République Algérienne Démocratique
Et Populaire
|
Ministère de l'Enseignement Supérieur et de
La
Recherche Scientifique
|
Université El-Hadj Lakhdar - BATNA
Faculté des Sciences de
l'Ingénieur
Département d'Informatique
pour l'obtention du diplôme d'Ingénieur
d'Etat en Informatique
Option : Informatique
Industrielle
par
Tegane Saher
Goudjil Hassen Rouagat waheb
Mise en place d'un système d'information
sous
Oracle basé sur une architecture
trois tiers
Encadreur:
Mr Dekhinet Abdelhamid
Remerciements
Nous remercions DIEU, le tout puissant qui nous a donné la
force et le courage d'élaborer ce modeste travail.
Nous tenons à remercier Monsieur : ABDELHAMID DEKHINET,
de nous avoir fait confiance, nous avoir permis de travailler avec autonomie,
pour ce sujet qu'il a proposé, de nous avoir conseillé et
aidé lorsque des problèmes se posaient.
Nous Remercions l'ensemble des personnes qui nous ont aidé
pour la réalisation de ce travail, qui sont particulièrement :
BENNEZAR AMOR
BOUMARAF DJAMEL EDDINE
Nous tenons à remercier particulièrement Monsieur
SEDRATI de ses conseils qui nous ont été très
bénéfiques dans la réalisation de ce travail, de nous
laisser son bureau pour compléter notre travail.
Plan de mémoire :
INTRODUCTION :
1 .1 Problématique Et Motivations
1.2 Description De La solution
CHAPITRE 1 :
Les préférences d'Oracle
1. modèle client/serveur
1.1 Présentation de l'architecture à 2 niveaux.
1.2. Présentation de l'architecture à 3 niveaux.
2. Le Choix D'oracle
2.1. L'entreprise oracle.
2.2 Les préférences d'oracle.
CHAPITRE 2 :
LE NIVEAU BASE DE DONNEES
1. Définition D'une Base De Données.
2. Le SGBD oracle.
3. Historique du SGBD oracle.
4. Structure Interne d'oracle.
4.1. Le serveur Oracle.
4.2. L'instance Oracle.
4.2.1. Le SGA ou System global Area :
4.2.1.1. La zone mémoire Shared Pool :
4.2.1.2. La zone mémoire Database Buffer Cache :
4.2.1.3. La zone mémoire Redo Log Buffer :
4.2.2. La zone mémoire Program Global Area (PGA) : 4.2.3.
Les processus d'une instance :
4.2.3.1. Les processus utilisateurs
4.2.3.2. Les processus systèmes (oracle process).
4.3. La base de données oracle.
4.3.1. La structure d'une base de données logiques.
4.3.1.1. Objets complexes
4.3.1.2. Objets simples.
1. Tablespaces.
2. Segments.
3. Extent.
4.3.2. Structure physique.
1. Les fichiers de données (datafile).
2. Blocks.
3. Les Redo log file.
4. Les fichiers de contrôles (Control files).
5. Le fichier d'initialisation.
6. Les fichiers de message.
5. Dictionnaire de données Oracle.
6. Démarrage et arrêt d'une instance.
LE NIVEAU INTERMEDIAIRE
1. Historique.
2. Le serveur d'application de point de vue conceptuel
3. Le serveur d'application de point de vue fonctionnel
CHAPITRE 4 :
CONCEPTION
1. Le modèle oracle de base de données
relationnelle.
2. Conception de la base de données. CHAPITRE 5
:
IMPLEMENTATION.
1. Construction de la base de données
2. Description des interfaces réalisées.
CHAPITRE 6 :
SECURITE
1. Authentification.
2. Contrôle et audit d'accès.
3. La base de donnée privée virtuelle vpd.
4. Répertoire Internet oracle.
5. La solution choisse.
CHAPITRE 7 :
MESSAGERIE
1. Oracle collaboration suite. 1.1. L'architecture d'Oracle
Collaboration Suite.
1.2. Distribution de la charge et la sécurité.
1.3. Détailles sur les composants et les protocoles
d'Oracle Collaboration Suite.
2. présentation générale d'émail
d'Oracle.
2.1. Introduction.
2.2. Les caractéristiques d'email d'Oracle.
2.3. Le stocke de messages.
2.4. Webmail d'Oracle.
3. serveurs et processus.
4.1. Gestion des services et des processus. 4.2. SMTP.
4.3. POP3/IMAP4. ailleurs
CONCLUSION.
introduction
Dans le monde moderne, les entreprises et les
établissements publics ont de plus en plus besoin de planifier ses
ressources. Par ailleurs, ils exploitent les nouvelles technologies de
l'information et de communication.
Problématique et motivations
Au sein d'une université l'effectif étudiants,
enseignants et employés ne cessent d'accroître d'une année
à une autre.
Cet accroissement engendre, évidemment, un volume
d'information considérable. Pour maintien ces informations, il est clair
donc de mettre en place un système d'information avec des applications
métiers adéquates.
Les objectifs attendus par un tel système peuvent se
résumé comme suit :

Faciliter les tâches d'administration, tel que
l'inscription et la réinscription des étudiants, orientation,
transfert, etc. ...
Améliorer les performances des services rendus.
Assurer la disponibilité de l'information.
Eviter l'inconsistance et l'incohérence des
données.
Diminuer les problèmes liés aux frottements
directs des étudiants et des enseignants avec l'administration.
Déterminer les responsabilités.
Etc. ...
Description du sujet
Le projet a pour but la création d'un serveur de
données et la réalisation d'un ensemble d'applications dans un
environnement Intranet/Internet.
L'ensemble des informations concernant l'étudiant,
l'enseignant et l'administration est centralisé dans une base de
données unique qui peut être atteint via une application
oracle.
CHAPITRE I
Avec la mise en place du réseau de communication de
l'information au sein de l'université de BATNA, la réalisation
d'application Intranet/Internet est devenue possible. En
générale, une telle réalisation n'est pas une tâche
simple, des choix judicieux doivent être faites et sur tous les plans:
matériels, système d'exploitation, SGBD, outils de
développements ... etc.
4. Intranet
Un intranet est un ensemble de services
Internet (par exemple un serveur web) internes à un réseau local,
c'est-à-dire accessibles uniquement à partir des postes d'un
réseau local, ou bien d'un ensemble de réseaux bien
définis, et invisible de l'extérieur. Il consiste à
utiliser les standards client/serveur de l'Internet (en utilisant les
protocoles TCP/IP), comme par exemple l'utilisation de navigateurs Internet
(client basé sur le protocoles HTTP) et des serveurs web (protocole
HTTP), pour réaliser un système d'information interne à
une organisation ou une entreprise.
Un intranet repose généralement sur une
architecture client serveur à trois niveaux.
5. Modèle client/serveur
Depuis des années, les innovations technologiques se
multiplient tant pour les matériels que pour les réseaux, et
améliorent constamment les performances tout en réduisant les
coûts. Plusieurs générations technologiques sont apparues
au rythme de ces innovations : les mainframes, le client/serveur, Internet.
De nombreuses applications fonctionnent selon un environnement
client/serveur, cela signifie que des machines clientes (des machines faisant
partie du réseau) contactent un serveur, une machine
généralement très puissante en terme de capacités
d'entrée-sortie, qui leur fournit des services.
Les services sont exploités par des programmes,
appelés programmes clients, s'exécutant sur les machines
clientes.
Dans un environnement purement Client/serveur, les ordinateurs du
réseau (les clients) ne peuvent voir que le serveur, c'est l'un des
principaux atouts de ce modèle.
3.1 Présentation de l'architecture à deux
niveaux
(Aussi appelée architecture deux tiers, tier signifiant
étage en anglais).
Elle caractérise les systèmes clients/serveurs dans
lesquels le client demande un service et le serveur la lui rendu directement,
l'architecture des base de données traditionnelle est
basée sur ce modèle. Dans cette architecture la
logique applicative et les tâches de traitement sont réparties
entre le client et le serveur de base de données (voir figure
01). Les inconvénients du modèle deux tiers c'est que
:
Le client est lourd, où une grande partie de la logique
d'application et de puissance de traitement y réside.
Le client peut travailler sur différentes plateformes ce
qui nécessite la construction de plusieurs versions de l'application.
Les clients doivent être mis à jour à
chaque fois que les fonctions de l'application évoluent.
.
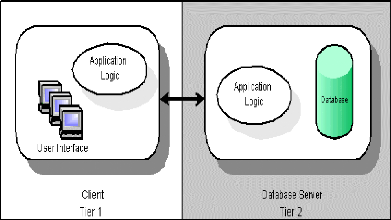
Figure 01: Modèle client serveur deux
tiers.
3.2 Présentation de l'architecture à trois
niveaux
Le modèle à trois niveaux est apparu pour
résoudre les problèmes du modèle précédent.
Dans cette architecture il existe un niveau intermédiaire entre le
client et le serveur. Cet intermédiaire est le serveur d'application qui
maintient le corps de la logique applicative. La logique applicative
réside dans un seul tiers (voir figure 02), dans cette
architecture le logiciel client est de taille très petite.
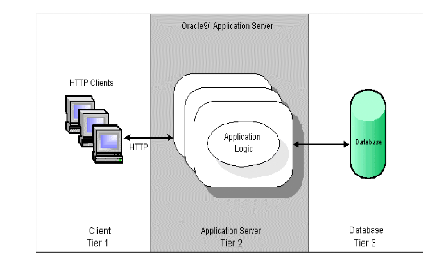
.
Figure 02: Modèle client serveur trois
tiers.
Les avantages de cette architecture sont les suivants:
Les clients sont légers.
Les modifications sur les applications ne pose pas le
problème de mise à jour.
Une plus grande sécurité (la
sécurité peut être définie pour chaque service).
l'amélioration des performances (les tâches sont
partagées).
Cette dernière architecture est bien supportée par
oracle où il établit une différence entre l'interface
utilisateur qui s'exécute sur le client et la logique d'application qui
s'exécute dans le serveur d'applications, quelle que soit la
localisation physique de ce dernier. La logique applicative est donc
déplacée vers le serveur d'applications.
Oracle s'appuie sur une architecture à trois niveaux :
· Le Poste Client qui assure la gestion de l'affichage avec
un simple navigateur Web,
· Le Serveur d'Applications qui gère la logique
d'application.
· Le Serveur de Données où est stockée
la base de données qui gère les transactions
orientées données.
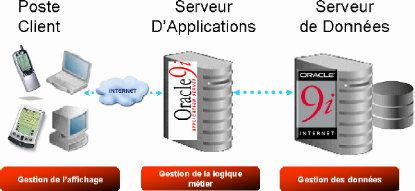
Figure 02: Modèle client serveur tois tiers en
oracle.
Le premier niveau est un serveur de base de données
oracle, le serveur d'application oracle représente le niveau
intermédiaire et dans le troisième niveau l'utilisateur peut
accéder aux applications dans le deuxième niveau par un
navigateur Web (Internet explorer, Netscape,etc )
4. le choix d'oracle 4.1. L'entreprise
oracle
Le métier d'Oracle, c'est l'information : la
gérer, l'utiliser, la partager et la protéger. Depuis près
de trois décennies, Oracle Corporation (NASDAQ : ORCL), le premier
éditeur mondial de logiciels d'entreprise, fournit les logiciels et les
services qui permettent aux entreprises d'obtenir de leurs systèmes
d'information les informations les plus récentes et les plus
précises.
Avec un chiffre d'affaires annuel de 11,8 milliards de dollars,
Oracle propose aux entreprises sa base de données, ses outils et ses
applications, ainsi que les services associés de conseil, de formation
et de support. Aujourd'hui, Oracle est l'éditeur qui aide les
gouvernements et les entreprises à travers le monde à placer
l'information au coeur de leur activité en suivant trois principes :
simplifier, normaliser et automatiser. Ces principes permettent aux entreprises
d'utiliser des informations de grandes qualités pour collaborer, mesurer
les résultats pour s'améliorer en permanence. Aujourd'hui, Oracle
est toujours à
l'avant-garde de l'innovation. On trouve les technologies
Oracle dans presque tous les secteurs à travers le monde, et dans 100
entreprises du classement Fortune 98.
L'objectif d'Oracle est de proposer à ses clients des
solutions de bases de données, de middleware et de progiciels fiables,
sécurisées et intégrées.
4.2 Les préférences d'oracle
De nombreux SGBD sont disponibles sur le marché, partant
des SGBD gratuits jusqu'aux SGBD destinés spécialement aux
professionnels, comportant de nombreuses fonctionnalités, mais plus
coûteux, donc on peut différencier entre les SGBD par leur
fonctionnalité, cette différence nous guide à faire le
meilleur choix parmi les SGBD disponibles mais selon les besoins du projet.
Dans notre cas on a opté pour oracle parmi les trois SGBD
les plus puissants et les plus utilisés:
- DB2 d'IBM.
- SQL serveur de Microsoft
- Oracle.

Les critères du choix du SGBD Oracle sont
récapitulés dans les points suivants : Le nombre
d'utilisateurs
Actuellement, le nombre d'étudiants de
l'université de Batna est 40000 étudiants, le nombre
d'enseignants est 1200 enseignants. En plus l'université a
bénéficié d'une enveloppe financière pour la
réalisation d'un deuxième pôle universitaire à une
consistance de 26000 places pédagogiques, donc il est nécessaire
d'utiliser un SGBD qui supporte ce grand nombre d'utilisateurs.

Le volume de donnés
Il est clair que la consistance de l'effectif engendre un volume
d'informations énorme, La gestion d'un tel volume d'information doit
être confié à un SGBD lourd.

Capacité Internet
Pour éviter les déplacements, les utilisateurs
doivent accéder au système via le web, ce qui nécessite un
SGBD soutenu par une capacité Internet.
A ce stade: On doit répondre à la
question suivante:
Est-ce que oracle peut répondre à ces
exigences?
y' Pour ce qui concerne le volume de données et
le nombre d'utilisateurs:
Oracle n'est pas un SGBDR optimisé pour des petites bases
de données. Sur de petits volumes de traitements (2 Go par exemple) et
peu d'utilisateurs (une trentaine) vous pourriez trouver la situation où
MySql offre des performances quasi comparables à
Oracle. Avec un volume important de donnée (>200Go)
et un grand nombre d'utilisateurs (>3 00). Les écarts de performance
entre MySql, Oracle et DB2 seront très visibles. En effet dans la
version 8i d'oracle la capacité de base de donnée est de 512
POctets, et en plus le serveur Oracle permet d'accueillir simultanément
15000 utilisateurs.
y' Et pour ce qui concerne la capacité
Internet:
Oracle a été le premier éditeur de
logiciels à développer et déployer des logiciels
d'entreprise 100% Internet pour l'ensemble de sa gamme de produits: Base de
données, logiciels de gestion, développement applicatif et outils
d'aide à la décision.
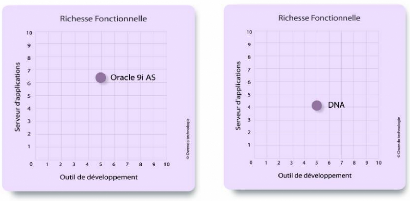
Figure 03 : la comparaison entre le serveur
d'application Oracle le serveur .net ou DNA de MicroSoft.
Et comme les applications web nécessitent une grande
sécurité, oracle prévoit des mécanismes de
sécurité plus efficaces et plus fiables (en 2002 oracle a
été nommé "unbroken"). Parmi les méthodes de
sécurité fournie par oracle on trouve :
· Oracle application server s'interface avec un annuaire
LDAP. On peut donc utiliser l'annuaire pour faire de l'authentification et du
contrôle d'accès, de manière déclarative.
· le support de SSL sous HTTP, garantissant un niveau de
sécurité supplémentaire entre client et serveur :
authentification forte et confidentialité/intégrité. Le
serveur est capable d'utiliser des certificats X.509 pour les utilisateurs
(stockés dans l'annuaire). Un outil de gestion des certificats X.509
(Wallet Manager) est fourni.
En conclusion on peut dire qu'oracle est approuvable. De plus
Oracle a d'autre avantages tel que:
|
Le SGBD est périodiquement mis à jour et en
évolution permanente (derniers versions: 9i et 10G).
Pérennité de l'éditeur : avec plus de 40% du
part de marché, ce n'est pas demain qu'Oracle disparaîtra.
Procédures stockées en PL/SQL ou en JAVA (depuis la
8.1.7) ce qui peut s'avérer utile pour les équipes de
développement.
Par rapport à d'autre SGBD Oracle supporte de nombreuse
plateforme :Unix, Windows et mainframe plateforme.
Disponibilité de la documentation autour d'oracle
http ://
www.otn.oracle
.com.
|
Comme tout système informatique oracle a aussi ses
défauts


Forte demande de ressources : Oracle est bien plus gourmand en
ressource mémoire que ses concurrents, ce qui implique un investissement
matériel non négligeable. La connexion utilisateur
nécessite par exemple près de 700 Ko/utilisateur, contre une
petite centaine sur des serveurs M S-SQL.
Il est quasi impossible d'obtenir des informations concernant le
fonctionnement interne du moteur Oracle.
Chapitre 2
1. Introduction
Etant donnée qu'une partie du projet consiste en la
création d'une base de données sous ORACLE, nous
avons suggéré de commencer par donner une vision
générale qui couvre tout ce qui concerne ORACLE
comme: un SGBD très puissant,
des outils de développement d'application plus efficaces.
2. Les bases de données


Il n'y a aucun doute que les bases de données sont plus
efficaces que les fichiers, mais on essaye d'évoquer les limitations des
fichiers et les extensions des bases de données: Les
fichiers: l'utilisation des fichiers a été restreint par
certains contraintes entre outre:
+ Prolifération des programmes de gestion des
données pour traiter les différents formats des fichiers.
+ Particularisation des fichiers en fonction de traitement, ce
qui implique la redondance des données stockées.
+ Le contrôle différé des fichiers peut
impliquer une incohérence des données. Les bases de
données:
Une base de données est un ensemble d'informations
cohérentes et structurées. Elle est
constituée d'un regroupement de données modélisant les
objets d'une partie du monde réel et servant de support à une
application informatique. Cet ensemble cohérent d'informations
correspond à une unité logique de gestion et représente
une ressource partagée.
Ce regroupement d'informations doit être interrogeable
par son contenu (trouver les données qui satisferont à un certain
critère) par une ou plusieurs personnes de façon
simultanée; la recherche devant aboutir dans un temps opportun.
Les bases de données ont été
créées dès les années 1 960s, elles sont
considérés le bon alternatif des fichiers, et
caractérisées par:
+ Centralisation et partage des données entre plusieurs
traitements. + L'indépendance des données et des programmes
+ Le contrôle immédiat de la validité de
données.
+ Le SGBD c'est le seul qui performe les
routines et les opérations de gestion.
+ Un administrateur de la BD qui est responsable de
l'installation, la gestion et la maintenance de la BD.
3. Système de gestion de bases de données
(SGBD)
Un SGBD est un outil qui permet de gérer et interagir
avec une base de données. Différents types de SGBDs ont
été conçu pour supporter certaines exigences, on peut les
classer comme suit:

Le SGBD hiérarchique: stocke les
données dans une structure semblable à un arbre et assume une
relation père et fils entre les données, le sommet s'appel la
racine et peut être relier à plusieurs dépendants, le
dépendant par son tour peut être relier à un nombre
quelconque de sous- dépendants et ainsi de suite, se type de SGBD et
maintenant obsolète.

