Chapitre I

Chapitre 1 : La logique floue
La logique floue
I.1 Introduction :
Depuis l'apparition de la logique floue , la philosophie
de commande des procédés mal définis ou
complètement inconnus qui ne peuvent pas être modélises
soigneusement d'une manière mathématique , a connu un changement
radical , ceci est du au fait que les lois de commande conventionnelles sont
remplacées par une série de règles linguistique de
type :
SI (condition ) ALORS( action
)
La logique floue s'avère mieux adaptée au monde
réel que la logique binaire , du fait de sa maîtrise du concept
d'incertitude et d'imprécision qui sont des conséquences logique
de la complexité des systèmes .
La logique floue est une technique très puissante issue de
la théorie des ensembles flous , pour combler la lacune entre la
précision de la logique classique et l'imprécision du monde
réel .
Sa caractéristique fondamentale est l'utilisation des
variables linguistiques au lieu des variables numériques dans des
situations conditionnelles floues .
La logique floue est très utile dans des situations ou il
y a de large incertitude set des variations inconnus dans les paramètres
et la structure du systèmes , ou bien , lorsque des experts
humains sont disponibles pour fournir des descriptions subjectives et
qualitatives du comportement du système avec des termes en langage
naturel .
I.2 Historique :
Le pionnier était un mathématicien polonais J.
Lukasiewiczi qui a développé en premier le concept de la logique
multi-variable durant les années 1920 .
Cette logique admet des valeurs de vérité
appartenant à l'intervalle [ 0 , 1 ] , ce qui ne suffit pas pour
traiter des connaissance imprécises , puisque cette extension de la
logique classique n'admet une gradualité que dans les valeurs de
vérité et qu'elle n'autorise pas une proposition à
être imprécisement énoncée .
Et c'est par là que la logique floue est entrer en
scène .
La théorie des ensembles flous est apparaît en
1965 avec Pro . Zadeh Lotfi (Californie) , et cela comme
un outil mathématique capable de représenter et manipuler
l'information qualitative convoyée dans des termes du langage naturel
[ 1 ] .
En 1974 Mamdani proposa la premier application
du contrôleur flou pour moteur à
vapeur .
En 1987 , l'explosion du flou au japon et
qui atteint son apogée en1990 .
Depuis lors, les systèmes flous soulèvent un large
intérêt dans une variété de domaines (commande ,
identification , traitement du signal .... ) [ 2 ] .
Et aujourd'hui , une vaste gamme de nouveaux produits ont une
étiquette
« produit flou » .
Chapitre 1 : La logique floue
I.3 La théorie de la logique flou :
La logique floue vise a modéliser les models
imprécis du raisonnement qui jouent un rôle très important
dans la capacité humaine de prendre des décisions rationnelles
dans un environnement incertain et imprécis .
L'avantage d'un tel système flou est que seules les
connaissances du comportement de procédé à commander sont
suffisante pour la synthèse de la loi de commande , et ils
soulèvent un large intérêt , tant théorique que
pratique , dans la commande du processus complexes et N-L .Cela est dû
essentiellement a trois traits principaux :
1- Le premier est que les systèmes flous
permettent une simple inclusion d'informations qualitatives dans la conception
du contrôleur .
2- Le second est que les systèmes flous
n'exigent pas l'existence d'un modèle analytique du processus à
contrôler , et peu d'information est suffisant pour mettre en oeuvre la
boucle de commande .
3- Le troisième est que les
systèmes flous sont des systèmes non linéaire et de ce
fait plus adaptés à la commande des processus non linéaire
.
I.4 Concepts fondamentaux :
I.4.1 Univers de discours :
Un univers de discours continue est un sous ensemble de R qui
décrit dans le cas général le domaine d'une variation
d'une variable donnée .
I.4.2 Les ensembles flous :
La théorie des ensembles flous permet de traité des
domaines non exactes , incertaines et mal quantifiées , contrairement
à la théories des ensembles nets , notant que les incertitudes
d'un système flou sont représentés par les ensembles flous
[ 3 ] .
Dans la théorie classique des ensembles , un objet
appartient ou n'appartient pas à un ensemble alors qu'en logique floue ,
un objet peut appartenir à un ensemble et en même temps à
son complément .
Tout élément x d'un référentiel (
univers de discours ) U est muni d'un degré d'appartenance à un
ensemble flou A , noté
qui d'écrit le « degré
avec le quel l'élément x appartient à A
» [ 4 ] , et qui prend ses valeurs dans
l'intervalle [ 0 , 1 ] au lieu du doublet { 0 , 1 }.
Chapitre 1 : La logique floue
Exemple :
ìA(x) Petit
ìA(x) grand
ìA(x) petit grand
1.65m x
1.65m x 1.65m x
1 si x A
ìA(x) =
ìA(x) [ 0 , 1 ]
0 sinon
Figure I.1 :
théorie classique .
Figure I.2: théorie floue .
Un ensemble flou A en extension est représenté par
des couples < ìA(x) / x > , et par convention on ne
fait pas apparaître les doublets dont le degré d'appartenance est
nul .
Par exemple si on cherche à définir l'ensemble flou
des tailles voisines de (1,24) on pourra avoir :
{ <0,6 / 1,22>,<0,9 / 1,23>,<1 /
1,24>,<0,9 / 1,25>,<0,6 / 1,26>,<0,6 / 1,26> }.
I.4.3 Propriété d'un sous-ensemble
flou :
Les propriétés d'un sous ensemble flou A de U les
plus utiles pour le décrire , sont celles qui montrent à quel
point il diffère d'un sous ensemble classique de U . [5]
[6]
La première de ces propriétés est le support
de A , c-a-d l'ensemble des élément , de U qui appartiennent , au
moins un peu à A .
A. support :
Le support de A , noté sup(A) , est la partie de U sur la
quelle la fonction d'appartenance de A n'est pas nulle :
Supp (A) = { x U
/ ìA(x) >0 } ( I . 1 )
Chapitre 1 : La logique floue
B. La hauteur :
L'élément x de U pour le quel le degré
d'appartenance ìA(x) est maximal est appelé centre de
l'ensemble flou ou la « hauteur
» noté par hgt(A) [7] .
Si hgt (A) = 1
A est appelé normal .
Si hgt (A)
< 1 A est appelé sous ,normal . ( I . 2 )
C. Ensemble flou singleton :
Si l'ensemble flou a comme support un seul élément
tel que :
ìA(x) = 1 si x = x0 .
ìA(x) = 0 si x = x0 .
( I . 3 )
donc il est appelé ensemble flou singleton .
D. Le noyau :
Le noyau d'un ensemble flou A est noté par nucleus (A) est
définie comme suit :
Nucleus (A) = {
x U / ìA(x) =1 } . ( I . 4 )
S'il y a un seul point avec un degré d'appartenance
égal à 1 , Alors ce point est appelé le
« point pic De A » .
E. La convexité :
Un ensemble flou F est convexe si et seulement si :
x1 ,x2 U , [0 ,1] :
ìA( x1 , x2 ) min [
ìA (x1) , ìA
(x2) ] . ( I . 5 )
ìA(x)
ìA(x)
x
x
Figure I.3 : Ensemble
flou non convexe Figure I.4 : ensemble flou
convexe
Chapitre 1 : La logique floue
F. Distance de hamming entre deux sous-ensembles
flous :
La distance de Hamming entre deux sous ensembles flous A et B est
une mesure qui indique le degré global avec le quel le
éléments de U appartiennent à A et/ou B :
DH(A , B) =
?xU ( ìA(x) - ìB(x) )
( I . 6 )
I.4.4 Opérateurs en logique floue :
A et B deux ensembles flous définis sur l'univers de
discoure U . Soit x et y deux valeurs définis sur des domaines
différants :
Si ìA(x) = ìB(y) = , x .On
a les définitions suivantes :
A. L'opérateur NON ( complément
) :
x U , Â = {
x / x A } .
ou bien : non
ìA(x) = ì (x) = 1-
ìA(x) ( I . 7 )
B. L'opérateur ET ( intersection
) :
x U : AnB = { x /
x A x B} .
ou bien : ìAnB(x)
= ìA(x) ìB(x) = min (
ìA(x) , ìB(x) ) ( I . 8
)
C. L'opérateur OU ( union ) :
x U : A ? B = { x /
x A ? x B }
ou bien : ì
A?B(x) = ìA(x) ?
ìB(x) = max ( ìA(x) ,
ìB(x) ) ( I . 9 )
Ces opérations d'intersection , d'union et de
complémentations de sous ensembles flous habituellement employées
, peuvent être remplacées par d'autres opérations
construites à l'aide d'autre opérateurs différents de
minimum , de maximum et de la complémentation à 1 .
On fait appel à eux lorsque les opérations
habituelles ne s'avèrent pas satisfaisantes [6] , [7]
.
Chapitre 1 : La logique floue
Exemple :
ìA(x) non
ìA(x)
70 80
70 80
ìA(x)
ìB(x)
ìAnB(x)
100
130 100
130
ìA(x)
ìB(x) ì
A?B(x)
40 60 80
60 80 40 60 80
Figure I.5 :
opérateurs ( non , et , ou ) en logique floue .
Exemple en logique classique :
Soit un ensemble de référence U = { a , b , c , d ,
e , f , g }.
Soit A et B deux sous-ensembles de U .
|
A
|
0
|
1
|
0
|
1
|
1
|
0
|
1
|
|
B
|
1
|
1
|
0
|
0
|
1
|
0
|
1
|
b c
d e f g
AnB
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
|
A?B
|
1
|
1
|
0
|
1
|
1
|
0
|
1
|
Chapitre 1 : La logique floue
Â
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
|
A?Â
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
On obtiens A ?  = U et A ? =
.
Exemple en logique floue :
Soit un ensemble de référence U = { a , b , c , d ,
e , f , g }.
Soit C et D deux sous-ensembles de U .
|
C
|
0.4
|
0.8
|
1
|
0.8
|
0.2
|
0.5
|
0.1
|
|
D
|
0
|
0.5
|
0.3
|
0.9
|
1
|
0.7
|
0
|
a b c
d e f g
|
0.6
|
0.2
|
0
|
0.2
|
0.8
|
0.5
|
0.9
|
CnD
|
0
|
0.5
|
0.3
|
0.8
|
0.2
|
0.5
|
0
|
C?D
|
0.4
|
0.8
|
1
|
0.9
|
1
|
0.7
|
0.1
|
Cn
|
0.4
|
0.2
|
0
|
0.2
|
0.2
|
0.5
|
0.1
|
C?
|
0.6
|
0.8
|
1
|
0.8
|
0.8
|
0.5
|
0.9
|
On obtiens : Cn ET C ? U .
D. Le produit cartésien :
Soient A1 , A2 , ... , An des ensembles flous
définis sur les univers de discours U1 , U2 , ... , Un respectivement ,
leur produit cartésien est un ensemble flou ( relation flou )
noté par :
A = A1 . A2 . .... An , avec une fonction d'appartenance
définis par :
ìA1. A2.... An ( x1 x2
... xn ) = min [ ìA1 (x1) ,
ìA2 (x2) , ... ,
ìAn(xn) ] . ( I . 10)
Chapitre 1 : La logique floue
Exemple :
ìA1
(x1) ìA2 (x2)
ìA1 (x1) ìA2
(x2)
Figure I.6
: le produit cartésien en logique floue .
E. La concentration de A :
La concentration de A noté con (A) est défini
par :
ì
conA (x) = ì²A(x)
( I . 11)
F. La dilatation :
La dilatation de A noté dil (A) est défini
par :
ì dil(x) =
vìA(x) ( I . 12)
G. Egalité et inclusion des sous ensemble
flous :
Deux sous ensembles flous A et B sont égaux , si leur
fonctions d'appartenance prennent la même valeur pour tout
élément de U :
x U :
ìA(x) = ìB(x) (
I . 13)
H. Normes et conormes triangulaire :
une norme triangulaire (t-norme) est une fonction :
T : [0.1] .
[0.1] [0.1]
qui vérifie la commutativité l'associativité
et un élément neutre 1 .
Chapitre 1 : La logique floue
cas particulier :
L'opérateur T = min est une norme triangulaire , toute
t-norme peut servir à définir l'intersection de deux sous
ensembles flous A et B , tel que C = A nT B , que l'on associe une
fonction d'appartenance définis par :
x U :
ìc(x) = T (ìA (x) ,
ìB(x) ) (I . 14)
Une conorme triangulaire ( t-conorme ) est une fonction :
?: [0.1] . [0.1]
[0.1]
qui vérifie la commutativité ,
l'associativité et un élément neutre 0 .
