|
Application de la Méthodologie de Box & Jenkins sur
une chronique mensuelle de la consommation de cigares de 1969 à 1976.
LUYINDULADIO MENGA
Adresse e-mail :
ericmenga@yahoo.fr
Licencié en Sciences Economiques et de Gestion
Copyright 2006 ®
LA METHODOLOGIE DE BOX & JENKINS
La méthodologie de Box & Jenkins vise à
formuler un modèle permettant de représenter une chronique avec
comme finalité de prévoir des valeurs futures. De ce fait,
l'objet de cette méthodologie est de modéliser une série
temporelle en fonction de ses valeurs passées et présentes afin
de déterminer le processus ARIMA adéquat par principe de
parcimonie.
Cette méthodologie suggère une procédure
à trois étapes :
- Identification du modèle
- Estimation du modèle
- Validation du modèle (Test de diagnostique)
A. IDENTIFICATION DU MODELE
Dans cette première étape, l'objet est de
déterminer à partir de l'observation des fonctions
d'autocorrélation simple et partielle dans la famille des modèles
de types ARIMA (p, d, q) le modèle adéquat.
Les tests informels consistent à l'analyse des moments
et des plots afin de détecter la stationnarité ; mais ce ne
sont que des tests de présomption de stationnarité. Puis une
vérification de ces intuitions (tests informels) est faite par
l'application des tests formels notamment le test de racine unitaire de Dickey
Fuller.
B. ESTIMATION DU MODELE
Cette étape consiste à estimer les
paramètres du modèle adéquat retenu.
C. VALIDATION DU MODELE
La validation du modèle se réfère
à divers tests statistiques de spécification pour vérifier
si le modèle est congru c'est-à-dire qu'il ne peut être mis
a défaut. Ces tests statistiques consistent à tester que les
résidus du modèle estimer ne suivent pas exactement le bruit
blanc mais s'en rapprochent en d'autres termes les résidus doivent
être autocorrélés et ne présentent pas
d'hétéroscédasticité.
1. IDENTIFICATION DU MODELE
1.1. Etude de la stationnarité
a) Tests Informels
- Analyse du graphique
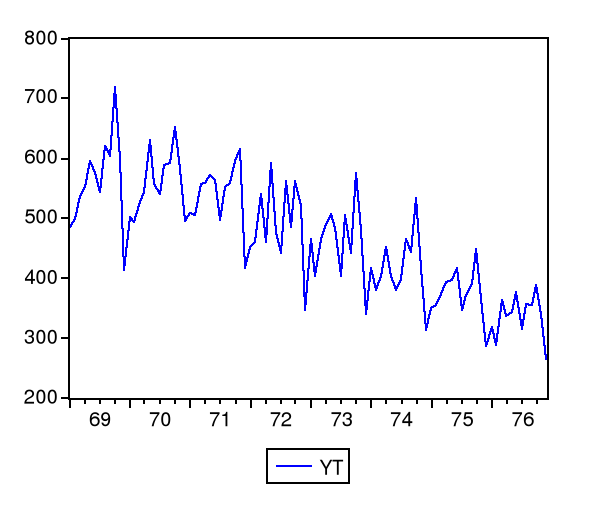
L'analyse visuelle du plot montre la présence d'une
tendance linéaire mais affectée par une saisonnalité. (Un
lissage exponentiel par ratio de moyenne mobile avec une approche
multiplicative a été appliqué pour pré-blanchire la
série). La nouvelle série désaisonnalisé s'appelle
YTSA.
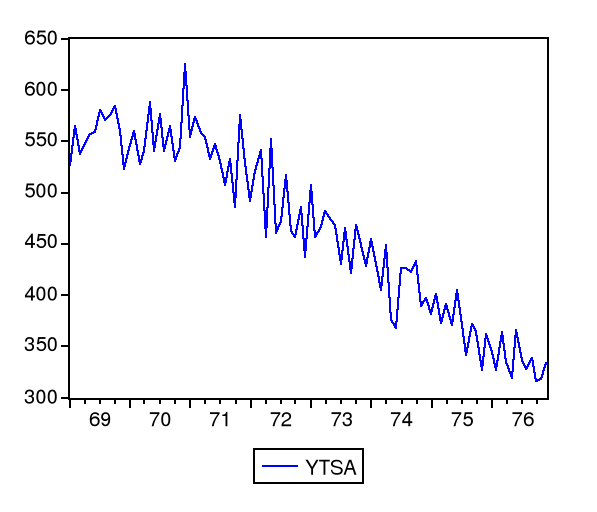
L'observation du plot de la série YT
désaisonnalisée (YTSA) présume une non
stationnarité.
