L'impact de taux de fécondité sur la croissance économique de la rdcongo de 1997 à 2017par prosper Kangolo shako UNIKI - LICENCIE 2019 |

III.2. Analyse de la stationnarité des variables et de la cointégrationLa cointégration est une propriété statistique des séries temporelles introduite dans l'analyse économique, notamment par Engle et Newbold (1974). En des termes simples, la cointégration permet de détecter la relation de long terme entre deux ou plusieurs séries temporelles. Sa formalisation rigoureuse est due à Granger (1981), Engle et Granger (1987) et Johansen (1991, 1995). Techniquement, la notion de cointégration implique implicitement celle d'intégration. Pour R. Bourbonnais77(*) (2015), en régressant une série non stationnaire (de type DS) sur une autre série du même type, on peut obtenir des coefficients significatifs mais avec une statistique DW proche de 0. Ce qui illustre le risque de régresser entre elles deux séries affectées d'une tendance stochastique. Il faut donc, au préalable, stationnariser des séries non stationnaires ; dans le cas contraire, il existe un risque de « régression fallacieuse » (« spuriousregression »). Par ailleurs, poursuit-il, l'analyse de la cointégration permet d'identifier clairement la relation véritable entre deux variables en recherchant l'existence d'un vecteur de cointégration et en éliminant son effet, le cas échéant. Pour Valéry Mignon78(*) (2008), si
Cependant, il est possible que
â est le paramètre de cointégration et le
vecteur L'idée sous-jacente est la suivante : A court
terme, Le tableau ci-dessous les résultats issus du test ADF de stationnarité de diverses variables : Tableau N°1 : Test de racine unitaire et de cointégration des variables
Source : Nos calculs sur Eviews 9.0 Ce tableau indique que la seule variable stationnaire à niveau est la RD. Certaines variables (PIB, POPA, TAA, TF et TI) sont stationnaires en différence première, du fait que la valeur calculée de la statistique ADF, en termes absolus, est supérieure à la valeur théorique. Mutatis mutandis, la probabilité associée à la statistique calculée est inférieure au seuil de 5%. En appliquant l'algorithme en deux étapes d'Engle et Granger, nous remarquons que les séries PIB, POPA, TAA, TF et TI sont cointégrées d'ordre 1, du fait qu'elles ont nécessité la différenciation d'ordre 1 pour devenir stationnaires. La condition nécessaire de cointégration étant vérifiée, les variables étant intégrées de même ordre, nous pouvons estimer la relation de long terme par les MCO. Les résultats des estimations sont consignés au niveau des annexes (annexe 2). Avant de tester la stationnarité des résidus issus de la relation de long terme, condition suffisante de l'application de l'algorithme, vérifions les hypothèses fondant la méthode des MCO (normalité des résidus, autocorrélation des erreurs, constance des variances quelle que soit la période d'observation). Le tableau ci-dessous reprend les principaux résultats de tests sur les résidus : Tableau N°2 : Test sur les résidus de la relation de cointégration
Source : Nos calculs sur Eviews 9.0 La lecture de ce tableau indique que les résidus suivent la loi normale, la probabilité de Jarque-Bera étant supérieure à 5%. Par ailleurs la statistique LM, produit du nombre d'observations par le coefficient de détermination, reste largement inférieure à la valeur calculée de Fisher pour le test de Breusch-Godfrey. Autrement dit, la probabilité critique est inférieure au seuil de signification de 5%. Nous rejetons l'hypothèse nulle d'absence d'autocorrélation des erreurs. En plus, les probabilités associées aux tests de Breusch-Godfrey-Pagan et Ramsey Reset sont respectivement en-dessous et au-dessus de 0,05. Dans ce dernier cas, les résidus sont hétéroscédastiques et le modèle, quant à lui, est correctement spécifié. Pour Régis Bourbonnais79(*) (2015), lorsque l'hypothèse d'homoscédasticité et/ou l'hypothèse d'indépendance des erreurs ne sont plus vérifiées, la matrice des variances-covariances de l'erreur n'a plus la forme particulière et l'estimateur des Moindres Carrés Ordinaires (MCO) n'est plus à variance minimale. Dans le cas de la violation de l'une de ces hypothèses, il convient alors d'utiliser un estimateur présenté par Aitken appelé estimateur des MCG (Moindres carrés généralisés). Cet estimateur est efficace quelle que soit la forme de la matrice des variances-covariances de l'erreur. Cette méthode n'est cependant pas utilisable que dans le cas où la variance du terme de l'erreur est connue. Dans la pratique, nous ne connaissons cette matrice, sauf dans les cas exceptionnels. Il convient d'utiliser des procédures d'estimation opérationnelles. Valéry MIGNON80(*), abondant dans le même sens, affirme que la présence d'hétéroscédasticité a pour conséquence que les estimateurs des MCO restent sans biais, mais ne sont