2.2.2. Description des critères d'une base de
données
- Structuration : Ce terme fait allusion aux
conditions de stockage des informations et à la manière dont ces
dernières seront utilisées.
- Non redondance : C'est un critère
qui interdit à la Base de données de contenir des informations
répétitives. Nous avons deux formes de redondance à savoir
:
La synonymie : c'est lorsque deux objets ont la
même signification. Par exemple : Nom et Name ; Désignation et
libellé.
La polysémie : c'est lorsqu'un objet
renvoie a plusieurs significations.
Exemple :
Animal
|
Nom
|
|
Nom d'une personne
Nom d'un article
|
10
- Exhaustivité : C'est le principe selon
lequel la Base de données doit contenir n toutes les informations
nécessaires afin de répondre aux besoins des utilisateurs et ce,
à tous les niveaux de hiérarchie.
Pour ce faire, l'Analyste ou le Concepteur est obligé
à bien recenser
les besoins des utilisateurs à partir desquels, il va
collecter les données qui seront logées dans la Base.
2.2.3. Planification d'une base de données
Une base de données doit être conçue, raison
pour laquelle, il est conseillé de la concevoir sur papier avant son
implémentation sur un micro-ordinateur.
C'est pareil avec le travail d'un architecte qui avant de
construire une maison, conçoit d'abord son plan sur papier.
Ainsi, la conception d'une base de données exige la mise
en application de ses trois critères techniques : la structuration, la
non redondance et l'exhaustivité, cela, en utilisant une méthode
de conception des systèmes d'information telle que MERISE
(Méthodes d'Etudes et de Réalisation Informatiques des
Systèmes d'Entreprise), ou une technique de modélisation comme
UML et autres (Mvibudulu & Konkfie, 2010).
2.2.4. Système de gestion de base de
données(SGBD)
2.2.4.1. Quid SGBD
Un SGBD (Système de gestion de base de données)
est un système de stockage de l'information qui assure la recherche et
la maintenance. Les données sont persistantes (gestion de disques),
partagées entre de nombreux utilisateurs ayant des besoins
différents, qui les manipulent à l'aide de langage
appropriés. Le système assure également la gestion de la
sécurité et des conflits d'accès.
Il faut remarquer que les données sont accessibles
directement, alors que les systèmes de banques de données
antérieures ne fournissaient qu'un accès à un ensemble
plus ou moins vaste au sein duquel il fallait encore faire une recherche
séquentielle. On retrouve ce dernier mode de fonctionnement quand on
utilise sur Internet des navigateurs de recherche qui exploitent des moteurs de
bases de données.
11
A. Historique
Le mot Data Base est un apparu en 1964 lors d'une
conférence sur ce thème aux USA, organisée dans le cadre
du programme spatial américain.
Auparavant, on ne connaissait que des systèmes de
gestion de fichiers (SGF), basés sur la gestion de bandes
magnétiques, destinés à optimiser les accès
séquentiels. Les disques étaient alors chers et
réservés à de petits fichiers.
Peu après (~ 1970) apparaissent les premiers SGBD,
conçus selon les modèles hiérarchiques, puis
réseaux. On voit apparaitre des langages de navigation et la description
des données est indépendante des programmes d'application. Cette
première génération suit les recommandations du DTBG
CODASYL (Data Base Task Group - Conference On Data System Language),
influencé par le système IMS d'IBM.
Le modèle relationnel voit jour en 70 et met 20 ans
pour s'imposer sur le marché. Ce modèle permet la naissance de
langages assertionnels, basés sur la logique du premier ordre et les
traitements ensemblistes. Dans le même temps, l'emploi des disques se
généralise, les accès directs deviennent la règle,
le développement des techniques d'optimisation assurent aux SGBD des
performances largement équivalentes à celles des anciens
modèles de données.
Au cours des années 80, de nouveaux besoins se font
jour. Les systèmes mis jusque-là sur le marché
privilégiaient des données de gestion. On cherche de plus en plus
à manipuler des données techniques, des images, du son. De
nombreux travaux de recherche tentent de faire le lien avec le monde
Orienté-Objet ainsi qu'avec les systèmes
d'inférence utilisés en Intelligence Artificielle.