Le SGBD réseau: stocke les donnée
dans une format d'enregistrements et de liens, ce système est
très flexible avec les relations m:m que le
précédant, il est caractérisé par
l'efficacité et la rapidité de stockage, ce système
supporte les données complexes mais il été inflexible et
requit une conception très fastidieuse.

Le SGBD relationnel: probablement a la structure
simple qu'une base peut avoir, il consiste de tables, chacune table consiste
d'enregistrements, et chaque enregistrement consiste de champs. Un seul champ
correspond à une unité de donnée. Ce type est
prospéré dans la dernière décade. Oracle, Informix
et Sybase sont quelque populaires incarnés SGBDRs.
4. Historique du SGBD oracle
Oracle est un SGBD édité par la
société (Oracle Corporation), leader mondial des bases de
données.
La société Oracle Corporation a été
créée en 1977 par Lawrence Ellison, Bob Miner, et Ed Oates. Elle
s'appelle Relational Software Incorporated (RSI).
Larry Ellison a identifié une opportunité que
d'autres entreprises ont manqué : il a pris connaissance de la
description d'un prototype opérationnel d'une base de données
relationnelle, et découvert qu'aucune entreprise n'avait pris
l'initiative de commercialiser cette technologie. Larry Ellison et ses
co-fondateurs Bob Miner et Ed Oates ont réalisé que
le modèle de la base de données relationnelle
représentait un potentiel énorme, mais ils n'imaginaient pas
qu'ils transformeraient pour toujours l'informatique professionnelle.
4.1 Caractéristiques du SGBD oracle
Oracle est un SGBD permettant d'assurer :

La définition et la manipulation des données. La
cohérence des données.
La confidentialité des données.
L'intégrité des données.
Extraction rapide de données sélectionner par un
mécanisme d'indexation efficace. La sauvegarde et la restauration des
données.
La gestion des accès concurrents.
4.2 Les produits oracle
Les produits oracle sont classés en trois types: + Base
de donnée oracle.
+ Suite développeur oracle.
+ Serveur d'application oracle.

Figure 04 : les produit oracle.
Ces trois types de produits constituent la plateforme des
applications Internet, chacun a une importance dans une échelle bien
spécifiée

Oracle BD (DB CLUSTER)
Ce produit est caractérisé par la diversité
d'outils de manipulation de données (SQL*plus, SQL plus Worcksheet,
iSQL*plus) et de programmation (pro c-c++, pro cobol,pro perl ) on basant sur
les langage SQL et PL/SQL.
De plus il procure des assistants graphiques pour aider à
la gestion et d'autres pour diagnostiquer les données et d'autres
plusieurs outils qui peuvent être optionnels selon l'édition
d'oracle.
Il existe trois éditions d'oracle DB utilisés
selon les besoins et l'environnement où réside la base de
données qui sont : Edition entreprise, édition standard,
édition personnel.
Cet ensemble intégré d'outils a justifié le
nom DB CLUSTER. Oracle a délivré plusieurs versions de base de
donnée on citons :
Oracle 8i: cet produit a été
réalisé en 1997. C'est un SGBDR OBJET, il a
permis de stocker des objets (vidéo, image, photo,... etc.) dans les
tables de même que les nombres et les caractères.

Oracle 9i: cette version a donné des
particularités pour améliorer le système: Rend la BD plus
disponible.
Plus des opérations de maintenance on-line.
L'autogestion des fichiers principaux de système
d'exploitation requis par la BD.
La gestion de la BD devient plus facile.
Les performances sont améliorées.
...etc.......
Oracle 10g: le 'g' signifié 'grid'
réseau. Le calcul réseau est une technologie qui permet
d'accéder continûment et massivement à un réseau
distribué d'ordinateurs homogènes et
hétérogènes. Ce produit a apporté plusieurs
propriétés pour améliorer les performances et
l'efficacité d'administration tel que :

La gestion automatique de stockage (ASM).
Ajustement automatique.
La modification automatique de la taille de la mémoire
SGA.

La suite Oracle développeur
Elle se constitue de l'ensemble des outils permettant de
développer des différentes applications on note:
|
L'outil Forms:Pour construire les interfaces
web et particulièrement basée sur les formulaires.
L'outil Report: générer les
états de sortie et des rapports dans différents formats.
L'outil Graphic: un outil de génération
automatique de graphiques dynamiques pour présenter graphiquement des
statistiques réalisées à partir des données de la
base. L'outil Disigner et L'outil Jdeveloper.
Le serveur d'application oracle
Comme son nom indique il s'agi d'un intermédiaire entre
le Web et la BD qui s'intéresse de servir aux clients web les
applications voulues, les gérer, exécuter et les synchroniser
avec la BD, on note: OAS 9i et OAS 10g.
|
|
5.
La structure interne d'Oracle
5.1 Le serveur Oracle
IL s'agit du système installé sur
une machine qui va permettre la gestion de toutes les
bases de données disponibles sur la machine. Le serveur
oracle est basé sur une
Architecture MultiServeurs. Le serveur est responsable de
traitement de toutes les activités
de la base de données tel que l'exécution des
instructions SQL, gestion des ressources et utilisateur, et gestion du
stockage,
Pour consulter les données, l'utilisateur doit tout
d'abord se connecte à un Serveur
Oracle. Il existe trois types de connexions grâce
auxquelles un utilisateur peut accéder à un Serveur Oracle :
1. Connexion locale.
2. Connexion Deux Tiers.
3. Connexion Multi Tiers.
Un serveur Oracle = une base de données sur disque
+ des données chargées en mémoire ou SGA+ Des processus
d'arrière plan.
Lorsque un utilisateur est connecté à une machine
sur laquelle réside un Serveur Oracle, deux
processus supplémentaire sont invoqués : Le
processus utilisateur et le processus serveur. Une connexion spécifique
entre un utilisateur et un serveur Oracle est appelé une
Session.
La session démarre lorsque la connexion de l'utilisateur
est validée par le serveur Oracle et se
termine lorsqu'il se déconnecte ou lorsqu'une fin de
connexion prématurée se produit.
De nombreuses sessions concurrentes d'un même utilisateur
ou de plusieurs peuvent s'exécuter sur le serveur Oracle.
La figure suivante illustre l'architecture du serveur Oracle qui
consiste en les structures du stockage, les processus, et les fichiers.
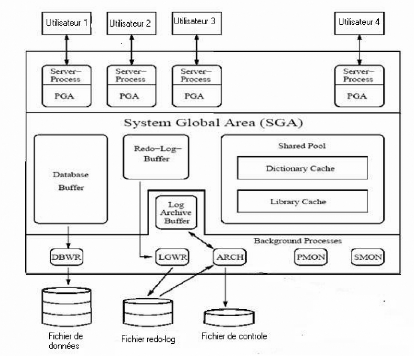
Figure 05 : l'architecture du système
oracle.
5.2. L'instance Oracle
Lors du démarrage d'une base, une partie de la
mémoire principal de l'ordinateur est allouée appelée SGA
; En outre, plusieurs processus d'arrière plan sont lancés, La
combinaison de SGA et les processus d'arrière plan constituent ce que
l'on appelle une instance.
Une fois qu'une instance est démarrée, la base peut
être montée et les utilisateurs peuvent avoir accès aux
informations présentes dans la base.
L'instance est en fait la composition de 2 sous ensembles :
· Une zone mémoire SGA
:assurant le partage des données des différents
utilisateurs, c'est- à-dire qu'il s'agit de la zone contenant les
structures de données accessibles par tous les processus ; Elle va
servir à stocker les données issues des fichiers de
données sur le disque dur. Afin de pouvoir les partager entre les
différents processus.
· Des processus d'arrière plan :
Ils vont servir à gérer les transferts de données entre la
mémoire et le disque dur, plus d'autres actions nécessaires au
bon fonctionnement de la base de données.

Le SGA ou System global Area
Le SGA sert comme la partie de la mémoire où
toutes les opérations de la base de données ont se produire. Par
exemple si plusieurs utilisateurs se connectent en même temps, ils
partagent tous le SGA.
Le dimensionnement de cette zone peut être important
pour les performances de la base. Augmenter la taille de
certaines zones du SGA permet de diminuer les entrées sorties disque,
par exemple.
Le SGA se compose de plusieurs structures de groupe de
mémoire, les trois principales étant :
|
La zone mémoire Shared Pool
|
|
Shared Pool est la partie du SGA qui est utilisé par
tous les utilisateurs. Il Contient les requêtes SQL les
plus récemment exécutées et l'information du dictionnaire
de données la plus récemment utilisée. Elle est
utilisée pour partager les informations sur les objets de la base de
données ainsi que sur les droits et privilèges accordés
aux utilisateurs.
Cette zone mémoire se découpe en 2 blocs :
· Le Library Cache.
· Le Dictionnary Cache.
La zone mémoire Database Buffer Cache
Cette zone mémoire sert à stocker les blocs de
données utilisés récemment. Ce qui signifie que lorsque
vous allez lancer une première fois la requête Oracle, cette
dernière va se charger de rapatrier les données à partir
du disque dur. Mais lors des exécutions suivantes les blocs de
données seront récupérés à
partir de cette zone mémoire, entraînant ainsi un gain de temps.
La zone mémoire Redo Log Buffer
Ce buffer conserve les traces des transactions. Il permet de
stocker les enregistrements redo log. Cette zone mémoire sert
exclusivement à enregistrer toutes les modifications apportées
sur les données de la base. C'est une zone mémoire de type
circulaire et séquentielle.
Le fait que cette zone mémoire soit de type
séquentielle, signifie que les modifications effectuées par une
transaction peuvent être imbriquées avec celles d'autres
transactions.
Le fait que ce buffer soit circulaire signifie que Oracle ne
pourra écraser les données contenues dans ce buffer que si elles
ont été écrites dans les fichiers REDOLOG FILE.

La zone mémoire Program Global Area
(PGA)
Similairement au SGA, il existe La zone mémoire PGA,
cette mémoire est associé à un processus (et inversement).
Ce PGA sert à temporiser les données que manipule le processus,
toujours dans un souci d'optimisation.
Contrairement aux autres zones mémoire celle-ci n'est
pas partagée. Elle est seulement utilisée par des processus
serveur ou d'arrière plan. Elle est allouée lors du
démarrage du processus et libérée lors de l'arrêt du
processus.
|
Les processus d'une instance
|
Le fonctionnement de la base Oracle est régi par un
certain nombre de processus chargés en mémoire permettant
d'assurer la gestion de la base de données. On distingue
généralement deux types de processus :
Les processus utilisateurs (appelés aussi user
process ou noyau oracle)
Ces processus assurent la liaison entre les programmes
utilisateurs, les processus de la base de données, la zone SGA et les
fichiers qui composent la base. Le processus utilisateur affiche aussi
l'information demandée par l'utilisateur
Un processus utilisateur est créé pour chaque
programme exécuté par un utilisateur (par exemple Oracle Forms)
afin de fournir l'environnement nécessaire à l'exécution
de celui-ci.
1. Les processus serveurs (process server)
Les processus serveur, aussi connu comme Shadow
Processes, il communiquent avec l'utilisateur et réagissent
réciproquement avec Oracle pour exécuté les demandes de
l'utilisateur. Par exemple, si le processus utilisateur demande des
données qui ne sont pas dans le SGA, le processus serveur est
responsable pour lire les blocs de données correspondants du datafiles
dans le SGA.
Il existe deux types de processus serveurs
1. Les processus dédiés : une
relation un à un (one to one) est fait entre processus utilisateur et
processus de serveur. Donc un processus s'occupe d'un client unique (comme dans
une configuration dedicated server).
2 .Les processus multi-thread : Un processus
s'occupe de plusieurs clients (comme dans une configuration serveur du
multi-thread), faire donc réduit l'utilisation de ressources de
système.
Le lien entre le processus utilisateur et le processus serveur
est appelé une connexion.

Si l'utilisateur se connecte localement sur le serveur, le chemin
de communication est établi via un mécanisme de communication
inter processus.
Si l'utilisateur se connecte via une machine cliente, un
logiciel réseau est utilisé.
2. Les processus d'arrière-plan (background
process)
Ils sont utilisés pour exécuter plusieurs
tâches dans le système RDBMS, Ces tâches varient entre la
communication avec autre instance Oracle et d'assurer le fonctionnement interne
du SGBD Oracle (gestion de la mémoire, écriture dans les
fichiers, ...).
Oracle 9i comprend cinq processus d'arrière plan
obligatoires pour une instance : 1. Le processus
DataBase WRiter (DBWR)
Ce processus chargé du transfert des blocks de
données modifiés du buffer mémoire du SGA dans les
fichiers disque de la base de données. Ce processus est aussi là
pour vérifier en permanence le nombre de blocks libres dans le Database
Buffer Cache afin de laisser assez de place disponible pour l'écriture
des données dans le buffer.
2. Le processus System MONitor (SMON)
Ce processus, père de tous les processus de l'instance,
s'occupe de plusieurs tâches. Il permet de surveiller la base de son
démarrage puis au cours de son fonctionnement, Il se charge notamment
d'optimiser l'utilisation de la mémoire dans le système. Il se
charge aussi d'assurer la reprise du système lors de tout
démarrage d'une instance.
3. Le processus Process MONitor (PMON)
Ce processus se charge notamment de libérer toutes les
ressources acquises par un processus client, lorsque celui-ci se termine. Il se
charge du nettoyage de la zone mémoire SGA, Il est aussi chargé
de surveiller les processus serveurs et les processus dispatchers : si l'un
d'eux s'arrêtait anormalement, le PMON se chargerait de libérer
les ressources de ce processus et de le relancer.
4. Le processus LGWR (Log Writer)
Le processus LGWR est responsable d'écrire le contenu
des buffers dans des fichiers journaux appelés fichiers Redo Log.
Ce processus garanti la sécurité de la base de
donnés,en fait dés qu'une transaction est validée,oracle
écrit les données modifiées à deux emplacement
différents, de façon a pouvoir repartir si un
problème matériel survient. La première copie est
assurée par le processus DBWR dans les fichiers contenant les
données, cette copie n'est pas forcement immédiate: pour
augmenter les performances et éviter des goulots d'étranglement,
un délai d'écriture peut exister. Pour conserver
l'intégralité des données présentes en
mémoire mais en attente d'écriture sur disque, une seconde copie
immédiate est assurée par le processus LGWR dans les fichiers
Redo Log.
5. Check point (CKPT)
Le processus de point de reprise CKPT enregistre les
données dans le fichiers de contrôle a intervalle
réguliers. Pour identifier l'emplacement de départ de la
récupération. Cette opération appelée point de
reprise.
Il existe également d'autres processus d'importance
secondaire : Recoverer (RECO)
Archiver (ARCn)
Lock (LCKn)
Dispatcher (Dnnn)
Shared Server (Snnn)
Parallel Query Slaves (Pnnn)
5.3 La base de données oracle
Dans l'architecture d'une base de données Oracle, nous
distinguons entre structures d'une base de données logique et physique
qui construit une base de données.
Les structures logiques décrivent des zones logiques de
stockage (nom d'espaces) où les objets tels que les tables peuvent
être stocker, par contre, la structure physique correspond à
l'utilisation des objets du système d'exploitation, elle est
donc en étroite relation avec ce dernier.
5.3.1. La structure logique d'une base de données
: La structure logique inclut: Objets complexes : Les
objets « complexes » sont les suivants :
Schéma : c'est un ensemble d'objets. Il
contient les objets suivants :