plus de variance minimale. Ceci poste problème, continue-t-elle, notamment parce que cela affecte la précision des tests... A cette fin, on peut utiliser les corrections suggérées par White (1980) et Newey et West (1987). Ces deux techniques ne modifient pas la valeur estimée par les Moindres Carrés Ordinaires des coefficients du modèle de régression, mais modifient uniquement les écarts-types estimés de ces coefficients (et donc leurs t de student), il est également possible d'utiliser les résultats de certains tests, tels que celui de Glesjer afin de corriger l'hétéroscédasticité. Le tableau ci-dessous reprend l'output de la relation de long terme, après avoir corrigé l'autocorrélation des erreurs et centré les variables. Tableau N°3 : Estimation de la relation de cointégration
Source : Nos estimations sur Eviews 9.0 ( )= la valeur empirique de Student au seuil de signification de 5% La stationnarité des résidus de ces estimations, dont l'interprétation est faite dans la dernière section, du chapitre, doit être testée pour que l'algorithme d'Engle et Granger soit opérant. Ils doivent en effet être stationnaires à niveau. Ci-dessous le test de racine unitaire appliqué aux résidus (voir annexe). Tableau N°4 : Test de racine unitaire sur les résidus de la relation de long terme
Source : Nos calculs sur Eviews 9.0 Il ressort de ce tableau que les résidus sont stationnaires à niveau quel que soit le seuil de signification retenu. Les deux conditions essentielles de la cointégration dans l'approche d'Engle et Granger sont satisfaites ; nous disons que les variables citées ci-haut sont cointégrées. Par ailleurs, Lorsque les séries sont non stationnaires et cointégrées, il convient d'estimer leurs relations au travers d'un modèle à correction d'erreur. Pour Valéry, une des propriétés
fondamentales des séries cointégrées est qu'elles peuvent
être modélisées sous la forme d'un modèle
à correction d'erreur. Ce résultat a été
démontré dans le cadre du théorème de
représentation de Granger (1981), valable pour des
séries Soient
Où ?t est un bruit blanc.
Le coefficient ã associée à - Des variables en différence première (stationnaires) qui représentent les fluctuations de court terme, - Des variables en niveau, ici une variable L'output des estimations de court terme est reporté dans le tableau ci-contre : Tableau N°5 : Estimation de la relation dynamique
Source : Nos calculs sur Eviews 9.0 La valeur des résidus décalés d'une période étant significativement négative, nous validons le théorème de représentation de Granger. Il existe un mécanisme de correction des décalages entre les coefficients de court terme et leur cible de long terme. * 77 Bourbonnais, R., Econométrie, cours et applications, Dunod, Paris, 2015, p.213 * 78 Mignon, V., Econométrie, théorie et applications, Economica, Paris, 2008, pp.306-307 * 79 Bourbonnais, R., Op. cit., p.314 * 80 Mignon, V., Op. cit., p.321 * 81 Mignon, V., Op. cit., pp.307-308 |
|


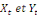
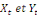 sont deux séries
sont deux séries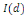
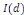 , alors en général la combinaison linéaire
zt :
, alors en général la combinaison linéaire
zt : 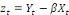
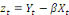 est aussi I(d).
est aussi I(d).
 ne soit pas
ne soit pas 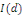
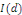 mais
mais 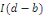
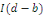 où b est un entier positif
où b est un entier positif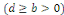
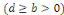 . En d'autres termes,
. En d'autres termes, 
 est intégré d'un ordre inférieur à l'ordre
d'intégration des deux variables considérées. Dans ce cas,
est intégré d'un ordre inférieur à l'ordre
d'intégration des deux variables considérées. Dans ce cas,
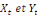
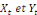 sont dites cointégrées, ce que l'on
note :
sont dites cointégrées, ce que l'on
note :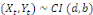
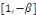
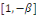 est le vecteur de cointégration. Le cas le plus
étudié correspond à :
est le vecteur de cointégration. Le cas le plus
étudié correspond à : 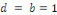
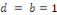 . Ainsi, deux séries non stationnaires
. Ainsi, deux séries non stationnaires 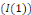
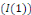 sont cointégrées s'il existe une combinaison
linéaire stationnaire
sont cointégrées s'il existe une combinaison
linéaire stationnaire 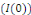
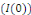 de ces deux séries.
