4.2.1.3 La méthode LOOCV
LOOCV (Leave One Out Cross-Validation) est un type d'approche
de validation croisée dans laquelle chaque observation est
considérée comme l'ensemble de validation et
Mémoire de Master II en Informatique 69 c~NJAMEN M.
ZELKIF 2020-2021
4.2. LES DIFF'ERENTES TECHNIQUES D''EVALUATIONS DES MOD`ELES
CHAPITRE DE 4. MACHINE R'ESULTATS LEARNING ET DISCUSSIONS
les autres observations (N - 1) sont
considérées comme l'ensemble d'apprentissage. Dans LOOCV,
l'ajustement du modèle est effectuéet la prédiction
à l'aide d'un ensemble de validation d'observation. De plus,
répéter cela N fois pour chaque observation en tant
qu'ensemble de validation. Le modèle est ajustéet le
modèle est utilisépour prédire une valeur pour
l'observation. Il s'agit d'un cas particulier de validation croisée
K-fold dans lequel le nombre de plis est le même que le nombre
d'observations (K = N). Cette méthode permet de réduire
les biais et le caractère aléatoire.La méthode vise
à réduire le taux d'erreur quadratique moyen et à
éviter le surajustement Lima [45].
4.2.2 La matrice de confusion
La matrice de confusion est un outil qui permet de savoir
à quel point le modèle de machine learning est « confus
», ou qu'il se trompe. Il s'agit d'un tableau avec en colonne les
différents cas réels et en ligne les différents cas
d'usage prédits.
Prenons l'exemple d'un test d'orientation scolaire pour les
spécialités »Scientifiques» et
»Littéraires», la matrice sera la suivante :
Si l'élève doit aller en Scientifique ou
Littéraire
|
Scientifique
|
Littéraire
|
Scientifique
|
Nombre de Vrai Positif
|
Nombre de Faux Positif
|
Littéraire
|
Nombre de Faux Négatif
|
Nombre de Vrai Négatif
|
|
Tableau 4.1 - Exemple d'une Matrice de
Confusion
On obtient donc les quatre valeurs suivantes :
· Vrai positif (VP), les valeurs réelles et
prédites sont identiques et positives. L'élève est
orientée en Scientifique et le modèle le prédit.
· Vrai négatif (VN), les valeurs réelles
et prédites sont identiques et négatives. L'élève
n'est pas en Scientifique et le modèle prédit qu'il ne l'est pas
donc qu'il est en littéraire.
· Faux positif (FP), les valeurs réelles et
prédites sont différentes. L'élève n'est pas
Scientifique, mais le modèle prédit qui l'est.
· Faux négatif (FN), les valeurs réelles
et prédites sont différentes. L'élève est
Scientifique, et le modèle prédit qui l'est.
4.3. RÉSULTAT ET DISCUSSION CHAPITRE 4. RÉSULTATS
ET DISCUSSIONS
Mémoire de Master II en Informatique 70 c~NJAMEN M.
ZELKIF 2020-2021
L'étude de ces valeurs prédictives permet de
définir si le modèle de machine learning est fiable, dans quels
cas il commet des erreurs et dans quelle mesure.
à partir de ce tableau (de la matrice de confusion) on
peut calculer :
· L'exactitude : qui mesure l'adéquation d'un
modèle de classification sous forme de proportion de résultats
réels sur le nombre total de cas.
· La précision : qui correspond à la
proportion de résultats réels sur tous les résultats
positifs. Précision = TP/(TP+FP)
· Le Rappel : qui est la fraction de la
quantitétotale d'instances pertinentes qui ont
étéréellement récupérées. Rappel =
TP/(TP+FN)
· Le score F1 : qui est calculécomme la moyenne
pondérée de précision et de rappel comprise entre 0 et 1,
la valeur de score F1 idéale étant 1.
· AUC mesure la zone sous la courbe tracée avec
les vrais positifs sur l'axe y et les faux positifs sur l'axe
x. Cette métrique est utile car elle fournit un nombre unique
qui vous permet de comparer les modèles de types différents. AUC
est un invariant de seuil de classification. Il mesure la qualitédes
prédictions du modèle, quel que soit le seuil de classification
choisi.
4.3 Résultat et Discussion
Dans cette section nous allons présenter les
résultats que nous avons obtenu après avoir appliquéles
modèles d'apprentissage sur notre jeu de donnée (data-set).
Les modèles que nous avons choisi sont ceux de
classification car notre problème est une sorte de classification
binaire dont la classe à prédire a deux valeurs (Scientifique et
Littéraire). Ainsi, ces modèles (Algorithmes) sont : la
Régression Logistique, Les Arbres de Décision, les K-PPV, les SVM
et les Forêts Aléatoire (Random Forest).
