PARTIE II. BASES DE DONNEES REPARTIES
SOUS ORACLE
Dans le cadre de notre travail, nous avons utilisé le
SGBD réparti Oracle 10 g (grid). Comme tout SGBD, il a pour rôle
de gérer l'accès au bases de données qu'il stocke et
restitue à volonté. Oracle 10 g se démarque des autres
gestionnaires de bases de données par son côté
administration très développé (Gestion des utilisateurs,
des profils, des rôles et privilèges, des tablespaces) et aussi de
part son architecture complexe qui repose sur la notion d'instance et qui
assure un traitement rapide, sécurisé, efficace des
données. Aussi, Oracle possède son propre langage de
définition de procédures SQL (Structured Query Langage), le
PL/SQL qui est assez simple a utilisé.
Dans la suite, nous parlerons des caractéristiques
d'Oracle 10 g dans la répartition des données, qui sont
légèrement évoluées par rapport aux versions
précédentes (9i,8i)
I. PRESENTATION DE ORACLE NET
Afin de communiquer avec une base de donnée Oracle
10g, plusieurs logiciels ou middleware peuvent être utilisés,
selon les besoins. Pour ce qui est de la connexion à une base de
donnée distante, l'outil Oracle Net est employé pour
gérer différents modes d'accès aux serveurs. Ses
prédécesseurs sont respectivement Net8, Sql *Net pour les
versions antérieures à la 10g.
Oracle Net permet de spécifier pour le
client, une liste de services oracle qu'il peut atteindre, et pour chaque
serveur, la liste des services oracle qu'il gère et les clients qui
peuvent s'y connecter. Bref il est utilisé comme middleware ou
passerelle entre le client et le serveur, selon les différentes
architectures ci- dessous présentées.
I.1. ARCHITECTURES
I.1.A. ARCHITECTURE MONOPOSTE
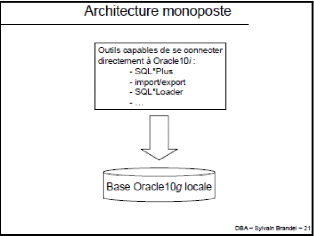
Figure 7 : Architecture Monoposte
I.1.B. ARCHITECTURE CLIENT - SERVEUR (A)
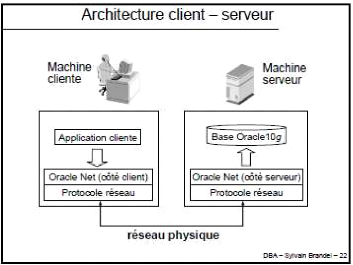
Figure 8 : Architecture Client - Serveur A
I.1.C. ARCHITECTURE CLIENT - SERVEUR (B)
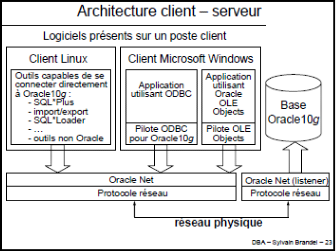
Figure 9 : Architecture Client - Serveur B
I.1.D. ARCHITECTURE SERVEUR - SERVEUR
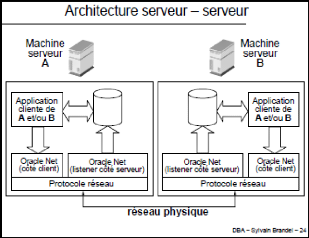
Figure 10 : Architecture Serveur- Serveur
I.2. INSTALLATION ET CONFIGURATION
I.2.A. PARAMETRES DE CONFIGURATION
Pour se connecter à Oracle, il faut fournir trois
paramètres :
· Le nom d'utilisateur
· Le mot de passe
· L'alias
L'Alias renseigne sur plusieurs données à la fois
:
· le protocole réseau utilisé pour
accéder à la machine cible (TCP/IP),
· le nom ou l'adresse de la machine cible sur laquelle se
situe le serveur,
· le SID cible (la machine distante peut héberger
plusieurs bases) ou le nom global de la base,
· le port d'écoute du serveur
· d'autres paramètres dépendants du protocole
réseau utilisé. Afin d'accéder à un serveur
distant, l'application cliente doit pouvoir déterminer ses 3
indications, et pour cela il utilise Oracle Net. En effet, ce dernier
permet de définir 3 principaux paramètres utilisés pour la
connexion à distance :
> Le listener
Le Listener est le processus d'écoute qui
s'exécute sur le serveur. Il faut le configurer en indiquant par exemple
le port d'écoute (par défaut le 1521)
> Les méthodes de résolution de
nom
Pour se connecter à un serveur Oracle, on peut utiliser
plusieurs méthodes :
· La résolution locale de noms
Cette méthode consiste à indiquer que des noms
locaux ou Alias seront utilisés pour désigner des services Oracle
distants.
