|
REpuBLiQuE ALGERiENNE
DEMocRATiQuE ET
PopuLAiRE
MiNisTERE DE
L'ENsEiGNEMENT SupERiEuR ET DE LA
REcHERcHE SciENTiFiQuE
UNivERsiTI AMMAR
TELiDji
LAGHouAT

FAcuLTE DEs SciENcEs
ET SciENcEs DE
L'INGENiEuR
DEpARTEMENT DE
GENiE INFoRMATiQuE
MiMoiRE DE MAsTER
DoMAiNE: MATHEMATiQuEs
ET INFoRMATiQuE (MI)
FiLiERE:
INFoRMATiQuE
OpTioN:
RisEAuX, sysTEMEs ET AppLicATioNs RtpARTis
(ReSar)
Présenté par:
OuBBATi OMAR
SAMi
Thème:
PRoposiTioN ET siMuLATioN
D'uN
ALGoRiTHME DE pARTAGE DE
REssouRcEs DANs LEs MANETs BAsé
suR L'ALGoRiTHME DE NAiMi
ET TREHEL
Soutenu publiquement devant le jury composé
de:
|
Mr.
Mr.
Mlle.
Mr.
|
M.B. YAGouBi M. DjouDi
r . 7 A
Z. ABDELHAFiDHi T. ALLAoui
|
Maître de Conférences (A)
Maître-assistant (A) Maître-assistant (A) Maître-assistant
(A)
|
Université de Laghouat Université de
Laghouat Université de Laghouat Université de
Laghouat
|
(Président) (Examinateur) (Examinatrice)
(Rapporteur)
|

Je dédie ce
mémoire
à
mes parents
qui m'ont toujours soutenu et
encouragé
au cours de la réalisation de ce mémoire de
fin d'étude.
à
tous les professeurs et enseignants
universitaires
qui m'ont permis, par leurs efforts, d'atteindre un tel
niveau deformation.
REMERCIEMENTS
J
E remercie Dieu tout Puissant de m'avoir permis de mener
à terme ce mémoire de fin d'étude. En préambule
à ce mémoire, je souhaite adresser ici tous mes remerciements aux
per-
sonnes qui m'ont apporté leur aide et qui ont
ainsi contribué à l'élaboration de ce
mémoire.
Qu'il me soit permis de rendre un vibrant hommage
à mon encadreur Mr Allaoui Tahar, qui était pour moi
un immense honneur de travailler avec lui durant mon projet de fin
d'étude d'ingénieur, et par coïncidence Dieu a voulu que je
travail encore une fois avec lui dans ce mémoire. Donc un grand
remerciement à lui pour avoir bien voulu superviser ce travail et donner
de son temps et de son intelligence à la réussite de ce projet
qui pour moi représente un modèle de réussite et une
source de motivation permanente, je le remercie également pour sa
disponibilité, son sens aigu de l'humanisme pédagogique, et enfin
sa rigueur intellectuelle et morale qui est pour moi plus qu'un exemple
à suivre, un modèle.
J'aimerais aussi témoigner ma reconnaissance
à Mr Nasreddine Lagraa, Maître de conférences
à l'université de Laghouat, pour son aide précieuse et le
temps qu'il a bien voulu nous consacrer à développer et
améliorer l'idée de base de ce projet.
Enfin je remercie les membres du jury qui ont bien voulu
accepter, et ce malgré, leur lourdes et exaltantes
responsabilités pour procéder à l'évaluation de ce
modeste travail.
RéSUMé
C
E mémoire traite le problème de la
K-exclusion mutuelle dans les réseaux mobiles AD HOC.
Dans ce mémoire nous allons d'abord introduire
le concept des systèmes répartis et les réseaux AD HOC, ce
qui va nous permettre de mettre l'accent sur le problème de l'exclusion
mutuelle, et sa généralisation en K ressources.
Nous proposons également un algorithme traitant
le problème de la K-exclusion mutuelle dans les réseaux AD HOC,
cet algorithme sera amélioré et validé par une simulation
en utilisant l'outil NS-2.
Un
2ème algorithme qui traite
le même problème sera proposé, ce nouvel algorithme permet
d'assurer un nombre réduit de messages échangés.
L'efficacité de cette solution est prouvée par rapport aux
algorithmes déjà évalués.
Mots-clés : Réseaux AD HOC, algorithmique
répartie, Exclusion mutuelle, K-exclusion mutuelle, Routage, Simulation,
NS-2.
ABSTRACT
T
HIS thesis treats the K-mutual exclusion problem in
the AD HOC networks.
In this thesis, we will first introduce the concept of
distributed systems and the AD HOC networks, which will allow us to focus on
the mutual exclusion problem and its generalization to K resources.
We also propose an algorithm that treats the K-mutual
exclusion problem in the AD HOC networks, this algorithm will be improved and
validated by a simulation using NS-2 tool.
A second algorithm that treats the same problem will
be proposed, this new algorithm ensures a reduced number of messages exchanged.
The effectiveness of this solution is proven compared to the algorithms already
evaluated.
Key-words : Mobile AD HOC Network (MANET), Distributed
algorithm, Mutual exclusion, K-mutual exclusion, Routing, Simulation,
NS-2.
TABLE DEs MATièREs
TABLE DEs MATièREs vi
LisTE DEs FiGuREs ix
INTRoDucTioN GéNéRALE
1
1 NoTioNs GéNéRALEs
3
1.1 INTRoDucTioN 4
1.2 LEs sysTèMEs
RépARTis 4
1.3 LEs RésEAux MoBiLEs
4
1.3.1 Les
réseaux mobiles avec infrastructures 5
1.3.2 Les
réseaux mobiles sans infrastructures (AD HOC) 5
1.3.2.1
Définition d'un réseau AD HOC 5
1.3.2.2
Les caractéristiques des réseaux AD HOC 6
1.3.2.3
Les avantages des réseaux AD HOC 7
1.3.2.4
Les inconvénients des réseaux AD HOC 7
1.3.2.5
Les domaines d'applications des réseaux AD HOC 7
1.3.2.6
Les problèmes liés aux réseaux AD HOC
9
1.3.3 Problème
de routage dans les réseaux AD HOC 9
1.3.3.1
Définition d'un routage 9
1.3.3.2
Classification des protocoles de routage 9
1.3.3.2.a
Les protocoles de routage proactifs 10
1.3.3.2.b
Les protocoles de routage réactifs (à la demande) .
10
1.3.3.2.c
Les protocoles de routage hybrides 10
1.4 L'ExcLusioN MuTuELLE DANs
LEs RésEAux AD HOC 10
1.4.1 L'exclusion
mutuelle en réparti 10
1.4.1.1
La notion de l'exclusion mutuelle 10
1.4.1.2
Les états d'un processus 11
1.4.1.3
Notions de base 11
1.4.1.4
Propriétés d'un algorithme d'exclusion mutuelle
11
1.4.1.5
Les classes de solutions d'exclusion mutuelle 12
1.4.1.5.a
Algorithmes utilisant des permissions 12
1.4.1.5.b
Algorithmes utilisant des jetons 12
1.4.2 Le
problème de la K-exclusion mutuelle 12
1.4.2.1
Description du problème 12
1.4.2.2
Résolution du problème 13
1.4.2.2.a
Solution utilisant des permissions 13
1.4.2.2.b
Solution utilisant des jetons 13
1.4.3 Les solutions de
l'EM dans les réseaux ADHOC 13
1.4.4 Les solutions de
la K-EM dans les réseaux AD HOC 14
CoNcLusioN 14
2 PRoposiTioN D'uN ALgoRiThME
BAsé suR L'ALgoRiThME DE NAiMi ET
TREhEL 15
|
2.1
2.2
|
INTRoDucTioN
L'ALgoRiThME
2.2.1 Structure logique
utilisée
2.2.2 Le principe de
fonctionnement
2.2.3 Hypothèses
2.2.4 Description de
l'algorithme
|
16
16
16
17
18
18
|
|
|
2.2.4.1
Les variables locales
|
18
|
|
|
2.2.4.2
Les messages utilisés
|
19
|
|
|
2.2.4.3
Initialisation des variables
|
19
|
|
|
2.2.4.4
Les procédures de l'algorithme
|
19
|
|
2.3
|
MoDiFicATioN N°1
|
22
|
|
2.4
|
MoDiFicATioN N°2
|
23
|
|
CoNcLusioN
|
24
|
|
3
|
DiscussioN DEs RésuLTATs DE
siMuLATioNs
|
25
|
|
3.1
|
INTRoDucTioN
|
26
|
|
3.2
|
LE siMuLATEuR NS-2
|
26
|
|
|
3.2.1
Présentation de l'outil de simulation
|
26
|
|
3.3
|
LEs éTApEs DE siMuLATioN
|
26
|
|
3.4
|
CoMMENT RéALisER uNE
siMuLATioN?
|
27
|
|
3.5
|
LEs pARAMèTREs DE siMuLATioN
|
29
|
|
|
3.5.1 Les
paramètres fixes
|
29
|
|
|
3.5.2 Les
paramètres variables
|
29
|
|
3.6
|
EvALuATioN DE pERFoRMANcEs
|
30
|
|
3.7
|
LEs éTApEs D'uN
scéNARio
|
31
|
|
3.8
|
RésuLTATs ET iNTERpRéTATioNs
|
31
|
|
|
3.8.1 Variation du
nombre de requêtes
|
31
|
|
|
3.8.2 Variation de la
portée de communication
|
32
|
|
|
3.8.3 Variation du
nombre de ressources
|
32
|
|
|
3.8.4 Variation de la
vitesse de mouvement
|
33
|
|
|
3.8.5 Variation du
nombre de sites
|
33
|
|
3.9
|
RésuLTATs DEs MoDiFicATioNs
|
34
|
|
|
3.9.1 Variation du
nombre de requêtes
|
34
|
|
|
3.9.2 Variation de la
portée de communication
|
34
|
|
|
3.9.3 Variation du
nombre de ressources
|
35
|
|
|
3.9.4 Variation de la
vitesse de mouvement
|
35
|
|
|
3.9.5 Variation du
nombre de sites
|
35
|
|
CoNcLusioN
|
36
|
|
4
|
UN NouvEL ALgoRiThME BAsé suR LE
pRoTocoLE DE RouTAgE AODV
|
37
|
|
4.1
|
L'iDéE DE BAsE
|
38
|
|
4.2
|
L'ALgoRiThME
|
38
|
|
|
4.2.1 Hypothèses
|
39
|
|
|
4.2.2 Description de
l'algorithme
|
39
|
|
|
4.2.2.1
Les variables locales
|
39
|
|
|
4.2.2.2
Les messages utilisés
|
39
|
|
|
4.2.2.3
Initialisation des variables
|
40
|
|
|
4.2.2.4
Les procédures de l'algorithme
|
40
|
|
|
4.2.3 Les
paramètres de simulation
|
42
|
4.2.4 La comparaison de
tous les résultats 43
4.2.4.1
Variation du nombre de requêtes 43
4.2.4.2
Variation de la portée de communication 43
4.2.4.3
Variation du nombre de ressources 43
4.2.4.4
Variation de la vitesse de mouvement 44
4.2.4.5
Variation du nombre de sites 44
CoNcLusIoN 44
CoNcLusIoN ET PERsPEcTIVEs
45
BIBLIoGRAPHIE 47
A ANNEXE : ScRIPT DE sIMuLATIoN
49
A.1 LE ScRIPT TCL
50
AcRoNYMEs 55
LISTE DES FIGURES
1.1 Structure d'un système
réparti 4
1.2 Le modèle des réseaux
mobiles avec infrastructure.[Bou07] 5
1.3 Le modèle des réseaux
mobiles sans infrastructure. 6
1.4 Topologie dynamique dans un
réseau AD HOC 6
1.5 Application de secours des
réseaux AD HOC. 8
1.6 Application collaborative des
réseaux AD HOC 8
1.7 Applications commerciales des
réseaux AD HOC 8
1.8 Le chemin utilisé dans le
routage entre la source et la destination. 9
1.9 Classification des protocoles de
routage. 9
1.10 Les états d'un
processus.[Ray92] 11
1.11 Les catégories des solutions
d'exclusion mutuelle 12
2.1 Structure de la file des
requêtes. 16
2.2 Structure d'arbre de chemins vers le
dernier demandeur 17
2.3 Les états d'arborescence
après chaque requête 18
3.1 Exemple de Création d'une
topologie 27
3.2 Les étapes de
simulation.[OB10] 28
3.3 Réalisation d'une
simulation.[LK09] 28
3.4 Variation des paramètres de
simulation 30
3.5 Les étapes de
réalisation d'un scénario. 31
3.6 Influence du nombre de
requêtes sur le NMM et le TAM. 31
3.7 Influence de la portée de
communication sur le NMM et le TAM 32
3.8 Influence du nombre de ressources
sur le NMM et le TAM. 32
3.9 Influence de la vitesse de mouvement
sur le NMM et le TAM 33
3.10 Influence du nombre de sites sur le
NMM et le TAM 33
3.11 Influence du nombre de
requêtes sur le NMM et le TAM. 34
3.12 Influence de la portée de
communication sur le NMM et le TAM 34
3.13 Influence du nombre de ressources
sur le NMM et le TAM. 35
3.14 Influence de la vitesse de
mouvement sur le NMM et le TAM 35
3.15 Influence du nombre de sites sur le
NMM et le TAM 35
4.1 Influence du nombre de
requêtes sur le NMM et le TAM. 43
4.2 Influence de la portée de
communication sur le NMM et le TAM 43
4.3 Influence du nombre de ressources
sur le NMM et le TAM. 43
4.4 Influence de la vitesse de mouvement
sur le NMM et le TAM 44
4.5 Influence
du nombre de sites sur le NMM et le TAM 44
INTRODUCTION GéNéRALE
L
'évolution récente de la technologie
sans fll et l'apparition des unités de calcul portables poussent
aujourd'hui les chercheurs à faire des efforts afln de réaliser
le but des
réseaux : (L'accès à
l'information n'importe ou , et n'importe quand). Les réseaux sans fll
ne sont pas une exception, car ils ont gagné un intérêt
majeur et une popularité croissante grâce aux avantages qu'ils
offrent, ces réseaux occupent de plus en plus de place dans les
communications personnelles et d'entreprise.
