INTRODUCTION
Un réseau informatique est un ensemble
d'équipements interconnectés qui servent à acheminer un
flux d'informations. Sa naissance est le fruit du mariage entre Informatique et
Télécommunications.
Afin de pouvoir bien acheminer l'information, le réseau
informatique utilise ce qu'on appelle le processus de routage. Le routage
cherche le chemin le plus efficace entre les différents noeuds du
réseau d'une unité à une autre. Le matériel au
centre de ce processus est le routeur.
Un routeur est une unité de couche réseau qui
utilise des protocoles de routage pour déterminer le chemin optimal
par lequel acheminer le trafic réseau. Les protocoles de routage prenant
en charge le protocole routé IP sont par exemple les protocoles RIP,
IGRP, OSPF, BGP et EIGRP.
Les protocoles OSPF utilisent comme algorithme de routage,
l'algorithme de dijkstra pour déterminer le chemin optimal à
assigner au flux de l'information. Cependant l'information n'étant plus
seulement transmise comme donnée, plusieurs autres facteurs entrent
maintenant en jeu parmi lesquels on peut citer celui de la qualité de
service. Les processeurs ordinaires sur lesquels tournent ces algorithmes de
routage éprouvent de plus en plus des difficultés croissantes
avec les qualités et les exigences de plus en plus grandes des services
devant être rendu par les réseaux. En effet, l'augmentation en
complexité du calcul est exponentiellement transformée en une
augmentation en qualité de service, et pour que le réseau puisse
atteindre des performances acceptables, il y a nécessité d'une
augmentation en ressource opératoire.
A ce stade donc, le réseau doit pourvoir combiner
flexibilité et vitesse, aucun compromis ici n'est
toléré ; d'où la nécessité de se
tourner vers de nouvelles technologies plus performantes que celles
rencontrées sur les processeurs actuels, des technologies permettant de
combiner à la fois la reconfigurabilité et la rapidité
des calculs, en d'autres termes d'allier à la flexibilité du
software, la vitesse du hardware. La technologie FPGA est une technologie
pareille.
Il est vrai que le premier réflexe face à ce
problème de flexibilité et de rapidité, la solution
première ne fut pas tout d'abord de se tourner vers les circuits
reprogrammables mais plutôt vers la conception de nouveaux protocoles de
routage encore plus complexe que les précédents. Mais
heureusement les concepteurs de protocoles se rendirent vite compte que le
problème n'était autre que le processeur qui effectue les
calculs. Plusieurs versions d'implémentation d'algorithmes sur FPGA
virent donc le jour.
L'objectif de notre travail est donc de présenter la
méthodologie d'implantation d'un de ces algorithmes de routage qui est
ici celui de DIJKSTRA sur un circuit FPGA. Le plan de notre travail est donc
réparti de la manière suivante : au premier chapitre nous
allons présenter très clairement ce que c'est que le routage
dans les réseaux informatiques.
Dans ce chapitre nous allons tout particulièrement
insister sur le protocole de routage OSPF. Ensuite dans le chapitre deux, nous
présenterons très clairement les circuits reprogrammables en
détaillant les processeurs FPGA et en insistant sur leur structure, leur
fonctionnement et leur programmation. Dans le chapitre trois, nous allons
présenter de façon brève mais concise, le langage VHDL et
la conception de circuits. Dans le chapitre quatre, nous allons
présenter la méthodologie d'implémentation
c'est-à-dire comment à l'aide du langage VHDL nous avons
implémenté l'algorithme de DIJKSTRA dans un circuit FPGA. Dans le
chapitre cinq, après simulation, nous présenterons les
résultats et nous effectuerons une comparaison avec les résultats
obtenus par les processeurs ordinaires. Nous clôturerons ce travail par
une conclusion générale.
CHAPITRE 1 :
LE ROUTAGE DANS LES RESEAUX INFORMATIQUES
1.1 Introduction
Le routage est une fonction de la couche 3 (couche réseau)
du modèle OSI (Open System Internet). C'est un système
d'organisation hiérarchique (voir figure1.1) qui permet de regrouper des
adresses individuelles. Ces dernières sont traitées comme un tout
jusqu'à ce que l'adresse de destination soit requise pour la livraison
finale des données.
LIAISON DE DONNEES
RESEAU
TRANSPORT
SESSION
PRESENTATION
APPLICATION
PHYSIQUE
APPLICATION
PRESENTATION
SESSION
TRANSPORT
RESEAU
LIAISON DE DONNEES
PHYSIQUE
7
6
5
4
ROUTAGE
3
2
1
UFigure1.1 :Ucouche
réseauU
Le routage cherche le chemin le plus efficace d'une
unité à une autre (voir figure 1.2). Le matériel au centre
du processus de routage est le routeur (figure1.3).
A
F
![]() Figure1.2 : lLle
routage Figure1.2 : lLle
routage
 Figure1.3 : Routeur Figure1.3 : Routeur
Il possède les deux fonctions principales suivantes:
· Le routeur gère les tables de routage et
s'assure que les autres routeurs ont connaissance des modifications
apportées à la topologie du réseau. Il se sert des
protocoles de routage pour échanger les informations de réseau.
· Le routeur détermine la destination des paquets
à l'aide de la table de routage lorsque ceux-ci arrivent à l'une
de ses interfaces. Il les transfère vers la bonne interface, ajoute les
informations de trame de cette interface, puis transmet la trame vers
l'extérieur.
Un routeur est une unité de couche réseau qui
utilise une ou plusieurs métriques pour déterminer le chemin
optimal par lequel acheminer le trafic réseau. Les métriques de
routage sont les valeurs qui permettent de définir le meilleur
chemin.
Les routeurs permettent d'interconnecter les segments d'un
réseau ou des réseaux entiers. Leur rôle consiste à
acheminer les trames de données entre les réseaux, en fonction
des informations de la couche 3. Ils prennent des décisions logiques
quant au meilleur acheminement possible des données, puis redirigent les
paquets vers le port de sortie approprié afin qu'ils soient
encapsulés pour la transmission. Les phases d'encapsulation et de
désencapsulation se produisent à chaque passage d'un paquet dans
un routeur. Le routeur doit en effet dés encapsuler la trame de
données de la couche 2 pour accéder à l'adresse de couche
3 et l'examiner. L'encapsulation consiste à fractionner le flux de
données en segments et à ajouter les en-têtes et les en
queues appropriés avant de transmettre les données. Le processus
de dés encapsulation, quant à lui, consiste à retirer les
en-têtes et les en-queues, puis à recombiner les données en
un flux continu (voir figure1.4 et figure1.5).
Réseau
Liaison de données
Physique
Réseau
En-tête
Données
Trame
En-tête
Réseau
En-tête
Données
Trame
En-queu
![]() Figure1.4 :
UencapsulationU Figure1.4 :
UencapsulationU
Réseau
Liaison de données
Physique
Réseau
En-tête
Données
Trame
En-tête
Réseau
En-tête
Données
Trame
En-queu
![]() UFigure1.5U :
UdésencapsulationU UFigure1.5U :
UdésencapsulationU
1.2 UProtocole routé et protocole de routage
[1]
Les protocoles routés ou routables sont utilisés
au niveau de la couche réseau afin de transférer les
données d'un hôte à l'autre via un routeur. Les protocoles
routés transportent les données sur un réseau. Les
protocoles de routage permettent aux routeurs de choisir le meilleur chemin
possible pour acheminer les données de la source vers leur
destination.
Le protocole routé englobe notamment les fonctions
suivantes:
· Il inclut n'importe quelle suite de protocoles
réseau capable de fournir assez d'informations dans l'adresse de couche
réseau pour permettre au routeur d'effectuer le transfert vers
l'unité suivante, jusqu'à la destination finale.
· Il définit le format et l'usage des champs dans
un paquet.
Le protocole IP (Internet Protocol) et le protocole IPX
(Internetwork Packet Exchange) de Novell, mais aussi DECnet, AppleTalk, Banyan
VINES et Xerox Network Systems (XNS), sont des exemples de protocoles
routés.
Les routeurs utilisent des protocoles de routage pour
échanger des tables de routage et partager d'autres informations
d'acheminement. En d'autres termes, les protocoles de routage permettent aux
routeurs d'acheminer les protocoles routés.
Les fonctions du protocole de routage sont en partie les
suivantes:
· Il fournit les processus utilisés pour partager
les informations d'acheminement.
· Il permet aux routeurs de communiquer entre eux afin de
mettre à jour et de gérer les tables de routage.
Les protocoles de routage prenant en charge le protocole
routé IP sont par exemple les protocoles RIP, IGRP, OSPF, BGP et EIGRP.
1.3 ULa détermination du chemin [1]
La détermination du chemin se produit au niveau de la
couche réseau. Ce processus permet au routeur de comparer l'adresse de
destination aux routes disponibles dans sa table de routage et de choisir le
meilleur chemin possible. Les routeurs acquièrent ces chemins soit par
l'intermédiaire du routage statique, soit par l'intermédiaire du
routage dynamique. Les chemins configurés manuellement par
l'administrateur réseau sont appelés «routes
statiques». Ceux que le routeur a acquis d'autres routeurs à l'aide
d'un protocole de routage sont dits «routes dynamiques».
La détermination du chemin permet au routeur de choisir
le port à partir duquel envoyer un paquet pour que celui-ci arrive
à destination. On appelle ce processus le routage d'un paquet. Chaque
routeur rencontré sur le chemin du paquet est appelé un saut. Le
nombre de sauts constitue la distance parcourue. La détermination du
chemin peut être comparée à la situation où une
personne conduit sa voiture d'un endroit de la ville à un autre. Le
conducteur consulte une carte qui lui indique les rues par lesquelles passer
pour arriver à sa destination, tout comme le routeur consulte sa table
de routage. Il passe d'un carrefour à un autre, de la même
façon qu'un paquet circule d'un routeur à un autre lors de chaque
saut. À chaque carrefour, le conducteur peut choisir de prendre à
gauche, à droite ou de continuer tout droit. Il en va de même pour
le routeur lorsqu'il choisit le port de sortie à partir duquel le paquet
sera envoyé.
Le conducteur prend ses décisions en fonction de
certains facteurs, comme l'état du trafic, la limitation de vitesse, le
nombre de voies, les péages et si une route est fréquemment
fermée ou pas. Il est parfois plus rapide de prendre le chemin le plus
long en passant par des petites routes peu fréquentées que de
prendre l'autoroute embouteillée. De même, les routeurs vont
prendre leurs décisions en fonction de la charge, de la bande passante,
du délai, du coût et de la fiabilité d'une liaison de
réseau.
Les processus impliqués dans la sélection du
chemin pour chaque paquet sont illustrés dans la figure 1.6 :
Transmission du paquet de données à l'interface de
l'entrée de la table de routage
Application du masque de l'entrée de la table de routage
sur l'adresse IP de destination
Retrait de l'en tête de trame du paquet
Réception du paquet sur l'interface
Encapsulation du paquet de données dans la trame
appropriée
Comparaison de l'adresse de destination masquée avec
l'adresse réseau de l'entrée
Extraction de l'adresse IP de destination du paquet
Les données sont elles
destinées
au routeur ?
Oui
Transmission de la nouvelle trame
Existe il une
Correspon-
dance ?
Utilisation de la première entrée de la table
routage
Non
Oui
Rejet des données
Fin
Fin
Non
Existe il une route par défaut ?
Existe il une autre entrée de la table de
routage ?
Non
Fin
Oui
Non
Rejet des données
Accès à l'entrée suivante
UFigure1.6 :
UProcessus de routage [1]
U
1.4 UTables de routage
Les routeurs emploient des protocoles de routage pour
construire et gérer les tables de routage contenant les informations
d'acheminement. Le processus de sélection du chemin en est ainsi
facilité. Les protocoles de routage placent diverses informations
d'acheminement dans les tables de routage. Le contenu de ces informations varie
selon le protocole de routage utilisé. Les tables de routage contiennent
les informations nécessaires à la transmission des paquets de
données sur les réseaux connectés. Les équipements
de couche 3 interconnectent les domaines de broadcast ou les réseaux
LAN. Le transfert des données nécessite un système
d'adressage hiérarchique.
Les routeurs conservent les informations suivantes dans leurs
tables de routage:
· Type de protocole: cette information identifie le type
de protocole de routage qui a créé chaque entrée.
· Associations du saut suivant: indique au routeur que la
destination lui est directement connectée, ou qu'elle peut être
atteinte par le biais d'un autre routeur appelé le «saut
suivant» vers la destination finale. Dès réception d'un
paquet, le routeur vérifie l'adresse de destination et tente de trouver
une correspondance dans sa table de routage.
· Métrique de routage: les métriques
utilisées varient selon les protocoles de routage et permettent de
déterminer les avantages d'une route sur une autre. Par exemple, le
protocole RIP se sert d'une seule métrique de routage : le nombre de
sauts. Le protocole IGRP crée une valeur de métrique composite
à partir des métriques de fiabilité, de délai, de
charge et de bande passante.
· Interfaces de sortie: cette information désigne
l'interface à partir de laquelle les données doivent être
envoyées pour atteindre leur destination finale.
Les routeurs s'envoient des messages afin de mettre à
jour leurs tables de routage. Certains protocoles de routage transmettent ces
messages de manière périodique. D'autres ne les envoient que
lorsque des changements sont intervenus dans la topologie du réseau.
Certains transmettent l'intégralité de la table dans leurs
messages de mise à jour alors que d'autres se contentent d'envoyer les
modifications. L'analyse des mises à jour de routage provenant de
routeurs directement connectés permet aux routeurs de créer et de
gérer leur table de routage.
Exemple d'une table de routage sous Windows
XP :
Itinéraires actifs :
Destination réseau Masque réseau Adr.
Passerelle Adr. Interface Métrique
0.0.0.0 0.0.0.0
192.168.0.1 192.168.0.23 20
127.0.0.0 255.0.0.0 127.0.0.1
127.0.0.1 1
192.168.0.0 255.255.254.0 192.168.1.23
192.168.1.23 20
192.168.1.23 255.255.255.255 127.0.0.1
127.0.0.1 20
192.168.1.255 255.255.255.255 192.168.1.23
192.168.1.23 20
224.0.0.0 240.0.0.0 192.168.1.23
192.168.1.23 20
255.255.255.255 255.255.255.255 192.168.1.23
192.168.1.23 1
Passerelle par défaut : 192.168.0.1
UTableau1.1U :
UTable de routage [2]
U Explication de la tableU
1. Destination 0.0.0.0
C'est la route que les paquets vont prendre lorsqu'ils n'on
pas trouvé un meilleur chemin. En fait, c'est la route
par défaut, reprise à la ligne 8.
C'est la ligne la plus intéressante, parce qu'elle fait
intervenir une adresse de passerelle et une adresse d'interface (192.168.0.23)
différentes.
Cette ligne veut dire en français, "Lorsqu'on ne sait
pas par où il faut passer, on va emprunter l'interface 192.168.0.23 pour
joindre la passerelle 192.168.0.1. C'est elle qui décidera pour la suite
du chemin".
2. Destination 127.0.0.0
C'est la boucle interne, celle qui permet à
l'hôte de se parler à lui même.
3. Destination 192.168.0.0
C'est mon réseau local. Cette ligne indique que la
passerelle est 192.168.1.23, de même que l'adresse de l'interface.
4. Pour atteindre 192.168.1.23, c'est à dire
moi-même, il faudra utiliser 127.0.0.1 (adresse interne toujours la
même sur tous les hôtes quelque soit l'OS).
5. Pour réaliser un broadcast sur mon réseau, il
faudra utiliser 192.168.1.23
6. Si l'on souhaite faire du multicast, même chose
7. Si l'on souhaite faire du broadcast étendu, encore
la même chose.
8. La passerelle par défaut est indiquée de
façon explicite.
1.5 UAlgorithmes et métriques de routage [1]
Un algorithme est une solution détaillée d'un
problème. Les algorithmes utilisés pour définir le port
auquel envoyer un paquet diffèrent selon les protocoles de routage. Ils
reposent sur l'utilisation de métriques pour prendre ce type de
décision.
Les protocoles de routage sont conçus pour
répondre à un ou plusieurs des objectifs suivants :
· Optimisation : capacité d'un algorithme de
routage à sélectionner le meilleur chemin. Ce dernier sera choisi
en fonction des métriques et de la pondération utilisées
dans le calcul. Par exemple, un algorithme peut utiliser à la fois le
nombre de sauts et le délai comme métriques, mais
considérer que le délai doit prévaloir dans le calcul.
· Simplicité et réduction du temps
système : plus l'algorithme est simple et plus il sera traité
efficacement par le processeur et la mémoire du routeur. Ce
paramètre est important si le réseau veut pouvoir évoluer
vers des proportions plus conséquentes, comme Internet.
· Efficacité et stabilité : un algorithme
de routage doit pouvoir fonctionner correctement dans des circonstances
inhabituelles ou imprévues, comme les défaillances de
matériels, les surcharges et les erreurs de mise en oeuvre.
· Flexibilité : un algorithme de routage doit
pouvoir s'adapter rapidement à toutes sortes de modifications du
réseau, touchant par exemple la disponibilité et la
mémoire du routeur, la bande passante ou le délai réseau.
· Rapidité de convergence : la convergence est le
processus par lequel tous les routeurs s'entendent sur les routes disponibles.
Lorsqu'un événement sur le réseau entraîne des
modifications au niveau de la disponibilité d'un routeur, des mises
à jour sont nécessaires afin de rétablir la
connectivité du réseau. Une convergence lente des algorithmes de
routage peut empêcher la livraison des données.
Les algorithmes de routage utilisent différentes
métriques pour déterminer la meilleure route (voire
tableau1.5a).
|
Protocole
|
Métrique
|
Nombre maxi de routeur
|
Origine
|
|
Protocole RIP
|
Nombre de sauts
|
15
|
Xerox
|
|
Protocole IGRP
|
· Bande passante
· Charge
· Délai
· Fiabilité
|
255
|
Cisco
|
UTableau1.2U :
UAlgorithmes et métriques de
routageU
Chacun d'eux interprète à sa façon ce qui
est le mieux. L'algorithme génère un nombre, appelé valeur
métrique, pour chaque chemin traversant le réseau. Les
algorithmes de routage perfectionnés effectuent la sélection du
chemin en fonction de plusieurs métriques combinées en une valeur
composite. Généralement, les valeurs métriques faibles
indiquent le meilleur chemin.
Les métriques peuvent être calculées sur
la base d'une seule caractéristique de chemin, comme elles peuvent
l'être sur la base de plusieurs. Les métriques les plus
communément utilisées par les protocoles de routage sont les
suivantes:
· Bande passante : la bande passante représente la
capacité de débit d'une liaison. Une liaison Ethernet de 10
Mbits/s est généralement préférable à une
ligne louée de 64 Kbits/s.
· Délai : le délai est le temps
nécessaire à l'acheminement d'un paquet, pour chaque liaison, de
la source à la destination. Il dépend de la bande passante des
liaisons intermédiaires, de la quantité de données pouvant
être temporairement stockées sur chaque routeur, de la congestion
du réseau et de la distance physique.