- Analyse Du Correlogramme de
YTSA
|
Date : 06/22/07 Time : 00 :04
|
|
Sample: 1969:01 1976:12
|
|
Included observations: 96
|
|
Autocorrelation
|
Partial Correlation
|
|
AC
|
PAC
|
Q-Stat
|
Prob
|
|
. |*******|
|
. |*******|
|
1
|
0.892
|
0.892
|
78.721
|
0.000
|
|
. |*******|
|
. |*** |
|
2
|
0.887
|
0.447
|
157.40
|
0.000
|
|
. |*******|
|
. |** |
|
3
|
0.878
|
0.257
|
235.36
|
0.000
|
|
. |****** |
|
.*| . |
|
4
|
0.822
|
-0.152
|
304.43
|
0.000
|
|
. |****** |
|
. | . |
|
5
|
0.810
|
-0.001
|
372.25
|
0.000
|
|
. |****** |
|
. |*. |
|
6
|
0.798
|
0.104
|
438.82
|
0.000
|
|
. |****** |
|
.*| . |
|
7
|
0.750
|
-0.091
|
498.25
|
0.000
|
|
. |****** |
|
. | . |
|
8
|
0.740
|
-0.003
|
556.73
|
0.000
|
|
. |***** |
|
. | . |
|
9
|
0.711
|
-0.033
|
611.37
|
0.000
|
|
. |***** |
|
.*| . |
|
10
|
0.670
|
-0.063
|
660.51
|
0.000
|
|
. |***** |
|
. | . |
|
11
|
0.655
|
-0.005
|
707.93
|
0.000
|
|
. |***** |
|
. | . |
|
12
|
0.619
|
-0.043
|
750.81
|
0.000
|
|
. |**** |
|
.*| . |
|
13
|
0.578
|
-0.079
|
788.68
|
0.000
|
|
. |**** |
|
. |*. |
|
14
|
0.572
|
0.079
|
826.15
|
0.000
|
|
. |**** |
|
. | . |
|
15
|
0.542
|
0.053
|
860.22
|
0.000
|
|
. |**** |
|
.*| . |
|
16
|
0.498
|
-0.124
|
889.33
|
0.000
|
|
. |**** |
|
. | . |
|
17
|
0.490
|
0.006
|
917.96
|
0.000
|
|
. |*** |
|
. | . |
|
18
|
0.448
|
-0.038
|
942.16
|
0.000
|
|
. |*** |
|
. | . |
|
19
|
0.411
|
-0.055
|
962.81
|
0.000
|
|
. |*** |
|
. | . |
|
20
|
0.404
|
0.044
|
982.98
|
0.000
|
L'examen visuel du corrélogramme montre une
décroissance brusque de la fonction d'autocorrélation et que seul
les trois premiers coefficients des fonctions d'autocorrélation
partielles sont significatifs.
1.1 b) Tests Formels
Trois modèles seront estimés afin de
déterminer si la variable YTSA est stationnaire ou non stationnaire
de type déterministe ou stochastique, avec comme
hypothèse :
Ho= 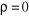 et et 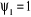
H1=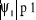 , ,
1° 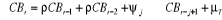
2° 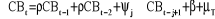
3° 

Le tableau ci-dessous reprend les critères de
Akaike et de Schwartz qui
nous permet de déterminer le décalage optimal pour
réaliser un test efficace de Dickey-Fuller.
