|
|
Université Paris Diderot-Paris 7
U.F.R. Géographie, Histoire, et Sciences de la
Société
|
|
Master : M1, Géographie et Sciences des territoires
Parcours : Télédétection et
Géomatique Appliquées à l'Environnement Année
universitaire : 2012-2013
|
RECHERCHE D'UN PROCESSUS D'HISTORISATION DE BASE DE
DONNÉES
D'OCCUPATION DES SOLS APPLIQUÉ AU
RÉFÉRENTIEL GÉOGRAPHIQUE
FORESTIER DE L'IGN
Mémoire présenté et soutenu par
Romain LOUVET
Le 25 juin 2013
|
Maître de stage : Thierry TOUZET, chef de produit «
Forêt et
Environnement », IGN
Tutrice universitaire : Clélia BILODEAU, maître de
conférences à Paris
Diderot-Paris 7, Laboratoire Ladyss UMR 7533
|
|
Membres du jury : Catherine MERING
Nicolas DELBART Clélia BILODEAU Malika MADELIN Thierry
TOUZET
Paris 7 Paris 7 Paris 7 Paris 7 IGN
Professeur de géographie
Maître de conférences
Maître de conférences
Maître de conférences
Chef de produit « Forêt et Environnement »
1
2

|
Université Paris Diderot-Paris 7
U.F.R. Géographie, Histoire, et Sciences de la
Société
|
|
Master : M1, Géographie et Sciences des territoires
Parcours : Télédétection et
Géomatique Appliquées à l'Environnement Année
universitaire : 2012-2013
|
RECHERCHE D'UN PROCESSUS D'HISTORISATION DE BASE DE
DONNÉES
D'OCCUPATION DES SOLS APPLIQUÉ AU
RÉFÉRENTIEL GÉOGRAPHIQUE
FORESTIER DE L'IGN
Mémoire présenté et soutenu par
Romain LOUVET
Le 25 juin 2013
|
Maître de stage : Thierry TOUZET, chef de produit «
Forêt et
Environnement », IGN
Tutrice universitaire : Clélia BILODEAU, maître de
conférences à Paris Diderot-Paris 7, Laboratoire Ladyss UMR
7533
|
|
|
Membres du jury : Catherine MERING
Nicolas DELBART Clélia BILODEAU Malika MADELIN Thierry
TOUZET
|
Professeur de géographie Maître de
conférences Maître de conférences Maître de
conférences Chef de produit « Forêt et Environnement
»
|
Paris 7 Paris 7 Paris 7 Paris 7 IGN
|
3
4
« Nous reléguons au passé l'espace et
le temps indépendant l'un de l'autre. Seule désormais une forme
d'association entre ces deux concepts existe de plein droit. »
Herman Minkowsky,
21 septembre 1908, Cologne
(traduction libre)
« Après plusieurs décennies de
recentrage de la géographie sur la catégorie spatiale,
s'intéresser à la place du temps dans notre discipline peut
sembler au mieux iconoclaste, au pire suspect. C'est évidemment en
dépassant les crispations disciplinaires que nous voudrions aborder
cette thématique. »
Bernard Elissalde,
L'Espace géographique, 2000, n°3
« Constable: «Blimey, Inspector, where
have we wound up this time?» The Inspector: «The question,
Constable, isn't where... but when!» »
Community, « Biology 101 »
5
Remerciements
Je tiens à exprimer ma profonde reconnaissance à
mon maître de stage, Thierry Touzet, ainsi qu'à ma directrice de
mémoire, Clélia Bilodeau, pour m'avoir encadré et
guidé tout au long du stage et de la rédaction du
mémoire.
Je souhaite remercier Claude Vidal à qui j'ai en
premier exprimé le souhait d'effectuer un stage à l'IGN.
Je remercie le personnel du siège national de
l'Institut qui m'a chaleureusement accueilli pendant quatre mois. Un grand
merci à Clothilde Mohsen, Laurent Breton, Frank Fuchs, Bruno Bordin,
Fabien Gruselle, Mickaël Michaud, Ana-Maria Olteanu-Raimond, et Sylvie
Gras pour leur contribution à ce travail. Merci également aux
documentalistes de l'ENSG pour leur aide.
Merci aux personnes qui ont répondu à mes
questions lors des entretiens : Christine Plumejeaud, Sophie Foulard, et Marie
Christine Schott.
Enfin, je remercie mes camarades géographes de Paris 7,
mes amis Geoffroy, Amandine, Francesca, et ma mère pour leur soutien.
6
Résumé
Le temps dans les SIG est une question encore complexe et peu
étudiée par les producteurs de bases de données
géographiques. Pourtant, cette dimension est de plus en plus importante
pour satisfaire les besoins des utilisateurs, en particulier de données
d'occupation des sols. Ce mémoire aborde la problématique du
temps dans le cadre de la mise à jour du référentiel
géographique forestier participant à la production d'une nouvelle
base de données d'occupation des sols à grande échelle
à l'Institut national de l'information géographique et
forestière. Il propose une analyse synthétique des
différents aspects théoriques des bases de données
spatio-temporelles ainsi qu'une étude de cas de trois bases de
données géographiques intégrant le temps. Ce travail
aboutit à une proposition de solution pour l'implantation du suivi des
évolutions d'occupation des sols fondée sur un modèle
orienté-objet avec une typologie des événements.
Mots clés : temps, SIG, base de données,
occupation des sols, suivi des évolutions.
Abstract
Time in GIS is a complex question and is still scarcely
studied by producers of geographic databases. Yet, this aspect is particularly
important to meet the users' needs, especially with respect to land cover data.
This master's dissertation addresses the problem of integrating time in the
updating of the forest geographic frame of reference involved in the production
of a new large scale land cover database at the French National Institute of
Geographic and Forest Information. It provides a summary analysis of the
various theoretical aspects of spatiotemporal databases and a case study of
three geographic databases that integrate time. This work suggests a solution
for the implementation of land cover change monitoring, based on an
object-oriented model with a typology of events.
Key words : time, GIS, data base, land cover, changes
monitoring.
7
8
Table des matières
Remerciements 5
Résumé 6
Abstract 6
Table des matières 8
Table des figures 13
Index des tableaux 13
Index des acronymes 15
Introduction 17
Contexte 17
Demande de la structure d'accueil 18
Cadre du sujet 19
Problématique 19
Méthodologie, moyens 21
CHAPITRE I - Caractéristiques techniques et besoins
spécifiques du RGFor quant à l'intégration de la
dimension temporelle 23
I.A - Présentation 23
I.B - Contenu 24
I.C - Production 26
I.C.1 - Préparation des données 27
I.C.2 - Saisie des zones arborées 28
I.C.3 - Préparation des données pour le RGFor 30
I.C.4 - Saisie du milieu forestier 31
I.C.5 - Archivage 31
I.D - Besoins et principaux utilisateurs 31
I.D.1 - Un outil d'aide aux politiques environnementales,
d'aménagement et de gestion 32
I.D.2 - Utilisateurs 33
I.D.3 - Utilisations internes à l'IGN 34
I.D.4 - Demandes des utilisateurs sur le temps 35
I.E - Évolutions de la forêt dans le temps 35
I.E.1 - Tendances générales 36
I.E.2 - Événements 38
I.E.3 - Prospective 39
I.E.4 - Fausses évolutions 39
9
I.F - Conclusion 39
CHAPITRE II - État de l'art : le temps dans les SIG 41
II.A - Définir le temps 41
II.A.1 - Temps et espace : union et différence 41
II.A.2 - Une définition multiple du temps 43
II.A.3 - Temps géographique 44
II.A.4 - Temps géomatique 46
II.B - Notions de modélisation des données
temporelles 48
II.B.1 - Formalisme : modèle, entité, objet,
relation, cardinalité 48
II.B.2 - Sémantique temporelle : granularité,
intervalle, événement, changement 49
II.B.3 - Typologie du temps : transaction et validité
52
II.C - Approche quantitative du temps 53
II.C.1 - Modèles de base de données en fonction du
temps 53
II.C.2 - Modèles de base de données en fonction de
la mise à jour 54
II.D - Approche qualitative du temps : modèles de base de
données spatio-temporelle 57
II.D.1 - Capacités qualitatives des modèles de
mises à jour 57
II.D.2 - L'espace fixe 58
II.D.3 - Le paradigme identitaire, ou modèle
orienté-objet 60
II.D.4 - Modèle orienté-objet avec
modélisation des événements 61
II.E - Illustration des différents modèles de base
de données spatio-temporelle à l'aide d'un
exemple de synthèse 63
II.E.1 - Archivage 64
II.E.2 - Versionnement par ligne 65
II.E.3 - Journalisation 66
II.E.4 - PPDC spatial vectoriel 67
II.E.5 - PPDC spatial matriciel 68
II.E.6 - Orienté objet 69
II.E.7 - Orienté objet et modélisation des
événements 70
II.F - Conclusion 71
CHAPITRE III - Analyse de l'existant 73
III.A - BdOCS CIGAL 73
III.A.1 - Présentation 73
III.A.2 - Contenu 74
III.A.3 - Mise à jour 74
10
III.A.4 - Avantages et inconvénients du modèle
74
III.B - MOS IAU IDF 75
III.B.1 - Présentation 75
III.B.2 - Contenu 75
III.B.3 - Mise à jour 76
III.B.4 - Avantages et inconvénients du modèle
79
III.C - BD Uni IGN 80
III.C.1 - Présentation 80
III.C.2 - Contenu 81
III.C.3 - Mise à jour 82
III.C.4 - Avantages et inconvénients du modèle
86
III.D - Normes concernant les données d'occupation des
sols et l'intégration du temps 88
III.D.1 - INSPIRE 88
III.D.2 - Norme ISO 8601 91
III.D.3 - Pratiques préconisées par Esri 91
III.D.4 - Outils temporels d'ArcGis 92
III.E - Conclusion 92
CHAPITRE IV - Préconisations 93
IV.A - Adaptabilité des modèles existants au RGFor
93
IV.A.1 - BdOCS : l'archivage 93
IV.A.2 - MOS : le PPDC spatial vectoriel 93
IV.A.3 - BDUni : Orienté-objet avec modélisation
d'événements 94
IV.A.4 - Choix du modèle orienté-objet avec
événements 95
IV.A.5 - Test du modèle 96
IV.B - Modèle conceptuel 97
IV.B.1 - Schéma conceptuel 97
IV.B.2 - Définition des entités
géographiques 97
IV.B.3 - Définition des événements 98
IV.C - Modèle logique 99
IV.C.1 - Tables 99
IV.C.2 - Relations 102
IV.C.3 - Versionnement 102
IV.C.4 - Règles d'identité 102
IV.C.5 - Règles d'événements 103
11
IV.C.6 - Règles topologiques 104
IV.D - Test des traitements : méthodologie de la
création du fichier « test_rgfor65.gdb » 105
IV.D.1 - Contenu du dossier « test_histoRGFOR_OCS »
105
IV.D.2 - Table des actualités : classe d'entités
« RGFOR65_test », classe d'entités
« AVANT2010 » et « APRES2010 » 106
IV.D.3 - Table d'historique : classe d'entités «
RGOFOR65H_test » 107
IV.D.4 - Table des événements : table «
evenements », 108
IV.D.5 - Table des réconciliations : table «
reconciliations » 108
IV.D.6 - Tables extraites par date de mise à jour : classe
d'entités et topologies « ext2006 »,
« ext2010 » 108
IV.D.7 - Table des évolutions : classe d'entités
« matrice_eve » 108
IV.D.8 - Relations 109
IV.E - Exemples de requêtes, capacités de la base
110
V - Conclusion 112
Bibliographie 114
Annexes 118
12
13
Table des figures
Figure 1 : Structure du mémoire d'après un
schéma de construction d'une base de données 20
Figure 2 : Extrait de la BD Forêt® version 2,
centré sur Baud dans le département du Morbihan. 23
Figure 3 : Exemple de coupe rase et de peupleraie. 26
Figure 4 : Exemple d'images IRC et en couleur naturelle
extraites de la BD Ortho 2008. 27
Figure 5 : Segmentation de niveau 1 à gauche, de niveau
3 à droite. 28
Figure 6 : Exemple de saisie d'un linéaire. 29
Figure 7 : Résultat de la première
photo-interprétation. 30
Figure 8 : Résultat du lissage, à l'aide de
generalisation.exe. 30
Figure 9 : Résultat de la vectorisation, à l'aide
de contour.exe et découpage selon les réseaux. 31
Figure 10 : Taux d'accroissement annuel moyen de superficie
forestière de 1981 à 2009. 36
Figure 11 : Exemple d'évolution, au sud de la commune de
Solférino dans les Landes. 38
Figure 12 : Représentation du temps comme une dimension
géométrique à l'aide d'un tesseract, ou
hypercube. 42
Figure 13 : Définition du temps selon deux axes :
absolu/relatif et discret/continu. 44
Figure 14 : « Carte figurative des pertes successives en
hommes de l'armée française dans la
campagne de Russie 1812-1813 », Minard. 45
Figure 15 : Parcours spatio-temporels de femmes
afro-américaines à Portland en 1994-1995. 45
Figure 16 : Carte animée de la population mondiale de
1960 à 2011. 46
Figure 17 : Schéma de la modélisation 48
Figure 18 : Illustration des principaux concepts de
modélisation temporelle. 49
Figure 19 : Différents niveaux de résolution
temporelle et spatiale. 50
Figure 20 : Exemple probable d'évolution de l'occupation
des sols à la carrière de granulats de
Guernes (78). 77
Figure 21 : Exemple de saisie d'une correction de limite (a) et
d'un changement réel (b). 78
Figure 22 : Schéma d'une base de données 82
Figure 23 : Exemple d'une mise à jour du réseau
routier à l'aide d'une zone de réconciliation 83
Figure 24 : Schéma conceptuel entité-relation de
l'historisation dans la BDUni 84
Figure 25 : Schéma de structure logique de
l'historisation dans la BDUni 85
Figure 26 : Cas d'une mise à jour illustrant deux
résultats différents en fonction de la saisie 87
Figure 27 : Le temps dans INSPIRE 91
Figure 28 : Outil Time slider d'ArcGis version 10
92
Figure 29 : Intégration du temps réel et maintien
de la cohérence des données spatiales 94
Figure 30 : Schéma conceptuel du modèle
proposé. 97
Figure 31 : Relations et cardinalités entre les tables
102
Figure 32 : Contenu du fichier de géodatabase
affiché dans ArcCatalog 105
Index des tableaux
Tableau 1 : Matrice d'évolution de l'occupation des sols
entre 2000 et 2006 en ha, niveau 1 de la
nomenclature CLC 37
Tableau 2 : Tableau de synthèse de la définition
du temps selon différents penseurs 43
Tableau 3 : Topologie temporelle selon l'algèbre d'Allen
51
Tableau 4 : Événements de vie et territoriaux.
51
Tableau 5 : Événements de vie et
événements territoriaux 63
Tableau 6 : Typologie des événements 98
14
15
Index des acronymes
BDUni : Base de Données Unifiée
CarHab : Cartographie des Habitats
CERTU : Centre d'Études sur les Réseaux, les
Transports, l'Urbanisme et les constructions publiques
CIGAL : Coopération pour l'Information
Géographique en Alsace
CLC : Corine Land Cover
CMPFE : Conférence Ministérielle pour la
Protection des Forêts en Europe
CNUED : Conférence des Nations Unies sur
l'Environnement et le Développement
COGIT : Conception Objet et Généralisation de
l'Information Topographique
CRPF : Centre Régionaux de la Propriété
Forestière
CRPF : Centres Régionaux de la Propriété
Forestière
DDT : Direction Départementale des Territoires
DGALN : Direction Générale de
l'Aménagement, du Logement et de la Nature
DRAAF : Direction Régionale de l'Alimentation, de
l'Agriculture et de la Forêt
HELM : Harmonised European Land Monitoring (gestion
territoriale européenne harmonisée)
IFN : Inventaire Forestier National
IGN : Institut national de l'information géographique
et forestière (anciennement Institut Géographique
National)
INRA : Institut National de Recherche Agronomique
INSPIRE : Infrastructure for Spatial Information in the
European Community (infrastructure pour l'information
spatiale dans la Communauté européenne)
IRC : Infra-Rouge Couleur
IRIS : Îlots Regroupés pour l'Information
Statistique
IRSTEA : Institut national de Recherche en Sciences et
Technologies pour l'Environnement et l'Agriculture
MATIS : Méthodes d'Analyses et de Traitement d'Images
pour la Stéréo-restitution
MOS : Mode d'Occupation du Sol
OCS GE : Occupation du Sol à Grande Échelle
OCSOL PACA : Occupation du Sol Provence Alpes Côtes
d'Azur
ONF : Office National des Forêts
PLU : Plan Local d'Urbanisme
PSG : Plan Simple de Gestion
PVA : Prise de Vue Aérienne
RGE : Référentiel à Grande
Échelle
RGFor : Référentiel Géographique
Forestier
SBV : Service des Bases Vecteurs
SCoT : Schéma de Cohérence Territorial
SGBD : Système de Gestion des Bases de
Données
SIF : Service de l'Inventaire Forestier
SIG : Système d'Information Géographique
SIGALE : Système d'Information Géographique et
d'Analyse de L'Environnement
SIGS : Service Informations Géographiques et
Statistiques
SOeS : Service de l'Observation et des Statistiques
SQL : Standard Query Language (langage standard de
requête)
SRGS : Schémas Régionaux de Gestion Sylvicole
16
17
Introduction
Contexte
L'information géographique connaît un fort
développement depuis les dernières décennies.
L'avènement d'une nouvelle société à «
l'ère de l'information » (Castells, 2001), grâce aux
progrès des technologies de l'information et de la communication, et la
prise de conscience générale des enjeux environnementaux (Gayte
et al., 1997) expliquent en grande partie ce développement.
L'accroissement d'un besoin politique et gestionnaire s'inscrivant dans le
cadre du développement durable s'est traduit concrètement en
outils et en informations relevant de la géomatique1.
Parmi ces outils de géomatique appliquée
à l'environnement, les bases de données d'occupation du sol
apparaissent primordiales. Elles fournissent des informations utiles à
l'aide à la décision et à la concertation en politique
d'aménagement du territoire, de prévention des risques naturels
et technologiques, de mesure d'impacts des activités humaines sur
l'environnement, de gestion durable des ressources naturelles, etc.
De nombreuses bases de données d'occupation du sol
existent actuellement, entres autres : CLC (Corine Land Cover), la plus
utilisée et couvrant l'Europe entière, et des bases
régionales telles que le MOS (Mode d'Occupation du Sol,
Île-de-France), CIGAL (Coopération pour l'Information
Géographique en Alsace), SIGALE (Système d'Information
Géographique et d'Analyse de L'Environnement, Nord-Pas-de-Calais), ou
encore Ocsol PACA (Occupation du sol en Provence-Alpes-Côte-D'azur).
L'échelle moyenne de CLC limite toutefois ses applications par sa trop
grande généralisation. Les bases régionales, quant
à elles, ne permettent pas les comparaisons entre des espaces
éloignés. Elles ne couvrent pas la France entière.
Face à ces constats, un point important émerge
alors : la nécessité de produire une base de données
d'occupation du sol à grande échelle de l'ensemble du territoire
national pour permettre un suivi plus précis et l'analyse au-delà
des frontières régionales. Au niveau européen, c'est ce
que la directive INSPIRE (Infrastructure for Spatial Information in the
European Community2) (Parlement et Conseil européens,
2007) propose d'encadrer à l'aide d'un socle de nomenclature unique dans
le but d'harmoniser les bases de données géographiques, notamment
à travers l'HELM (Harmonised European Land
Monitoring3).
C'est dans ce contexte que l'État a commandé
à l'IGN (Institut national de l'information géographique et
forestière4) la « réalisation d'un thème
occupation du sol à grande échelle, par intégration des
différents thèmes en partenariat » (IGN, 2010). Cette
commande a donné lieu à la mise en place à l'IGN du projet
OCS GE (Occupation du Sol à Grande Échelle) ayant pour objectif
la production d'une base de données d'information géographique
d'occupation du sol sur l'ensemble du territoire national d'une
précision compatible avec d'autres produits de l'IGN, comme le RGE
(Référentiel à Grande Échelle) dont elle deviendra
une des composantes, et la directive INSPIRE, avec une nomenclature nationale
approuvée par les utilisateurs.
1 « The expansion of information technologies occured at
about the same time as political and scientific interest in global
environmental change intensified » (Balstad Miller, 1996).
2 Infrastructure pour l'information spatiale dans la
Communauté européenne.
3 Gestion territoriale européenne
harmonisée.
4 Anciennement : Institut Géographique
National.
18
Cette base de données doit permettre de répondre
aux demandes des utilisateurs de mesures d'évolution de la tâche
urbaine, de consommation des espaces agricoles (De Blomac, 2012), et de
cartographie de la trame verte et bleue (IGN, 2010), liées aux nouvelles
exigences législatives concernant l'aménagement et
l'environnement5. La production de certains thèmes est
déjà lancée, dont celui d'un référentiel
géographique forestier, le RGFor.
Demande de la structure d'accueil
Le stage réalisé à l'IGN s'inscrit dans
le projet de l'OCS GE et la production du RGFor. Intégré à
l'équipe du projet, constituée de trois personnes, dont le pilote
projet Thierry Touzet qui dirigea ce stage, il a été
demandé d'effectuer un travail de recherche sur un thème
précis : la question du temps dans les bases de données
géographiques.
Il s'agissait d'étudier les processus d'historisation
d'une base de données d'occupation du sol afin de proposer des solutions
compatibles avec les spécificités du RGFor. Ce travail devait
être fondé notamment sur la description du processus interne
à l'IGN d'historisation de la base géographique
centralisée, la BDUni (Base de Données Unifiée). À
partir des méthodes déjà implémentées dans
cette base, il a été demandé d'analyser si celles-ci
étaient adaptées à une base d'occupation du sol. Ce
travail a donné lieu à la rédaction de ce mémoire
et d'un rapport décrivant le processus d'historisation de la BDUni.
La raison de cette demande tient au fait que la production du
RGFor doit être terminée d'ici 2015. L'élaboration du
processus de mise à jour est donc désormais nécessaire
pour les prochaines versions. Par ailleurs, historiquement, la
problématique de la mise à jour d'une base vecteur de
données surfaciques est nouvelle à l'IGN. L'évolution de
la technique apportant des images plus précises entre chaque campagne de
collecte, la gestion de l'historique n'avait jusque-là pas de sens. Le
RGFor actuel atteignant la grande échelle, avec une résolution
métrique, il est acquis que ce référentiel ne devrait plus
changer pour des raisons de support image. La mise à jour des
données au sein d'une même base de ce type étant
désormais possible, elle doit être élucidée.
L'objet du stage demande d'approfondir cette question. Il
s'agit de réfléchir à la mise à jour des bases de
données d'occupation du sol pour la prise en compte de la dimension
temporelle des données, cette dimension étant indispensable au
suivi des évolutions d'occupation du sol. En effet, la connaissance d'un
territoire passe par sa description à un instant donné mais
l'essentiel est d'observer et de mesurer son évolution. Intégrer
la dimension temporelle aux données signifie donc qu'il faudra proposer
une solution, sous la forme d'un modèle spécifique de base de
données capable de répondre aux besoins temporels : dater et
suivre les données dans le temps. Il doit être possible de
consulter la base à une date choisie, d'évaluer et de suivre les
évolutions dans le temps, montrant les dynamiques à l'oeuvre,
afin de répondre aux attentes des utilisateurs.
Enfin, ce modèle doit permettre de tracer les
corrections géométriques (correction de lisière),
thématiques ou sémantiques (changement de nomenclature pour un
objet), et de distinguer les corrections strictes des évolutions
réelles, afin de produire une base de données améliorant
le suivi des espaces forestiers.
5 Loi Grenelle II ; code de l'urbanisme relatif aux
PLU (Plan Local d'Urbanisme), aux SCoT (SChéma de Cohérence
Territorial).
19
Cadre du sujet
Le temps dans les Systèmes d'Information
Géographique (SIG) est une question étudiée depuis les
années 80. Les auteurs ayant écrit sur le sujet se sont
attachés à décrire des modèles de bases de
données spatio-temporelles. La première étude approfondie
sur le sujet fut publiée au début des années 90 (Langran,
1992), puis d'autres suivirent (Peuquet, 2002 ; Ott et Swiaczny, 2001). C'est
toutefois toujours un sujet de recherche d'actualité, ces modèles
ne pouvant être mis en place techniquement que depuis peu et posant
encore des problèmes techniques et conceptuels. La gestion de la
temporalité dans les SIG manque en effet encore d'outils ; c'est une
préoccupation relativement nouvelle des concepteurs de bases de
données, ceux-ci s'étant d'abord concentrés sur les
problèmes de collecte d'information pour la constitution des bases
(Bordin, 2002, p. 90).
Le projet OCS GE a lui-même généré
des travaux de recherche. Sa phase de réflexion, longue du fait de la
nouveauté des problématiques traitées6, est
toujours en cours. Depuis le lancement du projet, l'IGN a participé avec
le CERTU (Centre d'Études sur les Réseaux, les Transports,
l'Urbanisme et les constructions publiques) et DGALN (Direction
Générale de l'Aménagement, du Logement et de la Nature) au
groupe de travail pour la production d'une nomenclature nationale. Un
état de l'art des productions d'autres pays comme l'Espagne, et
l'Autriche, et sur CLC a été réalisé. Une
thèse au laboratoire COGIT de l'ENSG a été
réalisée sur le suivi des phénomènes
géographiques (Bordin, 2006). Une thèse au laboratoire MATIS de
l'IGN sur l'utilisation de différents capteurs pour la mise à
jour a été lancée, de même que des tests sur
l'identification automatique de la végétation en milieu urbain
(De Blomac, 2012).
Ce mémoire ne propose pas de nouveaux
éléments dans les recherches sur l'intégration du temps
dans les SIG. Il reprend leurs modèles afin de participer à la
réflexion autour du projet OCS GE dans le cadre plus restreint du RGFor.
Il comportera donc également une analyse plus spécifique sur les
données forestières et le suivi des espaces forestiers (Felten,
1997 ; Andrault, 1997).
Problématique
Le sujet de ce mémoire est en premier lieu une
recherche en vue de résultats : fondée sur l'état de l'art
et l'analyse de l'existant, elle doit aboutir à des propositions. Ces
propositions décriront un processus, c'est-à-dire un
modèle, une méthodologie d'historisation. Nous définissons
l'historisation comme l'intégration de la dimension temporelle aux
données. Pour pouvoir faire ces propositions, nous devrons
décrire les aspects techniques, et analyser les aspects
thématiques, propre aux bases de données d'occupation du sol :
bases composées d'objets surfaciques complexes représentant des
entités géographiques. Pour être appliqués au RGFor,
ces aspects devront être approfondis pour la forêt en France, sa
définition, sa composition, sa gestion, son évolution.
Pour répondre à cette demande, il faudra donc
nous interroger sur les concepts de temps, d'objet, de suivi et
d'évolution ; des procédés techniques tels que la mise
à jour ; et les modèles d'intégration du temps dans les
SIG.
6 L'OCS GE est un projet original, de par son
échelle, sa production à partir de sources multiples aux
spécifications de productions différentes (collectes,
télédétection) en partenariat avec les utilisateurs, et sa
nomenclature fondée sur INSPIRE qui distingue quatre aspects de
l'occupation du sol : couverture, fonction/usages, morphologie et
caractéristiques.
20
Ces interrogations peuvent être résumées par
deux questions :
? Comment modéliser une base de données
permettant de visualiser, d'interroger, un instant T, et de répondre aux
requêtes spatiales « quoi, comment, où ?» et à la
requête temporelle « quand ? » ?
? Et plus spécifiquement : selon quel modèle
modifier le RGFor afin de pouvoir intégrer la dimension temporelle des
données géographiques lors de la mise à jour ?
Ce questionnement doit résoudre la problématique
de l'observation d'un territoire géographique à un instant
donné dans le passé ou dans le futur. L'enjeu est le suivi
environnemental. Pour l'IGN, c'est un défi technique qui a pour but de
satisfaire la demande des utilisateurs (collectivités,
ministères, services de l'État, ...). C'est également un
enjeu conceptuel, lié à l'histoire de l'institut et à sa
tradition cartographique. La prise en compte de la dimension temporelle dans la
base de données implique le détachement du modèle
cartographique statique vers un modèle de SIG
cinématique/dynamique libéré du format papier. Enfin, il
s'agit également de proposer une solution fondée sur le
modèle de la BDUni afin de fournir une description absente de la
documentation de l'IGN d'une part, et, d'autre part, de promouvoir le
développement d'une solution interne.
Afin de répondre à ces questions, nous
décrirons, dans un premier temps, le RGFor (Chapitre I), ses
caractéristiques techniques et ses besoins spécifiques quant
à l'intégration de la dimension temporelle. Puis, nous
étudierons les réflexions sur la dimension temporelle, les
processus de mise à jour des bases de données
géographiques numériques ainsi que sur les méthodes
conceptuelles et techniques permettant la prise en compte de la dimension
temporelle dans les SIG (Chapitre II). Suite à cela, nous
réaliserons une analyse des processus d'historisation des bases de
données d'occupation du sol, d'abord internes à l'IGN (BDUni)
puis externes (CLC, bases régionales), et des outils de gestion de la
temporalité existants (Chapitre III). Enfin, à partir des
spécificités du RGFor, de la théorie et de la pratique,
nous proposerons des solutions concrètes, notamment afin d'adapter le
processus interne pour l'historisation et la gestion de la mise à jour
du RGFor (Chapitre IV).
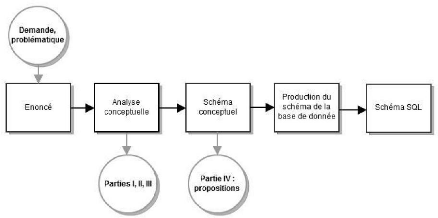
Figure 1 : Structure du mémoire d'après un
schéma de construction d'une base de données (Source : Hainaut,
2011)
21
Méthodologie, moyens
Le mémoire a été rédigé
à partir des sources documentaires internes, complétées
par des recherches bibliographiques et des entretiens avec les personnes
ressources.
Notre sujet relevant de l'évolution d'une base de
données, nous avons repris dans notre raisonnement le schéma
classique de méthode de construction de base de données
illustré par la Figure 1 (les cercles représentent les
étapes du mémoire, les rectangles celles de la mise en place
d'une base de données). Plusieurs terminologies sont employées
pour décrire le contenu d'une base de données : fichiers,
enregistrements, champs ; relations, n-uplets, attributs ; tables,
lignes, colonnes. Par souci de cohérence et de simplicité, nous
n'emploierons que la troisième terminologie, celle associée au
langage SQL (Date, 2004, p. 6).
Un bureau équipé d'un ordinateur avec
accès à l'Internet et à la documentation de l'IGN a
été mis à disposition au cours du stage. Les logiciels
PGAdmin, OpenJump, GeoConcept, et ArcGis ont été installés
sur ce poste. Un jeu de données de la dernière version du RGFor
et des ortho-photographies (de 2006 et de 2010) du département des
Hautes-Pyrénées furent également mis à
disposition.
Notre maître de stage fut la personne de
référence sur le RGFor. Les informations sur la BDUni ont
été recueillies lors d'entretiens réalisés avec
Laurent Breton, Frank Fuchs, Bruno Bordin, Clothilde Mohsen, Fabien Gruselle et
Mickaël Michaud du service des bases vecteurs, du service
développement et de la MAJEC à l'IGN. Sophie Foulard, responsable
du MOS à l'IAU IDF, et Marie Christine Schott, chef du Service
Informations Géographiques et Statistiques (SIGS) à la Direction
de l'Environnement et de l'Aménagement de la région Alsace ont
été interrogées sur le processus d'historisation des bases
régionales d'occupation des sols. Nous avons également
interrogé, sur la modélisation du temps dans les bases de
données, Ana-Maria Olteanu Raimond du laboratoire COGIT de l'IGN et
Christine Plumejeaud, ayant travaillé dans le même laboratoire.
Le processus d'historisation de la BDUni a fait l'objet de la
rédaction d'un rapport détaillé joint en annexe du
mémoire.
Le stage s'est déroulé de février
à mai 2013. Il fut prolongé d'un mois en août. L'objectif
de ce mois de stage supplémentaire était d'évaluer
concrètement les capacités et la faisabilité des
propositions énoncées dans la première version du
mémoire soutenue en juin, en montrant les résultats possibles et
en identifiant les besoins d'automatisation des traitements.
22
23
CHAPITRE I - Caractéristiques techniques et
besoins spécifiques du RGFor quant à l'intégration de la
dimension temporelle
L'objectif de ce chapitre est de définir le
référentiel géographique forestier. Nous
présenterons le RGFor, son contenu, les besoins de ses utilisateurs et
les évolutions de son thème au cours du temps.
I.A - Présentation
Le RGFor est la base de production des données
d'occupation des sols qui sert à constituer la cartographie
forestière de la BD Forêt® version 2, distribuée
depuis 20077, et la couche végétation de la BD
Topo®. Il est issu de la collaboration entre l'IGN et l'IFN
(Inventaire Forestier National) qui étaient chargés de sa
production en partenariat jusqu'à la fusion entre les deux
établissements au premier janvier 2012. Depuis cette fusion, une
nouvelle section environnement est en train de se mettre en place au Service
des Bases Vecteurs, chargé du RGFor, de la couche
végétation, et du projet OCS GE.
L'IFN était un établissement public,
chargé par le ministère de l'Agriculture et de la Pêche
d'assurer la permanence de l'évaluation des ressources
forestières métropolitaines. De 1986 à 2006, il a
assuré le fonctionnement d'un SIG permettant la réalisation des
cartes forestières départementales de la BD
Forêt® version 1. Cette première version
possédait une nomenclature d'une précision variant de la
quinzaine à la soixantaine de postes entre les départements,
selon leur diversité forestière.
Depuis 2006, l'information produite a fortement
évolué. La BD Forêt® version 2 (Figure 2) a
été créée : sa précision est passée
de 2,25 ha à 0,5 ha, avec une nomenclature nationale unique plus
détaillée, un cycle de production de 10 ans, et une
méthode de mise à jour qui doit évoluer.
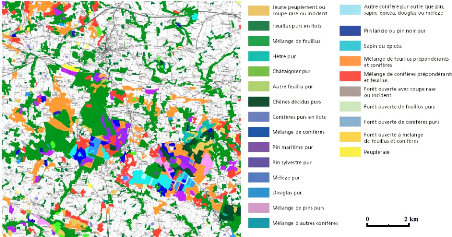
Figure 2 : Extrait de la BD Forêt® version
2, centré sur Baud dans le département du Morbihan (Source :
Plaquette de présentation BD Forêt®, IGN).
En version 1, la mise à jour consistait à
relancer entièrement le processus de production, sans réutiliser
les données précédentes. Cette méthodologie
était due à « l'évolution des
référentiels
7 « BD Forêt® version 2 »,
http://inventaire-forestier.ign.fr/spip/spip.php?rubrique53,
consulté le 29/04/2013.
24
numériques disponibles à un instant
donné, des techniques de production et de stockage de l'information,
ainsi qu'en raison de l'évolution des nomenclatures
utilisées8 ». Elle était consommatrice de temps
de production et d'espace de stockage, puisque la base devait être
entièrement recréée à chaque mise à jour.
La version 2 ne connait plus ces problèmes. Les
ortho-photographies utilisées comme référentiels
numériques pour la production de la cartographie ont atteint un seuil de
précision permettant d'affirmer qu'une précision plus importante
ne sera plus utile à la photo-interprétation. De même les
outils de production et de stockage, et la nomenclature ne doivent plus changer
(Source : entretien avec T. Touzet).
Il est donc désormais techniquement possible
d'intégrer la mise à jour des données au sein d'une base
de données unique, et donc d'élaborer un nouveau modèle de
mise à jour de façon différentielle.
I.B - Contenu
Le RGFor comprend les « formations
végétales forestières et des terrains naturels et
semi-naturels que sont les landes et la formation herbacées » (IGN,
2013, p. 4) sur l'ensemble de la France métropolitaine et permet de
produire la couche végétation de la BD Uni et la cartographie
forestière de la BD Forêt (voir Annexes).
La couche végétation est intégrée
à la chaîne de production du RGFor depuis la mise en place du
partenariat entre l'IFN et l'IGN (Guinaudeau, 2006). Les deux bases devraient
fusionner à terme (les landes sont déjà communes aux deux
bases). Elles se différencient par leur contenu : la couche
végétation correspond au milieu arboré ; le RGFor au
milieu forestier. Il constitue un sous ensemble de la couche
végétation et dont la nomenclature est plus précise.
La cartographie forestière repose sur la
définition de la forêt (FAO, 2005, p. 169) qui permet de
distinguer le milieu forestier du milieu arboré. La forêt est tout
d'abord définie par une couverture en termes de seuil :
- Surface > ou = à 0,5 ha. Moins, il s'agit d'un
bosquet (entre 500 et 5000m2).
- Largeur > ou = à 20 m. Moins, c'est une haie, un
alignement ou cordon boisé.
- Couvert d'arbres > ou = à 10% (par projection des
houppiers au sol). Moins, ce sont des arbres épars, une lande, ou une
formation herbacée.
- Capacité des arbres à atteindre 5 m de haut.
Moins, il s'agit de la lande.
À cela s'ajoute une exclusion en fonction de l'usage :
- Pas d'utilisation urbaine, récréative, agricole
;
- Uniquement des forêts de production. Sont exclus, par
exemple, les vergers, parcs, et espaces verts.
8
http://inventaire-forestier.ign.fr/carto/carto/afficherDescription
25
La nomenclature comprend 32 postes (IGN, 2012-A, p. 14).
Chaque poste correspond à un peuplement unique, c'est-à-dire
à un type de couverture homogène distinct des autres postes :
· Forêt fermée
o 1 - Jeune peuplement ou coupe rase ou incident
o Feuillus purs
· 2 - Feuillus purs en îlots (entre 0.5 et 2 ha)
· 3 - Chênes décidus purs
· 4 - Chênes sempervirents purs
· 5 - Hêtre pur
· 6 - Châtaignier pur
· 7 - Robinier pur
· 8 - Autre feuillu pur
· 9 - Mélange de feuillus
o Conifères purs
· 10 - Conifères purs en îlots (entre 0.5 et 2
ha)
· 11 - Pin maritime pur
· 12 - Pin sylvestre pur
· 13 - Pin laricio ou pin noir pur
· 14 - Pin d'Alep pur
· 15 - Pin à crochets ou pin cembro pur
· 16 - Autre pin pur
· 17 - Mélange de pins purs
· 18 - Sapin ou épicéa pur
· 19 - Mélèze pur
· 20 - Douglas pur
· 21 - Autre conifère pur autre que pin
· 22 - Mélange d'autres conifères
· 23 - Mélange de conifères
· 24 - Mélange de feuillus
prépondérants et conifères
· 25 - Mélange de conifères
prépondérants et feuillus
o Forêt ouverte
· 26 - Coupe rase ou incident
· 27 - Forêt ouverte de feuillus purs
· 28 - Forêt ouverte de conifères purs
· 29 - Forêt ouverte à mélange de
feuillus et conifères
· 30 - Peupleraie
· Lande
o 31 - Lande ligneuse
o 32 - Formation herbacée
La nomenclature est emboitée. Elle permet d'approfondir
la précision de la classification selon un arbre logique en quatre
niveaux (IGN, 2013, p. 14 et 42) :
· Niveau 1 : Distinction ente la
forêt et les landes, ainsi que les autres terrains arborés hors
forêt (vergers, haies, cordons boisés) dont la surface est > ou
= à 50 ha.
· Niveau 2 : Distinctions des modes
d'occupation forestiers des sols selon la densité de recouvrement des
arbres. C'est aussi le niveau de la peupleraie.
· Niveau 3 : Distinction des peuplements
par composition majoritaire (feuillus, conifères, mixte) et division des
landes en lande ligneuse et herbacée selon le recouvrement de ligneux
bas.
· Niveau 4 : Distinction selon les
essences.
26
La nomenclature en arbre logique est un socle de
référence qui permet à l'utilisateur, s'il le souhaite,
d'aller plus loin en ajoutant de nouveaux postes. L'IGN ne s'engage pas
à être plus précis dans sa production, sauf dans le cas
d'une commande spécifique. Une discrimination plus précise des
essences entrainerait de coûts supplémentaires de production
générés par les contrôles nécessaires sur le
terrain et les moyens humains additionnels à mettre en oeuvre pour la
photo-interprétation si les mêmes délais de production sont
maintenus.
La peupleraie est distinguée dès le niveau 2
« du fait de la sylviculture spécifique qui lui est
appliquée (plantation à densité définitive et cycle
court) ». C'est par ailleurs une des principales essences
exploitées en France, seconde en superficie (environ 190 000 ha)
après le chêne pédonculé, dont les plantations
géométriques sont reconnaissables (Figure 3).
Les coupes rases et les incidents (maladies, feux...) en
forêts ouvertes et en forêts fermées sont
intégrés à la nomenclature (Figure 3). Ces
événements sont importants pour la gestion de la forêt et
l'analyse des évolutions. Les jeunes reboisements sont associés
à ce type d'événements dans la forêt fermée.
En effet, il est difficile de discriminer la composition majoritaire du
peuplement à ce stade de la plantation. Et, par ailleurs, on
considère a priori qu'un jeune reboisement appartient à
la forêt fermée, jamais en forêt ouverte, partant du
principe que le gestionnaire plantera toujours ainsi.

Figure 3 : Exemple de coupe rase et de peupleraie
(Source : données RGFor Hautes-Pyrénées).
I.C - Production
La production représente un potentiel de travail pour
25 photo-interprètes. La nomenclature est prévue en fonction des
capacités de l'équipe et du rythme de la production.
La production est en cours, au rythme de 10
départements par an. La couverture de l'ensemble du territoire doit
prendre 10 ans. Les mises à jour seront effectuées tous les 3 ans
pour chaque département. Il est prévu de réaliser la mise
à jour de façon différentielle, c'est-à-dire en
fonction de la version précédente.
La cartographie forestière est produite à partir
de prises de vue aériennes ortho-rectifiées, ou
ortho-photographies. L'ortho-rectification consiste à corriger les
effets de déformations de la photographie numérique originale
causées par le relief et l'angle de la prise de vue afin de permettre la
projection plane de l'image. Ce sont des images dites IRC, ou infrarouge
couleur. Elles se distinguent des photographies aériennes
numériques classiques, dites « couleur naturelle », par le
fait d'utiliser des
27
mesures de valeur de luminance dans les longueurs d'ondes du
proche infrarouge, du rouge et du vert au lieu du rouge, du vert et du bleu
(Figure 4).

Figure 4 : Exemple d'images IRC et en couleur naturelle
extraites de la BD Ortho 2008 (Source : IGN, 2013-B).
L'avantage de l'infrarouge sur les longueurs d'ondes du
visible est qu'il permet de différencier plus facilement la
végétation des autres types d'occupation des sols et accroit
également le contraste entre les formations végétales.
Cette propriété tient à la signature spectrale
spécifique des végétaux vivants qui se caractérise
par une chute des valeurs de luminance dans le rouge et une augmentation
brutale dans le proche infrarouge causée par l'activité
chlorophyllienne. Il permet de distinguer les essences, notamment entre les
résineux et les feuillus (IGN, 2007-B, pp. 7-14).
La production repose sur une segmentation des images, puis sur
une classification par photo-interprétation. La chaîne de
production de la couche initiale se divise en cinq étapes :
- Préparation et segmentation des images,
préparation des chantiers
- Saisie des zones arborées : saisie de premier niveau
(zones arborées rurales, puis des espaces
verts urbains)
- Préparation des données pour le RGFor :
traitements morphologiques, vectorisation,
découpage des réseaux, extraction des haies.
- Saisie des essences forestières
- Archivage : validation et montée en base de la couche
végétation BDuni et RGFor
I.C.1 - Préparation des données
La première étape consiste à découper
les images d'un département, dont les contours ont été
découpés sous GeoConcept, en carré d'un
km de côté. À partir de là, le programme pyram.exe
analyse les valeurs des pixels puis la texture de l'image afin de produire une
segmentation. La segmentation sert à détecter et à tracer
l'extension non connue de la forêt pour constituer l'état initial
de la base.
Le programme pyram.exe fonctionne grâce à un
algorithme de segmentation multi-échelles allant jusqu'à six
niveaux d'échelles emboitées, de la plus petite à la plus
grande échelle. La plupart des algorithmes de segmentation fonctionne
simplement à l'aide d'un seuil de dissimilitude entre deux
régions adjacentes (Trias-Sanz, 2006, p. 13). Or ce type d'algorithme
pose un problème car le résultat, plus ou moins fin, varie en
fonction du seuil employé. On obtient une segmentation
détaillée avec un seuil faible de dissimilitude et l'inverse avec
un seuil élevé. Cela suppose de choisir
28
à l'avance le seuil pertinent en fonction de l'image
à segmenter. Il n'est alors pas possible de prendre en compte la notion
d'échelle qui implique que des informations pertinentes peuvent exister
à différents niveaux de segmentation (Trias-Sanz, 2006, p.
30).
Un algorithme de segmentation multi-échelles permet de
résoudre ces problèmes. Le programme pyram.exe est ainsi capable
de délimiter des régions homogènes à
différentes échelle d'analyse, et permet d'aller de la
distinction entre la forêt et les espaces ouverts jusqu'à la
délimitation des arbres isolés au sein des espaces ouverts
(Figure 5). Ce sera ensuite au moment de la saisie manuelle que le niveau de
précision pertinent sera sélectionné afin d'avoir un
tracé le plus précis possible.
Le découpage en dalles d'un km de côté
permet de traiter rapidement un nombre important d'images. Chaque dalle est
traitée séparément, ce qui accélère les
calculs. Si une erreur est détectée pour une dalle, le programme
passe automatiquement à la suivante. Avec cette méthode, un
département, qui correspond à environ 6000 images, est
segmenté en 30 heures. Si des dalles de 5 km de côté
étaient utilisées, le temps de calcul augmenterait de
façon exponentielle. Le découpage en dalle implique un
défaut de continuité, qui est pallié au cours des
étapes suivantes par les consignes de saisie et la vectorisation.

Figure 5 : Segmentation de niveau 1 à gauche,
de niveau 3 à droite (Source : IGN, « Processus de production de la
couche Végétation de la BD Uni », document de
travail).
Des parcelles sont découpées en fonction de leur
couleur et de leur texture par ensemble plus important (niveau 1) puis plus
détaillé (niveau 3) (Figure 5).
Le résultat du traitement est enregistré sous la
forme d'un fichier par niveau de segmentation et un fichier
supplémentaire contenant les informations sur l'arbre de segmentation
à partir du premier niveau. Enfin, le département est
découpé en secteur de travail réparti entre les
photo-interprètes pour l'étape de saisie.
I.C.2 - Saisie des zones arborées
C'est l'étape 1 de la photo-interprétation. Le
logiciel utilisé est seve.exe (système d'extraction de la
végétation). Il permet de sélectionner les
découpages par niveau de segmentation, pour être plus ou moins
précis, et de leur associer un thème afin de constituer
l'ensemble de la couche végétation
29
multi-thèmes. Cette saisie est divisée entre les
zones arborées rurales, assurées par les photo-interprètes
du RGFor, et les espaces verts urbains confié au SBV (Service des Bases
Vecteurs).
