6.2 Classification des utilisateurs
Cette phase de classification est réalisée en
trois étapes. La première consiste à classifier les
requêtes effectuées par les internautes afin de découvrir
des motifs de navigation. Les résultats de cette première
classification sont injectés dans la base des visites utilisée
pour classifier les internautes et découvrir des groupes
d'utilisateurs.
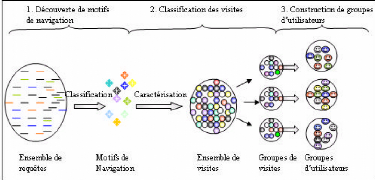
FIG. 6.10 : Etapes de classification des utilisateurs
6.2.1 Découverte de motifs de navigation
Un motif de navigation est un usage du site par ses
utilisateurs. La découverte de motifs de navigation est effectuée
à deux niveaux en combinant deux méthodes de classification (Fig.
6.11). La première est l'analyse des correspondances multiples
utilisée pour réduire la dimension de l'espace d'entrée
(la base des requêtes). La seconde est la carte topologique de Kohonen
utilisée pour déterminer des groupes de requêtes.
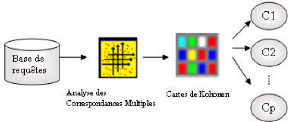
FIG. 6.11 : Etapes de classification des requêtes Analyse
des correspondances multiples
L'analyse des correspondances multiples (ACM) met en
évidence des types d'individus (les requêtes dans notre cas) ayant
des profils semblables relativement aux attributs choisis pour les
décrire. Les variables utilisées dans cette analyse sont
présentées dans le tableau 6.1.
Les axes factoriels résultant de l'application de l'ACM
servent de variables d'entrée (inputs) pour la seconde méthode de
classification. Dans notre cas, 15 axes factoriels expliquent plus de 82% de
l'inertie totale.
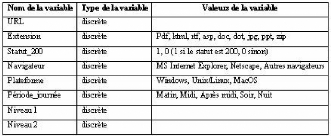
TAB. 6.1 : Variables utilisées dans l'ACM
La projection de la variable »statut_200» sur les
deux premiers axes factoriels a permis de catégoriser les requêtes
en deux classes nettement séparées. Une classe de requêtes
réussies »statut = 200», et une classe de requêtes non
réussies (fig. 6.12).
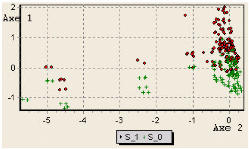
FIG. 6.12 : Projection de la variable »Statut_200»
sur les deux premiers axes
factoriels
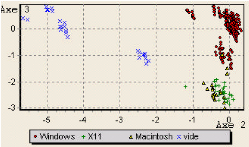
La projection de la variable »plateforme» sur le
deuxième plan factoriel (axe 1, axe 3) catégorise les
requêtes en quatre classes. La classe majoritaire (95% de l'ensemble de
requêtes) est celle de requêtes effectuées par des
utilisateurs du système d'exploitation »Windows». Par contre,
une minorité utilise »Macintosh» (0.97%) ou
»Unix/Linux» (2.31%).
La projection des autres variables descriptives sur les axes
factoriels permet de dégager d'autres informations sur les internautes
à savoir le navigateur utilisé, l'extension des fichiers les plus
demandés, la période de la journée pendant laquelle la
majorité des requêtes sont effectuées.
Cartes de Kohonen
En plus des axes factoriels résultant de l'application
de l'analyse des correspondances multiples (ACM), nous avons ajouté la
variable »durée de la requête» comme variable
d'entrée. L'application des cartes de Kohonen a aboutit à une
grille de 16 noeuds. Comme l'obtention des groupes très similaires est
possible s'ils sont associés à des neurones proches au sens du
voisinage, il est nécessaire de diviser la carte en aires logiques
composées par des groupes cohérents de noeuds en se basant sur
leurs profils et attribuer des labels à chaque groupe de noeuds.
FIG. 6.14 : Grille résultant de l'application des cartes
de Kohonen
La caractérisation des classes obtenues par les
variables »niveau 1» et »niveau 2»
déterminées à partir de la variable »URL» a
donné le résultat présenté dans la figure 6.15.
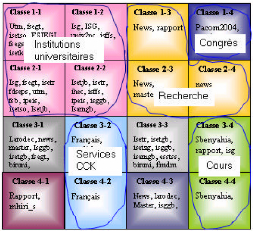
En examinant les éléments caractérisant
chaque classe, il est possible d'attribuer un label à chaque classe. La
figure 6.16 présentant la carte après division en aires logiques
et labellisation met en évidence cinq classes de requêtes
correspondant à cinq motifs de navigation: institutions universitaires,
activités de recherche, congrès, services CCK et cours. Ainsi,
à chaque requête est attribuée une rubrique
sémantique. L'ensemble de ces rubriques est injecté dans la base
des visites afin d'attribuer à chaque visite un ou plusieurs motifs de
navigation qui serviront à la classification des utilisateurs.
|
Classe 1 1
|
Classe 1 2
|
|
|
|
|
|
Classe 1 3
|
|
Classe 1 4
|
|
|
Utm, fsegt, isetso, FSJEGJ, fsegs, isetjb,
|
|
|
News, rapport
|
|
|
|
|
|
emcis,
|
Pacom2004,
news
|
|
|
|
Isg, ISG, univ7nc, isffs, Utm, Isetr
|
|
|
|
|
|
isetke, isci,
|
|
|
|
|
|
|
|
|
Classe 2 1
|
Classe 2 2
|
|
|
|
|
|
|
Classe 2 3
|
|
Classe 2-4
|
|
Isg, fsegt, isetr fdseps, utm, fsb, ipeis,
|
|
|
|
|
|
|
|
|
|
|
News, master,
|
|
news
|
|
|
Isetjb, ihec,
|
isetr, isffs,
|
|
|
ipeis,
isggb,
|
|
|
|
|
|
isetso, Isetjb,
|
|
|
Isamgb,
|
|
|
|
|
|
|
|
|
Classe 3-3
Isetr, isetgb, isetzg, isggb, isamgb, esstss, biruni, fmdm
|
Classe 3-4
|
|
|
Classe 3 1
|
|
|
Classe 3 2
|
|
Larodec, master,
isetgb,
news, Isggb, fsegt,
|
|
Français, english,
|
|
|
Sbenyahia, rapport,
isg
|
|
Arabe
|
|
|
biruni,
|
|
|
|
|
|
|
|
|
Classe 4 2
|
|
|
Classe 4 3
|
|
Classe 4-4
|
|
Classe 4 1
|
|
|
|
|
|
|
|
|
mhiri_s
|
Rapport,
|
|
News,
larodec, Master, isggb,
|
|
Sbenyahia,
|
|
|
Français
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
FIG. 6.15 : Caractérisation des classes résultant
de l'application des cartes de
Kohonen
|
|


