|
|
|
Un
Ministère
Institut d'Études et de Formation en Statistique
MéMOIRE DE FIN D'éTUDES D'INGéNIEUR EN
STATISTIQUE
|
RÉPUBLIQUE
de
|
Peuple
|
************ -Un
DU
l'Enseignement
POUR
THÈME
|
Appliquée
SAGEP)
SÉNÉGAL
But-Une foi
Supérieur
et en Gestion et Évaluation de Projets
L'OBTENTION DU DIPLôME INFORMATIQUE APPLIQUéE
:
|
|
|
(INEF
|
|
|
|
|
|
|
|
|
|
ANNéE ACADéMIQUE
|
|
|
: 2008-2009
|
|
Mémoire de fin d'études
Avant-propos
L'élève Ingénieur de Statistique
Informatique Appliquée à l'Institut d'Études et de
Formation en Statistique Appliquée et en Gestion et Évaluation de
Projets (INEF-SAGEP) est tenu en quatrième année de
rédiger et de soutenir publiquement un mémoire sanctionnant la
fin de sa formation. Ce mémoire a pour but l'initiation du futur
ingénieur statisticien à la recherche. C'est une occasion pour
l'étudiant de mettre en pratique les connaissances acquises au cours de
son cycle scolaire.
C'est pour répondre à cette exigence
académique que nous avons opté sur le thème « Profil
de pauvreté en République de Guinée : une approche
multidimensionnelle ». L'objectif de cette étude est d'analyser
à partir des données de l'ELEP 2007 la pauvreté selon une
approche multidimensionnelle. Cette étude va contribuer non seulement
à enrichir la connaissance sur la pauvreté, mais aussi, à
orienter utilement les politiques de lutte contre la pauvreté dans le
ciblage des groupes vulnérables.
Mes études ont été rendues possibles
grâce au soutien financier de mes parents. Qu'ils trouvent ici
l'expression de mes remerciements. Mes remerciements vont également
à Monsieur DIA Aboubacar qui a mis à ma disposition les
données et toutes les informations indispensables à sa
compréhension.
II
Ce mémoire est une initiation à la recherche, de ce
fait nous sommes entièrement réceptifs et ouverts à toutes
les critiques et suggestions émanant de la part des membres du jury et
pouvant l'améliorer.
Résumé
L'étude de la pauvreté en République de
Guinée s'est toujours appuyée sur l'approche dite
monétaire dans l'analyse de la pauvreté utilisant le revenu ou
dépense comme le seul indicateur du bien-être. Pour approcher le
phénomène de la pauvreté, l'Institut National de la
Statistique n'utilise que les dépenses de consommation. Celle-ci est,
cependant, limitée. Elle ne prend pas en compte, certaines dimensions du
bien-être (éducation, santé, eau potable, nutrition,
habitat, assainissement, énergie, communication, bien
d'équipements et de confort, etc.).
Notre travail de recherche se base sur les données
fournies par l'Enquête Légère d'Évaluation de la
Pauvreté de l'année 2007. Cette enquête
réalisée par l'Institut National de la Statistique de
Guinée porte sur un échantillon de 7552 ménages.
À l'aide de la classification ascendante
hiérarchique, nous avons pu classer les ménages selon leurs
conditions de vie en deux groupes (les pauvres et les non pauvres)
homogènes de telle sorte que les ménages d'un même groupe
se ressemblent le plus possible, et ceux appartenant à deux groupes
différents soient très différenciés. Les pauvres
représentent 71,1 % de la population des ménages
enquêtés et les non pauvres 28,9 %.
L'analyse discriminante nous a permis d'identifier les
déterminants ou facteurs de la pauvreté des deux groupes
constitués. 0n constate que la pauvreté est un
phénomène essentiellement rural. Les plus touchés sont les
chefs de ménages qui sont des indépendants agricoles ou non
agricoles, ceux qui n'ont aucun niveau d'instruction et ceux qui
résident dans les régions administratives de
N'Zérékoré, Kankan, Faranah, Labé et Kindia. Les
moins pauvres demeurent dans la capitale Conakry.
Mots clés :
Pauvreté multidimensionnelle, Classification ascendante
hiérarchique, Analyse discriminante, Profil de pauvreté,
Guinée.
Mémoire de fin d'études
III
Dédicace
Je dédie ce travail qui est le couronnement de quatre
longues et laborieuses années d'études à mes adorables
parents pour tous les efforts consentis pour mon éducation. Qu'ils
trouvent ici le sentiment d'une tâche bien accomplie.
Mémoire de fin d'études
iv
Remerciements
Au terme de ce travail, je remercie tout d'abord Dieu le
Clément et le Miséricordieux.
IL m'est agréable d'adresser mes plus vifs
remerciements à mon Directeur de mémoire Monsieur Ndiappe NDIAYE
pour avoir accepté de me diriger. Sa disponibilité, sa rigueur
scientifique et ses encouragements m'ont disposé à
réaliser ce mémoire dans de bonnes conditions.
Je remercie également tout le personnel enseignant de
l'INEFSAGEP, pour son dévouement et la qualité des enseignements
qu'il nous a donné durant toute notre formation.
Ma reconnaissance va ensuite à l'endroit de tous les
étudiants de l'Institut pour leur sollicitude permanente. Ils ont
toujours su manifester un esprit de camaraderie et de partage.
Enfin, je tiens à remercier respectivement tous ceux
qui m'ont aidé, soutenu, et encouragé pour la réalisation
de ce modeste travail.
Mémoire de fin d'études
V
TABLE DES MATIÈRES
Avant-propos ii
Résumé iii
Dédicace iv
Remerciements v
Introduction 1
Problématique 3
Objectif de l'étude 4
CHAPITRE 1 : CADRE DE L'ÉTUDE 5
1.1 Présentation générale de la
République de Guinée 5
1.2 Revue de la littérature 9
1.2.1 Les approches conceptuelles de la pauvreté 9
1.2.1.1 L'école welfariste 9
1.2.1.2 L'école non welfariste 11
1.2.1.2.1 L'École des capacités de Amartya Sen
11
1.2.1.2.2 L'École des besoins de base 11
1.2.2 Travaux empiriques sur la pauvreté
multidimensionnelle 12
CHAPITRE 2 : MÉTHODOLOGIE DE L'ÉTUDE 15
2.1 Sources des données 15
2.2 Présentation de la base des données et
traitement des données 16
2.3 Méthodes d'analyse utilisées 17
2.3.1 Principe de la classification ascendante
hiérarchique (CAH) 17
2.3.2 Principe de l'analyse discriminante 18
2.4 Variables de l'étude 19
2.4.1 Variables utilisées pour la classification
ascendante hiérarchique 19
2.4.2 Variables utilisées pour l'analyse discriminante
22
2.5 Transformation des variables 23
CHAPITRE 3 : PRÉSENTATION ET INTERPRÉTATION DES
RÉSULTATS 24
3.1 Résultats de la classification ascendante
hiérarchique 24
3.1.1 Choix du nombre optimal de groupes 24
3.1.2 Récapitulatif des classements des ménages
26
3.1.3 Baptême des groupes 28
3.1.3.1 Caractéristiques des ménages du Groupe 1
28
Mémoire de fin d'études
vi
3.1.3.2 Caractéristiques des ménages du Groupe 2
29
3.2 Résultat de l'analyse de relation entre la variable
dépendante et les variables
indépendantes 31
3.3 Profil de Pauvreté 34
3.3.1 Résultats de l'analyse discriminante 34
3.3.1.1 Vérification de l'existence de différence
entre les deux groupes 34
3.3.1.2 Vérification de la validité de
l'étude 36
3.3.1.3 Choix des variables les plus discriminantes 39
3.3.1.4 Estimation des coefficients de la fonction discriminante
42
3.3.1.5 Qualité de la représentation 47
3.3.1.6 Choix du meilleur ou des modèles entre l'analyse
factorielle discriminante et
celle bayésienne 49
3.3.1.7 Adéquation du modèle de classement retenu
50
Conclusions et Recommandations 53
Bibliographie 56
Annexes 58
Mémoire de fin d'études
VII
Liste des tableaux
Tableau 01 : Liste des variables utilisées par domaine
dans la classification ascendante
hiérarchique
Tableau 02 : Liste des variables utilisées dans
l'analyse discriminante
Tableau 03 : Récapitulatif des critères pour le
choix de la meilleure classification
Tableau 04 : Récapitulatif des classements
Tableau 05 : Résultats des tests et intensité
des liens entre la variable dépendante
le niveau de vie) et les variables indépendantes
Tableau 06 : Tests d'égalité des moyennes des
groupes
Tableau 07 : Résultats du test M de Box
Tableau 08 : logarithme népérien du
déterminant de la matrice de variance covariance pour
chaque groupe du niveau de vie
Tableau 09 : Valeur propre et coefficient de
corrélation canonique associé à la fonction
linéaire
discriminante
Tableau 10 : Récapitulatif de la fonction
discriminante
Tableau 11 : Liste des variables
introduites/éliminées de l'analyse
Tableau 12 : Liste des variables absentes de l'analyse
discriminante
Tableau 13 : Lambda de Wilks de chaque pas de l'algorithme
Tableau 14 : Coefficients standardisés de la fonction
discriminante
Tableau 15 : Matrice de structure
Tableau 16 : Coefficients de la fonction discriminante non
standardisés
Tableau 17 : Fonctions aux barycentres des groupes
Tableau 18 : Coefficient des fonctions de classement
Tableau 19 : Matrice de confusion (résultats du
classement bayésien)
Tableau 20 : Groupe d'affectation prévu par la fonction
discriminante
Tableau 21 : Comparaison entre les modèles issus de
l'analyse factorielle discriminante et celle
bayésienne
Tableau 22 : Aire sous la courbe de ROC du modèle de
classement retenu
Mémoire de fin d'études
VIII
Mémoire de fin d'études
Liste des graphiques
Graphique 01 : Répartition (%) des ménages selon
leurs caractéristiques Graphique 02 : Profils des groupes
constitués
ix
Graphique 03 : Courbe de ROC du modèle de classement
retenu
Mémoire de fin d'études
Liste des abréviations
ACP Analyse en Composante Principale
AD Analyse Discriminante
AUC Aire Sous la Courbe
BIT Bureau International du Travail
CAH Classification Ascendante Hiérarchique
CR Commune Rurale
CU Commune Urbaine
DSRP Document de Stratégie de Réduction de la
Pauvreté
EIBC Enquête Intégrale Budget et Consommation
EIBEP Enquête Intégrée de Base pour
l'Évaluation de la Pauvreté
ELEP Enquête Légère pour l'Évaluation
de la Pauvreté
FMI Fonds Monétaire International
GNF Guinée Nouveau Franc
GSE Groupe Socio-économique du chef de ménage.
IDH Indice de Développement Humain
IMP Indicateur multidimensionnelle de pauvreté
INEFSAPEP Institut d'Études et de Formation en Statistique
Appliquée et en Gestion et Évaluation de Projets
INS Institut National de la Statistique
IPH Indice de Pauvreté Humaine
IPPTE Initiative Pays Pauvre Très Endettés
IQV Indice de Variation Qualitative
ISF Indice Synthétique de Fécondité
OMD Objectifs du Millénaire pour le
Développement
ONU Organisation des Nations Unies
OPHI Oxford Poverty and Human Development Initiative
PIB Produit Intérieur Brut
PNB Produit National Brut
PNUD Programme des Nations Unies pour le Développement
PPTE Pays Pauvre Très Endettés
QUIBB Questionnaire des Indicateurs de Base du Bien Être
RGPH Recensement Général de la Population et de
l'Habitat.
ROC Receiver Operating Characteristic
SMART Standardized Monitoring and Assessment of Relief and
Transitions
SPSS Statistical Package for the Social Sciences
SRP Stratégie de Réduction de la Pauvreté
TBM Taux Brut de Mortalité
TBN Taux Brut de Natalité
TBS Taux Brut de Scolarisation
UNICEF Fond des Nations Unies pour l'Enfance
X
ZD Zone de Dénombrement
Introduction
La République de Guinée a été
dotée d'importantes potentialités agricoles et minières
par la nature qui constituent des atouts majeurs pour son développement
économique et social. La pluviométrie, le climat et la
végétation sont propices à l'agriculture, l'élevage
et la pêche. Cette abondance des ressources, notamment minières,
lui vaut l'appellation de « scandale géologique ». La
Guinée est le premier pays mondial pour ses réserves
prouvées de bauxite, le deuxième derrière l'Australie pour
la production. Cependant, au fil des ans ce pays, lourdement endetté, ne
fait que s'appauvrir au point où le gouvernement milite activement,
depuis quelques années, pour bénéficier de l'initiative de
la Banque Mondiale en faveur des pays pauvres très endettés
(initiative PPTE).
Un profil de pauvreté sert à caractériser
les principales manifestations de la pauvreté. Il met en évidence
comment le phénomène varie d'une région à l'autre,
d'un groupe particulier de population à l'autre, d'un secteur
d'activité à l'autre, d'un milieu à l'autre. En outre, le
profil permet d'apprécier l'évolution du phénomène
de pauvreté pour différents segments de la population afin
d'identifier ceux pour lesquels une attention particulière mérite
d'être accordée.
La réduction de la pauvreté est devenue de nos
jours un objectif prioritaire des politiques publiques des pays en
développement. À cet égard, l'analyse de la
pauvreté constitue à la fois une préoccupation majeure et
un défi, autant pour les gouvernements que pour leurs partenaires au
développement. En effet, réunis en Septembre 2000, lors du sommet
du millénaire pour le développement, les dirigeants des
États membres de l'Organisation des Nations Unies (ONU) adoptaient la
« Déclaration du Millénaire » dans laquelle ils se
fixaient d'ici à l'horizon 2015, huit objectifs de développement.
Le premier de ces huit objectifs s'intéresse justement, comme notre
étude, à la pauvreté. Il vise en effet à
réduire de moitié l'extrême pauvreté et la faim dans
le monde d'ici à l'horizon 2015.
Face aux multiples défis qui s'imposent au pays, les
autorités guinéennes ont adopté une attitude volontariste
pour lutter contre la pauvreté. La volonté des autorités
guinéennes de lutter contre la pauvreté connait depuis 2002 un
début de concrétisation par l'élaboration, avec l'appui
des divers partenaires, d'un Document de Stratégie de Réduction
de la Pauvreté (DSRP) qui est appelé à terme à
devenir le seul cadre de référence pour les interventions.
Mémoire de fin d'études
1
La littérature sur la pauvreté montre que les
travaux récents accordent plus d'importance à l'approche
multidimensionnelle de la pauvreté. La pauvreté ne doit pas
être définie comme une insuffisance de ressources. Il est
nécessaire, voire même indispensable de comprendre les multiples
aspects qui se cachent derrière le phénomène de
pauvreté, afin de proposer des politiques pertinentes pour doter les
individus de moyens essentiels pour sortir de la pauvreté.
Le présent document, qui est le résultat de
notre travail de recherche est divisé en trois chapitres. Le premier
chapitre présente le cadre de l'étude. Nous faisons ici dans un
premier temps une présentation de la Guinée, et ensuite faire une
revue de littérature sur la pauvreté ; le deuxième
chapitre fait état de la méthodologie utilisée et le
troisième chapitre présente les principaux résultats,
ainsi que leurs interprétations. Nous conclurons par quelques
recommandations pour diminuer la pauvreté en Guinée.
Mémoire de fin d'études
2
Problématique
Les études sur la pauvreté en République
de Guinée se réfèrent toujours à l'approche
unidimensionnelle (monétaire) d'analyse de la pauvreté utilisant
le revenu (dépense) comme le seul indicateur du bien-être.
Celle-ci est, cependant, limitée. Elle ne prend pas en compte, certaines
dimensions du bien-être (éducation, santé, eau potable,
nutrition, habitat, assainissement, énergie, communication, bien
d'équipements et de confort), absence de relation et l'exclusion
(extrême pauvreté).
La question essentielle peut être posée en ces
termes : pourquoi certains individus privés de ressources
monétaires ne sont-ils pas démunis dans d'autres dimensions ?
Selon l'économiste Amartya SEN, la pauvreté est avant tout une
privation des capacités élémentaires même si «
cette définition ne vise en aucune manière à nier
l'évidence : un revenu faible constitue bien une des causes essentielles
de la pauvreté, pour la raison, au moins que l'absence des ressources
est la principale source de privation d'un individu ». (SEN, 2000).
Cette approche ne fait pas l'unanimité parmi les
économistes comme étant le seul cadre d'analyse de la
pauvreté. En effet, un consensus s'est dégagé, depuis
quelques années prouvant que la pauvreté est un
phénomène multidimensionnel. Certains indicateurs sociaux
apportent une information qui n'est pas reflétée par l'approche
monétaire d'évaluation de la pauvreté.
En République de Guinée, de nombreuses sources
d'informations sont disponibles, notamment les deux grandes enquêtes sur
la pauvreté l'EIBC (94/95) et l'EIBEP (2002/2003). Si ces études,
nous ont permis d'avoir une idée sur les manifestations et les facteurs
de la pauvreté au niveau national, elles n'ont pas permis
d'apprécier l'impact des différentes politiques sur la
pauvreté.
Bien que la politique de lutte contre la pauvreté
basée sur le revenu domine les autres, elle est limitée en ce
sens que, l'accroissement du revenu des ménages pauvres n'est pas la
meilleure façon d'accroitre la satisfaction des besoins de base.
Vu que la pauvreté est multiforme et recouvre diverses
dimensions, l'on se pose les questions suivantes de savoir comment cerner et
mettre en place des politiques efficaces de lutte contre ce
phénomène.
Mémoire de fin d'études
3
Mémoire de fin d'études
V' Qui sont les pauvres ?
V' Où sont-ils ?
V' Qu'est-ce qui les caractérise ?
Pour répondre à toutes ces questions, il nous
faut des analyses approfondies. Dès lors, une étude de la
pauvreté par l'approche multidimensionnelle s'avère
nécessaire, car elle est plus large et plus riche que l'approche
monétaire qui ne serait basée que sur un seul indicateur et
favorise des politiques ciblées. Cependant, l'adoption d'une approche
multidimensionnelle nécessite naturellement l'utilisation de plusieurs
données individuelles sur plusieurs dimensions du bien-être.
Dans notre étude en particulier, nous utiliserons comme
technique d'analyse la classification multiple qui servira à classer les
ménages, en prenant pour variables celles relatives aux conditions de
vie des ménages c'est-à-dire celles qui sont signe de
pauvreté et l'analyse discriminante pour dresser le profil de
pauvreté.
Objectif de l'étude Objectif
général
De façon globale, l'étude cherche à
analyser la pauvreté en République de Guinée selon une
approche multidimensionnelle. Cette étude va contribuer non seulement
à enrichir la connaissance sur la pauvreté, mais aussi, à
orienter utilement les politiques de lutte contre la pauvreté dans le
ciblage des groupes vulnérables.
Objectifs spécifiques
De façon spécifique il s'agira à travers la
réalisation de l'étude :
(i) de dresser une typologie des ménages selon leurs
caractéristiques ;
(ii) d'identifier les facteurs ou déterminants de
pauvreté dans les différents groupes, il s'agit en fait de
dresser le profil de pauvreté des groupes constitués ;
(iii) de mettre en place un modèle de classement qui
servira de classer les ménages selon les caractéristiques
sociodémographiques, socio-économiques et du capital humain des
chefs de ménage ;
(iv) de proposer des politiques ou stratégies
ciblées en fonction des résultats obtenus.