Tables : elles représentent la
structure élémentaire du SGBD. Elles sont formées de
lignes et de colonnes. Une table est enregistrée dans un tablespace;
souvent, plusieurs tables partagent un tablespace.
Vues : Une vue est une fenêtre
sur une table ou plus. Une vue n'enregistre pas de données; il
présente les données de la table. Les vues sont
utilisées typiquement pour simplifier l'accès aux données
par les utilisateurs en fournissant des informations limitées d'une
table.
Séquence : c'est une suite de
numéros uniques générés par le SGBD.
Unités de programmes: ils regroupent un
ensemble de procédures et fonctions gérées par le SGBD. On
parle de package, procédures, fonctions ou triggers.
Index, cluster, et hash cluster : les clusters
sont des regroupements de tables souvent accédées en
simultané, leurs temps d'accès s'en trouvent
améliorés.
Types objets : ces informations
définissent de nouveaux types que se crée le développeur.
Ces types pourront être utilisés pour créer des tables
utilisant directement ce nouveau type de données.
Objets simples : Les objets de type simple sont
les suivants :
1. Tablespaces :
Un Tablespaces est une division logique d'une base de
données, Tous les objets de la base de données sont logiquement
Enregistrer dans un tablespace, Chaque base de données a au moins un
tablespace. Le tablespace du SYSTÈME, qui contient le dictionnaire de
données. Les autres tablespaces peuvent être créés
et peuvent être utilisés pour différentes applications ou
tâches.
|
Il est conseillé de disposer d'au moins deux
tablespaces : un pour le système et l'autre pour les
données.
|
Le tablespace permet de:
o Limiter l'utilisation de l'espace par
utilisateur (quota). L'administrateur peut induire
des limites de l'utilisation de l'espace disponible pour chaque utilisateur sur
un tablespace donné.
o sauvegarder et restaurer des informations
(c'est l'unité de base de la sauvegarde).
On essaiera donc de rendre cohérent le contenu d'un
tablespace, l'administrateur y
regroupera des informations de même type (toutes les
informations d'une application,
par exemple) ou possédant des caractéristiques de
« variation » commune.
o Contrôler la disponibilité des
données. Ce contrôle est effectué par la mise
online
ou offline des tablespaces individuel.
o Stocker des informations sur plusieurs disques
(répartition des charges
disque).ce qui Concrétise l'indépendance
physique de la base de données
.
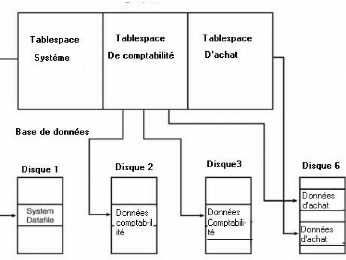
Figure 04 : l'indépendance physique par les
tablespaces.
Le tablespace système:Le
tablespace système contient :
· le dictionnaire de données.
· le segment de rollback.
· les zones de code.
· des zones temporaires qui lui serviront d'extension quand
la mémoire centrale (pour la zone de tri) sera saturée (sorte de
zone de « swap » pour Oracle).
2. Segments:
Si un objet de la base de données (par exemple, une
table ou un cluster) est créé, automatiquement une portion du
tablespace est allouée, Cette portion est appelée un segment. En
effet une table est constituée d'au moins deux segments : les data
segments et le rollback segment. Deux autres segments peuvent apparaître
dans une table : l'index segment et le temporary segment.
3. Extent :
Un Extent est le plus petite unité logique de stockage
qui peut être alloué pour un objet de la base de
données, et il consiste une séquence
contiguë de blocks de données! Si la taille d'un objet de
la base de données augmente (par exemple, dû à l'insertion
d'un enregistrement dans une table), Un Extent supplémentaire est
allouée pour l'objet.
Un type spécial de segments est rollback segments. Ils
ne contiennent pas d'objet de la base de données, mais contient un
"avant image" de données modifiées pour lesquelles la transaction
modifiante n'a pas cependant s'été commettre. Les modifications
sont annulées en utilisant les rollback segments. ORACLE utilise les
rollback segments en ordre pour maintenir la lecture cohérente entre
multiples utilisateurs. En outre, les rollback segments sont utilisés
pour restaurer le "avant image" de l'enregistrement modifiés dans le cas
d'une reprise (rollback) de la transaction modifiante.
Typiquement, un tablespace supplémentaire est
utilisé pour enregistré les rollback segments, Ce tablespace peut
être définis pendant la création d'une base de
données, La taille de ce tablespace et ses segments dépend du
type et taille de transactions qui sont exécutées typiquement par
les programmes d'applications.
Une base de données consiste typiquement en un
tablespace du SYSTÈME qui contient le dictionnaire de données et
tables supplémentaire internes, procédures ...etc., et un
tablespace pour les rollback segments. Les tablespaces supplémentaires
incluent un tablespace pour les données utilisateur, un tablespace pour
les résultats de la question temporaires et les tables (TEMP), et un
tablespace a utilisé par les applications tel que SQL*Forms (OUTILS).
5.3.2 Structure physique
La structure de la base de données physique est
déterminée par les fichiers et les blocks de données:
1. Les fichiers de données (datafile)
: Ces fichiers représentent la partie visible de la base de
données. Chaque donnée liée aux applications (structure et
contenu) est mémorisée dans ce type de fichier. Un groupe de Data
Files forme un tablespace. Donc une base de données est essentiellement
une collection de fichiers de données qui peuvent être
enregistrés sur différents dispositifs de stockage. Multiples
fichiers de données pour un tablespace permettent au serveur de
distribuer un objet de la base de données sur différents disques
(selon la dimension de l'objet).
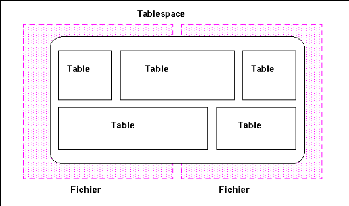
Figure 05: la relation entre les fichiers de
données et les tablespaces.
Il est possible, depuis Oracle 8, de stocker une table sur
plusieurs tablespaces. On parle de la table
partitionnée.
2. Blocks: Un extent consiste en un ou plus
de blocks de données Oracle contigus. Un block représente la
granulosité minimum dans la gestion du stockage. Un block de
données correspond à un nombre spécifique d'octets
d'espace sur le disque de la base de données physique. La taille de
block est définie pour chaque base de données Oracle quand la
base de données est créée. Bien que le bloc de
données dans la plupart des systèmes est 2KO
3. Les Redo log file: Oracle utilise un
ensemble des Redo Log Files. Ces fichiers mémorisent toutes les
transactions effectuées par les utilisateurs. On les appelle aussi les
fichiers « journaux ». Ils représentent un historique complet
de toutes les commandes (amenant une modification) passées sur la base
de données. L'utilité de tels fichiers est de pouvoir
reconstruire les transactions de la base de données dans leur ordre
adéquat, si une panne apparaît.
4. Les fichiers de contrôles (Control files)
: Chaque instance de la base de données a au moins un fichier
de contrôle. Un fichier de contrôle contient les informations
suivantes :
· le nom de la base de données.
· le nom des tablespaces.
· les noms et les emplacements des fichiers physiques (Data
et Redo Log files),
· la date de création de la base de
données
A chaque fois qu'une base est activée, cette structure
est ouverte. Elle est aussi nécessaire lors d'une restauration
après un crash. Pour des raisons de
sécurité, le SGBD demande de posséder
plusieurs copies de ce type de fichier.
5. Le fichier d'initialisation : Ce fichier
est un fichier au format texte contenant l'ensemble des paramètres de
démarrage de la base (il est généralement nommé
initSID.ora, où SID représente le nom donné
à l'instance). Son existence n'est toutefois pas majeure car il peut
être facilement reconstruit. Un fichier d'initialisation par
défaut est créé lors de la création d'une base.
Celui-ci est largement documenté et des exemples de valeurs sont
donnés pour chaque paramètre. Toutefois parmi ces
paramètres, seul un nombre limité d'entre-eux est
réellement utile.
6. Les fichiers de message : Oracle
mémorise toutes les actions survenues sur une base de données
dans des fichiers dits alert. Il existe des fichiers de ce
type liés aux actions locales et des fichiers liés aux actions
réseau.
Ces fichiers mémorisent :
· toutes les actions importantes survenues sur la base de
données (CREATE/ALTER/DROP d'une structure de type tablespace ou segment
de rollback ou liées aux fichiers de contrôle),
· les actions de démarrage et d'arrêt (ou les
changements d'état) de la base de données,
· toutes les erreurs (corruption de blocs, table corrompue,
etc.),
·
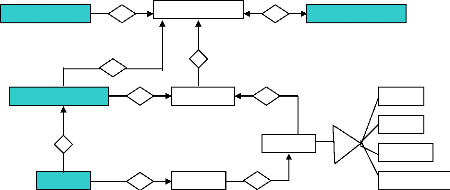
Fichier redo-log
Base de données
Fichier de controle
Segment
Table
Index
Cluster
Rollback seg
Fichier de données
Block
Extent
Tablespace
toutes les demandes de connexion passant par le réseau.
6. Dictionnaire de données Oracle
Le dictionnaire de données Oracle représente le
coeur de la base de données. Il s'agit d'un ensemble de tables
systèmes contenant les informations relatives à la structure de
la base de données :
· Utilisateurs de la base (ainsi que leurs
privilèges et leur rôle)
· Il mémorise la structure des tables et de tous les
objets manipulés par la base.
· Ressources physiques allouées à la base
· Il sera enrichi à chaque création d'une
nouvelle structure dans la base
· Il est utilisé par les administrateurs de la base,
les utilisateurs et le noyau.
Il doit être vu comme une zone en lecture seule, Il
n'existe pas d'ordre direct de mise à jour de cette partie de la base
(les ordres influant sur cette partie correspondent aux actions liées au
LDD create, drop, etc.).
Il appartient à l'utilisateur SYS, mais
l'utilisateur SYSTEM, c'est-à-dire l'administrateur de la base,
possède des droits de lecture sur des vues du dictionnaire. Enfin le
dictionnaire de données est conservé dans le tablespace
SYSTEM.
Le dictionnaire dispose de classes de vues :
De nombreuses vues permettent à des utilisateurs
d'accéder à certaines parties du dictionnaire de données.
Les vues du dictionnaire de données sont classées par famille et
nommées en fonction de l'appartenance à une de ces familles.
Voici la liste de ces familles de vues :
· USER : informations sur tous les objets
dont l'utilisateur connecté est propriétaire.
· ALL : fournissent des informations
sur les objets pour lesquels l'utilisateur a un droit d'accès,
c'est-à-dire les objets de la base créés par l'utilisateur
ainsi que tous les objets accessibles par cet utilisateur
· DBA : informations sur tous les
objets de la base.
· V$ : sont des vues dynamiques permettant
d'avoir des informations sur l'état courant de l'instance de la base de
données de son démarrage à son arrêt.
7. Démarrage et arrêt d'une
instance
Le démarrage d'une instance se fait en plusieurs
étapes. Elles sont au nombre de trois et se présentent tel que
suit :
· NOUMOUNT : Cette étape va
consister à lire le fichier init.ora, à démarrer
l'instance, allouer la mémoire, et démarrer les processus
d'arrière plan.
· MOUNT : Cette étape va
consister à ouvrir le ou les fichiers CONTROLEFILE afin de mettre en
mémoire les informations contenues par les fichiers CONTROLEFILE. Durant
cette étape les fichiers de données ne sont pas accessibles car
ils n'ont pas encore été ouverts.
· STARTUP : Cette étape va
consister à ouvrir tous les fichiers de données
enregistrés dans les fichiers CONTROLEFILE. Puis une fois tous les
fichiers ouverts et disponibles, à ouvrir complètement la base de
données aux utilisateurs.

r d'aPPIicatio Orai


chapitre 3
1. Introduction
Plusieurs serveurs d'application existent dans le marché,
parmi lesquels on peut citer:
· .Net Server de Microsoft.
· Oracle 9i Application Server de Oracle.
· WebSphere Application Server de IBM.
· Borland appServer (BES).
· ColdFusion de Allaire (Macromédia).
· iPlanet Application Server (Com one) de Sun.
· JBoss (logiciel libre).
Au milieu des années 1990s, oracle commença de
réaliser les produits oracle web server et oracle application server. Ce
dernier est devenu un système très sophistiqué qui se
compose de modules interconnectés configurable selon les besoins des
utilisateurs. Il y a deux aspects pour voir l'architecture du SAO (serveur
d'application oracle).
2. L'aspect conceptuel
Les produits oracle sont évolués d'où on
peut figurer des architectures à deux niveaux, trois niveaux et à
quatre niveaux conformément aux exigences des utilisateurs.
Les produits oracle résident dans tous les niveaux de
l'architecture (figure 07), où chaque niveau représente un palier
de matériel, la règle c'est que plus de matériel puisant
plus de serveurs supportés.
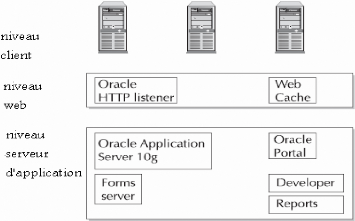
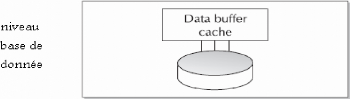
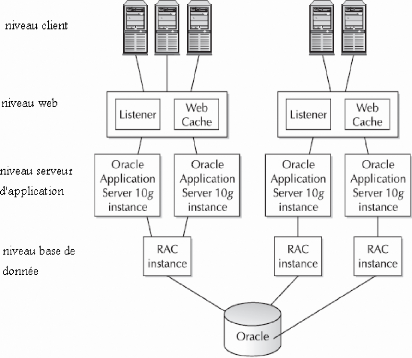
Figure 07: Niveaux Application oracle et produits
composant Les composants du serveur d'application résidents
dans chaque niveau:
· Niveau client: contient le navigateur
web pour le client.
· Niveau web: contient le serveur HTTP
oracle et le web cache.
· Niveau serveur d'application: contient
le noyau du serveur d'application et les produits auxiliaires comme oracle
portal, oracle developer, oracle report et oracle forms server.
· Niveau base de donnée: contient
le serveur de base de donnée, qui peut composer d'un ou plusieurs
instances.
Les petites entreprises travaillent sur une architecture à
deux niveaux, avec une machine puissante le plus souvent avec plusieurs RAM et
plusieurs CPU, regroupant les produits des trois niveaux (figure 08). Le profit
de cette architecture est le partage des ressources du serveur.
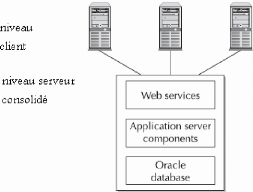
Figure08: architecture serveur d'application deux
niveaux
Le modèle à trois niveau est prédominant
dans les entreprise moyenne, dans ce modèle (figure 09) le niveau client
est suivi par le niveau serveur web et serveur d'application dans une machine
séparée, et le serveur base de donnée c'est le
troisième niveau. Le profit de ce modèle sur le
précédent est que l'incrémentation des demandes de
traitement au niveau du serveur de base de donnée ou du serveur
d'application n'affecte pas les autres composants, au plus des instances du
serveur d'application et des instances du SGA peuvent être créer
selon les besoin de traitement.
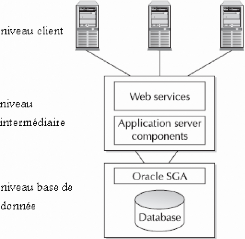
Figure 09: architecture serveur d'application trois
niveaux
Chaque niveau peut contenir plusieurs instances de ces composants
(figure 10).
Figure 10: architecture multi instances
S'il y a eu de surcharge dans un niveau, l'administrateur peut
créer des instances sur des autres serveurs et les adaptent au
système, ce qui montre l'extensibilité de l'architecture du
serveur d'application.
Niveau web
Niveau serveur d'application
Niveau base de donnée
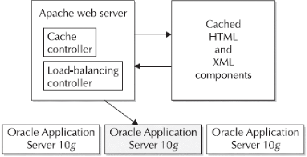
3. L'aspect fonctionnel
Chaque niveau de l'architecture a des fonctions bien
spécifiées réalisables par ces composants

|
- écoute les requêtes des clients. - cache le
contenu.
- équilibre la charge sur les serveurs d'application.
|
|
- Gère la logique de travail.
- Formate les documents générés.
- Développe les pages web, forms, report. - Gère la
sécurité.
|

|
- Stocke et retrouve les données. - gère les
relations des données. - préserve les données d'usage.
|
3.1 Le niveau client
Le niveau client consiste en une application JAVA ou un
navigateur web. Dans le cas d'un navigateur web l'application réside
complètement dans le niveau serveur d'application. L'avantage est que le
client utilise le navigateur web de n'importe quel emplacement, et travaille
sur la dernière version de l'application.
3.2 Le niveau web
Les deux composants principaux dans ce niveau sont le serveur
HTTP Oracle et le web cache. Les fonctions de ce niveau sont la gestion des
requêtes arrivantes, cacher les messages du web et renvoyer les page XML
et HTML aux clients. Voici un peu de détail sur les composants de ce
niveau :
· Le serveur HTTP oracle (OHS) :
Tout système web d'oracle doit contenir assez de port
d'écoute pour traiter la gamme des requêtes arrivantes. L'OHS
écoute sur un port spécifique et adresse les requêtes
J2EE arrivantes au récipient OC4J le moins chargé
utilisant le module mod_OC4J. Il
est nécessaire que le serveur web dispose d'une
intelligence de balancement de charge pour ne pas surcharger un container
OC4J.