Connexion : Nom _utilisateur/mot_de_passe@alias
· La résolution de noms Easy connect
Encore appelée méthode Basic, elle permet
d'indiquer qu'à la place d'alias, on aura une nomination complète
sous la forme
Nom _utilisateur/m ot _de_passe@nom_du _serveur:port
_ecoute/nom _du _service
· La résolution de noms d'annuaire (LDAP)
Ici, on précise qu'on utilisera un service d'annuaire
pour identifier le service Oracle à joindre. Le service d'annuaire peut
être Oracle Internet Directory ou Active Directory.
Connexion : Nom _utilisateur/mot_de_passe@alias
· Etc.
> Les noms de services locaux
Un nom de service local est un Alias, défini plus haut.
Il permet de réunir plusieurs paramètres de connexion en une
seule appellation unique.
> Les noms d'annuaire
Si on prévoit utiliser la méthode de
résolution de nom d'annuaire, il faut créer des noms d'annuaire
sur un serveur LDAP.
Voilà les principaux paramètres à
configurer pour Oracle Net.
I.2.B. OUTILS DE CONFIGURATION
Oracle met à la disposition des DBA (Data Base
Administrators) deux outils principaux JAVA pour faire la configuration de
Oracle Net, afin d'indiquer les paramètres cités plus
haut Il s'agit de :
· netca (Oracle Net
Configuration Assistant) : simple, l'utilisateur est guidé pas
à pas pour entrer les paramètres nécessaires à une
configuration,
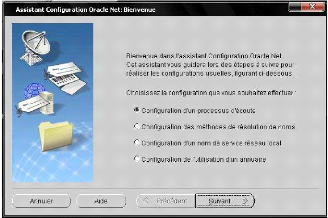
Figure 11 : netca
· netmgr (Oracle Net
Manager) : plus complet, il permet d'accéder à l'ensemble
des paramètres qui peuvent figurer dans les fichiers de configuration
Oracle Net.
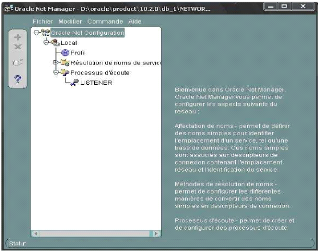
Figure 12: netmgr
I.2.C. FICHIERS DE CONFIGURATION
Oracle Net utilise 3 principaux fichiers de
configuration se trouvant dans $ORA CLE_HOME/network/admin :
> Listener.ora
Ce fichier détermine les paramètres du Listener sur
le serveur
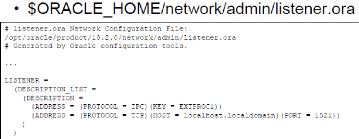
Figure 13: listener.ora
> Sqlnet.ora
Ici est précisé l'ordre des méthodes de
résolution de noms à utiliser

Figure 14: sqlnet.ora

> Tnsnames.ora
Ce dernier contient tous les noms locaux de services ou alias
avec leurs paramètres.
Figure 15 : tnsnames.ora
II. REFERENCEMENT DANS UN SYSTEME DISTRIBUE
II.1. NOM GLOBAL
Dans une architecture distribuée, un système
d'identification unique des bases doit exister ; car, si plusieurs bases ont le
même nom le référencement sera ambigu et donc impossible.
Oracle utilise donc le concept de nom global
(global_name) constitué de :
> Le nom de domaine : domain_
name
> Le nom de la base (SID):
db_name
Pour le définir, on peut le faire à la
création de la base avec l'utilitaire de création de base de
données dbca, ou modifier le fichier d'initialisation de la
base init.ora de la façon suivante :
global_names = true
domain_name = nom_domaine
db_name = nom_base
Ainsi Oracle considèrera comme nom global de la base
nom_base.nom_domaine
II.2. LES DATA BASE LINKS
Pour interroger une BD distante, il faut créer un lien
de base de données. Un lien de base de données est un chemin
unidirectionnel d'un serveur à un autre. En effet, un client
connecté à une BD A, peut utiliser un lien stocké
dans la BD A pour accéder à la BD distante B et vice
versa.