4
CHAPITRE 1 : CADRE DE L'ÉTUDE
1.1 Présentation générale de la
République de Guinée
La République de Guinée est un pays côtier
situé en Afrique de l'Ouest (7030 de latitude Nord et
150 de longitude Ouest). Couvrant une superficie de 245.857
km2. Elle est limitée à l'Ouest par l'Océan
Atlantique, au Nord-Ouest par la République de Guinée Bissau, au
Nord par le Sénégal et la République du Mali, au Nord-Est
par le Mali, à l'Est par la Côte d'Ivoire et au Sud par le
Libéria et la Sierra Léone.
Carte : Carte administrative de la
République de Guinée
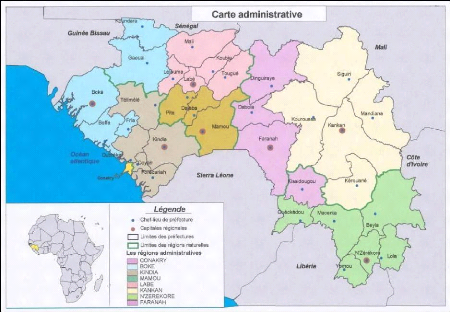
Sur le plan administratif, la Guinée compte sept
régions administratives : Boké, Faranah, Kankan, Kindia,
Labé, Mamou, N'Zérékoré. Les régions sont
subdivisées en préfectures (33 au total). Ces préfectures
sont subdivisées en 303 sous-préfectures dont le découpage
correspond à celui des 304 communes rurales (CR) et des 38 communes
urbaines (CU). En milieu rural, les CR sont des regroupements de districts
comportant des villages alors que, en milieu urbain, les CU sont des
regroupements de quartiers comportant des secteurs.
La ville de Conakry, la Capitale, jouit d'un statut
particulier. Elle est divisée en 5 communes (Dixinn, Kaloum, Matam,
Matoto et Ratoma).
Mémoire de fin d'études
5
Du point de vue géo-écologique, la Guinée
est divisée en quatre régions naturelles: la Basse Guinée
qui correspond à la zone côtière du pays, la Moyenne
Guinée qui est une zone montagneuse comprenant le massif du Fouta
Djalon, la Haute Guinée qui est une zone de savanes au nord du pays et
la Guinée Forestière qui est une zone de forêt au sud-est
du pays. De nombreux fleuves, tels que le Niger, le Sénégal, la
Gambie ainsi que leurs principaux affluents trouvent leur source en
Guinée. Le massif du Fouta Djalon offre un potentiel de production
électrique important. En plus de son potentiel hydrographique, la
Guinée renferme d'importantes richesses minières telles que la
bauxite (il en est le deuxième pays producteur), le fer, l'or, le
diamant, le cobalt et l'uranium.
Le climat du pays est globalement de type tropical à
deux saisons : la saison des pluies et la saison sèche. La durée
de ces deux saisons varie en fonction des régions climatiques : il
existe quatre régions climatiques distinctes en Guinée. L'Ouest,
au bord de l'Atlantique, est très humide. Le climat est plus
tempéré au Centre (deux saisons égales, pluies de mai
à novembre). Au Nord-Est, le climat est tropical sec avec des pluies
plus faibles, des températures élevées sauf de
décembre à février lorsque le vent souffle (20 °C
contre 40 °C). Le Sud-Est de la Guinée est de subéquatorial
avec une longue saison des pluies (8 à 10 mois) et des
températures moyennes de 24 °C à 28 °C.
L'environnement en Guinée semble être
préservé grâce à la faible densité de
population et l'industrialisation limitée. Les principales menaces sont
la déforestation, la pollution issue de l'exploitation minière,
l'absence de traitement des eaux usées, auxquelles on peut ajouter le
braconnage de la faune sauvage.
Selon les données du deuxième Recensement
Général de la Population et de l'Habitat
(RGPH), la Guinée avait une population résidente
de 7.156.406 habitants en 1996 dont
51,1 % de femme et 48,9 % d'hommes. Elle est estimée en
2007 à 9,68 millions (ELEP 2007) dont 51,9 % de femmes et 48,1 %
d'hommes avec un rapport de masculinité de 92,5 soit moins de 93 hommes
pour 100 femmes. La densité est estimée à 39 habitants au
kilomètre carré. Une personne sur deux a moins de 15 ans et 4,5 %
seulement des individus sont âgés de 65 ans ou plus. La population
guinéenne est caractérisée par une extrême jeunesse.
Le taux brut de natalité (TBN) est de 38,4 pour 1000 et l'indice
synthétique de fécondité (ISF) de 5,7 enfants par femme.
Le taux brut de mortalité (TBM) est estimé à 14,2 pour
1000.
L'espérance de vie à la naissance est de 54 ans.
L'âge médian à la première union est de 16 ans pour
les femmes et de 26 ans pour les hommes. La population croît à un
rythme rapide de
Mémoire de fin d'études
6
Mémoire de fin d'études
3,1 % par an. La majeure partie de la population vit en milieu
rural (69,3 %) et la capitale Conakry abrite près de 58 % de la
population urbaine et près de 18 % de la population totale.
En ce qui concerne les mouvements migratoires (internes et
internationaux), très peu d'informations sont disponibles en dehors des
résultats de l'enquête sur la migration et l'urbanisation en
Guinée réalisée en 1993. Cependant, le pays a connu
d'intenses mouvements de population ces dernières années. Sur le
plan intérieur, l'exode en direction des zones minières et des
centres urbains, particulièrement Conakry, s'est intensifié. Il
faut également noter que les attaques rebelles de septembre 2000 le long
des frontières avec le Libéria et la Sierra Léone ont
occasionné des déplacements importants de population vers
l'intérieur du pays. Quant à la migration internationale, elle
s'est aussi accrue. Ce qui retient l'attention à ce niveau, c'est
surtout l'afflux de milliers de réfugiés Sierra-Léonais,
Libériens et Ivoiriens d'une part et d'autre part le retour massif de
Guinéens qui résidaient dans les pays voisins où des
conflits armés ont éclaté.
En matière de scolarisation, des progrès ont
été accomplis, le taux brut de scolarisation se situe à
78,3 % en 2010 et celui des filles à 70,1 %. Le taux
d'alphabétisation est de 34,5 % (ELEP 2007).
L'état sanitaire se caractérise, entre autres,
par un quotient de mortalité infanto juvénile
de 163 %o (EDS 2005), un taux de mortalité infantile de
91 %o, un taux de mortalité maternelle de 980 décès pour
100.000 naissances vivantes et des taux de malnutrition des enfants de moins de
5 ans assez importants. Selon les données de l'enquête
nutritionnelle (SMART 2012), plus du tiers (34,5 %) des enfants de moins de 5
ans souffrent de retard de croissance, 5 % d'émaciation et 12 %
d'insuffisance pondérale.
L'agriculture reste la principale activité de la
population. Elle se pratique de manière traditionnelle : pluviale,
itinérante et sur brûlis. Les cultures principales étant le
riz, le manioc, la banane plantain, la patate douce, le fonio, le maïs,
l'ananas et la mangue. Il n'en demeure pas moins, par exemple, que la grande
partie du riz consommé est importée (faible
compétitivité de la production locale).
L'activité économique est largement dominée
en guinée par le secteur primaire qui emploie environ 69 % des actifs
occupés et qui procurent de faibles revenus. La population active,
c'est-à-dire celle en âge de travailler (individus dont
l'âge varie entre 15-64 ans), elle représente 50,5 % de la
population. Les résultats de l'ELEP montrent également que 77,5
%
7
sont occupées. Selon l'ELEP 2007, le taux de
chômage entre 2002 et 2007 est passé de 10,2% à 15%
à Conakry et de 6,7% à 3,2% dans les autres villes. Globalement,
le sous-emploi concerne 9,1 % de la population active en 2007 contre 11,8% en
2002. Les femmes sont beaucoup plus touchées par le
phénomène de sousemploi que les hommes, avec 7,5 % pour les
hommes et 10,5 % pour les femmes correspondant à un rapport de
féminité de 1,4 en 2007.
Malgré ses importantes potentialités agricoles
et minières, la Guinée demeure un pays pauvre confronté
à une situation économique difficile et
régulièrement secoué par des tensions sociopolitiques. Sur
le plan économique, depuis 1984, la Guinée s'est engagée
dans un processus de transition d'une économie planifiée vers une
économie de marché. Son économie est dominée par le
secteur rural et le secteur minier qui contribuent respectivement pour 18 % et
19 % au PIB. Le secteur rural assure l'emploi et les moyens de subsistance
à la majorité de la population.
En 2010, tous les indicateurs macroéconomiques
indiquent que le pays est dans une situation difficile. Le taux de croissance
de l'économie est calculé à 1,9 % insuffisant pour faire
reculer la ligne de pauvreté. Le taux d'inflation de 20,8 % prévu
pour 2010 est élevé et, de toute évidence, il contribue
à éroder sérieusement le pouvoir d'achat des populations.
Selon les résultats de l'Enquête Légère pour
l'Évaluation de la Pauvreté (ELEP-2007), l'incidence de la
pauvreté qui était de 49,2 %, en 2002 a atteint 53 % en 2007 et
serait de 58 % en 2010.
En outre, le poids de la dette continue de peser sur les
maigres ressources publiques. En effet, le stock de la dette extérieure
de la Guinée s'élève à fin 2010 à 3
milliards de dollars pour un service moyen d'environ 175 millions dollars.
Cette situation est aujourd'hui très préoccupante, car elle
empêche le financement des secteurs essentiels à la
réduction de la pauvreté. La dette représente 67 % du PIB
pour un ratio du service de la dette sur les recettes fiscales 2010 de 31,95 %.
Il apparaît donc très clairement que la dette rend très
difficile l'intervention de l'État dans le financement budgétaire
de ses programmes de lutte contre la pauvreté.
L'impact de la crise financière et économique
mondiale est perceptible sur les recettes budgétaires. En effet, au
cours des huit premiers mois de 2009, les recettes budgétaires provenant
du secteur minier ont baissé fortement au rythme de 3 % en moyenne par
mois contre une hausse d'environ 16 % par mois au cours de la même
période en 2008. À ce
Mémoire de fin d'études
8
rythme, l'atteinte du point d'achèvement de
l'Initiative Pays Pauvre Très Endettés (IPPTE) sera une
tâche difficile pour le pays si la tendance n'est pas rapidement
inversée.
1.2 Revue de la littérature
1.2.1 Les approches conceptuelles de la pauvreté
Il existe trois principales écoles de pensée sur
la mesure de la pauvreté : l'école welfariste, l'école des
besoins de base et l'école des capacités. Ces trois écoles
semblent être d'accord sur le point suivant (Asselin et Dauphin, 2000) :
est considéré comme pauvre toute personne qui n'atteint pas un
minimum de satisfaction raisonnable d'une « chose ». Ce qui les
distingue, c'est la nature et le niveau de ce minimum.
1.2.1.1 L'école welfariste
L'approche utilitariste d'inspiration néo-classique est
basée sur le concept de bien-être économique. Il se base
sur le principe selon lequel chaque individu satisfait son bien-être
selon ses préférences. Ces derniers varient selon les
caractéristiques individuelles, les besoins, les capacités et le
temps.
Selon cette approche, un individu est considéré
comme pauvre s'il ne parvient pas à atteindre un niveau de
bien-être économique considéré comme un minimum
raisonnable selon les standards de la société où il
vit.
En effet, l'évaluation du bien-être individuel se
base sur l'ordre des préférences révélées
par ses choix libres. Par exemple, une personne a pu être
considérée comme pauvre en se basant sur la consommation totale,
alors qu'il pourrait être en mesure à des non pauvres vu sa
capacité de travail. Ceci est expliqué par le choix de cet
individu qui choisit de travailler et dépenser peu pour, par exemple, le
bénéfice de plus de loisirs.
La liberté de choix engendre une
hétérogénéité des préférences,
qui ne sont pas directement observables, ce qui limite leur utilisation
pratique pour mesurer la pauvreté. En effet, l'utilisation du
bien-être économique se heurte à deux problèmes
majeurs.
Le premier est lié à l'observation des
préférences révélées. En fait, la
catégorisation des individus en pauvres et riches n'est pas liée,
seulement, à ses caractéristiques sociodémographiques et
ses conditions de vie. Mais, il faut se référer au niveau
d'utilité
Mémoire de fin d'études
9
procurée par un individu, s'il est inférieur ou
non à un certain niveau d'utilité critique selon sa perception.
Pour cela, il faut disposer de toutes les informations sur les
préférences de chaque individu, mais leur collecte est difficile
à réaliser. Ce qui rend l'approche utilitariste peu pratique.
Le deuxième problème porte sur la mesurer de
« bonheur physique » ou le plaisir provenant du choix de
consommateur. En fait, la comparaison d'utilité entre les individus
devient difficile vu que les préférences sont
hétérogènes et que les caractéristiques
personnelles, les besoins et les capacités sont divers. De même,
les ménages se diffèrent selon la taille et la composition et les
prix varient dans le temps et l'espace. Pour cela, la comparaison du
bien-être n'a pas de sens.
Entre autres, cette approche considère comme pauvre une
personne qu'on n'a pas satisfait ses besoins, même s'il est
matériellement aisé, comme il peut considérer une personne
comme non pauvre, car il est content et satisfait de son niveau
économique, même s'il est privé de certains attributs.
Dans la pratique, vu que l'utilité est un état
procuré par une personne suite à la consommation de biens ou de
services, les économistes utilitaristes prennent comme mesure de
bien-être le revenu ou les dépenses des ménages. En fait,
un ménage qui n'atteint pas un niveau de revenu acceptable selon les
standards de sa société, est considéré comme
pauvre. Donc, la faiblesse du revenu est un critère d'identification de
la pauvreté.
Néanmoins, il est à rappeler que la
pauvreté en se basant sur la consommation ou le revenu ne prend pas en
compte le bien-être procuré des biens publics et des biens non
marchands, tels que la sécurité, la liberté, la paix et la
santé. Ces derniers sont difficiles à préciser en
pratique. Selon cette approche, les politiques de réduction de la
pauvreté sont axées sur l'augmentation du revenu. Par
conséquent, les forces du marché sont supposées amener aux
pauvres les fruits de la croissance économique, alors que la taxation,
les services sociaux et les autres interventions de l'État ne sont
favorables qu'à la répartition des fruits de la croissance
économique.
À côté de l'approche utilitariste, il
existe l'école non utilitariste qui définit le bien-être
selon une autre logique.
Mémoire de fin d'études
10
1.2.1.2 L'école non welfariste
Selon l'approche non utilitariste, le niveau de bien-être
se présente selon les normes et les valeurs de chaque
société, indépendamment des perceptions de chaque
individu. Contrairement à l'approche utilitariste qui utilise un
indicateur agrégé (le revenu ou l'utilité) pour analyser
les niveaux de vie, l'approche non utilitariste utilise les multiples
dimensions du bien-être.
On distingue deux principaux types d'approches non
utilitaristes : l'approche basée sur les capacités et l'approche
basée sur les besoins essentiels.
1.2.1.2.1 L'École des capacités de Amartya
Sen
Les capacités représentent les
différentes combinaisons de « fonctionnements » qu'un individu
ou un ménage peut réaliser. Ces capacités sont
définies comme étant une combinaison fonctionnelle du
savoir-être et du savoir-faire que chaque personne doit l'atteindre et
qui lui permet d'avoir un type de vie bien déterminé. À
cet effet, l'individu doit être adéquatement nourri, avoir une
éducation, être en bonne santé, être
adéquatement logé, prendre part à la vie communautaire,
apparaitre en public sans avoir honte, etc.
Cette condition est suffisante pour ne pas considérer
une personne comme pauvre. En effet, la « chose » manquante n'est ni
l'utilité ni la satisfaction des besoins de base, mais des
habilités ou capacités humaines.
L'école des capacités considère ainsi,
comme pauvre, une personne qui n'a pas les capacités d'atteindre un
certain sous-ensemble de fonctionnements. Selon cette approche, la
réalisation des résultats n'est pas importante. En effet, on ne
considère pas comme pauvre une personne qui ne choisit pas d'atteindre
certains fonctionnements tant qu'il peut les atteindre s'il veut.
Cette distinction entre les résultats et la
capacité de les atteindre montre bien la diversité des
préférences dans la détermination des choix de
fonctionnements.
Il s'avère alors qu'en se basant sur cette approche,
les stratégies de réduction de la pauvreté cherchent
à favoriser le renforcement des capacités des pauvres.
1.2.1.2.2 L'École des besoins de base
Cette approche de Sen (1985) met l'accent sur la
nécessité de pouvoir satisfaire certains besoins fondamentaux qui
sont nécessaires à l'atteinte d'une certaine qualité de
vie. Les
Mémoire de fin d'études
11
principaux besoins de base pris en compte sont :
éducation, santé, hygiène, assainissement, eau potable,
habitat, accès aux infrastructures de base, etc.
La mesure de bien-être, dans ce cas, consiste en une
agrégation des fonctionnements de base multidimensionnelle.
La détermination des besoins de base, jugés
essentiels pour mener une vie décente, dépend des
caractéristiques des individus et des sociétés dans
lesquelles ils vivent. Elles sont généralement définies en
termes de moyens plutôt que des résultats. Ainsi, la satisfaction
des besoins de base est un élément important pour juger qu'une
personne a obtenu des fonctionnements.
Selon P.Streeten (1981), les besoins de base sont
nécessaires pour prévenir la mauvaise santé, la
sous-alimentation et l'insécurité sociale. Par exemple, une
personne non pauvre doit avoir accès aux services sociaux, comme
l'éducation et la santé, mais il n'est pas nécessaire
d'être en bonne santé et bien éduquée.
Toutefois, l'approche des besoins essentiels se heurte
à un problème de détermination de la liste des besoins. En
fait, cette liste n'est pas limitée d'un nombre précis des
domaines, et il n'y a pas de consensus sur ce que devrait être cette
liste.
Un autre problème concerne le niveau minimum qui
devrait être requis, au niveau des besoins de chaque domaine, pour ne pas
être considéré comme pauvre.
Il en résulte que les politiques réductrices de
pauvreté qui caractérisent cette approche reposent sur la
satisfaction des besoins essentiels comme l'amélioration de logement,
l'éducation des enfants, l'éradication des maladies, la
réduction de la malnutrition, etc.
1.2.2 Travaux empiriques sur la pauvreté
multidimensionnelle
De nombreuses études s'intéressent à
l'analyse de la pauvreté multidimensionnelle. En général,
elles mettent un accent particulier sur les conditions de vie : accès
aux services sociaux de base, biens durables des ménages, etc.
Sabina ,A. et Maria, E.S.,(2010), de l'Oxford Poverty and
Human Development Initiative (OPHI) de l'Université d'Oxford et le
Bureau du Rapport sur le Développement humain du Programme des Nations
Unies pour le Développement (PNUD) ont lancé une nouvelle mesure
de la pauvreté présentant un tableau « multidimensionnel
» des personnes vivant dans
Mémoire de fin d'études
12
Mémoire de fin d'études
la pauvreté qui selon ses créateurs pourrait
contribuer à cibler les ressources de développement de
manière plus efficace. L'IPM a remplacé l'indice de
pauvreté humaine, qui figurait dans les rapports sur le
développement humain depuis 1997.
