Marwa AMARA
Dédicaces
A ma très chère Maman
Fouzia
Pour tout l'amour dont tu m'as entouré, pour tout ce
que tu as fait pour moi.
Que ce modeste travail soit l'exaucement de tes
voeux tant formulés et de tes prières
quotidiennes.
A mon très cher Papa
Belgacem
Pour ton amour, ton soutien et tes
encouragements.
J'espère que j'étais et que je resterais
à la hauteur de vos espérances.
Je te dédie ce travail
en gage de ma gratitude éternelle et de mon profond respect.
A mes chères frères Marwen
et Oussama
Vous étiez toujours à mes
côtés, à m'encourager et à me soutenir.
Je vous
souhaite une bonne continuation dans vos études,
et une vie pleine de
joie et de bonheur.
A tous ceux qui m'ont soutenu jusqu'au
bout.
Marwa AMARA
Remerciements
C
'EST avec un grand plaisir que je réserve cette page en
signe de gratitude et de profonde reconnaissance à tous ceux qui m'ont
aidé à la réalisation de ce travail. Je tiens à
remercier spécialement :
Professeur Faouzi GHORBEL, mon Superviseur de
mastère, directeur du laboratoire CRISTAL à l'Ecole Nationale des
Sciences de l'Informatique, pour ses conseils fructueux et pour ses
précieuses directives.
Docteur Kamel ZIDI, mon Encadrant de
mastère, pour son aide, sa disponibilité et sa
compréhension. Ses conseils et ses encouragements m'ont
été très utiles pour mener à bien ce travail.
Je tiens aussi à remercier Mm Ibtissem BEN OTHMEN
pour ses conseils, ses suggestions et pour sa contribution à
l'enrichissement de ce travail.
Je remercie également les membres du jury qui ont pris la
peine d'évaluer cette modeste contribution :
Je tiens à remercier Docteur Riadh ABDELFATTAH
qui m'a fait l'honneur de présider le jury de ma soutenance.
Je tiens à remercier Docteur Slim MHIRI,
pour avoir accepter la charge de rapporter mon travail.
Enfin, je tiens à remercier tous ceux qui ont
contribué, de près ou de loin, à l'achèvement de
cette mémoire.

Résumé
C
E travail porte sur la reconnaissance des textes arabes
imprimés multifontes. L'approche proposée concerne l'association
de deux techniques la sélection des primitives et la reconnaissance des
caractères. La méthode de reconnaissance est basée sur une
technique hybride consistant à mettre en coopération les
réseaux de neurone perceptron multicouche et les algorithmes
génétiques. L'un des objectifs de ce travail est de proposer une
hybridation pour la sélection des primitives pertinentes. Le choix d'une
telle hybridation est motivé par son succès en reconnaissance des
chiffres. En effet, l'intérêt de ce modèle
Neuro-Génétique réside dans le fait qu'il est capable
d'améliorer la capacité de discrimination du perceptron
multicouche pur.
Mots clés : Reconnaissance des caractères arabes
, Sélection des primitives, Perceptron multicouche, Algorithme
génétique.
Abstract
I
N this work we aim at developping a multifonts printed arabic
texts recognition system. the proposed approache is about the combination of
two techniques Feature selection and character recognition. The adopted
recognition method is based on a hybrid technique which consists of putting
together; the neural networks multilayer perceptron and the genetic algorithms.
One objective of this work is to propose a hybrid approach for the feature
selection. The choice of this technique is motivated by its success in the
recognition of digits. Indeed, the interest of this Neuro-Genetic model is the
fact that it is able to improve the discriminatory capacity of pure perceptron
multilayer.
Key words : Arabic character recognition ,
Feature selection, Perceptron multilayer, Genetic algorithm.
Table des matières
|
Introduction générale
1 La Reconnaissance Optique des
Caractères
1.1 Différents aspects de l'OCR
|
1
3
3
|
|
1.1.1
|
Type d'acquisition
|
4
|
|
|
1.1.1.1 Les systèmes en-lignes
|
5
|
|
|
1.1.1.2 Les systèmes hors-lignes
|
5
|
|
1.1.2
|
Approche de reconnaissance
|
6
|
|
|
1.1.2.1 Approche globale
|
6
|
|
|
1.1.2.2 Approche analytique
|
6
|
|
1.2
|
Caractéristiques de l'écriture arabe
|
7
|
|
1.3
|
Organisation d'un système de reconnaissance
|
10
|
|
1.3.1
|
Prétraitement
|
11
|
|
|
1.3.1.1 Binarisation
|
11
|
|
|
1.3.1.2 Lissage
|
12
|
|
|
1.3.1.3 Normalisation
|
12
|
|
|
1.3.1.4 Squelittisation
|
12
|
|
1.3.2
|
Segmentation
|
12
|
|
|
1.3.2.1 Segmentation en lignes
|
13
|
|
|
1.3.2.2 Segmentation en mots
|
13
|
|
|
1.3.2.3 Segmentation en caractère
|
14
|
|
1.3.3
|
Extraction des primitives
|
14
|
|
|
1.3.3.1 Primitives locales
|
14
|
|
|
1.3.3.2 Primitives globales
|
15
|
|
1.3.4
|
Apprentissage
|
15
|
|
|
1.3.4.1 Apprentissage Supervisé
|
15
|
|
|
TABLE DES MATIÈRES
|
|
|
1.3.4.2 Apprentissage Non Supervisé
1.3.5 Reconnaissance
1.3.5.1 Approche structurelle
1.3.5.2 Approche stochastique
1.3.5.3 Approche statistique
1.3.5.4 Les approches hybrides
1.3.6 Post-traitement
|
16
16
16
17
18
18
19
|
|
2
|
Fondements Théoriques
|
20
|
|
2.1
|
Le réseau perceptron multicouche
|
20
|
|
|
2.1.1 Le perceptron simple
|
21
|
|
|
2.1.2 Architecture d'un perceptron multicouche
|
23
|
|
|
2.1.3 Apprentissage d'un perceptron multicouches
|
25
|
|
2.2
|
Les algorithmes génétiques
|
27
|
|
|
2.2.1 Génération de la population initiale
|
28
|
|
|
2.2.2 Codage
|
29
|
|
|
2.2.3 Fonction d'évaluation
|
29
|
|
|
2.2.4 Sélection
|
30
|
|
|
2.2.5 Croisement
|
31
|
|
|
2.2.6 Mutation
|
32
|
|
|
2.2.7 Insertion
|
33
|
|
|
2.2.8 Critère d'arrêt
|
34
|
|
2.3
|
L'hybridation neuro-génétique
|
34
|
|
|
2.3.1 Système de OLIVEIRA
|
35
|
|
|
2.3.2 Système de KROUCHI et DJEBBAR
|
36
|
|
3
|
Contributions à la reconnaissance Des
caractères arabes imprimés
|
38
|
|
3.1
|
Position du problème
|
38
|
|
3.2
|
Justification de l'approche choisie
|
39
|
|
|
3.2.1 Les procédures de recherche
|
40
|
|
|
3.2.2 Les fonctions d'évaluation
|
41
|
|
3.3
|
Système proposé
|
42
|
|
|
3.3.1 Description générale
|
42
|
|
|
3.3.2 Description détaillée
|
43
|
|
|
3.3.2.1 Prétraitement
|
44
|
|
|
3.3.2.2 Segmentation
|
46
|
|
|
3.3.2.3 Extraction des primitives
|
49
|
|
|
|
ii
|
TABLE DES MATIÈRES
3.3.2.4 Sélection des primitives 51
3.3.2.5 Reconnaissance 53
3.3.2.6 Post traitement 54
4 Expérimentation et évaluation
56
4.1 Méthodes d'évaluation d'un OCR 56
4.1.1 Evaluation globale 57
4.1.2 Evaluation locale 57
4.2 Expérimentation 57
4.2.1 Prétraitement 58
4.2.2 Segmentation 59
4.2.3 Extraction des primitives 61
4.2.4 Sélection des primitives 63
4.2.5 Apprentissage 68
4.2.6 Reconnaissance 70
4.3 Evaluation de notre système 72
Conclusion et perspectives 73
Bibliographie 76
A Segments classés par leurs positions
81
B Description de la base 86
iii
Table des figures
1.1 Différents Systèmes et Approches de
Reconnaissance 4
1.2 les quartres positions possibles du caractère "
Hha" 8
1.3 Chevauchement et Ligature 9
1.4 Les sept caractères qui ne se relient pas à
leurs successeurs 9
1.5 Influence de la voyellisation sur le sens du mot 9
1.6 Caractères classés par corps commun 10
1.7 Schéma général d'un Système de
Reconnaissance de Caractères 10
1.8 Résultat de certaines opérations de
prétraitement 11
1.9 Segmentation Horizontale [HB02] 13
1.10 Segmentation verticale [HB02] 13
1.11 Segmentation en graphèmes [CBB01] 14
1.12 Approches de Classification 16
2.1 Modèle d'un réseau de neurone de type
perceptron simple 22
2.2 Deux situations pour lesquelles un perceptron simple ne
peut pas discriminer
les classes [Héb99] 23
2.3 Structure d'un perceptron multicouche 24
2.4 Frontière de décision obtenue à
l'aide d'un perceptron multicouche [Gos96] 24
2.5 Fonctionnement général de l'algorithme
génétique 28
2.6 Croisement en 1-point de deux chromosomes 32
2.7 Croisement en 2-points de deux chromosomes 32
2.8 Exemple de mutation 33
3.1 Approche de selection de primitives [YH97] 41
3.2 Structure de la phase d'apprentissage 43
3.3 Aperçu détaillé sur le système
de reconnaissance 44
v
TABLE DES FIGURES
3.4 Modèles utilisés pour numériser une
image dans l'algorithme Stentiford . . . 45
3.5 Processus de segmentation 46
3.6 Processus de
construction des composantes connexes à partir de balayage de
lignes d'image »Ta» 47
3.7 Extraction de vecteurs
de primitives avec des fenêtres glissante: (a) horizontale
et (b) verticale 49
3.8 Exemple de codage d'un vecteur de primitives 51
3.9 Un automate utilisé pour corriger les signes
diacritiques de caractère "Waw" 53
3.10 Détection des espaces dans une ligne 54
4.1 Image de test 58
4.2 Extraction de squelette 58
4.3 Segmentation en ligne 59
4.4 Séparation des mots et détection des signes
diacritiques 59
4.5 Sous-segmentation du caractère"Lam Alef" 60
4.6 Sur-segmentation des caractères " Sad"et " Sin "
60
4.7 Sur-segmentation des caractères isolés 61
4.8 La détection des boucles par l'algorithme Flood-fill
61
4.9 Mesure de la distance acendante et descendante 62
4.10 Larguer du caractère 62
4.11 Courbe représentant l'évaluation du
Fitness dans le cas de probabilité de mu-
tation Pmut= 0.04 et une variation
de probabilité de croisement Pcross . . . .
64
4.12 Courbe représentant l'évaluation du Fitness
dans le cas de probabilité de croi-
sement Pcross = 0.65 et une variation de
probabilité de mutation Pmut . . . . 65
4.13
Comparaison de la convergence du Fitness pour deux populations de
tailles
différentes 66
4.14 Distribution des individus dans l'espace de recherche
67
4.15 Les positions possibles des caractères dans un mot
68
4.16 Apprentissage du réseau perceptron multicouche
70
4.17 Reconaissance du segments du caractère 70
4.18 Image du mot et le mots reconnu 71
4.19 Image de la ligne et la ligne reconnue 72
4.20 Image du texte et texte reconnu 72
4.21 Variation du taux de reconnaissance par caractères
72
B.1 Aperçu sur la base 86
Liste des tableaux
|
3.1
|
Existence de boucle dépendant de la position du
caractère
|
50
|
|
4.1
|
Choix de paramètres de l'algorithme
génétique
|
63
|
|
4.2
|
Paramètres finales de l'algorithme
génétique
|
67
|
|
4.3
|
Paramères des réseaux
|
69
|
|
4.4
|
Caractéristiques des signes diacritiques
|
71
|
|
4.5
|
Comparaison des résultats
|
73
|
|
A.1
|
Segments Initials
|
82
|
|
A.2
|
Segments Milieux
|
83
|
|
A.3
|
Segments finals
|
84
|
|
A.4
|
Segments isolés
|
85
|
|
B.1
|
Caractères utilisés pour l'apprentissage du
réseau de neurone
|
86
|
Introduction générale
L
A communication Homme-machine tend à limiter
l'intervention de l'être humain. Ceci
est possible par la conception et la réalisation de
machines capables d'écouter et de
reconnaitre la parole, de lire les
documents et de manipuler correctement les caractères qui les composent.
La reconnaissance optique des caractères, connue sous la
dénomination anglaise OCR-Optical Character Recognition fait
partie du domaine de reconnaissance des formes. Ce domaine a fait l'objet de
multiples recherches. Son but est de traduire un document imprimé ou
manuscrit en fichier informatique apte à être manipulé par
le logiciel de traitement de texte.
La lecture des documents imprimés,
dactylographiés et même manuscrits, présente un grand
intérêt pour plusieurs domaines. Si l'ordinateur savait lire
couramment, il pourrait trier le courrier, traiter automatiquement les
chèques ou les factures et accéder à toutes les formes
d'information écrites dont l'existence commence par un papier.
Malgré les progrès réalisés sur le plan
matériel (tablette à digitaliser, crayon otique, etc.) et
logiciel (interface graphique, système conversationnel, etc.), le
processus de communication Homme-Machine reste lent et pénible. Par
conséquent, il constitue un obstacle pour tous les traitements
envisagés. Contrairement au latin, l'écriture arabe
présente des caractéristiques morphologiques complexes qui sont
l'origine de la défaillance des traitements. Les caractères
arabes s'écrivent de manière cursive. Ils sont ligaturés
horizontalement et parfois verticalement, ce qui complique la tâche de
segmentation.
La reconnaissance d'un caractère commence d'abord par
l'analyse de sa forme et l'extraction des traits caractéristiques dits
encore primitives qui seront exploitées pour son identification. A ce
niveau, les primitives peuvent être décrites comme un outil
permettant de distinguer un objet d'une classe d'un autre objet d'une autre
classe. Il est nécessaire de définir des primitives
significatives lors du développement d'un système de
reconnaissance. Les primitives sont définies par expérience ou
par intuition. Plusieurs primitives peuvent être extraites dont certaines
sont non pertinentes ou redondantes. La représentation des primi-
2
INTRODUCTION GENERALE
tives utilisée est vectorielle. La taille de ce vecteur
peut être large si un grand nombre de primitives est extrait. La
performance du système de reconnaissance devient mauvaise, alors, et le
temps de calcul augmente en mesure que le nombre de primitives augmente.
L'approche proposée présente une méthode
d'optimisation pour la sélection des primitives d'un système de
reconnaissance des caractères arabes imprimés multifontes. La
méthode de reconnaissance est fondée sur une technique hybride
qui consiste à mettre en coopération les réseaux
perceptron multicouche et les algorithmes génétiques. En effet,
ce travail propose une technique hybride pour la reconnaissance des textes
arabes. Le choix de cette technique est motivé par son succès en
reconnaissance des chiffres. L'intérêt de ce modèle
neuro-génétique vient de fait qu'ils semblent capables
d'améliorer les performances du système de reconnaissance en
optimisant le nombre de primitives sélectionné.
Notre présent document est partitionné de la
manière suivante :
Dans le premier chapitre, nous commencerons par
présenter une étude bibliographique sur le domaine de
reconnaissance d'écriture. Ensuite, nous présenterons les
caractéristiques morphologiques de l'écriture arabe. Enfin, nous
exposons les aspects généraux de la reconnaissance optique de
l'écrit ainsi que les problèmes qui lui sont liés tout en
soulevant les problèmes rencontrés dans le domaine d'OCR
arabe.
Dans le second chapitre, nous exposerons les notions de base
relatives au perceptron multicouche et l'algorithme génétique
nécessaire à la compréhension de notre travail. Dans la
dernière section, nous préciserons la motivation de l'usage des
modèles hybrides.
Le troisième chapitre présentera, d'abord, le
problème ainsi que la solution que nous aurons adopté. Ensuite,
nous présenterons un aperçu général sur notre
système de reconnaissance d'écriture arabe imprimée
proposée. Enfin, nous détaillerons chaque processus de ce
système.
Le dernier chapitre sera consacré aux tests et aux
résultats enregistrés. Il décrira l'application du
modèle hybride dans le cadre de reconnaissance d'écriture arabe
imprimé. De même, nous donnerons les résultats des
performances de notre système ainsi que les expérimentations
réalisées pour le valider.
Enfin, une conclusion générale fera une
synthèse du présent travail, exposera ses limites et proposera de
nouvelles perspectives de recherche.
Chapitre1
La Reconnaissance Optique des Caractères
L
A reconnaissance de l'écriture relève du domaine
de reconnaissance des formes qui s'inté-
ressent aux formes des caractères. Depuis les
années 40, la reconnaissance des caractères
a fait l'objet de
recherches très poussées. Les chercheurs ont
réalisé des travaux intenses qui ont donné lieu à
la publication de plusieurs articles portants sur la reconnaissance des
caractères.
Dans ce chapitre, nous rappelons certaines notions d'OCR
1en se référant aux différents travaux
réalisés sur ce sujet. Ensuite, nous présentons les
caractéristiques morphologiques de l'écriture arabe. Enfin, nous
exposons les aspects généraux de la reconnaissance optique de
l'écrit ainsi que les problèmes qui lui sont liés tout en
soulevant les problèmes rencontrés dans le domaine d'OCR
arabe.
1.1 Différents aspects de l'OCR
La reconnaissance optique des caractères est un
processus qui permet de convertir un texte écrit sur papier en format
numérique. Des aperçus historiques à propos des
méthodes de reconnaissance peuvent être trouvés à
[AY01, Man86, SFK96, Gov90, AM11]. La reconnaissance de l'écriture arabe
remonte aux années 80. Néanmoins, la majorité des travaux
ayant déjà été publiés ont été
axés sur les caractères latins puis appliqués tels quels
pour la reconnaissance de l'écriture arabe. Pour un tour d'horizon dans
le domaine de reconnaissance d'écriture arabe, nous citons les articles
[Bel95, AS95]. Quant à l'état de l'art dans le domaine de
reconnaissance hors ligne les aperçus dans [LV06, Ami97] sont à
consulter.
1. Optical Character Recognition
4
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
Tandis qu'on trouve dans [KA08] une présentation de la
reconnaissance en lignes. En outre, d'autres travaux décrivent les
méthodes manuscrites [Men08] et imprimées [Ben99, Feh99] sont
à consulter.
Il n'existe pas un système universel d'OCR qui peut
traiter tous les cas d'écritures mais plutôt des
différentes approches dépendantes du type de données
traitées et de l'application visée. La figure ci-dessous
présente la structure générale d'un système OCR
.
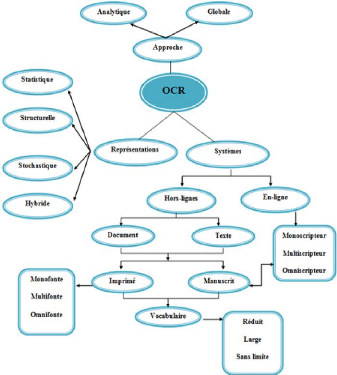
FIGURE 1.1 - Différents Systèmes et Approches de
Reconnaissance
1.1.1 Type d'acquisition
La première étape dans un système de
reconnaissance consiste à l'acquisition de l'image (texte) et sa
numérisation. La reconnaissance hors-ligne et en-ligne sont deux
systèmes différents d'OCR, ayant chacun ses outils propres et ses
algorithmes correspondants de reconnaissance.
5
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
1.1.1.1 Les systèmes en-lignes
Les systèmes en-lignes reconnaissent le texte en temps
réel. Les symboles sont reconnus en même temps qu'ils sont
écrits à la main. L'écriture est présentée
par un vecteur (x, y) dont les coordonnées sont en fonction du temps.
L'acquisition de l'écriture est assurée par une tablette
graphique équipée d'un stylo électronique. Ce
système est généralement conçu pour la
reconnaissance du manuscrit [Poi05]. Il opère en temps réel
pendant l'écriture.
1.1.1.2 Les systèmes hors-lignes
Les systèmes Hors-lignes démarrent suite
à l'acquisition. Ils servent à la reconnaissance des textes
écrits sur papier après leurs numérisation sous forme
d'image. Les sytèmes Hors-lignes jouent un rôle très
important dans le développement de la société
d'information, puisque la plupart des textes qui nous intéressent
existent sur papier.
Dans la littérature, il existe des systèmes hors
ligne qui reconnaissent le manuscrit et d'autres qui reconnaissent
l'imprimé. Dans le cas du manuscrit, la plus part des caractères
sont ligaturés d'ou la nécessite de l'emploi de techniques de
délimitation spécifiques pour guider la lecture. Les variations
inter et intra-scripteurs sont accentuées par la nature calligraphique
de l'écriture arabe [Ben99]. Nous distinguons trois types de
systèmes de reconnaissance d'écriture qui dépend de ces
variations :
- Monoscripteur : Le système
de reconnaissance peut reconnaître l'écriture d'un seul scripteur
après apprentissage de son écriture;
- Multiscripteur : Le système
de reconnaissance est capable de reconnaître les écritures d'un
groupe restreint de scripteurs soit par aprentissage de leurs écritures,
soit sans apprentissage;
- Omniscripteur : Le système
est capable de reconnaître toutes les écritures. Dans ce type de
système, la variabilité intra-scripteur s'ajoute à la
variabilité inter-scripteur.
Dans le cas de l'imprimé, les caractères sont
souvent séparés verticalement, ce qui simplifie la lecture.
Certaines fontes présentent des accolements qu'il faut défaire.
Dans le cas de l'imprimé la reconnaissance peut être
:
- Monofonte : Le système ne
traite qu'une fonte à la fois. L'apprentissage est simple puisque
l'alphabet représenté est réduit;
- Multifonte : Le système est
peut reconnaître un mélange de fontes parmi un ensemble
préalablement apprises. Le prétraitement doit, alors,
réduire les écarts entre
6
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
les caractères (taille, épaisseur et
inclinaison). De même, l'apprentissage doit gérer les
ressemblances de caractères des différentes fontes;
- Omnifonte : Le système est
capable de reconnaître toutes fontes sans l'avoir apprise.
1.1.2 Approche de reconnaissance
La nature des textes à reconnaitre permet de
différencier deux principales approches de reconnaissance : l'approche
globale et l'approche analytique.
1.1.2.1 Approche globale
Elle est dite encore holistique. Ce type d'approche
considère le mot comme une entité à reconnaitre. La
reconnaissance générale des mots se base sur une description
unique de toute l'image du mot. Cette approche présente l'avantage que
la reconnaissance se fait sans prise de décision préalable. Elle
est très rapide pour un vocabulaire réduit. L'étape de
post-traitement n'est plus nécessaire dans ce cas vu la nature de
l'approche. Cependant, cette approche est pénalisée par la taille
de mémoire, le temps de calcul et la complexité du traitement qui
croient linéairement avec la taille du vocabulaire. Elle
présente, aussi, la difficulté de discrimination entre les mots
qui ont une orthographe proche. L'apprentissage nécessite un très
grand nombre d'échantillon de mots. De plus, un changement de
vocabulaire nécessite l'apprentissage de tous les nouveaux mots. BEN
AMARA et BEL AID utilisent une approche globale basée sur les
MMCs2 pour la reconnaissance des mots arabes imprimés
[Ben99].
1.1.2.2 Approche analytique
Dans cette approche les mots sont segmentés en
caractères ou fragments inférieurs aux caractères
appelés graphèmes. La reconnaissance débute par
reconnaitre ces entités, puis, tend vers une reconnaissance des mots. Un
processus de reconnaissance, selon cette approche, est basé sur une
alternance de phase de segmentation et la phase d'identification des segments
[Ken73]. Deux procédures de segmentation sont possibles:
- La segmentation explicite ou externe
Le mot est segmenté en caractères ou en
graphèmes. Les caractères sont trouvés par
concaténation des graphèmes, de même les mots sont
trouvés par concaténation des caractères. Une autre
solution est utilisée. C'est la segmentation en caractère. La
plupart des techniques utilisées pour cette segmentation en
caractères dérivent des techniques utilisées pour la
segmentation en graphèmes. Elles sont adoptées de manière
de ne pas couper les caractères soit par des règles heuristiques
soit par une estimation de la hauteur de l'écriture et il suppose une
certaine relation entre la hauteur et la largeur moyenne des caractères
[Feh99].
2. Modèle de Markov Caché
7
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
- La segmentation implicite ou interne:
La segmentation et la reconnaissance sont effectuées
simultanément. La reconnaissance des caractères se fait sur des
hypothèses de segmentation le long de l'axe horizontal du mot. Il existe
plusieurs techniques de segmentation interne telles que la fenêtre
glissante-SWS3 qui consiste à faire balayer une fenêtre
de largeur fixe le long de l'image indiquant pour chaque position le
caractère le plus probable.
Les méthodes analytiques, par opposition aux
méthodes globales, sont envisageables dans le cas de reconnaissances de
grand vocabulaire. Elles s'adaptent facilement au changement de vocabulaire.
Elles ne sont pas couteuse en mémoire et en temps de calculs car la
complexité en mémoire ne dépend pas de la taille de
vocabulaire. Cependant, la reconnaissance du mot se base sur la reconnaissance
de caractères. Si un caractère est mal reconnu, le mot l'est
aussi. Il existe des travaux qui combinent les deux approches globales et
analytiques tels que [AAM06].
Les caractères arabes se différencient des
autres écritures par leurs modes de liaison pour la formation des mots.
Cette particularité rend les travaux développés pour les
caractères latins et chinois difficilement applicables pour l'arabe.
L'écriture arabe a plusieurs autres spécificités que nous
citons ci-après
1.2 Caractéristiques de l'écriture
arabe
L'arabe est parlé par environ 250 millions de
personnes. IL est écrit par plus de 100 millions de gens, dans plus de
20 pays différents . L'alphabet arabe est utilisé dans plusieurs
langages tels que le Persan (Farsi) et l'Urdu (langage national du Pakistan).
Il existe deux variantes de la langue arabe. L'arabe littéraire, qui es
très proche de la langue du Coran. Il est utilisé essentiellement
à l'écrit. Il est commun à tous les pays arabes. Et
l'arabe dialectal qui varie d'un pays à l'autre. Dans ce qui suit, nous
exposons une synthèse des particularités morphologiques de
l'arabe :
- L'arabe est une écriture consonantique qui utilise un
alphabet de 28 lettres auxquels il faut ajouter le hamza qui est le plus
souvent utilisé comme un signe complémentaire.
Le hamza peut s'écrire seul ou sur le support de voyelles
( ). L'alphabet arabe
3. Sliding Window Segmentation
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
comporte d'autres caractères additionnels tels que et .
SCHWARTZ, MAKHOUL et RAPHAEL [SLM+96] considèrent dans leur
papier l'alphabet arabe comprenant 31 lettres au lieu de 29. En plus, le
symbole Madda qui s'écrit uniquement sur le support du caractère
Alef, fait apparaitre d'autres graphismes.
- L'arabe s'écrit de la droite vers la gauche.
L'écriture est semi-cursive soit sous forme imprimée soit
manuscrite. Chaque caractère a un point de connexion droite et/ou gauche
avec la ligne de base. La ligne de base est détectable en examinant le
profil horizontal de l'image du mot ou sous-mot. L'alphabet arabe est plus
riche que son équivalent latin, la plupart des lettres changent de
formes selon leur apparition au début, au milieu ou à la fin du
mot.
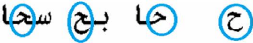
8
FIGURE 1.2 - les quartres positions possibles du
caractère " Hha"
- Un mot arabe peut être composé d'une ou
plusieurs composantes connexes. Les caractères d'une même
composante connexe peuvent être ligaturés horizontalement ou
verticalement pour des raisons d'héstitique. Dans certaines fontes, nous
pouvons aller jusqu'à quatre caractères ligaturés
verticalement. Ceci rend la segmentation en caractères presque
impossible. Pour des raisons de justification de texte ou d'esthétique,
les ligatures horizontales peuvent être allongées en
insérant entre les caractères une ou plusieurs élongations
qui correspond aux symboles Matta . De même, les chevauchements verticaux
peuvent se produire par l'intersection des composantes connexes pour quelques
combinaisons de caractères. Les chevauchements et les ligatures
dépendent de la fonte utilisée.
9
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES

FIGURE 1.3 - Chevauchement et Ligature
- Dans un mot arabe, la plupart des caractères sont
connectés les uns aux autres, excepté sept caractères qui
ne peuvent pas être connectés à ceux qui les suivent.
Alors, un mot arabe pourrait compter jusqu'à sept composantes connexes,
chacune d'elles est appelée sous-mots.
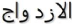
FIGURE 1.4 - Les sept caractères qui ne se relient pas
à leurs successeurs
- Les voyelles sont utilisées pour assurer la lecture
d'un texte à haute voix sans erreurs de prononciation. Certains livres
tels que le coran, la poésie et les livres d'apprentissage de la langue
arabe utilisent les voyelles de manière systématique. L'existence
de voyelle change le sens des mots. Les mêmes mots avec des voyelles
peuvent être compris comme
verbe, nom ou adjectif. Par exemple, peut signifie "drapeau",
"savoir" ou encore
"enseigner" selon sa voyellisation.
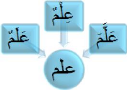
FIGURE 1.5 - Influence de la voyellisation sur le sens du
mot
10
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
- Certains groupes de lettres ne se différentient que par
le nombre et/ou la position de leurs signes diacritiques.
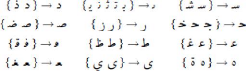
FIGURE 1.6 - Caractères classés par corps
commun
Les spécificités de l'écriture arabe
compliquent la tâche de l'OCR. Nous tendrons, dans la partie suivante, de
mettre en oeuvre les différents problèmes liés à la
reconnaissance d'écritures arabes et les localiser dans leurs phases de
traitement.
1.3 Organisation d'un système de
reconnaissance
Généralement, un OCR fait appel aux étapes
présentées dans la figure-1.7:
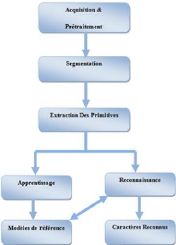
FIGURE 1.7 - Schéma général d'un
Système de Reconnaissance de Caractères
11
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
1.3.1 Prétraitement
L'objectif des prétraitements est de simplifier la
caractérisation de la forme (caractère, chiffre, mot) à
reconnaître soit en nettoyant l'image ou en diminuant la quantité
d'information à traiter. Le prétraitement est une technique qui
permet de préparer les données reçues à la phase de
segmentation. A ce stade, le problème de l'écriture arabe est
lié aux boucles. Ces boucles risquent d'être bouché ou
ouverte. Aussi bien, les points diacritiques peuvent être
éliminés suite à ces opérations grace à leur
confusion avec le bruit. Pour cette raison là, la plupart des travaux
éliminent les points diacritiques au début du traitement. Pour
identifier le caractère aprés identificartion de son corps, les
chercheurs utilisent un algorithme d'assemblage corps/points diacritiques. La
phase de prétraitement regroupe plusieurs techniques de nettoyage. Parmi
les opérations, généralement, utilisées nous citons
: la binarisation, la normalisation et la squelettisation.
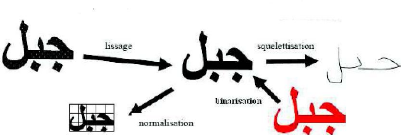
FIGURE 1.8 - Résultat de certaines opérations de
prétraitement
1.3.1.1 Binarisation
La binarisation est la première étape importante
d'un système de reconnaissance. Elle consiste à séparer le
texte du fond qui n'est pas utile lors de la reconnaissance. Cette étape
permet de réduire l'espace mémoire et le temps de calcul. La
binarisation permet de passer d'une image aux niveaux de gris à une
image binaire composée des valeurs 0 et 1. En général,
nous utilisons un seuil de binarisation qui traduit la limite des contrastes
forts et faibles dans l'image.
12
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
1.3.1.2 Lissage
L'image des caractères peut être munie de bruits
dus de l'acquisition et à la qualité du document. Ce bruit
conduit soit à une absence soit à une surcharge de points. Les
techniques de lissage permettent de résoudre ces problèmes par
des opérations locales [Bur04] :
- L'opération de nettoyage :
Permettant de supprimer les petites tâches de la forme; -
L'opération de bouchage : Permet d'égaliser
les contours et de boucher les trous internes à la forme du
caractère en lui ajoutant des points noirs.
1.3.1.3 Normalisation
Après la normalisation, les caractères sont
définis dans une matrice de même taille. L'opération se
limite à une normalisation des hauteurs, dans le cas des mots cursifs.
Cette opération facilite les traitements ultérieurs tels que la
segmentation et l'extraction des caractéristiques. C'est une
transformation non linéaire de l'image. La normalisation traduit souvent
une opération d'homothétie.
1.3.1.4 Squelittisation
La squelettisation est une opération qui permet de
passer d'une image à sa représentation en "fil de fer" [Men08].
C'est une manière de représenter l'information
indépendamment de l'épaisseur initiale de l'écriture. Elle
permet d'extraire des caractéristiques importantes, telles que les
intersections, le nombre de tracés et leurs positions relatives. La
squelette doit : être aussi fin que possible (typiquement 1 pixel
d'épaisseur), respecter la connexité et centrer dans la forme
qu'elle représente [Men08].
1.3.2 Segmentation
Après l'étape de prétraitements, la
majorité des systèmes de reconnaissances se trouvent
confrontés au problème de la segmentation des entités
à reconnaitre. Dans le cas d'un document imprimé, la segmentation
s'effectue à différents niveaux. Elle peut s'attacher à la
localisation des blocs de lignes (les colonnes), des groupes de lignes (les
paragraphes), des lignes, des mots, des caractères et enfin des parties
de caractères. Chaque entité possède ses propres
caractéristiques. Généralement, la performance d'un
système de reconnaissance dépend essentiellement du taux de
réussite de la segmentation du mot en caractères. Ceci est vrai
pour la reconnaissance du texte cursif et en particulier dans le cas de
l'écriture arabe. Nous traiterons la phase de segmentation dans la
partie suivante.
13
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
1.3.2.1 Segmentation en lignes
Cette étape consiste à détecter les
lignes de texte (Figure-1.9). La méthode la plus courante consiste
à chercher des intervalles, nuls ou minimaux dans l'histogramme de la
projection horizontale de l'image du texte. Cependant, la présence des
points diacritiques complique cette tâche car ces intervalles peuvent
correspondre à l'espace compris entre les mots et leurs points
diacritiques [ERK90]. Ces points peuvent exister au dessus ou au dessous de
mots. Une fusion des lignes est aussi possible à cause des hampes et de
jambes, dans le cas d'un petit interligne. Pour remédier à ces
problèmes, la méthode de séparation des lignes de texte,
consiste à localiser la ligne de base (La ligne qui contient le maximum
de pixel noir) puis à fusionner toutes les lignes qui se trouvent
à proximité de la ligne de base.

FIGURE 1.9 - Segmentation Horizontale [HB02]
1.3.2.2 Segmentation en mots
La méthode la plus utilisée pour la
séparation en PAW4 consiste à chercher les intervalles
nuls dans l'histogramme de projection verticale de l'image de texte (voir
figure-1.10). Cette méthode est adoptée par plusieurs chercheurs
[HB02, ERK90]. Elle ne permet pas de séparer des sous-mots ou les
caractères se chevauchent. Dans ce cas, la détection du PAW se
fait à l'aide d'un parcours de contours de ces derniers et la
détection du contour fermé [TS90]. D'autres chercheurs,
détectent les PAWs soit par parcours de leurs squelettes [WZG09], soit
par étiquetage de leurs composantes connexes.

FIGURE 1.10 - Segmentation verticale [HB02]
4. Peace Of Arabic Word
14
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
1.3.2.3 Segmentation en caractère
La segmentation en caractère constitue le grand
problème lié à l'AOCR5 à cause de : la
diversité des formes des caractères arabes, la liaison qui existe
entre caractère successif, l'allongement des ligatures horizontales et
la présence des ligatures verticales. Des études des
problèmes de segmentation de l'arabe se trouvent dans [Zek05, MAS97].
Plusieurs méthodologies de segmentation ont été
développées en utilisant plusieurs techniques. Certains travaux
segmentent les mots en graphèmes [CBB01]. D'autres, prosent des
algorithmes de segmentation en caractères tels que [HD02]. Une
étude détaillée des méthodes de segmentation en
caractères peut être trouvée dans [Ben99].