Les réseaux mobiles sans fll, peuvent
être classés en deux grandes catégories : les
réseaux mobiles avec infrastructure ou cellulaire, et les réseaux
mobiles sans infrastructure ou les réseaux mobiles AD HOC.
Le concept des réseaux mobiles AD HOC essaie
d'étendre les notions de la mobilité à toutes les
composantes de l'environnement. Ici, contrairement aux réseaux
basés sur la communication avec infrastructure (cellulaire), aucune
administration centralisée n'est disponible, ce sont les hôtes
mobiles eux-mêmes qui forment une infrastructure du réseau. Aucune
supposition ou limitation n'est faite sur la taille du réseau AD HOC, le
réseau peut contenir des centaines ou des milliers d'unités
mobiles.
Les sites d'un réseau AD HOC peuvent partager
des ressources critiques dont l'accès simultané par plusieurs
noeuds conduit à des incohérences. Il faut donc assurer
l'accès exclusif à cette ressource, cette notion a donné
naissance au problème de l'exclusion mutuelle dans les réseaux AD
HOC. Et lorsque le système est doté de plusieurs ressources (K
ressources), nous pouvons donc parler de la généralisation de ce
problème au problème de la K-exclusion mutuelle.
L'étude des performances d'une nouvelle
solution apportée à ces problèmes nécessite une
intervention direct dans un réseau réel, une chose qui est
difflcile voir même impossible, vue la difflculté d'extraction des
données, et des coûts de matérielle exorbitant, c'est la
raison pour laquelle on utilise des outils de simulation qui nous permettent de
tester et évaluer les algorithmes proposés dans des conditions
très proches de la réalité.
Dans ce mémoire, nous allons proposer et
valider par une simulation, un algorithme de la K-exclusion mutuelle dans les
réseaux mobiles AD HOC. Des remarques nous ont permis d'améliorer
cet algorithme afln d'avoir une performance très acceptable en terme de
temps d'attente, un autre algorithme est également proposé, qui
va remplir les lacunes du premier algorithme en terme de nombre de messages
échangés.
Le reste de ce mémoire est organisé comme
suit:
Dans le
1er
chapitre, nous allons aborder des notions
générales sur les réseaux mobiles AD HOC et le
problème de l'exclusion mutuelle dans ces systèmes, ainsi qu'une
illustration par des exemples de solutions apportés à ce
problème.
Introduction générale
Le chapitre 2, est
entièrement consacré à l'étude de l'algorithme
proposé dans le cadre de la K-exclusion mutuelle dans les réseaux
mobiles AD HOC. Nous l'expliquons en donnant l'idée de base, le principe
de fonctionnement, ainsi que les améliorations
apportées.
Dans le chapitre suivant, nous présentons
la réalisation de la simulation de cet algorithme, et la discussion des
différents résultats obtenus durant la simulation.
Le dernier chapitre, un nouvel algorithme
sera proposé, cet algorithme vise à satisfaire toutes les
insuffisances qui sont survenues au niveau de l'algorithme proposé dans
le chapitre précédent.
La conclusion de ce mémoire résume
les travaux faits durant toutes nos études ainsi que des possibles
améliorations futures.
À la fin de ce mémoire, on met à la
disposition du lecteur, une annexe représentant un exemple d'un script
utilisé par l'outil de simulation.
NoTioNs géNéRaLEs 1
SoMMaiRE
1.1 INTRoDucTioN 4
1.2 LEs sysTèMEs
RépaRTis 4
1.3 LEs RésEaux MoBiLEs
4
1.3.1 Les
réseaux mobiles avec infrastructures 5
1.3.2 Les
réseaux mobiles sans infrastructures (AD HOC) 5
1.3.2.1
Définition d'un réseau AD HOC 5
1.3.2.2
Les caractéristiques des réseaux AD HOC 6
1.3.2.3
Les avantages des réseaux AD HOC 7
1.3.2.4
Les inconvénients des réseaux AD HOC 7
1.3.2.5
Les domaines d'applications des réseaux AD HOC 7
1.3.2.6
Les problèmes liés aux réseaux AD HOC
9
1.3.3 Problème
de routage dans les réseaux AD HOC 9
1.3.3.1
Définition d'un routage 9
1.3.3.2
Classification des protocoles de routage 9
1.4 L'ExcLusioN MuTuELLE DaNs
LEs RésEaux AD HOC 10
1.4.1 L'exclusion
mutuelle en réparti 10
1.4.1.1
La notion de l'exclusion mutuelle 10
1.4.1.2
Les états d'un processus 11
1.4.1.3
Notions de base 11
1.4.1.4
Propriétés d'un algorithme d'exclusion mutuelle
11
1.4.1.5
Les classes de solutions d'exclusion mutuelle 12
1.4.2 Le
problème de la K-exclusion mutuelle 12
1.4.2.1
Description du problème 12
1.4.2.2
Résolution du problème 13
1.4.3 Les solutions de
l'EM dans les réseaux ADHOC 13
1.4.4 Les solutions de
la K-EM dans les réseaux AD HOC 14
CoNcLusioN 14
D
aNs ce chapitre, nous allons présenter le
concept des réseaux AD HOC et les caractéristiques
inhérentes ainsi que quelques domaines d'application de ces
réseaux. Nous
introduisons également le concept du
problème de l'exclusion mutuelle dans ce type de
ré-
seaux, quelques exemples de solutions
déjà proposées dans ce domaine seront
présentées.
1.1 INTRoDucTioN
Au cours de ces dernières années, le
monde des réseaux sans fil est devenu l'un des axes de recherche les
plus importants. L'évolution récente des moyens de communication
sans fil a permis la manipulation de l'information à travers des
unités de calcul mobiles. Les environnements mobiles offrent aujourd'hui
une grande flexibilité d'emploi, en particulier, ils permettent la mise
en réseau des sites dont le câblage serait trop onéreux
à réaliser dans leur totalité, voire même
impossible.
1.2 LEs sysTèMEs RépaRTis
Un système réparti est un système
composé de plusieurs machines autonomes qui communiquent par
l'échange de messages via un réseau de communication quelconque
(filaire ou sans fil).(voir la figure
1.1).
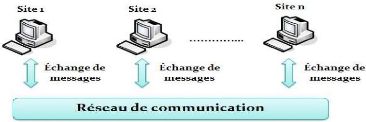
Figure 1.1 -
Structure d'un système réparti
Chaque ordinateur (dit aussi site), est une entité
autonome capable de réaliser des tâches indépendamment des
autres entités.
Au niveau de chaque site qui a une mémoire
propre et une horloge locale, un ensemble de processus s'exécute soit en
collaboration soit en compétition. Pour des raisons de
simplicité, on suppose qu'il y a un seul processus au niveau de chaque
site, donc, dans tout ce qui suit, les termes : site, noeud et processus seront
confondus, et ils représenteront la même
chose.[OB10]
1.3 LEs RésEaux MoBiLEs
Un environnement mobile est un ensemble de noeuds
mobiles qui permet aux usagers d'accéder à l'information
indépendamment de leurs positions géographiques, et sans utiliser
une infrastructure câblée.
Les réseaux mobiles (ou sans fil), peuvent
être divisés en deux classes:
- Des réseaux avec infrastructure.
- Des
réseaux sans infrastructure.
1.3.1 Les réseaux mobiles avec infrastructures
Dans ce modèle, le réseau est
composé de deux ensembles d'entités distinctes : les (sites
fixes) d'un réseau de communication filaire classique, et les (sites
mobiles). Certains sites fixes, appelés stations de bases (SB) sont
munis d'une interface de communication sans fil pour la communication directe
avec les sites ou les unités mobiles (UM) localisés dans une zone
géographique limitée, appelée cellule.
Les stations de base sont interconnectées par
un réseau de communication filaire, et délimite une cellule
à partir de laquelle des unités mobiles peuvent émettre et
recevoir des messages.
Dans ce modèle, une unité mobile ne peut
être, à un instant donné, directement connectée
qu'à une seule station de base. Elle peut communiquer avec les autres
sites à travers la station à laquelle elle est directement
rattachée. L'autonomie réduite de sa source d'énergie, lui
occasionne de fréquentes déconnexions du réseau, sa
reconnexion peut alors se faire dans un environnement nouveau, voir dans une
nouvelle localisation.[Lem00] (voir la figure
1.2).
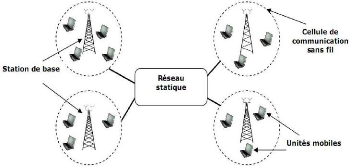
Figure 1.2 - Le
modèle des réseaux mobiles avec
infrastructure.[Bou07]
1.3.2 Les réseaux mobiles sans infrastructures (AD
HOC)
1.3.2.1 Définition d'un réseau AD HOC
Un réseau mobile AD HOC, appelé
généralement MANET (Mobile AD HOC NET-work), est un ensemble
d'unités mobiles qui se déplacent dans un territoire quelconque.
Le seul moyen de communication est l'utilisation des ondes radio qui se
propagent entre les différents noeuds mobiles, sans l'aide d'une
infrastructure préexistante ou d'une administration
centralisée.[LK09]
comme il est illustré dans la figure
1.3
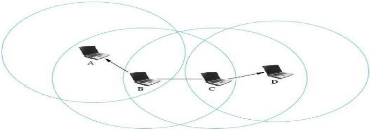
Figure 1.3 - Le
modèle des réseaux mobiles sans infrastructure.
À cause de la mobilité des sites, La
topologie du réseau peut changer à tout moment, elle est donc
dynamique et imprévisible.
1.3.2.2 Les caractéristiques des réseaux
AD HOC
Les réseaux AD HOC en tant qu'un nouveau
paradigme des réseaux sans fil, présentent de nombreuses
caractéristiques dont certaines leur sont bien spécifiques et les
différencient des réseaux mobiles classiques.
- Une topologie dynamique : les unités mobiles
du réseau, se déplacent d'une façon libre et arbitraire.
Par conséquent, la topologie du réseau peut changer à des
instants imprévisibles d'une manière rapide et aléatoire.
(voir figure 1.4).
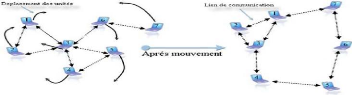
Figure 1.4 -
Topologie dynamique dans un réseau AD HOC.
- L'absence d'infrastructure : les réseaux AD
HOC se caractérisent par l'absence d'infrastructure préexistante
et de tout genre d'administration centralisée. Les hôtes mobiles
sont responsables d'établir et de maintenir la connectivité du
réseau d'une manière continue.
- Rapidité de déploiement : les
réseaux AD HOC peuvent être facilement installés dans des
endroits difficiles à câbler, ce qui élimine une bonne part
du travail et du coût généralement liés à
l'installation, et réduit d'autant le temps nécessaire à
la mise en route.
- Communication par lien radio : les communications
entre les noeuds se font par l'utilisation d'une interface radio. Il est alors
important d'adopter un protocole d'accès au médium qui permet de
bien distribuer les ressources radio, et ceci en évitant le plus
possible les collisions, et en réduisant les
interférences.[Mes98]
1.3.2.3 Les avantages des réseaux AD HOC
- Facile à déployer : il suffit de mettre
en place plusieurs machines pour que le réseau existe. Ceci rend la
construction d'un réseau AD HOC rapide et peu
onéreuse.
- Les noeuds sont mobiles : l'absence de câblages
autorise les noeuds à se déplacer l'un par rapport aux autres au
cours du temps.
- Évolutifs : pour ajouter un noeud à un
réseau AD HOC préexistant, il suffit d'approcher le nouveau venu
d'au moins l'un des membres du réseau. De même il suffit de l'en
éloigner pour le retirer du
réseau.[Man07]
1.3.2.4 Les inconvénients des réseaux AD
HOC
- Une bande passante limitée : une des
caractéristiques primordiales des réseaux basés sur la
communication sans fil est l'utilisation d'un médium de communication
partagé. Ce partage fait que la bande passante réservée
à un hôte soit modeste.
- Des contraintes d'énergie : les hôtes
mobiles sont alimentés par des sources d'énergie autonomes donc
restreintes, comme les batteries, par conséquent la durée de
traitement est réduite. Donc le paramètre d'énergie doit
être pris en considération dans tout contrôle fait par le
système.
- Une sécurité physique limitée :
les réseaux mobiles AD HOC sont plus touchés par le
paramètre de sécurité que les réseaux filaires
classiques. Cela se justifie entre autres par les vulnérabilités
des liens radio aux attaques, ainsi que les contraintes et limitations
physiques qui font que le contrôle des données
transférées doit être minimisé.
- Interférences : Les liens radios ne sont pas
isolés, deux transmissions simultanées sur
une même
fréquence ou utilisant des fréquences proches peuvent
interférer.[Mes98]
1.3.2.5 Les domaines d'applications des réseaux
AD HOC
La particularité du réseau AD HOC est
qu'il n'a besoin d'aucune installation fixe, ceci lui permettant d'être
rapide et facile à déployer. Les applications tactiques comme les
opérations de secours, militaires ou d'explorations trouvent en AD HOC,
le réseau idéal. La technologie AD HOC qui s'intéresse
à la recherche des applications civiles est également
apparue.
Parmi les applications des MANETs, on peut distinguer
[Man07] :
- Services d'urgence : opération de recherche et
de secours des personnes, tremblement de terre, feux, dans le but de remplacer
l'infrastructure filaire.(figure
1.5)
- Travail collaboratif et les communications dans des
entreprises ou bâtiments : dans le cadre d'une réunion ou d'une
conférence par exemple. (voir la figure
1.6).
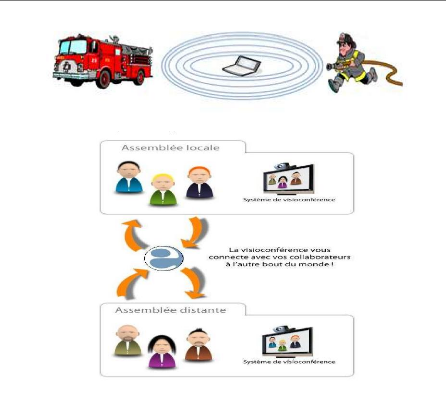
Figure 1.5 -
Application de secours des réseaux AD HOC.