La mesure de la pauvreté est le plus souvent
basée sur un seul indicateur essentiel, le revenu (par exemple le seuil
de pauvreté : 1,25 $ par jour). Cette approche de la pauvreté ne
fournit qu'une image partielle de celle-ci, les auteurs ont travaillé
à partir de dix indicateurs de la pauvreté à la fois,
d'où son caractère « multidimensionnel » :
la mortalité infantile (si un enfant est mort dans la
famille) ;
la nutrition (si un membre de la famille est en malnutrition)
;
les années de scolarité (si aucun membre n'a fait
cinq ans à école) ;
la sortie de l'école (si un des enfants a quitté
l'école avant 8 ans) ;
l'électricité (si le foyer n'a pas
l'électricité) ;
l'eau potable (s'il n'y en a pas à moins de 30 minutes de
marche) ;
les sanitaires (s'il n'y en a pas ou bien partagés avec
d'autres) ;
le sol de l'habitat (si le sol est couvert par de la boue, du
sable ou du fumier) ;
le combustible utilisé pour cuisiner (si c'est du bois, du
charbon de bois ou de la
bouse) ;
les biens mobiliers (si pas plus d'un bien parmi : radio,
télévision, téléphone, vélo,
moto).
Le travail statistique couvre 104 pays en développement
(37 de l'Afrique subsaharienne, 24 d'Europe/Communauté des États
indépendants , 18 d'Amérique latine/Caraïbes, 11 du monde
arabe, 9 de l'Asie orientale/Pacifique et 5 d'Asie du Sud), peuplés par
5,2 milliards d'habitants en 2007 (soit 78 % de la population mondiale). Parmi
eux : 1 milliard 659 millions d'humains sont considérés par
l'indice de pauvreté multidimensionnel comme étant pauvres, soit
les plus pauvres des pauvres du monde.
Si les pays d'Afrique subsaharienne sont très nombreux
dans le bas du classement (27 % des pauvres de la planète au sens du
MPI), l'Asie du Sud concentre 51 % des pauvres du Monde (pour 29,5 % de la
population des pays en développement). La répartition des pauvres
se fait comme suit :
Europe et Communauté des États
indépendants : 12,2 millions (3 % de la population) ; Amérique
latine et Caraïbes : 51 millions (10,4 % de la population) ;
13
Asie orientale et Pacifique : 255 millions (13,7 % de la
population) ;
Monde arabe : 38,9 millions (17,9 % de la population) ; Asie
du Sud : 843,8 millions (54,7 % de la population) ; Afrique subsaharienne : 458
millions (64,5 % de la population).
Pour la Guinée, l'IMP est de 0,505, la proportion de la
population atteinte de pauvreté multidimensionnelle est de 82,4 % soit
7.900.000 individus.
L'indice de pauvreté multidimensionnel se rajoute donc
aux autres outils de mesure des inégalités utilisés par
l'ONU pour répondre aux objectifs du millénaire : le produit
intérieur brut par habitant (PIB/hab.), l'indice de développement
humain (IDH) et l'indice de pauvreté humaine (IPH).
Des indicateurs composites ont été construits
pour le Sénégal, le Cameroun, la Tunisie, le Togo, la Cote
d'Ivoire, le Maroc (Ki et al. 2005, Foko et al. 2007, Ayadi et al. 2007, Lawson
et al. 2007, Sylla et al. 2005, Toumani, A. et Fouzia, E., 2009). La
pauvreté se relève plus marquée avec une approche
multidimensionnelle qu'avec une approche monétaire. La
corrélation des résultats est positive, mais imparfaite tandis
que les deux approches définissent deux ensembles différents de
ménages pauvres.
Mémoire de fin d'études
14
Mémoire de fin d'études
CHAPITRE 2 : MÉTHODOLOGIE DE L'ÉTUDE
Dans le cadre de cette étude, et compte tenu à
la fois de l'objectif qui lui est assigné et des limites
inhérentes à l'approche monétaire de la pauvreté,
nous adoptons l'approche multidimensionnelle.
Nous avons un ensemble de variables décrivant les
modalités que peuvent prendre les indicateurs des conditions de vie du
ménage, tels que le type de logement, le mode d'éclairage, la
possession d'un actif, l'accès à la santé, à
l'éducation, à l'eau potable, etc. Le problème que l'on
veut résoudre est comment analyser au cas au cas toutes les variables et
de tirer une conclusion quelconque de cette analyse.
C'est pourquoi il est préférable de classer les
individus par groupe. Le nombre de groupes n'est pas défini à
priori, mais puisque les individus appartenant à un même groupe
doivent se ressembler le plus possible et les individus n'appartenant pas dans
le même groupe soient très différenciés. La
méthode la plus appropriée est la classification multiple, car
elle a l'avantage de détecter non seulement le groupe des personnes
jugées pauvres, mais aussi d'autres classes se retrouvant dans la
société.
Les groupes étant constitués, nous utilisons
l'analyse discriminante pour caractériser les ménages de sorte
que, connaissant les caractéristiques d'un individu ou ménage
donné, il soit possible de les classer soit dans la catégorie des
pauvres, des moyens ou des nantis.
2.1 Sources des données
Les données proviennent de l'enquête
légère sur l'évaluation de la pauvreté de
l'année 2007, seconde enquête du genre réalisé par
l'Institut National de la Statistique (INS) dans le cadre du suivi de la
Stratégie de Réduction de la Pauvreté (SRP) et des
Objectifs du Millénaire pour le Développement (OMD) après
l'Enquête sur le Questionnaire des Indicateurs de Base du Bien-être
(QUIBB), de 2002.
L'Enquête Légère sur l'Évaluation
de la Pauvreté (ELEP ou QUIBB) fait partie de la dernière
génération d'enquêtes auprès des ménages
développées par la Banque Mondiale, en collaboration avec le
PNUD, l'UNICEF et le BIT.
Cette enquête a porté sur un échantillon
initial de 7.612 ménages tirés selon un sondage stratifié
à deux degrés en milieu rural et trois degrés en milieu
urbain au niveau de chaque région administrative et de la zone
spéciale de Conakry. La base de sondage issue du RGPH
15
de 1996 a servi pour le tirage des Villes et des ZD. Pour le
tirage des ménages, les organisateurs ont eu recours aux listings des
ménages établis lors du dénombrement des unités
primaires de sondage sélectionnées pour l'EIBEP 2002/2003.
La taille de l'échantillon pour le milieu rural
tiré au premier degré du tirage est de 179 zones de
dénombrement correspondant à 3.580 ménages
échantillons au second degré. La taille de l'échantillon
pour le milieu urbain tiré au deuxième degré du tirage est
de 336 zones de dénombrement correspondant à 4.032 ménages
échantillons au troisième degré.
Au total, la taille de l'échantillon porte sur 515
zones de dénombrement correspondant à 7.612 ménages.
Toutefois, il convient de remarquer que sur les 7.612 ménages
tirés, un effectif de 5816 (76,4 %) ont été
enquêtés, 319 (4,2 %) ont été remplacés pour
cause de refus, 1417 (18,6 %) ont été remplacé parce que
les ménages n'ont pas été trouvés et 60 ont
répondus partiellement et de ce fait les données de ces 60
ménages ont été éliminées des fichiers. De
ce fait, 7552 ménages ont été effectivement
enquêtés, soit un taux de couverture de 99,2 %.
L'unité statistique est le ménage ordinaire,
défini comme un ensemble composé d'une ou de plusieurs personnes
(unité socio-économique), ayant un lien de sang, de mariage ou
non, vivant dans un ou plusieurs logements de la même concession (cet
ensemble de logements constituant une unité d'habitation), mettant en
commun tout ou partie de leurs ressources, pour subvenir aux dépenses
courantes, prenant le plus souvent leurs repas en commun, et reconnaissant
l'autorité d'une seule personne appelée chef de ménage (ou
personne de référence).
2.2 Présentation de la base des données et
traitement des données
La base de données fournit est en format SPSS. Les
fichiers d'étude sont : le fichier des ménages (7.552
ménages et 143 variables) et le fichier des biens durables
possédés par le ménage (37.739 individus et 9
variables).
Le fichier des biens durables possédés par le
ménage a été agrégé en fonction des
variables « numéro » et « identifiant » du
ménage ; ces deux variables sont présentent dans tous les
fichiers de la base de données. Nous avons fait une fusion (ajout de
variables) entre les deux fichiers afin d'obtenir un seul. Ce dernier nous a
servi comme fichier de travail. Le traitement des données a
été effectué grâce au logiciel SPSS.
Mémoire de fin d'études
16
2.3 Méthodes d'analyse utilisées
Pour procéder à l'analyse des données de
notre étude, nous avons fait recours à trois méthodes.
Dans un premier temps, une classification ascendante
hiérarchique a permis de dresser une typologie des ménages selon
leurs caractéristiques.
Dans un second temps, une analyse bivariée a
été utilisée. On étudiera à l'aide du test
de Khi-deux et de l'Anova à un facteur la liaison entre la variable
dépendante et les différentes variables indépendantes ou
explicatives. Si une variable n'est pas liée avec la variable
dépendante, on l'élimine de l'étude.
Enfin, une analyse discriminante a été
réalisée afin d'identifier les variables discriminant la variable
dépendante en tant que variable nominale admettant comme
modalités le nombre de groupes constitués et décrivant
l'appartenance des individus (ménages) aux groupes identifiés
à l'issu de la CAH.
2.3.1 Principe de la classification ascendante
hiérarchique (CAH)
La classification hiérarchique constitue depuis
longtemps une forme de classification très populaire. Elle a l'avantage
d'être interprétable visuellement à l'aide des graphes ou
dendrogramme. Elle est utilisée dans différents domaines : la
taxinomie, la biologie, les réseaux de télécommunications,
le marketing, etc.
C'est une méthode de classification qui consiste
à fusionner deux objets (ou individus) au sens d'une mesure de
proximité de sorte que deux objets groupés à une
étape le restent jusqu'au terme du processus de classification. Il
s'agit ici, à partir des éléments terminaux, de former de
petites classes ne comportant que des individus les plus semblables, et on
continue le processus jusqu'à l'obtention d'une seule classe
formée de tous les éléments.
Les étapes d'une classification ascendante
hiérarchique
Avant de lancer une quelconque classification, il faut
respecter au préalable les étapes suivantes :
Étape 1 : Il faut sélectionner
les individus à classer ou les variables qui serviront pour
critère de classification.
Mémoire de fin d'études
17
Étape 2 : On choisit une distance ou
un indice d'écart entre paires d'individus. La distance
généralement utilisée dans les algorithmes de
classification hiérarchique est le carré de la distance
euclidienne.
Étape 3 : On choisit une règle de
calcul pour les distances entre classes.
Étape 4 : On détermine un
critère d'agrégation des individus dans les classes.
Pour rappel la méthode de Ward (la plus populaire) est
un critère d'agrégation, elle consiste à choisir à
chaque étape le regroupement de classes tel que l'augmentation de
l'inertie intra-classe, utilisée comme indice de niveau, soit
minimum.
2.3.2 Principe de l'analyse discriminante
L'analyse discriminante (AD) encore appelée analyse de
profil permet de construire un modèle de prévision de groupe
d'affectation basé sur les caractéristiques observées de
chaque individu. C'est une méthode utilisée notamment par les
banques pour le scoring, en assurance, en médecine, en
archéologie, en biologie, etc.
On dispose d'individus issus de deux ou plusieurs populations
connues, lesquels ont été mesurés par rapport aux
variables indépendantes métriques X1, X2,.....Xp. Le principe de
l'analyse discriminante est d'identifier une combinaison linéaire de
variables indépendantes permettant de mieux séparer ou dissocier
les populations à travers un tableau des données.
L'analyse discriminante cherche à :
? Préciser les variables les plus explicatives de
l'appartenance des individus à des groupes ;
? Identifier la combinaison linéaire des variables
explicatives qui affecte, avec le plus précision, les individus à
ces groupes ;
? Déterminer l'importance respective des variables
explicatives dans l'affectation des individus ;
? Faire des prévisions sur l'appartenance à l'un
des groupes d'un nouvel individu que l'on vient de mesurer par rapport aux
mêmes variables indépendantes.
Pour rappel : toutes les variables indépendantes
doivent être quantitatives et ne pas être corrélées
entre elles. La variable dépendante doit être une variable
nominale dichotomique ou multichotomique.
Mémoire de fin d'études
18
La procédure génère une fonction
discriminante (ou, pour plus de deux groupes, un ensemble de fonctions
discriminantes) basée sur les combinaisons linéaires des
variables explicatives qui donnent la meilleure discrimination entre
groupes.
Les fonctions sont générées à
partir d'un échantillon d'observation pour lesquelles le groupe
d'affectation est connu. Les fonctions peuvent alors être
appliquées aux nouvelles observations avec des mesures de variables
explicatives, mais de groupe d'affectation inconnu.
2.4 Variables de l'étude
2.4.1 Variables utilisées pour la classification
ascendante hiérarchique
Pour l'analyse de la classification ascendante
hiérarchique, on va utiliser les variables relatives aux
caractéristiques des ménages, celles qui sont signe de
pauvreté.
Dans le cadre de cette étude qui s'attache à
analyser la pauvreté multidimensionnelle, ce processus s'articule tout
d'abord autour du choix de neuf (9) dimensions ou domaines dans lesquels il
sera analysé les privations dont souffrent les individus. Le choix de
ces domaines tient aussi à deux raisons : la disponibilité des
informations contenues dans la base de données et la pertinence de
l'ensemble de ces domaines du point de vue de l'analyse des conditions de vie
des ménages.
Presque la totalité de ces dimensions figure parmi les
huit objectifs de la déclaration du millénaire et celui de
l'objectif général de la stratégie de réduction de
la pauvreté qui sont la réduction significative et durable de la
pauvreté en Guinée, à travers l'augmentation des revenus
et l'amélioration de l'état de bien-être des populations,
notamment des plus pauvres.
Mémoire de fin d'études
19
Mémoire de fin d'études
Tableau 01 : Liste des variables
utilisées par domaine dans la classification ascendante
hiérarchique
|
Éducation
Accès à l'éducation
Temps pour aller à l'école Primaire (moins de 30
minutes)
Distance école Primaire (moins de
1kilomètre)
Temps pour aller à l'école Secondaire
(moins de 30 minutes)
Distance école Secondaire (moins de 1kilomètre)
|
Énergie
Accès à l'électricité
Oui accès à l'électricité
Combustible principal utilisé pour faire la
cuisine
Bois
Charbon de bois
Source principale d'éclairage
Électricité/Secteur
Lampe tempête (Pétrole)
Bougie
Torche
|
|
Santé
Accès à la santé
Temps pour aller à l'établissement
sanitaire/service de santé (moins de 30 minutes)
Distance établissement
sanitaire/service de santé (moins de
1kilomètre)
|
Communication
Télévision
Radio
Téléphone
Accès au transport public
Temps pour aller au transport public: arrêt de bus, taxi,
etc. (moins de 30 minutes)
Distance transport public: arrêt de bus,
taxi, etc. (moins de 1kilomètre) Accès à la
route praticable
Temps pour aller à la route praticable (moins de 30
minutes)
Distance route praticable (moins de 1kilomètre)
|
|
Eau potable
Source eau potable
Robinet du ménage
Robinet du voisin
Forage
Puits aménagés
Puits non aménagés
Eau de surface
Accès à l'eau potable
Temps pour aller à la source d'eau
potable (moins de 30 minutes)
Distance source d'eau potable (moins
de 1 km)
|
Assainissement
Type de toilettes utilisé
Chasse d'eau avec fosse septique
Latrines couvertes
Latrines non couvertes
Nature
Principal mode d'évacuation des ordures
ménagères
Ramassage Privé
Poubelle publique
Incinération
Enfouissement
Nature
Principal mode d'évacuation des eaux usées
Canal à ciel ouvert
Trou creusé dans la cour
Dans la rue/la nature
|
20
|
Nutrition
Accès au marché de produits alimentaires
Temps pour aller au marché de produits alimentaires (moins
de 30 minutes)
Distance marché de produits alimentaires (moins de
1kilomètre)
|
|
Éléments de confort et
d'équipement
Automobile
Moto/motocyclette
Bicyclette
Téléphone
Congélateur/Réfrigérateur
Radio/radio cassette/lecteur CD
Téléviseur/magnétoscope/DVD/VCD
Lit
Armoire/Bibliothèque/Buffet
Fauteuil/canapé
Fusil de chasse
Machine à coudre
Groupe électrogène
Possession de moutons, chèvres et d'autres
animaux de taille moyenne
Possession de têtes de gros bétail
Possession de terre agricole
|
Habitat
Statut d'occupation du logement
Propriétaire
Copropriétaire familial
Location
Logé gratuitement
Type d'habitat
Maison individuelle
Appartement
Chambre/studio
Case
Case et maison
Plusieurs maisons
Principal matériau du sol du logement
Ciment
Carreau
Terre battue
Principal matériau du toit du logement
Béton/Ciment
Tôle ondulée
Chaume/Paille
Principal matériau des murs du logement
Briques Ciment
Briques Terre cuite
Terre stabilisée
Briques Terre/Banco
Mémoire de fin d'études
21
Mémoire de fin d'études
2.4.2 Variables utilisées pour l'analyse
discriminante
On va utiliser les informations relatives aux variables
indépendantes qui sont les variables sociodémographiques,
socio-économiques et du capital humain des chefs de ménages pour
le étudier le profil de pauvreté.
Tableau 02 : Liste des variables
utilisées dans l'analyse discriminante
|
Variables
|
Modalités
|
|
Sexe du chef de ménage
|
Homme Femme
|
|
Statut matrimonial du chef de ménage
|
Célibataire
Marié monogame
Marié polygame
Union libre/Concubinage
Divorcé/Séparé
Veuf (ve)
|
|
Niveau de scolarisation du chef de ménage
|
Aucun niveau d'instruction Primaire
Secondaire 1
Secondaire 2
Technique professionnelle Supérieur
|
|
Groupe socio-économique du chef de ménage
|
Salarié public Salarié privé
Employeur Indépendant agricole Indépendant non
agricole Autres employés
Sans emplois
|
|
Région d'habitation
|
Boké Conakry Faranah Kankan Kindia
Labé Mamou N'Zérékoré
|
|
Milieu de résidence du chef de ménage
|
Rural Urbain
|
|
Âgé du chef de ménage
|
|
Taille du ménage
|
Les variables « Femme », « Union
libre/Concubinage », « Secondaire 2 », « Employeur »,
« Autres employés », « Boké » et «
Urbain » ont été éliminées de l'analyse
discriminante pour des problèmes de redondance ou de très faibles
effectifs.
22
2.5 Transformation des variables
La nature des variables n'étant pas la même, ceci
pose un problème au niveau de l'analyse désirée. Pour
résoudre ce problème, on transforme les variables quantitatives
qui sont les variables d'accès aux infrastructures de base
(santé, éducation, marché de produits alimentaires,
transport public, eau potable et route praticable) en variables qualitatives,
admettant comme modalités (moins de 30 minutes et plus de 30 minutes
pour le temps mis ; moins d'un kilomètre et plus de 1 kilomètre
pour la distance à parcourir).
Cette transformation a été faite grâce
à la fonction « Calculer » offerte par SPSS.
Toutes les modalités des variables nominales ou
catégorielles ont été transformées en variables
binaires ou muettes et codées de la manière suivante : (0)
absence de la modalité et (1) présence de modalité.