À cet effet, nous avons obtenu les résultats
suivants :
· Régression Logistique : 64% (0.6418523)
· Arbre de décision : 60% (0.60123812)
· SVM : 69% (0.69012512)
·
4.3. RÉSULTAT ET DISCUSSION CHAPITRE 4. RÉSULTATS
ET DISCUSSIONS
Mémoire de Master II en Informatique 71 c~NJAMEN M. ZELKIF
2020-2021
K-PPV : 65% (0.6541210)
· Forêt Aléatoire : 68% (0.6854102)
D'oùle tableau ci-dessous :
Modèle Machine Learning (Algorithme)
|
|
Résultat
|
Régression Logistique
|
64%
|
(0.6418523)
|
Arbre de décision
|
60%
|
(0.60123812)
|
SVM
|
69%
|
(0.69012512)
|
K-PPV
|
65%
|
(0.6541210)
|
Forêt Aléatoire
|
68%
|
(0.6854102)
|
|
Tableau 4.2 - Synthèse des
différents Résultats obtenus
Pour valider ces résultats, nous avons utilisés
plusieurs métriques d'évaluation d'erreurs telles que : la
validation croisée et la matrice de confusion (AUC, F1-Score, la
Précision) comme le montre la figure ci-dessous :
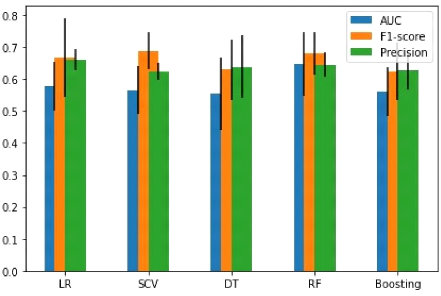
Figure 4.3 - Diagramme des
résultats
4.4. CONCLUSION CHAPITRE 4. RÉSULTATS ET DISCUSSIONS
Mémoire de Master II en Informatique 72 c~NJAMEN M.
ZELKIF 2020-2021
D'après ce diagramme, nous constatons que les SVM
(Support Vecteurs Machines) répondent bien sur le data-set par rapport
aux autres modèles utilisés. Outre les SVM il suit les
Forêts aléatoires ceci tout simplement parce-que les Random forest
sont des combinaisons de plusieurs sous-arbre de décision.
4.4 Conclusion
Parvenu au terme de ce chapitre, oùnous avons
détaillél'implémentation de notre approche de segmentation
issu du seuillage et de l'ouverture morphologique en vue de la detection des
noyaux; ce qui a fournit des résultats assez corrects. Il existe
néanmoins plusieurs autres méthodes de segmentation non
abordées dans ce travail qui offrent des perspectives très
intéressantes. Par ailleurs, nous avons extrait des descripteurs
morphologiques, d'intensitéet de texture à partir des images
segmentées. Ces descripteurs nous ont permis de tester trois algorithmes
d'apprentissage supervisékNN, SVM et les arbres de décision pour
la classification de nos images afin de différencier les tumeurs
malignes
des tumeurs bénignes. Ce qui nous a fournit
également de résultats acceptables, malgréle faible taux
faux positis enregistré.
73
? CONCLUSION ET
PERSPECTIVES ?
Le travail que nous avons présentédans ce
document est celui de l'automatisation (apprentissage) sur des données
académiques en vue de faciliter le processus de l'orienta-tion scolaire
et l'aide à la décision au moyen des algorithmes de Machine
Learning et du Profil de l'apprenant. Il construit tout d'abord le profil d'un
apprenant, puis applique ce dernier sur des algorithmes de Machine Learning en
vue de faciliter l'aide à la décision. Outre cela, il compare
plusieurs modèles de Machine Learning afin de sélectionner celui
qui répond le plus sur le data-set qui d'ailleurs est construit par
nous.
En effet, notre recherche s'intègre dans la
démarche de promouvoir la numérisation de l'enseignement et
surtout la valorisation de l'automatisation d'orientation dans le processus
enseignement apprentissage à l'ère du numérique. Bien que
les conseillers d'orientation le font déjàce travail
d'orientation, nous avons proposédans ce mémoire un Framework
(modèle) facilitant cette tâches contre tenu des effectifs
pléthorique des élèves dans nos établissements
scolaires et surtout de la raretédes conseillers d'orientations dans ces
établissements. La littérature nous a montrée qu'au
Cameroun nous avons en moyenne un (01) conseiller pour deux milles (2000)
élèves soit un pourcentage de 0.02% ce qui rend cette tâche
difficile et biaisée à la base.
