|
Sommaire
INTRODUCTION GENERALE 4
Chapitre1 : Représentation de l'entreprise 5
1. Introduction : 5
2. Environnement et classement de l'entreprise : 5
3. Organisation de l'entreprise : 5
3.1. Service Commercial : 6
3.2. Service Technique : 6
3.3. Service Informatique : 6
Chapitre2 : Cahier des charges 7
1. Introduction : 7
2. Besoins fonctionnels : 7
2.1. La recherche : 7
2.2.L'accès aux services Email : 8
2.3. L'administration : 8
3. Besoins non fonctionnels : 9
3.1. Temps du développement : 9
3.2. Outils a utilisé : 9
3.3. Les interfaces : 10
4. Conclusion : 11
Chapitre3:Etude théorique 12
1. Introduction : 12
2. Définition d'un moteur de recherche : 12
3. Description des moteurs de recherche : 12
3.1. Type de Service : 12
3.2. Type d'accès : 12
3.3. Fréquence de mise à jour : 13
3.4. Sites Miroirs : 13
4 .Fonctionnement du moteur de recherche : 13
4.1. Collecte des documents : 13
4.2. Indexation des documents : 14
5. Le robot de recherche : 15
5.1. Les différentes parties d'un robot : 15
6. CONCLUSION : 17
Chapitre4 : Etude Conceptuelle 18
1. Introduction : 18
2. Méthodologie de conception : 18
3. Les modèles de données : 18
3.1. Dictionnaire de donnée : 18
3.2. Règles de gestion : 19
3.3. Le modèle conceptuel de données (MCD) : 20
3.4. Modèle Physique de données : 23
3.5. Le modèle logique de données : 25
4. Le modèle conceptuel de traitement : 25
5. Conclusion : 29
Chapitre 5 : Réalisation 30
1. Introduction : 30
2. Analyse : 30
2.1. Outils de développements : 30
2.2. Langages utilisés : 31
2.3. Choix de la technologie : 34
3. Implémentation : 34
3.1. Configuration : 35
3.2. Système de gestion de base de données : 35
3.3. Les mots clés : 36
4. Réalisation : 37
4.1. Explication de schéma : 38
4.2. Un module utilisateur : 39
4.3. Un module administration : 40
5. Processus de fonctionnement de moteur de recherche : 41
5.1. Niveau utilisateur : 42
5.2. Niveau administration : 47
6. Conclusion : 50
Conclusion Général 51
BIBLIOGRAPHIE 52
GLOSSAIRE 53
Liste des tableaux
Tableau 1.4. Dictionnaire de données 19
Tableau 2.4. Liste des entités 20
Tableau 3.4. Liste des associations 21
Tableau 4.4. Listes des tables 23
Tableau 1.5. les serveurs Web 34
Liste des figures
Figure 1.1. Organigramme de l'entreprise 5
Figure 1.3. Les trois parties essentielles au bon fonctionnement
d'un robot 15
Figure 1.4. Model conceptuel de données (MCD) 22
Figure 2.4. Modèle physique de données (MPD) 24
Figure 3.4. MCT1 Accéder aux sites 26
Figure 4.4. MCT2 Accéder à l'email 27
Figure 5.4. MCT3 Administration des sites 28
Figure 1.5 : Schéma d'utilisation 38
Figure 2.5. : Un module utilisateur 39
Figure 3.5. : module utilisateur email 40
Figure 4.5. : module administration 41
Figure 5.5. : Figure principale 42
Figure 6.5. Erreur mot de passe 42
Figure 7.5. Résultats de recherche 43
Figure 8.5. Résultats de recherche nulle 43
Figure 9.5. Inscription 44
Figure 10.5. Erreur d'inscription 44
Figure 11.5. Mot de passe n'est pas saisis 44
Figure 12.5. Inscription validé 45
Figure 13.5. Identification email 45
Figure 14.5. Accès refusé 46
Figure 15.5. Erreur d'identification 46
Figure 16.5. Accès validé 46
Figure 17.5. Envoie d'email 47
Figure 18.5. Validation de l'inscription 48
Figure 19.5. Ajout des sites 48
Figure 20.5. Erreur sur les champs 49
Figure 21.5. Modification sur les sites 49
Figure 22.5. Suppression des sites 50
Figure 23.5. Site modifier 50
INTRODUCTION GENERALE
L'informatique est devenue de plus en plus importante,
dispersée et variée sur tout le monde ce qui impose un
problème de recherche des données d'où l'objectif des
moteurs de recherche est de mettre à la disposition du public une
constellation de sites divers et variés traitant aussi bien de
l'actualité que des sciences et des technologies ou encore de l'art et
de la culture. Dans ces moteurs de recherche ou annuaires, se côtoient
des sites de tout horizon.
L'offre étant pléthorique et la concurrence de
plus en plus forte, il devient considérablement difficile d'obtenir le
référencement dans les outils de recherche. Pour parvenir
à se référencer auprès de ces derniers, une bonne
connaissance de leur fonctionnement et de leurs méthodes d'indexation
est indispensable.
Ce projet de fin d'étude a pour but
l'implémentation et la conception d'un moteur de recherche qui
représente de nos jours une solution favorable pour atteindre
l'information dispersée sur le web.
Pour réaliser ce travail on procédera comme suit
:
-Le premier chapitre, donne une idée sur l'entreprise ou
on a effectué le stage de projet de fin d'étude.
- Le deuxième chapitre, sera consacré aux cahiers
des charges.
-Le troisième chapitre contiendra une étude
théorique et comparative des fonctionnalités des
différents moteurs de recherche existants.
-Le quatrième chapitre fera le point sur la conception du
projet.
-Et enfin un dernier chapitre pour la réalisation du
projet.
Chapitre1 : Représentation de l'entreprise
1. Introduction :
Dans ce chapitre on a essayé de présenter de
manière générale l'entreprise où on a
effectué ce stage de projet de fin d'étude son organigramme et
les différentes services quelle offre.
2. Environnement et classement de l'entreprise
:
Orient@ Info est situé à Moulares Gafsa Avenue 7
novembre, c'est une société SARL de taille moyenne, qui consiste
essentiellement à la vente et la maintenance des systèmes
informatiques et les développement des logiciels informatique. Comme
elle offre l'opportunité pour tous ses clients soit par un
dépannage au sein de la société, soit à la suite
d'un déplacement.
3. Organisation de l'entreprise :
Pour accomplir ses taches, la société est
subdivisée en trois services : Service informatique, service technique
et service commercial :
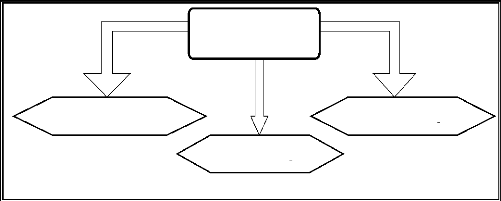
Service Commerciale
Direction générale
Service Technique
Service Informatique
Figure 1.1. Organigramme de l'entreprise
3.1. Service Commercial :
Le service commerciale à pour rôle :
-Achat de matériel et de fournitures d'exploitation,
-Publicité et commercialisation des articles vendus par la
société, -Abonnement INTERNET (TOPNET).
3.2. Service Technique :
Le service s'occupe de :
-Réparation de matériel informatique et
bureautique, -Maintenance des systèmes informatique,
-Réalisation des réseaux.
3.3. Service Informatique :
Le service informatique consiste en la : -Conception et
Création des cites web,
- Conception et Création des Sigles, Carte visites, des
affiches...
- Informatique générale (Word, Excel, Power point).
-Développement des logiciels.
Chapitre2 : Cahier des charges
1. Introduction :
Ce projet de fin d'étude a comme thème la
conception et l'implémentation d'un moteur de recherche qui a pour but
de répondre au besoin de notre client qui se manifeste par la recherche
de l'information souhaitée, l'accès a un service de messagerie
électronique et l'administration du moteur du recherche.
2. Besoins fonctionnels :
Dans cette partie on va essayer d'expliquer les
différentes parties fonctionnelles de moteur de recherche qui sont
demandés par notre client.
2.1. La recherche :
La recherche de l'information en utilisant ce moteur se fait par
deux manières soit local ou sur le Web :
2.1.1. La recherche dans le Web :
Après le choix de l'options de recherche sur le web, le
traitement des mots clés et activé le bouton recherche, un
programme fait envoyer une requête http aux robots de ces moteurs
(Google, Altavista,...), Ces derniers réagissent par l'envoi des pages
de résultas dont leurs liens seront récupérés
à l'ordre de répétition et d'importance .De plus, notre
moteur, après avoir fait la récupération des liens, fait
le filtrage de ces liens à l'aide de son propre programme de
perçage qui fait extraire les liens et leurs commentaires et les
afficher, et à partir des quels l'internaute peut naviguer.
2.1.2. La recherche Locale :
Après le stockage des sites dans la base de
donnée locale à partir de la page ajout de sites, si
l'utilisateur veut faire une recherche dans la base de données, il doit,
tout d'abord, saisir le mot clé. Notre robot va fouiller dans la base de
donnée
est extraire les résultats demandés par date de
création, date de modification et titre sous forme des liens.
2.2.L'accès aux services Email :
Pour accéder a ce service il faut passer par l'inscription
on remplissant un formulaire contient les champs suivants :
-Nom
-Prénom
-Sexe
-Email
-Adresse
-Age
- Téléphone
-Login
-Mot de passe
Après la validation de cette étape l'utilisateur
reçoit son login et son mot de passe alors il peut également
accéder au service par le traitement de son login et mot de mot passe
dans le menu principal de la partie Email. Si l'utilisateur est
identifié, les services suivants seront accessibles :
-l'envoie et la réception des messages.
-la manipulation des messages (suppression...).
2.3. L'administration :
Pour que l'administrateur peut accéder à cette
partie il faut être identifié par un login et un mot de passe une
fois l'identification est réussit les étapes suivantes sont
possibles :
-l'ajout des sites :
Dans cette étape on peut ajouter des sites on introduisons
leur adresse leur nom et la date de modification.
-la suppression des sites :
L'administrateur peut également dans cette étape de
supprimer les sites dans le cas ou en a changer le thème par exemple.
