Automatisation des lignes de produits logiciels en entreprisepar Thomas Petit - M2 Informatique 2019 |

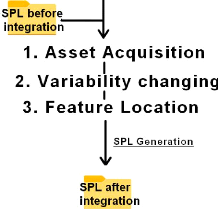
Résumé LPLL'ingénierie des lignes de produits logiciels est donc un ensemble de méthodes et de techniques qui tente de systématiser et d'encadrer la conception d'une famille de logiciels. Ses deux principes fondamentaux sont la promotion des principes de personnalisation de masse des logiciels et de réutilisation systématique. Pour réaliser ces deux principes, l'ingénierie des LPL propose la conception d'une plateforme logicielle configurable, capable de varier en fonction de caractéristiques logicielles que les utilisateurs sélectionnent pour aboutir au produit désiré (une personnalisation de masse). Les produits (logiciels) d'une LPL sont donc tous construits depuis la même plateforme, ils partagent ainsi une partie de leur implémentation. La notion de variabilité est intrinsèque aux LPL. Leur variabilité est généralement modélisée par un modèle de caractéristique (feature-model en anglais). Ce modèle met en relation les différentes caractéristiques d'une LPL par rapport des contraintes de variabilité (par exemple, implications, exclusion, co-occurrences, ou autres conditions). Chaque caractéristique dispose d'une implémentation spécifique dans la plateforme d'une LPL, sous la forme d'un ensemble d'artefacts. Les artefacts sont des éléments de nature hétérogène (éléments de code, fichier texte, base de données, ressource sonore, etc.) et sont souvent décrits avec une granularité définie par les concepteurs de la LPL (Fichier-Classe, Méthode-Fonction, Instruction, etc.). La plateforme configurable regroupe et structure l'ensemble des artefacts de sorte qu'une sélection des caractéristiques puisse permettre de générer le produit correspondant. Cette génération par sélection est rendue possible par l'implémentation de mécanismes de variabilité dans la LPL. Il existe deux types d'approches pour implémenter la variabilité de la plateforme, l'approche par annotation et celle par composition. Si ces deux approches possèdent leurs forces et leurs limitations, il faut noter que l'approche par annotation reste plus accessible et intuitive pour les concepteurs que l'approche par composition ; elle permet aussi une implémentation avec une granularité plus fine. Enfin, l'ingénierie des LPL dispose de nombreux avantages face à une ingénierie monoproduits (c.-à-d. Logiciels individuels). Grâce à la réutilisation systématique, les LPL permettent une réduction des coûts de développement, une réduction du temps de mise sur le marché des produits, une diminution de l'effort de maintenabilité et une amélioration de la qualité des logiciels. Cependant, ces bénéfices n'apparaissent qu'à partir du troisième produit mis sur le marché), du fait d'un investissement initial important à fournir pour les LPL. RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT Nous allons désormais vous présenter notre outil SPL Generator : ce dernier est dans l'étape finale de conception. Débuté en Novembre 2018, SPL Generator a pour but de faciliter l'adoption des Lignes de produits logicielles en entreprise en offrant aux développeurs une facilité d'exécution. 10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT SPL generator Les objectifs de l'approche Notre l'approche SPL Generator, est une approche réactive automatisé. Elle est schématisée dans la figure ci-dessous. C'est donc une approche construite sur un cycle en trois phases : L'intégration, la génération et la maintenance de la LPL.
10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT Nous proposons l'application de processus automatique pour réaliser l'ingénierie d'une LPL afin de réduire ses coûts. Notre hypothèse est que retirer l'effort lié à l'ingénierie manuelle permettra une meilleure adoption des LPL par les entreprises. Notre outil peut faciliter plus la construction d'une LPL puisque les risques liés aux coûts d'ingénierie sont réduits par l'automatisation des tâches. Cette réduction des coûts doit être accompagnée d'un effort d'adoption faible de l'approche, notamment pour limiter la résistance aux changements des développeur. Dans le chapitre précédent, nous avons exposé des différentes approches d'adoptions des Lignes de Produits Logiciels. Nous avons discuté des avantages et inconvénients de chacune d'entre elle, pour finalement retenir l'approche réactive comme étant la plus adapter aux métiers des développeurs et à celui des entreprises. Toutefois, nous avons mis en avant l'importance de proposer une automatisation de l'approche réactive, afin d'en réduire ses coûts. Ces coûts sont directement à la complexité de la réingénierie d'une Lignes de Produits. Mais également, nous avons fait le constat que les développeurs d'aujourd'hui préfèrent travailler sur une conception traditionnelle de logiciels, plutôt que sur une conception en vue d'incrémenter une Ligne de produits. Dans cette partie nous présentons notre outil : « SPL Generator », d'une approche réactive automatisé pour la création d'une Ligne de Produits Logiciels. Nous évoquerons les différentes étapes notre approche, de l'intégration à la génération de produits. Nous discuterons également des objectifs et des difficultés à surmonter pour réaliser cette approche. Cette partie répond à la question suivante : Comment construire une approche réactive automatique adapter aux développeurs ? Ces trois phases coïncident trois grands scénarios d'utilisation : Notre premier objectif est de s'appuyer sur les compétences existantes des développeurs de l'équipe IT, à savoir la conception efficace de logiciel en un minimum de temps et d'énergie. Cette compétence est maîtrisée et recherchée par les entreprises, qui favorise un développement rapide. Notre objectif vise donc à utiliser en entrée de la réingénierie les produits conçus par les développeurs : il s'agit du code source du logiciel. Cela confère à notre approche une meilleure conservation et une intégration aux processus de développement déjà en place dans les entreprises. Mais également, cela permettra de ne pas nécessiter l'acquisition de nouvelles compétences pour les développeurs et donc formations pour les entreprises. Le second objectif est la transparence de l'approche : son utilisation doit se faire en marge du développement des produits, afin de ne pas le retarder. Le principal défaut de l'adoption de l'ingénierie des LPL rapporté par l'industrie est l'investissement de départ pour la conception d'une ligne. Cet investissement perturbe les délais de mise sur le marché des entreprises. En souhaitant faciliter l'adoption de l'approche réactive, nous devons accepter ce constat et proposer une approche qui peut être déployée sans perturber les délais de conception déjà en place dans les entreprises. En claire, notre objectif est d'avoir un impact positif sur le temps de mise sur le marché, et non négatif, et cela dès les premiers produits. 