|
REpuBLiQuE ALGERiENNE
DEMocRATiQuE ET
PopuLAiRE
MiNisTERE DE
L'ENsEiGNEMENT SupERiEuR ET DE LA
REcHERcHE SciENTiFiQuE
UNivERsiTI AMMAR
TELiDji
LAGHouAT

FAcuLTE DEs SciENcEs
ET SciENcEs DE
L'INGENiERiE
DEpARTEMENT DE
GENiE INFoRMATiQuE
PRojET DE FiN
D'ÉTuDE
PouR L'OBTENTioN
Du DipLoME
D'INGÉNIEUR D'ÉTAT EN
INFORMATIQUE
OpTioNs :
INTELLiGENcE ARTiFiciELLE
Thème:
LA ToLERANcE AuX pANNEs DEs
ALGoRiTHMEs DE pARTAGE DE
REssouRcEs DANs LEs sysTEMEs
RépARTis ET LEs RésEAuX AD
HOC
(SiMuLATioN pAR
NS-2)
Réalisé par :
BENARFA ABDELMADjiD
ET OuBBATi OMAR
SAMi
Encadré par :
MR ALLAoui
TAHAR.
N° D'ORDRE :
/ 2010-PFE / DGI

Nous dédions ce
mémoire
à
nos parents
qui ont tant participés
à l'aboutissement de ce travail
à
tous les membres de la
famille
à
nos meilleurs amis de l'École Coranique (Chikh
Mohamed Azoz)
REMERciEMENTs
N
ous remercions Dieu de nous avoir donné la
force physique et intellectuelle pour accomplir ce travail, et pour les
richesses dont il nous comble.
Ces quelques lignes ne pourront jamais exprimer la
reconnaissance que nous éprouvons envers tous ceux qui, de près
ou de loin, ont contribué par leurs conseils, leurs encouragements ou
leurs amitiés à l'aboutissement de ce travail.
Nos vifs remerciements accompagnés de toute nos
gratitudes vont tout d'abord à notre encadreur Mr Allaoui
Tahar, pour nous avoir proposé cet intéressant sujet et pour les
précieux conseils et orientations qu'il nous a prodigués. Nous le
remercions pour sa disponibilité, son aide, ses précieux
conseils, ses critiques constructives, ses explications et suggestions
pertinentes et enfin, pour avoir apporté tant de soins à la
réalisation de ce projet de fin d'études.
Nous remercions tous les membres du jury pour l'immense
honneur qu'ils nous font en acceptant d'évaluer ce modeste
travail.
RéSUMé
L
E problème de la K-exclusion mutuelle est un
heritage important du problème de l'exclusion mutuelle dans les
systèmes repartis et dans les reseaux AD HOC, ce problème a connu
une evolution sans cesse dans un contexte où plusieurs algorithmes ont
ete proposes afin de resoudre ce problème.
Dans ce memoire nous allons d'abord introduire le
concept des systèmes repartis et les reseaux AD HOC, ce qui va nous
permettre de mettre l'accent sur le problème de l'exclusion mutuelle et
sa generalisation en K ressources d'un cote, et d'expliquer la notion de la
tolerance aux pannes qui permet d'augmenter la performance des algorithmes d'un
autre cote.
Nous presentons egalement des algorithmes traitant le
problème de la K-exclusion mutuelle, et assurant la tolerance aux pannes
dans les systèmes repartis et dans les reseaux AD HOC.
Nous avons utilise l'outil de simulation NS-2
afin d'etudier la performance des algorithmes proposes et pour
specifier les paramètres ayant une influence sur la performance de ces
algorithmes.
Mots-clés : Système reparti, Reseau AD HOC,
Algorithmique reparti, Exclusion mutuelle, K-exclusion mutuelle, Simulation,
NS-2.
ABSTRACT
T
HE K-mutual exclusion problem is an important legacy
of the mutual exclusion problem in distributed systems and in the AD HOC
networks, this problem has known a constantly evolution in context where many
algorithms have been proposed to solve this problem.
In this thesis, we will first introduce the concept of
distributed systems and the AD HOC networks, which will allow us to focus on
the mutual exclusion problem and its generalization to K resources on the one
hand, and explain the concept of the fault tolerance which can increase the
performance of algorithms on the other hand.
We also present algorithms that treat the K-mutual
exclusion problem, and ensuring the fault tolerance in distributed systems and
the AD HOC networks.
We used the NS-2 simulation tool, to
study the performance of proposed algorithms and to specify the parameters that
influence the performance of these algorithms.
Key-words : Distributed systems, Mobile AD HOC Network
(MANET), Distributed algorithm, Mutual exclusion, K-mutual exclusion,
Simulation, NS-2.
TABLE DEs mATièREs
TABLE DEs mATièREs vi
LisTE DEs FiGuREs x
INTRoDucTioN GéNéRALE
1
|
1
2
|
NoTioNs GéNéRALEs
1.1 SysTèmE
RépARTi
1.1.1 Introduction
1.1.2 Définition
d'un système réparti
1.1.3 Les
caractéristiques d'un système réparti
1.1.4 Les avantages et
les inconvénients
1.1.4.1
Avantages
1.1.4.2
Inconvénients
1.1.5 Problèmes
liés aux systèmes répartis
1.1.6 Conclusion
1.2 LEs RésEAux
AD HOC
1.2.1 Introduction
1.2.2 Réseaux
mobiles sans fil
1.2.2.1
Les réseaux mobiles avec infrastructure
1.2.2.2
Les réseaux mobiles sans infrastructure
1.2.3 Les
réseaux mobiles AD HOC
1.2.3.1
Les caractéristiques des réseaux AD HOC
1.2.3.2
Les avantages des réseaux AD HOC
1.2.3.3
Les inconvénients des réseaux AD HOC
1.2.3.4
Applications des réseaux AD HOC
1.2.3.5
Problèmes liés aux réseaux AD HOC
1.2.4 Problème
de routage dans les réseaux AD HOC
1.2.4.1
Définition du routage
1.2.4.2
Classification des protocoles de routage
1.2.4.2.a
Les protocoles de routage proactifs
1.2.4.2.b
Les protocoles de routage réactifs (à la demande) .
1.2.4.2.c
Les protocoles de routage hybrides
CoNcLusioN
LE pRoBLèmE DE
L'ExcLusioN muTuELLE ET LA ToLéRANcE Aux pANNEs
2.1 LE pRoBLèmE DE
L'ExcLusioN muTuELLE
2.1.1 Introduction
2.1.2 L'exclusion
mutuelle en réparti
|
3
4
4
4
5
5
5
6
7
7
8
8
8
8
9
9
10
11
11
12
14
14
14
14
15
15
15
16
17
18
18
18
|
2.1.2.1
La notion de l'exclusion mutuelle 18
2.1.2.2
Les états d'un processus 19
2.1.2.3
Notions de base 19
2.1.2.4
Propriétés d'un algorithme d'exclusion mutuelle
19
2.1.3 Bref historique
20
2.1.4 Les classes de
solutions d'exclusion mutuelle 20
2.1.4.1
Les algorithmes à permissions 21
2.1.4.1.a
Permissions individuelles 21
2.1.4.1.b
Permissions d'arbitres 21
2.1.4.1.c
Permissions mixtes 22
2.1.4.2
Les algorithmes à jeton 22
2.1.4.2.a
Les algorithmes à diffusion (non structuré) 23
2.1.4.2.b
Les algorithmes à structure logique (Structuré) . . .
23
2.1.5 Synthèse
et conclusion 23
2.2 LE pRobLèME DE LA
K-ExcLusioN MuTuELLE 25
2.2.1 Description du
problème 25
2.2.2 Résolution
du problème 25
2.3 LE pRobLèME DE
L'ExcLusioN MuTuELLE DANs LEs RésEAux AD HOC
25
2.4 LE pRobLèME DE LA
K-ExcLusioN MuTuELLE DANs LEs RésEAux AD HOC .
26
2.5 LA ToLéRANcE Aux
pANNEs 26
2.5.1 Solutions
26
2.5.2 Les types de la
tolérance aux pannes 26
2.5.2.1
Tolérance aux pannes par mémoire stable 27
2.5.2.2
Tolérance aux pannes par duplication 27
CoNcLusioN 28
3 SiMuLATioN DE L'ALgoRiThME
DANs LEs sysTèMEs RépARTis 29
3.1 INTRoDucTioN 31
3.2 L'ALgoRiThME 31
3.2.1 Objectif de
l'algorithme 31
3.2.2 Structure logique
utilisée 31
3.2.3 Principe de
fonctionnement 33
3.2.4 Hypothèses
34
3.2.5 Description de
l'algorithme 34
3.2.5.1
Variables locales 34
3.2.5.2
Les messages utilisés 35
3.2.5.3
Les procédures de l'algorithme 35
3.2.6 Preuve de
l'algorithme 40
3.2.6.1
La K-exclusion mutuelle 40
3.2.6.2
Absence d'interblocage 40
3.2.6.3
Absence de la famine 41
3.2.7 Complexité
de l'algorithme en nombre de messages 41
3.3 RésuLTATs DE
siMuLATioN 42
3.3.1 Les
paramètres de simulation 42
3.3.2 Evaluation de
performance 43
3.3.3 Les étapes
d'un scénario 43
3.3.4 Résultats
et interprétations 44
3.3.4.1
Variation du nombre de requêtes 44
3.3.4.2
Variation du nombre de ressources 44
3.3.4.3
Variation du nombre de sites 45
3.4 AMéLIoRATIoN
N°1 (LE MESSAGE
RECHERCHE) 46
3.4.1 Résultats
et interprétations 47
3.4.1.1
Variation du nombre de requêtes 47
3.4.1.2
Variation du nombre de ressources 47
3.4.1.3
Variation du nombre de sites 48
3.5 AMéLIoRATIoN
N°2 (ANNULER LA MéTHoDE
{UTILISER LE PLUS CoURT CHEMIN}) 48
3.5.1 Résultats
et interprétations 51
3.5.1.1
Variation du nombre de requêtes 51
3.5.1.2
Variation du nombre de ressources 51
3.5.1.3
Variation du nombre de sites 51
3.6 AMéLIoRATIoN
N°3 (ARRêT DES MoUVEMENTS
INUTILES) 52
3.6.1 Résultats
et interprétations 53
3.6.1.1
Variation du nombre de requêtes 53
3.6.1.2
Variation du nombre de ressources 53
3.6.1.3
Variation du nombre de sites 54
3.7 LES CoURBES FINALE ET
CoMPARAISoN 54
3.7.1 Variation du
nombre de requêtes 54
3.7.2 Variation du
nombre de ressources 55
3.7.3 Variation du
nombre de sites 55
3.8 CoNCLUSIoN 55
3.9 LA ToLéRANCE AUX
PANNES 56
3.9.1 L'idée de
base 56
3.9.2 Description de
l'algorithme 56
3.9.2.1
Les variables locales 56
3.9.2.2
Les messages utilisés 56
3.9.2.3
Les procédures de l'algorithme 57
3.9.3 Résultats
et interprétations 58
3.9.3.1
Variation du nombre de requêtes 58
3.9.3.2
Variation du nombre de ressources 58
3.9.3.3
Variation du nombre de sites 58
3.10 AMéLIoRATIoN
(ALGoRITHME ToLéRANT AUX PANNES
AMéLIoRé) 59
3.10.1 Résultats
et interprétations 60
3.10.1.1
Variation du nombre de requêtes 60
3.10.1.2
Variation du nombre de ressources 60
3.10.1.3
Variation du nombre de sites 60
CoNCLUSIoN 62
4 SIMULATIoN DE L'ALGoRITHME
DANS LES RéSEAUX AD HOC 63
4.1 INTRoDUCTIoN 64
4.2 L'ALGoRITHME 64
4.2.1 Hypothèses
du Système 64
4.2.2 Les
procédures de l'algorithme 64
4.2.3 Paramètres
de simulation 69
4.2.3.1
Les paramètres fixes 69
4.2.3.2
Les paramètres variables 69
4.2.4 Résultats
et interprétations 70
4.2.4.1
Variation du nombre de demandeurs 70
4.2.4.2
Variation de la portée de communication 71
4.2.4.3
Variation de la vitesse de mouvement 71
4.2.4.4
Variation du nombre de noeuds 72
4.2.5 Conclusion
72
4.3 ToLéRANcE AuX pANNEs
72
4.3.1 Résultats
et interprétations 73
4.3.1.1
Variation du nombre de demandeurs 73
4.3.1.2
Variation de la portée de communication 73
4.3.1.3
Variation de la vitesse de mouvement 73
4.3.1.4
Variation du nombre de noeuds 74
CoNcLusioN 74
CoNcLusioN ET PERspEcTivEs
75
BibLiogRAphiE 76
A ANNEXE ETuDE DE
L'ouTiL DE siMuLATioN NS-2
79
A.1 PREuvE Du
ThéoRèME TRuc 80
B ANNEXE LEs scRipTs DE Nos
siMuLATioNs 81
B.1 LE scRipT TCL
(sysTèME RépARTi) 82
B.2 LE ScRipT TCL AD
HOC 85
AcRoNyMEs 91
LISTE DES FIGURES
1.1 Structure d'un système
réparti 4
1.2 Le modèle des réseaux
mobiles avec infrastructure.[Bou07] 9
1.3 Le modèle des réseaux
mobiles sans infrastructure. 10
1.4 Un réseau AD HOC.
10
1.5 Topologie dynamique dans un
réseau AD HOC 10
1.6 Application de secours des
réseaux AD HOC. 12
1.7 Application collaborative des
réseaux AD HOC 13
1.8 Applications commerciales des
réseaux AD HOC 13
1.9 Le chemin utilisé dans le
routage entre la source et la destination. 14
1.10 Figure qui montre la classification
des protocoles de routage. 15
2.1 Les états d'un
processus.[All07] 19
2.2 Les catégories des solutions
d'exclusion mutuelle 21
2.3 Arbre des catégories de
solution d'exclusion mutuelle. 24
3.1 La structure des arbres statiques
32
3.2 La structure logique finale.
33
3.3 La complexité de notre
algorithme. 41
3.4 Variation des paramètres de
simulation 42
3.5 Les étapes de
réalisation d'un scénario. 43
3.6 Influence du nombre de requête
sur le NMM et TAM. 44
3.7 Influence du nombre de ressource sur
le NMM et TAM. 44
3.8 Influence du nombre de site sur le
NMM et TAM 45
3.9 Influence du nombre de requête
sur le NMM et TAM. 47
3.10 Influence du nombre de ressource
sur le NMM et TAM. 47
3.11 Influence du nombre de site sur le
NMM et TAM 48
3.12 Influence du nombre de
requête sur le NMM et TAM. 51
3.13 Influence du nombre de ressource
sur le NMM et TAM. 51
3.14 Influence du nombre de site sur le
NMM et TAM 51
3.15 Influence du nombre de
requête sur le NMM et TAM. 53
3.16 Influence du nombre de ressource
sur le NMM et TAM. 54
3.17 Influence du nombre de site sur le
NMM et TAM 54
3.18 Influence du nombre de
requête sur le NMM et TAM. 54
3.19 Influence du nombre de ressource
sur le NMM et TAM. 55
3.20 Influence du nombre de site sur le
NMM et TAM 55
3.21 Influence du nombre de
requête sur le NMM et TAM. 58
3.22 Influence du nombre de ressource
sur le NMM et TAM. 58
3.23 Influence du nombre de site sur le
NMM et TAM 59
3.24 Influence du nombre de
requête sur le NMM et TAM. 60
3.25 Influence du nombre de ressource
sur le NMM et TAM. 60
3.26 Influence du nombre de site sur le
NMM et TAM 60
4.1 Variation des paramètres de
simulation 70
4.2 Influence du nombre de demandeurs
sur le NMM et le TAM 70
4.3 Influence de la portée de
communication sur le NMM et le TAM 71
4.4 Influence de la vitesse de mouvement
sur le NMM et le TAM 71
4.5 Influence du nombre de noeuds sur le
TAM et NMM 72
4.6 Influence du nombre de demandeurs
sur le NMM et le TAM 73
4.7 Influence de la portée de
communication sur le NMM et le TAM 73
4.8 Influence de la vitesse de mouvement
sur le NMM et le TAM .. 73
4.9 Influence du nombre de noeuds sur le
TAM et NMM 74

