|
|
RÉPUBLIQUE DU CAMEROUN
Paix - Travail - Patrie
UNIVERSITÉ DE YAOUNDÉ I
|
REPUBLIC OF CAMEROON
Peace - Work - Fatherland
UNIVERSITY OF YAOUNDÉ I
|
|
ECOLE NATIONALE SUPÉRIEURE
POLYTECHNIQUE

|
|
DEPARTEMENT DE GENIE INFORMATIQUE

Laboratoire d'Informatique, du Multimédia et
Applications
|

Conception Intelligemment Assistée par Ordinateur
de Systèmes d'Information
(CIAO - SI)
|
ACQUISITION ET EXPLOITATION D'ELEMENTS DE PROCESSUS
D'INGENIERIE LOGICIELLE : CAS DU PROJET CIAO-SI
|
Mémoire de fin d'études présenté et
soutenu par
KOM MBOUMI Franck Gérard
En vue de
l'obtention du
Diplôme d'Ingénieur de Conception en
Informatique
|
|
Sous la direction de :
|
Dr. Roland YATCHOU TCHANA, UQAM Montréal
Dr. Claude TANGHA, ENSP, Yaoundé
|
|
Sous la supervision de :
|
Roger NKAMBOU, Ph.D, UQAM Montréal
Raphaël NBOGNI, Président LGI, Longueil
|
|
Devant le jury composé de :
|
Président :
Pr. AWONO ONANA
Membres :
Dr. Claude TANGHA
Dr. Roland YATCHOU TCHANA
Dr. Guillaume KOUM DISSAKE
Ing. Chantal MVEH
|
UNIVERSITÉ DE YAOUNDÉ I
UNIVERSITY OF YAOUNDÉ I
ACQUISITION ET EXPLOITATION D'ELEMENTS DE PROCESSUS
D'INGENIERIE LOGICIELLE : CAS DU PROJET CIAO-SI
KOM MBOUMI Franck Gérard,
Département de Génie Informatique,
Ecole Nationale Supérieure Polytechnique.
Mémoire soutenu en vue de l'obtention du
Diplôme d'Ingénieur de Conception en
Informatique,
Juin 2004.
(c) Franck Gérard KOM MBOUMI, 2004.
Dédicaces
A Toi ma source, pour que tous reconnaissent ton
Amour.
A toi Maman, dont la chaleur dans les moments difficiles m'a
toujours apporté du courage.
A toi Papa, mon meilleur exemple, de toutes tes forces tu me
soutiens chaque jour.
A mes frères et soeurs, tous vos gestes et conseils
m'ont à jamais marqué.
A Marlyse, réjouis-toi des échos de mon
travail portés à toi, jusqu'au jour où on les fêtera
ensemble.
A Armand et André, j'essaierai de faire mieux pour
vous ressembler.
Remerciements
Parce qu'aucun homme ne peut rien de lui-même, je tiens
à présenter mes très sincères remerciements
à tous ceux qui de loin comme de près ont contribué
à la réalisation de ce travail.
Je commence par témoigner ma reconnaissance à
Pr. AWONO ONANA pour l'honneur qu'il me fait en acceptant de présider ce
jury, car sa présence apporte une touche particulière à ce
travail.
Je tiens à exprimer toute ma gratitude à Dr.
Roland YATCHOU, dont l'ouverture, la disponibilité, la rigueur dans le
travail m'ont conduit durant mon passage au LABORIMA. La meilleure partie de
mon travail est encore soutenue par les acquis de son encadrement.
Au Dr. Claude TANGHA, j'exprime ma reconnaissance pour sa
disponibilité, ses conseils et surtout le rôle de père
qu'il a joué avec ardeur tout au long de notre parcours.
Particulièrement, je le remercie pour m'avoir accepté au sein du
LABORIMA et pour l'honneur de sa présence dans ce jury.
Au Dr. Guillaume KOUM, je tiens à exprimer mes
remerciements pour les conseils, la disponibilité et l'honneur qu'il me
fait en participant à ce jury.
A Ing. Chantal MVEH, j'exprime ma sincère gratitude
pour les enseignements reçus, sa compréhension et l'honneur
qu'elle me fait en participant à ce jury.
Je remercie particulièrement Pr. Roger NKAMBOU pour la
supervision de ce travail, ainsi que M. Raphaël NBOGNI, président
du groupe LGI, pour m'avoir fourni le cadre de définition de ce
travail.
Je tiens à remercier tous les membres de ma très
grande famille qui m'ont toujours soutenu dans mes entreprises, et surtout qui
m'ont écouté : Lily, Véronique, Gervais, Tonton
Engelbert,...
Toute ma gratitude à mes camarades de la promotion
GI2004, compagnons de tant d'épreuves qui nous ont rapprochés.
A tous les membres du LABORIMA, qui ont soutenu mes travaux et
m'ont aidé à m'améliorer sur de nombreux plans.
A mes amis et amies, dont la simple présence parfois
m'a encouragé dans mes efforts.
Spécialement : Blandine, Mohaman, Willy, Valéry,
Habiba, Claudia, Chimène, Danielle, Carine, Marietta ... A tous les
enfants de choeur de la Paroisse Saint-Pierre de Kong à Yaoundé,
et particulièrement au collège des responsables, j'exprime ma
gratitude.
Ni les mots, ni les pages ne suffisent à exprimer ma
gratitude à vous qui avez de près et de loin participé
à mon édification et contribué à ce travail.
Résumé
L'informatique a connu un essor sans précédent
durant la dernière décennie, une floraison d'entreprises offrant
des services aussi divers les uns que les autres. Du point de vue des
utilisateurs, consommateurs des produits et services ainsi fournis, les
possibilités s'élargissent. Elles vont de la gestion documentaire
avec la bureautique à la gestion des ressources humaines par les
systèmes de workflows. A cause de cette demande croissante, l'un des
domaines de l'industrie logicielle les plus florissants, la conception des
systèmes d'information, s'est développé, offrant aux
décideurs les moyens techniques efficaces de gérer de
manière tabulaire, la masse d'informations auxquelles ils sont
confrontés tous les jours. Dans la même lancée, la
définition et l'utilisation effective de processus de
développement logiciel sont devenues importantes, principalement pour
optimiser les gains tout en réduisant les risques encourus au sein des
industries du logiciel. Dans ce contexte, nous proposons un moyen de
définir et d'exploiter de tels processus d'ingénierie logicielle.
L'objectif principal est la mise sur pied d'un outil d'acquisition de
connaissances sur les processus d'ingénierie logicielle, en vue de leur
utilisation au sein du projet CIAO-SI. Nous axons notre travail sur l'aspect
réutilisation des connaissances acquises sur des processus
d'ingénierie logicielle, par des outils tiers. Nous procédons par
une analyse des métamodèles et des outils de développement
de processus d'ingénierie logicielle existants, pour choisir le
métamodèle approprié et ressortir les
fonctionnalités d'un outil adéquat. En nous appuyant sur le
processus Rational Unified Process, la technologie XML et la technique du
Reverse Engineering, nous aboutissons à l'outil spécifié.
Nous nous en servons pour peupler la base de connaissances de processus
d'ingénierie logicielle du projet CIAO-SI, cadre d'application de notre
travail.
Mots-clés : processus, ingénierie
logicielle, ontologies, métamodèles, SPEM,
réutilisation.
Abstract
Computer science made great strides during the last decade,
multiple companies offering as various services the ones as the others. For the
consumers, users, consuming the products and services thus provided, the
possibilities are widen going from document management with office automation
to human resources management by the systems of workflows. Because of this
increasing request, one field of software industry most flourishing, the
information systems design of information, developed, offering to the decision
makers effective techniques to manage in a tabular way, the mass of information
to which they are confront everyday. In the same impetus, the definition and
the effective use of software development processes became important, mainly to
optimize the profits while reducing the incurred risks within the software
industries. In this context, we propose a means of defining and of exploiting
such software engineering processes. Our principal objective is the development
of a tool for acquisition of knowledge on software engineering processes, for
their use within project CIAO-IS. We center our work on the re-use's aspect of
knowledge obtained from software engineering processes. By using the Rational
Unified Process, XML technology and the Reverse Engineering technique, we have
constructed the specified tool. We use it to populate the software processes
knowledge base of the project CIAO-IS, where we apply our work.
Key words : process, software engineering, ontology,
metamodel, SPEM, re-use.
Table des matières
Dédicaces
i
Remerciements
ii
Résumé
iii
Abstract
iv
Table des matières
v
Liste des figures
vii
Liste des sigles et abréviations
viii
Chapitre I.
Introduction
1
I.1. Contexte
1
I.2. Objectif
1
I.3. Plan
2
Chapitre II.