· Charge : la charge est la quantité de trafic sur
une ressource réseau telle qu'un routeur ou une liaison.
· Fiabilité : la fiabilité se rapporte
habituellement au taux d'erreurs de chaque liaison du réseau.
· Nombre de sauts : le nombre de sauts est le nombre de
routeurs par lesquels un paquet doit passer avant d'arriver à
destination. Chaque routeur équivaut à un saut. Un nombre de
sauts égal à 4 signifie que les données doivent passer par
quatre routeurs pour atteindre leur destination. Lorsque plusieurs chemins sont
possibles, c'est le chemin comportant le moins de sauts qui est
privilégié.
· Tops : délai d'une liaison de données
utilisant les tops d'horloge d'un PC IBM, un top d'horloge correspondant
environ à 1/18 seconde.
· Coût : le coût est une valeur arbitraire,
généralement basée sur la bande passante, une
dépense monétaire ou une autre mesure, attribuée par un
administrateur réseau.
1.6 UExemple de protocole de routageU : OSPF (Open
Shortest Path First) [3] [4]
Le protocole OSPF est un protocole de routage à
état de liens mis au point par l'IETF (Internet Engineering Task Force)
en 1988.
Nous allons le détailler dans cette partie parce qu'il
est basé sur l'algorithme de DIJKSTRA pour la détermination du
plus court chemin.
En fait le problème soumis à notre étude
est le suivant :
Nous sommes à l'entrée d'un réseau WAN
(Wide Area Network), nous recevons continuellement un flux de données
à notre entrée et nous devons acheminer ces données sur
le chemin (prochain routeur) le moins coûteux au travers de l'utilisation
d'un protocole approprier. Le protocole le plus efficace à
présent est le MPLS (Multi-Protocol Label Switching) [5]. Ce dernier
utilise pour le calcul du chemin répondant aux contraintes
spécifiées les extensions du protocole OSPF. C'est la raison pour
laquelle nous nous intéressons à OSPF.
Sans donc entrer trop dans les détails, nous allons
présenter ici de façon succincte le protocole OSPF.
1.6.1 UFonctionnement d'OSPF
À l'intérieur d'une même zone, les
routeurs fonctionnant sous OSPF doivent préalablement remplir les
tâches suivantes avant de pouvoir effectuer leur travail de routage :
1. Section 1.6.3, « Établir la liste des routeurs
voisins : Hello, my name is R1 and I'm an OSPF router. »,
2. Section 1.6.4, « Élire le routeur
désigné et le routeur désigné de secours »,
3. Section 1.6.5, « Découvrir les routes
»,
4. Section 1.6.6, « Élire les routes à
utiliser »,
5. Section 1.6.7, « Maintenir la base topologique
».
1.6.2 UETAT INITIALU
Le processus de routage OSPF est inactif sur tous les routeurs
de la Figure1.6.2a, « Exemple de topologie ».
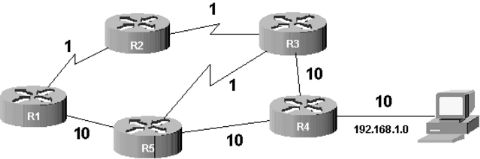
UFigure1.7 : UExemple
de topologie
1.6.3 UÉtablir la liste des routeurs voisins :
Hello, my name is R1 and I'm an OSPF router
Les routeurs OSPF sont bien élevés. Dès
qu'ils sont activés, ils n'ont qu'une hâte : se présenter
et faire connaissance avec leurs voisins. En effet, lorsque le processus de
routage est lancé sur R1 (commande router Ospf), des paquets de
données (appelés paquets HELLO) sont envoyés sur chaque
interface où le routage dynamique a été activé
(commande network).
L'adresse multicast 224.0.0.5 est utilisée, tout
routeur OSPF se considère comme destinataire. Ces paquets ont pour but
de s'annoncer auprès de ses voisins. Deux routeurs sont dits voisins
s'ils ont au moins un lien en commun. Par exemple, sur la Figure1.6.2a, «
Exemple de topologie », R1 et R2 sont voisins mais pas R1 et R3.
Lorsque le processus de routage OSPF est lancé sur R2,
celui-ci récupère les paquets HELLO émis par R1 toutes les
10 secondes (valeur par défaut du temporisateur appelé hello
interval). R2 intègre l'adresse IP de R1 dans une base de données
appelée «base d'adjacences» (adjacencies database). Cette base
contient les adresses des routeurs voisins. On peut visionner son contenu
grâce à la commande show ip Ospf neighbor. R2 répond
à R1 par un paquet IP unicast. R1 intègre l'adresse IP de R2 dans
sa propre base d'adjacences. Ensuite, on généralise ce processus
à l'ensemble des routeurs de la zone.
Cette phase de découverte des voisins est fondamentale
puisque OSPF est un protocole à état de liens. Il lui faut
connaître ses voisins pour déterminer s'ils sont toujours
joignables et donc déterminer l'état du lien qui les relie.
1.6.4 U Élire le routeur désigné et
le routeur désigné de secours
Dans une zone OSPF composée de réseaux de
diffusion (broadcast networks) ou de réseau à accès
multiples sans diffusion (non broadcast multiple access networks ou NBMA), l'un
des routeurs doit être élu «routeur
désigné» (DR pour Designated Router) et un autre
«routeur désigné de secours» (BDR pour Backup
Designated Router). Le «routeur désigné» (DR) est un
routeur particulier qui sert de référent pour la base de
données topologique représentant le réseau.
Pourquoi élire un routeur désigné ? Cela
répond à trois objectifs :
· réduire le trafic lié à
l'échange d'informations sur l'état des liens (car il n'y a pas
d'échange entre tous les routeurs mais entre chaque routeur et le
DR),
· améliorer l'intégrité de la base
de données topologique (car cette base de données doit être
unique),
· accélérer la convergence.
Comment élire le DR ? Le routeur élu est celui
qui a la plus grande priorité (Router ID ou RID). La priorité est
un nombre sur 8 bits fixé par défaut à 1 sur tous les
routeurs. Pour départager les routeurs ayant la même
priorité, celui qui est élu a la plus grande adresse IP sur une
interface de boucle locale (loopback interface) ou sur un autre type
d'interface active. Le BDR sera le routeur avec la deuxième plus grande
priorité.
Afin de s'assurer que votre routeur
préféré sera élu DR, il suffit de lui affecter une
priorité supérieure à 1 avec la commande Ospf priority.
Vous devrez faire ceci avant d'activer le processus de routage sur les routeurs
car, une fois élu, le DR n'est jamais remis en cause même si un
routeur avec une priorité plus grande apparaît dans la zone.
1.6.5 UDécouvrir les routes
Il faut maintenant constituer la base de données
topologique. Les routeurs communiquent automatiquement les routes pour les
réseaux qui participent au routage dynamique (ceux
déclarés avec la commande network). Zebra et son successeur
Quagga étant multiprotocoles, ils peuvent également diffuser des
routes provenant d'autres sources que OSPF, grâce à la commande
redistribute.
Chaque routeur (non DR ou BDR) établit une relation
maître/esclave avec le DR. Le DR initie l'échange en transmettant
au routeur un résumé de sa base de données topologique via
des paquets de données appelés LSA (Link State Advertisement).
Ces paquets comprennent essentiellement l'adresse du routeur,
le coût du lien et un numéro de séquence. Ce numéro
est un moyen pour déterminer l'ancienneté des informations
reçues. Si les LSA reçus sont plus récents que ceux dans
sa base topologique, le routeur demande une information plus complète
par un paquet LSR (Link State Request). Le DR répond par des paquets LSU
(Link State Update) contenant l'intégralité de l'information
demandée. Ensuite, le routeur (non DR ou BDR) transmet les routes
meilleures ou inconnues du DR.
L'administrateur peut consulter la base de données
topologique grâce à la commande show ip Ospf database.
1.6.6 Élire les routes à
utiliser
Lorsque le routeur est en possession de la base de
données topologique, il est en mesure de créer la table de
routage. L'algorithme du SPF est appliqué sur la base topologique. Il en
ressort une table de routage contenant les routes les moins coûteuses.
Il faut noter que sur une base de données topologique
importante, le calcul consomme pas mal de ressources CPU car l'algorithme est
relativement complexe.
1.6.7 Maintenir la base topologique
Lorsqu'un routeur détecte un changement de
l'état d'un lien (cette détection se fait grâce aux paquets
HELLO adressés périodiquement par le routeur à ses
voisins), celui-ci émet un paquet LSU sur l'adresse multicast 224.0.0.6
: le DR et le BDR de la zone se considèrent comme destinataires.
Le DR et le BDR intègrent cette information à
leur base topologique. Le DR diffuse l'information sur l'adresse 224.0.0.5
(tous les routeurs OSPF sans distinction). C'est le protocole d'inondation.
Toute modification de la topologie déclenche une nouvelle
exécution de l'algorithme du SPF et une nouvelle table de routage est
constituée.
1.7 Conclusion du chapitre
Le problème soumis à notre étude se
trouve donc au niveau de cet algorithme SPF (shortest path first), en effet
nous devons ici accélérer son exécution en
l'implémentant sur des processeurs FPGA.
Il y a lieu de préciser ici que ce chapitre ne fut
conçue qu'à fin de donner un aperçu du routage, mais il ne
s'agit en aucun cas d'un cours sur le routage ou sur les protocoles de
routage, le routage étant en effet un domaine très vaste de
l'informatique.
Faisons remarquer cependant que malgré le faite que
notre travail soit centré sur les circuits reprogrammables, nous en
avons expressément fais abstraction ici car dans le prochain chapitre
nous nous y consacrerons.
CHAPITRE 2 : LES COMPOSANTS FPGA (FIELD
PROGRAMABLE GATE ARRAY)
2.1 Introduction U
Les progrès technologiques continus dans le domaine des
circuits intégrés ont permis la réduction des coûts,
de la consommation, et c'est maintenant un lieu commun d'affirmer que les
circuits intégrés spécifiques d'une application ont permis
une réduction de la taille des systèmes numériques ainsi
que la réalisation de circuits de plus en plus complexes, tout en
améliorant leurs performances et leur fiabilité. Aujourd'hui les
techniques de traitement numérique occupent une place majeure dans tous
les systèmes électroniques modernes grand public, professionnel
ou de défense. De plus, les techniques de réalisation de circuits
spécifiques, tant dans les aspects matériels (composants
reprogrammables, circuits pré caractérisés et
bibliothèques de macro fonctions) que dans les aspects logiciels
(placement routage, synthèse logique) font désormais de la
microélectronique une des bases indispensables pour la
réalisation de systèmes numériques performants. Elle
impose néanmoins une méthodologie de développement en CAO
très structurée.
Nous allons examiner les diverses technologies utilisables
pour la conception de circuits logiques avec leurs avantages et leurs
inconvénients afin d'expliciter l'intérêt de la technologie
FPGA.
2.2 ULes ASICS (Application Specific Integrated
Circuit)U
Dans un premier temps, nous allons rappeler quelques concepts
autour des circuits intégrés pour applications spécifiques
ASIC. Les circuits ASIC constituent la troisième
génération de circuits intégrés qui a vu le jour au
début des années 80. En comparaison des circuits
intégrés standards et figés proposés par les
fabricants, l'ASIC présente une personnalisation de son fonctionnement,
selon l'utilisation, accompagnée d'une réduction du temps de
développement, d'une augmentation de la densité
d'intégration et de la vitesse de fonctionnement. En outre sa
personnalisation lui confère un autre avantage industriel, c'est
évidemment la confidentialité. Ce concept d'abord
développé autour du silicium s'est ensuite étendu à
d'autres matériaux pour les applications micro-ondes ou très
rapides (GaAs par exemple).
Par définition, les circuits ASIC regroupent tous les
circuits dont la fonction peut être personnalisée d'une
manière ou d'une autre en vue d'une application spécifique, par
opposition aux circuits standards dont la fonction est définie et
parfaitement décrite dans le catalogue de composants. Les ASIC peuvent
être classés en plusieurs catégories selon leur niveau
d'intégration, en fait un ASIC est défini par sa structure de
base (réseau programmable, cellule de base, matrice, etc.). Sous le
terme ASIC deux familles sont regroupées, les semi personnalisés
et les personnalisés (Voir figure2.1)
ASIC
PERSONNALISES
SEMI-PERSONNALISES
Circuits pré
caractérisés
Circuits à
la demande
Réseaux pré diffusés
Logiques programmables
FPGA
UFigure2.1 : Hiérarchie des circuits
ASIC
2.2.1 ULes circuits semi personnalisés
Les semi personnalisés sont des réseaux
prédéfinis de transistors ou de fonctions logiques qui
nécessitent une personnalisation de l'utilisateur pour réaliser
la fonction désirée. Cette famille comprend :
· · les réseaux logiques programmables,
· · les réseaux
prédiffusés.
2.2.1.1 ULes réseaux
logiques programmablesU
Ce composant ne nécessite aucune étape
technologique supplémentaire pour être personnalisé. Nous y
trouvons les PAL/PLD, ce sont des circuits standard programmables par
l'utilisateur grâce à différents outils de
développement. La programmation consiste à établir des
connexions en imposant un courant supérieur aux courants de
fonctionnement normaux (claquage de fusibles ou de jonctions). Les circuits
logiques programmables incluent un grand nombre de solutions, toutes
basées sur des variantes de l'architecture des portes ET OU.
Nous y trouvons : ·
· PAL (Programmable Array Logic) matrice ET
programmable, matrice OU figée),
· PLA (Programmable Logic Array) matrice ET ou
matrice OU programmable,
· EPLD (Erasable PLD) effaçables par rayons
ultraviolet, ils peuvent être reprogrammer,
· EEPLD (Electrically Erasable PLD) programmables et
effaçables électriquement, ils peuvent être
reprogrammés sur site. Les limites de l'architecture du PLD
résident dans le nombre de bascules, le nombre de signaux
d'entrées/sorties, la rigidité du plan logique ET OU et des
interconnexions.
Précisons que ces composants très souples
d'emploi sont limités à des fonctions numériques et
adaptés à des productions de petites séries et ne
présentent aucune garantie quant à la confidentialité.
2.2.1.2 ULes prédiffusés
U
Les réseaux pré diffusés sont des
circuits partiellement préfabriqués. L'ensemble des
éléments (transistors, diodes, résistances,
capacités, etc.) est déjà implanté sur le circuit
suivant une certaine topologie, mais les éléments ne sont pas
connectés entre eux. La réalisation des connexions dans le but de
définir la fonction souhaitée est la tâche du concepteur,
pour cela il dispose de bibliothèques de macro cellules et d'outils
logiciels d'aide à la conception. A partir de cette liste
d'interconnexions (netlist) le fondeur n'aura que quelques étapes
technologiques à effectuer pour achever le circuit, c'est à dire
le dépôt d'une ou plusieurs couches de métallisation.
Cette technique est intéressante sur le plan de la
conception et de la fabrication, par contre elle présente
l'inconvénient de ne pas permettre une optimisation en terme de
densité de composants puisque les éléments de base sont
pré implantés et pas forcément utilisés et que leur
positionnement a priori n'est pas forcément optimal pour le but
recherché.
2.2.2 ULes circuits
personnalisésU
Ce sont des circuits non préfabriqués. Pour
chaque application on optimise le circuit intégré, ce qui conduit
à la création de son propre composant. Cette famille comprend :
· les circuits à la demande,
· les circuits pré
caractérisés.
2.2.2.1 ULes circuits à la demande
Les solutions circuit à la demande (qu'on appelle full
custom en anglais) présentent l'avantage d'autoriser une meilleure
optimisation du placement puisque celui-ci n'est pas prédéfini.
On dispose d'une bibliothèque de modèles mathématiques de
comportement et via un "compilateur de silicium" logiciel très
sophistiqué on peut concevoir toute l'architecture du circuit en faire
une validation logicielle (simulation logique) puis dans une avant
dernière étape en déduire le dessin des divers masques de
fabrication.
Toutes les opérations, de la conception à la
fabrication, sont effectuées de façons spécifiques
adaptées aux exigences de l'utilisation. L'ensemble des critères
techniques est au choix du concepteur, que ce soit la taille du composant, le
nombre de broches, le placement du moindre transistor. C'est l'ASIC le plus
optimisé car aucune contrainte ne lui est imposée. Le placement
des blocs fonctionnels et le routage des interconnexions, même si ces
opérations sont assistées par ordinateur, sont effectués
avec beaucoup plus d'interventions manuelles pour atteindre l'optimisation au
niveau de chaque transistor. Cependant, les phases de mise au point sont
longues et onéreuses, il va de soi que la rentabilisation des
investissements de développement nécessite un fort volume de
production.
2.2.2.2 ULes circuits
précaractérisésU
Pour la réalisation de circuits pré
caractérisés on dispose d'une bibliothèque de circuits
élémentaires que le fondeur sait fabriquer et dont il peut
garantir les caractéristiques et on les associe pour réaliser le
circuit à la demande. Ici encore on utilisera en fabrication des masques
personnalisés pour chacune des couches diffusées et des
métallisations.
Le concept est très semblable de celui des circuits
à la demande. La seule différence réside dans la
réalisation du schéma puisque l'on accède à une
bibliothèque de cellules prédéfinies
générant de très nombreuses fonctions
élémentaires ou élaborées. Cette dernière
constitue un véritable catalogue dans lequel le concepteur se sert pour
constituer son schéma. Il existe trois types de cellules :
· les cellules standards (standard cells)
correspondent à la logique classique,
· les méga cellules (megacells) peuvent
être des blocs du type microprocesseur, périphérique,
· les cellules compilées (compilable cells) dont
les blocs RAM ou ROM. Il est nécessaire de personnaliser
complètement la diffusion, et par conséquent de créer tous
les masques. Cependant un avantage évident en découle : alors
qu'il est impossible avec les pré diffusés d'utiliser à
100% le réseau de cellules ou portes, ce qui se traduit par une perte de
silicium, les pré caractérisés permettent d'exploiter
complètement la surface du circuit.
UAvantages et inconvénients de
l'utilisation d'ASIC U
D'une manière générale l'utilisation d'un
ASIC conduit à de nombreux avantages provenant essentiellement de la
réduction de la taille des systèmes. Il en ressort :
· Réduction du nombre de composants sur le
circuit imprimé. La consommation et l'encombrement s'en trouvent
considérablement réduits. ·
· Le concept ASIC par définition assure une
optimisation maximale du circuit à réaliser. Nous disposons alors
d'un circuit intégré correspondant réellement à nos
propres besoins.
· La personnalisation du circuit donne une
confidentialité au concepteur et une protection industrielle.
· Enfin, ce type de composant augmente la
complexité du circuit, sa vitesse de fonctionnement et sa
fiabilité.
Dans l'approche des circuits pré diffusés et
personnalisés, l'inconvénient majeur réside dans le fait
du passage obligatoire chez le fondeur ce qui implique des frais de
développement élevés du circuit. En général
le fondeur ne souhaite pas intervenir dans la phase de conception ; sa
tâche est de réaliser le composant à partir des masques.
Dans le but de réduire les surcoûts dus aux modifications, il
s'avère nécessaire d'être rigoureux lors de la phase de
développement de telle sorte que le circuit prototype fonctionne
dès les premiers essais : c'est réussi dans environ 60% des cas.