Tableau 1 : Détermination du décalage (Lag)
par principe de parcimonie (1(*))
|
LAGS
|
AKAIKE
|
SCHWARZ
|
|
0
|
9.473292
|
9.553940
|
|
1
|
9.396911
|
9.505136
|
|
2
|
9.205466
|
9.341627
|
|
3
|
9.205466
|
9.341627
|
|
4
|
9.205466
|
9.341627
|
|
5
|
9.205466
|
9.341627
|
Le décalage optimal par principe de parcimonie est
égal de deux.
Tableau 2 : Test ADF
|
Null Hypothesis: YTSA has a unit root
|
|
Exogenous: Constant, Linear Trend
|
|
Lag Length: 1 (Automatic based on SIC, MAXLAG=1) (2(*))
|
|
|
|
t-Statistic
|
Prob.*
|
|
Augmented Dickey-Fuller test statistic
|
-5.074353
|
0.0004
|
|
Test critical values:
|
1% level
|
|
-4.058619
|
|
|
5% level
|
|
-3.458326
|
|
|
10% level
|
|
-3.155161
|
|
|
*MacKinnon (1996) one-sided p-values.
|
|
|
|
|
|
|
Augmented Dickey-Fuller Test Equation
|
|
Dependent Variable: D(YTSA)
|
|
Method: Least Squares
|
|
Date: 06/21/07 Time: 23:42
|
|
Sample(adjusted): 1969:03 1976:12
|
|
Included observations: 94 after adjusting endpoints
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
YTSA(-1)
|
-0.654058
|
0.128895
|
-5.074353
|
0.0000
|
|
D(YTSA(-1))
|
-0.289673
|
0.096016
|
-3.016913
|
0.0033
|
|
C
|
396.1054
|
78.43843
|
5.049890
|
0.0000
|
|
@TREND(1969:01)
|
-1.942398
|
0.384188
|
-5.055857
|
0.0000
|
|
R-squared
|
0.506748
|
Mean dependent var
|
-2.455438
|
|
Adjusted R-squared
|
0.490306
|
S.D. dependent var
|
36.44043
|
|
S.E. of regression
|
26.01585
|
Akaike info criterion
|
9.396911
|
|
Sum squared resid
|
60914.22
|
Schwarz criterion
|
9.505136
|
|
Log likelihood
|
-437.6548
|
F-statistic
|
30.82086
|
|
Durbin-Watson stat
|
2.259835
|
Prob(F-statistic)
|
0.000000
|
Hypothèse :
H0 : la variable est non stationnaire
H1 : la variable est stationnaire
Dans le tableau ci-dessus le t-statistic du test d'ADF, est
supérieure en valeur absolue aux valeurs critiques de Mackinnon à
tous les seuils (1%, 5%, 10%), confirme l'existence d'une stationnarité
de la variable YTSA de type déterministe avec constante et trend parce
que le p-value associé au trend et à la constante sont
statistiquement significatifs (leurs probabilités sont tous
inférieurs à la probabilité critique de 5%).
Vu que la chronique YTSA est stationnaire de type
déterministe, l'estimation du processus se fera par l'écart par
rapport à la tendance afin d'éliminer l'influence du choc
stochastique parce que dans un processus déterministe (TS) l'influence
du temps tend à disparaître au fur et à mesure que le temps
passe.
Etape à suivre :
- Premièrement il faut générer le temps
pour la série YTSA qui se fait par la commande genr t = @ trend
(1969 :01) et puis estimer le modèle YTSA =
1 + 1T.
- Deuxièmement éliminer l'influence du choc
stochastique dans le processus (faire l'écart par rapport à la
tendance) 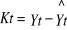
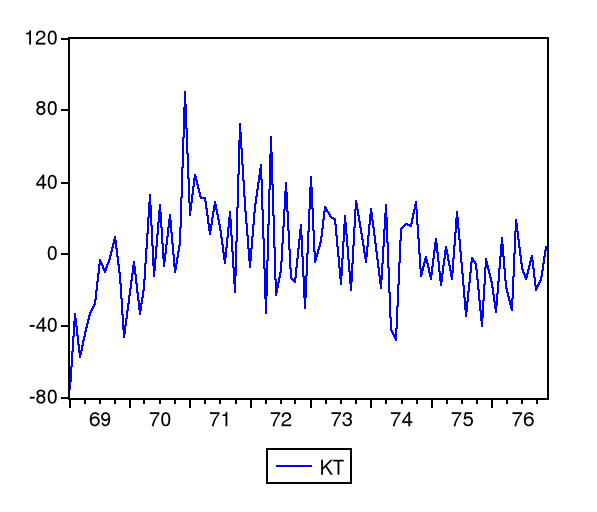
L'observation graphique de la chronique KT démontre une
stationnarité.