Pour éviter le problème de redondance, pour
chaque variable le nombre de variables binaires crées est égal au
nombre de modalités de la variable moins un.
Par exemple pour le sexe du chef de ménage, nous avons
construit une seule variable binaire notée "Homme chef
ménage" codée avec 1si le chef de ménage est
homme et 0 sinon.
Pour la variable « Temps pour aller à
l'école primaire (moins de 30 minutes) », elle est codée
avec 1 si le ménage fait moins de 30 minutes et 0 sinon.
Toutes les transformations des variables ont été
faites avec le logiciel SPSS, qui est notre logiciel de travail.
Toutes les modalités des variables qui ont des
effectifs très faibles ont été éliminées des
analyses.
Mémoire de fin d'études
23
Mémoire de fin d'études
CHAPITRE 3 : PRÉSENTATION ET
INTERPRÉTATION DES RÉSULTATS
Dans ce chapitre, après avoir présenté
les résultats de notre analyse nous procédons ensuite à
leurs interprétations.
3.1 Résultats de la classification ascendante
hiérarchique
À partir de la classification ascendante
hiérarchique, nous allons chercher à avoir la meilleure
classification, puis faire une description des groupes constitués et
essayer de les baptiser. Pour atteindre ces objectifs, nous avons
utilisé pour la CAH, la « méthode de Ward » comme
méthode d'agrégation, le « carré de la distance
euclidienne » comme distance et types de données « binaires
» comme mesure de variables sur notre logiciel de travail SPSS.
3.1.1 Choix du nombre optimal de groupes
Pour avoir la meilleure classification, nous avons fait des
simulations à 2, 3, 4 et 5 groupes. L'exploitation du dendrogramme de la
classification hiérarchique s'avère très difficile parce
que le nombre d'individus est très grand. Pour remédier à
ce problème, on crée une variable multichotomique dont les
modalités sont les classes ou groupes pour chaque partition.
Nous utiliserons une méthode moins empirique et plus
scientifique pour avoir le nombre optimal de groupes (évaluation de la
qualité de la partition).
La méthode scientifique repose sur :
y' Apprécier le nombre de variables qui sont
significatives au seuil de 0,05 pour chaque partition ;
y' Apprécier l'intensité des corrélations
(Eta2) des variables ;
y' Apprécier l'IQV (si les groupes sont
homogènes et bien équilibrés) pour chaque partition.
L'analyse de variance à un facteur (Anova) nous a
permis d'avoir le nombre de variables significatives et les corrélations
(Eta2).
L'indice de variation qualitative est une mesure qui permet de
déterminer le niveau d'homogénéité ou
d'hétérogénéité d'une variable nominale ou
continue.
Principe de décision
IQV est compris entre 0 et 1.
24
Mémoire de fin d'études
? Si IQV< 0,5 on est dans une situation
d'homogénéité parfaite. Dans ce cas, on dit que la
dispersion est presque nulle ;
? Si IQV> 0,5 on est dans une situation
d'hétérogénéité presque parfaite. Dans ce
cas, on dit que la dispersion est totale.
Tableau 03 : Récapitulatif des
critères pour le choix de la meilleure classification
|
Nombre de partitions
|
Nombre de variables non significatives
|
Intensité de Eta2 (plus grande valeur, plus
petite valeur et somme des valeurs de corrélation)
|
IQV
|
|
Groupage à 2
|
0
|
0,781
|
0,822
|
|
|
0,008
|
|
|
|
15,150
|
|
|
Groupage à 3
|
2
|
0,780
|
0,978
|
|
|
0,008
|
|
|
|
14,062
|
|
|
Groupage à 4
|
2
|
0,780
|
0,986
|
|
|
0,002
|
|
|
|
12,34
|
|
|
Groupage à 5
|
3
|
0,778
|
0,969
|
|
|
0,001
|
|
|
|
9,051
|
|
Source : Calcul de l'auteur sur les données de l'ELEP
2007
Au vu des résultats, la partition du groupage à
deux est la seule partition à posséder toutes les variables qui
sont significatives, mais aussi, elle a les Eta carré les plus
élevés, la partition du groupage à quatre a les groupes
les plus homogènes et les plus équilibrés.
De ce constat, la meilleure classification est la partition du
groupage à deux.
L'analyse discriminante, nous a permis aussi d'avoir la
meilleure classification à l'aide du pourcentage des observations
originales classées correctement par les fonctions linéaires de
Fisher (voir annexe tableau A1).
Le groupement à deux a le plus grand pourcentage des
observations originales classées correctement soit 90,3 %.
Ces deux méthodes, nous poussent à retenir le
groupement à deux dans le cadre de notre étude.
Pour rappel, si la signification (alpha) est inférieur
à 0,05, on dit alors que la variable concernée à un
pouvoir discriminant. C'est-à-dire la variable à des moyennes ou
proportions significativement différentes entre les groupes
constitués.
25
Mémoire de fin d'études
Toutes les variables retenues pour le classement des
ménages dans le groupage à deux selon leurs
caractéristiques ont des pouvoirs discriminants (tous les alpha sont
inférieurs à 0,05 signifiant ainsi, qu'elles peuvent être
retenues pour différentier les ménages entre eux) (voir annexe,
tableau A2).
3.1.2 Récapitulatif des classements des
ménages Tableau 04 : Récapitulatif des classements
|
Méthode de Ward
|
|
1
|
2
|
Total
|
|
Propriétaire
|
0,808
|
0,470
|
0,710
|
|
Copropriétaire familial
|
0,093
|
0,127
|
0,103
|
|
Location
|
0,067
|
0,312
|
0,138
|
|
Logé gratuitement
|
0,027
|
0,062
|
0,037
|
|
Maison individuelle
|
0,363
|
0,458
|
0,391
|
|
Appartement
|
0,175
|
0,348
|
0,225
|
|
Chambre/studio
|
0,030
|
0,102
|
0,051
|
|
Case
|
0,289
|
0,001
|
0,206
|
|
Case et maison
|
0,076
|
0,004
|
0,055
|
|
Plusieurs maisons
|
0,067
|
0,084
|
0,072
|
|
Ciment
|
0,431
|
0,852
|
0,553
|
|
Carreau
|
0,010
|
0,133
|
0,046
|
|
Terre battue
|
0,558
|
0,008
|
0,399
|
|
Béton/Ciment
|
0,011
|
0,047
|
0,022
|
|
Tôle ondulée
|
0,645
|
0,930
|
0,728
|
|
Chaume/Paille
|
0,340
|
0,003
|
0,243
|
|
Briques Ciment
|
0,070
|
0,764
|
0,271
|
|
Briques Terre cuite
|
0,217
|
0,192
|
0,210
|
|
Terre stabilisée
|
0,030
|
0,003
|
0,022
|
|
Briques Terre/Banco
|
0,667
|
0,027
|
0,482
|
|
Robinet du ménage
|
0,016
|
0,393
|
0,125
|
|
Robinet du voisin
|
0,049
|
0,418
|
0,156
|
|
Forage
|
0,546
|
0,055
|
0,404
|
|
Puits aménagés
|
0,092
|
0,075
|
0,087
|
|
Puits non aménagés
|
0,139
|
0,041
|
0,111
|
|
Eau de surface
|
0,144
|
0,004
|
0,103
|
|
Chasse d'eau avec fosse septique
|
0,003
|
0,098
|
0,030
|
|
Latrines couvertes
|
0,230
|
0,649
|
0,351
|
|
Latrines non couvertes
|
0,566
|
0,202
|
0,460
|
|
Nature
|
0,191
|
0,014
|
0,140
|
|
Oui accès à l'électricité
|
0,050
|
0,950
|
0,310
|
|
Bois
|
0,889
|
0,266
|
0,709
|
|
Charbon de bois
|
0,091
|
0,696
|
0,266
|
|
Électricité/Secteur
|
0,021
|
0,880
|
0,270
|
|
Lampe tempête (Pétrole)
|
0,599
|
0,041
|
0,438
|
|
Bougie
|
0,141
|
0,067
|
0,120
|
|
Torche
|
0,166
|
0,003
|
0,119
|
|
Ramassage Privé
|
0,009
|
0,227
|
0,072
|
26

Méthode de Ward
Total
1
2
Poubelle publique
0,013
0,128
0,046
Incinération
0,043
0,054
0,046
Enfouissement
0,027
0,014
0,023
Nature
0,897
0,546
0,796
Canal à ciel ouvert
0,008
0,111
0,038
Trou creusé dans la cour
0,040
0,070
0,049
Dans la rue/la nature
0,936
0,743
0,880
Possession de moutons, chèvres et d'autres animaux de
taille moyenne par le ménage
0,377
0,056
0,284
Possession de têtes de gros bétail par le
ménage
0,275
0,029
0,204
Possession de terre agricole par le ménage
0,617
0,115
0,472
Temps pour aller à la source d'eau potable (moins de 30
minutes)
0,924
0,984
0,942
Distance source d'eau potable (moins de 1 km)
0,883
0,986
0,913
Temps pour aller au marché de produits alimentaires
(moins de 30 minutes)
0,558
0,781
0,622
Distance marché de produits alimentaires (moins de 1
kilomètre)
0,428
0,734
0,517
Temps pour aller au transport public: arrêt de bus,
taxi, etc. (moins de 30 minutes)
0,634
0,897
0,710
Distance transport public: arrêt de bus, taxi, etc.
(moins de 1kilomètre)
0,525
0,879
0,628
Temps pour aller à l'école Primaire (moins de 30
minutes)
0,824
0,909
0,848
Distance école Primaire (moins de 1 kilomètre)
0,715
0,906
0,770
Temps pour aller à l'école Secondaire (moins de 30
minutes)
0,349
0,712
0,454
Distance école Secondaire (moins de 1 kilomètre)
0,221
0,656
0,347
Temps pour aller à l'établissement
sanitaire/service de santé (moins de 30 minutes)
0,551
0,783
0,618
Distance établissement sanitaire/service de
santé (moins de 1 kilomètre)
0,429
0,746
0,521
Temps pour aller à la route praticable (moins de 30
minutes)
0,794
0,975
0,846
Distance route praticable (moins de 1 kilomètre)
0,740
0,947
0,800
Automobile
0,012
0,078
0,031
moto/motocyclette
0,121
0,103
0,116
bicyclette
0,260
0,047
0,199
Téléphone
0,130
0,699
0,295
Congélateur/Réfrigérateur
0,009
0,361
0,111
radio/radio cassette/lecteur CD
0,471
0,601
0,508
téléviseur/magnétoscope/DVD/VCD
0,040
0,603
0,203
Lit
0,897
0,979
0,921
Armoire/Bibliothèque/Buffet
0,134
0,615
0,273
fauteuil/canapé
0,250
0,578
0,345
fusil de chasse
0,173
0,015
0,128
machine à coudre
0,021
0,046
0,028
groupe électrogène
0,022
0,032
0,025
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
27
Mémoire de fin d'études
Mémoire de fin d'études
3.1.3 Baptême des groupes
3.1.3.1 Caractéristiques des ménages du
Groupe 1
Le groupe 1 représente 71,1 % de notre
échantillon soit un effectif de 5366 ménages
enquêtés. Dans ce groupe 80,8 % des ménages sont
propriétaires de leurs logements. Nous notons une
précarité des principaux matériaux du logement. En effet,
55,8 % des ménages ont la terre battue comme matériel du sol, les
toits sont en tôles ondulées (64,5 %) et 66,7 % des maisons sont
construites en brique de terre ou banco. Leur principal mode
d'approvisionnement en eau de boisson est le forage (54,6 %). Les
ménages ont pour type de lieux d'aisance les latrines non couvertes
(près de 6 ménages sur dix). Les ménages utilisent le bois
comme source d'énergie pour la cuisine (88,9 %) et comme source
d'éclairage du logement la lampe tempête (59,9 %).
Dans ce groupe, 89,7 % des ménages utilisent la nature
pour se débarrasser des ordures ménagères et 93,6 %
utilisent la rue ou la nature pour évacuer les eaux usées.
Concernant l'accès à certaines infrastructures
de bases, 92,4 % des ménages font moins de 30 minutes pour se rendre
à la source d'eau potable la plus proche et 88,3 % font moins d'un
kilomètre pour l'atteindre. Pour aller au marché de produits
alimentaires le plus proche, 55,8 % des ménages font moins de 30 minutes
pour s'y rendre. Pour aller au transport public (arrêt bus, taxi, etc.)
le plus proche, 63,4 % des ménages font moins de 30 minutes pour s'y
rendre et 52,5 % parcourent moins d'un kilomètre pour l'atteindre. Pour
se rendre à l'école primaire la plus proche, 82,4 % des
ménages font moins de 30 minutes et 71,5 % parcourent moins d'un
kilomètre pour l'atteindre. Pour se rendre à
l'établissement sanitaire ou service de santé le plus proche 55,1
% des ménages font moins de 30 minutes. Pour aller à la route
praticable la plus proche, 79,4 % des ménages font moins de 30 minutes
et 74 % parcourent moins d'un kilomètre pour l'atteindre.
Dans ce groupe, l'accès à
l'électricité est inexistant. On note également ici une
rareté d'appareil d'équipement. Par contre, les ménages de
ce groupe possèdent des biens tels que : un lit (89,7 %), des terres
agricoles (61,7 %).
Au vu des caractéristiques des ménages du groupe 1,
caractéristiques liées aux mauvaises conditions de vie (une
précarité des principaux matériaux du logement, une
rareté d'appareil d'équipement, pas accès à
l'électricité, utilisation du bois comme source d'énergie
pour la cuisine et comme source d'éclairage du logement la lampe
tempête, faible accès à l'école
28
secondaire, à la santé, utilisation de la nature
et de la rue pour évacuer les ordures ménagères et les
eaux usées, etc.) on peut assimiler le groupe 1 comme étant celui
des ménages pauvres.
3.1.3.2 Caractéristiques des ménages du
Groupe 2
Le groupe 2 représente 28,9 % de notre
échantillon soit un effectif de 2186 ménages
enquêtés. Les matériaux d'habitat sont en matériaux
définitifs. Les murs des maisons sont en brique-ciment (76,4 %), le sol
est en ciment (85,2 %) et le toit est en tôle ondulée (93 %)
Leur principal mode d'approvisionnement en eau de boisson est
le robinet du ménage ou du voisin (81,1 %). Il est à noter que
64,9 % des ménages utilisent des latrines couvertes.
Les ménages utilisent le charbon de bois (69,6 %) comme
source d'énergie pour la cuisine et comme source d'éclairage du
logement l'électricité du secteur (88 %). Les ménages
utilisent la nature pour se débarrasser des ordures
ménagères (54,6 %) et utilisent la rue ou la nature pour
évacuer les eaux usées (74,3 %).
Concernant l'accès à certaines infrastructures
de bases, dans ce groupe 98,4 % des ménages font moins de 30 minutes
pour se rendre à la source d'eau potable la plus proche et 98,6 % font
moins d'un kilomètre pour l'atteindre. Pour aller au marché de
produits alimentaires le plus proche, 78,1 % des ménages font moins de
30 minutes et 73,4 % font moins d'un kilomètre pour l'atteindre. Pour se
rendre au transport public (arrêt bus, taxi, etc.) le plus proche, 89,7 %
des ménages font moins de 30 minutes et 87,9 % parcourent moins d'un
kilomètre pour s'y rendre. Pour aller à l'école primaire
la plus proche, 90,9 % des ménages font moins de 30 minutes et 90,6 %
parcourent moins d'un kilomètre pour l'atteindre. Pour aller à
l'école secondaire la plus proche, 71,2 % des ménages font moins
de 30 minutes et 65,6 % parcourent moins d'un kilomètre pour
l'atteindre. Pour se rendre à l'établissement sanitaire ou
service de santé le plus proche 78,3 % des ménages font moins de
30 minutes et 74,6 % parcourent moins d'un kilomètre pour l'atteindre.
Pour aller à la route praticable la plus proche, 97,5 % des
ménages font moins de 30 minutes et 94,7 % parcourent moins d'un
kilomètre pour l'atteindre.
Dans ce groupe, les ménages ont accès à
l'électricité (95 %). Contrairement au groupe 1, on note ici la
présence d'équipement de grande valeur dans ce groupe, 60,9 %
possèdent un téléviseur, 69,9 % possèdent un
téléphone, 60,1 % possèdent un poste radio ou cassette ou
un lecteur CD, 97,9 % possèdent un lit, 61,5 % possèdent une
armoire ou bibliothèque, 51,8 % possèdent un fauteuil ou
canapé.
Mémoire de fin d'études
29
Au vu des caractéristiques du groupe 2, on peut dire
que les ménages de ce groupe ont un niveau de vie élevé
(les matériaux d'habitat sont en matériaux définitifs,
accès à l'électricité, présence d'appareil
d'équipement de grande valeur, l'accès aux infrastructures de
base, etc.) on peut assimiler le groupe 2 comme étant celui des
ménages non pauvres(les nantis).
Graphique 01 : Répartition (%) des
ménages selon leurs caractéristiques
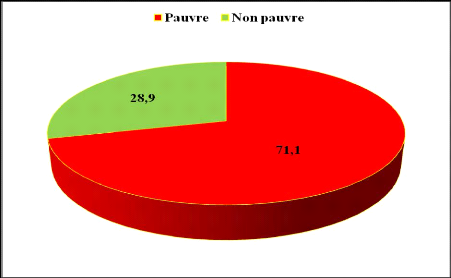
Source : Calcul de l'auteur sur les données de l'ELEP
2007
Mémoire de fin d'études
30
3.2 Résultat de l'analyse de relation entre la
variable dépendante et les variables indépendantes
Nous nommerons communément la variable
dépendante le « niveau de vie » pour des problèmes de
commodités.
Avant d'analyser nos données au moyen de l'analyse
discriminante, il est nécessaire de procéder à des
analyses bivariées pour voir s'il existe une relation entre la variable
« niveau de vie » des ménages et les variables
indépendantes qui sont les variables sociodémographiques,
socio-économiques des chefs de ménages et du capital humain,
c'est-à-dire si elles partagent quelque chose, la variation de l'une
influence la variation de l'autre.
Les analyses bivariées ont pour objet de mettre en
évidence les relations éventuelles qui existent entre deux
variables analysées simultanément. Le test d'association (ou
d'indépendance) consiste à éprouver l'existence d'une
liaison entre deux variables. Les techniques utilisées diffèrent
selon que les variables sont qualitatives nominales, ordinales ou
quantitatives.
Le test de Khi-deux est appliqué si on veut
étudier la relation entre la variable dépendante et une variable
nominale. Si le test de Khi-deux permet de dire oui ou non deux variables
nominales sont liées, ce même Khi-deux ne permet pas de donner
directement l'intensité du lien. Pour cela, il faudra alors recourir
à des coefficients qui dépendent du Khi-deux et permettront de
mesurer cette intensité.
y' Le Phi de Guilford sera calculé dans un tableau
où il ya deux lignes et deux colonnes. y' Le V de Cramer sera
calculé dans un tableau quelconque où le nombre de lignes est
différent du nombre de colonnes.
Le coefficient Eta carré issu de la
décomposition de la variance (Anova à un facteur) sera
calculé pour mesurer le lien qui existe entre la variable
dépendante et une variable continue.
Question problème
Peut-on dire qu'il existe une relation entre la variable
dépendante et chacune des variables indépendantes ou
explicatives?