De plus dans de nombreuses applications, l'utilisateur doit concevoir les
programmes de testabilité.
2.3 UFPGA (Field Programmable Gate Arrays) U [9]
2.3.1. UHistoriqueU
L'histoire des puces programmables
connue plusieurs phases :
En 1975, les concepteurs commencent à
remplacer des circuits logiques standards par des circuits programmables. Les
fonctions réalisées sont majoritairement des interfaces et des
transcodages.
Dans le courant des années 1980, la
société Californienne Xilinx invente une nouvelle famille de
puces programmable appelée FPGA.

Figure2.2 : Puce FPGA
Xilinx
Dès 1985 des contrôleurs et des circuits
périphériques complexes commencent à être
implantés autour des microprocesseurs. Ces cartes sont utilisées
de plus en plus pour effectuer du traitement du signal et dans le domaine des
télécoms. De leur côté, les FPGA se
développent.
En 1987, une première standardisation des
langages de descriptions du hardware est créée. Cette
standardisation permet d'étendre le design de circuit aux particuliers.
En effet, avant cette standardisation, les entreprises utilisaient leur propre
code propriétaire. Cela donna naissance à deux langages :
Le
VHDL, IEEE.1076, facile à appréhender mais peu compact,
principalement utilisé en Europe
Et le Verilog, proche du C,
propriétaire jusqu'à son acceptation IEEE.1364 en 1995,
principalement utilisé aux Etats-Unis.
Depuis les années 1995,
la puissance des circuits logiques programmables FPGA permettent d'implanter en
leur sein à la fois le microprocesseur (ou le DSP) et le pré ou
post traitement associé.
Au début du XXIe siècle, le
prix des puces FPGA commence à baisser et devient progressivement
abordable pour le grand public. Parallèlement à cela, la
modernisation des fonderies permet d'atteindre une finesse de gravure de plus
en plus réduite, donc de créer des puces FPGA de plus en plus
puissantes (fréquence en hausse et nombre de portes
accrues).
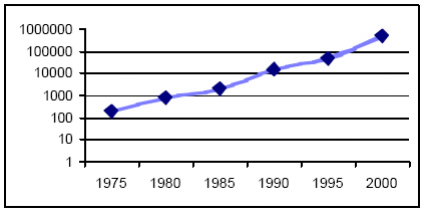
Figure2.3 : Evolution du
nombre de portes
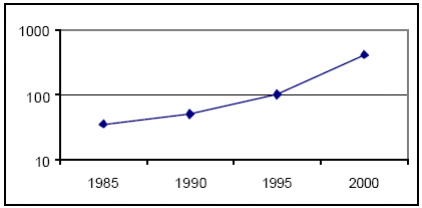
Figure2.4 : Evolution de la
fréquence d'horloge maximum (MHz) d'un compteur synchrone 16
bits
2.3.2. UUtilisation des puces FPGAU
Lors de leur
création vers 1980, les puces FPGA ont tout d'abord su séduire
les électroniciens. Ils y voyaient un moyen de prototypage rapide et peu
cher. En effet, les puces FPGA peuvent êtres reprogrammés sans
nécessiter de matériel lourd. Cela leur permet de tester un
nouveau circuit sans avoir à racheter des composants ou pire de les
reconcevoir à chaque amélioration.
Puis les informaticiens ont
commencé à s'y intéresser de près comme moyen
d'augmenter la rapidité de leur application en leur donnant une assise
matérielle (accélération hardware). Depuis le Geforce 3 de
nVidia (NV20), toutes les cartes graphiques du marché possèdent
un circuit figé et une partie programmable (vertex shader et pixel
shader).

Figure2.5 : vertex shader et pixel
shader
Depuis quelque temps, un certain nombre de chercheurs
intéressé par les principes d'évolution Darwinienne du
hardware utilisent des puces FPGA dans leurs expériences. Elles sont
pour eux intéressantes à plus d'un titre. Elles permettent de
faire évoluer des algorithmes génétiques à des
vitesses électroniques et de concevoir des processeurs
dédiés par ces mêmes
techniques d'algorithmes génétiques.
Les FPGA
ont été perçus par beaucoup comme une alternative à
la fonte même d'un composant : les universités par exemple y
voient un moyen concret d'enseigner le design digital. Les start-up de
l'électronique peuvent à moindre coût prouver que leur
idée est bonne et viable pour lever des fonds sans attendre un retour de
fonderie qui mobilise des capitaux importants, et pour plus d'un mois la
plupart de temps.
La technologie FPGA intéressa aussi l'armée
de par la possibilité de programmation des puces en cours de
fonctionnement. En effet, lors d'une guerre, la réactivité d'un
radar d'avion de chasse par exemple est déterminante pour la survie du
pilote. La possibilité de reprogrammer une puce de type FPGA permet
à ce radar de s'adapter à n'importe quelle situation tout en
ayant une accélération hardware permanente. Globalement,
l'armée est intéressée par des puces FPGA pour les
instruments de vols et les systèmes de communications militaires
nécessitant la possibilité d'être reconfigurés et de
fonctionner dans une large gamme de températures (les deux
dernières puces de marque Altera, EP1S80 et EP1S60, peuvent fonctionner
entre - 40° et 100° C).
Une puce FPGA de marque Xilinx fut
également choisie par la Nasa pour l'exploration de Mars par les Rovers
Spirit et Opportunity. Ces puces appartiennent à la famille Virtex et
sont spécialement étudiées pour résister aux
radiations solaires qui frappent Mars continuellement (la faible
atmosphère qui entoure Mars ne peut stopper ces radiations et une puce
classique serait détruite en peu de temps). Elle se charge de
contrôler le bras articulé du Rover et les divers appareils de
mesure qui le composent (une accélération hardware permet ici une
plus grande précision). Ce type de puce fut utilisé pour d'autres
missions spatiales tel que Mars orbiter (2005).

Figure2.6 : Rover Spirit sur
Mars
De par leur prix de moins en moins
élevé (une puce à la carte contenant 1 million de portes
s'achète 15 dollars), de plus en plus de personnes voient un moyen de
créer leur propres ordinateurs entièrement personnalisés
à bas prix. Le hardware libre est né vers 2000. Les concepteurs
digitaux en herbe peuvent acheter des puces FPGA puis créer leur propre
design de puce et mettre ce design à disposition d'autres concepteurs. A
l'instar du mouvement logiciel libre, une communauté de concepteurs
passionnés se développe, permettant de s'affranchir des grands
industriels de la micro-électronique.
2.3.3 UDescription du FPGAU
L'architecture, retenue par Xilinx, se présente sous
forme de deux couches :
· une couche appelée circuit configurable,
· une couche réseau mémoire SRAM.
La couche dite 'circuit configurable' est constituée
d'une matrice de blocs logiques configurables CLB permettant de réaliser
des H
TUfonctions
combinatoiresUTH et des H
TUfonctions
séquentiellesUTH. Tout autour de ces blocs logiques
configurables, nous trouvons des blocs entrées/sorties IOB dont le
rôle est de gérer les entrées-sorties réalisant
l'interface avec les modules extérieurs (cf. figure2.7). La
programmation du circuit FPGA appelé aussi LCA (logic cells arrays)
consistera par le biais de l'application d'un potentiel adéquat sur la
grille de certains transistors à effet de champ à interconnecter
les éléments des CLB et des IOB afin de réaliser les
fonctions souhaitées et d'assurer la propagation des signaux. Ces
potentiels sont tout simplement mémorisés dans le réseau
mémoire SRAM.
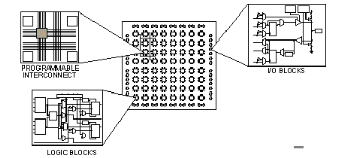
Figure2.7 :Architecture interne d'un
FPGA.
Les circuits FPGA du fabricant Xilinx utilisent deux types de
cellules de base :
· les cellules d'entrées/sorties appelés
IOB (input output bloc),
· les cellules logiques appelées CLB (configurable
logic bloc). Ces différentes cellules sont reliées entre elles
par un réseau d'interconnexions configurable.
2.3.3.1 Les CLB (configurable logic bloc)
Les blocs logiques configurables sont les éléments
déterminants des performances du FPGA. Chaque bloc est composé
d'un bloc de logique combinatoire composé de deux
générateurs de fonctions à quatre entrées et d'un
bloc de mémorisation synchronisation composé de deux bascules D.
Quatre autres entrées permettent d'effectuer les connexions internes
entre les différents éléments du CLB. La figure
ci-dessous, nous montre le schéma d'un CLB.
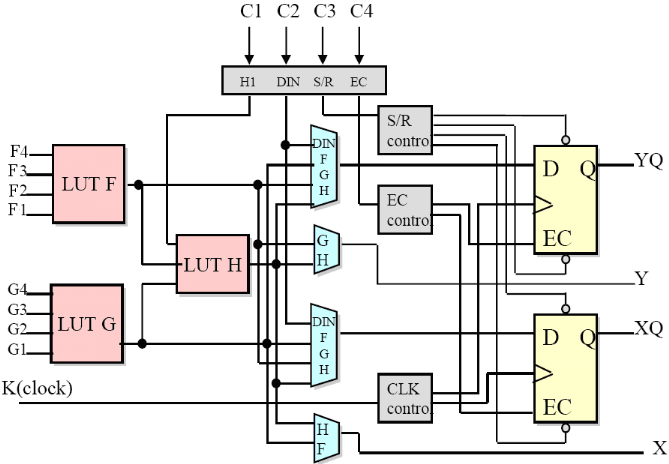
Figure2.8: Cellule logique (CLB)
Voyons d'abord le bloc logique combinatoire qui possède
deux générateurs de fonctions F' et G' à quatre
entrées indépendantes (F1...F4, G1...G4), lesquelles offrent aux
concepteurs une flexibilité de développement importante car la
majorité des fonctions aléatoires à concevoir
n'excède pas quatre variables. Les deux fonctions sont
générées à partir d'une table de
vérité câblée inscrite dans une zone mémoire,
rendant ainsi les délais de propagation pour chaque
générateur de fonction indépendants de celle à
réaliser. Une troisième fonction H' est réalisée
à partir des sorties F' et G' et d'une troisième variable
d'entrée H1 sortant d'un bloc composé de quatre signaux de
contrôle H1, Din, S/R, Ec. Les signaux des générateurs de
fonction peuvent sortir du CLB, soit par la sortie X, pour les fonctions F' et
G', soit Y pour les fonctions G' et H'. Ainsi un CLB peut être
utilisé pour réaliser:
· deux fonctions indépendantes à quatre
entrées indépendantes, plus une troisième fonction de
trois variables indépendantes
· ou toute fonction à cinq variables
· ou toute fonction à quatre variables et une
autre avec quelques fonctions à six variables
· ou certaines fonctions jusqu'à neufs
variables.
L'intégration de fonctions à nombreuses
variables diminue le nombre de CLB nécessaires, les délais de
propagation des signaux et par conséquent augmente la densité et
la vitesse du circuit. Les sorties de ces blocs logiques peuvent être
appliquées à des bascules au nombre de deux ou directement
à la sortie du CLB (sorties X et Y). Chaque bascule présente deux
modes de fonctionnement : un mode 'flip-flop' avec comme
donnée à mémoriser, soit l'une des fonctions F', G', H'
soit l'entrée directe DIN et un mode latch. La
donnée peut être mémorisée sur un front
montant ou descendant de l'horloge (CLK). Les sorties de ces deux
bascules correspondent aux sorties du CLB XQ et YQ. Un mode dit de "
verrouillage " exploite une entrée S/R qui peut être
programmée soit en mode SET, mise à 1 de la bascule, soit en
Reset, mise à zéro de la bascule. Ces deux entrées
coexistent avec une autre entrée laquelle n'est pas
représentée sur la figure, appelée le global Set/Reset.
Cette entrée initialise le circuit FPGA à chaque mise sous
tension, à chaque configuration, en commandant toutes les bascules au
même instant soit à '1', soit à '0'. Elle agit
également lors d'un niveau actif sur le fil RESET lequel peut être
connecté à n'importe quelle entrée du circuit FPGA.
Un mode optionnel des CLB est la configuration en
mémoire RAM de 16x2bits ou 32x1bit ou 16x1bit. Les entrées F1
à F4 et G1 à G4 deviennent des lignes d'adresses
sélectionnant une cellule mémoire particulière. La
fonctionnalité des signaux de contrôle est modifiée dans
cette configuration, les lignes H1, DIN et S/R deviennent respectivement les
deux données D0, D1 (RAM 16x2bits) d'entrée et le signal de
validation d'écriture WE. Le contenu de la cellule mémoire (D0 et
D1) est accessible aux sorties des générateurs de fonctions F' et
G'. Ces données peuvent sortir du CLB à travers ses sorties X et
Y ou alors en passant par les deux bascules.
2.3.3.2 Les IOB (input output bloc)
La figure ci-dessous présente la structure de ce bloc. Ces
blocs entrée/sortie permettent l'interface entre les broches du
composant FPGA et la logique interne développée à
l'intérieur du composant. Ils sont présents sur toute la
périphérie du circuit FPGA. Chaque bloc IOB contrôle une
broche du composant et il peut être défini en entrée, en
sortie, en signaux bidirectionnels ou être inutilisé (haute
impédance).
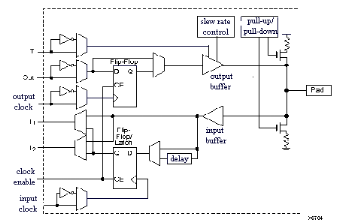
Figure2.9 : Input Output Block
(IOB).
2.3.3.2.1Configuration en
entrée
Premièrement, le signal d'entrée
traverse un buffer qui selon sa programmation peut détecter soit des
seuils TTL ou soit des seuils CMOS. Il peut être routé directement
sur une entrée directe de la logique du circuit FPGA ou sur une
entrée synchronisée. Cette synchronisation est
réalisée à l'aide d'une bascule de type D, le changement
d'état peut se faire sur un front montant ou descendant. De plus, cette
entrée peut être retardée de quelques nanosecondes pour
compenser le retard pris par le signal d'horloge lors de son passage par
l'amplificateur. Le choix de la configuration de l'entrée s'effectue
grâce à un multiplexeur (program controlled multiplexer). Un bit
positionné dans une case mémoire commande ce dernier.
2.3.3.2.2 Configuration en sortie
Nous distinguons les possibilités suivantes :
· inversion ou non du signal avant son application
à l'IOB,
· synchronisation du signal sur des fronts montants ou
descendants d'horloge,
· mise en place d'un " pull-up " ou " pull-down " dans le
but de limiter la consommation des entrées sorties inutilisées,
· signaux en logique trois états ou deux
états. Le contrôle de mise en haute impédance et la
réalisation des lignes bidirectionnelles sont commandés par le
signal de commande Out Enable lequel peut être inversé ou non.
Chaque sortie peut délivrer un courant de 12mA. Ainsi toutes ces
possibilités permettent au concepteur de connecter au mieux une
architecture avec les périphériques extérieurs.
2.3.3.3 Les différents types
d'interconnexions [8]
Les connexions internes dans les circuits FPGA sont
composées de segments métallisés. Parallèlement
à ces lignes, nous trouvons des matrices programmables réparties
sur la totalité du circuit, horizontalement et verticalement entre les
divers CLB. Elles permettent les connexions entre les diverses lignes,
celles-ci sont assurées par des transistors MOS dont l'état est
contrôlé par des cellules de mémoire vive ou RAM. Le
rôle de ces interconnexions est de relier avec un maximum
d'efficacité les blocs logiques et les entrées/sorties afin que
le taux d'utilisation dans un circuit donné soit le plus
élevé possible. Pour parvenir à cet objectif, Xilinx
propose trois sortes d'interconnexions selon la longueur et la destination des
liaisons. Nous disposons :
· d'interconnexions à usage général,
· d'interconnexions directes,
· de longues lignes.
2.3.3.3.1 Les interconnexions à usage
général
Ce système fonctionne en une grille de cinq segments
métalliques verticaux et quatre segments horizontaux positionnés
entre les rangées et les colonnes de CLB et de l'IOB.
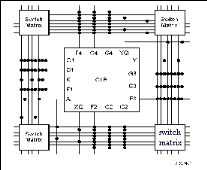 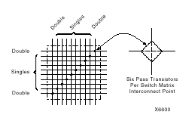
Figure2.10 : Connexions à usage
général et détail d'une matrice de
commutation
Des aiguilleurs appelés aussi matrices de commutation
sont situés à chaque intersection. Leur rôle est de
raccorder les segments entre eux selon diverses configurations, ils assurent
ainsi la communication des signaux d'une voie sur l'autre. Ces interconnexions
sont utilisées pour relier un CLB à n'importe quel autre. Pour
éviter que les signaux traversant les grandes lignes ne soient
affaiblis, nous trouvons généralement des buffers
implantés en haut et à droite de chaque matrice de commutation.
2.3.3.3.2 Les interconnexions directes
[8]
Ces interconnexions permettent l'établissement de
liaisons entre les CLB et les IOB avec un maximum d'efficacité en terme
de vitesse et d'occupation du circuit. De plus, il est possible de connecter
directement certaines entrées d'un CLB aux sorties d'un autre.
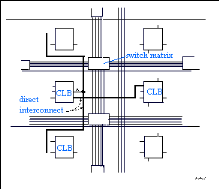
Figure2.11 : Les interconnexions
directes
Pour chaque bloc logique configurable, la sortie X peut
être connectée directement aux entrées C ou D du CLB
situé au-dessus et les entrées A ou B du CLB situé
au-dessous. Quant à la sortie Y, elle peut être connectée
à l'entrée B du CLB placé immédiatement à sa
droite. Pour chaque bloc logique adjacent à un bloc
entrée/sortie, les connexions sont possibles avec les entrées I
ou les sorties O suivant leur position sur le circuit.
2.3.3.3.3 Les longues lignes
Les longues lignes sont de longs segments
métallisés parcourant toute la longueur et la largeur du
composant, elles permettent éventuellement de transmettre avec un
minimum de retard les signaux entre les différents
éléments dans le but d'assurer un synchronisme aussi parfait que
possible. De plus, ces longues lignes permettent d'éviter la
multiplicité des points d'interconnexion.
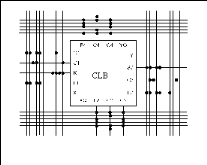
Figure2.12 : Les longues
lignes
2.3.3.3.4 Performances des interconnexions
Les performances des interconnexions dépendent du type
de connexions utilisées. Pour les interconnexions à usage
général, les délais générés
dépendent du nombre de segments et de la quantité d'aiguilleurs
employés. Le délai de propagation de signaux utilisant les
connexions directes est minimum pour une connectique de bloc à bloc.
Quant aux segments utilisés pour les longues lignes, ils
possèdent une faible résistance mais une capacité
importante. De plus, si on utilise un aiguilleur, sa résistance s'ajoute
à celle existante.