Toute t-conorme peut servir à définir l'union de
deux sous ensembles flous A et B ,
tel que :
D = A?T B , que l'on associe une fonction
d'appartenance définie par :
x U :
ìD(x) = ? ( ìA(x) ,
ìB(x) ) (I . 15)
Toute norme a une co-norme associé (et vis versa ) par les
lois de Morgan :
?( x , y ) = 1 - T (1-x , 1-y )
T ( x , y ) = 1- ? (1-x ,
1-y)
Parmi les couples normes/co-normes d'opérateurs T/ ? ,
min / max est le plus fréquemment utilisé car il maintien le plus
grand nombres des propriétés de l'intersection et de l'union
habituelles , bien qu'il existe d'autre opérateurs comme [8]
.
a)- Conjonction / disjonction de Lukasiewic
T(x ,y) = max ( x + y -
1 , 0 )
?(x , y) = min ( x + y , 1 )
(I . 16)
Chapitre 1 : La logique floue
b)- Le produit et la somme probabiliste
T(x , y) = x . y .
? (x , y) = x + y - ( x .y )
(I . 17)
I. L'entropie flou :
L'entropie floue est une mesure d'ambiguïté
d'un sous-ensemble :
E( A) = dH (A
Ac) / dH(A Ac) (I . 18)
Ou Ac est le complément de A .
- Si E(A)=1 alors l'ambiguïté est
maximale .
- Si E(A) =0 donc le sous ensemble est classique
et non flou .
1.5 Les fonctions d'appartenances :
Les formes des fonctions d'appartenances sont
généralement arbitraires , mais il est judicieux de choisir des
fonctions convexes de sorte qu'il existe au moins un point de degré
maximal et tel que le degré décroît ; lorsqu'on
s'éloigne de ce maximum .
Exemple :
Pour une variable d'entrée (e) , un univers de discours
continu , et des fonctions d'appartenance représentées par trois
triangles et des valeurs linguistiques :
( Positive , zéro , négative ) , l'ensemble flou
relatif à une valeur (0.3) de la variable d'entrée sera
alors : ( 0.2 , 0.8 , 0 ) .
Que l'univers du discours soit continu ou discret , les
règles flous activées seront celles dont la valeur linguistique
est différente de zéro .
ì(e)
N
Z P
0.8
0.2
0.3 e
Pour cette exemple , avec l'ensemble flou ( 0.2 , 0.8 , 0 ) . Les
règles linguistiques ayant pour prémise soit ( (e) est positive )
soit ( (e) est zéro ) seront activées .
Chapitre 1 : La logique floue
Les fonctions d'appartenances les plus utilisées sont
[9] :
A. Fonction triangulaire :
Triangle ( x ; a , b , c ) = max
min
x - a , c - x , 0 .
b - a c - b
B. Fonction trapézoidal :
Trpézoide ( x ; a , b , c , d )
=
max min x - a ,1, d - x , 0 .
b - a d - c
C. Fonction gaussienne :
- ( x - c )2
Gaussienne ( x ; ä , c ) = e 2 . ä2
.
Ou c représente le centre , et ä l'écart
type .
D. Fonction de cloche
généralisée :
Bell ( x ;
a , b , c ) = 1 / 1 + (x - c) / a2 b .
Où b est une constante positive permettant le
contrôle de la pente au point d'inflexion .
C et a sont le centre et la largeur respectivement .
E. Fonction sigmoïde :
Sigmoïde ( x , a , c ) = 1 / 1 + e - ( a ( x - c ) ) .
Où (a) permet le contrôle de la pente au point
d'inflexion x = a , dépendamment du signe a .
Remarque :
Les trois dernier fonctions sont généralement
utilisé dans le contrôle des procédés chimiques ,
car la pente supérieur de la fonction ( gaussienne , cloche ) , et la
pente inférieur de la fonction ( sigmoïde ) , permettent au
procédé d'avoir le temps pour réaliser ces
réactions chimiques .
Chapitre 1 : La logique floue
ì(x)
ì(x)
a b c
x a b c d x
(a)
(b)
ì(x)
ì(x)
1
0.5
c
x c -a c c + a
x
2a
(c)
(d)
ì(x)
1
a < 0 a > 0
x
(e)
Figure I.7 :(a) Fonction triangulaire .
:(b) Fonction trapézoïdal .
:(c) Fonction gaussienne .
:(d) Fonction de cloche généralisée
.
:(e) Fonction sigmoïde .
Chapitre 1 : La logique floue
I.6 variable linguistique
Notion de variable linguistique :
L'univers de discours permet de décrire le domaine de
variation de ce qu'on appelle « variable floue
» .
l'appellation associée à chaque sous ensemble flou
constitue ce qu'on appelle
« variable
linguistique» .
ils servent à modéliser les connaissances
imprécises ou vagues sur une variable dont la valeur précise peut
être inconnue [10] , [11] .
Le découpage d'un univers de discours U en ensemble
flous est tout à fait subjectif et complètement lié au
problème à traiter.
Exemple :
On donne un exemple d'un univers de discours à (05) sous
ensembles flous , où chacun de ces derniers prend un "code" ou un
non :
Ze : zéro .
PM : positif moyen .
PG : positif grand .
NM : négatif moyen .
NG : négatif grand .
les codes représentent les variables linguistiques qui
décrivent l'état d'un procédé ou
phénomène à étudier .
U(x)
NG NM ZE
PM PG
x
Figure I.8 : univers de discoure avec
(05) sous ensembles flous
Chapitre 1 : La logique floue
Dans de tels cas , il est préférable de
représenter une information incertaine par des sous ensembles flous
[12] .
En raison de leur capacité à
synthétiser des informations et à permettre une approche globale
de certaines caractéristiques du système .
De façon plus générale , les ensembles flous
peuvent intervenir efficacement dans la modélisation d'un
système complexe .
I.7 Relations floues :
I.7.1 Définition :
les relations floues généralisent la notion de
relation classiquement définie sur des ensembles .
Elles mettent en évidence des liaisons imprécises
ou graduelles entres les éléments d'un même ensemble
[5] , [7] .
Soient U1 , U2 ,......,
Un , n univers de discours ,
une relation floue R est un ensemble flou dans (U1 *
U2 * ......* Un ) définie par :
R = { [ (U1 , U2 ,......, Un )
, ìR (U1 , U2 ,......, Un
) ] / (U1 , U2 ,......, Un ) U1
* U2 *......* Un }
Exemple:
En parlant de l'expertise d'un diamant , on peut dire que son
prix est une fonction de la relation qui existe entre son poids , et sa
pureté :
U = { grand , petit } .
V = { poids , pureté}.
La relation flou binaire R , peut être défini
par :
R = { [ ( poids , grand ) , 0.8 ] , [ ( poids , petit ) ,
0.3 ] , [ ( pureté , grand ) , 0.9 ]
[ ( pureté , petit ) , 0.6 ] }.
La fonction d'appartenance peut être représenter
comme suit :
Grand petit
Poids 0.8 0.3
ìR (U ,V) =
pureté 0.9 0.6
I.7.2 Définition :
La composition de deux relation flous R1 sur (
U1 . U2 ) , et R2 sur (
U2 . U3 ) définie une relation
floue : R = R1 o R2 sur ( U1 .
U3 ) de fonction d'appartenance
définie par : (x , y) U1 .
U3 , ìR (x , z) = sup(y
U2) min ( ìR1 (x , y) , ìR2 (y , z)
).
Chapitre 1 : La logique floue
ou U1 , U2 et U3 sont des
univers de discours .
Cette définition correspond à la composition
max-min , la plus utilisée .
Il est cependant possible de remplacer l'opérateur min par
un autre opérateur T,
par exemple une norme triangulaire , et en particulier le produit
pour définir la composition max-T .
I.7.3 Implication floues :
soit une règle flous de la forme
« si V est A alors W est B » .
l'implication floue entre deux propositions floues
élémentaires « V est A
» et « W est B
» est une proposition floue , dont la fonction
d'appartenance ìR associée à cette relation
floue R entre X et Y est définie par :
(x, y) ( X
.Y ) / ìR (x, y) = Ö [
ìA(x) , ìB(y) ]
Pour une fonction Ö de [0, 1] . [0, 1] ? [0, 1] .
Les principales classes d'implications floues sont
indiquées dans le tableau de la figure suivante [5], [6], [7]
.
|
Notion
|
Valeur de vérité
|
Nom
|
|
ìRR (x ,
y)
|
1 - ìA(x) + ìA(x) .
ìB(y)
|
Reichenbach
|
|
ìRW (x ,
y)
|
Max [1- ìA(x),min [ìA(x),
ìB(y)]
|
Willmott
|
|
ìRRG (x ,
y)
|
1 si ìA(x) =
ìB(y)
0 sinon
|
Rescher-gaines
|
|
ìRKD (x ,
y)
|
Max [1 - ìA(x) , ìB(x)]
|
Kleene-dienes
|
|
ìRBG (x ,
y)
|
1 si ìA(x) =
ìB(y)
ìB(y) sinon
|
Brouwer-godel
|
|
ìRG (x ,
y)
|
1 si ìA(x) =0
min [ìA(y) /ìA(x), 1]
sinon
|
Goguen
|
|
ìRL (x ,
y)
|
Min [1- ìA(x)+ ìB(y) , 1]
|
Luksiewicz
|
|
ìRM (x ,
y)
|
Min [ìA(x) , ìB(y)]
|
Mamdani
|
|
ìRP (x ,
y)
|
ÌA(x) . ìB(y)
|
Larsen
|
Figure I.9 : Principales classes d'implication
floues .
Chapitre 1 : La logique floue
I.8 Contrôleur à logique flou :
un contrôleur flou peut être vu comme un
système expert fonctionnant à partir d'une représentation
des connaissances basées sur la théorie des ensembles
flous [12] .
Ce contrôleur fourni un algorithme de conversion d'une
stratégie de contrôle linguistique basée sur l'expertise
humaine en une stratégie de contrôle automatique ,
Il est décrit par un ensemble de règles de
contrôle flou du type :
R1 : IF x is A1 and y is
B1 them z is C1
R2 : IF x is A2 and y is
B2 them z is C2
Rn : Fl x is An and y is
Bn them z is Cn
I.9 La structure des systèmes a base de la logique
flou :
Le système à base de la logique
floue effectue un application de U Rn à V R
Avec : U = U1 . U2 . . .
Un .
Il est constitué de quatre blocks comme c'est
illustré sur la figure :
Base de connaissance
Interface de fuzzification
Interface de défuzzification
entrée
sortie
Engin d'inférence flou
floue
floue
Processus
entrée numérique
Sortie numérique
Figure I.10 :
structure de base d'un système flou
Chapitre 1 : La logique floue
Le contrôleur flou est composé de deux
interfaces ( fuzzification , defuzzification ) , et d'une base de
connaissance , et d'un engin d'inférence .
I.9.1 Interface de fuzzification :
Cet interface converti les variables d'entrées en valeurs
linguistiques à l'échelle de l'univers de discours choisi
[13] .
L'opération de fuzzification permet d'assurer le passage
des grandeurs physiques d'entrées du contrôleur en variables
linguistiques qui peuvent être traitées par les inférences
.
Un opérateur de conjonction ( une norme triangulaire ,
généralement TZadeh = min )
doit être déterminé pour définir le
sous ensemble flou conjoint associé à la partie condition de la
règle .
Il y a au minimum deux choix de convertir l'entrée
numérique en un ensemble flou A définie dans U .
A - fuzzification singleton :
ou l'opérateur de fuzzification convertie la valeur
numérique x U en un singleton flou Ai dans U tel que
1 si x= x0
ìAi(x) =
0 si x ?
x0
Exemple :
ìAi(x) min
ìAi(x)
1
x0 x
x0 x
Figure I.11 : fuzzification singleton
Cette stratégie est largement utilisée dans les
applications de contrôle flou, car elle est facile à
implémenter .
Chapitre 1 : La logique floue
B - Fuzzification non-singleton :
C'est une fuzzification pour la quelle ìAi(x)
est égal à l'unité si x =x0 et
décroît quand on s'éloigne de x .
Exemple :
min
ìAi(x)
ìAi(x)
ìAi(x) . ìAi(x)
x0
x x0
x
Figure I.12 : fuzzification non
singleton
I.9.2 Base de connaissances :
Elle permet la manipulation des données floues et
caractérise la commande au moyen d'un ensemble de règles
linguistiques du type « si -
alors » .
Ce bloc contient les définitions : des fonctions
d'appartenance , des variables
d'entrées /sorties (gaussienne, trapézoïdale
,....etc.) ainsi que les règles d'inférence .
La base de règles est une collection de règles
« si - alors » flou qui
définissent la relation entre une observation et une action .
Ces règles peuvent être exprimées par :
R(L) : SI (u1 est
A1L et u2 est A2L
et ... un est AnL) ALORS (
v est cL)
ou :
ui et v sont des variables linguistiques
avec : i = 1 , 2 , ..... n .
AiL et CL sont des termes
associés aux ensembles flous FiL et
GL
définie dans Ui et V, respectivement
.
avec : L = 1 , 2 , ..... , M .
M est le nombre total des règles dans la base
des règles .