Pour répondre aux objectifs de recherche, nous avons
au cours de se travail, construit le profil d'un apprenant pour une bonne
orientation. Il faut noter que, ce profil ne tient pas en compte la situation
familiale, ni l'environnement socioéconomique ou socioculturel de
l'apprenant mais seul ses acquis ou compétences scolaires.
En outre, nous avons aussi effectuéune étude
comparative des algorithmes de Machine Learning pour la recommandation afin de
choisir celui qui réponde le mieux sur les données d'exemples que
nous avons construit. Cela nous a permis de tirer la conclusion suivant
laquelle le Modèle SVM est celui qui répond le mieux suivit des
forêt aléatoires...
4.4. CONCLUSION CHAPITRE 4. RÉSULTATS ET DISCUSSIONS
Mémoire de Master II en Informatique 74 c~NJAMEN M.
ZELKIF 2020-2021
Cependant, nous avons rencontréquelques
difficultés notamment celles liées à l'acqui-sition des
données et aussi à la disponibilités de
l'électricité. La difficultéliée à
l'acquisition des données est due à la confidentialitédont
les gestionnaires des bases des données des établissements
scolaires sont tenus.
Comme tout travail de recherche, bien que le modèle
d'apprentissage présentédans ce travail soit utilisable à
70%, nous sommes convaincu qu'il est loin d'être parfait raison pour
laquelle nous souhaiterons apporter dans un futur proche quelques
améliorations telles que :
· L'augmentation des données de notre data-set
car tout travail de Machine Learning commence par l'acquisition des
données. En plus avec un data-set considérable, nous pourrions
appliquer du Deep Learning.
· Tester des modèles d'apprentissage non
supervisésur des données et les comparer avec les modèles
d'apprentissage superviséutilisés dans le cadre de ce travail.
· Modifier la formule du profil afin qu'elle puisse
prendre en compte les facteurs so-cioéconomiques et culturels de
l'apprenant.
· Considérer parmi nos attributs, l'attribut sexe
pour étudier les modèles d'appren-tissages qui sont sexistes ou
non.
75
4 Références 4
[1] Cartelis, «Modèle d'entrepôts en
étoile,» 01/08 2022,
https ://
www.cartelis.com/blog/data-warehouse-modelisation-etoile/.
[2] Wikipédia, «Orientation scolaire et
professionnelle,» Oct 2020,
www.wikipedia.org.
[3] MINESEC-CAMEROUN, Guide d'utilisation de la batterie
de tests d'aptitudes pour la classe de 3ème, Ministère des
Enseignements Secondaires du Cameroun, 2014.
[4] B. Eric and L. Michel, Data Science : Fondamentaux et
études des cas, Machine Learning avec Python et R, EDITIONS
EYROLLES 61, bd Saint-Germain 75240 Paris Cedex 05
www.editions-eyrolles.com,
2015.
[5] T.-N. Nguyen, D. Lucas, K.-G. Artus, and S. Lars,
«Recommender system for predicting student performance,» Procedia
Computer Science, pp. 1-9, 01 2010.
[6] E. F. Hanaa, Q. Mohammed, S. Intissar, and M. Khalifa,
«Personalized recommender system for e-learning environment based on
student's preferences,» International Journal of Computer Science and
Network Security, p. 173, oct 2018.
[7] K. KELLOU and A. MOKHTARI, Réalisation d'une
plateforme d'expérimentations et de tests d'algorithmes de data mining
www.ESIMiner.com,
Ecole Nationale Supérieure d'Informatique, 2011.
[8] J. Guichard and M. Huteau, «L'orientation scolaire
et professionnelle.» ISBN 2100485164, p. 120, 2005, paris,
Dunod.
[9] C. Chassagne,«L'education à
l'orientation.»Chemins de formation, p. 18, 1998, paris,
Magnard.
[10] ||,«L'education à
l'orientation.»Chemins de formation, p. 7, 1998, paris,
Magnard.
[11]
RÉFÉRENCES RÉFÉRENCES
Mémoire de Master II en Informatique 76 c~NJAMEN M. ZELKIF
2020-2021
B. Jean-Michel, «Ecole, orientation,
société,» PUF, p. 7, 1988, 2e Edition, Paris.
[12] G. Aurélien, Apprentissage supervisé,
June 2013.
[13] Wikipédia, «Apprentissage automatique,»
Dec 2021,
www.wikipedia.org.
[14] B. Alain, INTELLIGENCE ARTIFICIELLE: Apprentissage,
L'Institut de Technologie du Cambodge (ITC), June 2013.
[15] Z. Matthieu, «Apprentissage par renforcement
développemental,» Ph.D. dissertation, Universitéde Lorraine,
2018.
[16] Wikipédia, «Apprentissage non
supervisé,» Oct 2021,
www.wikipedia.org.
[17] ||, «Apprentissage par renforcement,» Dec
2021,
www.wikipedia.org.