2.3.3.4 L'oscillateur à quartz
Placé dans un angle de la puce, il peut être
activé lors de la phase de programmation pour réaliser un
oscillateur. Il utilise deux IOB voisins, pour réaliser l'oscillateur
dont le schéma est présenté ci-dessous. Cet oscillateur ne
peut être réalisé que dans un angle de la puce où se
trouve l'amplificateur prévu à cet effet. Il est évident
que si l'oscillateur n'est pas utilisé, les deux IOB sont utilisables au
même titre que les autres IOB.
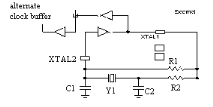
Figure2.13 : L'oscillateur à
quartz
2.3.4 ULes
caractéristiquesU [7]
Le tableau présenté ci-dessous désigne la
quantité de ressources disponible pour les différents composants
de la série 4000E proposée par le fabricant Xilinx.
|
Device
|
Logic cells
|
Max logic
Gates
(No RAM)
|
Max RAM
Bits
(No logic)
|
Typical
Gate Range
(Logic and RAM)
|
CLB
Matrix
|
Total
CLBs
|
Number
Of
Flip-Flops
|
Max.
User I/O
|
|
XC4003E
|
238
|
3,000
|
3,200
|
2,000- 5,000
|
10×10
|
100
|
360
|
80
|
|
XC4005E/XL
|
466
|
5,000
|
6,272
|
3,000-9,000
|
14×14
|
196
|
616
|
112
|
|
XC4006E
|
608
|
6,000
|
8,192
|
4,000-12,000
|
16×16
|
256
|
768
|
128
|
|
XC4008E
|
770
|
8,000
|
10,368
|
6,000-15,000
|
18×18
|
324
|
936
|
144
|
|
XC4010E/XL
|
950
|
10,000
|
12,800
|
7,000-20,000
|
20×20
|
400
|
1,120
|
160
|
|
XC4013/XL
|
1368
|
13,000
|
18,432
|
10,000-30,000
|
24×24
|
578
|
1,536
|
192
|
|
XC4020E/XL
|
1862
|
20,000
|
25,088
|
13,000-40,000
|
28×28
|
784
|
2,016
|
224
|
|
XC4025E
|
2432
|
25,000
|
32,768
|
15,000-45,000
|
32×32
|
1,024
|
2,560
|
256
|
|
XC4028EX/XL
|
2432
|
28,000
|
32,768
|
18,000-50,000
|
32×32
|
1,024
|
2,560
|
256
|
|
XC4036EX/XL
|
3078
|
36,000
|
41,472
|
22,000-65,000
|
36×36
|
1,296
|
4,576
|
352
|
|
XC4044XL
|
3800
|
44,000
|
51,200
|
27,000-80,000
|
40×40
|
1,600
|
3,840
|
320
|
|
XC4052XL
|
4598
|
52,000
|
61,952
|
33,000-100,000
|
44×44
|
1,936
|
4,576
|
352
|
|
XC4062XL
|
5472
|
62,000
|
73,728
|
40,000-130,000
|
48×48
|
2,304
|
5,376
|
384
|
|
XC4085XL
|
7448
|
85,000
|
100,352
|
55,000-180,000
|
56×56
|
3,136
|
7,168
|
448
|
UTableau2.1 : URessources de
la série 4000EU
Ces composants sont disponibles dans tous types de
boîtiers adaptés au nombre de sorties et à la technologie
utilisée pour le montage des circuits FPGA sur des cartes
électroniques. Nous pouvons utiliser des boîtiers de type PGA,
PLCC et PQFP.
2.3.5 Technique de programmation des FPGA [7]
Les circuits FPGA ne possèdent pas de programme
résident. A chaque mise sous tension, il est nécessaire de les
configurer. Leur configuration permet d'établir des interconnexions
entre les CLB et IOB. Pour cela, ils disposent d'une RAM interne dans laquelle
sera écrit le fichier de configuration. Le format des données du
fichier de configuration est produit automatiquement par le logiciel de
développement sous forme d'un ensemble de bits organisés en
champs de données. Le FPGA dispose de quatre modes de chargement et de
trois broches M0, M1, M2 lesquelles définissent les différents
modes. Ces modes définissent les différentes méthodes pour
envoyer le fichier de configuration vers le circuit FPGA, selon deux approches
complémentaires :
· configuration automatique, le circuit FPGA est
autonome,
· configuration externe, l'intervention d'un
opérateur est nécessaire.
· M0 M1 M2 Mode sélectionné
o 0 0 0 maître série
o 0 0 1 maître parallèle bas
o 0 1 1 maître parallèle haut
o 1 0 1 périphérique
o 1 1 1 esclave série
2.3.5.1 Mode maître série
Le mode maître série utilise une mémoire
à accès série de type registre à décalage
commercialisée par le fabricant Xilinx. Le programme est
préalablement chargé par le système de
développement utilisé pour le circuit FPGA. Le FPGA
génère tous les signaux de dialogue nécessaires pour la
copie du contenu de la PROM dans sa RAM interne, lorsque la copie est
terminée, il bascule le signal DONE pour le signaler au circuit. Comme
nous pouvons le remarquer sur la figure, une seule PROM peut configurer
plusieurs circuits FPGA avec la même configuration ou plusieurs PROM
peuvent configurer plusieurs FPGA en chaîne où le premier des
circuits FPGA est le maître et génère l'horloge. Les
données en provenance des PROM sont envoyées aux autres circuits
FPGA par la sortie DOUT de ce premier
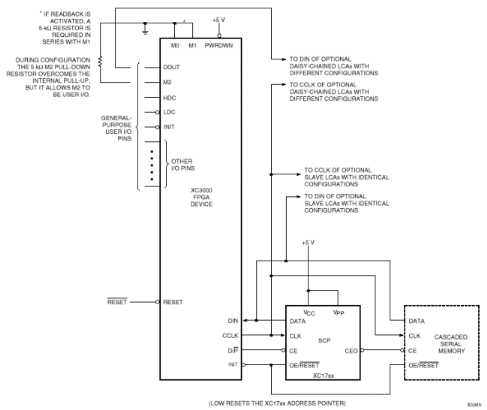
Figure2.14 : Mode maître
série
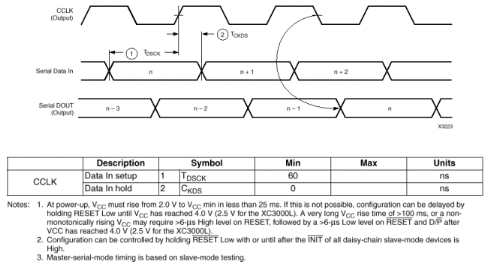
Figure2.15 : Schémas de programmation en
mode maître série
On dispose aussi d'un mode maître-parallèle
où le FPGA est relié en parallèle à une EPROM
classique, de même qu'un mode passif type périphérique dans
lequel le FPGA est considéré comme un périphérique
de uP et peut-être configuré à partir de celui-ci
2.3.5.2 Mode esclave
Dans ce mode, le programme de configuration peut être
envoyé à partir d'un PC, d'une station de travail ou à
partir d'un autre circuit FPGA. Le circuit FPGA maître peut être
interfacé à une mémoire en mode parallèle ou
série sans apporter aucune modification au niveau du câblage des
circuits FPGA esclaves. C'est souvent le mode exploité pour la mise au
point d'une configuration.
2.3.6 Les outils de développement des FPGA
[7]
Xilinx a développé des logiciels de
développement performants capables de fonctionner sur des stations de
travail telles que Sun, Appolo, Dec et sur des PC AT disposant d'une
mémoire suffisante. La programmation des circuits FPGA est
réalisée à l'aide des logiciels Viewlogic (Workview Office
7.31) et Xact (Design Manager 6.01). Elle est décomposée en
plusieurs étapes :
· la synthèse logique,
· la simulation fonctionnelle,
· l'optimisation, la projection et le placement /
routage,
· la simulation temporelle,
· la génération de fichier de
configuration.
2.3.6.1 La synthèse logique
La synthèse logique peut s'effectuer de diverses
manières avec différentes interfaces afin de
générer le circuit électrique, parmi lesquelles nous
pouvons citer :
· une entrée de type équations logiques de
" haut niveau ", de table de vérité et de machine d'état
avec une interface comme ABEL,
· une entrée de type schématique " bas
niveau " avec une interface comme ViewDraw,
· une entrée de type textuelle " haut niveau "
avec le VHDL à l'aide d'une interface comme ViewSynthesis, Synopsis,
Alliance et ISE ou le HDL de Verilog à l'aide d'une interface comme
Cadence Opus.
Nous allons voir en détail la synthèse logique
avec une entrée schématique et une entrée en VHDL.
2.3.6.1.1 Saisie de schéma
A l'aide de l'interface ViewDraw, la réalisation de
circuits se fait à base de cellules standards (portes logiques
pré caractérisées). On décrit la structure d'un
circuit à l'aide de connexions sur des cellules de base à partir
d'une librairie. Il existe deux types de cellules dans la librairie Xilinx :
· les soft-macros qui sont implantées en fonction
des flips-flops et des générateurs de fonctions disponibles,
· les hard-macros qui sont préroutées et
utilisent complètement les CLB qu'elles occupent.
La saisie de schéma à partir de cellules de base
permet un développement " bas niveau " qui rend difficile la
réalisation de circuits complexes où chaque changement ou
amélioration remet en cause toute la description. Cette contrainte a
conduit à étudier des techniques de génération de
circuits à partir de spécifications de " haut niveau " tel que le
VHDL (VHSIC Hardware Description Language avec VHSIC : Very High Speed
Integrated Circuits) qui se traduit en français par : langage de
description de matériel traitant des circuits intégrés
à très grande vitesse.
2.3.6.1.2 La synthèse en VHDL
La méthodologie [XILI98] [VIEW94] de la synthèse
en VHDL se compose de trois étapes :
· spécification en VHDL,
· synthèse du code VHDL,
· implantation physique.
2.3.6.1.2.1 Spécification en
VHDL
Le langage VHDL est un langage de description de
matériel qui permet de synthétiser des fonctions logiques
complexes. A l'aide de ce langage, la première description
définit la fonctionnalité du circuit en terme de blocs
définis " haut niveau ". Progressivement, les blocs sont
détaillés précisément jusqu'à une
description proche des ressources matérielles. En effet, le langage VHDL
autorise trois niveaux de description :
· le niveau structurel décrit le câblage des
composants élémentaires,
· le niveau flot de données décrit les
transformations d'un flot de données de l'entrée à la
sortie,
· le niveau comportemental décrit le
fonctionnement par des blocs programmes appelés Processus qui
échangent des données au moyen de signaux comprenant des
instructions séquentielles.
2.3.6.1.2.2 Synthèse du code
VHDL
La synthèse permet à partir d'une
spécification VHDL, la génération d'une architecture au
niveau transfert de registre RTL (register transfert level) qui permet
l'ordonnancement et l'allocation de ressources sans une représentation
physique, compilable par un outil de synthèse logique. Cette
étape est réalisable à condition de se limiter à un
sous ensemble du langage VHDL qui soit strictement synthétisable.
2.3.6.1.2.3 Implantation physique
La spécification VHDL est directement
émulée sur un support matériel tel qu'un circuit FPGA en
précisant la famille utilisée pour une implantation physique du
circuit. La compilation du code VHDL en code FPGA permet de
générer le schéma correspondant et une netlist (XNF)
constituée d'une liste d'équations booléennes et
d'informations portant sur les entrées / sorties du circuit. L'outil de
synthèse ViewSynthesis ne permet pas de faire une simulation
comportementale à partir du code VHDL, par conséquent il faut
réaliser ces trois étapes à tous les niveaux de conception
avant de faire une simulation fonctionnelle.
2.3.6.2 Simulation fonctionnelle
ViewSim est une interface qui, à partir de vecteurs
d'entrée (reset, clk...etc.) appliqués sur certains noeuds du
schéma et à partir d'une modélisation des composants, va
générer sur chaque noeud du schéma des signaux
représentant le fonctionnement réel du circuit. Nous pouvons
visualiser la forme des signaux à l'aide de l'interface ViewTrace. La
simulation fonctionnelle ne tient pas compte des capacités de liaison
dues au routage entre les différentes cellules. Elle permet donc de
vérifier uniquement la validité du circuit par rapport au cahier
des charges d'un point de vue fonctionnel et non d'un point de vue temporel.
2.3.6.3 Optimisation, projection et placement /
routage
2.3.6.3.1 Optimisation
Avant l'utilisation de la netlist, celle-ci est
optimisée. Cette étape gère les problèmes de
sortance des signaux par la duplication des fonctions logiques de sortance
insuffisante, afin de multiplier les sortances. Les signaux inutilisés
sont retirés, les expressions booléennes sont simplifiées,
les signaux équivalents sont détectés.
2.3.6.3.2 Projection
La phase de projection dépend du circuit
utilisé, les équations de la netlist sont transformées,
regroupées en de nouvelles équations ayant un nombre d'arguments
inférieur ou égal au nombre de paramètres du bloc logique
correspondant à la famille de circuit utilisée.
2.3.6.3.3 Placement / routage
L'étape suivante consiste à attribuer les
cellules (CLB) du circuit à chaque équation
délivrée par la projection et à définir les
connexions. L'algorithme de placement place physiquement les différentes
cellules et les chemins d'interconnexion dessinés entre les cellules
afin de faciliter le routage. Des directives jointes à la netlist
permettent une bonne répartition des cellules. Ces trois
opérations sont réalisées par le logiciel Xact (Designer
Manager).
2.3.6.4 Simulation temporelle
Il s'agit de vérifier la fonctionnalité du
circuit en prenant en compte par un calcul estimatif les longueurs
d'interconnexion et les retards apportés par les capacités
parasites liées au partionnement et au routage. La simulation temporelle
vérifie que la fonctionnalité n'a pas été
modifiée par l'introduction des délais de propagation et reste
conforme au cahier des charges.
2.3.6.5 Génération du fichier de
configuration
La dernière étape consiste à
générer un fichier de configuration appelé Bitstream dans
une PROM. Ce fichier contient les informations fournies au composant FPGA
Xilinx afin qu'il prenne la configuration souhaitée. Ci-dessous,
l'organigramme représentant la procédure de programmation des
circuits FPGA :
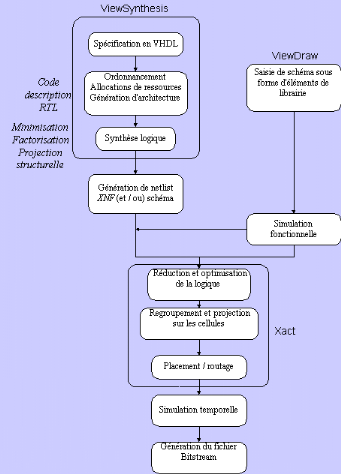
Figure2.16 : Programmation des composants FPGA
[7]
Conclusion
Dans ce chapitre, nous avons présenté les
circuits de type FPGA dont nous précisons ici les principaux avantages :
· Le premier argument est la souplesse de programmation
qui permet l'emploi conjoint d'outils de schématique aussi bien que
l'exploitation d'un langage de haut niveau tel VHDL. Ce qui permet de
multiplier les essais, d'optimiser de diverses manières l'architecture
développée, de vérifier à divers niveaux de
simulation la fonctionnalité de cette architecture.
· Le second argument est évidemment la nouvelle
possibilité de reconfiguration dynamique partielle ou totale d'un
circuit ce qui permet d'une part, une meilleure exploitation du composant, une
réduction de surface de silicium employé et donc du coût,
et d'autre part, une évolutivité assurant la possibilité
de couvrir à terme des besoins nouveaux sans nécessairement
repenser l'architecture dans sa totalité. L'un des points forts de la
reconfiguration dynamique est effectivement de permettre de reconfigurer en
temps réel en quelques microsecondes tout ou partie du circuit, c'est
à dire de permettre de modifier la fonctionnalité d'un circuit en
temps quasi réel. Ainsi le même CLB pourra à un instant
donné être intégré dans un processus de filtrage
numérique d'un signal et l'instant d'après être
utilisé pour gérer une alarme. On dispose donc quasiment de la
souplesse d'un système informatique qui peut exploiter successivement
des programmes différents, mais avec la différence fondamentale
qu'ici il ne s'agit pas de logiciel mais de configuration matérielle, ce
qui est infiniment plus puissant.
· Notons enfin que ces circuits n'ont pas vocation
à concurrencer les super calculateurs, mais plutôt à offrir
une alternative en fonction de critères comme l'encombrement, les
performances et le prix, et sont de ce fait bien adaptés à des
applications de qualité dans le domaine des systèmes ambulatoires
ou nomades.
· Enfin il semble que de plus en plus fréquemment
les concepteurs de circuits ASIC préfèrent passer par
l'étape intermédiaire d'un FPGA ce qui est moins risqué
économiquement, puis une fois que le modèle FPGA est au point, il
est alors relativement aisé de le retranscrire dans une architecture de
type prédiffusé ou précaractérisés. Ce que
tous les fondeurs de silicium savent effectivement faire pour en faire un
circuit réellement personnalisé et confidentiel. Le FPGA
n'étant évidemment pas un circuit très
sécurisé sur le plan de la confidentialité puisqu'il
suffit d'analyser le contenu de la ROM associée pour remonter à
la schématique imaginée.
CHAPITRE 3 : LE LANGAGE VHDL ET LA CONCEPTION DE
CIRCUITS
3.1 UIntroductionU
En analysant l'évolution de la production industrielle
d'ASICS (Application Specific Integrated Circuit) ou de FPGA (Field
Programmable Gate Array), on constate que ceux-ci, bénéficiant
des progrès technologiques, sont de plus en plus complexes. On sait
intégrer à l'heure actuelle sur silicium des millions de portes
pouvant fonctionner à des fréquences supérieures à
600 MHz. On parle beaucoup de SOC (System On a Chip). En effet, plus de 80% des
ASICS futurs comporteront un ou plusieurs microprocesseurs. Par ailleurs, si on
considère qu'un ingénieur confirmé valide 100 portes par
jour, il lui faudrait 500 ans pour un projet de 12 millions de portes et ceci
pour un coût de 75 millions de dollars. Ceci parait totalement absurde et
si c'est pourtant réalisable cela est uniquement dû à
l'évolution des méthodes de CAO (flot de conception en spirale,
équipes travaillent en parallèle) intégrant en particulier
la réutilisation efficace d'un savoir antérieur. Le concepteur va
travailler avec des IP (Intellectual Property) s'il est intégrateur de
système, mais il peut être lui-même développeur d'IP
et la méthode qui devra le guider est appelée Design Reuse. Ces
expressions désignent des composants génériques incluant
des méthodes d'interfaçages rigoureuses et suffisamment
normalisées pour pouvoir être rapidement inclus dans un design
quelconque.
Dans ce chapitre, nous ferons comme nous l'avons
précisé en introduction, une brève présentation du
langage VHDL en présentant ici dans un premier temps son historique et
ensuite sa syntaxe. Nous terminerons ce chapitre par des exemples de
programmes.
