|
REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET
POPULAIRE
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR ET DE LA
RECHERCHE
SCIENTIFIQUE
Université Des Sciences Et De La
Technologie
D'Oran Mohamed Boudiaf
U.S.T.O.M.B
Faculté des sciences
Département d'informatique
P
rojet de fin d'étude
Pour L'obtention Du Diplôme de
License En LMD Informatique
THEME
UN ATELIER DE GENIE LOGICIEL DEDIE A L'ESTIMATION
DU COUT LOGICIEL
Présenté Par
Encadré
Par

Melle MEFLAHI Soumia
F.guerroudji
Melle LAOUTI Houria
Examiné Par
Mme KIES
Promotion 2008 -
2009
remerciments
Ce n'est pas facile d'arriver à
accomplir notre travail sans aide ni conseils à cause des
problèmes rencontrés tant pratiques que théoriques.
Pour cela tout d'abord, nous rendons
grâce a « ALLAH » seigneur tout
puisant pour la force qu'il nous accordés tous au long de notre vie.
Nous exprimons aussi nos gratitudes et nos
plus vifs remerciements à notre encadreur Mme FATIHA
GUERROUDJI pour son soutien, sa patience, ses conseils judicieux et
pertinents.
De même nous tenons à
remercier Mme KIES pour l'honneur qu'elle nous fait d'avoir
examiner notre travail.
Nos remerciements s'adressent aussi à tous
nos enseignants pour la formation qu'ils nous ont inculquée.
Et finalement à tous ceux qui nous
ont aidés de prés ou de loin à accomplir ce travail nous
disons Merci.
Je souhaite dédier ce modeste travail synonyme de
concrétisations de tous mes efforts fournis ces dernières
années :
Tout d'abord
A
Mon père
Qui a été toujours pour moi l'exemple dans cette
vie
La chandelle de ma vie ma très chère
mère
qu'elle trouve ici l'expression de mes sentiments les plus
profonds pour le confort moral qu'elle m'assure tout au long de mes
études
Mon très cher oncle SAIID,
Que j'aime beaucoup
Mes soeurs
Mon frère MOHAMED.
A ma très chère amie SOUMIA
Pour ca précieuse collaboration et sa patience,
souhaitons que notre amitié durera longtemps incha allah
Et à tous mes proches et amies
qui m'ont toujours soutenue et encouragé au cours de la
réalisation de ce mémoire
RAHMA, RIMA, FATIMA...
Laouti houria
En préalable à ce mémoire je souhaite
adresser ici tous mes remerciements aux personnes qui m'ont apporté
leur aider et qui ont aussi contribué à l'élaboration de
ce travail :
Tout d'abord
A
Mes Très chers parents
qui se sont sacrifiés pour que je puisse terminer mes
études, et réussir dans ma vie professionnelle
Et je tiens à exprimer par ces quelques mots mon plus
grand amour à ma mère
Ainsi qu'à mes très chères soeurs
Mon oncle BOUKHARI
pour ses conseils, ses idées nombreuses, sa patience
(sans limite) et sa gentillesse, son aide a été plus que
précieuse dans les moments les plus délicats et les plus
difficiles du mémoire
Et Tous mes amies
HOURIA, FATIMA, RAHMA, RIMA, MOKHTARIA ..., avec qui j'ai
passé des années inoubliables
Tout ce qui m'on soutenue de loin et de prêt. Merci
MEFLAHI SOUMIA
L'estimation du coût d'un projet informatique est
l'un des plus grands défis dans le domaine du génie logiciel. Il
représente un des problèmes critiques qui sont à la base
de toutes les applications des techniques économiques relatives à
ce domaine.
A partir de cette constatation un certain nombre de
méthodes et techniques ont été reconnues efficaces pour
répondre à cette problématique. Ces méthodes ont
fait leur preuve dans divers domaines d'application.
Notre projet de fin d'étude présenté
dans ce mémoire porte sur deux de ces méthodes et qui sont
très utilisées dans le domaine du génie logiciel. Il
s'agit d'une part de la méthode des points de fonctions, qui a
été crée par Allan Albrecht en 1979 et dont le principe
consiste à identifier les fonctionnalités réclamées
par le projet, en comptant les éléments qui devront être
traités pour prévoir l'effort de développement et d'autre
part de la méthode Cocomo'81 développée par Barry Boehm
en 1981 pour estimer le coût, en s'appuyant sur une donnée de
base : le nombre de ligne de code source prévisible, exprimé
en Kilo Instruction Source
Livrées(KISL).
L'objectif principal de notre travail est de
développer un atelier de génie logiciel (AGL) qui intègre
ces deux méthodes. Pour aboutir à cet effet nous avons
constitué notre mémoire de quatre parties
complémentaires organisées comme suit:
La première, intitulée introduction
au génie logiciel, donne une présentation du
génie logiciel qui nous permettra de mettre l'accent sur les aspects
d'estimation de coût.
La deuxième partie, intitulée les
méthodes d'estimation de coûts de logiciel se compose
d'une présentation critique des différentes méthodes
d'estimation de coût, utilisables actuellement.
La troisième partie, décrit en
détail les deux méthodes précitées objet de notre
projet qui sont la méthode des Points de Fonctions et la
méthode Cocomo'81.
Le quatrième chapitre est consacré à
la description de notre AGL
Enfin, notre mémoire sera clôturée
par une conclusion et quelques perspectives futures.
CHAPITRE I


Introduction Au Génie Logiciel
1. INTRODUCTION
Dans ce premier chapitre nous donnerons les
différentes définitions du terme « Génie
Logiciel ». Ensuite, nous présenterons le cycle de
vie d'un logiciel dans ses différentes phases et ses différents
modèles en se focalisant tout particulièrement sur l'estimation
du coût d'un projet informatique.
2. GENIE LOGICIEL
2.1. Présentation
L'appellation génie logiciel concerne
l'ingénierie appliquée au logiciel informatique. [LAN 88]
Ce terme a été introduit à la
fin des années soixante pour répondre à la crise de
l'industrie du logiciel. Cette crise est apparue lorsqu' on a prit conscience
que la qualité des systèmes produits ne correspond pas a
l'attente des clients.
Depuis, le génie logiciel constitue un
véritable enjeu stratégique pour le développement des
applications informatiques, en particulier les évolutions
stratégiques des ateliers de génie logiciel qui
concernent :
· Les outils de développement (conception,
production, fiabilité, maintenance) ;
· Les outils d'analyse et d'expertise ;
· Les outils de gestion ;
· Les outils de création et des de gestion de base
de données ;
· Les outils de modélisation, de conception et
d'évolution des architectures. [ALP 95]
Ces outils portent sur une partie ou sur l'ensemble
du cycle de vie du logiciel.
2.2. Définitions
Le génie logiciel est le domaine
dédié à l'étude, la conception et la
réalisation de programmes informatiques. Ce terme a été
défini à l'origine par un groupe de travail en 1968, à
Garmisch-Partenkirchen, sous le parrainage de l'OTAN.
Actuellement, le Génie
Logiciel(en anglais software engineering),
peut se définir comme un ensemble composé de méthodes, de
modèles, d'outils d'aide au développement et de critères
d'évaluation de la qualité permettant à un maître
d'oeuvre de produire un logiciel répondant aux besoins exprimés
par un maître d'ouvrage.
Le Génie Logiciel est donc l'art de
spécifier, de concevoir, de réaliser, et de faire évoluer,
avec des moyens et dans des délais raisonnables, des programmes, des
documentations et des procédures de qualité en vu d'utiliser un
système informatique pour résoudre certains
problèmes.
Une définition plus précise
décrit le Génie Logiciel comme l'ensemble des activités
de conception et de mise en oeuvre des produits et des procédures
tendant à rationaliser la production du logiciel et son suivi.
Autrement dit, le Génie
Logiciel est « l'art »de produire
de bons logiciels, au meilleur rapport qualité/prix. Il utilise pour
cela des principes d'ingénierie et comprend des aspects à la fois
techniques et non techniques: le génie logiciel est basé sur des
méthodologies et des outils qui permettent de formaliser et même
d'automatiser partiellement la production de logiciels, mais il est
également basé sur des concepts plus informels, et demande des
capacités de communication, d'interprétation et d'anticipation.
L'utilisation du génie logiciel
dans la production d'un logiciel qui accompli les besoins attendu en même
temps qu'il satisfait les objectifs d'un processus d'ingénierie est
implantée avec un processus par étapes. Ces différentes
étapes forment le cycle de vie d'un logiciel.
2.3. Objectif du Génie logiciel
Le Génie logiciel se préoccupe des
procédés de fabrication des logiciels en s'assurant
que les 4 critères suivants soient satisfaits
[INT 1] :
· Le système qui est fabriqué répond
aux besoins des utilisateurs (contraintes
Fonctionnelles),
· La qualité correspond à celle
consignée dans le contrat de service initial,
· Les coûts restent dans les limites prévues
au départ,
· Les délais restent dans les limites
prévues au départ.
3. CYCLE DE VIE D'UN LOGICIEL
Il faut un temps considérable
pour développer un grand système logiciel qui, d'ailleurs, sera
utilisé pendant très longtemps .en identifie donc un certain
nombre d'étapes distinctes dans cette périodes de
développement et d'utilisation, ces étape constituent le cycle de
vie du logiciel [LAN 88], de sa conception à sa
disparition.
L'objectif d'un tel découpage est de permettre de
définir des jalons intermédiaires permettant la
validation du développement logiciel,
c'est-à-dire la conformité du logiciel avec les besoins
exprimés, et la vérification du processus de
développement, c'est-à-dire l'adéquation des
méthodes mises en oeuvre. [INT 3]
3.1. Les phases du cycle de vie du
logiciel
3.1.1. Etude préalable [INT4]
L'étude préalable consiste à
élaborer une version de base du cahier des charges, qui doit inclure
|
· la décision de faisabilité,
· le plan général du projet,
· une estimation approchée du coût et des
délais de réalisation.
· Les concepteurs doivent effectuer une enquête
précise au niveau des demandeurs de l'application (les
clients), et des utilisateurs (souvent le personnel
des clients),
· et une étude précise du système
d'information les concernant.
c'est-à-dire consiste à définir les
services qui seront rendus à l'utilisateur et les contraintes sous
lesquelles ce logiciel devra fonctionner. [INT3]
3.1.2. La spécification
La spécification a pour but
d'établir une première description du futur système. Cette
activité utilise les résultats de l'analyse des besoins, les
considérations techniques et la faisabilité informatique pour
produire une description de ce que doit faire le système mais sans
préciser comment il le fait (on précise le
quoi mais pas le comment). [INT3]
3.1.3. La conception
la phase de conception (design
phase), généralement décomposée en
deux phases successives dont la première est appelée conception
générale, conception globale, conception préliminaire ou
conception architecturale, et la deuxième conception
détaillée. A partir du document de spécification, la phase
de conception doit fournir une réponse à la question:
«Comment réaliser le logiciel
? ». [INT3]
3.1.3.1. La conception
générale
La conception générale consiste en
une description de l'architecture du logiciel, c'est à dire obtenir
à la fois :
· une décomposition du système
d'information en un ensemble de modules et de structures de données,
· et une description du rôle de chaque module
individuellement, et en interaction avec les autres. [INT4]
3.1.3.2. La conception
détaillée
La conception détaillée consiste à
obtenir une description détaillée des traitements et des
structures de données (requêtes et tables dans un
modèle S.G.B.D ou algorithme et lexique dans un modèle
fichiers).
On utilise pour cela des langages intermédiaires entre
le langage naturel (homme), et les langages de
programmation (ordinateur) par exemple
l'algèbre relationnel (S.G.B.D.) ou le
« Pseudo code » (programmation
classique). [INT4]
3.1.4. La codification
La codification permet de réaliser, à
partir de la conception détaillée, d'un ensemble de programme ou
de composants de programmes. [INT3]
3.1.5. Les tests unitaires
Les tests unitaires consistent à vérifier
le bon fonctionnement du programme et des différents modules le
composant (individuel et interactif) par
l'intermédiaire de jeux d'essai judicieusement choisis au sein du
domaine d'application de ce programme. [INT4]
3.1.6. Les tests systèmes
Les tests systèmes correspondent :
· A la phase d'intégration des divers programmes
pour obtenir le logiciel fini,
· Ainsi qu'à l'ensemble des testes qui permettra
de vérifier que le logiciel correspond exactement au cahier des
charges,
· Et enfin à la rédaction de la
documentation utilisateur. [INT4]
3.1.7. L'exploitation [INT4]
L'exploitation consiste à la mise à
disposition de l'ensemble des utilisateurs du logiciel fini, de telles
façons à ce que ce logiciel soit opérationnel en situation
réelle de production.
3.1.8. La maintenance
La maintenance prend trois formes :
· La maintenance corrective
permet de corriger les erreurs qui n'ont pas été
détectées lors des précédentes phases de tests.
· La maintenance adaptative
doit s'occuper de faire évoluer et d'adapter le logiciel à
l'apparition de nouvelles contraintes.
· La maintenance
perfective a pour objectif l'optimisation des performances du
logiciel.
3.2. Modèles cycle de vie
3.2.1. Modèle en cascade
Dans ce modèle le principe est très simple
: chaque phase se termine à une date précise par la production de
certains documents ou logiciels. Les résultats sont définis sur
la base des interactions entre étapes et activités, ils sont
soumis à une revue approfondie, on ne passe à la phase suivante
que s'ils sont jugés satisfaisants.
Certaines phases portent le nom d'une activité ce
qui signifie que l'activité est essentielle pour cette phase, mais
n'impose pas qu'elle n'ait lieu que dans cette étape. D'autres
activités interviennent, par exemple le contrôle technique et la
gestion de la configuration sont présents tout au long du processus.
Le modèle original ne comportait pas de
possibilité de retour en arrière. Celle-ci a été
rajoutée ultérieurement sur la base qu'une étape ne remet
en cause que l'étape précédente, ce qui, dans la pratique,
s'avère insuffisant.
Fig I.1 -le cycle de vie en cascade.
3.2.2. Modèle en V
Le principe de ce modèle est qu'avec toute
décomposition doit être décrite la recomposition, et que
toute description d'un composant est accompagnée de tests qui
permettront de s'assurer qu'il correspond à sa description.
Ceci rend explicite la préparation des
dernières phases (validation -
vérification) par les premières
(construction du logiciel), et permet ainsi
d'éviter un écueil bien connu de la spécification du
logiciel : énoncer une propriété qu'il est impossible de
vérifier objectivement après la réalisation.
Fig I.2 - le cycle de vie en V.
3.2.3. Modèle par
incrément
Dans les modèles par incrément
un seul ensemble de composants est développé à la fois :
des incréments viennent s'intégrer à un noyau
de logiciel développé au préalable. Chaque
incrément est développé selon l'un des modèles
précédents.
Avantage :
· chaque développement est moins complexe ;
· les intégrations sont progressives ;
· possibilité de livraisons et de mises en service
après chaque incrément ;
· meilleur lissage du temps et de l'effort de
développement à cause de la possibilité de recouvrement
des différentes phases.
Risque :
· mettre en cause le noyau ou les incréments
précédents ;
· ne pas pouvoir intégrer de nouveaux
incréments.
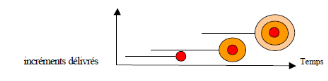
FigI.3 - le cycle de vie par
incrément
3.2.4. Le prototypage
Ce modèle consiste à produire une version
d'essai du logiciel un prototype utilisée pour tester les
différents concepts et exigences. Il sert à montrer au client les
fonctionnements que l'on se propose de mettre en oeuvre. Après que le
client a donné son accord, le développement du logiciel suit
généralement les phases du modèle en cascade. Les efforts
consacrés à la réalisation du prototype sont le plut
souvent compensés par ceux gagnés à ne pas
développer de fonctions inutiles.
Caractéristiques :
· Un degré élevé de participation du
client.
· Une représentation tangible des exigences du
client.
· Très utile quand les exigences sont instables ou
incertaines.
Avantages participation du client :
· Le client participe activement dans le
développement du produit.
· Le client reçoit des résultats tangibles
rapidement.
· Le produit résultant est plus facile à
utiliser et à apprendre.
Applicabilité :
· Pour des systèmes interactifs de petite et
moyenne taille.
· Pour des parties de grands systèmes (par exemple
l'interface utilisateur).
· Pour des systèmes avec une vie courte.
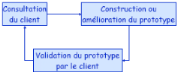
Fig I.4 -Modèle de
prototypage
3.2.5. Le modèle en spirale
Proposé par B. Boehm en
1988, ce modèle est beaucoup plus général
que le précédent. Il met l'accent sur l'activité
d'analyse des risques : chaque cycle de la
spirale se déroule en quatre phases:
1-) détermination, à partir
des résultats des cycles précédents, ou de l'analyse
préliminaire des besoins, des objectifs du cycle, des alternatives pour
les atteindre et des contraintes ;
2-) analyse des risques, évaluation
des alternatives et, éventuellement maquettage;
3-) développement et
vérification de la solution retenue, un modèle «
classique» (cascade ou en
V) peut être utilisé ici ;
4-) revue des résultats et
vérification du cycle suivant.
Avantage
· Un modèle simple est facile à suivre.
Risque :
· Impossibilité de suivre et assurer le bon
déroulement du projet ;
· Augmentation du risque cas validation tendit ;
· Modèle difficile à utiliser quand il
difficile d'obtenir un énoncé complet de besoins.
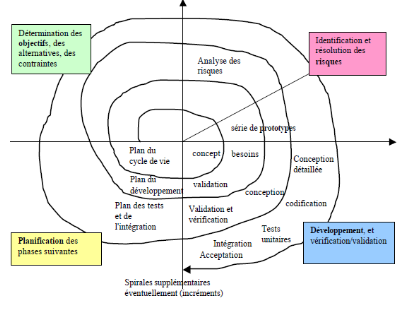
Fig I.5 - le cycle de vie
en spirale
|
|
|
|
|
|
|
|
|
|
|
4. CRISE LOGICIEL ET GENIE LOGICIEL
Alors que le matériel informatique a fait, et
continue de faire, des progrès très rapides,
Le logiciel, l'autre ingrédient de l'informatique,
traverse une véritable crise. Etant donné que cette crise a
été décelée en 1969
déjà et qu'elle dure toujours, il serait plus approprié de
parler d'une maladie chronique.
La crise du logiciel (software crisis)
peut tout d'abord se percevoir à travers ses symptômes:
· les logiciels réalisés ne correspondent
souvent pas aux besoins des utilisateurs;
· les logiciels contiennent trop d'erreurs
(qualité du logiciel insuffisante);
· les coûts du développement sont rarement
prévisibles et sont généralement prohibitifs;
· la maintenance des logiciels est une tâche
complexe et coûteuse;
· les délais de réalisation sont
généralement dépassés;
· les logiciels sont rarement portables.