FIGURE 1.11 - Segmentation en graphèmes [CBB01]
1.3.3 Extraction des primitives
L'extraction de primitives consiste à transformer une
image (caractère, graphème,...) en un vecteur de primitives de
taille fixe. Cette transformation consiste à changer l'espace de
représentation des données du plan de l'image vers un espace
à N dimensions. Le choix des primitives est critique car elles doivent
être discriminantes. Nous pouvons classer les primitives en deux
catégories :
1.3.3.1 Primitives locales
Ces primitives sont des objets extraite de la forme tels que
les boucles, les croisements de traits, ect . L'inconvénient de ces
derniers est que leurs extraction nécessite une squelettisation du
caractère, puisque l'épaisseur du trait ne contient pas
d'information [Ben02]. Néanmoins, les primitives locales sont robustes
vis à vis de la rotation, la translation, et l'homothétie [GPP
89].
5. Arabic Optical Character Recognition
15
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
1.3.3.2 Primitives globales
Les primitives globales sont dérivées de la
distribution des pixels [Ben02]. [HML+ 98] suggèrent trois
familles de primitives : les moments invariants, les projections, et les
profils. Ces caractéristiques sont extraites en tenant compte de la
distribution des pixels noirs de la forme. L'identification de la
méthode d'extraction de caractéristiques la plus performante
n'est pas évidente. [OAT96] rapportent que les moments de Zernike
s'appliquent bien sur des images aux niveaux de gris et que la projection
s'applique souvent sur les caractères segmentés.
Cependant, Il est possible de combiner plusieurs
méthodes d'extraction afin de donner une meilleure description de la
forme à classer. Les différents types de primitives locales (les
boucles, les courbes, ..) et globales (les moments invariants, les
projections,....) ont été utilisés pour la description de
l'écriture arabe. En outre, il est remarquable que les moments et les
descripteurs de fourier sont utilisés dans un nombre important des
travaux tels que [ERK90, KD07, Feh99]. Ces primitives sont connues par leur
invariance à la rotation, l'homothétie et les petites variations
de la forme.
Après l'extraction des primitives caractérisant
la forme, le système de reconnaissance passe à l'apprentissage.
Cette phase est décrite dans la section suivante.
1.3.4 Apprentissage
La reconnaissance nécessite de définir la
connaissance que nous avons sur les formes à traiter. Cette
définition repose sur l'apprentissage. L'apprentissage permet
d'acquérir la connaissance et de l'organiser en modèle de
référence. Il est impossible d'apprendre un grand nombre
d'échantillon et des formes d'écritures différents
à cause de leur variabilité. Nous tondons à remplacer ce
nombre par une meilleure qualité des traits caractéristiques. Les
procédures d'apprentissage sont différentes selon qu'il s'agit de
reconnaitre l'imprimé ou le manuscrit, monofonte, multifonte,....
D'une manière générale, nous
distinguerons deux type d'apprentissage : supervisé et non
supervisé.
1.3.4.1 Apprentissage Supervisé
Ce type d'apprentissage est guidé par un superviseur
dit professeur. Il est réalisé lors d'une étape qui
précède la reconnaissance en induisant un grand nombre
d'échantillon de référence. Le professeur indique, alors,
le nom de chaque échantillon. Le choix de caractère de
référence
16
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
se fait manuellement en fonction de l'application. Nous devons
choisir l'échantillon le plus représentatif de la typographie des
caractères de l'application. Le nombre d'échantillons varie de
quelques dizaines à quelques centaines ou plus.
1.3.4.2 Apprentissage Non Supervisé
Ce type d'apprentissage est appelé automatique. Il
consiste à doter le système d'un mécanisme qui s'appuie
sur des règles précises pour trouver automatiquement les classes
de référence. L'intervention extérieur doit être
minimale vue inexistante. Dans ce cas, les échantillons dapprentissage
sont illustrés en grand nombre par l'utilisateur sans précision
de leurs classes. Ce type d'apprentissage n'aboutit pas toujours à une
classification correspondant à la réalité.
1.3.5 Reconnaissance
Les approches de classification sont classées en trois
grandes familles, statistiques, structurelles et stochastiques (figure-1.12).
Il est possible de combiner ces approches afin d'obtenir à une approche
hybride regroupant leurs avantages. Dans ce qui suit, nous donnons une petite
présentation de ces approches.
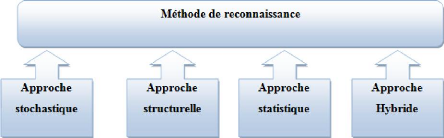
FIGURE 1.12 - Approches de Classification 1.3.5.1
Approche structurelle
C'est une approche basée sur l'extraction de
caractéristiques en tenant compte de l'information structurelle de la
forme [Ben02]. Elle cherche à structurer l'information en
décrivant la forme à partir de ses composantes les plus
élémentaires. Au cours de la reconnaissance, nous
17
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
déduisons l'identité du caractère
à partir de ces primitives qui correspondent à des formes
élémentaires du tracé et à des
événements produits lors du tracé et des relations
existantes entre elles. Citons quelques méthodes structurelles qui
utilisent ces primitives :
- Les méthodes de tests : Les
méthodes de tests consistent à appliquer sur chaque forme
traitée des tests de plus en plus fins sur la présence ou
l'absence de primitives de manière à répartir les
entrées en classe. Le processus consiste à deviser à
chaque test l'ensemble des choix en deux jusqu'a ce que nous obtenons une seule
forme correspondant à un caractère entré [Ben99]. Ce choix
dichotomique est très simple à mettre en oeuvre, mais il est
très sensible à la variation du tracé.
- Représentations à base de chaine
: Une forme (caractère, PAW, mot,..) est
représentée par une chaine de symboles. Ces symboles
représentent les primitives composant la forme ou des directions le long
de contour (codage de Freeman). Pour reconnaitre la forme nous la comparons
à des formes de références par des algorithmes de
comparaisons de chaines. Ces algorithmes donnent, généralement,
une mesure de ressemblance entre la forme testée et la formes prototype.
Pour plus de détails, le lecteur peut consulter [FGL+06].
- L'approche syntaxique : Chaque
caractère est représenté par une phrase dans un langage ou
le vocabulaire est constitué de primitive. Les formes qui appartiennent
à la même classe présente une structure commune peuvent
être représentées par une même grammaire. Une
étude détaillée sur les méthodes syntaxiques se
trouve dans [FGL+06].
1.3.5.2 Approche stochastique
La forme est considérée comme un signal continu
observable dans le temps à différents endroits. Ces états
sont décrits à l'aide de probabilité de transition
d'état et de probabilité d'observation d'état [BBE00].
- Les Modèles de Marko Cachés
: Les modèles de Markov connaissent un essor important en
reconnaissance des formes grâce à leurs capacités
d'intégration du contexte et d'absorption du bruit [BBE00]. En utilusant
les modèles de Markov, les formes sont décrites par une
séquence de caractéristiques qui seront observées dans les
états du modèle. La probabilité d'émission de la
forme est calculée en cherchant le maximum de la probabilité
d'observation des segments pondérée par les probabilités
de transitions entre états.
18
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
1.3.5.3 Approche statistique
Une forme est représentée par un vecteur de
paramètre. Une étude statistique effectuée sur l'ensemble
de ces vecteurs permet de les regrouper en classe. L'étude de
répartition des formes à reconnaitre dans un espace
métrique et la caractérisation statistique des classes permettent
de prendre une décision de reconnaissance. Cette décision est de
type plus fort probabilité d'appartenir à une classe. Une
étude détaillée sur les méthodes statistiques se
trouve dans [JDJ00]. Dans ce qui suit, nous décrivons trois
méthodes statistiques parmi les plus couramment utilisées.
- L'approche bayésienne : La
classification bayésienne consiste à calculer la
probabilité a posteriori de chaque classe de forme sur les
paramètres extraits, la probabilité conditionnelle du vecteur des
paramètres étant donnée la classe et la probabilité
à priori de chaque classe. Dans le domaine de reconnaissance des
caractères arabes, cette méthode a été
utilisée dans le travail de [TB07].
- La méthode de k plus proche voisin
: K plus proche voisin est une méthode de
raisonnement à partir des cas. Elle consiste à prendre des
décisions en recherchant des cas similaires déjà
résolus en mémoire. C'est l'une des méthodes les plus
simples. Etant donnée une base d'apprentissage d'images, pour classer un
nouveau cas, le classifieur KPPV6 cherche ces K plus proches voisins
et prédit la réponse la plus fréquente. Deux
paramètre sont utilisés par cette méthode : le nombre K et
la fonction de similarité. Cette méthode est utilisée dans
[Der09] pour la reconnaissance des chiffres imprimés.
- Les réseaux de neurones:
Les classifieur de type réseaux de neurones proviennent
d'une modélisation des neurones biologiques. Un neurone permet de
définir une fonction discriminante linéaire dans l'espace de
représentation des entrées. Les réseaux de neurones ont
connu un grand essor pour la reconnaissance de l'arabe. ILs sont
utilisés dans un nombre remarquable de travaux tels que [CBB01, Der09,
Tim01]. Nous viendrons sur les réseaux de neurones dans le
deuxième chapitre de cette mémoire.
1.3.5.4 Les approches hybrides
Dans [Feh99, Men08, Reb07], les chercheurs utilisent une
collaboration entre une approche statistique et une approche structurelle. Ces
systèmes opèrent sur deux niveaux : Le premier extrait puis
reconnaît les primitives des formes grâce à un classifieur
statistique. Le dexième
6. K plus proche voisin
19
CHAPITRE 1. LA RECONNAISSANCE OPTIQUE DES
CARACTÈRES
exploite les caractéristiques des formes pour
reconstruire des graphes pour chacun des formes, puis les reconnaît
à l'aide d'un classifieur structurel.
1.3.6 Post-traitement
Le post-traitement est un traitement ultérieur à
la classification. Cet opérartion est effectuée quand le
processus de reconnaissance aboutit à une liste de mots possibles.
L'objectif d'un post-traitement est de déterminer le meilleur mot du
lexique pouvant correspondre aux hypothèses de reconnaissance. Le
post-traitement, améliore les scores pour de l'AOCR. L'opération
de post-traitement la plus utilisée dans le domaine de l'AOCR est celle
de la vérification et la correction orthographique [Feh99]. La
vérification orthographique consiste, simplement, à rechercher un
mot dans un dictionnaire.
Conclusion
Ce chapitre nous a permis d'amener une étude
théorique des notions de l'OCR. Tout d'abord, nous avons
présenté les concepts généraux d'un système
de reconnaissance des caractères en précisant les méthodes
principaux. Nous avons, ensuite, expliqué les différentes
méthodes rencontrées par l'OCR. Après une
présentation, dans la deuxième section, des
propriétés de l'écriture arabe nous avons prouvé la
complexité des tâches d'un AOCR.
Dans notre travail, nous sommes intéressés
à l'ensemble des étapes d'un OCR (prétrai-tement,
extraction de primitives et classification). Notre objectif est la
sélection du sous-ensemble des primitives pertinentes. Ces primitives
appartient à l'ensemble des primitives extraites du système de
reconnaissance des caractères arabes imprimés. Le but de cette
sélection consiste à augmenter le taux de reconnaissance et
à minimiser le nombre des entrées du classifieur utilisé.
Nous aborderons en détails, dans le chapitre suivant, les outils de
sélection de primitives utilisés.
Chapitre2
Fondements Théoriques
L
ES méthodes de reconnaissance à base de
réseaux de neurone ont été étudiées
depuis
plusieurs années dans le but de réaliser des
performances proches de celles observées
chez l'humain. Ces
réseaux sont constitué par des éléments de calcul
opérant en parallèle de même manière que les
réseaux de neurones biologiques. De même, Les algorithmes
génétiques représentent une famille très
intéressante d'algorithmes d'optimisation fondés sur des
opérations de la sélection naturelle. La nature a
été source d'inspiration de beaucoup de travaux sur l'hybridation
des réseaux de neurones avec des algorithmes
génétiques.
Nous effectuons, dans ce chapitre, un survol des
réseaux de neurones artificiels de type perceptron multicouche, leurs
modélisations, leurs architectures et leurs principes d'apprentissage.
Ensuite, nous présenterons les algorithmes génétiques et
nous expliquerons leur principe de fonctionnement. Enfin, nous exposerons
quelques hybridations neuro-génétique dans le domaine d'OCR.
2.1 Le réseau perceptron multicouche
Le Réseau de neurones n'a pas une définition
universelle. Il est constitué d'un ensemble de neurones, ayant chacune
une mémoire locale. Ces neurones sont reliées par des canaux de
communication, qui transportent des données numériques. Les
neurones peuvent agir sur leurs données et sur les entrées
qu'elles reçoivent par leurs connexions. La plupart des RNs
1 ont une capacité
d'apprentissage. Ils apprennent à partir des exemples, de même que
les enfants apprennent à lire en lui présentant des exemples des
lettres et des chiffres, écrits
1. Réseau de Neurone
21
CHAPITRE 2. FONDEMENTS THÉORIQUES
avec des écritures et des fontes différentes. A
la fin de l'apprentissage, le RN obtient une capacité de
généralisation à partir de ces exemples. Il n'est pas
nécessaire de lui fournir une description analytique et discursive de la
forme et de la topologie des chiffres et des lettres [Dre04]. HAYKIN [Hay94]
définit le réseau de neurones comme étant un processus
distribué de manière massivement parallèle, qui a une
capacité naturelle de mémoriser des connaissances de façon
expérimentale et de les rendre disponibles pour utilisation. Les RNs
ressemblent au cerveau humain en deux points :
1. La connaissance est acquise à travers d'un processus
d'apprentissage;
2. Les poids des connections entre les neurones sont
utilisés pour mémoriser les connaissances.
De tous les RNs qui réalisent un apprentissage
supervisé des connaissances, le PMC 2 est le
plus connu et le plus populaire. Depuis plusieurs années, il est
utilisé dans divers domaines tels que la reconnaissance de
l'écriture, l'authentification de signatures, la segmentation de
documents, la localisation de cibles dans des images, etc. Nous verrons dans
les sections qui suivent que le PMC peut être un outil très utile
pour résoudre divers types de problèmes, à condition
d'être conscient de ses limites.
2.1.1 Le perceptron simple
L'origine du RN remonte à la fin des années 1950
lorsque ROSENBLATT [Héb99] propose un premier modèle de RN. Ce
modèle ne comporte qu'un seul neurone. C'est le perceptron simple. La
structure d'un perceptron simple est illustrée dans la figure-2.1 :
2. Perceptron Multicouches
22
CHAPITRE 2. FONDEMENTS THÉORIQUES
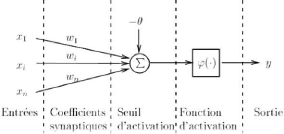
FIGURE 2.1 - Modèle d'un réseau
de neurone de type perceptron simple
L'action d'un neurone de type perceptron simple est
d'intégrer toute l'information conte-
nue dans un vecteur d'entrée x =
[x1, x2, , xn]T ?
IRn afin de produire une valeur de
sortie y. La fonction
de transfert entre les entrées d'un neurone et sa sortie tient compte du
fait que des connexions plus ou moins excitatrices relient le neurone à
chacune des variables d'entrée x ,i = 1,
2, ...n.
Le comportement d'une connexion est déterminé
par son poids w , i = 1, 2, ..., n. Un coefficient
synaptique w élevé tente d'activer le neurone pour
l'entrée x , tandis qu'à l'inverse, un coefficient
synaptique faible cherche à l'inhiber. Le neurone détermine son
niveau d'activation total en réalisant une somme pondérée
des entrées et des coefficients synaptiques. Lorsque son niveau
d'activation est supérieur ou égal à son seuil
d'activation le perceptron s'active et produit une sortie positive (y
= 1). Dans le cas contraire, il s'inhibe et produit une sortie
négative (y = -1). Mentionnons que couramment le seuil
d'activation est appelé le biais du neurone. Nous pouvons écrire
que le perceptron simple cherche à réaliser une transformation
? : IRn[-1; +1] telle que :
(?x ? IRn) ? y =
?( Xn x w - è ) ? [-1,1]
(2.1)
=1
Ou ?()est la fonction du seuil :
|
?
?
?
|
+1sií = 0 -1siv < 0
|
Selon l'équation (2.2), le comportement du perceptron
simple est entièrement commandé par l'équation de
l'hyperplan :
Xn x w - è = 0 (2.2)
=1
23
CHAPITRE 2. FONDEMENTS THÉORIQUES
Cet hyperplan permet de tracer une frontière de
décision séparant l'espace d'entrée en deux sous-espaces.
Le perceptron simple peut discriminer des données appartenant à
deux classes distinctes se situant de part et d'autre de cette
frontière. Un hyperplan ne peut pas avoir une forme concave ou convexe.
Les deux classes doivent être linéairement séparables pour
pouvoir être distinguées par un perceptron simple. L'objectif
visé par l'apprentissage supervise d'un perceptron simple consiste donc
à déterminer l'équation de l'hyperplan qui permet de
séparer correctement des données appartenant à l'une ou
l'autre des deux classes. Les perceptrons simples présentent des
limites. Un seul perceptron ne peut pas séparer des données
appartenant à plus de deux classes et même des données qui
ne sont pas linéairement séparables (figure-2.2).
FIGURE 2.2 - Deux situations pour lesquelles un perceptron
simple ne peut pas discriminer les classes [Héb99]
Il est donc nécessaire d'améliorer ce
réseau afin d'obtenir des frontières de décision mieux
adaptées à la complexité d'un problème posé.
Nous décrivons, dans la prochaine section, l'extension naturelle du
perceptron simple qui donnera solution à ces problèmes.
2.1.2 Architecture d'un perceptron multicouche
Tel qu'il est présenté dans la figure-2.3, un
PMC est composé d'une certaine couche de neurones de type perceptron. A
travers ces couches, l'information se propage des entrées vers les
sorties. Toutes les couches de neurones qui se trouvent avant la couche de
sortie sont appelées les couches cachées du réseau. Le PMC
est un réseau complètement connecté. La sortie d'un
neurone d'une couche cachée devient une entrée pour tous les
neurones situés sur la couche suivante et ainsi de suite jusqu'à
la couche de sortie. La propagation d'un vecteur
24
CHAPITRE 2. FONDEMENTS THÉORIQUES
d'entrée à travers tout le réseau, couche
par couche, permet d'obtenir des sorties classées par le réseau.
Par exemple, le réseau de la figure-2.3 contient une première
couche d'entrée de deux neurones, deux couche cachée l'une de
trois neurones et l'autre quatre neurones et enfin une couche de deux neurones
à la sortie.
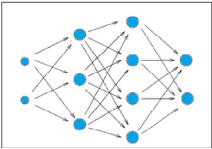
FIGURE 2.3 - Structure d'un perceptron multicouche
Un PMC peut être formé d'un nombre quelconque de
couches pouvant chacune contenir un nombre quelconque de neurones. Grâce
à sa structure, le PMC est capable de pouvoir former des
frontières de décision qui soient adaptées à la
complexité du problème posée (figure-2.4).