3.2 UHistorique du VHDL (Very
High Speed Integrated Circuit, Hardware
Description Language) [11]
1980 Début du projet VHDL
financé par le US DoD
1985 Première version 7.2
publique
1987 Première version du standard IEEE Std
1076-1987
1993 Mise à jour du standard (IEEE Std
1076-1993)
2002 Mise à jour du standard (IEEE Std
1076-2002)
UTableau3.2aU :
UHistorique du VHDLU
Le langage VHDL est un standard IEEE depuis 1987 sous la
dénomination IEEE Std. 1076-1987 (VHDL-87). Il est sujet à
révision tous les cinq ans. Une première révision, qui
corrige certaines incohérences de la version initiale et qui ajoute de
nouvelles fonctionnalités, a eu lieu en 1994 (IEEE Std. 1076-1993 ou
VHDL-93). La dernière révision est celle de 2002 (IEEE Std.
1076-2002 ou VHDL-2002).
L'IEEE (Institute of Electrical and Electronics Engineers) est
un organisme international qui définit entre autres des normes pour la
conception et l'usage de systèmes électriques et
électroniques.
3.3 USYNTAXEU [15]
Nous présentons d'abord la structure d'un module en
VHDL.
3.3.1 U Les librairies
U
Les librairies contiennent les fonctions et les types dont
nous avons besoin pour compléter le module défini ci-dessous.
Ces outils sont constitués en paquets (packages) et on
y accède par le mot clé use.
Voici la syntaxe de la déclaration d'une
bibliothèque :
library
<nom_librairie> ;
use
<nom_librairie>.<nom_package>.[all
| <part>] ;
U
ExempleU :
library IEEE ;
use
IEEE.std_logic_1164.all ;
use
IEEE.std_logic_arith.all;
use
IEEE.std_logic_unsigned.all;
3.3.2 ULa déclaration
d'entité
Une entité doit définir l'interface pour un
module. La déclaration d'une entité commence par le nom de
l'entité <nom_entité> et se termine bien sûr par le
end de la déclaration. Ensuite c'est la déclaration des ports
en précisant au cas échéant les ports d'entrées et
de sorties de notre module. Voici donc présenté ci-dessous
l'interface de notre conception, et précisons ici que les
déclarations sont lues ou établie non sans l'accompagnement
d'une architecture.
entity <nom_entite> is
port ( <nom_port> :
<mode> <type> ;
<autre_ ports>...
) ;
end <nom_entite> ;
U
ExempleU :
entity entite_or is
port (
input_1 : in std_logic;
Input_2: in std_logic;
Output: out std_logic);
end entité_or;
3.3.3 UArchitectureU
Une architecture présente plusieurs autres styles de
syntaxe VHDL, mais en ce qui nous concerne dans ce document nous n'allons pas
parler d'eux toutes mais nous présenterons ici celles qui sont les plus
utilisées dans ce chapitre. Pour maintenant donc, nous en
présentons juste une simple liste.
Voici donc la syntaxe d'une architecture :
architecture <nom_arc> of
<nom_entite> is
--liste de déclaration (déclarations des signaux,
déclaration des composants, etc.)
begin
-- corps de l'architecture
end <nom_arc>
UExempleU :
architecture arc_entite_or of
entite_or is
output: out std_logic;
Input_1, input_2: in std_logic;
begin
output <= input or input_2;
end arc_entité_or;
Maintenant nous allons présenter la syntaxe des
déclarations ne faisant obligatoirement partie de notre module.
3.3.4 UDéclarations des
signauxU
Très souvent, nous aurons besoin de signaux internes
dans le comportement de notre architecture. Ceci pourrait être une valeur
interne à stocker ou plutôt des composants à connecter,
toutefois les déclarations restent inchangées et sont toutes
faites entre les mots clés is et begin
de l'architecture.
En voici donc la syntaxe :
signal <nom_signal> :
type ;
UExemplesU :
signal port_i :
std_logic ;
signal bus_signal :
std_logic_vector(15 downto 0) ;
signal count : integer range 0 to
31;
3.3.5 UDéclaration des constantsU
Occasionnellement, nous aurons besoin de déclarer des
constants. Leur syntaxe est la suivante :
constant <nom_constant > :
type := < valeur_initiale> ;
UExemplesU :
constant etat_1 :
std_logic_vector := `'01'' ;
constant etat_2 :
std_logic_vector := `'10'' ;
constant addr_max :
integer :=1024 ;
3.3.6 UDéclaration de composantsU
Nous aurons à les utiliser assez fréquemment
puisqu'ils sont une clé pour la description structurale de nos modules.
Essentiellement, ceux-ci sont une déclaration d'interface, ainsi
l'architecture dont l'architecture devra en tenir compte. Les gammes de
syntaxe marcherons si cette déclaration correspond à son usage,
mais cela synthétisera uniquement si la déclaration correspond
à un composant existant. Très souvent, il est possible de
simplement recopier la déclaration de l'entité du composant et de
changer le mot clé `entity' par `component `.
En voici donc la syntaxe de la déclaration :
component <nom_component> is
port (
les déclarations de ports ayant aussi été
faite dans la déclaration « entity » ;
end component;
UExempleU :
component or_entit
is
port ( input_1 : in std_logic ;
input_2: in std_logic;
output : out std_logic);
end component;
3.3.7 UDeclarations de variableU
Les variables sont beaucoup utilisées pour garder la
trace de certaines valeurs dans le contexte d'un processus ou d'une fonction,
mais ne peuvent être utilisées en dehors des processus or
fonctions. Par ailleurs, elles ne représentent pas
nécessairement un fils dans l'appareil et sont traitées par
l'outil de synthétisation séquentielle. Ceci signifie qu'elles ne
se comportent pas nécessairement comme le font les signaux.
Leur syntaxe est la suivante :
variable <nom_variable> is :
type;
UExemplesU :
variable count_v : integer range 0
to 15;
variable data_v : std_logic_vector (7
downto 0);
variable condition_v: Boolean;
3.3.8 UDéclarations de typeU
Le mot clé type nous permet de
définir notre propre type de données en VHDL. Ceux-ci sont
interprétés et subséquentiellement
synthétisés par les outils de synthétisation. Nous pouvons
utiliser les types pour créer nos propres types de données ou des
tableaux de types de données existant.
Leur syntaxe est la suivante :
type <nom_type>
is (<value>);
UExemplesU :
type enum_type
is (a,b,c, ...,z);
type int_array is array
integer range 0 to 3;
3.3.9 UExpressions logiquesU
Le fondement de la plus part du VHDL que nous écrirons
est l'interaction logique entre les signaux dans notre module.
En voici la syntaxe :
[not] <identificateur>
[and | or |
nor | nand |
xor | xnor | ...]
[<identificateur>]
];
UExemple U:
not signal_1;
signal_1 and signal_2;
(not signal_1)
and (signal_2 xor (signal_3
or not signal_4))
3.3.10 UDéclarations
If-Then-elseU
En voici la syntaxe :
if <condition>
then instructions
[elseif <condition>
then instructions
else instructions]
end if.
UExempleU :
if condition_v_1='1'
then
out_vector <='001'
elseif condition_v_2='1'
then
out_vector <=»110»
else
out_vector <= «000»
end if ;
3.3.11 UDéclaration CaseU
Voici sa syntaxe :
case <expression>
is
when <choice(s)> =>
<assignments>;
when ...
[when others => ... ]
end case;
UExempleU :
case scancode
is
when x»14» =>
integer_signal<= 1;
when x»18» =>
integer_signal<= 2;
when x»19» |
x»20» | x»21» | => integer_signal<= 3;
when others
=> integer_signal <= 0;
end case ;
Maintenant dans ce qui suit nous présentons la syntaxe
structurale.
3.3.12 USignaux assignésU
Voici la syntaxe :
<signal_name> <= <expression> ;
UExempleU :
std_logic_signal_1 <= not
std_logic_signal_2;
std_logic_signal <= signal_a and
signal_b;
large_vector (15 downto 6) <= small_vector (10 downto 0);
3.3.13 UVariable assignéeU
Les variables assignées ne sont pas si
différentes des signaux assignés. La différence clé
se trouve dans l'opérateur d'assignation qui est différent. Nous
pouvons cependant assigner à partir des variables pour les signaux et
vice versa.
En voici la syntaxe :
<nom_variable> := <expression>
UExempleU :
boolean_v:= true;
temp_v (3 downto 0):= s1_vector_signal
(7 downto 4);
3.3.14 ULes processusU
Les processus sont généralement les piliers du
comportement de notre code. Ils facilitent la spécification des
horloges aussi bien que leur synchronisation parmi les signaux assignés.
En général, nous utiliserons les processus lorsque un signal
assigné est dépendant du changement d'un autre.
Syntaxe :
[<nom_processus> :] process
(<signaux sensibles>)
déclarations de variable
déclarations de constantes
begin
instructions
end process;
UExempleU :
output_process: process
(flag_signal)
begin
if flag_signal = `1'
then
output_vector <= «010»;
else
output_vector <= «101»;
end if;
end process;
3.3.15 UInstantiation de composantU
Juste au tant que les processus sont les pilliers du
comportement de notre code, l'instantiation de composant est la clé des
caractéristiques de notre code structural.
Voici sa syntaxe :
<identificateur_composant> : <nom_composant>
port map(
<nom_port> => <signal_assigne>,...
) ;
UExempleU :
or_ent_1 : or_entity
port map(
input_1 => input_1_sig,
input_2 =>input_2_sig,
output=> output_sig);
Dans cette partie nous présentons les différents
types de données que l'on rencontre dans le VHDL.
3.3.16 Ustd_logicU
Le type de données std_logic est le plus couramment
utilisé en VHDL. Il est une partie du package std_logic_1164 dans la
librairie IEEE et est utilisé pour représenter des valeurs
logiques à deux états réguliers (tels que `0' et `1')
aussi bien que d'autres valeurs logiques communes tel que la haute
impédance (`Z').
Par ailleurs pour ce type de données c'est le
std_logic_vector, qui représente des bus en VHDL. Ce type de
données agit comme un tableau de std_logic `bits' et en outre
représente une collection telle que
STD_LOGIC --
`U' ,'X','0','1','Z','W','L','H','-`
STD_LOGIC_VECTOR -- rangé naturelle de
STD_LOGIC
3.3.17 UbooleanU
Un autre type logique est le type booléen. C'est un
type standard de VHDL qui est typiquement utilisé comme une variable ou
comme une constante pour signifier le sort d'une condition.
BOOLEAN
-- vrai ou faux
3.3.18 UbitsU
BIT
-- `0','1'
BIT_VECTOR (Natural) --
Tableau de bits
3.3.19 Utypes rangésU
Il y a un couple de moyens permettant la représentation
des nombres en VHDL. L'un d'entre eux est utilisé pour la
représentation en binaire/hexadécimal qui n'est pas possible par
le std_logic_vector. Alors que ceci est pleinement possible pour
représenter des signaux physiques, les entiers quand à eux sont
plus faciles à utiliser. En tant que tel, un type entier et deux sous
types ont été définis en VHDL. Il y a cependant, un petit
problème. Les entiers ne sont pas implémentés en fils. Ils
sont translatés par bus. par conséquent, pour limiter les fils
physiques qui sont implémentés par la conception, et par la
suite rendre l'implémentation de la conception plus efficace, nous
préférons limiter les entiers à des rangées bien
spécifiées.
INTEGER
-- 32 or 64 bits
NATURAL
-- entiers >= 0
POSITIVE
-- entiers > 0
3.3.20 UOpérateurs logiques
et arithmétique définis dans le langage VHDLU [12]
[15]
Expression = formule pour calculer une valeur
Priorité des opérateurs (de la plus basse
à la plus haute)
· Logiques: and or nand nor xor xnor
· Relationnels: = /= < <= >
>=
· Décalage et rotations: sll srl sla
sra rol ror
· Addition: + - &
· Signe (unaires): + -
· Multiplication: * / mod
rem
· Divers: ** abs
not
UExemplesU
-- soient PI et R de type real
PI*(R**2) / 2
2.0*PI*R
-- soient A et B de type integer
B /= 0 and A/B > 1 -- court-circuit
A**2 + B**2
4*(A + B)
(A + 1) mod B
-- soient A, B et C de type boolean
A and B and C --
évaluation de gauche à droite
-- idem pour or, xor and
xnor
A nor (B nor C) --
parenthèses requises, nor pas associatif
-- idem pour nand
Une expression est une formule qui spécifie comment
calculer une valeur. Une expression est constituée d'opérandes
(termes) et d'opérateurs.
Les termes d'une expression sont typiquement des valeurs
littérales (p.ex. B"001101") ou des identificateurs représentant
des objets (constantes, variables, signaux).
Les opérateurs sont associés à des types.
Chaque opérateur appartient à un niveau de
précédance ou de priorité qui définit
l'ordre dans lequel les termes de l'expression doivent être
évalués. L'usage de parenthèse permet de rendre les
niveaux de priorité explicites ou de changer les niveaux par
défaut.
Les opérateurs logiques and,
nand, or et nor utilisent un
mécanisme de court-circuit lors de
l'évaluation.
L'opérateur and/nand
n'évalue pas le terme de droite si le terme de gauche
s'évalue à la valeur '0' ou false.
L'opérateur or/nor
n'évalue pas le terme de droite si le terme de gauche
s'évalue à la valeur '1' ou true.
Les opérateurs relationnels ne peuvent s'appliquer que
sur des opérandes de même type et retournent toujours une valeur
de type boolean. Les opérandes doivent être d'un type scalaire ou
de type tableau mono-dimensionnel avec éléments d'un type discret
(entier ou énuméré). Les opérateurs "=" et "/=" ne
peuvent pas avoir des opérandes de type fichier.
3.4 Ules paquetagesU
[11]
Un paquetage permet de grouper des déclarations et des
sous-programmes et de les stocker dans une bibliothèque.
package nom-paquetage
is
{ déclaration [ | corps-sous-programme ]
}
end [ package ] [
nom-paquetage ] ;
en-tête de paquetage
package body nom-paquetage
is
{ déclaration [ | corps-sous-programme ]
}
end [ package body ]
[nom-paquetage ] ;
corps de paquetage
Exemple: en-tête de paquetage ne contenant
que des déclarations de
constantes et de (sous-)types.
Ci-dessous nous avons donnés quelques paquetages et
leur description.
3.4.1 U Paquetage
STANDARDU
package STANDARD is
type boolean is (false,
true);
type bit is ('0', '1');
type character is ( ... 256
caractères 8 bits... );
type severity_level is (note,
warning, error, failure);
type integer is range
dépend de l'implantation;
subtype natural is integer
range 0 to integer'high;
subtype positive is integer
range 1 to integer'high;
type real is range
dépend de l'implantation;
type time is range
dépend de l'implantation
units
fs; ps = 1000 fs; ...; hr = 60 min;
end units;
subtype delay_length is time
range 0 to time'high;
impure function now return
delay_length;
type string is array (positive
range <>) of character;
type bit_vector is array
(natural range <>) of bit;
type file_open_kind is
(read_mode, write_mode, append_mode);
type file_open_status is
(open_ok, status_error, name_error, mode_error);
attribute foreign: string;
end package
Le paquetage STANDARD déclare les types et sous-types
prédéfinis du langage, la fonction now (qui retourne le temps
simulé courant) et l'attribut foreign.
Les déclarations du paquetage STANDARD sont
automatiquement visibles dans toute unité de conception. Il se trouve
dans bibliothèque STD.
3.4.2 UPaquetage
TEXTIOU
package TEXTIO is
type line is access string;
type text is file of string;
type side is (right, left);
subtype width is natural;
file input: text open read_mode is "std_input";
file output: text open write_mode is "std_output";
procedure readline (file f: text; l: out line);
procedure writeline (file f: text; l: inout line);
-- pour chaque valeur de type prédéfini:
procedure read (l: inout line; value: out bit; good: out
boolean);
procedure read (l: inout line; value: out bit);
...
procedure write (l: inout line; value: in bit; justified: in
side: = right; field: in width := 0);
...
procedure write (l: inout line; value: in real; justified: in
side := right;
field: in width := 0; digits: in natural := 0);
procedure write (l: inout line; value: in time; justified: in
side := right;
field: in width := 0; unit: in time := ns);
end package TEXTIO;
Le paquetage prédéfini TEXTIO déclare des
types et des sous-programmes pour la manipulation de fichiers textes. Il
déclare aussi des procédures pour lire et écrire les
valeurs d'objets de types prédéfinis.
La lecture d'un fichier texte est effectuée en deux
étapes: 1) lire une ligne complète avec la procédure
readline et stocker la ligne dans un tampon de type line, 2) lire chaque
élément de la ligne lue avec l'une des versions de la
procédure read relative au type de valeur à lire. La
procédure read peut retourner l'état de l'opération par le
paramètre good.
L'écriture dans un fichier est aussi effectuée
en deux étapes:
1) une ligne complète est construite dans un tampon de
type line au moyen d'une des versions de la procédure write, en fonction
des types de valeurs à écrire,
2) la ligne est écrite dans le fichier avec la
procédure writeline.
Notes:
· Si L est le tampon stockant une ligne lue dans un
fichier, chaque opération read sur L consomme un élément
et a pour effet que la valeur retournée par L'length
décroît. La fin de la ligne est ainsi atteinte lorsque L'length =
0.
· La fonction endfile qui teste la fin de fichier est
implicitement déclarée lors de la déclaration du type
fichier text.
L'utilisation du paquetage TEXTIO dans une unité de
conception requiert la spécification d'une clause de contexte.
Ce paquetage se trouve dans la bibliothèque STD
Requiert la clause de contexte use
STD.TEXTIO.all;
3.4.3 UPaquetage STD_LOGIC_1164
(déclaration)
package STD_LOGIC_1164 is
type std_ulogic is ('U', --
un-initialised
'X', -- forcing unknown
'0', -- forcing 0
'1', -- forcing 1
'Z', -- high impedance
'W', -- weak unknown
'L', -- weak 0
'H', -- weak 1
'-' -- don't care);
type std_ulogic_vector is array
(natural range <>) of
std_ulogic;
function resolved (s: std_ulogic_vector)
return std_ulogic;
subtype std_logic is resolved
std_ulogic;
type std_logic_vector is array
(natural range <>) of
std_logic;
-- opérateurs logiques surchargés
and, nand, or,
nor, xor, xnor,
not
-- fonctions de conversion: to_bit, to_bitvector, to_stdulogic,
to_stdlogicvector,
to_stdulogicvector
-- plus autres fonctions...
end package STD_LOGIC_1164;
Le paquetage STD_LOGIC_1164 ne fait pas partie de la
définition du langage VHDL, mais est défini comme un standard
séparé.
Le paquetage déclare deux types logiques à neuf
états std_ulogic (non résolu) et std_logic (résolu):
· Les états '0', '1' et 'X'
représentent respectivement l'état faux, vrai et inconnu (ou
indéterminé).
· Les états 'L', 'H' et 'W'
représentent des états résistifs du type pull-down
ou pull-up.
· L'état 'Z' représentent un
état haute-impédance.
· L'état 'U' est l'état initial par
défaut et identifie les signaux qui n'ont pas été
affectés en simulation.
· L'état '-' est parfois utilisé pour
des vecteurs de test ou en synthèse pour spécifier que certains
bits ne sont pas importants.