-la modification des sites (noms, thèmes) :
L'administrateur dans cette étape peut changer le nom de
site ainsi que le thème.
Remarque :
Chaque modification aura lieu sera notée par la suite dans
l'affichage des sites tels que la date de modification.
3. Besoins non fonctionnels :
Cette partie met le point sur tous ce qui est
nécessaire pour la réalisation de cette application en prendrons
en considération la fonctionnalité du moteur de recherche d'une
part et la demande de client d'autre part tels que les technologies, les
langages, le temps du développement estimé ... .etc.
3.1. Temps du développement :
Pour réaliser ce projet dans un temps globale de quatre
mois on a essayer de le diviser comme suit :
-On a disposé d'un mois pour se documenter sur le sujet
ainsi que prendre connaissance sur des différents outils tels que AMC
Designer, IIS ... etc.
-Deux mois comme temps estimé pour le
développement de cette application qui contient comme grandes parties la
création et la conception de base de donnée, la
réalisation des interfaces la création des différentes
pages, et le test de l'application sur un serveur IIS.
-Un mois pour l'assemblage des différentes partie et le
traitement du rapport.
3.2. Outils a utilisé :
On a essayé de se servir des outils suivants pour
atteindre les buts de ce projet a fin de prendre en considération les
moyens clientèles :
-Les logiciels :
* Macromedia dream Weaver pour la création des pages
HTML.
* Photoshop pour le design des interfaces.
* Ms Access pour l'implémentation de la base de
donnée.
*AMC Designer pour la conception de la base de donnée.
-Les langages :
* HTML (hypertext markup langage) c'est un langage de
création des page Web basé sur les balises fiable est le plus
rependu au besoin, il permet de créer des formulaire aussi il donne la
possibilité d'introduire d'autre langage de programmation tels que
Javascript, ASP...dans le même code du programme.
* Javascript c'est un langage de programmation orienté
objet, coté client basé sur les script ce langage est
nécessaire pour la manipulation des formulaire, Javascript est
créé et développé par Netscape. Contrairement
à Java, Javascript est un langage interprété.
*ASP Active Server Pages : c'est un langage de programmation
coté serveur basé sur les script. Technologie de Microsoft
analogue à PHP et JSP permettant le développement de pages
dynamiques coté serveur.
-Technologies :
Le fonctionnement de moteur de recherche nécessite un
serveur web pour cela on a disposé d'un serveur IIS Internet Information
Server Services qui prennent en charge la création, la configuration et
la gestion de site Web, ainsi que d'autres fonctions Internet. Les services
Internet comprennent le protocole NNTP (Network News Transfer Protocol), le
protocole FTP (File Transfer Protocol) et le protocole SMTP (Simple Mail
Transfer Protocol).
3.3. Les interfaces :
Les interfaces estimés pour répondre au besoin
clientèle et le bien fonctionnement du moteur de recherche sont :
-Page indexe :
C'est une page similaire a celle d'accueil qui contient les
objets suivantes : * Lien pour la recherche.
* Lien pour l'accès au service de messagerie.
*Lien pour l'administration.
* Choix de la recherche soit local soit sur le web.
* Zone texte pour le traitement des mots clés.
-Page résultat :
C'est une page qui contient les liens pour accéder
à l'information trouvé donc l'utilisateur peut naviguer a partir
de ces liens.
Si il n'y a pas des résultas convenable un message
s'affiche sur la même page. -Page administrateur :
Pour réaliser les taches de cette étape on se base
sur les objets suivants : * Deux zones textes pour le traitement de mot de
passe et le login.
* Deux radio l'un pour valider les cordonnées l'autre pour
annuler l'action.
Si les coordonnées sont acceptées, un tableau qui
classe les sites par nom et par date de modification s'affiche.
* Deux boutons pour l'ajout et la suppression des sites.
Si les coordonnées ne sont pas acceptés un message
d'erreur s'affiche. - Page Email :
Cette page dispose de deux zones texte pour traiter le login et
le mot de passe une fois l'identification est validée une page qui
contient les objets suivante s'affiche : * Zone texte pour traiter l'adresse du
correspondant.
* Zone texte pour traiter l'objet du message.
* Zone texte pour traiter le message a envoyé.
* Deux bouton l'un pour l'envoie et l'autre pour annuler
l'action.
* Un lien pour la page qui contient les emails reçus.
Si l'identification n'est pas validée un message d'erreur
sera afficher.
N.B : Tous les pages doivent contenir le sigle
de moteur de recherche plus un liens de la page index.
4. Conclusion :
On a essayé d'expliquer les besoins clientèle
dans ce chapitre et les besoins fonctionnels et non fonctionnels de moteur de
recherche. Dans le chapitre suivant on va expliquer théoriquement le
principe de fonctionnement de l'application mise en jeu.
Chapitre3 :Etude théorique
1. Introduction :
Dans ce chapitre on va définir les moteurs de
recherche, leurs fonctionnalités, les opérations logiques
utilisées dans la recherche sur le web, ainsi que leurs
architectures.
2. Définition d'un moteur de recherche
:
Un moteur de recherche (Searchbot) est une machine
spécifique (matérielle et logicielle) qui visite les sites, les
indexe, les trie, afin de trouver les documents cherchés.
Or des documents apparaissent tous les jours, il faut donc
constamment réactualiser cette base de données. Ainsi, aucun
moteur de recherche ne peut parcourir la totalité des pages en un jour
(ce processus peut prendre plusieurs semaines). Chacun adopte donc sa propre
stratégie, certains vont même jusqu' à calculer la
fréquence de mise à jour des sites.
Des robots (logiciels) parcourent des millions de pages Web,
et associent l'adresse à des mots clés qui ont été
définis en en-tête de la page, soit en piochant des mots dans la
page elle même. Lorsque l'utilisateur d'un moteur remplit le formulaire,
il spécifie les mots qu'il cherche (éventuellement qu'il ne
souhaite pas) grâce aux opérateurs booléens « et
», « ou », « non »... (Symbolisés par +,
-,...), la requête est envoyée au moteur qui consulte ses bases de
données pour chacun des mots puis affine la recherche en enlevant les
pages ne convenant pas, puis retourne une liste de liens vers des pages, avec
le début du texte de la page ou le texte spécifié par le
créateur de la page dans des balises spéciales, appelées
méta-tags.
Ces réponses sont classées dans un ordre de
pertinence, c'est-à-dire le pourcentage de mots correspondant aux
critères de l'utilisateur, et leur indice de densité.
3. Description des moteurs de recherche : 3.1. Type de
Service :
Le type de service fourni par le moteur : Index Automatique,
Index Manuel, Annuaire, Index Automatique et Annuaire, Index Manuel et
Annuaire.
3.2. Type d'accès :
L'accès à ce service est-il gratuit (Public) ou
payant (Commercial), ou bien les deux types d'accès sont-ils
proposés (Public et Commercial).
3.3. Fréquence de mise à jour :
Evaluation moyenne de la fréquence de mise à
jour de l'ensemble de l'index de la base. Evaluation moyenne du nombre de
requêtes adressées au service pour une période
donnée.
3.4. Sites Miroirs :
Les sites miroirs sont des répliques du site original
à des localisations différentes, afin de répartir la
charge des machines et de réduire les temps de communication. Cette
liste comprend, s'il y a lieu, le nom du site miroir, un lien vers ce site, son
URL ainsi que sa localisation.
4 .Fonctionnement du moteur de recherche : 4.1. Collecte
des documents :
4 .1.1. Méthode de collection :
Décrit la manière dont les documents qui seront
plus tard indexés sont collectés .Trois cas sont possibles :
> Manuelle : des internautes passent
leurs journées à parcourir le Web et à signaler les sites
intéressants.
> Automatique : un robot (petit
programme) se promène sur le Web et rapatrie les documents qu'il trouve
en se déplaçant de lien en lien.
> Soumission d' URL : dans ce cas,
ce sont les auteurs afin que ces derniers indexent leurs pages.
4.1.2. Méthode de parcours :
Pour parcourir le Web deux stratégies sont possibles :
-Parcours en largeur : A partir d'une page, on parcourt d'un seul
niveau les liens présents sur celle-ci.
-Parcours en profondeur : A partir d'une page, on explore le
premier lien, puis sur la page résultante on parcoure le premier lien,
etc.
A partir les stratégies de parcours, différents
services sont proposés :
-Protocole standard d'exclusion :
Deux réponses possibles, oui ou non. Dans le cas de
l'affirmative, cela signifie que le robot de collecte respecte le protocole
standard d'exclusion permettant à tout web master de spécifier
des pages Web ne devant pas être collectées par le robot.
-Serveurs collectés :
Ce critère décrit l'ensemble des types de
serveurs collectés par le moteur de recherche. On a restreint leur
nombre aux plus essentiels : WWW, Usenet, F.T.P, Gopher, et- une rubrique
`Autre', pour les outils collectant des documents à partir d'autres
sources.
-Couverture géographique :
Décrit la couverture géographique du robot de
collecte des documents. En effet, de plus en plus d'outils sont
spécifiques à un domaine géographique particulier (Europe,
France, Pays Francophones, Suisse,.....).
-Type de contenu :