· Le web cache :
Ce composant améliore les performances par la
réduction de la génération du page web statique et
dynamique. Il est situé au front du serveur http et il stocke le contenu
des pages statiques et dynamiques.
3.3 Le niveau serveur d'application
Dans ce niveau réside le noyau de serveur d'application
avec un ensemble d'outils et de produits. Les composants centraux de ce niveau
sont les instances du serveur d'application, et ces instances supportent le
container JAVA d'oracle (OC4J). L'OC4J réceptionner les javabeans des
applications d'entreprise, pourvoir la sécurité et maintenir la
connectivité. En plus des instances du serveur d'application, ce niveau
contient des outils pour les fonctions suivantes:
+ Oracle portal: ce composant permet la
création et le déploiement rapide des site web dynamique.
+ Oracle discoverer: ce composant permet
l'implémentation facile des requêtes de client.
+ Oracle forms server: ce composant est
utilisé pour formater, déployer et rendre des
présentations web au client se basant sur une base de données
oracle.
+ Oracle personalization: se basant sur un
historique des pages des utilisateurs
stocké dans une base, ce composant pourvoi des URL
personnalisées, on parle de la
garde de trace et la facilité de la création des
pages web personnalisées.
+ Oracle wireless: ce
composant permet la communication entre le serveur
d'application et les appareils sans fil comme les PDAs et la
cellule de téléphones.
Le Wireless reformate dynamiquement les informations pour
être afficher correctement sur les écrans limités de la
plus parts des appareils sans fil.
+ Oracle report server: ce composant permet le
déploiement rapide des rapports,
des documents et des commerce tableurs on utilisant les
données d'une base.
+ Single sign-on (SSO) : c'est un système
complet d'authenticité pour identifier les
utilisateurs et de gérer les rôles et les services
web.
+ Oracle Internet directory (OID) : cet
accommodant service d'annuaire (LDAP)
permet de centraliser les informations des utilisateurs, des
applications et des ressources de l'entreprise.
+ Metadata repository (infrastructure) : ce
composant critique permet le stockage
des Metadonnée du serveur
d'application et constitue une interface commune de
gestion entre les instances du serveur d'application et les
autres composants.
+ Oracle management server (OMS) : ce composant
de la console du chef d'entreprise permet la gestion des instances du serveur
d'application, bases de données et des autres applications.
+ Oracle application server toplink : Dans les
langages orienté objet (OO) telles que Java, C #, ou C++, les objets
peuvent être instanciers et détruits d'après les besoins du
programme, Pour les développeurs Java, TopLink fournit un
mécanisme pour rendre les objets Java persistants à travers les
sessions.
3.4 Le niveau base de donnée
La base de données relationnelle du serveur d'application
(ou toute autre base de données) réside dans le niveau base de
données. La fonction du niveau base de données est de fournir un
stockage persistant aux applications. Le Serveur d'application
aussi contient une instance spéciale appelée Infrastructure qui
utilise une base de données pour stocker la Metadonnée. Cette
base de données est plus correctement dans le niveau du serveur
d'application car elle ne fournit pas de stockage persistant pour
l'application.
Le serveur d'application fournit une méthode de placer le
schéma de la base de données de l'Infrastructure dans une base de
données dans le niveau base de données, cependant, meilleure
volonté des usages encore recommandée que le support de la base
de données de l'Infrastructure et le support de la base de
données client doivent être écartés pour des raisons
de performance.
chapitre 4
1. Introduction Le Modèle Conceptuel est
construit pour
|
décrit exactement les informations à besoin.
Prévenir les erreurs, et détecter les
éléments de projet mal comprendre. former une importante
documentation "système idéal ".
permet de construire une base solide pour la base de
données physique. fait un très bon entraînement entre le
groupe de développement.
Permet de faire un changement facile, Si les parties du
modèle ne sont pas satisfaisantes ou sont mal comprises.
|
|
2. Le modèle relationnel
Défini par EF Codd de la société IBM
dès 1970, ce modèle a été amélioré et
rendu opérationnel dans les années 80 sous la forme de SBGD-R
(SGBD Relationnels). Voici une liste non exhaustive de tels SGBD-R :
Access de Microsoft.
Oracle.
DB2 d'IBM.
Interbase de Borland.
SQL server de microsoft.
L'expérience montre que le modèle relationnel s'est
imposé parce qu'il était le plus simple en terme
d'indépendance des données par rapport aux applications et de
facilité de représenter les données dans notre esprit.
Toutes les relations entre les objets contenant les informations
sont décrites et représentées sous la forme de tableaux
à 2 dimensions.
Nous avons basé pour modéliser notre
système sur le modèle entité association selon la syntaxe
et les recommandations proposées par oracle, Et voici une petite
présentation et explication.
3. Modèle entité-association sous oracle
3.1 Représentation des entités
EMPLOYÉ
Commande
Emploi
3.2 Représentation des attributs :
|
indique l'attribut obligatoire, qui est connu et
disponible pour chaque instance. Indique l'Attribut
facultatif, qui est inconnu ou qui n'est pas important à savoir
pour quelques instances.
|
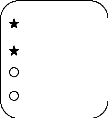
EMPLOYÉ NOM
Prénom
Date Naissance Email
3.3 Représentation d'une relation : Relation
obligatoires et Facultatifs :

Facultatif : obligatoires :
Un emploi peut être tenu par un employé ou
plus
Un employé peut avoir exactement un
travail.
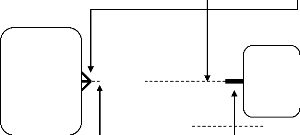
EMPLOYÉ
Avoir
Tenu par
Emploi
Relation et fin de la relation :
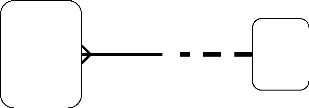
EMPLOYÉ
Avoir
Emploi
Tenu par
Quand vous avez lu la relation, imaginez qu'il est divisé
en deux perspectives:
EMPLOYÉ
Emploi
Chaque EMPLOYÉ doit avoir
exactement un emploi
EMPLOYÉ
Emploi
Un emploi peut être occupé
par un EMPLOYÉ ou plus.
Lire une fin de la relation :
P
Partager en
Partie de
Q
Chaque P peut être partager
en un Q ou plus.
Chaque Q doit être partie
d'exactement
un P.
Une relation d'une entité 1 à une entité 2
doit être lu:
|
Chaque entité 1 {doit être | peut
être}
Nom relation
{Un ou plus | exactement un} entité 2
|
les types de relations:on
distingue trois types de relations :
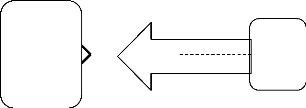
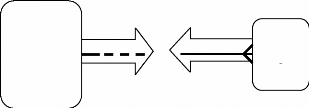
1. Un a m (1 : m)
2. Plusieurs a plusieurs (m : m)
3. Un a un (1 :1)
> la relation de type (1 : m) :
> La relation de type (m : m) :

(b)
> la relation de type (1 : 1) :
3.4 Les contraintes
d'intégrités
L'identificateur unique :
Un identificateur unique est un ensemble d'attributs et/ou de
relations permettant de distinguer les différentes occurrences d'une
même entité.
Représentation de l'identificateur
unique
Dans un diagramme entité relation les attributs qui
composent un identificateur unique sont marqués par :
1. # pour les attributs.
2. Avec une petite barre qui traverse la fin de la relation.
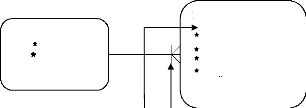
Bac
Type bac Session
ETUDIANT
#numéro inscription Nom
Prénom
Date Naissance Email
indiquer un identificateur unique 4. Etude du
cas
Le Modèle conceptuel (E-A):
Après cette petite présentation de la
méthode choisie, on passe maintenant à la phase de conception de
la base de donnée qui été simple et claire grâce
à la simplification offerte par cette méthode.
Le diagramme qui ce suit concerne seulement une partie de la base
de données globale, c'est la partie accordée à nos
interfaces (inscription, outils d'administration,..).
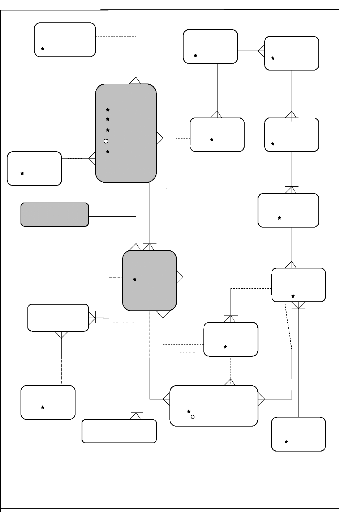
.
Année
universitaire
#Année
Transférer à
Dériver
WILAYA
#Code
Nom
UNIVERSITE
# Code Nom
Correspondre
Contient
Possède
BAC
# Code
Nom
Pour
Pour
Comprendre
Contient
Résulter de
Accorder à
Dépendre de
OPTIONS
# Code Nom
Associer
Transférer à
comprendre
Dériver de
DOSSIER RETIRER # Code
Couvre
Contient
FICHE ETUDE # Id
#Année univ Matricule
Dépendre de Associer
SPECIALITE
# Code Nom
Appartient à
Comprendre
DOSSIER BLOQUE
# Code
Justifier par
Justifier
TYPE CONGE
# Code Nom
DOSSIER_TRANSFERER
#Code
Spécialité destination
option
destination
DIPLOME
# Code Nom
LE Modèle conceptuel entité
association.
Posséder
Contient
ETUDIANT
# Id
Nom
Prénom
Date naissance Lieu naissance Adresse
Résider
Héberger
COMMUNE
# Code
Nom
FACULTE
# Code
Nom
Appartient à
Contient
Appartient à
Appartient à
Contient
Avoir
NATIONALITE
# Code
Lebel
DEPARTEMENT
# Code
Nom
Le modèle relationnel
A partir du modèle conceptuel on construit le
modèle relationnel qui est plus proche de la base de données
physique, ici on n'a pas dessiné le diagramme de ce modèle mais
on juste fait une description des tables finales.
BAC :
Colonnes:
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
designation
|
|
CODE
|
VARCHAR2
|
2
|
Non
|
Code
|
|
BAC_FR
|
VARCHAR2
|
40
|
Non
|
Le nom du bac en français
|
|
BAC_AR
|
VARCHAR2
|
40
|
Non
|
Le nom du bac en arabe
|
Contraintes:
|
Nom
|
Type
|
Table référencée
|
|
BAC AR UK
|
UNIQUE
|
|
|
BAC FR UK
|
UNIQUE
|
|
|
BAC PK
|
PRIMARY
|
|
|
WILAYA :
Colonnes.
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
designation
|
|
CODE
|
VARCHAR2
|
2
|
Non
|
Code
|
|
WILAYA_FR
|
VARCHAR2
|
30
|
Non
|
Nom wilaya en français
|
|
WILAYA_AR
|
VARCHAR2
|
30
|
Non
|
Nom wilaya en arabe
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
WIL AR UK
|
UNIQUE
|
|
|
WIL FR UK
|
UNIQUE
|
|
|
WIL PK
|
PRIMARY
|
|
COMMUNE :
Colonnes :
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
designation
|
|
CODE
|
VARCHAR2
|
5
|
Non
|
Code
|
|
COMMUNE_AR
|
VARCHAR2
|
40
|
Non
|
Nom commune en français
|
|
COMMUNE_FR
|
VARCHAR2
|
40
|
Non
|
Nom commune en arabe
|
|
CODE_WIL
|
VARCHAR2
|
2
|
Oui
|
Code wilaya
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
COMMUNE CODE UK
|
UNIQUE
|
|
|
COMMUNE FK
|
FOREIGN
|
WILAYA
|
|
COMMUNE UK
|
UNIQUE
|
|
NATIONALITE :
Colonnes :
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
designation
|
|
CODE_NATION
|
NUMBER
|
3
|
Non
|
Code
|
|
NATIONALITE_FR
|
VARCHAR2
|
40
|
Non
|
Nom nationalité en français
|
|
NATIONALITE_AR
|
VARCHAR2
|
40
|
Non
|
Nom nationalité en arabe
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
NATIONALITE AR UK
|
UNIQUE
|
|
|
NATIONALITE FR UK
|
UNIQUE
|
|
|
PK NATIONALITE
|
PRIMARY
|
|
|
UNIVERSITE :
Colonnes :
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
désignation
|
|
CODE
|
VARCHAR2
|
2
|
Non
|
Code
|
|
UNIV_FR
|
VARCHAR2
|
40
|
Non
|
Nom université en français
|
|
UNIV_AR
|
VARCHAR2
|
40
|
Non
|
Nom université en arabe
|
|
SIGLE
|
BLOB
|
|
Oui
|
Sigle d'université
|
|
DATE _OUVERTURE
|
DATE
|
7
|
Oui
|
Date d' ouverture
|
|
ADRESSE_FR
|
VARCHAR2
|
60
|
Oui
|
Adresse en français
|
|
ADRESSE_AR
|
VARCHAR2
|
60
|
Oui
|
Adresse en arabe
|
|
WILAYA
|
VARCHAR2
|
2
|
Oui
|
Wilaya d'université
|
|
TELEPHONE1
|
VARCHAR2
|
12
|
Oui
|
Téléphone 1
|
|
TELEPHONE2
|
VARCHAR2
|
12
|
Oui
|
Téléphone 2
|
|
FAX1
|
VARCHAR2
|
12
|
Oui
|
Fax 1
|
|
FAX2
|
VARCHAR2
|
12
|
Oui
|
Fax 2
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
UNIV AR UK
|
UNIQUE
|
|
|
UNIVERSITE FK
|
FOREIGN
|
WILAYA
|
|
UNIVERSITE PK
|
PRIMARY
|
|
|
UNIV FR UK
|
UNIQUE
|
|
FACULTE:
Colonnes:
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
désignation
|
|
CODE
|
VARCHAR2
|
4
|
Non
|
code
|
|
FAC_FR
|
VARCHAR2
|
40
|
Non
|
Nom français de faculté
|
|
FAC_AR
|
VARCHAR2
|
40
|
Non
|
Nom arabe de faculté
|
|
CODE _UNIV
|
VARCHAR2
|
2
|
Oui
|
Code université
|
|
TELEPHONE1
|
VARCHAR2
|
12
|
Oui
|
Telephone1
|
|
TELEPHONE2
|
VARCHAR2
|
12
|
Oui
|
Telephone2
|
|
FAX1
|
VARCHAR2
|
12
|
Oui
|
Fax1
|
|
FAX2
|
VARCHAR2
|
12
|
Oui
|
Fax2
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
FACULTE FK
|
FOREIGN
|
UNIVERSITE
|
|
FACULTE PK
|
PRIMARY
|
|
|
FACULTE UK
|
UNIQUE
|
|
DEPARTEMENT :
Colonnes :
|
Nom
|
Type de données
|
Taille
|
Null ?
|
désignation
|
|
CODE
|
VARCHAR2
|
6
|
Non
|
Code
|
|
DEPART_FR
|
VARCHAR2
|
30
|
Non
|
Nom département en français
|
|
DEPART_AR
|
VARCHAR2
|
30
|
Non
|
Nom département en arabe
|
|
CODE_FAC
|
VARCHAR2
|
4
|
Oui
|
Code faculté
|
|
DATE _OUVERTURE
|
DATE
|
7
|
Oui
|
Date d' ouverture
|
|
TELEPHONE1
|
VARCHAR2
|
12
|
Oui
|
Téléphone 1
|
|
TELEPHONE2
|
VARCHAR2
|
12
|
Oui
|
Téléphone 2
|
|
FAX1
|
VARCHAR2
|
12
|
Oui
|
Fax 1
|
|
FAX2
|
VARCHAR2
|
12
|
Oui
|
Fax 2
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
DEPARTEMENT FK
|
FOREIGN
|
FACULTE
|
|
DEPARTEMENT PK
|
PRIMARY
|
|
|
DEPARTEMENT UK
|
UNIQUE
|
|
|
SPECIALITE :
Colonnes :
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
designation
|
|
CODE
|
VARCHAR2
|
9
|
Non
|
Code
|
|
FR_SPECIAT
|
VARCHAR2
|
40
|
Non
|
Nom spécialité en français
|
|
AR_SPECIAT
|
VARCHAR2
|
40
|
Non
|
Nom spécialité en arabe
|
|
CODE_DEPL
|
VARCHAR2
|
1
|
Oui
|
Code diplôme
|
|
CODE_DEPART
|
VARCHAR2
|
6
|
Oui
|
Code département
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
SPECIALITE DEPART FK
|
FOREIGN
|
DEPARTEMENT
|
|
SPECIALITE DEPLOME FK
|
FOREIGN
|
DEPLOME
|
|
SPECIALITE PK
|
PRIMARY
|
|
|
SPECIALITE UK
|
UNIQUE
|
|
DEPLOME :
Colonnes :
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
désignation
|
|
CODE
|
VARCHAR2
|
1
|
Non
|
Code
|
|
DEPL_FR
|
VARCHAR2
|
30
|
Non
|
Nom diplôme en français
|
|
DEPL_AR
|
VARCHAR2
|
30
|
Non
|
Nom diplôme en arabe
|
|
FIN_CYCLE
|
NUMBER
|
1
|
Non
|
Année fin de cycle
|
Contraintes :
Type
Nom
|
|
Table référencée
|
|
DEPLOME AR UK
|
UNIQUE
|
|
|
DEPLOME FR UK
|
UNIQUE
|
|
|
DEPLOME PK
|
PRIMARY
|
|
OPTIONS :
Colonnes :
|
Nom
|
Type de données
|
Taille
|
Null
?
|
désignation
|
|
CODE
|
VARCHAR2
|
10
|
Oui
|
Code
|
|
OPTION_FR
|
VARCHAR2
|
40
|
Non
|
Nom option en français
|
|
OPTION_AR
|
VARCHAR2
|
40
|
Non
|
Nom option en arabe
|
|
ANNEE_DEBUT
|
VARCHAR2
|
9
|
Oui
|
Année début de l'option
|
|
Nom
|
Type
|
Table référencée
|
|
OPTIONS CODE UK
|
UNIQUE
|
|
|
OPTIONS FK
|
FOREIGN
|
SPECIALITE
|
|
OPTIONS UK
|
UNIQUE
|
|
|
ANNEE UNIV :
Colonnes :
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
designation
|
|
ANNEE
|
VARCHAR2
|
4
|
Non
|
Année universitaire
|
|
TITLE
|
VARCHAR2
|
9
|
Oui
|
Intitulé
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
ANNEE UNIV PK
|
PRIMARY
|
|
ETUDIANT :
Colonnes :
|
Nom
|
Type de données
|
Taille
|
Null ?
|
designation
|
|
IDENT
|
VARCHAR2
|
20
|
Non
|
L'identificateur d'étudiant
|
|
NOM_AR
|
VARCHAR2
|
30
|
Non
|
Nom en arabe
|
|
NOM_FR
|
VARCHAR2
|
30
|
Non
|
Nom en français
|
|
PRENOM_AR
|
VARCHAR2
|
30
|
Non
|
Prénom en arabe
|
|
PRENOM_FR
|
VARCHAR2
|
30
|
Non
|
Prénom en français
|
|
DATE _NAISSANCE
|
DATE
|
7
|
Non
|
Date de naissance
|
|
LIEU_NAISSANCE
|
VARCHAR2
|
20
|
Oui
|
Lieu de naissance
|
|
COMMUNE
|
VARCHAR2
|
5
|
Oui
|
Commune de résidence
|
|
NATIONALITE
|
NUMBER
|
3
|
Oui
|
Nationnalité
|
|
ADRESSE_AR
|
VARCHAR2
|
40
|
Non
|
Adresse en arabe
|
|
ADRESSE_FR
|
VARCHAR2
|
40
|
Non
|
Adresse en frainçais
|
|
BAC
|
VARCHAR2
|
2
|
Oui
|
Type de bac acquise
|
|
PAYS_BAC
|
NUMBER
|
3
|
Oui
|
Paye de bac
|
|
MOYENNE_BAC
|
NUMBER
|
2
|
Non
|
Moyenne de bac
|
|
PHOTO
|
BLOB
|
|
Oui
|
Photo
|
|
PRENOMP_AR
|
VARCHAR2
|
30
|
Non
|
Prénom père arabe
|
|
PRENOMP_FR
|
VARCHAR2
|
30
|
Non
|
Prénom père français
|
|
PRENOMM_AR
|
VARCHAR2
|
30
|
Non
|
Prénom mère arabe
|
|
PRENOMM_FR
|
VARCHAR2
|
30
|
Non
|
Prénom mère français
|
|
NOMM_AR
|
VARCHAR2
|
30
|
Non
|
Nom mère arabe
|
|
NOMM_FR
|
VARCHAR2
|
30
|
Non
|
Nom mère français
|
|
SEXE
|
VARCHAR2
|
1
|
Oui
|
sexe
|
|
Nom
|
Type
|
Table référencée
|
|
ETUDIANT BAC FK
|
FOREIGN
|
BAC
|
|
ETUDIANT COMM ADR FK
|
FOREIGN
|
COMMUNE
|
|
ETUDIANT COMM NAISS FK
|
FOREIGN
|
COMMUNE
|
|
ETUDIANT NATIONALITE FK
|
FOREIGN
|
NATIONALITE
|
|
ETUDIANT PK
|
PRIMARY
|
|
|
ETUDIANT SEXE CK
|
CHECK
|
|
FICHE ETUDE :
Colonnes :
|
Nom
|
Type de données
|
Taille
|
Null ?
|
designation
|
|
ANNEE_UNIV
|
VARCHAR2
|
4
|
Non
|
Année universitaire
|
|
IDENT
|
VARCHAR2
|
20
|
Non
|
L'identificateur d'etudiant
|
|
CODE_SPECIAT
|
VARCHAR2
|
9
|
Oui
|
Code de spécialité
|
|
CODE_OPTION
|
VARCHAR2
|
9
|
Oui
|
Code d'option
|
|
NIVEAU
|
NUMBER
|
1
|
Nom
|
Niveau d'etude
|
|
MATRICULE
|
VARCHAR2
|
20
|
Non
|
matricule
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
FICHE ANNEE UNIV FK
|
FOREIGN
|
ANNEE_UNIV
|
|
FICHE ETUDIANT FK
|
FOREIGN
|
ETUDIANT
|
|
FICHE OPTIONS FK
|
FOREIGN
|
OPTIONS
|
|
FICHE PK
|
PRIMARY
|
|
|
FICHE SPECIAT FK
|
FOREIGN
|
SPECIALITE
|
TYPE CONGE :
Colonnes :
|
Nom
|
Type de données
|
Taille
|
Null ?
|
designation
|
|
TYPE_CONGE
|
VARCHAR2
|
2
|
Non
|
Code de congé
|
|
TITLE _CONGE_FR
|
VARCHAR2
|
40
|
Non
|
Intitulé congé en français
|
|
TITLE _CONGE_AR
|
VARCHAR2
|
40
|
Non
|
Intitulé congé en arabe
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
TYPE AR CONGE TITLE UK
|
UNIQUE
|
|
|
TYPE CONGE PK
|
PRIMARY
|
|
|
TYPE FR CONGE TITLE UK
|
UNIQUE
|
|
|
DOSSIER BLOQUE :
Colonnes :
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
désignation
|
|
ANNEE_UNIV
|
VARCHAR2
|
4
|
Non
|
Année universitaire
|
|
IDENT
|
VARCHAR2
|
20
|
Non
|
L'identificateur d'etudiant
|
|
TYPE_CONGE
|
VARCHAR2
|
2
|
Oui
|
Type de congé
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
DOSSIER BLOQUE CONGE FK
|
FOREIGN
|
TYPE_CONGE
|
|
DOSSIER BLOQUE IDENT FK
|
FOREIGN
|
FICHE_ETUDE
|
|
DOSSIER BLOQUE PK
|
PRIMARY
|
|
DOSSIER TRANSFERER :
Colonnes :
|
Nom
|
Type de
données
|
Taille
|
Null ?
|
desiniation
|
|
ANNEE_UNIV
|
VARCHAR2
|
4
|
Non
|
Année universitaire
|
|
IDENT
|
VARCHAR2
|
20
|
Non
|
L'identificateur d'etudiant
|
|
SPECIAT_DEST
|
VARCHAR2
|
9
|
Oui
|
Spécialité destination
|
|
OPTIONS_DEST
|
VARCHAR2
|
10
|
Oui
|
Option destination
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
DOSSIER TRANSFERER ID FK
|
FOREIGN
|
FICHE_ETUDE
|
|
DOSSIER TRF OPTIONS FK
|
FOREIGN
|
OPTIONS
|
|
DOSSIER TRFR PK
|
PRIMARY
|
|
|
DOSSIER TRF SPECIAT FK
|
FOREIGN
|
SPECIALITE
|
DOSSIER RETIRER :
Colonnes :
|
Nom
|
Type de données
|
Taille
|
Null ?
|
designation
|
|
ANNEE_UNIV
|
VARCHAR2
|
4
|
Non
|
Année universitaire
|
|
IDENT
|
VARCHAR2
|
20
|
Non
|
L'identificateur d'etudiant
|
Contraintes :
|
Nom
|
Type
|
Table référencée
|
|
DOSSIER RETIRER ID FK
|
FOREIGN
|
FICHE_ETUDE
|
|
DOSSIER RETIRER PK
|
PRIMARY
|
|
Ces tables sont nécessaires pour stocké les
informations agissantes pour nos interfaces, associées avec l'ensemble
des contraintes qui maintiennent l'intégrité de la base de
données.
Le choix des tailles des champs est arbitraire. Les tailles
réel reste à la sélection de l'université.
le code de l'implémentation sera vu dans le chapitre
suivant.
cHAPITRE 06
1. Introduction
A la déférence des autres SGBD où il y a
seulement le développeur de la base de données, ORACLE
possède aussi un administrateur qui est responsable de l'installation,
la gestion et la maintenance de la base de donnée. Alors au moment du
développement, le développeur doit mis en considération
les tâches d'administration. Pour cela il faut qu'il exploite toutes les
notions que nous avons déjà vu tel que les tablespaces, les
utilisateurs, les schémas, et d'autres que oracle a construit (voir le
chapitre de la sécurité).
2. L'architecture OFA (Optimal flexible
architecture)
OFA est l'architecture standard qu'el est recommandé
d'utiliser dans une base de données Oracle. C'est un ensemble des
règles d'installation et de configuration qui donnent des bases oracle
rapides, fiables, faciles à faire évoluer et nécessitant
peu de maintenance. Les trois règles importantes pour respecter cette
architecture sont :
1. Etablir une structure de répertoires, où
n'importe quel fichier de base de données peut être
enregistré sur n'importe quel espace disque.
2. Séparer les objets avec un comportement
différent sur différents tablespaces.
3. Augmenter les performances de la base de données en
séparant les composants de la base de données sur des disques
différents.
OFA organise donc la base de données en fonction des
types de fichiers et de leurs utilisations. Les fichiers binaires, de
contrôles, de logs et administratifs peuvent être
séparés sur des disques différents.