[18] P. GitHub, «Introduction à l'apprentissage
automatique, régression,» Jan 2022, https//
projeduc.github.io.
[19] A. Lima, «Régression et classification
apprentissage automatique supervisé,» Jan 2022,
fr.acervolima.com.
[20] I. SOLLAH, Étude comparative entre des
techniques de reconnaissance de caractères arabes, July 2019.
[21] Wikipédia, «k-nearest neighbors
algorithm,» Fév 2022,
wwww.wikipedia.com.
[22] 123dok, «Méthode des k plus proches voisins
(kppv),» Fév 2022,
wwww.123dok.net.
[23] A. Marwa, «Développement d'une nouvelle
approche pour la reconnaissance d'écri-ture manuscrite,» Ph.D.
dissertation, UNIVERSITÉDE LA MANOUBA ÉCOLE NATIONALE DES
SCIENCES DE L'INFORMATIQUE, 2019.
[24] Wikipédia, «Arbre de décision
(apprentissage),» Mars 2022,
wwww.wikipedia.com.
[25] ||, «les support vecteur machines,» Mars 2022,
wwww.wikipedia.com.
[26] V. N. Vapnik, «The nature of statistical learning
theory,» N.Y : Springer-Verlag, p. 314, 1995, version
électronique disponible sur internet.
[27] Wikipédia, «Réseau de neurones
artificiels,» Mars 2022,
wwww.wikipedia.com.
[28]
RÉFÉRENCES RÉFÉRENCES
Mémoire de Master II en Informatique 77 c~NJAMEN M. ZELKIF
2020-2021
l. b. JURI'Predis, «Démystifier le machine
learning, partie 2 : Réseaux de neurones artifiiciels,» Nov 2021,
wwww.juripredis.com.
[29] Wikipédia, «Fonction d'activation,»
Mars 2021,
wwww.wikipedia.com.
[30] T. K. Inside Machine Learning, «Fonction
d'activation, comment ça marche? - une explication simple,» Avril
2022,
wwww.inside-machinelearning.com.
[31] P. Hervé, «Statistiques et rÉseaux de
neurones pour un systÈme de diagnostic : Application au diagnostic de
pannes automobiles,» Ph.D. dissertation, Laboratoire d'Analyse et
d'Architecture des Systèmes du CNRS, UniversitéPaul Sabatier de
Toulouse, Mai 1996.
[32] B. M. Deeply Learning, «Fonction
d'activation,» Sep 2018,
wwww.deeplylearning.fr.
[33] P. Philippe, Fouille de données Notes de
cours, Universitéde Lille 3, 2009.
[34] S. Patrick and N. Olfa, «Human-recommender systems
: From benchmark data to benchmark cognitive models,» ResearchGate,
pp. 127-130, september 2016.
[35] K. Danijel, J. Vedran, and a. Goran, «Machine
learning in education - a survey of current research trends,» 29TH
DAAAM INTERNATIONAL SYMPOSIUM ON INTELLIGENT MANUFACTURING AND AUTOMATION, pp.
0406-0410, July 2018, dOI : 10.2507/29th.daaam.proceedings.059.
[36] T. Ahajjam and F. Toussef, «Recommender system for
orientation student,» Springer Nature Switzerland AG 2020, pp.
367-370, Nov 2020, bDNT 2019, LNNS 81.
[37] O. Emeric, D. Christophe, D. Alexandre, and L. D.
Julien, «Une méthodologie d'ap-prentissage automatique pour l'aide
à la décision en contexte d'industrialisation,» ISTE Ltd
OpenScience, pp. 1-14, July 2019, conference Paper.
[38] Medium, «Les étapes du prétraitement
des données,» Fév 2021,
wwww.medium.com.
[39] T. D. Science, «6 étapes pour le nettoyage
des données et pourquoi c'est important,» Jan 2020,
www.datascience.eu.
[40] A. Lima, «Prétraitement des données
dans l'exploration de données,» Fév 2021,
fr.acervolima.com.
78
[41] M. P. DataScientest, «Cross-validation :
définition et importance en machine learning,» Mai 2021,
www.datascientest.com.
[42] B. scientifique de Jean-Charles RISCH, «Evaluer un
modèle statistique de classification,» Mai 2015,
jcrisch.wordpress.com.
[43] Saagie, «Machine learning : comment évaluer
vos modèles? analyses et métriques,» Oct 2021,
wwww.saagie.com.
[44] S. Learn, «Cross-validation : evaluating estimator
performance,» Mars 2022,
www.scikit-learn.org.
[45] A. Lima, «Loocv (leave one out cross-validation) dans
la programmation r,» Mars 2022,
fr.acervolima.com.
| 