10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 Il faut que cette génération automatique de la plateforme produise un résultat qui soit compréhensible par le plus grand nombre de développeurs, afin de renforcer le potentiel de maintenabilité de la LPL. C'est pourquoi dans notre approche, nous choisissons de construire une plateforme avec une représentation Annotative, car elle est réputée comme intuitive pour les développeurs. Comme annoncée précédemment, la construction de la LPL se fait au travers des produits. Dans notre approche, la LPL est utilisée pour faciliter le développement de nouveaux produits : au début d'un nouveau projet, on consulte la LPL pour générer un produit partiel, le plus proche possible des besoins exprimés. Une fois complété, ce produit sera intégré automatiquement dans la LPL et les nouveautés ou modification qu'il introduit seront ajoutés de façon disciplinée dans la LPL. Ainsi, le développement de nouveaux produits ne dépend plus d'une réingénierie manuelle et obligatoire de la LPL. Les développeurs sont libres de concevoir leurs produits comme ils ont l'habitude de le faire, i.e. sans se préoccuper de la gestion de la variabilité, de l'implémentation des caractéristiques, de l'impact des nouvelles caractéristiques sur les anciennes ou éventuellement de leurs interactions négatives. Cela a pour autre avantage de faire participer les développeurs non familiers avec les LPL aux développements de nouveaux produits. Nous faisons ici l'hypothèse que cela permettra aux entreprises de réduire l'effort de formation de leurs développeurs, voir même de le supprimer. Dernièrement, cette pratique permet s'adapter au processus de développement déjà en place dans l'entreprise. On permet aux équipes de développement de conserver une grande partie de leur façon de travailler (comme le choix de l'IDE par exemple). Ce qui permet de construire la LPL sans impacter la productivité des développeurs. Malheureusement, peu d'entreprises ont les moyens de construire l'ensemble de leur LPL en une seule traite. Il est de plus improbable que de nouveaux produits ne viennent pas s'ajouter à la LPL. Si l'on prend le cas des PME, ces entreprises fonctionnent de manière simple : elles ont un cycle de production réduit et occasionnel en fonction des mises a jours des logiciels nécessaires transmises par les maitrises d'ouvrages. Mon alternance Lors de mon alternance, les équipes métiers transmettaient un cahier des charges sur les nouvelles spécificités à intégrer dans la gamme de logiciel. Les équipes IT devaient donc comprendre les mises à jour à implémenter et ensuite appliquer ces modifications dans le logiciel. Ainsi il apparait nécessaire que le développement de la LPL soit compatible avec un cycle de production simple et occasionnel : on doit pouvoir construire et mettre en pause là RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT l'ingénierie de la LPL à tout moment. Notre outil peut également être appliqué dans un contexte de réingénierie d'une famille de produits vers une LPL (extractif). Cela peut se fait facilement si on considère que ce sont les produits qui motivent la construction de LPL : disposer en amont de tous les produits ou les créer un à un avec LPL, ne doit pas changer le résultat de notre approche. Enfin, nous pouvons aussi faire l'hypothèse que notre approche est adaptée à une production proactive de la LPL. Cette hypothèse suppose des prérequis. Les développeurs doivent réaliser en amont l'ingénierie du domaine pour acquérir des connaissances sur l'ensemble des caractéristiques et la variabilité de la LPL. Ils doivent également réaliser l'ingénierie d'application afin de connaitre l'ensemble des configurations de produits à réaliser. Dans ce cas-là, l'outil doit être applicable pour discipliner et accompagner l'ingénierie d'un LPL, en proposant de créer un à un les produits. La compatibilité de « SPL generator » avec les trois stratégies d'adoption (proactive, réactive, extractive) permet d'adapter notre approche à différents profils d'entreprises. Ce qui accentue le potentiel d'adoption de notre approche Voyons désormais l'étape d'intégration des produits, étape importante de la réingénierie Les étapes de L'intégration Nous définition quatre étapes interne aux processus de réingénierie par Intégration de la LPL. Ces étapes sont invisibles pour les développeurs, et donc entièrement automatique. En premier lieu, la réingénierie commence par une étape d'identification des artefacts. Cette identification a pour but de déterminer quels sont les assets (ou artefacts) du produit. Rappelons que les assets (ou artefacts) peuvent être l'ensemble des éléments se trouvant dans du code source ; des images, du contenu audio, web, des fichiers de configurations. L'identification fait donc l'inventaire de tous les assets d'un produit. Ensuite, la seconde étape est l'acquisition des artefacts au sein de la LPL existante. Chaque asset issu du produit est comparé avec les assets déjà présent dans la LPL, afin de déterminer s'il s'agit d'un nouvel élément. Cela permet d'incrémenter au fur et à mesure l'ensemble des artefacts de la LPL. L'acquisition de ces assets veillent également à préserver le comportement des produits. Vient ensuite la troisième étape, celle du calcul de la variabilité. Dans cette étape, la variabilité introduites par les artefacts et caractéristiques du produit vient modifier la variabilité de la LPL précédente. Cela permet de mettre à jour les modèles de variabilités qui seront présentés aux développeurs. Enfin la dernière est la localisation des caractéristiques parmi les artefacts de la LPL. Cette étape permet de tracer les liens entre les caractéristiques renseignés su nouveau produit, et les groupes d'artefacts qui seront désignés comme étant leurs implémentations, ou alors l'implémentation d'une interaction entre plusieurs caractéristiques. 