|

UNIVERSITE DE DOUALA UNIVERSITY OF DOUALA
Facultédes Sciences Faculty of Sciences
Département de Maths-Info Department of Mathematics and
CS
APPRENTISSAGE SUR DES DONNÉES
ACADÉMIQUES EN
VUE DE FACILITER
L'ORIENTATION ET L'AIDE À LA DÉCISION
Mémoire rédigéen vue de
l'obtention du diplôme de Master II
en informatique
Présentéet soutenu par:
NJAMEN MOUNGNUTOU ZELKIFILOU 21S65508
Sous l'encadrement de:
Douala, 2021
Dr NOUMSI Auguste. CC
4 Résumé4
De nos jours, la quasi-totalitédes systèmes des
établissements scolaires sont informatisés. Ce qui permet la
collecte et le stockage en leur sein des données issues de la gestion
des processus académiques, disciplinaires, administratifs et même
financiers. Les données ainsi collectées au cours de chaque
année permettent le contrôle des activités et la production
des effets académiques. Cependant, lorsqu'elles sont accumulées
sur plusieurs générations, elles constituent un réservoir
qui peut servir pour l'aide à la décision. Les perspectives en ce
sens sont nombreuses : la gestion courante, la compréhension des
facteurs d'échec ou du succès, l'impact de la discipline sur le
succès, l'orientation scolaire etc. Compte tenu de la raretédes
conseillers d'orientation, malgrél'importance de cette activité,
nous proposons dans ce mémoire une solution automatisée d'aide
à la décision pour l'orientation scolaire. Notre démarche
va s'appuyer sur l'existence des données collectées au fil des
années pour construire un système d'aide à la
décision.
Mots clés : Machine Learning,
Système de recommandation, classification, prédiction,
orientation, aide de décision...
4 Abstract 4
Nowadays, almost all school systems are computerised. This
allows the collection and storage of data from academic, disciplinary,
administrative and even financial processes. The data collected in this way
during each year allows the monitoring of activities and the production of
academic effects. However, when accumulated over several generations, they
constitute a reservoir that can be used to assist decision-making. The
perspectives in this sense are numerous: current management, understanding the
factors of failure or success, the impact of discipline on success, school
orientation, etc. Given the scarcity of guidance counsellors, despite the
importance of this activity, we propose in this dissertation an automated
decision support solution for school orientation. Our approach is based on the
existence of data collected over the years to build a decision support
system.
Keywords : Machine Learning, Recommender
system, classification, prediction, orientation, decision support...
4 Dédicace 4
Je dédie ce mémoire à ma famille et à
toutes mes connaissances.
4 Remerciements 4
Au terme de ce travail, nous exprimons notre gratitude infinie
à tous ceux qui ont participéde près ou de loin par leurs
encouragements et précieux conseils ou suggestions rendant possible ce
travail, Nous pensons notamment à:
· Pr. Marie Joseph NIDA NTAMAK Doyen de la
Facultédes Sciences pour le travail qu'elle fait pour que cette
institution soit toujours parmi les meilleurs.
· Pr. BOWONG Samuel chef de département de
Maths-Info de l'universitéde Douala pour tout ce qu'il fait pour les
étudiants en général.
· mon encadreur Dr. Auguste NOUMSI pour sa
disponibilitéillimitée, son soutien inconditionnel, sa constante
bienveillance et les mille critiques apportées pour améliorer ce
travail.
· Dr. Joseph MVOGO, Coordinateur du Laboratoire
d'informatique appliquée pour ses encouragements, ses critiques
scientifiques et sa rigueur.
· Je tiens à remercier sincèrement les
membres du jury qui me font l'immense honneur de juger et d'apprécier ce
travail.
· Je tiens à remercier chaleureusement mes
enseignants Dr Auguste NOUMSI, Dr MOSKOLAI, Dr MVOGO, M. DJEMEN pour les
précieux conseils et enseignements prodigués et la patience dont
ils avaient avec nous.
· Je remercie sincèrement Dr KAMENI E. de l'ENS
de Yaoundésans oublier Dr Victor LOUMGAM de l'Universitéde
YaoundéI et Patrick KENFACK du côtéde la Russie. pour leur
disponibilitéà répondre à mes questions et
sollicitations.
· Je remercie mes camarades, en particulier Taga
Martial, DONGMO APOLINAIRE et tous les autres pour leur esprit de
solidarité, de disponibilitéet de convivialitéqui nous ont
unis durant cette année d'études.
v
4 Table des matières 4
Résuméi
Dédicace iii
Remerciements iv
Liste des tableaux ix
Table des figures xi
INTRODUCTION 1
1 L'ORIENTATION SCOLAIRE 5
1.1 Introduction 5
1.2 Historique de l'orientation scolaire 5
1.3 Les niveaux d'orientation scolaire 6
1.4 Processus d'orientation au Cameroun 7
1.4.1 Les différents tests pour l'orientation 8
1.4.1.1 Le test BV11 8
1.4.1.2 Le test KRX 8
1.4.1.3 Le test PRC 9
1.4.1.4 Le test MECA 9
1.4.1.5 Le test D48 10
1.4.2 Le Tracédes Profils Psychologiques 10
1.5 Conclusion 13
2 REVUE DE LA LITTÉRATURE 14
2.1 Introduction 14
TABLE DES MATIÈRES TABLE DES MATIÈRES
2.2 Le Machine Learning (Apprentissage Automatique) 14
2.2.1 Les Types d'apprentissages 16
2.2.1.1 Apprentissage supervisé 16
2.2.1.2 Apprentissage non supervisé 18
2.2.1.3 Apprentissage par renforcement 19
2.3 Les Algorithmes de Machine Learning 19
2.3.1 Algorithmes de Classification 23
2.3.2 Classification Naïve Bayésienne 23
2.3.3 Algorithme des K-PPV (K-Plus Proches Voisins) ou en
anglais KNN
(K-Nearest Neighbors) 24
2.3.3.1 Principe du K-PPV 25
2.3.3.2 Avantages de la méthode des K-PPV 26
2.3.3.3 Inconvénients de la méthode des K-PPV
26
2.3.4 Les Arbres de décision 26
2.3.4.1 Généralités sur les arbres de
décision 26
2.3.4.2 Construction d'un arbre de décision 29
2.3.4.3 Avantages des Arbres de Décision 30
2.3.4.4 Inconvénients des Arbres de Décision
30
2.3.5 Machines à vecteurs support SVM 30
2.3.5.1 Le Principe des SVMs 31
2.3.5.2 Le SVM Linéaire 32
2.3.5.3 Cas linéairement séparable 33
2.3.5.4 Avantages de SVM 34
2.3.5.5 Inconvénients de SVM 35
2.3.6 Les Réseaux de neurones 36
2.3.6.1 Neurone Biologique 36
2.3.6.2 Les Réseaux de Neurones 36
2.3.6.3 Neurone formel (artificiel) 37
2.3.6.4 Fonctions d'activation 38
2.3.6.5 Les réseaux de neurones célèbres
39
2.3.6.6 Le Perceptron 40
2.3.6.7 Le perceptron multicouches 41
2.3.6.8 L'apprentissage 41
Mémoire de Master II en Informatique vi c~NJAMEN M.
ZELKIF 2020-2021
Mémoire de Master II en Informatique vii c~NJAMEN M.
ZELKIF 2020-2021
TABLE DES MATIÈRES TABLE DES MATIÈRES
|
|
2.3.6.9 Avantages des réseaux de neurones
2.3.6.10 Inconvénients des réseaux de neurones
|
42
43
|
|
2.4
|
État de l'art du ML appliquéà
l'éducation
|
44
|
|
|
2.4.1 Les travaux connexes
|
44
|
|
|
2.4.1.1 Dans le monde
|
44
|
|
|
2.4.1.2 Au Cameroun
|
47
|
|
|
2.4.2 L'aide à la décision
|
48
|
|
2.5
|
Conclusion
|
48
|
3
|
DÉMARCHE MÉTHODOLOGIQUE
|
50
|
|
3.1
|
Cahier de charge (Objectif visé)
|
51
|
|
3.2
|
L'acquisition (Collecte) des données
|
51
|
|
3.3
|
Pré-traitement des données
|
53
|
|
|
3.3.1 Nettoyage des données
|
54
|
|
|
3.3.2 Transformation des données
|
56
|
|
|
3.3.3 Intégration des données
|
57
|
|
|
3.3.4 Réduction des données
|
57
|
|
3.4
|
Modélisation de l'entrepôt de données
|
58
|
|
|
3.4.1 Les modèles logiques d'un entrepôt
|
58
|
|
|
3.4.1.1 Le Modèle en Étoile
|
59
|
|
|
3.4.1.2 Le Modèle en Flocon
|
59
|
|
|
3.4.1.3 Le modèle de galaxie (Constellation)
|
60
|
|
|
3.4.2 Modèle type de l'entrepôt des
données
|
62
|
|
|
3.4.3 Structure multidimensionnelle
|
62
|
|
3.5
|
Classification
|
63
|
|
3.6
|
Conclusion
|
64
|
4
|
RÉSULTATS ET DISCUSSIONS
|
65
|
|
4.1
|
Introduction
|
65
|
|
4.2
|
Les différentes techniques d'évaluations des
modèles de Machine Learning .
|
65
|
|
|
4.2.1 Validation Croisée
|
66
|
|
|
4.2.1.1 La méthode holdout
|
67
|
|
|
4.2.1.2 La méthode K-Folds
|
68
|
|
|
4.2.1.3 La méthode LOOCV
|
68
|
|
TABLE DES MATIÈRES TABLE DES MATIÈRES
Mémoire de Master II en Informatique viii c~NJAMEN M.
ZELKIF 2020-2021
4.2.2 La matrice de confusion 69
4.3 Résultat et Discussion 70
4.4 Conclusion 72
CONCLUSION ET PERSPECTIVES 73
Références 78
ix
4 Liste des tableaux 4
1.1
|
Dans cet exemple l'idée est de présenter la
mésentente
|
8
|
2.1
|
Similitude entre un Neurone biologique et un Neurone formel
|
38
|
2.2
|
Machine learning Algorithmus
|
43
|
4.1
|
Exemple d'une Matrice de Confusion
|
69
|
4.2
|
Synthèse des différents Résultats obtenus
|
71
|
|
x
4 Table des figures 4
1.1 Illustration d'un exercice de KRX (Test de raisonnement
numérique) . . . 9 1.2 Illustration d'un exercice de MECA (Test de
raisonnement Mécanique) . . 10
1.3 Exemple 1 : de Profil 11
1.4 Exemple 2 : de Profil 11
1.5 Exemple 3 : de Profil 12
1.6 Exemple 4 : de Profil 12
1.7 Exemple 5 : de Profil 12
2.1 Illustration du Cadre de l'apprentissage par renforcement
20
2.2 Résuméen image des classes d'apprentissage
20
2.3 Exemple de classification avec un KPPV 25
2.4 Exemple de classification avec les Arbres de
Décision 28
2.5 Exemple de classification avec les Arbres de
Décision 29
2.6 Exemple de classification avec SVM 31
2.7 Hyperplan optimal, marge et vecteurs de support 32
2.8 Exemple de classification avec SVM dans le cas non
séparables 35
2.9 Neurone biologique 36
2.10 Modèle d'un neurone formel (artificiel) 37
2.11 Les fonctions d'activation 39
2.12 Un exemple de perceptron 40
2.13 Un perceptron multicouche 42
2.14 Un autre exemple de perceptron multicouche 42
3.1 Schéma de la démarche méthodologique
50
3.2 Représentation des données après
requêtes SQL 52
3.3 Processus d'acquisition et Pré-traitement des
données 54
Mémoire de Master II en Informatique xi c~NJAMEN M.
ZELKIF 2020-2021
TABLE DES FIGURES TABLE DES FIGURES
3.4
|
Processus de prise de décision
|
59
|
3.5
|
Schéma d'un entrepôt de données en
étoile : tiréde Cartelis [1]
|
60
|
3.6
|
Exemple de dimension représentée en flocon
(Kimball, Ross, 2008, p.55) . .
|
60
|
3.7
|
Structure de la Base d'exemple (Data Frame)
chargéà l'aide de Python . .
|
61
|
3.8
|
Modèle type de l'entrepôt des données
|
62
|
3.9
|
Modèle type de l'entrepôt des données
|
63
|
4.1
|
Validation croisée : évaluation des performances
de l'estimateur
|
67
|
4.2
|
Exemple K-Folds pour la Cross Validation
|
67
|
4.3
|
Diagramme des résultats
|
71
|
|
1
4 INTRODUCTION 4
Selon Wikipédia [2], L'orientation scolaire et
professionnelle, universitaire et de carrière consiste à proposer
à une personne en âge de scolaritéet même aux adultes
(obligatoire ou post-obligatoire, voire permanente ou continue) les
différentes filières dans lesquelles elle pourrait
s'insérer en fonction de ses intérêts, de son parcours
scolaire antérieur, et de sa personnalité.
Le conseiller d'orientation est un professionnel de
l'éducation dont le rôle est d'assurer le suivi
psycho-pédagogique des élèves, d'informer les membres de
la communautéédu-cative sur les réalités du monde
scolaire, les possibilités de formation et leur débouchés
professionnels. À cet égard, il aide les élèves
à faire des choix scolaires et professionnels judicieux et
cohérents en tenant compte de leurs aptitudes, de leurs
intérêts, de leurs attitudes et des réalités du
monde du travail. Pour y parvenir, il fait usage d'un ensemble d'ou-tils, dont
la batterie de tests d'aptitudes pour la classe de 3e du MINESEC-CAMEROUN
[3].
Au cours de ces dernières années, nous avons
observéune forte informatisation des établissements des
systèmes éducatifs. Face à cette numérisation des
données des systèmes éducatifs, il nait le besoin
d'automatiser certaines tâches qui, sont d'une importance capitale dans
la concrétisation des objectifs de l'éducation qui ne sont rien
d'autres que la réussite scolaire. Ainsi, cette réussite commence
par une bonne orientation. Cependant, automatiser la tâche d'orientation
revient à résoudre un problème de prédiction ou de
recommandation. D'oùl'importance de donner au système
éducatif la capacitéd'apprendre à recommander à
partir des exemples existants sans être explicitement programmé.
Cette façon de faire est appelée Machine Learning (Apprentissage
Automatique).
même s'il est actuellement dopépar les nouvelles
technologies et de nouveaux usages, le machine Learning n'est pas un domaine
d'étude récent. On en trouve une première
définition dès 1959, due à Arthur Samuel, l'un des
pionniers de l'intelligence artificielle,
TABLE DES FIGURES TABLE DES FIGURES
Mémoire de Master II en Informatique 2 c~NJAMEN M. ZELKIF
2020-2021
qui définit le machine Learning comme « le
champ d'étude visant à donner la capacitéàune
machine d'apprendre sans être explicitement programmée
». En 1997, ~Eric and Michel
[4], de l'universitéde Carnegie Mellon, propose une
définition plus précise : « A computer program is said
to learn from experience E with respect to some class of tasks T and
performance measure P, if its performance at tasks in T, as measured by P,
improves with experience E ».
Les systèmes de recommandation (SR) sont des outils
logiciels basés sur l'apprentissage automatique (Machine Learning) et
les techniques de récupération des informations (Data Mining) qui
fournissent des recommandations pour des éléments potentiellement
utiles dans l'intérêt de quelqu'un selon Nguyen et al. [5]. Ils
sont largement utilisés dans de nombreux domaines, en particulier dans
le commerce électronique. Récemment, ils sont également
appliqués dans des tâches d'apprentissage en ligne telles que
recommander des ressources (par exemple, des articles, des livres) aux
apprenants (étudiants) et même des cours en fonction de leur
performance et préférence comme dans Hanaa et al. [6].
Compte tenu de la raretédes conseillers d'orientation,
malgrél'importance de cette activité, nous proposons dans ce
mémoire une solution automatisée d'aide à la
décision pour l'orientation scolaire.
Les systèmes d'orientation aujourd'hui se basent sur
plusieurs critères pour orienter les élèves en classe
scientifique ou littéraire. Ces critères sont : l'acquisition
scolaire qui est la moyenne des notes obtenues dans les matières par
groupe en classe de 3 ème; sur la batterie de tests d'aptitudes pour la
classe de 3 ème; sur les préférences des parents et de
l'élève et enfin de la disponibilitédes places dans
l'établissement pour les classes sollicitées. Cependant,
d'année en année nous remarquons une baisse du taux de
réussite des élèves aux examens officiels. Cette baisse du
taux de réussite est dûen majoritéà une mauvaise
orientation scolaire. Face à ce problème, beaucoup ont
tentés de proposer des systèmes de recommandation basésur
le profil de l'apprenant et de ses préférences dans un
système de e-learning. Comment appliquer l'apprentissage
automatique dans la recommandation des choix de série dans
l'enseignement?
Fort du constat fait sur l'importance des TIC dans
l'enseignement-apprentissage, et de l'importance d'une bonne orientation dans
le système éducatif, la présente étude tente de
répondre à la question fondamentale suivante :
Comment faire une bonne orientation
(recommandation) en tenant compte du profil de l'apprenant? Pour
mieux appréhender cette question, il a
TABLE DES FIGURES TABLE DES FIGURES
Mémoire de Master II en Informatique 3 c~NJAMEN M. ZELKIF
2020-2021
étéformulédeux questions qui lui sont
spécifiques :
· Quel profil d'apprenant pour quelle orientation?
· Quelle technique mettre en place afin de pouvoir faire
une bonne recommandation et ainsi appuyer la décision du conseiller
d'orientation?
L'objectif principal de notre recherche est de
produire un modèle d'ap-prentissage sur des données
académiques en vue de faciliter l'orientation et l'aide à la
décision. Étant donnéla quasi inexistence
d'une base d'exemple selon le contexte éducatif camerounais, nous
pouvons donc subdiviser cet objectif en plusieurs sous-objectifs qui suivent
:
1. Construction d'une base d'exemple permettant d'effectuer
l'apprentissage automatique;
2. Proposition d'un modèle d'apprentissage à
partir de la base d'exemple construite.
En ce qui concerne la méthode de travail, nous allons
construire un data-set (ensemble de données pour l'apprentissage ou
l'entrepôt de donnée) à partir des données
récoltées dans différents établissements scolaires
du Cameroun, labelliser ces données dans un cadre utiles pour la
recommandation de l'orientation scolaire puis, appliquer les algorithmes de
classifications existants et utilisés dans le Machine Learning
déçu pour la création d'un modèle d'apprentissage.
Ce data-set sera ouvert publiquement afin de permettre le développement
d'algorithme de plus en plus sophistiquépour l'orientation scolaire au
Cameroun.
Comme résultats attendus, à la fin de ce
mémoire, nous proposerons un Framework pour la recommandation et
l'orientation scolaire basésur le profil de l'apprenant.
Notre travail est subdiviséen quatre grands
chapitres.
· Chapitre 1 : L'orientation Scolaire qui
présente le travail du conseiller d'orientation et du processus
d'orientation au Cameroun.
· Chapitre 2 : L'état de l'art qui
présente les travaux qui ont étéfait dans le Machine
Learning appliquéà l'orientation tant à l'international
qu'au niveau national.
· Chapitre 3 : Démarche méthodologique qui
présente la démarche suivit pour arriver à la solution. En
outre, la conception de l'entrepôt des données.
