3.5 Classification
La classification est considérée comme
étant la dernière étape dans un système de
recommandation. Elle exploite le résultat du traitement et de l'analyse
des données pour pouvoir décider de l'orientation ou de la
recommandation du sujet (élèves ou étudiants). La notion
de classification signifie l'affectation d'une étiquette à des
échantillons d'une base de données en utilisant un certain nombre
de caractéristiques. Ces caractéristiques doivent bien
évidemment être capable d'identifier chaque échantillon.
Dans la e-orientation, l'échantillon peut désigner un profil, un
ensemble de matières, ou l'ensemble des compétences.
On distingue deux catégories de méthodes de
classification : les classifications non supervisées et celles
supervisées. Pour la classification des élèves, nous avons
utilisée plu-
sieurs classifieurs à apprentissage supervisé: les
k-proche voisins (kNN), les machines àsupport de vecteur
(SVM) en utilisant un noyau polynômial de second ordre, les arbres
de décisions (DT), les forêts aléatoires
(Random Forest). Il est à noter que ces classifieurs ont
étéutilisépar ? ] dans leurs travaux, obtenant ainsi des
résultats suivants : (KNN : 99.33%, SVM : 97.56% et Data Tree : 91.56%)
.
3.6. CONCLUSION CHAPITRE 3. DÉMARCHE
MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 64 c~NJAMEN M. ZELKIF
2020-2021
3.6 Conclusion
Ce chapitre nous a permis d'exposer les différentes
parties de notre modèle de l'orien-tation scolaire assistépar
ordinateur. La collecte des données a étéla
première phase de notre travail puis, le prétraitement des
données a étéla phase oùnous avons
nettoyéet
filtrer les données car plusieurs données ne
pouvant être utilisées à cause de leur mobilitédans
les BD utilisée (les élèves qui entrent et ressortent dans
des établissements scolaires
et n'ayant pas passés une certaine durée afin
d'être utilisés comme échantillons) ce travail a
étéfait à l'aide du logiciel Excel qui peut être
utilisécomme un logiciel de BI (Business Intelligence). Dans cette
méthode nous avons exposéles techniques de prétraitement
des données ou d'analyse des données car pour les systèmes
de recommandation, le plus gros travail est celui de l'analyse des
données. Enfin, nous avons ouvert une fenêtre sur la
classification supervisée en mentionnant les méthodes qui seront
utilisées pour catégoriser les élèves en deux
catégories (Scientifiques ou Littéraires) : les k-proches voisins
(KNN), les arbres de décision et la classification par Machines à
support de vecteurs (SVM), les forêts aléatoires.
65
RÉSULTATS ET DISCUSSIONS
4.1 Introduction
Dans ce dernier chapitre, nous allons présenter les
résultats obtenus après implémentation des
différents modèles d'apprentissage. Puis, nous discuterons de ces
résultats dans la deuxième section de notre chapitre sans oublier
de présenter les méthodes de validation que nous avons
utilisé.
4.2 Les différentes techniques d'évaluations des
modèles de Machine Learning
Pour implémenter les modèles d'apprentissage
dont nous avons sélectionnétels que : les K-PPV, les Arbres de
Décision, les Support Vecteur Machine (SVM), les Forêt
Aléatoire (Random Forest), etc. Nous avons utiliséle langage
Python notamment certaines de ces bibliothèques comme pandas, numpy,
sklearn etc. Avant de commencer nous allons définir ce qu'on entend par
baseline.
Une baseline est un élément vous permettant de
comparer votre modèle par rapport à autre chose.
Elle peut être de 2 types :
· Vous avez déjàconstruit un algorithme de
Machine Learning, vous comparez alors les performances de celui-ci avec celles
du nouvel algorithme que vous avez crée.
· Vous pouvez également comparer les performances
de votre modèle avec les connaissances métier d'expert de votre
entreprise. Un exemple : dans la métallurgie, vous
Mémoire de Master II en Informatique 66 c~NJAMEN M.