Problématique
3
II.1. Les ontologies et les bases de
connaissances
3
II.1.1. Définition, structure
et types
3
II.1.2. Méthodologies et
outils de construction
4
II.1.3. Représentation des
connaissances
5
II.1.4. Conclusion
7
II.2. Processus d'ingénierie
logicielle
8
II.2.1. Définition
8
II.2.2. Importance des processus
9
II.2.3. Ce qu'il faut pour un
processus d'ingénierie logicielle
9
II.2.4. Les processus
d'ingénierie logicielle aujourd'hui
10
II.3. Le projet CIAO-SI
12
II.3.1. Approche adoptée
12
II.3.2. Les grandes lignes du projet
CIAO-SI
12
II.3.3. Notre rôle dans le
projet CIAO-SI
13
II.4. Conclusion
13
Chapitre III. Etat
de l'art de la réutilisation des processus d'ingénierie
logicielle
15
III.1. Vers une solution d'ensemble
15
III.1.1. Diagrammes de Gant
15
III.1.2. Diagrammes PERT
16
III.1.3. PIF
16
III.1.4. PSL
18
III.1.5. CPR
18
III.1.6. WfMC
19
III.1.7. SPEM
20
III.1.8. Conclusion
22
III.2. Les solutions existantes
22
III.2.1. SPEARMINT/EPG
22
III.2.2. BORE
24
III.2.3. APES
25
III.2.4. RUP
28
III.2.5. IRIS
29
III.3. Solution proposée
30
III.3.1. Acquisition des
connaissances sur un processus de développement
31
III.3.2. Vérification de la
conformité d'un processus de développement au
métamodèle SPEM
31
III.3.3. Visualisation d'un
processus de développement
31
III.3.4. Importation d'un processus
de développement
31
III.4. Conclusion
32
Chapitre IV. Mise en
oeuvre du système
33
IV.1. Le processus de
développement RUP
33
IV.1.1. Présentation
33
IV.1.2. Caractéristiques de
RUP
33
IV.1.3. Les meilleurs exercices
(« best practices ») de RUP
35
IV.1.4. Pour notre cas
35
IV.2. Le langage de
modélisation : UML
36
IV.2.1. Présentation
36
IV.2.2. Les neuf diagrammes
d'UML
36
IV.2.3. Pour notre cas
37
IV.3. Vision du système
37
IV.4. Analyse préliminaire
37
IV.4.1. Architecture
systémique du système CIAO-SI
38
IV.4.2. Sous-système
Expert
39
IV.5. Identification des acteurs
42
IV.6. Les cas d'utilisation
42
IV.7. Réalisations des cas
d'utilisation
43
IV.8. Architecture du système
45
IV.9. Conclusion
49
Chapitre V.
Résultats
50
V.1. Environnement de
développement
50
V.1.1. NetBeans™ IDE 3.6
50
V.1.2. MySQL
50
V.1.3. XMLizer
50
V.2. Techniques utilisées
51
V.2.1. Reverse Engineering
51
V.2.2. Sérialisation
51
V.2.3. Correspondance (mapping)
51
V.3. Résultats : quelques
écrans
51
Chapitre VI.
Conclusion
55
VI.1. Bilan
55
VI.2. Difficultés
55
VI.3. Perspectives
56
Références
57
Annexes
60
Annexe A : Présentation du
LABORIMA
60
Annexe B : Présentation de l'Open
Source
62
Liste des figures
FIGURE 1. L'EXPRESSIVITÉ DES LANGAGES DE
REPRÉSENTATION D'ONTOLOGIES.
7
FIGURE 2. LE PROCESSUS D'INGÉNIERIE
LOGICIELLE : SON RÔLE.
8
FIGURE 3. SITUATION DU PROCESSUS
D'INGÉNIERIE LOGICIELLE DANS L'ENTREPRISE.
10
FIGURE 4. LE MODÈLE PIF : UNE
REPRÉSENTATION DES CONCEPTS DES PROCESSUS (BÉZIVIN
2003).
17
FIGURE 5. LE MODÈLE PSL : LES PRINCIPAUX
CONCEPTS ET LES RELATIONS ENTRE CES CONCEPTS (BÉZIVIN 2003).
18
FIGURE 6. LE MODÈLE CPR : PRISE EN COMPTE
DES INSTANCES DE PLAN (BÉZIVIN 2003).
19
FIGURE 7. LE MODÈLE DE
RÉFÉRENCE PROPOSÉ PAR WFMC (BÉZIVIN 2003).
19
FIGURE 8. LES FONDEMENTS DU
MÉTAMODÈLE SPEM : COLLABORATION
RÔLE-ARTEFACT-ACTIVITÉ (OMG 2002B).
20
FIGURE 9. LES NIVEAUX D'ABSTRACTION DE LA
MODÉLISATION SELON MOF (OMG 2002B).
21
FIGURE 10. CORRESPONDANCE ENTRE SPEM ET LES
ÉLÉMENTS DU MÉTAMODÈLE DE UML (OMG 2002B).
21
FIGURE 11. SPEARMINT/EPG : UN EXEMPLE DE
MODÉLISATION.
23
FIGURE 12. BORE : UN APERÇU DU
GESTIONNAIRE DE TÂCHES.
25
FIGURE 13. APES : UNE ILLUSTRATION DE L'OUTIL
D'EXÉCUTION.
27
FIGURE 14. RUP : UNE VUE DE L'OUTIL DE
PUBLICATION SOUS FORME DE SITE.
29
FIGURE 15. RUP : LA REPRÉSENTATION
SUIVANT DEUX AXES.
34
FIGURE 16. EXTRAK : UNE PREMIÈRE VUE DU
SYSTÈME.
38
FIGURE 17. VUE SYSTÉMIQUE DE
CIAO-SI.
38
FIGURE 18. SOUS-SYSTÈME EXPERT DE
CIAO-SI.
39
FIGURE 19. SCHÉMA DE LA BASE DE
CONNAISSANCES RELATIVES AUX PROCESSUS DE DÉVELOPPEMENT.
40
FIGURE 20. ARCHITECTURE GLOBALE DE
EXTRAK.
42
FIGURE 21. DIAGRAMME DES CAS D'UTILISATION DE
L'EXPERT.
43
FIGURE 22. DIAGRAMME DE SÉQUENCES :
VALIDER UN PROCESSUS.
44
FIGURE 23. DIAGRAMME DE COLLABORATIONS : VALIDER
UN PROCESSUS.
44
FIGURE 24. DIAGRAMME D'ACTIVITÉS : CAS
D'UTILISATION IMPORTER/EXPORTER UN PROCESSUS.
45
FIGURE 25. LES PAQUETAGES DU
SYSTÈME.
46
FIGURE 26. LES COMPOSANTS DU
SYSTÈME.
47
FIGURE 27. CLASSES DU PAQUETAGE DOMAIN.
48
FIGURE 28. QUELQUES CLASSES DU PAQUETAGE
METAMODEL.
48
FIGURE 29. EXTRAK : L'ÉCRAN
D'OUVERTURE.
52
FIGURE 30. EXTRAK : L'ÉCRAN D'ACCUEIL ET
LES FONCTIONNALITÉS.
52
FIGURE 31. EXTRAK : UN CAS D'UTILISATION POUR LA
RECHERCHE DES PROCESSUS.
53
FIGURE 32. EXTRAK : LE PROCESSUS RUP DE LA BC
CIAO-SI OUVERT.
53
FIGURE 33. EXTRAK : OUVERTURE D'UN AUTRE
PROCESSUS.
54
Liste des sigles et
abréviations
|
UML
|
« Unified Modeling Language » (langage
unifie pour la modélisation). Langage de modélisation objet,
permettant de spécifier, construire, visualiser et décrire les
artefacts d'un système logiciel (
http://www.omg.org ).
|
|
OMG
|
« Object Management Group ». Organisme
international de promotion de la théorie et de la pratique de la
technologie orienté-objet dans le développement logiciel (
http://www.omg.org ).
|
|
XML
|
« eXtensible Markup Language ». Langage
développé par le groupe de travail XML du consortium W3C,
permettant de décrire une semi-structure d'information et de
l'échanger et de la manipuler (
http://www.w3.org/TR/REC-xml
).
|
|
DAML
|
« DARPA Agent Markup Language ». Langage
de description d'ontologies, base sur RDF et RDFs (
http://www.daml.org ).
|
|
OKBC
|
« Open Knowledge Base Connectivity ».
Modèle uniforme de Systèmes de Représentation des
Connaissances basé sur la conceptualisation commune des classes,
individus, slots, facettes, et héritages.
|
|
OIL
|
« Ontology Inference Layer ». Langage
standard pour la spécification et l'échange d'ontologies.
|
|
KIF
|
« Knowledge Interchange Format ». Langage
informatique pour l'échange de connaissances entre programmes
disparates
|
|
RDF
|
« Resource Definition Framework ». Langage
de description de ressources, base sur XML (
http://w3c.org/RDF ).
|
|
RDFS
|
« RDF Schema ». Langage de
représentation de schémas RDF (
http://www.w3.org/TR/WD-rdf-schema
).
|
|
OWL
|
« Web Ontology Language » (Langage
d'ontologies pour le web). Un des langages dérivés de DAML+OIL,
destiné lui aussi au partage et à la publication d'ontologies sur
le web (
http://www.w3.org/TR/2003/PR-owl-features-20031215/).
|
|
IDL
|
« Interface Definition Language » (Langage
de définition d'interfaces) (
http://www.omg.org/technology/documents/formal/corba_2.html
)
|
|
CORBA
|
« Common Request Object Broker
Architecture » (
http://www.omg.org/corba/beginners.html
)
|
|
|
Introduction
I.1 Contexte
Le travail que nous présentons ici a été
réalisé au sein du LABORIMA (Laboratoire d'Informatique, du
Multimédia et Applications), situé au Département de
Génie Informatique au sein de l'ENSP (Ecole Nationale
Supérieure Polytechnique), dans le cadre d'un projet mené en
partenariat avec le laboratoire GDAC (Gestion, Diffusion & Acquisition
de connaissances), dénommé CIAO-SI (Conception
Intelligemment Assistée par Ordinateur des Systèmes
d'Information), situé au sein de l'Université du
Québec A Montréal (UQAM), à Montréal au Canada. Le
projet CIAO-SI a pour objet la conception et la mise en oeuvre d'un
système permettant d'offrir une assistance au concepteur pendant le
processus de développement logiciel, et de partager l'expérience
des projets par la constitution d'une mémoire de modèles de
conception réutilisables. Ce projet est réalisé suivant
plusieurs grandes lignes dont la gestion des ontologies et des connaissances de
domaines d'application et de processus de développement, ainsi que la
gestion de l'assistance. La gestion des ontologies et des connaissances
relatives à certains domaines d'application a été
examinée par Ing. Ghislain NGANTCHAHA (Ngantchaha 2002) et Hervé
DONFACK au cours de précédents travaux. Celle des ontologies des
processus RUP et MERISE, qui a permis la construction de bases de connaissances
exploitables par un système multi-agents, et la validation des
artefacts produits au cours de ces processus, a été
réalisée par Ing. Francis Michel KONHAWA (Konhawa 2003) et Ing.