FIGURE 2.4 - Frontière de décision obtenue à
l'aide d'un perceptron multicouche [Gos96]
Malgré son pouvoir de modélisation
intéressant, le PMC a été inexploité durant
plusieurs années. C'est à cause de l'absence d'algorithme
d'apprentissage adéquat pour ajuster ses nombreux paramètres.
C'est en 1986, que D.E. RUMELHART et AL [Héb99] ont proposé
une
25
CHAPITRE 2. FONDEMENTS THÉORIQUES
généralisation de l'algorithme d'apprentissage
original de ROSENBLATT afin de permettre l'ajustement des poids d'un
réseau de structure quelconque. L'ajustement se fait en minimisant de
manière satisfaisante l'erreur engendrée à la sortie du
réseau. Cet algorithme, connu sous le nom d'algorithme de
rétropropagation du gradient, a permis au PMC de prendre
définitivement son envol. Nous décrivons le fonctionnement
d'algorithme de rétropropagation du gradient dans la section
suivante.
2.1.3 Apprentissage d'un perceptron multicouches
L'apprentissage d'un PMC par rétropropagation des erreurs
consiste à lui présenter un
ensemble deN données d'entraînement
D = {(x1, o1), (x2,
o2), , (xn, on)} . Ceci est
dans
le but d'ajuster itérativement ses différents
paramètres de manière à minimiser l'erreur
qua-dratique3 de sortie. Une donnée d'entraînement
(x; o)E D est en fait un couple de vecteurs
(x; o) E IRn --+ IRm
tel que x est un vecteur d'entrée qui est propagé
à travers toutes les couches du PMC, jusqu'à la couche de sortie,
et o est le vecteur de sortie désirée.
BISHOP [Bis95] a démontré qu'un réseau de
type PMC à une couche cachée peut estimer n'importe quelle
fonction dans un IRn avec une précision arbitraire.
Ainsi, le PMC est capable d'estimer des hyper-surfaces discriminantes
très complexes. En effet, la difficulté majeure rencontrée
lors de l'utilisation de ce type de classifieur est de déterminer le
nombre de couches cachées, le nombre de neurones dans chaques couches et
les poids de connexions entre les différentes couches. De ce fait, la
construction du classifieur de type PMC utilise des règles empiriques.
Afin d'obtenir des performances de généralisation
intéressantes, il est nécessaire d'éffectuer un certain
nombre d'essais. L'utilisation des algorithmes d'apprentissage permet de
déterminer les poids de connexions du réseaux. L'objectif de cet
algorithmes est de minimiser l'erreur de décision effectuée par
le RN en ajustant les poids à chaque présentation d'un vecteur
d'entraînement.
Nous utiliserons pour l'apprentissage du réseau
l'algorithme de rétropropagation du gradient qui est défini par
les étapes suivantes :
1. Initialiser les poids et les seuils du réseau à
des petites valeurs;
2. Présenter à l'entrée du réseau
un vecteur de caractéristiques de la base de données, puis
calculer la valeur d'activation et la fonction d'activation de ce vecteur en
utilisant la
3. Somme des carrés de l'erreur de chaque composante
entre la sortie réelle et la sortie désirée
26
CHAPITRE 2. FONDEMENTS THÉORIQUES
formules (2.3);
Xni =
j
Avec : oj désigne la valeur d'activation du
neurone i tel quen i = f (ni), où
f (ni) est la fonction d'activation. Nous avons
utilisé la fonction sigmoïde définie par :
1
f (ni) = (2.4)
1 +
e-ni
3. Évaluer l'erreur générer dans les
sorties du réseau en utilisant la formule (2.5);
äj = (dj - oj)oj (1 -
oj) (2.5)
avec djest la valeur désirée du neurone
j
4. Ajuster les poids en utilisant la formule (2.6);
Lwij = çäjoj (2.6)
Où ç est la valeur de la constante
d'apprentissage. En général: 0.1 < ç <
0.9
5. Évaluer l»erreur générer pour
chaque couche cachée en utilisant la formule (2.7);
äj = oj(1 - oj) X
wjkäk (2.7)
k
6. Adapterr les poids de la couche cachée en utilisant la
formule (2.6);
7. Répéter les étapes ( 2) et (6) pour
l'ensemble des vecteurs de caractéristiques de la base d'apprentissage
tant que le critère d'arrêt n'est pas encore atteint.
Pour accélérer la vitesse de convergence de
l'algorithme d'apprentissage, il est possible d'ajouter un momentum. La formule
(2.5) devient :
Awij(n + 1) = çäjoj +
áAwij(n) (2.8)
Où á est le momentum tel que
0.1 < á < 0.8 et
Awij(n) représente l'ajustement à
l'étape précédente.
Il existe plusieurs critères d'arrêts. Parmis les
critères les plus utilusés, nous citons :
- Fixer un seuil que l'erreur quadratique ne doit pas
dépasser. Ceci exige une connaissance
27
CHAPITRE 2. FONDEMENTS THÉORIQUES
préalable de la valeur minimale de l'erreur qui n'est
pas toujours disponible. Il suffit de s'arrêter lorsque tous les objets
sont correctement classés;
- Déterminer un nombre fixe de cycles à
atteindre;
- La méthode du cross-validation peut être
utilisée pour contrôler l'apprentissage du réseaux.
L'algorithme d'apprentissage s'arrête lorsqu'il n'y a pas
d'amélioration de la performance du système de reconnaissance. La
méthode de cross-validation fonctionne sur deux bases : la base
d'apprentissage et la base validation.
L'inconvénient des réseaux de neurones de type
perceptron multicouche est le manque d'une théoriques permettent de
déterminer le nombre de couches cachées et le nombre de neurones
par couche en prenant compte de la complexité du problème
à traiter. Certaines heuristiques permettent pour déterminer le
nombre de neurones dans une couche cachée. Pour définir le nombre
de couches cachées et de neurones par couches, le concepteur doit
effectuer un grand nombre d'expériences. Par exemple, nous varions la
taille du réseau, puis, nous effectuons un apprentissage complet pour
chaque taille. Enfin, nous choisissons la structure qui conduit aux meilleurs
résultats.
De nos jours, les PMCs sont les réseaux les plus
utilisés par les développeurs. Des résultats satisfaisants
ont été mis en valeur dans des domaines d'applications divers.
Dans la partie suivante, nous présenterons les algorithmes
génétiques. Puis, nous mettrons en évidence la relation
entre les algorithmes génétiques et les PMCs.
2.2 Les algorithmes génétiques
Les algorithmes génétiques ont été
mis au point par HOLLAND dans les années 60 [Gue09]. Ils ont
été ensuite raffinés par DEJHON. Les fondements
mathématiques ont été, enfin, exposés par GOLBDERG
[Gol89]. Les AGs4 sont des algorithmes d'optimisation
évo-lutionnaires inspirés de l'évolution Darwinienne des
populations. Ils sont des algorithmes d'optimisation s'appuyant sur des
techniques dérivées de la génétique et des
mécanismes d'évolution de la nature. L'idée fondatrice de
ces algorithmes est d'utiliser la théorie de l'évolution comme
modèle informatique pour trouver une solution optimale. Le but des AGs
est d'optimiser une fonction prédéfinie, appelée fonction
objectif, ou Fitness.
Dans un AG, chaque individu représente un point de
l'espace d'état auquel nous associons un vecteur de valeur de
critères à optimiser. Nous générons, ensuite, une
population d'indi-
4. Algorithme génétique
28
CHAPITRE 2. FONDEMENTS THÉORIQUES
vidus aléatoirement. L'AG s'attache à
sélectionner les meilleurs individus tout en assurant une exploration
efficace de l'espace d'état. La figure ci-dessous présente les
étapes d'un AG. Une description plus détaillée sera
présentée dans les parties ultérieures.
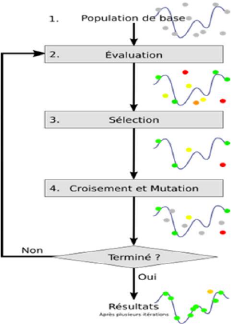
FIGURE 2.5 - Fonctionnement général de
l'algorithme génétique
Un AG a pour but de faire évoluer un ensemble de
solutions candidates à un problème posé vers la solution
optimale. Cette évolution s'effectue sur la base de transformations
inspirées de la génétique, assurant de
génération en génération, l'exploration de l'espace
des solutions. Les différentes étapes suivies par un AG sont
celles de cycle de l'évolution décrit dans les sections
suivantes.
2.2.1 Génération de la population
initiale
Dans la littérature, plusieurs mécanismes de
génération de la population initiale sont utilisés . Cette
population est crée soit aléatoirement, soit par des heuristiques
soit par une hybridation de solutions aléatoires et heuristiques. Le
problèmede la création de la population
29
CHAPITRE 2. FONDEMENTS THÉORIQUES
est le choix de sa taille. Si la taille est trop grande, le
temps de calcul augmente et demande un espace mémoire important. Par
contre, pour une population de petite taille, la solution obtenue n'est pas
satisfaisante. Il faut donc trouver la bonne taille. La population initiale
doit être diversifiée pour que l'algorithme ne se bloque pas dans
un optimum local.
2.2.2 Codage
Pour implémenter un AG, il faut commencer par
créer une population des individus initiaux. Chaque individu de la
population est codé par un chromosome. Chaque chromosome code une
solution possible de problème. L'efficacité de l'AG va donc
dépendre du choix du codage d'un chromosome. Il excite principalement
deux types de codage : binaire et réel.
- Codage binaire: Ce codage a
été le premier à être utilisé dans le domaine
des AGs. Le codage binaire consiste à représenter chaque vecteurs
de paramètres X par une chaine de bits. Chaque champs prend la valeur 0
ou 1. Ce type de codages présente plusieurs avantages . Il se
caractérise par un alphabet minimal {0,1}.De plus, il facilite la mise
au point des opérateurs génétiques. Néanmoins, ce
type de codages présente l'inconvénient [Gue09] que les
performances des AGs sont dégradées devant les problèmes
d'optimisation de grande dimension à haute précision
numérique.
- Codage réel : Le codage
réel utilise directement les valeurs réelles des
paramètres. Un chromosome est en fait un vecteur dont les composantes
sont les paramètres de processus d'optimisation. Par exemple, si nous
cherchons à optimiser une fonction de n variables f
(x1, x2,.....,
xn-1, xn), nous pouvons
utiliser un chromosome ch contenant n variables. Ce type de
codage présente quelques avantages [Gue09]. La procédure
d'évaluation des chromosomes est plus rapide vu que le codage utilise
les valeurs réelles. Ainsi, la représentation réelle
aboutit souvent à une bonne précision et un gain de temps
d'exécution.
2.2.3 Fonction d'évaluation
Dans la nature, l'adaptation d'un individu traduit sa
capacité de survie dans son environnement. Dans le cadre des AGs,
l'adaptation d'un individu va être traduite par une mesure de sa
capacité de vie qui est appelée Fitness. Celle-ci sera
définie par l'utilisateur. La force de chaque chromosome de la
population est calculée afin de favoriser la chance des plus forts
lors
CHAPITRE 2. FONDEMENTS THÉORIQUES
de la sélection. Les chromosomes
sélectionnés seront modifiés dans la phase de croisement
et de mutation.
2.2.4 Sélection
La sélection est l'opérateur le plus important
pour améliorer la qualité d'une population. Son objectif est de
retenir les meilleurs individus qui participerontà l'opération de
croisement. La sélection élimine les plus mauvais. Sans tenant
compte du codage utilisé, la littérature propose
différents types de sélection.
- Sélection par Rang : Le
principe de la sélection par rang consiste à ranger les individus
de la population dans un ordre croissant ou décroissant, selon
l'objectif. La spécificité de cette méthode est de ne pas
prendre en compte des valeurs propres. Elle fait une disjonction de la fonction
d'adaptation et de la fonction à optimiser ce qui conduit à des
résultats non décisifs [Gol89]. DEJONG et SAMARA [DS95] ont
cité, dans leur papier, que cette méthode empêche la
dominance d'un individu en préservant des proportions de descendants
adéquates.
- Sélection par Roulette Biaisé
: Le principe de la roulette biaisée consiste à
associer à chaque individu une probabilité de sélection
proportionnelle à sa fitness. Selon cette méthode, chaque
chromosome est copié dans la nouvelle population proportionnellement
à sa Fitness. Nous effectuons autant de tirages avec remise que
d'éléments existant dans la population. Pour un chromosome
particulier chi de Fitness f (chi), la
probabilité de sa sélection est :
p (chi) = f (chi)
Pn (2.9)
j=1 f (chj)
Plus la performance d'un individu est élevée
plus il a une chance d'être reproduit dans la population. Les individus
ayant une grande Fitness relative ont donc plus de chance d'être
sélectionnés. Le nombre de copies espérées pour
chaque individu chi qui va résulter de la sélection est
alors égal à :
ni = N X p (chi) = f
(chi)
Pn
1 j=1 f (chj) n
f (chi)
= (2.10)
f
30
L'inconvénient de ce type de sélection vient du
fait qu'il peut favoriser la dominance d'un individu qui n'est pas
forcément le meilleur.
31
CHAPITRE 2. FONDEMENTS THÉORIQUES
- Sélection par Tournoie :
Cette technique de sélection s'effectue en deux étapes, tout
d'abord nous réalisons un tirage aléatoire sur l'ensemble de la
population des N individus qui vont participer au tournoi. M
5 individus sont tirés au sort dans la population
[Jou03]. Dans cette première étape, tous les individus ont la
même chance d'être sélectionnés. Dans la seconde
étape, nous comparons les Fitness des M individus
sélectionnés pour garder le meilleur. Il existe
différentes sélections par tournoi :
1. Tournoi déterministe : Le meilleur des M
individus gagne le tournoi. La probabilité qu'un mauvais individu soit
sélectionné est très faible avec cette technique;
2. Tournoi probabiliste : Chaque individu peut
être choisi comme gagnant avec une probabilité proportionnelle
à sa Fitness.
Commençant d'une population initiale souvent non
homogène, la diversité de la population doit être
entretenue aux cours des générations. C'est le rôle des
opérateurs de crsoisement et de mutation qui seront traités dans
les sections suivantes.
2.2.5 Croisement
Le croisement est l'opérateur principal des AGs. Son
rôle consiste à choisir aléatoirement deux individus
parents pour les combiner et créer deux nouveaux individus enfants. Ila
une infliance sur la convergence de l'AG, en lui permettant de concentrer une
partie de la population autour des meilleurs individus. Plusieurs
opérateurs de croisement ont été proposés [NA04],
nous citons ici les plus utilisés :
- Croisement en-1point : Ce type de
croisement consiste, d'abord, à couper chacun des deux parents en deux
parties à une position choisie au hasard ,puis, à recopier la
partie inférieure du parent à l'enfant. Enfin, compléter
les gènes manquants de l'enfant à partir de l'autre parent en
respectant l'ordre des gènes [Cha11]. La figure suivante présente
un exemple illustratif de ce type de croisement :
5. la taille du tournoi
32
CHAPITRE 2. FONDEMENTS THÉORIQUES
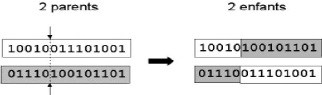
FIGURE 2.6 - Croisement en 1-point de deux chromosomes
- Croisement en 2-point : Ce type de
croisement conciste à choisisr aléatoirement deux points de
coupure pour découper chaque parent en trois fragments. Les deux
premiers fragments pour le Parent1 (respectivement Parent2) sont copiés
à l'Enfant1 (respectivement Enfant2). Nous complètons la partie
restante de l'Enfant1 par les éléments du Parent2 et la partie
restante de l'Enfant2 par les éléments du Parent1 en parcourant
de gauche à droite et en ne reprenant que les éléments non
encore transmis. La figure ci-dessous présente un exemple illustratif de
ce type de croisement.
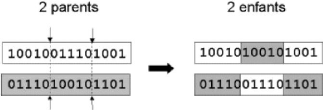
FIGURE 2.7 - Croisement en 2-points de deux chromosomes
Certaines autres opérateurs de croisement sont
proposés dans la littérature comme le croisement PMX5, OX6, CX7,
JOX8, ER9 , ... [Cha11] .
2.2.6 Mutation
La mutation est l'opérateur de base d'une
stratégie d'évolution. Il est une source de la variation
génétique. Il garantit la globalité de la recherche, en
permettant d'explorer l'ensemble de l'espace de recherche.
33
CHAPITRE 2. FONDEMENTS THÉORIQUES
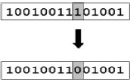
FIGURE 2.8 - Exemple de mutation
Comme pour les croisements, de nombreuses méthodes de
mutation ont été présentées dans la
littérature [NA04]. Nous citons les plus connues :
- Opérateur d'inversion simple:
Consiste à choisir deux points de coupure
aléatoirement et inverser les positions des gènes situées
au milieu;
- Opérateur d'insertion :
Consiste à sélectionner un gène et une position dans
le chromosome à muter au hasard , puis à insérer le
gène sélectionné dans la position choisie;
- Opérateur d'échange
réciproque : Permet de sélectionner deux
gènes et de les changer.
2.2.7 Insertion
Après l'étape de mutation, nous utilisons une
méthode d'insertion. Plusieurs stratégies ont été
présentées dans la littérature :
- Première stratégie :
Consiste à choisir les
Psize individus à partir
des Psizeenfants créés par les
opérateurs de croisement et mutation. Dans ce cas, les parents sont,
alors, remplacés par les enfants mutés [Cha11];
- Deuxième stratégie :
Consiste à choisir les
Psize individus à partir
des Psize parents de la
population précédente et de
Psize nouveaux enfants. A chaque
itération, les individus de meilleures Fitness
seront sélectionnés afin de créer des individus enfants.
Ces derniers remplaceront les plus mauvais parents. Le reste sera copié
dans la nouvelle génération [Cha11];
- L'élitisme : Consiste
à copier quelques meilleurs individus dans la nouvelle population
[Cha11].
34
CHAPITRE 2. FONDEMENTS THÉORIQUES
L'objectif d'insertion est d'éviter que les meilleurs
individus soient perdus après l'application des opérateurs de
croisement et de mutation. Cette méthode permet de conserver les
meilleurs individus trouvsé dans toutes les populations
générées antérieurement.
2.2.8 Critère d'arrêt
L'arrêt de l'évolution d'un AG est l'un des
difficultés majeur car il est souvent difficile de savoir si nous avons
trouvé l'optimum. Les critères d'arrêt les plus
utilisés, dans la littérature, sont les suivants :
1. Arrêt de l'algorithme après un nombre de
générations (un nombre fixé a priori);
2. Arrêt de l'algorithme lorsque le meilleur individu
cesse d'évoluer pendant un certain nombre de
génération;
3. Arrêt de l'algorithme lorsqu'il ya perte de la
diversité génétique.
Une façon d'améliorer les performances d'un
algorithme est le combiner avec une autre méthode. L'idée dans ce
cas est de lancer l'AG en premier lieu, ensuite, une autre technique s'occupera
du raffinement des solutions générées par l'AG. Dans ce
qui suit, nous allons étudier l'hybridation
neuro-génétique dans le domaine d'OCR.
2.3 L'hybridation neuro-génétique
De nos jours, l'informatique participe à la plupart des
systèmes décisionnels, ce qui rend la reconnaissance de formes un
domaine majeur de l'informatique, dans lequel les recherches sont
particulièrement actives. La répartition de l'information sur
chaque outil de classement contribue à une meilleure reconnaissance.
Le souci d'améliorer les performances des
systèmes de reconnaissance est une raison déterminante pour
l'introduction de nouvelles stratégies de classification dans les
techniques de reconnaissance d'écriture telle que le RN. Une
caractéristique des RNs est leur capacité à apprendre. Ils
peuvent reconnaitre les lettres, les sons,....Mais cette connaissance n'est pas
acquise dès le départ. Les RNs apprennent par l'exemple en
suivant un algorithme d'apprentissage. Les méthodes de reconnaissance
à base de RN ont été étudiées depuis
plusieurs années dans le but de réaliser des performances proches
de celles observées chez l'humain.
35
CHAPITRE 2. FONDEMENTS THÉORIQUES
Ces réseaux sont composés de plusieurs
éléments de calcul opérant en parallèle et
arrangés à la manière des réseaux de neurones
biologiques. LIPPMAN [Lip87] a précisé que la force des RNs
réside dans leur capacité à générer une
région de décision de forme quelconque, requise par un algorithme
de classification, au prix de l'intégration de couches de cellules
supplémentaires dans le réseau de type PMC.
De même, Une approche de type génétique
est conçue, dans la littérature, pour adapter la partition de
l'espace des paramètres relativement à l'ensemble des outils
disponibles. L'AG est un exemple de procédure d'exploration qui utilise
un choix aléatoire comme outil pour guider une exploration dans l'espace
des paramètres codés. Cette technique garantit non pas
d'atteindre l'optimum global de la fonction, mais de converger vers cet
optimum. Dans la littérature, il y a plusieurs chercheurs qui ont essaie
de profiter des caractéristiques des AGs et PML dans le domaine
d'imagerie.
L'hybridation neuro-génétique, bien que
relativement à ses débuts, elle signale des résultats
encourageants dans le domaine de l'OCR.
2.3.1 Système de OLIVEIRA
OLIVERI et ces collègues proposent dans leur papier
datant le 2002 [OSB+02] une hybridation
neuro-génétique pour la reconnaissance des chiffres manuscrits.
Ils ont tenté de proposer une méthode d'optimisation pour la
sélection des primitives pertinentes. La sélection des primitives
est une étape importante dans tout système de reconnaissance de
formes. Cette sélection est considérée comme un
problème d'optimisation combinatoire. Elle a fait l'objet de recherche
dans de nombreuses disciplines. L'objectif visé par cette recherche est
de réduire le nombre des primitives en éliminant celles qui sont
redondantes et non pertinentes sans affecté la performance du
classifieur utilisé par la reconnaissance. Les AGs sont utilisés
pour résoudre ce type de problème de sélection des
primitives dans la reconnaissance de chiffres isolés. Le classifieur
utilisé est un PMC.
Les tests sont effectué sur la base de chiffres
isolés NIST-SD19. Les résultats obtenus lors de
la sélection des primitives ont permis de réduire la
complexité du réseau de neurones utilisé. Le nombre de
primitives a été réduit de 25% par rapport à
l'ensemble des primitives extraites.
Le second aspect de ce travail est la pondération des
primitives qui consiste à déterminer les primitives les plus
discriminantes en leur attribuant un poids. Les expériences
effectuées n'ont pas donné de bonnes solutions. OLIVERI et ces
collègues ont observé que les valeurs des poids accordés
aux primitives se rapprochent de la valeur initiale (valeur égale
à 1). Ils ont conclu donc que la pondération des primitives n'est
pas adaptée pour l'optimisation de
36
CHAPITRE 2. FONDEMENTS THÉORIQUES
ce type de système de reconnaissance de chiffres
isolés Cependant, il a été rapporté dans la
littérature que cette approche peut fonctionner avec d'autres types de
classificateur tel que la méthode du plus proche voisin.
2.3.2 Système de KROUCHI et DJEBBAR
En 2007, KROUCHI et DJEBBAR proposent une extention dans le
domaine d'OCR qui consiste à éffectuer une hybridation entre un
réseau de neurone de type PMC et un AG [KD07]. Ce système traite
la reconnaissance hors ligne des chiffres manuscrits isolés par une
approche Neuro-Génétique. L'apprentissage de ce réseau est
composé de deux grandes étapes :
1. Une initialisation effectuée par les AGs : l'AG
verra le RN en tant qu'individu d'une population. Le réseau
utilisé est composé de trois couches de neurones avec vingts
neurones en entrée relatives aux vecteurs de caractéristiques
obtenus par la technique des moments de Zernike, quatre vingts en couche
cachée, et dix en sortie relatives au nombre de classes de chiffres
(0,1,2,3,4,5,6,7,8,9).
2. Etape d'apprentissage réalisée par
l'algorithme de rétro-propagation du gradient. Cette étape est
basée sur la descente du gradient d'erreur quadratique moyenne commise
par le réseau PMC.
Ce système de classification permet d'obtenir un taux
de reconnaissance de 87.51% en utilu-sant un PMC. Ensuite, le même
classifieur est utilisé (architecture, paramètres
d'entrées) en remplacent la technique de la rétropropagation par
la méthode génétique. Ce dernier permet d'obtenir un taux
de reconnaissance de 97.1%.
Conclusion
Ce chapitre nous a permis d'avoir un aperçu
général sur les réseaux de neurones. Notre étude
s'est intéressée principalement aux réseaux de neurones de
type PMC. Nous avons décrit leur architecture et leur algorithme
d'apprentissage. De même, ce chapitre nous a permis d'avoir une vue
générale sur les concepts des AGs. Nous pouvons conclure que les
AGs peuvent résoudre des problèmes assez complexes grâce
aux opérateurs de reproduction. Les AGs sont des procédures
robustes pour résoudre un problème d'optimisation pour la
sélection des primitives. Dans la dernière partie de ce chapitre,
nous avons illustré quelques hybridations entre les PMCs et les AGs dans
le domaine d'OCR.
37
CHAPITRE 2. FONDEMENTS THÉORIQUES
L'objectif de notre projet est de minimiser les entrées
du réseau de neurone tout en améliorant la performance du
système de reconnaissance. Pour se faire, nous utilisons les
éléments da la théorie de l'optimisation basée sur
les principes de la sélection naturelle qui donne, d'après la
littérature, de meilleurs résultats dans la sélection des
primitives. En ce sens, les chapitres suivants seront consacrés à
la présentation des étapes de notre système de
reconnaissance des caractères arabes en utilisant une hybridation
neuro-génétique.
Chapitre3
Contributions à la reconnaissance Des
caractères arabes imprimés
N
OUS désignons par une approche "hybride" un
modèle faisant coopérer un ou plusieurs réseaux de
neurones et un algorithme génétique. L'avantage de ce type de
modèle par rapport à l'usage d'un réseau de neurones pur
est qu'il améliore le taux de reconnaissance de système.
Nous consacrons ce chapitre à la description de notre
approche. Dans un premier temps, nous présentons le problème
à résoudre, nous justifions le choix de l'approche et nous
donnons un aperçu sur le système de reconnaissance que nous avons
développé. Dans un deuxième temps, nous présentons
les opérations de prétraitement effectués sur l'image du
texte. Ensuite, nous décrivons la phase de segmentation du document.
Puis, nous expliquons la méthodologie adoptée pour la
sélection des primitives par les algorithmes génétiques.
Enfin nous détaillons le processus de reconnaissance.
3.1 Position du problème
Le but de notre travail est de déterminer la
méthodologie la plus appropriée pour résoudre le
problème de sélection des primitives dans un système de
reconnaissance des caractères arabes imprimés multifontes.
Malgré les nombreux travaux menés sur la reconnaissance de
l'écriture arabe imprimée, plusieurs problèmes existent
encore. Ces problèmes concernent plusieurs aspects. La diversité
de l'alphabet arabe ainsi que les caractéristiques compliquées
des caractères (boucle, contour similaire,..) rend la méthode de
sélection des primitives la plus appropriée difficile. De plus,
les primitives extraites peuvent être pertinentes pour certains
39
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
caractères mais pas pour les autres. Au cours de ce
travail, nous proposons un système qui répond aux
problèmes suivants : La squelettisation, la segmentation , l'extraction
et la sélection des primitives, la reconnaissance et le
post-traitement.
Partant d'un document imprimé, la squelettisation de ce
dernier permet de le représenter en "fil de fer". Notre but est de
décomposer ce texte en lignes, les lignes en mots ou sous mots et les
mots ou sous-mots en caractères. Puis, nous passons à
l'extraction des primitives.
L'extraction de primitives consiste à transformer le
caractère en un vecteur de primitives de taille fixe. Les primitives
doivent être discriminantes. Nous proposons, dans notre système,
la sélection des primitives en utilisant l'optimisation par les AGs.
Tout en effectuant cette sélection, il est important de maintenir ou
d'améliorer la performance du système de reconnaissance. Enfin,
nous clôturons par la phase de reconnaissance.
3.2 Justification de l'approche choisie
L'extraction des primitives est l'étape la plus
difficile dans un système de reconnaissance d'écriture.
L'ensemble des primitives sélectionnées doivent avoir un pouvoir
discriminant entre les formes de différentes classes, mais demeurent
presque les mêmes pour une même classe. L'extraction des primitives
est étroitement liée à la classification.
La reconnaissance du caractère passe d'abord par
l'analyse de la forme et l'extraction de ces traits caractéristiques,
qui seront exploitées pour son identification. A ce niveau, se pose le
problème de choix des traits caractéristiques, auquel nous
imposons de distinguer des formes proches mais différentes. Ces
caractéristiques doivent tolérer les variations normales du
caractère et être peut sensible à la variation
d'échelle. Ceci constitue un premier paradoxe dans la définition
des traits caractéristiques. Il existe une très grande
variété de caractéristiques mesurables sur des images.
Trop souvent, nous pensons que chaque caractéristique est importante
pour discriminer une forme d'une autre.
En se référant à l'état de l'art,
GYEONGHWANet SEKWANG [GS00] ont observé que la performance d'un
système de reconnaissance devient mauvaise et le temps de calcul
augmente à mesure que le nombre de primitives augmente. Dans certains
cas, ils existent quelques caractéristiques qui n'aideront pas à
discriminer les classes. Autrement dit, il existe des caractéristiques
redondantes ou non pertinentes. Ces caractéristiques seront inutiles
dans la classification de la forme d'où l'utilité d'effectuer la
sélection des primitives les plus pertinentes. Cette sélection a
parfois un impact considérable sur l'efficacité des
résultats de la classification. Les méthodes d'optimisation
peuvent être déterministes ou non déterministes. Les
méthodes déterministes sont, généralement,
efficaces lorsque l'évaluation de la fonction
40
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
à optimiser est très rapide ou lorsque la forme
de la fonction est connue a priori. Elles nécessitent comme étape
préliminaire la localisation des extremas. Au temps que, les
méthodes non déterministes font appel à des tirages de
nombres aléatoires. Elles permettent une exploration efficace de
l'espace de recherche. Nous adaptons alors une méthode non
déterministe pour notre approche.
DASH et LIU [DL97] et YANG et HONAVAR [YH97] proposent deux
étapes essentielles dans la sélection des primitives; les
procédures de recherche et les fonctions d'évaluation.
3.2.1 Les procédures de recherche
Si l'ensemble des caractéristiques contient N
primitives définies initialement alors le nombre total de
possibilités des candidats générés est de
2N. Ce nombre est très élevé. Le but
est de trouver une solution parmi ce nombre de probabilités. Pour
résoudre cette problématique, la procédure de recherche
regroupe trois approches : complète, heuristique et aléatoire.
- Complète : Cette
procédure fait une recherche complète dans les sous-ensembles
opti-mals de primitives selon la fonction d'évaluation utilisée.
Plusieurs fonctions d'évaluation sont employées pour
réduire l'espace de recherche sans compromettre les chances de trouver
le sous-ensemble optimal. Bien que l'espace de recherche
soit2N, peu de sous-ensembles
sont évalués. L'optimalité du sous-ensemble de primitives,
selon la fonction à optimiser, est garantie car le procédé
peut faire des retours arrière.
- Heuristiques : À chaque
itération, toutes les caractéristiques qui restent à
être sélectionnées sont considérées pour la
sélection des primitives. L'espace de recherche est
N2. Ces procédures sont très
simples et rapides car l'espace de recherche est quadratique en termes de
nombre de primitives.
- Aléatoire : Cette
procédure de recherche est nouvelle dans son utilisation en comparaison
avec les deux autres méthodes de sélection des primitives. Bien
que l'espace de recherche soit2N, ces méthodes
cherchent dans les sous-ensembles en effectuant un maximum d'itérations.
Chaque procédure de recherche aléatoire exige des valeurs de
quelques paramètres pour l'appliquer au problème à
résoudre. La tâche d'attribution de valeurs appropriées
à ces paramètres est importante afin d'obtenir des
résultats satisfaisants.
41
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
3.2.2 Les fonctions d'évaluation
Les fonctions d'évaluation mesurent l'ensemble des
solutions candidates générées par les procédures de
recherche. Ces valeurs sont comparées aux valeurs
précédentes. La meilleure valeur sera gardée. Il existe
plusieurs types d'évaluation :
- La mesure de la distance (distance euclidienne) permettant
de mesurer les capacités de discrimination;
- La mesure d'information permettant d'estimer le gain d'une
caractéristique;
- La mesure de dépendance permettantde quantifier la
corrélation des caractéristiques; - La mesure de consistance de
l'ensemble des caractéristiques et la mesure du taux d'erreur lors de la
classification.
Dans la littérature, les chercheurs ont classé
les approches de sélection des primitives en deux catégories :
Filter et Wrapper.
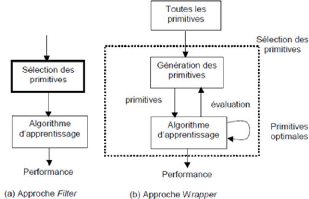
FIGURE 3.1 - Approche de selection de primitives [YH97]
Les primitives sont sélectionnées
indépendamment de l'algorithme d'apprentissage dans le cas de l'approche
Filter, tandis qu'un sous-ensemble de primitives est
généré et évalué par l'algorithme
d'apprentissage dans l'approche Wrapper. YANG et HONAVAR [YH97] ont
mentionné que le temps de calcul de l'approche Filter est beaucoup plus
rapide que l'approche
42
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
Wrapper. Ainsi ,l'approche Filter explore de manière
efficace tous les sous-ensembles des caractèristiques en
sélectionnant les sous-ensembles minimales et suffusants afin de
déterminer l'étiquette indiquant la classe.
KUDO et SKLANSKY [KS00] ont étudié les
différentes techniques d'optimisation et ont trouvé que les AGs
conviennent parfaitement lorsque le nombre de primitives à
sélectionner est grand. Ils ont rajouté que les AGs ont une
grande probabilité de trouver les meilleures solutions par rapport aux
autres techniques d'optimisation. Ils recommandent d'appliquer les AGs
plusieurs fois avec différents paramètres.
L'application des AGs dans la sélection de primitives a
été utilisée dans des différents domaines de
recherche tels que l'étalonnage de caméras par JI et ZHANG dans
[JZ01], la vérification de signatures par Ramesh et Murty [RM99], le
diagnostic médical par YANG et HONOVAR [YH97], la reconnaissance de
visages par HO et HUANG [HH01], la reconnaissance de caractère optique
par SHAMIK et DAS [SD01] et la reconnaissance des chiffres par GYEONGHWAN et
SEKWANG [GS00]. Bien que cette procédure d'optimisation a
été appliquée dans plusieurs domaines mais aucune
application n'a traité l'écriture arabe.
Dans le cadre de ce travail, nous proposons un système
de reconnaissance des caractères arabes imprimés qui met en
oeuvre le problème de sélection des primitives. L'objectif
principal de notre approche est la réduction du nombre de
caractéristiques utilisées tout en essayant de maintenir et/ou
d'améliorer la performance de la classification du système de
reconnaissance. Cet objectif est défini par une fonction objective
à optimiser. Pour ce faire, il suffit de choisir une méthode
d'optimisation qui peut être adaptée au problème à
résoudre. La suite de ce mémoire décrit la conception et
l'implémentation d'un système de reconnaissance des
caractères arabes qui utilise une méthodologie optimale pour
répondre aux exigences de sélection des primitives.
3.3 Système proposé
Dans cette section, nous commençons par
présenter un vue globale sur notre sytème de reconnaissance
proposé. Ensuite, nous traiterons chaque compsante par
détails.
3.3.1 Description générale
Notre approche suggérée est basée sur un
modèle analytique : Nous avons en entrée une image d'un texte
arabe imprimé, cette image sera nettoyée par un processus de
prétraitement qui comporte trois sous modules: un sous module de
binarisation qui se charge de la conver-
43
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
sion de l'image en entrée en une image bitonale,
ensuite un sous module qui se charge de nettoyage de l'image, enfin cette
même image passera à un autre sous module qui se charge de la
squelettisation du texte. L'image obtenue va être segmenter en
caractères (graphèmes). Par la suite, le processus
d'apprentissage commence (figure-3.2).
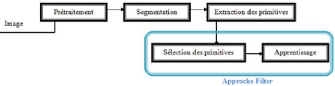
FIGURE 3.2 - Structure de la phase d'apprentissage
Chaque lettre issue de la segmentation est
représentée sur la base de données d'apprentis-sage sous
quatre formes différentes (début, milieu, fin, isolée). Le
vecteur de primitive obtenu sera optimisé en utilusant les AGs.Une fois
la phase de sélection est terminée, l'apprentissage se lance.
En ce qui concerne le sous système de reconnaissance,
son objectif est la reconnaissance du texte : Nous avons en entrée une
image bruitée d'un texte imprimé qui sera nettoyé par un
processus de nettoyage comportant les mêmes modules cités
ci-dessus. Ensuite, l'image prétraitée sera envoyée vers
la segmentation. Une fois que nous avons eu une image segmentée,
l'extraction des primitives commence. Le vecteur obtenu, suite à la
sélection, va être reconnu par le réseau de neurone de type
PMC. Une fois le caractère est reconnu, nous passons à la
reconnaissance du sous-mots (mots), des lignes et enfin du texte. Le texte
reconnu passera au module du post-traitement afin de valider les mots en
solution et les évaluer. Si le vecteur est non reconnu, il sera
ajouté à la base d'apprentissage du réseau.
Par la suite, nous expliquerons en détail chaque
composant de notre système et son processus de fonctionnement.
3.3.2 Description détaillée
Notre idée, pour la reconnaissance, se focalise sur
l'ajout d'un module de sélection de primitives au modèle
classique de reconnaissance. Les étapes suivies lors de la
reconnaissance sont présentées dans la figure suivante :
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
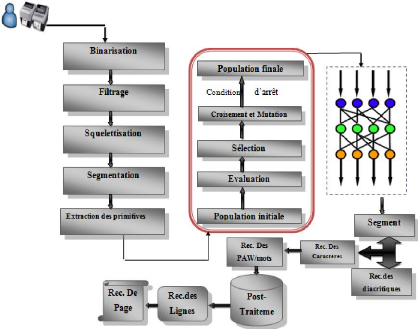
44
FIGURE 3.3 - Aperçu détaillé sur le
système de reconnaissance
3.3.2.1 Prétraitement
L'objectif des prétraitements est de faciliter la
caractérisation du texte à reconnaître en le nettoyant. Le
prétraitement est une technique qui sert à préparer les
données reçues à la phase de segmentation.
- Binarisation : La binarisation est
la première étape de prétraitement. Elle consiste à
convertir une image numérisée en une image binaire. La
binarisation permet de mieux distinguer les caractères du fond, elle
consiste à attribuer à chaque pixel de l'image une valeur de 0 ou
1.
- Filtrage : Après la
binarisation de l'image, nous passons à l'élimination des bruits.
Le filtre moyenneur est une méthode simple, intuitive et facile à
mettre en oeuvre. Il réduit la quantité de variation
d'intensité entre un pixel et l'autre. Il est souvent utilisé
pour réduire le bruit dans les images. L'idée de filtrer
moyenneur est de remplacer chaque valeur de pixel dans une image avec la valeur
"moyenne" de ses voisins, y compris lui-même. Cela a pour effet
d'éliminer les valeurs de pixels qui ne sont pas
représentatives.
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
Souvent, un noyau carré 3 x 3 est utilisé.
[HB02] prouve dans son papier, aprés le test de certains filtres, que le
filtre moyenneur donne les meilleurs résultats sur l'écriture
arabe.
- Extraction des squelettes
: La squelettisation consiste, par
définition, à réduire la forme en un ensemble de courbes,
appelées "squelettes", tout en respectant la topologie de la forme
considérée. Il existe plusieurs algorithmes de squelettisation.
Les Templates basés sur les algorithmes de squelettisations de
type Marquer-et-Supprimer sont très populaires en raison de leurs
fiabilités et leurs efficacités. Ils sont des algorithmes
itératifs, qui érodent les couches extérieures de pixel
jusqu'à il n'y a plus de couches qui peuvent être
supprimées. L'une des manières d'obtenir la squelette est
l'algorithme de Stentiford. L'algorithmee Stentiford tend à produire des
lignes qui suivent bien les courbes, ce qui entraîne des vecteurs qui
reflètent plus exactement l'image originale1. Il utilise
quatre modèles de 3 x 3 pour numériser l'image. La figure
ci-dessous montre ces quatre modèles :
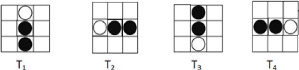
45
FIGURE 3.4 - Modèles utilisés pour numériser
une image dans l'algorithme Stentiford L'algorithme de Stentiford fonctionne
comme suit :
1. Trouver l'emplacement de pixel (j, i) où
les pixels dans l'image correspondent à celui du squelette T1.
Avec ce modèle, tous les pixels dans la partie supérieure de
l'image sont éliminés en se déplaçant de la gauche
vers la droite;
2. Si le pixel central n'est pas un critère
d'évaluation, et il a le numéro de la connectivité
égale à 1, alors, ce pixel est marqué pour la
suppression;
3. Répétez les étapes 1 et 2 pour tous
les emplacements de pixels correspondants à T1;
4. Répétez les étapes 1 et 3 pour le
reste des modèles : T2, T3 et T4. T2
correspond à des pixels sur le côté gauche de l'objet,
déplaçant de bas en haut et de gauche à droite.
1. http ://
homepage.ntlworld.com/heatons/softsoft/wintopo/help/html/vectorise.htm
46
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
T3 sélectionne des pixels le long du fond de
l'image et se déplace de droite à gauche et du bas vers le haut.
T4 localise les pixels sur le côté droit de l'objet, en
se déplaçant de haut en bas et de droite à gauche;
5. Définir en blanc les pixels marqués pour la
suppression.
3.3.2.2 Segmentation
Après l'extraction de squelette, nous passons à
la séparation des caractères,dite auusi segmentation. Notre
proposition suppose que les textes ne contiennent pas des ligatures sauf
ces deux types . L'algorithme de segmentation est expliqué
dans la figure suivante :
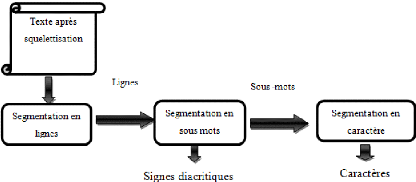
FIGURE 3.5 - Processus de segmentation
- Localisation des lignes de texte :
La première étape de la segmentation, après la
squelettisation de la page, est la détection de tous les lignes et les
segmenter en des lignes séparées. La séparation en lignes
se base sur la projection horizontale de l'image de texte [Feh99, HB02].
L'image étant codée sous forme de segments noirs et blancs,
l'histogramme de la projection horizontale est calculé par addition des
largeurs de segments noirs pour chaque ligne d'image. Les lignes de pixels sont
d'abord regroupées en bloc de lignes ayant un histogramme horizontal non
nul. Les blocs sont séparés par des lignes de pixels à
histogramme nul. L'algorithme suivi pour obtenir des lignes
séparées est le suivant :
1. Obtenir la projection horizontale de l'image de la page;
2. Trouver toutes les positions verticales de tous les pics dans
la projection horizontale;
47
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
3. Obtenir les pics représentant les positions des lignes
de base de lignes dans la page;
4. Chercher au-dessus de chaque ligne de base
détectée la plus faible densité de pixels, et marquer
cette position comme la limite supérieure de la ligne (X1);
5. Rrechercher la position au dessous de la ligne de base la
plus basse densité de pixels, et la marquer comme la limite
inférieure de la ligne (X2);
6. Répétez l'opération pour chaque ligne
de base détectée.
- Segmentation en mots /sous-mots
: Après la séparation des lignes,
nous passons à la localisation des sous mots (ou mots) et des points
diacritiques. [EI01] proposent la méthode Bounding Box pour
l'obtention des sous mots et des points diacritiques séparés.
L'algorithme utilisé pour obtenir les composantes connexes est une
simple procédure itérative qui compare les lignes par balayages
successives des lignes de l'image afin de déterminer si les pixels noirs
dans n'importe quelle paire de lignes sont connectés ensemble. Les
rectangles de délimitation sont étendus pour inclure tout
regroupement de pixels noirs connectés par balayage successives des
lignes. La figure suivante décrit les étapes suivies pour la
lettre »Ta» :