Le paquetage déclare des versions des opérateurs
logiques pour ces nouveaux types. Il n'est par contre pas possible d'utiliser
sans autre des opérateurs arithmétiques sur des objets
appartenant à ces types.
L'utilisation du paquetage STD_LOGIC_1164 dans une
unité de conception requiert la spécification d'une clause de
contexte. Il se trouve dans bibliothèque IEEE.
Requiert la clause de contexte
library IEEE;
use IEEE.std_logic_1164.all;
3.4.4 UPaquetage STD_LOGIC_1164 (corps)
Corps du paquetage (extrait)
package body STD_LOGIC_1164 is
...
type stdlogic_table is array (std_ulogic, std_ulogic) of
std_ulogic;
constant resolution_table : stdlogic_table := (
--| U X 0 1 Z W L H - |
('U', 'U', 'U', 'U', 'U', 'U', 'U', 'U', 'U'), -- | U |
('U', 'X', 'X', 'X', 'X', 'X', 'X', 'X', 'X'), -- | X |
('U', 'X', '0', 'X', '0', '0', '0', '0', 'X'), -- | 0 |
('U', 'X', 'X', '1', '1', '1', '1', '1', 'X'), -- | 1 |
('U', 'X', '0', '1', 'Z', 'W', 'L', 'H', 'X'), -- | Z |
('U', 'X', '0', '1', 'W', 'W', 'W', 'W', 'X'), -- | W |
('U', 'X', '0', '1', 'L', 'W', 'L', 'W', 'X'), -- | L |
('U', 'X', '0', '1', 'H', 'W', 'W', 'H', 'X'), -- | H |
('U', 'X', 'X', 'X', 'X', 'X', 'X', 'X', 'X') -- | - |);
...
...
function resolved (s : std_ulogic_vector) return std_ulogic is
variable result : std_ulogic := 'Z'; -- default state
begin
if s'length = 1 then return s(s'low); -- single driver case
else
for i in s'range loop
result := resolution_table(result, s(i));
end loop;
end if;
return result;
end function resolved;
...
end package body STD_LOGIC_1164;
Le corps de paquetage inclut les corps des sous-programmes
déclarés dans la déclaration de paquetage
correspondante.
A titre d'exemple, la fonction de résolution resolve
utilise une table constante resolution_table pour définir les valeurs
résolues de toutes les paires de sources possibles. Le corps de la
fonction traite d'abord le cas pour lequel le signal résolu n'a qu'une
seule source de manière à optimiser le temps de calcul. Dans le
cas contraire, une boucle est utilisée pour appliquer la table de
résolution à chaque source du signal.
3.4.5 UPaquetages
mathématiques U
package MATH_REAL is
-- constantes e, pi et dérivées
-- fonctions sign, ceiling, floor, round, min, max
-- procédure random
-- racine carrée, racine cubique, exponentiation
-- fonction exponentielle et logarithmes
-- fonctions trigonométriques (sin, cos, tan, etc.)
-- fonctions hyperboliques (sinh, cosh, tanh, etc.)
end package MATH_REAL;
package MATH_COMPLEX is
-- type complexe (formes cartésienne et polaire)
-- constantes 0, 1 et j
-- fonctions abs, argument, negation, conjugate
-- racine carrée, exponentiation
-- fonctions arithmétiques avec opérandes
cartésiens et polaires
-- fonctions de conversion
end package MATH_COMPLEX;
Seuls les opérateurs arithmétiques de base sont
a priori disponibles pour un objet du type prédéfini real. Les
paquetages MATH_REAL et MATH_COMPLEX ne font pas partie du standard VHDL de
base, mais sont définis comme des standards séparés.
Il se trouve dans bibliothèque IEEE
Requièrent la clause de contexte
library
IEEE;
use
IEEE.math_real.all;
use
IEEE.math_complex.all;
3.4.6 UPaquetage
NUMERIC_BITU
package NUMERIC_BIT is
type unsigned is array (natural range <>) of bit; --
équiv. à type entier non signé
type signed is array (natural range <>) of bit; --
équiv. à type entier signé
-- opérateurs abs et "-" unaire
-- opérateurs arithmétiques: "+", "-", "*", "/",
rem, mod
-- opérateurs relationnels: "<", ">", "<=",
">=", "=", "/="
-- opérateurs de décalage et rotation: sll, srl,
rol, ror
-- opérateurs logiques: not, and, or, nand, nor, xor,
xnor
-- fonctions de conversion:
-- to_integer(arg)
-- to_unsigned(arg, size)
-- to_signed(arg, size)
end package NUMERIC_BIT;
Utile pour disposer d'opérateurs arithmétiques sur
des opérandes de
types similaires (mais pas équivalents) au type
bit_vector.
Requiert la clause de contexte
library IEEE;
use
IEEE.std_logic_1164.all;
use
IEEE.numeric_bit.all;
Un objet de type (un) signed n'est pas directement compatible
avec un objet de type bit_vector. Une conversion de type est requise:
signal
S1: unsigned (7 downto 0);
signal
S2: bit_vector (7 downto 0);
S1 <=
unsigned (S2);
S2 <=
bit_vector (S1);
3.4.7 UPaquetage
NUMERIC_STDU
package NUMERIC_STD is
type unsigned is array (natural range <>) of std_logic; --
équiv. à type entier non signé
type signed is array (natural range <>) of std_logic; --
équiv. à type entier signé
-- opérateurs abs et "-" unaire
-- opérateurs arithmétiques: "+", "-", "*", "/",
rem, mod
-- opérateurs relationnels: "<", ">", "<=",
">=", "=", "/="
-- opérateurs de décalage et rotation: sll, srl,
rol, ror
-- opérateurs logiques: not, and, or, nand, nor, xor,
xnor
-- fonctions de conversion:
-- to_integer(arg)
-- to_unsigned(arg, size)
-- to_signed(arg, size)
end package NUMERIC_STD;
Utile pour disposer d'opérateurs arithmétiques
sur des opérandes de types similaires (mais pas équivalents) au
type std_logic_vector requiert la clause de contexte
library IEEE;
use
IEEE.std_logic_1164.all;
use
IEEE.numeric_std.all;
Un objet de type (un)signed n'est pas directement compatible avec
un objet de type std_logic_vector. Une conversion de type est requise:
signal S1: unsigned(7 downto 0);
signal S2: std_logic_vector(7 downto 0);
S1 <= unsigned (S2);
S2 <= std_logic_vector (S1);
3.5 Uliste des mots clés en
VHDL [12]
Ci dessous est rassemblé tous les mots
réservés du langage VHDL :
ABS ACCESS AFTER ALIAS ALL AND ARCHITECTURE ARRAY ASSERT
ATTRIBUTE BEGIN BLOCK BODY BUFFER BUS CASE COMPONENT CONFIGURATION CONSTANT
DISCONNECT DOWNTO ELSE ELSIF END ENTITY EXIT FILE FOR FUNCTION GENERATE GENERIC
GUARDED IF IN INOUT IS LABEL LIBRARY LINKAGE LOOP MAP MOD NAND NEW NEXT NOR NOT
NULL OF ON OPEN OR OTHERS OUT PACKAGE PORT PROCEDURE PROCESS RANGE RECORD
REGISTER REM REPORT RETURN SELECT SEVERITY SIGNAL SUBTYPE THEN TO TRANSPORT
TYPE UNITS UNTIL USE VARIABLE WAIT WHEN WHILE WITH XOR.
3.6 U les
littérauxU [12]
n Caractères: `0', `X', `a', `%'
n Chaînes: `'1110101'', `'XX'', `'bonjour'', `'$^&@!''
n Chaînes de bits: B''0010_1101'', X''2D'', O''055''
n Décimaux : 27, -5, 4E3, 76_562, 4.25
n Basés : 2#1001#, 8#65_07#, 16#C5#E+2
3.7 UExemples de quelques petits programmes
écris en VHDLU [11]
3.7.1 U Porte
« additionneur»
opa
opb
cin
cout
sum
![]()
UFigure3.1U :
UPorte « additionneur»U
entity add1 is
generic (
TP: time := 0 ns -- temps de propagation
);
port (
signal opa, opb, cin: in bit;
-- opérandes, retenue entrante
signal sum, cout : out bit --
somme, retenue sortante
);
end entity add1;
architecture dfl of add1
is
begin
sum <= opa xor opb xor
cin after TP;
cout <= (opa and opb) or
(opa and cin) or (opb and
cin) after TP;
end architecture dfl;
Ou encore avec un comportement séquentiel
architecture algo of add1
is
begin
process (opa, opb, cin)
variable tmp: integer;
begin
tmp := 0;
if opa = '1' then tmp
:= tmp + 1; end if;
if opb = '1' then tmp
:= tmp + 1; end if;
if cin = '1' then tmp
:= tmp + 1; end if;
if tmp > 1 then
cout <= '1' after TP;
else cout <= '0'
after TP; end if;
if tmp mod 2 = 0
then sum <= '0' after TP;
else sum
<= '1' after TP; end if;
end process;
end architecture algo;
3.4.2 UDeuxième
exempleU : Mémoire Set-Reset
UFigure3.2 :
UMémoire Set-ResetU
Ce deuxième exemple est purement didactique et non
synthétisable. Il modélise une mémoire Set-Reset avec
différenciations des retards à la montée et à la
descente.
entity memoire_rs is
port (s, r: in bit; q, qb :
OUT BIT);
end;
architecture processus of
memoire_rs is
constant Tplh : time := 2
ns;
constant Tphl : time := 1 ns;
signal qi : bit := `0';
signal qbi : bit := `1';
begin
n1 : process
variable qtmp : bit;
begin
wait on s, qi ;
qtmp := s nor qi; -- la primitive
nor
if qtmp /= qbi then --
Test du changement éventuel
if qtmp = `0'
then qbi <= qtmp after Tphl;
else
qbi <= qtmp after
Tplh;
end if;
end if;
end process;
n2 : process
variable qtmp : bit;
begin
wait on r, qbi ;
qtmp := r nor qbi; -- la
primitive NOR
if qtmp /= qi
then -- Test du changement eventuel
if qtmp = `0'
then
qi <= qtmp
after Tphl;
else
qi <= qtmp
after Tplh;
end if;
end if;
end process;
q <= qi;
qb <= qbi;
end;
CHAPITRE 4 : METHODOLOGIE
4.1 UIntroduction
Le problème de trouver les chemins les plus courts joue
un rôle central dans la conception et l'analyse des réseaux.
Plusieurs problèmes de routage peuvent être résolus comme
des problèmes de recherche du chemin le plus court une fois que le
coût approprié est assigné à chaque lien, en
reflétant par exemple sa bande passante disponible, le délai ou
taux d'échec de bit.
Il existe plusieurs algorithmes de détermination du
chemin le plus court si le coût dans un réseau est
caractérisé par une métrique additive positive. Le plus
populaire algorithme du plus court chemin est bien entendu l'algorithme de
Dijkstra qui est utilisé comme nous l'avons déjà dis dans
le protocole de routage OSPF (Internet's Open Shortest Path First).
Dans les chapitres qui précèdes, nous avons
parlé du routage, des composants FPGA et du langage VHDL, dans ce
chapitre nous allons faire comme une sorte de synthèse
c'est-à-dire que nous allons présenter à partir de tous ce
qui a déjà été dis la méthodologie
d'implémentation de l'algorithme de Dijkstra sur les processeurs
FPGA.
Dans un premier temps, nous allons d'abord présenter
de façon générale la synthèse des circuits en VHDL,
ensuite nous expliquerons le fonctionnement de l'algorithme de Dijkstra,
Et nous terminerons ce chapitre en présentant le
programme complet d'implémentation.
4.2 USynthèse des circuitsU
[12]
4.2.1 ULe synthétiseurU
Le synthétiseur est un compilateur particulier capable,
à partir du langage de descriptions VHDL ou Verilog, de
générer une description structurelle du circuit. A travers le
style d'écriture de la description synthétisable
(niveau RTL Registre Transfer Level), le synthétiseur va
reconnaître un certain nombre de primitives qu'il va
implanter et connecter entre elles. Ce sera au minimum des portes NAND, NOR,
NOT, des bascules D, des buffers d'entrées-sorties, mais cela peut
être aussi un compteur, un multiplexeur, une RAM, un registre, un
additionneur, un multiplieur ou tout autre bloc particulier.
Le VHDL décrit la fonctionnalité
souhaitée et ceci indépendamment de la technologie. Le nombre de
primitives trouvées par le synthétiseur donne une
évaluation de surface (pour un ASIC) ou de remplissage (pour un FPGA).
La technologie choisie apporte toutes les données
temporelles relatives aux primitives, notamment les temps de traversée
de chaque couche logique sont connus. Une première évaluation de
vitesse d'ensemble du circuit peut ainsi être réalisée par
le synthétiseur (en considérant des retards fixes par porte, ce
qui constitue une approximation grossière).
Outre la description VHDL, le concepteur a la
possibilité de fournir au synthétiseur des contraintes
temporelles (réalistes) ou de caractéristiques
électriques des entrées-sorties. Le synthétiseur, par un
certain nombre d'itérations, essaiera d'optimiser le
produit surface-vitesse.
Le synthétiseur idéal est un outil capable
d'avoir jusqu'à la vision physique du circuit projeté. De tels
outils sont en train de sortir sur le marché. De façon plus
classique, l'optimisation du circuit final sera obtenue après avoir fait
remonter les informations temporelles d'après routage au niveau du
synthétiseur et après avoir procédé à
plusieurs itérations.
4.2.2 ULa cible
technologiqueU
4.2.2.1 UAsic et PLDU
Les ASIC (Application Specific Integreted Circuit) sont des
circuits intégrés numériques ou mixtes originaux. En ce
qui concerne l'aspect numérique, on dispose en général
d'une bibliothèque de fonctions pré-caractérisées
c'est à dire optimisées par le fondeur et quant au reste du
Design, le VHDL ou VERILOG ciblera des primitives NAND, NOR, Multiplexeur,
Bascules D, et Mémoires RAM ou ROM.
Avantages de l'ASIC
n Originalité
n Intégration mixte analogique numérique
n Choix de la technologie
n Consommation
Inconvénients
n Coût de développement très
élevés (ne peut être amorti en général que
pour de très grand nombre de circuits)
n Délais de fabrication et de test
n Dépendance vis à vis du fondeur.
Les PLD (Programmable Logic Device) sont des circuits disponibles
sur catalogue mais exclusivement numériques.
Avantages des PLD
n Personnalisation et mise en oeuvre simple
n Outils de développement peu coûteux (souvent
gratuits)
n Pas de retour chez le fabriquant
n Idéal pour le prototypage rapide
Inconvénients des PLD
n Peut être cher pour de grandes séries
n Consommation globale accrue par les circuits de configuration
n Les primitives du fabricant pouvant être complexes, la
performance globale est dépendante pour beaucoup de l'outil
utilisé.
Afin d'annuler en partie les inconvénients des PLD, les
fabricants proposent des circuits au Top de la technologie (ce qui rend encore
plus cher l'ASIC équivalent). Ainsi actuellement on trouve des circuits
en technologie 0,13um tout cuivre basse tension. La consommation est ainsi
réduite et la vitesse augmentée d'autant.
4.2.2.2 UArchitecturesU
n CPLD (Complex Programmable Logic Device) : Ce sont des
assemblages de macro-cellules programmables « simples »
réparties autour d'une matrice d'interconnexion. Les temps de
propagation de chaque cellule sont en principe prévisibles.
n FPGA (Field Programmable Gate Array) sont formés
d'une mer de petits modules logiques de petite taille, noyés dans un
canevas de routage. Du fait de la granularité plus fine des FPGA, les
temps de propagation sont le résultat d'additions de chemins et sont
plus difficiles à maîtriser que celui des CPLD.
4.2.2.3
UTechnologiesU
Les circuits sont des pré-diffusés, c'est
à dire qu'une grande quantité de fonctions potentielles
préexistent sur la puce de silicium. La programmation est
l'opération qui consiste à créer une application en
personnalisant chaque opération élémentaire.
n EEprom : Le circuit se programme normalement et conserve sa
configuration même en absence de tension.
n Sram : La configuration doit être
téléchargée à la mise sous tension du circuit. S'il
y a coupure d'alimentation, la configuration est perdue.
n Antifusible : La configuration consiste à faire
sauter des fusibles pour créer des connexions. L'opération est
irréversible mais en contre-partie offre l'avantage d'une grande
robustesse et de sécurité au niveau du piratage possible du
circuit.
n Flash : Le circuit se programme normalement et conserve sa
configuration même en absence de tension.
4.2.3 USaisie du code
RTLU [12]
4.2.3.1 UTexte et
graphiqueU
Un simple éditeur de texte suffit bien
évidemment pour saisir le code. Tous les synthétiseurs incluent
leur propre éditeur plus ou moins élaboré. Certains outils
généralistes comme emacs (GNU) offrent
un mode VHDL personnalisable très sophistiqué permettant de
gagner du temps lors de la saisie du texte.
Le graphique n'est pourtant pas exclu des outils de saisie. Il
est toujours primordial de pouvoir dessiner graphiquement un diagramme
d'état. De nouveaux outils sont apparus capable de générer
automatiquement du VHDL à partir de graphique. Nous ne citerons que
HDL_Designer de Mentor Graphics qui permet de
créer des schémas blocs, des tables de vérité, des
diagrammes d'état, des organigrammes avec intégration
complète de la syntaxe VHDL et génération automatique du
texte. Celui-ci reste en fin de compte la véritable source du projet.
4.2.3.2
UStyleU
Le VHDL offre de nombreuses possibilités de style
d'écriture pour une même fonctionnalité. Il est donc
impératif de faire dans chaque cas le meilleur choix. La meilleure
solution sera toujours Ula plus lisible Uc'est à
dire simple, claire, UdocumentéeU. Pour cela, outre les autres
problèmes de conception, il n'est pas mauvais de se fixer quelques
règles de conduite comme
n Tous les identificateurs seront en minuscule, les mots clefs
du langage en majuscule et les constantes commenceront par une majuscule et
seront ensuite en minuscule.
n Les identificateurs auront un sens fort : adresse_ram
plutôt que ra
n Les horloges s'appelleront toujours h ou clock
n Les signaux actifs à l'état bas seront
terminés par _b ou _n
n Privilégier les DOWNTO aux TO pour la
définition des vecteurs
n Donner au fichier le même nom que l'entité
qu'il contient.
n Privilégier au niveau de l'entité les types
std_ulogic, unsigned ou signed
4.2.3.3 UPrincipesU
Le VHDL est un langage à instructions concurrentes, il
faut savoir en profiter lorsqu'on décrit un circuit. La règle
simple est de séparer les parties franchement combinatoires des parties
comportant une horloge.
n Les parties combinatoires seront décrites par des
instructions concurrentes
n Les parties séquentielles seront décrites par
des processus explicites.
4.2.3.4 ULimitation du
langageU
Lors des descriptions VHDL en vue de synthèse, c'est le
style d'écriture et lui seul qui va guider le synthétiseur dans
ses choix d'implantation au niveau circuit. Il est donc nécessaire de
produire des instructions ayant une équivalence non ambiguë au
niveau porte.
