan Area Network), permettent l'interconnexion des entreprises ou
éventuellement des particuliers sur un réseau
spécialisé à haut débit qui est géré
à l'échelle d'une métropole. Ils doivent être
capables d'interconnecter les réseaux locaux des différentes
entreprises pour leur donner la possibilité de dialoguer avec
l'extérieur.
· Les réseaux régionaux, ou RAN
(Regional Area Network), ont pour objectif de couvrir une large surface
géographique. Dans le cas des réseaux sans fil, les RAN peuvent
avoir une cinquantaine de kilomètres de rayon, ce qui permet, à
partir d'une seule antenne, de connecter un très grand nombre
d'utilisateurs. Cette solution devrait profiter du dividende numérique,
c'est-à-dire des bandes de fréquences de la
télévisionanalogique, qui seront libérées
après le passage au tout-numérique, fin 2011 en France.
· Les réseaux étendus, ou WAN (Wide
Area Network), sont destinés à transporter des données
numériques sur des distances à l'échelle d'un pays, voire
d'un continent ou de plusieurs continents. Le réseau est soit terrestre,
et il utilise en ce cas des infrastructures au niveau du sol, essentiellement
de grands réseaux de fibre optique, soit hertzien, comme les
réseaux satellite.
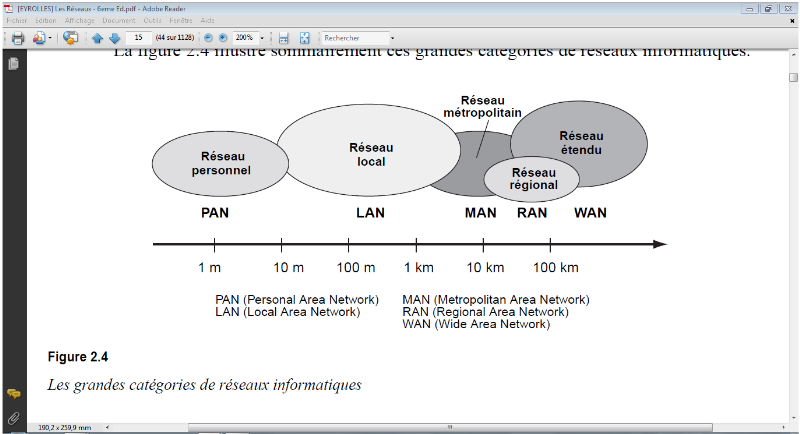
FIGURE IV-1 LES GRANDES
CATÉGORIES DE RÉSEAU INFORMATIQUE
Les techniques utilisées par les réseaux
informatiques proviennent toutes du transfert de paquets, comme le relais de
trames, Ethernet, IP (Internet Protocol), etc.
Une caractéristique essentielle des réseaux
informatiques, qui les différencie des autres catégories de
réseaux, est la gestion et le contrôle du réseau, qui sont
effectués par les équipements terminaux. Par exemple, pour qu'il
n'y ait pas d'embouteillage de paquets dans le réseau,
l'équipement terminal doit se réguler lui-même de
façon à ne pas inonder le réseau de paquets. Pour se
réguler, l'équipement terminal mesure le temps de réponse
aller-retour. Si ce temps de réponse grandit trop, le terminal ralentit
son débit. Cette fonctionnalité est rendue possible par
l'intelligencequi se trouve dans les machines terminales commercialisées
par l'industrie informatique.
Généralement beaucoup plus simple,
l'intérieur du réseau est constitué de noeuds de transfert
élémentaires et de lignes de communication. Le coût du
réseau est surtout supporté par les équipements terminaux,
qui possèdent toute la puissance nécessaire pour réaliser,
contrôler et maintenir les communications.
Les réseaux informatiques forment un environnement
asynchrone. Les données arrivent au récepteur à des
instants qui ne sont pas définis à l'avance, et les paquets
peuvent mettre un temps plus ou moins long à parvenir à leur
destinataire en fonction de la saturation du réseau. Cette
caractéristique explique la difficulté de faire passer de la
parole téléphonique dans ce type de réseau, puisque cette
application fortement synchrone nécessite de remettre au combiné
téléphonique des octets à des instants précis.
Aujourd'hui, le principal réseau informatique est
Internet. Le réseau Internet transporte des paquets dits IP (Internet
Protocol). Plutôt que de parler de réseau Internet, nous
préférons parler de réseau IP, qui marque une plus grande
généralité. Les réseaux IP sont des réseaux
qui transportent des paquets IP d'une machine terminale à une autre. En
un certain sens, Internet est un réseau IP particulier. D'autres
réseaux, comme les réseaux intranet, transportent
également des paquets IP, mais avec des caractéristiques
différentes l'Internet.
1.2 1.2 TOPOLOGIES DE
RESEAUX
Les réseaux grande distance, appelés aussi WAN
(Wide Area Network), relient plusieurscentaines de milliers, voire des
millions d'équipements terminaux sur un territoire nationalou à
l'international. Il n'est donc pas possible de partager le même support
de transmission,ni de raccorder directement deux abonnés désirant
communiquer. On crée unestructure de communication qui, en mettant bout
à bout des tronçons de lignes raccordéspar un ensemble de
commutateurs, réalise une connexion entre deux abonnés
d'unréseau ; on parle alors de réseau à
commutation. De ce fait, un réseau à commutation
fournitl'équivalent d'une liaison de données point à point
entre deux équipements terminauxquelconques abonnés au
réseau.
Des commutateurs, qui ont pour fonction de concentrer,
d'éclater et de rediriger les informations, relient les
équipements terminaux. Ils communiquent entre eux par des
circuitspoint à point, qui constituent les artères de
communication du réseau. On considère un réseau de
communication comme un graphe, où les noeuds représentent les
commutateurset les arcs figurent les circuits (quelquefois appelés
canaux, jonctions, lignes de transmissionou même liaisons, selon les
cas). La figure 1.2 montre la structure d'un réseau
àcommutation.
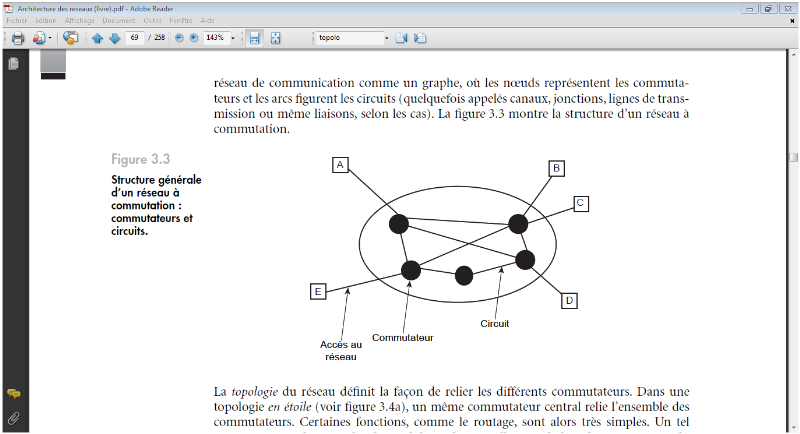
FIGURE IV-2 STRUCTURE GÉNÉRALE D'UN
RÉSEAUX À COMMUTATION : COMMUTATEURS ET CIRCUITS
La topologie du réseau définit la
façon de relier les différents commutateurs.
1.1.1. Topologie en
étoile
Dans unetopologie en étoile, un même
commutateur central relie l'ensemble descommutateurs. Chaque noeud est
relié directement sur un noeud central: l'information passe d'un noeud
périphérique au noeud central, celui-ci devant gérer
chaque liaison.Certaines fonctions, comme le routage, sont alors très
simples. Un telréseau est cependant très fragile car il
dépend essentiellement du bon fonctionnement ducommutateur central.
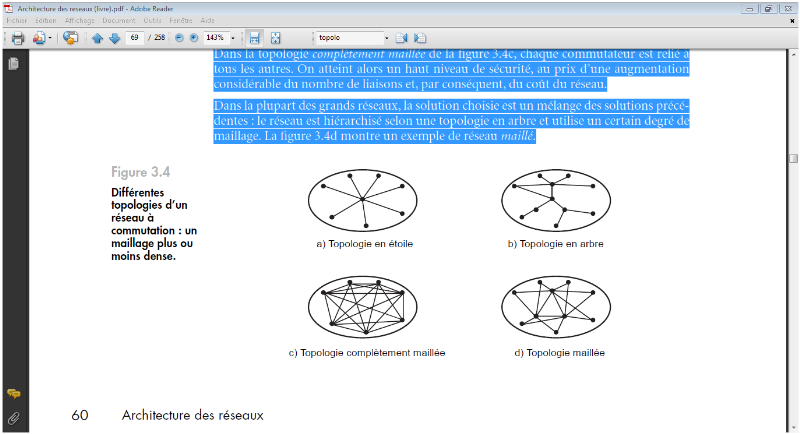
FIGURE IV-3 TOPOLOGIE EN ÉTOILE
1.1.2 Topologie en Arbre
La généralisation du cas
précédent, avec introduction d'une hiérarchie, donne la
topologieen arbre. Chaque commutateur est relié à un
ensemble de commutateursdu niveau inférieur. Dans les topologies en
arbre ou en étoile, il n'y a toujours qu'un cheminpossible entre deux
commutateurs : toute rupture de liaison entre eux empêche ledialogue
entre certains équipements terminaux.
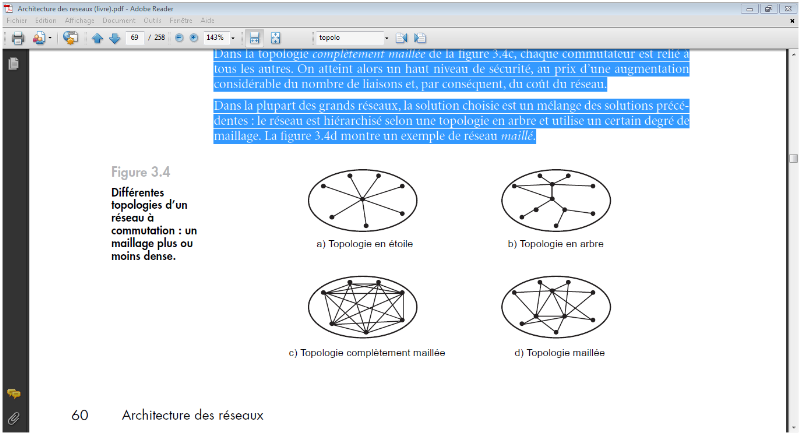
FIGURE IV-4 TOPOLOGIE EN ARBRE
1.1.3 Topologie
maillé
Dans la topologie complètement maillée,
chaque commutateur est relié àtous les autres. On atteint alors
un haut niveau de sécurité, au prix d'une
augmentationconsidérable du nombre de liaisons et, par
conséquent, du coût du réseau.Dans la plupart des grands
réseaux, la solution choisie est un mélange des solutions
précédentes: le réseau est hiérarchisé selon
une topologie en arbre et utilise un certain degré de maillage. La
figure 1.5 montre un exemple de réseau maillé.
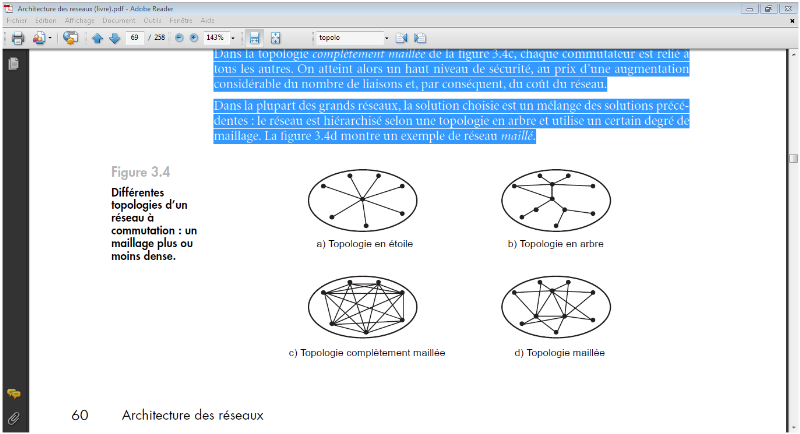
FIGURE IV-5 TOPOLOGIE MAILLÉ
1.1.4 Topologie en Anneau
Chaque noeud est relié au noeud suivant et au noeud
précédent et forme ainsi une boucle: l'information transite par
chacun d'eux et retourne à l'expéditeur.
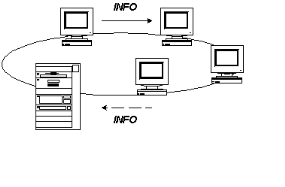
FIGURE IV-6 TOPOLOGIE EN ANNEAU
La fonction de routage prend une importance
particulière dans un réseau à commutationpuisqu'en
règle générale il n'y a pas de lien direct entre
équipements terminaux, mais unemultitude de chemins possibles qui
traversent plusieurs commutateurs et empruntent plusieursliaisons.
1.3 1.2
L'ARCHITECHTURE EN COUCHE
Du fait du grand nombre de fonctionnalités
implémentées dans les réseaux, l'architecture de ces
derniers est particulièrement complexe. Pour tenter de réduire
cette complexité, les architectes réseau ont
décomposé les processus à l'oeuvre dans les réseaux
en sept couches protocolaires plus un support physique. Un tel découpage
permet au réseau de traiter en parallèle les fonctions
attribuées aux différentescouches.
1.2.1. Le modèle de
référence
Les concepts architecturaux utilisés pour
décrire le modèle de référence à sept
couches proposé par l'ISO sont décrits dans la norme ISO 7498-1.
La figure 1.7 illustre cette architecture.
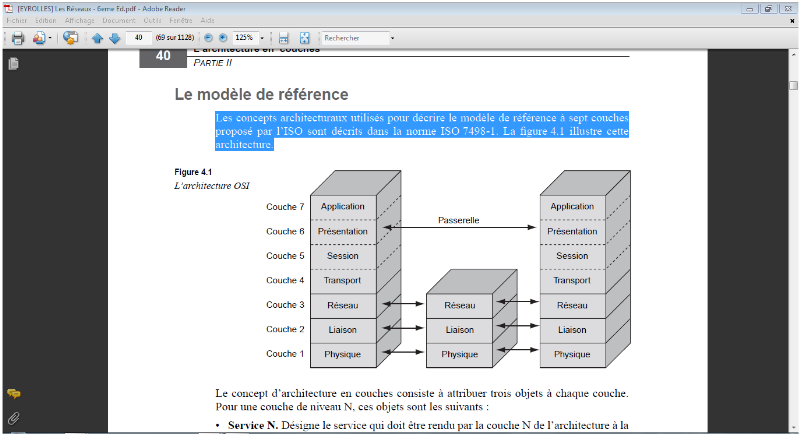
FIGURE IV-7 ARCHITECTURE OSI
1.2.2. Les couches du modèle de
référence
Le modèle de référence OSI comporte sept
niveaux, ou couches, plus un médium physique. Le médium physique,
que l'on appelle parfois couche 0, correspond au support physique de
communication chargé d'acheminer les éléments binaires
d'un point à un autre jusqu'au récepteur final. Ce médium
physique peut prendre diverses formes, allant du câble métallique
aux signaux hertziens, en passant par la fibre optique et l'infrarouge.
La Couche 1 (Niveau physique)
Le niveau physique correspond aux règles et
procédures à mettre en oeuvre pour acheminer les
éléments binaires sur le médium physique. On trouve dans
le niveau physique les équipements réseau qui traitent
l'élément binaire, comme les modems, concentrateurs, ponts, hubs,
etc.
Les différentes topologies de support physique
affectent le comportement du niveau physique. Dans les entreprises, les plans
de câblage ont une importance parfois déterminante pour le reste
de l'architecture). Le support physique nécessite de
surcroît un matériel fiable, et il faut parfois dupliquer ou
mailler le réseau pour obtenir des taux de défaillance
acceptables.
La Couche 2 (Niveau Trame)
La trame est l'entité transportée sur les lignes
physiques. Elle contient un certain nombre d'octets transportés
simultanément. Le rôle du niveau trame consiste à envoyer
un ensemble d'éléments binaires sur une ligne physique de telle
façon qu'ils puissent être récupérés
correctement par le récepteur. Sa première fonction est de
reconnaître, lors de l'arrivée des éléments
binaires, les débuts et fins de trame. C'est là, aujourd'hui, le
rôle principal de cette couche, qui a été fortement
modifiée depuis son introduction dans lemodèle de
référence.
Au départ, elle avait pour fonction de corriger les
erreurs susceptibles de se produire sur le support physique, de sorte que le
taux d'erreur résiduelle reste négligeable. En effet, s'il est
impossible de corriger toutes les erreurs, le taux d'erreur non
détectée doit rester négligeable. Le seuil à partir
duquel on peut considérer le taux d'erreur comme négligeable est
dépendant de l'application et ne constitue pas une valeur
intrinsèque.
Pour une communication téléphonique, un taux
d'erreur d'un bit en erreur pour mille bits émis ne pose pas de
problème, l'oreille étant incapable de déceler ces
erreurs. En revanche, lors du passage d'une valeur sur un compte bancaire, une
erreur en moyenne sur 1 000 bits peut devenir catastrophique. Dans ce cas, il
faut descendre à un taux d'erreur de 1018 bits, c'est-à-dire
d'une erreur en moyenne tous les 10-18 bits émis, ce qui
représente, sur une liaison à 1 Gbit/s, une erreur en moyenne
tous les deux cents jours ou, à la vitesse de 1 Mbit/s, une erreur tous
les cinq cents ans. On peut en conclure qu'un même support physique peut
être acceptable pour certaines applications et pas pour d'autres.
La solution préconisée aujourd'hui pour traiter
les erreurs est d'effectuer la correction d'erreur non plus au niveau trame
mais au niveau application. Pour chaque application, on peut déterminer
un taux d'erreur limite entre l'acceptable et l'inacceptable. Comme les
médias physiques sont de plus en plus performants, il est
généralement inutile de mettre en oeuvre des algorithmes
complexes de correction d'erreur. En fait, seules les applications pour
lesquelles un taux d'erreur donné peut devenir inacceptable doivent
mettre en place des mécanismes de reprise sur erreur.
La couche 2 comporte également les règles
nécessaires au partage d'un même support physique entre plusieurs
stations, par exemple lorsque la distance entre les utilisateurs est faible. La
vitesse du signal électrique étant de 200 m/ms, si un utilisateur
demande 20 ms pour envoyer son bloc d'information et que le réseau ait
une longueur de quelques centaines de mètres, il doit être seul
à transmettre, faut de quoi une collision des signaux se produit. Une
telle discipline d'accès est nécessaire dans les réseaux
partagés, mais aussi dans les réseaux locaux et certains
réseaux métropolitains.
Beaucoup de normes et de recommandations concernent la couche
2, dite aussi niveau liaison. Provenant de l'ISO, la norme HDLC a
été la première vraie norme à codifier les
procédures de communication entre ordinateurs et est encore largement
utilisée aujourd'hui. L'UIT-T a repris le mode équilibré,
dans lequel l'émetteur et le récepteur sont équivalents,
de la procédure HDLC pour son propre protocole LAP-B,
implémenté dans la norme X.25.2, de niveau 2. Les extensions
LAP-X, LAP-D, LAP-M et LAP-F, destinées à des canaux
spécifiques, comme le canal paquet du RNIS, ont également
été normalisées
Le niveau trame inclut toutes les techniques
nécessaires au label-switching, allant de l'ATM à l'Ethernet
commuté en passant par le relais de trames.