La crise du logiciel a ensuite des conséquences
économiques: aujourd'hui le coût du logiciel est
supérieur à celui du matériel. Même si des chiffres
précis font défaut, les experts sont unanimes quant à la
tendance: partant d'une proportion 50%-50% en 1965, et passant par 70%-30% en
1975, ce rapport avait atteint 80%-20% en 1985. Mais pas seulement en
proportion, en valeur également, le coût du logiciel croît
à une vitesse vertigineuse. On peut montrer que cette inflation des
coûts est surtout due aux frais de maintenance, situés
actuellement entre 40% et 75% du coût total d'un système
informatique (matériel et logiciel). Or ces frais de
maintenance résultent avant tout de la qualité déficiente
du logiciel, au moment de sa livraison déjà ou après qu'il
ait évolué.
La raison de fond de la crise du logiciel réside
dans le fait qu'il est beaucoup plus difficile de créer des logiciels
que le suggère notre intuition. Comme les solutions informatiques sont
essentiellement constituées de composants immatériels, tels des
programmes, des données à traiter, des procédures et de la
documentation, on sous-estime facilement leur complexité.
Déjà la taille des programmes montre que cette complexité
est souvent bien réelle: un million de lignes pour un logiciel de
commande et de navigation d'un avion moderne, le décuple pour une
station orbitale [INT 2].
5. DEFINITION D'UN ATELIER DE GENIE
LOGICIEL
Ensemble cohérent d'outils informatiques formant
un environnement d'aide à la conception, au développement et
à la mise au point de logiciels d'application spécialisés.
On retrouvera par exemple dans un AGL des dictionnaires de données, des
outils permettant de réaliser des diagrammes, pour faciliter la phase
d'analyse et de conception des applications. Puis des générateurs
de code ainsi que des aides à la mise au point (encore appelés
débogueurs) viendront accélérer la production et la
finalisation de l'application.
6. ESTIMATION DE COUT DE DEVLOPPEMENT DE
LOGICIEL
6.1. Introduction
Il n'est pas rare pour un projet logiciel de
dépasser le délai estimer de 25 à 100%, c'est même
à partir de ces constatations que la crise du logiciel est
apparue...Aujourd'hui si quelques projets ont encore des dérapages
parfois catastrophiques, certains ne dépassent les prévisions que
de 5 à 10% seulement.
Il est indispensable pour le client comme pour le
fournisseur (chef de projet et management) d'estimer à
l'avance la durée (calendrier) et le coût
(effort) d'un projet logiciel. Il convient également
d'en mesurer les risque en recensant les dépendances extérieures
qui influeront sur les coûts et délais .une remarque
préalable s'impose quant au processus d'estimation beaucoup trop
souvent, le management et les client ont de la peine à comprendre que
l'estimation est une activité comportant des difficultés
intrinsèques et la rendent encore plus difficile par ce manque de
compréhension .le processus requiert des raffinement successifs, il est
impossible de fournir une estimation correcte jusqu' a ce que le logiciel soit
appréhendé dans son intégralité.
Les estimations interviennent dans au moins quatre
phase du cycle de vie du projet :
· L'expression du besoin ;
· L'étude fonctionnelle ;
· L'étude technique ;
· La réalisation.
A chaque des phases correspond un besoin d'estimer
spécifique :
6.1.1. L'expression du besoin
C'est le démarrage du projet.
L'utilisateur(ou son représentant) :
Ø Décrit de façon macrocosmique les
fonctions nécessaires a la application ;
Ø Evalue les gains générés par le
nouveau produit.
A la fin de cette étape, il est
possible d'estimer de manière globale le coût de l'outille
souhaité. La comparaison entre les gains espérés et le
coût du projet rendra possible le calcul du retour sur investissement du
projet.
Les décideurs possèdent, de cette
étapes, les données suffisantes pour continuer(ou
non)de développer le projet.
6.1.2. L'étude fonctionnelle
Le projet prend forme.
Les fonctions qu'il regroupe sont décrites avec précision.
Cette étude reste fonctionnelle. On ne parle pas
encore technique, même si l'on les écrans ou les traitements qui
seront produites (les maquettes des écrans sont souvent
créées durant cette phase).
A cette étape, l'estimation va permettre de :
Ø confirmer les charges estimées de étape
précédente ;
Ø planifier les budgets.
Dans la majorité des cas, le délai d'un projet
s'étend sur plus d'une année. Les directions financières
se doivent de répartir dans le temps, le coût des étapes du
projet.
Par exemple, les études seront menées sur
le budget de l'année en cours, la réalisation sur l'année
suivante, voire sur les deux années suivantes pour les projets
importants.
6.1.3. L'étude technique
La maitrise d'oeuvre l'application .À chaque
fonctionnalité correspond au moins un objet informatique.
L'estimation est maintenant très proche de la
réalité ; elle est plus précise. Les métriques
utilisées sont différentes, plus précises elles aussi.
Le découpage en fonctions/taches, qui correspond
à la réalité du projet, facilite la lourde mission de
planification. L'approche de l'estimation correspond à la logique de la
plupart des outils de planification. Les taches élémentaires,
ainsi que leur charge, sont connus et facilement intégrées dans
les plannings.
Il est question a cette étape, de planifier la
réalisation du projet, de maitriser les éventuelles
dérives, et de construire une application maitrisée.
6.1.4. La réalisation
La mise à jour des estimations et la saisie
des consommés(ou leur intégration
automatique), présente trois avantages :
Ø Connaitre en permanence la charge estimée,
réactualisée du projet, s'appuyant sur des données
statistique issues de l'ensemble des projets terminés (base de
référence) ;
Ø Obtenir une planification vivante grâce a ses
mises a jour ;
Ø Maitriser la dérive éventuelle du
projet en comparant le réalisé et l'estimé. La comparaison
peut amener à réviser les métriques ou à
reconsidérer la complexité des taches sujettes à
dérive.
|
6.2. L'objectif de l'estimation de coût d'un
logiciel
· sensibiliser à l'existence de méthodes
pour l'estimation de l'effort de développement d'un projet
· donner les bases rudimentaires pour estimer l'effort
d'un nouveau projet ou l'effort de maintenance d'un projet
· donner les éléments qui permettent de
nuancer l'effort calculé d'un projet (cohésion de
l'équipe, maturité des processus,..)
· proposer aux personnes (chefs de projets et/ou
analystes) des outils utiles à la négociation de contrats
avec leur(s) client(s)
· proposer aux personnes (chefs de projets et/ou
analystes) un modèle de coût permettant de décider de
la stratégie de développement (coding ou reuse de certains
composants)
6.3. Les étapes d'estimation d'un
projet
L'estimation d'un projet informatique comprend quatre
étapes :
· Estimer la taille du produit à
développer. Celle-ci se mesure généralement en nombre
d'instructions (lignes de code) ou en points de fonction, mais il existe
d'autres unités de mesure possibles.
· Estimer la charge en mois hommes ou en jours
hommes.
· Construire le calendrier du planning.
· Estimer le coût du projet en monnaie locale.
6.4. Les difficultés de
l'estimation
L'estimation des charges des projets informatiques est
absolument nécessaire ; mais c'est aussi l'une des activités les
plus difficiles du développement de logiciels. Pourquoi est-ce si ardu ?
La liste suivante indique quelques-unes de ces difficultés que nous
devons surmonter.
· L'estimation de la taille est, intellectuellement,
l'étape la plus difficile (mais non impossible) ; elle est
souvent esquivée en passant directement à l'estimation des
délais. Cependant, si vous ne vous interrogez pas sur l'objectif que
l'on vous demande d'atteindre, vous n'aurez aucune base suffisante pour
prévoir un délai ou évaluer les conséquences d'un
changement de périmètre.
· Souvent, les clients et les techniciens de logiciels,
ne comprennent pas que le développement de logiciels est un processus de
raffinement progressif et que les estimations faites en a mon du projet sont
floues. Les bonnes estimations, elles-mêmes, ne sont que des paris, avec
des hypothèses sur les risques inhérents ; cependant, on a
quelquefois tendance à les considérer comme gravées dans
le marbre ! Il est pertinent de présenter les estimations comme une
plage de valeurs possibles, en exprimant, par exemple, que le projet prendra de
5 à 7 mois, au lieu d'affirmer qu'il sera achevé le 15 juin.
Méfiez-vous d'une plage trop étroite qui reviendrait à
donner une date précise ! Vous pouvez inclure l'incertitude sous forme
d'une probabilité en disant, par exemple, qu'il est probable, à
80 %, que le projet soit achevé avant le 15 juin.
· Souvent, l'Organisme ne recueille ni n'analyse les
mesures des performances des projets terminés. L'utilisation de
données historiques est cependant la meilleure manière pour
élaborer des estimations d'un nouveau travail. Il est très
important d'établir une liste de caractéristiques fondamentales
que vous mesurerez dans chaque projet.
· Il est souvent difficile d'obtenir un planning
réaliste accepté par l'encadrement et les
clients. Chacun préfère que les résultats soient
disponibles au plus tôt, mais pour chaque projet, il y a un délai
minimal qui vous permet d'intégrer toutes les fonctionnalités
avec la qualité requise. Vous devez définir ce que vous pouvez
faire dans un délai donné et expliquer à toutes les
parties concernées ce qui est possible et ce qui ne l'est pas. Oui, il
arrive, de temps en temps, que l'impossible se réalise ... mais c'est
très rare et très coûteux. Espérer l'impossible
relève d'une téméraire imprudence !
6.5. Pourquoi de mauvaises estimation ?
· les besoins sont vagues, et la qualité des
résultats difficile à évaluer,
· les « managers »
sont trop optimistes et pensent que tout ira bien ; ils espèrent le
succès parce qu'ils veulent le travail,
· on ne tira pas assez expérience du passé,
on utilise trop le « pif » ; il faut de
l'expérience pour bien estimer
· imprécision des notions d'homme-mois, de ligne
de code source.
6.5.1. Pièges à
éviter
· faire trop précis.
Ø travailler avec des marges d'erreur importantes.
· Sous-estimer.
Ø Etre exhaustif dans la liste chose à
estimer.
· Sur-estimer.
Ø Ne pas intégrer systématiquement tous
les coûts des aléas possibles.
· Confondre objectif et estimation.
Ø Résister à « il ne faut pas
que ça coûte plus de ... ».
· Vouloir tout estimer.
Ø Savoir avouer son ignorance.
6.5.2. Quelques règles d'or pour
l'estimation
· Eviter de deviner : prendre le
temps de réfléchir, ne jamais sans avoir étudié la
situation calmement.
· Prévoir de temps pour
l'estimation et la planification.
· Utiliser des données de projets
précédents.
· Prendre l'avis des développeurs
qui vont effectivement effectuer le travail.
· Estimer par consensus : consulter
les différentes équipes, converger sur des dates au plus
tôt et au plus tard.
· Estimer par difficultés
(facile, moyen, difficile).
· Ne pas oublier les tâches
récurrentes : documentation, préparation des
démonstrations utilisateurs, formation utilisateurs et
développeurs, intégration à l'existant,
récupération des données, revues, réunions,
maintenance de l'existant pendant le développement du nouveau produit,
gestion qualité, absentéisme (congés, maladie,
RTT).
· Utiliser plusieurs techniques d'estimation.
· Changer de méthodes d'estimation au fil de
l'avancement du projet.
· Prendre en compte les risques de gestion dans
l'estimation.
· Eviter de données une estimation qui s'appuie
sur un chiffre unique.
Mais recommandons plutôt d'encadrer les
prédictions par une fourchette optimiste/pessimiste.
Le tableau ci dessous (adapté de
« Cost Models For Future Software Life Cycle Processes :
COCOMO 2.0 », Bohem et Al.1995) donne une base d'estimation
pour passer d'un chiffre unique à une fourchette grâce à
des coefficients multiplicateurs.
PhaseTaille Et EffortDurée
OptimistePessimisteOptimistePessimisteAnalyse initiale
des besoins0.254.000.601.60Définition approuvée
des besoins0.502.000.801.25Spécification des
besoins0.671.500.851.15Conception
globale0.801.250.901.10Conception
détaillée0.901.100.951.05
Tableau : coefficient multiplicateurs
pour chaque phase du projet.
Pour utiliser les facteurs multiplicatifs de ce tableau, il
suffit de multiplier le point d'estimation unique par les coefficients
appropriés de manière à obtenir une fourchette
d'estimation dont on peut remarquer qu'elle se resserre au fur et à
mesure que l'on avance dans les phase (0.90 à 1.10 en conception
détaillée contre 0.25 à 4 en analyse initiale des besoins,
donc au moment de réponse à l'appel d'offres !) plutôt
que d'estimer la durée du projet dans son ensemble on peut le
décompose et estimer chacun de ses composants.
6.5.3. Qualités de l'estimation
· Rendue dans les délais.
· Homogène en précision.
· Honnête.
· Complète.
· Afficher les hypothèses.
· Réaliste.
· Proche du coût réel Best Estimate.
6.6. Exactitude et précision d'une
estimation
L'exactitude caractérise
l'approche de la réalité, alors que la précision
caractérise la finesse avec laquelle une grandeur est
mesurée. Par exemple, une estimation de taille de 70 ou 80
kilo-instructions peut être à la fois la plus exacte
et la plus précise que vous puissiez faire
à la fin de la phase de spécifications des besoins d'un projet.
Si vous simplifiez votre estimation en annonçant 75 000
instructions, celle-ci semble plus précise mais en
réalité elle est moins exacte. Vous pouvez
annoncer 75 281 avec une précision d'instruction, mais
on ne pourra mesurer cette taille qu'à la fin de la
phase de codage du projet, après décompte des instructions.
Si vous donnez l'estimation de la taille sous forme
d'une plage (intervalle entre une valeur minimale et une valeur maximale)
plutôt qu'avec une simple valeur, toutes les valeurs
ultérieurement calculées (charges, délais, coûts)
seront également représentées par des plages.
Si, lors du déroulement du projet, vous faites
plusieurs estimations au fur et à mesure que les spécifications
de l'ouvrage deviennent plus détaillées, l'intervalle peut se
resserrer et votre estimation se rapprochera du coût réel de
l'ouvrage que vous développez. (FigI. 6).
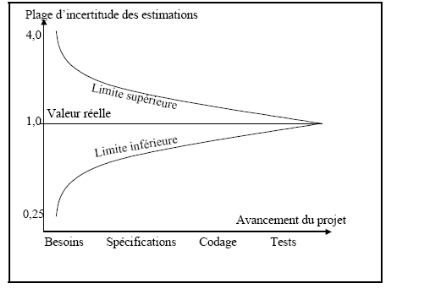
Fig I.6 -Graphe de convergence des estimations «
Développement rapide » (MCCONNELL1996) adapté de
Modèles de coûts pour le cycle de vie (BOEHM 1995).
Autres Facteurs :
d'autres facteurs importants qui affectent l'exactitude de vos
estimations :
· l'exactitude de toutes vos données
d'entrées des estimations (le vieil adage « flou en
entrée, flou en sortie » reste vrai) ;
· l'exactitude de tous les calculs (par exemple, la
conversion des points de fonction ou des nombres d'instructions en charges,
conserve une certaine marge d'erreur) ;
· la façon dont vos données historiques ou
les données classiques utilisées pour calibrer le modèle
s'appliquent au projet en cours d'estimation ;
· le respect du processus de développement
préconisé par votre Organisme ;
· les conditions de management du futur projet : rigueur
de la planification, conduite et contrôle ;
· l'absence d'incident majeur déclenchant des
retards intempestifs.
6.7. L'importance de l'estimation
Il est important de pouvoir mesurer la
productivité des programmeurs et ce au moins pour deux raisons. La
première c'est qu'elle est indispensable à la planification des
projets. La seconde, c'est que la démonstration des avantages qu'il
peut y avoir a utiliser des méthodes de programmation et de gestion de
projet évoluées ne peut être faite qu'en montrant des gains
de productivité sur l'ensemble du cycle de vie de logiciel.
6.8. les unités de mesure
Des unités de nature
différente ont été proposées pour mesurer la
productivité des
programmeurs par exemple :
· Nombre de lignes de code source écrites, par
programmeur et par mois.
· Nombre d'instructions de code objet produites, par
programmeur et par mois.
· Nombre de pages de documentation écrites, par
programmeur et par mois.
· Nombre de tests écrits et
exécutés, par programmeur et par mois.
L'unité la plus utilisée est le nombre de
ligne source écrites, par programmeur et par mois ou par homme-mois.
6.9. Les coûts d'un projet
le coût d'un projet est directement
proportionnel au nombre d'homme-mois nécessaire a la réalisation
du projet. Il y a, bien sur d'autres couts concernant le matériel, les
déplacements, la formation, etc.., mais ceux-ci sont moins difficiles a
établir. Ils ne sont pas basés sur des impondérables tels
que la productivité des programmeurs ou l'estimation de la taille du
code source.
6.9.1. Les différents coûts d'un
logiciel
6.9.1.1. Le coût de
développement
Le coût de développement d'un projet
logiciel est une valeur numérique .Ainsi, l'ensemble des valeurs
similaires au coût d'un projet logiciel dépend, en
général, des spécificités et des contraintes de
l'environnement impliqué.
Le coût détermine
l'effort jugé nécessaire pour réaliser le logiciel ;
s'exprime en homme- année ou en homme -mois.
6.9.1.2. Le coût de maintenance
Les coûts de maintenance sont supérieurs
aux coûts de développement, et leur est dramatique sous estimation
.Par exemple, un produit livré à des premiers clients avant
d'être complètement terminé, et dont la maintenance est
assurée par l'équipe de développement principale,
générée du coût de maintenance qui peuvent noyer
l'équipe, retardant «AD VITAM AETERNAM » les
échéances à venir.
Il est donc rentable d'investir
dés la conception sur la réduction de ces coûts, au moyen
d'actions organisationnelles et de contrôle qualité .On peut agir
ainsi sur :
· Des facteurs non techniques :
Ø Stabilité de l'équipe ;
Ø Durée de vie du programme ;
Ø Dépendance du programme vis à vis de
l'extérieur ;
Ø Stabilité du matériel.
· Des facteurs techniques :
Ø indépendance des modules ;
Ø Langage de programmation ;
Ø Style de programmation ;
Ø Méthodes et outils de validation et de test
Ø Documentation ;
Ø Gestion de configuration.
6.10. Quelle méthode d'estimation
choisir ?
· Chaque méthode a ses avantages et ses
inconvénients.
· L'estimation du coût du logiciel doit se baser
sur plusieurs méthodes.
· Le fait que les résultats fournit par les
différentes méthodes sont sensiblement différents montre
qu'il y a un manque d'information. Dans ce cas, des actions doivent être
entreprises pour obtenir plus d'information permettant d'améliorer la
précision des estimations.
· L'affectation du coût pour gagner est parfois la
seule méthode possible.
7. CONCLUSION :
Depuis sa naissance à la fin des années
soixante, le génie logiciel a connue beaucoup de développement et
d'évaluation. Les outils de développements, les méthodes
et les techniques du génie logiciel évoluent rapidement et ont un
cycle de vie très court.