Chapitre 1 : La logique floue
I.9.3 engin d'inférence flou (régulateur
flou) :
l'engin d'inférence flou dérive l'ensemble flou B
de sortie défini dans V à partir de l'ensemble flou
d'entrée Ax définie dans U de la manière
suivante :
Chaque règle floue , décrite par une implication
flou RL détermine un ensemble flou
BL = Ax O
RL dans V .
telle que :uU
ìBL(v) =
ìAoBL(v) = Sup uU {
ìAx(u) . ìRL
(u ,v) } (I . 19)
plus simplement :
c'est que ce bloc permet de définir la stratégie de
contrôle en utilisant les implications floues qui lient les
différentes variables de chaque règle .
Plusieurs mécanismes d'inférence se
présentent [8] , [14] :
§ Mécanisme d'inférence MAX - MIN
.
§ Mécanisme d'inférence MAX -
PROD.
§ Mécanisme d'inférence SOM-
PROD.
Le mécanisme d'inférence opère en deux
étapes :
A- Calcule de la conséquence de chaque
règle :
La conséquence de chaque règle est donnée
par :
ìBil(y) =
ìA(x0) .
ìRi(x0 , y)
ìBiL(y) = ìA(x0)
. ìAi (x0) .
ìB (y) (I . 20)
si non utilise la fuzzification singleton la formule
sera équivalente à :
ìBil =
ìAi (x0) .
ìBi(y) [8].
Pour qu'un système flou soit
« bien - défini »
il faut qu'il y est au moins une règle
active pour chaque point numérique d'entrée
possible .
B- Calcule de la conséquence du
système :
l'action (ensemble flou de sortie ) produit par le système
flou est construite par l'agrégation des conséquences de toutes
les règles soit :
ìBl(y) =
ìB1l(y) ìB2l(y)
... ìBnl (y) (I . 21)
la composition sup-star de Zadeh est un cas spécial de
(I . 21) puisqu'elle interprète l'opérateur
comme le supremum .
Chapitre 1 : La logique floue
Ou plus explicitement .
ìBil =
max [ ìB1l(y) ,
ìB2l(y) , ......,
ìBnl(y) ]
ce que donne pour (I . 21) :
ìB(y) = max [
ìA1(x0) .
ìB1(y) , ìA2(x0) .
ìB2(y) , ... , ìAn(x0)
. ìBn(y)]
Exemple :
Etant données les deux règles suivantes :
R(1) : SI (
x1 est A1) et ( x2
est B1 ) alors ( y est C1 ) .
R(2) : SI (
x1 est A2 ) et ( x2 est
B2 ) alors ( y est C2 ) .
Pour schématiser la procédure d'inférence on
utilise le mécanisme MAX-MIN et le mécanisme
MAX-PRODUCT comme suit :
ì prod (and)
ì ì
0.8
0.4
0.4 .
0.8 = 0.32
-1 1 x1 -2
2 x2 -5
5 y
if (x1 est proche de zéro)
and (x2 est proche de zéro)
then (y est proche de zéro)
ì prod (and)
ì ì
0.4
0.2
0.4 . 0.2 =0.08
-1 1 x1 0
4 x2 0
10 y
if (x1 est proche de zéro)
and (x2 est positive petit) then
(y est positive)
MAX ì
0.32
0.08
-5 0 5 10
y
Figure I.13 :
Mécanisme d'inférence
MAX -
PROD
Chapitre 1 : La logique floue
MIN
ì ì
ì
0.8
0.4
0.4
21
3 -1 1 x1 -2
2 x2 -5 5
y
if (x1 est proche de zéro)
and (x2 est proche de zéro)
then (y est proche de zéro)
ì ì
MIN ì
0.4
0.2
0.2
7
-1 1 x1 0
4 x2 0
10 y
if (x1 est proche de zéro)
and (x2 est positive petit) then
(y est positive)
MAX
ì
0.4
0.2
-5 0 5
10 y
Figure
I.14 : Mécanisme d'inférence
MAX-MIN
Note : Spécificité des
systèmes d'inférence floue :
En ce qui concerne les SIFs (système
d'inférence floue) , il est intéressant de les utiliser
quand :
? Soit il existe une expertise humaine que l'on veut exploiter et
introduire dans un système automatique .
? Soit on veut extraire des connaissances à partir de
données numériques , en les exprimant dans un langage proche du
langage naturel .
? Soit on veut réaliser une interface homme - machine ,
donner des explications ou établir des diagnostiques
immédiatement interprétables .
Chapitre 1 : La logique floue
I.9.4 La defuzzification :
Cet interface converti les l'ensemble floue de sortie en actions
de commande physiques selon un univers de discours choisi .
Le module constitue le lien de communication entre le monde de
raisonnement approximatif (système flou ) , et le monde réel
du processus (système à commander) . Plusieurs méthodes de
défuzzification sont proposées dans la littérature
[14] , [12] .
Les plus utilisées actuellement sont :
a) La stratégie du maximum :
Cette stratégie choisie comme sortie du système la
valeur y0 pour la quelle
ìA(B1 ,B2 , ...) (y0)
soit la plus grande valeur de la fonction d'appartenance de
A (B1, B2, ....) .
ì
(y0)
y0 y
Figure I.15 : stratégie du maximum
b) La stratégie de la moyenne des maximums :
La sortie du système flou représente la valeur
moyenne des yi pour les quelles ìA(yi)
soit maximal :
y0 = [ ?yi
Max (y) yi / | Max (y) | ] .
c) La stratégie du centre de
gravité :
C'est la stratégie la plus utilisé elle est
définie par :
?Ni = 1
yi ìB (yi)
y =
?Ni = 1
ìB (yi)
Ou :
N est le nombre de niveaux de quantification de la sortie
Chapitre 1 : La logique floue
Ou bien :
le nombre des sous-ensemble flous de l'espace de sortie .
y est la valeur numérique de sortie.
d)- La stratégie des hauteurs :
soit y L le centre de gravité de la
1ere règle .
Le calcule de la sortie est comme suit :
Y = ?ML = 1 y L
ìBL (y L) / ?ML =
1 ìBL (v L) .
Bien que cette stratégie est facile à utiliser
parce que le centre de gravité des fonctions d'appartenance les plus
utilisées est connu en avance .
e)- La stratégie des hauteurs
modifiée :
La sortie du système flou est calculée par la
formule suivante :
y L
ìBL (y L)
ìBL (y L)
Y = ?ML = 1
?ML = 1
G L.L
G L.L
Où GL est une mesure de support de la
fonction d'appartenance pour la 1er règle .
Pour les fonctions d'appartenance triangulaires et
trapézoïdales et gaussienne
GL représente la base du triangle ou du
trapézoïde ou l'écart type respectivement .
I.10 La modélisation par la logique flou :
Pour l'identification de la fonction d'un système
(processus) , on a besoin d'établir un modèle mathématique
.
Le modèle de raisonnement approximatif floue est
généralement formé d'un ensemble de règles qui
décrit le comportement du système .
La modélisation floue donc est déduite d'un
raisonnement élaboré des états des processus et d'une
liste des règles décrivant la manière selon laquelle le
modèle doit fonctionné .
I.11 Les règles floues :
Les règles floues représente une connaissance
humaine , exprimée en langage naturel ,
à l'aide de mots vagues , mal définis , flous .
chapitre 1 : La logique floue
Dans la théorie des systèmes flous il existe
deux types de règles :
I.11.1 règle de Mamdani :
Mamdani fut le premier à utilisé la logique floue
pour la synthèse de commandes .
Il utilise le minimum comme opérateurs de conjonction et
d'implication .
La règle utilisé par Mamdani est de la
forme :
IF x1 is A1 and x2 is A2 and ..... xn is An then y is
B
Où :
Ai , i = 1.......n , et B , sont des ensembles flous
caractérisant la parti premise et la partie conséquence ,
définis par la fonction d'appartenance :
ìAi
(xi) et ìB (y) .
La règle peut être aussi écrite
comme :
IF X is A then Y is B
Où :
A est l'ensemble flou définit par le produit
cartésien ,
et la valeur réelle de Y est exprimée par l'une des
méthode de défuzzification .
Dans cette méthode , l'inférence flou correspond
aux étapes suivantes pour un vecteur d'entrée x = ( x1 , x2 ,
..... , xn )i .
A. Calcul de degré d'appartenance de
chaque entrée aux différents sous
ensembles flous ìAji (xj
) pour :
j = 1? n et i= 1 ? N .
B. Calcule de la valeur de vérité
de chaque règle ,
pour i = 1 ? N :
i (x) =min j (
ìAji (xj ) ) .
avec j = 1 ? N .
C. Calcul de la contribution de chaque
règle .
ìi(y) = min (i
(x) , ìBi (y) ).
Bi représente les
conséquences des règles .
Chapitre 1 : La logique floue
D. Agrégation des règles :
ì(y) = max i (
ìi(y) ) .
Le résultat est donc un sous ensemble flou
caractérisé par sa fonction d'appartenance .
Pour obtenir une conclusion (nette) , il faut donc
défuzzifier la sortie .
Exemple :
If x1 is A11 AND x2 is A12 then y is B1.
If x1 is A21 AND x2 is A22 then y is B2.
A11 A12
B1
x1 x x2 x
y
A21 A22
A (B1,B2)
B2
y0
x1 x x2 x
y
Figure I.16 :
représentation graphique de la méthode de
Mamdani
I.11.2 Règle de Takagi Sugeno :
La règle de Takagi Sugeno présente à la
différence de celle de Mamdani [15] , une
conséquence qui n'est pas un ensemble flou mais une fonction des
entrées .
Soit :
If x1 is A1 and x2 is A2
.... Then y = B(x)
Ou B(x) est une fonction des entrées par exemple :
Bi = ?nj = 0 Bji .
x j .
Chapitre 1 : La logique floue
On parle parfois de méthode de Takagi Sugeno
simplifiée ou d'ordre zéro quand la conclusion est une constante,
dans ce cas on peut considérer la méthode de Takagi Sugeno comme
un cas limite de celle de Mamdani .
Pour un vecteur d'entrée x = ( x1 ,....,
xn ) i la sortie inférée est obtenue
par :
A. Calcul du degré d'appartenance de
chaque entrée aux différents sous ensemble flous,
ìAji (xj ) , pour
j = 1 ? n et i = 1 ? N .
B. Calcule de la valeur de vérité
de chaque règle ,
pour i=1 à N :
i
(x) = ET ( ìA1i (x1 ) , ... ,
ìAni (x n ) ) .
C. Calcule de la sortie du SIF :
y =
?ni = 1 i (x) . bi
?nj = 1 i (x) .
La sortie obtenue n'est pas floue , ce qui supprime une
étape dans l'inférence .
Les SIF de type Takagi Sugeno permettent donc le passage
aisé d'une expression symbolique (la base de règle) à sa
traduction numérique .
Chapitre 1 : La logique floue
Les étapes de conception d'un système
flou
La conception d'un FLC nécessite le choix des
paramètre suivants :
Définition du système en termes de ses
variable d'entrées et de sortie :
Généralement les variables d'entrées sont
l'erreur ( e ) et le changement de l'erreur (
e.)
De la variable d'état du processus .
Choix de la partition floue :
on associe un ensemble de terme linguistique
caractérisés par des fonctions d'appartenances définis sur
le même univers de discoure pour chaque variable d'E/S .
En fait , le choix de la partition floue consiste à
déterminer le nombre de termes dans cette ensemble .
Généralement ce nombre est impair et compris entre
3 et 9 . Ce choix dépend du
problème à traiter s'il exige la précision ou la
robustesse du système .
Choix des fonctions d'appartenance :
Les fonctions d'appartenances les plus utilisées sont les
fonctions :
Trapézoïdal et triangulaire .
Car elles sont prouvées d'être de bonne compensateur
entre l'efficacité et la facilité d'implémentation
(programmation) .
Le chevauchement de la fonction d'appartenance avec ses voisines
est compris entre
10% et 50 du support de la
fonction voisine .
Construction de la base de
règle :
De nombreuses méthodes ont été
proposées .
Ils peuvent être groupés selon leur principe en deux
catégories :
Méthodes d'extraction naturelle .
Méthode d'extraction automatique .
Choix de la méthode d'inférence et de la
stratégie de défuzzification .
Chapitre 1 : La logique floue
Conclusion :
Les systèmes flous ont connus un succès
considérable dans la command des procédés
industrielles complexes , du fait de leurs caractère
approximatif et qualitatif inspirés de la pensé humaine
[16] [17] .
Leurs performances sont liées à deux facteurs
importants :
1- la disponibilité de l'expertise
2- la validité de techniques
d'acquisition de connaissances et la justesse des données
acquises.
La logique floue est une théorie très puissante qui
permet d'obtenir des conclusion et de générer des réponses
à partir des informations incomplètes et imprécises , la
ou le monde mathématique du système est inconnu ou difficile
à extraire .