L'ISO a mis au point un ensemble de normes additionnelles de
niveau trame concernant les réseaux locaux, les méthodes
d'accès et les protocoles de liaison. Les principales de ces normes sont
les suivantes :
· ISO 8802.1 pour l'introduction des réseaux
locaux.
· ISO 8802.2 pour le protocole de niveau trame
(appelé procédure de ligne dans lanorme). Trois sous-cas sont
définis : LLC 1, LLC 2 et LLC 3, LLC (Logical LinkControl) étant
le nom de la procédure de niveau 2 pour les réseaux locaux.
· ISO 8802.3 pour l'accès CSMA/CD
(Ethernet).
· ISO 8802.4 pour l'accès par jeton sur un
bus.
· ISO 8802.5 pour l'accès par jeton sur une
boucle.
· ISO 10039 pour la définition du service
rendu par la méthode d'accès à un réseau local.
· ISO 10038 pour la définition d'une
passerelle de niveau 2 sur un réseau local.
La couche 3 (Niveau Paquet)
La couche 3, ou niveau paquet, peut aussi être
appelée couche réseau, puisque l'échange de paquets de
bout en bout donne naissance à un réseau. Le niveau paquet doit
permettre d'acheminer correctement les paquets d'information jusqu'à
l'utilisateur final. Pour aller de l'émetteur au récepteur, il
faut passer par des noeuds de transfert intermédiaires ou par des
passerelles, qui interconnectent deux ou plusieurs réseaux.
Un paquet n'est pas une entité transportable sur une
ligne physique, car si l'on émet les bits directement sur le support, il
n'est pas possible de détecter la limite entre deux paquets arrivant au
récepteur. Il y a donc obligation d'encapsuler les paquets dans des
trames pour permettre leur transport d'un noeud vers un autre noeud. Le niveau
paquet nécessite trois fonctionnalités principales : le
contrôle de flux, leroutage et l'adressage :
Dans la normalisation OSI, le standard de base du niveau
paquet est X.25. Ce protocole implique un mode commuté avec connexion.
Les paquets X.25 sont encapsulés dans des trames LAP-B pour être
émis sur les supports physiques. Le grand standard qui l'emporte
largement aujourd'hui est toutefois le protocole IP, normalisé par un
ensemble de RFC, qui définissent le protocole IP lui-même et
toutes ses extensions, allant de l'adressage au routage, en passant par les
méthodes de contrôle de flux.
La Couche 4 (Niveau Message)
Le niveau message prend en charge le transport du message de
l'utilisateur d'une extrémité à une autre du
réseau. Ce niveau est aussi appelé couche transport pour bien
indiquer qu'il s'agit de transporter les données de l'utilisateur. Il
représente le quatrième niveau de l'architecture, d'où son
autre nom de couche 4.
Le service de transport doit optimiser l'utilisation des
infrastructures sous-jacentes en vue d'un bon rapport qualité/prix. La
couche 4 optimise les ressources du réseau de communication en
gérant un contrôle de flux ou un multiplexage des messages de
niveau message sur une connexion réseau. Cette couche de transport est
l'ultime niveau qui s'occupe de l'acheminement de l'information. Elle permet de
compléter le travail accompli par les couches précédentes.
C'est grâce à elle que l'utilisateur obtient la qualité de
service susceptible de le satisfaire. Le protocole de niveau message à
mettre en oeuvre à ce niveau dépend du service rendu par les
trois premières couches et de la demande de l'utilisateur.
La couche 4 aujourd'hui la plus utilisée provient de
l'architecture du monde Internet et plus exactement de la norme TCP
(Transmission Control Protocol). Comme nous le verrons, une autre norme, UDP
(User Datagram Protocol), peut aussi être utilisée. La couche 4
inclut également les protocoles AAL (ATM Adaptation Layer),
normalisés pour l'architecture du monde ATM.
La Couche 5 (Niveau Session)
Le rôle du niveau session est de fournir aux
entités de présentation les moyens nécessaires à
l'organisation et à la synchronisation de leur dialogue. À cet
effet, la couche 5 fournit les services permettant l'établissement d'une
connexion, son maintien et sa libération, ainsi que ceux permettant de
contrôler les interactions entre les entités de
présentation.
Ce niveau est aussi le premier de l'architecture réseau
à se situer hors de la communication proprement dite. Comme son nom
l'indique, le niveau session a pour fonction d'ouvrir et de fermer des sessions
entre utilisateurs. Il est inutile d'émettre de l'information s'il n'y a
personne à l'autre extrémité pour récupérer
ce qui a été envoyé. Il faut donc s'assurer que
l'utilisateur que l'on veut atteindre, ou du moins son représentant, qui
peut être une boîte aux lettres électronique, par exemple,
est présent.
La couche 5 comporte des fonctionnalités rendant
possibles l'ouverture, la fermeture et le maintien de la connexion. Les mises
en correspondance des connexions de session et des connexions de transport sont
effectuées une à une.
De nombreuses autres possibilités peuvent être
ajoutées aux commandes de base, appelées primitives,
indispensables à la mise en place de la session. La pose de points de
resynchronisation, par exemple, est recommandée. Ils permettent, en cas
de problème, de disposer d'un point précis, sur lequel il y a
accord entre les deux parties communicantes, à partir duquel
l'échange peut redémarrer. La gestion des interruptions et des
reprises de session est également une fonctionnalité souvent
implémentée.
Pour ouvrir une connexion avec une machine distante, la couche
session doit posséder un langage qui soit intelligible par l'autre
extrémité. C'est pourquoi, avant d'ouvrir une session, il est
obligatoire de passer par le niveau présentation, qui garantit
l'unicité du langage, et le niveau application, qui permet de travailler
sur des paramètres définis d'une façon homogène.
La Couche 6 (Niveau Présentation)
Le niveau présentation se charge de la syntaxe des
informations que les entités d'application se communiquent. Deux aspects
complémentaires sont définis dans la norme :
· La représentation des données
transférées entre entités d'application.
· La représentation de la structure de
données à laquelle les entités se réfèrent
au cours de leur communication et la représentation de l'ensemble des
actions effectuées sur cette structure de données. En d'autres
termes, la couche présentation s'intéresse à la syntaxe
tandis que la couche application se charge de la sémantique. La couche
présentation joue un rôle important dans un environnement
hétérogène. C'est un intermédiaire indispensable
pour une compréhension commune de la syntaxe des documents
transportés sur le réseau. Les différentes machines
connectées n'ayant pas la même syntaxe pour exprimer les
applications qui s'y effectuent, si on les interconnecte directement, les
données de l'une ne peuvent généralement pas être
comprises de l'autre. La couche 6 procure un langage syntaxique commun à
l'ensemble des utilisateurs connectés.
Si Z est le langage commun, et si une machine X veut parler
à une machine Y, elles utilisent des traducteurs X-Z et Y-Z pour
discuter entre elles. C'est notamment le cas lorsque les machines X et Y ne
suivent pas la norme. Si toutes les machines terminales possèdent en
natif un langage syntaxique commun, les traductions deviennent inutiles.
La syntaxe abstraite ASN.1 (Abstract Syntax Notation 1)
normalisée par l'ISO est le langage de base de la couche
présentation. Fondée sur la syntaxe X.409 du CCITT, ASN.1 est une
syntaxe suffisamment complexe pour prendre facilement en compte les grandes
classes d'applications, comme la messagerie électronique, le transfert
de fichiers, le transactionnel, etc.
La Couche 7 (Niveau Application)
Le niveau application est le dernier du modèle de
référence. Il fournit aux processus applicatifs le moyen
d'accéder à l'environnement réseau. Ces processus
échangent leurs informations par l'intermédiaire des
entités d'application.
De très nombreuses normes ont été
définies pour cette couche, qui est décrites plus loin. En ce qui
concerne la définition de la couche même, c'est la norme ISO 9545,
ou CCITT X.207, qui décrit sa structure.
Le niveau application contient toutes les fonctions impliquant
des communications entre systèmes, en particulier si elles ne sont pas
réalisées par les niveaux inférieurs. Il s'occupe
essentiellement de la sémantique, contrairement à la couche
présentation, qui prend en charge la syntaxe.
Le niveau application a fortement évolué au
cours du temps. Auparavant, on considérait que la couche 7 devait
être découpée en sous-couches et qu'une communication
devait traverser l'ensemble des sous-couches, comme cela se passe dans les
couches 1 à 6. CASE (Common Application Service Elements) était
un des sous-niveaux contenant les différents services de communication
nécessaires aux applications les plus utilisées. En
réalité, certaines applications ne faisaient pas appel aux
fonctionnalités de CASE oudevaient faire des allers-retours entre les
couches du niveau application. De plus, les normalisations des
différentes applications ayant démarré en
parallèle, la cohérence entre les divers développements
était approximative.
Le concept de base de la couche application est le processus
applicatif, ou AP (Application Process), qui regroupe tous les
éléments nécessaires au déroulement d'une
application dans les meilleures conditions possibles. L'entité
d'application, ou AE (Application Entity), est la partie du processus
d'application qui prend en charge la gestion de la communication pour
l'application.
L'entité d'application fait appel à des
éléments de service d'application, ou ASE (Application Service
Element). L'entité contient un ou plusieurs ASE. En règle
générale, plusieurs ASE sont nécessaires pour
réaliser un travail, et certains sont indispensables à la mise en
place de l'association entre les entités d'application.
Tableau récapitulatif
Voici un tableau récapitulatif du modèle de
référence OSI.
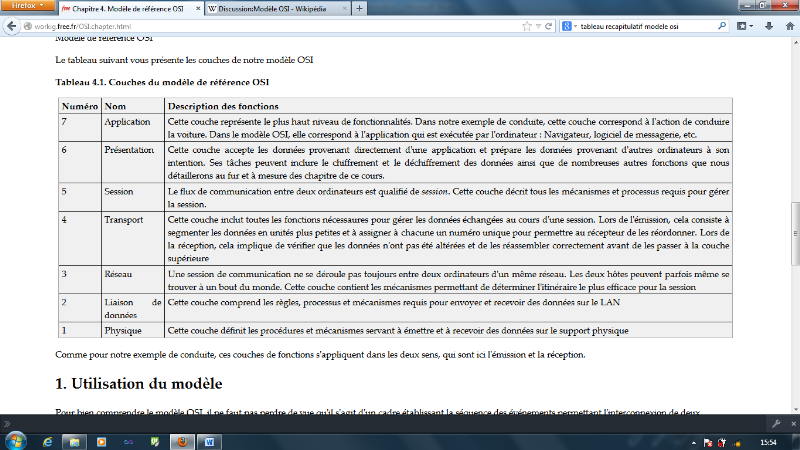
TABLEAU IV-1 LE MODÈLE OSI
Ce tableau donne une description avec certains protocoles
connus et leurs couches ou ils s'exécutent
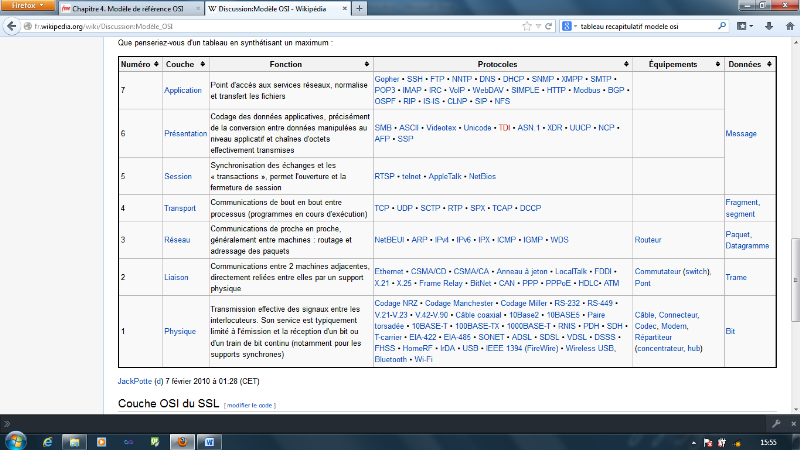
TABLEAU IV-2 LE MODÈLE OSI
DÉTAILLÉ
1.4 1.3 LES RESEAUX
IP
1.3.1 Architecture IP
L'architecture IP repose sur l'utilisation obligatoire du
protocole IP, qui a pour fonctions de base l'adressage et le routage des
paquets IP. Le niveau IP correspond exactement au niveau paquet de
l'architecture du modèle de référence.
Au-dessus d'IP, deux protocoles ont été choisis,
TCP et UDP. Ces protocoles correspondent au niveau message du modèle de
référence. En fait, ils intègrent une session
élémentaire, grâce à laquelle TCP et UDP prennent en
charge les fonctionnalités des couches 4 et 5. La principale
différence entre eux réside dans leur mode, avec connexion pour
TCP et sans connexion pour
UDP. Le protocole TCP est très complet et garantit une
bonne qualité de service, en particulier sur le taux d'erreur des
paquets transportés. En revanche, UDP est un protocole sans connexion,
qui supporte des applications moins contraignantes en matière de la
qualité de service.
La couche qui se trouve au-dessus de TCP-UDP regroupe les
fonctionnalités des couches 6 et 7 du modèle de
référence et représente essentiellement le niveau
application.
1.3.2 Fonctionnement des
réseaux IP
La plupart des réseaux sont des entités
indépendantes, mises en place pour rendre service à une
population restreinte. Les utilisateurs choisissent des réseaux
adaptés à leurs besoins spécifiques, car il est impossible
de trouver une technologie satisfaisant tous les types de besoins. Dans cet
environnement de base, les utilisateurs qui ne sont pas connectés au
même réseau ne peuvent pas communiquer. Internet est le
résultat de l'interconnexion de ces différents réseaux
physiques par des routeurs. Les interfaces d'accès doivent respecter
pour cela certaines conventions. C'est un exemple d'interconnexion de
systèmes ouverts.
Pour obtenir l'interfonctionnement de différents
réseaux, la présence du protocole IP est obligatoire dans les
noeuds qui assurent le routage entre les réseaux. Globalement, Internet
est un réseau à transfert de paquets. Ces paquets traversent un
ou plusieurs sous réseaux pour atteindre leur destination, sauf bien
sûr si l'émetteur se trouve dans le même sous-réseau
que le récepteur. Les paquets sont routés dans des passerelles
situées dans les noeuds d'interconnexion. Ces passerelles sont des
routeurs. De façon plus précise, les routeurs transfèrent
des paquets d'une entrée vers une sortie, en déterminant pour
chaque paquet la meilleure route à suivre.
Internet est un réseau routé, par opposition aux
réseaux X.25 ou ATM, qui sont des réseaux commutés. Dans
un réseau routé, chaque paquet suit sa propre route, qui est
à chaque instant optimisée, tandis que, dans un réseau
commuté, la route est toujours la même.
L'adressage IPv4 et IPv6
Comme Internet est un réseau de réseaux,
l'adressage y est particulièrement important.
Cette section donne un premier aperçu des
problèmes d'adressage au travers du protocole IP de première
génération IPv4 et de la nouvelle génération
IPv6.
Les machines d'Internet ont une adresse IPv4
représentée sur un entier de 32 bits.
L'adresse est constituée de deux parties : un
identificateur de réseau et un identificateur de la machine pour ce
réseau. Il existe quatre classes d'adresses, chacune permettant de coder
un nombre différent de réseaux et de machines :
· classe A : 128 réseaux et 16 777 216
hôtes (7 bits pour les réseaux et 24 pour les hôtes) ;
· classe B : 16 384 réseaux et 65 535
hôtes (14 bits pour les réseaux et 16 pour les hôtes) ;
· classe C : 2 097 152 réseaux et 256
hôtes (21 bits pour les réseaux et 8 pour les hôtes) ;
· classe D : adresses de groupe (28 bits pour les
hôtes appartenant à un même groupe).
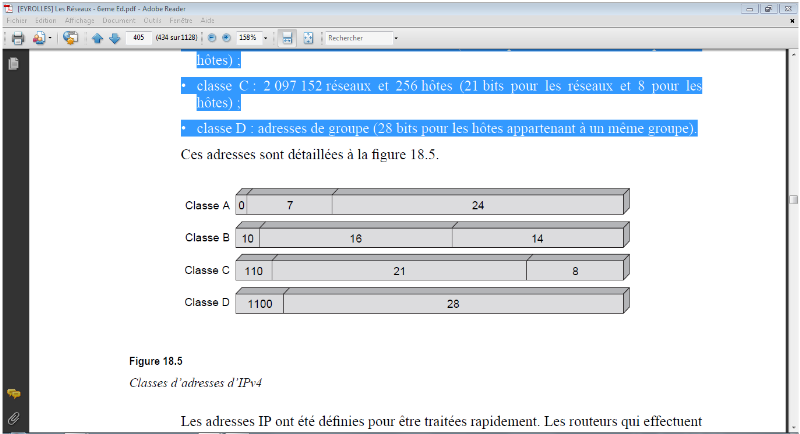
FIGURE IV-8 CLASSE D'ADRESSAGE IPV4
Les adresses IP ont été définies pour
être traitées rapidement. Les routeurs qui effectuent le routage
en se fondant sur le numéro de réseau sont dépendants de
cette structure. Un hôte relié à plusieurs réseaux a
plusieurs adresses IP. En réalité, une adresse n'identifie pas
simplement une machine mais une connexion à un réseau.
Pour assurer l'unicité des numéros de
réseau, les adresses Internet sont attribuées par un organisme
central, le NIC (Network Information Center). On peut également
définir ses propres adresses si l'on n'est pas connecté à
Internet. Il est toutefois vivement conseillé d'obtenir une adresse
officielle pour garantir l'interopérabilité dans le futur.
Comme l'adressage d'IPv4 est quelque peu limité, il a
fallu proposer une extension pour couvrir les besoins des années 2 000.
Cette extension d'adresse est souvent présentée comme la raison
d'être de la nouvelle version d'IP, alors qu'il ne s'agit que d'une
raison parmi d'autres.
L'adresse IPv6 tient sur 16 octets. Le nombre d'adresses
potentielles autorisées par IPv6 dépasse 1023 pour chaque
mètre carré de la surface terrestre. La difficulté
d'utilisation de cette immense réserve d'adresses réside dans la
représentation et l'utilisation rationnelle de ces 128 bits. La
représentation s'effectue par groupe de 16 bits et se présente
sous la forme suivante :
123 : FCBA : 1024 : AB23 : 0 : 0 : 24 : FEDC
Des séries d'adresses égales à 0 peuvent
être abrégées par le signe :: , qui ne peut
apparaître qu'une seule fois dans l'adresse. En effet, ce signe
n'indiquant pas le nombre de 0 successifs, pour déduire ce nombre en
examinant l'adresse, les autres séries ne peuvent pas être
abrégées.
L'adressage IPv6 est hiérarchique. Une allocation des
adresses (c'est-à-dire une répartition entre les potentiels
utilisateurs) a été proposée, dont le tableau 1.3 fournit
le détail.