INTRoDucTioN aNéRALE
D
Epuis l'apparition des réseaux informatiques,
ce domaine a connu une évolution sans cesse notamment sur le plan
physique et artistique qui ont participés à la
naissance
de l'informatique dite Répartie. Cette
informatique ne se limite pas aux réseaux filaires, les réseaux
sans fil offrent une flexibilité qui permet la mise en réseau des
sites mobiles. L'ensemble des sites (fixes ou mobiles) et les réseaux de
communication (filaire ou sans fil) peuvent être considérés
comme une seule entité appelée un Système
Réparti.
Un système réparti ou distribué
(Distributed System) est si important qu'on peut le rencontrer dans la vie de
tous les jours sans se rendre compte, par exemple : lorsqu'on visite notre
courrier électronique ou lorsqu'on utilise notre téléphone
portable, il facilite la communication entre les utilisateurs tout en
respectant le partage des ressources de manière optimale et
équitable mais également d'une façon exclusive donnant
naissance au problème de l'exclusion mutuelle.
L'exclusion mutuelle assure le partage d'une ressource
en prenant en considération la cohérence de celle-ci,
c'est-à-dire partager cette ressource sans arriver à un
état de conflit. Un conflit se produit lorsque plusieurs sites
désirent acquérir simultanément une ressource alors que
l'utilisation de cette dernière n'est autorisée qu'à un
seul site à la fois. Pour résoudre ce problème plusieurs
algorithmes ont été proposés.
Avec des systèmes informatiques de plus en plus
gourmands de ressources, le problème de l'exclusion mutuelle se
généralise au problème de la K-exclusion mutuelle qui
consiste à partager plusieurs ressources à la fois, ce
problème est devenu un axe intéressant de recherche oil plusieurs
solutions ont montrées leurs efficacités.
Les algorithmes proposés dans ces cadres
doivent être bien conçus de façon qu'ils garantissent une
fiabilité très élevée, mais malheureusement on ne
peut pas prévoir des éventuelles pannes, alors les chercheurs
sont penchés sur ce sérieux problème afin de garantir que
le système continu à fonctionner même en présence de
pannes, donnant naissance à la notion de tolérance aux
pannes.
L'évaluation des algorithmes dans des
réseaux réels est considéré trop difficile ou
même impossible vue les difficultés de réalisation et les
conditions économiques, c'est la raison pour laquelle on utilise des
outils de simulation permettant d'évaluer et de tester les algorithmes
proposés dans des conditions très proches de la
réalité.
Dans ce mémoire, nous avons
étudié et simulé un algorithme de la K-exclusion mutuelle
dans les systèmes répartis, les résultats de simulation
nous ont permis d'améliorer cet algorithme jusqu'à
l'intégration d'un mécanisme de tolérance aux pannes
à cet algorithme. La performance acceptable de notre algorithme nous a
motivé à adapter son
Introduction générale
principe dans les réseaux mobiles AD
HOC.
Dans le premier chapitre, nous présentons
des notions générales sur les systèmes répartis et
les réseaux mobiles AD HOC.
Dans le deuxième chapitre, on va
expliquer les problèmes qui font l'objet de ce travail: - l'exclusion
mutuelle.
- sa généralisation à la K-exclusion
mutuelle.
- la notion de la tolérance aux
pannes.
Le chapitre trois est consacré
à l'étude d'un algorithme de la K-exclusion mutuelle dans les
systèmes répartis, où nous présentons la
réalisation de simulation et les différentes améliorations
qui ont permis de rendre cet algorithme tolérant aux pannes.
Dans le chapitre suivant, l'algorithme de la
K-exclusion mutuelle tolérant aux pannes dans les réseaux AD HOC
qui est basé sur l'algorithme déjà étudié,
sera présenté et validé par une simulation.
La conclusion de ce mémoire résume
les travaux faits durant toutes nos études ainsi que des possibles
améliorations futures.
À la fin de ce mémoire, on met à
la disposition du lecteur deux annexes contenant les détails de notre
travail, dans la première annexe nous introduisons
NS-2, l'outil de simulation que nous avons utilisé dans
ce travail, cette annexe nous permet de suivre et comprendre toutes les
étapes de simulation, la deuxième annexe représente un
exemple des scripts utilisés par l'outil de simulation.
NoTioNs géNérales 1
Sommaire
1.1 SysTème
RéparTi 4
1.1.1 Introduction
4
1.1.2 Définition
d'un système réparti 4
1.1.3 Les
caractéristiques d'un système réparti 5
1.1.4 Les avantages et
les inconvénients 5
1.1.4.1
Avantages 5
1.1.4.2
Inconvénients 6
1.1.5 Problèmes
liés aux systèmes répartis 7
1.1.6 Conclusion
7
1.2 Les réseaux
AD HOC 8
1.2.1 Introduction
8
1.2.2 Réseaux
mobiles sans fil 8
1.2.2.1
Les réseaux mobiles avec infrastructure 8
1.2.2.2
Les réseaux mobiles sans infrastructure 9
1.2.3 Les
réseaux mobiles AD HOC 9
1.2.3.1
Les caractéristiques des réseaux AD HOC 10
1.2.3.2
Les avantages des réseaux AD HOC 11
1.2.3.3
Les inconvénients des réseaux AD HOC 11
1.2.3.4
Applications des réseaux AD HOC 12
1.2.3.5
Problèmes liés aux réseaux AD HOC 14
1.2.4 Problème
de routage dans les réseaux AD HOC 14
1.2.4.1
Définition du routage 14
1.2.4.2
Classification des protocoles de routage 14
CoNclusioN 16
D
aNs ce chapitre nous essayons de présenter un
aspect général des systèmes répartis et des
réseaux mobiles AD HOC, nous définissons aussi des notions de
base concernant ces systèmes, ainsi que leurs applications dans le monde
informatique actuel.
1.1 Système Réparti
1.1.1 Introduction
Depuis l'apparition des réseaux informatiques,
nos besoins en termes de calcul et de communication augmentent de jour en jour.
Alors un système appelé centralisé, basé sur une
seule machine fait son apparition et qui a résolu beaucoup de
problèmes, mais l'augmentation journalière des besoins a
contribué à l'émergence de l'informatique dite
répartie, pour répondre à ce problème.
L'informatique répartie est l'un des enjeux
majeurs de l'informatique à l'heure actuelle et dans le futur. Nous
sommes en train de passer d'une architecture où une machine fournissait
des services à un ensemble de machines (système
centralisé), à une architecture où un ensemble de machines
reliées par un réseau, compose un système qui fournit des
services (système réparti).
1.1.2 Définition d'un système
réparti
Ils existent plusieurs définitions d'un
système réparti qui se diffèrent d'un auteur à un
autre.
Tanenbaum [Tan94] a défini un
système réparti comme un système qui s'exécute sur
un ensemble de machines sans mémoire partagée, mais l'utilisateur
les voit comme une seule et unique machine.
Dans une autre définition, un système
réparti est défini comme étant un ensemble de sites
autonomes connectés par un réseau de communication, et
équipés d'un logiciel dédié à la
coordination des activités du système ainsi qu'au partage de
ressources [Cou94].
Nous pouvons dire donc qu'un système
réparti est un système composé de plusieurs machines
autonomes qui communiquent à l'intermédiaire d'un réseau
quelconque (filaire ou sans fil), par l'échange de messages.
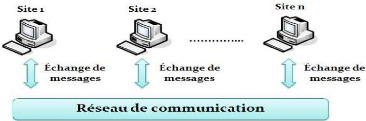
Figure 1.1 -
Structure d'un système réparti
Comme il est montré dans la figure
1.1, chaque ordinateur (dit aussi site), est
une entité
autonome capable de réaliser des tâches
indépendamment des autres entités.
Au niveau de chaque site qui a une mémoire
propre et une horloge locale, un ensemble de processus s'exécute soit en
collaboration soit en compétition. Pour des raisons de
simplicité, on suppose qu'il y a un seul processus au niveau de chaque
site, donc, dans tout ce qui suit, les termes : site, noeud et processus seront
confondus, et ils représenteront la même chose.
1.1.3 Les caractéristiques d'un système
réparti
Un système réparti est
caractérisé par:
- L'absence d'une mémoire commune et d'un
état global, cela signifier que chaque processus n'a qu'une vue
partielle du système.
- L'ensemble des machines doit posséder un
mécanisme de communication interprocessus unique et global. Cette
caractéristique permet à n'importe quel processus, de dialoguer
avec n'importe quel autre processus.
- Les noyaux de ces machines doivent avoir une
interface commune afin de permettre la portabilité des programmes mais
aussi pour donner l'illusion de la machine unique.
- Les composants défectueux peuvent se relancer et
de rejoindre le système, après que la cause de l'échec a
été réparée.
- Le système peut fonctionner correctement
alors même que certains aspects du système sont réduits.
Par exemple, nous pourrions augmenter la taille du réseau sur lequel le
système est en marche. Cela augmente la fréquence des pannes du
réseau. De même, on pourrait augmenter le nombre d'utilisateurs ou
de serveurs, ou de la charge globale sur le système.
- La performance s'obtient en réduisant le
nombre des messages transmis et en augmentant le parallélisme. On peut
dire que la performance s'obtient en réglant le grain de
parallélisme, c'est-à-dire l'intervalle de temps séparant
deux communications successives.[Eve04]
1.1.4 Les avantages et les inconvénients
1.1.4.1 Avantages
La répartition des applications informatiques
fait l'objet d'un fort développement depuis une vingtaine
d'années. Cet essor s'est accentué avec les progrès
technologiques des réseaux de télécommunication. C'est
pourquoi les systèmes répartis sont tant utilisés et
offrent un ensemble d'avantages par rapport aux systèmes
centralisés.
- Sécurité : les applications sont
conçues selon une approche modulaire permettant d'isoler les
données, et donc protéger les accès.
- Accélération des calculs : un calcul
peut être découpé en sous calculs réalisables en
même temps (en parallèle), le système réparti permet
alors de répartir les calculs sur les différents processus afin
de les exécuter simultanément. Lorsqu'un site est
surchargé, certaines tâches peuvent être
déplacées ou allouées à un site moins chargé
(la répartition des charges).
- Transparence : l'utilisation des ressources n'influe
pas sur leurs états.
- Flexibilité : l'ajout ou la suppression d'un
site est une opération simple, et n'influe pas sur le fonctionnement
total du système.
- Fiabilité : un des buts des systèmes
répartis est d'obtenir des systèmes plus fiables que les
monoprocesseurs. Si une machine tombe en panne, une autre machine devrait
prendre la relève, cette situation entraîne
généralement la duplication des données partagées
pour accroître la robustesse du système.
- Accès distant : un même service peut
être utilisé par plusieurs sites, situés à des
endroits différents.
- Redondance : des systèmes redondants permettent
de palier une faute matérielle, où de choisir le service
équivalent avec le temps de réponse le plus
court.[All04]
1.1.4.2 Inconvénients
Les inconvénients des systèmes
répartis sont des (pseudos) inconvénients, en effet ce sont des
problèmes concernant surtout la communication, les avantages offerts par
les systèmes répartis nous aident à exploiter le
matériel et à concevoir des systèmes informatiques larges
et performants, mais ces systèmes ont toujours des problèmes
à résoudre.
- L'absence d'une horloge globale : chaque noeud
possède sa propre horloge pour dater les événements qui
lui sont locaux. Par conséquent, si les horloges indépendantes de
chaque noeud ne sont pas parfaitement synchronisées, l'ordre des
événements n'est pas déductible à partir des
datations locales. Cette difficulté conduira à définir des
datations logiques qui permettent de corriger ce problème.
- La lenteur de la communication : malgré le
degré de fiabilité offert par les réseaux de
communication, et les vitesses de transmission qu'ils proposent(avec
l'arrivée des fibres optiques), les réseaux restent relativement,
et on dit bien relativement lents par rapport à la vitesse de calcul sur
les machines, ce qui implique un grand temps d'attente dans le cas d'un travail
coopératif entre les processus, et donc on obtient une perte concernant
la performance du système.
- La perte des messages : parfois, les réseaux de
communication ne sont pas fiables,
quelques messages transportés par ces
réseaux peuvent être perdus, et donc on doit
réémettre ces messages, les protocoles de détection, de
perte, et la génération des nouveaux messages reste jusqu'
à maintenant un des domaines de recherche dans les systèmes
répartis.[All04]
1.1.5 Problèmes liés aux systèmes
répartis
- L'absence des états globaux : le système
peut être bloqué, ou des parties peuvent se liguer et bloquer
d'autres parties, la consistance du système global doit être
assurée.
- Fiabilité des calculs et des communications :
les communications sont mises en oeuvre par des medias plus ou moins fiables,
les algorithmes mis en place ont pour rôle de fiabiliser les moyens de
communication, cette fiabilité doit être vérifiée ou
validée, les calculs doivent être corrects, c'est-à-dire
conformes aux spécifications, et les communications doivent garantir
l'intégrité des données transmises et respecter un certain
nombre de propriétés liées à l'acheminement des
données.
- L'élection : Certaines applications
réparties imposent qu'un site donné parmi les sites du
système joue un rôle particulier, ce site est appelé le
coordinateur, et il assure la communication entre tous les sites. La panne du
site coordinateur entraîne la fin de l'application utilisant ce
coordinateur, les autres sites doivent désigner un autre site pour
remplacer le coordinateur, ce nouveau site est choisi après une
opération d'élection.
- Détection de terminaison : Les sites d'un
système réparti peuvent réaliser des calculs
répartis, le problème de terminaison est celui de
détection de la fin de ce calcul réparti. On dit qu'un calcul est
terminé si tous les sites qui ont participé dans ce calcul ont
terminé le calcul, et il n y a aucun message en transit entre ces
sites.
- Partage des ressources : la répartition des
ressources conduit nécessairement à la compétition pour
l'obtention de celles-ci, si elles sont disponibles mais sous forme exclusive,
une compétition doit être gérée de manière
algorithmique par une mise en oeuvre d'une politique de gestion des ressources
partagées.[All07]
1.1.6 Conclusion
Les systèmes répartis ont résolus
beaucoup de problèmes, et avec l'évolution de la technologie du
monde actuel, un nouveau mode de communication sans fil a fait son apparition,
facilitant la mobilité des sites et rendant la mise en oeuvre des
réseaux plus facile sans utilisation du câblage. Les
réseaux AD HOC viennent de montrer leur efficacité.
1.2 LES RéSEAUX AD HOC 1.2.1
Introduction
Au cours de ces dernières années le
monde des réseaux sans fil est devenu l'axe de recherche le plus
important en réseaux. L'évolution récente des moyens de
communication sans fil a permis la manipulation de l'information à
travers des unités de calcul mobiles.
Les environnements mobiles offrent aujourd'hui une
grande flexibilité d'emploi. En particulier, ils permettent la mise en
réseau des sites dont le câblage serait trop onéreux
à réaliser dans leur totalité, voire même
impossible.
1.2.2 Réseaux mobiles sans fil
Un environnement mobile est un système
composé de sites mobiles et qui permet à ses utilisateurs
d'accéder à l'information indépendamment de leurs
positions géographiques, en utilisant les ondes radio pour communiquer
plutôt qu'une infrastructure câblée.
Les réseaux mobiles ou sans fil, peuvent
être divisés en deux classes:
- Les réseaux avec infrastructure. - Les
réseaux sans infrastructure.
1.2.2.1 Les réseaux mobiles avec
infrastructure
Dans cette classe de réseaux, nous avons des
unités fixes appelées station de base (SB), (en anglais Base
Station), ces stations, sont reliées entre elles par un réseau
filaire. Chaque station de base est munie d'une interface de communication sans
fil, et elle couvre une zone géographique limitée appelée
cellule, c'est la raison pour laquelle on appelle ces réseaux les
réseaux cellulaires.
Les autres unités dans ce réseau sont
des unités mobiles (UM), (en anglais Mobile Unit) ayant des liens sans
fil avec les stations de base, une unité mobile n'appartient qu'à
une seule SB à un moment donné, cette station offre tous les
services de communication tant que l'UM est à l'intérieur de sa
zone de couverture.
Une SB est aussi le point de passage de la
transmission d'une UM à une autre. Si les deux UM appartiennent à
la même SB, l'échange des informations est simplement
relayé par la SB. Si les deux UM appartiennent à deux SB
différentes, les informations échangées entre elles
doivent être relayées par le réseau filaire qui relie les
deux points d'accès.[Lem00] (Voir la figure
1.2).
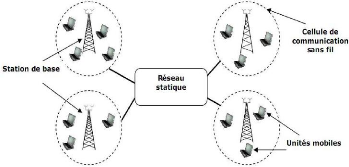
Figure 1.2 - Le
modèle des réseaux mobiles avec
infrastructure.[Bou07] 1.2.2.2
Les réseaux mobiles sans infrastructure
Ce modèle est représenté par les
réseaux Ad Hoc et étend les notions de mobilité à
tous les éléments composant le réseau.
1.2.3 Les réseaux mobiles AD HOC
Les réseaux AD HOC (en latin :" qui va vers ce
vers quoi il doit aller ", c'est-à-dire " formé dans un but
précis ", telle qu'une commission AD-HOC, formée pour
régler un problème particulier) sont des réseaux sans fil
capables de s'organiser sans infrastructure définie
préalablement.
Les réseaux ad hoc, dans leur configuration
mobile, sont connus sous le nom de MA-NET (Mobile Ad-hoc NETworks).
Un réseau mobile AD HOC est un environnement
mobile sans infrastructure, ce réseau est composé d'unités
mobiles qui se déplacent dans un territoire quelconque et dont le seul
moyen de communication est l'utilisation des interfaces sans fil, sans avoir
besoin d'une infrastructure préexistante ou d'une administration
centralisée.
L'absence de l'infrastructure rend le comportement des
unités mobiles à se comporter comme des noeuds
intermédiaires (Routeur) qui participent à la découverte
et à la maintenance des chemins pour les autres noeuds du
réseau.
Pour assurer la communication entre les noeuds, ces
derniers utilisent les signaux radio, le signal s'atténue au fur et
à mesure qu'il s'éloigne de son émetteur, le rayon de
couverture du signal est dit porté de communication. Un noeud ne peut
communiquer directement qu'avec les noeuds qui sont situés à
l'intérieur de sa portée de communication, ces noeuds forment
alors l'ensemble des voisins immédiats de ce
noeud.[LK09]
comme il est illustré dans la figure
1.3
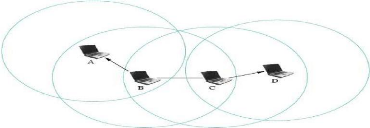
Figure 1.3 - Le
modèle des réseaux mobiles sans infrastructure.
La figure 1.4
représente un réseau AD HOC de 7
unités mobiles et leurs liens de communication.
Figure 1.4 - Un
réseau AD HOC. 1.2.3.1 Les caractéristiques des
réseaux AD HOC
Les réseaux AD HOC en tant que nouveau
paradigme des réseaux sans fil, présentent de nombreuses
caractéristiques dont certaines leur sont bien spécifiques et les
différencient des réseaux mobiles classiques.
- Une topologie dynamique : les unités mobiles
du réseau, se déplacent d'une façon libre et arbitraire.
Par conséquent, la topologie du réseau peut changer, à des
instants imprévisibles, d'une manière rapide et aléatoire
(voir figure 1.5).
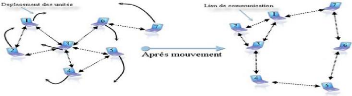
Figure 1.5 -
Topologie dynamique dans un réseau AD HOC.
- L'absence d'infrastructure : les réseaux AD
HOC se distinguent des autres réseaux mobiles par l'absence
d'infrastructure préexistante et de tout genre d'administration
centralisée. Les hôtes mobiles sont responsables d'établir
et de maintenir la connectivité du réseau d'une manière
continue.
- Equivalence des noeuds du réseau : dans un
réseau classique, il existe une distinction nette entre les noeuds
terminaux (stations, hôtes) qui supportent les applications et les noeuds
internes (routeurs par exemple) du réseau, en charge de l'acheminement
des données. Cette différence n'existe pas dans les
réseaux AD HOC car tous les noeuds peuvent être amenés
à assurer des fonctions de routage.
- Rapidité de déploiement : les
réseaux AD HOC peuvent être facilement installés dans les
endroits difficiles à câbler, ce qui élimine une bonne part
du travail et du coût, généralement liés à
l'installation, et réduit d'autant le temps nécessaire à
la mise en route.
- Communication par lien radio : les communications
entre les noeuds se font par l'utilisation d'une interface radio. Il est alors
important d'adopter un protocole d'accès au médium qui permet de
bien distribuer les ressources radio, et ceci en évitant le plus
possible les collisions, et en réduisant les
interférences.[Mes98]
1.2.3.2 Les avantages des réseaux AD HOC
- Faciles à déployer : il suffit de mettre
en place plusieurs machines pour que le réseau existe. Ceci rend la
construction d'un réseau AD HOC rapide et peu
onéreuse.
- Les noeuds sont mobiles : l'absence de câblages
autorise les noeuds à se déplacer l'un par rapport aux autres au
cours du temps.
- Évolutifs : pour ajouter un noeud à un
réseau AD HOC préexistant, il suffit d'approcher le nouveau venu
d'au moins l'un des membres du réseau. De même il suffit de l'en
éloigner pour le retirer du
réseau.[Man07]
1.2.3.3 Les inconvénients des réseaux AD
HOC
- Une bande passante limitée : une des
caractéristiques primordiales des réseaux basés sur la
communication sans fil est l'utilisation d'un médium de communication
partagé. Ce partage fait que la bande passante réservée
à un hôte soit modeste.
- Des contraintes d'énergie : les hôtes
mobiles sont alimentés par des sources d'énergie autonomes donc
restreintes, comme les batteries, par conséquent la durée de
traitement est réduite. Donc le paramètre d'énergie doit
être pris en considération dans tout contrôle fait par le
système.
- Une sécurité physique limitée :
les réseaux mobiles AD HOC sont plus touchés par le
paramètre de sécurité, que les réseaux filaires
classiques. Cela se justifie entre
autres par les vulnérabilités des liens
radio aux attaques, ainsi que les contraintes et limitations physiques qui font
que le contrôle des données transférées doit
être minimisé.[Mes98]
1.2.3.4 Applications des réseaux AD HOC
Bien que les projets relatifs aux réseaux sans
fil en général et aux réseaux AD HOC en particulier aient
débuté dans un cadre militaire pur, leurs domaines d'applications
s'étendent bien au-delà du cadre militaire. Les réseaux
mobiles AD HOC sont en fait plus faciles à déployer dans des
bâtiments où il est impossible d'installer des câbles
convenablement tels que les vieux bâtiments ou les sites classés
(châteaux et monuments historiques).
D'une façon générale, les
réseaux AD HOC sont utilisés dans toute application où le
déploiement d'une infrastructure réseau filaire est trop
contraignant, soit parce que il est difficile à mettre en place, soit
parce que la durée d'installation du réseau ne justifie pas de
câblage à demeure.[Man07]
Parmi les domaines d'applications des réseaux AD
HOC:
- Services d'urgence : opération de recherche et
de secours des personnes, tremblement de terre, Incendies, dans le but de
remplacer l'infrastructure filaire.

Figure 1.6 -
Application de secours des réseaux AD HOC.
- Travail collaboratif et les communications dans des
entreprises ou bâtiments : dans le cadre d'une réunion ou d'une
conférence par exemple (voir la figure
1.7).
- Applications commerciales : pour un paiement
électronique distant (restaurant, aéroport, hôtel) ou pour
l'accès mobile à Internet, ou service de guide en fonction de la
position de l'utilisateur.(voir la figure
1.8)
Figure 1.7 -
Application collaborative des réseaux AD HOC.
Figure 1.8 -
Applications commerciales des réseaux AD HOC.
1.2.3.5 Problèmes liés aux réseaux
AD HOC
Les réseaux AD HOC sont des systèmes
répartis dont le support de communication est un réseau sans fil,
il est évident de rencontrer les problèmes classiques des
systèmes répartis tels que la datation des
événements, l'élection, la détection de terminaison
et le partage de ressources dans les réseaux AD HOC. Et à cause
de la mobilité, on trouve également des problèmes propres
aux réseaux AD HOC tels que la bande passante limitée, la perte
de données et le problème de routage.
1.2.4 Problème de routage dans les réseaux AD
HOC
1.2.4.1 Définition du routage
Le routage est une méthode d'acheminement des
informations à la bonne destination à travers un réseau de
connexion donné. Le problème de routage consiste à
déterminer un acheminement optimal des paquets à travers le
réseau au sens d'un certain critère de performance. Le
problème consiste à trouver l'investissement de moindre
coût en capacités nominales et de réserves qui assure le
routage du trafic nominal et garantit sa serviabilité en cas de
n'importe quelle panne d'arc ou de noeud.[Lem00]