On trouve ici le sujet des documents collectés par le
système. Si la plupart s'intéressent à tous les documents
(dans ce cas, le type de contenu est étiqueté
général), certains vont restreindre leur processus de collecte
à certains sujets bien précis (médecine, brevets,
informatique,....)
-Fréquence de visite des documents :
Ce critère donne une évaluation de la
fréquence moyenne de visite des documents par le robot de collecte. En
effet, ce dernier doit parcourir le plus fréquemment possible les payes
qu'il a déjà récupérées afin de tenir compte
de toute modification du document. Ainsi, plus cette fréquence est
élevée, et plus les résultats d'une recherche seront
à jour par rapport à la réalité (si l'indexation
est aussi fréquente).
4.2. Indexation des documents :
4.2.1. Méthode d'indexation :
On distingue ici deux méthodes d'indexation, l'indexation
automatique et l'indexation manuelle.
4.2.2. Données indexées :
Les critères d'indexation peuvent être multiples et
variés. On a retenu : - Le titre du document.
-Ses différents sous-titres (balises <H1>... .
<Hn>).
-Son en-tête (le <META>tag).
-Sa date de création et/ou modification. -Sa taille.
-Les URLs qu'il cite.
-Le texte des URLs qu'il cite.
-D'autres balises éventuelles.
5. Le robot de recherche :
On va essayer de donner un aperçu du fonctionnement des
robots utilisés par un grand nombre de moteurs de recherche.
5.1. Les différentes parties d'un robot :
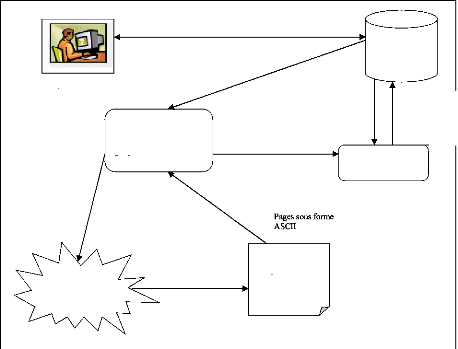
Requêtes de recherche
URLs à visiter
Module de récupération des pages
Bases de
données
Parser
Enregistrements ces URLs
Envoyer ces pages récupérées
Requêtes (HTTP ou autres)
Pages Web
Internet
Utilisateur
Indexation des pages selon algorithme ou robot
Figure 1.3. Les trois parties essentielles au bon
fonctionnement d'un robot.
5.1.1. Première partie :
Le module de récupération des pages il va
permettre, à partir d'une URL, de récupérer la page
correspondante. Cette partie fait intervenir d'importantes notions de
réseau tel que le fonctionnement client/serveur et le protocole HTTP.
5.1.2. Deuxième partie : (le parser)
Il est fortement dépendant des critères
d'indexation du robot, sur lesquels on reviendra. Le parseur sert à
extraire les informations des pages récupérés. Ce travail
est nécessaire car certaines parties de la page, notamment tous ce qui
concerne la mise en page, ne sont pas pertinentes pour le robot et
l'utilisateur.
De plus, il faut classer les informations selon les
critères d'indexations. Par exemple, le robot ne traite pas de la
même manière les liens de texte pur.
Il n' y a pas de règles d'implémentation
d'écriture d'un parseur, cela dépend fortement des
critères d'indexations. Cependant, là encore, des langages de
programmation tels que Java proposent des outils pour parser des pages HTML.
5.1.3. Troisième partie :( la base de
données)
Celle-ci stocke deux informations très importantes : d'une
part les URLs des pages, d'autre part un index des pages parsées. Cet
index permet d'associer des critères de recherche aux URLs. Lorsque
l'utilisateur émet une requête via un module de recherche, le
robot va interroger sa base de données et renvoyer les URLs qui lui
semblent pertinents. Il peut également, à l'image de Google,
renvoyer des morceaux de texte où sont présents les mots ou
expressions recherchés.
La complexité de la base de données
dépend du nombre d'informations différentes que le robot doit
stocker.
En effet, si on souhaite associer à chaque URL un (et
un seul) mot clé, la base sera très simple. En revanche, si on
souhaitons associer à chaque URL un grand nombre de mots clés,
pondérés en fonction de leur place dans le texte, ainsi que des
informations sur la popularité de la page ou le type de contenu (par
exemple .html .doc ...), l'indexation de la page sera autrement plus
compliquée.
Remarque importante :
On a essayé de présenter jusqu' a maintenant les
parties théoriques nécessaires à un robot de recherche .Il
faut cependant avoir à l'esprit que les grands moteurs de recherche
utilisant ce type d'outils traitent des volumes de données
considérables. Un ordinateur, aussi puissant soit-il, ne peut suffire
à réaliser tout ce travail. Il faut donc ajouter une couche de
complexité en répartissant le travail sur plusieurs machines,
elle-même utilisant plusieurs processus. Par exemple, google annonce
utilise plusieurs milliers de serveurs pour indexer les pages Web ainsi que
pour permettre aux utilisateurs d'effecteurs des recherches.
6. CONCLUSION :
Au cours de ce chapitre on a essayé de définir
et de donner une idée sur les fonctionnalités d'un moteur de
recherche. Suite à cette étude on cherchera à trouver des
solution pour le cas étudié, on commençons par la partie
conception qui sera détailler dans le chapitre suivant.
Chapitre4 : Etude Conceptuelle
1. Introduction :
La phase de conception est une phase fondamentale pour la
réalisation d'un projet, lors de cette phase on propose un ensemble des
solutions possibles et on va choisir celle qui demande moins de ressources et
satisfait plus la société. Dans ce chapitre, on a
déployé la méthodologie de conception afin de
réaliser ce projet.
L'étude conceptuelle est basée sur la conception
des différents modèles de données et de traitement.
2. Méthodologie de conception :
Pour valoriser le système d'information existant, on a
choisie la méthodologie de conception MERISE : méthode d'Etude de
Réalisation informatique par Sous Ensembles.
MERISE est une méthode classique de conception, de
développement et de réalisation de projet informatique. C'est une
simple méthode conceptuelle elle s'adapte avec toutes les langages de
programmation. Le but de méthode est d'arriver à concevoir un
système d'information. Elle est basée sur la séparation
des données et de traitements à effectuer en plusieurs
modèles de différents niveaux d'abstractions.
3. Les modèles de données : 3.1.
Dictionnaire de donnée :
Pour réaliser le modèle conceptuel de
données, il faut d'abord définir les données dans un
dictionnaire de données. Ce dernier est une liste complète des
propriétés utilisées dans les entités et les
associations. Chaque propriété représente une information
stockée et comporte un type. Les informations issues du dictionnaire de
données seront utilisées dans le cadre de modélisation du
MCD.
|
Code
|
Désignation
|
Type
|
|
adr_acceuil
|
adresse d'accueil de site
|
Text
|
|
date_ajout
|
date d'ajout d'un site
|
Date
|
|
date_modif
|
date de modification de site
|
Date
|
|
Date_supression
|
Date de suppression de site
|
Date
|
|
Adr _lien
|
adresse du lien
|
Text
|
|
nbre_mot_c
|
nombre de mot de passe associé au lien
|
entier
|
|
cade_mot_c
|
synonyme de mot clé
|
Text
|
|
syn_mot_c
|
synonyme de mot clé
|
Text
|
|
pwd_ad
|
mot de passe administrateur
|
Text
|
|
login_ad
|
login de l'utilisateur
|
Text
|
|
action_ad
|
action de l'administrateur
|
Text
|
|
date_acces
|
date d'accès
|
date
|
|
code_user
|
code de l'utilisateur
|
entier
|
|
pwd_prop
|
mot de passe de propriétaire
|
Text
|
|
login_prop
|
login de propriétaire
|
Text
|
|
nom_prop
|
nom de propriétaire
|
Text
|
|
pwd_e
|
mot de passe email
|
Text
|
|
login_e
|
login email
|
Text
|
|
date_acces_e
|
date d'accès à l'email
|
Date
|
Tableau 1.4. Dictionnaire de données
3.2. Règles de gestion :
Les règles de gestion concernant le modèle
conceptuelle de donnée sont résumé dans ce qui suit :
R1 : L'utilisateur traite un ou plusieurs mots clés.
R2 : Un mot clé peut avoir zéro ou plusieurs
synonymes.
R3 : Un lien est obtenu par un ou plusieurs mots clés.
R4 : Un site peut avoir un et un seul lien.
R5 : Un utilisateur peut visualiser un ou plusieurs sites.
R6 : Un administrateur peut administrer un ou plusieurs sites.
R7 : Un utilisateur peut être ou non un propriétaire
d'un email.
R8 : Un propriétaire accède à un email.
3.3. Le modèle conceptuel de données (MCD)
:
- listes des entités :
L'étude des différentes règles de gestion on
a permis de regrouper l'ensemble de données présentées
ci-dessous en ensemble d'entités comme suit :
|
Entité
|
Description
|
|
Site
|
Présentation du site
|
|
Lien
|
Présentation du lien
|
|
Mot_clé
|
Présentation du mot clés
|
|
Administrateur
|
Présentation d'administrateur
|
|
Utilisateur
|
Présentation d'utilisateur
|
|
Propriétaire
|
Présentation du propriétaire
|
|
Email
|
Présentation d'email
|
Tableau 2.4. Liste des entités
- Listes des associations :
Le tableau regroupe l'ensemble des associations possibles qui
relient l'ensemble des entités deux à deux :
|
Association
|
Entités participantes
|
|
Avoir
|
site, lien
|
|
Obtenir
|
lien, mot clé
|
|
synonyme
|
mot clé, mot clé
|
|
administrer
|
administrateur, site
|
|
visualiser
|
site, utilisateur
|
|
Traiter
|
mot clé, utilisateur
|
|
Etre
|
propriétaire, utilisateur
|
|
Accéder
|
Propriétaire, Email
|
Tableau 3.4. Liste des associations
- Présentation du modèle conceptuel de
données :
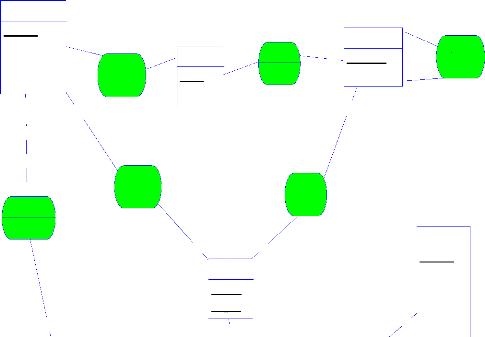
mot_clé
obtenir
1 ,n
1 ,n
codemotclé syn_mot
lien
adrlien description
1,n 1,n
Traiter
Email
1,n
1,n
1,1
0,n
1,1
1,n
avoir _lien
Utilisateur
0,n
0,n
0,n
synonyme
1,1
Visualiser
Administrer
passwordp login_p contenue date_envoie date _reçoit
codeuser
dateaccé
site
adraccueil
date_ajoÂdate_modif date_supressi on
administrateur
pwdadmin login_admin action_admin
1,1