·
TABLE DES FIGURES TABLE DES FIGURES
Mémoire de Master II en Informatique 4 c~NJAMEN M. ZELKIF
2020-2021
Chapitre 4 : Résultat et Discussion qui présente
la performance du modèle choisi obtenue sur le jeu de données et
une discussion sur ce résultat.
· Conclusion et Perspectives qui conclu ce travail de
recherche et ouvre des nouvelles perspectives futures.
5
L'ORIENTATION SCOLAIRE
1.1 Introduction
L'orientation, disent Guichard and Huteau [8]
désigne à la fois les modalités de production et de
reproduction de la division sociale et technique du travail et l'action de
donner une direction déterminée à sa vie... «
Scolairement, c'est conseiller un enfant sur le métier qu'il peut
choisir » selon Chassagne [9]. L'orientation concerne les jeunes, leurs
familles, de nombreux adultes qui doivent dans leur vie professionnelle se
reconvertir. Elle est également au coeur des politiques
d'éducation et d'emploi parce que l'école doit fournir à
l'économie le personnel qualifiédont elle a besoin. Aussi la
question de l'orien-tation occupe-t-elle depuis plus de cinquante ans une place
majeure dans les décisions d'organisation du système
éducatif. D'oùl'importance de l'étudier dans ce
chapitre.
1.2 Historique de l'orientation scolaire
À la fin du XIXe et au début
du XXe siècle l'orientation est définie dans
son rapport avec l'appartenance sociale de l'élève. Il existe
deux filières : la première « primaire supérieure
» qui débouche sur le certificat d'études et sur les
écoles primaires supérieures est réservée aux
enfants du peuple, la seconde « secondaire supérieure »,
réservée à la future élite, conduit au
baccalauréat et à l'université. À cette
époque le choix d'orienta-tion ne se posait pas parce que l'école
primaire conduisait à un métier. C'est en 1910 que l'orientation
apparaît et en 1922 qu'un décret définit ses
caractéristiques : « il s'agissait de s'occuper des jeunes filles
et jeunes gens cherchant un placement dans le commerce ou l'industrie »
selon Chassagne [10].
À cette époque on parle de l'orientation
professionnelle. Ce décret demande :
1.
1.3. LES NIVEAUX D'ORIENTATION SCOLAIRE CHAPITRE 1. L'ORIENTATION
SCOLAIRE
Mémoire de Master II en Informatique 6 c~NJAMEN M. ZELKIF
2020-2021
la délivrance d'un certificat d'orientation
professionnelle sur lequel doivent figurer les capacités des jeunes
gens;
2. la création d'un centre d'orientation
professionnelle par département, à la charge du
département.
L'orientation scolaire, constate Jean-Michel [11], fait son
apparition avec la loi de 1959. C'est la réforme scolaire de 1959
(appelée Réforme Berthoin) qui, en instituant un cycle
d'observation et d'orientation après le CM2, fait entrer l'orientation
dans le champ scolaire. Avec la poursuite des études jusqu'à16
ans, le palier d'orientation est déplacédu CM2 à la
cinquième. En fonction de leurs aptitudes évaluées
à la fin de ce cycle d'observation, les élèves devaient
être orientés dans cinq filières : un enseignement
général long, classique pour les futurs cadres; un
enseignement terminal court destinéaux futurs ouvriers
spécialisés, agriculteurs, artisans; un enseignement technique
long
destinéaux techniciens supérieurs, un
enseignement technique court destinéà former des ouvriers
qualifiés et enfin un enseignement général court
délivrédans un nouveau collège, le collège
d'enseignement général. De nos jours, l'orientation scolaire se
fait à cinq niveaux: après le CM2, après la classe de
cinquième, après la troisième, après la seconde,
après le Baccalauréat et des fois après la classe de
première.
1.3 Les niveaux d'orientation scolaire
L'orientation scolaire s'opère en trois temps :
· en troisième, premier palier d'orientation :
les élèves sont amenés à choisir entre trois voies
: filière générale, technologique ou professionnelle;
· en seconde, pour ceux qui se sont orientés en
lycée général ou technologique, deuxième palier
d'orientation : les demandes de passage en première
générale (S, ES, L) ou en première technologique (STT,
STI, SMS, STL);
· en terminale, troisième palier d'orientation :
après leur bac, les élèves intègrent soit les
filières plus sélectives comme CPGE, IUT, STS, ou les
filières universitaires.
Dans cette partie nous allons présenter uniquement le
premier niveau (celui qui se fait en troisième) en utilisant la batterie
de tests d'aptitudes pour la classe de
3ème du MINESEC-CAMEROUN [3].
1.4. PROCESSUS D'ORIENTATION AU CAMEROUN CHAPITRE 1.
L'ORIENTATION SCOLAIRE
Mémoire de Master II en Informatique 7 c~NJAMEN M. ZELKIF
2020-2021
La fin de la troisième représente le premier
palier d'orientation et propose aux collégiens plusieurs choix : seconde
générale et technologique, seconde professionnelle ou
redoublement. Ils peuvent aussi poursuivre leur formation initiale en
apprentissage ou, s'ils ont atteint l'âge de fin de la
scolaritéobligatoire, interrompre définitivement leurs
études. Dans la carrière scolaire d'un élève, les
phases d'orientation de fin de troisième et de fin de seconde
constituent des moments essentiels. À la fin de troisième
l'élève doit choisir entre voie professionnelle et voie
générale. Les décisions d'orientation prises à
l'is-sue de ces deux classes préfigurent largement le bagage scolaire
avec lequel le jeune va terminer sa formation initiale et s'insérer sur
le marchédu travail.
1.4 Processus d'orientation au Cameroun
Le conseiller d'orientation est un professionnel de
l'éducation dont le rôle est d'assurer le suivi
psycho-pédagogique des élèves, d'informer les membres de
la communautéédu-cative sur les réalités du monde
scolaire, les possibilités de formation et leur débouchés
professionnels. À cet égard, il aide les élèves
à faire des choix scolaires et professionnels judicieux et
cohérents en tenant compte de leurs aptitudes, de leurs
intérêts, de leurs attitudes et des réalités du
monde du travail. Pour y parvenir, il fait usage d'un ensemble d'ou-tils, dont
la batterie de tests d'aptitudes pour la classe de 3e du MINESEC-CAMEROUN
[3].
Toujours dans selon MINESEC-CAMEROUN [3], lors des missions
de suivi, d'encadre-ment et d'évaluation des activités des
Conseillers d'orientation en service dans les établis-
sements d'enseignements secondaire général,
technique et professionnel, il a étéconstatéque ces tests
n'étaient pas utilisés dans de nombreux établissements.
Plusieurs conseillers
ayant sollicités un outil d'accompagnement, il nait la
batterie de tests d'aptitudes pour la classe 3e.
Cet outil est constituéde cinq tests psychotechniques
destinés aux élèves des classes de Troisième et
Form III toujours selon MINESEC-CAMEROUN [3].
Il s'agit du : BV11, KRX, PRC, MECA et du D48.
1.4. PROCESSUS D'ORIENTATION AU CAMEROUN CHAPITRE 1.
L'ORIENTATION SCOLAIRE
Mémoire de Master II en Informatique 8 c~NJAMEN M. ZELKIF
2020-2021
1.4.1 Les différents tests pour l'orientation
1.4.1.1 Le test BV11
BV11 est un test de raisonnement verbal, permettant
d'évaluer la compréhension du vocabulaire. Ce test s'effectue en
20 min ; il permet aussi d'évaluer la capacitéd'un
élève à analyser un mot afin de trouver sa signification
ou sa définition et de dégager le type de similitude entre
plusieurs mots. En outre il aide l'élève à
apprécier l'étendue de son vocabulaire et la précision de
ses connaissances lexicales.
dans ce test nous avons 56 séries de mots. Chaque
série se compose de six mots qui véhiculent la même
idée.
L'exercice consiste d'abord à trouver l'idée
partagée par les mots de la série et ensuite, étant
donnécette idée, trouver le mot qui ne partage pas cette
idée et qui ne devrait pas être inclus dans cette série.
Une fois que vous avez découvert le mot qui ne devrait pas
apparaître dans la série, étant donnél'idée
que véhicule la série, vous cochez la lettre qui
représente ce mot sur la feuille de réponses en respectant le
numéro de l'item. Exemple :
A
|
B
|
C
|
D
|
E
|
F
|
Rupture
|
Brouille
|
Conciliation
|
Discorde
|
Désaccord
|
Désunion
|
|
Tableau 1.1 - Dans cet exemple l'idée
est de présenter la mésentente
1.4.1.2 Le test KRX
KRX est un test de raisonnement numérique, qui permet
d'identifier les aptitudes du sujet dans la manipulation des chiffres. Toujours
en 20 min ;
L'exercice consiste à identifier la logique qui
régit la série afin de déterminer les nombres qui manquent
en utilisant pour la plupart les opérations de base (addition,
soustraction, multiplication, division). Il arrive aussi que la progression
utilise la propriétédes nombres (nombres pairs ou impairs,
multiples, nombres premiers, ...).
les autres test sont également dans le document fourni
par le MINESEC-CAMEROUN [3] conçu spécialement pour
l'orientation.
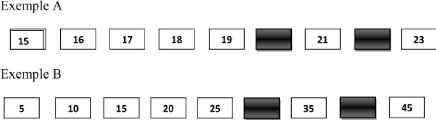
1.4. PROCESSUS D'ORIENTATION AU CAMEROUN CHAPITRE 1.
L'ORIENTATION SCOLAIRE
Mémoire de Master II en Informatique 9 c~NJAMEN M. ZELKIF
2020-2021
Figure 1.1 - Illustration d'un exercice de KRX
(Test de raisonnement numérique).
Tirée de MINESEC-CAMEROUN
[3].
1.4.1.3 Le test PRC
PRC est un test de compréhension verbale abstraite,
qui permet de mesurer la finesse de compréhension des proverbes et des
maximes et de déterminer la capacitéde décryptage des
messages et le sens de la nuance en 25 min ; il aide les élèves
à apprécier leurs niveaux de compréhension de la langue et
leurs capacités à analyser le sens d'une phrase, d'une
pensée, d'un proverbe, etc. pour faire ressortir le sens réel et
non le sens littéral.
Comme consigne : Vous avez un proverbe donné, suivi de
cinq phrases sensées être plus proches de la signification
réelle du proverbe. L'exercice consiste à trouver parmi les cinq
phrases celle qui explique le mieux le proverbe. Une fois cela fait, vous
transcrivez la lettre qui représente cette phrase sur la feuille de
réponses, en respectant le numéro de l'item : Exemple. UN
CHEF ALLANT VENDRE SON ESCLAVE FUT VENDU PAR CE DERNIER signifie:
· Un jour on est maître, un jour on est esclave.
· La sociétéest indifférente aux
classes sociales.
· Quand on est esclave, c'est pour la vie.
· Les situations peuvent se renverser
complètement.
· Le patron d'aujourd'hui peut travailler chez son
ouvrier.
1.4.1.4 Le test MECA
Le test Mécanique (MECA) : C'est le test de
raisonnement mécanique il permet de mesurer la capacitéd'observer
et de compréhension des schémas techniques toujours en 25 min ;
Exemple voir figure 1.2
1.4. PROCESSUS D'ORIENTATION AU CAMEROUN CHAPITRE 1.
L'ORIENTATION SCOLAIRE
Mémoire de Master II en Informatique 10 c~NJAMEN M.
ZELKIF 2020-2021
Figure 1.2 - Illustration d'un exercice de
MECA (Test de raisonnement Mécanique).
Tirée de
MINESEC-CAMEROUN [3].
1.4.1.5 Le test D48
D48 est un test de facteur G, il mesure le sens de la logique
chez le sujet en 25 min.
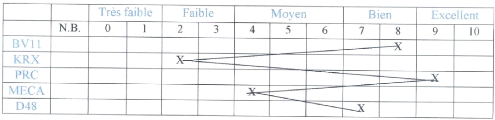
1.4.2 Le Tracédes Profils Psychologiques
Au vu des résultats aux différents tests, et
sur la base d'un étalonnage réalisésur un
échantillon de la population globale à laquelle appartiennent les
sujets, le Conseiller d'orientation inscrit les résultats de chaque
candidat dans un tableau qui comporte les différentes catégories
d'appréciations. Le score obtenu dans un test correspondra à une
catégorie dans le tableau de l'étalonnage. Il peut alors tracer
une courbe qui relie ces catégories aux différents tests. C'est
ce tracéqui est le profil psychologique du sujet. Le profil
psychologique peut aussi se présenter sous la forme d'un histogramme.
Nous présentons ici quelques exemples de profils parmi
des milliers de cas possibles et leurs interprétations selon
MINESEC-CAMEROUN [3] :
Le sujet présente un potentiel réel dans le
raisonnement verbal, et la compréhension de texte. En revanche, des
insuffisances apparaissent dans le raisonnement numérique. L'on peut
donc redouter des difficultés en mathématiques. Par ailleurs, le
raisonnement
1.4. PROCESSUS D'ORIENTATION AU CAMEROUN CHAPITRE 1.
L'ORIENTATION SCOLAIRE
Figure 1.3 - Exemple 1 : de Profil
mécanique est moyen et le facteur G est
développé.
Un tel profil met en évidence des aptitudes dans le
domaine littéraire, si les résultats scolaires le confirment.
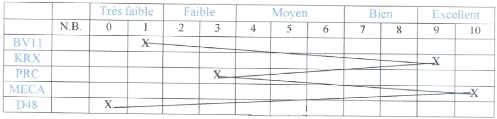
Figure 1.4 - Exemple 2 : de Profil
Ici le sujet présente un potentiel important dans le
raisonnement spatial. En revanche, d'importantes limites apparaissent dans le
raisonnement verbal, la compréhension d'un texte et le raisonnement
général. Ce profond contraste dans les performances doit susciter
la curiositédu conseiller d'orientation qui devra investiguer.
Dans ce cas le sujet présente d'excellentes
capacités dans le domaine de la compréhension et du vocabulaire.
Le facteur G et le raisonnement spatial sont moyens. Le raisonnement
numérique est faible. C'est la situation des élèves
doués mais en cours de maturité. Il est également probable
que le sujet ait rencontréun problème lors du test
numérique. La mise en évidence de la finesse de
compréhension prédispose le sujet à une adaptation aux
études littéraires et aux sciences humaines.
Mémoire de Master II en Informatique 11 c~NJAMEN M.
ZELKIF 2020-2021
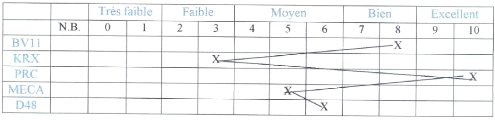
1.4. PROCESSUS D'ORIENTATION AU CAMEROUN CHAPITRE 1.
L'ORIENTATION SCOLAIRE
Figure 1.5 - Exemple 3 : de Profil
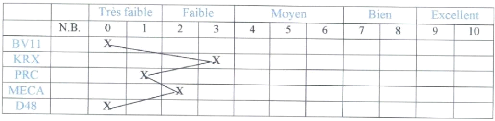
Figure 1.6 - Exemple 4 : de Profil
Dans ce cas, les performances sont très
limitées. Ce cas rappelle les élèves en difficultés
scolaires. A moins que le candidat ait eu un problème pendant les
épreuves. Ces performances ne suffisent pas à parler d'aptitude.
La références aux résultats scolaires ici est
nécessaire pour pouvoir se prononcer sur l'orientation du sujet.
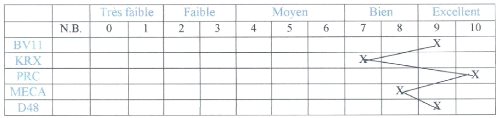
Figure 1.7 - Exemple 5 : de Profil
Dans ce cas, nous constatons un équilibre parfait. Les
performances dans les différents tests étant bons. De tels sujets
jouissent d'une grande marge de manoeuvre du point de
Mémoire de Master II en Informatique 12 c~NJAMEN M.
ZELKIF 2020-2021
1.5. CONCLUSION CHAPITRE 1. L'ORIENTATION SCOLAIRE
Mémoire de Master II en Informatique 13 c~NJAMEN M.
ZELKIF 2020-2021
vue du choix de filière, en cas de confirmation des
résultats scolaires.
1.5 Conclusion
En conclusion, nous pouvons retenir que les conseillers
d'orientation se servent de la batterie de tests d'aptitudes pour ceux qui en
ont pour la classe de 3ème et de
Form 3 respectivement pour le sous-système francophone et anglophone.
Pour ce faire, il est important que le conseiller d'orientation s'approprie les
différentes étapes de son utilisation à savoir : la
familiarisation avec la batterie de tests, le respect des conditions de son
utilisation et de son administration et enfin, l'interprétation des
résultats et la communication de ces résultats à
l'élève ou à ses parents.Dans le chapitre suivant, nous
verrons comment la tâche d'orientation peut être automatisée
en utilisant le Machine Learning.
14
REVUE DE LA LITTÉRATURE
2.1 Introduction
Les systèmes de recommandation sont largement
utilisés dans de nombreux domaines, en particulier dans le commerce
électronique. Récemment, ils sont également
appliqués dans des tâches d'apprentissage. Les systèmes de
tutorat assistés par ordinateur permettent aux étudiants de
résoudre certains problèmes (exercices) avec une interface
graphique qui peut automatiser certaines tâches fastidieuses, fournir des
conseils et fournir des commentaires à l'étudiant. Ces
systèmes peuvent profiter de l'anticipation du rendement des
élèves de plusieurs façons, par exemple, en
sélectionnant la bonne combinaison d'exercices, en choisissant une bonne
orientation en fonction de ses compétences et de ses aspirations. Dans
ce chapitre nous allons d'abord faire une étude des techniques
(Algorithmes) de Machine Learning utilisés dans les systèmes de
recommandation et ensuite de la revue de la littérature sur
l'automatisation du processus d'orientation scolaire.
2.2 Le Machine Learning (Apprentissage
Automatique)
L'apprentissage est une discipline visant à la
construction de règles d'inférence et de décision pour le
traitement automatique des données. Les variantes sont : Le Machine
Learning, Le Data-Mining (Fouille de données) selon Aurélien
[12].
L'apprentissage automatique (en anglais : machine learning,
litt. « apprentissage machine »), apprentissage artificiel ou
apprentissage statistique est un champ d'étude de l'in-telligence
artificielle qui se fonde sur des approches mathématiques et
statistiques pour donner aux ordinateurs la capacitéd'« apprendre
» à partir de données, c'est-à-dire
d'améliorer leurs performances à résoudre des tâches
sans être explicitement program-
Mémoire de Master II en Informatique 15 c~NJAMEN M.
ZELKIF 2020-2021
2.2. LE MACHINE LEARNING (APPRENTISSAGE
AUTOMATIQUE)CHAPITRE 2. REVUE DE LA LITTÉRATURE
més pour chacune. Plus largement, il concerne la
conception, l'analyse, l'optimisation, le développement et
l'implémentation de telles méthodes selon Wikipédia
[13].
