Section 2 : Estimation univariée de la demande
de monnaie
Dans cette partie, nous allons utiliser un modèle
univarié dans lequel la demande de monnaie M1_FID puis M1_SCR et enfin
M3_M1 seront expliquées par le PIB et par TAUXCC. Le but étant
d'essayer de capturer la demande incombant au motif de transaction et de
précaution et celle incombant au motif de spéculation selon la
théorie Keynésienne. A chaque fois, nous allons estimer un
modèle en niveau puis en logarithme.
I- Etude de la demande de monnaie fiduciaire (M1_FID)
I-1- Spécification en niveau :
Le modèle à estimer s'écrit comme suit :
M1_FIDt = C + a. PIBt + b.
TAUXCCt + åt
Dans cette spécification nous utilisons le PIB nominal
et par conséquent, M1_FID ne sera pas divisée par l'IPC.
Selon la théorie de Keynes le coefficient a doit
être positif et le coefficient b négatif, alors que la constante C
ne devrait pas être significativement différente de
zéro.
Les résultats de régression de ce modèle
sont comme suit :
|
Dependent Variable: M1_FID Method: Least Squares
Date: 06/10/13 Time: 10:14
Sample: 2002Q1 2011Q4 Included
observations: 40
|
|
|
|
Variable
|
Coefficient
|
Std. Error t-Statistic
|
Prob.
|
|
C
|
-36052.02
|
3774.096 -9.552492
|
0.0000
|
|
PIB
|
0.938953
|
0.017182 54.64664
|
0.0000
|
|
TAUXCC
|
-55292.24
|
115442.9 -0.478957
|
0.6348
|
|
R-squared
|
0.988238
|
Mean dependent var
|
106440.8
|
|
Adjusted R-squared
|
0.987602
|
S.D. dependent var
|
28967.35
|
|
S.E. of regression
|
3225.388
|
Akaike info criterion
|
19.06753
|
|
Sum squared resid
|
3.85E+08
|
Schwarz criterion
|
19.19420
|
|
Log likelihood
|
-378.3507
|
Hannan-Quinn criter.
|
19.11333
|
|
F-statistic
|
1554.353
|
Durbin-Watson stat
|
0.921204
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
|
|
|
Modèle 1 : M1_FID C,PIB,TAUXCC
Le coefficient relatif à la constante C est
significativement différent de zéro ce qui contredit notre
hypothèse.
85
Le coefficient relatif à PIB est positif et
significativement différent de zéro, en plus il est
inférieur à 1 ce qui est logique puisque la demande de monnaie ne
peut pas être supérieure au revenu.
Par contre, le coefficient relatif à TAUXCC n'est pas
significatif au seuil de 5% et même au seuil de 10%, ce qui contredit une
deuxième fois notre hypothèse.
Ces conclusions sont conditionnées par la validité
du modèle. C'est ce qu'on se propose de faire par la suite.
Le R2 est très satisfaisant (0.987), de
même que le R2 ajusté. Cependant, la statistique de
Durbin-Watson est proche de zéro ce qui laisse présager d'une
autocorrélation des erreurs.
En effet, l'analyse des résidus de cette régression
montre qu'on est en présence d'une autocorrélation des erreurs
:
|
Date: 06/10/13 Time: 10:17 Sample: 2002Q1 2011Q4 Included
observations: 40
|
|
|
|
|
|
|
Autocorrelation Partial Correlation
|
|
AC
|
PAC
|
Q-Stat
|
Prob
|
|
1
|
0.522
|
0.522
|
11.746
|
0.001
|
|
2
|
0.271
|
-0.00...
|
14.992
|
0.001
|
|
3
|
0.209
|
0.095
|
16.983
|
0.001
|
|
4
|
0.236
|
0.127
|
19.589
|
0.001
|
|
5
|
-0.06...
|
-0.35...
|
19.784
|
0.001
|
|
6
|
-0.41...
|
-0.43...
|
28.125
|
0.000
|
|
7
|
-0.18...
|
0.353
|
29.864
|
0.000
|
|
8
|
-0.14...
|
-0.12...
|
30.973
|
0.000
|
|
9
|
-0.34...
|
-0.37...
|
37.443
|
0.000
|
|
1...
|
-0.51...
|
-0.06...
|
52.118
|
0.000
|
|
1...
|
-0.35...
|
-0.14...
|
59.247
|
0.000
|
|
1...
|
-0.22...
|
-0.31...
|
62.259
|
0.000
|
|
1...
|
-0.39...
|
-0.07...
|
72.142
|
0.000
|
|
1...
|
-0.33...
|
0.056
|
79.390
|
0.000
|
|
1...
|
0.001
|
0.012
|
79.390
|
0.000
|
|
1...
|
0.234
|
0.069
|
83.225
|
0.000
|
|
1...
|
0.185
|
0.062
|
85.717
|
0.000
|
|
1...
|
0.158
|
-0.21...
|
87.627
|
0.000
|
|
1...
|
0.327
|
-0.21...
|
96.206
|
0.000
|
|
2...
|
0.335
|
0.025
|
105.64
|
0.000
|
|
|
|
|
|
|
|
En effet, les coefficients d'ordre 1, 6, 9 et 10 sont
significativement différents de zéro.