Etre
Acceder
propriétaire 1,1
Passwordprop login_prop nom_prop
Figure 1.4. Model conceptuel de données
(MCD)
3.4. Modèle Physique de données
:
C'est la traduction de modèle conceptuelle des
données (MCD) dans langage de description de données
spécifiques ou SGBDR (Système de Gestion de Base de
Données Relationnelle) retenu pour la réalisation du SI
(système informatique).
- Liste des tables :
Après la génération de modèle
physique, les entités et les associations se transforment en tables. On
distingue :
|
Entité
|
Description
|
|
Site
|
Présentation du site
|
|
Lien
|
Présentation du lien
|
|
Mot_clé
|
Présentation du mot clés
|
|
Administrateur
|
Présentation d'administrateur
|
|
Utilisateur
|
Présentation d'utilisateur
|
|
Propriétaire
|
Présentation du propriétaire
|
|
Email
|
Présentation d'email
|
Tableau 4.4. Listes des tables
- Présentation du modèle physique de
données :
LIEN
|
SITE
|
|
ADR_ACCUEIL = ADR_ACCUEIL
|
ADRLIEN long varchar
ADR_ACCUEIL long varchar
DESCRIPTION long varchar
|
= CODE
|
MOT _CLE
|
= CODE_MOT_CLE
= MOT_CODE_MOT_CLE CODE_MOT_CLE
|
|
ADRACCUEIL
|
long varchar long varchar date
date date
|
|
CODE MOT CLE
|
long varchar
long varchar
|
|
PWD_ADMIN DATE_AJOUT DATE_MODIF DATE _SUPRES
|
|
SYN _MOT
|
|
ADR_LIEN = ADR_LIEN CODE_MOT_CLE
|
_MOT _CLE
|
CODE_MOT_CLE
|
|
|
OBTENIR
ADR LIEN long varchar
CODE MOT CLE long varchar