Figure 01 : Schéma d'installation des fichiers
oracle
3. Description de la de données
Création de la base de donnée :
La création de la base de données est la
première étape. Lors de la création d'une nouvelle base,
il faut tenir compte du jeu de caractères que la base de données
utilisera (dans notre cas les langues arabe et français). Une fois que
la base de données est crées, le jeu de caractères
spécifié ne peut plus être changé, sauf si la base
de données est reconstituée (voir l'annexe).
Création des Schémas et des utilisateurs
:
Les Schémas et les utilisateurs : Un
schéma est un ensemble nommé d'objets tels que: tables, vues,
clusters, procédure et packages associés à un utilisateur
précis. Quand un utilisateur de base de données crée des
objets, son schéma est automatiquement crée. Un utilisateur ne
pourra alors être associé qu'à un seul schéma et
réciproquement.
Les privilèges : Un privilège
est un droit d'exécuter un type particulier d'ordre SQL. Un utilisateur
doit avoir un privilège de type système pour
accéder à la base de donnée et ses objets et un
privilège de type objet pour exécuter une action sur le
contenue des objets de la base.
Les rôles : sont des groupes de
privilèges qui sont accordé à des utilisateurs ou d'autres
rôles. Ils sont conçus pour faciliter l'administration des
privilèges.
Ces notions sont équivalentes au monde réel, en les
résume dans l'exemple suivant :
Organisation

Utilisateur chef
Service 1
Utilisateur chef
Service 2
Utilisateur chef
Service 3
Utilisateur 3.1 Utilisateur 3.2
Utilisateur3.2. 1
Ressources
Tâches