10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 Identification des assets et l'entrée des produits La première partie du projet est consacrée à l'identification des artefacts du produit à intégrer Nous y présentons notre solution concernant l'analyse à granularité fine d'un code source. Afin de répondre au problème de construction de l'ensemble des artefacts, nous proposons une identification automatique des artefacts depuis une analyse statique du code source des produits. Cette identification à plusieurs objectifs : Premièrement, le processus d'identification doit parcourir le code source d'un produit pour y détecter l'ensemble de ses artefacts. C'est-à-dire qu'elle identifie toutes les classes, interfaces, méthodes ou instructions du code source. Deuxièmement, le processus d'identification doit conserver la structure initiale du produit en structurant ses artefacts de façon à maintenir leurs ordres d'apparition des éléments ordonnés du code. Nous parlons notamment de conserver l'ordre des artefacts déclarés dans des séquences, comme p. ex. les instructions. Nous devons préserver ces séquences si l'on veut éviter de modifier le comportement du produit une fois intégré. Troisièmement, l'identification doit permettre de décrire un produit sous la forme d'un ensemble d'artefacts. Cet ensemble d'artefacts est le socle sur lequel repose la construction des configurations d'artefacts d'un produit, et donc la création du contexte formel des artefacts Nous avons dû faire face à de multiples enjeux et problématiques décrits ci-dessous Problématiques lors de mon alternance L'identification des artefacts est nécessaire pour construire la plateforme, et étudier la variabilité de la LPL. Son objectif est double : construire un ensemble d'artefacts de sorte à distinguer tous les artefacts dans un produit, et utiliser cet ensemble pour comparer les artefacts entre plusieurs produits. L'identification des artefacts est relativement simple si on considère une granularité Fichier-Classe ou Méthode-Fonction, mais l'identification se complexifie au niveau Instruction. Pour le comprendre, commençons par le cas d'une granularité Fichier-Classe. A cette granularité, pour identifier les artefacts dans un produit, il suffit de considérer l'ensemble de ses fichiers. Pour les fichiers, l'unicité des éléments s'obtient du fait que les systèmes d'exploitation rendent impossible la déclaration de deux fichiers au même nom déclaré dans un même dossier Il n'existe donc pas deux fichiers qui partagent à la fois le même nom et le même chemin. On distingue s'ils ont des fichiers homonymes, car ils ont des chemins différents. Le même principe s'applique globalement aux classes. On s'intéresse ici à la signature d'une classe dans son namespace lors de sa déclaration pour identifier l'artefact. L'identification est souvent triviale, car les compilateurs refusent l'ambiguïté d'avoir plusieurs classes homonymes dans un même fichier. Le cas des sous-classes homonymes est différent, car RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 elles sont deux classes déclarées dans des champs différents. L'unicité des artefacts au niveau Fichier-Classe est donc garantie par les règles du système d'exploitation et/ou du compilateur. Au niveau Méthode-Fonction, on utilise la signature de l'élément déclaré (méthode ou fonction) pour identifier l'artefact. Globalement, les compilateurs empêchent la déclaration de deux méthodes (ou fonctions) partageant la même signature dans un même champ de déclaration. Dans le cas de deux méthodes partageant la même signature (par exemple le polymorphisme), dans deux classes différentes, on utilise leurs chemins dans l'AST pour les distinguer L'entrée des produits L'intégration est donc le point d'entrée de notre approche. Son principe est de prendre en entrée un produit, accompagné d'une liste des caractéristiques implémentées dans celui-ci. La phase d'intégration a pour objectif de décomposer un produit en artefacts pour les ajouter à la LPL. L'intégration repose sur deux étapes : l'identification des artefacts et leurs acquisitions au sein de la plateforme. Ces deux étapes sont effectuées automatiquement à partir d'une analyse statique du code source du produit. Nous faisons l'hypothèse simplificatrice que le code source contient à lui seul l'implémentation complète des caractéristiques d'un produit. Cette hypothèse facilite notre conception pour SPL Genarator car elle restreint l'analyse de la variabilité aux artefacts de codes sources. Cependant, l'hypothèse déforme la réalité car l'implémentation d'une caractéristique peut dépendre d'éléments extérieurs au code (des images, du texte, des bases de données). La phase de réingénierie prend comme première entrée un produit (le code source d'un logiciel conçu par les développeurs). Dans la pratique, cela revient à passer à notre outil SPL Generator, le projet du produit : son code source, mais aussi ses ressources. En somme, l'ensemble des éléments logiciels constitutifs du produit. Son principe est de prendre en entrée un produit, accompagné d'une liste des caractéristiques implémenté par celui. La phase d'intégration a pour objectif d'intégrer ce produit et ses caractéristiques dans la LPL. En d'autres termes, l'intégration automatiquement réalise le processus de réingénierie L'entrée des caractéristiques du produit D'autre part, une seconde entrée correspond au nom des caractéristiques implémentées dans par le produit. Ces dernières prennent la forme d'une liste de noms, et sont renseignés par les développeurs. En renseignant manuellement la liste des caractéristiques implémentés dans un produit, les développeurs réalisent une analyse partielle du domaine dans la LPL. Cette analyse peut se réaliser par l'étude du cahier des charges associés au produit. Toutefois, cette tâche est loin d'être triviale et dépend principalement de la capacité des développeurs à faire émerger du cahier des charges un ensemble de RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 caractéristiques. Or, nous pouvons noter un manque de standard dans l'industrie et donc de formalisme sur la tenue de ces cahiers des charges. Ainsi certaines pratiques spécifiques aux entreprises, viendront faciliter ou non la réalisation de l'analyse du domaine par les développeurs de l'équipe IT après mon départ de l'entreprise. L'identification des assets du code source du produit. Les nouveaux produits qui sont soumis à la LPL prennent la forme de d'un arbre syntaxique. Abstrait (Abstract Syntax Tree en anglais). Ces arbres sont composés des artefact ou asset du nouveau produit à integrer.la première étape consiste à identifier les artefacts de ces produits à partir de leur AST. L'identification