CHAPITRE 1 : INTRODUCTION
1. Problématique
L'informatique aujourd'hui apparait comme une discipline
tentaculaire (Kanga, 2011) c'est-à-dire qui a un impact
considérable sur la plupart d'aspect de la vie sociale,
économique, juridique, etc...
Au regard de ce qui précède, nous pouvons dire
sans nous tromper que l'informatique couvre aujourd'hui la
quasi-totalité des secteurs de la vie
humaine et sociale.
L'organisation rigoureuse du travail parait indispensable et
constitue un atout majeur pour la survie de l'entreprise.
Vu les principaux besoins à satisfaire au sein de
l'entreprise, il règne une tendance générale à
l'harmonisation des supports utilisés au niveau des
entreprises qui ont comme service la distribution des
courriers (Par exemple : fiche de suivi des courriers, le bordereau de
dépôt, le relevé des clients...)
pour palier à des problèmes fastidieux et
répétitifs...Et par besoin d'évaluation
et de suivi des activités au sein de l'organisation. Le
souci d'optimisation des méthodes de gestion des clients à
travers la rationalisation de son dossier
s'impose.
Avec l'informatisation, la possibilité nous a
été donnée de suivre de manière
détaillée la gestion de chaque courrier, afin de permettre aux
responsables, de prendre de bonnes décisions et offrir la
possibilité de retrouver les traces ou opérations diverses
accomplies et surtout de générer les statistiques.
Dans le cadre d'une distribution des courriers, il offre la
possibilité de de faire le suivi des différents courriers vers
les clients destinateurs avec
beaucoup de facilité via internet, en s'affranchissant
de toutes les contraintes de temps ou de lieu.
Comme mentionner ci-haut, l'informatique touche presque tous
les
secteurs de la vie grâce au progrès
constaté dans chacune de ses branches, le site web dans notre cas.
2. Hypothèses
Il est évident qu'à ce jour l'apport des sites
web dans la vie des jeunes et des vieux est très significatifs, en
allant de sites de recherche,
d'information ,de rencontre, en passant par les réseaux
sociaux et plus encore
, ces différents sites offrent des
débouchés indispensables aux différentes catégories
des personnes qui les consultent.
1
Par ailleurs, ceux-ci ne sont pas à l'abri de certains
méfaits, tels les attaques web, les hackers, les pirates du web auxquels
ils devront faire face.
L'automatisation ne doit pas se faire d'une manière
arbitraire ;
La décision d'automatisation ne saurait être ni
immédiate, ni
spontanée.
Il a été remarqué, qu'à l'aide du
Système d'information actuel, on ne
pouvait pas automatiquement :
? Donner la liste des courriers traités ;
? Donner la liste des clients par catégories ;
? Produire une fiche de de suivi;
? Connaitre le statut du courrier ;
? Générer les statistiques.
Devant cette situation, les gestionnaires de l'entreprise est
confronté à un défi qui consiste à mettre sur pieds
un système d'information devant prendre en charge les problèmes,
susmentionnés.
Nous pouvons poser comme hypothèse que
l'informatisation du système d'information sera bénéfique
à HBC Sprl pour la gestion des courriers.
Face aux besoins des gestionnaires de l'entreprise, nous
pouvons anticiper une solution d'automatisation qui pourra remédier aux
différents problèmes qui se posent au sein de l'entreprise.
3. Choix et intérêt du sujet
Avec la vulgarisation de plus en plus poussée de
l'informatique, beaucoup d'utilisateurs d'ordinateurs, particulièrement
les internautes accordent une attention soutenue aux conditions d'exploitation
de cet outil pour en tirer le meilleur avantage.
C'est ainsi par exemple que certaines organisations disposent
d'un site web soit pour faire la promotion de leurs produits et services, mais
aussi certaines utilise carrément le site web comme l'outil qui rend
service à l'immédiat (online) selon les besoins de
l'internaute.
Mais le choix et l'intérêt que nous attachons
à ce sujet ne trouve pas leur fondement sur l'effet du « suivisme
» ni pour être à la mode, sans se soucier de
l'opportunité qu'il présente ni des potentialités des
matériels informatiques acquis et des différentes
fonctionnalités que présente l'application.
La perspective de notre étude revêt un triple
intérêt relatif aux catégories d'acteurs concernés
par une gestion électronique des courriers que nous avons relevé
dans le présent travail, en l'occurrence L'entreprise qui oeuvre dans le
domaine de distribution des courriers, l'Entreprise partenaire,
2
les clients de l'entreprise partenaire qui seront servis par
l'Entreprise de tutelle(en charge de distribution des courriers) ainsi que les
internautes.
Du côté de l'Entreprise de tutelle, Il n'est pas
rare en effet de
rencontrer aujourd'hui encore des organisations qui ne
disposent pas d'un site web ou encore qui en dispose mais sous-utilisé
et disposant aussi d'un
important parc d'ordinateurs dont la puissance
installée est sous-utilisée ou qui ne sert qu'au simple
traitement de texte. Et pourtant, l'acquisition de cet
outil requiert la mobilisation de beaucoup des moyens
financiers et son utilisation à bon escient aura un rendement
meilleur.
Concernant l'Entreprise partenaire, elle trouve un canal de
sous-traitance plus rapide et optimale qui gagne en temps et en cout. Une
facilité d'atteindre un grand nombre des clients en un temps record un
peu pour pallier à l'adage « Time is money ».
Concernant les clients et les internautes, ils disposent d'un
vaste
dispositif qui les permet de découvrir
différents services offerts par les deux Entreprise, l'Entreprise de
tutelle et l'Entreprise partenaire.
Enfin pour la communauté scientifique,
l'intérêt de cette étude a pour but de diagnostiquer, au vu
de ce qui se passe sous d'autres cieux, l'un des
artifices du développement fulgurant des nouvelles
technologies de
l'information et de la communication afin de proposer une
approche méthodique, explicative et objective qui permette
d'appréhender la gestion
par voie électronique des courriers.
4. Méthodes et techniques utilisées
Afin de mener à bien le déroulement de notre
recherche qui analyse les conditions de développement d'une application
de gestion des courriers
par voie électronique de l'Entreprise HBC (Holding
Business and Communication), nous avons opté pour la méthode
MERISE (Méthodes
d'Etudes et de Réalisations Informatiques des
Systèmes d'Entreprise). Grace à elle, le concepteur a la
possibilité de représenter le réel perçu. En
outre,
MERISE fait une approche systémique (une approche qui
repose sur la
théorie des systèmes).
Enfin, MERISE suit une démarche hiérarchique donc
une démarche
par niveau et cela de par son cycle d'abstraction.
Outre les méthodes informatiques qui nous ont
aidées à mener à
bien le déroulement de notre recherche qui analyse les
conditions de
développement d'une application de gestion des courriers
par voie
électronique, nous avons aussi fait recours aux
méthodes et techniques qui nous ont permis d'écrire ce
mémoire. Ces méthodes et techniques sont :
3
4.1. Méthodes de travail
- la méthode historique : cette méthode nous a
permis de cerner les raisons et contraintes explicatives du recours à un
logiciel de gestion ;
- la méthode descriptive : nous a permis de faire une
description ou mieux une monographie de la situation de l'organisation qui fait
l'objet de notre étude par une analyse de l'existant ;
- la méthode clinique : nous a permis de faire un
diagnostic de la situation actuelle de gestion au sein de l'entreprise HBC et
de proposer les possibilités d'améliorer le système de
gestion d'informations.
4.2. Techniques de travail
- technique documentaire : cette technique nous a permis de
collecter les informations relatives à notre sujet contenues dans les
ouvrages, articles, revues, etc. ;
- les statistiques nous ont permis de collecter les
informations quantitatives inhérentes à notre étude.
- l'interview
5. Délimitation dans l'espace du sujet
Notre étude trouve son outil d'analyse dans deux
catégories de documents en rapport avec la gestion par voie
électronique des courriers. La première catégorie comprend
toute la documentation ayant trait à l'usage à la gestion des
courriers et, laquelle documentation nous a servi tout au long de cette
étude.
Pour la seconde catégorie relative au développement
d'une application permettant la gestion des courriers nous nous proposons
d'implémenter cette application web.
Du cadre spatial, nous avons retenu HBC qui est une Entreprise
oeuvrant dans le domaine de courriers et de recouvrement en République
Démocratique du Congo.
4
5
PREMIERE PARTIE : NOTIONS
THEORIQUES
CHAPITRE 2 : REVUE DE LA LITTERATURE
2.1. Système d'information
Avant de parler du système d'information, nous allons
d'abord aborder respectivement les concepts « système » et
« information ».
? Système :
- Ensemble d'éléments de même nature qui
assure une fonction
commune,
- Dispositif ou ensemble d'éléments ayant une
fonction
déterminée,
- Ensemble de méthodes et de procédés
organisés qui concourent
au même résultat.
? Information :
- Ensemble de données (concernant un sujet particulier)
A. Système d'information
Le bon fonctionnement d'une entreprise dépend de la
manière dont l'information est perçue, stockée,
traitée et diffusée. Dès lors que l'entreprise en tant que
système complexe ne répond pas à cette règle, elle
ne pourra jamais atteindre ses objectifs (Mvibudulu & Konkfie, 2010).
Ainsi, l'entreprise en tant que système complexe est un
ensemble avec des sous-ensembles dont le but est commun, celui d'atteindre des
objectifs qu'elle s'est assignés.
Ces sous-ensembles constituent eux aussi des systèmes
dans un système. Il s'agit de :
? Système de pilotage (décisionnel) ;
? Système d'information ;
? Système opérant.
Les trois systèmes ou composants sont
représentés dans le schéma
ci-après :
6
Entreprise/Système
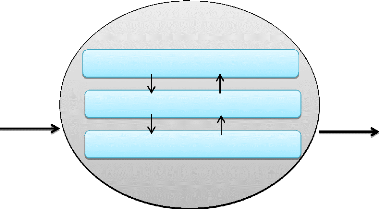
Système de pilotage (S.P)
Système d'information (S.I)
Input Output
Système opérant (S.O)
Figure 1. Présentation des composants du
système
Ainsi, chaque sous système de l'entreprise est
décrit de la manière suivante :
? Le système de Pilotage (SP) a pour objectif
d'arrêter des stratégies pour le bon fonctionnement de
l'entreprise. Il est appelé autrement système décisionnel,
car il décide du sort de l'entreprise à court, moyen et long
terme.
? Le système d'Information (SI) joue le rôle du
courroie de transmission entre le système de pilotage et le
système opérant. Il est un ensemble d'information et de moyens
utilisés pour exploiter ses informations. Il s'agit des moyens :
matériels, humains, logiciels, financiers, etc.
? Le système Opérant (SO) ou d'exécution
a pour objectif d'exécuter les ordres provenant du système
décisionnel via le système d'information et d'n faire un rapport
après exécution.
B. Le cycle d'abstraction de conception de système
d'information
Le cycle d'abstraction de merise repose sur les raisonnements
et comporte les différents niveaux ci-après :
- Le niveau conceptuel
- Le niveau organisationnel
- Le niveau logique
- Le niveau physique
7
Le système d'information organisationnel et le
système d'information informatisé.
|
Niveau
|
Regroupement
|
|
Conceptuel
Organisationnel
|
Système d'information organisationnel
|
|
Logique Physique
|
Système d'information informatisé
|
Il est à noter qu'en merise, il y a séparation
entre données et traitement. C'est ainsi que l'on parlera des aspects :
statique et dynamique.
C. Les composants du système d'information
Dans le système d'information, nous retrouvons des
sous-systèmes
ci-après :
? Le système manuel dont les informations sont
traitées manuellement;
? Le système informatique dont les informations sont
traitées automatiquement.
Comme toutes les informations de l'entreprise ne peuvent pas
être traitées avec des outils informatiques, celles qui les seront
pour assurer la cohérence du système d'information doivent suivre
la démarche d'information proposée par la méthode Merise,
car l'informatisation ne s'improvise pas.
2.2. Base de données
2.2.1. Quid Base des données
? Une base de données (BD en abrégé) est
un ensemble d'informations archivées dans des mémoires
accessibles à des ordinateurs en vue de permettre le traitement des
diverses applications prévues pour elles.
L'intérêt d'une BD est de regrouper les
données communes à une application dans le but :
- D'éviter les redondances et les incohérences
qu'entrainerait fatalement une approche où les données seraient
réparties dans différents fichiers sans connexion entre eux ;
- D'offrir des langages de haut niveau pour la
définition et la manipulation des données ;
- De partager les données entre plusieurs utilisateurs
;
8
- De contrôler l'intégrité, la
sécurité et la confidentialité des données ;
- D'assurer l'indépendance entre les données et
les traitements (Lemaitre, 2005).
La conception d'une Base de données nécessite au
préalable une connaissance en la matière afin que sa
réalisation soit bonne. Ainsi, la définition d'une Base de
données se fonde sur trois critères suivants (Mvibudulu &
Konkfie, 2010):
- Structuration
- Non redondance - Exhaustivité
A cet effet, nous définissons une Base de
données comme étant un ensemble des données
structurées, non redondantes et exhaustives.
De façon simpliste, une Base de données est
définie comme étant
un grand fichier dans lequel on retrouve des petits fichiers
ayant des liens entre eux, renfermant des informations nécessaires et
non répétitives et
permettant à plusieurs utilisateurs d'y accéder
simultanément.
Ex : T. BDD
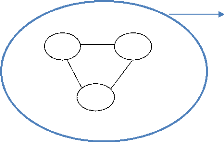
T
T3
T2
T_BDD : grand fichier (fichier
BDD)
Figure 2. Schéma théorique d'une Base de
Données
? Une base de données est aussi un ensemble volumineux,
structuré et minimalement redondant de données, reliées
entre elles, stockées
sur support numériques centralisés ou
distribués, servant pour les besoins
d'une ou plusieurs applications, interrogeables et modifiables
par un ou plusieurs utilisateurs travaillant potentiellement en
parallèle.
On peut parler d'une base de données aussi comme
étant une collection de données dans un domaine d'application
singulier et particulier où les propriétés des
données ainsi que les relations sémantiques entre ces
données sont spécifiées en utilisant les concepts
proposés par le modèle de données sous-jacent (Massimango,
2011).
9
? Une base de données (BD en
abrégé) est un ensemble d'information archivée dans des
mémoires accessibles à des ordinateurs en vue de permettre le
traitement des diverses applications prévues pour elles.
L'intérêt d'une BD est de regrouper les
données communes à une application dans le but (Lemaitre, 2005)
:
? D'éviter les redondances et les incohérences
qu'entrainerait fatalement une approche où les données seraient
réparties dans différents fichiers sans connexion entre eux,
? D'offrir des langages de haut niveau pour la
définition et le manipulation des données,
? De partager les données entre plusieurs
utilisateurs,
? De contrôler l'intégrité, la
sécurité et la confidentialité des données,
? D'assurer l'indépendance entre les données et
les traitements.
2.2.2. Description des critères d'une base de
données
- Structuration : Ce terme fait allusion aux
conditions de stockage des informations et à la manière dont ces
dernières seront utilisées.
- Non redondance : C'est un critère
qui interdit à la Base de données de contenir des informations
répétitives. Nous avons deux formes de redondance à savoir
:
La synonymie : c'est lorsque deux objets ont la
même signification. Par exemple : Nom et Name ; Désignation et
libellé.
La polysémie : c'est lorsqu'un objet
renvoie a plusieurs significations.
Exemple :
Animal
|
Nom
|
|
Nom d'une personne
Nom d'un article
|
10
- Exhaustivité : C'est le principe selon
lequel la Base de données doit contenir n toutes les informations
nécessaires afin de répondre aux besoins des utilisateurs et ce,
à tous les niveaux de hiérarchie.
Pour ce faire, l'Analyste ou le Concepteur est obligé
à bien recenser
les besoins des utilisateurs à partir desquels, il va
collecter les données qui seront logées dans la Base.
2.2.3. Planification d'une base de données
Une base de données doit être conçue, raison
pour laquelle, il est conseillé de la concevoir sur papier avant son
implémentation sur un micro-ordinateur.
C'est pareil avec le travail d'un architecte qui avant de
construire une maison, conçoit d'abord son plan sur papier.
Ainsi, la conception d'une base de données exige la mise
en application de ses trois critères techniques : la structuration, la
non redondance et l'exhaustivité, cela, en utilisant une méthode
de conception des systèmes d'information telle que MERISE
(Méthodes d'Etudes et de Réalisation Informatiques des
Systèmes d'Entreprise), ou une technique de modélisation comme
UML et autres (Mvibudulu & Konkfie, 2010).
2.2.4. Système de gestion de base de
données(SGBD)
2.2.4.1. Quid SGBD
Un SGBD (Système de gestion de base de données)
est un système de stockage de l'information qui assure la recherche et
la maintenance. Les données sont persistantes (gestion de disques),
partagées entre de nombreux utilisateurs ayant des besoins
différents, qui les manipulent à l'aide de langage
appropriés. Le système assure également la gestion de la
sécurité et des conflits d'accès.
Il faut remarquer que les données sont accessibles
directement, alors que les systèmes de banques de données
antérieures ne fournissaient qu'un accès à un ensemble
plus ou moins vaste au sein duquel il fallait encore faire une recherche
séquentielle. On retrouve ce dernier mode de fonctionnement quand on
utilise sur Internet des navigateurs de recherche qui exploitent des moteurs de
bases de données.
11
A. Historique
Le mot Data Base est un apparu en 1964 lors d'une
conférence sur ce thème aux USA, organisée dans le cadre
du programme spatial américain.
Auparavant, on ne connaissait que des systèmes de
gestion de fichiers (SGF), basés sur la gestion de bandes
magnétiques, destinés à optimiser les accès
séquentiels. Les disques étaient alors chers et
réservés à de petits fichiers.
Peu après (~ 1970) apparaissent les premiers SGBD,
conçus selon les modèles hiérarchiques, puis
réseaux. On voit apparaitre des langages de navigation et la description
des données est indépendante des programmes d'application. Cette
première génération suit les recommandations du DTBG
CODASYL (Data Base Task Group - Conference On Data System Language),
influencé par le système IMS d'IBM.
Le modèle relationnel voit jour en 70 et met 20 ans
pour s'imposer sur le marché. Ce modèle permet la naissance de
langages assertionnels, basés sur la logique du premier ordre et les
traitements ensemblistes. Dans le même temps, l'emploi des disques se
généralise, les accès directs deviennent la règle,
le développement des techniques d'optimisation assurent aux SGBD des
performances largement équivalentes à celles des anciens
modèles de données.
Au cours des années 80, de nouveaux besoins se font
jour. Les systèmes mis jusque-là sur le marché
privilégiaient des données de gestion. On cherche de plus en plus
à manipuler des données techniques, des images, du son. De
nombreux travaux de recherche tentent de faire le lien avec le monde
Orienté-Objet ainsi qu'avec les systèmes
d'inférence utilisés en Intelligence Artificielle.
Compte tenu de l'inertie du marché, il faudra attendre encore une
dizaine d'années pour qu'un modèle vraiment nouveau et performant
commence à l'envahir. On commence à parler en 96 d'une «
évolution progressive » vers le modèle relationnel-Objet
à partir de 1988.
B. Principes de fonctionnement
La gestion et l'accès à une base de
données sont assurés par un ensemble de programmes qui
constituent le Système de gestion de base de données (SGBD). Un
SGBD doit permettre l'ajout, la modification et la recherche de données.
Un système de gestion de bases de données héberge
généralement plusieurs bases de données, qui sont
destinées à des logiciels ou des thématiques
différentes.
Actuellement, la plupart des SGBD fonctionnent selon un mode
client/serveur. Le serveur (sous-entendu la machine qui stocke les
données)
12
reçoit des requêtes de plusieurs clients et ceci
de manière concurrente. Le serveur analyse la requête, la traite
et retourne le résultat au client.
Le modèle client/serveur est assez souvent
implémenté au moyen de l'interface des sockets (voir le cours de
réseau); le réseau étant Internet.
Une variante de ce modèle est le modèle ASP
(Application Service Provider). Dans ce modèle, le client s'adresse
à un mandataire (broker) qui le met en relation avec un SGBD capable de
résoudre la requête. La requête est ensuite directement
envoyée au SGBD sélectionné qui résout et retourne
le résultat directement au client.
Quel que soit le modèle, un des problèmes
fondamentaux à prendre en compte est la cohérence des
données. Par exemple, dans un environnement où plusieurs
utilisateurs peuvent accéder concurremment à une colonne d'une
table par exemple pour la lire ou pour l'écrire, il faut s'accorder sur
la politique d'écriture.
Cette politique peut être : les lectures concurrentes
sont autorisées mais dès qu'il y a une écriture dans une
colonne, l'ensemble de la colonne est envoyée aux autres utilisateurs
l'ayant lue pour qu'elle soit rafraîchie (Audibert, 2009).
C. Objectifs d'un SGBD
Des objectifs principaux ont été fixés
aux SGBD dès l'origine de ceux-ci et ce, afin de résoudre les
problèmes causés par la démarche classique. Ces objectifs
sont les suivants :
Indépendance physique : La
façon dont les données sont définies doit être
indépendante des structures de stockage utilisées.
Indépendance logique : Un même
ensemble de données peut être vu différemment par des
utilisateurs différents. Toutes ces visions personnelles des
données doivent être intégrées dans une vision
globale.
Accès aux données :
L'accès aux données se fait par l'intermédiaire d'un
Langage de Manipulation de Données (LMD). Il est crucial que ce langage
permette d'obtenir des réponses aux requêtes en un temps «
raisonnable ».
Le LMD doit donc être optimisé, minimiser le
nombre d'accès disques, et tout cela de façon totalement
transparente pour l'utilisateur.
Administration centralisée des données
(intégration) : Toutes les données doivent être
centralisées dans un réservoir unique commun à toutes les
applications. En effet, des visions différentes des données
(entre autres)
13
se résolvent plus facilement si les données sont
administrées de façon centralisée.
Non redondance des données : Afin
d'éviter les problèmes lors des mises à jour, chaque
donnée ne doit être présente qu'une seule fois dans la
base.
Cohérence des données : Les
données sont soumises à un certain nombre de contraintes
d'intégrité qui définissent un état cohérent
de la base. Elles doivent pouvoir être exprimées simplement et
vérifiées automatiquement à chaque insertion, modification
ou suppression des données.
Les contraintes d'intégrité sont décrites
dans le Langage de Description de Données (LDD).
Partage des données : Il s'agit de
permettre à plusieurs utilisateurs d'accéder aux mêmes
données au même moment de manière transparente. Si ce
problème est simple à résoudre quand il s'agit uniquement
d'interrogations, cela ne l'est plus quand il s'agit de modifications dans un
contexte multi-utilisateurs car il faut : permettre à deux (ou plus)
utilisateurs de modifier la même donnée « en même temps
» et assurer un résultat d'interrogation cohérent pour un
utilisateur consultant une table pendant qu'un autre la modifie.
Sécurité des données :
Les données doivent pouvoir être protégées contre
les accès non autorisés. Pour cela, il faut pouvoir associer
à chaque utilisateur des droits d'accès aux données.
Résistance aux pannes : Que se
passe-t-il si une panne survient au milieu d'une modification, si certains
fichiers contenant les données deviennent illisibles ? Il faut pouvoir
récupérer une base dans un état « sain ». Ainsi,
après une panne intervenant au milieu d'une modification deux solutions
sont possibles : soit récupérer les données dans
l'état dans lequel elles étaient avant la modification, soit
terminé l'opération interrompue (Audibert, 2009).
D. La notion de Modèle de
Données
C'est une notion très essentielle dans le sens
où elle sert de motivation quant au choix de l'utilisation ou non d'une
base de données lors de la conception d'un système.
En effet, la résolution d'un problème par un
automate nécessite de représenter l'information sur le domaine
traité appelé parfois mini monde ou univers du discours sous une
forme digitale qui soit interprétable et manipulable par un
ordinateur.
14
Le modèle doit donc être spécifié
en utilisant des données codées et stockées en
mémoire ainsi que par des opérations (programmes) qui
déterminent comment ces données peuvent être
utilisées pour résoudre le problème posé.
Un modèle peut se définir comme une
représentation abstraite de l'information et éventuellement des
opérateurs de manipulation de l'information.
Sur le plan fonctionnel, voilà ce dont on peut attendre
d'un Système de Gestion de Base de Données (Massimango, 2011)
:
- Supporter les concepts définis au niveau du
modèle de données. Ceci afin de pouvoir représenter les