Figure 1.6 -
Application collaborative des réseaux AD HOC.
- Applications commerciales : pour un paiement
électronique distant (taxi) ou pour l'accès mobile à
Internet.(voir la figure 1.7)
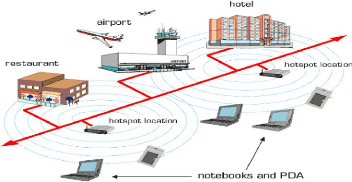
Figure 1.7 -
Applications commerciales des réseaux AD HOC.
1.3.2.6 Les problèmes liés aux
réseaux AD HOC
Comme les systèmes répartis, les
réseaux AD HOC ont également des problèmes propres
à eux, tels que la bande passante limitée, la perte des
données ainsi que le problème de routage.
1.3.3 Problème de routage dans les réseaux AD
HOC
1.3.3.1 Définition d'un routage
Le routage est une méthode à travers
laquelle on fait transiter une information donnée depuis un certain
émetteur vers un destinataire bien précis dans un réseau
de connexions défini. Son intérêt consiste à trouver
le chemin optimal au sens d'un certain critère de performance (bande
passante, délai, etc.) et de qualité des paquets de
données.[Bou07]

Figure 1.8 - Le
chemin utilisé dans le routage entre la source et la destination.
1.3.3.2 Classification des protocoles de routage
Suivant la manière de création et de
maintenance de routes lors de l'acheminement des données, les protocoles
de routage peuvent être séparés en trois catégories,
les protocoles proactifs, les protocoles réactifs et les protocoles
hybrides.[Lem00]
Comme il est illustré dans la figure
1.9.
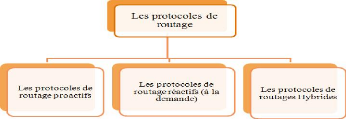
Figure 1.9 -
Classification des protocoles de routage.
1.3.3.2.a Les protocoles de routage proactifs
Les protocoles de routage proactifs exigent une mise
à jour périodique des données de routage qui doit
être diffusée par les différents noeuds de routage du
réseau. Le protocole le plus connus dans cette classe est OLSR
(Optimized link state routing protocol).
1.3.3.2.b Les protocoles de routage réactifs
(à la demande)
Les protocoles de routage appartenant à cette
catégorie, créent et maintiennent les routes selon les besoins.
Lorsque le réseau a besoin d'une route, une procédure de
découverte globale de routes est lancée, et cela dans le but
d'obtenir une information spécifiée, inconnue au
préalable. AODV (AD HOC On-demand Distance Vector), DSR (Dynamic Source
Routing), sont les plus connus dans cette classe.
1.3.3.2.c Les protocoles de routage hybrides
Dans ce type de protocole, on peut garder la
connaissance locale de la topologie jusqu'à un nombre
prédéfini (à priori petit) de sauts par un échange
périodique de trame de contrôle, autrement dit par une technique
proactive. Les routes vers des noeuds plus lointains sont obtenues par
schéma réactif, c'est-à-dire par l'utilisation de paquets,
et de requêtes en diffusion.[Lem00]. Le protocole ZRP
(Zone Routinier Protocol) est le plus connu dans cette classe.
1.4 L'EXcLusioN MuTuELLE DANs LEs RtsEAuX AD HOC
Pour mieux comprendre ce problème dans les
environnements mobiles, nous allons d'abord l'expliquer dans un contexte
réparti.
1.4.1 L'exclusion mutuelle en réparti
1.4.1.1 La notion de l'exclusion mutuelle
L'utilisation simultanée d'une ressource
critique par plusieurs sites va certainement provoquer des situations
incohérentes. Afin d'éviter cette incohérence, un seul
processus au plus peut exécuter sa section critique à la fois, en
d'autres termes, les sections critiques doivent être
exécutées en exclusion mutuelle.
Pour rendre exclusif l'accès à une
section critique, les sites désirant l'exécuter doivent
exécuter un protocole d'acquisition avant la SC, ce dernier ne permet
qu'à un seul site de passer à la SC, à la fin de la SC, le
processus exécute le protocole de libération pour informer les
sites qui peuvent être en attente que la SC est
libre.[All07]. La forme générale d'un processus
utilisant une ressource critique est :
Protocole d'acquisition
< Section Critique>
Protocole de libération
1.4.1.2 Les états d'un processus
Un processus Pi appartenant au système
réparti est doté d'une variable locale Etati qui
désigne son état, tel que :
Etati = {Dehors, Demandeur,
Dedans}.
La figure 1.10 suivante
illustre les transitions d'un processus entre les trois
états.
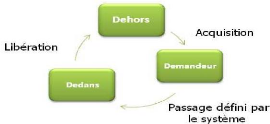
Figure 1.10 - Les
états d'un processus.[Ray92]
1.4.1.3 Notions de base
1. Ressource critique C'est une ressource
partagée qui ne doit être accessible que par un seul site à
la fois.
2. Section critique
Une partie du code du processus manipulant une
ressource critique. Un seul processus au plus doit être en section
critique afin de garantir une utilisation correcte de la
ressource.[Ray92]
1.4.1.4 Propriétés d'un algorithme
d'exclusion mutuelle
Une solution n'est considérée correcte que
si elle respecte les propriétés suivantes : -
Propriété de sûreté (safety) : à
tout instant, un seul site au plus exécute la SC.
- Propriété de vivacité
(liveness) : tout site demandeur de la ressource critique doit pouvoir
l'acquérir au bout d'un temps fini.
Un algorithme qui assure ces deux
propriétés assure également l'absence de deux
problèmes, l'interblocage et la famine:
- Interblocage (Deadlock) : est une situation du
système oü il y a plusieurs sites à l'état Demandeur
et aucun ne peut accéder à la SC.
- Famine (Starvation) : aura lieu si un site qui
se trouve à l'état Demandeur ne passe jamais à
l'état Dedans.
1.4.1.5 Les classes de solutions d'exclusion
mutuelle
Les solutions réparties peuvent être
classées en deux grandes familles selon le type de messages
utilisé, les algorithmes fondés sur les permissions et ceux
fondés sur l'utilisation du jeton.[Ray92]
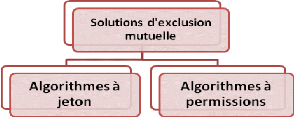
Figure 1.11 - Les
catégories des solutions d'exclusion mutuelle. 1.4.1.5.a
Algorithmes utilisant des permissions
Les algorithmes basés sur les permissions
utilisent le protocole suivant : Pour qu'un site i puisse
exécuter sa section critique, il doit d'abord demander la permission
à un ensemble Ri de sites et ne peut exécuter sa section
critique que s'il a reçu un nombre suffisant de permissions des autres
sites. Ce nombre est géré par ses variables locales. Ce
mécanisme assure l'exclusion
mutuelle.[All07]
1.4.1.5.b Algorithmes utilisant des jetons
Un jeton est un message particulier qui circule entre
les sites du système réparti, le site détenant le jeton
peut exécuter sa SC. L'algorithme de Lelann[Lan77],
était le 1er algorithme
utilisant un jeton. Et plusieurs autres solutions ont résolu le
problème, tels que l'algorithme de Ricart et Agrawala
[RA81], Suzuki et Kasami [SK85], Naimi et
Trehel[NT87], et plusieurs autres.
1.4.2 Le problème de la K-exclusion mutuelle
1.4.2.1 Description du problème
Le problème de la K-exclusion mutuelle est une
généralisation du problème de l'exclusion mutuelle simple.
Dans ce cas, les sites partagent non seulement une ressource mais K exemplaires
de la même ressource. Cette disponibilité de ressources n'autorise
pas l'accès simultané à une ressource, il faut toujours
assurer l'accès exclusif à chaque exemplaire.
1.4.2.2 Résolution du problème
Les solutions du problème de la K-exclusion
mutuelle sont basées sur les solutions utilisées pour
résoudre le problème de l'exclusion mutuelle simple, on peut donc
avoir deux types de solutions:
1.4.2.2.a Solution utilisant des permissions
Le processus désirant entrer en SC doit
demander des permissions à un ensemble de processus, la réception
d'un nombre suffisant de ces permissions permet au processus d'utiliser la
ressource. L'algorithme de Raymond est la première solution pour la
K-exclusion mutuelle basée sur les permissions
[Ray88].
1.4.2.2.b Solution utilisant des jetons
Dans ce cas, il n'existe pas un seul jeton mais k
jetons (k étant le nombre de ressources), seule la possession d'un jeton
permet à un site demandeur l'accès à la SC. Parmi les
solutions apportées basées sur les jetons, on distingue
l'algorithme de Srimani et Reddy [Sri89].
1.4.3 Les solutions de l'EM dans les réseaux
ADHOC
Les solutions proposées au problème de
l'exclusion mutuelle dans les réseaux mobiles AD HOC peuvent être
classées en deux grandes familles, les solutions utilisant des
permissions et celles utilisant un jeton, ces solutions devront prendre en
compte les caractéristiques des réseaux mobiles AD
HOC.
Le rôle des solutions proposées pour
résoudre le problème de l'exclusion mutuelle dans un
environnement mobiles ne se limite pas à assurer l'EM, mais aussi
à respecter les caractéristiques des MANETs, telles que la
mobilité et la perte des liens, donc il n'est pas évident
d'adapter directement les solutions classiques. Généralement, les
solutions proposées dans un environnement mobiles sont
originales.
L'algorithme proposé par J. Walter et S. Kini
[WK97] est une référence des solutions, et la
plupart des solutions sont basées sur son principe. Cet algorithme a
été amélioré par J. Walter et J. Welch et Vaidya
[WW01].
Plusieurs autres solutions ont résolu le
problème, tels que l'algorithme de R. Baldoni et A. Virgillito
[BVP02], l'algorithme de N.Malpani et N.Vaidya et L.Welch
[MVW01], et plusieurs autres.
1.4.4 Les solutions de la K-EM dans les réseaux AD
HOC
Dans ce cas, nous avons K exemplaires d'une ressource
critique, un processus ne peut utiliser qu'une seul ressource à un
moment donné.
Nous avons remarqué que ce problème
n'était pas bien traité dans un tel environnement, nous avons
trouvé un seul algorithme proposé par J.Walter et G.Cao et
M.Mohanty [WCM02] qui est basé sur l'algorithme de J.
Walter et S. Kini.[WK97].
CONCLUSION
Dans ce chapitre nous avons présenté une
vue générale des environnements mobiles et en particulier les
réseaux AD HOC, nous avons également présenté des
notions de base concernant le problème de l'exclusion mutuelle et son
extension à K-ressources, enfin nous avons cité les
catégories de solutions apportées à ces
problèmes.
Dans le chapitre suivant, nous allons décrire
notre algorithme proposé dans le cadre de la K-exclusion mutuelle dans
les réseaux mobiles AD HOC.
SommAiRE
|
2.1 INTRoDucTioN
|
16
|
|
2.2 L'ALgoRiThmE
|
16
|
|
2.2.1 Structure logique
utilisée
|
16
|
|
2.2.2 Le principe de
fonctionnement
|
17
|
|
2.2.3 Hypothèses
|
18
|
|
2.2.4 Description de
l'algorithme
|
18
|
|
2.2.4.1
Les variables locales
|
18
|
|
2.2.4.2
Les messages utilisés
|
19
|
|
2.2.4.3
Initialisation des variables
|
19
|
|
2.2.4.4
Les procédures de l'algorithme
|
19
|
|
2.3 MoDiFicATioN
N°1
|
22
|
|
2.4 MoDiFicATioN
N°2
|
23
|
|
CoNcLusioN
|
24
|
C
E chapitre à pour objectif de décrire et
d'étudier un algorithme proposé dans le cadre de la K-exclusion
mutuelle dans les réseaux AD HOC.
2.1 INTRODUCTiON
Le problème de la K-exclusion mutuelle n'est
pas bien traité dans les réseaux mobiles AD HOC, c'est pourquoi
il n y a pas beaucoup d'algorithmes qui sont proposés pour
résoudre ce problème dans un tel environnement.
C'est la raison pour laquelle nous avons pensé
à une nouvelle solution permettant de résoudre le problème
de la K-EM dans les réseaux AD HOC.
Dans ce chapitre, nous décrivons le principe de
fonctionnement de l'algorithme proposé.
2.2 L'ALGORiTHME
2.2.1 Structure logique utilisée
La structure logique qu'on a adoptée pour notre
algorithme est inspirée de l'algorithme de Naimi et Trehel
[NT87].
La structure logique de notre algorithme consiste
à diviser les sites en K groupes indépendants.
Initialement, chaque groupe à un site
détenant un jeton appelé Père, tous les sites du groupe
pointe vers ce père, et forme ainsi une arborescence. Ces arbres ne
couvrent pas la totalité des sites, par conséquent, certains
sites peuvent au début n'appartenir à aucun arbre
logique.
Chaque arborescence repose sur la construction dynamique
de deux structures de données :
- 1ère Structure (File de
requête {Suivant}) : Consiste a placé toujours le dernier site qui
a fait une requête pour la SC à la fin de la file. Alors que le
site qui détient le jeton est toujours en tête de la
file.
Cette structure est illustrée dans la figure
2.1 ci-dessous :
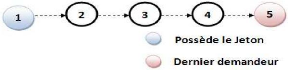
Figure 2.1 -
Structure de la file des requêtes.
- 2ème Structure (Arbre de chemins
vers le dernier demandeur {Père}) : La racine de l'arbre est toujours le
dernier demandeur c'est-à-dire le dernier élément de la
file des requêtes. Une nouvelle requête est transmise à
travers d'un chemin des pointeurs de Père jusqu'à la racine de
l'arbre.
Chaque nouveau demandeur devient la nouvelle racine de
l'arbre. Et Les sites dont le chemin compris entre la nouvelle et l'ancienne
racine changent leur pointeur {Père} vers la nouvelle
racine.
On peut illustrée cette structure dans la figure
2.2 :
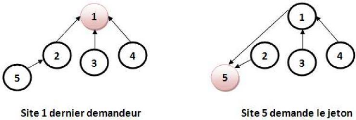
Figure 2.2 -
Structure d'arbre de chemins vers le dernier demandeur.