des assets (ou artefacts) vise à trouver tous les assets du code source d'un produit logiciel qui peuvent être intégrés dans une LPL. Cette technique peut être appliquée à n'importe quel langage possédant un arbre syntaxique L'étape d'identification permet de distinguer l'ensemble des artefacts qui compose un produit. Un asset (ou artefact) a une valeur, qui représente le code source de l'élément logiciel qu'il représente. L'identification crée un artefact pour chacun des noeuds principaux de l'AST. Les artefacts identifiés sont stockés dans une variable regroupant l'ensemble des Assets formant une structure d'asset (SA) sous forme d'arborescence. A la manière d'un Arbre Syntaxique, cette SA stocke les assets en suivant une hiérarchie de parent-enfants. Ainsi, une SA ressemble à l'arbre syntaxique d'un langage ciblé. Pour identifier ces artefacts depuis le code source, nous passons donc par sa représentation sous forme d`un arbre de syntaxe abstraite. Cela évite de devoir dépendre de la mise en forme du code et l'arborescence est simple à naviguer à l'aide d'un patron de conception Un parcours en profondeur permet de construire une structure de donnée formant un arbre à partir des caractéristiques des assets. En fonction du noeud visité dans l'Arbre syntaxique, un artefact est créé et ajouté à la SA. L'artefact considéré ici est un élément de l'AST. Il peut être la déclaration d'une classe, d'une méthode ou encore d'une instruction. Chaque artefact est défini dans un modèle des artefacts, modèle qui est entendu depuis un modèle des artefacts générique. Nous détaillerons ces modèles dans la section. Les assets ont tous un identifiant différent à l'intérieur d'une SA. Ces identifiants sont essentiels pour éviter l'acquisition d'artefacts déjà intégrés dans la LPL, et ainsi éviter la redondance, lié à la duplication de l'implémentation de fonctionnalités. Lorsque nous intégrons des artefacts à une implémentation SPL, nous devons nous assurer que nous n'ajoutons pas d'artefacts déjà intégrés et ainsi éviter d'ajouter l'implémentation de la même fonctionnalité. Ceci afin d'éviter l'effet indésirable de devoir maintenir deux versions de la même fonctionnalité dans une implémentation SPL. Par conséquent, il faut RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 que chaque artefact soit unique dans une implémentation SPL. Cette unicité doit être garantie lors de l'acquisition de nouveaux artefacts, en comparant les artefacts d'un nouveau produit avec ceux qui se trouvent déjà dans la SPL. Par exemple, les artefacts de classes, de méthodes et de champs sont facilement distinguables car ils ne sont déclarés qu'une seule fois par fichier. Cependant, avec notre objectif de granularité fine, l'unicité des artefacts doit prendre en compte le cas particulier des déclarations, qui peuvent apparaître plusieurs fois dans un produit. Ainsi, le premier problème est de conserver l'unicité de tous les artefacts pendant la réingénierie de la SPL, c'est-à-dire la phase d'intégration. La première question est donc la suivante : comment garantir cette unicité des identifiants dans la SA (Structure d'Asset) ? L'unicité des Identifiants Ces identifiants vont nous permettre de comparer les artefacts présents dans deux LPL. C'est à partir de cette comparaison que de nouveaux artefacts seront acquis : en comparant les deux structures d'asset de la LPL avec ceux d'un produit. Par exemple, nous pouvons comparer les deux ensembles d'artefacts de la SA et celui du nouveau produit pour trouver quels sont les nouveaux artefacts du produit. Par conséquent, nous savons qu'il existe une seule instance de chaque artefact, c'est-à-dire qu'il n'y a pas de duplication, si aucun artefact ne partage le même ID dans l'implémentation finale de la LPL. L'ID d'un artefact est calculé comme la clef de hachage de la valeur de l'artefact, ajouté à l'ID de son parent. Cette construction récursive des ID, qui démarre de la racine de la SA, garantit que chaque artefact a un ID unique dans une Structure d'Asset. De plus, nous pouvons étendre cette propriété d'unicité des ID à l'ensemble du produit. En effet, l'artefact de l'unité de compilation reçoit une valeur qui correspond au chemin relatif du fichier réel, à l'intérieur du produit. Comme deux fichiers différents auront nécessairement un chemin relatif différent, deux racines de la SA ne peuvent pas partager le même ID. Avec cette construction des ID, seuls les artefacts qui partagent la même hiérarchie parentale et qui ont la même valeur, partageront le même ID. Par exemple, cela peut se produire si deux déclarations de la même méthode partagent le même code. Si un produit possède deux artefacts identiques avec le même ID. Pour les différencier, nous ajoutons spécifiquement pour les artefacts de déclaration un autre paramètre pour construire leurs ID. Ce paramètre est défini comme étant le nombre de jumeaux qui précède l'artefact, plus un. Dans notre exemple, cela est symbolisé par l'indice donné à l'artefact. Ainsi l'étape d'acquisition des artefacts se présentent comme une fusion entre les SA d'un produit, et ceux d'une LPL. Cette étape a pour objectif d'ajouter à la LPL tous les nouveaux artefacts introduit par le produit. En d'autres termes, l'acquisition doit ajouter au bon endroits les artefacts du produit dans la Structure d'Asset d'une LPL et éviter d'ajouter une seconde fois un artefact déjà présent dans la LPL. Cela est essentiel pour construire correctement la plateforme, et éviter la génération de produit erroné. RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT Acquisition des artefacts Une fois les artefacts identifiés sur les nouveaux produits, il faut les intégrer dans la LPL et fusionner ces nouvelles fonctionnalités c'est tout l'objet de cette seconde partie nécessaire à la construction de notre outil SPL Genrator L'acquisition est donc l'étape d'ajout des artefacts identifiés dans la ligne de produits. L'objectif de l'acquisition est ainsi d'intégrer à la LPL l'ensemble des artefacts spécifiques aux produits, tout en respectant les critères suivants : l'absence de redondance ; la préservation des produits déjà intégrés ; et la préservation du produit que à intégrer. Pour réaliser cela, l'acquisition s'effectue en considérant les deux arbres d'artefacts : celui identifié depuis le produit, et celui de la plateforme d'une LPL. L'intégration se charge également d'actualiser la représentation interne d'une LPL. Chaque élément d'un produit fait l'objet d'un artefact. Nous adoptons