Analyse de la vulnérabilité de la santé de la femme: cas du cameroun( Télécharger le fichier original )par Monde MAMBIMONGO WANGOU Institut Sous-régional de Statistique et d'Economie Appliquée (ISSEA) - Ingénieur Statisticien 2009 |

CHAPITRE 4 : MODELISATION DE LA SITUATION SANITAIRE DE LA FEMME AU CAMEROUNComme il l'a été souligné au niveau de la méthodologie générale de l'étude (chapitre 3, section 3.2), la variable d'intérêt est l'état de santé des femmes durant les 12 mois ayant précédé la MICS 2006. Pour cela, nous comptons proposer un modèle de régression logistique capable de déterminer les groupes de femmes les plus vulnérables en terme de santé (femmes malades pendant au moins 3 mois pendant les 12 derniers mois avant la MICS). Ce chapitre va se diviser en deux sections. La première section traite exclusivement de la modélisation, alors la seconde parle des limites de l'étude et des propositions de politiques de santé publique sous-jacentes aux résultats de l'étude. 4.1 MODELISATION LOGISTIQUE DE LA SANTE DE LA FEMME AU CAMEROUNIl existe deux types d'analyses au niveau de la modélisation logistique : l'analyse pronostic et l'analyse étiologique. La première cherche à construire un modèle dont la finalité est de prédire le mieux possible les modalités de la variable d'intérêt alors que la seconde analyse s'intéresse plus particulièrement à évaluer le risque associé à un facteur. Nous avons retenu l'analyse étiologique. Nous disposons des données sur l'état de santé de la femme au Cameroun. Ces données sont issues de l'enquête MICS 2006 du Cameroun. Nous comptons les utiliser pour déterminer les facteurs de risque liés à la mauvaise santé (être malade pendant au moins 3 mois au cours des 12 derniers mois). L'échantillon concerne 7855 femmes âgées de 18 à 49 ans dont 379 ont été de mauvaise santé. Les facteurs de risques potentiels évalués (sur base de la littérature et de la description) sont l'âge de la femme (en année), l'état matrimonial de la femme (célibataire, mariée monogame, mariée polygame, veuve, séparée ou divorcée, union libre), le niveau d'instruction (sans niveau, primaire, secondaire et plus), nombre d'associations (aucune association, une association, deux associations, plus de deux associations), le quintile de pauvreté du ménage (le plus pauvre, second, moyen, le quatrième, le plus riche), l'occupation principale de la femme (sans occupation, agriculture, écoles/études, commerce, service et administration, ménages/travaux domestiques, autres) et la province (Douala, Yaoundé et les 10 autres provinces) et la taille du ménage. La variable dépendante (à expliquer) est nominale. Elle prend la valeur 1 si l'individu a été malade pendant au moins 3 mois au cours des 12 derniers mois et 0 si non. Les variables explicatives, excepté l'âge et la taille du ménage sont également qualitatives (nominales et ordinales). Le modèle approprié pour traduire les facteurs de risques associés à la variable dépendante est le modèle de régression logistique. 4.1.1 Présentation théorique du modèle logit La régression linéaire n'est plus appropriée lorsque la variable dépendante est qualitative ou catégorielle. Ainsi, lorsque la variable qualitative a deux modalités, on parle de variable dichotomique et lorsque ces modalités sont supérieures à deux, on parle de variable polytomique. La formulation mathématique du modèle logit telle que présentée dans les encadrés qui suivent est inspirée de Bourbonnais (2005) et de Taffé (2004). Encadré 1 : Aperçu sur le modèle logit Définition : On dispose d'une variable d'intérêt Y pour un individu i qui s'écrit :
Xi= (Xi1, ... Xip)
un ensemble de variables explicatives pour Yi. On
désire expliquer E(Yi) par Soit un modèle dichotomique : Le modèle logit définit donc la
probabilité associée à l'événement Y=1 comme
la valeur de la fonction de répartition de la loi logistique au point
A partir de cette expression, on peut faciliter l'interprétation des paramètres estimés par la construction de la quantité suivante : Logit = On peut aussi écrire le modèle de régression logistique sous la forme d'un modèle de régression linéaire : Y=F( Cependant, le modèle est non linéaire et le
résidu Estimation du modèle : l'estimation au niveau de la modélisation logistique se fait à partir de la méthode du maximum de vraisemblance. Ainsi, on décrit la vraisemblance de l'échantillon. Cette vraisemblance s'écrit comme suit : L ( On maximise cette vraisemblance par rapport aux