Hypothèses du test
y' H0 : il n'existe pas de lien entre la variable
dépendante et chacune des variables explicatives ;
Mémoire de fin d'études
31
Mémoire de fin d'études
y' H1 : il existe un lien significatif entre la variable
dépendante et les variables
explicatives.
Prise de décision
y' Si < 0.05 on rejette l'hypothèse nulle, les deux
variables sont liées ;
y' Si > 0.05 on accepte l'hypothèse nulle, les
variables ne sont pas liées.
Tableau 05 : Résultats des tests et
intensité des liens entre la variable dépendante (le niveau de
vie) et les variables indépendantes
|
Variables indépendantes
|
Type de test
|
Valeur du test
|
Signifi- cation (á)
|
Type de coefficient
|
Intensité du lien
|
|
Sexe du chef de ménage
|
Khi-deux de Pearson
|
0,308
|
0,579
|
Phi de Guilford
|
0,006
|
|
Statut matrimonial du
chef de ménage
|
Khi-deux de Pearson
|
181,486
|
0,000
|
V de Cramer
|
0,155
|
|
Niveau de scolarisation du chef de ménage
|
Khi-deux de Pearson
|
811,798
|
0,000
|
V de Cramer
|
0,328
|
|
Groupe socio-
économique du chef de ménage
|
Khi-deux de Pearson
|
1982,113
|
0,000
|
V de Cramer
|
0,512
|
|
Milieu de résidence du chef de ménage
|
Khi-deux de Pearson
|
2553,347
|
0,000
|
Phi de Guilford
|
0,581
|
|
Région d'habitation
|
Khi-deux de Pearson
|
3826,147
|
0,000
|
V de Cramer
|
0,712
|
|
Âgé du chef de ménage
|
Fisher
(Anova à un facteur)
|
12,574
|
0,000
|
Eta carré
|
0,002
|
|
Taille du ménage
|
Fisher
(Anova à un facteur)
|
51,222
|
0,000
|
Eta carré
|
0,007
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
Nous observons que tous les tests sont significatifs au seuil
de 0,05 sauf pour le test de la variable « sexe du chef de ménage
» ce qui nous pousse à rejeter l'hypothèse nulle H0 et
accepter l'hypothèse alternative H1 selon laquelle toutes les variables
indépendantes (excepté le sexe du chef de ménage) sont
liées au niveau de vie.
La variable « sexe du chef de ménage » a un
alpha supérieur à 0,05 soit (0,308), donc elle n'est pas
liée avec la variable dépendante. Cette variable ne sera pas
utilisée dans l'analyse discriminante. Par contre, toutes les autres
variables seront utilisées dans l'analyse de profil.
32
Pour rappel :
Le coefficient de corrélation Eta2 a une valeur
possible entre 0 et 1.
Le coefficient V de Cramer a une valeur approximativement
possible entre 0 et 0,7. Le coefficient Phi de Guilford a une valeur possible
entre 0 et 1.
Nous remarquons que la variable « région
d'habitation » est la plus liée avec le niveau de vie, suivie du
« Milieu de résidence du chef de ménage », du «
Groupe socio-économique du chef de ménage », du «
niveau d'instruction du chef de ménage » et du « statut
matrimonial du chef de ménage ».
Par contre, les variables « Age du chef de ménage
» et « Taille du ménage » ont des liens très
faibles avec la variable dépendante.
Seulement 0,7 % des variations de la taille du ménage
sont expliquées par le niveau de vie des ménages et 0,2 % des
variations de l'âge du chef de ménage sont expliquées par
le niveau de vie des ménages.
Mémoire de fin d'études
33
Mémoire de fin d'études
3.3 Profil de Pauvreté
L'analyse de profil de la pauvreté des ménages
est faite dans l'objectif de voir les caractéristiques des
ménages qui expliquent leur état de pauvreté.
L'idée est de caractériser ces ménages à travers
des facteurs comme le groupe socio-économique du chef de ménage,
son niveau d'instruction, son statut matrimonial, son milieu de
résidence, son âge, sa région d'habitation et la taille du
ménage.
3.3.1 Résultats de l'analyse discriminante
Dans notre étude, l'échantillon porte sur 7552
ménages. Dans notre exemple il n'y a pas de données manquantes,
toutes les unités ont été utilisées pour faire
l'analyse discriminante. Pour rappel toutes les analyses multidimensionnelles
ne tolèrent pas les données manquantes, dans de telles
conditions, deux options nous est offertes, soit corriger les données
manquantes, soit les exclure de l'analyse.
3.3.1.1 Vérification de l'existence de
différence entre les deux groupes
L'étude des profils des deux groupes à partir du
graphique 02 montre qu'il ya des différences notables entre scores
moyens sur les variables.
Graphique 02 : Profils des groupes
constitués
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
34
Mémoire de fin d'études
La significativité de ces différences peut
être davantage mise en évidence grâce aux tests de
Fisher et au lambda de Wilks réalisés dans le cadre
de l'analyse discriminante.
Hypothèses du test
y' H0 : moyenne du groupe des pauvres = moyennes du groupe des
non pauvres
y' H1 : moyenne du groupe des pauvres ? moyennes du groupe des
non pauvres
Prise de décision
y' Si la valeur de alpha est supérieure à 0,05,
nous devons accepter l'hypothèse nulle et
conclure qu'il n'y a pas de différence significative entre
les groupes.
y' Si la valeur de alpha est inférieure ou égale
à 0,05, on rejette l'hypothèse nulle et
conclure qu'il y a une différence significative entre les
groupes.
Tableau 06 : Tests d'égalité des
moyennes des groupes
|
Lambda de
Wilks
|
Fisher
|
ddl1
|
ddl2
|
Signification
(á)
|
|
Âge chef du ménage
|
0,998
|
12,574
|
1
|
7550
|
0,000
|
|
Taille du ménage
|
0,993
|
51,225
|
1
|
7550
|
0,000
|
|
Salarié public
|
0,954
|
366,513
|
1
|
7550
|
0,000
|
|
Salarié privé
|
0,958
|
331,030
|
1
|
7550
|
0,000
|
|
Indépendant agricole
|
0,757
|
2418,149
|
1
|
7550
|
0,000
|
|
Indépendant non agricole
|
0,971
|
222,406
|
1
|
7550
|
0,000
|
|
Sans emploi
|
0,979
|
164,477
|
1
|
7550
|
0,000
|
|
Célibataire
|
0,992
|
61,192
|
1
|
7550
|
0,000
|
|
Marié monogame
|
0,989
|
84,208
|
1
|
7550
|
0,000
|
|
Marié polygame
|
0,984
|
124,166
|
1
|
7550
|
0,000
|
|
Divorcé/Séparé
|
1,000
|
0,084
|
1
|
7550
|
0,772
|
|
Veuf (ve)
|
1,000
|
0,011
|
1
|
7550
|
0,918
|
|
Aucun niveau d'instruction
|
0,928
|
589,733
|
1
|
7550
|
0,000
|
|
Primaire
|
1,000
|
2,739
|
1
|
7550
|
0,098
|
|
Secondaire 1
|
0,997
|
22,696
|
1
|
7550
|
0,000
|
|
Technique professionnelle
|
0,977
|
181,418
|
1
|
7550
|
0,000
|
|
Supérieur
|
0,946
|
431,416
|
1
|
7550
|
0,000
|
|
Rural
|
0,662
|
3856,593
|
1
|
7550
|
0,000
|
|
Conakry
|
0,558
|
5979,317
|
1
|
7550
|
0,000
|
|
Faranah
|
0,969
|
241,101
|
1
|
7550
|
0,000
|
|
Kankan
|
0,957
|
336,970
|
1
|
7550
|
0,000
|
|
Kindia
|
0,999
|
4,704
|
1
|
7550
|
0,030
|
|
Labé
|
0,995
|
37,956
|
1
|
7550
|
0,000
|
|
Mamou
|
1,000
|
0,473
|
1
|
7550
|
0,491
|
|
N'Zérékoré
|
0,926
|
606,704
|
1
|
7550
|
0,000
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
35
Mémoire de fin d'études
Le tableau 06 présente les résultats d'analyse
de variance univarisée pour chacune des variables indépendantes.
Ces analyses vérifient s'il existe des différences entre les
moyennes des groupes sur chacune des variables prises isolément.
La comparaison des moyennes des groupes par le biais du test
de Fisher et le lambda de Wilks montre que pour un niveau de signification de
0,05 les moyennes des groupes diffèrent pour toutes les variables sauf
pour les quatre variables « Divorcé/Séparé »,
« Veuf », « Primaire » et « Mamou ».
Les variables « Divorcé/Séparé
», « Veuf », « Primaire » et « Mamou ».n'ont
aucun effet discriminant sur le niveau de vie, puisque leurs seuils de
signification sont supérieurs au seuil minimal de 0,05.
La valeur du lambda de Wilks univarié varie entre 0
(pouvoir discriminant absolu) et 1 (pouvoir discriminant nul). La valeur 1
signifie l'égalité des moyennes pour l'ensemble des groupes. Une
valeur quasi nulle signifie des différences fortes entre les groupes.
Les lambdas associés à ces quatre variables sont
très élevés puisque chacune d'elle a un lambda égal
à 1.
3.3.1.2 Vérification de la validité de
l'étude
On estime la validité d'une analyse discriminante à
partir des trois indicateurs ci-dessous :
V' Le test de Box.
V' La corrélation globale. V' Le Lambda
de Wilks.
La statistique M de Box, basée sur le logarithme
népérien du déterminant de chaque matrice de
variance-covariance, permet de construire un test multivarié pour la
comparaison des matrices de variance-covariance. Ce test permet de
vérifier le postulat d'homogénéité des matrices de
variance-covariance entre les deux groupes Le test de Box qui est un test
global, permet de dire si oui ou non les matrices de covariances sont
égales dans les différents groupes.
Hypothèses du test
V' H0 : les matrices de covariances sont identiques
dans les deux groupes. V' H1 : les matrices de covariances sont
différentes dans les deux groupes.
36
Prise de décision
y' Si alpha < 0,05 cela signifie qu'il est possible
d'utiliser les variables que nous avons
pour construire le modèle. Il ya au moins une variable
qui a un pouvoir discriminant. y' Si alpha > 0,05 cela signifie que
l'analyse n'est pas valide. Il est alors recommandé de
chercher d'autres variables pour continuer l'analyse.
Ce test a permis en effet de rejeter au seuil de 0,05
l'hypothèse nulle d'égalité des matrices des covariances,
puisque le Fisher est de 318,519 et le niveau de signification est de 0,000. Le
test M de box confirme que l'on ne peut pas accepter l'hypothèse H0 :
les matrices de covariances sont identiques pour les deux groupes (le test est
significatif au niveau de signification de 0.05). Donc, nous pouvons continuer
l'analyse discriminante.
Tableau 07 : Résultats du test M de
Box
|
M de Box
|
38323,236
|
|
Fisher
|
Approximativement
|
318,519
|
|
ddl1
|
120
|
|
ddl2
|
59226789
|
|
Signification (á)
|
0,000
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS Teste l'hypothèse nulle d'égalité de matrices de
covariance des populations.
Les valeurs apparaissant dans la colonne « Log
Déterminant » correspondent à des mesures de dispersion pour
chacun des groupes des matrices de variance-covariance.
Tableau 08 : logarithme
népérien du déterminant de la matrice de variance
covariance pour chaque groupe du niveau de vie
|
Niveau de vie
|
Rang
|
Déterminant Log
|
|
Pauvre
|
15
|
-32,019
|
|
Non Pauvre
|
15
|
-35,365
|
|
Intra-groupes combinés
|
15
|
-27,911
|
Les rangs et logarithmes naturels des déterminants
imprimés sont ceux des matrices de covariance du groupe.
Les valeurs du logarithme des déterminants des matrices de
variance-covariance relatives à chacun des groupes dans l'espace des
variables explicatives font apparaitre le groupe des pauvres avec l'espace
présentant le plus de variabilité relativement aux variables
explicatives retenues. Tandis que le groupe des non pauvres apparait comme le
plus homogène par rapport aux variables explicatives.
Puisque la variable à expliquer admet deux
modalités, l'analyse discriminante a fourni une seule fonction
discriminante. Le nombre de dimensions est le plus petit du nombre de
groupes
Mémoire de fin d'études
37
Mémoire de fin d'études
moins 1. La valeur propre de la fonction discriminante est
égale à 1,689. Le pourcentage de la variance totale
expliqué par la fonction discriminante est de 100 %.
On appelle corrélation canonique la corrélation
entre la fonction discriminante et la variable dépendante. Le
coefficient de corrélation canonique (qui doit être naturellement
le plus proche de 1) est de 0,793 pour la fonction discriminante canonique.
Plus elle est proche de 1, meilleur est le modèle.
Tableau 09 : Valeur propre et coefficient de
corrélation canonique associé à la fonction
linéaire discriminante
|
Fonction
|
Valeur propre
|
% de la variance
|
% cumulé
|
Corrélation
canonique
|
|
1
|
1,689a
|
100,0
|
100,0
|
0,793
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS a. Les 1 premières fonctions discriminantes canoniques ont
été utilisées pour l'analyse.
La corrélation canonique élevée au
carré s'interprète comme le pourcentage de la variable
dépendante expliqué globalement par le modèle. Dans notre
cas, les variables explicatives arrivent à expliquer 62,9 %
(0,7932) de la variance de la variable dépendante, ce qui
trouve que la fonction discriminante se dote d'un pouvoir explicatif fort.
La statistique associée au lambda de Wilks suit une
distribution du Khi-deux à 15 degrés de libertés sous
l'hypothèse nulle d'égalité des moyennes des deux groupes
pour les quinze variables introduites dans le modèle.
Le lambda de wilks de la fonction discriminante est
égal 0,372. Plus la valeur du Lambda de Wilks est proche de 0 meilleur
est le modèle.
Le test du lambda de wilks est significatif au seuil de 0,05
pour la fonction discriminante. Ce qui veut dire que les scores moyens des deux
groupes d'après la fonction linéaire discriminante
diffèrent significativement.
Tableau 10 : Récapitulatif de la fonction
discriminante canonique
|
Test de la ou des
fonctions
|
Lambda de Wilks
|
Khi-deux
|
ddl
|
Signification (á)
|
|
1
|
0,372
|
7460,988
|
15
|
0,000
|
38
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
Mémoire de fin d'études
3.3.1.3 Choix des variables les plus discriminantes
Dans un objectif de ne retenir dans la fonction discriminante
que les facteurs les plus pertinents, la méthode discriminante pas
à pas a été utilisée. La méthode pas
à pas progressive (stepwise) permet d'obtenir un modèle
performant évitant les variables qui n'apportent que peu d'information
au modèle et en même temps elle pallie certains problèmes
de redondance et de multicolinéarité.
Le tableau 11 nous donne les variables qui ont été
prises en compte dans le modèle. Tableau 11 : Liste des
variables introduites/éliminées de l'analyse
|
|
Variables
introduites/éliminéesa,b,c,d
|
|
Pas
|
Introduite
|
Lambda de Wilks
|
|
Statistique
|
ddl1
|
ddl2
|
ddl3
|
F exact
|
|
Statistique
|
ddl1
|
ddl2
|
Signification (á)
|
|
1
|
Conakry
|
0,558
|
1
|
1
|
7550
|
5979,317
|
1
|
7550
|
0,000
|
|
2
|
Rural
|
0,442
|
2
|
1
|
7550
|
4765,222
|
2
|
7549
|
0,000
|
|
3
|
N'Zérékoré
|
0,427
|
3
|
1
|
7550
|
3382,984
|
3
|
7548
|
0,000
|
|
4
|
Kankan
|
0,409
|
4
|
1
|
7550
|
2724,403
|
4
|
7547
|
0,000
|
|
5
|
Faranah
|
0,387
|
5
|
1
|
7550
|
2392,912
|
5
|
7546
|
0,000
|
|
6
|
Indépendant agricole
|
0,382
|
6
|
1
|
7550
|
2036,245
|
6
|
7545
|
0,000
|
|
7
|
Aucun niveau d'instruction
|
0,378
|
7
|
1
|
7550
|
1770,571
|
7
|
7544
|
0,000
|
|
8
|
Labé
|
0,377
|
8
|
1
|
7550
|
1560,125
|
8
|
7543
|
0,000
|
|
9
|
Indépendant non agricole
|
0,375
|
9
|
1
|
7550
|
1395,254
|
9
|
7542
|
0,000
|
|
10
|
Supérieur
|
0,374
|
10
|
1
|
7550
|
1260,866
|
10
|
7541
|
0,000
|
|
11
|
Technique professionnelle
|
0,373
|
11
|
1
|
7550
|
1149,931
|
11
|
7540
|
0,000
|
|
12
|
Marié
monogame
|
0,373
|
12
|
1
|
7550
|
1057,311
|
12
|
7539
|
0,000
|
|
13
|
Âge chef du ménage
|
0,372
|
13
|
1
|
7550
|
977,168
|
13
|
7538
|
0,000
|
|
14
|
Salarié public
|
0,372
|
14
|
1
|
7550
|
908,458
|
14
|
7537
|
0,000
|
|
15
|
Kindia
|
0,372
|
15
|
1
|
|
848,585
|
15
|
7536
|
0,000
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
À chaque pas, la variable qui minimise le lambda de Wilks
global est introduite.
a. Le nombre maximum de pas est 50.
b. Le F pour introduire partiel minimum est 3.84.
c. Le F partiel maximum pour éliminer est 2.71.
d. Seuil du F, tolérance ou VIN insuffisant pour la
poursuite du calcul.
39
Mémoire de fin d'études
La variable offrant la plus grande discrimination qui entre la
première dans le modèle est « Conakry » ensuite, la
deuxième variable choisie est « rural » de telle sorte que
cette paire de variables entraîne le plus de séparation possible
entre les groupes. Et ainsi de suite, les variables entrent dans le
modèle, une à la fois, de façon à augmenter la
discrimination entre les groupes. À chaque étape, on
vérifie s'il est possible de retirer du modèle une variable
déjà incluse. La dernière variable à rentrer dans
le modèle est « Kindia ».
Les variables « Conakry », «
N'Zérékoré », « Kankan », « Faranah
», « Rural », « Indépendant agricole », «
Aucun niveau d'instruction », « Labé », « «
Indépendant non agricole » « Supérieur », «
Technique professionnelle », « Marié monogame », «
Âge du chef de ménage », « Salarié public »
et « Kindia » retenues dans la construction du modèle sont
toutes significatives au seuil de 0,05.
Le tableau 12 permet d'identifier les variables responsables
de multicolinéarité entre les variables. Dès qu'une
variable est détectée comme étant responsable d'une
multicolinéarité, elle n'est pas prise en compte pour le calcul
des statistiques de multicolinéarité des variables suivantes.
Ainsi dans un cas extrême où deux variables seraient identiques,
seule l'une des deux variables sera éliminée des calculs. Les
statistiques affichées sont les tolérances.
La tolérance est une statistique utilisée pour
déterminer l'indépendance entre les variables
(c'est-à-dire en vérifiant s'il y a une relation linéaire
entre eux), si une variable a une tolérance faible alors il contribue
moins d'information au modèle, et il peut être une source de
problème.