Figure 02 : Exemple de modélisation d'une
organisation
Dans une organisation on ne peut pas recruter un utilisateur
seulement si on lui affecte des ressource et des tâches sur ces
ressources (les ressources dans notre système sont des
tables, vues ..., les tâches sont des privilèges et
rôles associés à un utilisateur).Chaque utilisateur est
responsable de la sécurité de leurs ressources, un autre
utilisateur ne peut pas utiliser ces ressources qu'après l'autorisation
de l'utilisateur propriétaire. Chaque utilisateur a un rôle dans
l'organisation selon leur niveau hiérarchique.
Par analogie on résume l'arborescence de
l'université dans ce graphe.
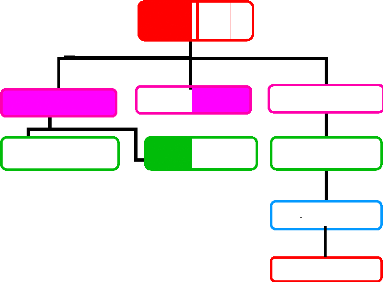
Chef université :
Administrateur
Chef de faculté 1 Chef de faculté 2 Chef de
faculté 3
Chef de département
1
Agent de saisie
Etudiant
Chef de département
3
Chef de département
2
Figure 03 : Modélisation de l'université de
Batna.
Ce graphe sera nous accompagnons pour crée l'annuaire
LDAP.
Alors nous avons trois types d'utilisateurs dans notre
système :
1. Chef université Administrateur :
responsables de :
- toutes les opérations sur l'université,
- ajouté les type de congé, les diplômes ...
etc.
- créer les utilisateurs " Chef de
faculté".
2. Chef de faculté : il travail sur les
tables du schéma"AD_Faculte". Responsable d'administrer
la faculté. Et la création des utilisateurs " Chef de
département ".
3. l'agent de saisie : il travail sur les
tables du schéma 'AD_Departement'. Responsables de
toutes opérations concernant les Etudiants :
- création des utilisateurs étudiant
- inscription.
- orientation et transfère.
Schéma : AD_Faculte
Tables: Département
Procédures :
Mise a jours de table : Département
Schéma : AD_Departement
Tables :
-
specialite
options
Etudiant
fiche _etude
dossier_bloque
dossier_retirer
dossier_Transferer VIEW fiche _etudiant
Procédures :
Mise a jours des tables : specialite, options ,Etudiant
fiche_etude, dossier_bloque
Schéma : AD_Universite Tables:
Nationalité Bac
Wilaya
Commune Université Faculté
type_conge Diplôme
annee_univ
Procédures :
Mise a jours des tables :
Nationalité, Bac, Wilaya,
Commune, Université, Faculté type_conge,
Diplôme, annee_univ
Schéma : Etudiant
Tables:
Crée selon les fonctions a ajoutées
Procédures :
- génération des états de sorties.
4. Chef de département : il travail sur
les tables du schéma 'département'.
- créer les utilisateurs "agent de
saisie".
- ajouté les spécialités et les options.
5. Etudiant:
- Consultation de la fiche d'étude.
- réinscription.
Les schémas: AD_Faculte,
AD_Universite, AD_Departement,
Etudiant, représentent Dans notre système Des
schémas partagées (voir chapitre de
sécurité), et les utilisateurs sera crées
séparément a chaque création d'une faculté, d'un
département et chaque inscription d'un étudiant.
Par exemple l'utilisateur informatique sera crée au moment
de la création du département informatique. Cet utilisateur sera
connecté et travaillé sur le schéma département.
La création des tablespaces :
On peut voir les tablespaces comme les partitions logiques de
disque dur ou les répertoires qui aident à l'organisation de
l'information selon son type.
Par les tablespaces on peut séparer entre les
données de système (on parlent des données de
l'utilisateur SYS "dictionnaire de données, ....") et les données
de l'utilisateur.
pour contrôler l'espace disque efficacement, il est
recommandé d'utiliser plusieurs tablespaces.
L'université est constituée de trois
éléments: l'enseignent, l'étudiant, et l'administration
pour cela nous avons crée trois tablespaces :
1. Administration: c'est l'espaces disque qui
sera alloué aux l'utilisateur AD_Universite, AD_Faculte,
AD_Departement.
2. Etudiant : pour sauvegarder les
données associées a l'étudiant,
3. Usertemp ( tablespace temporaire) :
Lorsque une base de données est crée sans
tablespace temporaire par défaut, le tablespaces qui est assigné
aux utilisateurs créés sans la clause TEMPORARY TABLESPACE est le
tablespaces SYSTEM.
Pour éviter que le tablespace système soit
utilisé comme tablespace temporaire, il est nécessaire de
créer un tablespace temporaire par défaut autre que SYSTEM. Un
segment temporaire permet d'avoir un gain de performance lorsque, par exemple,
plusieurs tris occupent trop de place pour la mémoire et doivent
être stockés sur le disque dur temporairement.
|
CREATE TABLESPACE administration
LOGGING
DATAFILE
C:\ORACLE\ORADATA\BASE\ADMIN.ora'
SIZE 5M AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO online
;
CREATE TABLESPACE etudiant LOGGING
DATAFILE
C:\ORACLE\ORADATA\BASE\etudiant.ora'
SIZE 5M AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED EXTENT MANAGEMENT LOCAL SEGMENT
SPACE MANAGEMENT AUTO online;
CREATE TEMPORARY TABLESPA CE USER
TEMP TEMPFILE 'C: \ORACLE\ORADATA\BASE \USERTEMP.ora' SIZE 10M EXTENT
MANAGEMENT LOCAL UNIFORM SIZE 5M;
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE USERTEMP;
|
il est préférable de stocker les datafile sur
plusieurs disques (répartition des charges disque).
Script de création des schémas :
|
CREATE USER AD_Universite PROFILE "DEFAULT"
IDENTIFIED by universite
DEFAULT TABLESPACE administration
TEMPORARY TABLESPACE "USERTEMP" ACCOUNT UNLOCK;
CREATE USER AD_Faculte PROFILE "DEFAULT"
IDENTIFIED by faculte DEFAULT TABLESPACE administration
TEMPORARY TABLESPACE "USERTEMP" ACCOUNT UNLOCK;
CREATE USER AD_Departement PROFILE "DEFAULT"
IDENTIFIED by Departement
DEFAULT TABLESPACE administration
TEMPORARY TABLESPACE "USERTEMP" ACCOUNT UNLOCK;
CREATE USER Etudiant PROFILE "DEFAULT"
IDENTIFIED by Etudiant DEFAULT TABLESPACE etudiant
TEMPORARY TABLESPACE "USERTEMP" ACCOUNT UNLOCK;
|
Création des rôles :
A l'exception de l'utilisateur Ad_universite (l'administrateur
de l'universite qui possède leur propre schéma) les utilisateurs
sont crées dynamiquement et ils ne peuvent rien faire initialement
même pas la connexion à la base de données, touts les
privilèges nécessaires sera donnés par l'utilisateur
créateur.
C'est pourquoi l'administrateur de l'université
(ad_université) doit avoir touts les rôles au départ.
1. Description des rôles:
admin_role: c'est le rôle qui regroupe
tout les privilèges nécessaire à la création des
schémas partagés.
inst_role: c'est le rôle qui permet au
tout nouvel utilisateur de connecté et de crée des
utilisateur.
user_fac: il permet aux chefs des
facultés de manipuler leurs tables.
user_dept: : il permet aux chefs des
départements de manipuler leurs tables. select_univ: il
permet aux utilisateurs de consulter les tables du schéma
ad_université. select_fac: : il permet aux utilisateurs
de consulter les tables du schéma ad_faculté.
user_dept_ag: un rôle qui sera
donné à l'agent de saisie pour lui permet d'accomplir ses
taches.
user_etud: un rôle spécifique aux
étudiants.
1.1 Rôles agent département : c'est
le rôle qui sera assigné à l'utilisateur agent de
saisie. Le script de la création est le suivant :
create role user_dept_ag ;
grant select, insert, update, delete on etudiant to
user_dept_ag;
grant select, insert, update, delete on fiche_etude to
user_dept_ag;
grant select, insert, update, delete on fiche_etudiant to
user_dept_ag;
grant select, insert, update, delete on dossier_retirer to
user_dept_ag;
grant select, insert, update, delete on dossier_bloque to
user_dept_ag;
grant select, insert, update, delete on dossier_transferer to
user_dept_ag;
grant select on specialite to user_dept_ag;
grant select on options to user_dept_ag;
1.2. Rôles chef de département :
c'est le rôle qui sera assigné à l'utilisateur Chef
département. Le script de la création est le suivant
:
create role user_dept;
grant select, insert, update, delete on specialite to
user_dept;
grant select, insert, update, delete on options to user_dept;
1.3. Rôles select_fac: c'est le rôle
qui sera assigné à l'utilisateur Chef de
departement. Le script de la création est le suivant :
create role select_fac;
grant select on departement to select_fac;
1.4. Rôles select_univ : c'est le
rôle qui sera assigné aux utilisateurs sauf
l'étudiant. Le scripte de la création est le suivant :
Create role select_univ;
grant select on faculte to select_univ;
grant select on nationalite to select_univ;
grant select on bac to select_univ;
grant select on wilaya to select_univ;
grant select on commune to select_univ;
grant select on universite to select_univ;
grant select on deplome to select_univ;
grant select on type_conge to select_univ;
grant select on annee_univ to select_univ;
Création des tables des
schémas:
2.1 Schéma Ad_université :
Le schéma Ad_université inclut les tables :
Nationalité, Bac, Wilaya, Commune Université, Faculté,
type_conge, Diplôme, annee_univ. Le scripte est le suivant :
Table N° :01 Nationalité :
|
CREATE TABLE nationalite (
code NUMBER(3) ,
nationa lite_fr VARCHAR2(40) NOT NULL CONSTRAI NT
nationalite_fr_UK UNIQUE, nationa lite_ar VARCHAR2(40) NOT NULL CONSTRAI NT
nationa lite_ar_UK UNIQUE, CONSTRAINT nationalite_PK PRIMARY KEY (code) );
|
Table N°:02 Bac:
|
CREATE TABLE Bac(
code VARCHAR2(2),
bac_fr VARCHAR2(40) not null constraint bac_fr_UK unique,
bac_ar VARCHAR2(40) not null constraint bac_ar_UK unique, CONSTRAINT Bac_PK
PRIMARY KEY (code) );
|
Table N°:03 Wilaya:
|
CREATE TABLE wilaya (
code varchar2(2),
wilaya_fr VARCHAR2(30) NOT NULL CONSTRAINT wil_fr_UK UNIQUE,
wilaya_ar VARCHAR2(30) NOT NULL CONSTRAINT wil_ar_UK UNIQUE, constraint wil_pk
PRIMARY KEY (code) );
|
Table N°:04 Communes:
|
CREATE TABLE commune (
code varchar2(5) NOT NULL CONSTRAINT commune_code_Uk UNIQUE,
commune_fr VARCHAR2(40) NOT NULL,
commune_ar VARCHAR2(40) NOT NULL,
code_wil varchar2(2),
CONSTRAINT commune_fk FOREIGN KEY (code_wil) REFERENCES
wilaya(code), constraint commune_UK unique(commune_fr,commune_ar,code_wil)
);
|
Table N°:05 Université:
|
CREATE TABLE universite (
code VARCHAR2(2) ,
univ_fr VARCHAR2(40) NOT NULL CONSTRAINT univ_fr_UK UNIQUE,
univ_ar VARCHAR2(40) NOT NULL CONSTRAINT univ_ar_UK UNIQUE, sigle blob,
|
|
date_ouverture date,
adresse_fr varchar2(60), adresse_ar varchar2(60), wilaya
varchar2(2),
telephone1 varchar2(12),
telephone2 varchar2(12),
fax1 varchar2(12),
fax2 varchar2(12),
CONSTRAINT universite_fk FOREIGN KEY (wilaya) REFERENCES
wilaya(code),
CONSTRAINT universite_pk PRIMARY KEY (code) );
|
Table N°:06 Faculté:
|
CREATE TABLE faculte ( code VARCHAR2(4) ,
fac_fr VARCHAR2(40) not null , fac_ar VARCHAR2(40) not null ,
code_univ varchar2(2), telephone1 varchar2(12), telephone2 varchar2(12),
fax1 varchar2(12),
fax2 varchar2(12),
CONSTRAINT faculte_fk FOREIGN KEY (code_univ) REFERENCES
universite(code),
constraint faculte_U K u nique(code_univ,fac_fr,fac_ar),
CONSTRAINT faculte_pk PRIMARY KEY(code) );
|
Table N°:07 type_conge:
|
CREATE TABLE type_conge (
type_conge VARCHAR2(2) ,
title_conge_fr VARCHAR2(40) NOT NULL CONSTRAINT
type_fr_conge_title_UK UNIQUE, title_conge_ar VARCHAR2(40) NOT NULL CONSTRAI NT
type_ar_conge_title_UK UNIQUE, CONSTRAINT type_conge_PK PRIMARY KEY
(type_conge) );
|
Table N°:08 Diplôme:
|
CREATE TABLE deplome (
code VARCHAR2(1) ,
depl_fr VARCHAR2(30) NOT NULL CONSTRAINT deplome_fr_UK UNIQUE,
depl_ar VARCHAR2(30) NOT NULL CONSTRAINT deplome_ar_UK UNIQUE, fin_cycle
number(1) NOT NULL,
CONSTRAINT deplome_PK PRIMARY KEY (code) );
|
Table N°:09 annee_univ:
|
CREATE TABLE annee_univ (
annee VARCHAR2(4),
title varchar2(9),
CONSTRAINT annee_univ_PK PRIMARY KEY (annee) );
|
Après la création de ces tables, un utilisateur
sera assignée au schémas ad_universite ce utilisateur prend le
même nom du schéma. Pour nous c'est l'utilisateur Chef
université (voir la liste des
utilisateurs).
Ces objets sont à la responsabilité de
ad_universite, et sans leur permettion, aucun utilisateur peut
référencer a ces objets .l'utilisateur ad_universite peut
attribuer des privilèges aux utilisateurs pour les autorisé de
crées des tables fait référence à ces objets,
|
grant references on faculte to role_faculte,
role_Departement;
grant references on nationalite to role_faculte,
role_Departement;
grant references on bac to role_faculte,
role_Departement;
grant references on wilaya to role_faculte,
role_Departement;
grant references on commune to role_faculte,
role_Departement; grant references on universite to
role_faculte, role_Departement; grant references on deplome to
role_faculte, role_Departement; grant references on type_conge
to role_faculte, role_Departement; grant references on
annee_univ to role_faculte, role_Departement;
|
Mais pour que les utilisateurs ad_faculte, ad_departement peut
accéder a ces objets il faut toujours prévenir de nom de la
propriétaire, exemple : "
AD_Universite. annee_univ". Pour fait une abstraction sur les
noms des objets du schémas, on a crée des synonymes :
|
create public synonym nationalite for
ad_universite.nationalite;
create public synonym bac for ad_universite.bac;
create public synonym wilaya for ad_universite.wilaya;
create public synonym commune for ad_universite.commune;
create public synonym universite for ad_universite.universite;
create public synonym faculte for ad_universite.faculte;
create public synonym deplome for ad_universite.deplome;
create public synonym type_conge for ad_universite.type_conge;
create public synonym annee_univ for ad_universite.annee_univ;
|
Création des tables de schéma Ad_
faculté:
Table N°:01 department:
|
CREATE TABLE departement (
code VARCHAR2(6) ,
depart_fr VARCHAR2(30) NOT NULL , depart_ar VARCHAR2(30) NOT
NULL , code_fac VARCHAR2(4),
date_ouverture date,
telephone1 varchar2(12),
|
|
telephone2 varchar2(12),
fax1 varchar2(12),
fax2 varchar2(12),
CONSTRAINT departement_fk FOREIGN KEY (code_fac) REFERENCES
faculte(code),
constraint departement_UK unique(depa
rt_fr,depart_ar,code_fac),
CONSTRAINT departement_pk PRIMARY KEY (code) );
|
Le script qui permet attribuer des privilèges aux
utilisateurs autorisés de référencer à la table
"département"est le suivant :
grant references on departement to ad_departement;
Création des synonymes :
create public synonym departement for ad_faculte.departement;
Création des tables de schéma
Ad_département: Table N°:01 spécialité:
|
CREATE TABLE specialite (
code VARCHAR2(9) ,
speciat_fr VARCHAR2(40) NOT NULL ,
speciat_ar VARCHAR2(40) NOT NULL ,
code_depl varchar2(1),
code_depart VARCHAR2(6),
CONSTRAINT specialite_depart_fk FOREIGN KEY(code_depart)
REFERENCES departement
(code),
CONSTRAINT specialite_deplome_fk FOREIGN KEY(code_depl)
REFERENCES deplome (code), constraint specialite_UK u
nique(speciat_fr,speciat_a r,code_depart),
CONSTRAINT specialite_pk PRIMARY KEY (code) );
|
Table N°:02 options:
|
CREATE TABLE options (
code VARCHAR2( 10) CONSTRAINT options_code_UK unique,
option_fr VARCHAR2(40) NOT NULL ,
option_ar VARCHAR2(40) NOT NULL ,
code_speciat VARCHAR2(9),
annee_debut number(1),
CONSTRAINT options_FK FOREIGN KEY (code_speciat) REFERENCES
specialite(code), constraint options_UK
unique(option_fr,option_ar,code_speciat) );
|
Table N°:03 Etudiant:
|
CREATE TABLE Etudiant (
ident VARCHAR2(20),
nom_fr VARCHAR2(30) NOT NULL,
nom_ar VARCHAR2(30) NOT NULL,
prenom_fr VARCHAR2(30) NOT NULL,
prenom_ar VARCHAR2(30) NOT NULL,
sexe VARCHAR2(1),
date_naiss DATE NOT NULL,
lieu_naiss VARCHAR2(20),
nationa lite NUMBER(3),
commune varchar2(5),
adresse_fr VARCHAR2(40) NOT NULL,
adresse_ar VARCHAR2(40) NOT NULL,
bac varchar2(2),
pays_bac NUMBER(3),
moyenne_bac NUMBER(4,2) not null,
photo Blob,
prenomp_fr VARCHAR2(30) ,
prenomp_ar VARCHAR2(30) ,
prenomm_fr VARCHAR2(30) ,
prenomm_ar VARCHAR2(30) ,
nom m_fr VARCHAR2(30) ,
nom m_ar VARCHAR2(30) ,
CONSTRAINT Etudiant_nationalite_FK FOREIGN KEY (nationalite)
REFERENCES
nationalite(code),
CONSTRAINT Etudiant_pays_bac_FK FOREIGN KEY (pays_bac) REFERENCES
nationalite(code), CONSTRAINT Etudiant_bac_FK FOREIGN KEY (bac) REFERENCES
Bac(code),
CONSTRAINT Etudiant_lieu_naiss_FK FOREIGN KEY (lieu_naiss)
REFERENCES com mune(code), CONSTRAINT Etudiant_commune_FK FOREIGN KEY (commune)
REFERENCES commune(code), CONSTRAINT Etudiant_sexe_CK CHECK (upper(sexe)='F' or
upper(sexe)='M' ),
CONSTRAINT Etudiant_PK PRIMARY KEY (ident) );
|
Table N°:04 fiche_etude:
|
CREATE TABLE fiche_etude (
annee_univ VARCHAR2(4),
ident VARCHAR2(20),
code_speciat VARCHAR2(9),
code_option VARCHAR2(9),
niveau NUMBER(1),
matricule VARCHAR2(20) NOT NULL,
CONSTRAINT fiche_etudiant_FK FOREIGN KEY (ident) REFERENCES
Etudiant(ident), CONSTRAINT fiche_speciat_FK FOREIGN KEY (code_speciat)
REFERENCES specialite(code),
CONSTRAINT fiche_options_FK FOREIGN KEY (code_option) REFERENCES
options(code), CONSTRAINT fiche_annee_univ_FK FOREIGN KEY (a nnee_univ)
REFERENCES
annee_univ(annee),
|
|
CONSTRAINT fiche_niveau_CK CHECK (niveau >=1 and niveau<=7
), CONSTRAINT fiche_PK PRIMARY KEY (annee_univ,ident) );
|
Table N°:05 dossier_bloque:
|
CREATE TABLE dossier_bloque (
annee_univ VARCHAR2(4),
ident VARCHAR2(20),
type_conge VARCHAR2(2),
CONSTRAINT dossier_bloque_ident_FK FOREIGN KEY (annee_univ,ident)
REFERENCES fiche_etude(annee_univ,ident),
CONSTRAINT dossier_bloque_conge_FK FOREIGN KEY (type_conge)
REFERENCES type_conge(type_conge),
CONSTRAI NT dossier_bloque_PK PRIMARY KEY (annee_univ,ident)
);
|
Table N°:06 dossier_retirer:
|
CREATE TABLE dossier_retirer (
annee_univ VARCHAR2(4) ,
ident VARCHAR2(20),
CONSTRAINT dossier_retirer_id_fk FOREIGN KEY (annee_univ,ident)
REFERENCES fiche_etude(annee_univ,ident),
CONSTRAINT dossier_retirer_PK PRIMARY KEY (annee_univ,ident)
);
|
Table N°:07 dossier_Transferer:
|
CREATE TABLE dossier_Transferer( annee_univ VARCHAR2(4) , ident
VARCHAR2(20),
speciat_dest VARCHAR2(9) ,
options_dest VARCHAR2(10) ,
CONSTRAINT dossier_tra nsferer_id_fk FOREIGN KEY
(annee_univ,ident) REFERENCES fiche_etude(annee_univ,ident),
CONSTRAINT dossier_trf_speciat_FK FOREIGN KEY (speciat_dest)
REFERENCES specialite
(code),
CONSTRAINT dossier_trf_options_FK FOREIGN KEY (options_dest)
REFERENCES options
(code),
CONSTRAINT dossier_trfr_PK PRIMARY KEY (annee_univ,ident) );
|
Table N°:08 fiche_etudiant:
|
CREATE or replace VIEW fiche_etudiant
AS SELECT etudiant.ident ,nom_fr , nom_ar , prenom_fr , prenom_ar
, sexe ,date_naiss , lieu_naiss ,nationalite ,commune , adresse_fr , adresse_ar
, bac ,pays_bac ,moyenne_bac ,photo,
prenomp_fr ,prenomp_ar ,prenomm_fr ,prenomm_ar ,
nomm_fr , nomm_ar , user_name ,psw ,annee_univ ,
code_speciat ,code_option ,niveau , matricule
FROM etudiant,fiche_etude
|
WHERE fiche_etude.ident=Etudiant.ident;
Création des synonymes :
|
create public synonym specialite for
ad_departement.specialite;
create public synonym options for ad_departement.options;
create public synonym etudiant for ad_departement.etudiant;
create public synonym fiche_etude for
ad_departement.fiche_etude;
create public synonym dossier_retirer for
ad_departement.dossier_retirer;
create public synonym dossier_bloque for
ad_departement.dossier_bloque;
create public synonym dossier_transferer for
ad_departement.dossier_tra nsferer; create public synonym dossier_transferer
for ad_departement.fiche_etudiant;
|
3. description des interfaces :
Le côté applicatif de notre projet consiste de
réaliser un ensemble d'interfaces. Et pour cela on a utilisé
l'outil de développement oracle forms qui
été apparut bien adapter aux nos besoins.
On peut groupé les interfaces réalisées en
deux types les quelles:
· interfaces des administrateurs,
comme il est expliqué précédemment on a trois
types d'administrateurs: chef université, chef faculté et chef
département, pour chacun d'ils on a associé à une
interface qui lui permet de faire leurs propres opérations.
· un autre type est constitué d'un ensemble
d'interfaces qui étaient orienté vers les opérations
désignées aux étudiants tel que l'inscription, la
consultation... etc. Et aussi pour les étudiants bloquant ses
études, transférant et retirant leurs dossiers on a
réalisé une interface qui permet les mises à jour sur les
tables associées.
L'accès aux ces interfaces est sécurisé de
tel manière à permettre seul au propriétaire de
les utilisé (voir Chapitre de sécurité).
L'interface UNIVERSITE:
L'administrateur d'université utilise cette interface pour
effectuer les opérations de mis à jours sur leur propre table tel
que l'insertion des wilayas, des universités, des facultés...
etc.
L'interface FACULTE:
Elle est désignée à l'administrateur de
faculté pour que elle lui permette d'effectuer les opérations de
mis à jours sur la seule table qui est département.
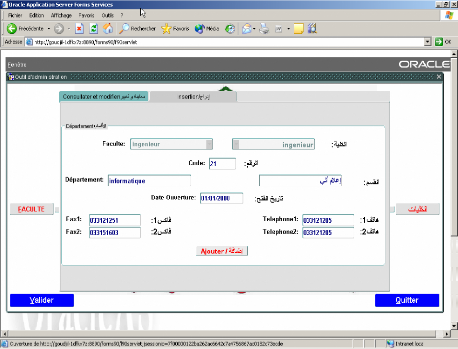
L'interface DEPARTEMENT:
Elle est désignée pour qu'elle permette à
l'administrateur de département d'effectuer les opérations de mis
à jours sur leurs propres tables telles que l'insertion des
spécialités, des options.
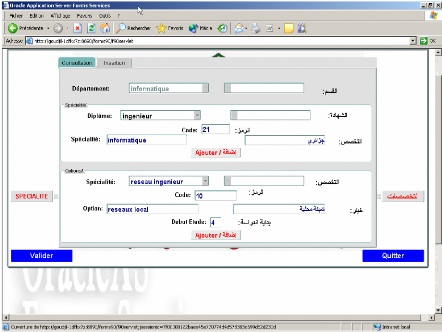
L'interface ETUDIANT:
L'agent de saisie dans le département utilise cette
interface pour rempli les informations d'inscriptions des
étudiants.
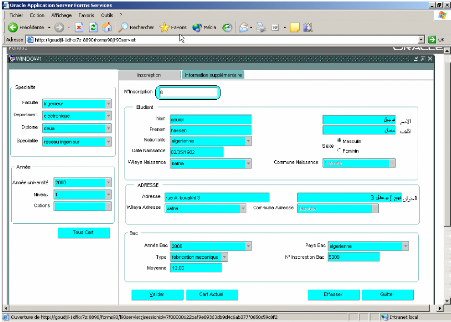
Génération des cartes des
étudiants:
Pour générer les cartes des étudiants on a
utilisé l'outil de développement Oracle Report,
et on a implémenté deux possibilités à
l'exécution des rapports qui sont:
1. Centraliser la génération des
cartes des étudiants dans un serveur d'impression, et pour cela on a
utilisé la fonction RUN_REPORT_OBJECT.
La fonction SET_REPORT_OBJECT_PROPERTY est
utilisée pour exécuter le rapport dynamiquement. Et on a encore
utilisé pour le passages des paramètres.
|
declare
rep varchar2(200);
begin
set_report_object_property('rep', REPORT_OTHER, 'ident='||:ident
|| 'paramform =no' ); rep:=run_report_object('rep');
end;
|
2. Alternativement au run_report_object, nous
avons utilisé le Web.show_document pour appeler le
rapport par le web vers le poste client.
L'interface METTRE A JOURS:
Cette interface est pour rempli les informations des
étudiant faisons les transfères, les retraits ou bloquons leurs
dossiers.
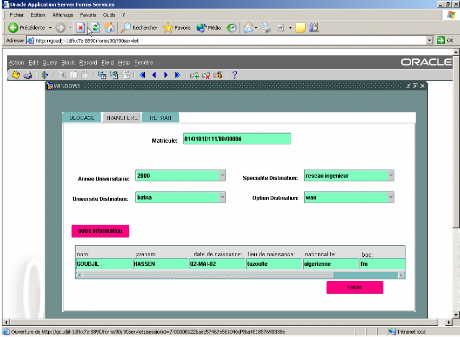
Ces interface sont réalisées d'une
manière très simples on évitant les animations et les
Roundtrips (va et vient) dans le réseaux que le plus possible en raison
d'augmenté les performances.
CHAPITRE 7
1. Introduction
Bien que la sécurité soit l'une des raisons de
l'architecture trois couches, plusieurs challenges praticables sont
enlevés lors de la construction du système tel que
l'authentification des utilisateurs, le contrôle des accès et
Audit les actions des utilisateurs, la protection des données entre les
couches, la limitation des privilèges de l'intermédiaire, et la
construction des systèmes extensibles.
2. Les moyens de sécurité
2.1 L'authentification des utilisateurs
Dans les architectures à deux niveaux où les
utilisateurs connectent directement au serveur, la base de donnée
authentifiée les utilisateurs lors de la connexion et leur
associée le nécessaire pour ses travails. Typiquement, dans les
architectures trois tiers, l'intermédiaire est le responsable de
l'authentification des utilisateurs, et de plus il traite les données
envoyées par les utilisateurs avant de les transmis vers le serveur de
base données. Un seul intermédiaire est commun entre les
utilisateurs et la base de données (un seul point d'entrée), pour
cette raison la base de donnée délègue l'authentification
des utilisateurs à l'intermédiaire, dans ce niveau la
réalisation d'une authentification est plus compliquée
que l'architecture deux tiers.
2.2 Le contrôle d'accès des
utilisateurs
Une fois que l'utilisateur est authentifié par
l'intermédiaire, le système doit contrôler quelles
données, applications et ressources l'utilisateur peut accédera
dans le système. Les données ne doivent pas être
protéger seulement contre les intrusions mais aussi les accès des
utilisateurs ayant des limites qui doivent être respecté. A
l'incrémentation des besoins des entreprises, oracle a défini
initialement deux méthodes pour protéger l'accès au niveau
des lignes des tables, qui sont basées sur les vues pour la
première et les procédures pour la deuxième, mais elles
étaient non praticables pour un non petit nombre des utilisateurs. Pour
contrôler l'accès il faut d'abord renforcer comment les
utilisateurs fait accès. La sécurité typique dans les
systèmes trois tiers, exige que chaque utilisateur soit limité
par l'exécution des applications spécifiques sur
l'intermédiaire, dépendant sur l'identité de l'utilisateur
et le rôle lui accorder dans l'organisation. Un utilisateur qui
accède à partir d'un intermédiaire ne doit pas avoir la
permission d'accéder directement à la base de données.
2.3 La protection des données de
l'utilisateur
Le changement des données entre les trois tiers doit
être protéger contre les révélation et les
modification non attendis, le cryptage est le mécanisme standard pour ce
but. Le SSL (Secure Sockets Layer) est le protocole qui assurer le cryptage et
la communication confidentielle dans le réseau entre le client et
l'intermédiaire aussi qu'entre l'intermédiaire et la base de
données.
2.4 L'audit des accès de l'utilisateur
L'audit des accès est nécessaire pour
déterminer l'utilisateur responsable de telle action dans la base de
données, et comme les utilisateurs accèdent à partir d'un
intermédiaire, il est difficile à un système audit de
garder la trace et de corréler les activités qui peuvent
être sensitives à la sécurité.
2.5 Limitation du privilège de
l'intermédiaire :
Puisque le mécanisme d'authentification de
l'intermédiaire est moins fort que celui de la base de données et
que l'intermédiaire situé en d'hors de la zone
protégée par le firewall en face des intrusions interviennes de
l'Internet, la base de données doit limiter les privilèges d'un
intermédiaire, et de le permis d'accéder au nom des utilisateurs
spécifiques.
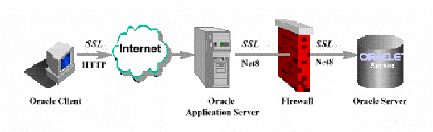
Figure 1 : La sécurité du système trois
tiers.
2.6 La base privée virtuelle (Virtual Private
Database ou VPD)
A l'incrémentation des besoins des organisations et des
entreprises, la base privée
virtuelle proposée par oracle
pourvoi un grand sécurité d'accès contrôle. Et ceci
par la
création d'une politique de sécurité -au
niveau de la base de données- commun entre toutes les applications, ce
qui permet au chaque utilisateur d'accéder seulement à ces
données, et quelque soit la manière de la quelle l'utilisateur
accède à la base il ne peut pas dépasser cette politique
de sécurité.
Figure 2 : les utilisateurs voir seul leurs données.
2.7 Le répertoire Internet d'oracle (OID Oracle
Internet Directory)
L'OID utilisant LDAP (Lightweight Directory Access Protocol) est
le meilleur mécanisme pour le but de centraliser les données
communes entre différentes parties d'une entreprise tel que les
identités des utilisateurs, en vue de faciliter la gestion, et
d'éviter la redondance et l'inconsistance des données.
Les privilèges et les informations du contrôle
d'accès sont les informations les plus supportées pour être
stocker dans un OID. Les administrateurs du système sont les seuls qui
ont le droit de modifier les informations d'un OID. L'OID avec le schéma
partagé construirent une bonne solution pour les grandes entreprises qui
utilisent plusieurs bases de données.
2.8 Les schémas partagés
Les schémas partagés permettent à la base de
données de déléguer la gestion des identités des
utilisateurs, tel que les privilèges, à un OID.
Par exemple dans une entreprise qui comporte un nombre de 500
utilisateur qui veulent accèdent aux données des plusieurs bases,
au lieu de maintient 500 schéma dans chaque base, oracle permet aux
administrateurs de créer un seul schémas commun, avec les
privilège approprier dans chaque base de données, et de
créer les 500 utilisateur dans un
OID, Quand ils connectent à une base spécifique,
les utilisateur sont dirigés vers le schémas commun, et ils
obtient les rôles qui les associés dans l'OID.
2.9 Signature unique « Single Sign On
»
Les utilisateurs ont accès avec un mot de passe unique
à l'ensemble des applications qu'il s'agisse d'applications Oracle ou
non (Yahoo,
LeMonde.fr, ...) via des
mécanismes de signature unique de Single Sign On (SSO). L'utilisateur
s'authentifie en toute sécurité auprès de multiples
applications en une seule séquence. La vérification de son
identité est valide pour la durée de la session utilisateur, et
pour chaque application participant à l'infrastructure
d'authentification.