Les sites n'ont pas une vue globale sur ces structures,
un site ne connait que son père et son suivant.
2.2.2 Le principe de fonctionnement
Pour assurer la K-exclusion mutuelle, nous utilisons
autant de jetons que de ressources disponibles. Initialement, chaque site
père détient un jeton, et doit informer ces voisins
immédiats pour leur permettre de lui adresser leurs requêtes, et
dans le but de former les K-arbres.
Lorsqu'un site désire entrer en SC, il envoie
une requête vers son père, et il devient un père à
son tour, le site qui reçoit cette requête répond par le
jeton s'il le détient, si non, il va propager la requête vers son
Père, et met à jour ses variables et pointe vers le nouveau
père (demandeur), et ainsi de suite jusqu'à ce que la
requête atteint la racine de l'arborescence, en effet, une nouvelle
arborescence est créée par le passage de cette requête, la
nouvelle racine est le dernier site demandeur.
Si un site est en SC et reçoit une
requête, il met à jour ses variables et pointe vers le nouveau
demandeur, après sa sortie de la SC, il envoie le jeton vers son
suivant, cet envoi ne modifie pas la structure de l'arborescence.
Dans le cas où un site en dehors des arbres
logiques créés, veut entrer en SC, il va envoyer sa requête
vers un voisin immédiat. .Si le site qui reçoit cette
requête n'a pas de père, il va propager cette demande à un
autre voisin immédiat différent du précédent, cette
propagation peut atteindre un site père ou un site possédant un
père, et donc la demande va alors transiter dans l'arbre des
pères jusqu'à arriver à la racine, et par
conséquent la racine ainsi que tous les sites parcourus pointent vers le
nouveau demandeur et la requête sera satisfaite directement ou au bout
d'un temps fini, cette requête permet au nouveau demandeur ainsi que tous
les sites parcourus et qui ne possèdent pas de père de joindre ce
nouvel arbre.
La figure 2.3 montre
l'évolution d'une arborescence selon des requêtes
émises.
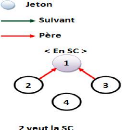
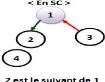
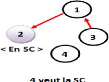
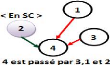
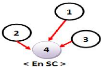
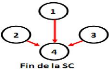
Figure 2.3 - Les
états d'arborescence après chaque requête.
2.2.3 Hypothèses
Pour assurer le bon fonctionnement de notre algorithme,
on suppose que :
- Le nombre N des noeuds et le K des pères sont
connus initialement. - Chaque noeud connaît ses voisins
immédiats.
- Les canaux de communication sont fiables, et il n'y a
pas de perte de messages. - Les sites du système ne tombent pas en
panne.
- Le réseau n'est pas
partitionné.
2.2.4 Description de l'algorithme
Dans cette partie nous allons décrire les
variables locales et les messages utilisés, et on va détailler
les procédures de notre algorithme, quelques explications sont
associées aux procédures pour faciliter la compréhension
du code.
2.2.4.1 Les variables locales
Chaque noeud i dans le système maintient
les variables locales suivantes :
- Perei : est l'identité du père
qui possède le jeton tel que :
Si (Perei = NIL) :
i est un père.
Si (Perei = 0) : i est
un noeud qui ne possède pas de père
Si (Perei ? {1 ... N}) : i
est un noeud possédant un père.
- Demandeuri : une variable booléenne
initialisée à Faux, indiquant si i a demandé une
ressource critique ou non.
- Jetoni : une variable booléenne
indiquant si i possède un jeton ou non, elle est
initialisée à Faux au niveau des sites simple et à Vrai au
niveau des sites père.
- Suivanti : une variable indiquant
l'identité du site auquel le jeton sera transmis à la sortie de
la SC.
2.2.4.2 Les messages utilisés
Dans cet algorithme, on utilise trois types de
messages:
- Information (Jeton, i) : envoyé par le site
i vers les voisins immédiats pour les informer qu'il est un
père.
- Requête (Jeton, i) : envoyé par le site
i vers le père lors de la demande de la Section
critique.
- Accord (Jeton) : envoyé par un père
à un site demandeur pour lui permettre d'utiliser la ressource critique
demandée.
2.2.4.3 Initialisation des variables
Initialisation : des variables
Demandeuri : Variable
booléenne.
Jetoni : Variable booléenne.
Perei : Variable qui peut prendre
{1,2,. . .,N} U NIL U 0
Suivanti : Variable qui peut prendre
{1,2,. . .,N} U NIL
Début
Demandeuri +- Faux; Jetoni +-
Faux;
Suivanti +- NIL;
Perei +- 0;
Si Je suis un père Alors
Perei
+- NIL;
Jetoni +- Vrai;
Finsi
Fin
2.2.4.4 Les procédures de l'algorithme
Procédure N°1 : Informer tous les voisins
immédiat (Initialement)
1 Début
2 Envoyer Information (Jeton, i) à tous les
voisins immédiat;
3 Fin
Cette procédure est utilisée lorsqu'un site
père désire informer ses voisins immédiats qu'il
détient un jeton (père).
2
3
4
Procédure N°2 : Demander la Section Critique
1 Début
|
2
|
Demandeuri ?- Vrai;
|
|
|
3
|
Si Perei =6 NIL Alors
/* Si je possède un père
|
*/
|
|
4
|
Envoyer Requête (Jeton, i) à
Perei;
|
|
|
5
|
Sinon
|
|
|
6
|
|
Si Perei = Ø Alors
/* Si je ne possède pas de père
|
*/
|
|
7
|
|
Envoyer Requête (Jeton, i) à un voisin
immédiat;
|
|
|
8
|
|
Finsi
|
|
|
9
|
Finsi
|
|
|
10
|
Perei ?- NIL;
|
|
|
11
|
Attendre (Jeton = Vrai);
|
|
|
12
|
< Entrer en Section Critique>
|
|
|
13 Fin
|
|
Quand un noeud désire entrer en SC, il met sa
variable Demandeuri à Vrai, s' il possède
déjà un jeton (Jetoni = Vrai) il entre
directement en SC, Sinon il doit attendre la réception d'un jeton
auprès de son père.
Procédure N°3 : Réception de
Information (Jeton,j)
1 Début
Si Perei = Ø Alors
/* Si je ne possède pas un père */
Perei ?- j;
Finsi
5 Fin
Lors de la réception d'un message de type
Information par un site, il doit mettre à jour sa variable Perei
dans le cas ou ce site ne possède pas de père.
Procédure N°4 : Libérer la Section
Critique 1 Début
|
2
|
Demandeuri ?- Faux;
|
|
|
|
|
|
|
|
3
|
Si Suivanti =6 NIL
Alors /* S'il
|
y
|
a une
|
demande
|
en
|
attente
|
*/
|
|
4
|
|
Envoyer Accord (Jeton) à
Suivanti;
|
|
|
|
|
|
|
|
5
|
|
Jetoni ?- Faux;
|
|
|
|
|
|
|
|
6
|
|
Suivanti ?- NIL;
|
|
|
|
|
|
|
|
7
|
Finsi
|
|
|
|
|
|
|
8 Fin
Si un site veut libérer la section critique, il
met à jour sa variable Demandeuri à Faux et il consulte
s'il possède déjà un noeud suivant auquel il retransmettra
le jeton.
Procédure N°5 : Réception de Accord
(Jeton)
1 Début
2 Jetoni +- Vrai;
3 Fin
Lorsqu'un site a déjà envoyé une
demande d'entrer en section critique à son père, il va recevoir
un message de type Accord, lors de la réception de ce message, le site
va mettre à jour sa variable Jetoni à Vrai et entre
à la SC.
Procédure N°6 : Réception de
Requête (Jeton, j)
1 Début
|
2
|
Si Perei = NIL Alors
/* Si je suis un père */
|
|
3
|
|
Si Demandeuri = Vrai
Alors /* Si je suis déjà demandeur */
|
|
4
|
|
Suivanti +- j;
|
|
5
|
|
Sinon /* Si je n'ai pas fait une demande */
|
|
6
|
|
|
Jetoni +- Faux;
|
|
7
|
|
|
Envoyer Accord (Jeton) à j;
|
|
8
|
|
Finsi
|
|
9
|
Sinon
|
|
10
|
|
Si Perei =6 Ø
Alors /* Si je possède un père */
|
|
11
|
|
Envoyer Requête (Jeton, j) à
Perei;
|
|
12
|
|
Sinon /* Si je ne possède pas un
père */
|
|
13
|
|
Envoyer Requête (Jeton, j) à un voisin
immédiat;
|
|
14
|
|
Finsi
|
|
15
|
Finsi
|
|
16
|
Perei +- j;
|
|
17 Fin
|
Lorsqu'un site père reçoit une
requête, et il n'est pas demandeur, donc il détient un jeton, il
va satisfaire la requête et envoie ce jeton vers le site demandeur, si le
site père est un demandeur ou en SC, il met à jour sa variable
Suivanti et après sa sortie de la SC, il envoie le jeton vers
son suivant. Si le site qui reçoit la requête est un site
possédant un père, la requête sera propagée dans
l'arbre des pères jusqu'à l'arrivée à la racine.
Sinon le site va simplement propager cette requête à un voisin
immédiat.
Remarque
L'étude théorique de notre algorithme nous
a permis de constater le problème suivant :
Lorsqu'un site qui ne possède pas un
père désire entrer en SC, il va envoyer une requête vers un
voisin immédiat (voir Procédure Demander la SC), ce voisin va
propager cette requête à un autre voisin s'il ne possède
aucun père et ainsi de suite jusqu'à l'arrivée à un
arbre donné et satisfaire la requête, cependant ce chemin peut
être long et pénalisant en terme du temps d'attente, alors qu'il
peut exister un autre chemin plus court permettant de satisfaire la
requête et minimiser ainsi le temps d'attente.
Solution proposée
Dans le cas où un site veut libérer la
SC, il va vérifier s'il possède déjà une
requête en attente, sinon il ne fait rien, alors qu'il peut diffuser un
message Information afin d'informer le plus possible de voisins qui ne
possèdent pas de père, et cela va leur permettre lorsqu'ils
veulent entrer en SC, d'envoyer directement leurs requêtes à ce
père et ne pas l'envoyer à un voisin immédiat qui peut ne
pas avoir de père et tomber dans la problématique
précédente.
2.3 MODIFICATION N°1
Pour mettre en place cette modification, on applique la
modification suivante :
Modification N°1 : Libérer la Section
Critique 1 Début
|
2
|
Demandeuri +-- Faux;
|
|
|
|
|
3
|
Si Suivanti =6 NIL
Alors /* S'il y a une demande
|
en
|
attente
|
*/
|
|
4
|
|
Envoyer Accord (Jeton) à
Suivanti;
|
|
|
|
|
5
|
|
Jetoni +-- Faux;
|
|
|
|
|
6
|
|
Suivanti +-- NIL;
|
|
|
|
|
7
|
Sinon
|
|
|
|
|
8
|
Envoyer Information (Jeton, i) à tous les voisins
immédiat;
|
|
|
|
|
9
|
Finsi
|
|
|
|
10 Fin
Une autre remarque
Si un site veut entrer en SC, il va automatiquement
envoyer sa requête vers son père, mais dans certains cas, ce
père peut être lui-même en SC, ou il a déjà
reçu plusieurs demandes, donc cette requête doit attendre la
satisfaction de toutes les requêtes de la file d'attente, une chose qui
est très pénalisante en terme de temps d'attente moyen, alors
qu'il peut exister des jetons libres au niveau des autres arbres, si on arrive
à utiliser l'un de ces jetons on pourra certainement minimiser le temps
d'attente.
Solution proposée
Initialement, et après chaque fin de la file
des requêtes, les sites qui détiennent les jetons informent leurs
voisins immédiats afin de former les k-arbres ou simplement informer le
plus de voisins immédiats qui n'appartiennent à aucun arbre,
cependant, il se peut qu'il y ait des sites qui reçoivent plusieurs
messages d'information de plusieurs sites différents, il vaut mieux donc
exploiter cette caractéristique, et ajouter les identifiants des
messages Information en plus dans une file des pères (secondaires), et
donc le site en question va avoir un père principale et une file des
pères secondaires auxquels il peut adresser sa requête dans le cas
où le père principale est en SC, ou dans le cas où il ne
détient plus le jeton.
Afin d'utiliser la file des pères, il faut que
le père principale informe ces voisins immédiats qu'il va entrer
en SC ou il va servir une requête, et donc les sites qui possèdent
une files des pères doivent mettre à jour leurs pères
principaux en mettant celui qui se trouve dans la tête de la file. Pour
informer les voisins immédiat, les pères vont utiliser un nouveau
message de type Rejet.