Tableau 12 : Liste des variables absentes de
l'analyse discriminante
|
Variables éliminées
|
Tolérance
|
Tolérance
minimale
|
F pour
introduire
|
Lambda de
Wilks
|
|
Taille du ménage
|
0,879
|
0,493
|
0,417
|
0,372
|
|
Salarié privé
|
0,660
|
0,403
|
0,837
|
0,372
|
|
Sans emploi
|
0,379
|
0,266
|
0,816
|
0,372
|
|
Célibataire
|
0,939
|
0,493
|
0,003
|
0,372
|
|
Marié polygame
|
0,452
|
0,449
|
0,371
|
0,372
|
|
Divorcé/Séparé
|
0,957
|
0,493
|
0,583
|
0,372
|
|
Veuf (ve)
|
0,845
|
0,492
|
1,041
|
0,372
|
|
Primaire
|
0,549
|
0,394
|
1,410
|
0,372
|
|
Secondaire 1
|
0,708
|
0,493
|
0,120
|
0,372
|
|
Mamou
|
0,599
|
0,493
|
0,596
|
0,372
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
40
Mémoire de fin d'études
Les variables « Taille du ménage », «
Salarié privé », « Sans emploi », «
Célibataire », « Marié polygame », «
Divorcé/Séparé », « Veuf (ve) », «
Primaire » et « Mamou » ont été
éliminées du modèle pour cause de
multicolinéarité ou de redondance d'information. Toutes ces
variables ont des tolérances faibles et elles ont des valeurs du Fisher
inférieures aux critères (le F pour introduire partiel minimum
est 3.84).
Le tableau 13 montre la valeur de lambda de chaque pas de
l'algorithme, on peut accepter les 13 variables au niveau de signification de
0,05.
Tableau 13 : Lambda de Wilks de chaque pas de
l'algorithme
|
Pas
|
Nombre de variables
|
Lambda
|
ddl1
|
ddl2
|
ddl3
|
F exact
|
|
Statistique
|
ddl1
|
ddl2
|
Signification
(á)
|
|
1
|
1
|
0,558
|
1
|
1
|
7550
|
5979,317
|
1
|
7550
|
0,000
|
|
2
|
2
|
0,442
|
2
|
1
|
7550
|
4765,222
|
2
|
7549
|
0,000
|
|
3
|
3
|
0,427
|
3
|
1
|
7550
|
3382,984
|
3
|
7548
|
0,000
|
|
4
|
4
|
0,409
|
4
|
1
|
7550
|
2724,403
|
4
|
7547
|
0,000
|
|
5
|
5
|
0,387
|
5
|
1
|
7550
|
2392,912
|
5
|
7546
|
0,000
|
|
6
|
6
|
0,382
|
6
|
1
|
7550
|
2036,245
|
6
|
7545
|
0,000
|
|
7
|
7
|
0,378
|
7
|
1
|
7550
|
1770,571
|
7
|
7544
|
0,000
|
|
8
|
8
|
0,377
|
8
|
1
|
7550
|
1560,125
|
8
|
7543
|
0,000
|
|
9
|
9
|
0,375
|
9
|
1
|
7550
|
1395,254
|
9
|
7542
|
0,000
|
|
10
|
10
|
0,374
|
10
|
1
|
7550
|
1260,866
|
10
|
7541
|
0,000
|
|
11
|
11
|
0,373
|
11
|
1
|
7550
|
1149,931
|
11
|
7540
|
0,000
|
|
12
|
12
|
0,373
|
12
|
1
|
7550
|
1057,311
|
12
|
7539
|
0,000
|
|
13
|
13
|
0,372
|
13
|
1
|
7550
|
977,168
|
13
|
7538
|
0,000
|
|
14
|
14
|
0,372
|
14
|
1
|
7550
|
908,458
|
14
|
7537
|
0,000
|
|
15
|
15
|
0,372
|
15
|
15
|
7550
|
848,585
|
15
|
7536
|
0,000
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
41
Mémoire de fin d'études
3.3.1.4 Estimation des coefficients de la fonction
discriminante
Les coefficients standardisés servent à indiquer
la contribution de chaque variable explicative dans le calcul d'un score
discriminant. Comme en régression, les valeurs et les signes des
coefficients non standardisés ne sont pas toujours directement
interprétables. Pour interpréter une fonction linéaire
discriminante, l'analyse des coefficients standardisés est plus
pertinente.
Tableau 14 : Coefficients standardisés de
la fonction discriminante
|
Fonction
|
|
1
|
|
Âge Chef du ménage
|
0,045
|
|
Salarié public
|
0,044
|
|
Indépendant agricole
|
0,210
|
|
Indépendant non agricole
|
0,095
|
|
Marié monogame
|
-0,051
|
|
Aucun niveau d'instruction
|
0,045
|
|
Technique professionnelle
|
-0,073
|
|
Supérieur
|
-0,100
|
|
Rural
|
0,496
|
|
Conakry
|
-0,601
|
|
Faranah
|
0,344
|
|
Kankan
|
0,348
|
|
Kindia
|
0,037
|
|
Labé
|
0,095
|
|
N'Zérékoré
|
0,423
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
L'équation de la fonction discriminante avec les
coefficients canoniques standardisés est :
F = 0,496*Rural +0,210*Indépendant agricole
+0,045*Aucun niveau d'instruction - 0,100*Supérieur
+0,044*Salarié public +0,095*Indépendant non agricole + 0,045*
Âge chef du ménage -0,073*Technique professionnelle
-0,051*marié monogame - 0,601*Conakry
+0,423*N'Zérékoré +0,344*Kankan +0,344*Faranah +
0,095*Labé + 0,035*Kindia
Dans le tableau 14, quinze facteurs ont été
identifiés, le milieu rural étant le facteur qui participe le
plus à la pauvreté alors que la capitale Conakry contribue le
plus à la non pauvreté comme l'indiquent les coefficients
standardisés.
Considérant le groupe socio-économique du chef
de ménage, il s'avère qu'être indépendant agricole,
indépendant non agricole et salarié du secteur public sont des
facteurs de pauvreté.
42
L'éducation au niveau supérieur et le niveau
technique professionnel sont des facteurs de mieux-être, lorsque n'avoir
aucun niveau d'instruction est un facteur de pauvreté.
L'âge du chef de ménage et être
salarié public sont des facteurs de pauvreté. Être
marié monogame est un facteur de mieux-être.
La capitale Conakry est un facteur de mieux-être lorsque
les régions de N'Zérékoré, de Kankan, de Faranah,
de Labé et de Kindia sont des facteurs de pauvreté.
Les facteurs « Rural », « Indépendant
agricole », « N'Zérékoré », « Aucun
niveau d'instruction », « Kankan », « Faranah »,
« Indépendant non agricole », « Labé »,
« Âge chef du ménage », « Salarié public
» et « Kindia » sont tous contributifs à la
pauvreté. Le milieu rural est le plus touché par la
pauvreté, suivi des indépendants agricoles, de la région
de N'Zérékoré, des chefs de ménage qui n'ont aucun
niveau d'instruction, de la région de Kankan, de la région de
Faranah, des indépendant non agricoles, de la région de
Labé, de l'âge du chef de ménage, des fonctionnaires
(salarié du secteur public), et de la région de Kindia.
Une augmentation de cette proportion d'une unité pour
chaque facteur fait augmenter les chances du ménage d'être
pauvre.
Les facteurs « Conakry », « supérieur
», « technique professionnelle » et « marié monogame
» sont tous des facteurs de mieux-être.
Une augmentation de cette proportion d'une unité pour
chaque facteur fait augmenter les chances du ménage d'être non
pauvre.
De ce constat, la pauvreté est un
phénomène essentiellement rural, les plus touchés sont les
chefs de ménages qui sont des indépendants agricoles ou non
agricoles, ils n'ont aucun niveau d'instruction, ils sont âgés et
ils résident dans les régions administratives de
N'Zérékoré, Kankan, Faranah, Labé et Kindia.
Le pouvoir discriminant des variables (les plus
discriminantes) peut être mis en évidence à partir de la
matrice de structure. Cette matrice indique les coefficients de
corrélation de Pearson, entre les scores discriminants des individus
ainsi que leurs valeurs réelles des variables. Elle donne une
idée sur l'impact des variables sur la fonction discriminante.
Mémoire de fin d'études
43
Tableau 15 : Matrice de structure
|
Fonction
|
|
1
|
|
Conakry
|
-0,685
|
|
Rural
|
0,550
|
|
Indépendant agricole
|
0,435
|
|
N'Zérékoré
|
0,218
|
|
Aucun niveau d'instruction
|
0,215
|
|
Supérieur
|
-0,184
|
|
Salarié public
|
-0,170
|
|
Kankan
|
0,163
|
|
Faranah
|
0,138
|
|
Indépendant non agricole
|
-0,132
|
|
Technique professionnelle
|
-0,119
|
|
Marié monogame
|
-0,081
|
|
Labé
|
0,055
|
|
Âge Chef du ménage
|
0,031
|
|
Kindia
|
0,019
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
Les corrélations intra-groupes combinées entre
variables discriminantes et les variables des fonctions discriminantes
canoniques standardisées sont ordonnées par tailles absolues des
corrélations à l'intérieur de la fonction.
On remarque que le coefficient de corrélation entre les
scores discriminants et la valeur réelle de la variable « Conakry
» est le plus élevé avec la fonction soit -0,685, suivi de
la variable « Rural » soit 0,550.
On peut conclure en disant que la variable la plus discriminante
est « Conakry », suivi de « rural ». Les deux moins
discriminantes sont « Kindia » et « Âge chef du
ménage ».
Les valeurs des coefficients non standardisés de la
fonction linéaire discriminante permettent d'utiliser directement les
valeurs des variables explicatives pour calculer les scores discriminants et
faire de la classification.
Mémoire de fin d'études
44
Mémoire de fin d'études
Tableau 16 : Coefficients de la fonction
discriminante non standardisés
|
Fonction
|
|
1
|
|
Âge chef du ménage
|
0,003
|
|
Salarié public
|
0,160
|
|
Indépendant agricole
|
0,489
|
|
Indépendant non agricole
|
0,212
|
|
Marié monogame
|
-0,103
|
|
Aucun niveau d'instruction
|
0,102
|
|
Technique professionnelle
|
-0,331
|
|
Supérieur
|
-0,446
|
|
Rural
|
1,222
|
|
Conakry
|
-2,212
|
|
Faranah
|
1,115
|
|
Kankan
|
1,173
|
|
Kindia
|
0,108
|
|
Labé
|
0,297
|
|
N'Zérékoré
|
1,179
|
|
(Constante)
|
-1,148
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
On peut construire le modèle suivant avec les coefficients
non standardisés :
F = 1,222*Rural +0,489*Indépendant agricole
+0,112*Aucun niveau d'instruction - 0,446*Supérieur
+0,160*Salarié public +0,212*Indépendant non agricole + 0,003*
Âge chef du ménage -0,331*Technique professionnelle
-0,103*marié monogame - 2,212*Conakry
+1,179*N'Zérékoré +1,173*Kankan +1,115*Faranah +
0,297*Labé + 0,108*Kindia -1,148
Le tableau 16 permet de faire le classement d'un ménage
quelconque en utilisant le modèle de la fonction discriminante.
Par exemple pour un ménage quelconque, on remplace les
variables explicatives par ses valeurs dans le modèle, on obtiendra un
score moyen pour ce ménage. La valeur trouvée doit être
confrontée au tableau des barycentres, notre ménage sera
classé dans le groupe qui a le barycentre le plus proche de cette valeur
(on doit respecter les signes). Ce type de classement est connu sous le nom
technique d'analyse factorielle discriminante.
45
Mémoire de fin d'études
Le tableau 17 donne les valeurs moyennes de la fonction pour
chaque groupe, c'est le score moyen par groupe et à la fonction : ce qui
signifie que si le score calculé pour un groupe est proche par exemple
de 0,829 on dit qu'il se rapproche des ménages pauvres.
Si le score calculé a une valeur négative pour la
fonction, on dit qu'il se rapproche des ménages non pauvres.
Tableau 17 : Fonctions aux barycentres des
groupes
|
Fonction
|
|
Niveau de vie
|
1
|
|
Pauvre
|
0,829
|
|
Non Pauvre
|
-2,036
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
Fonctions discriminantes canoniques non standardisées
évaluées aux moyennes des groupes
Les fonctions de classement peuvent être
utilisées pour déterminer à quelle classe doit être
affectée une observation sur la base des valeurs prises pour les
différentes variables explicatives. Une observation est affectée
à la classe pour laquelle la fonction de classement est la plus
élevée.
Tableau 18 : Coefficient des fonctions de
classement
|
Fonctions discriminantes linéaires de
Fisher
|
|
Niveau de vie
|
|
Pauvre
|
Non Pauvre
|
|
Âge Chef du ménage
|
0,392
|
0,383
|
|
Salarié public
|
6,868
|
6,409
|
|
Indépendant agricole
|
7,612
|
6,211
|
|
Indépendant non agricole
|
9,174
|
8,567
|
|
Marié monogame
|
4,163
|
4,457
|
|
Aucun niveau d'instruction
|
2,776
|
2,484
|
|
Technique professionnel
|
4,678
|
5,627
|
|
Supérieur
|
3,378
|
4,657
|
|
Rural
|
4,776
|
1,275
|
|
Conakry
|
4,432
|
10,771
|
|
Faranah
|
6,392
|
3,198
|
|
Kankan
|
5,445
|
2,084
|
|
Kindia
|
4,384
|
4,073
|
|
Labé
|
3,755
|
2,902
|
|
N'Zérékoré
|
7,000
|
3,622
|
|
(Constante)
|
-20,370
|
-18,808
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
46
Ce classement est appelé classement bayésien
parce qu'il est calculé sur les probabilités à posteriori
de Bayes. Ce type de classement est connu sous le nom de technique d'analyse
discriminante bayésienne.
L'équation fondamentale pour chaque groupe est :
Fpauvre = 4,766*Rural +7,612*Indépendant agricole
+2,776*Aucun niveau d'instruction
+4,657*Supérieur +6,868*Salarié public
+9,174*Indépendant non agricole +0,392*Age chef du ménage
+4,678*Technique professionnelle +4,163*marié monogame +4,432*Conakry
+1,179*N'Zérékoré +5,445*Kankan +6,392*Faranah
+3,755*Labé + 4,384*Kindia --20,370
Fnon pauvre = 1,275*Rural +1,275*Indépendant
agricole +2,484*Aucun niveau
d'instruction +0,446*Supérieur
+6,409*Salarié public +8,567*Indépendant non agricole +0,383*Age
chef du ménage +5,627*Technique professionnelle +4,457*marié
monogame +10,771*Conakry +3,622*N'Zérékoré +2,084*Kankan
+3,198*Faranah +2,902*Labé +4,073*Kindia -18,808
Après avoir trouvé les valeurs des fonctions, on
les compare entre elles et on prend la plus grande en valeur absolue.
3.3.1.5 Qualité de la représentation
La qualité de la représentation dépend de
la capacité de la fonction discriminante à reclasser correctement
les individus. Pour cela, on confronte dans un tableau à double
entrée la constitution d'origine des groupes et la constitution
prédite de ces derniers, c'est ce qu'on appelle matrice de confusion, on
calcule ensuite le pourcentage d'individus bien classés. Plus ce
pourcentage est élevé, meilleur est la qualité de
l'analyse.
Quand la taille de l'échantillon total est grande, on
peut calculer les fonctions discriminantes sur une partie de
l'échantillon (environ 70-80%) choisie au hasard, et à l'aide de
ces fonctions, classifier les individus écartés temporairement de
l'analyse. On obtient alors deux tableaux l'un pour l'échantillon
réduit et l'autre pour l'échantillon écarté
temporairement (parfois appelé échantillon de contrôle ou
de validation). Ceci devrait refléter plus adéquatement la
qualité de l'outil de classification.
Mémoire de fin d'études
47
Mémoire de fin d'études
Tableau 19 : Matrice de confusion
(résultats du classement bayésien)
|
Résultats du classementb,c
|
|
|
Niveau de vie
|
Classe(s) d'affectation prévue(s)
|
Total
|
|
|
Pauvre
|
Non Pauvre
|
|
Original
|
Effectif
|
Pauvre
|
4944
|
422
|
5366
|
|
Non Pauvre
|
311
|
1875
|
2186
|
|
%
|
Pauvre
|
92,1
|
7,9
|
100,0
|
|
Non Pauvre
|
14,2
|
85,8
|
100,0
|
|
Validé-croiséa
|
Effectif
|
Pauvre
|
4941
|
425
|
5366
|
|
Non Pauvre
|
315
|
1871
|
2186
|
|
%
|
Pauvre
|
92,1
|
7,9
|
100,0
|
|
Non Pauvre
|
14,4
|
85,6
|
100,0
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
a. La validation croisée n'est effectuée que pour
les observations de l'analyse. Dans la validation croisée, chaque
observation est classée par les fonctions dérivées de
toutes les autres observations.
b. 90,3 % des observations originales classées
correctement.
c. 90,2 % des observations validées-croisées
classées correctement.
Ainsi dans notre exemple, 4944 individus ont été
bien reclassés dans le groupe des pauvres et 422 individus ont
été mal classés, grâce aux fonctions
linéaires de Fisher, de même, pour le groupe non pauvre, 1875
individus ont été bien reclassés, et 311 individus ont
été mal reclassés. Au total, 6819 individus (4944+1875)
qui ont été correctement reclassés soit 93,3 % de
réussite ((6819/7552)*100=93,3 %).
Les fonctions discriminantes reclassent bien les individus
avec un taux de réussite de 93,3 %. Ceci démontre que les
fonctions linéaires de Fisher sont d'une très bonne
qualité.
Le groupe d'affectation prévu pour la fonction de
l'analyse factorielle discriminante se résume dans le tableau 20.
Tableau20 : Groupe d'affectation prévu
par la fonction discriminante canonique
|
Pauvre
|
Non pauvre
|
|
Valeur originale
|
5366
|
2186
|
|
Valeur prédite
|
5255
|
2297
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
Le taux de reclassement de la fonction discriminante canonique
est de 97,1 %. Donc la fonction discriminante canonique est d'une excellente
qualité.
48
Mémoire de fin d'études
3.3.1.6 Choix du meilleur ou des modèles entre
l'analyse factorielle discriminante et celle bayésienne
Tableau 21 : Comparaison entre les
modèles issus de l'analyse factorielle discriminante et celle
bayésienne
|
Modèles
|
|
Nombre de mal classés
|
Fonction discriminante (Analyse factorielle discriminante)
|
Fonctions discriminantes
linéaires de Fisher (Analyse discriminante
bayésienne)
|
|
Pauvres
|
111
|
422
|
|
Non pauvres
|
111
|
311
|
|
Total
|
222
|
733
|
|
Taux d'erreur de classement
|
2,9%
|
9,7%
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
Au vu de ces résultats, le taux d'erreur de classement est
:
Pour le modèle de la fonction discriminante, il est de
2,9% (222/7552)*100.
Pour les deux modèles des fonctions discriminantes
linéaires de Fisher, il est de 9,7% (733/7552)*100.
Le choix du meilleur modèle ou des modèles doit
porter sur celui ou ceux qui a ou ont le plus faible taux d'erreur de
classement. Donc, notre choix va porter sur le modèle de la fonction
discriminante de l'analyse factorielle discriminante, car il a le plus faible
taux d'erreur soit 2,9%.