propriétés des données. Ce niveau de représentation
n'est pas nécessairement lié à la représentation
interne sous forme de fichiers. Il regroupe en général la
définition de types spécifiques et la définition de
règles de cohérence ;
- Rendre transparent le partage des données entre
différents utilisateurs. Ceci signifie que plusieurs utilisateurs
doivent pouvoir utiliser la base de façon concurrente et transparente.
Le problème posé ici est du fait que le SGBD pour des raisons
évidentes de performances (partage du CPU) doit permettre des
exécutions concurrentes sur une même base de données ;
- Assurer la confidentialité des données. Il est
nécessaire de pouvoir spécifier qui a le droit d'accéder
ou de modifier tout ou partie d'une base de données. Il faut donc se
prémunir contre les manipulations illicites qu'elles soient
intentionnelles ou accidentelles. Cela nécessite d'une part, une
spécification des droits ajout, suppression, mis à jour). Il est
patent que garantir la confidentialité des données engendre un
surcout en temps au niveau des manipulations ;
- Assurer le respect des règles de cohérence
définies sur les données. A priori, après chaque
modification sur la base de données, toutes les règles de
cohérence doivent être vérifiées sur toutes les
données. Evidemment, une telle approche est irréalisable pour des
raisons de performances et il faut déterminer des moyens de trouver
précisément quelles règles et quelles données sont
susceptibles d'être concernées par les traitements
réalisés sur la base de données. Ces traitements doivent
pouvoir être effectués sans arrêter le système.
- Fournir différents langages d'accès selon le
profil de l'utilisateur. En général, on admet que le SGBD doit au
moins supporter un langage adressant les concepts du modèle. Dans le cas
du modèle relationnel, ce langage est le langage SQL. Néanmoins
ce type de langage ne permet pas tous les types de manipulations et les SGBD
proposent soit un langage plus complet au sens Turing du terme avec la
possibilité de définir des accès à la base de
données, soit un couplage d'un langage tel que SQL avec un langage de
programmation conventionnel (tels que le langage C ou le langage Cobol).
15
La définition d'une interface entre une base de
données et le Web pose ce type de problème de
spécification et de navigation dans une base de données ;
- Etre résistant aux pannes. Ceci afin de
protéger les données contre tout incident matériel ou
logiciel qu'il soit intentionnel ou fortuit. Il faut donc garantir la
cohérence de l'information et des traitements en cas de panne. Les
applications opérant sur des bases de données sont souvent par
nature amenées à opérer des traitements longs sur
d'importants volumes de données. Les possibilités de panne en
cours de traitement sont donc nombreuses et il faut fournir des
mécanismes de reprise en cas de panne ;
- Posséder une capacité de stockage
élevée. Permettre ainsi la gestion de données pouvant
atteindre plusieurs milliard d'octets. Les capacités de stockage des
ordinateurs sont en augmentation croissante. Cependant, les besoins des
utilisateurs sont également en croissance forte. Avec l'essor des
données multimédia (texte, image, son, vidéo) les besoins
sont encore accrus. Les unités de stockage sont passées du
mégaoctet(106) au gigaoctet (109), puis au
téraoctet (1012), pétaoctet (1016) et on
déjà à parler de exaoctet(1018) voir de
zettaoctet(1021) ;
- Pouvoir répondre à des requêtes avec un
niveau de performances adapté. Une requête est une recherche
d'information à effectuer sur une ou plusieurs bases de données
qui peut impliquer des caractéristiques descriptives sur l'information
ou des relations entre les données. La puissance des ordinateurs n'est
pas la seule réponse possible à apporter aux problèmes de
performance. Une requête peut généralement être
décomposée en opérations élémentaires.
L'ordre d'exécution des opérations en fonction de leurs
propriétés (associativités, commutativité) ainsi
que le regroupement de certaines opérations utilisant le même
ensemble de données sont des éléments qui permettent de
diminuer significativement le temps d'exécution d'une requête ;
- Fournir des facilités pour la gestion des
méta-données. Par exemple à travers un dictionnaire de
données ou un catalogue système. Les méta-données
concernent les données sur le schéma de la base de données
(relations, attributs, contraintes, vues), sur les données (vues), sur
les utilisateurs (identification, droits) et sur le système
(statistiques). Ces données doivent être gérées et
consultées de la même manière que les données
afférentes à l'application. Cette notion de catalogue assure
également une certaine flexibilité au niveau de l'utilisation du
SGBD. Cette flexibilité permettant l'ajout sous contrôle de
nouveaux utilisateurs ainsi que la modification de structures de données
existantes sous certaines conditions. De plus, ce type d'information permet
entre autre à l'administrateur de la base de données ou au SGBD
lui-même d'adapter la politique de stockage en fonction du contenu.
16
Les SGBD peuvent varier selon leur complexité. Il n'est
donc pas rare de rencontrer des systèmes de gestion qui possèdent
tout ou une partie des propriétés citées ci-haut.
Ainsi lorsque l'on prend par exemple le SGBD relationnel
Oracle 7 le SGBD relationnel Access. Ce sont deux produits assez
caractéristiques pour exprimer ce que nous venons de dire. Le SGBD
Oracle 7 est un SGBD relationnel utilisé pour des applications critiques
et qui offre un maximum des caractéristiques présentées
ici. Le SGBD Access est un SGBD dans le monde de l'informatique individuelle
qui présente l'avantage d'une grande facilité d'utilisation et
qui peut convenir à des applications de taille réduite ou
moyenne. L'aspect convivial de ce dernier étant évident. En
revanche, les niveaux de performance et de sécurité ne sont pas
comparables (Massimango, 2011).
E. Les Principaux Systèmes de Gestion de Base de
Données
Les éditeurs de SGBD se partagent un marché
mondial en lente régression depuis deux ans : 8-9 milliards de dollars
en 2000, 7-8 milliards de dollars en 2001 et 6-7 milliards de dollars en 2002,
les chiffres variant quelque peu selon les sources. Les principaux
éditeurs (avec leurs parts de marché en l'an 2002,
calculées sur le chiffre d'affaires) sont :
- IBM (36%), éditeur des SGBD DB2
(développé en interne - mis sur le marché en 1984) et
Informix (obtenu par achat de l'entreprise correspondante en 2001 ; la
société Informix avait été créée en
1981. Une version bridée de DB2 vient d'apparaitre sur le marché,
où elle concurrence SQL Server de Microsoft ;
- Oracle (34%) éditeur du SGBD qui porte le meme nom.
Cette entreprise a été créée en 1977 ;
- Microsoft (18%), éditeur de trois SGBD. SQL Server
est destiné aux gros systèmes, Access est un produit de
bureautique professionnelle, et Foxpro est destiné aux
développeurs. L'arrivée de Microsoft sur le marché des
SGBD date des années 90 ;
- Sybase (<3%). Cette entreprise, qui a été
créée en 1984, est aujourd'hui marginalisée.
Ces chiffres recouvrent des réalités
contrastées, quand on les fractionne par plate-forme. Dans le monde
Unix, Oracle est en tête avec 62% suivi d'IBM (Informix compris) avec
27%, alors que Microsoft n'est pas présent sur ce marché. Dans le
monde Windows, Microsoft a pris la tête avec 45%, suivi d'Oracle avec 27%
et d'IBM avec 22%.
Le classement par nombre d'exemplaires(ou licences) vendus est
très différent. Il met en avant les SGBD conçus pour
gérer les bases de taille
17
modeste ou modérée. Dans ce domaine
l'éditeur Microsoft, qui vend plusieurs millions d'exemplaires de son
logiciel Access par mois, pulvérise tous les records. L'usage des SGBD
se démocratise à toute vitesse, bien qu'un SGBD soit plus
difficile à maitriser qu'un traitement de texte ou un tableur (pour ne
citer que les logiciels les plus courants). L'image du SGBD servant uniquement
les très grosses bases, propriété d'une grande
multinationale, fonctionnant sous Unix sur une machine monstrueuse,
géré par un administrateur dictatorial, et coutant un prix fou- a
vécu. Bon débarras !
Un SGBD est principalement constitué d'un
moteur et d'une interface graphique. Le
moteur est le coeur du logiciel, c'est-à-dire qu'il assure les fonctions
essentielles : saisir les données, les stocker, les manipuler, etc.
l'interface graphique permet à l'utilisateur de communiquer
commodément avec le logiciel. Pour dialoguer avec le SGBD qui n'est pas
équipés d'une interface graphique, il faut utiliser le
langage SQL (Structured Query Language), et introduire les
instructions à l'aide d'un éditeur de lignes.
Langage normalisé de manipulation des bases de
données, SQL est utilisable avec pratiquement tous les SGBD du
marché. Cependant, chaque éditeur ayant développé
son propre « dialecte » --comme c'est toujours le cas en informatique
- il faut pouvoir disposer d'un « dictionnaire » pour transporter une
BD d'un SGBD à l'autre. Ce « dictionnaire » a
été développé par Microsoft sous le nom
ODBC (Open Data Base Connectivity) (MASSIMANGO Ntoya, op.cit.,
p.31-32).
Il existe de nombreux système de gestion de base de
données, en voici une liste non exhaustive :
- PostgreSQL
- MySQL
- Oracle
- IBM DB2
- Microsoft SQL
- Sybase
- Informix
F. Le matériel (serveur de BDD)
Le choix du matériel informatique sur lequel on
installe un SGBD est fonction, comme ce dernier, du volume des données
stockées dans la base du nombre maximum d'utilisateurs
simultanés.
Lorsque le nombre d'enregistrements par table n'excède
pas le million, et que le nombre d'utilisateurs varie d'une à quelques
personnes, un micro-ordinateur actuel de bonnes performances, un logiciel
système pour poste de travail, et un SGBD « Bureautique »
suffisent. Exemple : le logiciel
18
Access 2002 de Microsoft, installé sur un PC
récent, doté de 1Go de mémoire vive et fonctionnant sous
Windows XP.
Si ces chiffres sont dépassés, ou si le temps de
traitement des données devient prohibitif, il faut viser plus haut. Le
micro-ordinateur doit être remplacé par un serveur de BDD,
dont les accès aux disques durs sont nettement plus rapides.
Le logiciel système client doit être
remplacé par un logiciel système serveur (donc
multi-utilisateurs), et le SGBD bureautique par un SGBD prévu pour les
grosses BDD multi-clients. Ceci dit, la structure d'une grosse base n'est pas
différente de celle d'une petite, et il n'est pas nécessaire de
disposer d'un « mainframe » (une grosse machine) gérant des
milliers de milliards d'octets pour apprendre à se servir des BDD. Ce
n'est pas parce qu'il gère un plus grand volume de données qu'un
SGBD possède plus de fonctionnalités.
Quelle que soit la taille, le système constitué
de la machine et du SGBD doit être correctement équilibré.
Un serveur de BDD doit posséder à la fois les qualités de
serveur de fichier (bon accès aux disques) et celles d'un serveur
d'applications (unité centrale bien dimensionnée, mémoire
vive suffisante). En observant un serveur de BDD en cours de fonctionnement, on
peut observer les trois cas de déséquilibre suivants :
- La machine fait du « swapping »,
c'est-à-dire qu'elle passe son temps à promener des
données entre la mémoire vive et la mémoire virtuelle
(laquelle réside sur disque). Le remède consiste à
augmenter la mémoire vive -si la chose est matériellement
possible ;
- Si l'unité centrale est sous-occupée, alors
que le disque dur ne cesse de tourner, la machine est sous-dimensionnée
quant à sa mémoire de masse. Les remèdes : utiliser une
interface disque plus performante(SCSI), un disque dur plus rapide, un
système RAID 0. Ce cas est le plus fréquemment rencontré
;
- Si l'unité centrale est utilisé à fond,
alors que le les disques durs sont peu sollicités, la machine est
sous-motorisée. Les remèdes : utiliser une machine
possédant des processeurs plus rapides, ou un plus grand nombre de
processeurs.
Jusqu'à une date récente, les constructeurs de
serveurs (et les éditeurs de SGBD) conseillaient à leurs clients
de consolider leurs données, en les rassemblant dans un nombre minimum
de grosses BDD, installées sur un nombre minimum de serveurs
surpuissants. Comme le cout des serveurs croit exponentiellement avec le nombre
de processeurs, et que le cout des licences (des SGBD) est proportionnel au
nombre de processeurs, constructeurs et éditeurs ont gagné de
l'or pendant la dernière décennie. Avec l'éclatement de la
bulle Internet, les cordons de la bourse se sont resserrés, si
19
bien que les services informatiques des entreprises commencent
à recourir - de gré ou de force - à des systèmes
plus décentralisés et de taille plus raisonnable (Massimango,
2011).
G. Administration de la base de
données
L'ensemble « serveur BDD +SGBD » constitue un
système informatique dont l'importance ne cesse de croitre dans
l'Entreprise. La personne responsable de la maintenance et de
l'évolution de ce système s'appelle l'administrateur de la
base de données. Dès que l'Entreprise atteint la taille
d'une grosse PME, l'administrateur de la BDD peut nécessiter la
présence d'une personne à temps plein, voire plus.
Etre administrateur de BDD requiert des compétences
particulières, très différentes de celles requises pour
être administrateur de réseau ou de système informatique.
Il en résulte le développement de deux pôles de
compétences informatiques dans l'entreprise. On remarque que, dans
l'entreprise toujours, la spécialisation des informaticiens
s'accroit.
Pour être complet, il faut signaler que le
développement des sites web contribue à créer un
troisième pôle de compétence dans l'entreprise. Le
responsable correspondant est appelé webmestre, et non «
administrateur de site », parce que le poste requiert des
compétences multidisciplinaires (et pas seulement informatique)
(Massimango, 2011).
H. Les différents modèles de Bases de
Données
Les bases de données du modèle «
relationnel » sont les plus répandues (depuis le milieu des
années 80), car elles conviennent bien à la majorité des
besoins des entreprises. Le SGBD qui gère une BDD relationnelle est
appelé « SGBD relationnel », ce qui est souvent
abrégé an SGBDR.
D'autres modèles de bases de données ont
été proposés : hiérarchique, en réseau,
orienté objet, relationnel objet. Aucun d'entre eux n'a pu
détrôner le modèle relationnel, ni se faire une place
notable sur le marché (sauf le relationnel, prôné par
Oracle, qui connait un certain développement).
Malgré sa généralité, le
modèle relationnel ne convient pas à toutes les BDD
rencontrées en pratique. Il existe donc des SGBD
spécialisés. Les deux exemples les plus connus
concernent la gestion des BDD bibliographiques (ou documentaires), et celle des
BDD géographiques gérées à l'aide d'un SIG
(Système d'Information Géographique).
Voyons un peu les quatre principaux modèles :
a. Modèle relationnel
Une base de données relationnelle est une base de
données structurée suivant les principes de l'algèbre
relationnelle.
20
Le père des bases de données relationnelles est
Edgar Frank Codd. Chercheur chez IBM à la fin des années 1960, il
étudiait alors de nouvelles méthodes pour gérer de grandes
quantités de données car les modèles et les logiciels de
l'époque ne le satisfaisaient pas.
Une base de données relationnelle est constituée
par :
· Un ensemble de domaine : un domaine
est un ensemble de valeurs atomiques.
On distingue :
o Les domaines prédéfinis :
chaines de caractères, entiers, réels booléens, date...
o Les domaines définis :
i' En extension,
c'est-à-dire en énumérant les valeurs. Par exemple :
couleur= {`'rouge `',»vert», `'bleu», `'jaune''}
i' En intension,
c'est-à-dire en donnant la formule que doit vérifier chaque
valeur, par exemple : Mois= {m| m ? Entier et 1=m=12}
· Un ensemble de relations : une
relation R est un sous-ensemble du produit cartésien de n domaines
D1,..., Dn : une relation est définie par son nom,
par son type et par son extension.
i' Le type d'une relation est une expression de
la forme :
rel(A1 :D1 ,...,An :Dn)
Où chaque Di est un domaine et chaque Ai est un
nom
d'attribut qui indique le role du domaine Di
dans la
relation. Par exemple :
rel (Nom : Chaine, Age : Entier, Marié :
Booléen)
est le type d'une relation construite sur les domaines
chaines, Entier et Booléen et dont le premeier représente un nom,
le second un age et le troisieme le fait d'etre marié ou non...
i' L'extension d'une relation de type rel(A1
:D1,...,An :Dn) est un ensemble de nuplets :
{A1=v1,...,An=vn} tels que v1 ? D1,...,vn ?
Dn.
L'extension d'une relation est variable au cours de la vie de
la base de données. Par exemple : {{Nom= 'Dupont'', Age=36,
Marié= Vrai} {Nom=''Durand'', Age=22, Marié= Faux}} est une
extension de la relation de type : rel (Nom : Chaine, Age : Entier,
Marié : Booléen)
i' Nous appelons schéma d'une
relation l'expression :
R (A1 :D1,..., An : Dn) qui
désigne une relation de nom R et de type rel(A1 :D1,...,An
:Dn). Par exemple : Personne (Nom : Chaine, Age : Entier,
Marié : Booléen)
Lorsque l'indication des domaines n'est pas requise, un
schéma de relation peut se réduire à l'expression :
R(A1,...,An )
i' Deux visions d'une relation
o Vision tabulaire : l'extension d'une
relation de schéma R(A1 :D1,...,An :Dn) peut etre
vue comme une table de nom R possédant n colonnes nommées
A1,...,An et dont chaque ligne représente un n-uplet de cette
extension. Par exemple :
Personne
|
Nom
|
Age
|
Marié
|
Dupont
|
36
|
Vrai
|
Durand
|
22
|
Faux
|
|
21
o Vision assertionnelle
A toute relation de schéma R(A1 :D1,...,An
:Dn) il est associé un prédicat R tel que l'assertion
R t est vraie si le n-uplet t appartient à l'extension
de R et fausse sinon. Par exemple, l'assertion :
Personne
{Nom :»Dupont», Age =36, Marié= Vrai} est
vraie.
? Un ensemble de contraintes
d'intégrité
o 1er cas : Relation du type père-fils :
contrainte d'intégrité fonctionnelle (CIF)
Ce cas intervient lorsque dans le modèle conceptuel de
données, nous retrouvons les couples (0,1) ou (1,1) d'une part et (0,n)
ou (1,n) d'autre part.
C'est-à-dire nous pouvons avoir les combinaisons
suivantes :
(0,1)
|
(0, n)
|
(0,1)
|
(1, n)
|
(1,1)
|
(0, n)
|
(1,1)
|
(1, n)
|
|
0,1 : aucune ou une fois
1,1 : au moins une fois au plus une fois
0, n : aucune ou plusieurs fois
1, n : au moins une fois, au plus plusieurs fois
Dans ce cas, la relation disparait mais sa sémantique
demeure, car l'objet qui a la cardinalité (0, n) ou (1, n) est
considéré comme père et cède sa clé primaire
à l'objet qui a la cardinalité (0,1) ou (1,1) qui à son
tour est considéré comme fils.
Etant donné que le fils possède une clé
primaire, celle qu'elle vient d'hériter du père est une
clé étrangère parce qu'elle est clé primaire dans
sa table respective. Si la relation était porteuse des
propriétés, elles migrent vers la table fils.
o 2ème cas : la cardinalité multiple :
Relation du type père-père (contrainte d'intégrité
multiple : CIM)
Ce cas intervient lorsqu'on a d'une part le couple (0, n) ou
(1, n), d'autre part (0, n) ou (1, n). C'est-à-dire la combinaison
ci-après :
|
(0, n)
|
(0, n)
|
|
(0, n)
|
(1, n)
|
|
(1, n)
|
(1, n)
|
(0, n) : aucune ou plusieurs fois (1, n) : une fois ou plusieurs
fois
Dans ce cas (premier cas), la relation devient une table de
lien et autre comme clé primaire la concaténation des clés
primaires de deux tables
22
qu'elle reliait. Si la relation était porteuse des
propriétés, celles-ci deviennent ses attributs (Mvibudulu &
Konkfie, 2012).
Exemple d'une base de données relationnel
Client
Numcli # Nomcli Catcli
Adresse
vélo
Code_vel # Marque Couleur
Date_achat Numcli #
Figure 6.1 Schéma d'un modèle
relationnel
b. Modèle Hiérarchique
Une base de données hiérarchique est une forme
de système de gestion de base de données qui lie des
enregistrements dans une structure arborescente de façon à ce que
chaque enregistrement n'ait qu'un seul possesseur (par exemple, une paire de
lunettes n'appartient qu'à une personne).
Les structures de données hiérarchiques ont
été largement utilisées dans les premiers systèmes
de gestion de base de données conçus pour la gestion des
données du programme Apollo de la NASA. Cependant, à cause de
leurs limitations internes, elles ne peuvent pas souvent être
utilisées pour décrire des structures existantes dans le monde
réel.
Les liens hiérarchiques entre les différents
types de données peuvent rendre très simple la réponse
à certaines question, mais très difficile la réponse
à d'autres formes de questions. Si le principe de relation « 1 vers
N » n'est pas respecté (par exemple, un malade peut avoir plusieurs
médecins et un médecin a, à priori, plusieurs
patients), alors la hiérarchie se transforme en un réseau
(Massimango, 2011).
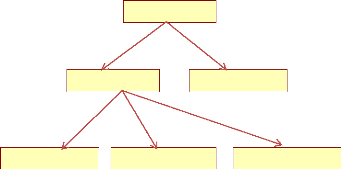
Figure 6.2 schéma d'un modèle
hiérarchique
23
c. Modèle Réseau
Le modèle réseau est en mesure de lever de
nombreuses difficultés du modèle hiérarchique grâce
à la possibilité d'établir des liaisons de type n-n,
les liens entre objets pouvant exister sans restriction. Pour retrouver une
donnée dans une telle modélisation, il faut connaitre le chemin
d'accès (les liens) ce qui rend les programmes dépendants de la
structure de données.
Ce modèle de base de données a
été inventé par C.W. Bachman. Pour son modèle, il
reçut en 1973 le prix Turing.
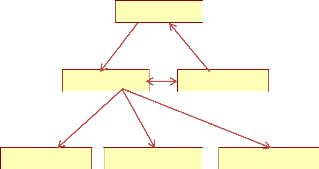
Figure 6.2 Schéma d'un modèle
Réseau
d. Modèle Objet
(SGBDO, Système de gestion de base
de données objet) : les données sont stockées sous
forme d'objets, c'est-à-dire de structures appelées classe
présentant des données membres. Les champs sont des
instances de ces classes.
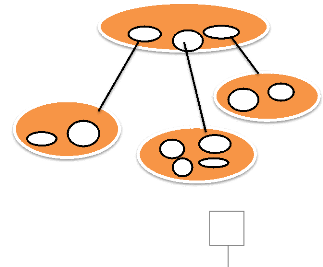
Figure 6.3 Schéma d'un modèle objet
24
La notion de bases de données objet ou
relationnel-objet est plus récente et encore an phase de recherche
et de développement. Elle sera très probablement ajoutée
au modèle relationnel (Massimango, 2011).
2.3. Internet
1. Historique de « Internet »
Dans les débuts des années 60, alors que le
communisme battait de l'aile, des chercheurs arrivent à créer un
réseau de communication qui puisse résister à une attaque
nucléaire, suite à la demande de l'US Air Force. Le concept de ce
réseau reposait sur un système décentralisé, ainsi
si jamais une ou plusieurs machines avait été détruites,
le réseau aurait continué à fonctionner. A l'époque
il n'était question que d'un réseau purement militaire, et ce
dernier était indestructible.
L'acte principal de la création d'internet revient
à Paul Baran, qui eut l'idée de créer, en 1962, un
réseau sous forme de grande toile. Il avait réalisé qu'un
système centralisé était vulnérable car la
destruction du noyau provoquait l'anéantissement des communications. Il
se proposa donc de mettre au point un réseau hybride d'architectures
étoilées et maillées dans lequel les données se
déplaceraient de façon dynamique, en « cherchant » le
chemin le moins encombré, et en 'patientant'' si toutes les
routes étaient encombrées.
Le projet Internet fut repris quelques années plus
tard, c'est-à-dire en 1969, sous le nom d'ARPANET
(Advanced Research Projects Agency Network).
Cela pour pouvoir relier quatre institutions américaines
suivantes :
? L'université de Californie à Santa Barbara ?
L'université d'Utah
? Le Stanford Institute
? L'université de Californie à Los Angeles
Et en 1972, vient le Courrier Electronique. Un nouveau mode de
communication mis au point par Ray Tomlinson. Il permettait l'échange
d'informations au sein du réseau, ainsi il était possible de
contacter un nombre impressionnant de personnes grâce à un seul
mail.
Ray Tomlinson mit au point me protocole TCP (Transmission
Control Protocol) permettant d'acheminer des données sur un
réseau en les fragmentant en petits paquets.
Lorsqu'en 1975 le réseau ARPANET (Advanced Research
Projects Agency Network). était quasiment au point, le
gouvernement américain décida de prendre son contrôle en le
confiant à une organisation : la United States Defense Communications
Agency,renommée par la suite
25
DISA('Defense Information Systems Agency ') traduit
en français par « Agence chargée des Systèmes
d'Informations à la Défense ».
2. Internet : « Le réseau des réseaux
»
Internet est un réseau informatique qui relie des
millions d'ordinateurs entre eux partout dans le monde. On l'appelle donc
« réseau des réseaux » vu le flux abondant des
connectés.
Un réseau est un ensemble de matériels
interconnectés. Il comprend des noeuds (ordinateurs, routeurs,...), que
des liens relient (lignes téléphones, câbles, fibres
optiques,...).
Donc Internet est composé de très nombreux
ordinateurs serveurs qui hébergent des fichiers d'information. Ces
fichiers leur sont envoyés par des ordinateurs clients connectés
par modem (appareil qui utilise une ligne téléphoniques pour
transmettre de l'information électronique) ou câble. Tous les
ordinateurs connectés à l'Internet peuvent accéder
à ces fichiers.
Nous pouvons dire que l'Internet se présente comme un
réseau mondial d'interconnexion des réseaux informatiques
grâce à l'utilisation d'un protocole de communication TCP/IP
(crée en 1983) commun à toutes les machines connectées au
réseau internet.
2.4. Principaux services offerts par Internet
Précédemment nous avons vu qu'internet