2. ESTIMATION DU MODELE
Kt = 1Kt-1 + 2K
t-2 + 3K t-3 + t +
1t-1+ 2t-2 3(*)
Tableau 3 : Estimation du modèle ARMA (3,2)
|
Dependent Variable: KT
|
|
Method: Least Squares
|
|
Date: 06/24/07 Time: 17:33
|
|
Sample(adjusted): 1969:04 1976:12
|
|
Included observations: 93 after adjusting endpoints
|
|
Convergence achieved after 7 iterations
|
|
Backcast: 1969:02 1969:03
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
AR(3)
|
0.392788
|
0.090896
|
4.321307
|
0.0000
|
|
MA(2)
|
0.252360
|
0.101390
|
2.488993
|
0.0146
|
|
R-squared
|
0.220079
|
Mean dependent var
|
1.788303
|
|
Adjusted R-squared
|
0.211508
|
S.D. dependent var
|
26.50553
|
|
S.E. of regression
|
23.53614
|
Akaike info criterion
|
9.176222
|
|
Sum squared resid
|
50409.42
|
Schwarz criterion
|
9.230686
|
|
Log likelihood
|
-424.6943
|
Durbin-Watson stat
|
2.106214
|
|
Inverted AR Roots
|
.73
|
-.37+.63i
|
-.37 -.63i
|
3.VALIDATION DU MODELE
- Corrélogramme des résidus
Lorsque le processus est bien estimé, les
résidus se retrouvent entre les valeurs observées et les valeurs
estimées par le modèle et ces derniers se comportent comme un
bruit blanc. Ainsi, il ne doit pas exister l'autocorrélation dans la
série.
La génération les résidus après
estimation (4(*)) permet
d'observer sur le correlogramme s'il y a des termes qui sont extérieurs
aux deux intervalles de confiance et de vérifier si la
probabilité des Q-Stat est proche ou non de 1. Si elle est proche de 1
ce qu'il y a réellement un bruit blanc. (statistique de Box-Pierce ou
statistique de portmanteau.)
Tableau 5 : Corrélogramme des résidus
5(*)
|
Date: 06/24/07 Time: 17:38
|
|
Sample: 1969:01 1976:12
|
|
Included observations: 96
|
|
Autocorrelation
|
Partial Correlation
|
|
AC
|
PAC
|
Q-Stat
|
Prob
|
|
.*| . |
|
.*| . |
|
1
|
-0.078
|
-0.078
|
0.5999
|
0.439
|
|
. | . |
|
. | . |
|
2
|
-0.012
|
-0.018
|
0.6147
|
0.735
|
|
.*| . |
|
.*| . |
|
3
|
-0.057
|
-0.060
|
0.9489
|
0.814
|
|
. | . |
|
. | . |
|
4
|
-0.001
|
-0.010
|
0.9490
|
0.917
|
|
. | . |
|
. | . |
|
5
|
0.019
|
0.016
|
0.9860
|
0.964
|
|
. | . |
|
. | . |
|
6
|
0.054
|
0.053
|
1.2860
|
0.972
|
|
.*| . |
|
. | . |
|
7
|
-0.062
|
-0.054
|
1.6946
|
0.975
|
|
. |*. |
|
. |*. |
|
8
|
0.072
|
0.068
|
2.2484
|
0.972
|
|
. |*. |
|
. |*. |
|
9
|
0.091
|
0.108
|
3.1466
|
0.958
|
|
. |*. |
|
. |*. |
|
10
|
0.100
|
0.115
|
4.2325
|
0.936
|
|
. |*. |
|
. |*. |
|
11
|
0.134
|
0.169
|
6.2101
|
0.859
|
|
.*| . |
|
. | . |
|
12
|
-0.081
|
-0.035
|
6.9366
|
0.862
|
|
.*| . |
|
.*| . |
|
13
|
-0.184
|
-0.183
|
10.770
|
0.630
|
|
. |*. |
|
. | . |
|
14
|
0.090
|
0.059
|
11.705
|
0.630
|
|
. |*. |
|
. |*. |
|
15
|
0.102
|
0.108
|
12.908
|
0.609
|
|
.*| . |
|
.*| . |
|
16
|
-0.117
|
-0.144
|
14.531
|
0.559
|
|
. |*. |
|
. |*. |
|
17
|
0.114
|
0.090
|
16.071
|
0.519
|
|
. | . |
|
. |*. |
|
18
|
0.037
|
0.080
|
16.236
|
0.576
|
|
. | . |
|
.*| . |
|
19
|
-0.024
|
-0.083
|
16.308
|
0.637
|
|
. | . |
|
. | . |
|
20
|
0.025
|
-0.034
|
16.386
|
0.692
|
Après observation du corrélogramme des
résidus nous constatons que les résidus se retrouvent à
l'intérieur de l'intervalle de confiance et ils se rapprochent
exactement d'un bruit blanc.
