2.2. Les
méthodes d'appariements
2.2.1. Appariement sur les
caractéristiques observables
Les méthodes d'appariement ont été
proposées par Rubin en 1977. Le principe de cette méthode est
d'utiliser les informations disponibles des individus non traités dans
le but de construire pour chaque individu traité son contrefactuel. Pour
Rubin, c'est la méthode qui se rapproche le plus des
expérimentations contrôlées. En effet, tandis que les
expérimentations contrôlées reposent sur un tirage
aléatoire des individus traités et non traités
indépendamment de ce que sera le résultat à
l'expérience, les méthodes d'appariement quat à elles
reposent sur un outil, le score de propension, qui n'en dépend pas
également. Le score de propension mesure la probabilité
d'accéder au traitement, indépendamment des résultats
à l'expérience. Il permet aussi d'équilibrer les variables
observables dans les groupes de traitements et de contrôles
c'est-à-dire de rendre les deux groupe semblable du point de vue de la
distribution des variables agissant sur la probabilité d'accéder
au traitement.
Donc on associe pour chaque individu i traité un
individu non traité, noté á(i) dont les
caractéristiques observables sont identiques à celle de i
c'est-à-dire que Xá(i)=Xi, avec X un
vecteur de caractéristiques individuelles.
L'estimateur ainsi proposé par Rubin dans ce cas
est :
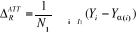
Où N1 est le nombre d'individus
traités, I1 est le sous ensemble des individus
traités défini par I1 = {i|Ti=1} et enfin
Yá(i)=.Ê
(Yi0|Ti=0,xi)= Ê
(Yi0|Ti=1,xi)
Cet estimateur consiste à prendre l'individu le proche
possible de l'individu non traité.
2.2.2. Appariement sur score de
propension
Cette méthode a été mise en oeuvre par
Rubin et Rosenbaum pour apporter une solution au problème de dimension
du vecteur X. Pour ces auteurs Si la variable de résultat Y0
est indépendante de l'accès au traitement T conditionnellement
aux observables X, alors elle est également indépendante de T
conditionnellement au score de propension P(X) :
Y0 -T|X ==> Y0 - T|P(X) avec
P(X)=Pr(T=1|X)
De cette propriété, l'appariement des individus
devrait se faire sur leur score de propension qui résume l'ensemble des
caractéristiques observables.
2.2.3. Appariement avec fonction de
noyau (Kernel Matching)
Cette méthode a été introduite par
Heckman, Ichimura et Todd en proposant un estimateur à noyau qui est
convergent en 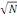 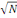 et asymptotiquement distribué selon la loi normale. Il
s'écrit de la façon suivante : et asymptotiquement distribué selon la loi normale. Il
s'écrit de la façon suivante :
Ê (Y0|P (xi)=P
(xi))=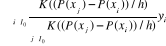
Où I0 est l'ensemble des individus non
traités, défini par I0= {i|Ti=0}, N0 est le
nombre d'individu non traités, K une fonction noyau continûment
différentiable, symétrique par rapport à 0 et telle
que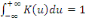 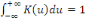 , et h la fenêtre d'estimation. Chaque individu non traité
contribue à la construction du contrefactuel de l'individu i, avec une
importance qui varie entre son score et celui de l'individu
considéré. Ainsi l'estimateur final de l'effet du traitement
conditionnellement au fait d'être traité est : , et h la fenêtre d'estimation. Chaque individu non traité
contribue à la construction du contrefactuel de l'individu i, avec une
importance qui varie entre son score et celui de l'individu
considéré. Ainsi l'estimateur final de l'effet du traitement
conditionnellement au fait d'être traité est :
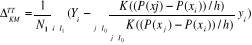
| 