3. La solution appliquée
Dans les architecture trois tiers où le dernier niveau est
un navigateur web accède via un réseau Intranet ou Internet, la
sécurité est une condition très importante pour le bon
fonctionnement du système, et puisque le réseau Internet est
publique le chalenge de construire un système fiable augmente, c'est le
cas de notre projet.
La sécurité en oracle nécessite une
administration au niveau base de donnée et autre au niveau serveur
d'application (security administrator) mais le développeur aussi a un
grand devoir ce qui concerne la sécurité de ses applications.
3.1 L'authentification
Les utilisateurs accèdent à notre système
via l'intermédiaire (le serveur d'application) où réside
la logique applicative, dans ce cas la base de données
délègue l'authentification des utilisateurs à
l'intermédiaire, si le client est un utilisateur de la base
données le serveur
d'application contrôle les droit d'accès
à l'application demandé, s'ils sont bien
confirmées, le serveur d'application connecte à la base de
données au nom de l'utilisateur (c'est un Proxy).
Dans ce cas les utilisateurs sont connu par la base de
donnée; et peuvent être stockées dans la base de
données lui même ou bien dans un Répertoire Internet
d'oracle (OID). L'utilisation d'un OID est la meilleure solution, car le OID
centralise ces identités entre plusieurs bases des données ce qui
empêche la redondance et l'incohérence des données.
Jusqu'au cette moment d'écriture de ce document, la solution
précédente reste typique pour nous mais sans réalisation
à cause d'un manque matériel et un manque de temps pour fini ce
modeste travail.
Et pour que ne laisse pas les mains croisées devant ces
contraintes, on a reculé vers une autre solution assurée par les
applications en profitant de la richesse du langage PL/SQL et l'outil Forms.
3.2 Le contrôle d'accès
Les trois éléments de l'université sont
restrictifs dans ses accès en deux niveaux :
Premièrement au niveau des applications,
l'étudiant ne doit pas pouvoir utilisé une application
d'enseignant ni d'administration, aussi le cas pour l'enseignant " il ne doit
pas pouvoir utilisé une application d'administration ni
d'étudiant " et le cas pour l'administration. Typiquement cette tache
est sur le compte du serveur d'application oracle, jusqu'à maintenant
elle est assurée par un contrôle juste après
l'authentification de l'utilisateur.
Le Deuxièmes c'est au niveau des
données, chaque élément de l'université ne
peut voir que ses données personnelles, malgré que touts les
étudiants accède aux mêmes tables par le même
rôle, et aussi le cas pour les enseignants et les administrateurs. On est
devant la notion de la base de donnée privée virtuelle.
Comme on a déjà expliqué, le VPD
(fine-grained access control) contrôle l'accès au niveau des
lignes de la table, et on a bien adapté cette solution pour notre base
de données. L'application est un moyen fort de la sécurité
des données, donc il est interdit qu'un utilisateur accède
à la base de données d'une manière direct,
c'est-à-dire sans passé par l'application.
La seule solution qui existe, et qu'on a réalisée
c'est l'utilisation des rôles. Pour qu'un utilisateur peut accéder
au données il faut qu'il possède des privilèges lui
offerts via un rôle, ce rôle ne doit pas activer si et seulement si
l'utilisateur connecte via un Proxy (le serveur d'application). Pour
éviter des catastrophes en cas d'intrusion, les privilèges
donnés aux utilisateurs via les rôles sont très
limités que possible.
Pour construire un système dans un environnement Internet,
il est très difficile de le doter par un mécanisme de
sécurité fiable et solide. Oracle fournit plusieurs
méthodes pour garantir une haute sécurité couvert toutes
les aspects du système, mais ça dépend de
l'expérience du développeur et de l'administrateur du
système.
4. Recommandations pour sécuriser
Oracle
La sécurisation parfaite d'un système Oracle n'est
pas une tâche simple. Cependant Il est possible d'améliorer
très nettement la sécurité d'Oracle en appliquant quelques
recommandations. Certaines de ces recommandations relèvent du bon sens,
mais la réalité montre qu'il n'est jamais inutile de les
rappeler, surtout dans un domaine aussi complexe que les systèmes Oracle
:
1. Installer et activer uniquement les fonctionnalités
indispensables. Même si l'installation est plus complexe et plus longue,
c'est un gain de temps et d'argent à moyen et long terme : tout module
non installé n'aura pas besoin d'être mis à jour, n'aura
pas besoin d'être sécurisé, et surtout ne pourra jamais
être attaqué !
2. Pour un serveur web Oracle HTTP Server ou Oracle Application
Server, supprimer toutes les pages d'exemple, et désactiver les modules
inutiles.
3. Sécuriser le système d'exploitation des
serveurs Oracle, ainsi que tous les postes clients employés par les
administrateurs.
4. Appliquer régulièrement tous les correctifs de
sécurité publiés par Oracle (cf. [CPUSA]). Bien sûr,
la pertinence de chaque correctif doit être analysée, le Correctif
doit d'abord être installé et vérifié dans un
environnement de test avant d'être appliquée en production.
5. A la création de toute nouvelle base Oracle,
désactiver tous les comptes Utilisateurs non indispensables.
6. Modifier les mots de passe de tous les comptes actifs.
7. Vérifier régulièrement ces mots de passe
à l'aide d'outils de test comme [OAT,ODPAT].
8. Appliquer des contraintes sur les mots de passe :
durée de vie, verrouillage, complexité, ...
9. Sécuriser le TNS Listener, en lui appliquant un mot de
passe d'administration et en ajoutant le paramètre ADMIN RESTRICTIONS
(cf. [TNS]).
10. Vérifier régulièrement la
sécurisation du TNS Listener à l'aide d'outils comme
[LCHK,NESSUS].
11. Eviter de laisser un serveur Oracle accessible à tout
le monde sur un réseau ouvert, surtout s'il s'agit d'Internet.
Eventuellement protéger son accès par un pare-feu, ou configurer
le TNS Listener pour n'autoriser qu'une liste d'adresses IP pour les clients
(cf. [TNS]).
12. Surveiller régulièrement la
sécurité et l'intégrité des bases Oracle sensibles,
ainsi que tous les journaux d'événements pouvant mettre en
évidence des actions malveillantes.
13. Envisager le chiffrement des connexions réseau, qu'il
s'agisse d'OracleNet avec SSL ou SSH, ou de HTTPS pour les applications web.
14. Pour une application web, vérifier que toutes les
données saisies par les utilisateurs sont bien filtrées pour
éviter les risques d'injection SQL.
15. Sur les postes clientsWindows, vérifier les ACLs sur
les répertoires du PATH.
16. Protéger correctement les sauvegardes des bases de
données. Cette liste est loin d'être exhaustive.
4. Conclusion