Le modèle retenu est le suivant :
F = 1,222*Rural +0,489*Indépendant agricole
+0,112*Aucun niveau d'instruction - 0,446*Supérieur
+0,160*Salarié public +0,212*Indépendant non agricole + 0,003*Age
chef du ménage -0,331*Technique professionnelle -0,103*marié
monogame - 2,212*Conakry +1,179*N'Zérékoré +1,173*Kankan
+1,115*Faranah + 0,297*Labé + 0,108*Kindia -1,148
Le modèle que nous avons construit, nous a permis de
constater que la pauvreté des ménages est fonction du milieu de
résidence (rural), du groupe socio-économique du chef de
ménage
49
(indépendant agricole, indépendant non agricole et
salarié du secteur public), du niveau d'instruction du chef de
ménage (aucun niveau d'instruction, technique professionnelle et
supérieur), du statut matrimonial du chef de ménage (marié
monogame), de l'âge du chef de ménage), mais également de
la région d'habitation (Conakry, N'Zérékoré,
Kankan, Faranah, Labé et Kindia).
C'est ce modèle qui permettra de classer les
ménages de sorte que, connaissant les caractéristiques d'un
ménage donné, il soit possible de les classer soit dans la
catégorie des pauvres, soit dans celle des non pauvres.
3.3.1.7 Adéquation du modèle de classement
retenu
Dans le but de construire le modèle de
prédiction, il est d'un intérêt de faire un examen de son
pouvoir discriminant. Cet examen se fait par calcul de l'aire au-dessous de la
courbe ROC (Receiver Operating Characteristic) ou courbe de
caractéristiques d'efficacité. Cette courbe permet
d'étudier les variations de la spécificité et de la
sensibilité d'un test pour différentes valeurs du seuil de
discrimination.
La courbe de ROC est utilisée dans les méthodes
de classement ne mettant en oeuvre qu'une seule variable à deux
modalités et utilisées pour la classification des sujets. Elle
est avant tout définie pour les problèmes à deux classes
(les positifs et les négatifs), elle indique la capacité du
classifieur à placer les positifs devant les négatifs, sa
construction s'appuie donc sur les probabilités d'être positif
fournies par les classifieurs. Il n'est pas nécessaire que ce soit
réellement une probabilité, une valeur quelconque dite «
score » permettant d'ordonner les individus suffit amplement.
Dans notre exemple, sur l'axe des abscisses, on porte la variable
1- spécificité donnant l'effectif (en pourcentage) de non pauvres
parmi les pauvres, sur l'axe des ordonnées, on place la
sensibilité égale à l'effectif (en pourcentage) de vrais
pauvres parmi les non pauvres. Si Se et Sp désignent respectivement la
sensibilité et la spécificité du test, nous avons :
y' Se=Pr(le test décide que l'individu est pauvre sachant
qu'il est effectivement pauvre) ;
y' Sp=Pr(le test décide que l'individu n'est pas pauvre
sachant qu'il n'est effectivement
pas pauvre).
La surface sous cette courbe nous permet d'évaluer la
précision du modèle pour discriminer les ménages pauvres
des ménages non pauvres.
Mémoire de fin d'études
50
On retiendra comme règle:
- Si aire ROC = 0.5 il n'y a pas de discrimination ;
- Si 0.5 < aire ROC < 0.7 la discrimination est
insuffisante ; - Si 0.7 < aire ROC < 0.8 la discrimination est acceptable
; - Si 0.8 < aire ROC < 0.9 la discrimination est excellente ; - Si aire
ROC = 0.9 la discrimination est exceptionnelle.
Graphique 03 : Courbe de ROC du modèle de
classement retenu
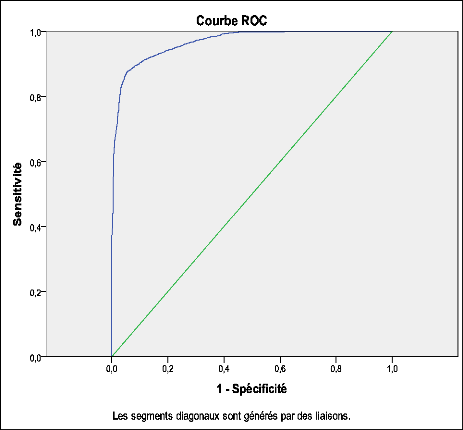
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
Un test avec un fort pouvoir discriminateur occupera la partie
supérieure gauche du graphique. Un test avec un pouvoir discriminant
moins puissant montrera une courbe ROC qui s'aplatira vers la première
diagonale du graphique.
Dans notre cas, nous avons un test qui a un fort pouvoir
discriminateur.
Mémoire de fin d'études
51
Tableau 22 : Aire sous la courbe de ROC du
modèle de classement retenu
|
Zone sous la courbe
|
|
|
Variable(s) de résultats tests: Probabilité
d'appartenance au groupe pour l'analyse
|
|
|
Zone
|
Erreur Standard.a
|
Signification
asymptotiqueb
|
Intervalle de confiance 95 % asymptotique
|
|
|
Borne inférieure
|
Borne supérieure
|
|
0,966
|
0,002
|
0,000
|
0,963
|
|
0,970
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
La ou les variables de résultats tests :
Probabilité d'appartenance au groupe pour l'analyse comporte au moins
une liaison entre le groupe d'état réel positif et le groupe
d'état réel négatif. Les statistiques peuvent être
déformées.
a. Dans l'hypothèse non-paramétrique
b. Hypothèse nulle / : zone vraie = 0.5
L'aire sous la courbe (AUC) indique la probabilité pour
que la fonction SCORE place un positif devant un négatif (dans le
meilleur des cas AUC = 1). Il existe une valeur seuil, si l'on classe les
individus au hasard, l'AUC sera égal à 0.5.
Dans notre exemple, nous remarquons que la valeur de l'aire sous
la courbe est très importante. Pour ce modèle, l'aire sur la
courbe ROC vaut 96,6%, ce qui traduit un pouvoir discriminant exceptionnel.
Ceci démontre encore une fois que le modèle retenu
est d'une excellente qualité.
Mémoire de fin d'études
52
Mémoire de fin d'études
Conclusions et Recommandations
L'objet de notre présente recherche est de contribuer
non seulement à enrichir la connaissance sur la pauvreté, mais
aussi, à orienter utilement les politiques de lutte contre la
pauvreté dans le ciblage des groupes vulnérables.
Pour atteindre nos objectifs, nous avons utilisé deux
méthodes d'analyse multidimensionnelles qui sont complémentaires
à savoir la classification ascendante hiérarchique et l'analyse
discriminante.
La classification ascendante hiérarchique a permis de
classer les ménages en groupes plus ou moins homogènes selon
leurs caractéristiques. Elle a permis de cerner plusieurs aspects de la
pauvreté. Nous avons pu distinguer deux groupes en fonction de leurs
conditions ou niveau de vie : les pauvres et les non pauvres. La
pauvreté multidimensionnelle affecte 71,1% des ménages en 2007
selon l'approche de la classification ascendante hiérarchique.
Les ménages pauvres sont caractérisés par
des mauvaises conditions de vie. Les ménages non pauvres (les nantis ou
riches) représentant 28,9% sont caractérisés par de bonnes
conditions de vie.
Par rapport au groupe socio-économique du chef de
ménage, les résultats montrent que les indépendants qu'ils
soient agricoles ou non agricoles, les salariés du secteur public sont
les plus touchés par la pauvreté. Quant au milieu de
résidence, les ménages ruraux sont les plus touchés.
Concernant le statut matrimonial, les mariés monogames sont les moins
touchés. Les chefs de ménages qui n'ont aucun niveau
d'instruction sont les plus pauvres alors que ceux qui ont un niveau de
formation professionnelle ou supérieur sont les moins pauvres. Les
régions administratives de N'Zérékoré, Kankan,
Faranah, Labé et Kindia demeurent les plus pauvres tandis que les moins
pauvres demeurent dans la capitale Conakry.
Sur la base des résultats obtenus, nous montrons
l'importance de l'approche multidimensionnelle de la pauvreté dans
l'identification des populations pauvres. Basée sur la seule approche
monétaire, toute politique de lutte contre la pauvreté risquerait
de ne pas être efficace. En effet, à supposer qu'elle est bien
ciblée, elle ne profiterait vraisemblablement pas aux ménages non
pauvres selon l'approche monétaire, mais qui seraient pauvres selon une
approche multidimensionnelle. Ce résultat nous permet de conclure
à la nécessité de considérer plusieurs dimensions
dans l'approche de la pauvreté (et pas uniquement la dimension
monétaire) au niveau de la Guinée dans son ensemble.
53
Au vue des résultats obtenus, pour des politiques
efficaces et durables de lutte contre la pauvreté, l'État et les
différents partenaires au développement devraient prendre en
compte les recommandations (renforcer les actions déjà
entreprises dans les axes de recommandations) suivantes :
y' Intensifier les investissements dans les infrastructures
sociales de base (éducation, santé, eau potable,
électricité, logements, routes, moyens de communications) en
milieu de résidence urbain mais davantage rural ;
y' Mettre en place des infrastructures adéquates, des
moyens logistiques et des mécanismes efficaces pour la gestion des
ordures ménagères et des eaux usées surtout en milieu
urbain ;
y' Vulgariser l'utilisation du gaz comme source
d'énergie pour la cuisine afin, de diminuer la consommation du bois et
du charbon de bois pour préserver l'environnement ;
y' Favoriser des activités génératrices
de revenus en milieu rural. Ceci permettrait sans doute aux populations rurales
de disposer de plus de moyens financiers pour augmenter leur pouvoir d'achat et
acquérir des biens durables ;
y' Améliorer l'accès des populations rurales aux
techniques modernes de culture à travers l'apprentissage de nouveaux
systèmes de culture pour sortir de l'agriculture de subsistance vers une
agriculture rentable, de conservation et de protection des produits agricoles
;
y' Réaliser des aménagements hydroagricoles ;
y' Favoriser l'accès aux intrants agricoles et l'octroi
de subvention pour la production agricole ;
y' Désenclaver les zones rurales pour faciliter
l'évacuation des produits vers les centres de distribution ;
y' Faciliter l'accès au crédit dans toutes les
localités du pays sans aucune discrimination. Ceci permettra le
développement des petites entreprises et d'assurer l'auto emploi des
jeunes ;
Mémoire de fin d'études
54
y' Faire une alphabétisation professionnelle des
adultes au profit des indépendants notamment les indépendants
agricoles qui apparaissent les plus pauvres ;
y' Promouvoir l'accès à l'éducation pour
tous ;
y' Réorienter la politique éducative vers des
objectifs visant à améliorer son efficacité en termes
d'opportunités dans le domaine minier, agricole et de création
d'activités plus porteuses en conformité avec le produit du
système éducatif ;
y' Renforcer les politiques de lutte contre la pauvreté
en faveur des personnes âgées (revoir les conditions de retraite
et diminuer les couts d'accès aux soins de santé) ;
y' Améliorer le pouvoir d'achat des salariés du
secteur public en augmentant leurs salaires ;
y' Réviser les codes d'investissement ;
y' Améliorer l'environnement des affaires dans le pays
;
y' Envisager des études d'impact sur
l'efficacité des projets et programmes de développement
intervenant dans le pays au bénéfice des populations. C'est de
cette façon qu'il sera possible d'identifier les insuffisances en termes
d'effets de ces programmes mobilisant des milliards de GNF au profit des
populations pauvres du pays.
Mémoire de fin d'études
55
Mémoire de fin d'études
Bibliographie
[1]: Achille BONSO, (2006) Secteur informel et Réduction
de la Pauvreté au Cameroun, Mémoire de Master en statistique
Appliquée, Université I de Yaoundé, Cameroun.
[2]: Aloysius, A.A et Jean-Luc, D., (2009) Croissance et
Développement au Cameroun : D'une Croissance Équilibrée
à un Développement Équitable, Institut Africain de
Développement et de Planification (IDEP des Nations Unies de Dakar,
Sénégal), Faculté des Sciences Économiques et de
Gestion, Université de Yaoundé II, Cameroun et Centre
d'Économie et d'Éthique pour l'Environnement (C3ED),
Université de Versailles St. Quentin en Yvelines (UVSQ), France.
[3]: Asselin, L-M., Dauphin, A., (2000), « Mesure de la
pauvreté : un cadre conceptuel ». Centre Canadien d'Étude et
de Coopération international.
[4]: Ayadi et al. , (2005), «Analyse multidimensionnelle
de la pauvreté en Tunisie entre 1988 et 2001 par une approche non
monétaire», PEP.
[5]: Direction Nationale de la Statistique - Ministère
du Plan. 2003. Questionnaire des Indicateurs de Base du Bien-être,
QUIBB.
[6]: Direction Nationale de la Statistique - Ministère
du Plan. Enquête intégrale sur les conditions de vie des
ménages Guinéens avec module budget et consommation (EIBC)
janvier 1994 - février 1995.
[7]: Direction Nationale de la Statistique-Ministère
du Plan. Enquête Intégrée de Base pour l'Évaluation
de la Pauvreté (EIBEP) en Guinée octobre 2002 - octobre 2003.
[8]: Document de Stratégie pour la Réduction de
la Pauvreté (DSRP), 2011 et 2002, Ministère de l'Économie
et des Finances, Secrétariat Permanent de la Stratégie de
Réduction de la Pauvreté (SP-SRP).
[9]: Dominique DESBOIS, (2003) Une Introduction à
l'Analyse Discriminante avec SPSS pour Windows, Revue MODULAD N°30.
[10]: E. NDORUHIRWE, (2005) Mesure, analyse et
caractérisation de la pauvreté infantile en Guinée,
Mémoire de Maîtrise en Économie, Université Laval,
Canada.
[11]: Enquête démographique et de Santé
Guinée (EDS) III 2005, Ministère du Plan.
[12]: Fatoumata SOW, (2006) Analyse de la Pauvreté
Multidimensionnelle en Guinée : Approche par les Ensembles Flous,
Mémoire d'Études Approfondies en Sciences Économiques,
Université Cheikh Anta Diop de Dakar, Faculté des Sciences
Économiques et de Gestion.
[13]: Jean de LAGARDE., (1983), «Initiation à
l'Analyse des Données», Dunod, Paris.
56
[14]: Jerôme DONGMO, (2007) Classification des
Catégories Socio-économiques au Cameroun, Mémoire de
Master en statistique Appliquée.
[15]: Keita, M.L. et Youla, D.2000. « La dimension
sociale de la pauvreté en Guinée », Institut de Formation et
de Recherche Démographique (lFORD).
[16]: KI, J.B et al., (2005) Pauvreté
multidimensionnelle au Sénégal : une approche non
monétaire par les besoins de base, Cahier de recherche PMMA 2005-05.
[17]: Marie CHAVENT, (1997) Contribution à la
Classification Automatique et à la Réduction de Dimension,
Synthèse Mémoire de Thèse, Université Paris 6.
[18]: Ministère du Plan- Institut National de la
Statistique. Enquête légère pour l'évaluation de la
pauvreté (ELEP) en Guinée 2007-2008.
[19]: PNUD, (2010), Rapport sur le Développement
Humain.
[20]: Sami BIBI, (2002) Mesurer la pauvreté dans une
perspective multidimensionnelle: une revue de la littérature,
Faculté des Sciences Économiques et de Gestion de Tunis et
CREFA-CIRPEE, Université Laval; Québec, Canada.
[21]: STAFFORD, J. et BODSON, P., (2006) L'analyse
multivariée avec SPSS, Presse de l'Université du
Québec.
[22]: Stéphane TUFFERY, (2007) Data Mining et
Statistique Décisionnelle, Université de Rennes I et ISUP
(Institut de l'Univers de Paris).
[23]: SYLLA, K. et al. (2005) Une Approche
Multidimensionnelle de la Pauvreté appliquée en Cote d'Ivoire,
Rapport Intérimaire N°3 Centre Ivoirien de Recherches
Économiques et Sociales (CIRES), Université d'Abidjan-Cocody.
[24]: Touhami, A. et Fouzia, E., (2009) Approche
Multidimensionnelle de la pauvreté : Présentation
Théorique et Application au Cas de la ville de Marrakech, INSEA
(Institut National de Statistique et d'Économie Appliquée), Rabat
Maroc et Université Cadi Ayyad, Faculté des sciences juridiques
économiques et sociales, Marrakech Maroc.