L'apprentissage automatique comporte
généralement deux phases. La première consiste à
estimer un modèle à partir de données, appelées
observations, qui sont disponibles et en nombre fini, lors de la phase de
conception du système. L'estimation du modèle
consiste à résoudre une tâche pratique,
telle que traduire un discours, estimer une densitéde
probabilité, reconnaître la présence d'un chat dans une
photographie ou faire une recommandation (série littéraire ou
scientifique : Orientation Scolaire). Cette phase dite « d'apprentissage
» ou « d'entraînement » est généralement
réalisée préalablement àl'utilisation
pratique du modèle. La seconde phase correspond à la mise en
production : le
modèle étant déterminé, de
nouvelles données peuvent alors être soumises afin d'obtenir le
résultat correspondant à la tâche souhaitée. En
pratique, certains systèmes peuvent poursuivre leur apprentissage une
fois en production, pour peu qu'ils aient un moyen d'obtenir un retour sur la
qualitédes résultats produits toujours selon Wikipédia
[13].
Selon les informations disponibles durant la phase
d'apprentissage, l'apprentissage est qualifiéde différentes
manières. Si les données sont étiquetées
(c'est-à-dire que la réponse à la tâche est connue
pour ces données), il s'agit d'un apprentissage supervisé. On
parle de classification ou de classement si les étiquettes sont
discrètes, ou de régression si elles sont continues. Si le
modèle est appris de manière incrémentale en fonction
d'une récompense reçue par le programme pour chacune des actions
entreprises, on parle d'apprentissage par renforcement. Dans le cas le plus
général, sans étiquette, on cherche à
déterminer la structure sous-jacente des données (qui peuvent
être une densitéde probabilité) et il s'agit alors
d'apprentissage non supervisé. Selon Wikipédia [13],
L'apprentissage automatique peut être appliquéà
différents types de données, tels des graphes, des arbres, des
courbes, ou plus simplement des vecteurs de caractéristiques, qui
peuvent être des variables qualitatives ou quantitatives continues ou
discrètes.
L'apprentissage automatique est utilisédans un large
spectre d'applications pour doter des ordinateurs ou des machines de
capacitéd'analyser des données d'entrée comme : perception
de leur environnement (vision, Reconnaissance de formes tels des visages,
schémas, segmentation d'image, langages naturels, caractères
dactylographiés ou manuscrits; moteurs de recherche, analyse et
indexation d'images et de vidéo, en particulier
Mémoire de Master II en Informatique 16 c~NJAMEN M.
ZELKIF 2020-2021
2.2. LE MACHINE LEARNING (APPRENTISSAGE
AUTOMATIQUE)CHAPITRE 2. REVUE DE LA LITTÉRATURE
pour la recherche d'image par le contenu; aide aux
diagnostics, médical notamment, bio-informatique,
chémoinformatique ou chimio-informatique; interfaces cerveau-machine;
détection de fraudes à la carte de crédit,
cybersécurité, analyse financière, dont analyse du
marchéboursier; classification des séquences d'ADN; jeu;
génie logiciel; adaptation de sites Web; robotique (locomotion de
robots, etc.); analyse prédictive dans de nombreux domaines
(éducation, financière, médicale, juridique, judiciaire).
Exemples :
· D'après Nguyen et al. [5] Un système de
recommandation pour la prédiction des performances des étudiants
dans un cours de E-learning.
· Selon Hanaa et al. [6], Un système de
recommandation et de prédiction basésur la performances des
étudiants dans un cours de E-Learning.
2.2.1 Les Types d'apprentissages
On peut séparer les tâches de l'apprentissage
automatique en trois grandes familles :
· Apprentissage supervisé;
· Apprentissage Non supervisé;
· Apprentissage par renforcement.
2.2.1.1 Apprentissage supervisé
Dans Wikipédia [13], Lorsque les classes (les sorties
désirées) sont prédéterminées et les
exemples connus, le système apprend à classer selon un
modèle de classification ou de classement; on parle d'apprentissage
supervisé(ou d'analyse discriminante).
La formulation du problème de l'apprentissage
superviséest simple: « on dispose d'un nombre fini d'exemples d'une
tàache à réaliser, sous forme de paires
(entrée,sortie désirée), et on souhaite obtenir, d'une
manière automatique, un système capable de trouver de
façon relativement fiable la sortie correspondant à toute
nouvelle entrée qui pourrait lui être présentée
».
Un expert (ou oracle) doit préalablement
étiqueter des exemples. Le processus se passe en deux phases. La
première phase (dite d'apprentissage) consiste à
déterminer un modèle à partir des données
étiquetées. La seconde phase (dite de test) consiste à
prédire l'étiquette d'une nouvelle donnée, connaissant le
modèle préalablement appris. D'où:
Mémoire de Master II en Informatique 17 c~NJAMEN M. ZELKIF
2020-2021
2.2. LE MACHINE LEARNING (APPRENTISSAGE
AUTOMATIQUE)CHAPITRE 2. REVUE DE LA LITTÉRATURE
Dn = {(x1, y1), ...,
(xn, yn)}, inférer la
relation entre x et y selon Alain [14].
Synonymes : discrimination, reconnaissance de formes.
Vocabulaire : xi =
Caractéristique = Feature = V
ariableexplicative. On distingue en général trois types de
problèmes auxquels l'apprentissage superviséest appliqué.
Ces tâches diffèrent essentiellement par la nature des paires
(entrée, sortie) qui y sont associées. Ainsi, on a :
A) Classification:
Dans les problèmes de classification, l'entrée
correspond à une instance d'une classe, et la sortie qui y est
associée indique la classe. Par exemple pour un problème de
reconnaissance de visage, l'entrée serait l'image bitmap d'une personne
telle que fournie par une caméra, et la sortie indiquerait de quelle
personne il s'agit (parmi l'ensemble de personnes que l'on souhaite voir le
système reconnaître).
B) Régression :
Dans les problèmes de régression,
l'entrée n'est pas associée à une classe, mais dans le cas
général, à une ou plusieurs valeurs réelles (un
vecteur). Par exemple, pour une expérience de biochimie, on pourrait
vouloir prédire le taux de réaction d'un organisme en fonction
des taux de différentes substances qui lui sont administrées.
C) Séries temporelles :
Dans les problèmes de séries temporelles, il
s'agit typiquement de prédire les valeurs futures d'une certaine
quantitéconnaissant ses valeurs passées ainsi que d'autres
informations. Par exemple le rendement d'une action en bourse. . . Une
différence importante avec les problèmes de régression ou
de classification est que les données suivent typiquement une
distribution non stationnaire.
Selon Matthieu [15], En classification, on essaie de
catégoriser les entrées dans les bonnes classes. En
régression, on estime une relation entre entrée et sortie.
Mémoire de Master II en Informatique 18 c~NJAMEN M. ZELKIF
2020-2021
2.2. LE MACHINE LEARNING (APPRENTISSAGE
AUTOMATIQUE)CHAPITRE 2. REVUE DE LA LITTÉRATURE
2.2.1.2 Apprentissage non supervisé
Dans l'apprentissage non superviséil n'y a pas de
notion de sortie désirée, on dispose seulement d'un nombre fini
de données d'apprentissage, constituées
»d'entrées», sans qu'aucun label n'y soit rattaché.
Autrement dit, il s'agit d'un apprentissage dans lequel les
données ne sont pas étiquetées d'après
Wikipédia [16]. L'absence d'étiquetage ou d'annotation
caractérise les tâches d'apprentissage non superviséet les
distingue donc des tâches d'apprentissage supervisé.
L'introduction dans un système d'une approche
d'apprentissage non superviséest un moyen d'expérimenter
l'intelligence artificielle. En général, des systèmes
d'apprentis-sage non supervisépermettent d'exécuter des
tâches plus complexes que les systèmes d'apprentissage
supervisé, mais ils peuvent aussi être plus imprévisibles.
Même si un système d'IA d'apprentissage non
superviséparvient tout seul, par exemple, à faire le tri entre
des chats et des chiens, il peut aussi ajouter des catégories
inattendues et non désirées, et classer des races inhabituelles,
introduisant plus de bruit que d'ordre d'après
Wikipédia [16]. Les techniques de résolution des
problèmes d'apprentissage non supervisésont multiples.
Cependant, nous allons citer quelques unes telles que :
1) Estimation de densité:
Dans un problème d'estimation de densité, on
cherche à modéliser convenablement la distribution des
données. L'estimateur obtenu f(x) doit pouvoir donner un bon
estiméde la densitéde probabilitéà un point de test
x issu de la même distribution (inconnue) que les données
d'apprentissage.
2) Le Partitionnement (clustering) :
Le problème du partitionnement est le pendant
non-superviséde la classification. Un algorithme de partitionnement
tente de partitionner l'espace d'entrée en un certain nombre de
classes en se basant sur un ensemble d'apprentissage fini, ne
contenant aucune information de classe explicite. Les critères
utilisés pour décider si deux points devraient appartenir
à la même classe ou à des classes différents sont
spécifiques à chaque algorithme, mais sont très souvent
liés à une mesure de distance entre points.
3) Réduction de
dimensionalité:
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 19 c~NJAMEN M. ZELKIF
2020-2021
Le but d'un algorithme de réduction de
dimensionalitéest de parvenir à résumer l'information
présente dans les coordonnées d'un point en haute dimension
(x E Rn, n grand) par un nombre plus réduit de
caractéristiques
(y = f(x), y E Rm, in < n). Le but
espéréest de préserver l'information importante, de la
mettre en évidence en la dissociant du bruit, et possiblement de
révéler une structure sous-jacente qui ne serait pas
immédiatement apparente dans les données
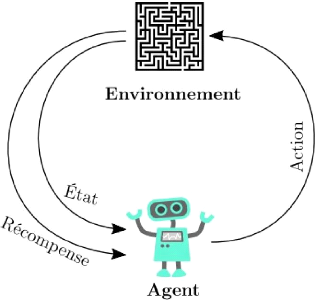
2.2.1.3 Apprentissage par renforcement
L'apprentissage par renforcement, au sens
général, est un cadre formel qui modélise des
problèmes décisionnels séquentiels. Au sein de ce cadre,
un agent apprend à prendre des décisions optimales en
interagissant avec l'environnement selon Matthieu [15].
En intelligence artificielle, plus précisément
en apprentissage automatique, l'appren-tissage par renforcement consiste, pour
un agent autonome (robot, etc.), à apprendre les actions à
prendre, à partir d'expériences, de façon à
optimiser une récompense quantitative au cours du temps. L'agent est
plongéau sein d'un environnement, et prend ses décisions en
fonction de son état courant. En retour, l'environnement procure
à l'agent une récompense, qui peut être positive ou
négative. L'agent cherche, au travers d'expé-riences
itérées, un comportement décisionnel
(appeléstratégie ou politique, et qui est une fonction associant
à l'état courant l'action à exécuter) optimal, en
ce sens qu'il maximise la somme des récompenses au cours du temps
d'après Wikipédia [17].
L'apprentissage par renforcement repose sur l'utilisation de
données indirectement étiquetées par des
récompenses. Cet étiquetage est moins informatif qu'en
apprentissage superviséselon Matthieu [15].
2.3 Les Algorithmes de Machine Learning
Marketing prédictif, maintenance industrielle,
reconnaissance faciale et vocale, éducation (orientation scolaire et
professionnelle). Les applications de Machine Learning (ou apprentissage
automatique) sont aujourd'hui de plus en plus nombreuses au sein des
organisations. À la croisée des statistiques, de l'intelligence
artificielle et de l'informatique, cette technologie consiste à
programmer des algorithmes pour permettre aux ordinateurs d'apprendre par
eux-mêmes.
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 20 c~NJAMEN M. ZELKIF
2020-2021
Figure 2.1 - Illustration du cadre
général de l'apprentissage par renforcement. Adaptédepuis
Wikipédia [17].
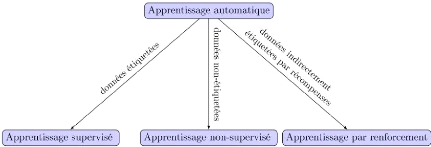
Figure 2.2 - Les trois grandes classes
d'apprentissage automatique. Schéma De
Matthieu [15]
En reconnaissance de formes, les phases d'apprentissage et de
classification constituent des étapes fondamentales qui conditionnent en
grande partie les performances du système. Classifier des formes ou
individus (par exemple des objets, des images, des phonèmes, ...)
décrits par un ensemble de grandeurs caractéristiques (taille ou
masse de l'objet, pixels de l'image numérisée, spectre acoustique
du phonèmes, ...), c'est les ranger en un certain nombre de
catégories ou classes définies à l'avance. La
classification c'est l'action de ran-
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 21 c~NJAMEN M. ZELKIF
2020-2021
ger par classes, par catégories des objets avec des
propriétés communes. Il existe deux catégories de
classification : classification supervisée et classification non
supervisée. La classification est l'élaboration d'une
règle de décision qui transforme les attributs
caractérisant les formes en appartenance à une classe; passage de
l'espace de représentation vers l'espace de décision. La
classification consiste alors à identifier les classes auxquelles
appartiennent les formes à partir des caractéristiques
préalablement choisies et calculés. L'algorithme ou la
procédure qui réalise cette application est
appeléclassifieur. Dans la littérature scientifique, plusieurs
méthodes de classification ont
étéprésentées. Dans cette partie, nous allons
présenter quelques techniques: Machines à vecteurs de support,
arbres de décision, les k-ppv, classification Naïve
Bayésienne et réseau de neurones.
Les algorithmes de Machine Learning se classent en quatre
familles ou types principaux:
· Régression
La régression sert à trouver la relation d'une
variable par rapport à une ou plusieurs autres. Dans l'apprentissage
automatique, le but de la régression est d'estimer une valeur
(numérique) de sortie à partir des valeurs d'un ensemble de
caractéristiques en entrée. Autrement dit, l'objectif est de
déterminer une fonction f qui étant donnéun
nouveau x E R prédise correctement y E R. Par exemple,
estimer le prix d'une maison en se basant sur sa surface, nombre des
étages, son emplacement, etc. Donc, le problème revient à
estimer une fonction de calcul en se basant sur des données
d'entrainement. deuxième exemple : Estimer la série (Scientifique
ou Littéraire) d'un élève en se basant sur ses
performances académiques, etc. Les principaux algorithmes de
régression sont : Régression Linéaire,
Polynomiale, Logistique, Quantile etc... tiréde GitHub [18].
Outre ces algorithmes, nous pouvons aussi avoir les arbres de
décision, SVR (Support Vector Regression ou Régression
Vectorielle de Soutien), les réseaux de neurones...
· Classification
Un problème de classification survient lorsque la
variable de sortie est une
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 22 c~NJAMEN M.
ZELKIF 2020-2021
catégorie, telle que « rouge » ou « bleu
» ou « maladie » et « pas de maladie » ou «
Scientifique » et « Littéraire » dans le cadre de
l'orientation scolaire. Un modèle de classification tente de tirer des
conclusions à partir des valeurs observées. Étant
donnéune ou plusieurs entrées, un modèle de classification
tentera de prédire la valeur d'un ou plusieurs résultats. Par
exemple, lors du filtrage des e-mails « spam » ou « pas de spam
», lors de la consultation des données de transaction, «
frauduleux » ou « autorisé». En bref, la classification
prédit les étiquettes de classe catégorielles ou classe
les données (construisez un modèle) en fonction de l'ensemble
d'apprentissage et des valeurs (étiquettes de classe) dans la
classification des attributs et l'utilise pour classer les nouvelles
données. Il existe plusieurs modèles de classification. Les
modèles de classification incluent la régression
logistique, l'arbre de décision, la forêt aléatoire,
l'arbre amplifiépar gradient, le perceptron multicouche, l'un contre le
repos et Naive Bayes. selon Lima [19]
· Partitionnement des données
Le partitionnement de données (ou data clustering en
anglais) est une méthode en analyse des données. Elle vise
à diviser un ensemble de données en différents «
paquets » homogènes, en ce sens que les données de chaque
sous-ensemble partagent des caractéristiques communes, qui correspondent
le plus souvent à des critères de
proximité(similaritéinformatique) que l'on définit en
introduisant des mesures et classes de distance entre objets.
Pour obtenir un bon partitionnement, il convient d'àla
fois :
- minimiser l'inertie intra-classe pour obtenir des grappes
(cluster en anglais) les plus homogènes possibles;
- maximiser l'inertie inter-classe afin d'obtenir des
sous-ensembles bien différenciés.
· Réduction de dimensions.
Le nombre de variables prédictives (features) pour un
set de données est ap-pelésa dimension. La réduction de
dimensionnalitéfait référence aux techniques
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 23 c~NJAMEN
M. ZELKIF 2020-2021
qui réduisent le nombre de variables dans un ensemble
de données, ou encore projettent des données issues d'un espace
de grande dimension dans un espace de plus petite dimension.
L'ensemble de données peut être un data-set
contenant un grand nombre de colonnes et un tableau de points constituant une
grande sphère dans un espace tridimensionnel. La réduction de
dimensionnalitéconsiste donc à réduire le nombre de
colonnes et à convertir la sphère en un cercle dans un espace
bidimensionnel respectivement.
Notre problème étant celui de classification,
nous allons parler des algorithmes de classification.
2.3.1 Algorithmes de Classification
2.3.2 Classification Naïve
Bayésienne
Les méthodes de classification na·ýve
Bayésienne sont un ensemble d'algorithmes d'ap-prentissage automatique
supervisébasés sur l'application du théorème de
Bayes avec l'hypothèse d'une forte indépendance
na·ýve entre chaque paire de features.
En d'autres termes, un classifieur bayésien naïf
suppose que l'existence d'une caractéristique pour une classe, est
indépendante de l'existence d'autres caractéristiques!
Problème :
Supposons que nous devions classer le vecteur A =
a1?an en in classes,
B1?Bm.
Nous devons calculer la probabilitéde chaque classe
possible sachant A pour que nous puissions étiqueter A
avec la classe Bi de plus grande probabilité.
Le théorème de Bayes nous permet de calculer la
probabilitéconditionnelle grâce à la formule
Pr[A B] = P r[B|A]P
r[A]
P r[B] C
où:
· Pr[B A, C] est la vraisemblance de
l'événement B si A et C sont
vérifiés;
· Pr[A C] est la probabilitéa priori
de l'événement A sachant C ;
· Pr[B C] est la probabilitémarginale de
l'événement B sachant C ;
· 2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 24 c~NJAMEN
M. ZELKIF 2020-2021
Pr[A|B, C] est la probabilitéa posteriori de
A si B et C.
Dans cette formulation de la règle de Bayes, C
joue le rôle de la connaissance que l'on
a.
2.3.3 Algorithme des K-PPV (K-Plus Proches Voisins) ou en
anglais KNN (K-Nearest Neighbors)
La méthode des plus proches voisins
(notéparfois k-PPV ou k-NN pour K-Nearest-Neighbor) consiste à
déterminer pour chaque nouvel individu que l'on veut classer, la liste
des plus proches voisins parmi les individus déjàclassés.
L'individu est affectéà la classe qui contient le plus
d'individus parmi ces plus proches voisins. Cette méthode
nécessite de choisir une distance, la plus classique est la distance
euclidienne, et le nombre de voisins à prendre en compte selon (SOLLAH
[20]).
La méthode K-PPV suppose que les données se
trouvent dans un espace de caractéristiques. Cela signifie que les
points de données sont dans un espace métrique. Les
données peuvent être des scalaires ou même des vecteurs
multidimensionnels selon les auteurs 'Eric and Michel [4]],[ SOLLAH [20].
La méthode des k plus proches voisins est
utilisée pour la classification et la régression. Dans les deux
cas, l'entrée se compose des k données d'entraînement les
plus proches dans l'espace de caractéristiques (SOLLAH [20]).
L'algorithme K-NN est l'un des plus simples de tous les
algorithmes d'apprentissage automatique. Il est un type d'apprentissage
basésur l'apprentissage paresseux (lazy learning).