Figure 1.9 - Le chemin utilisé dans le routage
entre la source et la destination. 1.2.4.2 Classification des protocoles de
routage
Suivant la manière de création et de
maintenance de routes lors de l'acheminement des données, les protocoles
de routage peuvent être séparés en trois catégories,
les protocoles proactifs, les protocoles réactifs et les protocoles
hybrides.[Lem00]
Comme il est illustré dans la figure
1.10.
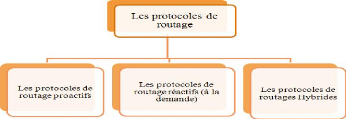
Figure 1.10 -
Figure qui montre la classification des protocoles de routage.
1.2.4.2.a Les protocoles de routage proactifs
Les protocoles de routage proactifs pour les
réseaux mobiles AD HOC, sont basés sur la même philosophie
des protocoles de routage utilisés dans les réseaux filaires
conventionnels. Les méthodes utilisées exigent une mise à
jour périodique des données de routage qui doit être
diffusée par les différents noeuds de routage du
réseau.
Un des protocoles qui appartient à cette classe
est OLSR (Optimized link state routing protocol).
1.2.4.2.b Les protocoles de routage réactifs
(à la demande)
Les protocoles de routage appartenant à cette
catégorie, créent et maintiennent les routes selon les besoins.
Lorsque le réseau a besoin d'une route, une procédure de
découverte globale de routes est lancée, et cela dans le but
d'obtenir une information spécifiée, inconnue au
préalable.
AODV (Ad hoc On-demand Distance Vector), DSR (Dynamic
Source Routing), sont les plus connus dans cette classe.
1.2.4.2.c Les protocoles de routage hybrides
Dans ce type de protocole, on peut garder la
connaissance locale de la topologie jusqu'à un nombre
prédéfini (à priori petit) de sauts par un échange
périodique de trame de contrôle, autrement dit par une technique
proactive. Les routes vers des noeuds plus lointains sont obtenues par
schéma réactif, c'est-à-dire par l'utilisation de paquets,
et de requêtes en diffusion.[Lem00]
Le protocole ZRP (Zone Routinier Protocol) est le plus
connu dans cette classe.
CONCLUSION
Dans ce chapitre, nous avons présenté une
vue générale sur les systèmes répartis et les
réseaux AD HOC, ainsi que les problèmes les plus connus dans ces
deux environnements.
Dans le chapitre suivant, nous allons expliquer en
détail le problème de l'exclusion mutuelle et la K-exclusion
mutuelle ainsi que la notion de la tolérance aux pannes dans les
systèmes repartis et dans les réseaux AD HOC.
LE probLèmE DE L'ExcLusioN muTuELLE 2
ET LA ToLérANcE Aux pANNEs
SommAirE
|
2.1 LE probLèmE DE
L'ExcLusioN muTuELLE
2.1.1 Introduction
|
18
18
|
|
2.1.2 L'exclusion
mutuelle en réparti
|
18
|
|
2.1.2.1
La notion de l'exclusion mutuelle
|
18
|
|
2.1.2.2
Les états d'un processus
|
19
|
|
2.1.2.3
Notions de base
|
19
|
|
2.1.2.4
Propriétés d'un algorithme d'exclusion mutuelle
|
19
|
|
2.1.3 Bref historique
|
20
|
|
2.1.4 Les classes de
solutions d'exclusion mutuelle
|
20
|
|
2.1.4.1
Les algorithmes à permissions
|
21
|
|
2.1.4.2
Les algorithmes à jeton
|
22
|
|
2.1.5 Synthèse
et conclusion
|
23
|
|
2.2 LE probLèmE DE LA
K-ExcLusioN muTuELLE
|
25
|
|
2.2.1 Description du
problème
|
25
|
|
2.2.2 Résolution
du problème
|
25
|
|
2.3 LE probLèmE DE
L'ExcLusioN muTuELLE DANs LEs résEAux AD HOC
|
25
|
|
2.4 LE probLèmE DE LA
K-ExcLusioN muTuELLE DANs LEs résEAux AD HOC .
. .
|
26
|
|
2.5 LA ToLérANcE Aux
pANNEs
|
26
|
|
2.5.1 Solutions
|
26
|
|
2.5.2 Les types de la
tolérance aux pannes
|
26
|
|
2.5.2.1
Tolérance aux pannes par mémoire stable
|
27
|
|
2.5.2.2
Tolérance aux pannes par duplication
|
27
|
|
CoNcLusioN
|
28
|
L
'exclusion mutuelle et sa généralisation
à K-ressources sont des problèmes classiques dans les
systèmes répartis. Dans ce chapitre, nous présentons des
notions de base de ces problèmes et les différentes
catégories des solutions apportées. On va étudier
également la tolérance aux pannes dans les algorithmes
d'exclusion mutuelle.
2.1 LE pRoBLEME DE L'EXcLusioN MuTuELLE
2.1.1 Introduction
Dans les systèmes répartis nous avons
rencontré plusieurs problèmes qui sont encore des axes de
recherche telle que le problème de partage de ressources.
Le problème de l'exclusion mutuelle, est un
problème d'allocation en exclusivité d'une seule donnée
(appelée ressource), Il s'agit d'un problème de
compétition dont l'énoncé est très simple : une
entité, appelée ressource non partageable ou critique, ne peut
être octroyée à un instant donné qu'à un seul
processus parmi N processus du système. L'utilisation simultanée
de cette ressource peut poser un problème d'incohérence, Pour
cette raison plusieurs solutions ont été proposées, qui
sont sous forme d'algorithmes afin de garantir le contrôle et la
cohérence de la ressource partagée, ces algorithmes sont
appelé les algorithmes répartis de l'exclusion
mutuelle.
Les réseaux AD HOC (en tant que système
réparti un peu particulier) ont hérité ce problème,
dans ce cas, les unités mobiles peuvent partager les ressources du
système. Les solutions apportées au problème de
l'exclusion mutuelle dans les systèmes répartis peuvent aussi
être utile dans les réseaux AD HOC, tout en prenant en
considération les problèmes des MANETs tel que la
mobilité.
Dans les systèmes distribués, le
contrôle, le calcul et les données sont distribués sur
différents noeuds du système. Il devient important et
nécessaire que le système soit fiable pour garantir
l'échange de données sans erreur et sans perte. Ces erreurs
peuvent se produire à cause de la défaillance d'un ou de
plusieurs noeuds du système.
2.1.2 L'exclusion mutuelle en réparti
2.1.2.1 La notion de l'exclusion mutuelle
Etant donné un système réparti de
N processus partageant une ressource physique (une imprimante par exemple) ou
logique (un fichier). Afin d'éviter des situations incohérentes,
la ressource partagée ne peut être utilisée que par un seul
processus à la fois, en d'autres termes, la ressource doit être
utilisée en exclusion mutuelle (EM).
Une telle ressource est dite ressource critique, et
les processus utilisant cette ressource exécutent une section du code
appelée section critique (SC) qui manipule la ressource partagée.
Pour garantir l'accès exclusif à la ressource critique, on doit
gérer cet accès par un protocole d'acquisition et un protocole de
libération. Un processus désirant entrer en SC doit appeler le
protocole d'acquisition, ce protocole permet de retarder l'accès de ce
processus à la SC si elle est utilisée par un autre site.
À la fin de la SC, le processus exécute le protocole de
libération pour informer les sites qui peuvent être en attente que
la SC est libre.[All07]. La forme générale d'un
processus utilisant une ressource critique est :
Protocole d'acquisition
< Section Critique>
Protocole de libération
2.1.2.2 Les états d'un processus
L'appel des protocoles d'acquisition et de
libération fait changer l'état d'un processus. En effet, un
processus Pi appartenant au système réparti est
doté d'une variable locale Etati qui désigne son
état, tel que :
Etati = {Dehors, Demandeur,
Dedans}.
Initialement, Etati =
Dehors. Le protocole d'acquisition fait passer Etati de
l'état Dehors vers l'état Demandeur, et le protocole de
libération fait passer cet état de Dedans vers Dehors. Le passage
de l'état Demandeur vers l'état Dedans et défini par le
système.[All07] Comme il est montré dans la
figure 2.1
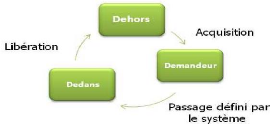
Figure 2.1 - Les
états d'un processus.[All07]
2.1.2.3 Notions de base
1. Ressource critique
C'est une ressource partagée qui ne doit
être accessible que par un seul site à la fois.
2. Section critique
Les sites utilisant les ressources critiques
exécutent une section du code manipulant la ressource appelée
section critique (SC) : un seul processus au plus doit être en section
critique afin de garantir une utilisation correcte de la ressource.
2.1.2.4 Propriétés d'un algorithme
d'exclusion mutuelle
Une solution n'est considérée correcte que
si elle respecte les propriétés suivantes :
- Propriété de sûreté
(safety) : à tout instant, un seul site au plus exécute
la SC.
- Propriété de vivacité
(liveness) : tout site demandeur de la ressource critique doit pouvoir
l'acquérir au bout d'un temps fini.
Un algorithme qui assure ces deux
propriétés assure également l'absence de deux
problèmes, l'interblocage et la famine:
- Interblocage (Deadlock) : est une situation du
système où il y a plusieurs sites à l'état
Demandeur et aucun ne peut accéder à la SC.
- Famine (Starvation) : aura lieu si un site qui
se trouve à l'état Demandeur ne passe jamais à
l'état Dedans.[LK09]
2.1.3 Bref historique
Le problème de l'exclusion mutuelle
était très bien traité dans les systèmes
informatiques centralisés, plusieurs algorithmes et mécanismes
assurant l'exclusion mutuelle ont été proposés, on peut
citer par exemple les sémaphores de Dijkstra [Dij65] et
les moniteurs. Par ailleurs, avec l'évolution des systèmes
informatiques on a vue ce problème se transformé de point de vue
centralisé à un point de vue réparti.
La première définition du problème
de l'exclusion mutuelle a été donnée par Dijkstra
[Dij65]. On peut résumer son propos dans les cinq
assertions suivantes :
1. A tout moment, il n'y a qu'un site du système
qui puisse exécuter la section critique.
2. La solution doit être symétrique,
c'est-à-dire que l'on ne "peut pas introduire de priorité
statique".
3. On ne peut pas faire d'hypothèse sur la
vitesse des participants.
4. En dehors de la section critique, tout site peut
quitter le système sans pour autant bloquer les autres.
5. Si plus d'un site désire entrer en section
critique, on doit pouvoir décider en un temps fini de l'identité
du site qui accédera à celle-ci.
Cette définition n'a pas évolué
jusqu'à aujourd'hui, et on la retrouve dans les principales
propriétés des algorithmes d'exclusion mutuelle.
2.1.4 Les classes de solutions d'exclusion mutuelle
C'est en 1977 avec l'algorithme de Le
Lann [Lan77] et en 1978 avec celui de Lamport
[Lam78] que l'on a commencé à considérer
pour l'exclusion mutuelle dans des systèmes répartis. Dans ces
systèmes les processus s'exécutent sur des sites distants et ne
peuvent communiquer entre eux que par envoi de messages.
Les algorithmes d'exclusion mutuelle se classent
usuellement en deux grandes familles : les algorithmes basés sur les
permissions et ceux basés sur l'utilisation des jetons.
Cette
classification a été introduite en
1991 par Raynal [Ray91]. On peut
illustré cette classification dans la figure
2.2
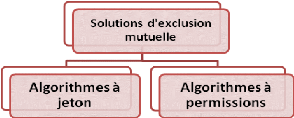
Figure 2.2 - Les
catégories des solutions d'exclusion mutuelle. 2.1.4.1 Les
algorithmes à permissions
Les algorithmes à permissions reposent sur une
idée simple et naturelle : chaque site demande aux autres, s'il le
désire, l'autorisation d'entrer en SC. Il ne pourra alors entrer en SC
qu'à la seule condition d'avoir bien reçu toutes les permissions
nécessaires.
Dans ce type d'algorithmes, la propriété
de sûreté de l'exclusion mutuelle est assurée par
l'invariant suivant : "À tout moment au plus un site possède
toutes les permissions nécessaires".
Pour garantir cet invariant, chaque algorithme à
permissions définit les conditions nécessaires à l'envoi
d'une permission à un autre site du système.
On peut diviser les algorithmes à permissions en
trois groupes selon le type de permission, la permission individuelle, la
permission d'arbitre et la permission
mixtes.[Sop08]
2.1.4.1.a Permissions individuelles
Dans ce type, un site peut donner sa permission
à plusieurs autres sites simultanément. S'il n'est pas demandeur,
il envoie son autorisation à tous les sites demandeurs, dans le cas
contraire, c'est-à-dire s'il est demandeur, il ne donnera son
autorisation qu'aux sites dont les requêtes sont plus anciennes.
(quelques algorithmes : [Lam78], [RA81],
[CR83], [CM84]).
2.1.4.1.b Permissions d'arbitres
Contrairement aux algorithmes à permissions
individuelles où un site finissait par recevoir l'accord explicite ou
tacite de tous les sites pour chaque entrée en SC, un site i
n'attend plus qu'un ensemble réduit de permissions.
Cet ensemble de sites Ri est propre à
chaque site i.
La deuxième différence des permissions
d'arbitres par rapport aux permissions individuelles, est qu'un site n'envoie
qu'une permission à la fois. Cet envoi n'est plus seulement
conditionné par l'état de l'application vis-à-vis de la
SC, mais aussi des permissions déjà émises par le site.
(exemple :[Mae85]).
Pour assurer la propriété de
sûreté il faut et il suffit que tous ces ensembles de diffusion
soient en intersection deux à deux, autrement dit :
V(i,
j), Ri n Rj =6
Ø
2.1.4.1.c Permissions mixtes
Cette dernière sous-classe d'algorithme
utilise, comme pour les permissions d'arbitres, des sous-ensembles Ri
pour diffuser ses requêtes diminuant ainsi la complexité en
nombre de messages. Mais, à l'instar des algorithmes à
permissions individuelles, les processus peuvent ici émettre plusieurs
permissions simultanément, ce qui écarte tout risque
d'interblocage.[Sop08]
La vivacité étant ainsi naturellement
assurée, ils peuvent s'affranchir du coûteux mécanisme de
reprise d'une permission. Le prix de cette économie est une contrainte
plus forte sur les ensembles Ri pour garantir la
propriété de sûreté :
V(i,
j),i E Rj V j E
Ri
Ce type d'algorithme a été introduit par
Mukesh Singhal en 1991 dans [Sin91]. Il a
noté que certaines taxonomies le classe comme un algorithme à
permissions d'arbitres "sans interblocage". C'est d'ailleurs le titre de
l'article. Le terme de permissions mixtes, utilisé ici, a
été introduit par Michel Raynal
[CM92].
2.1.4.2 Les algorithmes à jeton
Étudions maintenant la deuxième grande
famille que constituent les algorithmes à jeton. En considérant
un historique global des accès à la section critique, le
problème de l'exclusion mutuelle apparaît comme celui de la
séquentialisation de ces accès. Comme dans une course de relais,
la section critique passe de site en site. L'idée des algorithmes de
cette famille est alors de considérer un témoin appelé
"jeton" (token). Il peut être vu comme une super permission dont la seule
possession permet d'exécuter une section critique. Cette abstraction de
l'exclusion mutuelle permet d'obtenir facilement la propriété de
sûreté. Il suffit pour cela de maintenir l'invariant suivant " A
tout moment il n'y a dans le système qu'au plus un jeton ". Reste
à assurer la vivacité, c'est-à-dire la circulation du
jeton ainsi que celle des requêtes vers ce dernier.
Pour retrouver le jeton on distingue deux
stratégies : la première utilise des mécanismes de
diffusion, tandis que la deuxième repose sur l'utilisation des
propriétés de topologie particulière.
2.1.4.2.a Les algorithmes à diffusion (non
structuré)
Dans ce groupe d'algorithmes, un processus qui veut
demander la SC peut envoyer sa requête en parallèle à tous
les autres sites.
Ces algorithmes basés sur la diffusion de la
demande peuvent être aussi divisés en deux groupes :
- Les algorithmes statiques : un site qui a besoin du
jeton pour entrer en SC adresse sa demande à tous les autres
sites.[SK85], [HPR88].
- Les algorithmes dynamiques : le site qui veut
exécuter la SC doit envoyer sa requête de demande uniquement au
site qui a le jeton ou qui va l'avoir incessamment.[Sin89],
[CSL91].
2.1.4.2.b Les algorithmes à structure logique
(Structuré)
Dans ce groupe, les sites forment une configuration
logique grâce à leurs variables locales. Ces algorithmes peuvent
être aussi statiques ou dynamiques.
- Les algorithmes statiques : la structure logique
demeure inchangée et c'est uniquement le sens des arêtes qui
change. Les algorithmes statiques utilisent des graphes fixes qui
n'évoluent pas avec le système tels que l'arbre, l'anneau et
d'autres graphes.[Lan78], [Mar85],
[Ray89], [NM91], [vdS87]...
etc.
- Les algorithmes dynamiques : la configuration
logique adoptée au réseau change lorsqu'un processus demande et
exécute la SC. Grâce à cette structure logique dynamique,
on peut remonter l'historique des exécutions de la ressource critique.
Le fait de connaître celui qui détient le jeton ou celui qui va le
détenir nous permet de gagner beaucoup en nombre de messages et par
conséquent améliorer les performances de
l'algorithme.[NT87], [BAA89].
- Les algorithmes hybrides : D'après Hilary et
mostfaoui [HM94] ils proposent un algorithme hybride
basé sur une structure en "open-cube". Cet algorithme per-met de
s'adapter dynamiquement aux requêtes, tout en maintenant les
propriétés de symétries de cette structure arborescente
particulière. L'idée est ensuite d'utiliser ces
propriétés structurelles pour faciliter la mise en oeuvre de la
tolérance aux pannes.
2.1.5 Synthèse et conclusion
Cette taxonomie, résumée dans l'arbre de la
figure 2.3, nous a permis de mettre en
évidence la diversité des algorithmes. Les différentes
stratégies mises en oeuvre par ces
algorithmes présentent chacune des avantages et
des inconvénients. Il n'existe donc pas une classe d'algorithme
meilleure que les autres mais plutôt des classes adaptées à
un contexte et des objectifs de performances précis.
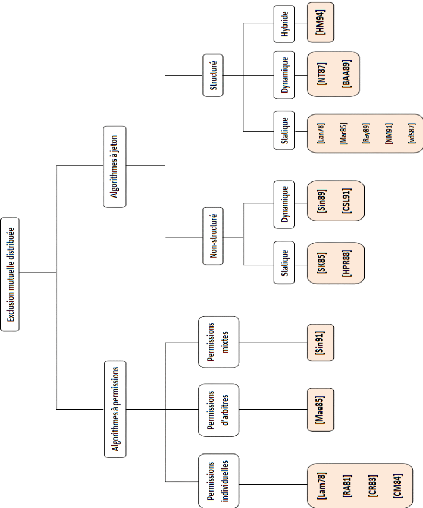
Figure 2.3 -
Arbre des catégories de solution d'exclusion
mutuelle.
2.2 LE probLèmE DE LA K-EXcLusioN
mutuELLE
2.2.1 Description du problème
Le problème de la K-exclusion mutuelle est une
généralisation du problème de l'exclusion mutuelle simple,
dans ce cas les sites partagent non seulement une ressource mais K exemplaires
de la même ressource.
Cette disponibilité de ressources n'autorise pas
l'accès simultané à une ressource, il faut toujours
assurer l'accès exclusif à chaque exemplaire.
2.2.2 Résolution du problème
Les solutions du problème de la K-exclusion
mutuelle sont basées sur les solutions utilisées pour
résoudre le problème de l'exclusion mutuelle simple, on peut donc
avoir deux types de solutions:
- Solution utilisant des permissions : le processus
désirant entrer en SC doit demander des permissions à un ensemble
de processus, la réception d'un nombre suffisant de ces permissions
permet au processus d'utiliser la ressource.
L'algorithme de Raymond est la première solution
pour la K-exclusion mutuelle basée sur les permissions
[Ray88].
- Solutions utilisant des jetons : dans ce cas, il
n'existe pas un seul jeton mais k jetons (k étant le nombre de
ressources), seule la possession d'un jeton permet à un site demandeur
l'accès à la SC.
Parmi les solutions apportées basées sur
les jetons on distingue l'algorithme de Srimani et Reddy
[Sri89].
2.3 LE probLèmE DE L'EXcLusioN mutuELLE DANs LEs
résEAuX AD HOC
Dans un environnement mobile, les unités mobiles
peuvent partager les ressources présentes dans le système, tout
en respectant l'exclusion mutuelle.
Les solutions proposées au problème de
l'exclusion mutuelle dans les réseaux mobiles AD HOC peuvent être
classées en deux grandes familles, les solutions utilisant des
permissions [Wei08] et celles utilisant un jeton
[WW01], ces solutions devront prendre en compte les
caractéristiques des réseaux mobiles AD HOC.
2.4 LE pRoBLEME DE LA K-EXcLusioN MuTuELLE DANs LEs
RtsEAuX AD
HOC
Dans ce cas, nous avons K exemplaires d'une ressource
critique, un processus ne peut utiliser qu'une seul ressource à un
moment donne.
Quelques algorithmes sont proposes dans ce cadre comme
[WK97].
2.5 LA ToLERANcE AuX pANNEs
Il se peut que dans un système qui fonctionne
correctement, d'avoir à un moment donne un problème qui va
influencer negativement sur son comportement, c'est le problème de panne
d'un site dans le système. Il existe plusieurs types de solutions
permettant de resoudre ce problème.
2.5.1 Solutions
Les solutions suivantes sont plus adequates à un
système centralise qu'a un système reparti.
- La prévention des fautes : qui s'attache aux
moyens permettant d'eviter l'occurrence de fautes dans le
système.
- L'élimination des fautes : qui se focalise sur
les techniques permettant de reduire la presence de fautes ou leurs
impacts.
- La prévision des fautes : qui predit
l'occurrence des fautes (temps, nombre, impact) et leurs
consequences.
Cependant dans un système reparti, ils
existent plusieurs sites qui sont reliees par un reseau de communication, cela
va permettre à un site de prendre les tâches d'un autre site qui a
subit une faute ou une panne :
- La tolérance aux pannes ou aux fautes : le
système peut fonctionner en depit des
fautes.[AK08]
2.5.2 Les types de la tolérance aux pannes
La tolerance aux pannes permet l'assurance de la
sûrete de fonctionnement, il existe deux types de tolerance : par memoire
stable, et par duplication.
2.5.2.1 Tolérance aux pannes par mémoire
stable
Une mémoire stable est
considérée comme étant un support persistant de stockage,
dont le rôle principal est d'assurer une accessibilité et une
protection des données contre les pannes pouvant affecter le
système. Ainsi, suite à une panne, un état correct ayant
été stocké antérieurement à cette panne sur
la mémoire stable reste accessible, cela permet au système un
retour à un état antérieur.
La tolérance aux fautes par sauvegarde
périodique de points de reprise sur mémoire stable est
très aisément mise en oeuvre dans le cas d'une application
séquentielle (et donc
non-répartie).[Abd07]
Cependant, la répartition d'une application
sur plusieurs processeurs ajoute une dimension supplémentaire au
problème car il faut éviter que la reprise de l'exécution
par un processus introduise des incohérences dans les exécutions
effectuées par les autres processus. Le problème de la
tolérance aux fautes par recouvrement arrière consiste à
assurer que, malgré la reprise d'un processus, l'état global du
système de processus reste
cohérent.[CL85]
2.5.2.2 Tolérance aux pannes par
duplication
La tolérance aux pannes par duplication
consiste à la création de copies multiples des composants sur des
processeurs différents. Cette technique fournit un moyen de traiter les
erreurs et de masquer ainsi le fait que des répliques ont
défailli. Cependant, afin de restaurer le niveau de redondance des
processus et d'être ainsi capables de tolérer d'autres
défaillances, cette technique doit être complétée
par un traitement de faute, qui consiste, entre autres, à la
réallocation et l'initialisation de nouvelles réplique.
[AK08]
CONCLUSION
Dans ce chapitre nous avons présenté
des notions de base concernant le problème de l'exclusion mutuelle et
son extension à K-ressources, nous avons cité également
les catégories de solutions apportées à ces
problèmes. Le problème de la tolérance aux pannes a aussi
fait l'objet de ce chapitre.
Dans le chapitre suivant, nous allons décrire
notre algorithme, proposé dans le cadre de la K-exclusion mutuelle, afin
de le simuler par un outil de simulation.
SiMuLATioN DE L'ALGoRiTHME DANs 3
LEs sysTèMEs RépARTis
SoMMAiRE
3.1
3.2
|
INTRoDucTioN
L'ALGoRiTHME
|
31
31
|
|
3.2.1
|
Objectif de l'algorithme
|
31
|
|
3.2.2
|
Structure logique utilisée
|
31
|
|
3.2.3
|
Principe de fonctionnement
|
33
|
|
3.2.4
|
Hypothèses
|
34
|
|
3.2.5
|
Description de l'algorithme
|
34
|
|
|
3.2.5.1
Variables locales
|
34
|
|
|
3.2.5.2
Les messages utilisés
|
35
|
|
|
3.2.5.3
Les procédures de l'algorithme
|
35
|
|
3.2.6
|
Preuve de l'algorithme
|
40
|
|
|
3.2.6.1
La K-exclusion mutuelle
|
40
|
|
|
3.2.6.2
Absence d'interblocage
|
40
|
|
|
3.2.6.3
Absence de la famine
|
41
|
|
3.2.7
|
Complexité de l'algorithme en nombre de
messages
|
41
|
3.3
|
RésuLTATs DE siMuLATioN
|
42
|
|
3.3.1
|
Les paramètres de simulation
|
42
|
|
3.3.2
|
Evaluation de performance
|
43
|
|
3.3.3
|
Les étapes d'un scénario
|
43
|
|
3.3.4
|
Résultats et interprétations
|
44
|
|
|
3.3.4.1
Variation du nombre de requêtes
|
44
|
|
|
3.3.4.2
Variation du nombre de ressources
|
44
|
|
|
3.3.4.3
Variation du nombre de sites
|
45
|
3.4
|
AMéLioRATioN N°1
(LE MEssAGE REcHERcHE)
|
46
|
|
3.4.1
|
Résultats et interprétations
|
47
|
|
|
3.4.1.1
Variation du nombre de requêtes
|
47
|
|
|
3.4.1.2
Variation du nombre de ressources
|
47
|
|
|
3.4.1.3
Variation du nombre de sites
|
48
|
3.5
|
AMéLioRATioN N°2
(ANNuLER LA MéTHoDE {UTiLisER LE pLus
couRT cHEMiN}) 48
|
|
3.5.1
|
Résultats et interprétations
|
51
|
|
|
3.5.1.1
Variation du nombre de requêtes
|
51
|
|
|
3.5.1.2
Variation du nombre de ressources
|
51
|
|
|
3.5.1.3
Variation du nombre de sites
|
51
|
3.6
|
AMéLioRATioN N°3
(ARRêT DEs MouvEMENTs iNuTiLEs)
|
52
|
|
3.6.1
Résultats et interprétations 53
3.6.1.1
Variation du nombre de requêtes 53
3.6.1.2
Variation du nombre de ressources 53
3.6.1.3
Variation du nombre de sites 54
3.7 LES COURBES FINALE ET
COMPARAISON 54
3.7.1 Variation du
nombre de requêtes 54
3.7.2 Variation du
nombre de ressources 55
3.7.3 Variation du
nombre de sites 55
3.8 CONCLUSION 55
3.9 LA TOLéRANCE AUX
PANNES 56
3.9.1 L'idée de
base 56
3.9.2 Description de
l'algorithme 56
3.9.2.1
Les variables locales 56
3.9.2.2
Les messages utilisés 56
3.9.2.3
Les procédures de l'algorithme 57
3.9.3 Résultats
et interprétations 58
3.9.3.1
Variation du nombre de requêtes 58
3.9.3.2
Variation du nombre de ressources 58
3.9.3.3
Variation du nombre de sites 58
3.10 AMéLIORATION
(ALGORITHME TOLéRANT AUX PANNES
AMéLIORé) 59
3.10.1
Résultats et interprétations 60
3.10.1.1
Variation du nombre de requêtes 60
3.10.1.2
Variation du nombre de ressources 60
3.10.1.3
Variation du nombre de sites 60
CONCLUSION 62
L
'objectif de ce chapitre est d'étudier un
algorithme de la K-exclusion mutuelle dans les systèmes répartis,
cet algorithme sera simulé et amélioré pour le rendre
tolérant aux pannes.
3.1 INTRODUCTiON
Notre travail consiste à réaliser une
simulation d'un algorithme proposé dans le cadre de la K-exclusion
mutuelle dans les systèmes répartis [All07] afin
d'étudier ses performances.
Des améliorations seront apportées au fur
et à mesure, afin d'obtenir les performances les plus
acceptable.
Dans ce chapitre, nous décrivons le principe
de fonctionnement de l'algorithme tout en expliquant les procédures et
les messages utilisés, et nous présentons sa complexité en
terme de nombre de messages, on va interpréter également les
courbes obtenues à partir des scénarios proposés pour
chaque amélioration apportée.
3.2 L'ALGORiTHME
3.2.1 Objectif de l'algorithme
Les sites dans un système réparti
communiquent entre eux par des échanges de messages seulement, c'est
pourquoi cet échange à une grande influence sur la performance du
système, en effet la performance d'un algorithme dépends de ces
messages échangés, alors on doit essayer de minimiser le nombre
de messages échangés afin d'assurer un degré acceptable de
performance.
Dans le problème de la K-exclusion mutuelle,
les N sites du système partagent K exemplaires de la même
ressource, généralement la complexité des solutions de ce
problème est exprimée en fonction de N, cela va rendre la
complexité très élevé et qui influe
négativement sur la performance du système, d'une autre part, la
valeur de K est largement inférieur à N, donc on a essayé
de proposer un algorithme dont la complexité est exprimé en
fonction de K, cela va certainement influencer positivement sur la performance
du système.
3.2.2 Structure logique utilisée
Afin de minimiser la complexité de notre
algorithme, nous avons créé une nouvelle structure logique
permettant d'assurer la K-exclusion mutuelle par l'échange de minimum de
messages.
Cette structure logique consiste à diviser les
sites en K groupes, chaque groupe à un site appelé Racine
qui joue le rôle d'un coordinateur, tous les sites d'un groupe
adressent leur requêtes à cette racine, chaque racine
détient initialement un jeton, et toutes les racines sont reliées
entre elles par un anneau bidirectionnel qui permet l'échange des jetons
entre les différents sites.
La création de cette structure passe par deux
étapes :
- 1er étape : créer des
arbres statiques tels que, pour 1 < i < K, le
site i est la racine d'un arbre noté
Arbrei, et pour le reste des sites : K+1,
K+2, . . ., N, chaque site doit appartenir
à un arbre selon son identité en utilisant la fonction suivante
:
si i = 1 mod k, ce site
E Arbre1 si i 2
mod k, ce site E Arbre2 si
i 3 mod k, ce site E Arbre3 . . .
si i k-1 mod k, ce site E
Arbrek_1 si i 0 mod k,
ce site E Arbrek
On obtient K arbres statiques ayant les
caractéristiques suivantes :
1. V i / 1 < i <
k, le site i est la racine de Arbrei.
2. Vi/iEArbrei,ijmod
k.
3. V i,j < k, Arbrei fl
Arbrej = 0.
- 2ème étape : consiste
à connecter les arbres entre eux, pour cela, seules les K
racines seront reliées entre elles par un anneau
bidirectionnel tel que, pour un site i, le voisin
gauche de ce site est le site i-1, et le voisin droit
est le site i+1. (Pour les sites 1 et
K, nous avons : voisin gauche du site 1 est
le site K, et voisin droit du site K est le site
1).
- Exemple : On suppose qu'on a un système
composé de 17 sites et 4 ressources,
on a donc 4 arbres : Arbre1,
Arbre2, Arbre3 et Arbre4, oil les racines respectives
sont les sites 1,
2, 3 et 4, les autres sites vont
constituer les arbres selon leurs identités, on obtient
les arbres suivants :
|
Arbre1 =
|
{1,
|
5,
|
9, 13, 17}
|
|
Arbre2 =
|
{2,
|
6,
|
10,
|
14}
|
|
Arbre3 =
|
{3,
|
7,
|
11,
|
15}
|
|
Arbre4 =
|
{4,
|
8,
|
12,
|
16}
|
Ces arbres sont illustrés dans la figure
3.1 ci dessous :
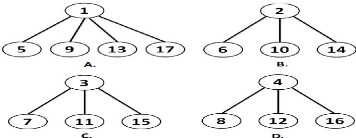
Figure 3.1 - La
structure des arbres statiques.
Afin d'obtenir la structure logique final de notre
algorithme suivant la figure 3.2
:
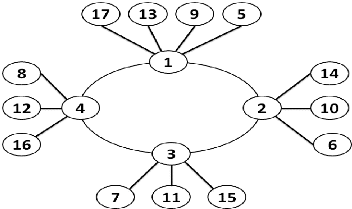
Figure 3.2 - La
structure logique finale.
3.2.3 Principe de fonctionnement
Pour assurer la K-exclusion mutuelle, nous utilisons
autant de jetons que de ressources disponibles, initialement, chaque racine
détient un jeton libre et les racines peuvent échanger les jetons
entre elles, une racine peut détenir jusqu'à K jetons libres
à la fois.
Lorsqu'un site demandeur désire entrer en SC,
il envoie une requête vers la racine de son arbre, cette racine va
satisfaire la requête par l'envoi d'un jeton si elle détient des
jetons libres, dans le cas contraire, la requête sera sauvegardée,
et la racine va demander un jeton supplémentaire à ses voisins
via l'anneau.
Si la racine qui reçoit la demande d'un voisin
détient des jetons libres, elle va répondre favorablement
à cette demande par l'envoi d'un jeton, sinon elle va propager cette
demande vers un autre voisin.
La réception d'un jeton par une racine permet
de servir la première requête en attente, le site demandeur qui
reçoit un jeton passe donc à la SC, et il envoie le jeton
à sa racine après la libération de la SC.
Afin d'éviter l'échange coûteux
des jetons entre les racines, nous utilisons une méthode judicieuse qui
permet d'envoyer les jetons via le plus court chemin entre le site envoyeur et
le site récepteur, cette méthode permet donc de minimiser le
nombre de messages échangés pour chaque entrée en
SC.
3.2.4 Hypothèses
Pour assurer le bon fonctionnement de notre algorithme,
on suppose que :
- Le nombre N des noeuds et le K des racines sont
connus.
- Le réseau physique est un réseau
complet.
- Les sites du système ne tombent pas en
panne.
- Les canaux de communication sont fiables, et il n'y a
pas de perte de messages.
3.2.5 Description de l'algorithme
Dans cette partie nous allons décrire les
variables et les messages utilisés, et on va détailler les
procédures de notre algorithme.
3.2.5.1 Variables locales
Cet algorithme possède deux types de noeud, les
sites racines et les sites simples. - Au niveau d'un Site i
simple:
Etati : Désigne l'état du site,
cet état appartient à {Dehors, Demandeur, En SC}, qui est
initialisé à Dehors.
Racinei : L'identité de la racine d'arbre
contenant ce site. - Au niveau d'une Racine i :
Etati : Désigne l'état du site,
cet état appartient à {Dehors, Demandeur, En SC}, et qui est
initialisé à Dehors.
Racinei : au début est initialisée
à Nil.
voisin_droiti : l'identité du
voisin droit dans l'anneau. voisin_gauchei :
l'identité du voisin gauche dans l'anneau.
Jetons_libresi : un entier qui donne le
nombre de jetons libres détenus par la racine, qui est initialisé
à 1.
Jetons_presentsi : un entier qui donne
le nombre de jetons qui se trouvent dans l'arbre, qui est initialisé
à 1.
Demandeursi : une file d'attente pour stocker
les requêtes, initialement vide.
Longueuri : la longueur de la file d'attente, et
puisque la file d'attente est vide initialement, donc il est initialisé
à 0.
Distance : une variable permettant de calculer la
distance entre deux sites dans l'anneau, qui est initialisé à
0.
3.2.5.2 Les messages utilisés
Dans cet algorithme, on utilise cinq types de
messages:
- Demande (Jeton, i) : envoyé par le site i
vers sa racine lors de la demande de la SC. - Libération (Jeton) :
envoyé par le site i vers sa racine après la
libération de sa SC.
- Accord (Jeton) : envoyé par une racine à
un site demandeur pour lui permettre d'utiliser la ressource critique
demandée.
- Requête (Jeton, i) : envoyé par une racine
i pour demander un jeton supplémentaire d'un
voisin.
- Aide (Jeton, i) : Réponse favorable à une
requête d'un voisin.
3.2.5.3 Les procédures de l'algorithme
Procédure 1: Demander la Section
Critique
1 Début
2
3
Etati ?-Demandeur;
Envoyer Demande (Jeton, i) à
Racinei;
4 Fin
Cette procédure est utilisée lorsqu'un site
simple appartenant à un arbre donné, désire d'entrer en
section critique.
Procédure 2: Réception de Accord
(Jeton)
1 Début
2
3
Etati ?-En SC;
< Entrer en Section Critique>
4 Fin
Lorsqu'un site de l'arbre a déjà
envoyé une demande d'entrer en section critique, il va
recevoir un message de type Accord si sa racine
possède au moins un jeton libre, lors de la réception de ce
message, le site va mettre son état EN SC, et entre à la section
critique.
Finsi
Procédure 3: Libérer la Section
Critique
1 Début
Etati ?-Dehors;
Envoyer Libération (Jeton) à
Racinei;
4 Fin
Cette procédure est utilisée si un site
veut libérer la section critique.
Procédure 4: Réception de Libération
(Jeton)
1 Début
|
2
|
Si Longueuri > 0
alors
|
|
3
|
Jeton Reçu ();
|
|
4
|
Sinon
|
|
5
|
Jetons_libresi ?-
Jetons_libresi + 1;
|
|
6
|
Finsi
|
7 Fin
lorsque la racine reçoit une libération
du jeton, elle va voir si sa file d'attente elle est vide, si c'est le cas elle
va incrémenter son compteur de jetons libres, sinon elle va appeler la
procédure Jeton_Reçu().
Procédure 5: Réception de Demande (Jeton,
j)
1 Début
Si Jetons_libresi > 0
alors
Envoyer Accord (Jeton) à j;
Jetons_libresi ?-
Jetons_libresi - 1;
2
3
Sinon
Si Jetons_presentsi = Longueuri
alors
Envoyer Requête (Jeton, i) à
voisin_droiti;
Finsi
Demandeursi ?- Demandeursi + {j};
Longueuri ?- Longueuri + 1;
2
3
4
5
6
7
8
9
10
11
12 Fin
Le site racine qui reçoit une demande d'un site
dans l'arbre, il va accorder cette demande en envoyant un jeton, s'il
détient des jetons libres. Dans le cas contraire, on a deux situations :
si le nombre de jetons utilisés dans l'arbre permet de satisfaire les
requêtes reçues au bout d'un temps fini, la racine va attendre la
libération d'un jeton, si non, le site racine va demander un jeton
supplémentaire d'un voisin dans l'anneau par l'envoi d'un message de
type Requête, dans les deux cas, la demande sera ajoutée à
la file d'attente.
Procédure 6: Réception de Requête
(Jeton, j)
1 Début
Si Jetons_libresi > 0
alors
Utiliser le plus court chemin (j);
Jetons_libresi +-
Jetons_libresi - 1;
Jetons_presentsi +- Jetons_presentsi -
1;
Sinon
Si Jetons_presentsi >
Longueuri alors
Demandeursi +- Demandeursi + {j};
Longueuri +- Longueuri + 1;
Sinon
Envoyer Requête (Jeton, j) à
voisin_droiti;
Finsi
Finsi
14 Fin
Lorsqu'un site racine reçoit une requête
d'un voisin, et il détient des jetons libres, il envoie un jeton vers le
voisin demandeur via le plus court chemin pour minimiser le nombre de messages
échangés. Si ce site ne détient pas des jetons libres,
mais le nombre de jetons dans l'arbre est suffisant pour satisfaire toutes les
requêtes au bout d'un temps fini, alors, la requête sera
ajoutée à la file d'attente. Si non, le site va simplement
propager la requête vers son voisin droit.
Procédure 7: Utiliser le plus court chemin(x :
noeud)
1 Début
Distance +- i - x;
Si Distance < 0
alors
Si Distance ~ -K / 2
alors
Envoyer Aide (Jeton, j) à
voisin_droiti;