Lorsqu'un lien est référencé par une
instruction SQL, Oracle ouvre une session dans la base distante et y
exécute l'instruction. La session demeure ouverte au cas où elle
serait de nouveau nécessaire.
En créant un lien de BD, on doit indiquer le nom du
compte auquel on se connecte, le mot de passe de ce compte, et le nom de
service associé à la base distante. En l'absence d'un nom de
compte, Oracle utilise le nom et le mot de passe du compte local pour la
connexion à la base distante.
Un lien est soit privé ou public. Seul l'utilisateur
qui a crée un lien privé peut l'utiliser, alors qu'un lien public
est utilisé par tous les utilisateurs de la base de données.
Instruction SQL :
CREATE [SHARED|PUBLIC|PRIVATE] DATABASE LINK NomLien CONNECT
TO
CURRENT_USER
User IDENTIFIED BY password
USING connect_string
CURRENT_USER : Oracle utilise l'utilisateur courant pour
ouvrir la session distante
SHARED : Lien partagé
connect_string: le nom du service représentant la
base à laquelle on veut se connecter
Si on utilise l'option connect to user identified by
password, l'utilisateur doit exister sur la base distante.
Exemple d'utilisation de Data Base Link :
Select * from scott.employe@db~link
Employe = objet de la base de données
référencée par db_link
N.B : Les Data Base Link peuvent fonctionner
sans système de nom global, mais si ce dernier existe, alors, les deux
doivent être identiques, si non une erreur sera
générée.
II.3. LES SYNONYMES
Pour référencer une base de données dans
un système distribué, on utilise le nom global ou le lien de base
de données. Pour référencer un objet (table, trigger,
procédure, etc) on ajoute y ajoute le nom de l'objet comme
mentionné dans l'exemple précédent. Mais afin de converger
plus vers l'un des objectifs de la répartition des bases de
données (voir IV-4) qui est la transparence vis-à-vis
de la localisation, Oracle utilise des synonymes qui masquent le
nom du lien de base de données. Exemple : nom_synonyme
=====scott.employe@db link Instruction SQL : create synonym for
scott.employe@db_link
III. LE MECANISME DE REPLICATION
III.1. LA COMMANDE COPY
La première option consiste à répliquer
régulièrement les données sur le serveur local au moyen de
la commande COPY de SQL*Plus.
Exemple:
COPY FROM user1/password1@db_link1 TO user2/password2@db_link2
CREATE table _2
USING
SELECT * FROM table_1
WHERE `condition' ;
Ici, la copie est faite du site référencé
par db_link1 à db_link2
La clause FROM ou TO peut être émise si l'origine ou
la destination est le site courant.
Aussi, en plus de la clause CREATE, on peut utiliser les clauses
REPLACE (remplacer une table existante), INSERT INTO (ajout de tuples).
III.2. LES SNAPSHOTS
Afin de répliquer les données d'une table à
l'autre, Oracle utilise le concept de SNAPSHOT ou clichés.
Un snapshot est une copie conforme d'une table située
sur une base de donnée du système distribué. Il permet de
diminuer les coûts réseau, en rendant local les données
situées à distance. Afin d'assurer la cohérence de
données, une mise à jour régulière et automatique
est effectuée à partir du site d'origine ou MASTER.
III.2.A. TYPES DE SNAPSHOTS
On distingue deux principaux types de snapshots :
> Les read-only snapshots
Ce sont les snapshots non modifiables à partir du site
esclave, ils ne sont accessibles qu'en lecture.
Création de read only snapshots :
CREA TE SNAPSHOT nom_snapshot REFRESH FAST
STAR T with SysDate
NEXT SysDate+ 7
AS SELECT * FROM Employes@db_link;
Cette instruction crée un snapshot appelé
nom_snapshot pour la table Employes avec un système de
rafraîchissement rapide qui commence au moment courant et se reproduira
chaque 7 jours.
> Les updateable snapshots
Les updateables snapshots ou snapshots de mise à jour
peuvent être directement modifiés. Dans ce cas, les données
mises à jour à leur niveau sont répliquées vers le
site Master lors du processus de rafraîchissement.