de ces deux séries.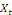
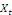 et
et 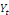
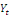 peuvent avoir une évolution divergente (elles sont toutes les
deux non stationnaires), mais elles vont évoluer ensemble à long
terme. Il existe donc une relation stable à long terme entre
peuvent avoir une évolution divergente (elles sont toutes les
deux non stationnaires), mais elles vont évoluer ensemble à long
terme. Il existe donc une relation stable à long terme entre 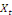
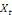 et
et 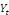
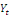 . Cette relation est appelée relation de
cointégration ou encore relation de long
terme. A long terme, les mouvements similaires de
. Cette relation est appelée relation de
cointégration ou encore relation de long
terme. A long terme, les mouvements similaires de 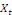
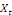 et
et 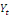
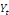 ont tendance à se compenser de sorte à obtenir une
série stationnaire.
ont tendance à se compenser de sorte à obtenir une
série stationnaire. 
 mesure l'ampleur du déséquilibre entre
mesure l'ampleur du déséquilibre entre 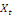
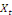 et
et 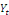
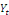 et est appelée erreur d'équilibre.
et est appelée erreur d'équilibre.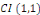
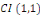 . De tels modèles permettent de modéliser les ajustements
qui conduisent à une situation d'équilibre de long terme. Il
s'agit ainsi des modèles dynamiques qui intègrent à la
fois les évolutions de court terme et de long terme des
variables81
. De tels modèles permettent de modéliser les ajustements
qui conduisent à une situation d'équilibre de long terme. Il
s'agit ainsi des modèles dynamiques qui intègrent à la
fois les évolutions de court terme et de long terme des
variables81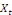
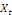 et
et 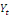
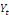 deux variables
deux variables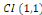
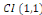 . Si l'on suppose que
. Si l'on suppose que 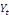
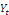 est la variable endogène et
est la variable endogène et 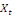
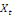 est la variable explicative, le modèle à correction
d'erreur s'écrit comme suit :
est la variable explicative, le modèle à correction
d'erreur s'écrit comme suit :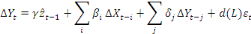
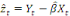
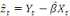 est le résidu de l'estimation de la relation de
cointégration entre
est le résidu de l'estimation de la relation de
cointégration entre 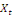
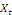 et
et 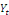
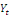 .
. 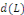
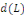 est un polynôme fini en L. en pratique, on a fréquemment
est un polynôme fini en L. en pratique, on a fréquemment
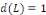
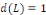 et le modèle à correction d'erreur s'écrit plus
simplement :
et le modèle à correction d'erreur s'écrit plus
simplement :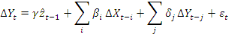
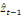
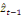 représente la force de rappel vers la cible de
long terme, donnée par la relation de cointégration. Le
coefficient ã doit être significativement différent de
zéro et négatif pour que le mécanisme à correction
d'erreur existe. Si tel n'est pas le cas, il n'existe pas de
phénomène de retour à l'équilibre. Le modèle
à correction d'erreur permet d'intégrer les fluctuations de court
terme autour de l'équilibre de long terme. Il décrit, termine
Valéry, un processus d'ajustement et combine deux types de
variables :
représente la force de rappel vers la cible de
long terme, donnée par la relation de cointégration. Le
coefficient ã doit être significativement différent de
zéro et négatif pour que le mécanisme à correction
d'erreur existe. Si tel n'est pas le cas, il n'existe pas de
phénomène de retour à l'équilibre. Le modèle
à correction d'erreur permet d'intégrer les fluctuations de court
terme autour de l'équilibre de long terme. Il décrit, termine
Valéry, un processus d'ajustement et combine deux types de
variables :
 , combinaison linéaire stationnaire de variables non
stationnaires, qui assurent la prise en compte du long terme.
, combinaison linéaire stationnaire de variables non
stationnaires, qui assurent la prise en compte du long terme.