D'après ce qu'on a fait, on peut limiter les aspects de la
sécurité postulée dans ce qui suit : Une meilleure
méthode d'authentification.
Le cryptage des données les plus sensibles pendant la
transmission. La sécurité doit prend sa place dans chaque
niveau.
Le contrôle d'accès au niveau des applications.
Le contrôle d'accès au niveau de la base de
données.
CHAPITRE 7
1. introduction
Il faut que nos étudiants soient informés par
toutes annonces et toutes notifications de l'université pour qu'ils
soient courants et accomplir ses travails dans le bon temps, la solution c'est
que chaque étudiant dispose d'un compte email où il peut
communiqué avec l'université. Oracle a posé devant nos
main un produit qui s'appel "Oracle collaboration suite". Ce dernier inclus le
service d'email qui nous permet d'implémenter cette solution.
2. Oracle Collaboration Suite
Oracle collaboration suite offre aux utilisateurs un nombre de
services logiciels qui peuvent être déployé dans des
configurations différentes. Dépend du choix de configuration, une
instance d'Oracle collaboration suite à des propriétés
variables de disponibilité, d'extensibilité, et de
flexibilité d'accroissement.
Oracle collaboration suite utilise le serveur d'application
Oracle et la base de donnée Oracle pour fournit les services qui
permettent la communication et la collaboration entre les utilisateurs
(voir figure1).
1. Les utilisateurs peuvent envoyer des emails, recevoir des
mails vocaux et des fax, organiser leurs rendez-vous, partager les documents,
chercher l'information et diriger les conférences en ligne.
2. les utilisateurs peuvent réagir avec ces services
par web, par fax, utilisant des applications clients tel que Outlook, par voix
ou par des réseaux sans fil utilisant les téléphones et
les PDAs.
Figure 1: Oracle Collaboration Suite
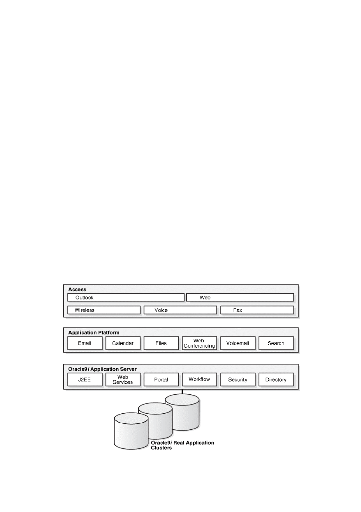
2.1. L'architecture d'Oracle Collaboration
Suite:
On va voir Oracle collaboration suite d'un
niveau d'architecture élevé, elle est composée de trois
niveaux principaux:
Le niveau stocke d'informations (infostore)
Ou le niveau de donnée, il est construit sur une base de
données Oracle et contient les bases de données des fichiers et
d'email.
Le niveau d'infrastructure
Il est construit sur le serveur d'application Oracle, et
comporte un ensemble commun des services utilisés par les applications,
celles-ci incluent l'exécution de java (j2EE), services Web, Workfolow,
sécurité et annuaire.
Le niveau intermédiaire
Inclut les applications d'email, de calendrier, de fichier, de
conférences web, de mail vocale et de la recherche des applications
elles-mêmes. Celles-ci peuvent être consultée par plusieurs
canaux tel que: sans fil, fax, web et Outlook
Le déploiement de L'architecture actuelle est très
flexible, et il y a plusieurs options concernons la façon dont ces
nivaux sont placées dans les machines serveurs et les manières
d'implémentations de la sécurité demandé, de la
disponibilité, de l'extensibilité et la facilité de la
gestion. (Voir figure2)
Figure 2: Une architecture simple d'Oracle Collaboration
Suite
2.2 Distribution de la charge et la
sécurité
Tant que les trois niveaux d'Oracle collaboration suite
peuvent être placés dans un seul noud, cela est peu susceptible de
répondre à vos exigences de sécurité et de
disponibilité dans tout, mais dans quelques scénarios de
système très réduit.
La distribution des couches devrait toujours être prise
en considération. La nature de charges de travail est
considérablement différente pour les trois niveaux.
o Tandis que le niveau intermédiaire emploie
l'unité centrale et la mémoire intensivement avec peu de disque
d'E/s, l'infrastructure et le stock d'information sont très intensifs
dans le disque d'E/s.
o Tandis que le disque d'E/s du stock d'information est
constitué de la lecture et
l'écriture, le disque d'E/s d'infrastructure est
principalement utilisé en lecture.
Pour obtenir une utilisation optimum de ressource d'une
configuration particulière de matériel et de logiciel, vous ne
devez pas mélanger différentes charges de travail sur une seule
machine. Pour cette raison, les architectures et particulièrement pour
les plus grands systèmes, préfèrent la distribution de ces
niveaux sur différentes machines.
Dans Oracle collaboration suite, les demandes de ressources
pour le niveau intermédiaire à un taux différent des
niveaux d'infrastructure et de stock d'information. Ceci ajoute plus de
justification pour une architecture distribuée qui permet aux niveaux
intermédiaire et stock d'information de se balanciers
indépendamment.
2.3 Les composants et les protocoles d'Oracle
Collaboration Suite
Le schéma ci-dessous fournit un détail
légèrement simplifié des trois niveaux d'Oracle
collaboration suite: le niveau intermédiaire (middle
tiers), stocke d'information (infostore tiers) et
l'infrastructure (infrastructure tiers) (voir figure
3).
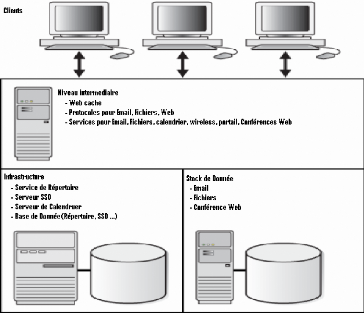
Figure 3: Niveaux d'Oracle collaboration
suite.
Niveau intermédiaire (middle tiers)
Le niveau moyenne est constitue des services suivants:
o protocoles d'email (SMTP, POP3, IMAP4)
o Protocoles de fichiers (FTP, SMB, NFS, AFP, WebDav).
o Protocoles de web (THHP, HTTP/S).
o Services d'email (Files/HTTP).
o Services De Calendrier (Webcal/HTTP, SyncML/HTTP, serveur de
calendrier). o Services de sans fil (sans fil/http).
o Services portail que (portique/http).
o Webcache.
Niveau d'infrastructure (infrastructure
tiers)
Le niveau d'infrastructure est constitue des services
suivants:
o Services d'annuaire (LDAP, DAS/HTTP).
o Single sign on (SSO/HTTP).
o Base de donnée (Répertoire, SSO, et donnée
portail). Niveau du stock d'information (infostore tiers)
Le niveau d'infostore est constitue des services suivants: o
Email.
o Fichiers.
o Ultrasearch.
3. présentation générale
d'émail Oracle
3.1. Définition
L'email d'Oracle est un système fiable, extensible et
sécurisé qui réduit le coût d'administration, de
matériel et de logiciel en fournissant un stocke consolider de courrier
électronique.
Email d'Oracle utilise une base de donnée Oracle comme
un stock unique de messages pour les courriers électroniques et profite
des compétences d'Oracle dans les privilèges d'accès,
stocker et diriger touts types d'informations. .
3.2. Les caractéristiques d'email
d'Oracle
L'email d'Oracle est conçu pour aller presque à
tout dimension on maintenait sa performance et sa facilité
d'administration. Le système d'email d'Oracle peut être
personnalisé en se basant sur combien de messages ayant besoin
d'être stocké, combien d'utilisateurs peut accéder au
système, et combien de message envoyé et reçu dans une
période de temps.
3.3. Le stockage de messages
L'email d'Oracle stocke touts les messages dans une base de
donnée Oracle. Les utilisateurs d'email d'Oracle peuvent accéder
et diriger touts les messages par une interface de leur choix, inclue le
navigateur web, le téléphone et les PDA. La base de donnée
Oracle permet d'offrir à l'email d'Oracle la disponibilité de
donnée, l'intégrité de donnée, un meilleur temps de
récupération et une tolérance au défaut.
L'email d'Oracle prend l'avantage d'une base de donnée
Oracle multithread, traitement de parallélisme, et un support
très disponible et très performant.
3.4. Webmail d'Oracle
Webmail est une interface web de consultation et de gestion des
messages électroniques.
On peut dire aussi que Webmail est une interface qui permet de
consulter et de gérer votre compte mail en utilisant un navigateur web
standard.
Vous pouvez utiliser webmail d'Oracle pour:
· Composez et dirigez des messages.
· Créez et dirigez des dossiers des messages.
· ...
L'accès au Webmail d'oracle
Pour accéder au webmail d'Oracle :
o Entrer l'url de webmail d'Oracle dans le champ d'adresse de
votre navigateur web.
Remarque: vous pouvez mettre l'URL de webmail d'Oracle comme un
signet ou le faire votre page de bienvenue qui utilise les
préférences de votre navigateur.
o Entrer votre nom d'utilisateur et le mot de passe.
o Cliquer sur connecter, la page d'Oracle collaboration suite est
apparu.
Remarque: après vous connecté au webmail
d'Oracle, vous pouvez accéder aux autre applications d'Oracle
collaboration suit, tel que calendriers d'Oracle, sans fait la
reauthentifications.
4. serveurs et processus
4.1. Gestion des services et des processus
Le démarrage d'un service d'email d'Oracle implique le
démarrage de tous les processus constituent ce service tel que IMAP et
POP.
L'arrêt d'un service d'email d'Oracle envoie une commande
d'arrêt au processus de ce service.
L'administrateur doit faire La maintenance du système
pour les raisons telles que l'amélioration de matériels et de
logiciels du serveur. Les processus de l'email d'Oracle ne peuvent pas marcher
pendant que ce genre d'amélioration est exécuté.
Quand un paramètre d'un processus d'email d'Oracle est
modifié, le service doit être
redémarré pour prendre les nouvelles
modifications.
Redémarrer un service d'email d'Oracle causé que
le processus rechargé leur cadre fonctionnel de dossier d'Internet
d'Oracle sans arrêté. Les utilisateurs continuer à recevoir
sans que le service interrompu.
Exemple: démarrer, arrêter ou
réinitialiser tous les processus du serveur: L'administrateur
de l'entreprise d'Oracle fait les suivants:
1. Aller à la page cible de service d'email d'Oracle.
2. Choisir le type de serveur, tel que IMAP, POP, SMTP,
Housekeeping...
3. Cliquer démarrer, arrêter ou
réinitialiser.
4.2 SMTP : (Simple Mail Transfer
Protocol) C'est le protocole utilisé pour le transfert de
messages de serveur à serveur. Quand vous envoyez un message, votre
ordinateur le transfère sur votre « serveur SMTP ». Ce dernier
se charge ensuite de contacter le serveur du destinataire et de lui transmettre
votre message.
4.3 POP3/IMAP4 : (Post Office
Protocol version3 et Internet Mail Advanced Protocol
version4) Ce sont les protocoles de communication que votre ordinateur utilise
pour se connecter à votre serveur de messagerie. POP3 est le plus
utilisé, il est voué à être remplacé par
IMAP4, plus performant. En effet, le protocole POP3 permet
essentiellement de lister, charger et effacer les courriers sur le serveur
tandis que le protocole IMAP4 permet de gérer à distance le
répertoire de courrier sur le serveur.
JIn' Ko
A. National Language Support (NLS)
Le support national de langage permet aux utilisateurs
d'interagir avec une base de données dans leur langue d'origine et de
lancer des applications dans des environnements comportant différents
langages.
En niveau de la base de donnée
Une base de données Oracle utilise un jeu de
caractères de la base de données et un jeu de caractères
National. Ces deux jeux de caractères sont configurés lors de la
création de la base de données et ne peuvent être
changés ensuite.
La meilleure façon Pour Sélectionnée la
langue arabe, Lors de la création d'une base de données :
1. Avant de lancée l'assistant de création de
la base de donnée, va au panneau de configuration, Dans l'option
"Options régionales, date, heure et langue" Sélectionnée
la langue arabe dans "Options régionales".
2. lancée l'assistant de création de la base de
donnée dans l'option " caractère sets " Vous trouvez :
National character set =AL 1 6UTF 16.
Character set =AR8MSWIN1256.
3. Crée la base de donnée.
En niveau de Forms
1. Lancer la base des registres:dans exécute/tapé
"regedit".
2. HKEY_LOCAL_MACHINE/SOFTWARE/ORACLE/HOME 1 /NLS_LANG.
3. NLS_LANG=French.france.AR8MSWIN1 256.
En niveau des modules Forms :
Changé la police "TAHOMA" avec un police de la langue
arabe exemple "ARABIC TRANPARENT".
Pour plus des options
Depuis votre navigateur, taper l'adresse :
http://localhost/iplus/help/f/global.htm#1
011319
B. Désinstallation d'Oracle
Malheureusement, la procédure de désinstallation de
produit oracle est assez complexe, pour cela voici une petite explication sur
ce sujet :
Nous avons choisi la virsion10g d'oracle puisque cette a
apporté une procédure simplifiée comparée aux
versions précédentes.
Pour commencer Désinstallation d'Oracle en utilise
généralement Oracle Installer. Oracle Installer
c'est l'outil qui - comme son nom l'indique - permet d'installer Oracle, permet
aussi - en théorie - de le désinstaller. Son action est cependant
très limitée, car il ne nettoie pas complètement la base
de registre.

Nettoyage sous Windows
Via Regedit, et avec les droits nécessaires, il
va nous falloir supprimer toute référence à Oracle, ou en
tout cas, à ses services.
Pour rappel, Oracle avait installé:
|
Catégorie
|
Clef
|
Valeur
|
|
Variable d'environement
|
PATH
|
C: \oracle\10g\perl\lib\5 .6.1;
C: \oracle\10g\perl\5.6. 1\lib\MSWin32-x86; C:
\oracle\10g\perl\site\5 .6.1;
C: \oracle\10g\perl\site\5 .6. 1\lib;
C: \oracle\10g\sysman\admin\scripts
|
|
|
C: \oracle\10g\perl\lib\5 .6. 1\MSWin32-x86; C:
\oracle\10g\perl\lib\5 .6.1;
C: \oracle\10g\perl\5.6. 1\lib\MSWin32-x86; C:
\oracle\10g\perl\site\5 .6.1;
C: \oracle\10g\perl\site\5 .6. 1\lib;
C: \oracle\10g\sysman\admin\scripts
|
|
Services
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Répertoires
|
c : \oracle\10g
c:\oracle\admin
c : \oracle\flash_recovery_area c : \oracle\oradata
|
Malgré notre désinstallation, il nous reste des
services encore actifs:
Nous allons donc détruire avant tout les entrées
suivantes de la base de registre:
· HKEY _LOCAL
_MACHINE\SYSTEM\CurrentControlSet\Services\OracleOraDb 1 0g_home 1
TNSListener
· HKEY _LOCAL
_MACHINE\SYSTEM\CurrentControlSet\Services\Oracle Service ORA10DB ... puis les
clefs
· HKEY _LOCAL
_MACHINE\SYSTEM\CurrentControlSet\Control\Session
Manager\Environment\TNS_ADMIN
· HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE
·
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer
\MenuOrder\Start Menu\Programs\Oracle Installation Products
·
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer
\ComDlg32\OpenSaveMRU\ORA
·
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer
\MenuOrder\Start Menu\Programs\Oracle - ORA1 0
·
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer
\MenuOrder\Start Menu\Programs\Oracle - OraDb 10g_home 1
·
HKEY_CLASSES_ROOT\Installer\Assemblies\Global\System.Data.OracleClient,
Version
Le reste du nettoyage dépend de vos compétences
concernant la base de registres. Il va sans dire que la suppression d'une clef
importante risque de déstabiliser votre système d'exploitation.
Faites cependant attention de ne pas laisser des clefs pointant sur un
répertoire qui n'existerait plus (par exemple un
HKEY _LOCAL _MA CHINE\SOFTWARE\JavaSoft\Java Runtime
Environment pointant sur un répertoire Oracle inexistant.)
En usant de la même prudence, vous pouvez supprimer toutes
les clefs contenant du Oracle des sous-répertoires de
· HKEY_CLASSES_ROOT\AppID\
· HKEY _CLASSES _ROOT\CLSID\
· HKEY _CLASSES _ROOT\ORA...
· HKEY _CLASSES _ROOT\Typelib\...
Pour ce faire, utilisez à bon escient la
recherche (via F3) de Regedit.
C. Oracle report
Car oracle report cause nous pas mal de problème on a
décidé de rédigé ce annexe pour donnée
quelques aide pour les gens.
C'est l'outil d'oracle developer suite utiliser
pour générer les états de sorties. Pour créer un
état de sortie utilisant oracle report, cela permet de
trois types de création (présentation) de l'état:
1. présentation Web et papier en même temps.
2. présentation Web seul.
3. présentation papier seul.
Les états peuvent être exécuté
localement ou à distant (cas de serveur
d'application). Les états report ont
certains nombres de propriétés tel que:
1. Type destination de report: inclus aperçu, fichier,
impriment, mail, écran, cache.
2. Nom destination de report: c'est le nom de la destination tel
que le nom de l'imprimante, le chemin d'un fichier... etc.
3. format destination de report: report développer permet
d'avoir des états dans différent format qui sont: PDF, HTML,
HTMLS,
4. le serveur de report: pour exécuté le report a
partir du forms il faut d'abord crée le serveur report. Les
étapes de création de ce dernier sont les suivant:
1. créé le serveur avec l'instruction suivant :
E:\forms\bin\rwserver
-install server tel que,
E:\forms\bin\rwserver:
c'est le chemin vers rwserver, dans le répertoire où
l'oracle developer suite a été installer.
-install: c'est un commande.
Server: c'est le nom de
serveur.
2. après la création du serveur une boite est
affiché pour lui indiquer de démarrer le serveur.
3. pour démarrer le serveur, cliquer panneau de
configuration, ensuite les outils d'administration, et dans les services;
chercher le nom de serveur qui été créer et le
démarrer.
Remarque: que l'ordinateur est arrêter ou
redémarrer, il est obligatoire de démarrer le serveur report
même si vous met le type de démarrage
automatique.
2. problèmes liée à
l'exécution d'un rapport: Les problèmes les plus
coïncidents dans l'exécution d'un rapport peut être
résumé dans certain erreurs parmi les:
1. FRM -41213: Unable to connect to the report server
server: cet erreur nécessite de démarrer le serveur
report.
2. FRM -41219: cannot find report: invalid ID:
il s'agit d'un erreur dans le nom de rapport. Vérifier la
compatibilité entre le nom de rapport dans le navigateur d'objet
et le nom qui été utilisé dans la fonction
d'exécution de rapport.
conlusion
Conclusion
L'objectif que nous avons visé dans ce projet est la
réalisation d'un système d'information basé sur une
architecture trois tiers, on exploitant le réseaux local
déjà existé.
Pour cela nous avons choisi ORACLE comme un SGBD et un serveur
d'application. Ce choix est justifié par sa puissance
et efficacité, en terme de sécurité, volume de
données traitées, documentation disponible..., et de sa richesse
comme un serveur d'application.
Pour atteindre cet objectif, nous avons commencé par la
création de la base de données qui modélise
l'université, par la suite nous avons construit les interfaces
permettant de réagir avec cette base.

Durant ce travail, une grande partie du temps a été
consacré aux élément suivants: La
représentation des utilisateurs
En tant qu'utilisateurs de la base, leurs gestion est prise en
charge par le SGBD ou par le développeur en les représentant dans
des tables.

L'authentification des utilisateurs
L'authentification dans l'architecture trois tiers pose des
nouveaux problèmes lors de délégation l'authentification
au serveur d'application.

La sécurité de données
A titre d'exemple l'utilisateur chef département
informatique doit travail uniquement sur les informations de son
département.
Des contraintes matérielles ont entravé la
réalisation complète de certaines parties. Le serveur
d'application est la messagerie électronique requiert plus de
mémoire et plus de performance de la part des serveurs
Bibliographie et cybergraphie
Cybergraphie:
http://www.oracle.com
http://lgl.isnetne.ch/ias/ias.htm
http://lgl.isnetne.ch/ias/
http://157.26.164.60/ias_doc/index.htm
http://www.labo-
oracle.com/cours/
http://www.oracle.com/technology/deploy/security/oracle9ias/
http://www.isnetne.ch/lbd/SGBD/oracle/
http://didier.deleglise.free.fr/
http://otn.oracle.com/pls/db92/
http://www.tafora.fr/sub/liensoracle.html
http://www.developpez.com
http://www.itssa.ch/Presentation/
wwww.commentçamarche.net
Bibliographie:
Manuel de stagiaire d'oracle édition:
ORACLE.
Oracle 8i sous linux auteur GILLES BRIARD
Edition : EYROLLES
Tegane saher :
tegane_saher@yahoo.fr.
Rouagat waheb :
rouag_souf@yahoo.fr. Goudjil
Hassen :
h.goudjil@yahoo.fr