paramètres Les informations relatives aux tests de significativité et aux interprétations des coefficients et odd ratio sont consignés dans l'encadre 2, placé en annexe D. 4.1.2 Spécification du modèle Les variables retenues pour traduire les facteurs de risques associés à la mauvaise santé sont de deux natures. Elles reflètent la situation sociodémographique (l'âge, l'état matrimonial, le niveau d'instruction, la province, le nombre d'associations) de l'individu et la situation du ménage (quintile de richesse et le nombre de membres). Pour faciliter l'interprétation de la constante du modèle, les variables continues (l'âge de la femme et le nombre de membres du ménage) sont centrées. Par contre, l'interprétation des coefficients et Odd ratio nécessite la définition des catégories de référence. Le tableau suivant expose les différentes variables explicatives et les modalités de référence associées. Tableau 16: variables et catégories de référence
La réussite d'une modélisation par régression logistique nécessite le respect de certaines étapes. La procédure à respecter est décrite dans l'encadré suivant. Encadre 3 : Etapes nécessaires pour réaliser une régression logistique
4.1.3 Estimation du modèleLe modèle est estimé par la méthode de maximum de vraisemblance à partir du logiciel STATA 9. Après 4 itérations, on obtient les résultats suivants : Tableau 17 : Résultats de l'estimation du modèle
Source : MICS 2006 et nos calculs 4.1.4 Diagnostic du modèle Diagnostiquer un modèle logistique consiste à déterminer la qualité d'ajustement du modèle aux données (en anglais « Goodness of fit »). Pour fixer les idées, nous allons nous appuyer sur l'analyse des résidus comme celui de Pearson et la distance de Cook25(*). L'analyse de ces résidus permet de statuer sur l'existence ou non des observations très mal ajustées et ayant possiblement un effet important sur l'estimation des coefficients. L'évaluation de la capacité du modèle à discriminer les modalités de la variable d'intérêt va se faire à partir des courbes de sensibilité, de spécificité et la courbe ROC (Receiving Operating Curve). Mais avant de s'intéresser aux résidus, il est important d'évaluer la calibration26(*) du modèle. Pour cela, on va utiliser le test d'Hosmer et Lemeshow. 4.1.4.1 Evaluation de la calibration du modèle Le principe du test de Hosmer et Lemeshow consiste à comparer les valeurs prédites et observées des modalités de la variable d'intérêt, après regroupement des individus en classes. On utilise ensuite la distance de Khi-deux pour calculer la distance entre les fréquences observées et prédites. Lorsque cette distance est relativement petite, on considère que le modèle est bien calibré. Le test repose sur les hypothèses suivantes : H0 : le modèle est bien calibré contre H1 : le modèle n'est pas bien calibré. Dans le cas présent, l'échantillon a été divisé en 10 groupes. La lecture du tableau suivant relatif aux résultats du test d'Hosmer et Lemeshow montre que l'ajustement global du modèle aux données est satisfaisant. Car, la valeur de la probabilité critique (Prob > chi2) est supérieure au seuil de signification de 5%. Tableau 18 : Résultats du test de Hosmer et Lemeshow
Source : MICS 2006 et nos calculs Néanmoins, certains « covariate patterns27(*) » très mal ajustés peuvent nous échapper, malgré l'ajustement global du modèle. L'analyse des résidus permet de savoir si l'ajustement est « bon » pour tous les « covariate patterns ». 4.1.4.2 Analyse des résidus du modèle L'examen des résidus a de multiples objectifs. Il permet entre autres de déterminer s'il y'a des observations mal expliquées (résidus extrêmes) et si certaines observations (outlier28(*) ou effet de levier) influencent catastrophiquement les résultats des estimations (changement de signe ou de valeurs des coefficients) et biaisent ainsi les analyses29(*). Une observation est mal expliquée lorsque la valeur du
résidu de Pearson associé est supérieure à 2. Elles
deviennent suspectes lorsque leur nombre dépasse 5% de l'ensemble des
observations. Dans notre cas, sur les 7855 observations, 370 ont
présenté des résidus extrêmes (voir graphique 8,
page 79). Il s'agit essentiellement des personnes qui ont été
malades au cours des 12 derniers mois ayant précédé
l'enquête MICS. Le graphique suivant illustre bien la dispersion des
observations. Une observation peut influencer l'estimation des coefficients du
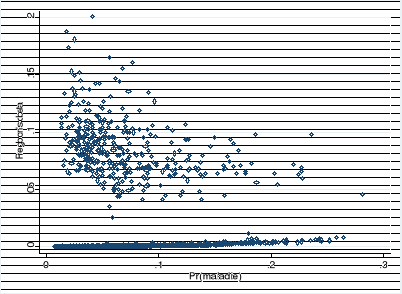
modèle lorsque la distance de Cook associée à
l'observation est supérieure à 4 divisé par le nombre