pour l'ensemble de ces artefacts une structure de donnée sous la forme d'une arborescence. Comme vu précédemment tous les assets peuvent être stocker dans la Structure d'Asset (SA) L'essentiel à retenir ici est qu'une SA peut-être est augmentée de nouveaux assets à chaque intégration, si le produit en contient de nouveaux. Pour acquérir les nouveaux artefacts d'un produit et les intégrer, nous devons fusionner deux ensembles : d'une part l'ensemble des Sas du produit ; et d'autre part l'ensemble des SAs déjà présents dans la SPL. Pour fusionner ces deux ensembles, nous formons des couples de Structure d'Asset : une SA provenant du produit et un de la LPL, s'ils correspondent au même fichier. Pour tout nouveau fichier introduit dans le produit, les SAs correspondantes ne correspondront pas dans la LPL, ils sont donc ajoutés sans fusion. Pour cela il existe des algorithmes permettant de fusionner des Arborescences. Algorithm 1: Algorithme de fusion de deux Structures d'Asset pour l'acquisition des artefacts Il est nécessaire de préserver la séquence des assets à l'intérieur de la SA. Puisque deux SAs peuvent contenir deux séquences d'instructions différentes, leur fusion doit assurer que la SA de sortie préserve ces séquences, sans doublons. Nous proposons de construire dans la SA fusionnée une super-séquence qui couvre les deux séquences de la Structure d'Asset produit et de la SA LPL. Notre solution repose sur l'algorithme Longest Common Subsequence (LCS) , mais une présentation complète de LCS sort du cadre de cette thèse. LCS calcule la plus longue séquence d'éléments qui sont communs aux deux séquences. Nous présentons notre algorithme de superséquence basé sur LCS. Tous les artefacts 10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 nouvellement ajoutés sont mis en évidence en gris. Cependant, dans certains cas, il est obligatoire de dupliquer les artefacts pour construire. Algorithm 2: l'algorithme Longest Common Subsequence (LCS)
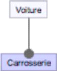
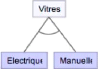
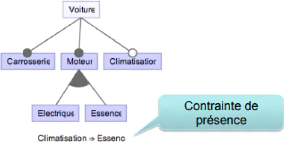
Une sous-séquence est la sous-séquence maximale d'une séquence donnée, où une sous-séquence est une liste consécutive et ordonnée d'éléments de l'ensemble initial. Qu'est-ce que le LCS ? Le problème de la plus longue sous-séquence commune consiste à trouver toutes les sous-séquences possibles d'une chaîne donnée ou, si elles sont finies, à calculer la plus longue. En général, de nombreux algorithmes fonctionnent bien pour trouver de longues séquences communes dans des chaînes de caractères dont les types de caractères sont aléatoires, mais dès que ces types de caractères deviennent suffisamment longs (100-150), il peut être très difficile de calculer des solutions optimales avec des algorithmes aléatoires qui ne se terminent pas après un certain nombre d'étapes. Parmi les autres problèmes informatiques qui peuvent avoir une complexité récursive similaire, citons la correspondance de chaînes de caractères et la recherche de similitudes DNF. Bien que le problème n'ait pas de solution pour toutes les chaînes de caractères, il existe des algorithmes qui peuvent le résoudre efficacement pour de grandes classes de chaînes de RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT caractères. Le plus efficace d'entre eux est l'algorithme de Hirschberg, mais il existe diverses améliorations et simplifications de celui-ci (par exemple, l'algorithme de Rabin-Karp). Le problème de la plus longue sous-séquence commune est un cas particulier de la correspondance optimale des sous-séquences et de la construction d'arbres de suffixes. Si nous connaissons toutes les sous-séquences de deux séquences données, nous pouvons utiliser la programmation dynamique pour trouver la plus longue de ces sous-séquences. Puisque ces séquences ne sont pas connues dans leur intégralité, nous pouvons construire un arbre de suffixes avec la plus longue sous-séquence commune comme feuille, et itérer sur le sous-arbre. Le problème de la plus longue sous-séquence commune est NP-dur pour toutes les chaînes de caractères. L'algorithme le plus efficace qui résout le problème de la plus longue sous-séquence commune pour les chaînes de longueur "n" avec une probabilité élevée (voir Algorithme) est appelé algorithme de Hirschberg (ou algorithme de Hirschberg), bien qu'il existe plusieurs améliorations basées sur la géométrie computationnelle qui rendent cette solution plus efficace. Il utilise à la fois l'algorithme glouton pour trouver les sous-chaînes et les arbres de suffixes pour trouver les sous-chaînes maximales. Lorsque les longueurs des deux chaînes sont éloignées l'une de l'autre, il peut être nécessaire de diviser la chaîne à un certain point et d'itérer en trouvant une sous-chaîne dans une chaîne qui contient un préfixe ou un suffixe de la partie. Cela peut être fait en un temps raisonnable dans la pratique, même lorsque la recherche d'une sous-séquence commune maximale n'est pas réalisable. Lorsqu'on travaille avec des graphes géométriques où les noeuds représentent des chaînes au lieu de sommets, on parle de problème de recherche d'arbre de suffixes de Hirschberg lorsqu'on travaille avec des graphes au lieu de chaînes. Dans ce cas, ce problème devient apparenté aux problèmes NP-complets en raison de sa similarité avec ces problèmes. Pour en revenir à nos Structures d'Asset : Ces deux structures du même type sont appairées et fusionnées au sein d'une Structure de donnée mère, contenant un exemplaire de chaque artefact en provenance des deux SAs. L'ordre des artefacts ordonnés est conservé au sein d'une super-séquence, qui est construite à partir d'un algorithme basé sur la plus longue sous-séquence commune Cet algorithme de super-séquence nous assure de pouvoir retrouver les séquences issues des deux structures d'asset. 