CODE_MOT_CLE = CODE_MOT_CLE
ADR_ACCUEIL = ADR_ACCUEIL
SYNONYME
CODE MOT CLE long varchar
MOT CODE MOT CLE long varchar

VISUALISER
CODE USER long varchar
DATE ACCE date
CODE MOT CLE long varchar

ADRACCUEIL long varchar
CODEUSER long varchar
DATEACCE date
PWD_ADMIN = PWD_ADMIN
TRAITER
CODE_USER = CODE_USER CODE_USER = CODE_USER
DATE_ACCE = DAT E_ACCE DATE_ACCE = DAT E_ACCE
UTILISATEUR
CODE USER long varchar DATE ACCE date

CODE_USER = CODE_USER
DATE_ACCE = DAT E_ACCE
EMAIL
PASSWORDP <non défini>
PASSWORD_PROP long varchar
LOGINP <non défini>
CONTENUE <non défini>
DATE _ENVOIE <non défini>
DATE_RECOIT <non défini>
ADMINISTRATEUR
PWD ADMIN long varchar
LOGIN_AD long varchar
ACTION_ADMIN long varchar
PASSWORD_PROP = PASSWORD_PROP
|
PROPRIETAIRE
|
|
|
PASSWORDPROP long varchar
PASSWORDP <non défini>
CODE_USER long varchar
DATE_ACCE date
LOGIN_PROP long varchar
NOM_PROP long varchar
|
PASSWORDP = PASSWORDP
|
Figure 2.4. Modèle physique de données
(MPD)
3.5. Le modèle logique de données :
Le modèle logique de données (MLD) consiste
à) décrire la combinaison de données utilisées sans
faire référence à) un langage de programmation. Ce
modèle est en fait la traduction du modèle conceptuel de
données en appliquant les règles de passages.
Le modèle logique de données est alors le suivant
:
- Site (adr_acceuil, date_ajout, date_modif,
date_supprission).
- Lien (adr lien, description, adr_acceuil#).
- Mot clé (code mot clé, syn_mot,
adr_lien#).
- Administrateur (pwd-ad, log_ad, action_ad,
adr_acceuil#).
- Utilisateur (code user, date_acces, pwd_prop#,
nom_prop#).
- Propriétaire (pwd prop, login_prop, nom_prop,
pwd_e#).
- Email (pwd e, login_e, date_acces_e,).
NB : Les attributs soulignées sont des
clés primaires, et sont qui se terminent par # sont des clés
étrangers.
4. Le modèle conceptuel de traitement :
La modélisation conceptuelle de traitement a pour objectif
la réalisation des activités formellement. Elle est
exprimée dans un formalisme spécifique qui propose une
présentation graphique destiné à faciliter le dialogue
entre concepteur et utilisateur. Ce formalisme comporte les concepts suivants :
Domaine, Acteur, Evénement/Résultat, Opérateur,
Synchronisation, Règle d'émission et Processus.
Les événements exercés par les acteurs se
transforment en processus. Dans ce qui suit, on va présenter les
différentes modèles conceptuels de traitements.
- Processus 1 : MCT1 : Accéder aux sites
:
Ce processus montre les étapes faites lors de la
visualisation des sites afin de trouver l'information souhaitée :
recherche de l'information
|
verification du mot clé
chercher le informations convenable
|
utilisateur
ok
lien affichés
resul tat nulle
affichage de lien
trié les liens
classé les liens par date de modification
site visualisés
sortie
Figure 3.4. MCT1 Accéder aux sites
-Processus 2 : MCT2 : Administration des
sites
Ce processus montre les étapes faites lors de
l'administration des sites :
identification de l' administrateur
|
verification de login verification de mot de passe
|
administrateur
ok
site a administré
veri ficat ion
administrer
ajouter
modifier
supprimer
site administré
retour
Figure 4.4. MCT2 : Administration des sites
-Processus 3 : MCT3 : accéder a
l'email
Ce processus montre les étapes faites lors de
l'accès à l'email après la validation de l'inscription
:
inscription
utilisateur
nom
prenom
age
login
mot de passe
inscription accepté

veri ficat ion
acceder a email
envoyer email recevoir emai l supprimer email

not ok
retour
accés réussit
ok
Figure 5.4. : MCT3 Accéder à
l'email
5. Conclusion :
On a essayé a partir de ce chapitre de donner une
idée sur la conception des données ainsi que les outils
utilisées pour réaliser cette tâche important. Les
résultats de cette étude seront la première étape
pour la partie réalisation qui sera expliqué dans le chapitre
suivant.
Chapitre 5 : Réalisation
1. Introduction :
Dans ce chapitre, on essayera de faire la réalisation
de moteur de recherche effectuant la recherche dans le Web et dans la base de
données locale, un accès aux services de messagerie, et un
aperçu de l'interface de recherche.
2. Analyse :
2.1. Outils de développements :
·
· Dreamweaver :