Mémoire de fin d'études
57
Mémoire de fin d'études
Annexes
Tableau A1 : Récapitulatif des
observations originales classées correctement (%)
|
Partition
|
% de bien classées
|
|
Groupage à 2
|
90,3
|
|
Groupage à 3
|
73,4
|
|
Groupage à 4
|
63,2
|
|
Groupage à 5
|
57,9
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
Tableau A2 : Anova du groupage à deux
|
Somme
des carrés
|
df
|
Moyenne
des carrés
|
Fisher
|
Significat ion (á)
|
|
Propriétaire * Ward Method
|
Inter-groupes
|
177,419
|
1
|
177,419
|
973,310
|
,000
|
|
Intra-classe
|
1376,243
|
7550
|
,182
|
|
|
|
Total
|
1553,662
|
7551
|
|
|
|
|
Copropriétaire familial * Ward
|
Inter-groupes
|
1,786
|
1
|
1,786
|
19,438
|
,000
|
|
Method
|
Intra-classe
|
693,682
|
7550
|
,092
|
|
|
|
Total
|
695,468
|
7551
|
|
|
|
|
Location * Ward Method
|
Inter-groupes
|
93,296
|
1
|
93,296
|
875,876
|
,000
|
|
Intra-classe
|
804,208
|
7550
|
,107
|
|
|
|
Total
|
897,504
|
7551
|
|
|
|
|
Logé gratuitement * Ward Method
|
Inter-groupes
|
1,874
|
1
|
1,874
|
52,843
|
,000
|
|
Intra-classe
|
267,745
|
7550
|
,035
|
|
|
|
Total
|
269,619
|
7551
|
|
|
|
|
Maison individuelle * Ward
|
Inter-groupes
|
14,065
|
1
|
14,065
|
59,530
|
,000
|
|
Method
|
Intra-classe
|
1783,810
|
7550
|
,236
|
|
|
|
Total
|
1797,875
|
7551
|
|
|
|
|
Appartement * Ward Method
|
Inter-groupes
|
46,459
|
1
|
46,459
|
275,885
|
,000
|
|
Intra-classe
|
1271,411
|
7550
|
,168
|
|
|
|
Total
|
1317,870
|
7551
|
|
|
|
|
Chambre/studio * Ward Method
|
Inter-groupes
|
7,952
|
1
|
7,952
|
168,824
|
,000
|
|
Intra-classe
|
355,624
|
7550
|
,047
|
|
|
|
Total
|
363,576
|
7551
|
|
|
|
|
Case * Ward Method
|
Inter-groupes
|
128,779
|
1
|
128,779
|
880,474
|
,000
|
|
Intra-classe
|
1104,272
|
7550
|
,146
|
|
|
|
Total
|
1233,051
|
7551
|
|
|
|
|
Case et maison * Ward Method
|
Inter-groupes
|
7,909
|
1
|
7,909
|
155,749
|
,000
|
|
Intra-classe
|
383,395
|
7550
|
,051
|
|
|
|
Total
|
391,305
|
7551
|
|
|
|
|
Plusieurs maisons * Ward Method
|
Inter-groupes
|
9,486
|
1
|
2,371
|
36,320
|
,000
|
|
Intra-classe
|
492,759
|
7550
|
,065
|
|
|
|
Total
|
502,245
|
7551
|
|
|
|
|
Ciment * Ward Method
|
Inter-groupes
|
276,040
|
1
|
276,040
|
1309,944
|
,000
|
|
Intra-classe
|
1590,985
|
7550
|
,211
|
|
|
|
Total
|
1867,025
|
7551
|
|
|
|
58
Mémoire de fin d'études
|
Somme
des carrés
|
df
|
Moyenne
des carrés
|
Fisher
|
Significat ion (á)
|
|
Carreau * Ward Method
|
Inter-groupes
|
23,378
|
1
|
23,378
|
573,672
|
,000
|
|
Intra-classe
|
307,678
|
7550
|
,041
|
|
|
|
Total
|
331,056
|
7551
|
|
|
|
|
Terre battue * Ward Method
|
Inter-groupes
|
469,846
|
1
|
469,846
|
2646,360
|
,000
|
|
Intra-classe
|
1340,459
|
7550
|
,178
|
|
|
|
Total
|
1810,305
|
7551
|
|
|
|
|
Béton/Ciment * Ward Method
|
Inter-groupes
|
1,955
|
1
|
1,955
|
94,281
|
,000
|
|
Intra-classe
|
156,570
|
7550
|
,021
|
|
|
|
Total
|
158,525
|
7551
|
|
|
|
|
Tôle ondulée * Ward Method
|
Inter-groupes
|
125,612
|
1
|
125,612
|
691,455
|
,000
|
|
Intra-classe
|
1371,561
|
7550
|
,182
|
|
|
|
Total
|
1497,173
|
7551
|
|
|
|
|
Chaume/Paille * Ward Method
|
Inter-groupes
|
176,103
|
1
|
176,103
|
1097,945
|
,000
|
|
Intra-classe
|
1210,967
|
7550
|
,160
|
|
|
|
Total
|
1387,070
|
7551
|
|
|
|
|
Briques Ciment * Ward Method
|
Inter-groupes
|
749,230
|
1
|
749,230
|
7618,798
|
,000
|
|
Intra-classe
|
742,464
|
7550
|
,098
|
|
|
|
Total
|
1491,694
|
7551
|
|
|
|
|
Briques Terre cuite * Ward
|
Inter-groupes
|
1083,146
|
1
|
270,786
|
2547,105
|
,000
|
|
Method
|
Intra-classe
|
802,333
|
7550
|
,106
|
|
|
|
Total
|
1885,478
|
7551
|
|
|
|
|
Terre stabilisée * Ward Method
|
Inter-groupes
|
1,085
|
1
|
1,085
|
50,792
|
,000
|
|
Intra-classe
|
161,266
|
7550
|
,021
|
|
|
|
Total
|
162,351
|
7551
|
|
|
|
|
Briques Terre/Banco * Ward
|
Inter-groupes
|
634,903
|
1
|
634,903
|
3833,050
|
,000
|
|
Method
|
Intra-classe
|
1250,575
|
7550
|
,166
|
|
|
|
Total
|
1885,478
|
7551
|
|
|
|
|
Robinet du ménage * Ward
|
Inter-groupes
|
220,577
|
1
|
220,577
|
2757,574
|
,000
|
|
Method
|
Intra-classe
|
603,922
|
7550
|
,080
|
|
|
|
Total
|
824,499
|
7551
|
|
|
|
|
Robinet du voisin * Ward Method
|
Inter-groupes
|
211,085
|
1
|
211,085
|
2038,518
|
,000
|
|
Intra-classe
|
781,788
|
7550
|
,104
|
|
|
|
Total
|
992,873
|
7551
|
|
|
|
|
Forage * Ward Method
|
Inter-groupes
|
373,966
|
1
|
373,966
|
1954,709
|
,000
|
|
Intra-classe
|
1444,433
|
7550
|
,191
|
|
|
|
Total
|
1818,399
|
7551
|
|
|
|
|
Puits aménagés * Ward Method
|
Inter-groupes
|
7,118
|
1
|
1,779
|
22,720
|
,000
|
|
Intra-classe
|
591,073
|
7550
|
,078
|
|
|
|
Total
|
598,191
|
7551
|
|
|
|
|
Puits non aménagés * Ward
|
Inter-groupes
|
15,069
|
1
|
15,069
|
156,193
|
,000
|
|
Method
|
Intra-classe
|
728,387
|
7550
|
,096
|
|
|
|
Total
|
743,456
|
7551
|
|
|
|
|
Eau de surface * Ward Method
|
Inter-groupes
|
30,174
|
1
|
30,174
|
340,799
|
,000
|
|
Intra-classe
|
668,471
|
7550
|
,089
|
|
|
|
Total
|
698,645
|
7551
|
|
|
|
|
Chasse d'eau avec fosse septique *
|
Inter-groupes
|
14,238
|
1
|
14,238
|
517,283
|
,000
|
|
Ward Method
|
Intra-classe
|
207,818
|
7550
|
,028
|
|
|
|
Total
|
222,056
|
7551
|
|
|
|
59
Mémoire de fin d'études
|
Somme
des carrés
|
df
|
Moyenne
des carrés
|
Fisher
|
Significat ion (á)
|
|
Latrines couvertes * Ward Method
|
Inter-groupes
|
271,823
|
1
|
271,823
|
1415,858
|
,000
|
|
Intra-classe
|
1449,482
|
7550
|
,192
|
|
|
|
Total
|
1721,305
|
7551
|
|
|
|
|
Latrines non couvertes * Ward
|
Inter-groupes
|
205,640
|
1
|
205,640
|
929,442
|
,000
|
|
Method
|
Intra-classe
|
1670,443
|
7550
|
,221
|
|
|
|
Total
|
1876,083
|
7551
|
|
|
|
|
Nature * Ward Method
|
Inter-groupes
|
48,926
|
1
|
48,926
|
429,817
|
,000
|
|
Intra-classe
|
859,413
|
7550
|
,114
|
|
|
|
Total
|
908,339
|
7551
|
|
|
|
|
Oui accès à l'électricité * Ward
|
Inter-groupes
|
1257,386
|
1
|
1257,386
|
26437,767
|
,000
|
|
Method
|
Intra-classe
|
359,080
|
7550
|
,048
|
|
|
|
Total
|
1616,466
|
7551
|
|
|
|
|
Bois * Ward Method
|
Inter-groupes
|
602,980
|
1
|
602,980
|
4765,548
|
,000
|
|
Intra-classe
|
955,294
|
7550
|
,127
|
|
|
|
Total
|
1558,275
|
7551
|
|
|
|
|
Charbon de bois * Ward Method
|
Inter-groupes
|
569,801
|
1
|
569,801
|
4757,311
|
,000
|
|
Intra-classe
|
904,292
|
7550
|
,120
|
|
|
|
Total
|
1474,093
|
7551
|
|
|
|
|
Électricité/Secteur * Ward Method
|
Inter-groupes
|
1146,342
|
1
|
1146,342
|
25364,604
|
,000
|
|
Intra-classe
|
341,219
|
7550
|
,045
|
|
|
|
Total
|
1487,560
|
7551
|
|
|
|
|
Lampe tempête (Pétrole) * Ward
|
Inter-groupes
|
484,367
|
1
|
484,367
|
2661,297
|
,000
|
|
Method
|
Intra-classe
|
1374,133
|
7550
|
,182
|
|
|
|
Total
|
1858,500
|
7551
|
|
|
|
|
Bougie * Ward Method
|
Inter-groupes
|
8,509
|
1
|
8,509
|
81,519
|
,000
|
|
Intra-classe
|
788,040
|
7550
|
,104
|
|
|
|
Total
|
796,549
|
7551
|
|
|
|
|
Torche * Ward Method
|
Inter-groupes
|
41,610
|
1
|
41,610
|
418,664
|
,000
|
|
Intra-classe
|
750,372
|
7550
|
,099
|
|
|
|
Total
|
791,982
|
7551
|
|
|
|
|
Ramassage Privé * Ward Method
|
Inter-groupes
|
74,037
|
1
|
74,037
|
1302,790
|
,000
|
|
Intra-classe
|
429,064
|
7550
|
,057
|
|
|
|
Total
|
503,101
|
7551
|
|
|
|
|
Poubelle publique * Ward Method
|
Inter-groupes
|
20,690
|
1
|
20,690
|
501,847
|
,000
|
|
Intra-classe
|
311,274
|
7550
|
,041
|
|
|
|
Total
|
331,964
|
7551
|
|
|
|
|
Incinération * Ward Method
|
Inter-groupes
|
3,951
|
1
|
,988
|
22,666
|
,000
|
|
Intra-classe
|
328,920
|
7550
|
,044
|
|
|
|
Total
|
332,872
|
7551
|
|
|
|
|
Enfouissement * Ward Method
|
Inter-groupes
|
,260
|
1
|
,260
|
11,608
|
,001
|
|
Intra-classe
|
168,777
|
7550
|
,022
|
|
|
|
Total
|
169,037
|
7551
|
|
|
|
|
Nature * Ward Method
|
Inter-groupes
|
191,984
|
1
|
191,984
|
1398,641
|
,000
|
|
Intra-classe
|
1036,347
|
7550
|
,137
|
|
|
|
Total
|
1228,331
|
7551
|
|
|
|
|
Canal à ciel ouvert * Ward Method
|
Inter-groupes
|
16,586
|
1
|
16,586
|
485,998
|
,000
|
|
Intra-classe
|
257,659
|
7550
|
,034
|
|
|
|
Total
|
274,245
|
7551
|
|
|
|
60
Mémoire de fin d'études
|
Somme
des carrés
|
df
|
Moyenne
des carrés
|
Fisher
|
Significat ion (á)
|
|
Trou creusé dans la cour * Ward
|
Inter-groupes
|
1,469
|
1
|
1,469
|
31,900
|
,000
|
|
Method
|
Intra-classe
|
347,696
|
7550
|
,046
|
|
|
|
Total
|
349,165
|
7551
|
|
|
|
|
Dans la rue/la nature * Ward
|
Inter-groupes
|
57,684
|
1
|
57,684
|
590,047
|
,000
|
|
Method
|
Intra-classe
|
738,104
|
7550
|
,098
|
|
|
|
Total
|
795,788
|
7551
|
|
|
|
|
Possession de moutons, chèvres et
|
Inter-groupes
|
160,427
|
1
|
160,427
|
880,402
|
,000
|
|
d'autres animaux de taille moyenne
|
Intra-classe
|
1375,759
|
7550
|
,182
|
|
|
|
par le ménage * Ward Method
|
Total
|
1536,186
|
7551
|
|
|
|
|
Possession de têtes de gros bétail
|
Inter-groupes
|
94,041
|
1
|
94,041
|
627,918
|
,000
|
|
par le ménage * Ward Method
|
Intra-classe
|
1130,738
|
7550
|
,150
|
|
|
|
Total
|
1224,779
|
7551
|
|
|
|
|
Possession de terre agricole par le
|
Inter-groupes
|
391,462
|
1
|
391,462
|
1983,029
|
,000
|
|
ménage (ha) * Ward Method
|
Intra-classe
|
1490,417
|
7550
|
,197
|
|
|
|
Total
|
1881,879
|
7551
|
|
|
|
|
Temps pour aller à la source d'eau
|
Inter-groupes
|
5,612
|
1
|
5,612
|
103,655
|
,000
|
|
potable (moins de 30 mn) * Ward
|
Intra-classe
|
408,753
|
7550
|
,054
|
|
|
|
Method
|
Total
|
414,364
|
7551
|
|
|
|
|
Distance source d'eau potable
|
Inter-groupes
|
16,458
|
1
|
16,458
|
213,298
|
,000
|
|
(moins de 1 km) * Ward Method
|
Intra-classe
|
582,559
|
7550
|
,077
|
|
|
|
Total
|
599,017
|
7551
|
|
|
|
|
Temps pour aller au marché de
|
Inter-groupes
|
77,315
|
1
|
77,315
|
343,850
|
,000
|
|
produits alimentaires (moins de 30
|
Intra-classe
|
1697,632
|
7550
|
,225
|
|
|
|
mn) * Ward Method
|
Total
|
1774,947
|
7551
|
|
|
|
|
Distance marché de produits
|
Inter-groupes
|
145,149
|
1
|
145,149
|
629,531
|
,000
|
|
alimentaires (moins de 1 km) *
|
Intra-classe
|
1740,782
|
7550
|
,231
|
|
|
|
Ward Method
|
Total
|
1885,931
|
7551
|
|
|
|
|
Temps pour aller au transport
|
Inter-groupes
|
107,350
|
1
|
107,350
|
560,221
|
,000
|
|
public: arrêt de bus, taxi, etc.
|
Intra-classe
|
1446,733
|
7550
|
,192
|
|
|
|
(moins de 30 mn) * Ward Method
|
Total
|
1554,083
|
7551
|
|
|
|
|
Distance transport public: arrêt de
|
Inter-groupes
|
194,019
|
1
|
194,019
|
932,469
|
,000
|
|
bus, taxi, etc. (moins de 1 km) *
|
Intra-classe
|
1570,928
|
7550
|
,208
|
|
|
|
Ward Method
|
Total
|
1764,947
|
7551
|
|
|
|
|
Temps pour aller à l'école Primaire
|
Inter-groupes
|
11,462
|
1
|
11,462
|
90,153
|
,000
|
|
(moins de 30 mn) * Ward Method
|
Intra-classe
|
959,938
|
7550
|
,127
|
|
|
|
Total
|
971,400
|
7551
|
|
|
|
|
Distance école Primaire (moins de
|
Inter-groupes
|
56,872
|
1
|
56,872
|
335,577
|
,000
|
|
1 km) * Ward Method
|
Intra-classe
|
1279,529
|
7550
|
,169
|
|
|
|
Total
|
1336,400
|
7551
|
|
|
|
|
Temps pour aller à l'école
|
Inter-groupes
|
204,390
|
1
|
204,390
|
925,334
|
,000
|
|
Secondaire (moins de 30 mn) *
|
Intra-classe
|
1667,666
|
7550
|
,221
|
|
|
|
Ward Method
|
Total
|
1872,056
|
7551
|
|
|
|
|
Distance école Secondaire (moins
|
Inter-groupes
|
293,004
|
1
|
293,004
|
1560,022
|
,000
|
|
de 1 km) * Ward Method
|
Intra-classe
|
1418,045
|
7550
|
,188
|
|
|
|
Total
|
1711,049
|
7551
|
|
|
|
|
Temps pour aller à l'établissement
|
Inter-groupes
|
83,213
|
1
|
83,213
|
369,737
|
,000
|
|
sanitaire/service de santé (moins de
|
Intra-classe
|
1699,193
|
7550
|
,225
|
|
|
|
30 mn) * Ward Method
|
Total
|
1782,406
|
7551
|
|
|
|
61
Mémoire de fin d'études
|
Somme
des carrés
|
df
|
Moyenne
des carrés
|
Fisher
|
Significat ion (á)
|
|
Distance établissement
|
Inter-groupes
|
156,380
|
1
|
156,380
|
683,099
|
,000
|
|
sanitaire/service de santé (moins de
|
Intra-classe
|
1728,398
|
7550
|
,229
|
|
|
|
1 km) * Ward Method
|
Total
|
1884,778
|
7551
|
|
|
|
|
Temps pour aller à la route
|
Inter-groupes
|
50,859
|
1
|
50,859
|
412,154
|
,000
|
|
praticable (moins de 30 mn)* Ward
|
Intra-classe
|
931,656
|
7550
|
,123
|
|
|
|
Method
|
Total
|
982,515
|
7551
|
|
|
|
|
Distance route praticable (moins de
|
Inter-groupes
|
66,320
|
1
|
66,320
|
437,856
|
,000
|
|
1 km) * Ward Method
|
Intra-classe
|
1143,559
|
7550
|
,151
|
|
|
|
Total
|
1209,879
|
7551
|
|
|
|
|
Automobile * Ward Method
|
Inter-groupes
|
6,657
|
1
|
6,657
|
226,440
|
,000
|
|
Intra-classe
|
221,968
|
7550
|
,029
|
|
|
|
Total
|
228,625
|
7551
|
|
|
|
|
moto/motocyclette * Ward Method
|
Inter-groupes
|
30,906
|
1
|
7,727
|
78,512
|
,000
|
|
Intra-classe
|
742,713
|
7550
|
,098
|
|
|
|
Total
|
773,620
|
7551
|
|
|
|
|
bicyclette * Ward Method
|
Inter-groupes
|
70,494
|
1
|
70,494
|
470,600
|
,000
|
|
Intra-classe
|
1130,968
|
7550
|
,150
|
|
|
|
Total
|
1201,463
|
7551
|
|
|
|
|
Téléphone * Ward Method
|
Inter-groupes
|
501,921
|
1
|
501,921
|
3549,751
|
,000
|
|
Intra-classe
|
1067,541
|
7550
|
,141
|
|
|
|
Total
|
1569,462
|
7551
|
|
|
|
|
Congélateur/Réfrigérateur * Ward
|
Inter-groupes
|
192,032
|
1
|
192,032
|
2618,192
|
,000
|
|
Method
|
Intra-classe
|
553,758
|
7550
|
,073
|
|
|
|
Total
|
745,790
|
7551
|
|
|
|
|
radio/radio cassette/lecteur CD *
|
Inter-groupes
|
26,209
|
1
|
26,209
|
106,313
|
,000
|
|
Ward Method
|
Intra-classe
|
1861,266
|
7550
|
,247
|
|
|
|
Total
|
1887,474
|
7551
|
|
|
|
|
téléviseur/magnétoscope/DVD/VC
|
Inter-groupes
|
493,212
|
1
|
493,212
|
5110,825
|
,000
|
|
D * Ward Method
|
Intra-classe
|
728,600
|
7550
|
,097
|
|
|
|
Total
|
1221,812
|
7551
|
|
|
|
|
Lit * Ward Method
|
Inter-groupes
|
10,495
|
1
|
10,495
|
146,237
|
,000
|
|
Intra-classe
|
541,836
|
7550
|
,072
|
|
|
|
Total
|
552,331
|
7551
|
|
|
|
|
Armoire/Bibliothèque/Buffet *
|
Inter-groupes
|
359,789
|
1
|
359,789
|
2382,582
|
,000
|
|
Ward Method
|
Intra-classe
|
1140,110
|
7550
|
,151
|
|
|
|
Total
|
1499,898
|
7551
|
|
|
|
|
fauteuil/canapé * Ward Method
|
Inter-groupes
|
167,428
|
1
|
167,428
|
821,368
|
,000
|
|
Intra-classe
|
1538,998
|
7550
|
,204
|
|
|
|
Total
|
1706,427
|
7551
|
|
|
|
|
fusil de chasse * Ward Method
|
Inter-groupes
|
38,882
|
1
|
38,882
|
366,343
|
,000
|
|
Intra-classe
|
801,320
|
7550
|
,106
|
|
|
|
Total
|
840,202
|
7551
|
|
|
|
|
machine à coudre * Ward Method
|
Inter-groupes
|
,961
|
1
|
,961
|
35,377
|
,000
|
|
Intra-classe
|
205,088
|
7550
|
,027
|
|
|
|
|
206,049
|
7551
|
|
|
|
|
groupe électrogène * Ward Method
|
Inter-groupes
|
3,428
|
1
|
,857
|
36,146
|
,000
|
|
Intra-classe
|
178,941
|
7550
|
,024
|
|
|
|
Total
|
182,370
|
7551
|
|
|
|
Source : Calcul de l'auteur sur les données de l'ELEP 2007
sous SPSS
62
|
|