Compte tenu de l'inertie du marché, il faudra attendre encore une
dizaine d'années pour qu'un modèle vraiment nouveau et performant
commence à l'envahir. On commence à parler en 96 d'une «
évolution progressive » vers le modèle relationnel-Objet
à partir de 1988.
B. Principes de fonctionnement
La gestion et l'accès à une base de
données sont assurés par un ensemble de programmes qui
constituent le Système de gestion de base de données (SGBD). Un
SGBD doit permettre l'ajout, la modification et la recherche de données.
Un système de gestion de bases de données héberge
généralement plusieurs bases de données, qui sont
destinées à des logiciels ou des thématiques
différentes.
Actuellement, la plupart des SGBD fonctionnent selon un mode
client/serveur. Le serveur (sous-entendu la machine qui stocke les
données)
12
reçoit des requêtes de plusieurs clients et ceci
de manière concurrente. Le serveur analyse la requête, la traite
et retourne le résultat au client.
Le modèle client/serveur est assez souvent
implémenté au moyen de l'interface des sockets (voir le cours de
réseau); le réseau étant Internet.
Une variante de ce modèle est le modèle ASP
(Application Service Provider). Dans ce modèle, le client s'adresse
à un mandataire (broker) qui le met en relation avec un SGBD capable de
résoudre la requête. La requête est ensuite directement
envoyée au SGBD sélectionné qui résout et retourne
le résultat directement au client.
Quel que soit le modèle, un des problèmes
fondamentaux à prendre en compte est la cohérence des
données. Par exemple, dans un environnement où plusieurs
utilisateurs peuvent accéder concurremment à une colonne d'une
table par exemple pour la lire ou pour l'écrire, il faut s'accorder sur
la politique d'écriture.
Cette politique peut être : les lectures concurrentes
sont autorisées mais dès qu'il y a une écriture dans une
colonne, l'ensemble de la colonne est envoyée aux autres utilisateurs
l'ayant lue pour qu'elle soit rafraîchie (Audibert, 2009).
C. Objectifs d'un SGBD
Des objectifs principaux ont été fixés
aux SGBD dès l'origine de ceux-ci et ce, afin de résoudre les
problèmes causés par la démarche classique. Ces objectifs
sont les suivants :
Indépendance physique : La
façon dont les données sont définies doit être
indépendante des structures de stockage utilisées.
Indépendance logique : Un même
ensemble de données peut être vu différemment par des
utilisateurs différents. Toutes ces visions personnelles des
données doivent être intégrées dans une vision
globale.
Accès aux données :
L'accès aux données se fait par l'intermédiaire d'un
Langage de Manipulation de Données (LMD). Il est crucial que ce langage
permette d'obtenir des réponses aux requêtes en un temps «
raisonnable ».
Le LMD doit donc être optimisé, minimiser le
nombre d'accès disques, et tout cela de façon totalement
transparente pour l'utilisateur.
Administration centralisée des données
(intégration) : Toutes les données doivent être
centralisées dans un réservoir unique commun à toutes les
applications. En effet, des visions différentes des données
(entre autres)
13
se résolvent plus facilement si les données sont
administrées de façon centralisée.
Non redondance des données : Afin
d'éviter les problèmes lors des mises à jour, chaque
donnée ne doit être présente qu'une seule fois dans la
base.
Cohérence des données : Les
données sont soumises à un certain nombre de contraintes
d'intégrité qui définissent un état cohérent
de la base. Elles doivent pouvoir être exprimées simplement et
vérifiées automatiquement à chaque insertion, modification
ou suppression des données.
Les contraintes d'intégrité sont décrites
dans le Langage de Description de Données (LDD).
Partage des données : Il s'agit de
permettre à plusieurs utilisateurs d'accéder aux mêmes
données au même moment de manière transparente. Si ce
problème est simple à résoudre quand il s'agit uniquement
d'interrogations, cela ne l'est plus quand il s'agit de modifications dans un
contexte multi-utilisateurs car il faut : permettre à deux (ou plus)
utilisateurs de modifier la même donnée « en même temps
» et assurer un résultat d'interrogation cohérent pour un
utilisateur consultant une table pendant qu'un autre la modifie.
