|
Université de la Manouba
Ecole
Nationale des Sciences de
l'Informatique
Cycle des
Etudes Doctorales
Mémoire
de Mastère
présenté en vue de l'obtention
du
Diplôme de Mastère en Informatique
Option : Génies Documentiel et
Logiciel
Par
Malika CHARRAD
Techniques d'extraction de connaissances appliquées
aux
données du Web
Réalisé au sein du

Laboratoire de Recherche en Génies Documentiel et
Logiciel
sous l'encadrement du
Professeur Mohamed BEN AHMED
(RIADI)
&
le co-encadrement
du
Professeur Yves LECHEVALLIER (INRIA)
Soutenu le Samedi 17 Décembre 2005 devant le jury d'examen
:
Pr. Khaled GHEDIRA : Président
Dr. Naoufel KRAIEM : Examinateur
Pr. Mohamed BEN AHMED : Encadrant Pr. Yves
LECHEVALLIER : Invité
« J'apprends encore, mon instruction n'est point
encore achevée. Le cours de ma vie n'est
qu'une longue
éducation »
C.A. Helvétius
A tous ceux qui me sont chers, Je dédie ce
travail

Remerciements
Que Monsieur Mohamed BEN AHMED,
professeur à l'Ecole Nationale
des Sciences de
l'Informatique et directeur du
laboratoire RIADI, trouve
ici le témoignage de
ma profonde reconnaissance. Ses
encouragements, mais
aussi ses
critiques, ont
largement contribué à
l'aboutissement de ce mémoire.
Je le remercie vivement de m'avoir
toujours poussé vers
l'avant.
Je tiens
également
à remercier
Monsieur Yves LECHEVALLIER,
professeur chercheur à l'Institut Nationalde
Recherche en Informatique et
Automatique (INRIA),
non seulement pour
ses précieux
conseils et ses
orientations, mais aussi pour sa
disponibilité. Sa sensibilisation à la
recherche et à
l'innovation m'ont aidé à la
réalisation de ce
travail.
Mes remerciements vont également aux membres du
jury d'avoir accepté
d'évaluer mon
travail.
Qu'il me soit permis de
remercier également mes amis et mes
collègues qui, tous
d'une manière
différente, mais
toujours dans un but
constructif, ont
contribué à ce que je puisse
aboutir à la réalisation de
ce
mémoire.
Enfin,
merci à mes
parents pour le soutien
et l'encouragement
qu'ils m'ont apporté tout au long de
travail.
Résumé- La croissance de
l'usage du WWW fût accompagnée d'un intérêt
particulier à l'analyse des données de l'usage de l'Internet afin
de bien servir les utilisateurs du Web et leur présenter un contenu
personnalisé. Un des axes les plus importants du Web mining est le Web
Usage Mining qui s'intéresse à l'extraction des patrons
d'accès au Web à partir des données de l'usage. L'approche
que nous proposons dans le cadre de ce mémoire afin d'aider à
comprendre le comportement des internautes comporte trois phases :
prétraitement des fichiers Logs, classification des pages et
classification des internautes. Dans la phase de prétraitement, les
requêtes sont organisées en visites qui représentent les
unités d'interaction entre les utilisateurs du Web et le serveur web.
Dans la phase de classification des pages, une représentation interne du
site Web est créée à partir des fichiers Logs afin
d'extraire des chemins de navigation. Des paramètres introduits à
partir des statistiques sur les accès aux pages sont utilisés
pour la catégorisation des pages Web en pages auxiliaires et pages de
contenu. Les requêtes aux pages de contenu servent à la
découverte des motifs de navigation. Afin de construire des segments
d'utilisateurs, deux méthodes hybrides de classification automatiques
basées sur l'analyse en composantes principales, l'analyse des
correspondances multiples et les cartes topologiques de Kohonen sont
appliquées aux visites. Une expérience effectuée sur les
fichiers Logs extraits du Centre de Calcul elKhawarizmi prouve
l'efficacité de cette méthodologie.
Abstract- With the ever growing
usage of the WWW, there is significant interest in analyzing web usage data to
better serve users, and apply the knowledge to be able to present personalized
content for different user segments. An important area in web mining is web
usage mining, the discovery of patterns in the browsing and navigation data of
web users. The approach we proposed to help understand users' behaviors on a
web site consists of three steps: preprocessing of log files, web pages
classification and users clustering. In Preprocessing, requests to the web site
are processed to be organized into sessions which represent units of
interaction between web users and the web server. In pages classification, an
internal representation of the web site is created from logs to extract
frequent paths and parameters are introduced from pages access statistics to
help classify web pages into two major categories: auxiliary pages and content
pages. Requests to content pages are used to discover browsing patterns. In
order to build users' profiles, two hybrid clustering methods based on
Principle Component Analysis, Multiple Correspondences Analysis and Self
Organizing maps are applied to web usage sessions. An Experiment on the HTTP
log files extracted from the Center of Calculation elKhawarizmi web server
shows that the approach is efficient and practical.
Table des figures
2.1 Schéma illustratif des champs d'une requête
10
2.2 Exemple d'arbre d'un site 12
3.1 Processus du Web Usage Mining 15
3.2 Réseau linéaire de compétition de type
»gagnant emporte tout» 26
4.1 Architecture de la carte de Kohonen 37
4.2 Caractéristiques d'un neurone de la grille de Kohonen
37
4.3 Algorithme de Kohonen 39
5.1 Processus de prétraitement 46
5.2 Processus de transformation des fichiers Log 50
5.3 Algorithme d'identification des utilisateurs 50
5.4 Algorithme d'identification des visites 52
5.5 Fichier Log avant transformation 53
5.6 Exemple d'exécution de l'algorithme d'identification
des visites . 53
5.7 Fichier Log après transformation 54
5.8 Exemple de pages contenant plusieurs images 54
5.9 URLs des images contenues dans la page 55
5.10 Algorithme de filtrage des visites et des requêtes
55
5.11 Succession chronologique des étapes de
prétraitement 59
5.12 Schéma relationnel 60
5.13 Fichier d'enregistrement d'accès 61
6.1 Exemple de visite 64
6.2 Indexation des pages de la visite 64
6.3 Arbre du site 65
6.4 Matrice d'hyperliens 65
6.5 Matrice d'accès 66
6.6 Projection des variables sur les axes factoriels 68
6.7 Projection des individus sur les axes factoriels 68
6.8 Caractérisation des pages 69
6.9 Classification des pages 69
6.10 Etapes de classification des utilisateurs 70
TABLE DES FIGURES ii
6.11 Etapes de classification des requêtes 70
6.12 Projection de la variable »Statut_200» sur les
deux premiers axes
factoriels 71 6.13 Projection de la variable
»plateforme» sur le troisième plan factoriel 71 6.14 Grille
résultant de l'application des cartes de Kohonen 72 6.15
Caractérisation des classes résultant de l'application des cartes
de
Kohonen 73
6.16 Carte de Kohonen après division en aires logiques et
labellisation 73
6.17 Etapes de classification des visites 74
6.18 Résultat de l'application de l'ACP à la base
des visites 75
6.19 Résultat de la classification des visites 75
6.20 Visite à classifier 77
7.1 Analyse en composantes principales à l'aide de SPAD
80
7.2 Hybridation des méthodes à l'aide de Tanagra
80
7.3 Représentation de la carte dans les deux espaces
d'entrée et de sortie 82
7.4 Etats de la carte en fonction du nombre
d'itérations. 83
Liste des tableaux
|
3.1
|
Niveaux de collecte des données
|
17
|
|
3.2
|
Principales techniques d'identification des internautes
|
20
|
|
5.1
|
Création de nouvelles variables
|
56
|
|
5.2
|
Transformation de la variable URL
|
57
|
|
5.3
|
Identification du système d'exploitation
|
58
|
|
5.4
|
Décryptage du User-Agent
|
59
|
|
5.5
|
Tableau récapitulatif des résultats
|
62
|
|
6.1
|
Variables utilisées dans l'ACM
|
71
|
|
6.2
|
Variables utilisées dans l'ACP
|
74
|
|
6.3
|
Caractérisation des classes d'utilisateurs par les
variables »naviga-
|
|
|
teur» et »plateforme»
|
76
|
Table des matières
1 Introduction 1
1.1 Contexte 1
1.2 Description du problème 2
1.3 Contribution du mémoire 2
1.4 Plan du mémoire 3
|
I
2
|
Etat de l'art
Web Mining et Web Usage Mining
|
4
5
|
|
2.1
|
Web Mining
|
5
|
|
|
2.1.1 Processus du Web Mining
|
5
|
|
|
2.1.2 Axes de développement du Web Mining
|
7
|
|
2.2
|
Web Usage Mining
|
8
|
|
|
2.2.1 Motifs du Web Usage Mining
|
8
|
|
|
2.2.2 Données de l'usage
|
9
|
|
|
2.2.3 Diverses approches d'analyse
|
12
|
|
2.3
|
Conclusion
|
13
|
|
3
|
Processus du Web Usage Mining
|
14
|
|
3.1
|
Processus du Web Usage Mining
|
14
|
|
3.2
|
Collecte des données
|
15
|
|
|
3.2.1 Données enregistrées au niveau du serveur
|
16
|
|
|
3.2.2 Données enregistrées au niveau du client
|
16
|
|
|
3.2.3 Données enregistrées au niveau du Proxy
|
16
|
|
3.3
|
Prétraitement des données
|
17
|
|
|
3.3.1 Nettoyage des données
|
17
|
|
|
3.3.2 Transformation des données
|
18
|
|
3.4
|
Fouille de données
|
21
|
|
|
3.4.1 Méthodes statistiques unidimensionnelles
|
22
|
|
|
3.4.2 Méthodes statistiques multidimensionnelles
|
22
|
|
TABLE DES MATIÈRES
3.4.3 Méthodes d'association
3.4.4 Méthodes basées sur l'intelligence
artificielle (réseaux de
neurones)
3.5 Analyse
3.5.1 Visualisation
3.5.2 OLAP
3.5.3 Bases des données relationnelles
3.5.4 Agents intelligents
3.6 Conclusion
|
v
24
25
27
27
27
27
28
28
|
|
4
|
Méthodes de classification
|
29
|
|
4.1
|
Méthodes factorielles
|
29
|
|
|
4.1.1
|
Analyse en composantes principales (ACP)
|
29
|
|
|
4.1.2
|
Analyse factorielle des correspondances (AFC)
|
34
|
|
|
4.1.3
|
Analyse factorielle des correspondances multiples
|
36
|
|
4.2
|
Cartes topologiques de Kohonen
|
37
|
|
|
4.2.1
|
Architecture de la carte topologique
|
37
|
|
|
4.2.2
|
Propriétés de la carte topologique
|
38
|
|
|
4.2.3
|
Algorithme d'apprentissage de Kohonen
|
38
|
|
|
4.2.4
|
Principaux paramètres de la carte topologique
|
39
|
|
|
4.2.5
|
Etude de la qualité d'apprentissage des cartes
topologiques
|
41
|
|
|
4.2.6
|
Analyse de la carte topologique
|
43
|
|
|
4.2.7
|
Avantages et limites de la carte de Kohonen
|
44
|
|
4.3
|
Conclusion
|
44
|
|
II Méthodologie et application
5 Prétraitement des données
|
45
46
|
|
5.1
|
Méthodologie de prétraitement
|
46
|
|
5.1.1
|
Processus de prétraitement
|
46
|
|
5.1.2
|
Nettoyage des données
|
46
|
|
5.1.3
|
Transformation des fichiers Log
|
50
|
|
5.1.4
|
Retraitement des fichiers Log
|
54
|
|
5.1.5
|
Modélisation des unités d'analyse
|
59
|
|
5.1.6
|
Schéma relationnel
|
60
|
|
5.2
|
Résultats de l'analyse des fichiers Log du CCK
|
61
|
|
5.2.1
|
Corpus expérimental
|
61
|
|
5.2.2
|
Résultats
|
61
|
|
5.3
|
Conclusion
|
62
|
TABLE DES MATIÈRES vi
6 Classification des utilisateurs 63
6.1 Classification des pages 63
6.1.1 Reconstruction de la topologie du site 63
6.1.2 Matrice d'hyperliens 65
6.1.3 Matrice d'accès 66
6.1.4 Collecte d'informations sur les accès 67
6.1.5 Application de l'analyse en composantes principales . . .
67
6.2 Classification des utilisateurs 69
6.2.1 Découverte de motifs de navigation 70
6.2.2 Construction de groupes d'utilisateurs 74
6.3 Procédure de classification d'une visite 76
6.4 Conclusion 77
7 Outils d'investigation 78
7.1 Langage SQL 78
7.2 Logiciels d'analyse des données et de classification
79
7.3 Matlab pour la visualisation des cartes de Kohonen 80
7.4 Conclusion 83
8 Conclusion 84
Bibliographie 86
Netographie 90
Glossaire 91
III Annexes 94
Chapitre 1
Introduction
La caractérisation des internautes fréquentant
un site Web et l'identification de leurs motifs de navigation est un
problème incontournable pour les concepteurs de sites Web qui visent
à assister l'internaute, prédire son comportement et
personnaliser la consultation. Ces trois considérations ont
motivé d'importants efforts dans l'analyse des traces des internautes
sur les sites Web et l'adaptation des méthodes de classification aux
données du Web durant ces dernières années. Le
présent travail s'inscrit dans ce courant de recherche, en proposant une
méthodologie de traitement des fichiers Logs permettant d'étudier
le comportement des utilisateurs d'un site Web et ce en exploitant
différentes méthodes de classification, en particulier les cartes
topologiques de Kohonen.
1.1 Contexte
Au cours de ces dernières années, avec la
croissance exponentielle du nombre des documents en ligne et des nouvelles
pages chaque jour, le Web est devenu la principale source d'information. Ce
développement a entraîné une croissance rapide de
l'activité sur le Web, et une explosion des données
résultant de cette activité. En effet, le nombre des utilisateurs
d'Internet dans le monde a atteint 938.7 millions au mois de Juillet
20051, ce qui correspond à un taux de
pénétration de 14.6% et le nombre de sites Web a atteint 70.39
millions au mois d'Août 2005, soit une augmentation de 2.8 millions par
rapport au mois de juillet selon l'enquête de Netcraft2. Pour
analyser ce nouveau type de données, sont apparues de nouvelles
méthodes d'analyse regroupées sous le terme »Web
Mining» dont les trois axes de développement actuels sont le Web
Content Mining (WCM) qui s'intéresse à l'analyse du contenu des
pages Web, le Web Structure Mining (WSM), qui s'intéresse à
l'étude des liens entre les sites Web et le Web Usage Mining (WUM) qui
s'intéresse à l'étude de l'usage du Web.
1www.
Internetworldstats.com
2www.netcraft.com
Cette dernière branche du Web Mining, définie
comme étant l'application du processus d'Extraction des Connaissances
à partir de bases de Données (ECD) aux données issues des
fichiers Logs HTTP est devenue une pratique de plus en plus courante et
indispensable. En effet, les créateurs des sites Web
intéressés par la fidélisation des internautes
fréquentant leurs sites et cherchant à attirer de nouveaux
visiteurs ont besoin d'analyser le comportement des internautes afin d'extraire
des patrons d'accès au Web en vue d'une amélioration et une
personnalisation des sites.
1.2 Description du problème
Récemment, de nombreux travaux en Web Usage Mining ont
été menés. Certains de ces travaux se sont
concentrés sur l'étude de la première phase du processus
du WUM à savoir le prétraitement des données [Tan, 03],
d'autres, se sont intéressés à la détermination des
modèles comportementaux des internautes fréquentant les sites
Web. Ce second axe est le centre d'intérêt de notre travail de
recherche, objet du présent mémoire. En effet, en supposant qu'il
existe une certaine corrélation entre les différentes pratiques
des visiteurs sur un site donné et leurs caractéristiques
personnelles, notre objectif consiste à construire des profils de
navigation enrichis de traits d'utilisateurs. En d'autres termes, nous
cherchons à identifier et à qualifier des groupes d'utilisateurs
par rapport à leurs motifs de navigation sur un site donné ou des
traits représentant des centres d'intérêts. Ce
problème de classification a été traité dans de
nombreux travaux en appliquant différentes méthodes :
BIRCH3 dans [Fu, 00], CLIQUE dans [Per, 98], EM4 dans
[Cad, 00], une classification non supervisée basée sur un
réseau de neurones dans[Ben, 03]. Notre propos dans cette étude
consiste à transformer les données présentes dans les
fichiers Logs d'un site Web en des connaissances utiles en procédant
à un prétraitement de ces fichiers et à une classification
non supervisée des visites effectuées par les internautes,
basée sur l'algorithme des cartes topologiques de Kohonen et ce afin
d'identifier des typologies de visites explicatives du comportement des
utilisateurs sur le site Web.
1.3 Contribution du mémoire
Nous proposons dans ce mémoire une méthodologie
de traitement des fichiers Logs permettant de passer d'un ensemble de
requêtes enregistrées dans les Logs à un modèle
comportemental des utilisateurs du site Web en considération. L'apport
de ce travail réside principalement dans trois points:
3Balanced Iterative Reducing and Clustering using
Hierarchies 4Expectation-Maximization algorithm
- Proposer une méthodologie détaillée de
prétraitement des fichiers Logs : proposer des heuristiques
d'identification des robots Web, des algorithmes pour l'identification des
sessions et des visites.
- Associer la classification des pages à la
classification des usagers du site Web. En d'autres termes, exploiter les
résultats de la classification des pages dans la classification des
internautes.
- Intégrer et combiner différentes techniques de
fouille des données pour la classification des utilisateurs.
1.4 Plan du mémoire
Ce mémoire est organisé en deux parties
distinctes. La première partie présente une étude de l'art
sur le Web Mining, le Web Usage Mining et les méthodes de
classification, objets des trois premiers chapitres. La seconde partie
composée des trois derniers chapitres est consacrée à la
présentation de la méthodologie proposée pour l'extraction
des connaissances à partir des fichiers Logs et les résultats de
son application sur des données réelles. Plus
précisément, le quatrième chapitre est dédié
au prétraitement des fichiers Logs permettant d'aboutir à des
données structurées et prêtes à l'application des
méthodes de fouille des données. Le cinquième chapitre
présente les résultats de l'application de ces méthodes
sur les données des fichiers Logs du Centre de Calcul elKhawarizmi. Le
dernier chapitre présente l'ensemble des outils utilisés pour le
prétraitement et la classification.
Première partie
Etat de l'art
Chapitre 2
Web Mining et Web Usage
Mining
Le Web Mining, défini comme l'application des
techniques du Data Mining* aux données du Web (documents, structure des
pages, des liens...), s'est développé à la fin des
années 1990 afin d'extraire des informations pertinentes sur
l'activité des internautes sur le Web. Dans ce chapitre,
structuré en deux sections, nous présentons dans la
première le Web Mining, en particulier ses objectifs et les axes de son
développement. Dans la seconde, nous nous intéressons au
troisième axe de développement du Web Mining, le Web Usage
Mining, en particulier les motifs du WUM, les données de l'usage et les
diverses approches d'analyse.
2.1 Web Mining
Le Web Mining poursuit deux principaux objectifs:
1. L'amélioration et la valorisation des sites Web :
L'analyse et la compréhension du comportement des internautes sur les
sites Web permet de valoriser le contenu des sites en améliorant
l'organisation et les performances des sites.
2. La personnalisation: Les techniques de Data Mining
appliquées aux données collectées sur le Web permettent
d'extraire des informations intéressantes relatives à
l'utilisation du site par les internautes. L'analyse de ces informations permet
de personnaliser le contenu proposé aux internautes en tenant compte de
leurs préférences et de leur profil.
2.1.1 Processus du Web Mining
Le processus du Web Mining se déroule en trois
étapes :
1. Collecte des données sur l'utilisateur,
2. Utilisation de ces données à des fins de
personnalisation,
3. Présentation à l'utilisateur d'un contenu
ciblé.
Données du Web et leurs sources
[Sri, 00]classifie les données utilisées dans le
Web Mining en quatre types :
- Données relatives au contenu : données contenues
dans les pages Web (textes, graphiques),
- Données relatives à la structure : données
décrivant l'organisation du contenu (structure de la page, structure
inter-page),
- Données relatives à l'usage: données
fournissant des informations sur l'usage telles que les adresses IP, la date et
le temps des requêtes,
- Données relatives au profil de l'utilisateur :
données fournissant des informations démographiques sur les
utilisateurs du site Web.
Ces données sont généralement
stockées dans un Data-Warehouse, appelé data-Webhouse, dont
l'objectif de construction est de collecter des données propres à
la fréquentation des sites Web afin d'analyser les comportements de
navigation. Les principales sources des données permettant d'alimenter
les Data-Webhouses sont :
- Les fichiers Logs du serveur Web: il s'agit du journal des
connexions qui
conserve une trace des requêtes et des
opérations traitées par le serveur.
- Les bases de données clients : ce sont les sources des
données des entreprises.
- Les cookies (ou Témoins) : ce sont des fichiers que
le serveur d'un site Web glisse au sein du disque dur de l'internaute le plus
souvent à son insu (fichiers temporaires ou dossier Cookies) afin de
stocker de l'information et mémoriser ses visites. Il permet, par
exemple de l'identifier lorsqu'il revient visiter un site
régulièrement.
Terminologie
La compréhension du processus du Web Mining
nécessite la définition de certains termes qui se
répèteront tout au long de ce mémoire. Cette
définition est faite sur la base des recommandations du W3C relatives
à la normalisation de la terminologie [Lav, 99].
- Une vue de page (ou »page diffusée») est le
chargement complet d'une page Web suite à une action de l'utilisateur
sur la page (un clic).
- Une session utilisateur est l'ensemble des requêtes
explicites effectuées par l'utilisateur durant la période
d'analyse.
- Une visite est un sous-ensemble des vues de pages
consécutives d'une session durant une connexion. On parle aussi de
»navigation». La pratique courante considère qu'une absence de
consultation de nouvelles pages sur le site dans un délai
excédant 30 minutes met fin à la visite.
- La notion de »visiteur» est à comprendre au
sens d'individu. On appelle ainsi »nombre de visiteurs» le nombre
d'individus ayant consulté le site pendant une période
donnée.
- Un épisode est un sous-ensemble de clics d'une visite
pour la réalisation d'un objectif. Il s'agit d'une phase de la
navigation.
- Un motif de navigation est un usage du site par ses
utilisateurs Limites du Web Mining
Plusieurs problèmes se posent lors d'une étude de
Web Mining:
- Le stockage des données requiert de très grands
espaces. Il nécessite souvent une machine spécifique.
- L'architecture des sites évolue
régulièrement. Par conséquent, il est parfois difficile
d'opérer des comparaisons entre les différentes périodes
d'analyse.
- La situation géographique des visiteurs est
déterminée à partir des extensions des adresses (.fr,
.uk,.com,). Cependant une adresse se terminant par .com n'est pas
forcément localisée aux Etats-Unis car cette extension est
également devenue une extension commerciale.
2.1.2 Axes de développement du Web Mining
Les trois axes de développement du Web Mining sont : le
Web Content Mining, le Web Structure Mining et le Web Usage Mining.
Web Content Mining
Le Web Content Mining (WCM) consiste en une analyse textuelle
avancée intégrant l'étude des liens hypertextes et la
structure sémantique des pages Web. Ainsi, les techniques de
description, de classification et d'analyse de chaînes de
caractères du Text Mining sont très utiles pour traiter la partie
textuelle des pages. Le WCM s'intéresse également aux images. Il
permet, par exemple, de quantifier les images et les zones de texte, pour
chaque page. Ainsi par l'analyse conjointe de la fréquentation des
pages, il est possible de déterminer si les pages contenant plus
d'images sont plus visitées que les pages contenant plus de texte.
Web Structure Mining
Il s'agit d'une analyse de la structure du Web i.e. de
l'architecture et des liens qui existent entre les différents sites.
L'analyse des chemins parcourus permet, par exemple, de déterminer
combien de pages consultent les internautes en moyenne et ainsi d'adapter
l'arborescence du site pour que les pages les plus recherchées soient
dans les premières pages du site. De même, la recherche des
associations entre les pages consultées permet d'améliorer
l'ergonomie du site par création de nouveaux liens.
Web Usage Mining
Cette dernière branche du Web Mining consiste à
analyser le comportement de l'utilisateur à travers sa navigation,
notamment l'ensemble des clics effectués sur le site (on parle d'analyse
du clickstream). Cette approche permet de mesurer l'audience et la performance
d'un site Web (combien de temps passé par page, combien de visites,
à quel moment, qui est l'utilisateur, quelle est la fréquence de
ses consultations,..). L'intérêt du WUM est d'enrichir les sources
de données de l'entreprise (bases de données clients, bases
marketing,...) par les données brutes du clickstream afin d'affiner les
profils clients ainsi que les modèles comportementaux.
2.2 Web Usage Mining
[Tan, 03] définit le WUM comme étant
l'application du processus d'Extraction des Connaissances à partir de
bases de Données (ECD) aux données issues des fichiers Logs HTTP
afin d'extraire des modèles comportementaux d'accès au Web en vue
de répondre aux besoins des visiteurs de manière
spécifique et adaptée (personnaliser les services) et faciliter
la navigation.
2.2.1 Motifs du Web Usage Mining
Selon [Mic, 02], il y a cinq motifs du WUM :
1. Évaluation et caractérisation
générale de l'activité sur un site Web : l'objectif est
l'observation et non pas la modélisation. Les techniques d'analyse
utilisées sont souvent simples. Elles relèvent, en effet, du
dénombrement et des statistiques simples (moyennes, histogramme,
indices, tris croisés).
2. Amélioration des modes d'accès aux
informations : le WUM permet de comprendre comment les utilisateurs se servent
d'un site, d'identifier les failles dans la sécurité et les
accès non autorisés.
3. Modification de la structure : le WUM peut
révéler le besoin de restructurer des pages et des liens afin
d'améliorer la structure du site Web. En effet,
les pages considérées comme similaires par des
techniques de classification peuvent être reliées de
manière hypertextuelle.
4. Personnalisation de la consultation : cet enjeu important
pour de nombreuses applications Internet ou sites de e-commerce consiste
à proposer des recommandations dynamiques à un utilisateur en se
basant sur son profil et une base de connaissances d'usages connus.
5. Mise en oeuvre de l'intelligence économique: cet
objectif concerne en particulier les sites marchands. Il s'agit de comprendre
quand, comment et pourquoi l'utilisateur est attiré par ce site, les
produits qu'il faut lui proposer à la vente...etc.
2.2.2 Données de l'usage
Les principales données exploitées dans le WUM
proviennent des fichiers Logs. Cependant, il existe d'autres sources
d'informations qui pourraient être exploitées à savoir les
connaissances sur la structure des sites Web et les connaissances sur les
utilisateurs des sites Web.
Fichiers Logs HTTP
Présentation des fichiers Log HTTP: Un Log file (en
français, journal de bord des connexions ou fichier journal) est un
fichier créé par un logiciel spécifique installé
sur le serveur Web permettant de garder une trace des requêtes
reçues et des opérations effectuées par le serveur. Il
existe plusieurs formats des fichiers Logs Web, mais le format le plus courant
est le CLF (Common Log file Format). Selon ce format six informations sont
enregistrées:
1. le nom du domaine ou l'adresse de Protocole Internet (IP) de
la machine appelante,
2. le nom et le login HTTP de l'utilisateur (en cas
d'accès par mot de passe),
3. la date et l'heure de la requête,
4. la méthode utilisée dans la requête (GET,
POST, etc.) et le nom de la ressource Web demandée (l'URL de la page
demandée),
5. le statut de la requête i.e. le résultat de la
requête (succès, échec, erreur, etc.),
6. la taille de la page demandée en octets.
Le format ECLF (Extended Common Log file Format),
supporté par certains serveurs Web, représente une version plus
complète du CLF. En effet, il indique en plus l'adresse de la page de
référence (où se trouvait l'internaute lorsqu'il a
lancé la requête (referrer)) et l'identification de l'agent client
(le nom du navigateur Web et le système d'exploitation).
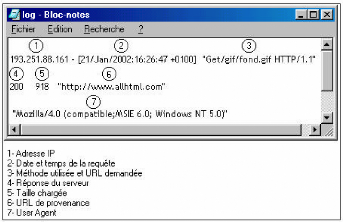
FIG. 2.1 : Schéma illustratif des champs d'une
requête
Problèmes spécifiques aux données des
fichiers Logs : Bien que les données fournies par les fichiers Logs
soient utiles, il importe de prendre en compte les limites inhérentes
à ces données lors de leur analyse et de leur
interprétation. Parmi les difficultés qui peuvent survenir:
- Les requêtes inutiles2 : Chaque fois qu'il
reçoit une requête, le serveur enregistre une ligne dans le
fichier Log. Ainsi, pour charger une page, il y'aura autant de lignes dans le
fichier que d'objets contenus sur cette page (les éléments
graphiques). Un prétraitement est donc indispensable pour supprimer les
requêtes inutiles.
- Les firewalls : Ces protections d'accès à un
réseau masquent l'adresse IP des utilisateurs. Toute requête de
connexion provenant d'un serveur doté d'une telle protection aura la
même adresse et ce, quel que soit l'utilisateur. Il est donc impossible,
dans ce cas, d'identifier et de distinguer les visiteurs provenant de ce
réseau.
- Le Web caching: Afin de faciliter le trafic sur le Web, une
copie de certaines pages est sauvegardée au niveau du navigateur local
de l'utilisateur ou au niveau du serveur proxy afin de ne pas les
télécharger chaque fois qu'un utilisateur les demande. Dans ce
cas, une page peut être consultée plusieurs fois sans qu'il y' ait
autant d'accès au serveur. Il en résulte que les requêtes
correspondantes ne sont pas enregistrées dans le fichier Log.
- L'utilisation des robots : Les annuaires du Web, connus sous
le nom de moteurs de recherche, utilisent des robots qui parcourent tous les
sites Web
afin de mettre à jour leur index de recherche. Ce
faisant, ils déclenchent des requêtes qui sont enregistrées
dans tous les fichiers Logs des différents sites, faussant ainsi leurs
statistiques.
- L'identification des utilisateurs : L'identification des
utilisateurs à partir du fichier Log n'est pas une tâche simple.
En effet, en employant le fichier Log, l'unique identifiant disponible est
l'adresse IP et »l'agent» de l'utilisateur. Cet identifiant
présente plusieurs limites [Sri, 00] :
- Adresse IP unique / Plusieurs sessions serveurs: La
même adresse IP peut être attribuée à plusieurs
utilisateurs accédant aux services du Web à travers un unique
serveur Proxy.
- Plusieurs adresses IP / Utilisateur unique: Un utilisateur
peut accéder au Web à partir de plusieurs machines.
- Plusieurs agents / Utilisateur unique : Un internaute qui
utilise plus d'un navigateur, même si la machine est unique, est
aperçu comme plusieurs utilisateurs.
- L'identification des sessions : Toutes les requêtes
provenant d'un utilisateur identifié constituent sa session. Le
début de la session est défini par le fait que l'URL de
provenance de l'utilisateur est extérieure au site [Lec, 03]. Par
contre, aucun signal n'indique la déconnexion du site et par suite la
fin de la session.
- Le manque d'information : Le fichier Log n'apporte rien sur
le comportement de l'utilisateur entre deux requêtes : Que fait ce
dernier? Est-il vraiment en train de lire la page affichée? De plus, le
nombre de visites d'une page ne reflète pas nécessairement
l'intérêt de celle-ci. En effet, un nombre élevé de
visites peut simplement être attribué à l'organisation d'un
site et au passage forcé d'un visiteur sur certaines.
Autres sources des données
Connaissances sur le site Web : Les pages d'un site sont
matérialisées par une adresse Internet spécifique,
appelée adresse d'allocation de la ressource (Uniform Resource Locator).
La structure d'un site Internet simple peut être
représentée par un arbre dont la racine correspond à la
page d'accueil du site.
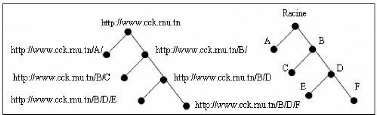
FIG. 2.2 : Exemple d'arbre d'un site
Chaque point (ou noeud) présente l'adresse d'une page
particulière, et les segments reliant ces points indiquent la
présence d'un lien hypertexte amenant aux sous-branches
immédiates de l'arbre. D'après le schéma ci-dessus, il est
possible de retracer le chemin de navigation de l'internaute sur le site.
Cependant, il n'est pas toujours aisé de représenter
l'architecture d'un site, en particulier les sites complexes.
Connaissances sur les utilisateurs du site : Les connaissances
sur les utilisateurs d'un site sont obtenues directement auprès des
utilisateurs eux-mêmes dans l'approche panéliste (âge, sexe,
ancienneté sur le Web). Dans le cas des sites à base
d'inscription, ces connaissances sont recueillies directement à partir
du login et du profil de l'utilisateur donnés par l'internaute au moment
de l'inscription. Ces données dites explicites, fournies directement par
les internautes sont très souvent erronées. Il est
également possible d'acquérir des connaissances sur les
utilisateurs du site en reconstituant leurs profils en fonction de leurs
activités passées sur le Web.
2.2.3 Diverses approches d'analyse
Il existe plusieurs méthodes d'analyse du trafic sur un
site Web dont les plus connues sont: l'analyse des Logs, l'analyse distante et
les panels.
Analyse des fichiers Logs
L'analyse des fichiers Logs consiste à collecter
automatiquement à partir des fichiers Logs les navigations de tous les
utilisateurs. Cette analyse permet de quantifier la fréquentation des
pages d'un site donné, déterminer les parcours de navigation, les
motifs de navigation et les profils des usagers du site
considéré. La faiblesse de cette approche est d'offrir peu
d'information sur l'utilisateur [Che, 02].
Analyse distante
L'analyse distante repose sur l'utilisation des marqueurs HTML
à placer sur chacune des pages du site étudié. Le marquage
consiste à placer une petite image (visible ou non) appelée
marqueur sur l'ensemble des pages Web à auditer. Le marqueur s'implante
sur un site Web afin de compter »les pages chargées». A chaque
chargement de page, le marqueur transmet au serveur les données
collectées (date et heure de la requête, informations sur le
navigateur, résolution de l'écran). Cette méthode fournit
une mesure directe de l'information (en temps réel). En revanche, elle
nécessite le marquage de toutes les pages, ce qui est presque impossible
dans le cas des sites volumineux.
Panels
Cette approche permet d'analyser les usages de l'Internet en
utilisant des panels d'utilisateurs représentatifs de la population des
internautes. Les données à analyser sont de deux types : d'une
part les données personnelles recueillies auprès de chaque
panéliste (âge, sexe, ancienneté sur le Web), d'autre part,
toutes les activités des panélistes sur Internet suivies et
capturées à l'aide d'un logiciel implanté sur leurs
ordinateurs. Cette approche présente l'inconvénient de ne pas
offrir une étude précise d'un site donné et n'est
utilisable que par des sites à très fort trafic.
Autres approches
[Che, 02] propose l'approche SurfMiner qui combine l'approche
panéliste et l'approche reposant sur l'analyse des fichiers Logs afin de
mettre en évidence les usages d'un site associés à des
descriptions d'utilisateurs. Cette approche repose sur l'hypothèse qu'il
existe une certaine corrélation entre les pratiques différentes
des utilisateurs et leurs caractéristiques personnelles. Elle consiste
à extraire des motifs fréquents de navigation des utilisateurs de
référence et découvrir des relations entre les motifs
découverts et des traits d'utilisateurs.
2.3 Conclusion
Ce premier chapitre a servi d'introduction au domaine
lié à notre étude. Nous avons défini certaines
notions relatives au Web Mining et plus particulièrement, au Web Usage
Mining sur lequel porte notre étude. Le chapitre suivant est
consacré à la présentation du processus du Web Usage
Mining, en particulier les différentes étapes de ce processus.
Chapitre 3
Processus du Web Usage Mining
Le processus du Web Usage Mining (WUM) est communément
divisé en trois étapes principales : prétraitement des
données, fouille de données et analyse des résultats. Une
étape préalable consiste à collecter les données du
Web à analyser. Nous présentons dans ce chapitre chacune de ces
étapes ainsi qu'une description détaillée des
données et traitements nécessaires à sa
réalisation.
3.1 Processus du Web Usage Mining
Le WUM (fig. 3.1) consiste en »l'application des
techniques de fouille des données pour découvrir des patrons
d'utilisation à partir des données du Web dans le but de mieux
comprendre et servir les besoins des applications Web» [Coo, 00]. La
première étape dans le processus de WUM, une fois les
données collectées, est le prétraitement des fichiers Logs
qui consiste à nettoyer et transformer les données. La
deuxième étape est la fouille des données permettant de
découvrir des règles d'association, un enchainement de pages Web
apparaissant souvent dans les visites et des »clusters»
d'utilisateurs ayant des comportements similaires en terme de contenu
visité. L'étape d'analyse et d'interprétation clôt
le processus du WUM. Elle nécessite le recours à un ensemble
d'outils pour ne garder que les résultats les plus pertinents.
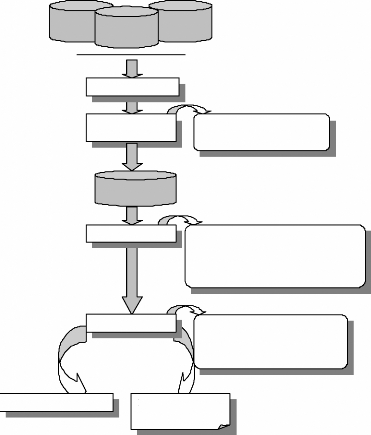
Serverside data
Intermediary
data
Client-side
data
Collecte des données
Prétraitement des
données
- Nettoyage des données
- Transformation des données
Data Webhouse
Fouille des données
- Méthodes statistiques unidimensionnelles -
Méthodes statistiques multidimensionnelles
- Méthodes d'association
- Méthodes basées sur l'IA
Analyse
- Visualisation
- OLAP
- Bases des données relationnelles - Agents
intelligents
Personnalisation du Web
Rapport d'évaluation
du Web
FIG. 3.1 : Processus du Web Usage Mining
3.2 Collecte des données
La première phase dans le processus du WUM consiste
à collecter les données du Web à analyser. Les deux
sources principales des données collectées sont les
données enregistrées au niveau du serveur et les données
enregistrées au niveau du client. Une autre source consiste aux
données enregistrées au niveau du serveur Proxy,
intermédiaire dans la communication client-serveur.
3.2.1 Données enregistrées au niveau du serveur
Chaque demande d'affichage d'une page Web de la part d'un
utilisateur, peut générer plusieurs requêtes. Des
informations sur ces requêtes (notamment les noms des ressources
demandées et les réponses du serveur Web) sont stockées
dans les fichiers Log du serveur Web. L'enregistrement des données dans
les Logs du serveur (server-side Log files) permet d'identifier l'ensemble
d'utilisateurs accédant au site Web. De plus, les Logs du serveur
fournissent des données sur le contenu, des informations sur la
structure et des méta-informations sur les pages Web (taille du fichier,
date de la dernière modification) [Sri, 00]. Cependant, les fichiers Log
des serveurs Web présentent des problèmes majeurs comme
signalé dans le chapitre précédent.
3.2.2 Données enregistrées au niveau du client
Les données sont collectées au niveau du poste
client à travers des agents implémentés en Java ou en Java
script. Ces agents sont incorporés dans les pages Web (sous forme
d'appliquettes java, par exemple) et utilisés pour une collecte directe
des informations à partir du poste client (exemples d'informations : le
temps d'accès et d'abandon du site, l'historique de navigation) .Une
autre technique de collecte des données consiste à utiliser une
version modifiée du navigateur [Tau, 97]. Cette technique permet
d'enregistrer les pages Web visitées par un utilisateur ainsi que le
temps d'accès et le temps de réponse et les envoyer au serveur.
La première méthode permet de collecter des données sur un
utilisateur navigant sur un seul site Web. Par contre, un browser
modifié permet la collecte des données sur un utilisateur
navigant sur plusieurs sites Web. Le problème qui se pose dans le second
cas est comment convaincre les internautes d'utiliser ce navigateur
modifié dans leurs navigations sachant qu'il peut être
considéré comme une menace de leur vie privée [Sri, 00].
Les informations enregistrées au niveau du poste client sont plus
fiables que les informations enregistrées au niveau du serveur
puisqu'elles permettent de résoudre le problème du caching et
l'identification des sessions [Pie, 03].
3.2.3 Données enregistrées au niveau du Proxy
Le serveur Proxy joue le rôle d'intermédiaire
entre des clients Web et des serveurs Web. C'est également un vaste
espace disque servant au stockage des pages Web consultées par les
utilisateurs (Web-cache server). En effet, pour toute requête
émise sur une page, le Proxy, après consultation de son disque
local, transmet la requête au serveur Web si le document n'est pas
disponible à son niveau. Une fois l'information retournée par le
serveur, le Proxy en effectue une copie locale sur son disque puis la transmet
à l'initiateur de la requête. Le serveur Proxy garde la trace de
toutes les communications établies dans des fichiers Logs
semblables à ceux des serveurs Web. Ces traces peuvent
révéler les requêtes HTTP émises par plusieurs
clients vers plusieurs serveurs Web et servir ainsi de source de données
pour caractériser le comportement de navigation d'un groupe anonyme
d'utilisateurs partageant un même serveur Proxy [Sri, 00]. Cependant, les
mêmes problèmes cités précédemment
(problème du caching et d'allocation des adresses IP) sont
présents au niveau du Proxy. Le tableau suivant présente les
différents niveaux de collecte des données résultant de la
navigation d'un ou de plusieurs utilisateurs sur un ou plusieurs sites.