L'objectif est de concevoir ou de réaliser des
systèmes qui peuvent prendre en charge certaines taches avec la
même habilité que possède l'être humain .
La phase d'acquisition des connaissances est la plus difficile
dans des cas ou le domaine d'expertise n'est pas disponible .
Pour cette raison , des recherches très poussées
ont conduit au développement des méthodes systématiques et
optimales pour la conception des contrôleurs flous .
Parmi ces méthodes on trouve :
Les réseaux de neurones qui sont très
puissants dans le domaine de l'apprentissage et de l'optimisation , et cela en
utilisant les fonctions qu'on veux optimisé comme poids à
ajusté.
De ce fait , le contrôleur flou peut être
utilisé avec d'autres techniques telles que les
réseaux de neurones pour la conception de ce contrôleur d'ou le
nom :
«
neuraux - flou » .
Chapitre II

Chapitre 11 : Les réseaux de
neurones
Les réseaux
de neurones
II.1 Introduction :
Dans le chapitre précèdent nous avons
expliqué le fonctionnement de la logique floue , qui n'est autre qu'une
technique que le cerveau utilise , donc l'outil de base de l'intelligence
artificielle est le réseau de neurones .
Le terme de réseaux de neurones
« formels » ou
« artificiels » fait
rêver certains , et fait peur à d'autres . La
vérité est plus rassurante ; les réseaux de neurones
constituent maintenant une technique de traitement de données bien
comprise et maîtrisée , qui devrait faire partie de la boite
à outils de tout ingénieur .
En effet , même si nous somme incapable
de réaliser des calcules avec la rapidité et la précision
d'un ordinateur , nous somme autrement mieux adaptés que ce dernier au
problèmes de traitement de l'information dans son ensembles :
traitement du signal , extraction de caractéristiques pertinentes dans
un monde complexe , et décision , sont des taches que nous accomplissons
couramment .
Ces taches sont accomplies avec une grandes rapidité , et
le cerveau adapte son comportement aux situations nouvelles , principalement
selon deux processus :
II.1.1 - L'adaptation rapide et automatique :
C'est le cas de notre pupille , par exemple , qui adapte son
diamètre en fonction de la quantité de la lumière , et
dans le cas d'un réseau neuronal ces poids sont adaptés
automatiquement par une fonction mathématique , ces poids peuvent
représentés des valeur ou des grandeurs physique ou chimique ou
mathématique que le réseau doit adapté et que le neurone
doit utiliser dans sa fonction de seuil .
II.1.2 - L'apprentissage :
Cet apprentissage autorise une adaptation lente d'un individu
à l'exécution d'une tache nouvelle, par exemple , l'utilisation
d'une nouvelle théorie des mathématiques .
Toutes ces constatations ont constitué un ensembles de
motivations important poussant à analyser le fonctionnement de cette
machine .
Les biologistes ayant isole sont élément de base ,
à savoir le neurone , une approche mécaniste de la pensée
a alors vu le jour .
En effet si l'on modélise le fonctionnement de
l'élément de base et si l'on reproduit les interactions des
élément de base entre eux , alors on est certainement capable de
reproduire artificiellement la pensée .
Les premiers essais de modélisation datte des
années 40 .
L'objectif de cette approche est de produire un dispositif
(machine) capable de jaillir quelques étincelles de l'intelligence qui
consiste un moyen efficace dans presque la totalité des domaines et en
particulier celui de l'ingénierie.
Chapitre 11 : Les réseaux de
neurones
II.2 Le neurone :
Ce neurone artificiel est une simplification extrême du
neurone biologique dont le comportement
temporel . C'est pourtant ce neurone simplifié , qui
est utilisé encore aujourd'hui dans la plupart des systèmes
mettant en oeuvre des réseaux neuronaux sur des applications .
Le modèle du neurone formel se comporte comme un
opérateur effectuant une somme pondérée de ses
entrées, suivie d'une non linéarité appelée
fonction d'activation.
Si la somme pondérée de ses entrées
dépasse un certain seuil qui est la propriété de la
fonction d'activation , le neurone est activé et transmet une
réponse dont la valeur est celle de son activation , sinon il ne
transmet rien.
Sa structure est la suivante [30] :
W1j
W0J =
OJ
X1j
W2j
X2j
F(SJ)
Yj
W3j
X3j
synapse
corps cellulaire axone
Figure II.1 : Model artificiel d'un neurone
La sortie du neurone est définie par la relation
suivante :
Yj = F ( ?ni=1 (W i j *
X i ) - O j ) . ( II . 1 )
Avec :
X1j , ........, X n
j : les entrées .
W1j , ......., W n
j : les poids synaptiques .
S j : La somme des sorties des
neurones connectés au neurone.
W0j = O j : La valeur
du seuil interne du neurone.
II.3 Quelques exemples de fonctions d'activation
[31] :
Les fonctions d'activation représentent
généralement certaines formes de non linéarité,
nous citrons quelques exemples :
Chapitre 11 : Les réseaux de
neurones
1- Fonction seuil (Heaviside ,
échelon ) : 1 S j
= 0
F ( S j ) =
0 S j < 0
Le seuillage introduit une non linéarité dans le
comportement du neurone.
Cependant il limite la gamme de ses réponses possibles
à deux valeurs.
2- Fonction linéaire bornée :
S j /
á- = S j ? á+
F ( S j ) = 1
S j > á+
-1 S j <
á-
3- Fonction sigmoïde exponentielle :
F ( S j ) = 1
1 + e (- â S j
)
Ce type de fonction est généralement
employées dans le perception multicouches.
Elle présente l'avantage de la simplicité de
calcul de sa dérivée .
4- Fonction sigmoïde tangentielle :
F ( S j ) = 1 + e (- â S
j )
1 + e (- â S j
)
Cette fonction présente l'avantage de la rapidité
de convergence de l'apprentissage et aussi la simplicité dans le calcul
de la dérivée .
5- Fonction gaussiene :
F ( S j ) = e x² / 2 *
ä²
Cette fonction est très utilisée dans les
réseaux RBF ( Radial Basis Function ) .
Chapitre 11 : Les réseaux de
neurones
F(SJ)
F(SJ)
1
+1
SJ
SJ
-1
Figure (a)
Figure
(b)
F(SJ)
F(SJ)
+1
SJ
SJ
-1
Figure (c)
Figure
(d)
F(SJ)
SJ
Figure (e)
Figure (a) : Fonction seuil .
Figure
(b) : Fonction linéaire bornée
.
Figure
(c) : Fonction sigmoïde
exponentielle .
Figure
(d) : Fonction sigmoïde
tangentielle .
Figure
(e) : Fonction
gaussiene .
Chapitre 11 : Les réseaux de
neurones
II.4 Réseau de neurones :
L'intérêt de ces cellules de traitements simple
apparaît lorsqu'on les agences sous forme de réseau .
En effet , ce sont les propriétés du réseau
de neurones qui sont réellement remarquables .
Parmi les métaphores biologiques employées de nos
jours pour la résolution de problème , les réseaux
neuronaux artificiels constituent certainement l'approche la plus
utilisée .
Ils constituent en des modèles plus ou moins
inspirés du fonctionnement cérébral de l'être
humain, en se basant principalement sur le concept de neurone.
La plupart des modèles ne retirent du fonctionnement
réel que les principes suivants :
· Les réseaux de neurones sont
caractérisés par des interconnexion entre des unités de
traitement simples agissant en parallèle.
· A chaque connexion est associé un poids qui
détermine l'influence réciproque des deux unités
connectées.
· Les poids des connexions sont modifiables et c'est cette
plasticité qui donne lieu aux facultés d'adaptation et
d'apprentissage.
Les dynamiques d'états et de paramètres
dépendent fort du modèle de réseau choisi
[34].
II.5 L'architecture d'un réseau de
neurones :
L'architecture d'un réseau de neurones joue un
rôle très important dans son comportement .
Si l'on se réfère aux études biologiques du
cerveau on constate que le nombre de connexions est énorme.
D'une manière générale l'architecture des
réseaux peut aller d'une connectivité locale [Réseaux
à couches] à une connectivité totale [Réseaux
entièrement connectés] .
Chapitre 11 : Les réseaux de
neurones
II.5.1 Réseaux à couches :
La connectivité des neurones dans les réseaux
à couches est locale , ou ils sont reliés qu'a leurs plus proche
voisins de la couche précédente et la couche suivante.
La couches d'entrée est une couche passive, ses neurones
n'effectuent aucun traitement leur rôle est de recevoir et transmettre
les configurations à mémoriser .
Les couches extrêmes correspondent à la couche qui
reçoit ses entrées du milieu extérieur, cette couche est
appelée la couche de sortie.
Les couches internes sont appelées les couches
cachées, leur nombre et variable et dépend de l'application.
Exemple :
Les Entrées
sortie
couche d'entrée
couche de sortie
trois couches cachées
Figure
II.3 : réseau à couche
Chapitre 11 : Les réseaux de
neurones
II.5.2 Réseaux entièrement
connectés :
Dans ce type de réseaux la connectivité des
neurones est totale où tous les neurones sont reliés les uns aux
autres.
Chaque neurone possède deux ensembles de poids, le
premier ensemble pour calculer la somme des entrées externes
pondérées et le deuxième pour contrôle des
interactions entre les neurones de réseaux .
Exemple :
entrées
sortie
Figure II.4 :
Réseau totalement connecté
Les flèches sur les deux schémas
précédant représentent les poids synaptiques qui relient
le neurones entre eux .
Pour une architecture de réseau donné , ces poids
synaptiques sont les seuls éléments qui peuvent varier au cour du
fonctionnement du réseau .
II.6 Propriétés des réseaux de
neurones :
ce qui rend les réseaux de neurone
différents des méthodes classiques dans la quête de la
robustesse qu'ils sont fondamentalement distingués selon quatre points
principaux :
Chapitre 11 : Les réseaux de
neurones
II.6.1 Parallélisme :
Le caractère distribué et parallèle et
simultané du traitement par le réseaux , offre des avantages de
robustesse par rapport à des données incertaines
incomplètes, contradictoires, et même par rapport à des
défectuosités locales du réseaux .
II.6.2 La généralisation :
L'intérêt des réseaux de neuronaus
réside précisément dans leur capacité à la
généralisation , c'est-à-dire leur aptitude à bien
se comporter sur des vecteurs qu'ils n'ont pas appris .
La capacité de généralisation d'un
réseaux de neurones est son aptitude de donner une
réponse satisfaisante à une entrée qui ne fait pas partie
des exemples à partir des quels il a appris.
II.6.3 Capacité d'adaptation :
C'est la capacité d'apprentissage de plus elle se
manifeste dans certains réseaux par leur capacité d'auto -
organisation qui assure leur stabilité.
II.6.4 La résistance aux pannes :
Les données bruitées ou les pannes locales dans un
certain nombre des éléments du réseaux de neurones
n'affectent pas ses fonctionnalités .
Cette propriété résulte essentiellement du
fonctionnement collectif simultané des neurones qui le composent.
II.6.5 L'Apprentissage :
En effet , dans les années 60 , on ne
savait pas réaliser correctement un apprentissage sur un réseau
à rebouclages ou sur un réseau à plusieurs couches .
Cela mit en sommeil les recherches sur les réseaux
neuronaux pendent plusieurs années .
Ce n'est qu'au début des années 80
que de nouveaux travaux ont conduit à des méthodes
d'apprentissages autorisant l'utilisation de réseaux neuronaux complexes
.
Chapitre 11 : Les réseaux de
neurones
Comme l'information que peut acquérir un réseau de
neurones est représentée dans les poids
des connexions entre les neurones, l'apprentissage consiste donc
à ajusté ces poids de telle
manière que le réseau présente certains
comportement désirées .[38]
L'apprentissage dans un réseau neuronal est donc tout
à fait différent de l'apprentissage dans un système
à base de règles ou il signifie dans ce cas
« engranger de nouvelles règles
»
Dans une base de données .
Dans un réseau de neurones , au contraire apprendre
signifie modifié les paramètres physiques internes du
systèmes (les poids) .
? L'apprentissage comprend quatre étapes de
calcules :
a- Initialisait les poids synaptiques du
réseau ( pratiquement leurs valeurs sont aléatoires et
très petites ) .
b- présentation de
l'ensemble de données d'entrées .
c- calcul de l'erreur .
d- calcul du vecteur d'ajustement
.
Les étapes b . c . d sont
répétées jusqu'à la fin de la procédure
d'apprentissage
( satisfaction du critère
d'arrêt ) .
Une fois l'entraînement est terminé , le
réseau devient opérationnel .
En général , on peut distinguer trois types
d'apprentissage .
II.6.5.1 Apprentissage non
supervisé :
Dans ce mode d'apprentissage , les poids synaptiques sont
modifiés en fonction d'un critère [31] .
L'apprentissage non supervisé consiste a découper
l'ensemble des vecteurs d'entrées en classes d'équivalences ,
sans qu'il soit nécessaire de donner au réseau neuronal les noms
des classes pour chaque exemple .