Du fait de l'importance de maîtrise des
coûts de production qui sont souvent imprévisibles un certain
nombre de méthodes et techniques permettant d'estimer le coût d'un
produit logiciel ont été mises à la disposition des
responsables de projet informatiques. Ces méthodes sont
détaillées dans le chapitre suivant
|
|
|
|
|
|
|
|
|
Chapitre2
CHAPITRE II


Les Méthodes D'estimation De Coûts
De Logiciel
1. INTRODUCTION
De nombreux projets d'informatisation sont
confrontés au problème de l'estimation de l'effort
nécessaire à leur réalisation. L'objectif des chercheur et
responsables informatiques est de fournir des estimations exactes et
précises de l'effort de développement de projets logiciels
à une étape prématurée du cycle de vie du logiciel
Pour répondre à ce type de
difficulté et atteindre cet objectif, plusieurs méthodes
d'estimations d'effort a été développées.
Dans ce chapitre, nous présentons les
différentes techniques d'estimation des coûts de
développement de logiciels, ainsi nous représentons celles se
basent sur l'expertise, analogie et la stratégie descendante ou
ascendante. Nous exposons, en particulier, deus modèles, les
modèles algorithmiques
(paramétriques) sont les plus cités dans
la littérature. Ils sont développés en appliquant des
méthodes statistiques (la régression simple ou multiple,
l'analyse en Composantes principales, l'analyse bayésienne, ...etc.) ou
des méthodes de l'analyse numérique telle que l'interpolation
polynomiale sur des données historiques. Des exemples de tels
modèles sont COCOMO'81, COCOMO II, PUTNAM-SLIM et ceux se basant sur les
points de fonction.
Et les modèle non algorithmiques
(non
paramétrique) utilisant des approches de
l'intelligence artificielle telles que les réseaux de neurones, le
raisonnement par analogie, les arbres de régression.
[ALI]
Pour chaque technique de modalisation, nous
représentons les avantages et les inconvénients.
2. LE CONCEPT JOURS HOMMES
Le « Jour*Homme» est
l'unité de mesure de la charge de travail dans le contexte d'un
projet.
Concrètement, si un projet est estimé
à «cent jours pour une personne à plein
temps» pour arriver à son terme, on pourra
considérer qu'il s'agit d'un projet estimé à
« 100 jours hommes» comme l'indique
l'intitulé du résultat de l'évaluation, si l'on confie la
réalisation de ce projet à un unique homme, ce dernier devrait
(sauf erreur d'estimation, et sauf évènements extérieurs
perturbant la réalisation du projet) passer exactement cent jours
à le réaliser.
Cependant, nous pouvons nous permettre de supposer que
tout projet, à un certain niveau, est
« scindable » :
c'est-à-dire que l'on va pouvoir le décomposer (dans
la mesure où ce projet est de taille intuitivement suffisamment
élevée) en un ensemble de tâches. Et ceci est
aussi vrai dans les projets informatiques
« classiques », que dans les projets de la
nouvelle économie.
Si ce projet est partitionnable (et ce sera
quasiment toujours le cas), il est raisonnablement possible
d'effectuer plusieurs de ces tâches en parallèle - donc de les
faire effectuer par plusieurs hommes simultanément. Partant de ce
postulat, et dans un cadre idéal (figure II.1), on peut
donc considérer qu'un projet de 36 J*H
(planifié pour 12 hommes sur 3 jours) pourra
être effectué en 9 jours par 4 hommes. [GEO]
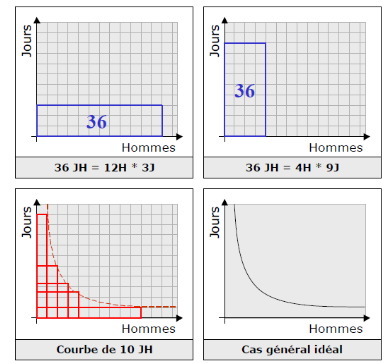
Fig II.1 -le principe de jour homme.
[GEO]
Une définition plus complète donnés par
SELON BROKS : « l'homme-mois comme
unité de mesurer la taille d'un travail est un mythe dangereux et
trompeur. Il implique que les hommes et les mois sont interchangeables. Les
hommes et les mois sont des biens interchangeables seulement lorsqu'une
tâche peut être partitionnée entre plusieurs employés
sans qu'il faille une communication entre eux ».
3. LIGNE DE CODE
Le nombre de milliers de ligne de code représente
la "taille" du projet. C'est principalement en fonction de cette "taille" que
l'on estimera le temps nécessaire à la réalisation du
projet.
On considère la définition de la ligne de
code donnée par N.E.Fenton (SOFTWARE
METRICS: A RIGOROUS AND PRACTICAL DATA, 1998)
:« Une ligne de code est toute ligne du texte d'un programme qui
n'est pas une ligne de commentaire, ou une ligne blanche, sans
considération du nombre d'instructions ou de fragments d'instructions
dans la ligne. Sont incluses toutes les lignes contenant des en-têtes de
programmes, des déclarations, et des instructions exécutables et
non exécutables. » [GEO]
On utilise les lignes de code dans les études
statistiques pour montrer que le ligne de code corrèle mieux que tout
autre mesure(par exemple, mesure de HLSTED, de McCABE) avec
les différentes autres données de mesure telles que celles sur
l'effort de développement et de maintenance et sur les erreurs.
4. TECHNIQUE D'ESTIMATION DES
COÛTS
Il existe plusieurs méthodes d'estimation de coût de
logiciel :
· Les modèles paramétriques(ou
algorithmique) ;
· Le jugement de l'expert(ou la méthode
Delphi);
· L'estimation par analogie ;
· Price to Win (gagner pour
plaire) ;
· La méthode descendante ;
· La méthode ascendante ;
· Les modèles non paramétriques(ou non
algorithmique).
4.1. Les modèles paramétriques d'estimation
des coûts (algorithmiques)
Les modèles paramétriques d'estimation des
coûts de développement de logiciels se basent essentiellement sur
une équation centrale exprimant l'effort en fonction d'un certain nombre
de variable considérées comme étant les principales
conductrices du coût.
En plus, le modèle pourra utilise des tables ou
des formules prédéterminées pour évaluer les
entrées de son équation centrale.la mise au point d'un
modèle paramétrique d'estimation suppose donc que la forme de
l'équation central du modèle est connu .cette équation
central représente la relation exprimant l'effort en fonction des
facteurs affectant les coûts.
Du fait que les modèles paramétriques
étaient les premières appliquées dans le domaine de
l'estimation des coûts .Plusieurs modèle paramétriques ont
été développés :
Des exemples de ces modèles sont :
· Les modèles linéaires.
· Les modèles analytiques.
Ø Halstead (1975)
Ø Putnam (1978)
· Point de fonction (Albert et Gaffney 1983)
· Cocomo (Boehm)
Ø Cocmo81 (Boehm 1981)
Ø CocomoII (Boehm 1995)
4.1.1. Les modèles
linéaires
Un modèle linéaire est de la forme :
Effort =
a0+a1x1+a2x2+ ...
+amxm (Equation 1).
Ou les xi sont les facteurs affectant l'effort et les ai
sont des coefficients choisis pour fournir le meilleur ajustement à
l'ensemble des données historiques observées.
Le coût de développement est
généralement obtenu par multiplication de l'effort par un
coût constant de la main d'oeuvre.
Une étude, réalisée par le system
développement corporation ver la moitié des années
soixante, examina plus de 100 conducteurs de coûts possibles, en
utilisant un échantillon de 169 projet.
Le meilleur modèle linéaire obtenue alors
était un modèle de 13 variables avec une estimation significative
de 40 homme-mois (HM) et une déviation standard de 62 HM.
4.1.2. Le modèle analytique
Les modèles analytiques adoptent une
équation centrale non-linéaire. Leur utilisation est
nécessaire quand la relation initiale, exprimant l'effort en fonction
des facteurs du coût, n'est pas toujours linéaire et qu'aucune
transformation des variables n'est possible afin de rendre cette relation
linéaire.
Dans la littérature, on ne trouve que peu de
modèles analytique qui ont été développés
(Halsted, 1975 ; Putnam, 1978). En effet :
· Souvent, un modèle linéaire satisfaisant et
concurrent peut être mis en place, éventuellement après la
transformation des variables.
· Quand cette relation n'est pas linéaire,
l'identification de la forme de la relation exprimant l'effort en fonction des
facteurs du coût est souvent très ardu.
· Les praticiens, dans leur majorité,
préfèrent apporter des améliorations de détail au
modèle linéaire concurrent plutôt que l'étudier le
modèle non-linéaire initial.
Fig II.2 - Exemple où relation
Effort-taille n'est pas linéaire.
Dans ce qui suit, nous représentons
brièvement deux exemples de modèles analytique : le
modèle d'Halstead et le modèle Putnam.
4.1.2.1. Le modèle d'Halstead
En 1972, Murice Halstead a entreprise une étude
empirique des algorithmes afin de tester l'hypothèse sel0n laquelle,
dans un programme, le comptage des opérateurs(expressions
verbales) et des opérandes(noms ou désignations
de données) pouvait faire apparaître des taille
corrélations avec le nombre des erreurs contenues dans les algorithmes
(Halstead,1975).
Suite de cette étude empirique, Halstead avait
défini quatre métriques basées sur l'analyse lexicale du
code source :
1 = nombre d'opérateurs distincts
2 = nombre d'opérandes distincts.
N1 = nombre totale d'utilisation des
opérateurs.
N2 = nombre total d'utilisation des
opérandes.
En suite, Halstead avait utilisé ces quatre
métriques pour développer une panoplie de formule
d'évaluation de certains attributs d'un logiciel tels que le vocabulaire
et le volume d'un programme, l'effort et la durée de codage d'un
programme. Les deux équations en rapport avec l'effort et la
durée de codage d'un programme sont respectivement :
Effort= (Equation
2)
Durée=
Où N=N1+N2. Cette équation d'estimation de
l'effort à partir des quatre métriques de base d'Halstead n'a pas
eu beaucoup d'intérêt dans la plupart des travaux de recherche en
estimation des coûts du fait que plusieurs hypothéses
adoptées par Halstead sont considérées comme
erronées (fenton et pflegger, 1997). En plus, la plupart des mesures
proposées par Halstead sont basées sur le code source d'un
logiciel ; les autres phases du cycle de développement telles que
la spécification et la conception ne sont pas prises en
considération bien qu'elles requièrent souvent un effort
considérable. [ALI]
4.1.2.2. Le modèle Putnam
En 1978, Putnam a proposé un modèle
d'estimation de l'effort de développement et de maintenance d'un
logiciel en se basant sur les remarques et sur les conclusions de Norden avait
déjà déduit en étudiant des projets de
développement dans beaucoup de domaine autres que le génie
logiciel (Putnam, 1978). En effet, Norden n'avait observé que la
distribution de l'effort total sur tout le cycle de la fonction de Rayleigh
(fig II.3).
Ainsi, Putnam avait utilisé cette fonction pour
exprimer la répartition de l'effort total de développement sur
tout le cycle de vie d'un logiciel (développement et maintenance).
Effort(t) = CT
(Equation 3)
Où Effort(t) représente l'effectif
cumulé à l'instant t, CT est l'effort total de tout le cycle de
vie du logiciel et td est le temps de développement.
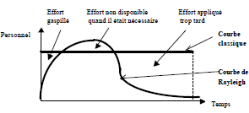
Fig II.3- répartition de
l'effort selon la courbe de Rayleigh et la courbe classique. [ALI]
A partir des résultats obtenus ci-dessus et
d'observation des projets réels, Putnam établi une relation entre
la charge totale, le nombre d'instruction et la durée du
développement. L'effort à fournir est en relation inverse
à la puissance 4 du temps de développement. Ce qui signifie que
par exemple un raccourcissement du temps de développement de 10% suppose
une augmentation de la charge totale de 40%. Dans le modèle de Putnam,
l'augmentation de la durée diminue la charge tandis que son
raccourcissement l'accroît. [ALI]
4.1.3. Point de fonction
4.1.3.1. Présentation historique de la
fonction
Les points de fonction constituent la
métrique de pointe dans le monde du logiciel. Alors qu'originellement,
la méthode des points de fonctions est une méthode
destinée à évaluer la taille d'un projet logiciel, et ce,
indépendamment de la technologie utilisée pour le
réaliser.la puissance et l'utilité de cette méthode se
sont étendues à d'autres usages, loin de leur propos initial. En
ce début de 21e siècle, les points de fonction s'appliquent
maintenant aux domaines suivants :
· Etudes de données de référence.
· Estimation des coûts de développement.
· Gestion des litiges en contrats informatique.
· Gestion des litiges en taxation des logiciels.
· Estimation de coûts de maintenance.
· Contrats d'externalisation.
· Analyse des processus d'amélioration.
· Estimation de la qualité.
· Dimensionnement de tous les livrables (documentation,
code source, jeux d'essai).
· Coûts de mise en conformité an
2000.
En octobre 1979, Alan Albrecht, d'IBM, propose une
première version de sa méthode. Cette parution n'a pas
été sans réactions. C'était en effet la
première fois que l'on proposait une mesure de la production de
logicielle basée sur les fonctions utilisateurs. Elle doit aider
à prévoir la taille d'un projet, son effort de
développement et la productivité du développement
informatique.
Cette méthode à l'origine était
fondée sur quatre entités (entrée, sortie,
interrogation, fichiers) sans catégorie de complexité
avec un intervalle d'ajustement de +/- 25%. Depuis 1984, les comptages se font
a partir des entités entrées, sorties, interrogations,
données externes et internes, avec pour chacune de ces entités un
niveau de complexité simple, moyen ou élevé.
Les points de fonction se voulaient une méthode
pour mesurer un « problème » contrairement aux
nombre de ligne de code (LOC) qui mesuraient une
« solution ».
4.1.3.2. Paramètres de points de
fonction
Les points de fonctions reposaient, à l'origine,
sur un calcul basé sur quatre entités (entrée, sortie,
interrogation, fichiers), et ce, sans catégorisation de
complexité. (Albrecht, 1979) Depuis le milieu des années 80, avec
l'IFPUG13, et la normalisation AFNOR, le comptage des points de fonctions se
fait à partir des entités suivantes :
· Données internes (GDI)
Relatif à l'aspect statique du Système
d'Information.
Groupe de données logiquement liées, ou de
groupe de paramètres de contrôle, et
identifiables par l'utilisateur. Ces données sont mises
à jour et utilisés à l'intérieur de la
frontière de l'application.
Notons que certaines entités reliées par une
cardinalité (1,1) sont susceptibles de former un seul
et même GDI.
· Données externes (GDE)
Relatif à l'aspect statique du Système
d'Information.
Groupe de données logiquement liées, ou groupe
de paramètre de contrôle, et identifiables par
l'utilisateur. Ces données sont utilisées par l'application, mais
mises à jour par une autre application. Le GDE est un
GDI dans un autre domaine.
· Entrées (ENT)
Relatif à l'aspect dynamique du Système
d'Information.
Ce sont les données, ou les paramètres de
contrôle, qui entrent dans l'application considérée. Ces
entrées maintiennent un ou plusieurs GDI, initialisent ou
contrôlent un traitement, et font l'objet d'un traitement unique.
Une Entrée correspond donc à un écran de
saisie, ou à une réception de données. Il est à
noter qu'à chaque GDI doit correspondre au moins une entrée,
permettant sa mise à jour.
· Sorties (SOR)
Relatif à l'aspect dynamique du Système
d'Information.
Ce sont les données, ou les paramètres de
contrôle qui sortent de l'application. Ces sorties sont le
résultat d'un traitement unique. (Ce traitement unique doit être
différent d'une simple extraction de données). Ce peut être
un écran de visualisation, ou un message vers une autre application.
· Interrogations (INT)
Relatif à l'aspect dynamique du Système
d'Information.
Ce sont des données élémentaires qui
correspondent à une extraction de données.
L'INT ne met à jour aucun GDI.
Ces entités peuvent être définies sur
trois acteurs (fig II.4) :
Ø L'application.
Ø L'utilisateur.
Ø Les autres Applications. [GEO]
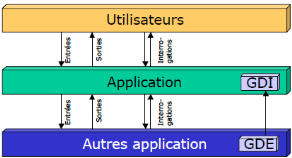
Fig II.4 - Principe des Points de
Fonctions.
4.1.4. Cocomo
4.1.4.1. Cocomo'81
COCOMO est un acronyme pour
COnstructive COst MOdel.
C'est une méthode pour estimer le coût d'un projet logiciel dans
le but d'éviter les erreurs de budget et les retards de livraison, qui
sont malheureusement habituels dans l'industrie de développement
logiciel.
Il a été développé par Dr.
Barry Boehm en 1981 pour estimer le coût, en s'appuyant sur une
donnée de base : le nombre de ligne de code source
prévisible, exprimé en Kilo
Instruction Source
Livrées(KISL). A l'origine il a
été construit sur une étude de 63 projets logiciels de
2000 à 100.000 lignes de code dans l'entreprise TRW Inc.
Il permet de formuler des estimations de l'effort et du
temps de développement ainsi que ceux de maintenance d'un logiciel. En
plus, il fournit la répartition de cet effort sur les quatre phases du
cycle de développement (Analyse, Conception, Codage et Tests unitaires,
Intégration et Tests) et sur les huit activités de chaque phase
(Analyse de besoins, Conception, Programmation, Plan de test,
Vérification et Validation, Gestion du projet, Gestion des
configurations et Assurance qualité, Documentation).
Le modèle COCOMO'81 existe en trois
modèles: le modèle de base, le modèle Intermédiaire
et le modèle Détaillé.
· Modèle de Base
Le
modèle de base est assez simpliste. Il estime l'effort (le
nombre de mois-homme) en fonction du nombre de lignes de code, la
productivité (le nombre de lignes de code par personne par mois) et un
facteur d'échelle qui dépend du type de projet. Les 3 types de
projet identifiés sont :
Ø organique :
organisation simple et
petites équipes expérimentées. (ex: système de
notes dans une école)
Ø semi-détaché :
entre
organique et imbriqué. (ex: système bancaire interactif)
Ø imbriqué :
techniques
innovante, organisation complexe, couplage fort avec beaucoup d'interactions.
(ex : système de contrôle aérospatial.)
· Modèle Intermédiaire
Le
modèle intermédiaire introduit 15 facteurs de productivité
(appelés 'cost drivers'), représentants un avis subjectif et
expert du produit, du matériel, du personnel, et des attributs du
projet.
Chaque facteur prend une valeur nominative de 1, et peut varier
selon son importance dans le projet. Ils sont semblables aux points de fonction
utilisés par d'autres modèles. Les 15 facteurs sont
multipliés pour donner un facteur d'ajustement - qui vient modifier
l'estimation donnée par la formule de base.
· Modèle Expert
Le modèle
expert inclue toutes les caractéristiques du modèle
intermédiaire avec une estimation de l'impact de la conduite des
coûts sur chaque étape du cycle de développement:
définition initiale du produit, définition
détaillée, codage, intégration. De plus, le projet est
analysé en termes d'une hiérarchie : module, sous système
et système. Il permet une véritable gestion de projet, utile pour
de grands projets.