s'appuyait sur le protocole TCP/IP (Transport Control Protocol/Internet
Protocol) pour l'envoi des paquets sur le réseau. Il existe de nombreux
autres protocoles en usage sur ce réseau, en particulier les principaux
services offerts par Internet sont :
2.4.1. Web
a. L'historique du Web
Le world-wide web, en anglais : toile
d'araignée mondiale, arrive et se développe dans un contexte
particulièrement déterminant :
? Les technologies numériques gagnent tous les secteurs
d'activité, particulièrement les domaines de l'information
(téléphone, son, image,...), qui, de plus en plus sont
intégrées et multimédia. Même les mondes des
télécommunications et de l'informatique, longtemps basés
sur des logiques opposées, se rapprochent.
? L'informatique change d'échelle, sous de nombreux
aspects : architecture du réseau mondial, taille des données
traitées, nombre d'utilisateurs, catégories d'utilisateurs.
Le web, par ailleurs, est un système orienté
document à l'usage direct des utilisateurs. Sa facilité de
désignation des diverses ressources en a
26
fait l'outil par excellence de l'intégration sous un
même type d'interfaces de très nombreux services.
Le Word Wide Web (www) a été mis en place par
Tim-Berners Lee qui est considéré comme le père fondateur
du web. Au milieu des années 1990, Internet fait son apparition au grand
public en version 1.0 via des pages statiques codés en HTML. Il s'agit
de sites non interactifs principalement destinés à la recherche
d'informations : encyclopédies, etc.
Au début des années 2000, le web a
évolué et est devenu
dynamique. Il s'agit de sa version 1.5. Il est maintenant
possible de consulter du contenu dynamique en ligne, via des bases de
données : boutique en ligne, etc. (A noter que c'est aussi
l'avènement des start-up qui surfent sur la vague du web dynamique,
accessible à tous).
En 2004, Dale Dougherty utilise le terme « Web 2.0 »
qui sera vite repris par Tim O'Reailly, spécialiste du World Wide Web.
Le web 2.0 se caractérise par la prise de pouvoir des internautes sur
internet, grâce notamment aux réseaux sociaux. Plus qu'un
bouleversement technologique (PHP5, AJAX, etc.), l'apparition du web 2.0 prend
une véritable dimension sociologique puisqu'il replace le consommateur
la source de l'information.
Pour Joshua Porter, le web 2.0 « c'est le partage de
l'information, fondé sur des bases de données ouvertes qui
permettent à d'autres utilisateurs de les employer. »
L'internaute est donc enfin devenu le centre
d'intérêt d'internet.
Depuis quelques mois, on entend de plus en plus parler du Web
3.0, c'est-à-dire un web encore plus humain, encore plus intelligent
(citons notamment l'exemple devenu célèbre du frigo intelligent
qui fait les courses tout seul selon vos habitudes lorsqu'il est vide) (Baugas,
2009).
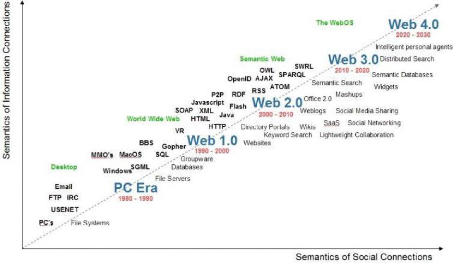
Source : Radar Networkds & Nova Spivack, 2007.
27
b. Philosophie du Web
Le web, la toile d'araignée en français ou le
World Wide Web(WWW) c'est-à-dire la toile d'araignée couvrant le
monde entier, est le plus récent des services offerts sur Internet,
c'est lui qui a contribué à son développement
récent et a provoqué un engouement auprès d'un grand
public.
Le Web repose sur quelques principes :
? L'universalité
> Lisibilité sur toutes les plateformes (Unix, Lunix,
Windows, Mac
Os...)
> Navigation hypertexte étendue. Un hypertexte est
un texte informatisé lu de manière non séquentielle.
Concrètement il contient des liens vers d'autres
documents. Les liens-commandes permettant d'activer un nouveau document
à partir d'un document source-peuvent être classés en
trois catégories :
- Internes à la page
- Vers une autre située sur le même site
- Vers une autre page située sur le Web, c'est dans ce
cas que l'on parle de « navigation hypertexte étendue
».
Il existe d'autres types de liens : comme ceux qui permettent
l'envoi d'un e-mail, ou encore ceux qui entrainent l'ouverture d'un fichier
PDF, et bien d'autres types de lien.
? Présentation de tous types de
documents
> Sous forme de pages
> Ou grâce au lancement de logiciels
permettant de lire (et travailler sur) les fichiers reçus
(Acrobat Reader, Word, Excel les logiciels graphiques, sons ou
vidéos,...).
? Simplicité
> La « Page » - qui,
contrairement à la feuille de papier, ne
possède ni largeur
fixe, ni hauteur fixe, mais s'adapte à la fenêtre - est un support
permettant :
- De stocker et éditer les informations
- De visualiser les éléments multimédia
(sons, images,
graphiques, séquence audio, séquence
vidéo)
- D'utiliser les éléments interactifs
- D'intégrer tous les systèmes préexistants
(e-mail, Telnet,
Gopher, News,...)
> Cette page est localisée de manière
unique et universelle grâce au système d'adressage
(URL)
28
? Gratuité des protocoles
? Le protocole http et le langage HTML
appartiennent au domaine publique, ils ne sont pas payant
(Un protocole est la description des formats de messages et
règles selon lesquelles deux ordinateurs échangent des
données).
c. les web services
Tout ordinateur ou système d'opération peut
supporter HTML (Hyper Text Mark-up Language), les serveurs Web ou les
navigateurs. Lorsqu'ils téléchargent un dossier sur le Web, ils
n'ont aucune idée avec quel type de système ils communiquent.
C'est la même chose pour les Web services. En fait, les Web services sont
des applications existantes, développés à l'aide de
langages tel que C# (se prononce C Sharp), Visual Basic, C++, Java ou autre, et
servent en quelque sorte de carte routière et de pont, pour que ces
programmes communiquent entre eux.
Les entreprises et les individus ont besoin d'outils
permettant de publier des liens vers leurs données et leurs applications
de la même manière qu'ils publient des liens vers leurs pages web.
C'est principalement ce à quoi servent les services. Les Web services
définissent non seulement les données mais aussi comment traiter
ces données et les relier à l'interne et à l'externe d'une
application logicielle sous-jacente. Grace à Internet et au Web services
nous pouvons entrevoir un nouveau concept qui ferait du réseau Internet
un système d'opération.
Contrairement au modèle client/serveur les Web services
ne fournissent pas de GUI (Graphic User Interface c.-à-d. une interface
graphique pour l'utilisateur). Ils seront surtout utilisés afin
d'envoyer des données et encore mieux des portions de programmes
destinées à être lues par des machines. Cependant, les
programmes peuvent tout de même développer une interface graphique
pour l'utilisateur, auxquels ils pourront ajouter une panoplie de Web services
afin de personnaliser une page Web ou pour offrir une fonctionnalité
spécifique à des utilisateurs. Les utilisateurs peuvent aussi
lire le fichier Web services manuellement à l'aide d'un éditeur
de texte car le fichier est écrit avec des phrases anglaises et
caractères alphanumériques. Ce qui est l'une des
particularités du protocole XML qui le sous-tend.
Le concept des web services est le nouveau cliché
à la mode émanant du monde informatique. Il se répand
depuis l'an 2000. L'expression Web services peut signifier plusieurs choses
soit :
1. les Web services sont des services technologiques Web
offerts à la communauté internaute commerciale et privée
tels que les services d'hébergement de sites Web ou des services de
recherche tels que Google ou encore les ASP (Application Service
Provider). Cette définition large et n'ayant
29
pas rapport avec le sujet de ce texte est pourtant la
première image que se fait le néophyte lorsque l'on mentionne le
terme Web services. Cet état de fait
ajoute à la confusion de celui qui cherche de
l'information (particulièrement en
français) sur le web services.
2. Des portions de programmes informatiques (services) qui
sont
disponible et accessibles à tous via les infrastructures
et les protocoles Web
standard (il s'agit du produit de l'infrastructure Web
services). Par exemple, cela pourrait être une application pouvant
fournir :
· Une autorisation de crédit,
· Le calcul de taxes,
· La conversion des devises,
· La facturation,
· Des nouvelles économiques,
· La météo,
· Des mécanismes de vérification de prix lors
d'enchères,
· Des mécanismes d'encryptions,
· Un service postal,
· La validation d'adresse,
· Tout processus d'affaires imaginables.
Pour une liste exhaustive de Web services déjà
disponibles, vous pouvez visiter le site X Method, de Microsoft avec sa
plate-forme.Net ou
encore ceux de
Webservicelist.com. ? L'avis
des spécialistes
Il est difficile de donner une définition stricte de
ce que sont les Web services. Les web services ne sont ni des programmes, ni
des applications, ni des langages de programmation (java,C++) ni des
systèmes d'exploitation (OS/2,Unix,Windows). Pourtant ils interagissent
avec chacun de ces éléments. Les Web services et le protocole qui
y sont associés sont en mouvance constante et n'en sont encore
qu'à leurs premières élaborations et
implémentations par les différents acteurs de la scène
informatique et les entreprises. De plus, malgré l'intérêt
croissant pour le phénomène, il n'existe pas encore de
définition universelle de ce que sont les Web services. Bien que tous
les joueurs majeurs de l'industrie informatique soient partis prenant de cette
technologie, ils se confrontent sur le terrain de la mise en marché et
des organismes de standardisations. Cette confrontation marketing est
l'explication derrière l'absence d'une définition unanime de
l'industrie. Cependant, il ne faut pas présumer que l'absence de
définition commune soit l'indice d'absence d'une technologie normative
(Leblanc, 2002).
d. Protocoles, langages et logiciels
Le web est un système hypermédia,
fonctionnant en mode client/serveur sur internet.
30
> Le client émet
une requête vers le serveur
> Le serveur
reçoit la demande et répond à la requête en
expédiant des fichiers informatiques correspondant à une page
(textes et éléments multimédia), puis la communication est
coupée.
e. Le logiciel client du web
C'est le browser en anglais, navigateur en français
(ou fureteur pour les québécois).
Il exploite les ressources des serveurs et permet leur
recherche. Internet Explorer, Mozilla Firefox et Netscape Navigator
sont des navigateurs (clients est plus exact) web, il en existe
d'autres...
f. L'adresse des pages visitées
La localisation des sites sur internet comme celle des
adresses postales conventionnelles que nous utilisons -nom, adresse, ville,
code, postal, pays-doit être sans équivoque. Les navigateurs
utilisent l'adresse URL (Uniform Ressource Locator), qui
permet de localiser l'endroit où se trouve une ressource (un
document).
Elle comprend les informations suivantes :
> Accès par un type de protocole
(http pour le web, parfois http, si
la page est « sécurisé »), suivi des
signes suivants://
> Le nom du serveur qui gère le site, suivi
de:/
> Le chemin d'accès au fichier.
? Exemple
http://www.hbc.com/utilisteur/administrateur.php,où:
> http est le protocole utilisé pour
recevoir cette page
> www.hbc.com:l'adresse du serveur
où elle se trouve > Utilisateur : le
répertoire
> Administrateur. PHP : le
nom du fichier
g. Le protocole http
HyperText
Transmission Protocole est le protocole
grâce auquel les documents peuvent être échangés
entre le client et el serveur.
h. Le langage HTML
HyperText
Markup Langage un langage qui permet de
décrire des documents hypertextes au moyen de marqueurs, ces derniers
sont les commandes de base des documents HTML. Le HTML est défini par
les recommandations du W3C, en français ou en anglais. Mais il est
à noter qu'il existe d'autres langages, le cas de PHP, qui permettent de
réaliser des sites
31
plus dynamiques qu'avec le HTML. Nous en reparlerons dans
plus loin dans un chapitre lui consacré.
Donc, le WWW relie des serveurs http qui envoient des pages
HTML à des postes munis d'un navigateur (Logiciel client).
i. La recherche d'informations
Si vous vous connecter à Internet et ouvrez votre
logiciel de navigation, celui-ci se connecte automatiquement à un site
et affiche la page.
Vous pouvez faire défiler la page affichée,
lire les informations et utiliser les liens hypertextes pour accéder
à une autre page.
Si vous souhaitez vous connecter à un site dont vous
connaissez l'adresse, il vous suffit de saisir directement celle-ci dans la
zone Adresse(Location) de votre navigateur et valider à l'aide de la
touche Entrée (Enter en anglais). Le navigateur recherche alors le site,
s'y connecte et affiche (télécharge) les données contenues
sur cette page.
Pour localiser les ressources susceptibles de vous
intéresser (dont vous ignorez l'adresse), vous pouvez utiliser les
systèmes de recherche d'informations.
Ils sont constitués de deux grands types de sites web ou
portails :
? Les moteurs de recherche, qui indexent le
contenu de différentes ressources Internet. L'internaute qui recherche
de l'information peut accéder à celle-ci, grâce à
des mots clés ; par exemple : Google, AltaVista ou encore Voila.fr ;
? Les annuaires, qui présentent un
inventaire, spécialiser dans un domaine ou non, dans lequel les sites
référencés sont classés par catégorie et
sont accessibles au moyen de liens hypertextes ; par exemple : Yahoo ! le guide
de voilà ou encore Lycos.
2.4.2. E-mail (Electronic-mail)
Service très utilisé, il permet
l'échange de messages classiques et la réception
régulière d'informations après inscription à un
thème (liste de diffusion). Chaque routeur consulte l'annuaire DNS
(Domain Name Server) pour acheminer le message.
a. Principes
Protocole SMTP :
Les messages sont au format SMTP (Simple
Mail Transfer Protocol) - (RFC 821/822) en ASCII 7 bits. L'en-tête
indique l'adresse réceptrice (To :)
32
l'émetteur (From :), la date, les
destinataires en copie (cc : carbon copy ou
bcc : blind carbon copy)...
Il n'y a ni confidentialité, ni authentification, ni
accusé de réception ; SMTP assure la communication entre
serveurs.
SMTP utilise TCP (port 25). La casse des adresses est
ignorée (minuscules ou majuscules). Le message à transmettre est
confié à une mémoire tampon (spool) puis le serveur de
messagerie tente d'établir une connexion TCP avec le serveur SMTP du
destinataire. Si le destinataire est disponible, que l'expéditeur est
accepté et que l'adresse destinataire est valide : la connexion est
établie et le transfert a lieu (texte ASCII, la fin du message est
indiquée par une ligne ne contenant qu'un point).
Si la connexion ne peut avoir lieu ou est rompue, le serveur
réessaye plus tard. Après un délai important, en cas
d'échecs répétés, le message est retourné
à l'expéditeur avec la cause de l'erreur.
Par cette méthode, un message ne peut se perdre : le
message est délivré ou l'expéditeur est prévenu de
d'échec.
Par mesure de sécurité et afin de ne pas
être un relais de « spam », la plupart des FAI n'autorisent
l'envoi de courrier que par une connexion directe sur leur site (connexion
authentifiée), la lecture reste souvent possible de n'importe
où.
Outils
Courrier via le web :
Ce type d'accès est surtout utilisé par les
fournisseurs de boites gratuites mais tend à se
généraliser. Les serveurs peuvent ainsi diffuser quelques
messages publicitaires pour se financer. L'usage est simple et l'utilisateur
n'a pas besoin de configurer un logiciel de messagerie, il peut aussi consulter
et surtout émettre son courrier de n'importe où.
www.mailclub.net/pop
offre un service gratuit de consultation via le web d'un serveur de courrier
n'acceptant que le protocole POP (Post Office Protocol). Un
utilisateur itinérant pourra alors consulter son courrier sans
être obligé de configurer un logiciel de messagerie sur le poste
de consultation, il peut aussi utiliser un logiciel de mail « disquette
» comme MailWarrior.
Services, tests :
Quelques serveurs sur internet offrent la possibilité
de récupérer des fichiers (ftp différé) ou des
pages web par e-mail (certains Fournisseurs d'Accès Internet à
leurs abonnés, les serveurs gratuits de ce type de services changent
souvent d'endroit suite aux abus...).
33
On pourra tester ses mails (vérifications des
informations reçues...) par l'envoi sur des serveurs « ECHO »
:echo@
univ-lille1.fr
ou sur
ping@oleane.net.
Le site
www.arobase.org
fournit des enregistrements très développés sur le
courrier électronique.
Les conditions d'accès à
l'Internet
Pour accéder à l'internet, il faut disposer
:
? D'un ordinateur. Si celui-ci est
récent, il sera donc sans doute doté d'un modem et d'une suite de
logiciels adaptés à l'usage d'internet. Sinon il est tout de
même possible de l'utiliser pour accéder à internet, mais
ce sera probablement un peu plus compliqué et dans la pratique
l'affichage des pages « multimédia » ne sera pas trop rapide
;
? D'un modem, c'est un dispositif
électronique (boitier externe ou carte insérée dans
l'unité centrale) permettant à deux ordinateurs de communiquer
entre eux par l'intermédiaire d'une ligne téléphonique ou
du câble.
Comme le signal analogique- porteur du flux de
données, qui arrive par les lignes téléphoniques ou
câble- ne peut être directement interprété par un
ordinateur, il doit être « modulé » en sortie ou «
démodulé » en entrée, grâce à un modem
afin de le transformer en un langage compréhensible par l'ordinateur.
Il existe différents types de modem, plus ou moins
rapides. C'est essentiellement de la vitesse du modem que va dépendre la
vitesse de la connexion à l'internet.
? De logiciels spécifiques, afin de
vous connecter à l'internet et d'utiliser ses services :
? Un navigateur web, qui vous permet de lire
cette page et de « surfer sur le web ». le navigateur le plus
utilisé est « Internet Explorer » de Microsoft qui
succède à Netscape Navigator (ou Communicator), on peut aussi
citer Mozilla Firefox, Google chrome, opéra, etc. ;
? Un logiciel de messagerie électronique,
destiné à vous permettre d'expédier et recevoir
des E-mail (mails ou courriers électroniques ou encore courriels) ;
? D'un compte auprès d'un Fournisseur
d'Accès Internet (F.A.I).
? Différence entre Internet et web
Dans ce paragraphe nous tentons d'apporter une
différence entre le concept « Internet » et le concept «
web » pour fixer l'opinion et éviter d'entretenir la confusion
entre ces deux concepts.
Avant de passer à cette différence proprement
dite, nous nous proposons de définir le « le site web » et
« internet »
34
? Site web :
Un site Web est un ensemble de pages web et
d'éventuelles autres ressources liées en un ensemble
cohérent, pouvant être consulté avec un navigateur à
une adresse donnée. Un site est publié (entendons par là
qu'il est mis en ligne sur un serveur web) par un propriétaire, à
une adresse Web. Les informations contenues dans ces pages web sont
formatées : un texte en UTF-8 ou ASCII, une image en GIF, JPEG ou PNG,
... Lorsque ces données sont stockées dans un fichier
(unité informationnelle stockée), on parle de format de documents
(Tahé Serge, introduction à la programmation web-PHP, novembre
2002, p. 6-7) : PDF, HTML, XHTML, CSS, JavaScript, ....
? Internet :
Internet est un réseau d'ordinateurs
interconnectés répartis sur la planète ou plus exactement
un réseau de réseaux.
Du fait qu'il relie une multitude de réseaux
régionaux, gouvernementaux et commerciaux, Internet est le plus grand
réseau informatique de la planète. Tous ces réseaux
discutent entre eux par le biais du même protocole de communication
appelé TCP/IP (Transmission Control Protocol/ Internet Protocol).
En résumé, Le web, c'est une toute petite
partie d'internet.
Internet n'est rien d'autre qu'un réseau de transport
de données. Il permet de transporter un paquet de données d'un
ordinateur A à un
ordinateur B, rien d'autre.
Le web est construit au-dessus
d'internet.
Il met en oeuvre plein de choses (protocole HTTP, formats
HTML, CSS, JPEG...).
Le web utilise internet pour transporter les
données.
Il y a plein d'autres applications que le web qui sont
construites au-dessus d'internet:
- le mail (protocoles SMTP, POP3...)
- les newsgroups (Usenet, protocole NNTP)
- le chat (protocoles Jabber, AIM...)
- la vidéo (protocoles Real, etc.)
- le
système DNS (pour donner des noms aux machines) - les VPN (pour relier
des réseaux informatique privés entre eux)
- et des centaines d'autres choses.
Bref, le web c'est la partie la plus visible et la plus
connue d'internet, mais c'est loin d'être la plus importante.
35
2.4.3. Le transfert de fichier (FTP)
Le cas le plus simple d'accès à des fichiers
est l'accès direct aux fichiers locaux via le système
d'exploitation.
L'URL, est, dans ce cas [file = fichier] :
file:///chemin
Une des toutes premières utilisations des
réseaux informatique (la première ?) a été
l'échange de documents.
Plusieurs services ont existé et continuent d'exister.
Le plus développé sur Internet et dans le monde Unix est le
service FTP : File Transfer Protocole, protocole de transfert de
fichiers [RFC0959]. Sa première version publiée date de 1970.
Celui-ci permet de travailler selon deux types de sessions :
les
sessions identifiées et les sessions anonymes. Une
session identifiée demande à l'utilisateur un nom de compte
(d'accès) et un mot de passe (code d'identification associé).
L'utilisateur a alors accès à un ensemble de fichiers
spécifique : personnel ou associé à un groupe de travail.
Une session anonyme correspond à un nom de compte blanc : ftp ou
anonymous. Il est d'usage de s'identifier en indiquant dans le champ "mot de
passe" son adresse de courrier électronique.
Les URI de sessions identifiées ont la forme
générale suivante :
ftp://compte@hôte/chemin
Le mot de passe doit alors (généralement)
être fourni par l'utilisateur. Dans certains cas très
précis, quand cela ne présente pas de problème de
sécurité, l'URL peut préciser le mot de passe
(conformément à la règle générale). Quand le
serveur n'est pas installé sur le port standard, il est également
possible de l'indiquer dans l'URL.
Finalement, le cas le plus général d'URL est
[RFC1738] :
ftp://compte:mot-de-passe@hôte:port/chemin
Le service FTP a été utilisé, quasiment
dès le début, pour la publication de fichiers et documents,
parfois même pour la communication, ne serait-ce que parce que le
courrier électronique ne permettait pas l'envoi efficace de
données volumineuses. Le fil en aiguille un système très
étendu de bases documentaires et logicielles s'est constitué sur
le service FTP anonyme, sorte d'ancêtre du web.
Pour limiter le trafic sur le réseau, les grands sites
de FTP anonymes ont été répliqués sur des sites
miroirs se mettant à jour régulièrement sur leurs
originaux. Ce réseau est toujours en place et continue de se
développer.
Parmi ces miroirs, signalons la présence forte des
universités, d'une part, et de centres de soutien subventionnés
par la société Sun Microsystems [
http://www.sun.com/], les sunsites [
http://www.sun.com/sunsite/].
Signalons aussi la longue absence de la France...
Les nombreux sites originaux et les innombrables miroirs ont
tôt fait des services FTP une jungle où il était difficile
de se repérer sans aide. Pour cette raison un service d'annuaire
a été mis en place, c'est à dire un service
référençant toutes les ressources disponibles et l'adresse
où les récupérer.
36
Cet annuaire, appelé Archie, est aujourd'hui
obsolète et remplacé par des services d'annuaire sur le web, par
exemple la rubrique « serveur FTP » de Lycos [
http://www.lycos.fr] (demander la
recherche avancée).
Note : le schéma file prévoit de pouvoir
spécifier un nom de machine :
file://hôte/chemin.
Toutefois, cette méthode est à proscrire parce qu'elle ne
précise pas quel type de transfert de fichier doit être
utilisé. En général, les navigateurs interprètent
file comme ftp dans ce cas.
2.4.4. Les pages web et les applications en ligne
Actuellement, on rencontre, pour faire court, trois grands
types de ressources sur le web :
· Les documents hypermedias : pages web, pages
WAP (pour téléphones mobiles et assistants personnels), PDF
hypertexte, « animations » et « images » Flash ou SVG...
· Les autres documents publiés : images fixes ou
animées, sons, PDF à imprimer, documents de traitements de
textes... sans lien incorporé permettant la navigation.
· Les pages produites dynamiquement servant d'interface
(sortie et/ou entrée) à une application sous-jacente.
Nous reviendrons ultérieurement en plus grand
détail sur ce que sont précisément ces
éléments. Ils sont supposés connus dans leur utilisation
courante.
2.5. Architecture client-serveur
a. Présentation de l'architecture
client-serveur
Il est vrai qu'aujourd'hui, le réseau est
considéré comme une valeur ajoutée en informatique. De ce
fait, l'architecture Client-serveur est appliquée dans un environnement
multiutilisateurs (réseau) c'est-à-dire on a d'une part des
machines clientes, d'autre part un serveur (une machine plus puissante que les
machines clientes).
Les machines clientes sollicitent des services auprès
du serveur qui leur sert à temps opportun.
Dans l'architecture Client-serveur, il existe trois
tâches importantes notamment :
? La présentation de l'application (user interface) ;
? La couche métier ou logique applicative qui s'occupe
du traitement de l'information ;
? L'accès et le stockage de données : Data
Access
37
Ces différentes tâches sont d'usage aux