Chapitre 11 : Les réseaux de
neurones
La séparation en classes d'équivalence
s'opère par mesure de ressemblance entre les vecteurs proposés .
La contrainte que l'on doit imposer au réseau neuronal est
le nombre de classes d'équivalence .
Pendant la phase d'apprentissage , le réseau neuronal
construit une topologie de l'espace des vecteurs d'entrées .
Dans ce cas , la connaissance à priori de sortie
désirée n'est pas nécessaires et la procédure
d'apprentissage est basée uniquement sur les valeurs d'entrées.
Le réseau s'auto- organise de manière
à optimiser une certaine fonction de coût , sans qu'on lui
présente la réponse désirée .
Les modèles de kohonen et de Grpossberg sont deux exemples
parfait qui utilisent l'apprentissage non supervisé .
L'intérêt de cette approche est que l'on a pas
besoin de disposé d'exemple de problèmes résolus ,c'est a
dire , de vecteur de sortie correspondant à chaque vecteur
d'entrée utilisée pour l'apprentissage .
II.6.5.2 Apprentissage
supervisé :
Ce mode dispose d'un comportement de référence ,
vers lequel il tente de faire converger le réseau .
Durant une première phase , appelée phase
d'apprentissage , on présente au réseau les valeurs
d'entrée et on calcule sa sortie actuelle correspondante, ensuite les
poids sont ajustés de façon à réduire
l'écart entre la réponse désirée et celle du
réseau en utilisant l'erreur de sortie qui est la différence
entre la réponse du réseau et celle désirée.
Pendant une seconde phase , appelée phase de test , on
présente au réseau de nouveaux vecteurs qui n'ont pas servi
à l'apprentissage et l'on observe ses réponses .
Les performances du réseau sont alors
évaluées par le pourcentage d'erreurs .
II.6.5.3 Apprentissage par renforcement :
Ce mode suppose qu'un comportement de référence
n'est pas disponible , mais en revanche le système à
entraîner est informé d'une manière indirecte sur l'effet
de son action choisie .
Chapitre 11 : Les réseaux de
neurones
Cette action est renforcée si elle conduit à une
amélioration des performances du système entraîné
[32] .
La différence entre ces trois types d'apprentissage
réside dans le critère de performances implicite on explicite
.
II.6.6 La non-linéarité :
Cette non-linéarité , est parfois récurrente
, autorise les réseaux neuraunos à modélisé des
associations très complexes .
La non-linéaruté de type seuil est
génératrice de capacité de
généralisation : cela est simple
à concevoir , puisque la sortie seuillée d'un neurone ne peu
prendre que deux valeurs alors que cette même sortie non seuillée
est multivaluée .
II.6.7 Certains réseau de neurones sont des
approximateurs parcimonieux :
Le plus souvent , le problème qui se pose à
l'ingénieur est le suivant : il dispose d'un ensembles de variables
mesurées (x) , et d'un ensembles de mesures
(z) d'une grandeur relative à un processus de nature
quelconque ( physique , chimique , économique ....) .
Il suppose qu'il existe une relation entre le vecteur des
variables (x) et la grandeur (z) , et il
Cherche à déterminé une forme
mathématique de cette relation , valable dans le domaine ou les mesures
ont été effectuées .
Sachant que toutes les variables qui déterminent
(z) ne sont pas forcément mesurées .
En d'autre termes , l'ingénieur cherche à
établir un « model » du processus qu'il
étudie , à partir des mesures dont il dispose , et d'elles
seules : on dit qu'il effectue une modélisation
« boite noire » .
Exemple :[36]
Considérons le model neuronal représenté sur
la figure , dont l'équation est :
G(x) = 0.5-2.th(10.x+5)+3.th(x+0.25)-2.th(3.x-0.25) . (1)
g
-2 3 -2 0.5
10 5 1 0.25 3 -0.25
x 1
Figure
II.5 : model neuronal représentant l'équation
(1)
Chapitre 11 : Les réseaux de
neurones
II.7 Equations d'un réseau :
soit un réseau MLP " maltilayered perception ou
perception à multiple couche " non récurrent (statique ) à
entrées (Rn) et m sortie (Rn) .
Supposons que le réseau est composé de (L)
couches :
(L -1) couches cachées plus une couche de sortie .
Les sorties de neurones de la couche K sont données par
l'expression suivante :
YKj (t) = f [SKj (L) ]
( II . 2 )
Telle que :
j = 1,........,nK .
K= 1 , 2 ,....., L .
j = l'indice de ces couches .
nK = le nombre de neurones correspondant
.
f = est la fonction d'activation choisie .
Ainsi [35] :
SjK (t) = ?j=0NK-1 WijK
yjK-1 (t) (
II . 3 )
Telle que :
y0K (t) = 1 , K = 1 ,
2 , ....., L .
yj0 (t) = xj (t) ,
j = 1 , 2 , ......, n . sont des éléments du vecteur
d'entrée .
yjL (t) = yj(t) ,
j = 1 , 2 ,.......,m . sont des éléments du vecteur de
sortie .
( yjL ) : est la sortie du neurone j
de la couches K et Wj0 est son seuil interne .
( WijK ) : est le poids de la
connexion du neurone j de la couche K et le neurone i de la couche (K-1) .
Chapitre 11 : Les réseaux de
neurones
II.8 Notion des minimums :
II.8.1 Minimum local :
si le système reste bloqué et la
convergence n'est pas complète on dit qu'il y a un minimum local .
II.8.2 Minimum global :
en ce point le système est stable et la
convergence est complète et la réponse actuelle coïncide
avec celle de la réponse désirée .
II.9 Le principe de minimisation :
Les règles d'apprentissages dont le rôle est de
trouver le plus rapidement possible le minimum d'une fonction d'énergie
sont des adaptation aux réseaux neuronaux des techniques classiques de
recherche de minimum , nous citeront les grandes lignes des principes les plus
importants vis-à-vis des applications .
II.9.1 La décente de gradient :
Ce principe est très simple : si l'on cherche un
endroit situé plus bas que les autres endroits c'est- à - dire un
minimum , alors déplaçons nous vert le bas en suivant les lignes
de plus grandes pente .
La pente étant mathématiquement calculé par
le gradient , on appel une telle méthode une descente de gradient .
Fonction d'énergie de
L'erreur
Etat initial
état final obtenu par poids synaptiques
Tiré au hasard
par descente du gradient
Figure
II.6 : La décente de gradient
Chapitre 11 : Les réseaux de
neurones
mais ce n'est que dans les années 80 ,
que l'adaptation aux réseaux neuronaux a pus être
réalisé .
En effet la notion de gradient , et donc de dérivé
, pour réalisé cette adaptation , on doit utilisé des
fonctions dérivables telle que ( fonction sigmoïde , tangente
hyperbolique...) :
L'erreur est calculé en sortie du réseau neuronal ,
et les contributions à cette erreur de chaque poids synaptique de chaque
couche sont calculées en utilisant des lois classiques de compositions
des dérivés partielles , par ce que les contributions
précitées sont évaluées en partant de la sortie (
dernière couche ) vert l'entrée du réseau ( premier couche
) .
On appel cette règle d'apprentissage rétro -
propagation du gradient
( en anglais Bac propagation ) .
En effet , le minimum recherché peut très bien
être entouré de pics qui interdiront le passage à une
descente de gradient .
Deux adaptation de cette heuristiques sont alors possible pour
amélioré les performances de la descente de gradient
[39].
II.9.1.1 La descente de gradient avec
inertie :
Cette méthode consiste à poussé encore un
peu plus loin la métaphore mécanique du processus de descente ,
et cela par l'inertie qui permet de remonter pour sortir d'un minimum local ,
mais elle induit aussi une oscillation amortie qui ralenti la stabilisation sur
le minimum absolu .
Fonction d'énergie
de l'erreur
Etat
initial minimum local minimum absolu poids synaptiques
tiré au hasard parasite
recherché
Figure
II.7 : La descente de gradient avec inertie
II.9.1.2 La descente stochastique :
Cette méthode à été proposé
par Windrow et Hoff dans les années 60 .
Au lieu de minimisé les l'erreur global due à
l'ensemble des vecteurs d'apprentissage , ils ont proposé de
minimisé itérativement l'erreur due à chaque exemples
d'apprentissage .
Mathématiquement , on cherche à minimiser
itérativement chaque terme d'une somme , au lieu de minimiser la somme
.
Chapitre 11 : Les réseaux de
neurones
II.10 Méthode de rétro -
propagation :
La rétro propagation est l'algorithme d'apprentissage
supervisé pour ajuster les poids d'un réseau MLP.
Dans cette méthode , de même que l'on est capable
de propager un signal provenant des cellules d'entrée vers la couche de
sortie . On peut , en suivant le chemin inverse
rétro- propager l'erreur commise en sortie vers les
couches cachées, d'ou le nom
rétro - propagation [37] .
II.10.1 Principe de fonctionnement de la
méthode :
Le calcul du signal d'erreur nous permet d'ajuster les poids
à partir de cette erreur, de telle sorte que sa sortie actuelle
coïncide avec la réponse désirée .
La loi d'apprentissage proposée est :
WijK (t+1) = WijK (t) - ì . ( dj(w)
/ dWijK (t) ) + á . ( WijK (t) -
WijK(t-1) ) ( II . 4 )
Où :
0<= á <1 est le moment , et (ì) est le pas
d`apprentissage , et (t) est l`indice des itérartions .
Les poids de connexions sont ajustés de sorte que la
fonction de cout :
J(w) = ½ .
?ni=1( di . yi )2
( II . 5 )
Soit minimisée , N: le nombre des exemples d`entrainement
.
La derivée de l'erreur par raport à un poids
WijK est :
dj(w) / dWijK (t) = (dj(w) /
dyjK (t)) . (dyjK (t) /
dWijK (t)) ( II . 6 )
et :
(dyjK (t) / dWijK (t)) =
(dfK (SjK (t)) / dWijK (t)) =
fK (SjK (t)) . (d SjK
(t) / dWijK (t)) . ( II . 7 )
et : i=nk-1
(d SjK (t) / dWijK (t)) = d
[? WijK . yjK-1 (t)] / dWijK (t) =
yjK-1 (t) .
( II . 8 )
i=1
D`où :
(dyjK (t) / dWijK
(t)) = fK (SjK (t)) .
yjK-1 (t) .
( II . 9 )
Donc :
dj(w) / dWijK (t) = (dj(w) /
dyjK (t)) . fK (SjK (t))
. yjK-1 (t) .
( II . 10 )
En prenant :
SjK (t) = -fK
(SjK (t)) . (dj(w) / dyjK (t)) .
( II . 11 )
D`où :
dj(w) / dWijK (t) = -
SjK (t) . yjK-1 (t) .
( II . 12 )
On remplace (dj(w) / dWijK (t)) dans ( II . 4 ) on
trouve :
WijK (t+1) = WijK (t) +
ì . SjK (t) . yjK-1 (t) +
á . ( WijK (t) - WijK(t-1) ) (
II . 13 )
Chapitre 11 : Les réseaux de
neurones
Bien que cet algorithme a donné de bons résultats
dans plusieurs applications les réseau multicouches avec rétro -
propagation présente certaines limitations [31]
[33].
1- Le manque de moyens systématiques pour
déterminer :
a- Le nombre de neurones dans les couches cachées qui est
le nombre des variables libres c'est à dire les poids du
réseau : ce nombre est particulièrement important pars qu'il
détermine la capacité de calcul de réseau.
b- Le nombre de couches cachées.
c- Le pas d'apprentissage.
d- Le moment.
2- Les minima locaux :
ce type de problème est particulièrement difficile
à éviter, notamment parce que la forme de la surface de l'erreur
n'est pas généralement connue.
3- Convergence lente et incertaine.
Chapitre 11 : Les réseaux de
neurones
Conclusion :
Dans ce chapitre , nous avons exposé les
éléments essentiels qui permettent de comprendre pourquoi , et
dans quels cas , il est avantageux de mettre en oeuvre des réseaux de
neurones .
Avant d'aller plus loin , il est sans doute utile de rappeler les
points fondamentaux qu'il convient de toujours garder à l'esprit lorsque
on cherche à mettre en oeuvre des réseaux de neurones :
? Les réseaux de neurones sont utilisés comme
outils statistiques , qui permettent d'ajuster des fonctions non
linéaires très générales à des ensembles de
points ,l'utilisation de réseaux de neurones nécessite que l'on
dispose de données suffisamment nombreuses
et représentative .
? Les réseaux de neurones à apprentissage
supervisé sont des approximateurs
parcimonieux , qui permettent de modéliser des
phénomènes .
? Les réseaux de neurones à apprentissage non
supervisé peuvent apporter des éléments précieux
pour la détermination d'une bonne représentation des formes .