Sécurité des données :
Les données doivent pouvoir être protégées contre
les accès non autorisés. Pour cela, il faut pouvoir associer
à chaque utilisateur des droits d'accès aux données.
Résistance aux pannes : Que se
passe-t-il si une panne survient au milieu d'une modification, si certains
fichiers contenant les données deviennent illisibles ? Il faut pouvoir
récupérer une base dans un état « sain ». Ainsi,
après une panne intervenant au milieu d'une modification deux solutions
sont possibles : soit récupérer les données dans
l'état dans lequel elles étaient avant la modification, soit
terminé l'opération interrompue (Audibert, 2009).
D. La notion de Modèle de
Données
C'est une notion très essentielle dans le sens
où elle sert de motivation quant au choix de l'utilisation ou non d'une
base de données lors de la conception d'un système.
En effet, la résolution d'un problème par un
automate nécessite de représenter l'information sur le domaine
traité appelé parfois mini monde ou univers du discours sous une
forme digitale qui soit interprétable et manipulable par un
ordinateur.
14
Le modèle doit donc être spécifié
en utilisant des données codées et stockées en
mémoire ainsi que par des opérations (programmes) qui
déterminent comment ces données peuvent être
utilisées pour résoudre le problème posé.
Un modèle peut se définir comme une
représentation abstraite de l'information et éventuellement des
opérateurs de manipulation de l'information.
Sur le plan fonctionnel, voilà ce dont on peut attendre
d'un Système de Gestion de Base de Données (Massimango, 2011)
:
- Supporter les concepts définis au niveau du
modèle de données. Ceci afin de pouvoir représenter les
propriétés des données. Ce niveau de représentation
n'est pas nécessairement lié à la représentation
interne sous forme de fichiers. Il regroupe en général la
définition de types spécifiques et la définition de
règles de cohérence ;
- Rendre transparent le partage des données entre
différents utilisateurs. Ceci signifie que plusieurs utilisateurs
doivent pouvoir utiliser la base de façon concurrente et transparente.
Le problème posé ici est du fait que le SGBD pour des raisons
évidentes de performances (partage du CPU) doit permettre des
exécutions concurrentes sur une même base de données ;
- Assurer la confidentialité des données. Il est
nécessaire de pouvoir spécifier qui a le droit d'accéder
ou de modifier tout ou partie d'une base de données. Il faut donc se
prémunir contre les manipulations illicites qu'elles soient
intentionnelles ou accidentelles. Cela nécessite d'une part, une
spécification des droits ajout, suppression, mis à jour). Il est
patent que garantir la confidentialité des données engendre un
surcout en temps au niveau des manipulations ;
- Assurer le respect des règles de cohérence
définies sur les données. A priori, après chaque
modification sur la base de données, toutes les règles de
cohérence doivent être vérifiées sur toutes les
données. Evidemment, une telle approche est irréalisable pour des
raisons de performances et il faut déterminer des moyens de trouver
précisément quelles règles et quelles données sont
susceptibles d'être concernées par les traitements
réalisés sur la base de données. Ces traitements doivent
pouvoir être effectués sans arrêter le système.
- Fournir différents langages d'accès selon le
profil de l'utilisateur. En général, on admet que le SGBD doit au
moins supporter un langage adressant les concepts du modèle. Dans le cas
du modèle relationnel, ce langage est le langage SQL. Néanmoins
ce type de langage ne permet pas tous les types de manipulations et les SGBD
proposent soit un langage plus complet au sens Turing du terme avec la
possibilité de définir des accès à la base de
données, soit un couplage d'un langage tel que SQL avec un langage de
programmation conventionnel (tels que le langage C ou le langage Cobol).