On s'attendait à ce résultat étant
donné qu'aucune des séries présentes dans ce modèle
n'est stationnaire. En effet, M1_FID est I(2), PIB et TAUXCC sont I(1).
Les conclusions ci-dessus ne sont donc pas à prendre en
compte étant donné que le modèle ne peut pas être
validé.
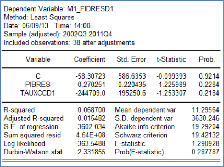
Nous allons donc estimer le modèle ci-dessus avec les
séries stationnarisées :
M1_FIDRESD1t = C + a. PIBRESt
+ b.TAUXCCD1 + Et
Avec les hypothèses suivantes : C non significativement
différent de zéro, 1> a >0 et b <0 Les résultats
de l'estimation de ce modèle sont comme suit :
86
Modèle 2 : M1_FIDRESD1
C,PIBRES,TAUXCC
Les résultats de cette estimation montrent qu'aucun des
coefficients n'est significatif, même si leurs signes sont conforme
à la théorie (1> a >0 et b <0). En plus, le
R2 et le R2 ajusté se sont beaucoup
détériorés (0.068700 pour R2 et 0.01548 pour
R2 ajusté).
L'analyse du corrélogramme des résidus issus de
cette régression montre en fait qu'il y a présence d'une forte
autocorrélation des erreurs. En effet, comme le montre la figure
ci-dessous, les coefficients d'ordre 2, 4 et 6 sont significativement
différents de zéro.
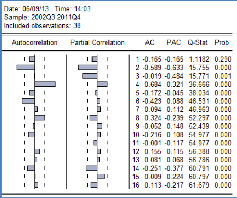
Cette autocorrélation est sûrement dû
à l'omission de quelque variables étant donnée le R2
très bas.
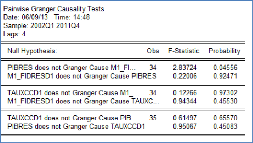
Nous allons donc voir à l'aide du test de
causalité de Granger si des retards de PIBRES et de TAUXCCD1 peuvent
améliorer le modèle :
En prenant un retard de 4, on obtient les résultats
suivants :
87
Comme on peut le voir sur ce tableau, l'hypothèse
« PIBRES ne cause pas M1_FIDRESD1 » est rejetée au seuil de 5%
(p-value = 0.04556). Par contre, l'hypothèse « TAUXCC ne cause pas
M1_FIDRESD1 » est acceptée au seuil de 5%.
On se propose donc d'introduire dans le modèle
précédent les retards jusqu'à l'ordre 4 de la variable
PIBRES. Les résultats de ce modèle sont comme suit :
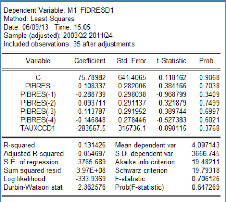
Modèle 3 : M1_FIDRESD1 C, PIBRES, PIBRES(-1
à -4) TAUXCCD1
D'après ces résultats on voit que le R2
s'est amélioré mais les coefficients sont toujours non
significatifs. En plus, les erreurs sont toujours
autocorrélées comme le montre le
corrélogramme
ci-dessous :
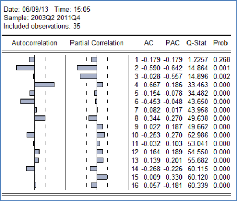
88
Pour remédier à ce problème, nous avons
testé plusieurs modèles incluant différents retards pour
les erreurs (termes MA : Moyenne mobile). Le meilleur modèle est celui
avec 4 retards des erreurs :
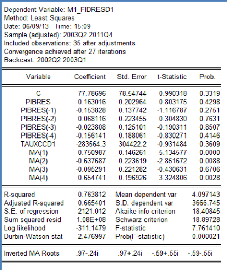
Modèle 4 : M1_FIDRESD1 C, PIBRES, PIBRES(-1
à -4) TAUXCCD1 MA(1 à 4)
En effet, comme on peut le constater, le R2 s'est
nettement amélioré en passant à 0,76 et le R2
ajusté à 0.66. Cependant, on constate que les coefficients
relatifs à PIBRES d'ordre 1, 3 et 4 sont négatifs ce qui
soulève des questions quant à leur signification et justification
économique.