? Il est toujours souhaitable , et souvent possible , d'utiliser
, pour la conception du réseau , les connaissances mathématiques
dont on dispose sur le phénomène à modéliser ;
les réseaux de neurones ne sont pas nécessairement des
« boites noires » .
L'entraînement et la conception d'un réseau de
neurones demeure aujourd'hui un art et non une science, à la fois objets
d'études et outils applicatifs les réseaux de neurones ont un
rôle à jouer dans un nombre rapidement croissant de domaines
autant en recherche qu'en industrie .
Ainsi l'association ou l'hybridation des techniques neuronales
avec d'autres méthodes et la connaissances disponibles sur le
comportement de système à traiter , pourrait améliorer les
performances du réseau et permet aussi de réaliser efficacement
les tâches désirées .
Parmi ces méthodes on trouve la logique floue , de fait de
son caractères approximatif et qualitatif inspires de la pensé
humaine .
Chapitre III

Chapitre III : Réseaux neuraux flous
III.1 Introduction :
Dans des systèmes employant une logique de raisonnement ,
l'apprentissage consiste soit à augmenter la base de connaissance en
créent de nouveaux objet correspondant au schémas
déjà connus , soit à créer de nouvelles structures
de connaissances , ce qui est beaucoup plus difficile .
Il s'agit en effet dans le second cas de
généré de nouvelles règles , par exemple , de faire
émerger une nouvelle connaissance , c'est a dire d'apprendre
effectivement .
Le fonctionnement d'un apprentissage demande essentiellement
d'être confronté à des exemples et d'être capable de
s'y adapter , et de généraliser la connaissance .
De ce fait , une technique très prometteuse aujourd'hui ,
il s'agit ( des réseaux de neurones )
Ceux ci correspond en effet parfaitement aux conditions
énoncées , ils sont capables de s'adapter à des exemples
donner , de les apprendre par coeur , mais aussi de
généralisé et de répondre sur des cas non appris
.
L'inconvénient de cette technique , est qu'on ne sait pas
encore très bien extraire des règles à partir d'un
réseau de neurones qui a appris , d'ou l'utilité d'employé
( la logique floue ) en combinaison avec les réseaux de
neurones .
La logique floue tel que Zadeh la cocus , est incapable
d'apprendre la connaissance , contrairement aux réseaux de neurones ,
d'un autre point de vue , les réseaux de neurones ont besoin d'un
minimum d'information , tandis que la logique floue demande une connaissance
détaillé sur le problème à résoudre .
La solution apporté est l'introduction de la notion
d'extraction automatique des connaissances sans besoin relatif de l'expert .
Cependant , la conjonction de la méthode d'extraction
automatique avec l'expérience humaine permet d'obtenir un FLC de
degré d'efficacité et de souplesse de manipulation
élevé.
III.2 Extraction automatique des
connaissances :
Ces méthodes sont basées sur l'apprentissage pour
déduire l'information suffisante pour traiter un problème
quelconque dans un environnement complexe .
Les deux approches les plus rencontrées dans la
littérature sont :
1- Approche à auto - apprentissage ou directe .
2- Approche connexionniste .
III.2.1 : Approche à auto - apprentissage ou
directe :
Les travaux de Mamdani et de Procyk ont conduit au
développement du premier contrôleur à auto - apprentissage
( SOC : Self Organizing Controller ) , il possède une structure
hiérarchique constituée de deux bases de règles :
La première est d'ordre général , la seconde
est construite à partir de méta - règles qui crée
et modifie la base de règle générale .
Donc ce contrôleur expose la capacité humaine
d'apprentissage et de modification .
Chapitre III : Réseaux neuraux flous
Les règles sont adaptées en cours de fonctionnement
et peuvent donc suivre les modifications du processus a contrôler , cette
stratégie est utilisée pour l'apprentissage des paramètres
d'un FLC par application directe d'une méthode
d'optimisation [18] [19] [20] [21] .
La méthode la plus utilisée est celle de descente
de gradient .
III.2.2 : Approche connexionniste :
L'approche connexionniste consiste à combiner les deux
méthode : La théorie de la logique floue avec celle des
réseaux de neurones .
Deux approche pour construire un réseaux neuraux flou
[22] [23] .
A : première approche :
Dans cette approche ( structurelle ) on
construis un système d'inférence flou sous forme d'un
réseau de neurones multicouches dans la quel les poids du réseau
correspondent aux paramètres du système flou , exemple :
l'écart type des fonctions d'appartenances .
B : deuxième approche :
Dans cette approche ( fonctionnelle ) le
réseau neuraux flou peut incorporer le processus de raisonnement
approximatif .
III.2.2.1: Approche structurelle :
L'architecture du réseau dépend du type de
règles et des méthodes d'inférence et de defuzzification
choisies .
Les formes d'architecture les plus rencontrées dans la
littérature sont :
A- L'architecture basée sur le raisonnement approximatif
de Takagi , Sugeno représentée par la structure ANFIS (Adaptive
Neural Fuzzy based Inference Systeme ) :
Cette architecture a été proposée par Takagi
, Sugeno et Kang [24] .
Un exemple est donné pour illustré cette
idée :
Exemple :
Soit deux entrées x1 , x2 et une sortie y :
Le model de Sugeno d'ordre un à deux règles est
donné par :
R : Si (x1 est A1 )
et ( x2 est B1 ) Alors (F1 = p1.x1+q1.x2+r1)
.
R : Si (x1 est A2 )
et ( x2 est B2 ) Alors (F2 = p2.x1+q2.x2+r2)
.
Chapitre III : Réseaux neuraux flous
L'ANFIS équivalent est le
suivant :
X1 X2
A1
N
*
W1 W1
X1
A2
W1.F1
?
N
*
B2
B1
F
W2.F2
X2
W2 W2
X1 X2
Couche 1 couche 2
couche 3 couche 4 couche 5
Figure
III.1 : Structure ANFIS de deux règles
Couche 1 :
Chaque neurones réalise l'opération de
fuzzification , la sortie est donnée par :
O1.1 = ìA1 (x1)
O1.2 = ìA1 (x1)
O1.3 = ìA1 (x1)
O1.4 = ìA1 (x1)
Couche 2 :
Couche d'inférence : chaque neurone calcul le
degré d'activation de chaque règle , appliquant une conjonction
MIN ou PROD .
O2.i = wi = ìAi (x1) .
ìBi (x2) . i =
1 , 2 . ( III . 1 )
Couche3 :
couche de normalisation , la sortie de chaque neurone est
donnée par :
O3i = w i = wi / (w1 + w2 ) .
i = 1 , 2 . ( III . 2 )
Couche4 :
Dans cette couche la sortie est
O1,i = O3i. Fi = O3i . ( pi .xi + qi.x2 + ri )
i = 1 , 2 . ( III . 3 )
Ou {pi , qi , ri }sont les paramètres de Takagi , Sugeno
.
Chapitre III : Réseaux neuraux flous
Couche 5 :
Couche de defuzzification , la méthode la plus
utilisée à cette situation est celle des moyennes
pondérées ( weited average defuzzification ) .
La sortie est :
F = ( w1.F1 + w2 . F2 ) / (w1+w2)
( III . 4 )
Les poids ou les paramètres des premises sont
optimisés par l'algorithme de la
Rétro - propagation basée sur la descente du
gradient .
A- L'architecture basée sur le raisonnement de Mamdani
représentée par la structure FLP
( fuzzy logic processor ) [25] .
La structure de cette architecture est la suivante :
X1
F
X2
Couche 1 couche 2
couche3 couche 4 couche 5
Figure
III.2 : structure d'un FLP à deux entrées et une
sortie
Couche 1 : Couche d'entrée .
Couche 2 : Couche de fuzzification .
Couche 3 : Couche d'inférence :
généralement on utilises l'opérateur de conjonction MIN
ou bien le produit pour faciliter les calcules
.
Couche 4 : On appliques la disjonction
(MAX) .
Couche 5 : Couche de
défuzzification : la méthode la plus utilisée est
celle du centre de
gravité .
Remarque :
l'apprentissage s'effectue par la méthode de la
rétro - propagation [26] [27] .
Chapitre III : Réseaux neuraux flous
III.2.2.2: Approche fonctionnelle :
Cette approche représente le réseau RBF flou ,
la structure d'un réseau RBF flou pour un système à deux
entrées x1 , x2 et une sortie F est donnée par :
RBF
Fonction
gaussienne
W1 . F1
x1
RBF
Fonction
gaussienne
W2 . F2
?
n
n
F=?(Fi .wi) / ?wi
RBF W3 . F3
i=1 i=1
Fonction
gaussienne
W4 . F4
x2 RBF
Fonction
gaussienne
Figure III.3
: structure d'un RBF flou
La fonction d'activation de chaque neurone caché est
calculé par :
wi = fi (xi - ci 2 / äi2 ) i = 1
, 2 ,.., n . (
III . 5 )
i : Représente le nombre de RBF ou de règles
flous .
X : Le vecteur d'entré .
fi : Peut être un fonction gaussienne ou sigmoïde
.
Fi = ai . x + bi i = 1 , 2
,.., n .
( III . 6 )
Ai : Représente les vecteurs de paramètres
.
Bi : Sont des constante scalaires .
On remarque que dans l'expression (III.6) le RBF correspond
à un model de Takagi Sugeno d'ordre un [23] .
La méthode de fuzzification adaptée à cette
architecture est celle des moyennes pondérées , et la
procédure d'apprentissage utilisée peut être celle
utilisée dans un réseau RBF traditionnel [23]
[28-29] .
Un troisième type d'association correspond à
l'utilisation série ou parallèle du réseau de neurone avec
le système flou [22] .
Chapitre III : Réseaux neuraux flous
III.2.3 Association série :
Un réseau de neurones effectue une tache de classification
ou de reconnaissance qui est suivi par un système d'aide à la
décision floue , ou bien , les variables d'entrées d'un
système flou sont déterminées à partir de la sortie
d'un réseau de neurones lorsqu'elles ne sont pas mesurables directement
.
x1
x2
y1
x3
y2
F1
x4
y3
F2
y4
Figure
III.4 : association en série
III.2.4 association en parallèle :
par exemple , dans le but d'ajuster les sorties d'un
système de commande floue à de nouvelle connaissances obtenus ,
les variables d'entrées étant celles du système flou et
des nouvelles obtenues .
les variables de sortie étant les erreurs sur les
variables de sortie du système flou .
Chapitre III : Réseaux neuraux flous
X1
Z1
X2
X3
Z2
X4
X1
Dz1
X2
X3
Dz2
X4
Figure III.5 : association en parallèle .
Chapitre III : Réseaux neuraux flous
Conclusion :
Dans les approches situées précédemment ,
l'objectif est de développer des systèmes hybrides qui
réunissent les capacités d'apprentissage des réseaux de
neurones avec la théorie très puissante de la logique floue qui
permet d'obtenir des conclusions et de générer des
réponses à partir des informations vagues ambiguës ,
imprécises et incomplètes , l'a ou le modèle
mathématique du système est inconnu ou difficile à
extraire .
Une combinaison de ces deux approche permet d'exploiter les
caractéristiques de chacune pour accomplir une tache performante et
efficace dans la commande des systèmes industriels complexes .
En conséquence nous obtiendrons un système qui peut
prendre en charge certaines taches avec la même habilitée que
possède l'être humain .
Chapitre IV

Chapitre IV : Méthodologie de conception
et application
IV.1 Introduction :
L'un des objectifs de l'intelligence artificielle est
précisément de réaliser des systèmes dotés
d'autonomie , capables de prendre des décisions dans des cas connus ,
mais aussi de généraliser leur savoir et de s'adapter à
l'inconnus .
Il s'agis bien évidemment aujourd'hui encore d'un voeu
pieux , mais c'est vers cet objectif
( contrôle des systèmes complexes) que tendent les
travaux de cette science .
Le contrôle des structures ou des systèmes complexes
, fortement non linéaires ou difficiles à modéliser ,
présente une tache très délicate ; De plus , les
performances désirées deviennent de plus en plus
sévères , c'est l'une des raisons pour les quelles
apparaissent de nouvelles méthodes de contrôle plus
sophistiquées telle que la logique floue , les réseaux de
neurones et les algorithmes génétiques .
La puissance de chaque méthode réside dans leurs
capacités de gérer l'imprécision et l'incertitude .
La logique floue telle que Zadeh la conçue est incapable
d'apprendre la connaissance , contrairement aux réseaux de neurones et
aux algorithmes génétiques , d'un autre point de vue les
réseaux de neurones ont besoin d'un minimum d'informations , tandis que
la logique floue demande une connaissance détaillée sur le
problème à résoudre .
Dans cette hybridation proposé , le type de processus
d'inférence utilisé est celui de Takagi Sugeno d'ordre un .
L'apprentissage permet d'ajuster les poids du réseaux ,
elle est effectuée par la méthode de la rétro -
propagation basée sur la descente du gradient .