En d'autres termes, il n'y a pas de phase
d'entraînement explicite ou très minime. Cela signifie que la
phase d'entraînement est assez rapide.
L'algorithme K-PPV figure parmi les plus simples algorithmes
d'apprentissage artificiel. Dans un contexte de classification d'une nouvelle
observation x, l'idée fondatrice simple est de faire voter les
plus proches voisins de cette observation. La classe de xest
déterminée en fonction de la classe majoritaire parmi les k
plus proches voisins de l'ob-servation x.
La méthode K-NN est donc une méthode à
base de voisinage, non-paramétrique, Ceci signifiant que l'algorithme
permet de faire une classification sans faire d'hypothèse sur la
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE
LA LITTÉRATURE
Mémoire de Master II en Informatique 25 c~NJAMEN M.
ZELKIF 2020-2021
fonction
y = f(x1, x2, ...,
xp) qui relie la variable dépendante aux variables
indépendantes.
Cette méthode utilise principalement deux
paramètres : une fonction de similaritépour comparer les
individus dans l'espace de caractéristiques et le nombre k qui
décide combien de voisins influencent la classification. Les choix de la
distance et du paramètre k sont primordiaux pour le bon fonctionnement
de cette méthode.
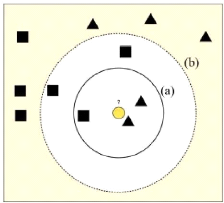
Figure 2.3 - Exemple de classification avec un
KPPV : (a) k= 3, (b) k=5. Tiréde
SOLLAH [20]
2.3.3.1 Principe du K-PPV
Son principe est le suivant : Une donnée de classe
inconnue est comparée à toutes les données
stockées. On choisit pour la nouvelle
donnée. la classe majoritaire
parmi ses K plus proches voisins (Elle peut donc être lourde pour des
grandes bases de données) au sens d'une distance choisie. Les k-PPV
nécessitent seulement :
· Un entier k
· Une base d'apprentissage L = {(yi,
xi), i = 1, ..., nL}
oùyi E {1, ..., c} dénote la
classe de l'individu i et le vecteur xi = (xi1,
..., xip) représente les variables prédicatrices de
l'individu i.
· Une métrique pour la proximité
· Une métrique pour la proximité(une
distance)
on peut choisir la distance euclidienne de.
Soient deux données représentées par
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
deux vecteurs x et y , la distance entre ces
deux données est donnée par :
|
de(x,y) =
|
v u u Xn ti=1
|
(xi - yi)2 (2.1)
|
Mémoire de Master II en Informatique 26 c~NJAMEN M. ZELKIF
2020-2021
Ainsi, pour une nouvelle observation (y, x) le plus
proche voisin (y1-x1) dans l'échantillon
d'apprentissage est déterminépar :
d(x, x1) = mini(d(x,
xi))
Et y = y1, la classe du plus proche voisin, est
sélectionnée pour la prédiction de y.
2.3.3.2 Avantages de la méthode des K-PPV
La méthode des k plus proches voisins représente
des avantages tels que:
1. L'algorithme K-NN est robuste envers des données
bruitées. Selon SOLLAH [20]
2. La méthode des k plus proches voisins est efficace
si les données sont larges et incomplètes. Selon Wikipédia
[21]
3. Cette méthode est l'une des plus simples de tous
les algorithmes d'apprentissage automatique. Selon 123dok [22]
2.3.3.3 Inconvénients de la méthode des
K-PPV
La méthode des k plus proches voisins comporte des
inconvénients tels que :
1. Le besoin de déterminer la valeur du nombre des
plus proches voisins (le paramètre k). Dans 123dok [22]
2. Le temps de prédiction est très long
puisqu'on doit calculer la distance de tous les exemples. Selon
Wikipédia [21]
3. Selon Marwa [23] Cette méthode est gourmande en
espace mémoire car elle utilise une grande capacitéde stockage
pour le traitement des corpus.
2.3.4 Les Arbres de décision
2.3.4.1 Généralités sur les arbres
de décision
L'apprentissage par arbre de décision est une
méthode classique en apprentissage automatique. Son but est de
créer un modèle qui prédit la valeur d'une variable-cible
depuis
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 27 c~NJAMEN M. ZELKIF
2020-2021
la valeur de plusieurs variables d'entrée.
Une des variables d'entrée est
sélectionnée à chaque noeud intérieur (ou interne,
noeud qui n'est pas terminal) de l'arbre selon une méthode qui
dépend de l'algorithme. Chaque arête vers un noeud-fils correspond
à un ensemble de valeurs d'une variable d'entrée, de
manière que l'ensemble des arêtes vers les noeuds-fils couvrent
toutes les valeurs possibles de la variable d'entrée.
Chaque feuille (ou noeud terminal de l'arbre)
représente soit une valeur de la variable-cible, soit une distribution
de probabilitédes diverses valeurs possibles de la variable-cible. La
combinaison des valeurs des variables d'entrée est
représentée par le chemin de la racine jusqu'àla
feuille.
L'arbre est en général construit en
séparant l'ensemble des données en sous-ensembles en fonction de
la valeur d'une caractéristique d'entrée. Ce processus est
répétésur chaque sous-ensemble obtenu de manière
récursive, il s'agit donc d'un partitionnement récursif.
La récursion est achevée à un noeud soit
lorsque tous les sous-ensembles ont la même valeur de la
caractéristique-cible, ou lorsque la séparation n'améliore
plus la prédiction. Ce processus est appeléinduction descendante
d'arbres de décision (top-down induction of decision trees ou TDIDT),
c'est un algorithme glouton puisqu'on recherche à chaque n ?ud de
l'arbre le partage optimal, dans le but d'obtenir le meilleur partage possible
sur l'ensemble de l'arbre de décision. C'est la stratégie la plus
commune pour apprendre les arbres de décision depuis les
données.
En fouille de données, les arbres de décision
peuvent aider à la description, la catégorisation ou la
généralisation d'un jeu de données fixé.
L'ensemble d'apprentissage est généralement
fourni sous la forme d'enregistrements du type:
(x,Y ) =
(x1,x2,x3,...,xk,Y )
La variable Y désigne la variable-cible que
l'on cherche à prédire, classer ou généraliser. Le
vecteur X est constituédes variables d'entrée
x1, x2, x3 etc. qui sont utilisées dans ce
but.
Selon Wikipédia [24], Un arbre de décision est
une structure graphique sous forme d'un arbre (feuilles et branches) qui
illustre un ensemble de choix pour aider à la prise de décision
et classer un vecteur d'entrée X.
Cet algorithme est très utilisédans les fouilles
de données et la sécurité.
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 28 c~NJAMEN M. ZELKIF
2020-2021
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 29 c~NJAMEN M. ZELKIF
2020-2021
Chaque noeud de l'arborescence contient une comparaison de
fonction simple par rapport à un champ (exemple : x = female?).
Le résultat de chaque comparaison est vrai ou faux, ce
qui détermine si nous devons continuer vers la feuille gauche ou vers la
droite du noeud. Une feuille correspond à la décision.
Chaque instance est décrite par un vecteur
d'attributs/valeurs En entrée : un ensemble d'instances et leur classe
(correctement associées par un »expert»)
Les arbres de décision sont également connus
sous le nom d'arbres de classification et de régression (CART).
D'après Alain [14] Les arbres de décision sont
des classifieurs pour des instances représentées dans un
formalisme attribut/valeur.
· Les noeuds de l'arbre testent les attributs
· Il y a une branche pour chaque valeur de l'attribut
testé
· Les feuilles spécifient les catégories
(deux ou plus)
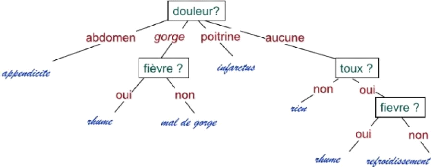
Figure 2.4 - Classification avec un Arbre de
Décision sur le jeu de donnée Maladies.
Tiréde Alain
[14]
Le choix des attributs est très important car :
· Si un attribut crucial n'est pas
représentéon ne pourra pas trouver d'arbre de décision qui
apprenne les exemples correctement.
· Si deux instances ont la même
représentation mais appartiennent à deux classes
différentes, le langage des instances (les attributs) est dit
inadéquat.
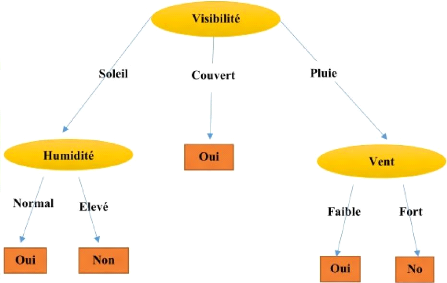
Figure 2.5 - Classification avec un Arbre de
Décision sur le jeu de donnée Jouer
Tennis. Tiréde
Alain [14]
2.3.4.2 Construction d'un arbre de décision
Le but est de trouver le plus petit arbre qui respecte
l'ensemble d'entraînement. Il ne s'agit pas uniquement de
mémoriser les observations, il faut trouver un arbre qui est capable
d'extrapoler des exemples qu'il n'a pas déjàvu.
L'arbre doit extraire des tendances ou des comportements
à partir des exemples.
1. Il construit les arbres de décision de haut en bas.
2. Il place à la racine l'attribut le plus important,
c'est-à-dire celui qui sépare le mieux les exemples positifs et
négatifs.
3. Par la suite, il y a un nouveau noeud pour chacune des
valeurs possibles de cet attribut.
4. Pour chacun de ces noeuds, on recommence le test avec le
sous-ensemble des exemples d'entraînement qui ont
étéclassés dans ce noeud.
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 30 c~NJAMEN M. ZELKIF
2020-2021
2.3.4.3 Avantages des Arbres de Décision
· Non-linéarité
· Support des
variables catégoriques
· Facile à interpréter
· Application à la régression
2.3.4.4 Inconvénients des Arbres de
Décision
· Prone au sur-ajustement
· Instable (non robuste)
· Forte variance
Enfin, il est rare que les modèles d'apprentissage
automatique utilisent un seul arbre de décision. Mais ils
agrègent plusieurs pour obtenir ce que l ?on appelle une forêt
d'arbres décisionnels ou forêts aléatoires.
2.3.5 Machines à vecteurs support SVM
Introduit par Vapnik en 1990, les machines à vecteurs
de support sont des techniques d'apprentissage supervisédestinées
à résoudre des problèmes de classification et de
régression.
Ce modèle était toutefois linéaire et
l'on ne connaissait pas encore le moyen d'induire des frontières de
décision non linéaires. En 1992, Boser et Al proposent
d'introduire des noyaux non-linéaires pour étendre le SVM au cas
non-linéaire dans SOLLAH [20].
Elles reposent sur deux notions principales : la notion de
marge maximale et la notion de fonction noyau. Les machines à vecteurs
support sont des algorithmes d'apprentis-sage automatique qui traitent des
problématique de classification et de régression d'après
Wikipédia [25].
Ces algorithmes ont l'avantages d'être simple à
utiliser, flexible et garantissent une soliditéthéorique.
leur but est de classer les données à l'aide
d'une frontière de sorte à maximiser la distance (appelée
marge) entre les données des différentes classes.
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 31 c~NJAMEN M.
ZELKIF 2020-2021
Les machines à vecteurs support sont utilisés
dans une variétéd'applications telles que la détection des
anomalie, la vision par ordinateur, la reconnaissance d'images etc.
Le tine-tuning des hyper-paramètres du SVM peut
être optimiséen utilisant la technique Grid-Search. Selon
Wikipédia [25]
2.3.5.1 Le Principe des SVMs
Le but des SVM est de trouver un séparateur entre deux
classes qui soit au maximum éloignéde n'importe quel point des
données d'entraînement. Si on arrive à trouver un
séparateur linéaire c'est-à-dire qu'il existe un hyperplan
séparateur alors le problème est dit linéairement
séparable sinon il n'est pas linéairement séparable et il
n'existe pas un hyperplan séparateur.
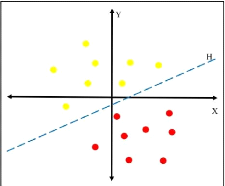
Figure 2.6 - Séparation de deux
ensembles de points par un Hyperplan H. Tiréde
SOLLAH [20]
Pour deux classes et des données linéairement
séparable, il y a beaucoup de séparateurs linéaires
possibles. Les SVM choisissent seulement celui qui est optimal,
c'est-à-dire la recherche d'une surface de décision qui soit
éloignée au maximum de tout point de données. Cette
distance de la surface de décision au point de données le plus
proche détermine la marge maximale du classifieur 2.6. En effet, pour
obtenir un hyperplan optimal, il faut maximiser la marge entre les
données et l'hyperplan.
Par intuition, le fait d'avoir une marge plus large fournit
plus de sécuritélorsque l'on
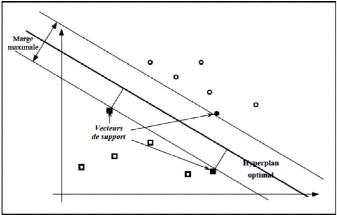
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE
LA LITTÉRATURE
Mémoire de Master II en Informatique 32 c~NJAMEN M.
ZELKIF 2020-2021
Figure 2.7 - Hyperplan optimal, marge et
vecteurs de support. Tiréde SOLLAH [20]
classe un nouvel exemple. De plus, si l'on trouve le
classificateur qui se comporte le mieux vis-à-vis des données
d'apprentissage, il est clair qu'il sera aussi celui qui permettra au mieux de
classer les nouveaux exemples. Comme nous avons mentionnéplus haut, il
existe plusieurs formes de SVM telles que les SVM linéaires, les SVM
multi-classe. Dans cette partie, nous nous limiterons aux SVM
linéaires.
2.3.5.2 Le SVM Linéaire
Le principe de base des SVM consiste de ramener le
problème de la discrimination àcelui, linéaire,
de la recherche d'un hyperplan optimal. Deux idées ou astuces permettent
d'atteindre cet objectif :
· La première consiste à définir
l'hyperplan comme solution d'un problème d'optimisa-tion sous
contraintes dont la fonction objective ne s'exprime qu'àl'aide de
produits scalaires entre vecteurs et dans lequel le nombre de contraintes
»actives» ou vecteurs supports contrôle la complexitédu
modèle. Tiréde SOLLAH [20]
· Toujours dans SOLLAH [20] Le passage à la
recherche de surfaces séparatrices non linéaires est obtenu par
l'introduction d'une fonction noyau (kernel) dans le produit scalaire induisant
implicitement une transformation non linéaire des données vers un
espace intermédiaire (feature space) de plus grande dimension.
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 33 c~NJAMEN M.
ZELKIF 2020-2021
2.3.5.3 Cas linéairement séparable
Considérons « l » points
{(x1, y1),
(x2, y2), ...,
(xi, yi)}, xi E RN
Avec i = 1...L et yi E {#177;1}
Ces points sont classés en utilisant une famille de
fonctions linéaires définis par :
(w,x) + b = 0 (Eq 1)
avec w E RN et b E
R de telle sorte que la fonction de décision concernant
l'apparte-nance d'un point à l'une des deux classes soit donnée
par :
f(x) = ((w,x) + b) (Eq 2)
La fonction (Eq 1) représente l'équation de
l'hyperplan H. La fonction de décision (Eq 2) va donc observer de quel
côtéde H se trouve l'élément de x.
On appelle la marge d'un élément la distance
euclidienne prise perpendiculairement entre H et x. Si on prend un
point quelconque t sur H, cette marge peut s'exprimer en :
Mx = w
1w11(x - t) (Eq 3)
La marge de toutes les données est définie comme
étant :
M = minxEEMx (Eq 4)
L'approche de classification par SVM tend à maximiser
cette marge pour séparer le plus clairement possible deux classes.
Intuitivement, avoir une marge la plus large possible sécurise mieux le
processus d'affectation d'un nouvel élément à l'une des
classes. Un SVM fait donc partie des classificateurs à marge
maximale.
Dans le cas simple linéairement séparable il
existe de nombreux hyperplans séparateurs. Selon la théorie de
Vapnik [26], l'hyperplan optimal est celui qui maximise la marge. Cette
dernière étant définie comme la distance entre un
hyperplan et les points échantillons les plus proches. Ces points
particuliers sont les vecteurs supports. La distance entre un point x
quelconque et l'hyperplan est donnée par l'équation suivante.
d(x) =
w.x+b
kwk (Eq 5)
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Donc maximiser la marge va revenir à minimiser
MwM.
1. Forme Primale :
Les paramètres w et b étant
définis à un coefficient multiplicatif près, on choisit de
les normaliser pour que les échantillons les plus proches
(xs) vérifient l'égalitésuivante :
ys(w.xs + b) = 1 (Eq 6).
Donc quelque soit l'échantillon xi on obtient
:
yi(w.xi + b) ~ 1 (Eq 7).
La distance entre l'hyperplan et un point support est donc
définie par1
kwk. La marge
géométrique entre deux classes est égale
à2
kwk. La forme primale (qui dépend seulement
de w et b ) des SVM est donc un
problème de minimisation sous contrainte qui s'écrit :
?
???
???
|
min(1
2MwM2)
V(xi,yi) EAR, yi(w.xi + b) ~
1
|
(Eq 8)
|
|
Mémoire de Master II en Informatique 34 c~NJAMEN M.
ZELKIF 2020-2021
2. Forme Duale:
La formulation primale peut être transformée en
formulation duale en utilisant les multiplicateurs de Lagrange.
L'équation (8) s'écrit alors sous la forme suivante :
L(w, b, a) = 1 2MwM2 -
'ç'Pi=1 ai(yi(w.xi + b) -
1) (Eq 9)
2.3.5.4 Avantages de SVM
Les SVMs présentent plusieurs avantages parmi
lesquels:
· Capacitéà traiter de grandes
dimensionnalités (variables élevés)
· Traitement des problèmes non linéaires avec
le choix des noyaux
· Non paramétrique
· Souvent performant dans les comparaisons avec les autres
approches
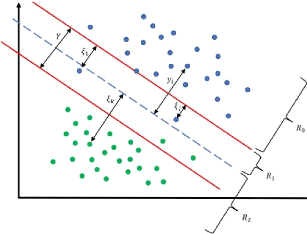
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 35 c~NJAMEN M.
ZELKIF 2020-2021
Figure 2.8 - Données dans le cas non
séparables. Tiréde SOLLAH [20]
· La résolution du problème est convertie en
résolution d'un problème quadratique convexe dont la solution est
unique et donnée par des méthodes mathématiques classiques
de programmation quadratique.
2.3.5.5 Inconvénients de SVM
Les SVMs n'ont pas que des avantages ils ont aussi des
inconvénients tels que :
· Difficultéà identifier les bonnes valeurs
des paramètres (et sensibilitéaux paramètres)
· Difficultéà traiter les grandes bases avec
observations très élevé
· Problème lorsque
les classes sont bruitées (multiplication des points supports)
· Pas de modèle explicite pour les noyaux non
linéaires (utilisation des points supports)
· Elles utilisent des fonctions mathématiques
complexes pour la classification.
· Le traitement des problèmes multi-classes reste
une question ouverte
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE
LA LITTÉRATURE
Mémoire de Master II en Informatique 36 c~NJAMEN M.