ZELKIF 2020-2021
4.2. LES DIFF'ERENTES TECHNIQUES D''EVALUATIONS DES MOD`ELES
CHAPITRE DE 4. MACHINE R'ESULTATS LEARNING ET DISCUSSIONS
souhaitez savoir si votre métal est de bonne ou
mauvaise qualité. Vous pouvez demander à un expert son point de
vue, il aura sans doute 90% de précision dans la prédiction qu'il
va réaliser (bonne ou mauvaise qualité) . Cela donne
également une baseline « à battre ».
Après avoir entraînéun modèle de
Machine Learning sur des données étiquetées, celui-ci est
supposéfonctionner sur de nouvelles données. Toutefois, il est
important de s'assurer de l'exactitude des prédictions du modèle
en production.
Pour ce faire, il est nécessaire de valider le
modèle. Le processus de validation consiste à décider si
les résultats numériques quantifiant les relations
hypothétiques entre les variables sont acceptables en tant que
descriptions des données.
Afin d'évaluer les performances d'un modèle de
Machine Learning, il est nécessaire de le tester sur de nouvelles
données. En fonction des performances des modèles sur des
données inconnues, on peut déterminer s'il est »
sous-ajusté», » sur-ajusté», ou »bien
généralisé». DataScientest [41]
Il existe plusieurs façons d'évaluer les
modèles de machine learning. L'une des techniques utilisées pour
tester l'efficacitéd'un modèle de Machine Learning est la
»cross-validation» ou validation croisée figure : 4.1. Cette
méthode est aussi une procédure de »re-sampling»
(ré-échantillonnage) permettant d'évaluer un modèle
même avec des données limitées. Outre la validation
croisée, nous pouvons citer les techniques telles que : L'exactitude, La
précision, Le Rappel (la sensibilité), Le score F1, AUC...
scientifique de Jean-Charles RISCH [42].
4.2.1 Validation Croisée
La validation croisée (Cross Validation) consiste
à effectuer cette opération à plusieurs reprises de telle
sorte que les ensembles de données connues soient à tour de
rôle utilisés comme données d'apprentissage et
données de test. On coupe donc les données connues en parties
égales dans la mesure du possible (folds en anglais) et on utilise
à chaque fois une partie comme jeu de test et le reste comme jeu
d'apprentissage figure : 4.2.
La validation croisée permet donc d'évaluer un
modèle de machine learning en ayant la moyenne des performances et
l'erreur type sur chacun des folds ou en évaluant les
4.2. LES DIFF'ERENTES TECHNIQUES D''EVALUATIONS DES MOD`ELES
CHAPITRE DE 4. MACHINE R'ESULTATS LEARNING ET DISCUSSIONS
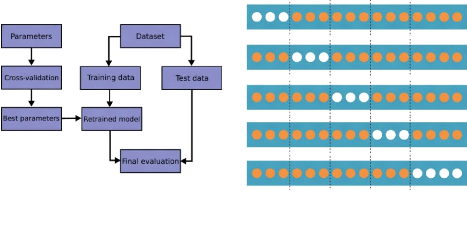
Figure 4.1 - Validation croisée
:
évaluation des performances de
l'estimateur Saagie [43]
Figure 4.2 - Validation croisée
à5-Folds Learn [44]
prédictions faites sur l'ensemble des données.
Pour des raisons de temps de calcul, on utilise
généralement cinq ou dix folds.
Pour cette méthode, il est important d'appliquer la
stratification. La stratification est un processus qui consiste à
diviser les données connues en folds homogènes avant
l'échantillonnage, c'est-à-dire répartir les
étiquettes pour que chaque fold ressemble au maximum à un petit
jeu de données connues.
Il existe 3 grandes méthodes de cross validation :
holdout, LOOCV et k-fold.
| 