Le synthétiseur est un compilateur un peu particulier
susceptible au fil des ans d'améliorer sa capacité à
implanter des fonctions de plus en plus abstraites. Cependant, il reste des
règles de bon sens comme « le retards des opérateurs est
d'ordre technologique » ou bien « un fichier n'est pas un circuit
» etc. En conséquence, les limitations du langage du niveau RTL les
plus courantes sont :
n Un seul WAIT par PROCESS
n Les retards sont ignorés (pas de sens)
n Les initialisations de signaux ou de variables sont
ignorées
n Pas d'équation logique sur une horloge
(conseillé)
n Pas de fichier ni de pointeur
n Restriction sur les boucles (LOOP)
n Restriction sur les attributs de détection de fronts
(EVENT, STABLE)
n Pas de type REAL
n Pas d'attributs BEHAVIOR, STRUCTURE,LAST_EVENT,
LAST_ACTIVE,TRANSACTION
n Pas de mode REGISTER et BUS
Exemple-1:
WAIT UNTIL h'EVENT AND h= `1';
x := 2;
WAIT UNTIL h'EVENT AND h= `1';
Ces trois lignes sont incorrectes. Il faut gérer
soi-même le comptage des fronts d'horloge:
WAIT UNTIL h'EVENT AND h= `1';
IF c = 1 THEN
x := 2;
Exemple-2:
On ne sait pas faire le ''ET'' entre un front et un niveau. Il
s'ensuit que la ligne suivante:
WAIT UNTIL h'EVENT AND h= `1' AND raz = `0';
doit être remplacée par
WAIT UNTIL h'EVENT AND h= `1' ;
IF raz = `0' THEN
Le synthétiseur fera le choix d'un circuit fonctionnant
sur le front montant de h (bascule D) et prenant raz comme niveau
d'entrée de validation.
Exemple-3:
SIGNAL compteur : INTEGER;
produira certainement un compteur 32 bits (l'entier par
défaut). Si ce n'est pas cela qui est voulu, il faut le préciser.
Par exemple pour 7 bits,
SIGNAL compteur : INTEGER RANGE 0 TO 99;
4.2.4 UCircuits combinatoires
Une fonction combinatoire est une fonction dont la valeur est
définie pour toute combinaison des entrées. Elle correspond
toujours à une table de vérité. La fonction peut
être complète (toutes les valeurs de sortie sont imposées
à priori) ou incomplète (certaines sorties peuvent être
définies comme indifféremment 1 ou 0 au grès de la
simplification). Ce dernier état sera noté "-" en VHDL.
Une fonction combinatoire est donc donnée :
n Par une table de vérité
n Par une équation simplifiée ou non
Une fonction combinatoire peut être décrite de
façon séparée
n Par une instruction concurrente (méthode à
privilégier)
n Par un processus avec toutes les entrées en liste de
sensibilité
n Par un tableau de constantes
n Par une fonction qui sera ensuite assignée de
façon concurrente ou séquentielle à un signal.
Il y a aussi un cas très fréquent correspondant
à une équation combinatoire noyée dans une description
comportant des éléments de mémorisation. Dans ce dernier
cas seule, la vigilance est conseillée.
4.2.5 UCircuits arithmétiques U
4.2.5.1
UReprésentations des nombres en virgule fixe
U
4.2.5.1.1 U Nombres non
signés
En base 2, avec n bits, on dispose d'un maximum de 2Pn
Pcombinaisons. Un nombre non signé peut être exprimé
par bBn-1B2Pn-1 P+bBn-2B2Pn-2 P+...
+bB0B+bB-1B2P-1P+bB-2B2P-2
P+...+bB-mB2P-m Pavec n bits de partie
entière et m bits de partie fractionnaire. Cette représentation
est appelée Uvirgule fixeU. La virgule est quelque chose de
totalement fictif d'un point de vue circuit et un tel nombre peut toujours
être vu comme un entier à condition de le multiplier par
2PmP. La suite 0101 sur 4 bits représente aussi bien 5 que
2.5 ou 1 .25.
4.2.5.1.2 UNombres signés :
complément à 2
A l'origine, on cherche une
représentation pour des nombres signés la plus simple possible au
niveau des circuits devant les traiter. En l'occurrence
l'addition. Quel est le nombre que je dois rajouter à A
pour avoir 0 ? Je déciderais qu'un tel nombre est une
représentation de .A. Par exemple sur 4 bits,
A = (a3 a2 a1 a0)
 = (/a3 /a2 /a1 /a0)
A + Â = (1 1 1 1)
A + Â + 1 = (1 0 0 0 0)
La somme sur n + 1 bits vaut 2n mais 0 sur n bits.
Privilégiant ce derniers cas, on admet alors que  + 1 est une
représentation possible de -A. Il en découle alors que sur n
bits, un entier signé sera représenté de -2n-1
à +2n-1-1. On peut aussi plus généralement
exprimer un nombre signé par la relation :
-bn-12n-1 + bn-22n-2
+. + b121 + b0
4.2.5.2 UAdditionneurs,
soustracteurs, décalages, comparateursU
Les opérateurs de base arithmétiques ou logiques
+, -, NOT, *, AND, >, >, =, shift_left, shift_right sont des fonctions
courantes disponibles dans des paquetages standards tels que IEEE.NUMERIC_STD.
Le synthétiseur les accepte tel quel avec des types integer, signed ou
unsigned. D'autres fonctions particulières pourraient enrichir le
catalogue de primitives Il n'y a aucun problème pour décrire une
quelconque opération mais attention à l'éventuel
dimensionnement des mots traités qui pourrait s'avérer incorrect
surtout lorsqu'on utilise des conversions de type.
Exemple: S <= a + b ;
S doit comporter le même nombre de bits que a ou b.
4.2.5.3 UMultiplication ou division
par une puissance de 2U
D'après ce qui précède,
nous déduisons une première règle en terme de circuit :
Une division ou une multiplication par une puissance de 2 ne
coûte rien sinon en nombres de bits significatifs. Diviser ou
multiplier un nombre par une puissance de 2 revient à un simple
câblage.
S <= `0' & e (7 DOWNTO 1); -- S est égal à
e/2
4.2.5 .4 UMultiplication par une
constante U
Cela sera le plus souvent très
facilement réalisé par un nombre limité d'additions ou
encore mieux, par un nombre minimal d'additions et de soustractions. Supposons
la multiplication 7 * A en binaire. Elle sera décomposée en A +
2*A + 4 *A. Comme les multiplications par 2 et 4 ne coûtent rien, la
multiplication par 7 ne nécessite que 2 additionneurs.
On remarque cependant que 7*A peut s'écrire 8*A-A, on
peut donc réaliser cette même multiplication par un seul
soustracteur.
De façon générale, l'optimisation du
circuit se ferra en cherchant la représentation ternaire (1, 0, -1) des
bits qui minimise le nombre d'opérations à effectuer (et maximise
le nombre de bits à zéro). Mais attention, une telle
représentation d'un nombre n'est pas unique. 6 = 4 + 2 = 8 -2.
4.2.5.5 UMultiplication
d'entiersU
A priori, la multiplication est une
opération purement combinatoire. Elle peut d'ailleurs être
implantée de cette façon. Disons simplement que cela conduit
à un circuit très volumineux et qui a besoin d'être
optimisé en surface et en nombre de couches traversées. De telles
optimisations existent assez nombreuses. Citons simplement le multiplieur
disponible en synthèse avec Leonardo, c'est le multiplieur de
Baugh-Wooley .
S <= a *
b ; -- multiplieur combinatoire
L'autre méthode beaucoup plus économique mais
plus lente car demandant n itérations pour n bits est la méthode
par additions et décalages. On peut en donner deux formes algorithmique,
une dite sans restauration et l'autre plus anticipative dite avec
restauration.
4.2.5.6 UDivision d'entiers non
signésU
Le diviseur le plus simple procède à l'inverse de
la multiplication par addition et décalage et produit un bit de quotient
par itération. On peut en donner une forme algorithmique dite «
sans restauration ». Le dividende n bits est mis dans un registre 2n + 1
bit qui va construire le reste et le quotient. Le diviseur est place dans un
registre n + 1 bits.
INIT : P = 0, A = dividende, B = diviseur
REPETER n fois
SI P est négatif ALORS
décaler les registres (P,A) d'une position
à gauche
Ajouter le contenu de B à P
SINON
décaler les registres (P,A) d'une position
à gauche
soustraire de P le contenu de B
FIN_SI
SI P est négatif mettre le bit de poids faible de A
à 0
SINON Le mettre à 1
FIN_SI
FIN_REPETER
On constate très facilement que cet algorithme implique
pour un circuit de division :
· Un additionneur/soustracteur 2n + 1 bits
· Un registre à décalage 2n + 1 bits avec
chargement parallèle
· Un registre parallèle n + 1 bits
Maintenant nous allons parler de la modélisation des
circuits en VHDL.
4.3 UModélisationU
Un modèle est une description valide pour la
simulation. En modélisation tout le langage VHDL est
donc utilisable. Une description synthétisable reste donc aussi un
modèle.
Modélisation et synthèse sont tout à fait
complémentaires. En effet, lors de la conception d'un circuit, il faut
être capable de le tester dans un environnement aussi complet que
possible. On a donc besoin pour cela de modèles comportementaux
comportant des aspects fonctionnel et temporel. Tel est le cas pour les
générateurs de stimuli, les comparateurs de sorties, les
modèles de mémoires RAM ou ROM ou tout autre circuit
décrit au niveau comportemental.
4.3.1 Modélisation des
retards U
4.3.1.1 U Les moyens de pris en
compte U
· Affectation de signal: s <= a AFTER Tp;
· Instruction FOR: WAIT FOR delay1; -- affecte tous les
signaux du Processus
· Fonction NOW: retourne l'heure actuelle de simulation.
Limitée au contexte séquentiel
· Attributs définis fonctions du temps: S'delayed
[(T)], S'Stable [(T)], S'Quiet [(T)].
· Bibliothèques VITAL
4.3.1.2 UTransport ou inertiel
?U
Deux types de retards sont à considérer : Retard
inertiel (par défaut) ou retard Transport. Toute
sortie affectée d'un retard inertiel filtre toute impulsion de
largeur inférieure à ce retard tandis qu'un retard de type
transport est un retard pur pour le signal auquel il est
appliqué.
4.3.2 UModèle de
RAMU [12]
-- Fichier : cy7c150.vhd
-- Date de creation : Sep 98
-- Contenu : RAM CYPRESS avec e/s separees
-- Synthetisable ? : Non
--------------------------------------------------------------------------------
LIBRARY IEEE;
USE IEEE.STD_LOGIC_1164.ALL;
USE ieee.numeric_std.ALL;
ENTITY cy7c150 IS
PORT ( a : IN unsigned( 9
DOWNTO 0);
d : IN unsigned( 3
DOWNTO 0);
o : OUT unsigned( 3
DOWNTO 0);
rs_l, cs_l, oe_l, we_l :
IN std_logic);
END cy7c150;
-- modèle sans-retard d'après catalogue CYPRESS
ARCHITECTURE sans_retard OF cy7c150 IS
TYPE matrice IS ARRAY
(0 TO 1023 ) OF unsigned( 3 DOWNTO 0);
SIGNAL craz , csort,
cecri : BOOLEAN;
SIGNAL contenu : matrice;
BEGIN
craz <= ( rs_l =
'0' AND cs_l = '0');
csort <= ( cs_l =
'0' AND rs_l = '1' AND oe_l = '0' AND we_l = '1');
cecri <= ( cs_l =
'0' AND we_l = '0');
ecriture:PROCESS
BEGIN
WAIT ON
craz, cecri;
IF craz
THEN
FOR i
IN matrice'RANGE LOOP
contenu (i) <= "0000";
END
LOOP;
ELSIF
cecri THEN
contenu(to_integer('0'& a)) <= d ;
ELSE
o
<= unsigned(contenu(to_integer('0'& a)));
END IF;
END PROCESS;
-- attention, il faut rajouter '0' en bit de signe de a afin que
l'entier correspondant soit positif
END;
4.3.3 ULecture de
FichierU
On doit fournir à un circuit de traitement d'images
des pixels extraits d'un fichier image noir et blanc au format PGM. Le format
de ce fichier est défini ainsi :
P2
#CREATOR XV
512 512
255
155 155 154 154 150.
P2 est l'indicateur du format. La ligne suivante est une
ligne de commentaire, 512 est le nombre de points par ligne, 512 est le nombre
de lignes d'une image et 255 est la valeur maximale du pixel dans
l'échelle de gis (codé sur 8 bits). Viennent ensuite la
succession des 262144 pixels. C'est un exemple de création de stimuli
complexes par lecture de données dans un fichier. On se sert du package
Textio et en particulier des procédures READLINE ET READ permettant de
parcourir séquentiellement un fichier ASCII.
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
USE ieee.numeric_std.ALL;
LIBRARY std;
USE std.textio.ALL;
ENTITY camerapgm IS
GENERIC (nom_fichier : string := "lena.pgm";
en_tete : IN string := "P2";
largeur : IN natural := 512;
hauteur : IN natural := 512 ;
couleur_max : IN natural := 255);
PORT (
pixel : OUT unsigned( 7 DOWNTO 0 ) ; -- pixels
h : IN std_logic); -- horloge pour appeller la sortie
END camerapgm ;
ARCHITECTURE sans_tableau OF camerapgm IS
BEGIN -- sans_tableau
lecture : PROCESS
FILE fichier : text IS IN nom_fichier;
VARIABLE index : natural := 0;
VARIABLE ligne : line;
VARIABLE donnee : natural;
VARIABLE entete : string (1 TO 2); -- on attend P3 ou P2
VARIABLE nx : natural := 15; -- nombre de caracteres
par ligne
VARIABLE ny : natural; -- nombre de lignes;
VARIABLE max : natural; -- intensite max
VARIABLE bon : boolean;
CONSTANT nbr_pixels : natural := largeur * hauteur ; -- 512 *
512 = 262144
BEGIN -- PROCESS charger
ASSERT false REPORT "debut de lecture du fichier " SEVERITY
note;
readline(fichier, ligne); -- ouverture du fichier
image
read(ligne,entete,bon);
ASSERT bon REPORT "l'en-tete n'est pas trouvee" SEVERITY error;
ASSERT entete = en_tete REPORT "en-tete incorrecte" SEVERITY
error ;
readline(fichier, ligne); -- 1 ligne de
commentaire
readline(fichier, ligne);
read(ligne,nx,bon);
ASSERT bon REPORT "erreur de format sur nx" SEVERITY error;
ASSERT nx = largeur REPORT "Dimension de ligne incorrect"
SEVERITY error;
read(ligne,ny,bon);
ASSERT bon REPORT "erreur de format sur ny" SEVERITY error;
ASSERT ny = hauteur REPORT "Nombre de lignes incorrect" SEVERITY
error;
readline(fichier, ligne);
read(ligne,max,bon);
ASSERT bon REPORT "erreur de format sur max" SEVERITY error;
ASSERT max = couleur_max REPORT "niveau max de couleur
incorrect" SEVERITY error;
index := 0;
l1: WHILE NOT ENDFILE(fichier) LOOP
readline(fichier, ligne);
read(ligne,donnee, bon);
WHILE bon LOOP
WAIT UNTIL rising_edge(h); -- pour synchroniser
index := index + 1;
pixel <= to_unsigned(donnee,8);
IF index = nbr_pixels /4 THEN
ASSERT false REPORT "Patience ... plus que 75%" SEVERITY note;
END IF;
IF index = nbr_pixels /2 THEN
ASSERT false REPORT "Patience ... plus que 50%" SEVERITY note;
END IF;
IF index = nbr_pixels *3 /4 THEN
ASSERT false REPORT "Patience ... plus que 25%" SEVERITY note;
END IF;
read(ligne,donnee, bon);
END LOOP;
END LOOP;
ASSERT false REPORT "Ouf !!, c'est fini" SEVERITY note;
ASSERT index = nbr_pixels REPORT "Nombre de pixels incorrect"
SEVERITY error;
WAIT;
END PROCESS;
END sans_tableau;
4.3.4 ULes bibliothèques
VITALU
VITAL (VHDL Initiative Towards ASIC Libraries) est un
organisme regroupant des industriels qui s'est donné pour objectif
d'accélérer le développement de bibliothèques de
modèles de cellules pour la simulation dans un environnement VHDL
(depuis 1992).
La spécification du standard de modélisation
fixe les types, les méthodes, le style d'écriture efficace pour
implémenter les problèmes de retards liés à la
technologie. L'efficacité est jauchée selon la hiérarchie
suivante :
· Précision des relations temporelles
· Maintenabilité du modèle
· Performance de la simulation
La plupart des outils de CAO utilisent les
bibliothèques VITAL au niveau technologique.
4.3.4.1 UNiveaux de
modélisation et conformitéU
Une cellule est représentée par un couple
entity/architecture VHDL. La spécification définie trois niveaux
de modélisation correspondant à des règles
précises.
· Vital Level 0
· Vital Level 1
· Vital Level 1 Memory
4.3.4.2 ULes packages
standardU [12]
4.3.4.2.1
UVITAL_TimingU
Il définie les types de données et les
sous-programmes de modélisation des relations temporelles.
Sélection des retards, pilotage des sorties, violation de timing (ex:
Setup, Hold) et messages associés.
4.3.4.2.2
UVital_PrimitivesU
Il définie un jeu de primitives combinatoires d'usage
courant et des tables de vérité
4.3.4.2.3
UVital_MemoryU
Spécifique pour modélisation des
mémoires.
Maintenant dans la partie qui suit nous allons
concrètement parler de l'algorithme de Dijkstra. 4.4
UDIJKSTRAU
Suivant de près Bellman, DIJKSTRA fut le second, en
1959, à proposer un algorithme cité par tous. Il y propose une
manière de trouver le chemin de poids le plus faible entre deux points
d'un graphe non-orienté pondéré dont les arêtes ont
un poids positif ou nul. Peu de temps après, en 1960, Whiting et Hillier
on présenté le même algorithme, en suggérant que la
méthode pouvait aisément être appliquée aux graphes
orientés.
Le temps d'exécution de l'algorithme est de
Ï(|V|P2P), et peut être réduit à
Ï(|E|log|V|) suivant l'implémentation.
4.4.1 UDescription
Soient les considérations suivantes :
V : l'ensemble des sommets du
graphe;
E : l'ensemble des arcs (ou
arêtes) du graphe;
T : un ensemble temporaire de sommets
d'un graphe;
S : l'ensemble des sommets
traités par l'algorithme;
y : un tableau de coût de
longueur |V| (le nombre de sommet
du graphe);
a : l'indice du noeud de
départ;
c(u, v) : permet d'obtenir le coût d'un
arc du sommet u au sommet v appartenant à E.