2
3
4
5
6
7
8
9
10
11
12
13
Sinon
Envoyer Aide (Jeton, j) à
voisin_gauchei;
Finsi
Sinon
Si Distance > K /
2 alors
Envoyer Aide (Jeton, j) à
voisin_droiti;
Sinon
Envoyer Aide (Jeton, j) à
voisin_gauchei;
Finsi
Finsi

2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Fin
Cette procédure représente la
stratégie qui nous permet d'améliorer la complexité en
nombre de messages, cette procédure est utilisée pour envoyer le
jeton via le plus court chemin, le site racine qui va répondre
favorablement à la requête de son voisin, doit
calculer
la distance, qui est le nombre d'arêtes qui les
séparent, si cette distance est inférieure à
K/2, le jeton sera donc envoyé vers le voisin gauche
(retour en arrière), si non, le jeton sera envoyé vers le voisin
droit.

2
3
4
5
6
7
8
9
10
11
12
13
14
Procédure 8: Réception de Aide (Jeton,
j)
1 Début
|
2
|
Si i =6 j
alors
|
|
3
|
Utiliser le plus court chemin (j);
|
|
4
|
Sinon
|
|
5
|
|
Si Longueuri > 0
alors
|
|
6
|
|
|
Jetons_presentsi +-
Jetons_presentsi + 1;
|
|
7
|
|
|
Jeton Reçu ();
|
|
8
|
|
Sinon
|
|
9
|
|
|
Jetons_libresi +-
Jetons_libresi + 1;
|
|
10
|
|
|
Jetons_presentsi +-
Jetons_presentsi + 1;
|
|
11
|
|
Finsi
|
|
12
|
Finsi
|
|
13 Fin
|
Après l'envoi d'un jeton vers un voisin, le
jeton peut passer par plusieurs sites avant d'atteindre sa destination, ces
sites peuvent être aussi des sites demandeurs, pour cela, on doit
garantir que chaque jeton doit être utilisé par son demandeur. Le
message Aide désigne l'identité du demandeur, le site qui
reçoit ce message va comparer son identité avec celle de
demandeur qui se trouve dans le message, dans le cas où les
identités sont différentes, le site doit propager le jeton vers
le voisin adéquat en utilisant le plus court chemin.
Procédure 9: Jeton Reçu ()
1 Début
Q +-
la_tete_de_la_file_d'attente;
Supprimer la tête de la file d'attente; Longueuri +-
Longueuri - 1;
Si Q = Site_Racine
alors
Utiliser le plus court chemin (Q);
Jetons_presentsi +- Jetons_presentsi -
1;
Finsi
Si Q = Site_Simple
alors
Envoyer Accord (Jeton) à Q;
Finsi
Si Q = i
alors
Etati +-En SC;
< Entrer en Section Critique>
Finsi
15
16 Fin
Lorsqu'un site racine reçoit un jeton à
partir d'un voisin ou d'un site de l'arbre, il doit mettre à jour ses
variables locales. Si la file d'attente des sites demandeurs n'est pas vide, on
doit donc satisfaire la plus ancienne requête dans cette file en
appliquant la procédure Jeton_Reçu.
- 1er cas : la tête de la file est un
site racine, le site doit donc envoyer le jeton vers le site demandeur et doit
encore mettre à jour les deux variables : Jetons libres et Jetons
présents.
- 2ème cas : la tête de la file
d'attente est un site régulier dans l'arbre, la racine va envoyer le
jeton et mettre à jour la variable Jetons_libres.
- 3ème cas : le site demandeur est
la racine elle-même, cette situation nous amène à
décrire le comportement d'un site racine lorsqu'il désire entrer
en SC, donc il passe directement en SC.