10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 Notre fusion évite donc bien la redondance et la construction de super-séquences valides qui préserve le comportement de tous les produits. Pour finir, l'acquisition et les super-séquences peuvent mettre en lumière l'existence des artefacts dupliqués. Tout comme les artefacts jumeaux, les artefacts duplicata sont différent d'une redondance au sens où ils sont nécessaires pour la création d'une super-séquence valide, et donc d'une plateforme valide. Ces artefacts duplicata disposent de leur propre indice, l'indice duplicata, ce qui permet de les distinguer et de maintenir la distinction des artefacts. Une fois l'acquisition réalisée, les structures d'Asset remplacent les anciennes de la ligne de produits. La LPL intègre désormais les nouveaux artefacts du produit, ce qui termine la première phase d'intégration de la réingénierie. Les nouvelles structure d'Asset serviront à la génération du code de la plateforme configurable et à la génération de nouveaux produits pour la LPL. Avec l'identification et l'acquisition, nous proposons une méthodologie pour identifier les artefacts d'un code source et les acquérir au sein de la LPL, afin d'en construire la plateforme. Comme nous l'avons décrit, ces étapes sont réalisées de sorte à minimiser la redondance du code intégré dans la plateforme. Les modèles de variabilité et leur extraction Dans les parties précédentes nous avons présenté l'identification des artefacts permet d'obtenir un ensemble cohérent contenant les artefacts d'un produit et comment l'acquisition des artefacts permet d'ajouter ces derniers aux arbres des assets (SA) qui composent notre représentation de la LPL. À la suite de l'intégration se déroule l'analyse de la variabilité et la localisation des caractéristiques de la ligne de produits. À travers ces deux étapes, notre objectif est de construire des modèles décrivant la variabilité et les contraintes des caractéristiques (et artefacts). Ainsi que d'extraire des liens de traçabilité entre les caractéristiques et les artefacts qui forment leurs implémentations. Pour réaliser ces deux étapes, nous nous appuyons sur l'analyse de concepts formels (ACF), et son extension l'analyse de concepts relationnels (ACR) Nous utiliserons également cette méthode pour la localisation de caractéristique(en plus d'autres méthodes tirée de papiers de recherches) Nous définirons rapidement en quoi consiste un modèle de variabilité avec des exemples simples puis dans un second temps l'extraction des modèles de variabilité. L'ACF est appliquée séparément, d'une part sur l'ensemble des artefacts, et d'autre part sur celui des caractéristiques, afin d'analyser la variabilité de ces deux ensembles et d'extraire RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT leurs contraintes de variabilité Nous présentons enfin succinctement l'ACR qui permet de réunir l'ensemble des artefacts et celui des caractéristiques afin de localiser l'implémentation des caractéristiques et de leurs interactions parmi les artefacts qui composent la LPL Qu'est-ce qu'un modèle de variabilité ? La variabilité d'une LPL se visualise grâce à un modèle de variabilité. Il existe différent modèle. Le modèle le plus répandu est le modèle de caractéristiques (ou feature-model en anglais). Le Feature-Model représente une arborescence où chaque caractéristique occupe la place d'un noeud. Les branches du feature-model mettent en relations les caractéristiques, comme l'implication, mais aussi des exclusions, ou des alternatives. Exemple : prenons l'exemple d'une voiture. Une voiture possède des éléments communs obligatoires. La carrosserie est donc une caractéristique obligatoire. Voici la notation adaptée pour le FM :
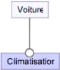
En revanche, une climatisation est optionnelle dans une voiture, la notation pour un feature Optionnelle se note
Nous pouvons avoir également une composition de feature, un choix, ou un choix exclusif 10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT
10 Mai 2019 Enfin nous avons également des contraintes de cohérence qui sont matérialisés par des dépendances de présence entre les features
Cette variabilité s'applique aux différentes caractéristiques découvertes et les développeurs ont pour objectifs d'obtenir les relations qui existent entre ces caractéristiques. Par exemple, ils doivent s'interroger les conditions d'utilisation d'une caractéristique particulier dans un produit. Cette conception de la variabilité s'accompagne de la réalisation de modèles de variabilité, comme des modèles de caractéristiques Le processus d'extraction. Elle se consacre à la récupération de la variabilité des différents produits, en l'étudiant au travers des artefacts des produits. L'objectif est donc étant de différencier les artefacts communs à l'ensemble des produits, des artefacts spécifiques à seulement quelques-uns d'entre eux. La détection s'accompagne souvent d'une localisation de l'implémentation des caractéristiques (ou feature location en anglais), qui permet de rétroactivement faire l'ingénierie du domaine de la ligne de produit L'étape d'analyse de la variabilité nous permet de découvrir la variabilité des artefacts et des caractéristiques, ainsi que les contraintes de variabilités (implications, cooccurrence et exclusion mutuelle). RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT Ces contraintes sont utilisées pour construire deux modèles de variabilités, celui des artefacts et celui des caractéristiques. Nous avons également expliqué comment ces deux modèles pouvaient être employés par les développeurs lors de la maintenance de la LPL ou lors de la génération de nouveaux produits, c'est à dire pour la sélection des caractéristiques d'une nouvelle configuration. Le processus décrit pour l'analyse de la variabilité adresse le défi présenté à la section Comment peut t on extraire automatiquement la variabilité SPL et ses contraintes ? Pour déterminer la variabilité des assets et des fonctionnalités, ainsi que leurs contraintes, nous appliquons l'analyse formelle des concepts (FCA) FCA pour la variabilité FCA travaille sur un contexte formel, qui est un ensemble d'associations entre objets et attributs. Chaque objet est décrit par un ensemble d'attributs qui le caractérisent. Par exemple, les produits logiciels peuvent être l'objet, chacun d'entre eux ayant un ensemble d'artefacts comme attributs. La FCA construit un ensemble de concepts à partir d'un contexte formel. Un concept est un regroupement maximal d'objets qui partagent un ensemble minimal d'attributs. Un concept est constitué d'une intention et d'une extension. L'intention du concept donne l'ensemble de ses attributs, et son extension donne l'ensemble des objets qui partagent ces attributs particuliers. De plus, FCA établit un ordre partiel sur ces concepts, où un concept A est supérieur à un concept B si les attributs des objets dans B sont dans A, ou vice versa si les objets avec les attributs dans A sont dans B. L'ordre partiel forme une hiérarchie sur ces concepts, ce qui permet de construire un treillis de conception donne l'ensemble des objets qui partagent ces attributs particuliers.