Macromedia Dreamweaver MX est un éditeur HTML
professionnel destiné à la conception, au codage et au
développement de sites, de pages et d'applications Web. Quel que soit
l'environnement de travail utilisé (codage manuel HTML ou environnement
d'édition visuel), Dreamweaver propose des outils qui permet la
création des applications Web.
Les fonctions d'édition visuelles de Dreamweaver vous
permettent de créer rapidement des pages sans rédiger une seule
ligne de code. Si vous préférez faire appel au codage manuel,
Dreamweaver intègre également de nombreux outils et fonctions de
codage. Avec Dreamweaver, vous pouvez créer des applications Web
dynamiques reposant sur des bases de données à l'aide de langages
serveur tels que ASP,
ASP.NET, Cold fusion Mark up Langages
(CFML), JSP et PHP.
·
· Adobe Photos hop :
C'est un logiciel de traitement d'images fixes. Le traitement
dans ce logiciel est basé sur l'utilisation des calques. Une image lors
de sa création prend l'extension de .psd qui peut être convertie
sous autre format tel que GIF ou JPEG (généralement les plus
utilisés).Ce logiciel est très puissant en utilisant des filtres
et plusieurs autres outils très évolués.
2.2. Langages utilisés :
2.2.1. HTML et Formulaire :
-Présentation du HTML
Le HTML (Hypertexte Mark up Langage) est un système qui
formalise l'écriture d'un document avec des balises de formatage
indiquant la façon dont doit être présenté le
document et les liens qu'il établit avec d'autres documents.
Il permet, entre autre, la lecture de documents sur Internet
à partir de machines différentes grâce au protocole HTTP,
permettant d'accéder via le réseau à des documents
repérés par une adresse unique, appelée URL.
En effet le Web est une énorme archive vivante de textes
formatés, d'images, de sons, de vidéo ... Ces documents sont
organisés autour d'une page d'accueil qui guide les visiteurs vers
d'autres pages HTML grâce à des liens hypertextes.
-Intérêt d'un formulaire
Les formulaires interactifs permettent aux auteurs de pages Web
de dialoguer avec leurs lecteurs, un peu comme les coupons-réponse que
l'on trouve dans les magazines. Le lecteur saisit des informations en
remplissant des champs ou en cliquant sur des boutons, puis appuie sur un
bouton de soumission (submit) pour l'envoyer soit à un URL,
c'est-à-dire de façon générale à une adresse
e-mail ou à un script CGI (Common Gateway Interface, traduisez
"Interface de passerelle généralisée") stocké sur
un serveur et écrit dans un langage de programmation comme un Shell
UNIX, PERL, TCL, etc.
2.2.2. Active Server Page :
-Présentation des Active Server Page (ASP)
:
ASP est un standard de propriétaire proposé par
Microsoft permettant de développer des pages dynamiques ASP. Sa
première version a été développée et
livrée au public à la fin de 1996. L'année suivante, ASP
est intégré dans la distribution de la nouvelle version du
principal serveur Web de la même entreprise, Microsoft IIS 11 3.0, dans
le but de tirer profit de la position privilégiée de ce produit
sur le marché pour lancer sa nouvelle technologie.
-Cas d'utilisation souhaité
ASP est une technologie très intéressante
lorsque l'on veut intégrer des technologies Microsoft, tels que les
produits de bureautique, la technologie d'accès aux données ADO
et des composants COM. Bien qu'il existe des produits permettant d'utiliser les
ASP sur des plate-forme différentes de IIS/Windows, c'est sur cette
plate-forme que ASP peut donner le mieux de soin en pouvant notamment utiliser
la large gamme de composants ActiveX développées pour ce
système d'exploitation.
Á coté de l'avantage de pouvoir très bien
s'intégrer avec les autres technologies Microsoft, ASP constitue une
solution très complète et performante en matière de
génération des pages dynamiques mais qui n'est pas nettement
supérieures aux autres alternatives sur les autres dimensions.
-Les fondements du choix de la Langage ASP :
Le choix de la solution côté serveur pour notre
application web dynamique est fixé suivant la nature d'application et
son niveau de difficulté d'une part et les environnements de
développement qu'on les familiarise d'autre part. Ces contraintes de
développement, à côté des notables avantages
étudiés précédemment de la solution ASP, face aux
autres solutions, on a amené à mettre en jeu la technologie ASP
comme la solution la plus adéquate et la plus adoptée à
notre application. Nos fondements pour ce choix se basent principalement sur
:
-Notre familiarisation avec l'environnement microsoft.
-La portabilité de l'asp.
-La performance d'asp.
-Le niveau de sécurité qu'on peut l'assurer.
Exemple de script ASP
Un script ASP est donc un fichier texte dont l'extension est
.asp, contenant des portions de script, c'est-à-dire des lignes de code
interprétées par le serveur Web, encadrés par des balises
spécifiques.
<°/0
Set Conn = Server.CreateObject ("ADODB.Connection")
Conn.Open DSN_BASE
Set Rs = Server.CreateObject ("ADODB.Recordset")
°/0>
<°/0
Rs.Open "Select * from site" , Conn
%>
2.2.3. JAVASCRIPT :
Java script est un Language de programmation interpréter
structuré et orientée objet : -un Language structuré
utilise des structures.
-un langage orienté objet : utilise des objets (bouton,
checkbox...).
Avec java script on peut programmer c à d écrire
des ordres qui seront exécutées par l'ordinateur sa syntaxe est
très souple, il est insérer au sein d'une page html.
Exemple de java script
<script Language="JavaScript">
Function verf()
{
var vvv=document.forms["recherche"].mots.value ;
if (vvv.length <3)
{alert (" Taper votre mot a recherché S.V.P");
return false ;
} else
{
return true ;
}
}
</script>
2.3. Choix de la
technologie :
2.3.1. Serveurs Web :
Les scripts ASP sont interprétés par les serveurs
Web suivants :
Microsoft Internet
|
Personal Web
|
Chili!
|
|
|
Information
|
|
|
Instant! ASP
|
|
Server
|
ASP
|
|
|
Server
|
|
|
|
|
Windows NT
|
Windows NT
|
Unix
|
Autres Systèmes
|
|
Server 4.0,
Windows 2000
|
Workstation, Windows 9x & Me
|
Linux
|
d'exploitation
|
Tableau 1.5. les serveurs Web
2.3.2. Internet Information Server (IIS) :
Microsoft Internet Information Server est un serveur Web qui
permet de publier des informations sur l'intranet d'une entreprise ou sur
Internet. Internet Information Server utilise le protocole HTTP (Hypertext
Transfer Protocol) pour la transmission des informations. Internet Information
Server peut aussi être configuré pour fournir les services FTP
(File Transfer Protocol) et Gopher. Le service FTP permet aux utilisateurs de
transférer des fichiers vers et depuis le site Web.
3. Implémentation :
Vous pouvez facilement installer Internet Information Server
en même temps que Windows NT Server. Lorsque le programme d'installation
vous propose d'installer Internet Information Server, activez la case à
cocher correspondante et cliquez sur OK. Si vous avez déjà la
connexion Internet ou intranet nécessaire, vous pouvez accepter toutes
les options par défaut durant l'installation, puis ajouter vos fichiers
de contenu HTML (Hypertext Mark up Language) au dossier
wwwroot. Vos fichiers seront immédiatement disponibles
pour les utilisateurs. Les configurations
adoptées par défaut lors de l'installation
conviennent, sans la moindre modification, à de nombreux
scénarios de publication.
Cette section décrit la configuration requise pour
l'installation et explique comment :
· configurer Windows NT avant l'installation.
· exécuter le programme d'installation.
· préparer les fichiers à publier.
· tester votre installation.
3.1. Configuration :
Microsoft Internet Information Server requiert :
-Un ordinateur présentant au moins la configuration
minimale nécessaire pour exécuter Windows NT Server ; voir la
section " Listes de contrôle de la configuration et de la
sécurité de Windows NT", plus loin dans ce chapitre.
-Windows NT Server version 4.0.
Remarque Vous pouvez administrer un serveur
exécutant Internet Information Server à partir d'un ordinateur
distant exécutant Windows NT Workstation. Installez le Gestionnaire des
services Internet des Services Web personnels sur cet ordinateur, puis
établissez une connexion au serveur que vous voulez administrer.
-Le protocole TCP/IP (Transmission Control
Protocol/Internet Protocol) inclus dans Windows NT. Utilisez
l'application Réseau dans le Panneau de configuration pour installer et
configurer le protocole TCP/IP et les composants apparentés.
-Un lecteur de CD-ROM pour le disque compact d'installation.
-Un espace disque suffisant pour les informations à
stocker. Il est recommandé de formater en NTFS (le système de
fichiers de Windows NT) tous les lecteurs utilisés avec Microsoft
Internet Information Server.
3.2. Système de gestion de base de données
:
i) Introduction :
Les bases de données sont actuellement au coeur du
système d'information des entreprises.
Dans un premier temps, et de façon informelle, on peut
considérer une Base de données (BD) comme une grande
quantité de données, centralisées ou non, servant pour les
besoins d'une ou plusieurs applications, interrogeables et modifiables par un
groupe d'utilisateurs travaillant en parallèle. Quant au Système
de Gestion de Bases de Données (SGBD), il peut être vu comme le
logiciel qui prend en charge la structuration, le stockage, la mise à
jour et la maintenance des données ; c'est, en fait, l'interface entre
la base de données et les utilisateurs ou leurs programmes.
ii) Ms Access :
Dans un système client/serveur l'échange de
données se fait généralement à travers une base de
données. La performance du système est liée en une grande
partie à l'efficacité de son système de gestion de base de
données mis en jeu. En effet, le temps d'accès et de
réponse ainsi que la gestion de multitâches influencent
profondément sur la performance de l'application et sa qualité de
service. En revanche le choix adéquat de SGBD a une importance
stratégique et technique pour l'application à
développer.
Dans notre application, le SGBD Access est apparu comme la
solution convenable et adoptée avec les autres composantes et les
technologies intervenantes au fonctionnement du site.
3.3. Les mots clés :
Les mots clés sont particulièrement sensible
puisque
-C'est par leurs intermédiaire que le site sera
trouvé et visité.
-Ils déterminent le classement dans le moteur de
recherche.
-Ils contribuent à valider l'inscription dans les outils
de recherche.
C'est-à-dire l'utilisateur traite les mots clés,
le programme visite la base des correspondance des liens et des mots
clés trouver les mots qui coïncide avec trois premiers
caractères de mot cherché.
Le mot peut avoir des synonymes, donc le même
résultat a les mêmes liens pour les mots clés.
4. Réalisation :