Malgré la segmentation multi-échelles, les
limites ne sont pas parfaites du fait du format raster utilisé et de la
segmentation automatique. C'est l'outil de segmentation qui détermine
les limites de lisières. Elles sont donc floues au moment de la saisie
car la segmentation distingue difficilement cette limite. La segmentation
s'appuie en effet sur les houppiers des arbres. Or les limites fondées
sur le houppier augmentent systématiquement la surface attribuée
à la végétation. Par ailleurs, il est parfois difficile de
distinguer le houppier de son ombre, les règles de saisie demandent
à ce que le photo-interprète aille du niveau le plus grossier au
plus fin pour délimiter au mieux des ensembles thématiquement
homogènes. Or il faut parfois inclure des ombres afin de garder une
certaine cohérence. La Figure 6 montre une première saisie (image
de gauche) intégrant des ombres mais permettant d'avoir une
continuité. La seconde saisie (image de droite) supprime les ombres et
la continuité. La première saisie sera
préférée, même si elle ajoute une fausse surface.

Figure 6 : Exemple de saisie d'un linéaire
(Source : IGN, 2013-C).
Enfin, cela prendrait trop de temps de corriger la
précision des limites en format vecteur. Il faut donc noter que la
constitution de la base à l'état 0 possède un
positionnement flou de la lisière, ce qui
posera sûrement un problème pour la mise à
jour.
Le photo-interprète a plusieurs outils à sa
disposition pour effectuer la saisie. Il doit élaborer une
stratégie et utiliser ces outils en fonction du massif forestier, du
contexte, du paysage qu'il observe. C'est ce qui assure une analyse de
meilleure qualité qu'un traitement entièrement automatique qui
n'est pas capable de tenir compte du contexte.
L'outil de base est une saisie manuelle par sélection. Les
outils supplémentaires sont :
? Une pré-saisie à partir de la couche de la
version 1 : tous les segments inclus dans la classification de la version
précédente du RGFor reprennent leur classification
précédente.
? La constitution d'une base d'apprentissage. Selon un
principe similaire aux classifications
supervisées pour le traitement
d'images satellites, on enregistre une classification dont on est sûr
puis l'outil calcule la valeur des pixels pour chaque thème issu de
cette classification de départ et classe les segments restants dans le
thème qui leur correspond le plus en fonction de la valeur des
pixels.
30
Pour cette étape, il faut en moyenne 6 semaines de
travail, pour deux photo-interprètes, par département. Le
résultat produit correspond à la couche végétation
de la BDUni, auquel il ne manque pour être complet que la distinction
entre feuillus et résineux réalisée à
l'étape 4, lors de la seconde photo-interprétation.
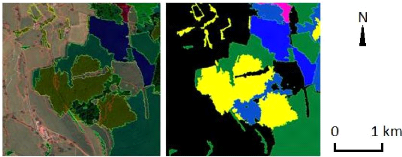
Figure 7 : Résultat de la première
photo-interprétation (Source : IGN, « Processus de production de la
couche Végétation de la BD Uni », document de
travail).
Le résultat (Figure 7) de la
photo-interprétation est contrôlé et enregistré dans
un nouveau fichier au format .tiff avec des masques de classification
codés numériquement en fonction de leur thème :
- 1 : la forêt fermée, les bosquets, les LHF
(ligneux hors forêt qui comprennent les haies,
alignements d'arbres, cordons boisés et arbres
épars),
- 2 : la forêt ouverte,
- 3 : les landes ligneuses,
- 4 : les landes herbacées,
- 5 : les vergers
I.C.3 - Préparation des données pour le
RGFor
Cette étape consiste, tout d'abord, à
améliorer les contours de la saisie avec un algorithme de lissage
(Figure 8) et à effectuer la transformation du format
raster au format vecteur (Figure 9).

Figure 8 : Résultat du lissage, à l'aide
de generalisation.exe (Source : IGN, « Processus de production de la
couche
Végétation de la BD Uni », document de
travail).
Puis, le découpage en dalles est supprimé et les
polygones voisins appartenant au même thème sont fusionnés
sous GeoConcept. Le logiciel Clarity est ensuite utilisé pour isoler et
classer automatiquement les haies et les bosquets. Les polygones sont
également découpés en fonction des
31
réseaux hydrographiques, routiers et ferrés pour
permettre la cohérence topologique entre les thèmes (Figure 9).
Enfin, des secteurs de saisie sont constitués pour la saisie du RGFor.
À la fin de cette étape, les fichiers sont au format
shape et au nombre de 30 par département.
Figure 9 : Résultat de la vectorisation, à
l'aide de contour.exe et découpage selon les réseaux (Source :
IGN, « Processus de production de la couche Végétation de la
BD Uni », document de travail).
I.C.4 - Saisie du milieu forestier
C'est la seconde étape de photo-interprétation,
à l'aide des outils CartoPrépa, CartoAdmin et CartoSaisie
développés à partir d'ArcGis Engine SDE à l'aide de
Microsoft Visual Studio. Les données sont enregistrées via ArcSDE
dans une base d'acquisition (BD Acquisition) sous PostGre SQL/PostGis.
CartoPrépa sert à découper les chantiers,
CartoAdmin sert d'outil de gestion et d'interface avec la base, et CartoSaisie
est utilisé pour la saisie. Le système est fondé sur la
synchronisation d'ArcSDE, fonctionnant comme un middleware, entre les
postes clients et la base de données sur un serveur. Le
photo-interprète travaille sur une zone qui reste bloquée tant
qu'elle est en chantier. Il découpe manuellement les polygones afin de
tracer les limites entre les peuplements qu'il classe en fonction de la
nomenclature, jusqu'au niveau des essences. Une fois terminée, la zone
est livrée dans la base d'acquisition en étant
synchronisée.
Les données sont contrôlées afin de
vérifier qu'elles correspondent bien aux spécifications (exemple
: aucune surface ne peut être inférieure à 0.5 ha ; les
bosquets ne peuvent pas être contigus avec une forêt...) et que les
règles de topologie sont bien respectées (pas de trou ni de
superposition). La topologie est enregistrée dans la base dès
l'étape de la base d'acquisition. Une tournée de
vérification sur le terrain est également effectuée. Un
premier contrôle a lieu par secteur, puis le contrôle final est
effectué après l'assemblage des données par
département.
I.C.5 - Archivage
La couche de végétation multi-thèmes est
créée, contrôlée, puis stockée dans la BDUni.
Le RGFor est archivé dans sa propre base de production.
I.D - Besoins et principaux utilisateurs
L'utilisation des données produites par le RGFor
relèvent d'enjeux réglementaires, économiques,
gestionnaires et écologiques. Il s'agit de pouvoir protéger,
aménager et exploiter les ressources forestières. En cela ces
données doivent satisfaire une demande officielle servant à la
connaissance
32
du territoire pour « répondre aux engagements de
l'État dans une politique volontariste de développement durable
» (Saffroy et Lambert, 2012). Nous allons maintenant détailler les
aspects réglementaires puis les besoins des utilisateurs.
I.D.1 - Un outil d'aide aux politiques environnementales,
d'aménagement et de gestion
La production du RGFor s'inscrit dans le cadre, très
général, du développement durable, de la lutte contre le
changement climatique, et, plus spécifiquement, de l'aménagement
du territoire en tant que composant de l'OCS GE et données de
référence pour les politiques forestières. Cette
production répond donc à la demande de nombreux utilisateurs qui
ont besoin de ces données par obligation légale.
Le développement durable et la lutte contre le
changement climatique furent d'abord définis lors de la
Conférence des Nations Unies sur l'Environnement et le
Développement (CNUED) de 1992 à Rio de Janeiro. La
Conférence Ministérielle pour la Protection des Forêts en
Europe (CMPFE), qui s'est tenue à Helsinki en 1993, a appliqué
aux forêts européennes ces enjeux pour définir la gestion
forestière durable selon six critères. L'IFN est chargé
depuis 1995 par l'État de l'évaluation de la forêt
française selon ces critères, mission que l'IGN a repris depuis
la fusion des deux établissements. La cartographie forestière
permet notamment d'évaluer le critère 1 « conservation et
amélioration appropriée des ressources forestières et de
leur contribution aux cycles mondiaux du carbone » et 4 « maintien,
conservation et amélioration appropriée de la diversité
biologique dans les écosystèmes forestiers »9.
Au niveau national, des engagements ont été pris
par les lois du Grenelle 1 et 2 afin de lutter contre la régression des
surfaces naturelles et agricoles, préserver et restaurer la
biodiversité, lutter contre le réchauffement climatique. Une des
mesures phares des Grenelles est la mise en place du schéma
régional de cohérence écologique et de la Trame verte et
bleue afin de protéger et de reconstituer des réservoirs de
biodiversité et des corridors écologiques pour les espèces
végétales et animales10. La cartographie des haies et
des cordons boisés est un élément permettant, par exemple,
de constituer la trame verte11.
Les engagements des Grenelles ainsi que la loi de
modernisation de l'agriculture et de la pêche de 2010 visent la
réduction de la consommation des espaces agricoles, naturels et
forestiers (Saffroy et al., 2012). Tous les huit ans en France, ce
sont 500 000 ha de terres agricoles qui disparaissent. Ce rythme doit
être diminué de 50% d'ici 2020 (Loi de modernisation de
l'agriculture de 2010 in De Blomac, 2012). A terme, l'objectif est une
réduction de la consommation des espaces naturels devant atteindre 0%
d'artificialisation supplémentaire d'ici 2025.
Les PLU et les SCoT du code de l'urbanisme traduisent
concrètement les obligations légales au niveau des
collectivités définies par les engagements du Grenelle en termes
de gestion de l'occupation des
9 L'If, numéro spécial
décembre 2011, « Les indicateurs de gestion durable des
forêts françaises métropolitaines ».
10 Source :
http://www.biodiversite2012.org/suivi-grenelle/engagements/engagement-3.html?d5779e40fd759177dbdc2266c
834a353=aed4dc70edb3c7426633dd7161. Consulté le 26/04/2013.
11 Source :
http://www.developpement-durable.gouv.fr/IMG/pdf/La_premiere_loi_du_Grenelle.pdf
;
http://www.developpement-durable.gouv.fr/IMG/pdf/Grenelle_Loi-2.pdf.
Consultés le 26/04/2013.
33
sols. A partir de 2017, les communes non couvertes par un SCoT
établissant les tendances de consommations des espaces naturels,
agricoles et forestiers sur 10 ans connaîtront des sanctions.
Enfin, la politique forestière doit prendre en compte
ces engagements dans les Schémas Régionaux de Gestion Sylvicole
(SRGS), rédigés par les Centres Régionaux de la
Propriété Forestière (CRPF). Les SRGS donnent les
orientations et les recommandations de gestion durable pour
l'établissement des Plans Simples de Gestion (PSG) sur 10 ans. Chaque
forêt privée de plus de 25 ha fait l'objet d'un Plan simple de
gestion validé par les autorités publiques et respectant le Code
forestier. Ce dernier a pour rôle d'assurer la
pérennité du patrimoine forestier français et la
préservation de la diversité et de la qualité des
écosystèmes et des paysages.
I.D.2 - Utilisateurs
Les utilisateurs se répartissent en deux domaines12
:
- Enjeux économiques et gestionnaires :
l'évaluation et l'exploitation des ressources forestières ;
- Enjeux écologiques et gestionnaires :
o L'aménagement du territoire ;
o la connaissance et la préservation de la
biodiversité, des milieux « naturels », de la qualité
et de la diversité de l'environnement et des paysages ;
o La prévention des risques naturels.
Les principaux utilisateurs correspondant à ces domaines
sont13 :
- La filière forestière :
o Services et établissements publics forestiers du
ministère de l'agriculture et de la pêche :
? DDT (Direction Départementale des Territoires) :
? DRAAF (Direction Régionale de l'Alimentation, de
l'Agriculture et de la Forêt) ;
? ONF (Office National des Forêts) ;
? CRPF (Centres Régionaux de la Propriété
Forestière)...
o Industriels, coopératives et exploitants de la
forêt privée ;
- Les services et établissements du ministère de
l'écologie :
o DREAL (Direction Régional de l'Environnement, de
l'Aménagement et du Logement) ;
o DDT (Directions Départementales des Territoires)...
- Les collectivités locales :
o Conseils généraux ;
o Conseils régionaux ;
o Communauté de communes ;
o Parcs Naturels Régionaux.
- Les bureaux d'études en environnement et
aménagement ;
- Le SDIS (Service Départemental des Incendies et des
Secours) ;
- Les organismes de recherche : IRSTEA (Institut National de
Recherche en Sciences et Technologies pour
l'Environnement et l'Agriculture), INRA (Institut National de
Recherche Agronomique)...
L'Office national des forêts (ONF) est chargé de
la gestion des forêts domaniales et les domaines des collectivités
locales. Les trois quarts des forêts appartiennent au domaine
privé est sont gérées par leurs propriétaires,
particuliers, syndicats, coopératives et forestiers, avec l'appui des
centres régionaux de la propriété forestière
(CRPF).
Les utilisateurs emploient ces données principalement
pour (IGN, 2011-B, p. 6) :
12 Source :
http://inventaire-forestier.ign.fr/carto/carto/afficherDescription.
Consulté le 26/04/2013.
13 Source :
http://inventaire-forestier.ign.fr/carto/carto/afficherDescription.
Consulté le 26/04/2013.
34
- des études et des évaluations,
- la cartographie,
- la gestion, les inventaires
- la communication
- des analyses spatiales
- des mesures de surfaces
- la gestion d'une base de données ou d'un système
d'information
Pour la filière forestière, couplée avec
inventaire statistique, la cartographie forestière est un outil
essentiel de délimitation des bassins d'approvisionnement et des zones
de prospection (IFN, 2008) mais aussi d'évaluation des
dégâts en forêt suite à une tempête.
Les linéaires (haies, cordons boisés), de
même que la connaissance des peuplements au sein des massifs sont
nécessaires à l'élaboration de la trame verte par les
collectivités locales. Certaines essences, comme le Douglas,
empêchent par exemple les migrations animales.
Les parcs naturels régionaux ont besoin de ces
données pour la rédaction de la charte forestière
constituant une vue globale de la forêt pour la politique
forestière prévue sur 10 à 20 ans.
Le SDIS utilise ces données, en complément
d'autres données comme l'humidité du sol, pour prévoir les
zones vulnérables aux incendies.
Ces données peuvent par ailleurs être
employées afin de :
- Suivre la consommation des surfaces agricoles et naturelles
par l'urbanisation via le
phénomène de l'étalement urbain.
- Observer les zones de déprise agricole.
- Étudier la biodiversité potentielle sur un
territoire donné.
- Gérer, aménager : préserver paysages
contre l'homogénéisation et la fragmentation
- Produire des données dérivées (calcul
d'indicateurs gestion durable) :
o Surface forestière par classe d'altitude
o Surface par taille de massif
o Longueur lisière par ha
o Longueur lisière à l'ha par type de
peuplement
o Etc.
I.D.3 - Utilisations internes à l'IGN
Le RGFor, en tant que base de production, fournit
également des données utilisées par l'IGN pour :
- constituer la couche végétation de la BD
Topo®
- réaliser la cartographie forestière de la BD
Forêt®
- réaliser les cartes du SDC (service de la
cartographie)
- créer de nouveaux produits :
o le projet CarHab (cartographie des habitats)
o le projet OCS GE
- compléter l'inventaire statistique du SIF (Service
de l'Inventaire Forestier) pour son modèle
de calcul de surface)
35
Ces données peuvent également servir aux
laboratoires de l'IGN, comme le MATIS (Méthodes d'Analyses et de
Traitement d'Images pour la Stéréo-restitution) et le COGIT
(Conception Objet et Généralisation de l'Information
Topographique).
I.D.4 - Demandes des utilisateurs sur le temps
L'information temporelle sert à connaitre l'état
actuel des données, mais aussi à comparer des
événements spatiaux à des époques
différentes, à analyser des évolutions passées
expliquant l'état actuel des données, à en déduire
les règles qui causent les changements, son rythme notamment, à
élaborer des scénarios de comportements futurs, avoir une vision
dynamique des phénomènes et de leur évolution, à
grouper l'information (des événements se produisant au même
moment peuvent être associé, de même que ceux se produisant
selon une même séquence) (Andrault, 1997, pp. 1-6) (Bordin, 2002)
L'information temporelle est primordiale à la compréhension des
processus naturels (Peuquet, 2000, pp. 8-12).
La demande des utilisateurs dans ce domaine a
été évaluée dans le cadre de l'OCS GE, dont l'usage
principal est le suivi temporel du territoire. Cette demande émane plus
particulièrement des utilisateurs cherchant à évaluer
l'extension de la tâche urbaine et la consommation des espaces agricoles
(bureaux d'études en urbanisme, collectivités locales).
Il n'y a pas eu d'études spécifiques concernant
le temps auprès des utilisateurs de la couche végétation
de la BD Topo® et ceux de la BD Forêt®. Cette
problématique est encore assez peu connue des utilisateurs et suscite
peu de demande.
Lors d'une étude marketing réalisée
auprès des utilisateurs de la couche végétation et de la
cartographie forestière (IGN, 2011-B), un nombre assez important
d'utilisateurs a émis le souhait de mises à jour plus
fréquentes et précisant des dates.
Marginalement, il a été également
demandé de développer (IGN, 2011-B) :
- « l'historisation des versions de séries de
données et des modifications des données >
- « un outil qui permettrait des analyses temporelles
d'évolution sur la base de plusieurs jeux
de données
disponibles, ou d'un jeu synthétique de données mêlant
état actuel et
précédents >
- « une orientation vers un mode plus différentiel
des mises à jour d'objet >
Le besoin en données temporelles est aussi enjeu pour
la recherche sur la modélisation de processus climatiques,
hydrologiques, écologiques. L'état de surface est un
élément essentiel pour ces modèles qui ont besoin de
données temporelles faire des prévisions.
Enfin, l'importance de l'analyse de l'évolution de la
structuration spatiale des éléments qui composent un paysage est
connue, notamment pour la recherche sur le fonctionnement des
écosystèmes (IFN, 2008).
I.E - Évolutions de la forêt dans le
temps
L'extension et la composition de la forêt varie dans le
temps. Elle évolue au rythme de sa croissance naturelle, soit un rythme
relativement lent, de l'ordre de la décennie. Le critère
principal régissant ces évolutions a longtemps été
(à l'échelle des temps géologiques) uniquement les
variations des
36
conditions climatiques. Depuis l'Holocène, bien qu'on
définisse encore la forêt comme un milieu « naturel »,
son évolution dépend surtout des activités humaines.
I.E.1 - Tendances générales
Le premier type d'évolution susceptible d'être
observée lors de la mise à jour est dû au cycle de gestion
: plantation, entretien, récolte. La futaie régulière,
composée d'arbre appartenant à la même classe d'âge,
représente en effet environ 50% de la forêt de
production14. Ce type de forêt est géré par un
cycle de coupe rase, ou coupe à blanc. D'autres régimes de coupes
existent (coupe à blanc partielle, coupes progressives, coupes
successives) et peuvent induire des changements plus progressifs et
nuancés dans la composition du peuplement d'une forêt (Andrault,
1997). Puisque l'âge des peuplements n'est plus indiqué dans la
version à venir, comme c'était le cas dans la v.1 de la BD
Forêt®, c'est essentiellement le régime de coupe qui
influencera la mise à jour.
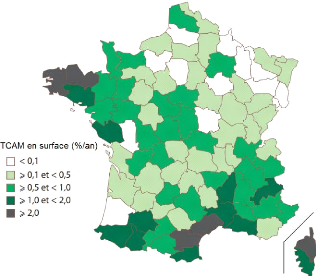
Figure 10 : Taux d'accroissement annuel moyen de
superficie forestière de 1981 à 2009 (Source : IFN,
2012).
Il est probable que la forêt s'accroisse au
détriment des territoires agricoles et diminue à la faveur de
l'artificialisation. La tendance principale des dernières
décennies est en effet à l'augmentation de la forêt en
France. Depuis le début du XIXème, sa superficie a presque
doublé. Si bien qu'elle occupe aujourd'hui environ 28% du territoire
métropolitain (IGN, 2007-B). Pour la période de 1981 à
2007, l'IFN a mesuré un accroissement de 75 000 ha de superficie par an,
soit 0,6% d'augmentation en moyenne par an. Les nouvelles forêts sont
apparues dans les régions traditionnellement agricoles (Normandie,
Bretagne, Centre, sud du Massif-Central) et de montagnes
(Pyrénées, Alpes, Corse) (voir Figure 10). Ceci est l'effet d'une
part de plantations d'origine artificielle pour les régions du
nord-ouest, et d'une reconquête forestière naturelle sur des
espaces précédemment défrichés observée
depuis plus d'un siècle. Ce phénomène est lié
à la dépréciation agricole qui se caractérise par
un
14 Source : inventaire forestier IGN,
http://inventaire-forestier.ign.fr/ocre-gp/tableaustandard/init.html.
Consulté le 26/04/2013.
37
abandon progressif des territoires agricoles peu productifs,
notamment de moyennes et de hautes montagnes (IFN, 2012). La France
métropolitaine a connu son maximum de défrichement en même
temps que ses densités de population maximales en milieu rural au
XIXème siècle. L'exode rural et l'intensification de
l'agriculture depuis cette période sont les principales causes de la
dépréciation agricole. Les espaces ouverts laissés
à l'abandon ont été progressivement colonisés par
la végétation et se referment, en suivant les étapes de la
succession végétale, jusqu'à devenir des forêts.
À cette tendance s'ajoute celle de la consommation des
espaces, essentiellement agricoles mais aussi forestiers, au
bénéfice de l'extension de la tache urbaine depuis le milieu du
XXème siècle. Les données d'évolution de
l'occupation du sol entre 2000 et 2006 de Corine Land Cover montrent que les
forêts et les milieux semi-naturels ont en effet plus gagné en
surface sur les territoires agricoles qu'ils n'ont perdu : 1717 ha de
croissance nette (3715 - 1998). Mais les territoires artificialisés ont
beaucoup plus gagné sur la forêt en surface et très peu
perdu : 8360 ha (10280 - 1920). L'accroissement de la forêt au
détriment des territoires artificialisés s'explique
essentiellement par l'abandon des carrières et autres mines à
ciel ouvert. L'artificialisation d'espaces forestiers est, quant à elle,
plutôt le fait de la périurbanisation.
Tableau 1 : Matrice d'évolution de
l'occupation des sols entre 2000 et 2006 en ha, niveau 1 de la nomenclature CLC
(Source : SOeS, Corine Land Cover, 2006)
|
2006
|
2000
|
Territoire artificialisés
|
Territoires agricoles
|
Forêts et
|
Zones humides
|
Surfaces en eau
|
Total
|
|
|
|
|
|
1 973
|
1 920
|
|
572
|
4 465
|
Territoires agricoles
|
76 147
|
|
3 715
|
158
|
2 242
|
82 262
|
|
|
10 280
|
1 998
|
|
0
|
339
|
12 617
|
milieux
|
|
|
semi-
|
|
|
132
|
5
|
0
|
|
0
|
138
|
Surfaces en eau
|
29
|
82
|
47
|
0
|
|
158
|
Total
|
86 588
|
4 059
|
5 682
|
158
|
3 152
|
99 640
|
|
La composition de la forêt a également
évolué au cours des dernières décennies. Dans les
années 60 et 70, la principale évolution a été le
remplacement massif de feuillus par des résineux. L'enrésinement
était le fait d'un choix gestionnaire justifié par les
qualités de croissance des résineux. Cette pratique a
été progressivement abandonnée avec la prise en compte de
facteurs environnementaux, et les dernières décennies ont vu au
contraire un accroissement de la part des feuillus : 61,2% en 1981, puis 63,71%
en 2007 du total de volume sur pied (IFN, 2011).
38
I.E.2 - Événements
L'évolution de la composition de la forêt peut
aussi être due à des événements marquants, comme la
tempête de 1999 et la tempête de Klaus de 2009. Ce type
d'événements a pour résultat l'accumulation de bois mort,
de nombreux arbres couchés (chablis) ou détruits par la violence
des intempéries (volis) (IGN, 2007-B). De 1993 à 2007, le volume
sur pied de pin maritime a diminué de 39% alors que toutes les autres
essences connaissaient un accroissement, même faible (IFN, 2011). Ce
chiffre montre l'importance des dégâts causés par la
tempête de 1999 dans le massif des Landes, composé en majeure
partie de ce type de peuplement. La Figure 11 montre les dégâts
causés par Klaus, quelques mois avant la prise de vue aérienne
utilisée pour constituer les premières données de la BD
Forêt® v.2 dans les Landes.
Les tempêtes, les maladies, les sécheresses et
les feux de forêts sont les principaux événements qui
touchent la forêt. Une maladie peut affecter fortement un type de
peuplement forestier, jusqu'à sa disparition, comme cela a
été le cas avec la graphiose de l'orme. Depuis quelques
années, le chancre coloré menace les platanes du canal du Midi,
et une grande partie de ces arbres ont été abattus pour endiguer
la progression du champignon parasite. Les insectes, tels que la chenille
processionnaire du pin ou le bostryche typographe s'attaquant aux forêts
d'épicéa, peuvent également être classés avec
les maladies affaiblissant les arbres et pouvant être à l'origine
de mortalité par défoliation, ou nécessiter une coupe
préventive. Un événement climatique extrême comme la
canicule de 2003 entraine une forte défoliation et peut causer la mort
de l'arbre du fait de la sécheresse. Enfin, les feux de forêts,
liés aux sécheresses, sont parmi les événements les
plus destructeurs en surface forestière, particulièrement dans le
sud de la France. De 1981 à 2007, 23 500 ha ont brûlé et
4300 départs d'incendie ont été recensés en moyenne
chaque année, avec un record de 73 275 ha incendiés en
200315.
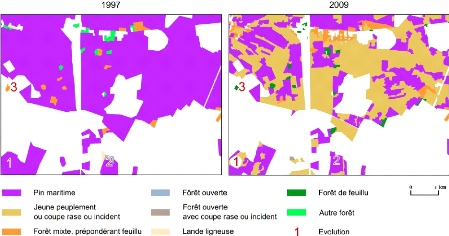
Figure 11 : Exemple d'évolution, au sud de la
commune de Solférino dans les Landes (Source : BD forêt version 1
et 2).
15 Source SOeS :
http://www.statistiques.developpement-durable.gouv.fr/lessentiel/ar/368/1239/feux-foret-lexposition-france.html.
Consulté le 05/04/2013.
39
I.E.3 - Prospective
A cause du changement climatique, la forêt
française risque d'évoluer et de devenir plus vulnérable
à ce type d'événements (Ministère de l'Ecologie, du
Développement durable, des Transports et du Logement - Direction
générale de l'Energie et du Climat, 2011). Ce
phénomène pourrait à l'avenir provoquer des modifications
dans la répartition géographique et la composition des
peuplements forestiers qui changeront probablement du fait de l'augmentation
des températures, de la baisse du degré d'humidité du sol
et des épisodes de sécheresse. Si la température moyenne
augmente de 2°C d'ici la fin du siècle, les régions
forestières se déplaceront de 360 km vers le nord. La zone de
sensibilité aux incendies s'étendra vers le nord dès 2040
(Ministère de l'Ecologie, du Développement durable, des
Transports et du Logement - Direction générale de l'Energie et du
Climat, 2011, p. 4).
I.E.4 - Fausses évolutions
La Figure 11 nous permet d'aborder un dernier type de
modification que sont susceptibles de rencontrer les données du RGFor au
cours des mises à jour : la correction d'erreur. Trois évolutions
notables ont été annotées sur la carte de 1997 et de 2009.
L'évolution numéro 1 correspond à la transformation d'une
forêt de pin maritime en parcelle agricole reconnaissable à sa
forme circulaire caractéristique de l'irrigation à pivot central
par aspersion16. L'évolution numéro 2 est un cas de
reconquête de la forêt sur des espaces ouverts (forêt
ouverte, lande ligneuse) plutôt du fait d'une plantation que de la
succession végétale vu le contexte géographique. Enfin,
l'évolution numéro 3 pourrait illustrer une erreur de
photo-interprétation corrigée grâce à la plus grande
précision de l'ortho-photographie utilisée en 2009. En effet, le
même bosquet est d'abord indiqué comme une forêt mixte
à prépondérant de feuillus en 1997, puis comme une
forêt de feuillus uniquement en 2009. De nombreuses évolutions de
ce type sont visibles entre les deux cartes et sont probablement dues aux
différences de nomenclatures entre les deux versions, mais aussi
peut-être à des erreurs de photo-interprétation. Il est
également possible que les pins maritimes aient été
victimes de la tempête alors que les feuillus ont mieux
résistés, ce qui expliquerait la transformation de forêt
mixte à feuillus. Quoiqu'il en soit en réalité pour cet
exemple, la mise à jour est aussi un moyen d'améliorer la
précision de la photo-interprétation précédente en
corrigeant des erreurs possibles.
Langran (Langran, 1992, p. 20) distingue deux types
d'erreurs. Elles peuvent être soit inhérentes soit
opérationnelles. Les erreurs inhérentes sont dues à la
source des données. Une erreur courante de ce type est un défaut
de positionnement malgré l'ortho-rectification, ce qui est souvent le
cas en zone de haute montagne. Les erreurs opérationnelles ont pour
origine une erreur de manipulation ou d'interprétation au moment de la
saisie des données.
I.F - Conclusion
La production et l'utilisation des données du RGFor
font apparaître des objectifs clairs quant à l'intégration
du temps dans la base de données :
- Stocker efficacement, c'est-à-dire éviter les
redondances et maintenir la cohérence des données ;
- Pouvoir consulter la cartographie forestière à
un instant donné ;
- Localiser les changements ;
- Connaître les différents états d'un
peuplement ; - Savoir comment se produisent les évolutions ;
16 Interprétation validée à
l'aide de données Google Map 2012.
40
- Remplir une matrice de transition.
Nous pouvons résumer les besoins des utilisateurs autour
de deux enjeux principaux :
- La mesure de la consommation de l'espace ;
- La connaissance des évolutions morphologiques de
l'occupation des sols.
Les évolutions transforment en profondeur la
forêt et le territoire français et sont variables selon les zones
géographiques et les peuplements. Les évolutions sont de deux
types dans l'espace et le temps :
- Continu, lorsqu'il s'agit de la reconquête
forestière par succession végétale et des
modifications du fait du changement climatique.
- Discret, dans le cas de perte de surface au
bénéfice de l'urbain notamment, ou à cause d'incidents
tels que les tempêtes, les maladies, ou les feux.
Il est donc important d'élucider la localisation de
ces changements, de les quantifier précisément, et de connaitre
les peuplements concernés. Le milieu forestier est un thème
essentiel vu sa surface pour suivre les évolutions de l'occupation des
sols en général, en termes de mesure et de connaissance des
échanges de surface entre les thèmes d'occupation.
La forêt évolue au rythme de sa croissance
naturelle, soit un rythme relativement lent, de l'ordre de la décennie.
Il est fort probable qu'il y ait peu de modifications avec une mise à
jour tous les trois ans, et que la mise à jour permette de corriger des
erreurs précédentes.
41
CHAPITRE II - État de l'art : le temps dans les
SIG
Les objectifs que nous avons définis en
première partie peuvent être résumés en trois
points. Intégrer le temps dans les SIG répond en effet à
« un triple besoin : estimer la pertinence des données, mesurer des
évolutions et caractériser des phénomènes
dynamiques » (Gayte et al., 1997). Pour cela, l'historisation des
données géographiques doit satisfaire des besoins techniques :
l'interrogation des données en fonction du temps et/ou de l'espace ; le
stockage et le traitement des informations dans le temps ; l'évolution
du support spatial des données (Langran, 1992, in Plumejeaud, 2001, p.
55).
La pertinence des données est fonction du temps, sa
mesure détermine si celles-ci sont toujours valables. Les
évolutions dépendent de la mise à jour qui
détermine comment sont intégrés les changements dans la
base de données. La caractérisation des phénomènes
géographiques dynamiques, enfin, dépend de la modélisation
de l'information spatiale et temporelle.
La gestion de l'historicité des données dans
les SIG demande donc de définir l'introduction du temps dans la base de
données, la méthode de mise à jour, et la
modélisation de l'information spatiale et temporelle dans la base de
données (Paque, 2004, p. 1).
Afin de proposer un modèle d'historisation permettant
d'observer un territoire géographique dans le temps, nous
tâcherons de définir ces conditions en répondant aux
questions suivantes : Qu'est-ce que le temps ? Comment modéliser le
temps ? Quels sont les modèles de base de données
intégrant le temps ? Quels sont les modèles de mises à
jour ? Et quels sont les modèles de base de données à la
fois spatiales et temporelles ?
II.A - Définir le temps
Le temps est une notion familière qui fait partie du
quotidien. L'évidence de ce concept s'arrête pourtant là
où commence la nécessité de l'expliquer
précisément. À la fois philosophique et physique, la
question « qu'est-ce que le temps ? » est un sujet de
réflexion transversal à de nombreuses disciplines et à
plusieurs époques. Selon les courants de pensées, la
définition du temps a varié dans l'histoire. Il suffit d'ouvrir
un dictionnaire pour constater cette richesse sémantique de la notion de
temps qui illustre la complexité réelle de cette apparente
évidence. Le Littré propose ainsi pas moins de quarante-cinq
définitions17. À titre de comparaison, la
définition du mot « espace » ne possède que six
entrées. Avant d'aller plus loin dans l'analyse, il est donc
nécessaire de réfléchir à la nature de ce concept
et à sa définition (Peuquet, 2000).
II.A.1 - Temps et espace : union et différence
L'espace et le temps sont parmi les notions les plus
fondamentales et intuitives. Elles fournissent les bases pour organiser nos
modes de pensée et de croyance (Peuquet, 2002 ; Ott et Swiaczny,
2001, p. 55) L'espace vécu a quatre dimensions, trois dimensions
spatiales et une dimension temporelle (Médici et al., 2011).
Partant de notre expérience quotidienne,
l'écoulement du temps est perçu à travers des successions
cycliques ou linéaires de changements dans un même espace (Ott et
Swiaczny, 2001, pp. 55-57) : jour, nuit ; succession des saisons ;
périodes des astres ; évolution d'un objet ; etc. Le temps
nous
17 Source :
http://littre.reverso.net/dictionnaire-francais/definition/temps.
Consulté le 03/05/2013
42
sert de référence pour situer des
événements, et introduire des relations, comme la
causalité, entre des phénomènes.
Nous avons besoin de ce concept pour comprendre et
décrire le monde qui nous entoure, où toutes choses existent
à une certaine époque et dans un espace donné. Le temps et
l'espace sont donc intimement connectés : se produire à
un moment, c'est avoir lieu dans un espace (Heres,
2000).
« Space is a still of time, while time is space in
motion. The two taken together consitute the totality of the ordered
relationships characterizing objects and their displacements»
(Piaget, 1969, p. 2 in Peuquet, 2000, p. 10).
La combinaison du temps et de l'espace a été
conceptualisée par le mathématicien et physicien allemand Herman
Minkowski, qui a créé une géométrie en quatre
dimensions dans un continuum espace-temps appelé depuis « espace de
Minkowski ». Le temps est y vu comme un vecteur supplémentaire
d'une géométrie à 4 dimensions : x, y, z, et t (Figure
12). Le temps, représenté par le vecteur « t », est
ainsi conçu comme une dimension géométrique. Ses travaux
ont notamment servi de base à ceux de son célèbre ancien
élève, Albert Einstein, sur la théorie de la
relativité.
Figure 12 : Représentation du temps comme une
dimension géométrique à l'aide d'un tesseract, ou
hypercube (Source :
travail personnel).
Le temps et l'espace sont interdépendants, ils ne sont
toutefois pas interchangeables (Peuquet, 2000, p. 8). Le temps est
linéaire et orienté, il permet la causalité (Plumejeaud,
2011, p. 30). La représentation métaphorique du temps est
traditionnellement celle d'une flèche symbolisant le progrès
(Pelekis et al., 2004). Que son écoulement soit orthogonal
(passage des années), ou cyclique (les saisons), il est inexorablement
unidirectionnel, du passé, vers le futur, en passant par la succession
d'instants présents. Les processus temporels sont linéaires et
irréversibles dans la nature. On continue de vieillir. Retourner dans le
passé est impossible. Au contraire, dans l'espace il est possible de se
déplacer dans toutes les directions.
43
Seconde différence notable, si le temps et l'espace
sont tous deux perçus comme des dimensions continues et
nécessitent d'être discrétisés en unités de
mesure (Ott et Swiaczny, 2001, p. 55), celles-ci ne sont pas les
mêmes18. L'espace se mesure en longueur, en surface, par
rapport aux coordonnées de points dans l'espace. Le temps se mesure en
date et en durée, dont les unités sont l'année, le mois,
le jour, l'heure, etc.
II.A.2 - Une définition multiple du temps
Ce que nous avons dit précédemment montre que
le temps est une notion complexe. D'autant plus qu'elle a beaucoup
variée avec les époques (Peuquet, 2000 ; Peuquet, 2002 ;
Plumejeaud, 2011). Dans ses travaux, Peuquet fait un rappel historique des
différentes définitions du temps et de l'espace depuis les
récits mythologiques (Hésiode, Homer), les mathématiciens,
physiciens et philosophes antiques (Anaxagore, Démocrite, l'atomisme, le
pythagorisme) jusqu'aux penseurs modernes (Newton, Minkowski, Einstein). Elle
relève la constance d'un parallélisme entre des
définitions contradictoires (Tableau 2).
Tableau 2 : Tableau de synthèse de la
définition du temps selon différents penseurs
Définitions
|
Auteurs
|
|
Définitions antonymes
|
Auteurs
|
Absolu, ordre abstrait universel, cadre, structure immuable,
rigide
|
Newton
|
|
Relatif, multitude d'événements particuliers, en
fonction du référentiel, ordinal
|
Hésiode, Einstein, Leibniz
|
Infini, sans limite
|
Homer, Anaxagore, pythagorisme, Aristote
|
|
Fini, borné
|
Hésiode, pythagorisme
|
Continu
|
Homer, Anaxagore
|
|
Discontinu, discret, atomique
|
Hésiode, atomisme,
|
Progression continue orthogonale
|
Homer
|
|
Cyclique sans progression, progression cyclique
|
Hésiode, mythologie hindoue
|
Réalité, absolu, objectif, abstrait
(l'idée)
|
Platon
|
|
Perception, relatif, subjectif
|
Platon
|
Contenant, cadre, mesure en soi de l'objet, discret,
quantifiable
|
Atomisme, Démocrite, Newton
|
|
Contenu, propriété de l'objet, mesure entre deux
objets, mesure de l'objet en soi et de sa relation avec d'autres objets,
topologique
|
Aristote
|
|
Ce parallélisme peut être résumé
à deux aspects du temps : il est à la fois absolu ou relatif et
continu ou discret (Peuquet, 2000 ; Ott et Swiaczny, 2001, pp. 1-4 ; Langran,
1992, p. 78). La définition du temps est un oxymore, elle est faite de
notions qui semblent se contredire, mais qui en fait se complètent. Le
temps, comme le cosmos selon les pythagoriciens, est l'union harmonieuse
d'opposés.
Le temps peut donc être uni à l'espace, comme
une dimension géométrique supplémentaire. Il a des
propriétés qui lui sont propres, en termes de progression
(unidirectionnel) et de mesure. Sa définition est faite d'opposés
se complétant et qui sont : l'absolu, le relatif, le continu et le
discret. Afin d'implémenter le temps dans une base de données
géographique, il sera nécessaire de prendre en compte ses
notions.
18 Les mesures de distances peuvent toutefois se
confondre avec les durées nécessaires pour les parcourir.
44
II.A.3 - Temps géographique
Figure 13 : Définition du temps selon deux axes
: absolu/relatif et discret/continu (Source : Peuquet, 2000).
La Figure 12 reprend les aspects multiples du temps selon
deux axes, absolu/relatif et continu/discret, en proposant une
délimitation volontairement floue, car sujette à
l'interprétation, de quelque exemples. Le temps de l'analyse
géographique est à la croisée des aspects
complémentaires du temps représenté par cette figure
(Isnard, 1985). Il existe en effet à la fois une géographie
physique, proche des sciences naturelles, de l'observation de l'espace physique
et de l'étude des lois naturelles, et une géographie humaine,
appartenant aux sciences sociales, de l'étude des perceptions et des
transformations de l'environnement, soit une géographie plutôt
quantitative et une géographie plutôt qualitative.
Le temps est un concept fondamental pour l'analyse
géographique. Les changements dans le temps et dans l'espace composent
tout processus géographique (Peuquet, 2000). Paradoxalement, pourtant,
la géographie s'est détachée du temps pour se concentrer
sur l'étude de l'espace, et se différencier ainsi d'autres
disciplines, comme l'histoire et la sociologie (Ellisalde, 2008 ; Ott et
Swiaczny, 2001, p. 3).
L'exemple classique des nombreuses études diachroniques
nécessite d'apporter une nuance à l'affirmation
précédente. Le temps n'est pas absent de la géographie.
Mais le temps en géographie s'identifie souvent au temps d'une
cartographie papier, c'est-à-dire à une représentation de
l'espace figé à un moment. Le passage du temps et les analyses
qui en découlent sont déduits par comparaison entre plusieurs
cartes d'un même espace à différentes époques. C'est
cette vision du temps qui prédomine encore actuellement en
géographie (Kraak, 2000 ; Bordin, 2002).
Toutefois, des travaux sur l'introduction du temps comme
sujet d'étude en géographie et des représentations plus
dynamiques de l'espace sont à noter. La carte de Minard sur la campagne
napoléonienne de Russie (Figure 14) est un exemple célèbre
de la représentation du temps dans une carte. La qualité de cette
carte, que Minard appelait lui-même plutôt une « carte
figurative », tient au fait qu'elle ne respecte pas les codes de la
cartographie usuelle. Elle fait correspondre un déplacement dans
l'espace et un déplacement dans le temps à l'aide de
l'épaisseur du trait symbolisant le nombre de soldats qui diminue au fur
et à mesure des pertes (Peuquet, 2002 p. 157).

45
Figure 14 : « Carte figurative des pertes
successives en hommes de l'armée française dans la campagne de
Russie 18121813 », Minard19.
Le géographe suédois Torsten Hägerstrand
est sans aucun doute parmi les principaux contributeurs dans l'étude du
temps en géographie (Langran, 1992 p. 15). La théorie de la
diffusion (Hägerstrand, 1952) et la géographie temporelle
(Hägerstrand, 1970), ou time geography, de Hägerstrand sont
fondés sur l'étude de parcours individuels et sur leurs
interactions dans l'espace au cours du temps. Ces théories ont
été appliquées à de nombreux sujets, de
l'étude de la diffusion de l'innovation en agriculture, à la
diffusion de l'instabilité politique, d'une épidémie, etc.
(Peuquet, 2000). La géographie temporelle est particulièrement
connue pour ses diagrammes spatio-temporels. La Figure 15 en est un exemple
dans le cadre des travaux de la géographe féministe Mei-Po Kwan
sur les femmes afro-américaines à Portland dans les années
1990. Cette étude a permis de montrer que ce groupe de population avait
une utilisation plus restreinte de l'espace dans ses déplacements
quotidiens.
Figure 15 : Parcours spatio-temporels de femmes
afro-américaines à Portland en
1994-199520.
Ce type de diagramme reprend le concept de Minkowski d'un
cube spatio-temporel en remplaçant la troisième dimension «
z » par « t ». Il est ainsi possible de visualiser en
perspective des déplacements individuels dans le temps symbolisé
par chaque tracé, en violet dans cet exemple. D'autres
représentations cartographiques du temps sont possibles.
19 Source :
http://en.wikipedia.org/wiki/File:Minard.png.
Consulté le 28/04/2013.
20 Source :
http://meipokwan.org/Gallery/STPaths.htm.
Consulté le 28/04/2013.
46
Il est également possible de représenter le
temps dans une carte par anamorphose, comme les temps de transports par
exemple. Enfin, les cartes animées constituent l'innovation la plus
récente dans ce domaine. Elles reposent sur l'utilisation d'un lecteur
multimédia affichant une succession de données en fonction du
temps (Figure 16) (Kraak, 2000).
Figure 16 : Carte animée de la population
mondiale de 1960 à 201121.
Bien que la théorie de la géographie temporelle
fût accueillie avec enthousiasme au moment de sa parution dans les
années 70, elle est tombée en désuétude par manque
de données temporelles exploitables aisément. De même, la
cartographie s'est penchée sérieusement sur le sujet de la
visualisation du temps depuis les années 60, sans pour autant trouver
d'application faute de support technique suffisant (Kraak, 2000).
Depuis le développement des technologies de
l'information et de la communication, les données sont présentes
et de nouveaux moyens permettent le développement de cartes dynamiques.
La question du temps est devenue un enjeu sérieux. La
représentation du temps en géographie a ainsi pendant longtemps
été limitée par le medium cartographique statique par
nature. La problématique est désormais de représenter
correctement ces données dans les bases de données afin de
pouvoir mettre en évidence facilement les évolutions spatiales et
temporelles (Peuquet, 2000, p. 10). Il s'agit donc de définir le temps
dans un SIG.
II.A.4 - Temps géomatique
Avec la géomatique, le temps peut sortir du paradigme
de la cartographie figée, et se diriger vers une intégration plus
générale du temps comme une représentation davantage
fidèle à la réalité, ouvrant des voies nouvelles
à l'analyse géographique. Un consensus se dégage des
travaux sur ce sujet : la question du temps dans les SIG est encore un sujet de
recherche d'actualité. En effet, la plupart des SIG sont actuellement
limités par rapport à cette problématique récente
et peu de bases fonctionnelles existent. Malgré de nombreux
modèles de bases de données spatio-temporelles, la gestion du
temps demeure souvent rudimentaire dans les SGBD relationnels (Peuquet, 2002,
pp. 304-308).
21 Source :
https://www.google.fr/publicdata/directory.
Consulté le 28/04/2013.
47
La question de la représentation de l'espace et du
temps dans un système informatique est donc loin d'être
parfaitement résolue. Malgré leurs capacités, les SIG
peinent à prendre en compte la dimension temporelle (Andrault, 1997 ;
Peuquet, 2000 ; Bordin, 2002 ; Médici et al., 2011). Trois
facteurs expliquent cela.
Premièrement, les SIG restent encore majoritairement
tributaires du temps géographique et de la cartographie traditionnelle
(Peuquet, 2000 et 2002). Ils ont été pour la plupart d'abord
conçu comme des outils remplaçant la carte papier, et/ou
facilitant son édition. Les SIG ne pouvaient représenter le temps
qu'indirectement, comme une succession de fichiers séparés.
Deuxièmement, le temps fut peut être pendant une
assez longue période une dimension négligée des
donnée. Face au développement rapide des SIG dans les
années 90, l'acquisition de nouvelles données et l'adaptation des
données existantes furent longtemps la priorité des principaux
utilisateurs des SIG en termes de questionnement et de stockage. Il a fallu
attendre la constitution des bases initiales pour que la question du temps en
géomatique apparaisse à travers celle de la mise à jour
des données. L'objectif fut d'abord que les données continuent
à être représentatives de la réalité et afin
de garantir la continuité du fonctionnement du SIG.L'intégration
du temps au moment de la mise à jour fut ensuite
déterminée par les capacités des machines à stocker
de l'information supplémentaire, en conservant des états
passés des données (Peuquet, 2002, pp. 304-308).
Troisièmement, une fois pris en compte, le temps a
répondu à des besoins techniques plus que d'analyse
thématique. Il fallait ainsi d'abord résoudre la question de la
maintenance et de la « fraicheur » des données assurant la
pérennité des investissements dans le SIG. Avec les besoins
d'analyse des phénomènes et de suivi des changements au cours du
temps, l'intégration du temps dans les SIG revêt un aspect
supplémentaire. Il implique de devoir « résoudre [...] les
problèmes de gestion des informations de mise à jour, non
seulement dans leur prise en compte et leur intégration, mais aussi
comme source d'information temporelle », il s'agit non seulement de
disposer d'une information « à jour » mais aussi « au
jour » (Bordin, 2002).