10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT En sortie d'intégration, la modification de la variabilité Après l'acquisition des artefacts, nous expliquons maintenant comment la variabilité est gérée : Chaque SPL est caractérisée par sa capacité à varier afin de générer des produits différents. Il est donc nécessaire pour le fonctionnement d'une SPL de distinguer dans son implémentation les parties communes, de ses parties variables. Nous désignons ces parties variables par le terme points de variation. La connaissance des points de variation permet aux développeurs de comprendre la variabilité dans l'implémentation de leur SPL. De plus, cela leur permet de concevoir leurs produits, en sélectionnant les artefacts appropriés d'un point de variation à inclure dans un produit. Il est donc essentiel pour les développeurs de savoir où se trouvent ces points de variation et quels assets variables peuvent y être sélectionnés. Cependant, une vision binaire de la variabilité, c'est-à-dire variable, est insuffisante. Les développeurs doivent également connaître les contraintes entre la fonctionnalité (et donc entre les artefacts). Cela nécessite d'extraire les contraintes de variabilité nécessaires entre les fonctionnalités et entre les assets. Le calcul de la variabilité dans notre Outils SLP generator Pour déterminer la variabilité des artefacts et des fonctionnalités, ainsi que leurs contraintes, l'idée est d'appliquer l'analyse formelle des concepts (FCA) Notre objectif est de construire des modèles décrivant la variabilité et les contraintes des assets. Ainsi que d'extraire des liens de traçabilité entre les caractéristiques et les artefacts qui forment leurs implémentations. Pour réaliser ces deux étapes, nous nous appuyons sur l'analyse de concepts formels (ACF), et son extension l'analyse de concepts relationnels. Nous effectuons l'analyse de la variabilité de la LPL. Cette étape a pour objectif de déterminer quels sont les assets communs et les assets optionnels de la LPL, et il en va de même pour les caractéristiques. Pour effectuer cette analyse, notre outil s'appuie sur l'Analyse de Context Formel. Cette méthode a été appliqué dans ce précédent travaux pour découvrir la variabilité et les contraintes entre les caractéristiques d'une famille de produits. L'analyse permet d'obtenir l'ensemble de savoir quel est l'ensemble des artefacts communs, et celui des assets optionnels (ou spécifique à quelques produits, mais pas tous). On peut faire de même pour les caractéristiques (partie suivante !) 10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT Cette d'analyse automatique de la variabilité s'intègre dans notre outil afin de déterminer la variabilité des assets de la LPL puis de construire des modèles de variabilité à destination des développeurs, afin de représenter la variabilité. L'objectif de cette section est donc de présenter notre processus d'analyse de la variabilité tel que nous le concevons dans pour l'automatisation. Nous savons d'après les prérequis et l'études de l'art que la FCA permet d'extraire au moins trois types de contraintes : l'implication, l'exclusion mutuelle et la cooccurrence. Pour expliciter ces trois contraintes, prenons deux groupes d'éléments A et B L'implication indique quels sont les éléments A qui sont toujours présents dans un produit quand les éléments B sont présents. L'exclusion mutuelle indique que les éléments de A ne sont jamais présents en même temps que les éléments de B. Et enfin la cooccurrence indique que les éléments A sont toujours présent avec B, et réciproquement, pour n'importe quel produit où apparaissent A ou B. L'analyse de la variabilité nous sert de deux manières lors de l'ingénierie automatique de la LPL : d'une part, elle permet de distinguer dans la plateforme quels sont les artefacts communs des artefacts optionnels. La même chose peut être effectuée pour les caractéristiques, ce qui permet de savoir lesquelles sont communes et lesquelles sont optionnels. D'autre part, l'analyse nous permettait de construire deux modèles de variabilités : celui des artefacts et celui des caractéristiques. Ces deux modèles sont construits sur la base des trois contraintes extraites grâce à l'application de FCA. Pour les développeurs, l'intérêt vient surtout de l'utilisation du modèle de variabilité des caractéristiques. Il permet d'une part la sélection des caractéristiques lors de la génération de nouveaux produits. Par ailleurs, il offre une vue globale des caractéristiques de la LPL et de leur la variabilité, ce qui est utile pour la compréhension et la maintenabilité de la LPL Les modèles de variabilités sont des diagrammes générés par notre outil. Ils permettent de rendre compte de la variabilité qui à lieux dans une LPL à une itération donnée. Puisque la LPL évolue à chaque itération, la réingénierie étant induite par l'aspect réactif de l'approche. Ces modèles évoluent également. La variabilité est automatiquement analysée depuis l'ensemble des produits passés en entrée de SPL Generator.Il existe dans notre outil deux types de modèles : le modèle de variabilité des artefacts, et le modèles de variabilités des features. Nous présentons ici les informations présentent dans le modèle de variabilité des artefacts, et comment elles peuvent être utiles aux développeurs :
10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT
10 Mai 2019
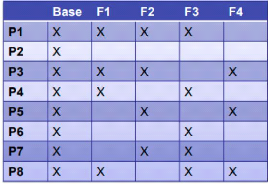
Création du contexte formel (PCM) à partir des assets
L'application de l'ACF sur le contexte formel des artefacts permet d'obtenir un ensemble de concepts. Chaque concept regroupe des produits partageant un ensemble maximum d'artefacts. Les concepts des artefacts sont ensuite hiérarchisés pour construire l'AOC-Poset; et respectivement les concepts des caractéristiques sont construit et hiérarchisés, afin d'obtenir un AOC-Poset des caractéristiques. Nous commençons par la variabilité des assets d'une SPL. Grâce aux ID uniques des artefacts, nous pouvons créer un contexte formel où nous garantissons que chaque ID RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 représente un artefact spécifique dans les produits. Pour créer ce contexte formel, nous assignons à chaque produit une liste de l'ID de l'asset, qui correspond à l'asset identifié dans ce produit. FCA construit ensuite un treillis à partir du contexte formel. Extraction de la variabilité à partir du Treillis Le but de cette partie est d'extraire les implications ainsi que les relations des contraintes à partir du treillis obtenu dans la partie précédente, Nous mettons en place la méthodologie décrite dans le papier de