architectures : deux tiers, trois tiers, n tiers. Ainsi, nous présentons
dans les lignes qui suivent les avantages, les inconvénients et les
schémas desdites architectures.
a.1. Avantages de l'architecture
client/serveur
· L'administration se fait au niveau du serveur ;
· La possibilité d'étendre ou de diminuer
les machines clientes sans pour autant perturber le fonctionnement du
réseau ;
· La centralisation de données
c'est-à-dire toutes les données sont exploitées à
partir du serveur. Cela permet d'éviter la redondance ;
· Une meilleure sécurité par le fait que
les autorisations sont données à partir du serveur.
a.2. Inconvénients de l'architecture
client/serveur
L'architecture client/serveur a tout de même quelques
lacunes parmi lesquelles :
· Coût élevé du serveur ;
· La centralisation des données autour du serveur
fait à ce qu'il soit un maillon faible du réseau. En cas de
pannes avec le système RAID.
a.3. Fonctionnement d'un système
client/serveur Un système client/serveur fonctionne selon le
schéma suivant :
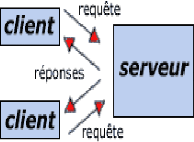
Source : MAMPUYA P., cour d'architecture
réseaux, UPC, Kinshasa, Note de cours L1 Administration des Affaires
2010-2011, p.35
a.4. Présentation de l'architecture
client-serveur à 3 niveaux
(architecture 3/3)
Si l'architecture à deux niveaux est constituée
des clients et du serveur dont le premier tiers représente les clients
et le deuxième tiers le serveur, dans l'architecture à trois
niveaux, il y a ajout d'un niveau. D'où, nous avons pour le
modèle à trois niveaux :
38
|
?
|
Le premier tiers
|
: les clients
|
|
?
|
Le deuxième tiers
|
: le serveur d'application
|
|
?
|
Le troisième tiers
|
: le serveur des bases de données
|
Elle est représentée comme suit :
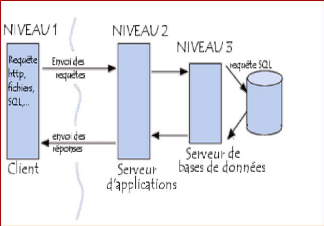
Source : MVIBUDULU KALUYIT J.A. & KONKFIE IPEPE L.,
Op.cit., p.20
2.6. Examination de la littérature
Les nouvelles technologies d'information gagnent tous les
secteurs d'activité, particulièrement les domaines de gestion,
qui, trouve de plus en
plus un moyen d'expansion et de vendre l'image d'une
organisation grâce aux fonctionnalités intégrées
qu'offrent ces technologies nouvelles.
Notre présente étude a fait l'objet des recherches
antérieures par
différents étudiants et ingénieurs en
informatique en vue de trouver des solutions optimales pour l'organisation.
C'est par curiosité scientifique que nous avons recouru
à ces
différentes études afin d'avoir une idée
en la matière et en tirer profit pour l'heureux aboutissement de notre
travail.
Nous nous sommes intéressés aux études
menées par différents étudiants :
1. Baugas Alexis de l'école supérieure de
Montpellier en France, laquelle étude consistait à en quoi la
gestion de l'E-réputation est-elle devenue un facteur de réussite
primordiale pour nos entreprises ? entendons par E-réputation « la
réputation par voie électronique ».
39
D'une manière concrète il visait les objectifs
ci-après :
- optimiser son référencement naturel ;
- créer un contenu
- attirer les internautes sur sa page ;
- convertir ses visiteurs en fans ;
- transformer ses fans en ambassadeurs ;
- transformer les visites en achats.
Cette étude met en exergue le E-commerce ou les sites
web
marchands, en ce sens que les détenteurs de ses sites
doivent rendre toute
activité que peut faire l'internaute puisse lu
être bénéfique.
Pour arriver à ses fins, il faut une conception qui
attire et un contenu
qui captive, c'est pourquoi l'usage des différents
langages de programmation
lui ont été nécessaire, à savoir
:
- PHP pour le traitement c'est-à-dire rendre le site
dynamique pour
interagir avec l'utilisateur ;
- Le html pour la construction des pages et la gestion de
leur
contenu ;
- Le JavaScript et le css pour le design et les animations
;
- Une base de données avec MySQL pour y stockées
différentes
informations et données.
2. Damien FURY de l'Université de FRANCHE COMPTE qui
a
travaillé sur la gestion éditoriale d'un site
web en 2005.
Il a orienté son étude sur les points essentiels
de la gestion de
contenu en ligne en décrivant les mécanismes
d'une stratégie éditoriale
efficace et aborde les étapes clés assurant un
contenu adapté aux
internautes.
Il détaille ensuite les outils nécessaires au
processus de gestion
éditoriale et les différentes
fonctionnalités qu'ils doivent remplir.
Il a au regard du tableau ci-dessous centrée son
étude sur le
contenu du site web et des traitements qui s'y font.
France : les opérations les plus courantes sur
le Web
(Plusieurs réponses possibles, en %)
Type d'opérations Déc 2003
Recherche d'informations liées à
l'actualité 67 %
Opérations ou consultations bancaires
50 %
Messagerie instantanée 33 %
Téléchargement de logiciels 31
%
Echange de photos avec d'autres internautes
30 %
Ecouter la radio en ligne 28 %
Regarder des bandes annonces de cinéma
22 %
Participer à un Chat 21%
Téléchargement de musique 21
%
Participer à un forum 18 %
Télécharger des vidéos
12 %
Téléchager des jeux en ligne 12
%
Consulter ou télécharger des
vidéos 11 %
Jeux en ligne ou en réseaux 10 %
Faire évoluer son site perso 6 %
Télécharger ou regarder des
émissions de TV 6 %
Suivre un programme de formation 4 %
Source : Ipsos, enquête profiling* Mis
à jour le 16/01/2004
40
Sur ce, il a proposé quelques outils de gestion
éditoriale de site web ou CMS (Content Management System) :
|
CMS
|
Caractéristiques
|
commentaires
|
|
phpNuke /
|
- PHP & MySQL
|
phpNuke a été l'un des
|
|
postNuke
|
- Articles, catégories, commentaires, sondages
|
premiers
CMS en PHP, et a été
|
|
- Extensible (système de
|
adopté par
|
|
modules et de blocs)
|
de nombreux sites. Réputé
|
|
- Moteur de recherche
|
pour son
manque de flexibilité, il est
remplacé peu à peu par
postNuke
|
|
SPIP
|
- PHP3 & MySQL
|
L'un des premiers CMS
|
|
- Articles, brèves, rubriques, forums de discussion,
pétitions, statistiques
|
français qui
permet de gérer facilement un site
|
|
- Multilinguisme
|
complet
|
|
- Interface modulable
|
|
|
- Extensible (système de boucles)
|
|
|
- Moteur de recherche
|
|
|
- Système de correction
|
|
|
Typographique
|
|
3. Massimango de l'Université de Kinshasa a
orienté son étude sur
l'implémentation d'un site web de vote
électronique en 2012.
Une méthode de plus en plus croissante et sensible en
raison de la
sécurité et la fiabilité des traitements
qu'elle doit effectuer doivent faire l'objet
vérification approfondie.
Son application consiste à créer un espace qui
permette aux
utilisateurs (électeurs) :
- De s'authentifier ;
- D'accéder aux listes des candidats ;
- De visualiser le projet de chaque candidat ;
- De voter ;
- De consulter les résultats
Pour y parvenir il a fait recours aux outils et langages
suivants :
- WAMP SERVER : un logiciel qui permet de travailler en
mode
local, il est composé d'un serveur APACHE, d'un
interpréteur PHP et d'une
base de données MySQL
- PHP comme langage de programmation et HTML
Ces différentes études nous ont données
un aperçu sur le domaine
qui concerne notre étude, à savoir
l'implémentation d'une application web pour
la gestion des courriers.
41
42
DEUXIEME PARTIE : ANALYSE
PREALABLE ET CONCEPTION
CHAPITRE 3 : ANALYSE PREALABLE
Section 1. Présentation de HBC SPRL
Cette étape présente le cadre de l'étude,
analyse les points forts et faibles de son fonctionnement et propose les
solutions correctives.
L'analyse de fonctionnement du système consiste
à évaluer objectivement le niveau d'adéquation des
objectifs atteints à la planification et de tirer les
conséquences qui s'imposent.
a. Présentation
Holding Business & Communication (HBC) SPRL est une
Société Privée à Responsabilité
Limitée constituée conformément au droit congolais.
- NRC 54297,
- N° d'Identification Nationale 01-9-N 56149L
- Siège social :
835, Boulevard du 30 juin, Concession Mwana-Nteba
2ème Etage Immeuble Mwana-Nteba(en face de Beltexco)
Kinshasa/Gombe
HBC SPRL fournit une gamme variée des prestations en
faveur de ses partenaires. En effet, HBC fournit directement des prestations
à ses partenaires ou assure, à la requête de ses
partenaires, la sous-traitance de certaines prestations faisant partie de leurs
fonctions naturelles (recouvrement, distribution des courriers...).
b. Objectif
L'objectif de HBC SPRL consiste à rendre disponible son
savoir-faire au profit de sa clientèle variée aussi bien du
secteur public que du secteur privé par un travail en synergie entre
d'une part, la supervision assurée par la Direction
Générale et, d'autre part, les différents points focaux en
charge des projets spécifiques.
Section 2. Analyse de l'existant
Le double visé de cette étude est de :
1. Prendre connaissance du domaine ;
2. Recenser l'ensemble des objectifs que l'entreprise a
assigné au domaine étudié.
Pour aborder de façon pertinente cette étude,
les points ci-après sont abordés :
L'étude des postes de travail, l'étude des
documents utilisés, l'étude des moyens de traitement et le
schéma de circulation des informations.
43
2.1. Analyse de la structure
Département de
service courrier
Superviseur principal
Sup. ajdt.
Agents
Source HBC sprl
Sup. ajdt.
Agents
Sup. ajdt.
Agents
a. Analyse des des postes
Dans cette phase d'étude de poste nous parlerons surtout
des activités ou tâches de chaque poste.
Il faut noter qu'une tâche est un ensemble
d'opération dont la réalisation se fait de façon non
interrompue dans un poste.
L'étude des postes remonte à l'étude du
système tout entier, en ce qui nous concerne, nous étudierons le
département du service courrier.
Voici la répartition des tâches du système
existant :
FICHE DESCRIPTIVE DU POSTE N°1
Nom du projet : conception et implémentation d'un
logiciel de gestion Domaine d'application : Gestion de courriers en ligne
Poste : Coordonnateur ou superviseur principal
Auteur : Tshibala Tshitoko Emmanuel Critères
:
|
- au moins une licence en économie ou diplôme
similaire
- Avoir une expérience de 2ans dans la coordination de
projet ou de team leader
- avoir en maitrise en français t la connaissance de
l'anglais est un atout - avoir une connaissance de la ville de Kinshasa et du
pays
Job description :
- Superviser les activités au sein du service courrier
- Elaborer un plan de distribution selon la segmentation de la
ville ou du pays
|
44
FICHE DESCRIPTIVE DU POSTE N°2
Nom du projet : conception et implémentation d'un logiciel
de gestion Domaine d'application : Gestion de courriers en ligne
Poste : Superviseur adjoint
Auteur : Tshibala Tshitoko Emmanuel
Critères :
- au moins un diplôme de licence en gestion
- une expérience dans ce domaine est un atout
- connaissance du français et connaissance de la ville
Job description :
- Superviser les activités au sein du sous
département
- Se faire rendre compte des déroulements des services au
sein de son sous
département
département par les agents de dispatch
- Rendre compte au superviseur principal des déroulements
des services
- veiller au bon fonctionnement du système par rapport
à ses objectifs.
FICHE DESCRIPTIVE DU POSTE N°3
|
Nom du projet : conception et implémentation d'un logiciel
de gestion Domaine d'application : Gestion de courriers en ligne
Poste : Agent chargé du dispatching Auteur : Tshibala
Tshitoko Emmanuel
|
Critères :
- au moins un diplôme d'Etat
- La connaissance de la ville de Kinshasa
- Pas d'expérience requise
- Agen compris entre 23 et 30 ans
Job description :
- Effectuer les dispatching des courrier partant de la
segmentation de la ville ou du pays
- rendre compte des déroulements
des services au superviseur adjoint
- veiller au bon fonctionnement du système par rapport
à ses objectifs.
2.2. Analyse des documents
Dans cette section nous allons pouvoir analyser les
différents documents qui entre dans la gestion quotidienne des courriers
au sein de l'entreprise HBC.
L'étude des documents consiste à recenser et
présenter les documents liés à l'application
indiquée.
En ce qui nous concerne, nous avons recensé les
documents suivants :
1. Bordereau d'expédition
2. Fiche de dispatch
3. Relevés de clients destinataires
45
Il est important de rappeler que dans cette partie, nous
n'avons traité que les documents qui sont nécessaires pour la
gestion des courriers.
? Description des documents
|
N°
|
Nom du document
|
But du document
|
|
01
|
Bordereau d'expédition
|
Permet de relever les détails du
courrier, notamment, pour réception courrier et
récupération accusé de réception du partenaire
|
|
02
|
Fiche de dispatch
|
Permet de certifier le dépôt du
courrier
|
|
03
|
Relevés des clients destinataires
|
Reprend toutes informations
relatives au courrier concerné
|
1. Bordereau d'expédition
CODE RUBRIQUE
|
DESIGNATION
|
CARACTERE
|
Nomcli
|
Nom du client
|
AN
|
Facture N°
|
Numéro du courrier
|
N
|
Période facturée
|
Période facturé
|
AN
|
Soldeavntfact
|
Solde avant facturation
|
N
|
Montant fact
|
Montant facturé
|
N
|
Montant total du
|
Montant total du
|
N
|
Adresse
|
Adresse client
|
AN
|
Nom agent
|
Nom agent de dispatch
|
AN
|
Heure de dépôt
|
Heure de dépôt du courrier
|
AN
|
Date
|
Date de dépôt du courrier
|
AN
|
Date
|
par l'agent
|
|
|
Date de réception courrier
|
AN
|
Nom
|
par le client
|
|
|
Nom de la personne
|
AN
|
Date
|
réceptionnée (client)
|
|
Date
|
Date d'accusé de
réception par le partenaire
|
AN
|
Nom
|
Nom de la personne qui accuse réception pour compte
partenaire
|
AN
|
|
2. Fiche de dispatch
|
CODE RUBRIQUE
|
DESIGNATION
|
CARACTERE
|
|
Nom du client destinataire Signature
Numero
|
Nom du client destinataire Signature de l'agent de dispatch
Numéro de la fiche
|
AN -
N
|
46
3. Relevé des clients destinataires
|
CODE RUBRIQUE
|
DESIGNATION
|
CARACTERE
|
|
Compte
|
Compte client
|
AN
|
|
Nom
|
Nom du client
|
AN
|
|
Numéro
|
Numéro du courrier
|
N
|
|
Période
|
Période facturée
|
AN
|
|
Montant du
|
Montant du
|
N
|
|
Date
|
Date de retrait du courrier
|
AN
|
|
Heure
|
Heure de retrait du courrier
|
AN
|
2.3. Analyse des moyens de traitement
Dans cette section nous allons passer en revue les
différents moyens de traitements qui sont à la disposition de HBC
pour lui permettre d'atteindre ses objectifs et satisfaire aux besoins ses
partenaires.
Pour traiter l'information, le département de la
médecine interne dispose de trois types de moyens.
Il s'agit des moyens matériels et des moyens humains.
2.3.1. Moyens matériels
Nous pouvons les catégorisés en deux :
? Fournir les accessoires de bureau
? Matériels spéciaux aux professionnels
1° Fournitures accessoires de bureau
Dans cette catégorie, les agents du service courrier
emploient
comme fourniture :
? Papiers,Stylo
? Agrafeuses,Machine à calculer
2° Matériels
Nous avons recensés les matériels suivants :
|
N°
|
Nature
|
Marque
|
Processeur
|
RAM
|
autres
|
|
1
|
4 Ordinateurs
portables et 2 desktops
|
Asus
Dell
Toshiba
Toshiba
|
Intel(R) Pentium(R)
CPUB950 @2.10GHz
2.10GHz
Pentium ® Dual-core CPU E5200@2.50GHz2.49Ghz
AMD E-300 APU with Radeon(tm) HD Graphics 1.30 GHz
AMD E-300 APU with Radeon(tm) HD Graphics 1.30 GHz
|
2.00 Go
3.00Go
4.00 Go(3.60 utilisable)
4.00 Go
|
Capacité mémoire: HDD: Lecteur: RW Ecran: LED
Capacité mémoire: HDD: Lecteur:RW Ecran: LED
Capacité mémoire: HDD: Lecteur:DVD RW
Ecran: LCD
|
47
|
Système d'exploitation
|
Périphériques
|
Logiciel
|
|
Windows 7
professionnel
Windows Edition
intégrale
|
3 Imprimantes(hp deskjet F380,
hp laserjet P2035, hp laserjet
P1005), 2 scanner, souris,
clavier.
|
Hbc
recouvrement
|
3° autres :
? Connexion wifi : airtel & standard télécom ?
Un électro projecteur
? Une photocopieuse Kyocera KM-ZOKO ? Un onduleur
2.3.2. Analyse des moyens humains
La gestion des courriers est un domaine sensible, elle exige
des agents dotés de certaines qualifications et de bonne formation dans
le domaine administratifs.
A ce jour, le département de service courrier compte un
personnel qualifé oeuvrant en son sein.
|
Poste
|
Titulaire
|
Expérience
|
Niveau d'étude
|
Age
|
Etat*civil
|
1. Coordonnateur
|
Mr.
|
3ans
|
Licencié
|
-
|
Marié
|
2. Superviseur adjoint
|
Auguste Mr.
|
2ans
|
Licencié
|
-
|
-
|
3. Agent chargé du dispatch
|
|
KALALA
Kevin, Mike...(en nombre)
|
1ans
|
Gradué et
licencié
|
-
|
-
|
|
48
2.4. Schéma de circulation des informations
|
Partenaire
|
Réception
|
Service courrier
|
Agent dispatcher
|
destinataire
|
49
+
Relevé des courriers
Bordereau
d'expédition
signé
Bordereau d'expédition signé/accusé
reception
Traitement5
Relevé des courriers
Relevé de dépôt
Courriers
re u
Relevé des
courriers reçu
Relevé des courriers
Courriers reçu
Traitement1
Courriers
Traitement6
Bordereau d'expédition signé/accusé
reception
Courriers reçu
Traitement2
Relevé de dépôt
Relevé des
courriers
reçu
Bordereau d'expédition
Fiche de dispatch
Fiche de
dispatch
remplie
Bordereau d'expédition signé/accusé
reception
Bordereau d'expédition
Bordereau
d'expédition
signé
Traitement3
Fiche de dispatch
Fiche de
dispatch
remplie
Traitement4
Bordereau
d'expédition
signé
d'expédi
Bordere
tion
au
2.5. Diagnostic de l'existant
Dans cette section, nous allons faire un diagnostic de
l'entreprise HBC en relevant les points forts et les points faibles.
2.5.1. Points forts
HBC SPRL constitue une boite à lettres au travers de
laquelle ses partenaires vont atteindre leurs clients ayant
bénéficié de leurs différentes prestations de
services. Il s'agit de ce que le jargon du métier désigne par
« circuit court ».
Ce « circuit court » offre un certains nombres
d'avantages à savoir :
HBC a établis des critères (cfr. Analyse des
Postes) qui qualifient son personnel en poste. Au regard de ces critères
nous constatons que chaque agent répond aux critères
établis.
Outre le respect de ces critères, HBC comprend aussi
des experts en recouvrements et administration.
2.5.2. Points faibles
Cependant, il sied de relever certaines faiblesses
liées au dispatching des courriers, notamment :
? Le service courrier constitue une nouvelle expérience
au sein de HBC et n'a pas encore une maitrise dans ce domaine ;
? Les agents doivent encore s'adapter ;
? Vu la courte expérience dans ce domaine, HBC ne
dispose pas encore des matériels adéquats et des logiciels
nécessaires ;
? Chaque agent doit déposer en dur la fiche de suivi
journalier de la distribution, ce qui prend beaucoup de temps pour faire un
rapport global ;
? Pour certains courriers qui sont mis à sa disposition
avec un délai de dépôt très court rend aussi la
tâche difficile, surtout les courriers qui doivent être
livrés en province ;
2.6. Proposition de solution
Au regard du diagnostic fait dans la section
précédente, nous allons tenter d'apporter une solution manuelle
ou informatique en relevant pour chaque solution les avantages et
inconvénients.
Après une étude de l'organisation en place,
traitée dans les chapitres précédents, il nous est
possible maintenant d'apporter des solutions aux besoins des utilisateurs ou
à l'amélioration des failles rencontrées.
Une solution étant le résultat d'une
réflexion permettant de résoudre un problème, de venir
à bout d'une difficulté, nous tenterons d'apporter des
50
solutions probables aux différentes tâches en
décortiquant les avantages et les inconvénients.
2.6.1. Solution manuelle
Décrit les tâches non automatisée d'un
système d'information, l'homme ne prend aucun soutien
matériel.
? Avantages
· Facilite les tâches de longue durée. ?
Inconvénient
· Temps de réponse relativement long ;
· Rendement du personnel selon leur humeur.
2.6.2. Solution informatique
Elle consiste à automatiser les tâches relatives,
en élaborant un
circuit d'information informatisé utilisant comme
premier atout des progiciels et des matériels informatiques
(unité centrale, scanner, modem, etc.).
? Avantages
· Rapidité dans le traitement ;
· Simplification de l'organisation à une
consultation et mise à jour (suppression, modification, création)
immédiat ;
· Dégagement de la circulation des informations
;
· Communication facile des rapports et des
données aux différents
environnements de travail (cas d'installation d'un
réseau). ? Inconvénients
· Coût élevé du matériel
informatique et de leur entretient.
2.7. Choix de la solution optimale
Au regard de la section précédente qui
consistait à la proposition d'une solution, nous allons opter pour une
solution, le choix peux se porter sur une seule solution ou une combinaison de
deux pour opérer un choix optimal aux regards de résultats
produits.
Nous en accord avec le futur utilisateur(HBC) avons
optés d'informatiser le système pour un rendement plus efficace
mais aussi pour une sécurité des données et leur partage,
mais la solution manuelle n'est pas exclue vue l'accomplissement de certaines
tâches qui ne peuvent être que manuelles et qui ont leurs
avantages.
51
CHAPITRE 4 : CONCEPTION DE LA BASE DE DONNEES EN
MERISE
Ce chapitre fera l'objet de la conception de la base d
données avec la méthode MERISE.
Il est subdivisé en deux sections, une consacrée
au système d'information organisé et l'autre au système
d'information informatisé.
La modélisation consiste à créer une
représentation virtuelle d'une réalité de telle
façon à faire ressortir les points auxquels on
s'intéresse. Ce type de méthode est appelé
analyse. Il existe plusieurs méthodes d'analyse, dont la
méthode MERISE (Méthode d'Etude et de Réalisation
Informatique des Système d'Entreprise).
Toute méthode informatique doit répondre
à quatre objectifs principaux :
? Définir ce que l'utilisateur final veut informatiser
(quitte à lui faire comprendre ce qu'il veut), et sa faisabilité
;
? Vérifier la cohérence de sa demande ;
? Structurer les données à informatiser. Cela
est primordial en informatique de gestion ;
? Rester simple. Ce point est largement battu en brèche
quand une méthode est appliquée « pour la
méthode». Elle doit rester un outil d'aide à la conception
ou à la réalisation.
Merise sert de méthode de référence entre
les différents acteurs, informaticiens et utilisateurs. Elle
représente, sous forme de représentations graphiques
appelées modèles, les différents concepts
manipulés. Merise possède des modèles
spécifiques.
Pour notre travail nous utiliserons la méthode MERISE
qui est basée sur la séparation des données et des
traitements à effectuer en plusieurs modèles. La
séparation des données et des traitements assure une
longévité au modèle.
La méthode MERISE repose sur les raisonnements et
comporte 4 niveaux différents regroupés en 2 systèmes :
Système d'information organisé
Ce système comprend : ? Le niveau conceptuel ;
? Le niveau organisationnel.
Système d'information informatisé
Ce système comprend : ? Le niveau logique ; ? Le niveau
physique.
Avant de voir en détail chaque composante de ces deux
système nous proposons un aperçu général sur de
chacune d'elle, que nous résumons dans le tableau ci-après :
52
LE CYCLE D'ABSTRACTION
NIVEAUX
DONNEES
M C D
Modèle conceptuel
des
données
Signification des
informations
sans
contraintes techniques,
organisationnelle
ou
économique.
Modèle entité
-
association
TRAITEMENTS
|
M C T
Modèle conceptuel
des
traitements
Activité du domaine
sans
préciser les
ressources et leur
organisation
|
|
ORGANISATIONNEL
QUI, OU, QUAND
|
|
M O D
Modèle organisationnel
des
données
Signification des informations avec contraintes
organisationnelles et économiques. (Répartition
et
quantification des données ; droit des utilisateurs)
|
M O T
Modèle
organisationnel
des
traitements
Fonctionnement
du
domaine avec les
ressources utilisées et
leur
organisation
(répartition des traitements
sur
les
postes de travail)
|
LOGIQUE
COMMENT
|
|
PHYSIQUE COMMENT
|
M L D
Modèle logique
des
données
Description des
données
tenant
compte de leurs conditions
d'utilisation
(contraintes
d'intégrité,
historique, techniques
de
mémorisation).
Modèle relationnel
|
M P D
Modèle physique
des
données
Description de la (ou des)
base(s) de
données dans la syntaxe
du Système
de Gestion des données
(SG.Fichiers
ou SG Base de Données) Optimisation des traitements
(indexation, dénormalisation, triggers).
|
|
M L T
Modèle logique
des
traitements
Fonctionnement du
domaine avec
les
ressources et leur
organisation
informatique.
|
|
M P T
Modèle physique
des
traitements
Architecture technique des
programmes
|
D'après ISIM, p. 37
53
Section 1. Système d'information
organisé
Dans cette section nous allons parler du système
d'information organisé qui comprend le niveau conceptuel et le niveau
organisationnel.
1.1. Niveau Conceptuel
Elle correspond aux finalités d'entreprise et
reflète les choix de gestion. Il s'agit de décrire le «
Quoi Faire » et avec « Quelles Données
», cela sans tenir compte ni du matériel ni de la
manière dont sera organisé le travail.
Il est élaboré grâce à deux
modèles :
? Modèle conceptuel des données (MCD) ;
? Modèle conceptuel des traitements (MCT).
1.1.1. Modèle conceptuel des données
(MCD)
Le MCD permet de décrire le réel perçu du
domaine d'information. Les concepts de base de données
nécessaires pour construire le MCD sont :
? Objet (entité) : est la
représentation dans le système d'information d'un objet
matériel ou immatériel ayant une existence propre et conforme aux
choix de gestion de l'entreprise.
Ex : un magasin, une personne, etc.
i. Association (relations) : est un lien entre plusieurs
entités.
Ex : un client qui vient visiter un magasin, la relation c'est
visiter.
Structure :
magasin
visiter
client

