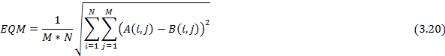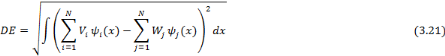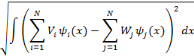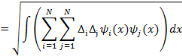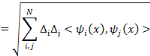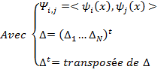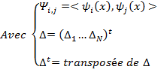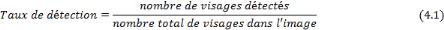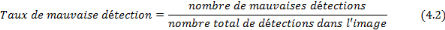Apprentissage des réseaux d'ondelettes bêta basé sur la théorie des frames : application à la détection de visages( Télécharger le fichier original )par Faouzi Hajjem Université de Gabés - Mastère de recherche en informatique 2008 |

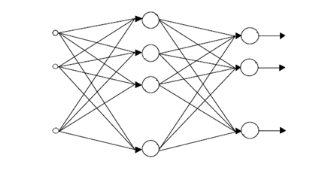
a. Le perceptron multicouche (PMC) :Le perceptron est la forme la plus simple de réseau de neurones, et permet de classifier correctement des objets appartenant à deux classes linéairement séparables. Il consiste en un seul neurone qui possède un seuil, ainsi qu'un vecteur de poids synaptiques ajustables. La mise en cascade de perceptrons conduit à ce qu'on appelle les perceptrons multicouches (Figure2.6). Lorsque le vecteur de caractéristiques d'un objet est présenté à l'entrée du réseau, il est communiqué à tous les neurones de la première couche. Les sorties des neurones de cette couche sont alors communiquées aux neurones de la couche suivante, et ainsi de suite. La dernière couche du réseau est appelée couche de sortie, les autres étant désignées sous le terme de couches cachées car les valeurs de sortie de leurs neurones ne sont pas accessibles de l'extérieur. Le théorème d'approximation prouve qu'un perceptron multicouche, à une seule couche cachée, est en théorie toujours suffisant. Toutefois, il ne préjuge en aucun cas du nombre d'unités cachées qui est nécessaire pour atteindre une qualité d'approximation suffisante. Ce nombre pouvant parfois être gigantesque, l'utilisation d'un perceptron multicouche à deux (ou plus) couches cachées ne comportant chacune qu'un nombre restreint de neurones peut parfois s'avérer être plus utile. x1 x2 xn y1 y2 ym Vecteur d'entrée Couche cachée Couche de sortie
Figure 2.6: Perceptron Multicouche à une couche cachée. Grâce à l'utilisation de fonctions d'activation non linéaires, le perceptron multicouche est à même de générer des fonctions discriminantes non linéaires. L'algorithme d'apprentissage supervisé du perceptron multicouche, connu sous le nom d'algorithme de rétropropagation, nécessite toutefois que les fonctions d'activation des neurones soient continues et dérivables. Les fonctions qui sont le plus couramment utilisées sont probablement de type sigmoïdal (Ondelettes par exemple). Avec la rétropropagation, la donnée d'entrée est, à plusieurs reprises, présentée au réseau de neurones. À chaque présentation, la sortie du réseau est comparée à la sortie désirée et une erreur est calculée. Cette erreur est alors réinjectée dans le réseau et employée pour ajuster les poids de façon qu'elle diminue à chaque itération et que le modèle neuronal arrive de plus en plus près de la reproduction de la sortie désirée. Ce processus s'appelle la formation. b. Le réseau à Fonction Radiale de Base (RBF) : Le réseau à fonction radiale de base comporte deux couches de neurones (Figure2.7). Les cellules de sortie effectuent une combinaison linéaire de fonctions de base non linéaires, fournies par les neurones de la couche cachée. Ces fonctions de base produisent une réponse différente de zéro seulement lorsque l'entrée se situe dans une petite région bien localisée de l'espace des variables. Bien que plusieurs modèles de fonctions de base existent, le plus courant est de type Gaussien. L'apprentissage du réseau à fonction radiale de base est généralement scindé en deux parties : Dans un premier temps, les poids des neurones de la couche cachée sont adaptés au moyen d'une quantification vectorielle. Il existe plusieurs manières d'effectuer cette dernière. Lorsque les poids des cellules cachées sont fixés, les paramètres de normalisation sont déterminés en calculant la dispersion des données d'apprentissage associées à chaque centroïde. La seconde couche du réseau peut alors être entraînée. L'apprentissage est cette fois supervisé (les valeurs de sortie désirées sont fournies), et s'effectue typiquement à l'aide d'un algorithme basé sur un critère des Moindres Carrés de l'Erreur. L'entraînement de la seconde couche est très rapide, car, d'une part, les sorties de la couche cachée peuvent être calculées une seule fois pour tous les exemples d'apprentissage, et d'autre part, les sorties des neurones de la seconde couche sont linéaires. Les méthodes d'apprentissage, tel que le critère des moindres carrés du perceptron, peuvent être appliquées.
w1 x1
w2 wN
Entrée xn
Figure 2.7: Un réseau à fonction radiale de base. Le fait que l'apprentissage de la couche cachée soit non supervisé, est toutefois un inconvénient de ce modèle de réseau vis-à-vis d'un perceptron multicouche. Pour pallier à ce dilemme, des méthodes d'apprentissage supervisé de réseaux à fonction radiale de base ont également été développées. Un avantage du réseau à fonction radiale de base est que sa phase d'apprentissage est plus rapide que celle du perceptron multicouche. Mais la non-linéarité, présente dans la couche de sortie du perceptron multicouche, est inexistante dans le réseau à fonction radiale de base, ce qui constitue un désavantage de ce dernier vis-à-vis du premier. L'efficacité (Erreur / taille du réseau) d'un réseau à fonction radiale de base et d'un perceptron multicouche est dépendante du problème traité. IV. Les réseaux d'ondelettes La notion de réseaux d'ondelettes existe depuis les années 90. Il s'agit d'une combinaison entre deux techniques de traitement de signaux : La transformée en ondelettes et les réseaux de neurones artificiels. Les réseaux d'ondelettes remplacent la fonction sigmoïde par des ondelettes comme fonction de transfert dans chaque neurone. Deux modèles différents ont été proposés pour différentes applications, telles que la classification et la reconnaissance de formes, et la compression de signaux. Rappelons de la relation (2.14) qui donne l'expression d'une
fonction f de carré sommable sous la forme d'une
intégrale sur toutes les dilatations et toutes les translations
