Chapitre 6
Classification des utilisateurs
Une fois les fichiers Logs nettoyés et
structurés dans une base des données, il est possible d'appliquer
les méthodes de fouille des données pour la classification des
utilisateurs. Cette classification est effectuée en deux étapes.
La première étape consiste à classifier les pages du site
visitées par les internautes de manière à ne garder dans
la base que les requêtes aux pages présentant un contenu
intéressant aux visiteurs. La seconde étape consiste à
classifier les visiteurs du site Web en se servant de la base de requêtes
aux pages intéressantes.
6.1 Classification des pages
On distingue deux types de pages : les pages de contenu et les
pages de navigation, appelées aussi pages auxiliaires. Les pages
auxiliaires sont utilisées pour faciliter la navigation de l'utilisateur
sur le site. Les pages de contenu sont les pages qui présentent
l'information recherchée par l'internaute. Cependant une page de contenu
pour un internaute peut être une page de navigation pour un autre. Comme
nous cherchons à comprendre le comportement de l'internaute
vis-à-vis du site visité, en particulier les motifs de sa visite,
nous ne considérons que les pages de contenu. Le problème qui se
pose dans ce cas est comment distinguer les pages de contenu des pages de
navigation. Notre approche consiste à reconstruire la topologie du site
Web à partir des requêtes enregistrées dans les fichiers
Logs et définir des variables servant à la caractérisation
des pages et leur classification.
6.1.1 Reconstruction de la topologie du site
La première étape consiste à indexer les
pages du site Web pour faciliter leur manipulation. L'exemple suivant illustre
cette étape.
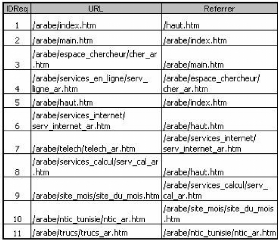
FIG. 6.1 : Exemple de visite
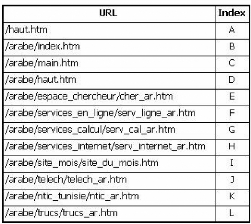
FIG. 6.2 : Indexation des pages de la visite
Une fois les pages visitées par les internautes
indexées, un arbre est construit. La racine de l'arbre est le premier
referrer non externe dans le ...chier log. Pour chaque requête, si le
referrer ou l'URL demandée n'est pas dans l'arbre, un noeud
représentant la page est crée. Pour chaque couple de noeuds, si
l'un est le referrer de l'autre alors un lien entre les deux noeuds est
établi. Il en résulte la construction d'un graphe
représentant la structure des hyperliens.
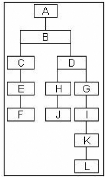
FIG. 6.3 : Arbre du site
6.1.2 Matrice d'hyperliens
L'arbre représentant la topologie du site Web peut
être traduit par une matrice. Cette représentation matricielle
présente l'avantage de simpli...er la représentation sous forme
d'arbre qui devient incompréhensible dans le cas où le nombre de
liens entre les pages est élevé. Chaque ligne de la matrice
correspond à un noeud de l'arbre et représente une page du site.
Il en est de même pour chaque colonne. Ainsi, s'il existe N pages
différentes visitées par les internautes, la matrice d'hyperliens
sera de dimension (N, N). Chaque entrée (i,j) de la matrice prend la
valeur 1 si l'utilisateur a visité la page j à partir de la page
i (présence d'un lien direct entre les deux pages) et la valeur 0 sinon.
Cette matrice est utilisée pour calculer le nombre d'inlinks (nombre
d'hyperliens qui mènent à la page en question à partir des
autres pages) et le nombre d'outlinks (nombre d'hyperliens dans la page qui
mènent vers d'autres pages). En effet, le nombre d'inlinks est le total
sur les lignes alors que le nombre d'outlinks est le total sur les colonnes.
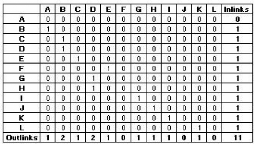
FIG. 6.4 : Matrice d'hyperliens
Toutefois, il ne faut pas oublier que certaines pages du site
ne sont pas visitées par les internautes et que certains liens dans les
pages visitées ne sont pas utilisés. Ces pages et hyperliens ne
sont pas considérés dans cette représentation matricielle
qui ne prend que les accès enregistrés dans les fichiers Logs.
| 