TAB. 3.1 : Niveaux de collecte des données
3.3 Prétraitement des données
Le prétraitement des données se décompose en
deux phases principales : une phase de nettoyage des données et une
phase de transformation.
3.3.1 Nettoyage des données
Le nettoyage des données est une étape cruciale
dans le processus du WUM en raison du volume important des données
enregistrées dans les fichiers Log Web. En effet, la dimension de ces
fichiers dans les sites Web et les portails Web très populaires peut
atteindre des centaines de géga-octets par heure. L'étape du
nettoyage consiste à filtrer les données inutiles à
travers la suppression des requêtes ne faisant pas l'objet de l'analyse
et celle provenant des robots Web. La suppression du premier type de
requêtes dépend selon [Tan, 03] de l'intention de l'analyste. En
effet, si son objectif est de trouver les failles de la structure du site Web
ou d'offrir des liens dynamiques personnalisés aux visiteurs du site
Web, la suppression des requêtes auxiliaires comme celles pour les images
ou les fichiers multimédia est possible. Par contre, quand l'objectif
est le »Web pre-fetching* », il ne faut pas supprimer ces
requêtes puisque dans certains cas les images ne sont pas incluses dans
les fichiers HTML mais accessibles à travers des liens, ainsi
l'affichage de ces images indique une action de l'utilisateur.
La suppression du second type de requêtes i.e. les
entrées dans le fichier Log produites par les robots Web (WR) permet
également de supprimer les sessions non intéressantes. En effet,
les WRs suivent automatiquement tous les liens d'une page Web. Il en
résulte que le nombre de demandes d'un WR dépasse en
général le
nombre de demandes d'un utilisateur normal. [Tan, 03] a
utilisé trois heuristiques pour identifier les requêtes et les
visites issues des WRs :
1. Identifier les adresses IPs qui ont formulé une
requête à la page »robots .txt».
2. Utiliser des listes des »User agents» connus comme
étant des WRs.
3. Utiliser un seuil pour »la vitesse de
navigation» BS (Browsing Speed), qui représente le rapport entre le
nombre de pages consultées pendant une visite de l'utilisateur et la
durée de la visite. Si BS est supérieure à deux pages par
seconde et la visite dépasse 15 pages, alors la visite a
été initiée par un WR.
3.3.2 Transformation des données
Cette phase regroupe plusieurs tâches telles que
l'identification des utilisateurs et des sessions et l'identification des
visites.
Identification des utilisateurs et des sessions
Plusieurs méthodes ont été proposées
pour identifier les internautes:
L'adresse IP Les adresses IP toujours disponibles et ne
nécessitant au-
cun traitement préalable peuvent être
utilisées pour identifier les internautes. Cependant, leur utilisation
présente principalement deux limites. D'une part, les internautes
utilisant un serveur Proxy sont identifiés par l'unique adresse IP de ce
serveur. Ainsi, le site visité ne peut déceler s'il s'agit d'un
ou de plusieurs visiteurs. D'autre part, l'attribution dynamique des adresses
IPs ne permet une identification valable que pour une seule session
ininterrompue i.e. si l'internaute interrompt sa visite en se
déconnectant un bref instant, son adresse IP aura changé bien
qu'il s'agit toujours du même utilisateur.
Les Cookies (Client Side Storage) Ces fichiers peuvent contenir
des
information telles que la date et l'heure de la visite, la
page visitée, un code d'identification du client, .. etc. Chaque fois
que l'utilisateur introduit une URL, le navigateur parcourt les cookies. Si
l'un d'entre eux contient cette URL, la partie du cookie contenant les
données associées est transférée conjointement
à la requête afin de permettre au serveur d'identifier la
provenance de cette requête. Cette méthode présente
plusieurs avantages. En effet, les cookies permettent une identification
s'étalant sur plusieurs sessions. Ils permettent également de
stocker plus qu'un simple code d'identification et de collecter et
d'enregistrer des informations directement exploitables par le serveur (comme
le mot de passe); Cependant, l'identification par cookies présente des
inconvénients. D'une part, les
cookies identifient la machine, et non
l'utilisateur1, d'autre part, ils nécessitent l'acceptation
de l'utilisateur qui peut à tout moment désactiver leur
chargement. Deux autres problèmes sont également à
considérer. Le premier est celui des firewalls qui peuvent interdire
l'écriture de cookies. Le second est relié au nombre
limité des cookies. En effet, un client ne peut pas avoir plus de 300
cookies sur son disque et un serveur ne peut créer que 20 cookies
maximum chez le client.
Le Mot de passe Pour qu'un serveur puisse identifier un visiteur
de
manière certaine, l'internaute doit s'identifier
lui-même à l'aide d'un pseudonyme (Login) et un mot de passe
(Password). Ainsi, le serveur est sûr de l'identité de son
visiteur. Cette technique permet d'identifier les internautes de façon
permanente et fiable mais elle requiert la participation de l'utilisateur et ne
peut être réalisée à son insu. Le serveur devra donc
attendre que son visiteur s'enregistre et ne pourra profiter des requêtes
effectuées en dehors de l'identification. Pour remédier à
cet inconvénient, les mots de passe et les pseudonymes sont souvent
enregistrés dans un cookie. L'indentification établie lors d'une
session ultérieure portera alors sur la machine et non plus sur
l'utilisateur2.
L'identifiant de session Les identifiants de session permettent
à un site
entièrement dynamique d'identifier les internautes
individuellement. Ils reposent sur la technologie PHP. Cette technique permet
d'attacher un identifiant à chacun des liens hypertextes présents
sur une page. Lors de la première requête émise, le serveur
attribue arbitrairement à cette requête un identifiant de session,
la réponse du serveur sera une page préparée
dynamiquement. Le serveur peut ainsi insérer l'identifiant de session
dans tous les liens hypertextes de cette page. Lorsque l'utilisateur clique sur
l'un de ces liens, sa requête contiendra automatiquement l'identifiant
qui lui a été attribué au départ. Cette technique
est très fiable mais limite l'identification du visiteur à une
seule session.
D'autres méthodes ont été
proposées afin de résoudre le problème de l'identification
de l'utilisateur. Dans [Coo, 99], la méthode proposée combine
l'utilisation de la topologie du site et des informations contenues dans le
referrer. Si une requête de page provient de la même adresse IP que
les requêtes précédentes sans qu'il y'ait d'hyperliens
directs entre les pages demandées, alors l'utilisateur n'est plus le
même. Cependant cette méthode n'identifie pas complètement
l'utilisateur. [Sch, 01] emploie une technique différente pour
identifier l'utilisateur. Cette technique consiste à inclure, pour
chaque utilisateur, un identifiant unique généré par le
serveur Web dans les URLs des pages Web du site. Cependant, cette technique
nécessite l'intervention de l'internaute qui doit créer un
signet, qui inclut
1Si plusieurs personnes utilisent un même
ordinateur, la pertinence du cookie est fortement réduite. De
même, si une personne emploie plusieurs ordinateurs, le site est
incapable de reconnaître l'utilisateur. Le cookie est donc
inadapté à la mobilité des internautes.
2Un utilisateur différent peut cependant
accéder au site sous la même identité.
l'identifiant comme une partie de l'URL dans l'une des pages afin
d'identifier l'utilisateur s'il revient au site.
Le tableau ci-dessous proposé par [Gav, 02]
présente une comparaison entre les principales techniques
d'identification des internautes.
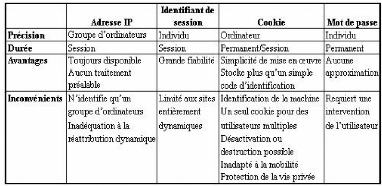
TAB. 3.2 : Principales techniques d'identification des
internautes Identification des visites
Une fois l'utilisateur identifié par l'une de
méthodes décrites ci-dessus, il est possible de reconstituer sa
session en regroupant les requêtes contenues dans les fichiers Log et
émises par cet utilisateur. Selon [Spi, 99], les méthodes
d'identification des sessions des utilisateurs peuvent être
classifiées en méthodes basées sur le contexte (exemple :
accès à des pages de types spécifiques) et méthodes
basées sur le temps (exemple : limite seuil de temps de consultation
d'une page). Les méthodes basées sur le temps sont les plus
couramment utilisées. Elles consistent à considérer que
l'ensemble des pages visitées par un utilisateur constitue une visite
unique si les pages sont consultées pendant un intervalle de temps ne
dépassant pas un certain seuil temporel3. Ce »temps de
vue de pages4» varie de 25,5 minutes [Cat, 95] à 24
heures [Yan, 96]. Le temps de vue de pages couramment utilisé est de 30
minutes [Coo, 99]. Cependant, l'utilisateur peut passer plus de trente minutes
à lire la même page ou quitter son poste pendant un moment et
retourner pour consulter la même page. De plus, l'utilisateur du cache
peut donner l'impression que la session est finie alors qu'il consulte les
pages enregistrées par le cache.
3Cet intervalle de temps correspond à une
absence de requêtes, on parle de seuil temporel d'inactivité.
4Page viewing time, terme introduit par Shahabi [Sha,
97].
Selon les critères empiriques de Kimball [Kim, 00], une
visite est caractérisée par une série d'enregistrements
séquentiellement ordonnés, ayant la même adresse IP et le
même nom d'utilisateur, ne présentant pas de rupture de
séquence de plus d'une certaine durée.
Identification des épisodes
L'objectif de l'identification des épisodes est de
créer des classes de référence significatives pour chaque
utilisateur. Selon [Coo, 97], les épisodes dépendent du
comportement de navigation de l'utilisateur. En se basant sur cette
hypothèse, les auteurs proposent de classifier les pages d'un site
en:
- Pages auxiliaires : contiennent les hyperliens primaires aux
autres pages Web et utilisées pour la navigation.
- Pages de contenu: contiennent des informations
intéressantes aux utilisateurs.
- Pages hybrides : contiennent les deux types d'information.
Cette classification basée sur le contexte
dépend de l'utilisateur. En effet, une page de navigation (ou
auxiliaire) pour un utilisateur peut être une page de contenu pour un
autre. Suivant cette classification, il existe trois méthodes
d'identification des épisodes : la référence-avant
maximale (MF-Maximal Forward reference), le typage des pages et la longueur de
la référence.
Selon la méthode »Référence-avant
maximale»5 , proposée par [Chen, 96], un épisode
est défini par un ensemble de pages visitées par un utilisateur
à partir de la première page enregistrée dans le fichier
Log jusqu'à l'apparition de la première référence
en arrière6. Ainsi, cette méthode ne considère
pas une deuxième fois les pages qui ont été
traversées par l'utilisateur lors de sa visite, ce qui ne convient pas
à certaines classes d'applications où il est important de
prédire les types de référence en arrière. D'autre
part, le Web caching empêche les références en
arrière d'être enregistrées dans les fichiers Log.
La méthode »typage de pages» [Coo, 99] est
semblable à la méthode »longueur de
référence». La différence entre les deux
méthodes consiste dans l'algorithme de classification basé sur
les données d'usage pour la méthode longueur de
référence et sur le contenu de la page pour la méthode
typage de page.
3.4 Fouille de données
Une fois les fichiers Log retravaillés en sessions, les
données sont analysées à l'aide de plusieurs outils
statistiques appropriés regroupés dans une boîte à
outils
5Les références avant-maximale sont des
pages de contenu accessibles à travers les pages auxiliaires.
6Une référence en arrière est une
page qui est déjà incluse dans l'épisode.
nommée »Data Mining».
Le Data Mining consiste à »utiliser un ensemble de
techniques statistiques qui, en »fouillant» un grand nombre de
données structurées, permettent de découvrir et de
présenter des informations à valeur ajoutée dans une forme
interprétable facilement par un individu». Dans le cadre du Web
Mining, il s'agit d'extraire des informations à valeur ajoutée
à partir des données collectées sur les internautes afin
de mieux les connaître. Les méthodes appliquées au WUM se
répartissent en quatre grandes familles [Mic, 02].
3.4.1 Méthodes statistiques unidimensionnelles
Ces méthodes permettent une analyse exploratoire des
données à travers les indicateurs statistiques (moyenne,
écart-type,...) et la représentation graphique (histogrammes,
boîte de dispersion,...);
Les indicateurs d'audience éditoriale selon la
terminologie du CRESP7 (Centre d'étude des supports de
Publicité) sont :
- Le nombre de pages demandées ou vues (i.e. totalement
téléchargées),
- Le nombre de pages provenant de mémoires caches ou de
serveurs Proxy, - Le nombre de visiteurs,
- Le nombre de pages vues par visite,
- L'origine géographique des consultations,
- La durée de consultation par visite.
3.4.2 Méthodes statistiques multidimensionnelles
Ces méthodes (Factorisation, segmentation,
classification, ) permettent, en réduisant l'espace et en fournissant
des représentations graphiques, d'exploiter, de fouiller et de
représenter des grands ensembles des données.
Méthodes factorielles
Les méthodes factorielles se proposent de fournir des
représentations synthétiques, souvent sous forme graphique, de
vastes ensembles de valeurs numériques. L'analyse en composantes
principales (ACP) est une technique permettant de réduire un
système complexe de corrélations en un nombre inférieur de
dimensions. Elle s'applique sur des tableaux dont les lignes sont des individus
et les colonnes des variables numériques. L'analyse factorielle des
correspondances (AFC) traite des variables qualitatives. Elle s'applique sur
des tableaux de contingence. Son extension, l'analyse factorielle des
correspondances multiples (AFCM) s'applique sur des grands tableaux de
variables nominales où les lignes sont les individus et les colonnes des
variables descriptives [Leb, 00].
7http ://www.cesp.org/
Méthodes de classification automatique
La classification automatique, appelée aussi
classification non supervisée, segmentation ou également
clustérisat ion, consiste à rechercher des groupes
homogènes inconnues au départ dans une population d'individus
représentés par une ou plusieurs variables. Le Data Mining
propose plusieurs méthodes de classification automatique telle que la
classification ascendante hiérarchique, la classification descendante
hiérarchique, la méthode des centres mobiles...etc. Cependant,
l'adaptation des méthodes de segmentation au données du Web est
difficile vu la taille des tableaux des données tant pour les sessions
que pour les pages différentes [Lec, 03]. En effet, dans [Fu, 00], les
données sont segmentées, après réduction de
dimension, en utilisant un algorithme BIRCH de segmentation hiérarchique
introduit par [Zha, 96]. Dans [Ben, 03], une classification non
supervisée basée sur un réseau de neurones est
utilisée pour grouper les sessions similaires en classes.
Dans le domaine du WUM, il existe deux types de classes
à découvrir [Sri, 00] : classes d'usagers et classes de pages. La
segmentation des utilisateurs a pour objectif d'établir des groupes
d'internautes ayant des comportements de navigation similaires. L'examen de ces
groupes permet d'associer un profil à chaque classe d'utilisateurs. La
segmentation des pages Web consultées par les internautes permet de
découvrir des groupes de pages ayant des contenus reliés ce qui
facilite la tâche des navigateurs et des robots. Ces deux types de
segmentation servent, dans le cadre d'anticipation de besoins, à
créer des pages Web statiques ou dynamiques et proposer des hyperliens
aux internautes suivant leurs profils ou leurs historiques de navigation.
Méthodes de classification supervisée
La classification8 supervisée cherche
à déterminer l'appartenance d'un événement à
des classes préalablement identifiées par segmentation. Dans le
domaine du WUM, la classification consiste à affecter chaque internaute
à une catégorie de comportement de navigation i.e. elle vise
à relier les caractéristiques sociodémographiques d'un
internaute à son comportement. Pour ce faire, de nombreuses
méthodes de classification sont utilisées telles que les arbres
de décision, les réseaux de neurones et le raisonnement à
base de mémoire.
D'autres méthodes ne faisant pas partie des techniques
du Data Mining ont été également utilisées. Une
première méthode consiste à utiliser les algorithmes de
filtrage collaboratif. Cette technique statistique effectue des comparaisons
entre les données sur le nouveau visiteur et celles sur les internautes
ayant visité le site avant lui afin de l'assigner à une
catégorie d'internautes ayant des profils similaires, à l'aide
d'un calcul de proximité suivi d'une fixation de seuil. Une
deuxième méthode d'attribution du visiteur au segment consiste
à impliquer l'utilisateur
qui devrait choisir sa catégorie. Cette méthode
est utilisée en cas de collecte de données ponctuelle
(l'utilisateur fournit les données lors de son enregistrement sur le
site, au début de la session) avec un profil temporaire. Une autre
façon de procéder à l'attribution d'un profil à un
segment est de minimiser un indice multicritère. Cette technique est
relativement similaire à celle employée par les algorithmes de
filtrage collaboratif. En effet, un indice est calculé pour chaque
profil et est comparé à ceux des segments
prédéfinis. L'attribution se fait au segment présentant la
distance minimale entre son indice et celui du profil du visiteur.
3.4.3 Méthodes d'association
Les règles d'association est une méthode de
fouille des données non supervisée qui consiste à
déterminer les valeurs associées parmi les données. Une
règle d'association est une règle de la forme : Si condition
(prémisse) alors résultat. Par exemple, Si X et Y alors Z.
Le choix d'une règle d'association nécessite de
définir des indicateurs servant à sa validation, à savoir
le support, la confiance et l'amélioration de la règle.
- Support d'une règle
Le support d'une règle indique le pourcentage
d'enregistrements qui vérifient la règle. C'est la
fréquence d'apparition simultanée des articles qui apparaissent
dans la prémisse et dans le résultat, soit
Support = freq (condition et résultat) Supp(X Y) = |
X&Y | / | BD |
où IX&YI est le nombre d'enregistrements contenant X
et Y et IBDI le nombre total de transactions.
- Confiance associée à une règle
La confiance d'une règle mesure la validité de
la règle. C'est égal au pourcentage d'enregistrements qui
vérifient la conclusion parmi ceux qui vérifient la
prémisse. La confiance est le rapport entre le nombre de transactions
où tous les articles figurant dans la règle apparaissent et le
nombre de transactions où les articles de la partie condition
apparaissent, soit
|
Confiance=freq (condition et résultat) /
freq(condition) Conf(X Y) = |X & Y|/|X|
Conf(X Y) = Supp(XY) / Supp(X)
|
La confiance est basée sur la probabilité
conditionnelle:
Conf(X Y) = P(XY) / P(X) = P(Y/X)
- Définition de l'amélioration
Amélioration = Confiance / freq(résultat)
Une règle est considérée
intéressante lorsque l'amélioration est supérieure
à 1.
Dans le WUM, les associations se font sur les pages dans le
but de découvrir les pages visitées ensembles et de
prévoir le comportement d'un internaute en se basant sur les
requêtes qu'il a effectué. Les règles d'association sont
surtout utiles dans le cas de l'étude du trafic sur les sites Web
commerciaux. Parmi les algorithmes d'association, l'algorithme APRIORI
développé par IBM est le plus souvent utilisé.
3.4.4 Méthodes basées sur l'intelligence
artificielle (réseaux de neurones)
Par analogie avec les neurones biologiques, les réseaux
de neurones sont des ensembles de calculateurs numériques (neurones
formels) agissant comme des unités élémentaires,
reliés entre eux par des interconnexions pondérées qui
transmettent des informations numériques d'un neurone formel à un
autre.
Apprentissage à l'aide d'un réseau de neurones
L'apprentissage d'un réseau de neurones artificiels est
induit par une procédure itérative d'ajustement de ses
paramètres internes (poids synaptiques et nombres de neurones). En
apprentissage supervisé, des exemples (observations) auxquels sont
associées des réponses désirées sont
présentés au réseau. La sortie produite par le
réseau en réponse à une observation donnée est
comparée à la réponse désirée (variable de
sortie). La différence entre la réponse désirée et
la réponse du réseau est alors utilisée pour adapter les
paramètres du réseau de façon à corriger son
comportement. Ce processus est répété de façon
itérative jusqu'à obtenir le meilleur comportement. En
apprentissage non supervisé, le réseau catégorise les
variables d'entrée sans avoir à déterminer les variables
de sortie c'est à dire il évolue tout seul vers son état
stable. Cet apprentissage est destiné à l'élaboration
d'une représentation interne de l'espace des données
d'entrée en identifiant la structure statistique des variables
d'entrée sous une forme plus simple ou plus explicite. Ce type
d'apprentissage est utilisé dans les réseaux compétitifs,
en particulier dans les cartes de Kohonen.
Dans le WUM, le but d'un réseau neuronal est de
recréer artificiellement l'expertise qu'aurait une personne
habituée à classifier les profils dans les segments
prédéfinis (apprentissage supervisé) ou découvrir
des nouveaux segments rassemblants des individus ayant des profils similaires
(apprentissage non supervisé).
Réseaux compétitifs
Les interconnexions des neurones formels donnent naissance
à des réseaux à structures variées dont la plus
utilisée est l'organisation en couches successives. Une telle structure
diffuse l'information de la couche d'entrée, composée par les
neurones formels recevant les informations primitives, vers la couche de
sortie, contenant les neurones finaux transmettant les informations de sortie
traitées par la totalité du réseau, tout en traversant une
ou plusieurs couches intermédiaires, dites couches cachées. Parmi
les réseaux de neurones structurés en couches successives, les
réseaux compétitifs. Les réseaux compétitifs sont
des réseaux qui reproduisent une particularité du fonctionnement
biologique des neurones, à savoir l'inhibition latérale. En
effet, chaque neurone d'entrée est relié à chaque neurone
de sortie et chaque neurone de sortie inhibe tous les autres et s'auto excite.
Le degré de l'inhibition est proportionnel à l'amplitude de
sortie du neurone9 et est une fonction de la distance. En effet,
lorsqu'un neurone est excité, il transmet son excitation aux neurones
voisins dans un rayon très court et inhibe par contre les neurones
situés à plus grande distance.
La figure 3.2 illustre les connexions de compétition
pour un des neurones du réseau compétitif. Les connexions
d'inhibition et la connexion de contre-réaction sont illustrées
pour le 2ème neurone seulement et se répètent pour chaque
neurone.
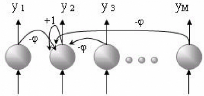
FIG. 3.2 : Réseau linéaire de compétition de
type »gagnant emporte tout»
Quand une forme est présentée à
l'entrée du réseau compétitif, elle est projetée
sur chacun de neurones de la couche de compétition. Une
compétition est alors organisée afin de déterminer le
neurone gagnant dont le vecteur de poids est le plus près de la forme
présentée à l'entrée. Cette architecture permet au
réseau de reproduire l'organisation topographique des formes
d'entrée. Il existe plusieurs types de réseaux compétitifs
tels que les mémoires auto-associatives et les cartes de Kohonen.
3.5 Analyse
L'analyse des modèles est la dernière
étape dans le processus du WUM. La méthodologie de l'analyse
dépend essentiellement des objectifs de la mise en oeuvre du WUM.
Plusieurs techniques ont été développées pour
permettre l'analyse des modèles découverts. Parmi ces techniques,
la visualisation des données, un mécanisme de requêtes de
bases des données relationnelles, les opérations OLAP (On Line
Analytical Processing) et les systèmes multi-agents.
3.5.1 Visualisation
La visualisation consiste à »représenter de
façon vivante et assimilable des informations (statistiques) en les
simplifiant et les schématisant» [Leb, 00]. Les techniques de
visualisation ont pour objectif de présenter de façon
intelligible la structure d'un ensemble d'objets. Il existe deux types de
techniques de visualisation : les techniques traditionnelles qui regroupent les
camemberts, les histogrammes, les boites à moustaches, les histogrammes
croisés.., et les techniques multidimensionnelles qui regroupent les
quatre catégories suivantes : les représentations par pixels*,
les techniques de factorisation*, les coordonnées parallèles
d'Inselberg* et les techniques hiérarchiques*. Certaines méthodes
de classification sont également utilisées pour la visualisation
à savoir les arbres (dendrogrammes,...) et les cartes de Kohonen.
3.5.2 OLAP
OLAP (On Line Analytical Processing) est une méthode
d'analyse en ligne des données stockées dans les bases de
données. Les solutions OLAP reposent sur un même principe :
restructurer et stocker dans une forme multidimensionnelle, connue sous le nom
d'hypercube, les données issues de fichiers ou de bases relationnelles.
Cet hypercube organise les données le long de dimensions
représentées par les variables à prendre en compte dans
l'analyse. Le processus d'analyse multidimensionnelle nécessite
l'accès à un volume important de données et des moyens
adaptés pour les analyser. Depuis 1993, OLAP a donné lieu
à plusieurs déclinaisons: MOLAP*, ROLAP*, HOLAP*...
3.5.3 Bases des données relationnelles
Le succès de la technologie des bases des
données relationnelles provient de l'existence d'un langage de
requêtes déclaratif et de haut niveau qui permet de
spécifier les conditions à remplir par les données et
restreindre l'analyse sur une partie de la base vérifiant certaines
conditions. Les bases de données permettent
de construire des »pages dynamiques»,
c'est-à-dire des pages qui n'existent pas a priori sur le Web ou sur
l'Intranet mais qui sont construites à partir des requêtes
particulières des utilisateurs. Le serveur garde en mémoire une
banque de données structurée par champs homogènes.
L'information souhaitée est retrouvée en formulant des
requêtes.
3.5.4 Agents intelligents
Dans un contexte de veille stratégique, les agents
intelligents sont susceptibles d'intervenir aux différentes
étapes du traitement de l'information. Ils assurent ainsi :
- la recherche et la collecte : celle-ci peut se faire de
manière »intelligente» par l'utilisation de
méta-moteurs perfectionnés (WebSeeker, Copernic Pro), d'outils
d'analyse linguistique des requêtes (Autonomy, DigOut4U) ou par
exploration de liens hypertextes à partir d'une URL donnée, sans
utilisation d'un moteur de recherche,
- l'analyse : les agents de recherche de l'information
permettent de traiter l'information de manière à faciliter son
utilisation soit en la condensant, soit en la représentant sous une
autre forme (graphiques, schémas, etc.),
- le Filtrage, l'édition, l'archivage et la mise
à jour des résultats (WebSeeker, BullsEye),
- la diffusion: ils permettent d'acheminer l'information à
la personne cible.
3.6 Conclusion
Dans ce chapitre, nous avons présenté les
différentes phases du processus du WUM. Comme la phase de la fouille des
données est le centre d'intérêt de notre étude, nous
consacrons le chapitre suivant à la description des méthodes de
classification que nous utiliserons ultérieurement.
Chapitre 4
Méthodes de classification
Si dans les années 80, on distingue deux grands types
de méthodes, les méthodes de partitionnement et les
méthodes hiérarchiques, depuis d'autres approches (réseaux
de neurones,...) ont vu le jour. Le choix de la méthode la plus
adaptée dépend de la nature des variables, de la
problématique posée et souvent des habitudes du domaine
d'étude. Dans ce chapitre, nous présentons deux méthodes
factorielles de classification, à savoir l'analyse en composantes
principales et l'analyse des correspondances et une méthode
connexioniste, les cartes topologiques de Kohonen.
4.1 Méthodes factorielles
L'objectif visé par l'analyse factorielle est la
réduction de l'information en passant d'un grand nombre de variables,
à un nombre restreint de méta-variables, appelés facteurs.
L'essentiel de la démarche des méthodes factorielles est commun
entre elles. Les »inputs» d'une analyse factorielle sont dans tous
les cas l'espace, les points, les masses affectées aux points et la
métrique. Les »outputs» sont les axes d'inertie, les
coordonnées des points sur ces axes et divers indicateurs nommés
»aides à l'interprétation». D'une méthode
d'analyse factorielle à une autre, seuls varient les »inputs»
i.e. les définitions des points, des masses et de la métrique
[Jam, 99].
4.1.1 Analyse en composantes principales (ACP)
L'ACP est une méthode factorielle ayant pour but de
déterminer un sous- espace vectoriel de dimension (k) inférieure
à la dimension de l'espace d'entrée (k<p) et qui offre le
maximum d'inertie expliquée pour y projeter le nuage de points de
l'espace d'entrée Rp. En d'autres termes, réduire le
nombre de variables à quelques facteurs significatifs et
déterminer les relations de proximité entre
points individus et points variables. La démarche d'une
ACP est présentée dans ce qui suit.
Calcul de la matrice d'inertie
Soit le tableau X (xij ; i=1..n; j=1. .p) formé de n
points Xi munis de masses pi positives, décrits chacun par p
variables:
|
V1
|
|
Vj
|
|
Vp
|
|
X1
|
|
|
|
|
|
|
|
|
|
|
|
|
Xi
|
x1 i
|
..
|
xj i
|
..
|
xp i
|
|
|
|
|
|
|
|
Xn
|
|
|
|
|
|
La matrice d'inertie V s'écrit V=X'MX où X est
la matrice à n lignes et p colonnes. Les lignes de X sont les vecteurs
Xi, M est la matrice carrée diagonale d'ordre n des poids pi
(généralement pi = 1/n).
V peut aussi s'écrire V=ZZ' avec Z=
X'M1=2. Cette matrice a les propriétés
suivantes :
- V est symétrique.
- V est diagonalisable et ses valeurs et vecteurs propres sont
réels.
- Les vecteurs propres associés à des valeurs
propres différentes sont orthogonaux.
- V est semi-définie positive et donc pour tout vecteur
U de Rn (espace d'entrée) on a U'VU positif. Toute valeur
propre de V est donc supérieure ou égale à zéro.
- La trace de V, qui est la somme de toutes les valeurs
propres, est égale à Tr(V)=P
i
i
Détermination des axes factoriels
Les axes engendrés par les vecteurs U1, . .Uk, vecteurs
propres associés aux valeurs propres de V sont les axes principaux
d'inertie. La k ième composante principale, ou le k ième facteur
est le vecteur dont les composantes sont les coordonnées des points du
nuage sur le k ième axe principal d'inertie Uk. Comme le nombre
d'individus est n, ce vecteur a n composantes, c'est donc un
élément de l'espace Rn des variables.
Pour déterminer l'espace de projection à inertie
expliquée maximale il faut déterminer ses k axes. Le premier est
l'axe à inertie expliquée maximum. Pour
le déterminer, il suffit de chercher l'axe
associé au premier vecteur propre de la matrice V. On désignera
par U1le vecteur associé à la plus grande valeur propre 1.
L'inertie expliquée par cet axe est égale à:
ë / ëi
1 ?i
Remarquons que l'inertie qui n'est pas expliquée par un
sous-espace vectoriel donné l'est totalement par le sous-espace
supplémentaire (ensemble des axes qui lui sont orthogonaux).
Connaître le reste de l'inertie expliquée revient donc à
déterminer les axes associés aux autres vecteurs propres.
Combien de facteurs faut-il retenir?
Retenir tous les facteurs équivaut à garder
toute l'information initiale mais sans contribuer à la simplification de
la structure des liaisons entres variables. Inversement, ne garder qu'un petit
nombre de facteurs peut revenir à n'expliquer qu'un pourcentage trop
faible de variance totale, et donc à résumer de façon
excessive la complexité de la structure des liaisons entres variables,
à moins que quelques facteurs seulement suffisent à expliquer une
proportion importante de la variance totale. Généralement, la
méthode adoptée est de garder les premiers axes factoriels dont
la proportion expliquée de la variance atteint une proportion
fixée, par exemple 80% (»critère» de
»Jolie»). Il s'agit des premiers facteurs car leur pouvoir
d'explication décroît du fait de leur ordonnancement par valeurs
décroissantes de leur variance ®.
Représentation des individus
Les axes factoriels constituent une nouvelle base de l'espace
Rp. Il est donc nécessaire de calculer les coordonnées des points
sur ces axes pour les représenter dans la nouvelle base et plus
précisément sur uniquement k axes.
La coordonnée ® d'un point Xi sur un axe
U® correspond à la projection du point sur l'axe, qui
est aussi égal au produit scalaire entre Xi et le vecteur
U® de l'axe:
p
uá i á ?= á
= =
'
( ) U X x u h
i ih
h 1
Pour interpréter les résultats d'une analyse en
composantes principales nous avons aussi besoin de connaître:
- Pour chaque point Xi, la contribution du point à
l'inertie du nuage. Cette contribution indique quels sont les points qui ont
joué un rôle important dans l'analyse.