Al-MsieDeen (2014). L'extraction de la variabilité s'effectue donc depuis les AOC-Posets obtenues des artefacts Nous allons donc ici décrire l'extraction sur l'AOC-Poset des. Le treillis nous permet d'abord d'extraire la variabilité binaire (c'est-à-dire commune ou variable) : les artefacts communs Nous savons que l'AOC-Poset peut être exploité pour extraire la variabilité et ses contraintes. Dans un premier temps, la variabilité binaire des attributs peut s'extraire d'un AOC-Poset en considérant le concept de plus haut niveau dans la hiérarchie. Dans un AOC-Poset, ce concept sommet regroupe l'ensemble des attributs partagés par l'ensemble des objets. Puisque ces attributs sont partagés par l'ensemble des objets, alors ils désignent l'ensemble des attributs communs à tous les produits jusqu'ici intégrés dans la ligne de produit. Le concept de sommet de l'AOC-Poset des artefacts contient dans ces attributs l'ensemble des artefacts communs Une fois l'ensemble des artefacts communs obtenu, on peut en déduire l'ensemble des artefacts optionnels, puisqu'il s'agit de tous les autres artefacts qui n'apparaissent pas dans le concept sommet. Ainsi, l'AOC-Poset nous permet donc de récupérer la variabilité binaire des éléments de la LPL. Dans un deuxième temps, nous utilisons chacun des AOC-Posets pour extraire les contraintes entre leurs attributs. Nous savons que trois contraintes portant sur les attributs d'un contexte formel peuvent être extraites depuis l'AOC-Poset : l'implication, la cooccurrence et l'exclusion mutuelle. Des algorithmes sont proposés pour récupérer ces trois contraintes de variabilité dans le papier de Al-MsieDeen (2014). L'étape d'analyse de la variabilité nous a permis de découvrir la variabilité des artefacts, ainsi que les contraintes de variabilités (implications, cooccurrence et exclusion mutuelle). Nous avons également expliqué comment ces deux modèles pouvaient être employés par les développeurs lors de la maintenance de la LPL ou lors de la génération de nouveaux produits, c'est-à-dire, pour la sélection des caractéristiques d'une nouvelle configuration. Une fois cette étape d'extraction de la variabilité terminée il reste a localiser les caracteristiques qui viendront implémenter les assets RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 La localisation des caractéristiques. L'étape de localisation des caractéristiques nous permet de tracer les caractéristiques aux artefacts qui ont été identifiés et intégrés à la LPL lors de l'intégration. Comme vu dans l'état de l'art, cette localisation des caractéristiques donc consiste à associer chaque artefact à au moins une caractéristique et vice versa. En général, les techniques de Feature Location supposent que les caractéristiques de chaque produit sont connues. Dans la première partie du mémoire d'alternance, nous avons discuté dans l'état de l'art des approches existantes appliquant une localisation de caractéristiques. Or beaucoup de techniques utilisées par ces approches étaient limitées par une granularité trop grosse (Méthode-Fonction) et par l'absence d'une localisation des interactions de caractéristiques. Ce faisant, l'application des techniques proposée par ces travaux est limitée, car les traces extraites ne pouvaient pas être employées pour reproduire les implémentations des produits initiaux. Nous avons utilisé plusieurs méthodes issues de différents papiers, notamment par l'analyse textuelle préalablement définie dans la section de l'état de l'art. Nous recherchons une approche hybride pour notre projet mais cette étape n'est pas encore terminée à ce jour, car les résultats ne sont pas satisfaisants et par manque de temps. Nous planifions de terminer cette étape courant Septembre 2019. Nos analyses basées sur la recherche textuelle pour la localisation des caracteristiques n'ont pas été probantes, donc nous allons donc chercher à mettre en pratique l'ACF, jadis utilisé pour les assets, mais cette fois dans l'optique d'une localisation de caractéristique. Comme dans le papier de Al-MsieDeen: feature-location-in-a-collection-of-software-product-variants-using-formal-concept-analysis (2014) L'implémentation de la localisation des caractéristiques est toujours en cours à ce jour et nous ne pouvons pas donner encore de résultats précis quant aux approches que nous allons décrire par la suite : L'analyse de concepts formels (ACF) pour réaliser la localisation. L'intérêt d'ACF est que son application est indépendante de la nature des artefacts pourvu qu'un contexte formel puisse être construit. Ainsi, dans cette section, notre objectif est de formuler une technique de localisation basée sur l'analyse de concepts formels. Notre outil proposera une localisation à granularité fine pour les caractéristiques et de leurs interactions. De plus, en appliquant l'analyse de concepts formels à la localisation, nous réutiliserons les contextes formels, créés à l'occasion de l'analyse de la variabilité, ce qui donnera une certaine cohérence aux méthodes déployées dans l'automatisation. L'étape de localisation des caractéristiques nous permet de tracer les caractéristiques aux artefacts qui ont été identifiés et intégrés à la LPL lors de l'intégration RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT Les contextes formels des artefacts et des caractéristiques, utilisés à l'étape d'analyse de la variabilité, sont utilisés pour construire un AOC-Poset relationnel. Les concepts de l'AOC-Poset relationnel introduisent à la fois des artefacts et des caractéristiques, et nous y appliquons nos algorithmes pour extraire des traces corps et des traces d'interactions. Ces traces seront ensuite transformées en formule logique puis réduite afin de simplifier leurs interprétations et compréhension par les développeurs. L'étape de localisation de caractéristiques extrait donc les traces les caractéristiques avec les artefacts de la plateforme configurable. L'implémentation d'une caractéristique est donc définie comme un ensemble distinct d'artefacts. La technique de localisation mise en place considère aussi bien la récupération des implémentations de chaque caractéristique, que celles des interactions entre caractéristiques. Ainsi grâce à la localisation, nous saurons quels sont les artefacts codant pour une caractéristique, ou pour une interaction spécifique. Le travail de maintenabilité des développeurs s'en voit facilité car les traces de la localisation permettent d'indiquer précisément où sont implémenté les caractéristiques parmi les artefacts de la plateforme configurable. 10 Mai 2019 RAPPORT D'ALTERNANCE 2018-2019 THOMAS PETIT 10 Mai 2019 |
|