2.2.2.2- Présentation des résultats du
modèle 2de disponibilité alimentaire.
Les résultats issus de l'estimation du modèle
à correction d'erreur (MCE), sont présentés dans le
tableau ci-après :
Tableau5 : Présentation des
résultats de l'estimation du modèle 2
|
Variables explicatives
|
Coefficient
|
Erreur standard
|
Test de Student
|
[Prob]
|
|
dPALH
dIMPORTnet
dAAL
|
-0,5020E-9
0,3409E-8
-0,4635E-7
|
0,1432E-9
0,9514E-9
0,2659E-7
|
-3,5065
3,5828
-1,7427
|
0,003
0,003
0,102
|
|
dPOPA
dINVEST
dSUBV
dPRIX
|
0,8071E-3
0,5547E-9
0,8935E-8
-1,7782
|
0,1640E-3
0,1136E-9
0,2615E-8
0,41086
|
4,9216
4,8823
3,4171
-4,3280
|
0,000
0,000
0,004
0,001
|
|
ecm (-1)
|
-0,66301
|
0,16283
|
-4,0718
|
0,001
|
|
dDIALJ = DIALJ-DIALJ(-1) ; dPALH = PALH-PALH(-1) ;
dIMPORTNET = IMPORTNET-IMPORTNET(-1);dAAL = AAL-AAL(-1) ; dPOPA =
POPA-POPA(-1) ; dSUBV = SUBV-SUBV(-1) ; dIPRIX =
IPRIX-IPRIX(-1) ; ecm = DIALJ -0,33699*PALH
+ 0,5020E-9*IMPORTNET -0,3409E-8*AAL + 0,4635E-7*POPA-0,8071E-3*INVEST
-0,5547E-9*SUBV -0,8935E-8*IPRIX
|
|
R-Squared
|
0,87646
|
R-Bar-Squared
|
0,81881
|
|
|
S.E. of Regression
|
139,1765
|
F-stat. F(7,15)
|
15,2029 [0,000]
|
|
|
Mean of Dependent Variable
|
58,7348
|
S.D. of Dependent Variable
|
326,9638
|
|
|
Residual Sum of Squares
|
290551,4
|
Equation Log-likelihood
|
-141,2421
|
|
|
Akaike Info. Criterion
|
-149,2421
|
Schwarz Bayesian Criterion
|
-153,7840
|
|
|
DW-statistic
|
2.4674
|
|
|
|
|
Diagnostic Tests
|
|
Test Statistics
|
LM Version
|
F Version
|
|
|
|
A:Serial Correlation
|
CHSQ(1)= 4.6830[.030]
|
F(1,14)= 3,5793[0,079]
|
|
|
|
B:Functional Form
|
CHSQ(1)= 1,5603[0,212]
|
F(1,14 )= 1,0188[0,330]
|
|
|
|
C:Normality
|
CHSQ(2)= 0,85741[0,651]
|
NA
|
|
|
|
D:Heteroscedasticity
|
CHSQ(1)= 0,0010151[0,975]
|
F(1,21) = 0,9268E-3[0,976]
|
|
|
Source : Estimation sous Microfit
De l'examen des résultats de la régression, il
ressort que le coefficient associé à la force de rappel est
négatif (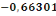 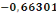 ) et significative au seuil de 1%. Il existe donc bien un
mécanisme à correction d'erreur. A long terme les
déséquilibres entre la disponibilité alimentaire par
habitant par jour et les variables explicatives se compensent de sorte que les
séries ont des évolutions similaires. ) et significative au seuil de 1%. Il existe donc bien un
mécanisme à correction d'erreur. A long terme les
déséquilibres entre la disponibilité alimentaire par
habitant par jour et les variables explicatives se compensent de sorte que les
séries ont des évolutions similaires.
· Qualité de
la régression
De l'examen des résultats
d'estimation (Tableau 2), il ressort que le coefficient de détermination
multiple R² = 0,88 indique que la qualité de la régression
du modèle est bonne. C'est-à-dire que les fluctuations de la
disponibilité alimentaire sont expliquées à 88% par les
variables explicatives du modèle.
·
Significativité des variables du modèle.
Il s'agit de tester si chacune des
variables figurant dans le modèle contribue significativement à
l'explication de la variable endogène. C'est-à-dire si chacun de
ces coefficients est significativement différent de zéro au sens
de Student.
De l'examen des résultats
d'estimation(Tableau 2), il ressort que les coefficients des différentes
variables significativement différents de zéro (0) sauf celui de
l'aide alimentaire qui est significatif au seuil de 10%. Il y a donc un rapport de cause à effet entre
ces variables explicatives et la variable expliquée. Pour
apprécier la qualité de notre modèle quelques tests sont
donc effectués.
· Tests classiques sur le modèle de
disponibilité alimentaire.
Ø Test de normalité
de Jarque-Bera
Le test de normalité
permet de savoir si les erreurs du modèle suivent une loi normale ou
pas. Le test de Jarque-Bera, encore appelé test de Skewness-Kurtosis
permet de tester la normalité des erreurs. Le test d'hypothèses
est le suivant :
Ho : les
erreurs suivent une loi normale ;
H1 : les
erreurs ne suivent pas une loi normale.
La statistique de Jarque-Bera est
définie de la façon suivante :
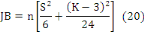
Où S est le coefficient de
dissymétrie et K le coefficient d'aplatissement.
On accepte Ho si la valeur de prob
> chi2 est supérieure à 5% et on accepte H1 dans le cas
contraire. La valeur de la probabilité prob
= 0,651 (Tableau 2) attachée à la statistique de Jarque-Bera est
supérieure à 5 %. Alors, les erreurs du modèle suivent une
loi normale.
Ø Test d'autocorrélation sérielle
des résidus
La probabilité attachée à la statistique
de Lagrange est Prob = 0,030 (Tableau 2), est inférieure à 5%. On
accepte l'hypothèse d'homoscédasticité des
résidus.
Ø Test de spécification de
Ramsey
Ce test permet d'observer si le
modèle souffre d'omission de variables importantes. La valeur de la
probabilité attachée à la statistique de Ramsey est 0,212
(Tableau 2) supérieure à 5 %. On en déduit que le
modèle ne souffre pas d'omission de variables importantes.
Ø Test du multiplicateur de
Lagrange
Ce test d'hétéroscédasticité
permet en réalité de savoir si la variance conditionnelle du
terme d'erreur sachant Xi est une constante ou non.
Le test d'hypothèses est le suivant :
Ho : Modèle
homoscédastique ;
H1 : Modèle
hétéroscédastique.
La probabilité (Prob = 0,975) est supérieure
à 5%. On accepte l'hypothèse d'homoscédasticité.
|
|