2
3
4
5
6
7
8
9
10
11
Procédure 10: Demande de la Section Critique par
une racine
1 Début
Si Jetons_libresi > 0
alors
Jetons_libresi ?-
Jetons_libresi - 1; Etati ?-En
SC;
< Entrer en Section Critique>
Sinon
Si Jetons_presentsi = Longueuri
alors
Envoyer Requête (Jeton, i) à
voisin_droiti; Finsi
Demandeursi ?- Demandeursi + {i};
Longueuri ?- Longueuri + 1;
Finsi
12
13 Fin
Lorsqu'une racine veut entrer en SC.
Finsi
Procédure 11: Libération de la Section
Critique par une racine
1 Début
Etati +-Dehors;
Si Longueuri > 0
alors
Q +-
la_tete_de_la_file_d'attente;
Supprimer la tête de la file d'attente;
Longueuri +- Longueuri -
1;
Si Q = Site_Racine
alors
Utiliser le plus court chemin (Q);
Jetons_presentsi +-
Jetons_presentsi - 1;
Finsi
Si Q = Site_Simple
alors
Envoyer Accord (Jeton) à Q;
Finsi
Sinon
Jetons_libresi +-
Jetons_libresi + 1;

2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 Fin
Si un site racine veut libérer la SC. 3.2.6 Preuve
de l'algorithme
3.2.6.1 La K-exclusion mutuelle
Pour prouver que cet algorithme assure la K-exclusion
mutuelle, on doit assurer que K sites au plus exécutent la SC
simultanément : dans les algorithmes utilisant les jetons, seule la
possession d'un jeton permet à un site l'exécution de la SC,
puisqu'on a K jetons dans l'algorithme, alors au plus K sites peuvent entrer en
SC. la K-exclusion mutuelle est donc assurée.
3.2.6.2 Absence d'interblocage
Nous allons montrer l'absence d'interblocage par
l'absurde, on suppose que le système est en interblocage, il existe donc
un cycle des sites x1, x2, ..., xn, tel
que x1 attend un jeton de x2, x2 attend un jeton de
x3, ..., et xn attend un jeton de x1
[Lai02].
Dans l'algorithme, seules les racines peuvent demander
des jetons via l'anneau, un site racine ne demande un jeton que s'il ne peut
pas satisfaire ses requêtes locales, avant de satisfaire ses
requêtes, cette racine n'a pas le droit de stocker de nouvelles
requêtes, si ce site reçoit une requête, il va la propager
vers un voisin, le cycle donné ci-dessus ne peut jamais apparaître
dans notre algorithme. Cet algorithme est donc exempt de
l'interblocage.
3.2.6.3 Absence de la famine
Un site demandeur i sera ajouté
à la file d'attente, toutes les requêtes qui arrivent après
cette requête seront ajoutées à la fin de la file
d'attente. La famine aura lieu si ces requêtes obtiennent un jeton avant
le site i, c'est à dire, une décision injuste est faite
au niveau du site racine. Dans notre algorithme, le site racine ajoute les
requêtes dans la file d'attente selon leur ordre d'arrivée, la
tête de la file est toujours la requête la plus ancienne. Si un
jeton libre est disponible, le site racine va l'envoyer vers la tête de
la file, les autres requêtes doivent attendre la libération de ce
jeton ou la disponibilité d'un autre. Notre algorithme n'a pas de
problèmes de famine.
3.2.7 Complexité de l'algorithme en nombre de
messages
On peut distinguer deux situations selon la nature du
site demandeur, si le site demandeur est une racine et il détient un
jeton libre, il passe directement à la SC, le nombre de message
nécessaire dans ce cas est 0, si non, il va demander
à ses voisins un jeton, le nombre de message nécessaire dans ce
cas est K messages au maximum. Pour un site dans un arbre, l'entrée en
SC nécessite au minimum deux messages : un message de demande est un
autre message de réponse si la racine détient un jeton libre, si
non, le site racine doit demander un jeton supplémentaire où on a
besoin de K messages au pire des cas, donc au maximum K+2
messages seront échangés pour répondre à la
demande d'un site.
En conclusion, notre algorithme nécessite entre
0 et K+2 messages par entrée en SC, ce
qui représente une grande amélioration par rapport aux
algorithmes proposés dans ce cadre, la complexité est
donnée en fonction de K. La figure 3.3
résume la complexité de notre algorithme :
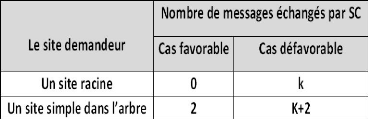
Figure 3.3 - La
complexité de notre algorithme.
Dans notre algorithme, on peut assurer la K-exclusion
mutuelle sans aucun échange de messages dans le meilleur cas, la K-EM
est assurée en échangeant K+2 messages seulement
dans le cas défavorable. On remarque que la valeur de N est absente dans
la complexité de notre algorithme.
3.3 RéSULTATS DE SIMULATION
Pour résoudre les problèmes liés
à un système donné, on fait appel à des algorithmes
ou des protocoles, ces algorithmes doivent être testés et
évalués pour les valider, et pour satisfaire leurs
insuffisances.
Vue à la difficulté de
l'implémentation réelle de notre algorithme, nous avons fait
appel à l'outil de simulation NS-2 qui a montré
sa puissance dans la simulation des systèmes
répartis.
3.3.1 Les paramètres de simulation
Afin de tirer des résultats par une simulation
on doit identifier des paramètres pouvant influencer sur le comportement
de l'algorithme, la variation de ces paramètres peut montrer son effet
sur les performances de notre algorithme.
Dans notre simulation nous avons fixé la
durée de la SC à une seconde et nous avons varié d'autres
paramètres ce qui nous permet d'obtenir les scénarios suivants
:
- Scénario 1 : Variation du nombre de
requêtes.
Nous avons varié le nombre de requêtes entre
5 et 40 requêtes.
- Scénario 2 : Variation du nombre de
ressources.
Nous avons varié le nombre de ressources entre
3 et 12 ressources.
- Scénario 3 : Variation du nombre de
sites
Nous avons varié le nombre de sites entre
10 et 55 sites.
Les scénarios sont illustrés dans la figure
3.4 ci-dessous :
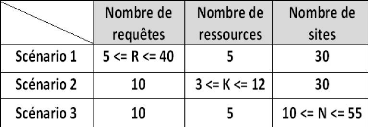
Figure 3.4 -
Variation des paramètres de simulation.
3.3.2 Evaluation de performance
Le but des différents scénarios
était d'identifier les paramètres ayant une influence sur la
performance de l'algorithme, cette performance est exprimée par deux
valeurs importantes :
- Le nombre de messages moyen (NMM) : Chaque
entrée en section critique nécessite un échange d'un
ensemble de messages, le nombre moyen de messages échangés par
entrée en section critique est calculé par la formule suivante
:
Nombre de messages total
NMM = Nombre d'entrée en
Section Critique
Cette valeur est considérée comme un
facteur important de performance des algorithmes de l'exclusion
mutuelle.
- Le temps d'attente moyen (TAM) : Un site qui demande
une section critique doit attendre un intervalle de temps appelé le
temps d'attente, le temps d'attente moyen est calculé par la formule
suivante :
?i Temps
d'attentei
TAM =
Nombre d'entrée en Section Critique
Comme le nombre moyen de messages, le temps d'attente
moyen est également l'un des facteurs importants pour
l'évaluation de la performance des algorithmes.
3.3.3 Les étapes d'un scénario
Pour réaliser un scénario donné,
nous devons introduire les différentes informations nécessaires
pour la simulation dans l'ordre suivant :
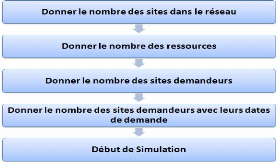
Figure 3.5 - Les
étapes de réalisation d'un scénario.
3.3.4 Résultats et interprétations
3.3.4.1 Variation du nombre de requêtes
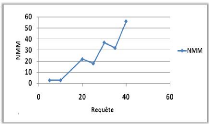
(a)
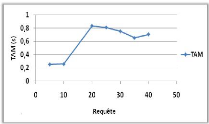
(b)
Figure 3.6 -
Influence du nombre de requête sur le NMM et TAM.
Dans la courbe (a) on remarque une augmentation du NMM
avec l'augmentation des requêtes, cette augmentation est
justifiée, car l'entrée en SC nécessite un échange
de messages, avec l'augmentation des demandes, les ressources deviennent
indisponibles, les messages de demande des autres sites tournent dans l'anneau
jusqu'à l'obtention d'une ressource, c'est la raison pour laquelle on
remarque cette augmentation.
Dans la courbe (b) on constate deux parties : une
augmentation ensuite une diminution : l'augmentation dans la courbe est
justifiée par la charge du système, les dates des demandes sont
très proches, donc plusieurs sites restent en attente. Dans la
deuxième partie, la diminution est justifiée par la sortie des
sites de leur section critique, donc les nouveaux sites demandeurs restent
moins de temps en attente.
3.3.4.2 Variation du nombre de ressources
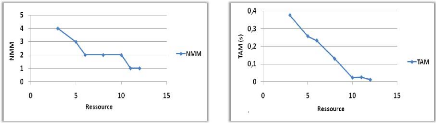
(a) (b)
Figure 3.7 -
Influence du nombre de ressource sur le NMM et TAM.
Dans la courbe (a) on remarque une diminution du
nombre de messages moyen avec l'augmentation de nombre de ressources, et on
remarque la même chose avec le temps d'attente moyen dans la courbe (b),
cela est justifié par la disponibilité des ressources (qui
dépasse même le nombre de demandes dans certains cas) qui permet
des entrées en SC avec le minimum d'échanges de messages et donc
le minimum de temps d'attente.

3.3.4.3 Variation du nombre de sites
|
|
|
|
|
|
|
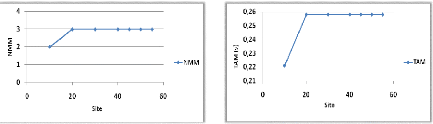
(a)
(b)
Figure 3.8 -
Influence du nombre de site sur le NMM et TAM.
Le NMM dans la courbe (a), et le TAM dans la courbe
(b) sont presque stable même avec l'augmentation du nombre de sites, une
chose qui est naturelle car les sites qui ne sont pas demandeurs n'ont pas une
influence sur le comportement de l'algorithme, on peut dire que l'augmentation
du nombre de sites n'a pas une influence sur les valeurs
étudiées.
D'après cette simulation on peut dire que le
NMM et le TAM dépendent proportionnellement de nombre de requêtes,
dépendent disproportionnellement de nombre de ressources, et
l'augmentation de nombre de sites n'a aucune influence sur le comportement de
l'algorithme.
Un problème : (le temps d'attente
moyen)
Dans notre algorithme nous avons constaté une
insuffisance concernant le TAM, ce temps augmente avec l'augmentation de
requêtes, cela est justifié par le mécanisme de
l'algorithme : lorsqu'un site racine reçoit une demande, il la
sauvegarde dans sa file d'attente en attendant la libération d'un jeton
(voir la procédure Demander SC), alors qu'il peut exister un jeton libre
au niveau d'autre site racine, si on arrive à utiliser ce jeton libre,
on pourra minimiser le temps d'attente.
Une solution proposée
Au lieu d'attendre la libération d'un jeton
utilisé, on va améliorer notre algorithme par l'utilisation d'un
nouveau message de type Recherche qui va rechercher un éventuel jeton
libre détenu par un voisin, l'utilisation de ce jeton va certainement
minimiser le temps d'attente.
3.4 AMéLIORATION N°1 (LE MESSAGE
RECHERCHE)
La forme de ce message est Recherche (Jeton, i), il sera
envoyé par une racine i pour demander un jeton
supplémentaire d'un voisin.
Pour utiliser ce message, on applique des modifications
sur la procédure Réception de Demande (Jeton,j) et l'ajout de la
procédure (Réception de Recherche (Jeton, j)) :
2
3
4
5
6
7
8
9
10
11
12
Procédure : Réception de Demande (Jeton,
j)
Amélioration N° : 1
1 Début
Si Jetons_libresi > 0
alors
Envoyer Accord (Jeton) à j;
Jetons_libresi ?-
Jetons_libresi - 1;
Sinon
Si Jetons_presentsi = Longueuri
alors
Envoyer Requête (Jeton, i) à
voisin_droiti; Sinon
Envoyer Recherche (Jeton, i) à
voisin_droiti; Finsi
Demandeursi ?- Demandeursi + {j};
Longueuri ?- Longueuri + 1;
Finsi
13
2
3
4
5
6
7
8
14 Fin
La réception du message Recherche par une racine
fait appel à la procédure suivante :
Procédure : Réception de Recherche (Jeton,
j)
Amélioration N° : 1
1 Début
Si Jetons_libresi > 0
alors
Utiliser le plus court chemin (j);
Jetons_libresi ?-
Jetons_libresi - 1;
Jetons_presentsi ?- Jetons_presentsi -
1;
Sinon
Envoyer Recherche (Jeton, j) à
voisin_droiti; Finsi
9 Fin
3.4.1 Résultats et interprétations
Après l'amélioration de notre algorithme
nous avons réalisé une nouvelle simulation par les mêmes
paramètres afin de cerner l'influence de cette amélioration sur
la performance de l'algorithme.
Remarque : le nouvel algorithme est appelé
A1. 3.4.1.1 Variation du nombre de requêtes
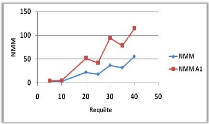
(a)
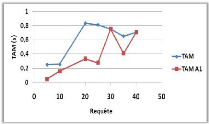
(b)
Figure 3.9 -
Influence du nombre de requête sur le NMM et TAM.
Dans la courbe (a), on remarque que le NMM de
l'algorithme amélioré dépasse le NMM du premier
algorithme, cela est justifié par l'utilisation de message
Recherche.
Cependant dans la courbe (b), nous avons réussi
à diminuer le TAM par rapport à la version
précédente car les sites demandeurs n'attendent pas la
libération des jetons utilisés mais ils vont compter sur le
message Recherche pour trouver des jetons libres au niveau des autres sites
voisins.
3.4.1.2 Variation du nombre de ressources
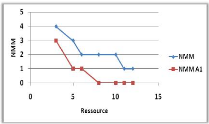
(a)
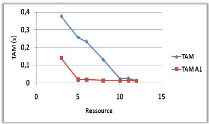
(b)
Figure 3.10 -
Influence du nombre de ressource sur le NMM et TAM.
La courbe (a) montre que le nombre de messages
échangés NMM-A1 est nettement meilleurs que la
version précédente cela est du à l'utilisation du nouveau
message Recherche qui a permis d'éviter le mouvement infini des messages
Requête, car les jetons
libres sont très rapidement
localisés.
On remarque dans la courbe (b) que le TAM-A1
est meilleur que le TAM grâce au message Recherche.
3.4.1.3 Variation du nombre de sites
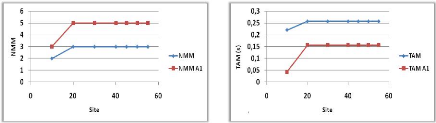
(a) (b)
Figure 3.11 -
Influence du nombre de site sur le NMM et TAM.
Nous savons que la variation du nombre des sites n'a
pas une influence sur l'algorithme, malgré ça on remarque une
diminution du TAM-A1 dans la courbe (b), l'augmentation du
NMM-A1 dans la courbe (a) est justifié par
l'utilisation du message Recherche.
Avec l'utilisation du nouveau message Recherche, on
remarque bien qu'on a pu minimiser le temps d'attente moyen.
Un problème : (nombre moyen de
messages)
Dans le premier algorithme étudié nous
avons constaté que le NMM à une valeur un peu
élevée car la réponse à une demande doit passer par
le plus court chemin dans l'anneau, si le nombre de racines augmente on aura
une nette augmentation de NMM, d'une autre part nous savons que le
réseau du système est complet, il vaut mieux donc exploiter cette
caractéristique afin de minimiser le NMM.
Une solution proposée
Au lieu de passer par plusieurs éléments
dans l'anneau le message Aide sera envoyé directement vers le site
demandeur, cela peut minimiser le NMM.
3.5 AMéLIORATION N°2 (ANNULER LA
MéTHODE {UTILISER LE PLUS COURT CHEMIN})
Pour mettre en place cette amélioration, on
applique les modifications suivantes :
2
3
4
5
6
7
8
Procédure : Réception de Requête
(Jeton, j)
|
2
|
Amélioration
1 Début
N° 2
Si Jetons_libresi > 0
alors
|
|
3
|
|
Envoyer Aide (Jeton, j) à j;
|
|
4
|
|
Jetons_libresi ?-
Jetons_libresi - 1;
|
|
5
|
|
Jetons_presentsi ?-
Jetons_presentsi - 1;
|
|
6
|
Sinon
|
|
7
|
|
Si Jetons_presentsi >
Longueuri alors
|
|
8
|
|
|
Demandeursi ?- Demandeursi +
{j};
|
|
9
|
|
|
Longueuri ?- Longueuri +
1;
|
|
10
|
|
Sinon
|
|
11
|
|
Envoyer Requête (Jeton, j) à
voisin_droiti;
|
|
12
|
|
Finsi
|
|
13
|
Finsi
|
14 Fin
Procédure : Réception de Recherche (Jeton,
j)
Amélioration N° 2
1 Début
Si Jetons_libresi > 0
alors
Envoyer Aide (Jeton, j) à j;
Jetons_libresi ?-
Jetons_libresi - 1;
Jetons_presentsi ?- Jetons_presentsi -
1;
Sinon
Envoyer Recherche (Jeton, j) à
voisin_droiti; Finsi
2
3
4
5
6
7
8
9 Fin
Procédure : Réception de Aide (Jeton,
j)
Amélioration N° 2
1 Début
Si Longueuri > 0
alors
Jetons_presentsi ?-
Jetons_presentsi + 1; Jeton Reçu
();
Sinon
Jetons_libresi ?-
Jetons_libresi + 1;
Jetons_presentsi ?- Jetons_presentsi +
1;
Finsi
9 Fin

2
3
4
5
6
7
8
9
10
11
12
13
14
Procédure : Jeton Reçu ()
Amélioration N° 2
1 Début
Q ?-
la_tete_de_la_file_d'attente;
Supprimer la tête de la file d'attente;
Longueuri ?- Longueuri - 1;
Si Q = Site_Racine
alors
Envoyer Aide (Jeton, j) Q;
Jetons_presentsi ?-
Jetons_presentsi - 1;
Finsi
Si Q = Site_Simple
alors
Envoyer Accord (Jeton) à Q;
Finsi
Si Q = i
alors
Etati ?-En SC;
< Entrer en Section Critique>
Finsi
15

2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Fin
Procédure : Libération de la Section
Critique par une racine
Amélioration N° 2
1 Début
Etati ?-Dehors;
Si Longueuri > 0
alors
Q ?-
la_tete_de_la_file_d'attente;
Supprimer la tête de la file d'attente;
Longueuri ?- Longueuri - 1;
Si Q = Site_Racine
alors
Envoyer Aide (Jeton, j) Q;
Jetons_presentsi ?-
Jetons_presentsi - 1;
Finsi
Si Q = Site_Simple
alors
Envoyer Accord (Jeton) à Q;
Finsi
Sinon
Jetons_libresi ?-
Jetons_libresi + 1;
Finsi
16
17 Fin
3.5.1 Résultats et interprétations
Cette nouvelle amélioration a été
validée par une simulation qui nous a permis d'obtenir les
résultats suivants :
3.5.1.1 Variation du nombre de requêtes
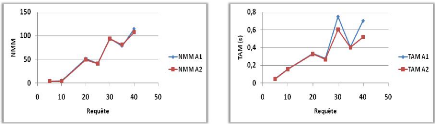
(a)
(b)
Figure 3.12 -
Influence du nombre de requête sur le NMM et TAM. 3.5.1.2
Variation du nombre de ressources
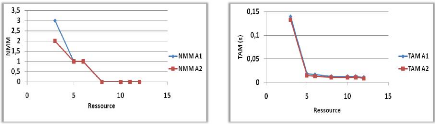
(a)
(b)
Figure 3.13 - Influence du nombre de ressource sur le
NMM et TAM. 3.5.1.3 Variation du nombre de sites

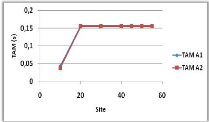
(b)
Figure 3.14 -
Influence du nombre de site sur le NMM et TAM.
L'utilisation de cette amélioration a
donnée des résultats presque identiques avec les autres
algorithmes, cela peut être justifié par la taille limitée
de l'anneau, l'avantage de cette amélioration peut apparaître avec
plusieurs racines et plusieurs demandes à la fois. Par conséquent
il nous reste toujours à résoudre le problème de NMM
élevé.
Un problème : (nombre moyen de
messages)
Puisque l'amélioration précédente
n'avait pas une grande influence sur la performance de notre algorithme, nous
devons penser à une nouvelle amélioration permettant de minimiser
le NMM.
Lorsqu'on remarque le comportement de notre algorithme
on constate que le NMM élevé est causé par le mouvement
perpétuel et inutile des messages Requête et Recherche surtout
lorsqu'il y a plusieurs demandes, si on arrive à éviter ce
mouvement perpétuel on pourra minimiser le NMM.
Une solution proposée
Puisque les demandes sont sauvegardées au
niveau des racines, il est inutile de continuer à tourner dans l'anneau
car le jeton ne sera envoyé qu'après sa libération, pour
cela le message Requête et Recherche seront arrêtés s'ils
arrivent à la racine qui les a initié.
3.6 AMéLIORATION N°3 (ARRêT DES
MOUVEMENTS INUTILES)
Cette amélioration nécessite des
changements au niveau de la procédure Réception de Requête
(Jeton, j) (ligne 11) et la procédure Réception
de Recherche (Jeton, j) (ligne 7).
Procédure : Réception de Requête
(Jeton, j)
Amélioration N° : 3 1
Début
|
2
|
Si Jetons_libresi > 0
alors
|
|
3
|
|
Envoyer Aide (Jeton, j) à j;
|
|
4
|
|
Jetons_libresi ?-
Jetons_libresi - 1;
|
|
5
|
|
Jetons_presentsi ?-
Jetons_presentsi - 1;
|
|
6
|
Sinon
|
|
7
|
|
Si Jetons_presentsi >
Longueuri alors
|
|
8
|
|
|
Demandeursi ?- Demandeursi +
{j};
|
|
9
|
|
|
Longueuri ?- Longueuri +
1;
|
|
10
|
|
Sinon
|
|
11
|
|
|
Si i =6 j
alors
|
|
12
|
|
|
Envoyer Requête (Jeton, j) à
voisin_droiti;
|
|
13
|
|
|
Finsi
|
|
14
|
|
Finsi
|
|
15
|
Finsi
|
16 Fin
Procédure : Réception de Recherche (Jeton,
j)
Amélioration N° : 3
1 Début
Si Jetons_libresi > 0
alors
Envoyer Aide (Jeton, j) à j;
Jetons_libresi +-
Jetons_libresi - 1;
Jetons_presentsi +- Jetons_presentsi -
1;
Sinon
Si i =6 j
alors
Envoyer Recherche (Jeton, j) à
voisin_droiti;
Finsi
Finsi