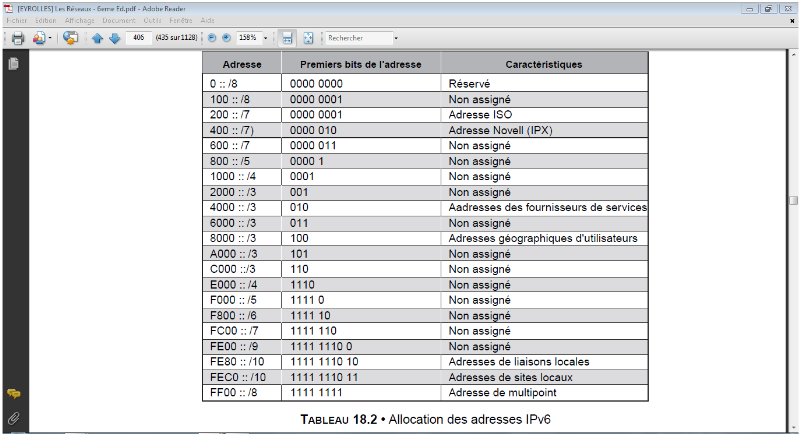
TABLEAU IV-3 ALLOCATION DES ADRESSE IPV6
DNS (Domain Name System)
Nous avons vu que les structures d'adresses étaient
complexes à manipuler, car elles se présentent sous forme de
groupes de chiffres décimaux de type abc : def : ghi : jkl,
avec une valeur maximale de 255 pour chacun des quatre groupes. Les
adresses IPv6 tiennent sur 8 groupes de 4 chiffres décimaux. La saisie
de telles adresses dans le corps d'un message deviendrait vite insupportable.
C'est la raison pour laquelle l'adressage utilise une structure
hiérarchique complètement différente, beaucoup plus simple
à manipuler et à mémoriser.
Le rôle du DNS est de permettre la mise en
correspondance des adresses physiques dans le réseau et des adresses
logiques. La structure logique est hiérarchique et utilise au plus haut
niveau des domaines caractérisant principalement les pays, qui sont
indiqués par deux lettres, comme frpour la France, et des
domaines fonctionnels comme :
· com: organisations commerciales ;
· edu: institutions académiques ;
· org: organisations, institutionnelles ou
non ;
· gov: gouvernement américain ;
· mil : organisations militaires
américaines ;
· net : opérateurs de réseau
;
· int: entités internationales.
À l'intérieur de ces grands domaines, on trouve
des sous-domaines, qui correspondent à de grandes entreprises ou
à d'importantes institutions. Par exemple, rpreprésente
le nom de l'équipe travaillant dans le domaine des réseaux et des
performances du laboratoire LIP6 de l'Université Paris VI, ce qui donne
l'adresse rp.lip6.fr pour le personnel de cette équipe au sein
du laboratoire.
Pour réaliser cette opération de traduction, le
monde IP utilise des serveurs de noms, c'est-à-dire des serveurs pouvant
répondre à des requêtes de résolution de nom ou
encore être capables d'effectuer la traduction d'un nom en une adresse.
Les serveurs de noms d'Internet sont les serveurs DNS. Ces serveurs sont
hiérarchiques. Lorsqu'il faut retrouver l'adresse physique IP d'un
utilisateur, les serveurs qui gèrent le DNS s'envoient des
requêtes de façon à remonter suffisamment dans la
hiérarchie pour trouver l'adressephysique du correspondant. Ces
requêtes sont effectuées par l'intermédiaire de
petitsmessages, qui portent la question et la réponse en retour.
La figure I.9 illustre le fonctionnement du DNS. Le client
guy.pujolle@reseau.lip6.fr
veut envoyer un message à xyz.xyz@systeme.lip6.fr.
Pour déterminer l'adresse IP de xyz.xyz@systeme.lip6.fr,
une requête est émise par le PC de Guy Pujolle, qui interroge
le serveur de noms du domaine réseau.lip6.fr. Si celui-ci a en
mémoire la correspondance, il répond au PC. Dans le cas
contraire, la requête remonte dans la hiérarchie et atteint le
serveur de noms de lip6.fr, qui, de nouveau, peut répondre
positivement s'il connaît la correspondance. Dans le cas contraire, la
requête est acheminée vers le serveur de
nomsdesysteme.lip6.fr, qui connaît la correspondance. C'est donc
lui qui répond au PC de départ.
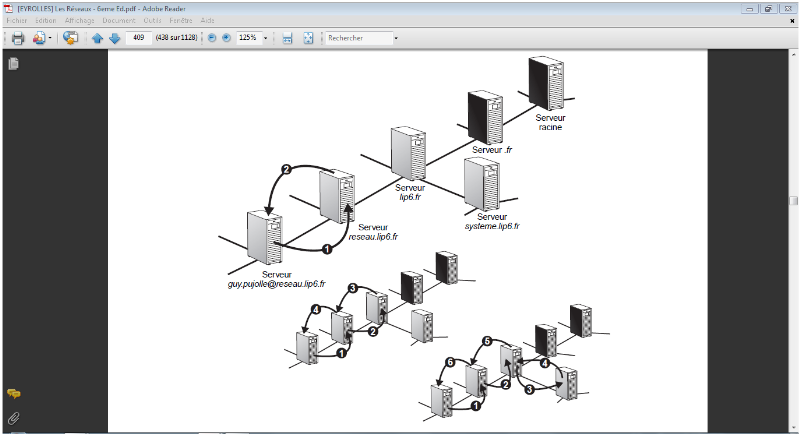
FIGURE IV-9 FONCTIONNEMENT DU DNS
Les deux premiers octets contiennent une
référence. Le client choisit une valeur à placer dans ce
champ, et le serveur répond en utilisant la même valeur, de sorte
que le client reconnaisse sa demande. Les deux octets suivants contiennent les
bits de contrôle. Ces derniers indiquent si le message est une
requête du client ou une réponse du serveur, si une demande
à un autre site doit être effectuée, si le message a
été tronqué par manque de place, si le message de
réponse provient du serveur de noms responsable ou non de l'adresse
demandée, etc. Pour le récepteur qui répond, un code de
réponse est également inclus dans ce champ.
Les six possibilités suivantes ont été
définies :
· 0 : pas d'erreur.
· 1 : la question est formatée de façon
illégale.
· 2 : le serveur ne sait pas répondre.
· 3 : le nom demandé n'existe pas.
· 4 : le serveur n'accepte pas la demande.
· 5 : le serveur refuse de répondre.
La plupart des requêtes n'effectuent qu'une demande
à la fois. Dans la zone Question, le contenu doit être
interprété de la façon suivante : 6 indique que 6
caractères suivent ; après les 6 caractères de
réseau, 4 désigne les 4 caractères de lip6, 2 les
deux caractères de fret enfin 0 la fin du champ.
Le champ Autorité permet aux serveurs qui ont
autorité sur le nom demandé de se faire connaître. La zone
Champs supplémentaires permet de transporter des informations sur le
temps pendant lequel la réponse à la question est valide.
1.5 1.4 L'INTRANET
Un intranet est un réseau informatique utilisé
à l'intérieur d'une entreprise ou de toute autre entité
organisationnelle qui utilise les mêmes protocoles qu'Internet (TCP, IP,
HTTP, SMTP, IMAP, etc...). Parfois, leterme se réfère uniquement
au site web interne de l'organisation, mais c'est souvent une partie bien
plusimportante de l'infrastructure informatique d'une organisation. Dans les
grandes entreprises, l'intranet fait l'objetd'une gouvernance
particulière en raison de sa pénétration dans l'ensemble
des rouages des organisations, et de lasécurité nécessaire
à sa circonscription à l'entreprise. Les grands chantiers de
l'intranetisationdes entreprises sont :
- La rapidité des échanges de données qui
engendre une diminution des coûts de gestion
- L'accessibilité des contenus et services
- L'intégration des ressources
- La rationalisation des infrastructures.
Le concept d'intranet rejoint de plus en plus les projets de
Poste de travail. Pour répondre aux besoins des utilisateurs dans leurs
situationsde travail professionnelles, l'intranet doit être conçu
selon trois principes fondamentaux:
- Toutes les ressources informatiques doivent être
référencées et rendues accessibles aux ayants droit
à partir d'un serveur Web. chaque ressource doit être
associée à un groupe d'utilisateurs habilités d'une part
et à un profil d'intérêt d'autre part.
- Tout utilisateur doit être identifié et
authentifié dans un seul référentiel (ou annuaire
d'entreprise LDAP) pour l'accès à l'ensemble des ressources
;dès l'authentification assurée, l'intranet doit être en
mesure de propager la session de l'utilisateur pendant toute son
activité sans qu'il ait besoin des'identifier à nouveau.
- Des mécanismes de mises en avant (profiling)
et d'alertes doivent être mises en place pour pousser l'information
pertinente vers l'utilisateur etrendre ainsi plus efficace l'utilisation des
ressources.
Les projets intranet sont devenus au fil du temps de
véritables projets de systèmes d'information et plus seulement
des outils de communication interne.
Selon Indus Khaitan un "Writable Intranet" est similaire au
concept de l'entreprise 2.0, ainsi des moteurs wiki comme MediaWiki en rendant
éditablel'intranet peuvent devenir une composante du Web 2.0 dans
l'entreprise
1.4.1 Architecture
Généralement, un réseau intranet
possède une architecture clients/serveur(s) n tiers qui repose
sur tout ou partie des composants suivants :
- Serveur(s) de fichiers, NAS, SAN (pour le partage des
données)
- Serveur(s) http de l'intranet (semblable(s) à un
serveur web)
- Serveur(s) de bases de données (pour le stockage des
informations)
- Serveur(s) de messagerie (pour l'échange de courriers
électroniques ou la messagerie instantanée)
- Serveur(s) d'authentification (pour l'identification des
utilisateurs et le stockage des annuaires)
- Serveur(s) et logiciel client de supervision
réseau/systèmes (le protocole SNMP est généralement
utilisé pour obtenir des informations sur le statut desdifférents
composants du réseau
- Serveur(s) de vidéoconférence
- Switches, routeurs, parefeu(éléments
de l'infrastructure)
L'intranet d'une entreprise héberge souvent son
système d'information.
Il est généralement indépendant et hors
« zone démilitarisée » (DMZ), et au cas
où il est connecté au réseau mondial Internet cela doit
être fait via une oudes passerelle(s) et surtout un ou des
parefeu(firewall) qui l'isolent sur le plan de la
sécurité.
Les fonctionnalités offertes aux utilisateurs d'un
intranet ont tendance à être rassemblées via un portail web
(qui s'affiche dans un navigateur web,comme Firefox, Internet Explorer, Opera
ou encore Google Chrome).
Le partage et stockage des fichiers sur un intranet s'effectue
de façon privilégiée sur un CMS, un NAS (Network
Attached Storage) ou SAN (StorageArea network) ou encore via
WebDAV qui formera une partie dédiée du réseau interne.
1.4.2. Intranet et
entreprise
1.4.2.1 Objectifs
Nous remarquons que les informations et les services proposes
majoritairement par un intranet se regroupent en quatre types
d'activités : s'informer, travailler, échanger et se former, il
s'avère que ces activités prennent forme au travers d'intranets
proposant des fonctionnalités différentes. Selon les
résultats de l'enquête menée par l'Observatoire de
l'Intranet, deux grands types de sites intranet se détachent
foncièrement : les intranets d'information et de communication
etles intranets de collaboration
- L'intranet d'information et de
communication (ou standards, ou communiquant) : il donne
accès à l'ensemble des documents et informations à tous
les collaborateurs de l'entreprise. C'est « l'outil de communication
» de l'entreprise, c'est-à-dire qui permet de faire circuler
l'information entre individus, au sein d'un groupe, entre différents
services, ou parfois vers l'extérieur. il est supposé
améliorer la circulation de l'informant et la recherche d'informations
stratégiques via des applications de messagerie, de forum, de
publication d'informations générales sur le réseau.
- L'intranet de collaboration (ou
collaboratif, ou managérial) : il propose des
propose des applications favorisant le travail et les échanges de
groupe. Il est davantage destine à partager des données davantage
orientées métier, il se caractérise ainsi par
l'appartenance à une communauté professionnelle et trouve ses
applications principalement dans le « groupeware », le
« workflow ». la mutualisation des connaissances,
intelligence économique ou le e-learning.
L'enquête del'Observatoire de l'intranetconclut
que les fonctions d'information et de communication transversales, c'est-a-dire
ouvertes à tous, sont largement majoritaires. Etes se stabilisent alors
que dans le même temps, les applications de collaboration progressent ce
qui vient confirmer l'orientation actuelle vers l'intégration des outils
en réseau et des fonctionnalités collaboratives.
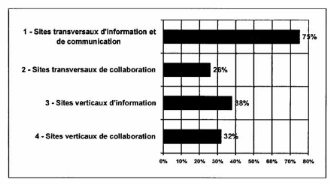
TABLEAU IV-4 POURCENTAGES DES CATÉGORIES DES
INTRANET
Mais Il nous semble que cette distinction n'est pas aussi
nette dans la réalité. En effet un intranet communiquant peut
proposer des applications de « groupeware » par exemple,
dites pourtant collaboratives. Les frontières ne sont pas si franches.
En effet, il apparaît clairement que les objectif des intranets varient
d'une entreprise àl'autre et offre des fonctionnalités
différentes a ses utilisateurs.
De plus, les technologies intranet donnent la
possibilité de construire un système d'information
évolutif. a la cartenous expose comment différents composants
peuvent être implantes en fonction de besoins spécifiques. Cette
approche modulaire permet ainsi de développer son intranet
progressivement et véritablement en fonction de ses besoins.
Les spécificités des intranets naissent ainsi
des origines organisationnelles du projet et sa mise en oeuvre nécessite
de prendre en compte un certain nombre des facteurs
propresal'organisation. Certains intranets seront plus axes
sur respect informationnel, d'autres cibleront des applications
particulières pour améliorer la profitabilité de
l'entreprise.
1.4.2.2. Impacts organisationnels
Les intranets sont à présent en phase de
croissance etil est possible de commencer à mesurer l'impact d leur
implantation sur les organisations, en terme structurelle et humain. Ils
revêtent des formes et apparences variées s'adaptant au secteur
d'activité, à la culture de l'entreprise et à ses choix
stratégiques.
En effet, il est essentiel de souligner qu'un intranet se
démarque par son implantation dans les organisations et son impact dans
leurs structures. « l'intranet correspond moins a une technologie
qu'a l'émergence eta l'articulations de processus liant variables
technologiques et organisationnelles ». L'intranetinteragit avec
les utilisateurs qui doivent s'approprier de nouveau mode de fonctionnement,
provoquant des changements dans les habitudes de travail.
Nous savons qu'une entreprise est de nos jours de plus en plus
souvent confronté a des changements technologiques ou
organisationnelles. Or, la mise en place d'un nouvel outil comme l'intranet va
générer un certain nombre de modifications dans la gestion
globale de l'information et bouleverser les habitudes de travail des
salariés, entrainant parfois une modification des processus de
l'entreprise. Certains auteurs vont jusqu'à dire que les systèmes
intranet influence la performance de l'organisation de l'entreprise et sa
culture interne. Quoi qu'il en soit,il touche certainement toutes les fonctions
de l'entreprise et l'ensemble de ses métiers
Chapitre 2 GESTION DES
UTILISATEURS
1.6 2.1
INTRODUCTION
La gestion des utilisateurs et des droits d'accès
(souvent connu sous l'acronyme IAM. pour Identity and Access Management) est un
maillon clé dans la chaîne de sécurité des
organisations. Elle permet de renforcer le niveau de sécurité
général en garantissant la cohérence dans l'attribution
des droits d'accès aux ressources hétérogènes du
système d'information.
La gestion des utilisateurs et des droits d'accès est
également devenue l'un des moyens majeurs permettant de répondre
aux exigences réglementations de plus en plus fréquentes
concernant la traçabilité. C'est aussi un moyen d'optimiser
l'administration des droits.
Mais qu'entend-on exactement par gestion des utilisateurs et
des droits d'accès ?
La gestion des utilisateurs consiste à gérer le
cycle de vie des personnes (embauche, promotion mutation, départ. etc.)
au sein de la société et les impacts induits sur le
système d'information (création de Comptes utilisateurs,
attribution de Profils utilisateurs, mise en oeuvre du contrôle
d'accès, etc.) Cette gestion des utilisateurs doit pouvoir être
faite d'un point de vue fonctionnel par des non-informaticiens (exemple :
Ressources Humâmes. Maîtrise d'ouvrage, l'utilisateur
lui-même) et d'un point de vue technique par des informaticiens (exemple
: administrateur. Maitrise d'oeuvre). La solution de gestion des utilisateurs
doit être une solution globale sur la base d'une infrastructure
centralisée avec une gestion fonctionnelle distribuée et qui
intègre les fonctionnalités suivantes :
· la gestion du référentiel central des
utilisateurs (alimentation a partir de référentiels utilisateurs
sources).
· la gestion du référentiel central des
ressources concernées par la gestion des droits d'accès.
· la gestion des habilitations; (gestion des Profils.
Rôles, gestion des utilisateur;,workflow).
· le provisioning (synchronisation des
référentiels cibles de se ointe).
· administration décentralisé
· auto-administration gestion par les utilisateurs des
mots de passe et des données privées.
· l'audit et le reporting.
· le contrôle d'accès (authentification
autorisation).
1.7 2.2. QUELQUES
CONCEPTS
Cette partie du chapitre introduit quelques concepts
couramment utilisé dans les entreprises, en l'absence de
standardisation, ces concepts sont définis du retour
d'expériences.
2.2.1. Personne
(Utilisateur)
Désigne une personne physique : les employés
d'entreprise, les prestataires, les partenaires et les clients de l'entreprise
qui, de par leur fonction, exercent une activée ayant vocation à
leur permettre de bénéficier des applications et des ressources
mises à disposition par l'entreprise.
Toute personne déclarée dans un
référentiel central de sécurité et de gestion des
habilitations est identifiée par un identifiant unique.
Des attributs supplémentaires fournissent les
informations concernant la personne. Ces attributs sont :
· un nom.
· un prénom
· une durée de validité.
· un état (actif, suspendu).
· les périmètres d'accès
autorisés.
· un niveau de confidentialité (par domaine
d'activité).
Etc.
Tout acteur du système est déclaré d'une
maniéré unique dans un référentiel central de
sécurité et de gestion des habilitations en tant que personne
physique et peut disposer de comptes dans différents environnement; et
applications en fonction des habilitations accordées.
La cohérence de ces information est maintenue
automatiquement par le système de gestion de: habilitations.
D'une manière générale les autorisations
ne sont pas attribuées directement aux personnes mais à travers
des profils rôles. Certaines autorisations particulières peuvent
être associées à la personne physique Elles sont
limitées aux autorisations d'accès global au SI d'entreprise
comme limitation temporelle ou géographique d'ouverture de session ou
suspension générale d'accès.
2.2.2. Compte
A chaque personne peuvent être associés des
comptes d'accès aux différents systèmes et applications
Le compte est défini par l'identifiant d'accès,
un mot de passe (ou un authentifiant d'une aune nature), et plusieurs attributs
supplémentaires en fonction de l'environnement dans lequel il est
créé comme : la politique de mot de passe associée,
l'accès externe autorise ou non, l'état du compte, les modes
d'authentification autorisé etc.
Il existe quatre types de comptes :
· le compte global Ce compte, unique
(à un utilisateur correspond un seul compte) identifie une personne dam
le référentiel central de gestion des habilitations et est
utilisé par tous les processus d'attribution des droits.
· le compte utilisateur Ce compte donne
l'accès à un utilisateur dans un environnement particulier auquel
cet utilisateur est habilite. Chaque compte utilisateur est obligatoirement
associe à une personne (et son identifiant unique). Sa création
suppression et la cohérence des informations associées est
maintenue automatiquement par le système de gestion des habilitations en
fonction des profils métiers attribues à la personne. Exemples :
compte d'OS. de NOS. de messagerie, de groupware. de LDAP. etc. Les
administrateurs locaux peuvent créer des comptes utilisateur uniquement
dans les cas exceptionnels (exemples : audit de plateforme, intervention
technique d'urgence. ...). Une procédure de «
réconciliation » doit être appliquée ensuite pour
définir les liens entre ce compte et la personne.