FIGURE 3.6 - Processus de construction des composantes
connexes à partir de balayage de lignes d'image »Ta»
L'algorithme, comme illustré dans la figure ci-dessus, est
le suivant :
48
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
1. Tout d'abord, tous les pixels noirs sont scannés et
représentés par un petit rectangle;
2. Dans chaque rangée, les limites qui se croisent sont
fusionnées en un seul rectangle;
3. De même, les limites qui se croisent verticalement sont
fusionnées en un seul rectangle;
4. Les étapes [2] et [3] sont
répétées jusqu'à ce qu'aucune autre fusion ne soit
possible.
La distinction entre les sous-mots et les signes diacritiques
se fait simplement en vérifiant si la ligne base passe par une
boîte englobant ou non. Si la boite englobante est située sur la
ligne de base alors c'est un sous-mot, si non c'est un signe diacritique.
- Segmentation en caractères
: Nous avons utilisé une méthode
simple pour la séparation des caractères. C'est l'histogramme de
projection verticale. La plupart des caractères arabes se connectent le
long de la ligne de base principale. Les caractères causent une
irrégularité dans l'histogramme de projection verticale.
L'étape de segmentation de caractères tente à segmenter
chaque sous-mot à un certain nombre de segments. Chaque segment peut
représenter une seule lettre arabe ou seulement une partie d'une lettre
arabe (graphème). La segmentation d'un sous-mot est
réalisée en quatre étapes principales :
1. Retirez tous les signes diacritiques existants dans le
sous-mot; Comme tous les composants étaient précédemment
classés en sous-mots et signes diacritiques. La suppression des signes
diacritiques se réalise en effaçant tous les pixels à
l'intérieur des boîtes englobant qui ont été
classés comme signes diacritiques;
2. Analyser chaque colonne de pixels dans l'image du
sous-mot. Si une colonne de pixels comprend un seul pixel qui se trouve sur la
ligne de base inférieure, marquer ce point comme un des points où
il est possible de faire une coupe de segmentation;
3. Obtenir la projection verticale de l'image sous-mot.
Rechercher tous les pics dans la projection et marquer leurs positions comme
des positions où la segmentation est nécessaire. Ce sont des
positions où l'irrégularité dans le texte se produit et
indique la détection d'un nouveau caractère;
4. A chaque position où la segmentation est
nécessaire, nous recherchons dans la direction droite le point le plus
proche où il est acceptable d'appliquer une coupe. La segmentation, est
donc faite à cette position.
Notez qu'une coupe de segmentation est faite au plus gauche de
sous-mot et que tout sous-mot doit inclure au moins un segment.
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
3.3.2.3 Extraction des primitives
L'extraction des paramètres a pour objectif non
seulement la réduction de dimension de l'espace de
représentation, mais aussi l'amélioration de la classification
des formes à recon-naitre. Nous avons sélectionné des
paramètres pour le codage du segment de caractère. Ces
paramètres sont décrits ci-dessous.
- Technique de fenêtre glissante
: Le principal avantage de ce type des primitives est la
simplicité et l'efficacité [SKJ+09]. Ils nécessitent,
généralement, un seul passage à travers les pixels. Chaque
image du caractère est transformée en une séquence de
vecteurs de caractéristiques calculée à partir d'une
fenêtre glissante de taille N pixels. Dans notre cas, la fenêtre
d'analyse se déplace de gauche vers la droite et de hauts vers le
bas.
49
FIGURE 3.7 - Extraction de vecteurs de primitives avec des
fenêtres glissante: (a) horizontale et (b) verticale
La méthode de représentation mentionnée
précédemment est une représentation générale
et peut être appliquée sur n'importe quelle image. En particulier,
les caractères arabes ont des caractéristiques qui peuvent
être utilisées comme des descripteurs.
- Existence des boucles : Les
caractères arabes peuvent être classés en deux
catégories : Les caractères qui comprennent des boucles et des
autres qui ne les comprennent pas. L'existence des boucles dans certains
caractères dépend aussi de la position de ces derniers au sein
d'un sous-mot (initial, milieu, final, isolé). Par exemple, un "Meem"
dans sa position initiale et milieu comprend une boucle, tandis que dans sa
position finale et isolée ne la comprend pas. Les caractères qui
incluent les boucles sont énumérés en fonction de leurs
positions dans le tableau suivant :
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
TABLE 3.1 - Existence de boucle dépendant de la position
du caractère