ZELKIF 2020-2021
2.3.6 Les Réseaux de neurones
2.3.6.1 Neurone Biologique
Le système nerveux compte plus de 1000 milliards de
neurones interconnectés. Les neurones ne sont pas tous identiques, ni
dans leurs formes ni dans leurs caractéristiques. En effet les neurones
n'ont pas tous un comportement similaire en fonction de leur position dans le
cerveau. La figure 2.9 montre le schéma d'un neurone biologique.
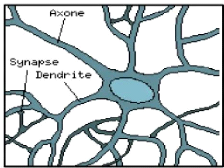
Figure 2.9 - Neurone biologique.
Tiréde SOLLAH [20]
Les neurones reçoivent des signaux (impulsions
électriques) par les dendrites et envoient l'information par les
axones.
2.3.6.2 Les Réseaux de Neurones
Les contacts entre deux neurones (entre axone et dendrite) se
font par l'intermédiaire des synapses. Les signaux n'opèrent pas
de manière linéaire : effet de seuil.
En réalité, les réseaux de neurones sont
une modélisation mathématique du fonctionnement du cerveau humain
selon Wikipédia [27].
Le principe consiste à la construction d'un
modèle simplifiédu neurone biologique communément
appeléneurone formel. Les réseaux de neurones, étant une
connexion de plusieurs neurones formels, peuvent réaliser des fonctions
logiques, arithmétiques et symboliques complexes. Les réseaux de
neurones ressemblent au cerveau en deux points :
· la connaissance est acquise au travers d'un processus
d'apprentissage. Dans JU-RI'Predis [28]
·
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 37 c~NJAMEN M.
ZELKIF 2020-2021
Les poids des connections entre les neurones sont
utilisés pour mémoriser la connaissance.
2.3.6.3 Neurone formel (artificiel)
Le modèle du neurone formel utiliséaujourd'hui
dans toutes les études des machines neuronales date des années
40. Cette modélisation est inspirée du neurone biologique 2.10
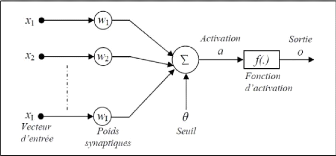
Figure 2.10 - Modèle d'un neurone
formel (artificiel). Tiréde Wikipédia [27]
Le neurone formel recalcule son état à chaque
instant en fonction de l'influence globale du réseau. Il multiplie la
valeur de l'état des neurones en entrée par
l'efficacitésynaptique correspondante, et additionne le tout
(sommateur). Enfin, il compare le résultat à son seuil interne et
déduit son nouvel état en utilisant une fonction appelée
une fonction d'activation ou de transfert : selon JURI'Predis [28]
où:
· O : est appelée la sortie du neurone.
· f : fonction d'activation ou de transfert.
· a = Pl =1 x w - e
: activation de neurone.
· x : Valeur de sortie de la
ième cellule de la
rétine.
· w : Intensitéde la connexion entre la
ième cellule d'entrée et la
cellule de sortie.
·
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 38 c~NJAMEN M. ZELKIF
2020-2021
è : le seuil.
Le fait d'utiliser un seuil è est
équivalent à avoir une cellule d'entrée, notée
généralement x0 = 1, toujours active. Dans ce cas, il
est facile de voir que w0 est égal à -è.
L'activation peut donc se réécrire comme :
|
O = f
|
Xl i=1
|
!xiwi
|
|
Neurone Biologique
|
Neurone formel
|
|
Synapse
|
Poids des connexions
|
|
Axones
|
Signal de sortie
|
|
Dendrites
|
Signal d'entrée
|
Tableau 2.1 - Similitude entre un Neurone
biologique et un Neurone formel
2.3.6.4 Fonctions d'activation
Dans sa première version, le neurone formel était
donc implémentéavec une fonction àseuil, mais
de nombreuses versions existent. Ainsi le neurone de McCulloch et Pitts a
étégénéraliséde
différentes manières, en choisissant d'autres fonctions
d'activations. Selon
les auteurs JURI'Predis [28]],[ Wikipédia [29]
La sortie du neurone dépend d'une fonction de transfert,
dont les principales sont :
A) Fonction binaire a seuil:
|
h(x) =
|
?
???
???
|
1 si x ~ 0 0 sinon
|
sgn(x) =
|
?
???
???
|
1 si x ~ 0 -1 sinon
|
B) Fonction linéaire:
C'est l'une des fonctions d'activations les plus simples, sa
fonction est définie par : F(x) = x
C) Fonction linéaire à seuil ou multi seuil :
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Cette fonction représente un compromis entre la
fonction linéaire et la fonction seuil, entre ses deux barres de
saturation, elle confère au neurone une gamme de réponses
possibles. En modulant la pente de la linéarité, on affecte la
plage de réponse du neurone.
|
F(x) =
|
?
????????
????????
|
x, x E [u,v] v, six ~ v u, six u
|
Mémoire de Master II en Informatique 39 c~NJAMEN M. ZELKIF
2020-2021
D) La fonction sigmo·ýde :
Elle est l'équivalent continu de la fonction
linéaire. Étant continu, elle est dérivable, d'autant plus
que sa dérivée est simple à calculer, elle est
définie par :
1
F (x) = 1 + e-x
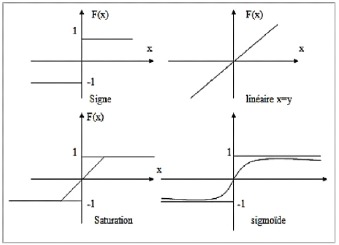
Figure 2.11 - Les fonctions d'activation
2.3.6.5 Les réseaux de neurones
célèbres
Il y a de très nombreuses sortes de réseaux de
neurones actuellement. Personne ne sait exactement combien. De nouveaux
réseaux (ou du moins des variations de réseaux plus anciens) sont
inventés chaque semaine. On en présente ici de très
classiques.
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 40 c~NJAMEN M. ZELKIF
2020-2021
2.3.6.6 Le Perceptron
Le perceptron est considérécomme le premier
modèle des réseaux de neurones, il fut mis au point dans les
années cinquante par Rosenblatt (1957-1961) dans Inside Machine Learning
[30].
Selon Hervé[31], Le perceptron se compose de deux
couches de neurones la rétine (n'est pas comptéd'oùle nom
de perception monocouche) et la couche de sortie. La fonction seuil de
Heaviside est utilisée comme fonction d'activation des neurones de la
couche de sortie. La figure 2.12 montre un exemple de perceptron.
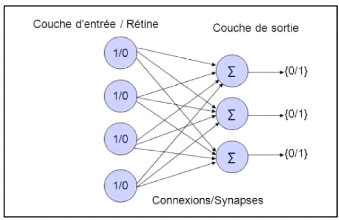
Figure 2.12 - Un exemple de perceptron
tiréde Hervé[31]
Les cellules de la première couche sont binaires,
répondent en oui / non (0/1).
Les cellules d'entrée sont reliées aux neurones
de sortie grâce à des liens synaptiques wij
d'intensitévariable.
La règle d'apprentissage du perceptron est la
règle de Widrow Hoff selon Alain [14] :
wt+1
ij = wt ij + ij(tj -
oj)xi = wt ij + /wij
· Äwij : Changement à effectuer pour
la valeur wij.
· xi : Valeur de sortie (0 ou 1) de la
ième cellule de la
rétine.
·
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 41 c~NJAMEN M. ZELKIF
2020-2021
oj : Réponse de la
jème cellule de sortie (0
ou 1).
· tj : Réponse théorique ou
(désirée) de la
jème cellule de sortie (0
ou 1).
· wt ij : Intensitéde la connexion entre
la ième cellule
d'entrée et la jème
cellule de sortie, au temps t (les valeurs
w(0)
ij sont généralement choisies au
hasard).
· : D'après les auteurs JURI'Predis [28]],[
Wikipédia [29]],[ Deeply Learning [32], Une constante positive
généralement comprise entre 0 et 1, sa valeur influe, en effet,
sur la vitesse d'apprentissage.
2.3.6.7 Le perceptron multicouches
Dans le modèle du Perceptron Multicouches, les
perceptrons sont organisés en couches. Les perceptrons multicouches sont
capables de traiter des données qui ne sont pas linéairement
séparables. Avec l'arrivée des algorithmes de
rétro-propagation, ils deviennent le type de réseaux de neurones
le plus utilisé. Les MLP sont généralement
organisés en trois couches, la couche d'entrée, la couche
intermédiaire (dite couche cachée) et la couche de sortie.
L'utilitéde plusieurs couches cachées n'a pas
étédémontrée dans Wikipédia [13]
Les PMC utilisent, pour modifier leurs poids, un algorithme
d'apprentissage, il existe une centaine mais le plus populaire est la
rétro-propagation du gradient, qui est une généralisation
de la règle de Widrow-Hoff. Il s'agit toujours de minimiser l'erreur
quadratique, on propage la modification des poids de la couche de sortie
jusqu'àla couche d'entrée, donc cet algorithme passe par deux
phases:
· Les entrées sont propagées de couche en
couche jusqu'àla couche de sortie.
· Si la sortie du PMC est différente de la sortie
désirée alors l'erreur est propagée de la couche de sortie
vers la couche d'entrée en modifiant les poids durant cette
propagation.
2.3.6.8 L'apprentissage
Selon les auteurs Aurélien [12]],[ Wikipédia
[16]],[ Marwa [23], La méthode de pa-ramétrage des poids
(apprentissage) est une caractéristique importante pour distinguer
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
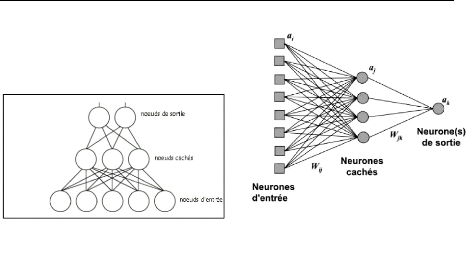
Figure 2.13 - Un perceptron
multicouche
tiréde SOLLAH [20]
Figure 2.14 - Un autre exemple
de
perceptron multicouche proposépar
Hervé[31]
différents types de réseaux de neurones. Deux modes
d'apprentissage existent : l'appren-tissage supervisé, et
l'apprentissage non supervisé.
1) L'apprentissage supervisé
Dans ce type d'apprentissage, les entrées et les
sorties sont fournies au préalable. Ensuite, le réseau traite les
entrées et compare ses résultats aux sorties souhaitées.
Les poids sont ensuite ajustés grâce aux erreurs propagées
à travers le système. Ce processus se produit à plusieurs
reprises tant que les poids sont continuellement améliorés.
L'ensemble de données qui permet l'apprentissage est
appelél'ensemble d'apprentissage. Selon Philippe [33]
2) L'apprentissage non supervisé
Dans l'apprentissage non supervisé, le réseau
est fourni avec des entrées mais pas avec les sorties souhaitées.
Le système lui-même doit alors décider quelles
fonctionnalités il utilisera pour regrouper les données
d'entrée. C'est ce qu'on appelle souvent l'auto-organisation ou
l'adaptation. Selon Wikipédia [16]
2.3.6.9 Avantages des réseaux de neurones
· Les réseaux de neurones sont souples et
génériques. Ils peuvent résoudre différents types
de problèmes dont le résultat peut être : une
classification, analyse de données, etc.
Mémoire de Master II en Informatique 42 c~NJAMEN M.
ZELKIF 2020-2021
·
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 43 c~NJAMEN M. ZELKIF
2020-2021
Ils traitent des problèmes non structurés sur
lesquels aucune information n'est disponible à l'avance.
· Les réseaux neuronaux se comportent bien parce
que même dans des domaines très complexes, ils fonctionnent mieux
que les arbres de statistique ou de décision.
· Les réseaux de neurones fonctionnent sur des
données incomplètes ou bruitées. Cette lacune
d'information peut être complétée par l'ajout d'autres
neurones à la couche cachée.
2.3.6.10 Inconvénients des réseaux de
neurones
· Détermination de l'architecture du réseau
est complexe.
· Paramètres difficiles à interpréter
(boite noire).
· Difficultéde paramétrage surtout pour
le nombre de neurone dans la couche cachée.
Il existe plusieurs algorithmes que l'on peut utiliser en
fonction des problèmes et surtout de la nature du jeu de données.
Ainsi, nous avons résumédans le tableau ci-dessous quelques
algorithmes à titre indicatif ou illustratif.
Supervised Learning
|
Unsupervised Learning
|
Reinforcement Learning
|
Artificial neural network
|
Artificial neural network
|
Q-learning
|
Bayesian statistics
|
Association rule learning
|
Learning automata
|
Case-based reasoning
|
Hierarchical clustering
|
|
Decision trees
|
Partitioned clustering
|
|
Learning automata
|
|
|
Instance-based learning
|
|
|
Regression analysis
|
|
|
Linear classifiers Decision trees
|
|
|
Bayesian networks
|
|
|
Hidden Markov models
|
|
|
|
Tableau 2.2 - Machine learning Algorithmus
2.4. ÉTAT DE L'ART DU ML APPLIQUÉÀ
L'ÉDUCATION CHAPITRE 2. REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 44 c~NJAMEN M.
ZELKIF 2020-2021
2.4 État de l'art du ML appliquéà
l'éducation
Faire un choix parmi une information pertinente non seulement
objectivement mais aussi subjectivement c'est-à-dire adaptée au
profil de la personne effectuant la recherche est le principe de la
recommandation et des systèmes de recommandation. L'apprentissage
amélioréest l'application de technologies de l'information et de
la communication (TIC) pour l'enseignement et apprentissage. Dans cette
section, nous parlerons de l'application du Machine Learning dans
l'éducation en général et dans l'orientation scolaire en
particulier selon Nguyen et al. [5].
2.4.1 Les travaux connexes
2.4.1.1 Dans le monde
Les systèmes de recommandation sont largement
utilisés dans de nombreux domaines tels que : le commerce, la
médecine, les finances, l'éducation etc. Récemment, ils
sont également appliqués dans des tâches d'apprentissage en
ligne telles que recommander des ressources (par exemple, des articles, des
livres) aux apprenants (étudiants) d'après Nguyen et al. [5].
La plupart des études menées dans le domaine de
l'éducation sont dans un contexte de e-learning tels que les travaux de
: Patrick and Olfa [34], Nguyen et al. [5], Danijel et al. [35] et Hanaa et al.
[6] pour ne citer que ceux-ci. Ceux qui sont dans un contexte hors ligne ne
sont pas contextualisés avec les données académiques de
notre système éducatif comme Ahajjam and Toussef [36] qui ont
travaillés dans le domaine du Machine Learning appliquéà
l'orientation comme nous le faisons. Cependant, nos données sont
collectés dans des établissements camerounais un peu reparties
sur trois régions (Centre, littoral et ouest).
Néanmoins, nous avons
sélectionnéquelques outils d'aide à la décision
pour faciliter l'orien-tation des jeunes et leur insertion
socioprofessionnelle.
Hello Charly, le chatbot d'orientation
Destinéaux 14-24 ans,
Hello Charly développe des chatbots gratuits au
service des jeunes pour les aider à s'orien-ter. D'abord,
l'étudiant passe par une phase d'échange avec son coach virtuel,
Charly, pour connaître son profil et mieux définir son projet.
Ensuite, celui-ci a accès à un tableau de
2.4. ÉTAT DE L'ART DU ML APPLIQUÉÀ
L'ÉDUCATION CHAPITRE 2. REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 45 c~NJAMEN M.
ZELKIF 2020-2021
bord personnaliséoùil peut consulter des fiches
métiers, un guide pour trouver un stage, des informations sur Parcoursup
ou encore des précisions sur certaines spécialités.
850 métiers sont référencés et 3
000 formations disponibles sur l'application de Hello Charly disponible sur
tous les stores. Si la crise a accentuéles inégalités
sociales, l'objectif affichéde la startup est « d'éviter le
décrochage scolaire et de mettre tous les moyens en ?uvre pour que les
jeunes choisissent l'orientation la plus adaptée à leur
personnalité, centres d'intérêts et objectifs de vie »
. Disponible 24h/24 et 7j/7, une version gratuite du chatbot est accessible via
un code disponible sur le serveur Discord de Hello Charly. Depuis sa
création en 2016, la startup revendique avoir
déjàaidé280 000 personnes dans leur orientation.
MyFuture favorise l'immersion pour découvrir les
métiers
Depuis 5 ans, la startup MyFuture anime la plateforme «
Stage découverte » , qui permet à n'importe quel jeune
âgéde 14 à 24 ans de solliciter gratuitement un ou
plusieurs mini-stages, de un à cinq jours, pour découvrir les
métiers de façon concrète et préciser
son orientation. Elle pilote aussi un dispositif aux
côtés du ministère chargéde
l'Egalitéfemmes-hommes, dont l'objectif est de permettre
à 3000 jeunes femmes, chaque année,
de découvrir les secteurs techniques et scientifiques
en rencontrant des professionnelles sur leur lieu de travail. Enfin, la jeune
pousse propose aux collégiens de 3ème, pour qui le stage est
facultatif cette année en raison du Covid-19, une alternative virtuelle.
L'idée est de leur faire découvrir un secteur
d'activitéqui leur plaît à travers une série de
conférences, d'interviews et de visites guidées, tout cela
à distance.
ExplorJob, à la rencontre des
professionnels
L'association pour la Valorisation et la Découverte de
Tous les Métiers (AVDTM) a développéune plateforme
numérique collaborative, ExplorJob, pour permettre à ses
utilisateurs et utilisatrices de rencontrer des pros de différents
secteurs. L'objectif : se rendre compte de la réalitéde leur
métier. L'outil est aussi bien destinéaux étudiants,
collégiens et lycéens qu'aux jeunes déscolarisés,
aux demandeurs d'emploi ou aux personnes en reconversion professionnelle. Une
fois le rendez-vous fixésur le site, le professionnel parle de son
parcours, de son travail et répond aux questions pendant une heure
environ. Le but? Donner à toutes et tous l'accès à un
vaste réseau de personnes envieuses de partager leur savoir.
2.4. ÉTAT DE L'ART DU ML APPLIQUÉÀ
L'ÉDUCATION CHAPITRE 2. REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 46 c~NJAMEN M.
ZELKIF 2020-2021
Pixis, la plateforme pour découvrir les métiers
de demain
Fondée en 2017, cette startup, basée à
Poitiers, part du constat que « 90% des métiers actuels vont
profondément évoluer afin de répondre aux enjeux de la
société, d'innovation, et finalement, il n'appartient
qu'àsoi de les construire » , comme on peut le lire sur le site de
nos confrères de France Bleu. Partant de cette thèse,
Alo·ýs Gaborit, lui-même fils d'une conseillère
d'orientation, a développéPixis, un assistant personnel gratuit
qui
aide les personnes à définir un champ
d'activitédans lequel elles aimeraient travailler.
Àpartir de là, la plateforme propose une trentaine de
métiers (sur 2900 références), tous
en lien avec les 17 objectifs pour le développement
durable, fixépar l'ONU en 2015. Un détail important puisque,
toujours selon son fondateur, les jeunes veulent aujourd ?hui «
privilégier le sens de leur futur métier » . Pixis compte
aujourd ?hui 50 000 inscriptions.
Impala, la plateforme ludique qui oriente
par le jeu
Impala propose de cartographier son orientation, avec des
schémas interactifs oùles points grossissent en fonction des
appétences renseignées dans leur moteur de recherche.
L'originalitéréside dans la possibilitéd'avancer dans ses
choix grâce à une série de mini-jeux qui
révèlent progressivement les points forts, centres
d'intérêts et motivations de chaque utilisateur. Tout cela dans
l'optique de créer, petit à petit, une carte plus affinée
de métiers et études et de voir se dessiner une tendance
d'orientation.