15
La définition d'une interface entre une base de
données et le Web pose ce type de problème de
spécification et de navigation dans une base de données ;
- Etre résistant aux pannes. Ceci afin de
protéger les données contre tout incident matériel ou
logiciel qu'il soit intentionnel ou fortuit. Il faut donc garantir la
cohérence de l'information et des traitements en cas de panne. Les
applications opérant sur des bases de données sont souvent par
nature amenées à opérer des traitements longs sur
d'importants volumes de données. Les possibilités de panne en
cours de traitement sont donc nombreuses et il faut fournir des
mécanismes de reprise en cas de panne ;
- Posséder une capacité de stockage
élevée. Permettre ainsi la gestion de données pouvant
atteindre plusieurs milliard d'octets. Les capacités de stockage des
ordinateurs sont en augmentation croissante. Cependant, les besoins des
utilisateurs sont également en croissance forte. Avec l'essor des
données multimédia (texte, image, son, vidéo) les besoins
sont encore accrus. Les unités de stockage sont passées du
mégaoctet(106) au gigaoctet (109), puis au
téraoctet (1012), pétaoctet (1016) et on
déjà à parler de exaoctet(1018) voir de
zettaoctet(1021) ;
- Pouvoir répondre à des requêtes avec un
niveau de performances adapté. Une requête est une recherche
d'information à effectuer sur une ou plusieurs bases de données
qui peut impliquer des caractéristiques descriptives sur l'information
ou des relations entre les données. La puissance des ordinateurs n'est
pas la seule réponse possible à apporter aux problèmes de
performance. Une requête peut généralement être
décomposée en opérations élémentaires.
L'ordre d'exécution des opérations en fonction de leurs
propriétés (associativités, commutativité) ainsi
que le regroupement de certaines opérations utilisant le même
ensemble de données sont des éléments qui permettent de
diminuer significativement le temps d'exécution d'une requête ;
- Fournir des facilités pour la gestion des
méta-données. Par exemple à travers un dictionnaire de
données ou un catalogue système. Les méta-données
concernent les données sur le schéma de la base de données
(relations, attributs, contraintes, vues), sur les données (vues), sur
les utilisateurs (identification, droits) et sur le système
(statistiques). Ces données doivent être gérées et
consultées de la même manière que les données
afférentes à l'application. Cette notion de catalogue assure
également une certaine flexibilité au niveau de l'utilisation du
SGBD. Cette flexibilité permettant l'ajout sous contrôle de
nouveaux utilisateurs ainsi que la modification de structures de données
existantes sous certaines conditions. De plus, ce type d'information permet
entre autre à l'administrateur de la base de données ou au SGBD
lui-même d'adapter la politique de stockage en fonction du contenu.
16
Les SGBD peuvent varier selon leur complexité. Il n'est
donc pas rare de rencontrer des systèmes de gestion qui possèdent
tout ou une partie des propriétés citées ci-haut.
Ainsi lorsque l'on prend par exemple le SGBD relationnel
Oracle 7 le SGBD relationnel Access. Ce sont deux produits assez
caractéristiques pour exprimer ce que nous venons de dire. Le SGBD
Oracle 7 est un SGBD relationnel utilisé pour des applications critiques
et qui offre un maximum des caractéristiques présentées
ici. Le SGBD Access est un SGBD dans le monde de l'informatique individuelle
qui présente l'avantage d'une grande facilité d'utilisation et
qui peut convenir à des applications de taille réduite ou
moyenne. L'aspect convivial de ce dernier étant évident. En
revanche, les niveaux de performance et de sécurité ne sont pas
comparables (Massimango, 2011).
E. Les Principaux Systèmes de Gestion de Base de
Données
Les éditeurs de SGBD se partagent un marché
mondial en lente régression depuis deux ans : 8-9 milliards de dollars
en 2000, 7-8 milliards de dollars en 2001 et 6-7 milliards de dollars en 2002,
les chiffres variant quelque peu selon les sources. Les principaux
éditeurs (avec leurs parts de marché en l'an 2002,
calculées sur le chiffre d'affaires) sont :
- IBM (36%), éditeur des SGBD DB2
(développé en interne - mis sur le marché en 1984) et
Informix (obtenu par achat de l'entreprise correspondante en 2001 ; la
société Informix avait été créée en
1981. Une version bridée de DB2 vient d'apparaitre sur le marché,
où elle concurrence SQL Server de Microsoft ;
- Oracle (34%) éditeur du SGBD qui porte le meme nom.
Cette entreprise a été créée en 1977 ;
- Microsoft (18%), éditeur de trois SGBD. SQL Server
est destiné aux gros systèmes, Access est un produit de
bureautique professionnelle, et Foxpro est destiné aux
développeurs. L'arrivée de Microsoft sur le marché des
SGBD date des années 90 ;
- Sybase (<3%). Cette entreprise, qui a été
créée en 1984, est aujourd'hui marginalisée.