Aujourd'hui, l'intégration du temps dans les SIG est
une capacité en voie de développement22. Ce
développement avance à mesure que les SIG s'éloignent du
modèle cartographique traditionnel, ayant comme finalité une
représentation n'incluant que partiellement le temps, et se rapprochent
des modèles de base de données. Ce type de modèle est
censé permettre une représentation aussi fidèle que
possible de l'information servant à la résolution de
problèmes. Ils incluent le temps et reposent sur l'utilisation optimale
de l'outil informatique (Peuquet, 2000). Une minorité de SIG ont ainsi
été créés pour remplacer des tableaux de listes
d'informations liées à des cartes. Dans ces listes, le temps
était couramment inclus. La tendance actuelle se dirige vers
l'intégration du modèle cartographique et de base de
données afin d'intégrer explicitement le temps aux données
géographiques (Heres, 2000).
La question du temps en géomatique a
émergé à partir des années 80 avec la
création de nombreux modèle spatio-temporel de base de
données. Les travaux de Gail Langran (Langran et al. 1988 ;
Langran, 1992) sur le sujet constituent la première oeuvre
théorique de référence en la matière (Peuquet,
2002, pp. 304-308).
22 Source :
http://support.esri.com/en/knowledgebase/GISDictionary/term/temporal%20GIS.
Consulté le 28/04/2013.
48
Les premiers travaux de modélisation ont cherché
à améliorer les bases de données relationnelles pour
incorporer le temps (Hazelton, 1991 ; Kelmelis, 1991 ; Langran, 1992) puis
l'attention s'est portée sur la technologie orientée objet
(Wachovicz, 1999)
Le temps dans les SIG est donc une question encore
récente, faisant face à de nombreux défis techniques.
L'implémentation du temps, sa complexité et ses capacités,
varient selon la modélisation (Bordin, 2002) que nous allons approfondir
dans les parties suivantes.
II.B - Notions de modélisation des données
temporelles
Avant de décrire les modèles, nous rappelons le
cadre conceptuel de la modélisation. Nous ne revenons pas sur la
modélisation de l'espace qui n'est pas le coeur du sujet.
II.B.1 - Formalisme : modèle, entité, objet,
relation, cardinalité
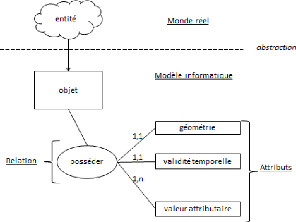
Figure 17 : Schéma de la modélisation
(Source : Ott et Swiaczny, 2001).
Un modèle conceptuel de données est une
définition logique qui sert à décrire les concepts et les
informations sans se soucier de leur implémentation informatique
(Hainaut, 2011 ; Date, 2004). C'est une abstraction du monde réel,
dépendante du choix subjectif et pragmatique des informations retenues.
La modélisation est également, in fine,
dépendante de la technologie utilisée par la base de
données. Du plus abstrait au plus concret, les modèles de bases
de données se classent ainsi : modèle conceptuel, modèle
logique, modèle physique (Ott et Swiaczny, 2001, pp. 21-26). La
modélisation dépend donc des données et des objectifs de
la base de données (Médici et al., 2011).
Il existe de nombreux formalismes servant à
généraliser la conception d'une base de données. Nous
reprenons le formalisme entité-relation développé dans les
années 70 qui est couramment employé pour décrire les
bases de données. Le formalisme entité-relation se
présente d'abord sous la forme d'un schéma conceptuel, abstrait,
puis d'un schéma logique de base de données, reprenant les
concepts communs à toutes les bases de données en dehors des
différences technologiques. La modélisation aboutit ensuite
à l'implémentation informatique sous la forme d'un modèle
physique.
49
Selon le modèle entité-relation, on identifie la
réalité que les données représentent en classes
d'entités. L'entité désigne toute chose, objet, personne,
événement ou concept, pour laquelle de l'information est voulue.
Elle est définie par un nom. Nous la différencions de l'objet,
qui est l'enregistrement informatique de l'entité du monde réel
(Langran, 1992, p. 8).
Une entité possède des attributs qui la
caractérisent, et des relations, qui sont des associations entre deux
entités. Une entité participe à une relation en fonction
de sa cardinalité mesurant le minimum et le maximum de sa participation
(0, 1 ou n fois). Par exemple dans le modèle d'historisation de la BDUni
(voir Figure 24, p. 84), la version actuelle d'un objet peut avoir de 0
à n objet historique (relation 0,1), et un objet historique a toujours
une version actuelle (relation 1,1).
II.B.2 - Sémantique temporelle :
granularité, intervalle, événement, changement
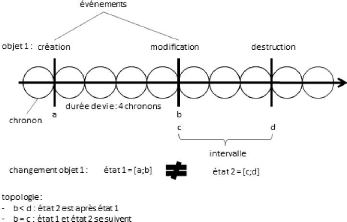
Figure 18 : Illustration des principaux concepts de
modélisation temporelle (Source : travail personnel).
Le temps est un phénomène continu du monde
réel. Pour être introduit dans un système informatique, il
doit d'abord être discrétisé en instants, classés de
manière ordinale sur une ligne continue représentant le temps
(Paque, 2004 ; Plumejeaud, 2011, pp. 31-32) (Figure 18).
La discrétisation du temps repose sur un
découpage en unités temporelles élémentaires
appelées « chronon ». La granularité
est la durée d'un chronon, soit le temps
minimal possible entre deux dates, ou instants, enregistrés dans la base
de données (Ott et Swiaczny, p. 59). La granularité
détermine la fréquence d'observation du phénomène
et donc la résolution temporelle, autrement dit la
précision avec laquelle les évolutions sont perçues au
cours du temps dans la base de données (Paque, 2004 ; Plumjeaud, 2011,
p. 32.).
Tout comme pour l'espace, la granularité est une
question d'échelle. Son degré de précision dépend
des besoins de l'utilisateur des données (Plumejeaud, 2011, p. 33). La
granularité pertinente en géologie est de l'ordre du millier
d'années, alors que la météorologie nécessite des
mesures toutes les heures. Il est important également d'adapter la
granularité à l'échelle spatiale, un
phénomène apparemment immobile à une certaine
échelle peut connaître des évolutions à une autre
échelle
50
(Ott et Swiaczny, 2001, pp. 59-60). Elle
détermine l'appréciation de la dynamique des changements (Yeh et
al., 1996).
Échelle
|
Phénomène
observé
|
Granularité
|
Intervalle
de 30 ans
|
Moyenne
|
Évolution du
massif forestier
|
|
1 chronon
|
Grande
|
Évolution du
peuplement
|
|
Très
grande
|
Croissance de
l'arbre
|
|
|
|
Figure 19 : Différents niveaux de
résolution temporelle et spatiale (Source : Plumejeaud, 2011, p.
32).
Une fois le temps discrétisé, sa mesure est
possible dans un système informatique par l'ajout aux données
d'attributs temporels, ou estampilles. Elles se
présentent généralement sous la forme d'un
intervalle. L'intervalle est une durée
délimitée par deux dates. Il sert de base à la
topologie temporelle fondée sur l'algèbre
d'Allen (Ott et Swiaczny, 2001, pp. 137-139 ; Plumejeaud, 2011, p.
31)
Les travaux d'Allen (Allen, 1983) définissent treize
relations topologiques binaires entres des objets datés par un
intervalle (Tableau 3).
L'intervalle de validité d'un objet
est l'équivalent de sa durée de vie, soit la période
pendant laquelle l'existence d'un état, ou version,
d'un objet a été mesurée. Les dates d'un intervalle de
validité correspondent à des événements
(Pelekis et al., 2004 ; Plumejeaud, 2011, p. 32).
L'évènement est l'instant du
changement marquant la transition entre deux états (Langran, 1992 p.
36). Cette transition peut être modélisée sous la forme
d'une relation cardinale. Il existe six types d'évènements,
divisés en deux catégories pour les données
géographiques surfaciques (Tableau 4).
Nous employons les termes « changement
», « évolution » et «
mutation » comme des synonymes désignant la
différence et le processus de différenciation entre deux
états d'une entité ou deux versions d'un objet au cours du
temps.
51
Tableau 3 : Topologie temporelle selon l'algèbre
d'Allen (Source : Ott et Swiaczny, 2001 ; Plumejeaud,
2011)
Soit x et y deux intervalles [a;b] [c;d]
|
Topologie temporelle
|
Opérateur booléen
|
Exemple
|
Équivalent spatial
|
before
|
x avant y
|
b<c
|
|
disjoint
|
|
|
|
x après y
|
a>d
|
|
|
|
|
x rencontré par y x précède y
|
b=c
|
|
joint
|
|
|
|
x rencontre y x suit y
|
a=d
|
|
|
|
|
x est égal à y
|
a=c ET b=d
|
|
superposition
|
|
|
|
x chevauche y
|
a<c ET b>c
|
|
|
|
|
x chevauché par y
|
c<a ET d<a
|
|
|
|
x débute y
|
a=c ET b<d
|
|
recouvre
|
|
|
x débuté par y
|
a=c ET d<b
|
|
|
x termine y
|
b=d ET a>c
|
|
|
|
x terminé par y
|
b=d ET c>a
|
|
|
x pendant y
|
a>c ET b<d
|
|
inclus
|
|
|
x contient y
|
a<c ET b>d
|
|
|
Tableau 4 : Événements de vie et
territoriaux (Source : Plumejeaud, 2011).
Événements
|
Relations
|
De vie
|
Création
|
0,1
|
|
Modification
|
1,1
|
|
Destruction
|
1,0
|
Territoriaux
|
Fusion
|
n,1
|
|
Morcellement
|
1,n
|
|
Déplacement
|
1,1
|
|
Les données géographiques peuvent connaître
des changements de formes et de tailles, de position et de description. Les
données géographiques peuvent connaître huit types de
changements au cours du temps (Pelekis et al., 2004) :
- Géométrie (formes, tailles et position),
- Topologie (position relative),
- Attribut (description, composante sémantique), -
Géométrie et topologie,
- Géométrie et attribut,
- Topologie et attribut,
- Géométrie, topologie et attribut.
52
Il existe deux catégories d'évolution mesurables
dans une base de données en fonction de la temporalité (Paque,
2004 ; Medici et al., 2011) :
- L'évolution discrète : dont
l'intervalle est inférieur à la granularité.
Observé à un moment
précis. Modification brusque, souvent qualifié
d'événement.
- L'évolution continue : dont
l'intervalle est supérieur à la granularité.
Observé à plusieurs
moments. Changement permanent, ou
durée longue dans le temps.
Exemples :
- Feux de quelques heures à plusieurs jours ; RGFor,
granularité trois ans : évolution discrète.
- Succession végétale : de l'ordre de la
décennie : évolution continue.
Il faut distinguer les évolutions
vraies, des corrections, ou fausses
évolutions. Les premières sont des différences entre
versions d'objets dues aux évolutions réelles des entités
observées dans le temps. Les corrections sont des différences
entre versions d'objets dues à une erreur.
II.B.3 - Typologie du temps : transaction et
validité
Le temps dans une base de données possède deux
dimensions qu'il est important de discerner : le
temps de transaction et le temps de validité. Cette
distinction est reprise par de nombreux travaux (Ritsema, 2000 ; Heres, 2000 ;
Kraak, 2000 ; Langran, 1992 ; Bordin, 2002 ; Paque, 2004 ; Plumejeaud, 2011)
avec un vocabulaire parfois différent : temps informatique, temps
d'enregistrement, temps de la base de données ; et temps du monde
réel, temps réel, temps de l'occurrence.
Le temps de validité considère la
temporalité des événements affectant les entités du
monde réel. Cette notion recouvre deux nuances : le temps de
l'observation, qui est l'instant d'un constat, et le temps des faits du monde
réel, qui est le moment exact des événements. Le temps du
monde réel est rarement facilement obtenu, le temps de validité
est le plus souvent celui de l'observation. Il est nécessaire au suivi
des évolutions.
Le temps de transaction est le moment de l'enregistrement
d'une information dans la base de données (entrée, modification,
sortie des données). Ce temps est utile au suivi du versionnement des
données d'un système informatique.
Lorsque le temps de validité n'est pas connu, le temps
de transaction est souvent la meilleure estimation de la temporalité
disponible (Heres, 2000). Néanmoins, il parait souvent nécessaire
de distinguer le temps de validité et le temps de transaction car il
peut exister un décalage important entre les deux (Heres, 2000). Cela
peut être le cas lorsque des prises de vue aérienne sont
utilisées comme sources principales des données. Il est possible
d'utiliser ce type de sources des années après la prise de vue.
De fait, ce décalage pour les phénomènes
géographiques est généralement de l'ordre de
l'année, voire plus (Heres, 2000). Autre point important, n'utiliser que
le temps de transaction fait conduire le risque d'introduire de
l'incohérence dans les données temporelles. Il n'est en effet pas
possible de corriger des données antérieures sans fausser
l'information temporelle (Heres, 2000). De même, il ne reste pas de trace
des corrections si le temps de validité est utilisé seul. (Paque,
2004)
Le temps de validité et temps de transaction
répondent à deux besoins distincts. Le temps de transaction est
plutôt technique. Sa perspective est celle du producteur des
données, de l'administrateur de la base, qui consiste à veiller
à la qualité des données. Enregistrer des versions d'objet
avec leur temps de transaction sert à sauvegarder les données
afin de pouvoir revenir sur des
53
manipulations. Le temps de validité relève d'une
perspective thématique qui cherche à analyser les
évolutions, à étudier l'information géographique
par rapport au temps (Bordin, 2002).
II.C - Approche quantitative du temps
Il existe beaucoup de modèles et de typologies
différents. Pour simplifier, nous reprenons la notion de temps absolu et
de temps relatif afin de distinguer deux aspects du temps à
implémenter une base de données ainsi que les modèles
correspondant. Tout d'abord, l'approche quantitative permet de
différencier les modèles en fonction de leur manière de
mesurer le temps et les changements. Ensuite, l'approche qualitative distingue
les modèles en fonction de leur capacité à suivre les
évolutions.
II.C.1 - Modèles de base de données en
fonction du temps
La distinction entre temps de validité et temps
d'enregistrement sert à différencier les bases de données
en quatre catégories (Snodgrass et al., 1985, in Paque, 2004 ;
Ott et Swiaczny, 2001, p. 73) :
- Base de données statique ;
L'historicité n'est pas prise en compte dans la base
de données statique. Les nouvelles données remplacent les
précédentes.
- Base de données rollback ;
Les données possèdent un ou des attributs de
temps de transaction. Chaque modification des données est
enregistrée.
- Base de données historique ;
Les données possèdent un ou des attributs de
temps de validité. Les données peuvent être
modifiées plusieurs fois, une seule version par temps de validité
est conservée.
- Base de données temporelle.
Les données possèdent des attributs de temps de
transaction et de temps de validité. Tout est conservé.
Prenons un exemple de trois opérations de mise
à jour successives sur un même objet « x »
représentant un peuplement forestier. Une prise de vue aérienne
est réalisée en 2009. Quelques mois après, on crée
l'objet « x », polygone représentant alors un peuplement de
pins maritimes dans la base de données. Trois ans après, une
nouvelle prise de vue est utilisée pour la mise à jour, ce
peuplement augmente de 5 ha. Après vérification sur le terrain,
quelques mois après, il s'avère que la
photo-interprétation était erronée : il s'agit en
réalité d'un peuplement de pins sylvestres depuis le
début. Le résultat final diffère en fonction du type de
base de données.
54
- Base de données statique : on ne dispose que du dernier
état.
ID
|
peuplement
|
ha
|
x
|
pin sylvestre
|
15
|
|
- Base de données rollback : on dispose des
différents états, mais les requêtes sur les états
antérieurs au 04/2013 donne un résultat faux.
ID
|
peuplement
|
ha
|
Temps transaction
|
x
|
pin maritime
|
10
|
01/2010
|
x
|
pin maritime
|
15
|
01/2013
|
x
|
pin sylvestre
|
15
|
04/2013
|
|
- Base de données historique : l'information correspond
à l'état réel du terrain, mais on perd la
trace de la correction.
ID
|
peuplement
|
ha
|
Temps de validité
|
x
|
pin sylvestre
|
10
|
2009
|
x
|
pin sylvestre
|
15
|
2012
|
|
- Base de données temporelle : toute l'information est
présente.
ID
|
peuplement
|
ha
|
Temps de validité
|
Temps de transaction
|
x
|
pin maritime
|
10
|
2009
|
01/2010
|
x
|
pin maritime
|
15
|
2012
|
01/2013
|
x
|
pin sylvestre
|
10
|
2009
|
04/2013
|
x
|
pin sylvestre
|
15
|
2012
|
04/2013
|
|
Tout comme le temps relatif et le temps absolu, temps de
validité et temps de transaction ne s'opposent pas mais, au contraire,
se complète. La base de données temporelle satisfait à la
fois des besoins techniques et thématiques. Elle est capable de retracer
à la fois les corrections et l'évolution réelle des
données, en fournissant par requête les différents
états du monde réel selon le temps de validité ainsi que
les différentes versions informatiques de ces états selon leur
temps de transaction.
II.C.2 - Modèles de base de données en
fonction de la mise à jour On distingue trois types de mise
à jour (Andrault, 1997, p. 6) :
- La mise à jour conceptuelle :
redéfinir le modèle conceptuel de données pour le
rendre conforme aux besoins des utilisateurs, à une nouvelle norme.
(exemple : le changement de nomenclature du MOS pour être compatible avec
CLC)
- La mise à jour technologique :
changement de système informatique, souvent du fait de
l'évolution rapide du matériel et des logiciels.
- La mise à jour des données :
intégration des changements afin de maintenir
l'actualité des données
Notre sujet porte sur la mise à jour des
données, c'est ce type de mise à jour que nous allons
spécifier.
55
D'après Bordin (Bordin, 2002), la mise à jour
d'une base de données est une question essentielle. Elle sert à
corriger l'écart entre les données et la réalité
que celles-ci représentent. Cet écart est lié aux erreurs
de numérisation à corriger et aux changements réels
survenus au cours du temps. La mise à jour permet ainsi
d'améliorer la qualité des informations contenues dans la base de
données et de remédier à leur obsolescence. Les
changements réels ont, en effet, pour conséquence de rendre
progressivement les données obsolètes car elles ne correspondent
plus à la réalité qu'elles sont censées
décrire.
La mise à jour est fondamentale pour assurer la
pérennité des données dont les utilisateurs
réclament des versions « à jour ». Mais elle
définit également la méthode d'intégration des
nouvelles données dans la base. Son rôle est donc
déterminant dans la prise en compte de la dimension temporelle de
l'information géographique.
Pour qu'une mise à jour permette l'historisation des
données, il est nécessaire que les nouvelles données ne
suppriment pas leur version antérieure. C'est ce critère qui
permet de différencier les bases de données temporelles des bases
de données non temporelles (Langran, 1992). Nous distinguons ainsi :
- Mise à jour non temporelle :
o L'écrasement.
- Mises à jour temporelles (Bordin, 2002) :
o L'archivage ;
o Le versionnement ;
o La journalisation ;
o L'historique.
L'historique correspond à l'approche qualitative,
cette méthode sera décrite dans la partie II.D. Les mises
à jour temporelles sont présentées dans l'ordre croissant
de leur capacité à implémenter le temps d'un point de vue
quantitatif.
II.C.2.a - Écrasement
L'écrasement correspond aux bases statiques : les
données mises à jour suppriment les données
antérieures. Cette méthode ne permet pas
l'historisation.
II.C.2.b - Archivage Également
appelé :
? mise à jour par relation level versionning ou
table versionning (Langran, 1992, p. 63)
? modèle snapshot (Bordin, 2006 ; Plumejeaud,
2011, p. 55 ; Pelekis et al., 2004 ; Langran, 1992, pp. 38-39)
? modèle par datation du support de collecte,
par couche datée (Plumejeaud, 2011, p. 55)
L'archivage consiste à enregistrer différentes
versions de la base entière en fonction de la date de mise à
jour, comme plusieurs versions d'une carte papier numérisée ou
plusieurs couches datées qui se succèdent. Chaque couche
possède des données attributaires et leur
référentiel spatial pour une date unique, en temps de
validité. C'est une observation du territoire sous la forme «
d'instantané » (en anglais snapshot).
56
L'archivage est un modèle d'historisation souvent
utilisé pour les bases de données d'occupation des sols produites
par traitement d'images de télédétection (satellite,
aérien). C'est notamment le cas pour Corine Land Cover, ou de la
première version de la cartographie forestière.
La principale qualité de ce modèle est qu'il
est intuitif. Son utilisation parait évidente lorsque la source des
données est une image étant fondée sur l'usage courant du
temps en cartographie et dans les SIG. Son principal défaut est qu'il
enregistre les données qui n'ont pas changé d'une version
à la suivante. Beaucoup de doublons sont donc stockés
inutilement. La résolution temporelle est donc limitée. Par
ailleurs, il limite la manipulation des données par l'utilisateur. Si
celui-ci attribue de nouvelles informations aux données en fonction de
ses besoins, il devra le faire pour chaque nouvelle version.
II.C.2.c - Versionnement
Également appelé :
? Modèle single time stamping (Pelekis et
al., 2004) ;
? Mise à jour tuple versionning (Langran, 1992)
;
? Mise à jour par horodatage (Bordin, 2006) ;
? Utilisé par le modèle base with amendments
(Langran, 1992).
La mise à jour par versionnement consiste à
enregistrer un premier état de la base, puis d'ajouter les
évolutions par date de mise à jour. Seules les données qui
ont changé sont à nouveau enregistrées dans la base. Les
différents états des données sont donc stockés, et
non plus différentes bases de données.
La technique utilisée est le versionnement par ligne.
Le temps est enregistré au niveau des objets informatiques, à
l'aide d'un intervalle mesurant les événements de vie. Chaque
objet, correspondant à une ligne de la table, possède au minimum
deux colonnes d'attributs temporels : une pour le début de sa
période de validité et une pour sa fin. Les nouveaux objets sont
enregistrés en ajoutant des lignes à la table, avec la date de la
mise à jour indiquée dans la colonne de début de
validité. Les anciennes versions des objets sont conservées en
remplissant la colonne de fin de validité avec la même date. La
colonne de fin de validité des objets courants peut être remplie
à l'aide des valeurs NULL, CURRENT, NOW ou INFINITY.
La principale qualité de ce modèle est qu'il
réduit les coûts de stockage. En ne stockant qu'une fois les
objets inchangés, la redondance des données est minimale en
comparaison avec l'archivage. Cela permet d'améliorer la
résolution temporelle en augmentant la fréquence entre les mises
à jour. Il est facile d'extraire ensuite des couches temporelles par
requête dans la base.
Le principal défaut de cette méthode est
qu'elle implique l'accroissement de la table d'enregistrement de la base de
données. Or plus la table est volumineuse et plus le temps de calcul des
requêtes sur les données est long. Il est possible
d'implémenter deux solutions à ce problème. L'indexation
du temps, sur le même modèle que l'indexation spatiale, permet
d'accélérer les requêtes temporelles. Il est
également possible de stocker les données dans plusieurs tables.
Cette solution, appelée partitionnement temporel, consiste à
séparer l'état courant et les versions antérieures des
données. Elle permet d'accéder plus rapidement au dernier
état des données et est souvent employée. Dernier
défaut, le versionnement implique lui aussi un certain nombre de
57
redondances, du fait de l'enregistrement complet d'un objet
à chaque modification d'un de ses attributs.
II.C.2.d - Journalisation
La mise à jour par journalisation consiste à ne
conserver que le dernier état des données et le journal (en
anglais log) des mises à jour effectuées pour obtenir ce
dernier état. Le temps est enregistré au niveau des
opérations notées dans le journal. La principale qualité
de cette méthode est le faible volume de stockage nécessaire. Par
ailleurs, elle facilite la livraison de la mise à jour aux utilisateurs
des données par transfert des opérations de mises à jour.
Elle facilite également l'affichage dynamique des données. Son
principal défaut est qu'il est nécessaire d'effectuer à
rebours les changements pour obtenir un état à une date
antérieure.
En conclusion de cette partie, l'approche quantitative du temps
est un aspect important à prendre en compte dans le choix du
modèle d'historisation. L'importance du volume nécessaire au
stockage des données est un paramètre qu'il ne faut pas
sous-estimer.
II.D - Approche qualitative du temps :
modèles de base de données spatio-temporelle
Les modèles suivant se distinguent de ceux que nous
venons de décrire par leur attention plus marquée à
l'implémentation du temps relatif. Il existe deux manières de
suivre les changements dans le temps des données géographiques
:
- En fixant une partition de l'espace ;
- En fixant une identité aux objets.
À cela s'ajoute la modélisation des
événements, qui permet de compléter l'intégration
du temps dans la base de données.
II.D.1 - Capacités qualitatives des modèles
de mises à jour
Les bases de données mises à jour par
archivage, versionnement, ou journalisation ne répondent
qu'imparfaitement aux requêtes temporelles. Elles sont limitées
dans leurs capacités d'analyse et de suivi des évolutions.
II.D.1.a - Archivage
Avec l'archivage, il est possible de suivre dans le temps les
valeurs des attributs d'une version à l'autre sur l'ensemble des
données, mais pas de connaître la dynamique exacte des
évolutions. Par exemple, on peut connaître le résultat des
différences de surfaces d'occupation du sol entre deux dates, mais on ne
connait pas directement la matrice de transition. Il est toutefois possible
d'extraire les changements et de connaître les transitions entre deux
couches datées en utilisant de manière détournée
les fonctions classiques d'un SIG, par exemple en comparant des
séquences temporelles de couches avec la fonction « overlay
» (Peuquet, 2000, p. 3).
Il n'existe pas de lien explicite entre les couches
datées. Les événements ne sont pas
implémentés. L'histoire individuelle des objets est
occultée : il n'est pas possible de savoir quelles données ont
été créées, modifiées ou supprimées.
Les opérations topologiques sont impossibles sur la dimension
temporelle. Ce modèle correspond au mode « spaghetti » en
topologie spatiale.
58
Il est donc impossible de répondre à des
requêtes complexes à l'aide de ce modèle. Il est fortement
limité dans sa description des changements dans le temps. Enfin, si les
caractéristiques techniques du support des mises à jour ou la
nomenclature des attributs sémantiques des données changent entre
deux versions, il est nécessaire de modifier les bases
précédentes pour pouvoir encore réaliser des comparaisons
entre les jeux de données.
II.D.1.b - Versionnement
Le versionnement est plus satisfaisant en termes de suivi des
évolutions. Les événements de vie sont décrits. On
peut extraire les changements par requête dans la base de données.
Il est possible d'utiliser l'algèbre d'Allen. La topologie temporelle
est plus évidente. Néanmoins, il n'y a toujours pas de lien
permettant de suivre dans la base de données l'évolution d'un
même objet au cours du temps à travers ses différentes
versions, ni de savoir quel objet créé en a remplacé un
autre détruit. L'information sur le changement est limitée : on
ne sait pas directement ce qui a évolué ni par quel processus.
II.D.1.c - Journalisation
La journalisation est plus satisfaisante sur ce point,
puisqu'elle correspond à historisation par le stockage des mutations.
Toutefois, ses capacités quantitatives limitent son utilisation pour le
suivi des évolutions.
Malgré les limites de ces modèles, il n'est pas
possible d'obtenir l'information temporelle relative à l'aide
d'opérations intervenant sur les données après leur mise
à jour. C'est notamment le cas pour les modèles par couches
datées et par versionnement. Nous avons déjà
mentionné l'utilisation des traitements spatiaux pour superposer et
extraire les changements de deux couches. La couche des changements des
données CLC en est un exemple. L'utilisation d'algorithme d'appariement
permet d'ajouter aux données l'information temporelle relative
manquante.
L'appariement des données géographiques
consiste à comparer les données entre deux dates et à
expliciter les relations entre les divers objets aux deux dates. Les objets
homologues représentant une même réalité sont
identifiés. Il est en par exemple possible d'implémenter une
identité aux objets de la base de données, permettant leur suivi,
en utilisant l'algorithme MD5, qui permet d'obtenir un code unique en fonction
de l'enregistrement informatique.
II.D.2 - L'espace fixe
Définir un référentiel spatial fixe dans
le temps permet de résoudre le problème du changement de forme
des attributs géométriques des données. Le suivi est
implémenté en établissant un lien entre les formes des
entités observées et qui évoluent, avec un
référentiel spatial qui, lui, est constant dans le temps.
Il est possible de distinguer trois modèles de bases
de données spatio-temporelles fondés sur ce principe. Les deux
premiers modèles reposent sur le principe de la définition d'un
référentiel le plus fin possible, appelé Least common
geometry (Ott et Swiaczny, 2001) traduit par Plumejeaud dans sa
thèse par « plus petit dénominateur commun », afin
qu'aucun référentiel ne soit le support spatial de plusieurs
entités au même moment.
59
Ces modèles se différencient par le format du
référentiel spatial utilisé :
- Format vecteur : le Space Time Composite (Langran,
1992), « Modèle à composition d'entités
Spatio-Temporelles » ou PPDC spatial vectoriel (Plumejeaud, 2011) ;
- Format raster : PPDC spatial matriciel (Plumejeaud, 2011).
Le dernier modèle appartenant à ce groupe est
la partition constante pour le suivi multi-niveaux (Bordin, 2006) qui consiste
à découper le territoire en portions qui peuvent faire
référence à plusieurs entités au même
moment.
II.D.2.a - PPDC spatial vectoriel
Le modèle PPDC spatial vectoriel reprend
l'idée des diagrammes spatio-temporels (Figure 15, p. 45). Son principe
revient à projeter les parcours des objets qui se déplacent dans
le temps et l'espace sur un espace plan afin de produire une
géométrie unique issue de l'intersection de ces
déplacements. Concrètement, ce modèle revient à
réaliser une couche unique issue de la fusion des couches datées
par mises à jour en un réseau de polygones. Chaque polygone
possède ses propres attributs pour l'ensemble du temps enregistré
dans la base de données. La modification de forme ou de taille du
support spatial des données doit être découpée dans
la géométrie unique à chaque mise à jour afin de
créer un polygone « plus petit dénominateur commun »
à tous les états successifs dans le temps pour cet espace.
La couche de géométrie unique résultante
n'est la représentation de la réalité à aucun
moment, mais le résultat de toutes ses évolutions.
La question de l'évolution spatiale est résolue
en étant assimilée à la représentation du
changement attributaire. Ce modèle est facilement
implémenté grâce au versionnement par colonne, ou
attribute level versionning (Langran, 1992). Les colonnes présentes
dans la table sont pour chaque ligne : un numéro de ligne, une
géométrie, et ses attributs sémantiques pour chaque date
de mises à jour.
Grâce à ce modèle, il est facile de
connaître les différents états d'occupation du sol qui se
sont succédé dans le temps pour un espace donné. En fixant
l'espace, le lien est explicite. Il est possible de reconstituer une couche
datée par requête et en fusionnant les objets voisins ayant la
même occupation du sol.
En revanche, ce modèle n'est pas capable de
répondre aux questions sur l'histoire d'un objet en particulier à
travers le temps, ni sur le processus de l'évolution, en saisissant les
mouvements ou les transformations des entités spatiales. Les
événements ne sont pas implémentés. Par exemple, il
n'est pas possible de savoir si un objet a augmenté en taille, ou s'il
est issu de la fusion de deux autres objets. La seconde principale faiblesse de
ce modèle vient de sa complexité. Chaque mise à jour peut
nécessiter le découpage de plus petits dénominateurs
communs auxquels il faut alors attribuer un historique des attributs pour
l'ensemble des dates de mises à jour. Ce type de modèle peut
devenir difficile à gérer si les entités observées
connaissent de nombreuses évolutions, ou des évolutions continues
(Plumejeaud, 2011, p. 68). Enfin, le découpage étant unique, les
erreurs sont propagées dans le temps. Ce point nécessite de
pouvoir différencier à la mise à jour les corrections des
évolutions réelles.
60
II.D.2.b - PPDC spatial matriciel
Le modèle matriciel repose sur le même principe.
Le plus petit dénominateur commun est cette fois-ci définit
dès le départ par le format : le pixel, dont la taille
définit l'unité minimale de collecte des données. La
représentation matricielle de l'espace permet d'associer à chaque
portion un attribut à une date donnée (Plumejaud, 2011, p.
59).
Ce type de modèle permet de détecter les
changements très facilement dans un SIG, ou n'importe quel programme
permettant d'additionner deux images. Il évite le problème de la
création de nouveaux plus petits dénominateurs communs.
Le principal inconvénient est le même que pour
le modèle PPDC spatial vectoriel : il n'y a toujours pas de liens
sémantiques entre des entités spatiales constituées de
plusieurs PPDC et qui évoluent dans leur positionnement dans le temps.
Les inconvénients spécifiques à ce modèle sont que
le support matriciel possède un degré de précision moins
important que le support vectoriel. Par ailleurs, il demande une plus grande
quantité d'espace de stockage. Enfin, le
géoréférencement des images utilisées comme source
des données peut poser un problème. Si celui-ci change, les
pixels peuvent être décalés et produire des changements dus
uniquement à la différence de
géoréférencement. Ce défaut est
particulièrement coûteux à corriger car il nécessite
un recalage de tous les pixels (Langran, 1992).
II.D.2.c - La partition constante
Ce dernier modèle préconise l'utilisation du
format vecteur et repose sur le principe d'un découpage fixe de l'espace
comme point de repère pour le suivi des évolutions et d'une
analyse à plusieurs niveaux des entités géographiques. Les
découpages ne correspondent toutefois pas nécessairement à
un PPDC. Ils ne résultent pas d'une intersection, mais se fondent sur
une limite géographique pertinente pour le suivi (les limites des
réseaux routiers et hydrographiques, les limites administratives) ou sur
un découpage mathématique de l'espace en parts égales.
Chaque objet enregistré dans la base possède
des attributs temporels et une référence au découpage
auquel il appartient. Le changement dans le temps est implémenté
au niveau des objets, et leur suivi au niveau supérieur de la portion de
territoire.
Le premier avantage de l'analyse à niveau multiple est
qu'elle permet d'enrichissement des données géographiques. On
délimite, par exemple, une commune puis on décrit au sein de
cette commune l'occupation des sols, le nombre de bâtiments, le nombre de
routes, et leurs évolutions. Par ailleurs, ce modèle permet
d'obtenir à faible coût un repère pour le suivi des
évolutions, et écarte les inconvénients des deux
modèles précédents. Toutefois, il n'est pas sans poser des
problèmes quant à la précision du suivi des
évolutions de l'occupation des sols. Le résultat des
évolutions sera suivi dans le temps pour chaque partition constante,
mais les dynamiques internes seront occultées. Il ne sera pas possible
de savoir comment l'évolution s'est produite.
II.D.3 - Le paradigme identitaire, ou modèle
orienté-objet
Une autre solution permet le suivi des évolutions.
Elle consiste à attribuer une identité fixe aux objets
enregistrés dans la base de données en fonction des
entités qu'ils représentent.
Ce type de modèle correspond à la mise à
jour par historique. Il s'attache le plus à l'aspect thématique
du suivi de données, c'est-à-dire à l'approche qualitative
du temps.
61
Également appelé modèle
orienté-objet, le modèle identitaire reprend son principe
à la programmation orienté-objet. Ce type de programmation,
plutôt que d'écrire des commandes successives sous une forme
impérative, consiste à définir un objet et son
comportement. La technologie orienté-objet se prête mieux d'un
point de vue conceptuel aux données géographiques, dont les
limites peuvent être floues et irrégulières.
L'implémentation du paradigme identitaire n'est toutefois pas
déterminée par le choix technologique pour la base de
données et est tout à fait possible dans une base de
données relationnelle en ajoutant une colonne pour l'identité et
en fixant des règles de conservation de celle-ci pour les nouveaux
enregistrements dans la base de données.
Selon ce modèle, un lien est établi entre les
différents états d'un objet qui permet de suivre les changements.
En plus des attributs temporels, chaque objet possède un identifiant et
l'information sur son successeur ou son prédécesseur.
L'identité de l'objet est définie par rapport à
l'entité géographique lui correspondant. Lorsqu'il est
modifié, on peut soit considérer que l'entité a
évolué, auquel cas l'objet conserve son identifiant, soit que
l'entité a été détruite et remplacée par une
autre. Dans ce cas, l'objet est indiqué comme détruit et son
successeur est indiqué.
Grâce à l'implémentation d'une
identité, les attributs temporels, spatiaux et sémantiques des
objets peuvent évoluer de manière indépendante. Le
repère fixe permettant le suivi temporel est l'identité.
Les évolutions sont enregistrées selon le
même principe que le versionnement. La différence tient au fait
que les versions successives d'une même entité pourront être
reconnues à l'aide d'un identifiant unique.
Le paradigme identitaire est intéressant, car il
nécessite une réflexion préalable sur les entités
géographiques observées ainsi que sur la nature du changement. Il
permet de répondre à un enjeu fondamental de
l'implémentation temporelle, à savoir l'identification à
travers différentes états d'objet d'une même entité
ayant subi différentes évolutions, ce que les modèles
précédents ne sont pas capables de produire. Ce modèle
possède les mêmes avantages que le versionnement, auxquels
s'ajoute la capacité d'extraire l'histoire d'une entité dans le
temps (Plumejeaud, 2011).
Toutefois, ce modèle très élaboré
peut être difficile à implémenter et lourd à
gérer. La réflexion nécessaire quant à
l'identité et à l'évolution des entités
géographiques peut être sujette à interprétations.
Elle peut donc varier selon les besoins des utilisateurs des données. Il
faudrait pouvoir définir des critères objectifs
d'identités.
Contrairement aux modèles précédents,
implémenter une identité permet de commencer à expliquer
comment une évolution a lieu. Les modèles
précédents peuvent, au mieux, permettre d'extraire les
changements à une date donnée et d'utiliser les opérateurs
topologiques d'Allen. Mais ils ne permettent pas de distinguer dans le
processus de l'évolution la succession entre les entités
géographiques. Pour cela, il faut d'abord définir
l'identité des entités afin de pouvoir les suivre. Puis il faut
définir des opérateurs topologiques liant les entités
interdépendantes entre elle (Ott et Swiaczny, 2001). Il est donc
nécessaire d'ajouter une modélisation des
événements au modèle identitaire.
II.D.4 - Modèle orienté-objet avec
modélisation des événements
Ce modèle consiste à ajouter
l'événement liant les différentes versions des objets et
des entités. Le principe est de considérer que chaque
entité géographique possède un historique et
peut-être
62
l'origine ou le produit d'une ou de plusieurs autres
entités. Grâce à ce modèle, la topologie temporelle
est implémentée dans la base en décrivant les relations de
succession entre les entités.
Le modèle identitaire ne mentionne pas explicitement
les relations temporelles liées aux événements. Ajouter
une modélisation des événements permet de compléter
ce modèle et de faciliter l'analyse des évolutions.
Dans sa thèse, Plumejaud choisit de développer
ce type de modèle afin de résoudre le problème du suivi
statistique sur de longues périodes de temps, alors que le support
spatial des données peut évoluer dans le temps. Elle distingue
deux catégories d'événements : les
événements de vie et les événements territoriaux
(Tableau 5). Les premiers se réfèrent à l'histoire
individuelle d'une entité, sa création, ses modifications et sa
destruction :
- La création est l'apparition d'une nouvelle
entité définie par une identité propre.
- La modification intervient lorsqu'un des attributs de
l'entité géographique est modifié sans
modifier son identité.
- La destruction est le moment de la suppression d'une
entité géographique. Son identité ne sera plus
attribuée à de nouveaux objets stockés dans la base.
Les seconds expriment le résultat du croisement des
entités dans l'espace au cours du temps, comme une combinaison, une
fragmentation, ou un déplacement de limite. Plumejeaud a défini
cette typologie d'événements afin de décrire les
évolutions des découpages administratifs, support spatial des
données statistiques. Cette nomenclature est affinée en fonction
du critère de conservation de l'identité d'une entité
précédente :
- Une combinaison intervient lorsque plusieurs entités
sont remplacées par une seule.
o Lors d'une fusion, il y a création d'une nouvelle
entité.
Exemple : la création de la ville nouvelle de
Saint-Quentin-en-Yvelines regroupant plusieurs communes.
o Lors d'une intégration, une des entités
précédentes est conservée. Exemple : l'intégration
des faubourgs de Paris.
- La fragmentation est l'événement inverse de la
combinaison.
o Il s'agit d'une scission lorsque l'entité de
départ à été remplacée par plusieurs
nouvelles entités.
Exemple : l'éclatement de l'URSS.
o Il s'agit d'une extraction lorsque l'entité de
départ existe encore après l'événement. Exemple :
la sécession du Soudan du Sud de la République du Soudan.
- La redistribution correspond à un déplacement de
limites entre deux entités.
o La réaffectation implique la destruction d'une des
entités précédentes.
Exemple : la frontière entre deux parcelles cadastrales
et le propriétaire d'une des parcelles changent.
o La rectification implique le maintien des deux entités
précédentes. Exemple : idem que précédent, sans
changement de propriétaire.
63
Tableau 5 : Événements de vie et
événements territoriaux (Source : Plumejeaud, 2011)
Évènements territoriaux
|
Combinaison
|
Fragmentation
|
Redistribution
|
|
Intégration
|
Scission
|
Extraction
|
Réaffectation
|
Rectification
|
Avant l'événement
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Évènements de vie
|
Création
|
X
|
|
X
|
X
|
X
|
|
|
|
X
|
|
X
|
X
|
X
|
|
X
|
X
|
X
|
|
X
|
|
|
Ce modèle est celui qui permet de répondre
pleinement aux besoins d'une approche qualitative du temps dans une base de
données. En décrivant les événements et en reliant
les entités par un même événement, il est possible
d'intégrer la succession ordinale des états et d'identifier
clairement les évolutions. Cela permet de connaître l'information
temporelle relative. Chaque entité possède différents
états qui sont reliés entre eux et avec les états d'autres
entités par des événements datés. Il est ainsi
possible de connaître précisément l'historique d'une
entité ou d'un territoire.
Ce modèle possède les mêmes
défauts que le modèle précédent. Il est
relativement complexe à mettre en oeuvre, car il demande de
définir non seulement l'identité et le changement, mais aussi les
événements. Son implémentation requiert donc une
automatisation, à l'aide d'un algorithme d'appariement.
II.E - Illustration des différents
modèles de base de données spatio-temporelle à l'aide d'un
exemple de synthèse
Afin de comparer concrètement les sept modèles
que nous avons évoqués, nous utilisons un exemple unique mettant
en évidence les différences entre ses modèles. Il s'agit
d'évolutions probables d'un territoire entièrement couvert par le
RGFor entre un jeu de données initial et une première mise
à jour. Les évolutions utilisées dans cet exemple sont
:
- Le fractionnement d'un peuplement avec la construction d'une
route.
- Un déplacement de limite entre un peuplement de
forêt fermée et de forêt ouverte et le
remplacement d'une lande herbacée par une lande ligneuse
pouvant être causé par la succession végétale.
- Une coupe rase au sein d'un peuplement.
II.E.1 - Archivage
T T+1
? Table T
id
|
poste
|
1
|
Mélange de feuillus
|
2
|
Peupleraie
|
3
|
Forêt ouverte de feuillus purs
|
4
|
Lande ligneuse
|
5
|
Formation herbacée
|
6
|
Hêtre pur
|
|
? Table T+1
64
id
poste
|
1
|
Mélange de feuillus
|
2
|
Mélange de feuillus
|
3
|
Peupleraie
|
4
|
Jeune peuplement ou coupe rase ou incident
|
5
|
Forêt ouverte de feuillus purs
|
6
|
Lande ligneuse
|
7
|
Hêtre pur
|
|
II.E.2 - Versionnement par ligne
T T+1
? Table
65
id
poste
|
depuis
|
jusqu'à
|
1
|
Mélange de feuillus
|
T
|
T+1
|
2
|
Peupleraie
|
T
|
T+1
|
3
|
Forêt ouverte de feuillus purs
|
T
|
T+1
|
4
|
Lande ligneuse
|
T
|
T+1
|
5
|
Formation herbacée
|
T
|
T+1
|
6
|
Hêtre pur
|
T
|
NOW
|
7
|
Mélange de feuillus
|
T+1
|
NOW
|
8
|
Mélange de feuillus
|
T+1
|
NOW
|
9
|
Peupleraie
|
T+1
|
NOW
|
10
|
Jeune peuplement ou coupe rase ou incident
|
T+1
|
NOW
|
11
|
Forêt ouverte de feuillus purs
|
T+1
|
NOW
|
12
|
Lande ligneuse
|
T+1
|
NOW
|
|
II.E.3 - Journalisation
T+1
? Table
id
|
poste
|
6
|
Hêtre pur
|
7
|
Mélange de feuillus
|
8
|
Mélange de feuillus
|
9
|
Peupleraie
|
10
|
Jeune peuplement ou coupe rase ou incident
|
11
|
Forêt ouverte de feuillus purs
|
12
|
Lande ligneuse
|
|
? Journal
66
id
opération
|
date
|
1
|
Création des objets 1, 2, 3, 4, 5, 6
|
T
|
2
|
Destruction des objets 1, 2, 3, 4, 5
|
T+1
|
3
|
Créations des objets 7, 8, 9, 10, 11, 12
|
T+1
|
|
67
II.E.4 - PPDC spatial vectoriel
? Table, versionnement par colonne
id
|
T
|
T+1
|
4
|
Lande ligneuse
|
Lande ligneuse
|
5
|
Formation herbacée
|
Lande ligneuse
|
6
|
Hêtre pur
|
Hêtre pur
|
7
|
Mélange de feuillus
|
Mélange de feuillus
|
8
|
Mélange de feuillus
|
Hors nomenclature (route)
|
9
|
Mélange de feuillus
|
Mélange de feuillus
|
10
|
Peupleraie
|
Peupleraie
|
11
|
Peupleraie
|
Jeune peuplement ou coupe rase ou incident
|
12
|
Forêt ouverte de feuillus purs
|
Mélange de feuillus
|
13
|
Forêt ouverte de feuillus purs
|
Forêt ouverte de feuillus purs
|
|
II.E.5 - PPDC spatial matriciel
T T+1
? Table, versionnement par ligne :
68
id
|
ligne
|
colonne
|
poste
|
depuis
|
jusqu'à
|
1
|
1
|
1
|
Mélange de feuillus
|
T
|
NOW
|
2
|
1
|
2
|
Mélange de feuillus
|
T
|
NOW
|
3
|
1
|
3
|
Mélange de feuillus
|
T
|
NOW
|
4
|
1
|
4
|
Mélange de feuillus
|
T
|
NOW
|
5
|
1
|
5
|
Mélange de feuillus
|
T
|
T+1
|
6
|
1
|
6
|
Mélange de feuillus
|
T
|
NOW
|
7
|
1
|
7
|
Forêt ouverte de feuillus purs
|
T
|
T+1
|
8
|
1
|
8
|
Forêt ouverte de feuillus purs
|
T
|
T+1
|
9
|
1
|
9
|
Forêt ouverte de feuillus purs
|
T
|
T+1
|
10
|
1
|
10
|
Forêt ouverte de feuillus purs
|
T
|
NOW
|
11
|
1
|
11
|
Forêt ouverte de feuillus purs
|
T
|
NOW
|
12
|
1
|
12
|
Forêt ouverte de feuillus purs
|
T
|
NOW
|
...
|
...
|
...
|
...
|
...
|
...
|
157
|
1
|
4
|
Hors nomenclature (route)
|
T+1
|
NOW
|
158
|
1
|
7
|
Mélange de feuillus
|
T+1
|
NOW
|
159
|
1
|
8
|
Mélange de feuillus
|
T+1
|
NOW
|
160
|
1
|
9
|
Mélange de feuillus
|
T+1
|
NOW
|
...
|
...
|
...
|
...
|
...
|
...
|
188
|
11
|
12
|
Lande ligneuse
|
T+1
|
NOW
|
|
II.E.6 - Orienté objet
T T+1
69
? Table, versionnement par ligne
id
|
identité
|
poste
|
depuis
|
jusqu'à
|
1
|
a
|
Mélange de feuillus
|
T
|
T+1
|
2
|
b
|
Peupleraie
|
T
|
T+1
|
3
|
c
|
Forêt ouverte de feuillus purs
|
T
|
T+1
|
4
|
d
|
Lande ligneuse
|
T
|
T+1
|
5
|
e
|
Formation herbacée
|
T
|
T+1
|
6
|
f
|
Hêtre pur
|
T
|
NOW
|
7
|
a
|
Mélange de feuillus
|
T+1
|
NOW
|
8
|
a
|
Mélange de feuillus
|
T+1
|
NOW
|
9
|
b
|
Peupleraie
|
T+1
|
NOW
|
10
|
h
|
Jeune peuplement ou coupe rase ou incident
|
T+1
|
NOW
|
11
|
c
|
Forêt ouverte de feuillus purs
|
T+1
|
NOW
|
12
|
d
|
Lande ligneuse
|
T+1
|
NOW
|
|
II.E.7 - Orienté objet et modélisation des
événements
? Table, versionnement par ligne
id iden- poste depuis jusqu'à
tité
? Événements territoriaux ?