Claude Albert MOGHOMAYE (Moghomaye 2003), dans des précédents
travaux. Dans la continuation de ce projet, il nous a été
demandé de peupler la base de connaissances de processus, de
manière à automatiser les travaux précédemment
effectués.
Ce mémoire portera sur la mise en place d'un outil
d'acquisition et d'exploitation d'éléments de processus
d'ingénierie logicielle, pour le cas du projet CIAO-SI.
I.2 Objectif
Principalement, ce travail a pour objectif d'automatiser le
peuplement de la base de connaissances des processus d'ingénierie
logicielle du projet CIAO-SI. En effet, nous devons fournir un outil qui
permettra d'acquérir des éléments de connaissances sur les
processus d'ingénierie logicielle existants et de les exploiter.
Il s'agira en ce qui concerne cette description, de renseigner
les connaissances sur un processus suivant un modèle que nous
déterminerons et pour l'exploitation, de permettre l'exportation des
processus sous divers formats standards. Ainsi, il comportera une
fonctionnalité permettant l'exportation des dits processus pour leur
réutilisation, notamment dans d'autres modules du projet CIAO-SI.
I.3 Plan
Ce mémoire est réparti en quatre (04)
chapitres.
Le premier chapitre porte sur la problématique de notre
travail. Nous y situons en trois étapes le contexte
général du problème, par la situation du domaine dans
lequel il se trouve. C'est ainsi nous y aborderons successivement les
ontologies et les bases de connaissances, les processus d'ingénierie
logicielle et enfin, le projet CIAO-SI et notre rôle dans ce projet.
Le deuxième chapitre porte sur l'état de l'art
de la réutilisation des processus d'ingénierie logicielle. C'est
dans ce chapitre que nous passons en revue l'existant en matière de
réutilisation dans l'ingénierie des processus. Nous
procédons en trois étapes. Premièrement, nous analyserons
l'évolution de la réutilisation par les modèles de
processus d'ingénierie logicielle, depuis les premiers jusqu'à
nos jours. Deuxièmement, nous étudions les principaux outils de
gestion des processus d'ingénierie logicielle. Troisièmement,
nous dressons une ébauche de solution résultant de ces
analyses.
Le troisième chapitre porte sur la mise en oeuvre de la
solution proposée. Nous procédons à l'analyse et à
la conception de celle-ci, en plusieurs étapes, passant de la
description de la méthode utilisée à l'architecture du
logiciel construit.
Le quatrième chapitre présente les
résultats obtenus. Nous y décrivons les choix importants
d'implémentation et les outils qui ont conduit à la
réalisation du logiciel, ainsi que quelques captures écrans de ce
dernier.
Nous achevons ce mémoire par une conclusion, qui
comprend le bilan du travail, les critiques, les difficultés
rencontrées et les perspectives.
Sont joints aussi à ce document, deux (02)
annexes : la présentation du LABORIMA et une présentation de
l'Open Source, justification des divers choix techniques.
Problématique
La démarche classique que nous avons empruntée,
commence par la définition et la modélisation du problème
à nous posé. Pour être sûr de lui apporter une
solution appropriée, il convient d'expliciter les aspects du domaine du
problème. Ainsi, nous jalonnons les concepts généraux du
domaine du problème, dans le but de mieux le cerner. Plus
concrètement, nous présentons dans un premier temps, les
ontologies et les bases de connaissances. Dans un second temps, les processus
d'ingénierie logicielle. Enfin, dans un troisième temps, le
projet CIAO-SI.
I.4 Les ontologies et
les bases de connaissances
De toutes les raisons qui ont orienté nos
investigations, celle qui justifie le mieux l'introduction de ces deux notions
se confond à leur utilisation la plus courante. En effet, l'ontologie
d'un domaine permet en premier de capturer le sens du domaine auquel elle
s'applique. Et une base de connaissances permet de la schématiser, voire
de la matérialiser sur des supports informatiques.
I.4.1 Définition, structure et types
Tout part d'un problème d'échange entre diverses
bases de connaissances, dont l'objectif était une représentation,
un langage commun entre diverses façons de représenter et de
manipuler les connaissances. Autour des années 1990, la
communauté d'ingénieurs de la connaissance se sont entendus sur
le terme Ontologie (Mille 2002). Des diverses définitions de ce terme,
une tentative de synthèse a été faite par Guarino (Guarino
2002). La mieux adaptée à notre contexte stipule que :
« Une ontologie est une spécification explicite d'un
ensemble de notions de concepts génériques »
(Mille 2002). Elle fait ressortir l'explicitation, la
généricité, même dans un domaine donné, et ce
qui est traduit par une ontologie, à savoir le sens.
Caractéristiques d'une ontologie
Selon (Mille 2002), une partie essentielle de la
définition d'une ontologie se trouve dans les concepts qu'elle
explicite. C'est pourquoi il est possible de caractériser une ontologie
par ces derniers. Un concept, sémantiquement parlant, est composé
de trois (03) choses :
- le(s) terme(s) exprimant le concept en langue ;
- la signification du concept, appelée également
« notion » ou « intension » du concept ;
- le(s) objet(s) dénoté(s) par le concept,
appelé(s) également « réalisation » ou «
extension » du concept.
Structure d'une ontologie
D'après (Mille 2002), une ontologie pourrait se
résumer en un ensemble de concepts et de relations entre ces derniers.
La principale relation entre ces concepts consiste en la relation de
généralisation/subsomption. Elle permet de représenter une
ontologie, en représentant les concepts avec des liens entre eux.
Il existe d'autres structurations des ontologies (Maedche
2001, Gómez 1999). Ainsi, pour définir une ontologie, il faut
d'abord cerner l'ensemble des concepts concernés, en mettant l'accent
sur leurs sens (leurs notions) ; puis, définir les relations entre les
concepts, qui peuvent être du type sous-classe de ou
connecté-à (Gómez 1999) ; puis, identifier les liens de
subsomption entre les concepts, ce qui peut être fait à
l'étape précédente ; enfin, définir les axiomes sur
les concepts pour structurer des phrases toujours vraies (Gómez
1999).
Types d'ontologies
Pour ce qui est de leur typologie, les ontologies sont
généralement différenciées soit à partir du
langage de spécification utilisé, soit à partir de la
nature des concepts étudiés. Ainsi, (Gómez 1999)
présente une typologie assez générale des ontologies, en
distinguant les ontologies de représentation des connaissances, les
méta-ontologies, les ontologies de domaine, les ontologies de
tâches, les ontologies de domaine-tâche, les ontologies
d'application, les ontologies d'index, les ontologies interactives, etc.
(Doniat 2000) associe des types divers à cette liste non-exhaustive.
C'est ainsi que nous avons ressorti successivement les aspects
définition et structuration des ontologies, et identifié les
types d'ontologies les plus connus.
I.4.2 Méthodologies et outils de construction
Nous connaissons différentes approches de
modélisation des systèmes (Merise, RUP, etc.). Elles disposent de
descriptions très détaillées des méthodologies
à suivre pour les utiliser à bon escient, allant de l'acquisition
de données au déploiement du système
modélisé. L'un des avantages de l'existence de celles-ci est
qu'elles définissent ainsi une sorte de langage universel pour les
différents concepteurs. En ce qui concerne les ontologies,
(Gómez 1999), de même que (López 1999), expliquent que les
directives et méthodes consensuelles étant absentes, il a
existé un problème d'entente entre les concepteurs d'ontologies.
En effet, leur construction des ontologies est très souvent
(malheureusement) guidée par le langage d'implémentation de
celles-ci, chose préférentielle. Il y a néanmoins des
efforts qui sont fournis en ce sens.
Méthodologies existantes
C'est ainsi que (López 1999) fait une analyse de quatre
(04) méthodologies parmi les principales et les compare au standard de
méthodologie pour les produits logiciels proposés par l'IEEE
(IEEE Standard 1074-1995). Il s'agit de :
- la méthodologie dite de Uschold et King ;
- la méthodologie dite de Grüninger et
Fox ;
- la méthodologie dite de Amaya Bernaras ;
- METHONDOLOGY;
- SENSUS.