Ces chiffres recouvrent des réalités
contrastées, quand on les fractionne par plate-forme. Dans le monde
Unix, Oracle est en tête avec 62% suivi d'IBM (Informix compris) avec
27%, alors que Microsoft n'est pas présent sur ce marché. Dans le
monde Windows, Microsoft a pris la tête avec 45%, suivi d'Oracle avec 27%
et d'IBM avec 22%.
Le classement par nombre d'exemplaires(ou licences) vendus est
très différent. Il met en avant les SGBD conçus pour
gérer les bases de taille
17
modeste ou modérée. Dans ce domaine
l'éditeur Microsoft, qui vend plusieurs millions d'exemplaires de son
logiciel Access par mois, pulvérise tous les records. L'usage des SGBD
se démocratise à toute vitesse, bien qu'un SGBD soit plus
difficile à maitriser qu'un traitement de texte ou un tableur (pour ne
citer que les logiciels les plus courants). L'image du SGBD servant uniquement
les très grosses bases, propriété d'une grande
multinationale, fonctionnant sous Unix sur une machine monstrueuse,
géré par un administrateur dictatorial, et coutant un prix fou- a
vécu. Bon débarras !
Un SGBD est principalement constitué d'un
moteur et d'une interface graphique. Le
moteur est le coeur du logiciel, c'est-à-dire qu'il assure les fonctions
essentielles : saisir les données, les stocker, les manipuler, etc.
l'interface graphique permet à l'utilisateur de communiquer
commodément avec le logiciel. Pour dialoguer avec le SGBD qui n'est pas
équipés d'une interface graphique, il faut utiliser le
langage SQL (Structured Query Language), et introduire les
instructions à l'aide d'un éditeur de lignes.
Langage normalisé de manipulation des bases de
données, SQL est utilisable avec pratiquement tous les SGBD du
marché. Cependant, chaque éditeur ayant développé
son propre « dialecte » --comme c'est toujours le cas en informatique
- il faut pouvoir disposer d'un « dictionnaire » pour transporter une
BD d'un SGBD à l'autre. Ce « dictionnaire » a
été développé par Microsoft sous le nom
ODBC (Open Data Base Connectivity) (MASSIMANGO Ntoya, op.cit.,
p.31-32).
Il existe de nombreux système de gestion de base de
données, en voici une liste non exhaustive :
- PostgreSQL
- MySQL
- Oracle
- IBM DB2
- Microsoft SQL
- Sybase
- Informix
F. Le matériel (serveur de BDD)
Le choix du matériel informatique sur lequel on
installe un SGBD est fonction, comme ce dernier, du volume des données
stockées dans la base du nombre maximum d'utilisateurs
simultanés.
Lorsque le nombre d'enregistrements par table n'excède
pas le million, et que le nombre d'utilisateurs varie d'une à quelques
personnes, un micro-ordinateur actuel de bonnes performances, un logiciel
système pour poste de travail, et un SGBD « Bureautique »
suffisent. Exemple : le logiciel
18
Access 2002 de Microsoft, installé sur un PC
récent, doté de 1Go de mémoire vive et fonctionnant sous
Windows XP.
Si ces chiffres sont dépassés, ou si le temps de
traitement des données devient prohibitif, il faut viser plus haut. Le
micro-ordinateur doit être remplacé par un serveur de BDD,
dont les accès aux disques durs sont nettement plus rapides.
Le logiciel système client doit être
remplacé par un logiciel système serveur (donc
multi-utilisateurs), et le SGBD bureautique par un SGBD prévu pour les
grosses BDD multi-clients. Ceci dit, la structure d'une grosse base n'est pas
différente de celle d'une petite, et il n'est pas nécessaire de
disposer d'un « mainframe » (une grosse machine) gérant des
milliers de milliards d'octets pour apprendre à se servir des BDD. Ce
n'est pas parce qu'il gère un plus grand volume de données qu'un
SGBD possède plus de fonctionnalités.
Quelle que soit la taille, le système constitué
de la machine et du SGBD doit être correctement équilibré.