La détection de l'existence des boucles dans un
caractère arabe est réalisée en utilisant l'algorithme
flood fill. L'algorithme de remplissage par diffusion prend trois
paramètres : un noeud de départ, une couleur cible et une couleur
de remplacement. L'algorithme cherche pour tous les noeuds qui sont
connectés au noeud de départ par un trajet de la couleur cible et
les transforme en couleur de remplacement.
Algorithm 3.1 L'algorithme flood fill

- Caractères ascendants et descendants
: Certains caractères arabes remontent au-dessus de la
ligne de base supérieure. Ces caractères sont les suivants :
Il existe, aussi, des caractères qui descendent au
dessous de la ligne de base. Ces caractères sont les suivants :
50
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
Les caractères arabes descendants peuvent
également être reconnus par la mesure de la distance d'un segment
au dessous de la ligne de base. Aussi que les caractères ascendants
peuvent être reconnus par la mesure de la distance dessous de la ligne de
base.
- Largeur des caractères :
Lorsque nous utilisons des polices différentes, des formes
différentes du même caractère ont des différentes
largeurs. La largeur de chaque segment de caractère est
considérée parmi les autres caractéristiques extraites
pour construire le vecteur de primitives.
Parmi les critères qui assurent une utilisation
efficace des informations dans les vecteurs de paramètres
l'indépendance au sens du non redondance. Pour assurer ce
critère, nous proposons dans la section suivante une technique de
sélection des primitives.
3.3.2.4 Sélection des primitives
Notre contribution vise à effectuer une
sélection de primitives pertinentes. Ces primitives sont
représentées dansun de taille N. Pour résoudre ce
problème, nous utilisons les AGs. Il faudra donc trouver M
primitives telles que M < N. Les étapes de construction
d'un AG utilisé sont :
- Le codage des chromosomes : Nous avons
choisit le codage binaire. Cela signifie que le chromosome sera sous la forme
d'une chaîne binaire. La présence du bit 1 signifie que la
primitive est sélectionnée et la présence du bit 0
signifie que la primitive ne l'est pas. La taille du chromosome est identique
à la taille du vecteur de primitives, soit N la taille du ce
vecteur.

51
FIGURE 3.8 - Exemple de codage d'un vecteur de primitives
- La définition de la fonction d'adaptation
: La fonction d'adaptation est une somme pondérée des
fonctions objectives. Le premier objectif consiste à minimiser le
nombre
52
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
de primitives. Le deuxième consite à minimiser
le taux d'erreu générerr lors de la classification. Alors, la
fonction d'adaptation est une combinaison des deux fonctions à
minimiser. Cette fonction est décrite par la formule
(3.1).Chaque chromosome de la population sera évalué par
cette dernière.
Fitness = Minimiser (á f1 +
o f2) (3.1)
Où f1 : Le taux d'erreur générer
lors de la classification;
f2 : Le rapport entre le nombre de primitives
sélectionnées du chromosome et le nombre de primitives total ;
á : Paramètre en fonction de la
normalisation ;
o : Paramètre en fonction de la
pondération.
Les deux paramètres á et o
sont fixés arbitrairement à 1000 et 1 en se basant sur les
travaux dans le domaine de reconnaissance des chiffres [Ben02]. La technique
utilisée pour trouver ces valeurs est la suivante :
á = c1.w1 et o =
c2.w2 (3.2)
Où ci : est le paramètre de normalisation
de l'objectif fi.
wi : est le paramètre de pondération de
l'objectif fi avec I wi = 1 Après remplacement de
á et o, l'équation (3.1) devient :
f = Minimiser
(c1.w1.f1 +
c2.w2.f2) (3.3)
|
Puisque w1 + w2 = 1, nous obtenons :
w1c1
f2 =
-w2c2
|
f
f1 + (3.4)
w2c2
|
La pente de la fonction f2 est w1c1 w2c2.
Notre but est de minimiser la fonction d'adaptation alors la valeur de
cette pente doit être petite. L'objectif le plus important pour notre
problème est de diminuer le nombre des primitives, alors, la plus grande
importance est donnée à la fonction objective f2 au lieu
de f1. D'où le choix des valeurs de á et de
o est respectivement 1000 et 1. D'ou, les pondérations de
chacun des objectifs sont :
w1 = 0.3 et w2 = 0.7 (3.5)
53
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
3.3.2.5 Reconnaissance
Il est évident de passer par la phase d'apprentissage
avant la phase de reconnaissance. Dans cette phase, les segments de
caractères sont divisés en quatre ensembles en fonction de la
position d'un caractère segment (initiale, médiale, finale et
isolée). Ces segments sont issus de la phase de segmentation. La
distinction de la position des segments s'effectue manuellement. Cette
répartition a plusieurs avantages. Elle améliore le processus de
reconnaissance, car chaque segment est pré-classée par sa
position dans un sous-mot. cette modélisation nécessite une
grande capacité de stockage, mais cet inconvénient est
négligeable face à l'amélioration des performances du
système [Feh99]. Chaque segment de caractères est appris (puis
reconnu) à l'aide d'un réseau de neurone distinct, d'où
nous avons quatre réseaux de neurones (initiale, médial, final,
isolé) à former, pour être utilisées plus tard dans
le processus de reconnaissance.
La phase de reconnaissance passe par trois niveaux : la
reconnaissance des caractères, des sous-mots, des lignes et enfin du
texte.
- Reconnaissance des caractères :
Après la reconnaissance du corps de caractères, nous devons
passer à la phase d'assemblage corps/caractère. La reconnaissance
des signes diacritiques se réalise à la base des
caractéristiques géométriques extraites de chaque
diacritiques. Nous attribuions à chaque signe diacritique un code en
fonction des caractéristiques géométriques et sa position
par rapport à la ligne de base (au-dessus, au-dessous). Après que
chaque segment de caractère a été associé à
un signe diacritique, la cohérence de chaque combinaison est
vérifiée. Par exemple, un caractère " " ne peut pas
être associée avec un "deux points" diacritique, alors nous
pouvons conclure que le caractère à reconnaitre est " ", mais il
était mal classés. Cela peut être représenté
comme un automate comme le montre la figure suivante :
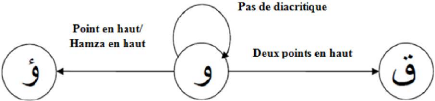
FIGURE 3.9 - Un automate utilisé pour corriger les signes
diacritiques de caractère "Waw" - Reconnaissance des sous
mots : Les caractères reconnus sont regroupés
pour
54
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
reconstruire un sous-mot selon les positions de segments de
caractères dans l'image de sous-mot. Certains segments de
caractères peuvent être des sous-mots.
- Reconnaissance des lignes : Les
lignes de texte en arabe sont composées des mots où chaque mot
est composé d'un ou plusieurs sous-mots. Dans un texte arabe
imprimé,
la taille d'espace inter-mots est supérieure à
celui de l'espace entre les sous-mots.

FIGURE 3.10 - Détection des espaces dans une ligne
Par conséquent, il existe une valeur de seuil qui peut
être utilisé pour établir une distinction entre l'espace
inter-mots et l'espace inter-sous mot. Un algorithme simple est utilisé
pour déterminer cette valeur seuil. Cet algorithme passe par les
étapes suivantes :
1. Déterminer toutes les distances des espaces au sein
d'une ligne;
2. Disposer ces distances dans l'ordre décroissant;
3. Obtenir la différence entre chacune des deux valeurs
successives;
4. Obtenir la différence maximale;
5. Obtenir les deux distances d'espaces donnant cette
différence maximale;
6. Considérer la plus grande valeur de ces deux distances
comme la valeur de seuil.
Une fois que la valeur seuil est obtenue, les mots et les
sous-mots sont alignés sur une seule ligne, et les espaces blanc sont
insérés entre eux selon ce seuil.
- Reconnaissance de la page :
Après la reconnaissance des lignes, elles sont toutes
regroupées dans un texte selon la position de chaque ligne dans l'image
de page originale.
3.3.2.6 Post traitement
Afin de vérifier l'exactitude des mots et sous-mots
reconnus, un modèle prédéfini vocabulaire est
utilisé. L'existence de chaque mot (ou sous-mot) est
vérifiée dans le vocabulaire. Si un mot n'est pas trouvé,
il est remplacé par le mot le plus proche dans le vocabulaire.
55
CHAPITRE 3. CONTRIBUTIONS À LA RECONNAISSANCE
DES CARACTÈRES
ARABES IMPRIMÉS
Conclusion
L'objectif de notre contrubition consiste à minimiser
le nombre de primitives sélectionnées tout en améliorant
ou en maintenant le taux de reconnaissance du système. La méthode
des AGs est utilisée pour assurer cette minimisation. L'utilisation de
l'approche Filter décrite à la section 3.2.2 consiste à
éffectuer une sélection de primitives pertinentes, par la suite,
l'apprentissage se lance.
Dans ce chapitre, nous avons présenté notre
contribution sous forme d'un diagramme décrivant les différents
composants qui la forme. Puis nous avons détaillé chaque
processus à part. Dans le chapitre suivant, nous effectuons une
étude expérimentale de notre système. Et nous mettons en
évidence l'apport de notre approche.
Chapitre4
Expérimentation et évaluation
L
A sélection des primitives est une étape
importante dans un système de reconnaissance
de formes. Cette sélection est
considérée comme un problème d'optimisation. Les
algo-
rithmes génétiques sont utilisés pour
résoudre ce problème de sélection des primitives dans
notre système proposé.
Après avoir décrit notre contribution et
spécifié les différents besoins de notre application, ce
chapitre traite les résultats expérimentaux relatifs à
notre approche. Nous commençons par décrire les
différentes méthodes d'évaluation d'un OCR. Ensuite, nous
illustrons les différentes étapes de notre système de
reconnaissance appliquées sur une image d'un texte arabe imprimé.
Nous discutons le choix des paramètres de l'algorithme
génétique. Enfin, une évaluation des résultats
obtenus est présentée.
4.1 Méthodes d'évaluation d'un OCR
Bien que plusieurs efforts sont déployés afin de
développer un système de reconnaissance d'écriture arabe
avec des bonnes performances, certains problèmes persistent encore. En
effet, aucun système n'est parfait. La méthode
d'évaluation se fait en se basant sur le type d'information qu'on
souhaite extraire d'un OCR [BC06]. Si l'OCR est considéré comme
une boîte noire de la quelle seul le résultat de la reconnaissance
des mots est accessible, l'évaluation est faite de manière
globale. Dans le cas où nous disposons d'une information plus
précise, nous pouvons affiner la mesure de la performance. Deux
méthode d'évaluation sont alors utilisées dans la
littérature : évaluation globale et évaluation locale.
57
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
4.1.1 Evaluation globale
Dans l'évaluation de boîte noire, un
système OCR est traité comme une unité indivisible. La
seule évaluation possible est de calculer le taux d'erreur ou le taux de
reconnaissance. Pour se faire, nous avons besoin de trouver les erreurs. Cela
revient à mesurer, par mise en correspondance entre les couples de
chaînes de références et de résultats, les ajouts,
les suppressions et les substitutions [BC06].
4.1.2 Evaluation locale
L'évaluation boîte blanche, caractérise la
performance de sous-modules individuels. La plupart des systèmes d'OCR
ont des sous-modules de détection et de correction d'inclinaison, la
page la segmentation, classification de zone, et l'extraction de texte.
L'évaluation boîte blanche n'est possible que si
l'évaluateur a accès à l'entrée et la sortie des
sous-modules du système de reconnaissance. Ainsi pour évaluation
de la segmentation, l'accès aux coordonnées des zones produites
par OCR est essentiel.
Tandis que l'évaluation de boîte noire ne
nécessite pas l'accès aux résultats intermédiaires,
elle ne fournit pas l'analyse de la performance au niveau sous-module. En
outre, les évaluations décrites dans la section-4.3 ne
déterminent que le taux de reconnaissance de système.
4.2 Expérimentation
Contrairement aux chiffres et à l'écriture
latine pour lesquels des bases d'images sont disponibles depuis un certain
nombre d'année (NIST, CEDAR. . .), ils n'existent actuellement que
quelques bases d'images des documents arabes. Vu à
l'indisponibilité totale de bases d'images de textes arabes au
début de notre étude, nous avons commencé par la
construction d'une petite base pour valider l'approche proposée.
Dans ce qui suit, nous présentons un exemple
détaillé sur les étapes suivies par notre système
de reconnaissance. L'image en entrée est présentée dans la
figure-4.1 :
58
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION

FIGURE 4.1 - Image de test
.
4.2.1 Prétraitement
Le premier module qui traite l'image est le module de
prétraitement. Il contient un sous module de binarisation, un sous
module de filtrage et un sous module de squelettisation. Ce module accepte
comme entrée une image numérisée de la page du document de
la part de l'utilisateur. Nous obtenons, suite à la l'application de ce
module, l'image suivante (figure-4.2) :
FIGURE 4.2 - Extraction de squelette
Ce module peut engendrer un plus d'amincissement qui cause une
perte de données. Après l'obtention du squelette. La phase
suivante est la segmentation.
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
4.2.2 Segmentation
La phase de segmentation est composée de trois
étapes : la segmentation en ligne, la séparation des mots
(sous-mots) et des signes diacritiques et enfin la segmentation en
caractères.
- Segmentation en lignes : Ce module
accepte comme entrées la squelette du document texte issue de la
squelettisation. Son but est de détecter les lignes dans l'image puis
les séparer. La figure-15 présente le résultat de la phase
de segmentation en ligne. La ligne bleu présente la ligne de base et la
ligne rose présente la ligne de base supérieure.