OrientaSchool, un coach virtuel sur
Messenger
Facilement accessible sur Messenger, OrientaSchool permet de
recevoir rapidement des ressources classiques mais adaptées aux
demandes, celles de l'Onisep notamment. L'outil propose de
réaliser un test de personnalité, mais aussi de s'immerger dans
son job rêvé, en réservant une semaine d'immersion chez des
professionnels. Contre 250 à 500 euros par semaine, 285 professionnels
font découvrir leur quotidien.
Premier cap, de vrais coachs à
distance
Cette plateforme d'orientation scolaire 100% en ligne permet
aux internautes de choisir
un coach professionnel? bel et bien réel cette fois?
et de construire avec lui, mais àdistance, un plan
d'études structuré, basésur les éléments de
personnalité, de motivation, de désirs et d'ambition.
2.4. ÉTAT DE L'ART DU ML APPLIQUÉÀ
L'ÉDUCATION CHAPITRE 2. REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 47 c~NJAMEN M.
ZELKIF 2020-2021
StudyAdvisor met les étudiants au
coeur de l'orientation de leurs cadets
Pour en finir avec le conseiller d'orientation dont les
étudiants se sentent souvent lointains, StudyAdvisor a
crééun site sur lequel les étudiants répondent
directement à toutes les questions des plus jeunes, sans tabou.
Créée en 2016, la structure propose de matcher les profils selon
les envies du lycéen, pour que « l'advisor » puisse ensuite
lui donner son ressenti et répondre à ses questions, par
écrit ou par téléphone. Ensuite, la plateforme propose une
recommandation d'un ou plusieurs établissements correspondant au projet
qui se dessine, et les met en contact.
MillionRoads mise sur l'IA et le Big Data
pour guider les jeunes
Cette startup avignonnaise développe des solutions
numériques pour analyser les potentielles trajectoires scolaires et
professionnelles de chaque utilisateur. Grâce à l'intelligence
artificielle et au Big Data, l'équipe propose deux solutions. «
Humanroads analytics » permet aux acteurs de la formation
d'anticiper les évolutions du secteur. Le « GPS des
carrières » de son côtédessine aux étudiants
une carte leur faisant apparaître les parcours d'études possibles,
adaptés à leurs envies. Le système équipe
déjàune soixantaine d'écoles, organismes de formation et
universités, comme Neoma Business School. Anciennement
HumanRoads, la startup devient MillionRoads et sera
bientôt disponible avec de nouvelles solutions.
2.4.1.2 Au Cameroun
Au niveau national, dans notre domaine, nous n'avons
recenséaucun article publiépar nos compatriotes.
néanmoins, nous avons recenséun groupe de jeune qui travaille
dans le domaine de Machine Learning appliquéà l'éducation
à travers leur startup nomméDES-TINY. Nous pouvons aussi citer le
COSUP (Centre d ?Orientation Scolaire, Universitaire et Professionnelle)
à travers leur plateforme
ecolesducameroun.net
qui guide en faisant
· La promotion de la « cyber-orientation »
à travers le développement d'un site in-ternet d'orientation;
· La création des synergies entre les services
nationaux d'orientation et d'emploi.
En dépit du déficit numériques des
conseillers d'orientation, ces outils que nous avons citédans cette
section sont pour la plupart payant ce qui conduit généralement
à leur non utilisation par les apprenants. En outre, beaucoup ne sont
pas contextualisés selon nos
2.5. CONCLUSION CHAPITRE 2. REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 48 c~NJAMEN M.
ZELKIF 2020-2021
deux sous-systèmes éducatifs. Toutes ces raisons
ont motivées notre désire d'automatiser cette tâche
d'orientation qui est d'une importance capitale dans la concrétisation
des objectifs de l'éducation qui ne sont rien d'autres que la
réussite. Ce procédérevient à résoudre un
problème de prédiction ou de recommandation.
D'oùl'importance de donner au système éducatif la
capacitéd'apprendre à recommander à partir des exemples
existants sans être explicitement programmé. Cette façon de
faire est le Machine Learning (Apprentissage Automatique)
appliquéà l'éducation plus précisément
à l'orientation scolaire.
2.4.2 L'aide à la décision
L'évolution des techniques de fouilles de
données, ainsi que l'accroissement des capacités de stockage et
de calcul suscite, dans tous les domaines, un intérêt pour les
données
produites. En ce sens, le domaine de l'éducation ne fait
pas exception. Au vu de la quantitéde données
créées lors de l'écriture des différents programmes
de gestion des notes, des
logiciels de gestions d'établissement, afin de
capitaliser les connaissances sur ces données académiques et de
faciliter l'aide à la décision, l'application de techniques de
fouille de données est considérée comme la solution
incontournable selon Emeric et al. [37].
L'apprentissage amélioréest l'application de
technologies de l'information et de la communication pour l'enseignement et
apprentissage. Les systèmes de recommandation (RS) sont des outils
logiciels basés sur l'apprentissage automatique (Machine Learning) et
les techniques de récupération des informations (Data Mining) qui
fournissent des recommandations pour des éléments potentiellement
utiles dans l'intérêt de quelqu'un Hanaa et al. [6]. Les
systèmes de recommandations se basent sur des données encore
appelés data-set.
2.5 Conclusion
Ce chapitre nous a permis d'étudier les
différentes étapes d'un système d'orientation scolaire
assistépar ordinateur. Une telle étude est nécessaire afin
de faire des choix appropriés pour une orientation automatisée.
En effet, le fait d'aborder quelques méthodes d'apprentissage
automatique (Machine Learning) a permis d'étudier les limites de chaque
méthode et par la suite, cela nous a permis de comprendre que pour un
tel travail, il
2.5. CONCLUSION CHAPITRE 2. REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 49 c~NJAMEN M.
ZELKIF 2020-2021
est mieux d'appliquer plusieurs méthodes et de choisir
celles qui répondent le mieux sur les jeux de données car
d'après la littérature, les méthodes répondent
différemment sur différentes données. Une
présentation plus ou moins générale concernant
l'étape de description dans la e-orientation est menée dans
l'objectif de préparer le terrain à une étude des
différents descripteurs dans le chapitre suivant. Ces différentes
étapes sont des outils, à la fois utiles et nécessaires
pour réussir une orientation scolaire automatique grâce aux
exemples existants constituants le data-set (l'entrepôt des
données).
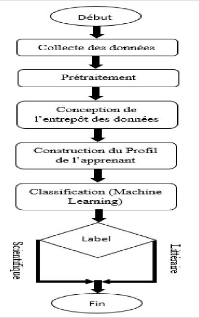
DÉMARCHE
MÉTHODOLOGIQUE
Ce chapitre dresse la synoptique de la démarche
préconisée qui comprend principalement cinq étapes
essentielles qui sont : le procédéd'acquisition des
données utilisées pour l'orientation scolaire (collecte des
données), le prétraitement effectuésur ces données
académiques, la conception de l'entrepôt des données, la
construction du profil de l'apprenant et enfin la classification
(recommandation) selon le schéma du système ci-dessous 3.1.
50
Figure 3.1 - Schéma de la
démarche méthodologique
3.1. CAHIER DE CHARGE (OBJECTIF VISÉ) CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 51 c~NJAMEN M.
ZELKIF 2020-2021
3.1 Cahier de charge (Objectif visé)
Selon Wikipédia [2], L'orientation scolaire et
professionnelle, universitaire et de carrière consiste à proposer
à une personne en âge de scolaritéet même aux adultes
(obligatoire ou post-obligatoire, voire permanente ou continue) les
différentes filières dans lesquelles elle pourrait
s'insérer en fonction de ses intérêts, de son parcours
scolaire antérieur, et de sa personnalité.
Compte tenu de la raretédes conseillers d'orientation,
malgrél'importance de cette activité, nous proposons dans ce
mémoire une solution automatisée d'aide à la
décision pour l'orientation scolaire.
Avant d'arriver à la solution d'aide à la
décision nous construisons un entrepôt de données qui
pourra à l'avenir d'aider à faire des multiples analyses telles
que disciplinaires, pédagogique, financière etc...
3.2 L'acquisition (Collecte) des données
Le but d'un projet de Machine Learning est de
développer des modèles d'apprentissage efficaces à partir
d'ensembles volumineux de données (les data-sets). La qualitéet
la quan-titédes données ont un impact direct sur
l'efficacitédu modèle résultant. Pour développer
leur capacitéà accumuler des connaissances et à prendre
des décisions de façon autonome, les machines ont en effet besoin
de consommer une grande quantitéd'informations : plus celles-ci sont
nombreuses et fiables, plus le résultat obtenu sera précis et
adaptéaux besoins de l'entreprise. C'est ainsi que pour notre sujet de
recherche, nous avons construit un jeu de donnée (data-set)
constituédes données de notes des évaluations
scolaires issues des bases de données des établissements
scolaires du Cameroun.
dans cette étape, nous avons commencépar tisser
des relations avec les détenteurs des logiciels de gestion des
établissements scolaires, car ce sont eux les sources de
génération des données. Cette étape a
étéla plus difficile de notre travail tout simplement à
cause de la confidentialitédes données des établissements
concernés, puisqu'elles (données) sont constituées des
informations financières, disciplinaires et scolaires (notes des
élèves par matières par classes).
Les données constituants notre data-set proviennent de
trois régions du Cameroun (Centre, Littoral et l'Ouest).
3.2. L'ACQUISITION (COLLECTE) DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 52 c~NJAMEN M.
ZELKIF 2020-2021
Nous avons collectéau total plus de 12.000
données issues des bases de données des établissements de
ces régions. Cependant après nettoyage et pré-traitement
sur ces données nous avons obtenu un data-set de 1000 données
à causes des bruits (les données qui disparaissent dans la BD
après une ou quelques années moins de quatre ans).
Ayant collectéles données de plusieurs sources
différentes, il nous a fallut réorganiser la base de
données suivant le schéma logique ci-dessous :
· Matières (CodeMat, NomMat)
· Enseignant(CodeEns, NomsEns, DateNais, SexeEns, CodeCls,
CodeMat)
· Élève(Matricule, NomsEl, DateNais, SexeEl,
CodeCls, CodeMat)
· Notes(CodeMat, CodeCls, CodeAnnee, E11, E12, E21,
E22, E31, E32)
· Classe(CodeCls, LibelleCls)
· Année(CodeAnne, Annee)
Les données collectées étant sur des
format différents, nous avons utiliséles requêtes SQL
(requêtes de jointures des tables) afin d'uniformiser une
représentation pour faciliter l'accessibilité, nous avons donc
obtenu le schéma ci-dessous 3.2 :
Figure 3.2 - Représentation des
données après requêtes SQL oùlesEij avec
i E {1, 2, 3} et j E {1, 2} sont
les différentes évaluations.
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 53 c~NJAMEN M.
ZELKIF 2020-2021
Le but du processus de préparation de données
est l'obtention de données fiables, en quantitéet en
qualité, cohérentes et structurées afin que l'analyse soit
la plus performante possible.
Cependant, les problématiques liées à la
préparation des données que rencontrent les chercheurs sont
proportionnelles à la quantitédes données avec lesquelles
ils doivent travailler.
Parmi ces problématiques on peut citer entre autres
:
· Comment exploiter au mieux les données?
· Comment enrichir ses données avec des
données cohérentes?
· Comment s'assurer de la qualitédes
données?
· Comment nettoyer les données?
· Comment mettre à jour les données et les
modèles?
· Comment rendre le processus plus rapide?
· Comment réduire les coûts liés au
processus de préparation des données?
3.3 Pré-traitement des données
Le pré-traitement des données est une technique
d'exploration de données qui est utilisée pour transformer les
données brutes dans un format utile et efficace.
Les données réelles sont souvent
incomplètes, incohérentes et / ou dépourvues de certains
comportements ou tendances, et sont susceptibles de contenir de nombreuses
erreurs. Le prétraitement des données est une méthode
éprouvée pour résoudre ces problèmes. Le
prétraitement des données prépare les données
brutes à un traitement ultérieur. Les données passent par
une série d'étapes pendant le prétraitement.
Le processus de traitement des données est
illustrépar le schéma ci-après 3.3 :
· Nettoyage des données : les données sont
nettoyées par des processus tels que le remplissage des valeurs
manquantes, le lissage des données bruyantes ou la résolution des
incohérences dans les données.
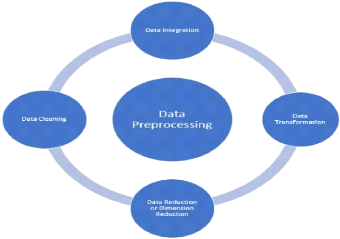
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 54 c~NJAMEN M.
ZELKIF 2020-2021
Figure 3.3 - Processus d'acquisition et
Pré-traitement des données Medium [38]
· Intégration des données : les
données avec différentes représentations sont
rassemblées et les conflits au sein des données sont
résolus.
· Transformation des données : les données
sont normalisées, agrégées et
généralisées.
· Réduction des données : cette
étape vise à présenter une représentation
réduite des données dans un entrepôt de données.
· Dans Science [39], la discrétisation des
données : implique la réduction d'un certain nombre de valeurs
d'un attribut continu en divisant la plage d'intervalles d'attribut.
3.3.1 Nettoyage des données
Les données peuvent comporter de nombreuses parties
non pertinentes et manquantes. Pour gérer cette partie, un nettoyage des
données est effectué. Cela implique le traitement des
données manquantes, des données bruitées, etc selon Lima
[40].
Le processus de Nettoyage de données est fondamental
à la préparation des données. Il permet d'améliorer
la qualitédes données en supprimant ou en modifiant les
données erronées.
Le but est d'éviter de retrouver dans la base de
données des données incorrectes. Les données peuvent
être incorrectes pour plusieurs raisons :
·
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 55 c~NJAMEN M. ZELKIF
2020-2021
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Erreurs de saisies
· Erreurs lexicales
· Erreurs de formats
· Doublons
· Données manquante
· Erreurs sémantiques
Le nettoyage des données est une étape cruciale
dans la préparation des données car toute erreur liée aux
données se répercutera inévitablement dans l'analyse des
données, c'est pourquoi les équipes portent une attention
particulière à cette étape et nous aussi.
L'augmentation de la quantitédes données
provoquent une augmentation des données incorrectes, ce qui oblige les
entreprises à adopter une multitudes de méthodes afin de les
éliminer.
Parmi ces méthodes on peut citer par exemple l'audit
de données, l'élimination des doublons par Algorithme ou encore
l'analyse syntaxique.
· (Une) ou Des. Données manquantes:
cette situation se produit lorsque certaines données
sont manquantes dans les données. Le problème des données
manquantes peut être traitéde diverses manières telles que
:
1) Ignorer les tuples
cette approche ne convient que lorsque l'ensemble de
données dont nous disposons est assez volumineux et que plusieurs
valeurs sont manquantes dans un tuple. Exemple : Au début de l'analyse
de notre data-set, nous hésitions entre considérer ou ne pas
considérer l'attribut sexe et pour finir nous avons supprimécette
colonne dans le data-set pour éviter d'avoir un modèle sexiste.
Cependant si nous avions décidéautrement, et que par exemple nous
avions eu des données manquantes pour cet attribut, nous aurions
procédécomme ci-dessous par exemple en considérant la
valeur la plus représentée si c'est F on aurait
remplacépar F et autrement par M dans le cas des M.
2) Remplissez les valeurs manquantes :
Mémoire de Master II en Informatique 56 c~NJAMEN M. ZELKIF
2020-2021
Il existe différentes manières d'effectuer cette
tâche. Vous pouvez choisir de remplir les valeurs manquantes
manuellement, par moyenne d'attribut ou par valeur la plus probable.
Par Exemple : dans notre data-set il y a eu des données
manquantes à cause de la mobilitédes élèves dans
les établissements scolaire. Certains commencent l'année dans un
établis-
sement et la termine dans un autre ce qui cause ce
problème de données manquantes. Dans ce cas, puisque ce sont des
données numériques, nous avons remplacépour chaque valeur
manquante d'un attribut, par la moyenne de toutes les valeurs de cet
attribut.
· Données bruyantes:
les données bruyantes sont des données
dénuées de sens qui ne peuvent pas être
interprétées par les machines. Elles peuvent être
générées en raison d'une mauvaise collecte de
données, d'erreurs de saisie de données, etc. Exemple dans notre
data-set, nous avons considérécomme données bruyantes les
attributs comme le TM, l'EPS etc car pour un début nous n'avons pas vu
comment ces attributs devaient contribuer ou faciliter le processus
d'orientation.
1. Méthode Binning: Cette méthode fonctionne
sur des données triées afin de les lisser. L'ensemble des
données est diviséen segments de taille égale, puis
diverses méthodes sont exécutées pour accomplir la
tâche. Chaque segmentéest traitéséparément.
On peut remplacer toutes les données d'un segment par sa moyenne ou les
valeurs limites peuvent être utilisées pour terminer la
tàache.
2. Régression : Ici, les données peuvent
être lissées en les adaptant à une fonction de
régression. La régression utilisée peut être
linéaire (ayant une variable indépendante) ou multiple (ayant
plusieurs variables indépendantes).
3. Clustering : Cette approche regroupe les données
similaires dans un cluster. Les valeurs aberrantes peuvent ne pas être
détectées ou elles tomberont en dehors des clusters.
3.3.2 Transformation des données
Cette étape est effectuée afin de transformer
les données sous des formes appropriées adaptées au
processus d'exploration de données. Cela implique les moyens suivants
:
1. Normalisation : Elle est effectuée afin de mettre
à l'échelle les valeurs des données dans une plage
spécifiée (-1,0 à 1,0 ou 0,0 à 1,0)
2.
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 57 c~NJAMEN M. ZELKIF
2020-2021
Sélection d'attributs : dans cette stratégie, de
nouveaux attributs sont construits àpartir de l'ensemble
d'attributs donnépour aider le processus d'exploration.
3. Discrétisation : Ceci est fait pour remplacer les
valeurs brutes de l'attribut numérique par des niveaux d'intervalle ou
des niveaux conceptuels.
4. Génération de la hiérarchie du
concept : ici, les attributs sont convertis du niveau inférieur au
niveau supérieur de la hiérarchie. Par exemple, l'attribut «
ville » peut être converti en « pays ».
3.3.3 Intégration des données
Le processus de combinaison de plusieurs sources dans un seul
ensemble de données (Processus d'intégration de données)
est l'un des principaux composants de la gestion des données. Il y a
quelques problèmes à prendre en compte lors de
l'intégration des données.
1. Intégration des schéma : Intégrer les
métadonnées (un ensemble de données qui décrit
d'autres données) de différentes sources.
2. Problème d'identification d'entité:
Identification d'entitéà partir de plusieurs bases de
données. Par exemple, le système ou l'application doit
connaître l'étudiant id d'une base de données et le nom de
l'étudiant d'une autre base de données appartient à la
même entité.
3. Détecter et résoudre les concepts de valeur
de données : Les données extraites de différentes bases de
données lors de la fusion peuvent différer. Comme les valeurs
d'attribut dans une base de données peuvent différer d'une base
de données à une autre. Exemple : le format de la date peut
différer car »MM/JJ/AAAA» ou »JJ/MM/AAAA».