2
( )
i
CONTR i p i X i
( ) =
I o
( )
avec I(o) = Tr(V)
- Pour chaque axe U® et chaque point Xi, la
contribution du point à l'inertie expliquée par l'axe:
=
CTRá
( )
i
pi
u á
ë á
Les CTRs permettent d'interpréter un axe en identifiant
les points qui ont le plus contribué à son positionnement. Notons
que nous avons toujours :
n
?= =
CTR i
á ( )1
1
i
2
- Pour chaque point Xi et pour chaque axe U®, on
calcule la part de l'inertie du point restituée par l'axe et
égale à:
2 ( )
u i
COS i á
( ) =

Xi
á 2
C'est en fait le carré du cosinus de l'angle formé
par l'axe U® et le point Xi.
COS i
2 =
á ( )1
p
?=
á 1
Représentation des points variables
Généralement, les variables utilisées
dans l'ACP sont centrées. Le nuage des individus est donc centré.
Son centre de gravité est situé à l'origine, ce qui n'est
pas le cas pour le nuage des variables. Chaque variable Y correspond à
une colonne du tableau X munie d'une masse unitaire. On utilisera comme
représentation des variables la notation Z® :
á 1 / 2 á 1 á
? ?
Z = M Y = n Y
? ?
? ?
car M est une matrice diagonale dont tous les termes sont
égaux à 1/n. Toutes les variables Z sont normées et les
points variables se situent à une
distance égale à 1 de l'origine. Elles sont donc
sur la sphère de rayon 1. D'autre
part la distance entre deux variables est :
d2(Za,Zfi
)= Za --Zfi2 = Za 2
#177; Zfi 2--2
Za,Zfi =2(1--
Za,Zfi )

avec <Z, , ZE,> désigne le
produit scalaire de deux variables.
Par ailleurs, le produit scalaire de deux vecteurs A et B est
égal au produit des normes et du cosinus de l'angle entre les des deux
vecteurs, donc
fi )
Za,Zfi =
Za Zfi
cos(Za,Zfi)=cosga,Z
car les variables sont normées. Ainsi,
)
d2(Za,Zfi)=2(1--cosga,Zfi
fi n
fi

Comme les variables sont centrées réduites, le
coefficient de corrélation 1/2,E, est égal à
a
Z
=
1,z72 xiaxi t
=
afi
i=1 n i4
On peut donc dire que
)
pafi =COSga,Zfi
Les remarques suivantes seront utilisées pour donner un
sens aux différents axes factoriels en fonction de la position des
variables :
- Deux points variables confondus ont un coefficient de
corrélation égal à 1.
- Deux points variables formant un angle de 90°ont un
coefficient de corrélation linéaire égal à
zéro.
- Deux points variables formant un angle de 180°ont un
coefficient de corrélation linéaire égal à -1
(anti-corrélées).
- Pour comparer des points entre eux, il faut qu'ils soient
proches de la circonférence du cercle de corrélation.
- Par contre, on ne peut rien dire quand les variables sont
agglomérées au centre du cercle, ou de la sphère
unité.
Aides à l'interprétation
L'ordre à suivre dans l'exploitation des indicateurs est
le suivant :
1. Chercher les i correspondant aux CTR,(i) les plus forts.
Sélectionner l'ensemble I' c I des points i tels que la somme
des CTR, soit élevée (par exemple 0.8). L'interprétation
de l'axe reposera sur l'examen de ces points.
2. Regarder le signe de 1,(i) pour i E
I'. Ce signe indique si les points interviennent sur l'axe du
côté positif ou du côté négatif.
. ?=
i 1 n ij
n =
j
, ?
n j =
.
i=1
n ij , n n i 1
= =
.. .
? ? =
i=1 j
n. j
3. Examiner les COS2 ®(i) pour i
I'. Si COS2 ®(i) est fort, le point i est
pratiquement aligné sur l'axe ®, il ne joue pas donc un grand
rôle sur les autres axes. Inversement, si COS2
®(i) est faible, le point i joue un rôle important sur
d'autres axes factoriels.
4.1.2 Analyse factorielle des correspondances (AFC)
L'analyse factorielle des correspondances (AFC) est une
technique statistique développée pour mettre en évidence
des correspondances entre des variables qualitatives décrivant une
population. L'AFC est également une méthode de réduction
de dimensionnalité qui facilite la représentation
géométrique des individus et des caractères.
Cette méthode a pour objectifs de :
- Représenter graphiquement et de manière optimale
des individus (lignes) en minimisant la déformation du nuage de
points,
- Représenter graphiquement les variables (colonnes) dans
un espace explici-
tant au mieux les liaisons initiales (corrélations) entre
ces variables,
- Réduire un système complexe de variables plus ou
moins corrélées en un plus petit nombre de dimensions.
L'AFC s'applique aux tableaux de contingence. Elle est
basée sur une métrique du Chi-2. Elle considère d'une
façon symétrique les lignes et les colonnes de la matrice. La
démarche de l'AFC est la suivante:
1. Transformation des données i.e. calcul du tableau XI
des pro...ls des lignes et du tableau XJ des pro...ls des colonnes,
2. Analyse en composantes principales des tableaux des
pro...ls,
3. Calcul des aides à l'interprétation: inertie
expliquée et contributions absolues et relatives.
Transformation des données
On considère un tableau Z de nombres positifs ou nuls,
comportant I lignes et J colonnes. On note nij son terme
générique, ni. et n.j les sommes
marginales, n la somme de tous les éléments du tableau:
J I I J
Les tableau des profils des lignes XI et des profils des colonnes
s'écrivent :
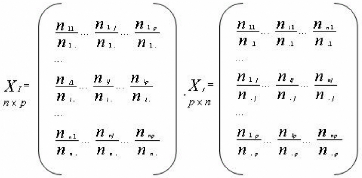
Analyse en composantes principales
L'AFC revient à appliquer l'ACP aux deux nuages N(I) et
N(J). Aux n lignes du tableau XI on associe le nuage N(I) et aux p lignes du
tableau XJ on associe le nuage N(J).
? ? n ? ?
N I I i n
( ) = , , 1, . . . ,
?? X i P
.
?? ?? ??
= ? R
?? ? n ? ??
..
? ? n ? ?
N J J j p
( ) = , , 1, . . . ,
n
?? ? X j
. ? ??
= ?
, R
?? ? n ?
..
? ? ??
La distance choisie sur N(I) pour mesurer la proximité
entre deux points lignes est la distance du Â2 associée
à la métrique:
n..
1
n.
n..
n. j
n..
0
0
n.
p
MI = p ×p
Dans l'ACP du tableau XI, la matrice à diagonaliser est la
matrice CI avec
1 / 2 1 / 2
CI M I V I M I =
où VI est la matrice d'inertie du nuage N(I).
Dans l'ACP du tableau XJ, la matrice à diagonaliser est
la matrice CJ avec
1 / 2 1 / 2
C
J M J V J M J = où VJ est la matrice d'inertie du
nuage N(J).
4.1.3 Analyse factorielle des correspondances multiples
L'analyse factorielle des correspondances multiples (AFCM) est
une généralisation de l'AFC. Elle s'applique sur un tableau
disjonctif complet au lieu d'un tableau de contingence. Le tableau disjonctif
complet est construit à partir de descripteurs nominaux (qualitatifs) ou
continus mis en classes. Il consiste à »disjoncter» chaque
colonne descripteur en autant de colonnes que de modalités. Pour chaque
individu, l'occurrence d'une modalité est codée par 1, les autres
modalités étant codées par 0.
Soit le tableau suivant composé de 5 individus et 3
variables nominales :
123 211 222 321 312
Le tableau disjonctif complet :
Ses principes sont donc ceux de l'analyse des correspondances
à savoir:
- mêmes transformations du tableau de données en
profils-lignes et en profils- colonnes,
- même critère d'ajustement avec pondération
des points par leurs profils marginaux,
- même distance, celle du Â2.
L'AFCM présente cependant des propriétés
particulières dues à la nature même du tableau disjonctif
complet.
Les règles d'interprétation des résultats
(coordonnées, contributions, cosinus carrés) concernant les
éléments actifs d'une analyse des correspondances multiples sont
sensiblement les mêmes que celles d'une analyse des correspondances
simple.
4.2 Cartes topologiques de Kohonen
Inspiré de l'auto-organisation des régions du
système nerveux1, Teuvo Kohonen [Koh, 95] introduit un type
particulier de réseau neuronal : les cartes topologiques (Self
Organizing Features Maps -SOFM), souvent appelées »cartes de
Kohonen», fondées sur l'apprentissage compétitif.
4.2.1 Architecture de la carte topologique
Une carte topologique est une grille composée
d'unités appelées neurones. Chaque neurone est lié aux
autres neurones suivant une topologie et connecté à toutes les
unités d'entrée dont le nombre correspond à la dimension
des données d'entrée. Comme les connexions sont
pondérées, chaque neurone peut être considéré
comme un vecteur de poids dont les composants représentent la force des
connexions synaptiques avec les données d'entrée. Le vecteur
d'entrée et les vecteurs de poids de tous les neurones ont les
mêmes dimensions.
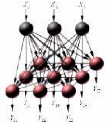
FIG. 4.1 : Architecture de la carte de Kohonen
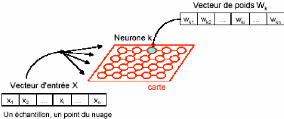
FIG. 4.2: Caractéristiques d'un neurone de la grille de
Kohonen
1Il a été observé que, dans de
nombreuses zones du cortex, des colonnes voisines ont tendance à
réagir à des entrées similaires. Dans les aires visuelles,
deux colonnes proches sont en correspondance avec deux cellules proches de la
rétine. Découvrant que ces propriétés au sein du
cerveau ne sont pas génétiques, mais dues à un
apprentissage, Kohonen a proposé un modèle de carte topologique
auto-adaptative.
4.2.2 Propriétés de la carte topologique
Quantification vectorielle
La carte de Kohonen a comme propriété de
réaliser une quantification vectorielle de l'espace des entrées
tout en respectant la distribution originale de ces entrées. En effet,
l'application de l'algorithme de Kohonen crée un ensemble, de taille
finie et fixée a priori, de prototypes, ou vecteurs codes, ayant les
mêmes dimensions que les données en entrée. Après
l'apprentissage, chacun de ces prototypes, reliés entre eux par une
relation de voisinage sur la carte, représente un sous-ensemble de
l'ensemble des entrées partageant certaines caractéristiques. A
la convergence, les neurones de la carte représentent des zones
formées autour de chacun des prototypes. Selon la terminologie de
Voronoï, ces prototypes sont considérés comme des
centroïdes des zones ou classes obtenues. Ces zones sont appelées
»cellules de Voronoï».
Réduction de la dimensionnalité
La réduction de la dimension de l'espace
d'entrée résulte de la combinaison de l'opération de
regroupement et de quantification citée précédemment, avec
la définition d'une structure de voisinage. Ainsi, en appliquant
l'algorithme SOM, l'espace d'entrée constitué par n individus
sera réduit en un espace de dimension inférieur (k<n)
constitué par un ensemble de micro-classes. Chaque classe est
représentée par la moyenne des caractéristiques des
individus qui la constituent.
Conservation de l'ordre topologique
La propriété de la conservation de la topologie
n'est pas vérifiée par d'autres méthodes de quantification
vectorielle. C'est une conséquence directe de l'équation de mise
à jour des vecteurs poids qui force le neurone gagnant et tous les
neurones appartenant à son voisinage topologique à se
déplacer vers le vecteur d'entrée. Ainsi, les entrées
ayant les mêmes caractéristiques sont projetées sur des
neurones voisins au niveau de la carte. Par conséquent, les
proximités des noeuds dans l'espace de sortie donnent une idée
sur la proximité des regroupements des individus dans l'espace
d'entrée.
4.2.3 Algorithme d'apprentissage de Kohonen
Le principe général de cet algorithme consiste
à initialiser les poids des neurones de la couche de Kohonen en leur
attribuant des valeurs aléatoires faibles, puis à chaque
itération, présenter un vecteur de données au
réseau, déterminer le neurone le plus proche à ce vecteur
selon une mesure de distance2 et modifier les poids des neurones
appartenant au voisinage du neurone élu. Ainsi, l'algorithme
2Ce processus est dénommé matching
(appariement, en français)
d'apprentissage de la carte topologique comprend
principalement deux étapes : la première consiste à
sélectionner un neurone gagnant et la seconde consiste à mettre
à jour le poids de ce neurone et des neurones de son voisinage.
Sélection du noeud gagnant (Compétition entre les
neurones)
soient X(t) = fx1(t); x2(t); :::;
xn(t)g un vecteur d'entrée sélectionné au temps
t et Wk(t) = fwk1(t); wk2(t); :::; wkn(t)g le
vecteur poids associé au noeud k au temps t. Une mesure de distance est
choisie, par exemple la distance euclidienne. Le noeud gagnant k*est
celui qui vérifie :
kX(t) Wk*(t)k = mink kX(t) Wk(t)k
Mise à jour des poids et sélection du voisinage
Une fois le noeud gagnant k* sélectionné, le
vecteur de poids associé à ce noeud ainsi que les vecteurs de
poids associés aux noeuds se trouvant dans un voisinage donné du
noeud gagnant sont ajustés selon l'équation suivante :
Wk(t + 1) = Wk(t) + ®(t)h(k; k*) [X(t)
Wk(t)]
Grâce à cette notion de voisinage, à la
fin de l'algorithme (après un certain nombre d'itérations) la
carte montre une certaine organisation: les neurones proches ont des poids
similaires. Il existe donc une préservation topologique entre l'espace
d'entrée et l'espace de sortie. L'auto-organisation de la carte est
conséquence de l'application de la notion de voisinage.
|
Algorithme
- Initialiser le réseau avec des valeurs aléatoires
des poids - Itérer
· Présenter une donnée d'entrée X
· Trouver l'unité gagnante k* dont le poids est le
plus proche de la donnée d'entrée X
- Calculer la distance euclidienne entre les poids des
unités k et la donnée d'entrée X
· Mettre à jour les poids de cette unité et
ceux des unités voisines suivant la formule suivante :
W t W t t h k k X t W t
( 1) ( ) ( ) ( , *) [ ( ) ( )]
+ = + á -
k k k
|
FIG. 4.3 : Algorithme de Kohonen
avec ®(t) est le taux d'apprentissage et h(k,k*) est la
fonction de voisinage.
4.2.4 Principaux paramètres de la carte topologique
Les principaux paramètres du modèle de Kohonen sont
: la taille de la grille, le taux d'apprentissage, la fonction de voisinage qui
détermine la décroissance
du voisinage dans l'espace et dans le temps, l'initialisation des
poids, le rayon de propagation, le nombre d'itérations et le nombre de
phases d'apprentissage.
Taille de la grille
La taille de la grille est parmi les paramètres qui
conditionnent la pertinence des résultats. En effet, plus il y'a de
noeuds, plus la carte est flexible et s'adapte facilement à la structure
des données à modéliser mais plus le temps d'apprentissage
augmente. Cependant, il n'existe pas de règle d'art pour définir
la taille optimale de la carte.
Initialisation des poids
Trois types d'initialisation des neurones sont
proposés:
1. Initialisation aléatoire : consiste à attribuer
à chaque neurone des poids au hasard.
2. Initialisation à partir d'un échantillon:
consiste à utiliser des éléments de l'ensemble
d'apprentissage comme des vecteurs poids.
3. Initialisation linéaire : les vecteurs poids des
neurones sont initialisés de sorte qu'ils se trouvent dans le même
plan que celui formé par les deux vecteurs principaux propres obtenus
à partir de l'analyse en composantes principales.
Fonction de voisinage
La fonction de voisinage dénote le voisinage
topologique autour du neurone gagnant. C'est une fonction de la distance d(k,
k*) entre les unités k et k* sur la carte. Les fonctions
utilisées pour le voisinage doivent respecter la condition de
non-croissance. Une étude d'Erwin et al. [Erw, 91] a montré
qu'une fonction de voisinage convexe est nécessaire afin d'éviter
que la carte ne passe, en cours d'apprentissage, par des états stables
avant que les vecteurs prototypes n'atteignent leur positions finales. Une
telle situation peut amener un blocage de l'organisation alors qu'elle n'est
pas terminée. Depuis cette étude, un noyau gaussien est souvent
utilisé. Dans ce cas, la fonction de voisinage s'exprime comme suit :

? ?
h k k
( , *) exp
= ?
??
?
2 ?
rkrk
- ? * ?
2 ó ( ) ??
t 2
?
où rk - rk* est la distance entre le neurone k et celui
gagnant k* (rk et rk sont les localisations vectorielles sur la grille de
visualisation) et 3/4(t) est une fonction décroissante du temps,
définissant le rayon d'influence du voisinage
autour de l'unité gagnante. Ce rayon d'influence ne
doit pas être trop restreint pour que la carte puisse s'ordonner
globalement. Il est donc recommandé de prendre une valeur initiale
hk;k (0) très grande, voire même plus grande que la
taille de la carte et de la laisser décroître jusqu'à 1 au
cours de l'apprentissage.
Taux d'apprentissage
C(t) est le taux d'apprentissage compris entre 0 et 1
(0<C(t)<1); C'est une fonction qui doit être positive,
décroissante et monotone. Sa valeur est en général assez
élevée pour les premières itérations et
décroît progressivement vers zéro. Soit C0 sa valeur
initiale. Selon [Koh, 95], C0 doit prendre des valeurs proches de 1 pour les
1000 premières étapes puis décroître
progressivement. La forme de la fonction (linéaire, exponentielle ou
inversement proportionnelle à t) n'a pas d'importance.
Nombre de phases d'apprentissage
Selon Kohonen [Koh, 95], le nombre de phases d'apprentissage
ou d'échantillons à présenter doit être au moins
égal à 500 fois le nombre de cellules constituant la carte pour
obtenir une bonne précision statistique.
4.2.5 Etude de la qualité d'apprentissage des cartes
topologiques
Une carte topologique doit satisfaire certains critères
pour que l'apprentissage soit efficace [Val, 00]. En effet, une SOM doit:
- Minimiser l'erreur de discrétisation i.e. minimiser les
distances d'un vecteur prototype aux entrées qui l'activent.
- Respecter les relations de voisinage de l'espace
d'entrée. Deux entrées proches doivent être
représentées par deux cellules proches sur la carte.
- Être organisée i.e. il faut que deux cellules
proches aient deux vecteurs prototypes proches.
Les mesures de qualité de la clustérisation
évaluent le compromis entre l'homogénéité de chaque
cluster (ressemblance entre données affectées à un
même groupe) et la séparabilité des clusters. Pour les
cartes de Kohonen, la mesure de la séparabilité n'est pas
importante. En effet, des groupes très similaires sont possibles, s'ils
sont associés à des neurones proches au sens du voisinage; le
compromis s'effectue donc entre l'homogénéité et le
respect de la topologie (organisation). Pour déterminer la
validité de la carte obtenue, la carte doit être
évaluée suivant deux axes : la qualité des regroupements
qu'elles proposent et la qualité d'organisation des clusters. Vers le
début des années 90, les deux critères suivants
ont été proposés. Le premier est relatif
à l'homogénéité. Le second rend compte de la
préservation de la topologie.
Evaluation de l'homogénéité de la carte
L'évaluation de l'homogénéité de
la carte est effectuée en fonction de la mesure de l'erreur de
quantification proposée par Kohonen en 2001. Elle correspond à la
distance entre chaque entrée X et le centroïde du cluster auquel
elle est affectée.

-
X i
Wr
qC1 =
1 ? ? K

N r x C
= ?
1 i
i r
2 N=Nombre des vecteurs d'entrée K= Nombre de clusters
Xi= Vecteur d'entrée
Wr= Poids du centroïde du cluster
Cr
Dans le cas des cartes topologiques, le centre d'un groupe est
distinct de sa moyenne puisque les centres sont influencés par leurs
voisins du fait de la contrainte d'organisation. Par conséquent, le
calcul de l'écart au centre introduit un biais dans la mesure
d'homogénéité et sous-estime la qualité du
regroupement. Pour pallier ce problème, [Les, 03] propose de mesurer la
moyenne des variances des groupes.
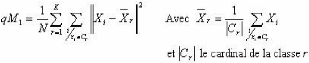
L'erreur de quantification doit tendre vers une valeur limite
en fin d'apprentissage, valeur que l'on souhaite proche de 0. [Rez, 98] propose
d'utiliser comme mesure d'homogénéité la variance moyenne
des groupes :
1 ? 1
K
*
K C
r 1
- -
X X
-
i r
Avec K* le nombre de clusters non vides.
qM2 =
2
?
=?
i
r i r
x C
Evaluation de la préservation de la topologie
L'évaluation de la préservation de la topologie
nécessite de considérer l'ordonnancement des cellules par rapport
aux relations de voisinage définies sur la carte. Ces relations sont
préservées lorsque deux vecteurs d'entrée proches sont
représentés par deux cellules proches sur la carte. Pour mesurer
la préservation du voisinage, plusieurs types de mesures essentiellement
dédiées à la formulation neuronale des cartes de Kohonen
sont proposés. La première mesure, concerne la
préservation de voisinage inverse qui consiste à vérifier
si deux cellules de la carte ont des vecteurs prototypes proches dans l'espace
d'entrée. Cette mesure a été proposée par Cottrell
et Fort [Cot, 87] pour des cartes unidimensionnelles et des


données unidimensionnelles et
généralisée à des cartes de dimension
supérieure par Zrehen et Blayo [Zre, 92]. Certaines mesures sont
calculées uniquement grâce aux neurones, sans utiliser les
données, ce qui permet une économie de temps de calcul. Elles
évaluent la corrélation entre la distance en termes de poids et
la distance imposée sur la carte i.e. entre
dWpq=
wp - wq
dZpq =
zp - zq
En effet, l'organisation impose que deux neurones soient
d'autant plus proches au sens dZ qu'ils ont des vecteurs proches en terme de
dW. Un autre type de mesures se base sur les neurones gagnants associés
aux données. Si la contrainte d'organisation est respectée, le
neurone gagnant et le second meilleur neurone sont adjacents sur la carte, pour
toute donnée. Par suite, l'erreur topographique est définie comme
la proportion de vecteurs de données pour laquelle les deux
premières unités de meilleur appariement (best matching units) ne
sont pas adj acentes.