Cette méthode souffre de problème de convergence ,
ce qui consiste une contrainte dégradant le degré de
l'efficacité des contrôleurs neuraux - flous .
IV.2 L'architecture du système de
contrôle :
Le but de cette architecture est de concevoir un contrôleur
neuraux - flou afin d'éviter le besoin d'un expert , nous pouvons
schématiser en blocs les modules du contrôleur avec le
modèle de simulation illustrée par la figure (IV.1)
Base de connaissance
floues
action de
état
e réseau commande
système du système
Contrôleur
(le modèle de
Yr
simulation)
Yd
Figure IV.1 :
Schéma en blocs du système de contrôle
Chapitre IV : Méthodologie de conception et
application
La figure (IV.1) illustre la structure du
système de commande qui contient deux blocs .
- Un bloc structurel qui représente le réseau
contrôleur .
- Le système à commander (procédé )
.
L'interaction entre ces trois blocs se résume comme
suit :
Au début de la simulation nous injectons la base de
connaissances floues ( coefficient de Takagi Sugeno ) sur le réseau
contrôleur , on donnes en suite une entrée ( l'angle et la vitesse
angulaire en cas du pendule inversé ) et une sortie ( la force)
initiales .
Après les calculs du réseau ( fuzzification ,
inférence , défuzzification ) l'action de commande sera
appliqué à l'entrée du procédé , ce qui
permet de connaître l'état du système pour calculer
l'erreur qui présente l'entrée du réseau controleur .
IV.3 Méthodologie de conception :
Dans l'évolution du contrôle flou , deux type de
systèmes flous ont été développées ,
notamment , le système flou de Mamdani ou système flou standard ,
basé sur des règles purement flous , et le système flou de
Takagi Sugéno (TS) dont les règles sont semis
floues .
La règle de Takagi Sugeno présente à la
différence de celle de Mamdani une conséquence qui n'est pas un
ensemble flou mais une fonction .
Soit : SI ( x1 est A1 ) ET
( x2 est A2 ) ET ..... ALORS ( y = B(x) )
.
Où : B(x) est une fonction analytique des
entrées x .
Dans notre cas on a deux entrées (l'angle (è)et la
vitesse angulaire(è.)) et une sortie (Force)
, donc :
y = F = a1 . è + a2 .
è. + r1.
Où a1 et a2 et r représentent les coefficients de
(TS) .
Généralement Fi (-) possède une forme
polynomiale de x1 , x2 , .... , xm .
Fi (x1,x2,...,xm) = a0i + a1i . x1+..... +ami . xm .
Cette forme est appelée le modèle de Sugeno d'ordre
un , la méthode de défuzzification la pus utilisée
à cette forme de règles est celle des moyennes
pondérés donnée par :
M
M
y = ? ìi.Fi
(x1,x2,...,xm) / ? ìi .
i=1
i=1
Où :
M : le nombre de règles .
ìi : le degré d'activation de la
ieme règle .
ìi = Min ( ìi(x1) ,
ìi(x2), ..... ìi (xm) ).
Chapitre IV : Méthodologie de conception
et application
Et pour simplifier les calcules nous pouvons prendre :
ìi = ìi(x1) .
ìi(x2) ..... ìi (xm) .
Fi (x1,x2,...,xm) = ki . f(x1,x2,...,xm) .
Où : ki sont les centres de gravité des
ensembles flous de sortie associés à chaque règle .
Et f(x1,x2,...,xm) = a0 + ai.x1 +....+ am.xm .
Donc :
M
M
y = ( ? ìi . ki ) . f(x1,x2,...,xm) / ?
ìi .
i=1
i=1
M
M
y = ( ? ìi . ki ) . ( a0 + a1.x1 +....+ am.xm
) / ? ìi .
i=1
i=1
Le système flou de (TS) se distingue de celui de Mamdani
par les avantages suivants :
1- Une règle du type TS convoi plus
d'information , et de ce fait moins de règles sont
nécessaires pour réaliser une tache
donnée .
2- Du fait de la forme analytique de la
conséquence d'une règle de TS , il est plus facile
d'incorporer une information mathématique .
3- Toujours pour la même raison
précédente , les systèmes flous de TS se présentent
mieux à l'analyse quantitative par les outils de contrôle
classique , d'un autre coté , il est plus difficile d'incorporer
l'information qualitative dans les conséquences des règles de
(TS) .
IV.4 Structure du réseau
contrôleur :
La structure du réseau neuraux flous adaptée
à cette forme de règle est celle de Hamaifar [89] il s'agit du
contrôleur de type 333 .
N
ì11
x1 ì12
Z
ì13
P
Y
N
couche de defuzzification
ì21
Z
x2 ì22
couche d'entrée
ì23
P
couche de fuzzification
couche d'inférence
Figure
IV.2 : Structure du réseau contrôleur
Chapitre IV : Méthodologie de conception et
application
La figure précédente présente un
contrôleur neuraux - flou à deux entrées x1, x2 , chaque
entrées à trois sous ensembles flous ( négative ,
zéro , positive ) , ce qui forme 09 règles .
Dans notre cas , la sortie dépend des entrées ,
donc il faut avoir une relation entre la sortie et l'entrée , donc le
raisonnement approximatif de Surgeon ne doit pas être d'ordre zéro
.
Cette structure est composé comme suit :
1- couche d'entrée :
Cette couche réalise le transfert direct des signaux
d'entrées .
2- Couche de fuzzification :
Dans cette couche on calcule le degré d'appartenance
de chaque entrée .
Exemple :
N
0
ìx
Z
0.6
N Z P
0.8
x
0.6
0.8
P
x
Mais dans notre cas la fonction d'activation associée
à chaque neurone n'est pas triangulaire car il n'existe pas de fonction
d'activation triangulaire , donc , on utilises la fonction d'activation
gaussienne car elle est la plus proche à la fonction triangulaire ou
trapézoïdal .
La sortie de chaque neurone est :
( x i - c / ä )
2
Si = e
Où : (xi) est l'entrée du neurone , (c) est le
centre de la fonction gaussienne et (ä) sont écart type .
Les poids entre la couche d'entrée et celle de
fuzzification représentent les écart types associés
à chaque variable linguistique .
3- Couche d'inférence ou de base de
règle :
Chaque neurone calcule le degré d'activation de chaque
règle utilisant l'opérateur de conjonction
MIN .
La sortie d'un neurone est :
Si = MIN (
ìi(x1) . ìi(x2) ) .
Les poids entre la couche d'inférence et celle de
fuzzification sont fixées à 1 .
Chapitre IV : Méthodologie de conception
et application
4- Couche de defuzzification :
Cette couche calcule la sortie numérique
(y) par la méthode des moyennes pondérées
comme nous l'avons cité précédemment .
Les poids entre cette couche et celle de base de règle
représentent les conséquences des règles qui sont les
centres des repartions flous de sortie de chaque règle .
Note :
En ce qui concerne les coefficients de Takagi Sugeno nous avons
trouvé l'idée suivante :
A partir du tableau des règles ;
Si la force suit l'angle , alors (a1) reçoit une valeur
numérique proche de (1) et (a2) reçoit
une valeur numérique proche de (0) .
Si la force suit la vitesse angulaire , alors (a2) reçoit
une valeur numérique proche de (1 )et (a1) reçoit une valeur
numérique proche de (0) .
Si la force suit la vitesse angulaire et l'angle ensemble , alors
(a1) et (a2) reçoivent des valeurs numérique proche de (1)
.
Très important :
Nous tenons à préciser un point de vocabulaire , un
algorithme de descente de gradient ne peut pas être
considéré comme un algorithme d'apprentissage comme on l'entend
très souvent dire , mais en effet rien ne permet de démontrer
qu'en réalisant la descente de gradient le réseau neuronal
« apprend » à ce comporter correctement .
La descente de gradient comme nous l'avons proposé ne
permet pas en pratique d'obtenir de bons résultats , en effet le
problème de cet algorithme de descente est qu'il s'arrête dans le
premier minimum local rencontré .
Remarque :
Le terme de connexion doit être pris dans un sens
métaphorique , dans la très grande majorité
Des applications les opérations effectuer par un
réseau de neurones sont programmé
« n'importe quel langage de programmation convient
» .
Le réseau de neurones n'est donc pas en
général un objet physique tel qu'un circuit électronique ,
et les « connexions » n'ont pas de réalité
matérielle .
IV.5 SIMULATION ET FIGURES
IV.5.1 Commande du pendule inversé :
De nombreuse méthode de commande ont été
testé sur le simple pendule inversé .
En effet il est possible de trouver dans la littérature
des travaux concernant la commande d'un simple pendule inversé par des
lois :
- Basées sur un problème de contrôle
d'énergie [Astroim et Futurai 1996 ] associées à une
séquence de balancement qui permet de relever le pendule de sa position
d'équilibre stable
[Wei et Al 1995 ] , [Vermeiren 1998 ] .
- Basées sur la méthode des moments [ Jacobi
1995]
- Basées sur la commande non linéaire [ Wei et Al
1995].
- Basées sur la commande floue , soit en utilisant la
notion d'ensembles flous et un régulateur du type Mamdani [ YAMAKAWA
1989][Kandel et Al 1993 ]
Chapitre IV : Méthodologie de conception et
application
[ Lo et Kuo 1998] .
Soit par la commande adaptative floue [Wang et Al 1996] ou encore
en utilisant les
Modeles de type Takagi Sugeno [ Vermeiren 1998 ] .
ce dernier est le modèle utilisé dans notre
application .
La structure globale de système de contrôle est le
suivant :
début
Base de connaissance flous
( coefficients de TS )
état initial du système
( è , è., F)
Données provenant du procédé
réseau contrôleur
- fuzzification
- base de règle flou (inférence )
- défuzzification
Modèle
De
simulation
Adaptation
Des écarts
Types (poids)
l'envoi du signal
de contrôle
fin du
temps
de
simulation
teste
d'erreur
E
< Ed
FIN
Figure IV.3 : Le
mécanisme de contrôle de la structure de commande
Chapitre IV : Méthodologie de conception et
application
Le pendule inversé est un système instable non
linaire et multivariable .
Le processus consiste en un pendule articulé placé
sur un chariot mobile comme l'illustre la figure :
è
2.L , mp
F
mc
Temps (s)
x
Figure
IV.4 : structure du pendule inversé
Le pendule et le chariot ne peuvent se mouvoir que dans un plan
vertical .
La commande de ce système doit maintenir le système
(è , è.) à l'interieur dune certaine zone
(proche de zéro ) par un choix judicieux de force horizontales (F)
à appliquer au chariot en partant d'une condition initial comprise entre
(-1800,+1800 ) .
Les frottements situés au niveau de l'axe de rotation sont
négligés , les frottements dus au déplacement du chariot
sont aussi négligés .
L'état du système est déterminé par
02 variables , (è , è.) désignant
respectivement la position angulaire du pendule inversé et sa vitesse
angulaire .
Les dynamiques du système sont caractérisées
par :
xÿ1 = x2
xÿ2 = g.sin (x1) +
cos(x1).(- F- m p.L.
(x2)2.sin(x1)) / (m c+ m
p) L 4/3 - (m p .cos2(x 1) / (
m c+ m p))
Où :
g : accélération gravitationnelle .
mc : masse du chariot .
mp : masse du pendule .
L : demi longueur du segment (pendule ) .
x1 : l'angle du pendule par rapport à
l'axe vertical .
x2 : la vitesse angulaire du pendule .
Chapitre IV : Méthodologie de conception et
application
Pour la simulation on a pris les conditions initiales
suivantes :
è =15 (deg) , è.= 0 (deg/s) , F = 12 (N)
.
Avec la contrainte :
F <= 25 N
.
Et les valeurs numériques utilisées sont :
mc = 1 kg , mp = 0.1kg , L = 0.5m
, g = 9.8m/s2
La création des règles représentait un grand
obstacle , et pour le surmonter nous nous sommes basés sur la
mécanique , pour illustrer cette idée nous donnons un
exemple :
exemple :
SI (è est positive) ET
(è.est zéro) ALORS (F est positive)
.
La force F doit être positive pour surmonter le pendule et
le rendre à sa position vertical .
- è
+ è
- è. +
è.
-F
+F
c'est de cette façons que nous avons créé
les 09 règles d'inférence suivante :
|
è.
è
|
N
|
Z
|
P
|
|
N
|
NG
|
NM
|
ZN
|
|
Z
|
NP
|
Z
|
PP
|
|
P
|
ZP
|
PM
|
PG
|
Tab.5 : base des règles
Chapitre IV : Méthodologie de conception et
application
La figure (IV.6) montre la variation de l'angle
et de la vitesse angulaire et la forme de la commande sera
représentée par la figure (IV.7) .