Événements de vie
1
a
Mélange de feuillus
T
T+1
2
b
Peupleraie
T
T+1
3
c
Forêt ouverte de feuillus purs
T
T+1
4
d
Lande ligneuse
T
T+1
5
e
Formation herbacée
T
T+1
6
f
Hêtre pur
T
NOW
7
a
Mélange de feuillus
T+1
NOW
8
a
Mélange de feuillus
T+1
NOW
9
b
Peupleraie
T+1
NOW
10
h
Jeune peuplement ou coupe rase ou incident
T+1
NOW
11
c
Forêt ouverte de feuillus purs
T+1
NOW
12
d
Lande ligneuse
T+1
NOW
|
|
|
|
num_ évé
|
num_ évé_modif
|
|
|
|
|
|
NULL
|
10 ; 20
|
|
|
|
|
|
NULL
|
30
|
|
|
|
|
|
NULL
|
20
|
|
|
|
|
|
NULL
|
40
|
|
|
|
|
|
NULL
|
40
|
|
|
|
|
|
NULL
|
NULL
|
|
|
|
|
|
10
|
NULL
|
|
|
|
|
|
10 ; 20
|
NULL
|
|
|
|
|
|
30
|
NULL
|
|
|
|
|
|
30
|
NULL
|
|
|
|
|
|
40
|
NULL
|
|
|
|
|
|
40
|
NULL
|
|
num_eve
|
événement
|
date
|
10
|
|
|
extraction
|
T+1
|
20
|
rectification
|
T+1
|
30
|
extraction
|
T+1
|
40
|
intégration
|
T+1
|
|
70
id
événement
|
date
|
a
|
création
|
T
|
b
|
création
|
T
|
c
|
création
|
T
|
d
|
création
|
T
|
e
|
création
|
T
|
f
|
création
|
T+1
|
a
|
modification
|
T+1
|
b
|
modification
|
T+1
|
c
|
modification
|
T+1
|
d
|
modification
|
T+1
|
e
|
destruction
|
T+1
|
|
71
II.F - Conclusion
Pour le RGFor, l'approche idéale nous semble
être celles des modèles qualitatifs. Le modèle
orienté-objet avec modélisation des événements
parait être la solution optimale pour répondre à l'ensemble
des besoins que nous avons identifiés (Chapitre I). La gestion de
l'identité des entités géographiques et des
événements est un aspect à la fois important et difficile
à mettre en oeuvre qui pourtant est nécessaire pour
implémenter les temps selon ses différents aspects (Plumejeaud,
2011). Ce modèle idéal n'a toutefois pas encore été
testé par de nombreuses bases de données ailleurs que dans la
recherche (Ott et Swiaczny, 2001). L'analyse des bases existantes nous montrera
les solutions concrètement employés par les gestionnaires des
bases de données afin d'intégrer le temps.
72
73
CHAPITRE III - Analyse de l'existant
Bien que l'intégration de la dimension temporelle soit
une préoccupation relativement nouvelle pour les bases de données
d'informations géographiques (Bordin, 2002, p. 90), des
expériences de mises en place de processus d'intégration et
d'outils de gestion de la dimension temporelle ont déjà
été conduites. Les recherches sur les modèles
théoriques ont en effet apporté des réponses à
cette question et les problèmes liés aux limites
matérielles ont pu, du moins en partie, se résoudre du fait des
progrès techniques. Par ailleurs, ces expériences
répondent de fait à un besoin croissant en informations
spatio-temporelles (Paque, 2004, p. 2) dont nous avons fait part en
décrivant les besoins à l'origine de cette étude.
Afin de répondre à notre problématique,
nous ferons donc un état de l'existant, non exhaustif, du processus
d'historisation de plusieurs bases de données géographiques
à grande échelle. Nous décrirons ces modèles en
suivant le même ordre de complexité que celui des modèles
décrits dans la partie précédente. Nous commencerons par
deux bases régionales, la BdOCS (Base de données d'Occupation des
Sols) d'Alsace, puis le MOS (Mode d'Occupation des Sols) d'Île-de-France
qui sont fondées respectivement sur l'historisation par archivage et le
modèle space-time composite. Enfin nous décrirons le
modèle d'historisation de la BDUni interne à l'IGN qui correspond
à un modèle identitaire incluant les événements.
Nous présenterons ces bases de données, leur processus de mise
à jour, et nous analyserons les avantages et les inconvénients de
leur méthode d'intégration du temps.
Nous ajouterons à la description des bases de
données une partie plus générale sur les normes existantes
quant à l'intégration du temps dans une base de données,
en particulier celles décrites dans le cadre d'INSPIRE, ainsi que sur
les recommandations et les outils mis en place par ESRI.
L'évaluation de l'existant nous servira à
compléter l'état de l'art afin d'aboutir à des
préconisations quant à l'adaptabilité des
modèles.
III.A - BdOCS CIGAL
III.A.1 - Présentation
La BdOCS (Base de données d'Occupation des Sols) est
une couverture continue de l'ensemble du territoire alsacien en format vecteur
et à grande échelle. Elle s'intègre dans la dynamique de
partenariat du CIGAL (Coopération pour l'Information Géographique
en Alsace) qui regroupe des collectivités territoriales (la
région Alsace, les conseils généraux, la communauté
urbaine de Strasbourg), deux parcs naturels régionaux, des agences
d'urbanisme et la Chambre de l'Agriculture.
La BdOCS répond à l'identification d'un besoin
dès 2000 de disposer de données d'occupation des sols à
grande échelle en Alsace. Ce besoin s'explique par le fait que les
données à l'époque étaient insuffisantes pour la
connaissance du territoire et de ses dynamiques. Cette connaissance
s'avère nécessaire afin d'observer un territoire se distinguant
de ses voisins par ses dynamiques et sa forte densité de population
(3ème région française la plus densément
peuplée).
L'enjeu est de mesurer l'artificialisation des territoires et
d'améliorer les connaissances sur les domaines agricoles et naturels
pour le maintien de la biodiversité. La production de cette base est
voulue régulière afin de suivre dans le temps ce type
d'évolution.
74
III.A.2 - Contenu
La nomenclature de la BdOCS comprend quatre niveaux de
précision, le quatrième incluant 55 postes différents
(voir Annexes). L'unité minimale de collecte varie selon les
thèmes d'un demi-hectare pour les espaces urbains, à un hectare
pour les espaces agricoles. Les données sont enregistrées sous la
forme de fichiers de couches, au format shape. Il existe une couche
pour la première version des données, puis une couche par mise
à jour. Deux versions de la base ont été produites pour le
moment : une pour l'année 2000 et une pour 2008 (BdOCS2000-CIGAL et
BdOCS2008-CIGAL). Une troisième version, pour l'année 2012, est
en cours de production. Chaque polygone d'une couche de données
possède un identifiant, une géométrie et un poste de la
nomenclature.
À cela s'ajoute une couche des mutations contenant
tous les changements entre deux versions (BdOCSmutation2000-2008). La couche
des mutations 2000-2008 contient une colonne indiquant l'identifiant de l'objet
à l'année 2000, une autre pour l'identifiant de 2008, et la
géométrie de la différence entre les deux
années.
III.A.3 - Mise à jour
La mise à jour est externalisée. Elle a lieu
tous les quatre ans. Les sources utilisées sont principalement
l'ortho-photographie (BD Ortho®) et les images satellites
à haute résolution (Spot), mais également la BD
Topo®, le MNT, le SCAN 25, et le registre parcellaire graphique de
l'IGN.
Il existe une base entière par mise à jour. Les
différentes versions de la base sont millésimées en
fonction de la date des images utilisées pour produire les
données. La couche des changements est produite par des traitements de
superposition entre les deux couches dans un logiciel SIG permettant d'extraire
les changements et des données statistiques sur les évolutions
entre deux millésimes.
La question de la mise à jour n'a pas
été abordée dès le départ. Il a d'abord
été question de créer une nomenclature partagée
entre les différents utilisateurs et de définir les sources ainsi
que la méthode de production des données. Une fois la production
définie, la mise à jour consiste simplement à reprendre
entièrement la production.
III.A.4 - Avantages et inconvénients du
modèle
Ce modèle correspond à une historisation par
archivage, utilisant un traitement a posteriori afin d'extraire les
changements nécessaires aux statistiques du suivi des
évolutions.
III.A.4.a - Capacités
Ce modèle permet de stocker toute l'information en
fonction de la date de validité. C'est un système robuste et qui
satisfait ses utilisateurs. Il permet de connaître facilement
l'état d'un territoire à une date donnée ainsi que les
évolutions de surface entre deux dates en utilisant les
différentes couches. C'est un modèle simple et qui semble logique
à utiliser dans un SIG permettant d'afficher plusieurs couches.
III.A.4.b - Inconvénients
Toutefois, ce modèle peut atteindre rapidement sa
limite. Il ne permet pas d'obtenir des informations sur les évolutions
directement par requête dans la base de données. L'enregistrement
de l'information est en grande partie redondant. Il n'existe pas de lien
explicite au départ entre les données des différentes
versions. Celui-ci est obtenu ponctuellement grâce à l'extraction
des changements entre deux versions. Or, les utilisateurs commencent à
demander plus d'informations,
75
notamment par rapport à la connaissance de
l'environnement sur l'évolution morphologique des espaces naturels et
agricoles (Source : entretien avec C. Schott).
Le principal inconvénient est la
nécessité de maintenir la cohérence
géométrique entre les différentes couches. Lorsqu'une
correction est nécessaire, il faut reprendre la correction pour toutes
les couches séparément. Les modifications
géométriques doivent correspondre à des changements
réels. Ceci est nécessaire pour ne pas fausser les
résultats lors de l'extraction des changements à cause de petits
polygones reliquats résultant, par exemple, d'une différence de
calage. Lorsque des images plus précises ont été
utilisées pour produire les données, comme ce fut le cas pour la
version 2008, il a été nécessaire de refaire
entièrement la base de 2000 pour la mettre en cohérence avec
celle de 2008. Ensuite, la base de 2008 a servi de référence
géométrique pour la mise à jour de 2012.
Par ailleurs, lorsqu'une correction intervient, les
données précédentes sont écrasées. Les
corrections doivent donc être contrôlées afin
d'éviter des manipulations pouvant réduire la qualité des
données, un retour en arrière n'étant pas possible.
Enfin, la base entière possède une date unique
en fonction de sa version. Mais les supports des données
utilisées peuvent posséder différentes dates de
validité qui sont renseignées en métadonnées.
III.B - MOS IAU IDF
III.B.1 - Présentation
Le MOS (Mode d'Occupation du Sol) est une base de
données à grande échelle (20 cm de résolution
spatiale23) en format vecteur couvrant en continu la totalité
du territoire de l'Île-de-France. Il a été conçu
dans les années 80, avec un logiciel propriétaire. Sa mise
à jour constitue une innovation technique importante puisqu'il
n'existait pas d'autre modèle de base spatio-temporelle à
l'époque. La première version du MOS date de 1982. La
première mise à jour a été réalisée
en 1987, la dernière en 2012. Il y a eu huit mises à jour au
total.
Le MOS et son modèle d'historisation ont
été mis en place pour que l'IAU ÎDF, le bureau
d'études en aménagement et en urbanisme du Conseil
régional, dispose d'un outil lui permettant d'effectuer ses missions :
« proc[éder] à toutes études, enquêtes et
recherches ayant pour objet l'aménagement et l'urbanisme dans la
région Île-de-France24. » Ce modèle a
donc été créé afin de permettre le suivi de
l'urbanisation et d'évaluer les schémas directeurs.
III.B.2 - Contenu
La nomenclature du MOS comprend 5 niveaux de
précisions, dont le dernier contient 81 postes différents (voir
Annexes). La base actuelle est composée d'environ 580 000 polygones
enregistrés dans une seule table. Celle-ci est composée de
plusieurs colonnes :
- Un identifiant unique.
- Une géométrie.
- Une colonne d'attribut sémantique pour la
première version, puis une par date de mise à jour (neuf en
tout).
23 Source :
http://www.iau-idf.fr/cartes/base-de-connaissance/mos.html
Consulté le 21/02/2013.
24 Source :
http://www.iau-idf.fr/fileadmin/user_upload/IAU-IDF/pdf_statuts_IAU.pdf.
Consulté le 21/02/20123.
76
À cela s'ajoutent des tables de statistiques de suivi
d'évolution (calculs numériques) de surface pour chaque poste de
la nomenclature calculées entre les dates de mises à jour, d'une
mise à jour à l'autre ou sur une période plus importante
(sur dix ans par exemple) en fonction des besoins des utilisateurs. Des couches
d'évolution et des couches d'occupation des sols à une date
donnée sont également pré-calculées en fonction des
mêmes besoins. Ces derniers calculs prennent du temps (de l'ordre du
mois), ils ne sont pas nécessairement effectués après
chaque correction de la base.
Il s'agit d'une base relationnelle, fondée sur la
technologie d'Esri : un fichier de géodatabase, c'est-à-dire un
support commun de stockage et de gestion des données d'ArcGis,
utilisable par un ordinateur ou par un serveur. Il est possible que le
fonctionnement change à l'avenir pour passer à ArcSDE (Spatial
Database Engine), logiciel d'Esri permettant la gestion des données
géographique sur un serveur et l'utilisation d'un SGBD comme
PostgreSQL/PostGis.
Ce système, dépendant de la technologie Esri, a
été choisi car il est capable de satisfaire les exigences d'une
base de données d'objets surfaciques en termes de topologie (ne supporte
pas les trous, les superpositions). Les règles topologiques sont d'abord
définies puis stockées dans la base de données.
III.B.3 - Mise à jour
III.B.3.a - Principe
La première version numérique du MOS a
été mise en place en 1982, puis la première mise à
jour en 1987, par André Ballu qui a développé les outils
informatiques nécessaires dans le cadre de travaux de recherche
(rédaction d'un mémoire sur le sujet en 1974). Le suivi de
l'occupation du sol s'appuie sur l'utilisation de photographies
aériennes. Le modèle n'a pas changé depuis sa
conception.
La mise à jour du MOS repose sur le principe de
partition constante de l'espace et correspond au modèle de PPDC spatial
vectoriel. Une seule couche de géométrie est enregistrée
et maintenue dans le temps. Tous les polygones possèdent un attribut
pour chaque date de mise à jour, c'est-à-dire pour l'année
de la prise de vue aérienne qui correspond. C'est le temps de
validité qui est enregistré dans la base.
La mise à jour est réalisée par
attribute versionning : une nouvelle colonne d'attribut sémantique
est ajoutée à la table. Celle-ci est remplie avec le même
poste de nomenclature pour les polygones qui n'ont pas subi de changement et
avec un nouveau poste pour ceux qui ont évolué.
La géométrie des polygones reste
inchangée, sauf si elle correspond à une évolution
réelle. Dans ce cas, on découpe à l'intérieur du
polygone concerné par le changement, sans en modifier les limites
d'origine. Les nouveaux polygones créés possèdent encore
tout l'historique du polygone dans lequel ils ont été
découpés. Les limites des polygones d'origine sont donc
conservées et ne doivent normalement pas être modifiées.
77
Exemple :
a) Tableau 1 : état de la base en 1982
Identifiant
|
géométrie
|
1982
|
1
|
x,y...
|
Carrières, sablières
|
2
|
x,y...
|
Bois ou forêt
|
|
b) Tableau 2 : état de la base en 2008
Identifiant
|
géométrie
|
1982
|
...
|
2008
|
3
|
x,y...
|
Carrières, sablières
|
|
Espace ruraux ouverts
|
4
|
x,y...
|
Carrières, sablières
|
|
Eau fermée
|
5
|
x,y...
|
Bois ou forêt
|
|
Bois ou forêt
|
6
|
x,y...
|
Bois ou forêt
|
|
Carrières, sablières
|
7
|
x,y...
|
Carrières, sablières
|
|
Bois ou forêt
|
|
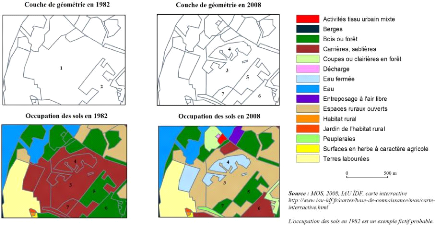
Figure 20 : Exemple probable d'évolution de
l'occupation des sols à la carrière de granulats de Guernes
(78).
Dans cet exemple, on observe la présence de deux
objets en 1982 identifiés par les numéros 1 et 2 : un bois ou une
forêt et la carrière exploitant les dépôts
alluvionnaires de la rive convexe de la Seine. Au moment de la saisie, en 1982,
l'état de la base pour ces deux objets correspondait au tableau 1 et
à la géométrie de 1982 de la Figure 20. Vingt-six
années plus tard (Tableau 2, couche de géométrie de 2008),
l'occupation des sols a évolué : ses ressources ayant
été épuisées, la carrière dans son extension
de 1982 a été abandonnée et l'exploitation se poursuit
désormais dans de nouvelles zones. La reconversion de l'ancienne
carrière a donné lieu à des aménagements : certains
trous ont été transformés en étangs (l'objet
identifié par le numéro 4 est aujourd'hui une réserve
ornithologique), des arbres ont été plantés (objet 7) et
le reste de l'espace demeure vacant, étant en zone inondable (objet
3).
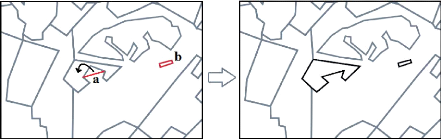
78
Concrètement, les mises à jour ont
été effectuées en découpant les objets 3, 4 et 7
dans l'objet 1, et les objets 5 et 6 dans l'objet 2. La couche unique de
géométrie en 1982 a été modifiée et les
attributs à chaque date ont été enregistrés dans la
table.
III.B.3.b - Consignes et méthodes de saisies
La saisie est effectuée à partir
d'ortho-photographies aériennes. Elle est sous-traitée depuis
2003 à une entreprise basée à Lille qui emploie une
équipe de quatre à six photo-interprètes. Les
ortho-photographies sont commandées en fonction de l'offre disponible au
moment de la mise à jour, tous les quatre à cinq ans. Il n'y a
pas de vérification effectuée sur le terrain mais une
documentation exogène importante est fournie (listes des
établissements d'enseignement par exemple) et d'autres sources de
données (IGN, Google Street View) peuvent être
utilisées.
La saisie lors de la mise à jour est effectuée
manuellement. La classification automatique n'a pas été retenue
car elle prendrait autant de temps uniquement à contrôler qu'une
production manuelle. L'ensemble de la région Île-de-France est
couverte par les photo-interprètes. Un prestataire externe
réalise des contrôles sur des points aléatoires et des
points orientés en fonction des erreurs courantes qui ne sont pas
communiquées aux photo-interprètes.
Un cahier des charges très strict a été
mis en place afin de conserver les limites de la couche
géométrique unique pour garantir sa validité pour chaque
date de mise à jour. Les polygones ne peuvent être modifiés
que si cela correspond à une évolution réelle. Il n'est
pas possible de déplacer les limites des polygones.
Dans le cas d'un doute quant au découpage
précédent des limites, seule la responsable de la base à
l'IAU ÎDF est habilitée à effectuer la correction. La
méthodologie actuelle demande qu'une impression d'écran de la
zone concernée par la correction lui soit envoyée. Pour faire une
correction, la nouvelle limite est découpée dans les voisins du
polygone concerné et le résultat de ce découpage est
attribué au polygone par fusion (Figure 21).
Figure 21 : Exemple de saisie d'une correction de
limite (a) et d'un changement réel (b) (Source : exemple fictif
fondé sur l'entretien avec S. Foulard et la carte interactive du MOS
2008 de la carrière de granulats de Guernes).
Dans l'exemple illustré par la Figure 21, les limites
d'une des pièces d'eau fermées avaient été mal
dessinées. La limite du polygone est corrigée (a). Une autre
pièce d'eau, de petite taille, n'avait pas été saisie. Le
polygone est découpé à l'intérieur du
précédent, puisqu'il correspond à un changement
réel (b).
79
III.B.4 - Avantages et inconvénients du
modèle
III.B.4.a - Capacités
Il a été possible d'utiliser la couche de
géométrie comme support de calcul des densités de
population (produit « densimos ») avant que l'INSEE ne crée
les IRIS (Îlots Regroupés pour l'Information Statistique).
Ce modèle est capable de contenir au sein d'une seule
table l'information complète dans le temps sur l'occupation des sols.
Comme le modèle n'a pas changé depuis le départ, il est
possible de comparer l'occupation des sols sur 30 ans de données. Il est
possible de réaliser des vues des données par dates de mise
à jour (outils de fusion d'ArcGis) en supprimant les découpages
des autres époques afin de faciliter la lecture, de localiser les
changements, de suivre les évolutions, de connaître leur rythme,
etc.
Les tableaux statistiques d'évolution de l'occupation
des sols, les couches d'occupation à date données et
d'évolution entre deux dates ont été calculés, ce
qui permet d'accélérer l'accès à l'information. La
technique de versionnement permet un stockage relativement réduit.
L'utilisation de la technologie d'Esri permet de se prémunir des
problèmes de topologie mettant en péril la cohérence des
données.
La méthodologie de saisie des évolutions
réelles et des corrections permet également de garantir la
cohérence et la qualité des données dans le temps. Ce
modèle pourrait permettre d'effectuer des mises à jour vers le
passé. Il est possible d'utiliser des sources de données plus
anciennes et d'ajouter des colonnes à la table possédant des
dates antérieures aux précédentes versions.
Les polygones ont des identifiants mais ceux-ci ne sont pas
utiles au suivi temporel, puisque le support spatial des données est
conservé et qu'il sert de point de repère. Ce modèle ne
demande pas de réflexion sur la conservation de l'identité des
objets ni son implémentation.
Ce modèle permet une mise à jour rapide et
économique. La base est simple d'utilisation. Elle remplit ses objectifs
et satisfait les utilisateurs. Ces points sont essentiels et soulignent
l'efficacité du MOS en tant que base de données d'occupation des
sols intégrant la dimension temporelle et permettant le suivi des
évolutions.
III.B.4.b - Inconvénients
Le principal problème de ce modèle est
l'évolution de la couche de géométrie unique dans le temps
: chaque évolution géométrique demande un nouveau
découpage, donc une nouvelle ligne dans la table qui correspond à
un nouvel objet. Ce système alourdit les mises à jour
ultérieures, au risque de perdre de son efficacité, voir se
bloquer. Il sera peut-être nécessaire de changer de modèle
ou de le faire évoluer. Il est possible, par exemple, que le principe du
modèle soit maintenu mais que la base évolue vers des
données au format « raster ».
Le temps de transaction n'est pas utilisé. L'outil de
versionnement d'ArcGis n'est pas utilisé pour éviter d'avoir
à gérer les conflits. La gestion des modifications et des
corrections est un peu lourde. Celles-ci ne pouvant être effectuée
qu'une fois validée par l'IAU ÎDF.
80
Bien que la saisie soit réalisée avec une
précision au 1/5000ème (unité minimale de
collecte de 30025 m2), le maintien des limites du passé
amoindrit la précision géométrique de la base qui
correspond plutôt à une utilisation au 25000ème.
L'objectif du suivi des évolutions sémantiques est
privilégié sur la précision des découpages
géométriques. Ce qui peut poser un problème pour l'analyse
des évolutions, notamment dans les milieux naturels.
Peu de découpage ont lieu dans ces milieux, parce
qu'il y a peu de postes (voir nomenclature, annexe II). Le MOS se concentre sur
les évolutions de l'urbanisation. Les lisières sont globalement
fixées sur les limites de la première version. Les limites des
bois et des forêts sont normalement protégées en
Île-de-France, elles ne devraient pas connaître d'évolution.
Et lorsque c'est le cas, il s'agit d'un passage clair dans un poste urbain
(construction d'un nouveau lotissement par exemple). Pourtant, les
lisières connaissent également des évolutions de perte de
surface qui ne sont pas répercutées dans la base parce qu'elles
sont trop fines. Et, par ailleurs, les évolutions inverses ne sont pas
non plus saisies. Pour la version 2012, des polygones d'espaces ruraux ouverts
correspondant à des anciennes carrières abandonnées et
laissées en friche vont devenir des bois ou des forêts, alors que
cette évolution a été plutôt continue que
discrète dans l'espace et dans le temps. Pour le domaine forestier, le
MOS risque ainsi d'indiquer une information a priori erronée :
une augmentation soudaine des surfaces de forêt d'une part, alors que les
milieux naturels régressent globalement d'autre part (Source : entretien
avec S. Foulard).
III.C - BD Uni IGN
Cette partie est issue du rapport rédigé au
cours du stage joint en annexe. Il contient notamment des exemples concrets du
fonctionnement de processus de ce processus d'historisation
III.C.1 - Présentation
Un modèle d'historisation a déjà
été développé au sein de l'IGN dans le cadre du
projet d'unification des bases de données, ou BD Uni.
La BD Uni est une base de production26 de
données vecteurs sur la France entière contenant l'ensemble des
domaines27 (également appelés thèmes ou encore
couches) qui constituent les produits commerciaux de l'IGN tels que la BD
Carto® et le RGE® (Référentiel
à Grande Échelle) vecteur qui est constitué de la BD
Topo® et de la BD Adresse®. Comme la majorité des bases de
données actuelles, la BD Uni est une base de données
relationnelles, c'est-à-dire que les données sont
réparties dans des tables, divisées en colonnes et en lignes
auxquelles il est possible d'accéder à l'aide de requêtes
SQL (Date, 2004, p. 27).
La BD Uni est régie par le processus de production
appelé MAJEC (Mise A Jour En Continu). Ce processus, confié au
service de bases vecteurs, au service de la cartographie et aux cinq directions
interrégionales de l'IGN, consiste à produire des
éléments de topographies et des adresses de la BDUni. Cette
production est assurée par les collecteurs de la MAJEC répartis
entre les différentes
25 L'UMC était auparavant de 625 m2. Elle a
été réduite à 300 m2 avec l'utilisation
d'ortho-photographies à 20 cm de résolution.
26 Les données produites à l'IGN sont
réparties en plusieurs bases - base d'acquisition, base de production,
base d'exploitation - en fonction des étapes de la chaîne de
production, allant de l'opérateur de saisie jusqu'à
l'utilisateur.
27 La BDUni regroupe les informations géographiques
appartenant à 10 domaines : le réseau routier, les voies
ferrées et autres moyens de transport terrestre, les réseaux de
distribution, le réseau hydrographique terrestre, le bâti, la
végétation, l'orographie, les zonages administratifs, les zones
d'activité ou d'intérêt, les adresses (IGN, 2011-A).
81
directions régionales de l'IGN. La table des
réconciliations permet d'ajouter des métadonnées sur la
mise à jour en indiquant la personne l'ayant réalisée et
sur quel ensemble de modifications.
III.C.2 - Contenu
Un des thèmes de cette base de données, la
couche végétation, est une couche d'occupation du sol, dont la
création est intégrée à la chaîne de
production du RGFor depuis la mise en place du partenariat entre l'IFN et l'IGN
(Guinaudeau, 2006) et la fusion des deux instituts au premier janvier 2012.
Cette couche comprend les milieux arborés et les landes (voir Annexes)
(IGN, 2011-A, p. 122).
La BDUni contient deux tables attributaires pour chacun de
ses thèmes : une table des objets actuels et des objets supprimés
(« zone_de_vegetation ») ; une table des anciennes versions des
objets, ou table d'historique (« zone_de_vegetation_h »). Une
troisième table commune à tous les thèmes complète
la base, appelée table des réconciliations («
reconciliations »). Elle contient des informations sur les mises à
jour.
Ces tables contiennent des nombreuses colonnes que nous ne
mentionnerons pas en détail (voir Annexes). Les colonnes importantes
pour la mise à jour sont :
- Pour les tables « zone_de_vegetation » et «
zone_de_vegetation_h » :
o Un numéro d'identifiant d'objet unique : « cleabs
»
o L'état de l'objet : « detruit »
o Des colonnes temporelles : ? « date_creation » ?
« date_modification » ? « date_destruction »
o Des colonnes renvoyant à la mise à jour :
? « numrec »
? « numrecmodif » (uniquement pour la table
d'historique)
- Pour la table des réconciliations :
o La géométrie de la zone de réconciliation
: « geometrie »
o Une colonne temporelle : « daterec »
o Un numéro d'identifiant : « numrec »
o Une colonne documentaire : « nom »
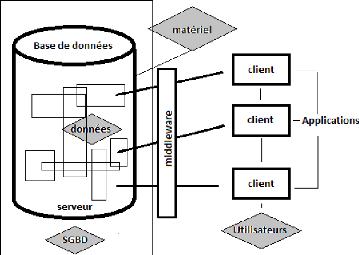
82
Figure 22 : Schéma d'une base de données
(Source : Date, 2004).
L'ensemble de la base de données se présente
sous la forme d'une architecture client-serveur (Figure 22). Cette architecture
est composée de trois programmes. Celui du poste client, ou utilisateur,
demande l'accès aux données par des requêtes et
réalisant des traitements. Les bases clients à l'IGN utilisent
les logiciels GeoConcept pour les opérations de visualisation,
requête, saisie et gestion des données (les collecteurs de la
MAJEC travaillent avec ce logiciel), OpenJump et pgAdmin pour la visualisation
et la consultation des données.
Le logiciel du poste central serveur assure la gestion des
données, garantissant et protégeant leur accès grâce
à un système de gestion de base de données (SGBD) et
répondant aux demandes des postes clients. La couche logicielle de la
BDUni gérant la base serveur est PostGIS, un logiciel libre qui est
l'extension permettant la manipulation d'informations spatiales du SGBD
PostgreSQL.
Le middleware sert d'interface de
communication28 (Bonneau, 2008, p. 7). Le middleware
développé par l'IGN s'appelle GCVS (Geographic Concurrent
Versionning System).
III.C.3 - Mise à jour
C'est le système GCVS qui permet la mise à jour
de la BDUni et l'historisation des données. Concrètement, GCVS se
présente sous la forme d'un module ajoutant de nouveaux outils à
GeoConcept : extraction, réconciliation, update seul,
édition de rapport, gestion des conflits, recherche des modifications
(IGN, 2007-A).
L'extraction crée la base client. GVCS permet ensuite
de synchroniser les bases clients, extraites de la base serveur contenant la
France entière, et la base centrale du serveur : c'est la
réconciliation. L'update seul est une synchronisation à sens
unique : du serveur au client. L'édition des rapports est
28 Un des intérêts du middleware est
qu'il permet de palier aux problèmes de compatibilité entre les
systèmes d'exploitation des postes clients (Windows, Mac) et du serveur
(Linux).
83
automatique après chaque réconciliation et
update seul. Ils permettent de savoir si les opérations de mise à
jour se sont bien déroulées. La gestion des conflits règle
les problèmes générés par la modification
simultanée d'un même objet par plusieurs clients au moment de la
réconciliation. La recherche des modifications est un « garde-fou
» servant à limiter les oublis de réconciliation
régulière en trouvant les zones de mise à jour client non
répercutées dans la base serveur.
La mise à jour est réalisée
principalement grâce au mécanisme de réconciliation.
D'autres mécanismes de mises à jour peuvent être
employés (voir Annexes pour plus de détails).
III.C.3.a - Mise à jour par zone de
réconciliation

Figure 23 : Exemple d'une mise à jour du
réseau routier à l'aide d'une zone de réconciliation
(Source : ortho-
photographie IGN, département des
Hautes-Pyrénées)
Les collecteurs de données modifient leur base client
et font remonter ces modifications à la base serveur. Les informations
fournies par les deux bases sont ainsi « réconciliées
».
L'opérateur réalise d'abord la mise à
jour sur sa base client en effectuant les modifications manuellement. Puis, il
délimite une « zone de réconciliation » qui intersecte
le ou les objets modifiés. Enfin, il fait remonter les modifications
à la base serveur, à travers GCVS. Ces outils (tracé,
réconciliation, etc.) se présentent sous la forme d'un module
ajouté au logiciel GeoConcept.
L'intérêt de la zone de réconciliation
est de mettre à jour la base de données serveur par ensemble
cohérent de modifications. Par exemple, la transformation d'un carrefour
en rond-point implique de nombreuses modifications. Créer une zone de
réconciliation sur le rond-point permet d'englober ces modifications
indiquant l'unique changement réel. L'ensemble des objets ayant subi la
modification sont liés par un même « numrecmodif ». La
Figure 23 montre un exemple fictif d'une mise à jour de ce type. Les
tronçons du départ ont été scindés en deux,
ce qui résulte en leur modification et la création de deux
nouveaux tronçons. Le rond-point a été créé.
Afin de répercuter ces modifications de façon cohérente,
la mise à jour est effectuée en traçant une zone de
réconciliation englobant toutes ces modifications.
84
III.C.3.b - Conservation de l'identifiant et
mécanisme de liste chaînée
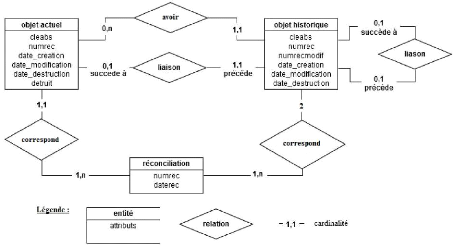
Figure 24 : Schéma conceptuel
entité-relation de l'historisation dans la BDUni (Source : travail
personnel)
GCVS réalise un appariement entre les données
de la base client en cours de réconciliation et les données du
serveur à l'aide des identifiants des objets. Les objets
créés sont reconnus par le fait de posséder un identifiant
encore inconnu dans la base serveur. Ils sont ajoutés à la base
serveur dans la table des objets actuels en tant qu'objets créés.
Les objets possédant un identifiant déjà connu et qui ont
été modifiés sont enregistrés dans la table des
objets actuels. Les objets détruits sont conservés dans la table
des objets courants en remplissant les colonnes « date_destruction »
et « detruit ». La version précédente des objets
modifiés ou détruit est copiée dans la table des objets
historiques (Figure 24). C'est un processus d'historisation de versionnement
par ligne avec partition temporelle.
Le même identifiant « cleabs » est
conservé pour chaque version historisée après une
modification. La conservation de l'identifiant constitue la base de la
création d'un historique et du suivi des objets dans le temps.
Pour chaque modification, lors de la réconciliation,
les informations sur celle-ci sont enregistrées dans la table des
réconciliations (colonne « nom », en texte libre) et la ou les
lignes du ou des objets concernés par la mise à jour sont
copiées dans leur intégralité dans la table
d'historique29.
A la conservation de l'identifiant s'ajoute la liste
chaînée des réconciliations. Pour chaque
réconciliation, la colonne « numrecmodif » est remplie avec le
numéro de la réconciliation en cours dont on connait le
numéro (le « numrec »). Ce numéro est le même que
le « numrec » de l'objet successeur, la dernière version de
l'objet, dans la table des objets courants qui vient alors écraser dans
cette table l'objet modifié désormais stocké. La liste
ordonnée des versions successives d'un même objet contenu dans la
table d'historique se retrouve de façon similaire de « numrecmodif
» à « numrec » s'enchaînant (Figure 24 et Figure
25).
29 La totalité des informations de l'objet est
stockée afin d'éviter les bugs et de devoir effectuer des
recherches de différentiel pour extraire les anciennes versions afin de
connaître l'intégralité des informations concernant
l'objet.
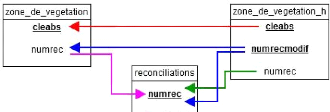
85
Figure 25 : Schéma de structure logique de
l'historisation dans la BDUni (Source : travail personnel)
La Figure 25 montre comment ce système permet des
relations entre les tables. Les flèches de couleurs joignent les
attributs qui se font références. Les colonnes constituant une
clé primaire sont soulignées et en caractère gras dans le
schéma. Une clé primaire est une colonne de la table dont la
valeur ne peut pas exister à l'identique dans deux lignes
différentes de la table.
Dans la table d'historique, la colonne « cleabs »
contient l'identifiant de chaque objet modifié qui est conservé
et renvoie à colonne « cleabs » (flèche rouge) de
l'état successeur de l'objet dans la table des objets actuels,
c'est-à-dire sa nouvelle version. Le second correspond au « numrec
», ou numéro de réconciliation, de la table «
zone_de_vegetation » (flèche bleue). Enfin, chaque
réconciliation est enregistrée dans la table «
reconciliations » par un « numrec » unique auquel renvoient le
« numrec » de la table « zone_de_vegetation », ainsi que le
« numrec » et le « numrecmodif » de «
zone_de_vegetation_h » (flèches mauve, verte et seconde
flèche bleue).
Ce système permet donc de suivre la filiation entre
les différentes versions d'objets à chaque mise à jour et,
de ce fait, est ce qui permet la prise en compte de la dimension temporelle
dans la BDUni. En effet, ces opérations s'accompagnent d'un
enregistrement dans les colonnes d'historique - « date_creation »,
« date_modification », « date_destruction », « daterec
» - du temps de la transaction informatique selon l'horloge du serveur.
Ces dates, indiquées en années, mois, jours et heures avec une
résolution temporelle30 de 1/100000ème de
seconde, sont générées automatiquement. Elles prennent en
compte l'instant de l'opération de réconciliation de la mise
à jour de la base de données : les ajouts (« date_creation
»), suppressions (date_destruction), modifications («
date_modificaiton »). Les « daterec », c'est-à-dire les
dates de réconciliation, marquent les bornes de la durée de vie
des objets : le « numrec » est la date de début, et le «
numrecmodif » la date de fin.
Grâce à ce système, l'ensemble des
versions antérieures des objets est donc conservé et les versions
successives d'un objet identifié par sa « cleabs » unique sont
reliées en liste chaînée par leur « numrec » et
le « numrecmodif ». La temporalité des
événements associés aux objets (création,
modification, destruction) et leur durée de vie (« daterec »
associé au « numrec » et au « numrecmodif ») est
enregistrée. La réconciliation constitue par ailleurs
l'événement reliant entre eux des objets sensés être
concernés par une même évolution. L'historisation de la
BDUni est donc proche du modèle identitaire avec modélisation
d'événement.
30 La résolution temporelle est similaire à la
résolution spatiale. Elle désigne la plus petite unité
atomique qu'il est possible de représenter par un intervalle dans la
base de données (Langran, 1992, p. 84)
86
III.C.3.c - Consignes et méthodes de saisie de
la MAJEC
S'appuyant sur de multiples sources
d'informations31, les collecteurs effectuent les modifications sur
leur base clients qu'ils répercutent ensuite sur le serveur grâce
aux outils du GCVS.
Il leur est demandé de suivre des consignes de saisie.
Une zone de réconciliation doit prendre en compte un ensemble
homogène ou cohérent de modifications que l'opérateur doit
décrire dans la colonne « nom » de la table des
réconciliations afin d'en faciliter l'exploitation. Cette zone doit
être suffisamment grande pour intersecter tous les objets modifiés
mais pas trop au risque de ralentir inutilement le temps de calcul du
traitement de la mise à jour (IGN, 2012-B, p. 45).
De nombreux contrôles sont réalisés
obligatoirement avant chaque réconciliation. Leur rôle est
d'éviter d'enregistrer des informations aberrantes dans la base centrale
qui, sans ces contrôles, ne seraient pas détectée.
Si une erreur apparait, mais qu'elle est justifiée, il
est possible de faire basculer l'erreur en exception légitime. La
colonne « exception_legitime » est alors remplie en fonction de
l'erreur et le contrôle associé ne sera plus effectué pour
l'objet en question. Un péage est un bon exemple d'exception
légitime à l'intersection : c'est un bâtiment qui coupe une
route, mais de fait il est au-dessus de celle-ci. La colonne «
exception_legitime » est régulièrement vidée de son
contenu pour effectuer à nouveau les contrôles afin de
vérifier la qualité des données.
III.C.4 - Avantages et inconvénients du
modèle
Comprendre le processus de mise à jour et la prise en
compte de la dimension temporelle dans la BDUni en étudiant une
méthodologie interne à l'IGN est particulièrement
intéressant pour tenter de répondre à la
problématique de l'historisation dans le cadre du RGFor. Reprendre le
modèle de la BDUni pour le RGFor représente en effet pour l'IGN
la solution a priori la plus simple, celle qui demanderait le moins de
développement et qui pourrait être la plus avantageuse en termes
de coûts et d'investissements.
III.C.4.a - Capacités
L'historisation dans la BDUni correspond à un
modèle avancé. Tant que la donnée n'est pas
modifiée, elle n'est enregistrée qu'une seule fois. Ce qui permet
de limiter la quantité d'information à stocker. Les
données possèdent une date de création, modification,
suppression. L'accès à des états temporels est ainsi plus
rapide (que dans un modèle de journalisation par exemple). Les
données sont stockées dans deux tables, ce qui permet
d'accéder plus rapidement à l'état courant des
données.
Le versionnement et l'horodatage des versions ont permis
à l'IGN de développer des outils :
- Extraction de différentiel pour la livraison de la mise
à jour (Bonneau, 2008).
- Visualisation d'un état de la base à une date
donnée.
- Prototypes de visualisation cartographique32.
31 Orthophotographies de l'IGN, registres des actes
communaux, courriers, appels, déplacement sur le terrain, l'Internet
(images Google Earth et Bing, les Pages Jaunes, les sites des mairies,...),
etc.
32 Évolutions BDUni - cartographie des évolutions,
sur
http://rks1009w117.ign.fr/map-evolution/
87
La base permet de contenir un lien entre les différents
états d'un objet. Elle permet de suivre le changement en
établissant un historique fondé sur la présence d'un
identifiant et d'un identifiant successeur. Pour la BDUni, ce modèle est
implémenté grâce à :
- La conservation de la « cleabs », permettant de
fonder l'identité fixe de l'objet informatique.
- La liste chaînée des « numrec » et
« numrecmodif » établissant le lien entre les objets.
III.C.4.b - Inconvénients
III.C.4.b.1 - Manque de typologie des
événements et d'automatisation du processus
La limite importante de ce modèle tient au fait qu'il
demande une réflexion sur l'interprétation de la modification ou
de la suppression de l'objet géographique. Or, bien que des consignes de
saisies existent dans ce sens (IGN, 2012-B), un réel manque de
définitions plus claires et qui ne soient plus simplement
attachées aux objets informatiques mais aussi aux objets réels,
géographiques, qu'ils représentent, demeure. En outre, le
processus comprend peu de contrôles ou de méthodes automatiques.
Or l'analyse du changement peut être complexe, surtout à
décomposer : une même zone de changement ou de
réconciliation peut avoir plusieurs causes et peut avoir des
conséquences sur plusieurs classes d'objets ou plusieurs objets dans la
même classe.
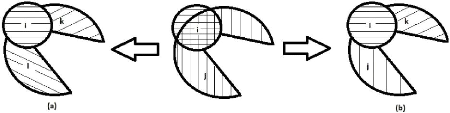
Figure 26 : Cas d'une mise à jour illustrant deux
résultats différents en fonction de la saisie (Source : travail
personnel)
La Figure 26 est un exemple concret d'une mise à jour
et des questions qu'elle peut soulever. Au moment du contrôle, une
incohérence est détectée : les objets « i » et
« j » se superposent. Ces deux objets représentent un phare,
« i » sa tour et « j » sa partie plus basse. Il s'agit
d'une erreur de digitalisation qui ne devrait pas avoir pu être
réconciliée auparavant. Considérons que l'opérateur
avait classé cette incohérence en erreur légitime. Nous
souhaitons corriger cette erreur, tout en conservant les identifiants « i
» et « j » d'origine. Or, en fonction de la méthode de
saisie, avec un outil de découpage (a) ou manuellement (b), le
résultat n'est pas le même. Dans un cas l'identifiant est perdu,
dans l'autre il est conservé. Si une zone de réconciliation est
dessinée uniquement pour cette modification, un lien direct existera
entre l'objet prédécesseur et ses successeurs. Mais si on
réalise plusieurs corrections en même temps, on peut estimer
qu'elles constituent un ensemble cohérent et les réconcilier en
même temps, perdant de ce fait le lien spécifique entre
prédécesseur et successeur. Enfin, au moment de nommer la
réconciliation à l'aide de la colonne « nom »,
plusieurs options sont encore possibles, ne facilitant pas le suivi : erreur,
correction d'erreur, superposition, incohérence, aberration, etc.
L'identification de la réconciliation par un texte libre est une
difficulté pour le suivi des évolutions en l'absence d'une
typologie des événements qui permettrait d'optimiser leur analyse
par la requête.
88
Cet exemple nous permet d'aborder un dernier point : celui du
découpage des objets. Si un objet est découpé, un ou
plusieurs nouveaux objets sont alors créés. Or un seul objet
conserve l'identifiant permettant la filiation, cette information est perdue
pour le ou les autres objets. De même, un objet qui serait détruit
puis recréé (comme cela pourrait être le cas d'un
bâtiment détruit puis reconstruit à l'identique) ne
possède plus l'identifiant de départ. L'identifiant
utilisé dans la BDUni référence des objets informatiques,
non des entités géographiques. L'analyse du suivi du changement
s'en trouve donc limitée.
La mise à jour par réconciliation
effectuée par la MAJEC permet théoriquement le suivi des objets
pour l'analyse des changements, mais elle dépend fortement de
l'appréciation de ce changement par l'opérateur, de
l'interprétation des consignes de saisie, de sa maîtrise des
outils et des contraintes temporelles de production des données.
III.C.4.b.2 - Une prise en compte incomplète de la
dimension temporelle
La prise en compte de la dimension temporelle dans la BDUni
est celle du temps informatique. C'est une base de données
rollback uniquement. Elle correspond aux besoins actuels des utilisateurs
de la base : une information à jour, le plus rapidement possible. Les
tables d'historiques servent à pouvoir revenir sur une mise à
jour dans le cas d'une erreur. L'historisation des données n'est pas
liée au suivi du terrain, mais au suivi de la donnée. Le
modèle d'historisation qui a été mis en place pour la
BDUni répond en premier lieu aux attentes de production.
Le suivi des évolutions est quant à lui un
autre besoin. Il demande l'enregistrement du temps de validité, comme
c'est le cas pour la BdOCS et le MOS. Le temps de validité peut
être retrouvé dans la BDUni, soit en considérant que le
temps de transaction est suffisamment proche du temps de validité
puisque la mise à jour est effectuée en continu, soit en
retrouvant la référence à la source de l'information
possédant une date de validité dans les
métadonnées.
La production en continu des thèmes tels que les
réseaux routiers et les bâtiments a pour avantage que le temps de
validité et le temps de transaction est en effet proche dans 99% des
cas. Néanmoins, il reste toujours un problème :
l'impossibilité de corriger à posteriori les données sans
compromettre leur temporalité (Heres, 2000, p. 46). Or, les
données peuvent être corrigées plusieurs années
après leur création au moment de la restitution. La restitution
est une étape dans la chaine de production de l'IGN qui consiste
à reprendre les ortho-photographies de références pour
corriger le positionnement et les estimations de hauteurs des objets
topographiques. L'information temporelle est donc très souvent
faussée.