- Test de ARCH
d'hétéroscédasticité
La détection de
l'hétéroscédasticité par le processus ARCH se fait
avec comme hypothèse :
H0 : il y a homoscédasticité
H1 : il y a
hétéroscédasticité
Le test s'effectue avec la commande residu.archtest(2)
où 2 est le nombre de retard à inclure. nous trouvons ce qui
suit :
|
ARCH Test:
|
|
F-statistic
|
0.027589
|
Probability
|
0.972797
|
|
Obs*R-squared
|
0.057023
|
Probability
|
0.971891
|
La probabilité critique du multiplicateur de Lagrange est
supérieure à 5% poussant à accepter H0,
d'où, le modèle est homoscédastique.
- Test de Normalité
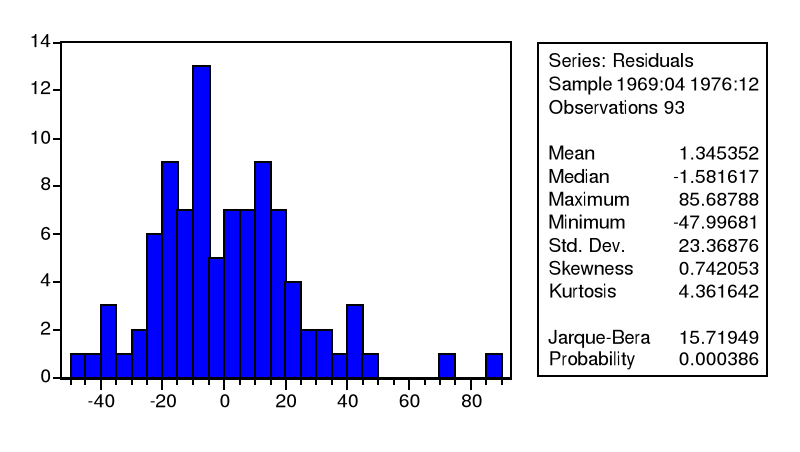
La probabilité critique de Jarque-Bera est
inférieure à 5%, ce qui amène à l'existence de la
normalité qui est également visible sur l'histogramme ci-dessus.
Donc la série des résidus est un bruit blanc non gaussien.
- Test d'autocorrelation des erreurs (Test de Breusch-Godfrey ou
test LM)
|
Breusch-Godfrey Serial Correlation LM Test:
|
|
F-statistic
|
0.402027
|
Probability
|
0.670171
|
|
Obs*R-squared
|
0.523872
|
Probability
|
0.769560
|
La probabilité calculée est supérieure
à la probabilité critique de 5%, ainsi nous pouvons accepter
Ho, d'où, le modèle est un bruit blanc. Il y a absence
d'autocorrelation des erreurs.
Après avoir effectuer les batteries de tests sur la
variable résiduelle nous pouvons dire que l'estimation du modèle
ARIMA (3,0,2) est donc validé, soit la série peut être
valablement représentée par un processus de type ARIMA
(3,0,2).