possibles de l'ondelette mère. Supposons que l'on ne dispose que d'un
nombre fini
La somme finie de la relation (2.17) est donc une approximation d'une transformée inverse. Elle peut être vue aussi comme la décomposition d'une fonction en une somme pondérée d'ondelettes, où chaque poids cj est proportionnel à wf (aj, bj). C'est dans cette perspective qu'a été proposée l'idée de réseaux d'ondelettes [41]. 1. Architecture des réseaux d'ondelettes a. Modèle1 de réseaux d'ondelettes L'architecture dans ce modèle, est proche de celle d'un réseau RBF. Le réseau est considéré constitué de deux couches : une première couche avec Ni entrées et une couche cachée constituée de Nw ondelettes, et un Sommateur de sortie recevant les sorties pondérées des ondelettes. Les cellules d'une couche sont connectées à toutes les cellules de la couche suivante uniquement. La propagation des valeurs se fait des cellules d'entrées vers les cellules de sortie. Cette architecture est donc tout à fait comparable aux
réseaux de neurones utilisant des fonctions sigmoïdales. Elle
présente également une similitude avec l'architecture des
réseaux RBF mais la fonction de transfert est remplacée par une
fonction ondelette L'algorithme d'apprentissage est hérité aussi de celui des réseaux de neurone RBF. Il vise à réduire l'erreur commise entre l'entrée du réseau et sa sortie en corrigeant les paramètres de ce réseau. La fonction de coût quadratique est utilisée pour mesurer cette erreur. L'apprentissage vise, ainsi, à minimiser le coût empirique donné par la quantité E [13]:
Où L'expression de la sortie du réseau est :
L'algorithme de la descente en gradient est utilisé à chaque itération de cet algorithme, en propageant le calcul d'une couche à une autre jusqu'à la couche de sortie. Remarque : L'algorithme d'apprentissage consiste à modifier les paramètres dans le sens opposé au gradient de la fonction d'erreur. x1 wkj wik ?
? y1 x2
ym xn Figure 2.8: Modèle1 de réseaux d'ondelettes b. Modèle2 de réseaux d'ondelettes Dans ce deuxième modèle, l'entrée est un ensemble de paramètre ti qui décrivent les positions ordonnées du signal à traiter. Les entrées ne sont pas des données proprement dites, mais seulement des valeurs décrivant des positions bien précises du signal. La couche cachée contient un ensemble de neurones, dans chaque neurone une ondelette translatée et dilatée. La couche de sortie contient un seul neurone qui somme les sorties de la couche cachée pondérées par les poids de connexion wi. L'algorithme de la descente de gradient est utilisé pour faire l'apprentissage. Ce modèle, introduit pour la première fois par Zhang et Benveniste, est un cas particulier de l'architecture du modèle1 des réseaux d'ondelettes présenté au dessus [13].
Sortie
Figure 2.9: Modèle2 de réseaux d'ondelettes 2. Comparaison des réseaux d'ondelettes aux réseaux de neurones La principale ressemblance entre ces deux réseaux réside au fait que les deux réseaux calculent une combinaison linéaire, de fonctions non linéaires dont la forme dépend de paramètres ajustables (dilatations et translations) de cette combinaison. Mais la différence majeure est la nature des fonctions de transfert utilisées par les cellules cachées. Nous présentons dans ce qui suit quelques différences : · Les ondelettes sont des fonctions qui décroissent rapidement, et tendent vers zéro dans toutes les directions de l'espace. Elles sont donc locales si a est petit. · La forme de chaque ondelette unidimensionnelle est déterminée par deux paramètres ajustables (translation et dilatation) qui sont des paramètres structurels de l'ondelette. · Chaque ondelette unidimensionnelle possède deux paramètres structurels, d'où pour chaque ondelette multidimensionnelle, le nombre de paramètres ajustables est le double du nombre de variables. 3. Techniques de construction des réseaux d'ondelettes Différentes techniques ont été proposées pour construire des réseaux d'ondelettes, fondées sur la transformée discrète à partir de l'ensemble d'apprentissage. Nous préciserons dans ce qui suit quelques unes ainsi que les avantages et les inconvénients de chacune d'elles [41]. a. Technique fondée sur l'analyse fréquentielle Cette technique a été proposée par Y. C. Pati en 93. Elle repose sur l'estimation du spectre d'énergie de la fonction à approcher. Le domaine de fréquence contenant le spectre d'énergie étant connu (il est obtenu en calculant la transformée de Fourier de la fonction à approcher), ainsi que le domaine des amplitudes des variables d'entrées couvert par la séquence d'exemples, on peut alors déterminer les ondelettes correspondant à ce domaine amplitude-fréquence. Cette technique présente l'avantage de tirer parti des propriétés de localité des ondelettes dans les domaines spatial et fréquentiel. En revanche, elles présentent un inconvénient majeur, notamment pour les modèles multivariables : le volume de calcul nécessaire à l'estimation du spectre de fréquence est très élevé. b. Technique fondée sur la théorie des ondelettes orthogonales Cette approche, utilisant des bases d'ondelettes orthogonales, a été proposée par J. Zhang en 95. Étant donné le domaine des amplitudes des entrées de l'ensemble d'apprentissage, on choisit les ondelettes ayant leurs centres à l'intérieur de ce domaine. Le nombre de dilatations différentes à considérer dépend de la performance désirée. Cette technique présente l'avantage de mettre à profit la propriété d'orthogonalité des ondelettes. En revanche, sa mise en oeuvre est malaisée, car à l'exception du système de Haar, on ne connaît pas, à ce jour, d'expression analytique simple pour les ondelettes mères qui engendrent des familles de fonctions orthogonales. Cet inconvénient rend cette technique peu efficace. c. Réseaux d'ondelettes pour un système adaptatif Cette technique a été proposée par M. Cannon et J. E. Slotine en 95 pour la construction des réseaux d'ondelettes en vue de leur utilisation dans un système adaptatif de commande. Une bibliothèque d'ondelettes est construite en considérant le domaine des valeurs des variables d'état du modèle. Le paramètre a, qui détermine l'échelle des dilatations, est estimé en utilisant le spectre d'énergie de la fonction à approcher. Le réseau est constitué