III.D - Normes concernant les données
d'occupation des sols et l'intégration du temps
III.D.1 - INSPIRE
L'information géographique s'est
développée en réponse aux enjeux d'ordres
environnementaux, de gestion et d'aménagement. La directive INSPIRE a
été votée par le Parlement européen en 2007 afin de
proposer une infrastructure commune pour favoriser la diffusion, l'utilisation
et le partage de ce type d'information en Europe. Le RGFor fait partie des
thèmes visés par la directive en tant qu'élément de
l' « occupation des terres » définie comme la «
couverture physique et biologique de la surface terrestre, y compris les
surfaces artificielles, les zones agricoles, les forêts, les zones
(semi)naturelles, les zones humides et les masses d'eau » (Directive
INSPIRE, Annexe II, alinéa 2).
89
L'article 8 de la directive indique plusieurs exigences
auxquelles doivent se conforter les bases de données
géographiques :
- Les objets géographiques doivent posséder un
identifiant unique.
- Ils sont liés entre eux.
- La base contient des informations sur la dimension temporelle
des données.
- Les données sont mises à jour.
- La cohérence des informations est assurée.
- Les informations obtenues à partir de
différentes séries de données sont comparables.
Des précisions au sujet de l'intégration du
temps ont par la suite été apportées par le groupe de
travail sur l'occupation des sols (INSPIRE, 2012, pp. 38-40). Le groupe de
travail a réalisé une synthèse des différentes
pratiques dans les bases de données d'occupation des sols. Le changement
au cours du temps y est défini comme un aspect important de ces
données. Pour le mesurer, il faut considérer plusieurs types de
dates à intégrer dans ce type de base de données.
Tout d'abord, le temps en rapport avec les versions des
objets informatiques au sein du jeu de données (désigné
ci-dessous par la lettre A) se distingue de celui des phénomènes
du monde réel qui est décrit par ces mêmes objets
(désigné ci-dessous par la lettre B). Ensuite, on peut distinguer
six types de dates différents :
- Date d'édition (A) : moment où
un objet est créé ou modifié dans la base de
données.
Le temps d'édition est enregistré par un
intervalle, avec des attributs du type "beginLifespanVersion" (début de
durée de vie d'une version) et "endLifespanVersion" (fin de durée
de vie d'une version) :
o "beginLifespanVersion" définit la date et le temps
d'introduction de la version de l'objet spatial dans un jeu de données a
été ajouté ou modifié
o "endLifespanVersion" définit la date où l'objet
a été supprimé ou remplacé par une nouvelle
version
Les durées de vie doivent être
enregistrées avec des dates aussi précises que possible et
inclure le fuseau horaire. Les durées de vie permettent deux choses :
connaître le contenu du jeu de données à une date
précise et connaître les changements selon une durée.
- Date d'événement (B): moment
ou période de temps où un type d'occupation du sol existe dans la
réalité (exemple : coupe forestière).
La date d'événement serait la date la plus
précise pour connaître le moment du changement d'occupation des
sols mais il est considéré comme peu probable d'obtenir cette
information facilement. Si nécessaire, elle peut être
modélisée sous la forme d'attributs facultatifs :
o «validFrom» (valide depuis): date à
partir de laquelle un phénomène existe dans le monde
réel.
o «validTo» (valide jusqu'à) : date
à partir de laquelle un phénomène cesse d'exister dans le
monde réel.
90
- Date d'observation (B) : date de la source
d'information utilisée, généralement celle des
images aériennes ou satellites.
Cette date devrait être attribuée à tous
les objets spatiaux inclus dans la scène couverte par l'image
utilisée comme source. Elle est enregistrée dans l'attribut
« observationDate ». Elle est souvent différente de la date
d'événement.
- Date de référence (B) :
moment ou période de temps où les informations d'un jeu de
données sont considérées comme valides.
Une date de référence est nécessaire
lorsque les images satellites ou aériennes employées couvrent une
durée pouvant aller de quelques jours à plusieurs années.
CL006 par exemple a utilisé des images satellite allant de 2005 à
2007.
- Date de dernière édition (A)
: moment à partir duquel un jeu de données est achevé. -
Date de publication (A) : moment où la base de
données est distribuée au public.
Plusieurs recommandations ont été formulées
:
- La date d'observation devrait être fournie au niveau du
jeu de données, dans les métadonnées, ou directement par
l'attribut « observationDate ».
- La date d'édition devrait être disponible au
niveau du jeu de données et des objets.
- La date de référence et la date de
dernière édition devraient être fournies dans les
métadonnées au niveau du jeu de données.
- Les métadonnées doivent contenir au moins un
type d'information temporelle.
Enfin, ces préconisations décrivent plusieurs
modèles permettant d'analyser les changements d'occupation du sol au
cours du temps :
- Les objets peuvent changer de géométrie les uns
par rapport aux autres d'un jeu de données à l'autre,
- Ou bien ils peuvent être fixes et leurs
propriétés géométriques maintenues dans le temps,
seuls leurs attributs sémantiques d'occupation pouvant changer.
Le premier modèle permet de représenter les
changements de manière analytique. L'utilisateur réalise des
différentiels en superposant deux couches à différentes
dates pour obtenir les changements. Les objets possèdent un format
vectoriel. Le second repose sur une analyse historique : pour chaque
unité spatiale fixe (d'une matrice par dalle ou raster par exemple) le
type d'occupation des sols est attribué pour une ou plusieurs dates
d'observation.
La Figure 27 fait la synthèse des définitions du
temps selon INSPIRE.
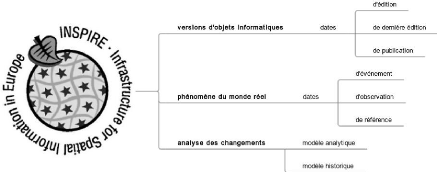
91
Figure 27 : Le temps dans INSPIRE (Source : INSPIRE,
2012).
III.D.2 - Norme ISO 8601
Cette norme définit un standard international,
utilisé dans les bases de données SQL, pour la
notation du temps, fondé sur le calendrier
grégorien, et selon six niveaux de granularité : l'année,
le mois, le jour, l'heure, la minute, et la seconde. Elle permet de
représenter des instants, des intervalles et des durées. Elle
permet également de connaître le fuseau horaire, noté par
le décalage avec l'heure UTC (Temps universel coordonnée).
Exemple : « Lundi 22 avril 2013 à 16h25, heure
d'été, en France » s'écrira «
2013-0422T16:25:24+1:00 ».
Il est possible d'omettre un élément de la
notation, par exemple d'indiquer l'année et le jour sans préciser
l'heure. Cette notation est parfaitement compréhensible par un
algorithme informatique, facile à trier et à comparer, concis et
de taille constante, et aisément lisible.
III.D.3 - Pratiques préconisées par Esri
Il n'existe pour le moment pas de normes supplémentaires
établies quant aux données spatio-
temporelles à cause du manque de pratique dans ce
domaine. Esri, leader et précurseur sur le marché des SIG,
conseille de suivre certaines règles pour stocker ce type de
données et pouvoir les utiliser facilement dans ArcGis :
- Stocker les données temporelles dans un format de
ligne possédant chacune une ou des
valeurs temporelles représentant sa validité
temporelle, plutôt que dans des colonnes attributaires datées.
- Stocker les valeurs temporelles dans une colonne de type date,
plus efficace pour les requêtes, plutôt qu'une colonne
numérique ou de type chaîne de caractères.
- Indexer les colonnes contenant des valeurs temporelles afin
d'améliorer les performances de visualisation et de requêtes.
- Utiliser l'heure standard, c'est-à-dire
éviter d'employer l'heure d'été pour éviter
toute
ambiguïté. Dans notre exemple, il vaudrait mieux
écrire « 2013-04-22T15:25:24+1:00 ».
92
III.D.4 - Outils temporels d'ArcGis
Les dernières versions d'ArcSDE permettent de
gérer l'historique des données au sein d'une même table.
ESRI a développé des fonctionnalités de versionnement pour
ArcSDE et des outils temporels pour ArcGis tels que le tracking analyst,
l'Editor tracking et le Time slider. Nous nous sommes
particulièrement intéressés à ce dernier, car il
permet une visualisation dynamique des données temporelles.
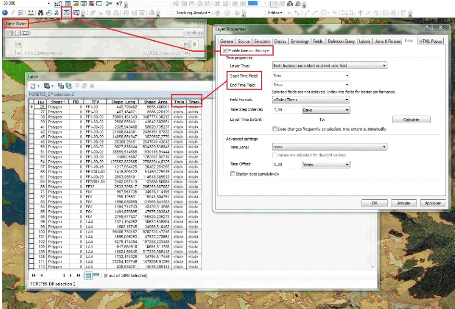
Figure 28 : Outil Time slider d'ArcGis
version 10 (Source : ArcView, ArcGis v. 10)
L'outil Time slider fonctionne lorsqu'on active la
propriété temporelle d'une couche et que cette couche
possède au moins un champ de date, ou deux si les objets ont une
durée de vie. Il faut ensuite sélectionner les champs
concernés, et l'unité temporelle utilisée. Puis, à
l'aide de la fenêtre du Time slider il est possible de lancer
une animation, contrôlable avec le curseur, faisant apparaître et
(si on choisit cette option) disparaître les objets en fonction de leur
durée de vie.
III.E - Conclusion
En conclusion, les modèles utilisés par les
bases de données d'occupation des sols que nous avons
étudiés correspondent aux demandes des utilisateurs qui sont
satisfaits des informations temporelles simples pour le moment alors qu'une
utilisation plus avancée est possible. Le modèle d'historisation
de la BDUni est par contre en avancé par rapport aux autres
modèles. Toutefois, celui-ci ne remplit pas toutes les conditions
nécessaires pour constituer un modèle pouvant être repris
sans modification. C'est ce que nous allons aborder dans le chapitre suivant,
en réfléchissant à l'adaptabilité des
différents modèles de bases existants et à ce que les
modèles théoriques peuvent leur apporter.
93
CHAPITRE IV - Préconisations
A partir de notre analyse de l'existant (Chapitre III), nous
retenons trois modèles d'intégration du temps déjà
utilisés : l'archivage avec extraction des changements, le PPDC spatial
vectoriel et le modèle identitaire avec modélisation des
événements. Nous allons maintenant analyser dans quelles mesure
ces modèles déjà appliqués sont adaptés au
RGFor. Nous utiliserons également les modèles théoriques
(Chapitre II) pour compléter notre proposition sous la forme d'un
modèle conceptuel et d'un modèle logique de base de
données. Un fichier de géodatabase « test_rgfor65.gdb »
a été créé afin d'évaluer et d'illustrer ces
préconisations. La création de ce fichier a également
servi à l'élaboration du modèle logique et d'un
modèle des traitements.
IV.A - Adaptabilité des modèles existants au
RGFor
IV.A.1 - BdOCS : l'archivage
Les limites de ce modèle montrent
l'intérêt qu'aurait le RGFor à intégrer le suivi des
évolutions morphologiques afin de répondre à la demande
émergente des utilisateurs dans l'étude de la fragmentation des
paysages. Par ailleurs, un tel modèle, efficace pour une base
régionale, risquerait d'être peu adapté à une base
de couverture nationale, du fait des nombreuses redondances dans
l'enregistrement des données à chaque mise à jour.
IV.A.2 - MOS : le PPDC spatial
vectoriel
Ce modèle a été conçu pour suivre
les évolutions de l'urbanisation. La nomenclature ne possède que
trois postes pour la forêt (bois ou forêts, coupes ou
clairières en forêts, peupleraies). Le nombre de postes du RGFor
et la nature des entités forestières risquent d'être
problématiques si le modèle du MOS est utilisé. Il serait
par contre plutôt compatible avec les objectifs du suivi de l'OCS GE.
La base ECOMOS, qui complète les données du MOS
au sein des limites des milieux naturels avec 140 postes, est mise à
jour selon le même principe. La première mise à jour est en
cours d'achèvement. En plus des ortho-photographies, les mesures des
capteurs du proche infrarouge et de l'infrarouge de Landsat ainsi que des
relevés de terrain sont utilisés. La nomenclature étant
très précise et laissant une grande partie à
l'interprétation, la pertinence du suivi des évolutions parait
toutefois douteuse. Ce modèle n'a donc pas encore fait ses preuves dans
ce domaine.
Le rythme prévu de mise à jour pour le RGFor -
3 ans - ne concorde pas avec celui du MOS - 4 à 5 ans - justifié
par le pourcentage d'évolution assez faible en Île-de-France :
entre 0,1 et 0,2% par an.
Avec la dernière mise à jour (2012) la
nomenclature a été modifiée et adaptée au cadre de
Corine Land Cover afin de faciliter les comparaisons avec les autres
régions, ce qui pose un problème pour la convergence avec la
nomenclature de l'OCS GE fondée sur la directive INSPIRE.
Une base de données surfaciques telle que le MOS
demande des outils garantissant le respect des règles topologiques
assurant la cohérence des données. Si un tel modèle est
repris par l'IGN, il faudra donc faire évoluer la technologie
employée pour la BDUni.
Ce modèle ne correspond pas nécessairement
à la meilleure solution. Il a été conçu selon les
capacités technologiques de son époque de création. Or les
modèles évoluent avec le matériel et les logiciels.
94
IV.A.3 - BDUni : Orienté-objet avec
modélisation d'événements IV.A.3.a -
Problème de cohérence spatiale et temporelle
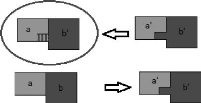
Figure 29 : Intégration du temps réel
et maintien de la cohérence des données spatiales (Source :
entretien Frank Fuchs).
GCVS n'est à l'heure actuelle pas capable de
gérer le versionnement fondé sur du temps de validité. Si
nous reprenons le fonctionnement de ce modèle dit rollback, il
intègre le temps comme une valeur unidirectionnelle : l'ordre de la
transaction définit l'ordre sur la ligne continue du temps. Il est
impossible qu'une modification effectuée après une autre puisse
être antérieure dans le temps enregistré dans la base.
GCVS, et les outils de contrôle lui étant associés dans
GeoConcept, assurent la cohérence et l'intégrité de la
base dans le temps et l'espace selon une direction unique. Pourtant, pouvoir
distinguer les corrections des évolutions réelles
nécessite la capacité d'enregistrer une temporalité
multidirectionnelle et donc de maintenir la cohérence spatiale et
temporelle des données selon ce type de temporalité.
La Figure 29 illustre cet enjeu. L'axe des abscisses
représente le temps réel, celui des PVA, et l'axe des
ordonnées l'ordre du temps informatique. La première étape
est une mise à jour simple, les deux objets (a) et (b) n'ont pas
été modifiés. La deuxième étape est
l'enregistrement d'une évolution. Puis, en troisième
étape, une erreur est corrigée, l'objet (b') successeur de (b)
existe en réalité depuis 2006. Or si on fait cette modification,
(b') et (a) sont superposés en 2006. Les données de la base ne
sont alors plus cohérentes.
IV.A.3.b - Le suivi des évolutions
Le suivi des évolutions thématiques n'est pas
facilité par le modèle d'historisation de la BDUni. De nombreuses
métadonnées existent, en particulier dans la table des
réconciliations, mais elles semblent difficilement exploitables,
étant des textes libres.
Le chaînage entre un objet et son successeur est
contraint par le processus de réconciliation. Cet outil est en effet
limité dans l'ampleur des modifications qu'il est possible de
répercuter à chaque réconciliation, puisque chaque
ensemble cohérent doit faire l'objet d'une zone de réconciliation
propre. Il se prête plutôt à une mise à jour en
continu d'éléments relativement ponctuels (bâti,
95
réseaux) et est donc difficilement extensible à
une utilisation pour une base d'occupation des sols. Les zones de
réconciliation sont plus difficiles à dessiner, par ailleurs,
pour une modification d'objets surfaciques, car les polygones partagent leur
géométrie. Une modification intervenant sur un objet est
répercutée sur les autres alentours, règle topologique
imposant des modifications « non-réelles »,
conséquentes de la première modification. Autrement dit, il
serait préférable que le lien entre les objets permettant leur
suivi soit réalisé par une procédure automatique et
systématique, ce qui n'est pas le cas du modèle actuel.
Le problème de la conservation de l'identifiant
(illustré par la Figure 26) est d'une autre ampleur lorsqu'il s'agit de
données surfaciques d'occupation du sol. Pour ce type de base de
données géographiques, par nature continue, une modification a
des répercussions sur tous les objets, posant dans le temps le
problème des découpages, des relations topologiques et de la
propagation de l'identifiant. Une surface est sujette au morcellement, à
la fusion. Dans ces deux cas, la conservation de l'identité de l'objet
est problématique : Quel objet conservera l'identifiant d'origine d'un
objet coupé en deux ? Quel identifiant sera conservé entre deux
objets fusionnant en un seul ? Le modèle développé pour la
BDUni n'apporte pour le moment pas de réponse à ces questions.
En conclusion, ce système a été
conçu pour répondre aux besoins de production des données
de la MAJEC. Son objectif est d'abord de permettre le suivi informatique de la
qualité des données dans le temps. Ce modèle est tout
à fait satisfaisant en tant que base de données temporelles
rollback. Il n'est par contre pas adapté à la gestion du
temps réel et présente de fortes contraintes au suivi des
évolutions des objets géographiques.
IV.A.4 - Choix du modèle orienté-objet avec
événements
Les capacités respectives des modèles par
rapport aux besoins du RGFor nous amène à recommander
l'utilisation du modèle identitaire avec modélisation des
événements. Ce modèle nous semble en effet être le
plus adapté pour répondre aux attentes des utilisateurs de la
base de données et pour représenter fidèlement les
différents aspects du temps (Chapitre II).
Il s'agit du modèle le plus avancé, et bien que
complexe, il a déjà été utilisé pour la
BDUni. Par ailleurs, des recherches ont été conduites sur ce
sujet dans un des laboratoires de l'IGN, le COGIT, où le modèle
décrit dans la thèse de Plumejeaud a été
appliqué pour les projets GEOPEUPLE et GEOPENSIM. Les recherches sur ce
modèle peuvent donc être mobilisées pour améliorer
le processus existant déjà à l'IGN. Nous recommandons donc
de reprendre le principe de fonctionnement du modèle d'historisation de
la BDUni et d'améliorer ses capacités en se fondant notamment sur
le modèle développé dans la thèse de Plumejeaud.
Nous recommandons plusieurs améliorations par rapport
au modèle original de la BDUni. Ce modèle devrait selon nous
intégrer à la fois le temps de validité et le temps de
transaction, pour permettre de suivre les évolutions et la
qualité des données. Ainsi il serait possible de
différencier les mises à jour correspondant à des
évolutions réelles des corrections pouvant être
nécessaires. Nous recommandons que des règles topologiques
spatiales et temporelles soient enregistrées dans la base de
données afin d'éviter les erreurs. Enfin, nous préconisons
l'utilisation d'un algorithme d'appariement pour le versionnement des
données fondé sur la définition de l'entité et
capable de renseigner une table supplémentaire sur les types
d'événements.
96
Ce modèle permet de restreindre la taille de la table
et ainsi d'accélérer les traitements par rapport à un
modèle enregistrant les doublons. Il définit une véritable
topologie temporelle en indiquant les successeurs et les informations sur les
événements. Ce modèle peut fournir les mêmes
informations statistiques que les autres modèles tout en allant plus
loin dans l'information grâce au suivi des entités
géographiques. Il permettrait, par ailleurs, d'utiliser les outils tels
que le Time slider d'ArcGis ou le prototype de l'IGN pour l'affichage
cartographique dynamique. Enfin, il est capable d'intégrer plus
efficacement que les autres modèles les évolutions
discrètes et continues du milieu forestier.
IV.A.5 - Test du modèle
Afin d'évaluer ces propositions, nous avons
créé une base de données test et nous l'avons mise
à jour. Nous avions pour objectif d'implémenter le modèle
logique, de valider la typologie des événements et d'identifier
les besoins d'automatisation.
Nous avions à disposition plusieurs données de
départ : les données du RGFor des Hautes-Pyrénées,
datée de 2006, fournies par l'IGN, et les données de CLC
téléchargeables pour toute la France à plusieurs
dates33. Les données du RGFor nécessitaient
d'effectuer les mises à jour manuellement, tandis que les mises à
jour de la couche « CLC 2006 » par rapport à la couche «
2000 révisée » pouvaient être directement extraites et
utilisées.
Nous avions également le choix des outils à
utiliser pour visualiser et manipuler les données (ArcGis, GeoConcept,
QGis, PGAdmin, OpenJump) et de la structure de la base de données (un
fichier de géodatabase, une base de données sous PostGis, un
espace de test sur le serveur de la BDUni). Nous avons finalement choisi
d'utiliser ArcGis (version 10.0), logiciel que nous maîtrisions
déjà, faute de temps pour évaluer les autres outils, mais
aussi afin d'étudier les capacités de versionnement
développées par ESRI sous ArcSDE (composante d'ArcGis Serveur
depuis la version 10.1) et déterminer si ce type d'outil peut être
employé pour la mise à jour du RGFor et la production de l'OCS
GE. Nous avons également choisi d'utiliser la technologie
développée par ESRI car elle permet de définir les
règles topologiques des classes d'entités.
Nous avons commencé par créer deux fichiers de
géodatabase, un avec des données CLC de 2000 et 2009
correspondant au département des Landes (« test_clc40.gdb »),
et un second pour les données du RGFor (« test_rgfor65.gdb »).
Nous avons ensuite choisi d'utiliser les données du RGFor pour
maîtriser les mises à jour à effectuer, notamment afin de
valider la typologie des événements en réalisant une mise
à jour par type d'événement34. Enfin, nous
avons effectué une centaine de modifications sur les données de
départ et enregistré manuellement leurs versions
historisées (voir IV.D pour plus de détails sur les traitements).
Nous avons effectué ces traitements d'historisation manuellement faute
d'avoir réussi à installer ArcSDE.
33 Voir : http://sd1878-2.sivit.org/ Consulté
le 05/08/2013.
34 Voir le fichier de géosignet «
evenements.dat ».
97
IV.B - Modèle conceptuel
IV.B.1 - Schéma conceptuel
Entité
(identité)
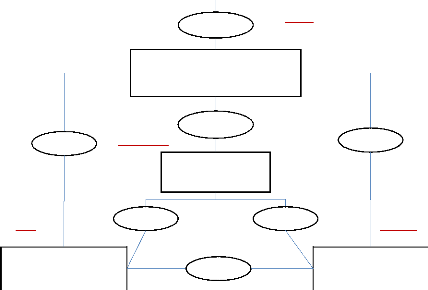
Quoi ?
posséder
1,n
1,1
1,n
1,n
Objet
(attributs semantique,
géométrie)
1,n
borner
localiser Comment ? dater
1,n
1,n
Événements
(vie, territoriaux)
1,n
1,1
1,1
Où ?
localiser dater
Quand ?
1,n
1,n
Espace
(coordonnées)
1,1
exister
1,1
Temps
(transaction, validité)
Figure 30 : Schéma conceptuel du modèle
proposé (Source : travail personnel).
La Figure 30 fait la synthèse des entités et de
leurs attributs nécessaires pour une modélisation satisfaisante
selon les concepts que nous avons abordés plus haut (Chapitre II). Ce
modèle répond aux quatre types de requêtes
générales : où, quoi, quand et comment (Plumejeaud, 2011).
Le temps n'est pas un simple attribut mais une dimension à part
entière des données. Le processus de l'évolution, ou
dimension relative du temps, est clairement décrit grâce aux
événements et à l'implémentation d'une
identité aux objets.
Chaque entité peut posséder plusieurs objets,
ou enregistrement dans la base de données. Ces enregistrements
possèdent des estampilles temporelles en fonction de leurs attributs
sémantiques et géométriques. Lorsque ceux-ci changent, de
nouvelles versions des objets sont créées, pouvant
posséder la même identité que les précédentes
selon des critères précis. Les versions sont
délimitées par des événements décrivant le
changement.
IV.B.2 - Définition des entités
géographiques
Le critère d'identité que nous
préconisons pour ce modèle est simple. Chaque polygone
possédant un poste de nomenclature nécessairement
différent de ses voisins immédiats, nous proposons que
l'identité soit fondée d'abord sur la colonne d'attribut
sémantique, puis sur la géométrie. Un nouvel objet pourra
retrouver l'identité de l'entité précédente s'il
possède toujours la même sémantique et qu'il partage en
partie le même espace. Nous choisissons ainsi les peuplements forestiers
comme entité géographique à suivre dans le temps.
98
IV.B.3 - Définition des
événements
Les événements de vie sont datés
à la fois en temps de transaction et en temps de validité, ce qui
permet de différencier les corrections des évolutions
réelles. Nous reprenons la typologie des événements de vie
et territoriaux de Plumejeaud (voir définitions et tableau p. 61-62) :
fusion (combinaison), intégration (combinaison), scission
(fragmentation), extraction (fragmentation), réaffectation
(redistribution), rectification (redistribution).
Après avoir testé ce modèle, nous avons
ajouté trois événements à la typologie de
départ (voir Tableau 6, ci-dessous) :
- Division (fragmentation).
- Remplacement.
- Inchangé.
La division est la fragmentation d'une entité en deux
géométries distinctes, conservant la même identité,
par une entité préexistante. Exemple : une haie continue
fragmentée en plusieurs morceaux.
Un remplacement peut survenir dans le cas où une
entité serait remplacée par une autre en conservant exactement la
même géométrie. Exemple : un polygone classé en
«Jeune peuplement ou coupe ou incident massif de moins de 5 ans >
correspondant à une parcelle déboisée suite à un
incident et qui est par la suite replantée.
L'événement « inchangé > sert
à qualifier les intersections qui n'évoluent pas entre deux
versions d'une entité subissant un événement. Tous les
types d'événements, exceptés la fusion, la scission et le
remplacement, peuvent impliquer qu'une intersection de l'entité soit
inchangée.
Tableau 6 : Typologie des événements
(Source : travail personnel d'après Plumejeaud, 2011)
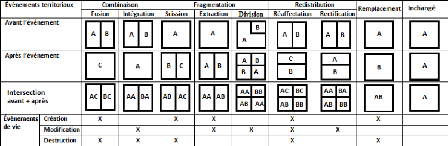
Le Tableau 6 montre que chaque événement se
distingue par un résultat différent de l'intersection des
entités avant et après l'évolution. Ce constat nous a
aidé à définir les règles d'appariement servant
à déterminer le type d'événement.
99
IV.C - Modèle logique
Notre modèle logique est fondé sur celui de la
BDUni, auquel nous rajoutons des tables supplémentaires et la
définition de l'identité et des événements.
IV.C.1 - Tables
Ce modèle comporte quatre tables principales... :
- Une table des actualités
- Une table historique
- Une table des réconciliations
- Une table des événements
... et des tables secondaires :
- Les tables extraites par date de mise à jour en temps
de validité - Une table des évolutions
Les clés primaires sont soulignées, les
clés étrangères sont suivies d'un astérisque.
IV.C.1.a - Table des actualités
Colonne
|
Définition
|
CLEABS
|
Identifiant unique de l'objet et de ses versions
historisées.
|
ENTITE_ID
|
Identifiant unique de l'entité associée à
cet objet.
|
PARTIE
|
Identifiant de la partie de l'entité associée
à cet objet.
|
NOMEN
|
Poste de nomenclature correspondant à cet objet.
|
NUMREC*
|
Identifiant de la réconciliation ayant créé
cette version de l'objet.
|
NUMREC_MOD
|
Champ vide pour cette table.
|
DATE_T_CREA
|
Date de création de l'objet en temps de transaction.
|
DATE_V_CREA
|
Date de création de l'entité en temps de
validité (date de la PVA).
|
DATE_V_FROM
|
Début de l'intervalle de vie en temps de validité
de l'entité (date de la PVA).
|
DATE_V_TO
|
Fin de l'intervalle de vie en temps de validité de cette
entité (date de la PVA).
|
SHAPE
|
Type de géométrie de l'objet (polygone).
|
SHAPE_Lenght
|
Longueur du polygone.
|
SHAPE_Area
|
Surface du polygone.
|
|
La table d'actualité contient toutes les versions des
entités en fonction du temps de validité qui sont
associées à une ou plusieurs lignes d'enregistrements dans la
table (voir II.E.7). À chaque mise à jour, les nouvelles
données et les données ayant été modifiées
sont ajoutées à la table. La colonne « Date_V_TO » des
versions précédentes est remplie avec la date de la prise de vue
utilisée pour la photo-interprétation.
100
IV.C.1.b - Table d'historique
Colonne
|
Définition
|
CLEABS
|
Idem que table des actualités.
|
ENTITE_ID
|
Idem que table des actualités.
|
PARTIE
|
Idem que table des actualités.
|
NOMEN
|
Idem que table des actualités.
|
NUMREC*
|
Idem que table des actualités.
|
NUMREC_MOD*
|
Identifiant de la réconciliation ayant modifié
cette version de l'objet.
|
DATE_T_CREA
|
Idem que table des actualités.
|
DATE_V_CREA
|
Idem que table des actualités.
|
DATE_V_FROM
|
Idem que table des actualités.
|
DATE_V_TO
|
Idem que table des actualités.
|
SHAPE
|
Idem que table des actualités.
|
SHAPE_Lenght
|
Idem que table des actualités.
|
SHAPE_Area
|
Idem que table des actualités.
|
|
Lorsqu'une correction intervient sur un ou des polygones
(c'est-à-dire objets ou lignes de la table), le processus est le
même que celui de l'historisation de la BDUni. Les lignes sont
entièrement copiées dans la table d'historique avant d'être
remplacées par leur dernière version.
IV.C.1.c - Table des événements
Colonne
|
Définition
|
NUMEVE
|
Identifiant unique de l'événement.
|
EVE
|
Poste de nomenclature définissant
l'événement.
|
DATE_EVE
|
Date de l'événement.
|
|
Cette table renseigne pour chaque ligne de la table des
évolutions le type d'événement selon la typologie du
modèle conceptuel.
IV.C.1.d - Table des réconciliations
Colonne
|
Définition
|
NUMREC
|
Identifiant de la réconciliation.
|
Géométrie
|
Géométrie de la réconciliation.
|
USER
|
Nom de l'opérateur ayant effectué la mise à
jour.
|
NOM
|
Colonne documentaire servant à décrire la
réconciliation.
|
DATE_REC
|
Date de la réconciliation, c'est-à-dire de
l'enregistrement informatique.
|
|
Cette table apporte des informations techniques sur la mise
à jour, ainsi que sa date en temps de transaction.
101
IV.C.1.e - Tables extraites par date de mise à jour
en temps de validité
Ces tables sont créées en sélectionnant
tous les objets de la table des actualités pour lesquels la date de PVA
intersecte la durée de vie.
Colonne
|
Définition
|
CLEABS
|
Idem que table des actualités.
|
ENTITE_ID
|
Idem que table des actualités.
|
PARTIE
|
Idem que table des actualités.
|
NOMEN
|
Idem que table des actualités.
|
NUMREC*
|
Idem que table des actualités.
|
NUMREC_MOD*
|
Idem que table des actualités.
|
DATE_T_CREA
|
Idem que table des actualités.
|
DATE_V_CREA
|
Idem que table des actualités. Date < ou = à la
date de PVA de référence.
|
DATE_V_FROM
|
Idem que table des actualités. Date < ou = à la
date de PVA de référence.
|
DATE_V_TO
|
Idem que table des actualités. Date > à la date
de PVA de référence.
|
SHAPE
|
Idem que table des actualités.
|
SHAPE_Lenght
|
Idem que table des actualités.
|
SHAPE_Area
|
Idem que table des actualités.
|
|
IV.C.1.f - Table des évolutions
Cette table enregistre pour chaque ligne une intersection des
entités subissant une évolution réelle,
c'est-à-dire étant valide « jusqu'à » ou «
depuis » la date de la mise à jour considérée.
Colonne
|
Définition
|
OBJECTID
|
Identifiant unique de l'intersection.
|
ENTITE_AV
|
Identifiant de l'entité correspondant à cette
intersection avant la mise à jour.
|
PARTIE_AV
|
Identifiant de la partie de l'entité correspondant
à cette intersection avant la mise à jour.
|
CLEABS_AV
|
Identifiant unique de l'objet et de ses versions
correspondant à cette intersection avant la mise à jour.
|
NOMEN_AV
|
Poste de nomenclature de l'objet correspondant à cette
intersection avant la mise à jour.
|
ENTITE_AP
|
Identifiant de l'entité correspondant à cette
intersection après la mise à jour.
|
PARTIE_AP
|
Identifiant de la partie de l'entité correspondant
à cette intersection après la mise à jour.
|
CLEABS_AP
|
Identifiant unique de l'objet et de ses versions
correspondant à cette intersection après la mise à
jour.
|
NOMEN_AP
|
Poste de nomenclature de l'objet correspondant à cette
intersection avant la mise à jour.
|
TRANSITION
|
Concaténation de NOMEN_AV et NOMEN_AP.
|
EVO_SURFACE
|
Colonne booléenne permettant de distinguer les
évolutions réelles de surfaces.
|
NUM_EVE*
|
Identifiant de l'événement propre à cette
intersection.
|
SHAPE
|
Idem que table des actualités.
|
SHAPE_Lenght
|
Idem que table des actualités.
|
SHAPE_Area
|
Idem que table des actualités.
|
|
102
IV.C.2 - Relations
extractions
|
|
réconciliations
|
|

NUMREC
événements
NUMEVE
0,n
1,n
0,n
1,n
CLEABS
NUMREC
CLEABS
NUMREC
CLEABS
NUMREC
NUMREC_MOD
historique
actualités
1,n
0,n
1,n
CLEABS_AV
CLEABS_AP
NUMEVE
évolutions
Figure 31 : Relations et cardinalités entre les
tables (Source : travail personnel)
Les relations entre la table des actualités,
d'historique, et des réconciliations suivent le même principe que
ceux de la BDUni (voir Figure 25, p. 85, et Figure 31 ci-dessus). La table des
actualités est la table principale. Les objets historisés sont
reconnus grâce à leur attribut « CLEABS » dans la table
d'historique. L'ensemble des tables d'extractions par date de mise à
jour contiennent au moins une fois chaque objet unique de la table des
actualités identifié par sa « CLEABS ». La table des
réconciliations sert d'origine aux attributs « NUMREC » et
« NUMREC_MOD ». Pour chaque ligne de la table des évolutions,
les colonnes « CLEABS_AV » et « CLEABS_AP » renvoient
à des lignes de la table des actualités. La table des
événements renseigne le type d'événement en
fonction de son « NUMEVE » dans la table des évolutions.
IV.C.3 - Versionnement
La mise à jour est effectuée à partir
des données précédentes puis est répercutée
dans la base : les objets ayant subi une modification sont reconnus en
comparant leurs attributs géométriques et sémantiques, ils
sont enregistrés dans la table d'historique avant d'être
remplacés par leur nouvelle version. Il n'est pas nécessaire de
définir une géométrie à la zone de
réconciliation grâce à la table des évolutions et
à l'identification des événements. L'appariement permet de
reconnaître les objets qui se suivent chronologiquement en temps de
validité.
IV.C.4 - Règles d'identité
L'attribution, ou non, d'une identité
préexistante d'une entité géographique à une
nouvelle ligne de la table d'actualités lors d'une mise à jour,
est assurée par un algorithme d'appariement. C'est cet algorithme qui
permet de suivre les évolutions d'une entité au cours du temps en
lui attribuant un identifiant unique. Ses règles de fonctionnement sont
donc particulièrement importantes puisqu'elles déterminent le
résultat et, in fine, la qualité du suivi des
évolutions. Les conditions que nous avons définies sont :
103
Soit « A » l'ensemble des objets « a »
extraits de la table des actualités et étant valides
jusqu'à la date de la mise à jour en temps de validité, et
« B » l'ensemble des objets « b » extraits de la table des
actualités et étant valides depuis la date de la mise à
jour en temps de validité.
o Condition 1 : la colonne « NOMEN » de « b
» est égale à la colonne « NOMEN » de « a
».
o Condition 2 : la géométrie de « b »
est contenue dans la géométrie de « a ».
o Condition 3 : la géométrie de « b »
contient la géométrie de « a », l'aire de « a
» est la plus grande des autres objets « a » pouvant être
contenu dans « b » et l'aire de « b » est inférieure
ou égale à 2,5 fois l'aire de « a ».
o Condition 4 : la géométrie de « b »
intersecte la géométrie de « a », l'aire de « a
» est la plus grande des autres objets « a » pouvant
intersectés « b » et l'aire de « b » est
inférieure ou égale à 1,4 fois l'aire de « a
».
La colonne « ENTITE_ID » de « b » est
égale à la colonne « ENTITE_ID » de « a » si
:
Condition 1 est vraie et (Condition 2 est vraie ou (Condition 2
est faux et Condition 3 est vraie) ou (Condition 2 et 3 sont fausses et
Condition 4 est vraie))
Sinon « ENTITE_ID » de « b » possède
une nouvelle valeur.
Les conditions 3 et 4 impliquent qu'une entité peut
croitre dans une certaine limite pour être toujours
considérée comme la même entité. Dans le cas de la
règle 3, si une entité englobe entièrement une
entité précédente mais que sa taille est beaucoup plus
importante, cette entité est susceptible de contenir d'autres
entités du même type. Concernant la règle 4, son seuil est
plus bas car il s'agit d'une intersection. Les limites de l'entité se
sont en partie déplacées, or les déplacements de limites
des peuplements forestiers sont assez lents, donc nous avons abaissé le
seuil.
Ces limites ont été fixées
grossièrement et pourraient être modifiées. L'utilisation
de l'attribut de surface des objets a été choisi pour des raisons
pratiques - c'est un critère facile à utiliser. Ce choix pourrait
être également discuté.
IV.C.5 - Règles d'événements
La table des événements est
complétée en appariant les objets avant et après une mise
à jour entre eux. Pour chaque ligne de la table des évolutions,
la colonne « NUMEVE », faisant référence à un
événement unique dans la table des événements, doit
être renseignée. Chacune de ses lignes ne peut être due
qu'à un seul et unique type d'événement. Ainsi, il est
possible qu'un même objet, identifié par sa « CLEABS »
unique, possède plusieurs « NUMEVE ». Comme l'illustre le
Tableau 6, des traitements spatiaux ne sont pas nécessaires pour
reconnaître le type d'événement. Une suite de conditions
logiques peut suffire. Par exemple :
- Inchangé : partie de l'entité qui
n'évolue pas. Il s'agit de l'intersection correspondant à la
même entité avant et après
l'événement
o Si « ENTITE_AV » = « ENTITE_AP » et «
PARTIE_AV » = « PARTIE_AP »
- Remplacement : intersection correspondant à
une entité nouvelle succédant à une entité qui
disparaît, et ayant les mêmes limites.
o Si les identifiants « ENTITE_AV » et «
PARTIE_AV » n'existent que pour cette ligne.
o
104
Si aucune ligne ne possède des identifiants «
ENTITE_AP » et « PARTIE_AP » égaux à «
ENTITE_AV » et « PARTIE_AV » de la ligne
considérée.
o Si les identifiants « ENTITE_AP » et «
PARTIE_AP » de la ligne considérée n'existent qu'une seule
fois dans la table.
- Intégration : l'entité est
remplacée par une entité préexistante.
o Si « ENTITE_AV » et « PARTIE_AV »
n'existent que pour cette ligne.
o Si aucune ligne ne possède des identifiants «
ENTITE_AP » et « PARTIE_AP » égaux à «
ENTITE_AV » et « PARTIE_AV » de la ligne
considérée.
o Si les identifiants « ENTITE_AP » et «
PARTIE_AP » de la ligne considérée existent pour une autre
ligne de la table.
La dernière étape consiste à identifier
les événements communs en leur attribuant un numéro
d'événement unique. Ainsi les intersections distinctes sont
reliées entre-elles. Par exemple, plusieurs lignes des tables des
événements sont reliées par un même « NUMEVE
» :
- De fusion, si on leur a attribué ce type
d'événement et qu'elles possèdent les mêmes
identifiants « ENTITE_AP » et « PARTIE_AP
».
- D'intégration, si on leur a attribué ce
type d'événement et qu'elles possèdent les mêmes
identifiants « ENTITE_AP » et « PARTIE_AP
».
- De scission, si on leur a attribué ce type
d'événement et qu'elles possèdent les mêmes
identifiants « ENTITE_AV » et « ENTITE_AV
».
IV.C.6 - Règles topologiques
Les données enregistrées dans la table
d'actualité ne devront présenter ni trou, ni superposition dans
l'espace pour un temps de validité, ni présenter de trou ni de
superposition dans le temps pour un même espace.
Les données d'occupation des sols, en
général, ne doivent pas se superposer, ni dans le temps, ni dans
l'espace. La couverture doit être continue, les données ne doivent
pas présenter de trou, afin de s'assurer qu'il n'y a pas des
données manquantes dans le temps. Les limites de la zone
géographique représentée par ces données sont alors
une exception à cette règle de continuité topologique.
Afin de contrôler ces deux règles, la solution la
plus simple consiste à utiliser les tables extraites de la table des
actualités. Si la topologie de chacune des extractions est correcte,
alors la topologie de la table des actualités est valide.
IV.D - Test des traitements :
méthodologie de la création du fichier «
test_rgfor65.gdb »
La méthodologie employée par ce test consista
à créer la structure du fichier de géodatabase selon le
modèle logique décrit dans la partie IV.C, à charger les
données du RGFor datées de 2006, et enfin à utiliser les
ortho-photographies de 2006 et de 2010, la couche des changements de CLC et des
scénarios d'évolutions forestières pour effectuer des
mises à jour35.
IV.D.1 - Contenu du dossier « test_histoRGFOR_OCS
»
Nous avons commencé par créer un dossier «
test_histoRGFOR_OCS »36 contenant les données
d'occupation des sols d'origine (dossiers « CLC », « RGFOR
»), des données supplémentaires
téléchargées sur le site de l'IGN37 (dossier
« GEOFLA »), des ortho-photographies (dossier « ORTHO »),
et deux fichiers de géodatabase : « test_rgfor65.gdb » et
« test_clc40.gdb ».
Le fichier de géodatabase « test_clc40.gdb »
contient les données d'occupation des sols de CLC de 2000 et 2009, pour
le département des Landes, extraites des données CLC de la France
entière à l'aide des données de découpages
administratifs du fichier « GEOFLA ». Ce département a
été choisi pour ses étendues forestières
importantes et parce qu'il a subi de nombreux changements sur la période
considérée.
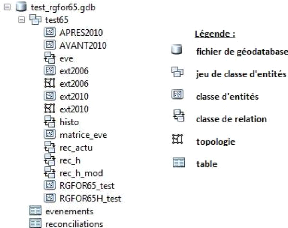
105
Figure 32 : Contenu du fichier de géodatabase
affiché dans ArcCatalog (Source : travail personnel)
Nous allons maintenant détailler la création du
fichier de géodatabase « test_rgfor65.gdb », dont le contenu
est illustré par la Figure 32, car c'est ce fichier qui a fait l'objet
du test.
35 Voir le site de ressource d'ESRI pour la
description du fonctionnement des outils que nous avons utilisé :
http://help.ArcGis.com/fr/ArcGisdesktop/10.0/help/index.html#/na/00r90000001n000000/
Consulté en août 2013.
36 Dossier chargée par la suite sur le disque
ETRAVE de l'intranet de l'IGN.
37 Voir :
http://professionnels.ign.fr/geofla#tab-3
Consulté en août 2013.
106
Après avoir créé le fichier, nous avons
défini ses domaines :
- « Booleen », champ texte, valeur
pré-codée (« 0 » pour « vrai », « 1
» pour « faux »).
- « Nome », champ texte, valeur pré-codée
(code nomenclature du RGFor).
- « Nomeve », champ texte, valeur
pré-codée (trois premières lettres en majuscule de
chaque
type d'événement).
- « PVA », champ date,
jour/mois/année38.
- « User », champ texte, valeur pré-codée
(initiale de l'opérateur, plus un chiffre).
Puis, nous avons créé le jeu de données
« test65 » et défini la projection du jeu de classe
d'entité « test65 » en « RGF_1993_Lambert_93 ». Nous
avons ensuite créé des tables dans la géodatabase et des
classes d'entités dans le jeu de données (voir Figure 32).
Enfin, nous avons créé un catalogue de raster dans
les dossiers d'ortho-photographies contenant les PVA des
Hautes-Pyrénées datées de 2006 et de 200939.
Puis nous avons créé un projet ArcGis appelé
« test_rgfor65.mxd » qui nous a servi aux traitements
sur les données. Les chemins d'accès aux fichiers ont
été paramétrés en chemins relatifs. Nous allons
maintenant préciser les traitements nécessaires aux
créations de ces tables et classes d'entités.
IV.D.2 - Table des actualités : classe
d'entités « RGFOR65_test », classe d'entités
« AVANT2010 » et « APRES2010 »
|
Nom
|
Data type
|
Length
|
Domain
|
|
OBJECTID
|
Objectid
|
|
|
|
CLEABS
|
Text
|
24
|
|
|
ENTITE_ID
|
Text
|
24
|
|
|
PARTIE
|
Text
|
3
|
|
|
NOMEN
|
Text
|
10
|
Nome
|
|
NUMREC*
|
Text
|
24
|
|
|
NUMREC_MOD*
|
Text
|
24
|
|
|
DATE_T_CREA
|
Date
|
|
|
|
DATE_V_CREA
|
Date
|
|
PVA
|
|
DATE_V_FROM
|
Date
|
|
PVA
|
|
DATE_V_TO
|
Date
|
|
PVA
|
|
SHAPE
|
Geometry
|
|
|
|
SHAPE_Lenght
|
Geometry
|
|
|
|
SHAPE_Area
|
Geometry
|
|
|
|
DATE_V_CREA_test
|
Date
|
|
|
|
ENTITE_IDtest
|
Text
|
24
|
|
|
PARTIE_test
|
Text
|
3
|
|
Nous avons créé la classe d'entités
« RGFOR65_test », défini son type (polygone). Après
avoir créé cette structure, nous y avons chargé les
géométries et les nomenclatures des données de la BD
Forêt : « BOSQUET65_DP », « FORET65_DP », «
LHF65_DP » et « VERGER65_65 », datés de 2009.
38 Le fichier « voronoi » est la source
des dates de PVA. Cette date est une approximation de plusieurs dates
d'observation.
39 En cas de problème d'affichage du catalogue
raster, supprimer son contenu et charger le à nouveau.
107
Notre modèle nécessitant une couverture continue
de l'espace, nous avons ensuite dû ajouter des données dîtes
« hors RGFOR ». Pour ce faire, nous avons utilisé les
découpages administratifs contenus dans le dossier « GEOFLA »
à l'échelle du département, sélectionné le
département des Hautes-Pyrénées, effectué une zone
tampon de 500 m pour les données de la BD Forêt dépassant
les limites du département, et supprimé les intersections. Puis,
nous avons sélectionné les découpages communaux des
Hautes-Pyrénées, sauf pour les enclaves, effacé cette
sélection dans notre couche de résultat précédente,
et additionné ce résultat à la sélection des
découpages communaux.
Nous avons divisé manuellement le polygone issu de la
zone tampon en plusieurs parties. Enfin, nous avons effacé la couche
« RGFOR65_test » dans notre couche de résultat afin d'obtenir
l'ensemble des polygones hors du RGFor que nous avons ensuite transformé
en parties uniques, puis chargé dans la classe d'entité «
RGFOR65_test ». Les divisions des polygones hors du RGFor ne correspondent
donc pas à une réalité de l'occupation des sols. Elles
sont néanmoins nécessaires afin d'éviter les bugs d'ArcGis
dus aux polygones de trop grandes tailles.