4.1.4.2. Cocomo II
Le modèle COCOMO II il basé sur
l'idée d'améliorer et de réactualiser le modèle
COCOMO'81 en considérant les besoins suivants :
- développer un modèle d'estimation fondé
sur une architecture de processus mieux adapté que le cycle en V aux
nouvelles pratiques de la programmation, en particulier en se positionnant sur
la problématique du maquettage / prototypage, de l'utilisation des
progiciels et des perspectives offertes par l'approche composants
réutilisables comme les
logiciels « libre/gratuit » ;
- adapter les paramètres qualitatifs du modèle
intermédiaire de COCOMO pour prendre en compte les progrès en
ingénierie du logiciel, ou tout simplement la plus grand
diversité des projets, tant en ce qui concerne les coûts que les
durées de réalisation des logiciel.
Le modèle COCOMO II prend en compte les pratiques
prévisibles de développement du logiciel aux états unis,
à l'horizon 2005, sur la base d'une répartition sociologique des
activités relevant de l'informatique en cinq secteurs, selon le niveau
d'expertise informatique requis.
COCOMO II est constitué en fait de trois
modèles :
· Modèle de composition
d'application
Ce modèle est utilisé pour les projets
fabriqués à l'aide des toolkits d'outils graphiques. Il est
basé sur les nouveaux « Object Points ».
· Modèle avant
projet
Modèle utilisé pour obtenir une estimation
approximative avant de connaître l'architecture définitive. Il
utilise un sous ensemble de facteurs de productivité (Cost drivers). Il
est basé sur le nombre de lignes de code ou les points de fonction non
ajustés.
· Modèle post-architecture
Il
s'agit du modèle le plus détaillé de COCOMO II. A utiliser
après le développement de l'architecture générale
du projet. Il utilise des facteurs de productivité (Cost drivers) et des
formules.
4.1.5. Limitation des modèles
paramétriques
Les modèles paramétriques d'estimation des
coûts (linéaires ou analytiques) supposent la connaissance de la
forme de la relation exprimant l'effort en fonction des facteurs conducteurs du
coût. Autrement dit, la forme de l'équation centrale du
modèle est bien connue et il suffit donc de déterminer les
paramètres de cette équation en utilisant des techniques
statistiques ou des méthodes théoriques du domaine de
l'approximation des fonctions. En estimation des coûts de logiciels, on
détermine souvent la forme de l'équation centrale du
modèle en utilisant des connaissances relevant de l'environnement
étudié ou en adoptant des formes déjà
établies dans d'autres environnements.
Une autre limitation des modèles
paramétriques d'estimation des coûts est qu'ils requièrent
une adaptation ou une calibration quand on veut les appliquer dans des
environnements différents de ceux où ils ont été
développés. En effet, le modèle paramétrique
représente l'état de l'environnement étudié
à l'aide de la forme de son équation centrale ainsi que les
conducteurs du coût qu'il considère. Cependant, vu que les
environnements de développement et/ou de maintenance de logiciels n'ont
pas généralement les mêmes caractéristiques,
l'application d'un modèle, initialement mis au point dans un
environnement à un autre, n'est pas souhaitable. Des exemples de
caractéristiques qui peuvent différencier deux environnements de
développement de logiciels sont le type d'applications logicielles
développées (Scientifique, Gestion, Business, etc.), les
méthodes et les outils de développement utilisés, et les
contraintes imposées sur l'application (fiabilité,
portabilité, complexité, etc.).
Selon Gulizian, la calibration d'un modèle
paramétrique est sa reformulation sur une base de données de
projets logiciels d'un environnement autre que celui du modèle initial.
Ainsi, les équations du modèle calibré, y compris son
équation centrale, ont les mêmes structures que celles du
modèle initial mais pour lesquelles les coefficients sont
recalculés. L'adaptation d'un modèle paramétrique est la
modification des formes de certaines de ses équations ainsi que l'ajout
ou la suppression de facteurs affectant le coût dans le modèle.
Souvent en estimation des coûts, les chercheurs et les industriels
utilisaient ces deux techniques (calibration et adaptation) pour mettre au
point des modèles propres à leurs environnements à partir
de modèles déjà mis au point dans d'autres environnements.
Bien que la calibration (ou l'adaptation) représente, dans certains cas,
une solution au problème de l'utilisation d'un modèle
paramétrique ailleurs que dans son environnement, elle reste
insuffisante quand les différences entre les environnements sont
très flagrantes. [ALI]
4.2. Jugement de l'expert (méthode
Delphi)
Cette technique consiste à consulter un ou
plusieurs experts qui utilisent leurs expériences ainsi que leur
compréhension du projet afin de fournir une estimation à son
coût. Elle était parmi les premières techniques
utilisées en estimation des coûts. Il est préférable
d'avoir plusieurs valeurs estimées du coût émanant de
plusieurs experts pour alléger les problèmes de
subjectivité, de pessimisme et d'optimisme (Boehm,
1981). Il y a plusieurs façons de combiner les
différentes valeurs estimées du coût d'un projet logiciel.
La plus simple est d'utiliser une des méthodes statistiques telles que
la moyenne, la médiane ou le mode de toutes les valeurs pour
déterminer une estimation du coût. Cette approche présente
l'inconvénient d'être sujette aux préjugés des
estimations extrêmes. Une autre méthode
référée souvent dans la littérature par la
méthode Delphi, consiste à réitérer ce processus
d'estimation plusieurs fois jusqu'à ce qu'un consensus soit
établi. L'idée principale de la méthode Delphi est qu'un
coordinateur distribue une description du projet logiciel (souvent le
dossier d'analyse des besoins du logiciel) ainsi qu'un formulaire
d'estimation aux experts; ensuite, les experts remplissent les formulaires et
les renvoient au coordinateur. Ce dernier pourra, dépendamment de la
version de la méthode Delphi, convoquer une réunion des experts
pour discuter des différentes estimations. Ce processus est
réitéré jusqu'à l'adoption d'une estimation par
tout le groupe. [ALI]
4.3. Estimation par analogie
Dans cette technique d'estimation, l'évaluateur
compare le projet logiciel dont on veut estimer le coût avec des projets
logiciels déjà achevés. Il doit identifier les
similarités et les différences entre le nouveau projet et tous
les anciens projets. Pour cela, il doit auparavant décrire les projets
logiciels par un ensemble de caractéristiques. Les ressemblances entre
les caractéristiques du nouveau projet avec celles des projets
achevés déterminent les degrés de similarité entre
les projets. Ensuite, il utilise ces degrés de similarité pour
déterminer une estimation au coût du nouveau projet.
Dans sa première version informelle, l'estimation
par analogie a été considérée comme une alternative
de l'estimation par les jugements des experts. En effet, les experts raisonnent
souvent par analogie quand on leur demande une évaluation du coût
d'un logiciel à partir de son dossier d'analyse des besoins. Ainsi, les
experts utilisent leurs connaissances sur des projets déjà
achevés et déterminent implicitement les similarités et
les différences entre le nouveau projet et les projets achevés.
Cependant, plusieurs versions formelles de l'estimation par analogie ont
été récemment développées (Vicinanza
et Prietula, 1990; Malabocchia, 1995; Shepperd et Schofield, 1997).
Par ce fait, on la considère de plus en plus comme une technique
d'estimation qui se base sur la modélisation. D'ailleurs, le
modèle d'estimation des coûts, que nous développons dans
cette thèse, adopte une version floue de l'estimation par analogie. Le
quatrième chapitre décrira l'état de l'art des versions
formelles de l'estimation par analogie ainsi que notre nouvelle
modélisation de l'estimation par analogie. Notre modèle
d'estimation par analogie aura comme avantage la prise en considération
de la tolérance des imprécisions, la gestion des incertitudes et
l'apprentissage.
4.3.1. Processus d'estimation par
analogie
· Caractérisation des projets logiciels par un
ensemble de variables (complexité logicielle, compétence des
analystes, méthodes de développement utilisées, ...).
· Evaluation de la similarité entre le nouveau projet
et les projets logiciels historiques.
· Utilisation des valeurs des coûts réels des
projets similaires au nouveau projet pour en déduire une estimation
à son coût.
4.3.2. Limitation de l'estimation par
analogie
· Elle ne traite pas convenablement le cas des projets
logiciels décrits par des valeurs linguistiques telles que
« bas »,
« élevé », et
« complexe »
· Elle ne permet pas la gestion de l'incertitude au niveau
des estimations fournies
· Elle ne permet pas l'apprentissage
4.4. La méthode « prise to
Win » (gagner pour plaire)
Pour illustre cette méthode, nous allons
présenter deux exemples :
Exemple1 :
« Nous savons que ce travail est
estimé a deux millions et aucun de nos experts ne croient pouvoir le
faire avec moins d'un million et demi. Mais nous savons aussi que le client ne
dispose gue d'un budget d'un million. Maintenant, nous allons arranger
l'estimation du coût et la rendre crédible ».
Exemple2 :
« Nous devons absolument annoncer ce produit
à la conférence national sur le génie logiciel en juin
prochain, et nous sommes encire en Septembre. Cela signifie que nous disposons
de 9 mois pour réaliser le logiciel ».
Ces deux exemples illustrent très bien le nom de
la méthode (Price to Win, gagner pour plaire).cette
méthode a permis de conclure un grand nombre de contrats de logiciels
pour un grand nombre de compagnies. Ceci n'a pas empêché que
certains contrats ont du être réalisés pour
différentes raisons (budgétaires) alors que
d'autres contrats ont permis la réalisation de projets de très
mauvaises qualité.
Dans ce type de méthode, le résultat est
que l'argent et le temps diminuent avant que le travail ne soit fait : le
personnel devient furieux, un grand nombre de programmeurs travaillent de
longues heures essayant justes d'éviter un désastre complet.
Néanmoins, la principale raison qui fait cette
méthode continue a être utilisée est que la technologie de
l'estimation du coût du logiciel n'a pas donné des techniques
assez puissantes pour aider les clients ou les développeurs a
différencier avec conviction une estimation légitime d'une
estimation « Price to Win »
4.5. Estimation ascendante et
descendante
4.5.1. Estimation ascendante
Dans l'estimation ascendante, le projet logiciel
(ou le logiciel) est décomposé en plusieurs
tâches (ou composantes) constituant ainsi une
arborescence de toutes les tâches (ou composantes) du
projet logiciel (ou du logiciel).
Tout d'abord, on estime l'effort nécessaire pour
chaque tâche du plus bas niveau dans l'arborescence; ensuite, on
détermine progressivement l'effort des autres tâches, se
retrouvant dans un niveau supérieur dans l'arborescence, en combinant
les efforts nécessaires associés aux sous-tâches. En
général, l'effort nécessaire d'une tâche sera la
somme de ceux de ses sous-tâches. Cependant, dans le cas des projets
logiciels complexes, d'autres techniques plus sophistiquées, telles que
celles se basant sur des formules mathématiques typiques ou sur des
règles d'induction (si-alors), peuvent être
utilisées afin de mettre en valeur la complexité des interfaces
de communication entre les tâches.
4.5.2. Estimation descendant
Dans l'estimation descendante, on évalue une
estimation globale de l'effort de tout le projet logiciel; ensuite, on
répartit cet effort total sur toutes les tâches du projet
logiciel. Dans les deux cas de l'estimation ascendante ou descendante, les
valeurs estimées de l'effort sont déterminées en utilisant
la technique du jugement de l'expert, l'estimation par analogie ou un
modèle d'estimation.
4.6. Les modèles non paramétriques
d'estimation des coûts (non algorithmique)
Les modèles non-paramétriques d'estimation
des coûts ont été développés pour
remédier aux inconvénients cités ci-dessus dans les
modèles paramétriques. Ils n'ont pas une équation centrale
d'estimation de l'effort. Ainsi, les modèles non-paramétriques
n'exigent au préalable aucune forme à la relation exprimant
l'effort en fonction des conducteurs du coût. Ils modélisent cette
relation en utilisant des techniques d'intelligence artificielle telles que le
raisonnement à base de cas, les réseaux de neurones, les
algorithmes génétiques, les systèmes à base de
règles et les arbres de décision. Les modèles
non-paramétriques représentent donc une alternative prometteuse
quand la relation entre l'effort et les conducteurs du coût semble
n'avoir aucune forme prédéfinie.
Dans cette section, nous présentons les
modèles non-paramétriques utilisant les réseaux de
neurones, les arbres de décision et les algorithmes.
4.6.1. Les réseaux de neurones
La modélisation par les réseaux de
neurones est inspirée de la structure biologique du cerveau humain. Un
réseau de neurones est caractérisé par son architecture,
son algorithme d'apprentissage et ses fonctions d'activation. Dans la
littérature, plusieurs modèles de réseaux de neurones ont
été développés. Ils peuvent être
classifiés en deux catégories principales: les réseaux de
neurones « feedforward »
où il n'y a aucune boucle dans l'architecture du réseau, et
les réseaux récurrents où une ou plusieurs
boucles récursives apparaissent dans l'architecture du réseau. Le
Perceptron multicouches utilisant l'algorithme d'apprentissage de
rétro-propagation est souvent le plus adopté en estimation des
coûts de logiciels. Dans ce modèle, les neurones sont
organisés en couches et chaque couche ne peut avoir des connexions que
vers la couche suivante. La figure II.5 illustre un exemple
d'un tel réseau pour l'estimation de l'effort de développement de
logiciels. Le réseau produit un résultat
(effort) en propageant ses entrées initiales
(facteurs du coût ou attributs du projet logiciel)
à travers les différents neurones du réseau jusqu'à
la sortie. Chaque neurone d'une couche calcule sa sortie en appliquant sa
fonction d'activation à ses entrées. Souvent, la fonction
d'activation d'un neurone est la fonction Sigmoïde définie par:
f(x)= (Equation
4)
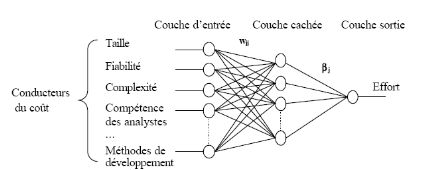
Fig II.5 -
Architecture d un réseau de neurones à trois couches pour
l'estimation de l'effort.
La configuration d'un réseau de neurones pour
l'estimation de l'effort de développement de logiciels nécessite
le choix d'une architecture adéquate, un algorithme d'apprentissage et
des fonctions d'activation. Dans le cas d'un Perceptron
multicouches, la configuration se restreint au choix des
différents paramètres de sa topologie tels que le nombre de
couches cachées, le nombre de neurones par couche, et les valeurs
initiales des poids de connexions (wij et
bj). Dans la pratique, ces paramètres sont
déterminés en se fiant sur une base de données de projets
logiciels déjà achevés. Ainsi, on divise la base de
données en deux ensembles: un ensemble de projets logiciels pour
entraîner le réseau et l'autre pour tester le réseau.
L'utilisation des réseaux de neurones pour estimer le
coût d'un logiciel a trois avantages principaux.
· Les réseaux neurones permettent l'apprentissage
automatique à partir des situations et des résultats
précédents. L'apprentissage est très important pour les
modèles d'estimation des coûts car l'industrie des logiciels est
en évolution croissante.
· Les réseaux neurones permettent un traitement
parallèle de l'information. Ainsi, le processus d'estimation du
modèle profitera de la grande puissance de calcul de toutes les machines
disponibles surtout que, souvent, le processus de formulation d'une estimation
engage des calculs très intensifs.
· Les réseaux neurones peuvent modéliser les
relations complexes existantes entre la variable dépendante (coût
ou effort) et les variables indépendantes du modèle (facteurs de
coût). En effet, les réseaux de neurones sont reconnus en tant
qu'approximateurs universels de fonctions continues à valeurs dans
l'ensemble des réels. Hornik,
Stinchcombe et White ont particulièrement montré
qu'un réseau de neurones
« feedforwad », avec une seule
couche cachée et des fonctions d'activation continues et
non-linéaires, peut approcher n'importe quelle fonction continue
à valeurs dans l'ensemble des réels et ceci au degré de
précision qu'on veut (Hornik, Stinchcombe et
White, 1989).
Cependant, L'approche neuronique a trois limitations qui
l'empêchent d'être acceptée comme une pratique usuelle en
estimation des coûts:
· L'approche neuronique est considérée comme
étant une approche boîte noire. Par conséquent, il
est difficile d'expliquer et d'interpréter son processus.
· Les réseaux de neurones ont été
utilisés spécifiquement pour les problèmes de
classification et de catégorisation, alors qu'en estimation des
coûts, nous traitons un problème de généralisation
et non pas de classification.
· Les réseaux neurones n'existe aucune
démarche standard pour le choix des différents paramètres
de la topologie d'un réseau de neurones (nombre de couches, nombre
d'unités de traitement par couche, valeurs initiales des poids de
connexions, etc.). [ALI]
4.6.2. Les arbres de régression
Les arbres de régression constituent un outil de
modélisation simple et de plus en plus répandu par la
diversité des applications qui lui font appel. Plusieurs approches de
construction de ces arbres ont été développées; ces
approches dépendent du type de la connaissance disponible du domaine
étudié selon qu'elle est discrète ou continue. Des
exemples de telles approches sont CART, ID3
et C4.5 .La construction de l'arbre de
régression s'effectue à partir d'un échantillon de
données historiques dit d'apprentissage.
Les arbres de régression, en particulier
binaires, ont été utilisés avec succès pour la mise
au point de plusieurs modèles d'estimation en génie
logiciel. En estimation des coûts, ils ont
été utilisés pour estimer l'effort de développement
d'un logiciel. Premièrement, chaque projet logiciel est décrit
par un ensemble de variables qui serviront à la prédiction de son
effort de développement. Ensuite et progressivement, à partir de
la racine de l'arbre, le projet logiciel auquel on veut estimer le coût
emprunte le chemin approprié, selon les valeurs de ses variables, en
descendant dans l'arborescence jusqu'à l'une des feuilles de l'arbre.
Chaque feuille contient une valeur numérique représentant
l'effort de développement des projets logiciels associés.
La figure II.6 illustre un arbre de
régression binaire construit à partir des projets du
COCOMO'81. Dans cet arbre de régression binaire, la
racine représente la variable AKDSI de chaque projet
logiciel; si la valeur de l'AKDSI du projet logiciel est supérieure
à 315,5, alors son effort est estimé à
9000H-M; sinon, on passe au deuxième niveau de l'arbre
où il y a un seul noeud représentant aussi la variable
AKDSI et ainsi de suite jusqu'à l'une des feuilles de
l'arbre.
Fig II.6- Arbre de
régression construit à partir des 63 projets logiciels du
COCOMO'81.