· le compte d'administration Ce compte
donne l'accès a un administrateur dam un environnement particulier. Ce
compte n'est pas associé à une personne E ne correspond donc
à aucune entrée dans le référentiel central.
Leur usage doit être limité aux actes d'administration techniques
des environnements et des applications dans les environnements où ces
tâches ne peuvent pas être effectuées via les rôles
d'administration Exemple : Compte « Root » d'Unix Les
procédures mises en oeuvre doivent garants- la traçabilité
et l'auditabilité des personnes physiques auxquelles ces comptes
administrateurs ont été autorisés d'emploi Un changement
d'affectation doit être associe a une procédure de changement des
mots de passe
· le compte « de service fonctionnel
on technique » Ces comptes sont utilisés par les
composants d'un système pour accéder aux services applicatifs et
ou données d'un autre système. La connexion au système
cible, utilisant ce compte, doit être authentifiée ou seulement
identifiée si la liaison se fart intégralement dans une zone
sécurisée Le compte est donc associé au système ou
application cliente et non à une personne. Aucune personne n'est
autorisée à l'utiliser. Les permissions sont définies et
gérées dans le cadre d'administration d'application et ne sont
pas prises en charge par le système de gestion des habilitations. Les
droits attribues à ce compte doivent être restreints au strict
minimum et n'autoriser que les fonctions invoquées Le système de
nommage adopte devrait différencier clairement ce type de comptes
Un compte unique (dans un environnement) est associé
à une et une seule personne à l'instant T (a l'exception de:
compte: d'administration et technique;).
À un compte peuvent être associés (en
fonction de la capacité de gestion de l'environnement) :
· une durée de validité.
· un état (actif, suspendu).
Etc.
2.2.3. Rôles
Un rôle définit les permissions
nécessaires à l'utilisation des objets (applications et ou des
ressources)
Le rôle applicatif est un ensemble de droits propres
à une seule fonction dans une application Par exemple : le droit d'usage
d'un jeu d'écrans et de menus correspondant a une fonction dans
l'application.
Une habilitation donne à un utilisateur un ensemble de
permissions dans une application. Elle est attribuée en fonction du
poste opérationnel au sein de l'organisation et non a titre individuel.
C'est le poste opérationnel qui détermine les rôles et les
périmètres nécessaires.
L'habilitation est affectée à la personne via
l'attribution des rôles applicatifs :
· un rôle applicatif appartient à une seule
application
· l'application admet plusieurs rôles.
· un rôle ne peut pas être affecté
directement à l'utilisateur mais uniquement par l'intermédiaire
d'un profil mener.
· sont associés au concept de rôle :
o les modes d'authentification autorisés,
o les périmètres d'accès
autorisés,
o la cardinalité (nombre d'occupants maximum
autorisés),
o la séparation statique des pouvoirs (rôles
interdits de cohabitation).
2.2.4. Profils
Pour faciliter la gestion des habilitations, il est courant de
lier l'attribution d'un ensemble d'habilitations à l'obtention d'un
profil « fonctionnel ».
Un profil fonctionnel regroupe un ensemble de rôles
nécessaires à l'exécution d'une fonction métier. Ce
profil peut également être vu comme un package de rôles
applicatifs ou un niveau supérieur dans la hiérarchie des
rôles. Un utilisateur peut avoir un ou plusieurs profils fonctionnels.
Le profil d'habilitation, auquel sont rattaches, via les
rôles, les droits d'accès aux applications, est
déterminé par le poste opérationnel. A chaque poste est
associé un ou plusieurs profils d'habilitation.
Le profil correspond généralement a la fonction
exercée par l'acteur affecté au poste opérationnel ainsi
qu'à son niveau d'expertise. Il peut aussi correspondre à un
ensemble d'habilitations spécifiques.
Dans le but d'optimisation de gestion des profils, on pourra
ajouter des profils utilisateur; dit de « factorisation » :
· profil « général » :
décrit l'accès standard messagerie, pages jaunes, pages blanches,
etc.
· profil « métier » : décrit
l'ensemble des services accédés en standard par une personne
appartenant à un métier de l'entreprise
Ainsi une personne pourra être associée à
plusieurs profils utilisateur : profil général. profil(s)
métier(s).
2.2.5.
Le poste opérationnel
Le poste opérationnel (position de travail) correspond
à une fonction métier exercée au sein d'un
élément de structure (service, département..). Un poste
opérationnel est toujours défini au sein d'un et un seul
élément de structure. Le responsable de structure indique les
postes qui lui sont attribués
Un poste peut éventuellement être partagé
par plusieurs acteurs Le poste opérationnel n'est pas
modélisé dans le référentiel central.
2.2.6. Groupe
Les utilisateurs peuvent être regroupés, dans le
référentiel central en groupes statiques ou dynamiques Ces
groupes sont utilisés pour faciliter la gestion en masse des
habilitations
2.2.7.
Périmètre
Le périmètre est utilisé par les
applications et ou systèmes pour affiner le contrôle
d'autorisation qu'ils réalisent
Le périmètre peut avoir trois types
différents (temporel, géographique et fonctionnel) et être
associe à :
· une personne
· un compte (uniquement dans le cas de limitation des
autorisations d'accès à des ressources d'un environnement)
· un rôle
Il ne peut pas être associé à un profil
2.2.8. Périmètre
temporel
Le périmètre temporel permet de restreindre les
possibilités d'accès d'un utilisateur dans le temps.
Plusieurs types de restrictions sont possibles :
· Période :
o définis par : -Date début - Date fin''.
o l'accès n'est autorisé que si la date du jour
se situe entre les deux dates spécifiées.
· Plage horaire :
o définie par : -Heure début - Heure fin'-.
o l'accès n'est autorisé, chaque jour, que si
l'heure (locale du système d'autorisation) se situe entre les heures
spécifiées.
· Calendrier :
o défini par <la liste des jours de la
semaine:».
o l'accès n'est autorisé que si le jour de la
semaine (local du système d'autorisation) correspond a une des
entrées de la liste :
§ <la liste des jours calendaires (es : 26/01. 30 06.
etc.).
§ <la liste des semaines (S2. S3. etc.).
§ <la liste des mois (Janvier. Fevr.er...)
calendaires.
Ces limitations sont appliquées par les
différents systèmes d'autorisation en fonction de la
capacité du système à gérer ce type de
restriction
Le périmètre temporel peut être associe
à :
· une personne.
· un rôle.
· une ressource.
Un périmètre temporel associé à
une personne limite son accès à l'ensemble des ressources et
applications en empêchant l'utilisateur d'établir une session en
dehors de périodes autorisées.
Un périmètre temporel associe à un
rôle limite l'accès à l'application ou à un ensemble
de ressources :
· dans le cas d'une application, il empêche
l'utilisateur d'exécuter l'application (contrôlé par
l'application elle-même) en dehors des périodes autorisées
Le profil de l'utilisateur présentera donc un ensemble des applications
disponibles variable dans le temps.
· dans le cas d'une ressource, il empêche
l'utilisateur d'établir une session, dans l'environnement qui
héberge les ressources concernées. en dehors des périodes
autorisées
De fait, la limitation temporelle s'applique donc à un
compte d'utilisateur dans ces environnements Cette association doit être
gérée par le système de gestion des habilitations (en
fonction des limitations des personnes ou des rôles) et transmise aux
différents systèmes de contrôle d'accès pour
application.
2.2.9. Périmètre
Géographique
Le périmètre géographique permet de
restreindre les possibilités d'accès d'un utilisateur en fonction
du lieu a partir duquel il accédé au SI
Plusieurs types de restrictions sont possibles :
· un lieu l'accès n'est
autorisé que si la session est ouverte à partir du ou des postes
situés dans un lieu ou dans un groupe des lieus autorisées.
· une typologie d'accès :
l'accès n'est autorisé que si la session est ouverte à
partir d'une ou des zones réseau autorisées. La typologie
d'accès est par exemple :
o soit un accès à partir du réseau
particulier,
o soit un accès à partir du service
d'accès distant,
o soit un accès distant à partir du
réseau partenaire.
· le poste de travail : l'accès n'est
autorisé que si la session est ouverte à parer du ou des postes
autorisés
o le poste de travail est un poste "physique" sur lequel on
souhaite autoriser ou interdire certaines opérations afin
d'éviter, par exemple, qu'un utilisateur ne puisse intervenir sur
certains postes dédiésà des cellules
spécialisées,
o le poste peut être identifié par :
§ n° du terminal (liste des numéros, un
sous-ensemble du numéro).
§ n° d'inventaire (gestion du parc) ... (liste des
numéros, un sous- ensemble du numéro).
§ l'adresse IP (ou le groupe des adresses I? de
sous-réseau).
§ etc.
Les limitations géographiques sont appliquées
par les différents systèmes d'autorisation en fonction de la
capacité du système à gérer ce type de
restriction.
Le périmètre géographique peut être
associé à :
§ une personne.
§ un rôle
Un périmètre géographique associé
à une personne limite son accès à l'ensemble de ressources
et applications en empêchant l'utilisateur d'établir une session
à partir des lieux non autorisée.
Un périmètre géographique associé
à un rôle limite l'accès à une application en
empêchant l'utilisateur d'exécuter l'application
(contrôlé par l'application elle-même) à partir des
lieux non autorisés. Le profil de l'utilisateur présentera donc
un ensemble des applications disponibles variable en fonction du lieu de
présence.
Cette relation permet de dédier certains postes de
travail à des opérations spécifiques
2.2.10. Périmètre
fonctionnel
On désigné sous ce terme les limitations
imposées par le programme de contrôle d'une application. Transmis
à l'application lors de l'appel des transactions associées au
rôle, il permet de gérer la sécurité applicative :
le programme autorisera ou non certain; traitement; en fonction des
donnée; qui lui seront communiquées par le système
d'habilitation (identifiant acteur, poste de travail éventuellement lieu
de présence ou d'affectation d'utilisateur, etc.).
Le périmètre fonctionnel peut être
associé à :
§ un rôle
Plusieurs types de données servant de base aux
restrictions sont possibles :
§ mode d'authentification.
§ périmètre géographique :
o poste de travail
o lieu de présence lors de la session courante,
o groupe de lieux de présence lors de la session
courante,
o entité d'attachement administratif.
§ Degré d'expertise associé au rôle.
Un acteur peut n'exercer aucune activité d'expertise. Il peu:
éventuellement être expert en plusieurs domaines.
Cette liste n'est pas exhaustive et peut être enrichie
par toute application si nécessaire
La nature d'information et surtout son interprétation
sont gérées exclusivement par l'application.
1.8 2.3. DIFFERENTS
NIVEAUX D'UTILISATEURS
Il existe plusieurs niveaux d'utilisateur, nous pouvons
citer :
- L'utilisateur humain qui n'a aucune
compétence en informatique, qui utilise le système dans le cadre
de son temps de loisir, celui-ci peut alors avoir un comportement proche d'une
entrée aléatoire. C'est aussi ce type d'utilisateur qu'il faut
convaincre dans le cadre de diffusion commerciale d'un système vers le
grand public. Il peut adopter des comportements d'utilisateur au sens
commercial.
- L'utilisateur professionnel qui aborde le
système dans le cadre de contraintes liées à son
activité, les contraintes sur l'utilisation du système peuvent
donc être très élaborées et arbitrairement
inhumaines. Dans un but d'améliorer l'efficacité de cet
utilisateur, l'utilisation massive de résultats issue des
expériences d'IHM est largement recommandée.
- L'utilisateur avancé, qui
connaît plusieurs détails de fonctionnement de son système,
attend des réactions spécifiques et en connaît plusieurs
limites. Cette catégorie regroupe essentiellement les humains qui sont
plongés à longueur de journée dans les nouvelles
technologies. Ce type d'utilisateur est pratique dans la mesure où il
peut fournir une analyse du fonctionnement d'un système (rapport de
bugs, évaluation d'interface, etc.).
- « L'utilisateur système »
humain : cette catégorie relève et du développeur
de système et de l'administrateur système. À ce niveau
d'utilisation d'un système, on voit l'émergence d'une ou
plusieurs formes de spécialisation sur des systèmes
donnés. L'utilisateur peut avoir des connaissances très
spécifiques d'un système et en maîtriser tous les aspects.
En contrepartie, il est très rare qu'il puisse avoir ce niveau de
connaissance pour une vaste catégorie de systèmes. (Par exemple,
le concepteur de système de TAL ne doit probablement pas avoir le
même niveau pour la conception d'une chaîne de construction
automobile.).
- « L'utilisateur système »
machine : celui-ci est presque toujours très
spécialisé, avec une mission définie formellement, il est
souvent construit pour remplacer les utilisateurs de niveau 2, ou les
décharger de contraintes arbitraires. Cet utilisateur est souvent une
abstraction des autres formes d'utilisateurs utilisés pour simuler,
modéliser le comportement d'un utilisateur inconscient ou
malveillant.
- L'objet, fonction, foncteur ou prédicat
d'ordre supérieur : ils peuvent tous être définis
comme étant des utilisateurs de ressources ou de résultats
fournis par d'autres utilisateurs du même niveau. Souvent, afin de
pouvoir les faire fonctionner séparément, ces utilisateurs
disposent d'une interface formelle récapitulant la manière dont
ils peuvent (utiliser/ou être utilisé) (une/par une)
(ressource/utilisateur) extérieurs.
On oppose également le simple utilisateur à
l'administrateur ou au technicien.
2.3.1. L'utilisateur en
fonction de son activité du point de vue applicatif et/ou
système
L'utilisateur qui utilise un système informatique n'est
pas forcément en permanence devant son écran en train de
soumettre des transactions à l'application, ce qui coté
applicatif et système a des conséquences sur la charge induite
effective. Ainsi, plusieurs profils d'utilisateur sont définis suivant
leur activité, notamment dans les tests de performance :
- Utilisateurs potentiels : ce sont les
utilisateurs déclarés ou non, susceptibles d'utiliser
l'application à un moment ou à un autre ;
- Utilisateurs simultanés : ce sont
les utilisateurs potentiels actuellement présents dans l'application
pour lesquels il existe au moins une session dans un des composants techniques
de l'application ;
- Utilisateurs actifs/concurrents : ce sont
les utilisateurs simultanés pour lesquels le système effectue un
traitement composé d'au moins une requête en cours ;
- Utilisateurs synchrones : ce sont les
utilisateurs concurrents pour lesquels le système effectue au même
instant le même traitement.
2.3.2. L'utilisateur dans la
sécurité des systèmes
2.3.2.1. En multiutilisateurs
L'utilisateur peut être vu comme un
élément d'identification. Pour un système, la
capacité d'identification d'une personne permet une amélioration
de la sécurité. Il est alors possible pour le système de
réagir à des ordres contradictoires. S'il n'y a pas de
différence entre deux utilisateurs alors le système ne peut pas
être robuste aux contradictions.
Exemple : la connexion sur un site de réservation de
train permet de résoudre le cas de l'attribution de la dernière
place, le système gère des utilisateurs différents, et
attribuera la dernière place à un unique utilisateur.
2.3.2.2. En mono utilisateur
L'utilisateur peut être vu comme un partenaire de
dialogue. Pour un système, la capacité de dialoguer avec un
utilisateur est importante. Le dialogue commence avant même que la
personne ne soit connectée au logiciel. Il est établi entre le
système de connexion et la personne. À ce niveau, la concurrence
sur l'interface de connexion ne peut pas être gérée par le
système.
Exemple : du point de vue du logiciel, ce sont plusieurs
utilisateurs qui se connectent au système de retrait d'argent. D'un
point de vue matériel, c'est une personne unique. Dans le cadre d'une
solution intégrée, c'est le système informatique qui doit
tenir compte de ce dilemme. Bien que dans la pratique il n'y ait souvent qu'une
caméra et des étoiles à la place du code secret pour
vérifier qu'il n'y a qu'une unique personne (sans contraintes
extérieures).
Le concept d'utilisateur peut aussi être
déployé afin de protéger la machine des bêtises.
Dans ce cas on parle alors d'espace utilisateur. La notion d'espace utilisateur
suppose que pour un utilisateur donné, il existe un utilisateur d'un
niveau plus évolué. Cet utilisateur d'un niveau plus
évolué autorise ou non les actions du premier utilisateur en
fonction d'un système de gestion de droits.
1.9 2.4. LA GESTION
DES UTILISATEURS DANS LES ENTREPRISES
2.4.1. Etat des lieux
Aujourd'hui, la multiplication et la diversité de
systèmes de contrôle d'accès liés aux
systèmes d'exploitation et aux applications est devenue
particulièrement contre-productive En effet, chaque «
système » (OS, NOS, messagerie, groupware, applications
métiers, ERP, CRM. etc.) est protégé par une
procédure de contrôle d'accès spécifique. De ce
fait, chaque fonction à réaliser peut nécessiter un code
d'accès et des droit; associés. Cette multiplicité de
contrôles d'accès est source de confusion pour l'utilisateur qui
par exemple, perd ou oublie ses mots de passe. Il lui reste alors deux
solutions : soit il sollicite le service de help-desk. au risque de l'engorger
en lui faisant perdre trop de temps à réinitialiser très
souvent des mots de passe, soit il note lesdits codes sur un support a sa
portée pour ne plus les oublier ! Ban entendu, aucune de ces solutions
n'est satisfaisante
D'une maniéré générale, chaque
système d'exploitation et ou application est géré par un
administrateur unique : de fait toute vision globale est impossible. Dans ce
cas, l'administration autonome de chaque système est
particulièrement source d'erreurs, de vulnérabilités et de
perte de temps. Par exemple, ne pas avoir la vision globale sur les droits de
l'ensemble des utilisateurs peut engendrer des problèmes de
responsabilité (devenus importants dans le cadre des nouvelles lois ou
réglementions). Tel qu'un acheteur qui validerait sa propre commande.
Généralement les nouveaux arrivants1(*) se voient attribuer plus ou
moins rapidement certaines ressources (un bureau, un
téléphoné, un badge d'accès, un PC. etc.). Mais ne
peuvent pas travailler, faute de droits d'accès. Ceci est notamment
dû au fait que le délai d'attribution des ressources et des droits
est trop long, que les circuits d'attribution sont trop « lourds ».
Etc. Es doivent même souvent se débrouiller seuls : trouver le bon
responsable pour l'accès à telle base de données, a telle
application, a l'Intranet, etc. La liste des interlocuteurs est à la
mesure de la complexité du Système d'Information
D'autre part, on est rarement certain d'avoir supprimé
tous les droits dont disposait un employé partant ou d'avoir mis
à jour les droits d'un employé en cas de changement de fonction
Le Système d'Information regorge souvent de comptes dits «
fantômes » (dormants et ou périmés).
De plus, les comptes techniques génériques,
installes par défaut, par les systèmes d'exploitation et ou les
applications, ne sont pas toujours modifiés, voire supprimes, induisant
d'autres failles. Ceci étant d'autant plus grave que ces mots de passe
sont facilement accessibles sur Internet... De même, certaines personnes
utilisent, lorsqu'elles arrivent dans l'entreprise des comptes utilisateurs
« génériques » et partages, simplement du fut de
la durée importante de création de leur propre compte.
Enfin, l'audit et la traçabilité sont souvent
les parents pauvres de la mise en oeuvre des droits d'accès des
utilisateurs. Pourtant, de plus en plus, les entrepris doivent respecter des
normes, des lois et ou des réglementations strictes en macère de
politique de contrôle interne.
2.4.2. Illustration
Si nous prenons l'exemple du référencement d'un
nouvel utilisateur dans un Système d'Information, nous pouvons
identifier les actions suivantes :
1. embauche dans une entreprise>
Référencement dans le système de gestion de la paie.