FIGURE 4.3 - Segmentation en ligne
La destination des lignes séparées obtenues est
la segmentation en mots (sou-mots).
- Segmentation en PAW : Ce sous
module détecte toutes les formes connectées dans l'image des
lignes. Il se charge de les classer en sous-mots et signes diacritiques. Les
mots sont encadrés en vert et les signes diacritiques sont
encadrés en rouge tel qu'il est présenté dans la figure
suivante :

FIGURE 4.4 - Séparation des mots et détection des
signes diacritiques
59

60
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
Notant que ce sous module se déroule dans un temps
d'exécution un peut long.
- Segmentation en caractères :
Suite à la détection des sous-mots et des signes
diacritiques, nous passons à la séparation des caractères.
L'entrée de ce sous module est un mot (sous-mot) issue de la phase de
segmentation précédente. Au cours de la segmentation, nous avons
observé dans certain caractères une sur-segmentation et/ou une
sous-segmentation.
- Sous-segmentation: La sous-segmentation se produit
seulement lors de la segmentation de la ligature " ", comme l'illustre la
figure-4.5. La ligature "Lam Alef" est une combinaison des deux
caractères, "Lam" et "Alef". Cette forme est considérée
comme un seul caractère. Nous avons attribué, à cette
forme, un code distinct qui lui sera associé plus tard à la phase
de reconnaissance.
FIGURE 4.5 - Sous-segmentation du caractère"Lam Alef"
- Sur-segmentation : La sur-segmentation est
observée dans les caractères "Sad" et "Sin" dans leurs
différentes positions. La figure-4.6 présente la sur-segmentation
de ces caractères dans leurs positions initiales. Ce problème a
été également résolu en attribuant à chaque
forme sur-segmentée un code distinct. Il faut prendre soin de ces formes
dans le processus de reconnaissance.
FIGURE 4.6 - Sur-segmentation des caractères " Sad"et "
Sin "
La sur-segmentation est, également, remarquée
dans certains caractères isolés et finals qui se terminent avec
une petite courbe comme le montre la Figure-4.7 (La courbe ignorée est
colorée en jaune). Cette problématique est résolue en
ignorant cette courbe, seulement la première partie du caractère
est prise en considération.
61
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
FIGURE 4.7 - Sur-segmentation des caractères
isolés
4.2.3 Extraction des primitives
La définition des primitives lors de l'extraction est
la partie la plus importante dans le système de reconnaissance. Les
chercheurs ont observé que meilleure solution est d'utiliser plusieurs
approches d'extraction afin de donner une meilleure description de la forme
à classer. De ce fait, plusieurs méthodes ont été
utilisées pour représenter les segments de caractères,
dans notre système, comme expliqué dans le chapitre
précédent. Le vecteur des caractéristiques utilisé
pour la reconnaissance de caractères est structuré comme suit
:
- 10 primitives issues du parcours horizontal de l'image de
caractère par une fenêtre glissante;
- 10 primitives issues du parcours vertical de l'image de
caractère par une fenêtre glissante;
- 7 primitives spécifiques à l'écriture
arabe.
Les sept descripteurs de caractère, qui
caractérisent les caractères arabes, sont calculés comme
suit :
- Existence de boucle : Après
application de l'algorithme Floud-fill, les segments de caractères qui
ne comprennent pas des boucles seront complètement colorés, alors
que ceux qui comprennent des boucles seront partiellement colorés et la
couleur de la boucle reste inchangée, comme illustré dans la
figure 4.8.
FIGURE 4.8 - La détection des boucles par l'algorithme
Flood-fill
Afin de normaliser le descripteur d'existence des boucles, le
rapport entre le nombre de pixels qui représentent la boucle et le
nombre de pixels qui représentent le caractère est
calculé. Ce rapport est considéré comme une
caractéristique de description.
62
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
- La distance descendante et la distance
ascendante : La distance (descen-dante/ascendante) est
mesurée par la distance d'un segment ascendant ou descendant par rapport
à la ligne de base, comme illustré dans la figure 4.9.
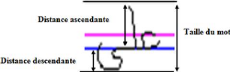
FIGURE 4.9 - Mesure de la distance acendante et descendante
Afin de normaliser cette distance, elle est divisée par
la taille de la ligne à la quelle le segment appartient.
- La largeur des caractères :
Cette mesure permet de localiser les pixels noirs dans la lettre. Nous
obtenons le nombre de pixels noirs : haut, bas, gauches et droits. Afin
de normaliser ces valeurs, elles sont divisées par la
taille de segment de caractère.

FIGURE 4.10 - Larguer du caractère
Nous avons proposé une approche hybride pour la
reconnaissance des caractères arabes imprimés. Cette technique
offre l'avantage de sélectionner les primitives les plus
représentatives ce qui améliore la qualité de
reconnaissance. La sélection des primitives sera détaillée
dans la section suivante.
63
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
4.2.4 Sélection des primitives
La sélection des primitives permet de réduire le
nombre de primitives N en M primitives telle que M N.
Les AGs sont utilisés pour résoudre ce type de
problème de sélection des primitives. Les paramètres de
l'AG pris par défaut sont :
TABLE 4.1 - Choix de paramètres de l'algorithme
génétique
|
Paramètres de l'AG
|
Valeurs choisies
|
|
Codage du chromosome
|
Binaire
|
|
Taille du chromosome
|
27
|
|
Taille de la population
|
100
|
|
Nombre de génération
|
1000
|
|
Initialisation de la population
|
Aléatoire
|
|
Technique de sélection
|
Roulette Biaisé
|
|
Fonction objectif
|
Minimiser le nombre des bits à 1
|
|
Technique de Croisement
|
Croisement à 1-point de coupure
|
|
Technique de Mutation
|
Opérateur d'échange réciproque
|
|
Insertion
|
Elitisme
|
|
Critère d'arrêt
|
Nombre de générations maximales
|
Dans le cadre de notre travail, nous avons effectué
plusieurs expériences pour déterminer les paramètres de
l'AG tels que : la taille de la population et les probabilités de
mutation et de croisement. Ces expériences sont décrites dans la
section suivante.
- Probabilité de Croisement Pcross
:
La méthode de croisement, que nous avons utilisé
est le croisement à un point de coupure. Pour déterminer le choix
de la probabilité de croisement Pcross, nous avons
varié les valeurs entre 0.6 et 0.7. L'ensemble des
probabilités de croisement que nous avons utilisé
est{0.6, 0.65, 0.7}.
64
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
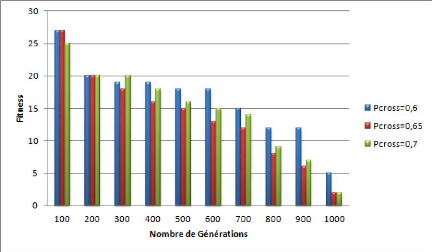
FIGURE 4.11 - Courbe représentant l'évaluation
du Fitness dans le cas de probabilité de mutation
Pmut= 0.04 et une variation de probabilité
de croisement Pcross
Une constatation peut être faite concernant le
Pcross = 0.6 est que la fonction d'adaptation n'atteignent
pas la solution optimale . Au temps qu'elle est atteinte dans le cas des
Pcross = 0.7et Pcross= 0.65.
Nous pouvons remarquer que la convergence est plus lente quand la
probabilité de croisement Pcross est égale
à 0.7. La solution optimale est obtenue quand une valeur qui
tend vers zéro de la fonction d'adaptation est atteinte, celle-ci est
observée à
Pcross = 0.65.
Dans la partie suivante, la probabilité de croisement est
fixé à Pcross = 0.65.
- Probabilité de Mutation Pmut :
Nous avons utilisé la technique de mutation à échange
reciproque pour construire notre AG. Pour déterminer le choix de la
probabilité de mutation Pmut, nous avons
varié les valeurs entre 0.02 et 0.04. L'ensembles des
probabilités de mutation que nous avons utilisé est {
0.02, 0.03, 0.04 }.
65
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
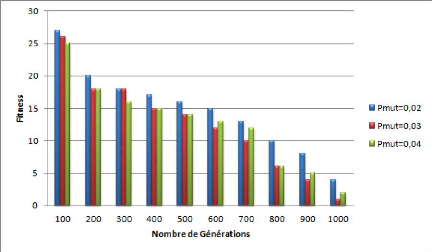
FIGURE 4.12 - Courbe représentant l'évaluation
du Fitness dans le cas de probabilité de croisement Pcross
= 0.65 et une variation de probabilité de mutation
Pmut
Une constatation peut être faite concernant la fonction
d'adaptation est que celle ci atteint la solution optimale dans le cas de
Pmut= 0.03.
Après certaines expériences, afin de choisir la
probabilité de croisement et de mutation, les valeurs choisies sont
égales respectivement à Pcross = 0.65 et
Pmut = 0.03, car la vitesse de convergence est plus rapide
avec ces valeurs.
- Taille de la population initiale
:
Dans le même contexte, nous avons effectué des
expériences pour observer l'influence de la taille de la population.
Nous avons utilisé les paramètres prédéfinis
initialement (Tableau-4.1) et les résultats des expériences
précédentes : le croisement à 1-point de coupure avec la
probabilité Pcross = 0.65 et la mutation à
échange réciproque avec la probabilité Pmut =
0.03
.
Nos résultats obtenues sont basés sur une
population initiale de 100 individus, nous avons effectué des
expériences avec une population de plus grande taille,
c'est-à-dire une population de 200 individus. La figure-4.13
représente l'évaluation moyenne de la fonction Fitness
sur notre population choisie et sur une population plus élargie.
66
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
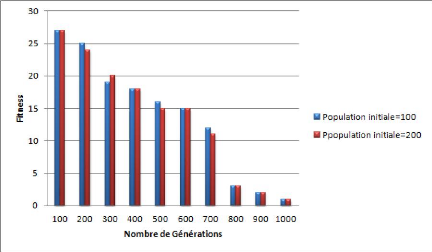
FIGURE 4.13 - Comparaison de la convergence du
Fitness pour deux populations de tailles différentes
Nous avons observé, que la vitesse de convergence des
deux populations, est presque la même. La solution optimale est atteinte
à la 800ème génération (figure-4.13). Donc, il est
mieux d'utiliser une population de taille égale à 100 individus
au lieu de 200 car le temps de calcul pour une population de grande taille est
plus lent.
Ces expériences nous ont permis de fixer certaines
valeurs des paramètres. Ces derniers concernent le choix des valeurs des
probabilités des opérateurs de mutation et de croisement et
l'influence de la taille de la population. Ces valeurs obtenues combiner avec
les valeurs prédéfinis initialement (Tableau-4.2) seront
utilisés pour la sélection de primitives.
67
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
TABLE 4.2 - Paramètres finales de l'algorithme
génétique
|
Paramètres de l'AG
|
Valeurs choisies
|
|
Codage du chromosome
|
Binaire
|
|
Taille du chromosome
|
27
|
|
Taile de population
|
100
|
|
Nombre de générations
|
1000
|
|
Initialisation de la population
|
Aléatoire
|
|
Technique de Sélection
|
Roulette Biaisé
|
|
Fonction Objectif
|
á f1 + 3
f2(voir-3.2.4)
|
|
Technique de Croisement
|
Croisement à 1-point de coupure
|
|
Probabilité de Croisement
|
Pcross =
0.65
|
|
Technique de Mutation
|
Opérateur d'échange
réciproque
|
|
Probabilité de Mutation
|
Pmut =
0.03
|
|
Insertion
|
Elitisme
|
|
Critère d'arrêt
|
Nombre de générations
maximales
|
Après le choix final des paramètres de l'AG, la
sélection des primitives se lance. La figure suivante représente
la répartition des individus, qui représentent les vecteurs de
primitives, d'une population de taille 100 pour une première
génération figure-4.14(a) et après 1000
générations figure-4.14(b).
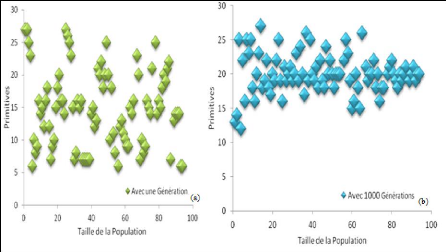
FIGURE 4.14 - Distribution des individus dans l'espace de
recherche
Nous observons que les individus deviennent de plus en plus
ordonnés d'une génération
68
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
à une autre. Le nombre de primitive sectionnée
vari tend vers 20 après 1000 générations. L'objectif de la
sélection des primitives pertinentes a été atteint car les
résultats obtenus par l'approche de la sélection des primitives
par les AGs sont satisfaisants. Nous avons pu supprimer 25% de nombre de
primitives. En effet, le nombre de primitives a diminué de 7, passant de
27 à 20 primitives pertinentes.
4.2.5 Apprentissage
Puisque un caractère arabe peut avoir des
différentes formes en fonction de sa position dans un sous-mot (un mot)
, alors, les segments résultants du processus de segmentation ont
également de différentes formes selon leurs positions dans le
sous-mot. Ils existent quatre types de segments, illustrés à la
figure-4.15 :
FIGURE 4.15 - Les positions possibles des caractères
dans un mot
Les segments de caractères sont divisés en
quatre ensembles en fonction de leurs positions dans le sous-mot (initiale,
milieu, finale et isolée) comme mentionné dans l'annexe. Chaque
segment de caractère est appris (puis reconnu) à l'aide d'un
réseau de neurones distincts, d'où nous avons quatre
réseaux de neurones (initiale - milieu - final - isolé) à
former, pour être utilisées plus tard dans le processus de
reconnaissance.
Il existe de nombreuses techniques pour déterminer le
choix de des paramètres du réseau de neurone. Dans tous les cas,
un nombre d'essai est nécessaire pour déterminer la structure
optimale. Pour l'apprentissage du perceptron multicouche nous avons
utilisé l'algorithme de rétropropagation du gradient. Le
réseau contient une seule couche caché car la plupart des
chercheurs disent qu'avec une couche cachée, le réseau est
capable, avec un nombre suffisant de neurones, d'approximer toute fonction
continue1. Pour déterminer le nombre de noeuds dans cette
couche nous avons utilisé l'heuristique suivante :
\/
H = M2 + N2 (4.1)
1. http ://
cict.fr/~stpierre/reseaux-neuronaux/node17.html
69
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
Avec H : Nombre des noeuds dans la couche cachée;
M : Nombre des noeuds d'entés;
N : Nombre des noeuds de sortis.
Après expérimentation, cette heuristique qui a
été déjà testée par des autres
chercheurs2 nous a donné des bons résultats. La
structure des quatre réseaux utilisés, ainsi que leurs
paramètres de formation sont énumérés dans le
tableau-4.3.
TABLE 4.3 - Paramères des réseaux
|
Types du réseaux
|
|
Isolée
|
Initiale
|
Milieu
|
Finale
|
|
Nombre de noeuds dans la couche
d'entrée
|
27
|
27
|
27
|
27
|
|
Nombre de noeuds dans la couche cachée
|
31
|
29
|
29
|
30
|
|
Nombre des noeuds dans la couche de sortie
|
16
|
11
|
11
|
14
|
|
Momentum
|
0.4
|
0.4
|
0.4
|
0.4
|
|
Fonction d'activation (voir-2.4)
|
Sigmoïde
|
Sigmoïde
|
Sigmoïde
|
Sigmoïde
|
|
Nombre des cycles
|
3000
|
3000
|
3000
|
3000
|
|
Signal d'erreur
|
0.006
|
0.006
|
0.006
|
0.006
|
L'apprentissage des réseaux est effectué en
utilisant les paramètres décrits au tableau-4.3. Le nombre de
cycles vont servir comme critère d'arrêt de l'apprentissage.
Lorsque un sur-apprentissage est rencontré l'apprentissage des
réseaux s'arrête si non l'algorithme se répète
jusqu'à atteindre le nombre de cycles maximal.
L'ensemble d'apprentissage a été
généré en utilisant le module d'extraction de
caractéristiques et leurs reconnaissance a été faite
manuellement. Les entrées et les classes ont été, ensuite,
introduites dans leurs correspondants des réseaux de neurones dans
MATLAB. Elles sont utilisées pour former les quatre
réseaux tels qu'il est illustré dans la figure 4.1.
2. http ://
cict.fr/~stpierre/reseaux-neuronaux/node18.html
70
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
FIGURE 4.16 - Apprentissage du réseau perceptron
multicouche
4.2.6 Reconnaissance
Les segments de caractères ont été
divisés en quatre ensembles en fonction de leurs positions dans le
sous-mot comme mentionné dans l'annexe. Chaque segment de
caractères est reconnu à l'aide d'un réseau de neurone
distinct, selon sa position dans le mot (figure-4.17).
FIGURE 4.17 - Reconaissance du segments du caractère
Les signes diacritiques jouent un rôle très
important dans la lecture du texte arabe. Le processus de reconnaissance des
signes diacritiques est basé sur les caractéristiques
géométriques de chaque type de diacritique. Nous avons
attribué à chaque signe diacritique un code en fonction de ces
caractéristiques géométriques et sa position par rapport
à la ligne de base. Ces caractéristiques sont
présentées dans le tableau suivant :
71
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
TABLE 4.4 - Caractéristiques des signes diacritiques
|
Diacritiques
|
Position
|
Les caractéristiques
géométriques
|
Code
Assignées
|
|
Acune signe
|
***
|
***
|
0
|
|
Au dessus de la ligne
de base
|
un seul pixel
|
1
|
|
Au dessous de la
ligne de base
|
Largeur égale à la
hauteur
|
2
|
|
Au dessus de la ligne
de base
|
La largeur est toujours
|
3
|
|
Au dessous de la
ligne de base
|
supérieure à la hauteur
|
4
|
|
Au dessus de la ligne
de base
|
Non reconnu
directement
|
5
|
|
Au dessus de la ligne
de base
|
La hauteur est plus
grande ou égale à
la
largeur
|
6
|
|
Au dessous de la
ligne de base
|
une fourche peut exister
|
7
|
|
Au dessus de la ligne
de base
|
La hauteur est plus
grande ou égale à
la
largeur
une fourche ne peut pas
exister
|
8
|
Le code (0) est attribué aux segments de
caractères qui ne portent pas des signes diacritiques. Chaque
diacritique est associée à l'un des segments de caractères
classés en fonction des règles linguistiques (voir-3.3.2.5). Les
segments de caractères avec leurs signes diacritiques associés
sont regroupés pour reconstruire les sous-mots (figure-4.18) selon les
positions de ces segments dans l'image.
FIGURE 4.18 - Image du mot et le mots reconnu
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
Les sous-mots sont, ensuite, regroupés pour former les
lignes de texte. La figure-4.19 présente un exemple de reconnaissance
d'une ligne de texte.