En général, la plupart des algorithmes de
construction d'un arbre de régression binaire, à partir d'un
ensemble de projets logiciels historiques, sont basés sur une
stratégie descendante. Cette stratégie consiste à choisir,
parmi tous les attributs décrivant le projet logiciel, celui qui divise
mieux l'ensemble de tous les projets
logiciels en deux sous-ensembles disjoints. Souvent, on choisit l'attribut qui
minimise l'erreur moyenne quadratique (MSE) de la variable
dépendante (l'effort de développement) des
projets logiciels historiques. L'erreur moyenne quadratique d'un sous-ensemble
S de projets logiciels est calculée par:
MSE(S) = (Equation 5)
Où Effort k est
l'effort réel du k ème projet logiciel de
S et Effort est la moyenne
arithmétique d'Effort k.
· L'attribut est mesuré par des valeurs
discrètes. Dans ce cas, pour chaque attribut Vi, on
divise l'ensemble de tous les projets logiciels T en des
sous-ensembles Tij contenant des projets logiciels ayant la
même valeur Aj de l'attribut Vi.
· L'attribut est mesuré par des valeurs
numériques continues. Dans ce cas, pour chaque attribut
Vi, on divise l'ensemble de tous les projets logiciels en
k-1 sous ensemble selon l'ordre des valeurs observées
de Vi (où k est le nombre de valeurs
observées de Vi).
Ainsi, on choisit l'attribut Ai qui maximise la
différence :
MSE = MSE(T) - (Equation 6)
L'expansion d'un noeud de l'arbre s'arrête quand le
nombre de projets logiciels classifiés dans ce noeud est assez petit ou
ces projets logiciels sont jugés similaires. Dans ce cas, le noeud
représente une feuille de l'arbre et l'effort estimé de tout
nouveau projet logiciel, qui sera classifié dans ce noeud, est
calculé en fonction des valeurs réelles des efforts de tous les
projets logiciels historiques de ce noeud (en général, on
considère la moyenne ou la médiane).
La modélisation de l'estimation des coûts
par les arbres de régression présente l'avantage d'être
facile à expliquer et à utiliser contrairement au cas de celle
utilisant les réseaux de neurones. En effet, un chemin dans l'arbre de
régression peut être représenté par une règle
du type:
Si condition1
et condition2 et ... et conditionN Alors
Effort=CTS
Par exemple, dans la figure II.5, le chemin
indiqué par des flèches peut être représenté
par la règle suivante:
Si (AKDSI =111.0) et (TIME= 1.415) et (TKDSI=26.0)
Alors Effort = 57.3H-H
Ce genre de règles est facilement
interprétable car les règles ressemblent à celles qu'on
Utilise dans notre quotidien. Ainsi, une modélisation par un arbre de
régression binaire n'est qu'un cas particulier d'un système
à base de règles Si-Alors.
4.6.3. Les algorithmes
génétiques
Les algorithmes génétiques sont
inspirés des concepts de l'évolution et de la sélection
naturelle élaborés par Charles Darwin. Ils ont
été utilisés comme des méthodes heuristiques dans
les problèmes d'optimisation où l'espace de recherche de la
solution est de taille assez grande. Le pionnier du domaine est John
Holland qui a le premier tenté d'implanter artificiellement des
systèmes évolutifs (Holland, 1975).
L'idée de base de la théorie Darwinienne de l'évolution
postule que seulement les meilleurs éléments d'une population
survivent et transmettent à leurs descendants leurs
caractéristiques biologiques à travers des opérations
génétiques telles que le croisement, la mutation
et la sélection. Dans l'implantation informatique du
principe de l'évolution, le problème étudié est
représenté par une chaîne binaire (formée de 0 et 1)
symbolisant les chromosomes de son équivalent biologique. Ainsi,
à partir d'une population, c'est-à-dire à partir d'un
ensemble de chaînes binaires (chromosomes).
· les chromosomes les mieux adaptés se
reproduisent le plus souvent et
Contribuent davantage aux populations futures
(sélection),
· lors de la reproduction, les chromosomes des parents
sont combinés et mélangés pour reproduire les chromosomes
des enfants (croisement),
· le résultat du croisement peut être
à son tour modifié par des perturbations aléatoires
(mutation) ;
En général, un algorithme
génétique est composé de trois étapes principales
bien que d'autres variations sont possibles (Goldberg, 1989; Davis, 1991):
1- Générer aléatoirement une population
initiale de N chromosomes (solutions);
2- répéter les sous étapes suivantes
jusqu'à une condition d'arrêt (souvent on
fixe un temps d'exécution ou un nombre d'itérations)
2.1- évaluer la fitness de chaque
chromosome de la population et sélectionner
Ceux ayant les meilleurs scores;
2.2- reproduire une nouvelle population de chromosomes en
appliquant les deux opérations génétiques (croisement et
mutation) aux chromosomes sélectionnés dans 2.1;
2.3- Remplacer l'ancienne population par la nouvelle
population obtenue de 2.1 et 2.2 ;
3- Choisir comme solution au problème qui a le
meilleur score dans la population finale.
Récemment, les algorithmes
génétiques ont été appliqués en estimation
des coûts de développement de logiciels. Shukla a utilisé
les algorithmes génétiques dans l'apprentissage d'un Perceptron
multicouches afin de trouver le vecteur des poids W qui permette au Perceptron
multicouches de fournir des estimations acceptables. Ses
expérimentations se sont basées sur la base de données du
COCOMO'81. Il identifie un Perceptron multicouches PN par un vecteur de poids
W(PN). À chaque vecteur de poids W(PN), il associe un chromosome de M
éléments où M est le nombre d'éléments de
W(PM). La figure II.7 illustre un exemple d'un Perceptron
multicouches ainsi que le chromosome qui lui est associé; ce Perceptron
comporte 18 poids de connexions auxquels il associe un chromosome de 18
éléments. Chaque élément du chromosome
représente un poids du vecteur W(PN). Pour coder un poids, il lui
réserve dix bits. Ainsi, le chromosome associé sera
composé de 180 bits. La fonction de fitness utilisée
pour sélectionner les chromosomes dans une population est:
F (W) = E (W) =
(Equation7)
Shukla utilise une technique hybride de sélection
des chromosomes qui vont survivre dans la prochaine population. Cette technique
considère les deux premiers chromosomes ayant les meilleurs scores F(W)
et applique sur les autres la stratégie de la roue roulante dans
laquelle chaque chromosome reçoit une part de la roue proportionnelle
à son score F(W). Pour l'opérateur de croisement, Shukla a
utilisé une version modifiée de l'opérateur standard afin
d'éviter que des bits, représentant des poids appartenant
à différentes couches du Perceptron, soient interchangés.
Les autres paramètres de l'algorithme, tels que la taille de la
population, la probabilité accordée à l'opérateur
de croisement ainsi que celle accordée à l'opérateur de
mutation, ont été choisis en exécutant plusieurs fois
l'algorithme sur les données du COCOMO'81.
Fig II.7 - Exemple d'un Perceptron multicouches et sa
représentation avec un chromosome.
Dolado, Burgess et
Lefley ont respectivement utilisé la programmation
génétique (Genetic Programing) pour le
développement de modèles d'estimation des coûts de
logiciels. La programmation génétique (GP) est une variante
des algorithmes génétiques qui n'exige pas que la
représentation des chromosomes soit seulement sous forme de
chaînes binaires, mais elle peut être sous d'autres formes telles
que des équations, des programmes, des circuits, et des plans.
Dans ces deux expérimentations de la programmation
génétique en estimation des coûts, l'équation,
exprimant l'effort en fonction des variables affectant le coût, a
été représentée par un arbre binaire dont
les noeuds sont soit des opérandes ou soit des opérateurs. Les
opérandes sont les conducteurs du coût tels que la
complexité et la fonctionnalité du logiciel, et la
compétence du personnel. Ils sont généralement
dans les feuilles de l'arbre binaire. Les opérateurs, quant
à eux, représentent les différentes opérations
susceptibles d'être dans l'équation exprimant
L'effort en fonction des conducteurs du
coût. Des exemples de ces opérateurs sont +, -,
*, /, Racine carrée, Logarithme, et l'Exponentiel. La
figure II.8 illustre la représentation de
l'équation Effort=0,03453*FP/Ln(FP)
par un arbre binaire:
Fig II.8 -
Représentation de l'équation Effort=0,03453*FP/Ln(FP)
par un arbre binaire. [ALI]
Les deux variantes de la programmation
génétique utilisées respectivement par Dolado, Burgess et
Lefley sont presque les mêmes avec des différences mineures au
niveau des choix de certains paramètres tels que la fonction
d'évaluation de la fitness de chaque arbre binaire, la taille
de chaque population, et la technique de sélection des arbres binaires.
Voici brièvement la description du programme génétique
utilisé par Dolado, Burgess et Lefley :
1- Générer aléatoirement une population de P
équations, c'est-à-dire P arbres binaires. Dolado a
utilisé les opérateurs suivants: +, -, *, /, Racine
carrée, Carrée, Logarithme, Exponentiel. Burgess et Lefley ont
utilisé les opérateurs suivants: +, -, *. Ils ont aussi
limité la taille de chaque population à 1 000, la profondeur de
chaque arbre binaire à quatre, et le nombre maximal des noeuds dans un
arbre à 64.
2- Répéter jusqu'à un nombre maximal de
génération ;
2.1- Évaluer la fitness de
chaque équation:
· Dolado utilise la fonction MSE (Mean Square
Error):
MSE =
(Equation8)
où N est le nombre de projets logiciels,
Effortréel,i est l'effort réel du ième
projet, et Effortestimé,i est l'effort estimé
du ième projet par l'équation.
· Burgess et Lefely ont utilisé la moyenne des
erreurs relatives (MMRE):
MMRS =
(Equation9)
2.2- sélectionner les équations ayant les meilleurs
scores de la fonction de fitness:
· Dolado utilise la technique de la roue roulante
(Roulette Wheel) en affectant à chaque équation, i, une
probabilité égale à fi fi où fi
est la fitness de l'ième équation.
· Burgess et Lefley choisissent les cinq premières
équations ayant les meilleurs scores.
2.3- Appliquer les deux opérateurs de croisement et de
mutation aux équations sélectionnées. Le croisement de
deux équations consiste au choix d'un noeud N1 dans l'arbre
représentant la première équation, d'un noeud N2 dans
l'arbre représentant la deuxième équation, et
échanger les deux sous-arbres de racine respectivement N1 et N2. La
figure II.9 illustre un exemple de l'opération de
croisement appliquée sur les deux équations:
Effort=0,03453*FP/Ln(FP) et Effort= 4.3
+2.1*FP+1.01*FP2. Certaines précautions sont
nécessaires pour éviter les problèmes
d'incompatibilité des opérateurs avec des opérandes
(valeur négative avec la fonction Logarithme par exemple).
L'opérateur de mutation est appliqué sur chaque équation
sélectionnée en choisissant aléatoirement un noeud de
l'arbre binaire (opérateur ou opérande) et en le remplacant par
un autre élément (opérateur ou opérande) ;
2.4- construire la nouvelle population ;
3- choisir l'équation ayant le meilleur score de
fitness.
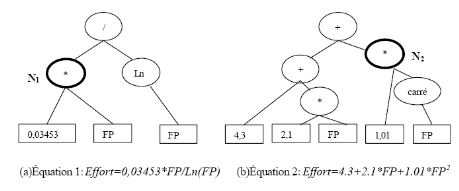
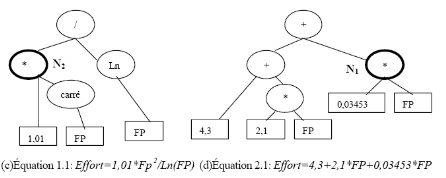
Fig II.9 -
Résultats de l'application de l'opérateur de croisement aux deux
équations:
Effort=0,03453*FP/Ln(FP) et Effort= 4.3
+2.1*FP+1.01*FP2.
L'utilisation du principe de l'évolution en
estimation des coûts présente l'avantage de fournir une recherche
heuristique de l'équation exprimant l'effort en fonction des conducteurs
du coût. Ainsi, à partir d'un ensemble d'équations
initiales, l'algorithme recherche celle qui représente
adéquatement la relation. Ceci présente un avantage sur les
techniques paramétriques classiques telles que la régression
linéaire où une seule forme de l'équation est
évaluée. Cependant, comme dans le cas des réseaux de
neurones, la configuration d'un algorithme génétique (ou
un programme génétique) nécessite le choix de
plusieurs paramètres tels que la fonction de fitness, la taille
de chaque population et la taille de l'arbre binaire représentant
l'équation. Ces paramètres sont souvent déterminés
par expérimentations. Ils dépendent donc de la base de projets
logiciels utilisée.
Les modèles non algorithmiques sont basés sur
des approches de l'intelligence artificielles telles que les réseaux de
neurones, le raisonnement par analogie et les arbres de régression. Les
avantages et les inconvénients de ces modèles sont :
[IDR]
· Avantages
Ils peuvent modéliser des relations complexes entre les
différents facteurs affectant le coût.
Dans le cas des réseaux de neurones, ils incluent
automatiquement des algorithmes d'apprentissages.
Leur comportement est facilement compréhensible sauf pour
le cas des réseaux de neurones.
· Inconvénients
Ils ne sont pas faciles à développer.
On ne peut pas les utiliser sont les programmer.
Ils impliquent des calculs très intensifs pour
générer l'estimation.
5. RESUME SUR LES METHODES D'ESTIMATION
Un certain nombre de méthodes d'estimation ont
été développés. Dans la figure
II.10 nous allons présenter les principales méthodes
utilisées pour l'estimation des coûts de développement de
logiciels.
Suite a notre recherche, nous avons distingué Sept
méthodes : modèles paramétrique, jugement de
l'expert, l'estimation par analogie, Price to Win, méthode descendante
et modèles non paramétrique.
Les modèles paramétriques fournissent plusieurs
algorithmes produisant une estimation du coût, les formes les plus
communes des algorithmes sont (les modèles linéaires, les
modèles analytiques, pionts de fonction et cocomo)
Les modèles non paramétriques sont
représentés par (les réseaux de neurones, les arbres de
régression et les algorithmes génétiques).
Fig II.10 - méthodes
d'estimation de coûts de développement de logiciel
6. CONCLUSION
L'estimation des coûts de
développement de logiciels est l'un des problèmes critiques les
plus débattus en métrologie de logiciels. La maîtrise et
l'évaluation de ces coûts semblent encore préoccuper aussi
bien les chercheurs que les responsables et les chefs de projets logiciels.
Dans ce chapitre, nous avons présenté un ensemble de techniques
d'estimation des coûts, spécifiquement celles se basant sur la
modélisation. Ainsi, nous avons décrit des exemples de
modèles paramétriques et non-paramétriques. Chaque type de
modèle d'estimation a des avantages et des inconvénients et aucun
modèle n'a pu prouver qu'il performe mieux que tous les autres dans
toutes les situations.
CHAPITRE III


La Méthode Des Point Fonction
Et La Méthode
Cocomo'81
1. INTRODUCTION
Dans ce chapitre nous décrirons
en particulier les méthodes cocomo'81 et point
de fonction qui sont des méthodes algorithmiques pour
l'estimation de coût d'un projet informatique. Nous donnerons aussi des
définitions des différents composants utilisés par la
méthode des points de fonctions et les étapes de comptage des
points de fonction pour prévoir le coût logiciel.
2. LA METHODE DES POINTS DE FONCTION (ALBRECHT
79)
2.1. Historique
La méthode des points de fonction a
été créée par Allan Albrecht en 1979.
Elle a été publiée pour la
première fois lors d'une conférence IBM. C'était en effet
la première fois que l'on proposait une mesure de production de
logicielle basée sur les fonctions utilisateurs. Elle doit aider
à prévoir la taille d'un projet, son effort de
développement et la productivité du développement
informatique.
En 1986, a été fondé par l'IFPUG
(International Function Points Use Group) pour assurer la plus grande diffusion
de cette méthode tout en garantissant son adéquation aux besoins
des utilisateurs et sa normalisation.
De même en France, la FFUP (French Function Point User's
Group) créée en 1992 a la même vocation.
La méthode des points de fonction est maintenant
normalisée par L'AFNOR, sous la référence normative
expérimentale XP Z 67-160.
2.2. Définition du contexte
2.2.1. Frontières de
l'application
Utiliser la cartographie applicative pour identifier les
limites de l'application à mesurer.
Ces limites définissent :
· Un ensemble de fonctions du métier identifiable
et comprises par l'utilisateur.
· Des frontières stables, correspondant à
la façon dont l'application est maintenue.
· Elles mettent en évidence les échanges de
données entre l'intérieur et l'extérieur de
l'application.
· Elles définissent la base des autres mesures
(efforts, coûts, défauts ...).
2.2.2. Identification de l'utilisateur
Les points de fonction mesurent ce que
l'utilisateur a demandé et reçu. Il faut identifier l'utilisateur
L'identification de l'utilisateur est dépendante
des objectifs de la mesure et modifie le périmètre de la mesures,
par exemple :
· Pour la mesure d'un progiciel, seules les
fonctionnalités utilisées par l'utilisateur doivent être
considérées.
· Lors de la mesure d'un développement, toutes les
fonctionnalités livrées dans le cadre du projet sont prises en
compte
Les règles de l'IFPUG font référence
à la notion de vue utilisateur, ou parle aussi de utilisateur
expérimenté.
2.2.3. Règles et procédures des
frontières du comptage
La frontière est déterminée sur la
base du point de vue utilisateur. L'important est de se concentrer sur ce que
l'utilisateur peut comprendre et décrire.
La frontière entre des applications qui sont
liées ne doit pas être basée sur des considérations
technologiques mais sur la séparation des fonctions de gestion telles
qu'elles sont vues par l'utilisateur
2.3. Définition des différents
composants utilisés par la méthode des points de fonction
2.3.1. Groupe logique de données
internes(GDI)
Groupe de données liées logiquement, ou de
paramètres de contrôle identifiables par l'utilisateur, mis
à jour et utilisés à l'intérieur de la
frontière de l'application.
Si un fichier réel contient 1000 entrées de
données personnelles, il sera compté comme un seul fichier.
Pour le comptage on peut partir d'un modèle de
données (considérer les entités, relations porteuses de
données), d'une liste de fichiers physiques, d'une liste de segments
tables utilisateur et ne par présumer qu'un fichier physique
égale un fichier logique.
Exemple : fichier logiques dans le
système.
2.3.2. Groupe de données externes
(GDE)
Groupe de données liées logiquement, ou de
paramètre de contrôle, identifiables par l'utilisateur,
utilisés par l'application, mis à jour par une autre
application.
Exemple : interfaces pour d'autres
systèmes.
2.3.3. les entrées(ENT)
Données ou paramétras de contrôle qui :
· Entrent dans l'application
· Maintiennent un ou plusieurs GDI
· Initialisent ou contrôlent un traitement
· Font l'objet d'un traitement unique (si on peut lancer le
même traitement par plusieurs moyens par exemple l'entrée du nom,
prénom et l'adresse d'un employé sera considérée
comme une seule entrée
Exemple : fichiers, menus, etc. fournis
par l'utilisateur.
2.3.4. Les sorties (SOR)
Données ou paramètres de contrôle
qui :
· Sortent de l'application
· Sont le résultat d'un traitement unique autre
qu'un simple traitement d'extraction de données (si on peut lancer un
traitement par plusieurs moyens par exemple commande « E »
ou « Editer », touche de fonction, il s'agit toujours
d'une même sortie).