Le corrélogramme des résidus ci-dessous, montre
qu'aucun des coefficients d'autocorrélation n'est significativement
différent de zéro :
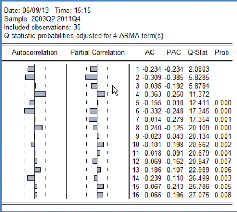
89
Cependant, le test de Breusch-Godfrey ne permet pas d'accepter
l'hypothèse H0 selon laquelle il y a absence de corrélation :
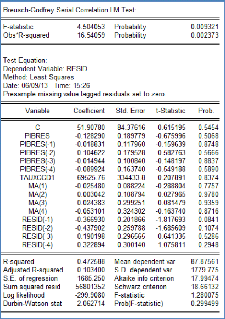
En effet, les p-value relatives aux statistiques F et
n*R2 sont toutes les deux inférieures à 5% et
même 1%.
Donc même si le R2 du dernier modèle est
assez satisfaisant, on ne peut pas le valider si on se fie au test de
Breusch-Godfrey.
Si on retire les retards de PIBRES, on obtient les
résultats suivants :
90
|
Dependent Variable: M1_FIDRESD1 Method: Least Squares
Date: 06/11/13 Time: 12:21
Sample (adjusted): 2002Q3 2011Q4 Included observations: 38 after
adjustments Convergence achieved after 25 iterations MA Backcast: 2001Q3
2002Q2
|
|
|
Variable
|
Coefficient
|
Std. Error t-Statistic
|
Prob.
|
|
C
|
29.25949
|
346.0383 0.084556
|
0.9332
|
|
PIBRES
|
0.237446
|
0.112671 2.107434
|
0.0433
|
|
TAUXCCD1
|
58860.98
|
162633.2 0.361925
|
0.7199
|
MA(1)
|
-0.181954
|
0.068648 -2.650542
|
0.0125
|
MA(2)
|
-0.594425
|
0.087771 -6.772448
|
0.0000
|
MA(3)
|
-0.153580
|
0.063892 -2.403742
|
0.0224
|
MA(4)
|
|
0.919146
|
0.042208 21.77641
|
0.0000
|
|
|
R-squared
|
0.709423
|
Mean dependent var
|
11.29564
|
|
Adjusted R-squared
|
0.653183
|
S.D. dependent var
|
3630.246
|
|
S.E. of regression
|
2137.896
|
Akaike info criterion
|
18.33785
|
|
Sum squared resid
|
1.42E+08
|
Schwarz criterion
|
18.63951
|
|
Log likelihood
|
-341.4192
|
Hannan-Quinn criter.
|
18.44518
|
|
F-statistic
|
12.61406
|
Durbin-Watson stat
|
2.534566
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
Inverted MA Roots
|
.84-.51i
|
.84+.51i -.75-.63i
|
-.75+.63i
|
Modèle 5 : M1_FIDRESD1 PIBRES, MA(1 à
4)
Comme on peut le voir, tous les coefficients relatifs aux
retards MA ainsi que celui relatif à PIBRES sont significativement
différents de zéro au seuil de 5% et le R2s'est
détérioré par rapport au modèle 4. En plus, le
corrélogramme ci-dessous, montre que les résidus sont
autocorrélés :
|
Date: 06/11/13 Time: 12:26
Sample: 2002Q3 2011Q4
Included observations: 38
Q-statistic probabilities adjusted for 4 ARMA term(s)
|
|
|
|
|
Autocorrelation Partial Correlation
|
|
AC
|
PAC
|
Q-Stat
|
Prob
|
|
1
|
-0.29...
|
-0.29...
|
3.5042
|
|
|
2
|
-0.17...
|
-0.27...
|
4.7278
|
|
|
3
|
0.049
|
-0.11...
|
4.8305
|
|
|
4
|
0.358
|
0.348
|
10.569
|
|
|
5
|
-0.10...
|
0.192
|
11.095
|
0.001
|
|
6
|
-0.28...
|
-0.18...
|
15.026
|
0.001
|
|
7
|
-0.03...
|
-0.35...
|
15.069
|
0.002
|
|
8
|
0.286
|
-0.07...
|
19.210
|
0.001
|
|
9
|
-0.05...
|
0.162
|
19.352
|
0.002
|
|
1...
|
-0.48...
|
-0.27...
|
31.946
|
0.000
|
|
1...
|
0.248
|
0.004
|
35.411
|
0.000
|
|
1...
|
-0.00...
|
-0.29...
|
35.412
|
0.000
|
|
1...
|
0.008
|
-0.08...
|
35.417
|
0.000
|
|
1...
|
-0.25...
|
0.023
|
39.602
|
0.000
|
|
1...
|
0.034
|
-0.13...
|
39.680
|
0.000
|
|
1...
|
0.152
|
-0.12...
|
41.274
|
0.000
|
|
|
|
|
|
|
On conclut donc que la spécification en niveau de la
demande de monnaie M1_FID ne permet pas de mettre en évidence la
présence d'un motif de spéculation comme c'est postulé par
la théorie Keynésienne. Ceci conforte tout de même notre
hypothèse (H).
| 