3.3.4 Réduction des données
Étant donnéque l'exploration de données
est une technique utilisée pour gérer une énorme
quantitéde données. Tout en travaillant avec un énorme
volume de données, l'analyse est devenue plus difficile dans de tels
cas. Afin de s'en débarrasser, nous utilisons la technique de
réduction des données. Il vise à augmenter
l'efficacitédu stockage, à réduire les coûts de
stockage et d'analyse des données.
3.4. MODÉLISATION DE L'ENTREPÔT DE DONNÉES
CHAPITRE 3. DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 58 c~NJAMEN M. ZELKIF
2020-2021
Les différentes étapes de la réduction des
données sont :
1. Agrégation du cube de données :
l'opération d'agrégation est appliquée aux données
pour la construction du cube de données.
2. Sélection du sous-ensemble d'attributs : les
attributs les plus pertinents doivent être utilisés, tout le reste
peut être supprimé. Pour effectuer la sélection
d'attributs, on peut utiliser le niveau de signification et la valeur p de
l'attribut. L'attribut ayant une valeur p supérieure au niveau de
signification peut être rejeté.
3. Réduction de la numérotation : Cela permet
de stocker le modèle de données au lieu de données
entières, par exemple : Modèles de régression.
4. Réduction de la dimensionnalité: Cela
réduit la taille des données par des mécanismes de codage.
Elle peut être avec ou sans perte. Si, après reconstruction
àpartir de données compressées, les
données d'origine peuvent être récupérées,
une
telle réduction est appelée réduction
sans perte, sinon elle est appelée réduction avec perte. Les deux
méthodes efficaces de réduction de la dimensionnalitésont
: les transformées en ondelettes et l'ACP (Analyse en Composantes
Principales).
3.4 Modélisation de l'entrepôt de
données
Un entrepôt de données, ou data Warehouse, est
une vision centralisée et universelle de toutes les informations de
l'entreprise. C'est une structure (comme une base de données) qui a pour
but, contrairement aux bases de données, de regrouper les données
de l'entreprise pour des fins analytiques et pour aider à la
décision stratégique. La déci-
sion stratégique étant une action entreprise par
les décideurs de l'entreprise et qui vise
àaméliorer, quantitativement ou qualitativement, la
performance de l'entreprise. En gros,
c'est un gigantesque tas d'informations épurées,
organisées, historisées et provenant de plusieurs sources de
données, servant aux analyses et à l'aide à la
décision. L'entrepôt de données est l'élément
central de l'informatique décisionnelle voir le figure 3.4
3.4.1 Les modèles logiques d'un
entrepôt
Lorsqu'on fait un schéma de BD pour un système
d'information classique comme ??, on parle en termes de tables et de relations,
une table étant une représentation d'une
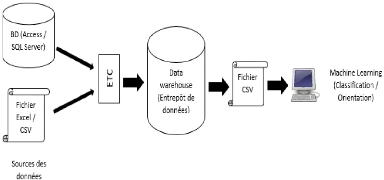
3.4. MODÉLISATION DE L'ENTREPÔT DE DONNÉES
CHAPITRE 3. DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 59 c~NJAMEN M. ZELKIF
2020-2021
Figure 3.4 - Processus de prise de
décision
entitéet une relation une technique pour lier ces
entités. Et bien en BI, on parle en termes de Dimension et de Faits.
C'est une autre approche des données, on entend par dimensions les axes
avec lesquels on veut faire l'analyse. Il peut y avoir une dimension
Élève, une dimension Enseignant, Matière, Notes, etc.
Une dimension est tout ce qu'on utilisera pour faire nos
analyses.
Les faits, en complément aux dimensions, sont ce sur
quoi va porter l'analyse. Ce sont des tables qui contiennent des informations
opérationnelles et qui relatent la vie de l'entreprise. Un fait est tout
ce qu'on voudra analyser.
ETC ou ETL sert à transposer le modèle
entité-relation des bases de données de production ainsi que les
autres modèles utilisés dans les opérations de
l'entreprise, en modèle à base de dimensions et de faits (nous
verrons ces modèles dans les deux prochaines définitions). Ces
modèles sont : le modèle en Étoile et Flocon.
3.4.1.1 Le Modèle en Étoile
Une étoile est une façon de mettre en relation
les dimensions et les faits dans un entrepôt de données. Le
principe est que les dimensions sont directement reliées à un
fait (schématiquement, ça fait comme une étoile). voir
figure 3.5.
3.4.1.2 Le Modèle en Flocon
Un modèle en flocon est un modèle pour lequel
chaque dimension est représentée avec plusieurs tables. Il est
donc plus normalisé(moins redondant) qu'un modèle en
étoile. Le
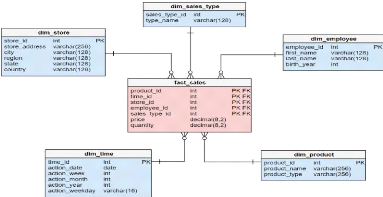
3.4. MODÉLISATION DE L'ENTREPÔT DE DONNÉES
CHAPITRE 3. DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 60 c~NJAMEN M. ZELKIF
2020-2021
Figure 3.5 - Schéma d'un entrepôt
de données en étoile : tiréde Cartelis [1]
principe étant qu'il peut exister des
hiérarchies de dimensions et qu'elles sont reliées aux faits,
ça fait comme un flocon voir figure 3.6.
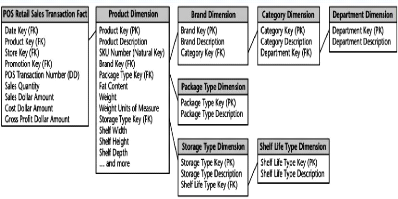
Figure 3.6 - Exemple de dimension
représentée en flocon (Kimball, Ross, 2008, p.55)
3.4.1.3 Le modèle de galaxie (Constellation)
Un schéma de galaxie est également connu sous le
nom de schéma de constellation des faits. Dans ce schéma,
plusieurs tables de faits partagent les mêmes tables de dimension. La
disposition des tables de faits et des tables de dimension ressemble à
une collection d'étoiles dans le modèle de schéma
Galaxy.
Ce type de schéma est utilisépour des exigences
sophistiquées et pour des tables de
3.4. MODÉLISATION DE L'ENTREPÔT DE DONNÉES
CHAPITRE 3. DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 61 c~NJAMEN M. ZELKIF
2020-2021
faits agrégées plus complexes à prendre
en charge par le schéma en étoile (ou) en flocon. Ce
schéma est difficile à maintenir en raison de sa
complexité.
Après traitement des données et conception de
l'entrepôt nous avons dans ce data-set deux classes à
prédire (Sc et Lt) pour signifier scientifique et littéraire. En
effet les colonnes de notre Data-Set sont représentées par des
matières, le matricule, le sexe et le label qui sont d'ailleurs les
informations recherchés par les conseillers d'orientation pour pouvoir
effectuer l'orientation scolaire des élèves. D'oùnous
avons :
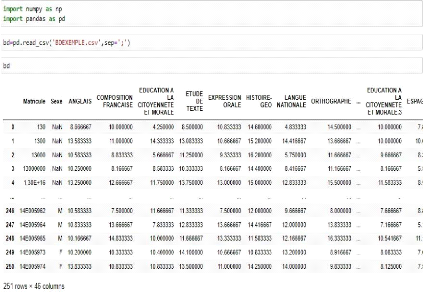
Figure 3.7 - Structure de la Base d'exemple
(Data Frame) chargéà l'aide de Python
En outre, la labelisation a étéfaite par nous
sur la base de quelques exemples de l'expert qui est le conseiller
d'orientation. Cependant, nous n'avons pas finalement utilisél'attribut
sexe car, cet attribut est peu représentatif dans notre data-set.
Le chargement du data-set s'effectue grâce au langage
Python en utilisant la bibliothèque pandas cette bibliothèque qui
nous a servit comme support à la place d'un logiciel de BI tels que :
Astera générateur d'entrepôt, DataPrep, Microsoft Power BI,
Zoho Ana-lytics, Arkieva, Google Data Studio, Microsoft Excel, pour ne citer
que ceux-ci car sont payant pour la plupart.
3.4. MODÉLISATION DE L'ENTREPÔT DE DONNÉES
CHAPITRE 3. DÉMARCHE MÉTHODOLOGIQUE
3.4.2 Modèle type de l'entrepôt des
données
Le modèle type d'entrepôt des données de
notre système est celui-ci dessous 3.8 :
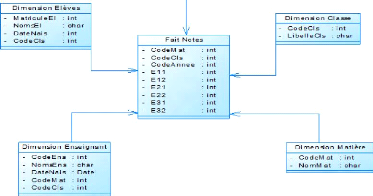
Mémoire de Master II en Informatique 62 c~NJAMEN M. ZELKIF
2020-2021
Figure 3.8 - Modèle type de
l'entrepôt des données
3.4.3 Structure multidimensionnelle
Les données à analyser doivent refléter
la vision des analystes, c'est-à-dire apparaître sous une forme
facilitant les prises de décision. Cette vision correspond à une
structuration des données selon plusieurs axes d'analyse
représentant des notions diverses telles que le temps, la localisation
géographique, une nomenclature de produits, etc. On parle d'analyse
multidimensionnelle.
La méthode de modélisation dimensionnelle est
basée sur une architecture de type « bus (2)». Une table de
fait est produite à partir des données transactionnelles et de
l'analyse d'un processus afin de répondre aux questions des analystes.
Une table de faits est constituée de mesures ainsi que de clés de
dimension. Ces clés de dimension permettent
la jointure entre la table de faits et les tables dimensions. Les
dimensions sont communes àl'ensemble des services de
l'organisation et représentent des axes d'analyses
stratégiques.
3.5. CLASSIFICATION CHAPITRE 3. DÉMARCHE
MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 63 c~NJAMEN M. ZELKIF
2020-2021
Figure 3.9 - Modèle type de
l'entrepôt des données
3.5 Classification
La classification est considérée comme
étant la dernière étape dans un système de
recommandation. Elle exploite le résultat du traitement et de l'analyse
des données pour pouvoir décider de l'orientation ou de la
recommandation du sujet (élèves ou étudiants). La notion
de classification signifie l'affectation d'une étiquette à des
échantillons d'une base de données en utilisant un certain nombre
de caractéristiques. Ces caractéristiques doivent bien
évidemment être capable d'identifier chaque échantillon.
Dans la e-orientation, l'échantillon peut désigner un profil, un
ensemble de matières, ou l'ensemble des compétences.
On distingue deux catégories de méthodes de
classification : les classifications non supervisées et celles
supervisées. Pour la classification des élèves, nous avons
utilisée plu-
sieurs classifieurs à apprentissage supervisé: les
k-proche voisins (kNN), les machines àsupport de vecteur
(SVM) en utilisant un noyau polynômial de second ordre, les arbres
de décisions (DT), les forêts aléatoires
(Random Forest). Il est à noter que ces classifieurs ont
étéutilisépar ? ] dans leurs travaux, obtenant ainsi des
résultats suivants : (KNN : 99.33%, SVM : 97.56% et Data Tree : 91.56%)
.
3.6. CONCLUSION CHAPITRE 3. DÉMARCHE
MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 64 c~NJAMEN M. ZELKIF
2020-2021
3.6 Conclusion
Ce chapitre nous a permis d'exposer les différentes
parties de notre modèle de l'orien-tation scolaire assistépar
ordinateur. La collecte des données a étéla
première phase de notre travail puis, le prétraitement des
données a étéla phase oùnous avons
nettoyéet
filtrer les données car plusieurs données ne
pouvant être utilisées à cause de leur mobilitédans
les BD utilisée (les élèves qui entrent et ressortent dans
des établissements scolaires
et n'ayant pas passés une certaine durée afin
d'être utilisés comme échantillons) ce travail a
étéfait à l'aide du logiciel Excel qui peut être
utilisécomme un logiciel de BI (Business Intelligence). Dans cette
méthode nous avons exposéles techniques de prétraitement
des données ou d'analyse des données car pour les systèmes
de recommandation, le plus gros travail est celui de l'analyse des
données. Enfin, nous avons ouvert une fenêtre sur la
classification supervisée en mentionnant les méthodes qui seront
utilisées pour catégoriser les élèves en deux
catégories (Scientifiques ou Littéraires) : les k-proches voisins
(KNN), les arbres de décision et la classification par Machines à
support de vecteurs (SVM), les forêts aléatoires.
65
RÉSULTATS ET DISCUSSIONS
4.1 Introduction
Dans ce dernier chapitre, nous allons présenter les
résultats obtenus après implémentation des
différents modèles d'apprentissage. Puis, nous discuterons de ces
résultats dans la deuxième section de notre chapitre sans oublier
de présenter les méthodes de validation que nous avons
utilisé.
4.2 Les différentes techniques d'évaluations des
modèles de Machine Learning
Pour implémenter les modèles d'apprentissage
dont nous avons sélectionnétels que : les K-PPV, les Arbres de
Décision, les Support Vecteur Machine (SVM), les Forêt
Aléatoire (Random Forest), etc. Nous avons utiliséle langage
Python notamment certaines de ces bibliothèques comme pandas, numpy,
sklearn etc. Avant de commencer nous allons définir ce qu'on entend par
baseline.
Une baseline est un élément vous permettant de
comparer votre modèle par rapport à autre chose.
Elle peut être de 2 types :
· Vous avez déjàconstruit un algorithme de
Machine Learning, vous comparez alors les performances de celui-ci avec celles
du nouvel algorithme que vous avez crée.
· Vous pouvez également comparer les performances
de votre modèle avec les connaissances métier d'expert de votre
entreprise. Un exemple : dans la métallurgie, vous
Mémoire de Master II en Informatique 66 c~NJAMEN M.
ZELKIF 2020-2021
4.2. LES DIFF'ERENTES TECHNIQUES D''EVALUATIONS DES MOD`ELES
CHAPITRE DE 4. MACHINE R'ESULTATS LEARNING ET DISCUSSIONS
souhaitez savoir si votre métal est de bonne ou
mauvaise qualité. Vous pouvez demander à un expert son point de
vue, il aura sans doute 90% de précision dans la prédiction qu'il
va réaliser (bonne ou mauvaise qualité) . Cela donne
également une baseline « à battre ».
Après avoir entraînéun modèle de
Machine Learning sur des données étiquetées, celui-ci est
supposéfonctionner sur de nouvelles données. Toutefois, il est
important de s'assurer de l'exactitude des prédictions du modèle
en production.
Pour ce faire, il est nécessaire de valider le
modèle. Le processus de validation consiste à décider si
les résultats numériques quantifiant les relations
hypothétiques entre les variables sont acceptables en tant que
descriptions des données.
Afin d'évaluer les performances d'un modèle de
Machine Learning, il est nécessaire de le tester sur de nouvelles
données. En fonction des performances des modèles sur des
données inconnues, on peut déterminer s'il est »
sous-ajusté», » sur-ajusté», ou »bien
généralisé». DataScientest [41]
Il existe plusieurs façons d'évaluer les
modèles de machine learning. L'une des techniques utilisées pour
tester l'efficacitéd'un modèle de Machine Learning est la
»cross-validation» ou validation croisée figure : 4.1. Cette
méthode est aussi une procédure de »re-sampling»
(ré-échantillonnage) permettant d'évaluer un modèle
même avec des données limitées. Outre la validation
croisée, nous pouvons citer les techniques telles que : L'exactitude, La
précision, Le Rappel (la sensibilité), Le score F1, AUC...
scientifique de Jean-Charles RISCH [42].
4.2.1 Validation Croisée
La validation croisée (Cross Validation) consiste
à effectuer cette opération à plusieurs reprises de telle
sorte que les ensembles de données connues soient à tour de
rôle utilisés comme données d'apprentissage et
données de test. On coupe donc les données connues en parties
égales dans la mesure du possible (folds en anglais) et on utilise
à chaque fois une partie comme jeu de test et le reste comme jeu
d'apprentissage figure : 4.2.
La validation croisée permet donc d'évaluer un
modèle de machine learning en ayant la moyenne des performances et
l'erreur type sur chacun des folds ou en évaluant les
4.2. LES DIFF'ERENTES TECHNIQUES D''EVALUATIONS DES MOD`ELES
CHAPITRE DE 4. MACHINE R'ESULTATS LEARNING ET DISCUSSIONS
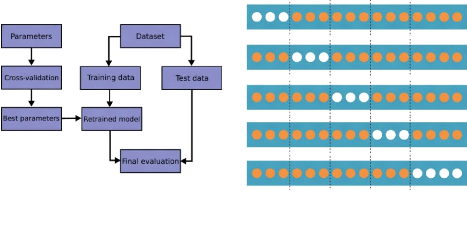
Figure 4.1 - Validation croisée
:
évaluation des performances de
l'estimateur Saagie [43]
Figure 4.2 - Validation croisée
à5-Folds Learn [44]
prédictions faites sur l'ensemble des données.
Pour des raisons de temps de calcul, on utilise
généralement cinq ou dix folds.
Pour cette méthode, il est important d'appliquer la
stratification. La stratification est un processus qui consiste à
diviser les données connues en folds homogènes avant
l'échantillonnage, c'est-à-dire répartir les
étiquettes pour que chaque fold ressemble au maximum à un petit
jeu de données connues.
Il existe 3 grandes méthodes de cross validation :
holdout, LOOCV et k-fold.
4.2.1.1 La méthode holdout
La plus simple de toutes (mais aussi la plus souvent
rencontrée) est la méthode Holdout (Train-Test Split). L'objectif
de cette méthode va être de séparer l'ensemble de
données
en deux sous ensembles. Le premier va donc être le
sous-ensemble de données réservéà l'apprentissage
du modèle. Le second va servir à tester ce modèle pour
ainsi l'évaluer. Le
sous ensemble de données d'apprentissage est
très généralement plus grand que celui de test. On
constate une proportion de 70% à 80% pour l'apprentissage et 20%
à 30% pour les tests.
Cette technique est efficace, sauf si les données sont
limitées. Il peut alors manquer certaines informations sur les
données qui n'ont pas étéutilisées pour
l'entraînement, et les résultats peuvent donc être hautement
biaisés.
En revanche, si l'ensemble de données est vaste et que
la distribution est égale entre les deux échantillons, cette
approche convient tout à fait. Il est possible de séparer ma-
Mémoire de Master II en Informatique 67 c~NJAMEN M.
ZELKIF 2020-2021
Mémoire de Master II en Informatique 68 c~NJAMEN M.
ZELKIF 2020-2021
4.2. LES DIFF'ERENTES TECHNIQUES D''EVALUATIONS DES MOD`ELES
CHAPITRE DE 4. MACHINE R'ESULTATS LEARNING ET DISCUSSIONS
nuellement les données, ou d'utiliser la méthode
train test split de scikit-learn.
4.2.1.2 La méthode K-Folds
La technique K-Folds est simple à comprendre, et
particulièrement populaire. Par rapport aux autres approches de
Cross-Validation, elle résulte généralement sur un
modèle moins biaisé.
Pour cause, elle permet d'assurer que toutes les observations
de l'ensemble de données original aient la chance d'apparaître
dans l'ensemble d'entraînement et dans l'ensemble de test. En cas de
données d'input limitées, il s'agit donc de l'une des meilleures
approches.
On commence tout d'abord par séparer l'ensemble de
données de manière aléatoire en K folds. La
procédure a un paramètre unique appelé» K »
faisant référence au nombre de groupes dans lequel
l'échantillon sera divisé.