d'ondelettes de la bibliothèque sélectionnées et pondérées périodiquement. Les pondérations des ondelettes sont comparées à un seuil. Une fonction est gardée ou exclue du réseau suivant que sa pondération est supérieure ou inférieure à ce seuil. Cette technique de construction de réseaux d'ondelettes présente l'inconvénient de nécessiter l'estimation du spectre d'énergie de la fonction à approcher. d. Technique fondée sur la construction de frames Étant donné les limites théoriques auxquelles on se heurte pour la construction des réseaux d'ondelettes orthogonales, A. Juditsky en 94 puis Q. Zhang en 97 ont utilisé des structures obliques (frames). La question qui se pose alors est le choix des paramètres structurels de dilatation a et de translation b. Pour éviter le calcul du spectre d'énergie de la fonction à approcher, la bibliothèque d'ondelettes est construite en utilisant l'échantillonnage dyadique2(*) : (a0 =2 et b0 = 1). 4. Domaines d'application des réseaux d'ondelettes Plusieurs domaines sont touchés par les réseaux d'ondelettes, malgré qu'ils aient été récents : la compression d'images, la classification et la reconnaissance des formes y compris le visage humain, le traitement des signaux vocaux,... Dans ce contexte, on peut citer les recherches de Daugman, qui a utilisé une décomposition sur une base de fonctions de Gabor pour la compression d'images 2D [13]. Les réseaux d'ondelettes sont utilisés aussi dans la localisation du trait facial. Cette technique utilise un réseau d'ondelettes hiérarchique à deux niveaux basé sur les ondelettes de Gabor. La construction d'une base de données contenant les réseaux d'ondelettes hiérarchiques de plusieurs visages permet aux traits d'être détectés dans la plupart des visages utilisés [40]. I. Boaventura et al. présentent une autre approche pour la détection du visage humain dans des images numériques. Deux techniques différentes sont combinées pour accomplir la tâche de détection de visages : la transformée en ondelettes discrètes est appliquée en se basant sur les fonctions Haar et Symlet. Un Perceptron multicouche est utilisé afin d'extraire les traits particuliers qui sont détectés [32]. Ces travaux ont motivé les applications des réseaux d'ondelettes à des problèmes de classification et autres. Les derniers résultats atteints plaident en faveur d'une implémentation de réseaux d'ondelettes dont les coefficients sont obtenus par apprentissage. Conclusion Dans ce chapitre, nous avons effectué une étude de la théorie des ondelettes : les concepts de base, les caractéristiques d'une ondelette mère, les ondelettes unidimensionnelles et multidimensionnelles, ainsi que la transformée en ondelettes continue et discrète. Dans la seconde partie, nous avons fait un survol sur les réseaux de neurones, ses principales caractéristiques et les différentes architectures utilisées. La dernière partie a été sacrifiée aux réseaux d'ondelettes : les modèles utilisés, leurs avantages et leurs domaines d'application. Nous profitons, dans ce sujet, des avantages des réseaux de neurones et de la capacité des ondelettes au traitement du signal pour présenter, dans le chapitre suivant, une nouvelle approche de détection de visages utilisant les réseaux d'ondelettes Bêta et basée sur la théorie des frames. Chapitre 3 Approche proposée pour la détection de visages par réseaux d'ondelettes Bêta Approche proposée pour la détection de visages par réseaux d'ondelettes Bêta Introduction Dans ce chapitre, nous commençons par une étude de la fonction Bêta et les ondelettes unidimensionnelles Bêta1D et bidimensionnelles Bêta2D ainsi que leurs dérivées. Ensuite, nous détaillons la phase d'apprentissage des réseaux d'ondelettes Bêta basée sur la théorie des frames. Enfin, nous présentons notre approche de détection de visages humains par réseaux d'ondelettes. I. Étude de l'ondelette Bêta 1. Présentation de l'ondelette Bêta a. L'ondelette Bêta1D L'ondelette Bêta1D est
générée à partir de la fonction
Bêta :
b. Propriétés de base de la fonction Bêta
Remarque : La fonction Bêta peut être considérée comme une fonction linéaire de x si on prend :
La fonction Bêta satisfait toutes les propriétés d'une ondelette mère précisées dans le chapitre précédent [13]: · L'admissibilité, · La localisation, · L'oscillation, · La dilatation et la translation.
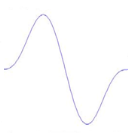
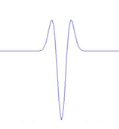
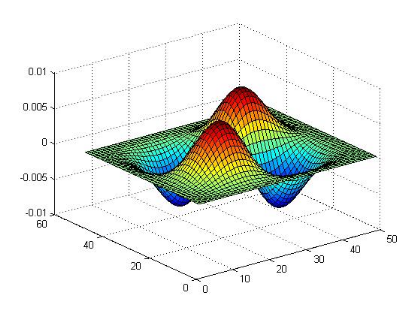
Figure 3.1: Exemple de l'ondelette Bêta1D Il est à noter que sous certaines conditions, toutes les dérivées de la fonction Bêta sont des ondelettes [49]: Sachant que p>0, q>0 (p, q)
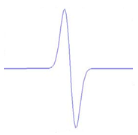
Figure 3.2: Exemples de la dérivée première de l'ondelette Bêta1D
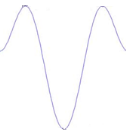
Figure 3.3 : Exemples de la dérivée seconde de l'ondelette Bêta1D c. L'ondelette Bêta2D Comme toute ondelette multidimensionnelle, une ondelette Bêta2D (ondelette bidimensionnelle) est séparable. Son expression est le produit de deux ondelettes unidimensionnelles.
Une ondelette Bêta2D doit vérifier les
propriétés d'une ondelette mère. La dilatation et la
translation sont présentes sur les deux axes (x,y). La
propriété de rotation s'y ajoute pour qu'elle tourne avec un
angle
Avec la rotation : Dans ce cas, la transformée en ondelettes continue d'une fonction f bidimensionnelle est :
La reconstitution de la fonction f reste possible si l'ondelette est admissible. Nous présentons ci-dessous un exemple d'ondelettes Bêta bidimensionnelles et ses deux dérivées première et seconde :
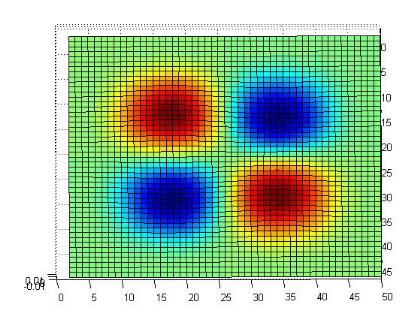
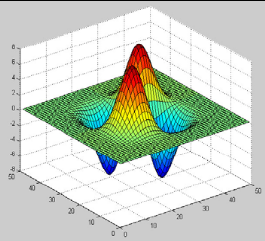
Figure 3.4: l'ondelette Bêta2D et le filtre associé
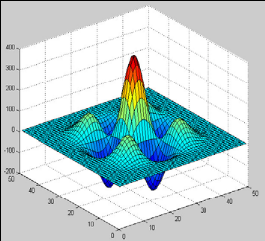
Figure 3.5: Exemples de la dérivée 1ére & 2éme de l'ondelette Bêta2D 2. Les frames En remplaçant la double somme de l'expression (2.17) de la transformée en ondelettes discrètes par une seule somme, la fonction f peut être exprimée par :
D'après Daubechies, cette relation n'est valide que si la famille d'ondelettes, obtenue lors de la discrétisation, forme une base orthogonale. Pour un cas plus général (cas des bases quelconques), des concepts comme les frames et les frames duales ont besoin d'être introduits pour pouvoir écrire un signal donné en termes des coefficients d'ondelettes. Soit
