5.1.3 Transformation des fichiers Log
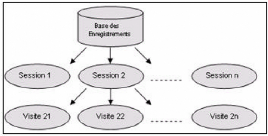
FIG. 5.2 : Processus de transformation des fichiers Log
Identification des utilisateurs et des sessions (T1)
Une session est composée de l'ensemble de pages
visitées par le même utilisateur durant la période
d'analyse. Plusieurs moyens d'indentification des utilisateurs ont
été proposés dans la littérature (login et mot de
passe, cookie, IP), cependant, tous ces moyens présentent des
défaillances à cause des systèmes de cache, des firewalls
et des serveurs proxy. Dans notre cas, nous considérons que deux
requêtes provenant de la même adresse IP mais de deux User-agents
différents, appartiennent à deux sessions différentes donc
elles sont effectuées par deux utilisateurs différents. Ainsi, le
couple (IP, User-Agent) représente un identifiant des utilisateurs.
Toutefois, nous ne pouvons nier la limite inhérente à cette
méthode. En effet, une confusion entre deux utilisateurs
différents utilisant la même adresse IP et le même
User-Agent est toujours possible surtout en cas d'utilisation d'un serveur
Proxy ou d'un firewall.
Chaque session est caractérisée par le nombre de
requêtes effectuées par l'utilisateur durant cette session, le
nombre de pages consultées (URLs différents) et la durée
de la session. L'algorithme que nous proposons pour l'identification des
sessions est le suivant :

FIG. 5.3 : Algorithme d'identification des utilisateurs
Identification des visites (T2)
Une visite est composée d'une série de
requêtes séquentiellement ordonnées, effectuées
pendant la même session et ne présentant pas de rupture de
séquence de plus de 30 minutes (d'après les critères
empiriques de Kimball [Kim, 00]). L'identification des visites sur le site, est
effectuée selon la démarche suivante:
- Ordonner la base suivant les variables »identifiant de
session» et temps de la requête.
- Déterminer la durée de consultation des pages
: la durée de consultation d'une page est le temps séparant deux
requêtes http diminué du temps nécessaire au chargement de
la page. Dans notre cas, nous n'avons pas considéré le temps
nécessaire au chargement des pages sachant que le site
étudié ne comporte pas de ressources sons ou vidéo. Ainsi,
la durée de consultation d'une page est calculée par la
différence entre les dates et heures des enregistrements successifs. Par
conséquent, seule la durée de consultation de la dernière
page de chaque session est inconnue. Pour l'estimer, nous avons
considéré la moyenne des durées de consultations des pages
de la même visite. Ce qui nécessite tout d'abord l'identification
des visites.
- Si la durée de consultation d'une page dépasse
30 minutes alors la page suivante dans la même session est
attribuée à une nouvelle visite (l'utilisateur a passé
plus de trente minute à lire la même page ce qui est peu probable
ou il a quitté le site pour y revenir 30 minutes après).
- Une fois les visites identifiées, la durée de
consultation de la dernière page de chaque visite (la dernière
page de chaque session et les pages dont la durée de consultation a
dépassé 30 minutes i.e. celles qui ont permis la construction des
visites) est obtenue à partir de la moyenne des durées de
consultation des pages précédentes appartenant à la
même visite.
Remarques
- Chaque visite est caractérisée par sa
durée, le nombre de requêtes effectuées et le nombre de
pages consultées par l'utilisateur pendant cette visite. La durée
d'une visite est la somme des durées de consultation des pages composant
cette visite.
- Notre analyse est entièrement basée sur les
visites et ne tient pas compte du fait que plusieurs visites peuvent provenir
d'un même utilisateur. Ceci réduit les problèmes
liés aux caches Web (Proxy), aux adresses IP dynamiques et au partage
d'ordinateurs.
Soient les variables suivantes :
· Ri= Requête i
· N = Nombre de requêtes dans la base
· V [Ri] = Visite à laquelle appartient la
requête i
· S [Ri] = Session à laquelle appartient la
requête i
· T [Ri] = Temps de déclenchement de la
requête i
· NV [Ri] = Nombre de requêtes dans la visite
à laquelle appartient la requête i
· Flag [Ri] = variable binaire
1. Ordonner les requêtes suivant la variable S [Ri] puis
la variable T [Ri].
2. Détermination de la durée de chaque
requête:
i=1;
Pour i de 1 à N-1
Si S [Ri] =S [Ri+1]
Alors
Durée [Ri] = T [Ri+1] - T [Ri] ;
Flag [Ri] = 1;
Sinon
Flag [Ri] = 0 ; (Ri est la dernière requête de la
session) FinSi
i = i+1 ;
FinPour
Flag [RN] = 0; (RN est la dernière requête dans la
base)
1. Construction des visites:
V [R1] = 1; Pour i de 1 à N
Si Durée [Ri] > 30 minutes ou Flag [Ri] = 0
Alors
V [Ri+1] = V [Ri] +1;
Sinon
V [Ri+1] = V [Ri] ;
FinSi
i = i+1 ; FinPour
2. Détermination de la durée de la dernière
requête de chaque visite:
i=1 ;
Pour i de 1 à N-1
Si Flag [Ri] = 0 ou Durée [Ri] > 30 minutes
Durée [Rk])/ NV [Ri] -1 Tel queV [Rk] = V
[Ri]
FinSi
i = i+1 ; FinPour
Alors Durée [Ri] = (
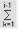
Dans la suite, nous présentons un fichier Log (fig.
5.5.) sur lequel nous appliquons l'algorithme d'identification des sessions
(fig. 5.3.) et celui d'identification des visites (fig. 5.4).
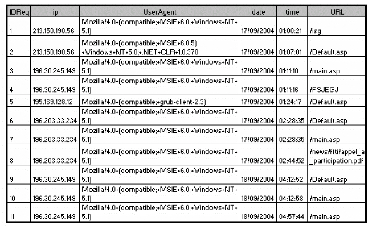
FIG. 5.5 : Fichier Log avant transformation
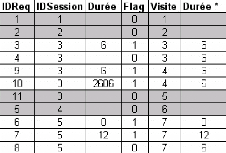
FIG. 5.6 : Exemple d'exécution de l'algorithme
d'identification des visites
* Il s'agit de calculer la durée de la dernière
requête de chaque visite et la durée de chaque requête dont
la durée initiale dépasse 30 minutes (internaute distrait, pause,
internaute qui a quitté son poste sans se déconnecter). Les
visites composées d'une seule requête ne sont pas
considérées car, d'une part, il n'est pas possible d'estimer la
durée d'une seule requête, d'autre part, elles sont
éliminées dans la phase de retraitement puisqu'elles ne
présentent aucun intérêt pour notre analyse.
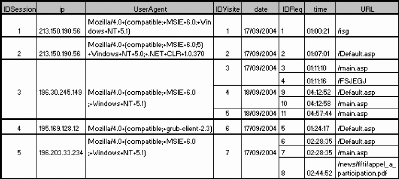
FIG. 5.7: Fichier Log après transformation
| 

