2.3.5.1 Le Principe des SVMs
Le but des SVM est de trouver un séparateur entre deux
classes qui soit au maximum éloignéde n'importe quel point des
données d'entraînement. Si on arrive à trouver un
séparateur linéaire c'est-à-dire qu'il existe un hyperplan
séparateur alors le problème est dit linéairement
séparable sinon il n'est pas linéairement séparable et il
n'existe pas un hyperplan séparateur.
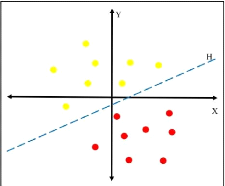
Figure 2.6 - Séparation de deux
ensembles de points par un Hyperplan H. Tiréde
SOLLAH [20]
Pour deux classes et des données linéairement
séparable, il y a beaucoup de séparateurs linéaires
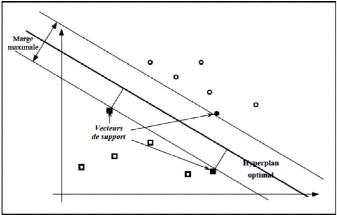
possibles. Les SVM choisissent seulement celui qui est optimal,
c'est-à-dire la recherche d'une surface de décision qui soit
éloignée au maximum de tout point de données. Cette
distance de la surface de décision au point de données le plus
proche détermine la marge maximale du classifieur 2.6. En effet, pour
obtenir un hyperplan optimal, il faut maximiser la marge entre les
données et l'hyperplan.
Par intuition, le fait d'avoir une marge plus large fournit
plus de sécuritélorsque l'on
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE
LA LITTÉRATURE
Mémoire de Master II en Informatique 32 c~NJAMEN M.
ZELKIF 2020-2021
Figure 2.7 - Hyperplan optimal, marge et
vecteurs de support. Tiréde SOLLAH [20]
classe un nouvel exemple. De plus, si l'on trouve le
classificateur qui se comporte le mieux vis-à-vis des données
d'apprentissage, il est clair qu'il sera aussi celui qui permettra au mieux de
classer les nouveaux exemples. Comme nous avons mentionnéplus haut, il
existe plusieurs formes de SVM telles que les SVM linéaires, les SVM
multi-classe. Dans cette partie, nous nous limiterons aux SVM
linéaires.
2.3.5.2 Le SVM Linéaire
Le principe de base des SVM consiste de ramener le
problème de la discrimination àcelui, linéaire,
de la recherche d'un hyperplan optimal. Deux idées ou astuces permettent
d'atteindre cet objectif :
· La première consiste à définir
l'hyperplan comme solution d'un problème d'optimisa-tion sous
contraintes dont la fonction objective ne s'exprime qu'àl'aide de
produits scalaires entre vecteurs et dans lequel le nombre de contraintes
»actives» ou vecteurs supports contrôle la complexitédu
modèle. Tiréde SOLLAH [20]
· Toujours dans SOLLAH [20] Le passage à la
recherche de surfaces séparatrices non linéaires est obtenu par
l'introduction d'une fonction noyau (kernel) dans le produit scalaire induisant
implicitement une transformation non linéaire des données vers un
espace intermédiaire (feature space) de plus grande dimension.
| 