Exemple : les rapports, messages,
fournis à l'utilisateur.
2.3.5. Les interrogations (INT)
Combinaison Entrée-sortie qui :
· Ne fait par de mise à jour de GDI
· Ne résulte pas d'un traitement autre que des
extractions de données
· Ne contient pas de données
dérivées (calculées en sortie)
Exemple : entrées interactives
nécessitant une réponse.
On associe à ces cinq entités Trois
paramètres supplémentaires, qui vont permettre de ces
paramètres sont les suivants :
Ø Données
Elémentaires(DE)
Chaque GDI ou GDE est composé de données
élémentaires .une DE équivaut à un champ de
données. On compte un seul DE par champ répétitif dans les
entrées, les sorties, et les interrogations.
Ø Sous-ensemble logique de données
(SLD)
Relatif aux GDE et aux GDI.
D'un point de vue fonctionnel, ce sont les groupements
logiques de GDI ou de GDE qui sont traitées simultanément dans
l'application.
Ø Groupe de données
référencées (GDR)
Relatif aux ENT, SOR ou INT.
D'un point de vue fonctionnel, ce sont les groupements
logiques de GDI ou de GDE qui sont mis à jour, ou consultés
simultanément par les différents ENT, SOR ou INT.
2.4. Les niveaux de complexité
Pour chaque composant (données ou traitements), on
détermine le niveau de complexité :
Ø Faible
Ø Moyen
Ø Elevé
Par exemple, pour les groupes de
données internes on peut s'appuyer sur le modèle conceptuel ses
données .dans un modèle entité relation on
détermine les entités primaires. Ce sont typiquement les objets
des bases de données -tables primaires-on évalue ensuite le
nombre de relations entre les tables .Au sein des tables on compte le nombre
d'éléments. Ces éléments permettent d'attribuer un
niveau de complexité.
Prenons, par exemple, un modèle de données
simple ou une table 1 est associée a deux autres par une relation 1 a
plusieurs. Supposons que la table 1 comporte 15 champs contre 6 champs pour la
table 2 et 4 pour la table 3.
Nous aurions 3 entités (les tables de
paramètres ne sont pas prises en compte).L'entité table 1 a deux
relations et moins de 20 éléments. Sa note de complexité
donc faible. C'est également le cas pour les deux autres entités
(1 seule relation et moins de 20 éléments).Dans cet exemple, nous
avons donc 3 groupes de données internes de complexité faible.
La même chose vaut pour l'autre fonction en tenant compte de leurs
caractéristiques.
Pour chaque composant, le niveau de complexité se
détermine de la même façon, on utilise une matrice dont les
entrées lui sont propres mais qui reposent sur un comptage simple. La
complexité (faible, moyenne, élevée) est
déterminée par les tableaux (tab2, tab3 et tab4).
2.4.1. Complexité des groupes logiques de
données (GDI et GDE)
Le niveau de complexité est
déterminé par le nombre se Sous-ensemble Logique de
Données(SLD) et de Données Elémentaire du groupe logique
de données (DE).
Les SLD sont des sous groupements de GDI(GDE) fondés
sur la vue logique de l'utilisateur des données. Les DE
sont des zones non récurrentes que l'utilisateur peut reconnaître
et qui figurent dans le GDI(GDE).
Une DE est un attribut au sens de
MERISE.les zones qui apprissent plusieurs fois dans un même GDI pour des
raisons techniques, ne sont comptées qu'une seule fois.
|
Elément de données
|
|
1 à 19 DE
|
20 à 50DE
|
51 DE ou plus
|
|
1 SLD
|
faible
|
faible
|
moyenne
|
|
2 à 5 SLD
|
faible
|
moyenne
|
élevée
|
|
6 SLD ou plus
|
Moyenne
|
élevée
|
élevée
|
Tableau 2: Matrice niveau de
complexité GDE/GDI
2.4.2. Complexité d'une entrée ou partie
entrée d'une interrogation
Le niveau de complexité d'une entrée est
déterminé par le nombre de groupe de données
référencées (GDR) et DE
de l'entrée ou de la partie entrée de l'interrogation.
Seules les DE mis a jour par l'Entrée
sont comptabilisées.
|
Elément de données
|
|
1 à 5 DE
|
6 à19 DE
|
20 DE ou plus
|
|
0 ou 1 GDR
|
faible
|
faible
|
moyenne
|
|
2 à3GDR
|
faible
|
moyenne
|
élevée
|
|
4GDR ou plus
|
moyenne
|
élevée
|
élevée
|
Tableau 3 : matrice
niveau de complexité d'une Entrée ou partie d'une
Interrogation
2.4.3. Complexité d'une sortie ou partie sortie
d'une interrogation
Le niveau de complexité d'une sortie est
déterminé par le nombre de groupe de données
référencées (GDR) et de DE de la sortie
ou de la partie sortie de l'interrogation.
Le nombre de DE est celui de
DE utilisées par la sorties.
|
Élément de données
|
|
5 à 15 DE
|
16 DE ou plus
|
|
0 ou1GDR faible
|
faible
|
moyenne
|
|
2 GDR faible
|
moyenne
|
élevée
|
|
3GSR ou plus moyenne
|
élevée
|
élevée
|
Tableau 4: Matrices niveau de
complexités sortie ou partie Sortie d'une Interrogation
2.5. Les étapes du comptage des points de fonction
Les étapes de comptages de cette méthode sont les
suivantes :
Ø Il faut identifier un ensemble de fonctions
identifiables par leurs spécificités.
Ø On classe chaque point de fonction comme simple,
moyen ou complexe. Un nombre de transactions définit le seuil de
chaque classification (simple, moyen ou complexe).
Ø On calcule ensuite le total non ajusté des
poids des points de fonction .Pour cela, on calcule pour chaque type de points
de fonction (simple, moyen...)le produit du poids par le nombre de cas. La
somme de ces trois produits est égale au nombre brut de points de
fonction du logiciel (non ajustés).
Ø Il faut déterminer le facteur de
complexité technique(Facteur d'ajustement FA).C'est un facteur
directement lié a la complexité du point de fonction( ex :
portabilité du programme) et a l'expérience des personnes
affectées au projet .On associe a chaque fonctionnalité du projet
(probabilité, système multi_utilisateur....) un poids de 0 a 5 en
fonction de l'importance de l tâche. En additionnant ces
résultats, on obtient le facteur égale à
?Fi .On calcule le facteur de
complexité suivant cette équation :
FA=0.6*(0.01*?Fi)
2.6. Calcul des Points de Fonction bruts (non
ajustés)
Une fois toutes les entités
isolés (ENT, SOR, INT, GDI, GDE) et leurs paramètres respectifs
calculés (DE, SLD ou GDR), on pourra donc, pour chacun des composants,
déterminer son niveau de complexité.
Une fois le niveau de complexité de chaque composant
déterminé, il suffit de sommer le nombre de chacun des
composants, pondérés par une valeur déterminée de
sa complexité.
|
Points de fonction Grille de
complexité
|
|
K (i, j)
|
Faible
|
Moyen
|
Elevé
|
|
GDI
|
7
|
10
|
15
|
|
GDE
|
5
|
7
|
10
|
|
ENT
|
3
|
4
|
6
|
|
SOR
|
4
|
5
|
7
|
|
INT
|
3
|
4
|
6
|
Tableau 5:
Affectation de point de fonction aux complexités
PFB=? (CI, J*KI, J)
Ø CI, J correspond au nombre de composants
calculés.
Ø KI, J correspond au coefficient à
attribuer à chacun des composants suivant son type et sa
complexité (tableau 5)
Ø PFB correspond au nombre de points de Fonctions bruts
calculés pour l'application
On peut, pour le calcule, utiliser également et
directement le tableau du tableau 6.
|
Type de composant
|
complexité
|
Nombre
|
Totale par complexité
|
Totaux par types de composant
|
|
GDI
|
F
|
...........x
|
7
|
=...........
|
|
M
|
...........x
|
10
|
=...........
|
|
E
|
...........x
|
15
|
=...........
|
|
GDE
|
F
|
...........x
|
5
|
=...........
|
|
M
|
...........x
|
7
|
=...........
|
|
E
|
...........x
|
10
|
=...........
|
|
ENT
|
F
|
...........x
|
3
|
=...........
|
|
M
|
...........x
|
4
|
=...........
|
|
E
|
...........x
|
6
|
=...........
|
|
SOR
|
F
|
...........x
|
4
|
=...........
|
|
M
|
...........x
|
5
|
=...........
|
|
E
|
...........x
|
7
|
=...........
|
|
INT
|
F
|
..........x
|
3
|
=...........
|
|
M
|
..........x
|
4
|
=...........
|
|
E
|
..........x
|
6
|
=............
|
|
Nombre de points fonction bruts
|
=............
|
Tableau
6: Affectation de point de fonction aux composants.
2.7. Résumé du comptage en nombre brut de
points de fonction
On peut résumer les différentes étapes d'un
comptage par le schéma ci-dessous (figure III.1)
|
Détermination du périmètre de
l'application
|
|
Identification de chaque composant
|
|
Evaluation de la complexité de chaque composant
|
|
Calcul du poids en points de fonction de chaque composant
|
|
Calcule du nombre brut de points de fonction
|
Fig
III.1: Etape de comptage en points de fonction.
2.8. Conversion de points de fonction aux lignes de code
Les points de fonction non ajustés doivent
être convertis en lignes de source de code dans la langue
d'exécution (c++, java, prolog, langue fourth generation ,etc...)afin
d'évaluer la taille du projet.
|
Langage
|
SLOC Par point de fonction
|
|
C
|
128
|
|
C++
|
52
|
|
JAVA 2
|
46
|
|
Cobol
|
107
|
|
ADA
|
41
|
|
prolog
|
64
|
|
Lisp
|
64
|
|
Assembleur
|
320
|
|
Basic
|
107
|
|
APL
|
32
|
|
2GL
|
107
|
|
4GL
|
20
|
|
Visuel basic 6
|
24
|
|
Delphi
|
18
|
|
HTML 4
|
14
|
|
SQL
|
13
|
2.9. Comptage du nombre de lignes de codes
2.9.1. Avantages
Ø Le nombre de lignes de code représente mieux
l'effort à fournir ou la quantité de travail effectuée
Ø les mesures de productivité fondée sur
le nombre de lignes de code ne varient pas en fonctions du langage
utilisé.
Ø les taux d'erreur étant
généralement proportionnel au nombre de lignes de code, sa
connaissance améliore la planification de la phase de test
Ø pour les langages de troisième
génération et orientées objet, le comptage du nombre de
ligne de code est très facile et peut se voir automatisé.
2.9.2. Inconvenient
Ø Le nombre de ligne de code ne permet pas
d'évaluer le coût prévisionnel d'un projet car il est
difficile de les compter avant qu'elles ne soient écrites.
Ø le nombre de lignes de code peut être
gonflé par le développeur suivant l'interprétation qui en
sera faite
Elles sont pratiquement impossibles à compter dans de
nouveaux environnements de développement de systèmes.
2.10. calcul de points de fonction Ajustés
L'étape suivante (facultative) consiste à
ajuster ces points de fonction. Le principe est le suivant : on corrige le
PDF grâce à un ensemble de 14 DI (degrés d'influence).
Chaque DI aura une valeur entre 0 et 5 en fonction de
l'importance du degré d'influence sur l'application.
Le degré d'influence est classé de 0 à
5
0 : ne pas
exister, ou pas influence
1 : influence
incidente
2 : influence
restreinte
3 : moyenne
influence
4 : influence
significative
5 : influence
forte
Facteur d'ajustement des points de
fonction
Le questionnaire qui sert à
ajuster les points comporte 14 facteurs qui font l'objet de réponses
à choix multiples .Suivant la repense choisie on attribue une valeur qui
varie de 0 à5.
Ces facteurs sont les suivants :
1. Transmission des données
Application traitée par lot-batch-, entrée des
données à distance, télétraitement interactif
2. Distribution
On évalue ici la contribution de l'application au
transfert des données (préparation des données sur un
autre système, traitement dynamique des données sur un
élément du système, etc,).
3. Performance
On évalue ici, le fait de savoir si des objectifs de
performance ont été dictés ou non par l'utilisateur.
4. configuration
On mesure ici l'existence éventuelle de restrictions
concernant l'exploitation de l'application
5. Taux de transaction
Plus le taux de transactions est élevé plus il
à d'influence sur la conception, la mise en oeuvre et le support de
l'application.
6. Entrées des données en temps
réel
Ce point du formulaire évalue l'importance des
fonctions de commande et d'entrées de données interactives.
0. toutes les transactions sont traitées en
différé.
1. de 1% à7% des transactions sont entrées en
mode interactif.
2. de 8% à 15%des transactions sont entrées en
mode interactif.
3. de 16%à 23%des transactions sont entrées en
mode interactif.
4. de 24% à30% des transactions sont entrées en
mode interactif.
5. Plus de 30% des transactions sont entrées en mode
interactif.
7. convivialité (Efficacité
d'interface)
Ce point permet dévaluer les contrainte
éventuelles posées par l'utilisateur concernant la
convivialité et l'efficacité de l'application pour ce dernier,
exemple (utilisation des menus, fonctions d'aide, mouvements automatiques du
curseur, sélection de données de l'écran à l'aide
du curseur l'impression à distance, une forte utilisation des options
d'inversion vidéo, de clignotement, de soulignement, de couleur...).
Le calcule des points se fait de la façon suivante
0. Aucune catégorie ne s'applique
1. Une à Trois catégories s'applique
2. Quatre à cinq catégories s'appliquent
3. Six catégories ou plus s'appliquent, mais il n'y a
aucun besoin relié spécifiquement à l'efficacité
4. Six catégories ou plus s'appliquent, et les besoins
d'efficacité sont suffisamment importants pour exiger un effort.
5. Six catégories ou plus s'appliquent et les besoin
d'efficacité é sont suffisamment important pour exiger
l'utilisation d'outils et de processus spéciaux pour démontrer
que les objectifs ont été atteints.
8. Mise à jour en temps
réel :
On évalue ici si les entités internes de
l'application sont mises à jour en ligne .On tient compte aussi de la
protection contre la perte des données et du coût de la
reprise.
1. Sans objet
2. Mise à jour en direct de 1 à 13 fichiers de
contrôle.
3. Mise à jour en direct de plus de 3 fichiers de
contrôle.
4. Mise à jour en direct des principaux
dépôts internes.
5. En plus des mises à jour en direct, la protection
contre les pertes de transactions.
6. Le programme offre des procédures de
récupération automatisée.
9. Complexité du traitement :
On prend en compte la complexité du
traitement défini de diverses manières : importance de la
sécurité et du contrôle, importance du traitement logique
et mathématique, importance des exceptions dans le traitement,
importance des transactions avant d'être retraitées ; etc. On
compte un point pour chaque catégorie.
10. Réutilisation :
On mesure ici l'effort accompli pour faciliter la
réutilisation des programmes dans d'autres applications et de
maîtrise.
11. Facilité d'implantation :
On évalue ici la facilité d'installation et
notamment l'importance des conversions et leur degré de planification et
de maîtrise
12. Simplicité d'utilisation :
Cette rubrique évalue la facilité d'exploitation
de l'application. Procédures de démarrage, de sauvegarde, de
relance, en cas de panne.
13. Installations multiples :
On évalue ici le fait de savoir si l'application a
été conçue pour être mise en place dans des
installations multiples.
14. Facilité des modifications,
maintenance :
On mesure ici, le fait de savoir si l'application à
été conçu pour faciliter les modifications (fonctions
d'interrogations souples, etc.)
Le tableau suivant représente le questionnaire qui sert
à ajuster les points de fonction :
|
Caractéristique générales du
système
|
Description
|
|
Transmission des données
|
Combien de facilités de communication pour aider
au transfert ou à l'échange d'information avec l'application ou
le système?
|
|
Distribution du traitement et des
données
|
Comment les données et les traitements
distribués sont ils gérés ?
|
|
Critères de performance
|
L'utilisateur a t il des exigences en matière de
temps de réponse?
|
|
Configuration matérielle
|
Quel est l'état de charge actuel de la plate-forme
matérielle sur laquelle le système sera mis en
exploitation?
|
|
Taux des transactions
|
Quelle est la fréquence d'exécution des
transactions (quotidien, hebdomadaire, mensuel...) ?
|
|
Entrées des données
|
Quel est le pourcentage de données saisies en
temps réel?
|
|
Efficacité des interfaces utilisateur
(Convivialité)
|
Les interfaces ont elles été
dessinées pour atteindre à l'efficacité maximale de
l'utilisateur
|
|
Complexité du traitement
|
L'application fait elle appel à des traitements
logiques ou mathématiques complexes?
|
|
Réutilisabilité
|
L'application est elle développée pour
satisfaire un ou plusieurs besoins clients?
|
|
Facilité d'installation
|
Quelle est la difficulté de conversion et
d'installation?
|
|
Simplicité d'utilisation
|
Quelle est l'efficacité et /ou l'automatisation
des procédures de démarrage, backup, et
récupération en cas de panne ?
|
|
Installation multiples
|
L'application est elle spécifiquement
conçue, développée maintenue pour être
installée sur de multiples sites pour de multiples
organisations?
|
|
Facilité des modifications,
maintenance
|
L'application est elle spécifiquement
conçue, développée maintenue pour faciliter le
changement?
|
|
Tableau 7:
caractéristiques générales du système. [ANN
01]
Ces 14 facteurs vont nous permettre de déterminer un
coefficient de complexité du projet. On fait la somme des
réponses (valeur comprise entre 0 et 5 pour chaque repense) fournies
à l'ensemble des facteurs recensés dans le questionnaire.
La somme des 14 facteurs, nous l'avons vu est comprise entre 0
et 70
|
|
FA=0.65 +0.01*
|
|
Avec
0.65<FA<1.35
|
Puis on en déduit le nombre ajusté de points de
fonction
PFA=PFA*FA
2.11. Calcul de la charge avec les points de fonctions
Le calcul de la charge (le point qui nous intéresse en
particulier) est une fonction linéaire de PFB. (Ou de PFA si on l'a
calculé).
Cette évaluation se fait grâce à un
facteur multiplicatif.
Ce facteur multiplicatif est d'environ 3 Jours*Homme par Pont
de Fonction en moyenne (2J*H si le projet est petit, 4 s'il s'agit d'un grand
projet).
Charge de travail pour le développement
(En jour x homme=Point de fonction ajustés*nombre de
jour x homme par points de fonction)
Charge=PFA * K
K : est le nombre de jour x homme par point
de fonction (K est d'environ 3 Jours*Homme par Point de Fonction en moyenne ,2
J*H si le projet est petit ,4 s'il s'agit d'un grand projet).
2.12. Avantage et Inconvénients des points de
fonction
2.12.1. Avantages
Ø La méthode des points de fonction est
normalisée.
Ø Elle est utilisée dans de nombreuse entreprise
pour mesurer la complexité ou la taille d'une application.