La valeur de K ne doit être ni trop basse ni trop haute,
et on choisit généralement une valeur comprise entre 5 et 10 en
fonction de l'envergure du dataset. Par exemple, si K=10, le dataset sera
diviséen 10 parties.
Une valeur K plus élevée mène à un
modèle moins biaisé, mais une variance trop large peut conduire
à un sur-ajustement. Une valeur plus basse revient à utiliser la
méthode Train-Test Split.
On ajuste ensuite le modèle en utilisant les folds K-1 (K
moins 1). Le modèle est validéen utilisant le K-fold restant. Les
scores et les erreurs doivent être notés.
Le processus est répétéjusqu'àce
que chaque K-fold serve au sein de l'ensemble d'entraînement. La moyenne
des scores enregistrés est la métrique de performance du
modèle confère figure 4.2.
Dans le cas de figure oùle modèle (estimateur)
est un classificateur et que la variable cible (y) est binaire ou
multiclasse, on utilise par défaut la technique
»StratifiedKfold». Cette méthode rapporte des folds
stratifiés, par exemple en maintenant le pourcentage
d'échantillons pour chaque classe dans tous les folds. Ainsi, les
données des folds d'entraî-nement et de test sont
équitablement distribuées.
4.2.1.3 La méthode LOOCV
LOOCV (Leave One Out Cross-Validation) est un type d'approche
de validation croisée dans laquelle chaque observation est
considérée comme l'ensemble de validation et
Mémoire de Master II en Informatique 69 c~NJAMEN M.
ZELKIF 2020-2021
4.2. LES DIFF'ERENTES TECHNIQUES D''EVALUATIONS DES MOD`ELES
CHAPITRE DE 4. MACHINE R'ESULTATS LEARNING ET DISCUSSIONS
les autres observations (N - 1) sont
considérées comme l'ensemble d'apprentissage. Dans LOOCV,
l'ajustement du modèle est effectuéet la prédiction
à l'aide d'un ensemble de validation d'observation. De plus,
répéter cela N fois pour chaque observation en tant
qu'ensemble de validation. Le modèle est ajustéet le
modèle est utilisépour prédire une valeur pour
l'observation. Il s'agit d'un cas particulier de validation croisée
K-fold dans lequel le nombre de plis est le même que le nombre
d'observations (K = N). Cette méthode permet de réduire
les biais et le caractère aléatoire.La méthode vise
à réduire le taux d'erreur quadratique moyen et à
éviter le surajustement Lima [45].
4.2.2 La matrice de confusion
La matrice de confusion est un outil qui permet de savoir
à quel point le modèle de machine learning est « confus
», ou qu'il se trompe. Il s'agit d'un tableau avec en colonne les
différents cas réels et en ligne les différents cas
d'usage prédits.
Prenons l'exemple d'un test d'orientation scolaire pour les
spécialités »Scientifiques» et
»Littéraires», la matrice sera la suivante :
Si l'élève doit aller en Scientifique ou
Littéraire
|
Scientifique
|
Littéraire
|
Scientifique
|
Nombre de Vrai Positif
|
Nombre de Faux Positif
|
Littéraire
|
Nombre de Faux Négatif
|
Nombre de Vrai Négatif
|
|
Tableau 4.1 - Exemple d'une Matrice de
Confusion
On obtient donc les quatre valeurs suivantes :
· Vrai positif (VP), les valeurs réelles et
prédites sont identiques et positives. L'élève est
orientée en Scientifique et le modèle le prédit.
· Vrai négatif (VN), les valeurs réelles
et prédites sont identiques et négatives. L'élève
n'est pas en Scientifique et le modèle prédit qu'il ne l'est pas
donc qu'il est en littéraire.
· Faux positif (FP), les valeurs réelles et
prédites sont différentes. L'élève n'est pas
Scientifique, mais le modèle prédit qui l'est.
· Faux négatif (FN), les valeurs réelles
et prédites sont différentes. L'élève est
Scientifique, et le modèle prédit qui l'est.
4.3. RÉSULTAT ET DISCUSSION CHAPITRE 4. RÉSULTATS
ET DISCUSSIONS
Mémoire de Master II en Informatique 70 c~NJAMEN M.
ZELKIF 2020-2021
L'étude de ces valeurs prédictives permet de
définir si le modèle de machine learning est fiable, dans quels
cas il commet des erreurs et dans quelle mesure.
à partir de ce tableau (de la matrice de confusion) on
peut calculer :
· L'exactitude : qui mesure l'adéquation d'un
modèle de classification sous forme de proportion de résultats
réels sur le nombre total de cas.
· La précision : qui correspond à la
proportion de résultats réels sur tous les résultats
positifs. Précision = TP/(TP+FP)
· Le Rappel : qui est la fraction de la
quantitétotale d'instances pertinentes qui ont
étéréellement récupérées. Rappel =
TP/(TP+FN)
· Le score F1 : qui est calculécomme la moyenne
pondérée de précision et de rappel comprise entre 0 et 1,
la valeur de score F1 idéale étant 1.
· AUC mesure la zone sous la courbe tracée avec
les vrais positifs sur l'axe y et les faux positifs sur l'axe
x. Cette métrique est utile car elle fournit un nombre unique
qui vous permet de comparer les modèles de types différents. AUC
est un invariant de seuil de classification. Il mesure la qualitédes
prédictions du modèle, quel que soit le seuil de classification
choisi.
4.3 Résultat et Discussion
Dans cette section nous allons présenter les
résultats que nous avons obtenu après avoir appliquéles
modèles d'apprentissage sur notre jeu de donnée (data-set).
Les modèles que nous avons choisi sont ceux de
classification car notre problème est une sorte de classification
binaire dont la classe à prédire a deux valeurs (Scientifique et
Littéraire). Ainsi, ces modèles (Algorithmes) sont : la
Régression Logistique, Les Arbres de Décision, les K-PPV, les SVM
et les Forêts Aléatoire (Random Forest).
À cet effet, nous avons obtenu les résultats
suivants :
· Régression Logistique : 64% (0.6418523)
· Arbre de décision : 60% (0.60123812)
· SVM : 69% (0.69012512)
·
4.3. RÉSULTAT ET DISCUSSION CHAPITRE 4. RÉSULTATS
ET DISCUSSIONS
Mémoire de Master II en Informatique 71 c~NJAMEN M. ZELKIF
2020-2021
K-PPV : 65% (0.6541210)
· Forêt Aléatoire : 68% (0.6854102)
D'oùle tableau ci-dessous :
Modèle Machine Learning (Algorithme)
|
|
Résultat
|
Régression Logistique
|
64%
|
(0.6418523)
|
Arbre de décision
|
60%
|
(0.60123812)
|
SVM
|
69%
|
(0.69012512)
|
K-PPV
|
65%
|
(0.6541210)
|
Forêt Aléatoire
|
68%
|
(0.6854102)
|
|
Tableau 4.2 - Synthèse des
différents Résultats obtenus
Pour valider ces résultats, nous avons utilisés
plusieurs métriques d'évaluation d'erreurs telles que : la
validation croisée et la matrice de confusion (AUC, F1-Score, la
Précision) comme le montre la figure ci-dessous :
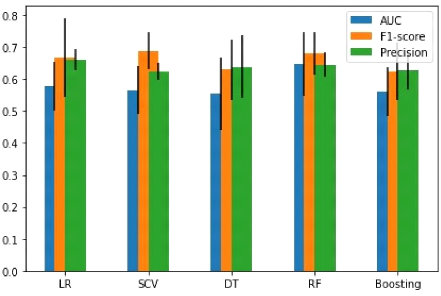
Figure 4.3 - Diagramme des
résultats
4.4. CONCLUSION CHAPITRE 4. RÉSULTATS ET DISCUSSIONS
Mémoire de Master II en Informatique 72 c~NJAMEN M.
ZELKIF 2020-2021
D'après ce diagramme, nous constatons que les SVM
(Support Vecteurs Machines) répondent bien sur le data-set par rapport
aux autres modèles utilisés. Outre les SVM il suit les
Forêts aléatoires ceci tout simplement parce-que les Random forest
sont des combinaisons de plusieurs sous-arbre de décision.
4.4 Conclusion
Parvenu au terme de ce chapitre, oùnous avons
détaillél'implémentation de notre approche de segmentation
issu du seuillage et de l'ouverture morphologique en vue de la detection des
noyaux; ce qui a fournit des résultats assez corrects. Il existe
néanmoins plusieurs autres méthodes de segmentation non
abordées dans ce travail qui offrent des perspectives très
intéressantes. Par ailleurs, nous avons extrait des descripteurs
morphologiques, d'intensitéet de texture à partir des images
segmentées. Ces descripteurs nous ont permis de tester trois algorithmes
d'apprentissage supervisékNN, SVM et les arbres de décision pour
la classification de nos images afin de différencier les tumeurs
malignes
des tumeurs bénignes. Ce qui nous a fournit
également de résultats acceptables, malgréle faible taux
faux positis enregistré.
73
? CONCLUSION ET
PERSPECTIVES ?
Le travail que nous avons présentédans ce
document est celui de l'automatisation (apprentissage) sur des données
académiques en vue de faciliter le processus de l'orienta-tion scolaire
et l'aide à la décision au moyen des algorithmes de Machine
Learning et du Profil de l'apprenant. Il construit tout d'abord le profil d'un
apprenant, puis applique ce dernier sur des algorithmes de Machine Learning en
vue de faciliter l'aide à la décision. Outre cela, il compare
plusieurs modèles de Machine Learning afin de sélectionner celui
qui répond le plus sur le data-set qui d'ailleurs est construit par
nous.
En effet, notre recherche s'intègre dans la
démarche de promouvoir la numérisation de l'enseignement et
surtout la valorisation de l'automatisation d'orientation dans le processus
enseignement apprentissage à l'ère du numérique. Bien que
les conseillers d'orientation le font déjàce travail
d'orientation, nous avons proposédans ce mémoire un Framework
(modèle) facilitant cette tâches contre tenu des effectifs
pléthorique des élèves dans nos établissements
scolaires et surtout de la raretédes conseillers d'orientations dans ces
établissements. La littérature nous a montrée qu'au
Cameroun nous avons en moyenne un (01) conseiller pour deux milles (2000)
élèves soit un pourcentage de 0.02% ce qui rend cette tâche
difficile et biaisée à la base.
Pour répondre aux objectifs de recherche, nous avons
au cours de se travail, construit le profil d'un apprenant pour une bonne
orientation. Il faut noter que, ce profil ne tient pas en compte la situation
familiale, ni l'environnement socioéconomique ou socioculturel de
l'apprenant mais seul ses acquis ou compétences scolaires.
En outre, nous avons aussi effectuéune étude
comparative des algorithmes de Machine Learning pour la recommandation afin de
choisir celui qui réponde le mieux sur les données d'exemples que
nous avons construit. Cela nous a permis de tirer la conclusion suivant
laquelle le Modèle SVM est celui qui répond le mieux suivit des
forêt aléatoires...
4.4. CONCLUSION CHAPITRE 4. RÉSULTATS ET DISCUSSIONS
Mémoire de Master II en Informatique 74 c~NJAMEN M.
ZELKIF 2020-2021
Cependant, nous avons rencontréquelques
difficultés notamment celles liées à l'acqui-sition des
données et aussi à la disponibilités de
l'électricité. La difficultéliée à
l'acquisition des données est due à la confidentialitédont
les gestionnaires des bases des données des établissements
scolaires sont tenus.
Comme tout travail de recherche, bien que le modèle
d'apprentissage présentédans ce travail soit utilisable à
70%, nous sommes convaincu qu'il est loin d'être parfait raison pour
laquelle nous souhaiterons apporter dans un futur proche quelques
améliorations telles que :
· L'augmentation des données de notre data-set
car tout travail de Machine Learning commence par l'acquisition des
données. En plus avec un data-set considérable, nous pourrions
appliquer du Deep Learning.
· Tester des modèles d'apprentissage non
supervisésur des données et les comparer avec les modèles
d'apprentissage superviséutilisés dans le cadre de ce travail.
· Modifier la formule du profil afin qu'elle puisse
prendre en compte les facteurs so-cioéconomiques et culturels de
l'apprenant.
· Considérer parmi nos attributs, l'attribut sexe
pour étudier les modèles d'appren-tissages qui sont sexistes ou
non.
75
4 Références 4
[1] Cartelis, «Modèle d'entrepôts en
étoile,» 01/08 2022,
https ://
www.cartelis.com/blog/data-warehouse-modelisation-etoile/.
[2] Wikipédia, «Orientation scolaire et
professionnelle,» Oct 2020,
www.wikipedia.org.
[3] MINESEC-CAMEROUN, Guide d'utilisation de la batterie
de tests d'aptitudes pour la classe de 3ème, Ministère des
Enseignements Secondaires du Cameroun, 2014.
[4] B. Eric and L. Michel, Data Science : Fondamentaux et
études des cas, Machine Learning avec Python et R, EDITIONS
EYROLLES 61, bd Saint-Germain 75240 Paris Cedex 05
www.editions-eyrolles.com,
2015.
[5] T.-N. Nguyen, D. Lucas, K.-G. Artus, and S. Lars,
«Recommender system for predicting student performance,» Procedia
Computer Science, pp. 1-9, 01 2010.
[6] E. F. Hanaa, Q. Mohammed, S. Intissar, and M. Khalifa,
«Personalized recommender system for e-learning environment based on
student's preferences,» International Journal of Computer Science and
Network Security, p. 173, oct 2018.
[7] K. KELLOU and A. MOKHTARI, Réalisation d'une
plateforme d'expérimentations et de tests d'algorithmes de data mining
www.ESIMiner.com,
Ecole Nationale Supérieure d'Informatique, 2011.
[8] J. Guichard and M. Huteau, «L'orientation scolaire
et professionnelle.» ISBN 2100485164, p. 120, 2005, paris,
Dunod.
[9] C. Chassagne,«L'education à
l'orientation.»Chemins de formation, p. 18, 1998, paris,
Magnard.
[10] ||,«L'education à
l'orientation.»Chemins de formation, p. 7, 1998, paris,
Magnard.
[11]
RÉFÉRENCES RÉFÉRENCES
Mémoire de Master II en Informatique 76 c~NJAMEN M. ZELKIF
2020-2021
B. Jean-Michel, «Ecole, orientation,
société,» PUF, p. 7, 1988, 2e Edition, Paris.
[12] G. Aurélien, Apprentissage supervisé,
June 2013.
[13] Wikipédia, «Apprentissage automatique,»
Dec 2021,
www.wikipedia.org.
[14] B. Alain, INTELLIGENCE ARTIFICIELLE: Apprentissage,
L'Institut de Technologie du Cambodge (ITC), June 2013.
[15] Z. Matthieu, «Apprentissage par renforcement
développemental,» Ph.D. dissertation, Universitéde Lorraine,
2018.
[16] Wikipédia, «Apprentissage non
supervisé,» Oct 2021,
www.wikipedia.org.
[17] ||, «Apprentissage par renforcement,» Dec
2021,
www.wikipedia.org.
[18] P. GitHub, «Introduction à l'apprentissage
automatique, régression,» Jan 2022, https//
projeduc.github.io.
[19] A. Lima, «Régression et classification
apprentissage automatique supervisé,» Jan 2022,
fr.acervolima.com.
[20] I. SOLLAH, Étude comparative entre des
techniques de reconnaissance de caractères arabes, July 2019.
[21] Wikipédia, «k-nearest neighbors
algorithm,» Fév 2022,
wwww.wikipedia.com.
[22] 123dok, «Méthode des k plus proches voisins
(kppv),» Fév 2022,
wwww.123dok.net.
[23] A. Marwa, «Développement d'une nouvelle
approche pour la reconnaissance d'écri-ture manuscrite,» Ph.D.
dissertation, UNIVERSITÉDE LA MANOUBA ÉCOLE NATIONALE DES
SCIENCES DE L'INFORMATIQUE, 2019.
[24] Wikipédia, «Arbre de décision
(apprentissage),» Mars 2022,
wwww.wikipedia.com.
[25] ||, «les support vecteur machines,» Mars 2022,
wwww.wikipedia.com.
[26] V. N. Vapnik, «The nature of statistical learning
theory,» N.Y : Springer-Verlag, p. 314, 1995, version
électronique disponible sur internet.
[27] Wikipédia, «Réseau de neurones
artificiels,» Mars 2022,
wwww.wikipedia.com.
[28]
RÉFÉRENCES RÉFÉRENCES
Mémoire de Master II en Informatique 77 c~NJAMEN M. ZELKIF
2020-2021
l. b. JURI'Predis, «Démystifier le machine
learning, partie 2 : Réseaux de neurones artifiiciels,» Nov 2021,
wwww.juripredis.com.
[29] Wikipédia, «Fonction d'activation,»
Mars 2021,
wwww.wikipedia.com.
[30] T. K. Inside Machine Learning, «Fonction
d'activation, comment ça marche? - une explication simple,» Avril
2022,
wwww.inside-machinelearning.com.
[31] P. Hervé, «Statistiques et rÉseaux de
neurones pour un systÈme de diagnostic : Application au diagnostic de
pannes automobiles,» Ph.D. dissertation, Laboratoire d'Analyse et
d'Architecture des Systèmes du CNRS, UniversitéPaul Sabatier de
Toulouse, Mai 1996.
[32] B. M. Deeply Learning, «Fonction
d'activation,» Sep 2018,
wwww.deeplylearning.fr.
[33] P. Philippe, Fouille de données Notes de
cours, Universitéde Lille 3, 2009.
[34] S. Patrick and N. Olfa, «Human-recommender systems
: From benchmark data to benchmark cognitive models,» ResearchGate,
pp. 127-130, september 2016.
[35] K. Danijel, J. Vedran, and a. Goran, «Machine
learning in education - a survey of current research trends,» 29TH
DAAAM INTERNATIONAL SYMPOSIUM ON INTELLIGENT MANUFACTURING AND AUTOMATION, pp.
0406-0410, July 2018, dOI : 10.2507/29th.daaam.proceedings.059.
[36] T. Ahajjam and F. Toussef, «Recommender system for
orientation student,» Springer Nature Switzerland AG 2020, pp.
367-370, Nov 2020, bDNT 2019, LNNS 81.
[37] O. Emeric, D. Christophe, D. Alexandre, and L. D.
Julien, «Une méthodologie d'ap-prentissage automatique pour l'aide
à la décision en contexte d'industrialisation,» ISTE Ltd
OpenScience, pp. 1-14, July 2019, conference Paper.
[38] Medium, «Les étapes du prétraitement
des données,» Fév 2021,
wwww.medium.com.
[39] T. D. Science, «6 étapes pour le nettoyage
des données et pourquoi c'est important,» Jan 2020,
www.datascience.eu.
[40] A. Lima, «Prétraitement des données
dans l'exploration de données,» Fév 2021,
fr.acervolima.com.
78
[41] M. P. DataScientest, «Cross-validation :
définition et importance en machine learning,» Mai 2021,
www.datascientest.com.
[42] B. scientifique de Jean-Charles RISCH, «Evaluer un
modèle statistique de classification,» Mai 2015,
jcrisch.wordpress.com.
[43] Saagie, «Machine learning : comment évaluer
vos modèles? analyses et métriques,» Oct 2021,
wwww.saagie.com.
[44] S. Learn, «Cross-validation : evaluating estimator
performance,» Mars 2022,
www.scikit-learn.org.
[45] A. Lima, «Loocv (leave one out cross-validation) dans
la programmation r,» Mars 2022,
fr.acervolima.com.
| 