(Fürst 2002) décrit une méthodologie de
construction d'ontologies, après un passage en revue similaire aux
analyses faites au paragraphe précédent, qui est une description
calquée sur le processus général de représentation
de connaissances (décrit dans le même document). Ce processus
comporte trois (03) phases :
- la conceptualisation : identification des connaissances
contenues dans un corpus représentatif du domaine ;
- l'ontologisation : formalisation, autant que possible, du
modèle conceptuel obtenu à l'étape
précédente ;
- l'opérationnalisation : transcription de l'ontologie
dans un langage formel et opérationnel de représentation de
connaissances.
Langages et outils de construction
Ils se basent sur les différents formalismes de
représentation de connaissances (Frames, logique de premier ordre,
etc.). (Gómez 1999) en présente une liste
non exhaustive : Ontolingua, Loom, Flogic, CycL1(*).
Quant aux outils de construction des ontologies, il en existe
plusieurs, qui peuvent se distinguer par le formalisme de représentation
utilisé. Nous pouvons citer : ODE (Ontology Design
Environment) dont la version web est WebODE, DOE (Differential
Ontology Editor), OntoEdit, Protégé-2000 (Fürst 2002),
OilEd (OIL Editor) (Bechhofer 2003), Ontolingua (Server), OntoSaurus,
Tadzebao et WebOnto (Gómez 1999).
Par ce travail, nous avons parcouru une grande partie des
méthodologies et langages de construction des ontologies existants. Nous
avons aussi pu tester quelques outils de construction d'ontologies. De tous,
Protégé-2000 est le plus utilisé par la communauté
des développeurs d'ontologies.
I.4.3 Représentation des connaissances
Nous nous intéressons dans cette partie à la
question de savoir ce qu'on représente dans les ontologies. De par sa
structure, représenter une ontologie revient à représenter
ses constituants, à savoir :
- les concepts et leurs propriétés : il
peut y en avoir plusieurs dont la généricité,
l'identité, la rigidité, l'anti-rigidité, l'unité,
l'équivalence, la disjonction, la dépendance (Guarino 2004)
;
- les relations et leurs propriétés : il
peut y en avoir plusieurs dont la symétrie, la
réflexivité, la transitivité, la cardinalité,
l'incompatibilité, l'inversion, l'exclusivité (Fürst
2002) ;
- les axiomes et leurs propriétés.
(Fürst 2002) explique quelques points
préliminaires importants pour la représentation des ontologies,
le plus important étant de prendre en compte le contexte d'usage de
l'ontologie. Lors de la représentation des ontologies, il faut choisir,
en fonction de l'opérationnalisation et du contexte d'utilisation de
l'ontologie, entre la représentation d'une notion sous forme de concept
ou de relation.
Tout ce qui précède permet la
représentation des concepts et des relations pour une ontologie. Les
principaux choix à faire doivent tenir compte de
l'opérationnalisation et du contexte d'utilisation de l'ontologie. Mais,
une spécificité de cette approche, qui intègre l'outil
informatique, et crée ainsi la différence avec une approche
théorique, qui pourrait se limiter au seul papier, est la
représentation des connaissances inférentielles.
Connaissances inférentielles
Il s'agit :
- des faits : qui sont des énoncés,
- des règles : qui peuvent inférer de nouvelles
connaissances à partie de faits existants,
- des contraintes : qui permettent d'exprimer des
impossibilités ou des obligations.
Elles seront stockées dans les bases de connaissances
sous la forme de connaissances implicites (utilisées par le
système, mais non exprimées à l'endroit des utilisateurs)
et de connaissances explicites (exprimées à l'endroit des
utilisateurs). Il existe ainsi divers formalismes permettant la
représentation de tous ces aspects des ontologies.
Formalismes de représentation
Les ontologies sont représentées au moyen de
langages formels dédiés, offrant des structures de données
adaptées à la représentation de concepts (Mille 2004).
Parmi ces langages, on distingue :
- les langages d'échange d'ontologies sur le Web, dont
la syntaxe est basée sur le langage XML : XML, RDF, RDFS, OIL,
DAML+OIL, OWL ;
- les langages opérationnels qui implémentent
les ontologies à des fins d'inférences, pour constituer un
composant d'un système d'information : KIF, OKBC, XOL, DefOnto
(Mille 2004).
Analyse comparative
Après ce parcours de quelques formalismes de
représentation d'ontologies, nous en présentons une comparaison.
Le format d'échange KIF pourrait nous permettre d'implémenter
n'importe quel langage et d'ajouter des propositions KIF aux axiomes
générés. Les langages basés sur XML tels que RDF
semblent intéressants car ils permettent le partage des ontologies sur
le WWW, en utilisant les URI et les espaces de noms, mais ils ne sont pas assez
expressifs. Tandis que ceux basés sur RDF, tout aussi
intéressants, sont riches d'expressivité pour la
représentation des concepts et leurs relations et aussi les axiomes les
plus fréquemment utilisés. En arrière-plan de ce langage,
se trouve sa lisibilité.
La figure suivante permet une première
évaluation des langages et leurs capacités
d'expressivité.
KIF
OIL, DAML+OIL
OKBC, XOL, RDF+RDFs
Langages de représentation
d'ontologies
Règles de production
Fonctions et procédures
Axiomes
Concepts, relations, instances et faits
Eléments du domaine de
connaissances
![]()
Figure 1.
L'expressivité des langages de représentation
d'ontologies.
I.4.4 Conclusion
C'est ainsi que nous achevons l'analyse des notions
d'ontologies et de bases de connaissances. Nous avons cerné l'ensemble
des méthodes, formalismes et outils permettant la manipulation de ces
notions de représentation de connaissances. L'un des points remarquables
soulignés par (Gómez 1999), est l'introduction d'un type
d'ontologie particulière : ontologie de domaine-tâche. Ce
type d'ontologie fournit un ensemble de termes au moyen desquels on peut
décrire dans un domaine donné comment résoudre un type de
problème. En ce qui nous concerne, nous nous intéressons au
domaine de l'ingénierie logicielle dans la suite, et en
présentons les principales notions.
I.5 Processus
d'ingénierie logicielle
Le logiciel fait de plus en plus partie intégrante de
notre vie. Dans notre environnement : les contrôles aériens, les
systèmes bancaires, les systèmes de gestion des
ministères, la télésurveillance et les systèmes de
santé en sont quelques exemples. Les exigences et la demande croissent
avec cette évolution des technologies, rendant le développement
de logiciels plus rapide. Cependant tout cela ne doit pas s'accomplir au
détriment de la qualité que nous voulons toujours meilleure. Les
ingénieurs logiciels doivent parfaitement maîtriser
l'ingénierie logicielle. Elle repose sur un ensemble de processus
constituant le cycle de vie du logiciel et permettant de fournir un produit
livrable. Chaque processus décrit une série de tâches
à accomplir et les livrables intermédiaires à fournir. Ces
processus ont été soumis à la normalisation internationale
et leur respect est un gage reconnu de qualité.
I.5.1 Définition
(Bézivin 2003) définit un processus comme
étant ce qui permet, pour atteindre un but donné, de
définir comment procéder. En d'autres termes, définir un
processus, c'est définir les différents travaux qu'il comporte,
et pour chacun de ceux-ci :
- Qui le fait (le qui) ?
- Ce qu'il faut faire (le quoi) ?
- À quel moment le faire (le quand) ?
- Dans quelles conditions il faut le faire (le comment) ?
- Quelles sont les raisons, les décisionnaires, le
contexte et les objectifs de l'action (le pourquoi) ?
Le schéma de la
Figure 2 résume la particularité des
processus d'ingénierie logicielle.
PROCESSUS D'INGENIERIE LOGICIELLE
SPECIFICATIONS NOUVELLES OU MODIFIEES
SYSTEME NOUVEAU OU MODIFIE
![]()
Figure 2. Le processus d'ingénierie
logicielle : son rôle.
(Ambler 1999) apporte une autre vision à cette notion,
en définissant un processus d'ingénierie logicielle comme un
ensemble de phases de projet, d'étapes, de méthodes, de
techniques et de pratiques que des personnes utilisent pour développer
et maintenir des logiciels et les artefacts associés (plans, documents,
modèles, code, tests, etc.).
I.5.2 Importance des processus
Le besoin réel généralement
exprimé est celui d'un processus à la mesure précise des
exigences de l'utilisateur. Un processus d'ingénierie logicielle
efficace permet à une organisation d'accroître sa
productivité lors du développement de logiciels pour plusieurs
raisons. Premièrement, parce que maîtriser les fondamentaux du
développement d'un logiciel permet de prendre des décisions
intelligentes. Deuxièmement, parce qu'il permet de standardiser les
efforts de l'organisation, de promouvoir la réutilisation et la
consistance entre plusieurs équipes de projets. Troisièmement,
parce qu'il fournit l'opportunité d'introduire les meilleurs exercices
en industrie (« industry best practices ») telles
que les inspections de code, la gestion de configuration, le contrôle des
changements et la modélisation de l'architecture dans l'organisation de
développement. Il permettra aussi d'améliorer la maintenance de
l'organisation et de supporter les efforts de plusieurs manières, telles
que la gestion des changements de logiciel.