2. attribution d'un bureau > Référencement
dans la base du service logistique.
3. attribution d'un numéro de téléphone
> Référencement dans la base téléphonique.
4. attribution d'un ordinateur, d'un identifiant et d'un mot
de passe pour accéder au réseau > Référencement
dans le système bureautique.
5. attribution d'un badge pour l'accès aux locaux >
Référencement dans le système de gestion des badges.
6. droits d'accès à un restaurant d'entreprise
> Référencement dans la base du restaurant d'entreprise.
7. droits d'accès sur une application
>Référencement dam la base de l'application.
Etc.
Dans la majorité des entreprises, ces opérations
font appel à des annuaires qui ne sont ni compatibles entre eux, ni
synchronisés (cf Figure II. 1 ci-dessous). Ainsi pour un nouvel
utilisateur il faut saisir plusieurs fois les mêmes informations dans des
systèmes différents par des personnes différentes et il en
va de même en cas de modification d'une information Cette mise à
jour est parfois très longue ou que partiellement
réalisée.
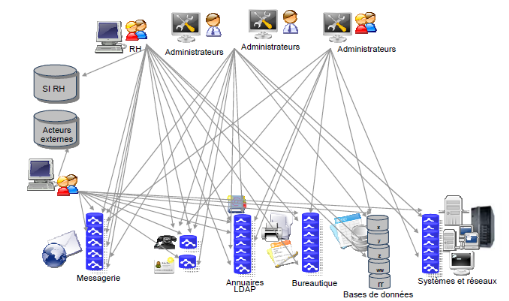
FIGURE V-1 EXTRAIT (STANDARD) DE LA GESTION DES
UTILISATEURS ET DES DROITS D'ACCÈS
1.10 2.5. LES COMPTES UTILISATEURS
Un compte informatique est l'ensemble des ressources
informatiques attribuées à un utilisateur ou à un appareil
(ordinateur, périphérique...) Un compte informatique ne peut
être utilisé qu'en s'authentifiant sur le système avec son
nom d'utilisateur (Identifiant username) et son mot de passe. Cette
procédure se dit "se connecter" (ou login). Il arrive que dans
ce domaine on utilise parfois abusivement le terme login pour
désigner le compte proprement dit.
2.5.1. Compte d'utilisateur
principal
Le compte d'utilisateur principal appelé aussi SSO
(pour Single SignOnen anglais) rassemble tous les comptes des différents
systèmes installés pour unmême utilisateur.
Pour les systèmes qui communiquent avec un serveur
d'annuaire Active Directory, le compte d'utilisateur principal aussi
appelé UPN (pour UserPrincipal Name en anglais) est au format de message
texte internet ARPA IETF RFC 822 . Il s'écrit sous la forme
utilisateur@domaineou le caractère@ sépare le
préfixe qui désigne l'utilisateur du suffixe UPN qui indique le
réseau sur lequel on se connecte. Ce réseau est appelé le
domaine. Cescomptes sont associés à un numéro unique
à l'échelle du monde appelé SID (pour Security IDentifier
en anglais.)
Historiquement on utilisait un serveur NIS comme serveur
d'annuaire pour s'authentifier sur un réseau de poste sous Unix, Linux
et Mac OS.
2.5.2. Compte d'utilisateur
d'un système d'exploitation
Le compte d'utilisateur d'un système d'exploitation
permet l'ouverture d'une session donnant des droits d'accès aux
différents éléments du système ainsi qu'a une
interface homme machine personnalisé.
Avec le système Microsoft Windows ils s'écrivent
sous la forme hôte\utilisateur ou l'hôte est le nom du
poste ou du serveur de domaine qui stockel'annuaire des comptes auprès
duquel on souhaite s'identifier. Ce nom de compte est associé à
un numéro unique à l'échelle d'un réseau
privé appelé RID(pour Relative IDentifier.) Avec les
systèmes de type Unix Linux et Mac OS cet identifiant est nommé
UID (pour User IDentifier en anglais.)
1.11 2.6. LE MODELE « RBAC »
Le modèle de sécurité RBAC (Rôle
Based Accès Control) est principalement issu d'Internet afin de prendre
en compte des applications déployées sur de vastes organisations
ou des applications inter-organisations (Extranet par exemple). Ce
modèle permet en particulier de simplifier l'administration des droits
et de prendre en compte la délégation de l'administration
Les concepts du RBAC ont servi de base à la norme
établie par American National Standard et
référencée sous le N°:AXSI INCITS 359-20W
(approuvée le 19 Février 2004).
Ce modèle tend à se généraliser
dans l'industrie et un nombre croissant de produits supportent un modèle
d'habilitation "oriente rôles"
Le modèle RBAC se distingue du modèle DAC
(Discretionary Access Control) popularisé par Unix. Le modèle DAC
est centre sur les ressources physiques (fichier, exécutable. etc.) et
identifie un propriétaire ainsi que des groupes d'utilisateurs ayant des
droits sur la ressource (lecture, écriture, etc.).
Le modèle RBAC modélise des fonctions
métiers plutôt que des accès à des ressources
informatiques. Un rôle correspond à une fonction au sein d'une
organisation. Le principe de base du RBAC est que deux utilisateurs ayant les
mêmes rôles ont les mêmes droits sur le système.
L'administration des rôles est ainsi facilement
compréhensible par des administrateurs métiers et peut être
déléguée. Les associations entre les rôles et les
ressources physiques sont modélisées séparément par
les concepteurs d'application et maitrise d'ouvrage métier.
2.6.1.
Modèle de base RBAC
Le standard propose un modèle de base (Core RBAC).
Les concepts manipulés par le modèle RBAC sont
les suivants :
o USERS (Utilisateurs) : comptes permettant aux utilisateurs
de se connecter au système.
o ROLES (Rôles) : fonctions métiers dans des
organisations ou des périmètres donné; (par exemple :
vendeur résidentiel dans l'agence X).
o OBS (Objets) : objets informatiques
àprotéger.
o OPS (Opérations) : opérations possibles sur
les objets.
o RMS (Permissions) : autorisation d'effectuer 1
opération X sur l'objet Y.
o SESSIONS (Sessions) : session temporelle, chaque session est
associée à un utilisateur pour une période de temps
limitée.
o un utilisateur possédé un rôle sur un
périmètre donne.
o un rôle donne droit à des permissions.
o une permission est un ensemble d'opération sur un
objet
o le contrôle d'accès se déroule au cours
d'une session.
o au cours d'une session. il peut être nécessaire
qu'un utilisateur n'ait qu'un et un seul rôle. C'est la notion de
rôle actif
o le périmètre est porte par un rôle et il
est transmis de manière aveugle à l'application (la
permission).
Note : le rôle est généralement
accompagné par un périmètre (par exemple le numéro
de compte client). La sémantique du périmètre est propre
à l'application et n'est généralement pas
contrôlée par le système de contrôle d'accès
Cette information est toutefois renseignée au cours du processus de
déclaration des droits et participe pleinement aux contrôles de
sécurité faits par l'application. Le système de
contrôle d'accès joue simplement le rôle de courtier pour
cette information.
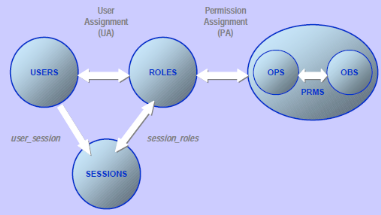
FIGURE V-2 MODÈLE DE BASE RBAC
Principe de privilège minimum
Le fonctionnement de ce modèle et
l'intégrité du système sont garantis si l'attribution des
permissions respecte le principe de privilège minimum.
Ce principe exige que l'utilisateur ne dispose pas de plus de
droits que nécessaire à son travail Ce qui implique que les
permissions affectées a un rôle constituent le strict minimum
nécessaire à l'accomplissement des tâches relatives
à ce rôle.
2.6.2. Modèle RBAC
Hiérarchique
Le modèle RBAC hiérarchique (Hierarchical RBAC)
ajoute au modèle de base le support de hiérarchie des
rôles.
La hiérarchie établit les liens de
parenté entre plusieurs niveaux des rôles et permet aux
rôles « parents » de disposer des permissions attribuées
aux rôles « enfants »
Le standard admet deux types de hiérarchies :
o le modèle hiérarchique
général (General Hierarchical RBAC) : cette variante
établie des relations multiples entre plusieurs « parents » et
« enfants ».
o le modèle hiérarchique
limité (Limited Hierarchical RBAC) : cette version limite la relation a
une simple structure d'arborescence. Ce qui veut dire qu'un rôle ne peut
avoir qu'un seul « parent ».
Cette extension du modèle permet une administration
plus efficace dans les grandes structures qui gèrent de très
nombreuses permissions d'un grand nombre d'utilisateurs. D'aune pan ce principe
permet de bien gérer les situations où certains rôles
différent; (du niveau supérieur) doivent bénéficier
de certaines permissions communes.
Remarque : Très souvent on applique une
version simple de l'extension au modèle hiérarchique limite. Elle
admet une hiérarchie des rôles a deux niveaux. Le niveau 1 est
appelé « un rôle » et le terne d'« un
profil » sera utilisé pour le deuxième niveau. Le profil
permettra donc les regroupements des rôles.
2.6.3. Modèle RBAC avec
contraintes
Le modèle RBAC avec contraintes (Constrained RBAC)
ajoute au modèle la contrainte de séparation des pouvoirs.
Cette contrainte permet d'inclure dans le modèle la
gestion de conflits d'intérêts et assurer que les utilisateurs
bénéficieront des permissions selon la politique définie
par l'organisation et ne pourront pas abuser de cumul non contrôle de
droits.
Séparation Statique des Pouvoirs (SSD -
Statk Séparation of Doty Relations)
La contrainte de séparation des pouvons est
utilisée pour assurer le respect de la politique des habilitations
Un conflit d'intérêts peut arriver (dans un
système du type RBAC) quand l'utilisateur obtient simultanément
les droits associés à des rôles incompatibles.
Une méthode pour éviter cette situation est la
mise en oeuvre de séparation statique de pouvoir (SSD pour Static
Séparation of Dutv)
L'exclusion mutuelle de certains rôles est
spécifiée par les régies de SSD. Ces règles sont
interprétées lors du processus d'affectation des rôles par
l'administrateur et l'empêchent d'affecter des rôles incompatibles
au même utilisateur
De cette manière, a une personne qui
bénéficie d'un rôle, on ne pourra pas affecter un
deuxième rôle interdit par la règle de SSD.
Pour éviter les incohérences les règles
SSD doivent prendre en compte les regroupements des rôles en fonction de
leur hiérarchie.
Séparation Dynamique des Pouvoirs (DSD -
Dynamic Séparation of Doty Relations)
La séparation dynamique limite comme la SSD le;
rôles accessibles à un utilisateur.
Par contre le conteste est différent. La limitation
n'est pas exploitée au moment de l'affectation des rôles mais au
moment de leur activation dans une session.
Dans une même session, un utilisateur a la
possibilité de ne pas activer tous ses rôles, mais uniquement le
sous-ensemble de ses rôles nécessaires à la
réalisation de la tâche à accomplir.
Ce mécanisme permet de garantir l'application des
permissions minimales nécessaires dans une période
d'exécution d'une tâche On peut parler, dans ce conteste, de
révocation temporaire des privilèges
La mise en oeuvre de ce mécanisme peut se
révéler très complexe et le plus souvent n'est pas
réalisée.
1.12 2.7. AUTRES MODELES
D'autres modèles de sécurité existent,
plus orientés ressources. Ces modèles tels que DAC et MAC sont
ces utilises dans certains contestes (militaire) mais sont moins adaptés
que le modèle RBAC à l'approche actuelle de la gestion des
identités;
2.7.1. Modèle DAC
Le DAC (Discretionary Access Controls) est un modèle
conceptuel dont le principe est de limiter l'accès à des objets
en regard de l'identité des utilisateurs (humain, machines, etc.) et/ou
des groupes auxquels ils appartiennent. Les contrôles sur une ressource
sont dit; discrétionnaires dansle sens où un utilisateur avec une
autorisation d'accès définie est capable de la transmettre
(indirectement ou directement) à n'importe quel autre utilisateur.
Ce modèle est principalement utilisé au sein
d'implémentations informatiques car les notions
développéessont surtout adaptéesa la gestion
d'accès sur des ressources informatiques Ainsi, les
implémentations adhérant à ce concept, doivent mettre en
oeuvre des mécanisme; permettant d'enregistrer un ensemble de droit;
d'accès ou d'action; représentée; sous la forme d'une
matrice de contrôle d'accès.
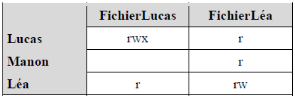
TABLEAU V-1MATRICE DE CONTRÔLE
D'ACCÈS
Parmi les différentes implémentations
réalisées les plus connues sont :
o Protection Bits Popularisée par le;
systèmes Unix, cette implémentation représente la matrice
de droits d'accès par colonne. Son principe consiste à
définir pour une ressource si elle est partagée pour tous les
utilisateurs, un groupe ou seulement son propriétaire.
o AccessControl Lists (ACLs) : Le principe
des ACLs implémente la matrice de contrôle d'accès par
colonne en créant des listes d'utilisateurs pouvant accéder
à la ressource et ou des listes d'utilisateurs interdits d'accès
à celle-ci
o Capabilities : Comme pour les ACL une liste
est créée, mais elle est liée à un utilisateur et
non à -une ressource, ainsi la représentation de la matrice est
faite par ligne.
Ce modèle convient à des systèmes
gérant l'accès d'objets peut sensibles et donne l'avantage de
minimiser les coûts d'administration car celle-ci peut-être
déléguée aux utilisateurs. Par contre, ses principes ne
sont pas suffisants au sein d'une organisation qui a défini une
politique de sécurité basée sur la sensibilité des
ressources ou le profil métiers des utilisateurs
2.7.2.
Modèle MAC
2.7.2.1. Introduction
En opposition avec le DAC ou le propriétaire d'une
ressource jouit de tous les droits sur une ressource qu'il a
créée, le modèle Mandatory Access Control est
utilisé quand la politique de secunté d'une organisation
définit que :
o les décisions de protection d'une ressource ne
doivent pas être sous la responsabilité de son
propriétaire.
o le système doit mettre en oeuvre les
mécanismes permettant de respecter la politique de
sécurité et interdire au propriétaire d'une ressource
d'agir à sa guise
Afin d'aboutir a ces principes, ce modèle introduit la
notion d'accès aux ressources en regard de la sensibilité des
informations qu'elles contiennent et repose sur la labellisation
systématique de ces ressources et des utilisateurs du système
considéré. En hiérarchisant ces entités en
plusieurs niveaux de confiance et sensibilité, puis en les
labélisant en conséquence, on aboutit à une
décomposition à laquelle il faudra ensuite ajouter de;
règle; d'accès. On notera qu'un système informatique
adhérant à ce principe est dit multi-levelsecuritv (MLS).
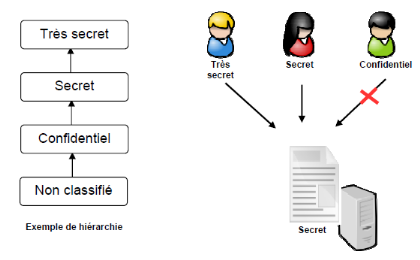
FIGURE V-3 EXEMPLE DE L'HABILITATION
Les labels suivent une logique hiérarchique (est
Confidentiel, Secret, Très secret, non classifié) et
décrivent ainsi différents niveaux d'habilitation. Les droits
d'accès aux ressources sont attribués en fonction du niveau
d'habilitation de l'utilisateur et sont définis selon la
problématique de sécurité à adresser :
Confidentialité ou Intégrité.
L'émergence de travaux sur ce sujet date de la
période de la Guerre Froide où la NSA a lancé
différents projets visant à publier des
référentiels pouvant être mis en application au sein des
organisations gouvernementales américaines
Chapitre 3
L'AUTHENTIFICATION
1.13 3.1. INTRODUCTION
L'Authentification est la vérification
d'informations relatives à une personne ou à un processus
informatique. L'authentification complète le processus d'identification
dans le sens où l'authentification permet de prouver une identité
déclarée. Dans un serveur, un processus de contrôle valide
l'identité et après authentification, donne l'accès aux
données, applications, bases de données, fichiers ou sites
Internet. Dans le cas contraire, l'accès est refusé.
L'authentification peut se faire de multiples manières,
et notamment par la vérification de :
« Ce que je sais », un mot de passe par exemple,
« Ce que je sais faire », une signature manuscrite
sur écran tactile/digital (de type PDA),
« Ce que je suis », une caractéristique
physique comme une empreinte digitale,
« Ce que je possède », une carte à
puce par exemple.
Le choix de telle ou telle technique dépend en grande
partie de l'usage que l'on souhaite en faire : authentification de
l'expéditeur d'un email, authentification d'un utilisateur qui se
connecte à distance, authentification d'un administrateur au
système, authentification des parties lors d'une transaction de
B2B (Business to Business), etc.
La combinaison de plusieurs de ces méthodes (aussi
appelées facteurs d'authentification) permet de renforcer le processus
d'authentification, on parle alors d'authentification forte.
Les techniques d'authentification les plus usitées
sont, de loin, les mots de passe mais aussi, de plus en plus, les
Certificats de clés publiques.
1.14 3.2. METHODES COURANTES D'AUTHENTIFICATION
3.2.1. Mots de passe
Les mots de passe pris dans leur ensemble sont le moyen
d'authentification le plus répandu à ce jour. On distingue deux
catégories : les mots de passe statiques et les mots de passe
Dynamiques.
Les mots de passe statiques sont des mots de passe qui restent
identiques pour plusieurs connexions sur un même compte. Ce type de mot
de passe est couramment rencontré sous Windows NT ou Unix. Cette
technique d'authentification est la plus utilisée dans les entreprises
mais aussi la moins robuste. En fait, les Entreprises
devraient restreindre l'usage des mots de passe statiques à une
authentification locale d'un utilisateur car les attaques qui permettent de
capturer un mot de passe qui circule sur un réseau sont nombreuses et
faciles à mettre en pratique.
Pour pallier les faiblesses de l'usage des mots de passe
statiques, sont apparues des solutions d'authentification combinant deux
facteurs (« ce que je possède » et « ce que je sais
») afin d'obtenir une authentification Forte. Les mots de
passe sont obtenus par des Générateurs de mots
de passe activés à l'aide d'un code d'identification personnel ou
PIN (Personal Identification Number). La mise en place d'un tel
mécanisme d'authentification forte rend la capture du mot de passe en
cours d'aucune utilité puisque, dès que le mot de passe dynamique
a été utilisé, celui-ci devient caduc. Parmi ces mots de
passe à usage unique - One Time Password (OTP) en Anglais - on trouve
notamment le programme SKEY dont la sécurité repose sur une
fonction à sens unique et qui permet de générer un mot de
passe différent pour chaque nouvelle connexion. En version logicielle,
ces générateurs de mots de passe dynamiques utilisent certains
composants du PC, comme le microprocesseur, le CPU ou l'Horloge
interne (on parle alors de méthode d'authentification en mode
synchrone dépendant du temps). Que le mot de passe à usage unique
soit obtenu à partir d'un générateur matériel ou
logiciel, l'utilisateur est authentifié de manière forte
grâce à la vérification du mot de passe dynamique par un
serveur appelé serveur d'authentification.
Afin d'éviter aux utilisateurs de retenir de nombreux
mots de passe, il est possible de mettre en place un outil qui rende
l'authentification de l'utilisateur unique pour chaque session : le Single Sign
On (SSO).