Enfin, nous avons complété les colonnes vides de
la table : « CLEABS » et « ENTITE_ID » à l'aide
d'une table jointe contenant des codes d'entités et de clés
obtenus à l'aide d'un programme codé en python40 ;
complété « DATE_V_CREA » et « DATE_V_FROM »
avec la date de PVA de 2010 ; « NUMREC » avec le premier
numéro de réconciliation ajouté à la table «
reconciliations » et « DATE_T_CREA » avec la valeur de la
colonne « DATE_REC » de la table « reconciliations ».
Les colonnes « DATE_V_CREA_test », «
ENTITE_IDtest » et « PARTIE_test » seront calculées par
le programme «
indentite.py » (voir Annexes VI)
une fois des mises à jour effectuées sur cette base afin de
pouvoir contrôler d'abord les résultats du programme. C'est ce
programme qui crée les classes d'entités « AVANT2010 »
et « APRES2010 » en sélectionnant les objets de la table des
actualités valides jusqu'à la date de la mise à jour, et
depuis la date de la mise à jour. Enfin, autre différence avec
notre modèle logique, la colonne « OBJECTID » a
été définie comme identifiant de la classe d'entité
et non pas « CLEABS » afin de disposer de plus de souplesse dans le
renseignement de cette colonne.
IV.D.3 - Table d'historique : classe d'entités
« RGOFOR65H_test »
La structure de cette classe d'entités est similaire
à la précédente. Les objets enregistrés dans cette
classe d'entités ont été copiés dans la classe
d'entités « RGFOR65_test » avant leur modification, puis
collés. La colonne « NUMREC_MOD » est alors remplie avec un
nouveau « NUMREC » de la nouvelle version de l'objet. Chaque
modification d'une ligne de la classe d'entité « RGFOR65_test
» implique une copie de sa version avant modification. La classe
d'entité d'historique contient donc à la fois des objets dont la
modification est une simple correction et d'autres dus à une
évolution, puisque la colonne « DATE_V_TO » de ces objets est
nécessairement modifiée lorsqu'il y a évolution.
40 Pour le moment, chaque ligne correspond à
une entité distincte.
108
IV.D.4 - Table des événements : table «
evenements »,
|
Nom
|
Data type
|
Length
|
Domain
|
|
OBJECTID
|
Objectid
|
|
|
|
NUMEVE
|
Text
|
24
|
|
|
EVE
|
Text
|
3
|
Nomeve
|
|
DATE_EVE
|
Date
|
|
PVA
|
La colonne DATE_EVE est remplie avec la date de la mise
à jour. Pour le reste, la table des événements est remplie
à l'aide des résultats du programme « evenements_test.py
» (voir Annexes VI). Elle nécessite le traitement de la table des
évolutions.
IV.D.5 - Table des réconciliations : table «
reconciliations »
|
Nom
|
Data type
|
Length
|
Domain
|
|
OBJECTID
|
Objectid
|
|
|
|
NUMREC
|
Text
|
24
|
|
|
USER
|
Text
|
3
|
User
|
|
NOM
|
Text
|
|
|
|
DATE_REC
|
Date
|
|
|
Cette table a été remplie manuellement, au fur
et à mesure des modifications des données de départ. La
colonne « DATE_REC » a été calculé avec la
fonction « now() ».
IV.D.6 - Tables extraites par date de mise à jour :
classe d'entités et topologies « ext2006 », «
ext2010 »
Les classes d'entités des extractions ont la même
structure que la table des actualités. Nous avons commencé par
créer ces classes d'entités puis nous avons chargé les
données issues de « RGFOR65_test » valides pour chacune des
dates de PVA leur correspondant. Pour « ext2006 », par exemple, la
requête est :
"DATE_V_FROM" <= date '2006-08-01 00:00:00' AND ("DATE_V_TO"
> date '2006-08-01 00:00:00' OR "DATE_V_TO" IS NULL)
Nous avons créé un fichier de topologie par
extraction, défini les règles « Ne doivent pas se superposer
» et « Ne doivent pas avoir de discontinuités »,
validé la topologie et corrigé les erreurs.
Le calcul de la topologie pouvant être long, nous
recommandons que des corrections ultérieures de la table des
actualités soient transmises aux extractions, plutôt que
d'extraire l'ensemble de la table, de remplacer son contenu
précédent et d'effectuer l'ensemble du calcul à
nouveau.
IV.D.7 - Table des évolutions : classe
d'entités « matrice_eve »
Pour produire les données de la classe d'entités
« matrice_eve », nous avons réalisé l'intersection de
la classe d'entités « AVANT2010 » avec « APRES2010 »
(dans cet ordre), puis transformé les parties multiples en parties
uniques, et enfin chargé le résultat dans la table. Nous avons
chargé le contenu des colonnes de la classe d'entités «
AVANT2010 » dans les colonnes « *_AV » et celles de «
APRES2010 » dans les colonnes « *_AP ». Nous avons ensuite
éliminé les polygones reliquats, ou slivers, issus de
décalage a priori non significatif, en sélectionnant les
lignes de la table pour lesquelles la colonne « SHAPE_Area »
était inférieure à 2 m2, puis nous avons
supprimé le contenu de la sélection. Une autre solution
consisterait à utiliser l'outil d'agrégation ou l'outil de
généralisation « éliminer ».
109
Nom
|
Data type
|
Length
|
Domain
|
|
OBJECTID
|
Objectid
|
|
|
|
ENTITE_AV
|
Text
|
24
|
|
|
PARTIE_AV
|
Text
|
3
|
|
|
CLEABS_AV
|
Text
|
24
|
|
|
NOMEN_AV
|
Text
|
10
|
Nome
|
|
ENTITE_AP
|
Text
|
24
|
|
|
PARTIE_AP
|
Text
|
3
|
|
|
CLEABS_AP
|
Text
|
24
|
|
|
NOMEN_AP
|
Text
|
10
|
Nome
|
|
TRANSITION
|
Text
|
23
|
|
|
EVO_SURFACE
|
Text
|
1
|
Booleen
|
|
NUM_EVE*
|
Text
|
24
|
|
|
SHAPE
|
Geometry
|
|
|
|
SHAPE_Lenght
|
Geometry
|
|
|
|
SHAPE_Area
|
Geometry
|
|
|
|
EVE
|
Text
|
3
|
Nomeve
|
|
EVE_test
|
Text
|
3
|
Nomeve
|
La colonne « EVO_SURFACE » sert à distinguer
les lignes utiles au calcul de la matrice de transition. Si « NOMEN_AV
» est égal à « NOMEN_AP », la valeur de la colonne
est « Faux », sinon « Vrai ». Ceux marqués «
Faux » sont utiles à l'attribution des types
d'événements mais ne constituent pas une évolution de
l'occupation des sols.
Les colonnes « EVETEST » et « NUMEVE »
sont remplies par le programme « evenements_test.py » (voir Annexe
VI). La colonne « EVE » peut être remplie manuellement afin de
comparer les résultats avec ceux du programme. Nous avons validé
le test du programme pour les événements de type inchangé,
intégration, fusion et remplacement et effectué une saisie
manuelle au minimum une fois par type d'événement.
IV.D.8 - Relations
|
Nom
|
Type
|
Cardinalité
|
Notification
|
Origine
|
Destination
|
Clé
primaire
|
Clé étrangère
|
|
eve
|
Simple
|
1M
|
Aucune
|
evenements
|
matrice_eve
|
NUMEVE
|
NUMEVE
|
|
histo
|
Simple
|
1M
|
Aucune
|
RGFOR65_test
|
RGFOR65H_test
|
CLEABS
|
CLEABS
|
|
rec_actu
|
Simple
|
1M
|
Aucune
|
reconciliations
|
RGFOR65_test
|
NUMREC
|
NUMREC
|
|
rec_h
|
Simple
|
1M
|
Aucune
|
reconciliations
|
RGFOR65H_test
|
NUMREC
|
NUMREC
|
|
rec_h_mod
|
Simple
|
1M
|
Aucune
|
reconciliations
|
RGFOR65H_test
|
NUMREC
|
NUMREC_MOD
|
Nous avons créé des relations simples, elles
permettent d'effectuer des jointures automatiquement entre les tables
reliées. Nous n'avons pas utilisé de relation composite avec
transmission du message pour éviter les erreurs de manipulation pendant
le test. Par ailleurs, nous n'avons pas non plus utilisé ce genre de
relation entre la table des actualités et les extractions afin
d'automatiser la transmission des corrections car la transmission ne prend en
compte que les modifications attributaires, pas les modifications
géométriques, et également parce qu'en cas de suppression
de la ligne dans la table d'origine, la relation est marquée « Null
» mais la ligne n'est pas supprimée dans la table de
destination.
110
IV.E - Exemples de requêtes, capacités de la
base
Les objectifs de départ quant à
l'intégration du temps dans la base de données étaient de
répondre à des enjeux techniques, et surtout thématiques
de suivi de l'évolution de l'occupation des sols. Les enjeux techniques
que nous avions identifiés sont la gestion des doublons, le suivi de la
qualité des données, la livraison de mise à jour
différentielle, et assurer la cohérence topologique.
La base créée est capable d'intégrer une
mise à jour sans doublon au sein d'une même table, ce qui
accélère les traitements. La table principale, «
RGFOR65_test » contient au total 133792 lignes ou objets. Divisée
en deux tables, la somme de 133738 lignes pour « ext2006 » et de
133711 lignes pour « ext2010 » donne pour résultat 267449
lignes. Une requête sur la table principale nécessite donc
grossièrement deux fois moins de temps de calcul que sur des jeux de
données complets à chaque date de mise à jour.
L'historisation des versions d'objets et le renseignement de
la table des réconciliations permettent le suivi de la qualité
des données (voir la seconde réconciliation effectuée du
jeu de données test qui est une correction). En cas d'erreur, il est
possible de revenir à la version précédente de l'objet.
En joignant la date de réconciliation au numéro
de réconciliation et en sélectionnant les dates
supérieures à la dernière mise à jour, il est
possible de ne livrer aux utilisateurs que les dernières versions des
données à ajouter à leur base personnelle.
Enfin, les topologies associées aux extractions
permettent de s'assurer que l'ensemble de la table des actualités est
cohérent topologiquement, et qu'il n'y a pas de trou ou de superposition
dû à un intervalle temporel mal défini.
Concernant l'analyse thématique, les principales
questions auxquelles la base devait pouvoir répondre en termes de suivi
de l'occupation des sols concernaient la localisation et le calcul des
évolutions de surface, des évolutions des surfaces en fonction
des types d'événement, et le suivi d'une entité.
En effectuant une requête de sélection par
attribut sur la table des évolutions, on peut quantifier la
quantité de surface totale en m2 ayant évolué
entre 2006 et 2010. La requête pour la base test est « "EVO_SURFACE"
= '0' », et les résultats statistiques de la sélection sont
:
- 942382 m2 d'évolution de surface
- 274425 m2 maximum
- 2 m2 minimum
- 10133 m2 en moyenne
- 31611 m2 d'écart-type
Dans le cas d'une base complète, il serait
nécessaire de faire la jointure avec la table des
événements pour avoir la date de l'événement, puis
de formuler la requête « matrice_eve.EVO_SURFACE = '0' AND
evenements.DATE_EVE = date '2010-08-01 00:00:00' ». Par ailleurs, en plus
de quantifier ces changements, la sélection nous permet de visualiser
leurs emplacements dans un SIG.
111
De même, il est possible d'obtenir des statistiques par
type d'évolutions qualifiée en transition d'occupation des sols
par type d'événements (voir Annexe VII) et de les localiser.
Enfin, il est possible de connaître l'histoire d'une
entité par simple requête dans la base. Par exemple, si nous
souhaitons suivre une entité de haie dont l'identifiant est «
RGFOR0650000000000044234 ». Il faut effectuer une sélection par
attribut dans la couche des actualités : "ENTITE_ID"
='RGFOR0650000000000044234'. Le résultat donne trois lignes
sélectionnées : l'entité a évolué en 2010 et
existe à partir de cette date pour deux objets distincts (les attributs
« PARTIE » sont différents). Ensuite, avec une requête
dans la table des réconciliations, « "ENTITE_AV"
='RGFOR0650000000000044234' OR"ENTITE_AP" ='RGFOR0650000000000044234' »,
nous constatons que cette entité est liée à «
RGFOR0650000000000101503 », de nomenclature « Hors RGFor », dans
son évolution et que son type d'événement est une
division. Nous pouvons alors formuler une analyse du suivi de l'occupation du
sol telle que le réseau de trame verte s'est ici morcelé.
Étendu à l'ensemble des données, ce type d'analyse
pourrait servir à l'étude de l'évolution du paysage, utile
potentiellement au SCOT et à l'élaboration de la trame verte et
bleue.
112
V - Conclusion
La demande de l'IGN était d'étudier les
différents processus d'historisation possible afin de proposer une
méthode de mise à jour des données du RGFor permettant
d'intégrer la dimension temporelle. Il était demandé
d'étudier particulièrement le processus de la BDUni, interne
à l'IGN, dans le but d'évaluer si celui-ci était
compatible avec les besoins des utilisateurs de données d'occupation des
sols.
Ce travail nous a amené à nous interroger sur la
modélisation des bases de données géographiques permettant
de répondre à la problématique de l'observation d'un
territoire au cours du temps. Nous avons étudié les
spécificités des données du RGFor ainsi que les besoins de
ses utilisateurs. Puis, nous avons effectué un travail de recherche sur
la modélisation du temps dans les bases de données. Cette
recherche nous a, par la suite, aidés à décrire les
modèles utilisés par des bases existantes, dont la BDUni, et
à évaluer leurs capacités.
Cette étude a permis de réaliser une
synthèse sur l'intégration du temps dans les SIG en
général, et plus spécifiquement dans les bases de
données, puis de montrer les limites des modèles existants. Le
temps a été défini comme une notion ayant de multiples
aspects, dont les plus importants sont la distinction entre le temps absolu et
le temps relatif, ainsi qu'entre le temps de transaction et le temps de
validité.
Nous avons montré que le processus d'historisation de
la BDUni était un modèle avancé mais qu'il ne
correspondait pas aux besoins spécifiques des données
d'occupation des sols. Nous avons donc proposé un modèle
fondé sur la BDUni et reprenant le principe du modèle
orienté-objet avec modélisation des événements.
Ces propositions ont fait l'objet d'un test sous la forme d'un
fichier de géodatabase créé à l'aide de la version
10.0 d'ArcGis. Ce test nous a servi à valider notre modèle
logique de base de données et à démontrer les
capacités de requête de la base. Il conviendrait toutefois de
poursuivre les tests selon plusieurs pistes de réflexion :
- en améliorant notamment le traitement des polygones hors
du RGFor ;
- en questionnant les critères d'identité et en
terminant le programme de reconnaissance des événements ;
- en automatisant la répercussion d'une mise à jour
de la table des actualités sur l'ensemble
des tables à l'aide
des attributs de « CLEABS » et « NUMREC » ;
- en indexant la table des actualités afin
d'accélérer les traitements et les requêtes et pallier
le
défaut de l'allongement de la table à chaque mise à
jour ;
- en poursuivant les tests avec d'autres données, comme le
jeu de données CLC, ou d'autres outils, comme le versionnement
d'ArcSDE.
Enfin, il serait intéressant de confronter ce
modèle à ses utilisateurs futurs pour en évaluer tous les
potentiels d'utilisation et définir les fonctionnalités
temporelles du produit final qui leur sera proposé à partir de la
base de production de l'IGN.
113
114
Bibliographie
Allen, J. F. 1983. Maintaining knowledge
about temporal intervals. ACM. 1983, Vol. 26, 11, pp. 832843.
Andrault, C. 1997. Elaboration d'une
méthode de tenue à jour et de suivi de l'historique des
données forestières de la forêt Montmorency.
Concervatoire national des arts et métiers, école
supérieuree des géomètres et topographes : Mémoire
de diplôme d'ingénieur ESGT, 1997. p. 55.
Balstad, M. 1996. Information Technology for
Public Policy. [ed.] M. F. Goodchild et al. GIS and Environmental
Modeling: Progress and Research Issues. Fort Collins (USA) : GIS World
Books, 1996, pp. 7-10.
Barbic, F and Percini, B. 1985. Time
modeling in office information systems. Austin, Texas : Proceedings,
SIGMOD', ACM Press, 1985.
Bonneau, M. E. 2008. Vérification
d'aptitude de l'extraction différentielle dans un système
client-serveeur utilisant l'historique. ENSG. 2008. p. 68.
Bordin, P. 2002. Chapitre 3.6.4 La question
Quand ? et chapitre 6.8 La mise à jour. Dans SIG : concept, outils
et donnéees (pp. 90-91 & 162-172). Hermès Science. 259
p. ISBN/ISSN : 9782746205543
Bordin, P. 2006. Méthode
d'observation multi-niveau pour le suivi de phénomèns
géographiques avec un SIG. Université de
Marne-La-Vallée : Thèse de sciences de l'information
géographique, 2006. p. 283.
Castells, M. 2001. L'ère de
l'information. s.l. : Fayard, 2001. p. 671. Vol. I.
Date, C. J. 2004. Introduction aux bases
de données. (M. Chalmond, & J.-M. Thomas, Trads.) Paris:
Vuibert. 1047 p. ISBN/ISSN : 2711748383.
De Blomac, F. 2012. L'ign
réfléchit à une occupation du sol nationale. SIG la
lettre. septembre 2012, 139, pp. 9-10.
Elissalde, B. 2008. Géographie, temps
et changement spatial. Espace géographique. 2008, Vol. 29, 3,
pp. 224-236.
FAO. 2005. Global Forest Ressources
Assessment. 2005.
Felten, V. 1997. Intégration de la
dimension temporelle dans les SIRS, application à la forêt de
Montmorency. Conservatoire national des arts et métiers,
école supérieuree des géomètres et topographes :
Mémoire de diplôme d'ingénieur ESGT, 1997. p. 92.
Gayte, O. et al. 1997. Conception
des systèmes d'information sur l'environnement. Paris :
Hermès, 1997. p. 153.
Guinaudeau, M. (2006). Etude
préalable pour la misee en oeuvre du "Fond vert" produit par l'IFN et
l'IGN. Mémoire d'examen professionel pour le recrutement
d'Ingénieur des Travaux Géographiques et Cartographiques de
l'Etat. 82 p.
115
Hägerstrand, T. 1952. The propagation of
innovation waves. [ed.] Dept. of Geography. Lund: Royal University of Lund.
Lund studies in geography: Series B, Human geography 4. 1952.
Hägerstrand, T. 1970 . What about people
in regional science? Papers of the Regional Science Association. 1970
, 24 (1), pp. 6-21.
Hainaut, J.-L. 2011. Bases de
données : concepts, utilisation et développement : cours et
exercicees corrigés. Paris : Dunod, 2011. p. 702. ISBN/ISSN :
978-2-10-057410-0.
Hazelton, N.W.J. 1991. Integrating Time,
dynamic modelling and geographical information systems: Dexelopment of
four-dimensional GIS. Melbourne, Australie : Thèse, Department of
Surveying and Land Information, Université de Melbourne, 1991.
Heres, L. 2000. « Hodochronologics:
History and time in the National Road Database ». Dans L. Heres
(Éd.), Time in GIS: issues in spatio-temporal modelling (pp.
45-56). Publication on Geodesy. Vol. 47. Deft. Pays-Bas: Netherlands Geodetic
Commision. 70 p. ISBN/ISSN : 978-9061322696
IFN. 2008. Nouvelle cartographie
forestière de la production à l'utilisation. L'IF. 2008,
20, pp. 1-8.
IFN. 2011. Volume de bois sur pied dans les
forêts françaises : 650 millions de mètres cubes
supplémentaires en un quart de siècle. L'IF. 2011, 27,
p. 12.
IFN. 2012. Quelles sont les ressources
exploitables ? Analyse spatialle et temporelle. L'IF. 2012, 30, p.
16.
Chaine de production du Référentiel
Géographique Forestier RGFor et de la « couche
végétation. VOIR DOC :
SBV-OCS-NT-005-chaine_de_production-Ed1-22-01-13_TT
IGN, direction de la communication. 2010.
Contrat d'objectifs de performance 2010-2013 entre l'Etat et
l'Institut géographique national. 2010.
IGN. 2007 (A). GCVS pour les nuls.
Service de la recherche. 11 p.
IGN. 2007 (B). La forêt français
- Un patrimoine en progression. IGN Magazine. 2007, 43, pp. 7-14.
IGN. 2011 (A). BDUni V1.1 Grande Echelle :
spécifications de contenu (éd. 5ème). 213 p.
IGN. 2011 (B). Synergies et rapprochement
éventuels de la couche végétation de la BD TOPO® de
l'IGN et de la cartographie forestière numérique de l'IFN -
étude auprès des utilisateurs de la BD TOPO® de l'IGN et des
clients de l'IFN. 2011.
IGN. 2012 (A). La cartographie
forestière - version 2 - de l'Inventaire Forestier National, guide
technique. 2012.
IGN. 2012 (B). Spécification de
saisie BDUni V1.1. 2012. édition 5.
IGN. 2013 (A). Manuel
végétation, formation naturelles et semi-naturelles : contenu,
définition. 2013.
IGN. 2013 (B). Chaine de production du
Référentiel Géographique Forestier RGFor et de la «
couche végétation. Édition 22/01/13.
116
IGN. 2013 (C). Manuel
végétation, formation naturelles et semi-naturelles ; contenu -
définition ; référentiel géographique forestier,
végétation multithèmes. Édition 18/02/13.
INSPIRE. 2012. INSPIRE Data Specification
on Land Cover - Draft Guidelines. Thématic Working Group Land
Cover, 2012.
Isnard, H. 1985. Espace et temps en
géographie. In: Méditerranée, Troisième
série, Tome 55. [Online] Mars 1985. [Cited: 05 29, 2013.] pp.
13-19.
http://www.persee.fr/web/revues/home/prescript
/article/medit_0025-8296_1985_num_55_3_2314. doi :
10.3406/medit.1985.2314.
Kelmelis, J. 1991. Time and space in
geographic information: Toward a four dimensional spatiotemporal data mode.
s.l. : Thèse, Univesité de Pennsylvannie, 1991.
Kraak, M-J. 2000. Visualization of the time
dimension. [book auth.] Luc Heres. Time in GIS: issues in spatio-temporal
modelling. 2000, pp. 27-35.
Langran, G and Chrisman, N.R. 1988. A framework
for temporal geographic information. Cartographica. 1988, Vol. 3, 25,
pp. 1-14.
Langran, G. 1992. Time in geographic
information systems. Londres, New York, Philadelphia : Taylor &
Francis, 1992. p. 189. ISBN/ISSN : 0748400036.
Médici, C. et al. 2011.
Intégration de la temporalité dans les donnéees
de référence - cas du sytème d'information du territoire
genevois. Géomatique Expert. 2011, 83, pp. 42-45.
Ministère de l'Ecologie, du
Développement durable, des Transports et du Logement - Direction
générale de l'Energie et du Climat. 2011.
http://www.developpement-durable.gouv.fr.
[Online] 2011. [Cited: 05 29, 2013.]
http://www.developpement-durable.gouv.fr/IMG/pdf/Tout-savoir-sur-le-PNACC.pdf
.
Ott, T. and Swiaczny, F. 2001.
Time-integrative geographic information systems : management and
analysis of spatio-temporal data. Berlin, Heidelberg, New York : Springer,
2001. p. 234. 3540410163.
Paque, D. 2004. « Gestion de
l'historicité et méthodes de mise à jour dans les SIG
» dans Cybergéo : Cartographie, Imagerie, SIG, article
278. Mis en ligne le 23 juin 2004. Consulté le 22
février 2013, sur
http://cybergeo.revues.org/2500.
22 p. DOI : 10.4000/cybergeo.2500
Parlement et Conseil européens. 2007.
Directive 2007/2/CE du Parlement européen et du Conseil du 14
mars 2007 établissant une infrastructure d'information
géographique dans la Communauté européenne (INSPIRE).
http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=OJ:L:2007:108:0001:
0014:fr:PDF. [Online] 2007.
Pelekis, N. et al. 2004. Literature
Review of Spatio-Temporal Database Models. The Knowledge Engineering Review
journal. 2004, 19, pp. 235-274.
Peuquet, D. J. 2000. Space-time
representation: An overview. [book auth.] Luc Heres. Time in GIS: issues in
spatio-temporal modelling. 2000, pp. 3-12 .
Peuquet, D. J. 2002. Representations of
space and time. s.l. : Guilford Press, 2002. p. 380.
117
Piaget, Jean. 1969. The Child's Conception
of Time. New York : Basic Books, 1969.
Plumejeaud, C. 2011. Modèles et
méthodes pour l'information spatio-temporelle évolutive.
s.l. : Université de Grenoble, 2011. Thèse,
spécialité informatique.
Ritsema, I. 2000. Time in relation to
geoscientific data. [book auth.] Luc Heres. Time in GIS: issues in
spatio-temporal modelling. 2000, pp. 57-66.
Saffroy, T. and Lambert, H. 2012. Etude
du besoin des utilisateurs en occupation du sol à grande échelle
(OCS GE), synthèse, version 1.0. s.l. : IGN, 2012.
Snograss, R. and Ahn, I. 1985. A taxonomy of
time in databases. Austin : s.n., 1985. proceeedings of the '85
Conference.
Trias-Sanz, Roger. 2006. Semi-automatic
rural land cover classification from high resolution remote sensing images.
Paris : Université Paris 5 - René Descartes, UFR de
Mathématiques et Informatique, 2006. Thèse.
Wachovicz, M. 1999. Object-oriented design
for temporal GIS. London : Taylor & Francis, 1999.
Yeh, T-S and Cambray (De), B. 1996. Time as a
Geometric Dimension For Modeling the Evolution of Entities: A Three-Dimensional
Approach. [book auth.] M. F Goodchild, et al. GIS and
Environmental Modeling: Progress and Research Issues. 1996, pp.
397-403.
118
Annexes
I - Nomenclature RGFor i
II - Nomenclature MOS IAU ÎDF ii
III - Nomenclature BdOCS CIGAL iv
IV - Questionnaire MOS v
V - Questionnaire BdOCS CIGAL vii
VI - Programmes ix
VII - Tableau statistique d'évolution de l'occupation
des sols du jeu de données « RGFOR65_test »
xxvi
VIII - Rapport BDUni xxx
i
I - Nomenclature RGFor
|
NIVEAU I
|
NIVEAU II
|
NIVEAU III
|
NIVEAU IV
|
Type de
végétation
BD
Topo®
|
|
>=0.5 ha
|
Couverture du sol
|
Composition
|
Essence majoritaire absolue (>=50 %)
|
|
BD Forêt®
|
Forêt F
|
Forêt fermée FF
|
Non discriminée FF0
Jeune peuplement ou coupe ou incident massif de moins de 5 ans
|
|
1 - forêt fermée de feuillu
|
|
Feuillus purs FF1
>= 75% de feuillus
|
Massif entre
0.5 et 2 ha
|
Feuillus essence FF1-00 non discriminée
|
|
Massif de plus de 2 ha
|
Chênes décidus FF1G01-01
Chênes sempervirents FF1G06-06
Hêtre FF1-09-09
Châtaignier FF1-10-10
Robinier FF1-14-14
Autre feuillu pur FF1-49-49
Mélange de feuillus FF1-00-00
|
|
Conifères purs FF2
|
Massif entre 0.5 et 2 ha
|
Conifères essence FF2-00
non discriminée
|
2 - forêt fermée de
conifères
|
|
>= 75% de conifères
|
Massif de plus de 2 ha
|
Peuplement de pins
|
Pin maritime FF2-51-51
Pin sylvestre FF2-52-52
Pin noir ou pin FF2G53-53 laricio ou en
mélange
Pin d'Alep FF2-57-57
Pin à crochets FF2G58-58 ou
pin cembro
ou en mélange
Autre pin pur FF2-81-81
Mélange de pins
FF2-80-80
|
|
Conifères
autres que
pins
|
Sapin ou épicéa
ou en mélange FF2G61-61
Mélèze FF2-63-63
Douglas FF2-64-64
Autre conifère pur FF2-91-91 Mélange
de conifères FF2-90-90
|
|
Mélange de pins FF2-00-00
et autres essences de conifères
|
|
Mélange de feuillus (>=25%) et conifères
(>=25%)
|
|
3 - forêt fermée mixte
|
|
Mélange à feuillus prépondérants
FF31
|
|
|
Mélange à conifères
prépondérants FF32
|
|
|
Forêt ouverte
FO
|
Incident / déboisement FO0
|
|
4 - forêt ouverte
|
|
Feuillus purs FO1
|
|
|
Conifères purs FO2
|
|
|
Mélange de feuillus FO3
et conifères
|
|
|
Mélange à feuillus prépondérants
FO31
|
|
|
Mélange à conifères
prépondérants FO32
|
|
|
Peupleraie FP
|
|
|
5 - peupleraie
|
|
Lande L
|
Lande LA
|
Ligneux bas >= 25 % LA4
= Lande ligneuse
|
|
6 - lande
ligneuse
|
|
Ligneux bas < 25 % LA6
= Formation herbacée
|
|
0 - Formation herbacée
|
|
Hors spé-
cifications
|
TAHF Terrain arboré ou arbustif Hors
forêt
|
Bosquet
Verger
Petit verger
|
|
|
Bois
Verger
Bois
|
|
Arbres épars
|
|
|
Bois
|
|
Formations linéaires
|
Haie arborée Haie non arborée Alignement Cordon
boisé
|
|
Haie
|
ii
II - Nomenclature MOS IAU ÎDF
|
3 postes
|
11 postes
|
24 postes
|
47 postes
|
81 postes
|
|
Rural
|
Bois ou forêts
|
Bois ou forêts
|
Bois ou forêts
|
Bois ou forêts
|
|
Coupes ou clairières en forêts
|
Coupes ou clairières en forêts
|
|
Cultures
|
Grandes cultures
|
Peupleraies
|
Peupleraies
|
|
Terres labourées
|
Terres labourées
|
|
Surfaces en herbe à caractère agricole
|
Surfaces en herbe à caractère agricole
|
|
Autres cultures
|
Vergers, pépinières
|
Vergers, pépinières
|
|
Maraîchage, horticulture
|
Maraîchage, horticulture
|
|
Cultures intensives sous serres
|
Cultures intensives sous serres
|
|
Eau
|
Eau
|
Eau
|
Eau fermée (étangs, lacs...)
|
|
Cours d'eau
|
|
Autre rural
|
Autre rural
|
Surfaces en herbe non agricoles
|
Surfaces en herbe non agricoles
|
|
Carrières, sablières
|
Carrières, sablières
|
|
Décharges
|
Décharges
|
|
Vacant rural
|
Espaces ruraux vacants (marais, friches...)
|
|
Berges
|
|
Urbain ouvert
|
Urbain ouvert
|
Parcs ou jardins
|
Parcs ou jardins
|
Parcs ou jardins
|
|
Jardins familiaux
|
Jardins familiaux
|
|
Jardins de l'habitat
|
Jardins de l'habitat individuel
|
|
Jardins de l'habitat rural
|
|
Jardins de l'habitat continu bas
|
|
Sport (espaces ouverts)
|
Terrains de sport en plein air
|
Terrains de sport en plein air
|
|
Tennis découverts
|
|
Baignades
|
|
Équipements sportifs de grande surface
|
Parcs d'évolution d'équipements sportifs
|
|
Golfs
|
|
Hippodromes
|
|
Tourisme et loisirs (espaces ouverts)
|
Camping, caravaning
|
Camping, caravaning
|
|
Parcs liés aux activités de loisirs
|
Parcs liés aux activités de loisirs
|
|
Terrains vacants
|
Terrains vacants
|
Terrains vacants en milieu urbain
|
|
Urbain construit
|
Habitat individuel
|
Habitat individuel
|
Habitat individuel
|
Habitat individuel
|
|
Ensembles d'habitat individuel identique
|
Ensembles d'habitat individuel identique
|
|
Habitat rural
|
Habitat rural
|
|
Habitat collectif
|
Habitat collectif
|
Habitat continu bas
|
Habitat continu bas
|
|
Habitat collectif continu haut
|
Habitat collectif continu haut
|
|
Habitat collectif discontinu
|
Habitat collectif discontinu
|
|
Activités
|
Habitat autre
|
Habitat autre
|
Prisons
|
|
Habitat autre
|
|
Activités
économiques et industrielles
|
Équipements pour eau, assainissement, énergie
|
Production d'eau
|
|
Assainissement
|
|
Électricité
|
iii
3 postes
|
11 postes
|
24 postes
|
47 postes
|
81 postes
|
|
Urbain construit
|
Activités
|
Activités
économiques et industrielles
|
Équipements pour eau, assainissement, énergie
|
Infrastructures autres
|
|
Gaz
|
|
Pétrole
|
|
Zones ou espaces affectés aux activités
|
Activités en tissu urbain mixte
|
|
Grandes emprises industrielles
|
|
Zones d'activités économiques
|
|
Entreposage à l'air libre
|
|
Entrepôts logistiques
|
Entrepôts logistiques
|
Entrepôts logistiques
|
|
Commerces
|
Commerces
|
Grandes surfaces commerciales
|
|
Autres commerces
|
|
Grands magasins
|
|
Stations-service
|
|
Bureaux
|
Bureaux
|
Bureaux
|
|
Équipements
|
Bâtiments ou installations de sport
|
Bâtiments ou installations de sport
|
Installations sportives couvertes
|
|
Centres équestres
|
|
Piscines couvertes
|
|
Piscines en plein air
|
|
Autodromes
|
|
Équipements d'enseignement
|
Équipements d'enseignement
|
Enseignement de premier degré
|
|
Enseignement secondaire
|
|
Enseignement supérieur
|
|
Enseignement autre
|
|
Équipements de santé
|
Équipements de santé
|
Hôpitaux, cliniques
|
|
Autres équipements de santé
|
|
Cimetières
|
Cimetières
|
Cimetières
|
|
Équipements culturels, touristiques et de loisirs
|
Grands centres de congrès et d'exposition
|
Grands centres de congrès et d'exposition
|
|
Équipements culturels et de loisirs
|
Équipements culturels et de loisirs
|
|
Autres
équipements
|
Administrations, organismes officiels
|
Sièges d'administrations territoriales
|
|
Équipements de missions de sécurité
civile
|
|
Équipements d'accès au public limité
|
|
Autres équipements accueillant du public
|
Mairies
|
|
Marchés permanents
|
|
Lieux de culte
|
|
Autres équipements de proximité
|
|
Transports
|
Transports
|
Emprises de transport ferré
|
Emprises de transport ferré
|
|
Emprises routières
|
Voies de plus de 25 m d'emprise
|
|
Parcs de stationnement
|
Parkings de surface
|
|
Parkings en étages
|
|
Gares routières, dépôts
|
Gares routières, dépôts de bus
|
|
Installations aéroportuaires
|
Installations aéroportuaires
|
|
Chantiers
|
Chantiers
|
Chantiers
|
Chantiers
|
iv
III - Nomenclature BdOCS CIGAL
|
Niveau 1
|
Niveau 2
|
Niveau 3
|
|
Niveau 4
|
|
|
Territoires artificialisés
|
Habitat
|
Habitat continu (centre ancien, centre-ville)
|
|
|
|
|
Habitat discontinu
|
|
Habitat collectif
|
|
|
Habitat mixte
|
|
|
Habitat individuel
|
|
|
Espaces urbains
spécialisés
|
Emprises scolaires et universitaires
|
|
|
|
|
Emprises hospitalières
|
|
|
|
|
Emprises culturelles et patrimoine
|
|
|
|
|
Cimetières
|
|
|
|
|
Autres espaces urbains spécialisés
|
|
|
|
|
Grandes emprises
|
Emprises industrielles
|
|
|
|
|
Emprises commerciales et artisanales
|
|
|
|
|
Zones d'activités tertiaires
|
|
|
|
|
Emprises militaires
|
|
|
|
|
Gravières et sablières
|
|
Bâtiments
|
|
|
Zones d'exploitation
|
|
|
Carrières
|
|
Bâtiments
|
|
|
Zones d'exploitation
|
|
|
Friches minières
|
|
Terrils
|
|
|
Bâtiments industriels
espaces associés
|
et
|
|
Chantiers et remblais
|
|
|
|
|
Emprise réseau ferré
|
|
|
|
|
Emprise réseau routier
|
|
|
|
|
Emprise aéroportuaires (aéroport
aérodrome)
|
&
|
Pistes
|
|
|
Bâtiments
|
|
|
Autres espaces
|
|
|
Emprises portuaires
|
|
|
|
|
Exploitations agricoles
|
|
|
|
|
Espaces verts
artificialisés
|
Espaces verts urbains
|
|
Pelouses et zones arborées
|
|
|
Jardins ouvriers
|
|
|
Golfs
|
|
|
|
|
Équipements sportifs et de loisirs
|
|
|
|
|
Espaces libres
|
Friches industrielles
|
|
|
|
|
Autres espaces libres
|
|
|
|
|
Territoires agricoles
|
Cultures annuelles
|
|
|
|
|
|
Cultures permanentes
|
Vignes
|
|
|
|
|
Houblon
|
|
|
|
|
Vergers
|
|
Vergers traditionnels
|
|
|
Vergers intensifs
|
|
|
Prairies
|
|
|
|
|
Bosquets et haies
|
|
|
|
|
Cultures spécifiques
|
|
|
|
|
Espaces forestiers
et semi-naturels
|
Forêts
|
Forêts de feuillus
|
|
|
|
|
Forêts de résineux
|
|
|
|
|
Forêts mixtes
|
|
|
|
|
Coupes à blanc et jeunes plantations
|
|
|
|
|
Ripisylve
|
|
|
|
|
Formations pré-
forestières
|
Pelouses et pâturage de montagne
|
|
|
|
|
Tourbières et marais
|
|
|
|
|
Landes
|
|
|
|
|
Fourrés et fructicées
|
|
|
|
|
Roches nues
|
|
|
|
|
|
Milieux
hydrographiques
|
Surfaces en eau
|
Cours d'eau principaux
|
|
|
|
|
Canaux principaux
|
|
|
|
|
Étangs et lacs
|
|
|
|
|
Bassins artificiels
|
|
|
|
IV - Questionnaire MOS
1) Objectifs
1a- Selon quels objectifs et pour quelles utilisations a
été conçu le MOS ? Sa mise à jour et son
intégration du temps ?
1b- Comment sont définis les entités
géographiques observées et les objets informatiques qui sont
enregistrés dans la base ? Comment sont définis les
évolutions et leur suivi ?
1c- Quels ont été les choix et les raisons de
ces choix ? (en fonction des besoins, des avantages)
1d- Est-ce que d'autres options ont été
envisagées ?
2) Système de la base de
données
2a- Comment fonctionne la base de données ? Selon
quelle architecture, structure ? (SGBD, middleware, logiciel, relation
entre les tables)
2b- Quel est le contenu de la base ? (table, type de
données...)
3) Principes et outils de mise à jour et
d'intégration de la dimension temporelle
3a- Intégration du temps :
- Quel temps ? (informatique, réel)
- À quel niveau ?
- Quelle implémentation des changements des versions
successives ?
3b- Quels outils (manuels, automatiques) ? Quelle
méthodologie de mise à jour (formation des
photo-interprètes, cahier des charges, source pour production) ? Quels
contrôles ?
3c- Comment est implémenté le suivi des
évolutions ? Comment fonctionne la partition constante ? Quelles ont
été les limites de départ et comment ont-elles
évolué dans le temps ? Est-ce qu'un identifiant unique est
conservé ?
3d- Est-il possible de différencier lors de la mise
à jour les évolutions réelles des corrections ?
3e- Combien de mise à jour ? La méthode
a-t-elle évoluée ? Depuis quand cette méthode de mise
à jour et de suivi a été mise en place ?
3f- Comment a-t-il été possible de travailler
avec des données anciennes, sur 30 ans, tout en maintenant la
cohérence ? (différence de calage, de résolution,
modification de la nomenclature) Est-ce que les spécifications des
données ont varié ? Comment ?
3g- Comment évolue l'occupation des sols, et les
données, correspondant au milieu rural et à la
végétation ?
3h- ECOMOS : première version terminée en 2004.
Est-ce que la mise à jour est en cours et est-ce qu'elle est
réalisée de la même manière ?
4) Avantages et les inconvénients de ce
modèle
v
4a- Quel retour sur la gestion d'une base de données de ce
type sur plusieurs décennies ?
4b-
vi
Quels sont les principaux avantages et inconvénients de
ce modèle ? (quantité d'informations à stocker, souplesse
et capacités du modèle) Comment pallier à ces
défauts ?
4c- Est-il possible de réaliser des mises à
jour de géométrie ? Par exemple en ce qui concerne les postes
d'occupation naturelle lorsque des évolutions d'occupation des sols
devraient se traduire par un nouveau découpage (changements continus :
déplacement de la lisière de forêt, succession
végétale ; changements ponctuels dans le temps : chablis par
exemple).
4d- Quels traitements, requêtes, sont possibles ? Quels
résultats, études possibles ? (localiser les changements,
calculer les rythmes d'évolution, représentation
cartographique)
4e- Comment a évolué la base sur 30 ans ?
(beaucoup de redécoupage ? accroissement en taille important ?) Quel est
l'impact de ce modèle sur la quantité de données ?
4f- Quelle solution (modèle, outils,
implémentation) recommandée pour une base telle que le RGFor ?
vii
V - Questionnaire BdOCS CIGAL
A- Objectifs
1- Selon quels objectifs et pour quelles utilisations ont
été conçus la BdOCS, sa mise à jour et son
intégration du temps ? Pour quels utilisateurs ?
2- Comment sont définis les entités
géographiques observées et les objets informatiques qui sont
enregistrés dans la base ? Comment sont définis les
évolutions et leur suivi ?
3- Quels ont été les choix et les raisons de
ces choix ? (en fonction des besoins, des avantages) Est-ce que le projet a
été inspiré par un autre modèle ? (CLC par
exemple)
4- Est-ce que d'autres options ont été
envisagées ?
B- Les données
5 - Quelles sont les sources des données ? Comment
fonctionne la chaîne de production ? La PIAO ?
À quoi sert le MNT ? Le registre parcellaire ?
6 - Pourquoi avoir utilisé des images satellites et des
ortho-photos de l'automne-hiver 2007-2008 ?
7 - Combien de personnes travaillent sur la BdOCS ?
8 - Comment a été conçue la nomenclature
? (INSPIRE ?) Il n'y a pas de forêt ouverte dans la nomenclature ?
9 - Est-ce qu'un identifiant unique est conservé ?
10 - Champ de fiabilité évalué et rempli
comment ?
11 - UMC de 200 m2 à 1 ha, selon quels critères
?
12 - Est-ce qu'il existe des différences entre
données dans la base et celles livrées aux utilisateurs ?
C- Système de la base de données
13 - Quel est le contenu de la base ? (table, type de
données...)
14 - Comment fonctionne la base de données ? Selon
quelle architecture, structure ? (SGBD, middleware, logiciel, relations entre
les tables)
D- Principes et outils de mise à jour et
d'intégration de la dimension temporelle
15- Intégration du temps :
- Quel temps ? (informatique, réel) - À quel
niveau ?
16- Quel est le principe de la mise à jour ? Quels
outils (manuels, automatiques) ? Quelle méthode de mise à jour
(formation des photo-interprètes, cahier des charges, source pour
production) ? Quels contrôles ?
17 - Quel est le principe du suivi des évolutions et
comment est-il implémenté ? (BdOCS mutations ?) Comment est-il
produit ?
viii
18 - Qu'est-ce que la mise en cohérence de la BdOCS 2000
et le calage de la BdOCS 2008 sur celle-ci ?
19 - Combien de mise à jour ? La méthode a-t-elle
évoluée ? Depuis quand cette méthode de mise à
jour et de suivi a été mise en place ? Des
données existent-elles avant 2000 ? Il est prévu d'actualiser la
base sur 10 ans, comment ?
20- Est-il possible de différencier lors de la mise
à jour les évolutions réelles des corrections ? Il y a une
phase corrective d'un an après livraison : comment sont
intégrées ces corrections ?
21- Comment évoluent l'occupation des sols, et les
données, correspondant au milieu rural et à la
végétation ?
22 - Comment est livrée la mise à jour ?
E- Capacités, avantages et inconvénients de
ce modèle
23 - Quelles sont les capacités de ce modèle, par
exemple en termes de :
- Quantité d'information à stocker
- Suivi de la qualité des données dans le temps
(cohérence spatiale et temporelle))
- Suivi de l'état de l'occupation des sols et de ses
évolutions (capacité de répondre aux requêtes «
où ? quand ? quoi ? » et « comment ? ») Quels
traitements, requêtes, sont possibles ? Quelles études ?
Résultats ? (localiser les changements, calculer les rythmes
d'évolution, représentation cartographique...)
- Coût de production
- Autre...
24- Quels sont les principaux avantages et
inconvénients de ce modèle ? Si défauts, comment y pallier
?
25- Quels retours des utilisateurs ?
ix
VI - Programmes
VI.A - « identite_1.py »
# User : Romain Louvet, stagiaire
# 28/08/2013
# IGN, equipe produit forêt environnement, projet OCS
& mise a jour du RGFor
# DESCRIPTION :
# test d'algorithme d'appariement attribuant automatiquement
une identite pre-existante a un
nouvel objet.
