2.4.1 Recherche d'information géographique 2.4.1.1
La Recherche d'information
Une définition classique de la recherche d'information
(RI) (Rijsberg 1979) est : la discipline qui fournit des techniques
d'indexation de texte et des mécanismes de recherche.
Un problème typique de la recherche d'information est
de sélectionner les documents pertinents parmi une collection de
documents en fonction de la requête de l'utilisateur. Cette requête
est souvent sous forme de quelques mots-clés décrivant
l'information voulue(Han et Kamber 2006).
Contrairement aux systèmes de gestion de bases de
données (SGBD), qui mettent l'accent sur la recherche et le traitement
des données structurées comme les bases de données
relationnelles, la recherche d'information concentre sur la recherche et
l'organisation d'informations non structurées, particulièrement
les documents textuels(Han et Kamber 2006).
La recherche d'information a deux procédures
principales : l'indexation et la recherche. Au temps de
l'indexation, une collection de documents est traitée document
par document et les termes clés de chaque document sont
extraits puis stockés dans un index. Au temps de la
recherche, un utilisateur encode un besoin

d'information dans une requête, qui est
analysée par le système de recherche. Ce dernier
sélectionne les documents dont leurs termes clés correspondent
aux termes clés de la requête, et une fonction de classement
classe les documents en ordre décroissant de pertinence à
l'égard de la requête (Leidner 2007).
2.4.1.2 La recherche d'information avec une dimension
géographique
L'espace est une dimension très intuitive pour la
recherche d'information, une étude faite sur le moteur de recherche
Excite12 a montré que 18.6% des requêtes sont
liées à la géographie, et 79.5% des requêtes
géographiques contiennent des toponymes(Sanderson et Kohler 2004). Le
problème ici est que les systèmes de RI classiques traitent les
termes géographiques, entre autre les toponymes, comme tous les autres
termes.
La recherche d'information géographique (RIG)
est un nouveau domaine, d'abord décrit et baptisé par Ray
Larson(1996)(Hill 2006). La RIG diffère de la RI par la reconnaissance
et la modélisation explicite de l'espace dans le cadre des
procédures d'indexation et de recherche d'information (Leidner 2007).
Dans un système de RIG, non seulement les termes clés qui sont
indexés mais aussi les termes géographiques avec leurs positions
unique dans la Terre appelées empreintes spatiales (spatial
footprint). La recherche dans ce cas, est basée sur la comparaison de
l'empreinte spatiale d'une requête avec les empreintes spatiales des
documents. Généralement, la comparaison n'est pas exacte, mais
elle est basée plutôt sur un certain degré de
chevauchement.
La Figure 2-9 montre le chevauchement de l'empreinte spatiale
d'une requête géographique et les empreintes spatiales de quatre
documents. Les documents A, B, C illustrés dans cette figure sont
pertinents pour la requête, tandis que D ne l'est pas.
12
http://www.excite.com
La désambiguïsation des toponymes : notions de
base

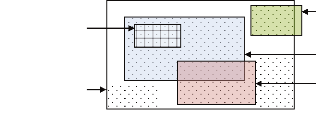
Empreinte spatiale du document B
(Le document B correspond à une partie de la
requête)
Empreinte spatiale du document A
(Une partie du document A correspond à la
requête)
A
D
B
Requête
C
Empreinte spatiale du document D
(Le document D ne
correspond pas à la requête) Empreinte spatiale de
la requête
Empreinte spatiale du document C
(Le document C croise la requête)
Figure 2-9. Les différents types de
chevauchements entre l'empreinte spatiale d'une requête et les
empreintes
spatiales des documents
La création des empreintes spatiales des documents
passe essentiellement par deux étapes qui sont : l'identification des
toponymes dans le texte puis la désambiguïsation des toponymes.
La désambiguïsation des toponymes est donc une
tâche d'une importance primordiale dans le processus de la recherche
d'information géographique. Elle est appliquée au niveau de la
recherche pour désambiguïser les toponymes de la
requête, et au niveau de l'indexation pour
désambiguïser les toponymes des documents textuels (voir Figure
2-10).
| 