N- 1
?d bmu bmu
( 1 2 ) 1
- ?
i=0
N
Avec N est le nombre des vecteurs d'entrée
4.2.6 Analyse de la carte topologique
Après la phase préliminaire d'apprentissage, la
carte doit être organisée de manière à fournir
unevue générale des résultats de la classification. Pour
ce faire deux phases sont proposées par Lamirel [Lam, 01] : la phase de
labellisation et la phase de la division de la carte en aire logiques.
Labellisation de la carte
C'est la première phase de l'assistance à
l'analyse des informations fournies par une carte topologique. Elle consiste
à attribuer aux classes obtenues des noms représentant au mieux
leur contenu. Cette phase de labellisation des noeuds de la carte
présente un problème. En effet, les profits des noeuds de la
carte contenant la description des classes représentent le plus souvent
des combinaisons complexes des composantes descriptives extraites des
données. Pour pallier ce problème, il est possible d'adopter les
stratégies dirigées par les profils des données qui
consistent à attribuer à chaque classe un nom représentant
la combinaison des labels des composantes dominantes du vecteur de profil du
membre le plus caractéristique de la classe, ou d'un vecteur de profil
calculé représentant le profil moyen de l'ensemble des membres de
la classe.
Division de la carte en aires logiques
La seconde phase de l'assistance à l'analyse des
informations fournies par une carte topologique consiste à diviser la
carte en »aires logiques fermées» représentées
par des groupes cohérents de noeuds. Chaque aire
considérée comme une macro-thématique, fournit une
information fiable sur l'importance relative des différentes
thématiques de base. En effet, les thématiques les plus riches en
données sont représentées par des aires plus importantes
que les thématiques correspondant à des données
marginales. Un processus de généralisation a été
proposé par [Lam, 01] afin de résumer le contenu de la carte sous
la forme d'un ensemble de classes plus génériques. Il s'agit,
à partir de la carte originale, d'introduire de nouveaux niveaux de
classification plus synthétiques, correspondant à de nouvelles
cartes, en réduisant progressivement le nombre de noeuds de ces
dernières. Comme les cartes originales ont été construites
sur la base d'une structure de voisinage carrée entre les noeuds, la
transition d'un niveau de généralisation vers un autre
s'opère alors en construisant un nouvel ensemble de noeuds, dans lequel
le profil de chaque noeud représente la composition moyenne des profils
de quatre voisins immédiats sur le niveau original.
4.2.7 Avantages et limites de la carte de Kohonen
Les cartes de Kohonen, appelées aussi cartes à
préservation de proximité, disposent de capacités
d'apprentissage automatique, d'un bon pouvoir illustratif des résultats
et d'une forte sensibilité aux données fréquentes. Elles
permettent également de réduire efficacement la complexité
calculatoire. Cependant, elles présentent certaines limites. En effet,
la gestion des paramètres tels que la taille de la grille, les valeurs
initiales des poids et le voisinage relèvent généralement
d'une certaine expertise. D'autre part, l'interprétation des groupes
constitués par les cartes de Kohonen nécessite souvent le recours
aux techniques statistiques pour comprendre les facteurs caractérisant
chacun des groupes. De plus, ce système considéré par la
communauté scientifique comme »boîte noire»
nécessite un grand ensemble d'apprentissage et ne garantie pas la
convergence pour les réseaux de grande dimension.
4.3 Conclusion
Dans ce chapitre nous avons présenté les cartes
topologiques de Kohonen, leurs caractéristiques et leurs principaux
paramètres. Nous avons également abordé le problème
de convergence de l'algorithme de Kohonen et sa qualité d'apprentissage.
Dans les chapitres suivants, nous proposons d'appliquer cet algorithme à
l'analyse de l'usage à travers la recherche de typologies de sessions
à partir des fichiers »Logs».
Deuxième partie
Méthodologie et application
Chapitre 5
Prétraitement des données
La première étape d'un processus du WUM consiste
en un prétraitement des fichiers Log. En effet, le format des fichiers
log Web est impropre à une analyse directe par les diverses techniques
de fouille des données. Leur nettoyage et leur structuration sont donc
nécessaires avant toute analyse. Dans ce chapitre, nous
présentons la méthodologie que nous avons adoptée pour le
prétraitement ainsi que les résultats de son application sur les
fichiers Log du CCK1 (Centre de Calcul elKhawarizmi).
5.1 Méthodologie de prétraitement
5.1.1 Processus de prétraitement
Différentes étapes de prétraitement
Le prétraitement des données du fichier Log
comprend les étapes illustrées par le schéma suivant :
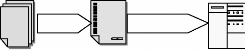
Nettoyage
Transformation
Retraitement
Base des
données
FIG. 5.1 : Processus de prétraitement
5.1.2 Nettoyage des données
Le nettoyage des données consiste à supprimer les
requêtes inutiles des fichiers »logs», à savoir :
Requêtes non valides (N1)
Ce sont les requêtes dont le statut est inférieur
à 200 ou supérieur à 399. En effet, le code d'état
(statut), entier codé sur trois chiffres, a un sens propre dont la
catégorie dépend du premier chiffre:
- 1xx indique uniquement un message informel, - 2xx indique un
succès,
- 3xx redirige le client sur un autre URL, - 4xx indique une
erreur côté client,
- 5xx indique une erreur côté serveur.
Requêtes provenant des robots Web (N2)
Il est presque impossible aujourd'hui d'identifier tous les
robots Web puisque chaque jour apparaissent des nouveaux. Pour les robots dont
l'adresse IP et le User-Agent sont inconnus, nous procédons à un
examen de leurs comportements sachant que les robots Web procèdent
à une visite relativement exhaustive (nombre de pages visitées
par un robot est supérieur au nombre de pages visitées par un
utilisateur normal) et rapide et qu'ils cherchent généralement un
fichier nommé »robot.txt». Ainsi, pour identifier les
requêtes provenant des robots ou leurs visites nous avons utilisé
cinq heuristiques en considérant qu'il suffit de vérifier une
d'entre elles pour considérer la requête correspondante comme
étant générée par un robot Web :
a. Identifier les adresses IP et les »User-Agents»
connus comme étant des robots Web. Ces informations sont fournies
généralement par les moteurs de recherche (N2a).
b. Identifier les IP ayant fait une requête à la
page »\robots.txt» (N2b).
c. Identifier les »User-Agents» comportant l'un des
mots clés suivants: »crawler», »spider» ou encore
»bot» (N2c).
d. Identifier les requêtes effectuées par des
aspirateurs de sites Web (HTTrack par exemple), ou par des modules de certains
navigateurs permettant la consultation de pages hors ligne tels que DigExt
d'Internet Explorer. L'identité de ces aspirateurs ou de ces modules est
trahie par la mention de leurs noms au niveau de leurs User-Agents. Pour les
aspirateurs qui cachent leurs User-Agents, leur identification est
effectuée ultérieurement en se basant sur la durée de
leurs requêtes généralement nulle (N2d).
e. Utiliser un seuil pour la vitesse de navigation BS
»Browsing Speed» égale au nombre de pages visitées par
seconde. Le calcul du Browsing Speed n'est possible qu'après
détermination des sessions et des visites (N2e).
Requêtes aux images (N3)
Cette étape de nettoyage consiste à supprimer
les fichiers dont les extensions sont : .jpg, .gif, .png, etc... et les
fichiers multimédia dont l'extension est : .wav, .wma, .wmv, etc. Deux
méthodes ont été utilisées pour supprimer les
requêtes aux images. La première (N3a) consiste à utiliser
la carte du site afin d'identifier les URLs des images nécessitant de
cliquer sur un lien pour être affichées. Les images inclues dans
les fichiers HTML sont supprimées car elles ne reflètent pas le
comportement de l'internaute. A titre d'exemple, la page dont l'URL est www.
cck. rnu. tn\ arabe\ ntic_ tunisie\ ntic_ ar. htm
comporte les images suivantes qui s'affichent sans avoir besoin
de cliquer sur un lien :

Cependant, ce n'est pas toujours possible d'identifier toutes
les images inintéressantes quand le site est volumineux. Dans ce cas,
nous proposons une autre méthode2 dont l'application
nécessite tout d'abord l'identification des sessions.
Requêtes dont la méthode est différente de
»GET» (N4)
Les méthodes généralement utilisées
sont: GET, HEAD, PUT, POST, TRACE et OPTIONS:
- La méthode GET est une requête d'information. Le
serveur traite la demande et renvoie le contenu de l'objet.
- La méthode HEAD est très similaire à la
méthode GET. Cependant le serveur ne retourne que l'en-tête de la
ressource demandée sans les données. Il n'y a donc pas de corps
de message.
- La méthode PUT permet de télécharger un
document, dont le nom est précisé dans l'URI, ou d'effacer un
document, toujours si le serveur l'autorise.
- La méthode POST est utilisée pour envoyer des
données au serveur.
- La méthode TRACE est employée pour le
déboguage. Le serveur renvoie, dans le corps de la réponse, le
contenu exact qu'il a reçu du client. Ceci permet de comprendre, en
particulier, ce qui se passe lorsque la requête transite par plusieurs
serveurs intermédiaires.
- La méthode OPTIONS permet de demander au serveur les
méthodes autorisées pour le document
référencé.
2voir »seconde étape de nettoyage des
images» à la page 54.
Vu que le WUM s'intéresse à l'étude du
comportement de l'internaute sur le Web et par conséquent aux ressources
qu'il demande, il faut garder seulement les requêtes dont la
méthode utilisée est GET.
Scripts (N5)
Généralement, le téléchargement
d'une page demandée par un utilisateur est accompagné
automatiquement par le téléchargement des scripts tels que les
scripts Java (fichiers .js), des feuilles de style (fichiers .css), des
animations flash (fichier .swf) ,etc. Ces éléments doivent
être supprimés du fichier Log étant donné que leur
apparition ne reflète pas le comportement de l'internaute.
Requêtes spécifiques à l'activité sur
le site (N6)
Ce sont les requêtes relatives au trafic sur le site
objet de l'analyse. Cette étape montre que la méthodologie
d'analyse du comportement des internautes sur le Web n'est pas unique et
qu'elle dépend de plusieurs facteurs, en particulier du site
analysé. Par exemple, en considérant le site du CCK, cette
étape consiste à supprimer:
- Les requêtes pour les pages »proxy.pac» (N6a).
- Les requêtes aux pages:
- http ://
www.cck.rnu.tn/haut.htm et
- http ://
www.cck.rnu.tn/haut.asp
car ces pages s'affichent automatiquement avec la page
d'accueil du site et servent d'entête (frame) pour toutes les autres
pages (N6b).
- Les requêtes pour les annonces (les popups). En effet,
les annonces apparaissent toutes seules dès que l'utilisateur se
connecte sur le site du CCK (N6c). De ce fait, les requêtes
correspondantes ne reflètent pas son comportement. Pour éliminer
ces requêtes, il faut identifier les URLs correspondantes de la forme:
www.cck.rnu.tn/popup/pop.htm
5.1.3 Transformation des fichiers Log
FIG. 5.2 : Processus de transformation des fichiers Log
Identification des utilisateurs et des sessions (T1)
Une session est composée de l'ensemble de pages
visitées par le même utilisateur durant la période
d'analyse. Plusieurs moyens d'indentification des utilisateurs ont
été proposés dans la littérature (login et mot de
passe, cookie, IP), cependant, tous ces moyens présentent des
défaillances à cause des systèmes de cache, des firewalls
et des serveurs proxy. Dans notre cas, nous considérons que deux
requêtes provenant de la même adresse IP mais de deux User-agents
différents, appartiennent à deux sessions différentes donc
elles sont effectuées par deux utilisateurs différents. Ainsi, le
couple (IP, User-Agent) représente un identifiant des utilisateurs.
Toutefois, nous ne pouvons nier la limite inhérente à cette
méthode. En effet, une confusion entre deux utilisateurs
différents utilisant la même adresse IP et le même
User-Agent est toujours possible surtout en cas d'utilisation d'un serveur
Proxy ou d'un firewall.
Chaque session est caractérisée par le nombre de
requêtes effectuées par l'utilisateur durant cette session, le
nombre de pages consultées (URLs différents) et la durée
de la session. L'algorithme que nous proposons pour l'identification des
sessions est le suivant :

FIG. 5.3 : Algorithme d'identification des utilisateurs
Identification des visites (T2)
Une visite est composée d'une série de
requêtes séquentiellement ordonnées, effectuées
pendant la même session et ne présentant pas de rupture de
séquence de plus de 30 minutes (d'après les critères
empiriques de Kimball [Kim, 00]). L'identification des visites sur le site, est
effectuée selon la démarche suivante:
- Ordonner la base suivant les variables »identifiant de
session» et temps de la requête.
- Déterminer la durée de consultation des pages
: la durée de consultation d'une page est le temps séparant deux
requêtes http diminué du temps nécessaire au chargement de
la page. Dans notre cas, nous n'avons pas considéré le temps
nécessaire au chargement des pages sachant que le site
étudié ne comporte pas de ressources sons ou vidéo. Ainsi,
la durée de consultation d'une page est calculée par la
différence entre les dates et heures des enregistrements successifs. Par
conséquent, seule la durée de consultation de la dernière
page de chaque session est inconnue. Pour l'estimer, nous avons
considéré la moyenne des durées de consultations des pages
de la même visite. Ce qui nécessite tout d'abord l'identification
des visites.
- Si la durée de consultation d'une page dépasse
30 minutes alors la page suivante dans la même session est
attribuée à une nouvelle visite (l'utilisateur a passé
plus de trente minute à lire la même page ce qui est peu probable
ou il a quitté le site pour y revenir 30 minutes après).
- Une fois les visites identifiées, la durée de
consultation de la dernière page de chaque visite (la dernière
page de chaque session et les pages dont la durée de consultation a
dépassé 30 minutes i.e. celles qui ont permis la construction des
visites) est obtenue à partir de la moyenne des durées de
consultation des pages précédentes appartenant à la
même visite.
Remarques
- Chaque visite est caractérisée par sa
durée, le nombre de requêtes effectuées et le nombre de
pages consultées par l'utilisateur pendant cette visite. La durée
d'une visite est la somme des durées de consultation des pages composant
cette visite.
- Notre analyse est entièrement basée sur les
visites et ne tient pas compte du fait que plusieurs visites peuvent provenir
d'un même utilisateur. Ceci réduit les problèmes
liés aux caches Web (Proxy), aux adresses IP dynamiques et au partage
d'ordinateurs.
Soient les variables suivantes :
· Ri= Requête i
· N = Nombre de requêtes dans la base
· V [Ri] = Visite à laquelle appartient la
requête i
· S [Ri] = Session à laquelle appartient la
requête i
· T [Ri] = Temps de déclenchement de la
requête i
· NV [Ri] = Nombre de requêtes dans la visite
à laquelle appartient la requête i
· Flag [Ri] = variable binaire
1. Ordonner les requêtes suivant la variable S [Ri] puis
la variable T [Ri].
2. Détermination de la durée de chaque
requête:
i=1;
Pour i de 1 à N-1
Si S [Ri] =S [Ri+1]
Alors
Durée [Ri] = T [Ri+1] - T [Ri] ;
Flag [Ri] = 1;
Sinon
Flag [Ri] = 0 ; (Ri est la dernière requête de la
session) FinSi
i = i+1 ;
FinPour
Flag [RN] = 0; (RN est la dernière requête dans la
base)
1. Construction des visites:
V [R1] = 1; Pour i de 1 à N
Si Durée [Ri] > 30 minutes ou Flag [Ri] = 0
Alors
V [Ri+1] = V [Ri] +1;
Sinon
V [Ri+1] = V [Ri] ;
FinSi
i = i+1 ; FinPour
2. Détermination de la durée de la dernière
requête de chaque visite:
i=1 ;
Pour i de 1 à N-1
Si Flag [Ri] = 0 ou Durée [Ri] > 30 minutes
Durée [Rk])/ NV [Ri] -1 Tel queV [Rk] = V
[Ri]
FinSi
i = i+1 ; FinPour
Alors Durée [Ri] = (
Dans la suite, nous présentons un fichier Log (fig.
5.5.) sur lequel nous appliquons l'algorithme d'identification des sessions
(fig. 5.3.) et celui d'identification des visites (fig. 5.4).
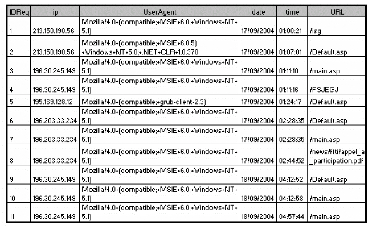
FIG. 5.5 : Fichier Log avant transformation
FIG. 5.6 : Exemple d'exécution de l'algorithme
d'identification des visites
* Il s'agit de calculer la durée de la dernière
requête de chaque visite et la durée de chaque requête dont
la durée initiale dépasse 30 minutes (internaute distrait, pause,
internaute qui a quitté son poste sans se déconnecter). Les
visites composées d'une seule requête ne sont pas
considérées car, d'une part, il n'est pas possible d'estimer la
durée d'une seule requête, d'autre part, elles sont
éliminées dans la phase de retraitement puisqu'elles ne
présentent aucun intérêt pour notre analyse.
FIG. 5.7: Fichier Log après transformation
5.1.4 Retraitement des fichiers Log
Seconde étape de nettoyage des images (N3b)
La seconde méthode que nous proposons pour
éliminer les images téléchargées sans intervention
de l'internaute consiste à supposer qu'un utilisateur ne peut cliquer
à la fois (au même instant) sur plusieurs images pour les
visualiser; Tenant compte de cette hypothèse, nous déterminons
pour chaque utilisateur l'ensemble des requêtes effectuées au
même instant. Les requêtes correspondantes à des fichiers
images sont éliminées.
L'exemple suivant montre que plusieurs images peuvent
apparaître en même temps (9 :56 :40) à l'écran d'un
utilisateur unique. Une simple vérification sur le site a montré
que plusieurs images sont contenues dans la page
www.cck.rnu.tn/default.htm
(fig 5.8)
et dont les URLs sont présentées dans la figure
5.9.

FIG. 5.8 : Exemple de pages contenant plusieurs images
FIG. 5.9 : URLs des images contenues dans la page Seconde
étape d'identification des robots (N2e)
La seconde phase d'identification des robots repose sur la
vitesse de navigation »Browsing Speed» obtenues en divisant la
durée de la visite par le nombre de requêtes effectuées par
visite.
BS = durée Vis ite/NbReqPar Vis ite
En adoptant les critères proposés par [Tan, 03],
nous considérons que les visites vérifiant les conditions
- BS[Vk] > 2 pages/seconde
Et
- N[Vk]>15 pages
sont effectuées par des robots Web. Elles sont, par
conséquent, supprimées. Filtrage des requêtes et des
visites
Cette phase vise à ne garder que les requêtes et
visites supposées porteuses d'informations. En d'autre termes, elle
consiste à supprimer »le bruit» dans les données. Pour
ce faire, nous considérons les deux variables suivantes :
- Durée _min : la durée minimale de consultation
d'une page par l'utilisateur, - Nbpages_min: le nombre minimal de pages que
peut contenir une visite.
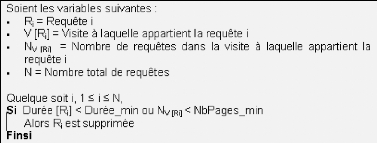
FIG. 5.10 : Algorithme de filtrage des visites et des
requêtes
Dans notre cas, en prenant Durée _min = 15 secondes et
NbPages_min = 2 pages nous avons considéré que les requêtes
dont la durée est nulle (ou presque nulle) et les visites
constituées d'une seule page sont inintéressantes pour notre
analyse. Généralement, les requêtes dont la durée
est nulle correspondent à des processus automatiques (indexation par un
robot ou enregistrement par un aspirateur) ou à des requêtes
interrompues avant chargement complet de la page. Les codes d'état le
montrent bien. En effet, environ 20.4% de ces requêtes ont
été servies en code 3xx i.e. redirection sur un autre URL ou en
206 i.e. document chargé partiellement. L'examen des User-Agents des
requêtes servies correctement (code 200) permet de penser que ce sont des
consultations des robots, en particulier des aspirateurs des sites Web. En
effet, environ 91% de ces requêtes sont effectuées par le
User-Agent de windows-IE (MSIE) qui permet le téléchargement des
pages Web pour consultation o- ine avec une durée nulle entre
l'enregistrement des pages. Les visites composées d'une seule page sont
considérées comme du »bruit» ne ramenant aucune
information utile. Cependant, l'examen des URLs de provenance (Referrer) des
requêtes composant ces visites montre que dans 30% des cas, l'internaute
parvient au site à travers un moteur de recherche (Google, Yahoo,
Altavista) ce qui explique pourquoi l'utilisateur ne visite qu'une seule page
dans le site (i.e. le moteur lui envoie la page qui répond le mieux
à sa requête).
Création de nouvelles variables
A partir des variables préexistantes, nous allons
créer de nouvelles variables permettant de faciliter l'analyse
envisagée. D'autres variables peuvent être créées
suivant la nature de l'analyse envisagée.
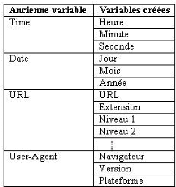
TAB. 5.1 : Création de nouvelles variables

TAB. 5.2 : Transformation de la variable URL
La création des variables »Navigateur»,
»Version» et »Plateforme» à partir de la variable
»User-Agent» n'est pas aisée pour plusieurs raisons:
- La difficulté de décryptage du User-Agent:
D'une part, les navigateurs utilisent des formats
différents pour s'identifier (absence de format standard). En effet,
Netscape présente généralement un User- Agent de la
forme:
Produit [langue] (plateforme; niveau de
sécurité3; description du système
d'exploitation)
Par exemple, Mozilla / 4.04 (X11; I; SunOS 5.4 sun4m)
Par contre, Internet Explorer présente un format
différent :
Mozilla/4. 0 (compatible; MSIE 5. 23; Mac_ PowerPC).
D'autre part, la version du navigateur n'est pas toujours
explicite. Il faut dans certains cas la dégager à partir du
»Build Number». Dans l'exemple Mozilla/5.0 (Macintosh; U; PPC Mac OS
X; de-de) Apple WebKit/85. 7 (KHTML, like Gecko) Safari/85.7, le »Build
Number» vaut 85.7 et le navigateur est Safari dont la version est 1.0
- La guerre entre les navigateurs:
Cette histoire remonte à la grande époque de
Netscape. En effet, plusieurs sites ne fournissent leurs versions riches
qu'à Netscape. Comme ce dernier utilise depuis toujours le nom de code
Mozilla dans la chaîne User-Agent pour s'identifier, Internet Explorer
reprend cette même identification dans ses premières versions, en
rajoutant la mention compatible. Par exemple,
Mozilla/4. 0 (compatible; MSIE 5. 22; Mac_ PowerPC) ne correspond
pas à Netscape 4.0 comme on peut le croire. Il s'agit plutôt
d'Internet Explorer 5.22.
Certains navigateurs peuvent être tentés de faire
de même pour se faire passer pour IE, comme IE se faisait passer pour
Netscape. C'est l'exemple du navigateur Opéra qui peut avoir un
User-Agent de cette forme:
Mozilla/4. 0 (compatible; MSIE 6.0; Windows NT 5.1) Opera 7.54
[fr]
- La difficulté d'identification du système
d'exploitation : En effet, souvent le système d'exploitation Windows
s'identifie en utilisant des noms de versions différentes de celles
réelles. Le tableau suivant présente les versions
mentionnées dans le User-Agent et les versions réelles
correspondantes.
3Prend les valeurs : » U » pour
sécurité de haut niveau et » I» pour
sécurité faible

TAB. 5.3: Identification du système d'exploitation
- Le changement du User-Agent par l'internaute:
Les utilisateurs de nombreux navigateurs (Opéra,
Mozilla, et autres navigateurs alternatifs) peuvent changer eux-mêmes la
chaîne User-Agent. Cette manipulation est souvent réalisée
pour contourner des filtrages de sites incompatibles avec ces nouveaux
navigateurs, pour effectuer des tests (par les développeurs) ou pour
faire face au blocage des User-Agents des aspirateurs par des sites
professionnels. »User-Agent Switcher»4 permet de faire
passer un navigateur pour un autre, voire de s'inventer un nouveau User-Agent.
Il est également possible de modifier le format de la ligne
»User-Agent» envoyée au cours de la requête http pour
cacher le type du navigateur utilisé.
L'examen des User-Agents des différents navigateurs
nous a permis de dégager les règles suivantes:
- Netscape utilise toujours le nom de code Mozilla dans la
chaîne User-Agent pour s'identifier. A partir de la version Mozilla 5.0,
on ne parle plus de Netscape, on parle plutôt de navigateurs Gecko.
- Internet Explorer, dans ses premières versions,
s'identifie également par le nom de code Mozilla, en rajoutant la
mention »compatible» suivie par la chaîne »MSIE».
Aucun autre nom de navigateur n'est présent dans le User- Agent.
- Mozilla, Netscape 6/7 et les autres navigateurs Gecko sont
définis par la présence de la chaîne »Mozilla
5.0» et le mot-clé »Gecko». La version de Mozilla est
précédée par l'abréviation »rv». Celle
des autres navigateurs est présentée à la fin,
précédée par le nom du navigateur.
- Les navigateurs »KHTML-based» tels que Konqueror
de Linux et Safari d'Apple se présentent par leurs noms, leurs versions
et la mention »compatible» ou (KHTML, like Gecko) pour montrer leur
compatibilité avec les navigateurs Gecko.
- Le navigateur Opera, qui s'identifie par défaut comme
Internet Explorer, est défini par la présence de la chaîne
»Opera» suivie de la version.
Le tableau 5.4 présente un exemple sur le
décryptage du User-Agent.
4http : //
www.chrispederick.com/work/firefox/useragentswitcher/
TAB. 5.4 : Décryptage du User-Agent
La succession chronologique de ces étapes est
illustrée par la figure 5.11.