Ø Cette méthode est indépendante du
langage et de la technologie utilisée.
2.12.2. Inconvénients :
Ø Problème d'assignation subjective: la
complexité des fonctions élémentaires et de quatorze
facteurs techniques est évaluée subjectivement sur
l'échelle : simple, moyen et complexe ou de zéro à cinq.
Le poids pour chaque catégorie et aussi déterminé
subjectivement par <<débat et essai>> [DET
03]
Ø L'utilisation de cette méthode demande encore
un travail important, la présence d'un spécialiste de cette
méthode et ne peut pas encore être automatisée.
Ø Le comptage d'une personne à une autre peut
varier de 10 %contrairement à ce que la méthode présente
théoriquement.
3. LA METHODE COCOMO'81 (BOEHM)
L'estimation de l'effort (en homme mois) fait suite
à l'estimation de la taille (en lignes de code source) et permettra de
définir un calendrier pour le projet.
La méthode COCOMO'81 fournit un algorithme permettant
de dériver une évaluation, de l'effort et du planning à
partir de l'estimation de la taille du logiciel. Nous donnons en
référence la méthode de (Putman and Myers 1992) qui
conduit également à une évaluation de l'effort
3.1. Historique
La méthode COCOMO, pour
COnstructive COst Model a
été développée par Dr. Barry Boehm pour estimer
l'effort et le temps de développement d'un produit logiciel. A l'origine
elle a été construite à partir d'une analyse des
données par régression pratiquée sur 63 projets logiciels
(gestion et informatique industrielle) comprenant de 2000 à 100.000
lignes de code dans l'entreprise TRW (USA). COCOMO à l'avantage
d'être un modèle
Ouvert. Les données de calibrage, les formules et tous
les détails des définitions sont disponibles. La participation
à son développement est encouragée.
Aujourd'hui, COCOMO II est un nouveau produit beaucoup
plus adapté à l'aspect réutilisation des composants
(modules existants). La version 1998 a été calibrée sur
161 points de données, en utilisant l'approche statistique Bayesienne
pour combiner les données empiriques avec les avis d'experts. De plus
elle peut être ré-calibrée sur les données de
l'entreprise. Un nouveau modèle appelé COCOTS, est en cours de
développement par l'équipe de COCOMO. Ce modèle permet
d'estimer les coûts et planifier des projets logiciels utilisant des
composants existants. C'est encore un projet de recherche. Pour les projets
basés sur une technologie traditionnelle, le modèle original de
1981 est encore valable, d'autant plus qu'il est maintenant rodé et bien
documenté.
3.2. COCOMO 81
Le modèle COCOMO 81 s'appuie sur une estimation de
l'effort en homme*mois (HM) calculée par la formule :
C : facteur de complexité
M : facteur multiplicateur
Taille : en milliers de lignes de code
source livrées (KDSI)
S : proche de 1
Hypothèses :
KDSI livré :
Ø Exclut en général les environnements de
tests, les supports de développement.
Ø Exclut les commentaires.
Ø Inclut le Shell.
Le modèle COCOMO 81 est en fait constitué de
trois modèles :
Ø Le modèle de base.
Ø le modèle intermédiaire.
Ø le modèle détaillé ou expert.
3.2.1. Le modèle de base
Le modèle de base estime l'effort (le nombre
d'homme mois) en fonction du nombre de milliers d'instructions source
livrées(KDSI), de la productivité (le nombre de lignes
de code par personne par mois) et d'un facteur d'échelle qui
dépend du type de projet. Les 3 types de projet identifiés sont
:
· organique
Il est défini par une innovation minimale, une
organisation simple en petites équipes
Expérimentées. (Ex: petite gestion,
système de notes dans une école, petits systèmes
D'exploitation, traducteurs).
· médian (semi-detached)
Il est défini par un degré d'innovation
raisonnable, (exemples: Compilateurs, Contrôle de Processus simple,
système bancaire interactif)
· imbriqué :
Dans ces projets le niveau d'innovation est important,
l'organisation complexe, couplage fort avec beaucoup d'interactions, (exemples:
Gros système d'exploitation, Systèmes Transactionnels complexes,
système de contrôle aérospatial.)
|
Type de projet
|
Effort en homme mis(HM)
|
Temps de développement
|
|
Organique
|
2.4(KDSI) 1.05
|
2.5(HM) 0.38
|
|
Médian
|
3.0(KDSI) 1.12
|
2.5(HM) 0.35
|
|
Imbriquer
|
3.6(KDSI) 1.20
|
2.5(HM) 0.32
|
Tableau 8: Formules d'estimation COCOMO pour le
modèle de base.
EXEMPLES
|
Effort(HM)
|
2KDSI
|
8KDSI
|
32KDSI
|
128KDSI
|
512KDSI
|
|
Organique
|
5
|
21.3
|
91
|
392
|
|
|
Médian
|
6.5
|
31
|
146
|
687
|
3250
|
|
Imbriqué
|
8.3
|
44
|
230
|
1216
|
6420
|
Tableau 9: Effort en
HOMMES MOIS (HM) en fonction de la taille et du type de projet
|
TDEV (mois)
|
2KDSI
|
8KDSI
|
32KDSI
|
128KDSI
|
512KDSI
|
|
organique
|
4.6
|
8
|
14
|
24
|
|
|
Médian
|
4.8
|
8.3
|
14
|
24
|
42
|
|
Imbriqué
|
4.9
|
8.4
|
14
|
24
|
41
|
Tableau 10: Temps de
développement (en mois) en fonction de la taille et du type de
projet
Le temps de développement commence après
les spécifications fonctionnelles et s'arrête après
l'intégration De ces chiffres on peut déduire la
productivité (KDSI/HM) et le nombre moyen de personnes
sur le projet (FSP=HM/TDEV).
Exemple :
Soit un projet estimé à 32 KDSI en mode
organique,
HM = 2.4 * (32)1.05 = 91 HM
TDEV = 2.5 * (91)0.38 = 14
Mois
PRODUCTIVITE = 32000 DSI/91 HM
= 352 DSI/HM
FSP = 91 HM / 14 MOIS = 6.5
FSP
3.2.2. Le modèle
intermédiaire
Le modèle de base ne prend en compte que le
nombre de lignes source et induit des discontinuités un peu brutales au
niveau du personnel entre chaque phase du cycle de vie; ce qui peut perturber
l'organisation du projet.
Le modèle intermédiaire introduit 15 facteurs
de productivité (appelés 'cost drivers'),
représentants un avis subjectif du produit, du matériel, du
personnel, et des attributs du projet. Chaque facteur prend une valeur
nominative de 1, et peut varier selon son importance dans le projet. Les 15
facteurs sont multipliés entre eux pour donner un facteur d'ajustement
qui vient modifier l'estimation donnée par la formule de base.
· Facteurs de productivité
F Logiciel :
RELY: Fiabilité requise.
DATA: Volume des données manipulées.
CPLX: Complexité du produit.
F Matériel :
TIME: Contraintes de temps d'exécution.
STOR: Contraintes de taille mémoire.
VIRT: Instabilité de la mémoire.
TURN : Contraintes de système de
développement
F Personnel :
ECAP: Aptitude de l'équipe.
AEXP: Expérience du domaine.
VEXP: Expérience de la machine virtuelle.
LEXP: Maîtrise du langage.
F Projet :
MODP: Pratique de développements
évolués.
TOOL: Utilisation d'outils logiciels.
SCED: Contraintes de délais.
|
Multiplicateur
|
Très bas
|
Bas
|
Normal
|
Elevé
|
Très élevé
|
Extrêmement élevé
|
|
RELY
|
0.75
|
0.88
|
1
|
1.15
|
1.4
|
|
|
DATA
|
|
0,94
|
1
|
1.08
|
1.16
|
|
|
CPLX
|
0.7
|
0.85
|
1
|
1.15
|
1.3
|
1.65
|
|
|
TIME
|
|
|
1
|
1.11
|
1.3
|
1.66
|
|
STOR
|
|
|
1
|
1.06
|
1.21
|
1.56
|
|
VIRT
|
|
0.87
|
1
|
1.15
|
1.3
|
|
|
|
ECAP
|
1.44
|
1.18
|
1
|
0.86
|
0.7
|
|
|
AEXP
|
1.29
|
1.13
|
1
|
0.91
|
0.82
|
|
|
VEXP
|
1.21
|
1.1
|
1
|
0.9
|
|
|
|
LEXP
|
1.14
|
1.07
|
1
|
0.95
|
|
|
|
|
MODP
|
1.24
|
1.1
|
1
|
0.91
|
0.82
|
|
|
TOOL
|
1.24
|
1.1
|
1
|
0.91
|
0.83
|
|
|
SCED
|
1.23
|
1.08
|
1
|
1.04
|
1.1
|
|
Tableau 11: coefficients
multiplicateurs pour chacun des facteurs de productivité
|
Type de projet
|
Effort en homme mois(HM)
|
Temps de développement
|
|
Organique
|
3.2(KDSI) 1.05
|
2.5(HM) 0.38
|
|
Médian
|
3.0(KDSI) 1.12
|
2.5(HM) 0.35
|
|
Imbriqué
|
2.8(KDSI) 1.20
|
2.5(HM) 0.32
|
|
Tableau 12: coefficients pour le
calcul d'effort et de temps dans le
Modèle intermédiaire
3.2.2.1. Calcul de l'effort (HM) dans le modèle
intermédiaire
Identifier le mode de développement - organique,
médian, imbriqué). Ceci donne 4 coefficients au modèle
:
p (productivité nominative),
e (échelle appliquée à
la taille du logiciel),
c (constante du modèle)
d (échelle appliquée au temps
de développement) conformément au tableau 12.
Estimer le nombre de lignes du code source (en KDSI), puis
calculer le nombre d'homme*mois par la formule appropriée du tableau
12. On obtient HM base.
Estimer les 15 facteurs de productivité et calculer
le facteur d'ajustement (a) en multipliant les facteurs ensemble
conformément au tableau 11
Multiplier l'effort 'nominal' par le facteur d'ajustement :
Calculer le temps de développement en utilisant le
tableau 12:
TDEV = c(HH)
d
(On notera que les coefficients restent inchangés par
rapport au modèle de base) Dans le modèle intermédiaire,
les coefficients multiplicateurs s'appliquent uniformément sur
l'ensemble des phases.
3.2.3. Modèle expert
Le modèle expert inclut toutes
les caractéristiques du modèle intermédiaire avec une
estimation de l'impact de la conduite des coûts sur chaque étape
du cycle de développement : définition initiale du produit,
définition détaillée, codage, intégration. De plus,
le projet est analysé en termes d'une hiérarchie : module, sous
système et système. Il permet une véritable gestion de
projet, utile pour de grands projets. Le modèle expert n'est pas
décrit ici.
· Démarche
Ø Estimation de la taille (nbr d'instruction source).
Ø Calcule de charge « brute ».
Ø Sélection des facteurs correcteurs.
Ø Application des facteurs correcteurs à la charge
brute pour obtenir la charge « nette ».
Ø Evaluation de délai normal.
4. CONCLUSION :
La gestion de projet est une des meilleures garanties de
l'assurance qualité, elle permet la maîtrise du processus de
développement.
Les méthodes COCOMO'81 et points fonction
peuvent être programmées très simplement sur des
tableurs.
Enfin pour la documentation technique des outils comme
Interleaf ou Framemaker seront préférés à Word pour
leur facilité d'interfaçage avec les outils d'analyse et
conception.
Chapitre 4 :
CHAPITRE IV


Conception Et
Implémentation
3. INTRODUCTION
Ce chapitre est consacré à la
présentation de notre AGL dédié à l'estimation du
coût logiciel à l'aide de la méthode des Points De Fonction
et de la méthode Cocomo'81.
4. CYCLE DE DEVELOPPEMENT DE NOTRE AGL
4.1. Objectif
Le but de notre travail est de concevoir et de réaliser
un AGL dédié à l'estimation de l'effort de
développement de logiciel, par la méthode des points de
fonction et la méthode cocomo'81 basée sur les lignes de code
source (KISL).
4.2. Spécification
Les listes exhaustives des spécifications
fonctionnelles relatives à chaque méthode
implémentée dans notre AGL sont exposées dans les
paragraphes qui suivent. (Figure IV.1 présente le diagramme de flot de
données de notre système)
Fig IV.1:
DFD global
4.2.1. Spécifications fonctionnelles pour la
méthode des points de fonctions
? Classification des fonctions selon le type et la
complexité.
? Calculer le nombre de points fonction brute.
? Entrer les valeurs de 14 facteur d'ajustement.
? Calculer le point fonction ajusté.
? Calculer la charge.
? Calculer la taille en LOC.
Ses fonctionnalités sont illustrées dans la figure
IV.2 :
Fig IV.2: DFD de la méthode
des points de fonction
4.2.2. Spécifications fonctionnelles pour la
méthode cocomo'81 de base
? Charger le programme selon le langage (delphi, c++, pascal,
builder).
? Compter la taille approximative du projet en KISL.
? Calculer l'effort (en HM et JH) et le temps de
développement, le nombre total de personnes et productivité.
Ses fonctionnalités sont illustrées dans la figure
IV.3 :
Fig IV.3: DFD de la méthode
cocomo'81 de base
4.2.3. Spécifications fonctionnelles pour la
méthode cocomo'81 intermédiaire
? Charger le programme selon le langage (delphi, c++, pascal,
builder).
? Compter la taille approximative du projet en KISL.
? Entrer les valeurs des facteurs d'ajustement.
? Calculer l'effort (en HM et JH) et le temps de
développement, le nombre total de personnes et productivité.
Ses fonctionnalités sont illustrées dans la figure
IV.4 :
)
Fig IV.4: DFD de la
méthode cocomo'81 intermédiaire
4.3. Conception
4.3.1. Conception architecturelle
Fig
IV.5: conception architecturelle
4.3.2. Conception détaillée
4.3.2.1. Algorithme
? Identification de mot de passe
Lire (mot de passe) ;
Si (mot de passe = mot de passe enregistrer) alors
Affichage de menu
Sinon écrire (`votre mot de passe est
incorrect') ;
? Point de fonction
Point de fonction brut
<-GDI_F*7+GDI_M*10+GDI_E*15+GDE_F*5+GDE_M*7+GDE_E*10+ENT_F*3+ENT_M*4+ENT_E*6+SOR_F*4+SOR_M*5+SOR_E*7+INT_F*3+INT_M*4+INT_E*6;
Facteur d'ajustement < - 0,65+0,01*SOM (fact_ajust) ;
Point fonction ajustée <- Point de fonction brut *
Facteur d'ajustement ;
Lire(K) ;
Charge <- Point fonction ajustée *K ;
? Cocomo'81 de base
Lire (taille) ;
Si (taille < 5) alors
début
a <- 2 ,4 ;
b <- 1,05 ;
c <- 0,38 ;
fin ;
Si (taille>5) et (taille<30) alors
début
a <- 3 ;
b <- 1,12 ;
c <- 0,35 ;
fin ;
Si (taille>30) alors
début
a <- 3 ,6 ;
b <- 1,20 ;
c <- 0,32 ;
fin ;
Effort <- a*(taille)b ;
Temps de développement <-2.5
(Effort)c ;
Nbr personne <- Effort/ Temps de
développement ;
Productivité <- taille/ Effort ;
? Cocomo'81 intermédiaire
Lire (taille) ;
Lire (facteur d'ajustement) ;
Fact < - Multi (facteur d'ajustement) ;
Si (taille < 5) alors
début
a <- 3,2 ;
b <- 1,05 ;
c <- 0,38 ;
fin ;
Si (taille>5) et (taille<30) alors
début
a < - 3 ;
b <- 1,12 ;
c <- 0,35 ;
fin ;
Si (taille>30) alors
début
a <- 2,8 ;
b <- 1,20 ;
c <- 0,32 ;
fin ;
Effort <- a*(taille)b * fact ;
Temps de développement <- 2.5
(Effort)c ;
Nbr personne <- Effort/ Temps de
développement ;
Productivité <- taille/ Effort ;
5. Implémentation
Notre prototype a été
développé en langage de programmation Delphi Version 5 sous
Windows xp professionnel.
Le Delphi est un environnement de programmation visuel
orienté objet pour le développement rapide d'application .on put
l'utiliser pour développer toutes sortes d'application, des utilitaires
généraux, des applications clients serveur et même des
programmes sophistiques d'accès aux données.
L'environnement de développement de Delphi inclut
un concepteur de fiche visuel, un inspecteur d'objet, une palette de
composant, un gestionnaire de projet, un explorateur de code, un
éditeur de code source, un débogueur et un outil d'installation.
C'est dans ces environnements que Delphi fournit tous les outils pour
concevoir, développé, testé et débogueur les
applications.
Avec ses bibliothèques complète de
composants réutilisables et un ensembles d'outils de conception incluant
des modèles d'application s et de fiches, il nous simplifie le pro
typage et le développement d'applications et réduit la
durée du développement.
6. Présentation de notre
logiciel
4.1. Interface générale
L'interface de notre logiciel d'estimation de coût en
points des fonctions et cocomo'81 est composée d'un menu principal,
comme le montre la figure IV.7.
4.2. Fenêtre d'accueil
Le premier écran permet à l'utilisateur
d'entrer son mot de passe pour accéder à l'interface principale
de l'application
Fig IV.6:
Insertion de mot de passe
Après validation du mot de passe, on accède
à l'interface principale de l'application
Cette fenêtre permet à l'utilisateur de choisir
entre deux méthodes soit la méthode points de fonction soit la
méthode de cocomo81 avec le mode de base ou le mode
intermédiaire.

Fig IV.7 : Fenêtre de
menue principal.
Un clic sur La méthode Point de Fonction
permet à l'utilisateur d'accéder aux sous menus de la
méthode Point de Fonction.
L'utilisateur peut accéder de la même
façon, en cliquant sur la méthode cocomo'81 de base ou cocomo '81
intermédiaire
Fig IV.8 : menu de la méthode de
point fonction, cocomo'81 de base et
intermédiaire.
4.3. Quelques opérations réalisables sur
notre Application
a)Ouverture d'un projet qui existe
déjà
À partir l'opération ouvrir projet qui existe
dans le menu fichier, on peut ouvrir un projet.
b) L'ajout ou la suppression d'un
projet
À partir l'opération Projet qui existe
dans le menu fichier, on ajoute un nouveau projet ou supprime un
projet qui existant.
c) Les étapes d'estimation de
coûts:
Ø Par la méthode points de
fonction
La fenêtre « projet à estimer par point
des fonction » (figure IV.9) contient les
étapes d'estimation du coût du projet.
? Elle est composé de 4 pages (Fonctions,
Points fonction ajusté, estimer le coût, calcul la taille en
LOC).
Ø La page foncions : Permet de
saisir les fonctions du projet elle contient aussi le nombre brut des points
de fonction.
Ø La page Points fonctions
ajustés : Permet d'affecter une valeur entre 0-5 pour
chaque facteur d'ajustement et ensuite de calculer le nombre ajusté des
points de fonctions.