L'intérêt qu'une entreprise a de nos jours
à adopter un processus de développement logiciel ou à
améliorer un existant réside dans le fait qu'autrement, ses
chances de succès s'aminciront. Car les moyens employés pour la
production de logiciels se doivent d'être efficaces. En plus, beaucoup
d'entreprises gèrent de multiples projets en parallèle, à
cause de la demande. L'objectif principal étant la réduction du
coût de développement en même temps que l'accroissement de
sa vitesse et de son efficacité.
I.5.3 Ce qu'il faut pour un processus d'ingénierie
logicielle
L'approche processus permet d'une part, d'identifier
clairement les activités nécessaires à la
réalisation des produits-clés de l'entreprise, et d'autre part,
d'articuler ces activités pour atteindre de manière
répétable et prévisible les objectifs des projets et de
l'entreprise. Une entreprise peut se baser sur des référentiels
tels que CMM ou SPICE pour définir ses processus (Renault 2004). Le CMM
(Capability Maturity Modeling) est un environnement,
développé par l'Institut de Processus Logiciel (SEI) de
l'Université de Carnegie Melon. Cet outil définit cinq (05)
niveaux de maturité (niveaux initial, répétable,
défini, dirigé, optimisé) permettant la classification des
entreprises par rapport aux processus qu'elles envisagent d'utiliser.
Adopté par des centaines d'entreprises de par le monde, ce moyen les
amène à augmenter leur degré de maturité, qui va
avec la réduction des risques, l'amélioration du contrôle
de la gestion dans le développement de produits logiciels. Quant
à SPICE (ou ISO 15504), c'est un modèle de maturité
accompagné d'une méthode d'évaluation proposés par
l'ISO. Mais ces référentiels s'avèrent assez lourds
à utiliser, en terme de volume d'information et de ressources
nécessaires. Cela constitue souvent un frein à leur diffusion
dans des petites et moyennes structures.
La
Figure 3 situe le processus d'ingénierie
logicielle dans l'entreprise et présente les facteurs extérieurs
pouvant l'influencer.
PROCESSUS D'ENTREPRISE
PROCESSUS D'INGENIERIE LOGICIELLE
PROCESSUS DE DEVELOPPEMENT
OUTILS
ARCHITECTURE
STANDARDS
CULTURE
LEGISLATION
PROCESSUS EXTERNES
![]()
Figure 3. Situation du processus
d'ingénierie logicielle dans l'entreprise.
I.5.4 Les processus d'ingénierie logicielle
aujourd'hui
Nous présentons sommairement où se situe ce
domaine aujourd'hui. Notre souci n'est pas de faire un état de l'art des
processus, mais de nous concentrer sur l'aspect évolution de ces
derniers, afin de mieux situer le contexte actuel.
Il existe en effet dans ce domaine une évolution
considérable. Car il y a quelques années encore, les termes les
plus couramment utilisés étaient méthode et
méthodologie. C'est ainsi que l'on a distingué trois (03)
générations de méthodes, depuis les années 1970,
suivant qu'un système soit perçu d'un point de vue fonctionnel,
systémique ou objet.
- Les méthodes cartésiennes :
caractérisées par les méthodes d'analyse fonctionnelle et
de décomposition hiérarchique, elles trouvent leur origine dans
les langages de programmation procéduraux ; brièvement,
elles proposent de fonctionner par affinage des fonctions mères en des
sous-fonctions ; on peut leur compter SADT, Jackson, Yourdon, CORIG
(Bouzeghoub 1997) ;
- Les méthodes systémiques :
développées dans les années 80, elles s'inspirent de la
théorie systémique des organisations où le système
d'information est perçu comme un objet complexe dont il faut
définir la structure et les objets fonctionnels ; ces
méthodes ont dominé le monde du génie logiciel
durant les années 80 et au début des années 90
et s'appliquent en grande partie aux systèmes d'information
orientés gestion tels que les applications bancaires, d'aide à la
gestion d'entreprise ; on peut leur compter Merise, Axial,
Information Engineering ;
- Les méthodes objets : advenues dans les
années 90, elles introduisent le concept objet dans la conception des
systèmes d'information et permettent ainsi la description de la
dynamique des systèmes par les opérations liées aux objets
des systèmes ; l'approche objet insiste sur les aspects de
modularité, réutilisabilité, extensibilité du code,
maintenabilité et évolutivité du système. Elle a
entraîné la distinction entre le langage de modélisation
(différents diagrammes et symboles utilisés pour
représenter les éléments de la modélisation),
processus de modélisation (enchaînement d'activités
à suivre pour la réalisation du produit) et langage
d'implémentation supportant les paradigmes objets. L'approche objet
s'est, depuis le milieu des années 90, imposée comme un standard
de fait dans l'industrie de l'ingénierie logicielle (Jacobson
1999) ; c'est pourquoi dans la suite, nous nous étendrons sur ces
méthodes.
Partant donc de cette dernière avancée, qui a
définitivement rendu l'approche objet dominante dans le monde du
génie logiciel, les nouvelles méthodes, plus couramment
désignées processus, ont vu le jour. Parmi les processus de
développement les plus utilisés au début des années
2000, se trouvent OPEN, OOSP et RUP.
OPEN est un processus unifié proposé par le
consortium OPEN. Il est issu de la fusion de plusieurs méthodes :
MOSES, SOMA, Firesmith, Synthesis, BON et OOram (Ambler 1999). Il supporte
notamment les notations UML et OML (Object Modeling Language). C'est
un processus guidé par les responsabilités. Les activités
y décrivent l'architecture globale du processus, et avec les
tâches, elles décrivent ce qui doit être fait au cours du
processus. Quant à comment cela doit être fait, un ensemble de
techniques est employé. OPEN prend en compte la gestion de programmes,
un programme étant ici un ou plusieurs projets ou encore une ou
plusieurs versions d'une application ou d'une suite d'applications. Ce
processus a malheureusement souffert d'une politique de marketing
défaillante, d'où sa faible vulgarisation.
Le processus logiciel OOSP (Object-Oriented Software
Process) propose une approche par phases, étapes et tâches
telles que l'assurance de la qualité, la gestion de projets,
l'entraînement et l'éducation, la gestion de personnes, des
risques, de la réutilisation, etc. Comme la précédente
elle n'est pas assez vulgarisée.
RUP (Rational Unified Process) est le processus phare
de la corporation Rational. C'est sans doute l'adaptation du
célèbre processus unifié UP (Unified Process) la
plus répandue dans le milieu industriel. Il s'est imposé
grâce à quelques atouts. Il est basé sur des principes
d'ingénierie logicielle solides tels que une approche de
développement itérative, guidée par les besoins et
basée sur l'architecture. De plus, Rational a largement investi dans son
produit RUP, une description basée sur HTML, que nous décrirons
plus loin.
Enfin, EUP (Entreprise Unified Process), une
proposition de Ronin International, est l'une des toutes dernières
adaptations de UP, qui se veut être l'adéquation de RUP aux
besoins réels des entreprises. Car, l'un des défauts de RUP
étant la prise en compte d'un unique projet, l'améliorer en
gérant plusieurs projets dans les mêmes délais est plus
proche des réalités industrielles. C'est principalement ce
qu'apporte EUP. Nous espérons que cette méthode connaîtra
un succès comparable à celui du RUP lui même.
Et c'est ainsi que s'achève cette brève revue de
l'état actuel des processus d'ingénierie logicielle. Nous avons
donc présenté les processus d'ingénierie logicielle et
nous nous sommes situés par rapport à ces processus dans le
contexte actuel de leur évolution. Le cadre de notre travail n'en est
que mieux défini.
I.6 Le projet
CIAO-SI
Le projet CIAO-SI vise l'étude de faisabilité,
la conception et la mise en oeuvre d'un système permettant d'offrir une
assistance au concepteur pendant le processus de développement de
logiciels et de capitaliser l'expérience acquise avec le
développement d'applications, en constituant une mémoire
réutilisable des modèles de conception.
I.6.1 Approche adoptée
L'approche adoptée pour aboutir à un tel
système s'appuie sur le CBR (Case-Based Reasoning). Le CBR est
une approche de résolution de problèmes qui propose de
résoudre de nouveaux problèmes par adaptation de solutions
viables aux problèmes similaires déjà résolus.
Les grandes questions que le projet se propose de
résoudre sont les suivantes :
- Comment intégrer le raisonnement à base de cas
dans le processus de conception de logiciels ?
- Comment produire des modèles génériques
adaptatifs et comment les indexer ? Comment mesurer la similarité entre
de tels modèles afin de sélectionner le plus adapté
à un contexte donné ?
- Comment assister le concepteur pendant l'adaptation d'un
modèle ?
- Quelles connaissances sont nécessaires au
système pour réaliser une assistance intelligente dans la
conception des systèmes d'information ? Comment représenter de
telles connaissances et les rendre utilisables par le système ?
I.6.2 Les grandes lignes du projet
CIAO-SI
Ce projet comporte sept (07) modules, en l'occurrence :
- La gestion des ontologies : il s'agit de spécifier
les ontologies du domaine d'application et ceux du processus de
développement, puis de construire les bases de connaissances
associées au domaines d'application, ainsi qu'aux deux processus de
développement MERISE et RUP.
- La gestion des cas : ce module s'occupe de la
définition de la structure d'un cas et permet la création et la
mise à jour des cas.
- L'exploitation des cas : elle consiste à mettre en
oeuvre des techniques d'indexation et de recherche des cas.