FIG. 5.11 : Succession chronologique des étapes de
prétraitement
5.1.5 Modélisation des unités d'analyse
Soit L le fichier Log composé de l'ensemble de
requêtes effectuées par les utilisateurs du site L = {R1,
R2;..., RN}. Sachant que le nombre d'utilisateurs du site est n, le
fichier L est décomposé en sessions L = {S1, S2, ...,
Sn}. Chaque session est décomposée en visites Si =
{Vi1, Vi2, ..., Vipi}, avecVij est la jème visite
effectuée par l'utilisateur i.
Une requête effectuée par l'utilisateur Uk
à la page Pk dont l'URL de provenance est refk et la réponse du
serveur est rk peut être représentée par le vecteur suivant
: Rk = (Uk, Pk, tk, rk, refk), avec tk est le temps passé par
l'utilisateur sur la page Pk. En ajoutant la visite et la session auxquelles
appartient chaque requête, le vecteur devient : Rk = (Uk, Pk, tk, rk,
refk, Vk, Sk)
Comme dans notre cas, nous ne disposons d'aucune information
sur les utilisateurs, chaque utilisateur est défini par sa session, par
suite, nous avons le vecteur suivant : Rk = (Pk, tk, rk, refk, Vk, Sk)
5.1.6 Schéma relationnel
Afin de pouvoir traiter l'information contenue dans la base le
plus simplement et le plus efficacement possible, il faut restructurer la base
selon le schéma relationnel. Nous disposons d'un ensemble de
règles telles que:
- Une même page peut être demandée par des
utilisateurs différents donc des »IPs» et des
»User-Agents» différents.
- Inversement, le même utilisateur peut demander plusieurs
pages du site.
- A la demande d'une page correspondent plusieurs types de
réponses du serveur donc plusieurs »statuts».
- Inversement, le même statut peut être
attribué à plusieurs demandes de pages différentes.
Comme la relation entre la variable »URL» et toutes
les autres variables (» IP», »User- Agent»,
»statut», »date», »time», »referrer»)
est de type plusieurs à plusieurs (n-m), il faut la scinder en deux
relations : une relation »un - plusieurs» et une relation
»plusieurs - un». Nous obtenons alors le schéma relationnel
suivant.
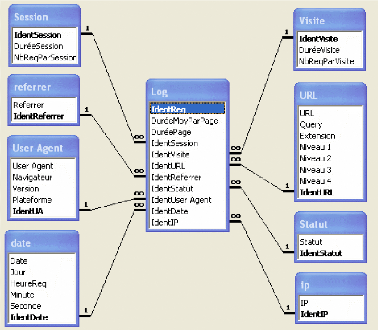
FIG. 5.12 : Schéma relationnel
5.2 Résultats de l'analyse des fichiers Log du
CCK
5.2.1 Corpus expérimental
Il est constitué de l'ensemble de requêtes
adressées au site du CCK (Centre de Calcul elKhawarizmi) pendant la
période allant du 17 Septembre au 14 Octobre 2004. Le fichier est
composé de 279879 requêtes enregistrées suivant la norme
ECLF (Extended Common Log Format). Pour chaque requête, nous disposons
des champs suivants: la date de réalisation de la requête (date),
l'heure à laquelle elle s'est produite (time) , l'adresse IP du client
ayant accédé au serveur (c- ip), le nom de l'utilisateur
authentifié ayant accédé au serveur (cs-username) ,
l'adresse IP du serveur (s - ip), le numéro du port auquel le client est
connecté (s - port), la méthode i.e. l'action que tentait de
réaliser le client (method), la ressource à laquelle un
accès a lieu (cs - uri - stem), éventuellement la requête
que le client a essayé d'effectuer (cs - uri - query), la réponse
du serveur (sc - status), le nombre d'octets reçus par le serveur (cs -
bytes), la durée de l'action (time - taken), l'agent utilisé par
l'utilisateur (cs(User - Agent)), le référant ou URL de
provenance (cs(Referer)). La figure 5.13 présente les données
dans leur forme brute:
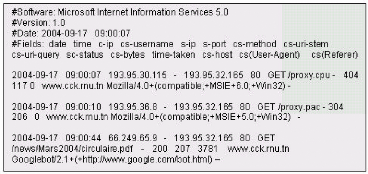
FIG. 5.13 : Fichier d'enregistrement d'accès
Les variables qui prennent une valeur unique sont
éliminées, à savoir csusername (tous les utilisateurs sont
anonymes), s- ip (car il s'agit d'un serveur unique), s-port (prend la valeur
80) et cs-host car nous travaillons sur un site unique (étude
mono-site).
5.2.2 Résultats
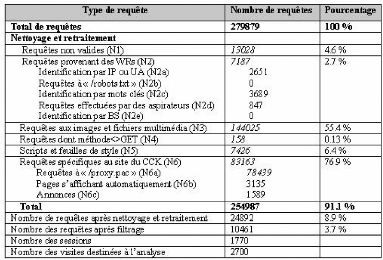
TAB. 5.5 : Tableau récapitulatif des résultats
Remarques
- L'étape N2a de suppression des requêtes des WRs
nécessite l'établissement d'une liste des adresses IP (2644
adresses collectées) et une liste de UserAgents5 (1073 User-
Agents collectés). Les requêtes provenant d'une des adresses IP ou
d'un des User-Agents présents dans les deux listes sont
supprimées.
- Dans le cas du traitement des fichiers Log du CCK, une seule
image est affichée à la demande de l'internaute. Cette image a
pour URL:
/français/reseau_ rnu/images/reseau.jpg
Toutes les autres images sont contenues dans les pages Web du
site et elles sont affichées sans intervention de l'utilisateur.
5.3 Conclusion
La nouvelle taille de la base (3.7% de la taille initiale)
montre bien l'importance de l'étape du prétraitement des fichiers
Log, en particulier la phase du nettoyage. Cette étape a abouti à
des fichiers nettoyés et structurés, prêts à
l'analyse par l'application des méthodes de fouille des
données.
Chapitre 6
Classification des utilisateurs
Une fois les fichiers Logs nettoyés et
structurés dans une base des données, il est possible d'appliquer
les méthodes de fouille des données pour la classification des
utilisateurs. Cette classification est effectuée en deux étapes.
La première étape consiste à classifier les pages du site
visitées par les internautes de manière à ne garder dans
la base que les requêtes aux pages présentant un contenu
intéressant aux visiteurs. La seconde étape consiste à
classifier les visiteurs du site Web en se servant de la base de requêtes
aux pages intéressantes.
6.1 Classification des pages
On distingue deux types de pages : les pages de contenu et les
pages de navigation, appelées aussi pages auxiliaires. Les pages
auxiliaires sont utilisées pour faciliter la navigation de l'utilisateur
sur le site. Les pages de contenu sont les pages qui présentent
l'information recherchée par l'internaute. Cependant une page de contenu
pour un internaute peut être une page de navigation pour un autre. Comme
nous cherchons à comprendre le comportement de l'internaute
vis-à-vis du site visité, en particulier les motifs de sa visite,
nous ne considérons que les pages de contenu. Le problème qui se
pose dans ce cas est comment distinguer les pages de contenu des pages de
navigation. Notre approche consiste à reconstruire la topologie du site
Web à partir des requêtes enregistrées dans les fichiers
Logs et définir des variables servant à la caractérisation
des pages et leur classification.
6.1.1 Reconstruction de la topologie du site
La première étape consiste à indexer les
pages du site Web pour faciliter leur manipulation. L'exemple suivant illustre
cette étape.
FIG. 6.1 : Exemple de visite
FIG. 6.2 : Indexation des pages de la visite
Une fois les pages visitées par les internautes
indexées, un arbre est construit. La racine de l'arbre est le premier
referrer non externe dans le ...chier log. Pour chaque requête, si le
referrer ou l'URL demandée n'est pas dans l'arbre, un noeud
représentant la page est crée. Pour chaque couple de noeuds, si
l'un est le referrer de l'autre alors un lien entre les deux noeuds est
établi. Il en résulte la construction d'un graphe
représentant la structure des hyperliens.
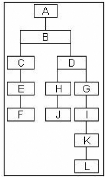
FIG. 6.3 : Arbre du site
6.1.2 Matrice d'hyperliens
L'arbre représentant la topologie du site Web peut
être traduit par une matrice. Cette représentation matricielle
présente l'avantage de simpli...er la représentation sous forme
d'arbre qui devient incompréhensible dans le cas où le nombre de
liens entre les pages est élevé. Chaque ligne de la matrice
correspond à un noeud de l'arbre et représente une page du site.
Il en est de même pour chaque colonne. Ainsi, s'il existe N pages
différentes visitées par les internautes, la matrice d'hyperliens
sera de dimension (N, N). Chaque entrée (i,j) de la matrice prend la
valeur 1 si l'utilisateur a visité la page j à partir de la page
i (présence d'un lien direct entre les deux pages) et la valeur 0 sinon.
Cette matrice est utilisée pour calculer le nombre d'inlinks (nombre
d'hyperliens qui mènent à la page en question à partir des
autres pages) et le nombre d'outlinks (nombre d'hyperliens dans la page qui
mènent vers d'autres pages). En effet, le nombre d'inlinks est le total
sur les lignes alors que le nombre d'outlinks est le total sur les colonnes.
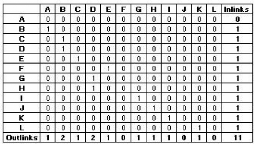
FIG. 6.4 : Matrice d'hyperliens
Toutefois, il ne faut pas oublier que certaines pages du site
ne sont pas visitées par les internautes et que certains liens dans les
pages visitées ne sont pas utilisés. Ces pages et hyperliens ne
sont pas considérés dans cette représentation matricielle
qui ne prend que les accès enregistrés dans les fichiers Logs.
6.1.3 Matrice d'accès
Cette matrice est utilisée pour identifier la
fréquence d'usage des pages et la fréquence d'usage des
trajectoires »usage paths». Chaque entrée (i ,j) de la matrice
représente le nombre de visites effectuées de la page i à
la page j. Si cette entrée est égale à zéro alors
la page j n'a jamais été visitée à partir de la
page i. Cette matrice permet d'identifier les pages les plus visitées et
les trajectoires les plus parcourues. Ces deux informations sont utiles pour la
réorganisation des sites Web en vue de la personnalisation des services
Web.
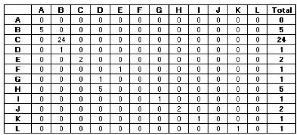
FIG. 6.5 : Matrice d'accès
En considérant les données log du CCK, nous
identifions les pages - »/main.asp» (15.11% des visites),
- »/isg» (10.18%),
- »/Default.asp» (7.53%)
- »/news/bourse _suedoise. htm» (2.41%)
comme étant les pages les plus visitées,
- »/arab e/index. htm» => »/arabe/main.
htm» (1.15%),
- »/haut .asp» =>
»/français/votrecompte/votre _compte.htm» (1.15%) -
»/haut .asp» => » /français/liens _utiles/liens
_utiles. htm» (0.82%) parmi les trajectoires les plus parcourues.
6.1.4 Collecte d'informations sur les accès
Afin de caractériser les pages visitées par les
internautes, les variables suivantes sont définies pour chaque page:
- Nombre de visites (NV) - Nombre des inlinks (NI) - Nombre
des outlinks (NO)
- Durée moyenne par page : temps passé en moyenne
par tous les internautes sur la page (DM)
- Taille du fichier1 (TF)
- Type du fichier (.html, .doc, .pdf, .rtf, etc) (TYF)
Ainsi, chaque page peut être représentée par
un vecteur: Page = {NV, NI, NO, DM, TF, TYF}
Hypothèses
1. Pour la variable TYF, nous supposons que les pages dont
l'extension est ».doc, .pdf, .rtf» sont des pages de contenu. Par
conséquent, nous ne considérons dans la suite que les pages
».asp» et ».html» auxquelles nous appliquons l'ACP.
2. Les pages de contenu, contrairement aux pages auxiliaires
sont caractérisées par un nombre faible de visites, d'inlinks et
d'outlinks et une durée moyenne de consultation assez
élevée.
6.1.5 Application de l'analyse en composantes
principales
En considérant les variables NV, NI, NO et DM, nous avons
appliqué l'ACP au tableau (pages £ variables).
A partir des coordonnées de ces variables sur les axes
factoriels, une étiquette est donnée aux deux premiers axes qui
représentent à 80% près l'allure du nuage initial (Fig.
6.6). Le premier axe factoriel est expliqué par les trois variables NV,
NI et NO. Il oppose les pages les plus fréquentées (nombre de
visites élevé) et ayant un nombre important d'inlinks et
d'outlinks aux pages les moins fréquentées et
caractérisées par un faible nombre d'inlinks et d'outlinks. Le
second axe factoriel est celui de la durée moyenne de consultation de
pages.
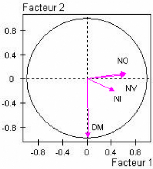
FIG. 6.6 : Projection des variables sur les axes factoriels
Il est possible d'interpréter les positions des points
individus (pages) sur les axes conformément au sens que nous lui avons
donné à partir des points variables. Les pages ainsi
projetées définissent quatre classes (Fig. 6.7).
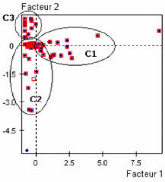
FIG. 6.7 : Projection des individus sur les axes factoriels
La première classe (C1) est composée de pages
visitées fréquemment et caractérisées par un nombre
important d'inlinks et d'outlinks. Elle correspond à la classe de pages
auxiliaires ou de navigation. La deuxième classe (C2) est celle de pages
de contenu caractérisées par une durée de consultation
assez élevée. L'intersection de ces deux classes est
composée de pages présentant à la fois les
caractéristiques des pages de contenu et des pages auxiliaires. C'est la
classe de pages hybrides (C4). La dernière classe (C3) est celle des
pages visitées rarement, qui ne pointent nulle part et vers lesquelles
pointent peu de pages. La durée moyenne de consultation de ces pages est
faible. Nous considérons que ces pages correspondent à ce que
[Rao, 96] appelle »pages de référence» utilisées
pour définir un
concept ou expliquer des acronymes ou présenter des
références bibliographiques. Cependant, nous considérons
que ces pages sont, dans une certaine mesure, des pages de contenu. En
examinant les coordonnées des points-individus sur les axes factoriels,
il est possible d'identifier les éléments qui composent chaque
classe.
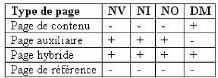
FIG. 6.8 : Caractérisation des pages
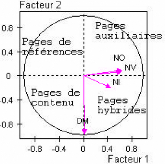
FIG. 6.9: Classification des pages
A partir d'un total de 652 pages, nous avons identifié
135 pages auxiliaires. Les autres pages sont des pages de contenu, des pages
hybrides et des pages de référence. L'ensemble des 517 pages
restantes et présentant un certain intérêt à
l'internaute fait l'objet de notre analyse.
6.2 Classification des utilisateurs
Cette phase de classification est réalisée en
trois étapes. La première consiste à classifier les
requêtes effectuées par les internautes afin de découvrir
des motifs de navigation. Les résultats de cette première
classification sont injectés dans la base des visites utilisée
pour classifier les internautes et découvrir des groupes
d'utilisateurs.
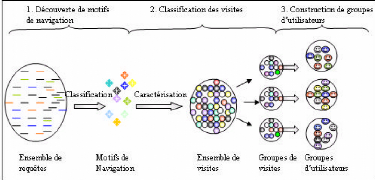
FIG. 6.10 : Etapes de classification des utilisateurs
6.2.1 Découverte de motifs de navigation
Un motif de navigation est un usage du site par ses
utilisateurs. La découverte de motifs de navigation est effectuée
à deux niveaux en combinant deux méthodes de classification (Fig.
6.11). La première est l'analyse des correspondances multiples
utilisée pour réduire la dimension de l'espace d'entrée
(la base des requêtes). La seconde est la carte topologique de Kohonen
utilisée pour déterminer des groupes de requêtes.
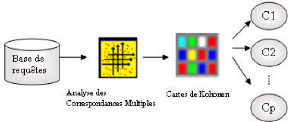
FIG. 6.11 : Etapes de classification des requêtes Analyse
des correspondances multiples
L'analyse des correspondances multiples (ACM) met en
évidence des types d'individus (les requêtes dans notre cas) ayant
des profils semblables relativement aux attributs choisis pour les
décrire. Les variables utilisées dans cette analyse sont
présentées dans le tableau 6.1.
Les axes factoriels résultant de l'application de l'ACM
servent de variables d'entrée (inputs) pour la seconde méthode de
classification. Dans notre cas, 15 axes factoriels expliquent plus de 82% de
l'inertie totale.
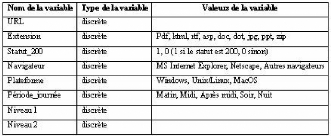
TAB. 6.1 : Variables utilisées dans l'ACM
La projection de la variable »statut_200» sur les
deux premiers axes factoriels a permis de catégoriser les requêtes
en deux classes nettement séparées. Une classe de requêtes
réussies »statut = 200», et une classe de requêtes non
réussies (fig. 6.12).
FIG. 6.12 : Projection de la variable »Statut_200»
sur les deux premiers axes
factoriels
La projection de la variable »plateforme» sur le
deuxième plan factoriel (axe 1, axe 3) catégorise les
requêtes en quatre classes. La classe majoritaire (95% de l'ensemble de
requêtes) est celle de requêtes effectuées par des
utilisateurs du système d'exploitation »Windows». Par contre,
une minorité utilise »Macintosh» (0.97%) ou
»Unix/Linux» (2.31%).
La projection des autres variables descriptives sur les axes
factoriels permet de dégager d'autres informations sur les internautes
à savoir le navigateur utilisé, l'extension des fichiers les plus
demandés, la période de la journée pendant laquelle la
majorité des requêtes sont effectuées.
Cartes de Kohonen
En plus des axes factoriels résultant de l'application
de l'analyse des correspondances multiples (ACM), nous avons ajouté la
variable »durée de la requête» comme variable
d'entrée. L'application des cartes de Kohonen a aboutit à une
grille de 16 noeuds. Comme l'obtention des groupes très similaires est
possible s'ils sont associés à des neurones proches au sens du
voisinage, il est nécessaire de diviser la carte en aires logiques
composées par des groupes cohérents de noeuds en se basant sur
leurs profils et attribuer des labels à chaque groupe de noeuds.
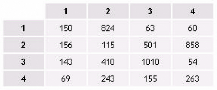
FIG. 6.14 : Grille résultant de l'application des cartes
de Kohonen
La caractérisation des classes obtenues par les
variables »niveau 1» et »niveau 2»
déterminées à partir de la variable »URL» a
donné le résultat présenté dans la figure 6.15.
En examinant les éléments caractérisant
chaque classe, il est possible d'attribuer un label à chaque classe. La
figure 6.16 présentant la carte après division en aires logiques
et labellisation met en évidence cinq classes de requêtes
correspondant à cinq motifs de navigation: institutions universitaires,
activités de recherche, congrès, services CCK et cours. Ainsi,
à chaque requête est attribuée une rubrique
sémantique. L'ensemble de ces rubriques est injecté dans la base
des visites afin d'attribuer à chaque visite un ou plusieurs motifs de
navigation qui serviront à la classification des utilisateurs.
|
Classe 1 1
|
Classe 1 2
|
|
|
|
|
|
Classe 1 3
|
|
Classe 1 4
|
|
|
Utm, fsegt, isetso, FSJEGJ, fsegs, isetjb,
|
|
|
News, rapport
|
|
|
|
|
|
emcis,
|
Pacom2004,
news
|
|
|
|
Isg, ISG, univ7nc, isffs, Utm, Isetr
|
|
|
|
|
|
isetke, isci,
|
|
|
|
|
|
|
|
|
Classe 2 1
|
Classe 2 2
|
|
|
|
|
|
|
Classe 2 3
|
|
Classe 2-4
|
|
Isg, fsegt, isetr fdseps, utm, fsb, ipeis,
|
|
|
|
|
|
|
|
|
|
|
News, master,
|
|
news
|
|
|
Isetjb, ihec,
|
isetr, isffs,
|
|
|
ipeis,
isggb,
|
|
|
|
|
|
isetso, Isetjb,
|
|
|
Isamgb,
|
|
|
|
|
|
|
|
|
Classe 3-3
Isetr, isetgb, isetzg, isggb, isamgb, esstss, biruni, fmdm
|
Classe 3-4
|
|
|
Classe 3 1
|
|
|
Classe 3 2
|
|
Larodec, master,
isetgb,
news, Isggb, fsegt,
|
|
Français, english,
|
|
|
Sbenyahia, rapport,
isg
|
|
Arabe
|
|
|
biruni,
|
|
|
|
|
|
|
|
|
Classe 4 2
|
|
|
Classe 4 3
|
|
Classe 4-4
|
|
Classe 4 1
|
|
|
|
|
|
|
|
|
mhiri_s
|
Rapport,
|
|
News,
larodec, Master, isggb,
|
|
Sbenyahia,
|
|
|
Français
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
FIG. 6.15 : Caractérisation des classes résultant
de l'application des cartes de
Kohonen
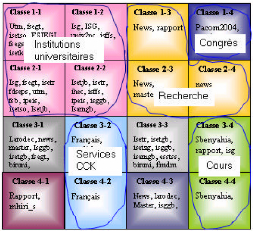
6.2.2 Construction de groupes d'utilisateurs
La construction de groupes d'utilisateurs est effectuée
en deux étapes. La première étape consiste à
attribuer à chaque visite un ou plusieurs motifs de navigation,
caractériser les visites par un ensemble de variables et les regrouper
en classes. La seconde étape consiste à construire à
partir des groupes de visites des groupes d'utilisateurs et les
caractériser. La classification des visites est effectuée selon
le schéma suivant.
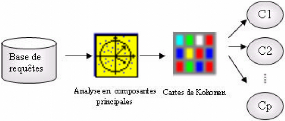
FIG. 6.17 : Etapes de classification des visites
En effet, afin de réduire l'espace des variables, nous
avons recourt à l'application de l'ACP. Les axes factoriels obtenus sont
utilisés comme des variables d'entrée pour les cartes de
Kohonen.
Analyse en composantes principales
L'ACP s'applique à un tableau (individus £
variables). Les variables considérées sont continues. Dans notre
cas, les individus sont les visites et les variables considérées
sont présentées ci-dessous.