Ø La page estimer le coût :
Permet à l'utilisateur de calculer l'effort du projet à partir du
nombre de jours x hommes par point de fonction.
Ø La page Calcul la taille en
LOC : Permet à l'utilisateur de calculer la taille du
projet en LOC.
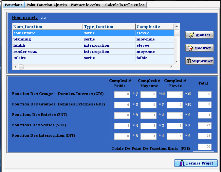
Fig IV.9 : les fonctions utilisées dans le
projet.
Ø Par la méthode cocomo'81 de base et
intermédiaire
La première étape de cette méthode en
charge le programme selon le langage de programmation et on calcule le nombre
d'instruction KLSL, et on calcule les facteurs d'ajustement pour Cocomo'81
intermédiaire. Et avec ces données en estime l'effort, la
productivité, le nombre total de personnes et le temps de
développement
d) Générer un rapport
L'utilisateur peut générer un rapport
détaillé du projet pour les trois modèles de notre
logiciel à partir du menu traitements.
e) Comparaison entre les résultats
Cette étape de notre application permet de faire une
comparaison entre les résultats d'estimation d'un programme
estimé par les deux méthodes (clic sur le bouton comparaison
d'effort). Les résultats sont affichés par un histogramme et
pourcentage.
La figure suivante montre la comparaison par histogramme.
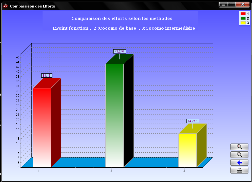
Fig IV.10 : Comparaison d'efforts par
histogramme.
f) L'aide
Cette fenêtre permet à l'utilisateur d'obtenir
une présentation soit par les méthodes cocomo'81 de base,
intermédiaire ou la méthode point de fonction à partir du
menu aide.
5. CONCLUSION
Prédire le coût d'un logiciel est une
opération très critique, ce qui explique l'existence de plusieurs
modèles pour achever ce but.
Parmi ces modèle nous avons choisit dans notre
logiciel deux modèles d'estimation la méthode des point de
fonction et la méthode cocomo'81 (de base et intermédiaire).
La méthode des point de fonction
représente une alternative intéressante en estimation des
coûts, parce qu'elle permet de quantifier la taille du logiciel
indépendamment de la technique et du langage de programmation.
Les estimations de cocomo'81 sont d'autant plus fiables,
que les paramètres du projet sont bien connus, c'est-à-dire qu'on
a profité des projets précédents pour étalonner ces
paramètres.
Conclusion générale :
Plusieurs chercheurs ont constaté l'absence d'une
théorie de base servant à guider les méthodes de mesure.
D'un côté pratique, on a besoin des mesures permettant de
prévoir de façon plus exacte l'effort et le coût de
développement ou de maintenance du logiciel indépendamment des
langages de programmation.
Ce projet nous a permis d'acquérir de nouvelles
connaissances en GL sur l'estimation de coût de logiciel.
Nous avons implémenté deux modèles
d'estimation de coûts de logiciel.
La première méthode « Points de
Fonctions » qui permet d'estimer l'effort de développement et
le coût du logiciel, elle est basée sur les principes
suivants:
Ø Identification des fonctions des projets logiciels.
Ø Comptage des points de fonction bruts.
Ø Ajustement des points de fonction.
Ø Calcul de la charge du projet.
La méthode des point de fonction est une alternative
intéressante en estimation des coûts des logiciels parce quelle
est indépendante des langages et technologies utilisés.
Toute fois, cette méthode présente quelques
difficultés comme l'application de la méthode à un projet
donné n'est pas chose aisée car l'identification et la
distinction des fonctions à partir du cahier des charges du projet n'est
pas évidente et nécessite la présence d'un
spécialiste en cette méthode.
Et la deuxième méthode
« Cocomo'81 » qui semble être le plus connu des
modèles d'estimation de coût de projet logiciel, et il reste la
référence en matière d'estimation détaillées
des coûts présente une faiblesse principale qui réside
dans la nécessité d'avoir une estimation du nombre de ligne
logiciel. Cette taille du logiciel n'est connue qu'à la fin de la
réalisation.
Dans ce travail nous avons essayé de regrouper ces
deux méthodes dans un AGL pour permettre l'estimation d'une part du
coût du logiciel, de la productivité, de l'équipe ainsi que
la distribution de l'effort et d'autre part pour comparer les résultats
obtenus selon les différentes méthodes
implémentées.
PERSPECTIVES
Notre AGL est extensible et peut être enrichi par toutes
les autres méthodes d'estimation de coût logiciel. Nous proposons
comme première perspectives la méthode expert de cocomo'81.
JEUX D'ESSAI
Ø Utilisation de la méthode point de
fonction
Premier exemple
Scénario d'un
système de contrôle de stock
Une compagnie vend 200 marchandises électriques
différentes au téléphone. Pour faire ça elles
veulent que vous créiez un système informatisé de
contrôle de stock. Ce système a les fonctionnalités
suivantes :
Ø Permet à l'opérateur de saisir le
nombre existant de clients, ou bien les détails des nouveaux clients
(jusqu'à 100 clients).
Ø Vérifier le crédit des clients bien
placés et rejeter ceux des clients mal placés.
Ø Permet à l'operateur d'enregistrer la
marchandise sur commande.
Ø Vérifier la disponibilité des
marchandises en commande.
- Là ou il y a une réserve de stock
suffisante.
- Là ou la réserve de la marchandise n'est pas
disponible et créer une commande pour fournir la marchandise dès
que disponible.
Ø Mettre à jour les détails des niveaux
de stock et des comptes de client.
Ø Produire le bon et la facture de livraison des
marchandises.
Ø Mettre à jour les niveaux de stock basé
sur la livraison des marchandises
Ø Mettre à jour du compte des clients
basés sur le paiement par un client.
? Identification des fonctions
|
Type
|
Complexité Faible
|
Total
|
|
Entrées (ENT)
|
- Nombre de clients.
- Détails du nouveau client.
- Détails de la commande.
- Détails du stock de la livraison.
- Détails du paiement du client.
|
15
|
|
Sorties (SOR)
|
- Ordre du crédit.
- Les factures.
- Bon de livraison.
- Information des détails du client.
- Information des détails de la commande.
- Information des détails du stock.
|
24
|
|
Interrogations(INT)
|
- Requête sur détail du client.
- Requête sur détails de commande.
- Requête sur détails du stock.
|
9
|
|
Groupe Données Internes (GDI)
|
- Fichier de transaction des marchandises.
- Dossiers de client.
- Dossiers des marchandises.
- Fichier de transaction du client.
|
28
|
|
Groupe Données Externes (GDE)
|
__
|
00
|
? Calcul du nombre de points de fonction non
ajustés (bruts)
PFB= 3*nombre total
d'entées + 4 *nombre total de
sorties+3*nombre total
d'interruptions+7 * nombre total de GDI.
PFB= (3*5) +
(4*6) + (3*3) + (7*4)=76.
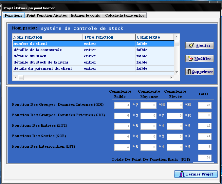
Figure AN.1 calcule de point fonction bruts
? Calcul du nombre des points de fonction
ajustés
|
Fi
|
Facture d'ajustement
|
Valeur
(0-5)
|
|
F1
|
Transmission des données
|
0
|
|
F2
|
Distribution
|
0
|
|
F3
|
Performance
|
4
|
|
F4
|
Configuration
|
3
|
|
F5
|
Taux de transaction
|
3
|
|
F6
|
Entrées des données
|
3
|
|
F7
|
Convivialité
|
4
|
|
F8
|
M.A.J en temps réel
|
5
|
|
F9
|
Complexité du traitement
|
2
|
|
F10
|
Réutilisation
|
4
|
|
F11
|
Facilité d'implantation
|
0
|
|
F12
|
Simplicité d'utilisation
|
0
|
|
F13
|
Installation multiples, partage
|
0
|
|
F14
|
Facilité des modifications, maintenance
|
3
|
|
Somme des Fi
|
31
|
On obtient les résultats suivants :
? Fi=31.
FA=0.65+31/100=0.96.
Nombre de points de fonction ajustés (PFA)
égal à
PFA=76*0.96=73
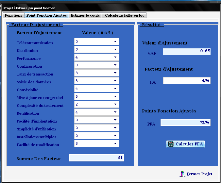
Figure AN.2 calcule de point fonction ajustés
? Calcul de la charge
Dans le cas d'un projet « Simple », la
méthode conseille une estimation 2 Jours*Homme
Par Point de fonction.
On obtient donc le résultat suivant :
Charge= 2*73 =146 JH.
Figure AN.3 calcule de la charge
Ø Utilisation de la méthode cocomo'81 de
base
Exemple : soit un projet chargé
de taille à 0.4275 KISL (mode organique)
Effort HM = 2.4*(0.4275)1.05
= 0.98 HM
Temps de développement = 2.5
(0.98)0.38 = 2.4 mois
Productivité = 0.4275KISL / 0.98 HM = 0.4 KISL
/ HM
Nombre total de personne = 0.98 HM / 2.4 mois = 0.43
personne
Figure AN.4
Les résultats obtenus par la méthode cocomo'81 de base
CHAPITRE I : Introduction
au Génie Logiciel

|
1.
Introduction .........................................................................................
|
1
|
|
2. Génie
logiciel .......................................................................................
|
1
|
|
2.1.
Présentation ...............................................................................
|
1
|
|
2.2.
Définition .................................................................................
|
1
|
|
2.3. Objectif du Génie logiciel
..................................................................
|
2
|
|
3. Cycle de vie d'un
logiciel.......................................................................
|
2
|
|
3.1. Les phases du cycle de vie du
logiciel ............................................
|
2
|
|
3.1.1. Etude
préalable ..................................................................
|
2
|
|
3.1.2. La spécification
...................................................................
|
2
|
|
3.1.3. La
conception .....................................................................
|
2
|
|
3.1.3.1. La conception générale
..........................................................
|
2
|
|
3.1.3.2. La conception
détaillé
.................................................
|
3
|
|
3.1.4. La
codification .........................................................................
|
3
|
|
3.1.5. Les tests
unitaires ................................................................
|
3
|
|
3.1.6. Les tests
systèmes .................................................................
|
3
|
|
3.1.7.
L'exploitation ............................................................................
|
3
|
|
3.1.8. La maintenance
.................................................................
|
3
|
|
3.2. Modèles cycle de vie
.................................................................
|
3
|
|
3.2.1. Modèle en
cascade .............................................................
|
3
|
|
3.2.2. Modèle en
V...................................................................
|
4
|
|
3.2.3. Modèle par
incrément
........................................................
|
5
|
|
3.2.4. Le
prototypage .....................................................................
|
5
|
|
3.2.5. Le modèle en
spirale ............................................................
|
6
|
|
4. Crise logiciel de génie
logiciel ................................................................
|
7
|
|
5. définition d'un atelier génie logiciel
.......................................................
|
8
|
|
6. Estimation de cout de développement de
logiciel ......................................
|
8
|
|
6.1.
Introduction ...............................................................................
|
8
|
|
6.1.1. L'expression du
besoin ..........................................................
|
8
|
|
6.1.2. L'étude
fonctionnelle .............................................................
|
8
|
|
6.1.3. L'étude
technique ..................................................................
|
9
|
6.1.4. La
réalisation..........................................................................
|
9
|
6.2. L'objectif de l'estimation de coût d'un
logiciel ...............................
|
9
|
|
6.3. Les étapes d'estimation d'un
projet .............................................
|
9
|
|
6.4. Les difficultés de
l'estimation ....................................................
|
10
|
|
6.5. Pourquoi de mauvaises
estimations ............................................
|
10
|
|
6.5.1. Pièges à
éviter ..................................................................
|
10
|
|
6.5.2. Quelques règles d'or pour
l'estimation ................................
|
11
|
|
6.5.3. Qualités de l'estimation
........................................................
|
12
|
|
6.6. Exactitude et précision d'une
estimation ...........................................
|
12
|
|
6.7. L'importance de
l'estimation .........................................................
|
13
|
|
6.8. Les unités de
mesures ..................................................................
|
13
|
|
6.9. Coût d'un
projet ........................................................................
|
13
|
|
6.9.1. Les différents coûts d'un logiciel
.............................................
|
13
|
|
6.9.1.1. Le coût de développement
.............................................
|
13
|
|
6.9.1.2. Le coût de
maintenance .................................................
|
14
|
|
6.10. Quelle méthode d'estimation choisir?
......................................................
|
14
|
|
7.
Conclusion................................................................................................
|
14
|
CHAPITRE II : les méthodes
d'estimation de coûts de logiciel

|
1.
Introduction ...........................................................................................
|
15
|
|
2. Le concept jours
hommes..........................................................................
|
15
|
|
3. Ligne de
code...........................................................................................
|
16
|
|
4. Technique d'estimation des
coûts ................................................................
|
17
|
|
4.1. Les modèles paramétriques d'estimation
des coûts ............................
|
17
|
|
4.1.1. Les modèles
linéaires .............................................................
|
17
|
|
4.1.2. Le modèle
analytique ............................................................
|
18
|
|
4.1.2.1. Le modèle d'halstead
.......................................................
|
18
|
|
4.1.2.2. Le modèle
putnam ...........................................................
|
19
|
|
4.1.3. Point de
fonction..................................................................
|
20
|
|
4.1.3.1. Présentation historique de la
fonction................................
|
20
|
|
4.1.3.2. Paramètres de points de
fonction .......................................
|
20
|
|
4.1.4.
Cocomo...............................................................................
|
22
|
|
4.1.4.1.
Cocomo'81 ....................................................................
|
22
|
|
4.1.4.2.
Cocomo II .....................................................................
|
23
|
|
4.1.5. Limitation des modèles
paramétriques......................................
|
24
|
|
4.2. Jugement de l'expert (méthode
delphi) ............................................
|
24
|
|
4.3. Estimation par
analogie .................................................................
|
25
|
|
4.3.1. Processus d'estimation par
analogie ...........................................
|
25
|
|
4.3.2. Limitation de l'estimation par
analogie.....................................
|
25
|
|
4.4. La méthode « prise to
win » (gagner pour
plaire) ..................................
|
25
|
|
4.5. Estimation ascendante et
descendante ..............................................
|
26
|
|
4.5.1. Estimation
ascendante............................................................
|
26
|
|
4.5.2. Estimation descendant
............................................................
|
26
|
|
4.6. Les modèles non paramétriques
d'estimation des coûts .......................
|
27
|
|
4.6.1. Les réseaux de neurones
...........................................................
|
27
|
|
4.6.2. Les arbres de régression
..........................................................
|
28
|
|
4.6.3. Les algorithmes génétiques
.....................................................
|
30
|
|
5. Résume sur les méthodes
d'estimation ........................................................
|
35
|
|
6. Conclusion
..............................................................................................
|
37
|
CHAPITRE III: La méthode des Point de
Fonction et la méthode cocomo'81

|
1.
Introduction ..........................................................................................
|
38
|
|
2. La méthode points de fonction (albrecht
79).................................................
|
38
|
|
2.1. Historique
....................................................................................
|
38
|
|
2.2. Définition du
contexte ..................................................................
|
38
|
|
2.2.1. Frontières de
l'application .....................................................
|
38
|
|
2.2.2. Identification de l'utilisateur
..................................................
|
38
|
|
2.2.3. Règles et procédures des
frontières du comptage ......................
|
38
|
|
2.3. Définition des différents composants
..............................................
|
39
|
|
2.3.1. Groupe logique de données
internes(GDI) ..............................
|
39
|
|
2.3.2. Groupe de données externes (GDE)
........................................
|
39
|
|
2.3.3. Les entrées
(ENT) ................................................................
|
39
|
|
2.3.4. Les sorties (SOR)
..............................................................
|
39
|
|
2.3.5. Les interrogations
(INT) .....................................................
|
39
|
|
2.4. Les niveaux de complexité
............................................................
|
40
|
|
2.4.1. Complexité des groupes logiques de
données .........................
|
40
|
|
2.4.2. Complexité d'une ENT ou partie ENT d'une
INT.....................
|
41
|
|
2.4.3. Complexité d'une SOR ou partie SOR d'une
INT......................
|
41
|
|
2.5. Les étapes du comptage des points de fonction
.................................
|
42
|
|
2.6. Calcul des points de fonctions bruts (non
ajustés) .............................
|
43
|
|
2.7. Résumé du comptage en nombre brut de
points de fonction ..................
|
44
|
|
2.8. Conversion de points de fonction aux lignes de code
.........................
|
44
|
|
2.9. Comptage du nombre de lignes de codes
........................................
|
44
|
|
2.9.1.
Avantages ...........................................................................
|
44
|
|
2.9.2. Inconvénient
.......................................................................
|
44
|
|
2.10. Calcul de points de fonction ajustés
..............................................
|
45
|
|
2.11. Calcul de la charge avec les points de fonctions
..............................
|
48
|
|
2.12. Avantage et inconvénients des points de
fonction .........................
|
48
|
|
2.12.1. Avantages
........................................................................
|
48
|
|
2.12.2. Inconvénients
..................................................................
|
48
|
|
3. La méthode cocomo'81 (boehm)
...............................................................
|
48
|
|
3.1. Historique
.................................................................................
|
48
|
|
3.2. COCOMO 81
.............................................................................
|
49
|
|
3.2.1. Le modèle de base
..............................................................
|
49
|
|
3.2.2. Le modèle intermédiaire
....................................................
|
50
|
|
3.2.2.1. Calcul de l'effort (hm) dans le modèle
intermédiaire .........
|
52
|
|
3.2.3. Le modèle expert
...............................................................
|
52
|
|
4. Conclusion
..........................................................................................
|
53
|
CHAPITRE VI :
Conception et Implémentation

|
1.
Introduction ..............................................................................................
|
54
|
|
2. cycle de développement de notre
AGL ......................................................
|
54
|
|
2.1. Objectif
........................................................................................
|
54
|
|
2.2. Spécification
...............................................................................
|
54
|
|
2.2.1. Spécifications fonctionnelles pour la
méthode points de fonctions
|
54
|
|
2.2.2. Spécifications fonctionnelles pour la
méthode cocomo'81 de base
|
55
|
|
2.2.3. Spécifications fonctionnelles pour la
méthode cocomo'81 intermédiaire
|
56
|
|
2.3. Conception
.................................................................................
|
57
|
|
2.3.1. Conception architecturelle
....................................................
|
57
|
|
2.3.2. Conception détaillée
............................................................
|
57
|
|
2.3.2.1. Algorithme
..................................................................
|
57
|
|
3.
Implémentation .....................................................................................
|
59
|
|
4. Présentation de notre
logiciel .............................................................................
|
59
|
|
4.1. Interface
générale ........................................................................................
|
59
|
|
4.2. Fenêtre d'accueil
.................................................................................................
|
59
|
5.3. Quelques opérations réalisables sous
notre Application .....................
|
60
|
|
5. Conclusion
...............................................................................................
|
63
|
| 