- L'adaptation des cas : ce module porte sur la
spécification et la construction d'un système pour l'adaptation
des cas ; le système pourrait être constitué d'un
agent spécialisé dans l'adaptation des cas et d'un agent
interface.
- L'intégration : il s'agit d'intégrer les
sous-systèmes déjà construits (gestion des cas, recherche
des cas, adaptation des cas) en vue de produire la première version
utilisable/prototype du système CIAO-SI.
- La gestion de l'assistance : elle va spécifier,
concevoir et construire un système pour l'assistance du concepteur
pendant le processus de développement.
- La réutilisation du code : c'est le lieu
d'étendre le système CIAO-SI à la réutilisation au
niveau du code source.
I.6.3 Notre rôle dans le projet
CIAO-SI
Du fait qu'il existe déjà des ontologies
associées à certains processus de développement (RUP par
exemple) ou encore à certains domaines d'applications (Gestion des
Ressources Humaines par exemple), il serait judicieux de pouvoir exploiter de
telles ontologies et d'éviter de reconstruire. C'est pourquoi nous
interviendrons dans la gestion des ontologies pour plusieurs
tâches :
- L'acquisition des éléments
d'ontologies liées aux processus de
développement :
Il s'agit de permettre à un
expert de décrire et mettre à jour les connaissances sur des
processus de développement, par le biais d'interfaces
génériques, d'importer des ontologies existantes (ontologies
développées avec des outils tiers et stockées dans un
format standard, XML par exemple), en extraire les éléments
utiles pour le système CIAO-SI et les stocker dans la base de
connaissances du projet CIAO-SI. Le métamodèle SPEM (OMG 2002b)
nous sert de base pour la description des processus.
- L'exploitation des éléments
d'ontologies liées aux processus de
développement :
Les éléments d'ontologies
liés aux processus de développement sont exploités par le
module de Gestion des cas (Ngantchaha 2002) et le module d'Assistance
(Moghomaye 2003). Il s'agira donc d'exporter les processus et de décrire
les interfaces de présentation des processus.
I.7 Conclusion
C'est ainsi que peut être posé le problème
à résoudre. En présentant les notions d'ontologies et de
bases de connaissances, en introduisant les processus d'ingénierie
logicielle, notre souci est de nous ramener au coeur du sujet même. Cela
a comme conséquence de faciliter la vision de la portée du
problème et de cerner le champ d'évolution du reste de notre
travail. Nous pouvons à présent procéder à une
analyse de l'existant dans le domaine des processus d'ingénierie
logicielle, particulièrement en ce qui concerne leur
réutilisation.
Etat de l'art de la
réutilisation des processus d'ingénierie logicielle
Réutiliser, c'est faire une nouvelle utilisation. La
conservation du patrimoine d'illustres prédécesseurs dans le
domaine de la science en général, et des génies en
particulier, a comme l'un des buts principaux leur réutilisation. En
effet, une évolution bien menée doit tenir compte de l'existant
pour éviter une rétrogradation. Nous avons eu à poser le
problème de la réutilisation dans le domaine de
l'ingénierie logicielle, qui s'avère important dans la mesure
où plusieurs étant reconnus et largement utilisés, le gain
à en disposer pour une exploitation illimitée à tous les
projets est considérable pour une entreprise de développement de
logiciel. Nous comprenons par là qu'elle suppose à la fois la
disponibilité de ces processus et leur exploitabilité.
Historiquement, l'on pourrait faire remonter le début des investigations
sur la réutilisation dans les processus d'ingénierie logicielle,
après l'essor des modèles dans les structures de données.
En effet, on est parti en complexité croissante depuis la technologie
procédurale, puis la technologie des objets pour celles des composants.
Plusieurs modèles sont alors apparus pour en faciliter l'uniformisation
et la réutilisation : IDL, Corba, UML, etc. Le même besoin
s'est produit en ingénierie logicielle, soutenu par les efforts
d'uniformisation pour les meilleurs échanges entre processus, et donc
une plus efficace réutilisation.
I.8 Vers une
solution d'ensemble
Les efforts de développement de modèles dans
l'ingénierie logicielle ont suivi une démarche que nous
récapitulons dans les lignes qui suivent (Bézivin 2003).
I.8.1 Diagrammes de Gant
Les diagrammes de Gantt ont été
créés par Henry Gantt dans les années 1920. Un diagramme
de Gantt permet de décrire l'ensemble des activités d'un
processus sous la forme de barres placées sur un calendrier. On a ainsi
une vue graphique de l'ensemble des activités, de leurs durées et
de leur ordonnancement. Le métamodèle des diagrammes de Gantt
définit un processus comme un ensemble d'activités, chaque
activité étant dotée d'une date de début et d'une
date de fin.
|
01/02
|
14/02
|
21/02
|
01/03
|
|
Activité 1
|
|
|
|
|
|
Activité 2
|
|
|
|
|
|
Activité 3
|
|
|
|
|
Tableau 1. Illustration d'un diagramme de
Gantt : les débuts de la planification.
I.8.2 Diagrammes PERT
Les PERT (Program Evaluation and Review Technique)
ont tout d'abord été utilisés par le département
américain de la défense. Un PERT est un graphe orienté qui
montre les activités, leur durée ainsi que leur ordonnancement.
Un processus vu comme un PERT est donc une suite d'activités, chaque
activité ayant une durée et pouvant suivre ou
précéder d'autres activités.
ACTIVITE 1
3 JOURS
ACTIVITE 2
2 JOURS
ACTIVITE 3
1 JOUR
ACTIVITE 4
3 JOURS
![]()
Tableau 2. Illustration du diagramme de
PERT : les délais remplacent les dates.
Contrairement à une activité d'un diagramme de
Gantt, une activité d'un PERT ne définit pas de date.
Il a été utile de présenter ces deux
exemples, car ce sont les premières tentatives de représentations
de processus, définissant déjà les concepts minimaux. Ils
montrent bien qu'il y a toujours eu de multiples façons de
modéliser les processus, chacune utilisant plus ou moins de concepts en
insistant sur certaines propriétés qui en font les avantages et
inconvénients.
I.8.3 PIF
PIF (Process Interchange Format) est issu des besoins
de diverses organisations (MIT, DEC, Stanford) de partager leurs modèles
de processus. Les spécifications de PIF définissent à la
fois un métamodèle de processus et une syntaxe basée sur
KIF. Le projet PIF a débuté en octobre 1993 et la notation a
progressivement évolué au cours des années. Aujourd'hui
PSL (
I.8.4
PSL) et PIF sont en train de fusionner pour
intégrer des concepts de processus tertiaires et industriels dans une
seule et unique ontologie. Le noyau du métamodèle de PIF
définit un ensemble d'entités plus ou moins minimal. Cet ensemble
de base peut être enrichi en utilisant le mécanisme d'extension
appelé Partially Shared View (PSV). Un module PSV hérite
du module racine (le noyau du métamodèle) ou d'un autre module
PSV. Ce nouveau module PSV définit de nouvelles entités en
spécialisant des entités d'autres entités
déjà définies dans des modules de plus haut niveau.
PIF définit un processus comme un ensemble
d'activités qui ont des relations entre elles ainsi qu'avec des objets
à des moments dans le temps. Tous ces concepts héritent d'une
entité commune nommée Entity. Le concept
d'activité, Activity, définit tout ce qui arrive dans le
temps, que ce soit un processus, une tâche ou même un
événement. Les instants, Timepoints, peuvent être
soit des dates précises soit des instants indéfinis (par exemple
l'instant auquel une tâche prend fin, où un
événement survient). Les Objects représentent
toutes les autres entités impliquées dans un processus. Cette
notion recouvre les artefacts, les données, les outils, ou même
les acteurs humains ou mécaniques (Agent). Toutes ces entités
sont reliées par des relations.
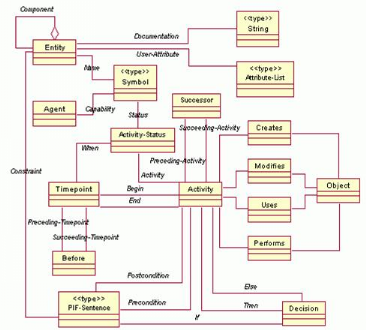
Figure 4. Le
modèle PIF : une représentation des concepts des processus
(Bézivin 2003).
I.8.4 PSL
L'objectif de PSL (Process Specification Language)
est de définir une ontologie et un format standard pour l'échange
des processus industriels. PSL définit un métamodèle noyau
basé sur des théories fondamentales qui définit les
concepts et les relations de base. En plus de ce module de base, un certain
nombre d'extensions ont été prédéfinies. Chacun de
ces modules spécialise une des entités basiques (ainsi
l'extension ProcessorAction spécialise le concept
d'Activity tandis que l'extension ResourcePools raffine la
notion d'Object).
L'ontologie PSL définit un processus comme un ensemble
d'activités (activity) dans lesquelles sont impliquées
des objets (object) à des instants donnés
(timepoint). Dans PSL, tout est activité, objet ou instant. PSL
introduit également la notion d'occurrence d'activité
(activity occurrence). Cette base minimale est enrichie dans des
modules d'extension qui définissent par exemple des activités non
déterministes, des quantités sur les objets ou un ordonnancement
temporel sur les instants.