2.4 MODIFICATION N°2
Cette modification nécessite des changements au
niveau des procédures suivantes :
Modification N°2 : Demander la Section
Critique
1 Début
|
2
|
Demandeuri ?- Vrai;
|
|
|
|
3
|
Si Perei =6 NIL Alors
/* Si je possède
|
un père
|
*/
|
|
4
|
Envoyer Requête (Jeton, i) à
Perei;
|
|
|
|
5
|
Sinon
|
|
|
|
6
|
|
Si Perei = Ø Alors
/* Si je ne possède pas
|
de père
|
*/
|
|
7
|
|
Envoyer Requête (Jeton, i) à un voisin
immédiat;
|
|
|
|
8
|
|
Finsi
|
|
|
|
9
|
Finsi
|
|
|
|
10
|
Perei ?- NIL;
|
|
|
|
11
|
Attendre (Jeton = Vrai);
|
|
|
|
12
|
Envoyer Rejet (Jeton, i) à tous les voisins
immédiat;
|
|
|
|
13
|
< Entrer en Section Critique>
|
|
|
|
14 Fin
|
|
|
Modification N°2 : Réception de Information
(Jeton,j) 1 Début
|
2
|
Si Perei = Ø Alors
/* Si
|
je
|
ne possède pas
|
un père
|
*/
|
|
3
|
Perei ?- j;
|
|
|
|
|
|
4
|
Sinon
|
|
|
|
|
|
5
|
|
Si (j ?/ Les_peresi) & (Perei
=6 j) Alors
|
|
|
|
|
|
6
|
|
Les_peresi ?- Les_peresi
+ {j};
|
|
|
|
|
|
7
|
|
Finsi
|
|
|
|
|
|
8
|
Finsi
|
|
|
|
|
|
9 Fin
|
|
|
|
|
Modification N°2 : Réception de Requête
(Jeton, j)
1 Début
|
2
3
4
5
|
Si
|
Perei = NIL Alors
/* Si je suis un père */
Si Demandeuri = Vrai
Alors /* Si je suis déjà demandeur */
Suivanti ?- j;
Sinon /* Si je n'ai pas fait une demande */
|
|
6
|
|
|
Jetoni ?- Faux;
|
|
|
|
7
|
|
|
Envoyer Accord (Jeton) à j;
|
|
|
|
8
|
|
|
Envoyer Rejet (Jeton, i) à tous les voisins
immédiat;
|
|
|
|
9
|
|
Finsi
|
|
|
|
10
|
Sinon
|
|
|
|
11
|
|
Si Perei =6 Ø
Alors /* Si je possède
|
un père
|
*/
|
|
12
|
|
Envoyer Requête (Jeton, j) à
Perei;
|
|
|
|
13
|
|
Sinon /* Si je ne possède pas
|
un père
|
*/
|
|
14
|
|
Envoyer Requête (Jeton, j) à un voisin
immédiat;
|
|
|
|
15
|
|
Finsi
|
|
|
|
16
|
Finsi
|
|
|
|
17
|
Perei ?- j;
|
|
|
|
18 Fin
|
|
|
Modification N°2 : Réception de Rejet (Jeton,
j)
1 Début
Si Les_peresi =6 {}
Alors
Si Perei = j
Alors
Perei ?- la_tete_de_la_file_des_peres;
Supprimer la tête de la file des
pères;
Sinon
Si j ? Les_peresi Alors
Les_peresi ?- Les_peresi
- {j};
Finsi
Finsi
Finsi

2
3
4
5
6
7
8
9
10
11
12 Fin
CONCLUSION
Après la description théorique de notre
algorithme et les modifications apportées au niveau de ces
procédures, nous présenterons dans le chapitre suivant les
étapes de simulation qui nous a permis d'évaluer la performance
de cet algorithme.
DiscussioN DEs R suLTATs DE 3
siMuLATioNs
SoMMAiRE
3.1 INTRoDucTioN 26
3.2 LE siMuLATEuR
NS-2 26
3.2.1
Présentation de l'outil de simulation 26
3.3 LEs TApEs DE siMuLATioN
26
3.4 CoMMENT R ALisER uNE
siMuLATioN? 27
3.5 LEs pARAMèTREs DE
siMuLATioN 29
3.5.1 Les
paramètres fixes 29
3.5.2 Les
paramètres variables 29
3.6 EvALuATioN DE pERFoRMANcEs
30
3.7 LEs TApEs
D'uN sc NARio 31
3.8 R suLTATs ET iNTERpR
TATioNs 31
3.8.1 Variation du
nombre de requêtes 31
3.8.2 Variation de la
portée de communication 32
3.8.3 Variation du
nombre de ressources 32
3.8.4 Variation de la
vitesse de mouvement 33
3.8.5 Variation du
nombre de sites 33
3.9 R suLTATs DEs MoDiFicATioNs
34
3.9.1 Variation du
nombre de requêtes 34
3.9.2 Variation de la
portée de communication 34
3.9.3 Variation du
nombre de ressources 35
3.9.4 Variation de la
vitesse de mouvement 35
3.9.5 Variation du
nombre de sites 35
CoNcLusioN 36
D
ANs ce chapitre, nous décrivons l'environnement
de simulation que nous avons utilisé, nous présentons
également les résultats obtenus par la simulation de notre
algorithme de la K-exclusion mutuelle dans les réseaux mobiles AD
HOC.
3.1 INTRoDucTioN
Vue à la difficulté de
l'implémentation réelle de notre algorithme, qui est dû au
manque de souplesse de la variation des différents paramètres, et
aux problèmes d'extraction de résultats, ce qui nous a
motivé à faire appel à la simulation, et
précisément à l'outil NS-2, qui a
montré sa puissance, grâce aux avantages qu'il offre, au niveau
des systèmes répartis, et dans les réseaux mobiles AD
HOC.
L'objectif de ce chapitre est de présenter les
résultats de simulation de notre algorithme afin d'identifier les
facteurs influant sur ces performances, et cela par l'interprétation des
courbes obtenues à partir de sa simulation.
3.2 LE siMuLATEuR NS-2
Pour résoudre les problèmes liés
à un système donné, on fait appel à des algorithmes
ou des protocoles, ces algorithmes doivent être testés et
évalués pour les valider, et pour satisfaire leurs insuffisances,
et cela à l'aide d'un outil de simulation.
3.2.1 Présentation de l'outil de simulation
NS-2 est un simulateur à
événements discrets, écrit en C++. C'est le simulateur le
plus célèbre dans le domaine de la simulation des réseaux.
Il fournit un environnement permettant de réaliser des simulations entre
des protocoles IP, TCP, UDP, routage et des protocoles multicast dans les
réseaux filaires ainsi que dans les réseaux sans fil avec un
support de mobilité des noeuds.[[Dio07]
3.3 LEs éTApEs DE siMuLATioN
La simulation avec NS-2 passe en
général par trois phases:
- Définition de la topologie du réseau :
on crée les noeuds, avec les caractéristiques de chacun, ainsi
que les liens entre les noeuds. On peut définir sur chaque lien, le
délai, la bande passante, le fait qu'il soit simplexe ou duplexe et le
type de file d'attente se trouvant à son
extrémité.
L'exemple suivant montre comment définir une
topologie Anneau :
|
#
=========================================================================
#
Creation d' une tolpologie #
#
=========================================================================
for { set i 0} {$i <
7} { incr i} { ;# Boucle de creation de
7 noeuds
set n($i) [$ns
node] ;# La creation d'un noeud
}
for { set i 0} {$i <
7} { incr i} { ;# Boucle pour creer les
liens
;# Creation d'un lien bidirectionel
$ns duplex-link $n($i) $n
( [ expr ($i+1)%7])
1Mb 10ms RED
} ;# Et les caracteristiques associees
|
Création d'une topologie
anneau
Afin d'obtenir la topologie 3.1
suivante :
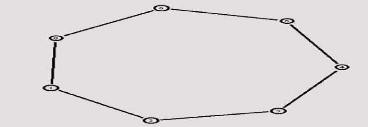
Figure 3.1 -
Exemple de Création d'une topologie.
- Spécification du scénario de la
simulation : l'utilisateur spécifie les différents agents de la
communication qui vont agir pendant la simulation. Il spécifie aussi la
succession des différentes opérations (à l'instant
t1, envoi des données, à l'instant t2
arrêt d'émission).
- Exploitation des résultats : cette
dernière phase consiste en un recueil des statistiques de la simulation.
Ces dernières peuvent être exploitées directement par
NS-2 en faisant appel aux outils qui l'accompagnent, ou bien
elles seront archivées pour une utilisation ultérieure par
d'autres outils de traitements statistiques.[OB10]
3.4 COMMENT RéALISER UNE SIMULATION?
La simulation nécessite des données qui
caractérisent l'environnement, tels que la surface du réseau, la
topologie utilisée, le protocole à simuler ... etc.
Généralement, ces données ne sont pas définies en
NS. Pour cela, l'utilisateur doit définir les informations
(données) en utilisant le langage C++.
Afin de réaliser un algorithme, nous devons
créer deux fichiers source écrits en langage C++ (*.h,
*.cc).
Le premier (*.h) est un fichier
d'en-tête, qui contient la structure des messages échangés
entre les sites, le deuxième (*.cc) contient les fonctions
nécessaires de l'algorithme (envoi et réception des messages, ..
.).
La compilation de ces fichiers nous permet d'avoir un
fichier de type objet (*.o), ce dernier doit être
intégré dans le simulateur NS-2, en lui ajoutant
à la variable OBJ_CC du fichier (makefile), enfin, on
recompile le noyau de NS par la commande make écrite dans un
terminal.
On peut résumer les étapes de
réalisation d'un algorithme dans la figure
3.2.
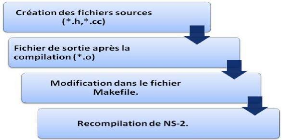
Figure 3.2 - Les
étapes de simulation.[OB10]
Pour tester et utiliser ces programmes, nous avons
crée les fichiers (*.tcl) qui contient la topologie du
réseau, ensuite on appel les fonctions du code C++, et enfin la
visualisation de simulation.
La sortie standard est un fichier d'animation
(*.nam) pour visualiser la simulation, et un fichier de trace
(*.tr) qui contient toutes les informations obtenues après la
simulation, ces informations sont très générales et
nécessitent des filtres pour bien les exploiter. C'est la raison pour
laquelle, nous avons utilisé un fichier texte (*.txt) qui ne
contient que les informations importantes pour notre
simulation.[OB10]
Nous pouvons résumer les étapes de
réalisation d'une simulation par la figure 3.3
:
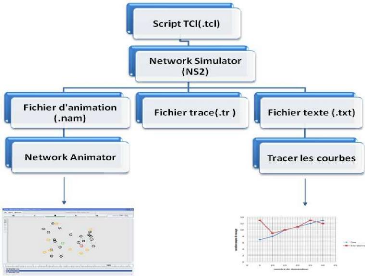
Figure 3.3 -
Réalisation d'une
simulation.[LK09]
3.5 Les pArAMèTres De siMuLATioN
Pour réaliser notre simulation, nous avons
défini plusieurs paramètres, certains paramètres sont
fixes et ne changent pas durant toute la simulation, d'autre sont variables et
leur changement permet d'obtenir à chaque fois un nouveau
scénario de simulation.
La variation de ces paramètres nous permet
d'identifier ceux ayant une influence sur la performance de notre
algorithme.
3.5.1 Les paramètres fixes
- Surface de réseau : C'est l'intervalle maximal
utilisé par les noeuds pendant leurs mouvements, nous avons choisi une
surface de 500m*500m.
- La durée de la SC : C'est la durée
d'exécution d'une SC par un site, nous avons fixé cette valeur
à 1 seconde.
- Protocole de routage : le protocole de routage
permet de définir les chemins entre les noeuds pour échanger des
messages. Nous pouvons choisir un protocole déjà
implémenté sur NS-2, ce protocole peut
être proactif ou réactif, les protocoles proactifs ne sont pas
adéquats pour notre simulation car ils nécessitent la
création de la table de routage avant de lancer la communication, nous
devrons alors choisir un protocole réactif. Parmi les protocoles
implanté sur NS-2, on a AODV et DSR
.nous avons choisi Le protocole DSR [Lem00] car
il nous a permis de déterminer automatiquement les routes
nécessaires à la communication entre les noeuds, et permet
également d'assurer la correction des routes tout au long de leur
utilisation.
- Modèle de propagation : Dans
NS-2, trois modèles de propagation sont
implémentés : Free Space, Shadowing,
Two-ray-ground. Dans notre simulation, le modèle
Two-ray-ground est choisi comme modèle de propagation, car ce
modèle est devenu un standard dans la recherche sur les réseaux
mobiles.
- Modèle de mobilité : NS-2
offre quelques modèles de mobilité basés sur la
génération aléatoire des positions des noeuds. Parmi ces
modèles, on peut citer RandomWayPoint, Random Walk,
Random Direction model, nous avons choisi le modèle
Random-WayPoint, car dans ce modèle, les noeuds sont
distribués uniformément dans l'espace de simulation, leurs
positions initiales sont aléatoire ainsi que leurs
déplacements.
3.5.2 Les paramètres variables
Nous avons changé à chaque fois le
nombre de noeuds et de ressources, le nombre de requêtes, la
portée de communication ainsi que la vitesse de déplacement, ces
changements permettent d'avoir différents scénarios.
- Scénario 1 : Variation du nombre de
requêtes
Dans ce scénario nous avons varié le nombre
de requêtes entre 3 et 18.
- Scénario 2 : Variation de la portée de
communication
Nous avons varié la portée de communication
entre 50 et 500 mètres.
- Scénario 3 : Variation de la vitesse de
mouvement
Dans ce cas la vitesse de mouvement est variable entre
2 et 8 m/s.
- Scénario 4 : Variation du nombre de
noeuds
Ce scénario a connu la variation du nombre de
noeuds entre 12 et 40.
- Scénario 5 : Variation du nombre de
ressources
Cette variation porte sur le nombre de ressources qui se
varient entre 3 et 15.
Nous pouvons illustrer les cinq scénarios dans la
figure 3.4 ci-dessous.
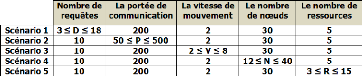
Figure 3.4 -
Variation des paramètres de simulation.
3.6 EVALUATION DE PERFORMANCES
Le but des différents scénarios
était d'identifier les paramètres ayant une influence sur la
performance de l'algorithme, cette performance est exprimée par deux
valeurs importantes :
- Le nombre de messages moyen (NMM) : Chaque
entrée en section critique nécessite un échange d'un
ensemble de messages, le nombre moyen de messages échangés par
entrée en section critique est calculé par la formule suivante
:
Nombre de messages total NMM =
Nombre d'entrée en Section Critique
Cette valeur est considérée comme un
facteur important de performance des algorithmes de l'exclusion
mutuelle.
- Le temps d'attente moyen (TAM) : Un site qui demande
une section critique doit attendre un intervalle de temps appelé le
temps d'attente, le temps d'attente moyen est calculé par la formule
suivante :
?i Temps
d'attentei
TAM = Nombre d'entrée en
Section Critique
Le temps d'attente moyen est également l'un des
facteurs importants pour l'évaluation de la performance des
algorithmes.
3.7 LEs éTApEs d'un scénArio
Pour réaliser un scénario donné,
nous devons introduire les différentes informations nécessaires
pour la simulation dans l'ordre suivant :
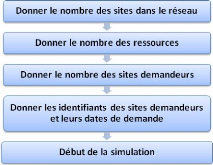
Figure 3.5 - Les
étapes de réalisation d'un scénario. 3.8 RésulTATs
ET inTErpréTATions
Notre algorithme a été validé par
une simulation qui a utilisée les scénarios
précédents. Cette simulation nous a permis de tirer un ensemble
de résultats intéressants.