# Les criteres d'appariement sont :
# - CRITERE 1 : le successeur possede la meme nomenclature que
l'anterieur
# - CRITERE 2 : le successeur est compris dans l'anterieur, le
successeur recupere l'identite de
l'anterieur
# - CRITERE 3 : le successeur contient l'anterieur et l'aire
de l'anterieur est > ou = a 40% de l'aire du
successeur
# - CRITERE 4 : le successeur intersecte l'anterieur et l'aire
du successeur est > ou = a 40% de l'aire du
anterieur
# Si CRITERE 1 ET (CRITERE 2 ou 3 ou 4) sont vrais, l'entite
successeur = l'entite anterieur
# Sinon, le successeur est une nouvelle entite.
# IMPORTANT :
# - ouvrir session de mise a jour avant de charger
# - charger dans fenetre python d'ArcGis sous arcmap (mode
immediat d'utilisation de python avec
ArcGis)
# - charger indentite_1, activer mode edition, charger
intendite_2
# - si erreur avec 'locks' au moment de sauvegarder, fermer
arcmap, redemarrer, effacer feature
class cree, relancer OU
# ouvrir dossier de la gdb rechercher "lock" et supprimer lock
sur "APRES..." et "AVANT..." (solution
non teste)
import arcpy
from datetime import datetime import sys
### I - VARIABLES a definir
fc = "
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/test_rgfor65.gdb/test65/RGFOR65_test"
# adresse de la table d'actualites
date = """ date '2010-08-01' """# date de la PVA utilisee pour la
mise a jour
date_fmt = '%Y-%m-%d'
gdb = "
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/test_rgfor65.gdb/test65/"
# adresse
d'enregistrement
AVANT = "AVANT2010" # nom de la table des objets valide jusqu'a
la date de PVA
APRES = "APRES2010" # nom de la table des objets valide depuis la
date de PVA
### II - creation couche AVANT - APRES date de la PVA a partir
d'une selection
arcpy.MakeFeatureLayer_management (fc, "actulyr")
x
arcpy.SelectLayerByAttribute_management ("actulyr",
"NEW_SELECTION", """ "DATE_V_TO" = """+date)
arcpy.CopyFeatures_management ("actulyr",gdb+AVANT)
arcpy.SelectLayerByAttribute_management ("actulyr",
"NEW_SELECTION", """ "DATE_V_FROM" =
"""+date)
arcpy.CopyFeatures_management ("actulyr",gdb+APRES)
identite_2.py
identite_3.py
evenements_test.py
xi
VI.B - « identite_2.py » import
arcpy
from datetime import datetime import sys
### I - VARIABLES a definir
fc = "
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/test_rgfor65.gdb/test65/RGFOR65_test"
# adresse de la table d'actualites
date = '2010-08-01'# date de la PVA utilisee pour la mise a
jour
date_fmt = '%Y-%m-%d'
gdb = "
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/test_rgfor65.gdb/test65/"
# adresse
d'enregistrement
AVANT = "AVANT2010" # nom de la table des objets valide jusqu'a
la date de PVA
APRES = "APRES2010" # nom de la table des objets valide depuis la
date de PVA
# liste des codes d'entites
code_ent = open("
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/code_RGFOR065.txt","r")
code_ent = code_ent.read()
code_ent = code_ent.split("\n")
### III - selection par localisation dans AVANT depuis APRES
# creation d'une liste contenant les identifiants absolus des
lignes listeOID = []
# creation d'un curseur de recherche pour parcourir la table
"APRES" lignes = arcpy.SearchCursor(APRES)
# boucle recherche ligne par ligne de la table "APRES" et ajout
des valeurs a la liste "listeOID" for ligne in lignes:
# recupere la valeur du champ OBJECTID, champ d'identifiant
absolu
value = ligne.getValue("OBJECTID")
# ajoute a la liste "listeOID" listeOID.append(value)
# fait de meme avec "CLEABS" value = ligne.getValue("CLEABS")
# mesure "listeOID" pour determiner le nombre d'iteration lgr =
len(listeOID)
# trouve la derniere valeur "ENTITE_ID"
# servira a appeler nouveau code pour nouvelle entite
arcpy.SelectLayerByAttribute_management ("actulyr",
"NEW_SELECTION", """ "ENTITE_ID" = (SELECT
MAX ("ENTITE_ID") FROM RGFOR65_test) """)
resultat = arcpy.SearchCursor("actulyr")
for cmax in resultat:
cle = cmax.getValue("OBJECTID")
xii
# boucle
for i in range(lgr):
# selection par attribut dans la table APRES de la ligne d'index
"i" dans "listeOID"
OID = str(listeOID[i])
select = """ "OBJECTID" = """+OID
arcpy.SelectLayerByAttribute_management (APRES, "NEW_SELECTION",
select)
# creation d'un curseur de recherche dans la table "APRES" lignes
= arcpy.SearchCursor(APRES)
# condition si l'objet est une nouvelle entite new = 0
# boucle de recherche ligne par lignee de la table "APRES" des
valeurs "NOMEN", "SHAPE_Area" et
"DATE_V_CREA"
for ligne in lignes:
tfvAP = ligne.getValue("NOMEN")
aireAP = ligne.getValue("SHAPE_Area")
# CRITERES 3 et 4 : calcul du % de l'aire dans "APRES" aireAP100a
= aireAP*40/100
aireAP100b = aireAP/1.4
# CRITERE 2 : selection par emplacement dans la couche "AVANT"
des polygones # qui contiennent polygones dans la couche "APRES"
arcpy.SelectLayerByLocation_management (AVANT, "CONTAINS",
APRES)
# creation d'un curseur pour la couche "AVANT" lignes2 =
arcpy.SearchCursor(AVANT)
# condition si selection ne fonctionne pas entIDAV = 0
# pour toutes les lignes de la selection for ligne2 in
lignes2:
# recupere valeur du champ "NOMEN" et "DATE_CREA"
tfvAV = ligne2.getValue("NOMEN")
# CRITERE 1 : si valeur "NOMEN" est identique a celle de l'objet
dans "APRES"
if tfvAP == tfvAV:
# recupere valeur du champ "ENTITE_ID", "PARTIE" et
"DATE_V_CREA" de "AVANT" et
l'attribue a celui de "APRES"
entIDAV = ligne2.getValue("ENTITE_ID")
entIDAV = str(entIDAV)
entiteID = '"'+""+entIDAV+""+'"'
partieAV = ligne2.getValue("PARTIE") partieAV = str(partieAV)
partie = '"'+""+partieAV+""+'"'
crea = ligne2.getValue("DATE_V_CREA")
xiii
crea = '"'+""+str(crea)+""+'"'
arcpy.CalculateField_management (APRES,"ENTITE_IDtest", entiteID,
"PYTHON") arcpy.CalculateField_management (APRES,"PARTIE_test", partie,
"PYTHON") arcpy.CalculateField_management (APRES,"DATE_V_CREA_test", crea,
"PYTHON")
# l'objet n'est pas une nouvelle entite new = 1
# si CONTAINS ne donne rien : if entIDAV == 0:
# CRITERE 3 : selection par emplacement dans la couche "AVANT"
des polygones # qui sont contenus par des polygones dans la couche "APRES"
arcpy.SelectLayerByLocation_management (AVANT, "WITHIN", APRES)
# creation d'un curseur pour la couche "AVANT" lignes2 =
arcpy.SearchCursor(AVANT)
# condition si selection ne fonctionne pas entIDAV = 0
# listes pour la selection liAIREAV = [] liENTITEAV = [] liPARTIE
= [] liCREA = []
# pour toutes les lignes dans la selection for ligne2 in
lignes2:
# recupere valeur du champ "NOMEN" tfvAV =
ligne2.getValue("NOMEN")
# CRITERE 1 : si valeur "NOMEN" de "AVANT" est identique a celle
de l'objet
# dans "APRES" ajoute valeur de son champ "SHAPE_Area" et
"ENTITE_ID" a une liste
if tfvAP == tfvAV:
aireAV = ligne2.getValue("SHAPE_Area")
entIDAV = ligne2.getValue("ENTITE_ID")
partieAV = ligne2.getValue("PARTIE")
crea = ligne2.getValue("DATE_V_CREA")
liAIREAV.append(aireAV) liENTITEAV.append(entIDAV)
liPARTIE.append(partieAV) liCREA.append(crea)
# trouve l'objet le plus grand et son "ENTITE_ID" try:
airemax = 0
airemax = max(liAIREAV)
xiv
ind = liAIREAV.index(airemax)
except (SyntaxError,ValueError,IndexError): pass
# si aire "AVANT" remplie condition par rapport a aire "APRES" if
airemax > aireAP100a:
# recupere valeur du champ "ENTITE_ID", "PARTIE" et "DATE_V_CREA"
de "AVANT" et
l'attribue a celui de "APRES"
entIDAV = liENTITEAV[ind]
partieAV = liPARTIE[ind]
crea = liCREA[ind]
entIDAV = str(entIDAV)
entiteID = '"'+""+entIDAV+""+'"' partieAV = str(partieAV)
partie = '"'+""+partieAV+""+'"' crea = '"'+""+str(crea)+""+'"'
arcpy.CalculateField_management (APRES,"ENTITE_IDtest", entiteID,
"PYTHON") arcpy.CalculateField_management (APRES,"PARTIE_test", partie,
"PYTHON") arcpy.CalculateField_management (APRES,"DATE_V_CREA_test", crea,
"PYTHON")
# l'objet n'est pas une nouvelle entite new = 1
# si WITHIN ne donne rien non plus if entIDAV == 0:
# CRITERE 4 : selection par emplacement dans la couche "AVANT"
des polygones # qui possedent une intersection avec les polygones dans la
couche "APRES" arcpy.SelectLayerByLocation_management (AVANT, "INTERSECT",
APRES)
# creation d'un curseur pour la couche "AVANT" lignes2 =
arcpy.SearchCursor(AVANT)
# listes pour la selection liAIREAV = [] liENTITEAV = [] liPARTIE
= [] liCREA = []
for ligne2 in lignes2:
# recupere valeur du champ "NOMEN" tfvAV =
ligne2.getValue("NOMEN")
# CRITERE 1 : si valeur "TFV" de "AVANT" est identique a celle de
l'objet
# dans "APRES" ajoute valeur de son champ "SHAPE_Area" et
"ENTITE_ID" a une liste
if tfvAP == tfvAV:
aireAV = ligne2.getValue("SHAPE_Area")
entIDAV = ligne2.getValue("ENTITE_ID")
xv
partieAV = ligne2.getValue("PARTIE") crea =
ligne2.getValue("DATE_V_CREA")
liAIREAV.append(aireAV) liENTITEAV.append(entIDAV)
liPARTIE.append(partieAV) liCREA.append(crea)
# trouve l'objet le plus grand et son "ENTITE_ID"
try:
airemax = 0
airemax = max(liAIREAV)
ind = liAIREAV.index(airemax)
except (SyntaxError,ValueError,IndexError):
pass
# si aire "AVANT" remplie condition par rapport a aire "APRES" if
airemax >= aireAP100b:
# recupere valeur du champ "ENTITE_ID", "PARTIE" et "DATE_V_CREA"
de "AVANT" et
l'attribue a celui de "APRES"
entIDAV = liENTITEAV[ind]
partieAV = liPARTIE[ind]
crea = liCREA[ind]
entIDAV = str(entIDAV)
entiteID = '"'+""+entIDAV+""+'"' partieAV = str(partieAV)
partie = '"'+""+partieAV+""+'"' crea = '"'+""+str(crea)+""+'"'
arcpy.CalculateField_management (APRES,"ENTITE_IDtest", entiteID,
"PYTHON") arcpy.CalculateField_management (APRES,"PARTIE_test", partie,
"PYTHON") arcpy.CalculateField_management (APRES,"DATE_V_CREA_test", crea,
"PYTHON")
# l'objet n'est pas une nouvelle entite new = 1
# si l'objet est une nouvelle entite if new == 0:
# cherche un nouveau code ENTITE_ID dans la liste entiteID =
'"'+""+str(code_ent[cle])+""+'"'
# attribue premier element de la liste de code pour PARTIE partie
= '"'+""+"aaa"+""+'"'
# attribue nouvelle date de creation crea =
datetime.strptime(date,date_fmt) crea = '"'+""+str(crea)+""+'"'
xvi
arcpy.CalculateField_management (APRES,"ENTITE_IDtest", entiteID,
"PYTHON") arcpy.CalculateField_management (APRES,"PARTIE_test", partie,
"PYTHON") arcpy.CalculateField_management (APRES,"DATE_V_CREA_test", crea,
"PYTHON")
# prochain code cle = cle + 1
xvii
VI.C - « identite_3.py » import arcpy
from datetime import datetime import sys
### I - VARIABLES a definir
fc = "
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/test_rgfor65.gdb/test65/RGFOR65_test"
# adresse de la table d'actualites
date = '2010-08-01'# date de la PVA utilisee pour la mise a
jour
date_fmt = '%Y-%m-%d'
gdb = "
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/test_rgfor65.gdb/test65/"
# adresse
d'enregistrement
AVANT = "AVANT2010" # nom de la table des objets valide jusqu'a
la date de PVA
APRES = "APRES2010" # nom de la table des objets valide depuis la
date de PVA
### IV- Partie
### Si plusieurs objets ont le meme code ENTITE_ID, ils doivent
avoir differents codes PARTIE
### Variables
# liste des codes PARTIE
code_partie =
open("
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/code_PARTIE065.txt","r")
code_partie = code_partie.read()
code_partie = code_partie.split("\n")
# Variables pour IVA
liOID = [] # liste OBJECTID liENT = [] # liste ENTITE
liPAR = [] # liste PARTIE depart
liENPAR = [] # liste id d'entite complet
liARE = [] # liste SHAPE_area
# Variable pour IVB
liTTL = [] # liste totale index liPAR2 = [] # liste PARTIE
arrivee
### IVA - Listes des valeurs des champs
# creation d'un curseur de recherche pour parcourir la table
"APRES" lignes = arcpy.SearchCursor(APRES)
# boucle recherche ligne par ligne de la table "APRES"
for ligne in lignes:
# recupere la valeur du champ "OBJECTID", "ENTITE_IDtest",
"PARTIE_test" et "SHAPE_Area"
vOID = ligne.getValue("OBJECTID")
vENT = ligne.getValue("ENTITE_IDtest")
vPAR = ligne.getValue("PARTIE_test")
vARE = ligne.getValue("SHAPE_Area")
# ajoute aux listes
xviii
liOID.append(vOID) liENT.append(vENT) liPAR.append(vPAR)
liENPAR.append(vENT+vPAR) liARE.append(vARE)
liPAR2 = liPAR
lgr = len(liOID) # longueur de la table
### IVB - Boucle de detection de nouvelle partie
for i in range(lgr):
# creation et remise a zero des variables calculees par la
boucle liIND = [] # liste index des lignes avec meme ENTITE_ID + PARTIE liARE2
= [] # valeur aire de ces lignes
liPAR1 = [] # liste PARTIE en cours
# si cette ligne n'a pas deja ete traitee
# essaye de trouver i dans liste totale index try:
test = liTTL.index(i)
# si ne fonctionne pas, lance la recherche except(ValueError):
# cherche si code ENTITE_ID plus PARTIE # existe plusieurs
fois
enpar = liENPAR[i]
# pour chacun des codes ENTITE_ID + PARTIE for indx, ID in
enumerate(liENPAR):
# si le code est egal au code recherche if ID == enpar:
# son index est ajoute a la liste liIND.append(indx)
# si cette liste est > 1, il existe plusieurs codes identique
lgi = len(liIND)
if lgi > 1:
# avec la liste d'index je trouve la valeur max du code PARTIE et
de l'airepour cette ENTITE_ID for j in liIND:
liARE2.append(liARE[j]) liPAR1.append(liPAR[j])
mxaire = max(liARE2) mxliPAR1 = max(liPAR1)
# trouve valeur PARTIE la plus grande dans liste num =
code_partie.index(mxliPAR1)
xix
# pour toutes les lignes, sauf celle avec la plus grande aire
# le champ PARTIE possede un nouveau code
for k in liIND:
aire = liARE[k]
if aire < mxaire:
# donne index du code suivant dans la liste de code PARTIE
num = num+1
# remplace ancien par nouveau code liPAR2[k]= code_partie[num]
# ajoute les lignes deja faites liTTL.extend(liIND)
### IVC - boucle calcul du champ PARTIE
for i in range(lgr):
arr = liPAR2[i]
# selection de la ligne a modifier
OID = str(liOID[i])
select = """ "OBJECTID" = """+OID
arcpy.SelectLayerByAttribute_management (APRES, "NEW_SELECTION",
select)
lignes = arcpy.SearchCursor(APRES)
# modification du champ "PARTIE" avec le nouveau code
arr = '"'+""+str(arr)+""+'"'
arcpy.CalculateField_management (APRES,"PARTIE_test", arr,
"PYTHON")
xx
VI.D - « evenements_test.py »
# User : Romain Louvet, stagiaire
# 28/08/2013
# IGN, equipe produit forêt environnement, projet OCS &
mise a jour du RGFor # Nom:
evenements.py
# DESCRIPTION :
# Ce programme lit la table attributaire de la feature classe
matrice_evenements sous forme d'un .csc convertit en
# convertit les colonnes en liste ; effectue des recherches dans
ces listes afin de determiner le type d'evenement
# en remplissant la colonne EVEtest, puis attribue un NUMEVE
# Ce programme ne reconnait et n'a ete teste que pour les
evenements "INC", "INT", "FUS" et "REM
# IMPORTANT :
# - avoir créé feature class matrice_evenements
# - avoir ajouté evenements de la mise a jour datee par la
PVA
# - avoir un fichier texte lisible de la table attributaire :
# - ouvrir matrice_evenements dans arcmap, ouvrir sa table
attributaire
# - "turn field off tous" les champs excepte OBJECTID, ENTITE_AV,
PARTIE_AV, ENTITE_AP,
PARTIE_AP, NUMEVE, EVEtest
# - "Table options" > "select all"
# - clic droit bordure grise côté gauche du tableau
> "copy selected"
# - coller selection dans tableau excel, enregistrer sous ex :
EVE2010_65.csv
# liste des codes numeve
fichier = open("
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/code_NUMEV065.txt","r")
lire = fichier.read()
code_numeve = lire.split("\n")
# dernier code NUMEVE dans table "evenements" (entrer
manuellement)
dernier = 0
try :
cle = code_numeve.index(dernier)
except ValueError:
cle = 0
fichier.close()
# ouvrir tableau en mode lecture
fichier = open("
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/EVE2010_65.csv",
"r") lire = fichier.read()
# les evenements
INC = "INC" INT = "INT" FUS = "FUS" SCI = "SCI" EXT = "EXT" REC =
"REC"
xxi
REA = "REA" REM = "REM" DIV = "DIV"
# creer les listes de colonne
objectid = [] entiteAV = [] entiteAP = [] partieAV = [] partieAP
= [] entparAV = [] entparAP = [] numeve = [] eveTEST = []
# listes lignes d'eve liINC = []
liNONINC = []
# transformation du contenu du fichier .csv en liste lignes =
lire.splitlines()
lgr = len(lignes)
for i in range(lgr):
if i > 0:
ligne = lignes[i]
colonne = ligne.split(";") objectid.append(colonne[0])
entiteAV.append(colonne[1]) partieAV.append(colonne[2])
entiteAP.append(colonne[3]) partieAP.append(colonne[4])
numeve.append(colonne[5]) eveTEST.append("<Nul>")
entparAV.append(colonne[1]+colonne[2])
entparAP.append(colonne[3]+colonne[4])
### INCHANGE ###
# definition : intersection correspondant a la meme entite avant
et apres le ou les evenements
for i in range(lgr-1): ii = int(i)-1
av = entparAV[ii] ap = entparAP[ii] if av == ap :
eveTEST[ii] = INC
liINC.append(objectid[ii])
numeve[ii] = code_numeve[cle] else:
liNONINC.append(objectid[ii])
xxii
lgrINC = len(liINC)
# prochain code cle = cle + 1
### INTEGRATION ###
# definition : l'entite est remplacee par entite preexistante
for i in liNONINC: ii = objectid.index(i)
eve = numeve[ii] av = entparAV[ii] ap = entparAP[ii]
# entite existant en T est unique rech = entparAV.count(av) if
rech == 1:
# entite existant en T n'existe plus en T+1 rech1 =
entparAP.count(av)
if rech1 == 0:
# successeur est inchange for j in liINC:
jj = objectid.index(j)
rechinv = entparAV[jj] if rechinv == ap: eveTEST[ii] = INT
### FUSION ###
# definition : l'entite est remplacee par une nouvelle entite qui
remplace au moins # deux entites distinctes
# attention ! prendre en compte PARTIE sinon confondu avec
reaffectation
for i in liNONINC: x = 0
ii = objectid.index(i) eve = numeve[ii] av = entiteAV[ii] ap =
entiteAP[ii]
# entite existant en T est unique rech = entiteAV.count(av) if
rech == 1:
# entite existant en T n'existe plus en T+1 rech1 =
entiteAP.count(av)
if rech1 == 0:
xxiii
# successeur n'est pas inchange
for j in liINC:
jj = objectid.index(j)
rechinv = entiteAV[jj]
if rechinv != ap:
x = x+1
if x == lgrINC:
# successeur existe au moins 2 fois if
entiteAP.count(ap)>=2:
# ce n'est pas une reaffectation a definir !!! eveTEST[ii] =
FUS
### REMPLACEMENT ###
# definition : nouvelle entite avec la meme geometrie que
precedente
for i in liNONINC: x = 0
ii = objectid.index(i) eve = numeve[ii] av = entparAV[ii] ap =
entparAP[ii]
# entite existant en T est unique rech = entparAV.count(av) if
rech == 1:
# entite existant en T n'existe plus en T+1 rech1 =
entparAP.count(av)
if rech1 == 0:
# successeur n'est pas inchange
for j in liINC:
jj = objectid.index(j)
rechinv = entparAV[jj]
if rechinv != ap:
x = x+1
if x == lgrINC:
# successeur existe une seule fois if
entparAP.count(ap)==1:
eveTEST[ii] = REM
numeve[ii] = code_numeve[cle]
# prochain code cle = cle + 1
### NUMEVE
# liste des num utilises
xxiv
num_ut = []
# pour chaque ligne de la colonne eveTEST
for i in range(lgr-1): oid = objectid[i] test = numeve[i]
# si la ligne n'a pas deja ete faite
if test == "<Nul>":
# cherche le type d'eve
eve = eveTEST[i]
# cherche l'identifiant ENTITE et PARTIE apres et avant
idAP = entparAP[i]
idAV = entparAV[i]
# INTEGRATION : if eve == INT:
for j in range(lgr-1): eve1 = eveTEST[j] oid1 = objectid[j]
idAP1 = entparAP[j]
# meme evenement si deux lignes ont le meme id apres et le meme
eve INT if idAP == idAP1 and eve == eve1:
numeve[j] = code_numeve[cle] # meme numeve
numeve[i] = code_numeve[cle]
# prochain code cle = cle + 1
# FUSION :
if eve == FUS:
for j in range(lgr-1): eve1 = eveTEST[j] oid1 = objectid[j]
idAP1 = entparAP[j]
# meme evenement si deux lignes ont le meme id apres et le meme
eve FUS if idAP == idAP1 and eve == eve1:
numeve[j] = code_numeve[cle] # meme numeve
numeve[i] = code_numeve[cle]
# prochain code cle = cle + 1
fichier1 = open("
C:/Users/Romain/Desktop/IGN/test_histoRGFOR_OCS/EVE2010_65test.csv",
"w")
for i in range(lgr):
if i == 0:
fichier1.write(lignes[i]+"\n") else:
xxv
fichier1.write(objectid[i-1]+";"+entiteAV[i-1]+";"+partieAV[i-1]+";"+entiteAP[i-1]+";"+partieAP[i-1]+";"+numeve[i-1]+";"+eveTEST[i-1]+"\n")
fichier.close() fichier1.close()
xxvi
VII - Tableau statistique d'évolution de
l'occupation des sols du jeu de données « RGFOR65_test
»
|
Transition
/
événements
|
Division en
m2
|
Division en % du total moins (vide)
|
Extraction en
m2
|
Extraction % du total moins (vide)
|
|
BOSQUET - HRGFOR
|
|
|
|
|
|
BOSQUET - LA4
|
|
|
|
|
|
FF0 - FF1-00-00
|
|
|
|
|
|
FF0 - FO32
|
|
|
|
|
|
FF0 - HRGFOR
|
|
|
|
|
|
FF1-00 - HRGFOR
|
|
|
|
|
|
FF1-00 - TLHF
|
|
|
|
|
|
FF1-00-00 - FF31
|
|
|
|
|
|
FF1-00-00 - FO1
|
|
|
|
|
|
FF1-00-00 - HRGFOR
|
|
|
39 348,51
|
100,00
|
|
FF1-00-00 - LA4
|
|
|
|
|
|
FF1G01-01 - HRGFOR
|
|
|
|
|
|
FF1G01-01 - TLHF
|
|
|
|
|
|
FF2G61-61 - FF0
|
|
|
|
|
|
FF2G61-61 - FF2-90-90
|
|
|
|
|
|
FF32 - HRGFOR
|
|
|
|
|
|
FF32 - LA4
|
|
|
|
|
|
FO2 - FF0
|
|
|
|
|
|
FO2 - LA6
|
|
|
|
|
|
HRGFOR - BOSQUET
|
|
|
|
|
|
HRGFOR - LA4
|
|
|
|
|
|
HRGFOR - TLHF
|
|
|
|
|
|
LA4 - HRGFOR
|
|
|
|
|
|
LA4 - TLHF
|
|
|
|
|
|
LA6 - FF0
|
|
|
|
|
|
LA6 - HRGFOR
|
|
|
|
|
|
LA6 - TLHF
|
|
|
|
|
|
TLHFC1 - HRGFOR
|
|
|
|
|
|
TLHFC1 - LA4
|
|
|
|
|
|
TLHF - BOSQUET
|
|
|
|
|
|
TLHF - HRGFOR
|
6 749,44
|
27,56
|
|
|
|
TLHF - LA4
|
|
|
|
|
|
|
|
|
|
|
Total général
|
6 749,44
|
2,16
|
39 348,51
|
12,59
|
xxvii
Transition
|
/
événements
|
Intégration en
m2
|
Intégration % du total moins (vide)
|
Réaffectation en
m2
|
Réaffectation % du total moins (vide)
|
|
BOSQUET - HRGFOR
|
|
|
|
|
|
BOSQUET - LA4
|
2 782,39
|
100,00
|
|
|
|
FF0 - FF1-00-00
|
44 049,24
|
100,00
|
|
|
|
FF0 - FO32
|
|
|
|
|
|
FF0 - HRGFOR
|
|
|
|
|
|
FF1-00 - HRGFOR
|
|
|
|
|
|
FF1-00 - TLHF
|
|
|
|
|
|
FF1-00-00 - FF31
|
|
|
|
|
|
FF1-00-00 - FO1
|
|
|
|
|
|
FF1-00-00 - HRGFOR
|
|
|
|
|
|
FF1-00-00 - LA4
|
|
|
|
|
|
FF1G01-01 - HRGFOR
|
|
|
|
|
|
FF1G01-01 - TLHF
|
|
|
|
|
|
FF2G61-61 - FF0
|
|
|
|
|
|
FF2G61-61 - FF2-90-90
|
|
|
|
|
|
FF32 - HRGFOR
|
|
|
|
|
|
FF32 - LA4
|
|
|
|
|
|
FO2 - FF0
|
|
|
27 024,90
|
100,00
|
|
FO2 - LA6
|
|
|
|
|
|
HRGFOR - BOSQUET
|
|
|
|
|
|
HRGFOR - LA4
|
|
|
|
|
|
HRGFOR - TLHF
|
|
|
|
|
|
LA4 - HRGFOR
|
|
|
|
|
|
LA4 - TLHF
|
|
|
|
|
|
LA6 - FF0
|
|
|
|
|
|
LA6 - HRGFOR
|
|
|
|
|
|
LA6 - TLHF
|
|
|
|
|
|
TLHFC1 - HRGFOR
|
2 369,71
|
100,00
|
|
|
|
TLHFC1 - LA4
|
245,86
|
100,00
|
|
|
|
TLHF - BOSQUET
|
|
|
|
|
|
TLHF - HRGFOR
|
17 744,19
|
72,44
|
|
|
|
TLHF - LA4
|
789,21
|
100,00
|
|
|
|
|
|
|
|
|
Total général
|
67 980,60
|
21,75
|
27 024,90
|
8,65
|
xxviii
Transition
|
/
événements
|
Rectification en
m2
|
Rectification % du total moins (vide)
|
Remplacement en
m2
|
Remplacement % du total moins (vide)
|
|
BOSQUET - HRGFOR
|
|
|
|
|
|
BOSQUET - LA4
|
|
|
|
|
|
FF0 - FF1-00-00
|
|
|
|
|
|
FF0 - FO32
|
|
|
14 922,75
|
100,00
|
|
FF0 - HRGFOR
|
|
|
|
|
|
FF1-00 - HRGFOR
|
|
|
|
|
|
FF1-00 - TLHF
|
|
|
|
|
|
FF1-00-00 - FF31
|
|
|
|
|
|
FF1-00-00 - FO1
|
|
|
|
|
|
FF1-00-00 - HRGFOR
|
|
|
|
|
|
FF1-00-00 - LA4
|
|
|
|
|
|
FF1G01-01 - HRGFOR
|
34 153,33
|
100,00
|
|
|
|
FF1G01-01 - TLHF
|
|
|
|
|
|
FF2G61-61 - FF0
|
|
|
|
|
|
FF2G61-61 - FF2-90-90
|
|
|
|
|
|
FF32 - HRGFOR
|
|
|
|
|
|
FF32 - LA4
|
|
|
|
|
|
FO2 - FF0
|
|
|
|
|
|
FO2 - LA6
|
|
|
|
|
|
HRGFOR - BOSQUET
|
|
|
|
|
|
HRGFOR - LA4
|
|
|
|
|
|
HRGFOR - TLHF
|
|
|
|
|
|
LA4 - HRGFOR
|
|
|
|
|
|
LA4 - TLHF
|
|
|
|
|
|
LA6 - FF0
|
|
|
|
|
|
LA6 - HRGFOR
|
|
|
|
|
|
LA6 - TLHF
|
|
|
|
|
|
TLHFC1 - HRGFOR
|
|
|
|
|
|
TLHFC1 - LA4
|
|
|
|
|
|
TLHF - BOSQUET
|
|
|
|
|
|
TLHF - HRGFOR
|
|
|
|
|
|
TLHF - LA4
|
|
|
|
|
|
|
|
|
|
|
Total général
|
34 153,33
|
10,93
|
14 922,75
|
4,77
|
xxix
Transition
|
/
événements
|
Scission en
m2
|
Scission
% du total moins (vide)
|
(vide)
|
Total général
|
Total
moins (vide)
|
% sur le total
|
|
BOSQUET - HRGFOR
|
|
|
2 063,40
|
2 063,40
|
0,00
|
0,22
|
|
BOSQUET - LA4
|
|
|
|
2 782,39
|
2 782,39
|
0,30
|
|
FF0 - FF1-00-00
|
|
|
|
44 049,24
|
44 049,24
|
4,67
|
|
FF0 - FO32
|
|
|
|
14 922,75
|
14 922,75
|
1,58
|
|
FF0 - HRGFOR
|
|
|
3 376,63
|
3 376,63
|
0,00
|
0,36
|
|
FF1-00 - HRGFOR
|
|
|
3 991,18
|
3 991,18
|
0,00
|
0,42
|
|
FF1-00 - TLHF
|
|
|
3 365,39
|
3 365,39
|
0,00
|
0,36
|
|
FF1-00-00 - FF31
|
|
|
10 929,70
|
10 929,70
|
0,00
|
1,16
|
|
FF1-00-00 - FO1
|
|
|
73 410,09
|
73 410,09
|
0,00
|
7,79
|
|
FF1-00-00 - HRGFOR
|
|
|
65 629,81
|
104
978,32
|
39 348,51
|
11,14
|
|
FF1-00-00 - LA4
|
|
|
7 723,93
|
7 723,93
|
0,00
|
0,82
|
|
FF1G01-01 - HRGFOR
|
|
|
72 144,78
|
106
298,11
|
34 153,33
|
11,28
|
|
FF1G01-01 - TLHF
|
|
|
2 745,01
|
2 745,01
|
0,00
|
0,29
|
|
FF2G61-61 - FF0
|
88 417,59
|
100,00
|
|
88 417,59
|
88 417,59
|
9,38
|
|
FF2G61-61 - FF2-90-90
|
33 982,37
|
100,00
|
|
33 982,37
|
33 982,37
|
3,61
|
|
FF32 - HRGFOR
|
|
|
4 179,52
|
4 179,52
|
0,00
|
0,44
|
|
FF32 - LA4
|
|
|
25 038,00
|
25 038,00
|
0,00
|
2,66
|
|
FO2 - FF0
|
|
|
|
27 024,90
|
27 024,90
|
2,87
|
|
FO2 - LA6
|
|
|
2,27
|
2,27
|
0,00
|
0,00
|
|
HRGFOR - BOSQUET
|
|
|
331,48
|
331,48
|
0,00
|
0,04
|
|
HRGFOR - LA4
|
|
|
15 784,22
|
15 784,22
|
0,00
|
1,67
|
|
HRGFOR - TLHF
|
|
|
1 101,39
|
1 101,39
|
0,00
|
0,12
|
|
LA4 - HRGFOR
|
|
|
291 547,67
|
291
547,67
|
0,00
|
30,94
|
|
LA4 - TLHF
|
|
|
159,99
|
159,99
|
0,00
|
0,02
|
|
LA6 - FF0
|
|
|
23 577,41
|
23 577,41
|
0,00
|
2,50
|
|
LA6 - HRGFOR
|
|
|
13 434,56
|
13 434,56
|
0,00
|
1,43
|
|
LA6 - TLHF
|
|
|
499,41
|
499,41
|
0,00
|
0,05
|
|
TLHFC1 - HRGFOR
|
|
|
|
2 369,71
|
2 369,71
|
0,25
|
|
TLHFC1 - LA4
|
|
|
|
245,86
|
245,86
|
0,03
|
|
TLHF - BOSQUET
|
|
|
29,76
|
29,76
|
0,00
|
0,00
|
|
TLHF - HRGFOR
|
|
|
8 737,27
|
33 230,90
|
24 493,63
|
3,53
|
|
TLHF - LA4
|
|
|
|
789,21
|
789,21
|
0,08
|
|
|
|
|
|
|
|
|
Total général
|
122
399,96
|
39,16
|
629 802,89
|
942
382,38
|
312 579,49
|
100,00
|
VIII - Rapport BDUni
|
Processus d'historisation de la BDUni et
adaptabilité au RGFor
|
|
REF : XXX DATE : 15/05/2013
|
Objet : XXX
NOM - FONCTION SIGNATURE
xxx
Commanditaire
Rédacteur
Relecteur
Valideur
Liste de diffusion
|
Participants - Service
|
Personnes à informer - Service
|
|
XXX - XXX
|
XXX - XXX
|
Date Visa Nom Service
xxxi
Introduction
Ce document porte sur l'historisation des données de la
BDUni (Base de Données Unifiée). Il s'inscrit dans un travail de
recherche, au cours d'un stage de février à mai 2013 sur
l'intégration de la dimension temporelle aux données pour la
future mise à jour du RGFor (Référentiel
Géographique Forestier), dans le cadre du projet OCS GE (OCcupation du
Sol à Grande Échelle). Il doit répondre par ailleurs
à un besoin interne de documentation sur l'historisation dans la
BDUni.
Nous commencerons par décrire le système de la
base de données BDUni et son processus d'historisation, en termes de
contenu, de structure, d'architecture et de production des données. Puis
nous évaluerons ses outils de mise à jour et d'intégration
de la dimension temporelle, les avantages et les inconvénients de ce
modèle, notamment afin d'envisager son adaptabilité aux besoins
spécifiques d'une base d'occupation du sol telle que le RGFor.
I - Système de base de données et processus
d'historisation
Bien que l'intégration de la dimension temporelle soit
une préoccupation relativement nouvelle pour les bases de données
d'informations géographiques (Bordin, 2002, p. 90), des
expériences de mises en place de processus d'intégration et
d'outils de gestion de la dimension temporelle ont déjà
été conduites, comme les projets GéoPeuple41 et
GéOpenSim42 au laboratoire COGIT (Conception Objet et
Généralisation de l'Information Topographique) de l'IGN. Les
recherches sur les modèles théoriques ont en effet apporté
des réponses à cette question et les problèmes liés
aux limites matérielles ont pu, du moins en partie, se résoudre
du fait des progrès techniques. Par ailleurs, ces expériences
répondent à un besoin croissant en informations
spatio-temporelles (Paque, 2004, p. 2).
Un modèle d'historisation a ainsi déjà
été développé au sein de l'IGN dans le cadre du
projet d'unification des bases de données, ou BDUni, afin de
répondre à ce besoin. Un des thèmes de cette base de
données, la couche végétation, est une couche d'occupation
du sol, dont la création est intégrée à la
chaîne de production du RGFor depuis la mise en place du partenariat
entre l'IFN et l'IGN (Guinaudeau, 2006) et la fusion des deux instituts au
premier janvier 2012. Cette couche comprend les milieux arborés et les
landes.
Plus précisément, la nomenclature de la couche
végétation inclut (IGN, 2011, p. 122) :
- les bois : bosquets, arbres épars, et espaces verts
- les vergers
- les landes ligneuses43
- les haies
- les vignes
- les bananeraies
- les mangroves
- les plantations de canne à sucre
- les peupleraies
41 http://geopeuple.ign.fr/
42 http://geopensim.ign.fr/
43 Les formations herbacées ont été
intégrées à la BDUni mais n'ont jamais été
diffusées avec la base produit BDTopo. Elles doivent être
supprimées de la BDUni au moment de l'archivage de mars 2013.
xxxii
- les forêts, divisées en cinq postes
(simplification de la nomenclature du RGFor) :
o forêt fermée ? feuillu, ? conifère,
? mixte
o forêt ouverte
Comprendre le processus de mise à jour et la prise en
compte de la dimension temporelle dans la BDUni en étudiant une
méthodologie interne à l'IGN est particulièrement
intéressant pour tenter de répondre en première approche
à la problématique de l'historisation dans le cadre du RGFor.
Reprendre le modèle de la BDUni pour le RGFor représente en effet
pour l'IGN la solution a priori la plus simple, celle qui demanderait
le moins de développement et qui pourrait être la plus avantageuse
en termes de coûts et d'investissement. Cela demande donc de
décrire ce modèle, d'évaluer ses capacités et son
adaptabilité.
I.A - Contenu et structure de la BDUni
La BDUni est une base de production44 de
données vecteurs sur la France entière contenant l'ensemble des
domaines45 (également appelés thèmes ou encore
couches) qui constituent les produits commerciaux de l'IGN tels que la BD
Carto® et le RGE® (Référentiel à Grande
Échelle) vecteur qui est constitué de la BD Topo®
et de la BD Adresse®. Comme la majorité des bases
de données actuelles, la BDUni est une base de données
relationnelles, c'est-à-dire que les données sont
réparties dans des tables, divisées en colonnes et en
lignes46 auxquelles il est possible d'accéder à l'aide
de requêtes SQL (Date, 2004, p. 27).
La structure de la BDUni se divise en trois tables
attributaires, séparées pour des raisons de performances
techniques :
· Deux tables pour chaque classe d'objets :
1. Table des objets actuels et des objets supprimés ;
2. Table des anciennes versions des objets, ou table
d'historique ;
· Une table documentaire, pour tous les domaines,
contenant les informations sur les mises à jour
considérées par ensembles et appelées
réconciliations :
3. Table des réconciliations.
44 Les données produites à l'IGN sont
réparties en plusieurs bases - base d'acquisition, base de production,
base d'exploitation - en fonction des étapes de la chaîne de
production, allant de l'opérateur de saisie jusqu'à
l'utilisateur.
45 La BDUni regroupe les informations géographiques
appartenant à 10 domaines : le réseau routier, les voies
ferrées et autres moyens de transport terrestre, les réseaux de
distribution, le réseau hydrographique terrestre, le bâti, la
végétation, l'orographie, les zonages administratifs, les zones
d'activité ou d'intérêt, les adresses (IGN, BDUni V1.1
Grande Échelle : spécifications de contenu, 2011, p. 10).
46 Plusieurs terminologies sont employées pour
décrire le contenu d'une base de données : fichiers,
enregistrements, champs ; relations, n-uplets, attributs ; tables, lignes,
colonnes. Par souci de cohérence et de simplicité, nous
n'emploierons que la troisième terminologie, celle associée au
langage SQL (Date, 2004, p.6).
xxxiii
Ces tables dans la couche végétation contiennent
plusieurs colonnes :
- Pour les tables 1 et 2, respectivement appelée «
zone_de_vegetation » et « zone_de_vegetation_h » :
o La géométrie :
n « geometrie »47
n « empreinte »
o La sémantique : « nature »
o Un numéro d'identifiant de l'objet : « cleabs
»
o L'état de l'objet : « detruit »
o Colonnes temporelles :
n « date_creation »
n « date_modification »
n « date_destruction »
o Le mécanisme de réconciliation :
n « numrec »
n « numrecmodif » (uniquement pour la table
d'historique)
o Des colonnes documentaires :
n « nom »
n « source_de_la_geometrie_2d »
n « nom_lot »
n « metadonnees_vegetation »
o Des colonnes documentaires communes à toutes les
tables utilisées pour suivre la production en MAJEC (non utilisés
pour la production actuelle de la végétation BDUni)48
:
n « etat_de_l_objet »
n « identifiant_gestionnaire »
n « commentaire_collecteur »
n « exception_legitime »
n « conventions »
n « liens_vers_evolutions »
- Pour la table 3, table des réconciliations
appelé « reconciliations »49:
o La géométrie de la zone de réconciliation
: « geometrie »
o La colonne temporelle : « daterec »
o Sur la réconciliation :
n « ordrefinevol »
n « numrec »
n « classeimpactees »
n « est_une_montee_en_base »
n « dureerec »
n « nbobjrec »
47 Cette colonne contient une description de l'objet (point,
ligne, polygone, polyligne, polypoint) et les coordonnées de ses points,
le tout en codage hexadécimal (6 lettres et dix chiffres).
48 Ces colonnes sont utilisées pour les tâches de
collecte de la MAJEC.
49 Il existe plusieurs tables des réconciliations
actuellement dans la BDUni. Les tables supplémentaires ont
été créées pour effectuer des manipulations et des
tests et n'ont jamais été supprimées.
o
xxxiv
Documentaires :
· « operateur »
· « commentaire »
· « numclient »
· « version_gcvs »
· « profil »
· « date_du_dernier_controle »
· « nature_operation »
o Autres :
· « changement »
· « complement_bdcarto_ texte »
· « complement_bdcarto_liste »
· « incoherences_detectees »
· « lien_vers_evolution_ponctuelle »,
o Colonnes documentaires communes à toutes les tables
:
· « nom »
· « conventions »
Enfin, il est possible d'établir des relations entre
les tables de la BDUni grâce au fonctionnement de la
réconciliation qui sera décrit avec plus de précision par
la suite. Les relations entre les tables passent par la colonne d'identifiant
« cleabs » et les colonnes de réconciliation « numrec
» et « numrecmodif » (voir schéma de structure de la
BDUni, ci-dessous).
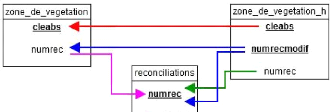
Figure 1 : schéma de structure logique de
l'historisation dans la BDUni.
Les colonnes d'identifiant (« cleabs ») et
d'historique des réconciliations (« numrec », «
numrecmodif ») constituent des clés primaires, et des clés
étrangères. Une clé primaire, soulignée et en
caractère gras dans le schéma, est une colonne de la table dont
la valeur ne peut pas exister à l'identique dans deux lignes
différentes de la table50. C'est ce qu'on appelle la
contrainte d'unicité. Par ailleurs, cette colonne doit être
remplie obligatoirement pour toutes les lignes : c'est la contrainte
d'intégrité d'entité. Les clés
étrangères sont des copies d'une clé cible dans une table
cible. Dans le schéma, les flèches représentent les
liaisons entre les tables : la colonne de départ correspond à une
clé étrangère, la colonne d'arrivée correspond
à la cible de la relation. Ce procédé permet de mettre en
relation des tables distinctes (Hainaut, 2009, chapitre 2). Pour bien jouer
leurs
50 Dans la table des réconciliations, c'est la colonne
« ordrefinevol » qui remplit réellement la fonction de
clé primaire. Bien que le « numrec » respecte aussi les
contraintes d'intégrité et d'unicité.
xxxv
rôles, toutefois, les relations fondées sur les
clés étrangères doivent répondre à des
contraintes et posséder des fonctionnalités qui ne sont pas
implémentées dans le système de la BDUni. Ce
système permet simplement des relations grâce au contenu de ses
tables (Figure 1). Nous utilisons néanmoins cette terminologie car elle
facilite la description de la structure d'une base de données.
Dans la table « zone_de_vegetation », l'identifiant
unique de chaque objet, la « cleabs », est la clé primaire. La
clé primaire de la table « zone_de_vegetation_h » est
constituée de deux colonnes : la « cleabs », ou clé
absolue, et le « numrecmodif », ou numéro de
réconciliation lors de la modification. Dans la table d'historique, la
colonne « cleabs » contient l'identifiant de chaque objet
modifié qui est conservé et renvoie à colonne «
cleabs » de la table « zone_de_vegetation » (flèche
rouge) de l'état successeur de l'objet, c'est-à-dire sa nouvelle
version. Le second correspond au « numrec », ou numéro de
réconciliation, de la table « zone_de_vegetation »
(flèche bleue). Enfin, chaque réconciliation est
enregistrée dans la table « reconciliations » par un «
numrec » unique auquel renvoient le « numrec » de la table
« zone_de_vegetation », ainsi que le « numrec » et le
« numrecmodif » de « zone_de_vegetation_h » (flèches
mauve, verte et seconde flèche bleue).
Cette structure est également illustrée par la
Figure 1. L'entité objet actuel est contenu dans la table
« zone_de_vegetation ». Ces versions
antérieures sont contenues dans la table
« zone_de_vegetation_h
». Il est possible de lier le contenu des deux tables grâce aux
colonnes « cleabs », « numrec » et « numrecmodif
».
I.B - Architecture du système de base de
données
L'architecture de la base est de type client-serveur avec un
logiciel intermédiaire, appelé middleware, gérant
les transferts d'informations (voir la Figure 2, illustrant les quatre
composantes d'une base de données - données, matériel,
logiciel, utilisateur - et les éléments - serveur,
middleware, client - composant une architecture client-serveur). Cette
architecture est composée de trois programmes : celui du poste client,
ou utilisateur, demandant l'accès aux données par des
requêtes et réalisant des traitements ; celui du poste central
serveur assurant la gestion des données, garantissant et
protégeant leur accès grâce à un
système de gestion de base de données (SGBD) et répondant
aux demandes des postes clients ; celui du middleware qui sert
d'interface de communication51
(Bonneau, 2008, p. 7).
La couche logicielle de la BDUni gérant la base serveur
est PostGis, un logiciel libre qui est l'extension permettant la manipulation
d'informations spatiales du SGBD PostgreSQL. Ce logiciel assure la
cohérence de la base de données lors des transactions
d'informations entre le client et le serveur, notamment grâce à la
règle d'atomicité52. Il permet la sélection, la
création, la modification et la destruction d'objet. Il permet
également de réaliser des requêtes SQL sémantiques
et topologiques afin de pouvoir manipuler des données
géographiques. Les bases clients à l'IGN utilisent les logiciels
GeoConcept pour les opérations de visualisation, requête, saisie
et gestion des données (les collecteurs de la MAJEC travaillent avec ce
logiciel), OpenJump et PGAdmin pour la visualisation et la consultation des
données (Bonneau, 2008, p. 8).
51 Un des intérêts du middleware est
qu'il permet de palier aux problèmes de compatibilité entre les
systèmes d'exploitation des postes clients (Windows, Mac) et du serveur
(Linux).
52 Toute transaction incomplète est entièrement
annulée. Cela permet d'éviter de générer des
erreurs en cas d'interruption de transaction. Concrètement, il n'est pas
possible de créer, modifier ou supprimer un objet sans que cette
modification ne soit entièrement répercutée dans toutes
les tables concernées de la base. Toute base de données doit
respecter les propriétés ACID : atomicité,
cohérence, isolation, et durabilité.
xxxvi
Le middleware développé par l'IGN s'appelle GCVS
(Geographic Concurrent Versionning System). C'est le système
GCVS qui permet la mise à jour de la BDUni et l'historisation des
données. Concrètement, GCVS se présente sous la forme d'un
module ajoutant de nouveaux outils à GeoConcept : extraction,
réconciliation, update seul, édition de rapport, gestion des
conflits, recherche des modifications (IGN, 2007).
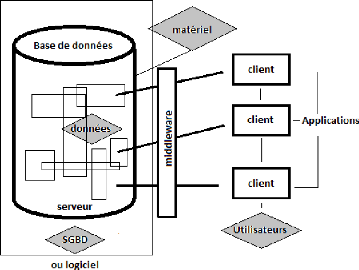
Figure 2 : schéma d'une base de
données53.
L'extraction crée la base client. GVCS permet ensuite
de synchroniser les bases clients, extraites de la base serveur contenant la
France entière, et la base centrale du serveur : c'est la
réconciliation. L'update seul est une synchronisation à sens
unique : du serveur au client. L'édition des rapports est automatique
après chaque réconciliation et update seul. Ils permettent de
savoir si les opérations de mise à jour se sont bien
déroulées. La gestion des conflits règlent les
problèmes générés par la modification
simultanée d'un même objet par plusieurs clients au moment de la
réconciliation. La recherche des modifications est un « garde-fou
» servant à limiter les oublis de réconciliation
régulière en trouvant les zones de mise à jour client non
répercutées dans la base serveur.
GCVS assure le lien entre les objets de la base client et le
serveur à l'aide de l'identifiant GeoConcept et de l'identifiant «
cleabs ». Les objets créés sont identifiés par le
fait de posséder une nouvel identifiant GeoConcept, c'est-à-dire
auquel il n'est pas encore associée de « cleabs ». Les objets
modifiés sont détectés par les modifications
géométriques, sémantiques ou documentaires qu'ils ont
subies.