2
3
4
5
6
7
8
9
10
11 Fin
3.6.1 Résultats et interprétations
Cette nouvelle amélioration a été
validée par une simulation et a donnée les résultats
suivants.
3.6.1.1 Variation du nombre de requêtes
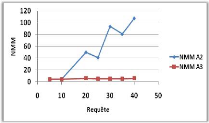
(a)
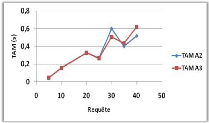
(b)
Figure 3.15 -
Influence du nombre de requête sur le NMM et TAM.
Dans la courbe (a) il est clair que le nombre de messages
échangés a été amélioré de
façon considérable dans NMM-A3, grâce
à la nouvelle amélioration.
Cependant dans la courbe (b) le TAM A3
est presque identique aux autres temps car le but de
l'amélioration était de réduire le nombre de messages
échangés et cela n'accélère pas l'échange
des jetons.
3.6.1.2 Variation du nombre de ressources
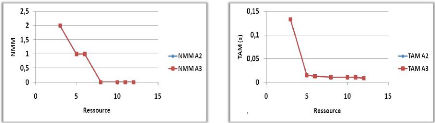
(a) (b)
Figure 3.16 -
Influence du nombre de ressource sur le NMM et TAM.
On remarque que le résultat obtenu est
identique aux résultats précédents car la
disponibilité des ressources permet de satisfaire les demandes sans
avoir besoin de propager inutilement les messages Requête et
Recherche.
3.6.1.3 Variation du nombre de sites
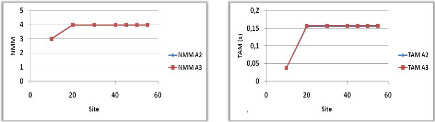
(a) (b)
Figure 3.17 -
Influence du nombre de site sur le NMM et TAM.
Puisque la variation du nombre de sites n'a pas une
influence sur le comportement du système nous avons obtenu les
mêmes résultats avec cette simulation.
3.7 LES COURBES FINALE ET COMPARAISON
3.7.1 Variation du nombre de requêtes
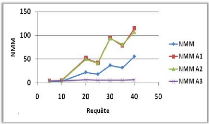
(a)
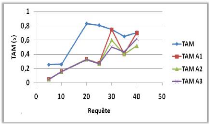
(b)
Figure 3.18 -
Influence du nombre de requête sur le NMM et TAM.
3.7.2 Variation du nombre de ressources
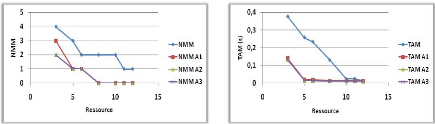
(a)
(b)
Figure 3.19 -
Influence du nombre de ressource sur le NMM et TAM.
3.7.3 Variation du nombre de sites
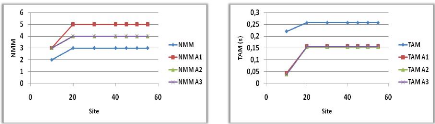
(a)
(b)
Figure 3.20 -
Influence du nombre de site sur le NMM et TAM.
3.8 CONCLUSION
D'après ces courbes on peut dire qu'on a
arrivé à une performance très acceptable en utilisant
toutes ces amélioration, il est clair que les résultats obtenus
avec l'amélioration 3 sont les meilleurs car cette
dernière amélioration utilise les améliorations
précédentes.
3.9 LA TOLéRANCE AUX PANNES
La simulation réalisée montre bien la
performance de notre algorithme, dans cet algorithme nous avons supposé
que les sites ne tombent pas en panne, mais dans la réalité le
système peut souffrir des éventuelles pannes, c'est la raison
pour laquelle nous avons pensé à intégrer la
tolérance aux pannes dans l'algorithme A3 qui a
donné les meilleurs résultats afin d'exploité sa
performance.
3.9.1 L'idée de base
Dans notre algorithme nous avons deux types de sites,
les sites simples et les sites racines, les informations nécessaires
pour la gestion des accès à la section critique se trouvent au
niveau des racines. Donc la panne qui peut poser un problème est la
panne de l'une des racines, les sites simples n'auront pas une influence sur le
comportement du système s'ils tombent en panne, il nous faut donc
d'avoir un moyen permettant de préserver les informations détenus
par les racines pour pouvoir les récupérer en cas de
panne.
L'idée de base de notre algorithme consiste
à désigner un site particulier dans l'arbre appelé
Sous_Racine. Le rôle de ce site consiste à stocker une copie
dupliquée des informations qui se trouvent au niveau de sa racine, ces
informations sont envoyées par la racine vers son Sous_Racine
après chaque mise à jour, en cas de panne d'une racine, les
informations stockées au niveau du Sous_Racine lui permettent de prendre
la place de la racine sans aucun problème et donc le système
continue à fonctionner normalement.
Le choix du Sous_Racine se fait en utilisant les
identités, on va choisir le site ayant la plus petite identité
dans l'arbre.
Si un Sous_Racine tombe en panne, la racine va
désigner tout simplement un nouveau Sous_Racine.
3.9.2 Description de l'algorithme
3.9.2.1 Les variables locales
Les sites vont utilisés les mêmes
variables locales sauf la racine qui va utiliser une nouvelle variable locale
(Sous_racine), tel que pour une Racinei, Sous_Racinei
= i+K. Si le Sous_Racine tombe en panne,
Sous_Racinei devient i+2K.
3.9.2.2 Les messages utilisés
Dans cette version on utilise les mêmes messages de
l'ancien algorithme et on ajoute deux nouveaux messages.
- Information : ce message contient les valeurs des
variables locales de la racine qui permettent au Sous_Racine de prendre la
relève en cas de panne de la racine, ces
informations sont : les identités des voisins
gauche et droit, le nombre de jetons libres et présents, ainsi que la
file d'attente Demandeursi.
- Nouveau_Racine (i, j) : envoyé par le
Sous_Racine j en cas d'une panne de la racine pour informer ces fils
de l'arbre ainsi que ces voisins qu'il va prendre la place de leur racine
originale.
3.9.2.3 Les procédures de l'algorithme
- Chaque racine va envoyer un message Information
à son Sous_Racine après chaque mise à jour de ses
variables locales.
- Le Sous_Racinei doit mettre à
jour toutes ces variables après chaque réception d'un message
Information.
- La panne d'un site simple ne provoque aucune action
sauf si ce dernier détient un jeton, dans ce cas le site racine doit
générer un nouveau jeton.
- Lorsque le Sous_Racinei tombe en
panne, la racine doit désigner un nouveau Sous_Racinej
dont l'identité sera i + 2*K, ensuite la racine
envoie un message de type Information à ce nouveau
Sous_Racinej.
- Lorsque la racine tombe en panne, le
Sous_Racinej détecte cette panne, et doit prendre sa
place en exécutant la procédure suivante :
Racinej +- Nil.
voisin_droitj +-
voisin_droiti.
voisin_gauchej +-
voisin_gauchei.
Envoyer Nouveau_Racine (i, j) à
voisin_droitj.
Envoyer Nouveau_Racine (i, j) à
voisin_gauchej.
Envoyer Nouveau_Racine (i, j) à tous les
éléments de l'arbre.
- Lorsque les membres de l'arbre reçoivent le
message de type Nouveau_Racine (i, j), ils doivent modifier l'identité
de leur racine.
Racinep +- j.
- Lorsque les voisins reçoivent le message de type
Nouveau_Racine (i, j), ils doivent mettre à jour leur nouveau
voisin.
- Au niveau du voisin gauche: voisin_droiti
+- j.
- Au niveau du voisin droit : voisin_gauchei
+- j.
- Lorsque la racine revient d'une panne, le
Sous_Racine va informer les voisins ainsi que tous les membres de l'arbre que
la racine va prendre sa place initiale en réalisant les taches suivantes
:
Envoyer Nouveau_Racine (j, i) à
voisin_droitj.
Envoyer Nouveau_Racine (j, i) à
voisin_gauchej.
Envoyer Nouveau_Racine (j, i) à tous les
éléments de l'arbre.
3.9.3 Résultats et interprétations
Afin d'étudier la performance de ce nouvel
algorithme, nous avons réalisé une simulation par les mêmes
paramètres précédents et on a fixé le nombre de
pannes à trois pannes dans chaque scénario.
3.9.3.1 Variation du nombre de requêtes
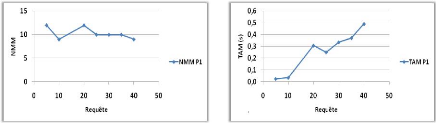
(a) (b)
Figure 3.21 -
Influence du nombre de requête sur le NMM et TAM. 3.9.3.2
Variation du nombre de ressources
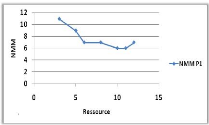
(a)
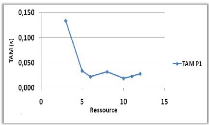
(b)
Figure 3.22 -
Influence du nombre de ressource sur le NMM et TAM.
3.9.3.3 Variation du nombre de sites
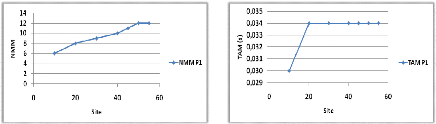
(a)
(b)
Figure 3.23 -
Influence du nombre de site sur le NMM et TAM.
D'après les courbes obtenues on remarque que le
nouvel algorithme propose a respecte le même comportement avec
l'algorithme initial, on peut dire donc que la tolerance aux pannes n'a pas
influence sur la performance de notre algorithme.
Il faut comme même dire qu'il y a une faible
augmentation dans le NMM, cela est justifie par l'echange continu des messages
Information et Nouveau_Racine.
Un problème : (Nombre de messages un peu
élevé)
Malgre que la solution precedente a rendu notre
algorithme tolerant aux pannes, nous avons remarque que le nombre de message
echanges de cet algorithme depasse celui de l'algorithme initial, cela est
justifie par les messages Information et Nouveau_Racine qui sont important pour
assurer la tolerance aux pannes, et par les autres messages echanges lorsqu'une
racine revient de son etat de panne.
Une solution proposée
Puisque le Sous_Racine peut remplacer son racine en
cas de panne sans aucun problème, il parait inutile que la racine
defaillante reprends sa place lorsqu'elle revient de l'etat de panne, donc on
peut eviter l'echange eleve de messages en respectant la même racine et
en considerant l'ancien racine comme un site simple. Cette amelioration va nous
permettre de minimiser le NMM, tout en gardant la performance de l'algorithme
A3.
3.10 AMtLioRATioN (ALGoRiTHME ToLtRANT AuX pANNEs
AMtLioRt) Nous allons effectuer le changement suivant :
- Lorsque la racine revient de son etat de panne, elle
sera consideree comme un site simple, ses prochaines requêtes seront
demandees de la racine de son arbre.
3.10.1 Résultats et interprétations
3.10.1.1 Variation du nombre de requêtes
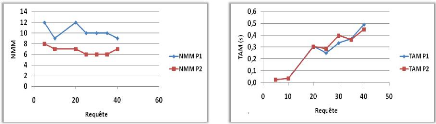
(a) (b)
Figure 3.24 -
Influence du nombre de requête sur le NMM et TAM.
3.10.1.2 Variation du nombre de ressources
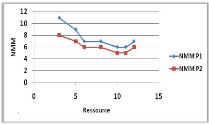
(a)
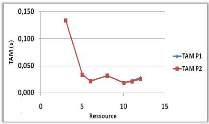
(b)
Figure 3.25 -
Influence du nombre de ressource sur le NMM et TAM.
3.10.1.3 Variation du nombre de sites
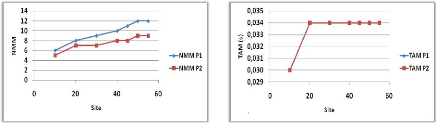
(a) (b)
Figure 3.26 -
Influence du nombre de site sur le NMM et TAM.
Le but de notre amélioration était de
minimiser le NMM, une chose qui a été atteinte comme on remarque
dans toutes les courbes, on constate que le NMM de l'algorithme
amélioré est meilleur que celui du
1er algorithme tolérant aux
pannes.
Il est clair que le TAM est pratiquement identique car le
but de l'amélioration vise de minimiser le NMM sans avoir besoin de
changer le comportement de l'algorithme.
CONCLUSION
À travers notre étude comparative mener
dans ce chapitre, nous avons pu améliorer notre algorithme initial d'une
façon incrémentale jusqu'à l'obtention d'une version
très performante en nombre de messages échangés et en
temps d'attente.
La performance prouvée de notre algorithme nous
a motivé à introduire un nouveau concept dans l'algorithme pour
le rendre tolérant aux pannes, cette amélioration a permis au
système de continuer à fonctionner même en présence
de pannes tout en gardant la performance de notre algorithme.
D'après l'étude réalisée on
peut conclure que :
- Le NMM et le TAM dépendent proportionnellement
du nombre de requêtes.
- Le NMM et le TAM dépendent
disproportionnellement du nombre de ressources. - La variation du nombre de
sites n'a pas une influence sur le NMM et le TAM.
SIMULATION DE L'ALGORITHME DANS 4
LES RéSEAUX AD HOC
SOMMAIRE
|
4.1 INTRODUCTION
4.2 L'ALGORITHME
|
64
64
|
|
4.2.1 Hypothèses
du Système
|
64
|
|
4.2.2 Les
procédures de l'algorithme
|
64
|
|
4.2.3 Paramètres
de simulation
|
69
|
|
4.2.3.1
Les paramètres fixes
|
69
|
|
4.2.3.2
Les paramètres variables
|
69
|
|
4.2.4 Résultats
et interprétations
|
70
|
|
4.2.4.1
Variation du nombre de demandeurs
|
70
|
|
4.2.4.2
Variation de la portée de communication
|
71
|
|
4.2.4.3
Variation de la vitesse de mouvement
|
71
|
|
4.2.4.4
Variation du nombre de noeuds
|
72
|
|
4.2.5 Conclusion
|
72
|
|
4.3 TOLéRANCE AUX PANNES
|
72
|
|
4.3.1 Résultats
et interprétations
|
73
|
|
4.3.1.1
Variation du nombre de demandeurs
|
73
|
|
4.3.1.2
Variation de la portée de communication
|
73
|
|
4.3.1.3
Variation de la vitesse de mouvement
|
73
|
|
4.3.1.4
Variation du nombre de noeuds
|
74
|
|
CONCLUSION
|
74
|
D
ANS ce chapitre, nous présentons les
résultats obtenus par la simulation d'un algorithme de la K-exclusion
mutuelle tolérant aux pannes dans les réseaux AD HOC.
4.1 INTRODUCTiON
Le problème de la K-exclusion mutuelle n'est
pas bien traité dans les réseaux mobiles AD HOC, c'est pourquoi
il n y a pas beaucoup d'algorithmes qui sont proposé pour
résoudre ce problème dans un tel environnement.
Dans ce chapitre, nous allons simuler la
dernière version améliorée de notre algorithme de la
K-exclusion mutuelle ainsi que la version améliorée
tolérante aux fautes dans le milieu des réseaux mobiles AD HOC
afin de mieux connaître les facteurs influent sur ces performances dans
cet environnement, enfin nous allons interpréter les courbes obtenues
à partir de ces simulations.
4.2 L'ALGORiTHME
La
3ème version
améliorée de notre algorithme dans les réseaux filaires
possède pas mal d'avantages, ces avantages nous a encouragé
à utiliser son principe afin de résoudre le problème de la
K-exclusion mutuelle dans les réseaux AD HOC.
On va utiliser le même principe de l'algorithme
mais on va respecter les caractéristiques des réseaux AD HOC tels
que la mobilité des noeuds, la communication sans fil...
etc.
4.2.1 Hypothèses du Système
Pour assurer le bon fonctionnement de notre algorithme,
on suppose que :
- Le nombre N des noeuds et le K des racines sont connus.
- Chaque noeud connaît ses voisins immédiats.
- La communication est fiable.
- Les noeuds ne tombent pas en panne.
- Le réseau n'est pas
partitionné.
4.2.2 Les procédures de l'algorithme
Procédure : Demander la Section
Critique
Environnement : AD HOC
1 Début
2
3
Etati ?-Demandeur;
Envoyer Demande (Jeton, i) à Racinei; 4
Fin

2
3
2
3
Finsi
Procédure : Réception de Accord
(Jeton)
Environnement : AD HOC
1 Début
Etati ?-En SC;
< Entrer en Section Critique>
4 Fin
Procédure : Libérer la Section
Critique
Environnement : AD HOC 1 Début
Etati ?-Dehors;
Envoyer Libération (Jeton) à
Racinei;
4 Fin
Procédure : Réception de Demande (Jeton,
j)
Environnement : AD HOC
1 Début
Si Jetons_libresi > 0
alors
Envoyer Accord (Jeton) à j;
Jetons_libresi ?-
Jetons_libresi - 1;
Sinon
Si Jetons_presentsi = Longueuri
alors
Envoyer Requête (Jeton, i) à
voisin_droiti;
Sinon
Envoyer Recherche (Jeton, i) à
voisin_droiti;
Finsi
Demandeursi ?- Demandeursi +
{j};
Longueuri ?- Longueuri +
1;
2
3
4
5
6
7
8
9
10
11
12
13
14 Fin
Procédure : Réception la Recherche (Jeton,
j)
Environnement : AD HOC
1 Début
Si Jetons_libresi > 0
alors
Envoyer Aide (Jeton, j) à j;
Jetons_libresi ?-
Jetons_libresi - 1;
Jetons_presentsi ?- Jetons_presentsi -
1;

2
3
4
5
6
7
8
9
10
Sinon
Si i =6 j
alors
Envoyer Recherche (Jeton, j) à
voisin_droiti; Finsi
Finsi
11 Fin
Procédure : Réception de Requête
(Jeton, j)
Environnement : AD HOC 1 Début
|
2
|
Si Jetons_libresi > 0
alors
|
|
3
|
|
Envoyer Aide (Jeton, j) à j;
|
|
4
|
|
Jetons_libresi ?-
Jetons_libresi - 1;
|
|
5
|
|
Jetons_presentsi ?-
Jetons_presentsi - 1;
|
|
6
|
Sinon
|
|
7
|
|
Si Jetons_presentsi >
Longueuri alors
|
|
8
|
|
|
Demandeursi ?- Demandeursi +
{j};
|
|
9
|
|
|
Longueuri ?- Longueuri +
1;
|
|
10
|
|
Sinon
|
|
11
|
|
|
Si i =6 j
alors
|
|
12
|
|
|
Envoyer Requête (Jeton, j) à
voisin_droiti;
|
|
13
|
|
|
Finsi
|
|
14
|
|
Finsi
|
|
15
|
Finsi
|
16 Fin
2
3
4
5
6
7
8
Procédure : Réception de Aide (Jeton,
j)
Environnement : AD HOC
1 Début
Si Longueuri > 0
alors
Jetons_presentsi +-
Jetons_presentsi + 1; Jeton Reçu
();
Sinon
Jetons_libresi +-
Jetons_libresi + 1;
Jetons_presentsi +- Jetons_presentsi +
1;
Finsi
2
3
4
5
6
9 Fin
Procédure : Réception de Libération
(Jeton)
Environnement : AD HOC
1 Début
Si Longueuri > 0
alors Jeton Reçu ();
Sinon
Jetons_libresi +-
Jetons_libresi + 1;
Finsi

2
3
4
5
6
7
8
9
10
11
12
13
14
7 Fin
Procédure : Jeton Reçu ()
Environnement : AD HOC
1 Début
Q +-
la_tete_de_la_file_d'attente;
Supprimer la tête de la file d'attente;
Longueuri +- Longueuri - 1;
Si Q = Site_Racine
alors
Envoyer Aide (Jeton, j) à Q;
Jetons_presentsi +-
Jetons_presentsi - 1;
Finsi
Si Q = Site_Simple
alors
Envoyer Accord (Jeton) à Q;
Finsi
Si Q = i
alors
Etati +-En SC;
< Entrer en Section Critique>
Finsi
15
16 Fin

Finsi
Finsi
Procédure : Demande de la Section Critique par une
racine
Environnement : AD HOC
1 Début
Si Jetons_libresi > 0
alors
Jetons_libresi ?-
Jetons_libresi - 1;
Etati ?-En SC;
< Entrer en Section Critique>
Sinon
Si Jetons_presentsi = Longueuri
alors
Envoyer Requête (Jeton, i) à
voisin_droiti;
Finsi
Demandeursi ?- Demandeursi +
{i};
Longueuri ?- Longueuri +
1;
13 Fin
Procédure : Libération de la Section
Critique par une racine
Environnement : AD HOC
1 Début
Etati ?-Dehors;
Si Longueuri > 0
alors
Q ?-
la_tete_de_la_file_d'attente;
Supprimer la tête de la file d'attente;
Longueuri ?- Longueuri -
1;
Si Q = Site_Racine
alors
Envoyer Aide (Jeton, j) à Q;
Jetons_presentsi ?-
Jetons_presentsi - 1;
2
3
4
5
6
7
8
9
10
11
12
Finsi
Si Q = Site_Simple
alors
Envoyer Accord (Jeton) à Q;
Finsi
Sinon
Jetons_libresi ?-
Jetons_libresi + 1;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 Fin
4.2.3 Paramètres de simulation
Pour réaliser une simulation, plusieurs
paramètres doivent être définis, certains paramètres
sont fixes et ne changent pas durant toute la simulation, d'autre sont
variables et leur changement permet d'obtenir un nouveau scénario de
simulation à chaque fois.
La variation des paramètres nous permet
d'identifier ceux ayant une influence sur la performance de notre
algorithme.
4.2.3.1 Les paramètres fixes
- Surface de réseau : c'est l'intervalle maximal
utilisé par les noeuds pendant leurs mouvements, nous avons choisi une
surface de 500m*500m.
- La durée de la SC : c'est la durée
d'exécution d'une SC par un site, nous avons fixé cette valeur
à 1 seconde.
- Protocole de routage : le protocole de routage
permet de définir les chemins entre les noeuds pour échanger des
messages. Nous pouvons choisir un protocole déjà
implémenté sur NS-2, ce protocole peut
être proactif ou réactif, les protocoles proactifs ne sont pas
adéquats pour notre simulation car ils nécessitent la
création de la table de routage avant de lancer la communication, nous
devrons alors choisir un protocole réactif. Parmi les protocoles
implanté sur NS-2, on a AODV et DSR .nous avons choisi
Le protocole DSR car il nous a permis de déterminer automatiquement les
routes nécessaires à la communication entre les noeuds, et permet
également d'assurer la correction des routes tout au long de leur
utilisation.
- Modèle de propagation: Dans
NS-2, trois modèles de propagation sont
implémentés : Free Space, Shadowing, Two-ray-ground. Dans notre
simulation, le modèle two-ray-ground est choisi comme modèle de
propagation, car ce modèle est devenu un standard dans la recherche sur
les réseaux mobiles.
- Modèle de mobilité : NS-2
offre quelques modèles de mobilité basés sur la
génération aléatoire des positions des noeuds. Parmi ces
modèles, on peut citer Random WayPoint, Random Walk, Random Direction
model, nous avons choisi le modèle Random WayPoint, car dans ce
modèle, les noeuds sont distribués uniformément dans
l'espace de simulation, leurs positions initiales sont aléatoire ainsi
que leurs déplacements.
4.2.3.2 Les paramètres variables
Nous avons changé à chaque fois le
nombre de noeuds, le nombre de demandeurs, la portée de communication
ainsi que la vitesse de déplacement, ces changements permettent d'avoir
différents scénarios.
- Scénario 1 : Variation du nombre de
demandeurs
Dans ce scénario nous avons varié le nombre
de demandeurs entre 3 et 18.
- Scénario 2 : Variation de la portée de
communication
Nous avons varié la portée de communication
entre 200 et 500 mètres.
- Scénario 3 : Variation de la vitesse de
mouvement
Dans ce cas la vitesse de mouvement est variable entre
1 et 8 m/s.
- Scénario 4 : Variation du nombre de
noeuds
Ce scénario a connu la variation du nombre de
noeuds entre 30 et 90.
Nous pouvons illustrer les quatre scénarios dans
la figure 4.1 ci dessous.
Figure 4.1 -
Variation des paramètres de simulation.
4.2.4 Résultats et interprétations
Notre algorithme a été validé par
une simulation qui a utilisée les scénarios
précédents. Cette simulation nous a permis de tirer un ensemble
de résultats intéressants.