Où A et B représentent les limites de la frame. Quand une famille d'ondelettes discrètes forme une
frame, elle fournit une représentation complète et sans perte de
toute fonction Pour fournir plus de détails, nous introduisons
d'autres termes:
Une frame est dite base si pour toute fonction f de L2, la combinaison linéaire (3.8) soit unique. Une famille d'ondelettes qui est à la fois orthogonale et base, s'appelle base orthogonale. En général, une frame n'est pas une base orthogonale sauf si A = B = 1. Aussi, elle fournit une représentation redondante de la fonction f. Le rapport (A / B) est appelé facteur de redondance. Pour d'autres valeurs de A et B, cette représentation reste valable, Bø n'est plus une base orthogonale mais une base dite biorthogonale. En plus, si la représentation de f en combinaison linéaire d'ondelettes n'est plus unique, la famille Bø est une frame. Dans ces deux derniers cas on est mené à écrire f en fonction de la frame duale :
Si la fonction On peut calculer les coefficients d'ondelettes wi par une projection orthogonale du signal f à analyser sur la base orthogonale des ondelettes analysantes. Pour le cas d'une base biorthogonale ou une frame la projection du signal f se fait sur une frame duale [13]. La formule suivante permet de calculer la famille duale des ondelettes Bêta :
Essayons de représenter les ondelettes par des vecteurs. On peut illustrer les trois bases possibles qui peuvent être reconstruites avec une famille d'ondelettes.
Frame Base Orthogonale Base Biorthogonale Figure 3.6: Représentation des bases orthogonale, biorthogonale et frame. II. Principe de l'apprentissage des réseaux d'ondelettes La phase d'apprentissage inclut la procédure de construction d'une bibliothèque d'ondelettes candidates à être utiliser dans la couche cachée de notre réseau. Nous détaillerons, dans ce qui suit, la manière de leurs sélections, puis nous expliquerons les étapes d'optimisation de ce réseau. 1. Construction de d'une bibliothèque d'ondelettes pour le réseau Pour obtenir une frame, une discrétisation des paramètres de dilatation a et translation b est nécessaire. La transformée en ondelettes discrète peut être mise en oeuvre sur des valeurs discrètes de ces deux derniers paramètres. En exploitant la transformée inverse en ondelettes discrètes (3.12), qui peut être interprétée comme la sortie d'un réseau d'ondelettes, nous pouvons construire notre bibliothèque d'ondelettes. Les coefficients a et b sont calculés par la formule :
Remarque : Pour Les ondelettes résultant de l'échantillonnage temps-fréquence vont constituer la bibliothèque des ondelettes candidates à joindre notre réseau d'ondelettes.
Figure 3.7: Les sept premieres ondelettes 2. Optimisation du reseau Pour optimiser un réseau d'ondelettes, l'échantillonnage dyadique sera utilisé pour sa simplicité. Ce qui va produire une ondelette ayant la décroissance la moins rapide dans la première échelle. Le nombre d'ondelettes sera multiplié par deux à chaque fois qu'on passe à l'échelle suivante. Les ondelettes d'une même échelle se diffèrent seulement par leurs positions (paramètre de translation) et elles sont réparties sur l'axe de temps pour couvrir la quasi-totalité du signal à analyser. En fait, avec les ondelettes de basses fréquences, on peut atteindre une approximation acceptable du signal, les autres ondelettes de hautes fréquences, qui sont les plus nombreuses, se servent juste pour affiner cette approximation. Pour calculer le nombre d'ondelettes introduites dans la bibliothèque, il faut calculer le nombre d'ondelettes sur l`échelle dyadique de l'espace temps-fréquence. Sachant que les échelles sont des puissances de 2 et N représente la taille du signal à approximer, le nombre d'échelles nécessaires pour couvrir tout le signal : j = log2(N) Le nombre d'ondelettes, à chaque échelle m donnée, est égal à 2 j - m ondelettes translatées. Le nombre total d'ondelettes sera donc : 1 + 2 + 22 + ... + 2j-1 = 2j - 1 = N - 1. Malgré que ce nombre d'ondelettes paraisse assez important, le nombre effectif d'ondelettes utilisées sera beaucoup plus réduit, puisque une seule ondelette sera suffisante pour interpoler plus qu'un échantillon du signal à analyser. a. Calcul direct des poids Pour des ondelettes orthogonales, le calcul des poids de connexion à chaque étape est possible par projection du signal à analyser sur la même famille d'ondelettes. Mais, pour une famille d'ondelettes quelconque, il n'est pas possible de calculer les poids par projection directe de la fonction f sur la même base. Une solution consiste à utiliser les ondelettes duales. Deux familles d'ondelettes
L'ondelette Si L'utilisation des ondelettes biorthogonales permet le calcul direct des poids de connexion du réseau d'ondelettes : Soit f un signal, Le poids, dans ce cas, peut être calculé en exploitant l'ondelette duale :
b. Algorithme d'optimisation Pour plus de détails, on définit la fonction Toutes les ondelettes de la bibliothèque doivent vérifier la condition de l'indépendance linéaire : · Dans le cas d'une famille d'ondelettes orthogonales ou biorthogonales, elles sont linéairement indépendantes. · Dans le cas d'une frame (famille d'ondelettes ne formant pas une base), les ondelettes, qui ne vérifient pas l'indépendance linéaire et qui forment une frame avec les anciennes ondelettes du réseau, ne seront pas totalement rejetées. Chaque ondelette qui dépend d'une ou plusieurs de ses précédentes ne sera pas introduite dans le réseau, mais elle améliore les poids des ondelettes du réseau dont elle dépend. La sortie du réseau est alors calculée en fonction des ondelettes qui sont linéairement indépendantes par projection du signal d'entrée sur la famille duale de toutes ces ondelettes. 3. Apprentissage des réseaux d'ondelettes 2D La fonction d'activation choisie pour l'analyse du signal est
la fonction bidimensionnelle Bêta2D. On rappelle qu'une ondelette
bidimensionnelle est le produit de deux ondelettes unidimensionnelles :