Notre essai de modélisation par Box & Jenkins de la
consommation de cigare est valablement représenté par : Kt =
1Kt-1 + 2K t-2 +
3K t-3 + t + 1t-1+
2t-2.
- Graphique de la valeur actuelle (actual), prédite
dans l'échantillon (fitted) et du résidu (résidual).
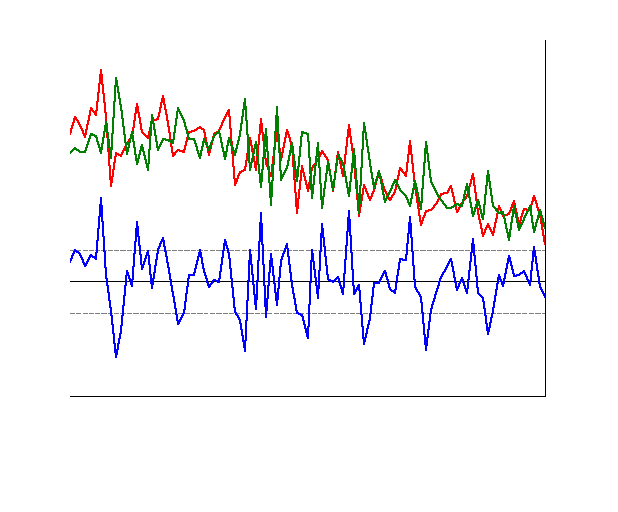
L'observation du graphique montre bel et bien que les
variables de la valeur actuelle sont collées avec celle de la variable
projetée (fitted value) et que le résidu se comporte maintenant
comme un bruit blanc.
4.PREVISiON
- La prévision dans l'échantillon
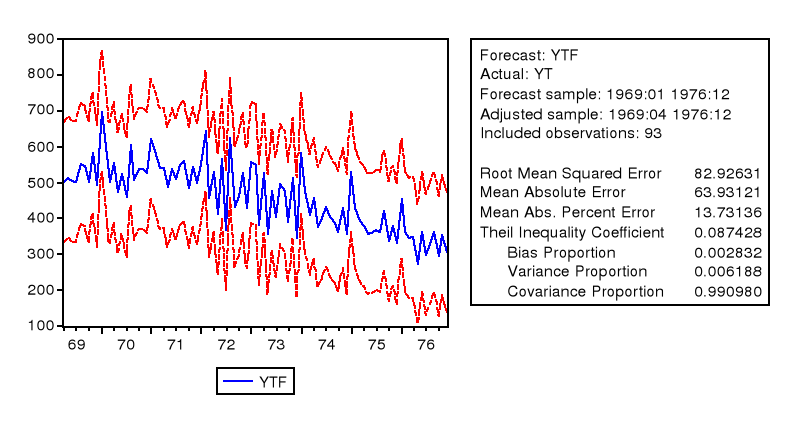
Après avoir réaliser cette projection dans
l'échantillon (variable YTSAF), il nous faut vérifier que le
coefficient d'inégalité de Theil tend vers 0 pour avoir une bonne
projection. Ce qui est démontré ici parce que le coefficient
d'inégalité de Theil donne une valeur de 0.087428. Une faible
variance de proportion (dans notre cas 0.006188), présume que la valeur
prédite dans l'échantillon YTSA (fitted value) suivra la variable
désaisonnalisée YT.
* 1 L'application du principe
de parcimonie veut dire minimiser le nombre de paramètres.
* 2 Nous cherchions un
décalage qui permette à ce que la valeur t-statistic du test
d'ADF soit supérieure en valeur absolue aux valeurs critiques de
Mackinon, c'est pour cela que nous avons choisit le décalage 1 ( lag 1)
en lieu et place du décalage 2 (lag 2).
* 3 La commande sur le logiciel
Eviews 4: LS KT AR(3) MA(2)
* 4 La commande sur le logiciel
Eviews 4 : GENR RESIDU = RESID
* 5 La commande sur le logiciel
Eviews 4 : KT.CORREL(20) où KT = résidu et n = le nombre de
décalage.
| 