Un serveur de BDD doit posséder à la fois les qualités de
serveur de fichier (bon accès aux disques) et celles d'un serveur
d'applications (unité centrale bien dimensionnée, mémoire
vive suffisante). En observant un serveur de BDD en cours de fonctionnement, on
peut observer les trois cas de déséquilibre suivants :
- La machine fait du « swapping »,
c'est-à-dire qu'elle passe son temps à promener des
données entre la mémoire vive et la mémoire virtuelle
(laquelle réside sur disque). Le remède consiste à
augmenter la mémoire vive -si la chose est matériellement
possible ;
- Si l'unité centrale est sous-occupée, alors
que le disque dur ne cesse de tourner, la machine est sous-dimensionnée
quant à sa mémoire de masse. Les remèdes : utiliser une
interface disque plus performante(SCSI), un disque dur plus rapide, un
système RAID 0. Ce cas est le plus fréquemment rencontré
;
- Si l'unité centrale est utilisé à fond,
alors que le les disques durs sont peu sollicités, la machine est
sous-motorisée. Les remèdes : utiliser une machine
possédant des processeurs plus rapides, ou un plus grand nombre de
processeurs.
Jusqu'à une date récente, les constructeurs de
serveurs (et les éditeurs de SGBD) conseillaient à leurs clients
de consolider leurs données, en les rassemblant dans un nombre minimum
de grosses BDD, installées sur un nombre minimum de serveurs
surpuissants. Comme le cout des serveurs croit exponentiellement avec le nombre
de processeurs, et que le cout des licences (des SGBD) est proportionnel au
nombre de processeurs, constructeurs et éditeurs ont gagné de
l'or pendant la dernière décennie. Avec l'éclatement de la
bulle Internet, les cordons de la bourse se sont resserrés, si
19
bien que les services informatiques des entreprises commencent
à recourir - de gré ou de force - à des systèmes
plus décentralisés et de taille plus raisonnable (Massimango,
2011).
G. Administration de la base de
données
L'ensemble « serveur BDD +SGBD » constitue un
système informatique dont l'importance ne cesse de croitre dans
l'Entreprise. La personne responsable de la maintenance et de
l'évolution de ce système s'appelle l'administrateur de la
base de données. Dès que l'Entreprise atteint la taille
d'une grosse PME, l'administrateur de la BDD peut nécessiter la
présence d'une personne à temps plein, voire plus.
Etre administrateur de BDD requiert des compétences
particulières, très différentes de celles requises pour
être administrateur de réseau ou de système informatique.
Il en résulte le développement de deux pôles de
compétences informatiques dans l'entreprise. On remarque que, dans
l'entreprise toujours, la spécialisation des informaticiens
s'accroit.
Pour être complet, il faut signaler que le
développement des sites web contribue à créer un
troisième pôle de compétence dans l'entreprise. Le
responsable correspondant est appelé webmestre, et non «
administrateur de site », parce que le poste requiert des
compétences multidisciplinaires (et pas seulement informatique)
(Massimango, 2011).
H. Les différents modèles de Bases de
Données
Les bases de données du modèle «
relationnel » sont les plus répandues (depuis le milieu des
années 80), car elles conviennent bien à la majorité des
besoins des entreprises. Le SGBD qui gère une BDD relationnelle est
appelé « SGBD relationnel », ce qui est souvent
abrégé an SGBDR.
D'autres modèles de bases de données ont
été proposés : hiérarchique, en réseau,
orienté objet, relationnel objet. Aucun d'entre eux n'a pu
détrôner le modèle relationnel, ni se faire une place
notable sur le marché (sauf le relationnel, prôné par
Oracle, qui connait un certain développement).
Malgré sa généralité, le
modèle relationnel ne convient pas à toutes les BDD
rencontrées en pratique. Il existe donc des SGBD
spécialisés. Les deux exemples les plus connus
concernent la gestion des BDD bibliographiques (ou documentaires), et celle des
BDD géographiques gérées à l'aide d'un SIG
(Système d'Information Géographique).
Voyons un peu les quatre principaux modèles :
a. Modèle relationnel
Une base de données relationnelle est une base de
données structurée suivant les principes de l'algèbre
relationnelle.