ii. Propriétés : est une
caractéristique associé à une entité ou une
association.
Ex : date de de visite, numéro du client, nom du
client, le nom du magasin, l'adresse etc...
54
Structure
iii.
client
num_cli nom_cli adr_cli
Identifiant : est constitué d'une ou plusieurs
propriétés de l'entité qui doivent avoir une valeur unique
pour chaque entité. Ce dernier est soit précédé
d'un #, soit est souligné.
Structure
|
client
|
|
client
|
|
num cli nom_cli adr_cli
|
ou
|
num_cli# nom_cli adr_cli
|
|
iv. Cardinalités : ils caractérisent
le lien entre une entité et une association. Il précise le nombre
de fois minimale et maximale d'intervention d'une entité dans une
association.
Ex : 1,1 ; 0,1 ; 0,n ; 1,n (min,max).
A. Recensement des règles de gestion
RG1 : le partenaire dépose les courriers à la
réception ;
RG2: l'agent est chargé de dispatcher les courriers ;
RG3 : tout courrier est accompagné d'un bordereau
d'expédition
RG4 : le destinataire reçoit le courrier ;
RG5 : le destinataire signe sur le bordereau ;
RG6 : le service courrier emploie les agents ;
55
B. Recensement et description des objets
|
Objets
|
Propriétés
|
Code propriétés
|
Taille
|
Identif iant
|
Occurrence
|
|
Partenair e
|
Numéro du partenaire
|
Num_part
|
15
|
#
|
2
|
|
Nom du partenaire
|
Nom_part Adr_part
|
50
|
|
|
|
Adresse du
|
|
60
|
|
|
|
partenaire
|
Tel_part
|
20
|
|
|
|
Téléphone du
|
|
|
|
|
|
partenaire e-mail du
|
Mail_part
|
40
|
|
|
|
partenaire catégorie de partenaire
|
Cat_part
|
20
|
|
|
|
Courrier
|
Code du courrier
|
Code_cour
|
10
|
#
|
1000
|
|
Nom du destinataire
|
Nom_dest
|
50
|
|
|
|
Adresse du destinataire
|
Adr_dest
|
60
|
|
|
|
Téléphone destinataire
|
Tel_dest
|
20
|
|
|
|
Montant du
|
Montant_du
|
10
|
|
|
|
Type de courrier
|
Type_cour
|
20
|
|
|
|
Date de retrait
|
Date_ret
|
8
|
|
|
|
Heure de retrait
|
H_ret
|
6
|
|
|
|
Date de dépôt
|
date_dep
|
8
|
|
|
|
Heure de dépôt
|
h_dep
|
6
|
|
|
|
Statut
|
statut
|
10
|
|
|
|
Service
|
Code_service
|
Code_serv
|
10
|
#
|
1
|
|
courrier
|
Noms du responsable
|
Nom_respo
|
50
|
|
|
|
Agent
|
Matricule agent
|
Mat_agent
|
10
|
#
|
50
|
|
Nom de l'agent
|
Nom_agent
|
25
|
|
|
|
Post nom de
|
Postn_agent
|
25
|
|
|
|
l'agent
|
Login_agent
|
20
|
|
|
|
Login de l'agent
|
Mail_agent
|
50
|
|
|
|
e-mail de l'agent
|
Pw_agent
|
32
|
|
|
|
mot de passe agent
droit d'accès de l'agent
|
droit_agent
|
30
|
|
|
|
Destinatai re
|
Numéro du destinataire
|
Num_dest
|
10
|
#
|
1000
|
|
Nom du de destinataire
|
Nom_dest
|
60
|
|
|
|
Adresse du destinataire
|
Adr_dest
|
60
|
|
|
|
Téléphone du destinataire
|
Tel_dest
|
15
|
|
|
|
e-mail du destinataire
|
Mail_dest
|
50
|
|
|
|
Borderea u
|
Numéro du bordereau
|
Num_bor
|
10
|
#
|
1000
|
|
Montant à payer
|
Mtnt_du
|
10
|
|
|
|
Adresse du destinataire
|
Adr_dest
|
60
|
|
|
|
Heure de depot
|
|
|
|
|
56
|
du courrier par
|
H_dep_agnt
|
6
|
|
|
|
l'agent
|
Date_dep_agnt
|
8
|
|
|
|
Date de depot du courrier par l'agent
|
Nom_pers_recep
|
60
|
|
|
|
Nom de la personne receptionnée (destinataire)
|
Date_ac_rec
|
8
|
|
|
|
Date d'accusé de reception pour partenaire
|
Nom_ac_rec
|
60
|
|
|
|
Nom de la personne qui accuse reception pour partenaire
|
|
|
|
|
C. Recensement des relations et description
des
contraintes
|
Relation
|
Dimension
|
Objets
|
Cardinalités
|
CIF
|
Père
|
Fils
|
|
Déposer
|
Binaire
|
Partenaire et courrier
|
(1,n)-(1,1)
|
Oui
|
Partenaire
|
Courrier
|
|
recevoir
|
Binaire
|
Courrier et destinataire
|
(1,1)-(1,n)
|
Oui
|
destinataire
|
courrier
|
|
Dispatcher
|
Binaire
|
Agent et courrier
|
(1,n)-(1,1)
|
Oui
|
Agent
|
courrier
|
|
Accompagner
|
Binaire
|
Courrier et bordereau
|
(1,1)-(1,1)
|
Oui
|
Courrier
|
Bordereau
|
|
Employer
|
Binaire
|
Agent et service courrier
|
(1,1)-(1,n)
|
Oui
|
Service courrier
|
Agent
|
|
Signer
|
Binaire
|
Destinataire et
bordereau
|
(1,n)-(1,1)
|
Oui
|
Destinataire
|
Bordereau
|
57
Présentation du MCD
|
Partenaire
|
Courrier
|
|
#Num_part Nom_part Adr_part Tel_part Mail_part
Cat_part
|