La discrétisation de cette ondelette pour analyser des signaux discrets, conserve les mêmes paramètres d'échantillonnage des translations et des dilatations proposés pour le cas unidimensionnel (3.16). En ajoutant l'angle Un réseau d'ondelettes bidimensionnelles possède la même structure qu'un réseau d'ondelettes unidimensionnelles, sauf que chaque neurone a deux entrées caractérisant les coordonnées spatiales des échantillons du signal à approximer. Dans le cas d'un signal 2D, l'échantillonnage dyadique des paramètres de dilatation, de translation et de rotation de la transformée 2D en ondelettes continues est utilisée. Le résultat est une base d'ondelettes constituant une frame 2D, commençant par une échelle contenant une seule ondelette centrée exactement au milieu, puis à chaque échelle le nombre d'ondelettes sera multiplié par quatre. Les ondelettes doivent être reparties sur le support du signal d'une manière uniforme. Une fois la base d'ondelettes bidimensionnelles candidates à joindre le réseau est construite, un algorithme d'apprentissage sera appliqué. De même, les ondelettes de la base ne seront pas toutes utilisées comme filtres d'approximation puisque quelques unes seront exploitées pour améliorer les poids de connexions du réseau. III. Approche proposée pour la détection de visages Notre travail consiste à déterminer, pour une image d'entrée quelconque, la présence ou non d'un ou de plusieurs visages. Dans le cas de détection, les visages seront repérés dans l'image par des carrés à travers leurs coordonnées. 1. Architecture des réseaux d'ondelettes Bêta2D utilisée Nous proposons une architecture qui comporte trois couches de cellules: une couche d'entrées, une couche cachées et une couche de sortie. Les cellules d'une couche sont connectées à toutes les cellules de la couche suivante, et à celles-ci uniquement. La propagation des valeurs se fait dans le sens `feedforward', c'est-à-dire des cellules d'entrées vers les cellules de sorties. Comme pour le modele2 de réseaux d'ondelettes3(*), Les entrées seront des valeurs décrivant des positions bien précises du signal (image). La couche de sortie contient une seule ondelette qui calcule la somme des sorties de la couche cachée pondérées par les poids de connexion wi. La sortie sera l'image d'entrée avec un marquage de tous les visages détectés par le réseau. w1
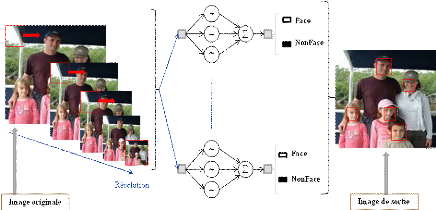
Image w2 1, 2, 3, 4, 5,... ? wi wn
Figure 3.8: Architecture de l'approche proposee 2. Démarche d'apprentissage basé sur la théorie des frames L'apprentissage consiste à présenter les images réservées pour cette phase aux entrées des réseaux. Les images d'apprentissage doivent être de même dimension et appartenant à l'une de deux classes : Visage ou Non-Visage. On aura, dans ce cas, un réseau par image. Chaque image d'apprentissage sera réinjectée dans le réseau et on calculera la valeur de son PSNR (Peak Signal Noise Ratio) en appliquant la formule :
Avec R est le nombre de bits avec lequel un pixel est
codé. Par exemple, si les images sont de 256 niveaux de gris, alors
R sera égal à Avec EQM est l'erreur quadratique moyenne, c'est la métrique qui mesure la distorsion dans une image. Elle est exprimée par la formule suivante :
Avec M et N représentent les dimensions de l'image. La condition d'arrêt d'un processus d'apprentissage sera l'arrivée de l'indice PSNR à un seuil satisfaisant fixé d'avance. Les paramètres de chaque image d'apprentissage (dilatation, translation, rotation,...) seront sauvegardés pour être exploités dans la phase de détection (Figure 3.9). Le réseau doit être entraîné d'une manière correcte, lors de la phase d'apprentissage, pour donner des bons résultats dans la phase de détection : · Nombre d'images dans la base d'apprentissage doit être satisfaisant, · Diversification des images en termes de sexe, couleur, éclairage, orientation,... Une fois le réseau est entraîné dans la phase d'apprentissage, il doit être prêt à recevoir les images de test qu'on lui présente.
Figure 3.9: Modele illustrant la demarche d'apprentissage adoptee. 3. Démarche de détection de visages par réseaux d'ondelettes Bêta2D Dans cette phase de détection, les images de test ne doivent absolument pas être choisies parmi les images de l'apprentissage, mais d'autres bases d'images doivent être réservées aux tests. Chaque image de test présentée à l'entrée du réseau, est explorée avec une fenêtre possédant les dimensions des images d'apprentissage. L'imagette extraite est mise à l'entrée de chacun des réseaux d'apprentissage ayant un poids Wi. Les poids de chaque réseau sont recalculés en projetant l'imagette sur la base duale formée par les ondelettes du réseau, pour obtenir des nouveaux poids Vi qui sont comparés au poids d'origine Wi en calculant la Distance Euclidienne DE (3.21). Pour comparer deux réseaux d'ondelettes la Distance Euclidienne est calculée par la formule suivante [13] :
Quelques transformations algébriques donnent :
La Distance Euclidienne entre deux réseaux de mêmes fonctions ondelettes se fait simplement en calculant le vecteur de différence entre les deux poids des deux réseaux d'ondelettes. DE peut être écrite comme suit :
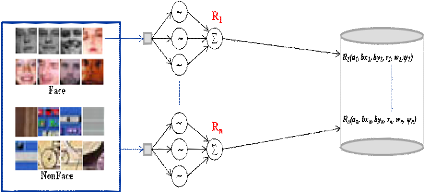
Si le réseau ayant la distance minimale (Dmin) appartient à la classe Visage, l'imagette comporte un visage, sinon, c'est la classe Non-Visage, et il s'agit d'un autre objet. Apres avoir exploré toute l'image, on réduit sa résolution grâce à la technique de la multirésolution et on reprend la même démarche jusqu'à ce que la taille de l'image soit strictement inférieure à la taille de la fenêtre utilisée pour l'apprentissage. Le choix des valeurs du Pas de translation de la fenêtre sur l'image et son taux de résolution est un critère déterminant pour la qualité des résultats de détection retournés. Les images de test sont des images quelconques comportant ou non des visages. Elles seront utilisées par le réseau en appliquant les étapes suivantes : 1) Parcourir l'image de test présentée à l'entrée du réseau, avec une fenêtre possédant les dimensions des images d'apprentissage. 2) Chaque imagette extraite sera mise à l'entrée de chaque réseau d'apprentissage de poids Wi. 3) Recalculer les poids de chaque réseau en projetant l'imagette sur la base duale formée par les ondelettes du réseau pour obtenir des nouveaux poids Vi. 4) Comparer chaque réseau de poids Vi à son origine de poids Wi en calculant la distance Euclidienne D. 5) Chercher la distance minimale séparant le réseau à son origine (Dmin). 6) Voir si le réseau de distance minimale appartient à la classe "Visage" ou à la classe "Non-Visage". 7) Réduire la résolution de l'image grâce à la technique de la multirésolution en changeant l'échelle. 8) Répéter les étapes (1?7) jusqu'à ce que la taille de l'image soit inférieure à la taille de la fenêtre utilisée pour l'apprentissage. 9) Rétablir l'image avec sa taille originale en précisant tous les visages détectés. Les étapes de cette démarche, présentées ci-dessus, peuvent être résumées dans la figure suivante :