TAB. 6.2: Variables utilisées dans l'ACP
A partir des coordonnées de ces variables sur les axes
factoriels, une étiquette est donnée aux trois premiers axes qui
expliquent environ 90% de l'inertie totale du nuage des points. Le premier axe
factoriel est expliqué par les deux variables »Duree _visite»
et »DureeMoyPage» . Le deuxième axe factoriel est
expliqué par les variables »PourcReqDiff» et »PourcReqO
k» . Le troisième axe factoriel est expliqué par la variable
»NbReqVisite» . La projection des visites sur le deuxième plan
factoriel montre trois nuages de points non disjoints.
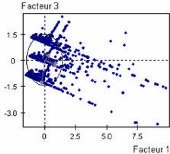
FIG. 6.18 : Résultat de l'application de l'ACP à la
base des visites
Pour aboutir à un meilleur résultat, nous avons
recourt à la combinaison de l'ACP avec une seconde méthode de
classification à savoir les cartes de Kohonen.
Cartes de Kohonen
L'application des cartes de Kohonen met en évidence
trois classes de visites. La première classe est composée de
visites dont la durée moyenne de la visite, le nombre moyen de
requêtes par visite et la durée moyenne de consultation des pages
sont assez élevées en comparaison avec les deux autres classes.
Ceci s'explique par le fait que ces visites sont effectuées
principalement dans le but de télécharger des cours ou visiter
des institutions universitaires. La troisième classe est
caractérisée par le pourcentage le plus élevé de
requêtes réussies (95%) et de requêtes différentes
(98%). Ces visites sont effectuées afin de profiter des services fournis
par le CCK tels que les services Internet, les services de calcul, le compte
Internet. La deuxième classe comporte des visites dont l'objectif est
d'avoir des informations sur les congrès, les colloques,.. etc.
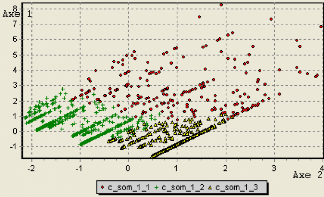
FIG. 6.19 : Résultat de la classification des visites
Pour chaque groupe de visites, un groupe d'utilisateurs est
construit contenant tous les utilisateurs possédant au moins une visite
dans ce groupe de visites. Ainsi, nous obtenons des groupes d'utilisateurs
ayant le même motif de navigation. Le premier groupe est celui des
universitaires dont l'objectif de la navigation sur le site est le
téléchargement des cours, l'inscription dans les
établissements universitaires et la visite des bibliothèques
universitaires. Le deuxième groupe est celui des chercheurs qui
demandent des informations sur les congrès, les colloques, les
mastères et les thèses et visitent les laboratoires de recherche
(Larodec2 par exemple). Le troisième groupe est celui des
visiteurs du site du CCK afin de profiter des services qu'il fournit. Un
dernier groupe est déjà défini lors du pré-
traitement des fichiers Logs et dont les requêtes ont été
supprimées. Il s'agit des agents et robots utilisés par les
moteurs de recherche pour parcourir les sites Web et mettre à jour leurs
index de recherche.
La caractérisation de ces groupes en se servant des
variables disponibles tels que le navigateur et la plateforme donne les
résultats suivants:

TAB. 6.3 : Caractérisation des classes d'utilisateurs
par les variables
»navigateur» et »plateforme»
La classe des chercheurs présente une certaine
différence par rapport aux deux autres classes. En effet, 10% des
utilisateurs appartenant à cette classe utilisent des navigateurs
différents de Microsoft Internet Explorer et 6% utilisent des
systèmes d'exploitation différents de Microsoft Windows.
6.3 Procédure de classification d'une visite
Dans cette section, nous avons pour objectif de classifier un
utilisateur du site dans l'une des catégories définies
précédemment en fonction de son comportement sur le site. Pour ce
faire, nous considérons une de ses visites au site i.e. un ensemble de
requêtes effectuées par un couple (IP, User Agent) dont le
délai séparant deux requêtes consécutives ne
dépasse pas 30 minutes. D'après la méthodologie que nous
avons proposée, il faut tout d'abord identifier les requêtes aux
pages de contenu de celles effectuées aux pages auxiliaires, ensuite,
découvrir le motif de navigation de l'internaute. Selon son motif de
navigation, l'internaute sera affecté à l'une des
catégories des utilisateurs du site. A titre d'exemple, prenons la
visite suivante effectuée par un utilisateur dont l'adresse IP et le
User Agent sont les suivants:
2Laboratoire de Recherche Opérationnelle, de
Décision et de Contrôle de processus
- 196.203.33.14
- Mozilla/4.0+(compatible ;+MSIE+6.0 ;+Windows+NT+5. 1)
Les requêtes effectuées par cet utilisateur sont
présentées dans la figure suivante:
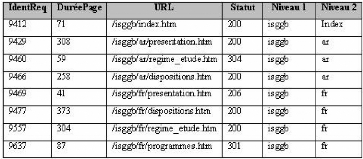
TAB. 6.4: Visite à classifier
D'après les résultats de la classification des
pages effectuée à la section 1 de ce chapitre, nous identifions
la requête 9412 comme une requête à une page auxiliaire. Les
autres requêtes sont effectuées sur des pages de contenu. La
variable »Niveau 1» permet d'identifier le motif de navigation en se
servant des figures 6.15 et 6.16. Ainsi, le motif de navigation correspondant
est »institutions universitaires». De plus, si nous examinons les
variables : durée de la visite (1501 secondes, environ 13 minutes),
durée moyenne par page (187, 6 secondes) et nombre de requêtes par
visite (8 requêtes) dont les valeurs sont assez proches des valeurs
moyennes de la première classe (Durée moyenne des visites = 1728,
Durée moyenne par page = 233 secondes et nombre moyen de requêtes
par visite=5, 5) nous pouvons affecter l'internaute, qui a effectué
cette visite, à la classe des universitaires dont l'objectif est la
visite des institutions universitaires et le téléchargement des
cours.
6.4 Conclusion
La classification des utilisateurs du site se résume en
deux étapes : classification de requêtes puis classification des
visites. Au niveau de chaque étape, nous avons effectué une
classification à deux niveaux en se servant de deux méthodes de
classification. Ce travail a aboutit à la découverte de quatre
groupes d'utilisateurs du site du CCK à savoir des universitaires ayant
pour centre d'intérêt les activités des institutions
universitaires et le téléchargement des cours, des chercheurs
ayant pour seul centre d'intérêt les activités de recherche
des unités et laboratoires de recherche, des visiteurs ayant pour
objectif la découverte du site et des agents ou robots web.
Chapitre 7
Outils d'investigation
Afin de mettre en oeuvre la classification des utilisateurs du
site Web, sur la base de la méthodologie proposée dans les
chapitres 5 et 6, nous avons eu recours à l'utilisation d'un ensemble
d'outils logiciels que nous présentons dans ce chapitre.
7.1 Langage SQL
SQL (Structured Query Language) est un langage de manipulation
de bases de données mis au point dans les années 70 par IBM. Il
permet trois types de manipulations sur les bases de données:
- La maintenance des tables: création, suppression,
modification de la structure des tables.
- Les manipulations des bases de données :
Sélection, modification, suppression d'enregistrements.
- La gestion des droits d'accès aux tables :
Contrôle des données : droits d'accès, validation des
modifications.
L'intérêt de SQL est que c'est un langage de
manipulation de bases de données standard permettant de gérer une
base de données Access, Paradox, dBase, SQL Server, Oracle ou Informix.
Une requête SQL prend généralement le format suivant :
SELECT [DISTINCT] attribut(s)
FROM table(s)
[WHERE condition] [GROUP BY field(s)] [HAVING condition]
[ORDER BY attribute(s)]
Dans ce mémoire, nous avons recours au langage SQL pour le
nettoyage de la base, la création des sessions et des visites et le
filtrage de la base nettoyée.
Exemples
- Requête SQL de suppression des requêtes non
valides:
SELECT *
FROM DataLog
WHERE (DataLog.Status) >=200 and (DataLog.Status)<400;
- Requête SQL de suppression des images:
SELECT *
FROM DataLog
WHERE (DataLog Like '*gif') Or (DataLog Like '*jpg') Or (DataLog
Like '*jpeg');
- Requête SQL de création des sessions :
SELECT DataLog.ip, DataLog.User_Agent GROUP BY DataLog.ip,
DataLog.UA;
7.2 Logiciels d'analyse des données et de
classi...cation
Nombreux sont les logiciels utilisés pour l'application
des méthodes d'analyse des données et de classification.
Cependant, le choix de l'utilisateur cherchant à tirer le meilleur parti
des données dépend du type de la méthode à
appliquer (méthode d'association, méthode neuronale,
méthode factorielle), la taille des données et la forme des
résultats donnés par le logiciel. Dans notre cas, nous avons
opté pour les deux logiciels suivants:
- SPAD pour l'application de l'analyse en composantes
principales à la classification des pages. Ce logiciel présente
deux avantages. Le premier est sa capacité à exploiter des bases
des données à forte volumétrie (plusieurs millions de
lignes et plusieurs milliers de colonnes). Le second est la capacité de
visualiser les résultats par des graphiques illustratifs très
expressifs, en particulier les résultats des analyses factorielles.
FIG. 7.1 : Analyse en composantes principales à l'aide
de SPAD
- Tanagra 1.1 pour la combinaison des méthodes
factorielles avec les cartes topologiques de Kohonen. Ce logiciel Open Source
destiné à la recherche et l'enseignement présente
l'avantage de permettre l'hybridation des méthodes différentes de
manière à utiliser les variables de sortie d'une méthode
comme variables d'entrée pour la méthode suivante. La figure
suivante illustre un exemple d'hybridation de l'analyse des correspondances
multiples et des cartes de Kohonen avec le logiciel Tanagra.
FIG. 7.2 : Hybridation des méthodes à l'aide de
Tanagra
7.3 Matlab pour la visualisation des cartes de
Kohonen
Comme la capacité de visualisation du logiciel Tanagra
est limitée, nous avons recours aux fonctions programmées en
Matlab par »SOM toolbox programming team» entre 1997 et 2000 pour
visualiser les différents états de la carte de Kohonen en
fonction du nombre d'itérations.
Ces fonctions1 sont :
- som_make: Création, initialisation et formation des
cartes topologiques. - som_randinit : initialisation des cartes topologiques de
Kohonen.
1http : //
www.cis
.hut.fi/projects /somtoolbox/
- som _lininit: Création et initialisation des cartes
topologiques de Kohonen. - som_seqtrain : apprentissage des cartes topologiques
de Kohonen.
- som_batchtrain : apprentissage des cartes topologiques de
Kohonen. - som _bmus : Trouver les best-matching units (BMUs).
- som_quality : Mesurer la qualité des cartes topologiques
de Kohonen.
Dans l'objectif de visualiser les différentes
étapes d'apprentissage de la carte de Kohonen, nous suivons ces
étapes en exploitant les fonctions décrites
ci-dessus2.
1. Lecture du ...chier des données :
D = som_read_data('session.data');
2. Décider de la taille de la grille, à titre
d'exemple 10£ 10 :
msize = [10 10];
3. Initialisation aléatoire des neurones à l'aide
de la fonction som_randinit
sMap = som_randinit(D, 'msize', msize);
4. Représentation de la carte dans l'espace
d'entrée (initialisation de la carte i.e. poids initiaux des neurones)
et l'espace de sortie. En effet, à chaque unité de la carte
correspondent deux types de coordonnées :
- le neurone dans l'espace d'entrée
- la position sur la carte dans l'espace de sortie
|
subplot(1, 3,1)
som_grid(sMap, 'coord',sMap.codebook(:,[1 2])) title('Map in
input space')
subplot (1, 3, 2) som_grid (sMap)
axis([0 11 0 11]),view(0,-90),title('Map in output space')
|
2Les codes source des fonctions utilisées sont
en annexe.
La figure suivante présente la carte dans les deux
espaces d'entrée et de sortie.
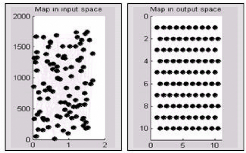
FIG. 7.3 : Représentation de la carte dans les deux
espaces d'entrée et de sortie
5. Apprentissage de la carte
Pour avoir une idée sur ce qui se passe au cours de
l'apprentissage de la carte, nous nous servons du programme suivant sur
Matlab.
|
sMap = som_randinit(D, 'msize' ,msize); sMap.codebook =
sMap.codebook + 1;
subplot(1,2, 1)
som_grid(sMap, 'coord', sMap.codebook(:, [1 2])) title ('Original
map')
pause % Appuyer sur une touche pour continuer
echo off
subplot (1, 2, 2) o = ones(5,1); r = (1-[1:200]/200);
for i=1:200,
sMap = som_seqtrain (sMap, D, 'tracking' ,0,... 'trainlen' ,5,
'samples',...
'alpha' ,0.1*o, 'radius', (4*r (i) +1) *o); som_grid(sMap,
'coord', sMap.codebook(:,[1 2])) title(sprintf(' %d training steps' ,5*i))
drawnow
end
echo on
clf
|
La figure 7.4 illustre les états de la carte pendant
l'apprentissage en fonction du nombre d'itérations.
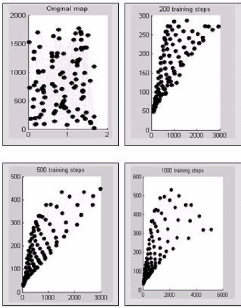
FIG. 7.4: Etats de la carte en fonction du nombre
d'itérations.
7.4 Conclusion
Outre les outils que nous avons utilisé dans le cadre
de ce mémoire, il existe d'autres outils tels que le langage MINT, de
type SQL, proposé par [Spi,99] permettant la recherche des motifs de
navigation, IntelligentMiner d'IBM pour la clusterisation, WebCANVAS
proposé par [Cad, 00] pour la visualisation des classes des
utilisateurs. ..etc. Le choix de l'outil à utiliser dépend de sa
disponibilité et de l'application à réaliser.
Chapitre 8
Conclusion
Nous avons tenté dans ce mémoire
d'étudier le comportement des usagers d'un site Web en exploitant
l'information disponible dans les fichiers Logs. L'enjeu est ici important,
à l'heure où le nombre d'utilisateurs de l'Internet et le nombre
de sites Web augmentent exponentiellement et par conséquent les
données à analyser deviennent de plus en plus volumineuses.
D'autre part, les propriétaires des sites Web cherchent à
comprendre le comportement des visiteurs de leurs sites pour leur offrir un
contenu personnalisé répondant à leurs besoins. Cette
course à l'exploitation des données contenues dans les fichiers
Logs se solde par un manque de méthodes de fouille des données
adaptées, en particulier à cause du volume important des
données.
Dans le cadre de mémoire, nous avons
développé une méthodologie de pré- traitement des
fichiers Logs permettant de transformer l'ensemble de requêtes
enregistrées dans les fichiers Logs à des données
structurées et exploitables. L'hybridation des méthodes de
classification nous a permis de surmonter l'obstacle de la quantité des
données et de tirer profit du pouvoir classificatoire de certaines
d'entre elles, à savoir les cartes topologiques de Kohonen. La
classification multiniveaux à laquelle nous avons eu recours a aboutit
à des »clusters» d'utilisateurs ayant des comportements
similaires en termes de motif de navigation.Ce résultat est important
dans la mesure où il permet aux concepteurs du site Web
étudié de connaître les profils des utilisateurs de leur
site et l'objectif de leur navigation. La personnalisation des services
fournies par le site devient alors possible.
Ce travail aurait été plus intéressant si
nous avions disposé des données sociodémographiques sur
les usagers du site Web étudié. En effet, Ces informations
permettent d'enrichir les profils de navigation par des traits personnels des
utilisateurs. Un nouveau visiteur pourra être classé dans un
groupe selon sa navigation sur le site et son profil. Ainsi, des services
pourront être personnalisés de façon adéquate
à cet utilisateur.
Le travail de recherche actuel peut être prolongé
dans un certain nombre de directions. En effet, il est possible d'appliquer
d'autres méthodes de fouille de données pour découvrir les
motifs de navigation des utilisateurs telles que les
règles d'association permettant d'identifier quelles
sont les pages visitées ensemble et de prédire le comportement du
visiteur. Il est également possible de concevoir un système de
réorganisation du site par rapport aux usages observés de
manière à répondre au mieux au plus grand nombre des
utilisateurs du site.
Bibliographie
[Bau, 92] H. U. Bauer et K. Pawelzik, »Quantifying the
neighborhood preservation of the Self Organizing Feature Map,» IEEE
Transactions on Neural Networks, pp.70-79, 1992.
[Baz, 01] M. Bazsalicza et P. Naïm, »Data Mining pour
le Web,» Eyrolles, pp.89, 2001.
[Ben, 03] A. Benedek et B. Trousse, »Visualization
Adaptation of SelfOrganizing Maps for Case Indexing,» In 27th Annual
Conference of the Gesellschaft fur Klassi...kation, Germany, 12-14 mars
2003.
[Cad, 00] V. Cadez, D. Heckerman, C. Meek, P. Smyth, et S.
White, »Visualization of navigation patterns on a web site using
model-based clustering,» In Proceedings ofthe sixth ACM SIGKDD
International Conference on KnowledgeDiscovery and Data Mining, Boston,
Massachusetts, pp. 280-284, 2000.
[Cat, 95] L.D. Catledge et J.E. Pitkow, »Characterizing
Browsing Strategies in the World Wide Web,» Computer Networks and ISDN
Systems 27, Elsevier Science, pp. 1065-1073, 1995.
[Chen, 96] M.S. Chen et J.S. Yu, »Data Mining for path
traversal patterns in a Web environment». In Sixteenth International
Conference on Distributed Computing Systems, pp. 385-392, 1996.
[Che, 02] K. Chevalier, V. Corruble, et C. Bothorel,
»SURFMINER: Connaître les utilisateurs d'un site,» in Documents
Virtuels Personnalisables, Brest, Juillet 2002.
[Coo, 97] R. Cooley, B. Mobasher, et J. Srivastava,
»Grouping Web page references into transactions for mining World Wide Web
browsing patterns,» Technical Report TR 97-021.Dept. of Computer science,
Univ. of Minnesota, Minneapolis, USA, 1997.
[Coo, 99] R. Cooley, B. Mobasher, et J. Sirvastava,» Data
preparation for mining World Wide Web browsing patterns,» Journal of
Knowledge and Information Systems, 1(1), pp. 55-32, 1999.
[Coo, 00] R. Cooley, »Web Usage Mining: Discovery and
application of inter- est ing patterns from Web data», Phd thesis,
University of Minnesota, May 2000.
[Cot, 87] M. Cottrell et J. Fort,» Etude d'un processus
d'auto-organisation,» Annales de l'Institut Poincaré 23(1),
pp.1-20, 1987.
[Cun, 95] C.A. Cunha, A. Bestavros, et M. E. Crovella,
»Characteristics of WWW Client-based Traces,» Technical Report
TR-95-010, Boston University, Department of Computer Science, 1995.
[Erw, 91] E. Erwin, K. Obermayer, et K.J. Schulten,
»Convergence properties of Self Organizing Maps,» Proceedings of
ICANN91, pp. 409-14, 1991.
[Fle, 01] A. Flexer, »On the use of self organizing maps for
clustering and visualization,» Intelligent Data Analysis 5(5), 2001.
[Fu, 00] Y. Fu, K. Sandhu, et M. Shih, »A
generalization-based approach to
clustering of web usage sessions », In Proceedings of the
1999 KDD Workshop on Web Mining, San Diego, Springer, pp. 21-38, 2000.
[Gav, 02] G. Gavray, »Personnalisation des sites Web :
Elaboration d'une méthodologie de mise en oeuvre et application au cas
de DGTRE,» mémoire projet envue de l'obtention du titre
Ingénieur de gestion, Université Catholique de Louvain,
département d'administration et de gestion, 2002.
[Hop,82] J. Hopfield, »Neural networks and physical
systems with emergent collective computational abilities», Proceedings of
the National Academy of Sciences, pp. 2554-2558, 1982.
[Jam, 99] M. Jambu, »Méthode de base de l'analyse des
données,» Paris, Edition Eyrolles et France Telecom-Cnet, 1999.
[Kim, 00] R. Kimball et R. Merz,» Le data webhouse :
Analyser des comportements clients sur le Web,» Editions Eyrolles, Paris,
310p, 2000.
[Koh, 95] T. Kohonen, »Self Organizing Maps,» volume
30 of Springer series of information sciences, Springer Verlag, 1995.
[Lam, 01] J.Ch. Lamirel, Y. Toussaint, J. Ducloy, C. Czysz et
C. François C., »Réseaux neuronaux avancés pour la
cartographie de la science et de la technologie : Application à
l'analyse des brevets,» VSST'2001 (Veille Stratégique Scientifique
& Technologique), 15-19 Octobre 2001, BARCELONE, ESPAGNE, Organisation
FPC/UPC - SFBA -IRIT, Actes II: Short paper / Poster, pp. 215 - 229.
[Leb, 00] L. Lebart, A. Morineau et M. Piron,» Statistique
exploratoire multidimensionnelle,» Editions DUNOD, Paris, 2000.
[Lec, 03] Y. Lechevallier, D. Tonasa, B. Trousse, et R. Verde,
»Classification automatique: Applications au Web Mining,» In Yadolah
Dodge and Giuseppe Melfi, editor, Méthodes et Perspectives en
Classification, Presse Académiques Neuchâtel, Suisse, pp. 157-160,
10-12 September 2003.
[Les, 03] M.J. Lesot, F. D'alché-Buc, et G. Siolas
»Evaluation des cartes auto- organisatrices et de leur variante à
noyaux ,» Conférence d'APprentissage (CAP'2003), 2003.
[Mic, 02] C. Michel, »Caractérisation d'usages et
personnalisation d'un portail pédagogique. État de l'art et
expérimentation de différentes méthodes d'analyse du Web
Usage Mining,» 7ème colloque de l'AIM Affaire électronique
et société de savoir : Opportunités et Défis, 29
mai-1er juin, 2002.
[Mob, 02] B. Mobasher, H. Dai, T. Lou, et M. Nakagawa,
»Discovery and evaluation of aggregate usage profiles for web
personalization,» Data Mining and Knowledge Discovery 6(1), pp. 61-82,
janvier 2002.
[Per, 98] M. Perkowitz, O. Etzioni, »Adaptive web sites :
Automatically syn-
thesizing web pages,» In AAAI/IAAI, pp. 727-732,
1998.
[Pie, 03] D. Pierrakos, G. Paliouras, C. Papatheodorou, et
C.D. Spyropoulos, »Web Usage Mining as a tool for personalization : A
survey,» User Modeling and User-Adapted Interaction 13 (4), pp.311-372,
2003.
[Rao, 96] R. Rao, P. Pirolli, et J.Pitkow, »Silk from a
sow's ear : Extracting usable structures from the web,» In proc. ACM Conf.
Human Factors in Computing Systems, CHI, 1996.
[Rez, 98] M. Rezaee, B. Lelieveldt, et J. Reiber, »A new
cluster validity index for the fuzzy c-means,» Pattern Recognition Letters
19, pp.237-246, 1998.
[Sch, 01] E. Schwarzkopf, »An adaptive web site for the
UM2001 conference,» In Proceedings of the UM2001Workshop on Machine
Learning for User Modeling, pp. 77-86, 2001.
[Sha, 97] C. Shahabi, A.M. Zarkesh, J. Abidi, et V.
Shah,» Knowledge dicovery form user's Web-page navigation,» In
Proceedings of the 7th IEEE Intl. Workshop on Research Issues in Data
Engineering (RIDE), pp. 20-29,1997.
[Spi, 99] M. Spiliopoulou, »Tutorial : Data Mining for the
Web,» PKDD'99, Prague, Czech Republic, 1999.
[Spi,99] M. Spiliopoulou, »Data mining for the web,» In
principles of Data
Mining and Knowledge Discovery, pp 588-589, 1999.
[Sri, 00] J. Srivastava, R. Cooley, M. Deshpande, et P. Tan,
»Web Usage Mi-
ning: discovery and applications of usage patterns from Web
data,» In SIGKDD Explorations, Volume1, Issue 2 edit ions ACM, pp. 12-23,
Jan 2000.
[Tan, 03] D. Tanasa et B. Trousse, »Le
prétraitement des fichiers Logs Web dans le Web Usage Mining
Multi-sites,» In Journées Francophones de la Toile, Juin-Juillet
2003.
[Tau, 97] L. Tauscher et S. Greenberg, »How People
Revisit Web Pages : Empirical Findings and Implications for the Design of
History Systems,» International Journal of Human Computer Studies, Special
issue on World Wide Web Usability 47(1), pp. 97-138,1997.
[Tra, 95] T. Trautmann, »Développement d'un
modèle de cartes topologiques auto-organisatrices à architecture
dynamique Application au diagnostic,» PhD thesis, Université de
Technologie de Compiègne, 1995.
[Val, 00] N. Valentin, »Construction d'un capteur
logiciel pour le contrôle automatique du procédé de
coagulation en traitement d'eau potable,» Thèse
présentée pour l'obtention du grade de Docteur de l'UTC, Centre
International de Recherche sur l'Eau et l' Environnement, soutenue le 20
Décembre 2000.
[Yan, 96] T.W. Yan, M. Jacobsen, H. Garcia-Molina, et U.
Dayal, »Forme User Access Patterns to Dynamic Hypertext Linking,» WWW
5/Computer Networks, 28(7-11), pp. 1007-1014, 1996.
[Zha, 96] T. Zhang, R. Ramakrishnan, et M. Livny, »Birch
: An efficient data clustering method for very large databases,» In H. V.
Jagadish and Inderpal Singh Mumick, editors, Proceedings of the 1996 ACM SIGMOD
InternationalConference on Management of Data, Montreal, Quebec, Canada, june
4-6, 1996, pp. 103-114, ACM Press, 1996.
[Zre, 92] S. Zrehen et F. Blayo, »A geometric organization
measure for Kohonen's map,» In Proceedings of Neuro-Nîmes, pp.
603-610, 1992.
Netographie
[Lav, 99] B. Lavoie et H. F. Nielson, Web characterisation
terminology & definitions sheet http ://
www.W3c.org/1 999/05/WCA-terms/,
Août 2004.
[Lis] http ://
www.iplists.com/, fevrier
2005.
[Rob] http ://
www.robotstxt.org/wc/active/html/index.html,
fevrier 2005
[Sea] http ://www
.searchturtle.com/search/Computers_Internet/Robots/,
fevrier 2005.
[Sel] H. M. Sellami, cours d'analyse des données,
http ://
www. tn. refer
.org/hebergement/analyse/Index .html
[Tou] C. Touzet, »Les réseaux de neurones artificiels
: Introduction au
connexionisme, cours, exercices et travaux pratiques» http
://
saturn.epm.ornl.gov/~touzetc/Book/Bouquin.htm,
Septembre 2004.
[Web] http ://
www.web-datamining.net,