4.2.4.1 Variation du nombre de demandeurs
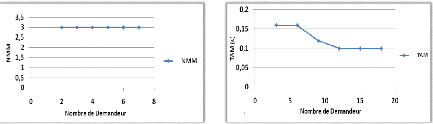
(a)
(b)
Figure 4.2 -
Influence du nombre de demandeurs sur le NMM et le TAM.
Dans la courbe (a) on remarque que le nombre de
message échangés est fixe, cela est justifié par un
échange constant de message pour chaque entrée en section
critique, il faut mentionner que le nombre de messages compté est le
nombre de messages logique, c'est-à-dire on considère tous les
sauts entre la source et la destination comme étant un seul
message.
Par contre dans la courbe (b), la variation du TAM est
justifiée par les positions des noeuds, lorsque le noeud demandeur est
loin de sa racine, le jeton nécessite plus de temps pour atteindre sa
destination par contre lorsqu'un noeud est proche de sa racine la requête
sera satisfaite dans un temps limité.
4.2.4.2 Variation de la portée de
communication
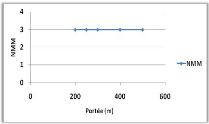
(a)
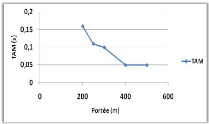
(b)
Figure 4.3 -
Influence de la portée de communication sur le NMM et le
TAM.
Après la variation de la portée de
communication nous constatons bien que dans la courbe (a), rien n'est
changé, le NMM reste fixe, car on s'intéresse au nombre de
messages logiques.
Par contre dans la courbe (b), le résultat est
clair, une diminution du temps d'attente après chaque augmentation de la
portée de communication, cela est dû à l'augmentation du
nombre de voisins immédiats par l'augmentation de la
portée.
4.2.4.3 Variation de la vitesse de mouvement
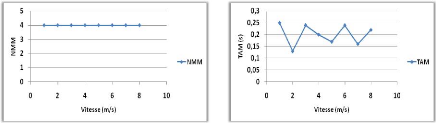
(a)
(b)
Figure 4.4 -
Influence de la vitesse de mouvement sur le NMM et le TAM.
Il est clair que dans la courbe (a), le NMM est stable
malgré la variation de la vitesse de déplacement et cela peut
être justifié par le mécanisme utilisé par
l'algorithme, donc le NMM n'a pas de relation avec la vitesse.
Dans la courbe (b), nous remarquons que le TAM n'a pas
une relation clair avec la variation de la vitesse, mais on peut dire qu'il est
presque stable (varie entre 0,15 et
0,25).
4.2.4.4 Variation du nombre de noeuds
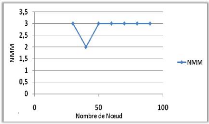
(a)
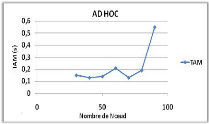
(b)
Figure 4.5 -
Influence du nombre de noeuds sur le TAM et NMM.
On voit dans la courbe (a) que le NMM est fixe dans la
plupart du temps.
Par contre dans la courbe (b) le résultat est
sans appel, une augmentation du TAM avec l'augmentation de noeuds, cela est
justifié par le nombre de sauts important effectué par le jeton
qui va retarder son arrivée à la destination.
4.2.5 Conclusion
D'après les courbes obtenues, nous avons
remarqué que notre algorithme a gardé pratiquement la performance
de sa version des réseaux filaire malgré les
caractéristiques des réseaux AD HOC telles que la
mobilité, la portée, ou la communication sans fil, ce n'est pas
étonnant car les réseaux AD HOC ne sont qu'un type particulier
des systèmes répartis.
4.3 TOLéRANCE AUX PANNES
La version améliorée de notre algorithme
tolérant aux pannes dans les systèmes répartis a
donnée la meilleure performance dans les tests effectués et cela
nous a motivés à utiliser son principe pour résoudre le
problème de la tolérance aux pannes dans les réseaux AD
HOC.
Le même principe de l'algorithme
amélioré tolérant aux pannes sera utilisé,
cependant on va respecter les caractéristiques des réseaux AD
HOC.
4.3.1 Résultats et interprétations
L'algorithme est validé par une simulation avec
les mêmes paramètres précédents et on a fixé
le nombre de pannes à trois dans chaque scénario.
4.3.1.1 Variation du nombre de demandeurs
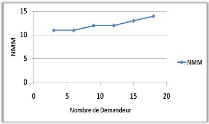
(a)
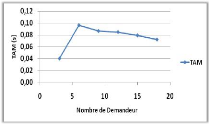
(b)
Figure 4.6 -
Influence du nombre de demandeurs sur le NMM et le TAM. 4.3.1.2
Variation de la portée de communication
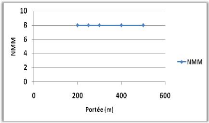
(a)
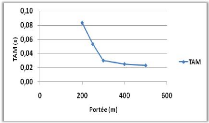
(b)
Figure 4.7 - Influence de la portée de
communication sur le NMM et le TAM.
4.3.1.3 Variation de la vitesse de mouvement
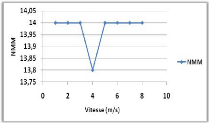
(a)
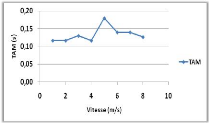
(b)
Figure 4.8 -
Influence de la vitesse de mouvement sur le NMM et le TAM.
4.3.1.4 Variation du nombre de noeuds
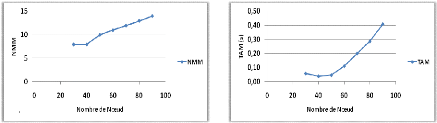
(a)
(b)
Figure 4.9 -
Influence du nombre de noeuds sur le TAM et NMM.
En générale l'algorithme tolérant
aux pannes a respecté le même comportement que l'algorithme
initial.
Cependant il ne faut pas négliger
l'augmentation du NMM dans certains courbes, tels que la variation du nombre de
noeuds ou la variation du nombre de demandeurs, cette augmentation est
justifiée par l'utilisation des messages Information et
Nouveau_Racine.
CONCLUSION
La simulation de notre algorithme dans les
réseaux mobile nous a permis d'identifier les paramètres ayant
une influence sur la performance de notre algorithme, nous avons pu tirer les
résultats suivants :
- La variation du nombre de demandeurs n'a pas une
influence sur le NMM et le TAM.
- Le TAM dépends disproportionnellement de la
portée de communication.
- La vitesse de mouvement n'a pas une relation claire
avec le NMM et le TAM. - La variation du nombre de noeuds a une relation
proportionnelle avec le TAM.
- La variation de la portée ou du nombre de
noeuds n'a pas d'influence sur le NMM.
CONCLUSION ET PERSPECTIVES
À
Travers notre étude menée dans ce
mémoire, qui avait pour but l'évaluation et l'amélioration
des algorithmes proposés dans le cadre de la K-exclusion mutuelle dans
les systèmes répartis et dans les réseaux AD
HOC.
Nous avons mets l'accent sur les notions de base de ce
problème, et nous avons également expliqué les algorithmes
proposés ainsi que les améliorations
apportées.
L'évaluation de cet algorithme a été
réalisée par NS-2, l'outil de simulation qui
permet de valider les algorithmes dans les conditions les plus
réelles.
Ce travail nous a permis de :
- Comprendre le problème de l'exclusion mutuelle
et son extension en K-ressources ainsi que la notion de la tolérance aux
pannes.
- Faire une recherche bibliographique pour recenser les
différentes solutions apportées à ces
problèmes.
- Identifier les facteurs influant sur le comportement
des algorithmes simulés.
- Comparer par simulation les performances des
différentes améliorations afin de juger la meilleure d'entre
elles.
- Maitriser l'outil de simulation
NS-2.
Il est évident qu'il n'existe pas un travail
parfait, nous pouvons penser toujours à des améliorations et des
perspectives futures, nous avons pensé à :
1. Minimiser encore le nombre de messages
échangés en utilisant une nouvelle structure de données
pour obtenir le minimum possible.
2. Réduire en plus le temps d'attente en
utilisant des nouvelles stratégies d'échanges de
messages.
3. Enrichir le mécanisme de tolérance aux
pannes pour pouvoir faire face à la panne de plusieurs
sites.
4. Utiliser le principe de notre algorithme pour
résoudre ce problème dans d'autres systèmes tels que : les
réseaux de capteurs, les VANETs ... etc.
BIBLIOGRAPHIE
[Abd07] Z. Abdelhafidi. Points de
reprise dans les systèmes répartis etude basée sur la
simulation des protocoles cic assurant la propriété rdt.
Thèse Magistère de l'université Amar Telidji-Laghouat
Spécialité informatique, pages
11-27, 2007. (Cité
page 27.)
[AK08] A. Alliliche and M. Kebir.
Etude comparative des protocoles de points de reprise de type cic. Projet
de fin d'étude, Université de Laghouat,
2008. (Cité pages 26 et
27.)
[All04] Krouba M. Allaoui, T. Etude
des systèmes répartis et réalisation d'un simulateur des
algorithmes répartis d'exclusion mutuelle. Projet de fin
d'étude, Université de Laghouat, 2004.
(Cité pages 6 et 7.)
[All07] T. Allaoui. Une nouvelle
solution du problème de la k-exclusion mutuelle dans les systèmes
répartis. Mémoire de Magister, Université de
Laghouat, 2007. (Cité pages x, 7,
18, 19 et 31.)
[BAA89] .J Bernabéu, M. Auban,
and M. Ahamad. Applying a path-compression technique to obtain an eficient
distributed mutual exclusion algorithm. In Proceedings of the
3rd International Workshop on Distributed Algorithms
London, UK, pages
33-44, 1989. (Cité
page 23.)
[Bou07] A. Boukhalkhal. Étude
par simulation des performances des protocoles de routage dans les
réseaux ad hoc sans fil. Mémoire de fin d'étude,
Université de Laghouat, 2007. (Cité pages x
et 9.)
[CL85] K-M. Chandy and L. Lamport.
Distributed snapshots : Determining global states of distributed systems.
ACM Transactions on Computer Systems, pages
63-75, 1985. (Cité
page 27.)
[CM84] K.M. Chandy and J. Misra. The
drinking philosopher's problem. ACM Transactions on Programming Languages
and Systems, pages 632-646,
1984. (Cité page 21.)
[CM92] M. Chandy and .J Misra.
Synchronisation et état global dans les systèmes répartis.
Eyrolles, 1992. (Cité page
22.)
[Cou94] G. Coulouris. Distributed
systems. Concept and Design, 2nd Ed Addison
Wesley Pubishers Ltd., 1994.
(Cité page 4.)
[CR83] S.F. Carvalho and G. Roucairol.
On mutual exclusion in computer networks. Communications of ACM, pages
146-147, 1983. (Cité
page 21.)
[CSL91] Y. Chang, M. Singhal, and M.T
Liu. A dynamic token-based distributed mutual exclusion algorithm.
Computers and Communications, Conference Proceedings, Tenth Annual
International Phoenix Conference, pages
240-246, 1991. (Cité
page 23.)
[Dij65] W. Dijkstra. Solution of a
problem in concurrent programming control. Communications of the ACM,
1965. (Cité page 20.)
[Eve04] C. Evequoz. Programmation
répartie. Ecole d'ingénieur du Canton de Vaud,
2004. (Cité page 5.)
[HM94] J.M. Hélary and M.
Mostefaoui. fault-tolerant distributed mutual exclusion algorithm based on
open-cube structure. 14th International Conference on
Distributed Computing Systems (ICDCS), pages
89-96, 1994. (Cité
page 23.)
[HPR88] J-M. Hélary, N.
Plouzeau, and M. Raynal. A distributed algorithm for mutual exclusion in an
arbitrary network. Computer journal, pages
289-295, 1988. (Cité
page 23.)
[Lai02] T.H. Lai. On distributed
dynamic channel allocation in mobile cellular networks. IEEE Transactions
on Parallel and Distributed Systems, pages
1024-1037, 2002.
(Cité page 40.)
[Lam78] L. Lamport. Time, clocks, and
the ordering of events in a distributed system. Communications of ACM,
pages 558-565, 1978.
(Cité pages 20 et 21.)
[Lan77] G. Lann. Distributed systems -
towards a formal approach. International Federation for Information
Processing(IFIP)Congress, pages 155-160,
1977. (Cité page 20.)
[Lan78] G. Lann. Algorithms for
distributed data-sharing systems which use tickets. Proceedings of the
Third Berkeley Workshop on Distributed Data Management and Computer
Networks, pages 259-272,
1978. (Cité page 23.)
[Lem00] T. Lemlouma. Le routage dans les
réseaux mobiles ad hoc. Mini projet, Université d'Alger
USTHB, 2000. (Cité pages 8,
14 et 15.)
[LK09] A. Lahag and Kouidri. Etude
des performances des algorithmes de l'exclusion mutuelle dans les
réseaux ad hoc {Simulation par NS2}. Projet de fin
d'étude, Université de Laghouat, 2009.
(Cité pages 9 et 20.)
[Mae85] M. Maekawa. A square root n
algorithm for mutual exclusion in decentralized systems. ACM Transactions
on Computer Systems(TOCS), 1985. (Cité page
22.)
[Man07] N. Mansouri. Protocole de
routage multi chemin avec équilibrage de charge dans les réseaux
mobiles ad hoc. Projet de fin d'étude, Ecole supérieur des
communications de Tunis, Tunisie, 2007. (Cité
pages 11 et 12.)
[Mar85] A.J. Martin. Distributed mutual
exclusion on a ring of processes. Science of Computer Programming,
pages 265-276, 1985.
(Cité page 23.)
[Mes98] P. Meskauskas. Mobile ad hoc
networking. Seminar on Telecommunications Technology, Helsinki,
1998. (Cité pages 11 et
12.)
[NM91] M.L. Neilsen and M. Mizuno. A
dag-based algorithm for distributed mutual exclusion. In International
Conference on Distributed Computing Systems (ICDCS), pages
354-360, 1991. (Cité
page 23.)
[NT87] N. Naimi and M. Trehel. An
improvement of the log(n) distributed algorithm for mutual exclusion. IEEE
7th international Conf. On Distributed Systems,
Berlin, Germany, 1987. (Cité page
23.)
[RA81] G. Ricart and K. Agrawala. An
optimal algorithm for mutual exclusion in computer networks. Communications
of ACM, pages 9-17,
1981. (Cité page 21.)
[Ray88] K. Raymond. A distributed
algorithm for multiple entries to a critical section. Information
Processing Letters 30, pages
189-193, 1988. (Cité
page 25.)
[Ray89] K. Raymond. A tree-based
algorithm for distributed mutual exclusion. ACM Transactions on Computer
Systems, pages 61-77,
1989. (Cité page 23.)
[Ray91] M. Raynal. A simple taxonomy for
distributed mutual exclusion algorithms. Operating Systems Review,
1991. (Cité page 21.)
[Sin89] M. Singhal. A
heuristically-aided algorithm for mutual exclusion in distributed systems.
IEEE Transactions on Computers, pages
651-662, 1989. (Cité
page 23.)
[Sin91] M. Singhal. A class of
deadlock-free meakawa-type algorithms for mutual exclusion in distributed
systems. Distributed Computing, pages
131-138, 1991. (Cité
page 22.)
[SK85] I. Suzuki and T. Kasami. A
distributed mutual exclusion algorithm. ACM Trans.Computer Systems,
pages 344-349, 1985.
(Cité page 23.)
[Sop08] J. Sopena. Algorithmes
d'exclusion mutuelle : tolérance aux fautes et adaptation aux grilles.
Thèse de doctorat de l'Université Pierre et Marie Curie-Paris
VI, 2008. (Cité pages 21 et
22.)
[Sri89] P.K. Srimani. Another
distributed algorithm for multiple entries to a critical
sec-
tion. Information Processing Letters
41, pages
51-57, 1989. (Cité
page 25.)
[Tan94] S. Tanenbum. Distributed
operating systems. Prentice Hall, 1994. (Cité
page 4.)
[vdS87] J.L.A. van de Snepscheut. Fair
mutual exclusion on a graph of processes. Distributed Computing, pages
113-115, 1987. (Cité
page 23.)
[Wei08] W. Weigang. A fault tolerant
mutual exclusion algorithm for mobile ad hoc networks. Department of
Computing, The Hong Kong Polytechnic University, 2008.
(Cité page 25.)
[WK97] J.E. Walter and S. Kini. Mutual
exclusion on multihop, mobile wireless networks. Texas A and M University
College Station, 1997. (Cité page
26.)
[WW01] J. WALTER and L. WELCH. A
mutual exclusion algorithm for ad hoc mobile
networks. Department of
Computer Science,Texas USA, 2001. (Cité page
25.)
ANNEXE : ETTuDE DE L'ouTiL DE A
siMuLATioN NS-2
SoMMAiRE
A.1 PREuvE Du TlgoREME TRuc
80
A. Annexe: Étude de l'outil de simulation
NS-2
A.1 Preuve Du
théorème truc
Ce théorème est un résultat
classique donné, par exemple, par. . .
|
ANNEXE : LEs scRipTs DE Nos
simuLATioNs
SommAiRE
B.1 LE scRipT TCL
(sysTèmE RépARTi) 82
B.2 LE ScRipT TCL AD
HOC 85
DANs cette annexe nous
présentons deux exmples parmi les scripts
réalisés.
|
B
|
B.1 LE script TCL
(systèmE réparti)
|
#
=========================================================================
#
Definition des options #
#
=========================================================================
set ns [new Simulator]
;# Creation d'un nouveau Objet simulateur
set bw akemac.dat ;# Le ficher
Trace
set nf [ open akemac.nam
w] ;# Ouverture du Visualisateur NAM
set f0 [ open $bw w] ;#
Declaration de f0 pour ecrire sur le fi c h ie r
$ns namtrace-all $nf ;# Afin de generer le fi c h ie r
Trace
set bw nbr_msg_tps.txt ;# ficher . t x t
qui contient les resultats
set mesure [ open $bw
w] ;# mesure pour ecrire sur le . t x t
set val(stop)
10 ;# Temps de simulation ( ( Durree ) )
#
========================================================================= # Le
Corps des Procedures #
#
=========================================================================
#
========================================================================= #
Procedure d' affichage concernant la simulation #
#
=========================================================================
proc Affichage { } {
global mesure nbr nbrk nbrequete ;#
Declaration de variables globales puts $mesure " "
puts $mesure " Les Resultats de la
Simulation . "
puts $mesure " " puts
$mesure "============ Informations de Simulation ==============="
puts $mesure " . " puts $mesure "Le Nombre de
Sites = $nbr "
puts $mesure "Le Nombre de Ressources K
= $nbrk "
puts $mesure "Le Nombre de Requetes =
$nbrequete "
puts $mesure " . "
puts $mesure
"=======================================================" puts
$mesure "================================="
puts $mesure " Resultats pour chaque
site : "
puts $mesure
"================================="
} ;# Ecriture dans le f i c hi e r des
resultats
#
========================================================================= #
Procedure de Terminaison de la simulation # #
=========================================================================
proc finish { } {
;# Declaration de variables globales global ns
nf f0 nbr nbrequete tpatt nmsg p mesure
for { set i 0} {$i <
$nbr} { incr i} { ;# compter le nombre de
message total set nmsg [ expr
[$p($i) set
nb_message_]+$nmsg]
} ;# la somme des messages de chaque noeud
puts $mesure
"=========================================================" puts
$mesure " Le NMM et le TAM . " puts $mesure
"=========================================================" puts
$mesure "Le nombre total des messages = $nmsg"
puts $mesure " "
puts $mesure "Le nombre de message moyen
=
$nmsg/$nbrequete = [ expr $nmsg/$nbrequete ] "
puts $mesure " "
set tpatt [ expr
$tpatt/$nbrequete] ;# Calcul du temps moyen d'
attente
puts $mesure "Le temps d' attente moyen = $tpatt
"
$ns flush-trace ;# Pour Confirmer l '
ecriture
close $f0 ;# Fermer le f ic hi er . t x
t
puts " running nam... " ;# Affichage de "Running NAM ...
"
|
exec nam akemac.nam & ; ;# lancer le
NAM automatiquement
exit 0 ;# Sortie de la
procedure
}
#
========================================================================= #
Procedure d' enregistrement des temps d' attente dans le f ic hi er text # #
=========================================================================
proc record {p n mutex hour} {
global f0 nbrequete tpatt mesure ;#
Declaration des variables globales
set ns [Simulator
instance] ;# Instancier la commande NS
set bw0 [$ns now] ;#
bw0 est le temps actuelle
set bw0 [ expr $bw0-
[$p set dem ] ] ;# bw0
:= bw0 - Temps de la demande puts
$mesure "Temps d' attente pour le site N° [$n node-addr]
=
$bw0 ==> ( ( Date_Requete = $hour **
Duree SC = $mutex ) ) "
puts $mesure
"-------------------------------------------------------"
set tpatt [ expr
$tpatt+$bw0] ;# le temps d' attente
}
#
========================================================================= #
Procedure de Diffusion des demandes d' entrer en Section Critique # #
=========================================================================
proc diffusion {p n mutex hour} {
global nbr ;# Variables
globales
set ns [Simulator
instance] ;# Instancier la commande NS
set nowe [$ns now] ;#
Le temps actuelle NOWE
set nbrk [$p
set nbracine] ;# nbrk := nbracine ;
$ns at $nowe " tester $p $n $mutex $hour" ;# execution de
tester
$ns at $nowe "$p demander-sc" ;# execution de
demander-sc
$ns trace-annotate " [ $n node-addr] demande la SC
"
$ns at $nowe "$n color limegreen " ;# Colorer noeud
demandeur
}
#
========================================================================= #
Procedure de test d' entrer et la liberation de la Section Critique # #
=========================================================================
proc tester {p n mutex hour} {
global nbr mesure ;# Variables
globales
set ns [Simulator
instance] ;# definir commande ns
set time 0.01 ;# Temps de test pour
SC
set now [$ns now] ;#
Definir now
set a [$p set
sc] ;# Affectation a := sc ;
set b [$p set
racine] ;# b := racine ;
i f { $a == 1} { ;# Condition entrer en
SC
$ns at $now " record $p $n $mutex $hour" ;# Record pour
le TAM
$ns at $now "$n label \"<SC> \" "
;# l ib e le <SC> au noeud
$ns at [ expr
$now+$mutex] "$n label \" \" " ;# Effacer
<SC>
$ns at [ expr
$now+$mutex] "$p liberation-sc";# Appel de
liberation-sc
$ns at [ expr
$now+$mutex] "$p set sc -1" ;# sc :=
-1 pour so r ti r
i f { $b == -1} { ;# racine devient
rouge
$ns at [ expr
$now+$mutex] "$n color red" ;# Colorer la racine }
else { ;# Sinon
$ns at [ expr
$now+$mutex] "$n color black";# Colorer noeud en
noir
}
} else { ;# noeud veut entrer SC
$ns at [ expr
$now+$time] "$p attendre " ;# attendre MAJ sc <-
1
$ns at $now "$n color blue" ;# Colorer BLEU
$ns at [ expr
$now+$time] " tester $p $n $mutex $hour"
} ;# rappeler la procedure