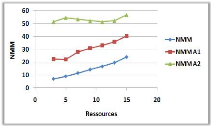
3.8.1 Variation du nombre de requêtes
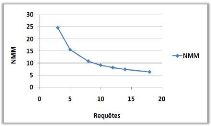
(a)
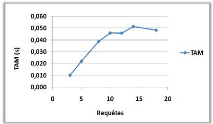
(b)
Figure 3.6 -
Influence du nombre de requêtes sur le NMM et le
TAM.
Dans la courbe (a) on remarque une diminution du NMM
avec l'augmentation du nombre de requêtes, cela est justifiée par
un échange important de messages au début qui est dû
à l'ignorance des sites demandeurs (ceux qui ne possède pas de
père) ou se trouvent les jetons, mais au fur et à mesure, le NMM
va diminuer jusqu'à devenir stable, à cause des mise à
jours faites par les sites dans leurs variables, qui est du à la
transition des requêtes par eux, et ceci va leur permettre de faire un
échange limité voir constant de messages
pour entrer en section critique.
Par contre dans la courbe (b) on constate une
augmentation du TAM avec l'augmentation des requêtes, cela est
justifié par la charge du système, les dates de demandes sont
très proches, et donc plusieurs sites restent en attente.
3.8.2 Variation de la portée de communication
(a)
(b)
Figure 3.7 -
Influence de la portée de communication sur le NMM et le
TAM.
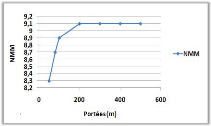
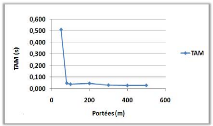
Après la variation de la portée de
communication, nous constatons bien que dans la courbe (a) une augmentation du
NMM jusqu'à ce qu'il devient constant, car les sites père vont
informer de plus en plus de voisins immédiat au fur et à mesure
de l'augmentation de la portée de communication, et donc cela va
nécessiter un échange de messages important, puis le NMM reste
fixe car on s'intéresse au nombre de messages logique durant la
simulation.
Cependant dans la courbe (b), le résultat est
clair, une diminution du TAM après chaque augmentation de la
portée, cela est dû à l'augmentation du nombre de voisins
immédiats par l'augmentation de la portée.
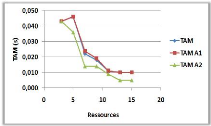
3.8.3 Variation du nombre de ressources
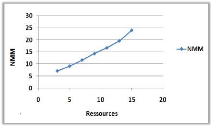
(a)
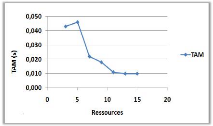
(b)
Figure 3.8 -
Influence du nombre de ressources sur le NMM et le TAM.
Dans la courbe (a) on remarque une augmentation du NMM
avec l'augmentation du nombre de ressources, car avec l'augmentation du nombre
de ressources on augmente le nombre de sites pères qui vont initialement
informer leurs voisins immédiat qu'ils
détiennent des jetons libres et cela va causer
l'augmentation du NMM.
Par contre dans la courbe (b) on constate une
diminution du TAM avec l'augmentation du nombre de ressources, cela est
justifié par la disponibilité des ressources (qui dépasse
même le nombre de demandes dans certains cas) qui permet des
entrées en SC avec le minimum de temps d'attente.
3.8.4 Variation de la vitesse de mouvement
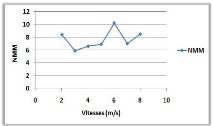
(a)
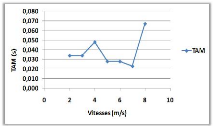
(b)
Figure 3.9 -
Influence de la vitesse de mouvement sur le NMM et le TAM.
Le NMM dans la courbe (a), et le TAM dans la courbe
(b), n'ont pas une relation clair avec la variation de la vitesse de
déplacement et cela peut être justifié par le
mécanisme utilisé par l'algorithme.
3.8.5 Variation du nombre de sites
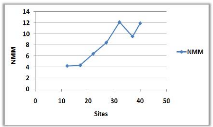
(a)
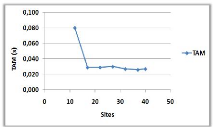
(b)
Figure 3.10 -
Influence du nombre de sites sur le NMM et le TAM.
Dans la courbe (a), on remarque qu'il y a une
augmentation du NMM avec l'augmentation du nombre de sites, cela est
justifié par l'augmentation des voisins immédiats dans les
portées des pères, qui vont être obligé de les
informer à leurs tours et donc le NMM va augmenter.
Dans la courbe (b), on constate deux parties : une
diminution ensuite une stabilisation du TAM : la diminution de la courbe est
dû au fait qu'à chaque fois on augmente le nombre des sites, les
demandeurs vont emprunter un chemin de plus en plus court jusqu'à
arriver à un arbre donné et donc attendre de moins en moins pour
entrer en SC, la stabilisation
est justifiée par l'ajout des sites qui ne jouent
aucun rôle dans la transition des requêtes et donc ils ne vont pas
influer sur le TAM.
3.9 RéSULTATS DES MODIFICATIONS
Après la proposition des modifications, nous
avons réalisé une nouvelle simulation par les mêmes
paramètres afin de cerner l'influence de ces modifications sur la
performance de l'algorithme.
Remarque : les modifications apportées sont
appelées A1 et A2.
3.9.1 Variation du nombre de requêtes
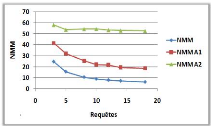
(a)
(b)
Figure 3.11 -
Influence du nombre de requêtes sur le NMM et le
TAM.
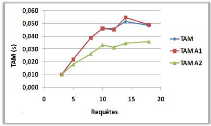
3.9.2 Variation de la portée de communication
(a)
(b)
Figure 3.12 -
Influence de la portée de communication sur le NMM et le
TAM.
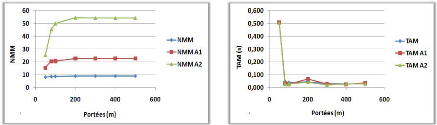
3.9.3 Variation du nombre de ressources
(a)
(b)
Figure 3.13 -
Influence du nombre de ressources sur le NMM et le TAM.
3.9.4 Variation de la vitesse de mouvement
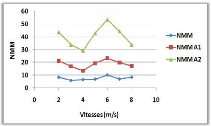
(a)
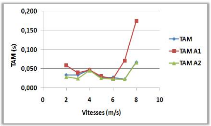
(b)
Figure 3.14 -
Influence de la vitesse de mouvement sur le NMM et le TAM.
3.9.5 Variation du nombre de sites
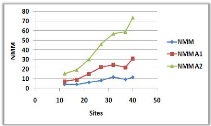
(a)
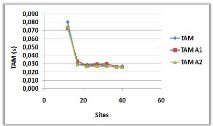
(b)
Figure 3.15 -
Influence du nombre de sites sur le NMM et le TAM.
D'après les résultats obtenus, on
remarque que le NMM des algorithmes améliorés dépasse le
NMM du premier algorithme, cela est justifié par la réutilisation
du message Information dans (A1 et A2) pour
informer les voisins immédiat à chaque fin d'une file de
requêtes, et l'utilisation d'un nouveau message de type Rejet dans
(A2).
Par contre nous avons réussi à diminuer le
TAM dans (A2) par rapport aux versions
précédentes, car les sites qui ont des pères secondaires
en plus, n'attendent pas la libération
des jetons utilisés par leurs propres
pères principaux ou des demandeurs qui ont fait une demande
auprès de leurs pères principaux, mais ils vont compter sur les
pères secondaires pour satisfaire leurs demandes grâce au nouveau
message Rejet et donc vont mettre moins de temps pour entrer en section
critique.
CONCLUSION
À travers notre étude comparative
menée dans ce chapitre, nous avons pu améliorer notre algorithme
initial d'une façon incrémentale jusqu'à l'obtention d'une
version très performante en terme de temps d'attente dans la
modification N°2. Par contre nous avons constaté
qu'au fur et à mesure des modifications apportées au TAM,
à chaque fois on augmente un peu plus le NMM qui est dû aux
changements effectués au niveau des procédures (ajout des
messages).
Cette simulation nous a permis d'identifier les
paramètres ayant une influence sur la performance de notre algorithme,
nous avons pu tirer les résultats suivants :
- La variation du nombre de requêtes a une relation
proportionnelle avec le TAM et disproportionnelle avec le NMM.
- Le TAM dépends disproportionnellement de la
portée de communication et du nombre de ressources.
- Le NMM dépends proportionnellement du nombre de
ressources et la portée de communication.
- La variation du nombre de noeuds a une relation
disproportionnelle avec le TAM et proportionnelle avec le NMM.
- La vitesse de mouvement n'a pas une relation claire
avec le NMM et le TAM.
Dans le chapitre suivant, nous essayons de proposer un
algorithme similaire qui utilise une autre stratégie d'échange de
message afin de minimiser le NMM qui est très élevé dans
les modifications apportées.
UN NouvEL ALgorithmE BAsé sur LE 4
protocoLE DE routAgE AODV
SommAirE
|
4.1 L'iDéE DE BAsE
4.2 L'ALgorithmE
|
38
38
|
|
4.2.1 Hypothèses
|
39
|
|
4.2.2 Description de
l'algorithme
|
39
|
|
4.2.2.1
Les variables locales
|
39
|
|
4.2.2.2
Les messages utilisés
|
39
|
|
4.2.2.3
Initialisation des variables
|
40
|
|
4.2.2.4
Les procédures de l'algorithme
|
40
|
|
4.2.3 Les
paramètres de simulation
|
42
|
|
4.2.4 La comparaison de
tous les résultats
|
43
|
|
4.2.4.1
Variation du nombre de requêtes
|
43
|
|
4.2.4.2
Variation de la portée de communication
|
43
|
|
4.2.4.3
Variation du nombre de ressources
|
43
|
|
4.2.4.4
Variation de la vitesse de mouvement
|
44
|
|
4.2.4.5
Variation du nombre de sites
|
44
|
|
CoNcLusioN
|
44
|
C
E chapitre est dédié à la
description de la nouvelle solution proposée dans le cadre de la
K-exclusion mutuelle dans les réseaux AD HOC, et fera l'objet
également d'une comparaison entre l'algorithme déjà
proposé précédemment et le nouvel algorithme.
4.1 L'iDéE DE BASE
Nous avons constaté dans le chapitre
précédent que plusieurs modifications ont été
proposées afin de minimiser le temps d'attente, cet objectif
était atteint, Néanmoins, avec chaque modification un autre
problème surgit, qui est l'augmentation du NMM, causé notamment
par l'ajout de nouveaux types de message, qui vont le rendre de plus en plus
important à chaque fois.
Dans les MANETs, il existe un échange continue de
messages de contrôle, tels que les messages utilisés par les
protocoles de routage avec les messages des applications.
Ce nombre élevé de message va certainement
avoir une influence sur le comportement de notre algorithme.
Il serait très utile d'exploiter les messages de
contrôle pour véhiculer des informations utilisées par les
applications, et on peut donc minimiser le nombre de messages
échangés.
Pour cela, nous avons pensé à
intégrer les informations nécessaires de la K-exclusion mutuelle
dans les messages utilisés par le protocole de routage AODV.
4.2 L'ALGORiTHME
L'idée de ce nouvel algorithme consiste
à ajouter deux champs dynamiques dans la table de routage de chaque
site, l'un pour le nombre de jetons libre et l'autre pour le nombre de jetons
présent qui sont propres pour chaque site.
À chaque fois qu'il y a une modification au
niveau de ces deux variables, le site doit modifier sa table de routage dans
les deux champs, et par conséquent les autres sites doivent aussi
modifier leurs tables de routage et faire des changements au niveau du site en
question et plus exactement au niveau des deux variables et cela grâce
aux messages de contrôle utilisés pour le routage.
Lorsqu'un site demandeur désire entrer en SC,
il doit d'abord consulter sa table de routage, et essayer de trouver les sites
qui possèdent des jetons libres, ensuite le site le plus proche selon le
champ Distance sera choisi pour adresser la requête. Dans le cas
où tous les sites sont en SC, le plus proche site possèdant un
jeton sera choisi.
Si un site reçoit une requête et ne
possède pas de jetons libre ni de jeton présent, il doit envoyer
un message au demandeur lui indiquant qu'il ne posséde rien, et il doit
réessayer de chercher un autre site adéquat. Cette méthode
permet donc de minimiser le nombre de messages échangés pour
chaque entrée en SC.
4.2.1 Hypothèses
Pour assurer le bon fonctionnement de notre algorithme,
on suppose que :
- Le nombre N des noeuds et le K des racines (qui
détiennent les jetons) sont connus. - Chaque noeud connaît ses
voisins immédiats.
- Les canaux de communication sont fiables, et il n'y a
pas de perte de messages. - Les sites du système ne tombent pas en
panne.
- Le réseau n'est pas
partitionné.
4.2.2 Description de l'algorithme
Nous allons décrire les changements
effectués au niveau des variables locales, les messages utilisés,
et enfin les procédures de l'algorithme.
4.2.2.1 Les variables locales
Chaque noeud i dans le système maintient
les variables locales suivantes :
- Demandeuri : une variable booléenne
initialisée à Faux, indiquant si i a demandé une
ressource critique ou non.
- Jetoni : une variable booléenne
indiquant si i possède un jeton ou non, elle
est
initialisée à Faux au niveau des sites simple et à
Vrai au niveau des sites racines.
- Suivanti : une variable indiquant
l'identité d'un site auquel on va retransmettre notre jeton une fois
servi.
- AODVi(B,C) : la table de routage du site en
question, avec l'utilisation et la modification de deux champs seulement
:
B : le nombre de jetons libre.
C : le nombre de jetons présent.
4.2.2.2 Les messages utilisés
Dans cet algorithme, on utilise trois types de
messages:
- Requête (Jeton, i) : envoyé par le site
i vers le site qui détient un jeton lors de la demande de la
Section critique.