Notons toutefois que la mise en place d'un SSO ne renforce en
aucun cas la robustesse du processus de contrôle d'accès au SI, il
sert juste de point d'entrée unique au SI : c'est une mesure pratique
pour les utilisateurs. Par conséquent, si ce point d'entrée
venait à céder à la suite d'une malveillance, d'un
disfonctionnement ou d'une attaque venant d'Internet, cela
pourrait avoir des conséquences désastreuses pour la
sécurité du SI de l'entreprise. Il est donc souhaitable de
coupler le contrôle d'accès des utilisateurs au système
d'information via un serveur SSO à une méthode d'authentification
forte comme un mot de passe Jetable (i.e. mot de passe
à usage unique), des certificats X.509 ou des systèmes
biométriques, suivant le niveau de risque des informations auxquelles
l'utilisateur nécessite un accès.
Par ailleurs, l'authentification peut aussi reposer sur un
protocole d'authentification réseau, le protocole
Kerberos, qui permet de sécuriser les mots de passe
statiques lorsqu'ils sont transmis sur le réseau. Ce protocole,
créé par le Massachusetts Institute of Technology (MIT), utilise
la cryptographie à clés publiques.
3.2.2. Certificats de
clés publiques
Comme nous venons de le voir, la cryptographie à
clé publique peut être utilisée pour chiffrer des mots de
passe. En outre, elle peut également être employée pour
signer des données, qu'il s'agisse d'un contrat afin que les parties qui
l'ont signé ne puissent pas en répudier le contenu a posteriori,
ou qu'il s'agisse d'une valeur aléatoire pour assurer
l'authentification.
En effet, les certificats de clés publiques sont l'une
des techniques d'authentification les plus usitées à ce jour,
certes loin derrière les mots de passe mais ce moyen d'authentification
devient de plus en plus populaire.
La cryptographie asymétrique fait intervenir deux
éléments qui sont mathématiquement liés entre eux :
la clé privée et la clé publique.
La clé publique est :
o Disponible pour tout le monde.
o Utilisée par une personne qui souhaite authentifier
l'émetteur d'un document électronique signé avec la
clé privée. Le contrôle de la signature permet aussi de
s'assurer de l'intégrité du fichier.
o Utilisée par une personne souhaitant chiffrer un
message afin que ce dernier soit uniquement lisible par le possesseur de la
clé privée associée.
La clé privée est :
o Conservée secrète par son possesseur.
o Utilisée par son possesseur pour signer un document
électronique (message, contrat ou autre).
o Utilisée par son possesseur pour déchiffrer un
message chiffré à son attention.
Connaissant la clé publique, il est impossible en un
temps raisonnable, avec des moyens raisonnables (i.e. en une journée
avec un seul PC), de deviner la clé privée associée. Mais
avec des moyens conséquents et connaissant la clé publique, il
est possible de retrouver la clé privée associée puisqu'en
août dernier le défi RSA-155 proposé par la
société américaine RSA Security Inc. a été
relevé: une clé de 155 chiffres (ce type de clé est
utilisé dans 95% des transactions de commerce électronique) a
été cassée grâce à 300 machines en
réseaux, ce qui est équivalent à 30 à 40
années de temps ordinateur (temps CPU). Ainsi, à ce jour, il est
admis qu'en connaissant la clé publique il est impossible en un temps
raisonnable avec des moyens raisonnables de deviner la clé privée
associée : l'usage de clés asymétriques est jugée
sûre.
L'Information Standard Organization (ISO) définit dans
le standard ISO/IEC 7498-2 (Systèmes de traitement de l'information -
Interconnexion de systèmes ouverts - Modèle de
référence de base - Partie 2 : Architecture de
sécurité), la signature numérique comme étant
« des données ajoutées à une unité de
données ou transformation cryptographique d'une unité de
données permettant à un destinataire de prouver la source et
l'intégrité de l'unité de données et
protégeant contre la contrefaçon » (par le destinataire, par
exemple).
Le principe de l'authentification de l'expéditeur d'un
message grâce à l'usage de la signature numérique est le
suivant : l'expéditeur calcule le Message Authentication Code
ou MAC à l'aide d'une fonction « hash ». Puis,
l'expéditeur signe le MAC avec sa clé privée. Le MAC
signé est joint au message et l'ensemble est envoyé.
Le destinataire fait le « hash » du message
reçu en utilisant le même algorithme que celui de
l'expéditeur et compare ce MAC au MAC envoyé avec le message.
S'ils ne sont pas égaux, cela signifie que le message a
été altéré : la modification d'un seul bit pendant
la transmission fait échouer le contrôle et permet d'alerter le
destinataire. Plus qu'un mécanisme d'authentification de
l'expéditeur d'un message, le MAC permet donc aussi de garantir
l'intégrité du message.
La question qui nous assaille à cet instant c'est
comment peut-on être sûr que cette signature (cf. modèle
ci-dessous) est belle et bien celle de notre correspondant ?
BEGIN
SIGNATUREQCVAwUBMARe7gvyLNSbw6ZVAQF6ygP/fDnuvdAbGIDWaSMXUIs&»%k3MuNHYzdZOOcqkDh/Tc2+DubuEa6GU03AgZY8K9t5r9lua34E68pCxegUz009b10cjNt6+o+704Z3j1yy9ijYM8BWNaSp9L2W4nUuWBdlWyel82PjjRVNZEtqtSRQuPEpJ2IHtx9tGevH10
END SIGNATURE
Cette certitude naît de la relation de confiance liant
l'expéditeur en question à son bi-clé (couple
constitué d'une clé privée et d'une clé publique).
Ce lien appelé certificat est, en fait, un fichier contenant les
paramètres cryptographiques (algorithme utilisé, taille des
clés, etc.) et les données d'identification de son possesseur, le
tout signé par un tiers qui en a validé le contenu. Ce tiers est
appelé autorité de certification (AC).
Maintenant que l'on peut avoir la garantie qu'une personne est
bien celle qu'elle prétend être i.e. que la signature
électronique de quelqu'un est bien de cette personne et que nous savons
qu'il faut pour cela, vérifier le certificat X.509 (cf. RFC 2459
Internet X.509 Public Key Infrastructure, Certificate and CRL Profile
pour plus de détails sur son contenu) associé à la
clé de signature et/ou remonter la chaîne de certification
jusqu'au certificat de l'AC racine (certificat auto signé), il reste
à savoir où trouver ce(s) certificat(s). Dans les entreprises,
les certificats de clés publiques sont stockés dans des annuaires
LDAP (Lightweight Directory Access Protocol). Pour un
usage personnel de MAC ou autres applications utilisant la
cryptographie asymétrique, les certificats des utilisateurs ainsi que de
leur AC (et éventuellement, hiérarchie de certification
jusqu'à l'AC racine) sont souvent stockés dans les
Navigateurs (Microsoft Internet Explorer et Netscape
Communicator). Ceux-ci comportent déjà par défaut un
certain nombre de certificats d'AC racines (cf. Outils/Options
internet/Contenu/Certificats).
Notons pour information, qu'une mesure de
sécurité est d'effacer (Remove) ces certificats lors de
l'installation et de ne rajouter que ceux autorisés par l'entreprise. Si
vous souhaitez avoir vos propres certificats d'authentification afin, par
exemple, de faire des transactions en ligne, vous pouvez contacter un
Opérateur de Service de Certification (OSC). De
nombreux OSC sont présents sur le marché français et
européen.
3.2.3. Biométrie
Le mot biométrie signifie « mesure + vivant »
ou « mesure du vivant », et désigne dans un sens très
large l'étude quantitative des êtres vivants. Parmi les principaux
domaines d'application de la biométrie, on peut citer l'agronomie,
l'anthropologie, l'écologie et la médecine.
L'usage de ce terme se rapporte de plus en plus à
l'usage de ces techniques à des fins de reconnaissance,
d'authentification et d'identification, le sens premier du mot biométrie
étant alors repris par le terme biostatistique.
Identification des personnes
Analyse morphologique
L'analyse morphologique peut se pratiquer avec les empreintes
digitales, l'iris, les réseaux veineux de la rétine, les
réseaux veineux de la paume de lamain, la morphologie de la main, le
poids, ainsi qu'avec les traits du visage.
Les deux moyens biométriques principaux sont les
empreintes digitales et l'iris :
Les empreintes digitales
Une empreinte digitale est le dessin formé par les
lignes de la peau des doigts, des paumes des mains, des orteils ou de la plante
des pieds. Ce dessin seforme durant la période foetale. Il existe deux
types d'empreintes : l'empreinte directe (qui laisse une marque visible) et
l'empreinte latente (saleté, sueurou autre résidu
déposé sur un objet). Elles sont uniques et immuables, elles ne
se modifient donc pas au cours du temps (sauf par accident comme
unebrûlure par exemple). La probabilité de trouver deux empreintes
digitales similaires est de 1 sur 10 puissance 24. Les jumeaux, par exemple,
venant de lamême cellule, auront des empreintes très proches
[réf. nécessaire] mais pas semblables.
Elles sont composées, de façon rudimentaire, de
terminaisons en crêtes, soit le point où la crête
s'arrête, et de bifurcations, soit le point où la crête
sedivise en deux. Le noyau est le point intérieur, situé en
général au milieu de l'empreinte. Il sert souvent de point de
repère pour situer les autres minuties.
D'autres termes sont également rencontrés : le
lac, l'île, le delta, la vallée, la fin de ligne... Ces
caractéristiques peuvent être numérisées. Une
empreintecomplète contient en moyenne une centaine de points
caractéristiques mais les contrôles ne sont effectués
qu'à partir de 12 points. , il est quasimentimpossible de trouver 2
individus présentant 12 points caractéristiques identiques,
même dans une population de plusieurs millions de personnes.
Reconnaissance de l'iris
L'utilisateur doit fixer l'objectif d'une caméra
numérique qui balaie l'iris d'une personne d'une distance de 30 cm
à 60 cm, et acquiert directement son dessin. Elle le compare ensuite
à un fichier informatisé d'identification personnelle (les
systèmes de reconnaissance en usage aujourd'hui sont en mesure de
fouiller une banque de données nationale à la vitesse de 100 000
codes iridiens par seconde).
Or, l'iris est un organe sensible, sa taille est petite et il
est obscurci par les cils, les paupières ou les lentilles de contacts.
De plus, elle est variable et les utilisateurs ont tendance à bouger. Il
est donc assez difficile d'avoir une bonne image de l'iris, il faut que ce soit
rapide, précis et qu'il n'y ait pas de lumière pouvant se
refléter sur l'oeil.
La prise de vue de l'iris est effectuée le plus souvent
par une caméra (caméra CCD monochrome 640 x 480) employée
avec une source de lumière de longueur d'ondes comprise entre 700 et 900
nm, invisible pour les humains.
D'autres systèmes emploient une caméra à
large vision qui permet la localisation des yeux sur le visage, puis une autre
caméra avec une vision étroite prend des images des yeux (il y a
une plus grande résolution) avec un capteur classique et un objectif
macro. Les différentes contraintes, en particulier de
l'éclairage, imposent une proximité entre le capteur et l'oeil
(30 à 60 cm), car plus l'oeil est éloigné plus il y a de
problèmes. Il faut également tenir compte des reflets ponctuels,
de la non uniformité de l'éclairage, et des images de
l'environnement qui se reflètent sur l'iris. On utilise alors un
éclairage artificiel (diodes DEL) infrarouge, tout en atténuant
le plus possible l'éclairage ambiant.
Pour le traitement numérique, la méthode
employée est celle de John Daugman : après la numérisation
de l'image de l'oeil, le logiciel détermine le centre de la pupille et
le contour de l'iris. Puis sur ces deux données le logiciel
établit des bandes de tailles égales (la taille varie selon la
dilatation de la pupille) pour former un fichier « gabarit »,
à partir de l'analyse de la texture de l'iris. Le fichier formé
est un code iridien accompli grâce à l'algorithme de Daugman.
La reconnaissance de visage
La reconnaissance de visage est un domaine de la vision par
ordinateur consistant à reconnaitre automatiquement une personne
à partir d'une image deson visage. C'est un sujet
particulièrement étudié en vision par ordinateur, avec de
très nombreuses publications et brevets, et des
conférencesspécialisées.
La reconnaissance de visage a de nombreuses applications en
vidéosurveillance,biométrie, robotique, indexation d'images et de
vidéos, recherched'images par le contenu, etc.
La reconnaissance de visage fait partie du domaine du
traitement du signal.
La biométrie pour le contrôle
d'accès
Le but de la biométrie dans le contrôle
d'accès est de gérer les accès physiques ou logiques afin
d'accroître la sécurisation des accès à des locaux
de tous types mais aussi sécuriser l'accès à des stations
informatiques et aux dossiers et fichiers présents sur ces
dernières. La biométrie commence à être
utilisée également afin d'authentifier
un utilisateur lors de transactions bancaires pour
sécuriser les paiements via des terminaux physiques ou encore pour des
paiements en ligne.
Il existe de nombreux systèmes biométriques pour
le contrôle d'accès que nous pouvons séparer en 2 grandes
familles : Avec ou Sans contact physique.
La biométrie avec contact physique est très
répandue. Elle comprend la reconnaissance de l'empreinte digitale, dela
morphologie de la main ou encore en mode multimodal avec analyse
combinée et simultanée de l'empreintedigitale et du réseau
veineux du doigt.
Dans le monde, l'une des technologies les plus
utilisées est la biométrie via l'empreinte digitale. Autant au
niveaudu contrôle des individus (passeport, carte d'identité
et permis de conduire biométrique), qu'au niveau ducontrôle
d'accès.
1.15 3.3. AVANTAGES ET INCONVENIENTS DES DIFFERENTES
TECHNIQUES D'AUTHENTIFICATION
Le tableau suivant recense les principaux avantages et
inconvénients des techniques d'authentification les plus connu :
|
Avantages
|
Inconvénients
|
|
Mot de passe statique
|
+ peu coûteux
+ facile à mettre en oeuvre
+ facile à utiliser
|
- vol du mot de passe en regardant par-dessus l'épaule
- oubli du mot de passe
- peu robuste (facilement devinable ou « craquable
»)
- partageable, et trop souvent partagé
- mot de passe rejouable par une personne malveillante
|
|
Mot de passe statique stocké dans une carte
magnétique activée par code PIN
|
+ robustesse du mot de passe (possibilité de choisir un
mot de passe aléatoire et comprenant des caractères
spéciaux)
+ pas de nécessité de mémoriser le mot de
passe
|
- vol, perte ou oubli de la carte
- carte partageable
- durée de vie du mot de passe souvent trop longue :
nécessité de renouveler régulièrement
l'enregistrement dans la carte
- mot de passe rejouable
|
|
Mot de passe dynamique généré par un
outil logiciel
|
+ robustesse du mot de passe (mot de passe souvent
aléatoire et comprenant des caractères spéciaux)
+ confort d'utilisation pour l'utilisateur (absence de
mémorisation du mot de passe)
|
- peu de confort d'utilisation (nécessité
d'utiliser un logiciel à chaque nouvelle connexion)
- protection de l'utilisation du logiciel par une personne non
autorisée
|
|
Mot de passe dynamique généré par un
outil matériel
|
+ confort d'utilisation pour l'utilisateur (absence de
mémorisation du mot de passe)
+ robustesse du mot de passe (usage unique)
|
- vol, perte ou oubli du générateur de mot de
passe
- le générateur peut se désynchroniser
avec le serveur qui contrôle la vérification du mot de passe
|
|
Certificat X.509 dans le navigateur de l'ordinateur
|
+ multi-usage
+ robustesse de la méthode d'authentification
+ confort d'utilisation pour l'utilisateur
|
- vol ou utilisation frauduleuse de l'ordinateur et copie de
la clé privée associée au certificat
|
|
Certificat X.509 dans un token USB
|
+ multi-usage
+ robustesse de la méthode d'authentification
+ attitude similaire à la possession de clés
(maison, voiture)
|
- vol, perte ou oubli du token
|
|
Certificat X.509 dans une carte a puce
|
+ multi-usage
+ robustesse de la méthode d'authentification
+ attitude similaire à la possession d'une carte
bancaire
|
- vol, perte ou oubli de la carte a puce
|
|
Biométrie et caractéristiques de
référence dans une base de données en réseau
|
+ pas d'oubli ou de vol possible
|
- technologie encore immature
- facilement falsifiable
|
|
Biométrie associée a une carte magnétique
|
|
- technologie encore immature
- vol, perte ou oubli de la carte magnétique
- coût élevé
|
|
Biométrie associée a un certificat X.509 dans un
token USB
|
+ multi-usage
+ attitude similaire à la possession de clés
(maison, voiture)
|
- technologie encore immature
- vol, perte ou oubli du token USB
- coût élevé
|
|
Biométrie associée a un certificat X.509 dans une
carte a puce
|
+ multi-usage
+ attitude similaire à la possession d'une carte bancaire
|
- technologie encore immature
- vol, perte ou oubli de la carte a puce
- coût élevé
|
Tableau 3.1. Avantage et inconvénient de quelques
techniques d'authentification
La Qualité d'une méthode
d'authentification ne se mesure pas uniquement à ses avantages et
inconvénients généraux ou à sa robustesse
théorique face aux attaques mais avant tout à sa capacité
à répondre aux besoins de sécurité de l'entreprise
tout en prenant en considération le secteur d'activité dans
lequel il est mis en place (son environnement) i.e. en tenant compte des
risques mais aussi des contraintes techniques, organisationnelles, temporelles
de même que financières et légales. En outre, le budget
alloué à l'informatique en général et à la
sécurité informatique en particulier, de même que la taille
de l'entreprise et les compétences internes sont des facteurs
très influents sur le choix de telle ou telle solution
d'authentification. Comme toute solution de sécurité, le choix de
la méthode d'authentification sera un compromis (parfois long à
obtenir...).
L'authentification est l'un des domaines de
sécurité qui engendrent le plus d'inquiétude au sein des
entreprises, ce qui génère une réaction d'investissement
afin de l'améliorer. Il est à noter que plus de la moitié
des entreprises sont en train d'investir ou prévoient d'investir en 2003
dans le secteur de l'authentification (source IDC, 2002).
De manière générale, une des raisons
principales des investissements des entreprises dans la sécurité
informatique est guidée par le soucis de fournir aux utilisateurs un
meilleur accès au réseau et un accès plus
sécurisé car elles ont de plus en plus conscience de courir le
risque d'être l'objet d'attaques de personnes malveillantes.
1.16 3.4. PROTOCOLES D'AUTHENTIFICATION COURAMMENT
UTILISES
3.4.1. Protocole RADIUS
Le protocole RADIUS (RemoteAuthentication
Dial-In User Service) développé par Livingston Enterprise et
standardisé par l'IETF (cf. RFC 2865 et 2866) s'appuie sur une
architecture client/serveur et permet de fournir des services
d'authentification, d'autorisation et de gestion des comptes lors
d'accès à distance.
Prenons le cas pratique d'un utilisateur nomade, souhaitant se
raccorder via Internet au réseau interne d'une entité du CNRS par
un canal protégé (circuit virtuel protégé CVP -
virtualprivate network VPN). Le principe de l'authentification de cet
utilisateur avec RADIUS est le suivant :
1. L'utilisateur exécute une requête de
connexion. Le routeur d'accès à distance (client RADIUS)
récupère les informations d'identification et d'authentification
de l'utilisateur (son identifiant et son mot de passe par exemple).
2. Le client RADIUS transmet ces informations au serveur
RADIUS.