} ;# TESTER ( ( Recursif ) )
#
========================================================================
#
========================================================================= # Le
programme Principale # #
========================================================================= #
========================================================================= #
========================================================================= #
Lecture des donnees a partir d'un f i c hi e r texte # #
=========================================================================
set f [ open " les_demandes.txt " " r "
] ;# lire ( les_demandes.txt )
set nbr [ gets $f] ;# (
( nbr ) ) <-- premier ligne
set nbrk [ gets $f] ;#
( ( nbrk ) )<-- deuxiemme ligne
set nbrequete [ gets
$f] ;# ( nbrequete )<-- troisiemme ligne
for { set j 0} {$j <
$nbrequete} { incr j} { ;# Boucle pour lire
les Scenarios for { set k 0} {$k <
2} { incr k} {
set table($j,$k) [
gets $f] ;# Remplir par ( s i t e , heur, duree )
}
}
close $f ;# Enfin Fermer le f i c h i e
r .
#
=========================================================================
#
Declaration des couleurs selon les numeros #
#
=========================================================================
)
$ns
|
color 0 blue
|
;#
|
Le
|
0
|
est
|
la
|
Couleur
|
Bleu ( (
|
Demande ) )
|
|
$ns
|
color 1 red
|
;#
|
Le
|
1
|
est
|
la
|
Couleur
|
Rouge (
|
( Requete ) )
|
|
$ns
|
color 2 limegreen
|
;#
|
Le
|
2
|
est
|
la
|
Couleur
|
Vert ( (
|
Liberation )
|
|
$ns
|
color 3 brown
|
;#
|
Le
|
3
|
est
|
la
|
Couleur
|
Marron
|
( ( Accord ) )
|
|
$ns
|
color 4 magenta
|
;#
|
Le
|
4
|
est
|
la
|
Couleur
|
Violet
|
( ( Aide ) )
|
|
$ns
|
color 5 black
|
;#
|
Le
|
4
|
est
|
la
|
Couleur
|
Noir ( (
|
Recherche ) )
|
#
=========================================================================
#
Affichage des informations dans le f i c hi e r des resultats #
#
=========================================================================
set now [$ns now] ;#
Definir now --> le temps actuelle
$ns at $now " Affichage " ;# Afficher les informations
dans . t x t
#
=========================================================================
#
Creation des noeuds et leurs connections aux agents " Akema " #
#
=========================================================================
for { set i 0} {$i <
$nbr} { incr i} { ;# i=0 a
i=nbr--1 --> creer ( nbr ) noeuds
set n($i) [$ns
node] ;# Creation d'un noeud
set p($i) [new
Agent/Akemac] ;# Creation d'un Agent
AKEMAC
$p($i) set nb_noeud_
$nbr ;# I n i t i a l i s e r ( nb_noeud_ ) par ( nbr )
$p($i) set nbracine
$nbrk ;# I n i t i a l i s e r ( nbracine ) par ( nbrk )
$ns at 0.0 "$p ( $i ) initial" ;# i n i t i a l i s e r
chaque agent AKEMAC
$ns attach-agent $n($i)
$p($i) ;# attacher les noeuds aux
agents
$p($i) set packetSize_
400 ;# La t a i l l e du paquet a envoyer
}
#
=========================================================================
#
Creation des liens et la connection des agents #
#
=========================================================================
for { set i 0} {$i <
$nbrk} { incr i} { ;# Boucle pour les
liens
$n($i) color " red " ;#
Colorer chaque noeud racine
$ns duplex-link $n($i) $n
( [ expr ($i+1)%$nbrk
] ) 1Mb 10ms DropTail $ns connect
$p($i) $p ( [ expr
($i+1)%$nbrk] ) ;# Creation
d'un lien
} ;# Connecter les agents entre eux
for { set i 0} {$i <
$nbrk} { incr i} { ;# Boucle pour les
liens
for { set j [ expr
($i+1) ] } {$j <
$nbrk} { incr j} {
$ns duplex-link $n($i)
$n($j) 1Mb 10ms DropTail ;#
Creation d'un lien
$ns connect $p($i)
$p($j) ;# Connecter les agents entre
eux
}
}
|
for { set i $nbrk} {$i
< $nbr} { incr i} { ;# Boucle pour
les liens
$ns duplex-link $n ( [ expr
($i)%$nbrk ] )
$n($i) 1Mb 10ms DropTail
$ns connect $p ( [ expr
($i)%$nbrk ] )
$p($i) ;# Creation d'un lien
} ;# Bi-directionnel Racine-Fils
#
========================================================================= #
Initialisation des variables globaux #
#
=========================================================================
set tpatt 0 ;# Initialisation de tpatt
pour calculer le temps d' attente
set nmsg 0 ;# Initialisation de nmsg
pour calculer le nombre de messages
set duree 1 ;# La durree de la Section
Critique
#
========================================================================= # L'
execution des scenarios de la simulation # #
========================================================================= for {
set j 0} {$j <
$nbrequete} { incr j} { ;# lire les Scenarios
du tableau
set site $table($j,0)
;# lire l ' identificateur du site
set heur $table($j,1)
;# lire l ' heur de la demande
$ns at $heur "$p ( $site ) set dem $heur " ;# affe cte r
la demande a l ' heur
$ns at $heur " diffusion $p ( $site ) $n ( $site ) $duree
$heur "
} ;# Appel de diffusion
#
========================================================================= #
Finalisation de la simulation et debut du RUN # #
=========================================================================
$ns at [ expr $val(stop) +
0.1] " finish" ;# Finir la Simulation apres (STOP)
puts " debut de la simulation ... " ;# Ecrire "debut de
la simulation.. "
$ns run ;# Debut de la Simulation NAM
|
le Script TCL (Système
réparti)
B.2 LE SCRIPT TCL AD HOC
|
#
=========================================================================
#
Definition des options #
#
=========================================================================
set val(chan)
Channel/WirelessChannel ;# type de
canal
set val(prop)
Propagation/TwoRayGround ;# model de
propagation
set val(netif)
Phy/WirelessPhy ;# type d' interface
reseau
set val(mac)
Mac/802_11 ;# type de mac
set val(ifq)
CMUPriQueue ;# type de file d' attente
set val(ll)
LL ;# link layer type
set val(ant)
Antenna/OmniAntenna ;# model d'
antenne
set val(x)
500 ;# X dimension du topology
set val(y)
500 ;# Y dimension du topology
set val(ifqlen)
50 ;# Nbre max Packets-> file
set val(seed)
0.0 ;# grain random
set val(adhocRouting)
DSR ;# protocole de routage
set val(sc)
"/home/A/ns-allinone-2.32/ns-2.32/
t c l /mobility/scene/vitesse5 " set
val(stop) 15 ;# temps de simulation (
duree )
#========================================================================== #
Definition des procedures # #
========================================================================= #
modification dans la portee de signal 300
Phy/WirelessPhy set RXThresh_
1.76149e-10
#
========================================================================= #
Creation d' instance de simulateur et topologie # #
=========================================================================
set ns_ [new Simulator] ;# nouvelle
simulation
|
$ns_ use-newtrace ;# nouveau f ic h i er
trace
set topo [new
Topography] ;# Nouvelle Topologie
#
========================================================================= #
Creation des f i c hi e rs trace pour NS et NAM #
#
=========================================================================
set tracefd [ open
adhoc.tr w]
set namtrace [ open adhoc.nam
w]
set bw nbr_msg_tps.txt ;# Ficher . t x t
( resultat simulation )
set mesure [ open $bw
w]
$ns_ trace-all $tracefd
$ns_ namtrace-all-wireless $namtrace
$val(x)
$val(y)
#
========================================================================= #
Procedure d' affichage concernant la simulation # #
=========================================================================
proc Affichage { } {
global mesure nbr nbrk nbrequete ;#
Declaration des variables globales puts $mesure " "
puts $mesure " Les Resultats de la Simulation ( K--Exclusion
Adhoc ) . " puts $mesure " " puts $mesure
"============ Informations de Simulation ================" puts
$mesure " . " puts $mesure "Le Nombre de Sites = $nbr
"
puts $mesure "Le Nombre de Ressources K
= $nbrk "
puts $mesure "Le Nombre de Requetes =
$nbrequete "
puts $mesure " . "
puts $mesure
"========================================================" puts
$mesure "================================="
puts $mesure " Resultats pour chaque
site : "
puts $mesure
"================================="
}
#==========================================================================
# Procedure de Terminaison de la simulation # #
=========================================================================
proc finish { } {
global ns_ nf f0 nbr nbrequete tpatt nmsg p
mesure ;# Variables globales
for { set i 0} {$i <
$nbr} { incr i} {
set nmsg [ expr
[$p($i) set
nb_message_]+$nmsg] ;# Somme des messages
puts $mesure
"================================= "
puts $mesure " Le NMM et le
TAM.
}
"
puts $mesure
"======================================================" puts
$mesure " Messages total = $nmsg" ;# Calcul du nombre moyen
puts $mesure " "
puts $mesure "Le NMM = $nmsg/$nbrequete
= [ expr $nmsg/$nbrequete ] " puts $mesure " "
set tpatt [ expr
$tpatt/$nbrequete] ;# Calcul du TAM
puts $mesure "Le TAM = $tpatt " ;#
Affichage du TAM
$ns_ flush-trace ;# Ecriture dans le f ic h i er
TEXT
close $mesure ;# Fermer le f ic hi er
des resultat
puts " running nam... " ;# Affichage de "Running NAM . .
. "
exec nam adhoc.nam & ;# lancer le
NAM automatiquement
exit 0 ;# Sortie de la
procedure
}
#==========================================================================
#
Procedure d' enregistrement des temps d' attente dans le f i c hi e r . t x t
#
# ============================
proc record
{p n mutex hour} {
global f0 nbrequete tpatt mesure ;#
Variables globales
set ns [Simulator
instance] ;# Instancier la commande NS
set bw0 [$ns now] ;#
bw0 est le temps actuelle
set bw0 [ expr $bw0-
[$p set dem ] ] ;# bw0
:= bw0 - Temps de la demande
puts $mesure "Temps d' attente pour le
site N [ $n node-addr] =
$bw0 ==> ( ( Date_Requete = $hour **
Duree SC = $mutex ) ) "
puts$mesure
"--------------------------------------------------------"
set tpatt [ expr
$tpatt+$bw0] ;# Le temps d' attente
}
#==========================================================================
# Procedure de Diffusion des demandes d' entrer en Section Critique # #
=========================================================================
proc diffusion {p n mutex hour} {
global nbr ;# Variables
globales
set ns_ [Simulator
instance] ;# Instancier la commande NS
set nowe [$ns_ now] ;#
Le temps actuelle
set nbrk [$p
set nbracine] ;# nbrk := nbracine ;
$ns_ at $nowe " tester $p $n $mutex $hour" ;# execution
de tester
$ns_ at $nowe "$p demander-sc" ;# execution de
demander-sc
$ns_ trace-annotate " [ $n node-addr] demande la SC
"
$ns_ at $nowe " colorLm $p $n" ;# Colorer noeud
demandeur
}
#==========================================================================
# Procedure de test d' entrer et la liberation de la Section Critique # #
=========================================================================
proc tester {p n mutex hour} {
global nbr mesure ;# Variables
globales
set ns_ [Simulator
instance] ;# definir commande ns_
set time 0.01 ;# Temps de test pour
SC
set now [$ns_ now] ;#
Definir now
set a [$p set
sc] ;# Affectation a := sc ;
set b [$p set
racine] ;# b := racine ;
i f { $a == 1} { ;# Condition entrer en
SC
$ns_ at $now " record $p $n $mutex $hour" ;# Record pour
le TAM
$ns_ at $now " colorRd $p $n" ;# Colorer le noeud en
SC
$ns_ at $now "$n label \"<SC> \" "
;# l ib el e <SC> au noeud
$ns_ at [ expr
$now+$mutex] "$n label \" \" " ;# Effacer
<SC>
$ns_ at [ expr
$now+$mutex] "$p liberation-sc";# Appel de
liberation-sc
$ns_ at [ expr
$now+$mutex] "$p set sc -1" ;# sc :=
-1 pour so r ti r
i f { $b == -1} { ;# racine devient
orange
$ns_ at [ expr
$now+$mutex] " colorOr $p $n" ;# Colorer la racine }
else { ;# Sinon
$ns_ at [ expr
$now+$mutex] " colorBk $p $n" ;# Colorer noeud en
noir
}
} else { ;# noeud veut entrer SC
$ns_ at [ expr
$now+$time] "$p attendre " ;# attendre MAJ sc <-
1
$ns_ at [ expr
$now+$time] " tester $p $n $mutex $hour"
}
}
#
========================================================================= #
========================================================================= # Le
programme Principale # #
=========================================================================
#
========================================================================= #
========================================================================= #
Lecture des donnees a partir d'un f i c hi e r texte # #
=========================================================================
set f [ open " les_demandes.txt " " r "
] ;# lire ( les_demandes.txt )
set nbr [ gets $f] ;# (
( nbr ) ) <-- premier ligne
set nbrk [ gets $f] ;#
( ( nbrk ) )<-- deuxiemme ligne
set nbrequete [ gets
$f] ;# ( nbrequete )<-- troisiemme ligne
for { set j 0} {$j <
$nbrequete} { incr j} { ;# Boucle pour lire
les Scenarios for { set k 0} {$k <
2} { incr k} {
set table($j,$k) [
gets $f] ;# Remplir par ( s i t e , heur, duree )
}
}
close $f ;# Enfin Fermer le f i c h i e
r .
#
========================================================================= #
Declaration des couleurs selon les numeros # #
=========================================================================
$ns_ color 0 Blue ;# Le O est la Couleur Bleu ( tous messages)
# ========================================================================= #
Definition de la topologie # #
=========================================================================
$topo load_flatgrid $val(x)
$val(y)
#
========================================================================= #
Creation du God ( voisinage ) # #
=========================================================================
set god_ [create-god $nbr]
#
=========================================================================
#
Configuration globale d'un noeud #
#
=========================================================================
$ns_ node-config -adhocRouting
$val(adhocRouting) \
-llType $val(ll) \
-macType $val(mac) \ -ifqType
$val(ifq) \ -ifqLen
$val(ifqlen) \ -antType
$val(ant) \ -propType
$val(prop) \ -phyType
$val(netif) \ -channelType
$val(chan) \ -topoInstance $topo \
-agentTrace ON \
-routerTrace ON \
-macTrace OFF
#
========================================================================= #
Creation des noeuds # #
========================================================================= for {
set i 0} {$i < $nbr} {
incr i} { ;# i=0 a i=nbr--1
--> creer ( nbr ) noeuds
set node_($i)
[$ns_ node] ;# Creation d'un noeud
$node_($i) random-motion
0 ;# desactiver mouvement aleatoire
$node_($i) color Black
;# Colorer chaque noeud en noir
$god_ new_node $node_($i) ;# chaque god
associe au noeud
set p($i) [new
Agent/Kradhoc] ;# Creation d'un Agent KRAD
HOC
$p($i) set nb_noeud_
$nbr ;# I n i t i a l i s e r (nb_noeud_ ) par ( nbr )
$p($i) set nbracine
$nbrk ;# I n i t i a l i s e r ( nbracine ) par ( nbrk )
$ns_ at 0.0 "$p ( $i ) initial" ;# i n i t i a l i s e r
chaque agent KRAD HOC
$ns_ attach-agent $node_($i)
$p($i) ;# attacher les noeuds aux agents
$p($i) set packetSize_ 1024
;# La t a i l l e du paquet a envoyer
}
#
# La connexion des agents pour permettre la communication
#
#
========================================================================= for {
set i 0} {$i < $nbr} {
incr i} {
for { set j [ expr
$i+1]} {$j <
$nbr} { incr j} {
$ns_ connect $p($i)
$p($j) ;# Connecter les agents entre
eux
}
}
#
========================================================================= #
Coloration des noeuds a chaque couleur associe # #
=========================================================================
proc colorRd {p node_ } {
set ns_ [Simulator
instance]
set nowe [$ns_
now]
$ns_ at $nowe "$node_ color red" ;# Coloration avec le
rouge <SC>
}
proc colorBl {p node_ }
{
set ns_ [Simulator
instance]
set nowe [$ns_
now]
$ns_ at $nowe "$node_ color blue" ;# Coloration avec le
Bleu
}
proc colorBk {p node_ }
{
set ns_ [Simulator
instance]
set nowe [$ns_
now]
$ns_ at $nowe "$node_ color black" ;# Coloration avec le
noir <Dehors>
}
proc colorLm {p node_ }
{
set ns_ [Simulator
instance]
set nowe [$ns_
now]
$ns_ at $nowe "$node_ color limegreen " ;# Coloration
avec le vert <Demande>
}
proc colorOr {p node_ }
{
set ns_ [Simulator
instance]
set nowe [$ns_
now]
$ns_ at $nowe "$node_ color Orange" ;# Coloration avec l
' orange<racine >
}
#
========================================================================= #
Coloration des racines # #
========================================================================= for {
set i 0} {$i < $nbrk} {
incr i} { ;# Boucle de coloration
$ns_ at 0.0 " colorOr $p ( $i ) $node_ ( $i ) " ;#
Colorer racines avec l ' orange } ;# des le debut de la simulation #
========================================================================= #
Appel des f i c hi e rs de mouvement # #
========================================================================= i f {
$val(sc) == " " }
{
puts " *** NOTE: no connection pattern specified.
"
set val(sc)
"none"
} else {
puts " Loading connection pattern..."
source
$val(sc)
}
#
=========================================================================
#
Initialisation des variables globaux #
#
=========================================================================
set nmsg1 0 ;# Initialisation de
nmsg1
set nmsg 0 ;# Initialisation de
nmsg
set tpatt 0 ;# Initialisation de
tpatt
#
=========================================================================
#
Fixation de la duree de la Section Critique #
|
#
=========================================================================
set duree 1 ;# la duree de la SC
#
========================================================================= #
Initialisation des positions des noeuds #
#
========================================================================= for {
set i 0} {$i < $nbr} {
incr i} {
$ns_ initial_node_pos $node_($i)
25 ;# se fait apres la definition
} ;# du modele de mobilite
#
========================================================================= #
Affichage du Menu dans le f i c hi e r des resultats #
#
=========================================================================
$ns_ at 0.0 " Affichage " ;# Appel a la procedure
Affichage
#
========================================================================= # L'
execution des scenarios de la simulation #
#
========================================================================= for {
set j 0} {$j <
$nbrequete} { incr j} { ;# lire les Scenarios
de la table set site $table($j,0) ;# lire l '
identificateur du site
set heure $table($j,1)
;# lire l ' heur de la demande
$ns_ at $heure "$p ( $site ) set sc 0"
;# sc <-- 0
$ns_ at $heure "$p ( $site ) set dem $heure " ;# aff ec
ter la demande a l ' heur $ns_ at $heure " diffusion $p (
$site ) $node_ ( $site ) $duree $heure "
puts " $site" ;# Appel de diffusion pour
} ;# executer les demandes
#
========================================================================= #
Finalisation de la simulation et debut du RUN # #
=========================================================================
$ns_ at [ expr $val(stop) +
0.01] " finish";# Finir la Simulation apres (STOP)
puts " debut de la simulation . . . " ;# Ecrire " debut
de la simulation.. "
$ns_ run ;# Debut du NAM
|
le Script TCL (AD HOC)
ACRONYMES
AODV Ad hoc On-Demand Distance Vector
API Application Programming Interface
ATM Asynchronous Transfer Mode
CBQ Class Based Queuing
CBR Constant Bit Rate
DARPA The Defense Advanced Research Projects
Agency
DSDV Dynamic Destination Sequenced Distance
Vector
DSR Dynamic Source Routing
FIFO First In, First Out
FQ Fair Queuing
FSM Free Space Model
FTP File Transfer Protocol
GSR Global State Routing
IEEE Institute of Electrical and Electronics
Engineers
IP Internet Protocol
MAC Medium Access Control
MANET Mobile Ad-hoc Networks
MRDM Modified Random Direction Model
NAM Network AniMator
NED NEtwork Description
NMM Nombre de Messages Moyen NS-2
Network Simulator 2
OMNET Optical Micro-Networks
OSI Open System Interconnexion
OTCL Object Tools Command Language
RDM Random Direction Model
RED Random Early Detection
RWM Random Waypoint Model
SB Station de Base
SC Section Critique
SFQ Stochastic Fair Queuing
SURAN SUrvivable RAdio Networks
TAM Temps d'Attente Moyen
TCL Tools Command Language
TCP Transport Control Protocol
Telnet Terminal Network
TORA Temporally Ordered Routing Algorithm
UDP User Datagram Protocol
UM Unités Mobiles
VINT Virtual InterNetwork Testbed ZRP Zone Routing
Protocol
| 