- Accord (Jeton) : envoyé par le site qui
détient le jeton à un site demandeur pour lui permettre
d'utiliser la ressource critique demandée.
- Rejet (Jeton) : envoyé par un ancien
détenteur du jeton à un site demandeur pour lui informer qu'il ne
détient plus le jeton.
4.2.2.3 Initialisation des variables
Initialisation : des variables
Demandeuri : Variable
booléenne.
Jetoni : Variable booléenne.
Suivanti : Variable qui peut prendre
{1,2,.. .,N} U NIL
Début
Demandeuri +- Faux; Jetoni +-
Faux;
Suivanti +- NIL;
Modification dans la table de routage AODVi
(0,0);
Si Je suis un père Alors
Jetoni
+- Vrai;
Modification dans la table de routage AODVi
(1,1);
Finsi
Fin
4.2.2.4 Les procédures de l'algorithme
Procédure N°1 : Demander la Section
Critique
1 Début
Demandeuri +- Vrai;
Si
(AODVi_[i]_Jeton_libre
= 0) Alors
Pere +- Chercher le père
adéquat(AODVi); Envoyer Requête (Jeton, i) à
Pere;
Finsi
Modification dans la table de routage AODVi
(0,1); Attendre (Jeton =
Vrai);
< Entrer en Section Critique>

2
3
4
5
6
7
8
9
10 Fin
Quand un noeud qui ne possède pas de jeton
désire entrer en SC, il devient demandeur et il cherche le père
adéquat afin de lui envoyer une requête et attend la
réception du jeton pour entrer en SC.
Procédure N°2 : Réception de Accord
(Jeton)
1 Début
2 Jetoni +- Vrai;
3 Fin
Lorsqu'un site reçoit un message de type Accord,
il va modifier sa variable booléenne Jeton à Vrai.
Procédure N°3 : Réception de
Requête (Jeton, j)
1 Début
Si
(AODVi_[i]_Jeton_libre
= 1) Ou
(AODVi_[i]_Jeton_present
= 1) Alors
Si Demandeuri = Vrai
Alors
Suivanti +-- j;
Sinon
Jetoni +-- Faux;
Envoyer Accord (Jeton) à j;
Finsi
Modification dans la table de routage AODVi
(0,0);
Sinon
Envoyer Rejet (Jeton) à j;
Finsi
13 Fin
Si un site reçoit un message de type
Requête, il va consulter sa table de routage, s'il est en SC il va mettre
ce site dans la file d'attente, sinon il va envoyer le jeton vers le site
demandeur. Dans le cas oü le site ne détient pas de jeton, il va
lui envoyer un message de type Rejet lui indiquant qu'il ne possède
aucun jeton.
Procédure N°4 : Réception de Rejet
(Jeton)
1 Début
Pere +-- Chercher le père
adéquat(AODVi);
Envoyer Requête (Jeton, i) à
Pere;
4 Fin
Lorsqu'un demandeur reçoit un message de type
Rejet, il va rechercher un autre père adéquat en consultant
toujours sa table de routage.
Procédure N°5 : Libérer la Section
Critique
1 Début
Demandeuri +-- Faux;
Si Suivanti =6 NIL
Alors
Envoyer Accord (Jeton) à Suivanti;
Jetoni +-- Faux;
Suivanti +-- NIL;
2
3

2
3
4
5
6
7
8
9
10
11
12
Sinon
Modification dans la table de routage AODVi
(1,1);
Finsi

2
3
4
5
6
7
8
9
10 Fin
Si un site veut libérer la SC, il va consulter
s'il possède déjà un site en attente dans sa file, afin de
lui envoyer un message de type Accord pour lui permettre d'entrer en
SC.
Procédure N°6 : Modification dans la table de
routage AODVi (B,C :entiers)
1 Début
AODVi_[i]_Jeton_libre ?- B;
AODVi_[i]_Jeton_present ?- C;
4 Fin
La modification dans la table de routage porte sur deux
variables (le nombre de jetons libre et le nombre de jetons présent)
selon les valeurs de B et C.
Procédure N°7 : Chercher le père
adéquat(AODVi)
1 Début
2
3
X ?- 8;
Pour Q=1 à
nombre de noeuds faire
Si
AODVi_[Q]_Jeton_libre
= 1 Alors
Min ?-
AODVi_[Q]_Distance;
Si Min < X Alors
Pere ?- Q;
X ?- Min;
Finsi Finsi
Finpour
Si X = 8 Alors
Pour Q=1 à
nombre de noeuds faire
Si
AODVi_[Q]_Jeton_present
= 1 Alors
Min ?-
AODVi_[Q]_Distance;
Si Min < X
Alors
Pere ?- Q;
X ?- Min; Finsi
Finsi
Finpour
Finsi
Retourner(Pere);

2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 Fin
Cette procédure représente la
stratégie qui nous permet de trouver le père adéquat dans
la table de routage avec le minimum de sauts.
4.2.3 Les paramètres de simulation
Afin d'étudier la performance de ce nouvel
algorithme, nous avons réalisé une simulation par les mêmes
paramètres utilisés dans le chapitre
précédent.
4.2.4 La comparaison de tous les résultats
Notre algorithme a été validé par
une simulation qui a utilisé les mêmes scénarios
proposés précédemment. Cette simulation nous a permis de
tirer un ensemble de résultats intéressants.
Remarque : le nouvel algorithme est appelé New.
4.2.4.1 Variation du nombre de requêtes
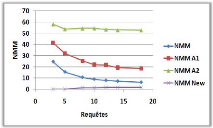
(a)
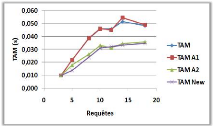
(b)
Figure 4.1 -
Influence du nombre de requêtes sur le NMM et le TAM.
4.2.4.2 Variation de la portée de
communication
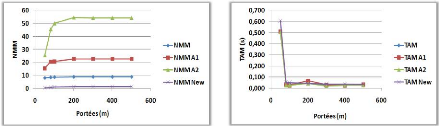
(a)
(b)
Figure 4.2 - Influence de la portée de
communication sur le NMM et le TAM. 4.2.4.3 Variation du nombre de
ressources
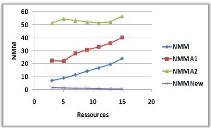
(a)
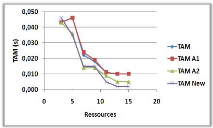
(b)
Figure 4.3 -
Influence du nombre de ressources sur le NMM et le TAM.
4.2.4.4 Variation de la vitesse de mouvement
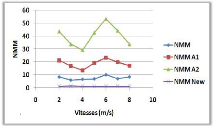
(a)
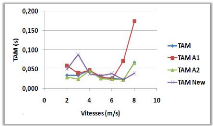
(b)
Figure 4.4 -
Influence de la vitesse de mouvement sur le NMM et le TAM. 4.2.4.5
Variation du nombre de sites
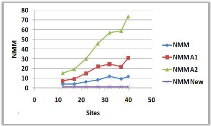
(a)
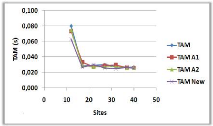
(b)
Figure 4.5 -
Influence du nombre de sites sur le NMM et le TAM.
Le but de notre amélioration était de
minimiser le NMM, une chose qui a été atteinte comme on remarque
dans toutes les courbes, on constate que le NMM du nouvel algorithme est
meilleur que ceux des autres versions, grâce à la stratégie
utilisée qui a permis de trouver les sites qui possèdent les
jetons en un minimum de sauts réduisant ainsi le NMM.
Il est clair que le TAM est pratiquement identique
avec la modification N°2 car le but de
l'amélioration vise de minimiser le NMM sans avoir besoin de changer le
comportement de l'algorithme.
CONCLUSION
D'après ces courbes on peut dire qu'on a
arrivé à une performance très acceptable en utilisant la
nouvelle stratégie, il est clair que le comportement du nouvel
algorithme est devenu stable par rapport aux autres versions et il a
donné les meilleurs résultats surtout dans le nombre de messages
échangés.
CONCLUSION ET PERSPECTIVES
L
ES réseaux mobiles AD HOC ont prouvé
leur place, et les problèmes liés à ces systèmes
restent d'actualité, en particulier le problème de l'exclusion
mutuelle et de la K-exclusion mutuelle.
Néanmoins, ces problèmes ne sont pas
bien traités, vue le nombre de solutions qui restent limité
à nos jours, ce qui nous a poussé à proposer et
améliorer deux nouvelles solutions pour résoudre le
problème de la K-exclusion mutuelle dans les réseaux AD HOC. Ces
algorithmes sont fondés sur l'utilisation des jetons.
L'évaluation de ces algorithmes a
été réalisée par NS-2, l'outil de
simulation qui permet de valider les algorithmes dans les conditions les plus
réelles.
Nous savons que ces algorithmes ne sont qu'une
1ère étape, les
modifications et les améliorations sont toujours possibles. C'est la
raison pour laquelle nous avons pensé à des améliorations
et des perspectives futures:
1. Réduire encore le temps d'attente en utilisant
des nouvelles stratégies d'échanges de messages.
2. La résistance aux pannes : dans les
hypothèses de nos algorithmes, nous avons supposé que les sites
ne tombent pas en panne, mais on peut améliorer la performance de nos
algorithmes en autorisant les pannes des sites.
3. Utiliser le principe de nos algorithmes pour
résoudre ce problème dans d'autres systèmes tels que : les
VANETs ... etc.
Bibliographie
[All07] T. Allaoui. Une nouvelle
solution du problème de la k-exclusion mutuelle dans
les systèmes répartis. Mémoire
de Magister, Université de Laghouat, 2007.
(Cité pages 10 et 12.)
[Bou07] A. Boukhalkhal. étude
par simulation des performances des protocoles de routage dans les
réseaux ad hoc sans fil. Mémoire de fin d'étude,
Université de Laghouat, 2007. (Cité pages
ix, 5 et 9.)
[BVP02] R Baldoni, A Virgillito, and R.
Petrassi. A distributed mutual exclusion algorithm for mobile ad-hoc networks.
Dans IEEE ISCC'02, 2002.
(Cité page 13.)
[Dio07] B. Dioum. Effets de la mobilite
sur les protocoles de routage dans les reseaux ad hoc. Projet de fin
d'étude, Université de Tizi Ouzou, 2007.
(Cité page 26.)
[Lan77] G. Lann. Distributed systems -
towards a formal approach. International Federation for Information
Processing(IFIP)Congress, pages 155-160,
1977. (Cité page 12.)
[Lem00] T. Lemlouma. Le routage dans les
réseaux mobiles ad hoc. Mini projet, Université d'Alger
USTHB, 2000. (Cité pages 5,
9, 10 et 29.)
[LK09] A. Lahag and Kouidri. Etude des
performances des algorithmes de l'exclusion
mutuelle dans les réseaux ad hoc {Simulation par
NS2}. Projet de fin d'étude, Université de
Laghouat, 2009. (Cité pages ix, 5
et 28.)
[Man07] N. Mansouri. Protocole de
routage multi chemin avec équilibrage de charge dans les réseaux
mobiles ad hoc. Projet de fin d'étude, Ecole supérieur des
communications de Tunis, Tunisie, 2007. (Cité page
7.)
[Mes98] P. Meskauskas. Mobile ad hoc
networking. Seminar on Telecommunications Technology, Helsinki,
1998. (Cité pages 6 et
7.)
[MVW01] N Malpani, H Vaidya, and J.L.
Welch. Distributed token circulation on mobile ad hoc networks. Technical
report., 2001. (Cité page
13.)
[NT87] N. Naimi and M. Trehel. An
improvement of the log(n) distributed algorithm for mutual exclusion. IEEE
7th international Conf. On Distributed Systems,
Berlin, Germany, 1987. (Cité
pages 12 et 16.)
[OB10] O.S. Oubbati and A. Benarfa.
évaluation de performances par ns-2 d'un
al-
gorithme de la k-em en présence de pannes.
Projet de fin d'étude, Université de Laghouat,
2010. (Cité pages ix, 4, 27
et 28.)
[RA81] G. Ricart and K. Agrawala. An
optimal algorithm for mutual exclusion in computer networks. Communications
of ACM, pages 9-17,
1981. (Cité page 12.)
[Ray88] K. Raymond. A distributed
algorithm for multiple entries to a critical section.
Information
Processing Letters 30, pages
189-193, 1988. (Cité
page 13.)
[Ray92] M. Raynal. Synchronisation et
état global dans les systèmes répartis. Edition
Eyrolles., 1992. (Cité pages ix, 11
et 12.)
[SK85] I. Suzuki and T. Kasami. A
distributed mutual exclusion algorithm. ACM
Trans.Computer Systems, pages
344-349, 1985. (Cité
page 12.)
[Sri89] P.K. Srimani. Another
distributed algorithm for multiple entries to a critical
section. Information Processing Letters
41, pages
51-57, 1989. (Cité
page 13.)
Bibliographie
[WCM02] J Walter, G Cao, and M. Mohanty.
A k mutual exclusion algorithm for wireless ad hoc networks. Dans IEEE
ISCC'02.,
2002. (Cité page 14.)
[WK97] J.E. Walter and S. Kini. Mutual
exclusion on multihop, mobile wireless networks.
Texas A and M University College Station,
1997. (Cité pages 13 et
14.)
[WW01] J. WALTER and L. WELCH. A mutual
exclusion algorithm for ad hoc mobile networks. Department of Computer
Science,Texas USA, 2001. (Cité page
13.)
