Disparités régionales en matière de scolarisation en Guinéepar Mamadou Dian Dilé Diallo Université Yaounde II - DESS 2003 |

3.5.2. L'Analyse explicativeAprès avoir considéré les caractéristiques individuelles, et les caractéristiques des ménages de manière indépendante. Nous nous intéresserons à l'analyse de leur mode d'action lorsqu'on contrôle toutes ces variables à la fois. Compte tenu de la nature dichotomique de la variable dépendante (a déjà fréquenté ou non), c'est la régression logistique qui est la méthode la plus adaptée4(*) pour notre étude. Mais son application requiert un certain nombre d'hypothèses : 1-Le modèle doit être complètement spécifié c'est à dire : Aucune variable importante ne doit être omise et aucune variable superflue ne doit être incluse dans le modèle ; Les variables indépendantes sont mesurées sans erreurs ; La fonction sous tendant le modèle est une fonction logistique ; 2- Les observations sont indépendantes entre elles ; 3- Les variables Xi sont non corrélés entre elles. a) Présentation du modèle Au moyen des modèles statistiques, les odds (ratios de chances ou de risques) d'être scolarisés ou non peuvent être mesurées pour les différentes modalités de chaque variable indépendante catégorielle, l'effet des autres variables étant contrôlé. Pour une variable dépendante binaire, les odds sont
définis comme étant les probabilités de succès par
rapport aux risques d'échec. Les odds prennent l'expression de
proportion, telle que Soit Y la variable dépendante et Xi (i= 1.2.....n) n variables indépendantes. Y prend la valeur 1 si l'enfant est scolarisé et 0 sinon. Puisque p est la probabilité que l'enfant soit scolarisé alors p = Prob (Y=1) et 1-p = Prob (Y=0) Le modèle de régression logistique permet de
transformer la grandeur On pose ln Et logit (p) = 0+1X1+ 2X2+....+nXn+ Alors En définitive. p = e ((0+1X1+ 2X2+....+nXn+ )/ [1+ e(0+1X1+ 2X2+....+nXn+ )] ) 1 - p = 1/ [1 + e (0+1X1+ 2X2+....+nXn+ )] Où 0représente la constante c'est
à dire le niveaumoyen de b) Test d'adéquation du modèle Dans la régression logistique tout comme dans la régression linéaire multiple. Il est difficile de déterminer la contribution individuelle de chaque variable. Elle dépend des autres variables du modèle. Ce qui cause des problèmes quand les variables considérées comme indépendantes sont fortement corrélées. Une mesure de la corrélation partielle entre la variable dépendante et chacune des variables indépendantes est la statistique du pseudo R². Cette grandeur donne la part de la variance expliquée par le modèle. Le pseudo R² varie entre zéro et un. Une valeur du pseudo R² proche de zéro indique une faible contribution partielle de la variable au modèle d'analyse. Mais en sciences sociales, la variance non expliquée par le modèle (la variance résiduelle) est souvent très importante. Et une variance résiduelle importante ne signifie pas que les variables sélectionnées ne sont pas pertinentes. Généralement, on s'attache d'abord à savoir si la variance expliquée par le modèle est suffisante au regard du nombre de variables que l'on a introduit dans le modèle à l'aide d'un test appelé F-test. Ce test est souvent plus rassurant que le pourcentage de la variance expliquée (BOCQUIER, 1996). Une autre façon de valider le modèle logistique est de considérer la vraisemblance (likelihood) des résultats de l'échantillon étant donné les paramètres estimés. C'est à dire la probabilité d'apparition des résultats obtenus. La mesure de l'ajustement du modèle aux données est égale à moins deux fois le logarithme de la vraisemblance (-2 Log likelihood ou -2LL). Plus la vraisemblance est proche de un plus le modèle est considéré comme bon. Sous l'hypothèse nulle que le modèle est parfaitement ajusté. -2LL a une distribution khi2 avec N-p degrés de liberté, où N est le nombre de cas et p le nombre de paramètres estimés. Pour évaluer la contribution de chaque facteur à la prédiction nette du modèle final, on utilise la procédure « lroc ». Celle-ci permet de comparer la sensibilité c'est à dire la proportion des réponses positives observées qui sont correctement classées par le modèle et la spécificité c'est à dire la proportion des réponses négatives observées qui sont correctement classées par le modèle. Sur un graphique, on met en rapport le complément à 1 de la spécificité (en abscisse) et la sensibilité (en ordonnée). Le pouvoir prédictif réel correspond à la surface séparant la courbe ROC (« Receiver Operating Characteristic ») et la diagonale principale. Il est apprécié par rapport aux limites inférieure (50%) et supérieure (100%). Le pouvoir prédictif réel (PPR) est donc calculé par rapport à ces limites dans une relation avec le pouvoir prédictif total (PPT) suivant la relation : PPR= (PPT-0,5) / 0,5 (BOCQUIER, 1996). c) Interprétation des résultats. L'interprétation des résultats se fait à l'aide des coefficients i (i= 1.2. .... n). Si i est positif, eiest supérieur à un. Cela signifie que les individus de la modalité considérée ont ei fois plus de chance que leurs homologues de la modalité de référence de subir l'événement étudié (i.e. plus de chance de réaliser l'événement Y=1) ou encore qu'ils ont (ei - 1) % fois plus de chance de connaître l'événement étudié. En revanche, si i est négatif. Les individus de la modalité considérée de la variable indépendante ont (1- ei)% moins de chance que leurs homologues de la modalité de référence de réaliser l'événement étudié. Les signes (-) et (+) traduisent les influences des variables Xi sur la variable dépendante (Y). * 4 La méthode la plus indiquée pour notre étude était l'analyse multiniveaux, voir annexe 2. |
|


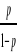 où p représente la proportion des enfants qui
ont été scolarisé et les valeurs des paramètres
sont calculées en utilisant la méthode de vraisemblance
maximale.
où p représente la proportion des enfants qui
ont été scolarisé et les valeurs des paramètres
sont calculées en utilisant la méthode de vraisemblance
maximale.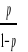 sous la forme linéaire
(0+1X1+
2X2+....+nXn+ ) à l'aide du
logarithme népérien.
sous la forme linéaire
(0+1X1+
2X2+....+nXn+ ) à l'aide du
logarithme népérien.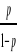 =logit (p)
=logit (p)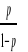 =
e (0+1X1+ 2X2+....+nXn+ )
=
e (0+1X1+ 2X2+....+nXn+ )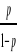 pour toutes les valeurs de Xi, i le vecteur de coefficient qui
mesure l'effet de la variable indépendante Xi sur p et constitue le
terme d'erreur ou variation aléatoire.
pour toutes les valeurs de Xi, i le vecteur de coefficient qui
mesure l'effet de la variable indépendante Xi sur p et constitue le
terme d'erreur ou variation aléatoire.