d'observation ( Graphique 4: Représentation de la distance de Cook en fonction de la probabilité critique
Source : MICS 2006 et nos calculs * 25 Distance qui mesure l'influence de la i e observation sur le modèle. * 26 Le modèle est bien calibré si les fréquences prédites sont proches de celles observées. * 27 Un covariate pattern est constitué de tous les individus qui présentent simultanément les mêmes caractéristiques (âge, taille du ménage, état matrimonial et autres). * 28 Un outlier est une observation qui ne suit pas le mouvement général des autres observations. * 29On cherche généralement à ajuster le modèle sur le centre de gravité du nuage des points et il est indésirable que quelques valeurs extrêmes modifient sensiblement les estimations. |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



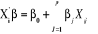 où
où 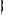
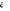 Rk avec k = p+1, sont des paramètres inconnus qu'on
désire estimer.
Rk avec k = p+1, sont des paramètres inconnus qu'on
désire estimer.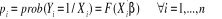 où F(.) désigne une fonction de répartition.
Ainsi, on appelle modèle logistique, le modèle dichotomique qui
admet pour fonction de répartition la fonction de distribution de la loi
logistique définie comme suit :
où F(.) désigne une fonction de répartition.
Ainsi, on appelle modèle logistique, le modèle dichotomique qui
admet pour fonction de répartition la fonction de distribution de la loi
logistique définie comme suit : 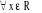 ;
;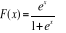
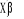 c'est-à-dire :
c'est-à-dire : 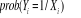 =
=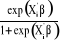 = pi .
= pi .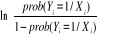 =
=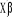
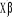 ) +
) +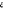
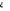 ne peut pas être distribué selon une loi normale. En
effet, si l'on admet le codage 0/1 (qui n'est pas unique), le résidu ne
pourra prendre que deux valeur, à savoir :
ne peut pas être distribué selon une loi normale. En
effet, si l'on admet le codage 0/1 (qui n'est pas unique), le résidu ne
pourra prendre que deux valeur, à savoir : 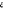 =1-F(
=1-F(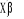 ) si Y=1 ou
) si Y=1 ou 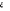 =-F(
=-F(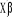 ) si Y=0. Delà, la variance n'est plus
) si Y=0. Delà, la variance n'est plus 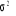 (cas de régression linéaire) mais plutôt V(
(cas de régression linéaire) mais plutôt V(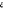 )=F(
)=F(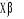 )[1-F(
)[1-F(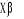 )]. Cette variance dépend de la variable X et par
conséquent, elle n'est pas constante mais heteroscédastique.
)]. Cette variance dépend de la variable X et par
conséquent, elle n'est pas constante mais heteroscédastique.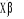 )=
)=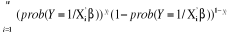
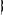 au moyen d'un algorithme numérique.
au moyen d'un algorithme numérique.
 ). Dans notre cas, les observations dont la distance de Cook est
supérieure à 0,0005 sont suspectes. Après examen de cette
distance, on constate que 1495 observations peuvent influencer
significativement les estimations du modèle. Ces observations n'ont pas
de comportement particulier hormis le fait que la totalité des femmes
malades font partie de ce groupe. Cependant, la lecture du graphique suivant
apporte l'information selon laquelle aucune observation n'influence
significativement l'estimation des observations car toutes les valeurs du
« pregibon dbeta » sont inférieures à
l'unité.
). Dans notre cas, les observations dont la distance de Cook est
supérieure à 0,0005 sont suspectes. Après examen de cette
distance, on constate que 1495 observations peuvent influencer
significativement les estimations du modèle. Ces observations n'ont pas
de comportement particulier hormis le fait que la totalité des femmes
malades font partie de ce groupe. Cependant, la lecture du graphique suivant
apporte l'information selon laquelle aucune observation n'influence
significativement l'estimation des observations car toutes les valeurs du
« pregibon dbeta » sont inférieures à
l'unité.