3. Le serveur RADIUS reçoit la requête de
connexion de l'utilisateur, la contrôle, et retourne l'information de
configuration nécessaire au client RADIUS pour fournir ou non
l'accès au réseau interne à l'utilisateur.
4. Le client RADIUS renvoie à l'utilisateur un message
d'erreur en cas d'échec de l'authentification ou un message
d'accès au réseau si l'utilisateur a pu être
authentifié avec succès.
3.4.2. Protocole SSL
Le protocole SSL (Secure Socket Layer)
développé par Netscape Communications Corp. avec RSA Data
Security Inc. permet théoriquement de sécuriser tout protocole
applicatif s'appuyant sur TCP/IP i.e. HTTP, FTP, LDAP, SNMP, Telnet, etc. mais
en pratique ses implémentations les plus répandues sont LDAPS et
HTTPS.
Le protocole SSL permet non seulement de fournir les services
d'authentification du serveur, d'authentification du client (par certificat
à partir de SSL version 3) mais également les services de
confidentialité et d'intégrité.
Le principe d'une authentification du serveur avec SSL est le
suivant :
1. Le navigateur du client fait une demande de transaction
sécurisée au serveur.
2. Suite à la requête du client, le serveur
envoie son certificat au client.
3. Le serveur fournit la liste des algorithmes
cryptographiques qui peuvent être utilisés pour la
négociation entre le client et le serveur.
4. Le client choisit l'algorithme.
5. Le serveur envoie son certificat avec les clés
cryptographiques correspondantes au client.
6. Le navigateur vérifie que le certificat
délivré est valide.
7. Si la vérification est correcte alors le navigateur
du client envoie au serveur une clé secrète chiffrée
à l'aide de la clé publique du serveur qui sera donc le seul
capable de déchiffrer puis d'utiliser cette clé secrète.
Cette clé est un secret uniquement partagé entre le client et le
serveur afin d'échanger des données en toute
sécurité.
Afin d'éviter des attaques, il est recommandé
d'utiliser la double authentification c'est-à-dire non seulement
l'authentification du serveur mais également celle du client, bien que
l'authentification du client avec SSL soit facultative.
Le protocole TLS version 1.0 (Transport
Security Layer) est la version normalisée de SSL version 3.0 (cf. RFC
2246 de l'IETF). Les versions de TLS sont amenées à
évoluer, au moins au fur et à mesure que de nouvelles attaques
apparaissent. En Février dernier, une faiblesse majeure a
été identifiée dans le protocole SSL : des chercheurs de
l'Ecole Polytechnique de Lausanne ont montré qu'il est possible en moins
d'une heure de trouver le mot de passe d'un internaute connecté à
un service d'e-Commerce. Que l'URL (Uniform Resource
Locator) soit « sûre » ou pas, c'est-à-dire qu'une
société dont la réputation n'est plus à faire
héberge ce site Internet ou bien qu'il s'agisse d'une compagnie dont la
sécurité des transactions n'est pas une priorité, la
faille de sécurité basée sur une usurpation
d'identité était bien présente pour les plates-formes
Linux, Unix, Solaris et dérivés. L'information a
été rapidement transmise à l'organisation OpenSSL afin de
mettre à jour le protocole et développer une nouvelle
Version de SSL qui résiste à cette attaque (cf.
le site www.openssl.org pour les différentes mises à
jour).
3.4.3. Protocole WTLS
Le protocole WTLS (Wireless Transport Layer
Security) est la transposition du protocole TLS dans le monde des
réseaux sans fil. Cependant, les négociations entre le client et
le serveur ont été adaptées afin derépondre aux
contraintes du réseau « wireless ». Ainsi le nombre
d'en-têtes du protocole WTLS est réduit par rapport au protocole
SSL et le taux de compression est supérieur pour le protocole WTLS
puisque la bande passante est plus faible.
Le principe d'une authentification utilisant WTLS est le
suivant :
Les données échangées entre la passerelle
WAP et un serveur Web sont codées en utilisant le protocole SSL ou TLS.
La passerelle WAP gère la conversion entre WTLS et SSL/TLS. Cette
étape de conversation est considérée comme critique car
les données au format SSL/TLS sont décodées par la
passerelle WAP qui les code ensuite au format WTLS. Les données entre le
terminal mobile (PDA, téléphone GSM, etc.) et la passerelle WAP
sont codées au format WTLS.
La passerelle WAP étant le coeur des échanges,
il est essentiel d'en garantir la sécurité non seulement sur le
plan logiciel mais également physique.
3.4.4. Protocole
802.1X-EAP
Le protocole 802.1X-EAP crée une structure
standardisée pour l'authentification mutuelle entre un poste client et
un élément du réseau tel qu'un commutateur réseau
(hub), un point d'accès sans fil, etc. en s'appuyant sur un serveur
d'authentification (souvent de type RADIUS) et l'un des protocoles EAP
(Extensible AuthenticationProtocols, RFC 2284 et 2716) possibles.
Après mutuelle authentification entre le client et le serveur, une
clé est dérivée pour le chiffrement de la communication.
Comme une nouvelle clé est dérivée par 802.1X pour chaque
nouvelle session entre le client et le serveur, cela s'apparente à une
gestion dynamique des clés.
Chapitre 4 CONCLUSION
Les systèmes d'authentification à base de
certificats X.509 semblent moins facilement attaquables et
donc plus robustes que les systèmes basés sur les mots de passe.
Mais un système jugé sûr aujourd'hui peut
révéler des failles ou faiblesses demain. Nous nous souvenons de
la chronique qui a fait la une de nombreux journaux en Fevrier 2000 racontant
comment un informaticien a fabriqué une fausse carte à puce,
appelée « Yescard», capable de tromper un
automate distribuant des tickets de métro et mettant ainsi en exergue
une vulnérabilité dans le système d'authentification du
porteur de carte bancaire. Il est donc primordial de garder à l'esprit
qu'une méthode d'authentification avec Zéro défaut
n'existe malheureusement pas. La sécurité absolue est
une utopie. Cependant il est possible de réduire à un
degré tolérable le niveau de risque lié à une
authentification permissive d'une personne non-autorisée à
accéder au système d'information en mettant en place des
solutions d'authentification forte. Toutefois, il est à noter que
quelque soit la robustesse de la méthode d'authentification
employée, la sécurité du système d'information ne
doit pas uniquement reposer dessus. En effet, la sécurité est un
tout et d'autres mesures de sécurité doivent compléter une
méthode d'authentification forte, comme la mise en place de
séances de sensibilisation à la sécurité
informatique, la diffusion aux utilisateurs de la politique de
sécurité du laboratoire ou de l'entreprise, le cloisonnement de
certains réseaux, etc. (De nombreux exemples sont
présentés dans l'article sur les tableaux de bord de la
sécurité du système d'information du numéro 45 de
la revue).
Chapitre 5 APPLICATION
L'application de gestion des utilisateurs est donc une
application importante. La réalisation de l'application commence par la
modélisation des besoins de l'administrateur de l'entreprise. Il est
donc question de savoir et d'identifier les taches que l'administrateur
souhaitera accomplir. Ceci nous amène à utiliser l'UML et ses
quelques diagrammes pour illustrer ses besoins. Nous aborderons une
méthodologie qui s'articule comme suit :
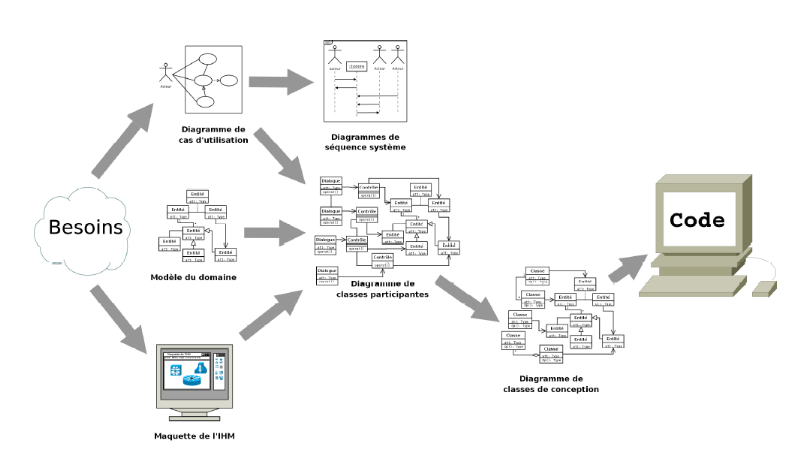
FIGURE VIII-1MÉTHODOLOGIE DE
TRAVAIL
Dans les sections qui suivent nous allons utiliser une
méthodesimple et générique qui se situe à mi-chemin
entre UP (UnifiedProcess), qui constitue un cadregénéral
très complet de processus de développement, et XP
(eXtremeProgramming) qui est uneapproche minimaliste à la mode
centrée sur le code. Cette méthode est issue de celle
présentéepar Pascal Roques (2008) dans son livre « UML -
Modéliser une application web » qui résulte de
plusieursannées d'expérience sur de nombreux projets dans des
domaines variés. Elle a donc montré son efficacité dans la
pratique et est :
- conduite par les cas d'utilisation, comme UP, mais bien plus
simple ;
- relativement légère et restreinte, comme XP,
mais sans négliger les activités de modélisationen analyse
et conception ;
- fondée sur l'utilisation d'un sous-ensemble
nécessaire et suffisant du langage UML (modéliser80% des
problèmes en utilisant 20% d'UML).
1.17 5.1. Identifications des besoins et spécification
des fonctionnalités
5.1.1. Identification et représentation des besoins
(diagramme de cas d'utilisation)
Dans cette partie il est question de recenser les
éléments de besoins des utilisateurs.
- L'administrateur du système devra pouvoir demander au
système des informations concernant l'utilisateur (les
caractéristiques détaillées du poste, les applications en
cours d'exécution, et bien d'autre encore).
- Les utilisateurs devront se connecter au système et
effectuer leurs tâches courantes sans se soucier d'une quelconque
surveillance
Il est donc judicieux de représenter l'essentiel des
besoins dans un diagramme de cas d'utilisation
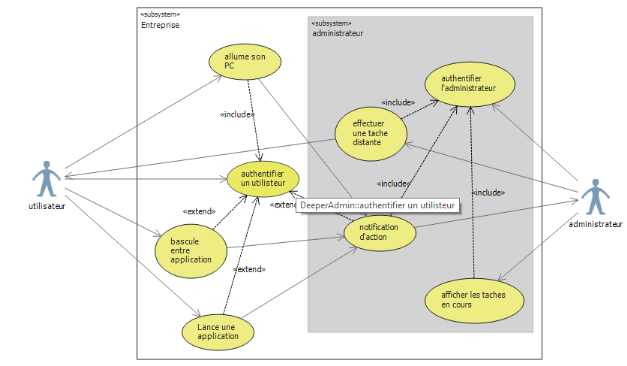
FIGURE VIII-2 DIAGRAMME DE
CAS D'UTILISATION
Dans ce diagramme, il peut être lu que :
· L'administrateur peut
afficher les taches en cours : ceci nous amène à tester
au préalable l'ordinateur dont on souhaite connaitre les taches en cours
· L'administrateur peut effectuer directement
une tache ou une opération distante selon une liste des dache
connu.
· L'utilisateur peut allumer son poste :
(il devra s'être authentifié au préalable) ce qui entraine
une notification dans le système, et ainsi avertir l'administrateur de
cette notification.
· L'utilisateur peut lancer une nouvelle application,
basculé entre applications : ce qui amène aussi
à une notification d'action.
Ces quelques fonctionnalités sont les
éléments de bases que l'application devra réaliser.
Il est donc question de les détailler pour obtenir une
vue plus claire de ses fonctionnalités. Ceci nous amène à
l'élaboration des détails par des diagrammes de
séquence.
5.1.2.
2.1.2. Spécification détaillée des
besoins (diagramme de séquence système)
Dans cette étape, on cherche à détailler
la description des besoins par la description des cas d'utilisation et la
production de diagrammes de séquence système illustrant cette
description.
Il sera donc défini une suite de séquence qui
vont décrire les interactions possible entre l'administrateur et le
système ; ainsi que entre le client et le système.
L'authentification
L'administrateur comme les utilisateurs sont obligé de
s'authentifier pour accéder au système. Le diagramme de
séquence système suivant présente les étapes
d'authentification
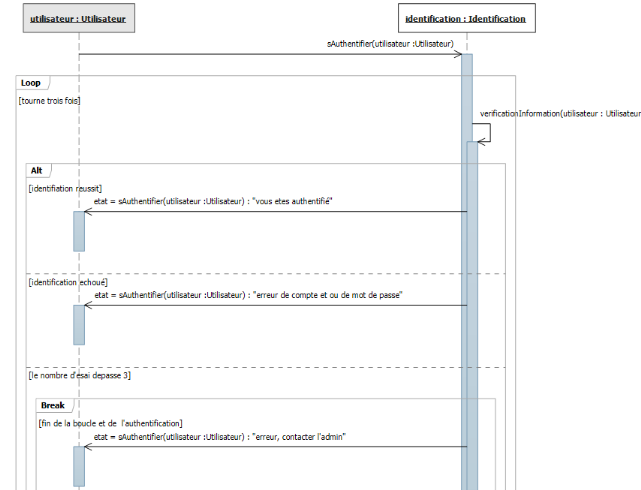
FIGURE VIII-3DIAGRAMME DE
SÉQUENCE: AUTHENTIFICATION
La création des serveurs
Dans le système, chaque poste est équipé
d'un serveur (y compris l'administrateur). Ses serveurs se charge de recevoir
et d'envoyer des requêtes a tous les autres serveurs existant dans le
réseau, y compris l'administrateur.
Remarque : Seul l'administrateur qui possède une
interface qui permet de manager les autres postes et répondre à
toutes les requêtes qui circulent dans le réseau, l'administrateur
possède donc une interface visuelle qui lui permet cette visualisation.
Sur les autres postes est implanté juste une application sans interface,
cette dernière créée un serveur et se charge d'envoyer et
de recevoir des requêtes des autres serveurs (des requêtes qui
peuvent se convertir en commande système interne).
Le diagramme de séquence qui suit présente la
création d'un serveur
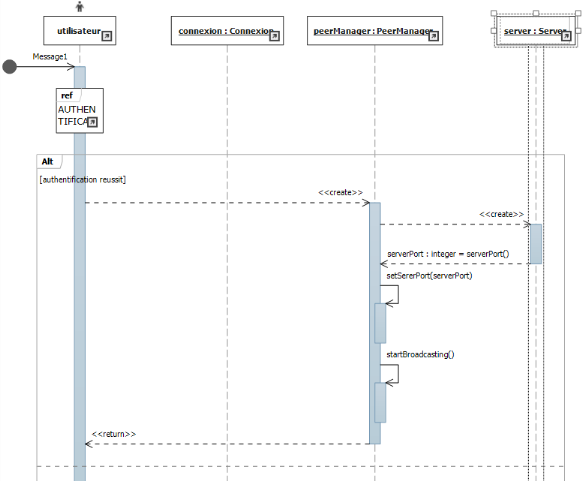
FIGURE VIII-4 DIAGRAMME DE
SÉQUENCE : CRÉATION DE SERVEUR
Interactions entre l'administrateur et le
système
L'administrateur peut vouloir afficher les taches en cours
d'exécution sur un poste distant, afficher les taches qui sont en cours
sur chaque poste. Nous présentons les deux séquences dans les
diagrammes qui suivent.
Afficher les taches en cours chez l'utilisateur
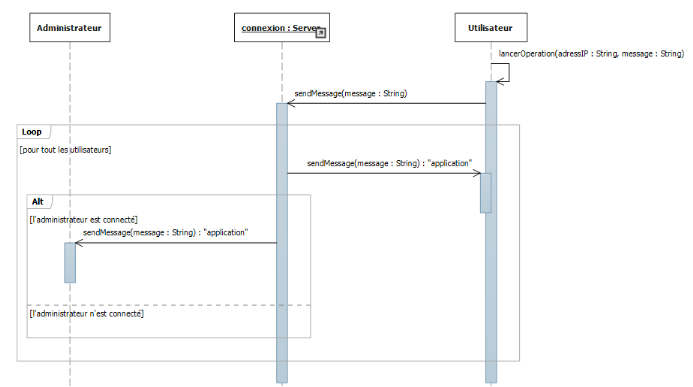
FIGURE VIII-5 DIAGRAMME DE
SÉQUENCE : AFFICHER LES TACHES EN COURS
Effectuer une tache distante
L'administrateur peut effectuer une tache distante directement
sur un poste bien précis et pour une opération bien
précise selon certains critères. Notamment le poste ou effectuer
l'action, la tâche à effectuer selon les programmes en cours...
nous avons ainsi un diagramme de séquence système qui
décris cette opération.
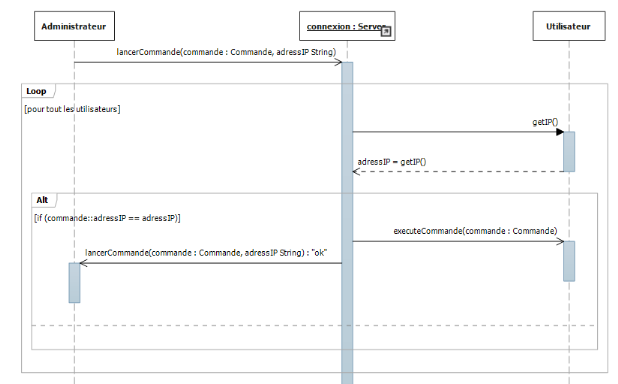
FIGURE VIII-6 DIAGRAMME DE
SÉQUENCE : EFFECTUER UNE TACHE DISTANTE
Interactions entre l'utilisateur et le
système
Certaines opérations du système peuvent provenir
du client comme l'allumage de son PC ou la mise en veille, lancer une
application ou basculer entre application. Ces opérations sont des
événements que le système d'exploitation effectue. Ces
opérations sont automatiquement notifiées chez l'administrateur.
Les diagrammes de séquence ici-basdécrivent ses
fonctions :
Allumer son PC
Lorsqu'un utilisateur allume son PC, une suite
d'opération estexécutée dans le système ainsi que
dans le réseau. Comme présente la figure ici-bas.
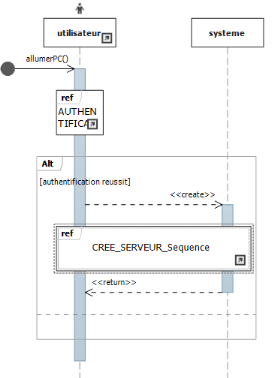
FIGURE VIII-7 DIAGRAMME DE
SÉQUENCE : ALLUMER LE PC DE L'UTILISATEUR
Basculer entre applications tout comme lancer une
application
Lorsque le poste du client est allumé, il peut lancer
une ou plusieurs applications. Ceci fait l'objet aussi d'une notification chez
l'administrateur. Le diagramme ci - bas donne les détails :
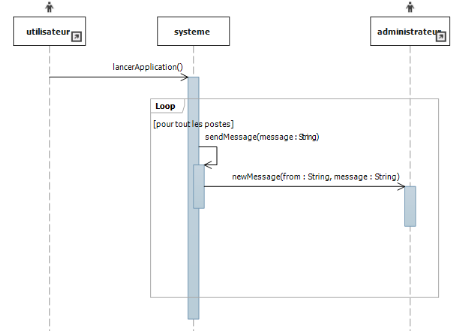
FIGURE VIII-8DIAGRAMME DE
SÉQUENCE : BASCULER ENTRE APPLICATION
1.18 5.2. Phase
d'analyse
Après élaboration des besoins de l'application,
piloté par le cas d'utilisation et de plusieurs diagramme de
séquence ; il devient plus facile d'élaborer les diagrammes
de classe. Et donc une suite de diagramme de classe nous permettra de
comprendre les différents modules de l'application. L'application sera
scindée en deux partis : une qui sera pour l'administrateur et
l'autre qui sera pour le client.