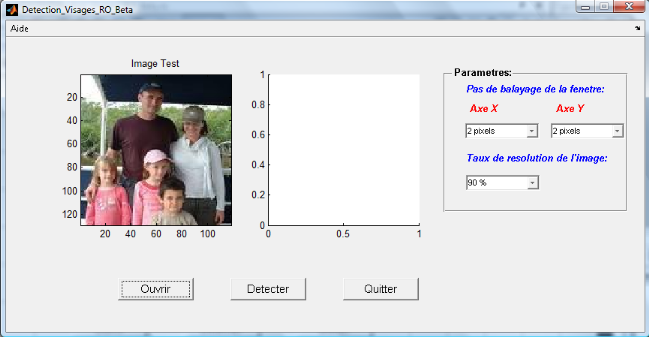
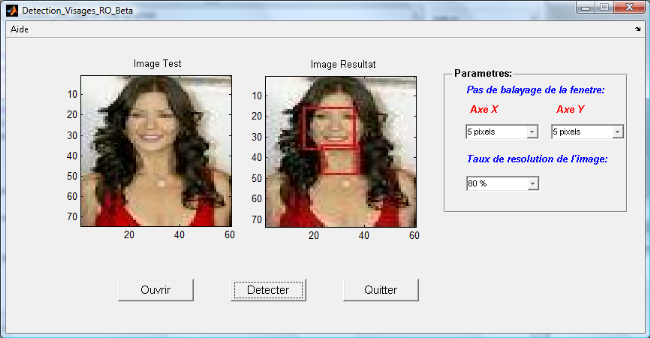
Figure 3.10: Modele illustrant la demarche de detection adoptee. Conclusion Ce chapitre nous a permis de présenter, dans une première partie, les ondelettes, unidimensionnelles et bidimensionnelles, générées à partir de la fonction Bêta, ainsi que la notion de frames. Ensuite, dans la deuxième partie, nous avons détaillé la phase d'apprentissage des réseaux d'ondelettes en expliquant ses étapes : la construction de la bibliothèque d'ondelettes, le calcul des poids et leur optimisation ainsi que le processus d'apprentissage dans un réseau d'ondelettes 2D. Dans la troisième section, nous avons présenté notre approche pour la détection de visages. Dans cette partie, nous avons introduit l'architecture des réseaux d'ondelettes proposée, ainsi que la démarche proposée pour l'apprentissage que pour la détection de visages. Dans le chapitre suivant, nous détaillerons l'implémentation de cette approche de détection de visages, et nous montrerons ses performances. Chapitre 4 Expérimentation Expérimentation & résultats Introduction Dans ce chapitre, nous présentons la mise en oeuvre de la méthode proposée et de la démarche présentée dans ce mémoire pour la détection de visages. Il est primordial de valider l'approche choisie sur un ensemble de données relativement volumineux. Ainsi, l'ensemble d'images utilisées propose une gamme à diverses conditions (visage, non-visage, plusieurs visages, grimaces, éclairage,...). Dans une première partie, nous exposons l'implémentation de notre application et les résultats expérimentaux de détection de visages par réseaux d'ondelettes Bêta. Ensuite, une évaluation objective des performances de ces réseaux d'ondelettes Bêta est effectuée en se basant sur certains critères de mesure. La dernière partie est réservée pour l'analyse et l'interprétation des résultats et des indices de performances calculés. I. Implémentation des réseaux d'ondelettes Bêta 1. Application L'application a été développée sous « MS Windows Vista» à l'aide du logiciel MATLAB7.0.4. (Figure 4.1) La démarche consiste à générer toutes les ondelettes à partir de l'ondelette mère par modification des paramètres de dilatation et de translation. Ces ondelettes seront pivotées à plusieurs ongles (par exemple : 3 * 120°), pour mieux approximer l'image d'entrée, avant d'être stockées dans une base d'ondelettes (matrice). A chaque étape, une ondelette duale sera construite à partir des ondelettes précédentes à une échelle plus basse. Le poids de chaque ondelette sera recalculé et ajusté. Enfin, à partir de la base d'ondelettes et des poids ajustés, un signal de sortie sera généré. Il est à noter que les ondelettes de la base ne seront pas toutes exploitées : Certaines d'entre elles seront utilisées par le réseau, mais les autres seront exploitées pour optimiser les poids. Pendant la phase d'apprentissage du réseau, une image de taille 15*15 sera remise à l'entrée de chaque réseau, l'algorithme d'apprentissage sera tourné. Une erreur (EQM) mesurant la distorsion entre l'entrée du réseau et sa sortie sera calculée et l'indice de performances PSNR sera mesuré pour définir un seuil à partir duquel on peut exiger si l'image d'entrée est un visage ou non. Deux classes d'images seront définies : classe Visage et classe Non-Visage. Dans la phase de détection, l'image de test sera parcourue par une fenêtre ayant la même taille que les images d'apprentissage (15*15). L'imagette extraite sera remise dans les différents réseaux en calculant la Distance Euclidienne qui la sépare des images d'apprentissage. On vérifie ensuite si la DE la plus proche (DEmin) appartient à la classe Visage ou à la classe Non-Visage. Une fois que l'image de test est totalement parcourue, on changera sa résolution et on reprendra la comparaison... Pour illustrer cette approche, nous avons développé une interface graphique présentée ci-dessous.
Figure 4.1: Interface de l'application de détection de visages développée Nous présentons, aussi, quelques images représentant les principales fonctionnalités assurées par notre application.
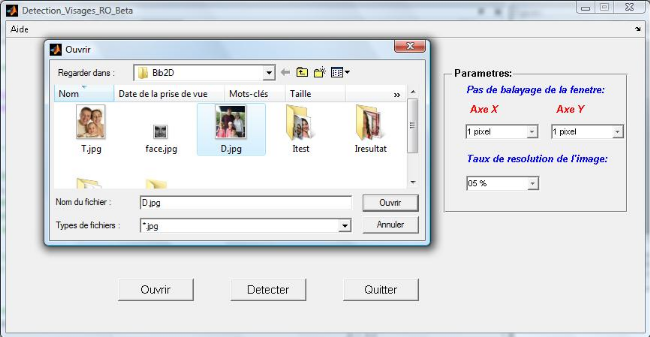
Figure 4.2: Interface d'insertion d'une nouvelle image de test
Figure 4.3: Interface d'ajustement des paramètres de la détection
Figure 4.4: Interface représentant le menu d'aide 2. Résultats expérimentaux Deux étapes sont indispensables pour faire fonctionner l'application : phase d'apprentissage et phase de détection. a. L'apprentissage Dans cette phase nous exploitons une base d'images contenant 200 exemples. Chaque exemple est une image de taille 15*15 pixels appartenant à l'une de deux classes Visage ou Non-Visage. Pour un meilleur apprentissage : · Pour la classe Visage, on trouve des images à diverses conditions : images en couleurs ou en niveau de gris, images claires ou sombres, visage avec des yeux fermés ou ouverts, visage avec ou sans lunettes, visage avec ou sans barbe et/ou moustache,... (Figure4.5) · Pour la classe Non-Visage, on trouve des images contenant des parties d'un visage, des parties du corps humain possédant la couleur de visage, des images dont la couleur est proche de la couleur de peau... (Figure 4.6).
Figure 4.5: Exemples d'images d'apprentissage de la classe Visage
Figure 4.6: Exemples d'images d'apprentissage de la classe Non-Visage Dans le tableau suivant, nous présentons les PSNR calculés pour quelques images d'apprentissage (Tableau 4.1)