(1,n) (1,1)
Déposer

(1,1)
#Code_cour Nom_dest Tel_dest Montant_du
Type_cour Date_ret H_ret date_dep h_dep
(1,1)
statut
(1,n)
Dispatcher
(1,1)
(1,1)
Agent
|
#Mat_agent Nom_agent Postn_agent Login_agent
Mail_agent Pw_agent droit_agent
|
Service_courrier
Employer
(1,n)

Recevoir Accompagner
#Num_bor Mtnt_du Adr_dest H_dep_agnt Date_dep_agnt Nom_pers_recep
Date_ac_rec Nom_ac_rec
(1,1)
(1,n)
Destinataire
(1,1)
|
Num_dest Nom_dest Adr_dest Tel_dest Mail_dest
|
(1,n)
|
Signer
|
Bordereau
58
1.1.2. Modèle conceptuel de traitement
(MCT)
Le MCT permet de savoir ce qu'on fait dans l'organisation. Les
concepts de base qui nous aide à le constitué sont :
? Opération : est un ensemble d'actions
accomplies par le système d'information ou réaction avec un
événement.
Structure :
? Evénement : est un fait actif qui provoque
une réaction du système d'information ou une opération. Il
est représenté par un cercle ovale
Structure :

?
Résultat : c'est la réponse à
une
opération déclenchée par
l'évènement. Il est représenté par un cercle
ovale
Structure :

? Synchronisation : est la condition logique ou
booléenne à satisfaire préalablement au
déclanchement de l'opération. Nous utilisons «et » ou
« ou » pour rendre explicite la synchronisation.
Structure :

? Relieur : reporte la suite du traitement sur une
nouvelle
page.
Structure :
59
Présentation du MCT
Arriver des courriers
ET
Relevé courrier
Reception des courrriers et relevés des clients
- La dénomination et l'adresse de chaque client
- Le n° d'appel ou autre référence
d'identification
- L'énumération des produits fournis
- Le mois de fourniture ou des services
- Montant réclamé (ventilé
éventuellement)
Ok Ko

Courriers et
relevés pas reçus

Courriers et relevés reçus
Elaboration du plan de distribution
- Segmentation de la ville ou du pays selon les courriers
- Affectation des agents dans chaque zone
Toujours
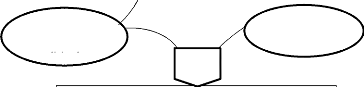
Plan de
distribution
ET
Bordereau d'expédition
distribution des courriers
- Chaque agent détient un bordereau de
dépôt
Ok
Ko
Courriers non distribués
Courriers
Bordereau
distribués
signés
ET
1
60
- Le bordereau contient la signature du client-destinataire
|
tenir une fiche de suivis
|
1
Ok
Ko

Fiche non tenue
Fiche tenue
- Attester l'effectivité de chaque dépôt
- Mise à jour quotidienne de la base de données
Toujours
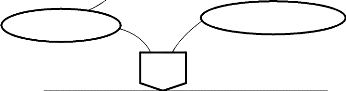
Responsable HBC
MAJ effectuée
ET
transmission du relevé de dépôt au
partenaire
|
- Les observations reprenant les problèmes et
difficultés
rencontrées sur terrain
|
Toujours

Relevé de dépôt des courriers
61
1.2. Niveau organisationnel
L'objet de cette étape est de mettre en évidence
l'organisation à mettre en place pour que le système
d'information atteigne ses objectifs.
Il est aussi élaboré grâce à 2
modèles :
? Le modèle organisationnel des données (MOD) ; ?
Le modèle organisationnel des traitements (MOT).
I.2.1. Modèle organisationnel des données
(MOD)
Le but du MOD est la répartition des données de la
BD en plusieurs sites, chaque site représentant un point de traitement
(Répartition client-serveur). Le MOD s'obtient à partir du
MCD.
Règles de passage du MCD au MOD :
? Toutes les entités (objets ou individus) du MCD qui
ne seront pas mémorisées informatiquement doivent être
supprimées.
? Certaines entités seront modifiées afin de
mieux les placés pour les informatiser.
? Suppression des relations dont leurs entités ont
disparu.
NB : il peut arriver que tous les
objets et relation du système soient mémorisables
informatiquement c'est-à-dire qu'ils répondent à la
Contrainte d'Intégrité Fonctionnelle (CIF) ou contrainte
d'intégrité multiple (CIM). Dans ce cas le MCD=MOD global.
Tel est le cas de notre modèle.
62
(1,1)
(1,1)
#Num_part Nom_part Adr_part Tel_part Mail_part
Cat_part
(1,n) (1,1)
Déposer
(1,1)
(1,1)
Bordereau
Présentation du MODG
Dispatcher
Agent
#Mat_agent Nom_agent Postn_agent Login_agent
Mail_agent Pw_agent droit_agent
(1,n)
(1,1) (1,n)
Employer
Recevoir
Service_courrier
#Code_serv Nom_respo
Accompagner
(1,n) (1,1)
Signer
#Num_bor Mtnt_du Adr_dest H_dep_agnt Date_dep_agnt Nom_pers_recep
Date_ac_rec Nom_ac_rec
Num_dest Nom_dest Adr_dest Tel_dest Mail_dest
Courrier
#Code_cour Tel_dest Montant_du Type_cour
Date_ret H_ret date_dep h_dep statut
Partenaire
(1,n)
Destinataire
63
a.1. Calcul du volume du MOD Global
A ce niveau, nous devons trouver le volume global du MOD pour
cela nous devons calculer le quantificateur de la multiplicité en
déterminant les valeurs de chaque objet et relation en passant par la
longueur des objets et des relations.
On utilise la cardinalité moyenne (Cm) afin
de calculer le nombre d'occurrence des relations :

Cm =
[(mi+2M+ma)/4]xP
Volume objet = taille x ma
M
P=
ma
Volume global = ma x Cm
Où mi =minimum : cardinalité minimale (0 exclu)
M=mode : valeur modale ou fréquence
ma =maximum : cardinalité maximale
P : taux de participation
CALCUL DU VOLUME DU MOD GLOBAL
Objets
|
Ma
|
mi
|
M
|
Taille
|
P
|
Cm
|
Volume
objet en
octet
|
Mode global
en octet
|
Partenaire
|
2
|
1
|
2
|
205
|
1
|
1,75
|
410
|
3,5
|
Courrier
|
1000
|
1
|
900
|
248
|
0,9
|
630,225
|
248000
|
630225
|
Service courrier
|
1
|
1
|
1
|
60
|
1
|
125,25
|
60
|
125,25
|
Agent
|
50
|
1
|
50
|
192
|
1
|
37,75
|
9600
|
1887,5
|
Bordereau
|
1000
|
1
|
900
|
222
|
0.9
|
630,225
|
222000
|
630225
|
Destinataire
|
1000
|
1
|
900
|
195
|
0.9
|
630,225
|
195000
|
630225
|
TOTAL
|
451870
|
1892691,25
|
|
a.2. Répartition du MOD en mode locaux et
prise de la
sécurité
La répartition est indispensable lorsque nous nous
décidons
d'interconnecter les machines en réseau.
On parle de la sécurité du MOD lorsque les machines
sont
protégées c'est-à-dire définir les
instructions d'accès aux données par
l'utilisateur.
Nous utiliserons 4 paramètres :
M : modification
C : création
S : suppression
L : lecture
64
Site : Réception
partenaire
L

Déposer
Recevoir
Destinataire
L
Site : Service Courrier
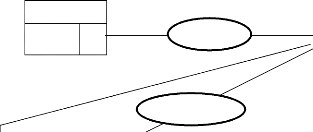
Déposer
Courrier
Dispatcher

Accompagner

Employer
|
Service
|
courrier
|
|
|
C
|
|
|
L
|
|
|
M
|
|
Destinataire
|
|
C
|
|
L
|
|
M
|
|
S
|