Nous aurons un premier diagramme qui montrera une vue
synthétique des entités qui constitue l'application, plusieurs
autres diagramme présenterons de manière groupé les grands
modules de l'application.
5.2.1. Les entités du domaine
Les entités du domaine sont les classes qui nous
permettrons de représenter les concepts présent dans le domaine.
Ils seront donc directement convertis en tables et relations de la base de
données.
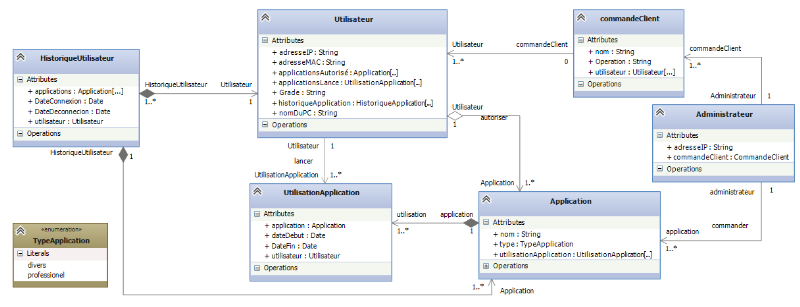
FIGURE VIII-9 DIAGRAMME DE
CLASSE : MODÈLE DU DOMAINE
Dans ce diagramme, nous pouvons constater qu'un client pourra
effectuer des opérations comme lancer une ou plusieurs applications. Ces
applications seront intégrées dans des historiques qui seront vue
par l'administrateur. L'administrateur quant à lui pourra voir ces
historiques sous forme de tache effectué par le client.
5.2.2. Navigation de
l'application
Ici est présentée la navigation de
l'application. Ainsi nous pouvons voir comment l'administrateur parcours les
fonctionnalités qui lui sont offerte.
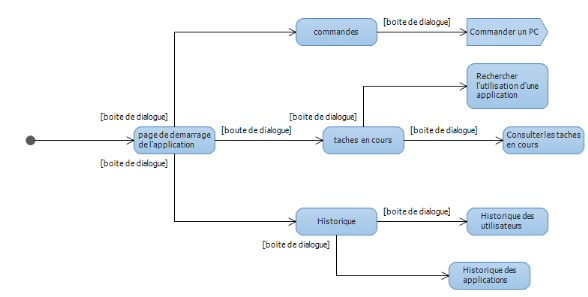
FIGURE VIII-10 DIAGRAMME DE
NAVIGATION : LA NAVIGATION DE L'UTILISATEUR
5.2.3. Les autres classe métier
Hors mis les classes du domaine,d'autres classe sont
nécessaire pour des fonctionnalités bien défini. Nous
pouvons citer les classes comme « peermanager »,
« server »... Et l'ensemble de ses classes constitue celle
sui seront responsable de l'accès au réseau.
En voici un diagramme qui donne les classes métiers de
la partie réseau.
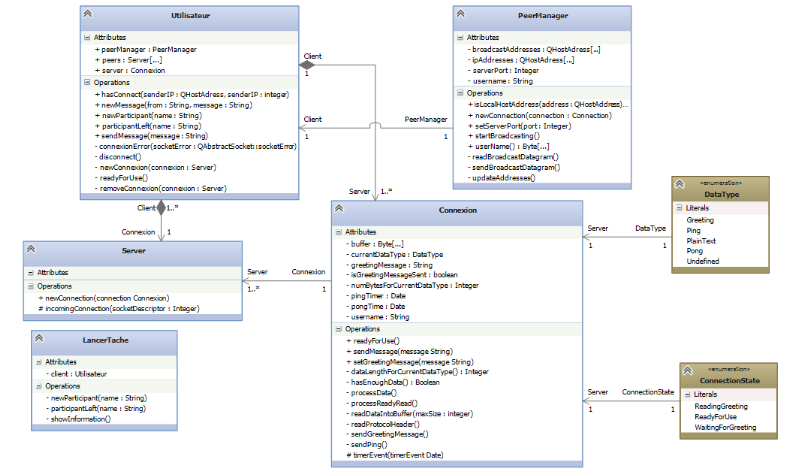
FIGURE VIII-11 DIAGRAMME DE
CLASSE : PARTIE RÉSEAU
1.19 Phase de
conception
L'implémentation de l'application s'effectue par les
étapes suivant :
- Choix de la plateforme (et du langage)
- Choix de l'IDE
- Ecriture de classes retenues
- Phases de test
5.2.4. Plateforme
La plateforme retenu est Qt, avec comme langage C++. Ceci dans
le but de pouvoir construire une application qui peut s'intégrer
facilement dans des systèmes d'exploitation différents.
Qt est un Framework orienté objet et
développé en C++ par QtDevelopementFramework , filiale
de Nokia. Il offre des composantes d'interface graphique (widgets),
d'accès aux données, de connexion réseau, de gestion des
fils d'exécution, d'analyse XML, etc. Qt est par certains aspects un
Framework lorsqu'on l'utilise pour concevoir des interfaces graphiques ou que
l'on architecture son application en utilisant les mécanismes des
signaux et slots par exemple.
Qt permet la portabilité des applications qui
n'utilisent que ses composantes par simple recompilation du code source. Les
environnements supportés sont les Unix (dont Linux) qui utilisent le
système graphique X Windows System et Mac OS X. Le
fait d'être une bibliothèque logicielle multiplateforme attire un
grand nombre de personne qui ont donc l'occasion de diffuser leurs programmes
sur les principaux OS existant.
Qt est notamment connu pour être la bibliothèque
sur lequel repose l'environnement graphique KDE, l'un des environnements de
bureau les plus utilisé dans le monde Linux.
5.2.5. L'environnement de développement
L'environnement de développement retenu est
QtCréator. Un outil qui fait partie le la Plateforme de
développement Qt.
QtCreator est un environnement de développement
intégré multiplateforme faisant partie de Framework Qt. Il est
donc orienté pour la programmation e C++.
Il intègre directement dans l'interface un
débogueur, un outil de création d'interface graphiques, des
outils pour la publication des code sur Git et
Mercurial ainsi que la documentation Qt.
L'éditeur de texte intégré permet l'auto complétion
ainsi que la coloration syntaxique. QtCreator utilise
sous Linux le compilateur gcc et
MinGW par défaut sous Windows.
1.20 5.3.
Présentation et fonctionnement de l'application
L'application est subdivisée en deux parties :
l'une pour l'administrateur et l'autre pour les autres postes à
surveiller. Seule la partie administrateur possède une interface
graphique. Ceci lui permettant de réaliser les opérations qu'il
souhaite.
La partie du client ou celle qui se trouve sur tous les autres
postes à surveiller n'a pas d'interface graphique. Elle est
destinée à communiquer avec le poste administrateur pour fournir
à ce dernier les éléments nécessaire ou recevoir
une commande spécifique à exécuter sur lui-même.
L'interface de l'application coté administrateur se
présente comme suit :
- Un menu principal renseigne sur toutes les
fonctionnalités que l'application comporte
251657216
Figure 4.12. Capture du formulaire de démarrage
(Partie administrateur)
- Le menu «tache» comporte la fonctionnalité
qui permet voir les applications en cours de toutes les machines sur le
réseau...
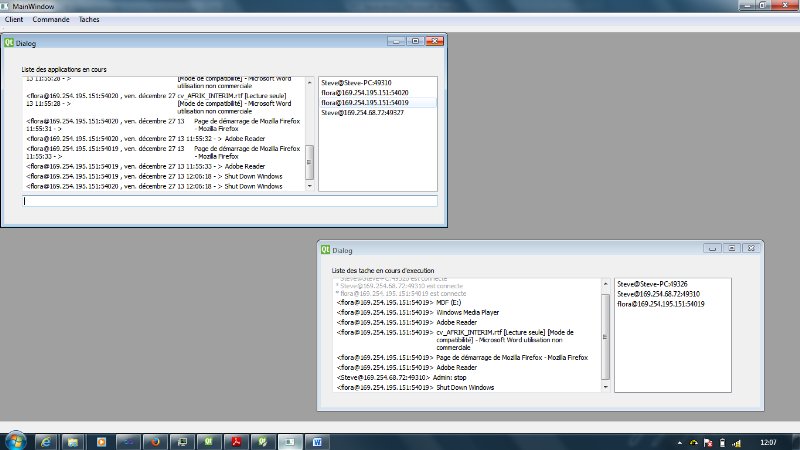
Figure 4.13. Capture du formulaire : Liste des taches
(Partie administrateur)
- Le menu « commande » contient une
fonctionnalité permettant a l'administrateur de commander,
exécuter une opération sur un autre poste
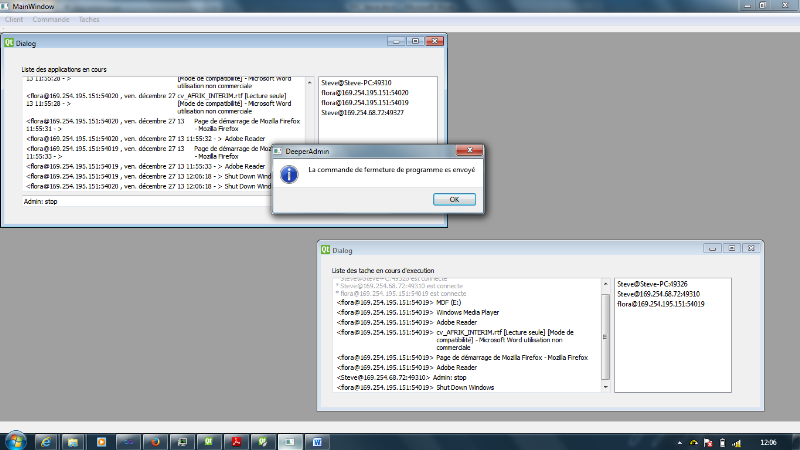
Figure 4.14. Capture du formulaire : Lancer commande
(Partie administrateur)
1.21 5.4. Code source
Le code source présenté est celui de l'interface
de la classe « Connexion »
1. #ifndefCONNECTION_H
2. #defineCONNECTION_H
3. #include<QHostAddress>
4. #include<QString>
5. #include<QTcpSocket>
6. #include<QTime>
7. #include<QTimer>
8. staticconstintMaxBufferSize=1024000;
9. classConnection:publicQTcpSocket
10. {
11. Q_OBJECT
12. public:
13. enumConnectionState{
14. WaitingForGreeting,
15. ReadingGreeting,
16. ReadyForUse
17. };
18. enumDataType{
19. PlainText,
20. Ping,
21. Pong,
22. Greeting,
23. Undefined
24. };
25. Connection(QObject*parent=0);
26. QStringname()const;
27. voidsetGreetingMessage(constQString&message);
28. boolsendMessage(constQString&message);
29. signals:
30. voidreadyForUse();
31.
voidnewMessage(constQString&from,constQString&message);
32. protected:
33. voidtimerEvent(QTimerEvent*timerEvent);
34. privateslots:
35. voidprocessReadyRead();
36. voidsendPing();
37. voidsendGreetingMessage();
38. private:
39. intreadDataIntoBuffer(intmaxSize=MaxBufferSize);
40. intdataLengthForCurrentDataType();
41. boolreadProtocolHeader();
42. boolhasEnoughData();
43. voidprocessData();
44. QStringgreetingMessage;
45. QStringusername;
46. QTimerpingTimer;
47. QTimepongTime;
48. QByteArraybuffer;
49. ConnectionStatestate;
50. DataTypecurrentDataType;
51. intnumBytesForCurrentDataType;
52. inttransferTimerId;
53. boolisGreetingMessageSent;
54. };
55. #endif
56. Chapitre 6
CONCLUSION
Les entreprises de parson essence visentà maximiser
leur travail pour un meilleur rendement. En passant par ses agents, son
matériel, sa production et tout ce qui concours a la réalisation
de ses objectifsvont toujours dans le sens de maximiser son rendement. Ainsi
un outil comme ce qui vient d'être présenté est un plus
dans la maximisation de ses recettes.
L'application ainsi présenté entre dans la
catégorie des applications de monitoring et se concentre plus sur les
taches quotidienne desutilisateurs, il permet de surveiller les utilisateurs et
leurs activité et ainsi produireune journalisation des taches
effectué quotidiennement. Cette journalisation
pourraêtreutilisée par des chefs de projets ou des
décideurs qui peuvent s'en inspirer pour mieux répartir les
tâches, réorganiser le travail des agentset ainsi gagner en
productivité.
Plusieurs notions ont intervenu dans la réalisation de
l'application. Nous pouvons citer :
- La communicationréseau en utilisant le protocole UDP
lors des échanges réseau entre modules de chaque
utilisateur ;
- L'API de Windows pour certains appels
systèmes : elle ont permis de se connecter au service d'affichage
de Windows et de pouvoir informer d'administrateur en temps réel des
applications qui sont en cours d'exécutions dans les postes des
utilisateurs;
- La plateforme de développement Qtpour les interfaces
graphique « QtGui » et ses bibliothèque
réseau tel « QtNetwork »
Bibliographie
Les ouvrages
[1.] Chantal Morley, « Management d'un projet
système d'information », DUNOD 6ème Edition, Paris,
1998
[2.] Guy PUJOLLE , « Les réseaux »,
Edition Eyrolles , Paris, 2008
[3.] Jean FrançoisCARPENTIER , « La
sécurité informatique dans la petite entreprise, état de
l'art et bonnes pratiques », Edition ENI , Paris, 2008
[4.] Jean-Luc BAPTISTE, « Merise Guide
pratique », Edition ENI, Paris, 2009
[5.] Richard SMITH,« Authentification »,Edition
Addison Wesley, USA, 2010
[6.] Thierry AUTRET, Marie-Laure OBLE LAFFAIRE et Laurent
BELLEFIN, "Sécuriser ses échanges électroniques avec une
PKI - Solutions techniques et aspects juridiques", Edition EYROLLES,2008.
[7.] Pascal Roques « Les cahier du
programmeur », Edition Eyrolles, Paris, 2008
Les cours
[8.] Laurent AUDIBERT, « Bases de données et
Langage SQL »,Institut Universitaire de Technologie de Villetaneuse -
Département Informatique, 2008
[9.] Laurent Audibert, «Cours de UML 2 »,
Institut Universitaire de Technologie de Villetaneuse - Département
Informatique ,2007 - 2008
Les mémoires
[10.] Valérie TRIQUENAUX MARTIN, « Quelques
démarche de qualité pour la gestion quotidienne d'un
Intranet », Conservatoire des arts et métier /Institut
National des Techniques de la Documentation, Mémoire de DESS, 2005
Les sites web
[11.] www.developpez.com en date
du 20 janvier 2016
[12.] www.siteduzero.comen date
du 20 janvier 2016
[13.] www.wikipédia.org en
date du 30 janvier 2016
[14.] http://www.ietf.org/rfcen
date du 3 février 2016
[15.] http://www.openssl.orgen date
du 3 février 2016
[16.]
http://web.mit.edu/kerberos/www/en date du 3 février 2016
Autres documents
[17.] Club de la sécurité de l'information
française (CLUSIF), « Gestion des
identités », Paris, 2007
Table de
matière
Epigraphie.........................................................................................................I
Dédicace............................................................................................................II
Remerciement.............................................................................................
...III
Liste des
abréviations..........................................................................................IV
Liste des
figures...................................................................................................V
Liste des
tableaux..............................................................................................VI
INTRODUCTION
GENERALE.................................................................................1
Chapitre I. LES RESEAUX INFORMATIQUES
3
1.1. INTRODUCTION
3
1.2. QUELQUES CONCEPTS
3
1.3. TOPOLOGIES DE RESEAUX
5
1.3.1. Topologie en étoile
6
1.3.2. Topologie en Arbre
6
1.3.3. Topologie maillé
7
1.3.4. Topologie en Anneau
7
1.4. L'ARCHITECHTURE EN COUCHE
8
1.4.1. Le modèle de
référence
8
1.4.2. Les couches du modèle de
référence
8
1.5. LES RESEAUX IP
14
1.5.1. Architecture IP
14
1.5.2. Fonctionnement des réseaux
IP
15
1.6. L'INTRANET
19
1.6.1. Architecture
20
1.6.2. Intranet et entreprise
21
Chapitre II. GESTION DES UTILISATEURS
23
2.1 INTRODUCTION
23
2.2. QUELQUES CONCEPTS
23
2.2.1. Personne (Utilisateur)
23
2.2.2. Compte
24
2.2.3. Rôles
25
2.2.4. Profils
26
2.2.5. Le poste opérationnel
26
2.2.6. Groupe
26
2.2.7. Périmètre
27
2.2.8. Périmètre temporel
27
2.2.9. Périmètre
Géographique
28
2.2.10. Périmètre
fonctionnel
29
2.3. DIFFERENTS NIVEAUX D'UTILISATEURS
29
2.3.1. L'utilisateur en fonction de son
activité du point de vue applicatif et/ou système
30
2.3.2. L'utilisateur dans la sécurité
des systèmes
30
2.4. LA GESTION DES UTILISATEURS DANS LES
ENTREPRISES
31
2.4.1. Etat des lieux
31
2.4.2. Illustration
32
2.5. LES COMPTES UTILISATEURS
33
2.5.1. Compte d'utilisateur principal
33
2.5.2. Compte d'utilisateur d'un
système d'exploitation
33
2.6. LE MODELE
« RBAC »
34
2.6.1. Modèle de base RBAC
34
Principe de privilège minimum
35
2.6.2. Modèle RBAC
Hiérarchique
35
2.6.3. Modèle RBAC avec
contraintes
36
2.7. AUTRES MODELES
37
2.7.1. Modèle DAC
37
2.7.2. Modèle MAC
38
Chapitre III. L'AUTHENTIFICATION
40
3.1. INTRODUCTION
40
3.2. METHODES COURANTES
D'AUTHENTIFICATION
40
3.2.1. Mots de passe
40
3.2.2. Certificats de clés
publiques
41
3.2.3. Biométrie
43
3.3. AVANTAGES ET INCONVENIENTS DES
DIFFERENTES TECHNIQUES D'AUTHENTIFICATION
45
3.4. PROTOCOLES D'AUTHENTIFICATION
COURAMMENT UTILISES
48
3.4.1. Protocole RADIUS
48
3.4.2. Protocole SSL
48
3.4.3. Protocole WTLS
49
3.4.4. Protocole 802.1X-EAP
50
3.5. CONCLUSION
50
Chapitre IV. APPLICATION
51
4.1. Identifications des besoins et
spécification des fonctionnalités
52
4.1.1. Identification et
représentation des besoins (diagramme de cas d'utilisation)
52
4.1.2. Spécification
détaillée des besoins (diagramme de séquence
système)
53
4.2. Phase d'analyse
58
4.2.1. Les entités du domaine
58
4.2.2. Navigation de l'application
60
4.2.3. Les autres classe métier
60
4.3. Phase de conception
61
4.3.1. Plateforme
61
4.3.2. L'environnement de
développement
62
4.4. Présentation et fonctionnement
de l'application
62
4.5. Code source
64
CONCLUSION
66
Bibliographie
67
Les ouvrages
67
Les cours
67
Les mémoires
67
Les sites web
67
Autres documents
67
Table de matière
68
* 1Ici il est question d'un
nouvel employé de l`entreprise
| 