20
Le père des bases de données relationnelles est
Edgar Frank Codd. Chercheur chez IBM à la fin des années 1960, il
étudiait alors de nouvelles méthodes pour gérer de grandes
quantités de données car les modèles et les logiciels de
l'époque ne le satisfaisaient pas.
Une base de données relationnelle est constituée
par :
· Un ensemble de domaine : un domaine
est un ensemble de valeurs atomiques.
On distingue :
o Les domaines prédéfinis :
chaines de caractères, entiers, réels booléens, date...
o Les domaines définis :
i' En extension,
c'est-à-dire en énumérant les valeurs. Par exemple :
couleur= {`'rouge `',»vert», `'bleu», `'jaune''}
i' En intension,
c'est-à-dire en donnant la formule que doit vérifier chaque
valeur, par exemple : Mois= {m| m ? Entier et 1=m=12}
· Un ensemble de relations : une
relation R est un sous-ensemble du produit cartésien de n domaines
D1,..., Dn : une relation est définie par son nom,
par son type et par son extension.
i' Le type d'une relation est une expression de
la forme :
rel(A1 :D1 ,...,An :Dn)
Où chaque Di est un domaine et chaque Ai est un
nom
d'attribut qui indique le role du domaine Di
dans la
relation. Par exemple :
rel (Nom : Chaine, Age : Entier, Marié :
Booléen)
est le type d'une relation construite sur les domaines
chaines, Entier et Booléen et dont le premeier représente un nom,
le second un age et le troisieme le fait d'etre marié ou non...
i' L'extension d'une relation de type rel(A1
:D1,...,An :Dn) est un ensemble de nuplets :
{A1=v1,...,An=vn} tels que v1 ? D1,...,vn ?
Dn.
L'extension d'une relation est variable au cours de la vie de
la base de données. Par exemple : {{Nom= 'Dupont'', Age=36,
Marié= Vrai} {Nom=''Durand'', Age=22, Marié= Faux}} est une
extension de la relation de type : rel (Nom : Chaine, Age : Entier,
Marié : Booléen)
i' Nous appelons schéma d'une
relation l'expression :
R (A1 :D1,..., An : Dn) qui
désigne une relation de nom R et de type rel(A1 :D1,...,An
:Dn). Par exemple : Personne (Nom : Chaine, Age : Entier,
Marié : Booléen)
Lorsque l'indication des domaines n'est pas requise, un
schéma de relation peut se réduire à l'expression :
R(A1,...,An )
i' Deux visions d'une relation
o Vision tabulaire : l'extension d'une
relation de schéma R(A1 :D1,...,An :Dn) peut etre
vue comme une table de nom R possédant n colonnes nommées
A1,...,An et dont chaque ligne représente un n-uplet de cette
extension. Par exemple :
Personne
|
Nom
|
Age
|
Marié
|
Dupont
|
36
|
Vrai
|
Durand
|
22
|
Faux
|
|
21
o Vision assertionnelle
A toute relation de schéma R(A1 :D1,...,An
:Dn) il est associé un prédicat R tel que l'assertion
R t est vraie si le n-uplet t appartient à l'extension
de R et fausse sinon. Par exemple, l'assertion :
Personne
{Nom :»Dupont», Age =36, Marié= Vrai} est
vraie.
? Un ensemble de contraintes
d'intégrité
o 1er cas : Relation du type père-fils :
contrainte d'intégrité fonctionnelle (CIF)
Ce cas intervient lorsque dans le modèle conceptuel de
données, nous retrouvons les couples (0,1) ou (1,1) d'une part et (0,n)
ou (1,n) d'autre part.
C'est-à-dire nous pouvons avoir les combinaisons
suivantes :
(0,1)
|
(0, n)
|
(0,1)
|
(1, n)
|
(1,1)
|
(0, n)
|
(1,1)
|
(1, n)
|
|
0,1 : aucune ou une fois
1,1 : au moins une fois au plus une fois
0, n : aucune ou plusieurs fois
1, n : au moins une fois, au plus plusieurs fois
Dans ce cas, la relation disparait mais sa sémantique
demeure, car l'objet qui a la cardinalité (0, n) ou (1, n) est
considéré comme père et cède sa clé primaire
à l'objet qui a la cardinalité (0,1) ou (1,1) qui à son
tour est considéré comme fils.