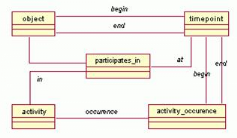
Figure 5. Le
modèle PSL : les principaux concepts et les relations entre ces concepts
(Bézivin 2003).
I.8.5 CPR
CPR (Core Plan Representation) est un projet du DARPA
qui se concentre principalement sur la planification (spécification
d'une liste d'actions ayant pour but de répondre à un ensemble
d'objectifs) ainsi que sur la prévision (spécification des
moments auxquels seront réalisés les activités et des
quantités de ressources utilisées).
CPR a pour but de modéliser un plan,
c'est-à-dire un ensemble d'actions réalisées pour
répondre à des objectifs. Les concepts de CPR sont les actions
(Action), les acteurs (Actor), les objectifs
(Objective) et les ressources (Resource). Une action est
réalisée par un acteur pour accomplir des objectifs. Des
ressources peuvent être consommées lors de la réalisation
d'une action. L'acteur d'une action peut être la ressource d'une
autre.
Le métamodèle présenté
précédemment est prévisionnel et ne permet pas de mettre
en relation un modèle de plan avec ses occurrences. C'est dans ce but
qu'a été ajouté le concept de WorldModel qui
permet de représenter des instances de plan. L'exécution d'un
plan est structurée de la même manière que sa conception
mais alors qu'une conception prévoit la façon dont doivent se
dérouler les occurrences, l'exécution du plan représente
ce qui s'est effectivement passé.
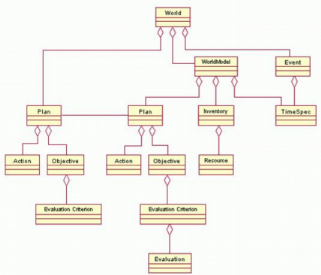
Figure 6. Le
modèle CPR : prise en compte des instances de plan (Bézivin
2003).
I.8.6 WfMC
La Workflow Management Coalition (WfMC) est un
consortium international d'éditeurs de worfklow, d'utilisateurs,
d'analystes et de groupes de recherches donc l'objectif est de promouvoir
l'utilisation du workflow. La WfMC propose un modèle de
référence de processus qui définit le
métamodèle de processus (
Figure 7).
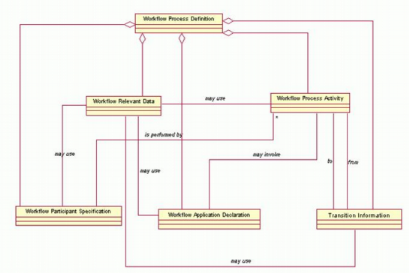
Figure 7. Le modèle de
référence proposé par WfMC (Bézivin 2003).
I.8.7 SPEM
SPEM (Software Process Engineering Metamodel), est
une recommandation de l'OMG utilisée pour décrire les processus
de développement logiciel ou les familles de processus liés. Lors
de la gestion de l'assistance dans les précédents travaux
(Konhawa 2003), ce métamodèle a servi de base à la
création des bases de connaissances des processus RUP et MERISE. Puisque
son importance a déjà été largement prouvée,
nous nous en servirons comme métamodèle pour les processus de
développement à décrire par les experts. Néanmoins,
nous rappelons dans ce paragraphe l'essentiel sur ce
métamodèle.
Présentation de SPEM
SPEM se fonde sur l'idée selon laquelle un processus de
génie logiciel met en collaboration des développeurs ayant des
Rôles, chaque développeur réalisant une ou plusieurs
Activités, et chaque activité prenant en entrée des
Artefacts et/ou produisant de nouveaux Artefacts ou ceux pris en entrée
et modifiés ; un artefact pouvant être un livrable ou un produit
de travail utilisé et/ou produit au cours du développement (OMG
2002b). La
Figure 8 illustre cette collaboration.
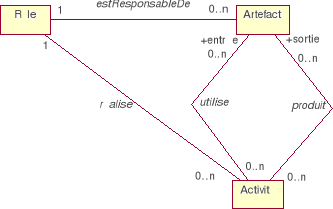
Figure 8. Les fondements du
métamodèle SPEM : collaboration
Rôle-Artefact-Activité (OMG 2002b).
En plus des notions de rôle, activité et
artefact, SPEM introduit plusieurs autres notions pour permettre la
modélisation d'un processus. Ainsi, la spécification fournit un
modèle générique pour la structure d'un processus,
contenant les principaux concepts manipulés par le processus.
Conformité au
méta-métamodèle MOF
MOF (MetaObject Facility) est la technologie
adoptée par l'OMG pour la définition de méta -
données et leur représentation comme des objets CORBA. MOF se
situe au niveau le plus élevé de la modélisation, le
niveau M3. Il peut donc servir pour la définition de SPEM qui se situe
au niveau M2. SPEM est le métamodèle de processus
d'ingénierie logicielle, c'est-à-dire qu'il définit un
modèle d'un niveau d'abstraction au dessus de celui d'un processus et
dont une instance serait la définition d'un processus effectif. La
Figure 9 montre l'architecture, à quatre
couches, de la modélisation telle que définie par l'OMG. Un
processus effectif, qu'on peut directement mettre en oeuvre, est au niveau M0.
La définition d'un tel processus est au niveau M1. SPEM se situe au
niveau M2, celui du métamodèle, et sert comme modèle
(template) pour le niveau M1.
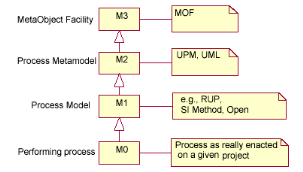
Figure 9. Les niveaux d'abstraction de la
modélisation selon MOF (OMG 2002b).
SPEM comme profil UML
Un profil UML est une adaptation de UML qui utilise les
mécanismes d'extension offerts par UML de façon
standardisée pour un but ou un domaine particulier. Un profil UML
fournit des stéréotypes pour les entités
caractérisant le domaine pour lequel il est défini.
SPEM est défini à la fois comme un
métamodèle de processus et comme un profil UML pour le domaine
que constitue l'ingénierie des processus de développement de
logiciels. Ce qui permet aux développeurs de tels processus d'utiliser
UML comme notation. La
Figure 10 donne la façon de décrire
les éléments d'un processus comme des stéréotypes
UML.
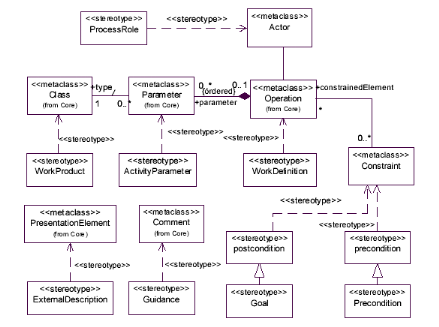
Figure 10. Correspondance entre SPEM et
les éléments du métamodèle de UML (OMG
2002b).
Une telle correspondance permet de définir un processus
de développement logiciel en UML en faisant usage de
stéréotypes propres à SPEM, ceci en représentant
les éléments stéréotypés propres au
processus par les éléments d'UML proposés par la figure de
correspondance, c'est-à-dire les classes et les diagrammes
d'activités.
SPEM comme DTD XMI
XMI (XML Metadata Interchange) est un format
d'échange de méta-données (c'est-à-dire de
modèles) définies conformément au standard MOF (OMG
2002a). Lorsque SPEM est vu comme un métamodèle basé sur
MOF, une DTD XMI correspondant à ce métamodèle peut
être élaborée pour l'échange des informations
contenues dans les modèles SPEM produits à partir du
métamodèle. Une telle DTD existe et est disponible dans la
spécification de SPEM publiée par l'OMG (OMG 2002a).
SPEM est déjà largement accepté. Ainsi,
il pourrait servir de moule, quelque soit le processus décrit par un
expert.
I.8.8 Conclusion
C'est ainsi que nous achevons ce parcours de
l'évolution de la réutilisation dans l'ingénierie des
processus de développement. Nous avons présenté comment
les efforts de la communauté du domaine ont conduit à l'adoption
de modèles et métamodèles. Ceci en partie dans le but
d'uniformiser les définitions, faciliter les échanges et bien
entendu améliorer la réutilisation des processus. SPEM ressort
comme le choix le plus consensuel.
I.9 Les solutions
existantes
La réutilisation des processus d'ingénierie
logicielle connaît à ce jour plusieurs approches concrètes
de réalisation. C'est ainsi que de par le monde, des applications sont
mises sur pied, utilisées et divulguées pour certaines. Mais nous
estimons que si pour la plupart, elles restent cantonnées au milieu
industriel, c'est dû à la vulgarisation encore jeune de
l'ingénierie logicielle, surtout pour des personnels. Néanmoins,
une certaine tendance dans ce développement voit le jour, mettant
à la disposition de personnels des solutions adéquates. Comme
nous l'avons mené jusqu'ici, nous nous intéresserons à
celles qui se basent sur le métamodèle SPEM. Dans les lignes qui
suivent, nous étudions un ensemble d'outils, qui supportent le
développement de processus d'ingénierie logicielle, conformes au
métamodèle SPEM.
I.9.1
SPEARMINT/EPG
Description
SPEARMINT™ (Fraunhofer 2004), de Fraunhofer IESE, est un
outil de modélisation graphique pour la description de processus de
développement logiciel. Le schéma conceptuel des informations sur
les processus de l'outil est un sous-ensemble simple mais expressif du
métamodèle SPEM. L'outil utilise une notation graphique proche
d'UML, qu'il est facile d'utiliser, et assez puissante pour décrire des
processus réalistes complexes.