Tableau 4.1: Les valeurs du PSNR de la classe Visage et de la classe Non-Visage D'après le tableau précédent on remarque un chevauchement des valeurs du PSNR dans l'intervalle [44.955 , 51.017]. Donc le choix du seuil est fixé à la valeur 45. b. La détection Dans cette phase de test, les images utilisées possèdent différentes caractéristiques : taille de l'image, sa résolution, avec ou sans couleurs,... pour assurer une meilleure évaluation du système développé. Certaines de ces images contiennent un seul visage, d'autres contiennent plusieurs visages à diverses positions et tailles.
Figure 4.7: Application de détection de visages sur une image à un seul visage A la fin de cette phase de détection, il faut rétablir l'image à sa taille originale en précisant tous les visages détectés. Voici quelques images de test retournées par notre système après détection de visages :
Figure 4.8 : Exemples de détection dans une image contenant un seul visage
Figure 4.9 : Exemple de détection dans une image contenant plusieurs visages II. Mesure des performances Pour mieux évaluer l'approche proposée pour la détection de visages, nous proposons quelques indices de mesure (Taux de détection et Taux de mauvaise détection) permettant d'apprécier les résultats trouvés. Quelques images de test seront utilisées, en appliquant l'algorithme proposé, ensuite nous essayons d'interpréter les indices trouvés. 1. Critères de performance a. Taux de détection Cette valeur permet de calculer le pourcentage des bonnes détections de visages dans une image. Elle est donnée par l'expression (4.1). Plus la valeur de cette expression est élevée, plus l'approche proposée est efficace (performante).
b. Taux de mauvaise détection Cette valeur permet de calculer le pourcentage des mauvaises détections, c'est-à-dire que la partie localisée dans l'image n'est pas un visage. Elle est donnée par l'expression (4.2). Plus la valeur de cette expression est réduite, plus l'approche proposée est efficace.
2. Évaluation des résultats L'application de deux critères de performance exprimés précédemment sur quelques images de test, comportant un ou plusieurs visages, a permis d'avoir les résultats donnés dans les tableaux ci-dessous en fonction de PSNR par rapport au seuil prédéfini (Seuil = 45): a. Calcul de performances de l'approche proposée
Tableau 4.2 : Calcul de performances de l'approche proposée b. Calcul de performances en fonction du PSNR
Tableau 4.3 : Calcul de performances de l'approche proposée avec PSNR III. Interprétation et discussion Les résultats ont montré que les performances des réseaux d'ondelettes exploitant la théorie des fra mes, présentent des caractéristiques intéressantes dans le domaine de la détection de visages dans une image. Pour les images contenant un nombre réduit de visages, le taux de détection peut atteindre un pourcentage de 100% avec un taux faible de mauvaise détection voir même un pourcentage de 0% pour certains cas d'un seul visage. Pour les images contenant un nombre important de visages le taux de détection décroît et le taux de mauvaise détection augmente mais avec un taux faible. En effet, les résultats de la détection ont montré aussi que le taux de détection décroît avec le nombre de visages dans une image, allant de 100% pour un nombre de visages inferieur ou égale à 2, jusqu'à la valeur de 75% pour les images dont le nombre de visages dépasse 3. De même, on remarque que le taux de mauvaise détection augmente en fonction de la complexité de l'image (Nombre de visage, Éclairage, Qualité de l'image, ...). Le nombre de visage dans l'image est un facteur ayant son poids sur le taux de détection et le taux de mauvaise détection. Mais, le nombre de visages n'est pas le seul facteur qui influe sur l'efficacité de l'approche dans la détection. La qualité de l'image, aussi, joue un rôle très important, ainsi que sa résolution... Nous avons fixé le seuil du PSNR à 45, c'est la valeur optimale pour que les réseaux d'ondelettes, exploités dans cette approche, convergent et donnent des résultats satisfaisants. En effet, nous avons effectué différents essais en utilisant une valeur inférieure au seuil (seuil = 43) et une autre supérieure au seuil (seuil = 47) et nous avons remarqué que lorsqu'on diminue le seuil, les performances des réseaux, en termes de taux de détection, restent importantes. Mais, le taux de mauvaise détection devient remarquable. A l'inverse, lorsqu'on augmente ce seuil, les performances des réseaux, en termes de taux de détection, se dégradent, mais avec des taux de mauvaise détection plus faible. Ces remarques peuvent être expliquées par la qualité de l'image reconstruite. · Lorsque le PSNR est faible (PSNR < Seuil), l'image retournée manque de précision, qu'elle soit Visage ou Non-Visage. Par conséquent plusieurs images d'apprentissage la ressemblent, ce qui explique ce taux élevé de détection et de mauvaise détection. · Lorsque le PSNR est élevé (PSNR > Seuil), l'image retournée est très précise. Par conséquent, sa ressemblance avec une image de la base d'apprentissage devient de plus en plus faible, ce qui explique le faible taux de détection de visages et de mauvaise détection aussi. Conclusion Dans ce chapitre, nous avons évoqué notre contribution dans le domaine de la détection de visages. Nous avons proposé une approche exploitant les réseaux d'ondelettes Bêta basée sur la théorie des frames, pour l'apprentissage et la détection de visages humains dans une image. Nous avons conçu un système capable d'exécuter la tâche de détection automatique de visages à l'aide d'un algorithme d'apprentissage. Les indices de performances dégagés, ont permis de conclure que notre approche présente des performances très intéressantes surtout pour des images ne contenant pas trop de visages, d'ailleurs on a eu des taux de détection de 100% pour ce type d'images et un taux dépassant 75% pour des images contenant plusieurs visages. Les performances des réseaux d'ondelettes Bêta, dont l'apprentissage est basé sur la théorie des frames, comme classificateurs pour la détection de visages sont évidentes à travers les résultats. La robustesse et la rapidité de cette approche font valoir les avantages de ces réseaux. * 2 Voir Chapitre 3 Page 52. * 3 Voir Chapitre2 Page 41. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||