4.4.2 UAlgorithmeU
POUR  sommets de i de V
FAIRE sommets de i de V
FAIRE
début
 yBiB
yBiB  +8 +8
fin
yBaB  0 0
S Ø Ø
T V V
TANT QUE T  Ø
FAIRE Ø
FAIRE
début
Sélectionner le sommet j de T de plus petite
Valeur yBjB
T T \ j T \ j
S S S j j
POUR 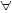 sommets k de T adjacents
à j FAIRE sommets k de T adjacents
à j FAIRE
début
yBkB  min(yBkB ,
yBjB +c(j, k)) {c(j, k) est le coût de j à k}dd min(yBkB ,
yBjB +c(j, k)) {c(j, k) est le coût de j à k}dd
fin
fin
4.4.3 UOrganigramme de l'algorithme de
DIJKSTRAU [17]
UFigure4.1 :
UOrganigramme de l'algorithme de DIJKSTRA
4.4.4 UExemple [17]
Considérons un réseau informatique
défini par le graphe valué = (X, A) et dont la
représentation est faite ci-dessous :
0
56
56
56
56
56
56
2
13
7
18
9
2
1
3
1
a
c
f
b
e
d
g
UFigure4.2U :
UGraphe1
UEtapes de l'exécutionU :
1) On attribue au sommet choisi (ici a) la marque 0, et
à tous les autres sommets une marque initiale infinie. En pratique, les
ordinateurs ne connaissant pas les ensembles infinis, il suffit de donner
à chaque sommet une marque initiale égale à la somme des
valuations de tous les arcs du graphe, soit ici 56 (voir figure ci-dessus).
2) a conserve sa marque 0. On remplace la marque des
successeurs k de 1 par la valeur de l'arc (a ; k) :
0
13
18
56
7
56
56
13
7
18
9
2
1
3
1
Ua
c
f
b
e
d
g
2
![]() Figure4.3U :
UGraphe2U Figure4.3U :
UGraphe2U
3) Dans l'ensemble des sommets X - {a} on choisit un (car il peut
ne pas être unique) sommet de plus petite marque (ici e, de marque
yBeB = 7) et on attribue à tous ses successeurs k la marque
Inf {yBkB, yBeB + cekB}. On obtient donc :
0
13
18
8
7
9
56
13
7
18
9
2
1
3
1
a
f
b
Ue
d
g
2
c
![]()
Figure4.4U :
UGraphe3
4) Dans l'ensemble des sommets X - {a, e} on choisit un sommet
de plus petite marque (ici f, de marque yBfB = 8) et on attribue
à tous ses successeurs k la marque Inf { yBkB,
yBfB + cfkB}. On obtient donc :
Uf
0
13
17
8
7
9
11
13
7
18
9
2
1
3
1
a
b
e
d
g
2
c
![]() Figure4.5U :
UGraphe4
Figure4.5U :
UGraphe4
5) On itère le procédé : dans
l'ensemble des sommets X - {a, e, f} on choisit un sommet de plus petite
marque (ici d, de marque yd = 9) et on attribue à tous ses
successeurs k la marque Inf {yBkB, yd +
cBdkB}
0
11
17
8
7
9
10
13
7
18
9
2
1
3
1
a
f
b
e
Ud
g
2
c
![]()
Figure4.6 :
UGraphe5U
6) Dans l'ensemble des sommets X - {a, e, f, d} on choisit un
sommet de plus petite marque (ici g, de marque yBgB = 6) et on
attribue à tous ses successeurs k la marque Inf
{yBkB, yBgB + cgkB}. On
constate que cette opération ne change aucune marque :
0
11
17
8
7
9
10
13
7
18
2
1
3
1
a
b
e
d
Ug
2
9
c
f
![]()
Figure4.7U :
UGraphe6U
7) Dans l'ensemble des sommets X - {a, e, f, d, g} on choisit
le sommet plus petite marque (ici b, de marque yBbB = 11). Ce
sommet n'a pas de successeur. On constate donc également que cette
opération ne change aucune marque.
Figure4.8U :
UGraphe7U
0
11
17
8
7
9
10
13
7
18
2
1
3
1
a
Ub
e
d
g
2
9
f
c
![]()
8) Enfin dans l'ensemble des sommets X - {a, e, f, d, g, b} on
choisit le dernier sommet (ici c, de marque yBcB = 17). Ce sommet
n'a pas de successeur. On constate donc également que cette
opération ne change aucune marque.
Tous les sommets du graphe ayant été choisis,
l'algorithme est terminé et on obtient les longueurs des plus courts
chemins de a aux autres sommets (voir figure4.4.4i).
0
11
17
8
7
9
10
13
7
18
2
1
3
1
a
b
e
d
g
2
9
f
Uc
1
![]()
Figure4.4.9 : UGraphe8
Les chemins les plus courts par rapport à `'a'' sont
:
a: a ; 0 c: c f f e e a ; 17
e: e a ; 17
e: e a ;
7 a ;
7
b: b d d e e a ; 119 d: d a ; 119 d: d e e a ; 9
f: f a ; 9
f: f e e a ;
8 a ;
8
g: g  d d e e  a ; 10 a ; 10
UFigure4.10U :
UGraphe9U
0
11
17
8
7
9
10
13
7
18
2
1
3
1
a(0)
b(d)
e(a)
d(e)
g(d)
2
9
f(e)
c(f)
![]()
4.5 Analyse du problème
Rappelons pour commencer quel est le problème que nous
voulons résoudre ; bien pour un paquet de données venant
d'un poste (voir figure4.11) et arrivant à l'entrée d'un
réseau (WAN par exemple) selon la métrique
spécifiée, la passerelle doit lui assigner le chemin optimale
afin d'éviter le phénomène de congestion. Le
problème n'est de réaliser ce processus mais c'est de
l'accélérer car il existe déjà (en l'occurrence
l'algorithme de dijkstra)). C'est pourquoi on utilise des circuits FPGA.
Notre travail fut donc d'implémenter cet algorithme sur
FPGA.
ligne 5
ligne 2
ligne 4
ligne 3
ligne 1
 Données Données
Passerelle d'entrée
Figure 4.11 : Modélisation du
problème
4.5.1 UArchitecture du programmeU [18]
Notre environnement intégré de
développement est l'outil ISE 8.1 dont nous nous servirons
pour l'implémentation sur FPGA de la compagnie Xilinx
et notre outil de simulation est ModelSim toujours de Xilinx Edition- III et
par ISE.
Pour mieux comprendre notre approche, examinons l'architecture
ci-dessous :
UFigure 4.12: Uarchitecture du
programme d'implémentation sur FPGA
Dans notre architecture, nous n'avons pas séparé
les bus d'adresses et de données pour besoin de clarté du
schéma, signalons seulement que lorsque deux blocks sont reliés
par un bus, alors il sont en relation et la description de cette relation sera
faite dans la suite.
Nous avons subdivisé l'algorithme en block de
description, c'est-à-dire par exemple que notre réseau exemple
est sauvegardé (sa description) dans une ROM qui elle, est codée
sous forme de package.
Ainsi qui est notre réseau (voir 4.4.4 exemple) sera
stocké dans une ROM. En faite cette ROM contiendra la valeur du
coût des liens entre les différents noeuds de notre réseau.
Elle est programmée sous forme de package et nous l'appellerons dans le
programme principal en mode lecture unique pour lire la description du
réseau car nous ne pourrons pas changer son contenu.
Signalons que si du point vue hardware nous accédons au
contenu de cette ROM par des lignes d'adresses, cependant dans son code, le
traitement de son contenu se fait de manière software ; en faite
pour être claire cette une matrice d'ordre 2 dont les indices sont des
noeuds et l'élément est le coût du lien entre ces deux
noeuds (exemple lien (a, b)=1).
Pour accéder à un élément de la
ROM, nous utilisons des lignes d'adresses qui sont des variables de type signal
(voir chapitre précédent), en faite ces lignes d'adresse
représentent un vecteur signal et dont le contenu est l'adresse d'un
élément de notre matrice.
La RAM1 contient la valeur courante des indices de chaque
noeud du réseau, au début du programme elle est
initialisée à 0 pour le noeud `a' et à infinie (c.a.d.
un nombre très grand) pour tous les autres noeuds (signalons que le
noeud `a' représente le noeud du réseau physique où se
trouve le paquet de données).
La RAM2 quant à elle contient la liste des noeuds
n'ayant pas été traités par le programme, c'est pourquoi
elle est initialisée à la liste de tous les noeuds.
Les blocks en V sont juste à titre
représentatives, ils n'ont aucune fonction opératoire ou
conservatoire, mais elles servent juste à préciser de type de
données il s'agit.
Le block opérateur est celui qui permet la mise
à jour des différents indices de chaque noeud.
Le block comparateur comme son nom l'indique, compare les
différents indices de chaque noeud et retient le plus petit.
Enfin, le block commande est celui d'où partent les
noeuds pour le lancement du programme.
4.5.2 UFonctionnement de
l'architectureU
Au lancement du programme, la ROM contient comme nous l'avons
déjà dis la description du réseau, la RAM1 est
initialisée à 0 pour `a' et à l'infini pour le reste des
noeuds. La RAM2 quant à elle contient la liste de tous les noeuds
(sauf `a') car
ceux-ci n'ont pas encore été traités par le programme. `a') car
ceux-ci n'ont pas encore été traités par le programme.
Le block de commande lit la liste des noeuds non
traités dans la RAM2 et les transmet avec le noeud de traitement courant
aux blocks RAM1 et ROM. Cette transmission est faite sous forme d'adresse, le
block RAM1 recevant donc ces adresses renvois non au block commande mais
plutôt au block opérateur les indices des noeuds qui lui sont
transmises, de même la ROM quant à elle renvoie également
au block opérateur non pas les indices de noeuds du réseau, mais
le coût de leurs liens. Le block opérateur réalise le
calcul attendu, et effectue ensuite une mise à jour des indices des
noeuds du réseau contenues dans la RAM1, et enfin bloque l'espace
contenant les données concernant le noeud traité (qui est ici
`a' à la première boucle du programme), c'est afin que le block
comparateur ne puisse pas y avoir accès.
Le block comparateur compare ensuite toutes les valeurs des
indices des noeuds qui lui sont visibles, et renvois le noeud d'indice minimal
au block commande. Celui-ci effectue une mise à jour de liste des noeuds
dans la RAM2 en effaçant de cette liste le noeud d'indice minimal qui
est maintenant devenu le noeud traité, et le cycle recommence.
Le programme s'arrêtera lorsque la RAM2 sera vide.
Lorsque le programme est terminé, il y a encore un
petit programme dont on ne s'étendra pas ici mais qui permet de
débloquer les données de la RAM1 et à partir de ces
données, de générer un fichier contenant les
différents chemins détaillés du noeud sur lequel se trouve
le paquet de données, vers tous les autres noeuds du réseau
physique (c'est en faite la table de routage).
UN.B.U : Tous
ces différents blocks de notre programme ne sont pas physiques, il
s'agit là juste d'une illustration des différents processus de
notre programme. Cependant, tous ces processus forme un tout et sont
décris au sein d'un ensemble commun qui est le programme principal (main
program).
4.5.2 Description des blocks mémoires
4.5.2.1 la ROM
Comme nous l'avons déjà dis, la ROM est un
package que nous allons définir dans la librairie work et ensuite nous
allons juste l'appeler dans le programme principal.
Signalons que d'un point de vue physique, pour changer de
configuration du réseau, il est nécessaire d'avoir une autre ROM
(d'un point de vue physique nous répétons).
Les données de la ROM sont des vecteurs de 16 bits.
Pourquoi 16 bits, et bien parce que les 4 premiers bits codent une
extrémité du lien, les 4 suivants l'autre extrémité
et les 8 derniers sont pour représenter la valeur du coût du lien
entre ces deux extrémités.
Par conséquent son bus de données aura 16 lignes
(souvenons nous que cela est une vue de l'esprit). Son bus d'adresse contient
5 lignes pour pouvoir adresser tous les couples de noeuds.
En ce qui concerne comment accéder à la ROM,
cela a déjà été dis, et son initialisation se fait
de manière interne au package.
Voila tout en ce qui concerne la ROM.
4.5.2.2 la RAM1
La RAM1 contient la valeur des indices des noeuds du
réseau son bus de données est constitués de 12 lignes
dont les 4 premiers sont pour coder le noeud et les 8 autres pour l'indice de
ce noeud. Son bus d'adresse possède 4 lignes pour représenter
tous les noeuds du réseau.
La RAM1 est un composant interne du programme principal.
4.5.2.3 la RAM2
La RAM2 contient la liste des noeuds du réseau non
encore traités. Son bus de données est constitué de 4
lignes pour coder le noeud non traité. Son bus d'adresse possède
4 lignes pour représenter tous les noeuds du réseau.
La RAM2 est aussi un composant interne du programme
principal.
En faite on peut concevoir le block opérateur comme un
processeur à part entière et la RAM1 est l'un de ses registres
internes, de même on regarder le block commande aussi comme un processeur
avec son registre interne comme RAM2.
Les blocks commande et opérateur sont eux aussi des
composant internes du programme principal.
CHAPITRE 5 : RESULTATS ET DISCUSSION
5.1 Introduction
Il ne fut pas dans la mesure du possible de réaliser
l'implémentation matérielle sur une carte FPGA car cette
dernière n'étant pas à notre disposition.
Toutefois des études similaires mais
précédant à notre travail ayant été
menées et réalisées avec ont produis des résultats
satisfaisant permettant de tirer des conclusions excellentes.
5.2 Résultats [18]
Le même programme implémenté sur FPGA a
été aussi implémenté sur un microprocesseur de
base. Un exemple commun d'architecture de réseau a été
testé séparément sur chacun des deux processeurs, les
résultats sont consignés dans le tableau ci-dessous :
|
Noeuds
(coût des liens sur 8 bits)
|
Eléments
logiques
|
Nombre
de bits mémoire
|
Temps d'exécution
Sur FPGA
|
Temps d'exécution
Sur un uP
|
Rapport
Temporel
uP/FPGA
|
|
8
|
834
|
632
|
10,6
|
250
|
23,58
|
|
16
|
1536
|
2116
|
13,4
|
434
|
32,39
|
|
32
|
2744
|
8287
|
17, 2
|
802
|
46,63
|
|
64
|
5100
|
32894
|
21,6
|
1456
|
67,41
|
Tableau5.2a :
Résultats
5.3 Discussions des
résultats
· La première remarque que nous pouvons faire
ressortir est que le nombre d'éléments logiques entrant en jeu
dans la configuration du FPGA croit avec l'importance du réseau ce qui
est tout à fait logique car il faut davantage de ressource
mémoire (voir colonne 3) et de ressource opératoire ce qui
produit une plus grande consommation d'énergie par le FPGA.
· La deuxième remarque que nous ferons ressortir
est évidemment sur les différents temps d'exécution de
l'algorithme. Tout d'abord sur le FPGA comme sur le microprocesseur seul, le
temps d'exécution de l'algorithme croit avec l'importance du
réseau, ce qui est évidemment tout à fait logique ;
ensuite la colonne des rapports temporels nous montre combien le FPGA
exécute de loin plus vite qu'un microprocesseur conventionnel.
Cela est dû à deux raisons fondamentales :
· Tout d'abord la différence est au niveau de
l'architecture interne du FPGA qui est conçue pour effectuer des
tâches dédiées c'est-à-dire bien spécifiques
en sorte que pendant son fonctionnement, il n'exécute que la tâche
qui lui a été assignée,c'est ce qui lui confère sa
rapidité. Le microprocesseur conventionnel quant à lui effectue
plusieurs tâches à la fois ce qui est une cause de son retard sur
le FPGA.
· Le FPGA a également cet avantage que sa
programmation allie la souplesse du software à la rapidité du
hardware, alors que celle du microprocesseur est réalisée de
manière soft uniquement et ne bénéficie donc pas de la
rapidité du hard qu'a le FPGA.
· Les instructions multiples sur les variables sont
exécutées de façon concurrentielle sur le FPGA.
· Les opérations arithmétiques multiples,
telles que les comparaisons, sont exécutées en
parallèle.
Voila ce que nous pouvons dire sur ces résultats.
Nous ne pouvons pas faire une analyse plus poussée car
on entrerait maintenant dans le cadre de l'architecture du programme qui a
été utilisé pour réaliser cette
implémentation, or nous n'avons pas la même architecture, c'est
donc la raison pour laquelle nous n'avons fait que des remarques d'ordre
général mais pertinentes.
Perspective
Afin de pouvoir améliorer cet algorithme
d'implémentation, il ne serait pas intéressant de réaliser
ce programme en un block compact d'instruction mais plutôt de pouvoir le
subdiviser en plusieurs blocks de petites tailles et les sauvegarder dans un
fichier sous forme de package. Ceux ci pourront être utilisés par
la suite pour réaliser des versions plus améliorées.
CONCLUSION GENERALE
Arrivés au terme de notre étude dont nous
rappelons ici le thème : « FPGA and Traffic
Network Analysis », il nous semble opportun de
rappeler les points suivants :
· les processeurs ordinaires sur lesquels tournent les
algorithmes de routage éprouvent de plus en plus des difficultés
croissantes avec les qualités et les exigences de plus en plus grandes
des services devant être rendu par les réseaux.
· afin de pourvoir combiner la souplesse du soft et la
vitesse du hard, la tendance fut donc de se tourner vers des architectures
reconfigurables à l'occurrence celle du FPGA.
· l'un des algorithmes de recherche du plus court chemin
le plus répandu dans les réseaux est celui de DIJKSTRA.
· L'implémentation de cet algorithme a
déjà fait l'objet d'études antérieures
sanctionnées par des résultats confirmant la théorie selon
laquelle l'exécution de l'algorithme est plus rapide sur FPGA que sur
des microprocesseurs ordinaires.
· Cela peut être attribué aux facteurs
suivant : les multiples instructions sur les variables sont
exécutées de manière concurrente, les opérations
arithmétiques multiples y compris les comparaisons sont
exécutées en parallèle et les tables et structures de
données sont directement implémentées dans les blocs de
mémoires internes.
Dans ce mémoire donc, nous avons d'abord parlé
du routage afin de situer le sujet dans son contexte, ensuite nous avons
présenté le processeur dont il était question dans ce
travail, puis nous avons abordé d'une manière succincte le
langage VHDL ; riche de ces connaissances, nous avons terminé par
la présentation de la méthodologie d'implantation et des
résultats.
Malgré leurs relatives lenteurs, de plus en plus de
personnes s'intéressent aux FPGA. Les personnes
intéressées par le Hardware libre les utilisent pour faire une
machine spécialisée dans une tâche (un petit ordinateur
servant de commutateur ou spécialisé dans la lecture de fichiers
multimédias par exemple, ou même pour le routage comme nous
l'avons vu). Une grande partie de ces personnes utilisent des puces FPGA en
parallèle avec un processeur classique. Cela leur permet
d'accélérer certaines tâches matériellement tout en
gardant une machine rapide quel que soit la tâche qui lui est
demandé.
Vu le développement de la technologie FPGA, il est
intéressant de se demander de quoi seront constitué les routeurs
et même l'ordinateur de demain. Y aura-t-il toujours des processeurs
classiques comme aujourd'hui ? Ces processeurs seront-ils épaulés
par des puces FPGA chargée d'accélérer certaines
tâches, ou bien est ce que les puces FPGA se développeront
suffisamment pour concurrencer les processeurs classiques en terme de vitesse ?
Y aura-t-il
des puces similaires à la Virtex II Pro XC2VP125
?
Rendez-vous dans une dizaine d'années pour les réponses
à ces questions ...
| 