WEB
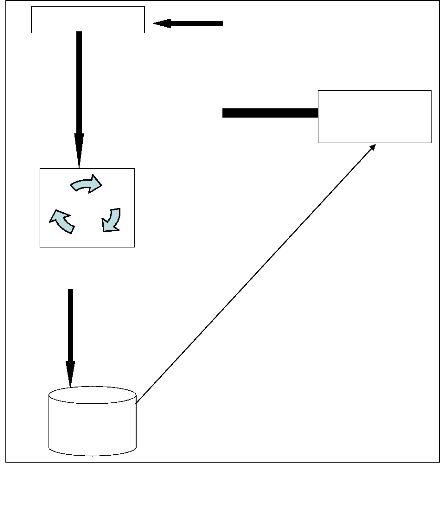
Recherche local
Programme de
recherche
Base de
données
Choisir l'environnement de recherche
Figure 1.5 : Schéma d'utilisation
4.1. Explication de schéma :
En récupérant le mot que l'utilisateur a
introduit un programme de recherche envoi une requête SQL vers le base de
données pour voir s'il existe un site ou page dont le libellé
coïncide avec le mot recherché, une fois qu'il a localisé le
champ de texte il
pointe sur le site et envoi vers la page résultas son nom
et lui donne un lien vers la page qui lui est destinée.
*Conception structurelle du moteur
La structure de notre moteur se fonde sur deux grandes parties
distinctes mais complémentaires:
4.2. Un module utilisateur :
4.2.1. Utilisateur site :
index1.asp
recherche.asp

you.mdb
Figure 2.5. : Un module utilisateur
Dans ce module l'utilisateur doit consulter la page index
(accueil) a partir de cette page il choisi le choix du recherche soit dans sur
le Web soit sur le local, une fois les mots clés sont traités, et
si la recherche sera sur le Web un programme interroge les autres moteurs de
recherche et envoie les résultats sous forme des liens. Si la recherche
sera sur le local le programme trouve les résultats les affiches sous
forme des liens a partir l'utilisateur peut naviguer. Si les mots clés
ne convient pas un message d'erreur s'affiche.
4.2.2. Utilisateur email :

reception.asp


Vide.asp

envoyeremail.asp rechercheemail.asp

ERREUR.asp

Loginemail.asp
ERREUR
insc.mdb
Figure 3.5. : module utilisateur email
Dans ce module utilisateur email l'utilisateur introduit un login
et mot de passe s'il y a une erreur après la vérification, un
message d'erreur sera affiché si non il peut faire
les taches suivantes :
- Envoie des messages.
- Réception des messages.
- Supprimer des messages.
- Rechercher des emails.
NB : chaque utilisateur ne peut pas accéder sans faire une
inscription acceptable.
4.3. Un module administration :
ajout.asp