Recevoir
65
Site : Agent de dispatch
Agent
L

Dispatcher

Accompagner
I.2.1. Modèle organisationnel de traitement
(MOT)
Il consiste à mettre en exergue l?organisation du nouveau
système
en indiquant le déroulement, la procédure, la
nature et le poste.
TM : Traitement manuel
TA : Traitement automatique
TR : Traitement réel
D : Différé
I : Immédiat
66
Présentation du MOT
|
Déroulement
|
Procedure function
|
Nature
tache
|
Poste
|
|
8h30-17h00 Lundi-vendredi
8h30-17h00 Lundi- vendredi
|
Arriver des
courriers(Parte
naire)
|
|
|
Relevé courrie
r
|
TR-I-U
TM-D-L
|
Reception
Service courrier
|
|
ET
|
|
|
Réception des courriers et relevés des clients
|
|
|
Ok
|
Ko
|
|
|
|
Courriers et
Courriers et
relevés reçus
relevés pas reçus
|
|
|
Elaboration du plan de distribution
|
|
|
Toujours
|
|
|
Plan de Bordereau
distribution d'expédition
|
|
élaboré
|
|
ET
1
|
|
|
67
|
8h30-17h00 Lundi- vendredi
8h30-17h00 Lundi- vendredi
8h30-17h00 Lundi- vendredi
Quand tous les courriers sont dispatcher
|
1
|
TM-D-L
TM-D-L
TA-I-U
TR
|
Agent de
dispatch
Agent de
dispatch
Service
courrier
Service
courrier
|
|
Distribution des courriers
|
|
- Chaque agent détient un bordereau d'expédition
- Le bordereau contient la signature du destinataire
|
|
Ok
|
Ko
|
|
Courriers
distribués
|
Courrier non
distribués
Bordereaux
signés
|
|
ET
|
|
|
tenir une fiche de suivis
|
|
- L'agent certifie que le courrier est déposé
|
|
Ok
|
Ko
|
|
|
Fiche non tenue
Fiche tenue
|
|
|
mise à jour de la BDD
|
|
-mise à jour quotidienne de la base de données
|
|
Toujours
|
|
|
MAJ faite
|
ET
|
Bordereau
signé/avec accusé
|
|
transmission au partenaire du relevé de
dépôt
(clients)
|
|
- Les observations reprenant les problèmes
rencontrés sur terrain
|
|
Toujours
|
|
|
Relevé de dépôt des courriers
|
68
Section 2. Système d'information
informatisé
Dans cette section nous allons parler du système
d'information informatisé qui est une composante du cycle d'abstraction
de MERISE. Ce système comprend le niveau logique et le niveau
physique.
Le système déjà décrit au niveau
conceptuel et organisationnel doit l'être ensuite au plan informatique.
Cette description est elle-même décomposée en deux niveaux
:
? Niveau logique ? Niveau physique
A. Choix du hardware
Ici nous définirons les contraintes du matériel
qui pourra faire tourner notre logiciel :
Nombre
|
Processeur
|
Ram
|
Capacité mémoire
|
Lecteur
|
5
|
AMD E-300
APU with
Radeon(tm)
HD Graphics
1.30
|
4.00Go
|
#177;600Go(+
un disque
externe)
|
DVD RW et CD
|
|
B. Choix du software
Afin de pouvoir mieux utilisé notre programme nous
suggérons les logiciel suivants :
? Windows (XP, SEVEN ou EIGHT) comme système
d'exploitation ou LUNIX.
? Mozilla ou Internet Explorer, au moins la version 10, comme
navigateur.
2.1. Niveau logique
C'est une vue en terme de données favorable à un
traitement ou à une sélection. Ce modèle implante les
données de la base dans un SGBD approprié.
2.1.1. Modèle logique de donnée
(MLD)
Deux modèles sont à présenter à ce
niveau, à savoir :
- Le modèle logique de données brut
- Le modèle logique de données valide
69
Il est obtenu en partant du MCD et du MOD. Ici on voie comment
organisé les données sur un support informatique.
Ainsi, pour passer du MCD au MLD, les règles sont les
suivantes :
a. Changement des vocabulaires
? Les objets du MOD deviennent des tables dans le ML ;
? Les propriétés des objets deviennent des
attributs des tables ; ? L'identifiant devient la clé primaire.
b. Traitement des relations
Plusieurs cas sont à épingler en ce qui concerne
le traitement des relations à savoir :
1er Cas : Relation du type père-fils :
Nous sommes en présence des couples suivants : (0,1)
ou(1,1) d'une part, et (0,n) ou (1 ,n) d'autre part. Il s'agit d'une contrainte
d'intégrité fonctionnelle.
La relation qui les lient disparait mais sa sémantique
demeure, car l'objet qui a la cardinalité (0,n) ou (1,n) est
considéré comme père et cède sa clé primaire
à l'objet qui a la cardinalité (0,1) ou (1,1) qui à son
tour est considéré comme fils.
Etant donné qu'il possède une clé
primaire, celle qu'elle vient d'hériter du père est une
clé étrangère parce qu'elle est clé primaire dans
sa table respective. Si la relation était porteuse des
propriétés, elles migrent vers la table fils.
2è Cas : La cardinalité multiple : Relation du
type père-père
(contrainte d'intégrité multiple). Ce cas
intervient lorsqu'on a d'une part le couple d'une part (0,n)ou(1,n), d'autre
part (0,n)ou(1,n), cas que nous n'avons pas rencontré. Par contre c'est
le premier cas que nous avons rencontré ; c'est donc à partir du
respect des règles que fixent ce cas que nous avons obtenu le MLD Brut
ci-après :
70
Présentation du MLD Brut
Destinataire
#Num_dest Nom_dest Adr_dest Tel_dest Mail_dest
Partenaire
#Num_part Cat_part Nom_part Adr_part Tel_part Mail_part
Bordereau
#Num_bor #code_cour #num_dest Mtnt_du
Adr_dest H_dep_agnt Date_dep_agnt Nom_pers_recep Date_ac_rec
Nom_ac_rec
Courrier
#Code_cour #num_part #mat_agent #num_dest
Adr_dest Tel_dest Montant_du Type_cour Date_ret H_ret date_dep h_dep
statut
Service
courrier
#code_serv Nom_respo
Agent
#Mat_agent #code_serv Nom_agent Postn_agent
Login_agent Mail_agent Pw_agent droit_agent
71
C. Processus de normalisation
La normalisation est un processus qui consiste à
éliminer les dernières redondances et les valeurs nulles
c'est-à-dire limiter les risques d'incohérences potentielles
(Mvibudulu & Konkfie , 2012)
Les formes normales (FN) à respecter pour qu'un MLD soit
valide :
1e FN : Tous les attributs doivent être
élémentaire c'est-à-dire non
subdivisible, non répétitive et possède au
moins une clé ;
Dans ce cas nous pouvons sortir les attributs non atomiques
dans
les tables destinataire et partenaire, qui sont :
- Adresse du destinataire
- Catégorie de partenaire
? Décomposition des attributs non atomiques
CATEGORIE (code_cat, lib_cat)
ADRESSE (Province,district,territoire,quartier)
Décomposons à présent les attributs de la
nouvelle table
ADRESSE :
PROVINCE (code_prov,lib_prov,lib_ville) ;
DISTRICT (code_dist,lib_dist ) ;
TERRITOIRE (code_ter,lib_ter) ;
QUARTIER (code_quart,lib_quart,lib_avenue).
NB : Bien que certains attributs des tables qui découlent
de la table
d'origine ADRESSE sont décomposable, nous allons le
laisser pour ne pas alourdir la base de données lors des
éventuels consultations, recherche,... et cette décomposition
concerne seulement l'attribut adresse de la classe
destinataire.
Ainsi, ADRESSE va générer quatre tables :
72

Destinataire
#Num_dest Nom_dest Adr_dest Tel_dest Mail_dest #code_ter
#code_dist #code_prov #code_quart
District
#code_dist Lib_dist
Province
#code_prov Lib_prov
Territoire
Quartier
#code_quart Lib_quart Lib_avenue
L'attribut CATEGORIE va aussi générer une table
:
|
Partenaire
|
Catégorie
|
|
#Num_part #code_cat Nom_part Adr_part Tel_part Mail_part
|
|
#code_cat Lib_cat
|
NB : la table destinataire
reçoit les clés primaires de nouvelles tables
crées, qui deviennent par conséquent des clés
étrangère dans celle-ci.
2e FN : Etre déjà à la 1FN, chacun de ses
attributs non membre de la clé dépendent totalement de la
clé primaire. Cette FN s'applique aux tables à clé
primaire composée ;
Cette forme est vérifiée.
3e FN : Etre déjà à la 2FN, les attributs
non clé de la table ne dépendent pas transitivement de la
clé primaire c'est-à-dire ne passe pas par un autre attribut non
clé.
Cette forme est aussi vérifiée.
Après avoir illustré la normalisation par les
différents schémas ci-haut, nous allons à présent
tracer le modèle logique de données valide issu du MLD Brut
ci-haut.
73
Présentation du MLD Valide (MLDV)
Partenaire
#Num_part #code_cat Nom_part Adr_part Tel_part Mail_part
Quartier
#code_quart Lib_quart Lib_avenue
Catégorie
Courrier
#Code_cour #num_part #mat_agent #Num_dest
Tel_dest Montant_du Type_cour Date_ret H_ret date_dep h_dep
statut
Agent
#Mat_agent #code_serv Nom_agent Postn_agent
Login_agent Mail_agent Pw_agent droit_agent
Service
courrier
#code_serv Nom_respo
Province
Bordereau
#Num_bor #code_cour #num_dest Mtnt_du
Adr_dest H_dep_agnt Date_dep_agnt Nom_pers_recep Date_ac_rec
Nom_ac_rec
Destinataire
#Num_dest Nom_dest Tel_dest Mail_dest #code_prov #code_dist
#code_ter #code_quart
Territoire
District
74
D. Schéma relationnel associé
Il nous permet de définir les fenêtres de menu et
nombre d'élément
à placer dans le programme à concevoir.
courrier : [# code_cour :car[10] ; #num_part: car[10];#mat_agent
:
car[15] ;#num_dest :car[10] ;tel_dest :car[20] ;montant_du
:car[10] ;type_cour :car[20] ;
date_ret :date[8] ;h_ret :Time[6] ;date_dep :Date[8] ;h_dep
:Time[6] ;statut :car[10]]
partenaire : [#num_part:car[10] ; #code_cat : car[10] ; nom_part:
car[50] ; adr_part : car[60] ;
tel_part: car[20] ;mail_part :car[40] ]
agent: [#mat_agent : car[15] ;#code_serv, nom_agent: car[25] ;
postn_agent :car[25] ;
login_agent :car[20] ;mail_agent :car[50] ;pw_agent :car[32]
;droit_agent :car[30]]
service courrier : [#code_serv : car[10] ; nom_respo: car[40]
;]
province : [#code_prov : car[10] ; lib_prov : car[40]]
district :[#code_dist :car[10] ;lib_dist[40]]
territoire: [#code_ter : car[10] ; lib_ter: car[40] ]
quartier :[#code_quart :car[10] ;lib_quart :car[40] ;lib_avenue
:car[50]]
categorie :[#code_cat :car[10] ;lib_cat :car[40]]
destinataire :[ #Num_dest :car[10,]Nom_dest :car[60],Tel_dest
:car[15],Mail_dest :car[50],#code_pro
v :car[10],#code_dist :car[10],#code_ter :car[10],#code_quart
:car[10]]
bordereau :[#num_bor :car[10],mtnt_du :car[10],adr_dest :car[60]
,h_dep_agnt :time[6],date_
dep _agnt:date[8],nom_pers_recep :car[60],date_ac_recep
:date[8],nom_ac_rec :car[60],#co
de_cour :car[10],#num_dest :car[10]]
E. Quantification de la Base de données
(BDD)
L'intérêt majeur de ce calcul est de nous permettre
de savoir si le matériel que nous allons utiliser répondra au
volume de la base.
1. Volume théorique de la BDD

Vthéo = ?ni x occurrences
Où
ni = taille
Occurrence = ma = nbre d'enregistrement de la table
|
Table
|
?ni
|
Ma
|
Vthéo
|
|
Courrier
|
223
|
1000
|
223000
|
|
partenaire
|
190
|
2
|
380
|
|
Agent
|
197
|
50
|
9850
|
|
Service courrier
|
25
|
1
|
25
|
|
Province
|
50
|
11
|
550
|
|
District
|
50
|
100
|
5000
|
|
Territoire
|
50
|
500
|
25000
|
|
Quartier
|
100
|
1000
|
100000
|
|
Catégorie
|
50
|
5
|
250
|
|
Bordereau
|
222
|
1000
|
222000
|
|
destinataire
|
195
|
1000
|
195000
|
|
Total Vthéo
|
781055
|
75
2. Volume des index

Vi = taille index x occurrences
|
Index
|
?ni
|
Occurrence
|
Vi
|
|
Code_cour
|
10
|
1000
|
10000
|
|
Num_part
|
10
|
2
|
20
|
|
Mat_agent
|
15
|
50
|
750
|
|
Code_serv
|
10
|
1
|
10
|
|
Code_prov
|
10
|
11
|
110
|
|
Code_dist
|
10
|
100
|
1000
|
|
Code_ter
|
10
|
500
|
5000
|
|
Code_quart
|
10
|
1000
|
10000
|
|
Code_cat
|
10
|
5
|
50
|
|
Num_dest
|
10
|
1000
|
10000
|
|
Num_bor
|
10
|
1000
|
10000
|
|
Totale Vi
|
46940
|
3. Volume de la BDD

Vbdd = Vthéo + Vi
Vbdd = 781055 + 46940
= 827995
4. Volume réel de la BDD

Vrbdd = Vtot x coef
Coef est une valeur quelconque. Vrbdd = 827995 x 3
= 2483985 octets
76
2.1.2. Modèle logique de traitement
(MLT)
Il concerne la description en unité de traitement des
phases
automatisables définis dans le MOT.
Règles de passage du MOT au MLT
? On identifie d'abord les ULT à partir du MOT ;
? Ont construit des procédures pour chaque domaine ;
? Les procédures fonctionnelles deviennent des
procédures
logiques ou ULT au MLT.
: Lecture
: imprimer
: Écriture
: Disque dure
Procédure logique : enregistrement des courriers
i. ULT1
ULT2
77
Chaque ULT repose sur des boites d'écran ou boites de
dialogue.
ULT1
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
Affichage page
d'accueil
|
|
|
|
|
|
|
Clic sur le lien
|
|
|
|
Affichage de la
|
|
|
|
|
|
page
d'authentification
|
|
|
Enchainement des boutons
|
Lien
|
Action
|
Résultat
|
|
Admin(logo)
|
Cliquer
|
Chargement ULT2
|
ii. ULT2
ULT3
ULT2
agent
ULT1
78
ULT2
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
Affichage page
d'authentification
|
|
|
|
Saisi identifiant et
mot de passe
|
|
|
|
|
|
|
|
|
|
Si
identifiant
|
|
Affichage page
espace
|
|
|
et mot de
passe
existent
|
administrateur
|
|
|
|
|
Enchainement des boutons
|
Boutons
|
Action
|
Résultat
|
|
Valider
|
Cliquer
|
Vérifier la validité de l'id et mot de passe et
chargement de ULT3
|
iii. ULT3
ULT1
ULT4
79
ULT3
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
|
|
|
Affichage page
espace
administrateur
|
|
|
Clic sur le lien
|
|
|
|
|
|
|
|
|
|
Affichage de la
page de gestion
|
|
|
Enchainement des boutons
|
Boutons
|
Action
|
Résultat
|
|
Courriers
|
Cliquer
|
Sélection les courriers
|
iv. ULT4
ULT5
ULT3
80
ULT4
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
|
|
|
Affiche la page de gestion
|
|
|
Clic le lien
sur
|
|
|
|
|
|
|
|
Affiche le formulaire
de de
saisi
|
|
|
|
|
|
courriers
|
|
|
Enchainement des boutons
|
Boutons
|
Action
|
Résultat
|
|
Gestion des courriers
Retour au menu
administrateur
|
Cliquer Cliquer
|
Selectionne gestion des
courriers
Déconnection de la session et chargement d?ULT3
|
v. ULT5
ULT4
ULT5
ULT5
courriers
81
ULT4
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
Affiche le
formulaire de
saisi de courriers
|
|
|
|
Clic le lien
sur
|
|
|
|
|
|
|
|
|
|
Insert les données
|
|
|
|
|
|
|
Enchainement des boutons
Procédure logique : création compte agent
i. ULT1
ULT2
82
Boutons
|
Action
|
Résultat
|
|
Valider
Retour au menu
administrateur
|
Cliquer Cliquer
|
Insert les détails du courrier
Déconnection de la session et chargement d?ULT4
|
ULT1
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
Affichage du site
|
|
|
|
|
|
|
|
Clic sur le lien
|
|
|
|
Affichage de la
|
|
|
|
|
|
page de
d?authentification
|
|
|
Enchainement des boutons
|
Lien
|
Action
|
Résultat
|
|
Admin(logo)
|
Cliquer
|
Chargement ULT2
|
ii. ULT2
ULT2
ULT3
agent
ULT1
83
ULT2
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
Affichage page
d'authentification
|
|
|
|
Saisi identifiant et
mot de passe
|
|
|
|
|
|
|
|
|
|
Si
identifiant
|
|
Affichage page
espace
|
|
|
et mot de
passe
existent
|
administrateur
|
|
|
|
|
Enchainement des boutons
|
Boutons
|
Action
|
Résultat
|
|
Valider
|
Cliquer
|
Vérifier la validité de l'id et mot de passe
|
iii. ULT3
ULT1
ULT4
ULT1
84
ULT3
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
|
|
|
Affichage page espace administrateur
|
|
|
Clic sur le lien
|
|
|
|
|
|
|
|
|
|
Affichage de la page de gestion
|
|
|
Enchainement des boutons
|
Boutons
|
Action
|
Résultat
|
|
Création compte
|
Cliquer
|
Sélection création compte
|
iv. ULT4
ULT4
ULT3
ULT4
85
ULT4
Logique de dialogue
|
HOMME
|
MACHINE
|
RESULTAT
|
|
|
|
|
Affiche la page de
gestion
|
|
|
|
Clic sur le lien
|
|
|
|
|
|
Affiche le formulaire de saisi du compte client
|
|
|
|
|
|
|
Enchainement des boutons
|
Boutons
|
Action
|
Résultat
|
|
Valider
Retour au menu
administrateur
|
Cliquer Cliquer
|
Insert les informations sur
l'agent
Déconnection de la session et chargement d'ULT3
|
i. ULT1
Processus logique : connaitre le statut du
ULT2
courriers
ULT1
86
Logique de dialogue ULT1
|
HOMME
|
MACHINE
|
RESULTAT
|
|
|
|
|
Affiche masque de
saisi
|
|
|
|
Saisir le track number
|
|
|
|
|
|
Insert le track number
|
|
|
|
Affiche la boite de
|
|
|
|
|
|
dialogue
|
|
|
Enchainement des boutons
|
Boutons
|
Action
|
Résultat
|
|
Valider Annuler
|
Cliquer Cliquer
|
Affiche le message et
charge ULT2
Vider le champ de saisi et
chargement du ULT1
|
ii. ULT2
ULT1
87
2.2. Niveau physique
Ce niveau est lié aux choix techniques informatiques en
rapport avec le système de gestion des bases de données. Il
permet de résoudre le problème d'implantation de la BDD recourant
au SGBD.
Il est subdivisé en deux :
· Modèle physique de donnée ;
· Modèle physique de traitement.
2.2.1. Modèle physique de donnée
(MPD)
Le MPD est un modèle de la base de données. Merise
n'a pas tenu compte de développement de cette étape, cependant
elle laisse le soin au SGBD choisi de le faire, toute en respectant les
contraintes établies.
Règles de passage du MLD valide au MPD :
· Les tables deviennent des fichiers. MySQL les nomme
aussi
tables ;
· Les attributs deviennent des champs ;
· Les clés demeurent clé.
a. Création de la base de données
· Structure de la Base de données
88
? Structure de la table agent
? Structure de la table courrier
89
? Structure de la table partenaire
? Structure de la table province
? Structure de la table catégorie
90
? Structure de la table quartier
? Structure de la table district
? Structure de la table territoire
91
? Structure de la table service courrier
? Structure de la table destinataire
? Structure de la table bordereau
2.2.2. Modèle physique de traitement
(MPT)
Il donne une vision globale de l?ensemble du programme qui
constitue notre projet.
92
? Page d?accueil