I.C - Modèle de mise à jour et
d'historisation
Le principe de la mise à jour de la BDUni repose sur le
fonctionnement de GCVS. La mise à jour est réalisée
principalement grâce au mécanisme de réconciliation. Les
collecteurs de données modifient
53 Source : Date, 2004
xxxvii
leur base client et font remonter ces modifications à
la base serveur. Les informations fournies par les deux bases sont ainsi «
réconciliées ». Durant cette réconciliation,
l'historisation intervient par une copie des objets de la table actuelle, dans
notre cas « zone_de_vegetation », vers la table d'historique, «
zone_de_vegetation_h », à chaque réconciliation pour les
objets modifiés ou détruits touchant la zone de
réconciliation. Grâce à la conservation de l'identifiant
« cleabs » pour chaque version d'un objet, et au chaînage des
numéros de réconciliation, il est possible de suivre les
différentes versions successives des données et, a fortiori,
de la base.
I.C.1 - Mécanismes de mise à jour
I.C.1.a - La création utilisateur par zone de
réconciliation

Figure 3 : exemple d'une mise à jour du
réseau routier à l'aide d'une zone de
réconciliation54.
L'opérateur réalise d'abord la mise à
jour sur sa base client en effectuant les modifications manuellement. Puis, il
délimite une « zone de réconciliation » qui intersecte
le ou les objets modifiés. Enfin, il fait remonter les modifications
à la base serveur, à travers GCVS. Ces outils (tracé,
réconciliation, etc.) se présentent sous la forme d'un module
ajouté au logiciel GeoConcept.
L'intérêt de la zone de réconciliation est
de mettre à jour la base de données serveur par ensemble
cohérent de modifications. Par exemple, la transformation d'un carrefour
en rond-point implique de nombreuses modifications. Créer une zone de
réconciliation sur le rond-point permet d'englober ces modifications
indiquant l'unique changement réel. L'ensemble des objets ayant subi la
modification sont liés par un même « numrecmodif ». La
figure 3 montre un exemple fictif d'une mise à jour de ce type. Les
tronçons du départ ont été scindés en deux,
ce qui résulte en leur modification et la création de deux
nouveaux tronçons. Le rond-point a été créé.
Afin de répercuter ces modifications de façon cohérentes,
la mise à jour est effectuée en traçant une zone de
réconciliation englobant toutes ces modifications.
I.C.1.b - La montée en base
Second mécanisme de mise à jour, la
montée en base est simplement un transfert de l'ensemble des
données du poste client vers le serveur. C'est ce procédé
qui est employé actuellement dans la chaîne de production du
RGFor. L'opérateur travaille sur des données en cours de
production. Elles ne sont pas encore présentes dans la BDUni. Une fois
que l'opérateur a terminé de travailler sur les
54 Source : ortho-photographie IGN, département des
Hautes-Pyrénées.
xxxviii
données, celles-ci sont enregistrées dans la
base serveur. L'opérateur n'a pas besoin de sélectionner les
données qu'il envoie sur le serveur, elles sont enregistrées sans
distinction (Figure 4).
Ce mécanisme possède l'avantage, par rapport au
précédent, de permettre le transfert sur le serveur d'un gros
volume d'informations. Il se prête ainsi aux exigences d'une base de
végétation étant réalisée d'un bloc,
à l'échelle de tout un département, contrairement à
la zone de réconciliation qui se prête plutôt à la
mise à jour en continu des opérateurs de la MAJEC.
Figure 4 : schéma de la montée en base de
la couche végétation55.
Toutefois, la montée en base se fait pour l'état
zéro des données, c'est-à-dire sur une base serveur
vierge. Elle est utilisée pour la création de la base de
données. S'il était utilisé pour la modification des
données, ce mécanisme correspondrait à une mise à
jour par écrasement des données précédentes. En
effet, les données sont « montées > en base et non
réconciliée avec les données déjà
présentes sur le serveur. La montée en base n'utilise donc pas
GCVS.
I.C.1.c - La simulation GCVS en script SQL
Le dernier mécanisme permet d'effectuer une mise
à jour concernant à la fois un volume important de données
et une base existante. Il permet donc de résoudre le problème
d'une mise à jour ciblée sur une surface importante, cas de la
végétation. Une centaine d'objets dispersés dans l'espace
peuvent en effet connaître la même évolution. Par exemple,
la mise à jour des donnés de la BD Forêt® après
une tempête entraîne la création de nombreux nouveaux
polygones de « coupes rases ou incidents > et la destruction ou la
modification des polygones de forêt existant auparavant. Ces
55 Source : ortho-photographies et BD Forêt v2 des
Hautes-Pyrénées.
xxxix
évolutions ont toutes la même origine et
constitue donc un ensemble cohérent qu'il serait judicieux de lier par
une seule réconciliation.
Pour une liste d'identifiants d'objet, la simulation de GCVS
en script SQL sur la machine client permet de générer un
historique de réconciliation répercuté en base serveur
avec la mise à jour. Dans le cas de notre exemple, il faudrait
connaître les identifiants de l'ensemble des objets concernés,
puis écrire une requête SQL qui simule le fonctionnement normal de
GCVS. Cet outil reste cependant aussi limité en volume, et il ne permet
que la modification de la valeur d'une colonne attributaire d'un objet, pas sa
géométrie.
I.C.2 - L'historique : conservation de l'identifiant
et mécanisme de liste chaînée
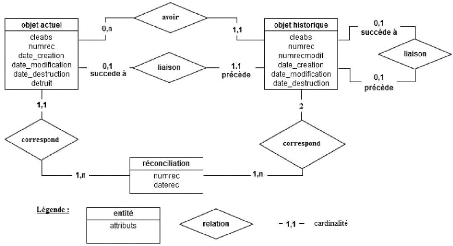
Figure 5 : schéma conceptuel
entité-relation de l'historisation dans la
BDUni56.
Le processus d'historisation de la BDUni est
géré grâce à GCVS lors des réconciliations.
Comme cela a été décrit dans la section sur l'architecture
du système de la base de données (p. xxxv), GCVS réalise
un appariement entre les données de la base client en cours de
réconciliation et les données du serveur à l'aide des
identifiants des objets. Les objets possédant un nouvel identifiant sont
ajoutés à la base serveur dans la table des objets actuels. Les
objets possédant un identifiant déjà connu et qui ont
été modifiés ou détruits sont enregistrés
dans la table des objets actuels. Leur version précédente est
copiée dans la table d'objet historique.
Le même identifiant « cleabs » est
conservé pour chaque version historisée après une
modification. La conservation de l'identifiant constitue la base de la
création d'un historique et du suivi des objets dans le temps. Il s'agit
d'un modèle d'historisation de type « tuple-level
versioning57 » (Langran, 1992,
p. 60). Pour chaque modification, lors de la
réconciliation, les informations sur celle-ci sont
56 Cardinalités : 0,1 = de zéro à un seul ;
1,1 = un seul ; 1,n = de un à plusieurs ; 0,n = de zéro à
plusieurs.
57 Versionnement par ligne, qui s'oppose au versionnement par
colonne.
xl
enregistrées dans la table des réconciliations
et la ou les lignes du ou des objets concernés par la mise à jour
sont copiées dans leur intégralité dans la table
d'historique58.
Contrairement aux objets ayant été
modifié mais existant toujours, les objets détruits sont
conservés dans la table des objets courant en remplissant les colonnes
« date_destruction » et « detruit ». Cette règle ne
repose pas sur une contrainte de référence mais sur une exigence
technique due à l'architecture client-serveur : la base client est
synchronisée avec la base actuelle, si un objet détruit
était supprimé de celle-ci, la modification ne serait pas
répercutée sur la base client.
A la conservation de l'identifiant s'ajoute la liste
chaînée des réconciliations. Pour chaque
réconciliation, la colonne « numrecmodif » est remplie avec le
numéro de la réconciliation en cours dont on connait le
numéro (le « numrec »). Ce numéro est le même que
le « numrec » de l'objet successeur, la dernière version de
l'objet, dans la table des objets courants qui vient alors écraser dans
cette table l'objet modifié désormais stocké. La liste
ordonnée des versions successives d'un même objet contenu dans la
table d'historique se retrouve de façon similaire de « numrecmodif
» à « numrec » s'enchaînant.
Ce système, illustré par la Figure 5, permet
donc de suivre la filiation entre les différentes versions d'objet
à chaque mise à jour et, de ce fait, est ce qui permet la prise
en compte de la dimension temporelle dans la BDUni. En effet, ces
opérations s'accompagnent d'un enregistrement dans les colonnes
d'historique - « date_creation », « date_modification »,
« date_destruction », « daterec » - du temps de la
transaction informatique selon l'horloge du serveur. Ces dates,
indiquées en années, mois, jours et heures avec une
résolution temporelle59 de 1/100000ème de
seconde, sont générées automatiquement. Elles prennent en
compte l'instant de l'opération de réconciliation de la mise
à jour de la base de données : les ajouts (« date_creation
»), suppressions (date_destruction), modifications («
date_modificaiton »). Les « daterec », c'est-à-dire les
dates de réconciliation, marquent les bornes de la durée de vie
des objets : le « numrec » est la date de début, et le «
numrecmodif » la date de fin.
Nous allons illustrer concrètement ce mécanisme
à l'aide d'un exemple fictif d'un objet créé,
modifié, puis détruit. Nous n'indiquerons que les colonnes
essentielles à cet exemple.
58 La totalité des informations de l'objet est
stockée afin d'éviter les bugs et de devoir effectuer des
recherches de différentiel pour extraire les anciennes versions afin de
connaître l'intégralité des informations concernant
l'objet.
59 La résolution temporelle est similaire à la
résolution spatiale. Elle désigne la plus petite unité
atomique qu'il est possible de représenter par un intervalle dans la
base de données (Langran, 1992, p. 84)
xli
Exemple du fonctionnement de l'historisation dans la
BDUni :
? Étape 1 : création de l'objet
: réconciliation 1. La colonne « date_creation » est
remplie.
o Table actuelle « zone_de_vegetation »
cleabs60
|
nature
|
geometrie
|
date_creation
|
date_modifi cation
|
date_destruction
|
numrec
|
detruit
|
ZONEVEGE000
0000000000001
|
Forêt fermée de conifères
|
xxx
|
01/01/12
|
|
|
1
|
|
|
o Table des réconciliations
numrec
|
daterec
|
nom
|
1
|
01/01/12
|
Montée en base
|
|
o Table d'historique « zone_de_vegetation_h »
nature
|
geo metrie
|
date_creation
|
date_modification
|
date_destruc tion
|
cleabs
|
numrec
|
num recmodif
|
|
|
|
|
|
|
|
|
|
? Étape 2 : modification
sémantique de l'objet évoluant d'une forêt fermée de
conifère vers une forêt mixte : réconciliation 2. La
première version de l'objet est copiée dans la table
d'historique. La colonne « date_modification » est remplie.
o Table actuelle « zone_de_vegetation »
cleabs
|
nature
|
geometrie
|
date_creation
|
date_modifi cation
|
date_destruction
|
numrec
|
detruit
|
ZONEVEGE000
0000000000001
|
Forêt
fermée
mixte
|
x, y
|
01/01/12
|
08/01/12
|
|
2
|
|
|
o Table des réconciliations
numrec
|
daterec
|
nom
|
2
|
08/01/12
|
Correction
|
1
|
01/01/12
|
Montée en base
|
|
o Table d'historique « zone_de_vegetation_h »
nature
|
geo- metrie
|
date_creation
|
date_modification
|
date_destruc tion
|
cleabs
|
numrec
|
num recmodif
|
Forêt
fermée de
conifère
|
x, y
|
01/01/12
|
|
|
ZONEVEGE0000
000000000001
|
1
|
2
|
|
60 Le système GCVS octroie un identifiant, dont le
caractère unique et la stabilité sont garantis. C'est la
clé absolue. Celle-ci est composée d'une chaîne de 24
caractères : 8 caractères alphanumériques qui
correspondent au domaine de l'objet et 16 chiffres (Bonneau, 2008, p. 10).
xlii
? Étape 3 : destruction de l'objet :
réconciliation 3. La deuxième version de l'objet est
également copiée dans l'historique. Les colonnes «
date_destruction » et « detruit » sont remplies.
o Table actuelle « zone_de_vegetation »
cleabs
|
nature
|
geometrie
|
date_creation
|
date_modifi cation
|
date_destruction
|
numrec
|
detruit
|
ZONEVEGE000
0000000000001
|
Forêt
fermée
mixte
|
x, y
|
01/01/12
|
08/01/12
|
15/01/13
|
3
|
detruit
|
|
o Table des réconciliations
numrec
|
daterec
|
nom
|
3
|
15/01/13
|
Destruction
|
2
|
08/01/12
|
Correction
|
1
|
01/01/12
|
Montée en base
|
|
o Table d'historique « zone_de_vegetation_h »
|
nature
|
geome trie
|
date_creation
|
date_modification
|
date_destruc tion
|
cleabs
|
numrec
|
numrecmodif
|
|
Forêt
fermée
mixte
|
x, y
|
01/01/12
|
08/01/12
|
|
ZONEVEGE0000
000000000001
|
2
|
3
|
|
Forêt
fermée de
conifère
|
x, y
|
01/01/12
|
|
|
ZONEVEGE0000
000000000001
|
1
|
2
|
Grâce à ce système, l'ensemble des
versions antérieures des objets est donc conservé et les versions
successives d'un objet identifié par sa « cleabs » unique sont
reliées en liste chaînée par leur « numrec » et
le « numrecmodif ». La temporalité des
événements associés aux objets (création,
modification, destruction) et leur durée de vie (« daterec »
associé au « numrec » et au « numrecmodif ») est
enregistrée. Dans notre exemple, on obtient ainsi trois états
successifs d'objet61 :
|
nature
|
date_creation
|
date_modification
|
date_destruction
|
detruit
|
numrec/daterec
|
numrecmodi f/daterec
|
objet version
|
|
Forêt
|
01/01/12
|
08/01/12
|
15/01/13
|
detruit
|
3
|
|
3
|
|
fermée mixte
|
|
|
|
|
15/01/13
|
|
|
|
Forêt
|
01/12/12
|
08/01/12
|
|
|
2
|
3
|
2
|
|
fermée mixte
|
|
|
|
|
08/01/12
|
15/01/13
|
|
|
Forêt
|
01/12/12
|
|
|
|
1
|
2
|
1
|
|
fermée de
conifère
|
|
|
|
|
01/01/12
|
08/01/12
|
|
61 Le tableau présenté comme résultat
final de notre exemple peut être obtenu à l'aide d'une
requête SQL réalisant l'unione de la table actuelle et historique
et joignant la table des réconciliations sur la colonne « numrec
» puis « numrecmodif » afin d'obtenir les intervalles de
durée de vie des objets. Cette manipulation est décrite dans la
partie II et en annexe.
xliii
I.D - Consignes et méthodes de saisie de la
MAJEC
La mise à jour de la BDUni est régie par le
processus de production appelé MAJEC (Mise A Jour En Continu). Ce
processus, confiés au service de bases vecteurs, au service de la
cartographie et aux cinq directions interrégionales de l'IGN, consiste
à produire des éléments de topographies et des adresses de
la BDUni. Cette production est assurée par les collecteurs de la MAJEC
répartis entre les différentes directions régionales de
l'IGN. La table des réconciliations permet d'ajouter des
métadonnées sur la mise à jour en indiquant la personne
l'ayant réalisée et sur quel ensemble de modifications.
S'appuyant sur de multiples sources
d'informations62, les collecteurs effectuent les modifications sur
leur base clients qu'ils répercutent ensuite sur le serveur grâce
aux outils du GCVS que nous avons décrits, principalement la zone de
réconciliation.
Il leur est demandé de suivre des consignes de saisie.
Une zone de réconciliation doit prendre en compte un ensemble
homogène ou cohérent de modifications que l'opérateur doit
décrire dans la colonne « nom » de la table des
réconciliations afin d'en faciliter l'exploitation. Cette zone doit
être suffisamment grande pour intersecter tous les objets modifiés
mais pas trop au risque de ralentir inutilement le temps de calcul du
traitement de la mise à jour (IGN, 2012, p. 45).
De nombreux contrôles sont réalisés
obligatoirement avant chaque réconciliation. Leur rôle est
d'éviter d'enregistrer des informations aberrantes dans la base centrale
qui, sans ces contrôles, ne seraient pas détectées sinon.
Les contrôles sont, par exemple, effectués sur :
- La dimension z. Exemple : des hauteurs absurdes, comme un
bâtiment plus haut à sa base qu'à son sommet.
- La géométrie. Exemple : l'intersection de deux
objets, comme deux bâtiments, ou une route et un bâtiment, ou un
objet s'intersectant.
- Doublon
- Contrôle de l'hydrographie. Exemple : la source doit
avoir une hauteur positive, puisqu'elle
sort du sol.
Si une erreur apparait, mais qu'elle est justifiée, il
est possible de faire basculer l'erreur en exception légitime. La
colonne « exception_legitime » est alors remplie en fonction de
l'erreur et le contrôle associé ne sera plus effectué pour
l'objet en question. Un péage est un bon exemple d'exception
légitime à l'intersection : c'est un bâtiment qui coupe une
route, mais de fait il est au-dessus de celle-ci. Cette colonne est
régulièrement vidée de son contenu pour effectuer à
nouveau les contrôles afin de vérifier la qualité des
données.
62 Orthophotographies de l'IGN, registres des actes communaux,
courriers, appels, déplacement sur le terrain, l'Internet (images Google
Earth et Bing, les Pages Jaunes, les sites des mairies,...), etc.
xliv
II - Apports et limites du modèle BDUni II.A -
Capacités et outils développés
Le modèle de mise à jour de la BDUni peut
être qualifié, selon les catégories définies par
Bordin (Bordin, 2002), comme un modèle de versionnement d'objets qui
s'approche d'un historique des données. En d'autres termes,
premièrement, la base enregistre les différents états des
données dans le temps, différentes versions, ce qui a plusieurs
avantages :
- Tant que la donnée n'est pas modifiée, elle
n'est enregistrée qu'une seule fois. Ce qui permet de limiter la
quantité d'information à stocker.
- Les données possèdent une date de
création, modification, suppression. L'accès à des
états
temporels est ainsi plus rapide (que dans un modèle de
journalisation par exemple)63.
- Les données sont stockées dans deux tables,
c'est le partitionnement temporel. Il permet d'accéder plus rapidement
à l'état courant des données.
Il y a cependant aussi des inconvénients :
- La destruction d'une version, ou plutôt son archivage,
puis la création d'une nouvelle version
entraine la duplication des informations ne variant pas entre les
deux.
Le versionnement et l'horodatage des versions ont permis à
l'IGN de développer des outils :
- Extraction de différentiel pour la livraison de la mise
à jour (Bonneau, 2008).
- Visualisation d'un état de la base à une date
donnée64.
- Des prototypes de visualisation cartographique65.
Deuxièmement, la base permet de contenir un lien entre
les différents états d'un objet. Elle permet de suivre le
changement en établissant un historique fondé sur la
présence d'un identifiant et d'un identifiant successeur. Pour la BDUni,
ce modèle est implémenté grâce à :
- La conservation de la « cleabs », permettant de
fonder l'identité fixe de l'objet informatique.
- La liste chaînée des « numrec » et
« numrecmodif » établissant le lien entre les objets.
Ce modèle est, toujours selon Bordin, un modèle
avancé. Il est en effet capable de s'attacher à l'aspect plus
thématique de la mise à jour, à savoir : le suivi des
évolutions. Toutefois, la limite importante de ce modèle tient au
fait qu'il demande une réflexion sur l'interprétation de la
modification ou de la suppression de l'objet géographique. Or, bien que
des consignes de saisies existent dans ce sens (IGN, 2012), un réel
manque de définitions plus claires demeure. Il manque des
définitions et de consignes thématiques, c'est-à-dire qui
ne soient plus simplement attachées aux objets informatiques mais aussi
aux objets réels, géographiques, qu'ils représentent.
D'autres questions demeurent. Il est demandé
d'effectuer les réconciliations sur des ensembles homogènes :
mais qu'est-ce qu'un ensemble homogène ? Il est possible de conserver
l'identifiant de l'objet : quand considère-t-on qu'un objet
géographique conserve son identité et quand est-il détruit
? La colonne « nom » doit identifier la réconciliation afin de
faciliter les traitements, mais sa saisie est laissée à la
discrétion de l'opérateur : les changements ne sont pas
définis, ce qui
63 La journalisation consiste à ne conserver que
l'état actuel de la base et à archiver toutes les modifications
qu'ont subies les données dans le temps. Pour connaître
l'état à une date donnée dans le passé, il faut
effectuer toutes les modifications à rebours.
64 Voir Annexes.
65 Évolutions BDUni - cartographie des évolutions,
sur
http://rks1009w117.ign.fr/map-evolution/
xlv
permettrait pourtant d'optimiser leur analyse par la
requête. L'analyse du changement peut être complexe, surtout
à décomposer : une même zone de changement ou de
réconciliation peut avoir plusieurs causes et peut avoir des
conséquences sur plusieurs classes d'objets ou plusieurs objets dans la
même classe.
La mise à jour par réconciliation
effectuée par la MAJEC peut permettre théoriquement le suivi des
objets pour l'analyse des changements, mais elle dépend fortement de
l'appréciation de ce changement par l'opérateur, de
l'interprétation des consignes de saisie, de sa maîtrise des
outils et des contraintes temporelles de production des données. Le
processus comprend en effet peu de contrôles ou de méthodes
automatiques. Les opérateurs doivent réaliser les mises à
jour selon des délais pour répondre aux objectifs de
productivité (mesurés dans le contrat d'objectifs par des
indicateurs de performance). Et la liberté du travail personnel de
saisie contribue en partie à la satisfaction de ces objectifs.
Figure 6: cas d'une mise à jour illustrant deux
résultats différents en fonction de la saisie.
La Figure 6 est un exemple concret d'une mise à jour et
des questions qu'elle peut soulever. Au moment du contrôle, une
incohérence est détectée : les objets « i » et
« j » se superposent. Ces deux objets représentent un phare,
« i » sa tour et « j » sa partie plus basse. Il s'agit
d'une erreur de digitalisation qui ne devrait pas avoir pu être
réconciliée auparavant. Considérons que l'opérateur
avait classé cette incohérence en erreur légitime. Nous
souhaitons corriger cette erreur, tout en conservant les identifiants « i
» et « j » d'origine. Or, en fonction de la méthode de
saisie, avec un outil de découpage (a) ou manuellement (b), le
résultat n'est pas le même. Dans un cas l'identifiant est perdu,
dans l'autre il est conservé. Si une zone de réconciliation est
dessinée uniquement pour cette modification, un lien direct existera
entre l'objet prédécesseur et ses successeurs. Mais si on
réalise plusieurs corrections en même temps, on peut estimer
qu'elles constituent un ensemble cohérent et les réconcilier en
même temps, perdant de ce fait le lien spécifique entre
prédécesseur et successeur. Enfin, au moment de nommer la
réconciliation, plusieurs options sont encore possibles, ne facilitant
pas le suivi : erreur, correction d'erreur, superposition, incohérence,
aberration, etc.
Cet exemple nous permet d'aborder un dernier point : celui du
découpage des objets. Si un objet est découpé, un ou
plusieurs nouveaux objets sont alors créés. Or un seul objet
conserve l'identifiant permettant la filiation, cette information est perdue
pour le ou les autres objets. De même, un objet qui serait détruit
puis recréé (comme cela pourrait être le cas d'un
bâtiment détruit puis reconstruit à l'identique) ne
possède plus l'identifiant de départ. L'analyse du suivi du
changement s'en trouve donc limitée.
xlvi
II.B - La dimension temporelle dans la BDUni
La dimension temporelle, nous l'avons abordée dans la
partie précédente, possède deux aspects : l'historisation
de la donnée et son suivi. Elle présente également deux
définitions, que nous avons mentionnées sans les
développer, l'une « informatique », l'autre «
thématique », qui correspondent à la différence entre
le temps de la mise à jour et le temps réel ou temps du
terrain.
La prise en compte de la dimension temporelle dans la BDUni
est celle du temps informatique. C'est une base de données
rollback (Paque, 2004, p. 10) : elle enregistre le temps de la
transaction. Elle correspond aux besoins actuels des utilisateurs de la base :
une information à jour, le plus rapidement possible. Les tables
d'historiques servent concrètement à pouvoir revenir sur une mise
à jour dans le cas d'une erreur. L'historisation des données
n'est pas liée au suivi du terrain, mais au suivi de la donnée.
Le modèle d'historisation qui a été mis en place pour la
BDUni répond en premier lieu aux attentes de production.
Le suivi des évolutions est quant à lui un autre
besoin. Il demande l'enregistrement du temps réel dans une base de
données historique - elle n'enregistre que le temps réel - ou
temporel - elle enregistre le temps informatique et réel (Paque, 2004,
p. 10). Le temps réel peut être évalué à
partir de la BDUni, c'est-à-dire qu'on peut considérer le temps
informatique comme un temps réel, mais il n'est pas contenu absolument
dans la base. Quelques exceptions existent : les routes, bâtiments, etc.,
en construction ou en projet, et les alertes ponctuelles saisies par les
collecteurs. Ces objets indiquent une information temporelle réelle.
Lors de leur saisie, il est possible de renseigner la date d'actualisation de
la modification (d'après un document daté avec précision
ou un déplacement sur le terrain).
Toutefois, considérant la production en continu et les
thèmes évoluant le plus dans la base (routier, bâti), on
peut dire que ce type d'intégration du temps est suffisant pour le suivi
des changements, le temps de saisie et le temps réel étant en
effet proche dans 99% des cas. Néanmoins, il reste toujours un
problème : l'impossibilité de corriger à posteriori les
données sans compromettre la temporalité des données
(Heres, 2000, p. 46)
Enfin, dernière remarque concernant
l'intégration du temps dans la BDUni, celle-ci nous parait ne pas
optimiser sa structure relationnelle. Les colonnes « daterec »,
« numrec » et « numrecmodif » sont nécessaires
à la création de l'intervalle de durée de vie d'un objet.
La colonne « date_creation » est utile, car elle évite de
devoir retrouver le premier état d'un objet pour connaître sa date
de création. Mais les colonnes « date_modifcation » et «
date_destruction » nous semble contenir, de ce point de vue, des
informations redondantes dans la base concernant la temporalité des
données. Ces colonnes pourraient être supprimées, puisque
les informations qu'elles contiennent sont aussi présentes dans la table
des réconciliations : elles correspondent à la date du «
numrec ». Toutefois, elles existent peut-être pour des raisons de
performances techniques.
xlvii
II.C - Adaptabilité au RGFor
Après avoir abordé les capacités du
modèle d'historisation de la BDUni, nous pouvons d'ores et
déjà affirmer que l'objectif de l'intégration du temps au
RGFor, dans le cadre de l'OCS GE, n'est pas le même que celui de la
BDUni. Le RGFor est une base de données d'objets surfaciques, mise
à jour à l'aide de PVA (prise de vue aérienne) tous les
trois ans, qui doit servir notamment à l'analyse et au suivi des
évolutions de surface dans le temps. Ce suivi thématique des
données dans le temps est, nous l'avons dit, présent dans le
modèle de la BDUni, mais reste limité. Est-ce alors la bonne
solution pour le suivi des évolutions ? Nous tenterons de
répondre à cette question en abordant les problèmes
liés à l'intégration du temps réel et au suivi des
évolutions.
II.C.1 - Intégrer le temps réel :
problème de cohérence spatiale et temporelle
Tout d'abord, la non-intégration du temps réel
et l'impossibilité de pouvoir réaliser des corrections a
posteriori est problématique lorsqu'on l'applique au RGFor. Pour le
RGFor, l'actualité de la végétation est déjà
contenue dans les métadonnées et correspond à la date de
la prise de vue de l'ortho-photographie. Pour la mise à jour, il est
prévu d'intégrer la dimension temporelle à partir du temps
réel. Par ailleurs, la production des données peut
s'étaler dans le temps, parfois un an après la date de la prise
de vue, et des corrections, c'est-à-dire des changements non
réels, peuvent être effectués à partir des nouvelles
PVA. Le positionnement peut par exemple s'améliorer avec de nouvelles
ortho-photographies.
Figure 7 : intégration du temps réel et
maintien de la cohérence des données
spatiales66.
Or, GCVS n'est à l'heure actuelle pas capable de
gérer le versionnement sur du temps réel. Si nous reprenons le
fonctionnement de ce modèle dit rollback, il intègre le
temps comme une valeur unidirectionnelle : l'ordre de la transaction
définit l'ordre sur la ligne continue du temps. Il est impossible qu'une
modification effectuée après une autre puisse être
antérieure dans le temps enregistrée dans la base. GCVS, et les
outils de contrôle lui étant associés dans GeoConcept,
assurent la cohérence et l'intégrité de la base dans le
temps et l'espace selon une direction unique. Pourtant,
66 Source : entretien Frank Fuchs.
xlviii
pouvoir distinguer les corrections des évolutions
réelles nécessite la capacité d'enregistrer une
temporalité multidirectionnelle et donc de maintenir la cohérence
spatiale et temporelle des données selon ce type de
temporalité.
La Figure 7 illustre cet enjeu. L'axe des abscisses
représentent le temps réel, celui des PVA, et l'axe des
ordonnées l'ordre du temps informatique. La première étape
est une mise à jour simple, les deux objets (a) et (b) n'ont pas
été modifiés. La deuxième étape est
l'enregistrement d'une évolution. Puis, en troisième
étape, une erreur est corrigée, l'objet (b') successeur de (b)
existe en réalité depuis 2006. Or si on fait cette modification,
(b') et (a) sont superposés en 2006. Les données de la base ne
sont alors plus cohérentes.
II.C.2 - Le suivi des évolutions
Le suivi des évolutions thématiques n'est pas
facilité par le modèle d'historisation de la BDUni. De nombreuses
métadonnées existent, en particulier dans la table des
réconciliations, mais elles semblent difficilement exploitables. Pour
être adapté au RGFor, ce modèle aurait besoin d'une
procédure de mise à jour spécifique, avec des
définitions claires de l'objet, des évolutions, des consignes de
saisies et des outils permettant d'intégrer clairement et facilement les
informations nécessaires au suivi des objets représentés
par les données dans le temps.
Après ces considérations
générales, nous développons deux points du suivi des
évolutions : le chaînage et la conservation de l'identifiant.
Le chaînage entre un objet et son successeur est
contraint par le processus de réconciliation. Cet outil est en effet
limité dans l'ampleur des modifications qu'il est possible de
répercuter à chaque réconciliation, puisque chaque
ensemble cohérent doit faire l'objet d'une zone de réconciliation
propre. Il se prête plutôt à une mise à jour en
continu d'éléments relativement ponctuels (bâti,
réseaux) et est donc difficilement extensible à une utilisation
pour une base de végétation. Les zones de réconciliation
sont plus difficiles à dessiner, par ailleurs, pour une modification
d'objets surfaciques, car les polygones partagent leur géométrie.
Une modification intervenant sur un objet est répercutée sur les
autres alentours, règle topologique imposant des modifications «
non-réelles », conséquentes de la première
modification. Autrement dit, il serait préférable que le lien
entre les objets permettant leur suivi soit réalisé par une
procédure automatique et systématique, ce qui n'est pas le cas du
modèle actuel.
Le problème de la conservation de l'identifiant
(illustré par la Figure 6) est d'une autre ampleur lorsqu'il s'agit de
données surfaciques d'occupation du sol. Pour ce type de base de
données géographiques, par nature continue, une modification a
des répercussions sur tous les objets, posant dans le temps le
problème des découpages, des relations topologiques et de la
propagation de l'identifiant. Une surface est sujette au morcellement, à
la fusion. Dans ces deux cas, la conservation de l'identité de l'objet
est problématique : Quel objet conservera l'identifiant d'origine d'un
objet coupé en deux ? Quel identifiant sera conservé entre deux
objets fusionnant en un seul ? Le modèle développé pour la
BDUni n'apporte pour le moment pas de réponse à ces questions.
xlix
Conclusion
Le processus d'historisation de la BDUni est un modèle
avancé. Il permet :
- De mettre à jour et de corriger les données tout
en gardant une trace de leurs états
antérieurs ;
- De limiter la redondance en ne stockant plusieurs fois que les
objets modifiés (pas de
doublon de mise à jour) ;
- D'accéder aisément par requête aux
différents états des données ;
- Et, dans une certaine mesure, de suivre qualitativement les
évolutions.
Toutefois, ce modèle reste limité par :
- Le manque d'automatisation de la mise à jour ;
- L'absence de normes et de règles précises
concernant les évolutions et la conservation de l'identifiant ;
- Et la non prise en compte du temps de validité,
empêchant notamment de distinguer les corrections des changements.
L'historisation dans la BDUni repose sur une architecture
client-serveur et le développement par l'IGN d'un middleware
permettant d'intégrer des outils de mise à jour dans
GeoConcept pour la base client. La mise à jour est effectuée par
la réconciliation des données de la base client avec la base
serveur. GCVS gère le versionnement des objets informatiques et leur
historique sous la forme d'une liste chaînée des mises à
jour dans la base serveur. Le versionnement repose sur un appariement
fondé sur l'identifiant de l'objet. La liste chaînée est
possible grâce aux numéros de réconciliation
enregistrée pour la création et pour la fin d'une version d'un
objet.
Ce système a été conçu pour
répondre aux besoins de production des données de la MAJEC. Son
objectif est d'abord de permettre le suivi informatique de la qualité
des données dans le temps. Ce modèle est tout à fait
satisfaisant en tant que base de données temporelles rollback.
Il n'est par contre pas adapté à la gestion du temps réel
et présente de fortes contraintes au suivi des évolutions des
objets géographiques. Il n'est donc pour le moment pas adapté au
RGFor, ou à l'OCS GE dans son ensemble.
Partant de ce constat, il semble nécessaire de
réfléchir au développement d'un processus différent
permettant de gérer une base de données géographique et
temporelle possédant des fonctionnalités adaptées à
l'occupation du sol :
- Travail de définition conceptuelle des entités
représentées - espace, temps, événement, objet - et
de leur relation dans la base de données.
- Intégration du temps réel et cohérence
spatio-temporelle grâce à l'implantation du temps comme dimension
géométrique de l'espace et la création d'un outil de
contrôle spécifique.
- Reprise du principe du système GCVS et son
automatisation pour le suivi thématique des évolutions
découpées et enregistrées dans une table
spécifique, sur le modèle de la table des
réconciliations.
- Mise en place d'outils permettant la conservation de
l'identifiant.
l
Ces pistes seront détaillées dans le
mémoire sur la recherche d'un processus d'historisation de base de
données d'occupation du sol appliqué au référentiel
géographique forestier de l'IGN.
li
Bibliographie
Bonneau, M. E. (2008). Vérification
d'aptitude de l'extraction différentielle dans un système
client-serveur utilisant l'historique. ENSG. 68 p.
Bordin, P. (2002). Chapitre 3.6.4 La question
Quand ? et chapitre 6.8 La mise à jour. Dans SIG : concept, outils
et donnéees (pp. 90-91 & 162-172). Hermès Science. 259
p. ISBN/ISSN : 9782746205543
Date, C. J. (2004). Introduction aux bases
de données. (M. Chalmond, & J.-M. Thomas, Trads.) Paris:
Vuibert. 1047 p. ISBN/ISSN : 2711748383.
Guinaudeau, M. (2006). Etude
préalable pour la misee en oeuvre du "Fond vert" produit par l'IFN et
l'IGN. Mémoire d'examen professionel pour le recrutement
d'Ingénieur des Travaux Géographiques et Cartographiques de
l'Etat. 82 p.
Heres, L. (2000). « Hodochronologics:
History and time in the National Road Database ». Dans L. Heres
(Éd.), Time in GIS: issues in spatio-temporal modelling (pp.
45-56). Publication on Geodesy. Vol. 47. Deft. Pays-Bas: Netherlands Geodetic
Commision. 70 p. ISBN/ISSN : 9789061322696
IGN. (2007). GCVS pour les nuls.
Service de la recherche. 11 p.
IGN. (2011). BDUni V1.1 Grande Echelle :
spécifications de contenu (éd. 5ème). 213 p.
IGN. (2012). Spécification de saisie BDUni
V1.1.
Langran, G. (1992). Time in geographic
information systems. Londres, New York, Philadelphia: Taylor &
Francis. 189 p. ISBN/ISSN : 0748400036.
Paque, D. (2004). « Gestion de
l'historicité et méthodes de mise à jour dans les SIG
» dans Cybergéo : Cartographie, Imagerie, SIG, article
278. Mis en ligne le 23 juin 2004. Consulté le 22
février 2013, sur
http://cybergeo.revues.org/2500.
22 p. DOI : 10.4000/cybergeo.2500.
xxxi
Annexes
Exemple de requête SQL temporelle dans la BDUni
Cette requête permet l'extraction des objets du
thème bâtiment correspondant à l'état de la base
pour un instant et un département donné.
1 SELECT T.*
2 FROM(
3 SELECT bh.*
4 FROM batiment_h bh, metadonnees_departement d
5 WHERE d.code_insee = $2
6 AND (d.detruit is NULL or d.detruit=")
7 AND isvalid(bh.geometrie)
8 AND isvalid(d.geometrie)
9 AND intersects(bh.geometrie,d.geometrie)
-- concaténation de la table historique avec la table
actuelle
-- pour avoir les numrec et les numrecmodif de tous les objets
10 UNION
11
-- on rajoute la colonne numrecmodif avec une valeur par
défaut -- dans la table actuelle qui ne possède pas cette colonne
SELECT b.*, 0 as numrecmodif
12 FROM batiment b, metadonnees_departement d
13 WHERE d.code_insee = $2
14 AND (d.detruit is NULL or d.detruit=")
15 AND isvalid(b.geometrie)
16 AND isvalid(d.geometrie)
17 AND intersects(b.geometrie,d.geometrie)) AS T
-- jointure simple avec la table des réconciliations
permettant d'éliminer toutes les versions de l'objet -- correspondant
à des réconciliations postérieures à la date qui
nous intéresse
18 JOIN(
19 SELECT *
20 FROM reconciliations
-- opérateur <= ; borne gauche de l'intervalle
fermée
21 WHERE daterec <= $1) AS R1
22 ON T.numrec = R1.numrec
-- jointure gauche avec la table des réconciliations
récupérant pour chaque version la date
-- de la réconciliation suivante sur cet objet (celle qui
a mis la version courante dans l'historique)
23 LEFT JOIN(
24 SELECT *
25 FROM reconciliations
-- condition suivante peut-être inutile au regard du WHERE
final
26 WHERE daterec > $1) AS R2
27 ON T.numrecmodif = R2.numrec
-- la date du numrecmodif (date de la réconciliation
suivante doit être postérieur à la date t afin de
vérifier -- que l'objet courant a bien été
réconcilié avant t ET que la réconciliation suivante a eu
lieu après t -- opérateur > ; borne droite de l'intervalle
ouverte
28 WHERE R2.daterec > $1
-- Toutefois, si on est sur l'objet courant, on n'a pas de date
de
-- numrecmodif et on se contente de s'assurer que l'objet n'est
pas -- détruit ou que sa destruction est postérieure à
t
29 OR (T.numrecmodif = 0 AND (T.date_destruction IS NULL OR
T.date_destruction > $1)
xxxii
Commentaires :
? Première étape : création d'une table
unique réunissant les objets actuels et l'historique
Lignes 1 et 2 : sélectionner toutes les lignes et
toutes les colonnes dans une table T qui correspondent au résultat de la
requête énoncée de la ligne 3 à 29.
Lignes 3 à 17 : création de la table T,
contenant toutes les lignes et colonnes de la table historique (lignes 3 et 4),
et (ligne 10) toutes les lignes et colonnes de la table des objets courants
(lignes 11 et 12).La colonne « numrecmodif » est ajoutée et
remplie avec la valeur « 0 » à la table des objets courants
(ligne 11).
? Deuxième étape : borne inférieure de
l'intervalle
Lignes 17, 18 et 21,22 : jointure de la colonne « numrec
» de table principale T sur la même colonne de R1, vue issue de la
table des réconciliations. C'est une inner join qui crée
une nouvelle table dont le résultat ne contient que les lignes
satisfaisant le prédicat de jointure.
Lignes 19 à 21 : R1est créé à
partir d'une sélection dans la table des réconciliations de
toutes les lignes et colonnes lorsque le contenu de la colonne « daterec
» est strictement inférieur à la date choisie.
? Troisième étape : borne supérieure de
l'intervalle
Lignes 23, 26 et 27 : jointure de la colonne «
numrecmodif » de T sur la colonne « numrec » de R2. Le left
join consiste à ajouter des colonnes et à remplir les lignes
satisfaisant le prédicat de jointure, tout comme le inner join,
mais sans supprimer les autres lignes.
Lignes 23 à 26 : une seconde vue, R2, est
créé à partir d'une sélection dans la table des
réconciliations de toutes les lignes et colonnes lorsque la colonne
« daterec » est inférieure ou égale à la date
choisie.
? Quatrième étape :
Lignes 28 et 29 : sélection finale des lignes où
la colonne R2.daterec est supérieure ou égale à la date
choisie (l'objet est compris dans l'intervalle), ou quand il s'agit d'un objet
actuel, borné à gauche mais pas à droite car il n'a pas
été modifié ou détruit (« numrecmodif » =
0 et « date_destruction » non renseignée ou strictement
supérieure à la date choisie).
xxxiii
Exemple :
s Table actuelle « zone_de_vegetation
»
|
cleabs
|
numrec
|
date_destruction
|
|
001
|
2
|
|
|
002
|
3
|
2002
|
|
003
|
3
|
|
|
004
|
4
|
2003
|
|
005
|
4
|
|
s Table d'historique « zone_de_vegetation_h
»
|
cleabs
|
numrec
|
numrecmodif
|
Date_destruction67
|
|
001
|
1
|
2
|
|
|
002
|
2
|
3
|
|
|
004
|
1
|
3
|
|
|
004
|
3
|
4
|
|
s Table des réconciliations
|
numrec
|
daterec
|
Nom
|
|
1
|
2000
|
Création 001, 004
|
|
2
|
2001
|
Création 002, modification 001
|
|
3
|
2002
|
Création 003, modification 004, destruction 002
|
|
4
|
2003
|
Création 005, destruction 004
|
s Table T
|
(Table d'origine68)
|
cleabs
|
date_destruction
|
numrec
|
numrecmodif
|
|
zone_de_vegetation
|
001
|
|
2
|
0
|
|
zone_de_vegetation
|
002
|
2002
|
3
|
0
|
|
zone_de_vegetation
|
003
|
|
3
|
0
|
|
zone_de_vegetation
|
004
|
2003
|
4
|
0
|
|
zone_de_vegetation
|
005
|
|
4
|
0
|
|
zone_de_vegetation_h
|
001
|
|
1
|
2
|
|
zone_de_vegetation_h
|
004
|
|
1
|
3
|
|
zone_de_vegetation_h
|
002
|
|
2
|
3
|
|
zone_de_vegetation_h
|
004
|
|
3
|
4
|
67 Colonne toujours vide mais bien présente
dans la table.
68 Cette colonne est ajoutée à titre
indicatif.
xxxiv
L'opération est simulée pour quatre dates
successives, le résultat final est souligné et noté en
caractères gras.
1) t = 2000
s R1
s R2
|
Numrec
|
daterec
|
|
2
|
2001
|
|
3
|
2002
|
|
4
|
2003
|
s Résultat
|
R2.numrec
|
R2.daterec
|
cleabs
|
T.date_des truction
|
T.numrec
|
T.numrec modif
|
R1.numrec
|
R1.date-rec
|
|
2
|
2001
|
001
|
|
1
|
2
|
1
|
2000
|
|
3
|
2002
|
004
|
|
1
|
3
|
1
|
2000
|
2) t = 2001
s R1
|
numrec
|
daterec
|
|
1
|
2000
|
|
2
|
2001
|
s R2
|
Numrec
|
daterec
|
|
3
|
2002
|
|
4
|
2003
|
s Résultat
|
R2.numrec
|
R2.daterec
|
cleabs
|
T.date_des truction
|
T.numrec
|
T.numrec modif
|
R1.numrec
|
R1.date-rec
|
|
|
001
|
|
1
|
2
|
1
|
2000
|
|
3
|
2002
|
004
|
|
1
|
3
|
1
|
2000
|
|
|
001
|
|
2
|
0
|
2
|
2001
|
|
3
|
2002
|
002
|
|
2
|
3
|
2
|
2001
|
xxxv
3) t = 2002
s R1
|
Numrec
|
daterec
|
|
1
|
2000
|
|
2
|
2001
|
|
3
|
2002
|
s R2
s Résultat
|
R2.numrec
|
R2.daterec
|
cleabs
|
T.date_des truction
|
T.numrec
|
T.numrec modif
|
R1.numrec
|
R1.date-rec
|
|
|
001
|
|
1
|
2
|
1
|
2000
|
|
|
004
|
|
1
|
3
|
1
|
2000
|
|
|
001
|
|
2
|
0
|
2
|
2001
|
|
|
002
|
|
2
|
3
|
2
|
2001
|
|
|
002
|
2002
|
3
|
0
|
3
|
2002
|
|
|
003
|
|
3
|
0
|
3
|
2002
|
|
4
|
2003
|
004
|
|
3
|
4
|
3
|
2002
|
4) t = 2003
s R1
|
Numrec
|
daterec
|
|
1
|
2000
|
|
2
|
2001
|
|
3
|
2002
|
|
4
|
2003
|
s R2
s Résultat
|
R2.numrec
|
R2.daterec
|
cleabs
|
T.date_des truction
|
T.numrec
|
T.numrec modif
|
R1.numrec
|
R1.date-rec
|
|
|
001
|
|
1
|
2
|
1
|
2000
|
|
|
004
|
|
1
|
3
|
1
|
2000
|
|
|
001
|
|
2
|
0
|
2
|
2001
|
|
|
002
|
|
2
|
3
|
2
|
2001
|
|
|
002
|
2002
|
3
|
0
|
3
|
2002
|
|
|
003
|
|
3
|
0
|
3
|
2002
|
|
|
004
|
|
3
|
4
|
3
|
2002
|
|
|
004
|
2003
|
4
|
0
|
4
|
2003
|
|
|
005
|
|
4
|
0
|
4
|
2003
|
xxxvi
Remarques :
L'intervalle temporel défini par la requête
(deuxième et troisième étape) pour obtenir l'état
de la base à un instant t choisi peut être exprimé de la
façon suivante :
? début de l'intervalle < ou = instant T choisi <
fin de l'intervalle ? ou encore : [Tmin ; Tmax[
Cette définition est cohérente, car elle exclut
une des valeurs des bornes, ce qui est nécessaire puisque le
système d'historisation de la BDUni utilise une datation discrète
: la fin d'un objet précédant et le début du suivant
possède la même date, et non deux dates immédiatement
consécutives. Deux états successifs ne peuvent pas en effet,
selon la logique, se superposer dans le temps. Il faut donc exclure une des
bornes. Dans l'absolu, il paraît plus conforme à la
réalité du changement de considérer la borne de fin de
l'intervalle comme ouverte, et non celle du début. Cela revient à
faire correspondre à l'idée de durée d'un objet
informatique la notion d'existence d'un objet du monde réel.
Néanmoins, la résolution temporelle des données
étant de l'ordre du cent-millième de seconde, ce point n'est pas
nécessairement très important, d'autant plus que l'utilisation du
temps dans la BDUni répond à un besoin de maintenance
informatique. L'utilisation du temps réel et le suivi des changements
dans le cadre de l'OCS GE demandera par contre de veiller au respect de ce
principe.
| 


{kind=link}