Création de updateable snapshot
CREA TE SNAPSHOT nom_snapshot REFRESH FAST
START with SysDate
NEXT SysDate+ 7
FOR update query rewrite
AS SELECT * FROM Employes@db_link;
Deux types de snapshots peuvent également
être considérés : simples et complexes. Un snapshot
simple ne contient pas de clause distinct, group by, connect by, de
jointure multitables ou d'opérations set.
III.2.B. RAFFRAICHISSEMENTS
III.2.B.a. Mode de rafraîchissements
On distingue trois principaux modes de rafraîchissement
pour un snapshot :
> Rapide
Le mode rapide indiqué par la clause FAST permet de
faire un rafraîchissement en tenant compte seulement des mises à
jour effectuées sur le site Maître. Dans ce cas, un SNAPSHOT LOG
doit être crée pour la table Maître afin de noter les
différents changements subvenus qui seront répercutés sur
le snaphot.
> Complet
Ici, à chaque rafraîchissement, toute la table est
transférée. Ce mode est obligatoire pour les snapshots complexes
et est indiqué par COMPLETE
> Forcé
Dans le mode FORCE, un rafraîchissement rapide est d'abords
tenté ; s'il ne marche pas le rafraîchissement complet est
effectué.
III.2.B.b. Temps de rafraîchissements
Le rafraîchissement peut se déclencher de plusieurs
manières : > Sur demande : ON DEMAND
> Sur validation : ON COMMIT
> De façon périodique :
START WITH sysdate NEXT sysdate+n
III.3. VUES MATERIALISEES
Une vue matérialisée est comme son nom
l'indique, une vue réelle d'une ou de plusieurs tables.
C'est-à-dire Oracle crée une représentation physique de la
vue. Ce terme est aussi utilisé dans la réplication, comme
cliché et possède toutes les spécifications citées
plus haut pour les snapshots. Mais il est beaucoup plus souple et permet
à l'optimiseur de requête de travailler de façon plus
performante. Aussi, à l'avenir le concept de snapshot va
disparaître et lui laisser la place.
Création d'une vue matérialisée :
CREA TE MA TERIALIZED VIE W nom_vue_m aterialisée
REFRESH FAST
START WITH sysdate
NEXT sysdate+ 1
AS SELECT * from Employes@db_link
III.4. LA REPLICATION AVANCEE
Oracle utilise le concept de réplication avancée
pour désigner une réplication qui se fait dans les deux sens
entre deux ou plusieurs serveurs de bases de données. Elle est encore
appelée réplication multi-maitre (Replication Multi Master). Dans
une telle implémentation, il faut aussi définir un système
de gestion de conflits afin de respecter la cohérence des données
sur tout le système.
Oracle a mis en place tout un ensemble de concepts permettant
de mettre sur pieds une réplication avancée appelée
replication advanced tools dont nous parlerons à une prochaine
occasion
IV. OPTIMISATION DES REQUETES REPARTIES
L'optimisation des requêtes distribuées est un
outil par défaut d'Oracle. Son principe de fonctionnement est de
réduire le volume des données transférées entre les
sites, lorsqu'on récupère des données distantes.
Oracle utilise une méthode basée sur le calcul
de coût pour trouver et générer la requête SQL qui
extrait uniquement les données nécessaires des tables distantes.
Les données subissent un premier traitement sur le site distant, puis le
site distant envoie le résultat au site local (qui a lancé la
requête) pour le traitement final. Les tables complètes ne sont
donc pas transférées.
Pour l'optimisation des requêtes, Oracle utilise des
« Collocated Inline Views », c'est à dire des vues de
plusieurs tables distantes et « en lignes » (en direct) afin de
forcer les restrictions sur les sites distants.
Oracle permet également, pour améliorer
l'optimisation, de collecter des statistiques sur les différentes tables
du système. Oracle peut ainsi faire une optimisation par calcul de
coût par trois méthodes différentes :
· Réaliser des estimations sur des jeux de
données pris au hasard
· Faire les calculs exacts
· Utiliser des méthodes statistiques définies
par les utilisateurs. Oracle permet de régler l'optimisation en fonction
des objectifs que l'on veut atteindre :
· Des débits importants (utiles par exemple pour des
applications de type reporting, Business Intelligence).
· Un temps de réponse performant (utile pour
toutes les applications utilisateurs pour lesquelles l'apparition des
premières lignes est importante).
| 