FIGURE 4.19 - Image de la ligne et la ligne reconnue
L'évaluation du taux de reconnaissance de ce texte qui
contient 139 caractères dont 122 sont reconnus est de 87,76%.
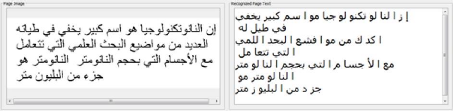
FIGURE 4.20 - Image du texte et texte reconnu
4.3 Evaluation de notre système
Dans la phase de reconnaissance, nous avons utilisé des
images des textes de bonne qualité. Un taux global de 87.94% a
été enregistré. La variation de taux de reconnaissance par
caractère est illustré dan la figure-4.21.
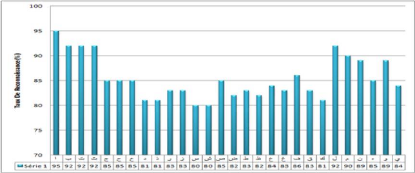
FIGURE 4.21 - Variation du taux de reconnaissance par
caractères
72
73
CHAPITRE 4. EXPÉRIMENTATION ET
ÉVALUATION
Nous proposons de comparer nos résultats avec d'autres
travaux. En fait, le tableau-4.5 présente les valeurs des mesures des
taux de reconnaissance trouvées par ces systèmes.
TABLE 4.5 - Comparaison des résultats
|
Auteurs
|
Taux de reconnaissance
|
Classifieur
|
|
Notre Contribution, 2012
|
87.94%
|
PMC-AG
|
|
[KD07]
|
97,1%
|
PMC-AG
|
|
[OSB+02]
|
87.54%
|
PMC-AG
|
Le taux de reconnaissance de notre contribution parait faible
par rapport à celle de [KD07]. Cette lacune se justifie par le fait que
[KD07] utilise une base des chiffres de 0 à 9, au temps que, notre
système est apliqué sur l'écriture arabe qui se
caractérise par un vocabulaire large.
Aussi bien, la phase de post-traitement peut améliorer
le taux de reconaissance jusqu'au 10%. Nous ne sommes pas arrivés
à terminer cette phase qui peut avoir une grande influence sur le taux
de reconnaissance du système.
Conclusion
L'objectif principal de notre contrubition est de
sélectionner les primitives pertinentes dans un système de
reconnaissance des caractères arabes imprimés multifontes. Cet
objectif est aboutu car les résultats par les AGs sont satisfaisants. En
effet, le nombre de primitives a chuté de sept primitives, passant de 27
à 20.
L'évaluation de notre système de reconnaissance
proposé permet d'évaluer les performances de l'algorithme
utilisé, son efficacité ainsi que ses faiblesses. En plus de
pouvoir apprécier les résultats obtenus, cette évaluation
peut donner des indices sur les points à améliorer
ultérieurement. Plusieurs systèmes de reconnaissances tant
analytiques que globales sont élaborés. Toutefois, aucune de ces
approches de reconnaissance ne donne des résultats parfaits du fait de
la complexité du sujet. Le problème reste ouvert et de nouveaux
efforts sont à déployer pour améliorer les approches de
reconnaissance d'écriture arabe.
Conclusion et Perspectives
L
A revue de la littérature relative à la
reconnaissance d'écriture, dans le premier chapitre du
présent rapport, nous a permis de comprendre que
l'objectif visé par les système d'OCR
est de diminuer
l'intervention de l'être humain. Parmi les problèmes qui peuvent
influencer sur la qualité d'un système de reconnaissance, le
choix de primitives qui caractérisent la forme à
reconnaître.
L'originalité de notre travail réside dans le
fait que le système de reconnaissance de texte arabe ne suit pas le
schéma classique qui consiste à segmenter les mots en
caractères, extraire les caractéristiques et faire la
classification. Notre approche part du fait que les primitives extraites ne
sont pas toujours fiable. En ce sens, notre système essaie d'adapter la
meilleure solution du problème en question. Pour se faire, nous
proposons une approche d'optimisation pour sélectionner les primitives
pertinentes.
Notre travail se situe dans le cadre de reconnaissance de
l'écriture arabe imprimé mul-tifonte. Nous avons
présenté une approche hybride pour la reconnaissance des
caractères arabes imprimés. Cette technique offre l'avantage de
sélectionner les primitives les plus représentatives, ce qui
améliore la qualité de reconnaissance. La sélection des
primitives est l'une des étapes les plus importantes dans un
système de reconnaissance. Elle a fait l'objet de recherche dans de
nombreuses disciplines. La sélection des primitives tends à
réduire le nombre de primitives en éliminant les primitives
redondantes du système de reconnaissance. Un second objectif de cette
sélection est de maintenir et/ou améliorer la performance du
classifieur utilisé par le système de reconnaissance.
De différentes études ont été
proposées dans la littérature pour la sélection de
primitives. Notre orientation s'est focalisée sur les algorithmes
génétiques. Une fois que nous avons déterminé les
paramètres de l'AG tels que : la taille de la population, le nombre de
génération et les méthodes de reproduction, la
séléction de primitives commence. Les paramètres de
l'algorithme génétique sont définis
expérimentalement.
Les résultats obtenus lors de la sélection de
primitives ont permis de réduire la complexité
75
Conclusion et Perspectives
du perceptron multicouche. Le nombre de primitives a
été réduit de 25% par rapport à l'ensemble extraits
du système de reconnaissance des caractères. Il est difficile
d'effectuer une comparaison objective et exhaustive entre la performance de
notre de système et celles d'autres systèmes publiés. En
effet, les ensembles de test sont différents et les mesures de
performance ne sont pas définies clairement. De plus, il n'est pas
possible de déterminer si les échantillons d'apprentissages et de
tests sont mutuellement exclusifs. De même, nous avons constaté
que le problème de sélection de primitives n'a pas
été traité.
L'effort requis pour la préparation d'un ensemble de
tests significatifs constitue en réalité un obstacle majeur pour
une expérimentation valable du point de vu statistique. Il est donc
nécessaire que les efforts concentrent dans l'élaboration d'une
base standard de l'écriture arabe qui pourrait servir dans
l'évaluation des différents systèmes de reconnaissance.
Comme perspectives, nous estimons qu'un post-traitement
lexical basé sur un dictionnaire peut encore améliorer le taux de
reconnaissance. Ceci à montrer son utilité dans plusieurs
systèmes de reconnaissances d'écritures arabes.
Autre perspective, sera d'effectuer une sélection en
utilisant les algorithmes génétiques itératifs non pas les
algorithmes génétiques simples.
Bibliographie
[AAM06] Abdallah.B, Abdellatif.E, Mokhtar.S :
Reconnaissance des Mots Manuscrits Arabes par Combinaison d'une Approche
Globale et une Approche Analytique, Actes du 9ème Colloque
International Francophone sur l'Ecrit et le Document, pp : 265-270, Nou-vembre
2006.
[AM11] Anshul.G, Mantisha.S : Offline Handwritten
Character Recognition, Mémoire de fin d'étude, Institut
Indienne de technologie, Guwahati-India, Avril 2011.
[Ami97] Amin.A : Off line Arabic character recognition a
survey, Document Analysis and Recognition, vol.2, pp : 596-599, Août
1997.
[AS95] Al-Badr.B, Sabri.A.M : Survey and bibliography of
Arabic optical text recognition, Signal Processing, vol.41, Issue 1, pp :
49-77, Janvier 1995.
[AY01] Arica.N, Yarman-Vural.F.T : An overview of
character recognition focused on off-line handwriting, Systems, Man, and
Cybernetics, Part C : Applications and Reviews, IEEE Transactions, vol.31, pp :
216-233, Mai 2001.
[BBE00] Ben Amara.N, Belaïd.A, Ellouze.N :
Utilisation des modèles markoviens en reconnaissance de
l'écriture arabe État de l'art, Colloque International
Francophone sur l'Ecrit et le Document, Septembre 2000.
[BC06] Belaïd.A, Cecotti.H : La numérisation
de documents Principe et évaluation des performances, Les documents
écrits : de la numérisation à l'indexation par le contenu,
Mullot, Rémy (Ed.), Juillet 2006.
[Bel95] A. Belaïd : OCR Print - An Overview,
Survey of the state of the art in Human Language Technology, Cole.R.A,
Mariani.J, Uszkoreit.H, Zaenen.A, Zue.V (réd.), Kluwer Academic
Plublishers, 1995.
[Ben99] Ben Amara.N : Utilisation des modèles de
Markov cachés planaires en reconnaissance de l'écriture arabe
imprimée, Thèse de doctorat, Université des sciences
des techniques et de médecine, Tunis II-Tunisie, 1999.
77
BIBLIOGRAPHIE
[Ben02] Benahmed.N : Optimisation de Réseaux de
neurones pour la reconnaissance de chiffres manuscrits isolés:
Sélection et pondération des primitives par les algorithmes
génétiques, Mémoire de mastère, Ecole de
technologie supérieure, Montréal-Canada, 2002.
[Bis95] Bishop.M.C : Neural networks for pattern
recognition, Oxford University Press, 1995.
[Bur04] Burrow.P : Arabic handwriting recognition,
Thèse de doctorat, university of Edinburg, England, 2004.
[CBB01] Cheung.A, Bennamoun.M, Bergmann.N.W : An Arabic
optical character recognition system using recognition-based segmentation,
Pattern Recognition,vol 34, pp : 215233, Nouvembre 2001.
[Cha11] Chaari.T : Un algorithme
génétique pour l'ordonnancement robuste :
application au problème du flow shop hybride,
Thèse de doctorat, Faculté des Sciences Économiques
et de Gestion, Sfax-Tunisie, 2011.
[Der09] Derdour.K : Reconnaissance de formes du
chiffre arabe imprimé : Application au code à
barre d'un produit, Mémoire de mastère, Faculté
des Sciences de l'Ingénieur, Batna-Algérie, 2009.
[DL97] Dash.M, Liu.H : Feature Selection for
Classification, Intelligent Data Analysis, pp : 131-156, Mars 1997.
[Dre04] Dreyfus.G : Réseaux de neurones
: méthodologie et applications, Eyrolles,
2004.
[DS95] Dejong.K.A, Sarma.J : On Decentralizing Selection
Algorithm, International Conference on Genetic Algorithms, pp : 17- 23,
1995.
[EI01] Elgammal.A.M : A Graph-Based Segmentation and
Feature-Extraction Framework for Arabic Text Recognition, Sixth
International Conference on Document Analysis and Recognition, 2001.
[ERK90] El-Dabi.S.S, Ramsis.R, Kamel.A : Arabic character
recognition system : A statistical approach for recognizing cursive typewritten
text, Pattern Recognition, vol.23, pp. 485-495, Mars 1990.
[Feh99] Fehri.M.C : Reconnaissance de textes arabes
multifontes à l'aide d'une approche hybride Neuro-markovienne,
Thèse de doctorat, Ecole nationale de science de
l'informatique, Tunis-Tunisie, 1999.
[FGL+] Faure.C,Grumbach.A, Lukforman-Sulem.L,Sujelle.M :
Reconnaissance Des Formes, Cours de l'école nationales
supérieur des télécommunications, 2006.
78
BIBLIOGRAPHIE
[Gol89] Goldberg.D.E : Genetic Algorithms in Search
Optimisation and Machine Learning, Addison-Wesley, Pages : 432,
1989.
[Gos96] Gosselin.B : Application De Réseaux De
Neurones Artificiel à La Reconnaissance Automatique De Caractères
Manuscrits, Faculté Polytechnique, Mons-France, 1996.
[Gov90] Govindan.V.K : Character Rrecognition - A Review,
Pattern Recognition, vol. 23, pp : 671-683, Février 1990.
[GPP+89] Guyon.I, Poujaud.I, Personnaz.L, Dreyfus.G, Denker.J,
LeCun.Y : Comparing different neural networks architectures for classifying
handwritten, Neural Networks IJCNNs, pp : 127-132, 1989.
[Gue09] Guenounou.O : Méthodologie de
conception de contrôleurs intelligents par l'approche
génétique- application à un bioprocédé,
Thèse de doctorat, l'Uni-versité Toulouse III -France,
2006.
[GS00] Gyeonghwan.K, Sekwang.K : Feature Selection Using
Genetic Algorithms for Handwritten character Recognition, 7th
International Workshop on Frontiers in Handwriting Recognition, pp : 103-112,
Octobre 2000.
[Hay94] Haykin.S : Neural Networks
- A comprehensive Foundation, United
States Edition, 1994.
[HB02] Hamami.L, Berkani.D : Recognition system for
printed multi-font and multi-size Arabic characters, Arabian Journal for
Science and Engineering, vol.27, pp : 57-72, Avril 2002.
[Héb99] Hébert.J.F : Architecture
Neuronale Hybride Pour L'apprentissage Incri-mentale Des Connaissances
: Application à La Reconnaissance D'écriture
Cursive, Thèse de doctorat, Faculté des sciences et de
génie, Laval-Québec, 1999.
[HH01] Ho.S.Y, Huang H.L : Facial Modeling from an
Uncalibrated Face Image Using a Coarse-to-Fine Genetic Algorithm, Pattern
Recognition, vol.34, pp : 1015-1031, May 2001.
[HML+98] Heutte.L, Paquet.T, Moreau. J.V, Lecourtier.Y,
Olivier.C : A structu-ral/statistical feature based vector for handwritten
character recognition, Pattern Recognition Letters, vol.19, pp : 629-641,
May 1998.
[JDJ00] Jain.A.K, DuinR.P.W, Jianchang.M.M : Statistical
pattern recognition : a review, Pattern Analysis and Machine Intelligence,
vol.22, pp : 4-37, Janvier 2000.
[Jou03] Jourdan.L : Métaheuristiques pour
l'extraction des connaissances : Application à la
génomique, Thèse de doctorat, Université des
Sciences et Technologies, Lille-France, 2003.
79
BIBLIOGRAPHIE
[JZ01] Ji.Q, Zhang.Y : Camera Calibration with Genetic
Algorithms, IRobotics and Automation, vol.31, pp : 120-130, May 2001.
[KA08] Kherallah.M, Alimi.A.M : A new lecture support
based on on-line arabic handwriting recognition, Innovations in
Information Technology, pp : 673-677, Décembre 2008.
[KD07] Krouchi.G, Djebbar.B : Reconnaissance hors ligne
des chiffres manuscrits isolés par l'approche
Neuro-Génétique, RIST, vol.17, 2007.
[Ken73] Kenneth.M.S : Machine recognition of handwritten
words :A project report, Pattern Recognition, vol.5, pp : 213-228,
September 1973.
[KS00] Kudo.M, Sklansky.J : Comparaison of Algorithms that
Select Features for Pattern Classifiers, Pattern Recognition, vol.33, pp :
25-41, cJanvier 2000.
[Lip87] Lippmann.R :An introduction to computing with
neural nets, ASSP Magazine, vol.4, pp : 4-22, Mars 1987.
[LV06] Liana M. L, and Venu.G : Offline Arabic Handwriting
Recognition :A Survey, Pattern Analysis and Machine Intelligence, vol.28,
May 2006.
[Man86] J.Mantas : An overview of character recognition
methodologies, Pattern Recognition, vol.19, pp : 425-430, Janvier 1986.
[MAS97] Motawa.D, Amin.A, Sabourin.R : Segmentation of
Arabic cursive script, Document Analysis and Recognition, vol.2, pp :
625-628, Août 1997.
[Men08] Menasri.F : Contributions à la
reconnaissance de l'écriture arabe manuscrite, Thèse de
doctorat, Université Paris Descates, France, 2008.
[NA04] Nearchou.C, Andreas.A.C : The effect of various
operators on the genetic search for large scheduling problems,
International Journal of Production Economics, vol. 88, pp :191-203 ,Mars
2004.
[OAT96] Oivid.D.T, Anil.K, Torfinn.T : Feature extraction
methods for character recognition - a survey, Pattern recognition, vol.29,
pp : 641-662, Avril 1996.
[OSB+02] Oliveira.L.S, SabourinR, Bortolozzi.F, Suen.C.Y :
Feature Selection Using Multi-Objective Genetic Algorithms for Handwritten
Digit Recognition, IEEE Computer Society, pp : 568-571, Aôut
2002.
[Poi05] Poisson.E : Architecture et Apprentissage d'un
Système Hybride Neuro-Markovien pour la Reconnaissance de
l'Écriture Manuscrite En-Ligne,Thèse de doctorat,
Université de Nantes Ecole doctorale STIM , France, 2005.
80
BIBLIOGRAPHIE
[Reb07] Rebiai.A : Une approche hybride pour la
reconnaissance d'écriture arabe manuscritre, Mémoire de
mastère, Faculté des science de
l'ingénieur,Constantine-Algérie, 2007.
[RM99] Ramesh.V.E, Murty.N : Off-Lin signature
Verification Using Genetically Optimized Weighted Features, Pattern
Recognition, pp : 217-233, Février 1999.
[SD01] Shamik.S, Das.P.K : A Genetic Algorithm for Feature
Selection in a Neuro-Fuzzy OCR System, 6th International Conference on
Document Analysis and Recognition, pp : 987-991, Septembre 2001.
[SFK96] Chin-Hui.L, Frank.K.S, Kuldip. K.P : Automatic
Speech and Speaker Recognition : Advanced Topics,
Kluwer Academic Publishers, 1996.
[SKJ+09] Slimane.F, Kanoun.S, Hennebert.J, Alimi.A ,Ingold.R
: Modèles de Markov Cachés et Modèle de Longueur pour
la Reconnaissance de l'Ecriture Arabe à Basse Résolution,
MajecSTIC, Novembre 2009.
[SLM+96] Schwartz.R, LaPre.C, Makhoul.J, Raphael. C, Ying.Z
: Language-independent OCR using a continuous speech recognition system,
Pattern Recognition, vol.3, pp : 99-103, Août 1996.
[TB07] Tlemsani.R, Benyettou.A : Application des
réseaux bayésiens dynamiques à la reconnaissance en-ligne
des caractères isolés, SETIT, Mars 2007.
[Tim01] Tim.K : Towards Neural Network Recognition Of
Handwritten Arabic Letters, Memoire de mastère, Faculté
des sciences de l'informatique, Dalhousie-Canada, 2001.
[TS90] Tolba.M.F, Shaddad.E : On the automatic reading of
printed Arabic characters, IEEE International Conference on Systems, Man
and Cybernetics, pp : 496-498, Nouvembre 1990.
[WZG09] Wshah.S, Zhixin.S, Govindaraju.V : Segmentation of
Arabic Handwriting Based on both Contour and Skeleton Segmentation,
Document Analysis and Recognition, ICDAR'09, pp :793-797, Juilet 2009.
[YH97] Yang .J, Honavar.V : Feature Subset Selection Using
A Genetic Algorithm, Intelligent Systems and their Applications, vol.13,
pp.44-49, Avril 1997.
[Zek05] Zeki.A.M : The Segmentation Problem in Arabic
Character Recognition The State Of The Art, Information and Communication
Technologies ICICT, pp : 11- 26, Août 2005.
AnnexeA
Segments classés par leurs positions
U
N segment peut représenter plusieurs caractères
suivants les signes diacritiques qui peuvent exister. Les tableaux ci-dessous
listent les segments de caractères classés selon leurs positions
dans le mot (initiale, milieu, final, isolé) ainsi que les
caractères possible qui peuvent correspondre à ces segments. Nous
avons attribué, à chaque segment, un code. Ces codes seront
utilisés comme code d'identification plus tard dans le processus de
reconnaissance.
82
ANNEXE A. SEGMENTS CLASSÉS PAR LEURS
POSITIONS
TABLE A.1 - Segments Initials
11
Ignorer
Toutes autres formes sont ignorées
4
3
1
2
5
6
7
8
9
10
Images de segments
|
Caractères possibles
|
Codes assignés
|
ANNEXE A. SEGMENTS CLASSÉS PAR LEURS
POSITIONS

Codes assignés
Images des segments
Caractères possibles
11
Ignorer
Toutes autres formes sont ignorées
3
1
2
4
5
6
7
8
9
10
TABLE A.2 - Segments Milieux
83
84
ANNEXE A. SEGMENTS CLASSÉS PAR LEURS
POSITIONS
Codes assignés
Caractères possibles
Images des segments
7
4
3
1
2
5
6
8
10
3
11
12
13
14
TABLE A.3 - Segments finals
ANNEXE A. SEGMENTS CLASSÉS PAR LEURS
POSITIONS
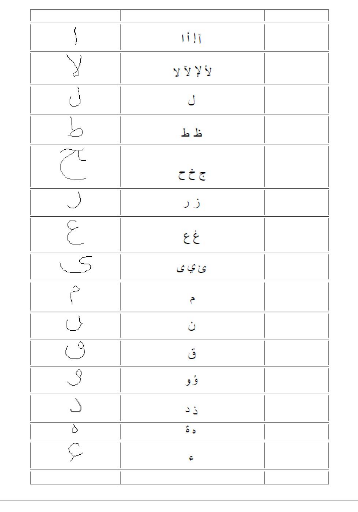
1
Images des segments
Caractères possibles
16
Ignorer
Toutes autres formes sont ignorées
6
8
9
10
11
12
85
TABLE A.4 - Segments isolés
TABLE B.1 - Caractères utilisés
pour l'apprentissage du réseau de neurone
Annexe113
Description de la base
Dans tout système de reconnaissance de formes, il est
nécessaire d'avoir une base de données afin d'effectuer les
traitements nécessaire. Les documents utilisés sont de mise en
page simple. Ils ne contiennent pas des images. Les fontes des textes dans ces
documents sont : Arial et Time New Roman dans des tailles variantes entre 12 et
20. L'interligne est uniforme entre les paragraphes. Le style de la fonte est
soit normale soit gras. La figure-B.1 présente un aperçu sur base
utilisée :

FIGURE B.1 - Aperçu sur la base
Cette base contient 40 textes dont le nombre de
caractère vari d'un texte à l'autre. Elle est devisée en
deux sections : 30 pour l'apprentissage et 10 pour le test. Les
caractères utilisés pour l'apprentissage sont devisés
selon leurs positions dans le mot (tableau-B.1).
|
Caractères Isolés
|
Caractères Initials
|
Caractères Milieux
|
Caractère Finals
|
|
Nombre de segments
|
384
|
418
|
356
|
372
|


