Chapitre2
L'édition coopérative des documents
structurés
Sommaire
2.1 - Documents structurés, conformité et
édition 19
2.2 - Vues, projection et répliques partielles 26
2.3 - Expansion des répliques partielles 27
2.4 - Fusion des répliques partielles 31
2.5 - Synthèse 32
Les documents structurés contiennent des informations
organisées suivant un modèle générique. Les
nombreux avantages de ces documents en ont fait d'importants outils
d'échange dans le monde informatique. Les applications
distribuées s'appuient sur eux pour permettre aux différents
acteurs de coopérer et de coordonner leurs actions. Ces documents sont
donc édités de manière asynchrone par plusieurs personnes
situées sur des sites géographiques potentiellement
éloignés. L'édition coopérative des documents
structurés nécessite que le procédé
d'édition soit défini à l'avance. BADOUEL Eric et
TCHOUPÉ TCHENDJI Maurice ont proposé une approche originale
d'édition coopérative des documents structurés dans
[BTT08, BTT07, TT09]. Étant donné que leur approche est la base
des travaux que nous menons, ce chapitre est majoritairement consacré
à la présentation de leurs travaux et il est organisé
comme suit : nous commençons par donner une représentation
formelle des documents structurés (sect. 2.1.1) et nous décrivons
l'approche de BADOUEL et TCHOUPÉ (que nous adoptons) pour
l'édition coopérative des documents structurés (sect.
2.1.3). Ensuite nous présentons les concepts utilisés pour
l'édition coopérative des documents suivant cette approche : les
notions de vue et de vue éditable (sect. 2.2.1), les
notions de projection et de réplique partielle (sect.
2.2.2), les notions d'expansion (sect. 2.3) et enfin de fusion
des mises à jour portées sur les répliques partielles
(sect. 2.4).
2.1. Documents structurés, conformité et
édition
Pour rappel, un document structuré est un document qui
présente une structure régulière définie par un
modèle générique. Il est usuel de représenter la
structure abstraite d'un
2.1. Documents structurés, conformité et
édition 20
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
document structuré par un arbre et son modèle
par une grammaire algébrique abstraite ; un document structuré
valide est alors un arbre de dérivation pour cette grammaire et on dit
que ce document est conforme à cette grammaire. Après avoir
défini formellement les grammaires algébriques abstraites, nous
représentons dans cette section les documents structurés valides
puis nous décrivons une démarche d'édition
coopérative de tels documents.
2.1.1. Représentation d'un document
structuré
Nous nous intéressons uniquement à la structure
des documents indépendamment de leurs contenus et des attributs qu'ils
peuvent contenir. De ce fait, un document est valide s'il est conforme à
une grammaire algébrique abstraite. Une telle grammaire définit
la structure de ses instances (les documents qui lui sont conformes) au moyen
des productions. Une production, généralement notée p
: X0 -+ X1...Xn est assimilable dans ce contexte à une
règle de structuration présentant comment le symbole X0
situé en partie gauche de la production se décompose en une
séquence d'autres symboles X1 ...Xn situés
dans sa partie droite. Plus formellement,
Définition 7 Une grammaire
algébrique abstraite est la donnée G = (S,P,A) d'un
ensemble fini S de symboles grammaticaux ou sortes qui correspondent aux
différentes catégories syntaxiques en jeu, d'un symbole
grammatical A E S particulier, appelé axiome, et d'un ensemble fini P c_
S x S* de productions. Une production P = (XP(0),XP(1)
···XP(n)) est notée P : XP(0) -+ XP(1)
···XP(n) et |P| désigne la longueur de la partie droite
de P.
L'annexe B contient la définition d'un type Haskell
[Has, HPHF99, GHC] pour les grammaires ainsi qu'un ensemble d'autres fonctions
implémentant les opérations définies dans ce
mémoire.
Exemple 8 Une grammaire algébrique
abstraite
Gexpl = (S,P,A) avec S = {A,B,C} et ayant les productions
suivantes :
P1 : A -+ C B P3 : B -+ C A P5 : C -+ A C
P2 : A -+ å P4 : B -+ B B P6 : C -+ C
C
P7 : C -+ å
est un exemple de grammaire algébrique. Signalons
qu'elle sera utilisée tout au long de ce manuscrit pour illustrer
certains de nos propos.
Un document structuré se présente sous la forme
d'un arbre dont les noeuds sont associés à des catégories
syntaxiques (symboles de la grammaire). Cette structure arborescente
reflète la structure hiérarchique du document. Pour certains
traitements sur les arbres (documents) il est nécessaire de
désigner précisément un noeud particulier. Plusieurs
techniques d'indexation existent parmi lesquelles celle dite de
numérotation dynamique par niveau (Dynamic Level Numbering - DLN - en
anglais) [BR04] basée sur des identificateurs à longueurs
variables inspirés de la classification décimale de
Dewey. Suivant ce système d'indexation, on peut définir
un arbre comme suit :
Définition 9 Un arbre dont les noeuds
sont étiquetés dans un alphabet S est
une fonction
t : N* -+ S
dont le domaine Dom(t) c_ N* est un
ensemble clos par préfixe tel que pour tout
u E Dom(t) l'ensemble {i E N | u · i E
Dom(t)} est un intervalle d'entiers [1,··· ,n] f1N non
vide (å E Dom(t)(racine)); l'entier n est l'arité du
noeud d'adresse u. t(w) est la valeur (étiquette) du noeud de t
d'adresse w. Un arbre tw, de racine le noeud d'adresse w E Dom(t) et
de domaine
2.1. Documents structurés, conformité et
édition 21
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Dom(tw) = {u | w.u E Dom(t)} et tw(u) =
t(w.u), est un sous-arbre de t si t1,··· ,tn sont des
arbres et a E S, on note t = a[t1,...,tn]
l'arbre t de domaine Dom(t) = {å} U {i · u | 1 < i <
n, u E Dom(ti)} avec t(å) = a et t(i · u) = ti(u).
L'arbre vide sera noté nil et next t =
[t1,··· ,tn] est la liste des sous-arbres de l'arbre
t = a[t1,...,tn].
La figure 2.1 est la représentation graphique de l'arbre
t définit sur l'alphabet {A,B,C}, dont une
linéarisation peut être donnée par t =
A[C[A[C[],B[C[],A[]]],C[]],B[C[C[],C[]],A[]]]. Les noeuds de t
sont identifiés suivant la technique de numérotation
dynamique par niveau.
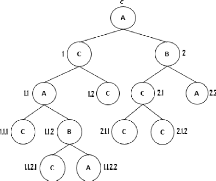
FIGURE 2.1 - Représentation graphique d'un arbre et
indexation de ses éléments.
| 