Etant donné que le fils possède une clé
primaire, celle qu'elle vient d'hériter du père est une
clé étrangère parce qu'elle est clé primaire dans
sa table respective. Si la relation était porteuse des
propriétés, elles migrent vers la table fils.
o 2ème cas : la cardinalité multiple :
Relation du type père-père (contrainte d'intégrité
multiple : CIM)
Ce cas intervient lorsqu'on a d'une part le couple (0, n) ou
(1, n), d'autre part (0, n) ou (1, n). C'est-à-dire la combinaison
ci-après :
|
(0, n)
|
(0, n)
|
|
(0, n)
|
(1, n)
|
|
(1, n)
|
(1, n)
|
(0, n) : aucune ou plusieurs fois (1, n) : une fois ou plusieurs
fois
Dans ce cas (premier cas), la relation devient une table de
lien et autre comme clé primaire la concaténation des clés
primaires de deux tables
22
qu'elle reliait. Si la relation était porteuse des
propriétés, celles-ci deviennent ses attributs (Mvibudulu &
Konkfie, 2012).
Exemple d'une base de données relationnel
Client
Numcli # Nomcli Catcli
Adresse
vélo
Code_vel # Marque Couleur
Date_achat Numcli #
Figure 6.1 Schéma d'un modèle
relationnel
b. Modèle Hiérarchique
Une base de données hiérarchique est une forme
de système de gestion de base de données qui lie des
enregistrements dans une structure arborescente de façon à ce que
chaque enregistrement n'ait qu'un seul possesseur (par exemple, une paire de
lunettes n'appartient qu'à une personne).
Les structures de données hiérarchiques ont
été largement utilisées dans les premiers systèmes
de gestion de base de données conçus pour la gestion des
données du programme Apollo de la NASA. Cependant, à cause de
leurs limitations internes, elles ne peuvent pas souvent être
utilisées pour décrire des structures existantes dans le monde
réel.
Les liens hiérarchiques entre les différents
types de données peuvent rendre très simple la réponse
à certaines question, mais très difficile la réponse
à d'autres formes de questions. Si le principe de relation « 1 vers
N » n'est pas respecté (par exemple, un malade peut avoir plusieurs
médecins et un médecin a, à priori, plusieurs
patients), alors la hiérarchie se transforme en un réseau
(Massimango, 2011).
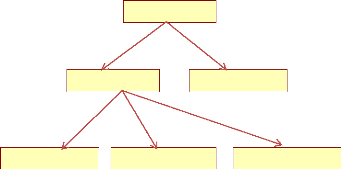
Figure 6.2 schéma d'un modèle
hiérarchique
23
c. Modèle Réseau
Le modèle réseau est en mesure de lever de
nombreuses difficultés du modèle hiérarchique grâce
à la possibilité d'établir des liaisons de type n-n,
les liens entre objets pouvant exister sans restriction. Pour retrouver une
donnée dans une telle modélisation, il faut connaitre le chemin
d'accès (les liens) ce qui rend les programmes dépendants de la
structure de données.
Ce modèle de base de données a
été inventé par C.W. Bachman. Pour son modèle, il
reçut en 1973 le prix Turing.
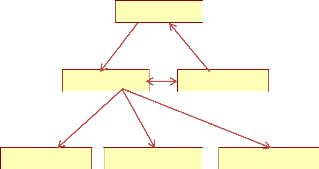
Figure 6.2 Schéma d'un modèle
Réseau
d. Modèle Objet
(SGBDO, Système de gestion de base
de données objet) : les données sont stockées sous
forme d'objets, c'est-à-dire de structures appelées classe
présentant des données membres. Les champs sont des
instances de ces classes.
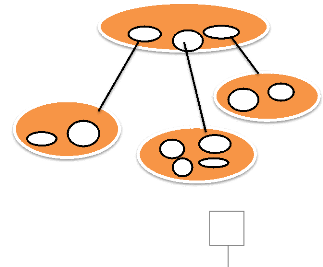
Figure 6.3 Schéma d'un modèle objet
24
La notion de bases de données objet ou
relationnel-objet est plus récente et encore an phase de recherche
et de développement. Elle sera très probablement ajoutée
au modèle relationnel (Massimango, 2011).
| 