ANNEXE : SCRIPT DE SIMULATION A
SOMMAIRE
A.1 LE SCRIPT TCL
50
#
===============================================================================
#
Definition des options #
#
===============================================================================
set val(chan)
Channel/WirelessChannel ;# type de
canal
set val(prop)
Propagation/TwoRayGround ;# model de
propagation
set val(netif)
Phy/WirelessPhy ;# type d' interface
reseau
set val(mac)
Mac/802_11 ;# type d' interface
mac
set val(ifq)
CMUPriQueue ;# type de la file d' attente
set val(ll)
LL ;# link layer type
set val(ant)
Antenna/OmniAntenna ;# model d'
antenne
set val(x)
500 ;# X dimension du topology
set val(y)
500 ;# Y dimension du topology
set val(ifqlen)
50 ;# Nbre max des Packets -> file
set val(seed)
0.0 ;# grain random
set val(adhocRouting)
DSR ;# protocole de routage
set val(sc)
"/home/sami/ns-allinone-2.32/ns-2.32/
t c l /mobility/scene/modele " set val(stop)
20 ;# temps de simulation ( duree )
#===============================================================================
# Definition des procedures #
#===============================================================================
|
#Phy/WirelessPhy
|
set
|
RXThresh_
1.92278e-06 ;
|
#10
|
meters
|
|
#Phy/WirelessPhy
|
set
|
RXThresh_
7.69113e-08 ;
|
#50
|
meters
|
|
#Phy/WirelessPhy
|
set
|
RXThresh_
3.00435e-08 ;
|
#80
|
meters
|
|
#Phy/WirelessPhy
|
set
|
RXThresh_
1.42681e-08 ;
|
#100
|
meters
|
|
#Phy/WirelessPhy
|
set
|
RXThresh_
8.91754e-10 ;
|
#200
|
meters
|
|
#Phy/WirelessPhy
|
set
|
RXThresh_
1.76149e-10 ;
|
#300
|
meters
|
|
#Phy/WirelessPhy
|
set
|
RXThresh_
5.57346e-11 ;
|
#400
|
meters
|
# modification dans la portee de signal 200
meters Phy/WirelessPhy set
RXThresh_ 8.91754e-10
#
==============================================================================
#
Creation d' instance de simulateur et topologie #
#
==============================================================================
set ns_ [new Simulator]
;# nouvelle simulation
$ns_ use-newtrace ;# nouveau f i c h ie r
trace
set topo [new
Topography] ;# Nouvelle Topologie
#
==============================================================================
#
Creation des f i c h ie rs trace pour NS et NAM #
#
==============================================================================
set tracefd [ open
adhoc.tr w]
set namtrace [ open adhoc.nam
w]
set bw nbr_msg_tps.txt ;# Ficher . t x t
( resultat simulation )
set mesure [ open $bw
w]
$ns_ trace-all $tracefd
$ns_ namtrace-all-wireless $namtrace
$val(x)
$val(y)
#
==============================================================================
# Procedure d' affichage concernant la simulation # #
==============================================================================
proc Affichage { } {
global mesure nbr nbracine nbrequete ;#
Declaration des variables globales puts $mesure "
"
puts $mesure " Les Resultats de la
Simulation . "
puts $mesure " " puts
$mesure "============= Informations de Simulation ============"
puts $mesure " . " puts $mesure "Le Nombre de
Sites = $nbr "
puts $mesure "Le Nombre de Racines R =
$nbracine "
puts $mesure "Le Nombre de Requetes =
$nbrequete "
puts $mesure " . "
puts $mesure
"====================================================="
A.1 LE SCRIPT TCL
puts $mesure
"================================="
puts $mesure " Resultas pour chaque site
: "
puts $mesure
"================================="
}
#
==============================================================================
# Procedure de Terminaison de la simulation # #
==============================================================================
proc finish { } {
global ns_ nf f0 nbr nbrequete tpatt nmsg p
mesure ;# Variables globales for { set i 0}
{$i < $nbr} { incr i}
{
set nmsg [ expr
[$p($i) set
nb_message_]+$nmsg] ;# Somme des messages
}
puts $mesure
"======================================================" puts
$mesure " Le NMM et le TAM. "
puts $mesure
"======================================================" puts
$mesure " Messages total = $nmsg" ;# Calcul du nombre moyen des
msg
puts $mesure " "
puts $mesure "Le NMM = $nmsg/$nbrequete
= [ expr $nmsg/$nbrequete ] " puts $mesure " "
set tpatt [ expr
$tpatt/$nbrequete] ;# Calcul du TAM
puts $mesure "Le TAM = $tpatt " ;#
Affichage du TAM
$ns_ flush-trace ;# Ecriture dans le f i c h ie r
TEXT
close $mesure ;# Fermer le fi c h ie r
des resultat
puts " running nam... " ;# Affichage de "Running NAM . .
. "
exec nam adhoc.nam & ;# lancer le
NAM automatiquement
exit 0 ;# Sortie de la
procedure
}
#
==============================================================================
# Procedure d' enregistrement des temps d' attente dans le fi c h ie r . t x t
# #
==============================================================================
proc record {p n mutex hour} {
global f0 nbrequete tpatt mesure ;#
Variables globales
set ns [Simulator
instance] ;# Instancier la commande NS
set bw0 [$ns now] ;#
bw0 est le temps actuelle
set bw0 [ expr $bw0-
[$p set dem ] ] ;# bw0
:= bw0 - Temps de la demande
puts $mesure "Temps d' attente pour le
site N [ $n node-addr] =
$bw0 ==> ( ( Date_Requete = $hour **
Duree SC = $mutex ) ) " puts $mesure " "
set tpatt [ expr
$tpatt+$bw0] ;# Le temps d' attente
}
#
==============================================================================
# Procedure de Diffusion des demandes d' entrer en Section Critique # #
==============================================================================
proc diffusion {p n mutex hour} {
global nbr ;# Variables
globales
set ns_ [Simulator
instance] ;# Instancier la commande NS
set nowe [$ns_ now] ;#
Le temps actuelle
set nbrk [$p
set nbracine] ;# nbrk := nbracine ;
$ns_ at $nowe " tester $p $n $mutex $hour" ;# execution
de tester
$ns_ at $nowe "$p demander-sc" ;# execution de
demander-sc
$ns_ trace-annotate " [ $n node-addr] demande la SC " ;#
noeud demandeur
}
#
==============================================================================
# Procedure de test d' entrer et la liberation de la Section Critique # #
==============================================================================
proc tester {p n mutex hour} {
global nbr mesure ;# Variables
globales
set ns_ [Simulator
instance] ;# definir commande ns_
set time 0.01 ;# Temps de test pour
SC
set now [$ns_ now] ;#
Definir now
set a [$p set
sc] ;# Affectation a := sc ;
i f { $a == 1} { ;# Condition entrer en
SC
$ns_ at $now " record $p $n $mutex $hour" ;# Record pour
le TAM
$ns_ at $now "$n label \"<SC> \" "
;# l i be le <SC> au noeud
$ns_ at [ expr
$now+$mutex] "$n label \" \" " ;# Effacer
<SC>
$ns_ at [ expr
$now+$mutex] "$p liberation--sc";# Appel de
liberation--sc
$ns_ at [ expr
$now+$mutex] "$p set sc --1" ;# sc :=
--1 pour s o rt ir
} else { ;# noeud veut entrer SC
$ns_ at [ expr
$now+$time] "$p attendre " ;# attendre MAJ sc <--
1
$ns_ at [ expr
$now+$time] " tester $p $n $mutex $hour"
}
}
#
==============================================================================
# Procedure d' initialisation de la simulation et coloration # #
==============================================================================
proc reaa {p n} {
set ns_ [Simulator
instance] ;# definir commande ns_
set now [$ns_ now] ;#
Le temps actuelle
$ns_ at $now "$p liaison" ;# appeler la procedure (
liaison)
$ns_ at $now " colorOr $p $n" ;# Coloration des
racines
}
#
==============================================================================
#
==============================================================================
# Le programme Principale # #
==============================================================================
#
==============================================================================
#
==============================================================================
# Lecture des donnees a partir d'un f ic h i er texte # #
==============================================================================
set f [ open " les_demandes.txt " " r "
] ;# lire ( les_demandes.txt )
set nbr [ gets $f] ;# (
nbr ) <-- premier ligne
set nbracine [ gets $f]
;# ( nbracine ) <-- deuxiemme ligne
set nbrequete [ gets
$f] ;# ( nbrequete ) <-- troisiemme ligne
for { set j 0} {$j <
$nbrequete} { incr j} { ;# Boucle pour lire
les Scenarios for { set k 0} {$k <
2} { incr k} {
set table($j,$k) [
gets $f] ;# Remplir par ( site, heur )
}
}
close $f
#
==============================================================================
# Declaration des couleurs selon les numeros # #
==============================================================================
$ns_ color 0 Blue ;# Le O est la Couleur Bleu ( tous les
messages) #
==============================================================================
# Definition de la topologie # #
==============================================================================
$topo load_flatgrid $val(x)
$val(y)
#
==============================================================================
# Creation du God ( voisinage ) # #
==============================================================================
set god_ [create-god $nbr]
#
==============================================================================
#
Configuration globale d'un noeud #
#
==============================================================================
$ns_ node-config -adhocRouting
$val(adhocRouting) \
-llType $val(ll) \
-macType $val(mac) \ -ifqType
$val(ifq) \ -ifqLen
$val(ifqlen) \ -antType
$val(ant) \ -propType
$val(prop) \ -phyType
$val(netif) \
-channelType $val(chan) \
-topoInstance $topo \ -agentTrace ON
\
-routerTrace ON \
-macTrace OFF
#
==============================================================================
# Creation des noeuds et des agents # #
==============================================================================
for { set i 0} {$i <
$nbr} { incr i} {
set node_($i)
[$ns_ node]
$node_($i) random-motion 0
$node_($i) color Black
$god_ new_node $node_($i)
set p($i) [new
Agent/Fifthalgo]
$p($i) set nb_noeud_ $nbr
$p($i) set nbracine
$nbracine
$ns_ at 0.0 "$p ( $i ) initialisation"
$ns_ attach-agent $node_($i)
$p($i)
$p($i) set packetSize_ 1024
}
#
==============================================================================
# La connexion des agents pour permettre la communication # #
==============================================================================
for { set i 0} {$i <
$nbr} { incr i} {
for { set j [ expr
$i+1]} {$j <
$nbr} { incr j} {
$ns_ connect $p($i)
$p($j)
} }
#
==============================================================================
# Coloration des noeuds a chaque couleur associe # #
==============================================================================
proc coloration {p node_ } {
set ns_ [Simulator
instance]
set nowe [$ns_
now]
set a [$p set
father]
set b [$p set
nbjeton]
set c [$p set
sc]
set d [$p set
numrequest]
i f {$a == -1} {
i f {$b > 0}
{
$ns_ at $nowe "$node_ color Orange"
}
} else {
$ns_ at $nowe "$node_ color Black"
}
i f {$d == 1} {
$ns_ at $nowe "$node_ color Limegreen"
}
i f {$c == 1} {
$ns_ at $nowe "$node_ color Red"
} } #
==============================================================================
# Appel des f i c hi e rs de mouvement #
#
==============================================================================
i f { $val(sc)
== " " } {
puts " *** NOTE: no connection pattern specified.
"
set val(sc)
"none"
} else {
puts " Loading connection pattern..."
source
$val(sc)
}
|
#
==============================================================================
#
Initialisation des variables globaux #
#
==============================================================================
set nmsg1 0 ;# Initialisation de
nmsg1
set nmsg 0 ;# Initialisation de
nmsg
set tpatt 0 ;# Initialisation de
tpatt
#
==============================================================================
# Fixation de la duree de la Section Critique # #
==============================================================================
set duree 1 ;# la duree de la Sc
#
==============================================================================
# Initialisation des positions des noeuds # #
==============================================================================
for { set i 0} {$i <
$nbr} { incr i} {
$ns_ initial_node_pos $node_($i)
50 ;# se fait apres la definition
} ;# du modele de mobilite
#
==============================================================================
# Initialisation et coloration des noeuds # #
==============================================================================
for { set i 0} {$i <
$nbracine} { incr i} {
$ns_ at 0.0 " reaa $p ( $i ) $node_ ( $i ) "
}
#
==============================================================================
# Affichage du Menu dans le f i c hi e r des resultats #
#
==============================================================================
$ns_ at 0.0 " Affichage " ;# Appel a la procedure
Affichage
set ns_ [Simulator
instance]
set nowe [$ns_
now]
#
==============================================================================
# Coloration des noeud selon leur etat actuelle # #
==============================================================================
for { set i 0} {$i <
$nbr} { incr i} {
set temps 0.0
for { set j 0} {$j <
2000} { incr j} {
set temps [ expr
$temps+0.01]
$ns_ at $temps " coloration $p ( $i ) $node_ ( $i )
"
}
}
#
==============================================================================
# L' execution des scenarios de la simulation # #
==============================================================================
for { set j 0} {$j <
$nbrequete} { incr j} { ;# lire les Scenarios
de la table
set site $table($j,0)
;# lire l ' identificateur du site
set heure $table($j,1)
;# lire l ' heur de la demande
$ns_ at $heure "$p ( $site ) set sc 0"
;# sc <- 0
$ns_ at $heure "$p ( $site ) set dem $heure " ;# aff ec
ter la demande a l ' heur $ns_ at $heure " diffusion $p (
$site ) $node_ ( $site ) $duree $heure "
puts " $site" ;# Appel de diffusion pour
} ;# afin d' executer les demandes
#
==============================================================================
# Finalisation de la simulation et debut du RUN # #
==============================================================================
$ns_ at [ expr $val(stop) +
0.01] " finish";# Finir la Simulation apres (STOP)
puts " debut de la simulation .. . " ;# Ecrire " debut de
la simulation.. "
$ns_ run ;# Debut du NAM
|
le Script TCL (Réseau AD
HOC)
ACRONYMES
AODV Ad hoc On-Demand Distance Vector
DSR Dynamic Source Routing
EM Exclusion Mutuelle
IEEE Institute of Electrical and Electronics
Engineers
IP Internet Protocol
K-EM K-Exclusion Mutuelle
MAC Medium Access Control
MANET Mobile Ad-hoc Networks MSG MeSsaGe
NbJeton Nombre de Jeton
NAM Network AniMator
NMM Nombre de Messages Moyen
NS-2 Network Simulator 2
OLSR Optimized Link State Routing protocol
RDM Random Direction Model
RED Random Early Detection
RWM Random Waypoint Model
SB Station de Base
SC Section Critique
TAM Temps d'Attente Moyen
TCL Tools Command Language
TCP Transport Control Protocol
TPATT TemPs d'ATTente
UDP User Datagram Protocol
UM Unités Mobiles
ZRP Zone Routing Protocol
| 