enregistrementsite.asp



modifsupprsite.asp admin.asp ERREUR.asp

sitesuppr.asp modifiersite.asp
sitemodif.asp
ERREUR
Figure 4.5. : module administration
Dans ce module l'administrateur est identifié par un login
et un mot de passe, si l'accès est refusé un message d'erreur
sera afficher, et une fois l'accès est accepté il peut
gérer les tâches suivants :
- Ajout des sites.
- Suppression des sites.
- Modification des sites.
5. Processus de fonctionnement de moteur de recherche :
Notre processus de fonctionnement se base sur deux niveaux
d'études principales:
-Premier niveau : utilisateurs
- Faire un recherche
-Création, envoi et réception email
-Deuxième niveau : Administration
5.1. Niveau utilisateur :
> la recherche
Pour faire la recherche, chaque utilisateur doit obligatoirement
saisie les mots clés ou l'adresse dans le champ de saisie pour avoir les
résultats estimées.
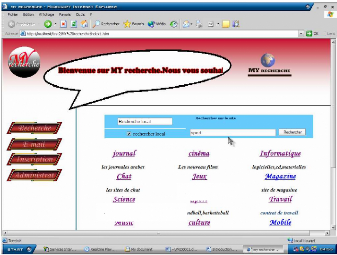
Le monde de sciences
jeuxde carte
Figure 5.5. : Figure principale
Dans cette phase plusieurs contraintes à respecter :
Si le nombre des caractères saisis inférieur
à deux caractères ou le champ est vide un message d'erreur sera
signalé.
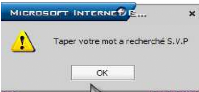
Figure 6.5. Erreur mot de passe
Si tous est passé bien une nouvelle page sera
affichée, c'est la deuxième phase. Deux résultats peuvent
être affichées :
-Si le mot saisi est trouvé la page suivant s'affiche.
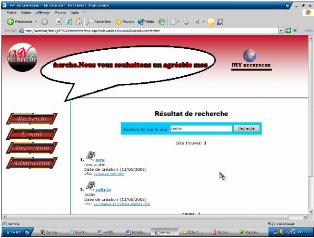
Figure 7.5. Résultats de recherche Cette
page contient les liens des pages ou sites trouvées.
-Si le mot n'est pas trouvé la page suivant s'affiche :
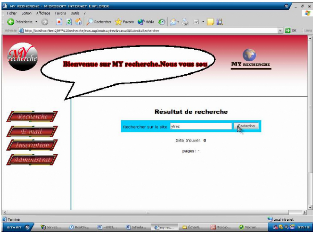
Figure 8.5. Résultats de recherche
nulle
> Création, envoi et réception d 'email
:
-Si vous n'avez pas un email vous pouvez faire une inscription
direct en cliquant sur
le bouton inscription qui vous amène à la page
inscription (page suivante).
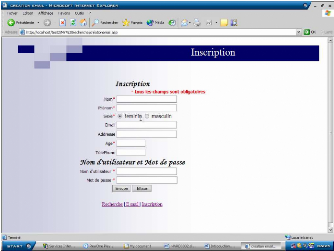
Figure 9.5. Inscription
Dans cette phase l'utilisateur doit remplir un formulaire qui
subit lui aussi à des contraintes. Les variables à saisir sont
strictement mis à des règles.
-En cas ou l'une des variables à saisir est erronée
un message d'erreur sera signalé :
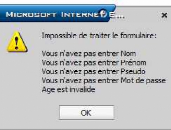
Figure 10.5. Erreur d'inscription
Tous les
variables ne sont pas saisis
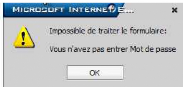
Figure 11.5. Mot de passe n'est pas saisis
-si tous sont passé bien et après la validation du
formulaire une autre page sera affichée qui confirme l'enregistrement
des données.
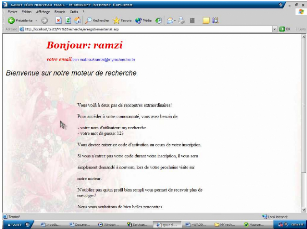
Figure 12.5. Inscription validé
-Si vous avez déjà un email il faut avoir un mot de
passe et nom d'utilisateur Dans cette phase plusieurs contraintes à
respecter:
Figure 13.5. Identification email -Le nom
d'utilisateur et le mot de passe peuvent être non validé.
Figure 14.5. Accès refusé
-En cas ou un champ manque un message d'erreur sera
signalé.
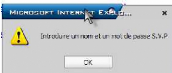
Figure 15.5. Erreur d'identification
-Si le mot de passe et le non d'utilisateur sont confirmés
la page suivante s'affiche.
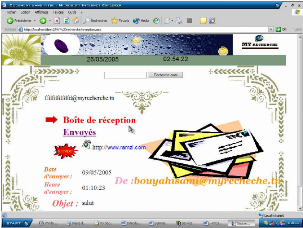
Figure 16.5. Accès validé
- C'est la page de réception des messages qui contient le
bouton envoyé qui amène à la page d'envoi d'email.
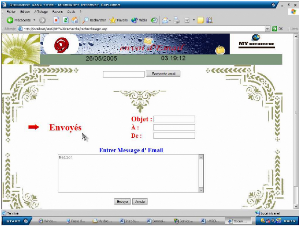
Figure 17.5. Envoie d'email
5.2. Niveau administration :
-administration de base de donnée :
Parmi les taches effectuées par l'administrateur la
gestion de base de donnée. En cliquant sur le bouton administration et
après la validation on a les cas suivants :
-Si l'administrateur veut ajouter, supprimer ou modifier un site
il doit avoir un mot de passe et un nom d'utilisateur qui doit entrer dans la
page précédent.
-Si le mot de passe et le nom d'utilisateur sont corrects la page
suivant s'affiche :
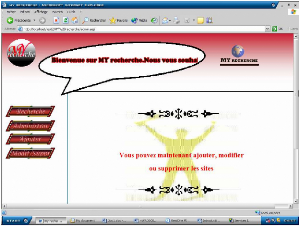
Figure 18.5. Validation de l'inscription
-Pour ajouter un site cliquer sur le bouton ajouter qui affiche
la page suivante :
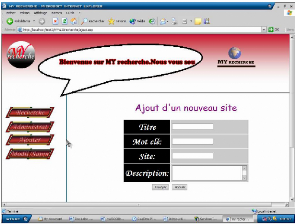
Figure 19.5. Ajout des sites
-Si les champs ne sont pas remplis correctement la page suivante
s'affiche :
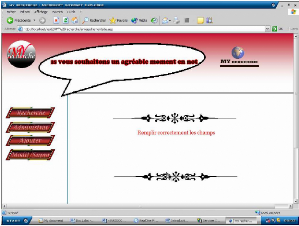
Figure 20.5. Erreur sur les champs
-Pour supprimer ou modifier le site cliquer sur le bouton
modif/suppr la page suivante s'affiche :
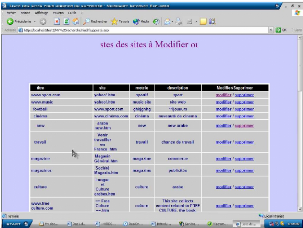
Figure 21.5. Modification sur les sites -Lorsque
vous cliquer sur supprimer la page suivante s'affiche :
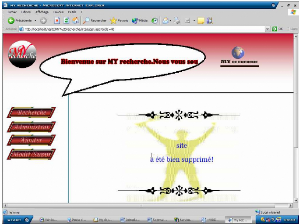
Figure 22.5. Suppression des sites -Lorsque vous
cliquer sur modifier la page suivante s'affiche :
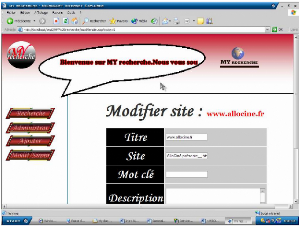
Figure 23.5. Site modifier
Cette page offre la possibilité de modifier titre, site,
mot clé et la description de site.
6. Conclusion :
L'implémentation de notre moteur de recherche à
pour but de simplifier les taches aux utilisateurs, donner une idée
générale sur le fonctionnement de moteur de recherche et de
présenter toutes les parties de moteur à partir des interfaces
graphiques décrivant le contenu des pages.
Conclusion Général
Les outils de recherche actuels ne parviennent pas à
absorber la formidable croissance des sites sur le web puisque l'ensemble des
moteurs ne référence que la moitié des documents
estimés sur Internet à cause de grandes quantités
d'informations trouvés.
Dans notre application on a essayé le maximum d'avoir une
résultas très proche des autres moteurs.
Mais, si l'on veut pouvoir un jour songer à
concurrencer dans ce domaine, il faudra bien q'on y travail encore et avoir
plus des matériels pour en faire un véritable portail consultable
par tous les internautes.
Finalement, même si l'on a équipé notre
moteur de recherche des meilleurs techniques de développements tel que
ASP, JAVA, ACCES S et HTML, il on est très difficile de prétendre
pouvoir un jour détrôner Yahoo, l'annuaire le plus populaire au
monde, ou encore Google qui dispose de plus de 10 000 serveurs à son
actif.
BIBLIOGRAPHIE
Livre :
V' je réussie mes recherches sur Internet : Thierry
Crouzet V' Introduction aux requêtes SQL : Hermandez, H-J
V' E-mail sur Internet
V' Total HTML : 382 solutions express : Steven .H
V' Pour mordu de la programmation HTML : Morris, B V' HTML et
java script : Chaleat
V' Photoshop.6 : pour le Web : Faster
V' Microsoft Access 2002 : Friedrichen,L
Sites Internet :
www.tout
javascript.com
www.oracle.com
www.sun.com
www.developer.com
www.ASP.net
www.scripts-fr.com
www.guide web
master.net
www.web developer.earth
web.com
www.java
soft.com
www.apache.com
GLOSSAIRE
ASP : Active Server Pages: technologie de
Microsoft analogue à PHP et JSP permettant le développement de
pages dynamiques coté serveur.
CGI: Common Gateway Interface. Interface
permettant à un serveur web de communiquer avec une application, dont
celui-ci a besoin pour traiter une information ou une requête issue d'une
page.
Client Serveur: Architecture visant à
répartir une application entre une ou plusieurs unités
fonctionnelles qui émettent des requêtes (côté
client) et l'unité fonctionnelle qui traite ces requêtes
(côté serveur).
FTP: File Transfer Protocol. Désigne un
protocole de niveau application de transfert de fichiers basé permettant
la copie de fichier d'un ordinateur vers un autre
HTML : Hypertexte Mark up Language langage
multi plateforme utilisé pour concevoir des pages sur le World Wide Web.
Il permet de décrire la présentation et la structure d'une page,
et surtout les liens avec d'autres documents hypertexte situés sur le
Réseau.
HTTP : Hypertexte Transfer Protocol protocole et
service TCP/IP de type requête réponse sans mémoire
d'état pour transférer des pages Web au travers d'Internet.
Hypertexte : Façon de structurer et présenter de
l'information en permet une lecture non linéaire de documents
grâce à la présence de liens sémantiques
définis de façon arbitraire.
Internet Explorer : Navigateur Internet
conçu par Microsoft et automatiquement inclut dans Windows depuis 1998.
S'abrège souvent en MSIE ou IE.
Java script : Langage de programmation de
scripts, créé et développé par Netscape.
Contrairement à Java, Java script est un langage
interprété.
JSP : Java Server Pages: solution cotée
serveur pour la génération de pages dynamiques
développée par Sun.
URL: Uniform Resource Locator. Syntaxe
permettant de spécifier le moyen aux différents types de
ressources du Réseau et composée par le protocole d'accès,
l'adresse de la machine et la localisation de la ressource sur la machine.
World Wide Web (www) : Désigne le service
le plus utilisé d'Internet actuellement, constitué d'un
réseau de documents hypertexte .
Remerciement
On a le plaisir, on terme de ce projet de fin d'étude
à l'institut supérieur des études technologiques deDJERBA
à exprimer mes sincères remerciement à mon enseignant Mr
BEN ZEKRI Yassine
On adresse mes chaleureux remerciements à tous les
personnels qui m'ont aidé
le long de mon travail.
Mr BEN MABROUK Ramzi l'encadreur à l'entreprise qui a
facilité
l'intégration dans cette direction.
Enfin je dis merci aux membres de jury, qui ont fait l'honneur
d'accepter d'évaluer ce projet.
| 