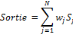


 d'ondelettes
d'ondelettes 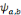
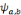 obtenues à partir de l'ondelette mère
obtenues à partir de l'ondelette mère 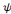
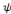 . On peut alors considérer la relation (2.17) comme une
approximation de la relation (2.14).
. On peut alors considérer la relation (2.17) comme une
approximation de la relation (2.14). 

 .
.
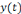
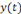 est la sortie réelle obtenue par le réseau et
est la sortie réelle obtenue par le réseau et 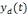
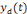 la sortie désirée.
la sortie désirée.
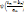
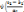

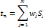
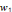
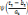
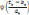
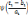
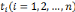
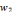
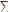
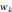
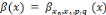
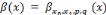
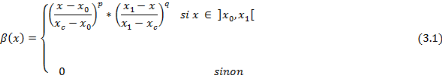
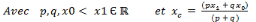
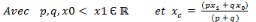




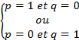
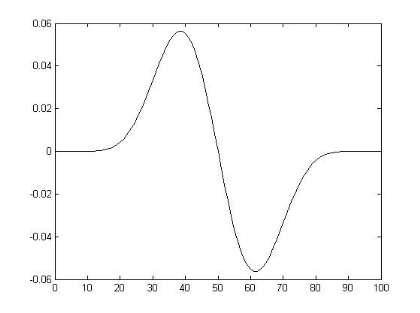
 , Si p = q, pour tout
, Si p = q, pour tout 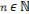
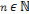 et quelque soit 0 < n < p,
et quelque soit 0 < n < p,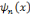
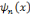 , la dérivée nième de la fonction
Bêta, est une ondelette.
, la dérivée nième de la fonction
Bêta, est une ondelette.

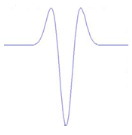

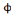
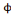 . L'équation d'une ondelette bidimensionnelle :
. L'équation d'une ondelette bidimensionnelle :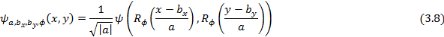
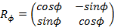
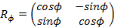
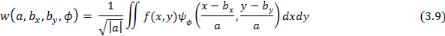

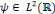
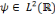 une ondelette,
une ondelette,
 un échantillonnage sur une grille
un échantillonnage sur une grille 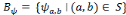
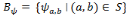 , une famille discrète d'ondelettes. On dit que
, une famille discrète d'ondelettes. On dit que 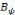
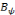 forme une frame, s'il existe
forme une frame, s'il existe 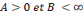
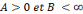 tel que pour tout
tel que pour tout 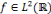
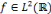 :
: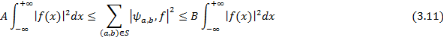
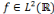
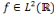 [13].
[13].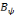
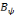 est dite orthogonale si pour toute
est dite orthogonale si pour toute 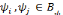
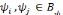 :
: 

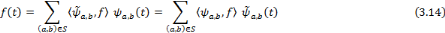
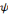
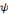 est l'ondelette analysante, les coefficients d'ondelettes sont obtenus
par le calcul du produit scalaire de cette ondelette dilatée et
translatée et la fonction à analyser. L`ondelette duale est
utilisée pour la reconstruction (l'inverse est aussi vrai). Pour une
famille d'ondelettes orthogonales une ondelette est égale à sa
duale.
est l'ondelette analysante, les coefficients d'ondelettes sont obtenus
par le calcul du produit scalaire de cette ondelette dilatée et
translatée et la fonction à analyser. L`ondelette duale est
utilisée pour la reconstruction (l'inverse est aussi vrai). Pour une
famille d'ondelettes orthogonales une ondelette est égale à sa
duale. 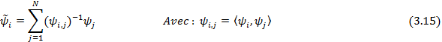
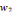
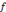
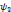
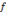
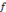
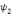
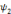
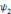
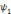
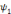
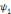
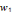



 , on parle d'un échantillonnage dyadique.
, on parle d'un échantillonnage dyadique.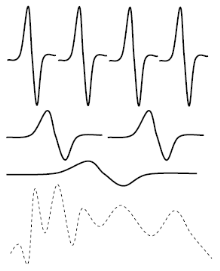
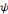
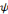 et
et 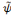
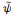

 sont dites biorthogonales, si pour toutes i et
j on a :
sont dites biorthogonales, si pour toutes i et
j on a : 
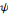
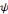 est dite primale alors que l'ondelette
est dite primale alors que l'ondelette 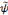
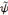 est dite duale.
est dite duale.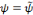
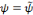 , la famille
, la famille 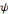
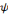 constitue une base orthogonale.
constitue une base orthogonale.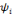
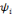

 une famille d'ondelettes qui forme une frame et
une famille d'ondelettes qui forme une frame et 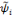
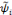


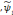
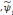 la famille d'ondelettes duales alors il existe des poids
wi vérifiant la relation (3.10).
la famille d'ondelettes duales alors il existe des poids
wi vérifiant la relation (3.10).
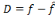
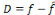 , avec f la fonction à approximer et
, avec f la fonction à approximer et 


 la sortie du réseau. Au début du processus d'optimisation
la sortie du réseau. Au début du processus d'optimisation
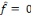
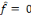 et D = f. Sur la première échelle
dyadique qui contient une seule ondelette analysante (celle de la
fréquence la plus basse), le poids de la première connexion est
calculé par
et D = f. Sur la première échelle
dyadique qui contient une seule ondelette analysante (celle de la
fréquence la plus basse), le poids de la première connexion est
calculé par 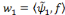
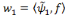 , la sortie du réseau est alors
, la sortie du réseau est alors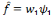
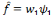 . L'ondelette suivante sur l'échantillonnage qui constitue une
base avec toutes les ondelettes du réseau, qui l'ont
précédé, va s'ajouter à la couche cachée de
ce dernier. Ce processus s'arrête lorsque l'erreur atteint un seuil
fixée d'avance.
. L'ondelette suivante sur l'échantillonnage qui constitue une
base avec toutes les ondelettes du réseau, qui l'ont
précédé, va s'ajouter à la couche cachée de
ce dernier. Ce processus s'arrête lorsque l'erreur atteint un seuil
fixée d'avance.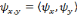
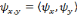 (3.7).
(3.7).


 de rotation tel que :
de rotation tel que : 
 , la discrétisation et la transformée inverse en
ondelettes discrètes restent vraies pour les ondelettes
bidimensionnelles en remplaçant la fonction intégrale par la
fonction somme.
, la discrétisation et la transformée inverse en
ondelettes discrètes restent vraies pour les ondelettes
bidimensionnelles en remplaçant la fonction intégrale par la
fonction somme.




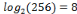
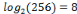 .
.