Septembre 2005.
Glossaire
- Classification
Deux types de classi...cation existent. Le premier type
consiste à classer des éléments dans des classes connues
(par exemple les bons et les mauvais clients). On parle alors d'apprentissage
supervisé. Le second consiste à regrouper les
éléments ayant des comportements similaires dans des classes,
inconnues au départ. On parle dans ce cas de clustering, de segmentation
ou d'apprentissage non supervisé.
- Cognitivisme
Le cognitivisme fait l'analogie de fonctionnement entre
l'esprit et l'ordinateur et envisage le fonctionnement du cerveau com me un
ensemble d'opérations logiques effectuées sur des symboles
élémentaires.
- Connexionnisme
Le connexionnisme se réfère aux processus
auto-organisationnels. Il envisage la cognition comme le résultat d'une
interaction globale des parties élémentaires d'un
système.
- Coordonnées parallèles d'Inselberg
Les coordonnées parallèles représentent
les variables principales sous la forme d'axes verticaux parallèles et
équidistants. Ainsi, pour une représentation à n
dimensions, n axes verticaux sont placés sur un plan. Un individu est
représenté par une ligne brisée dont la position sur
chaque axe est déterminée par la valeur observée sur
chacune des dimensions.
- Data Mining
Le data mining consiste à utiliser un ensemble des
techniques statistiques qui, en fouillant un grand nombre des données,
permettent de découvrir et de présenter des informations à
valeur ajoutée dans une forme interprétable facilement par un
individu.
-ECD
Extraction des Connaissances à partir des Données
i.e. Découverte des connaissances dans les bases des données
gigantesques
- HOLAP
Hybride OLAP désigne les outils d'analyse
multidimensionnelle qui récupèrent les données dans des
bases relationnelles ou multidimensionnelles, de manière transparente
pour l'utilisateur. Il présente l'avantage de mixer les avantages des
deux systèmes MOLAP et ROLAP en répartissant les requêtes
sur l'un ou l'autre des deux moteurs selon que l'un ou l'autre est susceptible
de répondre plus rapidement à la requête (ou de
façon plus précise).Cette dernière prend en charge les
contenus les plus souvent recherchés.
- Marqueur
En général, un marqueur est
représenté par une simple image gif pour une utilisation
gratuite. Pour une utilisation professionnelle (payante) celui-ci peut
être soit une image gif (transparente) dont la taille est de 1 pixel
£ 1 pixel, soit un simple code (qui fait appel à du Javascript)
à insérer dans les pages Web.
- MOLAP
Multidimensional On Line Analytical Processing est
conçu exclusivement pour l'analyse multidimensionnelle, avec un mode de
stockage optimisé. MOLAP agrège tout par défaut. Plus le
volume de données à gérer est important, plus les
principes d'agrégations implicites proposés par MOLAP sont
pénalisants dans la phase de chargement de la base, tant en termes de
performances que de volume. MOLAP surpasse ROLAP pour des
fonctionnalités avancées comme la prévision ou la mise
à jour des données pour la simulation.
- OLAP
On Line Analytical Processing caractérise
l'architecture nécessaire à la mise en place d'un système
d'information décisionnel. Il s'oppose à OLTP (On Line
Transaction Processing), adressant les systèmes d'information
transactionnels. OLAP est souvent utilisé pour faire
référence exclusivement aux bases de données
multidimensionnelles.
-Popup
Un pop up (ou une popup), trouvé également sous
l'orthographe »pop-up», »pop up», ou »popup»
désigne une page HTML qui s'ouvre souvent de petite taille pour faire
passer un message. Des images de publicité sont souvent placées
dans ces pop-ups. Pop-up devient trop souvent le synonyme de bannière de
publicité.
- Représentations par pixel
L'idée de base est d'associer à chaque
enregistrement un pixel dont la couleur varie selon la classe
d'appartenance.
- ROLAP
Relation al On Line Analytical Pro cessing caractérise
l'architecture nécessaire à la mise en place d'un système
multidimensionnel en s'appuyant sur les technologies relationnelles. Au travers
des méta-données, les outils ROLAP permettent de transformer
l'analyse multidimensionnelle demandée par l'utilisateur en
requêtes SQL. Ils proposent le plus souvent un composant serveur, pour
optimiser les performances lors de la navigation dans les données ou
pour les calculs complexes. ROLAP n'agrège rien, mais tire parti des
agrégats s'ils existent. De ce fait, il est plus lourd à
administrer que MOLAP, puisqu'il demande de créer explicitement certains
agrégats.
- Robots Web
Logiciels utilisés pour balayer un site Web afin
d'extraire son contenu. - Techniques de factorisation
Le principe consiste à regrouper les variables
initiales en facteurs sur la base d'une proximité de comportement
(coefficient de corrélation ou de contingence). Le regroupement des
variables en facteurs se traduit par la construction d'un plan sur lequel les
individus sont représentés. Cette technique est vulgarisée
sous le nom de mapping.
- Techniques hiérarchiques
Les techniques hiérarchiques cherchent à
subdiviser l'espace multidimensionnel en une succession de plans bipolaires. La
représentation la plus commune est l'arbre de décision.
- Web prefetching
En Français, préchargement. Il consiste à
anticiper la navigation future de l'internaute en téléchargeant
(préchargeant) les documents que l'utilisateur est susceptible de
vouloir visiter dans un proche avenir. Ainsi, quand l'internaute décide
de visiter un des documents préchargés, le navigateur ira le
piocher rapidement dans son cache, sur le disque dur de l'utilisateur qui
n'aura ainsi pas à attendre le chargement de la page depuis le site Web
distant.
Troisième partie
Annexes
som_read_data
%Cette fonction est utilisée pour la lecture du fichier
des données.
function sData = som_read_data(filename, varargin)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%
Vérification des arguments
error(nargchk(1, 3, nargin)) % check no. of input args is
correct
dont_care = 'NaN'; % default don't care string
comment _start = '#'; % the char a SOM _PAK command line starts
with
comp_name_line = '#n'; % string denoting a special command
line,
% which contains names of each component
label_name_line = '#l'; % string denoting a special command
line,
% which contains names of each label
block_size = 1000; % block size used in file read
kludge = num2str(realmax, 100); % used in sscanf
% open input file
fid = fopen(filename);
if fid < 0
error(['Cannot open ' filename]);
end
% process input arguments
if nargin == 2
if isstr(varargin { 1 })
dont_care = varargin { 1 };
else
dim = varargin{1};
end
elseif nargin == 3
dim = varargin{1};
dont_care = varargin{2};
end
% if the data dimension is not specified, find out what it is
if nargin == 1 | (nargin == 2 & isstr(varargin{1}))
fpos1 = ftell(fid); c1 = 0; % read first non-comment line
while c1 == 0,
line1 = strrep(fgetl(fid), dont_care, kludge);
[l1, c1] = sscanf(line1, '%f ');
end
fpos2 = ftell(fid); c2 = 0; % read second non-comment line
while c2 == 0,
line2 = strrep(fgetl(fid), dont_care, kludge);
[l2, c2] = sscanf(line2, '%f ');
end
if (c1 == 1 & c2 ~= 1) | (c1 == c2 & c1 == 1 & l1 ==
1)
dim = l1;
fseek(fid, fpos2, -1);
elseif (c1 == c2)
dim = c1;
fseek(fid, fpos1, -1);
warning on
warning(['Automatically determined data dimension is ' ...
num2str(dim) '. Is it correct?']);
else
error(['Invalid header line: ' line 1]);
end
end
% check the dimension is valid
if dim < 1 | dim ~= round(dim)
error(['Illegal data dimension: ' num2str(dim)]);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% Lecture des
données
sData = som_data_struct(zeros(1, dim), `name', filename);
lnum = 0; % data vector counter
data_temp = zeros(block_size, dim);
labs_temp = cell(block_size, 1);
comp_names = sData.comp_names;
label _names = sData.label_names;
form = [repmat(`%g' , [1 dim- 1]) `%g% [" \t]'];
limit = block_size;
while 1,
li = fgetl(fid); % read next line
if ~isstr(li), break, end; % is this the end of file?
% all missing vectors are replaced by value realmax because
% sscanf is not able to read NaNs
li = strrep(li, I_care, kludge);
[data, c, err, n] = sscanf(li, form);
if c < dim % if there were less numbers than dim on the input
file line
if c == 0
if strncmp(li, comp_name_line, 2) % component name line?
Li = strrep(li(3 :end), kludge, I_care); I = 0; c = 1;
while c
[s, c, e, n] = sscanf(li, `%s%[" \t]');
if ~isempty(s), I = I + 1; comp_names{i} = s; li = li(n:end);
end
end
if I ~= dim
error([`Illegal number of component names: ` num2str(i) ...
` (dimension is ` num2str(dim) `)']);
end
elseif strncmp(li, label_name_line, 2) % label name line?
Li = strrep(li(3 :end), kludge, I_care); I = 0; c = 1;
while c
[s, c, e, n] = sscanf(li, `%s%[" \t]');
if ~isempty(s), I = I + 1; label_names{i} = s; li = li(n:end);
end
end
elseif ~strncmp(li, comment_start, 1) % not a comment, is it
error?
[s, c, e, n] = sscanf(li, `%s%[" \t]');
if c
error([`Invalid vector on input file data line ` ...
num2str(lnum+1) `: [` deblank(li) `]']),
end
end
else
error([`Only ` num2strI ` vector components on input file data
line ` ...
num2str(lnum+1) ` (dimension is ` num2str(dim) `)']);
end else
lnum = lnum + 1; % this was a line containing data vector
data_temp(lnum, 1 :dim) = data'; % add data to struct
if lnum == limit % reserve more memory if necessary
data_temp(lnum+1 :lnum+block_size, 1 :dim) = zeros(block_size,
dim); [dummy nl] = size(labs_temp);
labs_temp(lnum+1 :lnum+block_size, 1 :nl) = cell(block_size,
nl);
limit = limit + block_size;
end
% read labels
if n < length(li)
li = strrep(li(n:end), kludge, I_care); I = 0; n = 1; c = 1;
while c
[s, c, e, n_new] = sscanf(li(n:end), `%s%[^ \t]');
if c, I = I + 1; labs_temp{lnum, i} = s; n = n + n_new - 1;
end
end
end end
end
% close input file
if fclose(fid) < 0, error([`Cannot close file ` filename]);
else fprintf(2, `\rdata read ok \n'); end
% set values
data_temp(data_temp == realmax) = NaN;
sData. data = data_temp( 1 :lnum,:);
sData. labels = labs_temp(1 :lnum,:);
sData.comp_names = comp_names; sData.label_names = label _names;
return;
som_randinit
%Cette fonction permet l'initialisation des cartes de Kohonen
function sMap = som_randinit(D, varargin)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% check
arguments
% data
if isstruct(D),
data _name = D.name;
comp_names = D.comp_names;
comp_norm = D.comp_norm;
D = D.data;
struct_mode = 1;
else
data_name = inputname(1);
struct _mode = 0;
end
[dlen dim] = size(D);
% varargin
sMap = [];
sTopol = som_topol_struct;
sTopol.msize = 0;
munits = NaN;
i=1;
while i<=length(varargin),
argok = 1;
if ischar(varargin{i}),
switch varargin {i},
case 'munits', i=i+1; munits = varargin{i}; sTopol.msize = 0;
case 'msize', i=i+1; sTopol.msize = varargin{i};
munits = prod(sTopol.msize);
case 'lattice', i=i+1; sTopol.lattice = varargin{i}; case
'shape', i=i+1; sTopol.shape = varargin{i};
case {'som_topol','sTopol','topol'}, i=i+1; sTopol =
varargin{i};
case {'som_map','sMap','map'}, i=i+1; sMap = varargin{i}; sTopol
= sMap.topol;
case {'hexa','rect'}, sTopol.lattice = varargin{i};
case {'sheet','cyl','toroid'}, sTopol.shape = varargin{i};
otherwise argok=0;
end
elseif isstruct(varargin {i}) & isfield(varargin {i}
,'type'), switch varargin{i} .type,
case 'som_topol',
sTopol = varargin{i};
case 'som_map',
sMap = varargin{i};
sTopol = sMap.topol;
otherwise argok=0;
end
else
argok = 0;
end
if ~argok,
disp(['(som_topol_struct) Ignoring invalid argument #'
num2str(i)]);
end
i = i+1;
end
if ~isempty(sMap),
[munits dim2] = size(sMap.codebook);
if dim2 ~= dim, error('Map and data must have the same
dimension.'); end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% create map
% map struct
if ~isempty(sMap),
sMap = som_set(sMap,'topol',sTopol);
else
if ~prod(sTopol.msize),
if isnan(munits),
sTopol = som_topol_struct('data',D,sTopol);
else
sTopol = som_topol_struct('data',D,'munits',munits,sTopol);
end
end
sMap = som_map_struct(dim, sTopol);
end
if struct_mode,
sMap =
som_set(sMap,'comp_names',comp_names,'comp_norm',comp_norm);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%
initialization
% train struct
sTrain = som_train_struct('algorithm','randinit');
sTrain = som_set(sTrain,'data_name',data_name);
munits = prod(sMap.topol.msize);
sMap.codebook = rand([munits dim]);
% set interval of each component to correct value
for i = 1:dim,
inds = find(~isnan(D(:,i)) & ~isinf(D(:,i)));
if isempty(inds), mi = 0; ma = 1;
else ma = max(D(inds,i)); mi = min(D(inds,i));
end
sMap.codebook(:,i) = (ma - mi) * sMap.codebook(:,i) + mi;
end
% training struct
sTrain = som_set(sTrain,'time',datestr(now,0));
sMap.trainhist = sTrain;
return;
som_seqtrain
%Cette fonction sert à l'apprentissage des cartes de
Kohonen
function [sMap, sTrain] = som_seqtrain(sMap, D, varargin)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% Check arguments
error(nargchk(2, Inf, nargin)); % check the number of input
arguments
% map
struct_mode = isstruct(sMap);
if struct_mode,
sTopol = sMap.topol;
else
orig_size = size(sMap);
if ndims(sMap) > 2,
si = size(sMap); dim = si(end); msize = si(1 :end-1);
M = reshape(sMap,[prod(msize) dim]);
else
msize = [orig_size(1) 1];
dim = orig_size(2);
end
sMap = som_map_struct(dim,'msize',msize);
sTopol = sMap.topol;
end
[munits dim] = size(sMap.codebook);
% data
if isstruct(D),
data _name = D.name;
D = D.data;
else
data_name = inputname(2);
end
D = D(find(sum(isnan(D),2) < dim),:); % remove empty vectors
from the data
[dlen ddim] = size(D); % check input dimension
if dim ~= ddim, error('Map and data input space dimensions
disagree.'); end
% varargin
sTrain = som_set('som_train','algorithm','seq','neigh', ...
sMap.neigh,'mask',sMap.mask,'data_name',data_name);
radius = []; alpha = []; tracking = 1; sample_order_type =
'random';
tlen_type = 'epochs';
i=1;
while i<=length(varargin),
argok = 1;
if ischar(varargin{i}),
switch varargin {i},
% argument IDs
case 'msize', i=i+1; sTopol.msize = varargin{i};
case 'lattice', i=i+1; sTopol.lattice = varargin{i};
case 'shape', i=i+1; sTopol.shape = varargin{i};
case 'mask', i=i+1; sTrain.mask = varargin{i};
case 'neigh', i=i+1; sTrain.neigh = varargin{i};
case 'trainlen', i=i+1; sTrain.trainlen = varargin{i};
case 'trainlen_type', i=i+1; tlen_type = varargin{i};
case 'tracking', i=i+1; tracking = varargin{i};
case 'sample_order', i=i+1; sample_order_type = varargin{i};
case 'radius_ini', i=i+1; sTrain.radius_ini = varargin{i};
case 'radius_fin', i=i+1; sTrain.radius_fin = varargin{i};
case 'radius',
i=i+ 1;
l = length(varargin{i});
if l==1,
sTrain.radius_ini = varargin {i};
else
sTrain.radius_ini = varargin {i} (1);
sTrain.radius_fin = varargin {i} (end);
if l>2, radius = varargin{i}; tlen_type = 'samples'; end
end
case 'alpha_type', i=i+1; sTrain.alpha_type = varargin{i};
case 'alpha_ini', i=i+1; sTrain.alpha_ini = varargin{i};
case 'alpha',
i=i+ 1;
sTrain.alpha_ini = varargin {i} (1);
if length(varargin {i} )>1,
alpha = varargin{i}; tlen_type = 'samples';
sTrain.alpha_type = 'user defined';
end
case {'sTrain','train','som_train'}, i=i+1; sTrain =
varargin{i};
case {'topol','sTopol','som_topol'},
i=i+ 1;
sTopol = varargin{i};
if prod(sTopol.msize) ~= munits,
error('Given map grid size does not match the codebook size.');
end
% unambiguous values
case {'inv','linear','power'}, sTrain.alpha_type =
varargin{i};
case {'hexa','rect'}, sTopol.lattice = varargin{i};
case {'sheet','cyl','toroid'}, sTopol.shape = varargin{i};
case {'gaussian','cutgauss','ep','bubble' }, sTrain.neigh =
varargin {i}; case {'epochs','samples'}, tlen_type = varargin{i};
case {'random', 'ordered'}, sample_order_type = varargin{i};
otherwise argok=0;
end
elseif isstruct(varargin {i}) & isfield(varargin {i}
,'type'),
switch varargin{i} (1).type,
case 'som_topol',
sTopol = varargin{i};
if prod(sTopol.msize) ~= munits,
error('Given map grid size does not match the codebook
size.');
end
case 'som_train', sTrain = varargin{i};
otherwise argok=0;
end
else
argok = 0;
end
if ~argok,
disp(['(som_seqtrain) Ignoring invalid argument #'
num2str(i+2)]);
end
i = i+1;
end
% training length
if ~isempty(radius) | ~isempty(alpha),
lr = length(radius);
la = length(alpha);
if lr>2 | la>1,
tlen_type = 'samples';
if lr> 2 & la<=1, sTrain.trainlen = lr;
elseif lr<=2 & la> 1, sTrain.trainlen = la;
elseif lr==la, sTrain.trainlen = la;
else
error('Mismatch between radius and learning rate vector
lengths.')
end
end end
if strcmp(tlen _type,'samples'), sTrain.trainlen =
sTrain.trainlen/dlen; end
% check topology
if struct_mode,
if ~strcmp(sTopol.lattice,sMap.topol.lattice) | ...
~strcmp(sTopol. shape,sMap.topol. shape) | ...
any(sTopol.msize ~= sMap.topol.msize),
warning('Changing the original map topology.');
end end
sMap.topol = sTopol;
% complement the training struct
sTrain = som_train_struct(sTrain,sMap,'dlen',dlen);
if isempty(sTrain.mask), sTrain.mask = ones(dim, 1); end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% initialize
M = sMap.codebook;
mask = sTrain.mask;
trainlen = Train.trainlen*dlen;
% neighborhood radius
if length(radius)>2,
radius _type = 'user defined';
else
radius = [sTrain.radius_ini sTrain.radius _fin];
rini = radius(1);
rstep = (radius(end)-radius(1 ))/(trainlen- 1);
radius _type = 'linear';
end
% learning rate
if length(alpha)>1,
sTrain.alpha_type ='user defined';
if length(alpha) ~= trainlen,
error('Trainlen and length of neighborhood radius vector do not
match.')
end
if any(isnan(alpha)),
error('NaN is an illegal learning rate.')
end
else
if isempty(alpha), alpha = sTrain.alpha_ini; end
if strcmp(sTrain.alpha_type,'inv'),
% alpha(t) = a / (t+b), where a and b are chosen suitably
% below, they are chosen so that alpha_fin = alpha_ini/100
b = (trainlen - 1) / (100 - 1);
a = b * alpha;
end
end
% initialize random number generator
rand('state',sum( 1 00*clock));
% distance between map units in the output space
% Since in the case of gaussian and ep neighborhood functions,
the
% equations utilize squares of the unit distances and in bubble
case
% it doesn't matter which is used, the unitdistances and
neighborhood
% radiuses are squared.
Ud = som _unit _dists(sTopol).^2;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% Action
update_step = 100;
mu_x_1 = ones(munits,1);
samples = ones(update_step, 1);
r = samples;
alfa = samples;
qe = 0;
start = clock;
if tracking > 0, % initialize tracking
track_table = zeros(update_step, 1);
qe = zeros(floor(trainlen/update_step), 1);
end
for t = 1 :trainlen,
% Every update_step, new values for sample indeces,
neighborhood
% radius and learning rate are calculated. This could be done
% every step, but this way it is more efficient. Or this could
% be done all at once outside the loop, but it would require
much
% more memory.
ind = rem(t,update_step); if ind==0, ind = update_step; end
if ind== 1,
steps = [t:min(trainlen,t+update_step- 1)];
% sample order
switch sample_order_type,
case 'ordered', samples = rem(steps,dlen)+1;
case 'random', samples = ceil(dlen*rand(update_step, 1 )+eps);
end
% neighborhood radius
switch radius_type,
case 'linear', r = rini+(steps-1)*rstep;
case 'user defined', r = radius(steps);
end
r=r.^2; % squared radius (see notes about Ud above)
r(r==0) = eps; % zero radius might cause div-by-zero error
% learning rate
switch sTrain.alpha_type,
case 'linear', alfa = (1-steps/trainlen)*alpha;
case 'inv', alfa = a ./ (b + steps-1);
case 'power', alfa = alpha *
(0.005/alpha).^((steps-1)/trainlen);
case 'user defined', alfa = alpha(steps);
end
end
% find BMU
x = D(samples(ind),:); % pick one sample vector
known = ~isnan(x); % its known components
Dx = M(:,known) - x(mu_x_1,known); % each map unit minus the
vector
[qerr bmu] = min((Dx.^2)*mask(known)); % minimum distance(^2) and
the BMU % tracking
if tracking>0,
track_table(ind) = sqrt(qerr); if ind==update_step,
n = ceil(t/update_step); qe(n) = mean(track_table);
trackplot(M,D,tracking,start,n,qe);
end
end
% neighborhood & learning rate
% notice that the elements Ud and radius have been squared!
% (see notes about Ud above) switch sTrain.neigh,
case 'bubble', h = (Ud(:,bmu)<=r(ind));
case 'gaussian', h = exp(-Ud(:,bmu)/(2*r(ind)));
case 'cutgauss', h = exp(-Ud(:,bmu)/(2*r(ind))) .*
(Ud(:,bmu)<=r(ind));
case 'ep', h = (1 -Ud(:,bmu)/r(ind)) .*
(Ud(:,bmu)<=r(ind));
end
h = h*alfa(ind);
% update M
M(: ,known) = M(: ,known) - h(: ,ones(sum(known), 1)). *Dx;
end; % for t = 1 :trainlen
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% Build / clean up the return arguments if tracking, fprintf(1
,'\n'); end
% update structures
sTrain = som_set(sTrain,'time',datestr(now,0)); if
struct_mode,
sMap =
som_set(sMap,'codebook',M,'mask',sTrain.mask,'neigh',sTrain.neigh);
tl = length(sMap.trainhist);
sMap.trainhist(tl+1) = sTrain;
else
sMap = reshape(M,orig_size);
end
return;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% subfunctions
function [] = trackplot(M,D,tracking,start,n,qe) l =
length(qe);
elap_t = etime(clock,start);
tot_t = elap_t*l/n;
fprintf( 1 ,'\rTraining: %3 .0f/ %3 .0f s',elap_t,tot_t) switch
tracking
case 1,
case 2,
plot(1 :n,qe(1 :n),(n+1):l,qe((n+1):l))
title('Quantization errors for latest samples') drawnow
otherwise,
subplot(2,1,1), plot(1 :n,qe(1 :n),(n+1):l,qe((n+1):l))
title('Quantization error for latest samples');
subplot(2, 1,2), plot(M(:, 1 ),M(:,2),'ro',D(:, 1
),D(:,2),'b.');
title('First two components of map units (o) and data vectors
(+)');
drawnow
end
% end of trackplot
| 