En plus de modéliser le support pour les processus,
SPEARMINT fournit des possibilités d'analyse et les moyens de produire
un guide de processus électronique (Electronic Process Guide ou
EPG) et/ou un manuel de processus d'un modèle de processus. En fait, le
guide est une documentation électronique, qui fournit toutes les
directives aux développeurs pour le bon déroulement d'un
processus précédemment décrit. Tandis que des
modèles de processus peuvent être stockés dans des bases et
être utilisés par des chefs de projet pour la planification de
projet, les EPGs sont mis sur l'Intranet d'une compagnie pour fournir
l'accès facile et distribué aux descriptions de processus
normalisées et/ou spécifiques au projet aux interprètes de
projet. Des manuels de processus sont basés sur la DTD DocBook et
servent de documentation imprimée de processus tel qu'exigée par
CMM, ISO 9000, et ISO 15504. Un bon exemple publiquement disponible est la
méthode KobrA2(*), un
EPG pour la ligne de produits de technologie basée sur les composants
avec UML.
Une version de démonstration de SPEARMINT™/EPG,
fournissant toutes les fonctionnalités, mais avec la taille
modèle limitée à de petits et moyens processus, est
disponible gratuitement sur le WWW3(*). Nous l'avons téléchargée et
testée.
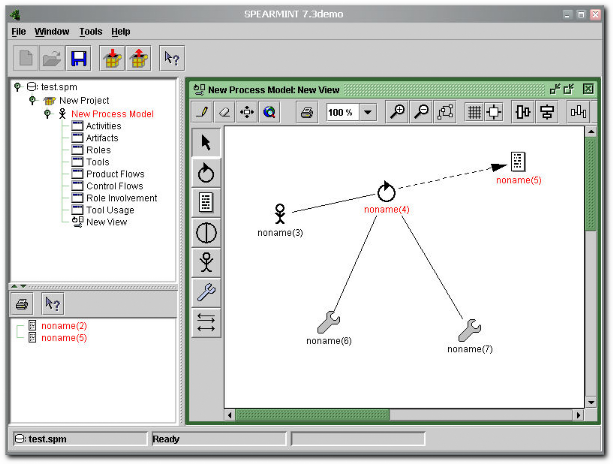
Figure 11.
SPEARMINT/EPG : un exemple de modélisation.
Avantages et
inconvénients
Ses fonctionnalités principales se résument en
la spécification d'un processus tel que SPEM le recommande
(définition des rôles, artefacts, etc.) (OMG 2002b).
L'édition graphique est assez avancée et simple d'utilisation.
Une fonctionnalité intéressante, est la vérification de la
consistance du modèle au métamodèle SPEM de manière
automatique (les objets causant ces erreurs sont surlignés en rouge). Il
faut préciser que cet outil dispose de son propre outil
métamodèle (dérivé de SPEM), et il définit
plus de cinquante (50) règles de vérification de la consistance
à ce métamodèle (Becker 2003).
Du fait de l'approche de modélisation multi-vues
(Multi-View Modeling ou MVM) utilisée par SPEARMINT, il peut
survenir des inconsistances lors de l'intégration des différentes
vues. C'est pourquoi cet outil dispose aussi d'un vérificateur
paramétrable de similarité entre modèles (Becker 2003).
Comme mentionné plus haut, il est possible de générer
l'EPG et le manuel du processus décrit. Il existe aussi des
possibilités d'importation et d'exportation au format XML, mais nous
n'avons pas pu expliciter cet aspect sans la documentation à propos.
SPEARMINT est portable, car développée avec le langage Java. Il
existe des plug-ins livrés avec SPEARMINT, notamment pour le calcul de
certaines caractéristiques de processus comme sa complexité. Il
faudrait aussi mentionner que la version complète est
commercialisée.
I.9.2 BORE
Description
BORE (Building an Organisational Repository of
Experiences) est un prototype conçu pour explorer et raffiner plus
tard les besoins d'outils supportant des approches basées sur
l'expérience. Son but a été comme prototype de
preuve-de-concept, qui est employé pour articuler l'étude
d'organisation et les techniques de développement de logiciel
basées sur l'expérience. Cet outil crée un cadre pour
l'usine d'expérience, en combinant une structure de panne de travail
avec des outils de dépôts pour concevoir des méthodologies
de processus de logiciel, et la technologie de dépôt pour capturer
et appliquer des artefacts (objets façonnés) de la connaissance.
L'outil et méthodologie BORE prolonge le concept d'usine
d'expérience par une mise sur pied de processus basée sur les
règles, le support de la modélisation et l'établissement
de processus, et les facilités d'étude d'organisation
basées sur les cas.
Le prototype BORE est une application disponible sur le
WWW4(*). C'est une applet
java.
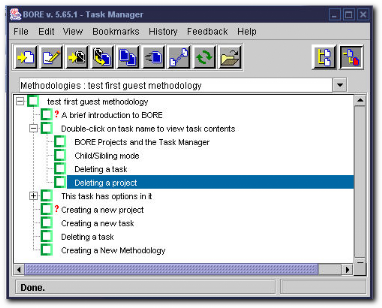
Figure 12. BORE
: un aperçu du gestionnaire de tâches.
Avantages et
inconvénients
De ce que nous avons pu tirer après les tests de cette
application, nous retenons principalement qu'elle permet de fournir, modifier
et utiliser les processus de développement dans un dépôt.
En effet, il est possible, pour un processus décrit, de spécifier
les rôles, les activités (tâches), etc. Il est aussi
possible d'exporter et importer d'autres processus (au format Microsoft
Project Files). Ce n'est pas un outil de modélisation graphique,
donc il est basé sur les rapports, qu'il est possible de
générer.
La documentation faisant défaut, nous n'avons pu aller
plus loin. Notamment, nous le pressentons comme étant inspiré de
SPEM mais sans certitude. Il pèche aussi par les formats d'exportation
limités à Microsoft Project Files. Bien que les publications de
déroulement de processus soient générées au format
.doc. Pour travailler sur BORE, il faut avoir des droits d'administrateur dont
l'attribution n'est pas explicite.
I.9.3 APES
Description
APES est une suite de logiciels de construction de processus,
développée par AubryConseil. AubryConseil est une
société spécialisée en génie logiciel et
processus. Claude AUBRY, son directeur, a ainsi pu avec des étudiants de
l'Université Paul Sabatier de Toulouse, réaliser cet outil dont
la principale fonction est de suivre la réalisation de processus de
développement logiciel, depuis leur modélisation jusqu'à
leur exécution.
Architecture
APES constitue une suite de quatre (04) outils
indépendants :
- L'outil de modélisation pour la conception du
processus sous forme de composants, avec la validation de la conformité
à SPEM (dénommé Apes2) (Aubry 2004a).
- L'outil de présentation pour la spécification
de la bibliothèque du processus (et des interfaces) (POG ou YGAEL)
(Aubry 2004b).
- L'outil de publication pour l'assemblage des composants, la
génération d'un site de présentation du processus et
l'exportation au format XML (IEPP) (Aubry 2004c).
- L'outil d'exécution pour la gestion d'un projet
à l'aide d'un processus précédemment publié, la
publication d'un site d'artefacts, le suivi de l'évolution du projet
(PEACH ou EUGES ou AGP) (Aubry 2004d).
Nous les avons téléchargés et
testés, pour en appréhender les fonctionnalités.
Distribution
APES est la première famille d'outils disponible en
Open Source dans le domaine de l'ingénierie des processus. Les sources
de tous les outils de la suite, développés par des
étudiants de l'IUP ISI5(*) de l'Université Paul Sabatier de Toulouse, sont
accessibles ainsi que leurs documents de développement sur le
WWW6(*). Chacun de ces
outils est en effet sous la licence GNU GPL. Nous étudions les
opportunités offertes par cette licence dans l'annexe B.
Approche
APES utilise une approche de développement par
composants, car il s'agit de définir un processus composant par
composant. Chaque composant étant en soi indépendant, les
composants peuvent être ensuite assemblés pour former un processus
complet. L'intérêt de cette approche se trouve surtout dans la
répartition des tâches pour le développement des processus,
car plusieurs équipes pourront développer chacune leur composant
pour plus tard les assembler.
Autres
caractéristiques
Modélisation visuelle
La représentation utilisée par APES est celle
des diagrammes UML, avec des extensions liées à la
modélisation des processus. Ainsi, chaque processus est
modélisé de manière entièrement graphique.
Indépendance des méthodologies et
processus
APES est indépendant de toute méthodologie et
permet de prendre en compte n'importe quel processus. L'outil
d'exécution (Aubry 2004d) est particulièrement adapté
à des processus itératifs (comme RUP ou XP).
* 1
http://www.cyc.com/cyc-2-1/cover.html
* 2
http://www.iese.fhg.de/Projects/Kobra_Method/
* 3
http://www.iese.fhg.de/Spearmint_EPG/Downloads/
* 4
http://cse-ferg41.unl.edu/bore.html
* 5 Institut Universitaire
Professionnalisé d'Ingénierie des Systèmes
Informatiques.
* 6
http://www.aubryconseil.com/apes/index.html
| 