93
? Page d'authentification
94
? Page de gestion courries
95
96
96
TROISIEME PARTIE : REALISATION
DE L'APPLICATION WEB SOUS LA
PLATE-FORME « EASY PHP »
97
CHAPITRE 5 : CODAGE DE L'APPLICATION WEB (HTML &
PHP)
Dans ce chapitre il est question de l'intérêt qu'on
a à opérer le choix sur le langage de programmation. Il est
subdivisé en deux sections.
Section 1. Le langage HTML
Tim Berners-Lee est l'inventeur du WWW en 1991. Il utilisait
le
maillage de l'internet, non pas uniquement à travers ses
différents chemins (gain en tolérance de panne) mais pour ses
noeuds. Il proposait une
ramification de documents stockés sur des serveurs et
accessibles par des
clics (liens). Il a créé un système
basé sur HTML, http et l'hypertexte. HTML est un dialecte du langage
très complexe SGML (Standard Generalized
Markup Language). HTML est lui simple : il structure
grossièrement un document, intègre des hyperliens, permet une
représentation à l'aide d'un
navigateur. La conception de sites progressait, le langage HTML
devenait plus
fourni et flexible. Les tableaux, dans lesquels on peut afficher
des données, furent vite détournés de leur objectif
initial et utilisés comme moyen de mise
en page.
A quoi sert HTML ?
Pour produire et publier de l'information avec
la distribution la plus
large possible, on a besoin d'un langage universel
que les ordinateurs
puissent interpréter : c'est HTML.
Il donne les moyens de :
- produire des pages web
- retrouver de l'information en ligne via un dispositif de
cliquage et de
liens
- concevoir des formulaires pour conduire des transactions
avec des services éloignés (réservation)
- inclure des applications directement dans un document
(téléchargement par exemple)
Le langage HTML a considérablement
évolué depuis sa première formalisation (1992) et a
montré ses limites : il a méprisé la notion de classes de
documents, il a sous-estimé la complexité des informations
à représenter dans un document, il est tombé dans le
piège de la compatibilité pour devenir ... trop tolérant.
Concluant que la meilleure façon d'avancer avec HTML (qui restera
longtemps présent sur le web) consiste à le reconstruire en tant
qu'application du langage XML, le W3C a créé la norme XHTML en
2000. Sa version 1.0 étend HTML
97
98
4.0 et c'est sa syntaxe que nous retiendrons pour
l'écriture d?un code
correct :
Le document commence par une DTD «
déclaration de type de document » : DOCTYPE ....
- les attributs ont toujours une valeur suivant un signe = et
placée entre guillemets
- les attributs sont séparés du nom de la
balise, et séparés entre eux, par un espace
- les balises sont bien imbriquées (derrière,
il y a la construction d'un
arbre)
- les balises et les attributs sont écrits de
préférence en minuscules
- toute balise ouverte doit être fermée. Celle
qui est «vide» s'auto-ferme (<img .... />)
Les syntaxes de HTML et XHTML sont très proches, celle
de XHTML héritant de XML l'obligation de réaliser des documents
bien formés, vérifiant en particulier les règles
énoncées ci-dessus et la conformité à une DTD
(définition de Type de Document).
Ce qui implique la déclaration suivante (toujours la
même) en haut du document
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
suivi d'un élément racine précisant un
espace de nom et une langue. <html xmlns="
http://www.w3.org/1999/xhtml"
xml:lang="fr" lang="fr">
Ossature d'un document HTML :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0
Strict//EN"
http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html
xmlns="
http://www.w3.org/1999/xhtml"
xml:lang="fr"
lang="fr">
<head>
<title>Ossature d'un document html</title>
<meta name="keywords" content="HTML, balise, tableau"
/>
<meta http-equiv="content-type" content="text/html" ;
charset="ISO-8859-1" />
<meta name="keywords" content="html, head, body" />
<script>function ...</script><link
type="text/css" href="style.css" />
</head>
<body>... ici le contenu du document détaillé
par la suite </body>
</html>
Ce qui donne à l'affichage dans le navigateur
98
99
Section 2. Le langage PHP
a. Historique
PHP, signifiait à l'origine "Personal Home Pages", a
été conçu durant l'automne 1994 par Rasmus Lerdorf. Il l'a
conçu pour surveiller les personnes qui venaient consulter son CV en
ligne. La première version est sortie au début de l'année
1995, à ce moment Rasmus a pensé qu'en le distribuant sous
licence Open Source, d'autres développeurs corrigeraient les bugs. La
première version était très simple et comprenait un
parseur qui était capable de reconnaitre quelques macros et fournissait
quelques outils utiles pour les pages Web.
Le parseur a été récrit durant
l'année 1995 et a été renommé PHP/FI version 2.
"FI" signifie "Form Interpreter" (Interpréteur de formulaire) qui a
été ajouté par Rasmus pour répondre au besoin
grandissant des pages Web. Le support de la base de données MySQL a
été ajouté à ce moment. PHP/FI est devenu populaire
et des développeurs ont commencé à contribuer au
développement en envoyant des morceaux de codes.
En 1997, Zeev Suraski et Andi Gutmans ont
réécrit le parseur et PHP est passé du projet de Rasmus
à un projet de groupe. Cela a permis la création des bases de
PHP3 qui se nomment maintenant PHP: HyperText Preprocessor (un acronyme
récursif).
La dernière version, PHP4, est une nouvelle
réécriture du parseur par Suraski et Gutmans et est basés
sur le moteur de script Zend. PHP est développé par plus
de 200 personnes du monde entier sur les différentes parties du projet.
Il y a des plus en plus de modules d'extensions pour supporter en natifs les
serveurs les plus populaires, par exemple un support MySQL et ODBC. Exemple
:
99
<html>
<Head> </head> <body>
<php
Echo ` Bonjour à tous ';
?>
</body> </html>
100
b. Fonctionnement
Contrairement à d'autres langage tel que Java, C++ qui
sont de langage compilé, le PHP est un langage interprété
par le serveur. Pour exécuter un script PHP, il est nécessaire
d'avoir un serveur web qui pourra transformer ces scripts et
gégèné une page HTML. De ce fait la plateforme minimale de
base pour l'exécution d'un site web développé en PHP
comprend
:
? l'interpréteur PHP (serveur PHP) ? un serveur web
(Apache, IIS, ...)
Lorsqu'un visiteur demande à consulter une page Web,
son navigateur envoie une requête à un serveur HTTP. Si la page
contient du code PHP, l'interpréteur PHP du serveur le traite et renvoie
du code généré (HTML).
Autres langages pour la génération de sites
dynamiques : ASP, PYTHON, JSP, Perl, CGI.
Nous avons opté de réaliser notre application
avec le langage PHP parce qu'Il possède des avantages par rapport aux
autres langages de programmation, nous pouvons cités :
- C'est un logiciel free ;
- Exécutable sur toutes les plates-formes ;
- Permet de créer de pages interactives ;
- Simple et efficace ;
- PHP s'est encore enrichi dans la version 5.3 en particulier
dans le domaine des objets avec, entre autres, l'apparition des namespaces
(espaces de noms) y compris l'emploi du mot-clé use, du namespace
global, des alias et des appels de variables statiques,ainsi que le Late
State Binding et la création de constantes et de fonctions dans les
namespaces ;
100
101
- Notons également l'apparition de l'extension mysqli,
qui permet un
accès objet riche à MySQL, et de la couche
d'abstraction PDO qui autorise l'accès aux bases de données les
plus diverses ;
-
|
Un langage professionnel et solide ;
|
|
Codage de l'application :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0
Transitional//EN"
"
http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="
http://www.w3.org/1999/xhtml">
<head>
<title>home page|hbc</title>
<meta http-equiv="Content-Type" content="text/html; "
/>
<link href="css/style.css" rel="stylesheet"
type="text/css" />
<link rel="stylesheet" type="text/css"
href="css/coin-slider.css" />
<script type="text/javascript"
src="js/cufon-yui.js"></script>
<script type="text/javascript"
src="js/cufon-yanone.js"></script>
<script type="text/javascript"
src="js/jquery-1.4.2.min.js"></script>
<script type="text/javascript"
src="js/script.js"></script>
<script type="text/javascript"
src="js/coin-slider.min.js"></script>
</head>
<body>
<div class="main">
<div class="header">
<div class="header_resize">
<div class="logo">
<h1><a href="index.php"><img
src="images/logo1.png"
height="60"</img> <span>Holding Business
&
Communication</span></a></h1>
</div>
<div class="clr"></div>
<div class="searchform">
<form id="formsearch" name="formsearch" method="post"
action="#">
<span>
<input name="editbox_search"
class="editbox_search"
id="editbox_search" maxlength="80" placeholder="Recherche:"
type="text" />
</span>
<input name="button_search"
src="images/search.gif"
class="button_search" type="image" />
</form>
</div>
<div class="menu_nav">
<ul>
<li class="active"><a
href="index.php"><span>Page
d'acceuil</span></a></li>
101
102
<li><a
href="logistique.php"><span>logistique</span></a></li>
<li><a href="about.php"><span>A propos de
Nous</span></a></li>
<li><a
href="blog.php"><span>services</span></a></li>
<li><a href="contact.php"><span>Contact
</span></a></li>
</ul>
</div>
<div class="clr"></div>
<div class="slider">
<div id="coin-slider"> <a href="#"><img
src="images/carte-monde2.png"
width="960" height="320" alt=""
/><span><big>
HBC Sprl vous suit partout dans le
monde!.</big><br
/>HBC Sprl étend ses services partout en vue de
servir sa clientèle
diversifiée</span></a> <a
href="#"><img src="images/p.jpg" width="960"
height="320" alt="" />
<span><big>HBC Sprl around the
world.</big><br />
</span></a> <a href="#"><img
src="images/slide3.jpg" width="960"
height="320" alt="" /><span><big>Des
équipements informatiques
mobiles,</big><br />permettant de travailler en
tout lieu moyennant une
connexion Internet illimitée.</span></a>
</div>
<div class="clr"></div>
</div>
<div class="clr"></div>
</div>
</div>
<div class="content">
<div class="content_resize">
<div class="mainbar">
<div class="article">
<h2><span> Solutions Excellentes</span>
Pour vos Affaires</h2>
<p class="infopost">Posted <span class="date">on
11 sep 2018</span>
by <a href="#">Admin</a> </p>
<div class="clr"></div>
<div class="img"><img src="images/img1.jpg"
width="630" height="140"
alt="" class="fl" /></div>
<div class="post_content">
<p>HBC SPRL, pris en tant que société
commerciale de service ainsi
que son personnel à divers degré de leur
position administrative dispose
d'une expéreince avérée en
matière de suivi de
la clientèle de ses partenaires
Elle dispose en effet:<br>
* des capacités en matière de suivi
de la clientèle de ses partenaires,
particulièrement,la distribution des
courriers;et<br>
* d'une logistique adéquate pour ce
faire.
.</p>
102
103
</p><p class="spec"><a href="W"
class="rm">Read more
»</a></p>
</div>
<div class="clr"></div>
</div>
<h2 class="star"><span>News
letter</span>
</h2>
<form method="post"
action="index.php?email=1">
<label for="email">Adresse e-mail</label> :
<input type="text" name="email"
size="20" /><br />
<input type="radio" name="new" value="0"
/>S'inscrire
<input type="radio" name="new" value="1" />Se
désinscrire<br />
<input type="submit" value="Envoyer" name="submit" />
<input type="reset"
name="reset" value="Effacer" />
</form>
</ul>
</div>
<div class="gadget">
<h2
class="star"><span>Partenaires</span></h2>
<div class="clr"></div>
<ul class="ex_menu">
<li><a
href="http://www.airtel.com/" rel="nofollow">Airtel</a><br />
commentaires sur airtel</li>
<li><a href="W">autre partenaire</a><br
/>
Commentaires & autres</li>
<li><a href="W">autre</a><br
/>
Services & autres</li>
<
<li>
<label for="message">Track number(Barre
code)</label>
<textarea id="message" name="message" rows="5"
cols="25"
required></textarea>
</li>
<input type="submit" value="Valider">
<input type="reset" value="Annuler">
</form>
</ul>
</div>
</div>
</body>
</html>
103
104
CHAPITRE 6 : TEST
? Authentification
? Menu général
104
105
? Formulaire enregistrement du courrier
105
106
CONCLUSION
Nous voici arriver au terme de notre étude qui a
consisté à concevoir puis implémenter une application web
permettant d'assurer la gestion des courriers au sein de la
société Holding Business & Communication.
Il ne s'agit pas d'une improvisation, mais d'une conception
qui a pris en compte le respect des règles de la méthode
MERISE.
Ainsi, ce système d'information informatisé
performant va garantir la rapidité et la fiabilité du traitement
automatique des données, en vue d'une bonne circulation et d'un
excellent archivage des documents, d'une part. D'autres parts, après
avoir analysé le système existant, nous avons opté pour
une solution informatique de premier plan dont le logiciel devrait se
caractériser par la fiabilité et la rentabilité du travail
à exécuter tout en maintenant certaines tâches qui
devraient se déroulaient manuellement tout en soulignant l'apport
très significatif du nouveau système .
Pour atteindre les objectifs fixés dans
l'élaboration de ce travail, nous l'avons subdivisé en trois
parties.
· Premier chapitre consacré à l'introduction
générale
La première partie a été
consacrée aux notions théoriques, repartit en un seul
chapitre:
· Premier chapitre relatif à la revue de la
littérature
La deuxième partie a été
consacrée à l'analyse préalable et la conception, repartit
en deux chapitres :
· Premier chapitre relatif à l'analyse
préalable
Ce chapitre comprend deux sections :
i' Section1 : Présentation de Holding
Business & Communication i' Section2 : Analyse de
l'existant
· Deuxième chapitre relatif à la
conception de la base de données en MERISE.
La troisième partie a été
consacrée à la réalisation de l'application sous la
plate-forme EASY PHP, repartit en deux chapitres :
· Premier chapitre relatif au codage de l'application
web
· Deuxième chapitre relatif au test de
l'application
Cependant, nous tenons à signaler que ce travail
constitue une première et passionnante expérience dans notre
domaine de formation, à savoir l'informatique de gestion ; nous croyons
donc modestement avoir apporter une solution informatique aux besoins des
utilisateurs de cette application et restons toujours ouverts aux
éventuels critiques constructifs et suggestions dans le seul but
d'améliorer cette oeuvre intellectuelle.
106
107
Nous ne pouvons finir sans remercier une fois de plus ceux
qui, de près ou de loin nous ont aidés à rendre ce travail
possible.
107
108
BIBLIOGRAPHIE
I. OUVRAGES
1. AUDIBET, L.2002. Base de données et langage SQL, notes
de cours, Université du Var ;
2. BAUGAS, A. 2009. En quoi la gestion de l'E-réputation
est-elle devenue un facteur de réussite primordiale pour nos entreprises
?, Ecole Supérieure de Commerce, Montpellier ;
3. ENGELS, J.2009. PHP5 cours et exercices, Saint-Germain 75240
Paris 61, bd Cedex 05 : Éditions EYROLLES ;
4. LE MAITRE, J.2005. Bases de données
relationnelles-généralités, Université de Toulan et
du Var : Éditions EYROLLES ;
5. LEMAITRE J.2005. les bases de données relationnelles
et leur système de gestion, Université de Toulan et du Var:
Éditions EYROLLES ;
6. MASSIMANGO, N. 2011. Implémentation d'un
système de vote électronique,
Mémoire, Université de Kinshasa ;
7. Michel, L.2002. les web services :
définition, technologie, acteurs, impacts sur les
entreprises et problèmes, Montréal ;
8. SOSA M.2011. Développement d'un système
d'information informatisé pour la gestion des cotes des
élèves « cas de l'école primaire DIZOLELE »,
Mémoire, UNIKIN;
9. MVIBUDULU K. et KONKFIE, F. 2010.Techniques de base de
données : études et cas. Kinshasa : édition CRIGED.
108
109
Table des matières
Epigraphe i
Dédicace ii
Avant-propos iii
CHAPITRE 1 : INTRODUCTION 1
1. Problématique 1
2. Hypothèses 1
3. Choix et intérêt du sujet
2
4. Méthodes et techniques utilisées
3
4.1. Méthodes de travail 4
4.2. Techniques de travail 4
5. Délimitation dans l'espace du sujet
4
PREMIERE PARTIE : NOTIONS THEORIQUES 5
CHAPITRE 2 : REVUE DE LA LITTERATURE 6
2.1. Système d?information 6
B. Le cycle d'abstraction de conception de
système d'information 7
2.2. Base de données 8
2.2.1. Quid Base des données 8
2.2.3. Planification d'une base de données
11
2.2.4. Système de gestion de base de
données(SGBD) 11
2.2.4.1. Quid SGBD 11
A. Historique 12
B. Principes de fonctionnement 12
C. Objectifs d'un SGBD 13
D. La notion de Modèle de Données
14
E. Les Principaux Systèmes de Gestion de Base
de Données 17
F. Le matériel (serveur de BDD) 18
G. Administration de la base de données
20
H. Les différents modèles de Bases de
Données 20
2.3. Internet 25
1. Historique de « Internet »
25
2. Internet : « Le réseau des
réseaux » 26
2.4. Principaux services offerts par Internet
26
2.4.1. Web 26
a. L'historique du Web 26
b. Philosophie du Web 28
c. les web services 29
d. Protocoles, langages et logiciels 30
e. Le logiciel client du web 31
f. L'adresse des pages visitées 31
g. Le protocole http 31
h. Le langage HTML 31
i. La recherche d'informations 32
109
110
2.4.2. E-mail (Electronic-mail) 32
2.4.3. Le transfert de fichier (FTP) 36
2.4.4. Les pages web et les applications en
ligne 37
2.5. Architecture client-serveur 37
2.6. Examination de la littérature 39
DEUXIEME PARTIE : ANALYSE PREALABLE ET CONCEPTION
42
CHAPITRE 3 : ANALYSE PREALABLE 43
Section 1. Présentation de HBC SPRL 43
Section 2. Analyse de l'existant 43
Voici la répartition des tâches du système
existant : 44
CHAPITRE 4 : CONCEPTION DE LA BASE DE DONNEES EN MERISE 52
Section 1. Système d'information organisé 54
Section 2. Système d'information informatisé 69
TROISIEME PARTIE : REALISATION DE L'APPLICATION WEB SOUS
LA PLATE-
FORME « EASY PHP » 96
CHAPITRE 5 : CODAGE DE L'APPLICATION WEB (HTML & PHP) 97
Section 1. Le langage HTML 97
Section 2. Le langage PHP 99
CHAPITRE 6 : TEST 104
CONCLUSION 106
BIBLIOGRAPHIE 108
110
| 