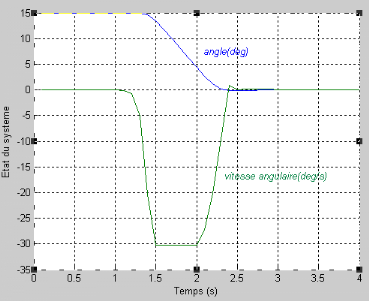
Figure
IV.6 :variation de l'angle et de la vitesse angulaire .
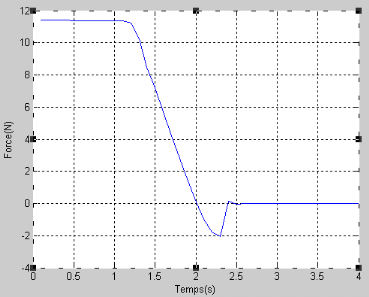
Figure
IV.7 : Forme de la commande
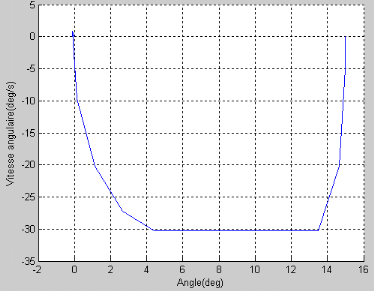
Chapitre IV : Méthodologie de conception et
application
Figure IV.8 : Plan de phase
La figure (IV.8) montre comment la trajectoire
s'approche à l'équilibre (00, 00/s)
à partir des conditions initiales (150,00/s) .
On remarque d'après les figures précédentes
que le contrôleur arrive à stabilisé le pendule autour de
la position d'équilibre pendant un temps inférieur à 2.5s
.
IV.5.1.1 Test de la robustesse
Pour tester la robustesse de notre contrôleur FLC
(333) on doit s'écarter des conditions normales d'utilisation
et voir si son aptitude réagi bien .
Pour cela nous avons testé notre contrôleur pour
plusieurs conditions initiales :
La premier condition est la suivante :
{ ( è , è., F) } = { ( 100 ,
00/s , 8 N ) } .
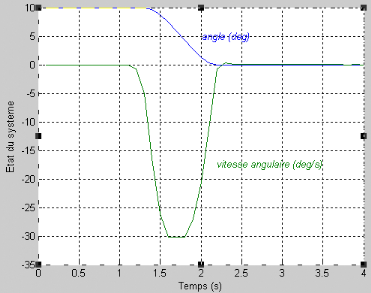
Figure
IV.9 : variation de l'angle et de la vitesse angulaire .
Chapitre IV : Méthodologie de conception et
application
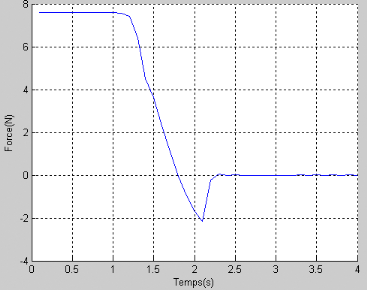
Figure
IV.10 : Forme de la force .
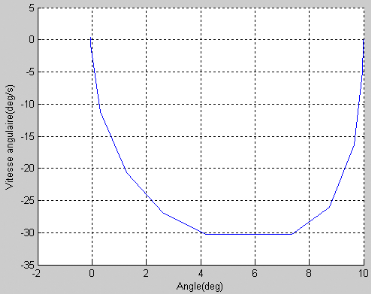
Figure
IV.11 : Plan de phase .
Et pour les conditions initiales suivantes :
{ ( 120 , 00/s , 10 N ) , ( 200
, 00/s , 16 N ) , ( 250 , 00/s , 20 N )
, ( 300 , 00/s , 25 N ) } .
Les figures (IV.12) , (IV.13)
, (IV.14) , (IV.15) ,montrent la
robustesse de notre contrôleur .
Remarque :
Si l'angle augmente on doit augmenté la force pour pouvoir
soulevé la tige ( le pendule) .
Chapitre IV : Méthodologie de conception et
application
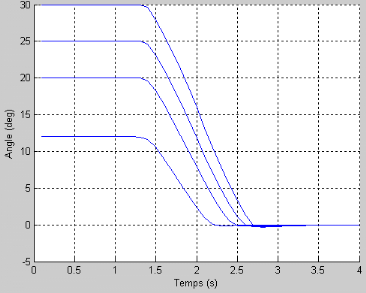
Figure
IV.12 : variations des angles .
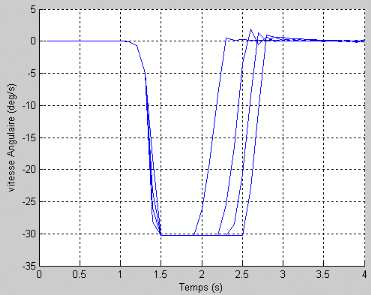
Figure
IV.13 : variations des vitesses angulaires .
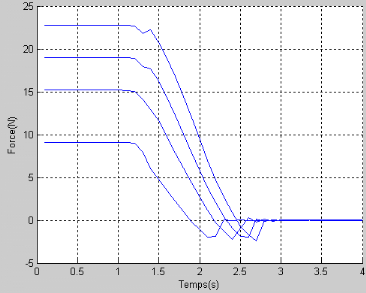
Figure
IV.14 : Formes des forces .
Chapitre IV : Méthodologie de conception et
application
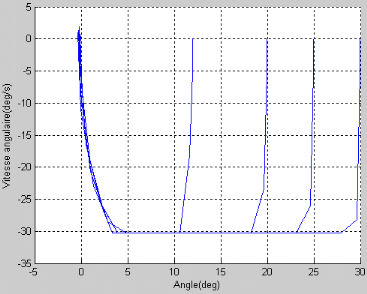
Figure IV.15 : le plan de phase .
Et enfin pour les conditions initiales suivantes :
{ ( 100 , -50/s , 7 N ) , ( 200
, -100/s , 14 N ) , ( 250 , -150/s , 17
N ) , ( -100 , 50/s , -7 N )
( -150 , 100/s , -8 N ) } .
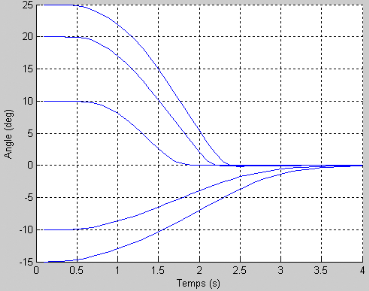
Figure
IV.16 : variations des angles .
Chapitre IV : Méthodologie de conception et
application
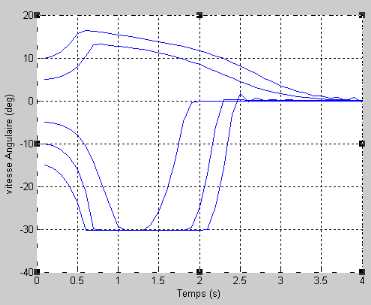
Figure
IV.17 : variations des vitesse angulaires .
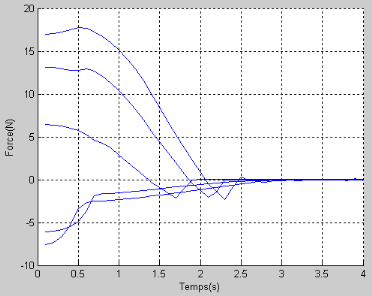
Figure IV.18 : Formes des forces .
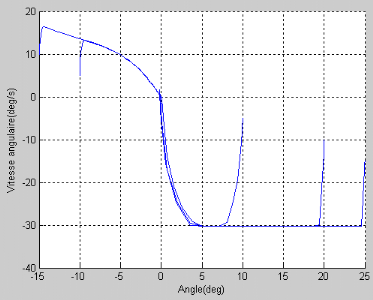
Figure IV.19 : le plan de phase
Chapitre IV : Méthodologie de conception et
application
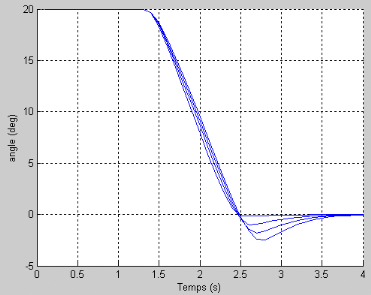
Pour mieux testé notre contrôleur , on fait des
teste sur le changement de la longueur de la tige ( 0.5 , 0.7 , 0.9 et
1.1m ) avec les conditions initiales suivantes ( 200 ,
00/s , 15 N ) .
Figure
IV.20 : variations des angles .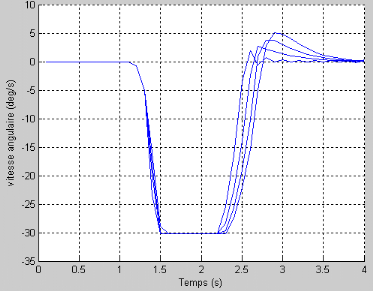
Figure
IV.21 : variations des vitesse angulaires .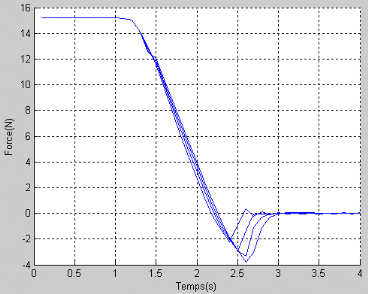
Figure IV.22 : Formes des forces .
Chapitre IV : Méthodologie de conception et
application
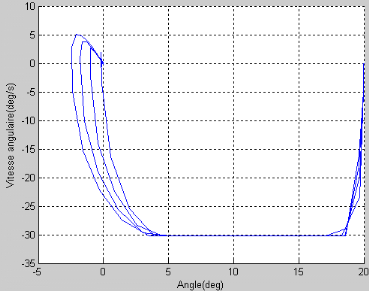
Figure
IV.23 : le plan de phase
Pour mieux le testé encore , on fait des teste sur le
changement du poids de la tige :
( 0.1 , 0.4 , 0.8 , 1.2 et 1.6 kg ) avec les conditions
initiales suivantes :
( 200 , 00/s , 15 N )
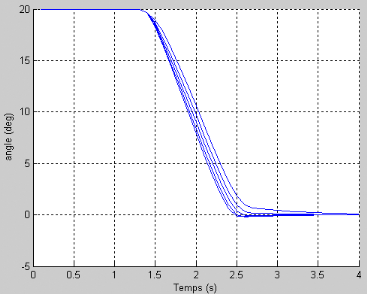
Figure IV.24 : variations des angles .
Chapitre IV : Méthodologie de conception et
application
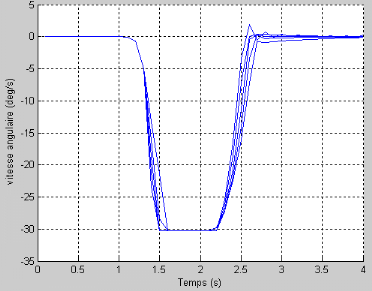
Figure IV.25 : variations des vitesses angulaires .
Figure IV.26 : Formes des forces
.
Figure
IV.27 : plan de phase .
Chapitre IV : Méthodologie de conception et
application
IV.5.1.2 CONCLUSION
Le contrôleur proposé FLC (333)
appliqué pour commandé le système de pendule
inversé a prouvé son efficacité de ramener le pendule
à sa position d'équilibre (vertical) correspondante à un
angle et une vitesse angulaire nulles et sans oscillations.
La robustesse a été prouvé pour les
différentes conditions initiales et les différentes valeurs du
poids et de la longueur du pendule .
On tien à cité que les trois grands obstacles
rencontré dans cette thèse sont :
1- trouvé les valeurs des écarts types des
fonctions d'appartenances .
2- créé le tableau de base de règles .
3- trouvé les coefficients de Takagi - Sugeno .

Conclusion générale
L'objectif fixé par notre étude a été
atteint par la conception d'un contrôleur (neuraux flou ) qui permet de
stabilisé le pendule inversé dans sa position vertical .
Cette nouvelle méthodologie est basée sur la notion
d'extraction automatique des connaissances nécessaires au
développement d'un système de commande à raisonnement
approximatif .
Le réseau contrôleur est un réseau de
neurones multicouches ou chaque couche a le fonctionnement d'une étape
de la logique floue .
Ce contrôleur utilise le domaine physique des variations
des variables d'entrées et de la sortie ( sans normalisation ) .
La robustesse du contrôleur est justifiée par sa
capacité de bien réagir vis à vis aux changement des
paramètres internes ( angle et vitesse angulaire du pendule
inversé )
Caractérisant le procédé à
commandé , ainsi qu'au changement de l'environnement de fonctionnent (
le poids et la longueur de la tige et la force appliqué au chariot )
.
L'hybridation des deux approches ( la logique floue et les
réseaux de neurones ) consistes un moyen efficace pour exploiter la
puissance et la souplesse des éléments manipulés par ces
différentes procédures et ajoutent aux contrôleurs
résultants une fonctionnalité ( intelligente ) qui est le but
visé par les contrôleurs ( intelligents ) .
| 

